Опыт внедрения PSR стандартов в одном легаси проекте |
Всем привет!
В этой статье я хочу рассказать о своем опыте переезда на “отвечающую современным трендам” платформу в одном legacy проекте.
Все началось примерно год назад, когда меня перекинули в “старый” (для меня новый) отдел.
До этого я работал с Symfony/Laravel. Перейдя на проект с самописным фреймворком количество WTF просто зашкаливало, но со временем все оказалось не так и плохо.
Во-первых, проект работал. Во-вторых, применение шаблонов проектирования прослеживалось: был свой контейнер зависимостей, ActiveRecord и QueryBuilder.
Плюс, был дополнительный уровень абстракции над контейнером, логгером, работе с очередями и зачатки сервисного слоя(бизнес логика не зависела от HTTP слоя, кое-где логика была вынесена из контроллеров).
Далее я опишу те вещи, с которыми трудно было мириться:
Сам по себе логгер работал и хорошо. Но были жирные минусы:
|
Метки: author Fantyk php slim |
Криптоалгоритмы. Классификация с точки зрения количества ключей |
|
Метки: author den_golub математика криптография информационная безопасность алгоритмы it- стандарты криптографические алгоритмы карманный справочник вместо конспекта |
На шаг ближе к С++20. Итоги встречи в Торонто |

v += data;
v -= data;
v *= data;
v /= data;
#include
template
void compute_vector_fast(Container& v, const Data& data) {
std::cout << "fast\n";
// ...
}
template
void compute_vector_slow(Container& v, const Data& data) {
std::cout << "slow\n";
// ...
}
template
void compute_vector_optimal(Container& v, const Data& data) {
// ??? call `compute_vector_slow(v, data)` or `compute_vector_fast(v, data)` ???
}
#include
template
concept bool VectorOperations = requires(T& v, const Data& data) {
{ v += data } -> T&;
{ v -= data } -> T&;
{ v *= data } -> T&;
{ v /= data } -> T&;
};
template
requires VectorOperations
void compute_vector_optimal(Container& v, const Data& data) {
std::cout << "fast\n";
}
template
void compute_vector_optimal(Container& v, const Data& data) {
std::cout << "slow\n";
}
#include
#include v2 = get_some_values_and_delimiter();
// Необходимо найти число 42 и отсортировать все элементы, идущие после него:
auto it = ranges::find(v.begin(), ranges::unreachable{}, 42);
ranges::sort(++it, v.end());
}
#include
#include
#include
#include struct S {
unsigned x1:8 = 42;
unsigned x2:8 { 42 };
};
if constexpr (std::endian::native == std::endian::big) {
// big endian
} else if constexpr (std::endian::native == std::endian::little) {
// little endian
} else {
// mixed endian
}
struct foo { int a; int b; int c; };
foo b{.a = 1, .b = 2};
auto bar = [](Args&&... args) {
return foo(std::forward(args)...);
};
fmt::format("The answer is {}", 42);|
|
Запуск регулярных задач на кластере или как подружить Apache Spark и Oozie |

