В поисках оптимальной диеты методом линейного программирования |
from cvxopt.modeling import variable, op
import time
start = time.time()
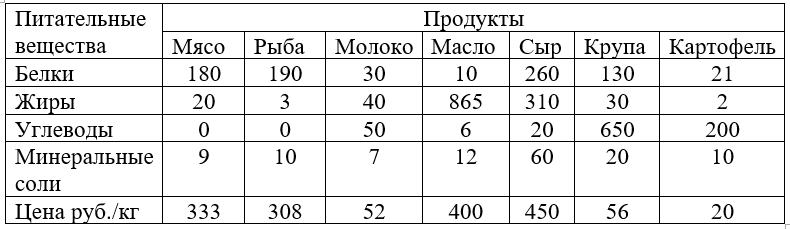
x = variable(7, 'x')
z=(333*x[0] + 308*x[1] +52* x[2] +400*x[3] +450*x[4] +56* x[5]+20*x[6])
mass1 =(- (180*x[0] + 190*x[1] +30* x[2] +10*x[3] +260*x[4] +130* x[5]+21*x[6]) <= -118)
mass2 =(- (20*x[0] + 3*x[1] +40* x[2] +865*x[3] +310*x[4] +30* x[5]+2*x[6]) <= -56)
mass3 =(- (50* x[2] +6*x[3] +20*x[4] +650* x[5]+200*x[6]) <= -500)
mass4 =(- (9*x[0] + 10*x[1] +7* x[2] +12*x[3] +60*x[4] +20* x[5]+10*x[6]) <= -28)
x_non_negative = (x >= 0)
problem =op(z,[mass1,mass2,mass3,mass4 ,x_non_negative])
problem.solve(solver='glpk')
problem.status
print("Результат:")
print(round(1000*x.value[0],1),'-грамм мяса, затраты -',round(x.value[0]*333,1),'руб.')
print(round(1000*x.value[1],1),'-грамм рыбы, затраты -',round(x.value[1]*308,1),'руб.')
print(round(1000*x.value[2],1),'-миллилитров молока, затраты -',round(x.value[2]*52,1),'руб.')
print(round(1000*x.value[3],1),'-грамм масла, затраты -',round(x.value[3]*400,1),'руб.')
print(round(1000*x.value[4],1),'-грамм сыр, затраты -',round(x.value[4]*450,1),'руб.')
print(round(1000*x.value[5],1),'-грамм крупы, затраты -',round(x.value[5]*56,1),'руб.')
print(round(1000*x.value[6],1),'-грамм картофеля, затраты -',round(x.value[6]*25,1),'руб.')
print(round(problem.objective.value()[0],1),"- стоимость рациона одного человека в день")
stop = time.time()
print ("Время :",round(stop-start,3))

from cvxopt.modeling import variable, op
import time
start = time.time()
x = variable(7, 'x')
z=(333*x[0] + 308*x[1] +52* x[2] +400*x[3] +450*x[4] +56* x[5]+20*x[6])
mass1 =(- (180*x[0] + 190*x[1] +30* x[2] +10*x[3] +260*x[4] +130* x[5]+21*x[6]) <= -118)
mass2 =(- (20*x[0] + 3*x[1] +40* x[2] +865*x[3] +310*x[4] +30* x[5]+2*x[6]) <= -56)
mass3 =(- (50* x[2] +6*x[3] +20*x[4] +650* x[5]+200*x[6]) <= -500)
mass4 =(- (9*x[0] + 10*x[1] +7* x[2] +12*x[3] +60*x[4] +20* x[5]+10*x[6]) <= -28)
x_non_negative = (x >= 0)
problem =op(z,[mass1,mass2,mass3,mass4 ,x_non_negative])
problem.solve(solver='glpk')
problem.status
print("Результат:")
print(round(1000*x.value[0],1),'-грамм хлеба')
print(round(1000*x.value[1],1),'-грамм мяса')
print(round(1000*x.value[2],1),'-грамм сыра')
print(round(1000*x.value[3],1),'-грамм бананов')
print(round(1000*x.value[4],1),'-грамм огурцов')
print(round(1000*x.value[5],1),'-грамм помидоров')
print(round(1000*x.value[6],1),'-грамм винограда')
print(round(problem.objective.value()[0],1),"-Калорийность рациона одного человека в день")
stop = time.time()
print ("Время :",round(stop-start,3))
from cvxopt.modeling import variable, op
import time
start = time.time()
x = variable(7, 'x')
z=( x[0] + x[1] +x[2] +x[3] +x[4] +x[5]+x[6])
mass1 =(- (61*x[0] + 220*x[1] +230* x[2] +15*x[3] +8*x[4] +11* x[5]+6*x[6]) <= -100)
mass2 =(- (12*x[0] +172*x[1] +290* x[2] +1*x[3] +1*x[4] +2* x[5]+2*x[6]) <= -70)
mass3 =(- (420*x[0] +0*x[1] +0* x[2] +212*x[3] +26*x[4] +38* x[5]+155*x[6]) <= -400)
mass4 =(-( 2060*x[0] + 2430*x[1] +3600* x[2] +890*x[3] +140*x[4] +230* x[5]+650*x[6]) <= -3000)
x_non_negative = (x >= 0)
problem =op(z,[mass1,mass2,mass3, mass4,x_non_negative])
problem.solve(solver='glpk')
problem.status
print("Результат:")
print(round(1000*x.value[0],1),'-грамм хлеба')
print(round(1000*x.value[1],1),'-грамм мяса')
print(round(1000*x.value[2],1),'-грамм сыра')
print(round(1000*x.value[3],1),'-грамм бананов')
print(round(1000*x.value[4],1),'-грамм огурцов')
print(round(1000*x.value[5],1),'-грамм помидоров')
print(round(1000*x.value[6],1),'-грамм винограда')
print(round(problem.objective.value()[0],1),"-килограмм-общая масса продуктов из \n рациона одного человека в день")
stop = time.time()
print ("Время :",round(stop-start,3))
|
Метки: author Scorobey разработка под windows математика python диета линейное программирование библиотека cvxopt |
[Перевод] ggplot2: как легко совместить несколько графиков в одном, часть 3 |
ggdensity() [в ggpubr]desc_statby() [в ggpubr]ggtexttable() [в ggpubr]ggparagraph() [в ggpubr]ggarrange() [в ggpubr].# График плотности "Sepal.Length"
#::::::::::::::::::::::::::::::::::::::
density.p <- ggdensity(iris, x = "Sepal.Length",
fill = "Species", palette = "jco")
# Вывести сводную таблицу Sepal.Length
#::::::::::::::::::::::::::::::::::::::
# Вычислить описательные статистики по группам
stable <- desc_statby(iris, measure.var = "Sepal.Length",
grps = "Species")
stable <- stable[, c("Species", "length", "mean", "sd")]
# График со сводной таблицей, тема "medium orange" (средний оранжевый)
stable.p <- ggtexttable(stable, rows = NULL,
theme = ttheme("mOrange"))
# Вывести текст
#::::::::::::::::::::::::::::::::::::::
text <- paste("iris data set gives the measurements in cm",
"of the variables sepal length and width",
"and petal length and width, respectively,",
"for 50 flowers from each of 3 species of iris.",
"The species are Iris setosa, versicolor, and virginica.", sep = " ")
text.p <- ggparagraph(text = text, face = "italic", size = 11, color = "black")
# Разместить графики на странице
ggarrange(density.p, stable.p, text.p,
ncol = 1, nrow = 3,
heights = c(1, 0.5, 0.3))
annotation_custom() [в ggplot2]. Упрощенный формат:annotation_custom(grob, xmin, xmax, ymin, ymax)density.p + annotation_custom(ggplotGrob(stable.p),
xmin = 5.5, ymin = 0.7,
xmax = 8)
ggscatter() [ggpubr].ggboxplot() [ggpubr].ggplotGrob() [ggplot2].annotation_custom() [ggplot2].# Диаграмма разброса по группам ("Species")
#::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
sp <- ggscatter(iris, x = "Sepal.Length", y = "Sepal.Width",
color = "Species", palette = "jco",
size = 3, alpha = 0.6)
# Диаграммы рассеивания переменных x/y
#::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
# Диаграмма рассеивания переменной x
xbp <- ggboxplot(iris$Sepal.Length, width = 0.3, fill = "lightgray") +
rotate() +
theme_transparent()
# Диаграмма рассеивания переменной у
ybp <- ggboxplot(iris$Sepal.Width, width = 0.3, fill = "lightgray") +
theme_transparent()
# Создать внешние графические объекты
# под названием “grob” в терминологии Grid
xbp_grob <- ggplotGrob(xbp)
ybp_grob <- ggplotGrob(ybp)
# Поместить диаграммы рассеивания в диаграмму разброса
#::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
xmin <- min(iris$Sepal.Length); xmax <- max(iris$Sepal.Length)
ymin <- min(iris$Sepal.Width); ymax <- max(iris$Sepal.Width)
yoffset <- (1/15)*ymax; xoffset <- (1/15)*xmax
# Вставить xbp_grob внутрь диаграммы разброса
sp + annotation_custom(grob = xbp_grob, xmin = xmin, xmax = xmax,
ymin = ymin-yoffset, ymax = ymin+yoffset) +
# Вставить ybp_grob внутрь диаграммы разброса
annotation_custom(grob = ybp_grob,
xmin = xmin-xoffset, xmax = xmin+xoffset,
ymin = ymin, ymax = ymax)
readJPEG() [в пакете jpeg], или функцию readPNG() [в пакете png] в зависимости от формата фоновой картинки.install.packages(“png”).# Импорт картинки
img.file <- system.file(file.path("images", "background-image.png"),
package = "ggpubr")
img <- png::readPNG(img.file)background_image() [в ggpubr].library(ggplot2)
library(ggpubr)
ggplot(iris, aes(Species, Sepal.Length))+
background_image(img)+
geom_boxplot(aes(fill = Species), color = "white")+
fill_palette("jco")
library(ggplot2)
library(ggpubr)
ggplot(iris, aes(Species, Sepal.Length))+
background_image(img)+
geom_boxplot(aes(fill = Species), color = "white", alpha = 0.5)+
fill_palette("jco")
mypngfile <- download.file("https://upload.wikimedia.org/wikipedia/commons/thumb/e/e4/France_Flag_Map.svg/612px-France_Flag_Map.svg.png",
destfile = "france.png", mode = 'wb')
img <- png::readPNG('france.png')
ggplot(iris, aes(x = Sepal.Length, y = Sepal.Width)) +
background_image(img)+
geom_point(aes(color = Species), alpha = 0.6, size = 5)+
color_palette("jco")+
theme(legend.position = "top")
ggarrange() [в ggpubr] предоставляет удобное решение, чтобы расположить несколько ggplot-ов на нескольких страницах. После задания аргументов nrow и ncol функция ggarrange() автоматически рассчитывает количество страниц, которое потребуется, чтобы разместить все графики. Она возвращает список упорядоченных ggplot-ов.multi.page <- ggarrange(bxp, dp, bp, sp,
nrow = 1, ncol = 2)multi.page[[1]] # Вывести страницу 1
multi.page[[2]] # Вывести страницу 2ggexport() [в ggpubr]:ggexport(multi.page, filename = "multi.page.ggplot2.pdf")marrangeGrob() [в gridExtra].library(gridExtra)
res <- marrangeGrob(list(bxp, dp, bp, sp), nrow = 1, ncol = 2)
# Экспорт в pdf-файл
ggexport(res, filename = "multi.page.ggplot2.pdf")
# Интерактивный вывод
resp1 <- ggarrange(sp, bp + font("x.text", size = 9),
ncol = 1, nrow = 2)
p2 <- ggarrange(density.p, stable.p, text.p,
ncol = 1, nrow = 3,
heights = c(1, 0.5, 0.3))
ggarrange(p1, p2, ncol = 2, nrow = 1)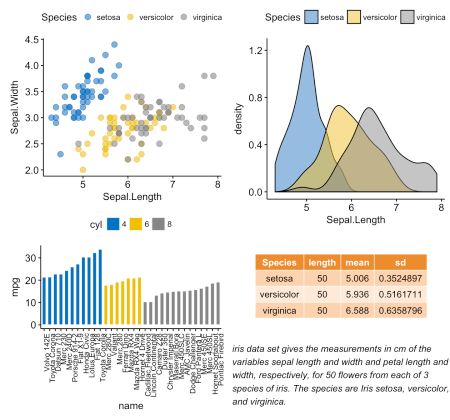
ggexport() [в ggpubr].plots <- ggboxplot(iris, x = "Species",
y = c("Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width"),
color = "Species", palette = "jco"
)
plots[[1]] # Вывести первый график
plots[[2]] # Вывести второй график и т.д.ggexport(plotlist = plots, filename = "test.pdf")ggexport(plotlist = plots, filename = "test.pdf",
nrow = 2, ncol = 1)|
Метки: author qc-enior визуализация данных визуализация ggplot2 |
Классический 2д квест или как прошли наши два года разработки. Часть 3 |



