[recovery mode] Вопросы и тестовые задания на позицию Junior PHP Developer |

$obj = $obj2; $obj = clone $obj2
- Стартовая страница сайта должна представлять собой список всех публикаций пользователя во фрейме с полосой прокрутки. Публикации должны быть представлены не полным текстом, а заголовок и 300 символов с начала поста. В конце публикации должна быть ссылка на страницу с полным текстом Read more
- На странице просмотра публикации необходимо отобразить блок поста, название и полный текст. Под ним находится блок комментариев. Комментарии добавляются с помощью ajax.
- Валидацию полей необходимо провести и со стороны сервера и со стороны браузера.
- Страница добавления/редактирования поста. При добавлении и редактировании использовать WYSIWYG редактор
- На главной странице записи должны быть отсортированы в порядке LIFO
- При выполнении задания использовать PHP 5.3+ и jQuery 1.7+
Создайте на *название вашего фреймворка* доску объявлений.
Должен присутствовать функционал регистрации и авторизации пользователей. После того как пользователь зарегистрировался и авторизовался он может заполнить информацию о себе и загрузить свое фото, добавить объявления с фото. К профилю пользователя можно добавлять текстовые комментарии и ставить оценку (рейтинг от 1 до 5). На главной странице сайта отображаются 20 последних добавленных объявлений и присутствует пагинация.
Готовый функционал нужно выложить на Git и прислать нам.
Задание:
1. Создать справочник журналов, с возможностью CRUD. У каждого журнала должны быть:
1.1 Название. (Обязательное поле)
1.2 Короткое описание. (Необязательное поле)
1.3 Картинка. (jpg или png, не больше 2 Мб, должна сохраняться в отдельную папку и иметь уникальное имя файла)
1.4 Авторы (Обязательное поле, может быть несколько авторов у одного журнала, должна быть возможность выбирать из списка авторов, который создается отдельно).
1.5 Дата выпуска журнала.
2. Список авторов создается отдельно. Также должна быть возможность добавления, удаления и редактирования. У каждого автора должны быть:
2.1 Фамилия (Обязательное поле, не короче 3 символов)
2.2 Имя (Обязательное, не пустое)
2.3 Отчество (Необязательное)
3. На выходе получаем:
3.1 Просмотр отдельно страниц журналов и авторов.
3.2 На странице авторов:
3.2.1 Должна быть возможность увидеть список всех журналов определенного автора.
3.2.2 Сделать сортировку авторов по фамилии
3.3.3 Сделать сотрировку таблицы по дате выпуска журнала.
3.4 Работа с каждой отдельной страницей должна происходить без её перезагрузки с использованием jQuery (или Angularjs).
3.5 Сделать пагинацию по журналам и авторам
4. Рекомендуемое время выполнения задания — 4 часа.
|
Метки: author Twitt php собеседование вопросы mysql тестовые задания |
Дайджест интересных материалов для мобильного разработчика #209 (19 июня — 25 июня) |

 |
Как написать максимально хреновый бэкенд для мобильного приложения |
 |
Google и Apple против инди-разработчиков |
 |
Усатый стрелок из двадцати трёх полигонов |
 iOS
iOS Культура Apple после 10 лет существования iPhone Воссоздаем новый App Store Компьютерное зрение в iOS 11 ReplayKit в iOS 11 Один странный совет для уменьшения размера приложения
Культура Apple после 10 лет существования iPhone Воссоздаем новый App Store Компьютерное зрение в iOS 11 ReplayKit в iOS 11 Один странный совет для уменьшения размера приложения DDViewSwitcher: скроллинг текста внутри View
DDViewSwitcher: скроллинг текста внутри View Android Обеспечение качества кода на Android Android Instant Apps шаг за шагом: как их использует Vimeo Firefox Focus: новый браузер для Android Google прекращает поддержку Android Market Не хотдог: компьютерное зрение на Kotlin Быстрые, определенные и аккуратные интеграционные тесты Alligator: современная библиотека для навигации BoxLoaderView: кастомный прогресс-бар GeoJson Viewer: просмотр GeoJson файлов на Android TriangulationDrawable: анимация треугольников Composer: Reactive Android Instrumentation Test Runner InfiniteCards: бесконечно листающиеся карточки VectorMaster: динамическое управление векторными изображениями
Android Обеспечение качества кода на Android Android Instant Apps шаг за шагом: как их использует Vimeo Firefox Focus: новый браузер для Android Google прекращает поддержку Android Market Не хотдог: компьютерное зрение на Kotlin Быстрые, определенные и аккуратные интеграционные тесты Alligator: современная библиотека для навигации BoxLoaderView: кастомный прогресс-бар GeoJson Viewer: просмотр GeoJson файлов на Android TriangulationDrawable: анимация треугольников Composer: Reactive Android Instrumentation Test Runner InfiniteCards: бесконечно листающиеся карточки VectorMaster: динамическое управление векторными изображениями Windows
Windows Разработка Машинное обучение на JavaScript Бесплатные мокапы iPhone, Mac, MacBook pro, iPad, Android Боязнь пустого пространства Лучшие инструменты прототипирования для всех Смерть гамбургеру Firebase Cloud Messaging: управление токенами и уведомлениями на Node.js
Разработка Машинное обучение на JavaScript Бесплатные мокапы iPhone, Mac, MacBook pro, iPad, Android Боязнь пустого пространства Лучшие инструменты прототипирования для всех Смерть гамбургеру Firebase Cloud Messaging: управление токенами и уведомлениями на Node.js Аналитика, маркетинг и монетизация Как монетизировать бота за 24 часа 16 стратегий от экспертов для стремительного роста загрузок Как создавать рекламу в Instagram Stories Монетизация и маркетинг приложений: интервью Эрика Сёферта
Аналитика, маркетинг и монетизация Как монетизировать бота за 24 часа 16 стратегий от экспертов для стремительного роста загрузок Как создавать рекламу в Instagram Stories Монетизация и маркетинг приложений: интервью Эрика Сёферта Устройства, IoT, AI Контролируем свет в офисе с помощью Android Things
Устройства, IoT, AI Контролируем свет в офисе с помощью Android Things|
|
[Из песочницы] Два в одном: как пользоваться Vim и Nano? |


Alt+< — Переход к предыдущему открытому файлу (Если nano запущен с несколькими файлами)
Alt+> — Переход к следующему открытому файлу.
Ещё пишут про команду Alt+F, которая не то включает такую возможность, не то позволяет зачем-то иметь отдельные буфера обмена на каждый файл, но как она работает я не понял.
Редактирование текста: Vim, немного крипоты
Vim, немного крипоты Приведу несколько цитат перед статьёй, которые как бы намекают читателю: "— Ужаснись и беги. Слышишь смертный? Беги! И не говори потом, что тебя не предупреждали..."

% этоShift+5) |
       |
|
Метки: author yuukoku системное администрирование *nix vim nano |
Редактор уровней для три в ряд |

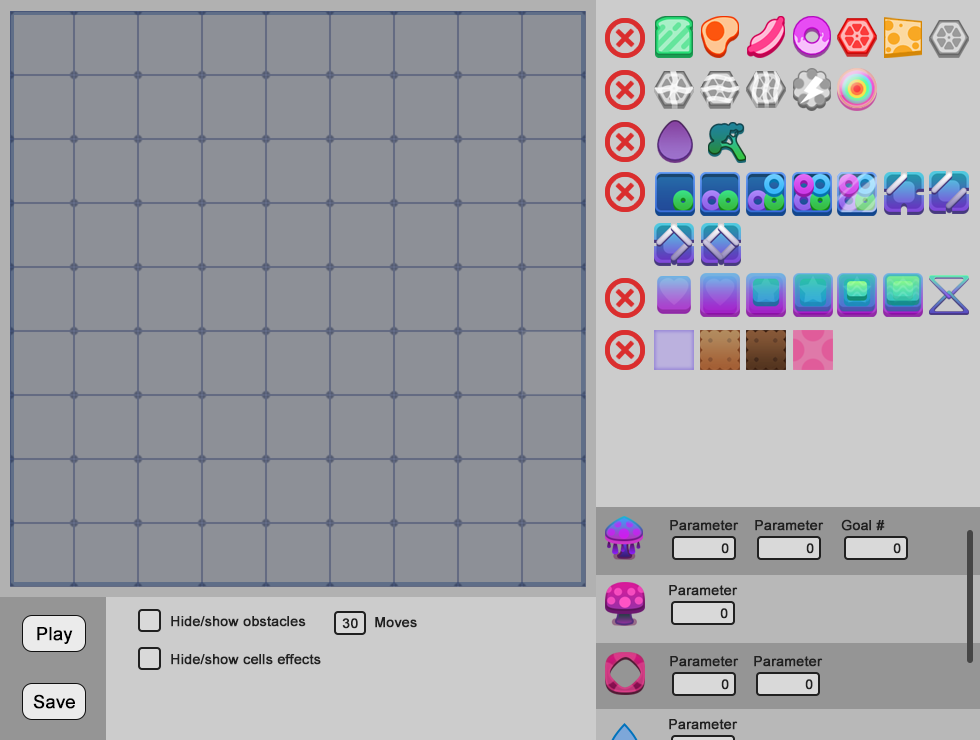
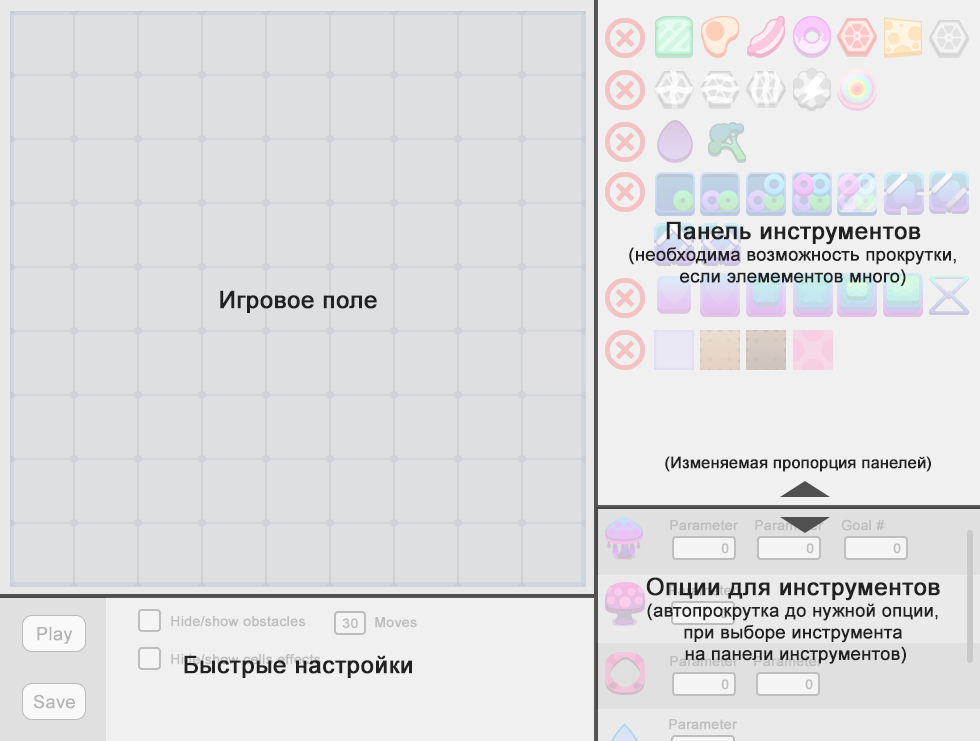

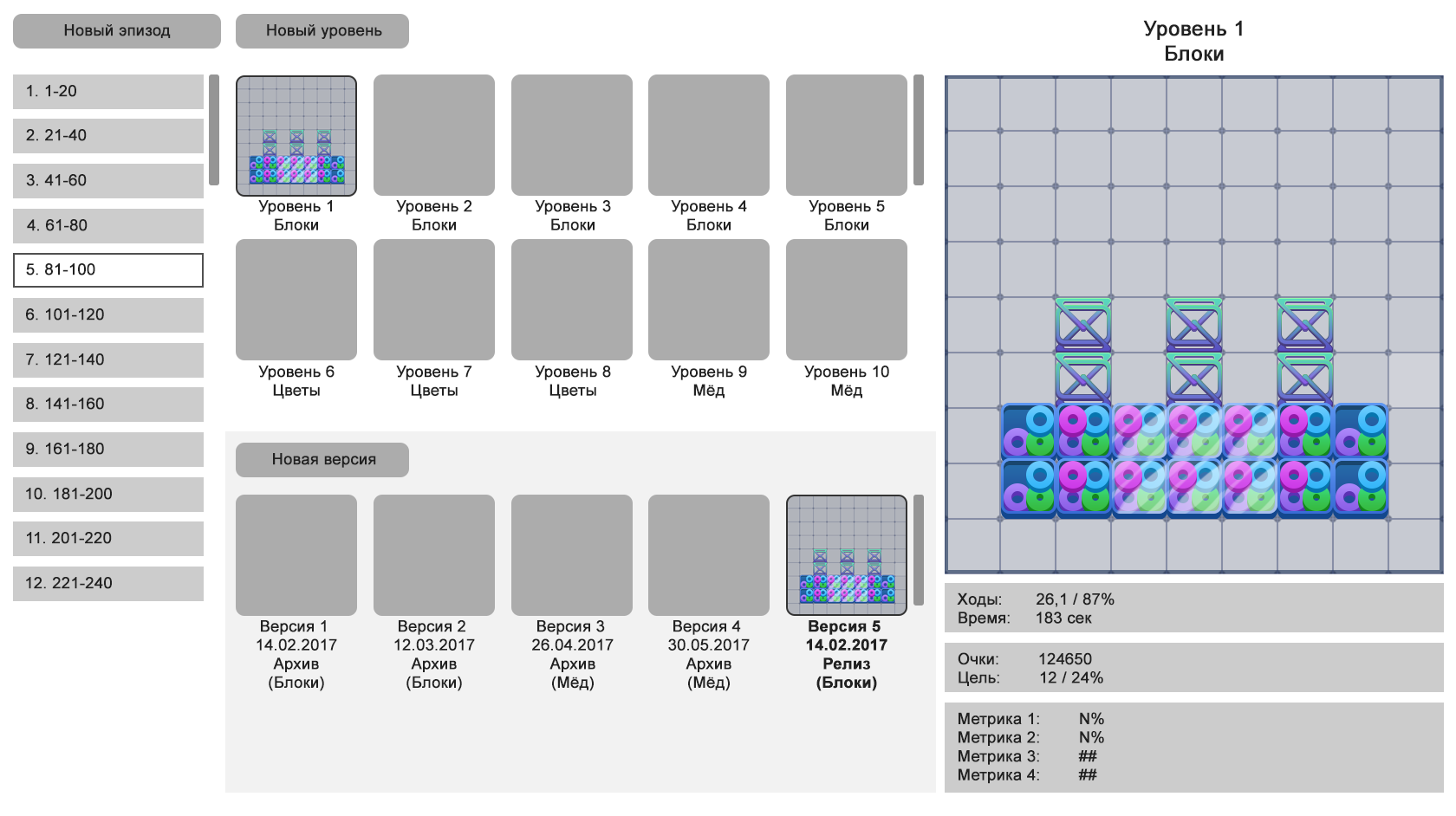
|
Метки: author Pricol разработка мобильных приложений разработка игр match 3 level editor редактор уровней три в ряд дизайн уровней головоломки |
[Из песочницы] Использование MapXtreme .Net |
MapInfo MapXtreme for .Net — это комплект разработчика программного обеспечения ГИС в среде Microsoft .Net, позволяющий встраивать картографические и ГИС функции в бизнес-приложения.
MapXtreme Developers Reference
MapXtreme Version 8.0 Developer Guide

«Мы передали ваш запрос нашим разработчикам»
«Пришлите ваш исходный код нам, мы не понимаем вашу проблему» и т.д.

