[Перевод] Как переусложнить дверной замок |
|
Метки: author m1rko разработка для интернета вещей iot дверной замок raspberry pi |
Тринадцатый опрос Developer Economics |

|
Метки: author RoboForm разработка под ios разработка под android разработка мобильных приложений опрос разработка |
[Перевод] Вебинар: Как будут развиваться направленные кибер-атаки? |

|
Метки: author PandaSecurityRus системное администрирование антивирусная защита блог компании panda security в россии pandalabs направленные атаки вебинар кибератаки |
Машинное обучение для страховой компании: Исследуем алгоритмы |



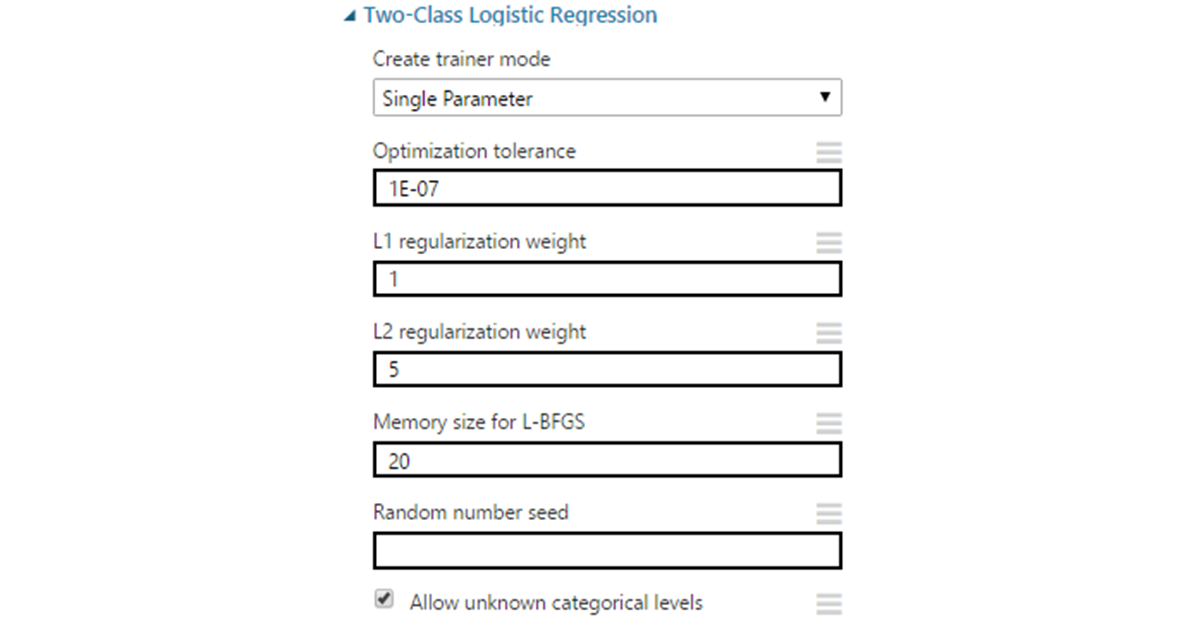




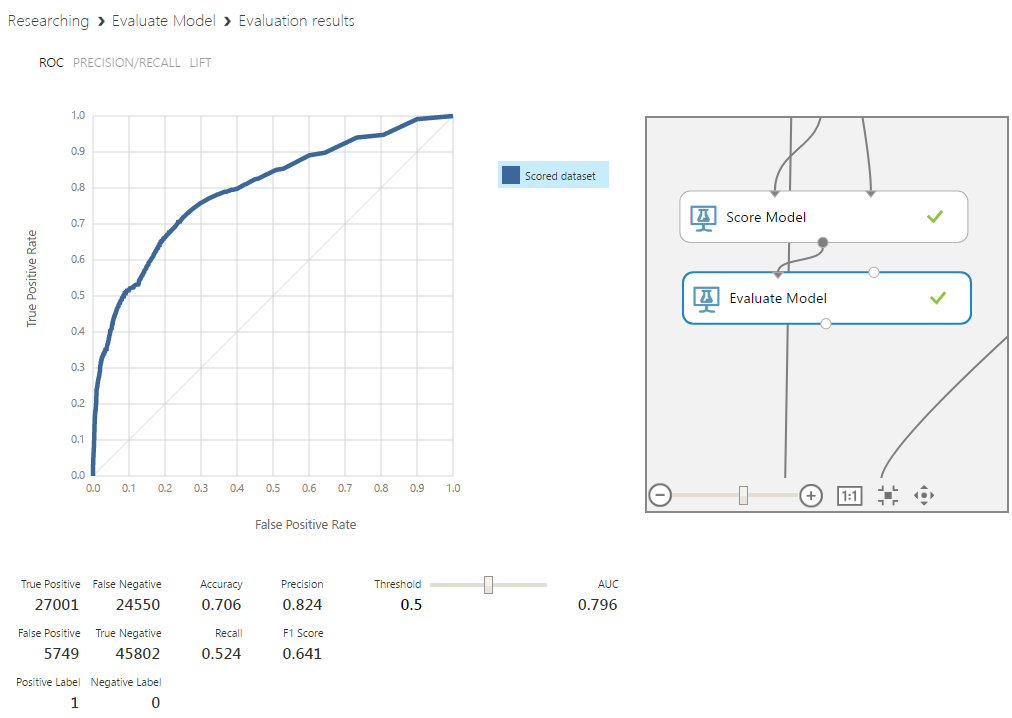
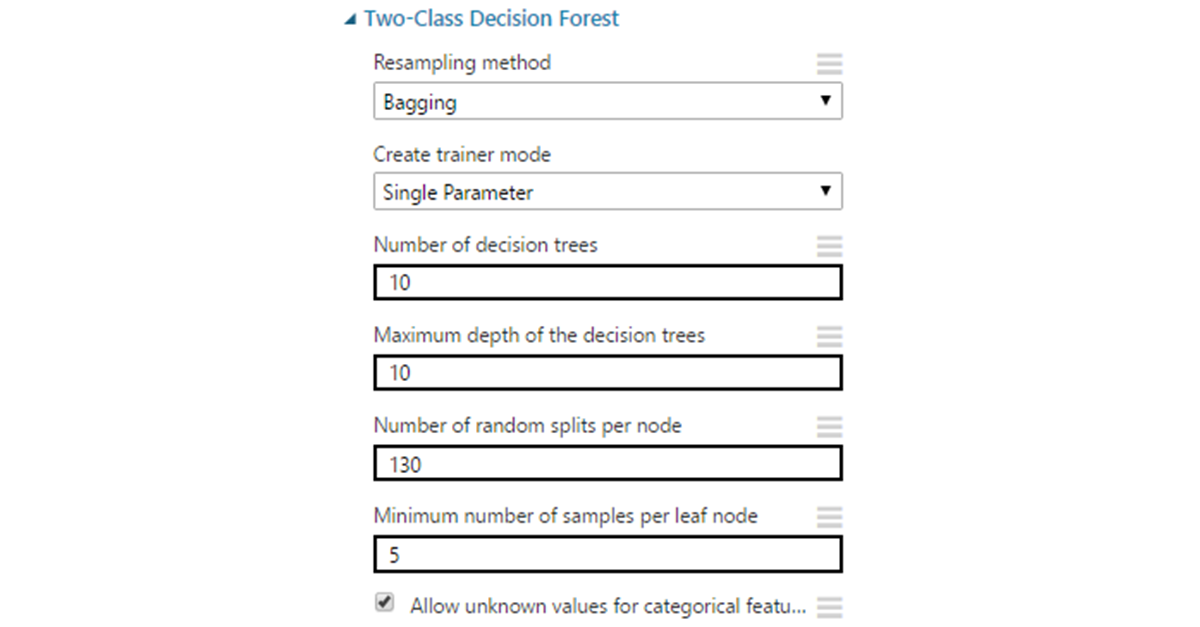
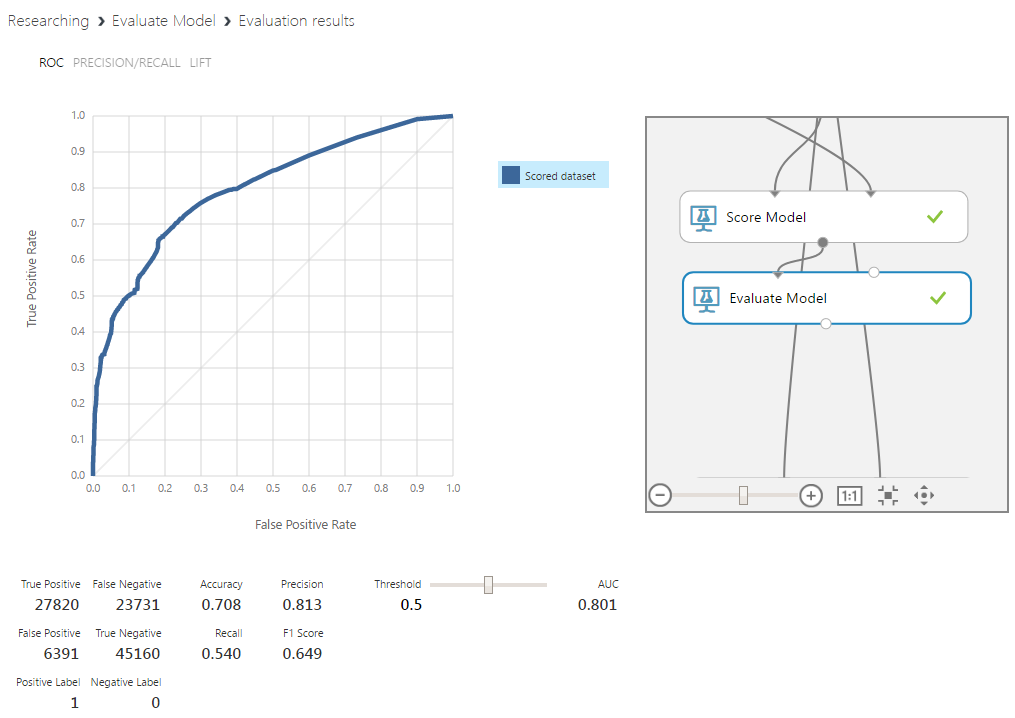

Машинное обучение позволяет автоматизировать области, где на текущий момент доминируют экспертные мнения. Это дает возможность снизить влияние человеческого фактора и повысить масштабируемость бизнеса.
|
Метки: author Schvepsss машинное обучение алгоритмы microsoft azure блог компании microsoft microsoft waveaccess страховая компания |
Используем template + constexpr для создания масок регистров периферии микроконтроллера на этапе компиляции (C++14) |
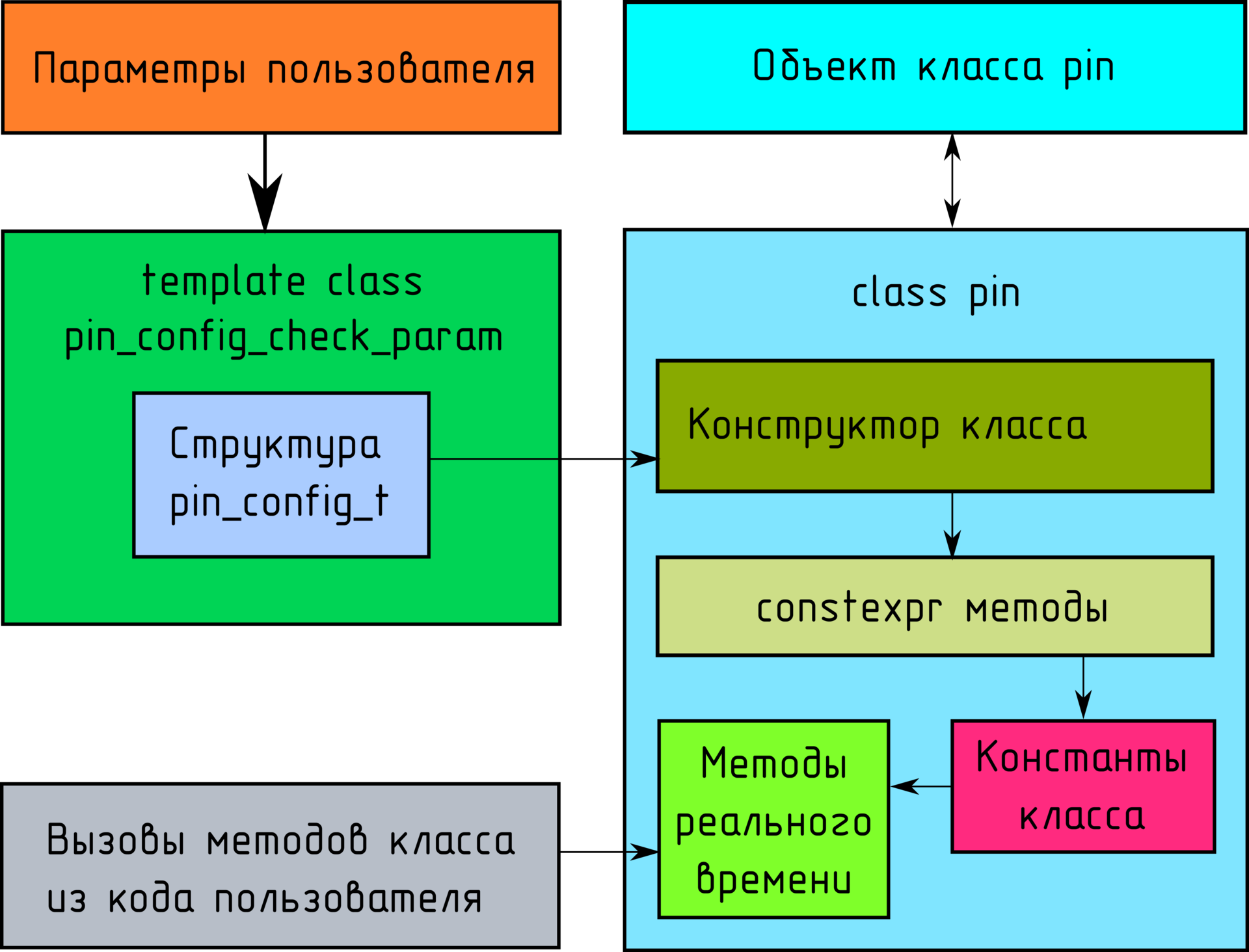