|
Метки: author MaikShamrock разработка под android разработка игр программирование libgdx corona sdk разработка игр под android программирование игр |
Liquibase: пример автоматизированного наката изменений на реляционную БД |
Статья будет интересна тем, кто хоть раз задумывался о вопросе наката изменений (патча) на реляционную БД. Статья не будет интересна тем, кто уже освоил и использует Liquibase. Главной целью данной статьи является указание ссылки на репозиторий с примером использования. В качестве примера я выбрал накат sample-схемы HR на БД Oracle (список всех поддерживаемых БД) — любой желающий может скачать себе репозиторий и поиграться в домашних условиях. Желание продемонстрировать пример вызвано обсуждением этого вопроса на ресурсе sql.ru.
Что такое Liquibase, можно узнать на официальном сайте продукта. Хочется отметить пару хороших статей и на этом ресурсе:
Управление миграциями БД с Liquibase
Использование Liquibase без головной боли. 10 советов из опыта реальной разработки
Мой выбор остановился на этом инструменте, так как:
1) Инструмент отслеживает, какие changeset-ы уже были применены к данному экземпляру БД и накатывает только те, которые еще не накатывались и какие нужно еще донакатить. Если в процессе наката применение какого-либо изменения упало с ошибкой, то, после устранения причины вы перезапускаете накат и Liquibase продолжает выполнение с того changeset-а, на котором остановился.
2) Возможность выставить changeset-у атрибуты runOnChange и runAlways существенно упрощает управление изменениями, в частности, recreatable-объектов.
3) Свойство context позволяет выполнять/не выполнять changeset-ы в зависимости от текущего окружения (например, не запускать юнит-тесты на проде).
Это был не полный список фич.
Он здесь. В нем приведены "hard" (таблицы, индексы, ограничения целостности) и "soft" (триггеры, процедуры, представления) объекты, changeset-ы с тегами sql и sqlFile, c атрибутами runOnChange и runAlways и без.
Ввиду отсутствия необходимости в репозитории нет таких полезных фич/шагов, которые я обычно использую в своих проектах:
|
Метки: author akk0rd87 sql postgresql oracle microsoft sql server database migrations database tools liquibase |
Swift Generics: cтили для UIView и не только #2 |
Данная публикация является продолжением выпуска, где была затронута тема декорирования объектов. Ознакомление с первой публикацией поможет лучше вникнуть в текущий в контекст, т.к. упомянутые ранее термины и решения буду описываться с упрощениями.
Подход получился весьма удачным и был многократно протестирован на реальных проектах. Кроме этого, появились дополнения к подходу и удобство его использования значительно возросло.
Напомню, что основным элементом представленного способа задания стилей является обобщенное замыкание:
typealias Decoration = (T) -> Void Использовать данное замыкание для придания свойств UIView можно следующим образом:
let decoration: Decoration = { (view: UIView) -> Void in
view.backgroundColor = .white
}
let view = UIView()
decoration(view) Используя оператор сложения и соблюдая порядок применения декораций можно получить механизм композиции декораций:
func +(lhs: @escaping Decoration, rhs: @escaping Decoration) -> Decoration {
return { (value: T) -> Void in
lhs(value)
rhs(value)
}
} Складывать можно не только замыкания, принимающие объекты одного класса. Однако, следует учесть, что класс объекта, передаваемого в одно из замыканий, должен быть подклассом объекта, передаваемого в другое замыкание:
Decoration + Decoration = Decoration
Decoration + Decoration = Decoration
Decoration + Decoration = нельзя Главным неудобством при создании декорации было написание кода самой конструкции декорации. Приходилось писать тип декорации, замыкание, тип класса внутри замыкания… Чаще всего это заканчивалось CTRL+C, CTRL+V.
Чтобы выйти из ситуации и генерировать замыкание через автокомплит была написана универсальная функция, которая принимала тип объекта:
func decor(_ type: T.Type, closure: @escaping Decoration) -> Decoration {
return closure
} Использовалось это следующим образом:
let decoration = decor(UIView.self) { (view) in
view.backgroundColor = .white
}Вот только self не автокомплитится и функцию нельзя было назвать decoration, т.к. чаще всего замыкание создавать с именем decoration и возникала ошибка:
error: variable used within its own initial value
let decoration = decoration(UIView.self) { (view) in
Более удачным решением стало создание универсальной static функции:
protocol Decorable: class {}
extension NSObject: Decorable {}
extension Decorable {
static func decoration(closure: @escaping Decoration) -> Decoration {
return closure
}
} Создавать декорирующее замыкание в итоге можно следующим образом:
let decoration = UIView.decoration { (view) in
view.backgroundColor = .white
}class MyView: UIView {
var isDisabled: Bool = false
var isFavorite: Bool = false
var isSelected: Bool = false
}Чаще всего сочетание подобных переменные применяется лишь для того, чтобы изменить стиль конкретного UIView.
Если попытаться описать состояние стиля UIView одной переменной, то можно использовать перечисления. Однако, еще лучше подойдет OptionSet, который позволяет предусмотреть сочетания.
struct MyViewState: OptionSet, Hashable {
let rawValue: Int
init(rawValue: Int) {
self.rawValue = rawValue
}
static let normal = TextPlaceholderState(rawValue: 1 << 0)
static let disabled = TextPlaceholderState(rawValue: 1 << 1)
static let favorite = TextPlaceholderState(rawValue: 1 << 2)
static let selected = TextPlaceholderState(rawValue: 1 << 3)
var hashValue: Int {
return rawValue
}
}Применять можно следующим образом:
class MyView: UIView {
var state: MyViewState = .normal
}
let view = MyView()
view.state = [.disabled, .favorite]
view.state = .selectedВ прошлой публикации была введена обобщенная структура, которая имеет указатель на экземпляр класса, к которому будут применяться декорации.
struct Style {
let object: T
} У обобщенной структуры Style введем дополнительную переменную, которая будет отвечать за состояние стиля.
extension Style where T: Decorable {
var state: AnyHashable? {
get {
//
}
set {
//
}
}
}Сохранять состояние объекта через обобщенную структуру стало возможным при использовании runtime функций ассоциации объектов. Введем класс, который будет ассоциирован объектом декорации и будет содержать нужные переменные.
class Holder {
var state = Optional.none
}
var KEY: UInt8 = 0
extension Decorable {
var holder: Holder {
get {
if let holder = objc_getAssociatedObject(self, &KEY) as? Holder {
return holder
} else {
let holder = Holder()
let policy = objc_AssociationPolicy.OBJC_ASSOCIATION_RETAIN_NONATOMIC
objc_setAssociatedObject(self, &KEY, holder, policy)
return holder
}
}
}
} Теперь обобщенная структура Style может сохранять состояние через ассоциированный с объектом Holder класс.
extension Style where T: Decorable {
var state: AnyHashable? {
get {
return object.holder.state
}
set(value) {
object.holder.state = value
}
}
}Если можно хранить состояние стиля, то точно так же можно хранить декорации для разных состояний. Это достигается путем создания словаря декораций [AnyHashable: Decoration, ассоциированного с объектом декорации.
class Holder {
var state = Optional.none
var states = [AnyHashable: Decoration]()
} Чтобы добавлять декорации в словарь введем функцию:
extension Style where T: Decorable {
func prepare(state: AnyHashable, decoration: @escaping Decoration) {
object.holder.states[state] = decoration
}
} Использовать можно следующим образом:
let view = MyView()
view.style.prepare(state: MyViewState.disabled) { (view) in
view.backgroundColor = .gray
}
view.style.prepare(state: MyViewState.favorite) { (view) in
view.backgroundColor = .yellow
}После наполнения словаря декораций, при изменении состояния стиля, следует применить соответствующую декорацию из словаря. Этого можно добиться немного изменив реализацию сеттера состояния стиля:
extension Style where T: Decorable {
var state: AnyHashable? {
get {
return object.holder.state
}
set(value) {
let holder = object.holder
if let key = value, let decoration = holder.states[key] {
object.style.apply(decoration)
}
holder.state = value
}
}
}Применяться декорация будет следующим образом:
let view = MyView()
// подготовка декораций
view.style.state = .selectedТак же стоит упомянуть случай, когда у объекта было установлено состояние стиля до того, как в словарь декораций попала соответствующая декорация. Для такой ситуации стоит доработать функцию подготовки декорации для состояния:
extension Style where T: Decorable {
func prepare(state: AnyHashable, decoration: @escaping Decoration) {
let holder = object.holder
holder.states[state] = decoration
if state == holder.state {
object.style.apply(decoration)
}
}
} Если внутри применяемой декорации содержится что-то, что можно анимировать,...
When positive, the background of the layer will be drawn with
rounded corners. Also effects the mask generated by the
'masksToBounds' property. Defaults to zero. Animatable.
open var cornerRadius: CGFloat
… то изменения стиля объекта внутри анимационного блока приведет к соответствующим анимациям:
UIView.animate(withDuration: 0.5) {
view.style.state = .selected
}Получен удобный инструмент создания, хранения, применения, переиспользования, композиции декораций. Полный код инструмента можно найти по ссылке. Как обычно есть возможно установить и опробовать через CocoaPods:
pod 'Style'
|
Метки: author iWheelBuy разработка под ios разработка мобильных приложений xcode swift generics ios uiview associatedtype typealias protocol |
160-терабитный трансатлантический кабель Marea закончен |

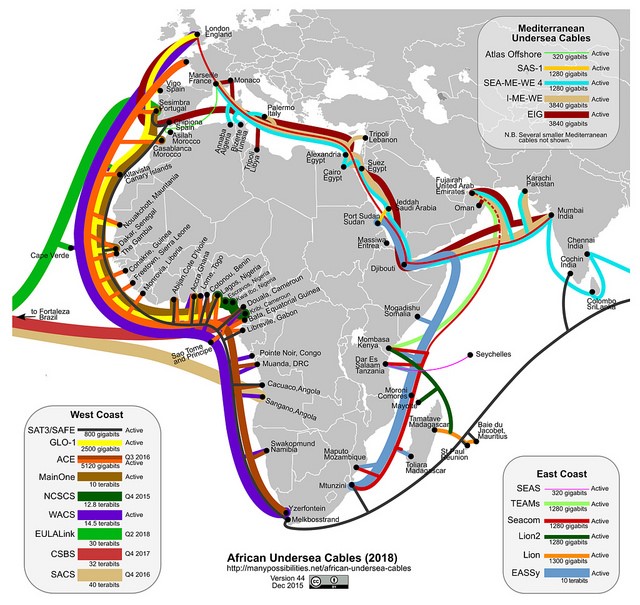
«Marea проложили вовремя. Через трансатлантические кабели проходит на 55% больше данных, чем через кабели Тихого океана. И на 40% больше, чем по кабелям, соединяющим США и Латинскую Америку.
Безусловно, поток данных через Атлантический океан будет расти, а Marea обеспечит необходимое качество соединения для США, Испании и других стран».
«Мы постоянно встречались с представителями Facebook на различных мероприятиях и поняли, что пытаемся решить одну и ту же проблему. Поэтому мы объединились и улучшили трансатлантическую сеть, спроектировав новый кабель», — рассказал Фрэнк Рей (Frank Ray), руководитель инфраструктурного направления облачных решений.
|
Метки: author it_man разработка систем передачи данных блог компании ит-град трансатлантический кабель marea |
Дайджест интересных материалов для мобильного разработчика #223 (25 сентября — 1 октября) |

 |
Разработка прибыльной Android игры двумя школьниками + Продолжение |
 |
Процесс релиза iOS-приложений в Badoo |
 |
Как работает Android, часть 3 |
 iOS
iOS Первое React Native приложение: от «Hello World» до App Store Отладка Swift с LLDB Как уйти из колледжа и стать iOS-фрилансером Управление разными средами в Swift-проекте Руководство по ARKit для новичков Чистая Swift архитектура В Xcode 9 цвета можно добавлять в каталог ассетов Измерение времени компиляции в Xcode 9
Первое React Native приложение: от «Hello World» до App Store Отладка Swift с LLDB Как уйти из колледжа и стать iOS-фрилансером Управление разными средами в Swift-проекте Руководство по ARKit для новичков Чистая Swift архитектура В Xcode 9 цвета можно добавлять в каталог ассетов Измерение времени компиляции в Xcode 9 React Native Game Center: интеграция Game Center в React Native ButtonProgressBar: прогресс бар в кнопке Detect.Location: история посещения мест по фотографиям LifetimeTracker: отслеживание ключевых проблем прямо во время разработки
React Native Game Center: интеграция Game Center в React Native ButtonProgressBar: прогресс бар в кнопке Detect.Location: история посещения мест по фотографиям LifetimeTracker: отслеживание ключевых проблем прямо во время разработки Android
Android Android Dev Подкаст. Выпуск 43. Обзор Devfest Siberia 2017 RxJava: делаем креш-логи лучше Многопотоковый рендеринг на Android с Litho и Infer Flutter: от дизайна до приложения Использование шрифтов с Support Library 26 Android Architecture Components: тестирование ViewModel LiveData Наслаждение тулбаром Воссоздаем “Бутылочку” на Android Используем buildSrc для кастомной логики сборок Gradle
Android Dev Подкаст. Выпуск 43. Обзор Devfest Siberia 2017 RxJava: делаем креш-логи лучше Многопотоковый рендеринг на Android с Litho и Infer Flutter: от дизайна до приложения Использование шрифтов с Support Library 26 Android Architecture Components: тестирование ViewModel LiveData Наслаждение тулбаром Воссоздаем “Бутылочку” на Android Используем buildSrc для кастомной логики сборок Gradle Как улучшить быстродействие Android Studio на машине с малым объемом памяти Frames: готовое приложение с обоями Tutorial View: простая организация туториалов Croller: круглый контрол
Как улучшить быстродействие Android Studio на машине с малым объемом памяти Frames: готовое приложение с обоями Tutorial View: простая организация туториалов Croller: круглый контрол Разработка Mission-driven интерфейс Мобильная типографика Как получить работу в продуктовом или UX дизайне без портфолио Вопросы и ответы по Code Review Лучший кодинг через тестирование Понимаем Progressive Web App: стоят ли они всей шумихи? Как неинтуитивный пользовательский интерфейс может создать превосходный пользовательский опыт 19 альтернатив Parse в 2017 году
Разработка Mission-driven интерфейс Мобильная типографика Как получить работу в продуктовом или UX дизайне без портфолио Вопросы и ответы по Code Review Лучший кодинг через тестирование Понимаем Progressive Web App: стоят ли они всей шумихи? Как неинтуитивный пользовательский интерфейс может создать превосходный пользовательский опыт 19 альтернатив Parse в 2017 году Аналитика, маркетинг и монетизация Три стадии мобильного маркетинга Аналитика против атрибуции — Работа с несоответствием установок
Аналитика, маркетинг и монетизация Три стадии мобильного маркетинга Аналитика против атрибуции — Работа с несоответствием установок Устройства, IoT, AI Microsoft запускает новые инструменты машинного обучения
Устройства, IoT, AI Microsoft запускает новые инструменты машинного обучения|
|
[Из песочницы] Как легализовать торговлю игровыми предметами |

|
Метки: author Hyperevolution продвижение игр монетизация игр игры игровая индустрия внутриигровые покупки внутриигровая валюта |
[Из песочницы] Информационная безопасность в АСУ ТП: вектор атаки преобразователи интерфейсов |




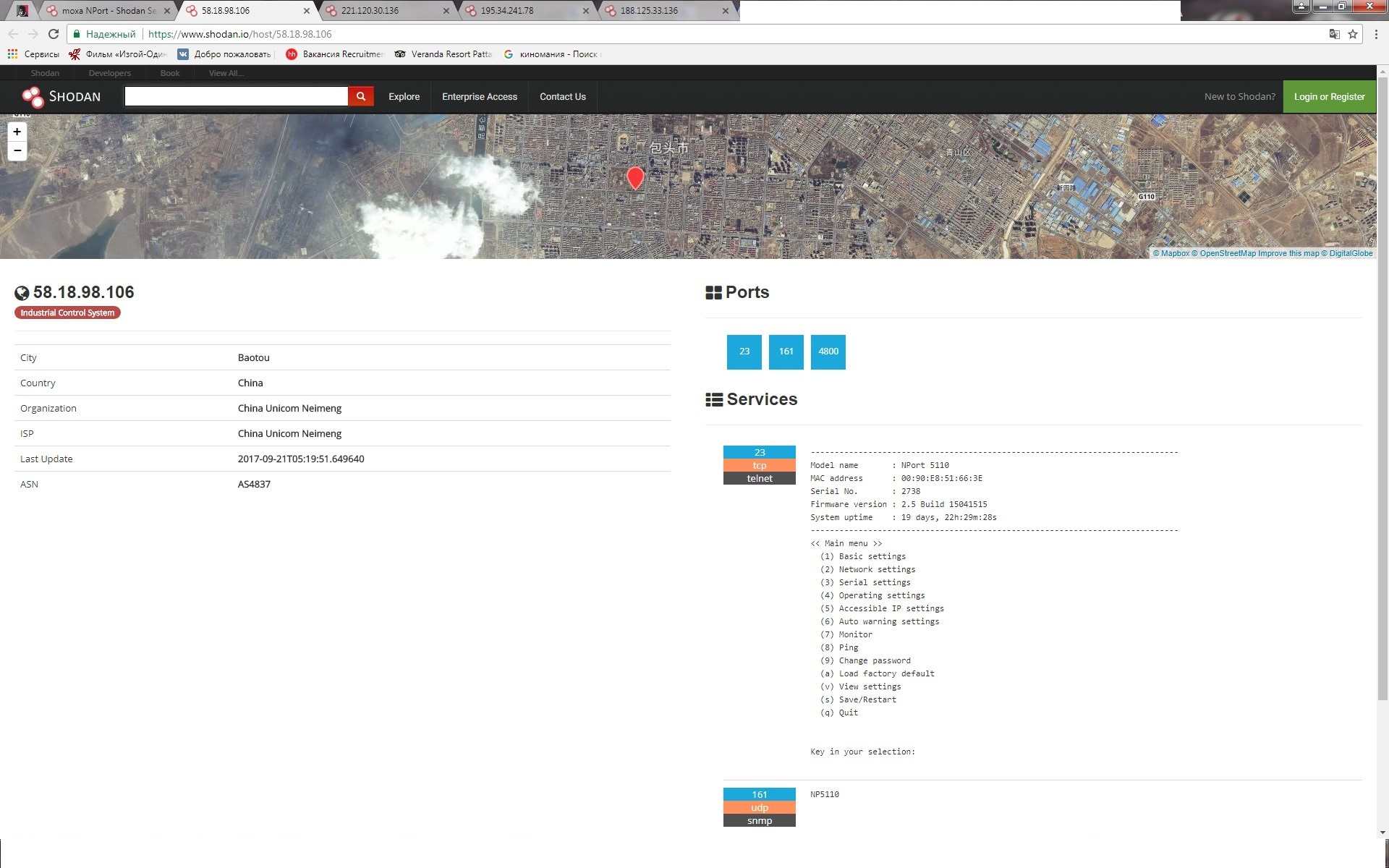
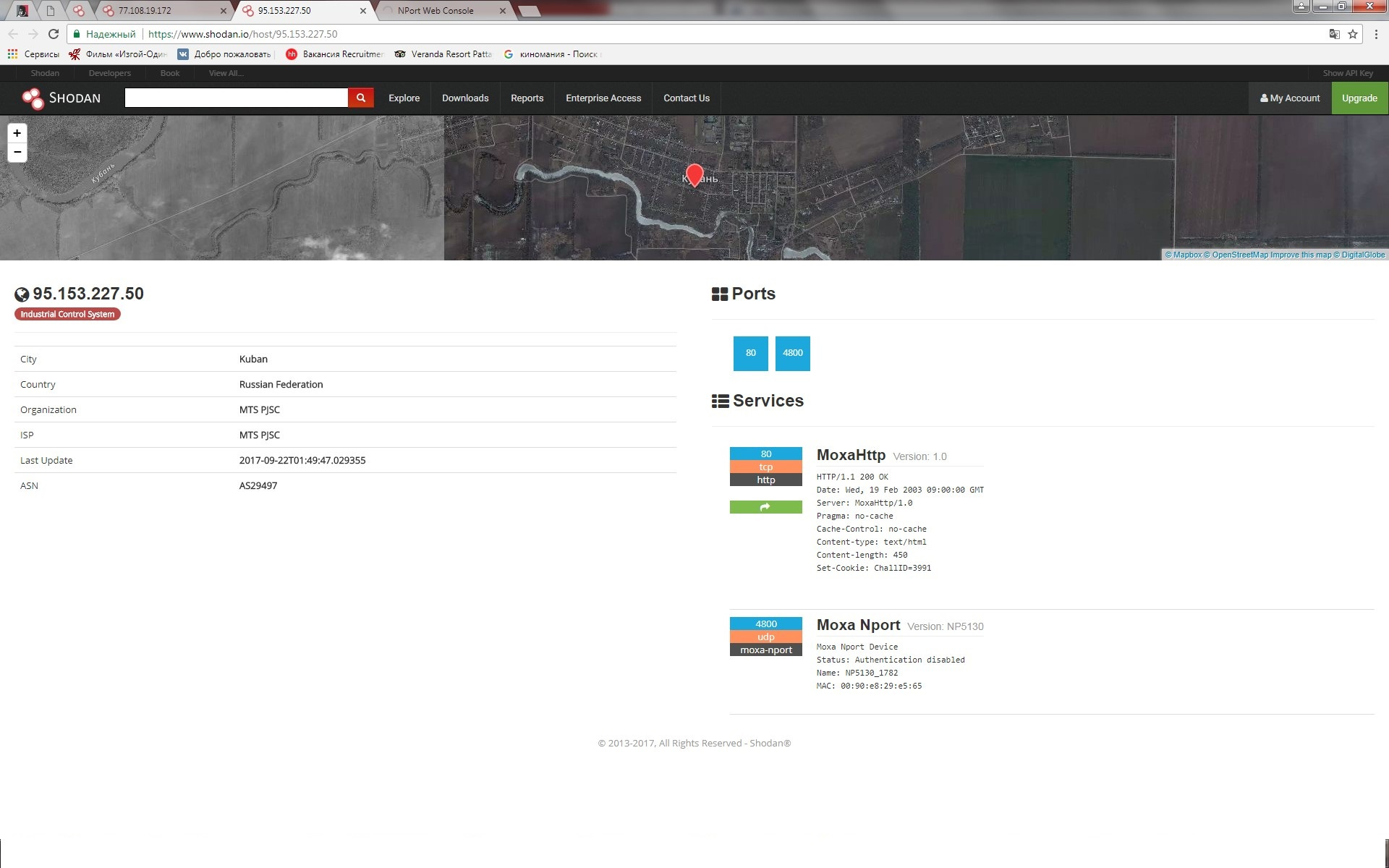

