Перевод книги Appium Essentials. Глава 4 |

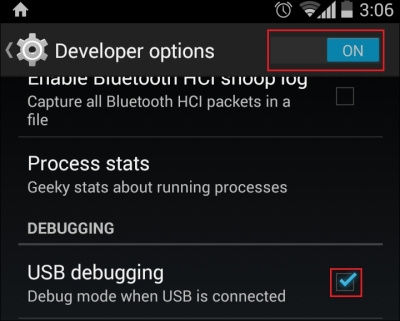
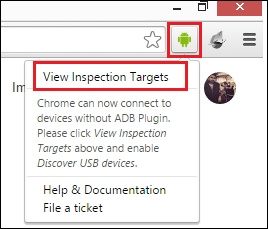
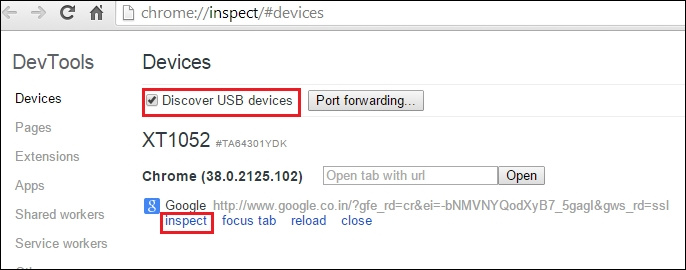
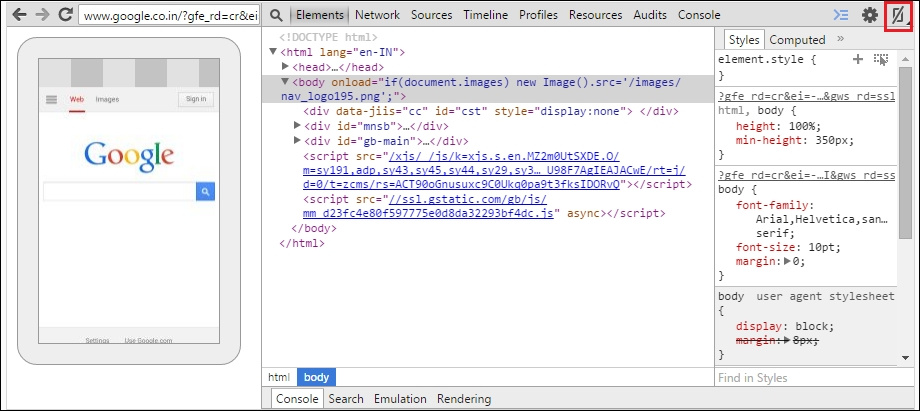
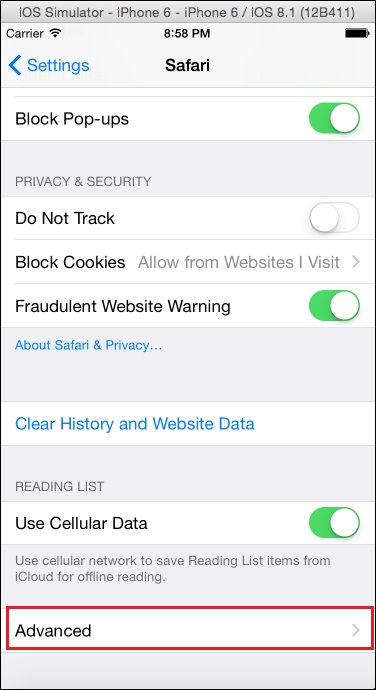
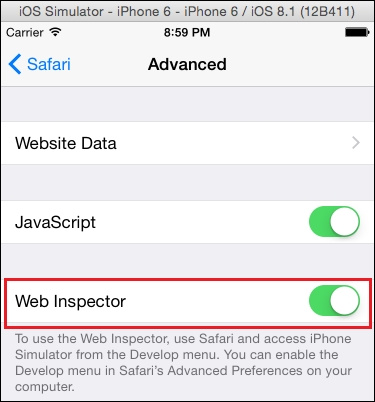
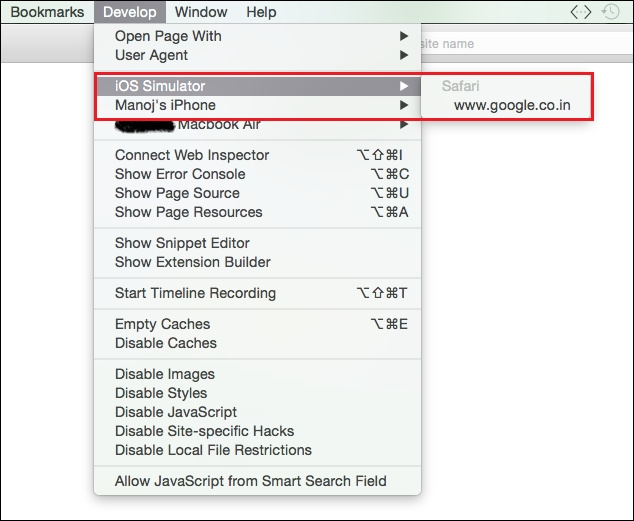
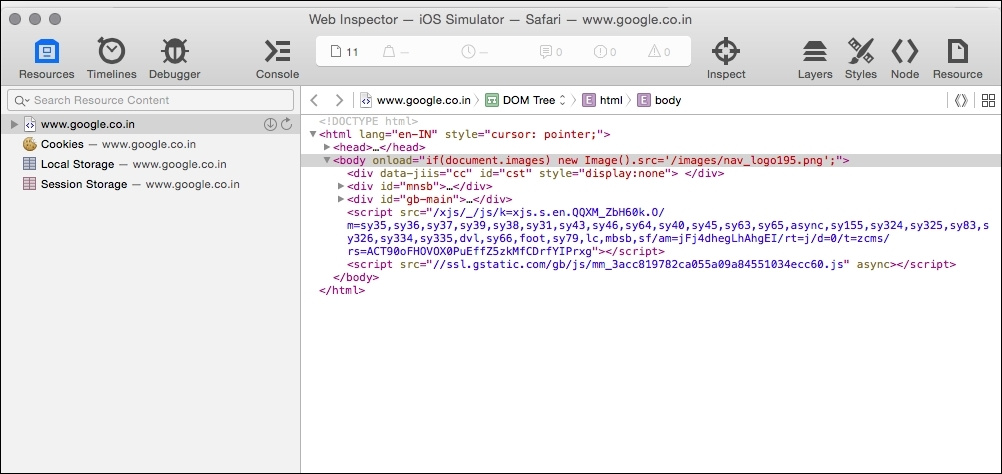
findElement(By.id(String id));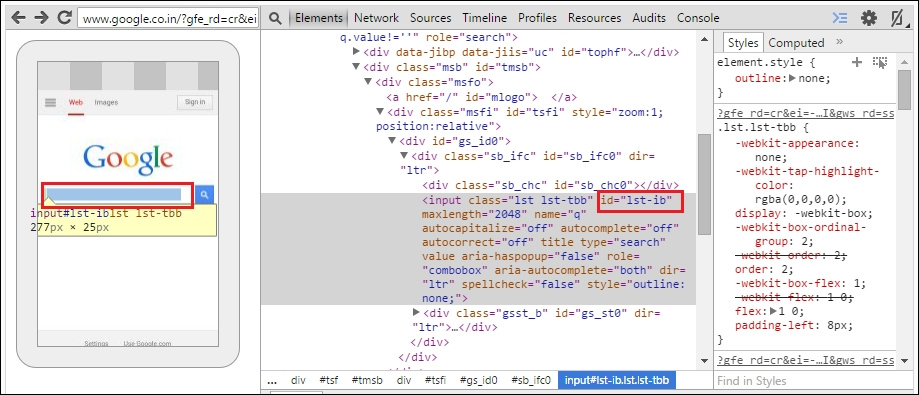
WebElement searchBox=driver.findElement(By.id("lst-ib"));searchBox.sendKeys("Manoj Hans");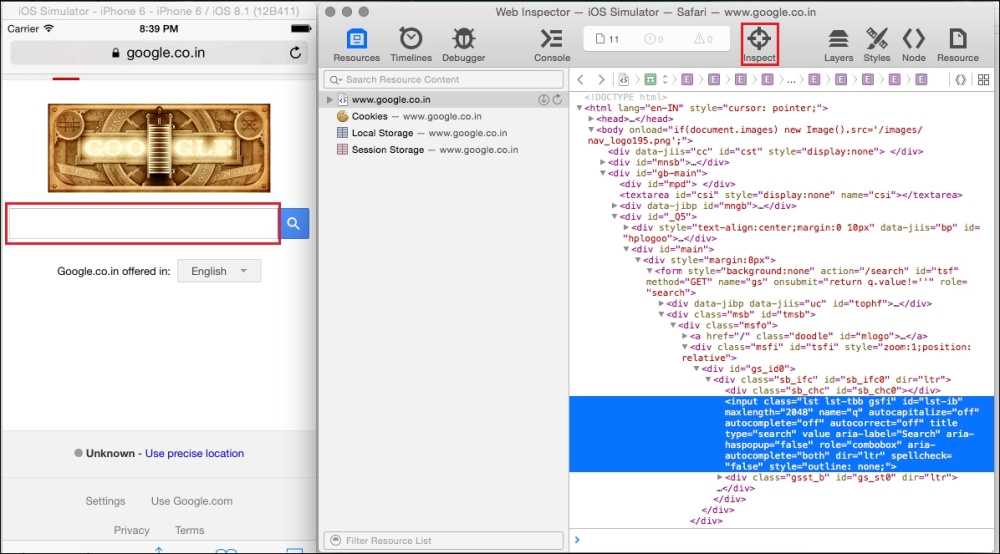
findElement(By.name(String Name));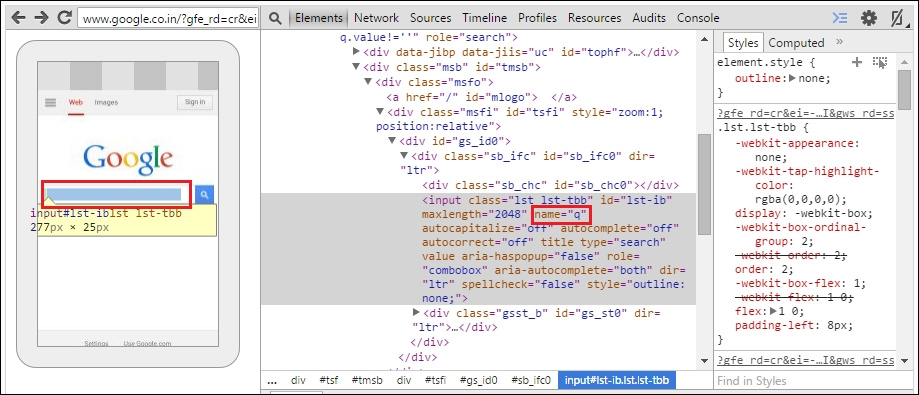
WebElement searchBox=driver.findElement(By.name("q"));findElement(By.linkText(String text));WebElement imagesLink=driver.findElement(By.linkText("Images"));findElement(By.xpath(String XPath));WebElement searchBox=driver.findElement(By.xpath("//input[@id='lst-ib']"));findElement(By.cssSelector(String cssSelector);WebElement searchBox=driver.findElement(By.cssSelector("#lst-ib"));
findElement(By.id(String id));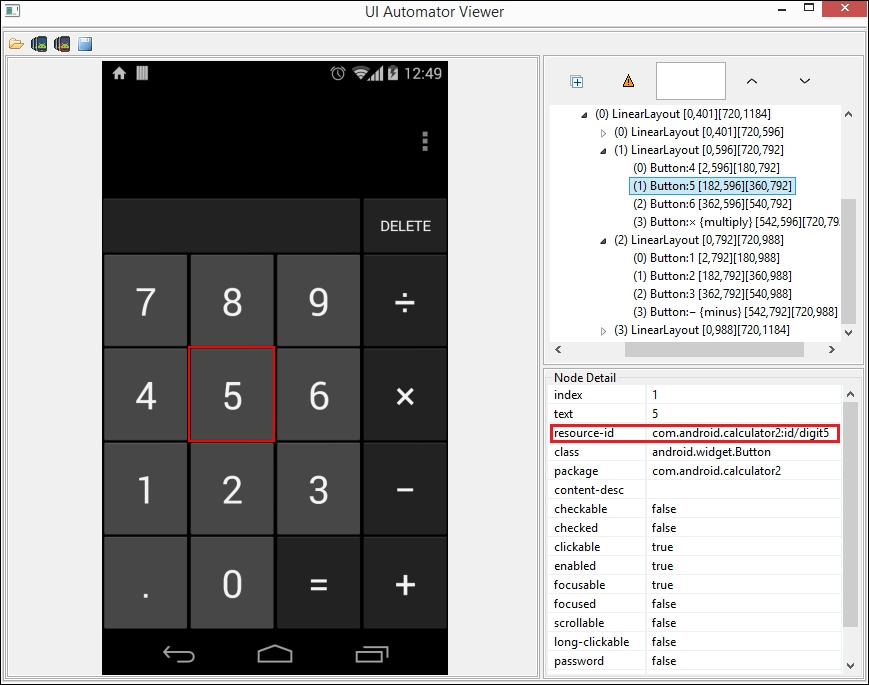
WebElement digit_5=driver.findElement(By.id("com.android.calculator2:id/digit5"));digit_5.click();findElement(By.name(String Name));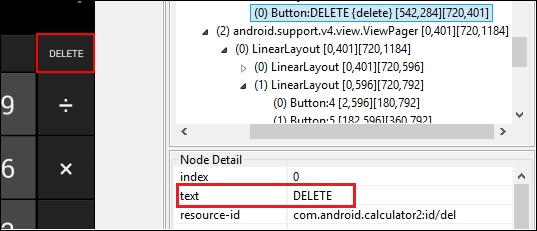
delete.click();
WebElement delete=driver.findElement(By.name("DELETE"));findElement(By.className(String ClassName));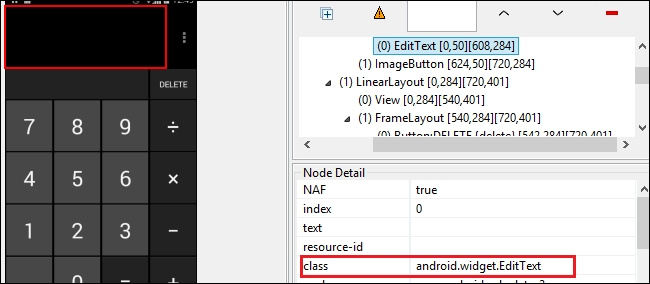
WebElement editBox=driver.findElement(By.className("android.widget.EditText"));editBox.getText();List editBox=driver.findElements(By.className("android.widget.Button"));
editBox.get(1).click(); findElement(By.AccessibilityId(String AccId));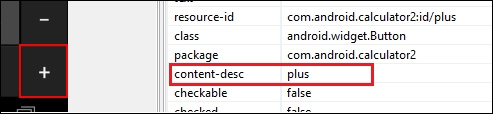
WebElement plusSign=driver. findElementByAccessibilityId("plus");
plusSign.click();findElement(By.AndroidUIAutomator(String UIAuto));WebElement equal=driver. findElementByAndroidUIAutomator("new UiSelector().resourceId(\"com.android.calculator2:id/equal\")";WebElement equal=driver. findElementBy.AndroidUIAutomator("new UiSelector().description(\"equals\")");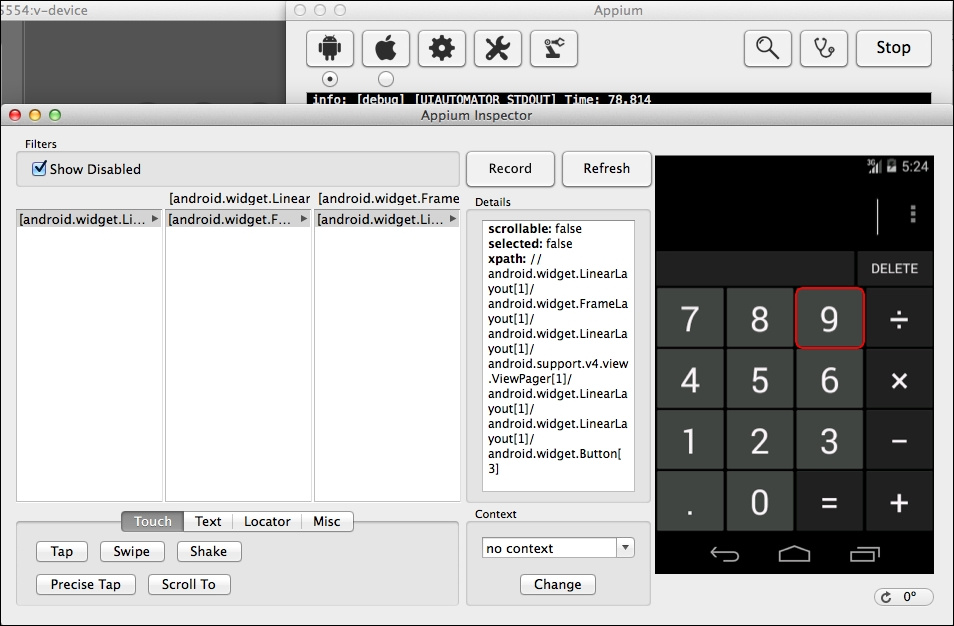
findElement(By.xpath(String XPath));WebElement digit_9=driver.findElement(By.xpath("//android.widget.LinearLayout[1]/ android.widget.FrameLayout[1]/ android.widget.LinearLayout[1]/ android.support.v4.view.viewPager[1]/ android.widget.LinearLayout[1]/ android.widget.LinearLayout[1]/ android.widget.Button[3]"));
findElement(By.name(String Name));WebElement editBox=driver.findElement(By.name("IntegerB"));editBox.sendKeys("12");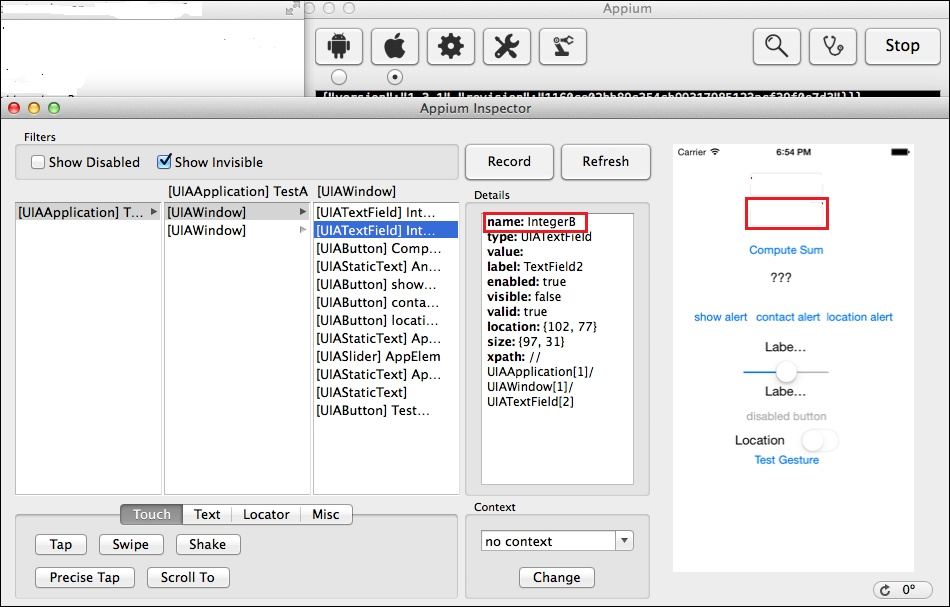
findElements(By.IosUIAutomation(String IosUIAuto));WebElement editBox=driver. findElements(By.IosUIAutomation(".elements()[0]")); //Здесь '0' - это индекс элементаeditBox.sendKeys("10");WebElement editBox=driver. findElements(By.IosUIAutomation(".textFields()[0]"));|
Метки: author EreminD читальный зал appium automation testing тестирование тестирование мобильных приложений |
[Из песочницы] Программный сбор данных о котировках |

