[Из песочницы] Марк, Джек и Алишер! Миру нужен новый фейсбук — образовательный |


|
Метки: author Svyatoslav_Abramov читальный зал исследования и прогнозы в it фейсбук образование марк цукерберг алишер усманов джек ма |
Постквантовая реинкарнация алгоритма Диффи-Хеллмана |
|
Метки: author Crittografo криптография информационная безопасность алгоритмы блог компании «актив» |
Мониторинг задержек системы с помощью JHiccup |

JHiccup это простая программа, которая позволяет измерить задержки операционной системы с точки зрения конечного приложения. Она была написана CTO компании Azul — Гилом Тени для измерения задержек ОС.
Мы в живем во времена сетевых приложений. Большинство программ запущенных на нашем компьютере регулярно ходят в интернет. Если мы запустим браузер и откроем google.com, то произойдет 50–60 запросов.
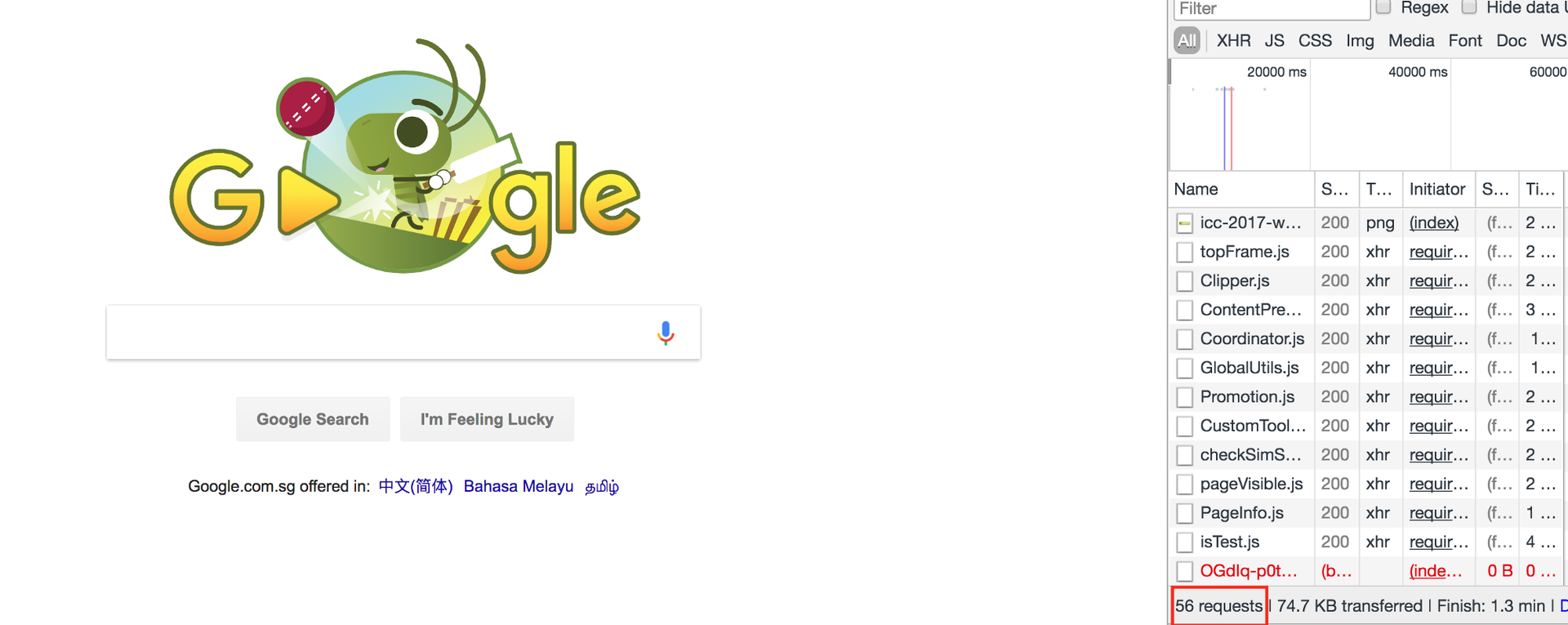
Для открытия google.com произошло 56 запросов
Если мы говорим о более сложных сайтах, то количество запросов будет исчисляться сотнями. И задержка любого из этого запросов может задержать отрисовку всего сайта.
Рассмотрев пример с сайтами, мы можем легко провести аналогию с клиент-серверным приложение или популярными микро-сервисами. Если в цепочке вызова микро-сервисом один из микро-сервисов вернет ответ позже обычного, то это может затормозить всю логику. Например, медленный ответ о цене продукта из БД может замедлить весь процесс покупки в интернет магазине.
Поэтому когда мы говорим о производительности и задержках программы, важен не только лучший и средний результат, но и худшие результаты.
Часто разработчикам поступают жалобы от клиентов или других систем о том, что приложение обрабатывало запрос слишком долго. К сожалению, такую проблему бывает трудно воспроизвести локально или даже заметить в реальном окружении.
Многие разработчики в этом случае сразу начинают искать проблемы в коде. Для этого используется например логи, метрики и профайлер. Но правильный анализ производительности должен начинаться снизу-вверх, начиная с уровня железа и ос и заканчивая программой.
Большинство ос не являются операционными системами реального времени. А значит они не могут давать гарантии на определенное время выполнение операций. Значит производительность программ, запущенный на таких ос, может сильно отличаться в течение времени работы программы. Попросту говоря, программа может даже не получать процессорное время в какой-то момент. И тогда абсолютно не важно какой код выполняется в программе.
Вот несколько причин почему программа может “спать” не имея возможности выполнять полезные действия:
Существует множество утилит и метрик, позволяющих увидеть загруженность разных компонентов системы с разной степенью детализации. Проблема в том, что таких метрик очень много и для каждой программисту нужно ответить на два вопроса:
jHiccup позволяет посмотреть на систему с точки зрения приложения. jHiccup это маленькое приложение с простой функцией : бесконечный поток засыпает и просит ос разбудить его через определенный период, например 1 секунду. Если ос была занят через 1 секунду и не смогла разбудить поток, то приложение это увидит сравнив время пробуждения с расчетным временем пробуждения (время засыпания + 1 сек). Мы можем построить график, где мы увидем задержки системы в течение выполнения программы.
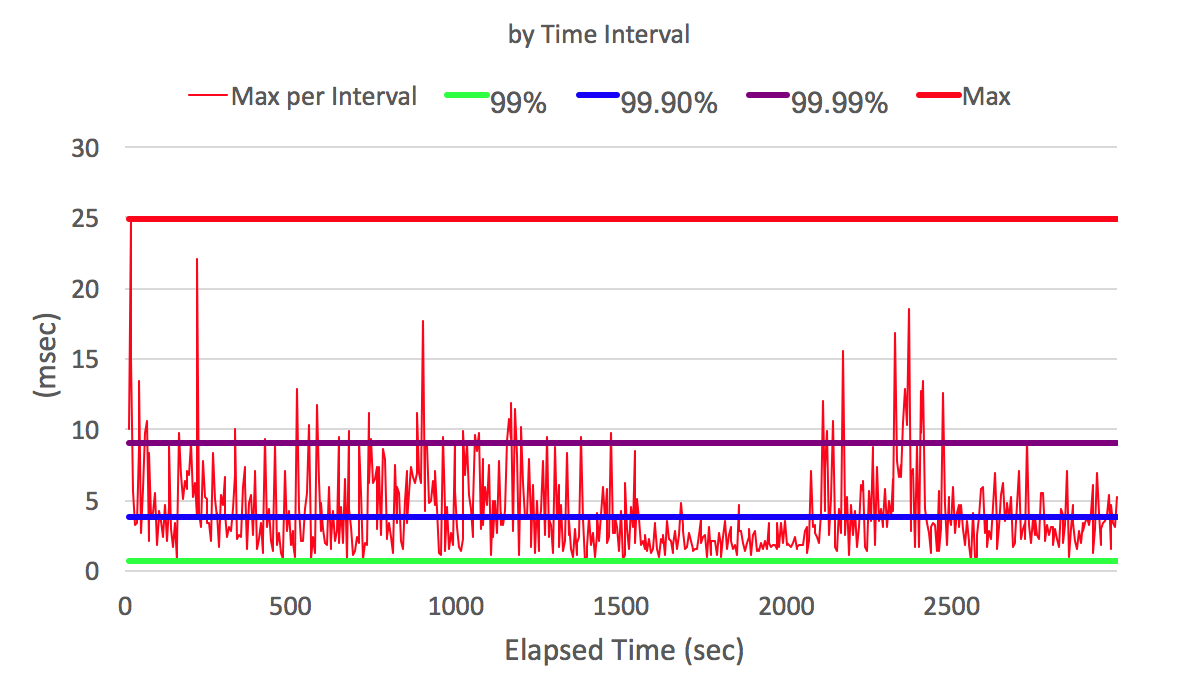
На оси X время выполнения программы в секундах. На оси Y задержка пробуждения в миллисекундах (то сколько программа ждала, когда ОС даст ей возможность выполняться)
Зная время жалобы на медленный ответ нашей системы клиенту и видя график задержек пробуждения нашей программы, мы можем сказать, была ли ос причиной задержки или нет.
На предыдущем графике мы рассмотрели задержки относительно времени выполнения программы. Кроме этого бывает удобно взять все задержки и отсортировать по возрастанию. Это даст нам представление о распределении задержек и их вероятности.

Задержка в миллисекундах на оси y и ее вероятность на оси x
Некоторые особенности JHiccup:
Внутри jHiccup использует гисторгамму как структуру данных. Обычная гисторамма разбивает весь интервал задержек (например от 1мс до 1 сек) на отрезки и подсчитывает сколько задержек попало в определенный интервал. Это позволяет представить данные о задержках в более компактном виде, чем просто список наблюдаемых значений (1.55мс, 2.6мс и тд).