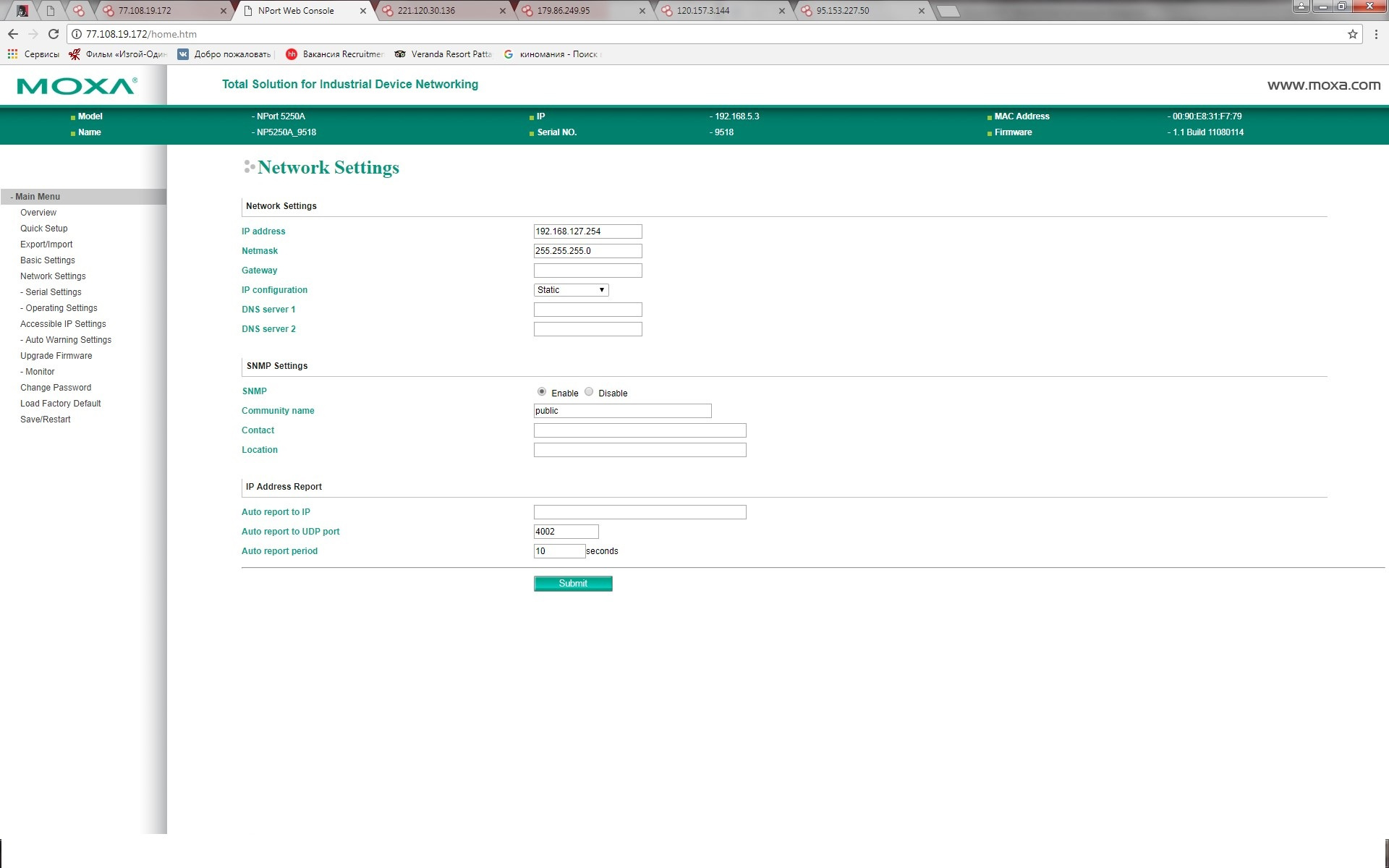
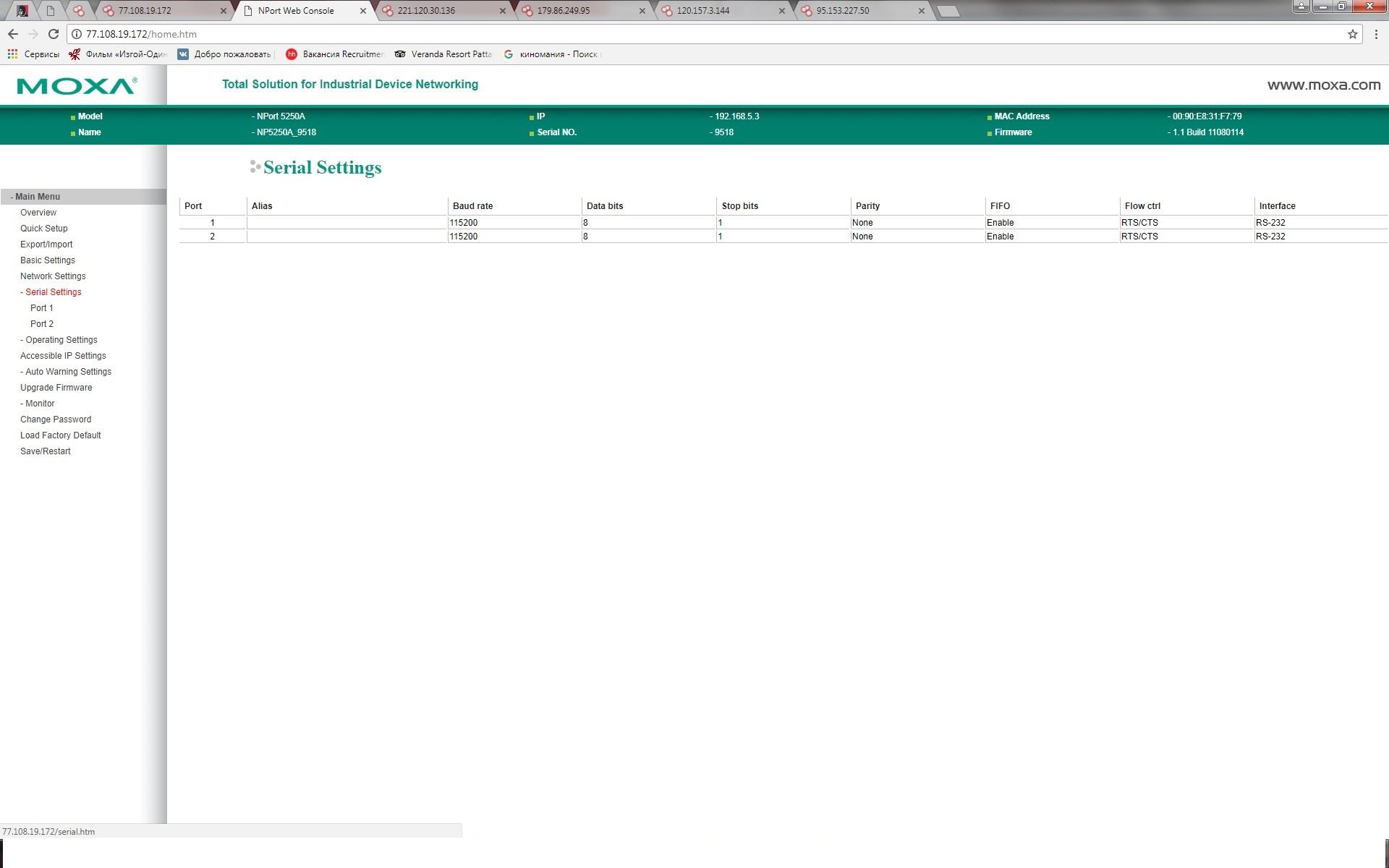
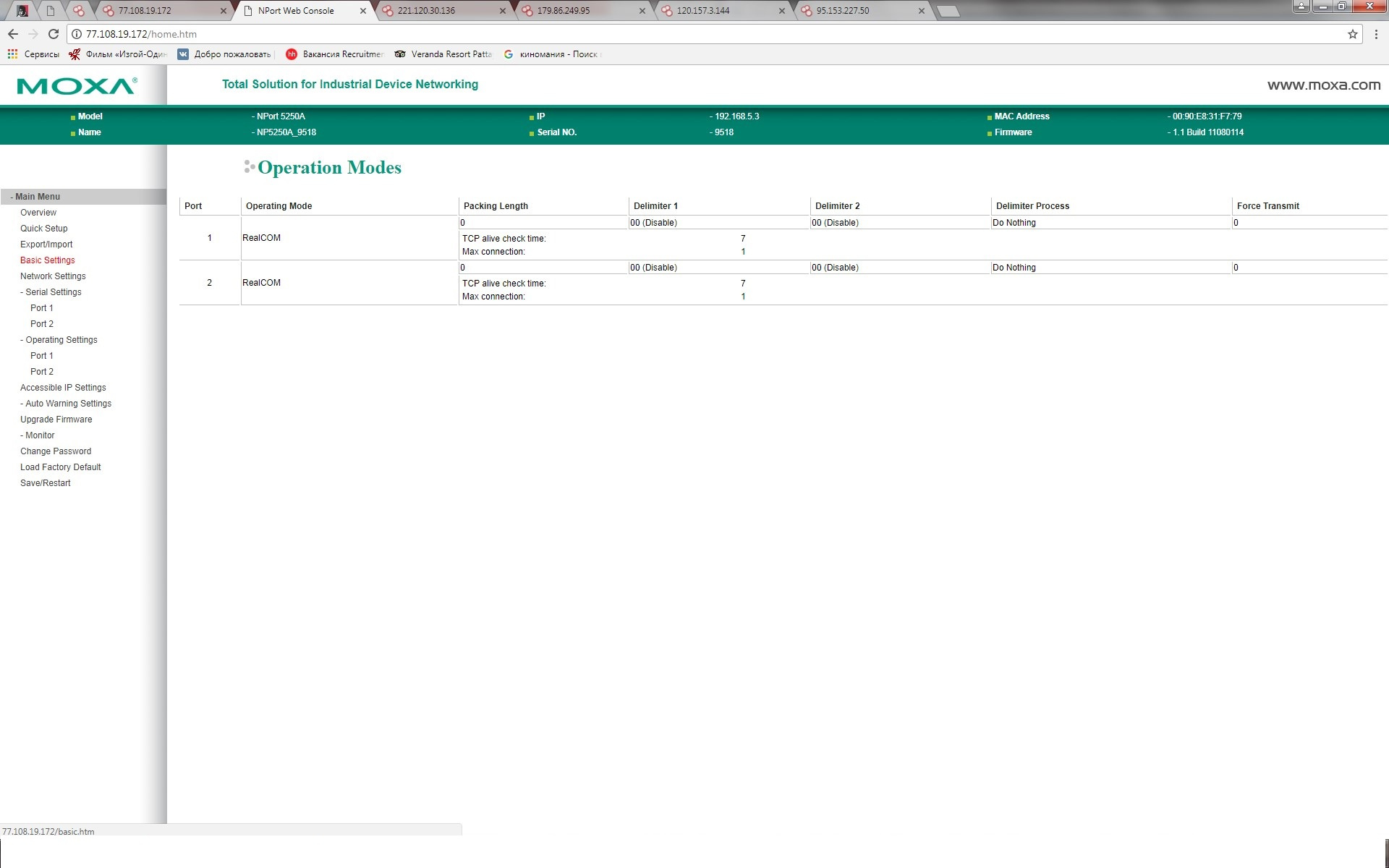
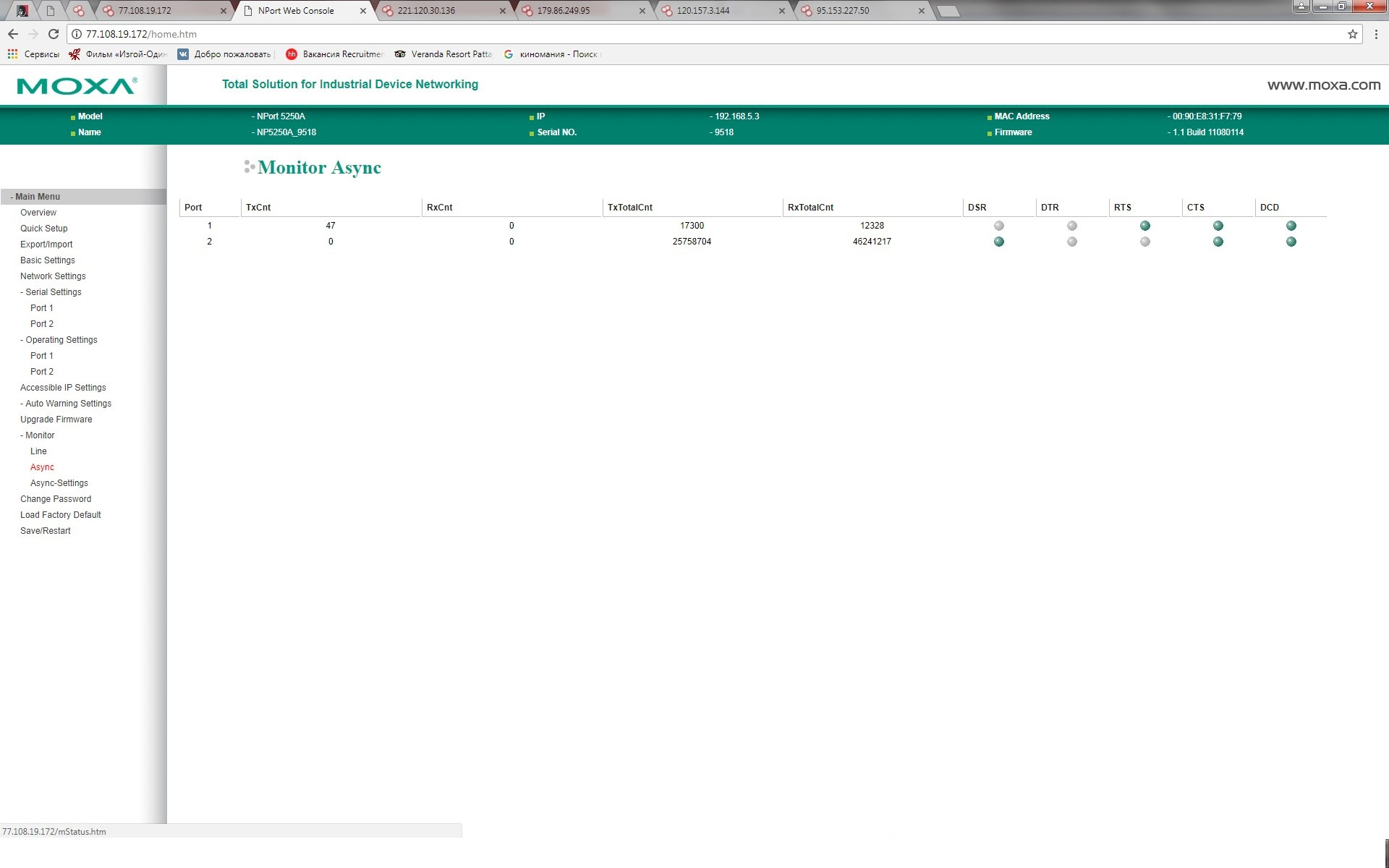

