Пять главных аспектов плохой безопасности интернета вещей |




|
Метки: author SmirkinDA разработка робототехники разработка для интернета вещей информационная безопасность блог компании parallels iot parallels security интернет вещей |
[Из песочницы] GraphQL запросы. От простого к более сложному |


user и сказать, какие значения сервер должен вернуть: firstName и lastName.query myQuery{
user {
firstName
lastName
}
}query перед фигурными скобками. При этом, при написании запросов на клиенте, если вы НЕ укажите явно тип запроса, будет ошибка. mutation myMutation{
UserCreate(data: {firstName: "Jane", lastName: "Dohe"})
}Queries выполняются асинхронно, а mutations — последовательно.
subscriptions mySubscription{
user {
firstName
lastName
}
}query myQuery($id: '1'){
user (id:$id){
firstName
lastName
}
}id = '1' и вернет нам его firstName и lastName.query myQuery($id: ID){ // запрос
user (id:$id){
firstName
lastName
}
}
{
"id": "595fdbe2cc86ed070ce1da52" // переменные
}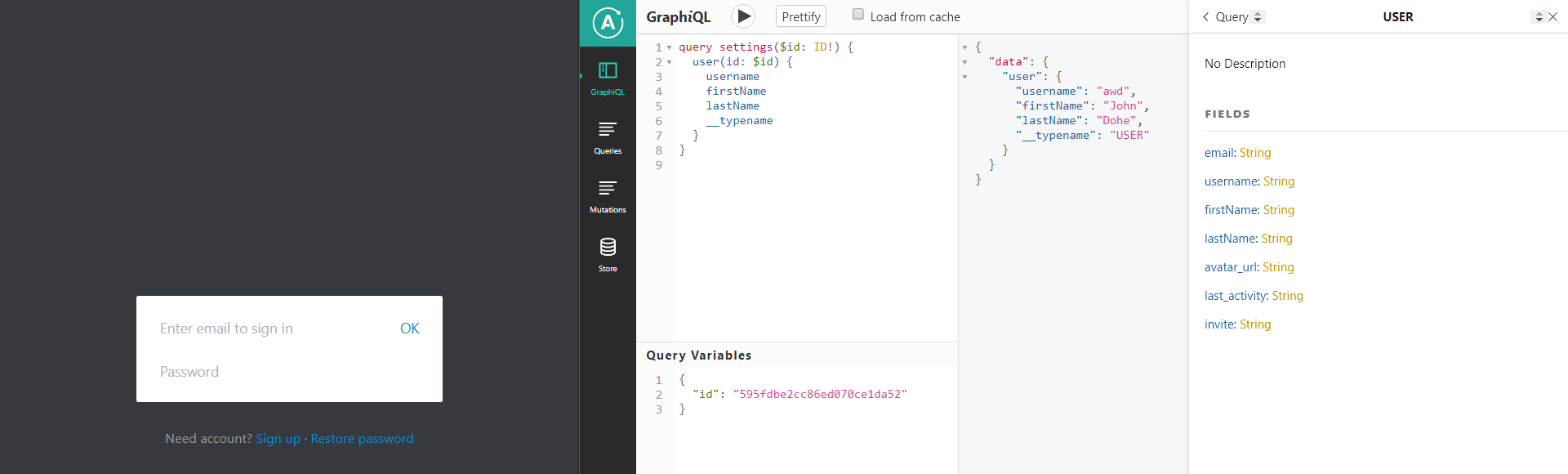
ID! — восклицательный знак в конце типа говорит GraphQL, что это поле обязательное.// MongoDB schema
const schema = new mongoose.Schema({
firstName: {
type: String
},
lastName: {
type: String
},
})
export const USER_MODEL = mongoose.model('users', schema)
// GraphQL type
const user = {
firstName: {
type: GraphQLString
},
lastName: {
type: GraphQLString
},
}
export const USER = new GraphQLObjectType({
name: 'USER',
fields: user
})
// MongoDB schema
const schema = new mongoose.Schema({
firstName: {
type: String
},
lastName: {
type: String
},
secure: {
public_key: {
type: String
},
private_key: {
type: String
},
},
})
. . .
const secure = new GraphQLObjectType({
name: "public_key",
fields: {
public_key: {
type: GraphQLString
}
}
})
export const USER = new GraphQLObjectType({
name: "USER",
fields: {
firstName: {
type: GraphQLID
},
secure: {
type: secure
}
}
})
query myQuery($id: ID){
user (id:$id){
firstName
secure {
public_key
}
}
}
true/false. Если на сервере в тип поля вместо GraphQLBolean указать тип из модели, то получиться следующее:mutation auth($email: String!, $password: String!) {
auth(email: $email, password: $password) {
id
secure {
public_key
}
}
}

|
Метки: author nikitamarcius0 node.js javascript graphql |
Pathfinder: как мы делаем интерфейс для CRPG |

Привет, Хабр! У нас в компании уже около года существует направление экспериментальных игровых разработок, и сегодня хотим рассказать об одной из них. Мы Owlcat Games, и в рамках кикстартерной компании разрабатываем игру Pathfinder: Kingmaker — это однопользовательская CRPG с изометрической графикой (привет, олдскульщики!). В этом посте расскажем о том, как мы делаем интерфейс для нашей игры.
Интерфейсы — очень большая часть игр жанра CRPG. В таких играх есть персонажи, навыки, умения, заклинания, характеристики — и это малая часть того, что требует внимания игрока. Неизбежна высокая насыщенность информацией, и наша задача — сделать так, чтобы таблицы цифр, формулы и бесконечные колонки текста обрели легкую и понятную форму. Мы постоянно балансируем между информативностью и тем, как это выглядит и насколько удобно этим пользоваться. Поэтому в работе над каждым интерфейсом мы руководствуемся двумя основными принципами: удобство и погружение. Причем в самом начале пути мы решили отдавать предпочтение погружению там, где эти два принципа будут конфликтовать и при этом не найдется хорошего компромисса.
Для реализации принципа «погружение» до начала работы над оформлением интерфейсов мы смотрим на реальные вещи той эпохи, которая ближе всего подходит к Pathfinder: Kingmaker. Это могут быть старые книги, свитки, сундуки, поясные кошельки и книги, письменные инструменты и кафедры, карты и походные журналы. Все это находит отражение в интерфейсах.

Для реализации принципа «удобство» нам помогают UX-исследования и правильно построенный pipeline производства.
Итак, давайте поговорим о том, как же мы ведем нашу работу. Каждый интерфейс — от больших, насыщенных окон до маленьких тултипов — проходит несколько этапов и итераций.
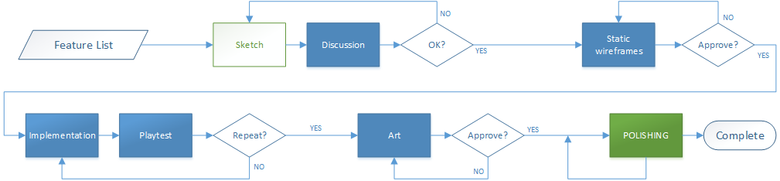
Мы придерживаемся следующей схемы работы. Вначале тщательно анализируем будущий контент и делаем первые наброски, которые представляем команде. Далее разрабатываем схемы взаимодействия и на основе этого создаем первые static wireframes, т. е. фактически «чертеж» интерфейса, чтобы понять, как он будет выглядеть, оценить информативность и компоновку элементов. Как правило, за этим следует горячее обсуждение. Например, наш геймдизайнер хочет видеть больше цифр, ВЕЗДЕ, чем больше цифр — тем лучше. При этом технический художник упорно настаивает на том, чтобы интерфейс был максимально атмосферным, а с информацией — как пойдет. И отказать ему бывает сложно. В общем, лавируя между мнениями, как Одиссей между Сциллой и Харибдой, мы находим удовлетворяющий всех баланс. Далее — реализация функционала, арт и плейтесты, после них — снова доработка функционала и арта. И так до того момента, пока результат не удовлетворит всю команду и игроков на фокус- и UX-тестах.
Внутри команды иногда бывает сложно оценить результат работы. Специально для этого мы проводим UX-исследования, привлекая и активных членов сообщества Pathfinder Society, и людей, которые просто любят игры в целом и CRPG в частности. Исследования помогают нам реализовывать принцип «удобство». Для первого тестирования в начале марта этого года мы пригласили своих коллег и друзей, отчасти — чтобы похвастаться, отчасти — для экспертной оценки. И хотя версия была довольно сырой и неполной, мы смогли получить много материала для анализа.

Heat map интерфейса Rest
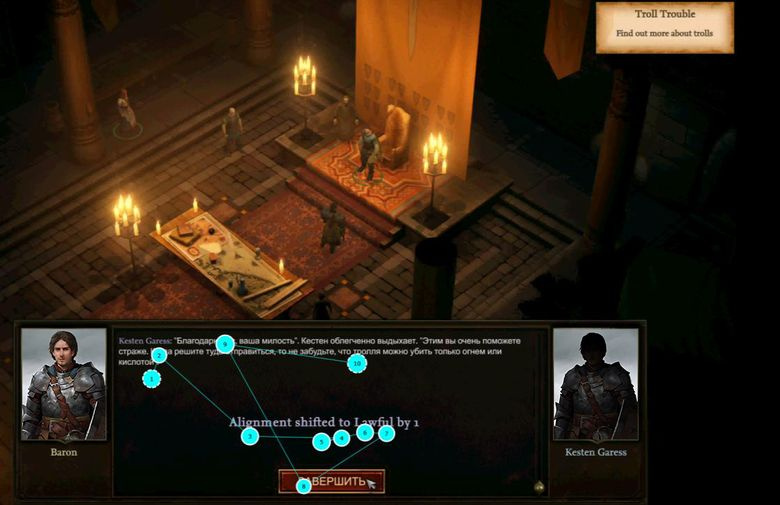
Eye tracking в диалоге

Heat map боевки
По результатам последнего исследования был составлен отчет на 66 страницах. При его разборе появилось более сотни уникальных задач. Часть из них выявила очевидные проблемы, а часть показала, что наши решения не всегда работают так, как мы ожидали. Например, при анализе интерфейса Rest мы обнаружили следующие проблемы (см. Heat map интерфейса Rest). Респонденты не понимали:
Вскоре мы будем проводить следующее исследование, в нем хотим сделать упор не на интерфейс, а на прохождение и ощущения, которые игрок испытывает при этом.
Одним из наших первых интерфейсов был журнал заданий. В нем мы экспериментировали и с формой, и с содержанием. И если с содержанием все оказалось более-менее понятно (список заданий, их описание и т. д.), то с формой было не так просто.
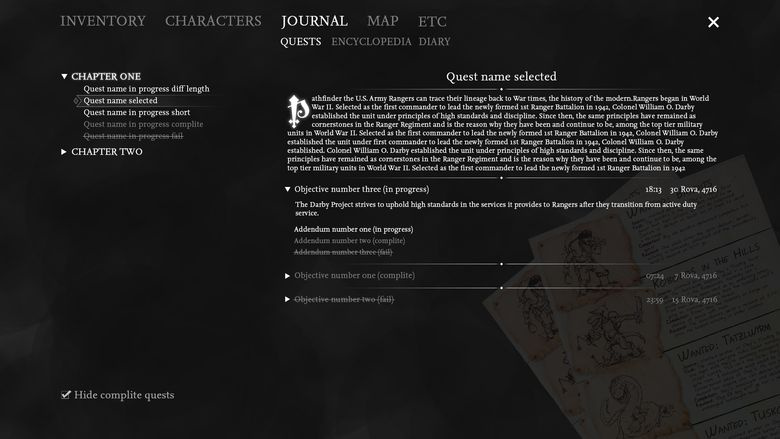
Скетч журнала
Поиски
В итоге мы пришли к следующему варианту, который и будем развивать в дальнейшем.

Благодаря интерфейсу журнала заданий мы создали концепцию полноэкранного интерфейса для системных окон и нашли свой стиль.
Следующим большим интерфейсом, о котором хочется рассказать, стал интерфейс текстовых событий, который внутри студии мы называем BookEvent. С виду все просто: текст, варианты ответов, картинка.
Но на деле все оказалось несколько сложней. Поиски были долгими и нелегкими.

В итоге, найдя форму, мы начали экспериментировать с содержанием.

И вот что у нас получилось в конце. Кажется, неплохо.

Но работа не заканчивается никогда, всегда есть возможность улучшить как арт, так и UX в целом.
И напоследок. Отдельным вызовом был основной шрифт. Мы устроили целое состязание, с финалистами и призовыми местами. Критериями отбора были поддержка разных языковых групп, варианты начертания, удобочитаемость (строчными и капителью), емкость, цифры и, самое главное, подходит шрифт к нашей игре или нет. Может ли он передать дух путешествия и приключений.

В итоге мы остановились на Book Antiqua. Он нам показался компромиссом между всеми требованиями.

Мы хотим, чтобы наша игра всеми своими сторонами показывала, что мы знаем и любим Pathfinder. И интерфейс как никакая другая часть игры помогает нам в этом.
|
Метки: author Barka дизайн игр usability блог компании mail.ru group mail.ru pathfinder |
Проблема непрерывной защиты веб-приложений. Взгляд со стороны исследователей и эксплуатантов. Часть 2 |





/login?_*********=/sitebuilder/****/myaccount/login/*******form
modify_order_bonus ":"{\"bonusAvailable\":18.0,\"bonus\":-20000}" reason: success
|
|
Исследование устойчивости национальных сегментов сети |
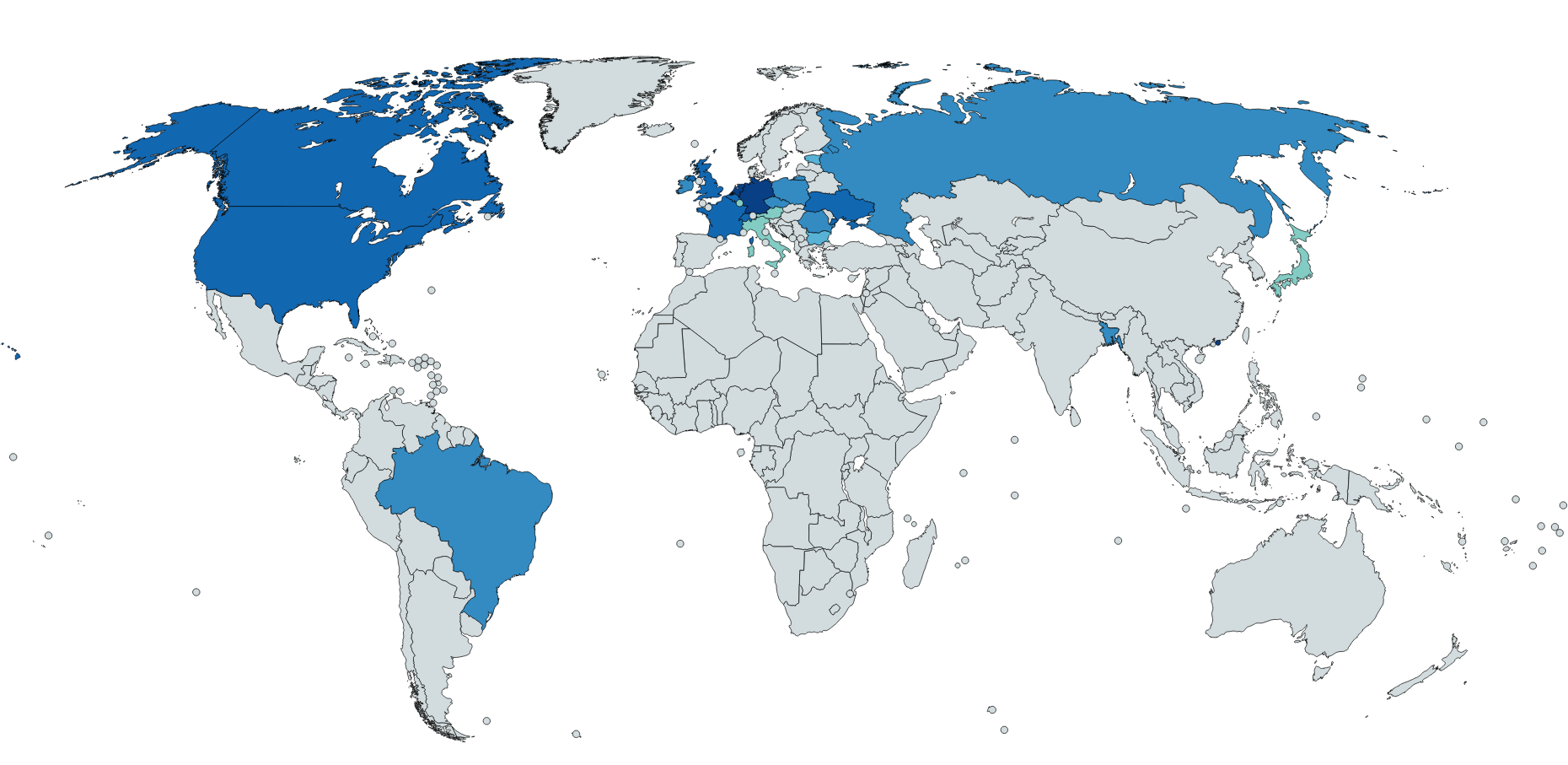
| % отказа |
2016 год |
Изменение 2016 — 2017 |
2017 год |
% отказа |
| 2.57478 |
Германия (DE) |
1 место |
Германия (DE) |
2.29696 |
| 3.14068 |
Канада (CA) |
Вниз на 2 позиции |
Гонконг (HK) |
2.65659 |
| 3.46469 |
Швейцария (CH) |
3 место |
Швейцария (CH) |
3.57245 |
| 4.03446 |
Великобритания (GB) |
Вниз на 2 позиции |
Канада (CA) |
3.67367 |
| 4.19754 |
Гонконг (HK) |
Вверх на 3 позиции |
Франция (FR) |
3.68254 |
| 4.34753 |
Украина (UA) |
Вниз на 2 позиции |
Великобритания (GB) |
3.76297 |
| 4.39691 |
США (US) |
Вниз на 2 позиции |
Бельгия (BE) |
3.93768 |
| 4.83975 |
Бельгия (BE) |
Вверх на 1 позицию |
Украина (UA) |
3.95098 |
| 5.68121 |
Испания (ES) |
Вниз на 8 позиций |
США (US) |
3.97103 |
| 5.78643 |
Польша (PL) |
Вниз на 6 позиций |
Бангладеш (BD) |
5.29293 |
| 5.99955 |
Франция (FR) |
Вверх на 6 позиций |
Румыния (RO) |
5.35451 |
| 6.00547 |
Россия (RU) |
Вниз 1 на позицию |
Бразилия (BR) — новичок |
5.39138 |
| 6.39252 |
Австралия (AU) |
Вылет из топ-20 |
Россия (RU) |
5.73432 |
| 6.88687 |
Ирландия (IE) |
14 место |
Ирландия (IE) |
5.87254 |
| 7.0508 |
Румыния (RO) |
Вверх на 4 позиции |
Чехия (CZ) — новичок |
5.88389 |
| 7.43945 |
Австрия (AT) |
Вниз на 3 позиции |
Польша (PL) |
5.99655 |
| 7.84456 |
Италия (IT) |
Вылет из топ-20 |
Болгария (BG) |
6.20975 |
| 7.97141 |
Бангладеш (BD) |
Вверх на 8 позиций |
Испания (ES) |
6.58064 |
| 8.14681 |
Болгария (BG) |
Вверх на 2 позиции |
Австрия (AT) |
7.14221 |
| 8.15989 |
Филиппины (PH) |
Вылет из топ-20 |
Люксембург (LU) — новичок |
7.28208 |