Давно уже витала в воздухе необходимость реализовать запуск регулярных Spark задач через Oozie, но всё руки не доходили и вот наконец свершилось. В этой статье хочу описать весь процесс, возможно она упростит Вам жизнь.
Мы имеем следующую структуру на hdfs:
hdfs://hadoop/project-MD2/data
hdfs://hadoop/project-MD2/jobs
hdfs://hadoop/project-MD2/statusВ директория data ежедневно поступают данные и раскладываются по директориям в соответствие с датой. Например, данные за 31.12.2017 запишутся по следующему пути: hdfs://hadoop/project/data/2017/12/31/20171231.csv.gz.
В директории jobs располагаются задачи, которые имеют непосредственное отношение к проекту. Нашу задачу мы также будем размещать в этом каталоге.
В директорию status должна сохраняться статистика по количеству пустых полей за каждый день в формате json. Например, для данных за 31.12.2017 должен будет появиться файл hdfs://hadoop/project-MD2/status/2017/12/31/part-*.json
{
"device_id_count_empty" : 0,
"lag_A0_count_empty" : 10,
"lag_A1_count_empty" : 0,
"flow_1_count_empty" : 37,
"flow_2_count_empty" : 100
}В нашем распоряжение есть кластер из 10 машин, каждая из которых имеет 8-и ядерный процессор и оперативную память в размере 64 Гб. Общий объём жёстких дисков на всех машинах 100 Тб. Для запуска задач на кластере отведена очередь PROJECTS.
Создадим структуру проекта, это можно очень просто сделать в любой среде разработки, поддерживающей scala или из консоли, как показано ниже:
mkdir -p daily-statistic/project
echo "sbt.version = 1.0.2" > daily-statistic/project/build.properties
echo "" > daily-statistic/project/plugins.sbt
echo "" > daily-statistic/build.sbt
mkdir -p daily-statistic/src/main/scalaЗамечательно, теперь добавил плагин для сборки, для этого в файле daily-statistic/project/plugins.sbt добавляем следующую строку:
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.14.5")Добавил описание проекта, зависимости и особенности сборки в файл daily-statistic/build.sbt:
name := "daily-statistic"
version := "0.1"
scalaVersion := "2.11.11"
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "2.0.0" % "provided",
"org.apache.spark" %% "spark-sql" % "2.0.0" % "provided"
)
assemblyJarName in assembly := s"${name.value}-${version.value}.jar"Перейдём в директорию daily-statistic и выполнил команду sbt update, для обновления проекта и подтягивания зависимостей из репозитория.
Создаём Statistic.scala в директории src/main/scala/ru/daily
package ru.daily
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.functions._
object Statistic extends App {
// инициализация
implicit lazy val spark: SparkSession = SparkSession.builder()
.appName("daily-statistic")
.getOrCreate()
import spark.implicits._
val workDir = args(0)
val datePart = args(1)
val saveDir = args(2)
try {
val date = read(s"$workDir/$datePart/*.csv.gz")
.select(
'_c0 as "device_id",
'_c1 as "lag_A0",
'_c2 as "lag_A1",
'_c3 as "flow_1",
'_c4 as "flow_2"
)
save(s"$saveDir/$datePart", agg(date))
} finally spark.stop()
// чтение исходных данных
def read(path: String)(implicit spark: SparkSession): DataFrame = {
val inputFormat = Map("header" -> "false", "sep" -> ";", "compression" -> "gzip")
spark.read
.options(inputFormat)
.csv(path)
}
// построение агрегата
def agg(data: DataFrame):DataFrame = data
.withColumn("device_id_empty", when('device_id.isNull, lit(1)).otherwise(0))
.withColumn("lag_A0_empty", when('lag_A0.isNull, lit(1)).otherwise(0))
.withColumn("lag_A1_empty", when('lag_A1.isNull, lit(1)).otherwise(0))
.withColumn("flow_1_empty", when('flow_1.isNull, lit(1)).otherwise(0))
.withColumn("flow_2_empty", when('flow_2.isNull, lit(1)).otherwise(0))
.agg(
sum('device_id_empty) as "device_id_count_empty",
sum('lag_A0_empty) as "lag_A0_count_empty",
sum('lag_A1_empty) as "lag_A1_count_empty",
sum('flow_1_empty) as "flow_1_count_empty",
sum('flow_2_empty) as "flow_2_count_empty"
)
// сохранение результата
def save(path: String, data: DataFrame): Unit = data.write.json(path)
} Собираем проект командой sbt assembly из директории daily-statistic. После успешного завершения сборки в директории daily-statistic/target/scala-2.11 появится пакет с задачей daily-statistic-0.1.jar.
Для запуска задачи через Oozie нужно описать конфигурацию запуска в файле workflow.xml. Ниже привожу пример для нашей задачи:
oozie.launcher.mapred.job.queue.name
${queue}
${jobTracker}
${nameNode}
yarn-client
project-md2-daily-statistic
ru.daily.Statistic
${nameNode}${jobDir}/lib/daily-statistic-0.1.jar
--queue ${queue}
--master yarn-client
--num-executors 5
--conf spark.executor.cores=8
--conf spark.executor.memory=10g
--conf spark.executor.extraJavaOptions=-XX:+UseG1GC
--conf spark.yarn.jars=*.jar
--conf spark.yarn.queue=${queue}
${nameNode}${dataDir}
${datePartition}
${nameNode}${saveDir}
Statistics job failed [${wf:errorMessage(wf:lastErrorNode())}]
В блоке global устанавливается очередь, для MapReduce задачи которая будет находить нашу задачи и запускать её.
В блоке action описывается действие, в нашем случае запуск spark задачи, и что нужно делать при завершении со статусом ОК или ERROR.
В блоке spark определяется окружение, конфигурируется задача и передаются аргументы. Конфигурация запуска задачи описывается в блоке spark-opts. Параметры можно посмотреть в официальной документации
Если задача завершается со статусом ERROR, то выполнение переходит в блок kill и выводится кратное сообщение об ошибки.
Параметры в фигурных скобках, например ${queue}, мы будем определять при запуске.
Для организации регулярного запуска нам потребуется ещё coordinator.xml. Ниже приведу пример для нашей задачи:
${workflowPath}
datePartition
${coord:formatTime(coord:dateOffset(coord:nominalTime(), -1, 'DAY'), "yyyy/MM/dd")}
Здесь из интересного, параметры frequency, start, end, которые определяют частоту выполнения, дату и время начала выполнения задачи, дату и время окончания выполнения задачи соответственно.
В блоке workflow указывается путь к директории с файлом workflow.xml, который мы определим позднее при запуске.
В блоке configuration определяется значение свойства datePartition, которое в данном случае равно текущей дате в формате yyyy/MM/dd минус 1 день.
Как уже было сказано ранее нашу задачу мы будем размещать в директории hdfs://hadoop/project-MD2/jobs:
hdfs://hadoop/project-MD2/jobs/daily-statistic/lib/daily-statistic-0.1.jar
hdfs://hadoop/project-MD2/jobs/daily-statistic/workflow.xml
hdfs://hadoop/project-MD2/jobs/daily-statistic/coordinator.xml
hdfs://hadoop/project-MD2/jobs/daily-statistic/sharelibЗдесь в принципе всё понятно без комментариев за исключением директории sharelib. В эту директорию мы положим все библиотеки, которые использовались в процессе создания зашей задачи. В нашем случае это все библиотеки Spark 2.0.0, который мы указывали в зависимостях проекта. Зачем это нужно? Дело в том, что в зависимостях проекта мы указали "provided". Это говорит системе сборки не нужно включать зависимости в проект, они будут предоставлены окружением запуска, но мир не стоит на месте, администраторы кластера могут обновить версию Spark. Наша задача может оказаться чувствительной к этому обновлению, поэтому для запуска будет использоваться набор библиотек из директории sharelib. Как это конфигурируется покажу ниже.
И так сё готово к волнительному моменту запуска. Мы будем запускать задачу через консоль. При запуске нужно задать значения свойствам, которые мы использовали в xml файлах. Вынесем эти свойства в отдельный файл coord.properties:
# описание окружения
nameNode=hdfs://hadoop
jobTracker=hadoop.host.ru:8032
# путь к директории с файлом coordinator.xml
oozie.coord.application.path=/project-MD2/jobs/daily-statistic
# частота в минутах (раз в 24 часа)
frequency=1440
startTime=2017-09-01T07:00Z
endTime=2099-09-01T07:00Z
# путь к директории с файлом workflow.xml
workflowPath=/project-MD2/jobs/daily-statistic
# имя пользователя, от которого будет запускаться задача
mapreduce.job.user.name=username
user.name=username
# директория с данными и для сохранения результата
dataDir=/project-MD2/data
saveDir=/project-MD2/status
jobDir=/project-MD2/jobs/daily-statistic
# очередь для запуска задачи
queue=PROJECTS
# использовать библиотеке из указанной директории на hdfs вместо системных
oozie.libpath=/project-MD2/jobs/daily-statistic/sharelib
oozie.use.system.libpath=falseЗамечательно, тереть всё готово. Запускаем регулярное выполнение командой:
oozie job -oozie http://hadoop.host.ru:11000/oozie -config coord.properties -runПосле запуска в консоль выведется id задачи. Используя это id можно посмотреть информацию о статусе выполнения задачи:
oozie job -info {job_id}Остановить задачу:
oozie job -kill {job_id}Если Вы не знаете id задачи, то можно найти его, показав все регулярные задачи для вашего пользователя:
oozie jobs -jobtype coordinator -filter user={user_name}Полечилось немного затянуто, но на мой взгляд лучше подробная инструкция чем квест-поиск по интернету. Надеюсь описанный опыт будет Вам полезен, спасибо за внимание!
|
Метки: author entony big data apache spark apache oozie |
Опционалы в Swift |
Несмотря на некоторый опыт в мобильной разработке (в том числе с применением Swift), регулярно на почве свифтовых опционалов возникали ситуации, когда я знал что нужно делать, но не совсем внятно представлял, почему именно так. Приходилось отвлекаться и углубляться в документацию — количество "заметок на полях" пополнялось с удручающей периодичностью. В определенный момент они достигли критической массы, и я решил упорядочить их в едином исчерпывающем руководстве. Материал получился довольно объемным, поскольку предпринята попытка раскрыть тему максимально подробно. Статья будет полезна как начинающим Swift-разработчикам, так и матерым профессионалам из мира Objective-C — есть ненулевая вероятность, что и последние найдут для себя что-то новое. А если не найдут, то добавят свое новое в комментарии, и всем будет польза.
Optionals (опционалы) — это удобный механизм обработки ситуаций, когда значение переменной может отсутствовать. Значение будет использовано, только если оно есть.
Во-первых, проверка на равенство/неравенство nil применима только к nullable-типам и не применима к примитивным типам, структурам и перечислениям. Для обозначения отсутсвия значения у переменной примитивного типа приходится вводить спецзначения, такие как NSNotFound.
NSNotFound не только нужно рассматривать как спецзначение, но и следить, чтобы оно не входило в множество допустимых значений переменной. Ситуация усложняется еще и тем, что NSNotFound считается равным NSIntegerMax, т.е. может иметь разные значения для разных (32-bit/64-bit) платформ. Это значит, что NSNotFound нельзя напрямую записывать в файлы и архивы или использовать в Distributed Objects.
Соответственно, пользователь этой переменной должен учитывать, что спецзначения возможны. В Swift даже примитивный тип можно использовать в опциональном стиле, т.е явным образом указывать на то, что значения может не быть.
Во-вторых: явная опциональность проверяется на этапе компиляции, что снижает количество ошибок в runtime. Опциональную переменную в Swift нельзя использовать точно так же, как неопциональную (за исключением неявно извлекамых опционалов, подробности в разделе Implicit Unwrapping). Опционал нужно либо принудительно преобразовывать к обычному значению, либо использовать специальные преобразующие идиомы, такие как if let, guard let и ??. Опционалы в Swift реализуют не просто проверку, но целую парадигму опционального типа в теории типов.
В-третьих, опционалы синтаксически более лаконичны, чем проверки на nil, что особенно хорошо видно на цепочках опциональных вызовов — так называемый Optional Chaining.
Опционал в Swift представляет из себя особый объект-контейнер, который может содержать в себе либо nil, либо объект конкретного типа, который указывается при объявлении этого контейнера. Эти два состояния обозначаются терминами None и Some соответственно. Если при создании опциональной переменной присваемое значение не указывать, то nil присваивается по умолчанию.
В документации значение по умолчанию в случае отсутсвия явного присвоения не упоминается, но сказано, что опционал represents either a wrapped value or nil, the absence of a value. Если опциональная переменная объявлена без явного присвоения (какое-либо Some не присваивалось), то логично следует, что неявно присваивается None — третьего "неинициализрованного" состояния у опционалов нет.
Опционал объявляется посредством комбинации имени типа и лексемы ?. Таким образом, запись Int? — это объявление контейнера, экземпляр которого может содержать внутри nil (состояние None Int) либо значение типа Int (состояние Some Int). Именно поэтому при преобразовании Int? в Int используетя термин unwrapping вместо cast, т.е. подчеркивается "контейнерная" суть опционала. Лексема nil в Swift обозначает состояние None, которое можно присвоить любому опционалу. Это логично приводит к невозможности присвоить nil (состояние None) переменной, которая не является опционалом.
По факту опционал представляет собой системное перечисление:
public enum Optional : ExpressibleByNilLiteral {
/// The absence of a value.
///
/// In code, the absence of a value is typically written using the `nil`
/// literal rather than the explicit `.none` enumeration case.
case none
/// The presence of a value, stored as `Wrapped`.
case some(Wrapped)
/// Creates an instance that stores the given value.
public init(_ some: Wrapped)
...
/// Creates an instance initialized with `nil`.
///
/// Do not call this initializer directly. It is used by the compiler
// when you initialize an `Optional` instance with a `nil` literal.
public init(nilLiteral: ())
...
} Перечисление Optional имеет два возможных состояния: .none и some(Wrapped). Запись Wrapped? обрабатывается препроцессором (Swift’s type system) и трансформируется в Optional, т.е. следующие записи эквивалентны:
var my_variable: Int?var my_variable: OptionalЛексема nil по факту обозначает Optional.none, т.е. следующие записи эквивалентны:
var my_variable: Int? = nilvar my_variable: Optional = Optional.none var my_variable = Optional.none Перечисление Optional имеет два конструктора. Первый конструктор init(_ some: Wrapped) принимает на вход значение соответсвующего типа, т.е. следующие записи эквивалентны:
var my_variable = Optional(42) // тип .some-значения Int опеределен неявноvar my_variable = Optional(42) // явное указание типа Int для наглядности var my_variable = Int?(42) // тип Int необходимо указать явноvar my_variable: Int? = 42 // тип Int необходимо указать явноvar my_variable = Optional.some(42) // тип Int опеределен неявноvar my_variable = Optional.some(42) // явное указание типа для наглядности Второй конструктор init(nilLiteral: ()) является реализацией протокола ExpressibleByNilLiteral
public protocol ExpressibleByNilLiteral {
/// Creates an instance initialized with `nil`.
public init(nilLiteral: ())
}и инициализирует опциональную переменную состоянием .none. Этот конструктор используется только компилятором. Согласно документации его нельзя вызывать напрямую, т.е следующие записи приведут к ошибкам компиляции:
var my_variable1 = Optional(nil) // ошибка компиляции
var my_variable2 = Optional.none(nil)// ошибка компиляции Вместо них следует использовать
var my_variable: Int? = nil // или var my_variable: Int? = Optional.noneили вообще не использовать явное присвоение
var my_variable: Int?поскольку nil будет присвоен по умолчанию.
Перечисление Optional также содержит свойство unsafelyUnwrapped, которое предоставляет доступ на чтение к .some-значению опционала:
public enum Optional : ExpressibleByNilLiteral {
...
/// The wrapped value of this instance, unwrapped without checking whether
/// the instance is `nil`.
public var unsafelyUnwrapped: Wrapped { get }
} Если опционал находится в состоянии .none, обращение к unsafelyUnwrapped приведет к серьезному сбою программы.
В режиме отладки debug build -Onone будет ошибка рантайма:
_fatal error: unsafelyUnwrapped of nil optional_В релизной сборке optimized build -O будет ошибка рантайма либо неопределенное поведение. Более безопасной операцией является Force Unwrapping (или Explicit Unwrapping) — принудительное извлечение .some-значения, обозначаемое лексемой !. Применение Force Unwrapping к опционалу в состоянии .none приведет к ошибке рантайма:
_fatal error: unexpectedly found nil while unwrapping an Optional value_let my_variable1 = Int?(42) // содержит 42, тип Optional Int
let my_value1A = my_variable1! // содержит 42, тип Int
let my_value1B = my_variable1.unsafelyUnwrapped // содержит 42, тип Int
let my_variable2 = Int?.none // содержит nil, тип Optional Int
let my_value2A = my_variable2! // ошибка рантайма
// ошибка рантайма в режиме -Onone, НЕОПРЕДЕЛЕННОЕ ПОВЕДЕНИЕ в режиме -O
let my_value2B = my_variable2.unsafelyUnwrappedНет особого смысла использовать обычное перечисление с двумя состояниями. Вполне можно реализовать подобный механизм самостоятельно: создать enum c двумя состояниями и конструкторами для соответствующих значений, добавить какой-нибудь постфиксный оператор для Force Unwrapping (например, как это сделано здесь), добавить возможность сравнения с nil или вообще придумать "свой" nil и т.д. Опционалы должны быть интегрированы непосредственно в сам язык, чтобы их использование было естественным, не чужеродным. Разумеется, можно рассматривать такую интеграцию как "синтаксический сахар", однако языки высокого уровня для того и существуют, чтобы писать (и читать) код на них было легко и приятно. Использование опционалов в Swift подразумевает ряд идиом или особых языковых конструкций, которые помогают уменьшить количество ошибок и сделать код более лаконичным. К таким идиомам относятся Implicit Unwrapping, Optional Chaining, Nil-Coalescing и Optional Binding.
Безопасное использование Force Unwrapping подразумевает предварительную проверку на nil, например, в условии if:
// getOptionalResult() может вернуть nil
let my_variable: Int? = getOptionalResult() // тип Optional Int
if my_variable != nil {
// my_value получит .some-значение опционала из getOptionalResult()
let my_value = my_variable!
} else {
// ошибка рантайма
let my_value = my_variable!
}Иногда из структуры программы очевидным образом следует, что переменная технически является опционалом, но к моменту первого использования всегда находится в состоянии .some, т.е. не является nil. Для использования опционала в неопциональном контексте (например, передать его в функцию с параметром неопционального типа) приходится постоянно применять Force Unwrapping с предварительной проверкой, что скучно и утомительно. В этих случаях можно применить неявно извлекаемый опционал — Implicitly Unwrapped Optional. Неявно извлекамый опционал объявляется посредством комбинации имени типа и лексемы !:
let my_variable1: Int? = 42 // тип Optional Int
let my_variable2: Int! = 42 // тип Implicitly Unwrapped Optional Int
var my_variable3: Int! = 42 // тип Implicitly Unwrapped Optional Int
...
my_variable3 = nil // где-то непредвиденно присвоен nil
...
func sayHello(times:Int) {
for _ in 0...times {
print("Hello!")
}
}
sayHello(times: my_variable1!) // обязаны извлекать значение явно
sayHello(times: my_variable1) // ошибка компиляции
sayHello(times: my_variable2!) // можем, но не обязаны извлекать значение явно
sayHello(times: my_variable2) // неявное извлечение
sayHello(times: my_variable3) // ошибка рантаймаВ вызове sayHello(times: my_variable2) извлечение значения 42 из my_variable2 все равно осуществляется, только неявно. Использование неявно извлекаемых опционалов делает код более удобным для чтения — нет восклицательных знаков, которые отвлекают внимание (вероятно, читающего код будет беспокоить использование Force Unwrapping без предварительной проверки). На практике это скорее анти-паттерн, увеличивающий вероятность ошибки. Неявно извлекаемый опционал заставляет компилятор "закрыть глаза" на то, что опционал используется в неопциональном контексте. Ошибка, которая может быть выявлена во время компиляции (вызов sayHello(times: my_variable1)), проявится только в рантайме (вызов sayHello(times: my_variable3)). Явный код всегда лучше неявного. Логично предположить, что такое снижение безопасности кода требуется не только ради устранения восклицательных знаков, и это действительно так.
Неявно извлекаемые опционалы позволяют использовать self в конструкторе для иницализации свойств и при этом:
self) — иначе код просто не скомпилируется;Наглядный пример, где требуется использовать self в конструкторе для иницализации свойств, приведен в документации:
class Country {
let name: String
var capitalCity: City!
init(name: String, capitalName: String) {
self.name = name
self.capitalCity = City(name: capitalName, country: self)
}
}
class City {
let name: String
unowned let country: Country
init(name: String, country: Country) {
self.name = name
self.country = country
}
}
var country = Country(name: "Canada", capitalName: "Ottawa")
print("\(country.name)'s capital city is called \(country.capitalCity.name)")
// Prints "Canada's capital city is called Ottawa"В этом примере экземпляры классов Country и City должны иметь ссылки друга на друга к моменту завершения инициализации. У каждой страны обязательно должна быть столица и у каждой столицы обязательно должна быть страна. Эти связи не являются опциональными — они безусловны. В процессе инициализации объекта country необходимо инициализировать свойство capitalCity. Для инициализации capitalCity нужно создать экземпляр класса City. Конструктор City в качестве параметра требует соответствующий экземпляр Country, т.е. требует доступ к self. Сложность в том, что экземпляр Country на этот момент еще не до конца инициализирован, т.е. self использовать нельзя.