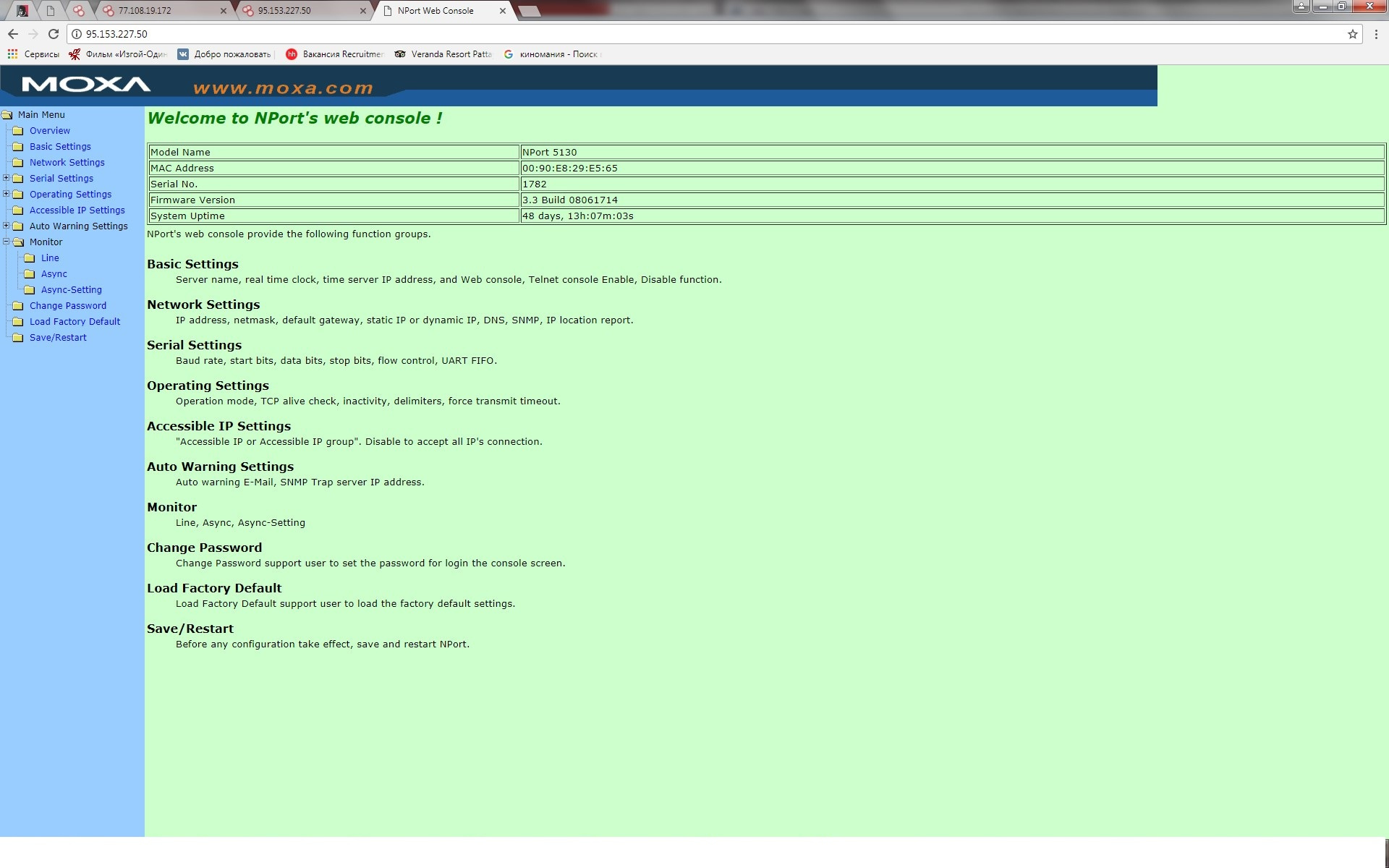
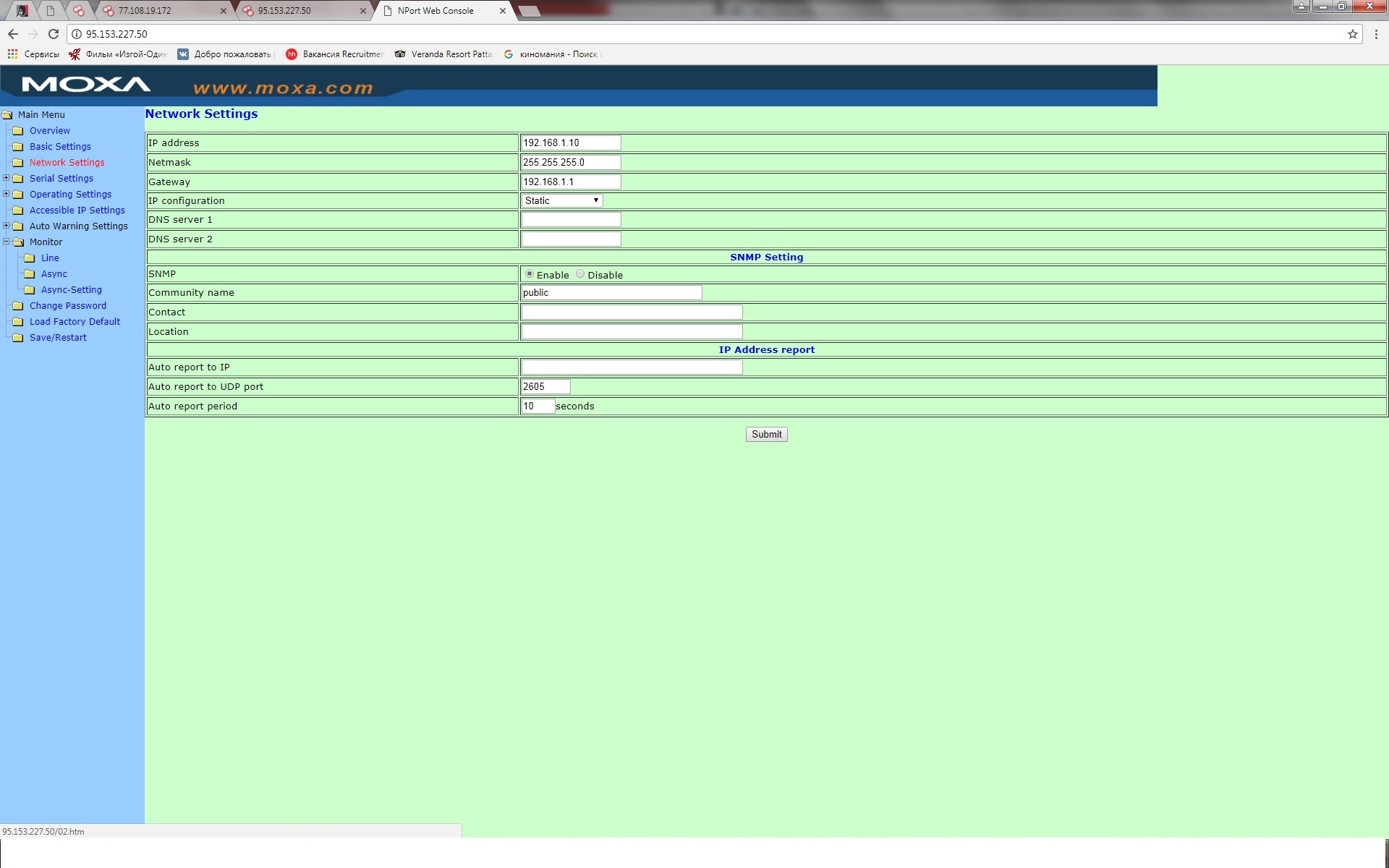




|
Метки: author 2younda исследования и прогнозы в it хабрахабр взлом информационная безопасность асу тп |
Предсказание про Стива Джобса от 31 сентября 1994 года |

«Возвращение в «Apple» было для меня очень заманчивой возможностью с тех пор, как Джон решил посвятить свои технические таланты отрасли мобильных телефонов» — заявил Джобс из штаб-квартиры «NeXT» в г. Редвуд-Сити (Калифорния), — «сначала я не придал особого значения предложению совета директоров «Apple». Однако я ведь сейчас стал отцом, поэтому мне нужен более стабильный источник дохода».
«Многие люди просили меня опубликовать ту вымышленную заметку, которую я написал в 1994 г., о том, что «Apple» покупает «NeXT», а Стив возвращается в «Apple». Возрождению интереса способствовал тот факт, что она упоминается в биографии Стива Джобса. Эта заметка появилась в ноябрьском номере интернет-журнала «Macworld» 1994 года. По правде говоря, я и забыл, что написал ее. Что ж, надеюсь, вам понравится!»
— Гай Кавасаки
|
Метки: author MagisterLudi исследования и прогнозы в it стив джобс шутка предсказание apple |
МУК становится дистрибутором Oracle |

|
Метки: author Muk блог компании мук oracle |
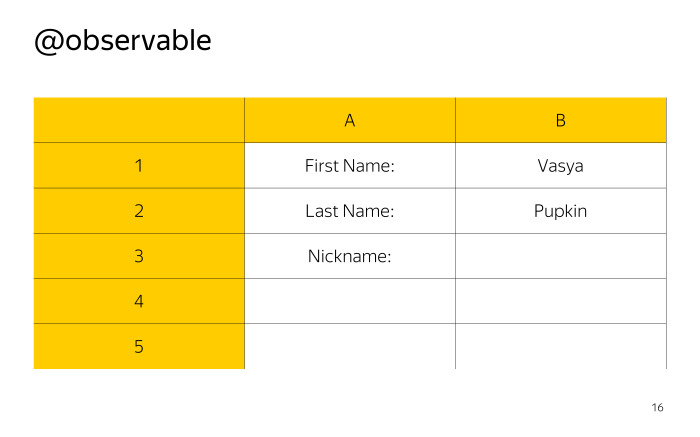
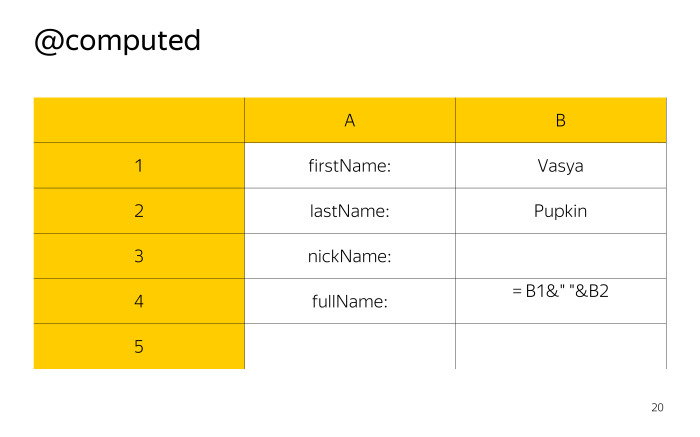
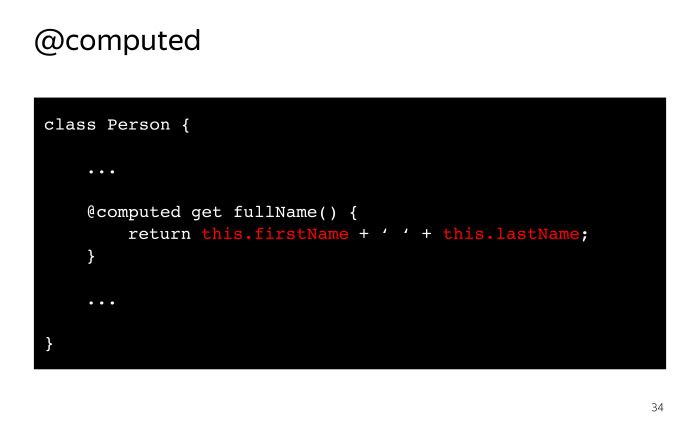
MobX — управление состоянием без боли. Лекция в Яндексе |
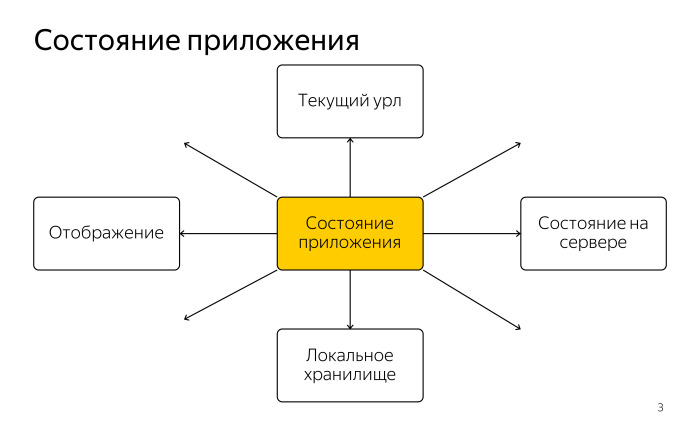







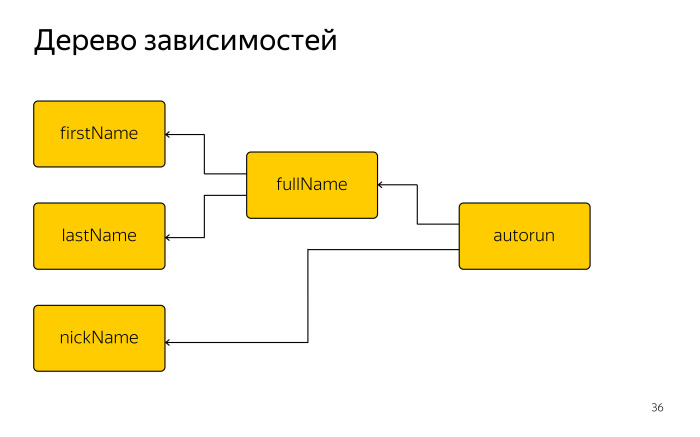




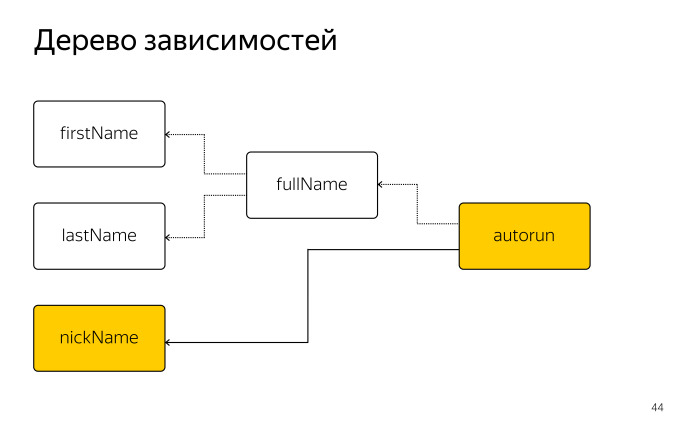
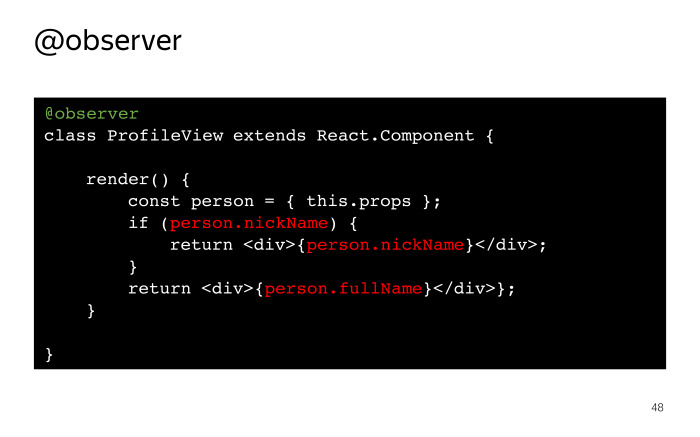



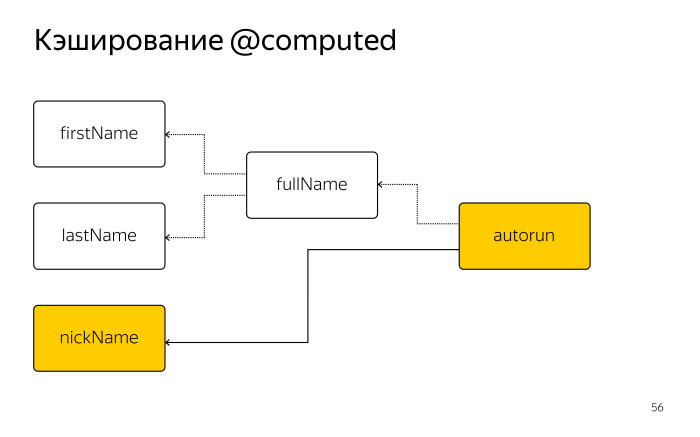












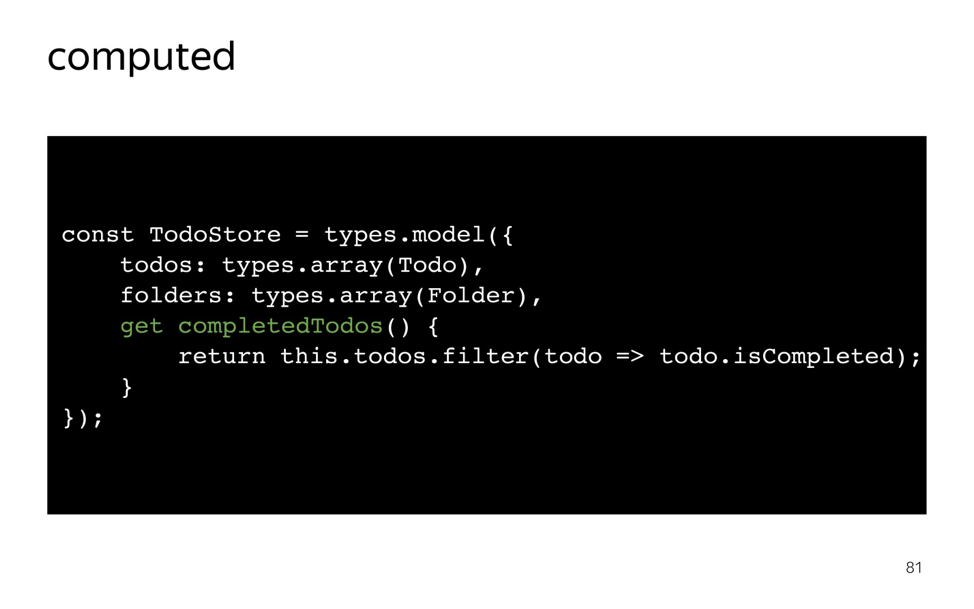
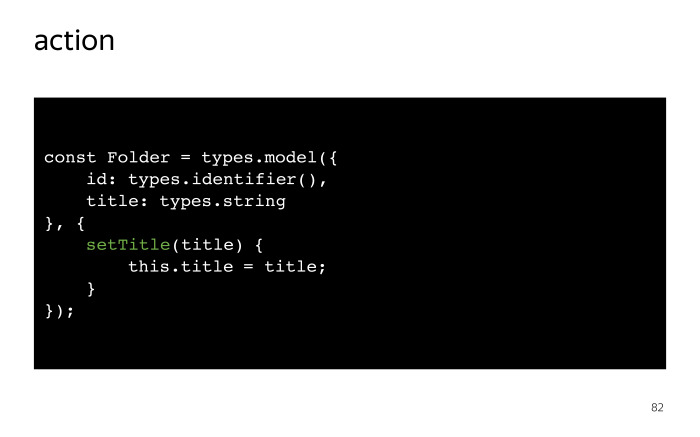