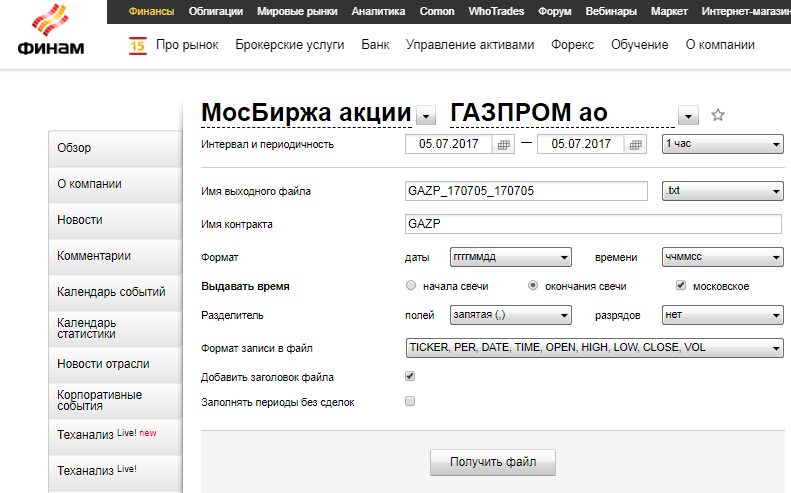

__http://export.finam.ru/POLY_170620_170623.txt?market=1&em=175924&code=POLY&apply=0&df=20&mf=5&yf=2017&from=20.06.2017&dt=23&
mt=5&yt=2017&to=23.06.2017&p=8&f=POLY_170620_170623&e=.txt&cn=POLY&dtf=1&tmf=1&
MSOR=1&mstime=on&mstimever=1&sep=1&sep2=1&datf=1&at=1
Finam.IssuerProfile.Main.issue = {"quote": {"id": 175924, "code": "POLY", "fullUrl": "moex-akcii/polymetal-international-plc", "title": "Polymetal", "decp": 1, "testDriveEnabled": false, "market": {"id": 1, "title": "МосБиржа акции", "volumeEnabled": true},"info": {"decp": 1, "last": 680, "pchange": 1.87266, "change": 12.50001, "bid": null, "ask": null, "open": 668, "high": 686, "low": 666, "close": 667.5, "volume": 53037, "date": "05.07.2017 18:47:18", "weekMin": 653.5, "weekMax": 688, "monthMin": 653.5, "monthMax": 753, "yearMin": 572, "yearMax": 1009.5,"currency": "руб.","volumeCode": "шт."},"
/*…тут еще куча важных параметров, но они нам не нужны …*/
175924, "url": "/profile/moex-akcii/polymetal-international-plc/secondary/", }, "corporativeEvents": {"quote": 175924, "url": "/profile/moex-akcii/polymetal-international-plc/corporate/", }, "blogsAndGraphs": {"quote": 175924, "url": "__http://whotrades.com/markets/instrument/polymetal-international-plc", "count": "1", "pageSize": 1, "pageNumber": 1, "pagesCount": 1}}};

__http://export.finam.ru/POLY_170620_170623.txt?market=1&em=175924&code=POLY&apply=0&df=20&mf=5&yf=2017&from=20.06.2017&dt=23&
mt=5&yt=2017&to=23.06.2017&p=8&f=POLY_170620_170623&e=.txt&cn=POLY&dtf=1&tmf=1&
MSOR=1&mstime=on&mstimever=1&sep=1&sep2=1&datf=1&at=1
# -*- coding: utf-8 -*-
"""
Created on Sat Jun 24 01:46:38 2017
@author: optimusqp
"""
import urllib
code='POLY';
e='.txt';
market='1'
em='175924';
e='.txt';
p='3';
yf='2017';
yt='2017';
month_start='05';
day_start='20';
month_end='06';
day_end='20';
dtf='1';
tmf='1';
MSOR='1';
mstimever='0'
sep='1';
sep2='3';
datf='1';
at='1';
year_start=yf[2:];
year_end=yt[2:];
mf=(int(month_start.replace('0','')))-1;
mt=(int(month_end.replace('0','')))-1;
df=(int(day_start.replace('0','')))-1;
dt=(int(day_end.replace('0','')))-1;
def quotes(code,year_start,month_start,day_start,year_end,month_end,day_end,e,market,em,df,mf,yf,dt,mt,yt,p,dtf,tmf,MSOR,mstimever,sep,sep2,datf,at):
page = urllib.urlopen('http://export.finam.ru/'+str(code)+'_'+str(year_start)+str(month_start)+str(day_start)+'_'+str(year_end)+str(month_end)+str(day_end)+str(e)+'?market='+str(market)+'&em='+str(em)+'&code='+str(code)+'&apply=0&df='+str(df)+'&mf='+str(mf)+'&yf='+str(yf)+'&from='+str(day_start)+'.'+str(month_start)+'.'+str(yf)+'&dt='+str(dt)+'&mt='+str(mt)+'&yt='+str(yt)+'&to='+str(day_end)+'.'+str(month_end)+'.'+str(yt)+'&p='+str(p)+'&f='+str(code)+'_'+str(year_start)+str(month_start)+str(day_start)+'_'+str(year_end)+str(month_end)+str(day_end)+'&e='+str(e)+'&cn='+str(code)+'&dtf='+str(dtf)+'&tmf='+str(tmf)+'&MSOR='+str(MSOR)+'&mstimever='+str(mstimever)+'&sep='+str(sep)+'&sep2='+str(sep2)+'&datf='+str(datf)+'&at='+str(at))
f = open("company_quotes.txt", "w")
content = page.read()
f.write(content)
f.close()
qq = quotes(code,year_start,month_start,day_start,year_end,month_end,day_end,e,market,em,df,mf,yf,dt,mt,yt,p,dtf,tmf,MSOR,mstimever,sep,sep2,datf,at)
|
Метки: author optimusqp машинное обучение python data mining программирование котировки данные парсинг финам трейдер phython java анализ |
Дайджест интересных материалов для мобильного разработчика #210 (03 июля — 09 июля) |

