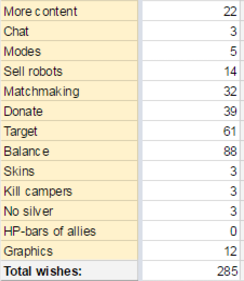
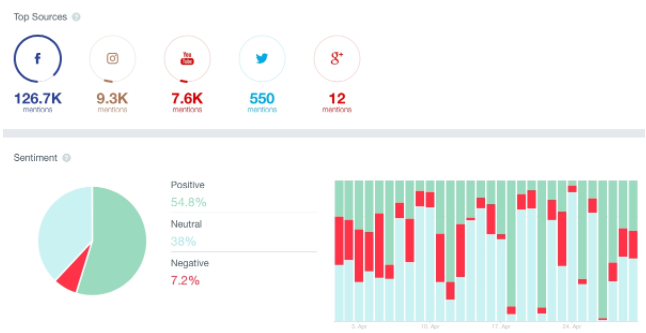
«Это не про деньги и не разработку»: 5 заблуждений о работе комьюнити-менеджера |




|
Метки: author IvoryBuk управление сообществом развитие стартапа блог компании pixonic комьюнити комьюнити-менеджер комьюнити-менеджмент сообщество community |
Предотвращение негативных последствий при разработке систем искусственного интеллекта, превосходящих человеческий разум |












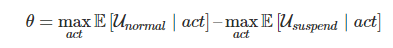



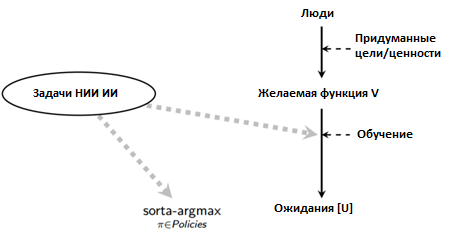
|
Метки: author SmirkinDA разработка робототехники разработка для интернета вещей машинное обучение блог компании parallels искусственный интеллект искусственные нейронные сети parallels ai |
Универсальная функция создания объектов на примере реализации $injector.instantiate в angularjs |
$injector, где их поджидает довольно занимательная конструкция, о которой сегодня и хотелось бы поговорить.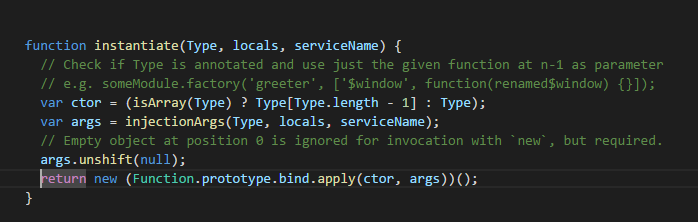
return new (Function.prototype.bind.apply(ctor, args))();bind, apply, new и (). Давайте разбираться. Начать я предлагаю от обратного, а именно: пускай у нас есть некий параметризованный конструктор, экземпляр которого мы и хотим создать:function Animal(name, sound) {
this.name = name;
this.sound = sound;
}var dog = new Animal('Dog', 'Woof!');. Оператор new — это первое, что нам потребуется, чтобы получить экземпляр вызова конструктора Animal. Небольшое отступление о том, как работает new:Когда исполняется new Foo(...), происходит следующее:
1. Создается новый объект, наследующий Foo.prototype.
2. Вызывается конструктор — функция Foo с указанными аргументами и this, привязанным к только что созданному объекту. new Foo эквивалентно new Foo(), то есть если аргументы не указаны, Foo вызывается без аргументов.
3. Результатом выражения new становится объект, возвращенный конструктором. Если конструктор не возвращет объект явно, используется объект из п. 1. (Обычно конструкторы не возвращают значение, но они могут делать это, если нужно переопределить обычный процесс создания объектов.)
Подробнее
Animal в функцию, чтобы код инициализации был общим для всех требуемых вызовов:function CreateAnimal(name, sound) {
return new Animal(name, sound);
}bind).$injector.instantiate был выбран второй путь:function Create(ctorFunc, name, sound) {
return new (ctorFunc.bind(null, name, sound));
}
console.log( Create(Animal, 'Dog', 'Woof') );
console.log( Create(Human, 'Person') );
bind:Метод bind() создаёт новую функцию, которая при вызове устанавливает в качестве контекста выполнения this предоставленное значение. В метод также передаётся набор аргументов, которые будут установлены перед переданными в привязанную функцию аргументами при её вызове.
Подробнее
null, т.к. планируем использовать новую созданную с помощью bind функцию с оператором new, который игнорирует this и создает для него пустой объект. Результатом выполнения функции bind станет новая функция с уже привязанными к ней аргументами (т.е. return new fn;, где fn — результат вызова bind).name и sound. «Но ведь не все аргументы, которые требуются для животных будут необходимыми и для людей»- скажете вы и будете правы- назревают 2 проблемы:Create и строку создания экземпляра return new (ctorFunc.bind(null, name, sound ));apply (или её аналог call, если количество аргументов известно заранее).Метод apply() вызывает функцию с указанным значением this и аргументами, предоставленными в виде массива (либо массивоподобного объекта).
Хотя синтаксис этой функции практически полностью идентичен функции call(), фундаментальное различие между ними заключается в том, что функция call() принимает список (перечень) аргументов, в то время, как функция apply() принимает массив аргументов (единым параметром).
Подробнее
bind наш конструктор (аналогично ctorFunc.bind), а в качестве аргументов для функции bind (не забывая о том, что первым аргументом является устанавливаемый контекст) передать смещенный на одну позицию вправо массив параметров конструктора, используя ctorArgs.unshift(null).
bind недоступна в контексте выполнения Create, т.к. им является объект window, зато доступна посредством прототипа функции Function.prototype.function Create(ctorFunc, ctorArgs) {
ctorArgs.unshift(null);
return new (Function.prototype.bind.apply(ctorFunc, ctorArgs ));
}
console.log( Create(Animal, ['Dog', 'Woof']) );
console.log( Create(Human, ['Person', 'John', 'Engineer', 'Moscow']) );
Animal и Human, например, выступают конструкторы фабрик или других типов, а в качестве массива аргументов ['Dog', 'Woof'] — найденные (разрезолвленные) по имени зависимости:angular
.module('app')
.factory(function($scope) {
// constructor
});
angular
.module('app')
.factory(['$scope', function($scope) {
// constructor
}]);
$injector.instantiate, это найти функцию конструктора и получить необходимые аргументы и можно создавать :)
|
Метки: author fsou11 javascript angularjs $injector |
«MDM vs CRM» или кто поможет больше продать? |
|
Метки: author AXELOT-IT управление проектами управление продажами терминология it erp- системы crm- система mdm- мастер данные управление нси |
Сломай голосовалку на РИТ++ за 50 наклеек |

