Используем PubNub: эмоциональный говорящий чат своими руками |

public class HomeController : Controller
{
public ActionResult Login()
{
return View();
}
[HttpPost]
public ActionResult Main(LoginDTO loginDTO)
{
String chatChannel = ConfigurationHelper.ChatChannel;
String textToSpeechChannel = ConfigurationHelper.TextToSpeechChannel;
String authKey = loginDTO.Username + DateTime.Now.Ticks.ToString();
var chatManager = new ChatManager();
if (loginDTO.ReadAccessOnly)
{
chatManager.GrantUserReadAccessToChannel(authKey, chatChannel);
}
else
{
chatManager.GrantUserReadWriteAccessToChannel(authKey, chatChannel);
}
chatManager.GrantUserReadWriteAccessToChannel(authKey, textToSpeechChannel);
var authDTO = new AuthDTO()
{
PublishKey = ConfigurationHelper.PubNubPublishKey,
SubscribeKey = ConfigurationHelper.PubNubSubscribeKey,
AuthKey = authKey,
Username = loginDTO.Username,
ChatChannel = chatChannel,
TextToSpeechChannel = textToSpeechChannel
};
return View(authDTO);
}
}
public class ChatManager
{
private const String PRESENCE_CHANNEL_SUFFIX = "-pnpres";
private Pubnub pubnub;
public ChatManager()
{
var pnConfiguration = new PNConfiguration();
pnConfiguration.PublishKey = ConfigurationHelper.PubNubPublishKey;
pnConfiguration.SubscribeKey = ConfigurationHelper.PubNubSubscribeKey;
pnConfiguration.SecretKey = ConfigurationHelper.PubNubSecretKey;
pnConfiguration.Secure = true;
pubnub = new Pubnub(pnConfiguration);
}
public void ForbidPublicAccessToChannel(String channel)
{
pubnub.Grant()
.Channels(new String[] { channel })
.Read(false)
.Write(false)
.Async(new AccessGrantResult());
}
public void GrantUserReadAccessToChannel(String userAuthKey, String channel)
{
pubnub.Grant()
.Channels(new String[] { channel, channel + PRESENCE_CHANNEL_SUFFIX })
.AuthKeys(new String[] { userAuthKey })
.Read(true)
.Write(false)
.Async(new AccessGrantResult());
}
public void GrantUserReadWriteAccessToChannel(String userAuthKey, String channel)
{
pubnub.Grant()
.Channels(new String[] { channel, channel + PRESENCE_CHANNEL_SUFFIX })
.AuthKeys(new String[] { userAuthKey })
.Read(true)
.Write(true)
.Async(new AccessGrantResult());
}
}
var pubnub;
var chatChannel;
var textToSpeechChannel;
var username;
function init(publishKey, subscribeKey, authKey, username, chatChannel, textToSpeechChannel) {
pubnub = new PubNub({
publishKey: publishKey,
subscribeKey: subscribeKey,
authKey: authKey,
uuid: username
});
this.username = username;
this.chatChannel = chatChannel;
this.textToSpeechChannel = textToSpeechChannel;
addListener();
subscribe();
}
function subscribe() {
pubnub.subscribe({
channels: [chatChannel, textToSpeechChannel],
withPresence: true
});
}
function addListener() {
pubnub.addListener({
status: function (statusEvent) {
if (statusEvent.category === "PNConnectedCategory") {
getOnlineUsers();
}
},
message: function (message) {
if (message.channel === chatChannel) {
var jsonMessage = JSON.parse(message.message);
var chat = document.getElementById("chat");
if (chat.value !== "") {
chat.value = chat.value + "\n";
chat.scrollTop = chat.scrollHeight;
}
chat.value = chat.value + jsonMessage.Username + ": " +
jsonMessage.Message;
}
else if (message.channel === textToSpeechChannel) {
if (message.publisher !== username) {
var audio = new Audio(message.message.speech);
audio.play();
}
}
},
presence: function (presenceEvent) {
if (presenceEvent.channel === chatChannel) {
if (presenceEvent.action === 'join') {
if (!UserIsOnTheList(presenceEvent.uuid)) {
AddUserToList(presenceEvent.uuid);
}
PutStatusToChat(presenceEvent.uuid,
"joins the channel");
}
else if (presenceEvent.action === 'timeout') {
if (UserIsOnTheList(presenceEvent.uuid)) {
RemoveUserFromList(presenceEvent.uuid);
}
PutStatusToChat(presenceEvent.uuid,
"was disconnected due to timeout");
}
}
}
});
}
function publish(message) {
var jsonMessage = {
"Username": username,
"Message": message
};
var publishConfig = {
channel: chatChannel,
message: JSON.stringify(jsonMessage)
};
pubnub.publish(publishConfig);
var emotedText = '';
var selectedEmotion = iconSelect.getSelectedValue();
if (selectedEmotion !== "") {
emotedText += '';
}
emotedText += message;
if (selectedEmotion !== "") {
emotedText += '';
}
emotedText += ' ';
jsonMessage = {
"text": emotedText
};
publishConfig = {
channel: textToSpeechChannel,
message: jsonMessage
};
pubnub.publish(publishConfig);
}
|
Метки: author Cromathaar системы обмена сообщениями программирование javascript .net pubnub iaas |
Энергоэффективный ЦОД: знакомство с мировым опытом |
 / кадр из видео о нашем дата-центре SDN + (подробнее об инфраструктуре 1cloud)
/ кадр из видео о нашем дата-центре SDN + (подробнее об инфраструктуре 1cloud)
|
Метки: author 1cloud хранилища данных блог компании 1cloud.ru 1cloud цод дата-центры фрикулинг |
Как попасть в Технопарк Университета ИТМО: большое интервью |
 Мастерская-лаборатория ФабЛаб — подразделение Технопарка
Мастерская-лаборатория ФабЛаб — подразделение ТехнопаркаВ последнее время стало приходить больше компаний, развивающихся в области Life Science, и нам очень интересно с ними сотрудничать. У нас уже размещаются компании, создающие решения в области биофармацевтики, биомедицинских технологий и сервисов, биоинформационных технологий, медицинского приборостроения и здравоохранения, и в ближайшее время мы планируем расширить присутствие таких компаний.
— Олеся Баранюк, Технопарк Университета ИТМО
На момент становления резидентом наш проект находился на начальной стадии. В принципе, была только базовая идея и ничего больше.
— Дмитрий Павлов, коммерческий директор VISmart (компании-создателя платформы Ontodia)
[На момент получения статуса резидента проект находился на стадии:] MVP [минимально жизнеспособный продукт], 1 внедрение, 1 контракт на подходе.
—Олег Шахов директор по развитию бизнеса компании «Оптимальное движение» (разрабатывает проект odgAssist)
[На момент появления в Технопарке] мы находились на стадии активной разработки программного обеспечения, хотя наша команда разработчиков состояла только из трех программистов. Также мы активно искали подходящее решение для самого устройства (процессор, оптику, сенсоры и так далее) и производителя, который сможет это устройство сделать. На тот момент у нас уже была запущена кампания на Indiцegogo.
— Александр Морено, технический директор Orbi
[Состояние на момент получения статуса резидента:] вывод пилотной разработки на рынок.
— Александр Павлов, директор компании Parseq Lab
Мы подумали, что хорошо быть рядом к центру компетенций в той области, в которой мы решили развивать свой продукт. Пока что нам кажется, что наше решение стать резидентом Технопарка было верным.
— Дмитрий Павлов, VISmart
Мы искали место, где можно заниматься инновационной деятельностью. Нам нужна была инфраструктура для запуска проекта. И нам были нужны не только стол и стул, но также возможность взаимодействовать с другими инновационными предприятиями, получить доступ к интересным событиям и мероприятиям и много чего другого.
Сначала мы определились с тем, что нам нужен технопарк. Всё-таки стартовать с поддержкой немного проще. Затем мы сделали мониторинг 4 ведущих технопарков в Санкт-Петербурге. В результате Технопарк ИТМО оказался в безоговорочных лидерах. Кроме того, у основателей уже имелись контакты с резидентами, что было для нас очень удобно. Также нам понравилась атмосфера технопарка и его представители
— Олег Шахов, odgAssist
Год назад, когда проект дошел до определенной стадии, встала необходимость расширения и поиска подходящего места, для дальнейшей работы над разработкой.
Найдя в интернете Технопарк ИТМО, узнав все условия и преимущества размещения в нем, а так же обнаружив, что среди его резидентов уже есть те, кто работают в области 360 видео, мы поняли, что это именно то место, где мы сможем наиболее эффективно развивать свой проект.
— Александр Морено, Orbi
Прежде всего, [для нас важна была] готовность руководства идти навстречу при решении вопросов размещения. Хорошая инфраструктура и месторасположение Технопарка.
— Александр Павлов, Parseq Lab
Довольно часто к нам обращаются крупные корпорации с просьбой разместить в Технопарке свои R&D-центры, чтобы иметь возможность находиться в эпицентре инновационной активности, сотрудничать с научными подразделениями Университета и резидентами технопарка, а также постепенно формировать портфель инновационных продуктов.
— Олеся Баранюк, Технопарк Университета ИТМО
Мы пришли в Технопарк с несколькими проектами на разных стадиях готовности, из которых уцелело только 50%. Нам кажется, что в большей степени мы заинтересовали Технопарк как команда.
В этой связи, я бы рекомендовал кандидатам в резиденты обратить внимание на представление своей команды. Направление деятельности может смениться, но команда — это величина, по моему мнению, более постоянная и важная, чем кажущийся сильным проект.
— Дмитрий Павлов, VISmart
Про наш проект могу так сказать: у нас были рекомендации от резидентов, мы подготовились к встрече. Не думаю, что сложно попасть в технопарк если у вас годный проект, есть MVP (мне кажется, это важно) и реалистичный план. И да – если вы делаете инновацию, а не интернет-магазин или рекламное агентство.
Мы прилично оделись на встречу, рассказали всю нашу историю, были честны, показали себя профессионалами, реалистами. Показали, что болеем своим делом.
— Олег Шахов, odgAssist
Мы разрабатываем инновационное устройство, находящееся действительно на переднем крае современных технологий в области камеростроения (например используемые нами процессор и объективы только появились на рынке, буквально год назад ничего подобного в принципе не существовало). Сама область 360 видео новая и очень активно развивается.
Плюс основным направлением нашей деятельности на базе Технопарка является именно разработка программного обеспечения, что явно близко как самому Технопраку так и Университету ИТМО в целом. Мы выражали готовность активно участвовать в жизни Технопарка, что также очень важно.
Совет — думаю, что на встрече важно сделать акцент на то, насколько ваш проект подходит по своей направленности Технопарку. Если среди резидентов уже присутствуют компании, с которыми вы могли бы плодотворно сотрудничать, это будет очень хорошим аргументом. Ну и важно быть готовым активно участвовать в жизни Технопарка.
Что касается потенциальных инвесторов, то наличие в их портфеле компаний, с которыми вы смогли бы плодотворно сотрудничать, также будет серьезным плюсом. Однако в первую очередь инвесторы, особенно на самых ранних стадиях, оценивают не только проект, но и вас самих. Важно презентовать не только идею — этого мало. Нужно презентовать команду, и убедить их [руководство Технопарка и/или инвесторов] что вы — именно те люди, которые лучше всех смогут данный проект реализовать.
— Александр Морено, Orbi
У нас есть несколько компаний, которые создают решения в области ДНК-диагностики тяжелых наследственных заболеваний; решения для идентификации личности на основе технологии высокопроизводительного секвенирования; занимаются вопросами создания инфраструктуры для анализа и хранения геномных данных; разработкой геннотерапии, направленной на победу над старостью, онкологией и даже ВИЧ.
Область для Университета не профильная, но, тем не менее, в Университете развивается такое направление как Биоинформатика в рамках Лаборатории и Института Биоинформатики [кстати, об этом направлении мы рассказывали в одном из наших материалов], и наличие резидентов с уникальными компетенциями в этой области значительно увеличивает исследовательские возможности студентов, аспирантов и сотрудников научных подразделений.
— Олеся Баранюк, Технопарк Университета ИТМО
В настоящий момент у нас сложился довольно интересный кейс взаимодействия резидентов Технопарка, сотрудников Университета и сотрудника Венского экономического Университета. Резидент Технопарка, компания VISmart занимается разработкой программного обеспечения в области семантического веба. Она довольно плотно сотрудничают с Международной лабораторией Университета ИТМО «Интеллектуальные методы обработки информации и семантические технологии» (несколько сотрудников VISmart также являются сотрудниками международной лаборатории и наоборот).
Сервис, над которым работала команда VISmart, очень заинтересовал ассистент-профессора Венского экономического университета Герхарда Вольгенаннта, что привело его вначале в компанию VISmart, а потом и в Университет ИТМО. В результате он стал участником программы ITMO Fellowship, влился в команду, в настоящий момент работает над усовершенствованием семантических технологий в области голосового управления устройствами.
— Олеся Баранюк, Технопарк Университета ИТМО
Да, наши разработки связаны с Университетом ИТМО. Дело в том, что наш продукт Ontodia ориентирован в том числе на поддержку стандартов semantic web, выпущенных w3c, а именно RDF, OWL, SPARQL.
В России, по нашим сведениям, есть только одно сильное научное подразделение, которое учит применять эти стандарты и ведет серьезные научно-исследовательские проекты в этой сфере — это Международная лаборатория Университета ИТМО “Интеллектуальные методы обработки информации и семантические технологии”, с которой у нас установлены тесные связи. Двое наших сотрудников является аспирантами ИТМО.
— Дмитрий Павлов, VISmart
Возможность совместного использования оборудования лабораторий Университета или других резидентов Технопарка является опцией, которой довольно часто пользуются наши резиденты. Они обращаются к нам со своим запросом, мы их представляем нашим коллегам из научных подразделений, в случае, если есть взаимная заинтересованность в сотрудничестве, рождаются совместные научные и бизнес-проекты.
— Олеся Баранюк, Технопарк Университета ИТМО
Для нас наиболее полезными оказались следующие услуги: возможность пользоваться конференц-залом Технопарка, возможности ФабЛаб. Нам удобно и приятно иметь помещения в здании Технопарка, потому что авторитет ИТМО помогает выглядеть убедительными, особенно на ранних этапах.
Но самое главное все же — это помощь инновационных менеджеров. Они знакомят нас с потенциальными клиентами, содействуют в продвижении и популяризации проекта, от них можно получить помощь практически в любом вопросе.
— Дмитрий Павлов, VISmart
Технопарк активно помогает находить интересные программы и конкурсы для стартапов. Например, Технопарк поспособствовал нашему участию в конкурсе проектов Polar Bear Pitching в Оулу (Финляндия), где мы заняли второе место. Это был интересный опыт, участие в котором дало возможность стать нам более узнаваемыми в мире, ведь на мероприятии присутствовали представители средств массовой информации со всего мира: CNN, BBC, Al Jazeera и др., многие вели он-лайн трансляцию, ведь не каждый день можно увидеть предпринимателя, вещающего о конкурентных преимуществах из ледяной проруби в феврале при температуре –25.
Также для нас очень полезна возможность общаться с другими компаниями, работающими в области 360 видео. Очень удобно, что в технопарке есть ФабЛаб, где много различных инструментов и оборудования, что позволяет, например, быстро напечатать на 3D принтере прототипы, детали и так далее.
— Александр Морено, Orbi
Куча крутых событий на которые нас зовут, крутой PR, участие в мероприятиях, бешеный нетворкинг, помощь в взаимодействии с различными инструментами гос. поддержки, трэкшн, добрый совет, тёплые слова поддержки.
— Олег Шахов, odgAssist
Попробуйте найти клиента. Пусть это будет не совсем профильный клиент. Но попробуйте начать зарабатывать как можно раньше. Нам на начальном этапе очень сильно помог грант от Фонда Содействия Инновациям
— Дмитрий Павлов, VISmart
Проект должен выполнять задачи, для которых он создаётся. Бизнес должен приносить деньги. То, что вы делаете, может приносить деньги? А что можно сделать, чтобы приносило больше?
Любыми способами (легальными) добейтесь первых продаж. Вы должны понимать, что вы делаете, за какие деньги, для кого и зачем (какую проблему решаете). Если всё ок, то сделайте SWOT-анализ своей идеи/бизнеса. Не стесняйтесь pivot’а и закрытия проекта.
Не взлетело – посмотрите, почему. Если ценности нет — что ж, так бывает. Если нет скорости, фокуса или execution – поработайте над собой, возможно, вам ещё рано делать стартап. И делайте CustDev, много CustDev’a, чтобы ваш продукт был кому-то нужен.
— Олег Шахов, odgAssist
Универсальных советов давать не буду. Просто приведу пример того, с чем мы столкнулись сами. Как правило, особенно когда делаешь не просто ПО, а устройство, то приходится взаимодействовать с большим количеством партнеров (фабрики, производители процессоров и других электронных компонентов и так далее).
Очень важно налаживать с ними не только деловые, но и личные отношения. Несмотря на то, что сейчас практически все можно обсудить удаленно, по почте, на звонке и так далее, не следует пренебрегать личной встречей. Во-первых, это помогает намного быстрее решить множество вопросов, а во-вторых, делает ваше партнерство более надежным.
— Александр Морено, Orbi
|
Метки: author itmo развитие стартапа блог компании университет итмо университет итмо технопарк университета итмо стартапы |
Без заголовка |
|
Метки: author kudzev разработка веб-сайтов javascript html css блог компании 2гис frontfest codefest гис iot spotify microsoft clojurescript |
[recovery mode] Переезды в облако: 5 разных историй |


|
Метки: author SZinkevich серверное администрирование виртуализация it- инфраструктура блог компании крок крок |
Как мы отмечали 256 день года и рисовали пиксели через API |
13 сентября в Контуре отмечали День программиста. В самом большом офисе разработки играли в Pac-Man и пытались съесть 280 коробок с пиццей. Одновременно полторы тысячи человек рисовали пиксели в онлайне. В этом посте четыре разработчика рассказывают, как делали праздник.

