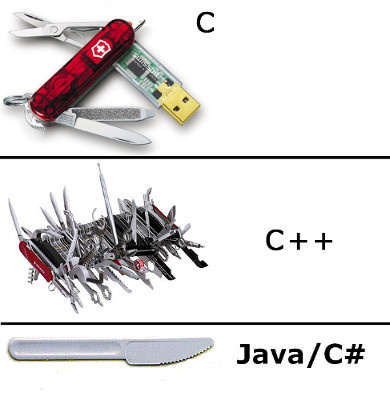
Место Java в мире HFT |
int doSmth(int i) {
if (i == 1) {
goo();
} else {
foo();
}
return …;
}cmpl $1, %edi
je .L7
call goo
NEXT:
...
ret
.L7:
call foo
jmp NEXTcmpl $1, %edi
jne .L9
call foo
NEXT:
...
ret
.L9:
call goo
jmp NEXTcmpl $1, %edi
je/jne .L3
call foo/goo
jmp NEXT:
.L3:
call goo/foo
NEXT:
…
retvoid doSmth(IMyInterface impl) {
impl.doSmth();
}class A {
int i;
};
class B {
long l;
};
class C {
A a;
B b;
};
C c;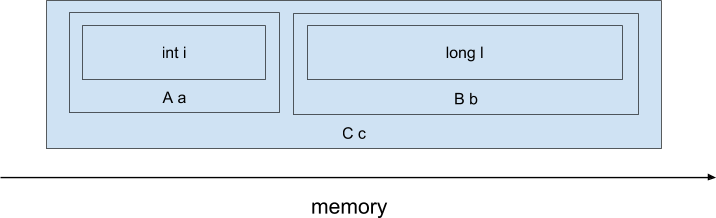
mov (%rdi), %rax ; << чтение c.a.i
add ANY_OFFSET(%rdi), %rax ; << чтение c.b.l и сложение с c.a.i
ret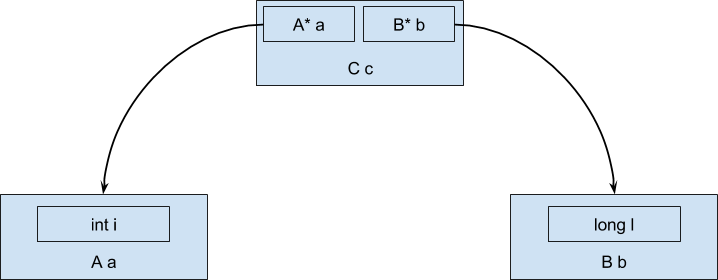
mov (%rdi), %rax ; << загружаем адрес объекта a
mov 8(%rdi), %rdx ; << загружаем адрес объекта b
mov (%rax), %rax ; << загружаем значение поля i объекта a
add (%rdx), %rax ; << загружаем значение поля l объекта b{
try (Connection c = createConnection()) {
...
}
}{
Connection c = createConnection();
try {
...
} finally {
c.close();
}
}{
Connection c = createConnection();
} // деструктор будет автоматически вызван при вызоде из scope'а{
Object obj = new Object();
.....
// Здесь объект уже не нужен, просто забываем про него
}{
Object obj = Storage.malloc(); // получаем объект из пула
...
Storage.free(obj); // возвращаем объект в пул
}|
Метки: author RainM высокая производительность java блог компании райффайзенбанк c++ low-latency high-performance |
Взгляд изнутри: «On Rails!» об участии в «Противостоянии» |




|
Метки: author ibm информационная безопасность блог компании ibm ibm on rails! противостояние |
Dlang Tour переведен на русский язык |
Dlang Tour — это интерактивное введение в язык D.
Сделан по образцу Golang Tour.
В большинстве статей есть примеры кода, которые можно запустить из браузера.
Helloworld, установка компилятора, компиляция и запуск программы из командной строки.
Введение в синтаксис и основные особенности языка.
Этот раздел будет интересен даже для знающих язык.
Практически каждая статья этого раздела — описание очередной killer feature языка.
Описаны особенности языка и стандартной библиотеки, облегчающие создание безопасного многопоточного кода.
Асинхронный фреймворк на основе Fibers (сопрограмм, легковесных потоков).
В основном используется для Web-разработки.
|
Метки: author Buggins программирование dlang golang |
[Перевод] Ubuntu для мобильных устройств: посмертный анализ |
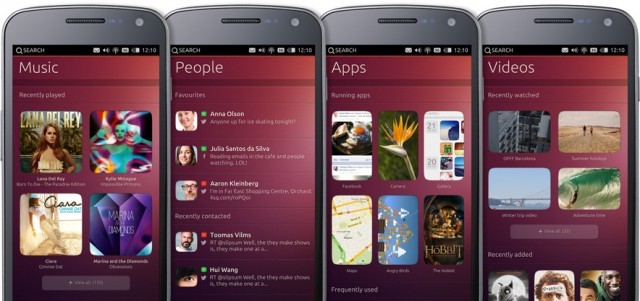

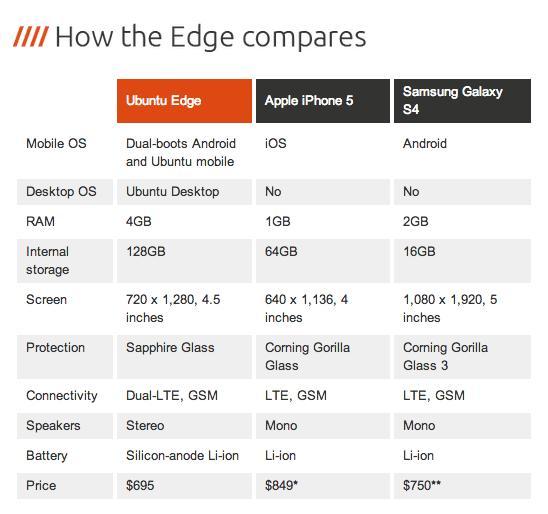


|
|
Когда мне вышлют оффер? Подсказки для соискателей от HR-менеджера |





Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
|
Автоэнкодеры в Keras, Часть 4: Conditional VAE |