Tools -> Choose ToolBox Items...


private void Form1_Load(object sender, EventArgs e)
{
addrectangleToolStripButton1.MapControl = mapControl1;
....
}
«Я сделал все правильно, выбрал инструмент для рисования, но у меня ничего не выходит! Почему?»

var layerTemp = mapControl1.Map.Layers["wldcty25"];
LayerHelper.SetInsertable(layerTemp, true);//дает возможность рисовать на слое инструментами
LayerHelper.SetEditable(layerTemp, true); //делает наш слой изменяемым

mapControl1.Map.Layers.Move(lastPosition, nextPosition);

Как я говорил ранее любая настройка может быть задана через интерфейс. Однако, заказчик чаще всего привередливый и ему нужны более гибкие/доступные элементы настройки поэтому далее я не буду рассказывать о том как настроить что либо через компоненты MapXtreme. Я покажу как это сделать через код.
SimpleLineStyle border;//стиль линейного объекта
border= new SimpleLineStyle(<ширина линии в единицах MapXtreme>, <код стиля линии>, <цвет линии>)
SimpleInterior interior;//стиль внутренней области объекта
interior = new SimpleInterior(<код стиля>, <цвет переднего плана>,<цвет фона>)
AreaStyle polygon;//стиль который используя предыдущие два задает стиль для площадного объекта
polygon = new AreaStyle(border, interior);
SimpleLineStyle line;//стиль линейного объекта
line = new SimpleLineStyle(<ширина линии в единицах MapXtreme>, <код стиля линии>, <цвет линии>)
BasePointStyle point;//стиль точечного объекта
point = new SimpleVectorPointStyle(<код стиля>, <цвет точки>, <размер точки>)
CompositeStyle compStyle;//стиль применяемый к слою
compStyle = CompositeStyle(polygon, line, null, point);
FeatureOverrideStyleModifier fosm;
fosm = new FeatureOverrideStyleModifier(parStyleName, parStyleAlias, compStyle);
myLayer.Modifiers.Append(featureOverrideStyleModifier);
Feature feature = null;
feature = new Feature(<класс описывающий наш объект>, compStyle);
//задаем первую часть мультиобъекта
DPoint[] pts1 = new DPoint[5];
pts1[0] = new DPoint(-20, 10);//произвольные координаты точек взятые для примера
pts1[1] = new DPoint(10, 15);
pts1[2] = new DPoint(15, -10);
pts1[3] = new DPoint(-10, -10);
pts1[4] = new DPoint(-20, 10);
//задаем вторую часть мультиобъекта
DPoint[] pts2 = new DPoint[5];
pts2[0] = new DPoint(-40, 50);
pts2[1] = new DPoint(60, 45);
pts2[2] = new DPoint(65, -40);
pts2[3] = new DPoint(25, 20);
pts2[4] = new DPoint(-40, 50);
//LineString создаем из массива элементов DPoint
LineString lineString1 = new LineString(coordSys, pts1);
LineString lineString2 = new LineString(coordSys, pts2);
//Ring в заданной системе координат coordSys создается через LineString
Ring ring1 = new Ring(coordSys, lineString1);
Ring ring2 = new Ring(coordSys, lineString2);
Ring[] rng1 = new Ring[2];
rng1[0] = ring2;
rng1[1] = ring1;
//MultiPolygon состоит из массива Ring
MultiPolygon multiPol = new MultiPolygon(coordSys, rng1);
//Curve в заданной системе координат coordSys создается через LineString
Curve curve4 = new Curve(coordSys, lineString1);
Curve curve5 = new Curve(coordSys, lineString2);
Curve[] crv = new Curve[2];
crv[0] = curve5;
crv[1] = curve4;
//MultiCurve состоит из массива Curve
MultiCurve mc = new MultiCurve(coordSys, crv);
CoordSys сoordSys= mapControl1.Map.GetDisplayCoordSys();CoordSys cs = Session.Current.CoordSysFactory.CreateCoordSys("EPSG:3395", CodeSpace.Epsg);
mapControl1.Map.SetDisplayCoordSys(cs);
mapControl1.Map.RasterReprojectionMethod = ReprojectionMethod.Always;
/**
*ReprojectionMethod имеет три состояния
* None = 0, //запрет на изменение растра
* Always = 1,//изменять всегда
* Optimized = 2//так и не понял зачем нужен, в моей практике он ничем не отличался от
* предыдущего
*/
private string CreateTabFile(List parImageCoordinate)//список координат углов
{
NumberFormatInfo nfi = new CultureInfo("en-US", false).NumberFormat;
var ext = m_fileName.Split(new Char[] { '.' });
var fileExt = ext[ext.GetLength(0) - 1];
string fileTabName = m_fileName.Substring(0, m_fileName.Length - fileExt.Length) + "TAB";
StreamWriter sw = new StreamWriter(fileTabName);
string header = "!table\n!version 300\n!charset WindowsCyrillic\n \n";
sw.WriteLine(header);
string definitionTables = "Definition Table\n ";
definitionTables += "File \"" + m_fileName + "\"\n ";
definitionTables += "Type \"RASTER\"\n ";
for (var i = 0; i < parImageCoordinate.Count; i++)
{
definitionTables += "(" + parImageCoordinate[i].Longitude.ToString("N", nfi) + "," + parImageCoordinate[i].Latitude.ToString("N", nfi) + ") ";
definitionTables += "(" + parImageCoordinate[i].PixelColumn.ToString() + "," + parImageCoordinate[i].PixelRow.ToString() + ") ";
definitionTables += "Label \"Точка " + (i + 1).ToString() + " \",\n ";
}
definitionTables = definitionTables.Substring(0, definitionTables.Length - 4);
definitionTables += "\n ";
definitionTables += "CoordSys Earth Projection 1, 104\n ";
definitionTables += "Units \"degree\"\n";
sw.WriteLine(definitionTables);
string metaData = "begin_metadata\n";
metaData += "\"\\IsReadOnly\" = \"FALSE\"\n";
metaData += "\"\\MapInfo\" = \"\"\n";
string hash;
using (MD5 md5Hash = MD5.Create())
{
hash = GetMd5Hash(md5Hash, m_fileName);
}
metaData += "\"\\MapInfo\\TableID\" = \"" + hash + "\"\n";
metaData += "end_metadata\n";
sw.WriteLine(metaData);
sw.Close();
return fileTabName;
}
|
Метки: author KvendyZ обработка изображений геоинформационные сервисы .net mapxtreme костыльное программирование |
Дизайн города, основанный на данных. Лекция в Яндексе |






















|
|
История оптимизации одного IoC контейнера |
В этой заметке мне хотелось бы поделиться информацией о небольшом, но, на мой взгляд, весьма и весьма полезном проекте, в котором Stef'an J"okull Sigurdarson добавляет все известные ему IoC контейнеры, которые мигрировали на .NET Core, и с использованием BenchmarkDotNet проводит замеры instance resolving performance. Не упустил возможности поучавствовать в этом соревновании и я со своим маленьким проектом FsContainer.

После миграции проекта на .NET Core (хочу заметить, что это оказалось совершенно не сложно) сказать что я не пал духом, значит ничего не сказать и связано это было с тем, что один из трех замеров мой контейнер не проходил. В прямом значении этого слова- замер просто-напросто длился свыше 20 минут и не завершался.
Причина оказалась в этом участке кода:
public object Resolve(Type type)
{
var instance = _bindingResolver.Resolve(this, GetBindings(), type);
if (!_disposeManager.Contains(instance))
{
_disposeManager.Add(instance);
}
return instance;
}Если задуматься, основной принцип работы benchmark'ов- измерение количества выполняемых операций за еденицу времени (опционально потребляемую память), а значит, метод Resolve запускается максимально возможное количество раз. Вы можете заметить, что после resolve полученный instance добавляется в _disposeManager для дальнейшего его уничтожения в случае container.Dispose(). Т.к. внутри реализации находится List, экземпляры в который добавляются посредством проверки на Contains, то можно догадаться, что налицо сразу 2 side-effect'a:
Contains, будет вычислять GetHashCode и искать среди ранее добавленных дубликат;TransientLifetimeManager), то и размер List будет постоянно увеличиваться посредством выделения нового, в 2 раза большего участка памяти и копирования в него ранее добавленных элементов (для добавления миллиона экземпляров операции выделения памяти и копирования будут вызваны минимум 20 раз);Признаться, я не уверен какое решение является наиболее корректным в данном случае, ведь в реальной жизни мне сложно представить, когда один контейнер будет держать у себя миллионы ссылок на ранее созданные экземпляры, поэтому я решил лишь половину проблемы, добавив (вполне логичное) ограничение на добавление в _disposeManager лишь тех объектов, которые реализуют IDisposable.
if (instance is IDisposable && !_disposeManager.Contains(instance))
{
_disposeManager.Add(instance);
}Как итог, замер завершился за вполне приемлимое время и выдал следующие результаты:
| Method | Mean | Error | StdDev | Scaled | ScaledSD | Gen 0 | Gen 1 | Allocated |
|---|---|---|---|---|---|---|---|---|
| Direct | 13.77 ns | 0.3559 ns | 0.3655 ns | 1.00 | 0.00 | 0.0178 | - | 56 B |
| LightInject | 36.95 ns | 0.1081 ns | 0.0902 ns | 2.69 | 0.07 | 0.0178 | - | 56 B |
| SimpleInjector | 46.17 ns | 0.2746 ns | 0.2434 ns | 3.35 | 0.09 | 0.0178 | - | 56 B |
| AspNetCore | 71.09 ns | 0.4592 ns | 0.4296 ns | 5.17 | 0.14 | 0.0178 | - | 56 B |
| Autofac | 1,600.67 ns | 14.4742 ns | 12.8310 ns | 116.32 | 3.10 | 0.5741 | - | 1803 B |
| StructureMap | 1,815.87 ns | 18.2271 ns | 16.1578 ns | 131.95 | 3.55 | 0.6294 | - | 1978 B |
| FsContainer | 2,819.01 ns | 6.0161 ns | 5.3331 ns | 204.85 | 5.24 | 0.4845 | - | 1524 B |
| Ninject | 12,812.70 ns | 255.5191 ns | 447.5211 ns | 931.06 | 39.95 | 1.7853 | 0.4425 | 5767 B |
Доволен ими я конечно же не стал и приступил к поиску дальнейших способов оптимизации.
В текущей версии контейнера определение необходимого конструктора и требуемых для него аргументов является неизменным, следовательно, эту информацию можно закешировать и впредь не тратить процессорное время. Результатом этой оптимизации стало добавление ConcurrentDictionary, ключём которого является запрашиваемый тип (Resolve), а значениями- конструктор и аргументы, которые будут использоваться для создания экземпляра непосредственно.
private readonly IDictionary> _ctorCache =
new ConcurrentDictionary>();Судя по проведённым замерам, такая нехитрая операция увеличила производительность более чем на 30%:
| Method | Mean | Error | StdDev | Scaled | ScaledSD | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|---|
| Direct | 13.50 ns | 0.2240 ns | 0.1986 ns | 1.00 | 0.00 | 0.0178 | - | - | 56 B |
| LightInject | 36.94 ns | 0.0999 ns | 0.0886 ns | 2.74 | 0.04 | 0.0178 | - | - | 56 B |
| SimpleInjector | 46.40 ns | 0.3409 ns | 0.3189 ns | 3.44 | 0.05 | 0.0178 | - | - | 56 B |
| AspNetCore | 70.26 ns | 0.4897 ns | 0.4581 ns | 5.21 | 0.08 | 0.0178 | - | - | 56 B |
| Autofac | 1,634.89 ns | 15.3160 ns | 14.3266 ns | 121.14 | 2.01 | 0.5741 | - | - | 1803 B |
| FsContainer | 1,779.12 ns | 18.9507 ns | 17.7265 ns | 131.83 | 2.27 | 0.2441 | - | - | 774 B |
| StructureMap | 1,830.01 ns | 5.4174 ns | 4.8024 ns | 135.60 | 1.97 | 0.6294 | - | - | 1978 B |
| Ninject | 12,558.59 ns | 268.1920 ns | 490.4042 ns | 930.58 | 38.29 | 1.7858 | 0.4423 | 0.0005 | 5662 B |
Проводя замеры, BenchmarkDotNet уведомляет пользователя о том, что та или иная сборка может быть не оптимизирована (собрана в конфигурации Debug). Я долго не мог понять, почему это сообщение высвечивалось в проекте, где контейнер подключался посредством nuget package и, какого же было моё удивление, когда я увидел возможный список параметров для nuget pack:
nuget pack MyProject.csproj -properties Configuration=ReleaseОказывается, всё это время я собирал package в конфигурации Debug, что судя по обновленным результатам замеров замедляло производительность ещё аж на 25%.
| Method | Mean | Error | StdDev | Scaled | ScaledSD | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|---|
| Direct | 13.38 ns | 0.2216 ns | 0.2073 ns | 1.00 | 0.00 | 0.0178 | - | - | 56 B |
| LightInject | 36.85 ns | 0.0577 ns | 0.0511 ns | 2.75 | 0.04 | 0.0178 | - | - | 56 B |
| SimpleInjector | 46.56 ns | 0.5329 ns | 0.4724 ns | 3.48 | 0.06 | 0.0178 | - | - | 56 B |
| AspNetCore | 70.17 ns | 0.1403 ns | 0.1312 ns | 5.25 | 0.08 | 0.0178 | - | - | 56 B |
| FsContainer | 1,271.81 ns | 4.0828 ns | 3.8190 ns | 95.09 | 1.44 | 0.2460 | - | - | 774 B |
| Autofac | 1,648.52 ns | 2.3197 ns | 2.0563 ns | 123.26 | 1.84 | 0.5741 | - | - | 1803 B |
| StructureMap | 1,829.05 ns | 17.8238 ns | 16.6724 ns | 136.75 | 2.37 | 0.6294 | - | - | 1978 B |
| Ninject | 12,520.08 ns | 248.2530 ns | 534.3907 ns | 936.10 | 41.98 | 1.7860 | 0.4423 | 0.0008 | 5662 B |
Ещё одной оптимизацией стало кеширование функции активатора, которая компилируется с использованием Expression:
private readonly IDictionary> _activatorCache =
new ConcurrentDictionary>();Универсальная функция принимает в качестве аргументов ConstructorInfo и массив аргументов ParameterInfo[], а в качестве результата возвращает строго типизированную lambda:
private Func GetActivator(ConstructorInfo ctor, ParameterInfo[] parameters) {
var p = Expression.Parameter(typeof(object[]), "args");
var args = new Expression[parameters.Length];
for (var i = 0; i < parameters.Length; i++)
{
var a = Expression.ArrayAccess(p, Expression.Constant(i));
args[i] = Expression.Convert(a, parameters[i].ParameterType);
}
var b = Expression.New(ctor, args);
var l = Expression.Lambda>(b, p);
return l.Compile();
}Соглашусь, что логичным продолжением этого решения должно стать компилирование всей функции Resolve, а не только Activator, но даже в текущей реализации это привнесло 10% ускорение, тем самым позволив занять уверенное 5-е место:
| Method | Mean | Error | StdDev | Scaled | ScaledSD | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|---|
| Direct | 13.24 ns | 0.0836 ns | 0.0698 ns | 1.00 | 0.00 | 0.0178 | - | - | 56 B |
| LightInject | 37.39 ns | 0.0570 ns | 0.0533 ns | 2.82 | 0.01 | 0.0178 | - | - | 56 B |
| SimpleInjector | 46.22 ns | 0.2327 ns | 0.2063 ns | 3.49 | 0.02 | 0.0178 | - | - | 56 B |
| AspNetCore | 70.53 ns | 0.2885 ns | 0.2698 ns | 5.33 | 0.03 | 0.0178 | - | - | 56 B |
| FsContainer | 1,038.13 ns | 17.1037 ns | 15.9988 ns | 78.41 | 1.23 | 0.2327 | - | - | 734 B |
| Autofac | 1,551.33 ns | 3.6293 ns | 3.2173 ns | 117.17 | 0.64 | 0.5741 | - | - | 1803 B |
| StructureMap | 1,944.35 ns | 1.8665 ns | 1.7459 ns | 146.85 | 0.76 | 0.6294 | - | - | 1978 B |
| Ninject | 13,139.70 ns | 260.8754 ns | 508.8174 ns | 992.43 | 38.35 | 1.7857 | 0.4425 | 0.0004 | 5682 B |
В качестве эксперимента я решил произвести замеры времени создания объектов используя разные конструкции. Сам проект доступен на Github, а результаты вы можете видеть ниже. Для полноты картины не хватает только способа активации посредством генерации IL инструкций максимально приближенных к методу Direct- именно этот способ используют контейнеры из топ 4, что и позволяет им добиваться таких впечатляющих результатов.
| Method | Mean | Error | StdDev | Gen 0 | Allocated |
|---|---|---|---|---|---|
| Direct | 4.031 ns | 0.1588 ns | 0.1890 ns | 0.0076 | 24 B |
| CompiledInvoke | 85.541 ns | 0.5319 ns | 0.4715 ns | 0.0178 | 56 B |
| ConstructorInfoInvoke | 316.088 ns | 1.8337 ns | 1.6256 ns | 0.0277 | 88 B |
| ActivatorCreateInstance | 727.547 ns | 2.9228 ns | 2.5910 ns | 0.1316 | 416 B |
| DynamicInvoke | 974.699 ns | 5.5867 ns | 5.2258 ns | 0.0515 | 168 B |
|
Метки: author fsou11 программирование c# .net ioc dependency injection benchmarkdotnet |
[recovery mode] Техподдержка 3CX отвечает: условия переключения на резервный маршрут (транк) в исходящих правилах |

