[Перевод] ES8: основные новшества |

String: padStart() и padEnd(). Слова «Начало» и «Конец» в названиях функций намекают на их роли в деле обработки строк. А именно, они позволяют задавать параметры дополнения строк до достижения ими заданной длины. Метод padStart() дополняет строку с её начала (слева), padEnd() — с конца (справа). Строки можно дополнять заданными одиночными символами, другими строками, или, по умолчанию, пробелами. Вот синтаксис функций, о которых идёт речь:str.padStart(targetLength [, padString])
str.padEnd(targetLength [, padString])targetLength. Он представляет собой целевую длину результирующей строки. Второй параметр, необязательный padString, это строка, которой будет дополняться исходная строка. Без указания этого параметра для дополнения будет использоваться пробел. Если длина строки, к которой применяется один из этих методов, превышает заданную, исходная строка остаётся неизменной.'es8'.padStart(2); // 'es8'
'es8'.padStart(5); // ' es8'
'es8'.padStart(6, 'woof'); // 'wooes8'
'es8'.padStart(14, 'wow'); // 'wowwowwowwoes8'
'es8'.padStart(7, '0'); // '0000es8'
'es8'.padEnd(2); // 'es8'
'es8'.padEnd(5); // 'es8 '
'es8'.padEnd(6, 'woof'); // 'es8woo'
'es8'.padEnd(14, 'wow'); // 'es8wowwowwowwo'
'es8'.padEnd(7, '6'); // 'es86666'
Object.values() возвращает массив собственных перечисляемых свойств переданного ему объекта в том же порядке, в котором это делает цикл for…in. Синтаксис метода предельно прост:Object.values(obj)obj — это тот объект, свойства которого надо получить. Он может быть объектом или массивом (иными словами, объектом с индексами наподобие [10, 20, 30] -> { 0: 10, 1: 20, 2: 30 }). Вот пример кода:const obj = { x: 'xxx', y: 1 };
Object.values(obj); // ['xxx', 1]
const obj = ['e', 's', '8']; // то же самое, что и { 0: 'e', 1: 's', 2: '8' };
Object.values(obj); // ['e', 's', '8']
Object.entries() возвращает массив собственных перечисляемых свойств объекта в формате [ключ, значение], в том же порядке, что и Object.values(). Синтаксис метода аналогичен Object.values(), да и в остальном эти методы похожи:Object.entries(obj)const obj = { x: 'xxx', y: 1 };
Object.entries(obj); // [['x', 'xxx'], ['y', 1]]
const obj = ['e', 's', '8'];
Object.entries(obj); // [['0', 'e'], ['1', 's'], ['2', '8']]
const obj = { 10: 'xxx', 1: 'yyy', 3: 'zzz' };
Object.entries(obj); // [['1', 'yyy'], ['3', 'zzz'], ['10': 'xxx']]
Object.entries('es8'); // [['0', 'e'], ['1', 's'], ['2', '8']]
Object.getOwnPropertyDescriptors() возвращает дескриптор собственного свойства переданного объекта. Собственное свойство определено непосредственно в объекте, а не получено через цепочку прототипов. Вот синтаксис метода:Object.getOwnPropertyDescriptor(obj, prop)obj — это объект, данные по свойству которого надо получить, аргумент prop — это имя свойства, дескриптор которого нас интересует. В результате успешного выполнения этого метода будет возвращён объект, в котором могут быть следующие ключи:configurable — true — если тип дескриптора свойства может быть изменён и если свойство может быть удалено из содержащего его объекта, иначе false.enumerable — true — если свойство доступно при перечислении свойств объекта, иначе — false.writable — true — если значение ассоциированное со свойством, может быть изменено, иначе false (для дескрипторов данных)get — функция, возвращающая значение свойства, либо, если она отсутствует — undefined (для дескрипторов доступа)set — функция, изменяющая значение свойства, либо, если она отсутствует — undefined (для дескрипторов доступа)value — значение, ассоциированное со свойством (для дескрипторов данных).const obj = { get es8() { return 888; } };
Object.getOwnPropertyDescriptor(obj, 'es8');
// {
// configurable: true,
// enumerable: true,
// get: function es8(){}, //функция-геттер
// set: undefined
// }
[10, 20, 30,] и { x: 1, }.SyntaxError. Теперь же этого не происходит. Вот пример объявления функции, в списке параметров которой есть завершающая запятая:function es8(var1, var2, var3,) {
// ...
}es8(10, 20, 30,);async позволяет определить асинхронную функцию, которая возвращает объект AsyncFunction. Внутри их работа во многом похожа на то, как работают генераторы.function fetchTextByPromise() {
return new Promise(resolve => {
setTimeout(() => {
resolve("es8");
}, 2000));
});
}
async function sayHello() {
const externalFetchedText = await fetchTextByPromise();
console.log(`Hello, ${externalFetchedText}`); // Hello, es8
}
sayHello();sayHello() приведёт к выводу в лог строки «Hello, es8» с задержкой в 2 секунды, при этом главный поток выполнения не блокируется. Вот как это выглядит:console.log(1);
sayHello();
console.log(2);1 // немедленно
2 // немедленно
Hello, es8 // через 2 секундыconsole.log() выполняются один за другим, а асинхронная функция, не блокируя главный поток, выполняется через 2 секунды.await можно использовать только в функциях, определённых с использованием ключевого слова async.
Atomics нельзя использовать как конструктор, он, в этом плане, похож на Math. Существуют методы объекта Atomics, которые позволяют выполнять различные безопасные операции с элементами типизированных массивов, служащих для доступа к объектам SharedArrayBuffer. Среди них, например, метод Atomics.add() для прибавления указанного числа к тому, что хранится в заданной позиции массива. Есть в Atomics и методы для организации управления блокировками, в частности, это Atomics.wait() и Atomics.wake().
const esth = 8;
helper`ES ${esth} is `;
function helper(strs, ...keys) {
const str1 = strs[0]; // ES
const str2 = strs[1]; // is
let additionalPart = '';
if (keys[0] == 8) { // 8
additionalPart = 'awesome';
}
else {
additionalPart = 'good';
}
return `${str1} ${keys[0]} ${str2} ${additionalPart}.`;
}esth записано число 8, функция возвратит «ES 8 is awesome». Если же в esth будет 7, то функция вернёт «ES 7 is good».\u или \x. В частности, например, после \u должен следовать код символа Unicode, иначе появится сообщение об ошибке. Ожидается, что в ES9 это ограничение будет снято.
|
Метки: author ru_vds javascript блог компании ruvds.com es8 новые возможности |
В IBM создали новое поколение транзисторов из углеродных нанотрубок |
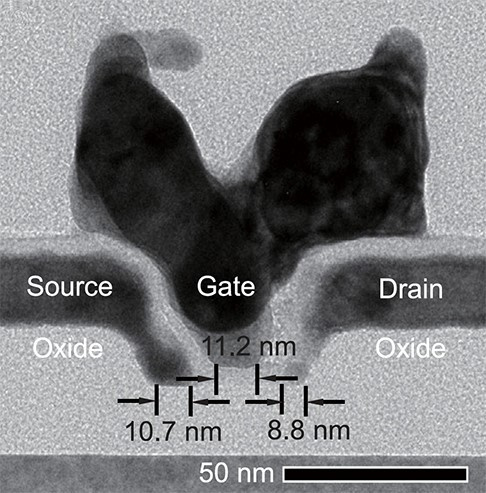
|
Метки: author ibm высокая производительность блог компании ibm транзисторы разработка электроники устройства процессоры |
Как сделать сложное простым. История создания «Проекта1917» |









|
Метки: author eapotapov laravel angularjs блог компании itsumma разработка |
Продуктивность и юзабилити |

|
Метки: author izhanov управление проектами управление продуктом управление e-commerce юзабилити сайтов |
Ссылочная TCP/IP стеганография |
|
Метки: author scidev разработка систем связи ненормальное программирование криптография информационная безопасность стеганография tcp/ip программирование |
[Из песочницы] Тестирование в Openshift: введение |
Здравствуйте уважаемые участники ИТ сообщества. Меня зовут Олег, я работаю в компании, которая занимается разработкой ПО. Я занимаюсь ручным и автоматизированным тестированием Linux и Unix продуктов и я хотел бы поделиться положительным опытом автоматизированного тестирования в Openshift Origin.
Цели, которые я преследую:
Весь материал изложен в трёх статьях:
Примечание: хотелось бы сразу заметить, что излагаемый материал касается Openshift v3, а не Openshift v2 (когда компания Red Hat еще не начала использовать Kubernetes в качестве ядра для своих продуктов и сервисов).
Почему был выбран Openshift Origin:
Так случилось, что после трудоустройства на текущее место работы, выяснилось, что автоматизированного тестирования нет в принципе. Проработав несколько месяцев в ручном режиме пришло понимание о необходимости двух вещей: инструмента для развертывания и поддержки тестируемых сред, framework для написания тестов.
На первоначальном этапе для развертывания и поддержки сред был организован автоматически обновляемый репозиторий Vagrant (VirtualBox), который обновляет и упаковывает различные ОС в автоматическом режиме. Это стало подспорьем не только для тестирования, но и для разработки, потому как: виртуальные машины были сконфигурированы согласно выработанным требованиям; виртуальные машины были обновлены, были предустановлены необходимые инструменты; имелись сценарии Vagrant для развертывания сложных окружений. Стоит отметить, что все среды Vagrant разворачиваются на локальных машинах участников разработки, а не в выделенном IaaS, что ожидаемо вызывало проблемы производительности рабочих станций.
Было выиграно время, стало удобнее работать, появились некий стандарт и предсказуемость, но главная проблема оставалась — долгое развертывание тестируемых сред (полная виртуализация, различные дистрибутивы Linux, дополнительные сервисы (которые участвуют в тестировании)). Развертывание тестируемых сред могло занимать десятки минут, в то время как сам тест проходил за считанные секунды. При этом количество автоматизированных тестов росло и ожидать результатов приходилось всё дольше.
Закономерным стал вопрос об организации обособленного IaaS, в котором происходили бы все задачи тестирования, но данный подход был не идеален: всё так же использовалась бы полная виртуализация, для построения IaaS требовались бы финансовые вложения на покупку аппаратного обеспечения (небольшой парк слабых рабочих станции присутствовал).
Следующим этапом стала проработка быстрого (в контексте быстродействия окружений) CI/CD c учетом новых требовании, а именно (основные, согласно приоритетам):
Я не буду утруждать читателей подробным пересказом о тернистом пути поиска подходящих продуктов, но хочу ознакомить со списком рассмотренного ПО (февраль 2016):
Одни инструменты плохо управлялись или требовали слишком много поддержки и обслуживания, другие плохо интегрировались с Jenkins и не предоставляли нужного функционала, третьи только начинали свой путь. Однозначным лидером вырисовывалась Kubernetes и её производные (коих не мало), но в чистом виде платформа от Google была сложна в освоении и развертывании (разработчики прилагают большие усилия для упрощения использования данной платформы).
Своими словами oб Openshift Origin:
Openshift Origin — это в первую очередь Open Source платформа для разработки и публикации ПО, которая базируется на платформе оркестрации контейнеров Kubernetes. Платформа расширяет возможности Kubernetes с помощью специальных объектов и механизмов.
Кластер:
Кластер может быть развернут или обновлен с помощью сценариев Ansible. Внутри кластера может использоваться как встроенный так и внешний Docker регистр. Узлы кластера могут быть закреплены на основе специальных меток за отдельными проектами. Присутствует сборщик мусора и настраиваемый планировщик. Кластер может быть развернут внутри Openstack и интегрирован с ним с целью автоматического масштабирования и предоставления хранилища данных. Среды могут быть осведомлены об опубликованных сервисах и других узлах с помощью переменных окружений и DNS имен. Возможна проверка доступности сервисов через HTTP/TCP запрос и/или через выполнение команды внутри контейнера. Ресурсы кластера могут быть квотированы на уровне проектов (процессор, память, количество объектов и т.д.). Присутствует возможность мониторинга кластера на уровне контейнеров и рабочих узлов.
Данные:
В качестве способа харанения данных могут выступать временные или постоянные тома, которые монтируются непосредственно в контейнеры. Backend для данных томов могут выступать: NFS, GlusterFS, OpenStack Cinder, Ceph RBD, AWS Elastic Block Store (EBS), GCE Persistent Disk и т.д. Присутствует возможность (hostPath) монтирования локального каталога того рабочего узла, на котором запущен контейнер.
Сеть:
По умолчанию все коммуникации осуществляются с помощью Open vSwitch, но существует поддержка других сетевых решений через систему плагинов Kubernetes. По умолчанию все среды могу коммуницировать друг с другом, но возможна изоляция на уровне проектов. Поддерживается разрешение DNS имен сервисов с помощью встроенной службы SkyDNS. Опубликованные внутри кластера сервисы могут быть доступны извне. Всю функциональность по изоляции и функциям NAT берет на себя Iptables.
Безопасность:
Разграничение прав пользователей на основе ролей. Изоляция контейнеров с помощью SELinux (и не только). Поддержка секретов, которые используются для доступа к различным ресурсам. Все коммуникации между рабочими узлами кластера и мастером осуществляется через шифрованные соединения (создается CA, выдаются клиентские сертификаты).
Управление:
Доступны интерфейсы API как для самого Openshift, так и для Kubernetes. Доступен кроссплатформенный консольный клиент. Доступен веб-интерфейс, с помощью которого пользователи могут: работать в изолированных проектах с учетом их полномочий, взаимодействовать с запущенными в кластере контейнерами, обозревать созданные объекты, отслеживать события и т.д.
Заключение:
Несмотря на обилие технологий и продуктов, которые представлены на рынке, найти подходящий инструмент достаточно сложно. Балансируя между унификацией и интеграцией процессов CI/CD, учитывая сложность сопровождения, отслеживая цепочки задействованных технологий, всё же была найдена Kubernetes, а затем и Openshift Origin. В отличии от базовой платформы оркестрации контейнерами Kubernetes, Openshift привносит необходимые элементы для удобной и эффективной работы.
|
Метки: author livelace анализ и проектирование систем openshift тестирование |
IceCash 2.0 Web АРМ Кассира и АИС по обмену данными с кассами под Linux на Python |