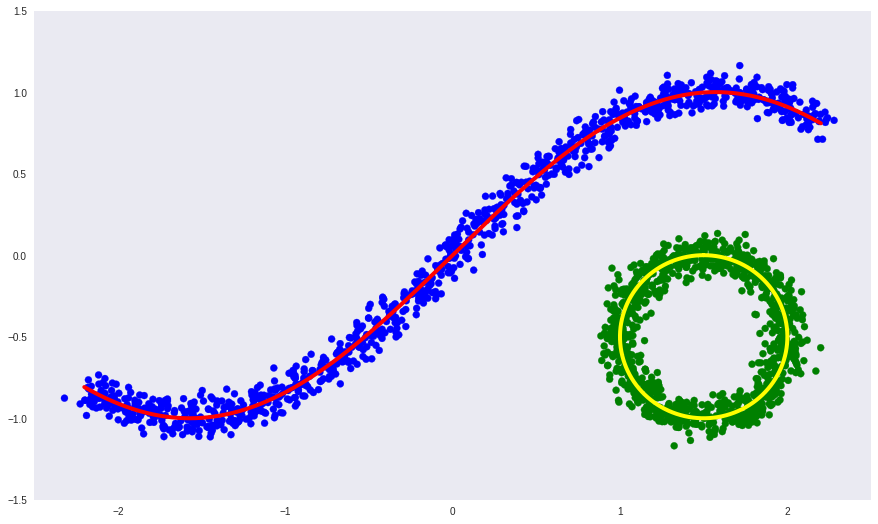
# Импорт необходимых библиотек
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
# Создание датасета
x1 = np.linspace(-2.2, 2.2, 1000)
fx = np.sin(x1)
dots1 = np.vstack([x1, fx]).T
t = np.linspace(0, 2*np.pi, num=1000)
dots2 = 0.5*np.array([np.sin(t), np.cos(t)]).T + np.array([1.5, -0.5])[None, :]
dots = np.vstack([dots1, dots2])
noise = 0.06 * np.random.randn(*dots.shape)
labels = np.array([0]*1000 + [1]*1000)
noised = dots + noise
# Визуализация
colors = ['b']*1000 + ['g']*1000
plt.figure(figsize=(15, 9))
plt.xlim([-2.5, 2.5])
plt.ylim([-1.5, 1.5])
plt.scatter(noised[:, 0], noised[:, 1], c=colors)
plt.plot(dots1[:, 0], dots1[:, 1], color="red", linewidth=4)
plt.plot(dots2[:, 0], dots2[:, 1], color="yellow", linewidth=4)
plt.grid(False)
# Модель и обучение
from keras.layers import Input, Dense
from keras.models import Model
from keras.optimizers import Adam
def deep_ae():
input_dots = Input((2,))
x = Dense(64, activation='elu')(input_dots)
x = Dense(64, activation='elu')(x)
code = Dense(1, activation='linear')(x)
x = Dense(64, activation='elu')(code)
x = Dense(64, activation='elu')(x)
out = Dense(2, activation='linear')(x)
ae = Model(input_dots, out)
return ae
dae = deep_ae()
dae.compile(Adam(0.001), 'mse')
dae.fit(noised, noised, epochs=300, batch_size=30, verbose=2)
# Результат
predicted = dae.predict(noised)
# Визуализация
plt.figure(figsize=(15, 9))
plt.xlim([-2.5, 2.5])
plt.ylim([-1.5, 1.5])
plt.scatter(noised[:, 0], noised[:, 1], c=colors)
plt.plot(dots1[:, 0], dots1[:, 1], color="red", linewidth=4)
plt.plot(dots2[:, 0], dots2[:, 1], color="yellow", linewidth=4)
plt.scatter(predicted[:, 0], predicted[:, 1], c='white', s=50)
plt.grid(False)
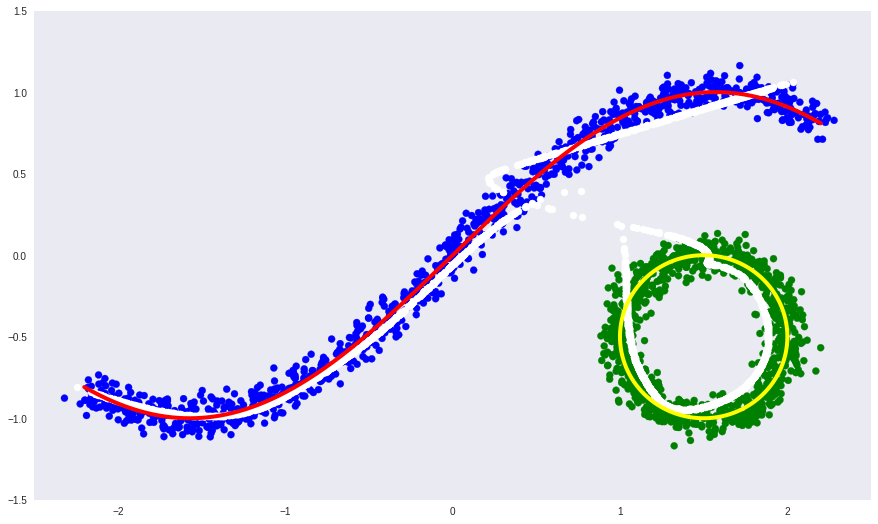
from keras.layers import concatenate
def deep_cond_ae():
input_dots = Input((2,))
input_lbls = Input((1,))
full_input = concatenate([input_dots, input_lbls])
x = Dense(64, activation='elu')(full_input)
x = Dense(64, activation='elu')(x)
code = Dense(1, activation='linear')(x)
full_code = concatenate([code, input_lbls])
x = Dense(64, activation='elu')(full_code)
x = Dense(64, activation='elu')(x)
out = Dense(2, activation='linear')(x)
ae = Model([input_dots, input_lbls], out)
return ae
cdae = deep_cond_ae()
cdae.compile(Adam(0.001), 'mse')
cdae.fit([noised, labels], noised, epochs=300, batch_size=30, verbose=2)
predicted = cdae.predict([noised, labels])
# Визуализация
plt.figure(figsize=(15, 9))
plt.xlim([-2.5, 2.5])
plt.ylim([-1.5, 1.5])
plt.scatter(noised[:, 0], noised[:, 1], c=colors)
plt.plot(dots1[:, 0], dots1[:, 1], color="red", linewidth=4)
plt.plot(dots2[:, 0], dots2[:, 1], color="yellow", linewidth=4)
plt.scatter(predicted[:, 0], predicted[:, 1], c='white', s=50)
plt.grid(False)