|
|
[Перевод] Оптимизация расходов на AWS в SaaS-бизнесе |
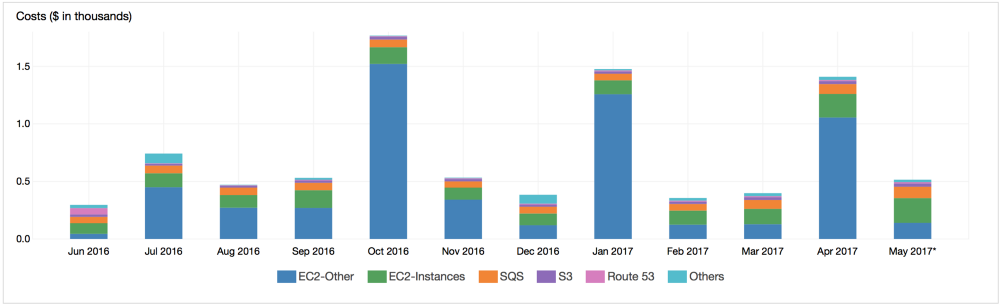



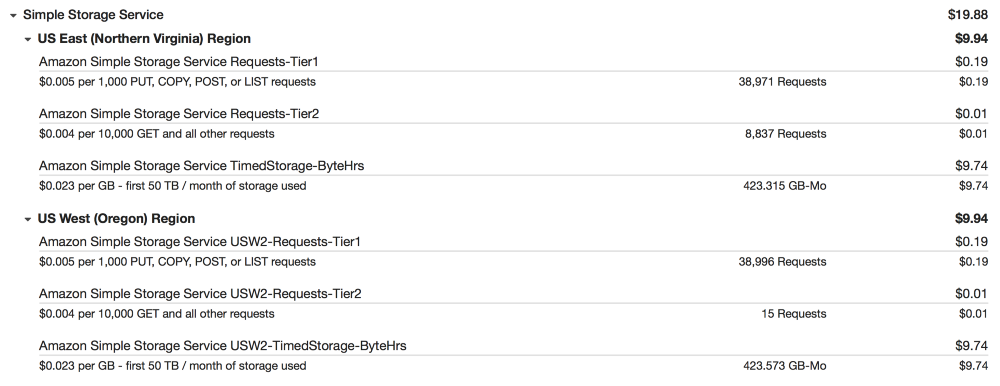
|
Метки: author m1rko хостинг серверное администрирование облачные вычисления aws ec2 s3 sqs |
Symfony 4: Тестируем плагин Symfony Flex |
composer require symfony/flex
composer req frameworkbundle
/etc
/src
/vendor
/web
.env
.env.dist
.gitignore
composer.json
composer.lock
Makefile
composer req symfony/dotenv
composer req symfony/yaml
{
"autoload": {
"psr-4": {
"App\\": "src/"
}
}
}
{
"scripts": {
"auto-scripts": {
"make cache-warmup": "script",
"assets:install --symlink --relative %WEB_DIR%": "symfony-cmd"
}
}
}
"post-install-cmd": [
"@auto-scripts"
],
"post-update-cmd": [
"@auto-scripts"
]
{
"require": {
"symfony/flex": "^1.0",
"symfony/framework-bundle": "^3.3",
"symfony/dotenv": "^3.3",
"symfony/yaml": "^3.3"
},
"autoload": {
"psr-4": {
"App\\": "src/"
}
},
"scripts": {
"auto-scripts": {
"make cache-warmup": "script",
"assets:install --symlink --relative %WEB_DIR%": "symfony-cmd"
},
"post-install-cmd": [
"@auto-scripts"
],
"post-update-cmd": [
"@auto-scripts"
]
}
}
composer dump-autoload
namespace App\Controller;
use Symfony\Component\HttpFoundation\Response;
class TestController
{
public function test()
{
return new Response('It's work!');
}
}
index:
path: /
defaults: {_controller: 'App\Controller\TestController::test'}
make serve
composer req sensio/framework-extra-bundle
composer req annot
controllers:
resource: ../src/Controller/
type: annotation
namespace App\Controller;
use Sensio\Bundle\FrameworkExtraBundle\Configuration\Route;
use Symfony\Component\HttpFoundation\Response;
class TestController
{
/**
* @return Response
* @Route("/test", name="test")
*/
public function test()
{
return new Response('It's work!');
}
}
composer rem annot
composer rem sensio/framework-extra-bundle
composer create-project "symfony/skeleton:^3.3" demo
|
Метки: author shude symfony php symfony 4 |
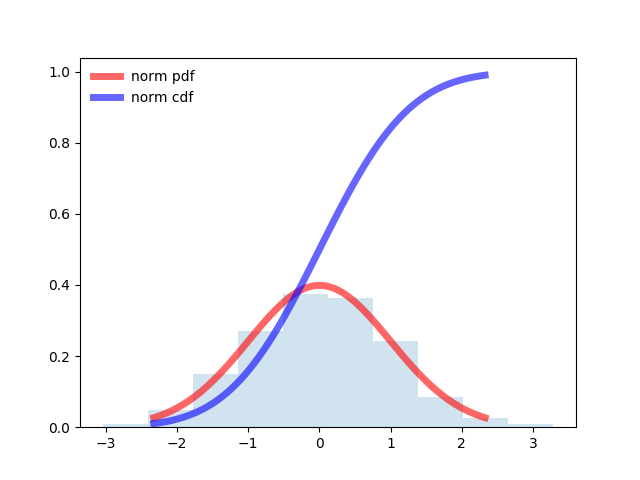
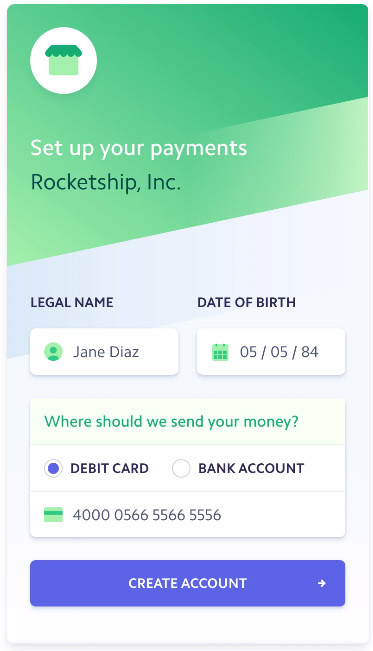
Подбор закона распределения случайной величины по данным статистической выборки средствами Python |
from scipy.stats import norm
import matplotlib.pyplot as plt
import numpy as np
fig, ax = plt.subplots(1, 1)
# Calculate a few first moments:
mean, var, skew, kurt = norm.stats(moments='mvsk')
# Display the probability density function (``pdf``):
x = np.linspace(norm.ppf(0.01), norm.ppf(0.99), 100)
ax.plot(x, norm.pdf(x),
'r-', lw=5, alpha=0.6, label='norm pdf')
ax.plot(x, norm.cdf(x),
'b-', lw=5, alpha=0.6, label='norm cdf')
# Check accuracy of ``cdf`` and ``ppf``:
vals = norm.ppf([0.001, 0.5, 0.999])
np.allclose([0.001, 0.5, 0.999], norm.cdf(vals))
# True
# Generate random numbers:
r = norm.rvs(size=1000)
# And compare the histogram:
ax.hist(r, normed=True, histtype='stepfilled', alpha=0.2)
ax.legend(loc='best', frameon=False)
plt.show()
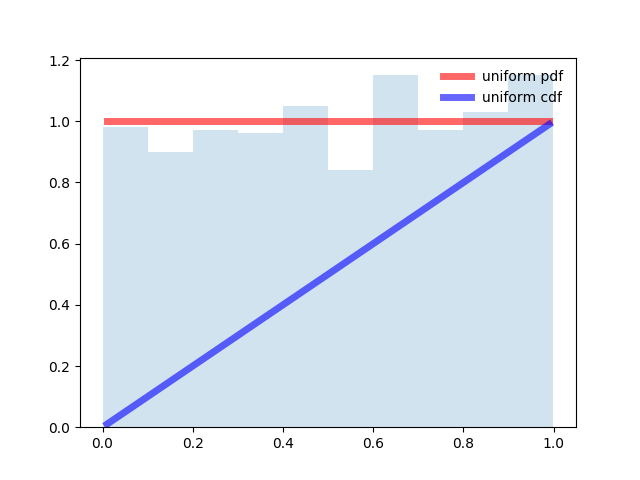
from scipy.stats import uniform
import matplotlib.pyplot as plt
import numpy as np
fig, ax = plt.subplots(1, 1)
# Calculate a few first moments:
#mean, var, skew, kurt = uniform.stats(moments='mvsk')
# Display the probability density function (``pdf``):
x = np.linspace(uniform.ppf(0.01), uniform.ppf(0.99), 100)
ax.plot(x, uniform.pdf(x),'r-', lw=5, alpha=0.6, label='uniform pdf')
ax.plot(x, uniform.cdf(x),'b-', lw=5, alpha=0.6, label='uniform cdf')
# Check accuracy of ``cdf`` and ``ppf``:
vals = uniform.ppf([0.001, 0.5, 0.999])
np.allclose([0.001, 0.5, 0.999], uniform.cdf(vals))
# True
# Generate random numbers:
r = uniform.rvs(size=1000)
# And compare the histogram:
ax.hist(r, normed=True, histtype='stepfilled', alpha=0.2)
ax.legend(loc='best', frameon=False)
plt.show()
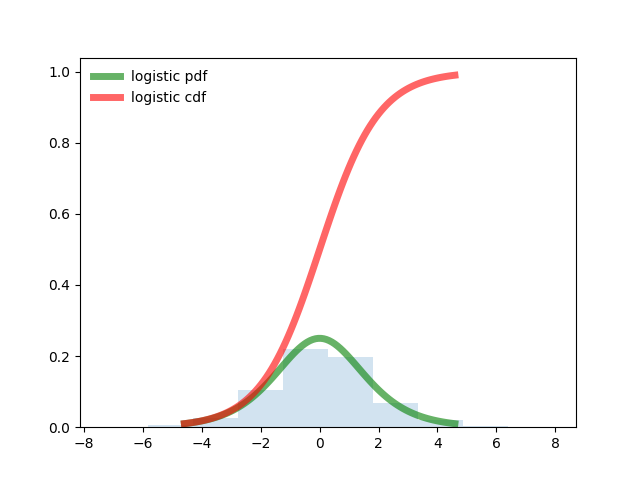
from scipy.stats import logistic
import matplotlib.pyplot as plt
import numpy as np
fig, ax = plt.subplots(1, 1)
# Calculate a few first moments:
mean, var, skew, kurt = logistic.stats(moments='mvsk')
# Display the probability density function (``pdf``):
x = np.linspace(logistic.ppf(0.01),
logistic.ppf(0.99), 100)
ax.plot(x, logistic.pdf(x),
'g-', lw=5, alpha=0.6, label='logistic pdf')
ax.plot(x, logistic.cdf(x),
'r-', lw=5, alpha=0.6, label='logistic cdf')
vals = logistic.ppf([0.001, 0.5, 0.999])
np.allclose([0.001, 0.5, 0.999], logistic.cdf(vals))
# True
# Generate random numbers:
r = logistic.rvs(size=1000)
# And compare the histogram:
ax.hist(r, normed=True, histtype='stepfilled', alpha=0.2)
ax.legend(loc='best', frameon=False)
plt.show()
from scipy.stats import logistic,uniform,norm,pearsonr
from numpy import sqrt,pi,e
import numpy as np
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1)
n=1000# объём выборки
x=uniform.rvs(loc=0, scale=150, size=n)#равномерное распределение
x.sort()#сортировка
print("Математическое ожидание по выборке(общее для сравниваемых распределений) -%s"%str(round(np.mean(x),3)))
print("СКО по выборке(общее для сравниваемых распределений) -%s"%str(round(np.std(x),3)))
print("Энтропийное значение погрешности-%s"%str(round(np.std(x)*sqrt(np.pi*np.e*0.5),3)))
pu=uniform.cdf(x/(np.max(x)))#равномерное интегральное распределение
ax.plot(x,pu, lw=5, alpha=0.6, label='uniform cdf')
pn=norm.cdf(x, np.mean(x), np.std(x))#нормальное интегральное распределение
ax.plot(x,pn, lw=5, alpha=0.6, label='norm cdf')
pl=logistic.cdf(x, np.mean(x), np.std(x))# логистическое интегральное распределение
ax.plot(x,pl, lw=5, alpha=0.6, label='logistic cdf')
p=np.arange(0,n,1)/n
ax.plot(x,p, lw=5, alpha=0.6, label='test')
ax.legend(loc='best', frameon=False)
plt.show()
print("Корреляция между нормальным распределением и тестовым - %s"%str(round(pearsonr(pn,p)[0],3)))
print("Корреляция между логистическим распределением и тестовым - %s"%str(round(pearsonr(pl,p)[0],3)))
print("Корреляция между равномерным распределением и тестовым - %s"%str(round(pearsonr(pu,p)[0],3)))
print('Взвешенная сумма квадратов отклонения нормального распределения от теста -%i'%round(n*sum(((pn-p)/pn)**2)))
print('Взвешенная сумма квадратов отклонения логистического распределения от теста -%i'%round(n*sum(((pl-p)/pl)**2)))
print('Взвешенная сумма квадратов отклонения равномерного распределения от теста -%i'%round(n*sum(((pu-p)/pu)**2))) 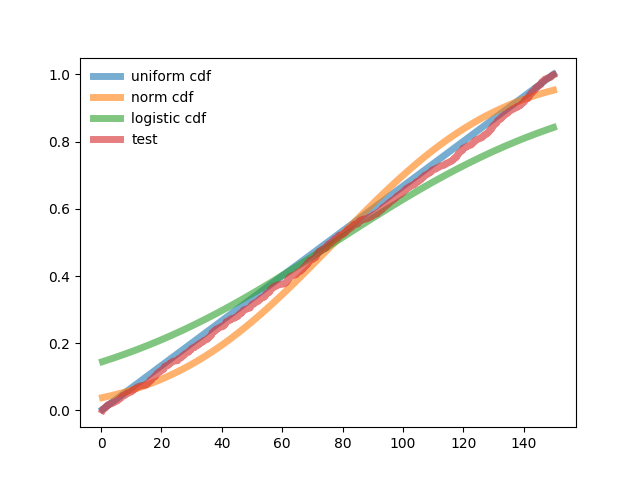
|
Метки: author Scorobey разработка под windows математика python закон распределения вероятности энтропийная погрешность измерения |
Ограничивать ли пользователей по ресурсам? |