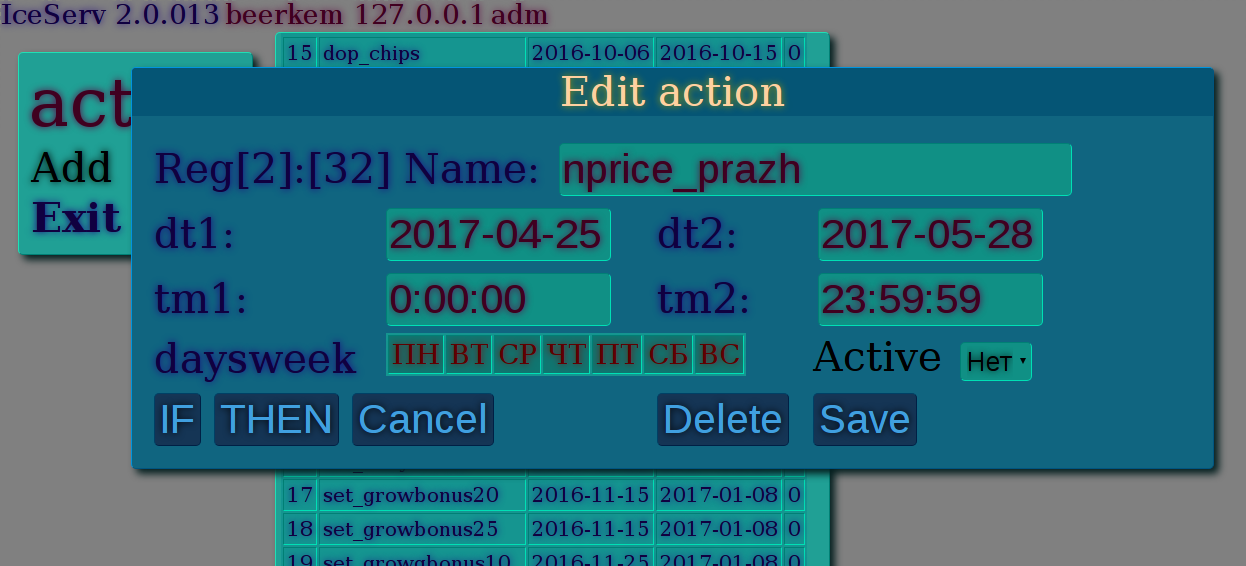


|
Метки: author redeyser разработка под linux python linux касса арм web егаис офд |
Linux Foundation представила бесплатный вводный онлайн-курс по Kubernetes |

|
Метки: author shurup системное администрирование devops блог компании флант kubernetes обучение linux foundation edx |
МТС ищет лучших IT-специалистов |

|
|
Яндекс.Такси и Uber поедут вместе |
|
Метки: author tigran блог компании яндекс такси общественный транспорт транспорт сервисы такси uber яндекс яндекс.такси |
Подготовка IT-инфраструктуры иностранного банка для переезда информационных систем в Россию |

Наверное, уже все слышали, что в соответствии с вступившим в силу Федеральным законом от 21 июля 2014 г. № 242-ФЗ "О внесении изменений в отдельные законодательные акты Российской Федерации в части уточнения порядка обработки персональных данных в информационно-телекоммуникационных сетях" необходимо организовать хранение и обработку персональных данных в России. Тема, конечно же, коснулась почти всех зарубежных финансовых организаций, представленных у нас в стране. Колесо завертелось и волею судьбы мы выиграли на исполнение проект одного зарубежного банка по созданию ИТ-инфраструктуры под миграцию его информационных систем (ИС) в Россию. Сорри, контракт включает NDA, поэтому назвать банк не можем. Но можем рассказать, как все это мы реализовали, какое решение предложили, архитектуру, СПД, какие вендоры – в общем, весь наш опыт передаем ниже.
Персональные данные – это любая информация, относящаяся к определенному или определяемому на основании этой информации физическому лицу. Сюда подпадает широкий класс данных в информационных системах. Практическая любая информация о клиентах в том или ином виде может быть отнесена к персональным данным.
Эта тема актуальна для иностранных представительств и дочерних компаний иностранных организаций, работающих в России. Представительствам и дочерним компаниям требуется интеграция для обмена данными с информационными системами материнской компании. Часто они пользуются ИТ-инфраструктурой материнской компании, которая консолидируется в нескольких дата-центрах по всему миру. В этих дата-центрах, почти как во внутреннем хостинге, размещаются информационные системы для множества представительств компании в различных странах целого региона.
Итак, с одной стороны для выполнения закона ФЗ-242 перед зарубежными компаниями встал вопрос переноса информационных систем, обрабатывающих персональные данные, на территорию РФ. В тоже время, на территории этих компаний работают бизнес-критичные ИС, которые содержат максимально важные для заказчика данные и обеспечивают работу бизнес-критичных процессов. Такие системы клиенты старались держать за границей ради консолидации и обеспечения защиты от пресловутых рисков в России, таких как рейдерские захваты и нежданные проверки различных органов или «слив» конфиденциальной информации конкурентам.
В частности, вопрос бесперебойной работы этих ИС встает очень остро для банков. Банки оказывают не только множество различных услуг в режиме 24x7x365 частным и корпоративным клиентам, но и должны предоставлять большое количество отчетности проверяющим органам на ежедневной, еженедельной, ежемесячной, ежеквартальной основе. В случае простоя ИС, банки несут как прямые потери – штрафы за не сдачу отчетности, так и косвенные – например, репутационные, вызванные потерей лояльности и оттоком клиентов.
Далее перейдем к конкретной задаче, которую нам пришлось решить для зарубежного банка ввиду вступившего в силу ФЗ.
Итак, задачу, которую поставил перед нами банк, можно сформулировать так — создать необходимую ИТ-инфраструктуру для работы переносимых бизнес-критичных информационных систем с заданными показателями производительности и надежности.
1. Новая ИТ-инфраструктура для переносимых информационных систем должна была обеспечивать непрерывность бизнеса, как в случаях локальных сбоев, так и в случае катастрофы. Иначе говоря, нужно было обеспечить высокую доступность и катастрофоустойчивость.