Но на этом проблемы не заканчиваются. Когда пишешь какую-то constexpr-функцию, которую потом будут часто использовать, хорошо бы возвращать читабельную ошибку. Тут можно ошибочно предположить, что static_assert как раз для этого подходит. Но static_assert использовать не получится, так как параметры функций не могут быть constexpr, из-за чего значения параметров не гарантированно будут известны на этапе компиляции.А так как исключения не поддерживаются в constexpr методах, то мы просто будем получать ошибку о том, что использование throw в constexpr невозможно. В случае, если мы обрабатывали что-то в цикле, то мы никогда не сможем узнать, на каком именно элементе мы упали (при проверке какого элемента мы вызвали исключение).
Как же выводить ошибки? Единственный более-менее нормальный способ, который я нашел, заключается в выбрасывании исключения:
/*
* Структура конфигурации вывода.
*/
struct __attribute__( ( packed ) ) pin_config_t {
EC_PORT_NAME port; // Имя порта
// ( пример: EC_PORT_NAME::A ).
EC_PORT_PIN_NAME pin_name; // Номер вывода
// ( пример: EC_PORT_PIN_NAME::PIN_0 ).
EC_PIN_MODE mode; // Режим вывода
// ( пример: EC_PIN_MODE::OUTPUT ).
EC_PIN_OUTPUT_CFG output_config; // Режим выхода
// ( пример: EC_PIN_OUTPUT_CFG::NOT_USE ).
EC_PIN_SPEED speed; // Скорость вывода
// ( пример: EC_PIN_SPEED::MEDIUM ).
EC_PIN_PULL pull; // Подтяжка вывода
// ( пример: EC_PIN_PULL::NO ).
EC_PIN_AF af; // Альтернативная функция вывода
// ( пример: EC_PIN_AF::NOT_USE ).
EC_LOCKED locked; // Заблокировать ли настройку данного
