[Перевод - recovery mode ] Почему я перешел с React на Cycle.js |

Нетрудно догадаться, что большинство разработчиков сейчас используют какие-либо фреймворки для разработки приложений. Они помогают нам структурировать сложные приложения и экономят время. Каждый день можно наблюдать большое количество обсуждений, какой фреймворк лучше, какой нужно учить, и тому подобное. Так что, в этот раз я поделюсь своим опытом и отвечу на вопрос: «Почему я перешел на Cycle.js с React?».
React, возможно, самый популярный frontend-фреймворк (на момент 2017) с огромным сообществом. Я большой фанат этого фреймворка и он мне помог изменить взгляд на веб-приложения и их разработку. Некоторые любят его, а кто-то считает, что он не так хорош.
Большинство использует React без мысли о том, что есть лучший инструмент или способ разработки веб-приложений. Это дало мне толчок попробовать Cycle.js, как новый реактивный фреймворк, который становится все более и более популярным изо дня в день.
map или filter. Эти функции возвращают новые потоки, которые могут быть так же использованы.Реактивное программирование предоставляет абстракции, а это дает возможность концентрироваться на бизнес-логике.

В Javascript есть пара замечательных библиотек для работы с потоками данных. Одна из них — это всем известный Rx-JS, расширение ReactiveX, — API для асинхронного программирования с отслеживаемыми потоками данных. Вы можете создать Observable (поток данных) и управлять им множеством функций.
Вторая библиотека — это Most.js. Она имеет лучшую производительность, что подтверждается тестами.
Также стоит отметить одну небольшую и быструю библиотеку xstream, написанную автором Cycle.js. Она содержит 26 методов и весит 30kb. Это одна из самых быстрых библиотек для реактивного программирования на JS.
Как раз, в примерах к этой статье используется библиотека xstream. Cycle.js создана быть небольшим фреймворкам и я хочу использовать именно легковесную библиотеку в паре с Cycle.js.
Cycle.js — это функциональный и реактивный Javascript-фреймворк. Он предоставляет абстракции для приложений в виде чистой функции main(). В функциональном программировании функции должны принимать на вход параметры и что-то возвращать без побочных эффектов. В Cycle.js функция main() на вход принимает параметры из внешнего мира и пишет тоже во внешний мир. Побочные эффекты реализуются с помощью драйверов. Драйверы — это плагины, которые управляют DOM'ом, HTTP-запросами, вебсокетами и так далее.

run() с двумя аргументами:run(app, drivers);
app — основная чистая функция, а drivers — это вышеуказанные драйверы.run-функция для работы с mostrun-функция для работы с xstreamrun-функция для работы с rxjsindex.html и main.js. index.html будет содержать только основной файл со скриптами, где и прописана вся логика. package.json, так что запустимnpm init -y
npm install @cycle/dom @cycle/run xstream --save
@cycle/dom, @cycle/xstream-run, and xstream. Также нужны babel, browserify и mkdirp, установим их:npm install babel-cli babel-preset-es2015 babel-register babelify browserify mkdirp --save-dev
.babelrc-файл в корне директории со следующим содержимым:{
"presets": ["es2015"]
}
package.json"scripts": {
"prebrowserify": "mkdirp dist",
"browserify": "browserify main.js -t babelify --outfile dist/main.js",
"start": "npm install && npm run browserify && echo 'OPEN index.html IN YOUR BROWSER'"
}
npm run start
index.html< !DOCTYPE html>
div с идентификатором main. Cycle.js свяжется с этим элементом и будет в него рендерить все приложение. Мы также подключили dist/main.js-файл. Это проведенный через babel, транспайленный и объединенный js-файл, который будет создан из main.js-файла.main.js и импортируем все необходимые зависимости:import xs from 'xstream';
import { run } from '@cycle/run';
import { div, button, p, makeDOMDriver } from '@cycle/dom';
xstream, run, makeDOMDriver и функции, которые помогут нам работать с Virtual DOM (div, button и p).main-функцию:function main(sources) {
const action$ = xs.merge(
sources.DOM.select('.decrement').events('click').map(ev => -1),
sources.DOM.select('.increment').events('click').map(ev => +1)
);
const count$ = action$.fold((acc, x) => acc + x, 0);
const vdom$ = count$.map(count =>
div([
button('.decrement', 'Decrement'),
button('.increment', 'Increment'),
p('Counter: ' + count)
])
);
return {
DOM: vdom$,
};
}
run(main, {
DOM: makeDOMDriver('#main')
});
main-функция. Она берет на вход параметры и возвращает результат. Входные параметры — это потоки DOM (DOM streams), а результат — это Virtual DOM. Давайте начнем объяснение шаг за шагом:const action$ = xs.merge(
sources.DOM.select('.decrement').events('click').map(ev => -1),
sources.DOM.select('.increment').events('click').map(ev => +1)
);
action$ (здесь используем соглашение о суффиксе "$" тех переменных, которые представлют собой поток данных). Один из потоков является кликом по кнопке (.decrement) уменьшающей на единицу счетчик, второй — по другой, увеличивающей счетчик, кнопке (.increment). Мы связываем эти события c числами -1 и +1, соответственно. В конце слияния, поток action$ будет выглядеть следующим образом:----(-1)-----(+1)------(-1)------(-1)------
count$const count$ = action$.fold((acc, x) => acc + x, 0);
fold прекрасно подходит для этой цели. Она принимает два аргумента: accumulate и seed. seed is firstly emitted until the event comes. Следующее событие комбинируется с первым, основываясь на accumulate-функции. Это практически функция-reduce() для потоков.count$ получает 0 как начальное значение, затем при каждом новом значении из action$-потока, мы суммируем с текущим значением count$-потока.run под main.const vdom$ = count$.map(count =>
div([
button('.decrement', 'Decrement'),
button('.increment', 'Increment'),
p('Counter: ' + count)
])
);
count$ и возвращаем Virtual DOM для каждого элемента в потоке. Virtual DOM содержит одну div-обертку, две кнопки и параграф. Как можно заметить, Cycle.js работает с DOM с помощью JS-функций, но JSX также можно использовать.main-функции нужно возвратить наш Virtual DOM:return {
DOM: vdom$,
};
main-функцию и DOM-драйвер, который подключен к и получаем поток событий для этого div-элемента. Мы завершаем наш цикл и создаем прекрасное Cycle.js-приложение.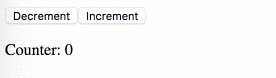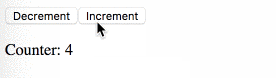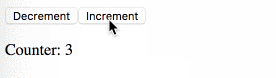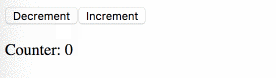
Вот и все! Таким образом и можно работать с DOM-потоками. Если вы хотите посмотреть как работать с HTTP-потоками в Cycle.js, я написал статью[eng]об этом.
Весь код можно найти на GitHub-репозитории.
Сейчас вы поняли базовые принципы реактивного программирования и уже увидели простой пример на Cycle.js, так что давайте поговорим, почему я буду использовать эту связку для следующего моего проекта.
При разработке веб-приложений управление огромным количеством кода и данными из разных источников является большой проблемой. Я фанат React и у меня было множество проектов, но React не решал всех моих проблем.
React хорошо себя проявлял, когда дело доходило до рендеринга небольших данных и изменения состояния приложения. На самом деле, его методология компонентов потрясающа и реально помогает писать качественный, поддерживаемый и тестируемый код. Но все время чего-то не хватало.
Давайте рассмотрим плюсы и минусы использования Cycle.js вместо React.
Когда приложение становится большим, при использовании React возникают проблемы. Представим, что у нас 100 компонентов внутри 100 контейнеров, и каждый из них имеет собственный функционал, тесты и стили. Это очень много строк кода внутри множества файлов внутри кучи директорий. В таком случае трудно переключаться между всеми этими файлами.
Для меня наибольшая проблема React — это потоки данных. React изначально не разрабатывался для работы с потоками данных, и этого нет в ядре React. Разработчики пытались решить это, и у нас есть множество библиотек и методологий, которые решают эту проблему. Наиболее популярный — это Redux. Но он не совершенен. Вам нужно потратить много времени, чтобы сконфигурировать его и нужно написать много кода, что позволит просто работать с потоками данных.
this, что порождает головную боль, если что-то пойдет не так.|
Метки: author Carduelis reactjs javascript react.js reactive programming cycle.js |
Canvas & SVG: работаем с графикой |
svg {
fill: blue;
}
const canvas = document.getElementById('canvas');
const context = canvas.getContext('2d');
context.beginPath();
context.moveTo(5, 5);
context.lineTo(500, 60);
context.lineWidth = 3;
context.strokeStyle = '#b4241b';
context.stroke();
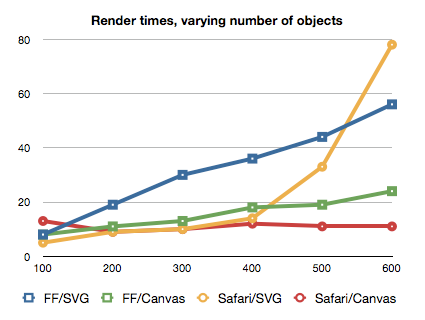
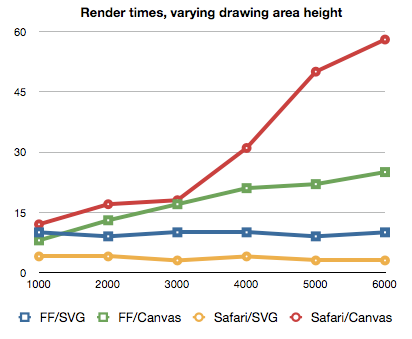

canvas.width = canvasWidth * window.devicePixelRatio;
canvas.height = canvasHeight * window.devicePixelRatio;
canvas.style.width = canvasWidth + 'px';
canvas.style.height = canvasHeight + 'px';
|
Метки: author SSul html canvas блог компании simbirsoft html5 верстка html5 canvas canvas2html css svg графика |
Первая российская материнская плата массового сегмента |
 Как мы уже писали, степень локализации отечественной серверной продукции массового сегмента выражена в большей степени в предоставлении различного рода услуг, нежели чем в производстве комплектующих. Комплектующие для серверов традиционно производятся в Китае, к какому бренду они не принадлежали бы. У одной российской компании была попытка создания полностью отечественной платформы, но продукт получился нишевой, так как платформа обладала характеристиками избыточными для классического применения серверов.
Как мы уже писали, степень локализации отечественной серверной продукции массового сегмента выражена в большей степени в предоставлении различного рода услуг, нежели чем в производстве комплектующих. Комплектующие для серверов традиционно производятся в Китае, к какому бренду они не принадлежали бы. У одной российской компании была попытка создания полностью отечественной платформы, но продукт получился нишевой, так как платформа обладала характеристиками избыточными для классического применения серверов.








Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
|
Анонс Гейзенбаг 2017 Moscow: удваиваем пользу |


 Саймон Стюарт известен как участник команды Selenium и создатель WebDriver. Неудивительно, что и тема доклада на Гейзенбаге будет связана с Selenium: речь пойдёт о масштабировании при его использовании. С какими проблемами можно столкнуться, когда число тестов устремляется в космос, и как решать эти проблемы?
Саймон Стюарт известен как участник команды Selenium и создатель WebDriver. Неудивительно, что и тема доклада на Гейзенбаге будет связана с Selenium: речь пойдёт о масштабировании при его использовании. С какими проблемами можно столкнуться, когда число тестов устремляется в космос, и как решать эти проблемы? Артём Ерошенко имеет прямое отношение к проекту Allure, и в июне на петербургском Гейзенбаге его доклад об Allure 2 оказался фаворитом зрителей. Но интересы Артёма не ограничиваются Allure — и выступление на московской конференции, вероятно, будет посвящено чему-то новому.
Артём Ерошенко имеет прямое отношение к проекту Allure, и в июне на петербургском Гейзенбаге его доклад об Allure 2 оказался фаворитом зрителей. Но интересы Артёма не ограничиваются Allure — и выступление на московской конференции, вероятно, будет посвящено чему-то новому. Илари Хенрик Эгертер выступал на обоих прошедших Гейзенбагах (московском и петербургском), оба его выступления понравились публике — неудивительно, что мы рады будем увидеть его в третий (и узнать, какой окажется длина его бороды в этот раз). Впрочем, мы получали и комментарии о том, что два его выступления слишком пересекались друг с другом. Учтём это: третье не окажется повторением двух первых.
Илари Хенрик Эгертер выступал на обоих прошедших Гейзенбагах (московском и петербургском), оба его выступления понравились публике — неудивительно, что мы рады будем увидеть его в третий (и узнать, какой окажется длина его бороды в этот раз). Впрочем, мы получали и комментарии о том, что два его выступления слишком пересекались друг с другом. Учтём это: третье не окажется повторением двух первых.  Владимир Ситников — эксперт в вопросах производительности. Многие знают его как коммиттера инструмента для нагрузочного тестирования JMeter, но в декабре он расскажет о другом. Зачастую под словами «тестирование производительности» подразумевают только тестирование серверной части, а непосредственно работу браузера тестируют гораздо реже — Владимир намерен устранить несправедливость и раскрыть на Гейзенбаге эту тему.
Владимир Ситников — эксперт в вопросах производительности. Многие знают его как коммиттера инструмента для нагрузочного тестирования JMeter, но в декабре он расскажет о другом. Зачастую под словами «тестирование производительности» подразумевают только тестирование серверной части, а непосредственно работу браузера тестируют гораздо реже — Владимир намерен устранить несправедливость и раскрыть на Гейзенбаге эту тему. Николай Алименков в июне на петербургском Гейзенбаге навёл шороху своей бурной дискуссией с Алексеем Виноградовым, а его доклад тогда получил от зрителей очень хорошие отзывы. В Москве в декабре он тоже будет очень активен: мало того, что выступит с докладом, так ещё и проведёт тренинг (об этом читайте ниже).
Николай Алименков в июне на петербургском Гейзенбаге навёл шороху своей бурной дискуссией с Алексеем Виноградовым, а его доклад тогда получил от зрителей очень хорошие отзывы. В Москве в декабре он тоже будет очень активен: мало того, что выступит с докладом, так ещё и проведёт тренинг (об этом читайте ниже). Алексей Лавренюк известен своей работой над проектом Яндекс.Танк, и неудивительно, что на петербургском Гейзенбаге рассказывал о нагрузочном тестировании. Но Алексей разбирается и в мобильном тестировании — так что не удивляйтесь, если тема его зимнего выступления в Москве будет сильно отличаться.
Алексей Лавренюк известен своей работой над проектом Яндекс.Танк, и неудивительно, что на петербургском Гейзенбаге рассказывал о нагрузочном тестировании. Но Алексей разбирается и в мобильном тестировании — так что не удивляйтесь, если тема его зимнего выступления в Москве будет сильно отличаться. Антон Архипов, которого Java-разработчики уже могли видеть на наших Java-конференциях, расскажет о том, как TestContainers помогает справляться с насущной проблемой — разворачиванием тестовой среды при интеграционном тестировании.
Антон Архипов, которого Java-разработчики уже могли видеть на наших Java-конференциях, расскажет о том, как TestContainers помогает справляться с насущной проблемой — разворачиванием тестовой среды при интеграционном тестировании.  Никита Макаров — руководитель группы автоматизации тестирования в Одноклассниках. А это значит, что его выступления становятся заведомо интересны: при работе над таким гигантским проектом неизбежно получаешь много ценного опыта, так что есть чем поделиться.
Никита Макаров — руководитель группы автоматизации тестирования в Одноклассниках. А это значит, что его выступления становятся заведомо интересны: при работе над таким гигантским проектом неизбежно получаешь много ценного опыта, так что есть чем поделиться.