Эта задача имеет изящное решение: capitalCity объявляется мутабельным неявно извлекаемым опционалом. Как и любой мутабельный опционал, capitalCity по умолчанию инициализируется состоянием nil, т. е. к моменту вызова конструктора City все свойства объекта country уже инициализированы. Требования двухэтапной инициализации соблюдены, конструктор Country находится во второй фазе — можно передавать self в конструктор City. capitalCity является неявным опционалом, т.е. к нему можно обращаться в неопциональном контексте без добавления !.
Побочным эффектом использования неявно извлекаемого опционала является "встроенный" assert: если capitalCity по каким-либо причинам останется в состоянии nil, это приведет к ошибке рантайма и аварийному завершению работы программы.
Другим примером оправданного использования неявно извлекаемых опционалов могут послужить инструкции @IBOutlet: контекст их использования подразумевает, что переменной к моменту первого обращения автоматически будет присвоено .some-значение. Если это не так, то произойдет ошибка рантайма. Автоматическая генерация кода в Interface Builder создает свойства с @IBOutlet именно в виде неявных опционалов. Если такое поведение неприемлемо, свойство с @IBOutlet можно объявить в виде явного опционала и всегда обрабатывать .none-значения явным образом. Как правило, все же лучше сразу получить "падение", чем заниматься долгой отладкой в случае случайно отвязанного @IBOutlet-свойства.
Optional Chaining — это процесс последовательных вызовов по цепочке, где каждое из звеньев возвращает опционал. Процесс прерывается на первом опционале, находящемся в состоянии nil — в этом случае результатом всей цепочки вызовов также будет nil. Если все звенья цепочки находятся в состоянии .some, то результирующим значением будет опционал с результатом последнего вызова. Для формирования звеньев цепочки используется лексема ?, которая помещается сразу за вызовом, возвращающим опционал. Звеньями цепочки могут любые операции, которые возвращают опционал: обращение к локальной переменной (в качестве первого звена), вызовы свойств и методов, доступ по индексу.
Optional сhaining всегда работает последовательно слева направо. Каждому следующему звену передается .some-значение предыдущего звена, при этом результирующее значение цепочки всегда является опционалом, т.е. цепочка работает по следующим правилам:
? должно быть следующее звено;.none, то цепочка прерывает процесс вызовов и возвращает nil;.some, то цепочка отдает .some-значение звена на вход следующему звену (если оно есть);.some-значению возвращаемого опционала).// цепочка из трех звеньев: первое звено — опционал `country.mainSeaport?`,
country.mainSeaport?.nearestVacantPier?.capacity
// ошибка компиляции, после `?` должно быть следующее звено
let mainSeaport = country.mainSeaport?
// цепочка вернет `nil` на первом звене
country = Country(name: "Mongolia")
let capacity = country.mainSeaport?.mainPier?.capacity
// цепочка вернет опционал — ближайший незанятый пирс в Хельсинки
country = Country(name: "Finland")
let nearestVacantPier = country.mainSeaport?.nearestVacantPier
// цепочка вернет опционал — количество свободных мест, даже если capacity
// является неопциональным значением
country = Country(name: "Finland")
let capacity = country.mainSeaport?.nearestVacantPier?.capacityВажно отличать цепочки опциональных вызовов от вложенных опционалов. Вложенный опционал образуется, когда .some-значением одного опционала является другой опционал:
let valueA = 42
let optionalValueA = Optional(valueA)
let doubleOptionalValueA = Optional(optionalValueA)
let tripleOptionalValueA = Optional(doubleOptionalValueA)
let tripleOptionalValueB: Int??? = 42 // три `?` означают тройную вложенность
let doubleOptionalValueB = tripleOptionalValueB!
let optionalValueB = doubleOptionalValueB!
let valueB = optionalValueB!
print("\(valueA)") // 42
print("\(optionalValueA)") // Optional(42)
print("\(doubleOptionalValueA)") // Optional(Optional(42))
print("\(tripleOptionalValueA)") // Optional(Optional(Optional(42)))
print("\(tripleOptionalValueB)") // Optional(Optional(Optional(42)))
print("\(doubleOptionalValueB)") // Optional(Optional(42))
print("\(optionalValueB)") // Optional(42)
print("\(valueB)") // 42Optional сhaining не увеличивает уровень вложенности возвращаемого опционала. Тем не менее, это не исключает ситуации, когда результирующим значением какого-либо звена является опционал с несколькими уровнями вложенности. В таких ситуациях для продолжения цепочки необходимо прописать ? в количестве, равном количеству уровней вложенности:
let optionalAppDelegate = UIApplication.shared.delegate
let doubleOptionalWindow = UIApplication.shared.delegate?.window
let optionalFrame = UIApplication.shared.delegate?.window??.frame // два '?'
print("\(optionalAppDelegate)") // Optional( ... )
print("\(doubleOptionalWindow)") // Optional(Optional( ... ))
print("\(optionalFrame)") // Optional( ... )Вообще говоря, необязательно, чтобы все уровни вложенности были "развернуты" с помощью лексемы ?.Часть из них можно заменить на принудительное извлечение !, что сократит количество "неявных" звеньев в цепочке. Отдельный вопрос, есть ли в этом смысл.
Цепочка UIApplication.shared.delegate?.window??.frame фактически состоит из четырех звеньев: UIApplication.shared.delegate?, .frame и два звена, объединенных в одном вызове .window??. Второе "двойное" звено представлено опционалом второго уровня вложенности.
Важной особенностью этого примера также является особый способ формирования двойного опционала, отличающийся от способа формирования doubleOptionalValue в предыдущем примере. UIApplication.shared.delegate!.window является опциональным свойством, в котором возвращается опционал. Опциональность свойства означает, что может отсутствовать само свойство, а не только .some-значение у опционала, возвращаемого из свойства. Опциональное свойство, также как и все прочие свойства, может возвращать любой тип, не только опциональный. Опциональность такого рода формируется в @objc-протоколах с помощью модификатора optional:
public protocol UIApplicationDelegate : NSObjectProtocol {
...
@available(iOS 5.0, * )
optional public var window: UIWindow? { get set } // модификатор optional
...
}В протоколах с опциональными свойствами и методами (иначе, опциональными требованиями) модификатор @objc указывается для каждого опционального требования и для самого протокола. На протокол UIApplicationDelegate из примера выше это требование не распространяется, т.к. он транслируется в Swift из системной библиотеки на Objective-C. Вызов нереализованного опционального требования у объекта, принимающего такой протокол, возвращает опционал соответствующего типа в состоянии .none. Вызов реализованного опционального требования возвращает опционал соответсвующего типа в состоянии .some. Таким образом, опциональные свойства и методы, в отличие от optional сhaining, увеличивают уровень вложенности возвращаемого опционала. Опциональный метод, как и свойство, "заворачивается" в опционал полностью — в .some-значение помещается метод целиком, а не только возращаемое значение:
@objc
public protocol myOptionalProtocol {
@objc
optional var my_variable: Int { get }
@objc
optional var my_optionalVariableA: Int? { get } // ошибка компиляции:
// модификатор @objc не применим к опционалу типа Int?, т.к. Int
// не является классом
@objc
optional var my_optionalVariableB: UIView? { get }
@objc
optional func my_func() -> Int
@objc
optional func my_optionalResultfuncA() -> Int? // ошибка компиляции:
// модификатор @objc не применим к опционалу типа Int?, т.к. Int
// не является классом
@objc
optional func my_optionalResultfuncB() -> UIView?
@objc
optional init(value: Int) // ошибка компиляции:
// модификатор optional не применим инициализаторам
}
@UIApplicationMain
class AppDelegate: UIResponder, UIApplicationDelegate, myOptionalProtocol {
var window: UIWindow?
func application(_ application: UIApplication,
didFinishLaunchingWithOptions launchOptions:
[UIApplicationLaunchOptionsKey: Any]?) -> Bool {
let protocolAdoption = self as myOptionalProtocol
// Optional
print("\(type(of: protocolAdoption.my_variable))")
// Optional>
print("\(type(of: protocolAdoption.my_optionalVariableB))")
// Optional<() -> Int>
print("\(type(of: protocolAdoption.my_func))")
// Optional
print("\(type(of: protocolAdoption.my_func?()))")
// Optional<() -> Optional>
print("\(type(of: protocolAdoption.my_optionalResultfuncB))")
// Optional
print("\(type(of: protocolAdoption.my_optionalResultfuncB?()))")
return true
}
} Для опциональных @objc-протоколов имеется ряд ограничений, в виду того, что они были введены в Swift специально для взаимодействия с кодом на Objective-C:
@objc (т.е. не могут быть реализованы в структурах и перечислениях);optional неприменим к требованиям-конструкторам init;@objc имеют ограничение на тип возвращаемого опционала — допускаются только классы.Попытка применить Force Unwrapping на нереализованном свойстве или методе приведет к точно такой же ошибке рантайма, как и применение Force Unwrapping на любом другом опционале в состоянии .none.
Оператор Nil-Coalescing возвращает .some-значение опционала, если опционал в состоянии .some, и значение по умолчанию, если опционал в состоянии .none. Обычно Nil-Coalescing более лаконичен, чем условие if else, и легче воспринимается, чем тернарный условный оператор ?:
let optionalText: String? = tryExtractText()
// многословно
let textA: String
if optionalText != nil {
textA = optionalText!
} else {
textA = "Extraction Error!"
}
// в одну строку, но заставляет думать
let textB = (optionalText != nil) ? optionalText! : "Extraction Error!"
// кратко и легко воспринимать
let textC = optionalText ?? "Extraction Error!"Тип значения по умолчания справа должен соответствовать типу .some-значения опционала слева. Значение по умолчанию тоже может быть опционалом:
let optionalText: String?? = tryExtractOptionalText()
let a = optionalText ?? Optional("Extraction Error!")Возможность использовать выражения в качестве правого операнда позволяет создавать цепочки из умолчаний:
let wayA: Int? = doSomething()
let wayB: Int? = doNothing()
let defaultWay: Int = ignoreEverything()
let whatDo = wayA ?? wayB ?? defaultWayOptional Binding позволяет проверить, содержит ли опционал .some-значение, и если содержит, извлечь его и предоставить к нему доступ через с помощью локальной переменной (обычно константной). Optional Binding работает в контексте конструкций if, while и guard.
В официальной документации детали реализации Optional Binding не описаны, но можно построить модель, хорошо описывающую поведение этого механизма.
В Swift каждый метод или функция без явно заданного return неявно возвращает пустой кортеж (). Оператор присваивания = является исключением и не возвращает значение, тем самым позволяя избежать случайного присвоения вместо сравнения ==.
Допустим, что оператор присваивания также обычно возвращает пустой кортеж, но если правый операнд является опционалом в состоянии nil, то оператор присваивания вернет nil. Тогда эту особенность можно будет использовать в условии if, так как пустой кортеж расценивается как true, а nil расценивается как false:
var my_optionalVariable: Int? = 42
// условие истинно, my_variable "привязана" к .some-значению my_optionalVariable
if let my_variable = my_optionalVariable {
print("\(my_variable)") // 42
}
my_optionalVariable = nil
// условие ложно, my_variable не создана
if let my_variable = my_optionalVariable {
print("\(my_variable)")
} else {
print("Optional variable is nil!") // Optional variable is nil!
}Переменную, сформированную в контексте ветки true, можно будет автоматически объявить неявно извлекаемым опционалом или даже обычной переменной. Не-nil как результат операции присвоения будет являться следствием .some-состояния правого операнда. В ветке true .some-значение всегда будет успешно извлечено и "привязано" к новой переменной (поэтому механизм в целом и называется Optional Binding).
Область видимости извлеченной переменной в условии if ограничивается веткой true, что логично, поскольку в ветке false такая переменная не может быть извлечена. Тем не менее, существуют ситуации, когда нужно расширить область видимости извлеченного .some-значения, а в ветке false (опционал в состоянии .none) завершить работу функции. В таких ситуациях удобно воспользоваться условием guard:
let my_optionalVariable: Int? = extractOptionalValue()
// чересчур многословно
let my_variableA: Int
if let value = my_optionalVariable {
my_variableA = value
} else {
return
}
print(my_variableA + 1)
// лаконично
guard let my_variableB = my_optionalVariable else {
return
}
print(my_variableB + 1)В Swift гарантированное компилятором приведение типов (например, повышающее приведение или указание типа литерала) выполняется с помощью оператора as. В случаях, когда компилятор не может гарантировать успешное приведение типа (например, понижающее приведение), используется либо оператор принудительного приведения as!, либо оператор опционального приведения as?. Принудительное приведение работает в стиле Force Unwrapping, т.е. в случае невозможности выполнить приведение приведет к ошибке рантайма, в то время как опциональное приведение в этом случае вернет nil:
class Shape {}
class Circle: Shape {}
class Triangle: Shape {}
let circle = Circle()
let circleShape: Shape = Circle()
let triangleShape: Shape = Triangle()
circle as Shape // гарантированное приведение
42 as Float // гарантированное приведение
circleShape as Circle // ошибка компиляции
circleShape as! Circle // circle
triangleShape as! Circle // ошибка рантайма
circleShape as? Circle // Optional
triangleShape as? Circle // nil Таким образом, оператор опционального приведения as? порождает опционал, который часто используется в связке с Optional Binding:
class Shape {}
class Circle: Shape {}
class Triangle: Shape {}
let circleShape: Shape = Circle()
let triangleShape: Shape = Triangle()
// условие истинно, успешное приведение
if let circle = circleShape as? Circle {
print("Cast success: \(type(of: circle))") // Cast success: (Circle #1)
} else {
print("Cast failure")
}
// условие ложно, приведение не удалось
if let circle = triangleShape as? Circle {
print("Cast success: \(type(of: circle))")
} else {
print("Cast failure") // Cast failure
}Методы map и flatMap условно можно отнести к идиомам Swift, потому что они определены в системном перечислении Optional:
public enum Optional : ExpressibleByNilLiteral {
...
/// Evaluates the given closure when this `Optional` instance is not `nil`,
/// passing the unwrapped value as a parameter.
///
/// Use the `map` method with a closure that returns a nonoptional value.
public func map(_ transform: (Wrapped) throws -> U) rethrows -> U?
/// Evaluates the given closure when this `Optional` instance is not `nil`,
/// passing the unwrapped value as a parameter.
///
/// Use the `flatMap` method with a closure that returns an optional value.
public func flatMap(_ transform: (Wrapped) throws -> U?) rethrows -> U?
...
} Данные методы позволяют осуществлять проверку опционала на наличие .some-значения и обрабатывать это значение в замыкании, полученном в виде параметра. Оба метода возвращают nil, если исходный опционал nil. Разница между map и flatmap заключается в возможностях замыкания-параметра: для flatMap замыкание может дополнительно возвращать nil (опционал), а для map замыкание всегда возвращает обычное значение:
let my_variable: Int? = 4
let my_squareVariable = my_variable.map { v in
return v * v
}
print("\(my_squareVariable)") // Optional(16)
let my_reciprocalVariable: Double? = my_variable.flatMap { v in
if v == 0 {
return nil
}
return 1.0 / Double(v)
}
print("\(my_reciprocalVariable)") // Optional(0.25)Выражения с map и flatmap обычно более лаконичны, чем конструкции с предварительной проверкой в if или guard, и воспринимаются легче, чем конструкции с тернарным условным оператором:
let dateFormatter = DateFormatter()
dateFormatter.dateFormat = "dd MMM yyyy"
let date: Date? = extractOptionalDate()
// многословно
let dateStringA: String
if date != nil {
dateStringA = dateFormatter.string(from: date!)
} else {
dateStringA = "Unknown date"
}
// в одну строку, но сложно воспринимать
let dateStringB =
(date == nil ? nil : dateFormatter.string(from: date!)) ?? "Unknown date"
// лаконично, с непривычки сложно воспринимать (если map используется редко)
let dateStringC = date.map(dateFormatter.string) ?? "Unknown date"Уместность той или иной идиомы во многом зависит от договоренностей по стилю кодирования, принятых на проекте. Вполне возможно, что явные проверка опционала и работа с извлеченным .some-значением будут выглядеть естественнее, чем применение map или flatmap:
// отдельно Optional Binding и явный вызов метода у извлеченного объекта
func prepareForSegue(segue: UIStoryboardSegue, sender: AnyObject?) {
if let cell = sender as? UITableViewCell,
let indexPath = tableView.indexPathForCell(cell) {
let item = items[indexPath.row]
}
}
// В одном вызове 3 этапа:
// 1) опционал как результат приведения типов;
// 2) передача неявного замыкания в метод flatMap полученного опционала;
// 3) Optional Binding к результату flatMap.
func prepareForSegue(segue: UIStoryboardSegue, sender: AnyObject?) {
if let indexPath =
(sender as? UITableViewCell).flatMap(tableView.indexPathForCell) {
let item = items[indexPath.row]
}
}Swift поддерживает несколько способов обработки исключений, и один из них — это преобразование исключения в nil. Такое преобразование можно осуществить автоматически с помощью оператора try? (примеры из документации):
func someThrowingFunction() throws -> Int {
// ...
}
// многословно
let y: Int?
do {
y = try someThrowingFunction()
} catch {
y = nil
}
// лаконично
let x = try? someThrowingFunction()Обе переменные x и y являются опциональными, независимо от того, какой тип возвращает someThrowingFunction(). Таким образом, семантика поведения оператора try? такая же, как и у оператора as?. Логично также наличие оператора try!, который позволяет проигнорировать возможность выброса исключения из функции. Если исключение все же будет выброшено, то произойдет ошибка рантайма:
// ошибка рантайма, если loadImage будет выброшено исключение
// photo не является опционалом (в отличие от x и y)
let photo = try! loadImage(atPath: "./Resources/John Appleseed.jpg")В Objective-C нет понятия опциональности. Лексема nil в Objective-C обозначает нулевой указатель, т.е. обращение к любой переменной ссылочного типа потенциально может вернуть nil. В Swift nil обозначает опционал в состоянии .none, неопциональная переменная не может быть nil, поэтому до Xcode 6.3 любой указатель из Objective-C транслировался в Swift как неявно извлекаемый опционал. В Xcode 6.3 в Objective-C для совместимости с семантикой опционалов были введены так называемые nullability annotations:
@interface myObject : NSObject
@property (copy, readonly) NSArray * _Nullable myValuesA;
@property (copy, readonly) NSString * _Nonnull myStringA;
@property (copy, readonly, nullable) NSArray * myValuesB;
@property (copy, readonly, nonnull) NSString * myStringB;
@endК ним относятся nullable (или _Nullable), nonnull (или _Nonnull), а также null_unspecified и null_resettable. Nullability-aннотациями могут быть обозначены ссылочные типы в свойствах, а также в параметрах и результатах функций. Помимо отдельных аннотаций можно использовать специальные макросы NS_ASSUME_NONNULL_BEGIN и NS_ASSUME_NONNULL_END для пометки участков кода целиком. Аннотации не являются полноценными модификаторами указателей или аттрибутами свойств, поскольку не влияют на компиляцию кода на Objective-C (если не считать предупреждений компиляции, например, при попытке присвоить nil свойству с аннотацией nonnull).
Аннотация null_resettable подразумевает, что сеттер свойства может принимать nil, но при этом геттер свойства вместо nil возвращает некоторое значение по умолчанию.
Трансляция из Objective-C в Swift осуществлятся по следующим правилам:
NS_ASSUME_NONNULL_BEGIN и NS_ASSUME_NONNULL_END импортируются в виде неопциональных (обычных) значений;nonnull или _Nonnull импортируются в виде неопциональных (обычных) значений;nullable или _Nullable импортируются в виде опционалов;null_resettable импортируются в виде неявно извлекаемых опционалов;null_unspecified (аннотация по умолчанию) импортируются в виде неявно извлекаемых опционалов.Правила передачи опционалов из Swift в Objective-C несколько проще:
.none, то возвращается экземпляр NSNull;.some, то возвращается указатель на .some-значение.Лексема ! может быть использована в четырех контекстах, связанных с опциональностью:
as!;try!.Унарный оператор логического отрицания ! не считается, поскольку относится к другому контексту.
Лексема ? может быть использована в четырех контекстах, связанных с опциональностью:
as?;nil в операторе try?.Тернарный условный оператор ? не считается, поскольку относится к другому контексту.
Лексема ?? может быть использована в двух контекстах:
Нулевой указатель — это ошибка на миллиард долларов. Вызывающая сторона все равно должна учитывать контекст и проверять результат на равенство специфичной константе, означающее отсутствие данных. Тот факт, что константа null всего одна, принципиально ситуацию не меняет и лишь добавляет неожиданностей при приведении типов.
Факт отсутствия данных должен обрабатываться отдельной сущностью, внешней по отношению к самим данным. В С++ или Java в область допустимых значений указателя включено специальный "адрес", обозначающий отсутствие адресата. "Правильный" указатель не может существовать без адресата, следовательно, не может "осознать" отсутствие адресата. Даже человеку, т.е. довольно сложной системе, приходится довольстоваться аксиомой Cogito, ergo sum (лат. — "Мыслю, следовательно существую"). У человека нет достоверных признаков собственного бытия или небытия, но у внешних по отношению к человеку сущностей эти критерии есть. В Swift такой внешней сущностью является опционал.
|
Метки: author IFITOWS разработка под ios разработка мобильных приложений программирование swift разработка |
[Из песочницы] Micromaster's degree как новая форма образования. Краткий обзор первого пилота программы |