 |
Тестирование и обзор Core ML |
 |
Сказ о том, как Android-разработчика спамеры задолбали, и что и из этого вышло |
 iOS
iOS Лучшие книги по Swift 2017 Топ-5 iOS-библиотек июля Руководство по Safe Area Layout
Лучшие книги по Swift 2017 Топ-5 iOS-библиотек июля Руководство по Safe Area Layout TNTutorialManager: интерактивные туториалы внутри iOS-приложения ARTetris: тетрис с помощью ARKit и SceneKit Legend Wings: Open Source игра на Swift и SpriteKit LGButton: красивые кнопки ZIPFoundation: библиотека для работы с архивами AXPhotoViewer: красивый просмотрщик для фотографий
TNTutorialManager: интерактивные туториалы внутри iOS-приложения ARTetris: тетрис с помощью ARKit и SceneKit Legend Wings: Open Source игра на Swift и SpriteKit LGButton: красивые кнопки ZIPFoundation: библиотека для работы с архивами AXPhotoViewer: красивый просмотрщик для фотографий Android Android и сохранение данных в безопасности Преимущества RxJava (примеры на Kotlin) Топ-5 Android-библиотеку июля Маленький секрет android:animateLayoutChanges Инструменты и библиотеки для распространенных задач Контролируем размер APK используя нативные библиотеки Android NDK: вызов Kotlin из нативного кода RubberStamp: водяные знаки для изображений MultiContactPicker: выбор контактов в материальном дизайне FABsMenu: плавающая кнопка с меню SQL Brite: оболочка для SQLiteOpenHelper и ContentResolver
Android Android и сохранение данных в безопасности Преимущества RxJava (примеры на Kotlin) Топ-5 Android-библиотеку июля Маленький секрет android:animateLayoutChanges Инструменты и библиотеки для распространенных задач Контролируем размер APK используя нативные библиотеки Android NDK: вызов Kotlin из нативного кода RubberStamp: водяные знаки для изображений MultiContactPicker: выбор контактов в материальном дизайне FABsMenu: плавающая кнопка с меню SQL Brite: оболочка для SQLiteOpenHelper и ContentResolver Windows
Windows Разработка Как создавать скилы для Amazon Echo Show Индустрия промышленного UX 2017-2018 Открытая платформа для автономных автомобилей Apollo Чему я научился за 5 лет разработки Исследование игрового пространства Тестирование дейтинг приложений ELF: платформа для тренировки Ai в играх Как мы сделали игру за 7 недель и не сошли с ума
Разработка Как создавать скилы для Amazon Echo Show Индустрия промышленного UX 2017-2018 Открытая платформа для автономных автомобилей Apollo Чему я научился за 5 лет разработки Исследование игрового пространства Тестирование дейтинг приложений ELF: платформа для тренировки Ai в играх Как мы сделали игру за 7 недель и не сошли с ума Аналитика, маркетинг и монетизация Почему онбординг самая важная часть вашей стратегии роста Запуск приложения с маленьким бюджетом Геймификация в 2017: 5 ключевых приницпов Как реализовать рост за 0 долларов Минимально жизнеспособная аналитика KPI для ASO
Аналитика, маркетинг и монетизация Почему онбординг самая важная часть вашей стратегии роста Запуск приложения с маленьким бюджетом Геймификация в 2017: 5 ключевых приницпов Как реализовать рост за 0 долларов Минимально жизнеспособная аналитика KPI для ASO Устройства, IoT, AI
Устройства, IoT, AI|
|
[recovery mode] Настройка BGP Looking glass на базе OpenBSD 6.1 |
ext_addr="0.0.0.0"
ext_addr6="::"
prefork 2
domain="lg.example.net"
server $domain {
listen on $ext_addr port 80
listen on $ext_addr6 port 80
block return 301 "https://$domain$REQUEST_URI"
}
server $domain {
listen on $ext_addr tls port 443
listen on $ext_addr6 tls port 443
tls {
certificate "/etc/ssl/server.crt"
key "/etc/ssl/private/server.key"
}
location "/cgi-bin/*" {
fastcgi
root ""
}
location "/" {
block return 302 "/cgi-bin/bgplg"
}
}
AS XXX
fib-update no
listen on 0.0.0.0
route-collector yes
router-id A.B.C.D
socket "/var/www/run/bgpd.rsock" restricted
neighbor D.E.F.G {
remote-as XXX
descr "r1"
announce none
}
neighbor D:E:F::G {
remote-as XXX
descr "r1v6"
announce none
}
chmod 0555 /var/www/cgi-bin/bgplg chmod 0555 /var/www/bin/bgpctl mkdir /var/www/etc cp /etc/resolv.conf /var/www/etc chmod 4555 /var/www/bin/ping* /var/www/bin/traceroute*
ext_if = "vio0" table{ 192.168.0.0/24 2001:67c:aaaa::/64 } table { 192.168.2.0/24 2001:67c:bbbb::/64 } set block-policy drop set skip on lo #block return # block stateless traffic #pass # establish keep-state match in all scrub (no-df random-id max-mss 1440) block all pass out quick pass in on egress proto tcp from to (egress) port { 22 } pass in on egress proto tcp from to (egress) port { 179 } pass in on egress proto tcp from any to (egress) port { 80 443 } pass in on egress proto icmp from any to (egress) pass in on egress proto icmp6 from any to (egress)
rcctl enable httpd rcctl enable slowcgi rcctl enable bgpd rcctl start httpd rcctl start slowcgi rcctl start bgpd pfctl -f /etc/pf.conf
|
Метки: author ugenk сетевые технологии openbsd bgp looking glass |
Автоматизация IP-сети. Часть2 – Мониторинг скорости открытия Веб страниц |
 Продолжаем серию статей по доступной автоматизации в IP-сети. У каждого из инженеров, работающих с сетью Интернет, так или иначе периодически возникает потребность измерения скорости загрузки Веб странницы. Для этого существует множество инструментов, один из них это утилита wget. Например, для измерения скорости загрузки можно из консоли (Unix/Linux) воспользоваться такой командой:
Продолжаем серию статей по доступной автоматизации в IP-сети. У каждого из инженеров, работающих с сетью Интернет, так или иначе периодически возникает потребность измерения скорости загрузки Веб странницы. Для этого существует множество инструментов, один из них это утилита wget. Например, для измерения скорости загрузки можно из консоли (Unix/Linux) воспользоваться такой командой:[root@localhost ~]# wget -E -H -p -Q300K --user-agent=Mozilla --no-cache --no-cookies --delete-after --timeout=15 --tries=2 habrahabr.ru 2>&1 | grep Downloaded
Downloaded: 7 files, 411K in 0.3s (1.22 MB/s)#!/usr/bin/env python
# -*- coding: utf-8 -*-
import datetime
import re
import os
import subprocess
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("-h_page", "--hostname_page", dest = "hostname_page")
args = parser.parse_args()
curent_time=str(datetime.datetime.now().strftime("%Y-%m-%d_%H:%M:%S_"))
pid=os.getpid()
fweb=open('/usr/TEST_Script/TMP_FILES/web_temp'+curent_time+str(pid)+'.txt', 'w')
web=subprocess.call(["timeout 120 wget -E -H -p -Q300K --user-agent=Mozilla --no-cache --no-cookies --delete-after --timeout=15 --tries=2 "+args.hostname_page+" 2>&1 | grep '\([0-9.]\+ [KM]B/s\)'"], bufsize=0, shell=True, stdout=(fweb))
fweb.close()
fweb=open('/usr/TEST_Script/TMP_FILES/web_temp'+curent_time+str(pid)+'.txt', 'r')
data=fweb.read()
os.remove('/usr/TEST_Script/TMP_FILES/web_temp'+curent_time+str(pid)+'.txt')
speed_temp=re.findall(r's \((.*?)B/s', str(data))
speed_temp_si=re.findall(r's \((.*?) [KM]B/s', str(data))
try:
if re.findall(r'M', str(speed_temp))==[] and re.findall(r'K', str(speed_temp))==[]:
speed_="{0:.3f}".format(float(speed_temp_si[0])*0.001*8)
elif re.findall(r'M', str(speed_temp))!=[]:
speed_="{0:.3f}".format(float(speed_temp_si[0])*1000*8)
elif re.findall(r'K', str(speed_temp))!=[]:
speed_="{0:.3f}".format(float(speed_temp_si[0])*1*8)
except:
speed_='no_data'
print ('web_speed_test:'+speed_)
[root@localhost ~]# python3.3 /usr/TEST_Script/web_open.py -h_page habrahabr.ru
web_speed_test:10160.000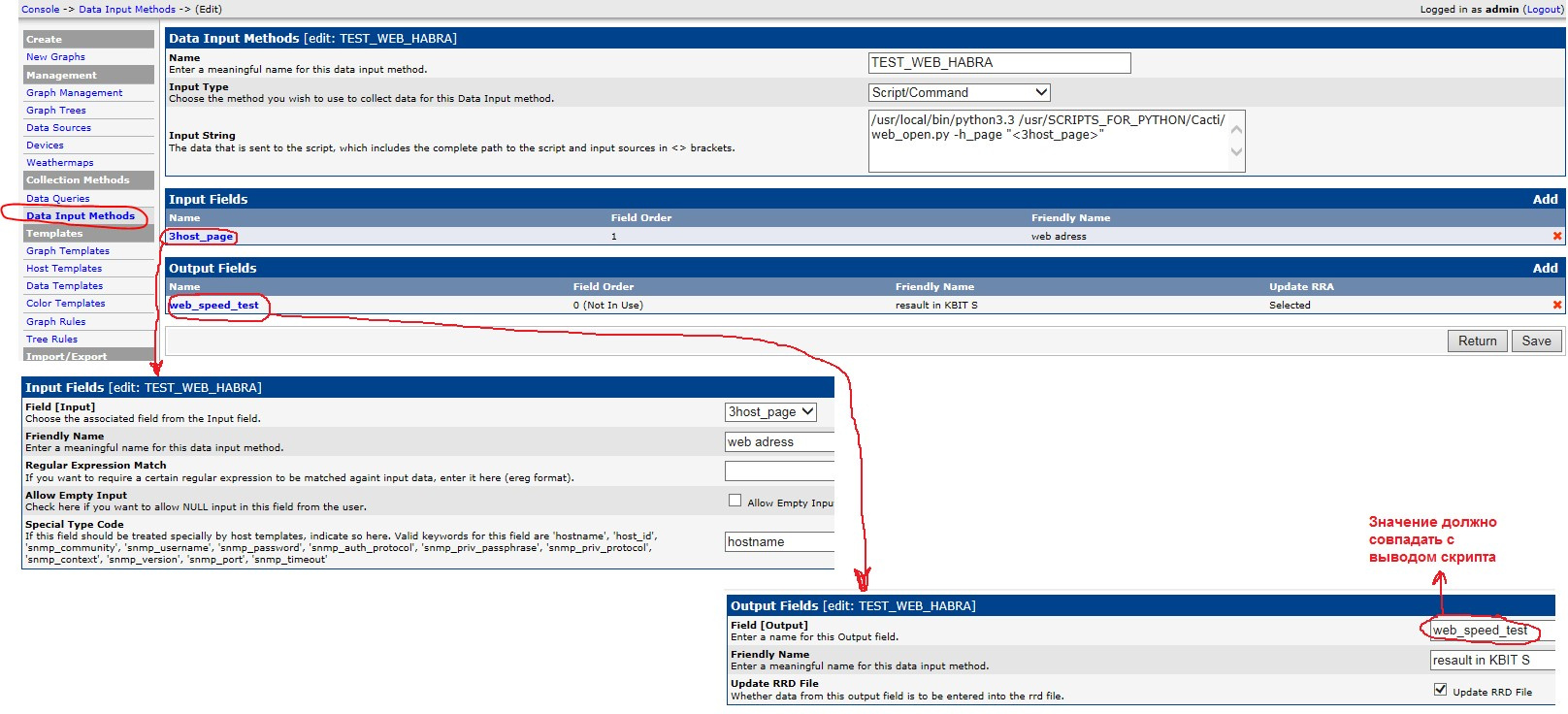
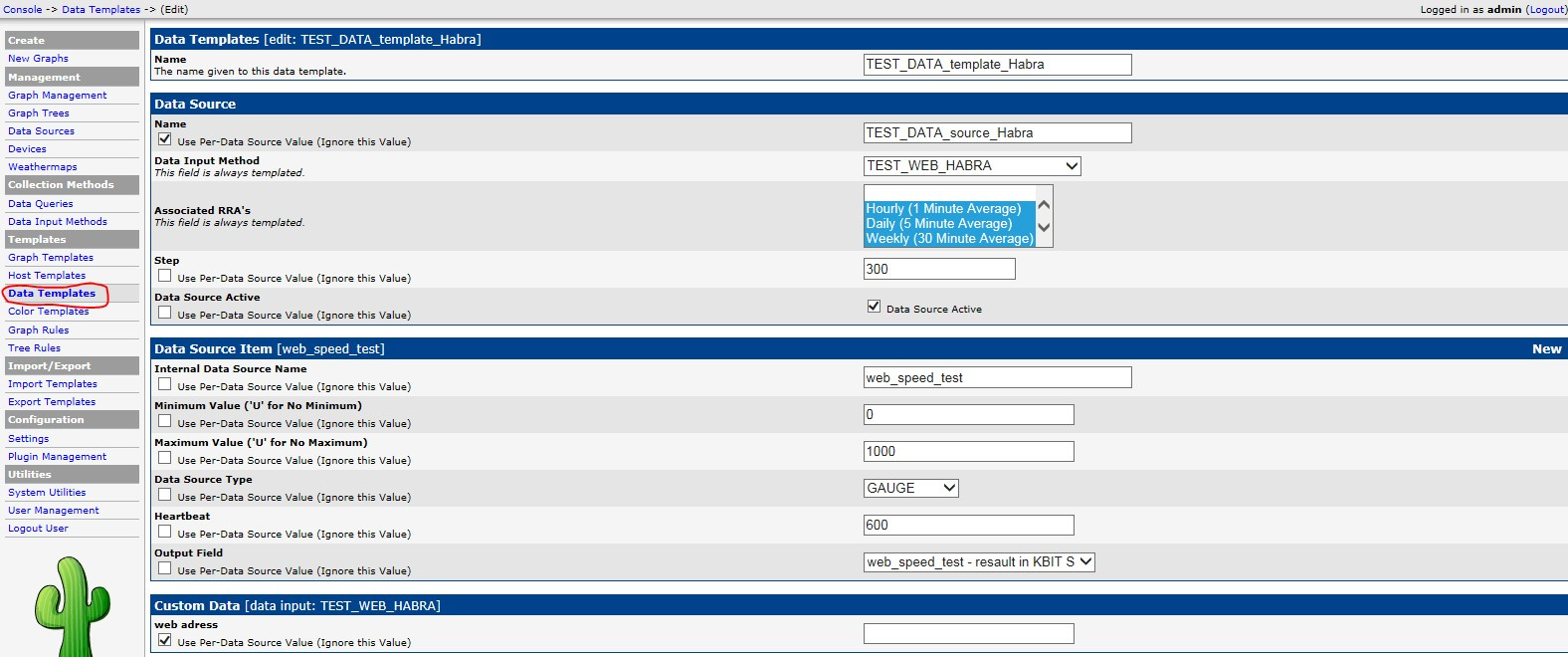




