[Перевод] Стек, который позволил Medium обеспечить чтение на 2.6 тысячелетия |
Предлагаю общественности мой перевод статьи Dan Pupius'а об архитектура сервиса Medium и используемых технологиях. Хочу особо отметить, что статья является переводом, поэтому местоимение "я", используемое в тексте далее относится к автору оригинального текста, а не к переводчику.
Medium это сеть. Это место, где обмениваются историями и идеями, которые важны — место, где вы развиваетесь, и где люди провели 1.4 миллиарда минут — 2.6 тысячелетия.
У нас более 25 миллионов уникальных читателей в месяц, и каждую неделю публикуются десятки тысяч постов. Но мы хотим, чтобы на Medium мерилом успеха было не количество просмотров, а точки зрения. Чтобы значение имело качество идеи, а не квалификация автора. Чтобы Medium был местом, где обсуждения развивают идеи, а слова по-прежнему важны.
Я руковожу инженерной командой. Раньше я работал в качестве инженером в Google, где я работал над Google+ и Gmail, а также был одним из со-основателей проекта Closure. В прошлой жизни я гонял на сноуборде, прыгал из самолёта и жил в джунглях.

Я не мог бы гордиться командой сильнее, чем сейчас. Это потрясающая группа талантливых, любознательных, внимательных людей, которые собрались вместе, чтобы делать великие вещи.
Мы работаем в многофункциональных, нацеленных на решение конкретной задачи, командах, благодаря чему, когда некоторые специализируются, у нас всякий может обратиться к любому компоненту стека. Мы верим, что обращение к различным дисциплинам делает инженера лучше. О других наших ценностях я писал ранее.
Команды имеют много свободы в том, как они организуют работу, однако как компания в целом, мы ставим квартальные цели и поощряем итеративный подход. Мы используем GitHub для код-ревью и отслеживания багов, а также Google Apps для электронной почты, документов и электронных таблиц. Мы интенсивно используем Slack — и его ботов — а многие команды используют Trello.
С самого начала мы использовали EC2. Основные приложения были написаны на Node.js, и мы мигрировали на DynamoDB перед публичным запуском.
У нас был node-сервер для обработки изображений, который делегировал GraphicsMagick фактические задачи по обработке. Другой сервер выступал в роли обработчика очереди SQS, и выполнял фоновые задачи. Мы использовали SES для электронной почты, S3 для статичных ресурсов, CloudFront в качестве CDN и nginx как обратный прокси. Для мониторинга мы использовали DataDog и PagerDuty для оповещений.
В качестве основы редактора, используемого на сайта был TinyMCE. К моменту запуска мы уже использовали Closure Compiler и некоторые компоненты Closure Library, но для шаблонизации использовали Handlebars.
Для такого, на первый взгляд, простого сайта как Medium, может быть удивительно, как много сложного находится за сценой. Это же просто блог, так? Вы, вероятно, можете просто выкатить что-то на Rails за пару дней. :)
В любом случае, довольно рассуждений. Начнём с самого низа.
Мы используем Amazon Virtual Private Cloud. Для управление конфигурацией мы используем Ansible, что позволяет хранить конфигурации в системе управления версиями и легко и контролируемо выкатывать изменения.
Мы придерживаемся сервис-ориентированной архитектуры, поддерживая дюжину сервисов (в зависимости от того, как их считать, несколько из них существенно мельче остальных). Основной вопрос при развёртывании нового сервиса в специфичности работы, которую он выполняет, какова вероятность того, что придётся вносить изменения в несколько других сервисов, а также характеристики потребления ресурсов.
Наше основное приложение по-прежнему написано на Node, что позволяет нам использовать один код как на сервере, так и на клиенте, так, кое-что мы активно используем как в редакторе, так и в обработке поста. С нашей точки зрения Node не плох, но проблемы возникают если мы блокируем цикл обработки событий (event loop). Чтобы сгладить эту проблему, мы запускаем несколько экземпляров на одной машине и распределяем "дорогие" подключения по разным экземплярам, изолируя их таким образом. Мы также обращаемся к среде исполнения V8, чтобы понять, какие задачи занимают много времени; в целом, задержки связаны с восстановлением объектов при десериализации JSON.
У нас есть несколько вспомогательных сервисов, написанных на Go. Мы обнаружили, что приложения на Go очень легко собирать и развёртывать. Нам нравится его типобезопасность без избыточности JVM и необходимости тонкой настройки, как в случае с Java. Лично я — фанат использования командой "упрямых" языков; это повышает согласованность, снижает неоднозначность и определённо снижает шанс выстрелить себе в ногу.
Сейчас мы раздаём статику через CloudFlare, хотя мы пропускаем 5% трафика через Fastly и 5% через CloudFront, чтобы держать их кеши прогретыми на случай если нам понадобится переключиться в экстренной ситуации. Недавно мы включили CloudFlare и для трафика приложений — в первую очередь для защиты от DDOS, но нас также порадовало повышение производительности.
Мы используем nginx и HAProxy совместно в качестве обратных прокси и балансировщиков нагрузки, чтобы перекрыть всю дианаграмму Венна наших потребностей.
Мы по-прежнему используем DataDog для мониторинга и PagerDuty для уведомлений, но теперь мы интенсивно используем ELK (Elasticsearch, Logstash, Kibana) для отладки возникших на продакшене проблем.
DynamoDB по-прежнему является нашей основной базой данных, однако это не было спокойным плаванием. Одной из извечных проблем, с которыми мы сталкнулись были ["горячие ключи"] (https://medium.com/medium-eng/how-medium-detects-hotspots-in-dynamodb-using-elasticsearch-logstash-and-kibana-aaa3d6632cfd) (Прим. переводчика: имеются ввиду ключи по которым выболняется большое количество запросов за небольшой промежуток времени), во время событий, ставших вирусными или при отправке постов миллионам подписчиков. У нас есть кластер Redis, который мы используем в качестве кеша перед Dynamo, что решает проблему для операций чтения. Оптимизации с целью повысить удобство разработчиков часто расходятся с таковыми для повышения стабильности, но мы работаем над этим.
Мы начали использовать Amazon Aurora для хранения новых данных из-за того, что она позволяет более гибко, чем Dynamo, извлекать и фильтровать данные.
Для хранения отношений между сущностями, которые представляют сеть Medium мы используем Neo4j, у нас запущен один мастер и две реплики. Люди, посты, теги и коллекции — это узлы графа. Рёбра создаются при создании сущности и при выполнении действий, таких как подписки, рекомендации или подсвечивания. Мы обходим граф чтобы фильтровать и рекомендовать посты.
С самого начала мы были очень жадными до данных, инвестировали в нашу инфраструктуру анализа данных, чтобы облегчить принятие бизнес и продуктовых решений. В последнее время мы также может использовать существующий конвейер данных для обратной связи с продакшеном, позволяя работать таким функциям, как Explore.
В качестве хранилища данных мы используем Amazon Redshift, он предосталвяет масштабируемую систему хранения и обработки данных, поверх которой строятся наши приложения. Мы постоянно импортируем наши основные данные (пользователи, посты) из Dynamo в Redshift и логи событий (просмотр поста, прокручивание страницы с постом) из S3 в Redshift.
Выполнение задач планируется Conduit, нашим внутренним приложением, которое управляет планированием, зависимостями данных и мониторингом. Мы используем планирование, основанное на требованиях (assertion-based scheduling), когда задачи запускаются только если их зависимости удовлетворены (например, ежедневная задача, которая зависит от логов со всего дня). Эта система доказала свою незаменимость — генераторы данных отделены от потребителей, что упрощает конфигурирование и делает систему предсказуемой и отлаживаемой.
Хотя SQL-запросы в Redshift нас устраивают, нам требуется загружать и выгружать данные в и из Redshift. Для ETL мы всё чаще обращаемся к Amazon Spark благодаря его гибкости и возможности масштабироваться в соотстветствии с нашими нужнами. С течением времени Spark скорее всего станет основным компонентом нашего конвейера данных.
Мы используем Protocol Buffers для схем данных (и правил изменения схем) чтобы держать все слои распределённой системы синхронизированными, включая мобильные приложения, веб-сервисы и хранилище данных. Мы аннотируем схемы деталями конфигурации, такими как имена талиц и индексов, правилами валидации записей, такими как максимальная длина строк или допустимые диапазоны значений чисел.
Людям хотятбыть на связи, так что разработчики мобильных и веб приложений могут подключатсья к нам единым образом, а исследователи данных (Data Scientists) могут интерпретировать поля единым образом. Мы помогаем нашим людям работать с данными, рассматривая схемы в качестве спецификаций, тщательно документируя сообщения и поля, и публикуя документацию, сгенерированную на основе .proto файлов.
Наш сервер обработки изображений написан на Go и использует стратегию "водопад" (waterfall strategy) для отдачи обработанных изображений. Серверы используют groupcache, который предоставляет альтернативу memcache и позволяет снизить объём выполняемой дважды работы. Кеш в памяти резервируется постоянным кешем в S3; после чего изображения обрабатываются по запросу. Это даёт нашим дизайнероам свободу изменять способы отображения изображений и оптимизировать для разных платформ без необходимости запускать большие пакетные задачи по генерированию масштабированных изображений.
Хотя в настоящий момент сервер обработки изображений, в основном, используется для масштабирования и обрезки изображений, ранние версии сайта поддерживали светофильтры, размытие и другие эффекты. Обработка анимированных GIF-файлов доставляла огромную боль, но это тема отдельного поста.
Прикольная функция TextShorts реализуется небольшим сервером на Go, использующим PhantomJS в качестве рендерера.
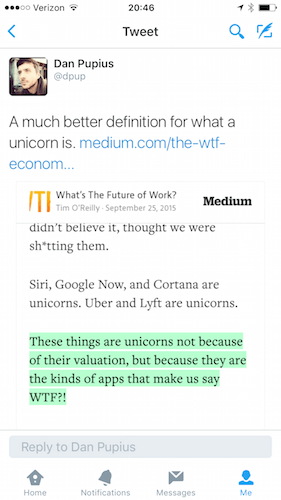
Мне всё время хотелось поменять движок рендеринга на что-нибудь вроде Pango, но на практике возможность выводить изображения в HTML гораздо более гибкая и удобная. А частота, с которой эта функция используется позволяет там довольно легко справляться с наргузкой.
Мы позволяем людям настроить произвольные домены для их публикаций на Medium. Мы хотели, чтобы можно было авторизовываться один раз и для всех доменов, а также HTTPS для всех, так что заставить это всё работать было не тривиально. У нас есть набор серверов HAProxy, которые управляют сертификатами и направляют трафик на основные серверы. При настройке домена по-прежнему требуется ручная работа, но мы автоматизировали большую часть, за счёт интеграции с Namecheap. Сертификаты и связывание с публикациями выполняется выделенными серверами.
В веб части мы предпочитаем оставаться близко к железу. У нас есть собственный фреймворк для одностраничных приложений (SPA), который использует Closure в качестве стандартной библиотеки. Мы используем Closure Templates для рендеринга как на стороне клиента, так и на стороне сервера, и Closure Compiler для минификации кода и разделения на модули. Редактор — это самая сложная часть нашего приложения, Ник о нём уже писал.
Оба наших приложения нативные, и минимально используют web view.
На iOS мы используем смесь и самодельных фреймворком и встроенных компонентов. На сетевом уровне мы используем NSURLSession для выполнения запросов и Mantle для парсинга JSON и восстановления моделей. У нас есть уровень кеширования, построенный поверх NSKeyedArchiver. Мы используем общий механизм рендеринга элементов списка с поддержкой произвольных стилей, что позволяет нам легко создавать новые списки с различными типами содержимого. Просмотр поста выполнен с помощью UICollectionView с собственным внешним видом (layout). Мы используем общие компоненты для рендеринга всего поста целиком и предпросмотра поста.
Мы собираем каждый коммит и распространяем сборку среди наших сотрудников, так что мы можем опробовать приложение так быстро, настолько это возможно. Частота выкладок приложения в AppStore привязана к циклу проверки приложений, но мы стараемся публиковать приложения даже если изменения минимальны.
Для тестов используем XCTest и OCMock.
На Android мы используем последнюю версию SDK и вспомогательных библиотек. Мы не используем всеохватывающие фреймворки, предпочитая вместо этого использовать стандартные подходы к решению распространённых проблем. Мы используем guava для всего, чего не хватает в Java. В то же время, мы предпочитаем использовать сторонние средства для решения более узких задач. Мы используем свой API на основе protocol buffers, а затем генерируем объекты, которые используем в приложении.
Мы используем mockito и robolectric. Мы пишем высокоуровневые тесты в которых обращаемся к активити и исследуем, что и как — мы создаём базовые версии тестов когда только добавляем экран или готовимся к рефакторингу. Они развиваются по мере того, как мы воспроизводим баги для защиты от регрессии. Мы пишем низкоуровневые тесты для исследования конкретных классов, по мере того, как мы добавляем новые возможности. Они позволяют судить о том, как наши классы взаимодействуют.
Каждый коммит автоматически выкладывается в Play Store как алфа-версия и разаётся нашим сотрудникам. (Это относится и к приложению для нашего внутреннего варианта Medium — Hatch). Как правило, по пятницам мы пердаём альфа версию нашим бета-тестерам и даём им поиграться с нею на выходных, после чего, в понедельник, выкладываем для всех. Так как последняя версия кода всегда готова к релизу, то если мы находим серьезный баг, то мы сразу же публикуем исправление. Если мы беспокоимся о новой функции, то даём бета-тестерам поиграть с ней подольше; если нам всё нравится, то релизим ещё чаще.
Все наши клиенты использую флаги функций (feature flags), выданные сервером и называемые variants. Они используются для A|B тестирования и отсключения не завершённых функций.
Есть ещё много всего вокруг продукта, о чём я не сказал: Algolia, которая позволяет быстрее работать с функциями поиска, SendGrid для входящей и исходящей электронной почты, Urban Airship для уведомлений, SQS для обработки очередей, Bloomd для фильтров Блума, PubSubHubbub и Superfeedr для RSS и так далее, и так далее.
Мы используем непрерывную интеграцию и доставку (continuous integration and delivery), выкладывая как можно быстрее. Всем этим управляет Jenkins.
Исторически, в качестве системы сборки мы использовали Make, но для более новых проектов мы мигрируем на Pants.
У нас есть как модульные тесты, так и функциональные тесты уровня HTTP. Все коммиты тестируются перед мерджем. Совместно с командой из Box мы работали над использованием Cluster Runner, чтобы распределять тесты и делать тестирование быстрее, у него есть также интеграция с GitHub.
Мы выкладываем в тестовое окружение так быстро, как только можем — в настоящий момент каждые 15 минут, успешные редакции затем становятся кандидатами для выклдывания на продакшен. Основные серверы приложений обновляются примерно пять раз в день, в некоторых случаях до 10 раз.
Мы используем синие/зелёные сборки (blue/green builds). Перед выкладкой на продакшен мы направляем трафик на тестовый экземпляр и отслеживаем частоту ошибок прежде чем продолжать. Откатывание назад выполняется средствами DNS.
Много всего! Есть много всего, что нужно сделать для усовершенствования продукта и чтобы сделать чтение и написание постов лучше. Мы также начинаем работать над монетизацией для авторов и издателей. Это новое для нас поле и мы вступаем на него с открытым разумом. Мы считаем, что будущему требуются новые механизмы для финасирования контента, и мы хотим убедиться, что наши функции стимулируют качество и ценность.
Обычно мы всегда заинтересованы в общении с целеустремлёнными инженерами, у которых есть опыт работы над приложениями для конечных потребителей. У нас нет требований касательно языков, которые вы знаете, так как мы считаем, что хорошие инженеры могут быстро разобраться в новой дисциплине, но вы должны быть любопытными, знающими, решительными и чуткими. За основу можно принять iOS, Android, Node или Go.
Мы также готовим команду Product Science, так что мы ищем людей с опытом построения конвейеров данных и больших аналитических систем.
Ещё я ищу инженерных лидеров, которые помогут развивать команду. Они должны интересоваться теорией управления организацией, хотеть работать руками и быть готовыми руководить подичнёнными.
Вы можете прочитать больше в Medium Engineering.
Блогадарности Nathaniel Felsen, Jamie Talbot, Nick Santos, Jon Crosby, Rudy Winnacker, Dan Benson, Jean Hsu, Jeff Lu, Daniel McCartney и Kate Lee.
|
Метки: author IvaYan разработка веб-сайтов программирование node.js amazon web services medium архитектура приложений блогинг-платформы elk golang |
Летайте самолетами UNIGINE: новый авиатренажер для МАКС-2017 |