День программиста у нас отмечает вся компания, а не только разработчики. Поэтому была нужна идея для онлайновой игры, в которой могут участвовать все желающие. Я вспомнил, что в апреле прошёл Reddit Place — социальный эксперимент по коллективному рисованию на холсте 1000x1000 пикселей, в котором участвовал миллион человек.
Я решил, что надо сделать свой Place, с таймлапсом и API.
На Reddit миллион человек рисовал на холсте размером один мегапиксель. Каждый мог закрасить не больше одного пикселя раз в 5–20 минут. Если сделать праздничный холст 256x256 пикселей (в 15 раз меньше) и учесть, что у нас не миллион сотрудников (а в 200 раз меньше), то задержку между пикселями тоже должна быть примерно в 10 раз меньше.
Поэтому для нашего поля 256x256 пикселей я выбрал задержку от 2:56 до 0:32. А после этого рассказал об идее коллегам, которые согласились помочь.
Я сразу поняла, что на фронте будет нужен холст, палитра и зум. Но дизайнеры (Владимир dzekh и Юлия krasilnikovayu) оказались хитрее и придумали ещё перемотку, статистику, лидерборд и скриншоты.
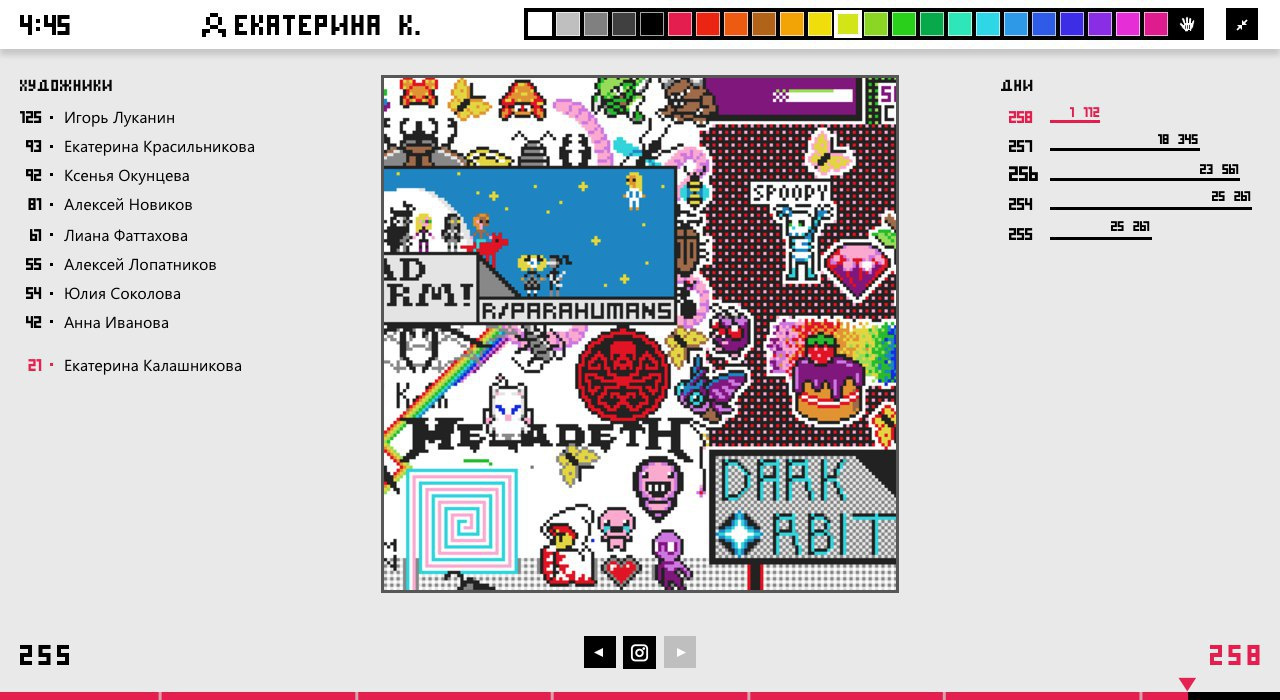
Кстати, сначала в палитре было меньше цветов, но потом ребята добавили коричневый, чтобы не ограничивать ничьи творческие порывы.
Тем временем я, как современный фронтендер, рефлекторно начала думать о том, чтобы настроить Webpack, Babel и Autoprefixer. А когда очнулась, узнала, что бэкенд-разработчик уже всё сделал. И оно даже работало. Криво-косо, но работало: точки на canvas ставились, зум зумился. Я отпилила от прекрасного дизайна все ненужное и красивенько сверстала.
Остались две проблемы: Edge и Safari.

В Safari и правда все тормозило со страшной силой. Сначала обнаружила, что canvas не вынесен в отдельный композитный слой. Поэтому браузер при каждом обновлении холста перерисовывал весь документ. Добавила канвасу transition: translateZ(0), и все стало тормозить быстрее. Потом отрефакторила остальной бакендерский код, избавилась ещё от десятка перерисовок. Интерфейс полетел на первой космической.
Об IE я сразу не заботилась, потому что знала, что игроки будут пользоваться нормальными браузерами. Беда пришла от старшего брата. Если просишь Edge нарисовать квадрат, он категорически отказывается. Говорит: «Но плавные переходы лучше!» — и размывает весь рисунок.

Такая же проблема была у ребят из Reddit. Сначала я решила её с помощью CSS-свойства image-rendering и флага CanvasRenderingContext2D.imageSmoothingEnabled. Но перед запуском оказалось, что Edge косячит при общении с сервером через вебсокеты. Поэтому я и его объявила ненормальным браузером.
Горжусь, что трижды пыталась принести в код React, Webpack, Babel, LESS и Autoprefixer, но смогла победить себя. В итоге всё написано на чистом ES6+ и CSS, но с модными гридами, вебсокетами и fetch-ем.
Я не хотел писать всё с нуля, поэтому поискал готовое. Оригинальный Place лежит на Github, но там слишком много кода. Я взял простой клон под NodeJS и прошёлся по нему напильником. Именно поэтому, когда за дело взялась Вероника, интерфейс уже как-то работал. Вообще, есть уйма клонов, выбирайте для себя любой.
В коде выбранного клона пришлось пофиксить уязвимости и добавить недостающее: таймер, расширенную палитру, перемотку в онлайне, сбор статистики, рисование через вебсокеты вместо REST-запросов, вход через Паспорт (наш внутренний аутентификатор).
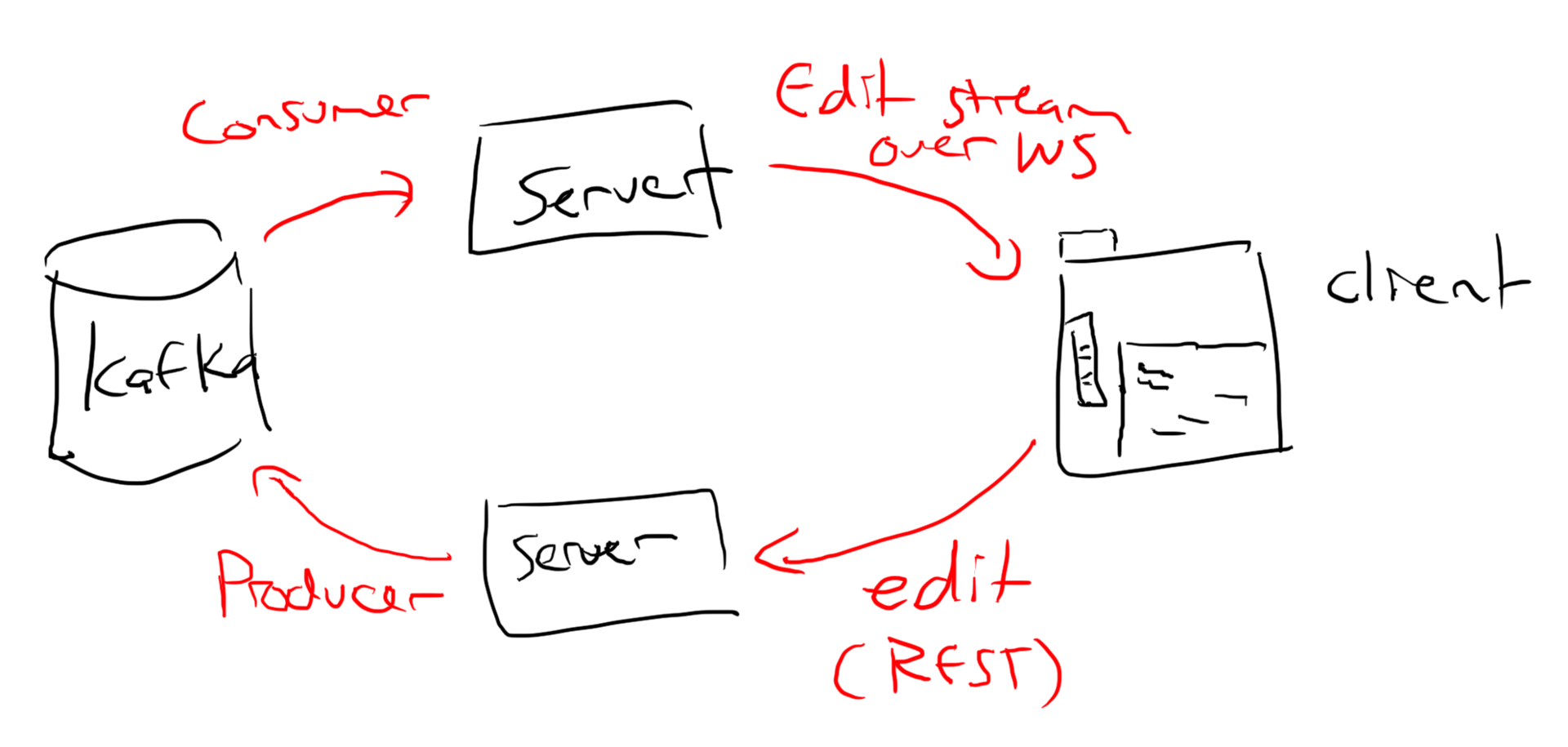
Архитектура была такая: пользователь ставил пиксель в браузере, браузер отправлял сообщение через вебсокет на сервер, сервер отправлял сообщение об изменении холста в очередь (Apache Kafka). Потом серверы забирали данные из очереди и отправляли всем клиентам. Выше оригинальная схема от автора клона, на которой клиенты ещё общаются с сервером с помощью REST-запросов.
Мы планировали сделать перемотку, поэтому я решил кэшировать снэпшоты холста с версиями. При старте сервер должен был взять последний снэпшот из кэша, а не строить его с нуля. Тот же снэпшот получал клиент при подключении к серверу, отчего загрузка холста была почти мгновенной. Можно было отправить клиенту снэпшот любой версии и таким образом организовать перемотку. Новый снэпшот сохранялся после изменения каждых ста пикселей.
Примерно через сутки после начала игры случился инцидент. Я исправил баг и перезапустил сервер. А пользователи увидели, что часть нарисованных точек пропала.

Дело было в том, что при подключении к серверу клиент запрашивал конкретную версию холста. Поэтому после старта сервер взял из кэша не последний снэпшот, а какую-то старую версию, которую запросил один из клиентов. Пользователи не увидели свежие пиксели и начали рисовать по-новой, а сервер продолжил складывать данные в очередь.
Когда я понял, в чём дело, я почистил кэш. Сервер заново загрузил данные из очереди и сгенерировал актуальную версию холста. Получился забавный эффект: новые рисунки пользователей наложились на предыдущие, так как вернулось всё потерянное и добавились новые изменения. Фикс был быстрый, поэтому ничего не испортилось:

В общем, не зря говорят, что инвалидация кэшей — это одна из двух сложнейших задач в компьютерных науках.
Забавно, что я, пока чинил кэш, случайно выключил аутентификацию. Тут же нашёлся коллега-кулхакер, который закрасил скриптом несколько тысяч пикселей за пару минут. Я выкатил фикс, но зелёная полоса осталась:

Ещё я хотел после окончания игры сделать хороший таймлапс и посчитать статистику. Для этого я решил завести базу данных и сохранять в ней для каждой нарисованной точки координаты, цвет, дату и время, а также идентификатор пользователя.
Сервер был под NodeJS, поэтому я выбрал LokiJS. Эту базу хвалили за простоту и скорость работы, потому что все данные хранятся в памяти и автоматически записываются на диск через заданные интервалы времени. Для моей задачи подходило.
Я настроил сохранение раз в 1 минуту. Протестировал локально, в том числе под нагрузкой — всё работало как часы. А на боевой площадке происходило что-то паранормальное. Данные сохранялись на диск не по расписанию, а по собственному желанию. Например, в течение нескольких часов не сохранялись ни разу. За три дня я так и не нашёл причины этого поведения. В итоге, много статистики потерялось при перезапусках сервера.
Однако я был готов к этому с самого начала, потому что таймлапс уж очень был нужен. Каждую минуту я сохранял холст в виде картинки в файл. Получилось несколько гигабайт картинок, зато видео с таймлапсом было записано и озвучено парой команд:
$ ffmpeg -pattern_type glob \
-i "*.png" \
-c:v libx264 \
-vf format=yuv420p \
timelapse.mp4
$ ffmpeg -i timelapse.mp4 \
-i sci-fi.mp3 \
256.mp4После начала игры все быстро поняли, что один в поле не воин. Началась самоорганизация в Стаффе, нашей внутренней соцсети:
Я тоже в этом поучаствовал:
Но даже с командой было неинтересно рисовать масштабную картинку. Я понял это после первых семи пикселей радуги. Не радовало даже, что коллеги сделали кучу полезных инструментов:


Я ждал от Дня программиста большего. И дождался — на второй день Игорь опубликовал в Стаффе такой фрагмент кода и стал раздавать желающим API-ключи:
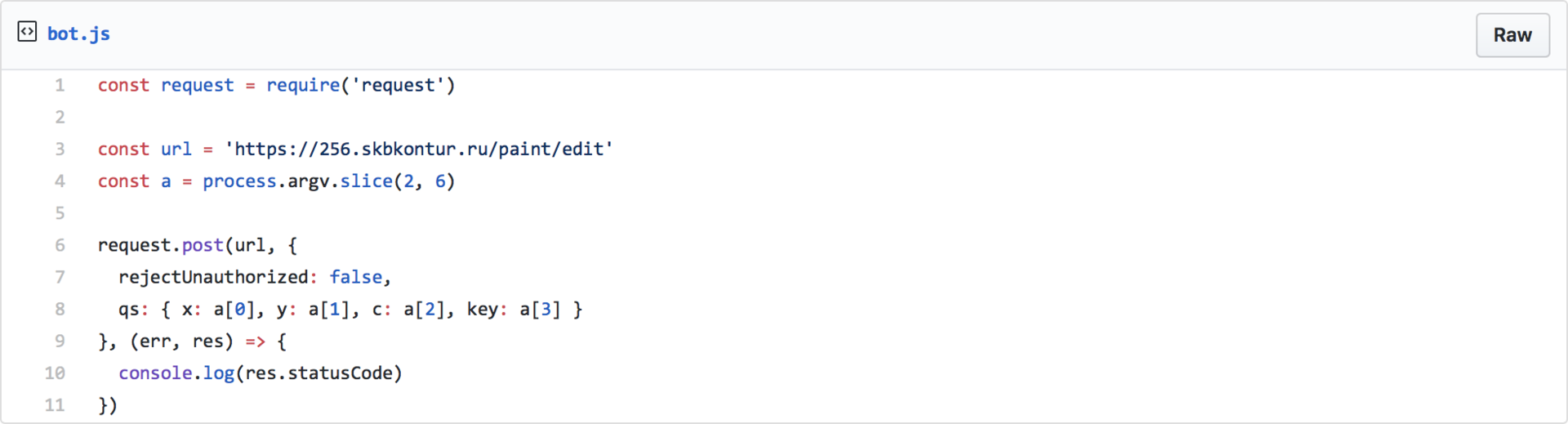
Это было уже что-то!
Для разминки я написал бота, который рисовал заданную картинку. Это было не очень весело. Потом придумал создавать картинку алгоритмически. Получился бот, который загнул идеально круглую радугу. Но это тоже было скучно.
Я понял, что нескучный бот должен не просто рисовать пиксели, а взаимодействовать с окружающим миром и чужим творчеством. Но нужно было избежать вандализма, потому что бот — это сила, а с силой должна идти ответственность.
Можно было нарисовать часы с текущим временем. Или движущуюся картинку, которая ползёт по холсту и затирает чужие рисунки… чтобы потом их восстановить. И тут я придумал сюжет, который объединил эти две идеи.
Часы стали таймером обратного отсчёта, движущаяся картинка — взлетающей ракетой. К тому же, ракету очень удобно рисовать — сначала на пиксель удлиняешь верхнюю часть, потом на пиксель укорачиваешь нижнюю. Это не только хорошо смотрится, но и экономит пиксели, ведь задержку при рисовании через API никто не отменял.
Это должен был быть самый медленный полёт ракеты в истории человечества. С текущей задержкой за пару часов я мог сдвинуть ракету всего на несколько пикселей. Нужно было либо уменьшать ракету, либо двигать её скачками, либо смириться с тем, что лететь она будет сутки. Поделился муками выбора с Игорем, а он со словами «Твори добро!» внезапно отсыпал без малого 50 ключей для API. С таким количеством ключей ракета могла достичь скорости один пиксель в секунду!

Осталось немного: выбрать дизайн ракеты и написать весь код. Я отбросил мультяшные ракеты и выбрал ракету-носитель «Восток». Сразу стало понятно, что полёт ракеты должен заканчиваться выводом на орбиту корабля Восток-1.
Почему «Восток»? Потому что прямо сейчас куча инженеров из Контура занимается секретным проектом с кодовым названием Vostok. Я хотел, чтобы парням было приятно.
Я настроил бота, запустил таймер обратного отсчёта, позвал зрителей через Стафф. Ракета взлетела. И тут я понял, как нелепо выглядит ракета в космосе с неотделёнными разгонными блоками и первой ступенью. Чудом нашёл 10 свободных минут, чтобы добавить отделение ступени и перезапустить бота. Так что это был не только самый медленный полет ракеты в истории человечества, но и первый полёт ракеты, в середине которого поменяли её конструкцию.
Было приятно наблюдать, как коллеги стирали копию ракеты, из-за бага оставшуюся на стартовом столе. Пририсовывают однопиксельного человечка в окошко ракеты. Переделывают слово «поехали» в «понаехали». Вообще, радовало, что все вели себя культурно, несмотря на отсутствие правил. Даже когда место на холсте закончилось:


Кстати, без NSFW-контента не обошлось. Кто-то из нарисованного моим первым нескучным ботом слова TRON упорно делал слово PRON.

Ваня потом рассказал, что 13 сентября на холсте одновременно рисовало 1630 человек и десяток ботов, то есть примерно треть всех работников компании. В среднем к серверам было подключено 440 клиентов, а в дневные часы — 840.
В итоге у нас получилась такая картинка:
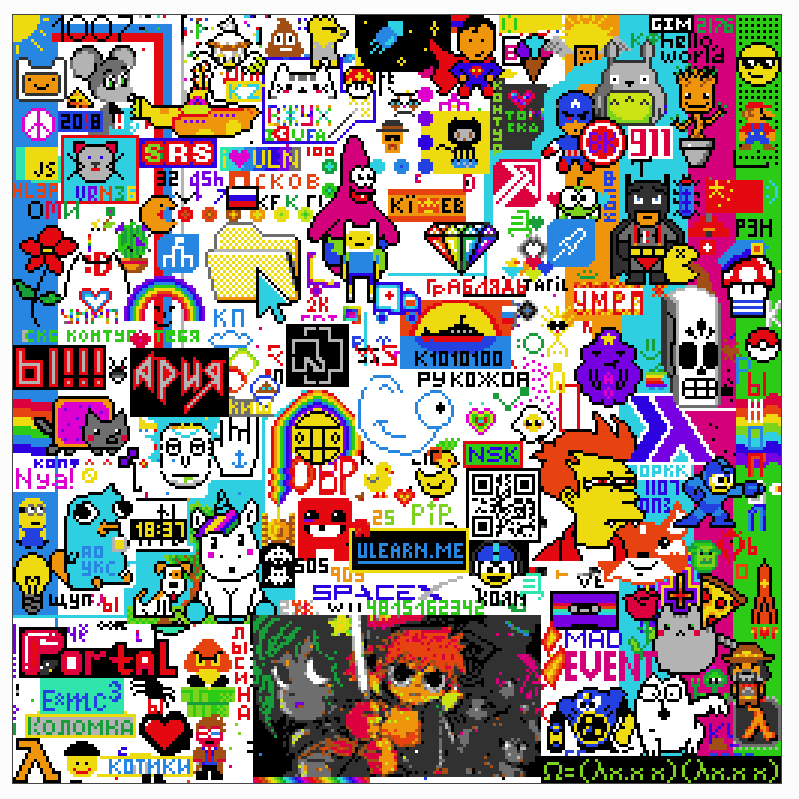
И такой таймлапс. Моя ракета взлетает на 27 секунде:
А вы программируете по праздникам и для праздников? Расскажите нам в комментариях.
P. S. Если интересно, о чём мы не рассказываем на Хабре, подписывайтесь на наш канал в Телеграме.
|
Метки: author green_hippo разработка игр программирование визуализация данных canvas блог компании скб контур день программиста reddit космос восток |
Наш рецепт отказоустойчивого VPN-сервера на базе tinc, OpenVPN, Linux |


ep1, ep2 и ep3). Кроме того, в сети присутствовал гипервизор с сервисами клиента (hpv1). На всех машинах установили Ubuntu Server 16.04.$ sudo apt-get update && sudo apt-get install tinсl2vpnnet. Создаем структуру каталогов:$ sudo mkdir -p /etc/tinc/l2vpnnet/hosts/etc/tinc/l2vpnnet создаем файл tinc.conf и наполняем его следующим содержимым:# Имя текущей машины
Name = ep1
# Тип сети, в нашем случае — L2
Mode = switch
# Интерфейс, который мы будем использовать
Interface = tap0
# По умолчанию используется протокол UDP
Port = 655
# Записываем имена всех остальных хостов, к которым мы будем подключаться
ConnectTo = ep2
ConnectTo = ep3
ConnectTo = hpv1/etc/tinc/l2vpnnet/ep1 и вносим в него параметры:# Публичный адрес и порт
Address = 100.101.102.103 655
# Используемые алгоритмы шифрования и аутентификации
Cipher = aes-128-cbc
Digest = sha1
# Для уменьшения задержек рекомендуем также выключать сжатие
Compression = 0$ cd /etc/tinc/l2vpnnet && sudo tincd -n l2vpnnet -K2048
Generating 2048 bits keys:
............................................+++ p
.................................+++ q
Done.
Please enter a file to save private RSA key to [/etc/tinc/l2vpnnet/rsa_key.priv]:
Please enter a file to save public RSA key to [/etc/tinc/l2vpnnet/hosts/ep1]: /etc/tinc/l2vpnnet/hosts/ep1|ep2|ep3|hpv1) необходимо разместить у всех участников сети в каталоге /etc/tinc/l2vpnnet/hosts./etc/tinc/nets.boot, чтобы tinc запускал VPN к нашей сети автоматически при загрузке:$ sudo cat nets.boot
#This file contains all names of the networks to be started
#on system startup.
l2vpnnet/etc/network/interfaces описание параметров устройства tap0:# Устройство запускается автоматически при старте системы
auto tap0
# Указываем режим конфигурации manual, так как IP мы назначим уже на bridge
iface tap0 inet manual
# Создание устройства перед запуском tinc
pre-up ip tuntap add dev $IFACE mode tap
# ... и его удаление после остановки
post-down ip tuntap del dev $IFACE mode tap
# Собственно, запуск tinc с настроенной нами сетью
tinc-net l2vpnnet10.10.10.0/24. Настроим bridge-интерфейс и назначим ему IP — для этого внесем в /etc/network/interfaces такую информацию:auto br0
iface br0 inet static
# Естественно, IP должен быть разным для хостов
address 10.10.10.1
netmask 255.255.255.0
# Указываем, что в бридже наш интерфейс tinc vpn
bridge_ports tap0
# Отключаем протокол spanning tree для bridge-интерфейса
bridge_stp off
# Максимальное время ожидания готовности моста
bridge_maxwait 5
# Отключаем задержку при форвардинге
bridge_fd 0$ sudo ifup tap0 && sudo ifup br0
$ ping -c3 10.10.10.2
PING 10.10.10.2 (10.10.10.2) 56(84) bytes of data.
64 bytes from 10.10.10.2: icmp_seq=1 ttl=64 time=3.99 ms
64 bytes from 10.10.10.2: icmp_seq=2 ttl=64 time=1.19 ms
64 bytes from 10.10.10.2: icmp_seq=3 ttl=64 time=1.07 ms
--- 10.10.10.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 1.075/2.087/3.994/1.349 ms$ sudo apt-get update && sudo apt-get install openvpn easy-rsavpn.compa.ny. IN A 100.101.102.103
vpn.compa.ny. IN A 50.51.52.53
vpn.compa.ny. IN A 1.1.1.1Node 1 10.10.10.100-10.10.10.129
Node 2 10.10.10.130-10.10.10.159
Node 2 10.10.10.160-10.10.10.189$ cd /etc/openvpn
$ sudo -s
# make-cadir ca
# mkdir keys
# chmod 700 keys
# exitvars, установив следующие значения:# Каталог с easy-rsa
export EASY_RSA="`pwd`"
# Путь к openssl, pkcs11-tool, grep
export OPENSSL="openssl"
export PKCS11TOOL="pkcs11-tool"
export GREP="grep"
# Конфиг openssl
export KEY_CONFIG=`$EASY_RSA/whichopensslcnf $EASY_RSA`
# Каталог с ключами
export KEY_DIR="$EASY_RSA/keys"
export PKCS11_MODULE_PATH="dummy"
export PKCS11_PIN="dummy"
# Размер ключа
export KEY_SIZE=2048
# CA-ключ будет жить 10 лет
export CA_EXPIRE=3650
# Описываем нашу организацию: страна, регион,
# город, наименование, e-mail и подразделение
export KEY_COUNTRY="RU"
export KEY_PROVINCE="Magadan region"
export KEY_CITY="Susuman"
export KEY_ORG="Company"
export KEY_EMAIL="info@compa.ny"
export KEY_OU="IT"
export KEY_NAME="UnbreakableVPN"# . vars
# ./clean-all
# ./build-ca
Generating a 2048 bit RSA private key
..........................+++
.+++
writing new private key to 'ca.key'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [RU]:
State or Province Name (full name) [Magadan region]:
Locality Name (eg, city) [Susuman]:
Organization Name (eg, company) [Company]:
Organizational Unit Name (eg, section) [IT]:
Common Name (eg, your name or your server's hostname) [Company CA]:
Name [UnbreakableVPN]:
Email Address [info@compa.ny]:
# ./build-dh
Generating DH parameters, 2048 bit long safe prime, generator 2
This is going to take a long time
…
# ./build-key-server server
# openvpn --genkey --secret keys/ta.key# ./build-key testuser
# ./revoke-full testuser# cd keys
# mkdir /etc/openvpn/.keys
# cp ca.crt server.crt server.key dh2048.pem ta.key crl.pem /etc/openvpn/.keys
# exit/etc/openvpn/server.conf:# Устанавливаем подробность ведения журнала
verb 4
# Порт и протокол подключения
port 1194
proto tcp-server
# Режим и способ аутентификации
mode server
tls-server
# Определяем MTU
tun-mtu 1500
# Определяем имя и тип интерфейса, который будет обслуживать клиентов
dev ovpn-clients
dev-type tap
# Указываем, что TA-ключ используется в режиме сервера
key-direction 0
# Описываем ключевую информацию
cert /etc/openvpn/.keys/server.crt
key /etc/openvpn/.keys/server.key
dh /etc/openvpn/.keys/dh2048.pem
tls-auth /etc/openvpn/.keys/ta.key
crl-verify /etc/openvpn/.keys/crl.pem
# Определяем протоколы аутентификации и шифрования
auth sha1
cipher AES-128-CBC
# Опция, указывающая, что устройство будет создаваться единожды
# на все время работы сервера
persist-tun
# Указываем тип топологии и пул
topology subnet
server-bridge 10.10.10.1 255.255.255.0 10.10.10.100 10.10.10.129
# Указываем маршрут по умолчанию через туннель и определяем
# внутренние DNS
push "redirect-gateway autolocal"
push "dhcp-option DNS 10.10.10.200"
push "dhcp-option DNS 10.20.20.200"
# Проверяем доступность подключенного клиента раз в 10 секунд,
# таймаут подключения — 2 минуты
keepalive 10 120
# То самое ограничение в 30 клиентов
max-clients 30
# Локальные привилегии демона openvpn
user nobody
group nogroup
# Позволяет удаленному клиенту подключаться с любого IP и порта
float
# Путь к файлу журнала
log /var/log/openvpn-server.log/etc/network/interfaces:auto ovpn-clients
iface ovpn-clients inet manual
pre-up ip tuntap add dev $IFACE mode tap
post-up systemctl start openvpn@server.service
pre-down systemctl stop openvpn@server.service
post-down ip tuntap del dev $IFACE mode tapbr0: ...
netmask 255.255.255.0
bridge_ports tap0
bridge_ports ovpn_clients
bridge_stp off
...$ sudo ifup ovpn-clients && sudo ifdown br0 && sudo ifup br0$ sudo -s
# cd /etc/openvpn/ca
# ./build-key PetrovIvan
# exit$ vim PetrovInan.ovpn
# Указываем тип подключения, тип устройства и протокол
client
dev tap
proto tcp
# Определяем MTU такой же, как и на сервере
tun-mtu 1500
# Указываем узел и порт подключения
remote vpn.compa.ny 1194
# Отказываемся от постоянного прослушивания порта
nobind
# Опция, которая позволяет не перечитывать ключи для каждого соединения
persist-key
persist-tun
# Корректируем MSS
mssfix
# Указываем, что будем использовать TA как TLS-клиент
key-direction 1
ns-cert-type server
remote-cert-tls server
auth sha1
cipher AES-128-CBC
verb 4
keepalive 10 40
### Сюда вставляем содержимое ca.crt
### Сюда вставляем содержимое ta.key
### Сюда вставляем содержимое PetrovIvan.crt
### Сюда вставляем содержимое PetrovIvan.key
$ ./revoke-all PetrovIvancrl.pem и выполняем:$ sudo service openvpn reloadserver.conf отсутствует опция persist-key. Это позволяет обновить ключевую информацию во время выполнения reload — иначе бы для этого потребовался рестарт демона.reload для OpenVPN мы используем Chef. Очевидно, для этой цели подойдут любые другие средства автоматического развертывания конфигураций (Ansible, Puppet…) или даже простой shell-скрипт.|
Метки: author gserge системное администрирование сетевые технологии настройка linux блог компании флант vpn openvpn tinc linux |
Разбираемся с новым sync.Map в Go 1.9 |
Одним из нововведений в Go 1.9 было добавление в стандартную библиотеку нового типа sync.Map, и если вы ещё не разобрались что это и для чего он нужен, то эта статья для вас.
Для тех, кому интересен только вывод, TL;DR:
если у вас высоконагруженная (и 100нс решают) система с большим количеством ядер процессора (32+), вы можете захотеть использовать sync.Map вместо стандартного map+sync.RWMutex. В остальных случаях, sync.Map особо не нужен.