|
|
Знакомьтесь, Apache BookKeeper — реплицируемый сервис журналов |

По роду своей деятельности мне достаточно часто приходится участвовать в проектах, в которых создаются высокодоступные, высокопроизводительные системы для различных рынков — реклама, финтех, сервисы классов SaaS, PaaS. В таких системах применяется вполне устоявшийся набор архитектур и компонентов, которые позволяют эффективно обеспечить соответствие продукта требованиям, например, lambda-архитектура для поточной обработки данных, масштабируемый микросервисный дизайн программного обеспечения, ориентированный на горизонтальное масштабирование, noSQL СУБД (Redis, Aerospike, Cassandra, MongoDB), брокеры сообщений (Kafka, RabbitMQ), распределенные серверы координации и обнаружения (Apache Zookeeper, Consul). Такие базовые инфраструктурные блоки чаще всего позволяют успешно решить большую часть задач и команда разработки не сталкивается с задачами разработки компонентов среднего уровня (middleware), которые, в свою очередь, будут использованы бизнес-ориентированной частью разрабатываемой системы.
В некоторых случаях возникают такие задачи, которые проектной команде не удается реализовать с помощью существующих решений, являющихся стандартными, тогда появляется потребность в поиске или разработке узкоспециализированных продуктов, предназначенных для решения специфических задач.
В одном из проектов у команды возникла достаточно специфичная задача, в рамках которой была необходимость организации строго-упорядоченной очереди данных, которое бы позволяло осуществлять "проигрывание" данных, поддерживало репликацию, горизонтальное масштабирование и было отказоустойчивым. Это классическая структура данных, которая называется журнал операций (Commit Log) и применяется практически во всех более-менее сложных СУБД.
Основное требования к журналу операций — это фиксация изменений в строгом порядке, таким образом структура гарантирует, что тот клиент, который инициировал запись первым гарантированно получит меньший порядковый номер записи в журнале, даже если запись заняла большее время чем у некоторого другого клиента. Широкое применение журналы операций имеют в системах, в которых имеется конкурентный доступ к объектам, который должен быть упорядочен. Обычная очередь, поддерживающая конкурентный доступ — это пример такого журнала (например, LinkedBlockingQueue в Java).
Ценность такой структуры в том, что она гарантирует неизменность конечного состояния при повторных проходах и часто используется именно для того, чтобы корректно отразить конечное состояние объекта при множественных изменениях.
Сложности начинаются в том случае, если множество агентов должны распространить упорядоченное изменение состояний на множестве узлов для множества объектов. Очевидный и самый низкопроизводительный подход основывается на использовании сервиса распределенных блокировок, например, Apache Zookeeper, с помощью которого осуществляется упорядоченный доступ к некоторому хранилищу. Вариант является рабочим, если изменения объектов происходят редко, однако, для реализации высокопроизводительной системы, в которой состояния объектов меняются часто, данный вариант не подходит. Частный случай с двумя агентами и двумя узлами изображен на рисунке.

Если внимательно посмотреть на вводное изображение с Риком, Морти и Саммер, то можно как раз это и заметить… Все вроде похоже, но уже есть небольшие рассогласования.
Нам требовалось разработать реплицируемую систему типа Leader/Followers, каждый узел которой бы поддерживал актуальное состояние объектов в RocksDB, а при потере узла его можно было бы легко восстановить из другого узла и существующего журнала операций, абстрактный вид представлен на диаграмме:

Основная инженерная проблема, которая существует в рамках данной задачи — это разработка распределенного реплицируемого журнала операций.
Сначала, как обычно, мысль пошла по пути — "нам нужен свой бар... мы же крутые разработчики — давайте сами все сделаем!". У нас была реализация для локального журнала и мы подумали, что, наверное, мы сможем расширить ее на сетевую и реплицируемую реализацию. Честно говоря, объем работы вызывал притупленную зубную боль, а ведь это был не основной продукт, а компонент нижележащего слоя.
Постойте, но есть же Apache Kafka, скажет удивленный читатель! И будет почти прав. Apache Kafka — прекрасная штука, но в рамках данной задачи ей не хватает следующих функций:
- Подтверждения завершения операции
- Гарантии порядка и уникальности данных
В большинстве случаев Apache Kafka будет работать так, как нужно, но при потере пакетов TCP или падении мастера Вы не имеете никаких гарантий, что ваше сообщение не продублируется. Это связано с тем, что сообщения в Kafka отправляются по принципу "fire-and-forget", а клиент не управляет порядком записей на сервере, что логично, поскольку Apache Kafka оптимизирована на пропускную способность.
Однако, начав анализ и обдумывание деталей решения, я обнаружил, что решение уже есть, просто мы о нем не знали. И это — Apache BookKeeper. Более того, он реализован идеологически и технологически практически так, как бы мы это стали делать сами — Apache Zookeeper, Java, Netty (наш проект на Scala, но стек Java сильно порадовал). Как результат, была инициирована новая фаза, в ходе которой мы протестировали Apache BookKeeper на предмет соответствия нашим потребностям.
Далее, я постараюсь рассказать о принципах и подходе, который используется в системе Apache BookKeeper для решения задачи реплицируемых, масштабируемых журналов операций.
Итак, продукт не так чтобы сильно известный, однако пользователи у него имеются. К примеру:
Возможно, надо было просто сделать перевод первой статьи, но, чукча в душе — писатель.
Сначала посмотрим на концептуальную архитектуру Apache BookKeeper, которая отображена на следующем рисунке:

Ключевые элементы схемы:
Теперь рассмотрим ключевые элементы подробнее, чтобы понять как устроена модель взаимодействия с Apache BookKeeper и его архитектура управления данными.
Сервер хранения данных. В рамках BookKeeper мы развертываем и запускаем множество серверов Bookie, на поле которых возникает реплицируемая среда хранения данных. Данные распределяются в рамках гроссбухов, способ распределения плоский, система не позволяет задавать какие-либо топологические метки (а жаль). Добавление серверов Bookie позволяет осуществлять горизонтальное масштабирование системы.
Организует набор строго упорядоченных записей, реплицируемых на одни и те же серверы. Гроссбухи упорядочены по возрастанию идентификаторов. Данные о серверах реплик хранятся в записи гроссбуха в Zookeeper.
Важное ограничение 1. В гроссбух может писать только один писатель. Таким образом, гроссбух — это единица масштабирования. Если ряд операций не позволяет разнести их по разным гроссбухам, то лимит производительности — это скорость записи в гроссбух, которая зависит от фактора репликации (хотя не линейно, поскольку BK Client пишет параллельно).
При записи в гроссбух каждой записи выдается уникальный возрастающий порядковый целочисленный номер, выдаваемый клиентом, что позволяет организовывать асинхронный подход к записи. При этом BookKeeper гарантирует, что операция записи с номером (n+1) завершится только тогда, когда все операции записи с младшими номерами завершились. Это очень полезное свойство, которое позволяет существенно улучшить производительность операций записи в некоторых кейсах, даже, если требуется упорядоченное уведомление клиентов о завершении операций.
Важное ограничение 2. Из гроссбуха может читать параллельно неограниченное количество читателей, при этом чтение разрешено тогда, когда гроссбух закрыт, то есть, в настоящий момент никем не пишется.
Вообще, вышеуказанные ограничения для гроссбухов — это существенные ограничения, которые в некоторых случаях могут значительно сузить сферу применения.
К примеру, вы открываете новый гроссбух каждую секунду, пишете в него и закрываете. Это означает, что обработка чтения будет отставать на 1 секунду. Поскольку гроссбух имеет тип идентификатора Long, то можно открывать каждую 1мс без особых проблем, но тогда вы столкнетесь с ситуацией, что возрастет нагрузка на Zookeeper, для которого это будет уже существенной нагрузкой. В решаемой нами задаче, это ограничение было допустимым.
Другой пример, интенсивность записи такова, что производительности серверов в рамках одного гроссбуха недостаточно, а логика приложения такова, что партиционировать запись по нескольким гроссбухам не представляется возможным. Все, как говорится, приехали. Данное ограничение в рамках нашей задачи тоже обходилось, мы смогли партиционировать все объекты таким образом, и у нас остался только один поток данных, для которого мы не смогли обойти данное ограничение.
Идентификаторы гроссбухов хранятся в Zookeeper, что позволяет осуществить по ним итерирование, однако, не все так просто. Если мы хотим иметь несколько параллельных цепочек гроссбухов, то необходимо хранить идентификаторы гроссбухов, которые относятся к конкретной цепочке где-то отдельно, BookKeeper нам с этим не поможет. Другой вариант — осуществлять развертывание изолированных серверов Bookie под каждую задачу отдельно, чтобы у них был отдельный путь в Zookeeper (что нам не подходило).
Надо отметить, что сам Apache Zookeeper накладывает дополнительные ограничения, которые тоже необходимо учесть:
Создатели Apache BookKeeper предоставляют решение для проблемы 2, вводя иерархический менеджер гроссбухов (Hierarchical Ledger Manager), который организует плоское пространство идентификаторов в иерархическое дерево путем дробления Long по уровням. По умолчанию используется Flat Ledger Manager, который явно неприменим при частом порождении новых гроссбухов.
Запись представляет собой элемент гроссбуха. Каждая запись в рамках гроссбуха имеет последовательный, возрастающий идентификатор — от 0… Запись содержит произвольные данные в виде байтового массива. Добавление записи может производиться в синхронном и асинхронном режиме. В асинхронном режиме, как обычно, можно добиться более высокой производительности для многопользовательских приложений. Как уже ранее упоминалось, вызов асинхронной части происходит тогда, когда запись добавляется в гроссбух, то есть упорядоченно.
Пожалуй, эти три концепта — Bookie, Ledger (гроссбух) и Ledger Entry (запись) являются важнейшими элементами для понимания работы Apache BookKeeper.
Надо сказать, что Apache BookKeeper не выглядит как серебряная пуля или как волшебная таблетка, это вполне специфическое решение, которое никак не противоречит CAP теореме и накладывает существенное количество ограничений на решаемую задачу, которые часто невозможно обойти. К счастью для нас, мы смогли обеспечить с помощью данного компонента горизонтальное масштабирование системы, но для поддержки наших требований пришлось решить попутно несколько инженерных задач, например, как корректно читать данные из двух гроссбухов и как хранить в Zookeeper "просеянные" списки для непересекающихся гроссбухов.
Эта статья носит вводный, ознакомительный характер. Сделать на Apache BookKeeper Hello World достаточно легко, авторы предоставляют подробное стартовое руководство, пока мы разбирались, переписали его реализацию на Scala.
RocksDB была выбрана в связи с тем, что она обладает высокой производительностью и поддерживает атомарную пакетную запись (все или ничего), что позволяет обеспечить корректное поведение при возникновении нештатных ситуаций. В рамках нашей задачи мы загружали предыдущее состояние из RocksDB, вычитывали все действия из гроссбуха (ов), формировали итоговое состояние в RAM и записывали атомарно в RocksDB, при этом в запись так же шли номера гроссбухов, которые мы обработали.
|
|
Superjob PHP-meetup |

|
|
Defender на стероидах: комплексная защита корпоративной сети в Windows 10 Fall Creators Update. Интервью с Робом Леффертсом |
|
Метки: author megapost информационная безопасность microsoft defender безопасность windows atp wdatp advanced threat protection |
Как организовать защищённый доступ при помощи VPN |