|
Метки: author Beatrix c++ блог компании unigine unigine макс-2017 3d- графика и анимация авиация авиатренажер авиасимулятор авиасалон |
Решение promo task от BI.ZONE CTF |


try_h4rd3r_try_h4rd3r_try_h4rd3r_try_h4rd3r_try_h4rd3r_try_h4rd3r_try_h4rd3r_try_h4rd3r_try_h4rd3r_try_h4rd3r




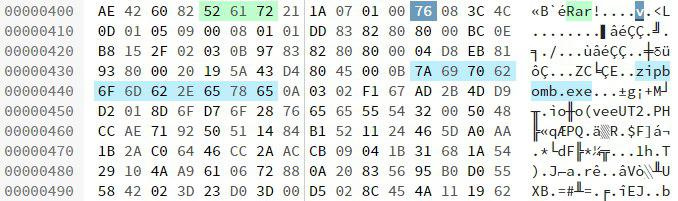
.7z, получаем архив, который можем открыть 32-x битным 7-Zip. Содержимое архива: zipbomb.exe — самая настоящая ZIP-бомба. «Перерезав красный провод» и поменяв расширение на .zip, получаем архив, в котором лежит файл "-" размером 38,1 ГБ (40 959 016 020 байт). Ясно было сразу, что такой файл не прочесть разом. Было принято решение написать простенький скрипт на языке Python, который бы читал его по частям.def read_in_chunks(file_object, chunk_size=1024):
while True:
data = file_object.read(chunk_size)
if not data:
break
yield data
def read_in_chunks(file_object, chunk_size=1024):
while True:
data = file_object.read(chunk_size)
if not data:
break
yield data
f = open('-')
for piece in read_in_chunks(f):
if piece.count("0") < 1023:
print(piece)