Если же интересны подробности, то давайте начнем с основ.
Если вы работаете с данными в формате "ключ"-"значение", то всё что вам нужно это встроенный тип map (карта). Хорошее введение, как пользоваться map есть в Effective Go и блог-посте "Go Maps in Action".
map — это generic структура данных, в которой ключом может быть любой тип, кроме слайсов и функций, а значением — вообще любой тип. По сути это хорошо оптимизированная хеш-таблица. Если вам интересно внутреннее устройство map — на прошлом GopherCon был очень хороший доклад на эту тему.
Вспомним как пользоваться map:
// инициализация
m := make(map[string]int)
// запись
m["habr"] = 42
// чтение
val := m["habr"]
// чтение с comma,ok
val, ok := m["habr"] // ok равен true, если ключ найден
// итерация
for k, v := range m { ... }
// удаление
delete(m, "habr")Во время итерации значения в map могут изменяться.
Go, как известно, является языком созданным для написания concurrent программ — программ, который эффективно работают на мультипроцессорных системах. Но тип map не безопасен для параллельного доступа. Тоесть для чтения, конечно, безопасен — 1000 горутин могут читать из map без опасений, но вот параллельно в неё ещё и писать — уже нет. До Go 1.8 конкурентный доступ (чтение и запись из разных горутин) могли привести к неопределенности, а после Go 1.8 эта ситуация стала явно выбрасывать панику с сообщением "concurrent map writes".
Решение делать или нет map потокобезопасным было непростым, но было принято не делать — эта безопасность не даётся бесплатно. Там где она не нужна, дополнительные средства синхронизации вроде мьютексов будут излишне замедлять программу, а там где она нужна — не составляет труда реализовать эту безопасность с помощью sync.Mutex.
В текущей реализации map очень быстр:
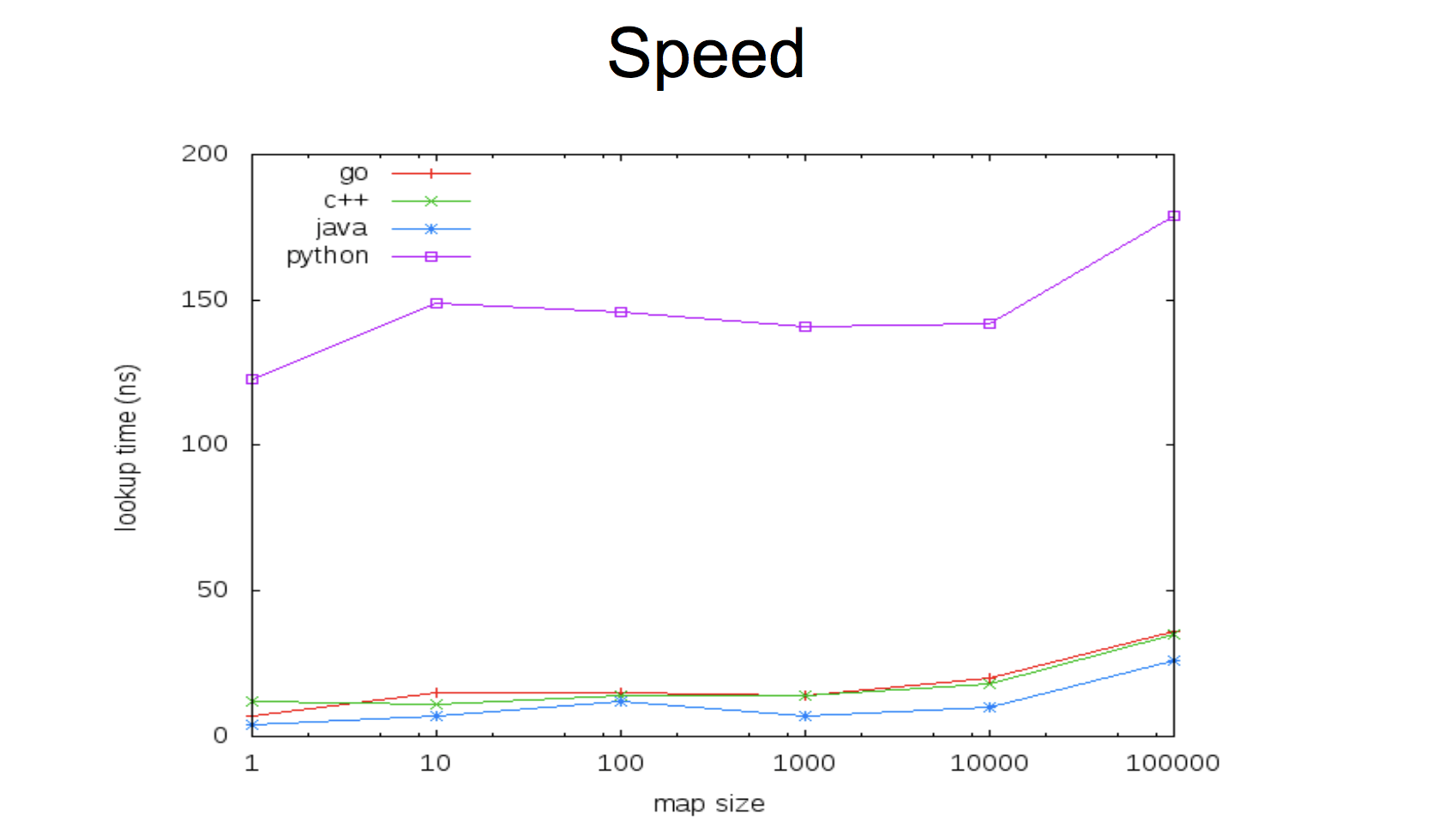
Такой компромисс между скоростью и потокобезопасностью, при этом оставляя возможность иметь и первый и второй вариант. Либо у вас сверхбыстрый map безо всяких мьютексов, либо чуть медленнее, но безопасен для параллельного доступа. Важно тут понимать, что в Go использование переменной параллельно несколькими горутинами — это не далеко единственный способ писать concurrent-программы, поэтому кейс этот не такой частый, как может показаться вначале.
Давайте, посмотрим, как это делается.
Реализация потокобезопасной map очень проста — создаём новую структуру данных и встраиваем в неё мьютекс. Структуру можно назвать как угодно — хоть MyMap, но есть смысл дать ей осмысленное имя — скорее всего вы решаете какую-то конкретную задачу.
type Counters struct {
sync.Mutex
m map[string]int
}Мьютекс никак инициализировать не нужно, его "нулевое значение" это разлоченный мьютекс, готовый к использованию, а карту таки нужно, поэтому будет удобно (но не обязательно) создать функцию-конструктор:
func NewCounters() *Counters {
return &Counters{
m: make(map[string]int),
}
}Теперь у переменной типа Counters будет метод Lock() и Unlock(), но если мы хотим упростить себе жизнь и использовать этот тип из других пакетов, то будет также удобно сделать функции обёртки вроде Load() и Store(). В таком случае мьютекс можно не встраивать, а просто сделать "приватным" полем:
type Counters struct {
mx sync.Mutex
m map[string]int
}
func (c *Counters) Load(key string) (int, bool) {
c.mx.Lock()
defer c.mx.Unlock()
val, ok := c.m[key]
return val, ok
}
func (c *Counters) Store(key string, value int) {
c.mx.Lock()
defer c.mx.Unlock()
c.m[key] = value
}Тут нужно обратить внимание на два момента:
defer имеет небольшой оверхед (порядка 50-100 наносекунд), поэтому если у вас код для высоконагруженной системы и 100 наносекунд имеют значение, то вам может быть выгодней не использовать deferGet() и Store() должны быть определены для указателя на Counters, а не на Counters (тоесть не func (c Counters) Load(key string) int { ... }, потому что в таком случае значение ресивера (c) копируется, вместе с чем скопируется и мьютекс в нашей структуре, что лишает всю затею смысла и приводит к проблемам.Вы также можете, если нужно, определить методы Delete() и Range(), чтобы защищать мьютексом map во время удаления и итерации по ней.
Кстати, обратите внимание, я намеренно пишу "если нужно", потому что вы всегда решаете конкретную задачу и в каждом конкретном случае у вас могут разные профили использования. Если вам не нужен Range() — не тратьте время на его реализацию. Когда нужно будет — всегда сможете добавить. Keep it simple.
Теперь мы можем легко использовать нашу безопасную структуру данных:
counters := NewCounters()
counters.Store("habr", 42)
v, ok := counters.Load("habr")В зависимости, опять же, от конкретной задачи, можно делать любые удобные вам методы. Например, для счётчиков удобно делать увеличение значения. С обычной map мы бы делали что-то вроде:
counters["habr"]++а для нашей структуры можем сделать отдельный метод:
func (c *Counters) Inc(key string) {
c.mx.Lock()
defer c.mx.Unlock()
c.m[key]++
}
...
counters.Inc("habr")Но часто у работы с данными в формате "ключ"-"значение", паттерн доступа неравномерный — либо частая запись, и редкое чтение, либо наоборот. Типичный случай — обновление происходит редко, а итерация (range) по всем значениям — часто. Чтение, как мы помним, из map — безопасно, но сейчас мы будем лочиться на каждой операции чтения, теряя без особой выгоды время на ожидание разблокировки.
В стандартной библиотеке для решения этой ситуации есть тип sync.RWMutex. Помимо Lock()/Unlock(), у RWMutex есть отдельные аналогичные методы только для чтения — RLock()/RUnlock(). Если метод нуждается только в чтении — он использует RLock(), который не заблокирует другие операции чтения, но заблокирует операцию записи и наоборот. Давай обновим наш код:
type Counters struct {
mx sync.RWMutex
m map[string]int
}
...
func (c *Counters) Load(key string) (int, bool) {
c.mx.RLock()
defer c.mx.RUnlock()
val, ok := c.m[key]
return val, ok
}Решения map+sync.RWMutex являются почти стандартом для map, которые должны использоваться из разных горутин. Они очень быстрые.
До тех пор, пока у вас не появляется 64 ядра и большое количество одновременных чтений.
Если посмотреть на код sync.RWMutex, то можно увидеть, что при блокировке на чтение, каждая горутина должна обновить поле readerCount — простой счётчик. Это делается атомарно с помощью функции из пакета sync/atomic atomic.AddInt32(). Эти функции оптимизированы под архитектуру конкретного процессора и реализованы на ассемблере.
Когда каждое ядро процессора обновляет счётчик, оно сбрасывает кеш для этого адреса в памяти для всех остальных ядер и объявляет, что владеет актуальным значением для этого адреса. Следующее ядро, прежде чем обновить счётчик, должно сначала вычитать это значение из кеша другого ядра.
На современном железе передача между L2 кешем занимает что-то около 40 наносекунд. Это немного, но когда много ядер одновременно пытаются обновить счётчик, каждое из них становится в очередь и ждёт эту инвалидацию и вычитывание из кеша. Операция, которая должна укладываться в константное время внезапно становится O(N) по количеству ядер. Эта проблема называется cache contention.
В прошлом году в issue-трекере Go была создана issue #17973 на эту проблему RWMutex. Бенчмарк ниже показывает почти 8-кратное увеличение времени на RLock()/RUnlock() на 64-ядерной машине по мере увеличения количества горутин активно "читающих" (использующих RLock/RUnlock):

А это бенчмарк на одном и том же количестве горутин (256) по мере увеличения количества ядер:
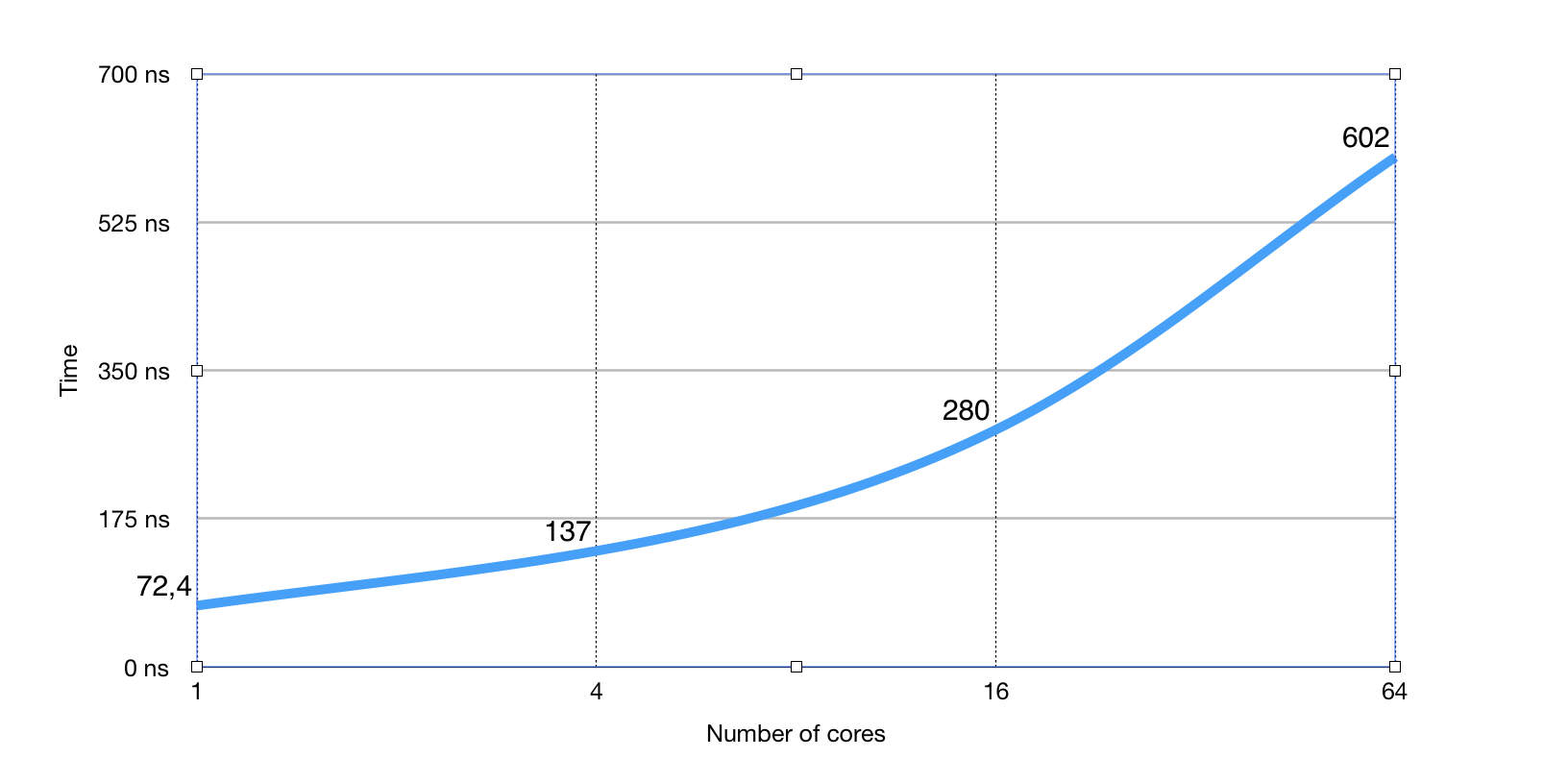
Как видим, очевидная линейная зависимость от количества задействованных ядер процессора.
В стандартной библиотеке map-ы используются довольно много где, в том числе в таких пакетах как encoding/json, reflect или expvars и описанная проблема может приводить к не очень очевидным замедлениям в более высокоуровневом коде, который и не использует напрямую map+RWMutex, а, например, использует reflect.
Собственно, для решения этой проблемы — cache contention в стандартной библиотеке и был добавлен sync.Map.
Итак, ещё раз сделаю акцент — sync.Map решает совершенно конкретную проблему cache contention в стандартной библиотеке для таких случаев, когда ключи в map стабильны (не обновляются часто) и происходит намного больше чтений, чем записей.
Если вы совершенно чётко не идентифицировали в своей программе узкое место из-за cache contention в map+RWMutex, то, вероятнее всего, никакой выгоды от sync.Map вы не получите, и возможно даже слегка потеряете в скорости.
Ну а если все таки это ваш случай, то давайте посмотрим, как использовать API sync.Map. И использовать его на удивление просто — практически 1-в-1 наш код раньше:
// counters := NewCounters() <--
var counters sync.MapЗапись:
counters.Store("habr", 42)Чтение:
v, ok := counters.Load("habr")Удаление:
counters.Delete("habr")При чтении из sync.Map вам, вероятно также потребуется приведение к нужному типу:
v, ok := counters.Load("habr")
if ok {
val = v.(int)
}Кроме того, есть ещё метод LoadAndStore(), который возвращает существующее значение, и если его нет, то сохраняет новое, и Range(), которое принимает аргументом функцию для каждого шага итерации:
v2, ok := counters.LoadOrStore("habr2", 13) counters.Range(func(k, v interface{}) bool {
fmt.Println("key:", k, ", val:", v)
return true // if false, Range stops
})API обусловлен исключительно паттернами использования в стандартной библиотеке. Сейчас sync.Map используется в пакетах encoding/{gob/xml/json}, mime, archive/zip, reflect, expvars, net/rpc.
По производительности sync.Map гарантирует константное время доступа к map вне зависимости от количества одновременных чтений и количества ядер. До 4 ядер, sync.Map при большом количестве параллельных чтений, может быть существенно медленнее, но после начинает выигрывать у map+RWMutex:
Резюмируя — sync.Map это не универсальная реализация неблокирующей map-структуры на все случаи жизни. Это реализация для конкретного паттерна использования для, преимущественно, стандартной библиотеки. Если ваш паттерн с этим совпадает и вы совершенно чётко знаете, что узкое место в вашей программе это cache contention на map+sync.RWMutex — смело используйте sync.Map. В противном случае, sync.Map вам вряд ли поможет.
Если же вам просто лень писать map+RWMutex обертку и высокая производительность совершенно не критична, но нужна потокобезопасная map, то sync.Map также может быть неплохим вариантом. Но не ожидайте от sync.Map слишком многого для всех случаев.
Так же для вашего случая могут больше подходить други реализации hash-таблиц, например на lock-free алгоритмах. Подобные пакеты были давно, и единственная причина, почему sync.Map находится в стандартной библиотеке — этого его активное использование другими пакетами из стандратной библиотеки.
|
Метки: author divan0 go mutex rwmutex map sync cache contention |
Eggs Datacenter: как Emercoin позволил реализовать идею распределённого дата-центра на блокчейне |