|
Метки: author AntonVirtual системное администрирование облачные вычисления cloud облако |
[Из песочницы] Автоматное программирование – новая веха или миф? |
Основное преимущество автоматного подхода проявляется на этапе проектирования ПО. Автоматный подход позволяет грамотно и наглядно проектировать программы, которые по окончании проектирования могут быть реализованы совсем не как автоматы (о способах реализации автоматов мы поговорим в следующей части), а как классические структурные конструкции.
Наверное, существует не так много программистов, не слышавших о цифровых автоматах, но чтобы не отсекать аудиторию, в двух словах опишем суть. Автоматом называется цифровое устройство, построенное по принципу:
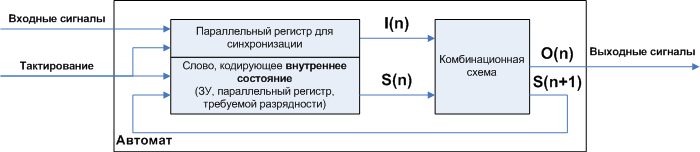
Если вы не были знакомы с автоматами, при всей ясности объяснения польза от таких устройств не очевидна, но существует математическая абстракция, хорошо иллюстрирующая суть. Работу автомата можно наглядно описать при помощи диаграммы состояний и переходов. Ниже изображена диаграмма, описывающая работу устройства, управляющего лифтом. Это очень упрощённая диаграмма, не учитывающая процессы открытия/закрытия дверей, разгона/остановки, но она даёт наглядное представление о том, как при помощи автоматов моделируется работа объектов реального мира. Над стрелками пишется условие, при котором произойдёт переход, в овале пишется
название_состояния/что_будет_на_выходе_пока_автомат_в_этом_состоянии.

Все более-менее сложные цифровые схемы проектируются именно как цифровые автоматы. Почему? Незаменимости автоматного подхода при проектировании цифровых схем способствуют три основных преимущества автоматного подхода:
В математической теории автоматов декомпозиция это создание из автомата, работающего по сложной диаграмме состояний и переходов, нескольких простых и понятных автоматов, которые имеют параллельное и/или последовательное соединение и дают в сумме исходный автомат. Это математическая и, следовательно, точная процедура.
Мы рассматриваем практическое автоматостроение, поэтому в первой части под декомпозицией будем понимать не математическую декомпозицию, а разбиение автомата в соответствии со здравым смыслом. Во второй части будут даны примеры математической декомпозиции.
Автоматы обычно разбиваются на операционные и на управляющие. Смысл очевиден из названия — операционный автомат это «руки», управляющий – «голова». Причём разбиение может быть многоуровневым: операционный автомат в свою очередь может быть разбит на исполнительную и руководящую части. Т.е. рука-манипулятор, может иметь свой «минимозг», транслирующий общие команды («взять предмет») в набор детальных команд, управляющих каждым «пальцем». Ещё более показательным примером является процессор, имеющий конвейеры, регистры, ALU и FPU – операционные автоматы и микропрограмму – управляющий автомат.
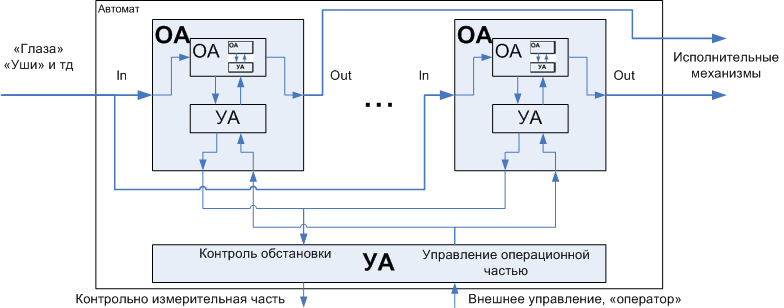
Принцип разбиения крупной задачи на мелкие подзадачи вообще-то и так широко распространён в практике программирования, это разбиение задачи на подпрограммы. Однако, автоматная интерпретация программ, т.е. представление любого программного обьекта в виде автомата, у которого есть операционная часть и управляющая часть, позволяет уйти от механистического и наивного (в хорошем смысле) дробления исходного кода и даёт набор практических соображений как именно это делать, которые заметно повышают качество программы уже на стадии её проектирования. Рассмотрим пример, который позволит вести разговор о программатах более предметно.
Пусть у нас есть ч/б графический дисплей. Его видеопамять имеет стандартную побайтную организацию, в которой каждый бит представляет некую точку. Предположим, что нам нужно осуществлять вывод текста разными, не моноширинными шрифтами.


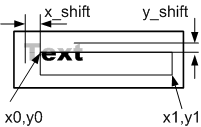
Все символы в шрифте одной высоты, но шрифт может быть поменян «на лету», в процессе вывода одной и той же строки. Аналогично могут быть поменяны атрибуты – жирный, курсив, подчёркивание. Для управления параметрами используются esc-последовательности, к которым относится управляющий символ '\n', перевод строки, т.е. текст одной строки может быть выведен на несколько строк на дисплее. Например текст:
"Text 1 \033[7m Text 2 \033[27m \033[1m Text 3 \033[21m \n Text 42"Текст выводится в область, ограниченную прямоугольником (рис.4, в) и может иметь смещение. Координаты области вывода задаются не в знакоместах, а в пикселах, координаты могут быть отрицательными, что означает выход за пределы области вывода. Текст, выходящий за границы области вывода, отсекается.
Нам нужно создать функцию, которая всё это реализует, с прототипом
void Out_text(int x0, int y0, int x1, int y1, int x_shift, int y_shift, char * Text);Составление автомата (то есть модели реализуемого процесса) выполняется от общего к частному, сверху вниз, но детальная проработка модели и её программная реализация наоборот происходят снизу вверх. Это продиктовано тем, что обычно самый нижний уровень непосредственно завязан на исполнительные механизмы, что ставит нас в определённые рамки и ограничивает возможность «манёвра», в то время как более высокие уровни являются в этом отношении более гибкими, и рамки для них вытекают из реализации нижележащих автоматов.
Процесс создания программной реализации итерационный, сначала реализуется самый нижний уровень модели (разработанной сверху вниз), затем разрабатывается следующий уровень, параллельно корректируется нижележащий, после чего разработка переходит к более высокому уровню, с корректировкой нижележащих по необходимости. Грамотное проектирование требует минимальной переработки нижележащих уровней, ограничиваясь их дополнением. Окончательная реализация автоматов в виде программного кода осуществляется после составления всех автоматов, но тем не менее наброски алгоритмов выполняются параллельно проектированию автоматов. Все нижележащие выкладки были выполнены мной не после составления программы, как иллюстрация, а до создания программного кода, как важный этап проектирования. Итак, приступим к разработке.
Как следует из условия задачи, исходная последовательность символов в общем случае выглядит как: Текст1 упр1 Текст2 упр2 Текст3 упр3 Текст4 упр4 Текст5 \0
где упрN управляющие esc-последовательности, символы перевода и окончания строки которые отделяют друг от друга текстовые блоки. Разбивка текста на блоки удобна тем, что позволяет в рамках одного блока использовать максимальное количество одинаковых настроек (например высота текста и координаты начала строки).
Разработка пары ОА-УА всегда начинается с разработки ОА. ОА строится на основе наших попыток смоделировать все аспекты процесса, которым будет управлять наш автомат. В случае с дисплеем мы имеем пару самостоятельных аспектов: разбиение текста на разделённые управляющими последовательностями блоки и сборку графических данных в буфере, который будет сброшен в видеопамять. Следовательно, автомат будет состоять из двух подавтоматов, изображённых на рис. 5.
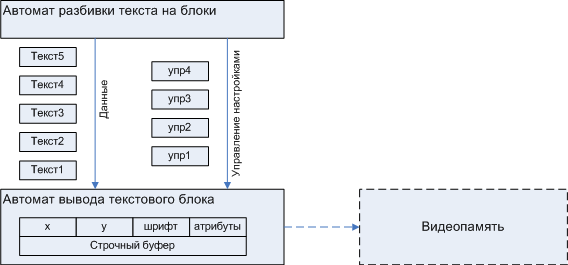
Операционная часть автомата разбивки на блоки состоит из входного потока байтов, который разбивается на блоки. Чтобы избежать ненужного копирования, текстовые блоки это части исходной строки, которые передаются в Автомат вывода текстового блока в виде двух указателей Text_begin и Text_end.

Автомат разбивки управляет настройками Автомата вывода текстового блока через непосредственный доступ к соответствующим переменным автомата.
Автомат разбивки текста на блоки — очень простой ОА, можно сказать, что и нет никакого автомата, всего пара указателей плюс набор меняемых переменных, но мы рассматриваем общий принцип, принцип который пригодится, при разработке второго автомата — Автомата вывода текстового блока
После того как разработан ОА несложно составить требуемый ему управляющий автомат
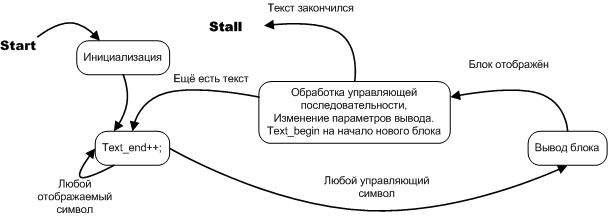
Управляющий автомат в данном случае хорошо описывается как в терминах алгоритмической блок-схемы, так и терминах диаграммы состояний, но поскольку речь идёт об автомате, мы используем диаграмму состояний. Диаграмма состояний не только подчёркивает «автоматность» задачи, она полезна тем, что это альтернативный, более удобный вариант записи обычных программных алгоритмов. Если всмотреться в суть вопроса, диаграмма состояний это естественная форма записи программного процесса в широком смысле, в то время как алгоритмическая блок-схема это искусственная конструкция, которая уже содержит в себе особенности реализации, которые чаще всего очевидны и не требуют того, чтобы их отдельно записывали. Более того, именно эти самые особенности реализации (когда они второстепенные детали), бывает, маскируют основной замысел, выпячивая себя на первый план наряду с действительно важными деталями. В следующей части будет приведён прекрасный пример, показывающий разницу между алгоритмом заданным блок-схемой и алгоритмом заданным диаграммой состояний. Диаграмма состояний элементарно преобразуется в программный код.
Автомат вывода текстового блока
Как было показано выше, управляющие последовательности могут в том числе задавать координаты вывода очередного текстового блока. Координаты текущего текстового блока задаются переменными x, y.

В примере используется шрифт размером 5х7, но описываемый модуль поддерживает работу с символами любого размера. В результате может потребоваться крупный буфер сборки строки, что для embedderов часто является немаловажным фактором. Для минимизации буфера вместо набора параллельных регистров может использоваться один, осуществляющий «вертикальную развёртку», речь идёт о вертикальной развёртке всего текстового блока, т.е. выводится строка высотой один пиксел и шириной во весь текстовый блок.