/solve <ответ> можно получить flag. Однако сегодня Вы получите только это: «Sorry all flags are gone». |
Метки: author malchikserega информационная безопасность ctf блог компании перспективный мониторинг ctfzone zip- бомбы python |
[Из песочницы] Реализация Elliptic curve Menezes-Vanstone cryptosystem на базе OpenSSL API |
//
// DESCRIPTION 'EC Menezes-Vanstone cryptosystem functions openssl/Linux'
// COMPILER 'gcc (GCC) 4.8.2'
// FILE 'ecmv.h'
// AUTHOR "Nick Korepanov"
// Linux-3.10.104, glibc-2.17, OpenSSL 1.0.1u
// ECC-192/224/256
// This program is free software; you can redistribute it and/or modify
// it under the terms of the GNU General Public License as published by
// the Free Software Foundation; either version 2 of the License, or
// (at your option) any later version.
//
// This program is distributed in the hope that it will be useful,
// but WITHOUT ANY WARRANTY; without even the implied warranty of
// MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
// GNU General Public License for more details.
//
// You should have received a copy of the GNU General Public License
// along with this program; if not, write to the Free Software
// Foundation, Inc., 675 Mass Ave, Cambridge, MA 02139, USA.
//
// Author of this program can be contacted by electronic mail
// korepanovnd@gmail.com
// Copyright (c) 2017 Nick Korepanov. All rights reserved.
// This product includes software developed by the OpenSSL Project
// for use in the OpenSSL Toolkit. (http://www.openssl.org/)
// COMPUTER SECURITY AND CRYPTOGRAPHY, ALAN G. KONHEIM
// Published by John Wiley & Sons, Inc., Hoboken, New Jersey, 2007
// Library of Congress Cataloging-in-Publication Data:
// Konheim, Alan G., 1934–
// Computer security & cryptography / by Alan G. Konheim.
// p. cm.
// Includes bibliographical references and index.
// ISBN-13: 978-0-471-94783-7
// ISBN-10: 0-471-94783-0
// 1. Computer security. 2. Cryptography. I. Title.
// QA76.9.A25K638 2007
// 005.8--dc22 2006049338
// 15.9 THE MENEZES–VANSTONE ELLIPTIC CURVE CRYPTOSYSTEM, p. 443
// Another very significant source - "A Weakness of Menezes-Vanstone Cryptosystem", Klaus Kiefer, member of research group of prof. J. Buchmann, 1997
// Shortly, this work show ability of "known plain text attack (KPTA)", with probability O(1/p) of false detection.
// What does it mean? If we encrypt 128-bit session key, for success KPTA we must search in 2^128 combinations of session key ...
// Known plaintext attack for EC MV cryptosystem
// Curve E(p,a,b) known from public key,
// y0, y1, y2 - ciphertext
// random select 1 < x1 < p and 1< x2 < p
// calculate inversion a=inv(x1)(mod p), b=inv(x2)(mod p)
// c1=a*y1(mod p), c2=b*y2(mod p)
// if C(c1,c2) is point of curve E, x1 and x2 is plaintext with error probability O(1/p)
// z=((c1)^3 + a*c1 + b)(mod p)
// if (z^((p-1)/2))(mod p) == 1 there are 2 points (c1,+-c2) in curve E(p,a,b)
//#include
#include
#include
//#include
#include //
// DESCRIPTION 'EC Menezes-Vanstone cryptosystem functions openssl/Linux'
// COMPILER 'gcc (GCC) 4.8.2'
// FILE 'ecmv.c'
// AUTHOR "Nick Korepanov"
// Linux-3.10.104, glibc-2.17, OpenSSL 1.0.1u
// ECC-192/224/256
// This program is free software; you can redistribute it and/or modify
// it under the terms of the GNU General Public License as published by
// the Free Software Foundation; either version 2 of the License, or
// (at your option) any later version.
//
// This program is distributed in the hope that it will be useful,
// but WITHOUT ANY WARRANTY; without even the implied warranty of
// MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
// GNU General Public License for more details.
//
// You should have received a copy of the GNU General Public License
// along with this program; if not, write to the Free Software
// Foundation, Inc., 675 Mass Ave, Cambridge, MA 02139, USA.
//
// Author of this program can be contacted by electronic mail
// korepanovnd@gmail.com
// Copyright (c) 2017 Nick Korepanov. All rights reserved.
// This product includes software developed by the OpenSSL Project
// for use in the OpenSSL Toolkit. (http://www.openssl.org/)
#include "ecmv.h"
int EC_MV_pubkey_encrypt(unsigned char *cipher, EC_KEY* pubkey, unsigned char* plaintext, size_t len, int format)
{
const EC_GROUP *curve; // curve, q and g are part of pubkey, it was allocated and free with pubkey
const EC_POINT *q;
EC_POINT *y0, *z;
BIGNUM *p, *a, *b, *ks, *o1, *z1, *z2, *y1, *y2, *x1, *x2, *ord;
int bits, i=0, err;
unsigned char buffer[250];
//size_t length;
BN_CTX *ctx;
curve=EC_KEY_get0_group(pubkey);
if(curve)
bits = EC_GROUP_get_degree(curve);
else
return 1; // no curve in key?
if(len%2)
return 2; // wrong plaintext has odd length
if(len > 2*bits/8)
return 3; // plaintext too long for this key
if( !(bits == 192 || bits == 224 || bits == 256) && format)
return 8; // binary format of encrypted block not defined for this key length
//prepare bignums
p=BN_new(); a=BN_new(); b=BN_new(); ks=BN_new(); o1=BN_new(); z1=BN_new(); z2=BN_new(); y1=BN_new(); y2=BN_new(); x1=BN_new(); x2=BN_new(); ord=BN_new();
ctx=BN_CTX_new();
//prepare points
//q=EC_POINT_new(curve); g=EC_POINT_new(curve);
y0=EC_POINT_new(curve); z=EC_POINT_new(curve);
// split plaintext at two parts, and assign it to BIGNUMs
BN_bin2bn(plaintext, len/2, x1);
BN_bin2bn(plaintext+len/2, len/2, x2);
// get public key q
q=EC_KEY_get0_public_key(pubkey);
// get generator point g
//g=EC_GROUP_get0_generator(curve);
// get order of g
EC_GROUP_get_order(curve, ord, ctx );
// get prime p
EC_GROUP_get_curve_GFp(curve, p, a, b, ctx );
BN_sub(o1, ord, BN_value_one()); // o1=ord-1
do
{
if( i>= 10)
break;
// make secret session key ks > 1 and ks < (o-1)
RAND_bytes(buffer, bits/8);
BN_bin2bn(buffer, bits/8, ks);
i++;
}
while( BN_cmp(BN_value_one(), ks) >=0 || BN_cmp(o1,ks) <=0 );
if(i>=10)
return 4; // ks is wrong, error in do-while
// y0=ks*g
err=EC_POINT_mul(curve, y0, ks, NULL, NULL, ctx );
if(err == 0)
return 5; // error in EC_POINT_mul y0=ks*g
// z=ks*q
err=EC_POINT_mul(curve, z, NULL, q, ks, ctx );
if(err == 0)
return 6; // error in EC_POINT_mul z=ks*q
// get z1,z2 = Z(z1,z2)
err=EC_POINT_get_affine_coordinates_GFp(curve, z, z1, z2, ctx );
if(err == 0)
return 7; //error EC_POINT_get_affine_coordinates_GFp
//y1 = z1*x1(modulo p)
//y2 = z2*x2(modulo p)
BN_mod_mul(y1, z1, x1, p, ctx);
BN_mod_mul(y2, z2, x2, p, ctx);
/* if bits=192, 24 bytes per every BIGNUM, point contains 2 Bignum + 1 byte header */
if(format)
{ // bin format
if(bits == 192)
{
struct BinFmt192 *out;
out=(struct BinFmt192 *)cipher;
EC_POINT_point2oct(curve, y0, POINT_CONVERSION_UNCOMPRESSED, (unsigned char*)&out->y0, sizeof(out->y0), ctx);
BN_bn2bin(y1, (unsigned char*)&out->y1);
BN_bn2bin(y2, (unsigned char*)&out->y2);
out->z1=out->z2=out->z3=0;
}
if(bits == 224)
{
struct BinFmt224 *out;
out=(struct BinFmt224 *)cipher;
EC_POINT_point2oct(curve, y0, POINT_CONVERSION_UNCOMPRESSED, (unsigned char*)&out->y0, sizeof(out->y0), ctx);
BN_bn2bin(y1, (unsigned char*)&out->y1);
BN_bn2bin(y2, (unsigned char*)&out->y2);
out->z1=out->z2=out->z3=0;
}
if(bits == 256)
{
struct BinFmt256 *out;
out=(struct BinFmt256 *)cipher;
EC_POINT_point2oct(curve, y0, POINT_CONVERSION_UNCOMPRESSED, (unsigned char*)&out->y0, sizeof(out->y0), ctx);
BN_bn2bin(y1, (unsigned char*)&out->y1);
BN_bn2bin(y2, (unsigned char*)&out->y2);
out->z1=out->z2=out->z3=0;
}
}
else
{ // hex format
strcpy((char*)cipher, EC_POINT_point2hex(curve, y0, POINT_CONVERSION_UNCOMPRESSED, ctx));
strcat((char*)cipher, "\n");
strcat((char*)cipher, BN_bn2hex(y1));
strcat((char*)cipher, "\n");
strcat((char*)cipher, BN_bn2hex(y2));
strcat((char*)cipher, "\n");
}
// free points
//EC_POINT_free(q); EC_POINT_free(g);
EC_POINT_free(y0); EC_POINT_clear_free(z);
BN_CTX_free(ctx);
BN_clear(ks);
BN_clear(x1);
BN_clear(x2);
BN_clear(z1);
BN_clear(z2);
//free bignums
BN_free(p); BN_free(a); BN_free(b); BN_free(ks); BN_free(o1); BN_free(z1); BN_free(z2); BN_free(y1); BN_free(y2); BN_free(x1); BN_free(x2); BN_free(ord);
return 0;
}
int EC_MV_privkey_decrypt(unsigned char* cipher, EC_KEY *privkey, unsigned char* plaintext)
{
const EC_GROUP *curve; // curve, d are part of privkey, it was allocated and free with privkey
const BIGNUM *d;
EC_POINT *y0, *z;
BIGNUM *p, *a, *b, *z1, *z2, *y1, *y2, *x1, *x2;
int err, bits, format;
unsigned char *ptr;
BN_CTX *ctx;
ctx=BN_CTX_new();
curve=EC_KEY_get0_group(privkey);
if(!curve)
return 1; // no curve in key?
bits = EC_GROUP_get_degree(curve);
if( cipher[0] == 0x04 )
format=FORMATBIN;
if( cipher[0] == 0x30 )
format=FORMATHEX;
if(cipher[0] != 0x04 && cipher[0] != 0x30)
return 8; // unknown format of ECMV encrypted block
if( !(bits == 192 || bits == 224 || bits == 256) && format)
return 9; // binary format of encrypted block not defined for this key length
if(format && bits == 192 && (cipher[48+1] || cipher[48+1+24+1] || cipher[48+1+24+1+24+1] ))
return 10; //wrong format of binary encrypted block
if(format && bits == 224 && (cipher[56+1] || cipher[56+1+28+1] || cipher[56+1+28+1+28+1] ))
return 10; //wrong format of binary encrypted block
if(format && bits == 256 && (cipher[64+1] || cipher[64+1+32+1] || cipher[64+1+32+1+32+1] ))
return 10; //wrong format of binary encrypted block
//prepare bignums
p=BN_new(); a=BN_new(); b=BN_new(); z1=BN_new(); z2=BN_new(); y1=BN_new(); y2=BN_new(); x1=BN_new(); x2=BN_new();
//prepare points
y0=EC_POINT_new(curve); z=EC_POINT_new(curve);
// get private key d
d=EC_KEY_get0_private_key(privkey);
// get prime p
EC_GROUP_get_curve_GFp(curve, p, a, b, ctx);
if(format)
{
if(bits == 192)
{
struct BinFmt192 *in;
in=(struct BinFmt192 *)cipher;
EC_POINT_oct2point(curve, y0, (const unsigned char *)&in->y0, sizeof(in->y0), ctx);
BN_bin2bn((const unsigned char *)&in->y1, sizeof(in->y1), y1);
BN_bin2bn((const unsigned char *)&in->y2, sizeof(in->y2), y2);
}
if(bits == 224)
{
struct BinFmt224 *in;
in=(struct BinFmt224 *)cipher;
EC_POINT_oct2point(curve, y0, (const unsigned char *)&in->y0, sizeof(in->y0), ctx);
BN_bin2bn((const unsigned char *)&in->y1, sizeof(in->y1), y1);
BN_bin2bn((const unsigned char *)&in->y2, sizeof(in->y2), y2);
}
if(bits == 256)
{
struct BinFmt256 *in;
in=(struct BinFmt256 *)cipher;
EC_POINT_oct2point(curve, y0, (const unsigned char *)&in->y0, sizeof(in->y0), ctx);
BN_bin2bn((const unsigned char *)&in->y1, sizeof(in->y1), y1);
BN_bin2bn((const unsigned char *)&in->y2, sizeof(in->y2), y2);
}
}
else
{
// read y0
ptr=cipher;
y0=EC_POINT_hex2point(curve, (const char *)ptr, y0, ctx);
if(y0 == NULL)
return 2; //invalid hex point representation
//read y1,y2
ptr=strchr((const char *)ptr,'\n');
if(ptr == NULL)
return 3; //wrong format of encrypted data
ptr++;
BN_hex2bn(&y1, (const char *)ptr);
ptr=strchr((const char *)ptr,'\n');
if(ptr == NULL)
return 4; //wrong format of encrypted data
ptr++;
BN_hex2bn(&y2, (const char *)ptr);
}
if( !EC_POINT_is_on_curve(curve, (const EC_POINT *)y0, ctx) )
return 11; // point is not on curve
// z=d*y0=d*ks*g=ks*q
err=EC_POINT_mul(curve, z, NULL, y0, d, ctx );
if(err == 0)
return 6; // error in EC_POINT_mul z=ks*q
// get z1,z2 = Z(z1,z2)
err=EC_POINT_get_affine_coordinates_GFp(curve, z, z1, z2, ctx );
if(err == 0)
return 7; //error EC_POINT_get_affine_coordinates_GFp
// a=inv(z1)(mod p)
BN_mod_inverse(a, z1, p, ctx);
// b=inv(z2)(mod p)
BN_mod_inverse(b, z2, p, ctx);
//x1 = a*y1(modulo p)
//x2 = b*y2(modulo p)
BN_mod_mul(x1, a, y1, p, ctx);
BN_mod_mul(x2, b, y2, p, ctx);
// decode plaintext from two parts
BN_bn2bin(x1, plaintext);
BN_bn2bin(x2, plaintext+BN_num_bytes(x1));
// free points
EC_POINT_free(y0); EC_POINT_clear_free(z);
BN_CTX_free(ctx);
BN_clear(x1);
BN_clear(x2);
BN_clear(z1);
BN_clear(z2);
BN_clear(a);
BN_clear(b);
//free bignums
BN_free(p); BN_free(a); BN_free(b); BN_free(z1); BN_free(z2); BN_free(y1); BN_free(y2); BN_free(x1); BN_free(x2);
return 0;
}
|
Метки: author NickKorepanov программирование криптография elliptic curve cryptography openssl public key |
Интервью с программистом из Тинькофф Банка Андреем Степановым о языке Python и ML |

|
Метки: author shulyndina программирование машинное обучение python блог компании it-people machine learning |
Константин Будник, EPAM: “Apache Hadoop перешел в фазу commodity — там почти не появляется ничего нового.” |

|
Метки: author NadiaMatukhno open source java блог компании epam epam hadoop big data amazon yahoo javaday java conference longread |
No rest for the wicked. Фотоотчет из дальних уголков России, где мы оказались благодаря Росгидромету |


































|
Метки: author sirgun5000 хранение данных системное администрирование it- инфраструктура блог компании гк ланит росгидромет погодные станции метео ланит метеорология |
[Из песочницы] Разворачиваем и демонизируем ASP.NET Core приложение под Linux в виде фонового сервиса |
sudo sh -c 'echo "deb [arch=amd64] https://apt-mo.trafficmanager.net/repos/dotnet-release/ xenial main" > /etc/apt/sources.list.d/dotnetdev.list'
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 417A0893

sudo apt-get updatesudo apt-get install dotnet-dev-1.0.4dotnet new мы можем создать шаблон для нашего приложения, подобно шаблонам из Visual Studio. Подробная документация к команде.
dotnet new mvc
ls -la.
dotnet restore.
dotnet build
dotnet run


Если вы выставляете ваше приложение в интернет, Вы должны использовать IIS, Nginx или Apache как обратный прокси-сервер.
Если Вы не знаете, что такое обратный прокси-сервер
Обратный прокси-сервер получает HTTP запросы из сети и направляет их в Kestrel после первоначальной обработки, как показано на след диаграмме:
Главная причина, по которой следует использовать обратный прокси сервер — безопасность. Kestrel относительно нов и ещё не имеет полного комплекта защиты от атак.
Ещё одна причина, по которой следует использовать обратный прокси-сервер — наличие на сервере нескольких приложений, использующих один порт. Kestrel не поддерживает разделение одного порта между несколькими приложениями.
Так же, использование обратного прокси-сервера может облегчить распределение нагрузки и поддержку SSL.
app.UseForwardedHeaders(new ForwardedHeadersOptions
{
ForwardedHeaders = ForwardedHeaders.XForwardedFor | ForwardedHeaders.XForwardedProto
});
sudo apt-get install nginxsudo service nginx startserver {
listen 8888; # указываем порт, по которому nginx будет слушать запросы
location / {
proxy_pass http://localhost:5000; # указываем порт нашего приложения
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection keep-alive;
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}sudo ln -s /etc/nginx/sites-available/aspnetcore.conf /etc/nginx/sites-enabled/aspnetcore.confsudo service nginx restart, чтобы созданные нами конфигурационные файлы вступили в силу. Проверяем:
sudo nano /etc/systemd/system/kestrel-test.service[Unit]
Description=Example .NET Web API Application running on Ubuntu
[Service]
WorkingDirectory=/home/robounicorn/projects/asp.net/core/test-lesson/bin/Debug/netcoreapp1.1/publish #путь к publish папке вашего приложения
ExecStart=/usr/bin/dotnet /home/robounicorn/projects/asp.net/core/test-lesson/bin/Debug/netcoreapp1.1/publish/test-lesson.dll # путь к опубликованной dll
Restart=always
RestartSec=10 # Перезапускать сервис через 10 секунд при краше приложения
SyslogIdentifier=dotnet-example
User=root # пользователь, под которым следует запускать ваш сервис
Environment=ASPNETCORE_ENVIRONMENT=Production
[Install]
WantedBy=multi-user.target
sudo systemctl enable kestrel-test.service
sudo systemctl start kestrel-test.servicesudo systemctl status kestrel-test.service

|
Метки: author Manv разработка под linux .net asp.net core linux ubuntu kestrel c# |
Как за 15 лет вырастить лучшую службу поддержки |