Блокчейн — это и база хранения информации, и гарант её неизменности. Одним из вариантов применения блокчейна стала запись и хранение в нем важной информации в виде параметров «имя-значение» (NVS). Реализованное в блокчейне Emercoin, это решение позволяет локально сохранять данные публичных SSH-ключей, SSL-сертификатов и DNS-записей, не доверяя конкретному центру. Блокчейн Emercoin позволяет базирующимся на нём проектам быть и децентрализованными, и защищеннёми одновременно. Такова сила криптографии.


|
Метки: author EmercoinBlog хранилища данных хранение данных хостинг it- инфраструктура блог компании emercoin emercoin eggs datacenter egs ico |
О классификации методов преобразования Фурье на примерах их программной реализации средствами Python |
#!/usr/bin/python
# -*- coding: utf-8 -*
from scipy.integrate import quad # модуль для интегрирования
import matplotlib.pyplot as plt # модуль для графиков
import numpy as np # модуль для операций со списками и массивами
T=np.pi; w=2*np.pi/T# период и круговая частота
def func(t):# анализируемая функция
if t=pi f(t)=-cos(t)")
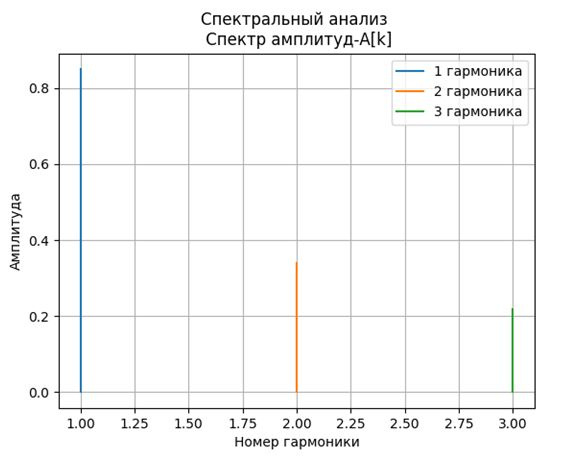
plt.plot(q, F1, label='1 гармоника')
plt.plot(q, F2 , label='2 гармоника')
plt.plot(q, F3, label='3 гармоника')
plt.xlabel("Время t")
plt.ylabel("Амплитуда А")
plt.legend(loc='best')
plt.grid(True)
F=np.array(a[0]/2)+np.array([0*t for t in q-1])# подготовка массива для анализа с a[0]/2
for k in np.arange(1,c,1):
F=F+np.array([a[k]*np.cos(w*k*t)+b[k]*np.sin(w*k*t) for t in q])# вычисление членов ряда Фурье
plt.figure()
P=[func(t) for t in q]
plt.title("Классический гармонический синтез")
plt.plot(q, P, label='f(t)')
plt.plot(q, F, label='F(t)')
plt.xlabel("Время t")
plt.ylabel("f(t),F(t)")
plt.legend(loc='best')
plt.grid(True)
plt.show()
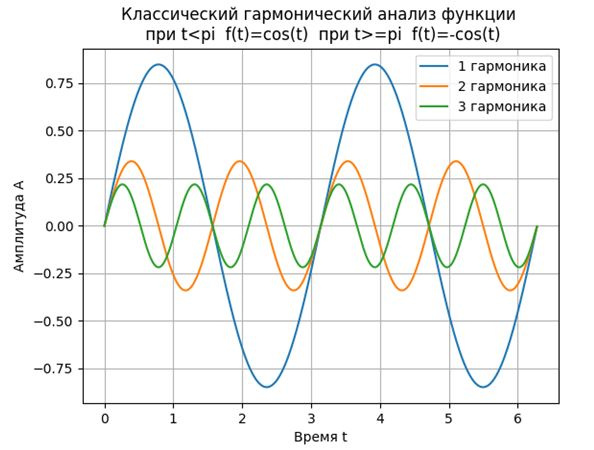
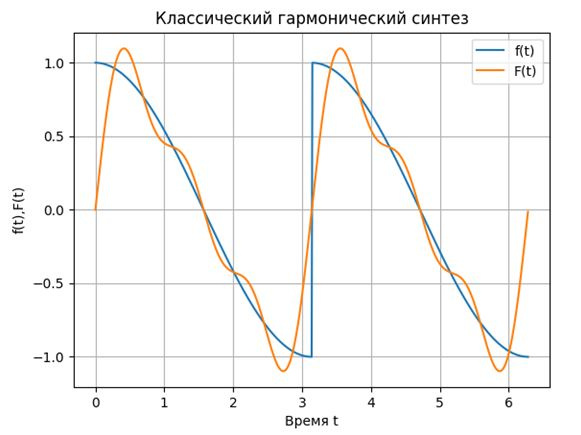
#!/usr/bin/python
# -*- coding: utf-8 -*
from scipy.integrate import quad # модуль для интегрирования
import matplotlib.pyplot as plt # модуль для графиков
import numpy as np # модуль для операций со списками и массивами
T=np.pi; w=2*np.pi/T# период и круговая частота
def func(t):# анализируемая функция
if ta[k]))
else:
g.append(-np.pi/2)# фаза когда тангенс равен бесконечности
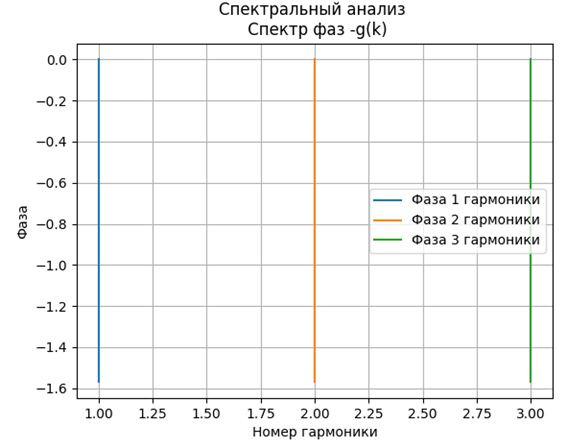
plt.figure()
plt.title("Спектральный анализ \n Спектр фаз -g(k)")
plt.plot([m[1],m[1]],[0, g[1]],label='Фаза 1 гармоники')
plt.plot([m[2],m[2]],[0, g[2]],label='Фаза 2 гармоники')
plt.plot([m[3],m[3]],[0, g[3]],label='Фаза 3 гармоники')
plt.xlabel("Номер гармоники")
plt.ylabel("Фаза")
plt.legend(loc='best')
plt.grid(True)
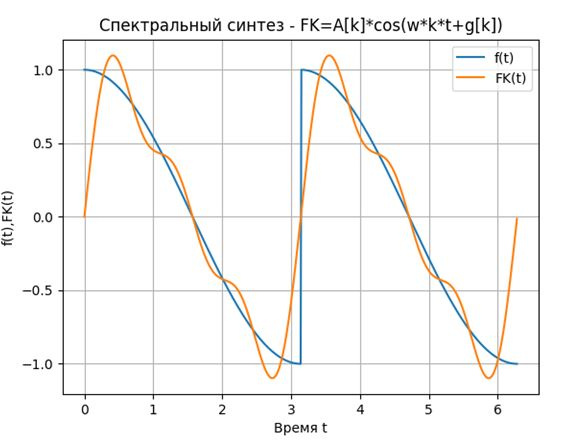
plt.figure()
plt.title("Спектральный синтез - FK=A[k]*cos(w*k*t+g[k])")
FK=-np.array(a[0]/2)+np.array([0*t for t in q-1])#подготовка массива длячисленного синтеза
for k in m:
FK=FK+np.array([A[k]*np.cos(w*k*t+g[k]) for t in q])# численный спектральный синтез
P=[func(t) for t in q]
plt.plot(q, P, label='f(t)')
plt.plot(q, FK, label='FK(t)')
plt.xlabel("Время t")
plt.ylabel("f(t),FK(t)")
plt.legend(loc='best')
plt.grid(True)
plt.show()
#!/usr/bin/python
# -*- coding: utf-8 -*
import matplotlib.pyplot as plt
import numpy as np
import numpy.fft
T=np.pi;z=T/16; m=[k*z for k in np.arange(0,16,1)];arg=[];q=[]# 16 отсчётов на период в пи
def f(t):# анализируемая функция
if t2)
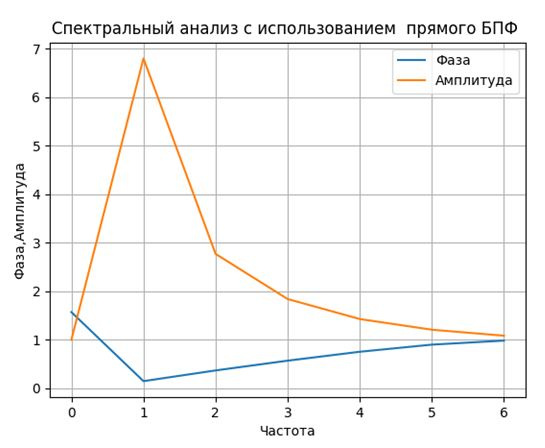
plt.figure()
plt.title("Спектральный анализ с использованием прямого БПФ ")
plt.plot(np.arange(0,7,1),arg,label='Фаза')
plt.plot(np.arange(0,7,1),A,label='Амплитуда')
plt.xlabel("Частота")
plt.ylabel("Фаза,Амплитуда")
plt.legend(loc='best')
plt.grid(True)
for i in np.arange(0,9,1):
if i<=7:
q.append(F[i])
else:
q.append(0)
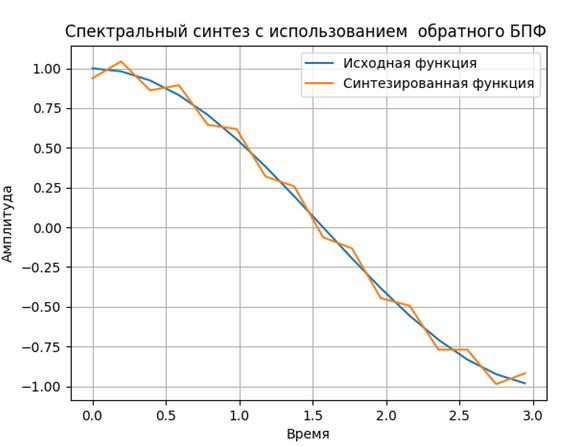
h=np.fft.irfft(q, n=None, axis=-1)# обратное быстрое преобразование Фурье во временную область
plt.figure()
plt.title("Спектральный синтез с использованием обратного БПФ ")
plt.plot(m, v,label='Исходная функция')
plt.plot(m, h,label='Синтезированная функция')
plt.xlabel("Время")
plt.ylabel("Амплитуда")
plt.legend(loc='best')
plt.grid(True)
plt.show()
#!/usr/bin/python
# -*- coding: utf-8 -*
import matplotlib.pyplot as plt
import numpy as np
from numpy.fft import rfft, irfft
from numpy.random import uniform
k=np.arange(0,128,1)
T=np.pi;z=T/128; m=[t*z for t in k]#задание для дискретизации функции на 128 отсчётов
def f(t):#анализируемая функция
if t=0:
q=1
else:
q=0
return q
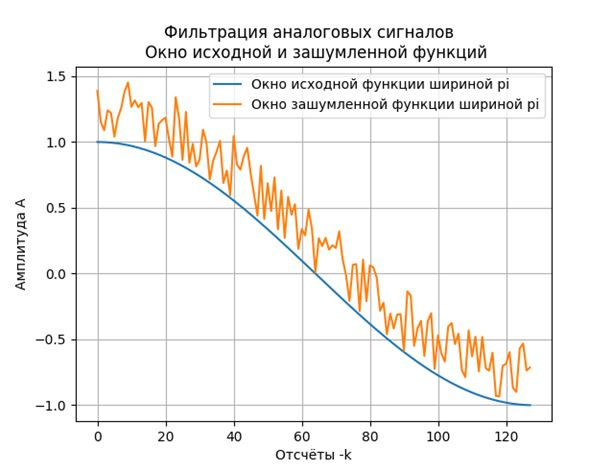
v=[f(t) for t in m]#дискретизация исходной функции
vs= [f(t)+np.random.uniform(0,0.5) for t in m]# добавление шума
plt.figure()
plt.title("Фильтрация аналоговых сигналов \n Окно исходной и зашумленной функций")
plt.plot(k,v, label='Окно исходной функции шириной pi')
plt.plot(k,vs,label='Окно зашумленной функции шириной pi')
plt.xlabel("Отсчёты -k")
plt.ylabel("Амплитуда А")
plt.legend(loc='best')
plt.grid(True)
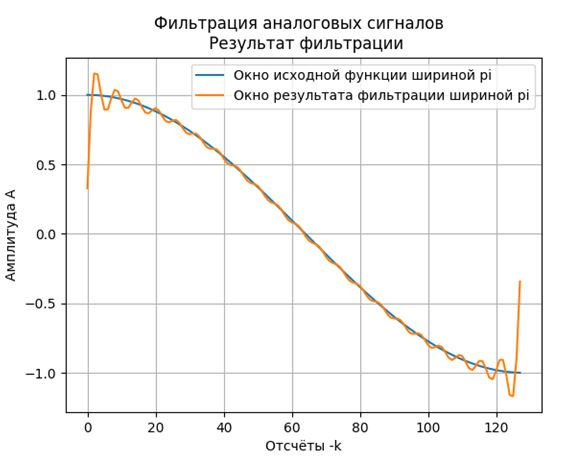
al=2# степень фильтрации высших гармоник
fs=np. fft.rfft(v)# переход из временной области в частотную с помощью БПФ
g=[fs[j]*FH(abs(fs[j])-2) for j in np.arange(0,65,1)]# фильтрация высших гармоник
h=np.fft.irfft(g) # возврат во временную область
plt.figure()
plt.title("Фильтрация аналоговых сигналов \n Результат фильтрации")
plt.plot(k,v,label='Окно исходной функции шириной pi')
plt.plot(k,h, label='Окно результата фильтрации шириной pi')
plt.xlabel("Отсчёты -k")
plt.ylabel("Амплитуда А")
plt.legend(loc='best')
plt.grid(True)
plt.show()
#!/usr/bin/env python
#coding=utf8
import numpy as np
from numpy.fft import fft, ifft # функции быстрого прямого и обратного преобразования Фурье
import pylab# модуль построения поверхности
from mpl_toolkits.mplot3d import Axes3D# модуль построения поверхности
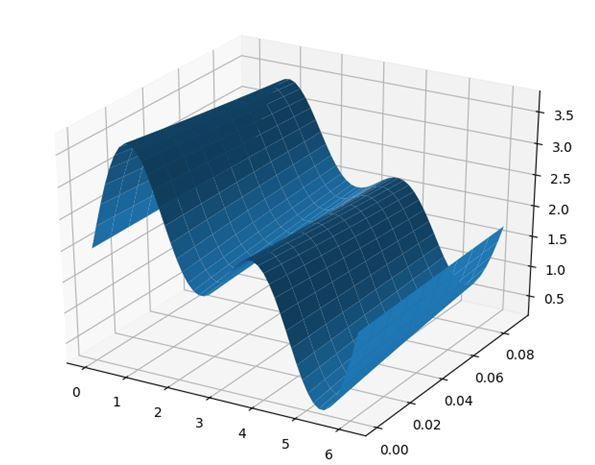
n=50# стержень длиной 2 пи разбивается на 50 точек
times=10# количества итераций во времени
h=0.01# шаг по времени
x=[r*2*np.pi/n for r in np.arange(0,n)]# дискретизация х
w= np.fft.fftfreq(n,0.02)# сдвиг нулевой частотной составляющей к центру спектра
k2=[ r**2 for r in w]# коэффициенты разложения
u0 =[2 +np.sin(i) + np.sin(2*i) for i in x]# дискретизация начального распределения температуры вдоль стержня
u = np.zeros([times,n])# матрица нулей размерностью 10*50
u[0,:] = u0 # нудевые начальные условия
uf =np.fft. fft(u0) # коэффициенты Фурье начальной функции
for i in np.arange(1,times,1):
uf=uf*[(1-h*k) for k in k2] #следующий временной шаг в пространстве Фурье
u[i,:]=np.fft.ifft(uf).real #до конца физического пространства
X = np.zeros([times,n])# подготовка данных координаты х для поверхности
for i in np.arange(0,times,1):
X[i:]=x
T = np.zeros([times,n])# подготовка данных координаты t для поверхности
for i in np.arange(0,times,1):
T[i:]=[h*i for r in np.arange(0,n)]
fig = pylab.figure()
axes = Axes3D(fig)
axes.plot_surface(X, T, u)
pylab.show()
|
Метки: author Scorobey разработка под windows математика python решение дифференциальных уравнений преобразование фурье |
«Открытое Воскресенье» на партнерском семинаре «1С» |