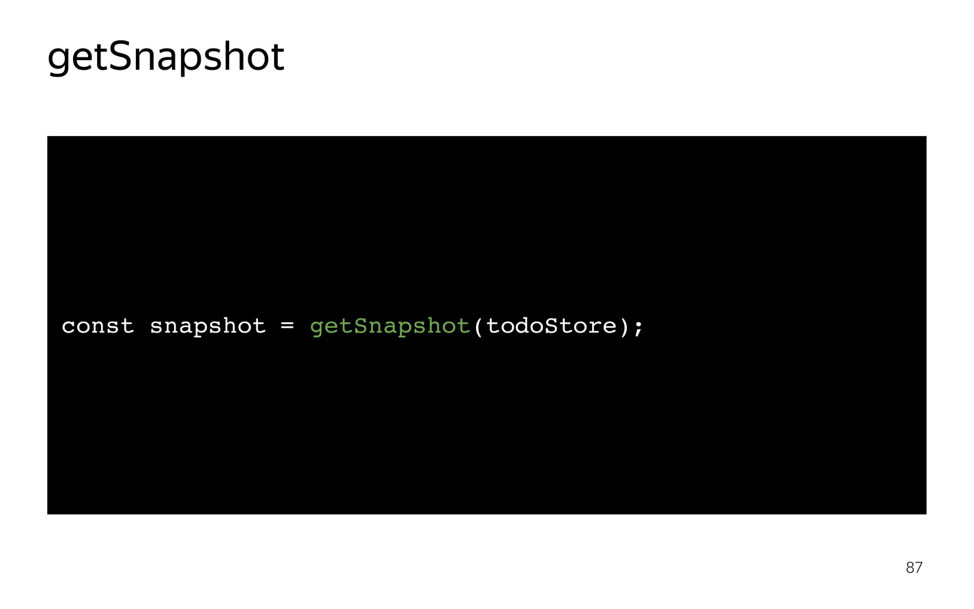





|
Метки: author Leono разработка веб-сайтов reactjs блог компании яндекс state react react.js mobx mobx-state-tree веб-приложения |
Чтение на выходных: 17 независимых блогов по математике, алгоритмам и языкам программирования |
 / Flickr / home thods / CC BY
/ Flickr / home thods / CC BY
|
Метки: author it_man профессиональная литература блог компании ит-град ит-град блоги подборка математика языки программирования |
DevOps приходит к нам домой? Домашний Minecraft server в Azure с применением современных DevOps практик |
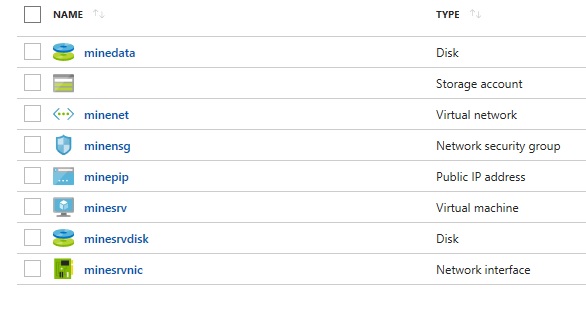
все артефакты, которые требуются для разворачивания приложения, должны быть опубликованы в подконтрольный сторадж с высокой доступностью.
az configure --defaults location=$LOCATION group=$GROUP
echo "create new group"
az group create -n $GROUP
echo "create storage account"
az storage account create -n $STORAGE_ACCOUNT --sku Standard_LRS
STORAGE_CS=$(az storage account show-connection-string -n $STORAGE_ACCOUNT)
export AZURE_STORAGE_CONNECTION_STRING="$STORAGE_CS"
echo "create storage container"
az storage container create -n $STORAGE_CONTAINER --public-access blobmkdir $DISTR_DIR
cd $DISTR_DIR
echo "download minecraft server from official site"
curl -Os https://s3.amazonaws.com/Minecraft.Download/versions/1.12.2/minecraft_server.$MVERSION.jar
echo "copy jre from this machine"
cp -r "$JRE" ./jre
echo "create ititial world folder"
mkdir initial_world
cd initial_world
echo "download initial map"
curl -Os https://dl01.mcworldmap.com/user/1821/world2.zip
unzip -q world2.zip
cp -r StarWars/* .
rm -r -f StarWars
rm world2.zip
cd ../
echo "create archive (zip utility -> https://ranxing.wordpress.com/2016/12/13/add-zip-into-git-bash-on-windows/)"
cd ../
zip -r -q $DISTR_ZIP $DISTR_DIR
rm -r -f $DISTR_DIR
Все зависимости должны быть точно определены и ресолвиться всегда однозначно
echo "prepare server configuration"
curl -s -L -o configuration/xPSDesiredStateConfiguration.zip "https://www.powershellgallery.com/api/v2/package/xPSDesiredStateConfiguration/7.0.0.0"
curl -s -L -o configuration/xNetworking.zip "https://www.powershellgallery.com/api/v2/package/xNetworking/5.1.0.0"
curl -s -L -o configuration/xStorage.zip "https://www.powershellgallery.com/api/v2/package/xStorage/3.2.0.0"
cd configuration
unzip -q xPSDesiredStateConfiguration.zip -d xPSDesiredStateConfiguration
rm -r xPSDesiredStateConfiguration.zip
unzip -q xNetworking.zip -d xNetworking
rm -r xNetworking.zip
unzip -q xStorage.zip -d xStorage
rm -r xStorage.zip
zip -r -q ../$CONFIG_ZIP . *
rm -r -f xPSDesiredStateConfiguration
rm -r -f xNetworking
rm -r -f xStorage
cd ../
echo "create network security group and rules"
az network nsg create -n $NSG
az network nsg rule create --nsg-name $NSG -n AllowMinecraft --destination-port-ranges 25556 --protocol Tcp --priority 100
az network nsg rule create --nsg-name $NSG -n AllowRDP --destination-port-ranges 3389 --protocol Tcp --priority 110
echo "create vnet, nic and pip"
NIC_NAME=minesrvnic
PIP_NAME=minepip
SUBNET_NAME=servers
az network vnet create -n $VNET --subnet-name $SUBNET_NAME
az network public-ip create -n $PIP_NAME --dns-name $DNS --allocation-method Static
az network nic create --vnet-name $VNET --subnet $SUBNET_NAME --public-ip-address $PIP_NAME -n $NIC_NAME
echo "create data disk"
DISK_NAME=minedata
az disk create -n $DISK_NAME --size-gb 10 --sku Standard_LRS
echo "create server vm"
az vm create -n $VM_NAME --size $VM_SIZE --image $VM_IMAGE \
--nics $NIC_NAME \
--admin-username $VM_ADMIN_LOGIN --admin-password $VM_ADMIN_PASSWORD \
--os-disk-name ${VM_NAME}disk --attach-data-disk $DISK_NAME echo "prepare dsc extension settings"
cat MinecraftServerDSCSettings.json | envsubst > ThisMinecraftServerDSCSettings.json
echo "configure vm"
az vm extension set \
--name DSC \
--publisher Microsoft.Powershell \
--version 2.7 \
--vm-name $VM_NAME \
--resource-group $GROUP \
--settings ThisMinecraftServerDSCSettings.json
rm -f ThisMinecraftServerDSCSettings.jsonxRemoteFile DistrCopy
{
Uri = "https://$accountName.blob.core.windows.net/$containerName/mineserver.$minecraftVersion.zip"
DestinationPath = "$mineHome.zip"
MatchSource = $true
}
Archive UnzipServer
{
Ensure = "Present"
Path = "$mineHome.zip"
Destination = $mineHomeRoot
DependsOn = "[xRemoteFile]DistrCopy"
Validate = $true
Force = $true
}
File CheckProperties
{
DestinationPath = "$mineHome\server.properties"
Type = "File"
Ensure = "Present"
Force = $true
Contents = "....."
}
File CheckEULA
{
DestinationPath = "$mineHome\eula.txt"
Type = "File"
Ensure = "Present"
Force = $true
Contents = "..."
DependsOn = "[File]CheckProperties"
}
xWaitForDisk WaitWorldDisk
{
DiskIdType = "Number"
DiskId = "2"
RetryIntervalSec = 60
RetryCount = 5
DependsOn = "[File]CheckEULA"
}
xDisk PrepareWorldDisk
{
DependsOn = "[xWaitForDisk]WaitWorldDisk"
DiskIdType = "Number"
DiskId = "2"
DriveLetter = "F"
AllowDestructive = $false
}
xWaitForVolume WaitForF
{
DriveLetter = 'F'
RetryIntervalSec = 5
RetryCount = 10
DependsOn = "[xDisk]PrepareWorldDisk"
}
File WorldDirectoryExists
{
Ensure = "Present"
Type = "Directory"
Recurse = $true
DestinationPath = "F:\world"
SourcePath = "$mineHome\initial_world"
MatchSource = $false
DependsOn = "[xWaitForVolume]WaitForF"
}
Script LinkWorldDirectory
{
DependsOn="[File]WorldDirectoryExists"
GetScript=
{
@{ Result = (Test-Path "$using:mineHome\World") }
}
SetScript=
{
New-Item -ItemType SymbolicLink -Path "$using:mineHome\World" -Confirm -Force -Value "F:\world"
}
TestScript=
{
return (Test-Path "$using:mineHome\World")
}
}
Script EnsureServerStart
{
DependsOn="[Script]LinkWorldDirectory"
GetScript=
{
@{ Result = (Get-Process -Name java -ErrorAction SilentlyContinue) }
}
SetScript=
{
Start-Process -FilePath "$using:mineHome\jre\bin\java" -WorkingDirectory "$using:mineHome" -ArgumentList "-Xms512M -Xmx512M -jar `"$using:mineHome\minecraft_server.$using:minecraftVersion.jar`" nogui"
}
TestScript=
{
return (Get-Process -Name java -ErrorAction SilentlyContinue) -ne $null
}
}
xFirewall FirewallIn
{
Name = "Minecraft-in"
Action = "Allow"
LocalPort = ('25565')
Protocol = 'TCP'
Direction = 'Inbound'
}
xFirewall FirewallOut
{
Name = "Minecraft-out"
Action = "Allow"
LocalPort = ('25565')
Protocol = 'TCP'
Direction = 'Outbound'
}git clone https://github.com/AndreyPoturaev/minecraft-in-azure
cd minecraft-in-azure
git checkout v1.0.0
export MINESERVER_PASSWORD=
export MINESERVER_DNS=
export MINESERVER_STORAGE_ACCOUNT=
az login
. rollout.sh