|
Метки: author Kosheleva_Ingram_Micro блог компании odin (ingram micro) розыгрыш рит++ рит2017 |
NeoQUEST-2017: что ждёт гостей на юбилейной «Очной ставке»? |
 29 июня 2017 года в Санкт-Петербурге состоится юбилейная, пятая «Очная ставка» NeoQUEST! И мы с радостью приглашаем всех, кто интересуется информационной безопасностью: студентов и абитуриентов IT-специальностей, разработчиков, тестировщиков, админов, матёрых специалистов и новичков в инфобезе, хакеров и гиков!
29 июня 2017 года в Санкт-Петербурге состоится юбилейная, пятая «Очная ставка» NeoQUEST! И мы с радостью приглашаем всех, кто интересуется информационной безопасностью: студентов и абитуриентов IT-специальностей, разработчиков, тестировщиков, админов, матёрых специалистов и новичков в инфобезе, хакеров и гиков!  Термин "мимикрия", знакомый нам по урокам биологии в школе, применим и к компьютерным девайсам. USB стал самым популярным компьютерным портом, к которому мы подключаем совершенно разные устройства, от мышки и флешки до телефона и фотоаппарата. Но можно ли быть уверенным, что устройство является именно тем, чем кажется?
Термин "мимикрия", знакомый нам по урокам биологии в школе, применим и к компьютерным девайсам. USB стал самым популярным компьютерным портом, к которому мы подключаем совершенно разные устройства, от мышки и флешки до телефона и фотоаппарата. Но можно ли быть уверенным, что устройство является именно тем, чем кажется? Все знают про возможность расшифрования SSL/TLS трафика с помощью закрытого ключа в Wireshark. Но далеко не всем известно, что это не единственный способ расшифрования: Wireshark также поддерживает расшифрование с помощью секретов сессий. А это значит, что любой шифрованный SSL/TLS трафик можно расшифровать, будучи на стороне клиента!
Все знают про возможность расшифрования SSL/TLS трафика с помощью закрытого ключа в Wireshark. Но далеко не всем известно, что это не единственный способ расшифрования: Wireshark также поддерживает расшифрование с помощью секретов сессий. А это значит, что любой шифрованный SSL/TLS трафик можно расшифровать, будучи на стороне клиента!|
Метки: author NWOcs криптография информационная безопасность занимательные задачки ctf блог компании необит neoquest neoquest2017 hackquest hacker hacking conference |
Динамическое подключение внешних собственных модулей в Gradle |
import java.text.SimpleDateFormat
apply plugin: 'java'
apply plugin: 'maven-publish'
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
jar.baseName = 'library'
publishing {
publications {
mavenJava(MavenPublication) {
groupId='name.alenkov.habr.gradle-dynamic-dependency'
version = new SimpleDateFormat('yyyyMMddHHmm').format(new Date())
from components.java
}
}
}apply plugin: 'java'
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
repositories {
mavenLocal()
jcenter()
}
dependencies {
compile 'name.alenkov.habr.gradle-dynamic-dependency:library:+'
}
cd ./app/ext
ln -s ../../library/ ./final extDir = new File(rootDir, 'ext')
if (extDir.exists()) {
extDir.eachDir { dir ->
if (new File(dir, 'build.gradle').exists()) {
logger.trace('found ext module: ' + dir.name)
final String prjName = ':' + dir.name
logger.lifecycle('include ext project: ' + prjName)
include prjName
project(prjName).projectDir = dir
project(prjName).name = 'ext-' + dir.name
}
}
}dependencies {
compile subprojects.find({ it.name == 'ext-library' }) ? project(':ext-library')
: 'name.alenkov.habr.gradle-dynamic-dependency:library:+'
}
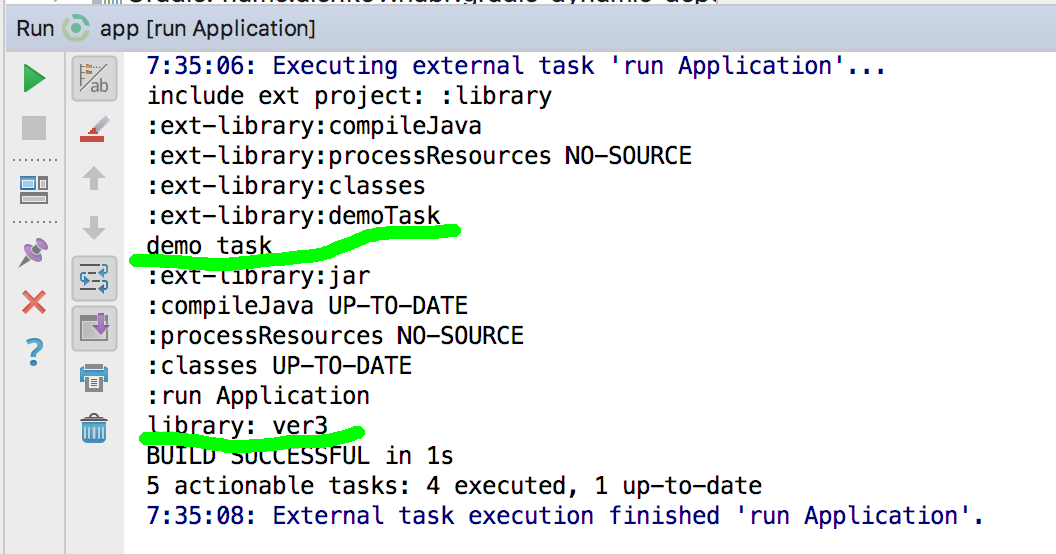
|
Метки: author Borz программирование java gradle dependency injection |
Новый старший брат в семье 3PAR |

8450 |
9450 |
Изменение |
|
Число контроллеров |
2 — 4 |
2 — 4 |
- |
Число процессоров (ядер) |
2 – 4 (40) |
4 – 8 (80) |
100% |
Число ASIC |
2 – 4 |
4 – 8 |
- |
Порты 16Gb Fiber Channel |
4 – 24 |
0 – 80 |
230% |
Порты 10Gb iSCSI Ports |
0 – 8 |
0 – 40 |
400% |
Порты 1Gb Ethernet IP Ports |
0 – 16 |
0 |
- |
Порты 10Gb Ethernet IP Ports |
0 – 8 |
0 – 24 |
300% |
Встроенные порты для репликации по IP |
2 – 4 (1GbE) |
2 – 4 (10GbE) |
- |
Объем кэша на контроллер/систему |
192 / 384 |
448 / 896 |
130% |
Число SSD в массиве |
6 – 480 |
6 – 576 |
20% |
Число SSD в базовой стойке |
480 SFF |
384 SFF |
-20% |
Сырая емкость |
3351 ТБ |
6000 ТБ |
79% |
|
Метки: author vlad_msk_ru хранение данных it- инфраструктура блог компании hewlett packard enterprise hpe hewlett packard enterprise 3par 3par storeserv |
Текстовый онлайн с фестиваля РИТ++ 2017. День первый |

|
Метки: author TM_content разработка мобильных приложений программирование высокая производительность блог компании конференции олега бунина (онтико) рит++ конференция фестиваль интернет-технологий |
[Перевод] Полезные утилиты для администраторов, обслуживающих Kubernetes |

