В данной статье я бы хотел поделиться методом быстрой валидации полей с помощью разметки и стилей. Данный метод не является кроссбраузерным и рекомендуется к использованию только как дополнительная фича. По ходу статьи мы будем уменьшать наши шансы на кроссбраузерность, но повышать функциональность.
Давайте попробуем собрать стандартную форму, которая будет включать в себя: Имя, E-Mail, Телефон, Ссылку на сайт и допустим Ваш рост, чтобы поэксперементировать с числовым полем.
HTML5
Сейчас уже никого не удивить атрибутами валидации input полей, которое принес нам стандарт HTML5. Однако, обходить стороной мы его не станем — этот метод валидации является наиболее поддерживаемым в современных браузерах.
Самый простой путь валидации — это определить тип input поля и расставить атрибуты required которые отвечают за обязательность заполнения.
Применение этих двух атрибутов позволит гораздо эффективнее валидировать вводимую информацию нативными методами. Ну и конечно же поддержка этих свойств браузерами наиболее широка.
Отдельно хотелось бы сказать про тип поля tel. Ожидается что браузер будет валидировать телефонные номера, но нет, поле с типом tel используется сейчас только для автозаполнения. Дело в том, что валидация телефонных номеров очень неоднозначная задача из-за слишком большого количества различных форматов телефонных номеров в разных странах, которые просто никак не получится унифицировать и записать в одно правило.
Однако, нам на помощь приходит атрибут pattern. Этот атрибут принимает в себя значение регулярного выражения. В нашем случае рассмотрим вариант паттерна для ввода мобильного телефона в РФ: +7 (123) 456-78-91. Для этого добавим простое регулярное выражение в наше поле с телефоном, а также ограничим минимальное и максимальное количество символов:
Обычно я использую данный паттерн в связке с маской для ввода номера, но тут к сожалению без JS пока что не обойтись. Если вы не используете маску, то я бы не стал использовать паттерны на вводе телефона, поскольку это в большинстве случаев вызовет больше неудобств для пользователя.
Поддержка браузерами атрибута pattern на данный момент очень хорошая. iOS начиная с версии 10.3 полностью поддерживает данное свойство, до этого наблюдалось отсутствие подсказок о неправильном вводе данных.
Стоит также учитывать, что атрибут minlength до сих пор не поддерживается в браузерах IE, EDGE и только с версии 10.3 появился в iOS. Однако maxlength поддерживается везде и очень давно. Нам в целом хватит и этого.
Давайте также поставим ограничение для поля с ростом. Допустим мы предполагаем, что пользователь нашего сайта определенно не может быть ниже 100 см и выше 250 см. Так и напишем:
С поддержкой этих атрибутов в браузерах, все хорошо.
Перейдем к стилизации!
CSS3
Для того чтобы кастомно стилизовать нашу валидацию, воспользуемся псевдоклассами :invalid и :valid. Поддержка этих псевдоклассов в браузерах позволяет использовать их максимально широко на данный момент.
Казалось бы, берем полученные знания и применяем! Но не все так просто как кажется, давайте проверим как это работает. В результате мы получим, что все наши поля изначально пустые и обязательные будут считаться не валидными, а все остальные валидными. Совсем не красиво и непонятно для пользователя, что от него хотят.
Мы можем пойти на небольшую хитрость и использовать псевдокласс :placeholder-shown. С помощью этого псевдокласса мы можем определить отображается ли сейчас значение placeholder в нашем поле ввода. Атрибут placeholder отображается только тогда, когда в наше поле ничего не введено. Соответственно, чтобы применить этот псевдокласс нам просто нужно обратить его свойство с помощью :not. В итоге получаем вот такую конструкцию:
Если прочитать дословно: окрасить красным цветом границу инпута, когда наше поле не валидно и когда в нем не отображается значение атрибута placeholder. Если ваше поле не имеет атрибута placeholder, можно просто поставить внутри пробел:
У данного метода есть только один минус: поддержка. Псевдоэлемент :placeholder-shown поддерживается во всех браузерах кроме IE и EDGE. К счастью :not не обладает таким недостатком.
Для примера я набросал все вышесказанное в CodePen и добавил еще немного возможностей:
Итог
Таким образом, не прибегая к JS мы с помощью двух строк в CSS смогли стилизовать и валидировать форму. На текущий момент такая конструкция будет хорошо работать в большинстве браузеров, к сожалению, как всегда, веб-разработку подводят детища Microsoft.
Напомним, SAP Кодер 2017 – это наш первый в СНГ онлайн-конкурс для разработчиков на открытой облачной платформе SAP. Среди десятка призеров было много любопытных проектов, включая системы диспетчеризации скорой помощи, управления инкассацией для сети банкоматов и оптимизации цен в ритейле. А сервис мониторинга отгрузки товаров настолько заинтересовал жюри, что в зале прозвучала фраза «почти купил».
Конкурс проводился с 3 апреля по 28 июня, у участников был примерно месяц на то, чтобы создать прототип бизнес-приложения на базе облачной платформы SAP Cloud Platform. Можно было предложить свою задачу или взять одно из трех предложенных направлений – массовый подбор персонала, стимулирование продаж в рознице или управление холодильным оборудованием.
В финале за победу в каждой из двух номинаций (для самостоятельных разработчиков и для компаний-разработчиков) сразились по 3 конкурсанта. Мероприятие прошло на территории Lexus Dome, находящегося в Москва-Сити.
На финал приехал Рольф Шуманн, наш вице-президент по платформе и инновациям. Он не только возглавил жюри, но и выступил с рассказом об изменениях, происходящих в нашей повседневной жизни благодаря высоким технологиям. Так, Рольф пришел на финал в «умных» кроссовках. С помощью мобильного приложения он смог узнать дистанцию, количество шагов и другие параметры своих перемещений. Интернет вещей ближе, чем нам кажется.
Также господин Шуманн продемонстрировал платформу SAP Sports One – решение на базе SAP Cloud Platform, позволяющее эффективно управлять спортивными командами и игроками. Он показал, как на основе массива данных о проведенных пенальти система позволяет предсказать сектор ворот, в который будет нанесен удар, и его результат в зависимости от внешних условий. И когда все практически уверовали в мощь предиктивного анализа, продемонстрировал на практике, что непредсказуемость – все еще сильная сторона человечества.
Наталия Парменова, исполнительный директор SAP СНГ, рассказала о работе по запуску SAP Cloud Platform в российском центре обработки данных. Запуск намечен на осень 2017 года.
Затем выступил еще один иностранный гость – Сёрен Йенс Лауингер, директор по инновациям в сфере продаж и услуг компании B.Braun. Он продемонстрировал возможности использования облачной платформы SAP и технологий интернета вещей в… хирургии. Компания создала для своих клиентов удобное приложение для контроля состояния и учета хирургических инструментов, формирования наборов для операций.
Участники с интересом слушали о новых технологиях, но напряжение не спадало – все ждали развязки.
Номинация для самостоятельных разработчиков
Итак, краткие выступления первых трех финалистов – индивидуальных участников. Третье место занял проект «Обход и контроль» от команды разработчиков TNT: Игоря Дочиева и Александра Петроченкова. Они предложили приложение для мобильных устройств, которое автоматизирует процесс постановки и учета задач осмотра приборов и оборудования. Прототип был реализован на SAP Cloud Platform и доведен до вполне рабочего состояния. Но жюри отдало предпочтение другим финалистам. Разработчики из TNT получили в качестве приза планшет iPad Pro.
Кстати, о жюри. Конкурс оценивали не только наши Рольф Шуманн, Андрей Горяйнов и Денис Савкин. К ним присоединились также Александр Талалыкин, директор по информационным технологиям компании «Евросеть», и Алексей Лафицкий из «Лаборатории Касперского». Так что нашим конкурсантам было непросто под серьезными взглядами ведущих IT-экспертов.
Второе место занял Олег Демьянюк, предложивший свою реализацию идеи «умного холодильника». Бизнес-решение на базе SAP CP позволяет контролировать наличие товара в холодильном оборудовании, легко добавлять новые холодильники, вести учет. До реализации физического прототипа дело не дошло, и, вероятно, именно это не позволило Олегу победить. В качестве приза он получил возможность выбрать курс обучения в SAP или 150 000 рублей.
Победителями в личном зачете стала семья Белозеровых. Илья и Татьяна представили виртуального торгового ассистента V-Saler. Это кросс-платформенное решение, дающее рекомендации, что еще можно предложить покупателю, на основе обработки больших данных, собранных магазином.
«Я являюсь разработчиком немного в другой области. Недавно решил заняться веб-разработкой, только-только начал это изучать, как мне прислали ссылку на данный конкурс. Стало интересно, это же неплохая мотивация, есть к чему стремиться и что изучать», — рассказал Илья Белозеров.
По его словам, основная часть решения – сервис предиктивной аналитики, один из компонентов облака SAP. Движок написан в фреймворке SAPUI5. Данные для тестирования системы предоставили мы, это деперсонализированная информация реального магазина, 12 млн записей. Илья сравнил работу в облаке с конструктором, в котором надо было просто настроить все звенья и добавить свой алгоритм.
Ребята сделали очень яркую презентацию, добавили хороших картинок, забавный пример, и жюри это оценило. Итог – первое место и поездка в Лас-Вегас на SAP TechEd (или 300 000 рублей).
Номинация для компаний-разработчиков
У финалистов из числа компаний-разработчиков также развернулась серьезная битва.
Третье место получила компания IBA IT Park. Разработчики выбрали задачу по управлению «умным холодильником» и сделали серьезную систему, которая учитывает загрузку холодильных камер, срок годности хранимых товаров, может в реальном времени учитывать изменение содержимого. Решение использует сервис Internet of Things, RFID-метки и платформу HANA для хранения и обработки информации.
Наверняка, если бы конкурсанты принесли холодильник и вживую продемонстрировали, как бутылка кефира и полбатона с RFID-меткой, попадая внутрь, тут же появляются в системе, это впечатлило бы жюри.
Второе место досталось представителям минского отделения компании EPAM Systems. Разработчики представили решение IACube (Якуб) – виртуальный помощник рекрутера. Приложение осуществляет интеллектуальный поиск на нескольких площадках и подбирает наиболее релевантные по опыту, навыкам и задачам резюме. При этом используются компоненты SAP HANA Text Analytics и Text Mining. IACube вполне может в скором времени начать принимать участие в подборе персонала в самой EPAM.
Наконец, первое место завоевал проект компании TeamIdea – сервис moTIon для контроля отгрузки товара, мониторинга транспорта и планирования комплектации. Решение использует возможности облачного приложения и Интернета вещей на платформе SAP CP.
«Почему мы решили участвовать в конкурсе? К тому времени мы уже делали разработки на этой платформе, ее активно изучали, были какие-то мысли. И конкурс для себя восприняли как проверку своих сил на фоне других компаний-конкурентов, как возможность посмотреть, чего мы стоим, куда мы продвинулись и в правильном ли направлении шагаем в целом», — сказал Павел Малько, руководитель направления SAP EWM/TM компании TeamIdea.
По его словам, это была по сути факультативная работа, для которой важно было найти у себя дополнительную мотивацию. До участия в конкурсе логика решения была проработана не более чем на 20%. За месяц она была доведена до работающего прототипа.
Сервис moTIon настолько заинтересовал жюри, что даже была сказана сакральная для многих стартаперов фраза «почти купил». И как результат – победа в конкурсе.
В качестве награды все три компании-победителя получили годовой доступ в SAP Cloud Platform и возможность продвигать свое решение на площадках SAP App Center и SAP Форум 2018.
Специальные номинации
Среди участников конкурса оказалось немало тех, кто уже имел готовый продукт и в рамках «SAP Кодер» перевел его на платформу SAP Cloud Platform. Мы отметили трех конкурсантов.
Это компания IPG, перенесшая в облако систему для централизованной диспетчеризации скорой помощи.
Компания «Сервис-модель» с сервисом для управления денежной наличностью и инкассацией для сети банкоматов.
И компания SAPRUN с решением для оптимизации цен и управления KPI в торговой сети. Об этом решении расскажем чуть подробнее. Интересно то, что основной алгоритм этого приложения был реализован на Python и подключался к облачному решению через Cloud Foundry.
«Мы переписали весь интерфейс на SAPUI5, питоновскую часть, которая отработала в Foundry, адаптировали для работы с HANA, плюс еще на HANA сделали приложение, которое отдавало в нужном виде данные», — рассказал представитель компании.
По словам разработчиков, были некоторые временные сложности с переносом, связанные с недостаточным количеством документации по существующим возможностям облачной платформы. «Но была поддержка со стороны SAP, мы задавали вопросы напрямую в SAP, нас коллеги поддерживали, объясняли», — сказал Руслан Зарипов, исполнительный директор SAPRUN.
Все три компании также получили годовой доступ в SAP Cloud Platform и возможность продвигать свое решение на площадках SAP App Center и SAP Форум 2018.
Специальный приз жюри получила еще одна конкурсантка – Екатерина Ляпина, участвовавшая с проектом OpenBanking API. Это решение реализует директиву PSD2 для банков, предоставляет сервисы для подключения к банковской системе с учетом новых правил. В ходе работы Екатерина не написала ни строчки кода, продукт был собран на базе стандартных компонентов облака SAP – API Management, который позволяет настраивать политики доступа к сервисам и вести их биллинг. Призом для финалистки стал планшет iPad Pro.
Конкурс «SAP Кодер» показал, что даже в сжатые сроки программисты могут создавать передовые решения. Для этого нужны перспективная идея, самомотивация и современная облачная платформа с широким набором функций — например, как наша SAP Cloud Platform.
Пару недель назад в Яндексе прошла встреча PyData, посвящённая анализу больших данных с использованием Python. В том числе на этой встрече выступил Василий Агапитов — руководитель группы разработки инструментов аналитики Яндекса. Он рассказал о двух наших библиотеках: для описания и запуска расчетов на MapReduce и для извлечения информации из логов.
Под катом — расшифровка и часть слайдов.
Меня зовут Агапитов Василий, я представляю команду интеллектуального анализа данных.
В Яндексе мы выполняем расчеты по большим данным, в частности по данным, лежащим на кластерах MapReduce. В основном это анонимизированные логи сервисов и приложений. Кроме того, мы предоставляем наши инструменты по обработке больших данных другим командам. Наши основные потребители — команды аналитиков-разработчиков. Для простоты я буду называть их аналитиками.
Хочу рассказать о двух инструментах, библиотеках, истории их появления, и том, как мир Hadoop оказал влияние на их появление.
Давайте синхронизируем некоторое представление о терминах. Источники данных. Мы будем говорить исключительно о логах, поэтому для примера давайте рассмотрим какой-нибудь лог доступа к сервисам.
У нас по горизонтали располагаются записи этого лога, каждая запись имеет поля: vhost — идентификатор хоста, yandexuid — идентификатор посетителя, iso_eventtime — дата и время обращения, request — сам запрос и многие другие поля.
Данные из некоторых полей уже можно использовать в расчетах. Из других полей данные сначала надо извлечь и нормализовать. Например, в поле request содержатся параметры запроса. У каждого сервиса такие параметры свои. Для поиска наиболее используемым является параметр text. После того, как мы извлечем его из поля request, нам надо его нормализовать, поскольку он может быть очень большим или иметь какую-то странную кодировку.
Во-вторых, мы будем рассматривать наши расчеты в части расчетов на кластерах MapReduсe. Как вы знаете, MapReduсe — технология изготовления сэндвичей. На самом деле нет, это технология обработки больших данных. Если вы с ней не знакомы, то для текущего доклада вам надо знать, что она предполагает обработку данных с использованием двух операций — Map и Reduce.
Задача аналитика в том, чтобы построить расчет по событиям лога с учетом некоторой бизнес-логики. С какими трудности может столкнуться аналитик, решая свою задачу на кластерах MapReduсe без использования каких-либо библиотек? Во-первых, ему придется реализовывать бизнес-логику на базе операций MapReduсe. Такой подход добавляет в расчет код, не относящийся к бизнес-логике этого расчета, что существенно ухудшает его читаемость и поддержку. Во-вторых, нам надо данные из логов сначала извлечь и нормализовать — например, параметр text из поля request.
Как принято решать первую проблему? Очевидно, нам нужна какая-то библиотека, которая упростит доступ пользователя к кластеру и взаимодействие с ним.
В мире Hadoop к таким библиотекам можно отнести Pig, Hive, Cascading и некоторые другие.
В Яндексе используется собственная реализация MapReduсe, называемая YT, о преимуществах которой вы можете почитать в статье на Хабре и которая предоставляет для обработки данных базовые операции MapReduсe. Но, к сожалению, YT не имела аналогов библиотек из мира Hadoop. Нам пришлось это исправить.
В самом начале, когда мы столкнулись с этой проблемой, мы действительно при каждом расчете отдельно описывали Map-стадии, отдельно — Reduce-стадии, и отдельно — связь между этими стадиями для запуска расчета на кластере.
Более того, у каждого был собственный запускатор. Поддерживать такой зоопарк очень дорого. Решением для нас стала библиотека Nile, библиотека для описания и запуска расчетов на кластере. При ее создании мы взяли идею Сascading из мира Hadoop и реализовали ее на языке Python — во многом потому, что Python использует аналитики для локальной обработки данных, а использовать один язык для расчетов на кластере и для локальной обработки данных очень удобно.
Если вы знаете Cascading, то процесс обработки данных на Nile вам также покажется знакомым. Мы создаем поток из таблиц на кластере, модифицируем его, группируем, например, считаем какие-то агрегаты, разбиваем поток на несколько потоков, объединяем несколько потоков в один поток, производим другие действия, после чего полученный поток с нужными данными сохраняем обратно в таблицу на кластер.
Какие у Nile есть операции модификации потока? Их очень много, здесь представлены наиболее часто используемые. Project, чтобы получить список нужных нам полей. Filter, чтобы отфильтровать, оставив только нужные нам записи. Groupby + aggregate, чтобы сгруппировать поток по заданному набору полей и посчитать некоторые агрегаты. Unique, random и take, чтобы построить выборки уникальную, случайную и с заданным числом записи. Join, чтобы объединить два потока по равенству заданного набора полей. Split, чтобы разбить поток на несколько потоков по некоторому правилу с дальнейшей индивидуальной обработкой каждого из них. Sort, чтобы отсортировать. Put, чтобы положить таблицу на кластер.
Операции Map и Reduce также доступны, но требуются крайне редко, когда нужно сделать что-то действительно нестандартное и сложное.
Давайте посмотрим на инициализацию Nile. Она довольно проста. После импорта мы создаем два объекта — cluster и job. Cluster требуется, чтобы указать, на каком кластере мы хотим запускаться и прочее примерное окружение. Job — чтобы описать процесс модификации потока.
Как создать поток? Поток можно создать двумя путями: из таблицы на кластере или из существующих потоков. Первые два примера показывают, как создать поток из таблицы на кластере. В качестве аргумента передан путь до таблицы на кластере. Последний пример показывает, как нам создать поток из двух существующих потоков путем их слияния.
Давайте рассмотрим какой-то пример реализации задачи на Nile.
По логам доступа нужно посчитать число посетителей на хосте yandex.com.tr. Вспомним, как выглядят наш логи доступа. Из всего множества представленных полей нас будут интересовать поля vhost, чтобы отфильтровать и оставить только записи, относящиеся к хосту yandex.com.tr, и yandexuid, чтобы посчитать число посетителей.
Сам код на Nile для этой задачи будет иметь следующий вид.
Тут мы создаем поток из таблицы на кластере, получаем поля vhost и yandexuid. Оставляем только записи со значением поля vhost, равным yandex.com.tr, и считаем число уникальных значений поля yandexuid, после чего сохраняем поток в таблицу на кластере. Job.run() запустит нас расчет.
Перед запуском расчета на кластере Nile переведет наш расчет в набор MapReduсe-операций. Слева граф преобразования потока в терминах Nile, справа — в терминах MapReduсe-операций. Кроме того, Nile автоматически оптимизирует наш расчет, а именно, если у нас есть несколько Map-операций, идущих подряд, то Nile может их склеить в одну Map-операцию, выполняемую на кластере. Мы видим, что так и произошло. Это довольно простая задача, и код для нее будет сравнительно просто выглядеть на любом языке программирования.
Чтобы рассмотреть что-то более сложное, давайте вспомним о второй проблеме, с которой сталкиваются аналитики: данные из логов нужно извлечь и нормализовать.
Как принято решать эту проблему? Обычно для решения этой проблемы используют ETL. Кто знает, что это? Процентов 30 знает. Кто не знает или знал, но забыл: ETL предполагает, что у нас есть сырые необработанные данные, мы из них производим извлечение нужных нам записей, полей и прочего, модифицируем их с учетом некоторой бизнес-логики и загружаем в хранилище. В дальнейшем мы будем производить все расчеты по данным из хранилища, то есть по нормализованным данным.
Мы выбрали другой путь. Мы храним сырые данные и выполняем расчеты по ним, а процесс извлечения и нормализации данных происходит в каждом расчете.