|
Метки: author Dronopotamus microsoft azure azure automation minecraft server |
История создания синхронизатора часов DCF77 |
|
Метки: author assad77 программирование микроконтроллеров microcontroller radio |
[Из песочницы] Работа с ресурсами, или как я пропихивал @Cleanup |
public class MigratorV1 {
private Connection conn; // Injected
private SAXParser xmlParser; // Injected
private XMLOutputFactory xmlFactory; // Injected
public void migrate() throws Exception {
PreparedStatement selectOldContent = conn.prepareStatement("select content from old_data where id = ?");
PreparedStatement insertNewContent = conn.prepareStatement("insert into new_data (id, scheme, data) values (?, ?, ?)");
ResultSet oldIdResult = conn.createStatement().executeQuery("select id from old_data");
while (oldIdResult.next()) {
long id = oldIdResult.getLong(1);
selectOldContent.setLong(1, id);
ResultSet oldContentResult = selectOldContent.executeQuery();
oldContentResult.next();
Blob oldContent = oldContentResult.getBlob(1);
Reader oldContentReader = new InputStreamReader(new GZIPInputStream(oldContent.getBinaryStream()));
StringWriter newSchemeWriter = new StringWriter();
XMLStreamWriter newSchemeXMLWriter = xmlFactory.createXMLStreamWriter(newSchemeWriter);
ByteArrayOutputStream newDataOutput = new ByteArrayOutputStream();
GZIPOutputStream newZippedDataOutput = new GZIPOutputStream(newDataOutput);
XMLStreamWriter newDataXMLWriter = xmlFactory.createXMLStreamWriter(newZippedDataOutput, "utf-8");
xmlParser.parse(new InputSource(oldContentReader), new DefaultHandler() {
// Usage of schemeXMLWriter and dataXMLWriter to write XML into String and byte[]
});
String newScheme = newSchemeWriter.toString();
byte[] newData = newDataOutput.toByteArray();
StringReader newSchemeReader = new StringReader(newScheme);
ByteArrayInputStream newDataInput = new ByteArrayInputStream(newData);
insertNewContent.setLong(1, id);
insertNewContent.setCharacterStream(2, newSchemeReader, newScheme.length());
insertNewContent.setBlob(3, newDataInput, newData.length);
insertNewContent.executeUpdate();
}
}
}
public class MigratorV2 {
private Connection conn; // Injected
private SAXParser xmlParser; // Injected
private XMLOutputFactory xmlFactory; // Injected
public void migrate() throws Exception {
try (
PreparedStatement selectOldContent = conn.prepareStatement("select content from old_data where id = ?");
PreparedStatement insertNewContent = conn.prepareStatement("insert into new_data (id, scheme, data) values (?, ?, ?)");
ResultSet oldIdResult = conn.createStatement().executeQuery("select id from old_data");
){
while (oldIdResult.next()) {
long id = oldIdResult.getLong(1);
selectOldContent.setLong(1, id);
try (ResultSet oldContentResult = selectOldContent.executeQuery()) {
oldContentResult.next();
String newScheme;
byte[] newData;
Blob oldContent = null;
try {
oldContent = oldContentResult.getBlob(1);
try (
Reader oldContentReader = new InputStreamReader(new GZIPInputStream(oldContent.getBinaryStream()));
StringWriter newSchemeWriter = new StringWriter();
ByteArrayOutputStream newDataOutput = new ByteArrayOutputStream();
GZIPOutputStream newZippedDataOutput = new GZIPOutputStream(newDataOutput);
){
XMLStreamWriter newSchemeXMLWriter = null;
XMLStreamWriter newDataXMLWriter = null;
try {
newSchemeXMLWriter = xmlFactory.createXMLStreamWriter(newSchemeWriter);
newDataXMLWriter = xmlFactory.createXMLStreamWriter(newZippedDataOutput, "utf-8");
xmlParser.parse(new InputSource(oldContentReader), new DefaultHandler() {
// Usage of schemeXMLWriter and dataXMLWriter to write XML into String and byte[]
});
} finally {
if (newSchemeXMLWriter != null) {
try {
newSchemeXMLWriter.close();
} catch (XMLStreamException e) {}
}
if (newDataXMLWriter != null) {
try {
newDataXMLWriter.close();
} catch (XMLStreamException e) {}
}
}
newScheme = newSchemeWriter.toString();
newData = newDataOutput.toByteArray();
}
} finally {
if (oldContent != null) {
try {
oldContent.free();
} catch (SQLException e) {}
}
}
try (
StringReader newSchemeReader = new StringReader(newScheme);
ByteArrayInputStream newDataInput = new ByteArrayInputStream(newData);
){
insertNewContent.setLong(1, id);
insertNewContent.setCharacterStream(2, newSchemeReader, newScheme.length());
insertNewContent.setBlob(3, newDataInput, newData.length);
insertNewContent.executeUpdate();
}
}
}
}
}
}
public class MigratorV3 {
private Connection conn; // Injected
private SAXParser xmlParser; // Injected
private XMLOutputFactory xmlFactory; // Injected
@RequiredArgsConstructor
private static class NewData {
final String scheme;
final byte[] data;
}
private List loadIds() throws Exception {
List ids = new ArrayList<>();
try (ResultSet oldIdResult = conn.createStatement().executeQuery("select id from old_data")) {
while (oldIdResult.next()) {
ids.add(oldIdResult.getLong(1));
}
}
return ids;
}
private Blob loadOldContent(PreparedStatement selectOldContent, long id) throws Exception {
selectOldContent.setLong(1, id);
try (ResultSet oldContentResult = selectOldContent.executeQuery()) {
oldContentResult.next();
return oldContentResult.getBlob(1);
}
}
private void oldContentToNewData(Reader oldContentReader, StringWriter newSchemeWriter, GZIPOutputStream newZippedDataOutput) throws Exception {
XMLStreamWriter newSchemeXMLWriter = null;
XMLStreamWriter newDataXMLWriter = null;
try {
newSchemeXMLWriter = xmlFactory.createXMLStreamWriter(newSchemeWriter);
newDataXMLWriter = xmlFactory.createXMLStreamWriter(newZippedDataOutput, "utf-8");
xmlParser.parse(new InputSource(oldContentReader), new DefaultHandler() {
// Usage of schemeXMLWriter and dataXMLWriter to write XML into String and byte[]
});
} finally {
if (newSchemeXMLWriter != null) {
try {
newSchemeXMLWriter.close();
} catch (XMLStreamException e) {}
}
if (newDataXMLWriter != null) {
try {
newDataXMLWriter.close();
} catch (XMLStreamException e) {}
}
}
}
private NewData generateNewDataFromOldContent(PreparedStatement selectOldContent, long id) throws Exception {
Blob oldContent = null;
try {
oldContent = loadOldContent(selectOldContent, id);
try (
Reader oldContentReader = new InputStreamReader(new GZIPInputStream(oldContent.getBinaryStream()));
StringWriter newSchemeWriter = new StringWriter();
ByteArrayOutputStream newDataOutput = new ByteArrayOutputStream();
GZIPOutputStream newZippedDataOutput = new GZIPOutputStream(newDataOutput);
){
oldContentToNewData(oldContentReader, newSchemeWriter, newZippedDataOutput);
return new NewData(newSchemeWriter.toString(), newDataOutput.toByteArray());
}
} finally {
if (oldContent != null) {
try {
oldContent.free();
} catch (SQLException e) {}
}
}
}
private void storeNewData(PreparedStatement insertNewContent, long id, String newScheme, byte[] newData) throws Exception {
try (
StringReader newSchemeReader = new StringReader(newScheme);
ByteArrayInputStream newDataInput = new ByteArrayInputStream(newData);
){
insertNewContent.setLong(1, id);
insertNewContent.setCharacterStream(2, newSchemeReader, newScheme.length());
insertNewContent.setBlob(3, newDataInput, newData.length);
insertNewContent.executeUpdate();
}
}
public void migrate() throws Exception {
List ids = loadIds();
try (
PreparedStatement selectOldContent = conn.prepareStatement("select content from old_data where id = ?");
PreparedStatement insertNewContent = conn.prepareStatement("insert into new_data (id, scheme, data) values (?, ?, ?)");
){
for (Long id : ids) {
NewData newData = generateNewDataFromOldContent(selectOldContent, id);
storeNewData(insertNewContent, id, newData.scheme, newData.data);
}
}
}
}
public class MigratorV4 {
private Connection conn; // Injected
private SAXParser xmlParser; // Injected
private XMLOutputFactory xmlFactory; // Injected
@RequiredArgsConstructor
private static class NewData {
final String scheme;
final byte[] data;
}
@RequiredArgsConstructor
private static class SmartXMLStreamWriter implements AutoCloseable {
final XMLStreamWriter writer;
@Override
public void close() throws Exception {
writer.close();
}
}
@RequiredArgsConstructor
private static class SmartBlob implements AutoCloseable {
final Blob blob;
@Override
public void close() throws Exception {
blob.free();
}
}
private List loadIds() throws Exception {
List ids = new ArrayList<>();
try (ResultSet oldIdResult = conn.createStatement().executeQuery("select id from old_data")) {
while (oldIdResult.next()) {
ids.add(oldIdResult.getLong(1));
}
}
return ids;
}
private Blob loadOldContent(PreparedStatement selectOldContent, long id) throws Exception {
selectOldContent.setLong(1, id);
try (ResultSet oldContentResult = selectOldContent.executeQuery()) {
oldContentResult.next();
return oldContentResult.getBlob(1);
}
}
private void oldContentToNewData(Reader oldContentReader, StringWriter newSchemeWriter, GZIPOutputStream newZippedDataOutput) throws Exception {
try (
SmartXMLStreamWriter newSchemeXMLWriter = new SmartXMLStreamWriter(xmlFactory.createXMLStreamWriter(newSchemeWriter));
SmartXMLStreamWriter newDataXMLWriter = new SmartXMLStreamWriter(xmlFactory.createXMLStreamWriter(newZippedDataOutput, "utf-8"));
){
xmlParser.parse(new InputSource(oldContentReader), new DefaultHandler() {
// Usage of schemeXMLWriter and dataXMLWriter to write XML into String and byte[]
});
}
}
private NewData generateNewDataFromOldContent(PreparedStatement selectOldContent, long id) throws Exception {
try (
SmartBlob oldContent = new SmartBlob(loadOldContent(selectOldContent, id));
Reader oldContentReader = new InputStreamReader(new GZIPInputStream(oldContent.blob.getBinaryStream()));
StringWriter newSchemeWriter = new StringWriter();
ByteArrayOutputStream newDataOutput = new ByteArrayOutputStream();
GZIPOutputStream newZippedDataOutput = new GZIPOutputStream(newDataOutput);
){
oldContentToNewData(oldContentReader, newSchemeWriter, newZippedDataOutput);
return new NewData(newSchemeWriter.toString(), newDataOutput.toByteArray());
}
}
private void storeNewData(PreparedStatement insertNewContent, long id, String newScheme, byte[] newData) throws Exception {
try (
StringReader newSchemeReader = new StringReader(newScheme);
ByteArrayInputStream newDataInput = new ByteArrayInputStream(newData);
){
insertNewContent.setLong(1, id);
insertNewContent.setCharacterStream(2, newSchemeReader, newScheme.length());
insertNewContent.setBlob(3, newDataInput, newData.length);
insertNewContent.executeUpdate();
}
}
public void migrate() throws Exception {
List ids = loadIds();
try (
PreparedStatement selectOldContent = conn.prepareStatement("select content from old_data where id = ?");
PreparedStatement insertNewContent = conn.prepareStatement("insert into new_data (id, scheme, data) values (?, ?, ?)");
){
for (Long id : ids) {
NewData newData = generateNewDataFromOldContent(selectOldContent, id);
storeNewData(insertNewContent, id, newData.scheme, newData.data);
}
}
}
}
public class MigratorV5 {
private Connection conn; // Injected
private SAXParser xmlParser; // Injected
private XMLOutputFactory xmlFactory; // Injected
@RequiredArgsConstructor
private static class NewData {
final String scheme;
final byte[] data;
}
private List loadIds() throws Exception {
List ids = new ArrayList<>();
try (ResultSet oldIdResult = conn.createStatement().executeQuery("select id from old_data")) {
while (oldIdResult.next()) {
ids.add(oldIdResult.getLong(1));
}
}
return ids;
}
private Blob loadOldContent(PreparedStatement selectOldContent, long id) throws Exception {
selectOldContent.setLong(1, id);
try (ResultSet oldContentResult = selectOldContent.executeQuery()) {
oldContentResult.next();
return oldContentResult.getBlob(1);
}
}
private void oldContentToNewData(Reader oldContentReader, StringWriter newSchemeWriter, GZIPOutputStream newZippedDataOutput) throws Exception {
XMLStreamWriter newSchemeXMLWriter;
XMLStreamWriter newDataXMLWriter;
try (
AutoCloseable fake1 = (newSchemeXMLWriter = xmlFactory.createXMLStreamWriter(newSchemeWriter))::close;
AutoCloseable fake2 = (newDataXMLWriter = xmlFactory.createXMLStreamWriter(newZippedDataOutput, "utf-8"))::close;
){
xmlParser.parse(new InputSource(oldContentReader), new DefaultHandler() {
// Usage of schemeXMLWriter and dataXMLWriter to write XML into String and byte[]
});
}
}
private NewData generateNewDataFromOldContent(PreparedStatement selectOldContent, long id) throws Exception {
Blob oldContent;
try (
AutoCloseable fake = (oldContent = loadOldContent(selectOldContent, id))::free;
Reader oldContentReader = new InputStreamReader(new GZIPInputStream(oldContent.getBinaryStream()));
StringWriter newSchemeWriter = new StringWriter();
ByteArrayOutputStream newDataOutput = new ByteArrayOutputStream();
GZIPOutputStream newZippedDataOutput = new GZIPOutputStream(newDataOutput);
){
oldContentToNewData(oldContentReader, newSchemeWriter, newZippedDataOutput);
return new NewData(newSchemeWriter.toString(), newDataOutput.toByteArray());
}
}
private void storeNewData(PreparedStatement insertNewContent, long id, String newScheme, byte[] newData) throws Exception {
try (
StringReader newSchemeReader = new StringReader(newScheme);
ByteArrayInputStream newDataInput = new ByteArrayInputStream(newData);
){
insertNewContent.setLong(1, id);
insertNewContent.setCharacterStream(2, newSchemeReader, newScheme.length());
insertNewContent.setBlob(3, newDataInput, newData.length);
insertNewContent.executeUpdate();
}
}
public void migrate() throws Exception {
List ids = loadIds();
try (
PreparedStatement selectOldContent = conn.prepareStatement("select content from old_data where id = ?");
PreparedStatement insertNewContent = conn.prepareStatement("insert into new_data (id, scheme, data) values (?, ?, ?)");
){
for (Long id : ids) {
NewData newData = generateNewDataFromOldContent(selectOldContent, id);
storeNewData(insertNewContent, id, newData.scheme, newData.data);
}
}
}
}
public class MigratorV6 {
private Connection conn; // Injected
private SAXParser xmlParser; // Injected
private XMLOutputFactory xmlFactory; // Injected
@RequiredArgsConstructor
private static class NewData {
final String scheme;
final byte[] data;
}
private List loadIds() throws Exception {
List ids = new ArrayList<>();
try (ResultSet oldIdResult = conn.createStatement().executeQuery("select id from old_data")) {
while (oldIdResult.next()) {
ids.add(oldIdResult.getLong(1));
}
}
return ids;
}
private Blob loadOldContent(PreparedStatement selectOldContent, long id) throws Exception {
selectOldContent.setLong(1, id);
try (ResultSet oldContentResult = selectOldContent.executeQuery()) {
oldContentResult.next();
return oldContentResult.getBlob(1);
}
}
private void oldContentToNewData(Reader oldContentReader, StringWriter newSchemeWriter, GZIPOutputStream newZippedDataOutput) throws Exception {
@Cleanup XMLStreamWriter newSchemeXMLWriter = xmlFactory.createXMLStreamWriter(newSchemeWriter);
@Cleanup XMLStreamWriter newDataXMLWriter = xmlFactory.createXMLStreamWriter(newZippedDataOutput, "utf-8");
xmlParser.parse(new InputSource(oldContentReader), new DefaultHandler() {
// Usage of schemeXMLWriter and dataXMLWriter to write XML into String and byte[]
});
}
private NewData generateNewDataFromOldContent(PreparedStatement selectOldContent, long id) throws Exception {
@Cleanup("free") Blob oldContent = loadOldContent(selectOldContent, id);
try (
Reader oldContentReader = new InputStreamReader(new GZIPInputStream(oldContent.getBinaryStream()));
StringWriter newSchemeWriter = new StringWriter();
ByteArrayOutputStream newDataOutput = new ByteArrayOutputStream();
GZIPOutputStream newZippedDataOutput = new GZIPOutputStream(newDataOutput);
){
oldContentToNewData(oldContentReader, newSchemeWriter, newZippedDataOutput);
return new NewData(newSchemeWriter.toString(), newDataOutput.toByteArray());
}
}
private void storeNewData(PreparedStatement insertNewContent, long id, String newScheme, byte[] newData) throws Exception {
try (
StringReader newSchemeReader = new StringReader(newScheme);
ByteArrayInputStream newDataInput = new ByteArrayInputStream(newData);
){
insertNewContent.setLong(1, id);
insertNewContent.setCharacterStream(2, newSchemeReader, newScheme.length());
insertNewContent.setBlob(3, newDataInput, newData.length);
insertNewContent.executeUpdate();
}
}
public void migrate() throws Exception {
List ids = loadIds();
try (
PreparedStatement selectOldContent = conn.prepareStatement("select content from old_data where id = ?");
PreparedStatement insertNewContent = conn.prepareStatement("insert into new_data (id, scheme, data) values (?, ?, ?)");
){
for (Long id : ids) {
NewData newData = generateNewDataFromOldContent(selectOldContent, id);
storeNewData(insertNewContent, id, newData.scheme, newData.data);
}
}
}
}
public class MigratorV7 {
private Connection conn; // Injected
private SAXParser xmlParser; // Injected
private XMLOutputFactory xmlFactory; // Injected
public void migrate() throws Exception {
@Cleanup PreparedStatement selectOldContent = conn.prepareStatement("select content from old_data where id = ?");
@Cleanup PreparedStatement insertNewContent = conn.prepareStatement("insert into new_data (id, scheme, data) values (?, ?, ?)");
@Cleanup ResultSet oldIdResult = conn.createStatement().executeQuery("select id from old_data");
while (oldIdResult.next()) {
long id = oldIdResult.getLong(1);
selectOldContent.setLong(1, id);
@Cleanup ResultSet oldContentResult = selectOldContent.executeQuery();
oldContentResult.next();
@Cleanup("free") Blob oldContent = oldContentResult.getBlob(1);
@Cleanup Reader oldContentReader = new InputStreamReader(new GZIPInputStream(oldContent.getBinaryStream()));
@Cleanup StringWriter newSchemeWriter = new StringWriter();
@Cleanup XMLStreamWriter newSchemeXMLWriter = xmlFactory.createXMLStreamWriter(newSchemeWriter);
ByteArrayOutputStream newDataOutput = new ByteArrayOutputStream();
@Cleanup GZIPOutputStream newZippedDataOutput = new GZIPOutputStream(newDataOutput);
@Cleanup XMLStreamWriter newDataXMLWriter = xmlFactory.createXMLStreamWriter(newZippedDataOutput, "utf-8");
xmlParser.parse(new InputSource(oldContentReader), new DefaultHandler() {
// Usage of schemeXMLWriter and dataXMLWriter to write XML into String and byte[]
});
String newScheme = newSchemeWriter.toString();
byte[] newData = newDataOutput.toByteArray();
@Cleanup StringReader newSchemeReader = new StringReader(newScheme);
@Cleanup ByteArrayInputStream newDataInput = new ByteArrayInputStream(newData);
insertNewContent.setLong(1, id);
insertNewContent.setCharacterStream(2, newSchemeReader, newScheme.length());
insertNewContent.setBlob(3, newDataInput, newData.length);
insertNewContent.executeUpdate();
}
}
}
|
Метки: author vtarasoff программирование java lombok cleanup |
Как довести первый проект до конца. Часть 2. Мифы, ошибки и провалы |