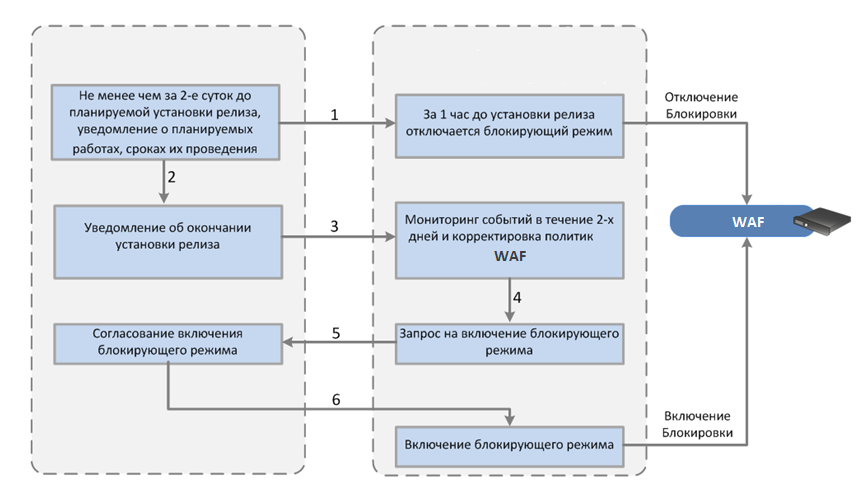
На март 2017 г. доля вакансий о работе с удаленным доступом, размещенных на hh.ru составляла 1,5% или 13 339 вакансий. За год их число удвоилось. В 2014 г. численность удаленных сотрудников оценивалась в 600 тыс. чел или 1% от экономически-активного населения (15–69 лет). J'son & Partners Consulting прогнозирует, что к 2018 г. около 20% всех занятых россиян будут работать удаленно. Например, до конца 2017 г. Билайн планирует перевести на удаленное сотрудничество от 50% до 70% персонала.
Зачем компании переводят сотрудников на удаленку:
Мы для себя открыли потребность в VPN более 10 лет назад. Для нас мотиватором предоставления VPN доступа сотрудникам была возможность оперативного доступа в корпоративную сеть из любой точки мира и в любое время дня и ночи.
Вариантов решений достаточно много. Зачастую решение стоит принимать исходя из того, какое оборудование и софт уже используются в компании, навыком настройки какого ПО обладает системный администратор. Начну с того от чего мы отказались сразу, а затем расскажу что мы попробовали в на чем мы в итоге остановились.
Так называемых “китайских решений” на рынке много. Практически любой роутер имеет функциональность встроенного VPN сервера. Обычно это простое вкл/выкл функционала и добавление логинов паролей для пользователей, иногда интеграция с Radius сервером. Почему мы не стали рассматривать подобное решение? Мы прежде всего думаем о своей безопасности и непрерывности работе сервиса. Подобные же железки не могут похвастаться ни надежной защитой (прошивки выходят обычно очень редко, или не выходят в принципе), да и надежность работы оставляет желать лучшего.
Если посмотреть на квадрат Гартнера то на VPN рынке уже давно лидирующие позиции занимают компании, которые производят сетевое оборудование. Juniper, Cisco, Check Point: все они имеют комплексные решения решения в составе которых есть и VPN сервис.
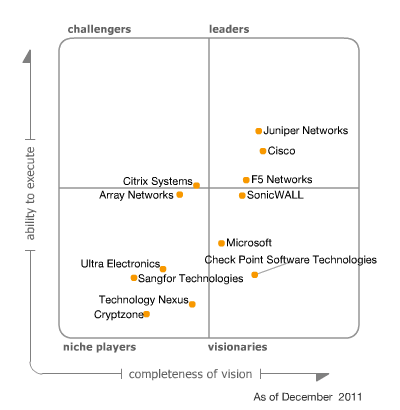
Минусов у подобных решений пожалуй два. Первый и главный — высокая стоимость. Второй — скорость закрытия уязвимостей оставляет желать лучшего, а если не платить ежегодные взносы за поддержку, то обновлений безопасности ждать не стоит. Не так давно появился и третий момент — закладки, встроенные в ПО крупных сетевых вендоров.
10 лет назад мы были компанией, ориентированной прежде всего на Windows. Microsoft предлагает бесплатное решение для тех, у кого вся инфраструктура построена на их базе. В простых случаях настройка не вызывает сложностей даже у начинающего системного администратора. В нашем случае мы хотели выжать из VPN все с точки зрения безопасности, соответственно использование паролей было исключено. Мы естественно хотели использовать сертификаты вместо паролей и для хранения ключевой пары использовать свой продукт Рутокен ЭЦП. Для реализации проекта нам нужно было: контроллер домена, радиус сервер и правильно поднятая и настроенная инфраструктура PKI. Подробно на настройке я останавливаться не буду, в интернете есть достаточно много информации по данным вопросам, а правильная настройка PKI вообще может потянуть на десяток статей. Первым протоколом,
который мы использовали у себя, был протокол PPTP. Долгое время данный вариант VPN нас устраивал, но в конечном итоге нам пришлось отказаться от него по двум причинам: PPTP работал далеко не везде и мы начинали пользоваться не только Windows, но и другими операционными системами. Поэтому мы стали искать альтернативы. Замечу, что поддержка PPTP не так давно была прекращена apple. Для начала мы решили посмотреть, что еще из протоколов может предложить на Microsoft. SSTP/L2TP. SSTP нас устраивал всем, за исключением того, что он работал только на Windows. L2TP данным недостатком не обладал, но его настройка и поддержание его в работе показались нам достаточно затратными и мы решили попробовать альтернативы. Хотелось более простого решения, как для пользователей, так и для администраторов.
Мы в компании “Актив” искренне любим open source. Выбирая замену Microsoft VPN мы не могли обойти стороной решение OpenVPN. Основным плюсом для нас было то, что решение из коробки работает на всех платформах. Поднять сервер в простом случае достаточно просто. Сейчас, используя docker и, к примеру готовый образ, это можно сделать за несколько минут. Но нам хотелось большего. Нам хотелось добавить в проект интеграцию с Microsoft CA, для того, чтобы использовать выданные ранее сертификаты. Нам хотелось добавить поддержку используемых нами токенов. Как настраивать связку OpenVPN и токены описано к примеру вот в этой статье. Сложнее было настроить интеграцию Microsoft CA и OpenVPN, но в целом тоже вполне реализуемо. Получившимся решением мы пользовались около трех лет, но все это время продолжали искать более удобные варианты. Пожалуй главной возможностью, которую мы получили, перейдя на OpenVPN, был доступ из любой ОС. Но остались еще две претензии: сотрудникам компании нужно пройти 7 кругов ада Microsoft CA для выписывания сертификата, а администраторам по-прежнему приходилось поддерживать достаточно сложную инфраструктуру VPN.
У нас есть знание, как использовать токены в любых операционных системах, у нас есть понимание, как правильно готовить инфраструктуру PKI, мы умеем настраивать разные версии OpenVPN и мы имеем технологии, которые позволяют управлять всем этим удобным для пользователя образом из окна браузера. Так возникла идея нового продукта.

Мы действительно постарались сделать настройку простой и понятной. Вся настройка занимает всего несколько минут и реализована как мастер начальной настройки. На первом шаге нужно настроить сетевые настройки устройства, думаю комментарии здесь будут лишними.
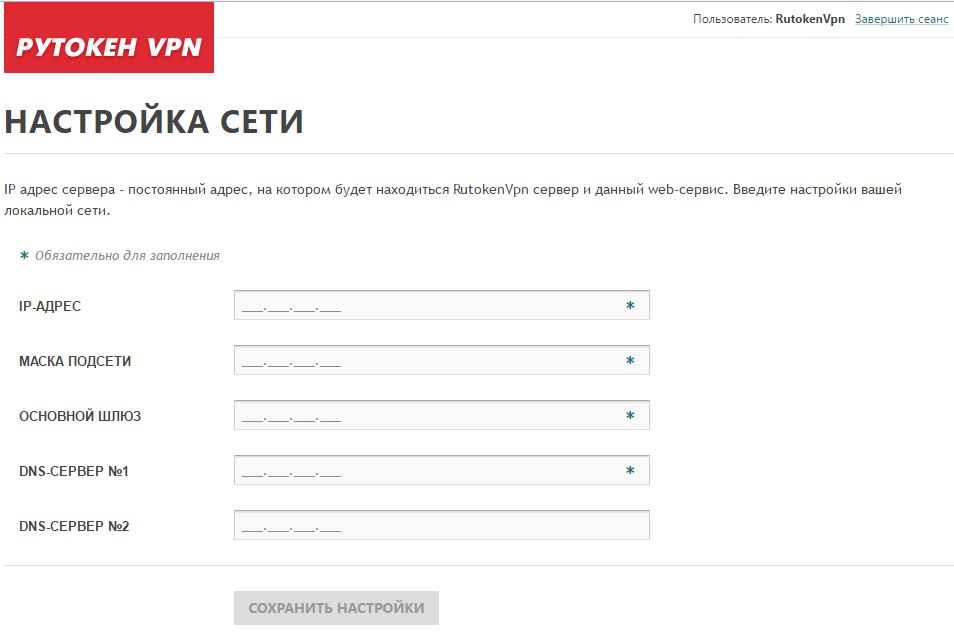
На втором шаге нужно ввести название компании и подождать несколько минут, пока устройство произведет настройку встроенного центра сертификации.


3м шагом необходимо настроить сам VPN сервис. Указать внешний IP, на который будет происходить подключение. Выбрать тип шифрования и адресацию сети.

4м шагом настройки мы создаем локальных пользователей, или добавляем их из AD

На этом настройку можно считать завершенной, все остальные действия может произвести сам сотрудник (хотя все может сделать и администратор).
После того, как администратор добавил пользователей, сотрудник может воспользоваться порталом самообслуживания.

В зависимости от операционной системы и браузера сотрудника, понадобится установить плагин и расширение для браузера, которые необходимы для работы с токенами.

После установки плагина/расширения нам остается лишь сгенерировать сертификат себе на Рутокен ЭЦП.
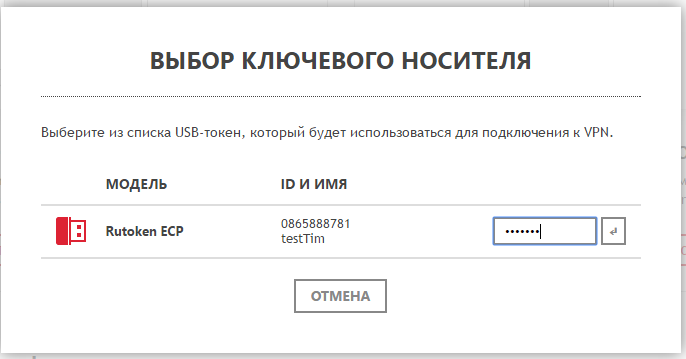

И установить клиент под нужную операционную систему,

Немного об аппаратной части. Изначально мы долго думали, какую “базу” использовать для нашего решения, так как нужно было соблюдать баланс между стоимостью, удобством, производительностью. После исследований, что предлагается на рынке, мы остановились на двух вариантах реализации и дальнейшего распространения решения:
Итак, теперь рассмотрим то, как работает наше решение. Первично хочется напомнить, что у нас реализована двухфакторная аутентификация. В качестве носителей клиентских закрытых ключей и сертификатов используются токены собственного производства, а также программное обеспечение для работы с ними.
Но изначально, нам все же нужно осуществить настройку сервисов, которые требуются для корректной работы продукта. Настройка сервисов осуществляется на текущий момент специалистами нашей компании в полуавтоматическом режиме. Это значит, что автоматизирован процесс деплоя программного обеспечения и первичных настроек, но инициализация данного процесса пока остается привилегией человека. Во время первичной настройки устанавливаются системные пакеты, python, django, OpenVPN, supervisor, OpenSSL и проч.
А что же дальше? Далее необходимо настроить всю инфраструктуру, которая собственно и отвечает в целом за безопасность. А именно: CA (центр сертификации), PKI (инфраструктура открытых ключей), выписать необходимые ключи и сертификаты.
Создание PKI и CA, а также формирование файла конфигурации OpenVPN-сервера, генерацияключей ивыписываниесертификатовосуществляетсяужепослепередачи продукта клиенту. Но это не значит, что для этого необходимо иметь какие-то специфические знания и прямой доступ к операционной системе. Все реализовано в бизнес-логике бэкенда системы администрирования, доступ к которой предоставляется через Web-интерфейс. От клиента требуется только ввести минимальный набор атрибутов (описано выше), после чего стартует процесс инициализации PKI и создания СА. Описывать конкретные вызовы системных команд смысла особого нет, так как уже давно все описано и разжевано до нас. Главное, что мы сделали — это автоматизировали данный процесс, избавив пользователя от необходимости обладать специфическими знаниями в администрировании.
Для работы с ключами и сертификатами мы решили не изобретать велосипед (хотя очень хотелось и до сих пор вынашиваем мысль его изобрести исходя из наших дальнейших планов развития продукта) и используем easy-rsa.
Самый долгий процесс при настройке инфраструктуры – это генерация файла Diffie-Hellman. Мы долго экспериментировали с параметрами и пришли к балансу “качество-производительность”. Хотя были мысли вообще избавиться от данного шага, нагенерировать таких файлов заранее, используя наши серверные мощности и просто “раздавать” их во время первичной инициализации. Тем более, что данные, содержащиеся в этом файле не являются приватными. Но пока мы оставили эти мысли для дальнейших “изысканий”.
Дальше необходимо предоставить конечному пользователю механизм самостоятельного создания ключевых пар, формирования запросов на выписку сертификата в CA и собственно получение данного сертификата с записью на токен. А так же необходим клиент, позволяющий установить VPN-соединение с предварительной аутентификацией на токене.
Первую задачу мы решили благодаря нашему плагину который реализует функциональность электронной подписи, шифрования и двухфакторной аутентификации для Web- и SaaS-сервисов. Для того, чтобы выписать сертификат и записать его на токен, пользователь должен установить данный плагин, перейти по ссылке чтобы попасть в личный кабинет сервиса RutokenVPN, предварительно подключив токен к компьютеру (подробнее о плагине можно прочитать на нашем ресурсе )
При инициализации процесса выписывания сертификата, осуществляется запрос на токен для генерации ключевой пары а также запрос на выписку сертификата в CA. Приватный ключ записывается на токен, а запрос на выписку сертификата отправляется в СА, который в свою очередь осуществляет его выписывание и возвращает в ответе. После чего сертификат так же записывается на токен.
Почти все готово для установления VPN-соединения. Не хватает клиента, который “знает”, как работать с сервером и нашими токенами.

Наш клиент реализован на Electron. Кто не в курсе, что это за зверь, то если совсем кратко – возможность реализовать десктопное приложение, используя js, css и html. Не вдаваясь в подробности, клиент является неким “враппером” над OpenVPN-клиентом, позволяющим осуществлять его вызовы с нужными параметрами. Почему именно так? На самом деле нам было так удобней, хотя выбранное решение и накладывает определенные ограничения.
Так как мы используем токен как носитель ключевой информации, необходимой для аутентификации при установлении VPN-сессии, то нам нужно сконфигурировать OpenVPN-клиент для работы с ним. Провайдером PKCS#11 является библиотека собственной разработки для работы с нашими токенами, путь к которой и прописывается в настройках OpenVPN клиента. Подробнее о ней можно почитать здесь.
При запросе на установку VPN-соединения, запрашивается PIN-код ключа, при корректном вводе извлекается сертификат для аутентификации клиента, осуществляется хэндшейк клиента с сервером и устанавливается VPN-соединение. Знающие люди могут возразить, что не все так просто, но целью данного описания не является рассказать все тонкости работы OpenVPN, а только осветить основные моменты нашей реализации.
Ну и немного о наших планах. Основное, над чем сейчас мы работаем — это реализация ГОСТ-шифрования. Уже пройден достаточно большой путь исследований, позволивший нам максимально приблизиться к ее реализации и сможем удовлетворить интерес потенциальных клиентов в данной функциональности в ближайшее время.
|
Метки: author shriek сетевые технологии децентрализованные сети it- инфраструктура блог компании «актив» vpn openvpn raspberry pi рутокен openssl |
[Перевод] Ограничение скорости в nginx |