|
Метки: author reedrefucher образование за рубежом учебный процесс в it образование онлайн mit mitx edx |
V8 под капотом |

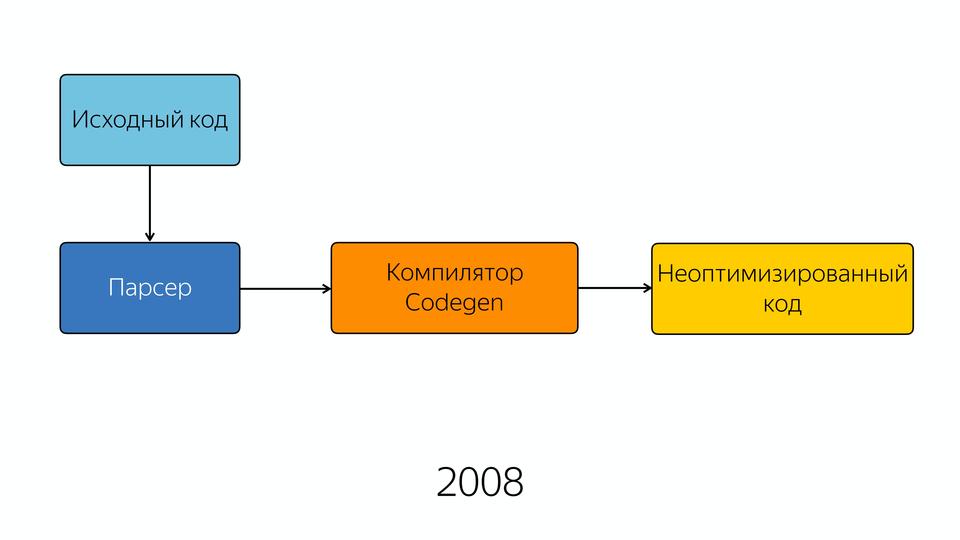
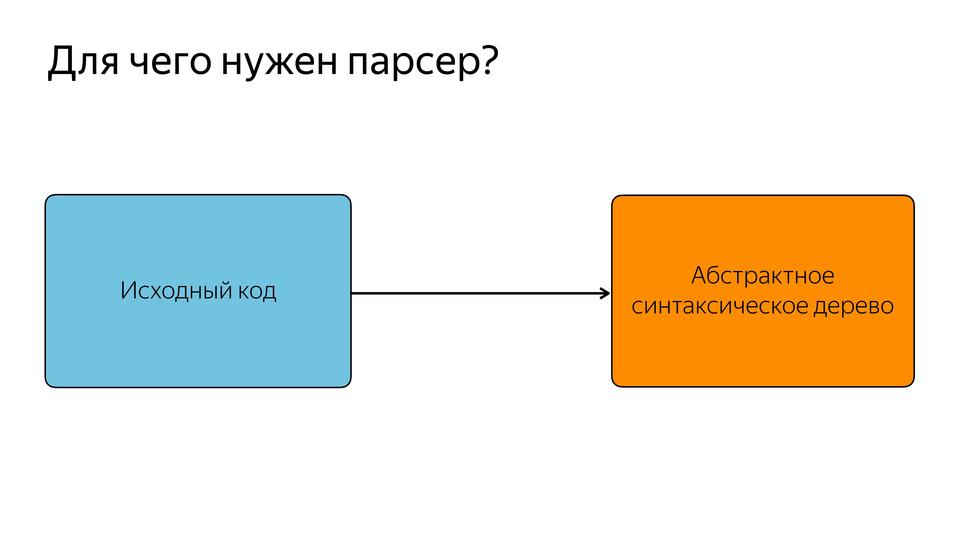
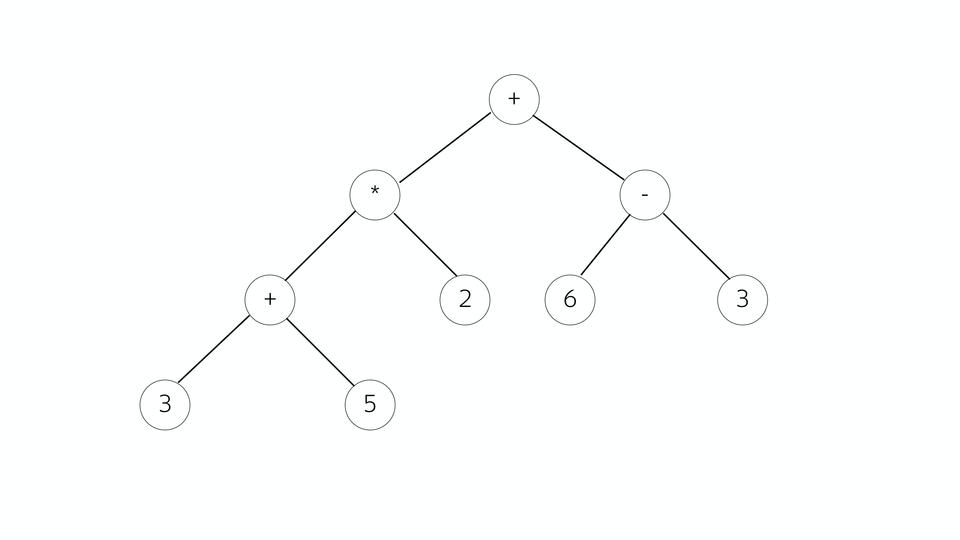
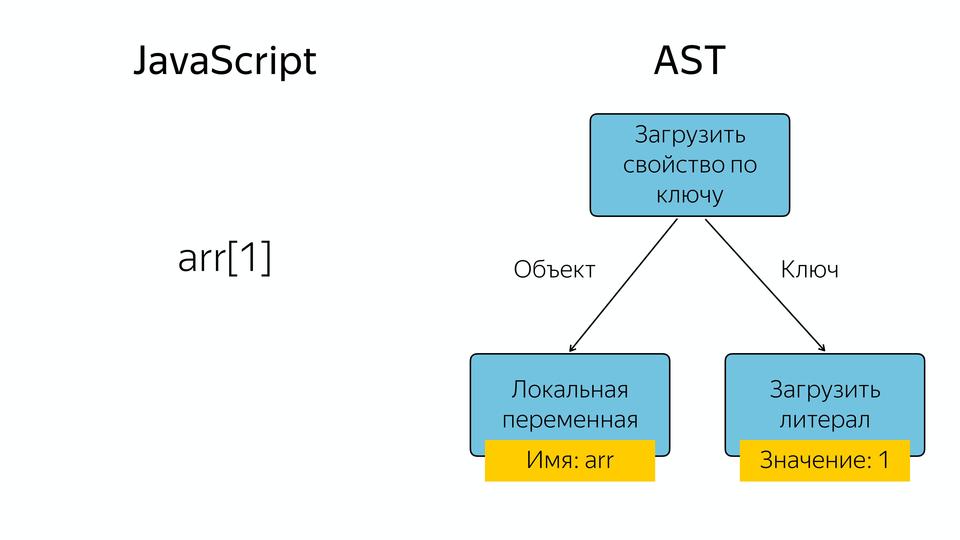


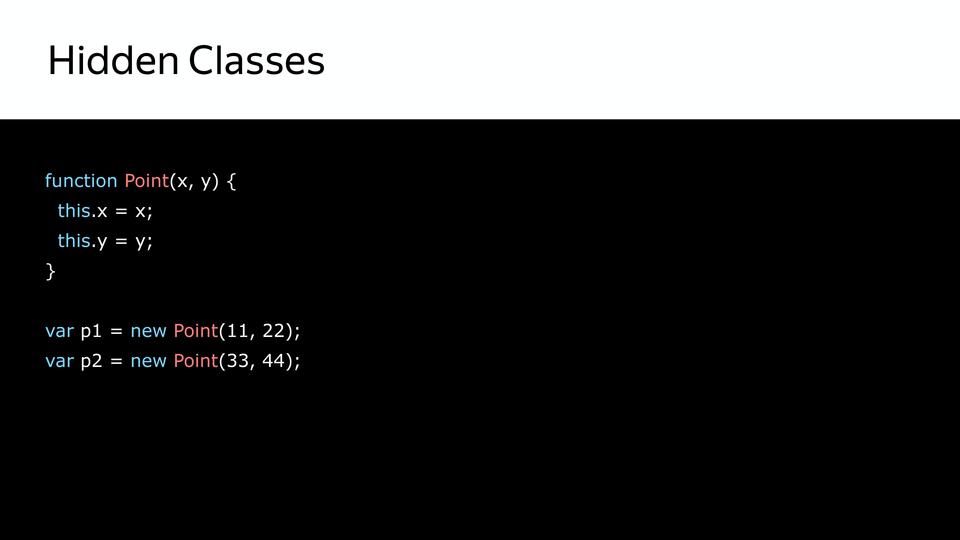

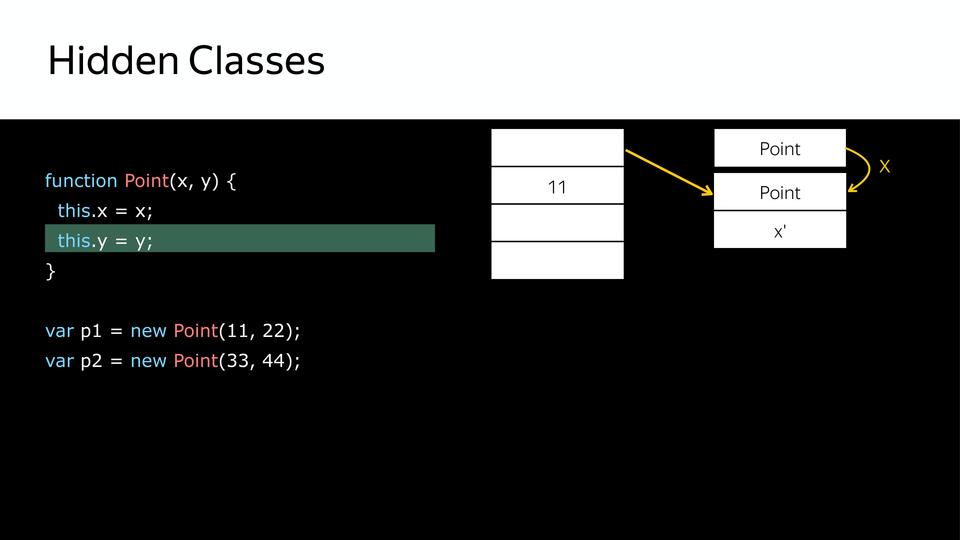
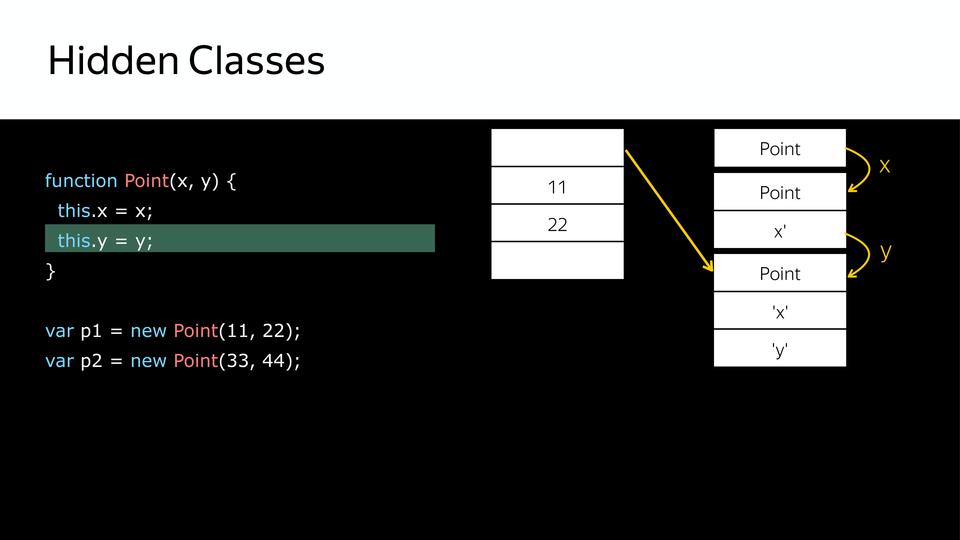
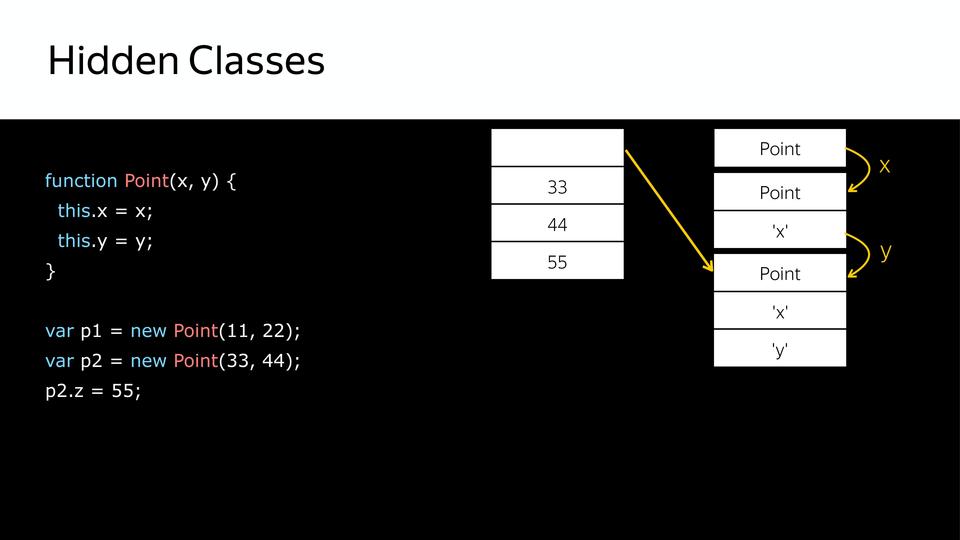