// вывода во время инициализации
// global_port объекта
// ( пример EC_LOCKED::NOT_LOCKED ).
EC_PIN_STATE_AFTER_INIT state_after_init; // Состояние на выходе после инициализации
// ( в случае, если вывод настроен как выход ).
// (пример EC_PIN_STATE_AFTER_INIT::NO_USE).
};
/**********************************************************************
* Область enum class-ов.
**********************************************************************/
/*
* Перечень выводов каждого порта.
*/
enum class EC_PORT_PIN_NAME {
PIN_0 = 0,
PIN_1 = 1,
PIN_2 = 2,
PIN_3 = 3,
PIN_4 = 4,
PIN_5 = 5,
PIN_6 = 6,
PIN_7 = 7,
PIN_8 = 8,
PIN_9 = 9,
PIN_10 = 10,
PIN_11 = 11,
PIN_12 = 12,
PIN_13 = 13,
PIN_14 = 14,
PIN_15 = 15
};
/*
* Режим вывода.
*/
enum class EC_PIN_MODE {
INPUT = 0, // Вход.
OUTPUT = 1, // Выход.
AF = 2, // Альтернативная функция.
ANALOG = 3 // Аналоговый режим.
};
/*
* Режим выхода.
*/
enum class EC_PIN_OUTPUT_CFG {
NO_USE = 0, // Вывод не используется как вывод.
PUSH_PULL = 0, // "Тянуть-толкать".
OPEN_DRAIN = 1 // "Открытый сток".
};
/*
* Скорость выхода.
*/
enum class EC_PIN_SPEED {
LOW = 0, // Низкая.
MEDIUM = 1, // Средняя.
FAST = 2, // Быстрая.
HIGH = 3 // Очень быстрая
};
/*
* Выбор подтяжки
*/
enum class EC_PIN_PULL {
NO_USE = 0, // Без подтяжки.
UP = 1, // Подтяжка к питанию.
DOWN = 2 // Подтяжка к земле.
};
/*
* Выбираем альтернативную функцию, если используется.