Фотография пользователя Wonderlane, Flickr
NGINX великолепен! Вот только его документация по ограничению скорости показалась мне, как бы это сказать, несколько ограниченной. Поэтому я решил написать это руководство по ограничению скорости (rate-liming) и шейпингу трафика (traffic shaping) в NGINX.
Мы собираемся:
В дополнение я создал GitHub-репозиторий и Docker-образ, с которыми можно поэкспериментировать и воспроизвести приведенные в этой статье тесты. Всегда легче учиться на практике.
В этой статье мы будем говорить о ngx_http_limit_req_module, в котором реализованы директивы limit_req_zone, limit_req, limit_req_status и limit_req_level. Они позволяют управлять значением кода состояния HTTP-запроса для отклоненных (rejected) запросов, а также логированием этих отказов.
Чаще всего путаются именно в логике отклонения запроса.
Сначала нужно разобраться с директивой limit_req, которой требуется параметр zone. У него также есть необязательные параметры burst и nodelay.
Здесь используются следующие концепции:
zone определяет «ведро» (bucket) — разделяемое пространство, в котором считаются входящие запросы. Все запросы, попавшие в одно «ведро», будут посчитаны и обработаны в его разрезе. Этим достигается возможность установки ограничений на основе URL, IP-адресов и т. д.
burst — необязательный параметр. Будучи установленным, он определяет количество запросов, которое может быть обработано сверх установленного базового ограничения скорости. Важно понимать, что burst — это абсолютная величина количества запросов, а не скорость.
nodelay — также необязательный параметр, который используется совместно с burst. Ниже мы разберемся, зачем он нужен.При настройке зоны задается ее скорость. Например, при 300r/m будет принято 300 запросов в минуту, а при 5r/s — 5 запросов в секунду.
Примеры директив:
limit_req_zone $request_uri zone=zone1:10m rate=300r/m;limit_req_zone $request_uri zone=zone2:10m rate=5/s;Важно понимать, что эти две зоны имеют одинаковые лимиты. С помощью параметра rate NGINX рассчитывает частоту и, соответственно, интервал, после которого можно принять новый запрос. В данном случае NGINX будет использовать алгоритм под названием «дырявое ведро» (leaky bucket).
Для NGINX 300r/m и 5r/s одинаковы: он будет пропускать один запрос каждые 0,2 с. В данном случае NGINX каждые 0,2 секунды будет устанавливать флаг, разрешающий прием запроса. Когда приходит подходящий для этой зоны запрос, NGINX снимает флаг и обрабатывает запрос. Если приходит очередной запрос, а таймер, считающий время между пакетами, еще не сработал, запрос будет отклонен с кодом состояния 503. Если время истекло, а флаг уже установлен в разрешающее прием значение, никаких действий выполнено не будет.
Поговорим о параметре burst. Представьте, что флаг, о котором мы говорили выше, может принимать значения больше единицы. В этом случае он будет отражать максимальное количество запросов, которые NGINX должен пропустить в рамках одной пачки (burst).
Теперь это уже не «дырявое ведро», «маркерная корзина» (token bucket). Параметр rate определяет временной интервал между запросами, но мы имеем дело не с токеном типа true/false, а со счетчиком от 0 до 1 + burst. Счетчик увеличивается каждый раз, когда проходит рассчитанный интервал времени (срабатывает таймер), достигая максимального значения в b+1. Напомню еще раз: burst — это количество запросов, а не скорость их пропускания.
Когда приходит новый запрос, NGINX проверяет доступность токена (счетчик > 0). Если токен недоступен, запрос отклоняется. В противном случае запрос принимается и будет обработан, а токен считается израсходованным (счетчик уменьшается на один).
Хорошо, если есть неизрасходованные burst-токены, NGINX примет запрос. Но когда он его обработает?
Мы установили лимит в 5r/s, при этом NGINX примет запросы сверх нормы, если есть доступные burst-токены, но отложит их обработку таким образом, чтобы выдержать установленную скорость. То есть эти burst-запросы будут обработаны с некоторой задержкой или завершатся по таймауту.
Другими словами, NGINX не превысит установленный для зоны лимит, а поставит дополнительные запросы в очередь и обработает их с некоторой задержкой.
Приведем простой пример: скажем, у нас установлен лимит 1r/s и burst равен 3. Что будет, если NGINX получит сразу 5 запросов?
1r/s, оставаясь в рамках установленного лимита, а также при условии, что не будут поступать новые запросы, которые также используют квоту. Когда очередь опустеет, счетчик пачки (burst counter) снова начнет увеличиваться (маркерная корзина начнет наполняться).В случае использования NGINX в качестве прокси-сервера расположенные за ним сервисы будут получать запросы со скоростью 1r/s и ничего не узнают о всплесках трафика, сглаженных прокси-сервером.
Итак, мы только что настроили шейпинг трафика, применив задержки для управления всплесками запросов и выравнивания потока данных.
nodelay говорит NGINX, что он должен принимать пакеты в рамках окна, определенного значением burst, и сразу их обрабатывать (так же как и обычные запросы).
В результате всплески трафика все же будут достигать сервисов, расположенных за NGINX, но эти всплески будут ограничены значением burst.
Поскольку я верю, что практика очень помогает в запоминании чего бы то ни было, я сделал небольшой Docker-образ с NGINX на борту. Там настроены ресурсы, для которых реализованы различные варианты ограничения скорости: с базовым ограничением, с ограничением скорости, использующим burst, а также с burst и nodelay. Давайте посмотрим, как они работают.
Здесь используется довольно простая конфигурация NGINX (она также есть в Docker-образе, ссылку на который можно найти в конце статьи):
limit_req_zone $request_uri zone=by_uri:10m rate=30r/m;
server {
listen 80;
location /by-uri/burst0 {
limit_req zone=by_uri;
try_files $uri /index.html;
}
location /by-uri/burst5 {
limit_req zone=by_uri burst=5;
try_files $uri /index.html;
}
location /by-uri/burst5_nodelay {
limit_req zone=by_uri burst=5 nodelay;
try_files $uri /index.html;
}
}Тестовая конфигурация NGINX с различными вариантами ограничения скорости
Во всех тестах, используя эту конфигурацию, мы отправляем одновременно по 10 параллельных запросов.
Давайте выясним вот что:
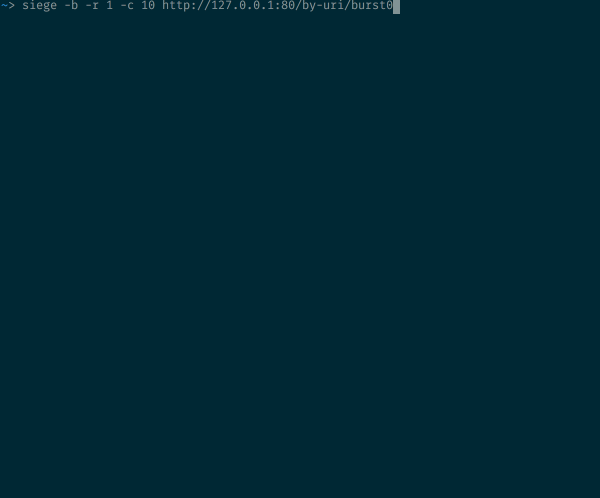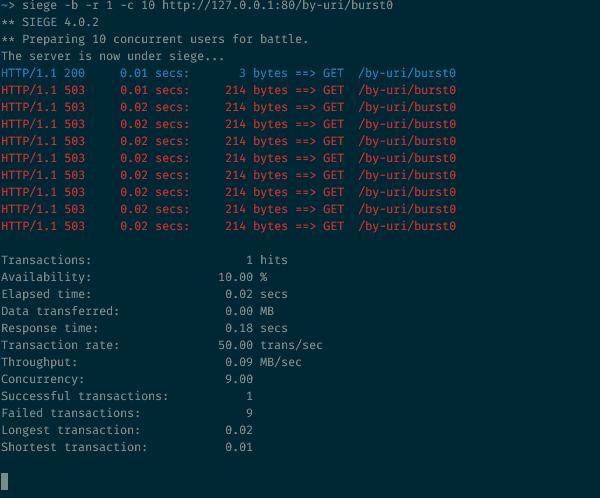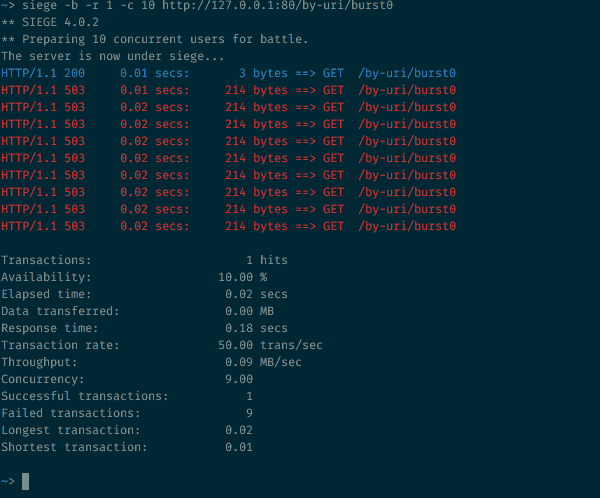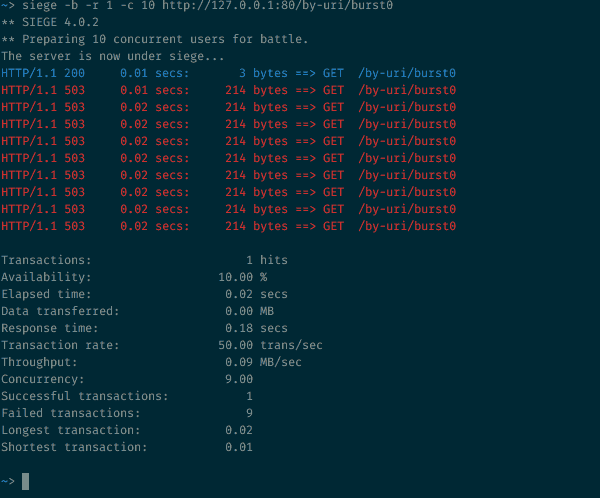
10 одновременных запросов к ресурсу с ограничением скорости
В нашей конфигурации разрешено 30 запросов в минуту. Но в данном случае 9 из 10 будут отклонены. Если вы внимательно читали предыдущие разделы, такое поведение NGINX не станет для вас неожиданностью: 30r/m значит, что проходить будет только один запрос в 2 секунды. В нашем примере 10 запросов приходят одновременно, один пропускается, а остальные девять отклоняются, поскольку NGINX они видны до того, как сработает таймер, разрешающий следующий запрос.
Хорошо! Тогда добавим аргумент burst=5, который позволит NGINX пропускать небольшие всплески запросов к данной конечной точке зоны с ограничением скорости:

10 одновременных запросов к ресурсу с аргументом burst=5
Что здесь произошло? Как и следовало ожидать, с аргументом burst было принято 5 дополнительных запросов, и мы улучшили отношение принятых запросов к общему их числу с 1/10 до 6/10 (остальные были отклонены). Здесь хорошо видно, как NGINX обновляет токен и обрабатывает принятые запросы — исходящая скорость ограничена 30r/m, что равняется одному запросу каждые 2 секунды.
Ответ на первый запрос возвращается через 0,2 секунды. Таймер срабатывает через 2 секунды, один из ожидающих запросов обрабатывается, и клиенту приходит ответ. Общее время, затраченное на дорогу туда и обратно, составило 2,02 секунды. Спустя еще 2 секунды снова срабатывает таймер, давая возможность обработать очередной запрос, который возвращается с общим временем в пути, равным 4,02 секунды. И так далее и тому подобное…
Таким образом, аргумент burst позволяет превратить систему ограничения скорости NGINX из простого порогового фильтра в шейпер трафика.
В этом случае может оказаться полезным аргумент nodelay. Давайте пошлем те же самые 10 запросов конечной точке с настройкой burst=5 nodelay:
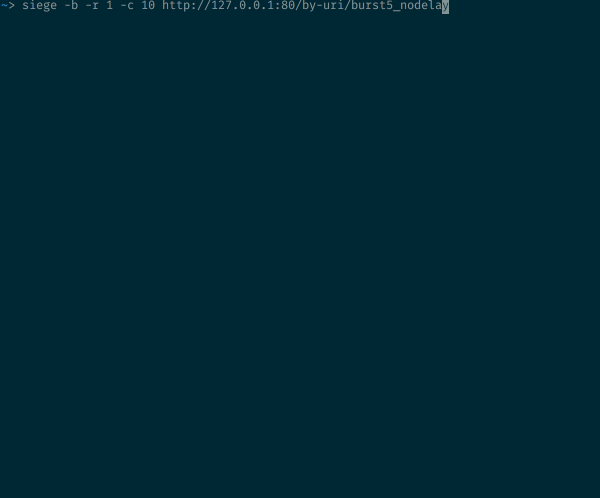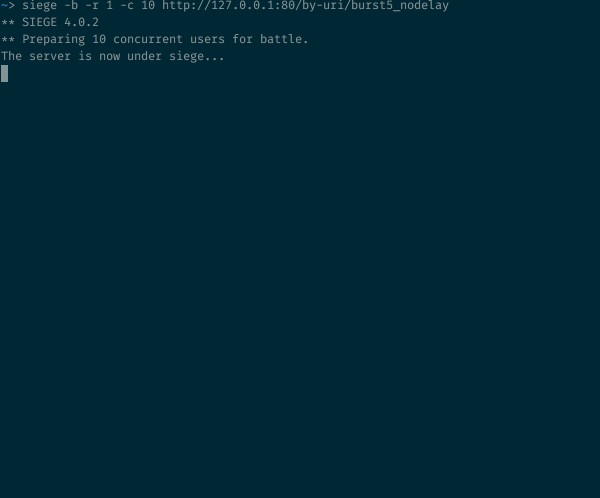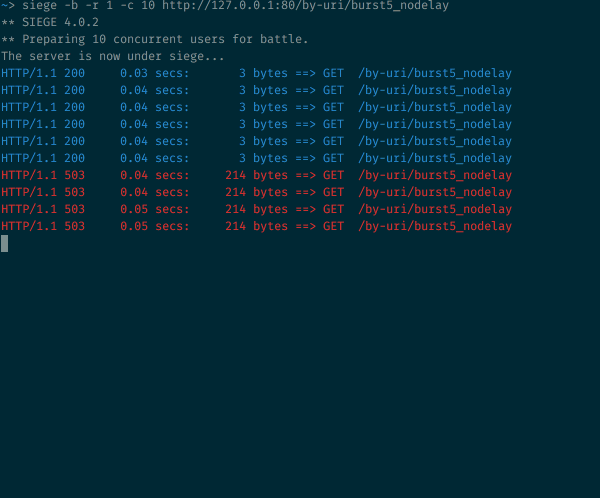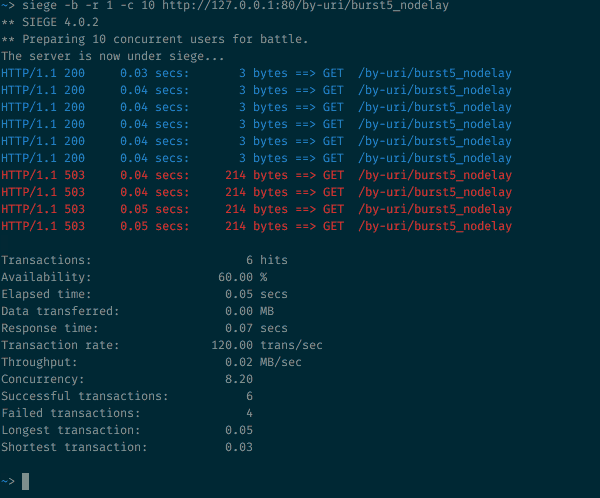
10 одновременных запросов к ресурсу с аргументом burst=5 nodelay
Как и ожидалось с burst=5, у нас останется такое же соотношение 200-х и 503-х кодов состояния. Но исходящая скорость теперь не ограничена одним запросом каждые 2 секунды. Пока доступны burst-токены, входящие запросы будут приниматься и тут же обрабатываться. Скорость срабатывания таймера все так же важна с точки зрения пополнения количества burst-токенов, но на принятые запросы задержка теперь не распространяется.
Замечание. В данном случае zone использует $request_uri, но все последующие тесты работают точно так же и для опции binary_remote_addr, при которой скорость ограничивается по IP-адресу клиента. У вас будет возможность поиграть с этими настройками, используя специально для этого подготовленный Docker-образ.
Попробуем визуализировать то, как NGINX принимает входящие запросы и обрабатывает их на основе параметров rate, burst и nodelay.
Чтобы не усложнять, отобразим количество входящих запросов (которые потом отклоняются либо принимаются и обрабатываются) на определяемой в настройках зоны временной шкале, разбитой на равные значению срабатывания таймера отрезки. Абсолютное значение временного интервала не существенно. Важно количество запросов, которое NGINX может обработать на каждом шаге.
Вот трафик, который мы будем прогонять через разные настройки ограничения скорости:
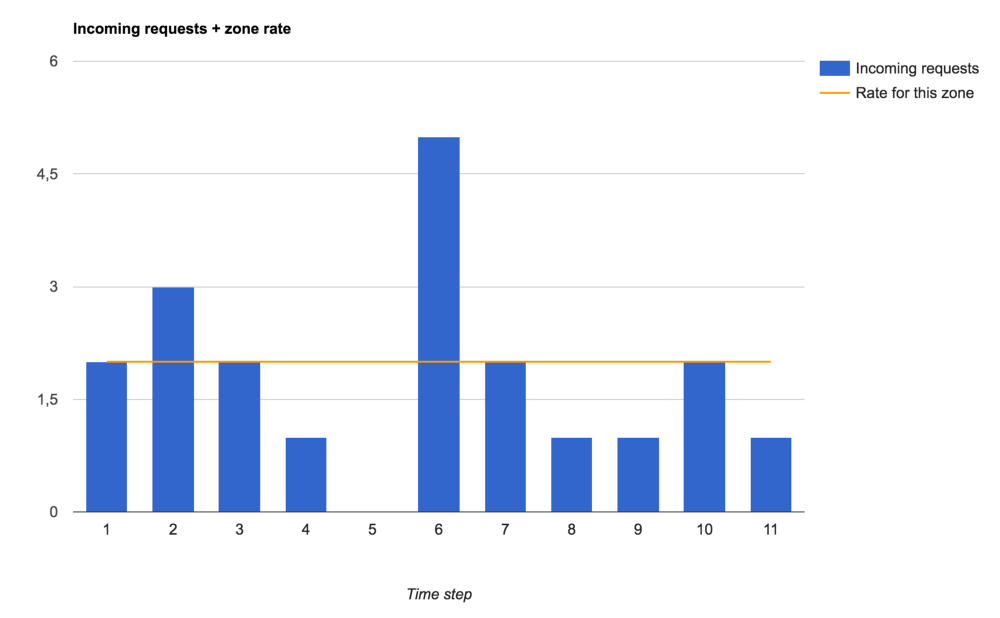
Входящие запросы и ограничение скорости, заданное для зоны
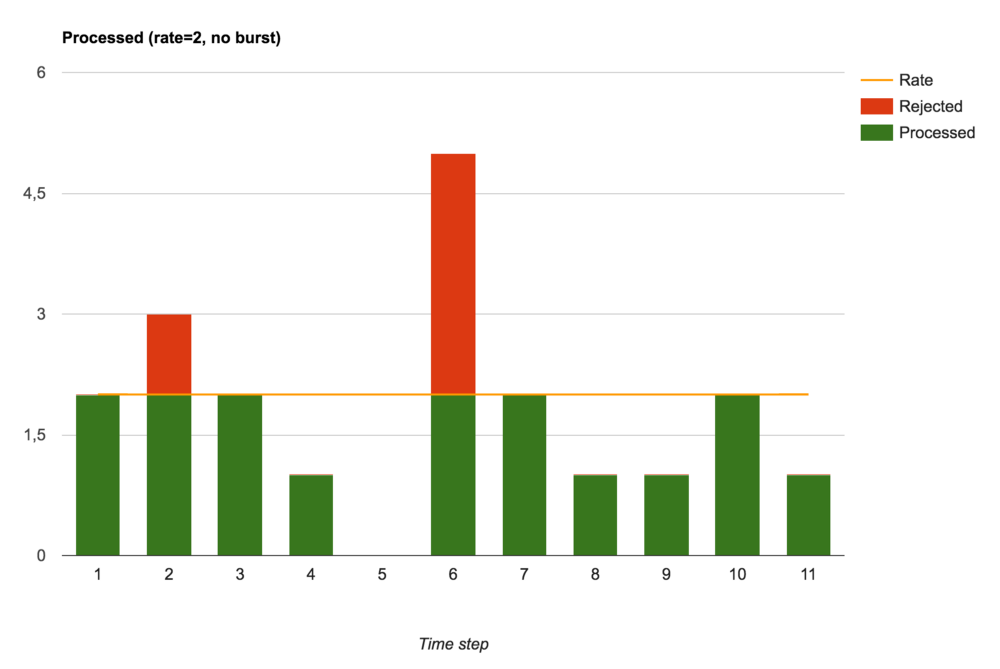
Принятые и отклоненные запросы (настройка burst не задана)
Без burst (то есть при burst=0) NGINX выполняет функцию ограничителя скорости. Запросы либо сразу обрабатываются, либо сразу отклоняются.
Если же мы хотим разрешить небольшие всплески трафика, например, чтобы дозагрузить мощности в рамках установленного лимита, тогда можно добавить аргумент burst, который подразумевает задержку при обработке запросов, принятых в рамках доступных burst-токенов:
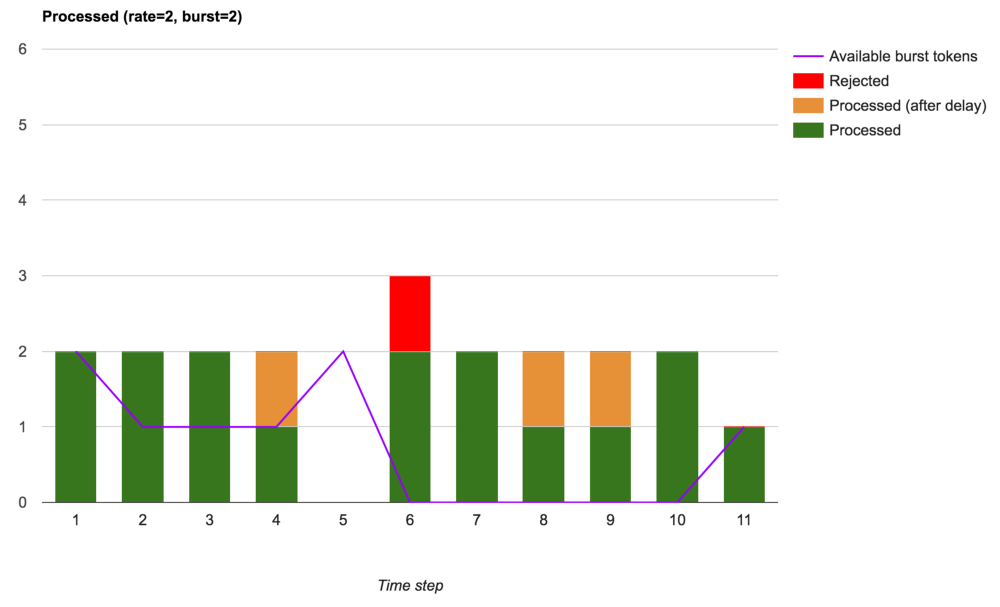
Принятые, принятые с задержкой и отклоненные запросы (с использованием burst)
Мы видим, что общее число отклоненных запросов уменьшилось. Были отклонены только те превышающие установленную скорость запросы, которые пришли в моменты, когда не было доступных burst-токенов. С такими настройками NGINX выполняет полноценный шейпинг трафика.
Наконец, NGINX можно использовать для управления трафиком путем ограничения размера пачки запросов (burst), но при этом всплески запросов частично будут доходить до их обработчиков (вышестоящих или локальных), что в конечном счете приведет к менее стабильной исходящей скорости, но улучшит сетевую задержку (если вы, конечно, можете обработать эти дополнительные запросы):
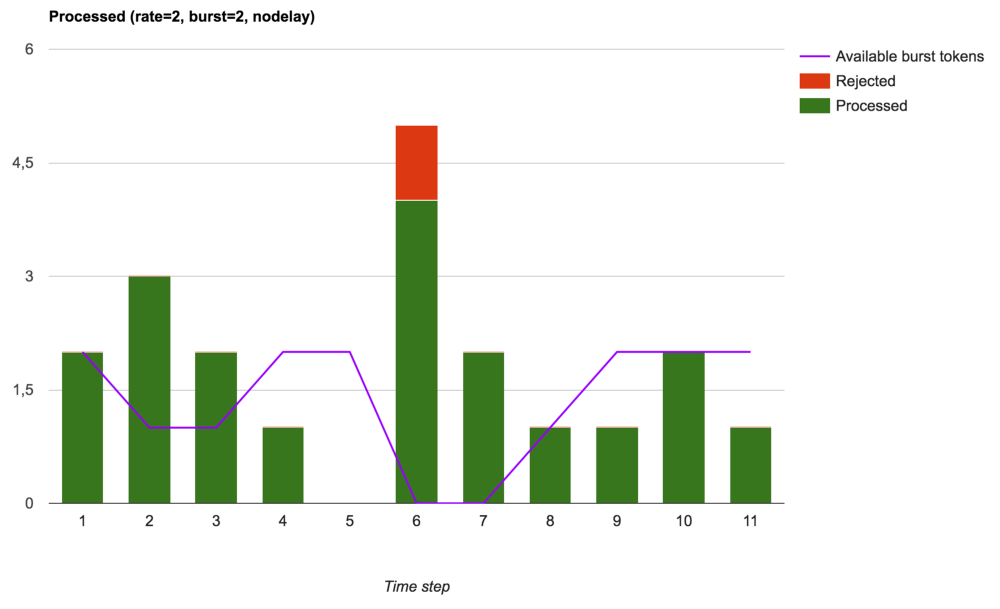
Принятые, обработанные и отклоненные запросы (burst используется с nodelay)
Теперь, чтобы лучше закрепить понимание изложенных концепций, вы можете изучить код, скопировать репозиторий и поэкспериментировать с подготовленным Docker-образом: https://github.com/sportebois/nginx-rate-limit-sandbox.
Ссылки:
|
Метки: author olemskoi системное администрирование серверная оптимизация nginx блог компании southbridge traffic shaping traffic policy |
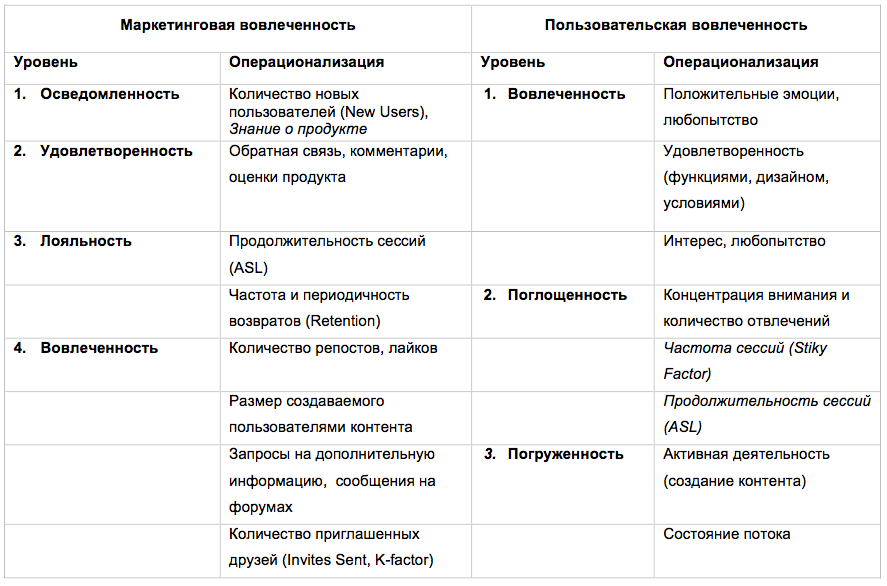
Какая вовлеченность нужна вашему продукту и как ее точнее измерить |

Все началось не просто так. Более двух лет назад я придумала идею SAAS сервиса для автоматизации рекрутинга и оценки, нашла инвестора, наши компании в партнерстве создали сервис и запустили его в работу. Кроме прочего, я занималась маркетингом, исследованиями и следила за тем, как пользователи воспринимают и покупают продукт. Об одном из таких исследований я писала в прошлой статье .
На тестирование маркетинговых ходов уходили время и деньги. Мы следили за изменением спроса и стали замечать, что наши маркетинговые усилия и доработки продукта под запросы клиентов не особенно влияли на изменение их поведения. Глобального прироста спроса и вовлеченности из-за этих изменений не происходило. И тогда мы отошли от метрик и маркетинга, перестали дорабатывать юзабилити и стали разбираться, что еще влияет на поведение клиентов. Здесь и оказалось, что метрики, которые мы использовали, в принципе не помогали нам понять, что нужно пользователям, и отвлекали внимание на суету с аналитикой.
Сейчас мы разрабатываем мобильное приложение для оценки профессиональных компетенций. Чтобы снова не потерять время, я решила с самого начала разобраться, как измеряется вовлеченность в мобильных приложениях и как ее можно повышать. Статьи описывают, в основном, метрики типа DAU, MAU, retention, ARPU. Но до того времени, как эти метрики смогут мне что-то сказать, будет уже много потрачено.


Как это применить к моему приложению?
Когда мне нужно будет понять, насколько пользователям хорошо в моем приложении, нравится ли им процесс, удобно ли им – я буду изучать пользовательскую вовлеченность. Когда я буду заинтересована в том, как пользователи воспринимают приложение, как реагируют на бренд, насколько они знают о нем и лояльны к нему, я буду изучать маркетинговую вовлеченность.
Дальше я покажу, как можно измерять каждый тип вовлеченности, как подобрать вовлеченность под тип приложения и как выглядит третий тип вовлеченности.
Франция, 2017 [19].
В исследовании пользователей цифровой камеры исследователи пришли к интересным наблюдениям. Чем дольше пользователи справлялись с задачей, тем ниже они оценивали камеру по шкале удовлетворения прагматических потребностей. Но, интересно, тем выше они оценивали ее, как стимулирующий удовольствие объект. То есть, пользователям было интересно вовлекаться в решение задачи, разбираться в функциях, хотя с точки зрения эффективности выполнения задачи они проигрывали.
Португалия, 2015 [16].
Гейм-аналитик компании «Miniclip» R. Vladimiro описал ситуацию, когда аналитика игры (гонки) показывала в целом хороший уровень возврата игроков, но его насторожила продолжительность сессий. Он обнаружил 2 группы игроков: первые возвращались в игру по 3-4 раза в день и играли в среднем по 6 минут, вторые приходили в игру в среднем 1 раз в день, но не выходили из приложения часами. Он начал анализировать поведение игроков и понял, что вторые игроки просто пассивно накапливают валюту для обновления автомобиля, но не участвуют в гонках. То есть, в сущности, не играют. В статье он написал, что вовлеченность логично увеличивает удержание, но высокое удержание игроков не обязательно означает их высокую вовлеченность: «Вовлеченность – это удовольствие от игры, а удовольствия не может быть без осмысленного взаимодействия».

Как это применить к моему приложению?
Теперь я знаю, какими показателями измерить маркетинговую и пользовательскую вовлеченность моего приложения. Раньше я спрашивала: хорошо ли иметь большую продолжительность и частоту сессий? Теперь я могу предположить: если пользователь долго проходит оценку компетенций в моем приложении, он либо увлечен, либо испытывает затруднения. Чтобы это понять, я смогу посмотреть эффективность выполненной задачи (как много пользователей доводят оценку до конца и получают результат). Если он заходит часто, он либо часто проводит собеседования, либо часто тестирует себя и готовится к собеседованиям. Это я смогу оценить по анализу времени дня, в которое пользователь заходит в приложение.


Как это применить к моему приложению?
Теперь я смогу следить, на каком уровне вовлеченности находятся мои пользователи, отслеживать, какой процент доходит до глубоких уровней вовлеченности и фиксировать, на каком уровне я теряю больше всего пользователей. А по состоянию потока и активному созданию контента я смогу понять, насколько глубоко мое приложение способно вовлекать людей на пользовательском уровне.
Остается вопрос: все ли пользователи ведут себя одинаково и справедливо ли смотреть аналитику в общем, не выделяя в ней разные группы пользователей? Похоже, что нет, не справедливо. О том, к чему это может привести, узнаем прямо сейчас.
США, 2013 [18].
Исследование поведения и удовлетворенности этих групп показало, что длительность использования приложения не связана с большим доходом. Сатисфайеры быстро выбирают и покупают, а максимайзеры могут много раз возвращаться и долго выбирать, но в итоге ничего не купить, или вернуть покупку. Максимайзерами чаще являются люди более молодого возраста, а также люди, имеющие больше денег и больше власти. Кроме того, максимайзеры способны значимо больше времени потратить на возврат покупки и написание негативных отзывов [18].
США, 2017 [10].
В исследовании участвовало 700 студентов. Им раздали браслеты Fitbit Charge HR и попросили регулярно надевать браслеты и синхронизировать данные.
Исследователи включили в анализ десятки переменных: пол, раса, образование, родители, социальное положение, психическое здоровье, физические параметры, личностные качества, друзья, сиблинги, даже данные телефонных звонков и политические взгляды и др. Оказалось, что значимую связь с регулярностью использования браслетов имели только личностные качества «Большой пятерки» и измерения самого браслета (продолжительность сна и подвижность).
Оказалось, что больше склонны следовать условиям эксперимента и регулярно носить и синхронизировать девайс люди:
1) интровертированные,
2) менее открытые новому опыту,
3) с более низким уровнем невротизма,
4) дольше спящие,
5) в общем более подвижные.
Авторы объясняют это тем, что экстраверты, готовые пробовать новое, быстро отвлекаются, меняют интересы и забывают надевать браслет. В то же время, низкий невротизм тоже помогает не отвлекаться и не страдать депрессией, тревогой и одиночеством. Люди, которые в общем заинтересованы здоровьем, больше спят и больше двигаются, по мнению авторов, логично чаще надевают браслет.
Великобритания, 2017 [8].
A.E. Whitehead и др. опросили 578 взрослых мужчин и женщин. Оказалось, что женщины гораздо реже использовали фитнес-устройства и реже считали, что есть причины для их использования.
Россия, 2015 [17].
Самое распространенное деление игроков – на персоны Бартла – показывает существенные различия в метриках вовлеченности в зависимости от типажа игрока. «Cоциальные» игроки проводят меньше всего времени в игре, но больше других приводят в игру друзей (у них высокий social ratio — коэффициент привлечения). Они могут привести «киллеров», которые приносят в игру больше всего денег. На втором месте по тратам «карьеристы». Максимальный «retention 28-го дня» у «исследователей» – они самые преданные, но приносят в игру меньше денег, чем остальные игроки.