|
Метки: author Lost63 визуализация данных python python3 мониторинг сайта сетевые технологии juniper cisco huawei wget ip |
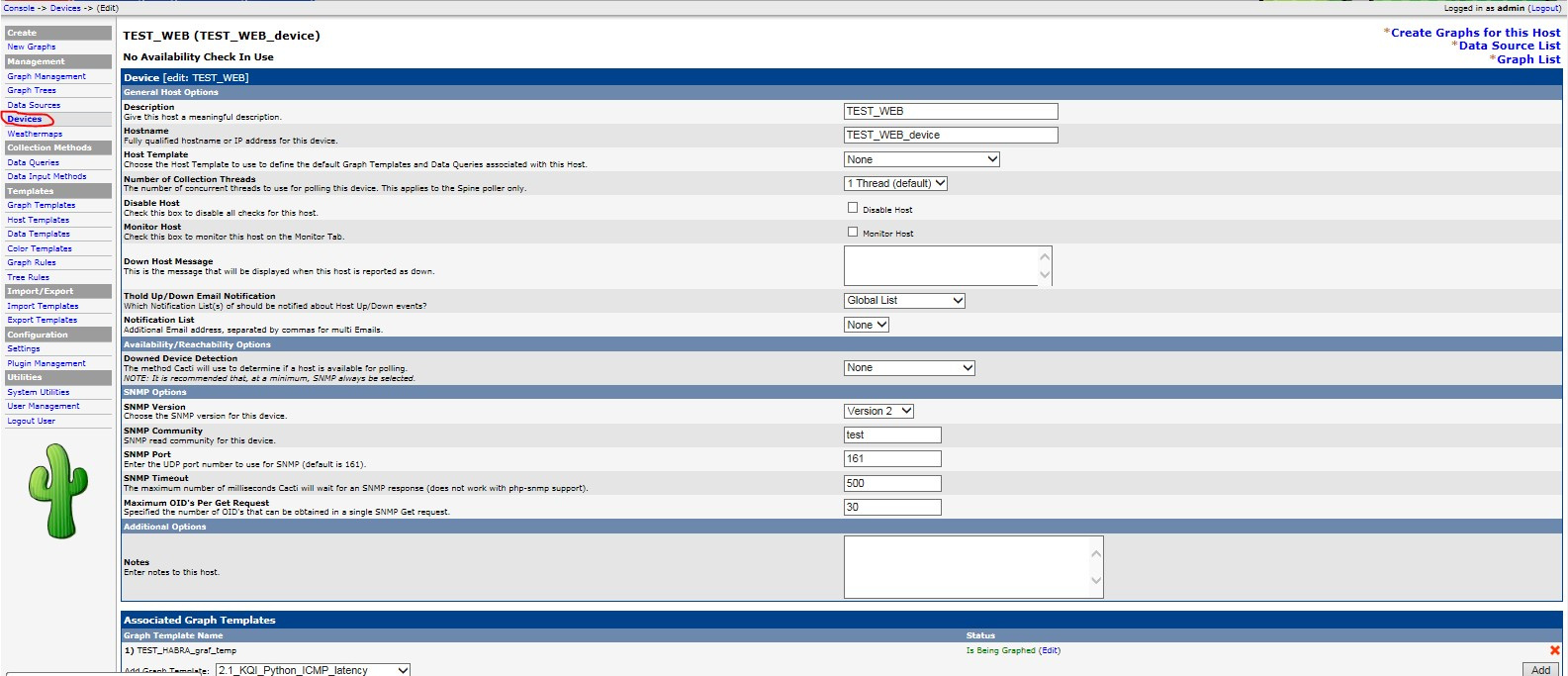
Алгоритм поиска наилучшего маршрута в linux |
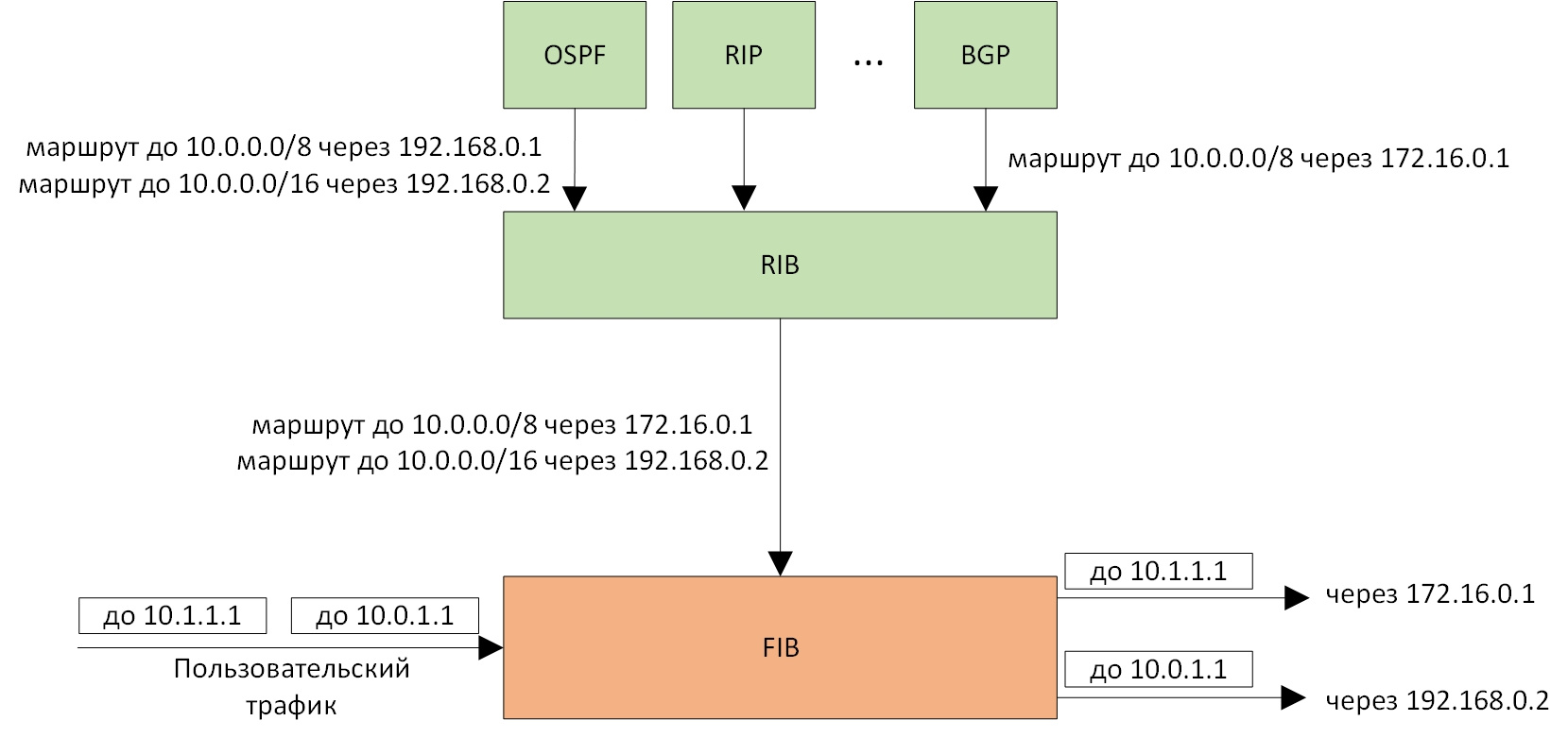
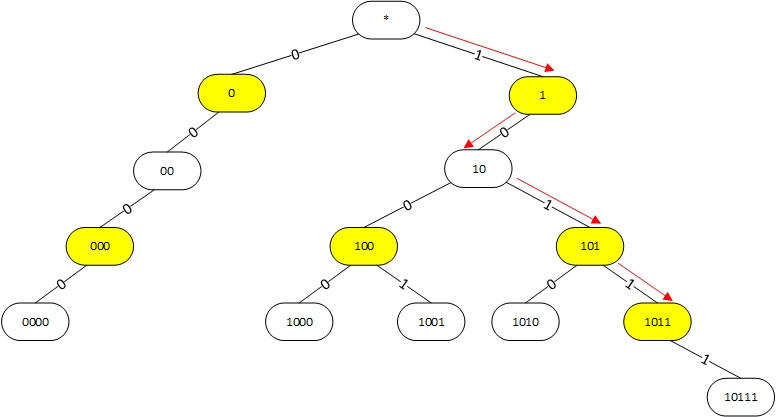
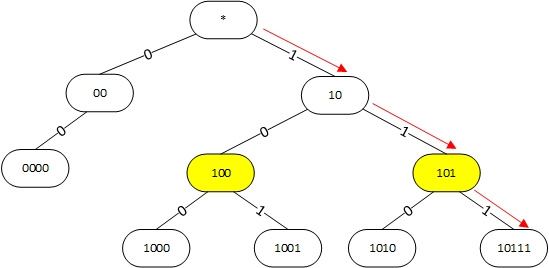
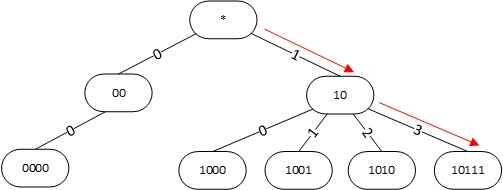
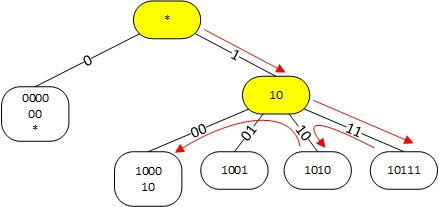
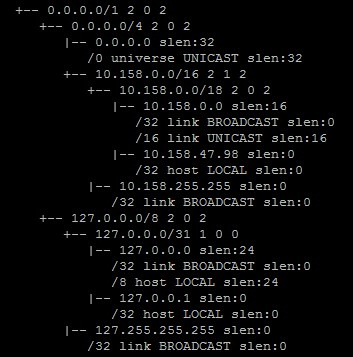


|
Метки: author andrew526d системное программирование математика высокая производительность алгоритмы trie linux таблица маршрутизации fib rib |
[Из песочницы] Бинарная сегментация изображений методом фиксации уровня (Level set metod) |
|
Метки: author 22dla обработка изображений математика алгоритмы сегментация matlab метод фиксации уровня level set method фильтрация машинное зрение компьютерная графика |
Признаки проблемного дизайна |
class A
{
B _b;
public A()
{
_b = new B();
}
public void Foo()
{
// Do some custom logic.
_b.DoSomething();
// Do some custom logic.
}
}
class B
{
public void DoSomething()
{
// Do something
}
}
interface IComponent
{
void DoSomething();
}
class A
{
IComponent _component;
public A(IComponent component)
{
_component = component;
}
void Foo()
{
// Do some custom logic.
_component.DoSomething();
// Do some custom logic.
}
}
class B : IComponent
{
void DoSomething()
{
// Do something
}
}
// Module 1 (Client)
static void Main()
{
var product = new Product("milk");
var productManager = new ProductManager();
productManager.AddProduct(product);
var consumer = new Consumer();
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
public class ProductManager
{
private readonly FileLogger _logger = new FileLogger();
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly FileLogger _logger = new FileLogger();
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (Logger implementation)
public class FileLogger
{
const string FileName = "log.txt";
public void Log(string message)
{
// Write the message to the file.
}
}
// Module 1 (Client)
static void Main()
{
var logger = new FileLogger();
var product = new Product("milk");
var productManager = new ProductManager(logger);
productManager.AddProduct(product);
var consumer = new Consumer(logger);
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
class ProductManager
{
private readonly ILogger _logger;
public ProductManager(ILogger logger)
{
_logger = logger;
}
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly ILogger _logger;
public Consumer(ILogger logger)
{
_logger = logger;
}
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (interfaces)
public interface ILogger
{
void Log(string message);
}
// Module 4 (Logger implementation)
public class FileLogger : ILogger
{
const string FileName = "log.txt";
public virtual void Log(string message)
{
// Write the message to the file.
}
}
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[] { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
private static double GetShapeArea(Shape shape)
{
if (shape is Rectangle)
{
return ((Rectangle)shape).W * ((Rectangle)shape).H;
}
if (shape is Circle)
{
return 2 * Math.PI * ((Circle)shape).R * ((Circle)shape).R;
}
throw new InvalidOperationException("Not supported shape");
}
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
if (shape is Rectangle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Rectangle's area is {area}");
}
if (shape is Circle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Circle's area is {area}");
}
}
}
}
public class Shape
{ }
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
}
public class Circle : Shape
{
public double R { get; set; }
}
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[]() { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
shape.Report();
}
}
}
public abstract class Shape
{
public abstract void Report();
}
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
public override void Report()
{
double area = W * H;
Console.WriteLine($"Rectangle's area is {area}");
}
}
public class Circle : Shape
{
public double R { get; set; }
public override void Report()
{
double area = 2 * Math.PI * R * R;
Console.WriteLine($"Circle's area is {area}");
}
}