|
|
[Перевод] Инструменты для разработчика Go: знакомимся с лейблами профайлера |
 Привет. Меня зовут Марко. Я системный программист в Badoo. Представляю вашему вниманию перевод поста замечательной rakyll о новой фиче в Go 1.9. Мне кажется, что лейблы будут очень полезны для профилирования ваших Go-программ. Мы в Badoo, например, используем аналогичную штуку для того, чтобы тегировать куски кода в наших программах на С. И если срабатывает таймер и в лог выводится стек-трейс, то в дополнение к нему мы выводим такой вот тег. В нем, например, может быть сказано, что мы обрабатывали фотографии пользователя с определенным UID. Это невероятно полезно, и я очень рад, что похожая возможность появилась и в Go.
Привет. Меня зовут Марко. Я системный программист в Badoo. Представляю вашему вниманию перевод поста замечательной rakyll о новой фиче в Go 1.9. Мне кажется, что лейблы будут очень полезны для профилирования ваших Go-программ. Мы в Badoo, например, используем аналогичную штуку для того, чтобы тегировать куски кода в наших программах на С. И если срабатывает таймер и в лог выводится стек-трейс, то в дополнение к нему мы выводим такой вот тег. В нем, например, может быть сказано, что мы обрабатывали фотографии пользователя с определенным UID. Это невероятно полезно, и я очень рад, что похожая возможность появилась и в Go.
В Go 1.9 появились лейблы профайлера: возможность добавить пару ключ-значение к семплам, которые делает CPU-профайлер. Профайлер собирает и выводит информацию о самых горячих функциях, где процессор проводит больше всего времени. Вывод обычного CPU-профайлера состоит из имени функции, названия файла исходника и номера строки в этом файле, и так далее. Из этих данных можно также понять, какие части кода вызвали эти горячие функции. Вы даже можете отфильтровать вывод, чтобы получить более глубокое представление о тех или иных ветках исполнения.
Информация о полном стеке вызовов очень полезна, но этого не всегда достаточно для поиска проблемы в производительности. Большое количество Go-программистов используют Go для написания серверов, а понять, где находится проблема производительности в сервере, еще труднее. Сложно отделить одни ветки исполнения от других или сложно понять, когда только одна ветвь исполнения вызывает проблемы (какой-то пользователь или определенный хэндлер). Начиная c Go 1.9 у нас появилась возможность добавлять дополнительную информацию о контексте того, что происходит в данный момент, и использовать в дальнейшем эту информацию в профайлере, чтобы получить более изолированные данные.
Лейблы могут быть полезны во многих случаях. Вот только самые очевидные из них:
В пакете runtime/pprof появятся несколько новых функций для добавления лейблов. Большинство пользователей будут использовать функцию Do, которая берет контекст, добавляет в него лейблы и передает новый контекст в функцию f:
func Do(ctx context.Context, labels LabelSet, f func(context.Context))Do записывает набор лейблов только в рамках текущей горутины. Если вы создаете новые горутины в f, вы можете передать контекст в качестве аргумента.
labels := pprof.Labels("worker", "purge")
pprof.Do(ctx, labels, func(ctx context.Context) {
// Делаем какую-либо работу...
go update(ctx) // пробрасывает лейблы дальше
})Работа выше будет помечена лейблом worker:purge.
Этот раздел продемонстрирует использование профайлера с лейблами. После того, как вы пометили все интересующие вас куски кода лейблами, время отпрофилировать код и посмотреть на вывод профайлера.
Я буду использовать пакет net/http/pprof в этом примере. Смотрите статью Profiling Go programs, если вам интересны подробности.
package main
import _ "net/http/pprof"
func main() {
// Много кода...
log.Fatal(http.ListenAndServe("localhost:5555", nil))
}Соберем данные по использованию CPU...
$ go tool pprof http://localhost:5555/debug/pprof/profileПосле того, как утилита переходит в интерактивный режим, вы можете посмотреть все записанные лейблы командой tags. Заметьте, что pprof-утилита называет из тэги, несмотря на то, что в стандартной библиотеке Go они называются лейблами.
(pprof) tags
http-path: Total 80
70 (87.50%): /messages
10 (12.50%): /user
worker: Total 158
158 ( 100%): purgeКак видите, тут два ключа (http-path, worker) и несколько значений для каждого. Ключ http-path указывает на HTTP-хендлеры, а worker:purge указывает на код из примера выше.
Фильтруя по лейблам, мы можем сфокусироваться, например, только на коде из хендлера /user.
(pprof) tagfocus="http-path:/user"
(pprof) top10 -cum
Showing nodes accounting for 0.10s, 3.05% of 3.28s total
flat flat% sum% cum cum%
0 0% 0% 0.10s 3.05% main.generateID.func1 /Users/jbd/src/hello/main.go
0.01s 0.3% 0.3% 0.08s 2.44% runtime.concatstring2 /Users/jbd/go/src/runtime/string.go
0.06s 1.83% 2.13% 0.07s 2.13% runtime.concatstrings /Users/jbd/go/src/runtime/string.go
0.01s 0.3% 2.44% 0.02s 0.61% runtime.mallocgc /Users/jbd/go/src/runtime/malloc.go
0 0% 2.44% 0.02s 0.61% runtime.slicebytetostring /Users/jbd/go/src/runtime/string.go
0 0% 2.44% 0.02s 0.61% strconv.FormatInt /Users/jbd/go/src/strconv/itoa.go
0 0% 2.44% 0.02s 0.61% strconv.Itoa /Users/jbd/go/src/strconv/itoa.go
0 0% 2.44% 0.02s 0.61% strconv.formatBits /Users/jbd/go/src/strconv/itoa.go
0.01s 0.3% 2.74% 0.01s 0.3% runtime.memmove /Users/jbd/go/src/runtime/memmove_amd64.s
0.01s 0.3% 3.05% 0.01s 0.3% runtime.nextFreeFast /Users/jbd/go/src/runtime/malloc.goЭтот вывод содержит только сэмплы, отмеченные лейблом http-path:/user. И вот в таком выводе мы с легкостью можем понять, где самые нагруженные места /user-хэндлера.
Также вы можете попробовать команды tagshow, taghide и tagignore для дополнительного фильтрования. Например, tagignore дает вам возможность получить данные по всем лейблам, кроме заданного. Фильтр ниже выдаст все, кроме /user хэндлера. В этом случае это worker:purge и http-path:/messages.
(pprof) tagfocus=
(pprof) tagignore="http-path:/user"
(pprof) tags
http-path: Total 70
70 ( 100%): /messages
worker: Total 158
158 ( 100%): purgeЕсли вы попробуете визуализировать отфильтрованные данные, вывод покажет сколько каждый лейбл привносит к полной “стоимости”.
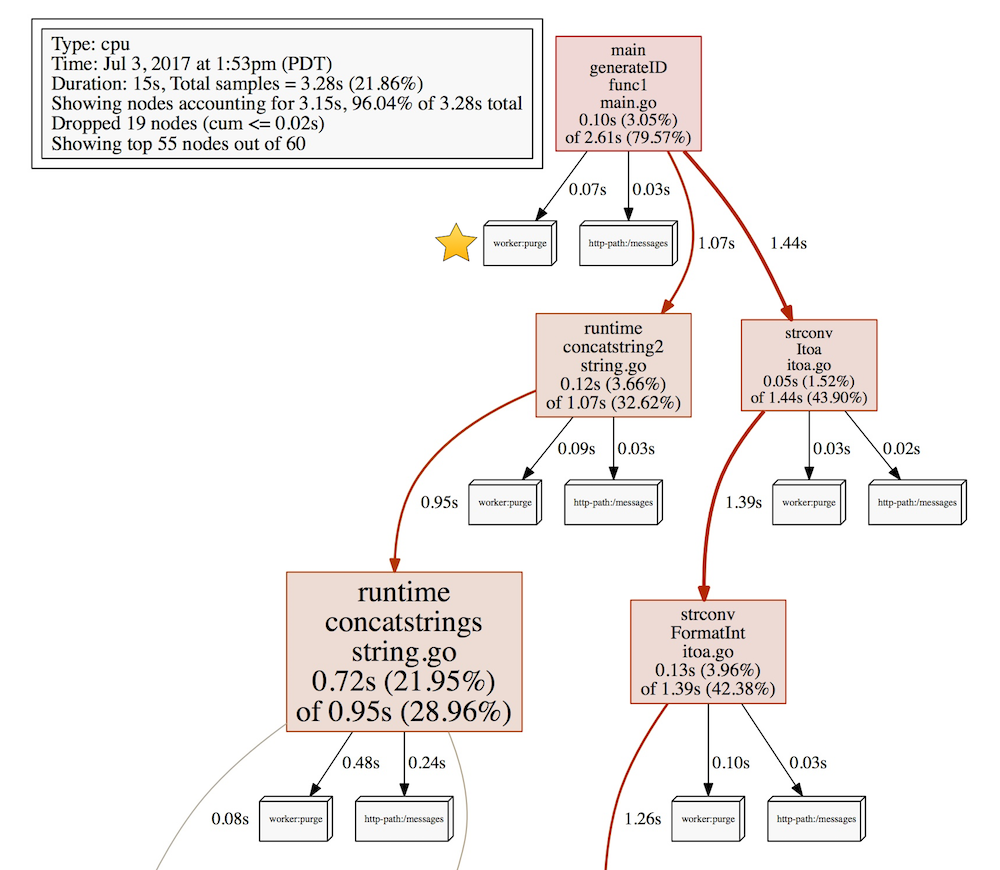
Тут видно что worker:purge привнес 0.07s, а хэндлер messages 0.03s в функции generateID.
Лейблы позволяют вам добавить дополнительную информацию к профайлеру, которая не доступна из простого стека вызовов. Попробуйте, скачав Go 1.9 beta, если вам нужны дополнительные размерности в вашем профайлере. Также попробуйте пакет pprofutil, чтобы автоматически обернуть ваши HTTP-пути лейблами.
На текущий момент доступна версия Go 1.9 beta 2. Известных багов в ней нет, но команда разработчиков просит попробовать ее на своих программах, а при возникновении проблем сообщить в баг-трекер. Я же хочу сказать, что собрать Go и быть на острие разработки очень и очень просто. Сама же сборка занимает не больше минуты. Дерзайте!
|
Метки: author mkevac программирование отладка go блог компании badoo профайлер лейблы |
[Перевод] Как создать свою метроидванию |