|
Метки: author PeterG блог компании 1с с предприятие 8 с программирование |
Своя система сборки на Linux |

target syncdb: virtualenv createmysqluser
source "$projectpath/venv/bin/activate"
python3 "$projectpath/manage.py" makemigrations
python3 "$projectpath/manage.py" migrate
deactivatepackage gunicorn: python
all:
name: python3-gunicorncheck syncdb()
# any code
return 1 # or return 0
endcheckaction
# any code with $1
endactioncheck
# any code with $1
return 1 # or return 0
endcheck|
Метки: author Ryder95 системы сборки разработка под linux bash linux система сборки велосипед |
[Из песочницы] Метод гарантирования доверия в блокчейнах |


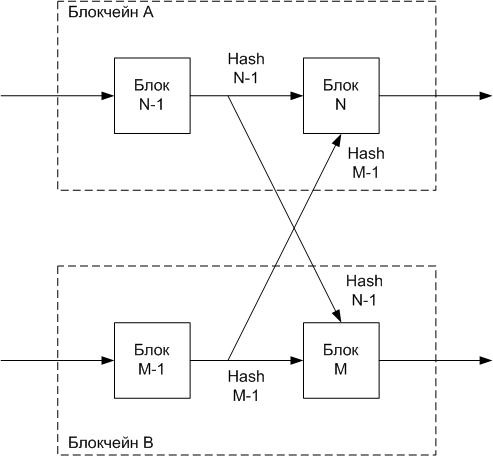

|
|
Ускоряем разработку с помощью интерактивных блоксхем |
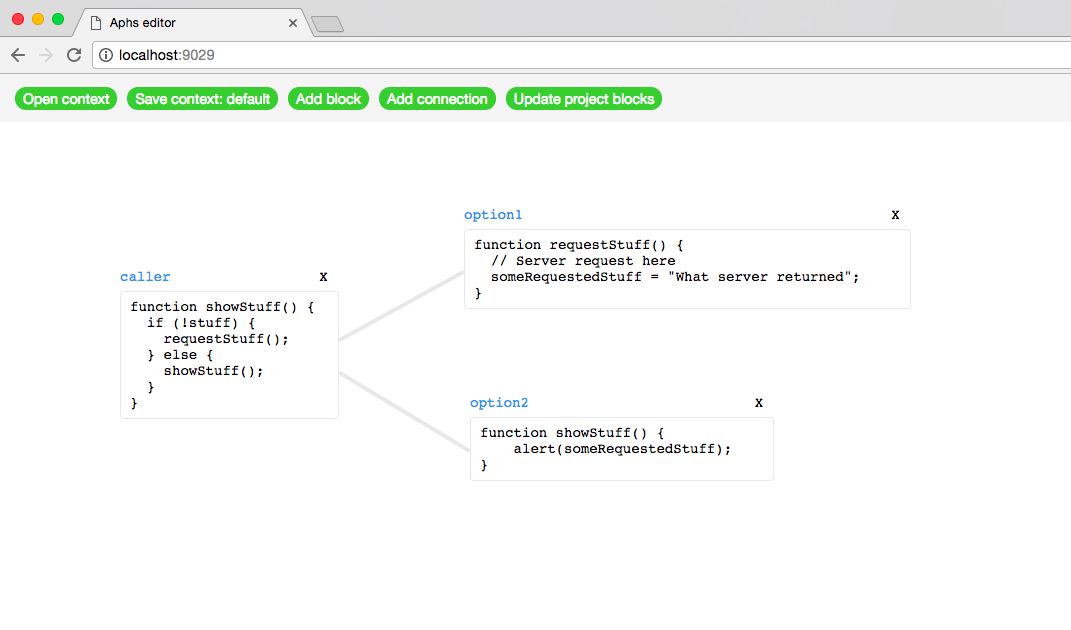
|
|
Конкурс статей о программировании, дизайне и управлении с общим призовым фондом в 500 тысяч рублей |

|
Метки: author blognetology контент-маркетинг блог компании нетология нетология конкурс конкурс статей |
[recovery mode] Финальный релиз 3CX Call Flow Designer и курсы 3CX в Беларуси |
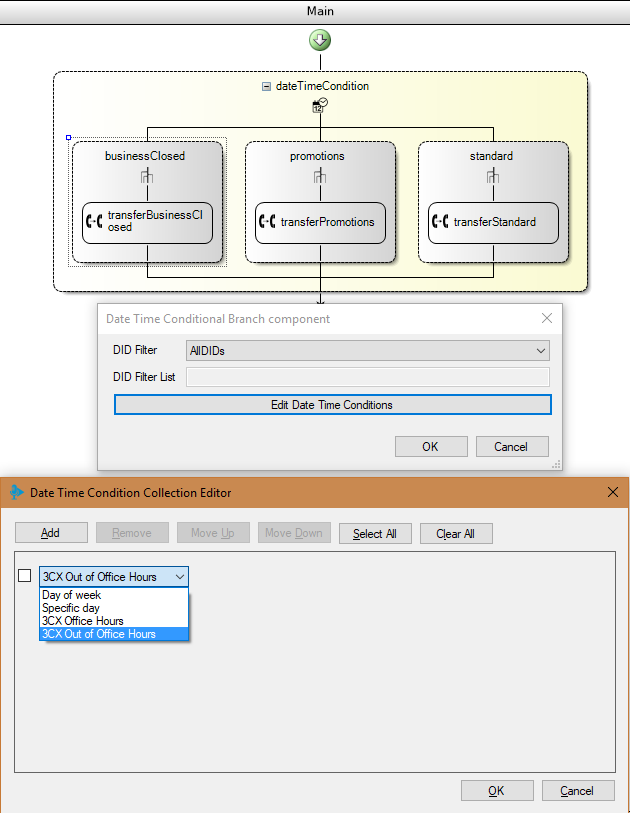
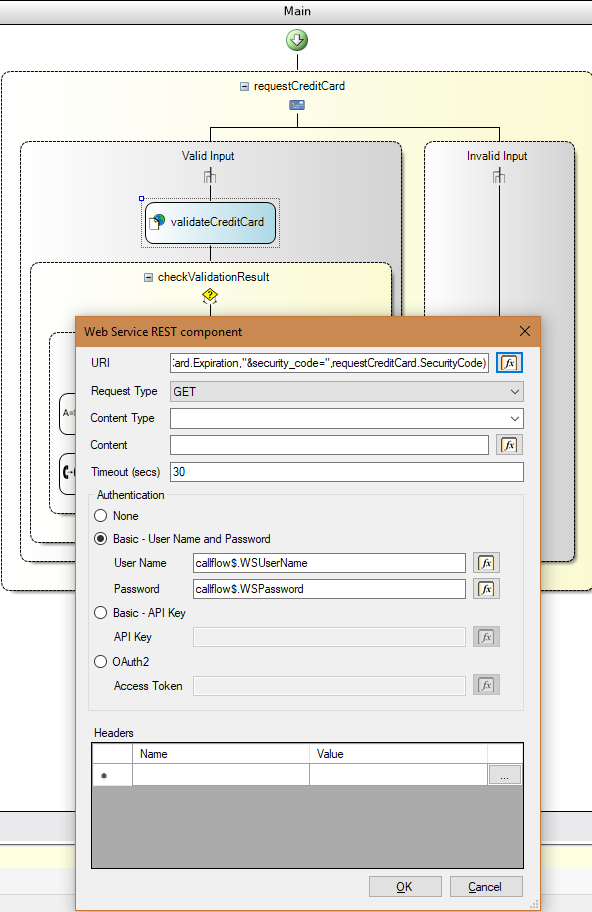

|
|
Machine Learning: State of the art |

 Знакомьтесь: Иван Ямщиков. Получил PhD по прикладной математике в Бранденбургском Технологическом университете (Котбус, Германия). В данный момент — научный сотрудник Института Макса Планка (Лейпциг, Германия) и аналитик/консультант Яндекса.
Знакомьтесь: Иван Ямщиков. Получил PhD по прикладной математике в Бранденбургском Технологическом университете (Котбус, Германия). В данный момент — научный сотрудник Института Макса Планка (Лейпциг, Германия) и аналитик/консультант Яндекса.
|
Метки: author varagian машинное обучение алгоритмы блог компании jug.ru group искусственный интеллект нейронная оборона музыка |
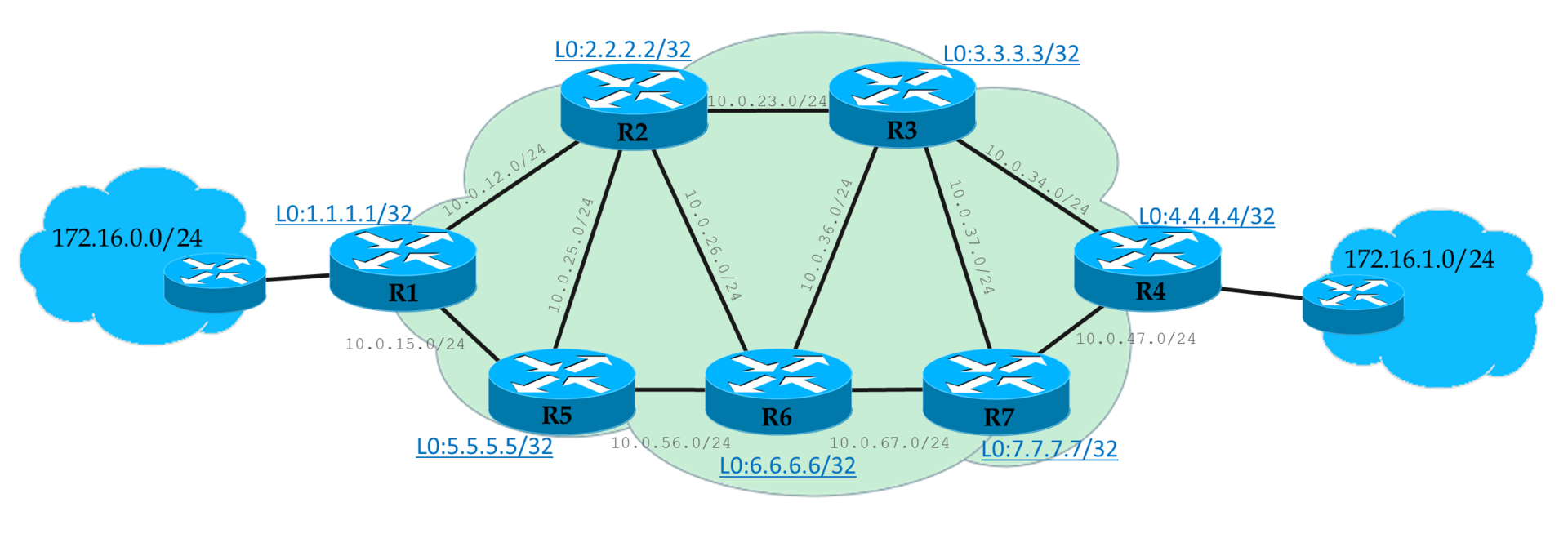
Сети для самых матёрых. Часть тринадцатая. MPLS Traffic Engineering |


Juniper здесь — исключение.
Итак, MPLS TE хочет строить LSP с учётом требуемых ресурсов и пожеланий оператора, поэтому столь простой LDP с его лучшим маршрутом тут не у дел.Терминология
LSP — Label Switched Path — вообще говоря, любой путь через сеть MPLS, но порой подразумевают LDP LSP. Однако мы не будем столь категоричны — при необходимости я буду указывать, что имею в виду именно LDP LSP.
RSVP LSP — соответственно LSP, построенный с помощью RSVP TE с учётом наложенных ограничений. Может также иногда называться CR-LSP — ConstRaint-based LSP.
Туннелем мы будем называть один или несколько MPLS LSP, соединяющих два LSR-маршрутизатора. Метка MPLS — это по сути туннельная инкапсуляция.
В случае LDP — каждый LSP — это отдельный туннель.
В случае RSVP туннель может состоять из одного или нескольких LSP: основной, резервный, best-effort, временный.
Говоря TE-туннель, мы будем подразумевать уже конкретно MPLS Traffic Engineering туннель, построенный RSVP-TE.
TEDB — Traffic Engineering Data Base — тот же LSDB протоколов IS-IS/OSPF, но с учётом ресурсов сети, которые интересны модулю TE.
CSPF — Constrained Shortest Path First — расширение алгоритма SPF, которое ищет кратчайший путь с учётом наложенных ограничений.
Linkmeup_R1(config) ip route 4.4.4.4 255.255.255.255 Tunnel 4Linkmeup_R1(config) ip access-list extended lennut
Linkmeup_R1(config-ext-nacl)) permit ip 172.16.0.0 0.0.0.255 172.16.1.0 0.0.0.255
Linkmeup_R1(config) route-map lennut permit 10
Linkmeup_R1(configconfig-route-map) match ip address lennut
Linkmeup_R1(config-route-map) set interface Tunnel4
Linkmeup_R1(config) interface Ethernet0/3
Linkmeup_R1(config-if) ip policy route-map lennut

Если есть IP-пути, которые не имеют общих сегментов с туннельным LSP, и при этом их метрики равны, будет иметь место балансировка.
Вот человек очень доступно объясняет, как работают метрики.Ну и вообще рекомендую ресурс: labminutes.com/video/sp
Forwarding adjacencies
Forwarding adjacencies — штука сходной c IGP Shortcut природы с той лишь (существенной) разницей, что туннель теперь будет анонсироваться Ingress LSR IGP-соседям, как обычный линк. Соответственно, все окружающие маршрутизаторы будут учитывать его в своих расчётах SPF.
IGP Shortcut же влияет только на таблицу маршрутизации на Ingress LSR, и окружающие соседи про этот туннель не знают.