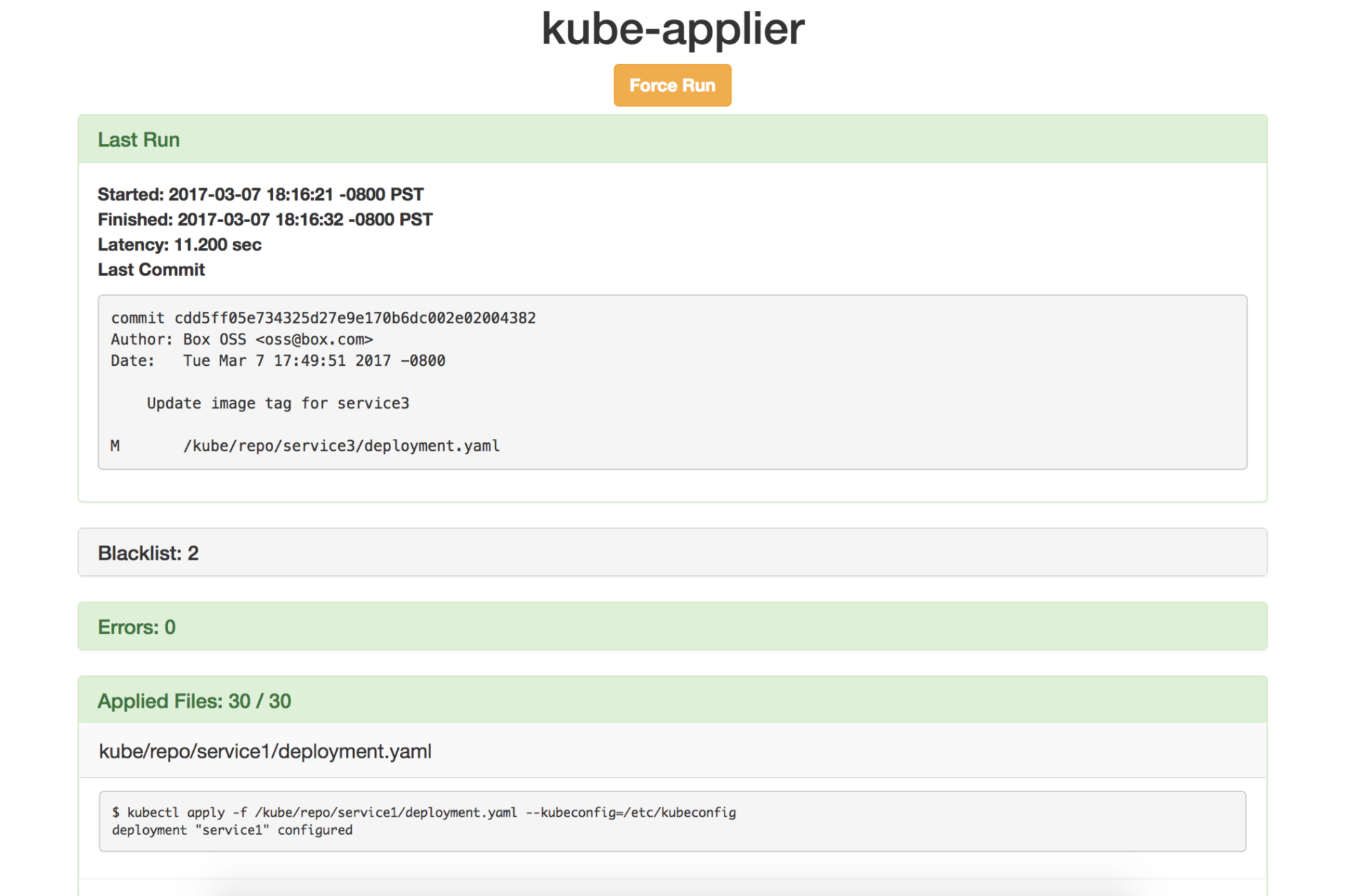
kubectl в составе Kubernetes есть похожая функция, но у Kubetop более наглядный вывод:kubetop - 13:02:57
Node 0 CPU% 9.80 MEM% 57.97 ( 2 GiB/ 4 GiB) POD% 7.27 ( 8/110) Ready
Node 1 CPU% 21.20 MEM% 59.36 ( 2 GiB/ 4 GiB) POD% 3.64 ( 4/110) Ready
Node 2 CPU% 99.90 MEM% 58.11 ( 2 GiB/ 4 GiB) POD% 7.27 ( 8/110) Ready
Pods: 20 total 0 running 0 terminating 0 pending
POD (CONTAINER) %CPU MEM %MEM
s4-infrastructure-3073578190-2k2vw 75.5 782.05 MiB 20.76
(subscription-converger) 72.7 459.11 MiB
(grid-router) 2.7 98.07 MiB
(web) 0.1 67.61 MiB
(subscription-manager) 0.0 91.62 MiB
(foolscap-log-gatherer) 0.0 21.98 MiB
(flapp) 0.0 21.46 MiB
(wormhole-relay) 0.0 22.19 MiBkubectl бывает не очень удобным, в результате чего появились сторонние методы решения этой задачи.$ kubectx minikube
Switched to context "minikube".
$ kubectx -
Switched to context "oregon".
$ kubectx -
Switched to context "minikube".
$ kubectx dublin=gke_ahmetb_europe-west1-b_dublin
Context "dublin" set.
Aliased "gke_ahmetb_europe-west1-b_dublin" as "dublin".kubeadm для запуска кластера, созданного из Docker-контейнеров вместо виртуальных машин (для этого применяется DIND, Docker in Docker — прим. перев.). Выбранная реализация позволяет быстрее перезапускать кластер, что особенно ценно, если необходимо быстро видеть результат изменений в коде при разработке самого Kubernetes. Также можно использовать KDC в окружениях непрерывной интеграции. Работает в GNU/Linux, Mac OS и Windows, не требует инсталляции Go, т.к. использует докеризированные сборки Kubernetes.$ wget https://cdn.rawgit.com/Mirantis/kubeadm-dind-cluster/master/fixed/dind-cluster-v1.6.sh
$ chmod +x dind-cluster-v1.6.sh
$ # запуск кластера
$ ./dind-cluster-v1.6.sh up
$ # добавление директории с kubectl в PATH
$ export PATH="$HOME/.kubeadm-dind-cluster:$PATH"
$ kubectl get nodes
NAME STATUS AGE
kube-master Ready,master 1m
kube-node-1 Ready 34s
kube-node-2 Ready 34s
$ # Kubernetes dashboard доступен на http://localhost:8080/ui
$ # перезапуск кластера, который произойдет намного быстрее первого старта
$ ./dind-cluster-v1.6.sh up
$ # остановка кластера
$ ./dind-cluster-v1.6.sh down
$ # удаление контейнеров и томов DIND
$ ./dind-cluster-v1.6.sh clean
tail -f для всех подов кластера.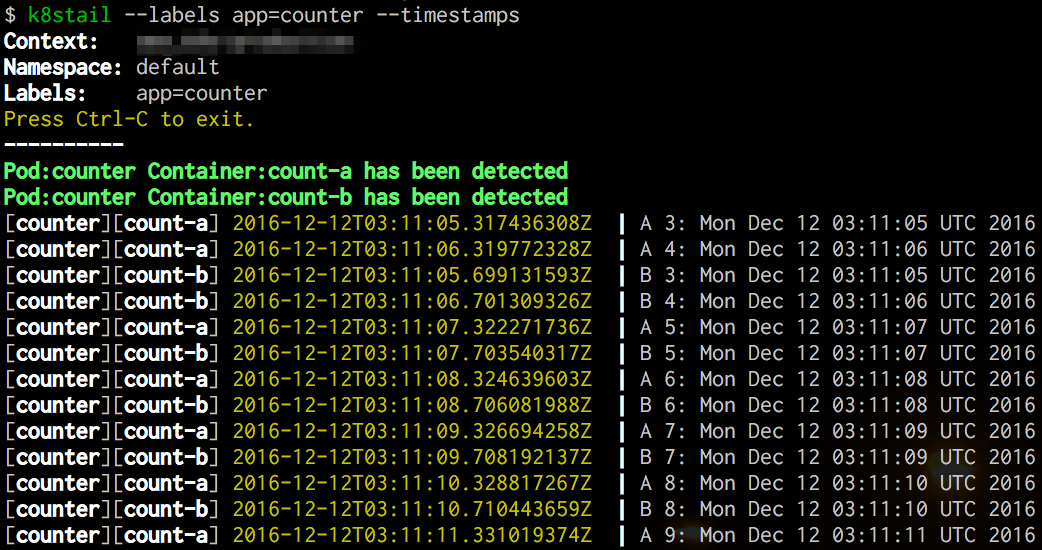
|
Метки: author shurup системное администрирование серверное администрирование devops *nix блог компании флант kubernetes docker контейнеры утилиты |
Понятия: множество, тип, атрибут |
|
Метки: author maxstroy семантика анализ и проектирование систем it- стандарты онтология множества типы атрибуты моделирование моделирование предметной области |
Pygest #10. Релизы, статьи, интересные проекты из мира Python [23 мая 2017 — 5 июня 2017] |
 Всем привет! Это уже десятый выпуск дайджеста на Хабрахабр о новостях из мира Python.
Всем привет! Это уже десятый выпуск дайджеста на Хабрахабр о новостях из мира Python. |
Метки: author andrewnester разработка веб-сайтов программирование python django digest pygest дайджест |
[Перевод] Развертывание и сопровождение Redmine, правильный путь |