Почему мы выбрали такой путь? Предположим, в процессе извлечения и нормализации полей используется внешняя библиотека, и в этой библиотеке была бага. После того, как мы багу исправим, нам надо будет пересчитать расчеты за прошлое. В нашем подходе мы просто запускаем расчеты за прошлое и получаем верные результаты. В случае ETL — если эта библиотека использовалась в процессе — нам придется сначала данные заново извлечь, обработать этой библиотекой, положить в хранилище и только потом выполнить расчеты.
Хороший вариант, если вы можете хранить как сырые данные, так и нормализованные. У нас, к сожалению, из-за большого объема данных такой возможности нет.
Вначале мы для каждого расчета выполняли извлечение и нормализацию данных индивидуально. Затем мы заметили, что для одних и тех же логов мы часто достаем похожие поля примерно одним и тем же образом, и мы объединили эти правила в одну библиотеку QB2. Сами правила назвали экстракторами, наборы таких правил для логов — деревьями разбора.
Итак, сейчас библиотека QB2 предоставляет абстрактный интерфейс к сырым логам и знает про деревья разбора.
Давайте познакомимся с деревом разбора. Это дерево разбора для логов мобильных приложений Яндекса. Не присматривайтесь, это глобальная карта.
В самом верху запись лога. Все остальные цветные прямоугольники — это виртуальные поля. Связи — это экстракторы. Таким образом, пользователь без библиотеки QB2 может обращаться только к полям лога. Пользователь, использующий библиотеку QB2, может использовать как поля лога, так и поля, предоставляемые библиотекой QB2 для данного лога.
Давайте рассмотрим преимущества этой библиотеки на конкретном примере. Рассмотрим задачу. Пусть у нас есть некоторое мобильное приложение Яндекса, идентифицируемое значением поля API_key, равным 10321. Мы знаем, что оно пишет логи в поля, в частности в поле event_value, содержащее словарь в виде JSON-объекта. Нас будет интересовать значение ключа stage этого словаря.
Нам надо посчитать число посетителей для каждого stage в разбивке по дате события. Какие поля нам для этого предоставляет библиотека QB2? Во-первых, API_key, идентификатор приложения. Во-вторых, device_id, идентификатор пользователя. И наконец event_date, дата события, которая получена не непосредственно из записи лога, а путем довольно большого числа преобразований. Без использования библиотеки QB2 нам бы пришлось в каждом расчете, где требуется это поле, выполнять преобразования вручную. Согласитесь, это неудобно.
Кроме того, нам нужны поля event_value и значение stage. Их в нашем дереве разбора нет, и это логично, потому что они пишутся только для одного конкретного приложения.
Нам придется дополнить наше дерево разбора до следующего вида путем применения экстракторов. Как поменяется инициализация для данной задачи? Мы дополнительно импортируем экстракторы и фильтры. Экстракторы потребуются, чтобы получить значения полей event_value и stage. Фильтры — чтобы отфильтровать записи, оставив только нужные.
Вы можете задаться вопросом: почему в данном примере мы использовали фильтрацию из библиотеки QB2, хотя в предыдущем использовали фильтрацию из Nile? QB2, как и Nile, старается оптимизировать ваш расчет, а именно она пытается получить значения для полей, используемых в фильтрациях, как можно раньше. Раньше, чем значения для остальных виртуальных полей.
Зачем это сделано? Чтобы мы не получали значения для остальных виртуальных полей, если наша запись не проходит по каким-то условиям фильтрации. Тем самым мы сильно экономим вычислительные ресурсы и ускоряем расчет на кластере.
Сам код расчета будет иметь следующий вид. Мы тут точно так же создаем поток из таблицы на кластере и модифицируем его оператором QB2, который инициализируем следующими вещами: именем дерева разбора, которое в нашем случае совпадает с именем лога, а также набором полей и фильтров.
В полях мы перечисляем поля API_key, device_id и event_date по их именам, потому что библиотека QB2 уже знает, как доставать эти поля.
Для извлечения поля event_value воспользуемся стандартным экстрактором json_log_field. Что он делает? По переданному ему имени он получает значение из соответствующего поля лога и загружает его как JSON-объект. Это загруженное значение мы сохраняем в поле event_value.
Чтобы получить значение stage, мы используем другой стандартный экстрактор — dictItem. По переданному ему имени ключа и имени поля он извлекает соответствующее значение из этого поля для этого ключа.
Про фильтрации. Нас будут интересовать только записи, у которых определено значение поля device_id и которые относятся к нашему приложению, то есть значение поля api_key у них равно 10321. После применения оператора QB2 наш поток будет иметь следующие поля: api_key, device_id, event_date, event_value и stage.
Модифицируем полученный поток следующим образом. Сгруппируем по паре полей event_date и stage и посчитаем число уникальных значений device_id. Это значение мы положим в поле users, после чего полученный поток сохраним на кластер. Job.run() запустит расчет.
После окончания расчета на кластере будет таблица следующего вида: для каждой пары полей event_date и stage в поле users будет лежать число уникальных значений пользователей. Таким образом, интеграция библиотек QB2 и Nile решает обе проблемы, которые я озвучил. Спасибо за внимание.
Гостевая статья от Алексея Федорова, научного сотрудника Российского квантового центра, соавтора разработки первого в мире квантового блокчейна
Квантовый компьютер, пожалуй, является самым сложным и самым интригующим устройством «второй квантовой революции». Можно считать, что эту революцию – волну технологий на основе использования индивидуальных квантовых объектов – идея квантового компьютера, собственно, и запустила. Действительно, стимулирующим фактором стремительного развития в последние годы таких технологий как квантовые коммуникации, квантовые генераторы случайных чисел, квантовое моделирование, а также квантовые сенсоры, можно считать именно квантовый компьютер.
На данный момент универсальный квантовый компьютер – гипотетическое устройство, а его создание – один главных вызовов для науки и инженерии. Предстоящая в рамках Международной конференции по квантовым технологиям (которая состоится в Москве 12-16 июля 2017 года) публичная лекция лидера квантового проекта Google Джона Мартиниса призвана раскрыть наиболее интересные аспекты гонки, разворачивающейся вокруг построения квантового компьютера.
Что может дать нам квантовый компьютер? Кроме революционных последствий для существующих инструментов информационной безопасности, квантовый компьютер откроет путь к новым материалам, новым методам поиска по базам данных, распознавания образов, машинного обучения, а также, как прогнозируется, к новой эре в развитии искусственного интеллекта.
Квантовый компьютер компании D-Wave на обложке журнала Time.
Двадцатый век подарил нам компьютеры. Несмотря на тот факт, что элементарная ячейка компьютера – транзистор – может также по праву считаться квантовой технологий, для описания работы имеющихся в нашем распоряжении компьютеров достаточно классической физики. Поэтому мы будем называть привычные нам компьютеры классическими. Для описания процесса вычисления понятие машины Тьюринга, полностью имитирующей исполнение алгоритма на компьютере.
К идее квантового компьютера научное сообщество подвели «три мысленных облачка» [1]. Первое «облачко» – развитие и обобщение классической теории информации Шеннона на квантовый случай. Несмотря на то, что поначалу интерес к такой задаче можно считать чисто академическим, а рассмотрение достаточно абстрактным (характерным больше для математики, чем для физики), эти исследования быстро выявили потенциал квантовых систем для теории информации. Важные парадигмы для квантовой теории информации возникли в работах Юрия Манина, Стивена Визнера (предложившего сопряженное кодирование и «квантовые деньги»), а также Александра Холево (доказавшего знаменитую «Теорему Холево»). Позднее, с помощью разработанной Дэвидом Дойчем квантовой машины Тьюринга начали исследоваться первые квантовые алгоритмы для гипотетических квантовых компьютеров.
Второе «облачко» – это интерес к вопросу о том, какие физические ограничения накладывает квантовая механика на возможности компьютеров. Этот вопрос поднимался Чарльзом Беннетом (одним из создателей квантовой криптографии), и был освещен Ричардом Фейнманом в одном из первых докладов, посвященным квантовым вычислениям. Оказалось, что сформулировать такие ограничения (за исключением, пожалуй, размерных, согласно которым вряд ли транзистор может быть меньше, чем один атом) достаточно трудно. А если мыслить в терминах размерных ограничений, то можно гипотетически построить очень миниатюрный компьютер, в котором все классические биты (0 и 1) будут заменены на квантовые биты (кубиты), реализуемые с помощью двухуровневых квантовых систем (системы, которые могут находиться в двух возможных состояниях). Такой миниатюрных компьютер будет описываться законами квантовой физики, а квантовые биты будут находится не только в двух состояниях, но и во всех возможных суперпозиции этих состояний.
Наконец, третье «облачко» связана с тем, что компьютеры продемонстрировали свой потенциал для сложных расчетных задач, например, в атомных или космических проектах. Однако в задачах, связанных с расчетом из нескольких квантовых частиц, серьезных продвижений не было. Тем не менее, актуальных задач для расчетов в области квантовой физики достаточно много.
Все эти идеи в совокупности представляли большой интерес для научного сообщества, но не отвечали на главный вопрос: что могли бы дать гипотетические квантовые вычислительные устройства? Преимущества в вычислениях? В каких задача? Расчет многочастичных квантовых систем? Каким образом?
В начале 90ых годов было предложено несколько квантовых алгоритмов, которые давали заметный выигрыш по сравнению с существующими классическими алгоритмами. В 1992 году Дэвид Дойч и Ричард Йожи (на основе предшествовавшей работы Дойча 1985 года) показали, что квантовой компьютер дает выигрыш в задаче в достаточно специфической задаче. Представим себе, что у нас есть функция, про которую точно известно, что она либо принимает всегда одинаковое значение (0 или 1) для всех аргументов, т.е. является постоянной величиной, либо является сбалансированной (для половины области определения принимает значение 0, для другой половины 1). Вопрос: сколько нужно раз посмотреть на результат вычисления этой функции, чтобы сказать сбалансированная она или постоянная? В этой (прямо скажем, достаточно непрактичной) задаче квантовый компьютер демонстрирует экспоненциальный выигрыш по сравнению с классическим.
Другим (тоже не больно практичным) важным шагом стал алгоритм Саймона. Алгоритм Саймона вычисляет период функции s за линейное время, в то время как любому классическому алгоритму требуется экспоненциальное время в зависимости от длины входного аргумента функции.
Тем не менее, именно алгоритм Саймона вдохновил Питера Шора на создание квантового алгоритма решения задачи факторизации (разложение числа на множители) и дискретного логарифмирования. Несмотря на опять же присутствующее изобилие сложны математических терминов, эти задачи гораздо практичнее, чем кажутся на первый взгляд. Такие задачи используются в криптографии с открытым ключом. Идея криптографии с открытым ключом состоит в том, чтобы использовать такую задачу, для которой прямое вычисление является простым, а обратная задача является сложной. В самом деле, перемножить два простых числа достаточно просто, а вот если задано большое число трудно сразу сообразить из каких простых множителей оно состоит. Трудно сообразить не только нам, но и даже самым лучшим классическим компьютерам.
Таким образом, если квантовый компьютер будет создан, то существующая информационная инфраструктура в части методов защиты информации должна быть модифицирована. Методы криптографии с открытым ключом используются в очень широком диапазоне продуктов для информационной безопасности, поэтому квантовый компьютер – настоящая угроза для конфиденциальности данных, атомная бомба информационного века.
Интересно отметить, что метод модификации, который гарантирует абсолютную стойкость шифрования даже при наличии квантового компьютера, был предложен за 8 лет до алгоритма Шора в работе Чарльза Беннета и Жиля Брассара, а также в работе Артура Экерта 1991 года. Однако лишь после создания алгоритма Шора работа Беннета и Брассара, предлагавшая использовать квантовые эффекты как способ защиты информации, получила заслуженное внимание научного сообщества.
Потенциал квантового алгоритма Шора, а также квантового алгоритма Гровера, который дает ускорение в другой практичной задаче поиска по базе данных, приковал пристальное внимание научного сообщества к задаче разработки квантового компьютера. В добавлении к упомянутым «трём облачкам» поспело четвертое – замечательный экспериментальный прогресс в области создания методов работы с квантовыми системам на уровне отдельных их индивидуальных объектов (фотонов, отдельных атомов, электронов и др). Этот прогресс был отмечен Нобелевской премией 2012 года Сержу Арошу и Дэвиду Вайнленд с формулировкой: «за создание прорывных технологий манипулирования квантовыми системами, которые сделали возможными измерение отдельных квантовых систем и управление ими».
Однако задача построения квантового компьютера чрезвычайно сложна. Построить большую систему, состоящую из квантовых объектов так, чтобы она была, с одной стороны, достаточно хорошо защищена от окружения (которое может деструктивно влиять на её квантовые свойства), при этом, с другой стороны, позволять объектам этой системы (кубитам) «разговаривать» друг с другом для реализации вычислений, действительно очень тяжело.
Позитивным фактом является то, что квантовые биты можно в принципе создать в совершенно разных физических системах. Это и ультрахолодные газы атомов и молекул в оптических решетках, сверхпроводящие квантовые цепи, фотоны и многие другие квантовые системы. При этом каждая из этих систем обладает рядом преимуществ и недостатков.
Например, с ультрахолодных атомов и молекул в оптических решетках можно создавать неуниверсальные квантовые компьютеры, называемые часто квантовыми симуляторами. Дело в том, что поведение таких частиц в оптических решетках очень напоминает поведение электронов в периодическом поле, создаваемом ионами. Установив некоторое соответствие между системами, можно с помощью системы атомов или молекул выявлять новые интересные фазы, которые должны при определенных условиях возникать и твердых телах. Наиболее интригующими здесь являются такие задачи как создание сверхпрочных сплавов или поиск материалов, переходящих в сверхпроводящее состояние уже при комнатной температуре. Последнее, конечно, приведёт к революции в электротехнической промышленности, поскольку позволит передавать энергию без потерь. Моделирование квантовых состояний огромного числа атомов на обычных компьютерах и суперкомпьютерах требует колоссальных ресурсов, а его результаты лишь ограниченно применимы к реальной физике, а квантовые симуляторы могут открыть новые пути для революционных инноваций в сотовой связи, медицине и бытовой технике.
Одной из наиболее перспективных технологий на пути к созданию квантового компьютера является использование сверхпроводниковых кубитов. Именно на основе сверхпроводниковых квантовых бит работает квантовый процессор (вычислитель) компании D-Wave. Продукт компании D-Wave не является полноценным и универсальным квантовым компьютером, поэтому сегодня мы еще можем совершать покупки в Интернете, шифруя данные своей банковской карты существующими средствами. Продукт компании D-Wave, объединяющий несколько тысяч кубитов, в данный момент предназначен в большей степени для решения задач оптимизации методом квантового отжига.
Отжиг – металлургический термин – означает класс методов решения оптимизационных задач, действующих по принципу отжига, т.е. нагрева до определённой температуры, выдержке в течение определенного времени при этой температуре и последующем, обычно медленном, охлаждении до комнатной температуры. В процессе охлаждения система «двигается» между состояниями, обеспечивающими минимальную энергию до тех пор пока не остынет, выбрав для себя лучшее состояния. За счет квантовых эффектов, таких как туннелирования, квантовые системы являются более «подвижной», поэтому позволяют эффективно находить наилучшее решение. Как и в случае с квантовыми симуляторами, квантовый отжиг не является универсальным методом. Он может быть направлен на решение задач определенного класса. Тем не менее, потенциал достаточно большой. Дело в том, что задачи оптимизации тесно связаны с задачами машинного обучения. Поэтому квантовый компьютер может потенциально принести большую пользу развитию новых высокоэффективных методов обучения нейронных сетей. Кроме того, большой интерес к квантовым методам оптимизации высказывают крупные индустриальные компании такие как NASA и Airbus [2].
Возможно, именно этот потенциал стал решающим для компании Google, сформировавшей не так давно исследовательские подразделения по созданию и изучению квантовых вычислений под руководством Джона Мартиниса. При чем компания исследует как потенциал уже существующего квантового компьютера D-Wave, так и ищет подходы к созданию универсального квантового компьютера на основе сверхпроводящих кубитов.
Другие компании, такие как IBM, Microsoft и Intel также демонстрируют интерес к созданию квантовых вычислений. Например, к квантовому компьютеру из 5 кубит, созданному IBM, открыт доступ [3]. Компании Microsoft и Intel налаживают тесные связи с научным сообществом. Совместные исследовательские программы, возможно, позволят раскрыть потенциал наиболее фундаментального подхода к квантовому компьютеру – топологическим защищенным от ошибок квантовым вычислениям. Дело в том, что от ошибок, вызываемых окружением можно защититься с помощью топологии. Некоторые параметры систем, называемые инвариантами, не меняются (при определенных ограничениях) при изменении внешних условий. Если связать кубиты с этими инвариантами, то можно защититься от ошибок. Однако создать такие состояния вещества достаточно трудно, сейчас исследования в области топологических квантовых вычислений с точки зрения эксперимента только начинаются.
Квантовый компьютер из-за воздействия окружения создать тяжело. Но если квантовые системы так чутко реагируют на изменения параметров окружения, то почему бы не использовать это? Например, квантовый сенсор в виде кристалла размером порядка нескольких нанометров может быть внедрен в клетку живого организма без нарушения её жизнедеятельности и затем использоваться для измерения микроскопических полей внутри этой клетки. С помощью этой технологии становится возможным проведение магнитно-резонансной томографии отдельных клеток, их частей и даже отдельных молекул. Это открывает совершенно новые горизонты для биологии и медицины. Становится доступным колоссальный объём знаний о жизнедеятельности частей клеток, развитии болезней, механизмов функционирования лекарств. Квантовые датчики помогут разобраться и в структуре синаптических связей головного мозга человека, сделав возможным лечение его болезней или позволив разобраться в других процессах мозговой активности.
Не стоит забывать, что квантовый компьютер – не только состоит из процессора. Он также предполагает наличие памяти и интерфейсов. Одним из наиболее перспективных кандидатов для построения памяти для квантовых состояния являются ультрахолодные атомы, а для интерфейсов – фотоны, ведь ни что не передаст информацию быстрее, чем частицы света. Поэтому возможным обликом будущего может быть гибридных квантовый компьютер, сочетающий все самые лучшие качества от всех самых лучших квантовых систем.
Необходимо также иметь ввиду, что квантовые компьютеры (в любых формах: симуляторы, «отжигающие» или универсальные) не решают все задачи лучше классических, а решают лишь специальные классы. Не хочется также ошибиться в прогнозах, как Кен Олсен, сказавший в 1977 «Вряд ли кому-то придет в голову установить компьютер дома», но есть основания полагать, что квантовые компьютеры войдут в нашу повседневную жизнь как часть общей и большой гибридной информационной инфраструктуры XXI века. Такое внедрение по-настоящему позволит раскрыть «сквозной» потенциал квантового компьютера и квантовых технологий вообще, открыв новые двери на пути к прогрессу.
Занимаемся мы маркетингом и бизнесом в качестве партнеров по маркетингу и продажам, уже более 5 лет. В этой статье хочу рассказать об ошибках, которые есть у большей части рекламных кампаний такого популярного источника трафика, как Яндекс Директ. И по нашей статистике 90% рекламных кампаний, которые к нам попадают на аудит или настройку, содержат минимум 5 из них.
Да, найдутся те, которые прочитав статью скажут – «Спасибо кэп». Вероятно будут те, которые начнут спорить – тоже хорошо, ждем в комментариях. Но вряд ли у вас самих идеальные кампании. Эта статья для тех, кто заказывает услуги, но не следит за трендами или просто не до конца в теме.
1. Одно ключевое слово = 1 объявление
Многие считают, что это правильно. На самом деле, это не совсем так.
На сегодняшний день Яндекс ввел статус «Мало показов», блокируя низкочастотные фразы, которые не набрали определенного количества показов в одной группе. Таким образом, рекомендация Яндекса, противоречат данному убеждению – 1 слово = 1 объявление.
Решение: Нужно делать на одно объявление и несколько ключевых фраз (если это низвокочастотники), чтобы группа набрала нужное количество показов. Если это не сделать, вы просто теряете долю трафика.
2. Ключевая фраза в теле объявления
Некоторые считают, что это повышает CTR. Хотя прямых доказательств нет. Так зачем до сих пор некоторые специалисты повторяют ключ в объявлении и теряют символы? Ведь явно лучше рассказать, что привлекательного в вашем предложении.
Решение: Писать в тексте объявления ваше УТП, а не повторять заголовок.
3. Тысячи слов для узких тематик
В большинстве случаев, в Директе, как и в законе Парето – 80% трафика, дают 20% ключевых слов. Остальной трафик размазан в сотнях ключах, которые впоследствии усложняют аналитику и оптимизацию. Поэтому оставшиеся низкочастотники чаще становятся лишь «дыркой» по сливу бюджета.
Поэтому, если цена у подрядчиков зависит от числа запросов, это демонстрация неверного подхода к контекстной рекламе. Квалифицированные специалисты знают, что для каждой тематики требуется разное количество запросов, да и не в количестве дело, а в качестве.
Решение: Собирать ключи которые дают большую часть трафика.