При корректной реализации быстродействие такого варианта алгоритма почти не уступает случаю с параллельными регистрами, хотя всё же требует накладных расходов: 3 байта на символ, но позволяет вообще отказаться от строчного буфера, что для дисплея шириной 256 пикселов и символов высотой 24 пиксела даёт экономию
Поскольку разработка пары ОА-УА всегда начинается с разработки ОА, а разработка ОА начинается с самого нижнего уровня, составим ОА для автомата вывода текста.
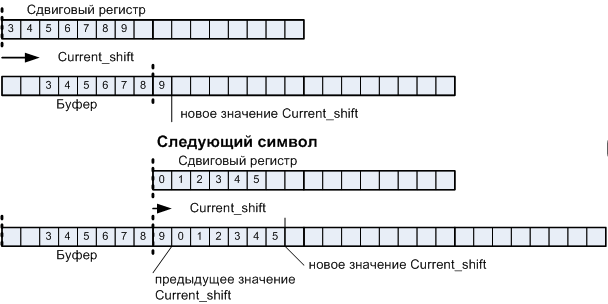
Операционный автомат вывода символов на экран состоит из буфера в котором собирается текстовая строка. Поскольку ширина символа не равняется ширине байта, каждый новый символ будет иметь некоторый сдвиг. Для осуществления сдвига применяется сдвиговый регистр. Если строчный буфер — набор параллельных регистров, соответствующих отдельным строкам, то сдвиговый регистр требуется один. Как видно из иллюстрации, у нас есть два сквозных счётчика Current_byte и Current_shift, которые, увеличиваясь от символа к символу, определяют величину сдвига и место, куда помещать сдвинутый символ.


Составляя операционный автомат обязательно нужно учесть все описанные пункты, поэтому обратимся к следующей абстракции (и это часть автоматного подхода).
Все символы строки разделены на категории:





Как было показано выше, шлифовка программной реализации происходит на последнем этапе, тем не менее, для ясности я буду приводить исходники в их окончательном виде, несмотря на то, что идея исключения двойного сдвига возникла уже в процессе оптимизации, после того, как весь модуль был отлажен, причём для этого пришлось лишь слегка изменить функцию Out_symbol. То же касается использования переменных Start_line и End_line, которые появятся лишь при разработке вышележащей функции Out_text, но при этом их добавление лишь немного повлияло на вид функции Out_symbol.
Полная версия исходника находится по ссылке, в файле Display.h/Display.cpp. Там же находится откомпилированный пример(Project1.exe). Сам проект под Builder 6
class tShift_register Symbol_buffer;
vector< tShift_register > Line_buffer;
// Значения всех этих переменных задаются на вышележащем уровне
int Start_line, End_line;
int Left_shift, Current_shift, Current_byte;
// Указатель на массив шириной Width байтов - битовое поле выводимого символа
u1x * Symbol_array;
int Width;
int bytes_Width;
//Может на байт превосходить bytes_Width, в зависимости от величины сдвига
int bytes_Width_after_shift;
inline void Out_symbol ()
{
for(int Current_line = Start_line; Current_line <= End_line; Current_line++)
{
Symbol_buffer.Clear();
////////////////////////
// Для типов 2 и 3 используется один метод Out_symbol, это фактически выбор типа символа
if(Left_shift)// тип 2
{
// Если сдвиг больше чем 8 бит имеет смысл заменить его сдвигом на целый байт
int Start_symbol_byte = Left_shift >> 3;
// void tShift_register::Load(int Start_index_in_destination, u1x * Source, int Width);
Symbol_buffer.Load(0,Symbol_array + bytes_Width * Current_line + Start_symbol_byte,\
bytes_Width - Start_symbol_byte);
// рис.15
// void tShift_register::Shift(int Start, int End, int Amount);
Symbol_buffer.Shift (0, bytes_Width_after_shift, Current_shift - (Left_shift & 7) );
Symbol_buffer[0] &= Masks_array__left_for_line_buffer[ Current_shift ];
// рис.16
Line_buffer[Current_line].Or(Current_byte, &Symbol_buffer[0], bytes_Width_after_shift );
}
else // тип 3
{
Symbol_buffer.Load(0,Symbol_array + bytes_Width * Current_line, bytes_Width);
// рис.14
Symbol_buffer.Shift(0, bytes_Width_after_shift, Current_shift);
// рис.16
Line_buffer[Current_line].Or(Current_byte, &Symbol_buffer[0], bytes_Width_after_shift );
}
}// for(int Current_line = Start_line, Current_line <= End_line, Current_line++)
}// inline void Out_symbol ()
Управляющий автомат вывода текстового блока реализуется следующим кодом:
class tShift_register Symbol_buffer;
vector< tShift_register > Line_buffer;
tVideomemory Videomemory;
// Значения этих переменных задаются на вышележащем уровне
int Start_line, End_line;
// НАЧАЛЬНЫЕ значения этих переменных задаются на вышележащем уровне
int Left_shift, Current_shift, Current_byte;
// Значения этих переменных задаются на вышележащем уровне
u1x * Text;
u1x * Text_end;
tFont * Current_font;
// Эти переменные полностью контролируются функцией Out_text_block
// Указатель на массив шириной Width байтов - битовое поле выводимого символа
u1x * Symbol_array;
int Width;
int bytes_Width;
//Может на байт превосходить bytes_Width, в зависимости от величины сдвига
int bytes_Width_after_shift;
// Значения этих переменных задаются на вышележащем уровне
// Полная длина текста в пикселах
int Line_width;
////////////////////////////////////////////////////////////////////////////////
////////////////////////////////////////////////////////////////////////////////
////////////////////////////////////////////////////////////////////////////////
inline void Out_text_block ()
{
Clear_line_buffer();
////////////////////////////////////////
// Далее всё как показано в диаграмме состояний
Type_1:
// Пока не конец строки
while(Text < Text_end)
{
Width = Current_font->Width_for(*Text);
// Прокручиваем символы пока не попадём в область отображения
if(Left_shift >= Width)
{
Left_shift -= Width;
Text++;
}
else
goto Type_2;
}// while(Text < Text_end)
// Конец строки
return;
////////////////////////////////////////
Type_2:
// Инициализируем
Current_byte = Current_shift >> 3;
Current_shift = Current_shift & 7;
Symbol_array = Current_font->Image_for(*Text);
bytes_Width = (Width + 7) >> 3;
bytes_Width_after_shift = (Width + Current_shift + 7) >> 3;
Line_width -= (Width - Left_shift);
// Достигли границы?
if(Line_width <= 0)
{
Width -= Left_shift;
goto Type_4;
}
Out_symbol();
// Компенсируем Left_shift
Width -= Left_shift;
Left_shift = 0;
// Любой следующий символ
Text++;
////////////////////////////////////////
Type_3:
// Конец строки?
while(Text < Text_end)
{
//Сдвигаем Current_byte, Current_shift на величину уже выведенного символа.
Current_shift += Width;
Current_byte += (Current_shift >> 3);
Current_shift = Current_shift & 0x7;
// Прокручиваем на следующий символ
Width = Current_font->Width_for(*Text);
Symbol_array = Current_font->Image_for(*Text);
bytes_Width = (Width + 7) >> 3;
bytes_Width_after_shift = (Width + Current_shift + 7) >> 3;
Line_width -= Width;
// Достигли границы?
if(Line_width <= 0)
goto Type_4;
Out_symbol();
Text++;
}// while(*Text < Text_end)
Current_shift += Width;
Current_byte += (Current_shift >> 3);
Current_shift = Current_shift & 0x7;
// Конец строки
goto Finalize;
////////////////////////////////////////
// фактически типа 4 нет это символы тип 2' и 3'
Type_4:
Out_symbol();
Current_shift += (Width + Line_width);
Current_byte += (Current_shift >> 3);
Current_shift = Current_shift & 0x7;
for(int Current_line = Start_line; Current_line <= End_line; Current_line++)
{
Line_buffer[Current_line][Current_byte] &= Masks_array__right_for_line_buffer[Current_shift];
}
Finalize:
Out_line_buffer_in_videomemory();
return;
}// inline void Out_text_block ()

Процесс вывода очевиден, но не будут излишними пояснения:

// Стартовая инициализация
// Проверяем корректность параметров окна
////////////////////////////////////////////////////////////////////////////////////
if(x1 < x0)
{
int temp = x0;
x0 = x1;
x1 = temp;
}
if(y1 < y0)
{
int temp = y0;
y0 = y1;
y1 = temp;
}
if(x0 < 0)
{
x_shift += x0;
x0 = 0;
}
if(y0 < 0)
{
y_shift += y0;
y0 = 0;
}
if(x1 > x_max)
{
x1 = x_max;
}
if(y1 > y_max)
{
y1 = y_max;
}
// для каждого блока
inline bool Init_text_block()
{
// Компенсируем сдвиг
////////////////////////////////////////////////////////////////////////////////////
x += ( x0 + x_shift);
y += ( y0 + y_shift);
// по горизонтали
////////////////////////////////////////////////////////////////////////////////////
if (x < x0)
{
Left_shift = x - x0;
x = x0;
}
else
{
Left_shift = 0;
}
if(x >= x1)
return false;
x_byte = x >> 3;
Start_shift = Current_shift = x & 7;
Current_byte = 0;
Line_width = x1-x;
// по вертикали
////////////////////////////////////////////////////////////////////////////////////
if (y < y0)
{
Start_line = y0 - y;
y = y0;
}
else
Start_line = 0;
if(Start_line >= Current_font->Height())
return false;
if( (Current_font->Height() - Start_line) < ( y1 - y) )
End_line = Current_font->Height() - 1;
else
End_line = Start_line + (y1 - y) - 1;
return true;
}
///////////////////////////////////////////////////////////////////////////////////
///////////////////////////////////////////////////////////////////////////////////
///////////////////////////////////////////////////////////////////////////////////
///////////////////////////////////////////////////////////////////////////////////
///////////////////////////////////////////////////////////////////////////////////
///////////////////////////////////////////////////////////////////////////////////
// Описана выше
void Out_text_block ();
inline void Control_processing ();
void Out_text (int arg_x0, int arg_y0,
int arg_x1, int arg_y1,
int arg_x_shift, int arg_y_shift,
unsigned char * argText)
{
// Инициализация
// ...
while(*Text_end)
{
//////////////////////////////////////
state__Inside_text_block:
while(1)
{
switch(*Text_end)
{
// Пока только два кода в следующей части рассмотрим этот вопрос подробнее
case '\0':
case '\n':
goto state__Out_text_block;
}
Text_end++;
}
//////////////////////////////////////
state__Out_text_block:
if( (Text_begin != Text_end) && Init_text_block())
Out_text_block();
Text_begin = Text_end;
//////////////////////////////////////
state__Control_processing:
if(*Text_end == 0)
return;
// Стоит выделить в отдельную функцию
Control_processing();
}//while(*Text_end)
}//void Out_text (int arg_x0, int arg_y0,|
Метки: author Dr_Dash совершенный код программирование микроконтроллеров автоматное программирование диаграмма состояний программные структуры |
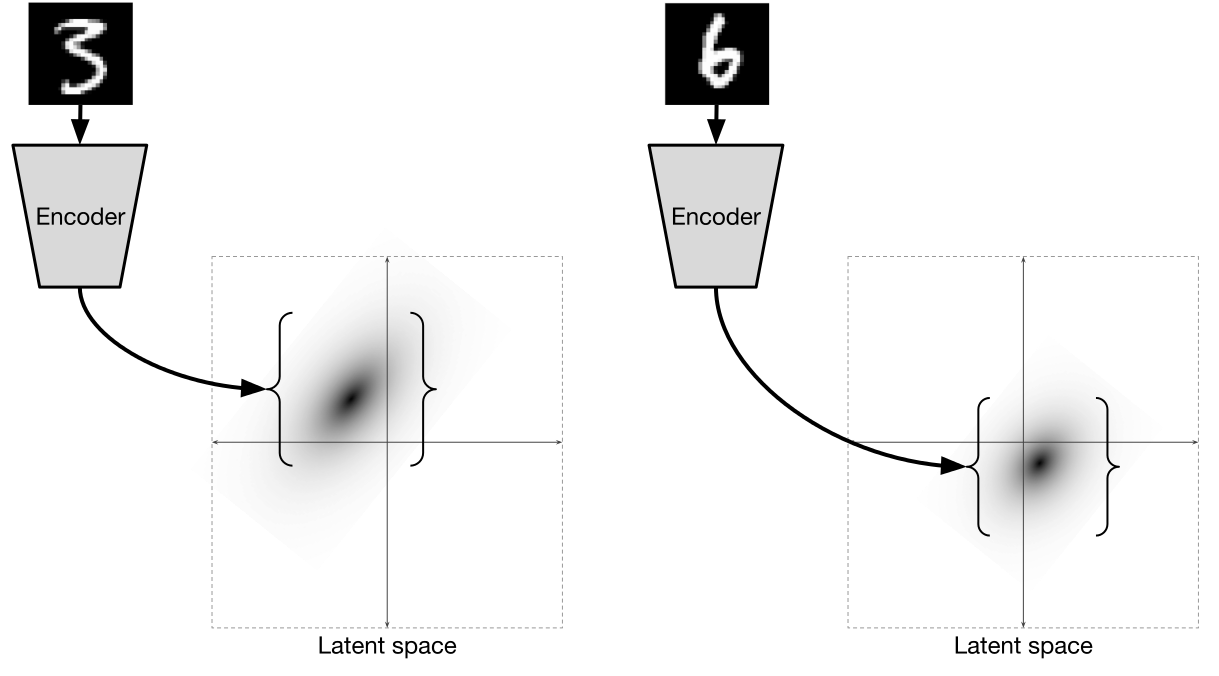
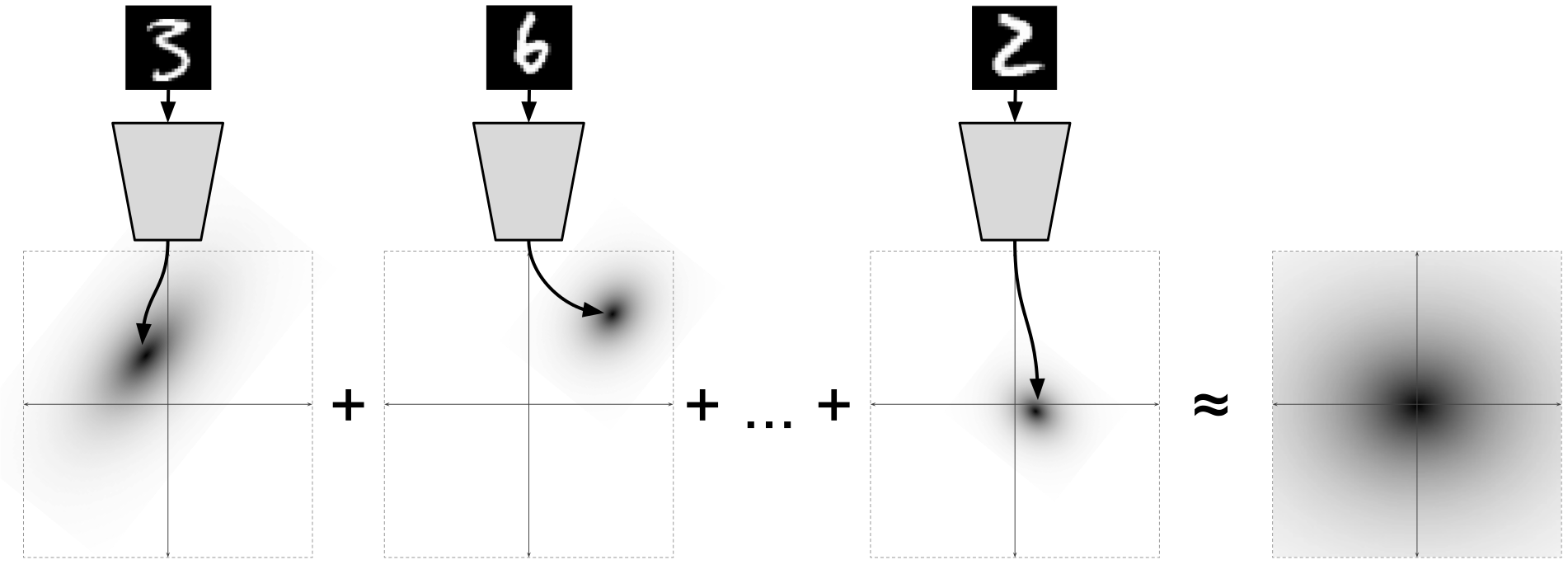
Автоэнкодеры в Keras, Часть 3: Вариационные автоэнкодеры (VAE) |