import sys
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# import seaborn as sns
from keras.datasets import mnist
from keras.utils import to_categorical
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test .astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
y_train_cat = to_categorical(y_train).astype(np.float32)
y_test_cat = to_categorical(y_test).astype(np.float32)
num_classes = y_test_cat.shape[1]
batch_size = 500
latent_dim = 8
dropout_rate = 0.3
start_lr = 0.001
from keras.layers import Input, Dense
from keras.layers import BatchNormalization, Dropout, Flatten, Reshape, Lambda
from keras.layers import concatenate
from keras.models import Model
from keras.objectives import binary_crossentropy
from keras.layers.advanced_activations import LeakyReLU
from keras import backend as K
def create_cvae():
models = {}
# Добавим Dropout и BatchNormalization
def apply_bn_and_dropout(x):
return Dropout(dropout_rate)(BatchNormalization()(x))
# Энкодер
input_img = Input(shape=(28, 28, 1))
flatten_img = Flatten()(input_img)
input_lbl = Input(shape=(num_classes,), dtype='float32')
x = concatenate([flatten_img, input_lbl])
x = Dense(256, activation='relu')(x)
x = apply_bn_and_dropout(x)
# Предсказываем параметры распределений
# Вместо того чтобы предсказывать стандартное отклонение, предсказываем логарифм вариации
z_mean = Dense(latent_dim)(x)
z_log_var = Dense(latent_dim)(x)
# Сэмплирование из Q с трюком репараметризации
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(batch_size, latent_dim), mean=0., stddev=1.0)
return z_mean + K.exp(z_log_var / 2) * epsilon
l = Lambda(sampling, output_shape=(latent_dim,))([z_mean, z_log_var])
models["encoder"] = Model([input_img, input_lbl], l, 'Encoder')
models["z_meaner"] = Model([input_img, input_lbl], z_mean, 'Enc_z_mean')
models["z_lvarer"] = Model([input_img, input_lbl], z_log_var, 'Enc_z_log_var')
# Декодер
z = Input(shape=(latent_dim, ))
input_lbl_d = Input(shape=(num_classes,), dtype='float32')
x = concatenate([z, input_lbl_d])
x = Dense(256)(x)
x = LeakyReLU()(x)
x = apply_bn_and_dropout(x)
x = Dense(28*28, activation='sigmoid')(x)
decoded = Reshape((28, 28, 1))(x)
models["decoder"] = Model([z, input_lbl_d], decoded, name='Decoder')
models["cvae"] = Model([input_img, input_lbl, input_lbl_d],
models["decoder"]([models["encoder"]([input_img, input_lbl]), input_lbl_d]),
name="CVAE")
models["style_t"] = Model([input_img, input_lbl, input_lbl_d],
models["decoder"]([models["z_meaner"]([input_img, input_lbl]), input_lbl_d]),
name="style_transfer")
def vae_loss(x, decoded):
x = K.reshape(x, shape=(batch_size, 28*28))
decoded = K.reshape(decoded, shape=(batch_size, 28*28))
xent_loss = 28*28*binary_crossentropy(x, decoded)
kl_loss = -0.5 * K.sum(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1)
return (xent_loss + kl_loss)/2/28/28
return models, vae_loss
models, vae_loss = create_cvae()
cvae = models["cvae"]
from keras.optimizers import Adam, RMSprop
cvae.compile(optimizer=Adam(start_lr), loss=vae_loss)
digit_size = 28
def plot_digits(*args, invert_colors=False):
args = [x.squeeze() for x in args]
n = min([x.shape[0] for x in args])
figure = np.zeros((digit_size * len(args), digit_size * n))
for i in range(n):
for j in range(len(args)):
figure[j * digit_size: (j + 1) * digit_size,
i * digit_size: (i + 1) * digit_size] = args[j][i].squeeze()
if invert_colors:
figure = 1-figure
plt.figure(figsize=(2*n, 2*len(args)))
plt.imshow(figure, cmap='Greys_r')
plt.grid(False)
ax = plt.gca()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
n = 15 # Картинка с 15x15 цифр
from scipy.stats import norm
# Так как сэмплируем из N(0, I), то сетку узлов, в которых генерируем цифры, берем из обратной функции распределения
grid_x = norm.ppf(np.linspace(0.05, 0.95, n))
grid_y = norm.ppf(np.linspace(0.05, 0.95, n))
def draw_manifold(generator, lbl, show=True):
# Рисование цифр из многообразия
figure = np.zeros((digit_size * n, digit_size * n))
input_lbl = np.zeros((1, 10))
input_lbl[0, lbl] = 1
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z_sample = np.zeros((1, latent_dim))
z_sample[:, :2] = np.array([[xi, yi]])
x_decoded = generator.predict([z_sample, input_lbl])
digit = x_decoded[0].squeeze()
figure[i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit
if show:
# Визуализация
plt.figure(figsize=(10, 10))
plt.imshow(figure, cmap='Greys_r')
plt.grid(False)
ax = plt.gca()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
return figure
def draw_z_distr(z_predicted, lbl):
# Рисование рпспределения z
input_lbl = np.zeros((1, 10))
input_lbl[0, lbl] = 1
im = plt.scatter(z_predicted[:, 0], z_predicted[:, 1])
im.axes.set_xlim(-5, 5)
im.axes.set_ylim(-5, 5)
plt.show()
from IPython.display import clear_output
from keras.callbacks import LambdaCallback, ReduceLROnPlateau, TensorBoard
# Массивы, в которые будем сохранять результаты для последующей визуализации
figs = [[] for x in range(num_classes)]
latent_distrs = [[] for x in range(num_classes)]
epochs = []
# Эпохи, в которые будем сохранять
save_epochs = set(list((np.arange(0, 59)**1.701).astype(np.int)) + list(range(10)))
# Отслеживать будем на вот этих цифрах
imgs = x_test[:batch_size]
imgs_lbls = y_test_cat[:batch_size]
n_compare = 10
# Модели
generator = models["decoder"]
encoder_mean = models["z_meaner"]
# Функция, которую будем запускать после каждой эпохи
def on_epoch_end(epoch, logs):
if epoch in save_epochs:
clear_output() # Не захламляем output
# Сравнение реальных и декодированных цифр
decoded = cvae.predict([imgs, imgs_lbls, imgs_lbls], batch_size=batch_size)
plot_digits(imgs[:n_compare], decoded[:n_compare])
# Рисование многообразия для рандомного y и распределения z|y
draw_lbl = np.random.randint(0, num_classes)
print(draw_lbl)
for lbl in range(num_classes):
figs[lbl].append(draw_manifold(generator, lbl, show=lbl==draw_lbl))
idxs = y_test == lbl
z_predicted = encoder_mean.predict([x_test[idxs], y_test_cat[idxs]], batch_size)
latent_distrs[lbl].append(z_predicted)
if lbl==draw_lbl:
draw_z_distr(z_predicted, lbl)
epochs.append(epoch)
# Коллбэки
pltfig = LambdaCallback(on_epoch_end=on_epoch_end)
# lr_red = ReduceLROnPlateau(factor=0.1, patience=25)
tb = TensorBoard(log_dir='./logs')
# Запуск обучения
cvae.fit([x_train, y_train_cat, y_train_cat], x_train, shuffle=True, epochs=1000,
batch_size=batch_size,
validation_data=([x_test, y_test_cat, y_test_cat], x_test),
callbacks=[pltfig, tb],
verbose=1)





