|
Метки: author PatientZero разработка игр метроидвания metroidvania гейм-дизайн |
[Из песочницы] STM32 + PPP (GSM) + LwIP |
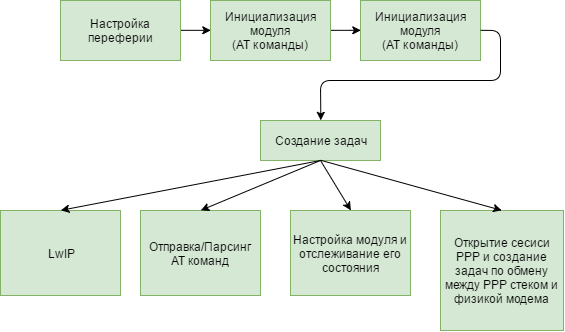
int main(void) {
HAL_Init();
SystemClock_Config();
MX_GPIO_Init();
MX_DMA_Init();
// Настройка gsm, периферии модуля и LwIP
InitGsmUart();
// Создание задачи по приему-отправке пакета и установки соединения
xTaskCreate(StartThread, "Start", configMINIMAL_STACK_SIZE*2, 0, tskIDLE_PRIORITY+1, &taskInitHandle);
// Старт процессов
osKernelStart(NULL, NULL);
while (1) {}
}
void StartThread(void * argument) {
gsmTaskInit();
// подлючение, отправка/прием данных
xTaskCreate(connectTask, "connectTask", configMINIMAL_STACK_SIZE*1, 0, tskIDLE_PRIORITY+1, NULL);
// После удаляем задачу
vTaskDelete(NULL);
}// Кол-во соединений. В этом примере 1, может быть больше, ограничено размером RAM контроллера и возможностями LwIP (последний легко настраивается)
#define GSM_MAX_CONNECTION 1
// Структура для работы с данными
typedef struct{
uint8_t *rxBuff;
uint16_t rxLen;
}sBuff[GSM_MAX_CONNECTION];
sBuff buff = {0};
void connectTask(void *pServiceNum) {
bool connectState = false;
eRetComm status = eError;
uint16_t delay = 0;
uint8_t serviceNum = *(uint8_t*)pServiceNum;
xSemaphoreHandle xRxPppData; // семафор на прием от ppp
xRxPppData = GsmLLR_GetRxSemphorePoint(serviceNum);
for(;;) {
/* Основной код задачи */
if(connectState == true) {
//Если есть подключение к серверу
while(GsmLLR_ConnectServiceStatus(serviceNum) == eOk) {
//Читаем данные в буфер
buff[serviceNum].rxLen = getRxData(serviceNum, xRxPppData,&(buff[serviceNum].rxBuff));
if(buff[serviceNum].rxLen != 0) {
//Если пришли данные то отправляем обратно
if(GsmLLR_TcpSend(serviceNum, buff[serviceNum].rxBuff,
buff[serviceNum].rxLen) == eOk) {
printf("Connect:#%i SendData OK\r\n", serviceNum);
}else{
printf("Connect:#%i SendData ERROR\r\n", serviceNum);
connectState = false;
}
}
}
//Если разрыв соединения
printf("Connect:#%i connection lost\r\n", serviceNum);
GsmLLR_DisconnectService(serviceNum);
connectState = false;
delay = 1000;
} else {
// соединение закрыто, настраиваем
printf("Connect:#%i connecting...", serviceNum);
// Устанавливаем соединение
if(GsmLLR_ConnectService(serviceNum) == eOk) {
printf("Connect:#%i connected", serviceNum);
connectState = true;
} else { // не получилось сконнектиться
printf("Connect:#%i ERROR", serviceNum);
delay = GSM_CONNECTION_ERROR_DELAY;
connectState = false;
}
}
vTaskDelay(delay/portTICK_RATE_MS);
}
}
// Прием данных
uint16_t getRxData(uint8_t serviceNum, xSemaphoreHandle xRxPppData, uint8_t **ppBufPacket) {
uint16_t retLen = 0;
uint16_t size = 0;
if(xSemaphoreTake(xRxPppData, 1000/portTICK_PERIOD_MS) == pdTRUE) {
size = gsmLLR_TcpGetRxCount(serviceNum);
if(size > 1512) {
retLen = 0;
}else {
retLen = GsmLLR_TcpReadData(serviceNum, ppBufPacket, size);
}
}
return retLen;
}void gsmTaskInit(void) {
xTaskCreate(vGsmTask, "GSM", configMINIMAL_STACK_SIZE*2, 0, tskIDLE_PRIORITY+1, &gsmInitTaskId);
while((!gsmState.init) || (!pppIsOpen)) {vTaskDelay(100/portTICK_PERIOD_MS);}
}
/* Задача инициализации и управления GSM модулем */
void vGsmTask( void * pvParameters ) {
// никзкоуровневые инициализации
GsmLLR_Init();
GsmLLR2_Init();
GsmPPP_Init();
// пока переферия не готова
while((gsmState.initLLR != true) && (gsmState.initLLR2 != true)){};
if(GsmLLR_PowerUp() != eOk) {
GsmLLR_ModuleLost();
}
for(;;) {
// инициализация
if(gsmState.init == false) {
// если модуль перестал отвечать
if(gsmState.notRespond == true) {
printf("GSM: INIT Module lost\r\n");
GsmLLR_ModuleLost();
continue;
}
// готовность модуля
if(GsmLLR_ATAT() != eOk) {
gsmState.notRespond = true;
continue;
}
// отключение предупреждений по питанию
if(GsmLLR_WarningOff() != eOk) {
gsmState.notRespond = true;
continue;
}
// настройки ответа
if(GsmLLR_FlowControl() != eOk) {
gsmState.notRespond = true;
continue;
}
// читаем IMEI
if(GsmLLR_GetIMEI(aIMEI) != eOk) {
gsmState.notRespond = true;
continue;
}
DBGInfo("GSM: module IMEI=%s\r\n", aIMEI);
// читаем IMSI
if(GsmLLR_GetIMSI(aIMSI) != eOk) {
gsmState.notRespond = true;
continue;
}
printf("GSM: module IMSI=%s\r\n", aIMSI);
// Версия Software
if(GsmLLR_GetModuleSoftWareVersion(aVerionSoftware) != eOk) {
gsmState.notRespond = true;
continue;
}
// вывод сообщения о регистрации сети (URC)
if(GsmLLR_AtCREG() != eOk) {
gsmState.notRespond = true;
continue;
}
printf("GSM: CREG OK\r\n");
// читаем уровень сигнала
if(GsmLLR_UpdateCSQ(&gsmCsqValue) != eOk) {
printf("GSM: Get CSQ ERROR, -RELOAD\r\n");
gsmState.notRespond = true;
continue;
}else{
printf("GSM: CSQ value %d\r\n", gsmCsqValue);
// формат SMS
if(GsmLLR_SmsModeSelect(sms_TEXT) != eOk) {
gsmState.notRespond = true;
continue;
}
//удаляем sms
vTaskDelay(DELAY_REPLY_INIT/portTICK_RATE_MS);
if(GsmLLR_SmsClearAll() != eOk) {
printf("GSM: clear SMS ERROR, -RELOAD\r\n");
gsmState.notRespond = true;
continue;
}
printf("GSM: Clear SMS Ok\r\n");
printf("GSM: INIT PPPP\r\n");
if(GsmLLR_StartPPP(&connectionSettings.gsmSettings) == eOk) {
printf("GSM: INIT PPPP - PPP RUN\r\n");
xQueueReset(uartParcerStruct.uart.rxQueue);
uartParcerStruct.ppp.pppModeEnable = true;
uartParcerStruct.uart.receiveState = true;
gsmState.init = true;
}else{
printf("GSM: INIT PPPP - PPP ERROR!!!\r\n");
gsmState.notRespond = true;
continue;
}
}
}
vTaskDelay(1000/portTICK_RATE_MS);
}
}char *comPPP_0[] = {"AT+CGDCONT=1,\"IP\","};
char *comPPP_2[] = {"AT+CGQMIN=1,0,0,0,0,0"};
char *comPPP_3[] = {"AT+CGQREQ=1,2,4,3,6,31"};
char *comPPP_4[] = {"ATD*99***1#"};
eRetComm GsmLLR_StartPPP(sGsmSettings *pSettings) {
printf("StartPPP\r\n");
sResultCommand resultCommand;
char **comPPP_Mass[3] = {comPPP_2, comPPP_3, comPPP_4};
uint8_t *pData = NULL;
if(GsmLLR_GetMutex() == true) {
pData = pvPortMalloc(GSM_MALLOC_COMMAND_SIZE);
if(pData != NULL) {
memset(pData, 0, GSM_MALLOC_COMMAND_SIZE);
sprintf((char*)pData, "%s%s", comPPP_0[0], (char*)pSettings->gprsApn);
RunAtCommand((char*)pData, &resultCommand);
// Счетчик команд, пока не отправили все
uint8_t stepIndex = 0;
while(stepIndex != (3)) {
uint16_t len = strlen((char*)*comPPP_Mass[stepIndex]);
sprintf((char*)pData, "%s", (char*)*comPPP_Mass[stepIndex]);
RunAtCommand((char*)pData, &resultCommand);
stepIndex++;
}
memset(pData, 0, GSM_MALLOC_COMMAND_SIZE);
vPortFree(pData);
}
GsmLLR_GiveMutex();
}
return eOk;
}void GsmPPP_Tsk(void *pvParamter) {
int timeout = 0;
uint8_t i;
bool stateInit = false;
uint16_t tskStackInit;
LwipStack_Init();
pppInit();
pppSetAuth(PPPAUTHTYPE_CHAP, connectionSettings.gsmSettings.gprsUser, connectionSettings.gsmSettings.gprsPass);
sioWriteSemaphore = xSemaphoreCreateBinary();
for(i=0; i/ Если выставлен флаг о использовании PPP и все было настроено
if(uartParcerStruct.ppp.pppModeEnable == true) {
if(!pppIsOpen) {
pppNumport = pppOverSerialOpen(0, linkStatusCB, &pppIsOpen);
pppStop = 0;
timeout = 0;
stateInit = false;
while(timeout < 300) {
if(pppIsOpen) {
printf("PPP init - OK\r\n");
lwip_stats.link.drop = 0;
lwip_stats.link.chkerr = 0;
lwip_stats.link.err = 0;
stateInit = true;
break;
}else{
timeout ++;
vTaskDelay(100/portTICK_RATE_MS);
}
}
if(stateInit != true) {
printf("PPP init - TIMEOUT-ERROR\r\n");
pppClose(pppNumport);
pppIsOpen = false;
uartParcerStruct.ppp.pppModeEnable = false;
gsmState.init = false;
gsmState.notRespond = true;
}
}else{
if((lwip_stats.link.drop !=0) || (lwip_stats.link.chkerr !=0)) {
lwip_stats.link.drop = 0;
lwip_stats.link.chkerr = 0;
printf("GSMM: DROPING FAIL!!! RESTART PPP\r\n");
for(i=0; iportTICK_PERIOD_MS);
}
}
}
vTaskDelay(500/portTICK_RATE_MS);
}
}bool GsmPPP_Connect(uint8_t numConnect, char *pDestAddr, uint16_t port) {
struct ip_addr resolved = {0};
bool useDns = false;
uint8_t ipCut[4] = {0};
if(!pppIsOpen) {
printf("GSMPPP: CONNECT ERROR - PPP closed\r\n");
return false;
}
sscanf(pDestAddr, "%i.%i.%i.%i", &ipCut[0], &ipCut[1], &ipCut[2], &ipCut[3]);
if((ipCut[0]!=0)&&(ipCut[1]!=0)&&(ipCut[2]!=0)&&(ipCut[3]!=0)) {
IP4_ADDR(&connectionPppStruct.ipRemoteAddr[numConnect], ipCut[0],ipCut[1],ipCut[2],ipCut[3]); //31,10,4,158);
useDns = false;
}else{
useDns = true;
}
if(connectionPppStruct.connected[numConnect] == false) {
connectionPppStruct.tcpClient[numConnect] = tcp_new(); // create tcpPcb
tcp_recv(connectionPppStruct.tcpClient[numConnect], server_recv);
if(useDns == true) {
switch(dns_gethostbyname(pDestAddr, &resolved, destServerFound, &numConnect)) {
case ERR_OK: // numeric or cached, returned in resolved
connectionPppStruct.ipRemoteAddr[numConnect].addr = resolved.addr;
break;
case ERR_INPROGRESS: // need to ask, will return data via callback
if(xSemaphoreTake(connectionPppStruct.semphr[numConnect], 10000/portTICK_PERIOD_MS) != pdTRUE) {
while(tcp_close(connectionPppStruct.tcpClient[numConnect]) != ERR_OK) { vTaskDelay(100/portTICK_PERIOD_MS); }
connectionPppStruct.connected[numConnect] = false;
printf("GSMPPP: dns-ERROR\r\n");
return false;
}else{ }
break;
}
}
tcp_connect(connectionPppStruct.tcpClient[numConnect], &connectionPppStruct.ipRemoteAddr[numConnect], port, &TcpConnectedCallBack);
if(xSemaphoreTake(connectionPppStruct.semphr[numConnect], 10000/portTICK_PERIOD_MS) == pdTRUE) {
connectionPppStruct.connected[numConnect] = true;
printf("GSMPPP: connected %s\r\n", inet_ntoa(connectionPppStruct.ipRemoteAddr));
return true;
}else{
tcp_abort(connectionPppStruct.tcpClient[numConnect]);//tcp_close(connectionPppStruct.tcpClient[numConnect]);
while(tcp_close(connectionPppStruct.tcpClient[numConnect]) != ERR_OK) { vTaskDelay(100/portTICK_PERIOD_MS); }
printf("GSMPPP: connectTimeout-ERROR\r\n");
return false;
}
}else{
if(GsmLLR_ConnectServiceStatus(numConnect) == eOk) {
printf("GSMPPP: CONNECT-already connected %s\r\n", inet_ntoa(connectionPppStruct.ipRemoteAddr));
return true;
}else{
printf("GSMPPP: CONNECT CLOSE!!!\r\n");
return false;
}
}
return false;
}
bool GsmPPP_Disconnect(uint8_t numConnect) {
if(!pppIsOpen) {
printf("GSMPPP: CONNECT ERROR - PPP closed\r\n");
return false;
}
if(connectionPppStruct.tcpClient[numConnect] == NULL) {
return false;
}
while(tcp_close(connectionPppStruct.tcpClient[numConnect]) != ERR_OK) { vTaskDelay(100/portTICK_PERIOD_MS); }
connectionPppStruct.connected[numConnect] = false;
return true;
}
bool GsmPPP_ConnectStatus(uint8_t numConnect) {
if(!pppIsOpen) {
printf("GSMPPP: CONNECT ERROR - PPP closed\r\n");
return false;
}
if(connectionPppStruct.tcpClient[numConnect]->state == ESTABLISHED) {
return true;
}
return false;
}
bool GsmPPP_SendData(uint8_t numConnect, uint8_t *pData, uint16_t len) {
if(!pppIsOpen) {
printf("GSMPPP: CONNECT ERROR - PPP closed\r\n");
return false;
}
if(tcp_write(connectionPppStruct.tcpClient[numConnect], pData, len, NULL) == ERR_OK) {
return true;
}else {
while(tcp_close(connectionPppStruct.tcpClient[numConnect]) != ERR_OK) { vTaskDelay(100/portTICK_PERIOD_MS); }
connectionPppStruct.connected[numConnect] = false;
connectionPppStruct.rxData[numConnect].rxBufferLen = 0;
memset(connectionPppStruct.rxData[numConnect].rxBuffer,0, sizeof(connectionPppStruct.rxData[numConnect].rxBuffer));
}
return false;
}
uint16_t GsmPPP_GetRxLenData(uint8_t numConnect) {
if(!pppIsOpen) {
printf("GSMPPP: CONNECT ERROR - PPP closed\r\n");
return false;
}
return connectionPppStruct.rxData[numConnect].rxBufferLen;
}
uint16_t GsmPPP_ReadRxData(uint8_t numConnect, uint8_t **ppData) {
if(!pppIsOpen) {
printf("GSMPPP: CONNECT ERROR - PPP closed\r\n");
return false;
}
if(connectionPppStruct.rxData[numConnect].rxBufferLen != 0) {
*ppData = (uint8_t *) connectionPppStruct.rxData[numConnect].rxBuffer;
uint16_t retLen = connectionPppStruct.rxData[numConnect].rxBufferLen;
connectionPppStruct.rxData[numConnect].rxBufferLen = 0;
return retLen;
}
return false;
}
static void destServerFound(const char *name, struct ip_addr *ipaddr, void *arg)
{
uint8_t *num = (uint8_t*)arg;
if(*num < SERVERS_COUNT) {
printf("GSMPPP: DEST FOUND %s\r\n", inet_ntoa(ipaddr->addr));
connectionPppStruct.ipRemoteAddr[num].addr = ipaddr->addr;
xSemaphoreGive(connectionPppStruct.semphr[num]);
}else{
printf("GSMPPP: DNS != SERVER%s\r\n", inet_ntoa(ipaddr->addr));
}
}
static err_t TcpConnectedCallBack(void *arg, struct tcp_pcb *tpcb, err_t err) {
for(uint8_t i=0; ilocal_ip.addr));
xSemaphoreGive(connectionPppStruct.semphr[i]);
break;
}
}
}
static err_t server_recv(void *arg, struct tcp_pcb *pcb, struct pbuf *p, err_t err)
{
LWIP_UNUSED_ARG(arg);
if(err == ERR_OK && p != NULL) {
tcp_recved(pcb, p->tot_len);
printf("GSMPPP:server_recv(): pbuf->len %d byte\n [%s]", p->len, inet_ntoa(pcb->remote_ip.addr));
for(uint8_t i=0; iremote_ip.addr == connectionPppStruct.tcpClient[i]->remote_ip.addr) {
printf("GSMPPP: server_recv (callback) [%s]\r\n", inet_ntoa(pcb->remote_ip.addr));
if(p->len < sizeof(connectionPppStruct.rxData[i].rxBuffer)) {
memcpy(connectionPppStruct.rxData[i].rxBuffer, p->payload, p->len);
connectionPppStruct.rxData[i].rxBufferLen = p->len;
xSemaphoreGive(connectionPppStruct.rxData[i].rxSemh);
printf("GSMPPP: server_recv (callback) GIVE SEMPH[%s][%d]\r\n", inet_ntoa(pcb->remote_ip.addr), p->len);
}else{
printf("GSMPPP: server_recv p->len > sizeof(buf) -ERROR\r\n");
}
}
}
pbuf_free(p);
}else{
printf("\nserver_recv(): Errors-> ");
if (err != ERR_OK)
printf("1) Connection is not on ERR_OK state, but in %d state->\n", err);
if (p == NULL)
printf("2) Pbuf pointer p is a NULL pointer->\n ");
printf("server_recv(): Closing server-side connection...");
pbuf_free(p);
server_close(pcb);
}
return ERR_OK;
}
xSemaphoreHandle * GsmPPP_GetRxSemaphorePoint(uint8_t numService) {
return (connectionPppStruct.rxData[numService].rxSemh);
}static err_t server_poll(void *arg, struct tcp_pcb *pcb)
{
static int counter = 1;
LWIP_UNUSED_ARG(arg);
LWIP_UNUSED_ARG(pcb);
printf("\nserver_poll(): Call number %d\n", counter++);
return ERR_OK;
}
static err_t server_err(void *arg, err_t err)
{
LWIP_UNUSED_ARG(arg);
LWIP_UNUSED_ARG(err);
printf("\nserver_err(): Fatal error, exiting...\n");
return ERR_OK;
}
static void server_close(struct tcp_pcb *pcb)
{
tcp_arg(pcb, NULL);
tcp_sent(pcb, NULL);
tcp_recv(pcb, NULL);
while(tcp_close(pcb) != ERR_OK) { vTaskDelay(100/portTICK_PERIOD_MS); }
for(uint8_t i=0; ilocal_ip.addr));
connectionPppStruct.connected[i] = false;
}else{
printf("GSMPPP: server_recv p->len > sizeof(buf) -ERROR\r\n");
}
}
}// Прослойка на чтение из очереди - отправка данных в LwIP
u32_t sio_read(sio_fd_t fd, u8_t *data, u32_t len)
{
unsigned long i = 0;
if(uartParcerStruct.ppp.pppModeEnable) {
while(xQueueReceive(uartParcerStruct.uart.rxQueue,&data[i], 0) == pdTRUE) {
if(i==0) {
printf("Reading PPP packet from UART\r\n");
}
printf("%0.2x ", data[i]);
i++;
if (pppStop||(i==len)) {
pppStop = false;
return i;
}
}
if (i>0) {
printf("\n");
}
}
return i;
}
// Запись из LwIP в UART (GSM)
u32_t sio_write(sio_fd_t fd, u8_t *data, u32_t len)
{
u32_t retLen = 0;
if(uartParcerStruct.ppp.pppModeEnable) {
if(HAL_UART_Transmit_IT(&huart3, data, len) == HAL_OK) {
xSemaphoreTake(sioWriteSemaphore, portMAX_DELAY);
retLen = len;
}else{
printf("HAL ERRROR WRITE [sio_write]\r\n");
}
}else{
printf("sio_write not in PPP mode!\r\n");
}
return retLen;
}
// Прерывание сессии, очистка очереди
void sio_read_abort(sio_fd_t fd)
{
pppStop = true;
xQueueReset(uartParcerStruct.uart.rxQueue);
}
u32_t sys_jiffies(void) {
return xTaskGetTickCount();
}
// Калбек вызывается после успешной или не успешной попытки соединения
static void linkStatusCB(void * ctx, int errCode, void * arg) {
printf("GSMPP: linkStatusCB\r\n"); /* just wait */
bool *connected = (bool*)ctx;
struct ppp_addrs * addrs = arg;
switch (errCode) {
case PPPERR_NONE: { /* We are connected */
printf("ip_addr = %s\r\n", inet_ntoa(addrs->our_ipaddr));
printf("netmask = %s\r\n", inet_ntoa(addrs->netmask));
printf("dns1 = %s\r\n", inet_ntoa(addrs->dns1));
printf("dns2 = %s\r\n", inet_ntoa(addrs->dns2));
*connected = 1;
break;
}
case PPPERR_CONNECT: {
printf("lost connection\r\n"); /* just wait */
*connected = 0;
break;
}
default: { /* We have lost connection */
printf("connection error\r\n"); /* just wait */
*connected = 0;
break;
}
}
}
|
Метки: author Khomin программирование микроконтроллеров stm32 ppp lwip микроконтроллеры си программирование разработка |
The Machine и экзафлопсные вычисления для эры Big Data |