На самом деле в jHicuup используется специальная имплементация гистограммы — HDR-Histogram, которая обладает следующими свойствами:
Библиотека HDR-Histogram получило широкое распространение. Можно найти имплементации на разных языках. Разные системы для сбора метрик стали поддерживать hdr-historgram как один из внутренних форматов, благодаря ее компактности и точности.
На графиках выше мы видели данные о 99.9999% случае. У многих возникает вопрос, нужна ли такая точность и надо ли рассматривать данные дальше 95% или 99% персентиля. Давайте рассмотрим два примера. В обоих примерах мы возьмем вероятность аномальной задержки P(A) как 5% и 1% соответственно. Нам надо ответь на вопрос, какова вероятность того, что пользователь увидит аномальный запрос P(B):
Как мы видим, рассматривать данные только до 95-ого или 99-ого персентеля недостаточно.
Скачать jhiccup можно с http://www.azul.com/downloads/jhiccup/ или https://github.com/giltene/jHiccup.
./jHiccup -d 4000 /usr/bin/java org.jhiccup.Idle -t 300000
# первые 4 секунды старта не буду записаны, всего будет записано 300 секунд. По умолчанию поток будет просыпаться каждые 5 секунд (настраивается с помощью параметра -i).
# создан hiccup.170617.1120.3461.hlog
./jHiccupLogProcessor -i hiccup.170617.1120.3461.hlog -o hiccup.170617.1120.3461
# создан hiccup.170617.1120.3461 и hiccup.170617.1120.3461.hgrmФайл hiccup.170617.1120.3461 можно просмотреть с помощью excel-файла jHiccupPlotter.xls.
Для просмотра hiccup.170617.1120.3461.hgrm можно воспользоваться онлайн приложением https://hdrhistogram.github.io/HdrHistogram/plotFiles.html. Оно также удобно для сравнения нескольких hdrm файлов (например, во время разной загрузки системы или с разных серверов).
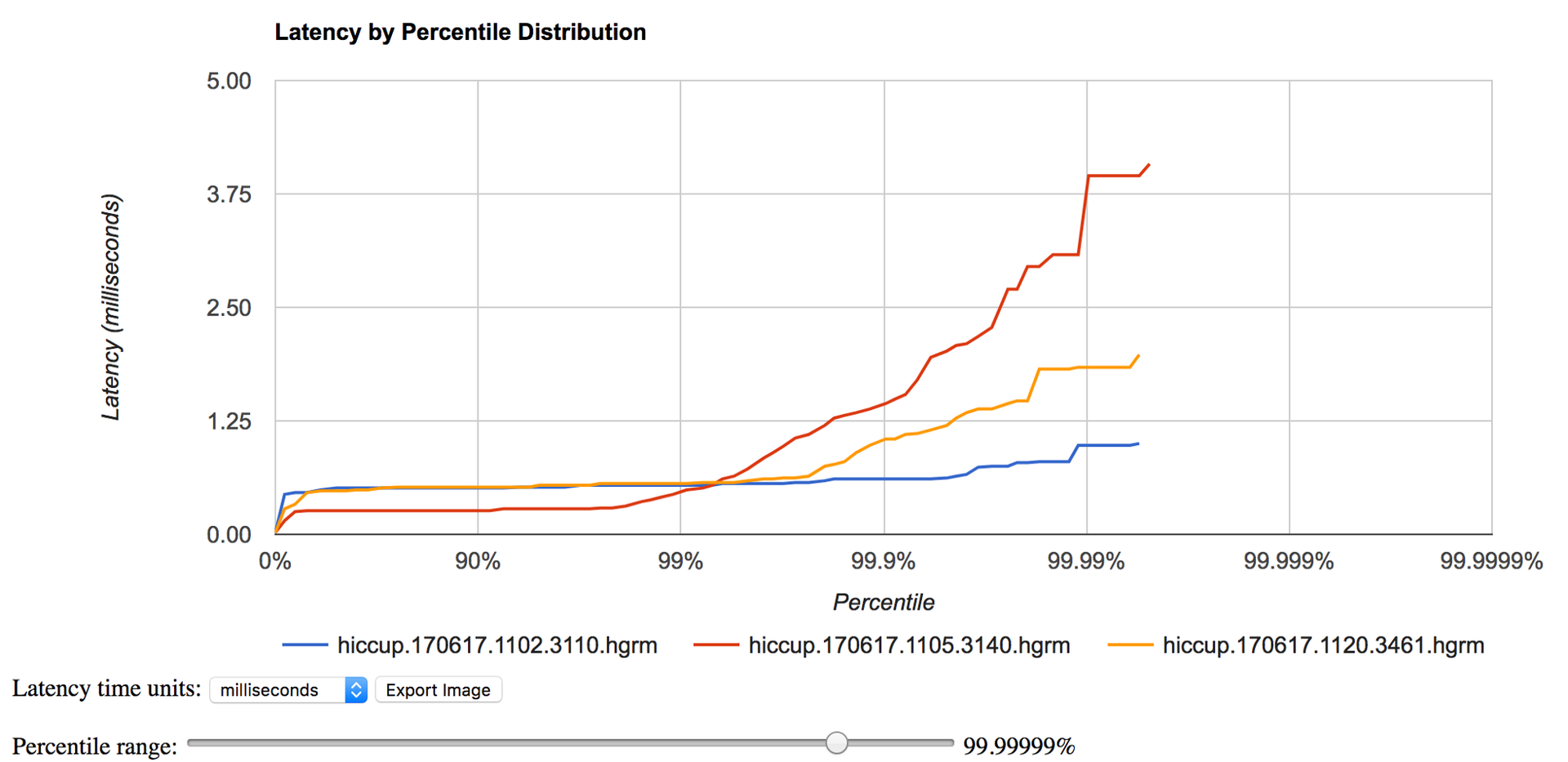
Сравнивая график производительности нашей программы (например, задержки http-ответов) с полученной hdr-диаграммой, мы можем понять работала ли вся система медленно в определенный период или только наша программа.
Мы запускали jhiccup как отдельный процесс. Другой способ это запуск javaagent-а вместе с нашей программой.
java -javaagent:jHiccup.jar="-d 0 -i 1000 -l hiccuplog -c" MyProgram.jar -a -b -cВ этом случае jhiccup будет просыпаться и сохранять информацию о задержках в течении всего времени выполнения программы.
В этих двух способах запуска есть одно важное различие. В первом случае jHiccup запускается на отдельной JVM в другом на той же JVM. То есть во втором случае мы увидим задержки связанные с работой JVM (например паузы GC), на которой запущено основное приложение.
В файле jHiccupPlotter.xls есть возможность добавить линии SLA на график.
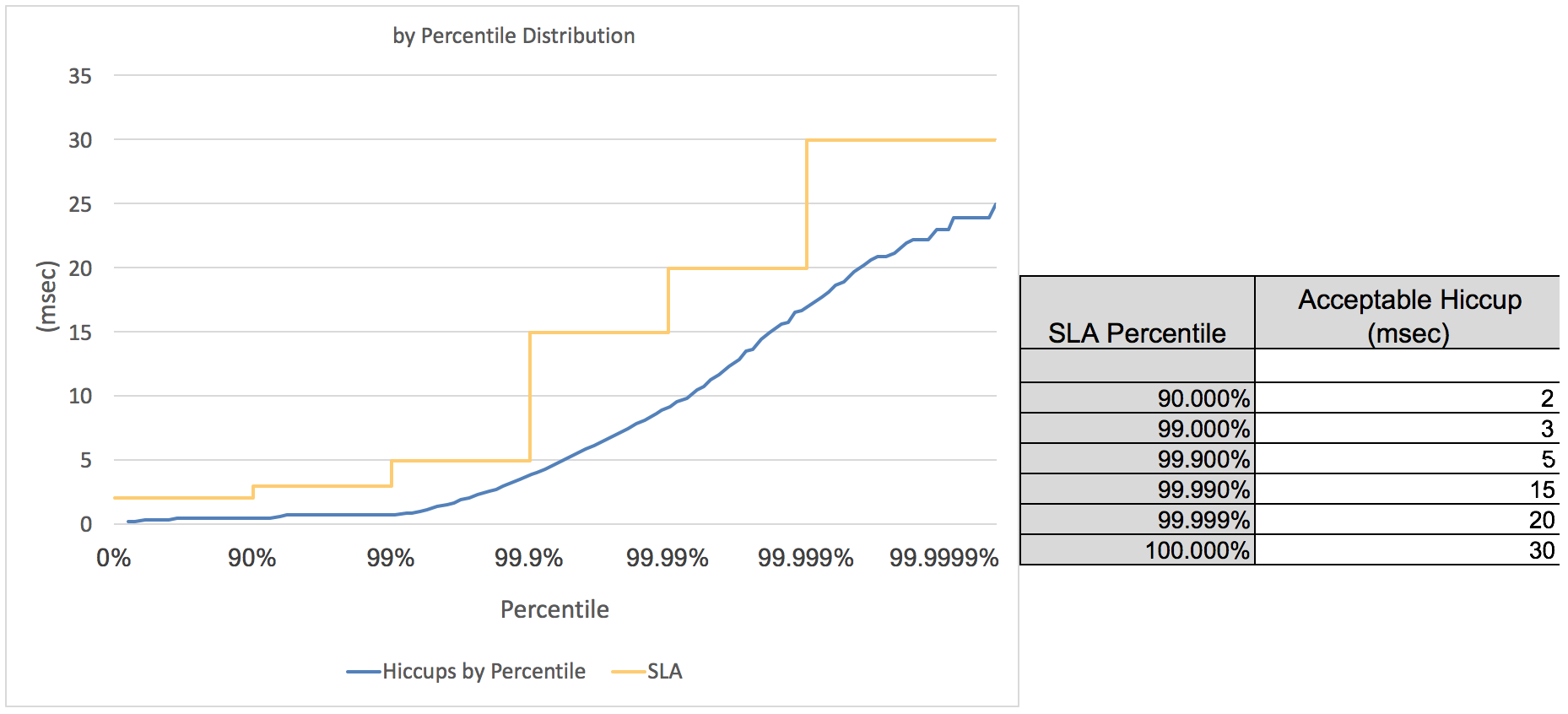
Я вижу два удобных применения для SLA:
|
Метки: author AlexeyPi визуализация данных java мониторинг производительность задержки |
[recovery mode] На каких проектах становятся хорошими инженерами, а на каких – менеджерами? |


|
Метки: author Volgafe87 разработка под android блог компании epam android mobile development epam epam systems личный опыт |
Книга «Сценарии командной оболочки. Linux, OS X и Unix. 2-е издание» |
 Сценарии командной оболочки помогают системным администраторам и программистам автоматизировать рутинные задачи с тех самых пор, как появились первые компьютеры. С момента выхода первого издания этой книги в 2004 году многое изменилось, однако командная оболочка bash только упрочила свои лидирующие позиции. Поэтому умение использовать все ее возможности становится насущной необходимостью для системных администраторов, инженеров и энтузиастов. В этой книге описываются типичные проблемы, с которыми можно столкнуться, например, при сборке программного обеспечения или координации действий других программ. А решения даются так, что их легко можно взять за основу и экстраполировать на другие схожие задачи.