*/
enum class EC_PIN_AF {
AF_0 = 0,
NO_USE = AF_0,
SYS = AF_0,
AF_1 = 1,
TIM1 = AF_1,
TIM2 = AF_1,
AF_2 = 2,
TIM3 = AF_2,
TIM4 = AF_2,
TIM5 = AF_2,
AF_3 = 3,
TIM8 = AF_3,
TIM9 = AF_3,
TIM10 = AF_3,
TIM11 = AF_3,
AF_4 = 4,
I2C1 = AF_4,
I2C2 = AF_4,
I2C3 = AF_4,
AF_5 = 5,
SPI1 = AF_5,
SPI2 = AF_5,
I2S2 = AF_5,
AF_6 = 6,
SPI3 = AF_6,
I2S3 = AF_6,
AF_7 = 7,
USART1 = AF_7,
USART2 = AF_7,
USART3 = AF_7,
AF_8 = 8,
UART4 = AF_8,
UART5 = AF_8,
USART6 = AF_8,
AF_9 = 9,
CAN1 = AF_9,
CAN2 = AF_9,
TIM12 = AF_9,
TIM13 = AF_9,
TIM14 = AF_9,
AF_10 = 10,
OTG_FS = AF_10,
AF_11 = 11,
ETH = AF_11,
AF_12 = 12,
FSMC = AF_12,
SDIO = AF_12,
AF_13 = 13,
DCMI = AF_13,
AF_14 = 14,
AF_15 = 15,
EVENTOUT = AF_15
};
/*
* Разрешено ли блокировать конфигурацию вывода методами set_locked_key_port и
* set_locked_keys_all_port объекту класса global_port.
* Важно! Блокировка применяется только один раз объектом global_port. Во время последующей
* работы заблокировать иные выводы или же отключить блокировку текущих - невозможно.
* Единственный способ снять блокировку - перезагрузка чипа.
*/
enum class EC_LOCKED {
NOT_LOCKED = 0, // Не блокировать вывод.
LOCKED = 1 // Заблокировать вывод.
};
/*
* Состояние на выходе после инициализации
* (в случае, если вывод настроен как выход).
*/
enum class EC_PIN_STATE_AFTER_INIT {
NO_USE = 0,
RESET = 0,
SET = 1
};class pin {
public:
constexpr pin ( const pin_config_t* const pin_cfg_array );
void set ( void ) const;
void reset ( void ) const;
void set ( uint8_t state ) const;
void set ( bool state ) const;
void set ( int state ) const;
private:
constexpr uint32_t p_bsr_get ( const pin_config_t* const pin_cfg_array );
constexpr uint32_t set_msk_get ( const pin_config_t* const pin_cfg_array );
constexpr uint32_t reset_msk_get ( const pin_config_t* const pin_cfg_array );
const uint32_t p_bsr;
const uint32_t bsr_set_msk, bsr_reset_msk;
};/*
* Метод устанавливает вывод порта в <<1>>,
* если вывод настроен как выход.
*/
void pin::set ( void ) const {
*M_U32_TO_P(this->p_bsr) = this->bsr_set_msk;
}
/*
* Метод устанавливает вывод порта в <<0>>,
* если вывод настроен как выход.
*/
void pin::reset ( void ) const {
*M_U32_TO_P(this->p_bsr) = this->bsr_reset_msk;
}
/*
* Метод выставляет на выход заданное состояние,
* если вывод настроен как выход.
*/
void pin::set ( uint8_t state ) const {
if ( state ) {
this->set();
} else {
this->reset();
}
}
void pin::set ( bool state ) const {
this->set( static_cast< uint8_t >( state ) );
}
void pin::set ( int state ) const {
this->set( static_cast< uint8_t >( state ) );
}// Преобразует число в uint32_t переменной в указатель на uint32_t.
// Данные по указателю можно изменять.
#define M_U32_TO_P(point) ((uint32_t *)(point))/**********************************************************************
* Область constexpr функций.
**********************************************************************/
/*
* Метод возвращает маску установки выхода в "1" через регистр BSR.
*/
constexpr uint32_t pin::set_msk_get ( const pin_config_t* const pin_cfg_array ) {
return 1 << M_EC_TO_U8(pin_cfg_array->pin_name);
}
/*
* Метод возвращает маску установки выхода в "0" через регистр BSR.
*/
constexpr uint32_t pin::reset_msk_get ( const pin_config_t* const pin_cfg_array ) {
return 1 << M_EC_TO_U8( pin_cfg_array->pin_name ) + 16;
}
/*
* Метод возвращает указатель на регистр BSR, к которому относится вывод.
*/
constexpr uint32_t pin::p_bsr_get( const pin_config_t* const pin_cfg_array ) {
uint32_t p_port = p_base_port_address_get( pin_cfg_array->port );
return p_port + 0x18;
}// Преобразует enum class в uint8_t.
#define M_EC_TO_U8(ENUM_VALUE) ((uint8_t)ENUM_VALUE)/*
* Возвращает указатель на базовый адрес выбранного порта ввода-вывода
* на карте памяти в соответствии с выбранным контроллером.
*/
constexpr uint32_t p_base_port_address_get( EC_PORT_NAME port_name ) {
switch( port_name ) {
#ifdef PORTA
case EC_PORT_NAME::A: return 0x40020000;
#endif
#ifdef PORTB
case EC_PORT_NAME::B: return 0x40020400;
#endif
#ifdef PORTC
case EC_PORT_NAME::C: return 0x40020800;
#endif
#ifdef PORTD
case EC_PORT_NAME::D: return 0x40020C00;
#endif
#ifdef PORTE
case EC_PORT_NAME::E: return 0x40021000;
#endif
#ifdef PORTF
case EC_PORT_NAME::F: return 0x40021400;
#endif
#ifdef PORTG
case EC_PORT_NAME::G: return 0x40021800;
#endif
#ifdef PORTH
case EC_PORT_NAME::H: return 0x40021C00;
#endif
#ifdef PORTI
case EC_PORT_NAME::I: return 0x40022000;
#endif
}
}/**********************************************************************
* Область constexpr конструкторов.
**********************************************************************/
constexpr pin::pin ( const pin_config_t* const pin_cfg_array ):
p_bsr ( this->p_bsr_get( pin_cfg_array ) ),
bsr_set_msk ( this->set_msk_get( pin_cfg_array ) ),
bsr_reset_msk ( this->reset_msk_get( pin_cfg_array ) ) {};/**********************************************************************
* Область template оболочек.