По показателям:
RPO (Recovery point objective – сколько данных будет потеряно при аварийном восстановлении) – в нашем случае заказчик хотел получить восстановлении RPO = 0 в случае локальных сбоев, и RPO стремящееся к 0 в случае катастрофы в основном ЦОД. Иными словами, в случае локального сбоя не должно быть потери данных, а в случае глобального сбоя потеря данных должна быть минимальна.
RTO (Recovery time objective – время, за которое возможно восстановить ИТ-систему) — заказчик хотел время восстановление <= 1 часа в случае самого худшего локального сбоя и RTO <= 2 часов в случае катастрофы в основном ЦОД.
Технические решения для обеспечения таких параметров стоят очень не дешево и «кусаются», но простои в работе дочерней организации крупного международного банка в течение 1 дня могут исчисляться убытками в миллионы долларов, что говорит само за себя.
2. Достаточная производительность информационных систем на новом оборудовании не хуже, чем до переезда. Это должно было обеспечиваться со всех точек зрения – например, как вычислительных ресурсов, так и с точки зрения СХД.
Часть ИТ-систем заказчика работала на платформе IBM Power. Для этой платформы мы собрали статистику использования ресурсов с учетом средней и пиковой нагрузки. При сайзинге важно знать, насколько могут отклоняться показатели от среднего значения в течение дня, недели или года, чтобы ИТ-системы сохраняли работоспособность даже в худшем случае максимальной нагрузки в случае пиковых нагрузок, например, при закрытии квартала.
Можно также посчитать производительность в неких условных синтетических показателях, таких как количество IOPS с определенным блоком и соотношением чтения к записи. Эти метрики мы учитывали при сайзинге нового оборудования.
Стоит правда сказать, что представителям бизнеса со стороны заказчика интереснее видеть более реальные показатели ИС, такие как время выполнения типовых операций до миграции и после. Эти показатели были замерены на старой платформе до начала миграции и использовали в качестве эталонных при сдаче проекта клиенту. Стояла задача, чтобы в новой системе при ограниченном бюджете эти показатели как минимум не ухудшились, а также был запас для роста производительности.
3. Эффективное вложение денег и эффективное использование оборудования. Заказчик ставил задачу с точки зрения бизнеса обеспечить выполнение требований №1 и №2 в минимальный бюджет. При этом в отличие от многих проектов российских заказчиков учитывалась не только стоимость первоначальных вложений – CAPEX, но и OPEX — стоимость поддержки и сопровождения решения в течение 5 лет.
Когда заказчик говорит о непрерывности в случае как локальных, так и глобальных сбоев, необходим резервный ЦОД. Если что-то в основном ЦОДе сгорит, то через некоторое время системы смогут возобновить работу, развернувшись на новом месте.
В нашем же случае ИТ-инфраструктура должна была быть готова не позднее 2 часов с момента сбоя. Поэтому холодный резерв в виде альтернативной площадки в лучшем случае с пустыми серверами нам не подходил.
Соответственно, требовался либо «теплый» резерв, либо «горячий». Заказчики, как нормальные иностранцы, предъявляли требования, чтобы между ЦОДами было не менее 100 км для исключения всякого влияния (веерного отключения ЛЭП или, например, глобальной катастрофы в Москве). С экономической точки зрения синхронная репликация была не целесообразна, так как потребовались бы существенные инвестиции в канал между ЦОД, трафик по которому должен был быть зашифрован. С технической точки зрения задержки на таком расстоянии между ЦОД уже могли начать влиять на скорость работы информационных систем, поэтому был выбран вариант с асинхронной репликацией между ЦОД.
Для информационных систем, работающих на архитектуре RISC, были выбраны сервера E870 на платформе IBM Power. Они предназначены для размещения бизнес-критичных нагрузок с самым высоким уровнем доступности и обладают полным набором функционала RAS (Reliability, Availability and Serviceability).
Эти серверы виртуализуются на аппаратном уровне с помощью IBM PowerVM, и в них создаются разделы виртуальных серверов (LPAR). В LPAR выделяют процессорные ядра для выполнения нагрузки. Их можно выделить в LPAR как монопольно – без переподписки ресурсов, так и в общий пул для совместного использования пулом виртуальных серверов. Можно ограничить предельное потребление ресурсов из общего пула виртуальных серверов сверху в пиковых режимах. Архитектура подсистем Power представлена на рисунке ниже.

Рис. Архитектура подсистем IBM Power
Любые серверы, даже такие надежные как IBM Power E870, где практически все задублировано, могут отказать. Поэтому для защиты от сбоя сервера используется программное обеспечение высокой доступности (HA). В нашем случае наиболее хорошо подходило кластерное ПО – Veritas Infoscale. Это ПО имеет существенное преимущество перед решениями с простым HA. Оно позволяет сделать одновременно локальный кластер (HA) как между серверами на одной площадке, так и между площадками (DR). В итоге заказчик будет застрахован от локального сбоя и сбоя всего основного ЦОДа.
Veritas Infoscale позволяет организовать 3-х стороннюю репликацию данных. Это когда данные дублируются в 2-ух местах на одной площадке и одновременно идет непрерывная IP репликация в РЦОД. Технически, возможно было бы сделать это и более простыми и дешевыми средствами, но существенный плюс ПО Veritas Infoscale в том, что в случае сбоя одной из реплик на локальной площадке не потребуется вручную перенастраивать репликацию. В результате данные клиента постоянно остаются под защитой, даже в случае локального сбоя.
Структурная схема созданной целевой архитектуры катастрофоустойчивого решения для банка на базе двух кластеров с внешними логическими томами представлена на рисунке ниже.

Рис. Структурная схема созданной целевой архитектуры катастрофоустойчивого решения
Сервера E870 стоят недешево. На этих серверах, в отличие от более простых серверов, лицензируются активации процессорных ядер. Ввиду этого был соблазн взять более простые машины типа S824, но они обладают меньшей надежностью, а самое главное — меньшей вертикальной масштабируемостью. У клиента есть одна функциональная задача, выполнение которой сейчас могло бы занять целый такой сервер S824. Сначала сервер работал бы, но через пару лет производительности бы уже не хватило.
Однако в серверах High End IBM Power (в том числе E870) можно максимально эффективно использовать активации процессоров и памяти, объединяя их в общий Enterprise Pool. Активации из пула можно использовать на любом из серверов пула. Для оптимизации стоимости решения на резервных серверах можно закупить меньше активаций по сравнению с основным, что и было нами сделано. В тоже время в случае сбоя на этих серверах можно будет использовать весь объем активаций пула.
Для информационных систем, работающих на x86/VMware, было выбрано решение на блейд-серверах HP Proliant Bl460 Gen9 и ПО виртуализации VMware vSphere Enterprise Plus. Архитектура подсистемы серверной виртуализации показана на рисунке ниже.

Рис. Архитектура подсистемы серверной виртуализации
Для защиты от сбоя одного хоста использовалась кластерная технология VMware High Availability, которая позволяет рестартовать виртуальные машины сбойного хоста на других.
Образы и данные виртуальных машин хранятся на нескольких СХД. Бизнес-критичные данные дублируются на как минимум 2-мя СХД и презентуются хостам через виртуализатор СХД EMC VPLEX. Это позволяет исключить одну СХД как точку отказа. Сбои на 2-ух контроллерной СХД обычно редки, но они бывают. Может отказать батарейка кэш-памяти одного контроллера, что приведет к выключению кэша и существенной деградации производительности.
Данные передаются через сеть хранения данных по Fibre Channel с использованием 2-ух фабрик для резервирования от логических и физических сбоев. Фабрики между ОЦОД и РЦОД не объединяются из-за существенного расстояния между ними (более 600 км).
Для защиты от катастрофы в ОЦОД применено апробированное решение на базе VMware SRM и репликации с помощью выделенных устройств — EMC RecoverPoint. Они дублируют все операции вывода из ОЦОД в РЦОД в асинхронном режиме. В случае достаточной пропускной способности канала такая репликация дает RPO близкое к 0. Устройства RecoverPoint позволяют сжимать трафик между площадками и передавать только уникальные блоки, что снижает требования к каналу.
Кроме того, они позволяют также откатить тома с данными на определенный момент времени, что дает защиту от логических сбоев. Если логический сбой случается в определенный момент времени, администратор имеет возможность откатиться на состояние до сбоя.
Сейчас многие банки задумываются или уже создают свой резервный ЦОД (или РЦОД). Однако этого может быть недостаточно, поскольку дата-центры в Москве могут иметь общую инфраструктуру. Оба дата-центра могут питаться через одну подстанцию, может произойти веерное отключение подстанций, оптические трасы к ЦОД могут подходить через одну точку…
Преимущество созданного нами комплекса решений EMC VPLEX + EMC RecoverPoint + VMware vSphere HA позволяет обеспечить защиту от сбоев на базе 3-ех ЦОД – двух близко расположенных и одного расположенного относительно далеко на случай катастрофы. Это позволяет банку получить синхронную репликацию с нулевой потерей данных в случае сбоя в одном ЦОД, а также защиту от глобальных катастроф.
В нашем проекте мы реализовали 2-е площадки – ОЦОД и РЦОД. Но в ОЦОД мы разместили 2-а комплекта оборудования. Получается, как 2-а ЦОД в одном. В обычном случае полезная нагрузка работает на обоих, но в случае отказа продуктивная нагрузка может работать и на одном комплекте. Это позволяет обеспечить самые высокие требования по доступности информационных систем в различных случаях сбоев.
Итак, в части СПД нам необходимо было построить катастрофоустойчивое решение на три ЦОДа для обеспечения максимальной доступности ИС.
Заказчик к началу проекта уже имел два ЦОДа с сетевым оборудованием Cisco. Использовались коммутаторы Nexus, включая FEX, а также DMVPN с филиальной сетью. Естественно, это определило сохранение вендора при модернизации сети.
В целом архитектура в основном ЦОДе у нас вышла классическая:
• в качестве ядра Nexus 5672;
• в качестве коммутаторов доступа Nexus 2000 серии;
• для портов управления использовался Catalyst 2960X.
В WAN и Internet сегментах:
• пара маршрутизаторов ASR 1001X для подключения к операторам с L3VPN облаками;
• пара маршрутизаторов ASR 1001X для организации функций DMVPN и QOS;
• маршрутизаторы ISR4431 для подключения к Интернет;
• файерволлы PaloAlto для связи с офисами;
• файерволлы Chackpoint для связи с Интернет.
В резервном ЦОДе все аналогично за исключением переиспользуемых моделей Nexus 5548UP и ASR1001. Также нужно упомянуть про Out of band (OOB) интернет-каналы в каждый ЦОД с отдельными межсетевыми экранами. Схемы там самые классические, поэтому здесь их даже не прилагаем.
Со связью с Интернетом получилось более интересное решение. У заказчика в наличии была только одна сеть PI /24. При этом было необходимо:
• анонсировать PI сеть только из основного ЦОД (ОЦОД) пока он жив (как в Интернет, так и вовнутрь СПД);
• PI сеть должна переезжать в РЦОД при отказе всего ЦОД;
• PI сеть должна переезжать при двойных отказах одного типа оборудования в ОЦОД: ядро, Интернет-каналы, маршрутизаторы, файерволлы или WAN коммутаторы;
• PI сеть не должна переезжать при двойных отказах аналогичного оборудования в резервном ЦОДе;
• PI сеть не должна переезжать при двойных отказах каналов между ЦОД;
• доступность Интернет-каналов должна проверяться по нескольким подсетям из Интернет (например, 8.8.8.0/24).
Таким образом, доступность ОЦОД из РЦОД нужно было проверять через внутреннюю сеть и через Интернет одновременно. Проверка доступности Интернета у нас осуществляется с помощью Cisco IP SLA. Естественно, в ОЦОД и РЦОД используется условное анонсирование PI сети по BGP в сторону операторов, а также условное анонсирование в локальную сеть в ОЦОД.
Ниже приведена логическая схема:

Как уже отмечалось, в проекте были использованы коммутаторы Nexus 5672UP. При их использовании обнаружено 2 бага, которые Cisco планирует переделать в фичи :)
Первое — медные breakout DAC кабели 40G на 4x10G. В нашем случае эти кабели были совместимы со всем оборудованием, но они периодически флаппали. Понятно, что даунтайм небольшой, но это происходило достаточно часто. Сами кабели изображены ниже:

В итоге после долгих тестов, медь заменили оптикой, и все проблемы исчезли. Оптические кабели, на которые заменили ниже:

Вроде бы Cisco пока планирует исправлять документацию – исключать данные кабели из списка совместимых. Так что лучше не экономить и покупать только оптические DAC кабели.
Про Nexus 7000 серии есть вот такой документ. Ключевая фраза «Passive copper optic cables are not supported on the non-EDC ports». Получается, что вся пассивная QSFP медь может некорректно работать и на Nexus 5600 серии.
Второе — Microsoft SLB. Все помнят режим, при котором на сети настраиваются статические ARP и MAC записи без IGMP. Причем, если не указать статические MAC записи, то пакеты будут флудиться по всему VLAN. Так вот, теперь последнее утверждение не будет верным для Nexus 5672UP. Чтобы данные передавались, нужно будет в обязательном порядке указывать статические mac записи. Под этот кейс Cisco тоже планирует изменить документацию.
При модернизации связь между Main ЦОД и DR ЦОД, а также между ЦОД и филиалами должна быть переведена на шифрование с ГОСТ алгоритмами. Между ОЦОД и РЦОД достаточно было L3 связности.
Сетевое оборудование Cisco ничего не должно знать о криптошлюзах, поэтому поверх шифрованных туннелей мы построили GRE/mGRE. Таким образом, остаются работать протокол динамической маршрутизации EIGRP.
Криптошлюзы в обоих ЦОД должны строить VPN-туннель между собой, а также до филиалов. В качестве криптошлюзов были выбраны S-Terra. Одной из причин стала очень похожая настройка на Cisco. В принципе такой вариант работы с S-Terra описан на их сайте, поэтому ничего сложного обычно не возникает.
Что касается времени восстановления при отказах для сети, то, как известно, оно зависит от используемых технологий и протоколов, а также схемы резервирования оборудования и каналов.
Все сетевое оборудование и каналы резервировались по схеме 1+1.Для резервирования на канальном уровне использовались популярные вещи LAСP и VPC с субсекундным временем восстановления после отказа.
В данном проекте у заказчика уже использовались протоколы EIGRP в локальной сети, между филиалами и BGP для взаимодействия с операторами. В случае локальной сети EIGRP делает конвергенцию с субсекундными таймерами при обнаружении отказа. По сравнению с OSPF протокол EIGRP для таких результатов гораздо проще настраивать. Нужно только выполнять одно из двух условий для резервного маршрута – equal cost multi path (ECMP) или feasible successor. В OSPF для этого придется тюнить много таймеров.
В целом, в локальной сети практически невозможны неявные отказы оборудования или кабелей. Поэтому общее время конвергенции будет меньше 1 секунды. Если говорить про WAN сегмент и всю распределенную сеть (связь между филиалами и ЦОД), то максимальное время восстановления при отказах составит 5 секунд.
В случае связи с интернетом, время восстановления получается, конечно, больше – до 1 минуты. У заказчика уже была своя PI сеть. В рамках модернизации в BGP стали принимать всю таблицу маршрутизации. Собственно это нужно, чтобы защититься от некоторых отказов внутри интернет провайдеров. Так, мы исключаем ситуацию, когда BGP peer виден, но дальше со связью все плохо.
Чтобы добиться восстановления интернета за 1 минуту при отказе оборудования или канала необходимо договариваться с операторами об уменьшении keepalive и hold таймеров. На практике у нас показывают хорошие результаты keepalive в 3 секунды и hold в 10 секунд. Флапов при таких значениях никогда не происходит, хотя при 2-х и 7 секунд соответственно — уже наблюдаются. Правда, не все операторы готовы по умолчанию поддерживать такие значения, но договориться можно. :)
На этом все. Заказчик доволен. Если есть вопросы по решению, будем рады ответить.
Авторы материала:
Артем Бурдин, инженер-проектировщик отдела вычислительных систем центра компетенций по вычислительным комплексам компании «Техносерв»
Михаил Шеронкин, руководитель направления корпоративных сетей центра компетенций по сетевым технологиям компании «Техносерв»
|
|
Вуз или техникум: куда поступать, чтобы удачно трудоустроиться и хорошо зарабатывать? |
|
|
[Из песочницы] Как я заказывал мобильное приложение |




|
Метки: author StanislavZh growth hacking увеличить продажи разработка мобильного приложения отдел продаж улучшить конверсию повысить конверсию |
Google Developer Days приходит в Европу |

Нам в Google очень нравится встречаться и общаться с разработчиками. Это помогает нам лучше понимать ваши потребности и улучшать наши продукты, чтобы они подходили для самых разных регионов, где вы работаете. Мероприятия для разработчиков — отличный способ сделать это. Именно поэтому мы проводим различные мероприятия, где мы можем общаться напрямую с разработчиками. Сегодня мы запустили специальный сайт и открываем регистрацию для европейской части нашей глобальной серии мероприятий для разработчиков – Google Developers Days (GDD).
Google Developers Days — это событие, на котором мы расскажем про последние обновления наших продуктов и платформ для разработчиков, которые помогут вам и дальше разрабатывать высококачественные приложения, развивать ваши продукты и сохранять активную базу пользователей. GDD Europe пройдет 5 и 6 сентября в Кракове в Польше. Вас ожидают технические доклады по целому ряду продуктов, включая Android, Mobile Web, Firebase, Cloud, Machine Learning и IoT. В дополнение к техническим докладам у всех участников будет возможность присоединиться к практическим занятиям, один на один пообщаться с сотрудниками Google и Google Developers Experts.

Если вы заинтересованы и хотите к нам присоединиться, то регистрация уже открыта. Сейчас билеты можно купить со скидкой, по цене в 199$ (полная цена 250$). Учтите, что количество билетов ограниченно.
Если вы по каким-то причинам не можете добраться до Кракова — никаких проблем! Все доклады будут доступны в прямом эфире на YouTube канале Google Developers, а после будут доступны в виде записей. Всегда здорово смотреть такие мероприятия в компании с другими разработчиками, поэтому в разных городах и регионах будут проходить GDD Extended. Это такой формат, когда разработчики собираются для совместного просмотра и обсуждения прямой трансляции. Как правило, Google Developers Groups в разных городах организуют такие мероприятия. Если в вашем регионе кто-то уже организовал GDD Extended, то подумайте о том, чтобы посетить его. Не нашли такое поблизости, но всё ещё хотите собрать коллег по цеху, чтобы вместе обсудить последние новинки? Вы можете организовать GDD Extended самостоятельно.
Независимо от того, есть ли у вас возможность присоединиться к нам лично или удаленно, будьте в курсе последних новостей, следите за специальным хештегом – #GDDEurope в Twitter, Facebook и Google+.
С нетерпением ждем скорой встречи с вами в Европе!
|
|
Агрегация интернет-каналов через операторов сотовой связи |