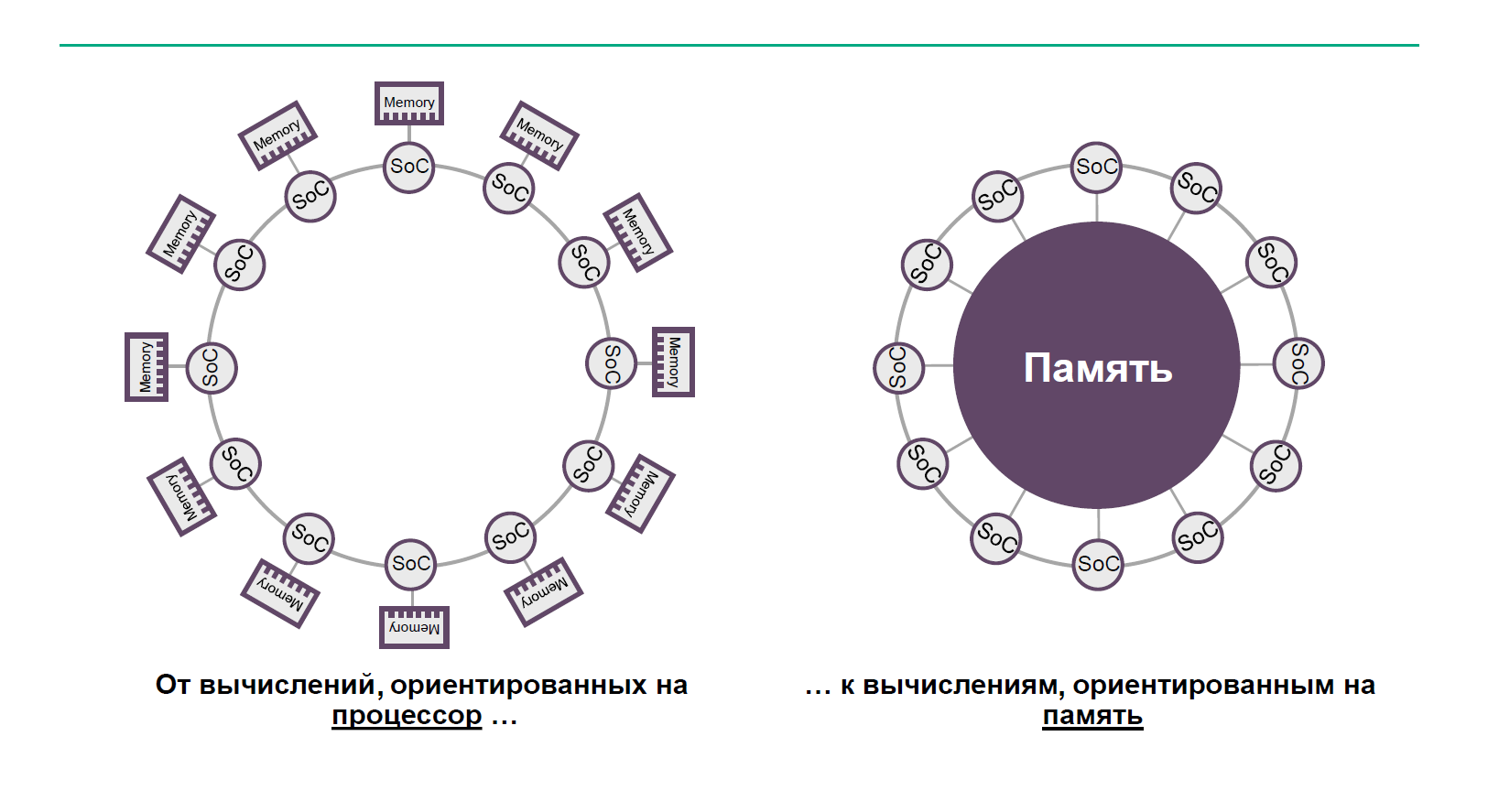
|
Метки: author tonyafilonenko блог компании hewlett packard enterprise the machine memory-driven computing высокопроизводительные вычисления hpe hewlett packard enterprise hp labs |
GitLab CI для непрерывной интеграции в production. Часть 1: наш пайплайн |
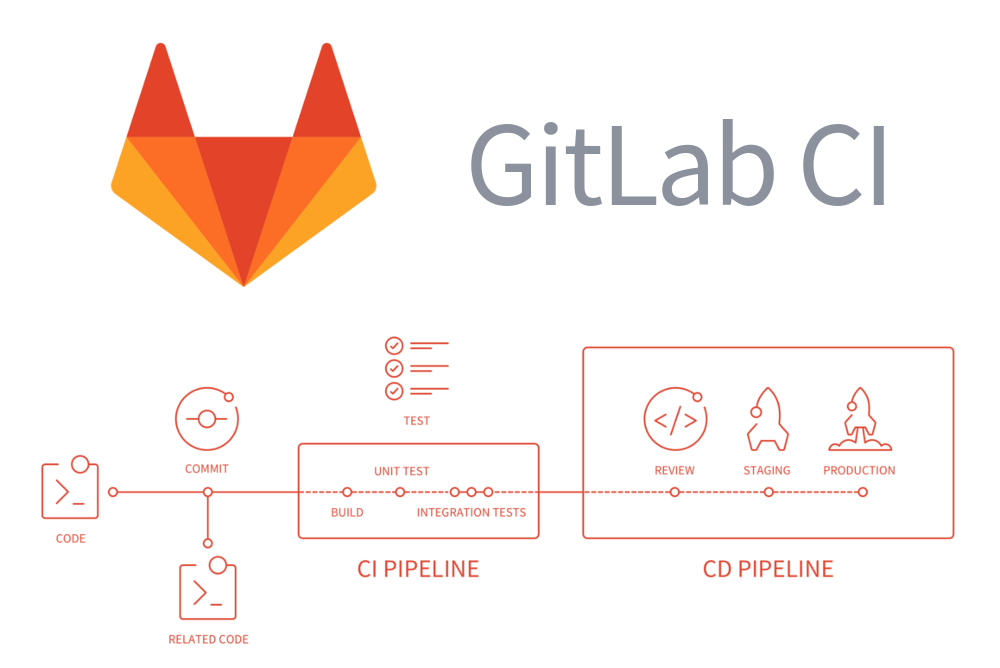
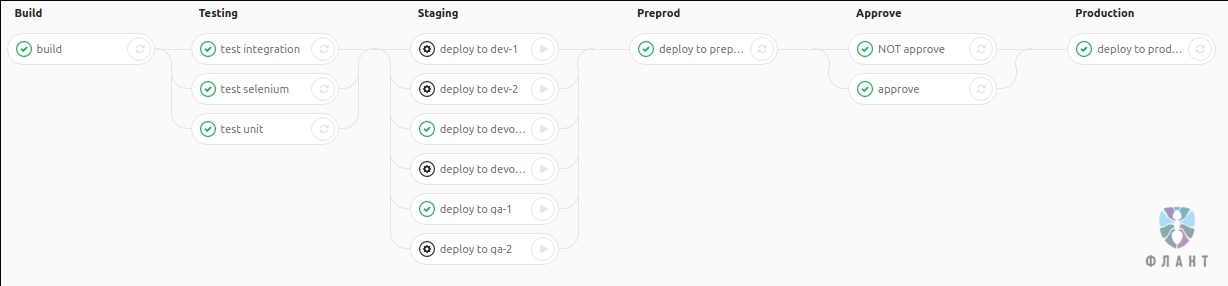

stages:
- build
- testing
- staging
- preprod
- approve
- production
## build stage
build:
stage: build
tags: [deploy]
script:
- echo "Build"
## testing stage
test unit:
stage: testing
tags: [deploy]
script:
- echo "test unit"
test integration:
stage: testing
tags: [deploy]
script:
- echo "test integration"
test selenium:
stage: testing
tags: [deploy]
script:
- echo "test selenium"
## staging stage
.staging-deploy: &staging-deploy
tags: [deploy]
stage: staging
when: manual
script:
- echo $CI_BUILD_NAME
deploy to dev-1:
<<: *staging-deploy
deploy to dev-2:
<<: *staging-deploy
deploy to devops-1:
<<: *staging-deploy
deploy to devops-2:
<<: *staging-deploy
deploy to qa-1:
<<: *staging-deploy
deploy to qa-2:
<<: *staging-deploy
## preprod stage
deploy to preprod:
stage: preprod
tags: [deploy]
when: manual
script:
- echo "deploy to preprod"
## approve stage
approve:
stage: approve
tags: [deploy]
when: manual
script:
- echo "APPROVED"
NOT approve:
stage: approve
tags: [deploy]
when: manual
script:
- echo "NOT APPROVED"
## production stage
deploy to production:
stage: production
tags: [deploy]
when: manual
script:
- echo "deploy to production!"
stage — определяет стадию, к которой относится задача;script — действия, которые будут произведены, когда запустится задача;when — вид задачи (manual означает, что задача будет запускаться из пайплайна вручную);tags — теги, которые в свою очередь определяют, на каком раннере будет запущена задача.script.
.staging-deploy: &staging-deploy
tags: [deploy]
stage: staging
when: manual
script:
- echo $CI_BUILD_NAME.gitlab-ci.yml это можно сделать с помощью директивы only. Она определяет ветки, для которых будет создаваться пайплайн, а с помощью ключевого слова tags можно разрешить создавать пайплайн для тегов. К сожалению, директива only есть только для задач — её нельзя указать при описании стадии.test unit:
stage: testing
tags: [deploy]
script:
- echo "test unit"
only:
- tags
- /^infra_.*$/
- /^feature_.*$/deploy to production:
stage: production
tags: [deploy]
script:
- echo "deploy to production!"
only:
- tagsonly вынесена в общий блок (пример такого .gitlab-ci.yml доступен здесь)..gitlab-ci.yml для описанного пайплайна затормаживается, т.к. GitLab CI не предоставляет директив, во-первых, для разделения задач по пользователям, а во-вторых, для описания зависимостей выполнения задач от статуса выполнения других задач. Также хотелось бы разрешить изменять .gitlab-ci.yml только отдельным пользователям.|
|
[Перевод] Создание chatbot-a с помощью sockeye (MXNet) на базе AWS EC2 и AWS DeepLearning AMI |
… the Sockeye project, a sequence-to-sequence framework for Neural Machine Translation based on MXNet. It implements the well-known encoder-decoder architecture with attention.
Sockeye это фреймворк для обучения нейронных сетей машинному переводу, который базируется на известной архитектуре encoder-decoder.





sudo pip3 install sockeye --no-deps# cd ~/src
src# git clone https://github.com/b0noI/dialog_converter.git
Cloning into ‘dialog_converter’…
remote: Counting objects: 59, done.
remote: Compressing objects: 100% (49/49), done.
remote: Total 59 (delta 33), reused 20 (delta 9), pack-reused 0
Unpacking objects: 100% (59/59), done.
Checking connectivity… done.
src# cd dialog_converter
dialog_converter git:(master)# git checkout sockeye_chatbot
Branch sockeye_chatbot set up to track remote branch sockeye_chatbot from origin.
Switched to a new branch 'sockeye_chatbot'
dialog_converter git:(sockeye_chatbot)# python converter.py
dialog_converter git:(sockeye_chatbot)# ls
LICENSE README.md converter.py movie_lines.txt train.a train.b test.a test.b
# cd ~
# mkdir training
# cd training
training# cp ~/src/dialog_converter/train.* .
training# cp ~/src/dialog_converter/test.* .
python3 -m sockeye.train --source train.a --target train.b --validation-source train.a --validation-target train.b --output model
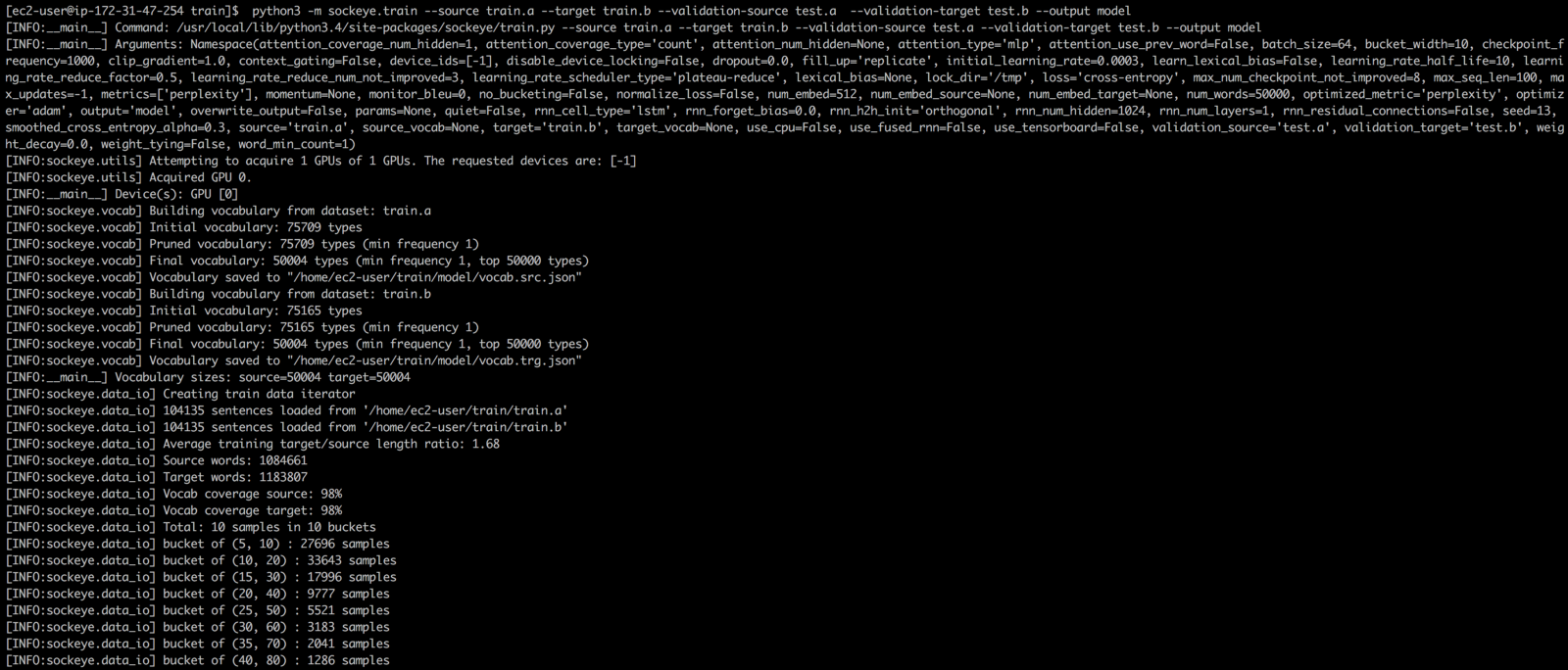
watch -n 0.5 nvidia-smi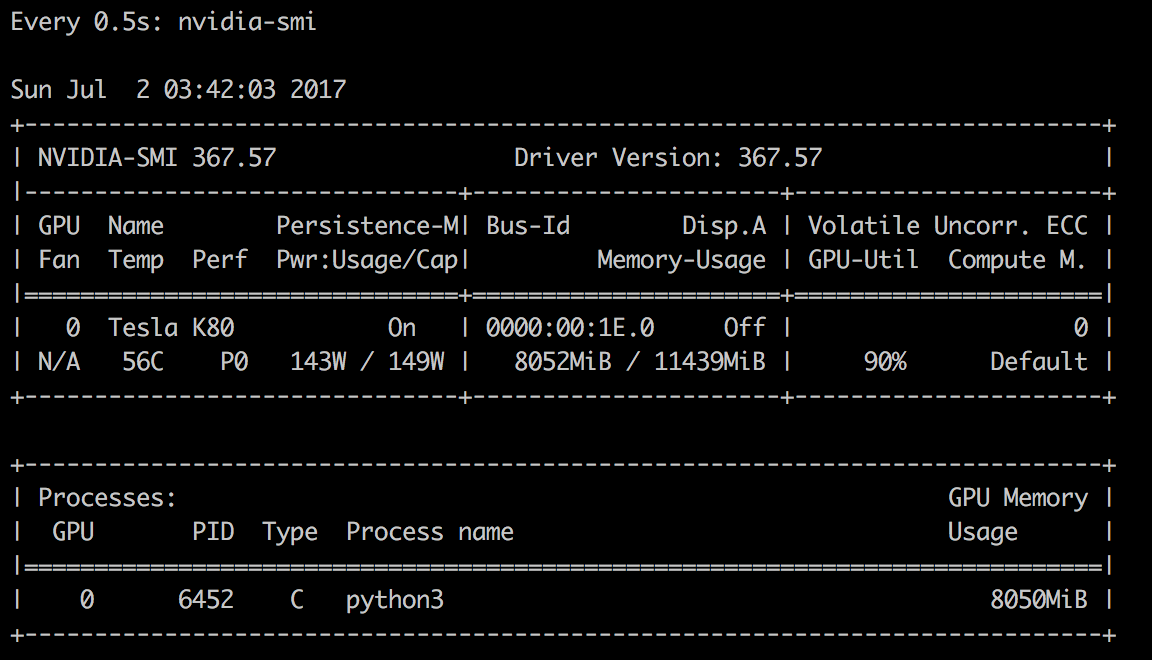