**********************************************************************/
template < EC_PORT_NAME PORT,
EC_PORT_PIN_NAME PIN_NAME,
EC_PIN_MODE MODE,
EC_PIN_OUTPUT_CFG OUTPUT_CONFIG,
EC_PIN_SPEED SPEED,
EC_PIN_PULL PULL,
EC_PIN_AF AF,
EC_LOCKED LOCKED,
EC_PIN_STATE_AFTER_INIT STATE_AFTER_INIT >
class pin_config_check_param : public pin_config_t {
public:
constexpr pin_config_check_param(): pin_config_t( {
.port = PORT,
.pin_name = PIN_NAME,
.mode = MODE,
.output_config = OUTPUT_CONFIG,
.speed = SPEED,
.pull = PULL,
.af = AF,
.locked = LOCKED,
.state_after_init = STATE_AFTER_INIT
} ) {
/*
* Проверяем введенные пользователем данные в структуру инициализации.
*/
#if defined(STM32F205RB)|defined(STM32F205RC)|defined(STM32F205RE) \
|defined(STM32F205RF)|defined(STM32F205RG)
static_assert( PORT >= EC_PORT_NAME::A &&
PORT <= EC_PORT_NAME::H,
"Invalid port name. The port name must be A..H." );
#endif
static_assert( PIN_NAME >= EC_PORT_PIN_NAME::PIN_0 &&
PIN_NAME <= EC_PORT_PIN_NAME::PIN_15,
"Invalid output name. An output with this name does not"
"exist in any port. The output can have a name PIN_0..PIN_15." );
static_assert( MODE >= EC_PIN_MODE::INPUT &&
MODE <= EC_PIN_MODE::ANALOG,
"The selected mode does not exist. "
"The output can be set to mode: INPUT, OUTPUT, AF or ANALOG." );
static_assert( OUTPUT_CONFIG == EC_PIN_OUTPUT_CFG::PUSH_PULL ||
OUTPUT_CONFIG == EC_PIN_OUTPUT_CFG::OPEN_DRAIN,
"A non-existent output mode is selected. "
"The output can be in the mode: PUSH_PULL, OPEN_DRAIN." );
static_assert( SPEED >= EC_PIN_SPEED::LOW &&
SPEED <= EC_PIN_SPEED::HIGH,
"A non-existent mode of port speed is selected. "
"Possible modes: LOW, MEDIUM, FAST or HIGH." );
static_assert( PULL >= EC_PIN_PULL::NO_USE &&
PULL <= EC_PIN_PULL::DOWN,
"A non-existent brace mode is selected."
"The options are: NO_USE, UP or DOWN." );
static_assert( AF >= EC_PIN_AF::AF_0 &&
AF <= EC_PIN_AF::AF_15,
"A non-existent mode of the alternative port function is selected." );
static_assert( LOCKED == EC_LOCKED::NOT_LOCKED ||
LOCKED == EC_LOCKED::LOCKED,
"Invalid port lock mode selected." );
static_assert( STATE_AFTER_INIT == EC_PIN_STATE_AFTER_INIT::NO_USE ||
STATE_AFTER_INIT == EC_PIN_STATE_AFTER_INIT::SET,
"The wrong state of the output is selected."
"The status can be: NO_USE, UP or DOWN." );
};
};const pin_config_check_param< EC_PORT_NAME::C, EC_PORT_PIN_NAME::PIN_4,
EC_PIN_MODE::OUTPUT, EC_PIN_OUTPUT_CFG::PUSH_PULL,
EC_PIN_SPEED::MEDIUM, EC_PIN_PULL::NO_USE,
EC_PIN_AF::NO_USE, EC_LOCKED::LOCKED,
EC_PIN_STATE_AFTER_INIT::SET > lcd_res;const constexpr pin pin_lcd_res( &lcd_res );void port_test ( void ) {
pin_lcd_res.reset();
pin_lcd_res.set();
}/*
* Метод возвращает указатель на bit_banding
* область памяти, в которой находится бит состояния входа.
*/
constexpr uint32_t pin::bb_p_idr_read_get ( const pin_config_t* const pin_cfg_array ) {
uint32_t p_port = p_base_port_address_get( pin_cfg_array->port );
uint32_t p_idr = p_port + 0x10;
return M_GET_BB_P_PER(p_idr, M_EC_TO_U8(pin_cfg_array->pin_name));
}
/*
* Метод возвращает указатель на bit banding область памяти,
* с выставленным пользователем состоянием на выходе вывода.
*/
constexpr uint32_t pin::odr_bit_read_bb_p_get ( const pin_config_t* const pin_cfg_array ) {
uint32_t p_port = p_base_port_address_get( pin_cfg_array->port );
uint32_t p_reg_odr = p_port + 0x14;
return M_GET_BB_P_PER(p_reg_odr, M_EC_TO_U8(pin_cfg_array->pin_name));
}//*********************************************************************
// Определения, не касающиеся основных модулей.
//*********************************************************************
#define BIT_BAND_SRAM_REF 0x20000000
#define BIT_BAND_SRAM_BASE 0x22000000
//Получаем адрес бита RAM в Bit Banding области.
#define MACRO_GET_BB_P_SRAM(reg, bit) \
((BIT_BAND_SRAM_BASE + (reg - BIT_BAND_SRAM_REF)*32 + (bit * 4)))
#define BIT_BAND_PER_REF ((uint32_t)0x40000000)
#define BIT_BAND_PER_BASE ((uint32_t)0x42000000)
// Получаем адрес бита периферии в Bit Banding области.
#define M_GET_BB_P_PER(ADDRESS,BIT) \
((BIT_BAND_PER_BASE + (ADDRESS - BIT_BAND_PER_REF)*32 + (BIT * 4)))/**********************************************************************
* Область constexpr конструкторов.
**********************************************************************/
constexpr pin::pin ( const pin_config_t* const pin_cfg_array ):
p_bsr ( this->p_bsr_get( pin_cfg_array ) ),
p_bb_odr_read ( this->odr_bit_read_bb_p_get( pin_cfg_array ) ),
bsr_set_msk ( this->set_msk_get( pin_cfg_array ) ),
bsr_reset_msk ( this->reset_msk_get( pin_cfg_array ) ),
p_bb_idr_read ( this->bb_p_idr_read_get( pin_cfg_array ) ) {};/*
* Метод инвертирует состояние на выходе вывода,
* если вывод настроен как выход.
*/
void pin::invert( void ) const {
if (*M_U32_TO_P_CONST(p_bb_odr_read)) { // Если был 1, то выставляем 0.
this->reset();
} else {
this->set();
}
}
/*
* Метод возвращает состояние на входе вывода.