Дисклеймер: это не обычное руководство вида «Как установить Redmine». В нем я не буду погружаться в настройку базы данных или установку веб-сервера. Я также не буду рассказывать о настройке Redmine. Документация по Redmine в этом плане является достаточно полной. А для того, что не упоминается в официальной документации, есть общая процедура запуска Rails-приложений, которую можно легко найти в Интернете.
Вместо этого речь пойдет о сопровождении собственной, более или менее кастомизированной версии Redmine, которая может быть развернута с помощью одной команды оболочки, когда это необходимо.
Готовы? Тогда начнём.
Установочные пакеты Bitnami или предварительно установленные виртуальные машины хороши для быстрой пробы Redmine, но не подходят для продуктивного использования. Почему? Потому что у них нет обновления. Ой, секундочку, у Bitnami есть. Правда, оно больше похоже на шутку. «Установите новую версию всего стека в другой каталог и переместите туда свои данные» — это не обновление. Ни слова о настройке, кастомизации и плагинах, которые, вероятно, также нужно сохранить и переустановить. Желаю удачи с таким «обновлением».
Релизы патчей Redmine выходят один или два раза в месяц. Исправления ошибок, связанных с безопасностью, выпускаются по мере необходимости — вы же не хотите пропустить их?
Факт, о котором люди часто забывают: время обновления не всегда зависит от вас. Конечно, можно отложить обновление до выхода следующей младшей версии Redmine — на несколько недель (наверное, даже и на более длительный срок). Но вы же не хотите при обнаружении новых проблем безопасности в Redmine или Rails сидеть с непатченной системой, пока не получится освободить время для установки и настройки нового стека Bitnami и вручную переместить все данные?
Установка — это только верхушка айсберга. Обновление — вот что придется делать регулярно.
Поиск простейшего способа установки определенно перестает быть актуальным, как только принимается решение использовать Redmine в производстве. Простое сопровождение и возможность модернизации — вот на чем нужно заострять внимание, чтобы минимизировать затраты и риски, связанные с использованием собственного Redmine.
Ниже я расскажу, как просто поддерживать Redmine в актуальном состоянии.
Даже если вы намереваетесь запустить стоковый Redmine без каких-либо настроек или плагинов, всё равно используйте репозиторий Git для хранения копии Redmine. По крайней мере, наличие специализированного репозитория даст вам место хранения всего необходимого для развертывания (позже это будет рассмотрено подробнее). Рано или поздно вы (или ваши пользователи) захотите установить какой-нибудь плагин или настраиваемую тему, и для этого уже будет готова инфраструктура. Эксперименты с изменениями и тестирование плагинов и тем в локальных ветвях без нарушений в производственном коде становятся очень простыми при наличии собственного репозитория git c Redmine. Так что сейчас мы начнем с настройки репозитория.
Хотя основной репозиторий Redmine является экземпляром Subversion, на Github есть полуофициальный репозиторий, который поддерживается основным коммиттером и постоянно обновляется. Используйте его для настройки собственного репозитория:
Настройка локального клона Redmine
$ git clone git@github.com:redmine/redmine.git
$ cd redmine
$ git remote rename origin upstream
$ git remote add origin git@yourserver.com:redmine.git
$ git checkout -b redmine/3.2-stable upstream/3.2-stable
$ git checkout -b local/3.2-stable
$ git push --set-upstream origin local/3.2-stableИзмените номер версии 3.2-stable на номер последней стабильной версии Redmine.
Удаленный репозиторий git@yourserver.com должен быть частным, так как в нем будет храниться конфигурация развертывания (а возможно, и прочая информация, публиковать которую не стоит). Поскольку описанный ниже процесс развертывания будет извлекать из этого репозитория код, то репозиторий должен быть доступен во время развертываний, поэтому не размещайте его на настольных компьютерах. Идеальной будет ситуация, когда репозиторий также будет доступен с веб-сервера, на котором происходит развертывание. Но это при необходимости можно обойти.
Теперь у вас есть две локальные ветви:
redmine/3.2-stable, который отслеживает Redmine 3.2 без дополнительного функционала из репозитория github/redmine, представленная вышеуказанным удаленным восходящим репозиторием,
local/3.2-stable, куда будут помещены все настройки развертывания, кастомизации, темы и плагины.
Redmine использует следующую схему нумерации версий: xyz Major/Minor/Patch. Каждая младшая версия имеет собственную стабильную ветку, в которой исправления и патчи безопасности будут применяться с течением времени (до тех пор, пока эта версия все еще поддерживается). В нашем случае это ветвь 3.2-stable.
Время от времени эта восходящая ветвь будет получать некоторые новые коммиты. Ваша задача — включить новые коммиты в локальную ветвь local/3.2-stable для развертывания.
Хотя возможно и просто регулярно дополнять восходящую ветвь, я предлагаю использовать git rebase для поддержки собственного набора изменений поверх стокового кода Redmine:
Перебазирование локальных изменений поверх «голого» Redmine:
$ git checkout redmine/3.2-stable
$ git pull # new upstream commits coming in
$ git checkout local/3.2-stable
$ git rebase redmine/3.2-stableКоманда rebase:
local/3.2-stable.local/3.2-stable, чтобы отразить изменения, произошедшие в redmine/3.2-stable.Итогом будет являться чистая история, в которой ваши (локальные) коммиты всегда находятся поверх последних (восходящих) коммитов Redmine.
Теперь, когда есть новая стабильная ветвь (скажем, 3.3-stable), делайте то же самое — перебазируйте ваши изменения поверх неё. Команды git будут немного отличаться из-за изменения восходящей ветви:
Перенос локальных изменений в новую стабильную ветвь
$ git fetch upstream
$ git checkout -b redmine/3.3-stable upstream/3.3-stable
$ git checkout -b local/3.3-stable local/3.2-stable
$ git rebase --onto redmine/3.3-stable redmine/3.2-stable local/3.3-stableЭти команды вначале создают две новые локальные ветви для версии 3.3: одну из восходящей, а другую — из локальной ветви 3.2. Затем они перебазируют локальные изменения поверх redmine/3.3-stable. Локальные изменения здесь — это разность между redmine/3.2-stable и local/3.3-stable (что по-прежнему является redmine/3.2-stable). Теперь local/3.3-stable содержит Redmine 3.3 плюс любые локальные изменения.
Для новой старшей версии требуется сделать то же самое.
Рано или поздно (вероятно, уже во время первого обновления до новой младшей версии) вы столкнетесь с конфликтами слияния. Во время ребазирования Git применяет коммиты один за другим и останавливается каждый раз, когда применение коммита происходит с ошибками. В этом случае команда git status покажет проблемные файлы.
Проверьте, какой из коммитов дал сбой, узнайте, для чего он предназначался (хорошо помогут осмысленные сообщения коммитов), исправьте файлы, командой git add добавьте каждый исправленный файл, когда закончите. Если конфликты были устранены, можно просмотреть изменения, которые будут зафиксированы, с помощью команды git diff --cached. Как только вы сочтете результат удовлетворительным, можно продолжить ребазирование с помощью команды git rebase --continue.
Если вы неожиданно получили кучу конфликтов, а времени на решение этой проблемы нет, можно просто прервать текущее ребазирование с помощью параметра --abort, который восстановит рабочую копию до исходного состояния.
Теперь, когда рабочий процесс Git настроен должным образом, пришло время автоматизировать развертывание, о котором я расскажу во второй части этого руководства (примечание: перевод второй части будет доступен в течение нескольких дней).
|
Метки: author olemskoi системное администрирование серверное администрирование devops блог компании southbridge redmine ruby rails git |
Однолинейные схемы в Revit |

UIApplication uiapp = commandData.Application;
UIDocument uidoc = uiapp.ActiveUIDocument;
Application app = uiapp.Application;
Document doc = doc.Document;
//Выбираем электрические цепи, относящиеся к щиту "ЩС"
ParameterValueProvider provider
= new ParameterValueProvider(new ElementId((int)BuiltInParameter.RBS_ELEC_CIRCUIT_PANEL_PARAM));
FilterStringRule rule = new FilterStringRule(provider, new FilterStringEquals(), "ЩС", true);
ElementParameterFilter filter = new ElementParameterFilter(rule);
ICollection docCircuits =
(new FilteredElementCollector(doc))
.OfCategory(BuiltInCategory.OST_ElectricalCircuit)
.WherePasses(filter)
.ToArray();
foreach (Element docCircuit in docCircuits)
{
//Номер цепи
num = docCircuit.get_Parameter(BuiltInParameter.RBS_ELEC_CIRCUIT_NUMBER)?
.Element.Name;
//Коэффициент мощности
powerFactor =
docCircuit.get_Parameter(BuiltInParameter.RBS_ELEC_POWER_FACTOR)?
.AsValueString();
//Тип кабеля
cableType =
docCircuit.get_Parameter(BuiltInParameter.RBS_ELEC_CIRCUIT_WIRE_TYPE_PARAM)?
.AsValueString();
//Материал жилы
Element wireType = new FilteredElementCollector(doc)
.OfClass(typeof(WireType))
.FirstOrDefault(
e => e.Name.Equals(cableType));
string coreMaterial = wireType.get_Parameter(BuiltInParameter.RBS_WIRE_MATERIAL_PARAM)
.AsValueString();
}
using (Transaction tx = new Transaction(doc))
{
tx.Start("Создание однолинейной схемы");
double xCoord = 0;
// Вставляем отходящие линии
foreach (Circuit circuit in panel.circuits)
{
//Получаем семейство из активного документа по имени.
FamilySymbol lineSymbol = FilteredElementCollector(doc)
.OfClass(typeof(FamilySymbol))
.Where(q => q.Name == "SLD_АВ")
.First() as FamilySymbol;
//Переводим координаты точки вставки из миллиметров в футы
XYZ coords = new XYZ(xCoord, 0, 0).ToFeets();
//Вставляем семейство с именем SLD_АВ
FamilyInstance line = doc.Create.NewFamilyInstance(coords, lineSymbol, uidoc.ActiveView);
//Получаем все параметры семейства
ParameterSet parametersLineOut = line.Parameters;
//Записываем значение в параметр семейства
foreach (Parameter param in parametersLineOut)
{
switch (param.Definition.Name)
{
case "Номер группы": param.Set(circuit.number); break;
case "Тип кабеля": param.Set(circuit.cableType); break;
case "Коэффициент мощности": param.Set(circuit.powerFactor); break;
}
}
xCoord = xCoord + 25;
}
tx.Commit();
}
|
Метки: author Nabiyev cad/cam c# api .net revit api c#.net cad проектирование |
ЧПУ (SEF URLs) в Symfony 3 — автогенерация slug, настройка и маршрутизация |

...
"require-dev": {
...
"phpunit/phpunit": "^6.2.1"
...
},
...
"config": {
"platform": {
"php": "7.0.15"
},
...
},
...
composer update
php composer.phar update
php bin/console doctrine:generate:entity --entity=AppBundle:Product --fields="name:string description:text seller:string publishDate:datetime slug:string(length=128 nullable=false unique=true)" -q
php bin/console doctrine:database:create #создаем базу данных
php bin/console doctrine:schema:create #создаем структуру данных в базе данных
php bin/console doctrine:generate:crud --entity="AppBundle:Product" --route-prefix=products --with-write -n #генерируем CRUD контроллер
php bin/console server:run localhost:2020

composer require stof/doctrine-extensions-bundle
class AppKernel extends Kernel
{
public function registerBundles()
{
$bundles = array(
// ...
new Stof\DoctrineExtensionsBundle\StofDoctrineExtensionsBundle(),
);
// ...
}
// ...
}...
stof_doctrine_extensions:
default_locale: en_US
orm:
default:
sluggable : true
...
...
use Gedmo\Mapping\Annotation as Gedmo;
...
/**
* Product
*
* @ORM\Table(name="product")
* @ORM\Entity(repositoryClass="AppBundle\Repository\ProductRepository")
*/
class Product
{
...
/**
* @var string
*
* @Gedmo\Slug(fields={"name"})
* @ORM\Column(name="slug", type="string", length=128, nullable=false, unique=true)
*/
private $slug;
...
}
@Gedmo\Slug(fields={"name"}), что я хочу, чтобы slug генерировался на основании поля name. Можно указать несколько полей, чтобы они конкантинировались при генерации. Например, часто вместо с именем сущности указывают дату создания: @Gedmo\Slug(fields={"publishDate", "name"})....
class ProductType extends AbstractType
{
/**
* {@inheritdoc}
*/
public function buildForm(FormBuilderInterface $builder, array $options)
{
$builder->add('name')->add('description')->add('seller')->add('publishDate'); //Удалили ->add('slug')
}
...
}