import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
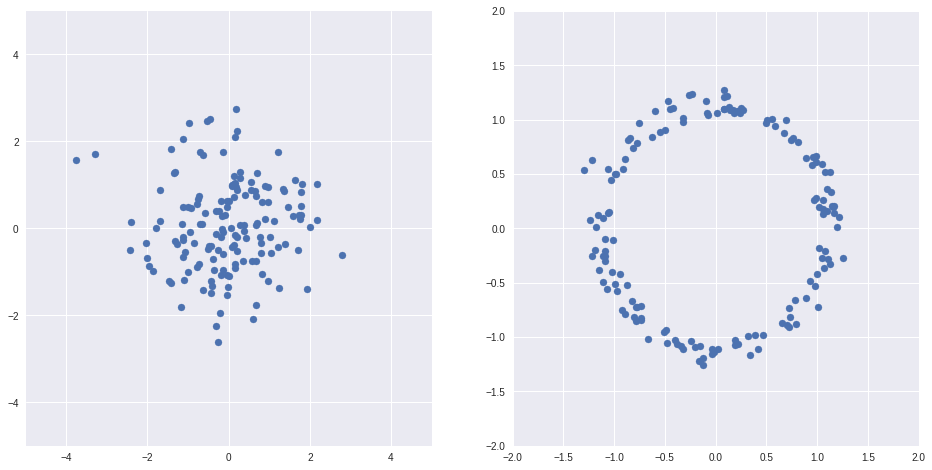
Z = np.random.randn(150, 2)
X = Z/(np.sqrt(np.sum(Z*Z, axis=1))[:, None]) + Z/10
fig, axs = plt.subplots(1, 2, sharex=False, figsize=(16,8))
ax = axs[0]
ax.scatter(Z[:,0], Z[:,1])
ax.grid(True)
ax.set_xlim(-5, 5)
ax.set_ylim(-5, 5)
ax = axs[1]
ax.scatter(X[:,0], X[:,1])
ax.grid(True)
ax.set_xlim(-2, 2)
ax.set_ylim(-2, 2)

import sys
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test .astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
batch_size = 500
latent_dim = 2
dropout_rate = 0.3
start_lr = 0.0001
from keras.layers import Input, Dense
from keras.layers import BatchNormalization, Dropout, Flatten, Reshape, Lambda
from keras.models import Model
from keras.objectives import binary_crossentropy
from keras.layers.advanced_activations import LeakyReLU
from keras import backend as K
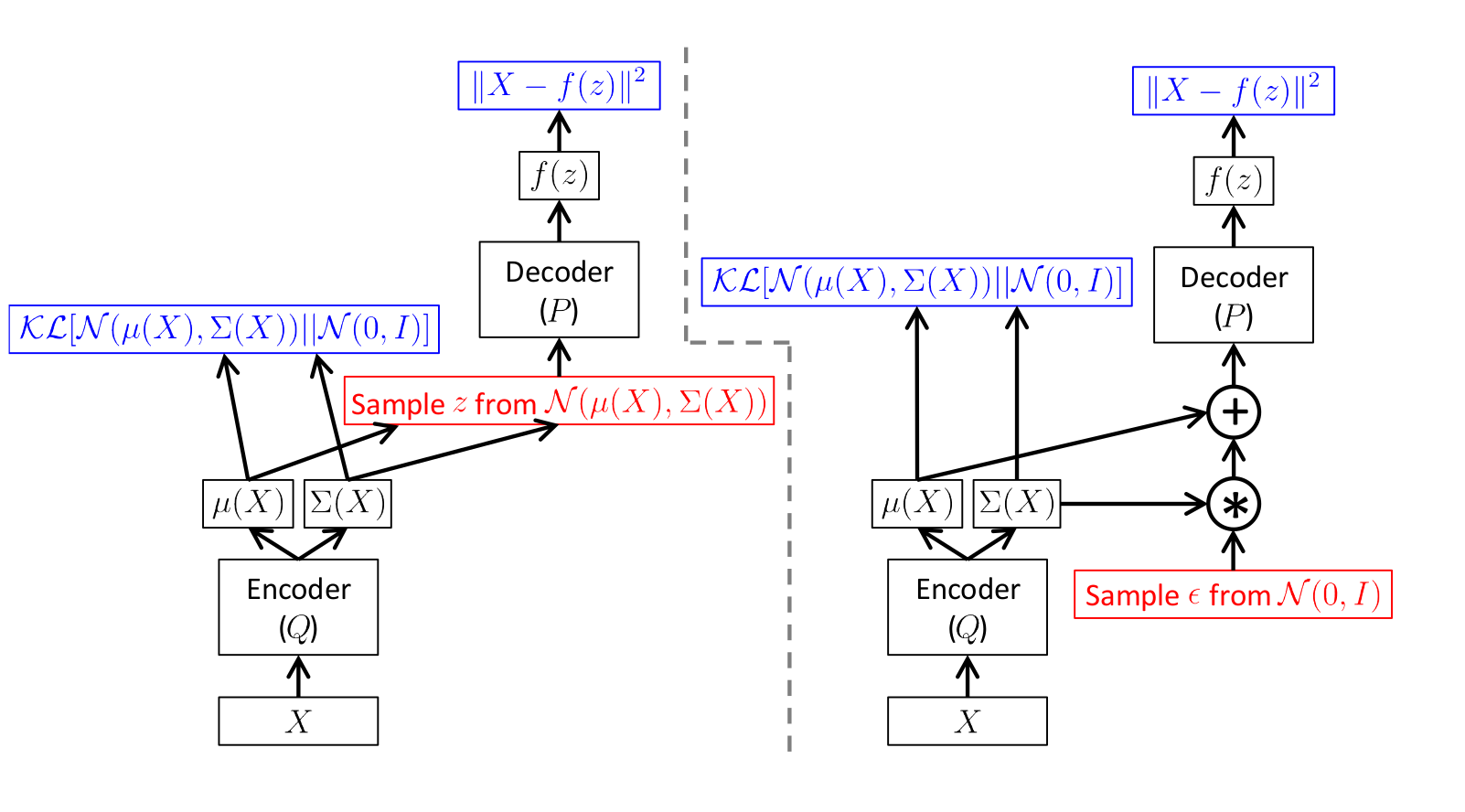
def create_vae():
models = {}
# Добавим Dropout и BatchNormalization
def apply_bn_and_dropout(x):
return Dropout(dropout_rate)(BatchNormalization()(x))
# Энкодер
input_img = Input(batch_shape=(batch_size, 28, 28, 1))
x = Flatten()(input_img)
x = Dense(256, activation='relu')(x)
x = apply_bn_and_dropout(x)
x = Dense(128, activation='relu')(x)
x = apply_bn_and_dropout(x)
# Предсказываем параметры распределений
# Вместо того, чтобы предсказывать стандартное отклонение, предсказываем логарифм вариации
z_mean = Dense(latent_dim)(x)
z_log_var = Dense(latent_dim)(x)
# Сэмплирование из Q с трюком репараметризации
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(batch_size, latent_dim), mean=0., stddev=1.0)
return z_mean + K.exp(z_log_var / 2) * epsilon
l = Lambda(sampling, output_shape=(latent_dim,))([z_mean, z_log_var])
models["encoder"] = Model(input_img, l, 'Encoder')
models["z_meaner"] = Model(input_img, z_mean, 'Enc_z_mean')
models["z_lvarer"] = Model(input_img, z_log_var, 'Enc_z_log_var')
# Декодер
z = Input(shape=(latent_dim, ))
x = Dense(128)(z)
x = LeakyReLU()(x)
x = apply_bn_and_dropout(x)
x = Dense(256)(x)
x = LeakyReLU()(x)
x = apply_bn_and_dropout(x)
x = Dense(28*28, activation='sigmoid')(x)
decoded = Reshape((28, 28, 1))(x)
models["decoder"] = Model(z, decoded, name='Decoder')
models["vae"] = Model(input_img, models["decoder"](models["encoder"](input_img)), name="VAE")
def vae_loss(x, decoded):
x = K.reshape(x, shape=(batch_size, 28*28))
decoded = K.reshape(decoded, shape=(batch_size, 28*28))
xent_loss = 28*28*binary_crossentropy(x, decoded)
kl_loss = -0.5 * K.sum(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1)
return (xent_loss + kl_loss)/2/28/28
return models, vae_loss
models, vae_loss = create_vae()
vae = models["vae"]
from keras.optimizers import Adam, RMSprop
vae.compile(optimizer=Adam(start_lr), loss=vae_loss)
digit_size = 28
def plot_digits(*args, invert_colors=False):
args = [x.squeeze() for x in args]
n = min([x.shape[0] for x in args])
figure = np.zeros((digit_size * len(args), digit_size * n))
for i in range(n):
for j in range(len(args)):
figure[j * digit_size: (j + 1) * digit_size,
i * digit_size: (i + 1) * digit_size] = args[j][i].squeeze()
if invert_colors:
figure = 1-figure
plt.figure(figsize=(2*n, 2*len(args)))
plt.imshow(figure, cmap='Greys_r')
plt.grid(False)
ax = plt.gca()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
n = 15 # Картинка с 15x15 цифр
digit_size = 28
from scipy.stats import norm
# Так как сэмплируем из N(0, I), то сетку узлов, в которых генерируем цифры берем из обратной функции распределения
grid_x = norm.ppf(np.linspace(0.05, 0.95, n))
grid_y = norm.ppf(np.linspace(0.05, 0.95, n))
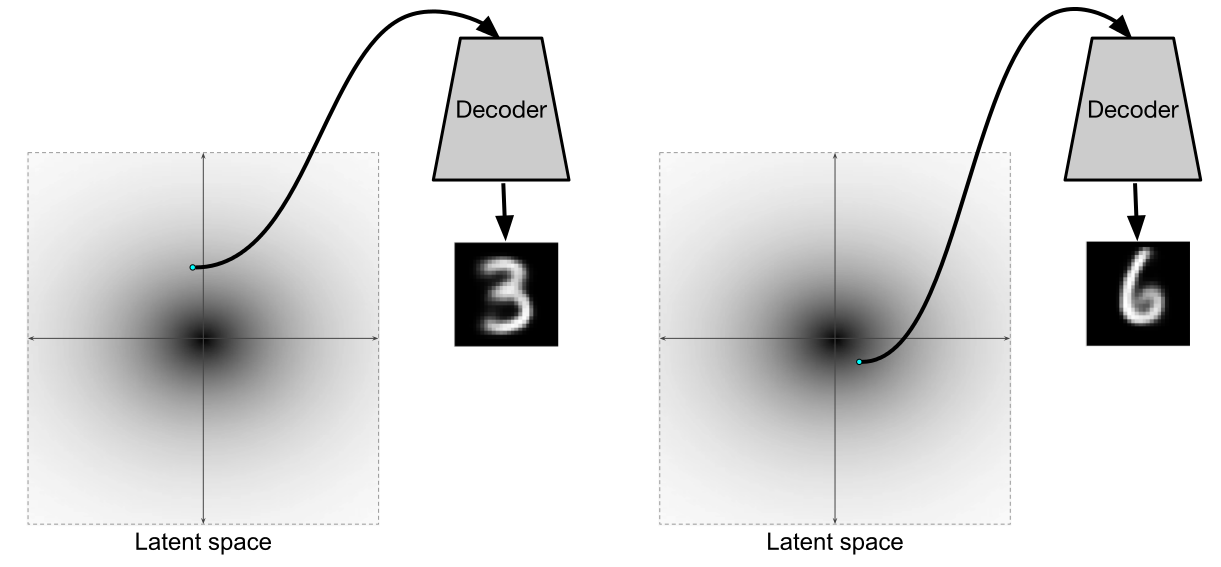
def draw_manifold(generator, show=True):
# Рисование цифр из многообразия
figure = np.zeros((digit_size * n, digit_size * n))
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z_sample = np.zeros((1, latent_dim))
z_sample[:, :2] = np.array([[xi, yi]])
x_decoded = generator.predict(z_sample)
digit = x_decoded[0].squeeze()
figure[i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit
if show:
# Визуализация
plt.figure(figsize=(15, 15))
plt.imshow(figure, cmap='Greys_r')
plt.grid(None)
ax = plt.gca()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
return figure
from IPython.display import clear_output
from keras.callbacks import LambdaCallback, ReduceLROnPlateau, TensorBoard
# Массивы, в которые будем сохранять результаты, для последующей визуализации
figs = []
latent_distrs = []
epochs = []
# Эпохи, в которые будем сохранять
save_epochs = set(list((np.arange(0, 59)**1.701).astype(np.int)) + list(range(10)))
# Отслеживать будем на вот этих цифрах
imgs = x_test[:batch_size]
n_compare = 10
# Модели
generator = models["decoder"]
encoder_mean = models["z_meaner"]
# Функция, которую будем запускать после каждой эпохи
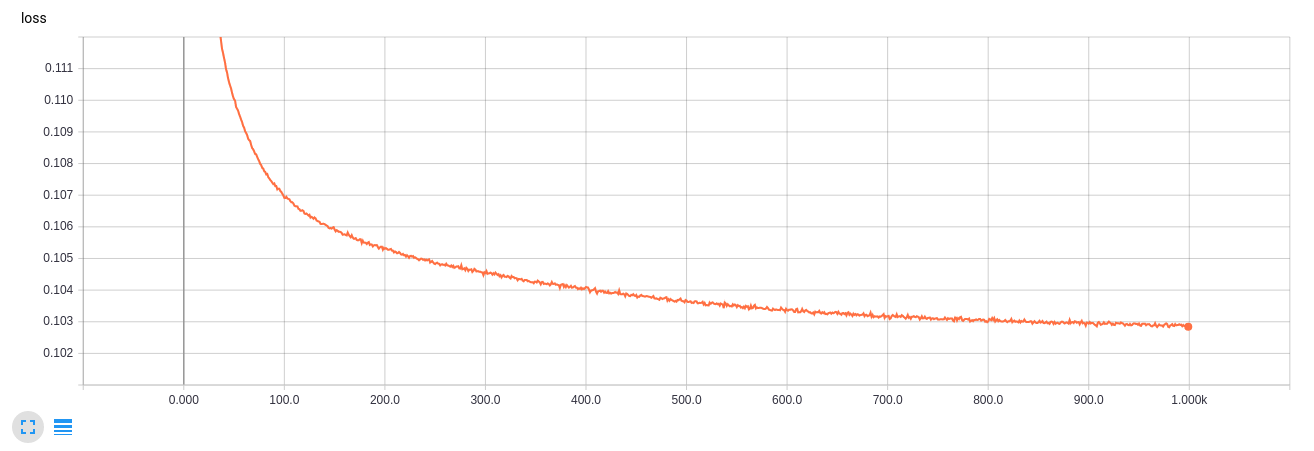
def on_epoch_end(epoch, logs):
if epoch in save_epochs:
clear_output() # Не захламляем output
# Сравнение реальных и декодированных цифр
decoded = vae.predict(imgs, batch_size=batch_size)
plot_digits(imgs[:n_compare], decoded[:n_compare])
# Рисование многообразия
figure = draw_manifold(generator, show=True)
# Сохранение многообразия и распределения z для создания анимации после
epochs.append(epoch)
figs.append(figure)
latent_distrs.append(encoder_mean.predict(x_test, batch_size))
# Коллбэки
pltfig = LambdaCallback(on_epoch_end=on_epoch_end)
# lr_red = ReduceLROnPlateau(factor=0.1, patience=25)
tb = TensorBoard(log_dir='./logs')
# Запуск обучения
vae.fit(x_train, x_train, shuffle=True, epochs=1000,
batch_size=batch_size,
validation_data=(x_test, x_test),
callbacks=[pltfig, tb],
verbose=1)