Приятно иметь в поездке надежный и быстрый интернет, особенно в поезде, когда ехать придется не один час! Если путь пролегает в густонаселенном районе — на любом современном телефоне с поддержкой сетей 4G обычно всё просто работает, мы продолжаем пользоваться интернетом, как привыкли. Естественно, всё меняется, когда выезжаешь за пределы населенных пунктов.
В движущийся транспорт интернет можно подать только двумя путями:
В нашем случае бюджета на создания своей инфраструктуры для передачи данных никто в здравом уме, конечно же, не выделит, поэтому в распоряжении есть только спутниковый канал и инфраструктура «сотовиков». Выбор еще раз упростился, когда финмодель заказчика не выдержала реализации через спутниковый канал. Поэтому дальше речь пойдет о том, как подать в движущийся транспорт максимально устойчивый канал через операторов сотовой связи.
Суть агрегации каналов передачи данных можно выразить коротко: суммировать емкость, предоставленную разными физическими линиями. Условно, если у нас есть четыре канала емкостью 1 Мбит/с каждый, на выходе мы должны получить один канал емкостью 4 Мбит/с. В нашем случае есть четыре оператора сотовой связи, через каждый из них в пределе можно выжать до 70 Мбит/с, а в сумме, если звезды сойдутся правильно, — 280 Мбит/с.
Кто-то скажет, что 280 Мбит/с никак не хватит на всех пассажиров поезда, коих в среднем 700 человек, и что получить такую скорость за пределами населенных пунктов нельзя. Более того, там, где связи нет совсем, никакой магии не произойдет: в транспорте также связи не будет. Конечно, этот кто-то совершенно прав. Поэтому мы решаем задачу не комфортного канала для всех, а хоть какого-то — там, где обычные смартфоны физически не в состоянии установить связь.
Этот пост о том, как нам пришлось с нуля изобрести велосипед, чтобы добыть интернет в автомобильном и железнодорожном транспорте для одного индийского оператора железнодорожных путей, как мы фиксировали перемещения этого транспорта и качество канала передачи данных в каждой точке пути с последующим хранением в кластере Tarantool.
Агрегация решает задачу отказоустойчивости и/или суммирования емкости каналов передачи данных, участвующих в агрегации. В зависимости от типа агрегации, топологии сети и оборудования реализация может кардинально отличаться.
Каждый тип агрегации достоин отдельной статьи, но у нас конкретная задача: насколько возможно, обеспечить надежным и максимально «широким» каналом ПД транспортные средства.
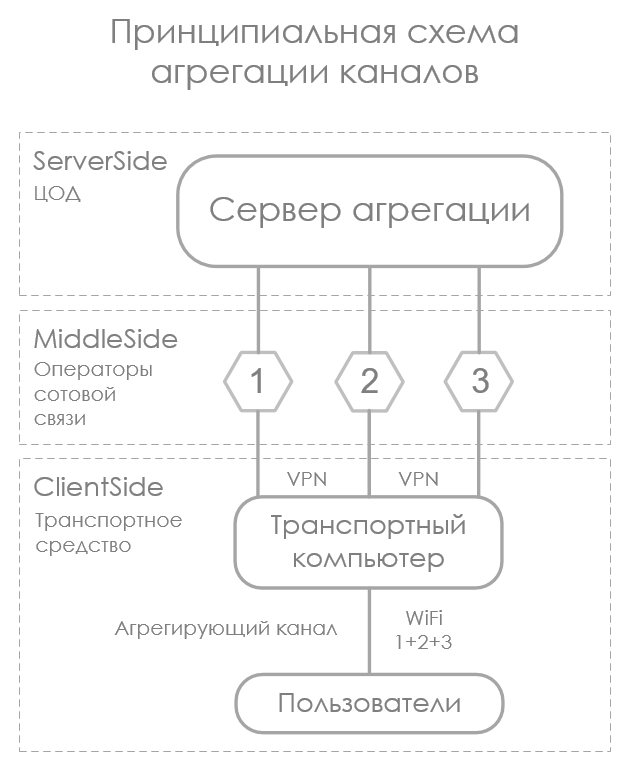
Инфраструктура операторов сотовой связи дает основу для задачи:
Технически агрегация очень проста и многократно описана, вы без труда сможете найти информацию любой глубины изложения. Вкратце суть такая.
Со стороны клиентского оборудования:
Необходимость самостоятельно анализировать каналы через разных операторов сотовой связи с мониторингом уровня сигнала оператора, типа связи, информации о загрузке базовой станции, ошибок в сети передачи данных оператора (не путать с L3-тоннелем) и на основе этих метрик распределять поток данных разрешает Google сообщить нам, что придется писать решение самостоятельно.
К слову, есть решения разного уровня приемлемости, в которых агрегация работает. Например, стандартный bonding интерфейсов в Linux. Поднимаем L3-тоннель через любой доступный инструментарий, хоть через VPN-сервер или SSH-тоннель, настраиваем вручную маршрутизацию и добавляем в бондинг виртуальные интерфейсы тоннелей. Всё будет нормально, пока емкость тоннелей в каждый момент времени одинакова. Дело в том, что при такой топологии сети работает только режим агрегации balance-rr, т. е. в каждый тоннель попадает равное количество байтов по очереди. Это значит, что если у нас будет три канала емкостью (Мбит/с) 100, 100 и 1, то результирующая емкость окажется 3 Мбит/с. То есть минимальная ширина канала умножается на количество каналов. Если емкость — 100, 100, 100, то результирующая будет 300.
Есть другое решение: прекрасный opensource-проект Vtrunkd, который после долгого забвения был реанимирован в 2016 году. Там уже есть почти всё, что нужно. Мы честно написали создателям, что готовы заплатить за доработку решения в части мониторинга метрик качества связи сотовых операторов и включить эти метрики в механизм распределения трафика, но ответа, к сожалению, так и не получили, поэтому решили написать свой вариант с нуля.
Начали с мониторинга метрик операторов сотовой связи (уровень сигнала, тип сети, ошибки сети и т. д.) Нужно отметить, что модемы выбирались как раз исходя из того, как хорошо они могут отдавать метрики операторов. Мы выбрали модем SIM7100 производства компании Simcom. Все интересующие нас метрики отдаются через обращение в последовательный порт. Этот же модем также отдает GPS/ГЛОНАСС-координаты с хорошей точностью. Также необходимо отслеживать статус метрик компьютера (температуру CPU, SSD, свободное количество оперативной памяти и дискового пространства, S.M.A.R.T. показатели SSD). Отдельно модуль мониторит статистику сетевых интерфейсов (наличие ошибок на прием и отправку, длина очереди на отправку, количество переданных байтов). Поскольку производительность устройства крайне ограничена и пакет передаваемых данных должен быть минимален, а также учитывая простоту мониторинга этих метрик под Linux через /proc/sys, вся подсистема мониторинга также была разработана с нуля.
После того как модуль мониторинга метрик был готов, приступили к сетевой части: программной агрегации каналов. К сожалению, детальный алгоритм — коммерческая тайна, опубликовать его я не могу. Всё же опишу в общих чертах, как работает модуль агрегации, установленный в транспорте:
Серверная часть агрегации работает радикально проще. При старте модуль агрегации обращается к серверу настроек, получает конфигурацию в JSON-формате и на ее основе запускает L3-интерфейсы. В целом всё тривиально.
Отдельно стоит описать систему сбора и визуализации всех метрик проекта. Она поделена на две большие части. Первая часть — мониторинг систем жизнеобеспечения клиентского и серверного оборудования. Вторая — мониторинг бизнес-метрик работы проекта.
Стек технологий проекта стандартный. Визуализация: Grafana, OpenStreetMap, сервер приложений на клиентской и серверной стороне: Go, СУБД Tarantool.
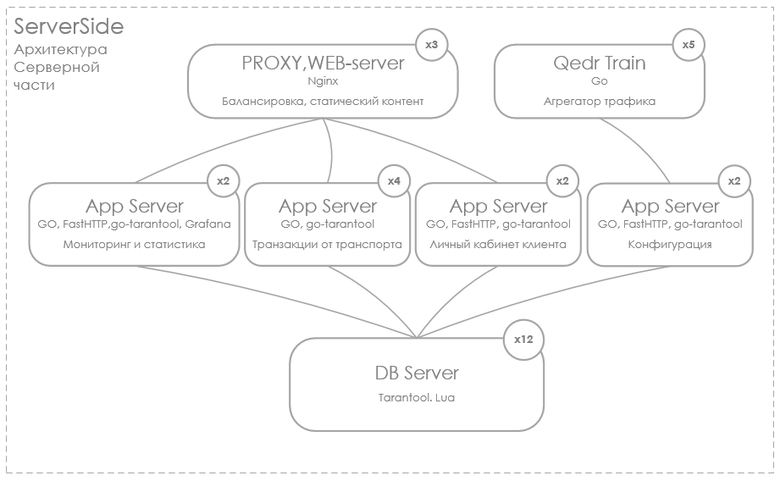
История эволюции СУБД в наших проектах начинается с PostgreSQL в 2009 году. Мы успешно хранили в нем геоданные от бортовых устройств, установленных на спецтранспорте. Модуль PostGIS вполне справлялся с задачами. Со временем очень сильно стало не хватать производительности в обработке данных без схемы хранения. Экспериментировали с MongoDB c версии 2.4 до версии 3.2. Пару раз не смогли восстановить данные после аварийного отключения (полностью дублировать данные не позволял бюджет). Далее обратили внимание на ArangoDB. Если учесть, что бэкенд в то время мы писали на JavaScript, стек технологий выглядел очень приятно. Однако и эта базейка, побыв с нами добрые два года, ушла в прошлое: мы не смогли контролировать потребление оперативной памяти на больших объемах данных. В этом проекте обратили внимание на Tarantool. Ключевым для нас было следующее:
На первый взгляд, всё в ней хорошо, за исключением того, что работает она только на одном ядре процессора. Ради науки провели ряд экспериментов, чтобы понять, будет ли это препятствием. После тестов на целевом железе убедились, что для этого проекта СУБД справляется с обязанностями прекрасно.
У нас всего три основных профиля данных: это финансовые операции, временные ряды (т. е. журналы работы систем) и геоданные.
Финансовые операции — это информация о движении денег по лицевому счету каждого устройства. Любое устройство имеет как минимум три SIM-карты от разных операторов связи, поэтому нужно контролировать баланс лицевого счета у каждого оператора связи и, чтобы не допустить отключения, заранее знать, когда пополнить баланс для каждого оператора каждого устройства.
Временные ряды — просто журналы мониторинга от всех подсистем, включая журнал совокупной пропускной полосы для каждого устройства в транспорте. Это дает нам возможность знать, в какой точке пути какой был канал по каждому оператору. Эти данные используются для аналитики покрытия сетью, что, в свою очередь, нужно для упреждающего переключения и развесовки каналов по операторам связи. Если мы заранее знаем, что в конкретной точке у такого-то оператора худшее качество, мы заранее отключаем этот канал из агрегации.
Геоданные — простой трек транспортного средства по пути следования. Каждую секунду мы опрашиваем GPS-датчик, встроенный в модем, и получаем координаты и высоту над уровнем моря. Трек длительностью 10 минут собирается в пакет и отправляется в ЦОД. По требованию заказчика эти данные должны храниться вечно, что при возрастающем количестве транспортных средств заставляет заранее очень серьезно планировать инфраструктуру. Однако в Tarantool шардинг сделан очень просто, и ломать голову над масштабированием хранилища под самые быстрорастущие данные никакой необходимости нет. Резервная копия данных не пишется, поскольку исторической ценности сейчас в этих данных нет.
Для всех типов данных мы использовали движок Vinyl (хранение данных на диске). Финансовых операций не так много, и нет смысла всегда хранить их в памяти, как и журналы, естественно, и геоданные, пока по ним не будет производиться аналитика. Когда аналитика потребуется, в зависимости от требований к быстродействию, возможно, будет иметь смысл подготовить уже агрегированные данные и хранить их на движке InMemory, а далее анализировать эти данные. Но всё это начнется, когда заказчик сформирует свои требования.
Важно отметить, что Tarantool прекрасно справился с нашей задачей. Он одинаково комфортно себя чувствует на ограниченном в ресурсах устройстве и в ЦОДе на десять шардов. Спецификация устройств, которые стоят в транспорте:
CPU: ARMv8, 4Core, 1.1 Ghz
RAM: 2 Gb
Storage: 32 GB SSD
Спецификация сервера ЦОДа:
СPU x64 Intel Corei7, 8Core, 3.2 Ghz
RAM: 32 Gb
Storage: 2 x 512 Gb (Soft Raid 0)
Как я уже говорил, репликация данных из транспорта в ЦОД налажена средствами самой СУБД. Шардинг данных между десятью шардами — также функционал «из коробки». Вся информация присутствует на сайте Tarantool, и описывать это тут, думаю, не нужно. В настоящий момент система обслуживает всего 866 транспортных средств. Заказчик планирует расширение до 8 тысяч.
Александр Родин, CIO и основной разработчик (да, такое случается не только в стартапах) проекта Qedr Train компании «Региональные телематические системы». Если возникнут вопросы, пишите в комменты или на a.rodin@r-t-s.ru. Постараюсь по возможности ответить всем.
|
Метки: author r1alex разработка систем передачи данных геоинформационные сервисы анализ и проектирование систем блог компании mail.ru group tarantool go агрегация каналов |
Вышел первый накопитель на 64-слойной 3D TLC NAND от компании Intel |
 / Flickr / Laineema / CC
/ Flickr / Laineema / CC
|
Метки: author 1cloud хранение данных блог компании 1cloud.ru сloud 3d nand |
[Перевод - recovery mode ] Import() из webpack вскоре освоит JS+CSS, а вот как вы можете пользоваться этим уже сейчас |

import() вернут вам 2 файла: JS + CSS.Большой план
В долгосрочной перспективе мы хотим сделать добавить “первоклассный” модуль поддержки CSS в webpack. Он будет работать следующим образом:
- Мы добавляем новый тип модуля в webpack: Stylesheet (рядом с Javascript)
- Мы настраиваем шаблоны фрагментов для записи двух файлов. Один для javascript и один для таблиц стилей (в файле .css).
- Мы настраиваем логику загрузки блока, чтобы можно было загружать таблицы стилей. Нам нужно дождаться применения CSS или, по крайней мере, его загрузки, перед выполнением JS.
- Когда мы генерируем загрузку фрагмента кода, мы можем параллельно загружать часть js и часть таблицы стилей (в сочетании с Promise.all)
extract-text-webpack-plugin не осуществляет этого. Доступная на сегодня бета-версия 3.0 не поддерживает данного функционала. Существует конечно мой extract-css-chunks-webpack-plugin, который какое-то время находился в активном пользовании, но он недостаточно хорош. Недостаточно хорошо он потому, что компиляция выполняется медленно и не увеличивает кеширование в браузере. Причина в том, что он создает 2 разных фрагмента JS для того, что в основе всей этой идеи должно идти как неделимое целое. Эти фрагменты:import() не хватает css.react-universal-component и webpack-flush-chunks по средствам которых вы можете легко и универсально рендерить свое приложение одновременно с разделением кода. Впервые в качестве общедоступного пакета NPM (не требуется никаких фреймворков). Для тех, кто не в курсе, вынос заключается в следующем: рендер на стороне сервера (SSR) — это решённая проблема, разделение кода — это решённая проблема, но до этих самых пор использование обоих разом оставалось проблемой не разрешённой.babel-plugin-dual-import преобразует ваш запрос в Promise.all и, в качестве бонуса, он автоматически выдает вам webpackChunkName. “Волшебные комментарии” настолько волшебны, что они исчезают! Разумеется, под капотом я использую их для генерации имен ваших фрагментов кода.extract-css-chunks-webpack-plugin 2.0, я обошёл серьезную проблему производительности с точки зрения времени сборки (не более двух JS-фрагментов), и теперь все, с чем вы имеете дело, это таблицы стилей, которые браузеры ваших пользователей могут кэшировать. И да, быстрая замена модулей (HMR) все еще работает (лучше, чем когда-либо на самом деле).yarn add --dev babel-plugin-dual-import{
"presets": [whatever you usually have],
"plugins": ["dual-import"]
}import('./Foo.js')
V V V V V V
import { importCss } from 'babel-plugin-dual-import/importCss.js'
Promise.all ( [
import( /* webpackChunkName: 'Foo' */ './Foo'),
importCss('Foo')
] ).then(promises => promises[0]);import('../base/${page}')
V V V V V V
import { importCss } from 'babel-plugin-dual-import/importCss.js'
Promise.all([
import( /* webpackChunkName: 'base/[request]' */ `./base/${page}`),
importCss(`base/${page}`)]
).then(promises => promises[0]);webpack-flush-chunks, новое дополнение — это cssHash, которое похоже на то, что webpack кладёт в bootstrap скрипт, сопоставляя фрагменты javascript с их идентификаторами. cssHash ориентирует имена фрагментов css в файлы их стилей. Babel-plugin-dynamic-import запрашивает таблицы стилей оттуда параллельно с импортом javascript.|
Метки: author Grinzzly *nix webpack javascript css |
[Из песочницы] Исторический очерк о великом математике Карле Фридрихе Гауссе |
Математик и историк математики Джереми Грей рассказывает Гауссе и его огромном вкладе в науку, о теории квадратичных форм, открытии Цереры, и неевклидову геометрию*