Да… ещё немного, и ваш сервис станет таким же отстойным, как и все остальные. Деньги дерут за всё. Рекомендую на пополнение счёта комиссию установить, на запуск passwd и ещё на каждый логин в ISPmanager
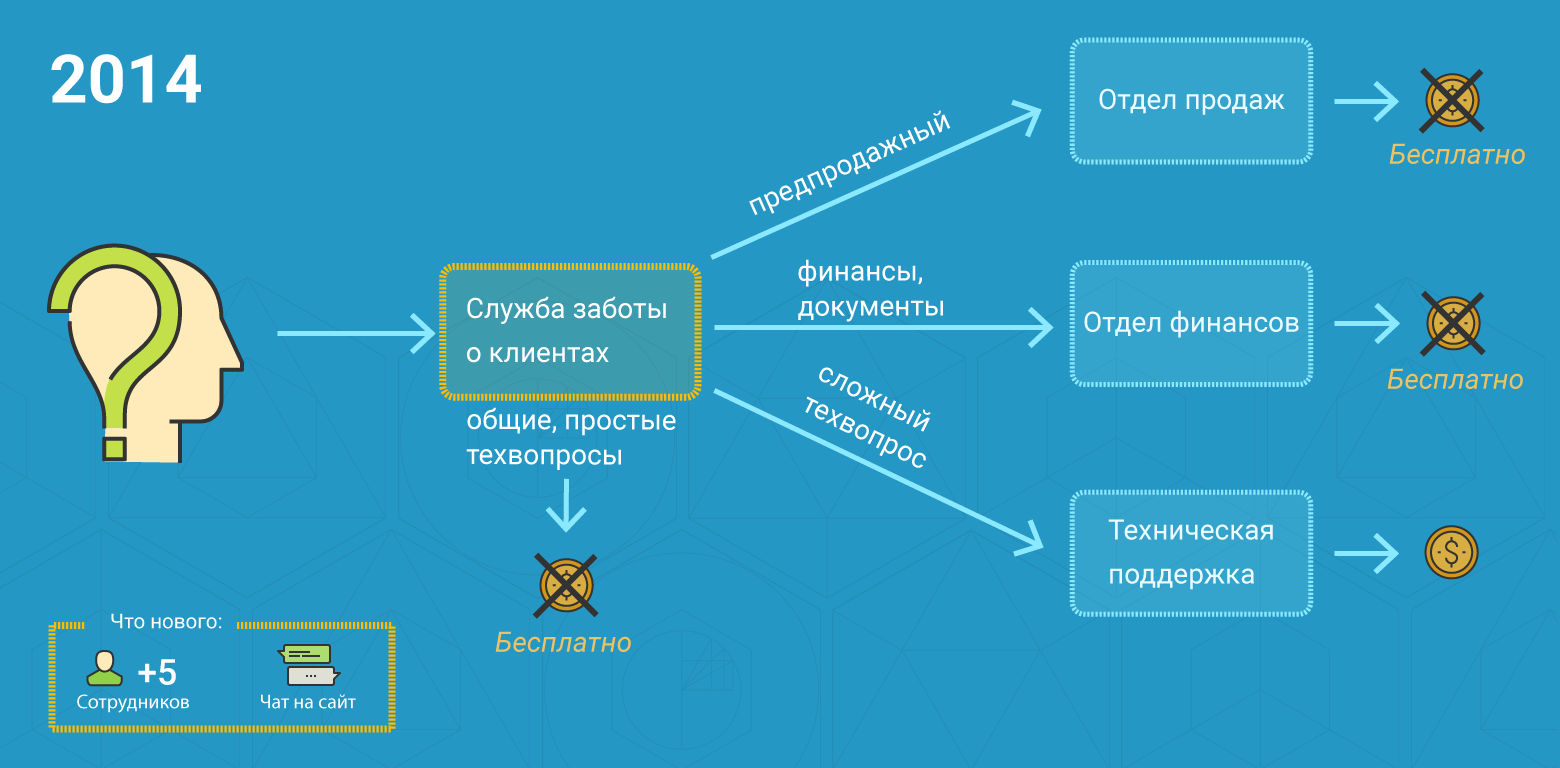

Коллеги из VDS, а у вас все в порядке? 45 руб за минуту поговорить с техподдержкой? Секс по телефону и то дешевле. Брррр
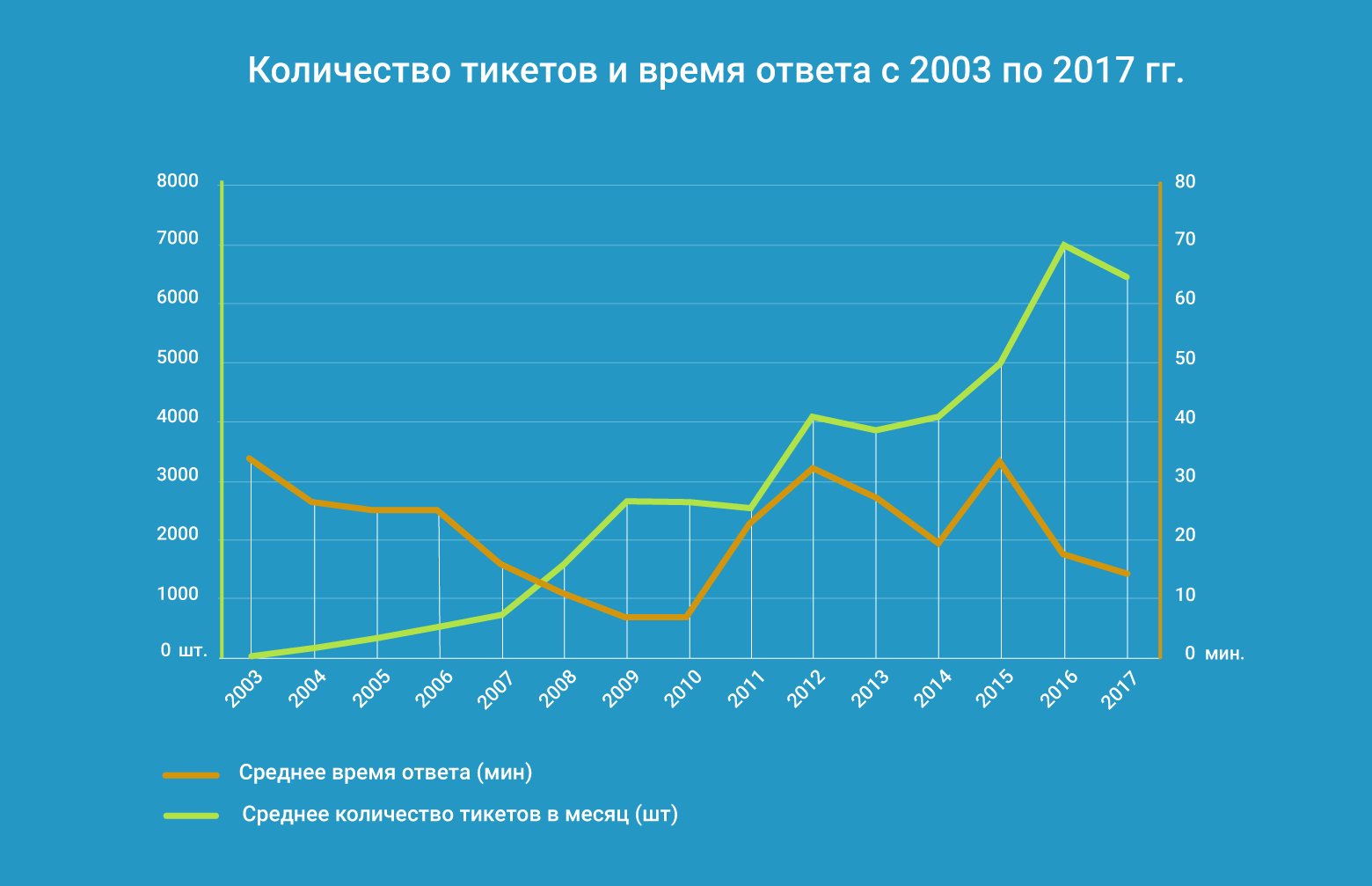
|
Метки: author FirstJohn управление проектами управление персоналом блог компании firstvds / firstdedic поддержка хостинг техподдержка саппорт суппорт |
[Из песочницы] Реализуем тач логгер под Android с помощью CVE-2016–5195 |
История о том, как уязвимость в ядре linux помогает мне собирать данные для диссертации
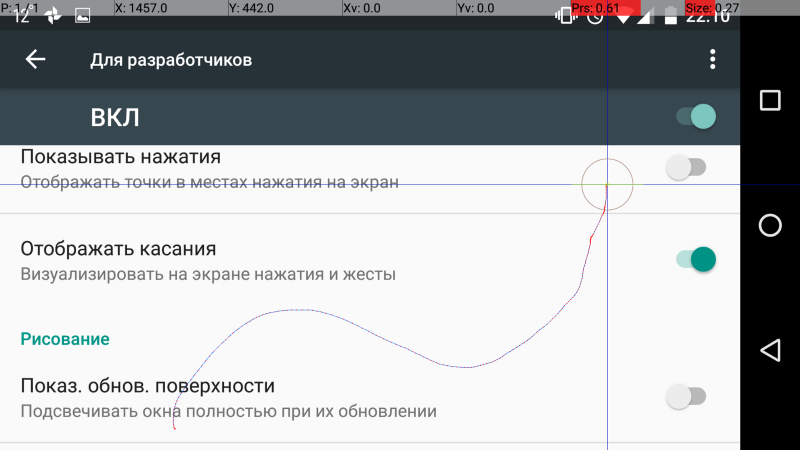

mPointerLocationView обрабатывать все события ввода, поступающие от сенсорного экранаregisterPointerEventListener у системного сервиса WindowManagerService. Последний через интерфейс WindowManager позволяет обычным приложениям вызывать свои методы удалённо. Кажется, достаточно получить в приложении доступ к WindowManager, вызвать этот метод, и приложение сможет обрабатывать координаты, приходящие из системы. Но есть подвох: в Android доступ к системным сервисам предоставляется через Binder IPC, и у WindowManager можно вызвать лишь те методы, которые находятся в соответствующем AIDL файле. К сожалению, нашего метода в AIDL нет, и удалённо вызвать его из пользовательского приложения не удастся. Но если вы вендор, и не знаете, как ещё можно следить за пользователями, можно изменить исходники android и добавить логгирование жестов прямо в прошивку устройства, что я и сделал ради интереса здесь. Правда в нашем случае такое решение не подходит. Можно прошить одно, два устройства для сбора данных, но десятки незнакомых тестовых пользователей на такой шаг не пойдут. Необходим более универсальный способ./dev/input/, откуда их можно прочитать. И уж напрямую от драйвера можно получить все данные, которые только можно пожелать: координаты, метки времени, площадь касания, тип жеста… Хватит не на одно исследование. Правда, здесь тоже есть подвох: в Android доступ к этим устройствам имеет либо root, либо пользователь, состоящий в группе input. Android приложения же запускаются от имени пользователей, которые такими правами похвастать не могут.
/system/bin/ping. Его можно найти практически во всех android-устройствах, и он доступен на чтение и исполнение всем желающим. Что примечательно, у этого файла выставлен SUID-бит. SUID (Set owner User ID up on execution — выставить UID владельца при исполнении) — один из атрибутов файла в Linux. Обычно процесс наследует права пользователя, запустившего его. Наличие SUID бита позволяет запустить процесс с правами владельца исполняемого файла, а так же с его UID и GID. Соответственно, поскольку владельцем ping является root, то и выполнится этот файл от имени root. Понимаете, к чему я клоню? Если мы перезапишем ping с помощью dirtyCOW и запустим его, то наш код выполнится от имени root и сможет прочитать устройства ввода! Что ж господа, поздравляю, у нас получилось, все большие молодцы, расходимся… Нет./system/bin/ping контекст system_file, и да, SELinux не разрешает запускать system_file на исполнение из контекста untrusted_app. Поэтому запустить ping из приложения на android 5.0+ мы не сможем, как и другие системные файлы с SUID-битом.На самом деле, контексты в SELinux состоят из нескольких частей, например, у ping контекст имеет полный видu:object_r:system_file:s0, а у пользователя —u:r:untrusted_app:s0. В нашем случае это не имеет значения, поэтому я буду использовать более короткую запись.