from matplotlib.animation import FuncAnimation
from matplotlib import cm
import matplotlib
def make_2d_figs_gif(figs, epochs, fname, fig):
norm = matplotlib.colors.Normalize(vmin=0, vmax=1, clip=False)
im = plt.imshow(np.zeros((28,28)), cmap='Greys_r', norm=norm)
plt.grid(None)
plt.title("Epoch: " + str(epochs[0]))
def update(i):
im.set_array(figs[i])
im.axes.set_title("Epoch: " + str(epochs[i]))
im.axes.get_xaxis().set_visible(False)
im.axes.get_yaxis().set_visible(False)
return im
anim = FuncAnimation(fig, update, frames=range(len(figs)), interval=100)
anim.save(fname, dpi=80, writer='imagemagick')
def make_2d_scatter_gif(zs, epochs, c, fname, fig):
im = plt.scatter(zs[0][:, 0], zs[0][:, 1], c=c, cmap=cm.coolwarm)
plt.colorbar()
plt.title("Epoch: " + str(epochs[0]))
def update(i):
fig.clear()
im = plt.scatter(zs[i][:, 0], zs[i][:, 1], c=c, cmap=cm.coolwarm)
im.axes.set_title("Epoch: " + str(epochs[i]))
im.axes.set_xlim(-5, 5)
im.axes.set_ylim(-5, 5)
return im
anim = FuncAnimation(fig, update, frames=range(len(zs)), interval=150)
anim.save(fname, dpi=80, writer='imagemagick')
make_2d_figs_gif(figs, epochs, "./figs3/manifold.gif", plt.figure(figsize=(10,10)))
make_2d_scatter_gif(latent_distrs, epochs, y_test, "./figs3/z_distr.gif", plt.figure(figsize=(10,10)))
|
Метки: author iphysic обработка изображений машинное обучение математика алгоритмы python autoencoder keras mnist deep learning machine learning |
[Перевод] Connect: советы по современному фронтенду |


header .stripes {
display: grid;
grid: repeat(5, 200px) / repeat(10, 1fr);
}
header .stripes :nth-child(1) {
grid-column: span 3;
}
header .stripes :nth-child(2) {
grid-area: 3 / span 3 / auto / -1;
}
header .stripes :nth-child(3) {
grid-row: 4;
grid-column: span 5;
}.stripes для получения эффекта наклона: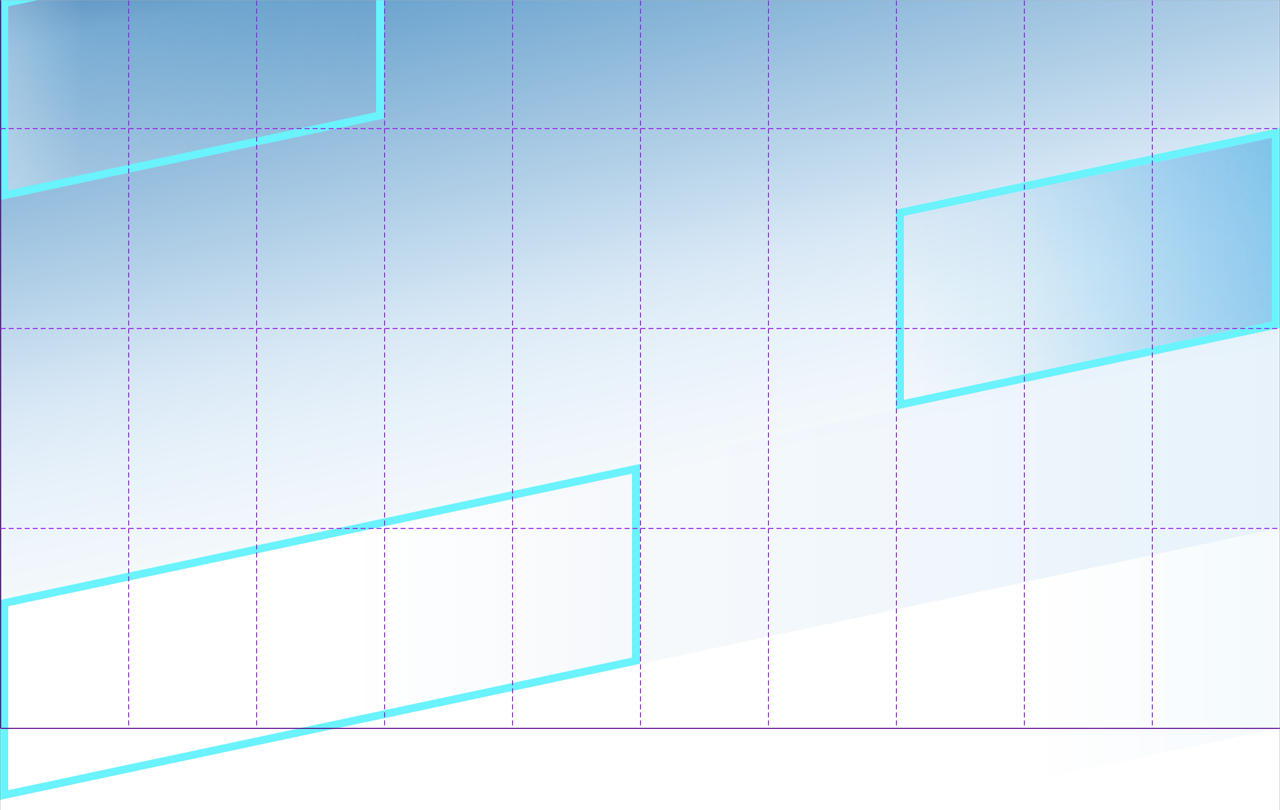
header .stripes {
transform: skewY(-12deg);
transform-origin: 0;
}justify-content и align-items.
template:
// JavaScript
const createCube = () => {
const template = document.getElementById("cube-template");
const fragment = document.importNode(template.content, true);
return fragment;
};.cube, .cube * {
position: absolute;
width: 100px;
height: 100px
}
.sides {
transform-style: preserve-3d;
perspective: 600px
}
.front { transform: rotateY(0deg) translateZ(50px) }
.back { transform: rotateY(-180deg) translateZ(50px) }
.left { transform: rotateY(-90deg) translateZ(50px) }
.right { transform: rotateY(90deg) translateZ(50px) }
.top { transform: rotateX(90deg) translateZ(50px) }
.bottom { transform: rotateX(-90deg) translateZ(50px) }requestAnimationFrame для вычисления и обновления каждой стороны в любой точке вращения. В каждом кадре нужно определить три вещи:requestIdleCallback на JavaScript и backface-visibility на CSS), но это главные основы для логики анимации.const getDistance = (state, rotate) =>
["x", "y"].reduce((object, axis) => {
object[axis] = Math.abs(state[axis] + rotate[axis]);
return object;
}, {});
const getRotation = (state, size, rotate) => {
const axis = rotate.x ? "Z" : "Y";
const direction = rotate.x > 0 ? -1 : 1;
return `
rotateX(${state.x + rotate.x}deg)
rotate${axis}(${direction * (state.y + rotate.y)}deg)
translateZ(${size / 2}px)
`;
};// Linear interpolation between a and b
// Example: (100, 200, .5) = 150
const interpolate = (a, b, i) => a * (1 - i) + b * i;
const getShading = (tint, rotate, distance) => {
const darken = ["x", "y"].reduce((object, axis) => {
const delta = distance[axis];
const ratio = delta / 180;
object[axis] = delta > 180 ? Math.abs(2 - ratio) : ratio;
return object;
}, {});
if (rotate.x)
darken.y = 0;
else {
const {x} = distance;
if (x > 90 && x < 270)
directions.forEach(axis => darken[axis] = 1 - darken[axis]);
}
const alpha = (darken.x + darken.y) / 2;
const blend = (value, index) =>
Math.round(interpolate(value, tint.shading[index], alpha));
const [r, g, b] = tint.color.map(blend);
return `rgb(${r}, ${g}, ${b})`;
};
prefers-reduced-motion (пока только в Safari), и все декоративные анимации на странице отключатся. Кубы одновременно используют анимации CSS для затенения и анимации JavaScript для вращения. Мы можем отключить эти анимации сочетанием блокировок @media и MediaQueryList Interface:/* CSS */
@media (prefers-reduced-motion) {
#header-hero * {
animation: none
}
}
// JavaScript
const reduceMotion = matchMedia("(prefers-reduced-motion)").matches;
const tick = () => {
cubes.forEach(updateSides);
if (reduceMotion) return;
requestAnimationFrame(tick);
};
.laptop .lid {
position: absolute;
width: 100%;
height: 100%;
border-radius: 20px;
background: linear-gradient(45deg, #E5EBF2, #F3F8FB);
box-shadow: inset 1px -4px 6px rgba(145, 161, 181, .3)
} В разделе Onboarding & Verification представлено демо Express, новой системы адаптации начинающих пользователей Connect. Вся анимация целиком построена на программном коде и в основном полагается на новые Web Animations API.
В разделе Onboarding & Verification представлено демо Express, новой системы адаптации начинающих пользователей Connect. Вся анимация целиком построена на программном коде и в основном полагается на новые Web Animations API.@keyframes в JavaScript, позволяя легко создавать плавную последовательность кадров анимации. В отличие от низкоуровневых интерфейсов requestAnimationFrame, здесь вы получаете все прелести анимаций CSS, такие как нативная поддержка смягчающих функций cubic-bezier. В качестве примера, взглянем на наш код для скольжения клавиатуры:const toggleKeyboard = (element, callback, action) => {
const keyframes = {
transform: [100, 0].map(n => `translateY(${n}%)`)
};
const options = {
duration: 800,
fill: "forwards",
easing: "cubic-bezier(.2, 1, .2, 1)",
direction: action == "hide" ? "reverse" : "normal"
};
const animation = element.animate(keyframes, options);
animation.addEventListener("finish", callback, {once: true});
};requestAnimationFrame, там всё-таки предоставляется более тонкий контроль над анимацией и допускаются эффекты, которые иначе не получишь, такие как Spring Curve и независимые функции трансформации. Если вы не уверены, какую технологию выбрать для своих анимаций, то вероятно, варианты можно расставить в следующем приоритетном порядке:hover.@keyframes, а часто и явного animation-fill-mode. (А именованные штуки всегда были сложнейшими частями компьютерной науки!)timing-function вроде ease-in, ease-out и linear. Вы сэкономите много времени, если глобально определите количество кастомных переменных cubic-bezier.transform и opacity) и сбрасывать анимации на GPU по возможности (применяя will-change).const observeScroll = (element, callback) => {
const observer = new IntersectionObserver(([entry]) => {
if (entry.intersectionRatio < 1) return;
callback();
// Stop watching the element
observer.disconnect();
},{
threshold: 1
});
// Start watching the element
observer.observe(element);
};
const element = document.getElementById("express-animation");
observeScroll(element, startAnimation);observeScroll упрощает нам детектирование (например, когда элемент полностью видим, то обратный вызов генерируется лишь однажды) без выполнения какого-либо кода в основном потоке. Благодаря Intersection Observer API мы теперь на шаг ближе к абсолютно плавным веб-страницам!const insert = name => {
const el = document.createElement("script");
el.src = `${name}.js`;
el.async = false; // Keep the execution order
document.head.appendChild(el);
};
const scripts = ["main"];
if (!Element.prototype.animate)
scripts.unshift("web-animations-polyfill");
if (!("IntersectionObserver" in window))
scripts.unshift("intersection-observer-polyfill");
scripts.forEach(insert);div { display: flex }
@supports (display: grid) {
div { display: grid }
}// Some browsers not supporting Grid don’t support CSS.supports
// either, so we need to feature-test it the old-fashioned way:
if (!("grid" in document.body.style)) {
const fallback = "";
document.head.insertAdjacentHTML("beforeend", fallback);
}|
Метки: author m1rko разработка веб-сайтов браузеры javascript css api css grid css 3d web animations api анимации intersection observer api полифиллы |
[Из песочницы] Установка ArchLinux ARM рядом с Android без chroot |
wget http://mirror.yandex.ru/archlinux-arm/os/ArchLinuxARM-armv7-latest.tar.gz
mv ArchLinuxARM-armv7-latest.tar.gz ArchLinuxARM.tar.gz
adb push ArchLinuxARM.tar.gz /sdcard/
cd sdcard
make_ext4fs -l 3221225472 arch.imgmount -o rw,remount /
mkdir /arch
busybox mount /sdcard/arch.img /arch
tar -xvf ArchLinuxARM.tar.gz -C /arch/busybox mount -t proc none /arch/proc
busybox mount -o rbind /dev /arch/dev
busybox mount -t tmpfs none /arch/tmp
busybox mount -o size=10%,mode=0755 -t tmpfs none /arch/run
chroot /arch /bin/bashping 8.8.8.8
socket: Permission denied
uid=2000(shell) gid=2000(shell) groups=1003(graphics),1004(input),1007(log),1009(mount),1011(adb),1015(sdcard_rw),1028(sdcard_r),3001(net_bt_admin),3002(net_bt),3003(inet),3006(net_bw_stats)groupadd -g 3003 inet
usermod -a -G inet root
su root
ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=59 time=89.6 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=59 time=88.6 ms
rm /etc/resolv.conf
echo "nameserver 8.8.8.8" > /etc/resolv.confpacman -S gcc htop iotop sudo opensshcd /root
nano main.cpp#include
int main() {
std::cout << "Hello World!\n";
return 0;
}
g++ main.cpp
./a.outls /etc/ > /sdcard/ls.txt
ls /arch/etc/ > /sdcard/ls2.txt
busybox grep -F -f /sdcard/ls.txt /sdcard/ls2.txtdhcpcd.conf
hosts
securitycp -Ra /etc/* /arch/etc/
cp -a /sbin/adbd /arch/usr/bin/passwd
mv /usr/bin/su /usr/bin/su.rmkdir /lib
mkdir /bin
mkdir /xbin
mkdir /opt
mkdir /usr
mkdir /home
mkdir /run
mkdir /srv
mkdir /tmp
mkdir /var
busybox mount --bind /arch/etc /etc
busybox mount --bind /arch/opt /opt
busybox mount --bind /arch/home /home
busybox mount -o size=10%,mode=0755 -t tmpfs none /run
busybox mount --bind /arch/srv /srv
busybox mount -t tmpfs none /tmp
busybox mount --bind /arch/sbin /sbin
busybox mount --bind /arch/usr/ /usr
busybox mount --bind /arch/var/ /var
busybox mount --bind /arch/lib/ /lib
busybox mount --bind /arch/usr/bin/ /bin
/bin/bash
|
Метки: author Gravit настройка linux *nix android archlinux |
Руководство: как использовать Python для алгоритмической торговли на бирже. Часть 1 |