Портрет Гаусса Эдуарда Ритмюллера на террасе обсерватории Геттингена // Карл Фридрих Гаусс: Титан науки Г. Уолдо Даннингтона, Джереми Грея, Фриц-Эгберт Дохе
Карл Фридрих Гаусс был немецким математиком и астрономом. Он родился у бедных родителей в Брауншвейге в 1777 году и скончался в Геттингене в Германии в 1855 году, и к тому времени все, кто его знал, считали его одним из величайших математиков всех времен.
Как мы изучаем Карла Фридриха Гаусса? Ну, когда дело доходит до его ранней жизни, мы должны полагаться на семейные истории, которыми поделилась его мать, когда он стал знаменитым. Конечно, эти истории склонны к преувеличению, но его замечательный талант был заметен, уже когда Гаусс был в раннем подростковом возрасте. С тех пор у нас появляется все больше записей о его жизни.
Когда Гаусс вырос и стал замечен, у нас начали появляться письма о нем людьми, которые его знали, а также официальными отчетами разного рода. У нас также есть длинная биография его друга, написанная на основе бесед, которые они имели в конце жизни Гаусса. У нас есть его публикации, у нас очень много его писем к другим людям, и много материала он написал, но так и не опубликовал. И, наконец, у нас есть некрологи.
Отец Гаусса занимался различными делами, был рабочим, мастером строительной площадки и купеческим ассистентом. Его мать была умной, но едва грамотной, и посвятила всю себя Гауссу до самой своей смерти в возрасте 97 лет. Похоже, что Гаусс был замечен как одаренный ученик еще в школе, в одиннадцать лет, его отца убедили отправить его в местную академическую школу, вместо того, чтобы заставить его работать. В то время Герцог Брауншвейгский стремился модернизировать своё герцогство, и привлекал талантливых людей, которые бы помогли ему в этом. Когда Гауссу исполнилось пятнадцать, герцог привел его в коллегию Каролинум для получения им высшего образования, хотя к тому времени Гаусс уже самостоятельно изучил латынь и математику на уровне высшей школы. В возрасте восемнадцати лет он поступил в Геттингенский университет, а в двадцать один уже написал докторскую диссертацию.
Первоначально Гаусс собирался изучать филологию, приоритетный предмет в Германии того времени, но он также проводил обширные исследования по алгебраическому построению правильных многоугольников. В связи с тем, что вершины правильного многоугольника из N сторон задаются решением уравнения (что численно равно . Гаусс обнаружил, что при n = 17 уравнение факторизуется таким образом, что правильный 17-сторонний многоугольник может быть построен только по линейке и циркуля. Это был совершенно новый результат, греческие геометры не подозревали об этом, и открытие вызвало небольшую сенсацию — новости об этом даже были опубликованы в городской газете. Этот успех, который пришел, когда ему едва исполнилось девятнадцать, заставил его принять решение изучать математику.
Но то, что сделало его знаменитым, было два совершенно разных явления в 1801 году. Первым было издание его книги под названием «Арифметические рассуждения», которая полностью переписала теорию чисел и привела к тому, что она( теория чисел) стала, и до сих пор является, одним из центральных предметов математики. Она включает в себя теорию уравнений вида x ^ n — 1, являющейся одновременно очень оригинальной и в то же время легко воспринимаемой, а также гораздо более сложную теорию, называемую теорией квадратичной формой. Это уже привлекло внимание двух ведущих французских математиков, Джозефа Луи Лагранжа и Адриена Мари Лежандра, которые признали, что Гаусс ушел очень далеко за пределы всего того, что они делали.
Вторым важным событием было повторное открытие Гауссом первого известного астероида. Он был найден в 1800 году итальянским астрономом Джузеппе Пьяцци, который назвал его Церерой в честь римской богини земледелия. Он наблюдал ее в течение 41 ночи, прежде чем она исчезла за солнцем. Это было очень захватывающее открытие, и астрономы очень хотели знать, где он появится снова. Только Гаусс рассчитал это правильно, чего не сделал никто из профессионалов, и это сделало его имя как астронома, которым он и остался на многие годы вперед.
Первая работа Гаусса была математиком в Геттингене, но после открытия Цереры, а затем и других астероидов он постепенно переключил свои интересы на астрономию, а в 1897 году стал директором Геттингенской обсерватории, и занимал эту должность почти до самой смерти. Он также оставался профессором математики в Геттингенском университете, но это, похоже, не требовало от него большого преподавания, а записи о его контактах с молодыми поколениями была довольно незначительной. Фактически, он, кажется, был отчужденной фигурой, более комфортной и общительной с астрономами, и немногими хорошими математиками в его жизни.
В 1820-х годах он руководил массированным исследованием северной Германии и южной Дании и в ходе этого переписывал теорию геометрии поверхностей или дифференциальную геометрию, как ее называют сегодня.
Гаусс женился дважды, в первый раз довольно счастливо, но когда его жена Джоанна умерла во время родов в 1809 году, он снова женился на Минне Вальдек, но этот брак оказался менее успешным; Она умерла в 1831 году. У него было трое сыновей, двое из которых эмигрировали в Соединенные Штаты, скорее всего, потому что их отношения с отцом были проблемными. В результате в Штатах существует активная группа людей, которые ведут свое происхождение от Гаусса. У него также было две дочери, по одной от каждого брака.
Рассматривая вклад Гаусса в этой области, мы можем начать с метода наименьших квадратов в статистике, который он изобрел, чтобы понять данные Пьяцци и найти астероид Церера. Это был прорыв в усреднении большого количества наблюдений, все из которых были немного не точными, чтобы получить из них наиболее достоверную информацию. Что касается теории чисел, говорить об этом можно очень долго, но он сделал замечательные открытия о том, какие числа могут быть выражены квадратичными формами, которые являются выражениями вида . Вам может казаться, что это важно, но Гаусс превратил то, что было собранием разрозненных результатов в систематическую теорию, и показал, что многие простые и естественные гипотезы имеют доказательства, которые лежат в том, что похоже на другие разделы математики вообще. Некоторые приемы, которые он изобрел, оказались важными и в других областях математики, но Гаусс обнаружил их еще до того, как эти ветви были правильно изучены: теория групп — пример.
Его работа по уравнениям вида и, что более удивительно, по глубоким особенностям теории квадратичных форм, открыла использование комплексных чисел, например, для доказательства результатов о целых числах. Это говорит о том, что многое происходило под поверхностью предмета.
Позже, в 1820-х годах, он обнаружил, что существует концепция кривизны поверхности, которая является неотъемлемой частью поверхности. Это объясняет, почему некоторые поверхности не могут быть точно скопированы на другие, без преобразований, как мы не можем сделать точную карту Земли на листе бумаги. Это освободило изучение поверхностей от изучения твердых тел: у вас может быть яблочная кожура, без необходимости представления яблока под ней.

Поверхность с отрицательной кривизной, где сумма углов треугольника меньше, чем у треугольника на плоскости //source:Wikipedia
В 1840-х годах, независимо от английского математика Джорджа Грина, он изобрел предмет теории потенциала, который является огромным расширением исчисления функций нескольких переменных. Это правильная математика для изучения гравитации и электромагнетизма и с тех пор используется во многих областях прикладной математики.
И мы также должны помнить, что Гаусс открыл, но не опубликовал довольно много. Никто не знает, почему он так много сделал для себя, но одна теория состоит в том, что поток новых идей, которые он держал в голове был еще более захватывающим. Он убедил себя в том, что геометрия Евклида не обязательно истинна и что по крайней мере одна другая геометрия логически возможна. Слава этому открытию досталась двум другим математикам, Бойяю в Румынии-Венгрии и Лобачевскому в России, но только после их смерти — настолько это было спорно в то время. И он много работал над так называемыми эллиптическими функциями — вы можете рассматривать их как обобщения синусоидальных и косинусных функций тригонометрии, но, если более точно, они являются сложными функциями комплексной переменной, а Гаусс изобрел целую теорию из них. Десять лет спустя Абель и Якоби прославились тем, что сделали то же самое, не зная, что это уже сделал Гаусс.
После своего повторного открытия первого астероида, Гаусс много работал над поиском других астероидов и вычислением их орбит. Это была трудная работа в докомпьютерную эпоху, но он обратился к своим талантам, и он, похоже, почувствовал, что это работа позволила ему выплатить свой долг принцу и обществу, которое дало ему образование.
Кроме того, во время съемки в северной Германии он изобрел гелиотроп для точной съемки, а в 1840-х годах он помог создать и построить первый электрический телеграф. Если бы он также подумал об усилителях, он мог бы отметиться и в этом, так как без них сигналы не могли путешествовать очень далеко.
Есть много причин, почему Карл Фридрих Гаусс по-прежнему так актуален сегодня. Прежде всего, теория чисел превратилась в огромный предмет с репутацией очень сложного. С тех пор некоторые из лучших математиков тяготеют к нему, и Гаусс дал им способ приблизиться к нему. Естественно, некоторые проблемы, которые он не смог решить, привлекли к себе внимание, поэтому вы можете сказать, что он создал целую область исследований. Оказывается, у этого также есть глубокие связи с теорией эллиптических функций.
Кроме того, его открытие внутренней концепции кривизны обогатило все изучение поверхностей и вдохновило на многие годы работы последующие поколения. Любой, кто изучает поверхности, от предприимчивых современных архитекторов до математиков, находится у него в долгу.
Внутренняя геометрия поверхностей простирается до идеи внутренней геометрии объектов более высокого порядка, таких как трехмерное пространство и четырехмерное пространство-время.
Общая теория относительности Эйнштейна и вся современная космология, в том числе изучение черных дыр, стали возможными благодаря тому, что Гаусс совершил этот прорыв. Идея неевклидовой геометрии, столь шокировавшая в свое время, заставляла людей осознавать, что может быть много видов строгой математики, некоторые из которых могут быть более точными или полезными — или просто интересными -, чем те, о которых мы знали.