Сценарии командной оболочки помогают системным администраторам и программистам автоматизировать рутинные задачи с тех самых пор, как появились первые компьютеры. С момента выхода первого издания этой книги в 2004 году многое изменилось, однако командная оболочка bash только упрочила свои лидирующие позиции. Поэтому умение использовать все ее возможности становится насущной необходимостью для системных администраторов, инженеров и энтузиастов. В этой книге описываются типичные проблемы, с которыми можно столкнуться, например, при сборке программного обеспечения или координации действий других программ. А решения даются так, что их легко можно взять за основу и экстраполировать на другие схожие задачи.|
Метки: author ph_piter разработка под os x разработка под linux профессиональная литература блог компании издательский дом «питер» книги |
[Перевод] Табы, пробелы и ваша зарплата — какая связь? |
|
Метки: author AloneCoder открытые данные математика визуализация данных open source блог компании mail.ru group пробелы табуляция никто не читает теги |
Как соответствовать ФЗ-152 «О персональных данных» c «Битрикс24» и «1С-Битрикс» |
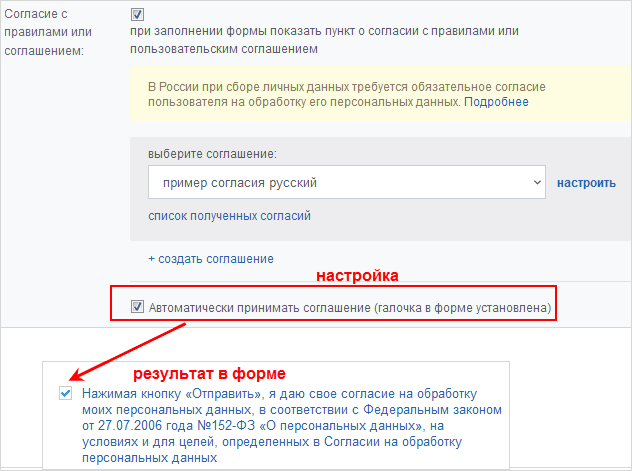


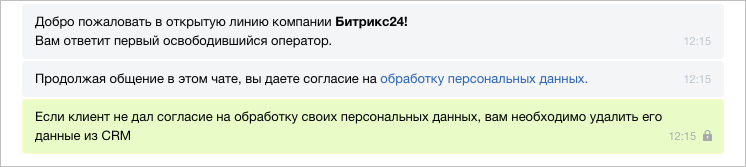
|
Метки: author 1cbitrix управление проектами управление e-commerce законодательство и it-бизнес блог компании 1с-битрикс битрикс24 фз-152 персональные данные |
Скорочтение: работает или нет? Часть 3: простые советы |
|
Метки: author itmo gtd блог компании университет итмо университет итмо скорочтение |
[Из песочницы] Тестирование или парсинг сайтов с динамическим дом и многое другое. Nightmare.js — ему все равно |
var Nightmare = require('nightmare');
var nightmare = Nightmare({ show: true });
nightmare
.goto('https://duckduckgo.com')
.type('#search_form_input_homepage', 'github nightmare')
.click('#search_button_homepage')
.wait('#zero_click_wrapper .c-info__title a')
.evaluate(function () {
return document.querySelector('#zero_click_wrapper .c-info__title a').href;
})
.end()
.then(function (result) {
console.log(result);
})
.catch(function (error) {
console.error('Search failed:', error);
});
const Nightmare = require('nightmare');
(async ()=>{
let nightmare;
try {
nightmare = Nightmare({ show: true });
await nightmare
.goto('https://duckduckgo.com')
.type('#search_form_input_homepage', 'github nightmare')
.click('#search_button_homepage')
.wait('#zero_click_wrapper .c-info__title a');
let siteData = await nightmare.evaluate(function () {
return document.querySelector('#zero_click_wrapper .c-info__title a').href;
});
// последующая работа с данными
} catch (error) {
console.error(error);
throw error;
} finally {
await nightmare.end();
}
})();|
Метки: author vshvydky javascript javascript library nightmare.js парсинг scraping site test |
[Перевод] Как HBO делала приложение Not Hotdog для сериала «Кремниевая долина» |
|
|
Использование Python и Excel для обработки и анализа данных. Часть 1: импорт данных и настройка среды |
|
Метки: author Dmitry21 разработка веб-сайтов python блог компании отус otus.ru otus обучение образование программирование |
Как организовать Performance Review в IT-компании: опыт Badoo |

Привет, Хабр! Меня зовут Алексей Рыбак, я – глава разработки в Badoo. В феврале в нашем московском офисе Badoo проходил Techleads-митап, где я рассказывал про наш процесс Performance Review. Эта статья написана по мотивам моего выступления.
Performance review – тема крайне спорная. В России до сих пор распространено мнение, что никакие KPI, “измерения”, performance review – в программистских компаниях не только не работают, но и вовсе вредны. Эта категоричность меня всегда удивляла, но окончательное решение осветить эту тему подробно созрело у меня после прочтения статьи аж на самом РБК.
В статье описывается отрицательный опыт компании ABBYY и делается достаточно распространенный вывод о том, что программистов лучше не измерять, а нужно просто дать им интересную работу и оставить в покое. И, дескать, всё будет замечательно. И ведь ABBYY – далеко не единственная компания, опыт которой приводится в качестве аргумента, есть и куда более известная история про Microsoft.
Бесспорную ценность этих отрицательных примеров для объективности стоить дополнить примерами других компаний: Google, Facebook и многих других, – в которых Performance Review как раз успешно работает. Это лишь иллюстрирует, что можно внедрить процесс ревью как успешно, так и неуспешно. Поэтому основной целью этой статьи является рассказать об одном из подходов, который приводит к работающему ревью. В Badoo этот подход работает уже почти семь лет, и, пользуясь случаем, я хочу выразить большую благодарность Жене Соколову (ex-Google, ex-Badoo), который нас этим подходом “заразил”.
В этом посте я:
Performance review, если очень кратко, – это один из системных методов повышения эффективности организации. Механически, максимально упрощая, ревью представляет собой ретроспективный процесс, позволяющий выявить “слабые” и “сильные” места в компании и подтянуть “слабые”. Каждый сотрудник рассказывает о своих результатах, получает “оценку” и комментарий, на какие проекты или личностные качества необходимо обратить внимание (иногда в форме общих рекомендаций, но лучше в виде конкретных верифицируемых целей).
Однако прежде чем приступить к ревью, необходимо рассказать пару слов о Badoo и о наших ценностях. У каждой компании есть какие-то свойства – внешние или внутренние – которые нельзя или очень сложно изменить. Примерами таких “граничных условий” могут быть направление деятельности, как именно компания зарабатывает деньги, какие ценности превалируют в ее корпоративной культуре. В разных компаниях “быть эффективным” означает разное, поэтому обсуждение ревью в отрыве от ценностей практического смысла не имеет.
Badoo занимается разработкой dating-приложений и социальных сетей для знакомства с новыми людьми. Наши основные продукты находятся в нише “dating”, но мы также развиваем проекты в области social discovery – поиск поблизости людей по интересам. В некотором смысле Badoo представляет платформу, на базе которой делается много разных приложений. Внутри проекты могут быть очень сложные, но снаружи всё выглядит достаточно просто. Очень большое количество команд в мире одновременно делают примерно такие же проекты. Таким образом, на рынке, на котором мы работаем, нужно быть очень быстрым: очень быстро пилить фичи, тестировать их, если они не пошли – закрывать, если пошли – что-то подкручивать и снова повторять цикл экспериментов. Это определяет всю культуру нашей компании. И всю боль инженеров: им достаточно сложно найти баланс между этой скоростью и комфортной неспешной разработкой, когда везде, что называется, соломка постелена.
Когда в процессе тестирования проекта на аудитории начинаются меняться требования, то на уровне идеи кажется, что ничего особенно не поменялось: одни синтаксические предложения заменяются другими, однако на уровне дизайна изменения могут потребовать серьезной переработки интерфейсов, а уж на уровне программирования и вовсе дело может закончиться неделями работы. Именно поэтому инженеры болезненно воспринимают изменения в требованиях, и требуется особенное сопровождение этих изменений, чтобы у команд сохранялась высокая мотивация. Поскольку одна из составляющих мотивации инженера – авторская, и инженеру комфортнее работать на «долгоиграющих» проектах, испытывать гордость за то, что он делает годами, – ему бывает тяжело расставаться с какими-то классными штуками, которые нужно было сделать в достаточно короткий срок, но они не выстрелили.