// Module 1 (Constants)
static class Constants
{
public const decimal MaxSalary = 100M;
public const int MaxNumberOfProducts = 100;
}
// Finance Module
#using Module1
static class FinanceHelper
{
public static bool ApproveSalary(decimal salary)
{
return salary <= Constants.MaxSalary;
}
}
// Marketing Module
#using Module1
class ProductManager
{
public void MakeOrder()
{
int productsNumber = 0;
while(productsNumber++ <= Constants.MaxNumberOfProducts)
{
// Purchase some product
}
}
}
class DataManager
{
object[] GetData()
{
// Retrieve and return data
}
}
void Process_true_false(string trueorfalsevalue)
{
if (trueorfalsevalue.ToString().Length == 4)
{
// That means trueorfalsevalue is probably "true". Do something here.
}
else if (trueorfalsevalue.ToString().Length == 5)
{
// That means trueorfalsevalue is probably "false". Do something here.
}
else
{
throw new Exception("not true of false. that's not nice. return.")
}
}
public void Process(bool value)
{
if (value)
{
// Do something.
}
else
{
// Do something.
}
}
public void Process(string value)
{
bool bValue = false;
if (!bool.TryParse(value, out bValue))
{
throw new ArgumentException($"The {value} is not boolean");
}
if (bValue)
{
// Do something.
}
else
{
// Do something.
}
}
static void Main()
{
if (Helper.Authorize(1, "/pictures"))
{
Console.WriteLine("Authorized");
}
}
class Helper
{
public static bool Authorize(int roleId, string resourceUri)
{
if (roleId == 1 || roleId == 10)
{
if (resourceUri == "/pictures")
{
return true;
}
}
if (roleId == 1 && roleId == 2 && resourceUri == "/admin")
{
return true;
}
return false;
}
}
static void Main()
{
var picturesResource = new Resource() { Uri = "/pictures" };
picturesResource.AddRole(1);
if (picturesResource.IsAvailable(1))
{
Console.WriteLine("Authorized");
}
}
class Resource
{
private List _roles = new List();
public string Uri { get; set; }
public void AddRole(int roleId)
{
_roles.Add(roleId);
}
public void RemoveRole(int roleId)
{
_roles.Remove(roleId);
}
public bool IsAvailable(int roleId)
{
return _roles.Contains(roleId);
}
}
|
Метки: author szolotarev проектирование и рефакторинг ооп c# .net solid design patterns |
[Из песочницы] Уязвимость ВКонтакте: отправляем сообщение с кодом восстановления страницы на чужой номер |


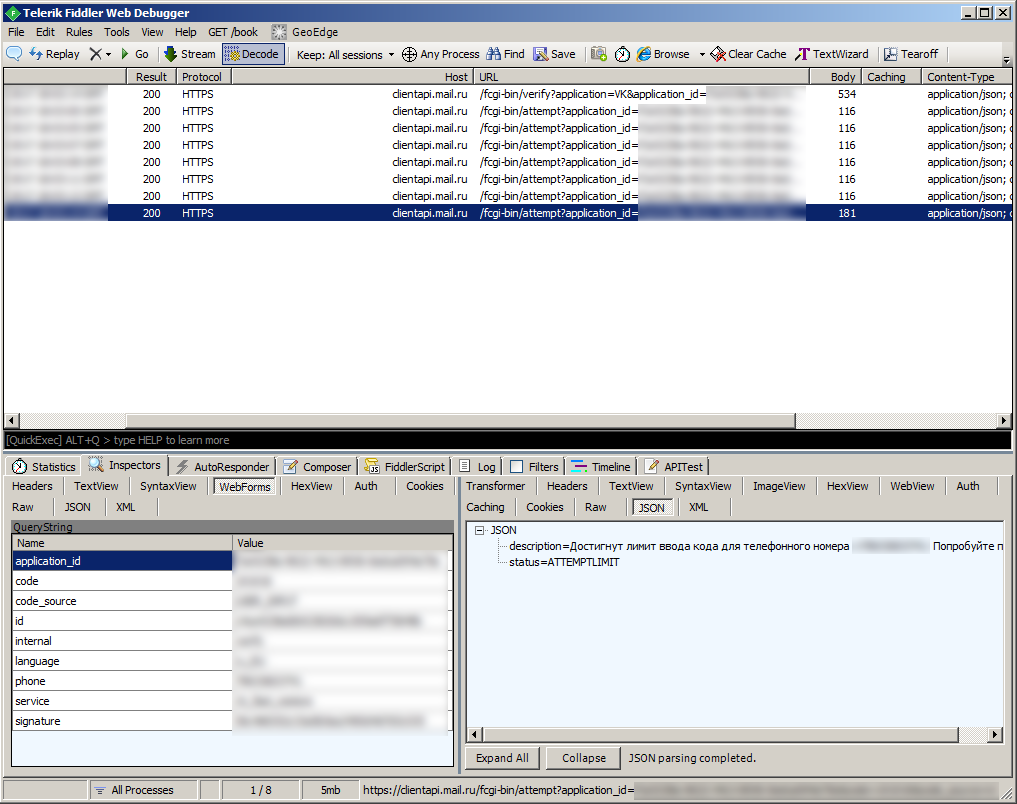
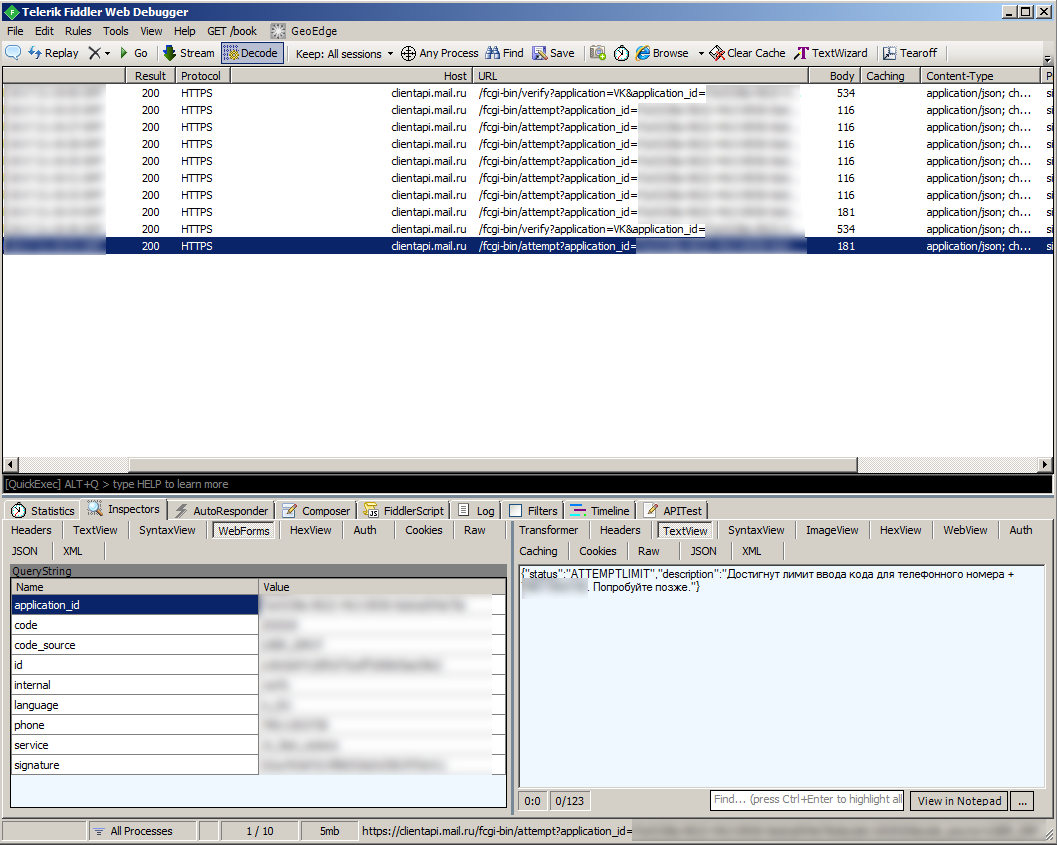
phone — номер на который отправляется SMSПопытка отправить запрос изменив его не увенчалась успехом. Мешает параметр «signature», который выступает в роли «подписи», как она генерируется разберемся немного позже.
session_id — рандомно генерирующаяся сессия операции восстановления
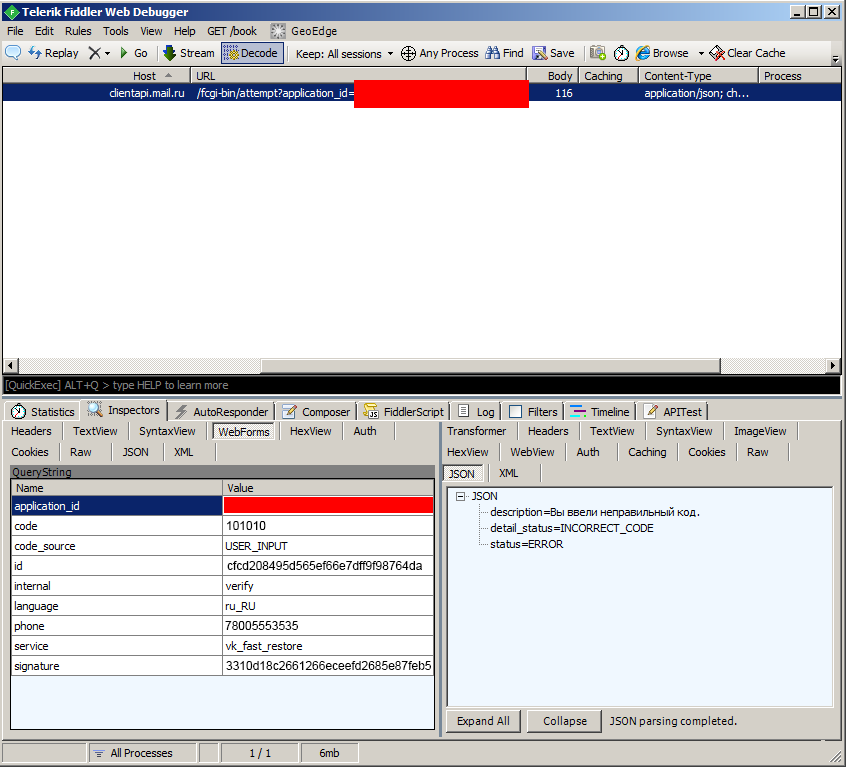

localObject3 = String.format(Locale.US, "%s%s?%s&signature=%s", new Object[] { d(), e(), localObject3, URLEncoder.encode(ru.mail.libverify.utils.m.b(f() + (String)localObject4 + ru.mail.libverify.utils.m.c(a.b())), "UTF-8") });
apktool.jar d vk.apk -r
(ключ -r для игнорирования ресурсов)...
.method public static b(Ljava/lang/String;)Ljava/lang/String;
.locals 8
.param p0 # Ljava/lang/String;
.annotation build Landroid/support/annotation/NonNull;
.end annotation
.end param
:try_start_0
const-string/jumbo v0, "UTF-8"
invoke-virtual {p0, v0}, Ljava/lang/String;->getBytes(Ljava/lang/String;)[B
:try_end_0
.catch Ljava/io/UnsupportedEncodingException; {:try_start_0 .. :try_end_0} :catch_2
move-result-object v0
:try_start_1
const-string/jumbo v1, "MD5"
invoke-static {v1}, Ljava/security/MessageDigest;->getInstance(Ljava/lang/String;)Ljava/security/MessageDigest;
move-result-object v1
invoke-virtual {v1}, Ljava/security/MessageDigest;->reset()V
invoke-virtual {v1, v0}, Ljava/security/MessageDigest;->update([B)V
invoke-virtual {v1}, Ljava/security/MessageDigest;->digest()[B
move-result-object v0
......
.method public static b(Ljava/lang/String;)Ljava/lang/String;
.locals 8
.param p0 # Ljava/lang/String;
.annotation build Landroid/support/annotation/NonNull;
.end annotation
.end param
# PATCH
# String v0 = "vk-research";
const-string/jumbo v0, "vk-research"
# Log.d(v0, p0), где p0 параметр метода
invoke-static {v0, p0}, Landroid/util/Log;->d(Ljava/lang/String;Ljava/lang/String;)I
:try_start_0
const-string/jumbo v0, "UTF-8"
...apktool.jar b vk -o newvk.apkadb devices
adb logcat