|
Метки: author AllSoliton разработка игр unity3d |
[CppCon 2017] Бьёрн Страуструп: Изучение и преподавание современного C++ |
Сейчас проходит конференция CppCon 2017, и на их youtube-канале уже стали появляться видео оттуда. И я подумал, почему бы не попробовать сделать конспекты интересных лекций. Конечно, не очень уверен, надолго ли меня хватит, зависит от того насколько вам это понравится.
Это первое вступительное видео. Оно не такое интересное для меня, но пропустить тоже не мог, это же Страуструп. Далее, текст от его лица. Заголовки взяты из слайдов.
Disclaimer: весь дальнейший текст — достаточно краткий пересказ, являющийся результом работы моего восприятия, и то, что я посчитал "водой" и проигнорировал, могло оказаться важным для вас. Иногда выступление было таким: "(важная мысль 1)(минута воды)(важная мысль 2)". Эти две мысли плавно перетекали друг в друга, а у меня получались довольно резкие скачки. Где можно сгладил, но посчитал нецелесообразным полностью причесывать текст, на это бы потребовалось много времени.
Когда меня попросили выступить на открытии конференции, я задумался, о чем же я могу рассказать такого, что важно для вас, и чего вы не слышали миллион раз. И я решил рассказать про обучение языку C++.
Зададимся вопросом кого мы учим, чему, зачем и как. Нужно делать это лучше. Я не критикую кого-то в частности, но чувствую, что мы должны делать это лучше. Не все из нас преподаватели, но тем не менее постоянно возникают случаи, когда мы занимаемся обучением. Например, рассказываем коллегам о последних фичах или даем советы. Общаемся на StackOverflow, Reddit, ведем блоги и т.д. Но нужно давать хорошие советы. Советы, которые двигают мир вперед.
Есть одна вещь, которая сильно беспокоит меня — зачастую у людей бывают очень странные представления о том, что собой представляет C++. Чуть позже я вернусь к этой проблеме.
Когда учите, задумайтесь, чего вы хотите достичь. И от от этого и начинайте. Не отталкивайтесь от "что мы уже сделали" и "что проще, чтобы начать", а если вы преподаватель, то от "что проще проверить".
Не нужно фокусироваться на языковых фичах. Например, вы встречали примеры в которых объясняется проблема приведения signed short к unsigned int [рассказывается о преподавании языка в общем, а не об особенностях C++]. Это неинтересно и можно увидеть в отладчике или прочитать в руководстве. Учите так, чтобы такая проблема не появлялась.
Не пытайтесь учить всему, вы не сможете. Внимательно выберите подмножество языка.
Одна из встечающихся проблем обучения C++ — то что язык изучается сам по себе, отдельно от библиотек. Вектор на 697 странице, sort через 100 страниц. Это учит, что stl скучная, сложная фигня. И в то же время: свой Linked List или Hash table это круто, круче чем stl.
[в выступлении автор использует слово clever с негативным оттенком, что-то вроде человека, который пытается казаться быть умным]
Люди которые хотят и требуют "самое последнее" часто не знают основ. Пересмотрите основы.
Будьте проще. Не бросайтесь в самое сложное и изощренное. Не используйте самый продвинутый алгоритм, который только можно найти. Я бы не выбрал пузырьковую сортировку, но также не выбрал бы и "полный общий алгоритм для всего". Предлагайте самый простой пример, который иллюстрирует технику или фичу.
Фокусируйтесь на общих случаях. Будьте рациональными. Не говорите ученикам "Делай только так, это правильно, это закаляет характер. И можете получить пятерку, если ответите именно так". Нужно объяснить, почему нужно следовать правилам, дать ученикам хорошие идеалы, идеи, техники.
Конечно, обучая, очень заманчиво, стоять перед коллегами, группой людей и всем своим видом показывать: "Смотрите, эта сложная вещь, которую вы не поняли. Это означает, что я умный". Это не очень хорошее обучение.
Если изучать только сам язык, то попав в реальность можно просто "утонуть".
Используйте различные инструменты. Не только компилятор и учебник, но и IDE, отладчики, системы контроля версий, профилировщики, модульное тестирорвание, статические анализаторы, онлайн компиляторы. Интрументы должны быть современными (иногда получаю вопросы по Turbo C++ 4.0 :( )
Нужно изучать принципы и закреплять на практике. Используйте графику, сети, интернет, Raspberry Pi, робототехнику и т.д. Это очевидно для вас, но не очевидно для университетов. Не говорите что это просто и быстро. И помните, что никто не умеет делать все.
Как мы часто учим? Объясняем язык плюс немного стандартную библиотеку. Без всякой графики, пользовательского интерфейса, веба, электронной почты, баз данных… И многие ученики считают, что C++ скучный бесполезный язык. Но это же не так, ведь такие вещи как браузеры, СУБД, САПР и прочие пишутся на C++. Перед началом лекции потратьте 5 минут о практическом применении.
Нам, сообществу C++, очень важно упростить начало работы, возможность пользоваться "прямо сейчас".
Как пользователи в различных отраслях разделяются на группы? Приведем пример с фотографией. Результат зависит от оборудования и от пользователя. Лично я новичок в фотографии. Большинство возможностей профессиональной фотокамеры будут для меня бесполезными. Она много весит, дорого стоит. Для нее существует множество аксессуаров в которых можно утонуть. Но с ее помощью можно делать превосходные фотографии, если потратить много времени на обучение. Аналогично существует много людей, которые не могут использовать разнообразные фичи языка и библиотеки.
С другой стороны, у нас есть устройства, которыми можно пользоваться сразу. Такое устройство дешевое, простое, "милое". Прощает ошибки, не требует много усилий для освоения. Является "вещью в себе". Мало расширений и дополнений, если таковые вообще есть. Отсуствуют взаимозаменяемые части.
Как-то во время преподавания мне было нужно, чтобы у студентов была установлена библиотека GUI. Оказалось, что установить одну и ту же библиотеку на студенческие Mac, Linux, Windows, весьма болезненно.
Каждый произвожитель фототехнии предлагает "систему", которая предполагает, что вы можете постепенно обновлять оборудование и переходить на следующий уровень по мере обучения.
Не обязательно давать новичку профессиональную камеру со всеми наворотами. В этом случае у него будут трудности и результат вероятно будет хуже, чем если бы он использовал "мыльницу". Поэтому какое-то одно решение не будет подходящим для всех.
Язык должен быть представлен тремя дистрибутивами. Для новичков, любителей и профессионалов.
База:
import bundle.entry_level; //Для новичков
import bundle.enthusiast_level; //Для продвинутых
import bundle.professional_level; //Для профессионаловРасширения (которые не входят в базу):
import grahics.2d;
import grahics.3d;
import professional.graphics.3d;
import physlib.linear_algebra;
import boost.XML;
import 3rd_party.image_filtering;Как ученик на вторую неделю после начала обучения может установить библиотеку графического интерфейса и работы с базами данных? Различные библиотеки и системы собираются по разному. Различные библиотеки могут быть плохо совместимыми. Десяток несовметимых пакетных менеджеров — это не решение. Нужно сделать простым выполнение простых задач
> download gui_xyz
> install gui_xyzИли эквивалетным способом, например в IDE:
import gui_xyz; //в кодеМое видение современного C++ (как обычно):
Современный C++ это не C, Java, C++98 и не тот язык, на которым вы программировали 10 лет назад. Инерция — враг хорошего кода. Преподаватели, оправдывая неиспользование современных стандартов, говорят, что "мы так не делаем", "это не вставить в мою учебную программу", "может быть через 5 лет". У студентов появляется большее доверие к интернету, чем к преподавателям. Некоторые считают, что они умнее преподавателей, и иногда они правы. У меня стабильно каждый год на курсе были студенты, абсолютно убежденные, что они умнее меня в программировании. В этих частных случаях, я обоснованно уверен, что оне не правы [смех в зале].
Для реализации этого 2 года назад был открыт проект C++ Core Guidelines. Он дает конкретные ответы на вопросы. У него много много участников, включая Microsoft и Red Hat.
Не отделяйте примеры от объяснения. 5 страниц голой теории это лишняя трата. Давайте примеры и объяснения к ним. Без объяснения люди не обобщают. Они просто копипастят и сами изобретают трактовку, причем иногда очень странную.
Всегда объясняйте причины. Например:
//1
int max = v.size();
for(int i = 0; i < max; ++i)
//2
for (auto x : v)Почему 2 лучше чем 1? Пример 2 явно показывает намерение, v может быть изменен без переписывания цикла, и менее подвержен ошибкам. Следует заметить, что 1 предоставляет более гибкие возможности. Но ведь goto еще более универсален, и поэтому мы избегаем его.
[I.4 означает пункт из Core Guidelines]
void blink_led1(int time_to_blink) //Плохо - неясный тип
void blink_led2(milliseconds time_to_blink) //Хорошо
void use()
{
blink_led2(1500); //Ошибка: какая единица измерения?
blink_led2(1500ms);
blink_led2(1500s); //Ошибка: неверная единица измерения
}[Здесь milliseconds какой-то простой тип не из библиотеки Chrono, поэтому последняя строчка приводит к ошибке. Ниже по тексту описано обобщение типа для единицы измерения, взятого из Chrono. Если интересно, можете почитать мое описание этой библиотеки]
template
void blink_led(duration time_to_blink)
{
auto ms_to_blink = duration_cast(time_to_blink);
}
void use()
{
blink_led(2s);
blink_led(1500ms);
} Error_code err; //неинициализировано: потенциальная проблема
//...
Channel ch = Channel::open(s, &err); //out-параметр: потенциальная проблема
if(err) { ... }
Лучше:
auto [ch, err] = Channel::open(s) //structured binding
if(err) ...А должен ли этот код использовать возврат двух параметров?
auto ch = Channel::open(s);Лучше? Да, если неуспешное открытие было предусмотрено в программе.
Слово "умный" в контексте использования C++ — ругательное. Найдите баг:
istream& init_io()
{
if(argc > 1)
return *new istream { argv[1], "r" };
else
return cin;
}//Плохо
auto x = m * v1 + vv //Перемножение m с v1 и прибавление vv
//Хорошо
void stable_sort(Sortable& c)
//cортирует "c" согласно порядку, задаваемым "<"
//сохраняет исходный порядок равных элементов (определяемыми "==")
{
//...несколько строк нетривиального кода
}Я рекомендую вам отправиться на github и почитать раздел Philosophy rules, содержащий основные концепции.
Моя цель очень проста. Мы можем писать типо- и ресурсобезопасный код без утечек, повреждения памяти, сборщика мусора, ограничений в выразительности, ухудшения производительности.
Сейчас разрабатываются 2 открытых проекта: анализатор, для проверки провил Core Guidelines, и библиотека GSL — guidelines support library (реализация от Microsoft).

Нет, я расказал далеко не все про обучение. Лишь едва царапнул поверхность.
[У Страуструпа есть сверхспособность отвечать по 5 минут на простые вопросы, поэтому я очень сильно сократил его ответы да и сами вопросы тоже]
Core Guidelines слишком всеобъемлющие. как учить?
Не нужно читать всё. Прочитать введение, затем раздел с философией. Не нужно искать правило, правило само найдет вас.
Нужны ли стандартной библиотеке нужны простые функции? Например random [я полагаю, что имеется в виду функция без необходимости установки начального значения и возможностью задания закона распределения]?
Да, нужны.
Вы говорили про 3 дистрибутива C++. Кто должен этим заниматься?
Вряд этим будет заниматься комитет, поэтому, я думаю, это нужно делать силами сообщества. Это будет проще с развитием единого пакетного менеджера и модулей
Моя дочь учится в колледже и мы вместе делали проект термостата. Так вот, для того, чтобы получить температуру и отобразить на экране, потребовался целый семестр изучения C++. Что вы думаете по этому поводу?
Да, есть такая проблема. С модулями будет лучше.
Нужно ли преподавать программирование как общий предмет, так же как математику
Я не компетентен в этом вопросе.
mmatrosov: вы говорили о том, что в обучении нужно пользоваться билиотеками. Не будет ли такого, что новое поколение программистов не будет знать основ?
Зависит от цели. Я учу студентов как реализовать вектор, они должны знать об указателях, но не каждому нужно реализовывать lock-free код.
|
Метки: author Fil c++ c++17 cppcon изучение программирования страуструп |
Продолжение поста от школьников. Как Хабрахабр смог изменить нашу судьбу? |


|
Метки: author Noobariouse разработка под android разработка мобильных приложений разработка игр программирование java android google play indie издание игр |
[Из песочницы] Как запустить Java-приложение с несколькими версиями одной библиотеки в 2017 году |