/system/bin/app_process, он же zygote, доступен на чтение всем пользователям!
/system/bin/app_process на наш payload и уронить сервис zygote, android перезапустит его и наш код в файле app_process выполнится от имени root. /system/bin/app_process нашим payload-ом zygote упадёт “сама”. Но нет никаких гарантий, что это будет срабатывать всегда. Давайте разберёмся, что происходит при перезаписи файла app_process и почему это может привести, а может и не привести к падению.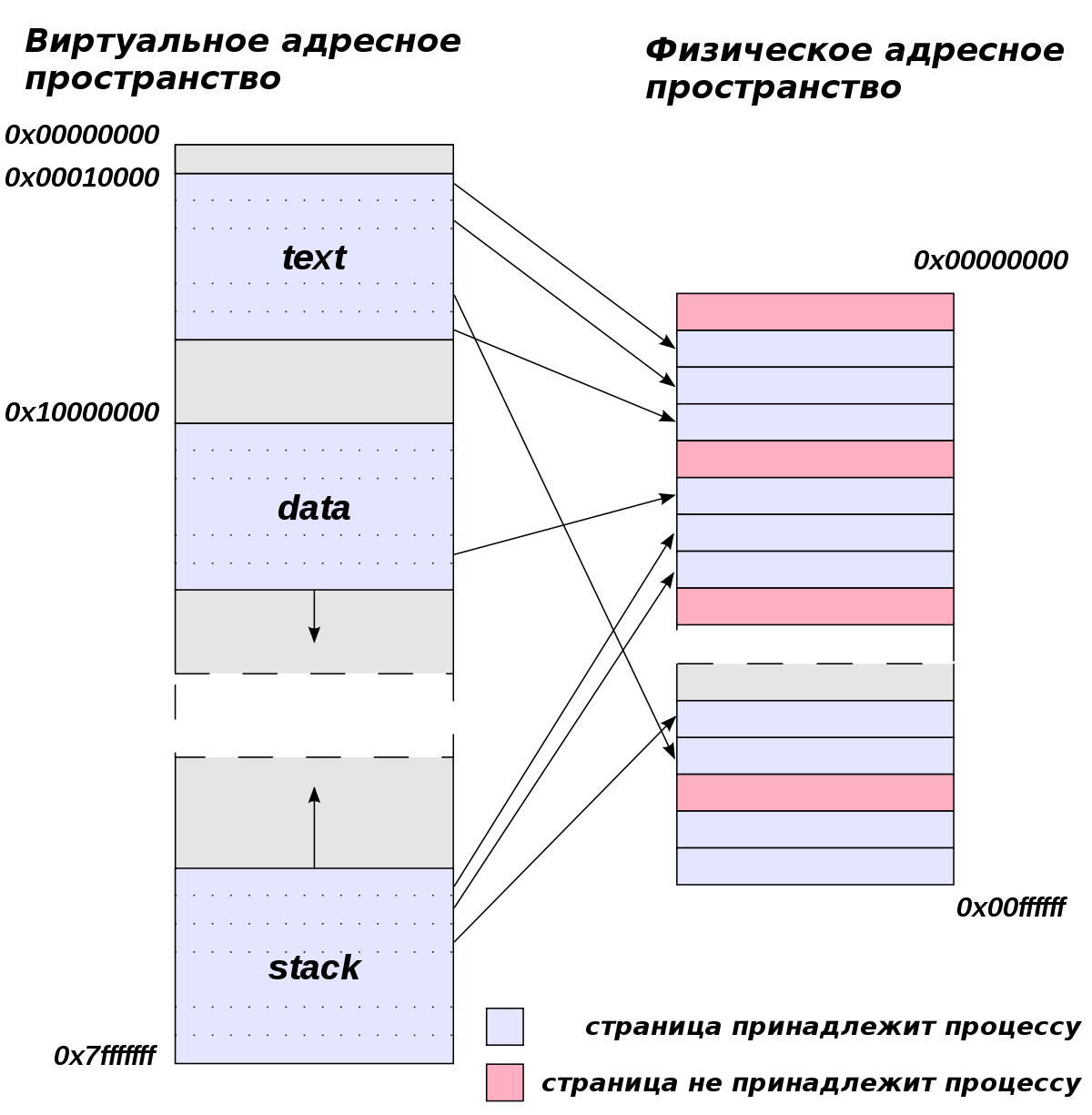


Кстати, практически все процессы в linux запускаются связкой fork()+execve().

/dev/input тоже есть свой контекст: input_device. И, ожидаемо, SELinux не разрешает процессам с контекстом zygote получать доступ к файлам с контекстом input_device. Неужели мы проделали весь этот путь только для того, чтобы снова упереться в SELinux?#ifdef __aarch64__
void * selinux = dlopen("/system/lib64/libselinux.so", RTLD_LAZY);
#else
void* selinux = dlopen("/system/lib/libselinux.so", RTLD_LAZY);
#endif
if (selinux)
{
void* getcon = dlsym(selinux, "getcon");
const char* error = dlerror();
if (!error)
{
getcon_t* getcon_p = (getcon_t*) getcon;
char* secontext;
int ret = (*getcon_p)(&secontext);
void* setcon = dlsym(selinux, "setcon");
const char* error = dlerror();
if (!error)
{
setcon_t* setcon_p = (setcon_t*) setcon;
if ((*setcon_p)("u:r:shell:s0") != 0)
{
LOGV("Unable to set context: %s!", strerror(errno));
}
(*getcon_p)(&secontext);
LOGV("Current context: %s", secontext);
}
}
dlclose(selinux);
}
else
{
LOGV("SELinux not found.");
}
/dev/input/event[X]? Возможно несколько вариантов. К сожалению, самые адекватные из них (UNIX socket, FIFO) недоступны нам (коварный SELinux!). Остаётся писать данные на SD-карту одним процессом и читать их оттуда другим процессом. Не самый крутой вариант, но всё же. Помимо этого, можно отправлять данные в приложение через специальные intent с помощью встроенной утилиты am (по сути, это командный интерфейс для Activity Manager). Возможно, есть другие способы, до которых я не додумался./data/local/tmp (куда у shell есть доступ), и оттуда запустить его — демон начнёт работать точно так же, как если бы его запустило наше приложение. Единственное, будет отличаться UID (2000 вместо 0), но на доступе к устройствам ввода это никак не отразится. Так что в третьей версии своего тач-логгера (которая сейчас доводится до ума) я собираюсь предусмотреть и такой вариант в качестве крайней меры, оставив при этом и возможность запуска на рутованных устройствах как ещё один запасной вариант..init и .init_array. Функции, адреса которых будут помещены в эти секции, выполнятся при подгрузке библиотеки в процесс. Соответственно, если мы скомпилируем библиотеку с функцией в секции .init_array и перезапишем ей файл /system/lib/libcutils.so, то при его подгрузке в процесс эта функция благополучно выполнится с привилегиями процесса.__attribute__((constructor)) void say_hello()
{
payload_main();
}
.init_array библиотеки.objdump -p:Динамический раздел:
[.....]
STRTAB 0x00001660
STRSZ 0x000014ec
GNU_HASH 0x00002b4c
NEEDED liblog.so
NEEDED libc++.so
NEEDED libdl.so
NEEDED libc.so
NEEDED libm.so
SONAME libcutils.so
FINI_ARRAY 0x0000fbf0
[.....]
Динамический раздел:
[.....]
STRTAB 0x00001660
STRSZ 0x000014ec
GNU_HASH 0x00002b4c
NEEDED liblog.so
NEEDED libc++.so
NEEDED libdl.so
NEEDED libc.so
NEEDED libm.so
NEEDED libmtp.so
FINI_ARRAY 0x0000fbf0
[.....]
Стоит сказать спасибо авторам вируса Android.Loki.28.origin, у которых я почерпнул эту замечательную идею с внедрением зависимости в библиотеку.
|
Метки: author BOOtak разработка под linux разработка под android информационная безопасность android linux dirtycow cve-2016-5195 logger |
27000 ошибок в операционной системе Tizen |