def style_transfer(model, X, lbl_in, lbl_out):
rows = X.shape[0]
if isinstance(lbl_in, int):
lbl = lbl_in
lbl_in = np.zeros((rows, 10))
lbl_in[:, lbl] = 1
if isinstance(lbl_out, int):
lbl = lbl_out
lbl_out = np.zeros((rows, 10))
lbl_out[:, lbl] = 1
return model.predict([X, lbl_in, lbl_out])
n = 10
lbl = 7
generated = []
prot = x_train[y_train == lbl][:n]
for i in range(num_classes):
generated.append(style_transfer(models["style_t"], prot, lbl, i))
generated[lbl] = prot
plot_digits(*generated, invert_colors=True)

from matplotlib.animation import FuncAnimation
from matplotlib import cm
import matplotlib
def make_2d_figs_gif(figs, epochs, c, fname, fig):
norm = matplotlib.colors.Normalize(vmin=0, vmax=1, clip=False)
im = plt.imshow(np.zeros((28,28)), cmap='Greys', norm=norm)
plt.grid(None)
plt.title("Label: {}\nEpoch: {}".format(c, epochs[0]))
def update(i):
im.set_array(figs[i])
im.axes.set_title("Label: {}\nEpoch: {}".format(c, epochs[i]))
im.axes.get_xaxis().set_visible(False)
im.axes.get_yaxis().set_visible(False)
return im
anim = FuncAnimation(fig, update, frames=range(len(figs)), interval=100)
anim.save(fname, dpi=80, writer='imagemagick')
def make_2d_scatter_gif(zs, epochs, c, fname, fig):
im = plt.scatter(zs[0][:, 0], zs[0][:, 1])
plt.title("Label: {}\nEpoch: {}".format(c, epochs[0]))
def update(i):
fig.clear()
im = plt.scatter(zs[i][:, 0], zs[i][:, 1])
im.axes.set_title("Label: {}\nEpoch: {}".format(c, epochs[i]))
im.axes.set_xlim(-5, 5)
im.axes.set_ylim(-5, 5)
return im
anim = FuncAnimation(fig, update, frames=range(len(zs)), interval=100)
anim.save(fname, dpi=80, writer='imagemagick')
for lbl in range(num_classes):
make_2d_figs_gif(figs[lbl], epochs, lbl, "./figs4/manifold_{}.gif".format(lbl), plt.figure(figsize=(7,7)))
make_2d_scatter_gif(latent_distrs[lbl], epochs, lbl, "./figs4/z_distr_{}.gif".format(lbl), plt.figure(figsize=(7,7)))
|
Метки: author iphysic обработка изображений машинное обучение математика алгоритмы python autoencoder keras mnist deep learning machine learning |
[Перевод] Создание шейдерного эффекта 3D-принтера |

worldPos к структуре Input поверхностного шейдера Unity 5.struct Input {
float2 uv_MainTex;
float3 worldPos;
};Albedo в структуре SurfaceOutputStandard.float _ConstructY;
fixed4 _ConstructColor;
void surf (Input IN, inout SurfaceOutputStandard o) {
if (IN.worldPos.y < _ConstructY)
{
fixed4 c = tex2D(_MainTex, IN.uv_MainTex) * _Color;
o.Albedo = c.rgb;
o.Alpha = c.a;
}
else
{
o.Albedo = _ConstructColor.rgb;
o.Alpha = _ConstructColor.a;
}
o.Metallic = _Metallic;
o.Smoothness = _Glossiness;
}
#pragma surface surf Unlit fullforwardshadows
inline half4 LightingUnlit (SurfaceOutput s, half3 lightDir, half atten)
{
return _ConstructColor;
}SurfaceOutput, который использовался в Unity 4. Если мы хотим создать собственную модель освещения, работающую с PBR и глобальным освещением, то нужно реализовать функцию, получающую в качестве входных данных SurfaceOutputStandard. В Unity 5 для этого используется следующая функция:inline half4 LightingUnlit (SurfaceOutputStandard s, half3 lightDir, UnityGI gi)
{
return _ConstructColor;
}gi здесь относится к глобальному освещению (global illumination), но в нашем неосвещённом шейдере он не выполняет никаких задач. Такой подход работает, но у него есть большая проблема. Unity не позволяет поверхностному шейдеру выборочно изменять функцию освещения. Мы не можем применить стандартное освещение по Ламберту к нижней части объекта и одновременно сделать верхнюю часть неосвещённой. Можно назначить единственную функцию освещения для всего объекта. Мы должны сами менять способ рендеринга объекта в зависимости от его положения.
building), которую мы зададим в функции поверхности. Эту переменную может проверять наша новая функция освещения.int building;
void surf (Input IN, inout SurfaceOutputStandard o) {
if (IN.worldPos.y < _ConstructY)
{
fixed4 c = tex2D(_MainTex, IN.uv_MainTex) * _Color;
o.Albedo = c.rgb;
o.Alpha = c.a;
building = 0;
}
else
{
o.Albedo = _ConstructColor.rgb;
o.Alpha = _ConstructColor.a;
building = 1;
}
o.Metallic = _Metallic;
o.Smoothness = _Glossiness;
}building для изменения способа вычисления освещения. Часть объекта, которая в текущий момент строится, будет неосвещённой, а на оставшейся части будет правильно рассчитанное освещение. Если мы хотим, чтобы наш материал использовал PBR, мы не можем переписывать весь код для фотореалистичного освещения. Единственное разумное решение — вызывать стандартную функцию освещения, которая уже реализована в Unity.#pragma, определяющая использование функции освещения PBR, имеет следующий вид:#pragma surface surf Standard fullforwardshadowsLightingStandard. Эта функция находится в файле UnityPBSLighting.cginc, который можно при необходимости подключить.LightingCustom. В обычных условиях она просто вызывает стандартную функцию PBR из Unity под названием LightingStandard. Однако при необходимости она использует определённую ранее LightingUnlit.inline half4 LightingCustom(SurfaceOutputStandard s, half3 lightDir, UnityGI gi)
{
if (!building)
return LightingStandard(s, lightDir, gi); // Unity5 PBR
return _ConstructColor; // Unlit
}inline void LightingCustom_GI(SurfaceOutputStandard s, UnityGIInput data, inout UnityGI gi)
{
LightingStandard_GI(s, data, gi);
}
discard. С его помощью можно отрисовывать только границу вокруг верхней части модели:void surf (Input IN, inout SurfaceOutputStandard o)
{
if (IN.worldPos.y > _ConstructY + _ConstructGap)
discard;
...
}Cull Off
viewDir в поверхностном шейдере) и нормалью треугольника. Если оно отрицательное, то треугольник повёрнут от камеры. То есть мы видим его «изнанку» и можем отрендерить её сплошным цветом.struct Input {
float2 uv_MainTex;
float3 worldPos;
float3 viewDir;
};
void surf (Input IN, inout SurfaceOutputStandard o)
{
viewDir = IN.viewDir;
...
}
inline half4 LightingCustom(SurfaceOutputStandard s, half3 lightDir, UnityGI gi)
{
if (building)
return _ConstructColor;
if (dot(s.Normal, viewDir) < 0)
return _ConstructColor;
return LightingStandard(s, lightDir, gi);
}
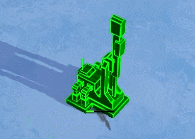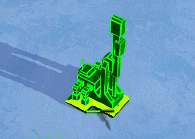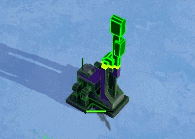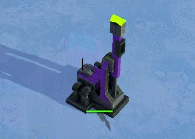
void surf (Input IN, inout SurfaceOutputStandard o)
{
float s = +sin((IN.worldPos.x * IN.worldPos.z) * 60 + _Time[3] + o.Normal) / 120;
if (IN.worldPos.y > _ConstructY + s + _ConstructGap)
discard;
...
}
_ConstructY. Об остальном позаботится шейдер. Можно управлять скоростью эффекта или через код, или с помощью кривой анимации. При первом варианте вы можете полностью контролировать его скорость.public class BuildingTimer : MonoBehaviour
{
public Material material;
public float minY = 0;
public float maxY = 2;
public float duration = 5;
// Update is called once per frame
void Update () {
float y = Mathf.Lerp(minY, maxY, Time.time / duration);
material.SetFloat("_ConstructY", y);
}
}
|
Метки: author PatientZero разработка игр unity3d шейдеры unity туториал программирование шейдеров |
Защищенное рабочее место на базе VDI Huawei FusionCloud Desktop Solution 6.1 |