*/
int pin::read() const {
return *M_U32_TO_P_CONST(p_bb_idr_read);
}
// Преобразует число в uint32_t переменной в указатель на uint32_t.
// Причем запрещает переписывать то, что по указателю (только чтение).
#define M_U32_TO_P_CONST(point) ((const uint32_t *const)(point))class pin {
public:
constexpr pin ( const pin_config_t* const pin_cfg_array );
void set ( void ) const;
void reset ( void ) const;
void set ( uint8_t state ) const;
void set ( bool state ) const;
void set ( int state ) const;
void invert ( void ) const;
int read ( void ) const;
private:
constexpr uint32_t p_bsr_get ( const pin_config_t* const pin_cfg_array );
constexpr uint32_t set_msk_get ( const pin_config_t* const pin_cfg_array );
constexpr uint32_t reset_msk_get ( const pin_config_t* const pin_cfg_array );
constexpr uint32_t odr_bit_read_bb_p_get ( const pin_config_t* const pin_cfg_array );
constexpr uint32_t bb_p_idr_read_get ( const pin_config_t* const pin_cfg_array );
const uint32_t p_bsr;
const uint32_t bsr_set_msk, bsr_reset_msk;
const uint32_t p_bb_odr_read, p_bb_idr_read;
};
template < EC_PORT_NAME PORT,
EC_PORT_PIN_NAME PIN_NAME >
class pin_config_adc_check_param : public pin_config_check_param< PORT, PIN_NAME,
EC_PIN_MODE::INPUT,
EC_PIN_OUTPUT_CFG::NO_USE,
EC_PIN_SPEED::LOW,
EC_PIN_PULL::UP,
EC_PIN_AF::NO_USE,
EC_LOCKED::LOCKED,
EC_PIN_STATE_AFTER_INIT::NO_USE > {
public:
constexpr pin_config_adc_check_param() {};
};const pin_config_adc_check_param< EC_PORT_NAME::B, EC_PORT_PIN_NAME::PIN_1 > adc_left;|
Метки: author Vadimatorikda программирование микроконтроллеров отладка c++ stm32 микроконтроллеры constexpr c++14 |
Apache Cassandra + Apache Ignite — как совместить лучшее |

$ cd ~/Downloads
$ tar xzvf apache-cassandra-3.10-bin.tar.gz
$ cd apache-cassandra-3.10$ bin/cassandra$ cd ~/Downloads/apache-cassandra-3.10
$ bin/cqlshCREATE KEYSPACE IgniteTest WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 1};
USE IgniteTest;
CREATE TABLE catalog_category (id bigint primary key, parent_id bigint, name text, description text);
CREATE TABLE catalog_good (id bigint primary key, categoryId bigint, name text, description text, price bigint, oldPrice bigint);
INSERT INTO catalog_category (id, parentId, name, description) VALUES (1, NULL, 'Бытовая техника', 'Различная бытовая техника для вашего дома!');
INSERT INTO catalog_category (id, parentId, name, description) VALUES (2, 1, 'Холодильники', 'Самые холодные холодильники!');
INSERT INTO catalog_category (id, parentId, name, description) VALUES (3, 1, 'Стиральные машинки', 'Замечательные стиралки!');
INSERT INTO catalog_good (id, categoryId, name, description, price, oldPrice) VALUES (1, 2, 'Холодильник Buzzword', 'Лучший холодильник 2027!', 1000, NULL);
INSERT INTO catalog_good (id, categoryId, name, description, price, oldPrice) VALUES (2, 2, 'Холодильник Foobar', 'Дешевле не найти!', 300, 900);
INSERT INTO catalog_good (id, categoryId, name, description, price, oldPrice) VALUES (3, 2, 'Холодильник Barbaz', 'Люкс на вашей кухне!', 500000, 300000);
INSERT INTO catalog_good (id, categoryId, name, description, price, oldPrice) VALUES (4, 3, 'Машинка Habr#', 'Стирает, отжимает, сушит!', 10000, NULL);cqlsh:ignitetest> SELECT * FROM catalog_category;
id | description | name | parentId
----+--------------------------------------------+--------------------+-----------
1 | Различная бытовая техника для вашего дома! | Бытовая техника | null
2 | Самые холодные холодильники! | Холодильники | 1
3 | Замечательные стиралки! | Стиральные машинки | 1
(3 rows)
cqlsh:ignitetest> SELECT * FROM catalog_good;
id | categoryId | description | name | oldPrice | price
----+-------------+---------------------------+----------------------+-----------+--------
1 | 2 | Лучший холодильник 2027! | Холодильник Buzzword | null | 1000
2 | 2 | Дешевле не найти! | Холодильник Foobar | 900 | 300
4 | 3 | Стирает, отжимает, сушит! | Машинка Habr# | null | 10000
3 | 2 | Люкс на вашей кухне! | Холодильник Barbaz | 300000 | 500000
(4 rows)
org.apache.ignite
ignite-spring
2.0.0
org.apache.ignite
ignite-cassandra-store
2.0.0
import org.apache.ignite.cache.query.annotations.QuerySqlField;
public class CatalogCategory {
@QuerySqlField private long id;
@QuerySqlField private Long parentId;
@QuerySqlField private String name;
@QuerySqlField private String description;
// public getters and setters
}
public class CatalogGood {
@QuerySqlField private long id;
@QuerySqlField private long categoryId;
@QuerySqlField private String name;
@QuerySqlField private String description;
@QuerySqlField private long price;
@QuerySqlField private long oldPrice;
// public getters and setters
}import org.apache.ignite.cache.query.annotations.QuerySqlField
data class CatalogCategory(@QuerySqlField var id: Long,
@QuerySqlField var parentId: Long?,
@QuerySqlField var name: String?,
@QuerySqlField var description: String?) {
constructor() : this(0, null, null, null)
}
data class CatalogGood(@QuerySqlField var id: Long,
@QuerySqlField var categoryId: Long,
@QuerySqlField var name: String?,
@QuerySqlField var description: String?,
@QuerySqlField var price: Long,
@QuerySqlField var oldPrice: Long) {
constructor() : this(0, 0, null, null, 0, 0)
}
java.lang.Long
com.gridgain.test.model.CatalogCategory
java.lang.Long
com.gridgain.test.model.CatalogGood
cacheConfiguration, которое будет содержать список кешей, запускаемых на кластере:
...