/*
* Copyright (c) 2015 Samsung Electronics Co., Ltd All Rights Reserved
....
*///TIZEN_ONLY(20161121)
// Pre-rotation should be enabled only when direct
// rendering is set but client side rotation is not set
if ((sfc->direct_fb_opt) &&
(!sfc->client_side_rotation) &&
(evgl_engine->funcs->native_win_prerotation_set))
{
if (!evgl_engine->funcs->native_win_prerotation_set(eng_data))
ERR("Prerotation does not work");
}
//m_ptr = (int *)realloc(m_ptr, newSize);
if (!m_ptr) return ERROR;
bool operator <(const TSegment& other) const {
if (m_start < other.m_start)
return true;
if (m_start == other.m_start)
return m_len < m_len; // <=
return false;
}return m_len < other.m_len;static void __page_focus_changed_cb(void *data)
{
int i = 0;
int *focus_unit = (int *)data;
if (focus_unit == NULL || focus_unit < 0) { // <=
_E("focus page is wrong");
return ;
}
....
}if (focus_unit == NULL || *focus_unit < 0) {static void __page_count_changed_cb(void *data)
{
int i = 0;
int *page_cnt = (int *)data;
if (page_cnt == NULL || page_cnt < 0) {
_E("page count is wrong");
return ;
}
....
}int audio_io_loopback_in_test()
{
....
while (1) {
char *buffer = alloca(size);
if ((ret = audio_in_read(input, (void *)buffer, size)) >
AUDIO_IO_ERROR_NONE)
{
fwrite(buffer, size, sizeof(char), fp);
printf("PASS, size=%d, ret=0x%x\n", size, ret);
} else {
printf("FAIL, size=%d, ret=0x%x\n", size, ret);
}
}
....
}char *buffer = alloca(size);
while (1) {
if ((ret = audio_in_read(input, (void *)buffer, size)) >
AUDIO_IO_ERROR_NONE)
{
fwrite(buffer, size, sizeof(char), fp);
printf("PASS, size=%d, ret=0x%x\n", size, ret);
} else {
printf("FAIL, size=%d, ret=0x%x\n", size, ret);
}
}void extract_input_aacdec_m4a_test(
App * app, unsigned char **data, int *size, bool * have_frame)
{
....
unsigned char buffer[100000];
....
DONE:
*data = buffer;
*have_frame = TRUE;
if (read_size >= offset)
*size = offset;
else
*size = read_size;
}typedef int gint;
typedef gint gboolean;
#define BT_REQUEST_ID_RANGE_MAX 245
static gboolean req_id_used[BT_REQUEST_ID_RANGE_MAX];
void _bt_init_request_id(void)
{
assigned_id = 0;
memset(req_id_used, 0x00, BT_REQUEST_ID_RANGE_MAX);
}memset(req_id_used, 0x00, BT_REQUEST_ID_RANGE_MAX * sizeof(gboolean));memset(req_id_used, 0x00, sizeof(req_id_used));static void _on_atspi_event_cb(const AtspiEvent * event)
{
....
char buf[256] = "\0";
....
snprintf(buf, sizeof(buf), "%s, %s, ",
name, _("IDS_BR_BODY_IMAGE_T_TTS"));
....
snprintf(buf + strlen(buf), sizeof(buf),
"%s, ", _("IDS_ACCS_BODY_SELECTED_TTS"));
....
}snprintf(buf + strlen(buf), sizeof(buf) - strlen(buf),
"%s, ", _("IDS_ACCS_BODY_SELECTED_TTS"));#define BT_ADDRESS_STRING_SIZE 18
typedef struct {
unsigned char addr[6];
} bluetooth_device_address_t;
typedef struct {
int count;
bluetooth_device_address_t addresses[20];
} bt_dpm_device_list_t;dpm_result_t _bt_dpm_get_bluetooth_devices_from_whitelist(
GArray **out_param1)
{
dpm_result_t ret = DPM_RESULT_FAIL;
bt_dpm_device_list_t device_list;
....
for (; list; list = list->next, i++) {
memset(device_list.addresses[i].addr, 0, BT_ADDRESS_STRING_SIZE);
_bt_convert_addr_string_to_type(device_list.addresses[i].addr,
list->data);
}
....
}memset(device_list.addresses[i].addr, 0, BT_ADDRESS_STRING_SIZE);char *voice_setting_language_conv_lang_to_id(const char* lang)
{
....
} else if (!strcmp(LANG_PT_PT, lang)) {
return "pt_PT";
} else if (!strcmp(LANG_ES_MX, lang)) { // <=
return "es_MX";
} else if (!strcmp(LANG_ES_US, lang)) { // <=
return "es_US";
} else if (!strcmp(LANG_EL_GR, lang)) {
return "el_GR";
....
}#define LANG_ES_MX "\x45\x73\x70\x61\xC3\xB1\x6f\x6c\x20\x28\" \
"x45\x73\x74\x61\x64\x6f\x73\x20\x55\x6e\x69\x64\x6f\x73\x29"
#define LANG_ES_US "\x45\x73\x70\x61\xC3\xB1\x6f\x6c\x20\x28\" \
"x45\x73\x74\x61\x64\x6f\x73\x20\x55\x6e\x69\x64\x6f\x73\x29"void
isf_wsc_context_del (WSCContextISF *wsc_ctx)
{
....
WSCContextISF* old_focused = _focused_ic;
_focused_ic = context_scim;
_focused_ic = old_focused;
....
}WSCContextISF* old_focused = _focused_ic;
_focused_ic = context_scim;
context_scim = old_focused;std::swap(_focused_ic, context_scim);void create_privacy_package_list_view(app_data_s* ad)
{
....
Elm_Genlist_Item_Class *ttc = elm_genlist_item_class_new();
Elm_Genlist_Item_Class *ptc = elm_genlist_item_class_new();
Elm_Genlist_Item_Class *mtc = elm_genlist_item_class_new();
....
ttc->item_style = "title";
ttc->func.text_get = gl_title_text_get_cb;
ttc->func.del = gl_del_cb; // <=
ptc->item_style = "padding";
ptc->func.del = gl_del_cb;
mtc->item_style = "multiline";
mtc->func.text_get = gl_multi_text_get_cb;
ttc->func.del = gl_del_cb; // <=
....
}status = Foo(0);
status = Foo(1);
status = Foo(2);static FilterModule *__filter_modules = 0;
static void
__initialize_modules (const ConfigPointer &config)
{
....
__filter_modules = new FilterModule [__number_of_modules];
if (!__filter_modules) return;
....
}void QuickAccess::setButtonColor(Evas_Object* button,
int r, int g, int b, int a)
{
Edje_Message_Int_Set* msg =
(Edje_Message_Int_Set *)malloc(sizeof(*msg) + 3 * sizeof(int));
msg->count = 4;
msg->val[0] = r;
msg->val[1] = g;
msg->val[2] = b;
msg->val[3] = a;
edje_object_message_send(elm_layout_edje_get(button),
EDJE_MESSAGE_INT_SET, 0, msg);
free(msg);
}int cpp_audio_in_peek(audio_in_h input, const void **buffer,
unsigned int *length) {
....
CAudioInput* inputHandle =
dynamic_cast(handle->audioIoHandle);
assert(inputHandle);
inputHandle->peek(buffer, &_length);
....
}CAudioInput* inputHandle =
dynamic_cast(handle->audioIoHandle);
if (inputHandle == nullptr) {
assert(false);
THROW_ERROR_MSG_FORMAT(
CAudioError::EError::ERROR_INVALID_HANDLE, "Handle is NULL");
}int main(int argc, char *argv[])
{
....
char *temp1 = strstr(dp->d_name, "-");
char *temp2 = strstr(dp->d_name, ".");
strncpy(temp_filename, dp->d_name,
strlen(dp->d_name) - strlen(temp1));
strncpy(file_format, temp2, strlen(temp2));
....
}static void _content_resize(...., const char *signal)
{
....
if (strcmp(signal, "portrait") == 0) {
evas_object_size_hint_min_set(s_info.layout,
ELM_SCALE_SIZE(width), ELM_SCALE_SIZE(height));
} else {
evas_object_size_hint_min_set(s_info.layout,
ELM_SCALE_SIZE(width), ELM_SCALE_SIZE(height));
}
....
}static Eina_Bool _move_cb(void *data, int type, void *event)
{
Ecore_Event_Mouse_Move *move = event;
mouse_info.move_x = move->root.x;
mouse_info.move_y = move->root.y;
if (mouse_info.pressed == false) {
return ECORE_CALLBACK_RENEW; // <=
}
return ECORE_CALLBACK_RENEW; // <=
}int _read_request_body(http_transaction_h http_transaction,
char **body)
{
....
*body = realloc(*body, new_len + 1);
....
memcpy(*body + curr_len, ptr, body_size);
body[new_len] = '\0'; // <=
curr_len = new_len;
....
}body[new_len] = '\0';
(*body)[new_len] = '\0';unsigned m_candiPageFirst;
bool
CIMIClassicView::onKeyEvent(const CKeyEvent& key)
{
....
if (m_candiPageFirst > 0) {
m_candiPageFirst -= m_candiWindowSize;
if (m_candiPageFirst < 0) m_candiPageFirst = 0;
changeMasks |= CANDIDATE_MASK;
}
....
}if (m_candiPageFirst > 0) {
if (m_candiPageFirst > m_candiWindowSize)
m_candiPageFirst -= m_candiWindowSize;
else
m_candiPageFirst = 0;
changeMasks |= CANDIDATE_MASK;
}void
QuickAccess::_grid_mostVisited_del(void *data, Evas_Object *)
{
BROWSER_LOGD("[%s:%d]", __PRETTY_FUNCTION__, __LINE__);
if (data) {
auto itemData = static_cast(data);
if (itemData)
delete itemData;
}
}typedef enum {
BT_HID_MOUSE_BUTTON_NONE = 0x00,
BT_HID_MOUSE_BUTTON_LEFT = 0x01,
BT_HID_MOUSE_BUTTON_RIGHT = 0x02,
BT_HID_MOUSE_BUTTON_MIDDLE = 0x04
} bt_hid_mouse_button_e;
int bt_hid_device_send_mouse_event(const char *remote_address,
const bt_hid_mouse_data_s *mouse_data)
{
....
if (mouse_data->buttons != BT_HID_MOUSE_BUTTON_LEFT ||
mouse_data->buttons != BT_HID_MOUSE_BUTTON_RIGHT ||
mouse_data->buttons != BT_HID_MOUSE_BUTTON_MIDDLE) {
return BT_ERROR_INVALID_PARAMETER;
}
....
}if (buttons != 1 ||
buttons != 2 ||
buttons != 4) {typedef enum {
WIFI_MANAGER_RSSI_LEVEL_0 = 0,
WIFI_MANAGER_RSSI_LEVEL_1 = 1,
WIFI_MANAGER_RSSI_LEVEL_2 = 2,
WIFI_MANAGER_RSSI_LEVEL_3 = 3,
WIFI_MANAGER_RSSI_LEVEL_4 = 4,
} wifi_manager_rssi_level_e;
typedef enum {
WIFI_RSSI_LEVEL_0 = 0,
WIFI_RSSI_LEVEL_1 = 1,
WIFI_RSSI_LEVEL_2 = 2,
WIFI_RSSI_LEVEL_3 = 3,
WIFI_RSSI_LEVEL_4 = 4,
} wifi_rssi_level_e;static int
_rssi_level_to_strength(wifi_manager_rssi_level_e level)
{
switch (level) {
case WIFI_RSSI_LEVEL_0:
case WIFI_RSSI_LEVEL_1:
return LEVEL_WIFI_01;
case WIFI_RSSI_LEVEL_2:
return LEVEL_WIFI_02;
case WIFI_RSSI_LEVEL_3:
return LEVEL_WIFI_03;
case WIFI_RSSI_LEVEL_4:
return LEVEL_WIFI_04;
default:
return WIFI_RSSI_LEVEL_0;
}
}int bytestream2nalunit(FILE * fd, unsigned char *nal)
{
unsigned char val, zero_count, i;
....
val = buffer[0];
while (!val) { // <=
if ((zero_count == 2 || zero_count == 3) && val == 1) // <=
break;
zero_count++;
result = fread(buffer, 1, read_size, fd);
if (result != read_size)
break;
val = buffer[0];
}
....
}const int GT_SEARCH_NO_LONGER = 0,
GT_SEARCH_INCLUDE_LONGER = 1,
GT_SEARCH_ONLY_LONGER = 2;
bool GenericTableContent::search (const String &key,
int search_type) const
{
....
else if (nkeys.size () > 1 && GT_SEARCH_ONLY_LONGER) {
....
}if (nkeys.size () > 1 && search_type == GT_SEARCH_ONLY_LONGER)struct sockaddr_un
{
sa_family_t sun_family;
char sun_path[108];
};
struct sockaddr_in
{
sa_family_t sin_family;
in_port_t sin_port;
struct in_addr sin_addr;
unsigned char sin_zero[sizeof (struct sockaddr) -
(sizeof (unsigned short int)) -
sizeof (in_port_t) -
sizeof (struct in_addr)];
};
struct sockaddr
{
sa_family_t sa_family;
char sa_data[14];
};class SocketAddress::SocketAddressImpl
{
struct sockaddr *m_data;
....
SocketAddressImpl (const SocketAddressImpl &other)
{
....
case SCIM_SOCKET_LOCAL:
m_data = (struct sockaddr*) new struct sockaddr_un; // <=
len = sizeof (sockaddr_un);
break;
case SCIM_SOCKET_INET:
m_data = (struct sockaddr*) new struct sockaddr_in; // <=
len = sizeof (sockaddr_in);
break;
....
}
~SocketAddressImpl () {
if (m_data) delete m_data; // <=
}
};static int _write_file(const char *file_name, void *data,
unsigned long long data_size)
{
FILE *fp = NULL;
if (!file_name || !data || data_size <= 0) {
fprintf(stderr,
"\tinvalid data %s %p size:%lld\n",
file_name, data, data_size);
return FALSE;
}
....
}void subscribe_to_event()
{
....
int error = ....;
....
PRINT_E("Failed to destroy engine configuration for event trigger.",
error);
....
}static void _show(void *data)
{
SETTING_TRACE_BEGIN;
struct _priv *priv = (struct _priv *)data;
Eina_List *children = elm_box_children_get(priv->box); // <=
Evas_Object *first = eina_list_data_get(children);
Evas_Object *selected =
eina_list_nth(children, priv->item_selected_on_show); // <=
if (!priv) { // <=
_ERR("Invalid parameter.");
return;
}
....
}static void _show(void *data)
{
SETTING_TRACE_BEGIN;
struct _priv *priv = (struct _priv *)data;
if (!priv) {
_ERR("Invalid parameter.");
return;
}
Eina_List *children = elm_box_children_get(priv->box);
Evas_Object *first = eina_list_data_get(children);
Evas_Object *selected =
eina_list_nth(children, priv->item_selected_on_show);
....
}static Evas_Object *_ticker_window_create(struct appdata *ad)
{
....
// нет проверки указателя 'ad'
....
evas_object_resize(win, ad->win.w, indicator_height_get());
....
}static int _ticker_view_create(void)
{
if (!ticker.win)
ticker.win = _ticker_window_create(ticker.ad); // <=
if (!ticker.layout)
ticker.layout = _ticker_layout_create(ticker.win);
if (!ticker.scroller)
ticker.scroller = _ticker_scroller_create(ticker.layout);
evas_object_show(ticker.layout);
evas_object_show(ticker.scroller);
evas_object_show(ticker.win);
if (ticker.ad) // <=
util_signal_emit_by_win(&ticker.ad->win,
"message.show.noeffect", "indicator.prog");
....
}static void SHA1Final(unsigned char digest[20],
SHA1_CTX* context)
{
u32 i;
unsigned char finalcount[8];
....
memset(context->count, 0, 8);
memset(finalcount, 0, 8);
}void
GenericTableContent::set_max_key_length (size_t max_key_length)
{
....
std::vector *offsets;
std::vector *offsets_attrs;
offsets = new(std::nothrow) // <=
std::vector [max_key_length];
if (!offsets) return;
offsets_attrs = new(std::nothrow)
std::vector [max_key_length];
if (!offsets_attrs) {
delete offsets; // <=
return;
}
....
} static void __draw_remove_list(SettingRingtoneData *ad)
{
char *full_path = NULL;
....
full_path = (char *)alloca(PATH_MAX); // <=
....
if (!select_all_item) {
SETTING_TRACE_ERROR("select_all_item is NULL");
free(full_path); // <=
return;
}
....
}Eext_Circle_Surface *surface;
....
if (_WEARABLE)
surface = eext_circle_surface_conformant_add(conform);
....
app_data->circle_surface = surface;|
|
О мобильной библиотеке и любви к React Native |

Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author EFS_programm разработка под ios разработка мобильных приложений reactjs javascript мобильная разработка react.js objective-c swift ефс react native |
Немного о багах в BIOS/UEFI ноутбуков Lenovo/Fujitsu/Toshiba/HP/Dell |
typedef EFI_STATUS (EFIAPI *EFI_USB_IO_CONTROL_TRANSFER) (
IN EFI_USB_IO_PROTOCOL* This,
IN EFI_USB_DEVICE_REQUEST* Request,
IN EFI_USB_DATA_DIRECTION Direction,
IN UINT32 Timeout,
IN OUT VOID* Data OPTIONAL,
IN UINTN DataLength OPTIONAL,
OUT UINT32* Status
); typedef enum {
EfiUsbDataIn,
EfiUsbDataOut,
EfiUsbNoData
} EFI_USB_DATA_DIRECTION; #pragma pack( push, 1 )
struct RDR_to_PC_DataBlock {
UINT8 bMessageType;
UINT32 dwLength;
UINT8 bSlot;
UINT8 bSeq;
UINT8 bStatus;
UINT8 bError;
UINT8 bChainParameter;
UINT8* abData[0];
};
#pragma pack( pop ) 
|
Метки: author anatolymik системное программирование реверс-инжиниринг блог компании аладдин р.д. lenovo fujitsu toshiba hp dell bios uefi |
Что нового в CUBA Platform 6.5 |
java -jar app-core.jarjava -jar app.jar


|
Метки: author aleksey-stukalov программирование open source java блог компании haulmont cuba platform haulmont apache 2.0 |
Проблемы безопасности Android-приложений: классификация и анализ |

Автор: Михаил Романеев (@melon)
|
Метки: author ptsecurity разработка под android информационная безопасность блог компании positive technologies android мобильные приложения уязвимости |
«Наэкономили»: К чему ведет в магазине чрезмерное урезание бюджетов на ИТ |



|
Метки: author pilot-retail монетизация it-систем брендинг блог компании пилот ит бюджет маркетинг |
Как поднять продажи в Москве на 60% в период кризиса? История успеха одной компании |

«Мы начинали бизнес в Москве, затем вышли в регионы. К 2014 году построили более 40 площадок, 90% из них – в столице и области. Клиентов привлекали путем рекламирования продукции с помощью каталогов, буклетов и презентаций. 40% продаж приносил нам сайт и продвижение в Интернете. С учетом расширения производства возникла острая проблема нехватки новых клиентов, не было роста продаж. Мы понимали, что наш сайт и его продвижение нуждаются в доработке»Алексей Красников, генеральный директор ГК «Забава»
«Сегодня компании делают полный редизайн сайта в среднем 1 раз в 4-5 лет, и этот срок сокращается каждый год. Это связано с развитием новых технологий и инструментов, возможностей CMS, изменением поведения пользователей Сети. К 2014 году сайт ГК «Забава» сильно устарел в технологическом плане – он был не адаптивным, CMS не позволяла серьезно улучшить SEO-продвижение. Высокая конкуренция на московском рынке усложняла удержание позиций компании в поисковых системах»Роман Плотников, директор интернет-агентства «Веб-Центр»






«Продажи растут в соответствии с показателями аналитики сайта как в Москве, так и в других регионах Центральной России. С 2014 по 2017 годы продажи выросли на 60%, валовая прибыль – на 30%, мы увеличили долю рынка на 3,5%. Прирост объемов работ составил 250%. Кроме того, на 40% выросло производство в регионах»Алексей Красников, генеральный директор ГК «Забава»
|
Метки: author vasyk поисковая оптимизация повышение конверсии интернет-маркетинг веб-аналитика growth hacking seo разработка сайтов кейс |
[Перевод] ES8 вышел и вот его основные новые возможности |

ES2017 (the 8th edition of the JavaScript Spec) was officially released and published yesterday! https://t.co/1ITn5bzaqj
— Kent C. Dodds (@kentcdodds) June 28, 2017
str.padStart(targetLength [, padString])
str.padEnd(targetLength [, padString])
targetLength – это полная длина итоговой строки. Второй опциональный параметр padString – это строка для дополнения исходной строки. По умолчанию – пробел.'es8'.padStart(2); // 'es8'
'es8'.padStart(5); // ' es8'
'es8'.padStart(6, 'woof'); // 'wooes8'
'es8'.padStart(14, 'wow'); // 'wowwowwowwoes8'
'es8'.padStart(7, '0'); // '0000es8'
'es8'.padEnd(2); // 'es8'
'es8'.padEnd(5); // 'es8 '
'es8'.padEnd(6, 'woof'); // 'es8woo'
'es8'.padEnd(14, 'wow'); // 'es8wowwowwowwo'
'es8'.padEnd(7, '6'); // 'es86666'

Object.values возвращает массив собственных перечисляемых свойств переданного объекта в том же порядке, который предоставляет цикл for in. Object.values(obj)
obj – исходный объект для операции. Это может быть объект или массив (который является объектом с такими индексами [10, 20, 30] -> { 0: 10, 1: 20, 2: 30 } ).const obj = { x: 'xxx', y: 1 };
Object.values(obj); // ['xxx', 1]
const obj = ['e', 's', '8']; // same as { 0: 'e', 1: 's', 2: '8' };
Object.values(obj); // ['e', 's', '8']
// когда мы используем числовые ключи, значения возвращаются
// в порядке сортировки по ключам
const obj = { 10: 'xxx', 1: 'yyy', 3: 'zzz' };
Object.values(obj); // ['yyy', 'zzz', 'xxx']
Object.values('es8'); // ['e', 's', '8']

Object.entries возвращает массив собственных перечисляемых свойств переданного объекта парами [ключ, значение] в том же порядке, как и Object.values.const obj = { x: 'xxx', y: 1 };
Object.entries(obj); // [['x', 'xxx'], ['y', 1]]
const obj = ['e', 's', '8'];
Object.entries(obj); // [['0', 'e'], ['1', 's'], ['2', '8']]
const obj = { 10: 'xxx', 1: 'yyy', 3: 'zzz' };
Object.entries(obj); // [['1', 'yyy'], ['3', 'zzz'], ['10': 'xxx']]
Object.entries('es8'); // [['0', 'e'], ['1', 's'], ['2', '8']]

getOwnPropertyDescriptors возвращает дескрипторы собственных свойств указанного объекта. Дескриптор собственного свойства это тот, который определён прямо у объекта, а не унаследован от его прототипа.Object.getOwnPropertyDescriptor(obj, prop)obj – исходный объект и prop – имя свойства, дескриптор которого нужно получить. Возможные ключи в результате: configurable, enumerable, writable, get, set и value.const obj = { get es8() { return 888; } };
Object.getOwnPropertyDescriptor(obj, 'es8');
// {
// configurable: true,
// enumerable: true,
// get: function es8(){}, // функция геттер
// set: undefined
// }

SyntaxError) когда мы добавили запятую в конце списка:function es8(var1, var2, var3,) {
// ...
}
es8(10, 20, 30,);
{ x: 1, } и литералах массива [10, 20, 30,].async function определяет асинхронную функцию, которая возвращает объект AsyncFunction. Внутреннее устройство асинхронных функций работает подобно генераторам, но они не транслируются в функции генератора.function fetchTextByPromise() {
return new Promise(resolve => {
setTimeout(() => {
resolve("es8");
}, 2000);
});
}
async function sayHello() {
const externalFetchedText = await fetchTextByPromise();
console.log(`Hello, ${externalFetchedText}`); // Hello, es8
}
sayHello();
sayHello выведет Hello, es8 через 2 секунды.console.log(1);
sayHello();
console.log(2);
1 // сразу
2 // сразу
Hello, es8 // через 2 секунды
async function всегда возвращает промис и ключевое слово await может использоваться только в функциях с ключевым словом async.
SharedArrayBuffer и объект Atomics со статическими методами.Atomics – это набор статических методов как Math, так что мы не сможем вызвать его конструктор. Примеры статических методов этого объекта:
const esth = 8;
helper`ES ${esth} is `;
function helper(strs, ...keys) {
const str1 = strs[0]; // ES
const str2 = strs[1]; // is
let additionalPart = '';
if (keys[0] == 8) { // 8
additionalPart = 'awesome';
}
else {
additionalPart = 'good';
}
return `${str1} ${keys[0]} ${str2} ${additionalPart}.`;
}
esth равным 7 вернётся -> ES 7 is good.
|
Метки: author sefus javascript ecmascript es8 nodejs |
GitLab CI для непрерывной интеграции и доставки в production. Часть 2: преодолевая трудности |