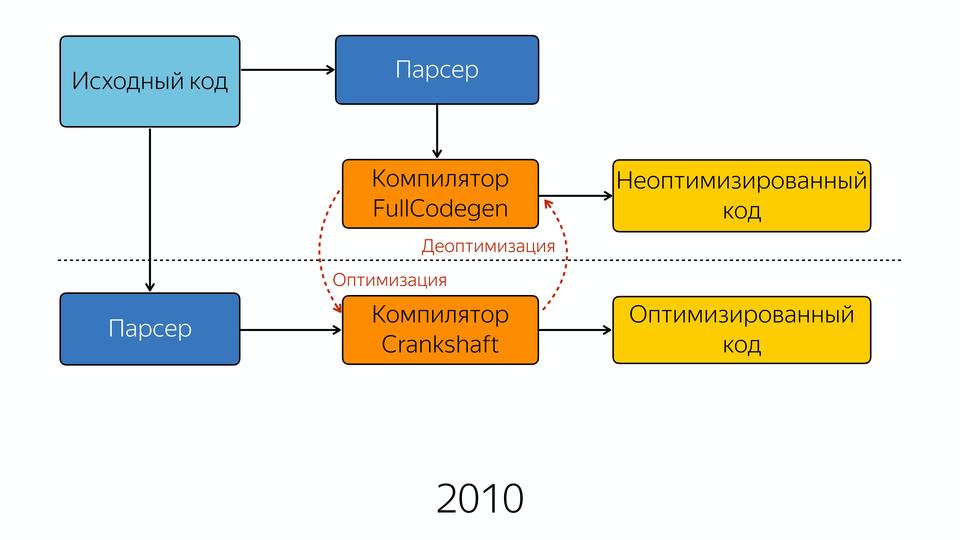

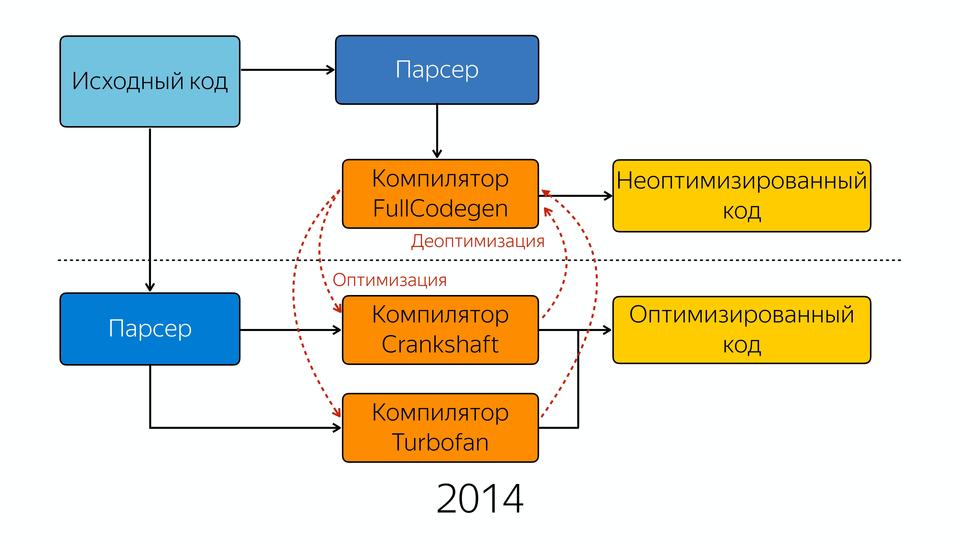

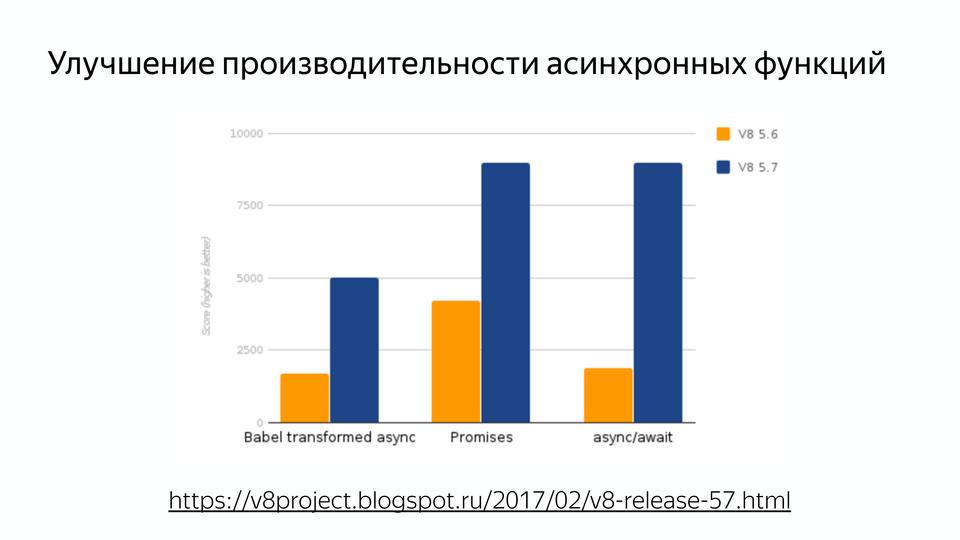
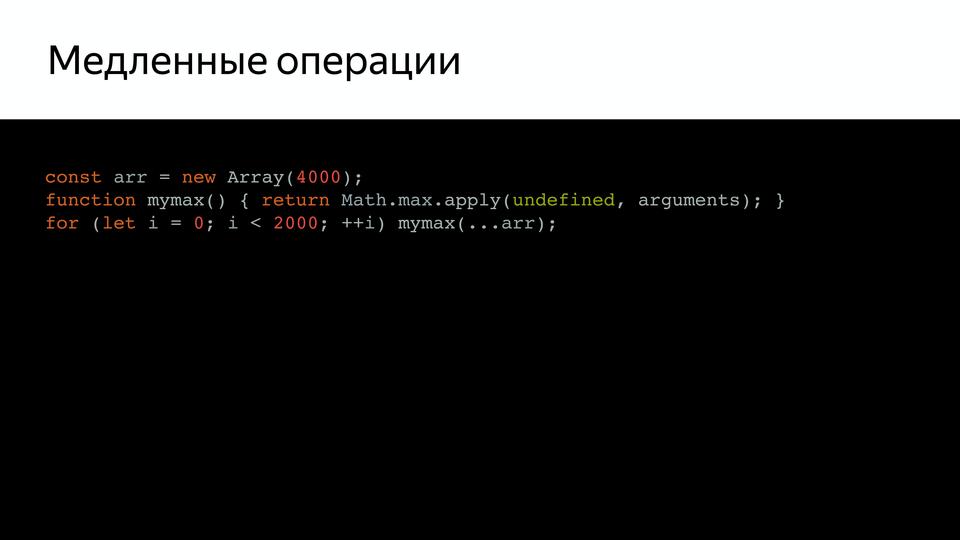
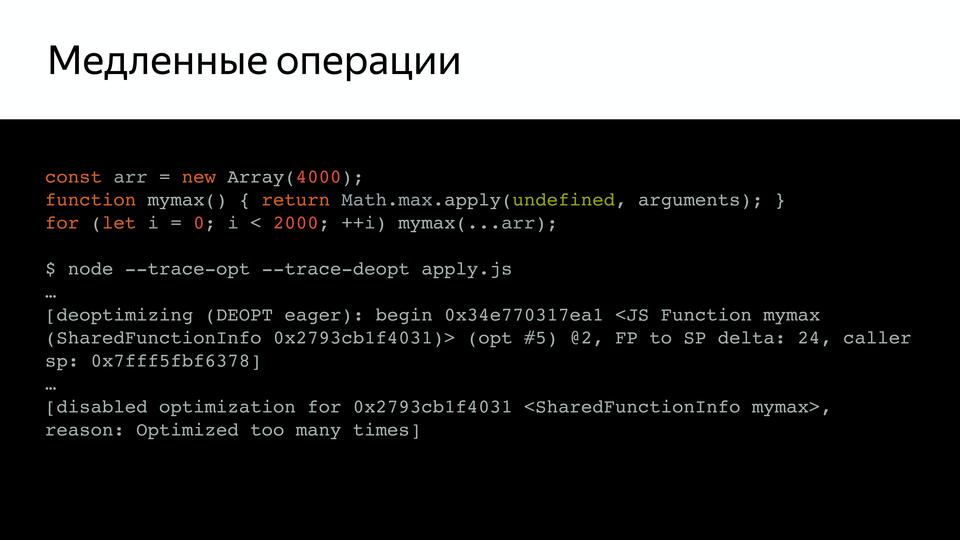


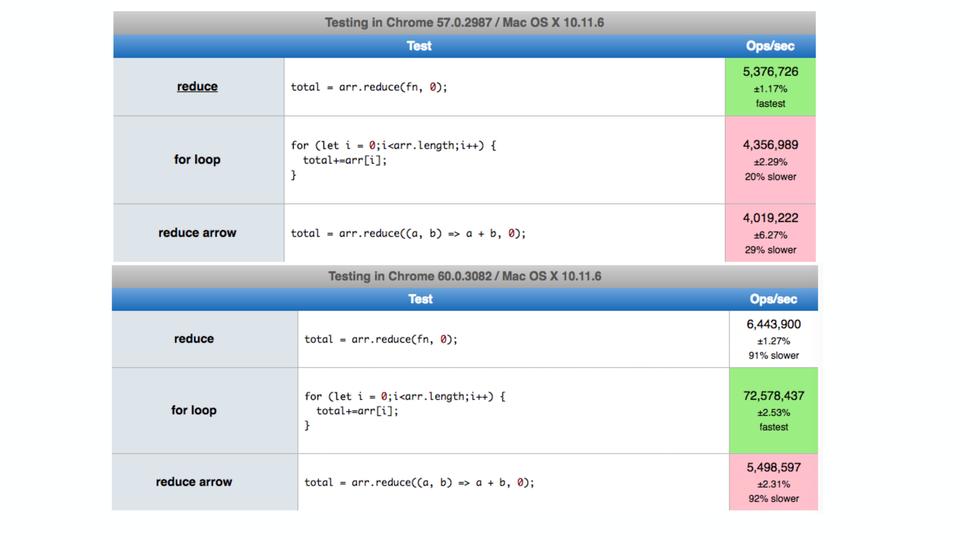
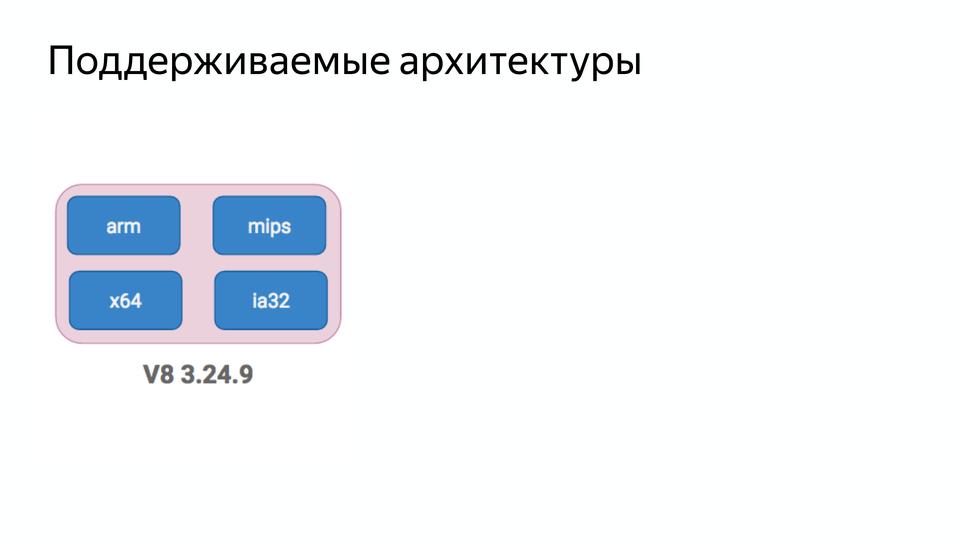
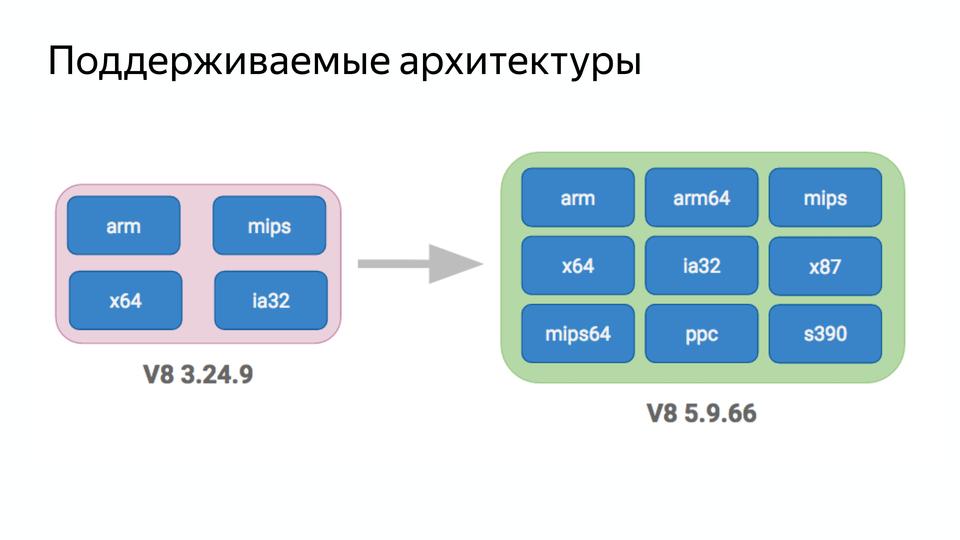


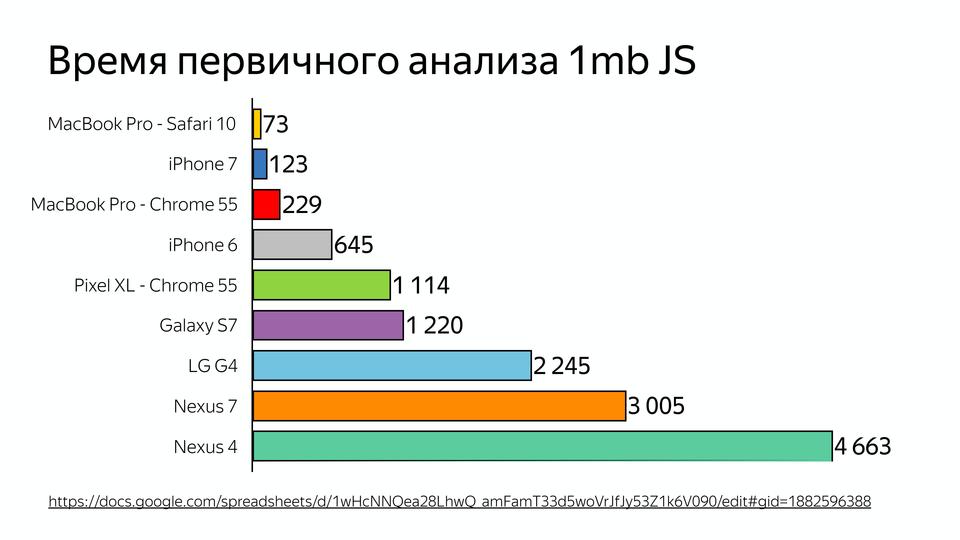
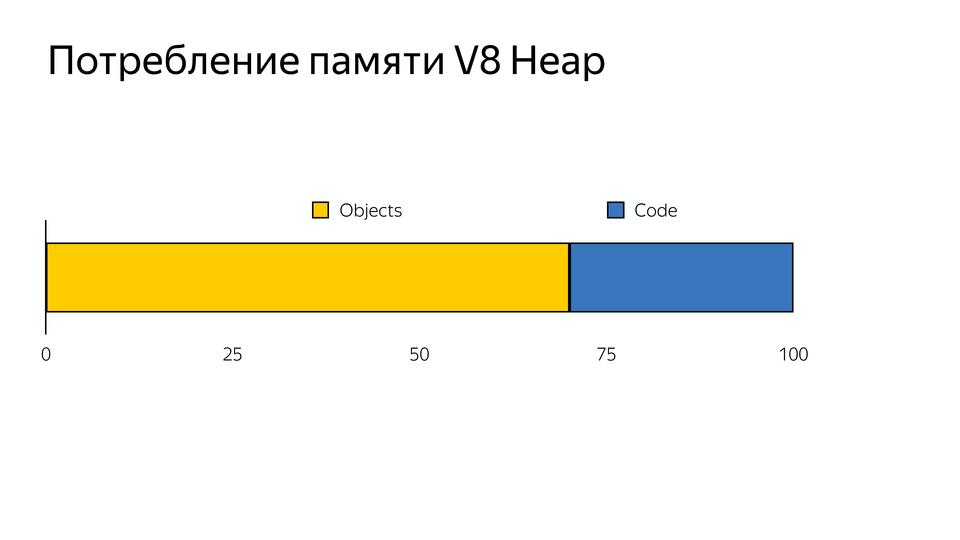