|
Метки: author ru_vds хостинг it- инфраструктура блог компании ruvds.com ruvds vdi huawei fusioncloud |
Скорочтение: работает или нет? Часть 2: разбор методик |
|
Метки: author itmo gtd блог компании университет итмо университет итмо чтение |
Make QR Codes Great Again или камерная революция от Apple |

На недавнем WWDC Keynote Крэйг Фидеричи мельком анонсировал нативную поддержку QR-кодов в iOS11. Новость эта прошла почти незаметно. А зря.
Под катом расскажем: ностальгически о прошлом QR-кода, обстоятельно – о настоящем и, вангуя, – о ближайшем будущем. А еще о том, почему нас, людей разрабатывающих продукты, чтобы смешить других, так с этого прёт.
QR-код появился на свет в Японии в 1994 году в семье-подразделении TOYOTA, занимавшейся разработкой сканеров для штрих-кодов (DENSO WAVE). Отцом был записан Хара Масахиро.
В то время клиенты атаковали корпорацию просьбами создать такой штрих-код, в который можно было бы инкапсулировать больше данных. За полтора года силами Хара Масахиро и всего одного помощника задача была решена.
Благодаря инженерному трюку разработчиков – уникальному шаблону детектирования позиции в виде трех квадратов – удалось добиться не только высокой емкости (2953 байт), но и беспрецедентной скорости считывания по сравнению с конкурентами.

В честь этого преимущества детку и нарекли – QR (Quick Response).
Существенно подрасти, набрать вес и стать самым распространённым в мире двумерным кодом среди десятков конкурентов QR-коду помогли два фактора:

Свои первые уверенные шаги технология сделала в направлении японских автопроизводителей, которые внедрили QR-коды в текущие Kanban-процессы. Затем подтянулись другие индустрии, увидевшие пользу применения квадратиков в своих циклах.
Но по-настоящему в люди из душных производственных стен QR-код вывели первые японские камерофоны в начале 2002 года. QR-архитектура позволяла беспроблемное считывание на самых допотопных аппаратах.
QR-код зрел, а вокруг маячили соблазнительные и уже оформившиеся мобильные платформы iOS и Android. Произошедшая смартфонная революция дала возможность каждому бомжу заиметь телефон с камерой и начать пользоваться приложениями. Тут же появились сотни сторонних сканеров QR-кодов.

Технология вышла за пределы Азии, но наиболее широкое применение в этот период могла получить только и только в Китае. Здесь свою роль сыграли:

Получить широкое распространение во всем мире и наконец стать взрослым QR-коду мешала всего одна вещь – нужно было постоянно таскать с собой контрацептивы и предохраняться с помощью сторонних приложений для сканирования. Естественному контакту со смартфонами мешало отсутствие нативной поддержки на iOS/Android-устройствах.
А вот здесь начинается самое интересное. С сентября 2017 благодаря волевому решению Apple у QR-кода начнется новый жизненный этап. После релиза iOS11 сотни миллионов устройств по всему миру окажутся на расстоянии всего одного свайпа до:
Посмотреть на все это своими глазами можно уже сейчас. Достаточно скачать beta-версию iOS11 и воспользоваться каким-нибудь мощным генератором QR-кодов.

Очевидно, что сотни тысяч оффлайн-бизнесов и онлайн-бизнесов, размещающих рекламу в оффлайне, начнут эксплуатировать те преимущества, которые дает этот короткий мостик между реальным и цифровым миром.
Возможно, именно этот шаг яблочной корпорации, за которой со временем последуют Google и его hardware-партнеры, даст старт эре “Camera is the New Keyboard”. Мы же ожидаем, что уже к концу этого года QR-код можно будет назвать двумерным кодом в самом расцвете сил.
Но это если серьезно. А если несерьезно, то решение Apple создает беспрецедентные возможности в первую очередь для FunTech-индустрии. Пока прикладные бизнесы будут долго просчитывать эффективность и сомневаться, самые смелые – а это обычно порно и развлечения – начнут нагло орудовать на новом поле.