4. Один раз настроил и забыл
Настроенная кампания на запуске даёт до 40% результата, дальнейшая работа с кампанией и ее оптимизация – оставшуюся часть.
Ниже пример кампании, которая попал к нам на аудит. Почти 500 000 рублей слито и не разу не оптимизировали кампанию.
Решение: Ежедневно оптимизируйте и улучшаете ваши кампании, в противном случае вы просто теряете деньги.
5. Тариф «без лимитный» за 35 000 рублей
Пакет за Х рублей, контекст под ключ, 100% гарантия лидов и т.д. – очень заманчиво звучит. До тех пор, пока вы не получили первые результаты.
В большинстве случаев, те кто предлагает настройку по тарифам не заинтересован в вашем результате.
Решение: Не платить по тарифам. На сегодняшний день, в большинстве случаев мы не берем плату за настройку. Сначала показываем результат в виде заявок и звонков, потом общаемся о цене.
6. Как дела у конкурентов?
А ведь вероятнее всего есть конкуренты, у которых и объявления лучше, и сайт с оффером, а не как у вас. Ведь скорее всего вы даже не отслеживаете своих конкурентов. Ну так потратьте несколько часов и придумайте хороший оффер и текст объявления.
Решение: Упаковать сайт, сделать мощный оффер и отразить это в объявлениях. Стремитесь стать №1.
7. Не в тему, но важно
На мой взгляд это одна из важнейших вещей которую нужно понимать в маркетинге. Я. Директ – это лишь источник трафика, а не решение всех проблем с клиентами. И как любой источник трафика это не более 30% успеха. Не так сложно сделать трафик, как проработать ЦА и подготовить оффер. Откройте 10 сайтов из любой ниши, и вы увидите, что в почти везде, (а может и везде) отсутствует оффер, хотя вроде все знают, что он нужен.
Решение: прорабатывать ЦА, делать оффер, упаковывать продукт и только после настраивать трафик.
На фоне всех этих эпидемий шифровальщиков как-то теряется работа — опасна и трудна — тех бэкдоров, которые работают по-тихому, и на первый взгляд как будто не видны. А зря! Ведь апдейты обычно делают только тогда, когда «дом уже горит» — хотя казалось бы, если вовремя найти у себя бэкдор и закрыть его, а не продолжать делать вид, что всё в порядке, ситуаций вроде этой можно избегать.
Ну да чего уж там. В истории с аптечными кибератаками есть продолжение. Компания «Доктор Веб» отвечает на обвинения компании «Спарго Технологии» и поясняет выявленные факты промышленного шпионажа за российскими аптеками.
После того как компания «Доктор Веб» опубликовала результаты расследования целенаправленной атаки на множество сетей российских аптек и фармацевтические компании с использованием вредоносной программы семейства BackDoor.Dande, на официальном сайте акционерного общества «Спарго Технологии» было размещено сообщение, утверждающее, что «компания DrWeb», нарушая нормы деловой этики, распространяет заведомо ложную и недостоверную информацию о содержании вирусных файлов в программе «ePrica». «Доктор Веб» вступается за тезку и помогает компании «Спарго Технологии» разобраться в ситуации.
Необходимо отметить, во-первых, что компания «Спарго Технологии» перед публикацией своего обращения за дополнительной информацией в компанию «Доктор Веб» не обращалась и сочла возможным обвинить нас, при этом намеренно исказив суть опубликованной нами информации.
Во-вторых, на момент, когда компания «Доктор Веб» в 2012 году начала свое расследование, заражению подверглись более 2800 аптек и российских фармацевтических компаний (по данным Службы вирусного мониторинга нашей компании). К слову сказать, жалобы от наших клиентов и стали причиной начала расследования. На данный же момент обнаруженный специалистами компании «Доктор Веб» шпионский модуль BackDoor.Dande.61 определяет как вредоносное программное обеспечение 41 производитель антивирусных программ из 63, представленных на ресурсе Virustotal.
В-третьих, важно отметить, что в программе ePrica вредоносных файлов не содержалось, соответственно, компания «Доктор Веб» и не могла об этом ничего писать. ePrica — это приложение, разработанное компанией «Спарго Технологии», которое позволяет руководителям аптек проанализировать расценки на медикаменты и выбрать оптимального поставщика. Используемая этой программой динамическая библиотека PriceCompareLoader.dll имеет экспортируемые функции, выполняющие запуск библиотек в памяти. PriceCompareLoader.dll вызывается из PriceComparePm.dll. Эта библиотека пытается скачать с сайта полезную нагрузку, расшифровать ее с помощью алгоритма AES и запустить из памяти. Троянец загружался с сайта ws.eprica.ru, принадлежащего компании «Спарго Технологии» и предназначенного для обновления программы ePrica. При этом модуль, скрытно загружавший вредоносную программу сразу в память компьютера, имел действительную цифровую подпись «Спарго», и именно такая схема скрытной загрузки вредоносной программы и привела к необходимости столь длительного расследования с целью определения источника заражения. Похищенную с зараженных компьютеров коммерческую информацию троянец выгружал на серверы за пределами России. Иными словами, как и в ситуации с Trojan.Encoder.12544, распространявшимся через ПО M.E.Doc, бэкдор был скрыт в модуле обновления программы.
В-четвертых, заявления «Спарго Технологии» о чистоте и безопасности выпускаемых решений в связи с внесением программы ePrica в Единый реестр российских программ являются безосновательными, так как этот реестр никак не связан с вопросами безопасности программных продуктов. Комментирует Евгения Василенко, исполнительный директор АРПП «Отечественный софт», член Экспертного совета по развитию отрасли информационных технологий, эксперт Временной комиссии Совета Федерации по развитию информационного общества:
«При рассмотрении заявлений в реестр российских программ для ЭВМ и баз данных, исходный код программного обеспечения не запрашивается. Заявитель вправе предоставить исходные коды. Но в любом случае, дистрибутив программного обеспечения проверяется экспертами на соответствие критериям российского программного обеспечения, утвержденным законодательством. В первую очередь экспертный совет осуществляет проверку дистрибутива на соответствие заявленным классам программного обеспечения, а также на отсутствие компонентов сторонних разработчиков, на которые у заявителя нет исключительных прав.
Реестр является подтверждением страны происхождения программного обеспечения. По вопросам безопасности программных продуктов существуют другие процедуры сертификации и лицензирования».
Таким образом, информация, распространяемая компанией «Спарго Технологии» относительно гарантированной безопасности программного обеспечения «Спарго Технологии» только на основании включения его в Единый реестр отечественного ПО, может ввести в заблуждение и дезинформировать клиентов данной компании.
Если вы читали мою предыдущую статью, вероятно вам интересна эта тема и вы хотите узнать больше. В этой статье рассмотрим очень частную, не простую, но от этого не менее необходимую задачу запуска двух разных Baremetal приложений на разных ядрах SoC Cyclone V. По сути такие системы называются AMP — asyncronus multi-processing. Чуть не забыл сказать, что на русском языке вы не найдете другого более правильного и подробного руководства к созданию таких систем, так что читаем!
Введение
Подразумевается, что читатель уже знаком со стандартными библиотеками Altera HW Manager и SoCAL. Но все же скажем пару слов о них. SoC Abstraction Layer (SoCAL) содержит в себе низкоуровневые функции для удобного установления/чтения битов, байтов, слов для прямого управления регистрами HPS. Hardware Manager (HW Manager) представляет из себя набор более сложных функций для написания baremetal приложений, драйверов, BPS и прочего. Обязательно читайте документацию по этому адресу /ip/altera/hps/altera_hps/doc/ или в .h файлах.
Загрузка программы
Для начала необходимо вспомнить как происходит загрузка программы, в моей первой статье об этом было сказано не много.
Процесс загрузки HPS имеет несколько стадий, попробуем разобраться в них…
Сразу после включения выполняется код расположенный прямо на Flash памяти Cortex-A9 называемый BootRom. Вы не можете изменить его или даже посмотреть его содержание. Он служит для первичной инициализации и в следующем этапе передает процесс загрузки в SSBL (Second Stage Boot Loader называемый коротко Preloader). Что необходимо знать для понимания процесса — это то, что код BootRom, в первую очередь, выбирает источник загрузки Preloader, ориентируюсь на внешние физические пины BSEL…
И так после выполнения кода BootRom начинает загружаться Preloader, необходимый для настройки Clock, SDRAM и прочего. После начинает выполняться программа...
Рассмотрим подробнее, что происходит после загрузки Preloader. Собственно после этого начинает выполняться программа, но не сразу с главной функции main(). Перед ней выполняется функция _main(), основная задача которой мэппинг приложения по заданным в scatter файле, адресам в памяти. Это значит что точка входа у приложения находится не в начале кода функции main() который мы пишем, а в специальной, невидимой при написании кода, служебной функции _main(), появляющаяся перед main() в процессе компиляции. Возможно это все уже знают, но на тот момент для меня это было откровением, я считал что точка входа находится в начале main().
Работа ядер
Все описанные процессы всегда выполняются на первом ядре cpu0, второе ядро всегда находится в состоянии сброса. Чтобы запустить второе ядро, необходимо сбросить соответствующий бит регистра MPUMODRST в группе RSTMGR. Ну и задать стартовый адрес PC в регистре CPU1STARTADDR в группе SYSMGR. Однако после включения PC cpu1 равен 0x0. После выполнения Preloader по адресу 0x0 ничего полезного нет, поэтому до запуска cpu1 необходимо разместить код BootROM в 0x0. Много времени потратил я, чтоб узнать, что только из кода BootROM происходит чтение регистра CPU1STARTADDR, после чего PC устанавливается в нужное значение. Как оказалось, разместить этот код не столь тривиально, как кажется на первый взгляд. Для этого нам понадобится функция alt_addr_space_remap из HW manager, из файла alt_address_space.h.
Не спешите радоваться, этого не достаточно для того, чтобы BootROM оказался по адресу 0x0. Необходимо настроить фильтр адресов кэша L2. В описании функции alt_addr_space_remap сказано, если вам необходимо расположить BootROM по адресу 0x0, то настройте этот фильтр следующим образом, расположив код после функции.
Только после этого зададим стартовый адрес и можем запустить ядро.
alt_write_word(ALT_SYSMGR_ROMCODE_CPU1STARTADDR_ADDR, ALT_SYSMGR_ROMCODE_CPU1STARTADDR_VALUE_SET(0x100000)); //set PC of cpu1 to 0x00100000
alt_write_word(ALT_RSTMGR_MPUMODRST_ADDR, alt_read_byte(ALT_RSTMGR_MPUMODRST_ADDR) & ALT_RSTMGR_MPUMODRST_CPU1_CLR_MSK);
Ну и что дальше? А дальше надо чуть-чуть разобраться со структурой проекта.
Именно такая структура для AMP проектов является самой оптимальной. Блок Vectors задает вектора прерывания и делает ветвление для разных процессоров. Вектора прерывания являются общими для каждого процессора. К сожалению этот блок может быть написан только на ассемблере, но к счастью мы не будем писать его с нуля а лишь только отредактируем файл библиотеки HW lib alt_interrupt_armcc.s. В нем объявлены необходимые вектора прерываний, стек прерываний, поддержка FPU VFP\NEON. Допишем необходимый разветвитель.
alt_interrupt_armcc.s до редактирования
PRESERVE8
AREA VECTORS, CODE, READONLY
ENTRY
EXPORT alt_interrupt_vector
IMPORT __main
EXPORT alt_int_handler_irq [WEAK]
alt_interrupt_vector
Vectors
LDR PC, alt_reset_addr
LDR PC, alt_undef_addr
LDR PC, alt_svc_addr
LDR PC, alt_prefetch_addr
LDR PC, alt_abort_addr
LDR PC, alt_reserved_addr
LDR PC, alt_irq_addr
LDR PC, alt_fiq_addr
alt_reset_addr DCD alt_int_handler_reset
alt_undef_addr DCD alt_int_handler_undef
alt_svc_addr DCD alt_int_handler_svc
alt_prefetch_addr DCD alt_int_handler_prefetch
alt_abort_addr DCD alt_int_handler_abort
alt_reserved_addr DCD alt_int_handler_reserve
alt_irq_addr DCD alt_int_handler_irq
alt_fiq_addr DCD alt_int_handler_fiq
alt_int_handler_reset
B alt_premain
alt_int_handler_undef
B alt_int_handler_undef
alt_int_handler_svc
B alt_int_handler_svc
alt_int_handler_prefetch
B alt_int_handler_prefetch
alt_int_handler_abort
B alt_int_handler_abort
alt_int_handler_reserve
B alt_int_handler_reserve
alt_int_handler_irq
B alt_int_handler_irq
alt_int_handler_fiq
B alt_int_handler_fiq
;=====
AREA ALT_INTERRUPT_ARMCC, CODE, READONLY
alt_premain FUNCTION
; Enable VFP / NEON.
MRC p15, 0, r0, c1, c0, 2 ; Read CP Access register
ORR r0, r0, #0x00f00000 ; Enable full access to NEON/VFP (Coprocessors 10 and 11)
MCR p15, 0, r0, c1, c0, 2 ; Write CP Access register
ISB
MOV r0, #0x40000000 ; Switch on the VFP and NEON hardware
VMSR fpexc, r0 ; Set EN bit in FPEXC
B __main
ENDFUNC
;=====
AREA ALT_INTERRUPT_ARMCC, CODE, READONLY
EXPORT alt_int_fixup_irq_stack
; void alt_int_fixup_irq_stack(uint32_t stack_irq);
; This is the same implementation of GNU but for ARMCC.
alt_int_fixup_irq_stack FUNCTION
; r4: stack_sys
MRS r3, CPSR
MSR CPSR_c, #(0x12 :OR: 0x80 :OR: 0x40)
MOV sp, r0
MSR CPSR_c, r3
BX lr
ENDFUNC
END
alt_interrupt_armcc.s после редактирования
PRESERVE8
PRESERVE8
AREA VECTORS, CODE, READONLY
ENTRY
EXPORT alt_interrupt_vector
IMPORT __main
EXPORT alt_int_handler_irq [WEAK]
IMPORT secondaryCPUsInit
alt_interrupt_vector
Vectors
LDR PC, alt_reset_addr
LDR PC, alt_undef_addr
LDR PC, alt_svc_addr
LDR PC, alt_prefetch_addr
LDR PC, alt_abort_addr
LDR PC, alt_reserved_addr
LDR PC, alt_irq_addr
LDR PC, alt_fiq_addr
alt_reset_addr DCD alt_int_handler_reset
alt_undef_addr DCD alt_int_handler_undef
alt_svc_addr DCD alt_int_handler_svc
alt_prefetch_addr DCD alt_int_handler_prefetch
alt_abort_addr DCD alt_int_handler_abort
alt_reserved_addr DCD alt_int_handler_reserve
alt_irq_addr DCD alt_int_handler_irq
alt_fiq_addr DCD alt_int_handler_fiq
alt_int_handler_reset
B alt_premain
alt_int_handler_undef
B alt_int_handler_undef
alt_int_handler_svc
B alt_int_handler_svc
alt_int_handler_prefetch
B alt_int_handler_prefetch
alt_int_handler_abort
B alt_int_handler_abort
alt_int_handler_reserve
B alt_int_handler_reserve
alt_int_handler_irq
B alt_int_handler_irq
alt_int_handler_fiq
B alt_int_handler_fiq
;=====
AREA ALT_INTERRUPT_ARMCC, CODE, READONLY
alt_premain FUNCTION
IF {TARGET_FEATURE_NEON} || {TARGET_FPU_VFP}
; Enable VFP / NEON.
MRC p15, 0, r0, c1, c0, 2 ; Read CP Access register
ORR r0, r0, #0x00f00000 ; Enable full access to NEON/VFP (Coprocessors 10 and 11)
MCR p15, 0, r0, c1, c0, 2 ; Write CP Access register
ISB
MOV r0, #0x40000000 ; Switch on the VFP and NEON hardware
VMSR fpexc, r0 ; Set EN bit in FPEXC
ENDIF
MRC p15, 0, r0, c0, c0, 5 ; Read CPU ID register
ANDS r0, r0, #0x03 ; Mask off, leaving the CPU ID field
BEQ primaryCPUInit ; jump to cpu0 code init
BNE secondaryCPUsInit ; jump to cpu1 code init
primaryCPUInit ;jump to main()
B __main
ENDFUNC
;=====
AREA ALT_INTERRUPT_ARMCC, CODE, READONLY
EXPORT alt_int_fixup_irq_stack
; void alt_int_fixup_irq_stack(uint32_t stack_irq);
; This is the same implementation of GNU but for ARMCC.
alt_int_fixup_irq_stack FUNCTION
; r4: stack_sys
MRS r3, CPSR
MSR CPSR_c, #(0x12 :OR: 0x80 :OR: 0x40)
MOV sp, r0
MSR CPSR_c, r3
BX lr
ENDFUNC
END
Конечно теперь необходимо дописать функцию secondaryCPUsInit в другом файле
start_cpu1.s
PRESERVE8
AREA CPU1, CODE, READONLY
ENTRY
IMPORT eth
IMPORT ||Image$$ARM_LIB_STACKHEAP$$ZI$$Base||
IMPORT ||Image$$ARM_LIB_STACKHEAP$$ZI$$Length||
IMPORT ||Image$$ARM_LIB_STACKHEAP$$ZI$$Limit||
cpu1_stackheap_base DCD ||Image$$ARM_LIB_STACKHEAP$$ZI$$Base||
cpu1_stackheap_lenth DCD ||Image$$ARM_LIB_STACKHEAP$$ZI$$Length||
cpu1_stackheap_limit DCD ||Image$$ARM_LIB_STACKHEAP$$ZI$$Limit||
Mode_USR EQU 0x10
Mode_FIQ EQU 0x11
Mode_IRQ EQU 0x12
Mode_SVC EQU 0x13
Mode_ABT EQU 0x17
Mode_UNDEF EQU 0x1B
Mode_SYS EQU 0x1F
Len_FIQ_Stack EQU 0x1000
Len_IRQ_Stack EQU 0x1000
I_Bit EQU 0x80 ; when I bit is set, IRQ is disabled
F_Bit EQU 0x40 ; when F bit is set, FIQ is disabled
EXPORT secondaryCPUsInit
secondaryCPUsInit FUNCTION
; stack_base could be defined above, or located in a scatter file
LDR R0, cpu1_stackheap_limit
MRC p15, 0, r1, c0, c0, 5 ; Read CPU ID register
ANDS r1, r1, #0x03 ; Mask off, leaving the CPU ID field
SUB r0, r0, r1, LSL #14 ; Stack -0x4000 for cpu1
; Enter each mode in turn and set up the stack pointer
MSR CPSR_c, #Mode_FIQ:OR:I_Bit:OR:F_Bit ; Interrupts disabled
MOV sp, R0
SUB R0, R0, #Len_FIQ_Stack
MSR CPSR_c, #Mode_IRQ:OR:I_Bit:OR:F_Bit ; Interrupts disabled
MOV sp, R0
SUB R0, R0, #Len_IRQ_Stack
MSR CPSR_c, #Mode_SVC:OR:I_Bit:OR:F_Bit ; Interrupts disabled
MOV sp, R0
; Leave processor in SVC mode
; Enables the SCU
MRC p15, 4, r0, c15, c0, 0 ; Read periph base address
LDR r1, [r0, #0x0] ; Read the SCU Control Register
ORR r1, r1, #0x1 ; Set bit 0 (The Enable bit)
STR r1, [r0, #0x0] ; Write back modifed value
;
; Join SMP
; ---------
MRC p15, 0, r0, c0, c0, 5 ; Read CPU ID register
ANDS r0, r0, #0x03 ; Mask off, leaving the CPU ID field
MOV r1, #0xF ; Move 0xF (represents all four ways) into r1
;secureSCUInvalidate
AND r0, r0, #0x03 ; Mask off unused bits of CPU ID
MOV r0, r0, LSL #2 ; Convert into bit offset (four bits per core)
AND r1, r1, #0x0F ; Mask off unused bits of ways
MOV r1, r1, LSL r0 ; Shift ways into the correct CPU field
MRC p15, 4, r2, c15, c0, 0 ; Read periph base address
STR r1, [r2, #0x0C] ; Write to SCU Invalidate All in Secure State
;joinSMP
; SMP status is controlled by bit 6 of the CP15 Aux Ctrl Reg
MRC p15, 0, r0, c1, c0, 1 ; Read ACTLR
MOV r1, r0
ORR r0, r0, #0x040 ; Set bit 6
CMP r0, r1
MCRNE p15, 0, r0, c1, c0, 1 ; Write ACTLR
;enableMaintenanceBroadcast
MRC p15, 0, r0, c1, c0, 1 ; Read Aux Ctrl register
MOV r1, r0
ORR r0, r0, #0x01 ; Set the FW bit (bit 0)
CMP r0, r1
MCRNE p15, 0, r0, c1, c0, 1 ; Write Aux Ctrl register
B main_cpu1
ENDFUNC
END
Признаюсь, этот код я только дописывал, а оригинал брал из примеров в папке DS-5. Я написал только настройку стека, и в конце B main_cpu1 для перехода в функцию. Ну вроде как SCU нужен, я оставил его, да и остальное не стал трогать Необходимо разобрать scatter файл, чтоб лучше понять, что происходит.
scatter файл
LD_SDRAM 0x00100000 0x80000000 ;SDRAM_load region for MPU from 1 Mb to 3 Gb. DE1-SoC has 2 Gb of DDR memory
{
VECTORS +0
{
* (VECTORS, +FIRST)
}
VECTORS располагается в начале SDRAM по адресу 0x00100000 (написано в alt_interrupt_armcc.s), в 0x0 поставить нельзя, почему так посмотрите в Cyclone V Hard Processor System Technical Reference Manual. В области APP_CODE располагается весь код (main() первого ядра и остальные внешние функции), кроме функции main() для второго ядра.