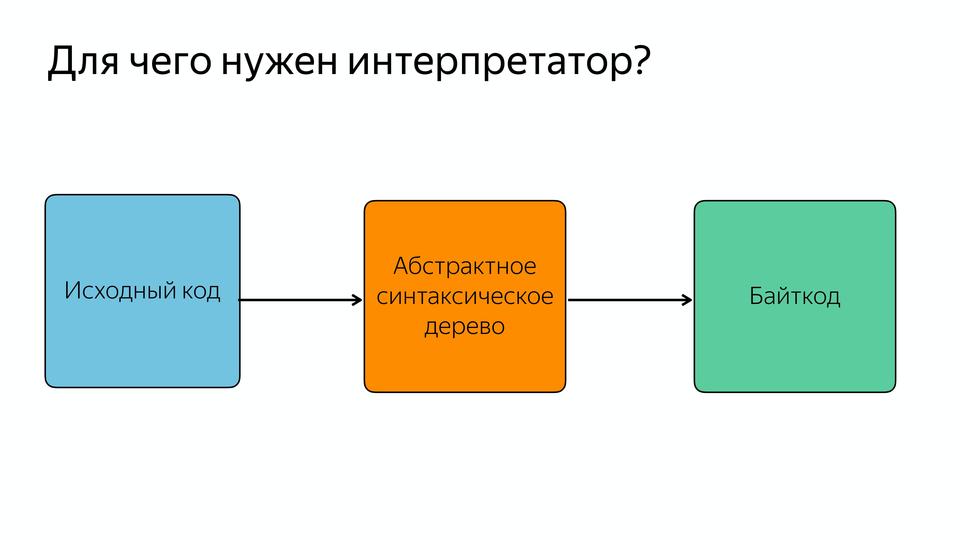




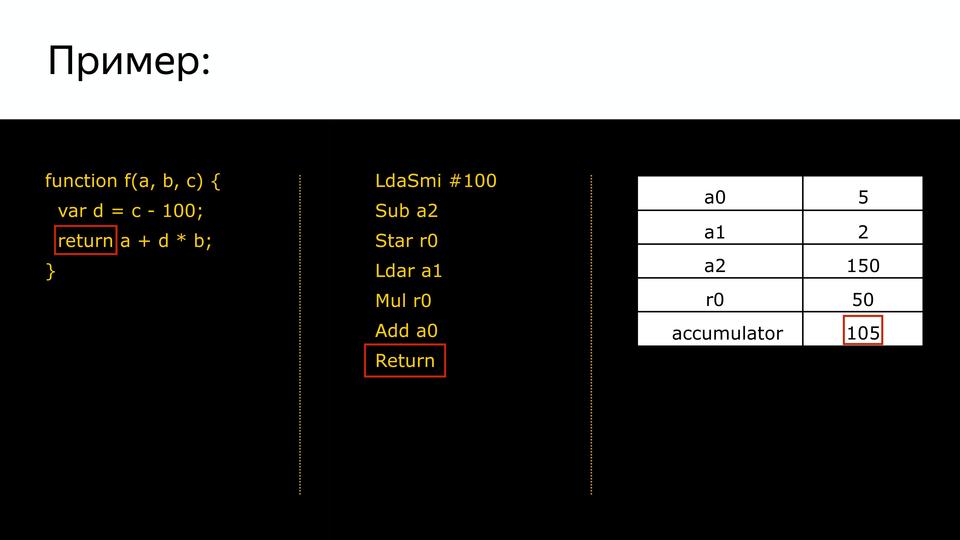
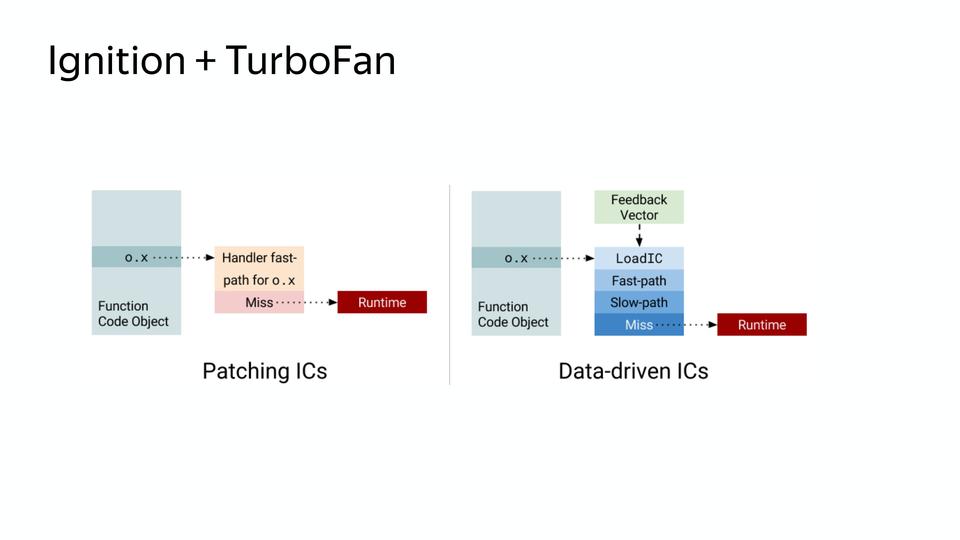
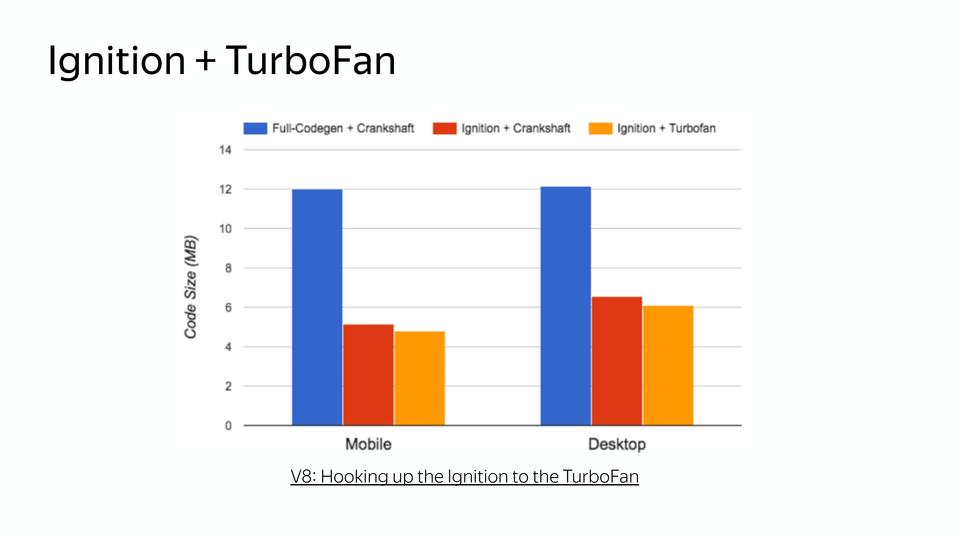

|
Метки: author MaxJoint javascript блог компании jug.ru group v8 |
В поисках перформанса, часть 2: Профилирование Java под Linux |


|
Метки: author ValeriaKhokha разработка под linux высокая производительность java блог компании jug.ru group performance performance optimization linux perf profiling |
Материалы с VLDB, конференции о будущем баз данных |
Конференция VLDB (Very Large Data Bases, www.vldb.org), как несложно понять из названия, посвящена базам данных. Очень большим базам данных. О чем её название не говорит, так это о том, что там регулярно выступают очень серьезные люди. Много ли вы знаете конференций, где почти каждый год докладывается Майкл Стоунбрекер (Michael Stonebraker, создатель Vertica, VoltDB, PostgreSQL, SciDB)? Не думали ли вы, что было бы здорово узнать, над чем такие люди работают сейчас, чтобы через несколько лет, когда новая база разорвет рынок, не грызть локти?
VLDB — именно та конференция, которую вам нужно посетить, если вы думаете о будущем.
Она вам не очень поможет, если вы выбираете из существующих баз. Там есть небольшая доля industrial докладов (Microsoft, Oracle, Teradata, SAP Hana, Exadata, Tableau (!)), но самое интересное — это исследовательские доклады от университетов. Xотя очень быстро обнаруживается, что в командах университетов есть один-два человека, работающих на Google, Facebook, Alibaba… или перешедших туда сразу после подачи статьи.
Надеюсь, мне удалось вас базово заинтересовать, а теперь давайте пройдемся, собственно, по докладам.

Описать все 232 доклада не буду и пытаться, а постараюсь выделить ключевые группы, и для каждой группы продемонстрировать несколько выдающихся представителей.
Очень скоро у нас появится дешевая энергонезависимая память (совмещение RAM+Hard Drive). Оперативная память, ядра и видеокарты стремительно дешевеют. Какими должны быть базы будущего, чтобы выиграть от всего этого технологического великолепия? Какие новые проблемы возникают?
Понятно по названию: это исследование работы алгоритмов распределенного Join на системах с тысячами ядер.
Распределение задач по разнородному кластеру.
Первые эксперименты с энергонезависимой памятью.
Хорошо и легко жить на одном сервере. А вдруг базу нужно развернуть в кластер? Вдруг одну базу нужно расколоть на десятки мелких, согласно микросервисной архитектуре? Как быть с транзакциями?
Статья Стоунбрекера. Просто и честно — взяли и написали с нуля базу, чтобы сравнить с полдюжины алгоритмов распределенных транзакций для OLTP-систем. Никакого пиара и рекламы: просто честные графики и асимптотика для разных сценариев.
Очень оптимистичная заявка о возможности масштабировать производительность распределенных транзакций.
Модный подход сейчас — подменить у старых баз инфраструктуру хранения и подложить туда что-то быстрое. Например, in-memory key-value хранилище. Или, например, сразу два параллельных хранилища — строчное и колоночное. Или шесть хранилищ на разных физических машинах...
Что нужно сделать для решения OLAP-задач на key-value базе.
Статья о том, как устроены базы данных у TenCent (WeChat). 800 миллионов активных пользователей — расскажите им про высокую нагрузку.
OLTP + OLAP нагрузка на одной базе.
Насколько я понял, главный тренд сейчас — оптимизация запросов в распределенных системах. В идеале — на лету, с подстройкой/перестройкой плана прямо по ходу поступления данных.
Вы считаете запрос на кластере, кластер нагружен параллельными задачами, причем неравномерно. Что делать, если отдельные узлы начинают работать явно медленнее других? Ответ — в статье.
Как сгладить графики, убрав шум, но оставив аномалии.
Очень любопытный интерактивный инструмент.
"Data Vocalization" звучит совершенно фантастически, но суть проста: как сжать выборку, выданную запросом, в ограниченный набор слов, чтобы вы дослушали Siri, а не разбили телефон.
<Лучшая статья VLDB 2017>. Да, именно так. Про то, как писать запросы к данным на естественном языке. Точнее так: как транслировать вопросы на естественном языке в запросы к данным, а результаты — обратно на человеческий язык.
Собственно, на этом всё. Казалось бы немного: я собрал тут для вас всего 14 статей. Но мне было бы очень интересно узнать, сколько людей реально прочтут их все до конца. Если возьмётесь, напишите в комментариях, сколько времени это заняло. Для тех, кто смелый, по ссылке — оставшиеся 218 статей: http://confer.csail.mit.edu/vldb2017/papers. И вот фото с доклада организаторов конференции.

PS. VLDB 2017 была в Мюнхене, для участников был маленький Октоберфест (хороший :)). Следующая VLDB будет в Бразилии, вливайтесь! Я постараюсь пройти с докладом (в 2015 не смог).
|
Метки: author azathot визуализация данных big data блог компании avito конференция базы данных наука data science vldb |
Сахарный JavaScript |