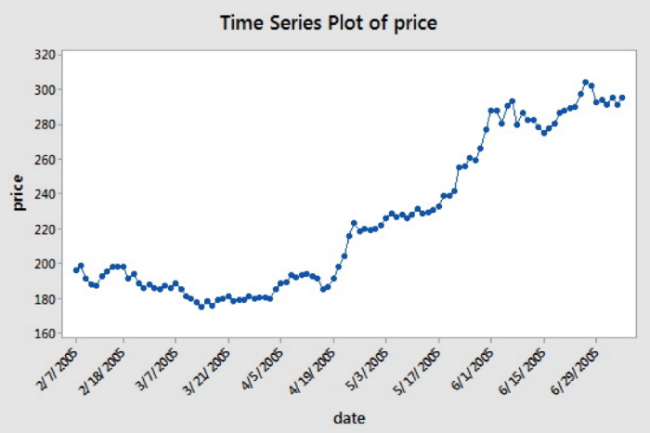
pip install pandas-datareaderimport pandas_datareader as pdr
import datetime
aapl = pdr.get_data_yahoo('AAPL',
start=datetime.datetime(2006, 10, 1),
end=datetime.datetime(2012, 1, 1))import quandl
aapl = quandl.get("WIKI/AAPL", start_date="2006-10-01", end_date="2012-01-01")import pandas as pd
aapl.to_csv('data/aapl_ohlc.csv')
df = pd.read_csv('data/aapl_ohlc.csv', header=0, index_col='Date', parse_dates=True)# Inspect the index
aapl.index
# Inspect the columns
aapl.columns
# Select only the last 10 observations of `Close`
ts = aapl['Close'][-10:]
# Check the type of `ts`
type(ts)# Inspect the first rows of November-December 2006
print(aapl.loc[pd.Timestamp('2006-11-01'):pd.Timestamp('2006-12-31')].head())
# Inspect the first rows of 2007
print(aapl.loc['2007'].head())
# Inspect November 2006
print(aapl.iloc[22:43])
# Inspect the 'Open' and 'Close' values at 2006-11-01 and 2006-12-01
print(aapl.iloc[[22,43], [0, 3]])# Sample 20 rows
sample = aapl.sample(20)
# Print `sample`
print(sample)
# Resample to monthly level
monthly_aapl = aapl.resample('M').mean()
# Print `monthly_aapl`
print(monthly_aapl)# Add a column `diff` to `aapl`
aapl['diff'] = aapl.Open - aapl.Close
# Delete the new `diff` column
del aapl['diff']# Import Matplotlib's `pyplot` module as `plt`
import matplotlib.pyplot as plt
# Plot the closing prices for `aapl`
aapl['Close'].plot(grid=True)
# Show the plot
plt.show()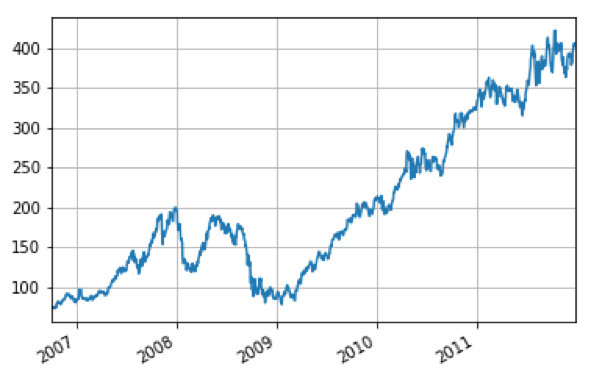
|
Метки: author itinvest python блог компании itinvest финансы разработка торговля на бирже |
Россия — Мексика: исторический футбольный матч роботов, управляемый болельщиками через Твиттер |

|
Метки: author T-Fazullin блог компании innopolis university роботы футбол футбол роботов россия мексика университет иннополис образование вро2017 робототехническая олимпиада |
Интегрируем Copy-Paste-Detector для Swift в Xcode |

Одним из основных мета-принципов программирования является DRY (Don’t Repeat Yourself). Суть данного мета-принципа проста и должна являться негаснущим маяком для любого разработчика. Она гласит, что в разрабатываемой системе не должно быть кусков кода, имеющих одинаковый код. Выражаясь более простым языком, в программе не должно быть копипасты!
Для начала, давайте точно определим, что будем считать за копипасту. Если в проекте если одинаковые файлы — это грубейшая копипаста. Если есть одинаковые классы с разным названием и выполняющие одно и тоже — грубейшая копипаста. Даже если 10 строк одинакового кода — это тоже является копипастой. Возможно вы возразите, что 10 строк кода продублировать иногда позволительно. Из моего опыта, проект в 100000 строк вполне реально писать без подобной копипасты.
Какие же минусы несёт нам копипаста?
Одним из основных способов нахождения некачественного кода, к коему относится и нарушение принципа DRY, является code-review.
Важно отметить, что у этого способа есть ряд существенных недостатков, что заставляет искать другие способы поиска некачественного кода.
Подавляющее большинство программистов вам скажет, что лучший этап обнаружения багов, плохого кода — это этап компиляции проекта. Поэтому почему бы не воспользоваться инструментами, которые позволят найти дублирование кода сразу при запуске проекта и не дадут ему собраться пока это не будет исправлено?
Для языка Swift было найдено всего 2 детектора дублирования кода.
Второй является более кастомизируемым, поддерживаемым и в целом более стабильным.
Для начала работы необходимо установить pmd путем выполнения команды в консоли “brew install pmd”.
Важно заметить, что для других языков в пакете pmd содержатся и статические анализаторы кода. В пакете для языка Swift есть только CPD (copy paste detector). Поэтому анализаторы кода нужно ставить дополнительно. Лучшим выбором на данный момент будет: https://github.com/realm/SwiftLint
Как ранее было выяснено, самым удобным способом обнаружения ошибок и копипасты является этап прекомпиляции проекта. В Xcode можно добавлять свои скрипты во вкладке Build Phases, чтобы они также отрабатывали на этом этапе и не давали скомпилироваться проекту успешно, если был найден дублирующийся код.
Для подключения в проект необходимо создать новый build script с именем “CopyPaste Detection” во вкладке Build Phases и добавить внутрь следующий скрипт:
# Running CPD
pmd cpd --files ${EXECUTABLE_NAME} --minimum-tokens 50 --language swift --encoding UTF-8 --format net.sourceforge.pmd.cpd.XMLRenderer > cpd-output.xml --failOnViolation true
# Running script
php ./cpd_script.php -cpd-xml cpd-output.xmlРазберем подробнее, что означает эта магия. Первая часть скрипта означает, что мы запускаем CPD для файлов, лежащих в корневой папке нашего проекта. minimum-tokens означает минимальное количество токенов, при нахождении которые скрипт будет помечать фрагмент кода как копипасту. Токеном является некая абстрактная единица, поэтому не нужно принимать это за букву, слово и конструкцию. Эмпирическим путём было выяснено, что цифра 50 является оптимальной для языка Swift. Если взять меньше, то можно найти то, что не является копипастой, если больше, то есть большой шанс пропустить дублирование. Следующий параметр — format означает, что вывод будет происходить в xml-файл. И последний — failOnViolation говорит о том, что приложение не соберется, если найден хоть 1 фрагмент дублирующегося кода.
В результате выполнения первой части скрипта, у нас есть xml файл с логами анализа проекта. Теперь необходимо показать нашу копипасту прямо в Xcode в привычном для разработчика формате в виде warnings. Для этого добавим еще один скрипт прямо в корень проекта:
Вторая часть нашего первого скрипта запустит второй скрипт и преобразует сгенерированный xml файл в warnings в Xcode. Подробнее о том, как можно самому генерировать warnings в Xcode можно прочитать здесь.
Теперь запустим наш проект, cmd+B/R и убедимся, что наш скрипт работает. Получаем следующую картину после запуска.
В Issue Navigator:

Внутри файла:

Бытует мнение, что любая методология или техника хороша, если её использовать с умом и знать меру. Так вот, к copypaste в проекте это не относится. Это явное зло, с которым нужно бороться и которое является растущим техническим долгом. И никаких проявлений слабости или половинчатости здесь допускать нельзя.
Теперь у вас есть средство для борьбы с этим злом, интегрированное прямо в Xcode в качестве скрипта в билд фазу. Да поможет вам это перейти на светлую сторону!
|
Метки: author niklnd тестирование мобильных приложений разработка под ios xcode swift блог компании touch instinct ios copy-paste ios development |
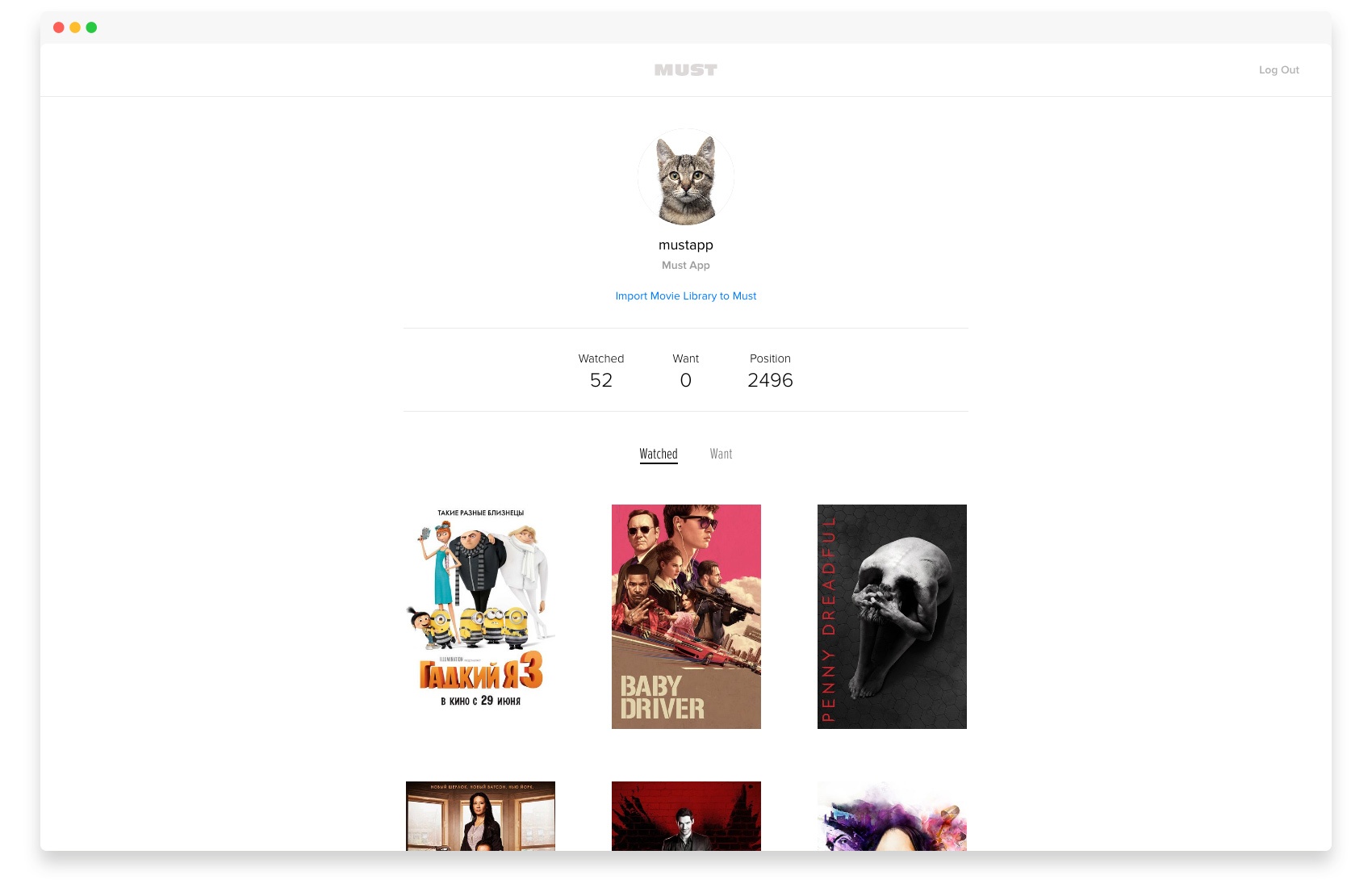
Переносим оценки из Имхонет в Must App |


|
Метки: author emuravjev я пиарюсь mustapp имхонет оценки фильмы кино сериалы |