...
class ProductController extends Controller
{
...
/**
* Finds and displays a product entity.
*
* @Route("/{slug}", name="products_show")
* @Method("GET")
* @param string $slug
* @return \Symfony\Component\HttpFoundation\Response
*/
public function showAction(string $slug)
{
$product = $this->getDoctrine()
->getRepository('AppBundle:Product')
->findOneBySlug($slug);
$deleteForm = $this->createDeleteForm($product);
return $this->render('product/show.html.twig', array(
'product' => $product,
'delete_form' => $deleteForm->createView(),
));
}
/**
* Displays a form to edit an existing product entity.
*
* @Route("/{slug}/edit", name="products_edit")
* @Method({"GET", "POST"})
* @param Request $request
* @param string $slug
* @return \Symfony\Component\HttpFoundation\RedirectResponse|\Symfony\Component\HttpFoundation\Response
*/
public function editAction(Request $request, string $slug)
{
$product = $this->getDoctrine()
->getRepository('AppBundle:Product')
->findOneBySlug($slug);
$deleteForm = $this->createDeleteForm($product);
$editForm = $this->createForm('AppBundle\Form\ProductType', $product);
$editForm->handleRequest($request);
if ($editForm->isSubmitted() && $editForm->isValid()) {
$this->getDoctrine()->getManager()->flush();
return $this->redirectToRoute('products_edit', array('slug' => $product->getSlug()));
}
return $this->render('product/edit.html.twig', array(
'product' => $product,
'edit_form' => $editForm->createView(),
'delete_form' => $deleteForm->createView(),
));
}
...
}
{% extends 'base.html.twig' %}
{% block body %}
Products list
Id
Name
Description
Seller
Publishdate
Actions
{% for product in products %}
{{ product.id }}
{{ product.name }}
{{ product.description }}
{{ product.seller }}
{% if product.publishDate %}{{ product.publishDate|date('Y-m-d H:i:s') }}{% endif %}
{% endfor %}
{% endblock %}
{% extends 'base.html.twig' %}
{% block body %}
Product
Id
{{ product.id }}
Name
{{ product.name }}
Description
{{ product.description }}
Seller
{{ product.seller }}
Publishdate
{% if product.publishDate %}{{ product.publishDate|date('Y-m-d H:i:s') }}{% endif %}
Slug
{{ product.slug }}
-
Back to the list
-
Edit
-
{{ form_start(delete_form) }}
{{ form_end(delete_form) }}
{% endblock %}

@Route("/{slug}", name="products_show")@Route("/{slug}/edit", name="products_edit")|
Метки: author BotCoder symfony php doctrine orm slug doctrineextension doctrine symfony 3 чпу sef urls |
Дайджест свежих материалов из мира фронтенда за последнюю неделю №265 (29 мая — 4 июня 2017) |

| Веб-разработка |
| CSS |
| Javascript |
| Браузеры |
| Занимательное |
 Веб-разработка
Веб-разработка Обзор изменений в новом мажорном релизе Node 8
Обзор изменений в новом мажорном релизе Node 8 Кастомные свойства — HTML Шорты
Кастомные свойства — HTML Шорты Browserslist — это хорошая идея Webpack vs Gulp Как я могу сделать сделать доступной свою иконочную систему? Как улучшать проекты с устаревшим кодом Песочница для GraphQL WebAssembly: Mozilla победила Более быстрая загрузка страницы с помощью легкой анимации CSS и SVG (без JavaScript) Приключения новичка в веб-производительности Проверка производительности CSS анимации с помощью браузерных инструментов для разработчика Ловля мусора: как мы обнаружили самые медленные части UI Использование метрик производительности, которые наиболее влияют на UX Чеклист производительности фронтенда для продакшена HTTP/2 push более сложный, чем я думал
Browserslist — это хорошая идея Webpack vs Gulp Как я могу сделать сделать доступной свою иконочную систему? Как улучшать проекты с устаревшим кодом Песочница для GraphQL WebAssembly: Mozilla победила Более быстрая загрузка страницы с помощью легкой анимации CSS и SVG (без JavaScript) Приключения новичка в веб-производительности Проверка производительности CSS анимации с помощью браузерных инструментов для разработчика Ловля мусора: как мы обнаружили самые медленные части UI Использование метрик производительности, которые наиболее влияют на UX Чеклист производительности фронтенда для продакшена HTTP/2 push более сложный, чем я думал CSS 11 вещей которые я узнал, читая спецификацию flexbox CSS в JavaScript: будущее компонентных стилей CSS Media Queries Level 4 by Florian Rivoal Создание руководства по стилю прямо из кода Sass Обречен ли CSS всегда быть отстойным? Любовное письмо к CSS CSS-фильтры для регулировки яркости, контрастности, непрозрачности и инверсии Отчет в цифрах: полтора года с атомарным CSS Новая отзывчивость в вебе — единицы вьюпорта Подробно о нюансах создания кастомных чекбоксов и радиокнопок Искусство анимации единственного Div на странице < css-doodle /> — веб-компонент для рисования шаблонов с помощью css. Объяснение техники разрыва колонки широким блоком с помощью CSS Grid scssfmt — быстрый и простой форматор SCSS кода Трендовые тени на CSS ctr — очередной CSS Framework Подборка палитр для эффектной анимации градиентов
CSS 11 вещей которые я узнал, читая спецификацию flexbox CSS в JavaScript: будущее компонентных стилей CSS Media Queries Level 4 by Florian Rivoal Создание руководства по стилю прямо из кода Sass Обречен ли CSS всегда быть отстойным? Любовное письмо к CSS CSS-фильтры для регулировки яркости, контрастности, непрозрачности и инверсии Отчет в цифрах: полтора года с атомарным CSS Новая отзывчивость в вебе — единицы вьюпорта Подробно о нюансах создания кастомных чекбоксов и радиокнопок Искусство анимации единственного Div на странице < css-doodle /> — веб-компонент для рисования шаблонов с помощью css. Объяснение техники разрыва колонки широким блоком с помощью CSS Grid scssfmt — быстрый и простой форматор SCSS кода Трендовые тени на CSS ctr — очередной CSS Framework Подборка палитр для эффектной анимации градиентов JavaScript Must see: видеозаписи митапа MoscowJS 37 Переосмысливая JavaScript: break и функциональный подход Что означет Google AMP для JavaScript сообщества Управление состоянием в CSS с помощью переиспользуемых функций JavaScript — часть 2 Реактивный UI с помощью VanillaJS – часть 1: чистый функциональный стиль Введение в наиболее часто используемые функции ES6 Как отслеживать изменения в DOM с помощью Mutation Observer Почему JavaScript? Cоздание простого Twitter бота с Node.js всего в 38 строк кода Airbnb перешел на React для создания более отзывчивого фронтенда Зачем использовать React JS для создания быстрых интерактивных UI? Получаем лучшую React-цию с помощью прогрессивных веб приложений Оптимизация рендеринга в React (часть 1) React как платформа: путь к кросс-платформенному UI — Leland Richardson Динамический Angular или манипулируй правильно Вот что вы должны знать о динамических компонентах в Angular React vs Angular vs Vue в примерах Какие плюсы и минусы AngularJS и ReactJS? Начианем современную разработку фронтенда с Vue.js Прототипирование Filter UX в Instagram с помощью Vue Использование фильтров в Vue.js vue-recyclerview — дозагрузка элементов больших списков с vue-recyclerview Клевая скролл-анимация с помощью библиотеки AOS t-scroll — плагин для создания анимации по скроллу Timeline.js — плагин для создания хронологического слайдера с временной шкалой AmplitudeJS — современный HTML аудио-плеер o — браузерный загрузчик/бандлер для JS. Без зависимостей, node и cli taxi-rank — JSDom на базе Selenium Webdriver API picodom — 1Kb Virtual DOM Chrome победил FF Developer Edition 54: новые функции инспектора и отладчика, помощь MDN в netmonitor и многое другое Chrome 59 — что нового в DevTools Технические детали Safari Technology Preview 31
JavaScript Must see: видеозаписи митапа MoscowJS 37 Переосмысливая JavaScript: break и функциональный подход Что означет Google AMP для JavaScript сообщества Управление состоянием в CSS с помощью переиспользуемых функций JavaScript — часть 2 Реактивный UI с помощью VanillaJS – часть 1: чистый функциональный стиль Введение в наиболее часто используемые функции ES6 Как отслеживать изменения в DOM с помощью Mutation Observer Почему JavaScript? Cоздание простого Twitter бота с Node.js всего в 38 строк кода Airbnb перешел на React для создания более отзывчивого фронтенда Зачем использовать React JS для создания быстрых интерактивных UI? Получаем лучшую React-цию с помощью прогрессивных веб приложений Оптимизация рендеринга в React (часть 1) React как платформа: путь к кросс-платформенному UI — Leland Richardson Динамический Angular или манипулируй правильно Вот что вы должны знать о динамических компонентах в Angular React vs Angular vs Vue в примерах Какие плюсы и минусы AngularJS и ReactJS? Начианем современную разработку фронтенда с Vue.js Прототипирование Filter UX в Instagram с помощью Vue Использование фильтров в Vue.js vue-recyclerview — дозагрузка элементов больших списков с vue-recyclerview Клевая скролл-анимация с помощью библиотеки AOS t-scroll — плагин для создания анимации по скроллу Timeline.js — плагин для создания хронологического слайдера с временной шкалой AmplitudeJS — современный HTML аудио-плеер o — браузерный загрузчик/бандлер для JS. Без зависимостей, node и cli taxi-rank — JSDom на базе Selenium Webdriver API picodom — 1Kb Virtual DOM Chrome победил FF Developer Edition 54: новые функции инспектора и отладчика, помощь MDN в netmonitor и многое другое Chrome 59 — что нового в DevTools Технические детали Safari Technology Preview 31 Занимательное
ЗанимательноеПросим прощения за возможные опечатки или неработающие/дублирующиеся ссылки. Если вы заметили проблему — напишите пожалуйста в личку, мы стараемся оперативно их исправлять.
|
|
«Прикорнуть немножечко»: чек-лист для короткого перерыва на сон |