ARM_LIB_STACKHEAP является зарезервированным словом для обозначения стека и хипа, и имеет размер 8000 байт, число большое, взял с запасом. Эта строчка позволяет провести настройку стека автоматически в функции _main(). Для второго ядра мы делаем это самостоятельно в файле start_cpu1.s. От нижней границы STACKHEAP отступаем вверх 4000 байт, перекрытия стеков возникнуть не должно. Пока не придумал способ выбора оптимального размера стека.
Область CPU1_CODE начинается с адреса 0х00200000 и имеет размер 1 Мб. Перед функцией main_cpu1(), написанной в отдельном файле main_sc.с располагается ассемблерный код нашего файла для старта второго ядра start_cpu1.s. В scatter файле необходимо указывать расширение .o, если вы хотите отдельно размещать код файлов по нужным адресам.
Таким образом имеем в одном проекте фактически две разные программы. В настройках дебаггера следует поменять Target на Debug Cortex-A9x2 SMP, тогда можно переключаться в процессе между двумя ядрами.
Бонус
Если вам пришлось решать задачу запуска двух разных программ на двух ядрах, то вам будет полезно знать как включать MMU и Кэш для обоих ядер. Без этого, любая программа сложнее мигания светодиодом, будет выполняться крайне медленно.
Так выглядит часть кода для первого ядра. Поскольку MMU и Кэш данных и инструкций для каждого ядра свои, то в коде для второго ядра необходимо написать аналогичную функцию инициализации MMU и включения только соответствующих кэшей, поскольку L2 уже инициализирован первым ядром.
MMU и Cache для второго ядра
int main_cpu1()
{
mmu_init2();
alt_cache_l1_enable_all();
}
Такая конфигурация точно работает.
Стоит сказать пару слов о прерываниях. Тут все тривиально, сначала включаем GIC (это достаточно сделать только на первом ядре один раз), затем в каждом ядре нужно отдельно инициализировать и включить прерывание чисто для CPU. Для этого используются функции
По возникновению прерываний счетчик должен уходить по нужному вектору, который может быть объявлен только один раз. Именно по этой причине инициализация второго ядра начинается также из области VECTORS, а затем через условие переходит в файл start_cpu1. Потому, что иначе пришлось бы объявлять заново те же вектора, с теми же именами, но так сделать в одном проекте нельзя.
Вообще я даже пробовал сделать крайнее «извращение». Создал и скомпилировал два совершенно разных проекта, но разместил код в разные места, чтоб не было перекрытия. Преобразовал .axf в .bin. В коде первого ядра настроил адрес счетчика ровно в место main() кода второго ядра. Затем, через Hex редактор сшил два файла в один, с правильным размещением кода по адресу. Все работало, но как то хреново. Да и отлаживать такое чудо совершенно не удобно. Я подозревал, что это плохая затея, но было просто интересно проверить. На этом у меня все, спасибо всем, кто прочитал!
Сфера гейм-дизайна на сегодняшний день является одной из самых быстроразвивающихся в мире. Среднегодовые темпы роста игровой индустрии составляют 4,8%, и ожидается, что к 2020 году стоимость рынка достигнет 90 млрд долларов.
В значительной степени этот рынок «подпитывают» мобильные проекты. Количество пользователей мобильных устройств увеличивается — по данным statista.com, в 2017 году их число достигнет 2,32 млрд — поэтому растет и стоимость рынка мобильных игр.
Не так давно я заинтересовался этой темой, но пока до полноценного подкаста по игрострою мне далеко. Начать знакомство с этой индустрией я решил на примере одного из реально действующих и успешных проектов — своими подходами для работы с технологиями со мной поделился Дмитрий Дегтярев, CEO компании Inventain.
Disclaimer: с учетом того, что мы говорим о примере отдельной компании, я решил поместить этот материал в хаб «Я пиарюсь».
/ фото офиса компании
Inventain — маленькая и мобильная компания с узким и профессиональным кругом специалистов. Это позволяет не отвлекаться на рутину и полностью концентрироваться на создании продуктов.
Сейчас в компании активно развиваются две сферы деятельности: игровое и стартап-направление. В первом случае речь идет об игровых продуктах, а во втором — о приложениях для людей с элементами геймификации (без нее зачастую просто сложно показать пользователю нечто новое и устроить ему «визуальную встряску»).
Одной из основных проблем многих сервисов является сложность в освоении. Геймификация позволяет представить процесс освоения сервиса как игру: просчитать, где от пользователя требуется усилие, в чем его цель, и чем мы можем наградить его за труды. Похожие методики применяются и для удержания клиента: когда он должен вернуться на сервис, с какой целью, как он об этом узнает и так далее.
Помимо этого сделана существенная ставка на художественную составляющую и пользовательский опыт с точки зрения удобства UI и понимания того, где человек пользуется продуктом (например, запускает игру в общественном транспорте). Все это не может существовать «в воздухе» — труд проектировщиков и дизайнеров должен быть реализован на оптимальном технологическом стэке, а в итоге — необходимо издать готовый продукт и «доставить» его аудитории.
Разработка и инфраструктура
В компании Inventain разработка приложений ведется с применением языка программирования Swift и движка Unity. Unity 3D используется для создания игровых проектов и был выбран благодаря своей простоте, функциональности и доступности. Также на момент выбора, его цена была более лояльная, нежели у Unreal Engine. Игровой движок Unity гораздо популярнее среди разработчиков, чем любое другое программное обеспечение. Например, 34% из топ-1000 бесплатных мобильных игр разработаны на Unity.
Что касается Swift, то он был выбран для «неигровых» проектов. Популярность Swift, как и Unity 3D, также постоянно растет — в 2017 году он впервые вошел в десятку самых используемых языков программирования, согласно индексу Tiobe. В данном случае Swift пришел на смену Objective C из-за его функциональных преимуществ (короткий синтаксис и производительность).
Один из значимых подходов, с помощью которых достигается «мобильность» и «легкость» разработки, заключается в использовании готовых инструментов. Прежде чем браться за любую сложную задачу, команда разработчиков проводит анализ уже существующих решений (в том числе и платных).
Дешевле и быстрее взять что-то готовое, нежели самим тратить на это время и силы, изобретая велосипед. Конечная цель для команды — это продукт, путь к нему следует выбирать наиболее оптимальный
— Дмитрий Дегтярев, CEO Inventain
Для Unity есть собственная площадка Asset Store, на которой собраны тысячи готовых решений и ресурсов. Для Swift можно использовать открытые решения, которые есть на площадках вроде Github. При этом, внедрение не стоит производить в формате «один в один» — любые общедоступные решения не могут учитывать все особенности вашего продукта, их нужно дорабатывать для конкретного приложения.
Помимо этого стоит обращать внимание те материалы, которые выходят по теме в профильных блогах. Примером может служить код для реализации линейной регрессии. Такие заметки стоит использовать для поиска свежего взгляда на ту или иную проблему, а потом уже возвращаться к реализации собственного решения.
Еще одно неплохое решение — создание собственного пула наработок, которые используются от проекта к проекту. Начать можно с простейшей wiki.
Если говорить о тестировании, то в масштабах такой компании как Inventain (и аналогичных проектах) нет смысла создавать целое подразделение. Здесь достаточно одного специалиста по QA, который будет задавать вектор. Реализацию этой задачи стоит отдать разработчикам, которые постараются добиться сбалансированного покрытия кода тестами. Приоритет — уход от временных затрат на рутинные действия тестировщика и устранение его потенциальных «промахов» за счет автоматизации. Таким образом, огромное количество сценариев и возможные ошибки в «далеких углах» приложения будут всегда под контролем.
Желание не тратить усилия на рутинную работу отражается и на организации инфраструктуры — она облачная (AWS), хотя вектор на облако был выбран не сразу. Облаком гораздо проще управлять. В случае АWS не нужны особые специализированные данные по инфраструктуре — достаточно ознакомиться с очень полной и хорошо структурированной документацией. Получается, что всем могут управлять инженеры-программисты, и не нужны системные администраторы. Помимо этого, с облаком гораздо легче подстраиваться под реальную нагрузку и добавлять (убирать) сервера динамически, не переплачивая за простой железа. Все это выливается в реальную выгоду по цене и гибкости: платишь только за то, что по факту используешь.
«Тяжелой» должна быть только специфика
Чтобы поспевать за эволюцией современных технологий и использовать в своих продуктах решения, которые набирают популярность, нужно тратить время и силы. Это — плата за возможность конкурировать с лучшими продуктами и командами в индустрии.
В данном случае речь идет о накоплении собственной экспертизы в таких сферах как машинное обучение и технологии захвата движений. Если говорить о конкретных примерах, то команда Inventain может похвастаться тем, что научила нейронные сети распознавать лицо человека и создавать на экране похожий на него трехмерный аватар. В контексте работы с машинным обучением и нейросетями — это реализация переноса стилей изображения на другие объекты плюс возможность накладывать на лица пользователей виртуальные маски и удерживать их при движении.
Подобная «кастомизация» невозможна исключительно благодаря поиску открытых проектов и «быстрых» решений, но именно она является «ядром» продукта и оправдывает значительные временные инвестиции.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
В конце июня в офисе Туту.ру состоялся митап, который мы организовали и провели совместно с CocoaHeads. Несмотря на погоду за окном, встреча получилась горячей, а гости довольно высоко оценили мероприятие. Но довольно слов, под катом вас ждут видео с митапа!
Анимация как средство самовыражения
Бессменный ведущий, организатор CocoaHeads, микроблогер, специалист по UI/UX и просто хороший парень Саша Зимин рассказывал про анимации. Отличный доклад, в котором все разложено по полочкам. Множество красочных примеров, все рассказывается простыми словами, да и просто вдохновляющее выступление.
Team Lead. Структурирование мыслей
Николай Ашанин, iOS-Lead из Touch Instinct, порефлексировал и рассказал о том, куда может вырасти разработчик, а если вырос, то что с этим всем делать. Разобраны как технические, так и психологические аспекты лидерства. А еще его мысли можно прочитать.
Реактивный VIPER
iOS-разработчик Туту.ру Дима Котенко рассказал об интересной идее "на подумать". Реактивный VIPER несет в себе довольно интересную идею: "архитектура без строгого каркаса, но с теми же ответственностями компонентов". Степень интересности и зрелости идеи оценивать, конечно же, вам, но ознакомиться, определенно, стоит.
В этой статье я хочу поговорить об основных принципах моделирования бизнеса, о тех подходах, которые применяются в этой сфере, и на основе которых создаются языки моделирования и нотации.
С одной стороны, применение схем для наглядности при описании моделей бизнеса в ни у кого не вызывает вопросов. Это действительно очень удобно. С другой стороны, многие бизнесмены и даже мои коллеги недоумевают, зачем нужны специальные нотации и правила для разработки бизнес-процессов, ведь можно в любом графическом редакторе (visio) или при помощи других удобных инструментов просто нарисовать интуитивно понятную схему.
О том, почему так важна стандартизация, а также о том, в каком случае применяется тот или иной подход, я и хочу поговорить.
Основные подходы
Сегодня существует множество различных инструментов для разработки бизнес-моделей, они используют различные языки моделирования, как стандартные, так и какие-то собственные разработки. Но все их можно объединить по принципу работы в три основных подхода:
Функциональный;
Процессный;
Ментальный (с применением ментальных карт).
На самом деле, конечно, существуют и другие подходы, их много так же, как и языков моделирования. Но они большей частью являются гибридными решениями, объединяющих перечисленные подходы. Кроме того, именно процессная и функциональная модели уже стали стандартами, по крайней мере, на западе. И у нас они получают все большее распространение. Об этих основных направлениях я и хочу поговорить подробнее.
Функциональное моделирование
Функциональное моделирование рассматривает бизнес как функцию (лат. functio — совершение, исполнение) или иными словами «черный ящик». В функциональной модели функция не имеет временной последовательности, а только точку входа и точку выхода. Функциональное моделирование помогает рассматривать бизнес-модель с с точки зрения результативности, т.е. при моделировании мы исходим из того, что имеем на входе, и того, что желаем получить на выходе.
Например, компания разрабатывает какую-то CRM-систему для своего бизнеса. В случае применения функционального подхода к моделированию уже сама выбранная среда для работы подсказывает, с чего начинать. Точка входа – «входящий интерес клиента или лид», точка выхода – желаемый результат: «покупка и получение лояльного клиента», «получение постоянного клиента», «получение максимум информации о потенциальном клиенте» и т.д.
Таким образом, в функциональной модели изначально известны точка входа и желаемый результат, а последовательность действий и является объектом разработки. При этом использование функциональных моделей как «черных ящиков» позволяет детализировать каждый этап по мере необходимости. А вся работа при моделировании направлена на поиск оптимального решения для достижения цели.
Функциональные модели вы можете также использовать для демонстрации своих идей и вариантов решений. Это также очень удобно, ведь в процессе демонстрации вы можете двигаться от общего к деталя, по мере необходимости разделять и декомпозировать функции. Но декомпозировать вы будете при этом именно функции, и, разделяя одну функцию на несколько, вы не получите описание процесса.
Некоторые путают описание процесса и функциональную модель. Например, в системе Business Studio функцию называют процессом, хоть это и не совсем верно. Все же описание функций и процессный подход – несколько разные вещи. И я лично считаю, что функциональное моделирование оптимально реализовано в нотации IDEFO. Сам я для такого варианта работы использую именно ее, и всем также рекомендую.
О процессном моделировании я буду рассказывать с точки зрения нотации BPMN, как одного из наиболее распространенных стандартов процессного моделирования. При этом я полностью согласен, что существует множество языков моделирования и различных систем. И каждый может пользоваться тем, что ему удобнее. Но все же BPMN — это уже сложившийся стандарт процессного моделирования, а потому его я и беру за основу в описании.
Процесс с точки зрения бизнес-модели — это последовательность каких-то событий и действий, которые имеют начало и конец.
В этом кроется основное отличие процессного моделирования от функционального. Функциональное моделирование рассматривает бизнес-модель с точки зрения входа и выхода (имеющихся ресурсов и желаемого результата). А процессное основано на последовательности действий в определенных границах, в случае BPMN это будут начало и конец события.
Все процессы могут разбиваться (детализироваться) на подпроцессы вплоть до детализации на уровне задач, т.е. действий, дальнейшая детализация которых невозможна. Процесс – это некая последовательность действий, которую необходимо выполнить, чтобы получить определенный результат. Необходимо отметить что в модели бизнеса как процесса результат может и не быть явным в отличии от функциональной модели.
Принципиальное отличие процессного моделирования от функционального заключается в том, что при процессном моделировании основное внимание уделяется не тому, что мы хотим получить, а тому, что нужно сделать для получения результата, т.е. не итогам той или иной деятельности, а самой последовательности действий.
Например, в BPWIN или Business Studio в процессе детализации каждой функции происходит переход от функционального подхода к процессному. Т.е. в общем, мы рассматриваем модель с точки зрения – возможностей и желаемого результата, а когда переходим к решениям для каждой функции, здесь уже практикуется явно процессный подход, т.е. пошаговый алгоритм действий для достижения результата.
Представьте себе что в функциональной модели есть «черный ящик» — функция «Принять заказ». А при декомпозировании мы уже рассматриваем ее не как функцию, а как процесс, и последовательность действий при приеме заказа – это уже процессный подход.
Есть и еще одно очень важное отличие. Функциональную модель невозможно использовать при реализации какой-то либо системы, только для проектирования. А процессный подход позволяет создавать исполняемые модели, т.е. описания последовательности действий, которые мы можем в дальнейшем перевести в какую-то среду для создания системы совместной работы предприятия, основанной на процессном подходе.
Ментальный подход (ментальные карты)
При создании ментальных моделей специалист подходит к моделированию не как к процессу или набору функций, а как к некому набору связанных между собой понятий. Для наглядности я приведу пример — ментальная карта понятия “Процедура снабжения” (см. рисунок).
Такой вариант подхода применяется, прежде всего, для себя. Рисование схемы в свободной форме помогает структурировать свои знания, так сказать, “разложить по полочкам” в свободной форме полученную информацию. Также подобные ментальные карты помогают найти решение, которое уже позже, по мере необходимости, будет воплощаться в рамках строгих правил процессного или функционального подхода.
Можно применять ментальные карты и для демонстрации клиентам: и существующей ситуации, и вариантов решения поставленной задачи. Ментальные карты помогут наглядно продемонстрировать, какие методы могут быть использованы, показать в наглядной форме различные идеи.
Плюсы применения таких ментальных карт очевидны:
Не нужно знать какие-то специальные языки;
Нет строгих рамок и ограничений при создании схемы;
Ментальная карта в большинстве случаев интуитивно понятна;
Создавать такие схемы просто.
Минусом подхода является отсутствие устоявшегося подхода и стандартизированной методологии. Если в нотациях функциональных и процессных имеется некоторая вариативность, но все же она ограничена строгими рамками языков моделирования, то ментальные карты создаются в произвольной форме. И даже специализированные программы для их создания также почти не ограничивают человека в процессе моделирования. Т.е. какие-то правила могут вводиться в рамках определенного программного продукта, но стандарта не существует.
В результате для понимания модели и заложенных в ней идей требуется присутствие и комментарии ее разработчика (аналитика).
Конечно, существуют очень простые карты, которые интуитивно читаются и без дополнительных комментариев. Но при отсутствии стандартов всегда есть вероятность, что даже в этом случае автор что-то другое имел в виду или где-то недостаточно детализировал свою схему. Т.е. существует вероятность разного прочтения. А бизнес — это не философия. При всей умозрительности и разнообразии подходов к описанию бизнес-процессов, здесь очень важны однозначные решения.
Методология и языки бизнес-моделирования
Очень часто даже в профессиональной литературе возникает путаница, когда люди смешивают понятия методологии анализа работы бизнеса и описания языков бизнес-моделирования.
Методология — это система принципов и стандартов описания бизнес моделей и их последующего анализа. В то время как язык бизнес-моделирования – это не более чем инструмент для разработки моделей бизнеса.
Здесь напрашивается сравнение с программированием вообще и применением конкретного языка программирования. Программирование включает в себя и построение алгоритма, и выбор подходящего языка программирования, и реализацию алгоритма программы в рамках того или иного языка. А, например, программирование на языке Си++ – это уже заведомо ограничение определенными рамками, так как средствами определенного языка можно решить только четко ограниченный круг задач, и, одновременно, даже если задачу можно решить средствами Си++ совсем не обязательно, что именно этот язык будет в конкретном случае оптимальным. В общем, разницу между понятием «программирование» и «программированием в рамках определенного языка», я думаю, большинство понимают даже без таких пояснений.
Отличие языков разработки бизнес-моделей в от языков проектирования систем
Существует целое семейство языков проектирования систем, которые внешне схожи с языками бизнес-моделирования, например, это Ares Studios, целое семейство языков UML и другие, которые используются для проектирования IT-систем.
Основное различие этих языков от языков разработки бизнес-процессов лежит в их предназначении. Если языки проектирования IT-систем рассматривают бизнес-процессы с точки зрения возможности их автоматизации, воплощении в IT-системах, то языки бизнес-моделирования рассматривают последовательность действий именно с точки зрения бизнеса, включая работу как IT-систем, так и сотрудников, движения товаров и т.д.
Соответственно, в языках проектирования систем нет элементов, которые помогут полноценно описать действия подразделений, сотрудников, взаимодействие между ними, работу с поставщиками, общение с клиентами и так далее. Инструменты этой группы языков помогут именно автоматизировать процессы бизнеса, которые поддаются автоматизации. А все остальное будет оставлено «за кадром», например, как некие «функции» без расшифровки.
В то же время языки разработки бизнес-процессов охватывают максимально именно работу бизнеса как такового, а вот те или иные нюансы автоматизации и алгоритмизации систем в них описать далеко не всегда возможно с достаточной степенью детализации.
Преимущества разработки моделей бизнеса
И все же, зачем применять языки бизнес-моделирования, которые налагают строгие ограничения, требуют придерживаться жестко заданных правил при моделировании? Ведь всегда можно «нарисовать схему» в графическом редакторе или даже на бумаге, используя ментальный подход, при этом изучение языков моделирования вообще не потребуется.
На самом деле, стандарты и правила – это огромный плюс:
Языки моделирования помогают максимально качественно передать информацию. Стандартизация повышает простоту восприятия.