|
Метки: author norver реверс-инжиниринг информационная безопасность вконтакте mail.ru android |
[Из песочницы] Oracle Data Integrator. SubstitutionAPI: Порядок выполнения подстановок. Часть 1 |
|
Метки: author nmaqsudov oracle oracle fusion middleware beanshell odi |
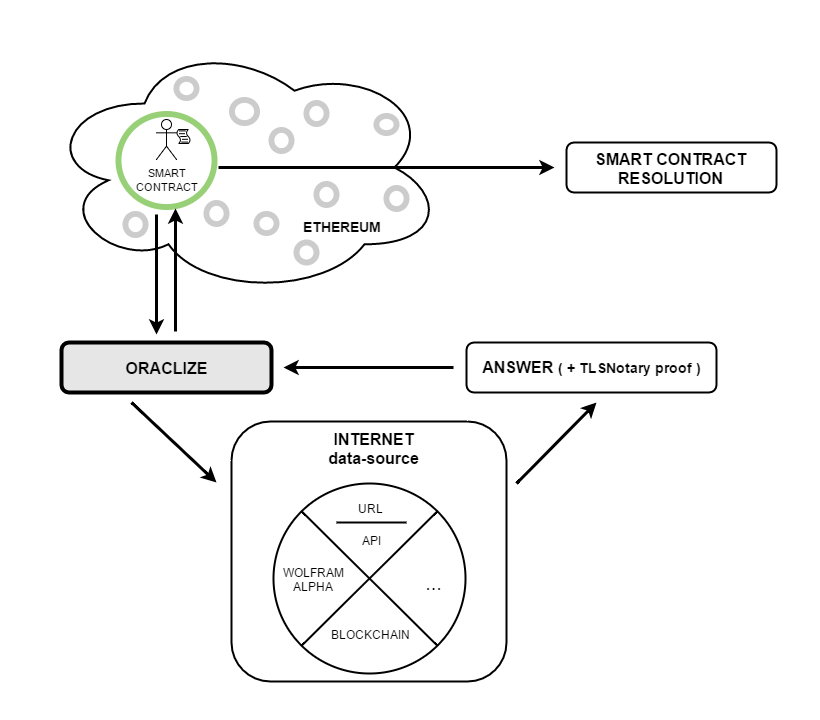
Понимание оракулов в блокчейне |
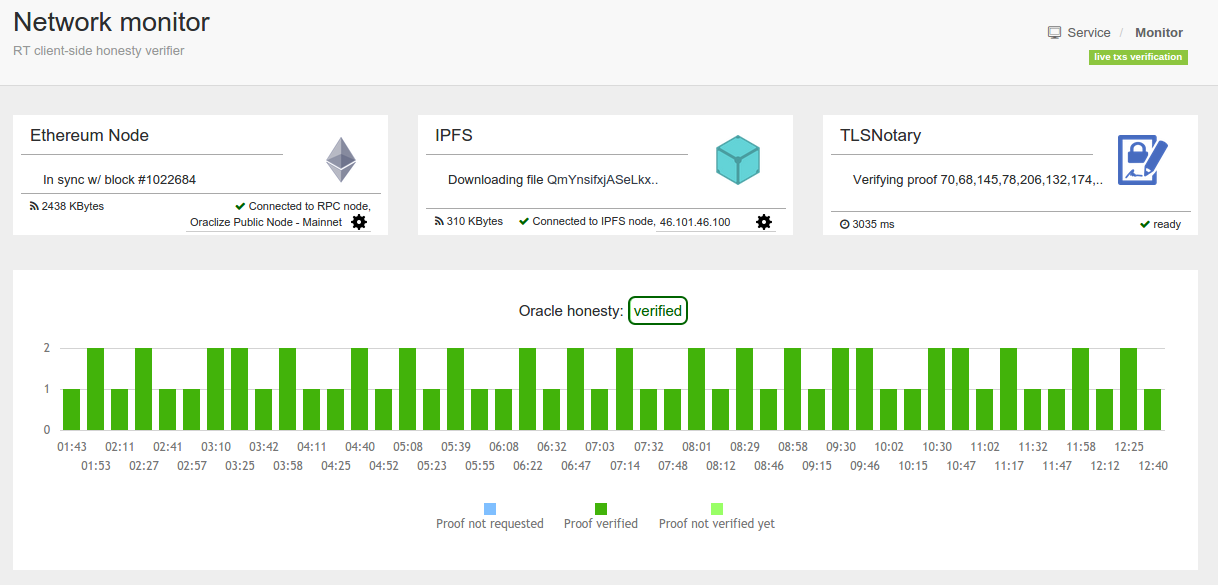
|
|
Google в скором времени перестанет доверять всем сертификатам WoSign и StartCom |
 Согласно сообщению от компании Google, в скором времени (а именно — начиная с выпуска Chrome 61, который ожидается в середине сентября) будет полностью прекращено доверие к сертификатам, выданным удостоверяющими центрами WoSign и StartCom. Речь ведётся о сертификатах, выданных до 21 октября 2016 года, срок действия которых ещё не истёк (более новые сертификаты были заблокированы в прошлом году).
Согласно сообщению от компании Google, в скором времени (а именно — начиная с выпуска Chrome 61, который ожидается в середине сентября) будет полностью прекращено доверие к сертификатам, выданным удостоверяющими центрами WoSign и StartCom. Речь ведётся о сертификатах, выданных до 21 октября 2016 года, срок действия которых ещё не истёк (более новые сертификаты были заблокированы в прошлом году).Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author dmitry_ch хостинг серверное администрирование администрирование доменных имен wosign startcom google chrome mozilla firefix |
Как запутать аналитика — 4. Вероятность и точность |
|
Метки: author maxstroy семантика математика анализ и проектирование систем it- стандарты вероятность точность |
Применение LibVirt API, InfluxDB и Grafana для сбора и визуализации статистики выполнения VM |
В своей практике я достаточно много времени посвящаю проектированию и администрированию облачных инфраструктур различного назначения. В основном это Apache CloudStack. Данная система обладает отличными возможностями, но в части мониторинга, функциональности явно недостаточно (читайте — отсутствует), особенно, если на мониторинг смотреть шире чем мониторинг индивидуального объекта наблюдения (сервер, виртуальная машина).
В целом, в связи с более широкими требованиями к систем визуального анализа информации и потребностями в части интеграции с источниками данных стали распространяться специализированные решения для ad-hoc анализа данных, такие как Kibana, Grafana и иные. Данные системы могут интегрироваться со специализированными хранилищами временных рядов данных, одним из которых является InfluxDB. Статья расскажет о готовом решении, распространяемом в виде образа Docker, использующем LibVirt API, Grafana и InfluxDB, предназначенном для сбора и анализа параметров исполняющихся VM для гипервизора KVM.
Решение представлено в форме Docker-контейнера, распространяемого по лицензии Apache License v2, поэтому оно может без ограничений применяться в любых организациях и изменяться, отражая потребности конкретной задачи. Контейнер размещается на выделенном сервере, python-утилита сбора данных удаленно подключается по протоколу TCP к LibVirt и отправляет данные в InfluxDB, откуда они могут быть запрошены с помощью Grafana для визуализации и анализа.
Контейнер доступен в виде исходных кодов на GitHub и в виде доступного для установки образа на DockerHub. Язык реализации — python.
Данное решение является конечным и удобным для внедрения, а так же не требует каких-либо дополнительных настроек и установки дополнительного ПО на серверах виртуализации, кроме разрешения доступа к API LibVirt по сети. Если доступ к API LibVirt снаружи не представляется возможным, то возможно установить Docker на хосте виртуализации и запускать контейнер локально.
В рамках решений, которые я применяю в своей практике, всегда существует защищенная сеть, доступ к которой ограничен для неавторизованных пользователей, соответственно, я не ограничиваю доступ к LibVirt паролем, и представленный контейнер не поддерживает аутентификацию. В том случае, если такая функция требуется, ее можно достаточно просто добавить.
Сенсор собирает следующие данные о виртуальных машинах, доступные через LibVirt:
CPU:
{
"fields": {
"cpuTime": 1070.75,
"cpus": 4
},
"measurement": "cpuTime",
"tags": {
"vmHost": "qemu+tcp://root@10.252.1.33:16509/system",
"vmId": "i-376-1733-VM",
"vmUuid": "12805898-0fda-4fa6-9f18-fac64f673679"
}
}RAM:
{
"fields": {
"maxmem": 4194304,
"mem": 4194304,
"rss": 1443428
},
"measurement": "rss",
"tags": {
"vmHost": "qemu+tcp://root@10.252.1.33:16509/system",
"vmId": "i-376-1733-VM",
"vmUuid": "12805898-0fda-4fa6-9f18-fac64f673679"
}
}Статистика по каждому сетевому адаптеру с привязкой к MAC-адресу:
{
"fields": {
"readBytes": 111991494,
"readDrops": 0,
"readErrors": 0,
"readPackets": 1453303,
"writeBytes": 3067403974,
"writeDrops": 0,
"writeErrors": 0,
"writePackets": 588124
},
"measurement": "networkInterface",
"tags": {
"mac": "06:f2:64:00:01:54",
"vmHost": "qemu+tcp://root@10.252.1.33:16509/system",
"vmId": "i-376-1733-VM",
"vmUuid": "12805898-0fda-4fa6-9f18-fac64f673679"
}
}Статистика по каждому диску:
{
"fields": {
"allocatedSpace": 890,
"ioErrors": -1,
"onDiskSpace": 890,
"readBytes": 264512607744,
"readIOPS": 16538654,
"totalSpace": 1000,
"writeBytes": 930057794560,
"writeIOPS": 30476842
},
"measurement": "disk",
"tags": {
"image": "cc8121ef-2029-4f4f-826e-7c4f2c8a5563",
"pool": "b13cb3c0-c84d-334c-9fc3-4826ae58d984",
"vmHost": "qemu+tcp://root@10.252.1.33:16509/system",
"vmId": "i-376-1733-VM",
"vmUuid": "12805898-0fda-4fa6-9f18-fac64f673679"
}
}Общая статистика по хосту виртуализации, как ее "видит" LibVirt:
{
"fields": {
"freeMem": 80558,
"idle": 120492574,
"iowait": 39380,
"kernel": 1198652,
"totalMem": 128850,
"user": 6416940
},
"measurement": "nodeInfo",
"tags": {
"vmHost": "qemu+tcp://root@10.252.1.33:16509/system"
}
}В конфигурационном файле /etc/libvirt/libvirtd.conf необходимо установить:
listen_tls = 0
listen_tcp = 1
tcp_port = "16509"
auth_tcp = "none"
mdns_adv = 0Внимание! Вышеуказанные настройки позволят соединяться с API LibVirt по TCP, настройте корректно файрвол для ограничения доступа.
После выполнения данных настроек LibVirt необходимо перезапустить.
sudo service libvirt-bin restartУстановка InfluxDB осуществляется по документации, например, для Ubuntu:
curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
source /etc/lsb-release
echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
sudo apt-get update && sudo apt-get install influxdb
sudo service influxdb startВыполним команду influx для открытия сессии к СУБД:
$ influxСоздадим администратора (он нам понадобится когда мы активируем аутентификацию):
CREATE USER admin WITH PASSWORD '' WITH ALL PRIVILEGES Создадим базу данных pulsedb и обычного пользователя pulse с доступом к этой базе данных:
CREATE DATABASE pulsedb
CREATE USER pulse WITH PASSWORD ''
GRANT ALL ON pulsedb TO pulse Активируем аутентификацию в конфигурационном файле /etc/influxdb/influxdb.conf:
auth-enabled = trueПерезапустим InfluxDB:
service influxdb restartЕсли все сделано правильно, теперь при открытии сессии необходимо указывать имя пользователя и пароль:
influx -username pulse -password secretdocker pull bwsw/cs-pulse-sensor
docker run --restart=always -d --name 10.252.1.11 \
-e PAUSE=10 \
-e INFLUX_HOST=influx \
-e INFLUX_PORT=8086 \
-e INFLUX_DB=pulsedb \
-e INFLUX_USER=pulse \
-e INFLUX_PASSWORD=secret \
-e GATHER_HOST_STATS=true
-e DEBUG=true \
-e KVM_HOST=qemu+tcp://root@10.252.1.11:16509/system \
bwsw/cs-pulse-sensorБольшинство параметров самоочевидны, поясню лишь два:
После этого в журнале контейнера с помощью команды docker logs должна отражаться активность и не должны отражаться ошибки.
Если открыть сессию к InfluxDB, то в консоли можно выполнить команду и убедиться в наличии данных измерений:
influx -database pulsedb -username admin -password secret> select * from cpuTime limit 1
name: cpuTime
time cpuTime cpus vmHost vmId vmUuid
---- ------- ---- ------ ---- ------
1498262401173035067 1614.06 4 qemu+tcp://root@10.252.1.30:16509/system i-332-2954-VM 9c002f94-8d24-437e-8af3-a041523b916aНа этом основная часть статьи завершается, далее посмотрим каким образом с помощью Grafana можно работать с сохраняемыми временными рядами.
Устанавливаем, как описано в документации
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana_4.4.1_amd64.deb
sudo apt-get install -y adduser libfontconfig
sudo dpkg -i grafana_4.4.1_amd64.deb
sudo service grafana-server start
sudo update-rc.d grafana-server defaultsЗапускаем web-браузер и открываем административный интерфейс Grafana http://influx.host.com:3000/.
Детальная инструкция по добавлению источника данных на сайте проекта. В нашем же случае добавляемый источник данных может выглядеть следующим образом:
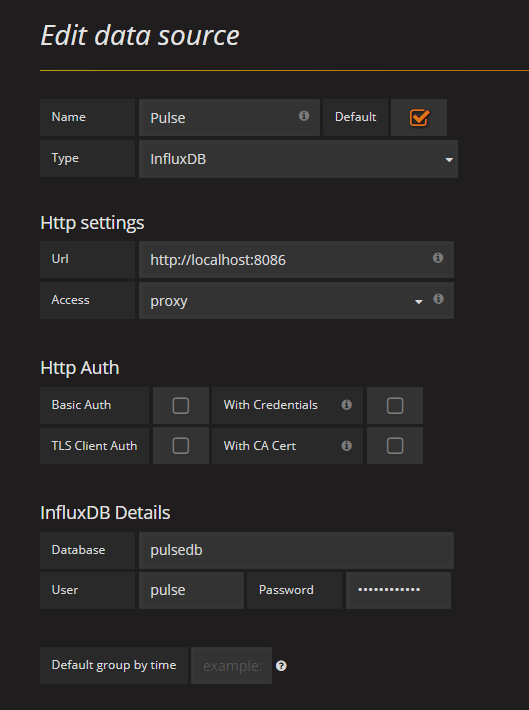
После сохранения источника данных, можно создать "дэшборды" и попробовать создавать запросы для графиков (поскольку данная инструкция не о том, как пользоваться Grafana, то привожу лишь выражения для запросов):
Загрузка CPU (минутки):
select NON_NEGATIVE_DERIVATIVE(MAX("cpuTime"), 1m) / LAST("cpus") / 60 * 100 from "cpuTime" where "vmUuid" = '6da0cdc9-d8ff-4b43-802c-0be01c6e0099' and $timeFilter group by time(1m)Загрузка CPU (пятиминутки):
select NON_NEGATIVE_DERIVATIVE(MAX("cpuTime"), 5m) / LAST("cpus") / 300 * 100 from "cpuTime" where "vmUuid" = '6da0cdc9-d8ff-4b43-802c-0be01c6e0099' and $timeFilter group by time(5m)Загрузка CPU (все VM):
select NON_NEGATIVE_DERIVATIVE(MAX("cpuTime"),1m) / LAST("cpus") / 60 * 100 as CPU from "cpuTime" WHERE $timeFilter group by time(1m), vmUuid
Память VM (пятиминутная агрегация):
SELECT MAX("rss") FROM "rss" WHERE "vmUuid" = '6da0cdc9-d8ff-4b43-802c-0be01c6e0099' and $timeFilter GROUP BY time(5m) fill(null)Статистика ReadBytes, WriteBytes для диска (пятиминутная агрегация):
select NON_NEGATIVE_DERIVATIVE(MAX("readBytes"),5m) / 300 from "disk" where "image" = '999a1942-3e14-4d04-8123-391494a28198' and $timeFilter group by time(5m)
select NON_NEGATIVE_DERIVATIVE(MAX("writeBytes"),5m) / 300 from "disk" where "image" = '999a1942-3e14-4d04-8123-391494a28198' and $timeFilter group by time(5m)Статистика ReadBits, WriteBits для NIC (пятиминутная агрегация):
select NON_NEGATIVE_DERIVATIVE(MAX("readBytes"), 5m) / 300 * 8 from "networkInterface" where "mac" = '06:07:70:00:01:10' and $timeFilter group by time(5m)
select NON_NEGATIVE_DERIVATIVE(MAX("writeBytes"), 5m) / 300 * 8 from "networkInterface" where "mac" ='06:07:70:00:01:10' and $timeFilter group by time(5m)Вся мощь языка запросов InfluxDB к вашим услугам, и Вы можете строить такие дэшборды, которые отвечают Вашим потребностям и позволяют производить наглядный анализ данных. Например, один из самых полезных для меня кейсов — это разбор инцидентов, бывает, что клиент жалуется на то, что "ваш код ****о" © и говорит, что его VM чудесно работала, а потом раз и все. Строим выражение, смотрим на картинку, видим как CPU его VM в течение часа уходил в пике и таки ушел. Скриншот — отличный аргумент при решении конфликта.
Еще можно анализировать самых интенсивно использующих различные ресурсы VM, чтобы мигрировать их на отдельные хосты. Да все, что угодно. В этом смысле Grafana, Kibana и подобные системы выгодно отличаются от традиционных систем мониторинга (например, Zabbix) тем, что позволяют делать анализ по требованию и строить комплексные аналитические наборы, а InfluxDB помогает обеспечить высокую производительность анализа даже на большом наборе данных.
Код, получающий данные из LibVirt тестировался с VM, которые используют тома в QCOW2 формате. Я постарался учесть варианты LVM2 и RBD, но не тестировал. Если у кого-то получится протестировать код на других вариантах томов VM и прислать исправления для кода, буду признателен.
PS: При мониторинге сетевого трафика VM Вы можете обнаружить, что данные по PPS значительно меньше тех, которые Вы получаете посредством Sflow/Netflow на маршрутизаторе или tcpdump в VM. Это известное свойство KVM, сетевая подсистема которого не придерживается стандартного MTU в 1500 байт.
PPS: Документация по API LibVirt для python ужасна и мне пришлось продираться через разные версии, чтобы все же выяснить в каком виде возвращаются данные и что они означают.
PPS2: Если что, как говорят на Газорпазорпе, "Я рядом, если надо поговорить" ©
|
Метки: author ivankudryavtsev серверное администрирование виртуализация devops influxdb мониторинг сервера python libvirt grafana kvm |
Скрипт для экспресс-восстановления Excel-файлов после повреждения |