Как это применить к моему приложению?
Теперь перед тем, как собирать аналитику и исследовать в общем поведение моих пользователей, я разделю их на группы. Затем я смогу анализировать, как отличается поведение разных групп, какая группа больше вовлечена и для какой группы нужно что-то переделать, или усилить вовлечение. Но мне еще не понятно, какие сегменты / персоны нужно выбрать, как их найти и назначить. Об этом поговорим дальше.
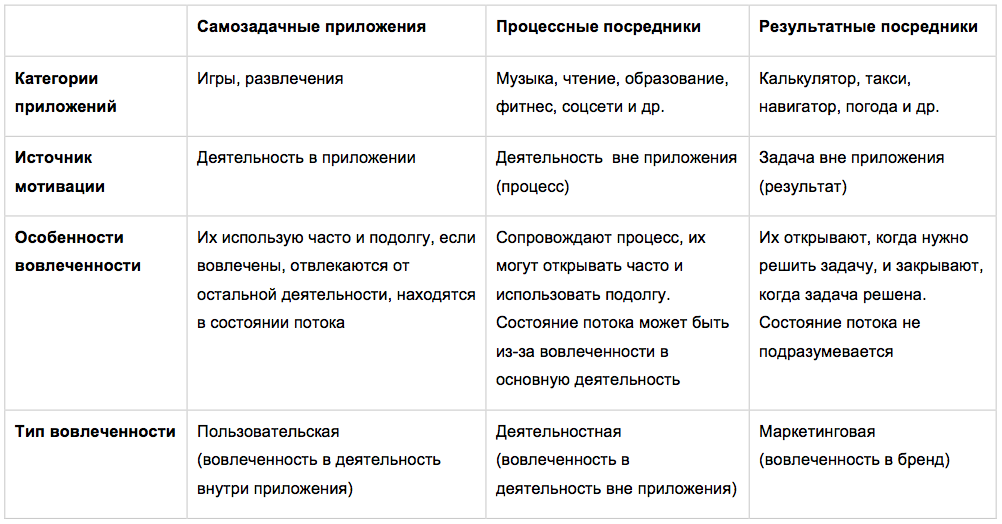

Как это применить к моему приложению?
Теперь я могу определить, к какому типу относится мое приложение, а значит, определить, какой тип вовлеченности стоит для него измерять.
Приложением будут пользоваться, когда нужно будет оценить профессиональные компетенции. Это задача вне приложения. Ее решают и закрывают приложение. Значит, мое приложение относится к результатным посредникам. Меня будут интересовать только измерения маркетинговой вовлеченности, так как вовлеченность в приложение и состояние потока в данном случае не имеют смысла.
Теперь вернемся к моим группам пользователей. Задача, которую они будут решать в приложении: оценить компетенции и получить характеристику. Это может быть интересно рекрутерам, руководителям команд и соискателям. Рекрутеры будут использовать приложение периодически, непродолжительно и часто возвращаться (в рабочие дни, в дневное время, во время собеседований). Руководители команд тоже будут его использовать во время собеседований, непродолжительно, но возвращаться реже (когда вакансии будут появляться в их команде). Соискатели будут использовать приложение вначале часто и подолгу, пытаясь разобраться в вопросах и вариантах ответа, понять логику и просмотреть как можно больше вопросов, чтобы потренироваться. Но затем, по мере насыщения, будут оставлять приложение и редко возвращаться к нему.
Благодаря анализу деятельности моих пользователей и Jobs-to-be-done приложения я начинаю понимать, какие метрики мне стоит ожидать от каждой группы пользователей, а что вовсе не имеет смысла исследовать.
Теперь мне становится интересно, смогу ли я увеличивать не только вовлеченность в бренд, но и вовлеченность в деятельность. Какие механики вовлечения мне применять, чтобы они сработали? Начинаем об этом говорить прямо сейчас.
Англия, США, 2007.
Исследования эффективности геймификации, проведенные Baker et al. показали, что иногда дети учатся играть в игру, созданную для обучения математике, типа Zombie Division, показывают хорошие успехи в игре, но не начинают лучше разбираться в математике (рис. 2).

США, 2010 [20].
T. Bickmore с соавторами провели лонгитюдные исследования влияния виртуального помощника на вовлеченность пользователей в использование фитнес-сервиса (рис. 3). Каждый день участники должны были вносить в систему количество пройденных шагов и получали обратную связь от виртуальной помощницы Лауры. Для разных экспериментальных групп Лаура либо вступала в коммуникацию, либо была молчаливой, либо вовсе не использовалась в системе. Оказалось, что участники более высоко оценивали качество взаимодействия с разговорчивой Лаурой и были больше к ней привязаны. Но при этом удовлетворенность и вовлеченность в общение с Лаурой не влияла на увеличение количества шагов.
Другое лонгитюдное исследование – с помощницей Карен – должно было показать, насколько вариативность обратной связи влияет на вовлеченность и успешность деятельности (количество шагов). На этот раз исследование показало, что, чем более разнообразными были фразы от Карен, тем больше участники вовлекались в общение с ней, но тем меньше шагов они проходили за день. Здесь уже вовлеченность в сервис снижала вовлеченность в деятельность, ради которой оно было создано [20].


Как это применить к моему приложению?
Теперь я буду внимательнее относиться к советам по вовлечению пользователей и использованию геймификации. Я не буду использовать мотиваторы, связанные только с приложением (ачивки, звездочки и монетки за пройденные вопросы, а также уровни, звания, награды). Я хочу, чтобы моим приложением пользовались для работы, но не заигрывались с ним. Мне важно, чтобы вовлеклись не в приложение, а в деятельность, которой оно помогает. Еще я подумаю, стоит ли подключать опцию «поделиться результатом» в соцсетях. С одной стороны, это может мотивировать моих пользователей проходить оценку и привлечь их друзей. С другой стороны, это может превратить рабочий инструмент в игрушку и обесценить его экспертность. Это еще нужно исследовать.
Наконец, что я могу использовать, чтобы с помощью приложения побуждать рекрутеров и руководителей команд чаще использовать профессиональные вопросы с вариантами ответов при оценке компетенций (а значит, и мое приложение)? У меня появилась идея создания базы результатов, добавления функции вычисления средних результатов по отрасли и по должности и чего-то еще такого же профессионально-полезного. Эти опции могут создавать дополнительную ценность для рекрутеров и руководителей и повторно вовлекать их в приложение.
Мне уже хочется узнать, какими методами исследовать эффект от моих идей и как это делают другие. Сейчас посмотрим.
Испания, США, 2012 [3].
J. Lehman с коллегами подчеркивали, что в зависимости от назначения ресурса вовлеченность пользователей нужно понимать и измерять по-разному. И не стоит сравнивать едиными метриками вовлеченности ресурсы разной направленности. Они предложили другую классификацию метрик вовлечения. Ее логика хорошо подходит для анализа мобильных приложений:
Популярность (общее количество пользователей, количество визитов, количество кликов).
Активность (количество просмотренных страниц за один визит, время, потраченное за один визит).
Лояльность (количество дней, в течение которых пользователь заходит на сайт, количество визитов, общее время, проведенное на сайте).

Литва, 2017 [5].
A. Tarute с соавт. в операционализации разделили вовлеченность на привычные для социальных исследований аспекты анализа (когнитивный, эмоциональный и поведенческий) и добавили социальный аспект.
1. Когнитивный аспект. Проявляет ли пользователь интерес к товару, или бренду?
2. Эмоциональный аспект. Испытывает ли пользователь воодушевление, или гордость от использования продукта, или сопричастности с брендом?
3. Поведенческий аспект. Вероятно ли, что пользователь предпримет какое-то действие навстречу бренду, или товару, сделает покупку и др.
4. Социальный аспект. Взаимодействует ли пользователь с брендом в социальном окружении, вовлекает ли других людей, участвует ли в совместном создании продукта?
Затем исследователи выделили четыре основных качества мобильных приложений, от которых, по их мнению, зависит вовлеченность. Они решили проверить, как вовлеченность связана с этими качествами, а также насколько она влияет на использование мобильного приложения в будущем.
1. Функциональность (доступный пользователю набор функций: камера, определение месторасположения, мультитач, распознавание голоса, дополненная реальность, виртуальное зеркало, мобильное видео и мобильные платежи и др.).
2. Дизайн (эстетическое оформление приложения, не юзабилити, а эмоции, которые у пользователя вызывает дизайн интерфейса).
3. Взаимодействие с пользователем (контент, генерируемый пользователем, персонализация контента (тегирование), фолловинг, возможность оценить контент, поделиться им и прокомментировать).
4. Качество информации (возможность получить своевременную и релевантную информацию, качественный контент).
Для исследования были случайным образом отобраны активные пользователи мобильных приложений. Средний возраст 25 лет, 42.5% мужчин и 57.5% женщин. Участников просили выбрать мобильное приложение, которое они используют чаще всего, и отвечать на вопросы анкеты, имея в виду это приложение.
В результате факторного анализа были отобраны 27 вопросов анкеты (см. Дополнения, № 4). Анкета оценивала вовлеченность, готовность продолжать использование приложения, а также четыре качества мобильных приложений. Интересно, что в итоговую версию анкеты в блок оценки вовлеченности вошли только 4 вопроса про эмоции и 1 про поведение. Авторы хоть и упоминали когнитивный и социальный аспекты вовлеченности, но не использовали их в диагностике.
Большинство участников исследования (61,3%) сообщили, что чаще всего используют мобильные приложения социальных сетей (Facebook Messenger, Instagram, Viber, WhatsApp). Кроме приложений социальных сетей, наиболее используемыми оказались приложения для навигации (Trafi, Busas Kaunas, Here WeGo Maps), банкинга (Swedbank, DNB bank, SEB bank), обучения (Duolingo, Todoist, MyStudyLife) и здоровья (e.g. Endomondo Sports tracker, Noom Walk, WaterDrink). Их называли в 14,1% случаев.
В результате проверки гипотез оказалось, что только дизайн приложения и качество контента были статистически значимо связаны с вовлеченностью пользователей. Функциональность приложения и возможности для взаимодействия не влияли на вовлеченность. Вовлеченность пользователя имела позитивное влияние на его готовность продолжать использование приложения в будущем.
США, 2013 [4].
Y. H. Kim с соавторами предложили теоретическую модель вовлечения пользователей мобильных устройств (MoEN) (рис. 4).

Они изучали вовлеченность, как аттитюд (социальную установку, тип убеждения, влияющий на поведение) и также использовали разделение на три аспекта: когнитивный, аффективный (эмоциональный) и конативный (поведенческий).
Дополнительно Y. H. Kim и коллеги ввели конструкт мотивации пользователей мобильных устройств и разделили ее на 3 группы:
– функциональная (эффективность, простота использования, экономия времени),
– гедонистическая (радость, наслаждение, приятные эмоции),
– социальная (желание быть связанным и делиться эмоциями и информацией с другими).
Модель исследует взаимодействие мотивации пользователей и пользовательскую вовлеченность по стадиям использования продукта: на стадии знакомства – когнитивной стадии – пользователем движут утилитарные мотивы и воспринимаемая ценность приложения, на аффективной стадии подключается гедонистическая мотивация и удовлетворенность, социальная мотивация проявляется между когнитивной и аффективной стадиями и, наконец, на поведенческой стадии включается пользовательское вовлечение.
Для проверки модели исследователи разработали опросник (см. Приложения, №3). В основном исследовании приняли участие 297 студентов (50,3% мужчин и 49,3% женщин). Модель подтвердилась, подробнее: [4].
Испания, 2017 [13].
В этом исследовании снова все параметры – от простоты использования до вовлеченности – измерялись опросником (см. Дополнения, №6). В исследовании участвовало 750 испанских студентов (16–35 лет). Авторы хотели проверить, как бесплатный доступ, простота использования и тип контента влияют на удовлетворенность сервисом. И как удовлетворенность, в свою очередь, влияет на лояльность, вовлеченность, взаимодействие и желание рекомендовать сервис.
Оказалось, что только простота использования была связана с удовлетворенностью. А удовлетворенность оказалась связана с лояльностью и вовлеченностью и – меньше – с желанием рекомендовать и взаимодействием (рис. 9).

Италия, 2015 [11].
В исследовании в приложении была запрограммирована функция случайного разделения пользователей на контрольную и экспериментальную группы. Контрольной группе предлагалось пройти тест о здоровом образе жизни в начале и в конце исследования. А экспериментальная группа на время исследования получала доступ к расширенному тесту и push-уведомления на почту, вовлекающие проходить тест и знакомиться с его материалами. И хотя доказательства различий вовлеченности авторы построили только по 2 участникам исследования (из 29), заполнившим равное количество вопросов теста с разной успешностью, их метод экспериментального исследования вовлеченности заслуживает внимания.
Авторы намеренно измеряли вовлеченность двумя способами: 1) вовлеченность в приложение – через количество заполненных вопросов теста и 2) вовлеченность в проблему – через кривую научения (по количеству ошибок в тесте).
Россия, 2017.
Скорее всего, сохранившиеся пельмени стали бы показателем более глубокого уровня вовлеченности.

США, 2017 [6].
Д. Леджер и Д. МакКафри провели анализ фитнес-устройств и выделили факторы, которые обеспечивают долгосрочную вовлеченность пользователей. Авторы измеряют вовлеченность просто, как длительность использования устройства, но все же обратили внимание на психологические условия для ее возникновения. Они сравнили устройства по 9 техническим и 3 психологическим условиям создания вовлеченности. По мнению авторов, даже если одно условие не будет соблюдено, вовлечение может не состояться. 3 психологических условия напрямую связаны с назначением устройств и могут быть применимы только к ограниченной группе приложений. Так, для фитнес-устройств психологическими факторами вовлечения являются: формирование привычки, социальная мотивация и подкрепление целей. На картинке представлен результат сравнения 8 устройств.
К сожалению, мне не удалось найти методологию назначения баллов по каждому условию (возможно, это был метод опроса экспертов). Тем не менее, графическое сравнение выглядит любопытно и дополняется подробным описанием каждого условия с примерами (рис. 7). Отчет находится в открытом доступе в Интернете [6].

США, 2017 [7].
S. Asimakopoulos с коллегами продолжили исследование вовлеченности пользователей фитнес-устройств и обратились к мотивации и теории самодетерминации. Они решили уточнить, как с мотивацией и долгосрочной вовлеченностью связано ощущение самоэффективности пользователей.
Методы:
– заполнение on-line дневников дважды в неделю в течение 4 недель (см. Дополнения, №5),
– опросник самоэффективности «Healthcare Technology Self-efficacy (HTSE)» с 7-ступенчатой шкалой Лайкерта (от «полностью не согласен» до «полностью согласен»),
– участники присылали исследователям фотографии интерфейсов мобильного приложения, которые мотивируют их.
Выборка: 34 пользователя фитнес-трекеров Fitbit и Jawbone. Исследование показало, что на мотивацию пользователей больше всего влияют 3 аспекта: данные, геймификация и контент.
Создатели приложений часто все решают сами, а при вопросах об исследовании пользователей ссылаются на высказывания Г. Форда («Если бы я спросил людей, чего они хотят, они бы попросили более быструю лошадь»), С. Джобса «Создавать продукт, опираясь на фокус-группы, по-настоящему трудно. Чаще всего люди не понимают, что им на самом деле нужно, пока сам им этого не покажешь» и А. Лебедева («Ответ одного дурака с улицы никого не волнует. Но ответы сотни дураков называются результатом исследования фокус-группы и продаются за деньги»).
Португалия, 2017 [21].
Исследователи решили проверить, насколько применимы программы по распознаванию эмоций в изучении вовлеченности игроков компьютерных игр. Оборудованием служила камера, снимающая лицо игрока, и программное обеспечение: скрипт, написанный Ergo VR Laboratory c использованием Affdex SDK для Unity от Affectiva.
Проверка прошла удачно. Распознанные программой эмоции соответствовали тому, что выражали игроки, и хорошо отражали затруднения, которые испытывали некоторые пользователи во время игры (рис. 12).