|
Метки: author 1cloud gtd блог компании 1cloud.ru 1cloud сон napping |
Inperfo – минималистичный мониторинг сети |

В первую очередь Inperfo предназначен для мониторинга сетевых интерфейсов на свитчах и роутерах. Конечно же, можно мониторить сетевые интерфейсы непосредственно на серверах, когда, например, у вас нет доступа к сетевому оборудованию, но есть десятки или сотни арендуемых серверов (физических или виртуальных).
Сервис предназначен для мониторинга именно физических Ethernet-интерфейсов. Что, кстати, позволяет видеть перекосы трафика в Port Channel'ах при неверной настройке или каких-то других проблемах. Если у вас другие задачи, и нужно мониторить и другие типы интерфейсов, то посмотрите в сторону Observium'a и собратья (LibreNMS, NetXMS, etc) или на SolarWind NPM.
Основной целью создания сервиса было желание видеть топы по загрузке интерфейсов, ошибкам, чтобы все проблемные или потенциально проблемные места были как на ладони. В zabbix'e или cacti сделать такой динамический скрин мягко говоря проблематично. К тому же хотелось иметь топ по истории за неделю, а не в текущий момент – неделя, оптимальный вариант для многих сетей, когда нагрузка растёт после выходных и снижается к концу недели, или же наоборот – в выходные пики, а будние дни нагрузка ниже.
И вторая не менее важная цель — минималистичный интерфейс без излишних наворотов, сложностей и финтиплюшек. Подойдёт и понравится не всем, да.
И само собой, автоматически отслеживает изменения – переименование интерфейсов, описаний (ifDescr), изменение статуса интерфейса и так далее. Единственная ручная работа – добавление новых устройств или серверов в конфиг агента. Со временем добавится возможность auto discovery, но пока её нет.
Вам точно не подойдёт Inperfo, если вам нужны:
– Мониторинг CPU/Memory
– Мониторинг hdd, temperature и другие не Ethernet-вещи
– Возможность рисовать карты и схемы сети
Сервис состоит из двух компонентов: сервера и агента. Агент собирает snmp-данные об интерфейсах и отправляет их на сервер. Сервер обрабатывает (сортирует, обновляет rrd-файлы и прочая) полученные данные и отображает через web-интерфейс.
Сервер — это docker-контейнер со "стандартным" набором софта: nginx/php-fpm/memcached/mysql/rrdtool. Сервер ожидает, что агенты будут присылать данные каждые 5 минут. Данные сохраняются в базе – по нагрузке интерфейсов и ошибкам ведётся недельная history, по которой рассчитываются 95-й перцентиль и топ по max/avg. Сделано это для того, что "видеть" сеть в разных "разрезах" – без редких всплесков или наоборот, когда нужно посмотреть только всплески.
Данные контейнера хранятся на хостовой системе для удобства обновления, бекапа и переноса сервера на другие хосты. Обновиться можно буквально одной командой (идея взята у докера, см. https://get.docker.com)
Агент – это тоже docker-контейнер, в котором по крону раз в 5 минут запускается агент, собирающий snmp-данные об интерфейсах с сетевых устройств или серверов. Пока что интервал обновления (опроса) устройств изменить нельзя.
Клиент поддерживает две версии SNMP – v2 и v3.
Конфигурация агента, логи, и отправляемые данные хранится на хостовой системе. Это позволяет легко редактировать конфиги, переносить агента на другие хосты при необходимости.
В идеале нам нужно установить и настроить по одному агенту на каждый из дата центров или удалённых офисов, чтобы агент мог локально опрашивать устройства внутри дата центра по snmp и отправлять собранные данные на центральный сервер, который может находится в одном из датацентров или где-нибудь в облаке (Amazon, DigitalOcean, Azure, etc).
Если же у вас один дата центр или есть "быстрые" линки до остальных ДЦ, то достаточно установить сервер и агента на одной и той же linux-машине, с которой и будут опрашиваться все устройства сети. Или, например, на той же машине, где у вас уже стоит cacti – не нужно будет настраивать snmp-доступ на сетевом оборудовании (если он у вас есть :)
Основной "минус" этой схемы: нужен snmp-доступ к сетевому оборудованию.
Для мониторинга сетевых интерфейсов на серверах нам нужно на каждый из них установить snmp-демона, например, через ansible-playbook. В этом случае каждый linux-сервер для агента будет выглядеть как отдельное сетевое устройство с одним или несколькими сетевыми интерейсами.
Плюсы:
Тут всё ясно, можно мониторить и свитчи/роутеры и серверы вместе – агент не различает тип устройства, а информацию по интерфейсам берёт из MIBv2-базы. Кстати, это ещё один минус – если у вас есть девайс, у которого информация по интерфейсам отдаётся с "нестандартных" MIB'ов (например, BTI 7000), то Inperfo, на данный момент, вам не подойдёт.
Хорошо себя чувтсвует на "среднем" железе (16CPU/16GB) до 100 устройств (6000+ портов), на большем кол-ве запускать и наблюдать работу пока что не приходилось. Но посколько агент для опроса каждого устройства создаёт отдельный процесс (fork), то golang с go-рутинами просто изнывает и просится в этот кусок кода. Аналогично работает и сервер при получении данных.
– Указание максимальной скорости для интерфейса. Нужно в ситуациях, когда к провайдеру вы подключены по 1Гб-линку, но оплаченный канал по факту меньше, аля ограничен до 500Мб.
– Еженедельные отчёты по топам на почту.
– Уведомления на почту.
– Отдельная сборка docker-контейнера с сервером и агентом. Для небольших сетей это идеальный вариант. Плюс появится возможность добавлять хосты через web-интерфейс.
– Топы/графики по пакетам
– Поиск по имени устройства, по интерфейсу, по описанию и по алиасу
– Переписать агента и часть сервера на golang.
На данных момент сервис не шлёт никаких алертов и прочего, но по URI /export/ можно импортировать данные в тот же заббикс, и получать уведомления. Сервис ещё немного сыроват, но поставленные задачи решает.
Install & enjoy.
|
Метки: author nesterwsx системное администрирование сетевые технологии it- инфраструктура *nix snmp- мониторинг сети |
Блокчейн + распределённое хранилище = Sia |
Всем привет!
У всех нас есть данные, которые хочется держать под контролем. Мы не хотим потерять к ним доступ и не хотим, чтобы доступ был у кого-то ещё. Где хранить такие данные? Я считаю, что Sia может стать идеальным местом для этого и расскажу, почему.