option explicit
Const THIS_SCRIPT_NAME = "ST1_XLSX_FIXER_v1.vbs"
Const SUBDIR_XLS_SRC = "ST1_XLSX_FIXER_DATA_v1"
Const SUBDIR_OUT = "ST1_XLSX_FIXED"
Const RES_SUFFIX = "_fixed_ST1_v1"
Dim fso: Set fso = CreateObject("Scripting.FileSystemObject")
'если запускаем скрипт автономно
if WScript.ScriptName = THIS_SCRIPT_NAME then
if WScript.Arguments.Count > 0 then
Dim fname
for each fname in WScript.Arguments
if fso.GetExtensionName(fname) = "xls" then
WScript.Echo "Файлы формата Excel 2003 и ранее (.xls) не поддерживаются"
else
FixCorruptedExcel fname
end if
next
else
WScript.Echo "Для работы перенесите выбранные xlsx-файлы на скрипт"
end if
end if
Set fso = Nothing
Sub FixCorruptedExcel(fpath)
Dim out_dir: out_dir = fso.GetParentFolderName(fpath) & "\" & SUBDIR_OUT
if Trim(out_dir) <> "" then
'создание папки результатов
If not fso.FolderExists(out_dir) Then
fso.CreateFolder(out_dir)
end if
End If
'cоздать копию xlsx-файла с расширением .zip
Dim extract_dir: extract_dir = out_dir & "\" & fso.GetBaseName(fpath)
Dim fpath_zip: fpath_zip = extract_dir & ".zip"
fso.CopyFile fpath, fpath_zip
'выходной файл
Dim fpath_fixed: fpath_fixed = extract_dir & RES_SUFFIX & ".xlsx"
if fso.FileExists(fpath_fixed) then fso.DeleteFile fpath_fixed
'распаковка zip
UnzipFile fpath_zip, extract_dir
'удаление zip-файла
fso.DeleteFile fpath_zip
'восстановление битых файлов из папки
Dim script_path: script_path = fso.GetParentFolderName(Wscript.ScriptFullName)
fso.CopyFolder script_path & "\" & SUBDIR_XLS_SRC, extract_dir
'создание zip
CreateEmptyZipFile fpath_zip
'архивирование extract_dir
Dim shell: set shell = CreateObject("Shell.Application")
Dim extract_dir_obj: set extract_dir_obj = fso.GetFolder(extract_dir)
shell.NameSpace(fpath_zip).CopyHere shell.NameSpace(extract_dir).Items
do until shell.namespace(fpath_zip).items.count = shell.namespace(extract_dir).items.count
wscript.sleep 1000
loop
'zip -> xlsx
fso.MoveFile fpath_zip, fpath_fixed
'удаление unzip-папки
fso.DeleteFolder extract_dir, true
WScript.Echo "Исправленный файл: " & vbCrLf & fpath_fixed
Set shell = Nothing
end sub
sub UnzipFile(fpath_zip, extract_dir)
'создание папки для распаковки
If not fso.FolderExists(extract_dir) Then
fso.CreateFolder(extract_dir)
End If
'извлечение xlsx - аналог операции контекстного меню "Распаковать в ..."
Dim shell: set shell = CreateObject("Shell.Application")
Dim sub_files: set sub_files = shell.NameSpace(fpath_zip).items
Const FOF_SILENT = &H4&
Const FOF_RENAMEONCOLLISION = &H8&
Const FOF_NOCONFIRMATION = &H10&
Const FOF_ALLOWUNDO = &H40&
Const FOF_FILESONLY = &H80&
Const FOF_SIMPLEPROGRESS = &H100&
Const FOF_NOCONFIRMMKDIR = &H200&
Const FOF_NOERRORUI = &H400&
Const FOF_NOCOPYSECURITYATTRIBS = &H800&
Const FOF_NORECURSION = &H1000&
Const FOF_NO_CONNECTED_ELEMENTS = &H2000&
Dim args: args = FOF_SILENT + FOF_NOCONFIRMATION + FOF_NOERRORUI
shell.NameSpace(extract_dir).CopyHere sub_files, args
Set shell = Nothing
end sub
sub CreateEmptyZipFile(fname)
if fso.FileExists(fname) then
WScript.Echo "Файл " & fname & " уже существует", vbCritical, WScript.ScriptFullName
end if
Const ForWriting = 2
Dim fp: set fp = fso.OpenTextFile(fname, ForWriting, True)
fp.Write "PK" & Chr(5) & Chr(6) & String(18, Chr(0))
fp.Close
end sub


|
Метки: author shtr разработка под windows информационная безопасность excel восстановление скрипт |
Интервью в SD podCast с Павлом Одинцовым, автором FastNetMon, инструмента для обнаружения и отражения DDoS атак |
|
Метки: author pavelodintsov информационная безопасность ddos безопасность bgp |
Libdispatch. Как сделать приложение отзывчивым |