В лаборатории ограничение интерфейса — 10000 кб/с. Поэтому при задании требований туннеля и доступных полос, отталкиваемся исключительно от этой цифры.Поехали!
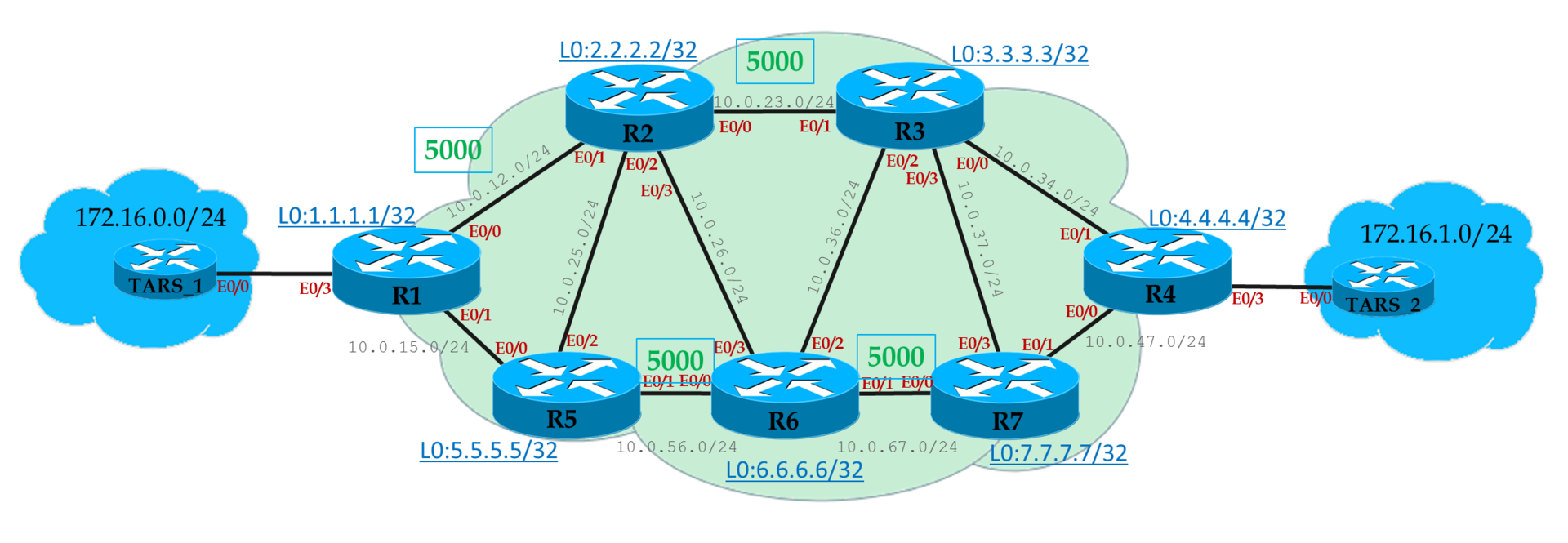
Linkmeup_R1(config) mpls traffic-eng tunnels Router(config-if) ip rsvp bandwidth значение_ограниченияСледует всегда помнить, что это только референсное значение для расчёта пути TE, и фактически команда никак не ограничивает реальную скорость TE-трафика, через интерфейс.
Linkmeup_R1(config) interface FastEthernet 0/0
Linkmeup_R1(config-if) mpls traffic-eng tunnels
Linkmeup_R1(config-if) ip rsvp bandwidth 5000
Linkmeup_R1(config) interface FastEthernet 0/1
Linkmeup_R1(config-if) mpls traffic-eng tunnels
Linkmeup_R1(config-if) ip rsvp bandwidth 10000Обратите внимание, что команда ip rsvp bandwidth указывает полосу только в одном направлении. То есть если мы настроили её на интерфейсе E0/0 в сторону Linkmeup_R2, то это означает, что в 5Мб/с ограничена полоса только для исходящего трафика.
Чтобы ограничить в другую сторону, нужно настроить интерфейс E0/1 со стороны Linkmeup_R2.
Linkmeup_R2(config) mpls traffic-eng tunnels
Linkmeup_R2(config) interface FastEthernet 0/0
Linkmeup_R2(config-if) mpls traffic-eng tunnels
Linkmeup_R2(config-if) ip rsvp bandwidth 5000
Linkmeup_R2(config) interface FastEthernet 0/1
Linkmeup_R2(config-if) mpls traffic-eng tunnels
Linkmeup_R2(config-if) ip rsvp bandwidth 10000
Linkmeup_R2(config) interface FastEthernet 0/2
Linkmeup_R2(config-if) mpls traffic-eng tunnels
Linkmeup_R2(config-if) ip rsvp bandwidth 10000
Linkmeup_R2(config) interface FastEthernet 0/3
Linkmeup_R2(config-if) mpls traffic-eng tunnels
Linkmeup_R2(config-if) ip rsvp bandwidth 10000
Linkmeup_R3(config) mpls traffic-eng tunnels
Linkmeup_R3(config) interface FastEthernet 0/0
Linkmeup_R3(config-if) mpls traffic-eng tunnels
Linkmeup_R3(config-if) ip rsvp bandwidth 10000
Linkmeup_R3(config) interface FastEthernet 0/1
Linkmeup_R3(config-if) mpls traffic-eng tunnels
Linkmeup_R3(config-if) ip rsvp bandwidth 10000
Linkmeup_R3(config) interface FastEthernet 0/2
Linkmeup_R3(config-if) mpls traffic-eng tunnels
Linkmeup_R3(config-if) ip rsvp bandwidth 10000
Linkmeup_R3(config) interface FastEthernet 0/3
Linkmeup_R3(config-if) mpls traffic-eng tunnels
Linkmeup_R3(config-if) ip rsvp bandwidth 10000
Linkmeup_R4(config) mpls traffic-eng tunnels
Linkmeup_R4(config) interface FastEthernet 0/0
Linkmeup_R4(config-if) mpls traffic-eng tunnels
Linkmeup_R4(config-if) ip rsvp bandwidth 10000
Linkmeup_R4(config) interface FastEthernet 0/1
Linkmeup_R4(config-if) mpls traffic-eng tunnels
Linkmeup_R4(config-if) ip rsvp bandwidth 10000
Linkmeup_R5(config) mpls traffic-eng tunnels
Linkmeup_R5(config) interface FastEthernet 0/0
Linkmeup_R5(config-if) mpls traffic-eng tunnels
Linkmeup_R5(config-if) ip rsvp bandwidth 10000
Linkmeup_R5(config) interface FastEthernet 0/1
Linkmeup_R5(config-if) mpls traffic-eng tunnels
Linkmeup_R5(config-if) ip rsvp bandwidth 5000
Linkmeup_R5(config) interface FastEthernet 0/2
Linkmeup_R5(config-if) mpls traffic-eng tunnels
Linkmeup_R5(config-if) ip rsvp bandwidth 10000
Linkmeup_R5(config) interface FastEthernet 0/3
Linkmeup_R5(config-if) mpls traffic-eng tunnels
Linkmeup_R5(config-if) ip rsvp bandwidth 10000
Linkmeup_R6(config) mpls traffic-eng tunnels
Linkmeup_R6(config) interface FastEthernet 0/0
Linkmeup_R6(config-if) mpls traffic-eng tunnels
Linkmeup_R6(config-if) ip rsvp bandwidth 10000
Linkmeup_R6(config) interface FastEthernet 0/1
Linkmeup_R6(config-if) mpls traffic-eng tunnels
Linkmeup_R6(config-if) ip rsvp bandwidth 10000
Linkmeup_R6(config) interface FastEthernet 0/2
Linkmeup_R6(config-if) mpls traffic-eng tunnels
Linkmeup_R6(config-if) ip rsvp bandwidth 10000
Linkmeup_R6(config) interface FastEthernet 0/3
Linkmeup_R6(config-if) mpls traffic-eng tunnels
Linkmeup_R6(config-if) ip rsvp bandwidth 10000
Linkmeup_R7(config) mpls traffic-eng tunnels
Linkmeup_R7(config) interface FastEthernet 0/0
Linkmeup_R7(config-if) mpls traffic-eng tunnels
Linkmeup_R7(config-if) ip rsvp bandwidth 10000
Linkmeup_R7(config) interface FastEthernet 0/1
Linkmeup_R7(config-if) mpls traffic-eng tunnels
Linkmeup_R7(config-if) ip rsvp bandwidth 10000
Linkmeup_R7(config) interface FastEthernet 0/3
Linkmeup_R7(config-if) mpls traffic-eng tunnels
Linkmeup_R7(config-if) ip rsvp bandwidth 10000Linkmeup_R1(config) router isis
Linkmeup_R1(config-router) metric-style wide
Linkmeup_R1(config-router) mpls traffic-eng router-id Loopback0
Linkmeup_R1(config-router) mpls traffic-eng level-1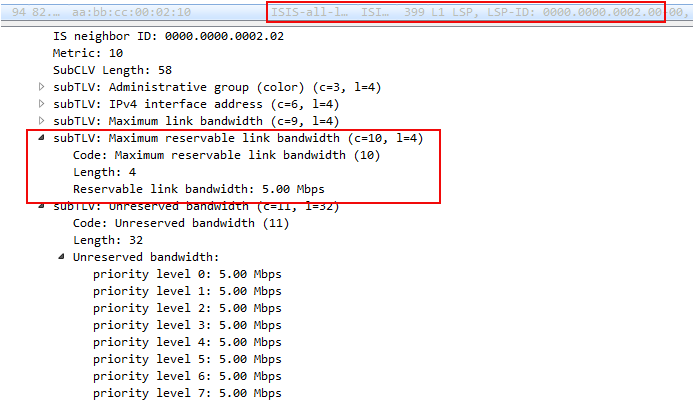
Linkmeup_R1(config) interface Tunnel4
Linkmeup_R1(config-if) description To Linkmeup_R4
Linkmeup_R1(config-if) ip unnumbered Loopback0
Linkmeup_R1(config-if) tunnel mode mpls traffic-eng
Linkmeup_R1(config-if) tunnel destination 4.4.4.4
Linkmeup_R1(config-if) tunnel mpls traffic-eng bandwidth 8000
Linkmeup_R1(config-if) tunnel mpls traffic-eng path-option 1 dynamic
Трассировка показывает, что путь проложен ровно так, как мы этого хотели.То же самое на обратной стороне:
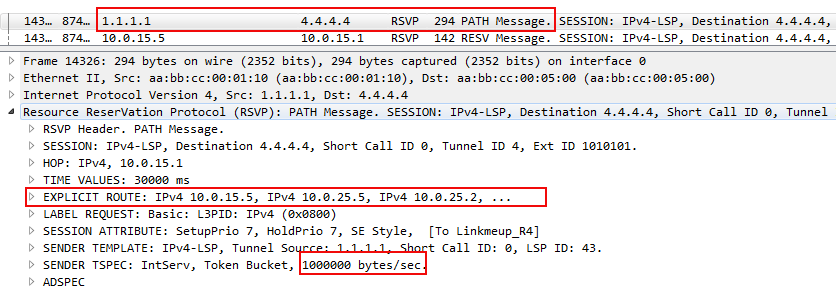
А в сообщении RSVP PATH можно увидеть, что он несёт информацию о требуемой полосе.
В дампе вы можете видеть начало объекта ERO с перечислением всех узлов по пути будущего RSVP LSP и запрос резервирования полосы пропускания.
Здесь стоит 1000000 Байтов в секунду или ровно 8 Мегабит в секунду (если мы не путаем Мега с Меби). Величина эта дискретная и меняется с некоторым шагом. В случае данной лабы — это 250 кб/с.
Можете поиграться с параметрами и увидеть, как туннель реагирует на изменения в сети.
Linkmeup_R4(config) interface Tunnel1
Linkmeup_R4(config-if) description To Linkmeup_R1
Linkmeup_R4(config-if) ip unnumbered Loopback0
Linkmeup_R4(config-if) tunnel mode mpls traffic-eng
Linkmeup_R4(config-if) tunnel destination 1.1.1.1
Linkmeup_R4(config-if) tunnel mpls traffic-eng bandwidth 8000
Linkmeup_R4(config-if) tunnel mpls traffic-eng path-option 1 dynamicLinkmeup_R1(config) ip vrf TARS
Linkmeup_R1(config-vrf) rd 64500:200
Linkmeup_R1(config-vrf) route-target export 64500:200
Linkmeup_R1(config-vrf) route-target import 64500:200
Linkmeup_R1(config-vrf) interface Ethernet0/3
Linkmeup_R1(config-if) description To TARS_1
Linkmeup_R1(config-if) ip vrf forwarding TARS
Linkmeup_R1(config-if) ip address 172.16.0.1 255.255.255.0
Linkmeup_R1(config-if) router bgp 64500
Linkmeup_R1(config-router) neighbor 4.4.4.4 remote-as 64500
Linkmeup_R1(config-router) neighbor 4.4.4.4 update-source Loopback0
Linkmeup_R1(config-router) address-family vpnv4
Linkmeup_R1(config-router-af) neighbor 4.4.4.4 activate
Linkmeup_R1(config-router-af) neighbor 4.4.4.4 send-community both
Linkmeup_R1(config-router) address-family ipv4 vrf TARS
Linkmeup_R1(config-router-af) redistribute connectedLinkmeup_R4(config) ip vrf TARS
Linkmeup_R4(config-vrf) rd 64500:200
Linkmeup_R4(config-vrf) route-target export 64500:200
Linkmeup_R4(config-vrf) route-target import 64500:200
Linkmeup_R4(config-vrf) interface Ethernet0/3
Linkmeup_R4(config-if) description To TARS_2
Linkmeup_R4(config-if) ip vrf forwarding TARS
Linkmeup_R4(config-if) ip address 172.16.1.1 255.255.255.0
Linkmeup_R4(config-if) mpls traffic-eng tunnels
Linkmeup_R4(config-if) router bgp 64500
Linkmeup_R4(config-router) neighbor 1.1.1.1 remote-as 64500
Linkmeup_R4(config-router) address-family vpnv4
Linkmeup_R4(config-router-af) neighbor 1.1.1.1 activate
Linkmeup_R4(config-router-af) neighbor 1.1.1.1 send-community both
Linkmeup_R4(config-router-af) address-family ipv4 vrf TARSLinkmeup_R1(config) interface Tunnel4
Linkmeup_R1(config-if) tunnel mpls traffic-eng autoroute announceLinkmeup_R4(config) interface Tunnel1
Linkmeup_R4(config-if) tunnel mpls traffic-eng autoroute announceLinkmeup_R1(config-if) tunnel mpls traffic-eng autoroute metric relative -5Linkmeup_R4(config-if) tunnel mpls traffic-eng autoroute metric relative -5



Итак, что произошло?
- Сначала мы настроили базовую поддержку TE,
а) Включили поддержку TE в глобальном режиме,
б) Включили функцию TE на магистральных интерфейсах,
г) Указали доступную пропускную способность физических интерфейсов,
д) Заставили IGP анонсировать данные TE.
На этом шаге IGP уже составил TEDB.
- Создали туннель (прямой и обратный):
а) Указали точку назначения,
б) Режим работы — TE,
в) Указали требуемую полосу,
г) Разрешили строить LSP динамически.
На этом шаге сначала CSPF вычисляет список узлов, через которые нужно проложить LSP. Выхлоп этого процесса помещается в объект ERO. потом RSVP-TE с помощью сообщений PATH и RESV резервирует ресурсы и строит LSP.
Но этого ещё недостаточно для практического использования туннеля.
- Настроили L3VPN (см. как).
Когда MP-BGP обменялся маршрутными данными VRF, Next Hop'ом для этих маршрутов стал Loopback адрес удалённого PE.
Однако маршруты из таблицы BGP не инсталлируются в таблицу маршрутизации данного VRF, поскольку трафик в LSP мы пока не запустили.
- Заставили IGP рассматривать TE-туннель, как возможный выходной интерфейс.
Это не влечёт никаких изменений в других частях сети — исключительно локальное действие — IGP только меняет таблицу маршрутизации этого узла.
Теперь LoopBack удалённого PE стал доступен через туннель, а маршруты добавились в таблицу маршрутизации VRF.
То есть когда IP-пакет приходит от клиента,
а) он получает метку VPN (16).
б) из FIB VRF TARS ему известно, что для данного префикса пакет должен быть отправлен на адрес 4.4.4.4
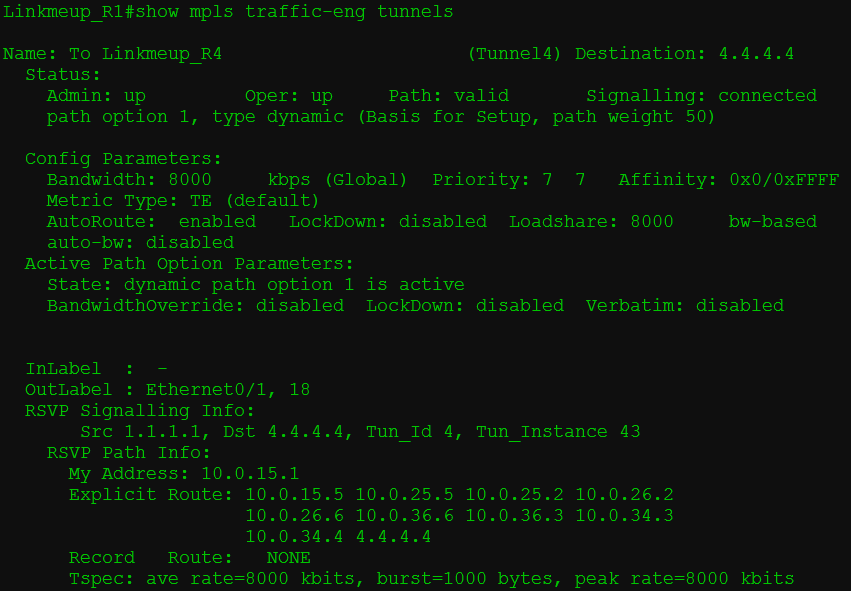
в) До 4.4.4.4 есть TE-туннель (Tunnel 4) и известна его пара выходной интерфейс/метка — Ethernet0/1, 18 — она будет транспортной.
На этой иллюстрации решительно нечего выделить — всё абсолютно прекрасно — вся информация о TE-туннеле в одной команде.