Таким образом баланс между скоростью и инженерными ценностями определяет культуру компании. И мы стараемся всем сотрудникам регулярно объяснять свои ценности; человеку со стороны они могут показаться варварскими. Нельзя сказать, что они идеально подходят всем инженерам: это сильно зависит от характера.
На данном этапе наша система ценностей состоит из трёх составляющих.
 Самое главное для нас – это delivery, доставка рабочего продукта до пользователей. В какой-то степени нам даже неважно, насколько он идеален в использовании во всех аудиториях. Мы стараемся максимально использовать всякие фичи-флаги для запуска в какой-то части кластера или в какой-то аудитории, что-то измерять в процессе. Если мы не понимаем, как фича должна работать на какой-то части аудитории, нам будет проще пустить её только на “понятной” нам части: вдруг она вообще окажется бесполезной.
Самое главное для нас – это delivery, доставка рабочего продукта до пользователей. В какой-то степени нам даже неважно, насколько он идеален в использовании во всех аудиториях. Мы стараемся максимально использовать всякие фичи-флаги для запуска в какой-то части кластера или в какой-то аудитории, что-то измерять в процессе. Если мы не понимаем, как фича должна работать на какой-то части аудитории, нам будет проще пустить её только на “понятной” нам части: вдруг она вообще окажется бесполезной.
Достаточно много времени тратится на проведение А/В-тестов, чтобы практически без участия программистов обкатывать разные идеи. Мы в первую очередь пишем софт в экспериментальном ключе: в этом преимущество разработчиков “неотчуждаемого” софта (строго говоря, небыстрый цикл публикации в магазинах мобильных приложений нашу скорость существенно ограничивает, но серверная разработка и веб/мобильный веб могут релизиться очень быстро, обычно мы релизимся строго два раза в день, за исключением дней перед выходными).
 На втором месте quality – качество. Один из наших подходов заключается в том, что quality и QA в целом – это часть организации, которая владеет процессами наравне с инженерами и программистами, и даже в большей степени, чем они. Таким образом, мы получаем сбалансированное распределение ролей, потому что программисты (особенно те, кто работают быстро) на какие-то вещи, которые их ограничивают, попросту забивают, и без баланса в виде QA – полностью независимого от разработки – мы рискуем получить продукт низкого качества. А это совсем не то, к чему мы стремимся.
На втором месте quality – качество. Один из наших подходов заключается в том, что quality и QA в целом – это часть организации, которая владеет процессами наравне с инженерами и программистами, и даже в большей степени, чем они. Таким образом, мы получаем сбалансированное распределение ролей, потому что программисты (особенно те, кто работают быстро) на какие-то вещи, которые их ограничивают, попросту забивают, и без баланса в виде QA – полностью независимого от разработки – мы рискуем получить продукт низкого качества. А это совсем не то, к чему мы стремимся.
 Наконец, как я сказал выше, нам очень важно, чтобы люди в компанию приходили и оставались в компании подольше. Эта ценность – retention, удержание. Порог вхождения у нас довольно высокий, и найти людей непросто.
Наконец, как я сказал выше, нам очень важно, чтобы люди в компанию приходили и оставались в компании подольше. Эта ценность – retention, удержание. Порог вхождения у нас довольно высокий, и найти людей непросто.
Когда компания маленькая, все друг друга знают, работают одной командой, празднуют дни рождения и другие праздники и даже обмениваются подарками, всё происходит естественным образом просто – ведь размер компании укладывается в привычные всем масштабы – семьи, группы друзей, класса или студенческой группы. Но когда она (компания) начинает расти, и количество сотрудников увеличивается, “привычные” методы мгновенно перестают работать, вместо найма пары человек в год нужно нанимать десятки. И ключевым параметром успеха (в первую очередь – в разработке) становится то, с какой скоростью вы можете расти, нанимать и удерживать людей. Поэтому вопрос найма и удержания квалифицированных и эффективных сотрудников для нас очень важен.
Дайте теперь вернемся к Performance Review. Какие бы хорошие люди в компании ни работали, чем больше она становится, тем сильнее усложняется взаимодействие. Если представить любую компанию в виде модели, мы получим такую ветвистую структуру, когда из одной части в другую идёт много условных стрелочек. Чем больше компания, тем больше этих стрелочек и тем больше потерь на этих стрелочках – на взаимодействии, коммуникации.
Если у вас маленькая компания, вам достаточного одного человека – лидера, энтузиаста – который в состоянии всех обежать и «зажечь». Когда компания большая, очень важно иметь «прослойку» техлидов, желательно синхронизированных между собой, каждый из которых решает задачи в своей области. Если что-то в этой схеме не работает – нечеткие цели, слабые неактивные лиды, криво разделенные полномочия, провоцирующие вялое сотрудничество либо вовсе вражду и саботаж – производительность начинает проседать, а в особенно запущенных случаях компания попросту начинает “протухать”.
Так вот ревью – это процесс, позволяющий системно бороться с подобным “протуханием”. Ревью не является панацеей, но я смотрю на него как на один из способов обеспечить регулярную проверку производительности по всей компании. И сделать это ценой небольшого “налога” (бонусной системы).
Badoo уже больше десяти лет, и нам важно, чтобы люди у нас росли, оставаясь с нами надолго. Некоторые ребята работают здесь по девять–десять лет. Мы стремимся всегда держать руку на пульсе и быть в курсе ожиданий сотрудников, знать, что происходит в их жизни. Конечно, не всегда их ожидания совпадают с позицией руководителей, но, по крайней мере, мы гарантируем регулярное взаимодействие и предоставляем сотрудникам возможность расти внутри компании. Проецируя на общество в целом, можно сказать, что оно счастливо, если его лучшие представители имеют возможность возглавить общество и повести за собой. А отсутствие социальных лифтов для наиболее активных представителей общества может привести к тому, что эти люди будут в лучшем случае апатичны, а в худшем – склонны к революционным настроениям.
Но вернёмся к “ревью”. Это некий процесс, часть фреймворка, который показывает вам, где у вас что тупит. Ключевой вопрос здесь – наличие людей, которые оценивают других людей и не просто дают фидбэк, а получают детальную информацию об их проектах.
Среди прочего ревью актуализирует ожидания, о которых я говорил выше. Каждый раз после него происходит разговор между руководителями и членами их команд. Когда компания растёт быстро и менеджерами становятся бывшие айтишники, важно, чтобы люди понимали смысл этих регулярных разговоров, общения, регулярного выражения благодарности за проделанную работу, нельзя этот процесс пускать на самотёк. В первую очередь, это имеет большое значение как раз для удержания сотрудников в компании. Если где-то есть фреймворк, который всех к этому подталкивает, то число таких взаимодействий и число сказанных “спасибо” неуклонно растёт. И это число очень важно для компании.
К сожалению, в некоторых организациях ревью делается в отрыве от бонусной системы: чаще всего получается «для галочки». Это плохо и неэффективно – я убеждён, что оно обязательно должно приводить к каким-то поощрениям, люди должны участвовать в этом процессе, чтобы в итоге что-то получить.
Итак, ревью:
Несколько слов о плохом ревью. Самое ужасное – когда оно слишком бюрократичное и сложное. «Оно бюрократично всегда», – скажете вы и будете правы. Но здесь, как и во всём, должна быть мера.
Ещё одно свойство плохого ревью – неактуальность. Например, когда премия выплачена за то, что было сделано давно, уже потерялся фокус, уже нет возможности качественно ни собрать информацию, ни получить фидбэк. В этом случае люди наверняка будут считать ревью несправедливым. Заметьте, что большой процент таких людей будет всегда – полностью удовлетворить всех не получится, поэтому очень важно прийти к консенсусу.
Наконец, плохое ревью не содержит явных ценностей, и нет никакого смысла в нём участвовать. Этих ценностей может быть много, но все-таки основная (что бы вы думали?) – деньги.
Каким должно быть хорошее ревью? Прежде всего – максимально простым; оно должно быть применимо абсолютно к любой ситуации. Кроме того, оно должно быть актуальным и желательно (если мы говорим о бонусной составляющей или о сборе обратной связи) максимально приближенным к тому, что подвергается анализу. А поскольку наши проекты существуют какое-то определённое время (пусть даже очень долго, условно месяц, две недели из которого мы что-то делали, ещё две – смотрели, как это живёт в проде, и в итоге решили, что нужно полностью менять или выкидывать), сдвигать по времени ревью в данном случае очень неправильно.
Таким образом, хорошее ревью
Я смотрю на ревью как на процесс вокруг какого-то фреймворка. Из чего он состоит? 3 части:
Ревью – это сложный процесс, и за него должен кто-то отвечать. В идеале – эйчар-специалист, кто-то с административной функцией. Правильное ревью проходит в несколько этапов, и, поскольку, как мы выяснили, это всегда некая бюрократия, само по себе оно двигаться не будет – кто-то должен постоянно подталкивать людей, смотреть, что где осталось, и переводить систему из одного состояния в другое.
Сам по себе процесс состоит из выдачи оценок – грейдов (grades); это могут быть грейды за ревью-период (хорошо/не очень), или глобальные грейды относительно прогресса в профессиональном росте. Существуют разные подходы к формированию шкал грейдов, но в целом они все построены вокруг неких ожиданий.