Для повышения отзывчивости приложения необходимо грамотно разбивать выполнение задач на несколько потоков. Набор технологий в руках iOS-разработчика представляет из себя следующее. Способы представлены по возрастанию уровня абстракции.
performSelector и различными параметрами (например, performSelectorOnMainThread:withObject:waitUntilDone:). ДокументацияNSInvocationOperation и NSBlockOperation.В этой статье поговорим о вопросах CGD.
Libdispatch — это библиотека компании Apple, предназначенная для работы с многопоточностью. GCD впервые была представлена в Mac OS X 10.6. Исходные коды библиотеки libdispatch, реализующей сервисы GCD, были выпущены под лицензией Apache 10 сентября 2009. Также существуют версии библиотеки для других операционных систем семейства Unix, таких как FreeBSD и Linux. Для остальных пока поддержки нет. Правда есть неофициальные сборки libdispatch от пользователей.
Поговорим о внутреннем устройстве библиотеки. Сделаем предположение, на основе какой технологии она была разработана. Варианты: pthreads, background selectors, NSThread. Второй вариант однозначно не подходит — поскольку основу libdispatch составляет работа с блоками. Тогда из предположений остается NSThread или pthreads. А теперь рассмотрим поподробнее.
Все началось с того, что был обнаружен сборник заголовочных файлов всех библиотек и протоколов в Obj-C для одной из самых последних версий операционной системы (на тот момент это была iOS 10). В проекте присутствуют публичные фреймворки — большинство тех, с которыми знакомы практически все разработчики, начиная от AVFoundation и заканчивая WebKit. К удивлению, даже в публичных фреймворках присутствуют такие свойства и методы, которые недоступны в оригинальной документации Apple. Например, свойство trustedTimestamp у объекта CLLocation.
Далее обнаруживается большой раздел приватных библиотек, например, PhysicsKit. К слову, есть интересный timeline жизни приватных фреймворков — рекомендую ознакомиться. Это стоит того, чтобы потратить несколько часов и поизучать интересные и частично вскрытые внутренности iOS (сильно не радуйтесь, там только сгенерированные заголовочные файлы). Оставшаяся часть отведена библиотекам и протоколам. Библиотек там не так много, да и именование у них похожие: lib + название. Например, libobjc или libxpc. А вот протоколов там настолько много, что даже github не отображает их все.
И да, среди всего прочего была обнаружена libdispatch. Как и для остальных библиотек в репозитории, для нее присутствуют только заголовочные файлы. Среди них намеков на устройство библиотеки нет. Сгенерированные заголовочные файлы для классов в большинстве случаев содержат несколько стандартных методов, среди которых: debugDescription, description, hash и superclass. В таком случае единственным вариантом остается исследование открытых исходников Apple.
Рассмотрим из чего состоит репозиторий libdispatch. Это исходники и заголовочные файлы нескольких уровней. Уровни включают в себя публичный (то, о чем вы привыкли думать как о libdispatch), внутренний и приватный уровень доступа. Стоит обратить внимание на документацию, которая предоставляется для утилиты командной строки. Среди всего прочего можно наткнуться на файлы конфигурации cmake и xcodeconfig, а также тесты в большом количестве.
Наиболее интересные места для нас:
Репозиторий библиотеки активно поддерживается — регулярные коммиты от разработчиков несколько раз в месяц, которые активно чинят сломанную поддержку и компиляцию на различных платформах. Проект считается законченным, а некоторые проблемы, например, построение библиотеки на El Capitan, остаются нерешенными до сих пор.
Рассмотрим, что такое очередь в libdispatch. Очередь определена тремя макросами, определение можно найти в файле — queue_internal.h.
Определение очереди начинается с включения DISPATCH_STRUCT_HEADER — так сделано для всех объектов проекта. Этот общий заголовок состоит из определения OS_OBJECT_HEADER (сам OS_OBJECT_HEADER необходим для виртуальной таблицы операций — vtable и подсчета ссылок), нескольких полей, включая поле целевой очереди. Целевая очередь (target queue) представляется одной из базовых очередей — обычно очередью по умолчанию.
Далее очередь определяется макросами DISPATCH_QUEUE_HEADER и DISPATCH_QUEUE_CACHELINE_PADDING. Последнее нужно, чтобы убедиться, что структура оптимально поместится в линию кэша процессора. Макрос DISPATCH_QUEUE_HEADER служит для определение метаданных очереди, которые включают в себя «ширину» (количество потоков в пуле), номер для дебаггинга, обычный номер и список задач на выполнение.
Базовый тип для работы представлен как continuation. Он определен как включение единственного макроса DISPATCH_CONTINUATION_HEADER. В определение макроса входят указатель на таблицу операций, различные флаги, приоритет, указатели на контекст, функции, данные и следующую операцию.
Путем исследования приватных заголовочных файлов и исходников библиотеки было обнаружено, что libdispatch может быть скомпилирован используя библиотеку libpqw или POSIX Thread API.
Итак, последняя версия GCD построена над оберткой над библиотекой pthread — libpwq, в состав разработчиков которых записана и компания Apple. Главная идея библиотеки состоит в добавлении уровня абстракции. Первая версия вышла в 2011 году, на данный момент последней стабильной является версия 0.9 от 2014 года.
Библиотека является прямой надстройкой над , внося новый уровень абстракции. Он включает в себя работу не с потоками, а с очередями задач: создание, установка приоритетов, добавление задач на исполнение. Например, добавление задачи осуществляется вызовом pthread_workqueue_additem_np, где передается очередь, указатель на функции для задачи и её аргументы.
Внутри библиотеки главной управляющей частью выступает некий менеджер, который оперирует очередями и списком задач. У менеджера всегда есть как минимум одна рабочая очередь. Очередь представлена обычной структурой с идентификатором, приоритетом (их существует всего три — высокий, низкий и приоритет по умолчанию), различными флагами и указателем на первую задачу. Задачи организованы в виде списка. Сама задача — структура с указателем на функцию, флагами, аргументами и указателем на следующую задачу, если таковая имеется.
Конечно, возможна компиляция libdispatch без библиотеки libpwq, тогда в таком случае будут использоваться pthreads. Это обусловлено тем, что он был анонсирован значительно раньше выхода этой библиотеки (в Mac OS X Snow Leopard в 2009 году).
Давайте для примера реализации рассмотрим какое-нибудь существующее решение в libdispatch. Возьмем всеми любимый вызов
DispatchQueue.main.async {
// some asynchronous code...
}На самом деле реализация тривиальна. Про саму swift'овую обертку будет рассказано чуть позже в данной статье. Скажем только, что CDispatch — скомпилированная библиотека GCD на С для Swift проекта.
public class DispatchQueue : DispatchObject {
...
}
public extension DispatchQueue {
...
public class var main: DispatchQueue {
return DispatchQueue(queue: _swift_dispatch_get_main_queue())
}
...
@available(OSX 10.10, iOS 8.0, *)
public func async(execute workItem: DispatchWorkItem) {
CDispatch.dispatch_async(self.__wrapped, workItem._block)
}
...
}В приведенном выше участке кода мы видим, как создается главная очередь и что из себя представляет асинхронный вызов кода. Разбор устройства GCD под капотом будет начинаться от всем известного dispatch_async.
Базовое дерево вызовов от момента запуска асинхронной задачи до момента создания потока (pthread_create) или же отправки задачи в более низкоуровневую библиотеку (lipbwq) будет следующим:
dispatch_async_dispatch_continuation_async_dispatch_continuation_async2_dispatch_async_f2_dispatch_continuation_pushdx_push_dispatch_queue_push_dispatch_queue_push_inlinedx_wakeup_dispatch_queue_class_wakeup_dispatch_queue_class_wakeup_with_override_dispatch_queue_class_wakeup_with_override_slow_dispatch_root_queue_push_override_stealer_dispatch_root_queue_push_inline_dispatch_global_queue_poke_dispatch_global_queue_poke_slowpthread_create или pthread_workqueue_additem_npПройдемся по структуре наиболее интересных вызововов. Оригинальный метод dispatch_async:
void
dispatch_async(dispatch_queue_t dq, dispatch_block_t work)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DISPATCH_OBJ_CONSUME_BIT;
_dispatch_continuation_init(dc, dq, work, 0, 0, dc_flags);
_dispatch_continuation_async(dq, dc);
}Что же здесь происходит? Во-первых, выделяется память на ранее определенный тип — continuation. Стоит напомнить принятую концепцию, согласно которой под типом тип_t понимается указатель на структуру тип_s. В таком случае, где-то в заголовочных файлах будет находиться определение (например, typedef struct dispatch_queue_s *dispatch_queue_t;). Во-вторых, устанавливаем флаги для инициализации данной структуры, которые передаются вместе с типом блока и очередью для исполнения инструкций блока. Например, четвертый параметр определяет приоритет, который по умолчанию устанавливается в 0.
Выделив память на структуру и проинициализировав ее, управление передается дальше в две функции (_dispatch_continuation_async и _dispatch_continuation_async2). Первая функция представляет собой невстраиваемую (noinline) заглушку для вызова другой уже встраиваемой (inline) функции, попутно разыменовывая флаги, и проверяя наличие барьера. Задача второй функции — выполнить соотвествующие проверки и отправить continuation на асинхронное выполнение в очередь. Под отправкой подразумевается использование функции _dispatch_continuation_push. Это происходит только в случае того, что очередь не переполнена или при отсутствии барьера.
В случае попадания в барьер, управление может передаться функции _dispatch_async_f2, где осуществляется проверка и устанавливается уровень QoS для continuation — иначе приоритет. Однако следующей все равно вызывается функция _dispatch_continuation_push, которая под собой вызывает макрос dx_push. Макрос разворачивается в довольно громоздкую конструкцию, а в конечном итоге это ведет к вызову функции _dispatch_queue_push_inline. Ее невстраиваемая обертка намеренно пропускается.
Главная причина, по которой так часто встраивают функции в одну невстраиваемую — уменьшение количества вызовов, но в тоже время управление сложностью кода. Таким образом достигается приемлемый баланс. Громоздкие конструкции с разыменованием указателей и их указателей легко помещаются в маленькие функции, которые уже потом компилятор встраивает в места вызова. Ну а разбираться с меньшим объемом данных с точки зрения человека всегда легче.
Функция _dispatch_queue_push_inline построена на большом количестве макросов. Среди наиболее интересных низкоуровневых конструкций (которые, кстати, используются по всему исходному коду libdispatch) можно отметить следующие:
atomic_load_explicit находится в стандартной библиотеке для атомарной работы и обеспечивает атомарное разыменование указателя. Любая логика указателей в проекте использует вызовы из заголовочного файла — __builtin_expect() и __builtin_unreachable(), равно как и остальные вызовы __builtin-подобных конструкций имеют отношение к низкоуровневым оптимизациям для компилятора — к branch prediction.Главная задача этой функции — выполнить проверку на переполнение очереди или на заблокированный барьер и передать управление. Далее управление попадает в функцию _dispatch_async_f_redirect и выполняется проверка был ли continuation перенаправлен в эту же очередь. В данной функции также происходит обновление начала и конца очереди — атомарная смена указателей.
Далее следует еще один макрос dx_wakeup — или вызов _dispatch_queue_class_wakeup. Это один из главных методов, в котором происходит обработка задач в очереди. Он проверяет условия барьеров, состояния очереди, а в случае несоблюдения условий, задача снова может повторно отправиться в очередь через уже известный dx_push.
В случае соблюдения условий задача передается в метод _dispatch_queue_class_wakeup_with_override, который является оберткой над _dispatch_queue_class_wakeup_with_override_slow с проверкой на изменение приоритетов задачи и возможностью их перезаписи. Наличие slow в названии соотносится с механизмом встраивания функций — логика разбивается на несколько функций с целью упрощения ее поддержки.
Далее следуют вызовы, которые непосредственно обрабатывают задачи в цикле и содержат в себе большое количество логики по взаимодействию и настройке указателей, проверке различных флагов и т. п. В процессе выполнения последним вызовом становится pthread_create или pthread_workqueue_additem_np. Конечно, если диспатч будет построен без использования libpwq, то в дело вступит внутренний менеджер управления потоками, а принцип его работы похож на описанный выше.
Оставшаяся часть вызовов намеренно пропущена, так как цель данного описания показать, что даже в случае обычного вызова кода на асинхронное выполнение — это превращается в многослойную логику.
А теперь давайте вкратце посмотрим, в чем особенности промежуточной swift-библиотеки, которая непосредственно взаимодействует с libdispatch. Как известно, появилась она с третьей версии Swift. Представляет из себя обертку над оригинальным libdispatch c добавлением приятных swift'овых перечислений и вынесением функциональности в расширения. Все это, конечно же, входит в главную задачу библиотеки — предоставление удобного API для работы с GCD.
Начнем с файла, в котором громоздкие типы libdispatch данных превращаются в элегантные классы Swift — Wrapper.swift. Этот файл может служить отображением всего проекта.
Общий подход состоит в том, что создаются несложные оболочки для большинства объектов. Объекты оригинального libdispatch, такие как dispatch_group_t или dispatch_queue_t, хранятся в объектах-обертках в свойстве __wrapped. Большинство функций делают один-единственный вызов непосредственно функций оригинального libdispatch над свойствами __wrapped.
Рассмотрим простенький пример:
public class DispatchQueue : DispatchObject {
// объект для работы с libdispatch
internal let __wrapped:dispatch_queue_t
...
final internal override func wrapped() -> dispatch_object_t {
return unsafeBitCast(__wrapped, to: dispatch_object_t.self)
}
...
public func sync(execute workItem: ()->()) {
// вызов функции с одноименным названием
dispatch_sync(self.__wrapped, workItem)
}
...
}С другой стороны, существуют и вызовы, которые не состоят из одной строчки. В них происходит приведение типов, подсчет промежуточных значений, проверка на версию системы и вызов соответствующих методов. Стоит также упомянуть, что в файле Private.swift происходит запрет прямых вызовов методов библиотеки libdispatch. Пример приведен ниже. Поэтому Вы никак уже не сможете писать менее swift'овый код (кроме, конечно старых версий свифта или собранной самостоятельно библиотеки libdispatch).
@available(*, unavailable, renamed:"DispatchQueue.async(self:group:qos:flags:execute:)")
public func dispatch_group_async(_ group: DispatchGroup, _ queue: DispatchQueue, _ block: @escaping () -> Void)
{
fatalError()
}Итого, получилось описание о принципах работы libdispatch. Предположения относительно ее внутреннего устройства подтвердились. libdispatch действительно построен на POSIX Thread API — как на самом минимальном API для обеспечения работы с многопоточностью.
Последняя версия libdispatch использует другую библиотеку (libpwq), но суть остается та же.
И вот у вас возник вопрос — а зачем вообще понимать что там на низком уровне? Понимание низкоуровневых вещей аналогично знанию базовых концепций. С их помощью вы не сделаете что-то быстро, но будете избегать глупых ошибок в будущем.
Понимание и знание низкоуровневых вещей позволит решать нетривиальные задачи в данной области. Если вам придется писать что-то на pthread для iOS, теперь уже будете подготовленным.
|
Метки: author glyerk разработка под ios программирование swift cocoa блог компании touch instinct touch intinct ios gcd разработка |
Личный опыт: как ИТ-специалисту переехать на работу в США, надеясь только на себя |
|
Метки: author alexlash карьера в it-индустрии сша работа в сша переезд |
Moneyball на бирже: как новые технологии меняют не только трейдинг, но и работу хедж-фондов |

|
Метки: author itinvest big data блог компании itinvest финансы онлайн-трейдинг хедж-фонды экономика фондовый рынок |
Чем занимались пиарщики РПЦ в день встречи Путина и Трампа на G20? |





Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author daocrawler визуализация данных data mining путин рпц трамп g20 иформационное поле данные statoperator |