Скорость разработки моделей значительно увеличивается. Языки содержат все необходимые инструменты и графические блоки в готовом виде. Вам не придется «рисовать» или придумывать свою терминологию. Инструментарий уже готов, и работа в его рамках значительно ускоряется. Конечно, язык нужно выучить. Но один раз изучить – это намного быстрее, чем каждый раз придумывать и пояснять собственный набор обозначений.
Снижается число возможных ошибок. Сами элементы системы уже будут «подсказывать» перечень возможных и необходимых действий. А в случае создания исполняемых моделей или неисполняемых, но в строгих рамках правил, всегда можно проверить работу бизнес-модели в исполняемой среде и провести отладку, как при программировании.
Применение моделей бизнеса на практике
Лично я считаю, что бизнес-моделирование стоит применять при решении любых задач, связанных с выявлением проблем и «узких мест», с оптимизацией и модернизацией бизнеса и т.д. Как бизнес-консультант я практически всегда строю модели работы компании или ее подразделений при работе со своими клиентами. Это дает четкое понимание всех этапов работы и позволяет избежать «белых пятен» в этом вопросе.
Кроме того, наглядные схемы бизнес-моделей помогают мне в процессе взаимодействия с клиентами. Проекты у меня часто бывают сложными, и обычного текста или устной речи бывает недостаточно для понимания, в то время как использование наглядных бизнес-моделей снижает затраты времени клиента на чтение и понимание моих предложений, и практически исключает проблемы взаимопонимания в этом вопросе. И если несколько лет назад я еще сталкивался с недоумением со стороны клиентов, то сейчас вариант описания «на словах» без наглядных и удобных схем практикуется крайне редко.
А в случае автоматизации какого-либо этапа работы или создания автоматизированной системы управления бизнесом на основе проектно-ориентированного подхода качественная бизнес-модель, выполненная в том или ином языке моделирования, станет готовым руководством для технических специалистов.
Удобство, универсальность, простота восприятия – это те причины, по которым от словесных описаний в бизнес-сфере все больше переходят к бизнес-моделированию. А применение готовых языков позволяет работать с моделями быстро, избегать ошибок, и также без проблем вносить любые изменения.
Мы уже рассказывали об основах работы с async/await в Node.js, и о том, как использование этого нового механизма позволяет сделать код лучше. Сегодня поговорим о том, как создавать, используя async/await, RESTful API, взаимодействующие с базой данных Firebase. Особое внимание обратим на то, как писать красивый, удобный и понятный асинхронный код. Можете прямо сейчас попрощаться с адом коллбэков.
Для того, чтобы проработать этот материал, у вас должны быть установлены Node.js и Firebase Admin SDK. Если это не так — вот официальное руководство по настройке рабочей среды.
Запись данных
В примерах мы будем рассматривать фрагменты кода API, которое представляет собой серверную часть приложения, предназначенного для работы со словами. Пользователь приложения, найдя новое слово и желая сохранить его для того, чтобы позже выучить, может сохранить его в базу. Когда дело дойдёт до заучивания слова, его можно запросить из базы.
Создадим конечную точку POST, которая будет сохранять слова в базу данных:
// Зависимости
const admin = require('firebase-admin');
const express = require('express');
// Настройка
const db = admin.database();
const router = express.Router();
// Вспомогательные средства
router.use(bodyParser.json());
// API
router.post('/words', (req, res) => {
const {userId, word} = req.body;
db.ref(`words/${userId}`).push({word});
res.sendStatus(201);
});
Тут всё устроено очень просто, без излишеств. Мы принимаем идентификатор пользователя (userId) и слово (word), затем сохраняем слово в коллекции words.
Однако, даже в таком вот простом примере кое-чего не хватает. Мы забыли об обработке ошибок. А именно, мы возвращаем код состояния 201 даже в том случае, если слово в базу сохранить не удалось.
Добавим в наш код обработку ошибок:
// API
router.post('/words', (req, res) => {
const {userId, word} = req.body;
db.ref(`words/${userId}`).push({word}, error => {
if (error) {
res.sendStatus(500);
// Логируем сообщение об ошибке во внешний сервис, например, в Sentry
} else {
res.sendStatus(201);
}
};
});
Теперь, когда конечная точка возвращает правильные коды состояний, клиент может вывести подходящее сообщение для пользователя. Например, что-то вроде: «Слово успешно сохранено», или: «Слово сохранить не удалось, попробуйте ещё раз».
Если вы неуверенно чувствуете себя, читая код, написанный с использованием возможностей ES2015+, взгляните на это руководство.
Чтение данных
Итак, в базу данных Firebase мы уже кое-что записали. Попробуем теперь чтение. Сначала — вот как будет выглядеть конечная точка GET, созданная с использованием традиционного подхода с применением промисов:
Здесь, опять же, нет обработки ошибок. Обратите внимание на ключевое слово async, добавленное перед параметрами (res, req) стрелочной функции, и на ключевое слово await, которое предшествует выражению db.ref().
Метод db.ref() возвращает промис. Это означает, что тут мы можем задействовать await для того, чтобы «приостановить» выполнение скрипта. Ключевое слово await можно использовать с любыми промисами.
Метод res.send(), расположенный в конце функции, будет вызван только после того, как разрешится промис db.ref().
Всё это хорошо, однако, по-настоящему оценить красоту решений, использующих async/await, можно в случаях, когда нужно объединить в цепочку несколько асинхронных запросов.
Скажем, надо последовательно запустить некое количество асинхронных функций:
Такой код выглядит вполне достойно. Теперь поговорим о параллельных запросах и async/await.
Параллельные запросы и async/await
Что если нужно одновременно прочитать из базы данных множество записей? На самом деле — ничего особенно сложного тут нет. Достаточно использовать метод Promise.all() для параллельного выполнения запросов:
Создавая конечную точку API, которая будет возвращать то, что получено из базы данных Firebase, постарайтесь не возвращать весь snapshot.val(). Это может вызвать проблемы с разбором JSON на клиенте.
То, что будет в snapshot.val(), возвращённом Firebase, может оказаться либо JSON-объектом, либо значением null, если ни одной записи найти не удалось. Если возвратить null, тогда json.response() в вышеприведённом коде выдаст ошибку, так как он попытается этот null, не являющийся объектом, разобрать.
Чтобы от этого защититься, можно использовать Object.assign() для того, чтобы всегда возвращать клиенту объект:
// API
router.get('/words', async (req, res) => {
const {userId} = req.query;
const wordsSnapshot = await db.ref(`words/${userId}`).once('value');
// Плохо
res.send(wordsSnapshot.val())
// Хорошо
const response = Object.assign({}, snapshot.val());
res.send(response);
});
Итоги
Как видите, конструкция async/await помогает избежать ада коллбэков и прочих неприятностей, делая код понятнее и облегчая обработку ошибок. Если вы хотите взглянуть на реальный проект, построенный с применением Node.js и базы данных Firebase, вот Vocabify — приложение, которое разработал автор этого материала. Оно предназначено для запоминания новых слов.
Уважаемые читатели! Используете ли вы async/await в своих проектах на Node.js?
Все уходят в облака и Parallels не исключение. Наконец-то мы запилили новый релиз. Под катом рассказ об основных плюшках свежеиспеченного Parallels RAS 16.0. История будет полезна руководителям ИТ и системным администраторам, стремящимся упростить свою жизнь и сэкономить на поддержке инфраструктуры.
В январе мы уже писали о том, что компания IDC в своём отчёте о рынке VCC (Virtual Client Computing) включила наш продукт Parallels Remote Application Server (RAS) в состав «Основных мировых игроков». Сам бог велел оправдывать возложенные на нас международными экспертами ожидания, предложив продвинутую функциональность. И так, что нового?
Версия 16.0
Серверные компоненты Интеграция с Turbo.net. Появилась возможность публикации приложений в песочнице в контейнере Turbo.net. Обратите внимание, что в версии 16.0 поддерживается только публичный репозиторий.
Ряд улучшений VDI. В качестве VDI-хостов теперь поддерживаются гипервизоры Nutanix Acropolis (есть бесплатная версия) и KVM (бесплатный).
В Hyper-V, VMware (ESX, vCenter), Nutanix и KVM появились связанные клоны (linked clones), благодаря чему можно быстрее создавать виртуальные машины. Каждый десктоп, развёрнутый из шаблона, получает новое имя и MAC-адрес, ему присваивается новый IP и новый аккаунт в Active Directory. Появилась возможность пересоздания гостевой машины из темплита с сохранением имени.
Также внедрён визард тестовых шаблонов, с помощью которого можно проверять работоспособность шаблона виртуальной машины.
Внедрена RASprep — расширенная версия SysPrep.
RAS PowerShell API v2.0. Поддерживаются VDI, HALB и командлеты, относящиеся к лицензиям. White-labeling v1.0. Можно брендировать (создавать кастомные темы) клиентское приложение Parallels HTML5 Client. Безопасный 64-битный клиентский шлюз. Теоретический предел одновременных подключений увеличен до 6 000+. Оптимизации, связанные с Publishing Agent. Появилась возможность выбирать предпочтительный PA, а также внесён ряд других улучшений.
Консоль
Мы внесли много улучшений в UX при работе с консолью RAS. Самые заметные из них: Отдельная инсталляция консоли. Теперь можно установить консоль на любую машину под управлением Windows. Также появилась возможность удалённого подключения к PA. Для запуска приложения консоли больше не нужны локальные или доменные права администратора.
Переработаны интерфейсы Site и Remote Desktop Server Hosts. Внешний вид Site и RDSH был переработан с целью повышения продуктивности администраторов, а также чтобы можно было получать информацию о серверах в реальном времени. Улучшено управление сессиями. Теперь можно увидеть, что публикуется для пользователя или группы, а также для RDS-хоста или RDSH-группы.
Вы можете видеть работающие экземпляры опубликованного приложения, а также просматривать список удалённых пользователей, которые используют его в данный момент.
Улучшен диспетчер устройств. Можно отключать монтирование USB-устройств, а также удалённо блокировать управляемые устройства.
Возможность использования AD-групп в списке администраторов. Вместо того, чтобы добавлять пользователей по одному, теперь можно добавлять пользовательские AD-группы.
Оптимизирован механизм хранения статусов агентов. Теперь в ходе запуска, когда выполняется проверка статусов агентов, консоль не блокирует сама себя. Можно запрещать доступ конкретным пользователям к серверному рабочему столу.
Возможность назначения для TS, шлюза, удалённого ПК и VDI конкретного Publishing Agent. Улучшена работа со шлюзом. Теперь можно перенаправлять веб-запросы напрямую на сервер шлюза, а также отключать HTTP-форвардинг.
Клиенты
Windows-клиент. Еcли клиент нельзя установить целиком (нет прав администратора), то инсталлятор переключается на базовую версию клиента. Если пользователь принимает приглашение установить клиент, но не является администратором, то по умолчанию запускается установка базовой версии.
Также в клиенте появился инструмент для контроля за сетью, в котором отображается информация о стабильности сетевого подключения.
Linux-клиент. Редирект USB-устройств: теперь можно локальные микрофон и камеры сделать доступными приложению, выполняемому на сервере. Добавлена поддержка редиректа PnP-устройств (MTP, PTP). Mac-клиент. Реализовано журналирование, лог пишется по адресу ~/Library/Containers/com.2X.Client.Mac/Data/ParallelsClient.log. Поддержка передачи файлов в HTML5- и Chrome-клиентах. Мы добавили возможность передачи файлов между клиентскими устройствами и сервером. Поддержка Network Level Authentication (NLA) в HTML5-клиенте. Более гибкое конфигурирование HTML5-клиента. Наложение кастомной иконки поверх иконки опубликованного приложения. Это позволяет пользователю отличать локальные приложения от опубликованных.
Таймаут RAS-подключения (листинг приложения). Улучшение системы безопасности: после определённого периода неактивности совершается принудительный выход из приложения. Эта функция работает в клиентах:
Windows
Linux
Mac
Android
iOS
HTML5
Chrome
Настройка управления редиректом клипборда (clipboard redirection) в политике RAS-подключений. Улучшение системы безопасности: позволяет отключать редирект клипборда посредством настройки политики.
Автоматическое определение UX-настроек. В зависимости от конкретных параметров клиентского подключения система сама выбирает оптимальные UX-настройки. Эта возможность добавлена в политики.
iOS- и Android-клиенты
Поддержка режима управления мышью Dumbo (iOS/Android). Раньше этот режим управления поддерживался в legacy-клиенте, а теперь портирован и в новый. Быстрые кейпады. Теперь можно задавать комбинации клавиш кнопкам панели инструментов в мобильном устройстве (конфигурируется RAS-администратором).
Интеграция с мышью SwiftPoint (iOS). Вы можете использовать с iOS-устройствами аппаратную мышь Swiftpoint. Разблокирование клиентского приложения с помощью PIN’а или отпечатка пальца (iOS). Внесён ряд улучшений в процедуру запуска приложения. Если приложение уже работает, то система переключается на него, а не создаёт новое окно. Улучшено определение области ввода текста, улучшена работа всплывающей клавиатуры, более удобная функция выделения текста. В iOS 9 для выделения текста теперь можно использовать 3D-жесты. Возможность импорта/экспорта RAS- и RDP-подключений. В приложениях Office 2013 / 2016 автоматически включается «сенсорный режим управления». Новые настройки разрешения экрана с поддержкой DPI-масштабирования. Поддержка политик RAS-подключения. Администратор может изменять настройки существующего клиентского подключения через параметры политики.
Прочие особенности
Нативная печать PDF-файлов с помощью библиотеки DynaPDF. Теперь к клиентскому окружению предъявляется меньше требований, стало меньше зависимостей (не нужно устанавливать Acrobat). Обеспечивается стабильность печати PDF-файлов: выполняется редирект всех свойств драйвера в соответствии с настройками принтера.
Появилась поддержка R-UDP. Это позволило ускорить обновления экрана при использовании не-Windows-клиентов посредством WAN-подключений.
Пишите в комментариях, если вас заинтересовало наше решение или возникли вопросы о том, как и что мы реализовали под капотом нашей машинки. Ну и ничего не мешает вам протестировать нашего зверя.
В конце июня MicroFocus-Serena выпустила версию 11.3 платформы автоматизации бизнес-процессов. Релиз минорный, однако в нем есть ряд очень востребованных и полезных изменений. Давайте пройдемся по списку наиболее значимых из них.
Папки и Быстрые ссылки появились и в WorkCenter
Инструменты организации своего рабочего пространства, известные как Папки (Folders) и Быстрые ссылки (Quick Links) еще с версии TeamTrack 6.2, были незаслуженно забыты и исключены из новой разметки пользовательского интерфейса WorkCenter. Быстрые ссылки позволяли быстро «прикопать» на рабочий стол ссылочку или на постоянно нужный отчет, или текущий релиз, или диаграмму бэклога спринта, или сохраненный шаблон формы дефекта в UI текущей версии, или ссылку на ТЗ. А Папки позволяли всё это богатство удобно хранить и быстро находить. Более того, содержимым папок можно еще и делиться с коллегами. Например, собрал в папку все полезные отчеты по KPI и предоставил всем доступ – пользуйтесь на здоровье… В WorkCenter конечно, было придумано много новых инструментов, например, фильтры поиска отчетов, но Папки и Ссылки точно лишними не будут.
В этой версии для Папок добавлены роли Владельца (owner), Совладельца (co-owner), Участника(collaborators), На добавление (contributors), На просмотр (viewers).
Новый скриптовый движок
Программисты могут теперь использовать SBM ModScript для реализации скриптов бизнес-логики, исполняющихся на сервере приложений SBM. SBM ModScript – наследник ChaiScript, и содержит расширения для работы с объектами SBM. Детали можно узнать в документации — SBM ModScript Reference Guide. Понять основные отличия от предыдущей технологии SBM AppScript можно в другом документе — SBM ModScript Transition Guide.
Напомним, что в основе SBM AppScript лежал VB Script. Этому движку уже точно более 20 лет. Работает очень быстро, и со своими задачами справляется хорошо. К недостаткам можно отнести отсутствие мощных готовых библиотек для работы со строками или XML, а также отсутствие некоторых привычных удобств в отладке.
Улучшение коммуникаций с внешним миром
Долгое время SBM была изолирована от пользователей, у которых нет своего профиля в системе. Некоторое время назад появилась возможность из системы отправлять электронные письма на произвольные email адреса. Теперь таких возможностей стало существенно больше: Анонимное создание записей по E-mail
Итак, внешние пользователи (у которых нет своего профиля в SBM) теперь могут отправить электронное письмо на почтовый ящик, который обрабатывается SBM, и если Администратор настроит возможность создания записей в соответствующих проектах от неизвестных отправителей, то запись будет создана. Дополнительно можно настроить блокирование вложений к письмам, спам фильтры, правила маршрутизации входящих писем от неизвестных пользователей. Детали по настройке смотрите в документации SBM Application Administrator Guide.
Сложно переоценить важность этой функции для компаний, где SBM используется для автоматизации процессов технической поддержки пользователей или ServiceDesk. Теперь есть нормальный канал общения со всеми своими клиентами! Управление профилями внешних пользователей
Понятно, что если мы получили обращение от ранее неизвестного нам клиента, то нужно с ним как-то взаимодействовать. Для этого был добавлен новый виджет (доступный через меню Действий на форме объекта), позволяющий посмотреть на email адрес, с которого было получено обращение, ввести имя клиента, а также добавить дополнительных внешних пользователей.
После настройки система будет автоматически подставлять адреса и имена внешних пользователей в форму отправки письма.
Примечание: Для управление профилями внешних пользователей добавлена новая привилегия External Communication. Не забудьте включить ее в соответствующую роль. E-mail Recorder и Коммуникации
Модуль E-mail Recorder позволяет автоматически прикреплять электронную переписку между пользователями к объекту обсуждения. Модуль будет обрабатывать переписку и с внешними пользователями. В SBM можно настроить правила автоматических переходов (смены состояний) по факту получения ответа от внешнего пользователя. Шаблоны писем внешним пользователям
Дополнительные шаблоны email сообщений добавлены в систему для отправки внешним пользователям писем сервером уведомлений. Кроме того, встроенный редактор писем автоматически подставляет в поле Кому email адреса внешних пользователей, ассоциированных с данной записью. Шаблоны писем можно редактировать в настройках каждого проекта.
Улучшения в представлении доски Канбан
Широко популярные в узких кругах доски Канбан появились в 11 версии SBM и доступны в WorkCenter. Что появилось нового:
В качестве источника данных для доски Канбан теперь можно выбрать бэклог. В чем прелесть? У бэклога есть признак включения/исключения задачи в/из бэклога спринта или продукта. Соответственно на доске Канбан будут показаны не все задачи, а только те, что были включены в бэклог на реализацию. Детали в документации SBM Work Center Guide.
Теперь на доску Канбан можно выводить данные из связанных с основным объектом реляционных таблиц (только через отношение — Single Relational). Например, можно дополнительно вывести scrum команду или ссылку на environment, или ссылку на глобальный проект, или ссылку на карточку Клиента и т.д. Более того, записи на доске Канбан можно визуально группировать и выделять по этому признаку в отдельных полосах (swimlanes).
Функция drag-n-drop на доске Канбан теперь корректно отрабатывает ветвления модели процессов (ромбы decision points).
Добавлена сортировка записей в колонках доски Канбан по системным атрибутам или атрибутам карточки Канбан Card ID, Card Title или Card Status. Также можно использовать приоритет из бэклога.
Улучшения в календарном представлении
Календарные отчеты и представления появились Work Center достаточно давно. Как понятно из названия, данный инструмент позволяет “спроецировать” записи на календарь день/неделя/месяц, динамически применять систему раскраски/прикрепления иконок по значениям полей, а также динамически удобно фильтровать отображения записей на календаре по выбранной системе раскраски/иконкам. На одном календаре можно объединять данные из нескольких потоков данных одновременно. Что здесь нового:
Work Center научили брать ленту событий для календаря из внешних источников через сервисы JSON/REST. Это может быть удобно для поиска конфликтов/ пересечений при планировании.
Появилась возможность экспортировать информацию о событии в формате ICS, чтобы затем импортировать в другое календарное приложение типа Microsoft Outlook или любое другое совместимое по формату.
Отслеживание изменений в отчетах. Контроль удаления отчетов
Пользователям с привилегией Global Administration теперь доступны отчеты Deleted Items и Change History, которые покажут соответственно список удаленных отчетов и историю изменений отчетов SBM.
SBM System Analytics
Пользователям с привилегией Remote Administration в меню настроек доступны новые аналитические отчеты по производительности компонент SBM, утилизации системных ресурсов и т.д. SBM System Analytics включает в себя Real-Time Monitoring и Run-Time Statistics.
Повторное использование вложенных моделей Workflows для скриптов Orchestration
Скрипты и модели оркестрации на языке BPEL широко используются для реализации сценариев взаимодействия процессов как внутри SBM, так и с внешними системами. Возможны как синхронные, так и асинхронные модели. В этой версии появилась возможность выделить часто встречающиеся шаги или действия в отдельные модели, а потом их включить через палитру элементов оркестрации. В целом, изменение полезное для больших проектов, где широко используется движок оркестрации, где есть потребность в упрощении сценариев и снижении стоимости поддержки решения.