Есть совсем простые формулы, есть улётные варианты с хитрыми KPI. Я придерживаюсь принципа простоты, поэтому считаю что лучше всего выстроить шкалу либо вокруг степеней “хорошо”, либо вокруг степеней “соответствия ожиданиям”. Например, сотрудник полностью соответствует ожиданиям, или с какими-то предложениями по улучшению, или не соответствует им, или наоборот превышает ожидания, или превышает ожидания настолько, что заслуживает продвижения (promotion) и так далее. Promotion – это долгосрочная часть фреймворка, которая позволяет двигать человека по карьерной лестнице.
Карьерная лестница в больших компаниях зачастую достаточно длинная, с кучей цифр: вице-президент №1, вице-президент №2 и так далее. Мы в Badoo практикуем более простую систему и, как многие софтверные компании, даём возможность инженерам двигаться как по карьерной лестнице менеджера, так и по карьерной лестнице инженера. И одна из самых важных составляющих документа, который это регламентирует, – работа с ожиданиями сотрудника. Если он хочет расти как эксперт, вот ему описание уровней по этой лестнице. Таким образом, у человека есть понимание, на какой ступени карьерной лестницы он находится. Это довольно скучная история, но в компаниях с большим количеством сотрудников без этого не обойтись.
Если в вашей компании тоже есть карьерные уровни, необходимо регулярно проводить ревью зарплатных вилок. Делается это путём анализа данных, которые собирает либо ваша команда, либо внешние консультанты. Часто анализ выглядит не очень информативно, но так или иначе даёт ориентиры для изменения заработных плат, например, при продвижении сотрудников или проведении переговоров, выдачи контрофферов.
Что же представляет собой процедура ревью? Есть практика, в которой предметом оценки являются данные ранее обещания или какой-то план. Мы никогда не предлагаем людям заранее рассказывать, что они собираются сделать: планы могут поменяться по не зависящим от человека причинам, и он расстроится, а ревью несправедливым быть не должно. В форму, которую заполняет каждый сотрудник, просто нужно внести список наиболее значимых результатов, и далее предлагается выбрать пиров.
Как правило, в течение отчётного периода человек работает над тремя/пятью/десятью проектами, и он их указывает. Мы просим, чтобы люди указывали только то, что оказывается на продакшене, либо в крайнем случае те части проектов, которые были завершены и уже работают на девелоперской площадке. Таким образом, мы лишний раз говорим: ребята, главное – полностью завершенная задача, степень усталости мы не оцениваем – только окончательный результат.
У нас есть OKRs (objectives and keys results) для сотрудников, которые работают над долгосрочными задачами. Иногда мы занимаемся сравнением того, что мы планировали и что сделали, но в целом эти показатели отвязаны от ревью. Повторюсь, это очень важно, потому что может приводить к серьезному раздражению. Поскольку Badoo – очень динамичная компания, мы не можем использовать такой подход. Поэтому ревью делается по факту: сделано это и то.
Чтобы получить оценку, сначала нужно собрать отзыв от коллег. Самая важная часть фреймворка – пиры (peers). Сотрудники выбирают пиров, коллег, с которыми работали на проектах, тестировщиков, с которыми тестировали задачи, членов продуктовой команды, с которыми взаимодействовали, – кого угодно, кроме их менеджера. После этого менеджер смотрит на пиров и говорит что-то вроде: «Слушай, а почему я не вижу ни одного QA-инженера здесь? У тебя была важная задача, был хороший (или не очень хороший) фидбэк. Хотелось бы получить отзыв QA-инженера для полноты картины». Происходит некий процесс согласования, менеджер может добавить или убрать сотрудника.
Причём «убрать» – это довольно распространенная история: если в граничном случае все добавят в пиры всех, получится такая бюрократия, что мотивация сотрудников будет стремиться к нулю. Желательно, чтобы пиров было три–пять; в крайнем случае – семь, но, на мой взгляд, семь – это уже много.
Пиры смотрят на то, что сделано, дают этому оценку и пишут комментарии; причём, у них есть возможность написать как комментарий, доступный всем, так и приватный. Далее всё это собирается, и свою оценку даёт менеджер.
Но это ещё не всё. Впереди важный процесс – калибрация. В Badoo это работает так: в одной комнате собираются практически все менеджеры и начинают рассматривать оценки. Есть ключевые моменты (слишком высокая оценка, слишком низкая, была высокая, а стала – низкая), по которым сразу видно, что есть необходимость обсудить и понять точку зрения того или иного менеджера. В ходе этой встречи происходит обмен информацией, мы решаем, что для нас хорошо, что – плохо, что – хороший результат, что – ожидаемый, что – суперрезультат. Когда человек растёт, мы говорим, что нужно ему повысить зарплату, дать другой уровень, поставить другой тайтл внутри нашей системы и так далее.
И это тоже ещё не всё! Главное – разговор один на один, который обязательно должен провести менеджер с каждым членом своей команды: рассказать, что и почему получилось, что ожидается, что необходимо изменить.
Так в целом работает наш фреймворк.
Кстати, у Badoo два офиса: один – в Москве, другой – в Лондоне, оба занимаются разработкой. В московском офисе с 2011 года, когда мы переехали и сильно выросли, число команд не меняется, а вот лондонский – растёт. И сначала мы запустили ревью в Москве, обкатали этот процесс: договорились, что и как, добились синхронизации между менеджерами, решили для себя, что означает та или иная оценка, и так далее. Только после этого был подключён лондонский офис.
Сейчас он довольно большой, ревью идёт параллельно в двух городах, и всех вместе, конечно, уже не собрать. Мы пытаемся разделить весь наш большой коллектив на команды, которые работают между собой, и калибровать раздельно. Обычно получается отдельно Москва, отдельно – Лондон, но значительное число команд распределены между двумя городами и нужно, чтобы все они присутствовали на калибрации.
 Первая проблема, с которой мы столкнулись, – разное отношение к бонусам. Здесь есть два подхода. Один подход (он особенно популярен на Западе) опирается на почти гарантированный годовой бонус: в процентах к годовому он у тебя составляет столько-то, и если всё нормально, он выплачивается в полном объёме. Если есть какие-то вопросы или были установлены какие-то KPI, то, как говорится, возможны варианты… В общем, при таком подходе бонус, как правило, выплачивается либо полностью, либо почти полностью – то есть изменение бонуса однозначно является “наказанием”. Но чем сильнее пытаться играть им, тем хуже, потому что сотрудник ожидает, что эта часть дохода ему гарантирована.
Первая проблема, с которой мы столкнулись, – разное отношение к бонусам. Здесь есть два подхода. Один подход (он особенно популярен на Западе) опирается на почти гарантированный годовой бонус: в процентах к годовому он у тебя составляет столько-то, и если всё нормально, он выплачивается в полном объёме. Если есть какие-то вопросы или были установлены какие-то KPI, то, как говорится, возможны варианты… В общем, при таком подходе бонус, как правило, выплачивается либо полностью, либо почти полностью – то есть изменение бонуса однозначно является “наказанием”. Но чем сильнее пытаться играть им, тем хуже, потому что сотрудник ожидает, что эта часть дохода ему гарантирована.
Мы выбрали другой подход. Мы говорим, что если в целом сотрудник соответствует ожиданиям компании, то он получает такой-то годовой бонус. Но он может превышать эти ожидания или наоборот чуть-чуть не дотягивать до них. Поэтому мы используем фреймворк, который даёт возможность получить как очень хорошую оценку, так и похуже.
Что будут делать люди, которые считают, что «наказывать» нужно только тех, кто откровенно не справляется со своей работой? Они будут стараться выдать в этом фреймворке максимальные оценки. Максимальная оценка удваивает бонус. Так что нам очень важно донести до них, что, если им всё нравится и всё в порядке, это обычная оценка, всё соответствует ожиданиям. В таком же ключе приходится разговаривать и с сотрудниками. И вообще это очень важно – бонусом надо управлять, ленивый менеджер будет просто раздавать максимальный бонус, и тем самым система не только не будет улучшать эффективность, а наоборот, будет работать на усиление протухания.
Кстати, помимо текстовых описаний, у нас есть ещё номера, которые мы используем для более короткой записи. И это является для нас проблемой. Если человек мыслит в категориях школьных оценок, он думает: «Почему у меня не максимальный балл? Он должен быть максимальный! Я всегда был отличником, я – самый крутой. Почему у меня не самая крутая оценка?» Над изменением такого мышления нужно работать всем: менеджерам и эйчарам.
 Следующая проблема – попытка найти простой “алгоритм оценки”. Большинство программистов по природе своей аналитики и пытаются выстроить чёткую схему получения максимальной оценки. Более того, менеджеры перенимают этот подход и начинают придумывать свои истории о том, как и почему они дали ту или иную оценку, тем самым снимая с себя ответственность (это не я! – это машина тебе посчитала).
Следующая проблема – попытка найти простой “алгоритм оценки”. Большинство программистов по природе своей аналитики и пытаются выстроить чёткую схему получения максимальной оценки. Более того, менеджеры перенимают этот подход и начинают придумывать свои истории о том, как и почему они дали ту или иную оценку, тем самым снимая с себя ответственность (это не я! – это машина тебе посчитала).
Ещё пример такого “аналитического” поведения. Каждый раз, когда мы делаем ревью зарплат, какой-нибудь менеджер обязательно говорит: «Этот сотрудник находится не на медиане. Несправедливо – надо его подтянуть на медиану!». Но если следовать такому подходу, то в результате у сотрудников зарплата может вырасти непропорционально успехам. На самом деле в этой медиане изначально уже заложена очень большая ошибка. Поэтому медиана – это очень приблизительный ориентир, к нему не нужно ничего специально “подтягивать”! А в действительности нужно анализировать очень много факторов в комплексе. В первую очередь, – успехи человека и как повышалась зарплата этому человеку в течение нескольких лет, если он работает в компании достаточно давно.