java.lang.Long
com.gridgain.test.model.CatalogCategory
persistenceSettings, в котором лучше сослаться на внешний XML-файл с конфигурацией меппинга, но для простоты встроим этот XML непосредственно в Spring-конфигурацию как CDATA-элемент:
persistence) указывается Keyspace (IgniteTest в данном случае) и Table (catalog_category), которые мы будем соотносить. Затем указывается, что ключом Ignite-кеша будет тип Long, который является примитивным и должен соотноситься с колонкой id в таблице Cassandra. При этом значением является класс CatalogCategory, который должен при помощи Reflection (stategy="POJO") формироваться из колонок таблицы Cassandra.com.gridgain.test.Starter:package com.gridgain.test;
import org.apache.ignite.Ignite;
import org.apache.ignite.Ignition;
public class Starter {
public static void main(String... args) throws Exception {
final Ignite ignite = Ignition.start("apacheignite-cassandra.xml");
ignite.cache("CatalogCategory").loadCache(null);
ignite.cache("CatalogGood").loadCache(null);
}
}
Ignition.start(...) для запуска узла Apache Ignite, указав в качестве источника конфигурации лежащий на classpath файл apacheignite-cassandra.xml.

SELECT cg.name goodName, cg.price goodPrice, cc.name category, pcc.name parentCategory
FROM catalog_category.CatalogCategory cc
JOIN catalog_category.CatalogCategory pcc
ON cc.parentId = pcc.id
JOIN catalog_good.CatalogGood cg
ON cg.categoryId = cc.id;| goodName | goodPrice | category | parentCategory |
|---|---|---|---|
| Холодильник Buzzword | 1000 | Холодильники | Бытовая техника |
| Холодильник Foobar | 300 | Холодильники | Бытовая техника |
| Холодильник Barbaz | 500000 | Холодильники | Бытовая техника |
| Машинка Habr# | 10000 | Стиральные машинки | Бытовая техника |
SELECT cc.name, AVG(cg.price) avgPrice
FROM catalog_category.CatalogCategory cc
JOIN catalog_good.CatalogGood cg
ON cg.categoryId = cc.id
WHERE cg.price <= 100000
GROUP BY cc.id;| name | avgPrice |
|---|---|
| Холодильники | 650 |
| Стиральные машинки | 10000 |
|
Метки: author artemshitov программирование java big data блог компании gridgain apache ignite cassandra |
Возможности CodeRush for Roslyn для XAML |
Редактировать XAML-разметку в Visual Studio достаточно удобно благодаря таким фичам как IntelliSense, автозакрытие тэгов, сворачивание тэгов. Но при реальной работе с этими фичами приходит понимание, что XAML в чистой студии достаточно обособлен: например, плохо отслеживаются связи между кодом и разметкой. Это не позволяет чистой студии делать многие полезные вещи, которые умеет делать студия c CodeRush for Roslyn. Под катом подробности...

Одна из наиболее важных задач среды разработки — поиск ссылок. В Visual Studio он есть, но CodeRush for Roslyn делает его полноценным: с этим расширением вы можете искать вхождения идентификатора не только в XAML, но и по коду во всем солюшне.
У нас также есть лёгкая версия поиска ссылок. Просто нажмите Tab. Если курсор находится на идентификаторе, он мгновенно переместится к следующему его использованию и одновременно подсветятся все вхождения. Чтобы перемещаться назад, можно использовать Shift+Tab.
F12 работает в XAML. Можно переходить на ResourceDictionary.Source или на Image.Source.
Помимо референсов, можно быстро перейти к месту объявления идентификатора, причем не важно где идентификатор объявлен, в коде или в разметке.
XAML полезно форматировать. Есть разные подходы к форматированию XAML: можно вручную, можно использовать онлайн-инструменты для форматирования XML, а можно воспользоваться фичей CRR.
Прямо в Visual Studio.
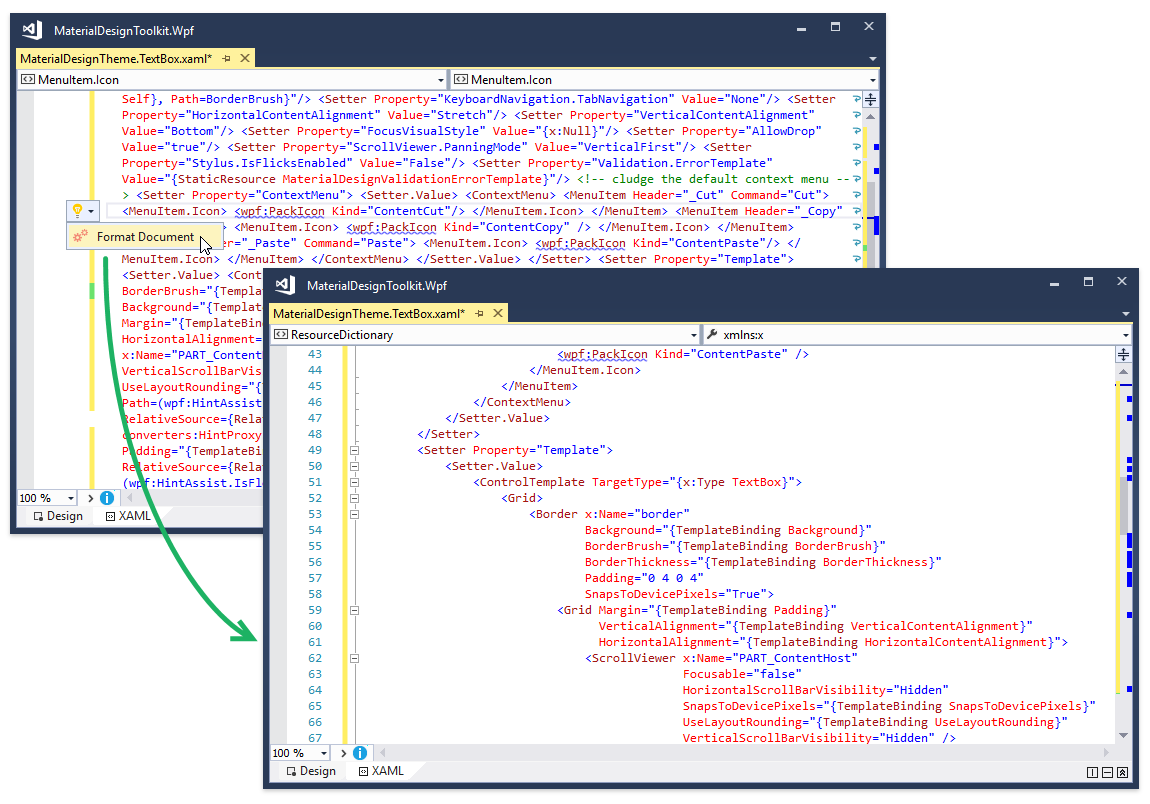
У нашего форматтера гибкая конфигурация и он крайне удобен в работе.