В чём разница между нейтив JavaScript и TypeScript?
Браузеры не поддерживают других языков, кроме JavaScript. Поэтому любой язык будет компилироваться в JavaScript. Помните, несколько выпусков назад мы говорили с вами про обёртки? Так вот язык — это просто более удобная обёртка над какой-нибудь функциональностью. Разные языки предлагают разные возможности: зачастую это сводится к модульности, типизации или особенностям других парадигм программирования. Например:
Да простит бог, тех кто придумал CoffeeScript, они не ведали что творили. Впрочем, стрелочные функции оттуда в JavaScript всё-таки попали. А вот обёртки над классами не будем ставить им в заслугу, потому что слова class и extends были зарезервированы в языке ещё задолго до появления CoffeeScript.
Теперь посмотрим, что нам предлагает TypeScript. В TypeScript есть: модульность, типизация и некоторые фичи, которых не было в JavaScript. Dart предлагал то же самое, так почему же он не взлетел? А TypeScript используется в Angular версии 2 и 4, на которых написано полмира.
Дело в том, что TypeScript использует эволюционный подход. Для того чтобы начать писать на TypeScript, вам не нужно учить новый синтаксис. Создатели языка вообще утверждают, что TypeScript — это надмножество JavaScript. Получается, что любой JavaScript будет валидным TypeScript. Даже те фичи, которых не было в JavaScript, они оформили по стандарту ES2015, с заделом на будущее, чтобы не нужно было переписывать код.
Каким образом TypeScript стал популярен — ясно, теперь давайте разберёмся, чего все так гоняются за этой типизацией, что же она даёт. Дело в том, что типизация есть во всех языках программирования, другое дело какая. Типизация бывает сильная и слабая.
JavaScript использует слабую типизацию. Это когда в любую переменную можно записать любое значение.
let anyVariable = 'It’s a string';
anyVariable = ['No,', 'I’ve', 'changed', 'my', 'mind'];В TypeScript же используется сильная или строгая типизация. При строгой типизации, когда вы создаёте переменную, нужно сначала сказать, какого типа будет эта переменная. То же самое работает и для параметров функций.
let anyVariable: string = 'It’s a string';
anyVariable = ['I', 'can’t', 'do', 'this']; // ExceptionСторонники сильной типизации приводят два аргумента в её пользу:
Эффективная работа с памятью в случае с TS неактуальна, потому он в любом случае будет скомпилирован в слабо типизированный JavaScript. А вот от некоторых ошибок приведения типов, которые возникают в рантайме, сильная типизация действительно может помочь.
Представьте, что вы программируете онлайн-калькулятор. У вас есть текстовое поле, пользователь вводит туда числа, вы достаёте строковое значение и полученную строку передаёте в функцию, которая подставляет её в математическую формулу.
function getMonthlyIncome(val) {
return val * 0.055 / 12;
};Слабо типизированный JS пропустит эту строку в любом виде, даже если она не переводится в число. И в результате таких вычислений пользователь может получить NaN рублей. В TypeScript же вам придётся сначала перевести эту строку в число самостоятельно, а потом уже передать в функцию в надлежащем виде. А если вы забудете это сделать, то вы увидите ошибку ещё на этапе компиляции вашего кода.
function getMonthlyIncome(val: number): number {
return val * 0.055 / 12;
};Получается, что какие-то преимущества в строгой типизации всё-таки есть, но не забывайте, что TypeScript — это не единственное решение. В самом JavaScript на уровне функций вы можете добавить дополнительные проверки типов. Да, ваш код будет немного более избыточным, но не забывайте, что другие языки компилируют свои проверки типов примерно в то же самое.
У Facebook есть инструмент для типизации, он называется Flow. Он добавляет систему типов, похожую на систему из языка OCaml, в ваш JavaScript-код. Библиотека Google Closure Library использует хитрый механизм типизации на основе комментариев JSDoc. Вообще, написание комментариев JSDoc, даже без компиляции и хитрой системы типов, поможет вам решить некоторые проблемы. Во-первых, вы сами будете понимать интерфейс тех функций, которые пишете. А во-вторых, некоторые редакторы, которые поддерживают JSDoc, будут подсказывать вам что вы что-то не то передаёте куда-то не туда.
Да и другие языки программирования со строгой типизацией тоже есть. Тот же Elm — он подойдёт вам гораздо лучше, если вам функциональный подход ближе объектно-ориентированного.
В любом случае помните: все эти языки и компиляторы делают ваш проект сложнее в поддержке и настройке, да и кода меньше не становится. Получается, что в их сторону нужно смотреть только в том случае, если накладные расходы действительно того стоят, например, в больших проектах. Если вы делаете небольшой одностраничный лендинг, где почти нет JS и важна скорость загрузки, то лишняя сложность может только навредить.
Вопросы можно задавать здесь.
|
|
Как Алексей Моисеенков дошел до Prisma и пошел дальше |
|
Метки: author Anrewer управление продуктом развитие стартапа моисеенков prisma развитие продукта фотофильтры нейросети мобильные приложения фильтры маски |
[Из песочницы] Вышел React v16.0 |
Это перевод поста Эндрю Кларка о выходе столь ожидаемой версии React. Оригинальный пост в блоге React.
Мы с удовольствием сообщаем о выходе React v16.0! Среди изменений некоторые давно ожидаемые нововведения, например фрагменты, обработка ошибок (error boundaries), порталы, поддержка произвольных DOM-атрибутов, улучшения в серверном рендере, и уменьшенный размер файла.
Теперь вы можете вернуть массив элементов из render-метода компонента. Как и с другими массивами, вам надо добавлять ключ к каждому элементу, чтобы реакт не ругнулся варнингом:
render() {
// Нет необходимости оборачивать в дополнительный элемент!
return [
// Не забудьте добавить ключи :)
Первый элемент ,
Второй элемент ,
Третий элемент ,
];
}В будущем мы, вероятно, добавим специальный синтакс для вывода фрагментов, который не будет требовать явного указания ключей.
Мы добавили поддержку и для возврата строк:
render() {
return 'Мама, смотри, нет лишних спанов!';
}Полный список поддерживаемых типов.
Ранее ошибки рендера во время исполнения могли полностью сломать ваше приложение, и описание ошибок часто было малоинформативным, а выход из такой ситуации был только в перезагрузке страницы. Для решения этой проблемы React 16 использует более надёжный подход. По-умолчанию, если ошибка появилась внутри рендера компонента или в lifecycle-методе, всё дерево компонентов отмонтируется от корневого узла. Это позволяет избежать отображения неправильных данных. Тем не менее, это не очень дружелюбный для пользователей вариант.
Вместо отмонтирования всего приложения при каждой ошибке, вы можете использовать error boundaries. Это специальные компоненты, которые перехватывают ошибки в своём поддереве и позволяют вывести резервный UI. Воспринимайте их как try-catch операторы, но для React-компонентов.
Для дальнейшей информации проверьте наш недавний пост про обработку ошибок в React 16.
Порталы дают удобный способ рендера дочерних компонентов в DOM-узел, который находится за пределами дерева родительского компонента.
render() {
// React не создаёт новый див. Он рендерит дочерние элементы в domNode.
// domNode - это любой валидный DOM-узел,
// вне зависимости от его расположения в DOM-дереве.
return ReactDOM.createPortal(
this.props.children,
domNode,
);
}Полный пример находится в документации по порталам.
React 16 содержит полностью переписанный серверный рендерер, и он действительно быстрый. Он поддерживает стриминг, так что вы можете быстрее начинать отправлять байты клиенту. И благодаря новой стратегии сборки, которая убирает из кода обращения к process.env (хотите верьте, хотите — нет, но чтение process.env в Node очень медленное!), вам больше не надо бандлить React для получения хорошей производительности серверного рендеринга.
Ключевой разработчик Саша Айкин написал замечательную статью, рассказывающую об улучшениях SSR в React 16. Согласно Сашиным бенчмаркам, серверный рендеринг в React 16 примерно в 3 раза быстрее, чем в React 15. При сравнении с рендером в React 15 c убранным из кода process.env получается ускорение в 2.4 раза в Node 4, около 3-х раз в Node 6 и аж в 3.8 раза в Node 8.4. А если вы сравните с React 15 без компиляции (без убранного process.env), React 16 оказывается на порядок быстрее в последней версии Node! (Как Саша указал, к этим синтетическим бенчмаркам надо относиться осторожно, так как они могут не отображать производительность реальных приложений).
Более того, React 16 лучше в восстановлении отрендеренного на сервере HTML, когда последний приходит в браузер. Больше не требуется начальный рендер, используемый для проверки результатов с сервера. Вместо этого он будет пытаться переиспользовать как можно больше существующего DOM. Больше не будут использоваться контрольные суммы! В целом мы не рекомендуем рендерить на клиенте отличающийся от сервера контент, но это может быть полезно в некоторых сценариях (например вывод меток времени).
Больше в документации по ReactDOMServer.
Вместо игнорирования неизвестных HTML и SVG атрибутов, теперь React будет просто передавать их в DOM. Вдобавок это позволяет нам отказаться от длиннющих списков разрешённых атрибутов, что уменьшает размер бандла.
Несмотря на все эти нововведения, React 16 меньше, чем React 15.6.1!
react весит 5.3 kb (2.2 kb gzipped), по сравнению с 20.7 kb (6.9 kb gzipped) ранее.react-dom весит 103.7 kb (32.6 kb gzipped), по сравнению с 141 kb (42.9 kb gzipped) ранее.react + react-dom вместе 109 kb (34.8 kb gzipped), по сравнению 161.7 kb (49.8 kb gzipped) ранее.В общей сложности размер уменьшился на 32% по сравнению с прошлой версией (30% после gzip-сжатия).
На уменьшение размера частично влияют изменения в сборке. React теперь использует Rollup для создания "плоских" бандлов (по-видимому Эндрю Кларк тут имел ввиду "scope hoisting", что давно было в Rollup, но в Webpack появилось только в третьей версии) всех поддерживаемых форматов, что привело к выигрышу и в размере и в скорости работы. Также плоский формат бандла приводит к тому, что воздействие React на бандл приложения остаётся одинаковым, независимо от того, как вы доставляете свой код конечным пользователям, напр. используя Webpack, Browserify, уже собранные UMD-модули или любой другой способ.
Если вы вдруг пропустили, React 16 теперь доступен под MIT лицензией. А для тех, кто не может обновиться немедленно, мы выложили версию React 15.6.2 под MIT.
React 16 — это первая версия React, построенная на основе новой архитектуры, называемой Fiber. Вы можете почитать всё об этом проекте в инженерном блоге Facebook. (Спойлер: мы полностью переписали React!)
Fiber затрагивает большинство новых фич в React 16, такие как error boundaries или фрагменты. Через несколько релизов вы увидите несколько новых фич, так как мы будем постепенно раскрывать потенциал React.
Наверно наиболее впечатляющее нововведение, над которым мы работаем — это асинхронный рендеринг, позволяющий компонентам использовать кооперативную многозадачность в рамках рендера через периодическую передачу управления браузеру. Итог — с асинхронным рендерингом приложения более отзывчивы, так как React не блокирует главный поток.
Следующее демо даёт нам взглянуть на суть проблемы, решаемую асинхронным рендерингом (подсказка: обратите внимание на крутящийся черный квадрат).
Ever wonder what "async rendering" means? Here's a demo of how to coordinate an async React tree with non-React work https://t.co/3snoahB3uV pic.twitter.com/egQ988gBjR
— Andrew Clark (@acdlite) September 18, 2017
Мы думаем, что асинхронный рендеринг — очень важная вещь, двигающая React в будущее. Чтобы сделать переход на v16.0 как можно более безболезненным, мы пока не включили какие-либо асинхронные фичи, но мы рады выкатить их в ближайшие месяцы. Следите за обновлениями!
React v16.0.0 доступен в npm репозитории.
Для установки React 16 используя Yarn:
yarn add react@^16.0.0 react-dom@^16.0.0Для установки React 16 используя npm:
npm install --save react@^16.0.0 react-dom@^16.0.0Мы также предоставляем UMD-вариант, выложенный на CDN:
Ссылка на документацию по детальным инструкциям по установке.
Хотя React 16 включает значительные внутренние изменения, в случае обновления вы можете относится к этому релизу как к любому обычному мажорному релизу React. Мы используем React 16 в Facebook и Messenger.com с начала этого года, мы выкатили несколько бета-версий и релиз кандидатов, чтобы максимально исключить возможные проблемы. Если не учитывать некоторые нюансы, то ваше приложение должно работать с 16-й версией, если с 15.6 оно работало без каких-либо варнингов.
Восстановление отрендеренного на сервере кода теперь имеет явное API. Для восстановления HTML вам надо использовать ReactDOM.hydrate вместо ReactDOM.render. Продолжайте использовать ReactDOM.render, если вы рендерите только на клиентской стороне.
Как ранее было объявлено, мы прекращаем поддержку React Addons. Мы ожидаем, что последняя версия каждого дополнения (кромеreact-addons-perf; см. ниже) будет работоспособна в ближайшем будущем, но мы не будем публиковать новых обновлений.
По ссылке есть ранее опубликованные предложения по миграции.
А react-addons-perf вообще не будет работать в React 16. Скорее всего мы выпустим новую версию этого инструмента в будущем. А пока вы можете использовать браузерные инструменты для измерения производительности.
React 16 включает несколько небольших изменений без обратной совместимости. Они влияют на редко используемые сценарии и затронут малую часть приложений.
unstable_handleError. Этот метод теперь переименован в componentDidCatch. Вы можете использовать codemod для автоматической миграции на новое API.ReactDOM.render и ReactDOM.unstable_renderIntoContainer теперь возвращают null, если вызваны из lifecycle-метода. Вместо этого теперь используйте порталы или ссылки.setState:setState с null больше не будет вызывать реконсиляцию. Это позволит определять в коллбеке надо ли вызывать перерендер.setState напрямую в рендере всегда вызывает реконсиляцию, чего раньше не было. Независимо от того, вам однозначно не надо вызывать setState из метода рендера.setState'а (второй аргумент) теперь вызывается немедленно после componentDidMount / componentDidUpdate, вместо того чтобы ждать полного рендера дерева компонентов.B.componentWillMount будет вызываться всегда перед A.componentWillUnmount. Ранее A.componentWillUnmount мог вызываться раньше в некоторых случаях.ReactDOM.unmountComponentAtNode. Посмотрите на этот пример.componentDidUpdate больше не получает параметр prevContext. (см.#8631)componentDidUpdate, т.к. ссылки на DOM недоступны. Это изменение делает его консистентным с методом componentDidMount (который тоже не вызывался в предыдущих версиях).unstable_batchedUpdates.react/lib/* и react-dom/lib/*. Даже для CommonJS окружений, React и ReactDOM теперь собраны в отдельные файлы (“flat bundles”). Если ваш проект ранее зависел от недокументированных внутренних возможностей React'а и они больше не работают, дайте нам об этом знать в новом тикете, а мы постараемся придумать способ миграции для вас.react-with-addons.js. Все аддоны из этого билда уже опубликованы по отдельность в npm и имеют однофайловые браузерные версии, если они нужны вам.React.createClass теперь доступен как create-react-class, React.PropTypes как prop-types, React.DOM как react-dom-factories, react-addons-test-utils как react-dom/test-utils, а shallow рендерер как react-test-renderer/shallow. См. посты в блоге 15.5.0 и 15.6.0 для инструкций по миграции кода и автоматических кодемодов.react/dist/react.js -> react/umd/react.development.jsreact/dist/react.min.js -> react/umd/react.production.min.jsreact-dom/dist/react-dom.js -> react-dom/umd/react-dom.development.jsreact-dom/dist/react-dom.min.js -> react-dom/umd/react-dom.production.min.jsReact 16 зависит от коллекций Map и Set. Если вы поддерживаете старые браузеры и устройства, в которых нет этого нативно (напр. IE < 11), используйте полифилы, такие как core-js или babel-polyfill.
Окружение с полифилами для React 16 используя core-js для поддержки старых браузеров может выглядеть как-то так:
import 'core-js/es6/map';
import 'core-js/es6/set';
import React from 'react';
import ReactDOM from 'react-dom';
ReactDOM.render(
Hello, world!
,
document.getElementById('root')
);React также требует requestAnimationFrame (даже в тестовых средах). Простая заглушка для тестовых окружений может выглядеть так:
global.requestAnimationFrame = function(callback) {
setTimeout(callback, 0);
};Как обычно, этот релиз был бы невозможен без наших контрибьюторов-волонтёров (open source contributors). Спасибо всем, кто заводил баги, открывал пулл-реквесты, отвечал в тикетах, писал документацию.
Отдельное спасибо нашим корневым контрибьюторам, особенно за их героические усилия в последние несколько недель пререлизного цикла: Brandon Dail, Jason Quense, Nathan Hunzaker, и Sasha Aickin.
|
Метки: author dagen reactjs javascript react react.js facebook |
[Перевод] 30 новых ресурсов для android-разработчика (лето 2017) |

LayoutManager - тускнеет и сжимает при прокрутке. Создан по мотивам Dribble project.
LinearLayout.







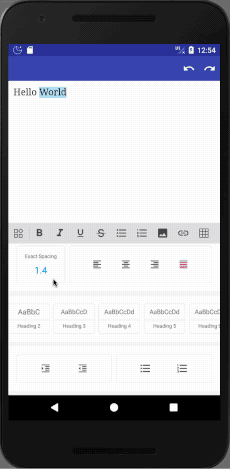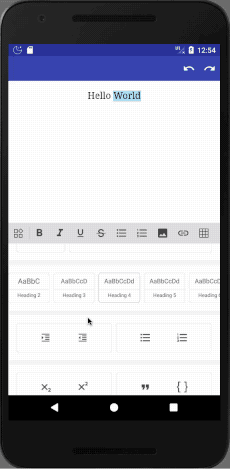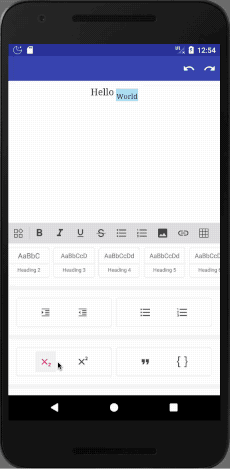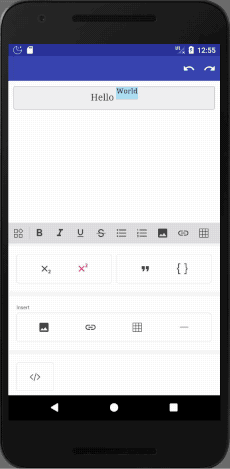
Minimum SDK: API 21
Default settings:
targetLength: 1080
quality: 80
outputFormat: JPEG
outputDirPath: the external files directory of your app
Supported input formats:
BMP
GIF
JPEG
PNG
WEBP
Supported output formats:
JPEG
PNG
WEBP
Supported quality range: 0~100
The higher value, the better image quality but larger file size
PNG, which is a lossless format, will ignore the quality setting