С тем, что программисты пытаются применять аналитические инструменты, чтобы выдать ту или иную оценку, связано множество проблем. Если у вас есть очень сложные KPI, которые прямо выражаются формулой, то существует большая вероятность того, что люди просто начнут подтягивать свои показатели, чтобы получить балл повыше: «Эх, сейчас как взломаю эту бюрократическую систему!..» – и потирают ручки. Именно поэтому фреймворк должен давать как можно меньше возможностей использовать аналитические инструменты.
Скажу банальность: чем больше компания, тем меньше взаимодействия между разными отделами. И тем больше людей считают, что они не обязаны никому ничего рассказывать – они просто двигают «своих», у них образовались некие маленькие государства. Проблема? Безусловно. И единственная возможность с этим бороться – объяснять всем сторонам необходимость коммуникации. Если же кто-то считает, что они вообще никак не пересекаются, стоит рассмотреть возможность проводить их ревью отдельно с кем-то ещё, просто в офисе не калибровать.
Более того, чем больше компания, тем тяжелее идёт процесс калибрации, особенно при promotion. Люди могут быть просто не в курсе этого. И отчасти это говорит о том, что в целом разъяснение деятельности структурных подразделений компании не очень эффективно и с этим нужно бороться.
 Следующий момент – инфляция. Различают инфляцию оценок и инфляцию уровней.
Следующий момент – инфляция. Различают инфляцию оценок и инфляцию уровней.
С инфляцией оценок всё достаточно просто – она происходит, как правило, в нормальном диапазоне. Что такое превышение ожиданий и чем оно отличается от оценки «Полностью соответствует ожиданиям»? Моя позиция такова, что, если было какое-то количество проектов и они все реализованы в срок или с небольшой задержкой (до 25% – но единого правила нет), то это – превышение ожидания. Не мне вам рассказывать, что обычно сроки срываются. :) Некоторые менеджеры придерживаются другого подхода. Но в любом случае, как только речь заходит о сроках, это значит, что в процедуру ревью должен попасть какой-то документ, содержащий информацию о том, какие сроки были установлены и когда в итоге всё было выполнено. Это само по себе очень здорово – приучает к ответственности за дедлайны.
Борьба с инфляцией уровней сложнее. Если кратко, то верхние уровни обычно сформулированы не очень конкретно. Например, эксперт. Сама по себе, без разъяснений, это достаточно расплывчатая формулировка. Получается, менеджеры видят, что люди растут, развиваются. Вот они уже достойны уровня эксперта – значит, нужно их продвигать. Здесь очень важно сравнивать одних экспертов с другими и постоянно совершенствовать описания или хотя бы рассказывать друг другу, что предполагает тот или иной уровень.
Не могу сказать, что Badoo в этом плане – пример для подражания. С одной стороны, мы стараемся эту систему формализовать, с другой – мы понимаем, что как только начинаешь её трогать и чуть более подробно описывать уровни, сотрудники начинают больше ошибаться в ожиданиях, спрашивать: «Я же всё это делаю, я же достоин! Что не так?» Поэтому борьба с инфляцией уровней чаще всего решается не путём более детального описания каждого из них, а более качественной калибрацией.
В этом смысле очень важна процедура разрешения споров. При калибрации могут возникать ситуации, когда люди упёрлись – и всё, а процесс должен работать. Я не уверен, что мы используем максимально эффективный способ, но сейчас правила следующие. Если мы просто даём грейд за работу в отчётный период, то больше доверяем менеджеру, который этот грейд выдаёт, даже если кто-то считает, что это не очень справедливо. А если речь идёт о продвижении сотрудника на следующий уровень, и есть достаточное количество людей, которые против этого, то больше доверяем этому большинству. Логика ясна: если человек работает в команде, то менеджер лучше знает, как его мотивировать. Но когда менеджер продвигает своего сотрудника, он начинает влиять на всю систему и показывать другим, что этот человек, грубо говоря, молодец. И если это происходит несправедливо – это сильно подрывает доверие ко всей системе.
Поэтому, если у нас есть достаточное количество людей, которые предлагают ещё какое-то время понаблюдать за работой этого сотрудника, его кандидатура рассматривается в следующий раз.
Ещё один момент: в ревью всегда есть две составляющие. С одной стороны, есть профессиональный рост, который никогда не происходит в течение короткого времени – он происходит годами, и все эти истории про социальные лифты и карьерную лестницу должны быть привязаны к изменению профессионального уровня сотрудника. С другой стороны, если человек эффективно и качественно поработал в какой-то короткий период времени, он тоже должен получить весомое “спасибо” от компании, но оно не должно заключаться в продвижении до эксперта – чаще всего для этого человеку нужно ещё какое-то время поработать. Поэтому у нас для таких случаев есть правило: если мы хотим поставить кому-то очень высокую оценку за долгосрочное ревью, то менеджер обязан объяснить, доказать, что этот человек действительно работает на следующем уровне.
Мы начинали с квартального ревью. На этом этапе у нас всё было в одном ревью. Но впоследствии мы перешли на два полугодовых ревью, в течение которых мы продвигаем сотрудников, и месячные ревью, когда мы оцениваем эффективность работы по проектам. На самом деле, это достаточно сложно организовать, но вот уже год мы стараемся сделать так, чтобы процесс проходил легко и непринуждённо — максимально онлайн. Как это работает? Если сотрудник молодец и хорошо поработал, прошёл месячное ревью, получил высокую оценку и хороший бонус, то это никак не влияет на его карьерный рост. Если по результатам полугодового ревью видно, что сфера его ответственности расширяется, что он профессионально растёт, происходит стандартная процедура калибрации – и сотрудник получает повышение.
Как решить, нужно ли вашей компании ревью? Большое значение имеет размер организации. В небольших компаниях вполне можно обойтись без ревью, а вот в крупных оно зачастую просто необходимо. Когда число сотрудников увеличивается, можно «резать» организацию вертикально, создавая более компактные команды, компании внутри компании, в которых ревью вовсе не понадобится.
Вы также можете пропагандировать отсутствие любых ревью, лестниц и ориентироваться на так называемые сквады, давать сотрудникам возможность периодически менять команды и работать над разными проектами. Я не очень понимаю, при каком размере компании такой подход будет эффективен, но он существует. При каком размере стоит задуматься о ревью? Думаю, это несколько десятков человек – когда в компании начинаются заметными потери на взаимодействии между командами.
Очень важен ритм компании. От него зависит, как часто нужно проводить ревью. Если оно будет редким, не очень понятно, какой вообще в нём смысл. “Каждый месяц” – для кого-то это будет чересчур часто. Ведь в этом деле крайне важна актуальность – и ритм компании: как часто выпускаются продукты, как часто меняются планы, – это отправная точка для ревью.
И ещё один важный момент – сложившаяся культура. Вот пример, несколько гиперболизированный, конечно. Бывают руководители, которые хотят работать только с молодыми людьми. А когда люди взрослеют, обзаводятся семьями, они уже не могут, условно, работать в выходные… Распространённая ситуация: молодые руководители хотят, чтобы сотрудники разделяли их ценности, чтобы они с радостью работали сутками и были готовы организовать хакатон в ночь с пятницы на понедельник.
Для большой компании это звучит дико (и, строго говоря, дискриминация по возрасту просто незаконна), но есть большое количество компаний, в которых подобная “безбашенность” – фундаментальная часть культуры. Для таких компаний ревью будет чересчур бюрократично.
В общем, размер и культура определяют, нужно ли вашей компании ревью, будет ли оно эффективным и не обернется ли пустой тратой времени (и денег). Но главное, что хотелось бы отметить – ревью вряд ли получится внедрить успешно силами внешних консультантов, либо HR-отдела. Для успешной разработки и внедрения процесса ревью обязательно участие менеджеров, которые определяют стратегию и ценности компании.
В этой статье я попытался разрушить миф о бесполезности ревью для программистских компаний и показать на примере, как сделать работающий процесс ревью.
Ревью должно быть регулярным, своевременным, простым и полезным – и для компании, и для сотрудников. Все известные мне "громкие" отрицательные примеры служат не доказательством “неприменимости” ревью, а доказательством наличия ошибок в процессе ревью.
Мучают сложные формулы и KPI? Может, стоит отказаться от них в пользу простых оценок? R&D задачи сложны в планировании? Возможно, стоит научиться планировать исследовательские проекты – независимо от сложности общей задачи каждый проект все равно разделяется на более мелкие подпроекты, планирование которых по отдельности прекрасно укладывается в традиционный подход, даже если это проверка гипотез.
Фиксирован премиальный бюджет таким образом, что вы вынуждены занижать некоторые оценки, делая их несправедливыми? Хорошим решением будет перекалибровка шкалы оценок так, чтобы наиболее вероятные оценки уже назывались “отличным результатом” и не вызывали бы ощущение несправедливого занижения. Другим решением может быть просто пересмотр бюджетных ограничений и отказ от практики “квотирования” отличных оценок.
Тем не менее, ряд проблем ревью фундаментальны, из которых особенную опасность представляет две. Первая – это инфляция оценок и уровней. С инфляцией борется калибрация. Вторая проблема – постоянное желание аналитического ума выработать простой “алгоритм” оценки. Эта проблема решается принципиальным отсутствием в базовой системе ревью предпосылок для создания подобных алгоритмов и разъяснительной работой.
Если вы хотите подробнее узнать, как устроены системы ревью в других компаниях, рекомендую прочитать книжку Ласло Бока “Работа рулит!”, где в нескольких главах подробно рассматривается система оценки производительности в компании Google (наш процесс во многом повторяет процесс в Google).