Мы предлагаем орудовать вместе :)
Для начала приглашаем вас в совместный мозговой штурм в комментариях к этой статье. Включите фантазию, отбросьте ограничения (в том числе этические) и предложите свои идеи для взрывного будущего QR-кодов в развлекательной индустрии. Кроме фана в самом обсуждении у вас есть шанс довести свою идею до MVP, а то и полноценного продукта.
Такая возможность доступна в рамках запущенного нами акселератора развлекательных проектов FunCubator. В нем достаточно денег, экспертизы и трафика, чтобы сделать из идеи продукт, которым будут пользоваться миллионы. Кстати, если идея уже готова – и не обязательно про QR – идите туда напрямую.
В любом случае будьте готовы к сомнительному поощрению из Китая – страны-фаната технологии. Трое комментаторов, которые внесут самый крупный вклад в дискуссию, получат “Низкая стоимость ручной qr-код принтер bluetooth прочный может напечатать испанский, Португальский, арабский и т. д. (QS5806)” с сайта Alibaba.com. Подробнее об устройстве можно узнать, конечно же, считав QR-код.

И да зародится в комментах Хабра первый FunTech-стартап. Аминь.
|
Метки: author gladiolus исследования и прогнозы в it блог компании funcorp qr- коды qr-code apple iphone ios funtech funcorp funcubator |
Развлечения для интеллектуалов: играем во «Что? Где? Когда?» — как? |









|
Метки: author polarowl блог компании «veeam software» veeam veeam team развлечения интеллектуальные игры что? где? когда? |
Как перестать искать хороший дата-центр и начать жить |



|
Метки: author bofh666 системное администрирование серверное администрирование it- инфраструктура блог компании pixonic администрирование дата-центр датацентры провайдер сервер |
Как Pony Express удается вам доставлять |

|
Метки: author i-cat разработка систем связи программирование javascript блог компании voximplant курьерская доставка |
«В Тарантуле нет такой проблемы как сильная деградация со временем и под нагрузкой» – Василий Сошников |

|
Метки: author rdruzyagin разработка веб-сайтов высокая производительность блог компании pg day'17 russia tarantool interview интервью oltp |
Анонс Mobius 2017 Moscow: покорение Москвы |




 Денис Неклюдов (90Seconds) — «ветеран» конференции и обладатель почётного статуса Google Developer Expert. Этой весной на петербургском Mobius особенно активно говорили об архитектуре — и одной из причин этого было выступление Дениса со Степаном Гончаровым «Современный подход к архитектуре Android-приложения».
Денис Неклюдов (90Seconds) — «ветеран» конференции и обладатель почётного статуса Google Developer Expert. Этой весной на петербургском Mobius особенно активно говорили об архитектуре — и одной из причин этого было выступление Дениса со Степаном Гончаровым «Современный подход к архитектуре Android-приложения». David Gonz'alez — а вот этот известный андроидовод, в отличие от Дениса, ранее на Mobius не выступал. Зато с Денисом он похож в другом: во-первых, тоже обладает званием GDE, а во-вторых, он на Mobius тоже поговорит об архитектуре — интересно будет сравнить их доклады.
David Gonz'alez — а вот этот известный андроидовод, в отличие от Дениса, ранее на Mobius не выступал. Зато с Денисом он похож в другом: во-первых, тоже обладает званием GDE, а во-вторых, он на Mobius тоже поговорит об архитектуре — интересно будет сравнить их доклады. Александр Зимин (Uberchord GmbH) — тоже заметный спикер, но уже не по Android, а по iOS. Победитель программы WWDC 2015 Scholarships, вёл первые курсы Swift в России, организатор CocoaHeads Russia — перечислять его заслуги можно долго. Ещё не можем огласить тему его нового доклада, но можем напомнить предыдущую: на Mobius 2017 Piter он рассказывал об измерении UX в iOS-приложении.
Александр Зимин (Uberchord GmbH) — тоже заметный спикер, но уже не по Android, а по iOS. Победитель программы WWDC 2015 Scholarships, вёл первые курсы Swift в России, организатор CocoaHeads Russia — перечислять его заслуги можно долго. Ещё не можем огласить тему его нового доклада, но можем напомнить предыдущую: на Mobius 2017 Piter он рассказывал об измерении UX в iOS-приложении. Матвей Мальков — в 2015-м его доклад о реактивном программировании под Android попал в топ докладов Mobius 2015 по оценкам зрителей. В 2016-м, развив тему реактивщины, Матвей снова оказался с ней в топе, а также выступил с докладом об использовании Scala в Android. Mobius 2017 Piter он пропустил, а вот в Москве будет — так что в 2017-м москвичам больше повезло с ним, чем петербуржцам.
Матвей Мальков — в 2015-м его доклад о реактивном программировании под Android попал в топ докладов Mobius 2015 по оценкам зрителей. В 2016-м, развив тему реактивщины, Матвей снова оказался с ней в топе, а также выступил с докладом об использовании Scala в Android. Mobius 2017 Piter он пропустил, а вот в Москве будет — так что в 2017-м москвичам больше повезло с ним, чем петербуржцам.  Максим Соколов (Avito), доклад которого «Advanced Swift Generics — перейдём на
Максим Соколов (Avito), доклад которого «Advanced Swift Generics — перейдём на  Aleksander Piotrowski — польский спикер, на петербургском Mobius рассказывавший о ConstraintLayout, тогда оказался благодарен за то, что мы не против использовать эту его фотографию: «Некоторые конференции, когда я присылаю её, просят прислать какую-нибудь другую. Не понимаю, чем им не понравился мой лоб?» В общем, ждём осенью в Москве Александра с его лбом, скрывающим много знаний об Android.
Aleksander Piotrowski — польский спикер, на петербургском Mobius рассказывавший о ConstraintLayout, тогда оказался благодарен за то, что мы не против использовать эту его фотографию: «Некоторые конференции, когда я присылаю её, просят прислать какую-нибудь другую. Не понимаю, чем им не понравился мой лоб?» В общем, ждём осенью в Москве Александра с его лбом, скрывающим много знаний об Android. Игорь Кашкута (Badoo) выступал на Mobius уже дважды (с темами «Пизанская башня мобильной разработки» и «Процесс разработки iOS-приложения»), и во второй раз зрители остались ощутимо более воодушевлены. Работа в Badoo должна дать много материала и для нового доклада в Москве — постараемся, чтобы там зрителям понравилось ещё больше.
Игорь Кашкута (Badoo) выступал на Mobius уже дважды (с темами «Пизанская башня мобильной разработки» и «Процесс разработки iOS-приложения»), и во второй раз зрители остались ощутимо более воодушевлены. Работа в Badoo должна дать много материала и для нового доклада в Москве — постараемся, чтобы там зрителям понравилось ещё больше. Алексей Денисов (Uberchord GmbH) — в прошлый раз рассказывал про мутационное тестирование. Тему нового выступления пока не сообщим, но, когда на мобильной конференции появляется спикер, погружённый в мир низкоуровневого программирования и знающий не понаслышке о технологиях вроде LLVM, это интересно в любом случае.
Алексей Денисов (Uberchord GmbH) — в прошлый раз рассказывал про мутационное тестирование. Тему нового выступления пока не сообщим, но, когда на мобильной конференции появляется спикер, погружённый в мир низкоуровневого программирования и знающий не понаслышке о технологиях вроде LLVM, это интересно в любом случае.  Йонатан Левин на Mobius 2017 Piter выступал сразу с двумя докладами: «IPC: AIDL — это не ругательство» погружался в технические детали, а закрывающий кейноут «Как сделать из вашего приложения продукт» был рассчитан на всех. Оба выступления понравились зрителям, и было бы глупо не позвать Йонатана снова. Сейчас он ещё не знает точно свой график поездок и пока не подтвердил участие, но надеемся, что громкий голос комьюнити заставит Йонатана найти время в своём плотном графике (и вы можете этому поспособствовать — например, в комментариях).
Йонатан Левин на Mobius 2017 Piter выступал сразу с двумя докладами: «IPC: AIDL — это не ругательство» погружался в технические детали, а закрывающий кейноут «Как сделать из вашего приложения продукт» был рассчитан на всех. Оба выступления понравились зрителям, и было бы глупо не позвать Йонатана снова. Сейчас он ещё не знает точно свой график поездок и пока не подтвердил участие, но надеемся, что громкий голос комьюнити заставит Йонатана найти время в своём плотном графике (и вы можете этому поспособствовать — например, в комментариях). 