python3 -m sockeye.translate --models model --use-cpu --checkpoints 0005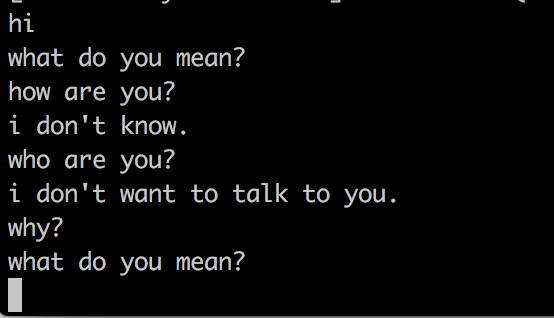


|
Метки: author b0noII машинное обучение amazon web services aws chatbot mxnet deep learning |
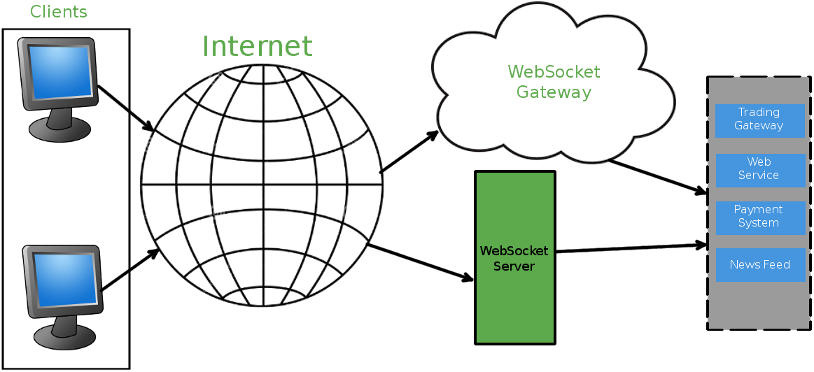
Вебсокеты на php. Выбираем вебсокет-сервер |
|
Метки: author morozovsk разработка веб-сайтов php websocket ws wss phpdaemon ratchet workerman |
[Перевод] Отзыв сертификатов не работает |
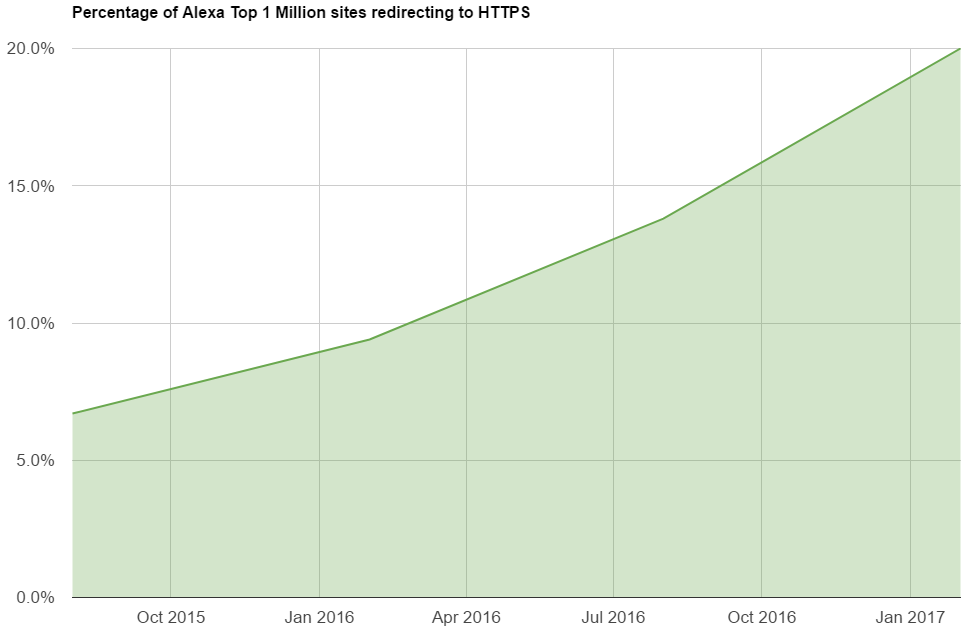
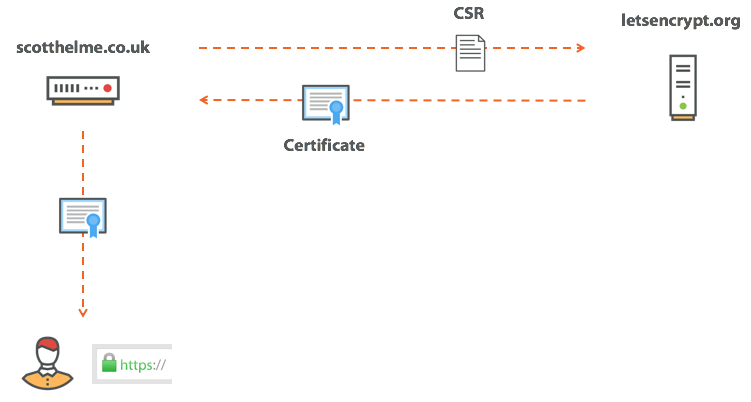
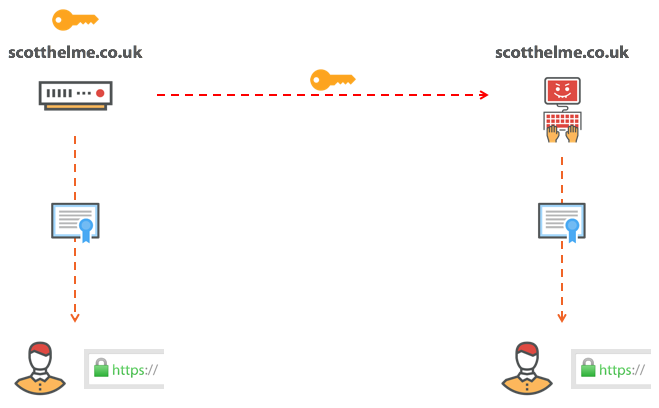
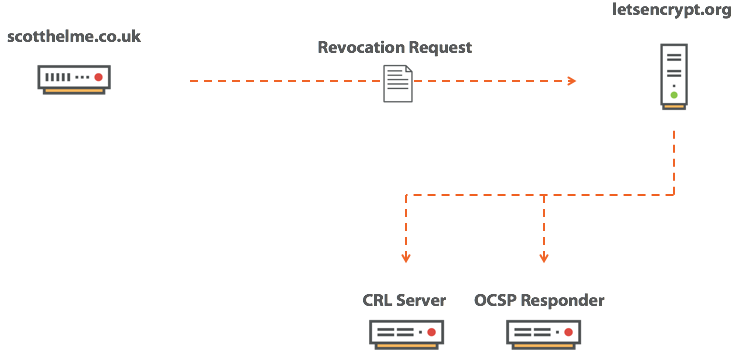
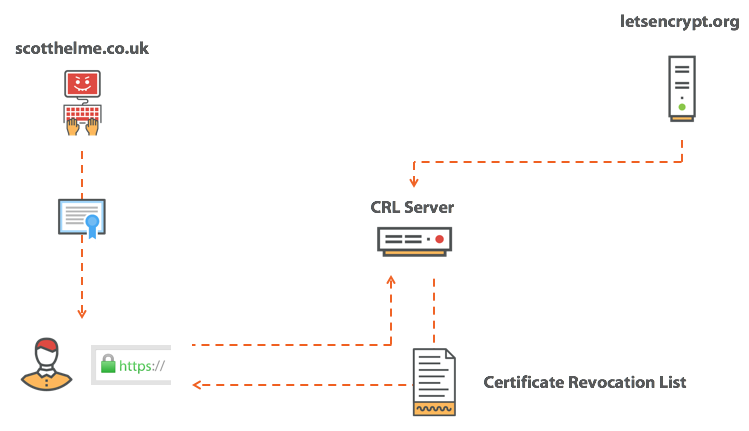
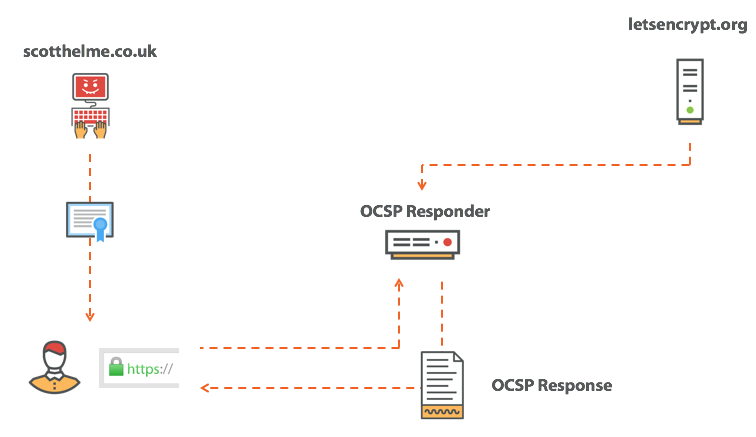
Сертификат для pornhub.com валидный?


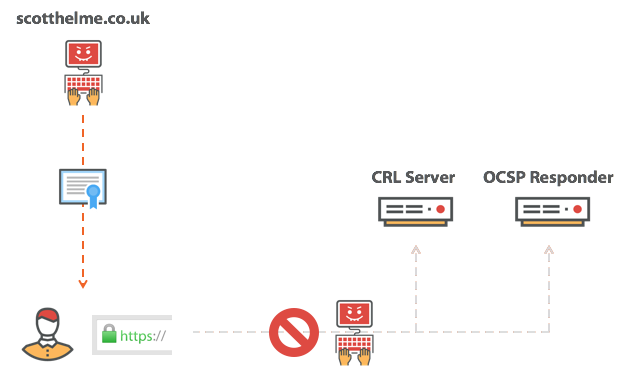
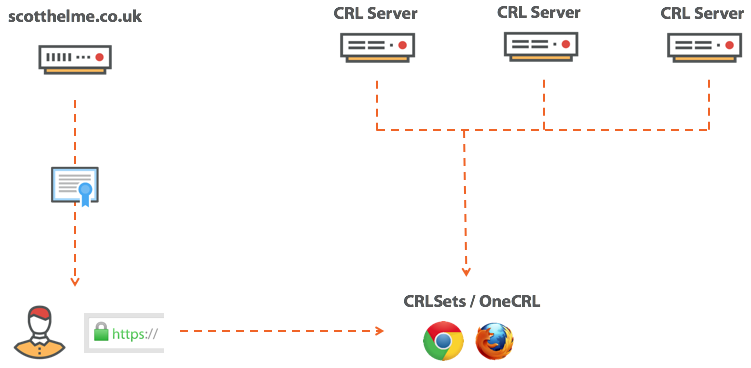
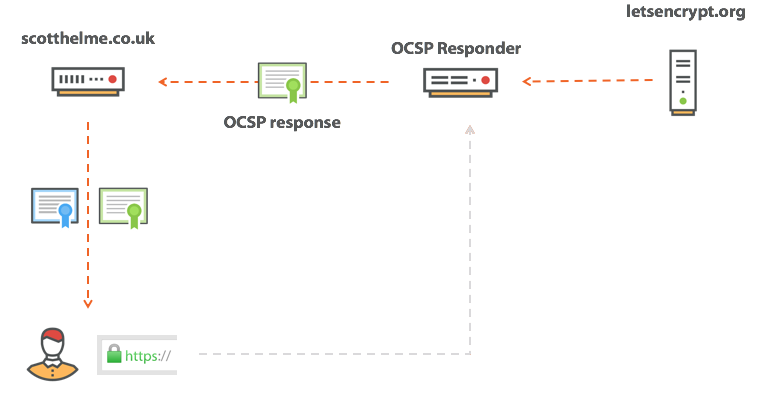
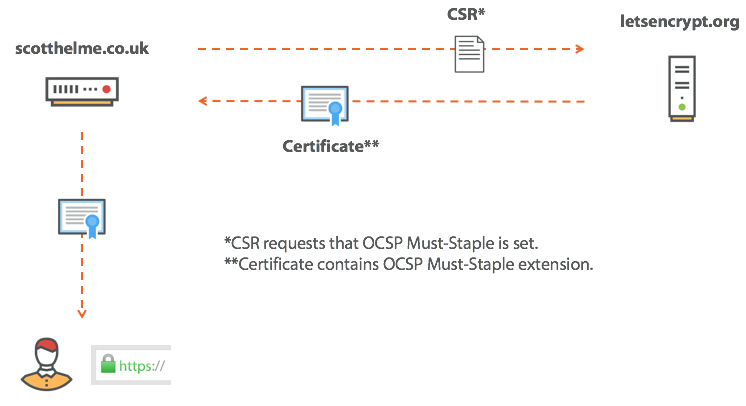
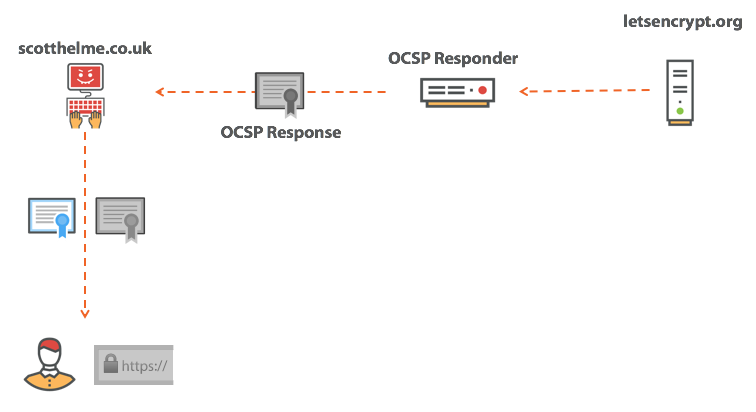
Expect-Staple: max-age=31536000; report-uri="https://scotthelme.report-uri.io/r/d/staple"; includeSubDomains; preload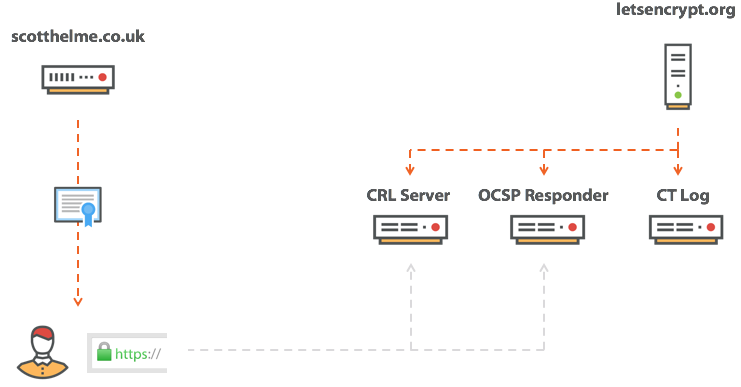
scotthelme.co.uk. IN CAA 0 issue "letsencrypt.org" hosts домен ocsp.int-x3.letsencrypt.org с IP-адресом 127.0.0.1 или блокировать его каким-нибудь другим способом — и повторить попытку подключения. На этот раз страница нормально загрузится, потому что проверка отозванного сертификата не сработает, а браузер продолжит загружать страницу. Толку от такой проверки…|
|
Игровое управление моделям в условиях неполной информации |
(В соавторстве с Юлией Филимоновой jul305a@gmail.com)
Представьте себе, что летите такой весь победитель на базу, бомб уже нет, и ничего не предвещает беды…