Disclaimer: Sia активно развивается и, по словам разработчиков, всё ещё не подходит для того, чтобы быть единственным местом для бекапа.
Sia (произносится "Сая") — это распределённая система на основе блокчейна, участники которой хранят информацию на жестких дисках друг друга за плату. Участник системы может решить быть только пользователем, загружающим данные (в терминологии Sia — renter), или же сервером, принимающим данные (в терминологии Sia — host), или совмещать эти две роли. Хосты заинтересованы в хранении данных, так как они уходят в убыток, если теряют данные. Это обеспечивается следующим образом: при заключении контракта на хранение данных хост вносит депозит и ежедневно подтверждает факт хранения загруженных данных; если он этого не делает, то лишается части депозита. Подробности процесса оставим на десерт :-)
Чтобы данные уцелели даже в случае отказа нескольких хостов, используются коды Рида — Соломона. Данные загружаются на 40 хостов и остаются доступными, если хотя бы 10 из этих хостов доступны. Избыточность хранения составляет 3x. В будущем ожидается рост uptime хостов, после чего избыточность можно будет снизить.
В Sia используется свой альткоин — Siacoin. Есть свой блокчейн, в котором хранятся как обычные транзакции, так и контракты на хранение файлов. (Блокчейн биткоина не подошёл бы для Sia, так как в нём нет возможности заключать такие контракты.) Есть и свой explorer, и майнеры, и биржи для обмена — одним словом, всё, что прилагается к альткоину.
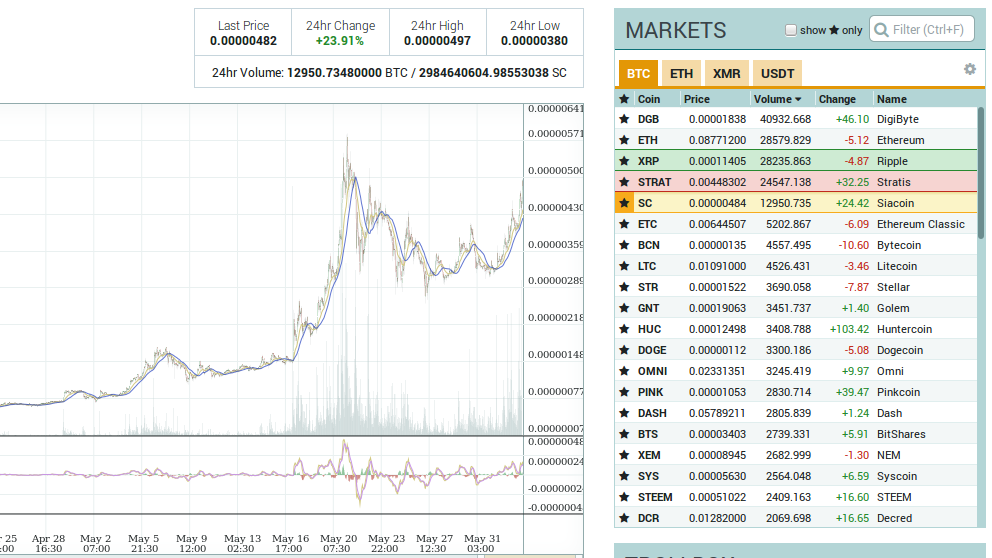
Страница Siacoin на бирже Poloniex.
Так почему мне нравится хранить данные в такой системе? А вы не задумывались, какие ещё способы есть в нашем распоряжении? Есть огромное количество способов, имещих единую точку отказа. А единая точка отказа оправдывает своё название и рано или поздно отказывает. Кроме того, такие системы тяготеют к централизации и отказу от анонимности и становятся удобным местом для насаждения государственного контроля за данными пользователя. Мне претит мысль о том, что кто-то может лишить меня доступа к моим же данным. Какой же выбор остаётся у людей, желающих децентрализованно хранить данные? Например, покупать место или серверы в нескольких централизованных системах. Для большинства людей это означает огромные накладные расходы в виде потраченного времени и денег, особенно если делать это анонимно.
Пара слов о том, почему так важна анонимность при хранении данных. Если государство знает о твоей собственности, то на самом деле она тебе не принадлежит, так как государство определяет правила игры и завтра может решить забрать её у тебя (или частично забрать, обложив налогом). Например, в США изымали золото у людей во времена Великой депрессии. Единственный надёжный способ обезопасить собственность — это отвязать её от любой информации, которой располагает государство.
Когда я осознал это, я решил было сделать систему, лишённую этих недостатков: децентрализованную, анонимную и надёжную. Сначала я решил проверить, нет ли чего готового на гитхабе. И нашёл Sia — именно то, что нужно! С точки зрения пользователя, Sia — это готовый аналог покупки кучи серверов для ручной загрузки данных. И аналог более эффективный, так как один сервер хранит данные тысяч пользователей. Калькулятор стоимости хранения на сайте Sia показывает, что хранение 5Тб в течение месяца обойдётся в 10 долларов. (Disclaimer: реальная цена будет выше из-за комиссий на создание контрактов и тройной избыточности хранения, но всё равно остаётся очень и очень привлекательной.)
См. также руководство на официальном сайте.
Все приватные ключи, использующиеся в кошельке, получаются из seed, который программа выдаёт в начале работы. Для восстановления доступа к сиакоинам кошелька (но пока, к сожалению, не к файлам) достаточно знать этот seed.
Если честно, Sia-UI я ни разу не запускал, так как я живу в командной строке, а Sia предоставляет отличные инструменты для этого: siad и siac. (Кстати, весь код Sia написан на Go, что не может не радовать.) Основы работы с siad и siac можно почерпнуть из статьи про запуск хоста и из хеплов этих программ. Программу siad обычно достаточно просто запустить, а взаимодействовать с ним уже через siac.
Примеры команд:
siac wallet unlock — разблокировать кошелёк (требуется ввод seed),siac wallet balance — показать текущий баланс кошелька,siac renter setallowance money time_period — заключить контракты с хостами, siac renter upload /path/to/source/file path/in/sia — загрузить файл в Sia,siac renter contracts — вывести все заключённые контракты с хостами.siac взаимодействует с siad через HTTP API. С помощью него можно строить свои системы, использующие Sia в качестве хранилища. Команда Sia делает ставку на то, что в будущем компании будут хранить свои данные в Sia.
Для хранения данных необходима информация, находящаяся в папке renter/. Есть планы о восстановлении данных исключительно из seed (см. в разделе "планы").
По желанию можно сохранить информацию об объёме загруженного с помощью siac renter export и загрузить её в "пузомерку": rankings.sia.tech.