Что при этом происходило?Если у нас не останется путей, удовлетворяющих заданным условиям — беда — LSP не будет.
- Сначала R1 через сообщение RSVP PATH ERROR узнал о том, что линия испорчена.
- R1 отправил RSVP PATH TEAR по направлению к 4.4.4.4, а обратно идущий RSVP RESV TEAR удалил LSP.
- Тем временем на R1 CSPF рассчитал новый маршрут в обход сломанного линка.
- Потом RSVP-TE сигнализировал новый LSP R1->R5->R2->R6->R3->R7->R4
Для чего может понадобиться настраивать TE-метрику отличной от IGP?Используется для этого команда
Например, есть линия с высоким значением задержки. Ей задаём бОльшее значение TE-метрики.
Тогда:
При построении туннелей для голосового трафика будем использовать TE-метрику,
В туннелях для прочих данных — IGP.
Router(config-if) mpls traffic-eng administrative-weight значение TE-метрикиRouter(config) mpls traffic-eng path-selection metric {igp | te}Router(config-if) tunnel mpls traffic-eng path-selection metric {igp | te}Router(config-if) tunnel mpls traffic-eng bandwidth значение требуемой полосыRouter(config-if) tunnel mpls traffic-eng path-option 1 dynamic bandwidth значение требуемой полосыБлиже к телу.Терминология
Adjust Interval — время, в течение которого маршрутизатор наблюдает за трафиком и отслеживает пики.
Adjust Threshold — порог, после которого RSVP перезапрашивает резервирование.


Router(config) mpls traffic-eng auto-bw timers frequency [sec]Router(config) tunnel mpls traffic-eng auto-bw max-bw Значение min-bw ЗначениеRouter(config) tunnel mpls traffic-eng auto-bw [overflow-limit количество раз overflow-threshold Процент изменения]Linkmeup_R1(config) interface Tunnel42
Linkmeup_R1(config-if) ip unnumbered Loopback0
Linkmeup_R1(config-if) tunnel mode mpls traffic-eng
Linkmeup_R1(config-if) tunnel destination 4.4.4.4
Linkmeup_R1(config-if) tunnel mpls traffic-eng priority 4 4
Linkmeup_R1(config-if) tunnel mpls traffic-eng bandwidth 4000
Linkmeup_R1(config-if) tunnel mpls traffic-eng path-option 1 dynamic




Explicit-Path — это строго локальное ограничение — только Ingress LSR о нём знает и не передаёт ни в анонсах IGP, ни в сообщениях RSVP-TE.Настройка Explicit-path выполняется в два этапа:
Router(config) ip explicit-path name Имя
Router(cfg-ip-expl-path) next-address IP-адрес
Router(cfg-ip-expl-path) exclude-address IP-адрес
...Router(config-if) tunnel mpls traffic-eng path-option 1 explicit name ИмяRouter(config-if) mpls traffic-eng srlg номер группыRouter(config) mpls traffic-eng auto-tunnel backup srlg exclude force/prefferedПока вы не согнулись под тяжестью знаний, расскажу вам такую историю.Каждый раз, настраивая туннель, учитывать в Explicit Path все эти детали — с ума можно сойти.
Огромнейшая сеть linkmeup. Своя оптика, свои РРЛ пролёты, куски лапши, доставшиеся от купленных домонетов, куча арендованных каналов у разных операторов. И через всё это хозяйство MPLS, хуже того — TE-туннели.
И для разных сервисов важно, чтобы они шли определённым путём.
Например, трафик 2G ни в коем случае не должен идти через РРЛ-пролёты — проблемы с синхронизацией нас съедят.
Трафик ШПД нельзя пускать через линии Балаган Телеком, потому что эти паразиты из 90-х берут деньги за объём пропущенного трафика.
Разрешать строить туннели через сети доступа вообще запрещено категорически.
И с этим нужно что-то делать.
Например,
считаем с наименее значимых битов (с конца):
первый бит в 1 означает, что это оптика
второй бит в 1 означает, что это РРЛ
третий бит в 0 означает, что это линия в сторону сети доступа, а 1 — магистральный интерфейс.
четвёртый бит в 1 означает, что это аренда
пятый бит в 1 означает, что это Балаган-Телеком
шестой бит в 1 означает, что это Филькин-Сертификат
седьмой бит в 1 означает, что это канал через интернет без гарантий.
…
десятый бит в 1 означает, что полоса пропускания меньше 500 Мб/с
итд. я так могу все 32 утилизировать.
(AFFINITY && MASK) == (ATTRIBUTE && MASK)






Linkmeup_R1(config) interface Tunnel4
Linkmeup_R1(config-if) tunnel mpls trafаic-eng affinity 0x0 mask 0x1Linkmeup_R3(config) interface e0/0
Linkmeup_R3(config-if) mpls trafаic-eng attribute-flags 0x1
Linkmeup_R1(config) interface Tunnel4
Linkmeup_R1(config-if) tunnel mpls trafаic-eng affinity 0x0 mask 0x0Если бы эволюция строила людей по этому принципу, мы бы умирали преимущественно от старости (вторая причина по числу смертей была бы «погиб под собственным весом»).Защита на физическом уровне обычно предоставляет время сходимости в ±50 мс.




Давайте сначала с Link Protection разберёмся?Терминология
PLR — Point of Local Repair — точка расхода. Это узел, который инициирует защиту линии или узла. Может быть Ingress PE или любой транзитный P, но не Egress PE
MP — Merge Point — точка схода, куда приземляется защитный туннель. Любой транзитный P или Egress PE, но не Ingress PE.
Primary LSP или Protected LSP — исходный LSP, который требует защиты.
Bypass LSP — защитный LSP.
NHOP — Next Hop — следующий после PLR узел в Primary LSP.
NNHOP — Next Next Hop — соответственно следующий узел после Next Hop.
|
|
[Перевод] Профилирование сборки проекта |
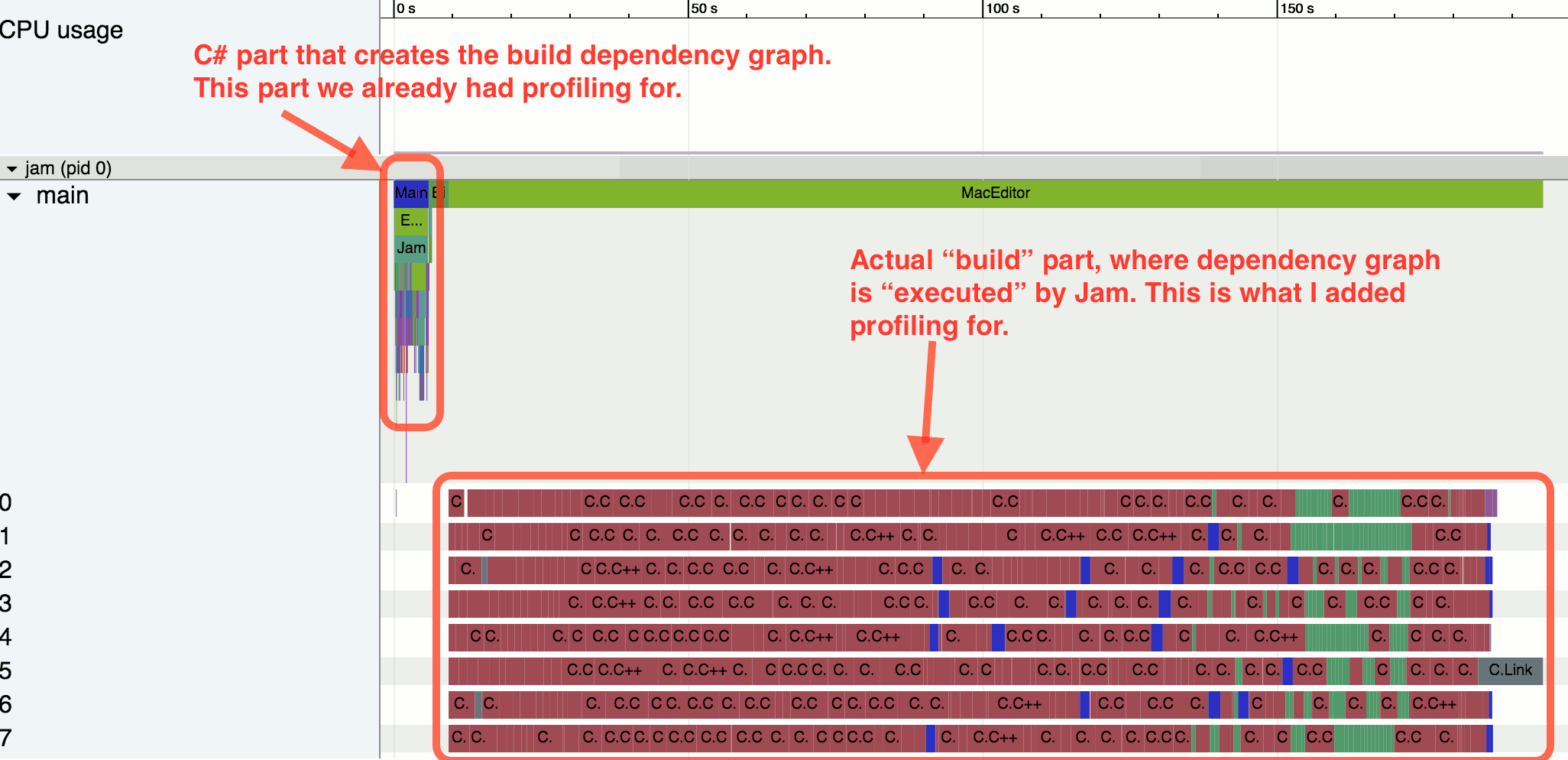

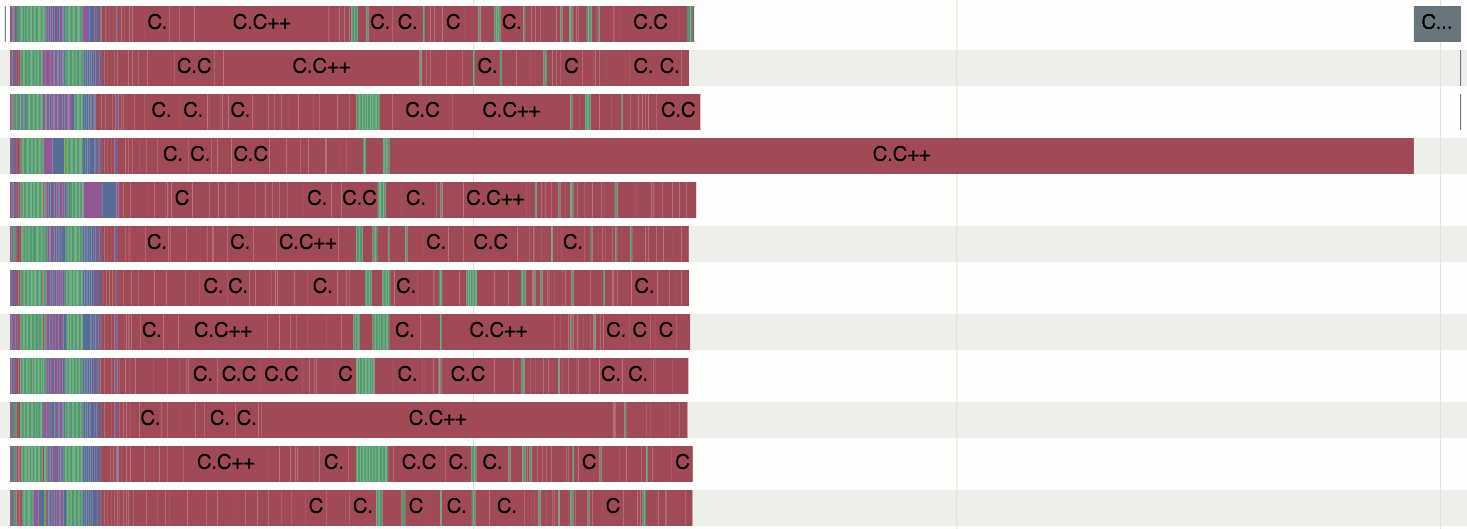
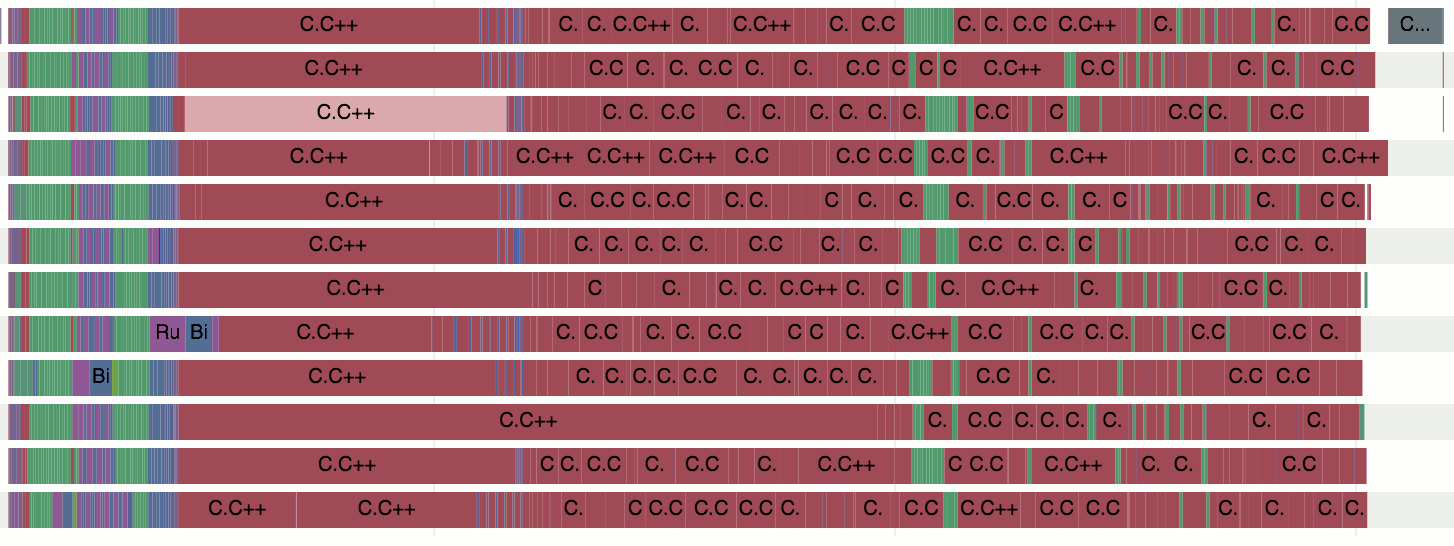
|
Метки: author tangro системы сборки отладка визуализация данных c++ блог компании инфопульс украина профилирование |
[Перевод] Kali Linux: мониторинг и логирование |
|
Метки: author ru_vds системное администрирование серверное администрирование настройка linux блог компании ruvds.com администрирование linux безопасность мониторинг логирование |