А тут, скажем, горочка из тумана/облаков выступает неожиданно, или, что несколько хуже, — вот это… И вам рады, но исключительно в качестве цели:

#поравалить — а вот как это делать с математическим уклоном сейчас и будем разбираться.
Да и вообще есть множество случаев, когда необходимо уклониться от неожиданно возникшей помехи/преграды, нашЛось, как говорят в Яндексе, например.
Оговорка для математиков. Изложение направлено скорее на объяснение принципов и понятность, а не на формальность и строгость. Почему так: если интересно - будет мотив разобраться с теорией дифференциальных игр, которая лежит в основе, и с первоисточниками, часть из которых перечислена в конце.
Простые движения это не то о чём в попсе поют, а самая простая модель динамического объекта, выражаемая следующей дифференциальной моделью:
где , -управление ограничено
Что это нам даёт? Если проинтегрировать уравнение, то мы получим траекторию движения — прямую линию , то есть, куда направлено управление, туда и летим. Значит, при отсутствии помех вектор управления сонаправлен с вектором движения .
Плюс данной модели в её крайней простоте для анализа, минус — моделирует она только безынерционные движения, но это не очень страшно так как моделирование инерционных движений будет выглядеть (упрощённо) как:
и к моделям соответствующего типа мы перейдем чуть позже.
Описанная модель отражает наши динамические возможности. Добавим в нее противника , который всячески старается нам помешать:
Здесь аналогично ограниченное управление
При этом мы заранее не знаем, где притаился противник, а он, при этом, знает всё и ждёт себе, пока мы подлетим поближе, для того чтобы при помощи своего управления достать нас множеством .
Поскольку наша цель — всё--таки попасть на , гарантированно уклонившись от , и мы должны знать от чего, собственно, мы уклоняемся, то рано или поздно помеху мы обнаружим. В случае безынерционного движения мы можем не знать о ней ничего до предпоследнего момента времени, так как в этом случае мы всегда можем направить вектор скорости (и, соответственно, траекторию) в сторону от помехи.
При этом, как можно заметить, помеха типа <<гора>> не самая страшная ситуация, так как она неподвижна, хотя и является большим препятствием, — хуже если противник подвижен, поэтому надо обсудить ещё пару моментов:
Воспользовавшись приведенными выше эвристическими рассуждениями, посмотрим, как можно решить приведенную выше задачу при следующих условиях в пространстве :
Здесь — координаты объекта на плоскости,
Пусть объект начинает движение из точки
Ограничения на управления имеют вид
Первый игрок стремится перевести траекторию системы за конечное время на терминальное множество — круг радиуса 1 с центром в точке , избежав при этом попадания на множество помехи — круг радиуса 2 с центром в точке .
Время успешного завершения игры первым игроком .
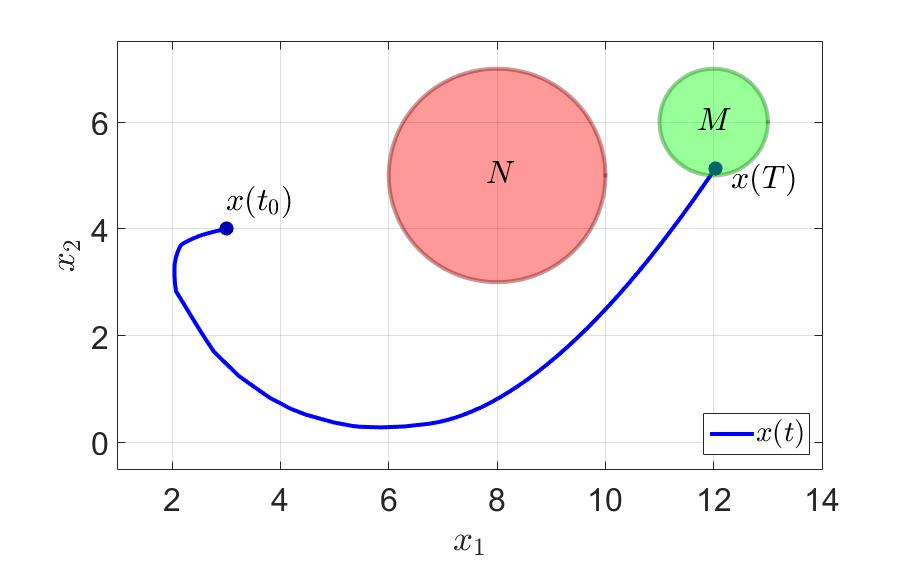
Траектория движения системы и компоненты управления первого игрока показаны на следующих рисунках.
Траектория движения системы.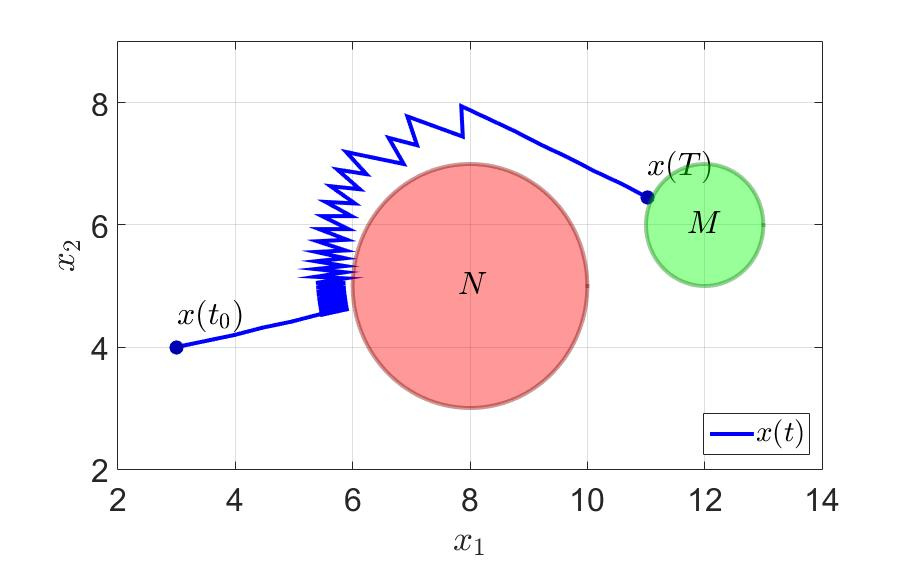
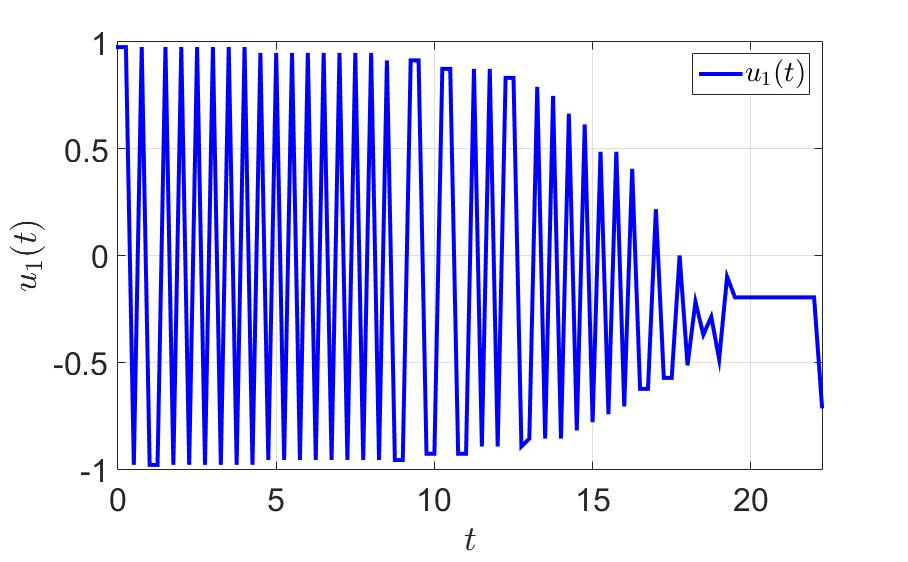
Зависимость первой компоненты управления от времени.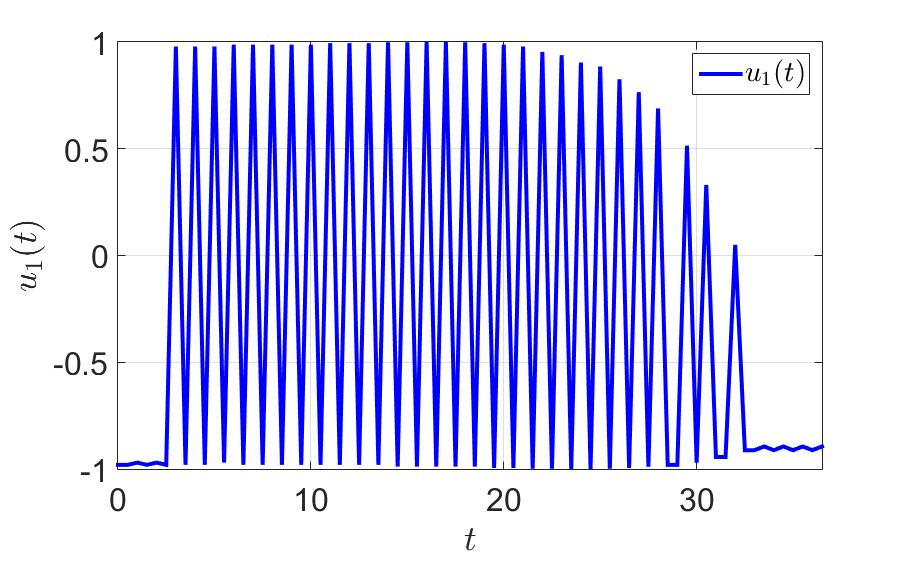
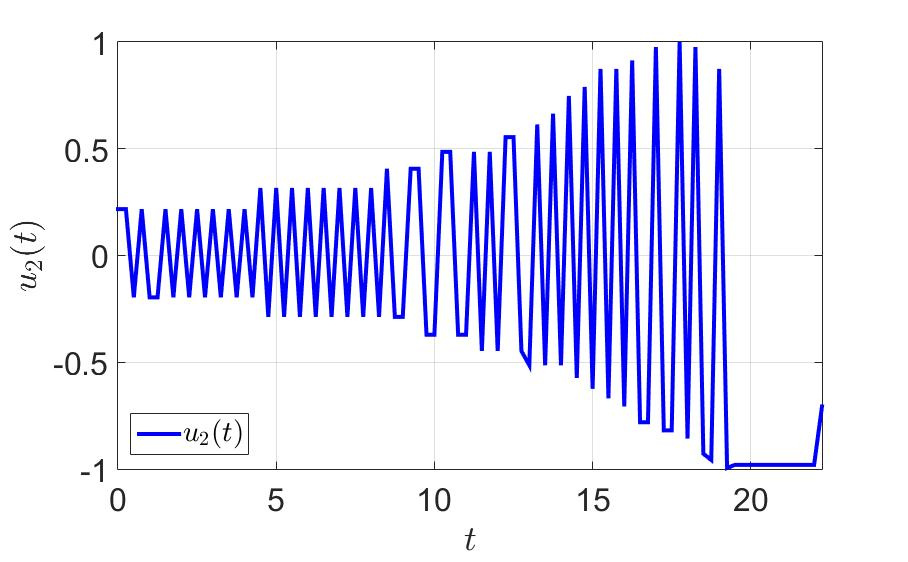
Зависимость второй компоненты управления от времени.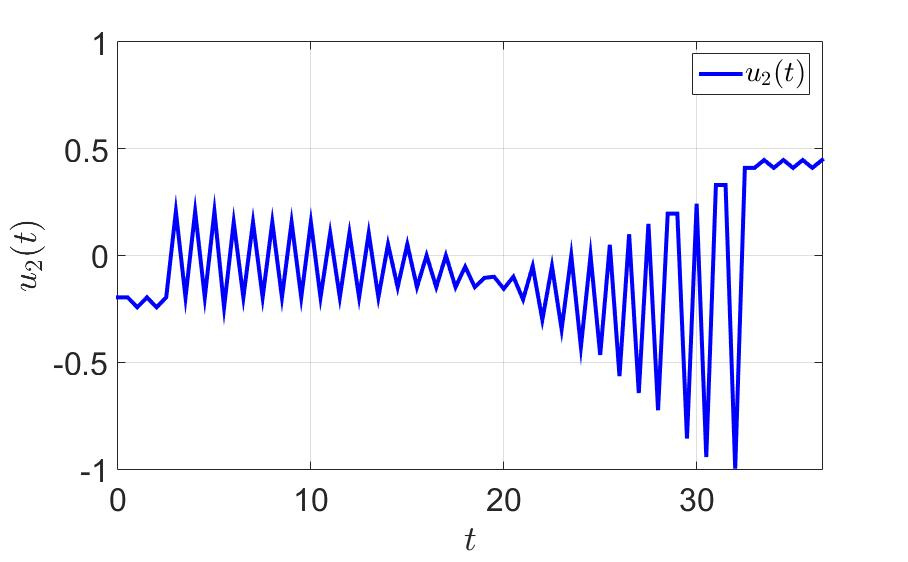
Данный подход, очевидно имеет несколько недостатков, а именно:
Ввиду того, что модель простая и позволяет нам двигаться по плоскости из любой точки в любую точку (это в дальнейшем будет являться существенным предположением, а пока просто берём на заметку), ничто не мешает нам рассуждать следующим образом.
Давайте думать на один шаг вперёд: если наша система сначала наводилась на цель, а на следующем шаге начала уклонятся, то можно найти точку, в которую система придёт через два шага, и наводиться сразу на неё как на промежуточную цель. Можем? По нашему предположению — ДА.
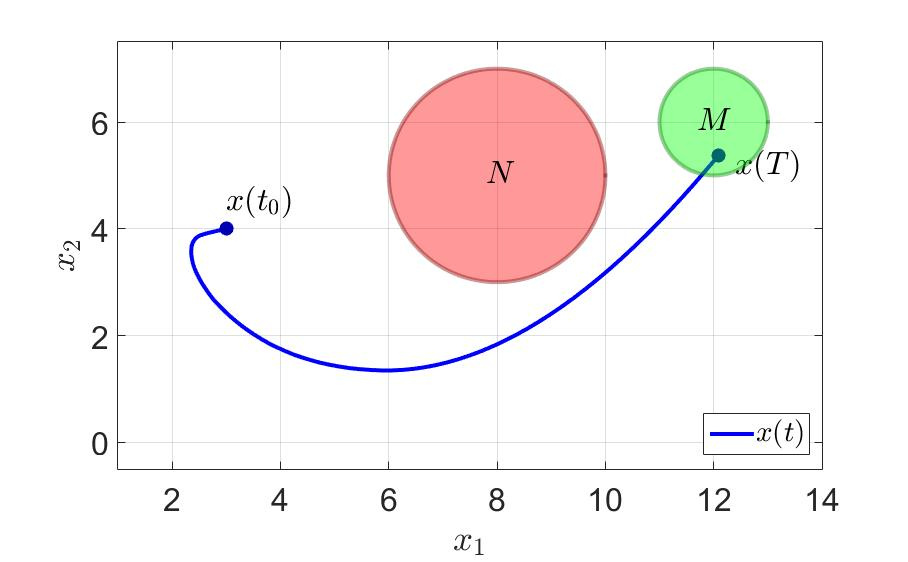
На том же примере посмотрим, что получается. Время успешного завершения игры первым игроком сократилось почти в три раза с до . Количество переключений тоже резко уменьшилось. Берём на заметку — думать хотя бы на шаг вперёд эффективно и вообще полезно для здоровья.
Траектория движения системы и компоненты управления первого игрока показаны на на следующих рисунках.
Траектория движения системы.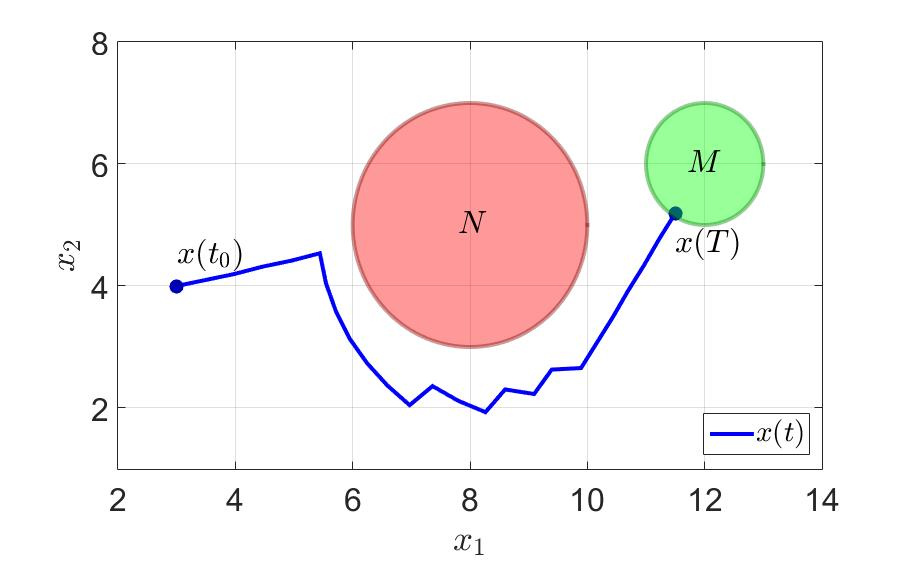
Зависимость первой компоненты управления от времени.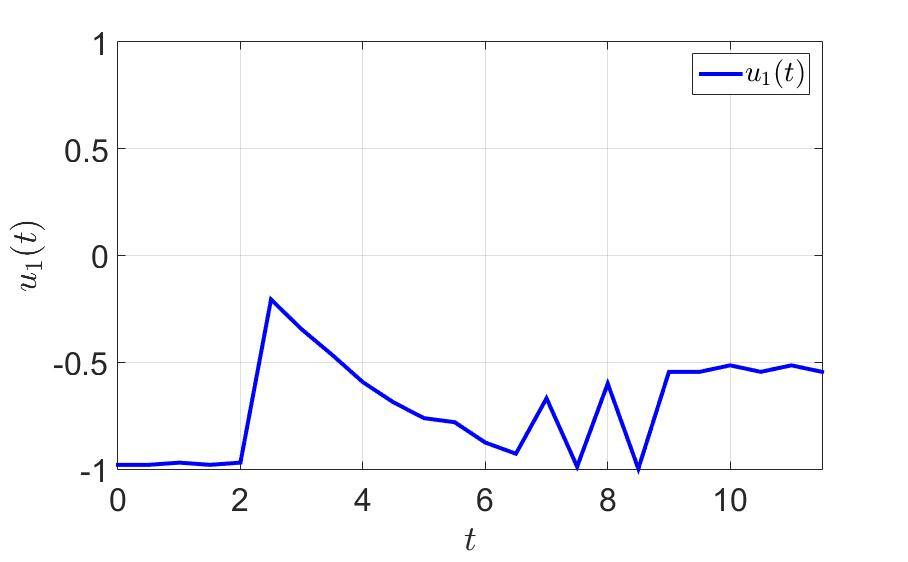
Зависимость второй компоненты управления от времени.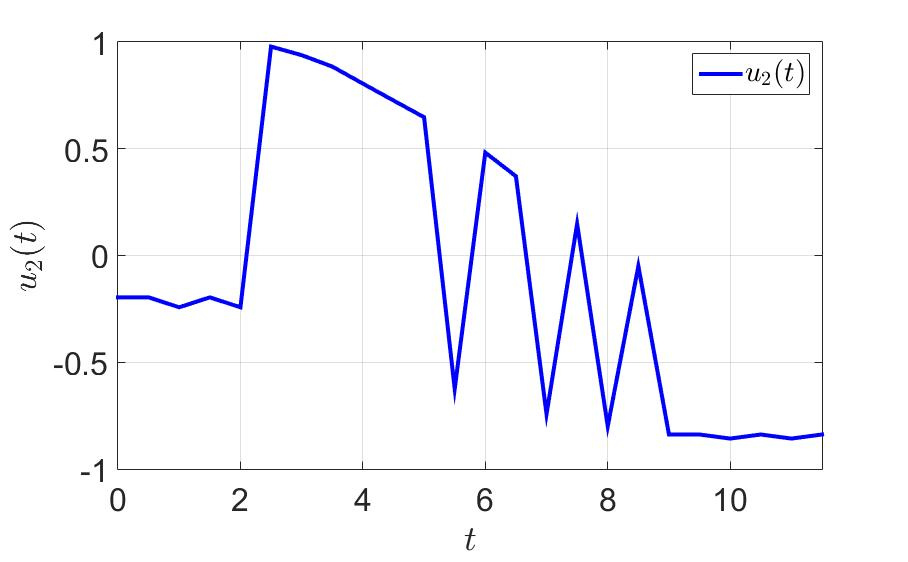
Так как мы умеем уклоняться от одного множества в один момент времени, то ничто нам не мешает построить дополнительное множество таким образом, чтобы, уклоняясь от него, мы ( возможно с измельчением шага по времени) гарантированно через два шага попадали в точку, отличную от той, в которой находимся сейчас. И сделаем мы это следующим образом:
Построение дополнительного множества избегания для траектории.
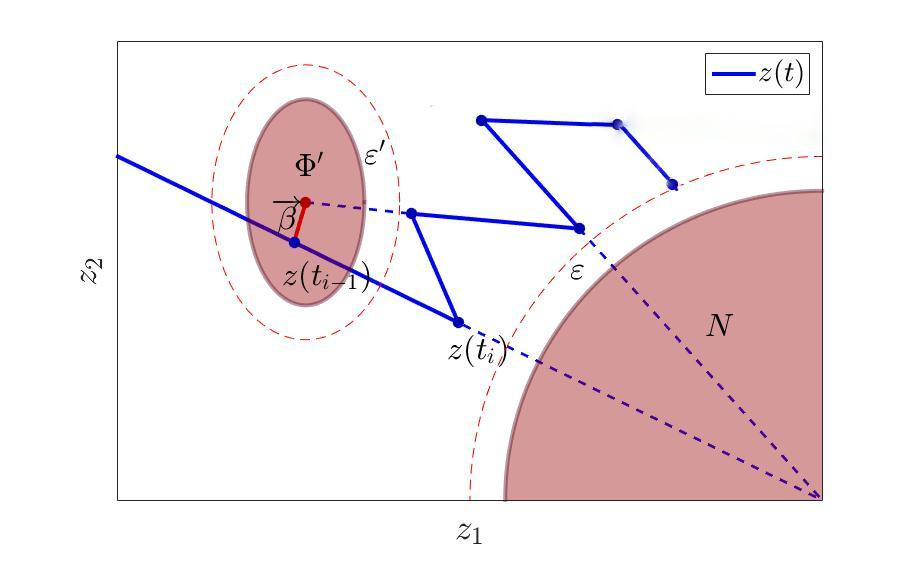
То есть просто построим дополнительное множество, от которого будем уклоняться, содержащее в себе «проблемную» точку не как центр, а с некоторым смещением, как на рисунке.
Для того, чтобы построить управления инерционными объектами необходимо всё таки погрузиться в теорию, так как простые эвристические рассуждения в этом случае работать перестают и, соответственно, необходимо подобрать теоретическую основу решения. Если у вас жёсткий приступ лени не хватает времени, то раздел можно, пропустить и воспользоваться сразу результатами, интересующиеся же — смотрим дальше.
В качестве основы будем использовать теорию дифференциальных игр, которые в нашей стране развивались Львом Семёновичем Понтрягиным [1] (если не знаете кто такой — обязательно почитайте, Личность с большой буквы, как говорится, таких уже не делают) и Красовским Николаем Николаевичем [2].
Для решения нам потребуются два множества:
С первым множеством, при отсутствии помехи всё более или менее понятно, если можем построить его таким образом, чтобы включить конечное множество — значит игру завершим успешно, не сможем — значит игра точно не сможет быть завершена. Строится оно в теории следующим образом — для каждой точки начиная с начальной путём перебора всех доступных управлений строим множество в которое можем попасть через , после чего операцию повторяем. Выглядит довольно сложно, но для выпуклых множеств и линейных систем можно всё радикально упростить, используя аппарат выпуклого анализа, — опорные функции и введя соответствующие сетки [4]. Построение такого множества решает задачу наведения первого игрока, назовём её — задача А.
Наведение на множество $M$ в условиях отсутствия помехи.
Что касается второго множества — множества откуда второй игрок может поймать нас и от которого нам и нужно уклоняться, то здесь несколько сложнее — следите за пальцами:
То есть что получается множество от которого мы уклоняемся должно быть с одной стороны большим (при приближении), а с дугой стороны (при удалении) может быть едва превышающим то, от которого необходимо уклониться?
Уклонение от множества .
Совпадение? Противоречие? Не думаю. Подобно Доку в "Назад в будущее" с его "пространственно-временным континуумом" вспомним, что у нас есть ещё одна переменная — время и будем трактовать термины "приближаемся" и "удаляемся" приведенные в кавычках как поведение системы вдоль траектории, что не всегда совпадает с прямолинейным движением и уж точно не характеризуется расстоянием в евклидовом пространстве. Зато временем движения до конкретной точки понятия "далеко-близко" и "приближаемся-удаляемся" характеризуются очень неплохо.
В этом случае давайте будем строить управление уклонения не от множества от которого нам надо уклоняться , а от множества в которое оно преобразуется (а оно уменьшится ввиду превосходства первого игрока) к моменту его приближение на соответствующее временной интервал в множеству — т.е. построим этакую воронку направленную к первому игроку своей узкой стороной и будем отталкиваться уже от неё. Построение такого множества в каждый момент игры и уклонение от него будет решает задачу уклонения первого игрока, назовём её — задача Б.
Соответственно общее управление управление первого игрока так, чтобы в каждый момент времени он решал только одну из этих подзадач.
Формализуем теперь движение нашего объекта , в --мерном евклидовом пространстве следующей системой дифференциальных уравнений:
где ; — выпуклые компакты из евклидовых пространств ; — постоянные матрицы, , что обеспечивает существование, единственность и продолжимость при всех решения задачи Коши.
Вектор находится в распоряжении первого игрока, вектор находится в распоряжении второго игрока.
Движение начинается при из начального состояния и протекает под воздействием измеримых по Лебегу функций .
В выделены некоторые непустые выпуклые замкнутые множества и . Множество является терминальным множеством первого игрока. Цель первого игрока — добиться выполнения включения при некотором . Множество является терминальным множеством второго игрока и множеством помехи первого игрока. Цель второго игрока — добиться выполнения включения при некотором . В момент первого попадания точки на игра считается успешно завершенной вторым игроком. Дополнительная задача первого игрока — избежать попадания точки на .
Игра считается успешно завершенной первым игроком в момент первого попадания точки на при условии, что для всех предыдущих моментов времени точка ни разу не попадала на . Таким образом, цели игроков не совпадают, и точка находится под воздействием противоборствующих управлений .
Будем отдельно рассматривать дифференциальную игру с точки зрения первого и второго игроков.
A: Предполагается, что первый игрок знает:
Предполагается также, что первый игрок способен обнаружить множество не позднее чем за время , значению которого определим ниже.
Определим стратегию первого игрока как отображение, определенное на множестве произвольных измеримых функций , и обладающее следующим свойством: для произвольной измеримой , функция измерима по и .
Задача A: Найти начальные состояния , для которых первый игрок обладает такой стратегией, что она обеспечивает окончание игры для произвольной измеримой не позже некоторого конечного момента. Такие состояния будем называть решениями задачи A.
Б:Второй игрок обладает полной информацией о ходе игры.
Определим стратегию второго игрока как отображение, определенное на множестве произвольных измеримых функций , и обладающее следующим свойством: для произвольной измеримой , функция измерима по и .