Хочу поделиться решениями одной проблемы, с которой мне пришлось столкнуться, плюс исследование данного вопроса в контексте Java 9.
Писатель из меня ещё тот (пишу в первый раз), поэтому закидывание вкусными помидорами с указанием причин только приветствуется.
Сразу договоримся, что статья не годится в качестве руководства по:
Если по последним именам информации в сети полно, то по первому… со временем появится, по крайней мере здесь есть необходимая информация.
Представим себе простую ситуацию: разворачиваем кластер Elasticsearch и загружаем в него данные. Мы пишем приложение, которое занимается поиском в этом кластере. Поскольку постоянно выходят новые версии Elasticsearch, мы привносим в кластер новые проблемы фичи с помощью rolling upgrade. Но вот незадача — в какой-то момент у нас сменился формат хранимых данных (например, чтобы максимально эффективно использовать какую-то из новых фич) и делать reindex нецелесообразно. Нам подойдёт такой вариант: ставим новый кластер на этих же машинах — первый кластер со старой схемой данных остаётся на месте только для поиска, а поступающие данные загружаем во второй с новой схемой. Тогда нашему поисковому компоненту потребуется держать на связи уже 2 кластера.
Наше приложение использует Java API для общения с кластером, а это значит, что оно тянет в зависимостях сам Elasticsearch. Стоит отметить, что вместе с 5-ой версией вышел и Rest Client, избавляющий нас от таких проблем (а также от удобного API самого Elasticsearch), но мы переместимся во времени на момент релиза 2-ой версии.
Рассмотрим возможные решения на примере простого приложения: поиск документа в 2-х кластерах Elasticsearch 1.7 и 2.4. Код доступен на гитхабе, и повторяет структуру данной статьи (отсутствует только OSGi).
Перейдём к делу. Создадим Maven-проект следующей структуры:
+---pom.xml
+---core/
| +---pom.xml
| +---src/
| +---main/
| | +---java/
| | | +---elasticsearch/
| | | +---client/
| | | +---SearchClient.java
| | | +---Searcher.java
| | +---resources/
| +---test/
| +---java/
+---es-v1/
| +---pom.xml
| +---src/
| +---main/
| | +---java/
| | | +---elasticsearch/
| | | +---client/
| | | +---v1/
| | | +---SearchClientImpl.java
| | +---resources/
| +---test/
| +---java/
+---es-v2/
+---pom.xml
+---src/
+---main/
| +---java/
| | +---elasticsearch/
| | +---client/
| | +---v2/
| | +---SearchClientImpl.java
| +---resources/
+---test/
+---java/Очевидно, что в одном модуле подключить несколько версий одной библиотеки не получится, поэтому проект должен быть многомодульным:
Модуль core содержит класс Searcher, который является "испытателем" наших модулей es-v1 и es-v2:
public class Searcher {
public static void main(String[] args) throws Exception {
List clients = Arrays.asList(
getClient("1"),
getClient("2")
);
for (SearchClient client : clients) {
System.out.printf("Client for version: %s%n", client.getVersion());
Map doc = client.search("test");
System.out.println("Found doc:");
System.out.println(doc);
System.out.println();
}
clients.forEach(SearchClient::close);
}
private static SearchClient getClient(String desiredVersion) throws Exception {
return null; // см. далее
}
} Ничего сверхестественного: выводится версия Elasticsearch, используемая модулем, и проводится тестовый поиск через него — этого будет достаточно для демонстрации.
Взглянем на одну из реализаций, вторая почти идентична:
public class SearchClientImpl implements SearchClient {
private final Settings settings = ImmutableSettings.builder()
.put("cluster.name", "es1")
.put("node.name", "es1")
.build();
private final Client searchClient = new TransportClient(settings)
.addTransportAddress(getAddress());
private InetSocketTransportAddress getAddress() {
return new InetSocketTransportAddress("127.0.0.1", 9301);
}
@Override
public String getVersion() {
return Version.CURRENT.number();
}
@Override
public Map search(String term) {
SearchResponse response = searchClient.prepareSearch("*")
.setQuery(QueryBuilders.termQuery("field", term))
.execute()
.actionGet();
if (response.getHits().getTotalHits() > 0) {
return response.getHits().getAt(0).getSource();
} else {
return null;
}
}
@Override
public void close() {
searchClient.close();
}
}Тоже всё просто: текущая версия, зашитая в Elasticsearch, и поиск по полю field во всех индексах (*), возвращающий первый найденный документ, если есть.
Проблема здесь кроется в том, как именно вызвать реализации интерфейса SearchClient в методе Searcher#getClient и получить желаемый результат.
Даже если вы не знаток Java, наверняка слышали, что там властвует ClassLoader. Он не позволит нам совершить задуманное, если оставить по умолчанию, поэтому такое решение влоб не сработает:
private static SearchClient getClient(String desiredVersion) throws Exception {
String className = String.format("elasticsearch.client.v%s.SearchClientImpl", desiredVersion);
return (SearchClient) Class.forName(className).newInstance();
}Соберём, запустим и увидим результат… вполне неопределённый, например, такой:
Exception in thread "main" java.lang.IncompatibleClassChangeError: Implementing class
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:763)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:467)
at java.net.URLClassLoader.access$100(URLClassLoader.java:73)
at java.net.URLClassLoader$1.run(URLClassLoader.java:368)
at java.net.URLClassLoader$1.run(URLClassLoader.java:362)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:361)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at elasticsearch.client.Searcher.getClient(Searcher.java:28)
at elasticsearch.client.Searcher.main(Searcher.java:10)Хотя мог и ClassNotFoundException бросить… или ещё чего...
Так как URLClassLoader найдёт и загрузит первый попавшийся класс с заданным именем из заданного набора jar-файлов и директорий, это будет необязательно требуемый класс. В данном случае эта ошибка возникает из-за того, что в списке class-path библиотека elasticsearch-2.4.5.jar идёт до elasticsearch-1.7.5.jar, поэтому все классы (которые совпадают по имени) будут загружены для 2.4.5. Поскольку наш Searcher сначала пытается загрузить модуль для Elasticsearch 1.7.5 (getClient("1")), URLClassLoader загрузит ему совсем не те классы...
Когда загрузчик классов имеет в своём распоряжении пересекающиеся по имени (а значит и по именам файлов) классы, такое его состояние называют jar hell (или class-path hell).
Становится очевидным, что модули и их зависимости нужно разнести по разным загрузчикам классов. Просто создаём URLClassLoader на каждый модуль es-v* и указываем каждому свою директорию с jar-файлами:
private static SearchClient getClient(String desiredVersion) throws Exception {
String className = String.format("elasticsearch.client.v%s.SearchClientImpl", desiredVersion);
Path moduleDependencies = Paths.get("modules", "es-v" + desiredVersion);
URL[] jars = Files.list(moduleDependencies)
.map(Path::toUri)
.map(Searcher::toURL)
.toArray(URL[]::new);
ClassLoader classLoader = new URLClassLoader(jars); // parent = app's class loader
return (SearchClient) classLoader.loadClass(className).newInstance();
}Нам нужно собрать и скопировать все модули в соответствующие директории modules/es-v*/, для этого используем плагин maven-dependency-plugin в модулях es-v1 и es-v2.
Соберём проект:
mvn packageИ запустим:
сент. 29, 2017 10:37:08 ДП org.elasticsearch.plugins.PluginsService
INFO: [es1] loaded [], sites []
сент. 29, 2017 10:37:12 ДП org.elasticsearch.plugins.PluginsService
INFO: [es2] modules [], plugins [], sites []
Client for version: 1.7.5
Found doc:
{field=test 1}
Client for version: 2.4.5
Found doc:
{field=test 2} Бинго!
если не пропатчить JvmInfo, о чём упоминается ниже в пересборке Elasticsearch 1.7.
Совсем хардкорный случай предполагает, что модуль core тоже использует какие-нибудь утилитные методы из библиотеки Elasticsearch. Наше текущее решение уже не сработает из-за порядка загрузки классов:
- Invoke findLoadedClass(String) to check if the class has already been loaded.
- Invoke the loadClass method on the parent class loader. If the parent is null the class loader built-in to the virtual machine is used, instead.
- Invoke the findClass(String) method to find the class.
То есть в этом случае будут загружены классы Elasticsearch из core, а не es-v*. Присмотревшись к порядку загрузки, видим обходной вариант: написать свой загрузчик классов, который нарушает этот порядок, поменяв местами шаги 2 и 3. Такой загрузчик сможет загрузить не только отдельно свой модуль es-v*, но и увидит классы из core.
Напишем свой URLClassLoader, назовём его, например, ParentLastURLClassLoader:
public class ParentLastURLClassLoader extends URLClassLoader {
...
}и переопределим loadClass(String,boolean), скопировав код из ClassLoader и убрав всё лишнее:
@Override
protected Class c = findLoadedClass(name);
if (c == null) {
try {
if (getParent() != null) {
c = getParent().loadClass(name);
}
} catch (ClassNotFoundException e) {
}
if (c == null) {
c = findClass(name);
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}Меняем местами вызовы getParent().loadClass(String) и findClass(String) и получаем:
@Override
protected Class c = findLoadedClass(name);
if (c == null) {
try {
c = findClass(name);
} catch (ClassNotFoundException ignored) {
}
if (c == null) {
c = getParent().loadClass(name);
if(c == null) {
throw new ClassNotFoundException(name);
}
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}Поскольку наше приложение вручную будет загружать классы модуля, загрузчик должен бросить ClassNotFoundException, если класса нигде не найдено.
Загрузчик написан, теперь используем его, заменив URLClassLoader в методе getClient(String):
ClassLoader classLoader = new URLClassLoader(jars);на ParentLastURLClassLoader:
ClassLoader classLoader = new ParentLastClassLoader(jars);и запустив приложение снова, видим тот же результат:
сент. 29, 2017 10:42:41 ДП org.elasticsearch.plugins.PluginsService
INFO: [es1] loaded [], sites []
сент. 29, 2017 10:42:44 ДП org.elasticsearch.plugins.PluginsService
INFO: [es2] modules [], plugins [], sites []
Client for version: 1.7.5
Found doc:
{field=test 1}
Client for version: 2.4.5
Found doc:
{field=test 2} В Java 6 добавили класс java.util.ServiceLoader, который предоставляет механизм загрузки реализаций по интерфейсу/абстрактному классу. Этот класс тоже решает нашу проблему:
private static SearchClient getClient(String desiredVersion) throws Exception {
Path moduleDependencies = Paths.get("modules", "es-v" + desiredVersion);
URL[] jars = Files.list(moduleDependencies)
.map(Path::toUri)
.map(Searcher::toURL)
.toArray(URL[]::new);
ServiceLoader serviceLoader = ServiceLoader.load(SearchClient.class, new URLClassLoader(jars));
return serviceLoader.iterator().next();
} Всё очень просто:
Чтобы ServiceLoader увидел реализации интерфейсов, нужно создать файлы с полным именем интерфейса в директории META-INF/services:
+---es-v1/
| +---src/
| +---main/
| +---resources/
| +---META-INF/
| +---services/
| +---elasticsearch.client.spi.SearchClient
+---es-v2/
+---src/
+---main/
+---resources/
+---META-INF/
+---services/
+---elasticsearch.client.spi.SearchClientи написать полные имена классов, реализующих этот интерфейс, на каждой строке: в нашем случае по одному SearchClientImpl на каждый модуль.
Для es-v1 в файле будет строка:
elasticsearch.client.v1.SearchClientImplи для es-v2:
elasticsearch.client.v2.SearchClientImplТакже используем плагин maven-dependency-plugin для копирования модулей es-v* в modules/es-v*/. Пересоберём проект:
mvn clean packageИ запустим:
сент. 29, 2017 10:50:17 ДП org.elasticsearch.plugins.PluginsService
INFO: [es1] loaded [], sites []
сент. 29, 2017 10:50:20 ДП org.elasticsearch.plugins.PluginsService
INFO: [es2] modules [], plugins [], sites []
Client for version: 1.7.5
Found doc:
{field=test 1}
Client for version: 2.4.5
Found doc:
{field=test 2} Отлично, требуемый результат снова получен.
Для упомянутого хардкорного случая придётся выносить интерфейс SearchClient в отдельный модуль spi и использовать следующую цепочку загрузчиков:
core: bootstrap -> system
spi: bootstrap -> spi
es-v1: bootstrap -> spi -> es-v1
es-v2: bootstrap -> spi -> es-v2т.е.
SearchClient),Признаюсь сразу и честно — мне не доводилось сталкиваться с фреймворками OSGi (может оно и к лучшему?). Взглянув на маны для начинающих у Apache Felix и Eclipse Equinox, они больше походят на контейнеры, в которые (вручную?) загружают бандлы. Даже если есть реализации для встраивания, это слишком громоздко для нашего простого приложения. Если я не прав, выскажите обратную точку зрения в комментариях (да и вообще хочется увидеть, что его кто-то использует и как).
Я не стал углубляться в этом вопросе, т.к. в Java 9 модули теперь из коробки, которые мы сейчас и рассмотрим.
На прошлой неделе релизнулась 9-ая версия платформы, в которой главным нововведением стали модуляризация рантайма и исходников самой платформы. Как раз то, что нам надо!
Hint: Для того, чтобы использовать модули, нужно сначала скачать и установить JDK 9, если вы ещё этого не делали.
Здесь дело осложняет только способность используемых библиотек запускаться под девяткой в качестве модулей (на самом деле, я просто не нашёл способа в IntelliJ IDEA указать class-path вместе с module-path, поэтому далее мы всё делаем в контексте module-path).
Прежде чем переходить к модификации кода нашего приложения под модульную систему, сначала узнаем, как она работает (я могу ошибаться, поскольку сам только начал разбираться в этом вопросе).
Кроме упомянутых модулей, есть ещё слои, содержащие их. При старте приложения создаётся слой boot, в который загружаются все указанные в --module-path модули, из которых состоит приложение, и их зависимости (от модуля java.base автоматически зависят все модули). Другие слои могут быть созданы программно.
Каждый слой имеет свой загрузчик классов (или иерархию). Как и у загрузчиков, модульные слои также могут быть построены иерархически. В такой иерархии модули одного слоя могут видеть другие модули, находящихся в родительском слое.
Сами модули изолированы друг от друга и по умолчанию их пакеты и классы в них не видны другим модулям. Дескриптор модуля (им является module-info.java) позволяет указать, какие пакеты может открыть каждый модуль и от каких модулей и их пакетов зависят они сами. Дополнительно, модули могут объявлять о том, что они используют некоторые интерфейсы в своей работе, и могут объявлять о доступной реализации этих интерфейсов. Эта информация используется ServiceLoader API для загрузки реализаций интефрейсов из модулей.
Модули бывают явными и автоматическими (типов больше, но мы ограничимся этими):
module-info.class в корне jar-архиа (модуль или модуляризованный jar),class-path.Теперь этой информации будет достаточно, чтобы применить её на нашем проекте:
elasticsearch.shaded.Searcher будет вручную загружать модули es-v* в отдельные дочерние слои со своим загрузчиком классов, используя ServiceLoader API.Всё так просто?...
Модулям не разрешено иметь пересекающиеся имена пакетов (по крайней мере в одном слое).
Например, есть некая библиотека, которая предоставляет какое-то API в публичном классе Functions. В этой библиотеке есть класс Helpers с пакетной областью видимости. Вот они:
com.foo.bar
public class Functions
class HelpersНа сцену выходит вторая библиотека, которая предоставляет которая дополняет функционал первой:
com.foo.baz
public class AdditionalИ ей требуется некоторый функционал из закрытого класса Helpers. Выходим из положения, поместив какой-нибудь класс в этот же пакет:
com.foo.baz
public class Additional
com.foo.bar
public class AccessorToHelpersПоздравим себя — мы только что создали себе проблему разделения пакетов (split package) с точки зрения модульной системы. Что можно сделать с такими библиотеками? Нам предлагают оставить такие библиотеки в class-path и дотянуться до них из модулей, используя автоматические модули в качестве моста. Но мы не ищем лёгких путей, поэтому используем другой вариант: докладём в библиотеку все его зависимости и получим один единственный jar-архив (известный под названиями fat jar и uber jar), его-то и можно использовать в module-path как автоматический модуль, минуя class-path. Проблемой может стать сборка такого all-in-one jar.
Elasticsearch активно использует доступ к package-private методам/полям для доступа к некоторому функционалу Lucene. Чтобы использовать его в виде автоматического модуля, сделаем из него uber jar и установим в локальный репозиторий под именем elasticsaerch-shaded для дальнейшего использования в нашем проекте.
В первых версиях проект приложения представляет из себя единственный Maven-модуль, поэтому здесь проблем особо не возникнет: нужно поправить pom.xml и некоторые классы, если собираем 8-кой.
Клонируем репозиторий в какую-нибудь директорию, чекаутим тег v1.7.5 и начинаем править:
maven-shade-plugin, поэтоу для сборки uberjar потребуется закомментировать включение некоторых пакетов, чтобы включались все:и желательно в оригинале, без перемещений:
org.codehaus.groovy:groovy-all
org.slf4j:*
log4j:*
pom.xml закончили, осталось устранить UnsupportedOperationException, которое кидает java.lang.management.RuntimeMXBean#getBootClassPath. Для этого найдём такую строку в классе JvmInfo:info.bootClassPath = runtimeMXBean.getBootClassPath();и оборнём её в "правильные":
if (runtimeMXBean.isBootClassPathSupported()) {
info.bootClassPath = runtimeMXBean.getBootClassPath();
} else {
info.bootClassPath = "";
}Эта информация используется всего лишь для статистики.
Готово, теперь можно собрать jar:
$ mvn packageи после компиляции и сборки получим требуемый elasticsearch-1.7.5.jar в директории target. Теперь его нужно установить в локальный репозиторий, например, под именем elasticsearch-shaded:
$ mvn install:install-file \
> -Dfile=elasticsearch-1.7.5.jar \
> -DgroupId=org.elasticsearch \
> -DartifactId=elasticsearch-shaded \
> -Dversion=1.7.5 \
> -Dpackaging=jar \
> -DgeneratePom=trueТеперь этот артефакт можно использовать как автоматический модуль в нашем Maven-модуле es-v1:
org.elasticsearch
elasticsearch-shaded
1.7.5
...
Откатим локальные изменения и зачекаутим тег v2.4.5. Начиная со 2-ой версии проект разбит на модули. Нужный нам модуль, выдающий elasticsearch-2.4.5.jar — модуль core.
$ mvn versions:set -DnewVersion=2.4.5Shading and package relocation removed
Elasticsearch used to shade its dependencies and to relocate packages. We no longer use shading or relocation.
You might need to change your imports to the original package names:
com.google.commonwasorg.elasticsearch.commoncom.carrotsearch.hppcwasorg.elasticsearch.common.hppcjsr166ewasorg.elasticsearch.common.util.concurrent.jsr166e
...
Нам придётся добавить shade-плагин заново в модуль core, добавив в настройках трансформер сервис-файлов и исключение логгеров:
org.apache.maven.plugins
maven-shade-plugin
package
shade
org.slf4j:*
log4j:*
com.twitter:jsr166e (там используется sun.misc.Unsafe, которого в 9-ке "нет") у модуля core:и сменим импорты com.twitter.jsr166e на java.util.concurrent.atomic.
animal-sniffer-maven-plugin задетектит изменение на предыдущем шаге (в 7-ке нет jsr166e), убираем:Готово, теперь проделываем те же шаги по сборке и установке, что и для es-v1, с небольшими отличиями:
$ mvn clean package -pl org.elasticsearch:parent,org.elasticsearch:elasticsearch -DskipTests=trueПосле того, как мы выяснили, что используемые нами библиотеки способны работать в модульной системе Java, сделаем из наших Maven-модулей явные Java-модули. Для этого нам потребуется в каждой директории с исходниками (src/main/java) создать файлы module-info.java и в них описать взаимоотношения между модулями.
Модуль core не зависит ни от каких других модулей, а только содержит интерфейс, который должны реализовать другие модули, поэтому описание будет выглядеть так:
// имя модуля - elasticsearch.client.core
module elasticsearch.client.core {
// очевидно, нужно открыть пакет с интерфейсом,
// чтобы он был доступен для модулей
exports elasticsearch.client.spi;
// и этим модулям скажем, что мы используем интерфейс SearchClient
// для динамической загрузки ServiceLoader'ом
uses elasticsearch.client.spi.SearchClient;
}Для модулей es-v1 и es-v2 будет похожее описание:
elasticsearch.client.core, т.к. в нём находится интерфейс,SearchClient.Итого имеем для es-v1:
// имя модуля - elasticsearch.client.v1
module elasticsearch.client.v1 {
// в core лежит SearchClient
requires elasticsearch.client.core;
// этот автоматический
requires elasticsearch.shaded;
// говорим модулю core, что у нас есть реализация его интерфейса
provides elasticsearch.client.spi.SearchClient with elasticsearch.client.v1.SearchClientImpl;
}Для es-v2 почти всё тоже самое, только в именах должна фигурировать версия v2.
Теперь как загрузить такие модули? Ответ на этот вопрос есть в описании класса ModuleLayer, который содержит небольшой пример загрузки модуля с ФС. Предположив, что модули es-v* находятся каждый всё в тех же директориях modules/es-v*/, можно написать примерно такую реализацию:
private static SearchClient getClient(String desiredVersion) throws Exception {
Path modPath = Paths.get("modules", "es-v" + desiredVersion);
ModuleFinder moduleFinder = ModuleFinder.of(modPath);
ModuleLayer parent = ModuleLayer.boot();
Configuration config = parent.configuration().resolve(moduleFinder, ModuleFinder.of(), Set.of("elasticsearch.client.v" + desiredVersion));
ModuleLayer moduleLayer = parent.defineModulesWithOneLoader(config, Thread.currentThread().getContextClassLoader());
ServiceLoader serviceLoader = ServiceLoader.load(moduleLayer, SearchClient.class);
Optional searchClient = serviceLoader.findFirst();
if (searchClient.isPresent()) {
return searchClient.get();
}
throw new Exception("Module 'elasticsearch.client.v" + desiredVersion + "' not found on " + modPath);
} ModuleLayer#defineModulesWithManyLoaders нам здесь не подойдёт, так как у нас получатся совсем изолированные модули и наши es-v* не смогут увидеть свои зависимости.
Итак, теперь нужно собрать все модули. Для компиляции потребуется плагин maven-compiler-plugin поновее, на данный момент последняя версия — 3.7.0:
org.apache.maven.plugins
maven-compiler-plugin
3.7.0
Укажем Java 9 для исходников:
1.9
1.9
И не забываем про maven-dependency-plugin, поэтому пересоберём модули:
$ mvn clean packageТеперь можно запустить, и видим такой же вывод:
сент. 29, 2017 10:59:01 ДП org.elasticsearch.plugins.PluginsService
INFO: [es1] loaded [], sites []
сент. 29, 2017 10:59:04 ДП org.elasticsearch.plugins.PluginsService
INFO: [es2] modules [], plugins [], sites []
Client for version: 1.7.5
Found doc:
{field=test 1}
Client for version: 2.4.5
Found doc:
{field=test 2} Может показаться, что решение с загрузчиком классов — проще, но решение из коробки просто глупо игнорировать, если только вы не собираетесь остаться на Java 8 или более ранней.
Загрузка библиотеки разных версий выливается в механизм, очень напоминающий систему плагинов/модулей. Для этого можно:
P.S. Желаю всем джавистам удачного перехода на Java 9!
|
Метки: author CyberSoft java java 9 osgi jarhell split package classloader serviceloader плагины модули jpms elasticsearch |