|
|
Бизнес-планирование в игровой индустрии |
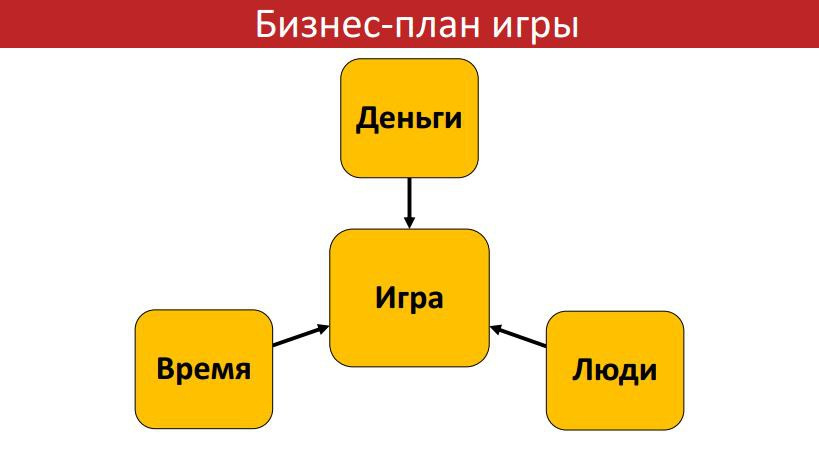









|
Метки: author viacheslavnu управление проектами бизнес-модели бизнес-план игровая индустрия вшби бизнес-планирование геймдев |
Как я сдал экзамен на сертификат CISSP |
|
Метки: author bogatrev информационная безопасность блог компании перспективный мониторинг cissp экзамен cissp сертификат cissp |
Azure-IaaS-Дайджест №16 (Май) |
|
Метки: author 4c74356b41 microsoft azure azure oms azure stack |
Головная боль от использования математического софта |