Задача Б: Найти начальные состояния , для которых второй игрок обладает такой стратегией, что она обеспечивает окончание игры для произвольной измеримой не позже некоторого конечного момента. Такие состояния будем называть решениями задачи Б.
Будем считать, что , где — линейное подпространство пространства , — выпуклый компакт, . Аналогично , где — линейное подпространство пространства , — выпуклый компакт, . При этом — оператор ортогонального проектирования из в , . Данные построения нужны для того, чтобы учесть, что игра у нас в общем случае (а при наличии инерционных объектов это так и есть) ведётся в пространстве меньшей размерности чем размерность системы дифференциальных уравнений.
Рассмотрим задачу Б — задачу преследования вторым игроком первого и построим для неё множество точек, из которого данная задача будет иметь решение. Так вот, для подобного типа задач Понтрягин придумал способ построения нужного множества — альтернированная сумма — [3], [5]. Так вот альтернированная сумма мало того является выпуклым компактом, так ещё и -стабильно (т.е. позволяет строить нужные нам стратегии второго игрока), а также обеспечивает выполнение условия существования седловой точки маленькой игры [6, стр. 56] (что означает, что игра в принципе разрешима) — т.е. всё и сразу.
Из [6, стр. 69 — теорема 17.1] следует, что в этих условиях можно воспользоваться теоремой об альтернативе:
Для всякой начальной позиции и выбранного верно одно из двух утверждений:
1) Либо найдется стратегия , которая для всех движений обеспечит встречу за конечное время . То есть, в классе позиционных стратегий второго игрока разрешима задача преследования (задача Б).
2) Либо, в противном случае, найдется стратегия , которая для всех движений , обеспечит уклонение от множества -окрестности множества $N$ вплоть до момента времени . То есть, в классе позиционных стратегий первого игрока разрешима задача уклонения (задача А).
При этом, ввиду -стабильности множества на сновании [6, стр. 62 — теорема 15.1] получим, что условие:
является достаточным условием решения задачи уклонения первого игрока из начальной позиции от -окрестности множества в течение времени .
Если ресурсы первого игрока, определяемые множеством , превосходят ресурсы второго игрока, определяемые множествами и , то найдется такое время , что .
Существование момента , для которого выполнено включение , обеспечивает разрешимость задачи Б за время из диапазона .
То есть можно построить стратегию , удовлетворяющую условию:
Следовательно, для того, чтобы обеспечить уклонение от множества , необходимо проверять приведенное выше условие как для текущего момента времени , так и для всех последующих моментов времени на глубину .
Множество , построенное в виде:
характеризует минимальное расстояние между преследователем и убегающим в момент времени , на котором преследование может быть завершено успешно. Откуда в общем-то и следует, что обнаруживать помеху мы должны за такое время (не за расстояние), за которое сможем от неё уклониться, что логично.
И, если настоящие математики на некоторое время закроют глаза, так как следующее рассуждение является ооочень частным случаем, то на пальцах это выглядит следующим образом: пусть множество помехи у нас шарик радиуса 5, множество управления шарик радиуса 2, а помехи -- соответственно 1, тогда время за которое мы должны обнаруживать помеху никак не должно быть меньше 4. Математики могут открывать глаза.
Аналогичным образом можно решить задачу наведения на множество в условиях отсутствия помехи. При этом достаточным условием наведения траектории системы на множество является условие:
Пусть первый игрок может заметить множество помехи не раньше, чем за время . Это означает, если ввести равномерное разбиения временного отрезка , что первый игрок может заметить помеху не раньше, чем за шагов по времени:
Тогда возможность перехвата вторым игроком первого (успешного завершения задачи Б) в момент определяется условием:
Здесь первый мы в момент времени проверяем, возможна ли поимка первого игрока на следующем шаге .
Будем строить управление первого игрока, считая, что выполнены следующие предположения.
На второго игрока наложены следующие ограничения:
второй игрок никогда не сможет достичь терминального множества :
в противном случае стратегия "закрыть собой" обеспечит победу второму игроку;
что гаратнирует нас от того, что мы при появлении откажемся внутри множества где нас поймают и игра потеряет всякий смысл.
Рассмотрим задачу уклонения первого игрока от множества отдельно от задачи наведения на целевое множество .
При этом, если для нашей игры выполнено приведенное выше предположение, то при любом начальном значении , можно показать, что существует такая стратегия уклонения, что расстояние между траекторией и множеством избегания может будет больше и зависеть только от хода игры, а не от её начального значения.
Что, переводя с математического на русский, означает, что в зависимости от параметров игры всегда существует ненулевое расстояние между нами и множеством из которого нас можно поймать.
При этом, в качестве стратегии уклонения можно выбрать управление экстремального сдвига, обеспечивающее, согласно теореме об альтернативе [6, стр. 69], уклонение от множества в виде:
где
Так как выполняются условия леммы 15.2 [6, стр. 65], то, повторяя её доказательство, получаем нужную оценку для минимального евклидового расстояния между траекторией и множеством , которая стремится к при измельчении шага разбиения по времени.
Рассмотрим теперь задачу наведения траектории системы на терминальное множество . При отсутствии каких-либо помех в виде множества и выполнении условия теоремы об альтернативе задача наведения разрешима, если начальная точка принадлежит множеству управляемости, а само управление наведения будет иметь вид:
Будем строить управление наведения--уклонения в следующем виде:
Проверяем для следующего шага пустоту пересечения:
Отметим, что в общем случае условие окончания игры наведения может быть нарушено, т.е. , где , — это найденные ранее значения времени окончания игры и соответствующий ему альтернированный интеграл. В данном случае необходим пересчёт альтернированного интеграла Л.С. Понтрягина и поиск соответствующего ему нового времени окончания игры , -натуральное число.
Применяя описанную стратегию, первый игрок в каждый момент времени будет либо наводиться на терминальное множество , сокращая расстояние до него, либо уклоняться от множества помехи , не попадая внутрь него.
Поскольку множество — строго выпуклый компакт, то для его огибания по описанной стратегии потребуется конечное время, а теорема об альтернативе гарантирует уклонение от множества в течение конечного времени. Поскольку задача наведения в условиях отсутствия помехи имеет решение за конечное время, то общее время завершения игры тоже конечно. При этом
— время завершения игры не меньше времени наведения, а в общем случае оценить невозможно, хотя оно и существует.
Проверим теперь на практике, что даёт построенный способ управления сначала без учёта снижения колчества перекючений, а потом с учётом данной оптимизации. Для чего рассмотрим одну из типовых задач имеющих имя собственное — "Два крокодила", моделирующую движения двух инерционных объектов с разными динамическими параметрами. Соотвественно пусть теперь первый игрок стремится решить задачу А.
Соотвествующая система дифференциальных уравнений будет иметь вид:
Здесь — координаты объекта на плоскости, а — компоненты его скорости,
объект начинает движение из точки
Ограничения на управления имеют вид
Первый игрок стремится перевести траекторию системы за конечное время на терминальное множество
избежав при этом попадания на множество помехи
В случае если первый игрок не занимается снижением количества переключений, то время завершения игры будет
Траектория движения системы и компоненты управления первого игрока показаны на следующих рисунках.
Траектория движения системы.
Зависимость первой компоненты управления от времени.
Зависимость второй компоненты управления от времени.
В случае же использовани способа, обеспечивающего снижение количества переключений управления время успешного завершения игры первым игроком будет почти в трираза меньше:
а соответствующие траектории показаны на следующих рисунках.
Траектория движения системы.
Зависимость первой компоненты управления от времени.
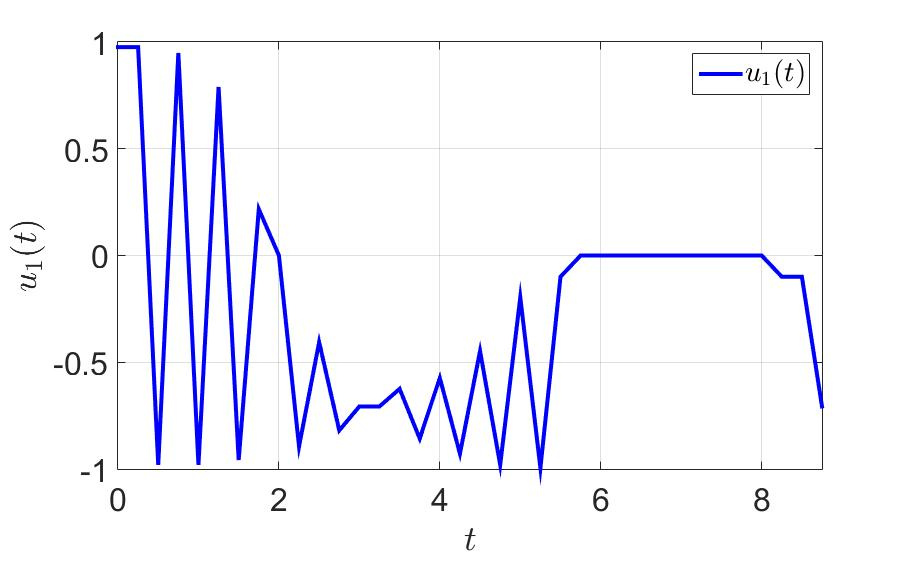
Зависимость второй компоненты управления от времени.
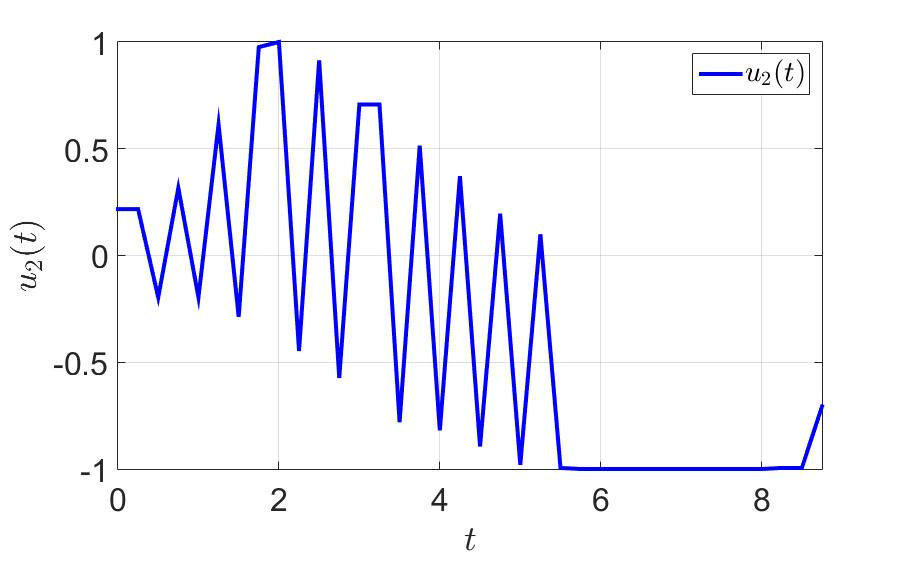
На рисунках видно, что управление, полученное в ходе решения задачи описанным выше методом, обладает достаточно небольшим количеством переключений.
Что в итоге получаем (если дочитали, конечно, до этого места), — "наивный" и "продвинутый" способы управления динамической моделью, позволяющие конструктивно строить управление зависящие исключительно от позиции (см. книги Н.Н. Красовcкого, А.И. Субботина и Л.С. Понтрягина), причем не обладая полными знаниями о помехе.
Исходники посмотреть можно здесь: репозитарий на GitHub
Предупреждаю сразу, что некоторым элементам кода уже порядка 19 лет, и они делались в то время, когда в C++ не было синтаксического сахара, да так и остались, т.к. работают. За конструктивую критику будем признательны.
Сейчас, т.к. жизнь не может быть полностью описана линейными дифференциальными уравнениями, занимаемся нелинейными моделями, но там нет серебряной пули, т.е. "на пальцах" простое объяснение дать не получится.
Отдельное спасибо Екатерине Кудешовой за критику.
[1] Понтрягин Л.С. Жизнеописание Л. С. Понтрягина, математика, составленное им самим», М, 1983
[2] Красовский Н.Н. Теория управления движением: Линейные системы, М, Наука, 1968
[3] Григоренко Н.Л. Математические методы управления несколькими динамическими процессами, М, Издательство Московского Университета, 1990
[4] Ю.Н. Киселёв, С.Н. Аввакумов, М.В. Орлов ОПТИМАЛЬНОЕ УПРАВЛЕНИЕ. ЛИНЕЙНАЯ ТЕОРИЯ И ПРИЛОЖЕНИЯ, М, 2007
[5] Григоренко Н.Л., Камзолкин Д.В., Пивоварчук Д.Г. Линейные дифференциальные игры, М, 2007
[6] Красовский Н.Н., Субботин А.И. Позиционные дифференциальные игры, М, Наука, 1974
[7] Ли Э.Б., Маркус Л. Основы теории оптимального управления, М, Наука, 1972
[8] Понтрягин Л.С., Болтянский В.Г., Гамкрелидзе Р.В., Мищенко Е.Ф. Математическая теория оптимальных процессов, М, Наука, 1969
|
Метки: author Rumyantsev разработка робототехники разработка игр математика c++ динамическое управление дифференциальные игры моделирование систем |
Дайджест свежих материалов из мира фронтенда за последнюю неделю №270 (3 — 9 июля 2017) |
|
|
Отменяется ли бунт роботов? |