А с какими проблемами сталкивались вы? Давайте обсудим это в комментариях.
|
Метки: author fisher управление разработкой управление персоналом развитие стартапа карьера в it-индустрии блог компании badoo управление компанией |
Как внедрить процессы управления конфигурацией |
 Изображение Kenny Louie CC
Изображение Kenny Louie CC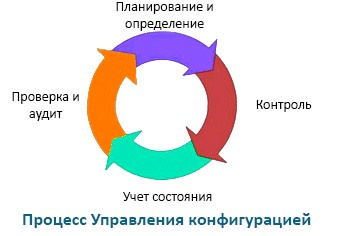
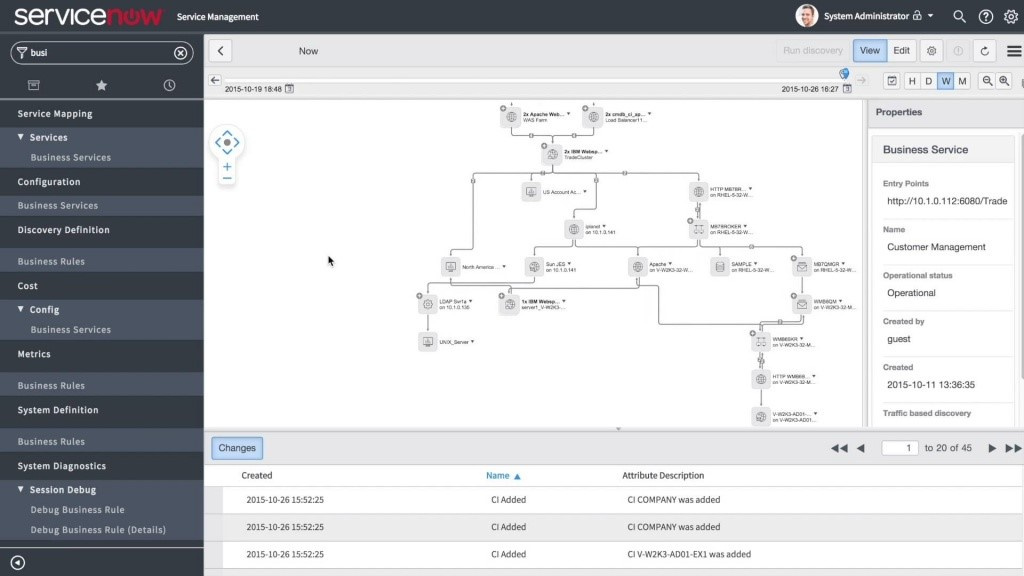
|
Метки: author it-guild service desk блог компании ит гильдия ит гильдия cms управление конфигурацией |
Визуализация целей повышает их достижение на 46%. Как мы решаем это в WebCanape? |




|
|
Бешеные псы: Angular 2 vs React: доклад Евгения Гусева и Ильи Таратухина |

|
|
Статический анализ как часть процесса разработки Unreal Engine |

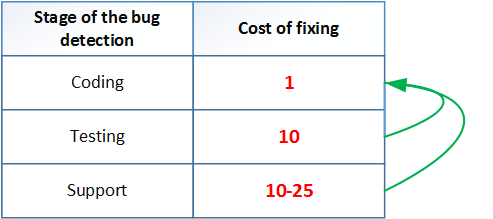
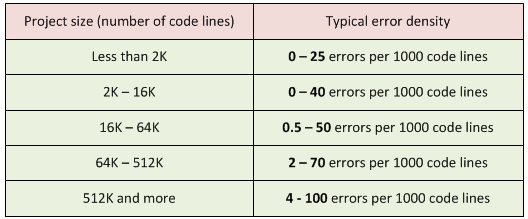
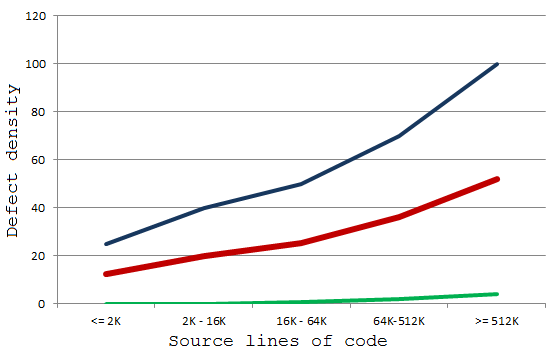
uint8* Data = (uint8*)PointerVal;
if (Data != nullptr || DataLen == 0)
{
NUTDebug::LogHexDump(Data, DataLen);
}
else if (Data == nullptr)
{
Ar.Logf(TEXT("Invalid Data parameter."));
}
else // if (DataLen == 0)
{
Ar.Logf(TEXT("Invalid DataLen parameter."));
}if (Data != nullptr && DataLen > 0)for (TSharedPtr SlateWidget : SlateWidgets)
{
SlateWidget = nullptr;
} for (TSharedPtr &SlateWidget : SlateWidgets)
{
SlateWidget = nullptr;
} for(int i = 0; i < SelectedObjects.Num(); ++i)
{
UObject* Obj = SelectedObjects[0].Get();
EdObj = Cast(Obj);
if(EdObj)
{
break;
}
} UObject* Obj = SelectedObjects[i].Get();bool FCreateBPTemplateProjectAutomationTests::RunTest(
const FString& Parameters)
{
TSharedPtr NewProjectWizard;
NewProjectWizard = SNew(SNewProjectWizard);
TMap> >& Templates =
NewProjectWizard->FindTemplateProjects();
int32 OutMatchedProjectsDesk = 0;
int32 OutCreatedProjectsDesk = 0;
GameProjectAutomationUtils::CreateProjectSet(Templates,
EHardwareClass::Desktop,
EGraphicsPreset::Maximum,
EContentSourceCategory::BlueprintFeature,
false,
OutMatchedProjectsDesk,
OutCreatedProjectsDesk);
int32 OutMatchedProjectsMob = 0;
int32 OutCreatedProjectsMob = 0;
GameProjectAutomationUtils::CreateProjectSet(Templates,
EHardwareClass::Mobile,
EGraphicsPreset::Maximum,
EContentSourceCategory::BlueprintFeature,
false,
OutMatchedProjectsMob,
OutCreatedProjectsMob);
return ( OutMatchedProjectsDesk == OutCreatedProjectsDesk ) &&
( OutMatchedProjectsMob == OutCreatedProjectsMob );
} return ( OutMatchedProjectsDesk == OutCreatedProjectsDesk ) &&
( OutMatchedProjectsMob == OutCreatedProjectsMob );static void CreateProjectSet(.... int32 OutCreatedProjects,
int32 OutMatchedProjects)
{
....
OutCreatedProjects = 0;
OutMatchedProjects = 0;
....
OutMatchedProjects++;
....
OutCreatedProjects++;
....
}static void CreateProjectSet(.... int32 &OutCreatedProjects,
int32 &OutMatchedProjects){
case EWidgetBlendMode::Opaque:
ActualBackgroundColor.A = 1.0f;
case EWidgetBlendMode::Masked:
ActualBackgroundColor.A = 0.0f;
}checkf(GPixelFormats[PixelFormat].BlockSizeX
== GPixelFormats[PixelFormat].BlockSizeY
== GPixelFormats[PixelFormat].BlockSizeZ
== 1,
TEXT("Tried to use compressed format?"));{
case EWidgetBlendMode::Opaque:
ActualBackgroundColor.A = 1.0f;
case EWidgetBlendMode::Masked:
ActualBackgroundColor.A = 0.0f;
}|
|
Анонс SmartData 2017 Piter: Можно ли говорить о больших и умных данных без булшиттинга? |

 Алексей Потапов – мы, если честно, сильно рады, что на первую же конференцию удалось вытянуть столь замечательного человека, светило науки, в свое время занимавшегося промышленными решениями в области компьютерного зрения. Если посмотреть доклады Алексея, можно найти как те, в которых спикер рассказывает сложные вещи простыми словами, так и те, которые выносят сознание самым искушенным инженерам. Мы, конечно, остановимся на втором варианте и дадим вам хорошего наукообразного хардкора.
Алексей Потапов – мы, если честно, сильно рады, что на первую же конференцию удалось вытянуть столь замечательного человека, светило науки, в свое время занимавшегося промышленными решениями в области компьютерного зрения. Если посмотреть доклады Алексея, можно найти как те, в которых спикер рассказывает сложные вещи простыми словами, так и те, которые выносят сознание самым искушенным инженерам. Мы, конечно, остановимся на втором варианте и дадим вам хорошего наукообразного хардкора.  Сергей Николенко – Data Scientist из ПОМИ РАН, работающий с машинным обучением и сетевыми алгоритмами. Ранее занимался криптографией, теоретической computer science и алгеброй. Сергей готовит доклад, посвященный научному подходу в разработке глубоких свёрточных сетей для сегментации изображений.
Сергей Николенко – Data Scientist из ПОМИ РАН, работающий с машинным обучением и сетевыми алгоритмами. Ранее занимался криптографией, теоретической computer science и алгеброй. Сергей готовит доклад, посвященный научному подходу в разработке глубоких свёрточных сетей для сегментации изображений. Александр Сербул — куратор направления контроля качества интеграции и внедрений «1С-Битрикс», а также направления AI, deep learning и big data. Архитектор и разработчик в проектах компании, связанных с высокой нагрузкой и отказоустойчивостью, эффективным использованием технологий кластеризации продуктов «1С-Битрикс» в современных облачных сервисах (Amazon Web Services и др.)
Александр Сербул — куратор направления контроля качества интеграции и внедрений «1С-Битрикс», а также направления AI, deep learning и big data. Архитектор и разработчик в проектах компании, связанных с высокой нагрузкой и отказоустойчивостью, эффективным использованием технологий кластеризации продуктов «1С-Битрикс» в современных облачных сервисах (Amazon Web Services и др.) Виталий Худобахшов — ведущий аналитик в Одноклассниках, где занимается различными аспектами анализа данных, на конференции расскажет о том, как правильно готовить Spark из Kotlin.