template
SparseMatrix& SparseMatrix::operator *= (const T& V)
{
for( int i=0 ; i void rollBack(const AllocatorState& state){
....
if(state.index/ <=
memory[index][j].~T();
new(&memory[index][j]) T();
}
remains=state.remains;
}
....
}types::Function::ReturnValue sci_mscanf(....)
{
....
std::vector pITTemp = std::vector<...>();
....
case types::InternalType::ScilabString :
{
....
pITTemp.pop_back(); // <=
pITTemp.push_back(pType);
}
break;
case types::InternalType::ScilabDouble :
{
....
pITTemp.back(); // <= ???
pITTemp.push_back(pType);
}
break;
....
}types::Function::ReturnValue sci_model2blk(....)
{
....
Block.inptr[i] = MALLOC(size);
if (Block.inptr == nullptr)
{
freeBlock(&Block);
Scierror(888, _("%s : Allocation error.\n"), name.data());
return types::Function::Error;
}
memset(Block.inptr[i], 0x00, size);
....
}Block.inptr[i] = MALLOC(size);
if (Block.inptr[i] == nullptr)
{
....
}int mgetl(int iFileID, int iLineCount, wchar_t ***pwstLines)
{
*pwstLines = NULL;
....
*pwstLines = (wchar_t**)MALLOC(iLineCount * sizeof(wchar_t*));
if (pwstLines == NULL)
{
return -1;
}
....
}wchar_t **getDiaryFilenames(int *array_size)
{
*array_size = 0;
if (SCIDIARY)
{
std::list wstringFilenames = SCIDIARY->get....
*array_size = (int)wstringFilenames.size();
if (array_size > 0)
{
....
}
....
}static int ParseNumber(const char* tx)
{
....
else if (strlen(tx) >= 4 && (strncmp(tx, "%eps", 4) == 0
|| strncmp(tx, "+%pi", 4) == 0 || strncmp(tx, "-%pi", 4) == 0
|| strncmp(tx, "+Inf", 4) == 0 || strncmp(tx, "-Inf", 4) == 0
|| strncmp(tx, "+Nan", 4) == 0 || strncmp(tx, "-Nan", 4) == 0
|| strncmp(tx, "%nan", 4) == 0 || strncmp(tx, "%inf", 4) == 0
))
{
return 4;
}
else if (strlen(tx) >= 3
&& (strncmp(tx, "+%e", 3) == 0
|| strncmp(tx, "-%e", 3) == 0
|| strncmp(tx, "%pi", 3) == 0 // <=
|| strncmp(tx, "Nan", 3) == 0
|| strncmp(tx, "Inf", 3) == 0
|| strncmp(tx, "%pi", 3) == 0)) // <=
{
return 3;
}
....
}types::Function::ReturnValue sci_sparse(....)
{
bool isValid = true;
....
for (int i = 0 ; isValid && i < in.size() ; i++)
{
switch (in[i]->getType())
{
case types::InternalType::ScilabBool :
case types::InternalType::ScilabSparseBool :
{
isValid = (i == (in.size() > 1) ? 1 : 0);
}
....
}isValid = (i == (in.size() > 1 ? 1 : 0));void ScilabView::createObject(int iUID)
{
int iType = -1;
int *piType = &iType;
getGraphicObjectProperty(....);
if (iType != -1 && iType == __GO_FIGURE__)
{
m_figureList[iUID] = -1;
setCurrentFigure(iUID);
}
....
}void cdf_error(char const* const fname, int status, double bound)
{
switch (status)
{
....
case 10:
if (strcmp(fname, "cdfchi") == 0) // <=
{
Scierror(999
_("%s: cumgam returned an error\n"), fname);
}
else if (strcmp(fname, "cdfchi") == 0) // <=
{
Scierror(999,
_("%s: gamma or inverse gamma routine failed\n"), fname);
}
break;
....
}const std::string fname = "winqueryreg";
types::Function::ReturnValue sci_winqueryreg(....)
{
....
if (rhs != 2 && rhs != 3)
{
Scierror(77, _("%s: Wrong number...\n"), fname.data(), 2, 3);
return types::Function::Error;
}
....
else
{
Scierror(999, _("%s: Cannot open Windows regist..."), fname);
return types::Function::Error;
}
....
}int sci_scinotes(char * fname, void* pvApiCtx)
{
....
try
{
callSciNotesW(NULL, 0);
}
catch (GiwsException::JniCallMethodException exception)
{
Scierror(999, "%s: %s\n", fname,
exception.getJavaDescription().c_str());
}
catch (GiwsException::JniException exception)
{
Scierror(999, "%s: %s\n", fname,
exception.whatStr().c_str());
}
....
}void Data3D::getDataProperty(int property, void **_pvData)
{
if (property == UNKNOWN_DATA_PROPERTY)
{
*_pvData = NULL;
}
else
{
*_pvData = NULL;
}
}void *MyHeapAlloc(size_t dwSize, char *file, int line)
{
LPVOID NewPointer = NULL;
if (dwSize > 0)
{
_try
{
NewPointer = malloc(dwSize);
NewPointer = memset (NewPointer, 0, dwSize);
}
_except (EXCEPTION_EXECUTE_HANDLER)
{
}
....
}
else
{
_try
{
NewPointer = malloc(dwSize);
NewPointer = memset (NewPointer, 0, dwSize);
}
_except (EXCEPTION_EXECUTE_HANDLER)
{
}
}
return NewPointer;
}int sci_sorder(char *fname, void* pvApiCtx)
{
....
if (iRows * iCols > 0)
{
dblTol1 = pdblTol[0];
}
else if (iRows * iCols > 1)
{
dblTol2 = pdblTol[1];
}
....
}BOOL translatePolyline(int uid, double x, double y, double z,
int flagX, int flagY, int flagZ)
{
double *datax = NULL;
double *datay = NULL;
double *dataz = NULL; // <=
int i = 0;
if (x != 0.0)
{
datax = getDataX(uid);
if (datax == NULL) return FALSE;
....
if (z != 0 && isZCoordSet(uid))
{
if (flagZ) {
for (i = 0; i < getDataSize_(uid); ++i)
{
dataz[i] = pow(10.,log10(dataz[i]) + z); // <=
}
} else {
for (i = 0; i < getDataSize_(uid); ++i)
{
dataz[i] += z; // <=
}
}
}
return TRUE;
}int scilab_sscanf(....)
{
....
wchar_t* number = NULL;
....
number = (wchar_t*)MALLOC((nbrOfDigit + 1) * sizeof(wchar_t));
memcpy(number, wcsData, nbrOfDigit * sizeof(wchar_t));
number[nbrOfDigit] = L'\0';
iSingleData = wcstoul(number, &number, base);
if ((iSingleData == 0) && (number[0] == wcsData[0]))
{
....
}
if (number == NULL)
{
wcsData += nbrOfDigit;
}
else
{
wcsData += (nbrOfDigit - wcslen(number));
}
....
}char **CreateOuput(pipeinfo *pipe, BOOL DetachProcess)
{
char **OuputStrings = NULL;
....
OuputStrings = (char**)MALLOC((pipe->NumberOfLines) * ....);
memset(OuputStrings, 0x00,sizeof(char*) * pipe->NumberOfLines);
if (OuputStrings)
{
char *line = strtok(buffer, LF_STR);
int i = 0;
while (line)
{
OuputStrings[i] = convertLine(line, DetachProcess);
....
}types::Function::ReturnValue sci_grand(....)
{
....
int* piP = new int[vectpDblInput[0]->getSize()];
int* piOut = new int[pDblOut->getSize()];
....
delete piP;
delete piOut;
....
}int sci_buildDoc(char *fname, void* pvApiCtx)
{
....
try
{
org_scilab_modules_helptools::SciDocMain * doc = new ....
if (doc->setOutputDirectory((char *)outputDirectory.c_str()))
{
....
}
else
{
Scierror(999, _("...."), fname, outputDirectory.c_str());
return FALSE; // <=
}
if (doc != NULL)
{
delete doc;
}
}
catch (GiwsException::JniException ex)
{
Scierror(....);
Scierror(....);
Scierror(....);
return FALSE;
}
....
}void killScilabProcess(int exitCode)
{
HANDLE hProcess;
/* Ouverture de ce Process avec droit pour le tuer */
hProcess = OpenProcess(PROCESS_TERMINATE, FALSE, ....);
if (hProcess)
{
/* Tue ce Process */
TerminateProcess(hProcess, exitCode);
}
else
{
MessageBox(NULL, "....", "Warning", MB_ICONWARNING);
}
}
|
Метки: author SvyatoslavMC разработка под windows open source c++ блог компании pvs-studio статический анализ кода компиляторы pvs-studio static code analysis scilab |