Как это ни забавно, именно такая высокотехнологичная компания, как Google, в своей риторике шагает назад в XX век, архаически выставляя водителя пассивным наблюдателем. Их «новый» подход становится жертвой всех трех порожденных XX веком мифов о роботах и автоматизации: 1) автомобильная техника должна логически развиваться до полной, утопической автономности (миф о линейном прогрессе); 2) автономные системы управления освободят водителя от обязанности водить (миф замещения); 3) автономные машины могут действовать полностью самостоятельно (миф о полной автономности).
– У меня вчера была галлюцинация: я так перепугалась, что плохо спала всю ночь, – сказала мне больная. – Вхожу вечером в комнату и вижу: в лучах луны стоит какой-то человек. Я удивилась – кто бы это был? Подхожу ближе, а это мой халатик висит на стене, а вверху шляпа. Вот тогда я перепугалась еще больше: раз у меня галлюцинация, значит, я тяжело больна.
А пугаться-то было нечего. Это была не галлюцинация, а иллюзия, то есть неправильное, искаженное отражение реального предмета. Халат и шляпа показались человеком.
(Константин Платонов, Занимательная психология, «РИМИС», 2011.)
|
|
[recovery mode] Техподдержка 3CX отвечает: не открывается файл конфигурации клиента для Android и плохое качество звука на Android |

|
|
ПЛК от производителей Овен, Segnetics и Schneider Electric для HVAC |







Var
Var1 : bool;
Var2 : bool;
End_var
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author levWi промышленное программирование программирование микроконтроллеров segnetics pixel овен плк плк63 schneider m172 m171 |
Android Architecture Components. Часть 2. Lifecycle |

@OnLifecycleEvent(Lifecycle.Event.ON_ANY)
void stateUpdated() {
//будет вызваться при каждом изменении состояния жизненого цикла у овнера.
}
public class MyFragment extends Fragment implements LifecycleRegistryOwner {
LifecycleRegistry lifecycleRegistry = new LifecycleRegistry(this);
@Override
public LifecycleRegistry getLifecycle() {
return lifecycleRegistry;
}
}public class SomeObserver implements LifecycleObserver {
private Owner owner;
public SomeObserver(Lifecycle lifecycle, Owner owner) {
this.owner = owner;
lifecycle.addObserver(this);
}
@OnLifecycleEvent(Lifecycle.Event.ON_CREATE)
void onCreate() {
Log.d(«Observer», owner + «: onCreate»);
}
@OnLifecycleEvent(Lifecycle.Event.ON_STOP)
void onStop() {
Log.d(«Observer», owner + «: onStop»);
}
enum Owner {
ACTIVITY, FRAGMENT, PROCESS, SERVICE
}
}public class MainActivity extends LifecycleActivity {
SomeObserver someObserver = new SomeObserver(getLifecycle(), SomeObserver.Owner.ACTIVITY);
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
Log.d(«Owner», «onCreate»);
setContentView(R.layout.activity_main);
}
@Override
protected void onStop() {
super.onStop();
Log.d(«Owner», «onStop»);
}
}public class MyFragment extends LifecycleFragment {
SomeObserver someObserver = new SomeObserver(getLifecycle(), SomeObserver.Owner.FRAGMENT);
public MyFragment() {
}
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container,
Bundle savedInstanceState) {
return inflater.inflate(R.layout.fragment_my, container, false);
}
}public class MyService extends LifecycleService {
SomeObserver someObserver;
@Override
public int onStartCommand(Intent intent, int flags, int startId) {
someObserver = new SomeObserver(getLifecycle(), SomeObserver.Owner.SERVICE);
final Handler handler = new Handler();
handler.postDelayed(new Runnable() {
@Override
public void run() {
stopSelf();
}
}, 5000);
return super.onStartCommand(intent, flags, startId);
}
}public class CustomApplication extends Application {
private SomeObserver processObserver;
@Override
public void onCreate() {
super.onCreate();
processObserver = new SomeObserver(ProcessLifecycleOwner.get().getLifecycle(), SomeObserver.Owner.PROCESS);
Intent intent = new Intent(this, MyService.class);
startService(intent);
}
}|
|
[Из песочницы] Шифр Хила. Подробнй разбор |


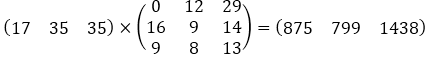
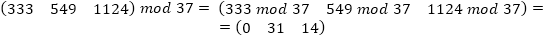


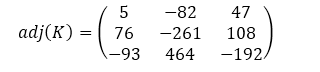






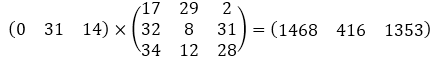

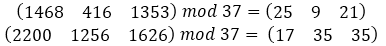
|
Метки: author All_iN_asmile криптография алгоритмы |
[Перевод] Быстрое удаление пробелов из строк на процессорах ARM |
 Предположим, что я дал вам относительно длинную строку, а вы хотите удалить из неё все пробелы. В ASCII мы можем определить пробелы как знак пробела (‘ ’) и знаки окончания строки (‘\r’ и ‘\n’). Меня больше всего интересуют вопросы алгоритма и производительности, так что мы можем упростить задачу и удалить все байты со значениями меньшими либо равными 32.
Предположим, что я дал вам относительно длинную строку, а вы хотите удалить из неё все пробелы. В ASCII мы можем определить пробелы как знак пробела (‘ ’) и знаки окончания строки (‘\r’ и ‘\n’). Меня больше всего интересуют вопросы алгоритма и производительности, так что мы можем упростить задачу и удалить все байты со значениями меньшими либо равными 32.size_t i = 0, pos = 0;
while (i < howmany) {
char c = bytes[i++];
bytes[pos] = c;
pos += (c > 32 ? 1 : 0);
}movemask). На процессорах ARM такой инструкции нет. Можно эмулировать movemask с помощью нескольких инструкций.static inline uint8x16_t is_white(uint8x16_t data) {
const uint8x16_t wchar = vdupq_n_u8(' ');
uint8x16_t isw = vcleq_u8(data, wchar);
return isw;
}static inline uint64_t is_not_zero(uint8x16_t v) {
uint64x2_t v64 = vreinterpretq_u64_u8(v);
uint32x2_t v32 = vqmovn_u64(v64);
uint64x1_t result = vreinterpret_u64_u32(v32);
return result[0];
}uint8x16_t vecbytes = vld1q_u8((uint8_t *)bytes + i);
uint8x16_t w = is_white(vecbytes);
uint64_t haswhite = is_not_zero(w);
w0 = vaddq_u8(justone, w);
if(!haswhite) {
vst1q_u8((uint8_t *)bytes + pos,vecbytes);
pos += 16;
i += 16;
} else {
for (int k = 0; k < 16; k++) {
bytes[pos] = bytes[i++];
pos += w[k];
}
}| скаляр | 1,40 нс |
| NEON | 1,04 нс |
perf stat. Вот сколько циклов нам символ нам нужно:| скаляр | ARM | Недавний x64 |
|---|---|---|
| скаляр | 2,4 цикла | 1,2 цикла |
| векторизованные (NEON и SS4) | 1,8 цикла | 0,25 цикла |
movemask/pshufb и алгоритм без ветвлением с очень малым количеством инструкций. Версия для ARM NEON гораздо слабее.movemask может ограничить вас в работе.|
Метки: author m1rko программирование высокая производительность алгоритмы open source assembler arm neon x64 x86 ss4 sse avx movemask |