Виталий Худобахшов — ведущий аналитик в Одноклассниках, где занимается различными аспектами анализа данных, на конференции расскажет о том, как правильно готовить Spark из Kotlin.  Татьяна Ландо — какая же бигдата, да без Google? Сейчас мы работаем над тем, чтобы к нам приехала Татьяна Ландо, эксперт в области лингвистики и анализа данных и организатор AINL: Artificial Intelligence & Natural Language, предварительное подтверждение уже получено. В этом месте возможны изменения, однако кто-то из Google к нам точно приедет.
Татьяна Ландо — какая же бигдата, да без Google? Сейчас мы работаем над тем, чтобы к нам приехала Татьяна Ландо, эксперт в области лингвистики и анализа данных и организатор AINL: Artificial Intelligence & Natural Language, предварительное подтверждение уже получено. В этом месте возможны изменения, однако кто-то из Google к нам точно приедет. Владимир Красильщик — разработчик в Яндекс, уже довольно давно замеченный «в связях» с большими данными. Владимир уже не первый раз выступает на наших конференциях, и каждый его доклад стабильно собирает хорошую оценку, потому что в них обычно есть все: и технологичность, и правильная подача, и даже сюжетные твисты. Если вы не видели докладов Владимира, советую посмотреть (доклад несложный, так как расчитан на студентов, зато позволяет понять, как выступает Владимир).
Владимир Красильщик — разработчик в Яндекс, уже довольно давно замеченный «в связях» с большими данными. Владимир уже не первый раз выступает на наших конференциях, и каждый его доклад стабильно собирает хорошую оценку, потому что в них обычно есть все: и технологичность, и правильная подача, и даже сюжетные твисты. Если вы не видели докладов Владимира, советую посмотреть (доклад несложный, так как расчитан на студентов, зато позволяет понять, как выступает Владимир). Иван Бегтин – Директор лаборатории интеллектуального анализа данных, специализирующийся на работе с открытыми данными в машиночитаемых форматах, которые раскрывает правительство: экология, криминология, демография и т.д. Самая соль встречи с Иваном заключается в возможности задать ему вопросы в дискуссионной зоне — есть мнение, что он сможет в течение одного разговора сказать, имеет ли смысл развивать задуманный проект, или дело не выгорит. И это не гадание на кофейной гуще, а чистой воды аналитика.
Иван Бегтин – Директор лаборатории интеллектуального анализа данных, специализирующийся на работе с открытыми данными в машиночитаемых форматах, которые раскрывает правительство: экология, криминология, демография и т.д. Самая соль встречи с Иваном заключается в возможности задать ему вопросы в дискуссионной зоне — есть мнение, что он сможет в течение одного разговора сказать, имеет ли смысл развивать задуманный проект, или дело не выгорит. И это не гадание на кофейной гуще, а чистой воды аналитика.

 Программа конференции будет постепенно пополняться, и следить за её самым актуальным состоянием можно на сайте SmartData 2017 Piter. А уже сейчас на этом сайте открыта продажа билетов — ближайшие две недели действует early bird цена. Поэтому за развитием программы лучше следить с билетом в кармане:)
Программа конференции будет постепенно пополняться, и следить за её самым актуальным состоянием можно на сайте SmartData 2017 Piter. А уже сейчас на этом сайте открыта продажа билетов — ближайшие две недели действует early bird цена. Поэтому за развитием программы лучше следить с билетом в кармане:)|
Метки: author ARG89 открытые данные big data блог компании jug.ru group smart data data science smartdataconf конференция |
[Перевод] Постмортем Age of Empires |
|
Метки: author PatientZero разработка игр age of empires история создания |
Как эффективнее читать данные с диска (при условии, что у вас .Net) |

| Сценарий |
Время |
| ScenarioAsyncWithMaxParallelCount4 |
00:00:00.2260000 |
| ScenarioAsyncWithMaxParallelCount8 |
00:00:00.5080000 |
| ScenarioAsyncWithMaxParallelCount16 |
00:00:00.1120000 |
| ScenarioAsyncWithMaxParallelCount24 |
00:00:00.1540000 |
| ScenarioAsyncWithMaxParallelCount32 |
00:00:00.2510000 |
| ScenarioAsyncWithMaxParallelCount64 |
00:00:00.5240000 |
| ScenarioAsyncWithMaxParallelCount128 |
00:00:00.5970000 |
| ScenarioAsyncWithMaxParallelCount256 |
00:00:00.7610000 |
| ScenarioSyncAsParallel |
00:00:00.9340000 |
| ScenarioReadAllAsParallel |
00:00:00.3360000 |
| ScenarioAsync |
00:00:00.8150000 |
| ScenarioAsync2 |
00:00:00.0710000 |
| ScenarioNewThread |
00:00:00.6320000 |
| Сценарий |
Время |
| ScenarioAsyncWithMaxParallelCount4 |
00:00:00.4070000 |
| ScenarioAsyncWithMaxParallelCount8 |
00:00:00.2210000 |
| ScenarioAsyncWithMaxParallelCount16 |
00:00:00.1240000 |
| ScenarioAsyncWithMaxParallelCount24 |
00:00:00.2430000 |
| ScenarioAsyncWithMaxParallelCount32 |
00:00:00.3180000 |
| ScenarioAsyncWithMaxParallelCount64 |
00:00:00.5100000 |
| ScenarioAsyncWithMaxParallelCount128 |
00:00:00.7270000 |
| ScenarioAsyncWithMaxParallelCount256 |
00:00:00.8190000 |
| ScenarioSyncAsParallel |
00:00:00.7590000 |
| ScenarioReadAllAsParallel |
00:00:00.3120000 |
| ScenarioAsync |
00:00:00.5080000 |
| ScenarioAsync2 |
00:00:00.0670000 |
| ScenarioNewThread |
00:00:00.6090000 |
| Сценарий |
Время |
| ScenarioAsyncWithMaxParallelCount4 |
00:00:00.6830000 |
| ScenarioAsyncWithMaxParallelCount8 |
00:00:00.5440000 |
| ScenarioAsyncWithMaxParallelCount16 |
00:00:00.6620000 |
| ScenarioAsyncWithMaxParallelCount24 |
00:00:00.8690000 |
| ScenarioAsyncWithMaxParallelCount32 |
00:00:00.5630000 |
| ScenarioAsyncWithMaxParallelCount64 |
00:00:00.2050000 |
| ScenarioAsyncWithMaxParallelCount128 |
00:00:00.1600000 |
| ScenarioAsyncWithMaxParallelCount256 |
00:00:00.4890000 |
| ScenarioSyncAsParallel |
00:00:00.7090000 |
| ScenarioReadAllAsParallel |
00:00:00.9320000 |
| ScenarioAsync |
00:00:00.7160000 |
| ScenarioAsync2 |
00:00:00.6530000 |
| ScenarioNewThread |
00:00:00.4290000 |
| Сценарий |
Время |
| ScenarioAsyncWithMaxParallelCount4 |
00:00:00.3410000 |
| ScenarioAsyncWithMaxParallelCount8 |
00:00:00.3050000 |
| ScenarioAsyncWithMaxParallelCount16 |
00:00:00.2470000 |
| ScenarioAsyncWithMaxParallelCount24 |
00:00:00.1290000 |
| ScenarioAsyncWithMaxParallelCount32 |
00:00:00.1810000 |
| ScenarioAsyncWithMaxParallelCount64 |
00:00:00.1940000 |
| ScenarioAsyncWithMaxParallelCount128 |
00:00:00.4010000 |
| ScenarioAsyncWithMaxParallelCount256 |
00:00:00.5170000 |
| ScenarioSyncAsParallel |
00:00:00.3120000 |
| ScenarioReadAllAsParallel |
00:00:00.5190000 |
| ScenarioAsync |
00:00:00.4370000 |
| ScenarioAsync2 |
00:00:00.5990000 |
| ScenarioNewThread |
00:00:00.5300000 |
| Сценарий |
Время |
| ScenarioAsyncWithMaxParallelCount4 |
00:00:00.6880000 |
| ScenarioAsyncWithMaxParallelCount8 |
00:00:00.2160000 |
| ScenarioAsyncWithMaxParallelCount16 |
00:00:00.5870000 |
| ScenarioAsyncWithMaxParallelCount32 |
00:00:00.5700000 |
| ScenarioAsyncWithMaxParallelCount64 |
00:00:00.5070000 |
| ScenarioAsyncWithMaxParallelCount128 |
00:00:00.4060000 |
| ScenarioAsyncWithMaxParallelCount256 |
00:00:00.4800000 |
| ScenarioSyncAsParallel |
00:00:00.4680000 |
| ScenarioReadAllAsParallel |
00:00:00.4680000 |
| ScenarioAsync |
00:00:00.3780000 |
| ScenarioAsync2 |
00:00:00.5390000 |
| ScenarioNewThread |
00:00:00.6730000 |
| Сценарий |
Время |
| ScenarioAsyncWithMaxParallelCount4 |
00:00:00.5230000 |
| ScenarioAsyncWithMaxParallelCount8 |
00:00:00.4110000 |
| ScenarioAsyncWithMaxParallelCount16 |
00:00:00.4790000 |
| ScenarioAsyncWithMaxParallelCount24 |
00:00:00.3870000 |
| ScenarioAsyncWithMaxParallelCount32 |
00:00:00.4530000 |
| ScenarioAsyncWithMaxParallelCount64 |
00:00:00.5060000 |
| ScenarioAsyncWithMaxParallelCount128 |
00:00:00.5810000 |
| ScenarioAsyncWithMaxParallelCount256 |
00:00:00.5540000 |
| ScenarioReadAllAsParallel |
00:00:00.5850000 |
| ScenarioAsync |
00:00:00.5530000 |
| ScenarioAsync2 |
00:00:00.4440000 |
|
|