Secure Response Headers
В конфигураторе SBM можно включить дополнительные средства защиты от атак — Secure Response Headers. Детали в документации- SBM Installation and Configuration Guide.
Изменения в пользовательском интерфейсе
SBM Work Center
Новые действия с виджетами: Copy и Save As
В бэклогах появилась возможность независимой сортировки списков – Принятых в бэклог и Кандидатов в бэклог.
В разделе истории изменений бэклога добавилась информация о пользователе, который внёс изменения в бэклог, времени этих изменений, самой записи блога.
Новые системные отчеты
SLA Items Panel. Прогнозируемый отчет после включения модуля SLA в базовую поставку SBM.
Requests Monitor. Этот отчет более любопытный. Он показывает список отчетов SBM, исполняющихся на текущий момент. Из этого представления отчеты можно останавливать, если есть соответствующие права. В целом, отчет будет востребован в высоконагруженных конфигурациях.
Улучшения Query At Runtime для текстовых полей
Фильтры выборки данных в отчетах допускают опцию указания значений фильтрации в момент исполнения отчета – это и есть Query At Runtime. Однако для работы с тестовыми полями зачастую одного условного оператора маловато. Поэтому появились логические операторы «AND», «OR» ,«contains», «like», «not contains» ,«not like». Весьма полезно, надо сказать.
Изменения в Администрировании
SBM System Administrator
Импорт данных из ODBC источников
Возможность указать пользователя, от имени которого будут импортироваться данные
Возможность исполнения скриптов пре- и пост- обработки данных (AppScript / ModScript)
Опция обновления данных, только если были обнаружены какие-то изменения.
Но вот что особенно интересно, так это то, что в этот релиз вошла утилита командной строки- ttadmin.exe. Таким образом, можно написать скрипт операционной системы и запускать этот скрипт по расписанию. А результате получаем полностью автономную загрузку данных из внешних источников штатными средствами!
SBM Composer Changes
Open Custom Popup Now a Modal Dialog Box
Добавлен новый мощный инструмент форм пользовательского интерфейса — Open Custom Popup. Работает новый элемент просто. Когда пользователь нажимает на кнопку, ссылку или картинку появляется дополнительное меню возможных вариантов действий, что открывает широкую палитру реализаций новых удобных сценариев работы с системой. Можно использовать свой код на Javascript или CSS.
Вот такой получился релиз. Задавайте вопросы. Следите за нашими новостями.
ЖивоСкрипт это графический (визуальный) язык программирования который компилируется в JavaScript. В нём используются только простые и понятные детям возможности языка JavaScript, и только сильные стороны, и только строгий режим. Это ядро (хардкор) js-программирования, максимальный минимализм — всего 50 графических элементов из которых состоит программа.
Я выделил простое подмножество языка JavaScript, которое использую в своей работе. Освоить ЖивоСкрипт возможно за один день, но грызть гранит науки надо несколько лет, потому что
Исторический контекст
В начале, в 1995 году, этот язык назывался Mocha, потому что программисты любят кофе. Затем он был переименован в LiveScript, серверная версия языка должна была называться LiveWire. После этого внезапно название сменилось на JavaScript, потому что тогда Java было модным словом. Стандартизированная версия языка называется ECMAScript. Недавно Jeremy Ashkenas создал одноименный LiveScript, который компилируется в JavaScript, ранее им был создан CoffeeScript.
От буржуйского названия ЖаваСкрипт происходит русское название ЖивоСкрипт. Я отечественный не модный суровый инженер-любитель, говорю и пишу код по-русски. ЖивоСкрипт это родной отечественный графический язык программирования, который я создал в первую очередь для русскоязычных детей. В этой теме мне не интересна обычная стандартная профессиональная веб-разработка, и её проблемы, догматы и священные войны — прошу понять и простить.
Редизайн JavaScript
Я люблю JavaScript — для любителя нет языка проще и эффективнее, это Лисп в шкуре Си. За 22 года веб-программирование достаточно созрело, и таки наступила эпоха комфортной веб-разработки, например можно верстать таблицы и текст флексбоксами. Для полного счастья осталось дождаться WebCL или WebGPU и WebAssembly.
Живоскрипт настолько прост что скриншоты понятны и без пояснения.
Программа это блок-последовательность действий и других блоков. Пустая программа:
Комментарий и блоки. Блоки могут быть именованными:
Действия связывания адресов со значениями:
Удаление свойства:
Ветвление IF-ELSE, в условии — адрес, сравнение или проверка существования свойства:
Ветвление-варианты SWITCH-CASE:
Циклы WHILE, DO-WHILE, FOR, FOR IN:
Простые значения. Строки четырех типов: с одинарными и двойными кавычками, для id-имен и для имен css-классов:
Продолжаем серию интервью с докладчиками конференции PyCon Russia, которая пройдёт 16-17 июля в 95 км от Москвы.
Под катом — короткое интервью c Ниной Захаренко (Портленд, США), старшим инженером-программистом в Venmo, ранее — в Reddit и HBO. Нина рассказала, как начала писать на Python, какие проблемы есть у Python-сообщества и почему она ждет своё выступление на PyCon Russia.
— Hi Nina, please tell us a little bit about yourself. It looks like your family has an interesting story. You were born in Ukraine; how did your family get to the US? Do you maintain relations with the Motherland? Do you speak Ukrainian and Russian?
— I was only 3 when we left the country, so I don't remember much. I do speak some Russian, but not Ukranian. Unfortunately I don't have many Russian friends or family to practice speaking with. I’m looking forward to the opportunity to practice while I’m at PyCon Russia.
— How did you get into programming and specifically in the Python community?
— I always had a strong interest in computers and I started programming when I was 12 years old, by looking at webpage source code to teach myself HTML. When I was younger, we didn't have great computer classes in school. I learned most of the basics in University.
After University, I spent a long time working as an enterprise Java developer. At the time, I didn't know anything about the open source community because my job didn't expose me to it. I became unhappy with the beauracracy of larger corporations, so I took a summer off to teach myself Python at the Recuse Center, which is like a summer program like a writers retreat for programmers. Learning Python gave me the skill set to work for smaller, more creative, and more innovative companies. What sealed the deal for me was attending my first PyCon in Santa Clara in 2013. Everyone was incredibly friendly and welcoming. It felt like one big family. I've been lucky to be part of the community ever since.
— You work at Venmo and probably know what happens in the financial industry. How do you change the financial world? Does Python make a difference there?
— Venmo has redefined person to person payments, and come out on top even as big companies like Apple are struggling in the space. Python makes a difference by allowing us to be extremely agile: the time between dreaming up new ideas and innovations to launching features is much shorter than at other companies I've worked for.
— What are you working on currently?
— I’m currently on a small team that’s working to improve our internal engineering practices — optimizing our builds, and removing pain points from daily development work. I’m passionate about clean code and architecture, and I also work on tackling large refactoring projects in our eight-year-old codebase.
— In my free time, I’ve been working on learning how to solder hardware circuits and program microcontrollers.
— You worked for such well-know companies as Reddit and HBO. What did you do there? What was the most fascinating / remarkable / surprising about your work there?
The best thing about being a developer for companies like HBO and Reddit is gaining experience — and contributing meaningfully — in many different areas. When I worked at HBO, the most interesting part of my job was working on software for satellite control computers.
Выступление Нины на PyCon 2016
— What’s the best and the worst part of your job as a programmer?
— I work 100% remotely for a company based in New York, which is a double-edged sword — It's amazing having the freedom to work in sweatpants, and I'm able to get more done with less distractions. The downside is sometimes working remotely feels isolating, especially since most of my team is three hours ahead of me. I'm trying to tackle this problem by socializing with other developers at co-working spaces, coffee shops, and meetups.
— What do you consider your biggest achievement in life / job at this point?
— That's a difficult question to answer. I believe life isn't about one great achievement, but all the small ones that move you forward and make you a better person.
The achievements I'm most proud of involve conquering fears. I was proud to graduate with an engineering degree even though I constantly battled unfounded fears of not being a good enough software engineer. I'm also proud to share my python knowledge with the community by giving talks and teaching classes. A few years ago, I had an extreme phobia of public speaking. I started small by speaking at Meetups to small audiences, but these days I'm much more comfortable at the podium. Developing these skills has given me the opportunity to speak at amazing conferences around the world, such as DjangoCon, PyCon, and WebExpo in Prague.
— What’s the biggest problem of the Python community?
— In my opinion, some of the biggest problems in the Python community revolve around open source projects. I’ve seen many new contributors get turned off by bike-shedding, or too many people giving comments and feedback. Unlike other communities I’ve seen, the Python community is actively aware of its issues, and works hard to make improvements. I was impressed with many of the project maintainers who sprinted at PyCon US this year because many of them made it a point to welcome new contributors. I also love seeing a more diverse collection of pythonistas in the hallway of PyCon every year, although we still have a long way to go.
— Which tools do you use in your everyday work?
For maximum productivity, I enjoy spending most of my day on the command line. I use emacs for my editor, tmux for window management, and oh-my-zsh for a shell. I tweet about some of my command line tips and productivity tools, on topics such as useful plugins, command line pro-tips, and git tips and tricks.
— Do you read any Python blogs? Which sources about Python would you recommend?
— I mostly keep up to date with the Python community on twitter. I like to keep busy, so it's great getting my news in 140 characters or less. I'm also a fan of the Python Weekly newsletter.
— You do lots of outdoor sports: skiing, snowboarding, mountain biking, rock climbing. Which style do you prefer: reckless or careful? :) What’s your greatest adventure so far?
— I love adventuring, but I'm always careful! My brain is my money maker, so I take extreme care to protect myself. I have quite the helmet collection, one for each sport. I have gotten in some precarious situations, but to me the benefit of enjoying the great outdoors outweighs the risks.
I've had too many amazing adventures to count. Some of my favorite have been ski trips — to Argentina, Canada, and when I lived in Salt Lake City. There's nothing more exhilirating than standing at the top of a mountain peak!
16-17 июля на PyConRu Нина расскажет об общих антипаттернах в программах на python и покажет практические решения на python для улучшения вашего кода с помощью таких инструментов, как Decorators, Context Managers, Mixins и Lambdas. Остальных докладчиков можно посмотреть на сайте конференции.
Спасибо нашим спонсорам, которые делают конференцию возможной: золотому спонсору — компании Adcombo, серебряным спонсорам — Rambler&Co и ДомКлик, бронзовому спонсору — MediaScope. Спасибо за поддержку партнеру энергии и хорошего настроения компании ЦИАН и Python Software Foundation.
Привет, гении! Чертовски долго некоторые девочки стараются быть нормальными. Вот я одна из них. Молекулярная цитогенетика, психология детей с аутизмом, организация музыкальных фестивалей и хиппование, рекламный и детский бизнесы, семья.
12 лет Москвы. 12 лет терпения. И каждый раз я ать ножкой в сторону разработки — и снова что-то другое затягивало и кружило голову. А внутри точит. Надо бросить все и заниматься тем, что действительно манит. Вот тогда начнутся настоящие сложности, вот тогда придет ко мне сладкая жизнь.
Ахтунг, статья написана гуманитарием! Здесь кода нет
Моя история про то, как пытаться быть нормальной девушкой и как не получается ей быть. Как получать кайф от преодоления трудностей в новом, а не от стабильности в старом. И как бросить все, чтобы жить своей жизнью.
В 20 лет, когда я только-только окончила университет, мне очень хотелось иметь стабильную жизнь, крепкую семью и красивое хобби. Я была уверена, что в 30 лет я буду заплетать косички дочке, ругать двух непослушных сыновей за выбитые стекла, готовить вкусное мясо мужу и шить мягкие игрушки. Но в какой-то момент, выходя с работы, поняла, что жить стабильно мне скучно. Спустя пару дней мне попалась западная статья, в которой рекомендовали менять сферу деятельности или город каждые 3-5 лет.
Тогда я долго решалась, но было совершенно очевидно, что стоит сменить профобласть. И настолько мне это понравилось, что теперь я со своим дурацким характером меняю сферу деятельности каждые два-три года, много чего более-менее умею, живу впечатлениями и постоянно начинаю с чистого листа, просто потому, что мне это нравится. Не получается быть нормальной. Да пофиг на этот образ, в принципе.
Тернистый путь к Mac Os
Первый свой ноутбук я купила сама на 3 курсе, это был 2007 год. Родители в детстве категорически отказывались покупать компьютер. И не потому, что не было денег, мы как раз жили в достатке. Мама прямо заявляла: ты же папина дочка, перестанешь учиться и уйдешь с головой в свой компьютер. А папа в конце 90-х тайком приносил домой огроменные ноутбуки Dell и мы вместе пытались в них разобраться.
Через полгода борьбы с виндой я установила на свой на HP autoruns.exe и программу, которая генерирует ключи для Eset Nod32. Тем не менее, за сутки до сдачи курсовой комп все равно полетел, не сохранив работу. Переустановила винду, сидела по памяти и из новых кусочков восстанавливала курсовую. Мозг кипел.
Знакомство с микрочипами и базами данных произошло в науке. На первой своей официальной работе я занималась анализом тканей мозга и крови, чтобы найти случайные и неслучайные мутации, которые приводят к аутизму. Работали in vitro и in silico, собирая материал на диссер, которого так и не случилось. Зато случилась любовь к IT.
На Linux я сидела некоторое время на 4-5 курсе и уже позже на работе в частной школе для одаренных детей. И это было классно, потому что гордость просто распирала, когда кто-то из коллег подходил с просьбой настроить комп. Но большая часть «я сломала интернет», «компьютер сдох» и «почини форум» доставалась системному администратору, а я была училкой.
Тогда же купила свой первый iPad, а один из старшеклассников (ныне — основатель сервиса PilotHub) сделал джейлбрейк — в 2013 это было модно. Но не полезно, мне не понравились глюки (я точно не гик, исправила бы), да и комп был нужен, поэтому вскоре обменяла iPad на Macbook White. Монстр работать почти не хотел, сделка была неоправданная. Поэтому продала, перезаняла, доложила накопления и приобрела Macbook Pro Mid 2012, чтобы обрабатывать тяжелое видео.
Сейчас мой макбук уже старичок, но в течение 5 лет вложений не требовал: буквально на днях заменила шлейф жесткого диска и купила новую зарядку, так как провод чутка износился. Кто думает, переходить или нет — однозначно да. Я окончательно соскочила с других операционных систем и мечтаю потихоньку освоить Swift.
Мотивационный пинок
Жизнь так и шла бы своим чередом, но год назад со мной случился привет из 90-х — за то время, что занималась делами в другой стране, у меня отжали детский бизнес, после чего довольно стремительно развалилась семья. Не принято о таком говорить, но эти потери — именно тот пинок под зад, который поставил точку в старой жизни. Никому такого не пожелаю, но мне пошло на пользу. Бизнес-вумен со стальными нервами отпустила ситуацию и решила сделать то, о чем мечтала всю жизнь.
Знакомые крутили пальцем у виска и говорили, что надо бороться и искать инвестора под новый проект в Москве. Друзья поддерживали и с удовольствием наблюдали за событиями, понимая, что для меня это самый кайф.
Я покинула столицу окончательно и бесповоротно. Уехала жить на Юг и развивать бизнес на Черноморское побережье. Южное солнце, теплое море, вкусное вино и старый добрый Macbook. Именно то, что хочется видеть в новой жизни.
Первые три месяца были очень тяжелыми, но самыми яркими по эмоциям и событиям. Я поменяла не только город, но и сферу деятельности. Расставшись с детским бизнесом, решила, что пора погружаться в айти. Мне всегда нравилась вся эта магия.
По образованию я клинический психолог, поэтому поискала удаленные вакансии и остановилась на рекрутинге айтишников. Благо, отправляли мы ребят в Европу и США. Как-то так получилось, что сразу вышла на позицию тимлида — стартап был достаточно молодой, пригодился мой бэкграунд в бизнесе.
Но уже через пару месяцев мы с другом организовали собственную компанию по разработке ПО. Сейчас у нас просторный офис с панорамными окнами, видом на море и горы. Именно в такое место хочется приходить каждый день. В обеденный перерыв можно прогуляться по пляжу и перекусить в уютном ресторанчике, а вечером — сходить в фитнес-клуб или на йогу в этом же здании. В общем, вдохновляет!
Если вы планируете переехать к морю
Если вы давно мечтаете о том, чтобы переехать поближе к морю, дерзайте. Да, переезд — это всегда неизвестность и отсутствие готовых ответов. Но все временные трудности решаются в течение полугода. На этот период лучше иметь небольшую финансовую подушку или нескольких постоянных клиентов, если вы фрилансер.
В отличие от дауншифтинга в Таиланде, откуда в связи с ростом курса доллара множество людей вернулось обратно в Россию, переезд на Черноморское побережье — это отсутствие языкового барьера, неплохая медицина, понятная модель трудоустройства и создания бизнеса. Из минусов — здесь такие же вкусные фрукты и морепродукты (например, отличные устрицы и мидии), но о том разнообразии, которое есть в Юго-Восточной Азии, говорить не приходится.
Для разработчиков, дизайнеров, интернет-маркетологов, менеджеров проектов, переводчиков, копирайтеров, бухгалтеров, рекрутеров и других специалистов, которые могут работать на аутсорсе (удаленно), работа будет везде. Переезд в таком случае не связан с необходимостью искать работу, поэтому некоторые мои знакомые работают на удаленке и одновременно путешествуют. Найти ценных сотрудников в нашу компанию было крайне сложно.
Далее немного отойду от основной линии и расскажу о других вариантах трудоустройства из позиции человека, который не планирует работать удаленно.
Вакансии на hh тут не размещают, но зато периодически что-то появляется на Авито. Выбрать в общем-то не из чего. Самые теплые места традиционно занимают по знакомству, очень хорошо работают сарафанное радио и социальные сети. В фейсбуке пустынно, поэтому при поиске работы (или сотрудников) делайте упор на группы вк. А еще лучше по старинке: veni, vidi, vici. Заходите в понравившиеся компании и разговаривайте с руководством. Если переезжаете в мае-июне, есть возможность устроиться на сезонную работу, пока не обустроитесь.
Для тех, кто хочет работать в море, но не имеет образования — есть краткосрочные курсы. Зарплата у моряков очень приличная. Как у разработчиков под macOS и в 2-3 раза выше, если есть корочка и нужные люди в нужных кругах. Работа по графику: 6 месяцев ты «бессмертный пони» на судне и 6 месяцев приходишь в себя на суше. Строители и автомеханики имеют 50-70к+, иногда и более внушительные суммы, если это свой бизнес. Поймать волну непросто, но ловят.
Свой бизнес (как и везде) — есть помещение в собственности, магический кубик сложится, нет — будете работать на аренду. Цены на коммерческую недвижимость приближены к московским. Небольшой метраж осилить можно. Цены на услуги в 2-3 раза ниже московских, закладывайте в бизнес-план, если планируете создавать бизнес с привязкой по территориальному признаку. Если у вас есть готовая экселевская табличка, лучше сделать так: расходы умножить на два, а доходы разделить на два. Вот где-то там и есть правда.
Финансовая часть вопроса
Расходы на переезд
Временное хранение вещей (грузоперевозки по Москве) — 7000 руб.
Отправка вещей по России — 9 000 руб.
Дорога на Юг с друзьями — бесплатно
Постоянные расходы
Аренда частного дома или квартиры (с коммуналкой) — 15 000 руб.
Закупка в гипермаркете «Лента» на 2 недели — 5 000 руб.
Вода питьевая — 1000 руб.
Йога или качалка — 2500 руб.
Медицинские расходы — ОМС
Транспортные расходы — 3600 руб.
Непредвиденные расходы
Химчистка — 1000 руб.
Ремонт часов — 500 руб.
Покупка новой посуды — 2000 руб.
Бартер
Замена шлейфа харда — пицца
Курс массажа — продвижение студии
Свежие цветы на столе — аренда дома с садом
Для девочек-программистов и жен программистов
Маникюр и педикюр с покрытием — 1600 руб.
Шугаринг «все включено» — 1000 руб.
Микроблейдинг бровей — 2000 руб.
Косметолог — 1300 руб.
Ботокс для волос — 1500 руб.
Развлечения*
Рестораны, кафе, бары — 1500 руб.
Аренда яхты — 5000 руб.
Аренда вертолета — 5000 руб.
SUP серфинг — 1000 руб.
Аквапарк — 1700 руб.
Сафари-парк и канатная дорога — 2000 руб.
Гольф-клуб без инструктора — 5000 руб.
Мастер-классы — 500 руб.
Квесты — 2000 руб.
Кино — 250 руб.
Хобби (столярка) — 100 руб./час.
* развлекательная сфера развита, но классического культурного досуга (музеи, выставки, театры, консерватории) тут практически нет
Квартирный вопрос (информация к размышлению)
ПИК, готово через год — 2,3 млн за 40 кв.м
Местный застройщик, готово — 1,6 млн. за 40 кв.м
Вторичка с ремонтом — 2 млн. за 30 кв.м
Коттедж в элитном районе с ремонтом — 6 млн. за 130 кв.м
Адреналин, дофамин и эндорфин
Мой переезд не был запланирован, возможность уехать возникла случайно. Когда вам нечего терять, решения принимаются быстрее и без оглядки на прошлое. Самым рискованным для меня был шаг в сторону всей этой магии.