Как это применить к моему приложению?
Скорее всего, я буду смотреть на эти примеры, когда буду выбирать методы и проводить исследования. Но сейчас я только создаю прототип приложения. Собирать метрики и проводить эксперименты мне еще рано. А понять пользователей хочется как можно раньше. Стоит ли мне уже что-то исследовать? И какие методы тогда можно использовать? Я нашла ответ и на этот вопрос.
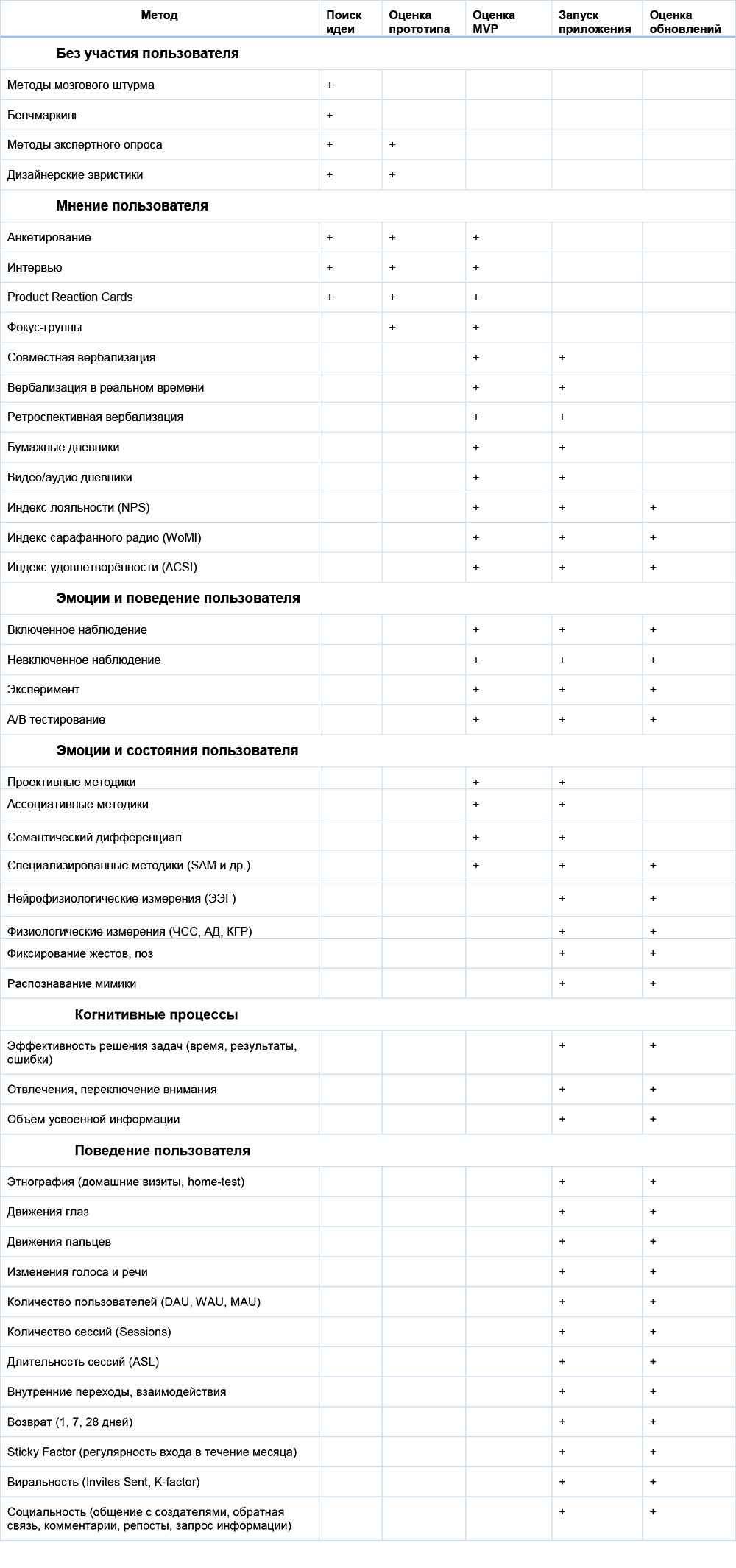
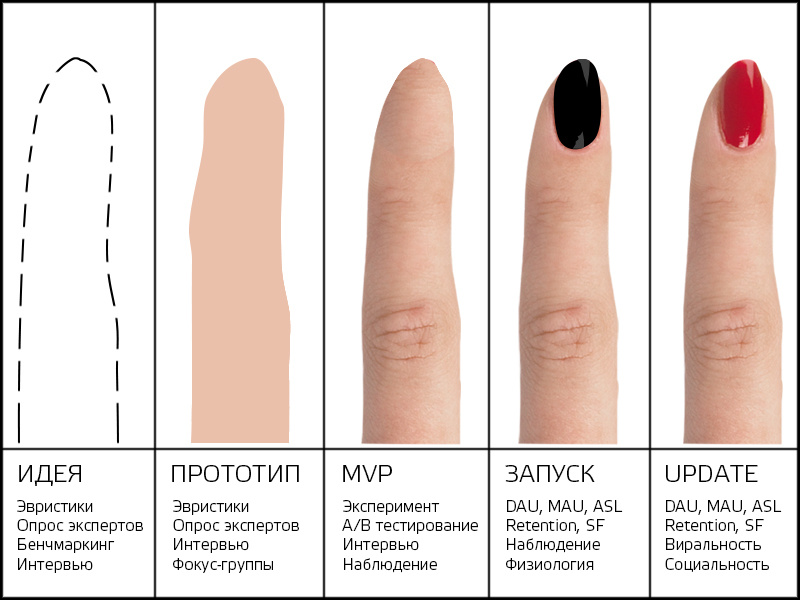
Как это применить к моему приложению?
Я прошла стадию разработки идеи и использовала на ней дизайнерские эвристики и бенчмаркинг. Теперь у меня есть набор методов для каждой стадии развития моего приложения.

|
|
Financial Management: Как оценить затраты на предоставляемые услуги |
 / Flickr / GotCredit / CC
/ Flickr / GotCredit / CC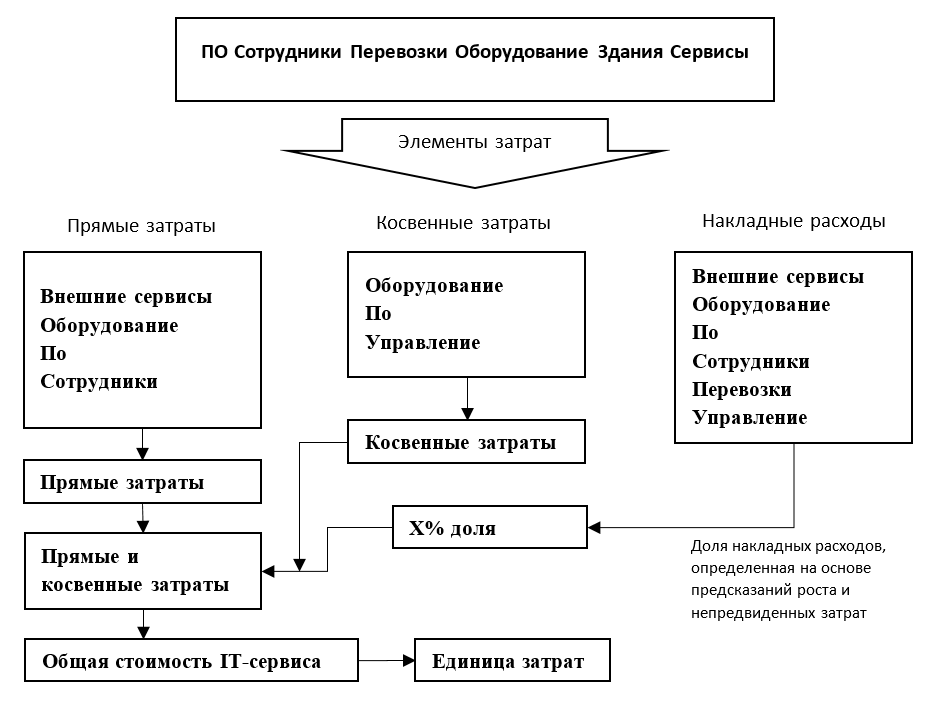
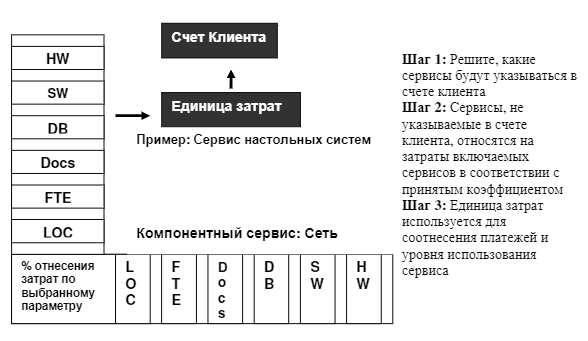
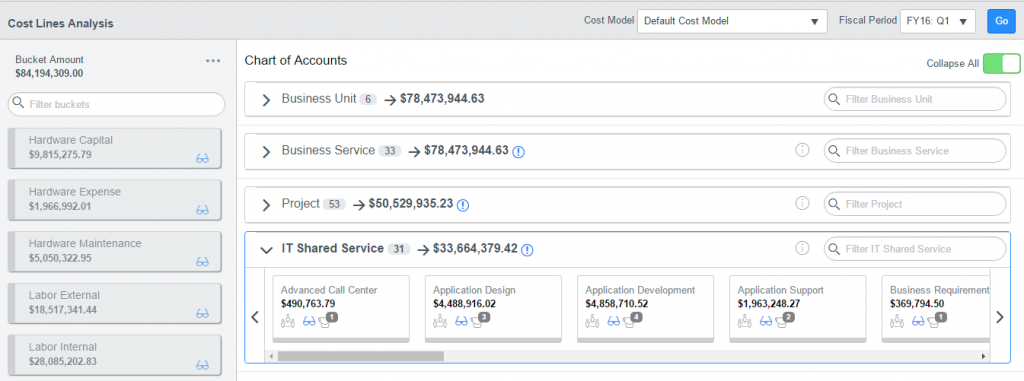
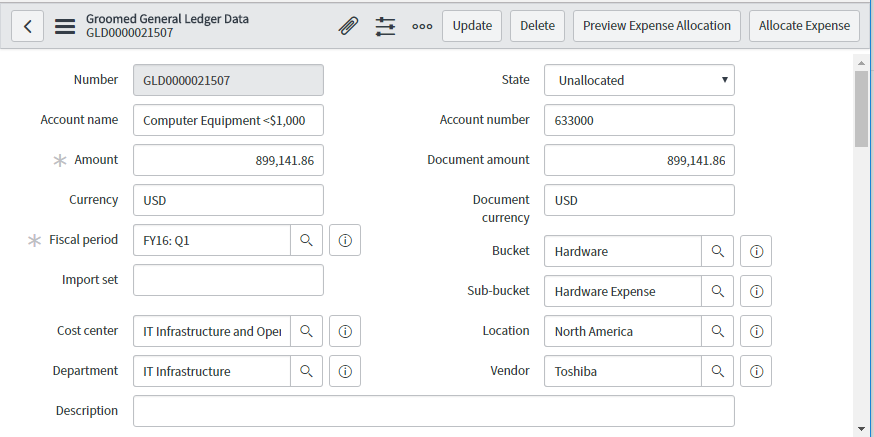
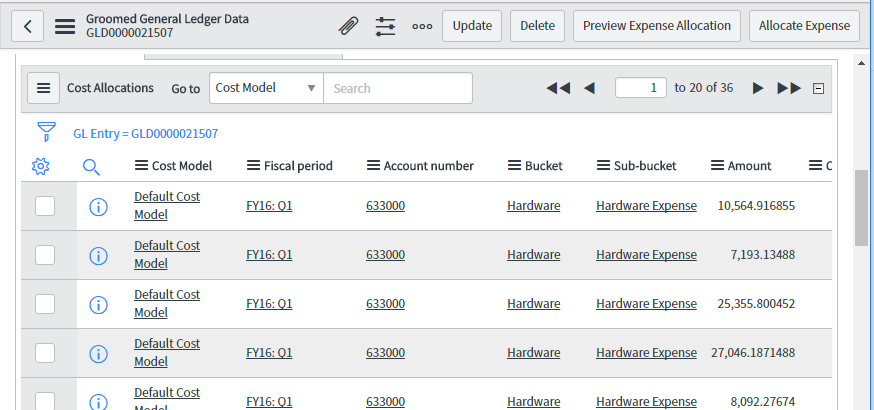
|
Метки: author it-guild управление e-commerce блог компании ит гильдия ит гильдия servicenow financial management |
[Перевод] 24-ядерный CPU, а я не могу сдвинуть курсор |
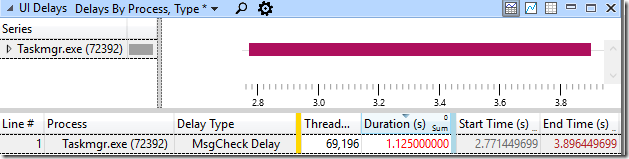
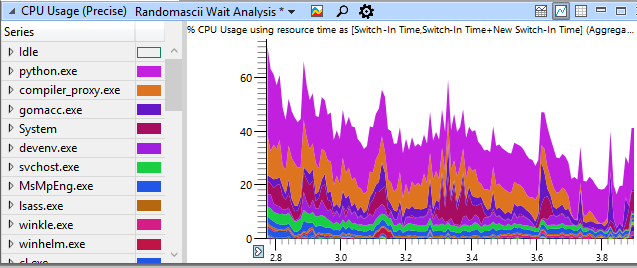

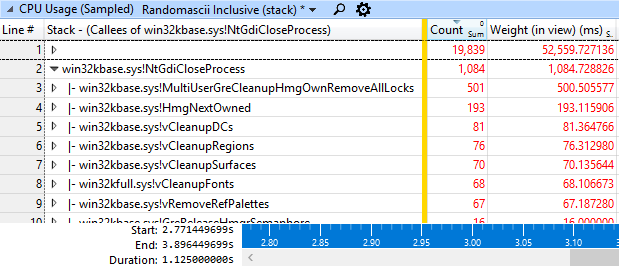
Taskmgr.exe (72392) завис на 1,125 с (MsgCheckDelay) на треде 69,196. Наибольшая задержка была 115,6 мс на win32kbase.sys!EnterCrit, который был подготовлен процессом conhost.exe (16264), тред 2560 на 3.273101862. conhost.exe (16264), 2560 был подготовлен на 3.273077782 после ожидания 115,640.966 мс, процессом mstsc.exe (79392), 71272. mstsc.exe был подготовлен (то же время, та же задержка) процессом TabTip.exe (8284), 8348, который был подготовлен процессом UIforETW.exe (78120), 79584, который был подготовлен процессом conhost.exe (16264), 58696, который был подготовлен процессом gomacc.exe (93668), 59948, который был подготовлен процессом gomacc.exe (95164), 76844.



|
|
Как складывается карьера после Университета ИТМО – рассказывают выпускники |
|
Метки: author itmo учебный процесс в it блог компании университет итмо университет итмо выпускники |
Как запутать аналитика — 5. Понятийный аппарат |
|
Метки: author maxstroy семантика машинное обучение it- стандарты моделирование предметной области |
Linux все еще не торт |

$ slabtop
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
441920 441450 99% 1.00K 13810 32 441920K kmalloc-1024
224070 222908 99% 0.19K 5335 42 42680K kmalloc-192
38304 21198 55% 0.19K 912 42 7296K dentry
25602 25133 98% 0.12K 753 34 3012K kernfs_node_cache
19380 19380 100% 0.04K 190 102 760K Acpi-Namespace
$ uname -a
Linux zdtm.openvz.org 4.10.17-200.fc25.x86_64 #1 SMP Mon May 22 18:12:57 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
[root@zdtm ~]# iptables -w -t filter --protocol tcp -A INPUT --dport 12345 -j DROP
[root@zdtm ~]# iptables -w -t filter --protocol tcp -D INPUT --dport 12345 -j DROP
iptables: Bad rule (does a matching rule exist in that chain?).
[root@zdtm criu]# cat /proc/slabinfo | grep mnt
mnt_cache 36456 36456 384 42 4 : tunables 0 0 0 : slabdata 868 868 0
[root@zdtm criu]# python test/zdtm.py run -t zdtm/static/env00 --iter 10 -f ns
========================= Run zdtm/static/env00 in ns ==========================
Start test
./env00 --pidfile=env00.pid --outfile=env00.out --envname=ENV_00_TEST
Run criu dump
Run criu restore
Run criu dump
....
Run criu restore
Send the 15 signal to 339
Wait for zdtm/static/env00(339) to die for 0.100000
Removing dump/zdtm/static/env00/31
========================= Test zdtm/static/env00 PASS ==========================
[root@zdtm criu]# cat /proc/slabinfo | grep mnt
mnt_cache 36834 36834 384 42 4 : tunables 0 0 0 : slabdata 877 877 0
[ 699.207570] BUG: Bad page state in process ip6tables-save pfn:1499f4
unreferenced object 0xffff88006342fa38 (size 1024):
comm "ip", pid 15477, jiffies 4295982857 (age 957.836s)
hex dump (first 32 bytes):
b8 b0 4d a0 ff ff ff ff c0 34 c3 59 00 88 ff ff ..M......4.Y....
04 00 00 00 a4 01 00 00 00 00 00 00 00 00 00 00 ................
backtrace:
[ffffffff8190510a] kmemleak_alloc+0x4a/0xa0
[ffffffff81284130] __kmalloc_track_caller+0x150/0x300
[ffffffff812302d0] kmemdup+0x20/0x50
[ffffffffa04d598a] dccp_init_net+0x8a/0x160 [nf_conntrack]
[ffffffffa04cf9f5] nf_ct_l4proto_pernet_register_one+0x25/0x90
unreferenced object 0xffff9f79442cd980 (size 112):
comm "kworker/1:4", pid 15416, jiffies 4307432421 (age 28687.562s)
hex dump (first 32 bytes):
00 00 00 00 ad 4e ad de ff ff ff ff 00 00 00 00 .....N..........
ff ff ff ff ff ff ff ff b8 39 1b 97 ff ff ff ff .........9......
backtrace:
[ffffffff9591d28a] kmemleak_alloc+0x4a/0xa0
[ffffffff95276198] kmem_cache_alloc_node+0x168/0x2a0
[ffffffff95279f28] __kmem_cache_create+0x2b8/0x5c0
[ffffffff9522ff57] create_cache+0xb7/0x1e0
[ffffffff952305f8] memcg_create_kmem_cache+0x118/0x160
[ffffffff9528eaf0] memcg_kmem_cache_create_func+0x20/0x110
[ffffffff950cd6c5] process_one_work+0x205/0x5d0
[ffffffff950cdade] worker_thread+0x4e/0x3a0
[ffffffff950d5169] kthread+0x109/0x140
[ffffffff9592b8fa] ret_from_fork+0x2a/0x40
[ffffffffffffffff] 0xffffffffffffffff
unreferenced object 0xffff9f798a79f540 (size 32)
> [22458.504137] BUG: Dentry ffff9f795a08fe60{i=af565f,n=lo} still in
> use (1) [unmount of proc proc]
> [22458.505117] ------------[ cut here ]------------
> [22458.505299] WARNING: CPU: 0 PID: 15036 at fs/dcache.c:1445
…
> [22458.515141] ---[ end trace b37db95b00f941ab ]---
> [22458.519368] VFS: Busy inodes after unmount of proc. Self-destruct
> in 5 seconds. Have a nice day...
> [22458.813846] BUG: unable to handle kernel NULL pointer dereference
> at 0000000000000018
…
|
|
Почему нет русского Amazon, или где @ зарыта? Мифы, которые надо закрыть |
|
Метки: author Menaskop финансы в it исследования и прогнозы в it ecommerce юлмарт wildberries объединение техносилы электронная коммерция исследование рынка рунета |
[Перевод] Stupidly Simple DDoS Protocol (SSDP) генерирует DDoS на 100 Гбит/с |
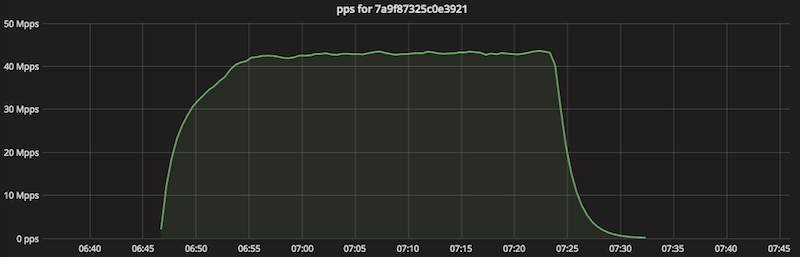