Optional для Kotlin.View для Android, имитирующий Apple TV App Icons.
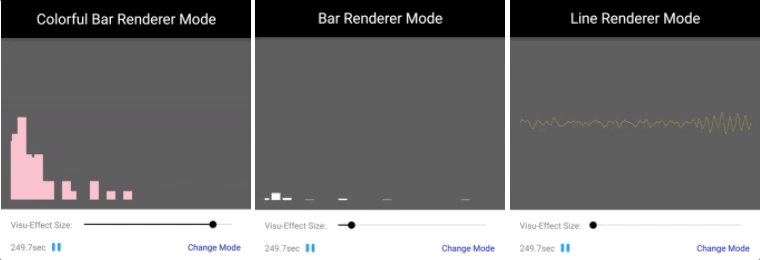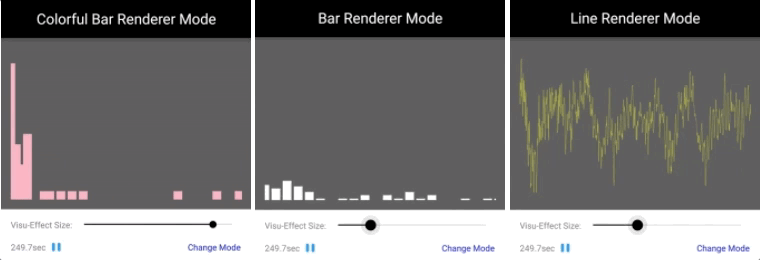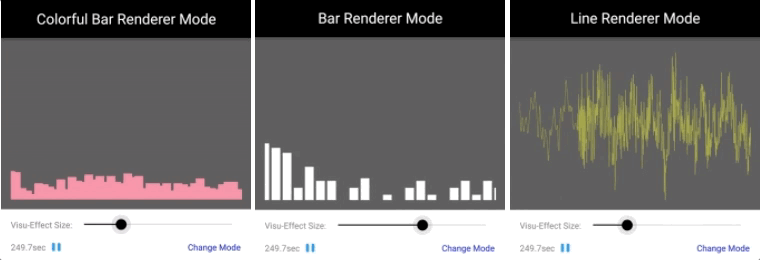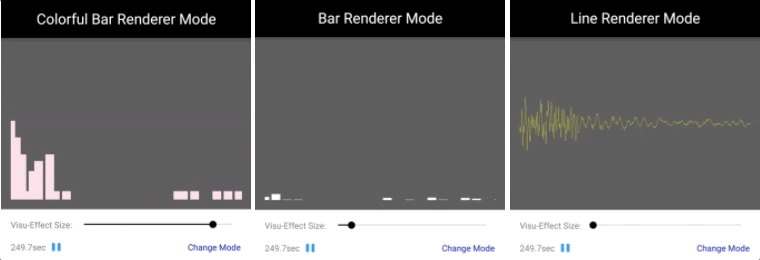

|
Метки: author MagisterLudi разработка под android программирование kotlin блог компании edison разработка android edisonsoftware |
Аналитика в госсекторе: особенности больших систем хранения данных |
 Читать дальше ->
Читать дальше ->|
|
[Из песочницы] Моделирование смешанных схем на System Verilog |
Жили были, не, не так… Однажды рано утром, придя в очередной раз на работу, я узнал, что у нас в серверной всего один ввод электропитания и он может отгорать. Целый день было нечего делать, и я решил написать статью на Хабр. Статья ориентирована на начинающих и праздно интересующихся.
Технология КМОП достигла такого уровня, что современные микросхемы представляют собой огромные и очень сложные структуры и системы, собранные из систем. В то же время, стоимость запуска в производство растет экспоненциально с уменьшением технологических норм. Поэтому, при разработке, требуется моделировать и верифицировать все в максимально возможном объеме. Идеальный случай, который даже иногда реализуется на практике, когда микросхема заработала с первого запуска.
Так как мы живем в аналоговом мире, то даже цифровая микросхема должна уметь с этим миром общаться. Цифровые микросхемы содержат на кристалле десятки больших аналоговых блоков, таких как АЦП, ЦАП, ФАПЧ, блоки вторичного питания и т.д. Исключением из этого правила, вероятно, являются только большие процессоры, типа Core i и т.п., где все это хозяйство вынесено в чипсет.
Традиционно для моделирования аналоговых блоков используются spice симуляторы, такие как pi-spice, mmsim, hspice и т.д. В таких симуляторах схема описывается системой дифференциальных уравнений огромной размерности (или матрицей, ее представляющей). Spice симуляторы на каждом шаге вычислений находят решение этой системы уравнений численными методам. Конечно, используются методы ускорения этих вычислений, такие как: разбиение матрицы на подматрицы, распараллеливание на некоторое количество потоков и вычислительных ядер, переменный шаг вычислений и т.д.
К сожалению, числовые методы являются фундаментально итеративными и плохо распараллеливаются, поэтому этот вид моделирования, все равно, остается достаточно медленным для моделирования системы в целом. Тем не менее, он широко применяется при разработке самих аналоговых блоков и аналоговых микросхем. Мы же, поведем рассказ о цифровых (в целом) микросхемах, содержащих аналоговые блоки и аналого-цифровые системы, где нам хотелось бы описать наши блоки в виде формул и уравнений, и решать эти уравнения Навье-Стокса(шутка) аналитически. Использование данной техники не отменяет гораздо более точный расчет на spice симуляторе, а лишь дополняет его позволяя ускорить разработку и моделирование.
Для представления аналоговых сигналов хорошо подходит тип с плавающей точкой. В System Verilog это типы shortreal (эквивалентен float в С) и real. Необходимо отметить, что это типы данных с памятью. Значение в них обновляется только в момент присваивания, т.е. это тип аналогичный reg, но в котором запомненное значение представляется не 0 или 1, а напряжением или током, представленном, в свою очередь, в виде числа с плавающей точкой.
Теперь, нам очень нужен тип аналогичный wire, который обновляется непрерывно, а не только в момент записи. Надо сказать, что в System Verilog такого типа нет. Ходят слухи, что при обсуждении стандарта, было некое движение, дабы вставить в него этот функционал, но оно не реализовалось ни во что конкретное. Тем не менее, если вы используете симулятор ncsim, то в нем есть модификатор var, который делает из типа real и других типов аналог wire. Пример:
real a;
var real b;
assign a = in1+in2; //тут будет ошибка
assign b = in1+in2; // это будет работать, b – всегда будет равно in1+in2Программа на verilog – это параллельная программа. Все строчки кода, в принципе независимы и выполняются как последовательно, так и параллельно, в зависимости от некоторых условий. В данном случае assign сработает при запуске этой программы и будет работать до самого его конца, вычислять сумму непрерывно.
Если ваш симулятор не поддерживает var, то можно сделать так:
real b;
always @( * ) // симулятор входит в этот always при любом изменении in1 или in2
b <= in1+in2;Запись менее удобная, тем не менее вполне рабочая.
В verilog встроены следующие функции для преобразования данных
$itor() // integer to real
$rtoi() // real to integer
$bitstoreal() //reg [ : ] to real
$realtobits() // real to reg [ : ] Если код, который вы хотите преобразовать в real — знаковый и представлен в дополнительном коде, нужно быть аккуратным при использовании этих функций, возможно понадобиться еще конвертация или расширение знака. Если вы, по каким-то причинам, не хотите использовать эти функции, то можно воспользоваться следующей техникой.
reg [7:0] code;
int a;
real voltage;
always @( * )
begin
a = {{24{code[7]}}, code[7:0]}; // расширяем знак до размера int
voltage = a;
endmodule amp(input var real in, output real out);
parameter k = 10; //коэффициент усиления
parameter seed = 60;
parameter noise_power = -20; //мощность шума в dB
real noise;
always @(*)
begin
noise = $sqrt(10**(noise_power/10))* $itor($dist_normal(seed, 0 , 100_000))/100_000;
out = in * k + noise;
end
endmodule`timescale 1ns / 1ps
module DAC(input signed [7:0] DAC_code, output real out);
parameter fs = 10e-9;
parameter ffilt = fs/64; //частота расчета фильтра
parameter CUTOFF = 100e6; //частота среза фильтра
parameter a = ffilt/(ffilt+(1/(2*3.141592* CUTOFF)));
real DAC_out;
//ЦАП
always @( * )
DAC_out <= $bitstoint(DAC_code[7:0]);
//ФНЧ 1го порядка
always #(0.5*ffilt)
out <= a* DAC_out + (1-a)*out;
endmodulemodule ADC (input real in, input clk, output reg [7:0] ADC_code)
real adc_tf[0:255];
real min_dist;
int i,j;
int dnl_file;
initial
begin
dnl_file=$fopen("DNL_file","r");
if(dnl_file==0)
$stop;
for(i=0;i<256;i=i+1)
$fscanf(dnl_file, "%f;", adc_tf[i]);//считываем из файла характеристику АЦП
end
always @(posedge clk)
begin
min_dist = 10;
for(j=0;j<256; j=j+1) //находим ближайший к входному сигналу код
if($abs(in- adc_tf[j]) < min_dist)
begin
min_dist = delta_abs;
ADC_code[7:0]=j;
end
end
endmodulemodule MPLL (input en, input [5:0]phase, output clk_out);
parameter REFERENCE_CLOCK_PERIOD=10e-6;
parameter PHASES_NUMBER=64;
reg [PHASES_NUMBER-1:0]PLL_phase=64'h00000000_FFFFFFFF; //ГУН на кольцевом генераторе
always #(REFERENCE_CLOCK_PERIOD/PHASES_NUMBER)
if(en===1)
PLL_phase[PHASES_NUMBER-1:0] <= {PLL_phase[PHASES_NUMBER-2:0], PLL_phase[PHASES_NUMBER-1]}; //сдвигаем кольцевой генератор по кругу
assign clk_out = PLL_phase[phase]; //мультиплексор клока
endmoduleИспользование таких и подобных, но более сложных аналитических моделей, на порядки ускоряет расчёты по сравнению со spice моделированием и позволяет реально моделировать и верифицировать систему в сборе на System Verilog.
К сожалению, современные системы уже настолько сложны, что данного ускорения бывает недостаточно, в этом случае приходится прибегать к распараллеливанию. Многопоточных Verilog симуляторов, насколько я знаю, пока не изобрели, поэтому придется в рукопашную.
В SystemVerilog введен новый механизм для обращения к внешним программным модулям – Direct Programming Interface (DPI). Т.к. этот механизм проще, по сравнению с другими двумя, будем использовать его.
В начале модуля, где мы хотим вызвать внешнюю функцию нужно вставить строчку import.
import "DPI-C" function int some_funct(input string file_name, input int in, output real out);
Далее можно в Verilog ее использовать обычным образом, например, так:
always @(posedge clk)
res1 <= some_funct (“file.name”, in1, out1);Как правильно скомпилировать и где лежат библиотеки описано в документации на симулятор.
Далее приведу пример программы, работающей в несколько потоков
#include
typedef struct
{
//work specific
double in; // данные для расчета
double out; //результат расчета
…
//thread specific
char processing; //флаг разрешения расчета
pthread_mutex_t mutex;
pthread_cond_t cond_start;
pthread_cond_t cond_finish;
void *next_th_params;
pthread_t tid;
}th_params;
static th_params th_pool[POOL_SIZE];Расчётная функция:
void* worker_thread(void *x_void_ptr)
{
th_params *x_ptr = (th_params *)x_void_ptr;
while(1) //бесконечный цикл
{
// ждем поступления новых данных
pthread_mutex_lock (&x_ptr->mutex); //блокируем
x_ptr->processing = 0; //Окэй, рэди фор ворк
pthread_cond_signal(&x_ptr->cond_finish); //даем гудок, что закончили
while(x_ptr->processing == 0)
pthread_cond_wait(&x_ptr->cond_start, &x_ptr->mutex); //ждем ответного гудка
x_ptr->processing = 1; //ставим флаг - занят
pthread_mutex_unlock(&x_ptr->mutex); //разблокируем
// здесь что-то считаем, вероятно ассемблерная вставка SSE2
…
}
}
Функция запуска расчётных функций
void init(th_params *tp)
{
int i=0;
for(;i<12;i++)
{
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
pthread_create(th_pool->tid, &attr, &worker_thread, tp);
}
}Функция, раздающая работу расчётным функциям (ее будем вызывать из Verilog постоянно)
int ch(double in, double *out)
{
int i;
for(i=0;i<12;i+=1)
{
//ждем если рабочие функции еще не досчитали
pthread_mutex_lock(&th_pool[i].mutex); //блокируем
while(th_pool[i].processing == 1)
pthread_cond_wait(&th_pool[i].cond_finish, &th_pool[i].mutex); //ждем гудок
pthread_mutex_unlock(&th_pool[i].mutex); //разблокируем
}
//присваиваем результаты в массив на выходе для передачи в Verilog
for(i=0;i<12;i+=1)
out[i] = th_pool[i].out;
for(i=0;i<12;i+=1)
{
pthread_mutex_lock (&th_pool[i].mutex); //блокируем
th_pool[i].in = in; //передаем расчетной функции данные
th_pool[i].processing = 1; //ставим флажок разрешения расчета
pthread_cond_signal (&th_pool[i].cond_start); //даем ответный гудок, что бы проснулась
pthread_mutex_unlock (&th_pool[i].mutex); //разблокируем
}
}К сожалению, современные системы уже настолько сложны, что и этого ускорения бывает недостаточно. В этом случае приходится прибегать к использованию OpenCL для расчетов на видеокарте (не сложнее DPI), расчетов на кластере или в облаке. Во всех этих случаях серьезным ограничением является транспортная составляющая, т.е. время передачи данных на расчетное устройство и с него. Оптимальной задачей, в этом случае являются такая, где нужно много считать, при этом имеется, относительно этого расчета, малое количество данных, как исходных, так и результата. Тоже самое относится и к представленной программе, но в меньшей степени. Если это условие не выполняется, то зачастую, считать на одном лишь процессоре, оказывается быстрее.
Необходимо учесть, что ничего из представленных методов не работает, когда в серверной нет питания, впрочем, его только что подали, youtube опять заработал. На этой радостной ноте, спешу закончить мой рассказ, работа ждет.
|
|
DevFest North в Питере уже 30 сентября |

|
Метки: author DaryaGhor разработка под android блог компании trinity digital баласс group google conference gdg android |
Как мы строили свой мини ЦОД. Часть 5 — пережитый опыт, обрывы, жара |






















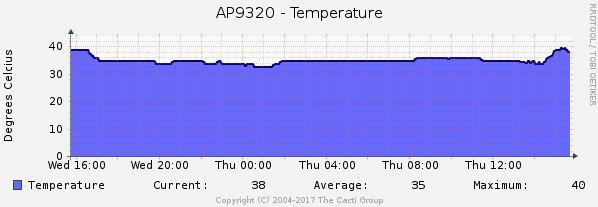







|
Метки: author TakeWYN системное администрирование сетевые технологии серверное администрирование it- инфраструктура ит-инфраструктура цод дата-центр аварии дата-центра |
Какие конференции работают и как туда ездить |

Сначала я попал на какого-то чувака, который рассказывал про то, что 65% людей отваливаются на оплате картой. Типа, ужас-ужас, денег нет только у 11%, у остальных — блок от фрода, херовый интерфейс, косой 3D-секьюр, пользуйтесь нашим продуктом. Это все заказы с оплатой картой, которые не были сделаны. Самое полезное в выступлении — это факт о том, что 7 лет назад за подтверждением транзакции надо было ходить к банкомату, а сейчас код приходит на телефон.
Наш общий друг *** выступает, слегка принял перед выступлением. Ликбезы…
Ещё один чувак рассказывает про оперативную реакцию. Каждый заказ на сайте порождает SMS на нокию, прикрученную скотчем в колл-центре. Запищала противно — обновили заказы. Они же по средам анализируют все звонки (среды же) по чеклисту, чтобы понять, когда КЦ расслабился…
Выступает ***, SEO. Говорит, по куче товаров до 50% запросов — уникальные. В смысле, что люди ищут редкостную фигню вроде «настольная игра монополия с фигуркой машины». Советует *** для семантики (платная), говорит, видит связанные запросы, которые не видит Яндекс. Я написал, попросил триал. Много говорили про кластеризацию запросов, но я не понял практических выводов…
Аааа: «Было слишком много заказов, и нам пришлось закрыть магазин»…
Дима, увидишь Артема — скажи, что уходя со стенда, надо забирать личные визитки и вывеску, а не только баннер. Я там постоял, продавал его платформу потом, обещал скидки 80%, раздал оставшиеся визитки.
|
Метки: author Milfgard управление проектами управление e-commerce блог компании мосигра конференции розница здравый смысл |
Avamar не копирует дважды |
|
Метки: author DellEMCTeam хранилища данных хранение данных резервное копирование блог компании dell emc dell avamar |
[Из песочницы] Из жизни оборотней |






|
Метки: author kate_amell карьера в it-индустрии блог компании parallels parallels bmstu бауманка карьера программиста карьера для it студентов |