Вообще, о рисках мне говорить сложно. Для меня риски — это прыгнуть с парашютом или продать недвижимость, чтобы вложить деньги в проект. А переезд в другой город, отсутствие работы, новый круг общения, новая сфера деятельности — это то, что вдохновляет и стремительно тащит вперед. Просто потому, что однажды решившись на это, у тебя не остается другого выбора. А потом тебе это уже настолько нравится, что хочется повторить еще раз. Эй, бармен, нам с командой еще по одной через пару лет. Люблю новые впечатления.
Где там надо прочитать и расписаться про то, что я в здравом уме и трезвой памяти? Я хорошо понимаю, что предстоит долгий путь освоения и ошибок, что для организации бизнес-процессов необходимы глубокие предметные знания не только твоего партнера по бизнесу и команды, но и твои собственные. И понимаю, что раньше надо было начинать. А сейчас — просто заниматься организацией и маркетингом. Но я потихоньку погружаюсь в Swift и наблюдаю, что из всего этого получится.
Резюмирую
Если вы успели обзавестись семьей и дорожите стабильной работой, забудьте о переезде, — конечно, проще путешествовать.
Если вы только учитесь программировать и хотите уехать жить на остров, хорошо взвесьте все за и против: можно жить на море и продолжать говорить на родном языке.
Если вы ждете волшебного пенделя, не забудьте о том, это может быть больно, а удовольствие можно получать от более простых и предсказуемых вещей.
Если вы хотите развивать бизнес в России, помните, что это хорошо и совсем не сложно, просто очень ответственно.
После завершения (с любым итогом) проекта менеджер обязан написать т.н. «post mortem». Цель очевидна: сделать хорошее и плохое, что было в ходе проекта явным как для себя, так и для других. Если бы жанр таких post mortem стал более популярен у нас, уверен, процент успешных проектов от этого вырос бы, какими бы ни были критерии «успешности».
В этом тексте я опишу часть истории проекта в весьма бурно сейчас развивающемся домене TNC (Transportation Network Companies), а более точно – ROD (Ride on Demand). Если совсем по-простому, сервис заказа такси. В середине прошлого года одна достаточно крупная западная TNC (далее – «Энтерпрайз») приобрела в России игрока регионального уровня, б.ч. бизнеса которого была сосредоточена в средней полосе России. У этого игрока, назовём его «Такси 666», имелось семейство продуктов собственной разработки: приложения на Андроиде для клиентов и водителей, а также ряд Delphi-приложений, необходимых для управления таким бизнесом (принятие водителей, просмотр статистики и пр.). Отдельно стоит упомянуть Delphi-приложение для операторов, принимающих заявки по телефону. Особенностью, отличавшей модель бизнеса Такси 666 от наиболее известных TNC вроде Uber’а, было то, что телефонные заказы занимали долю около 80%, при этом никакой тенденции к увеличению доли заказов через приложение не наблюдалось. Тем не менее, Энтерпрайз воспринял такое положение вещей не как проблемную ситуацию (за которой много чего скрывалось – см. ниже), а как своего рода конкурентное преимущество для России с её необъятными просторами и в целом ещё низкой (но быстро растущей) долей проникновения мобильного Интернета.
Итак, аудит, в т.ч. технологический, был проведён, и сделка состоялась. Первые ошибки были допущены ещё в тот момент:
Ошибка №1. У агентов Энтерпрайза не было никакого запасного плана на случай, если основатель Такси 666 и его бессменный гендиректор (далее – «Генерал») решил бы покинуть компанию. Искать замену ему даже не начинали. Поняв это, Генерал использовал данный факт для постепенного установления почти полного контроля над агентами. Так «хвост стал вилять собакой».
Ошибка №2. IT-аудит был проведён поверхностно, и не выявил один из двух основных рисков для осуществления наполеоновских планов Энтерпрайза по экспансии вглубь России. Имя этому риску – «Firebird». Все Delphi-приложения были завязаны на использование данной СУБД, выбранной в качестве стандарта главой команды R&D (далее – «Главный Гад», «ГГ») Такси 666 около 15 лет назад. Основной проблемой, в дальнейшем постоянно тревожившей весь комплекс, стала нестабильность работы, обусловленная неспособностью Firebird справиться с резкими пиковыми нагрузками в ЧНН (Часы Наибольшей Нагрузки). Особенно же трудноустранимый характер данная проблема имела в свете наличия в БД хранимых процедур, в которых была сосредоточена б.ч. логики комплекса. Численность этих «хранимок» измерялась сотнями. Был и второй важный риск, не выявленный аудитом. О нём будет сказано ниже.
Как уже было сказано, в Такси 666 существовал собственный R&D отдел, бессменно возглавляемый ГГ. Отношения между ГГ с его отделом и остальной частью бизнеса были сложными. Настолько сложными, что некоторые рядовые члены отдела приторговывали «на сторону» продуктами компании, а сам ГГ незадолго до сделки с Энтерпрайзом сговорился с конкурентом. В результате, спустя без малого 2 месяца со дня закрытия сделки, весь R&D в полном составе снялся с места, сел на самолёт и улетел к конкуренту в далёкие тёплые края. Справедливости ради скажу, что такой форс-мажор трудно было предугадать, и это был риск, который ни в какие матрицы не укладывался. Тем не менее, его можно было минимизировать по крайней мере двумя способами:
Способ №1. Прописать требованием к сделке создание подробной документации комплекса. Оной документации в Такси 666 не существовало от слова «вообще», и как потенциальный риск данный факт также воспринят не был.
Способ №2. Прописать для продавца приобретаемой компании обязанность обеспечить сохранение R&D отдела в течение некоторого переходного периода. С драконовскими санкциями в случае невыполнения. Спецы по M&A, если вы меня читаете – возьмите это на заметку.
Прежде чем продолжить, мне следует сказать пару слов о «наполеоновских планах» Энтерпрайза на момент приобретения Такси 666. Они предполагали увеличение кол-ва городов присутствия с десятков до сотен в срок, измеряемый 1,5-2 годами. Иметь амбициозные планы – это хорошо. Не иметь процесса пересмотра таких планов в случае резкого изменения обстоятельств – очень плохо. Вот так и была сделана ещё одна ошибка:
Ошибка №3. Внезапная полная потеря отдела разработки не была расценена как резкое изменение обстоятельств. Наполеоновские планы остались прежними.
Тем не менее, не признать, что в компании разразился кризис, было невозможно: комплекс элементарно требовал людей для техподдержки. Поскольку медлить было нельзя, агентами, срочно прибывшими из Москвы, были наняты несколько толковых специалистов за умопомрачительные зарплаты. Они смогли стабилизировать работу комплекса. Это, кстати, стало одним из немногих правильных шагов на протяжении всего проекта.
Правильный шаг №1. Под угрозой worst case scenario надо действовать стремительно и не считаться с расходами.
В то же время, после прохождения пика кризисной ситуации не было предпринято необходимых мер по сворачиванию «антикризисного штаба»: замены крайне дорогих спецов на более дешёвых и нахождения постоянного руководителя в отдел. Так была допущена следующая ошибка:
Ошибка №4. Антикризисный IT-менеджер Энтерпрайза был назначен IT-директором Такси 666. Это было плохим решением по целому ряду причин. Во-первых, человеку, имеющему троих маленьких детей, приходилось бывать в командировках по графику «4 дня через 3» на протяжении нескольких месяцев. Во-вторых, этот человек совершенно не знал местной специфики рынка труда в IT-сфере, что привело как к досадным ошибкам (вроде найма Junior Developer’а на позицию Senior’а за з.п. в 100 т.р.), так и в целом очень медленному процессу найма персонала. В-третьих, его назначение прошло «мимо» Генерала, в результате чего работа обоих вскоре дополнительно осложнилась тлеющим конфликтом.
Дальнейшее развитие событий проще всего описать как ряд следствий из ранее сделанных предпосылок:
Ошибки №2 и №3 привели к тому, что вместо необходимой паузы на глубокую переработку архитектуры комплекса, когда все ресурсы команды были бы направлены на решение этой задачи, команда была разделена на тех, кто поддерживал комплекс, остававшийся для них «чёрным ящиком», и тех, кто готовил его к переводу «в облако» (где ждали такие прогрессивные вещи, как удалённое открытие новых городов, распределённые диспетчерские центры, недосягаемость для Кровавой Гэбни и пр.). В результате, за следующие полгода не было качественно решено ни одной из этих задач.
Ошибка №4 обусловила «дыры» в штатном расписании, которые долгое время не давали «расшифровать» тот самый «чёрный ящик» внутри комплекса, что порождало всё новые проблемы со стабильностью его работы. Это злило Генерала и подталкивало его ко всё более активному противодействию планам Энтерпрайза.
Ошибки №1, №2 и №4 привели к тому, что инвесторы из Энтерпрайза, устав от не приносящих никакого профита расходов, смирились, наконец, с крахом наполеоновских планов. Тем самым они полностью уступили инициативу Генералу, который (под предлогом «сокращения расходов») с радостью вычистил лишь недавно доукомплектованный R&D отдел от всех, кто мешал вести бизнес «как раньше». Т.е. без «облаков» и обладающих собственным видением менеджеров. Включая и меня, бывшего Product Manager’а.
Безусловно, примером полного провала данная история не является. Оставшаяся часть команды наверняка сможет, наконец, разобраться в запутанной архитектуре комплекса и стабилизировать его работу. Бизнес продолжит быть прибыльным ещё долгое время – пока не уйдёт старшее поколение, которому привычнее делать заказ голосом, нежели через экран смартфона. В то же время, мечте сделать Best Product силами региональной команды сбыться не суждено…
Для кого я написал этот текст? В первую очередь, для высшего руководящего звена. Коль скоро в вашем распоряжении большие финансовые ресурсы, убедитесь, что управляют ими компетентные менеджеры, которые умеют находить скрытые риски и понимают, что на каждый из них должен быть заранее разработан план действий. Во вторую – для амбициозных молодых людей вроде меня, которые думают, что своими идеями могут изменить мир к лучшему. Прежде чем пускаться в новое предприятие, здраво оцените не только цели и ресурсы ваших партнёров, но также адекватность и профессионализм их менеджеров. Работать надо в команде единомышленников.
К сожалению, нет магической формулы для разработки высококачественного программного обеспечения, но очевидно, что тестирование улучшает его качество, а автоматизация тестирования улучшает качество самого тестирования.
В данной статье мы рассмотрим один из самых популярных фреймворков для автоматизации тестирования с использованием BDD-подхода – Cucumber. Также посмотрим, как он работает и какие средства предоставляет.
Первоначально Cucumber был разработан Ruby-сообществом, но со временем был адаптирован и для других популярных языков программирования. В данной статье рассмотрим работу Cucumber на языке Java.
Gherkin
BDD тесты – это простой текст, на человеческом языке, написанный в форме истории (сценария), описывающей некоторое поведение.
В Cucumber для написания тестов используется Gherkin-нотация, которая определяет структуру теста и набор ключевых слов. Тест записывается в файл с расширением *.feature и может содержать как один, так и более сценариев.
Рассмотрим пример теста на русском языке с использованием Gherkin:
# language: ru
@all
Функция: Аутентификация банковской карты
Банкомат должен спросить у пользователя PIN-код банковской карты
Банкомат должен выдать предупреждение, если пользователь ввел неправильный PIN-код
Аутентификация успешна, если пользователь ввел правильный PIN-код
Предыстория:
Допустим пользователь вставляет в банкомат банковскую карту
И банкомат выдает сообщение о необходимости ввода PIN-кода
@correct
Сценарий: Успешная аутентификация
Если пользователь вводит корректный PIN-код
То банкомат отображает меню и количество доступных денег на счету
@fail
Сценарий: Некорректная аутентификация
Если пользователь вводит некорректный PIN-код
То банкомат выдает сообщение, что введённый PIN-код неверный
Как видно из примера, сценарии описаны на простом нетехническом языке, благодаря чему, понимать и писать их может любой участник проекта.
Обратите внимание на структуру сценария:
1. Получить начальное состояние системы;
2. Что-то сделать;
3. Получить новое состояние системы.
В примере жирным выделены ключевые слова. Ниже представлен полный список ключевых слов на русском языке:
Дано, Допустим, Пусть – используются для описания предварительного, ранее известного состояния;
Когда, Если – используются для описания ключевых действий;
И, К тому же, Также – используются для описания дополнительных предусловий или действий;
Тогда, То – используются для описания ожидаемого результата выполненного действия;
Но, А – используются для описания дополнительного ожидаемого результата;
Функция, Функционал, Свойство – используется для именования и описания тестируемого функционала. Описание может быть многострочным;
Сценарий – используется для обозначения сценария;
Предыстория, Контекст – используется для описания действий, выполняемых перед каждым сценарием в файле;
Структура сценария, Примеры – используется для создания шаблона сценария и таблицы параметров, передаваемых в него.
Ключевые слова, перечисленные в пунктах 1-5, используются для описания шагов сценария, Cucumber их технически не различает. Вместо них можно использовать символ *, но делать так не рекомендуется. У этих слов есть определенная цель, и они были выбраны именно для неё.
Список зарезервированных символов:
# – обозначает комментарии; @ – тэгирует сценарии или функционал; | – разделяет данные в табличном формате; """ – обрамляет многострочные данные.
Сценарий начинается со строки # language: ru. Эта строчка указывает Cucumber, что в сценарии используется русский язык. Если её не указать, фреймворк, встретив в сценарии русский текст, выбросит исключение LexingError и тест не запустится. По умолчанию используется английский язык.
Простой проект
Cucumber-проект состоит из двух частей – это текстовые файлы с описанием сценариев (*.feature) и файлы с реализацией шагов на языке программирования (в нашем случае — файлы *.java).
Для создания проекта будем использовать систему автоматизации сборки проектов Apache Maven.
Первым делом добавим cucumber в зависимости Maven:
info.cukescucumber-java1.2.4
Для запуска тестов будем использовать JUnit (возможен запуск через TestNG), для этого добавим еще две зависимости:
junitjunit4.12info.cukescucumber-junit1.2.4
Библиотека cucumber-junit содержит класс cucumber.api.junit.Cucumber, который позволяет запускать тесты, используя JUnit аннотацию RunWith. Класс, указанный в этой аннотации, определяет каким образом запускать тесты.
Создадим класс, который будет являться точкой входа для наших тестов.
import cucumber.api.CucumberOptions;
import cucumber.api.SnippetType;
import cucumber.api.junit.Cucumber;
import org.junit.runner.RunWith;
@RunWith(Cucumber.class)
@CucumberOptions(
features = "src/test/features",
glue = "ru.savkk.test",
tags = "@all",
dryRun = false,
strict = false,
snippets = SnippetType.UNDERSCORE,
// name = "^Успешное|Успешная.*"
)
public class RunnerTest {
}
Обратите внимание, название класса должно иметь окончание Test, иначе тесты не будут запускаться.
Рассмотрим опции Cucumber:
features – путь к папке с .feature файлами. Фреймворк будет искать файлы в этой и во всех дочерних папках. Можно указать несколько папок, например: features = {«src/test/features», «src/test/feat»};
glue – пакет, в котором находятся классы с реализацией шагов и «хуков». Можно указать несколько пакетов, например, так: glue = {«ru.savkk.test», «ru.savkk.hooks»};
tags – фильтр запускаемых тестов по тэгам. Список тэгов можно перечислить через запятую. Символ ~ исключает тест из списка запускаемых тестов, например ~@fail;
dryRun – если true, то сразу после запуска теста фреймворк проверяет, все ли шаги теста разработаны, если нет, то выдает предупреждение. При false предупреждение будет выдаваться по достижении неразработанного шага. По умолчанию false.
strict – если true, то при встрече неразработанного шага тест остановится с ошибкой. False — неразработанные шаги пропускаются. По умолчанию false.
snippets – указывает в каком формате фреймворк будет предлагать шаблон для нереализованных шагов. Доступны значения: SnippetType.CAMELCASE, SnippetType.UNDERSCORE.
name – фильтрует запускаемые тесты по названиям удовлетворяющим регулярному выражению.
Для фильтрации запускаемых тестов нельзя одновременно использовать опции tags и name.
Создание «фичи»
В папке src/test/features создадим файл с описание тестируемого функционала. Опишем два простых сценария снятия денег со счета — успешный и провальный.
# language: ru
@withdrawal
Функция: Снятие денег со счета
@success
Сценарий: Успешное снятие денег со счета
Дано на счете пользователя имеется 120000 рублей
Когда пользователь снимает со счета 20000 рублей
Тогда на счете пользователя имеется 100000 рублей
@fail
Сценарий: Снятие денег со счета - недостаточно денег
Дано на счете пользователя имеется 100 рублей
Когда пользователь снимает со счета 120 рублей
Тогда появляется предупреждение "На счете недостаточно денег"
Запускаем
Попробуем запустить RunnerTest со следующими настройками:
@RunWith(Cucumber.class)
@CucumberOptions(
features = "src/test/features",
glue = "ru.savkk.test",
tags = "@withdrawal",
snippets = SnippetType.CAMELCASE
)
public class RunnerTest {
}
В консоль появился результат прохождения теста:
Undefined scenarios:
test.feature:6 # Сценарий: Успешное снятие денег со счета
test.feature:12 # Сценарий: Снятие денег со счета - недостаточно денег
2 Scenarios (2 undefined)
6 Steps (6 undefined)
0m0,000s
You can implement missing steps with the snippets below:
@Дано("^на счете пользователя имеется (\\d+) рублей$")
public void наСчетеПользователяИмеетсяРублей(int arg1) throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
@Когда("^пользователь снимает со счета (\\d+) рублей$")
public void пользовательСнимаетСоСчетаРублей(int arg1) throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
@Тогда("^появляется предупреждение \"([^\"]*)\"$")
public void появляетсяПредупреждение(String arg1) throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
Cucumber не нашел реализацию шагов и предложил свои шаблоны для разработки.
Создадим класс MyStepdefs в пакете ru.savkk.test и перенесем в него методы, предложенные фреймворком:
import cucumber.api.PendingException;
import cucumber.api.java.ru.*;
public class MyStepdefs {
@Дано("^на счете пользователя имеется (\\d+) рублей$")
public void наСчетеПользователяИмеетсяРублей(int arg1) throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
@Когда("^пользователь снимает со счета (\\d+) рублей$")
public void пользовательСнимаетСоСчетаРублей(int arg1) throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
@Тогда("^появляется предупреждение \"([^\"]*)\"$")
public void появляетсяПредупреждение(String arg1) throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
}
При запуске теста Cucumber проходит по сценарию шаг за шагом. Взяв шаг, он отделяет ключевое слово от описания шага и пытается найти в Java-классах пакета указанного в опции glue аннотацию с регулярным выражением, подходящим описанию. Найдя совпадение, фреймворк вызывает метод с найденной аннотацией. Если несколько регулярных выражений удовлетворяют описанию шага, фреймворк выбрасывает ошибку.
Как было сказано выше, для Cucumber технически нет отличия в ключевых словах, описывающих шаги, это верно и для аннотации, например:
@Когда("^пользователь снимает со счета (\\d+) рублей$")
и
@Тогда("^пользователь снимает со счета (\\d+) рублей$")
для фреймворка являются одинаковыми.
То, что в регулярных выражениях записано в скобках передается в метод в виде аргумента. Фреймворк самостоятельно определяет, что необходимо передавать из сценария в метод в виде аргумента. Это числа — (\\d+). И текст, экранированный в кавычки — \"([^\"]*)\". Это самые распространённые из передаваемых аргументов.
Ниже в таблице представлены элементы, используемые в регулярных выражениях:
регулярных выражениях:
Выражение
Описание
Соответствие
.
Один любой символ (за исключение
переноса строки)
Ф
2
j
.*
0 или больше любых символов
(за исключением переноса строки)
Abracadabra
789-160-87
,
.+
Один или больше любых символов
(за исключением переноса строки)
Все, что относилось к
предыдущему, за исключением пустой
строки.
.{2}
Любые два символа (за
исключением переноса строки)
Фф
22
$х
JJ
.{1,3}
От одного до трех любых
символов (за исключением переноса
строки)
Жжж
Уу
!
^
Якорь начала строки
^aaa соответствует aaa
^aaa соответствует aaabbb
^aaa не соответствует bbbaaa
$
Якорь конца строки
aaa$ соответствует aaa
aaa$ не соответствует aaabbb
aaa$ соответствует bbbaaa
\d*
[0-9]*
Любое число (или ничего)
12321
5323
\d+
[0-9]+
Любое число
Все, что относилось к
предыдущему, за исключением пустой
строки.
\w*
Любая буква, цифра или нижнее
подчеркивание (или ничего)
_we
_1ee
Gfd4
\s
Пробел, табуляция или перенос
строки
\t, \r
или \n
"[^\"]*"
Любой символ (или ничего) в
кавычках
"aaa"
""
"3213dsa"
?