$ cat ips-nf-ct.txt|uniq|cut -f 2|sort|uniq -c|sort -nr|head
439126 CN
135783 RU
74825 AR
51222 US
41353 TW
32850 CA
19558 MY
18962 CO
14234 BR
10824 KR
10334 UA
9103 IT
... $ cat ips-nf-asn.txt |uniq|cut -f 2|sort|uniq -c|sort -nr|head
318405 4837 # CN China Unicom
84781 4134 # CN China Telecom
72301 22927 # AR Telefonica de Argentina
23823 3462 # TW Chunghwa Telecom
19518 6327 # CA Shaw Communications Inc.
19464 4788 # MY TM Net
18809 3816 # CO Colombia Telecomunicaciones
11328 28573 # BR Claro SA
7070 10796 # US Time Warner Cable Internet
6840 8402 # RU OJSC "Vimpelcom"
6604 3269 # IT Telecom Italia
6377 12768 # RU JSC "ER-Telecom Holding"
... M-SEARCH — основном методе обнаружения:Когда в сеть добавляется контрольная точка, протокол обнаружения UPnP позволяет этой контрольной точке поиск интересующих устройств в сети. Он делает это с помощью мультивещания поискового сообщения на зарезервированный адрес и порт (239.255.255.250:1900) с шаблоном, или целью, соответствующей типу идентификатора для устройства или сервиса.
M-SEARCH:Чтобы быть найденным поисковым запросом, устройство должно отправить одноадресный ответ UDP на IP-адрес источника и порт, который прислал сообщение с помощью мультивещания. Ответ требуется, если в поле заголовка ST в запросеM-SEARCHуказано “ssdp:all”, “upnp:rootdevice”, “uuid:”, а далее следует UUID, который в точности соответствует UUID устройства, или если запросM-SEARCHсоответствует типу устройства или типу сервиса, поддерживаемому устройством.
$ sudo tcpdump -ni eth0 udp and port 1900 -A
IP 192.168.1.124.53044 > 239.255.255.250.1900: UDP, length 175
M-SEARCH * HTTP/1.1
HOST: 239.255.255.250:1900
MAN: "ssdp:discover"
MX: 1
ST: urn:dial-multiscreen-org:service:dial:1
USER-AGENT: Google Chrome/58.0.3029.110 Windows ST (search-target), должны ответить.ST:upnp:rootdevice: поиск корневых устройствssdp:all: поиск всех устройств и сервисов UPnP#!/usr/bin/env python2
import socket
import sys
dst = "239.255.255.250"
if len(sys.argv) > 1:
dst = sys.argv[1]
st = "upnp:rootdevice"
if len(sys.argv) > 2:
st = sys.argv[2]
msg = [
'M-SEARCH * HTTP/1.1',
'Host:239.255.255.250:1900',
'ST:%s' % (st,),
'Man:"ssdp:discover"',
'MX:1',
'']
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM, socket.IPPROTO_UDP)
s.settimeout(10)
s.sendto('\r\n'.join(msg), (dst, 1900) )
while True:
try:
data, addr = s.recvfrom(32*1024)
except socket.timeout:
break
print "[+] %s\n%s" % (addr, data)$ python ssdp-query.py
[+] ('192.168.1.71', 1026)
HTTP/1.1 200 OK
CACHE-CONTROL: max-age = 60
EXT:
LOCATION: http://192.168.1.71:5200/Printer.xml
SERVER: Network Printer Server UPnP/1.0 OS 1.29.00.44 06-17-2009
ST: upnp:rootdevice
USN: uuid:Samsung-Printer-1_0-mrgutenberg::upnp:rootdevice
[+] ('192.168.1.70', 36319)
HTTP/1.1 200 OK
Location: http://192.168.1.70:49154/MediaRenderer/desc.xml
Cache-Control: max-age=1800
Content-Length: 0
Server: Linux/3.2 UPnP/1.0 Network_Module/1.0 (RX-S601D)
EXT:
ST: upnp:rootdevice
USN: uuid:9ab0c000-f668-11de-9976-000adedd7411::upnp:rootdevice M-SEARCH:$ python ssdp-query.py 192.168.1.71
[+] ('192.168.1.71', 1026)
HTTP/1.1 200 OK
CACHE-CONTROL: max-age = 60
EXT:
LOCATION: http://192.168.1.71:5200/Printer.xml
SERVER: Network Printer Server UPnP/1.0 OS 1.29.00.44 06-17-2009
ST: upnp:rootdevice
USN: uuid:Samsung-Printer-1_0-mrgutenberg::upnp:rootdevice M-SEARCH, который пришёл из интернета. Требуется только чуть неправильная настройка файрвола, когда порт 1900 открыт внешнему миру — и вот идеальная мишень для умножения флуда UDP.$ python ssdp-query.py 100.42.x.x
[+] ('100.42.x.x', 1900)
HTTP/1.1 200 OK
CACHE-CONTROL: max-age=120
ST: upnp:rootdevice
USN: uuid:3e55ade9-c344-4baa-841b-826bda77dcb2::upnp:rootdevice
EXT:
SERVER: TBS/R2 UPnP/1.0 MiniUPnPd/1.2
LOCATION: http://192.168.2.1:40464/rootDesc.xmlssdp:all ST. Его ответы намного больше по размеру:$ python ssdp-query.py 100.42.x.x ssdp:all
[+] ('100.42.x.x', 1900)
HTTP/1.1 200 OK
CACHE-CONTROL: max-age=120
ST: upnp:rootdevice
USN: uuid:3e55ade9-c344-4baa-841b-826bda77dcb2::upnp:rootdevice
EXT:
SERVER: TBS/R2 UPnP/1.0 MiniUPnPd/1.2
LOCATION: http://192.168.2.1:40464/rootDesc.xml
[+] ('100.42.x.x', 1900)
HTTP/1.1 200 OK
CACHE-CONTROL: max-age=120
ST: urn:schemas-upnp-org:device:InternetGatewayDevice:1
USN: uuid:3e55ade9-c344-4baa-841b-826bda77dcb2::urn:schemas-upnp-org:device:InternetGatewayDevice:1
EXT:
SERVER: TBS/R2 UPnP/1.0 MiniUPnPd/1.2
LOCATION: http://192.168.2.1:40464/rootDesc.xml
... и ещё 6 ответных пакетов....M-SEARCH вызвал 8 пакетов в ответ. Просмотр в tcpdump:$ sudo tcpdump -ni en7 host 100.42.x.x -ttttt
00:00:00.000000 IP 192.168.1.200.61794 > 100.42.x.x.1900: UDP, length 88
00:00:00.197481 IP 100.42.x.x.1900 > 192.168.1.200.61794: UDP, length 227
00:00:00.199634 IP 100.42.x.x.1900 > 192.168.1.200.61794: UDP, length 299
00:00:00.202938 IP 100.42.x.x.1900 > 192.168.1.200.61794: UDP, length 295
00:00:00.208425 IP 100.42.x.x.1900 > 192.168.1.200.61794: UDP, length 275
00:00:00.209496 IP 100.42.x.x.1900 > 192.168.1.200.61794: UDP, length 307
00:00:00.212795 IP 100.42.x.x.1900 > 192.168.1.200.61794: UDP, length 289
00:00:00.215522 IP 100.42.x.x.1900 > 192.168.1.200.61794: UDP, length 291
00:00:00.219190 IP 100.42.x.x.1900 > 192.168.1.200.61794: UDP, length 291 $ cat results-first-run.txt|cut -f 1|sort|uniq -c|sed -s 's#^ \+##g'|cut -d " " -f 1| ~/mmhistogram -t "Response packets per IP" -p
Response packets per IP min:1.00 avg:6.99 med=8.00 max:186.00 dev:4.44 count:350337
Response packets per IP:
value |-------------------------------------------------- count
0 | ****************************** 23.29%
1 | **** 3.30%
2 | ** 2.29%
4 |************************************************** 38.73%
8 | ************************************** 29.51%
16 | *** 2.88%
32 | 0.01%
64 | 0.00%
128 | 0.00% ssdp:all M-SEARCH, злоумышленник может получить:Server:104833 Linux/2.4.22-1.2115.nptl UPnP/1.0 miniupnpd/1.0
77329 System/1.0 UPnP/1.0 IGD/1.0
66639 TBS/R2 UPnP/1.0 MiniUPnPd/1.2
12863 Ubuntu/7.10 UPnP/1.0 miniupnpd/1.0
11544 ASUSTeK UPnP/1.0 MiniUPnPd/1.4
10827 miniupnpd/1.0 UPnP/1.0
8070 Linux UPnP/1.0 Huawei-ATP-IGD
7941 TBS/R2 UPnP/1.0 MiniUPnPd/1.4
7546 Net-OS 5.xx UPnP/1.0
6043 LINUX-2.6 UPnP/1.0 MiniUPnPd/1.5
5482 Ubuntu/lucid UPnP/1.0 MiniUPnPd/1.4
4720 AirTies/ASP 1.0 UPnP/1.0 miniupnpd/1.0
4667 Linux/2.6.30.9, UPnP/1.0, Portable SDK for UPnP devices/1.6.6
3334 Fedora/10 UPnP/1.0 MiniUPnPd/1.4
2814 1.0
2044 miniupnpd/1.5 UPnP/1.0
1330 1
1325 Linux/2.6.21.5, UPnP/1.0, Portable SDK for UPnP devices/1.6.6
843 Allegro-Software-RomUpnp/4.07 UPnP/1.0 IGD/1.00
776 Upnp/1.0 UPnP/1.0 IGD/1.00
675 Unspecified, UPnP/1.0, Unspecified
648 WNR2000v5 UPnP/1.0 miniupnpd/1.0
562 MIPS LINUX/2.4 UPnP/1.0 miniupnpd/1.0
518 Fedora/8 UPnP/1.0 miniupnpd/1.0
372 Tenda UPnP/1.0 miniupnpd/1.0
346 Ubuntu/10.10 UPnP/1.0 miniupnpd/1.0
330 MF60/1.0 UPnP/1.0 miniupnpd/1.0
... ST:298497 upnp:rootdevice
158442 urn:schemas-upnp-org:device:InternetGatewayDevice:1
151642 urn:schemas-upnp-org:device:WANDevice:1
148593 urn:schemas-upnp-org:device:WANConnectionDevice:1
147461 urn:schemas-upnp-org:service:WANCommonInterfaceConfig:1
146970 urn:schemas-upnp-org:service:WANIPConnection:1
145602 urn:schemas-upnp-org:service:Layer3Forwarding:1
113453 urn:schemas-upnp-org:service:WANPPPConnection:1
100961 urn:schemas-upnp-org:device:InternetGatewayDevice:
100180 urn:schemas-upnp-org:device:WANDevice:
99017 urn:schemas-upnp-org:service:WANCommonInterfaceConfig:
98112 urn:schemas-upnp-org:device:WANConnectionDevice:
97246 urn:schemas-upnp-org:service:WANPPPConnection:
96259 urn:schemas-upnp-org:service:WANIPConnection:
93987 urn:schemas-upnp-org:service:Layer3Forwarding:
91108 urn:schemas-wifialliance-org:device:WFADevice:
90818 urn:schemas-wifialliance-org:service:WFAWLANConfig:
35511 uuid:IGD{8c80f73f-4ba0-45fa-835d-042505d052be}000000000000
9822 urn:schemas-upnp-org:service:WANEthernetLinkConfig:1
7737 uuid:WAN{84807575-251b-4c02-954b-e8e2ba7216a9}000000000000
6063 urn:schemas-microsoft-com:service:OSInfo:1
... M-SEARCH. Насколько я понимаю, M-SEARCH имеет практический смысл только как многоадресный запрос в локальной сети.M-SEARCH нужно либо отменить, либо ограничить по скорости, как действует ограничение DNS Response Rate Limit.M-SEARCH должны отправляться только получателям в локальной сети. Ответы за пределы локальной сети имеют мало смысла и открывают возможность использования описанной уязвимости.|
|
Поиска игроков пост |

|
Метки: author peroon2 тестирование мобильных приложений тестирование игр тестирование дополненная реальность квест |
[Из песочницы] Как я оживлял VCSA 6.0 |
service-control –status –allvmware-invsvc (VMware Inventory Service) vmware-rbd-watchdog (VMware vSphere Auto Deploy Waiter) vmware-sps (VMware vSphere Profile-Driven Storage Service) vmware-vdcs (VMware Content Library Service) vmware-vpx-workflow (VMware vCenter Workflow Manager) vmware-vpxd (VMware vCenter Server) vmware-vsan-health (VMware VSAN Health Service) vmware-vsm (VMware vService Manager) vmware-vws (VMware System and Hardware Health Manager) vsphere-client ()
service-control –start vmware-invsvc/var/log/vmware/vmdird/vmdird-syslog.log/storage/log/vmware/invsvc/ inv-svc.logservice-control –start vmware-invsvc в логах вижу следующее:2017-07-07T09:50:01.022945+06:00 err vmdird t@140238302082816: VmDirSendLdapResult: Request (96), Error (49), Message (), (0) socket ([3] ip_server:636<-ip_server:46241)
2017-07-07T09:50:01.022955+06:00 err vmdird t@140238302082816: Bind Request Failed ([3] ip_server:636<-ip_server:46241) error 49: Protocol version: 3, Bind DN: «cn=accountname,ou=Domain Controllers,dc=vsphere,dc=local», Method: 128
/usr/lib/vmware-vmdir/bin/vdcadmintool==================
Please select:
0. exit
1. Test LDAP connectivity
2. Force start replication cycle
3. Reset account password
4. Set log level and mask
5. Set vmdir state
==================
accountname@vsphere.local, значение accountname – берем из /var/log/vmware/vmdird/vmdird-syslog.log, а именно из строк:2017-07-07T09:50:01.022955+06:00 err vmdird t@140238302082816: Bind Request Failed ([3] ip_server:636<-ip_server:46241) error 49: Protocol version: 3, Bind DN: «cn=accountname,ou=Domain Controllers,dc=vsphere,dc=local», Method: 128
/opt/likewise/bin/lwregshellcd HKEY_THIS_MACHINE\services\vmdir\ — жмем Enter
set_value dcAccountPassword «сгенерированный пароль»
quit
|
Метки: author Alexey_Shalin виртуализация vmware восстановление работы vcsa |