Хост Sia будет приносить доход в сиакоинах своему владельцу. Это неплохой способ монетизировать неиспользуемые части жестких дисков. Оплачивается не только хранение, но и трафик.
Про запуск своего сервера есть целая статья. Я тут опять пробегусь по верхам.
siad и siac. Программа siad запускается, а все действия осуществляются через siac. Надо подождать, пока siad скачает блокчейн. Это занимает несколько часов, есть планы по значительному ускорению.siac wallet address), закинуть на него сиакоинов, купленных любым способом.siac host folder add /path/to/dir sizesiac config.siac host announce.Через некоторое время хост начнёт получать контракты и на него будут загружать данные.
Доходы хостеров можно посмотреть на сайте siahub.info. Пример графика доходов хоста, на который загружено 585 из доступных 999 Гб:
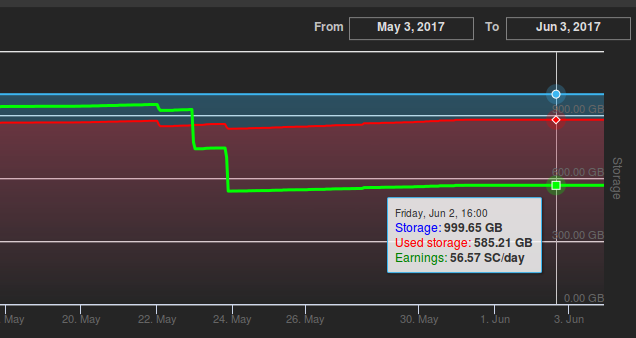
Данный хост получает 57 сиакоинов каждый день. 1 сиакоин сегодня стоит примерно 1.5 цента, а значит этот хост ежедневно получает примерно 50 рублей. Пусть есть NAS на 4Тб за 20к рублей. При аналогичном проценте заполнения он выдавал бы примерно 200 рублей в день, то есть 6к рублей в месяц — неплохая окупаемость.
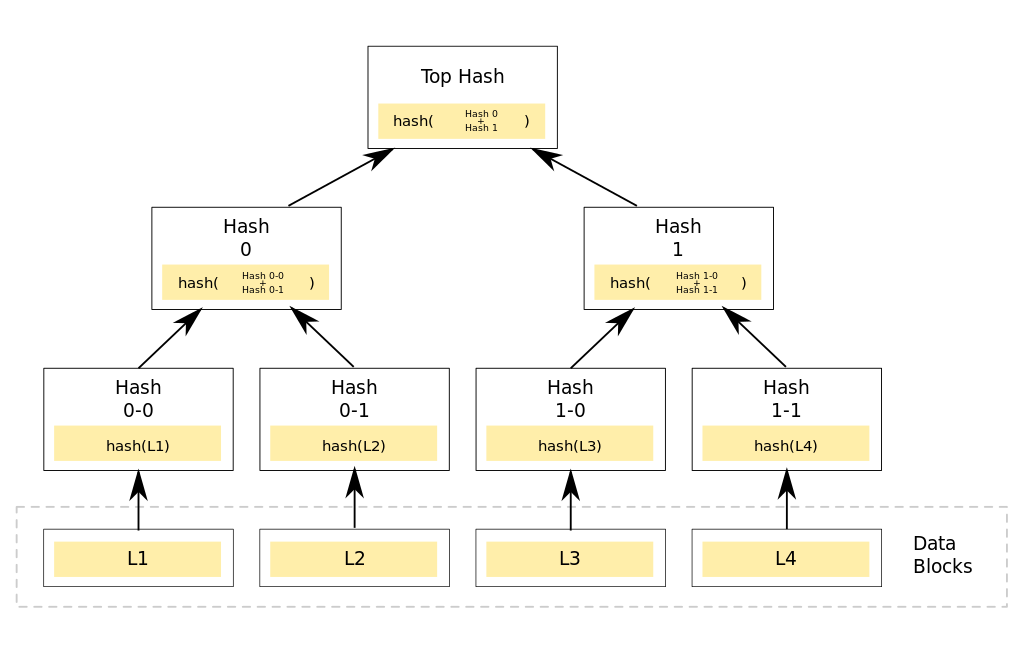
В Sia хосты регулярно доказывают, что хранят загруженные данные. Это важный момент, так как иначе недобросовестные хосты могли бы сбрасывать все данные в /dev/null, продолжая получать плату. Выше я обещал рассказать, как устроено доказательство хранения. Это подробно описано в статье от создателя Sia. Ниже моё объяснение на пальцах.
Данные контракта можно представить как массив из фрагментов одинакового размера. Устроим древовидное хеширование этих фрагментов. Для этого рассчитаем сильные криптографические хеши этих фрагментов. Потом разобъем полученные хеши на пары и рассчитаем хеши от соединённых хешей каждой пары. Полученные хеши снова разобьём на пары и так, пока не получим один хеш. Он-то и хранится в контракте и обновляется, когда пользователь загружает новые данные по этому контракту. Теперь вернёмся к отдельному фрагменту файла и проследим его "путь" до корня дерева. На каждом шагу в хеширование будет "примешиваться" хеш, приходящий от другой группы фрагментов. Если мы предоставим данный фрагмент и эти дополнительные хеши, находящиеся на пути от фрагмента до корня, то сможем доказать, что данный фрагмент присутствует на данной позиции в данных. Подделка такого доказательства равносильна нахождению коллизии хеш-функции.
Как же это применяется в Sia? Номер фрагмента, хранение которого хост должен доказать, определяется в зависимости от хешей предыдущих блоков, поэтому его сложно предсказать заранее. В определённый промежуток времени (по блокам, а не по часам) хост должен загрузить доказательство хранения выбранного фрагмента, иначе он теряет деньги.
У внимательного читателя мог возникнуть вопрос — а что, если зловредный хост будет хранить данные, но не будет давать их скачивать пользователю? Или просто иметь низкий uptime, из-за чего пользоваться им будет невозможно. Для борьбы с этим в Sia придумали систему рейтинга хостов. Каждый запущенный клиент вычисляет этот рейтинг независимо, в том числе измеряет uptime, поэтому лучше дать программе поработать вхолостую перед заключением контрактов, чтобы набралась статистика по хостам. Все факторы, влияющие на рейтинг, разбираются в статье про рейтинг. Рейтинги хостов можно смотреть командой siac hostdb -v и на сайте siahub.info.
В Siacoin есть одна особенность, которую я не встречал раньше в альткоинах. Siafund — это особый вид ресурсов, который может храниться в том же блокчейне и на таких же адресах, как и Siacoin. Адреса, на которых хранится Siafund, получают часть доходов хостов. Отчисления в размере 3.9% от выплат по успешным контрактам распределяются пропорционально между держателями Siafund. В природе существует ровно 10к Siafund. Большая их часть находится у разработчиков (Nebulous Inc.), но немногим больше 1000 были в своё время распроданы. Siafund продаются на бирже bitsquare.io и на канале #siafunds Slack-чата. В настоящее время цена одного Siafund составлет примерно 2 биткоина. Siafund'ы неделимы.
Siafund — это альтернатива предмайнингу собственной криптовалюты разработчиками альткоина. По задумке создателей, из-за высокой цены обладателями Siafund будут только люди, приверженные идеям проекта, включая разработчиков. Чем больше Sia будет использоваться для хранения файлов, тем больший доход будeт приносить Siafund.
На siapulse.com и siahub.info есть красивые карты хостов.
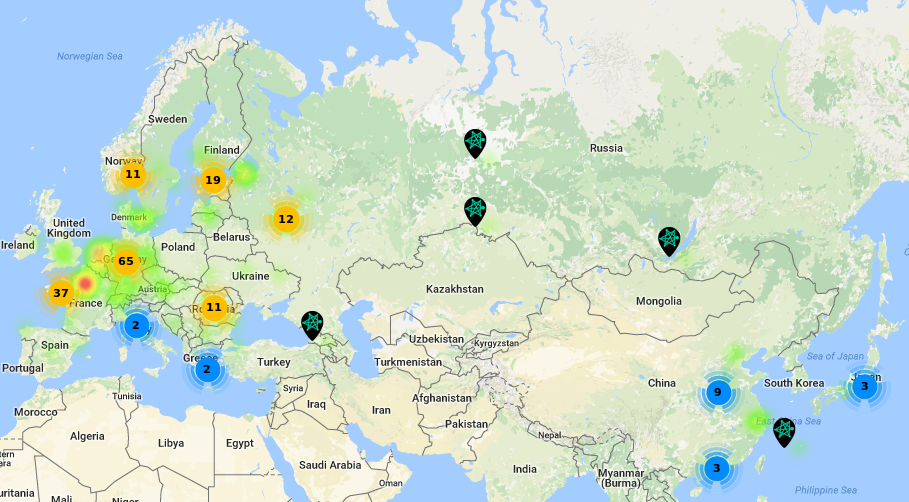
Хосты уже есть на всех материках, кроме Африки. Общее количество активных — 275. В том числе хосты есть в нескольких городах России и Украины. Приглашаю всех, кому нужна помощь с запуском хоста и вообще с Sia, на каналы Slack-чата, включая #help, #russian и #farming.
Некоторые планы из официального roadmap:
Жду всех в Slack-чате. Спасибо всем, кто дочитал до конца!
|
|
Дайджест интересных материалов для мобильного разработчика #205 (29 мая-04 июня) |

 |
Как инди-игре обогнать Angry Birds? |
 |
Реалистичный Realm. 1 год опыта |
 iOS
iOS Как сделать Table View со сворачивающимися ячейками Collapsible Sections Сломанный App Store Тестирование UI для iOS Уведомления в подходящее время при помощи Set SDK
Как сделать Table View со сворачивающимися ячейками Collapsible Sections Сломанный App Store Тестирование UI для iOS Уведомления в подходящее время при помощи Set SDK FanMenu: FAB с круговым меню SwiftKotlin: конвертер кода из Swift в Kotlin SplitViewDragAndDrop: простое перетаскивание между приложениями QueryGenie: создание и выполнение безопасных запросов к БД на Swift TinyCrayon: маски и вырезание объектов для фотографий
FanMenu: FAB с круговым меню SwiftKotlin: конвертер кода из Swift в Kotlin SplitViewDragAndDrop: простое перетаскивание между приложениями QueryGenie: создание и выполнение безопасных запросов к БД на Swift TinyCrayon: маски и вырезание объектов для фотографий Android
Android Android Dev Подкаст. Выпуск 34. Впечатления от Google I/O Исследуя новую библиотеку Android Architecture Components Google I/O 2017: 8 важных выводов для Android разработчиков Секрет хранения Android View State Красивая анимация с помощью Android ConstraintLayout Домашнее наблюдение на Raspberry Pi за 150 строчек кода Использование Gradle Kotlin Script для Android Экзамен на сертифицированного Android-разработчика Мои выводы из I/O 2017 Android: руководство по интентам Presento: кроссплатформенное управление презентациями Konfetti: показ конфетти Swipe-Button: кнопка со свайпом
Android Dev Подкаст. Выпуск 34. Впечатления от Google I/O Исследуя новую библиотеку Android Architecture Components Google I/O 2017: 8 важных выводов для Android разработчиков Секрет хранения Android View State Красивая анимация с помощью Android ConstraintLayout Домашнее наблюдение на Raspberry Pi за 150 строчек кода Использование Gradle Kotlin Script для Android Экзамен на сертифицированного Android-разработчика Мои выводы из I/O 2017 Android: руководство по интентам Presento: кроссплатформенное управление презентациями Konfetti: показ конфетти Swipe-Button: кнопка со свайпом Разработка Как сделать собственные Action для Google Home используя API.AI Отзывчивый UI в React Native Flutter для кроссплатформенной мобильной разработки Видео UIKonf 2017
Разработка Как сделать собственные Action для Google Home используя API.AI Отзывчивый UI в React Native Flutter для кроссплатформенной мобильной разработки Видео UIKonf 2017 Аналитика, маркетинг и монетизация Мой стек App Store Optimization
Аналитика, маркетинг и монетизация Мой стек App Store Optimization Устройства и IoT
Устройства и IoT|
|