Неевклидова геометрия // источник: Numberphile
Жизнь Гаусса породила много историй и анекдотов. Например, как ни невероятно, его мать любила говорить, что никто не преподавал основы арифметики Гауссу, но он сам справился с ней, слушая своего отца на работе. Несомненно, он был одним из немногих математиков с необычайной способностью к умственной арифметике и мог быстро и аккуратно проводить длинные вычисления в уме. Также сообщалось, что его сыновья говорили, что он отговаривал их от продолжения карьеры в науке, потому что «он не хотел, чтобы имя Гаусса ассоциировалось со второсортной работой».
В том же духе у него была пугающая привычка говорить людям, что он уже знал то, что они только что обнаружили. Наиболее известный случай, когда его старый университетский друг Фаркаш Бойаи написал ему, приложив копию открытия своего сына Яноса неевклидовой геометрии, Гаусс ответил, что он не может похвалить работу, заявив — «потому, что делать это все равно, что хвалить себя». Это не только преувеличивало то, что знал Гаусс в 1831 году, он и не сделал ничего, чтобы помочь молодому Бойи получить признание за его работу, и Янош настолько разочаровался, что больше никогда не публиковал его.
Однако у вас не должно создаться впечатления, что Гаусс был неприятным человеком. Он был принципиальным человеком, он был счастлив принять Софи Жермен как серьезного математика в то время, когда женщины были исключены из высшего образования, и он всегда стремился использовать свои таланты для продуктивного использования. Но его исключительные таланты, и, хотя мы можем только порадоваться за них, Радакторвероятно, сделали его очень одиноким.
Джереми Грей, доктор, заслуженный пр.фессор истории математики, Открытый университет.
* Неточный перевод.
|
|
[Перевод] 35 советов для тех, кто собирается на техническую конференцию |

|
|
[Перевод] Как создаются изометрические миры |


[
[1,1,1,1,1,1],
[1,0,0,0,0,1],
[1,0,0,0,0,1],
[1,0,0,0,0,1],
[1,0,0,0,0,1],
[1,1,1,1,1,1]
]0 обозначает тайл травы, а 1 — тайл стены. Расположив тайлы согласно данным уровня, мы создадим огороженную лужайку, показанную на рисунке:
[
[3,1,1,1,1,4],
[2,0,0,0,0,2],
[2,0,0,0,0,2],
[2,0,0,0,0,2],
[2,0,0,0,0,2],
[6,1,1,1,1,5]
]
for (i, loop through rows)
for (j, loop through columns)
x = j * tile width
y = i * tile height
tileType = levelData[i][j]
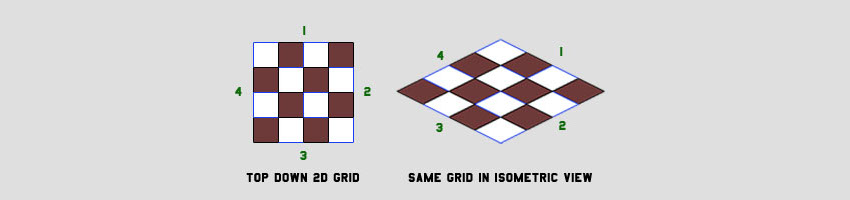
placetile(tileType, x, y)Мы наклоняем камеру по двум осям (поворачиваем камеру на 45 градусов вбок, потом на 30 градусов вниз). При этом создаётся ромбическая сетка, в которой ширина ячеек в два раза больше высоты. Такой стиль стал популярным благодаря стратегическим играм и экшн-RPG. Если посмотреть в этом виде на куб, то мы видим три его стороны (верхнюю и две боковые).
placeTile().x и y, а для изометрического вида нам нужно вычислить соответствующие изометрические координаты. Уравнения для этого представлены ниже. isoX и isoY обозначают изометрические координаты X и Y, а cartX и cartY — декартовы координаты X и Y://Преобразование из декартовых в изометрические координаты:
isoX = cartX - cartY;
isoY = (cartX + cartY) / 2;//Преобразование из изометрических в декартовы координаты:
cartX = (2 * isoY + isoX) / 2;
cartY = (2 * isoY - isoX) / 2;Point:function cartesianToIsometric(cartPt){
var tempPt=new Phaser.Point();
tempPt.x=cartPt.x-cartPt.y;
tempPt.y=(cartPt.x+cartPt.y)/2;
return (tempPt);
}function isometricToCartesian(isoPt){
var tempPt=new Phaser.Point();
tempPt.x=(2*isoPt.y+isoPt.x)/2;
tempPt.y=(2*isoPt.y-isoPt.x)/2;
return (tempPt);
}cartesianToIsometric для преобразования входных 2D-координат в изометрические внутри метода placeTile. За исключением этого, код отображения остаётся тем же, но нам нужно создать новые картинки тайлов. Мы не можем использовать старые квадратные тайлы из вида сверху. На рисунке ниже показаны новые изометрические тайлы травы и стен вместе с готовым изометрическим уровнем: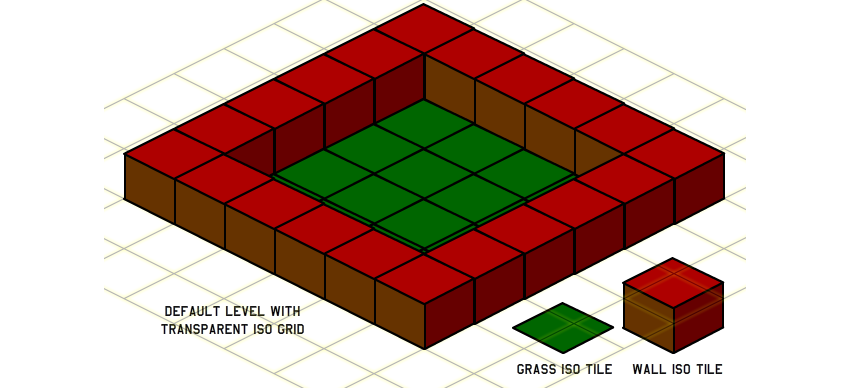
2D point = [100, 100];
// изометрическая точка вычисляется следующим образом
isoX = 100 - 100; // = 0
isoY = (100 + 100) / 2; // = 100
Iso point == [0, 100];[0, 0] преобразуются в [0, 0], а [10, 5] — в [5, 7.5].0 в нужной координате. Если равно, то это трава. Для этого нам нужно определять координаты массива. Мы можем найти координаты тайла в данных уровня из его декартовых координат с помощью этой функции:function getTileCoordinates(cartPt, tileHeight){
var tempPt=new Phaser.Point();
tempPt.x=Math.floor(cartPt.x/tileHeight);
tempPt.y=Math.floor(cartPt.y/tileHeight);
return(tempPt);
}getTileCoordinates(isometricToCartesian(screen point), tile height);[0,0]. Аналогом этого в Phaser является Pivot. Когда мы располагаем графику, скажем, в точке [10,20], то эта точка Pivot соответствует [10,20]. По умолчанию [0,0] или Pivot считается левая верхняя точка. Если вы попробуете создать приведённый выше уровень с помощью этого кода, то вы не получите нужного результата. Вместо этого у вас получится плоская земля без стен, как показано ниже:

y в двухмерных координатах, а затем преобразовать конечное положение в изометрические координаты:y = y + speed;
placetile(cartesianToIsometric(new Phaser.Point(x, y)))assets в репозитории исходного кода на git.for (i, loop through rows)
for (j, loop through columns)
x = j * tile width
y = i * tile height
tileType = levelData[i][j]
placetile(tileType, x, y)[1,1], то есть на самом верхнем зелёном тайле в изометрическом виде. Для правильной отрисовки уровня персонаж нужно отрисовывать после отрисовки углового тайла стены, левого и правого тайла стены, а также земли, как показано на рисунке:


dX и dY, значение которых зависит от нажатых клавиш управления. По умолчанию эти переменные равны 0, а значения им присваиваются согласно таблице внизу, где В, Н, П и Л означают, соответственно верхнюю, нижнюю, правую и левую клавиши направления. Значение 1 под клавишей означает, что клавиша нажата, 0 — что она не нажата.Клавиша Положение
В Н П Л dX dY
================
0 0 0 0 0 0
1 0 0 0 0 1
0 1 0 0 0 -1
0 0 1 0 1 0
0 0 0 1 -1 0
1 0 1 0 1 1
1 0 0 1 -1 1
0 1 1 0 1 -1
0 1 0 1 -1 -1dX и dY мы можем обновлять декартовы координаты следующим образом:newX = currentX + (dX * speed);
newY = currentY + (dY * speed);dX и dY представляют собой изменение положения персонажа по X и Y в зависимости от нажатых клавиш. Как сказано выше, мы легко можем вычислить новые изометрические координаты:Iso = cartesianToIsometric(new Phaser.Point(newX, newY))dX и dY мы можем понять, в каком направлении смотрит персонаж и использовать соответствующую анимацию. После перемещения персонажа не забывайте перерисовать уровень с соответствующей сортировкой по глубине, потому что тайловые координаты персонажа могут измениться.tile coordinate = getTileCoordinates(isometricToCartesian(current position), tile height);
if (isWalkable(tile coordinate)) {
moveCharacter();
} else {
//ничего не делать;
}isWalkable() мы проверяем, является ли значение массива данных уровня в заданной координате проходимым тайлом. Нам нужно также обновлять направление, в котором смотрит персонаж, даже если он не движется, на случай, если он столкнулся с непроходимым тайлом.tile[0][0]) к ближним, строка за строкой. Если персонаж занимает тайл, то сначала мы рисуем тайл земли, а потом отрисовываем тайл персонажа. Это сработает хорошо, потому что персонаж не может занимать тайл стены.[
[1,1,1,1,1,1],
[1,0,0,0,0,1],
[1,0,8,0,0,1],
[1,0,0,8,0,1],
[1,0,0,0,0,1],
[1,1,1,1,1,1]
]8 для обозначения предмета на тайле травы (1 и 0, как и раньше, обозначают траву и стены). Это может быть тайловое изображение с тайлом травы, на которое наложено изображение предмета. По этой логике нам понадобятся два различных состояния тайла для каждого тайла, на котором может находиться предмет: один с предметом, и другой без него, который отображается после получения предмета.pickupArray для хранения данных о предметах, отдельно от levelData. Законченный уровень с предметом показан ниже:
if(onPickupTile()){
pickupItem();
}
function onPickupTile(){//проверяем, есть ли предмет на тайле с персонажем
return (levelData[heroMapTile.y][heroMapTile.x]==8);
}onPickupTile(), мы проверяем, является ли значение массива levelData в координате heroMapTile тайлом с предметом. Число в массиве levelData в координате этого тайла обозначает тип предмета. Мы проверяем коллизии до перемещения персонажа, но проверка предметов выполняется после: в случае коллизий персонаж не сможет занять точку, если она уже занята непроходимым тайлом, а в случае предметов персонаж может свободно может сдвинуться на тайл.levelData, например, с 8 на 0.)levelData изменяется при поднятии предмета. Решение заключается в использовании копии массива уровня в процессе игры и сохранении неизменного массива levelData. Например, мы используем levelData и levelDataLive[], клонируем последний из первого при начале уровня, а затем меняем в процессе игры только levelDataLive[].pickupCount. Функция pickupItem выглядит следующим образом:function pickupItem(){
pickupCount++;
levelData[heroMapTile.y][heroMapTile.x]=0;
//создаём следующий собираемый предмет
spawnNewPickup();
}levelData значение 0 при первом обнаружении поднятия предмета, все последующие проверки onPickupTile() будут возвращать для тайла false. Посмотрите этот интерактивный пример.
levelData на массив нового уровня, а затем назначить новое положение и направление heroMapTile персонажа. Допустим, есть два уровня с дверями, через которые можно проходить. Поскольку тайл земли рядом с дверью будет активным тайлом в обоих уровнях, можно использовать его в качестве нового положения персонажа, появляющегося на уровне.levelData. В нашем примере 2 будет означать тайл с дверью, а значение рядом с ним будет триггером. Я использовал 101 и 102, решив, что любой тайл со значением больше 100 будет активным тайлом, а значение минус 100 будет уровнем, на который он ведёт:var level1Data=
[[1,1,1,1,1,1],
[1,1,0,0,0,1],
[1,0,0,0,0,1],
[2,102,0,0,0,1],
[1,0,0,0,1,1],
[1,1,1,1,1,1]];
var level2Data=
[[1,1,1,1,1,1],
[1,0,0,0,0,1],
[1,0,8,0,0,1],
[1,0,0,0,101,2],
[1,0,1,0,0,1],
[1,1,1,1,1,1]];var xKey=game.input.keyboard.addKey(Phaser.Keyboard.X);
xKey.onUp.add(triggerListener);// добавление Signal listener для события up
function triggerListener(){
var trigger=levelData[heroMapTile.y][heroMapTile.x];
if(trigger>100){//активный тайл
trigger-=100;
if(trigger==1){//переход на уровень 1
levelData=level1Data;
}else {//переход на уровень 2
levelData=level2Data;
}
for (var i = 0; i < levelData.length; i++)
{
for (var j = 0; j < levelData[0].length; j++)
{
trigger=levelData[i][j];
if(trigger>100){//находим новый активный тайл и помещаем на него персонажа
heroMapTile.y=j;
heroMapTile.x=i;
heroMapPos=new Phaser.Point(heroMapTile.y * tileWidth, heroMapTile.x * tileWidth);
heroMapPos.x+=(tileWidth/2);
heroMapPos.y+=(tileWidth/2);
}
}
}
}
}triggerListener() проверяет, больше ли 100 значение массива данных триггеров в заданной координате. Если это так, то мы определяем, на какой уровень нам нужно перейти, вычтя 100 из значения тайла. Функция находит тайл-триггер в новом levelData, который будет координатой создания персонажа. Я сделал так, чтобы триггер активировался при отпускании клавиши x; если просто считывать нажатую клавишу, то мы окажемся в цикле, который будет перебрасывать нас между уровнями, пока нажата клавиша, потому что персонаж всегда создаётся на новом уровне на активном тайле.zValue. Для начала представим, что сила отскока мяча равна 100, то есть zValue = 100.incrementValue, которая изначально имеет значение 0, и gravity, имеющая значение -1. В каждом кадре мы будем вычитать incrementValue из zValue и вычитать gravity из incrementValue для создания эффекта затухания. Когда zValue достигает 0, это значит, что мяч достиг земли. В этот момент мы меняем знак incrementValue, умножив её на -1, и превратив в положительное число. Это значит, что со следующего кадра мяч начнёт двигаться вверх, то есть отскочит.if(game.input.keyboard.isDown(Phaser.Keyboard.X)){
zValue=100;
}
incrementValue-=gravity;
zValue-=incrementValue;
if(zValue<=0){
zValue=0;
incrementValue*=-1;
}zValue. Ниже показано, как zValue прибавляет к значению изометрической координаты y мяча при отрисовке.function drawBallIso(){
var isoPt= new Phaser.Point();//Не рекомендуется создавать точки в цикле обновления
var ballCornerPt=new Phaser.Point(ballMapPos.x-ball2DVolume.x/2,ballMapPos.y-ball2DVolume.y/2);
isoPt=cartesianToIsometric(ballCornerPt);//находим новое изометрическое положение для персонажа из положения на двухмерной карте
gameScene.renderXY(ballShadowSprite,isoPt.x+borderOffset.x+shadowOffset.x, isoPt.y+borderOffset.y+shadowOffset.y, false);//отрисовка тени на текстуре рендера
gameScene.renderXY(ballSprite,isoPt.x+borderOffset.x+ballOffset.x, isoPt.y+borderOffset.y-ballOffset.y-zValue, false);//отрисовка персонажа на текстуре рендера
}levelData является двухмерным массивом, то всё гораздо проще, чем могло бы быть. У нас есть чётко заданные уникальные узлы, которые может занимать игрок, и мы можем легко проверить, можно ли по ним пройти.easystar = new EasyStar.js();
easystar.setGrid(levelData);
easystar.setAcceptableTiles([0]);
easystar.enableDiagonals();// мы хотим, чтобы в пути были диагонали
easystar.disableCornerCutting();// без диагональных путей при движении в углах стенlevelData содержатся только 0 и 1, мы можем сразу передать его в массив узлов. Значением 0 мы обозначили проходимый узел. Также мы включили возможность движения по диагонали, но отключили её, когда движение происходит рядом с углами непроходимых тайлов.findPath. Callback-метод plotAndMove получает массив узлов созданного пути. Мы помечаем найденный путь на миникарте.game.input.activePointer.leftButton.onUp.add(findPath)
function findPath(){
if(isFindingPath || isWalking)return;
var pos=game.input.activePointer.position;
var isoPt= new Phaser.Point(pos.x-borderOffset.x,pos.y-borderOffset.y);
tapPos=isometricToCartesian(isoPt);
tapPos.x-=tileWidth/2;//настройка для нахождения нужного тайла для ошибки из-за округления
tapPos.y+=tileWidth/2;
tapPos=getTileCoordinates(tapPos,tileWidth);
if(tapPos.x>-1&&tapPos.y>-1&&tapPos.x<7&&tapPos.y<7){//нажатие мышью внутри сетки
if(levelData[tapPos.y][tapPos.x]!=1){//не тайл стены
isFindingPath=true;
//алгоритм делает своё дело
easystar.findPath(heroMapTile.x, heroMapTile.y, tapPos.x, tapPos.y, plotAndMove);
easystar.calculate();
}
}
}
function plotAndMove(newPath){
destination=heroMapTile;
path=newPath;
isFindingPath=false;
repaintMinimap();
if (path === null) {
console.log("No Path was found.");
}else{
path.push(tapPos);
path.reverse();
path.pop();
for (var i = 0; i < path.length; i++)
{
var tmpSpr=minimap.getByName("tile"+path[i].y+"_"+path[i].x);
tmpSpr.tint=0x0000ff;
//console.log("p "+path[i].x+":"+path[i].y);
}
}
}aiWalk, частично показанном ниже:function aiWalk(){
if(path.length==0){//путь закончился
if(heroMapTile.x==destination.x&&heroMapTile.y==destination.y){
dX=0;
dY=0;
isWalking=false;
return;
}
}
isWalking=true;
if(heroMapTile.x==destination.x&&heroMapTile.y==destination.y){//достигли текущей точки назначения, задаём новую, меняем направление
//перед поворотом ждём, пока не войдём на несколько шагов на тайл
stepsTaken++;
if(stepsTaken/ставим персонажа в центр тайла
heroMapSprite.x=(heroMapTile.x * tileWidth)+(tileWidth/2)-(heroMapSprite.width/2);
heroMapSprite.y=(heroMapTile.y * tileWidth)+(tileWidth/2)-(heroMapSprite.height/2);
heroMapPos.x=heroMapSprite.x+heroMapSprite.width/2;
heroMapPos.y=heroMapSprite.y+heroMapSprite.height/2;
stepsTaken=0;
destination=path.pop();//узнаём следующий тайл в пути
if(heroMapTile.xdestination.x){
dX = -1;
}else {
dX=0;
}
if(heroMapTile.ydestination.y){
dY = -1;
}else {
dY=0;
}
if(heroMapTile.x==destination.x){
dX=0;
}else if(heroMapTile.y==destination.y){
dY=0;
}
//......
}
}
(0, 0). Поэтому при парсинге и отрисовке данных уровня мы вычитаем это значение из изометрического положения каждого тайла. Мы можем определить, находится ли новое положение тайла в пределах экрана.var cornerMapPos=new Phaser.Point(0,0);
var cornerMapTile=new Phaser.Point(0,0);
var visibleTiles=new Phaser.Point(6,6);
//...
function update(){
//...
if (isWalkable())
{
heroMapPos.x += heroSpeed * dX;
heroMapPos.y += heroSpeed * dY;
//перемещаем угол в противоположном направлении
cornerMapPos.x -= heroSpeed * dX;
cornerMapPos.y -= heroSpeed * dY;
cornerMapTile=getTileCoordinates(cornerMapPos,tileWidth);
//получаем новый тайл персонажа
heroMapTile=getTileCoordinates(heroMapPos,tileWidth);
//сортировка по глубине и отрисовка новой сцены
renderScene();
}
}
function renderScene(){
gameScene.clear();//удаляем предыдущий кадр, потом отрисовываем заново
var tileType=0;
//ограничиваем цикл видимой областью
var startTileX=Math.max(0,0-cornerMapTile.x);
var startTileY=Math.max(0,0-cornerMapTile.y);
var endTileX=Math.min(levelData[0].length,startTileX+visibleTiles.x);
var endTileY=Math.min(levelData.length,startTileY+visibleTiles.y);
startTileX=Math.max(0,endTileX-visibleTiles.x);
startTileY=Math.max(0,endTileY-visibleTiles.y);
//проверяем граничное условие
for (var i = startTileY; i < endTileY; i++)
{
for (var j = startTileX; j < endTileX; j++)
{
tileType=levelData[i][j];
drawTileIso(tileType,i,j);
if(i==heroMapTile.y&&j==heroMapTile.x){
drawHeroIso();
}
}
}
}
function drawHeroIso(){
var isoPt= new Phaser.Point();//Не рекомендуется создавать точки в цикле обновления
var heroCornerPt=new Phaser.Point(heroMapPos.x-hero2DVolume.x/2+cornerMapPos.x,heroMapPos.y-hero2DVolume.y/2+cornerMapPos.y);
isoPt=cartesianToIsometric(heroCornerPt);//находим новое изометрическое положение персонажа из положения на 2D-карте
gameScene.renderXY(sorcererShadow,isoPt.x+borderOffset.x+shadowOffset.x, isoPt.y+borderOffset.y+shadowOffset.y, false);//отрисовываем тень на текстуре рендера
gameScene.renderXY(sorcerer,isoPt.x+borderOffset.x+heroWidth, isoPt.y+borderOffset.y-heroHeight, false);//отрисовываем персонажа на текстуре рендера
}
function drawTileIso(tileType,i,j){//располагаем изометрические тайлы уровня
var isoPt= new Phaser.Point();//не рекомендуется создавать точку в цикле обновления
var cartPt=new Phaser.Point();//Добавлено для лучшей читаемости кода.
cartPt.x=j*tileWidth+cornerMapPos.x;
cartPt.y=i*tileWidth+cornerMapPos.y;
isoPt=cartesianToIsometric(cartPt);
//Можно оптимизировать дальше и не отрисовывать ничего за пределами экрана.
if(tileType==1){
gameScene.renderXY(wallSprite, isoPt.x+borderOffset.x, isoPt.y+borderOffset.y-wallHeight, false);
}else{
gameScene.renderXY(floorSprite, isoPt.x+borderOffset.x, isoPt.y+borderOffset.y, false);
}
}|
Метки: author PatientZero разработка игр изометрия изометрические игры phaser.js html5 |