Делает символ или группу
символов необязательными
abc?
соответствует ab
или abc, но не b или bc
|
Логическое ИЛИ
aaa|bbb
соответствует aaa
или bbb, но не aaabbb
()
Группа. В Cucumber
группа передается в определение шага
в виде аргумента.
(\d+) рублей соответствует 10 рублей,
при этом 10 передается в метод шага в
виде аргумента
(?: )
Не передаваемая группа.
Cucumber не воспринимает
группу как аргумент.
(\d+) (?:рублей|рубля) соответствует 3
рубля, при этом 3 передается в метод,
а «рубля» - нет.
Передача коллекций в аргументы
Часто возникает ситуация, когда из сценария в метод необходимо передать набор однотипных данных – коллекций. Для подобной задачи в Cucumber есть несколько решений:
Фреймворк по умолчанию оборачивает данные, перечисленные через запятую, в ArrayList:
Дано в меню доступны пункты Файл, Редактировать, О программе
@Дано("^в меню доступны пункты (.*)$")
public void вМенюДоступныПункты(List arg) {
// что-то сделать
}
Для замены разделителя, можно воспользоваться аннотацией Delimiter:
Дано в меню доступны пункты Файл и Редактировать и О программе
@Дано("^в меню доступны пункты (.+)$")
public void вМенюДоступныПункты(@Delimiter(" и ") List arg) {
// что-то сделать
}
Данные, записанные в виде таблицы с одной колонкой, Cucumber также может обернуть в ArrayList:
Дано в меню доступны пункты
| Файл |
| Редактировать |
| О программе |
@Дано("^в меню доступны пункты$")
public void вМенюДоступныПункты(List arg) {
// что-то сделать
}
Данные, записанные в таблицу с двумя колонками, Cucumber может обернуть в ассоциативный массив, где данные из первой колонки – это ключ, а из второй – данные:
Дано в меню доступны пункты
| Файл | true |
| Редактировать | false |
| О программе | true |
public void вМенюДоступныПункты(Map arg) {
// что-то сделать
}
Передача данных в виде таблицы с большим количеством колонок возможна двумя способами:
DataTable
Дано в меню доступны пункты
| Файл | true | 5 |
| Редактировать | false | 8 |
| О программе | true | 2 |
@Дано("^в меню доступны пункты$")
public void вМенюДоступныПункты(DataTable arg) {
// что-то сделать
}
DataTable – это класс, который эмулирует табличное представление данных. Для доступа к данным в нем имеется большое количество методов. Рассмотрим некоторые из них:
public List> asMaps(Class keyType,Class valueType)
Конвертирует таблицу в список ассоциативных массивов. Первая строка таблицы используется для именования ключей, остальные как значения:
Дано в меню доступны пункты
| Название | Доступен | Количество подменю |
| Файл | true | 5 |
| Редактировать | false | 8 |
| О программе | true | 2 |
Этот метод делает то же, что и предыдущий метод, за исключением того, что нельзя определить какого типа данные находятся в таблице, всегда возвращает список строк – List. В качестве аргумента метод принимает номер первой строки:
Дано в меню доступны пункты
| Файл | true | 5 |
| Редактировать | false | 8 |
| О программе | true | 2 |
Class Cucumber может создать объекты из табличных данных, переданных из сценария. Существует два способа это сделать.
Создадим для примера класс Menu:
public class Menu {
private String title;
private boolean isAvailable;
private int subMenuCount;
public String getTitle() {
return title;
}
public boolean getAvailable() {
return isAvailable;
}
public int getSubMenuCount() {
return subMenuCount;
}
}
Для первого способа шаг в сценарии запишем в следующем виде:
Дано в меню доступны пункты
| title | isAvailable | subMenuCount |
| Файл | true | 5 |
| Редактировать | false | 8 |
| О программе | true | 2 |
Реализация:
@Дано("^в меню доступны пункты$")
public void вМенюДоступныПункты(List
Вывод в консоль:
Файл true 5
Редактировать false 8
О программе true 2
Фреймворк создает связанный список объектов из таблицы с тремя колонками. В первой строке таблицы должны быть указаны наименования полей класса, создаваемого объекта. Если какое-то поле не указать, оно не будет инициализировано.
Для второго способа приведем шаг сценария к следующему виду:
Дано в меню доступны пункты
| title | Файл | Редактировать | О программе |
| isAvailable | true | false | true |
| subMenuCount | 5 | 8 | 2 |
А в аргументе описания шага используем аннотацию @Transpose.
@Дано("^в меню доступны пункты$")
public void вМенюДоступныПункты(@Transpose List
Cucumber, как и в предыдущем примере, создаст связанный список объектов, но, в данном случае, наименования полей записывается в первой колонке таблицы.
Многострочные аргументы
Для передачи многострочных данных в аргумент метода, их необходимо экранировать тремя двойными кавычками:
Тогда отображается форма с текстом
"""
На ваш номер телефона был выслан одноразовый пароль.
Для подтверждения платежа необходимо ввести полученный
одноразовый пароль.
"""
Данные в метод приходят в виде объекта класса String:
@Тогда("^отображается форма с текстом$")
public void отображаетсяФормаСТекстом(String expectedText) {
// что-то сделать
}
Date
Фреймворк самостоятельно приводит данные из сценария к типу данных, указанному в аргументе метода. Если это невозможно, то выбрасывает исключение ConversionException. Это справедливо и для классов Date и Calendar. Рассмотрим пример:
Дано дата создания документа 04.05.2017
@Дано("^дата создания документа (.+)$")
public void датаСозданияДокумента (Date arg) {
// что-то сделать
}
Все прекрасно сработало, Cucumber преобразовал 04.05.2017 в объект класса Date со значением «Thu May 04 00:00:00 EET 2017».
Рассмотрим еще один пример:
Дано дата создания документа 04-05-2017
@Дано("^дата создания документа (.+)$")
public void датаСозданияДокумента (Date arg) {
// что-то сделать
}
Дойдя до этого шага, Cucumber выбросил исключение:
cucumber.deps.com.thoughtworks.xstream.converters.ConversionException: Couldn't convert "04-05-2017" to an instance of: [class java.util.Date]
Почему первый пример сработал, а второй нет?
Дело в том, что в Cucumber встроена поддержка форматов дат чувствительных к текущей локали. Если необходимо записать дату в формате, отличающемся от формата текущей локали, нужно использовать аннотацию Format:
Дано дата создания документа 04-05-2017
@Дано("^дата создания документа (.+)$")
public void датаСозданияДокумента (@Format("dd-MM-yyyy") Date arg) {
// что-то сделать
}
Структура сценария
Бывают случаи, когда необходимо запустить тест несколько раз с различным набором данных, в таких случая на помощь приходит конструкция «Структура сценария»:
# language: ru
@withdrawal
Функция: Снятие денег со счета
@success
Структура сценария: Успешное снятие денег со счета
Дано на счете пользователя имеется <изначально> рублей
Когда пользователь снимает со счета <снято> рублей
Тогда на счете пользователя имеется <осталось> рублей
Примеры:
| изначально | снято | осталось |
| 10000 | 1 | 9999 |
| 9999 | 9999 | 0 |
Суть данной конструкции заключается в том, что в места, обозначенные символами <>, вставляются данные из таблицы Примеры. Тест будет запускаться поочередно для каждой строки из данной таблицы. Названия колонок должно совпадать с названием мест вставки данных.
Использование хуков
Cucumber поддерживает хуки (hooks) – методы, запускаемые до или после сценария. Для их обозначения используется аннотация Before и After. Класс с хуками должен находиться в пакете, указанном в опциях фреймворка. Пример класса с хуками:
import cucumber.api.java.After;
import cucumber.api.java.Before;
public class Hooks {
@Before
public void prepareData() {
//подготовить данные
}
@After
public void clearData() {
//очистить данные
}
}
Метод c аннотацией Before будет запускаться перед каждым сценарием, After – после.
Порядок выполнения
Хукам можно задать порядок, в котором они будут выполняться. Для этого необходимо в аннотации указать параметр order. По умолчанию значение order равно 10000, чем меньше это значение, тем раньше выполнится метод:
@Before(order = 10)
public void connectToServer() {
//подключиться к серверу
}
@Before(order = 20)
public void prepareData() {
//подготовить данные
}
В данном примере первым выполнится метод connectToServer(), затем prepareData().
Тэгирование
В параметре value можно указать тэги сценариев, для которых будут отрабатывать хуки. Символ ~ означает «за исключением». Пример:
@Before(value = "@correct", order = 30)
public void connectToServer() {
//сделай что-нибудь
}
@Before(value = "~@fail", order = 20)
public void prepareData() {
//сделай что-нибудь
}
Метод connectToServer будет выполнен для всех сценариев с тэгом correct, метод prepareData для всех сценариев за исключением сценариев с тэгом fail.
Scenario class
Если в определении метода-хука в аргументе указать объект класса Scenario, то в данном методе можно будет узнать много полезной информации о запущенном сценарии, например:
# language: ru
@all
Функция: Аутентификация банковской карты
Банкомат должен спросить у пользователя PIN-код банковской карты
Банкомат должен выдать предупреждение если пользователь ввел неправильный PIN-код
Аутентификация успешна если пользователь ввел правильный PIN-код
Предыстория:
Допустим пользователь вставляет в банкомат банковскую карту
И банкомат выдает сообщение о необходимости ввода PIN-кода
@correct
Сценарий: Успешная аутентификация
Если пользователь вводит корректный PIN-код
То банкомат отображает меню и количество доступных денег на счету
Cucumber — очень мощный и гибкий фреймворк, который можно использовать в связке со многими другими популярными инструментами. Например, с Selenium – фреймворком для автоматизации веб-приложений, или Yandex.Allure – библиотекой, позволяющей создавать удобные отчеты.
Всем удачи в автоматизации.
 В данной статье я бы хотел поделиться методом быстрой валидации полей с помощью разметки и стилей. Данный метод не является кроссбраузерным и рекомендуется к использованию только как дополнительная фича. По ходу статьи мы будем уменьшать наши шансы на кроссбраузерность, но повышать функциональность.
В данной статье я бы хотел поделиться методом быстрой валидации полей с помощью разметки и стилей. Данный метод не является кроссбраузерным и рекомендуется к использованию только как дополнительная фича. По ходу статьи мы будем уменьшать наши шансы на кроссбраузерность, но повышать функциональность.



























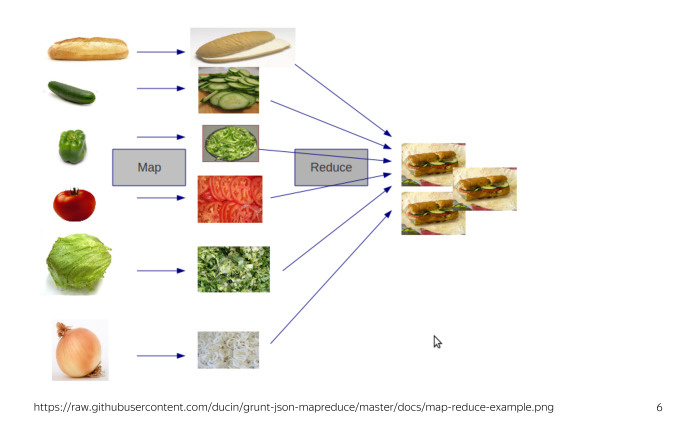

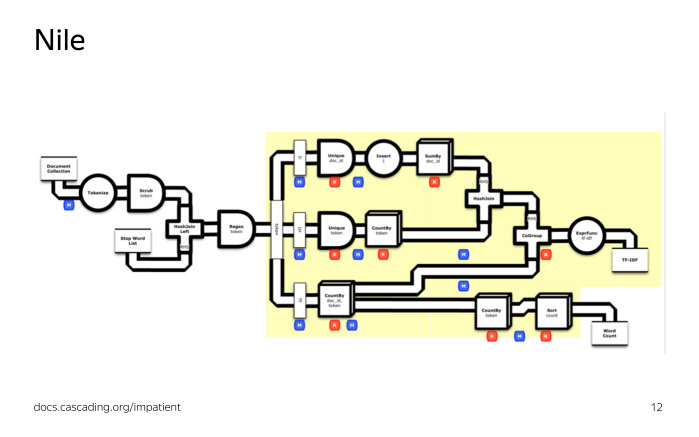


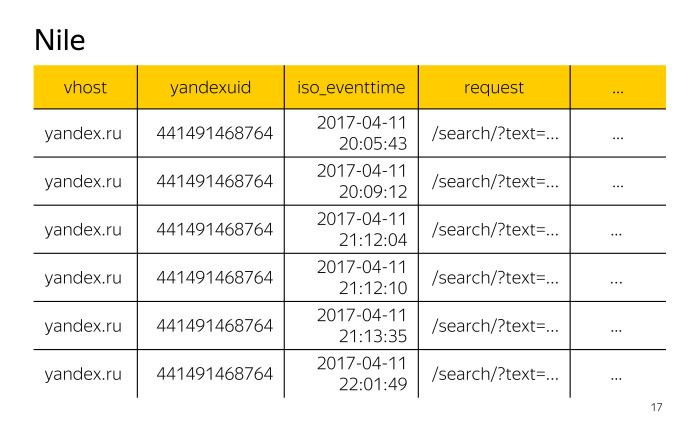
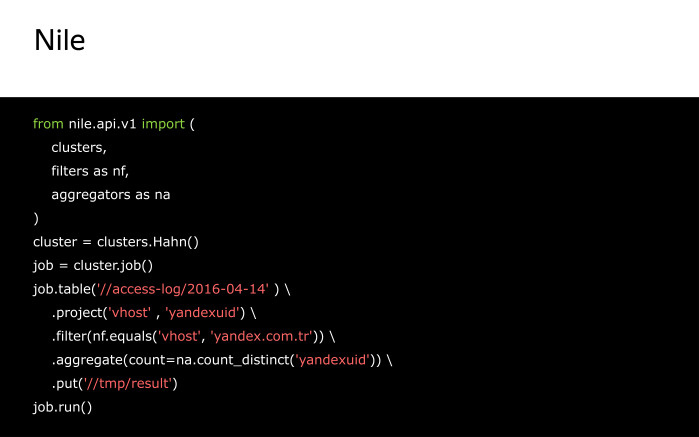
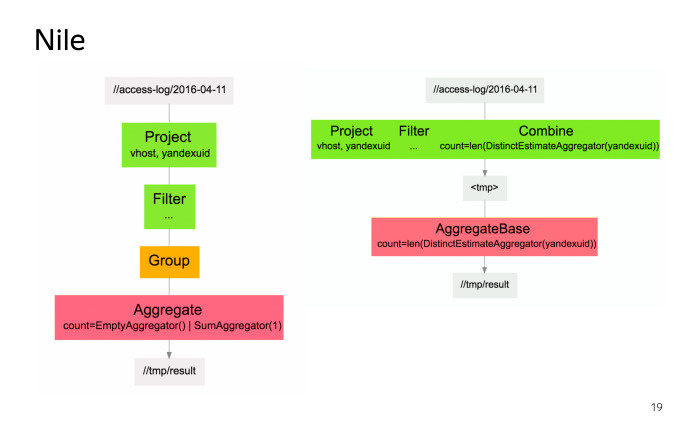

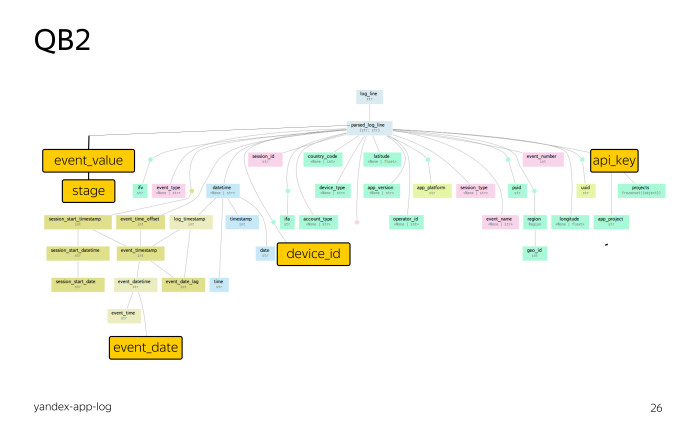
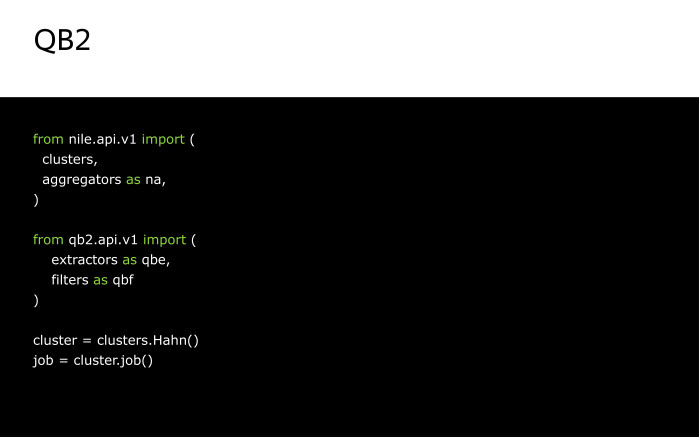

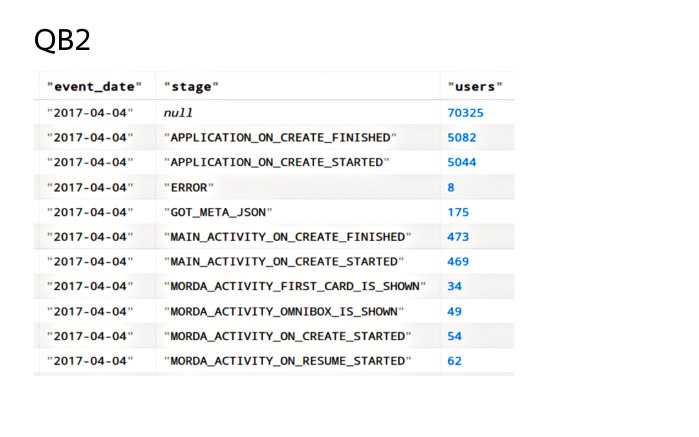




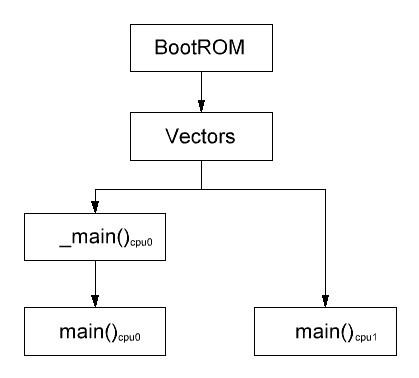
 / фото офиса компании
/ фото офиса компании
 В этой статье я хочу поговорить об основных принципах моделирования бизнеса, о тех подходах, которые применяются в этой сфере, и на основе которых создаются языки моделирования и нотации.
В этой статье я хочу поговорить об основных принципах моделирования бизнеса, о тех подходах, которые применяются в этой сфере, и на основе которых создаются языки моделирования и нотации. Функциональное моделирование рассматривает бизнес как функцию (лат. functio — совершение, исполнение) или иными словами «черный ящик». В функциональной модели функция не имеет временной последовательности, а только точку входа и точку выхода. Функциональное моделирование помогает рассматривать бизнес-модель с с точки зрения результативности, т.е. при моделировании мы исходим из того, что имеем на входе, и того, что желаем получить на выходе.
Функциональное моделирование рассматривает бизнес как функцию (лат. functio — совершение, исполнение) или иными словами «черный ящик». В функциональной модели функция не имеет временной последовательности, а только точку входа и точку выхода. Функциональное моделирование помогает рассматривать бизнес-модель с с точки зрения результативности, т.е. при моделировании мы исходим из того, что имеем на входе, и того, что желаем получить на выходе. О процессном моделировании я буду рассказывать с точки зрения нотации BPMN, как одного из наиболее распространенных стандартов процессного моделирования. При этом я полностью согласен, что существует множество языков моделирования и различных систем. И каждый может пользоваться тем, что ему удобнее. Но все же BPMN — это уже сложившийся стандарт процессного моделирования, а потому его я и беру за основу в описании.
О процессном моделировании я буду рассказывать с точки зрения нотации BPMN, как одного из наиболее распространенных стандартов процессного моделирования. При этом я полностью согласен, что существует множество языков моделирования и различных систем. И каждый может пользоваться тем, что ему удобнее. Но все же BPMN — это уже сложившийся стандарт процессного моделирования, а потому его я и беру за основу в описании. При создании ментальных моделей специалист подходит к моделированию не как к процессу или набору функций, а как к некому набору связанных между собой понятий. Для наглядности я приведу пример — ментальная карта понятия “Процедура снабжения” (см. рисунок).
При создании ментальных моделей специалист подходит к моделированию не как к процессу или набору функций, а как к некому набору связанных между собой понятий. Для наглядности я приведу пример — ментальная карта понятия “Процедура снабжения” (см. рисунок).