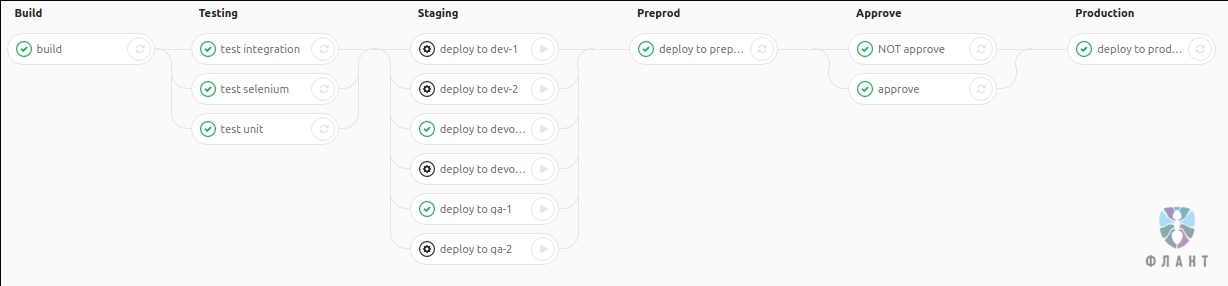
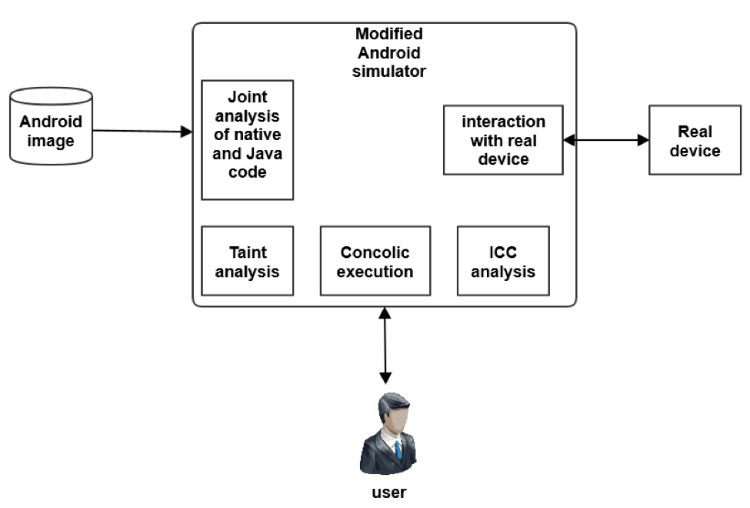
.gitlab-ci.yml только для отдельных пользователей.git push, может изменить .gitlab-ci.yml и сломать production. Эту проблему обсуждают в тикетах GitLab: как минимум — в #24794 и #20826 с подачи нашего коллеги..gitlab-ci.yml могут только некоторые пользователи — обычно это команда DevOps, т.к. сборка и развёртывание в их зоне ответственности.ci_admin в таблицу с пользователями. Кому в столбце установлено true, тот может делать git push с изменениями в .gitlab-ci.yml.GITLAB_USER_ID и GITLAB_USER_EMAIL для скрипта задачи с идентификатором пользователя и его почтой. Эти переменные можно использовать, чтобы определить, может ли пользователь запустить задачу. Реализовано как решение тикета #21825, принято в основную ветку (upstream) и доступно в GitLab CI начиная с версии 8.12: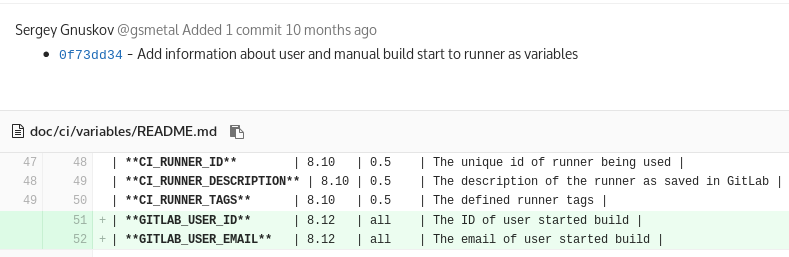
artifact, которые будут доступны (после успешного завершения задачи) всем остальным задачам на последующих стадиях. Тут, правда, есть свои подводные камни: файлы со всех задач стадии будут доступны на дальнейших стадиях и удалить что-то из этого набора нельзя. В то же время файлы артефакта задачи недоступны в других задачах той же стадии.
touch файла с именем задачи, а в начале выполнения задач deploy to qa-*, на стадии staging, проверяется наличие этих файлов.test integration:
stage: testing
tags: [deploy]
script:
- mkdir -p .ci_status
- echo "test integration"
- touch .ci_status/test_integration
artifacts:
paths:
- .ci_status/
deploy to qa-1:
tags: [deploy]
stage: staging
when: manual
script:
- if [ ! -e .ci_status/test_unit -o ! -e .ci_status/test_integration -o ! -e .ci_status/test_selenium ]; then echo "Нужно успешное выполнение всех тестов"; exit 1; fi
- echo "execute job ${CI_BUILD_NAME}"
- touch .ci_status/deploy_to_qa_1
artifacts:
paths:
- .ci_status/artifact, которая определяет пути в репозитории, сохраняемые GitLab CI в архив после выполнения задачи и разархивируемые перед выполнением следующей задачи. Чтобы не перечислять все файлы, указывается директория .ci_status, которую не помешает создать во время выполнения задачи (mkdir -p).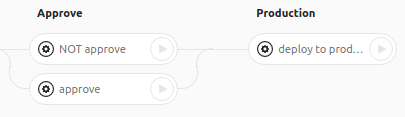
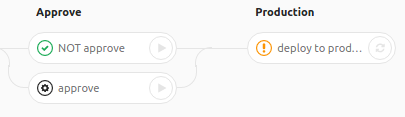
approve:
script:
- mkdir -p .ci_status
- echo $(date +%s) > .ci_status/approved
artifacts:
paths:
- .ci_status/
NOT approve:
script:
- mkdir -p .ci_status
- echo $(date +%s) > .ci_status/not_approved
artifacts:
paths:
- .ci_status/
deploy to production:
script:
- if [[ $(cat .ci_status/not_approved) > $(cat .ci_status/approved) ]]; then echo "Нужно разрешение от релиз-инженера"; exit 1; fi
- echo "deploy to production!"
GITLAB_USER_ID и GITLAB_USER_EMAIL. Создание такого REST API выходит за рамки данной статьи..gitlab-ci.yml. Это очень неудобно, если проектов много и нужно что-то поправить, например, если появится новое окружение для qa или окружений для pre-production станет больше. Мы это решили с помощью вынесения скриптов в один внешний скрипт, который не хранится в каждом репозитории, а устанавливается на машины с раннерами.
.gitlab-ci.yml по адресу https://мой-гитлаб/ci/lint. Поможет сэкономить время!
|
|
Asterisk. На этот раз в качестве системы трансляции фоновой музыки с возможностью экстренного оповещения |

[tmpl](!)
type = peer
host = dynamic
canreinvite=no
dtmfmode = rfc2833
insecure = invite
nat = force_rport,comedia
call-limit=2
qualify = yes
context = from-internal
disallow=all
allow=alaw
allow=ulaw
directmedia=no
[780](tmpl)
defaultuser=780
secret=780
callerid="Dispatcher" <780>
[790](tmpl)
defaultuser=790
secret=790
callerid="Speaker1" <790>
[800](tmpl)
defaultuser=800
secret=800
callerid="Speaker2" <800>
exten => _XXX,1,NoOp(Testing calls to speakers. Dialing ${EXTEN} from ${CALLERID})
same => n,Page(SIP/${EXTEN},qA(hello-world))
same => n,Hangup()
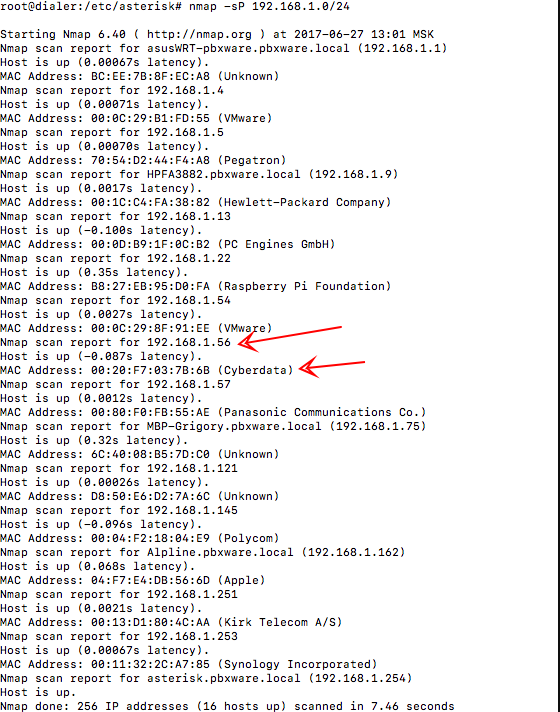



sudo dd if=path_of_your_image.img of=/dev/diskn bs=1M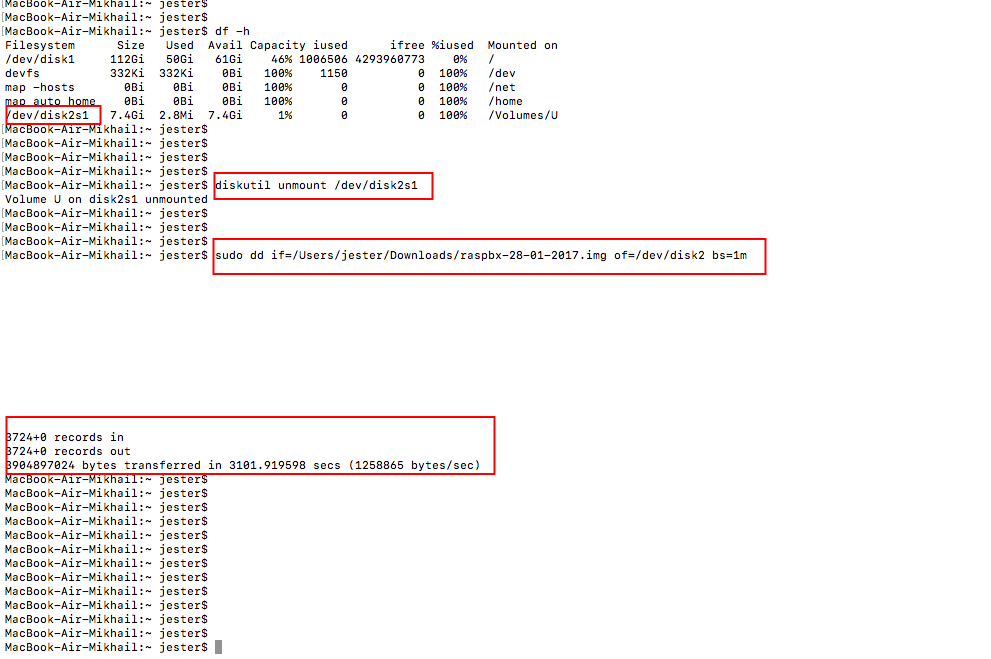
type=peer
host=192.168.1.254 ;;ip "головного" Asterisk
qualify=yes
insecure = port,invite
directmedia=no
context=speakers
canreinvite=no
disallow=all
allow=alaw
allow=ulaw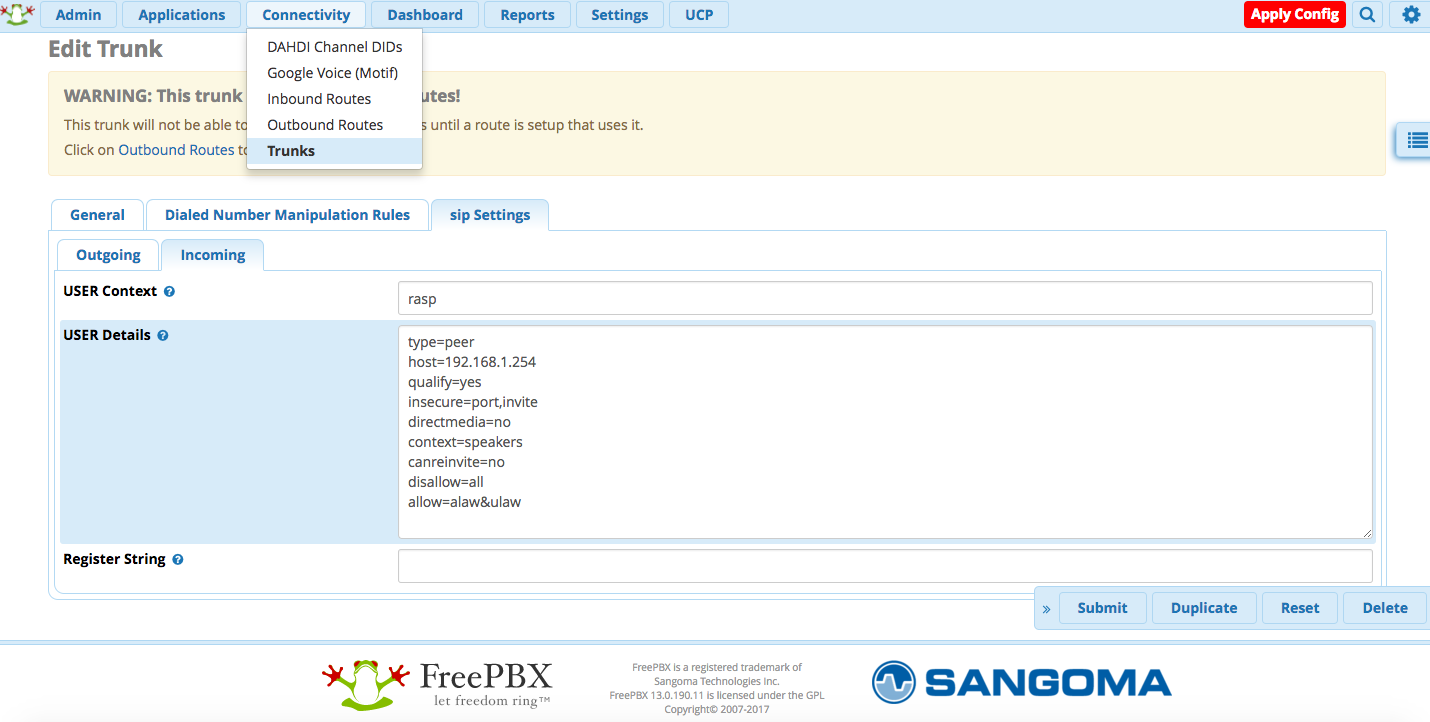
[speakers]
exten => s,1,System(killall /usr/bin/omxplayer.bin)
same => n,Wait(2)
same => n,Dial(console/sdp)
same => n,Hangup()
exten => h,1,System(omxplayer -o local rtp://@236.0.0.1:2000)|
Метки: author j3st3r asterisk блог компании southbridge vlc ffmpeg система оповещения фоновая музыка |