Часть возможностей форматтера доступна в виде отдельных фич, например одним кликом можно разбивать атрибуты по одному на строку, или сворачивать все в одну строку.

При копировании фрагмента кода в проект, CRR помогает правильно заполнить заголовок XAML файла.
У нас есть рефакторинг Optimize Namespace References, он приводит в порядок референсы на пространства имен в XAML: сортирует их и убирает ненужные.
Этот рефакторинг будет полезен тем, кто еще работает в Visual Studio 2015. В последней версии студии он есть из коробки.
Этот рефакторинг позволяет вытащить аттрибут из тэга и сделать его вложенным элементом. Так же, у нас есть обратный рефакторинг — можно сделать вложенные элементы аттрибутами.
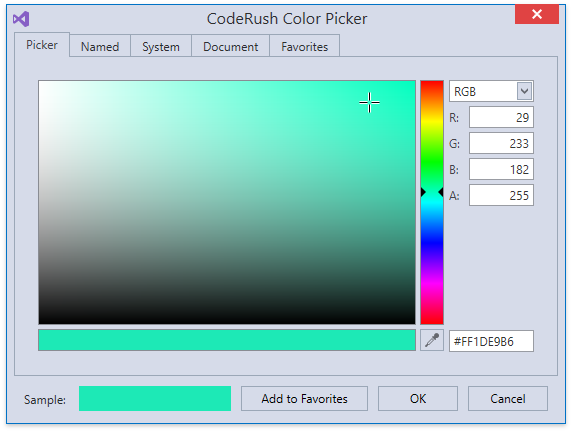
Эта фича представляет собой декоратор, который визуализирует цвет, заданный шестнадцатеричным значением в XAML.
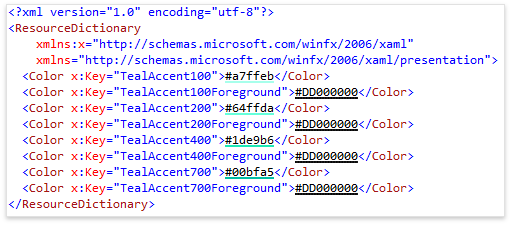
По клику на полосу открывается диалог в котором можно поменять цвет.
В CRR по-своему реализованна отрисовка регионов. Наша версия удобнее тем, что имя региона отображается на закрывающем тэге.

Шаблоны CodeRush работают в XAML в полном объеме. Можно использовать встроенные шаблоны или писать свои с учётом ваших потребностей.
Когда нужно положить определённый блок разметки внутрь какого-либо тэга, приходится несколько раз перемещать курсор, потом форматировать. Чтобы упростить этот процесс у нас есть фича Selection Embedding, которая помещает выделение внутрь тэга одним кликом. Благодаря фичам Selection Expand и Include Previous/Next Element, можно даже не выделять необходимый блок мышкой/стрелочками, а просто нажимать горячие клавиши для управления выделением.
Копируем из иллюстратора
Переключаемся на Visual Studio и вставляем в XAML-файл. Рисунок вставится в векторном формате, его можно дальше масштабировать и менять как угодно.
Также мы поддерживаем копирование векторов из Microsoft Visio, Microsoft PowerPoint.
Для ускорения написания однотипных конструкций с небольшими изменениями у нас есть Smart Duplicate Line пытается определить изменяемые части в дублированной строке и помогает, например, инкрементирует числа и создает филды на переменных частях.
Большинство примеров этой статьи было сделано на исходных текстах открытой библиотеки Material Design in XAML Toolkit.
Скачать попробовать можно в Visual Studio Marketplace.
|
Метки: author xtraroman xml visual studio .net блог компании devexpress coderush xaml |
Как провести розыгрыш призов среди Java программистов |

|
Метки: author Tully программирование java блог компании отус online education online- курс lottery |
Видеозаписи: Android meetup в офисе Badoo |

В прошлую субботу, 17 июня, мы снова проводили митап в офисе. На этот раз принимали Android-сообщество. Эта встреча, вероятно, была самой разнообразной по темам докладов, поэтому каждый интересующийся найдет что-то для себя.
Тема: Компонентные тесты: как сделать жизнь вашего QA немного проще?
Филипп говорил о компонентных тестах, о лучших практиках, которые выработала команда Филиппа в Avito. И как эти самые практики помогают делать качественный продукт.
Тема: Android Studio умеет больше, чем вы думаете
Я провел небольшой воркшоп в Android Studio. Показал некоторые полезные приемы, которые помогают разработчику не тратить время впустую.
Тема: Измерение энергопотребления мобильных и внедрение в Continuous Integration
Андрей рассказал о том, как команда Яндекс.Браузера спроектировала устройство, с помощью которого измеряла энергопотребление приложением, о том, как автоматизировали процессы тестирования энергопотребления, как оптимизировали и контролировали потребление энергии в браузере.
Тема: Как перестать беспокоиться и начать запускать фичи
Гриша рассказал о том, как Android-команда Одноклассников запускает новые фичи и о том, с какими проблемами приходится сталкиваться.
Фотоотчет вы можете найти в нашей группе на Facebook, а посмотреть все видео в одном плейлисте – на нашем Youtube-канале.
|
Метки: author ArkadyGamza тестирование мобильных приложений разработка под android разработка мобильных приложений блог компании badoo android мобильная разработка митап meetup |
Знакомство с ServiceNow и управлением ИТ-инфраструктурой: Дайджест #2 |
 Изображение Bruno Cordioli CC
Изображение Bruno Cordioli CCЧто читать в 2017 году для успешного внедрения ServiceNow
Лучшие бесплатные ресурсы для специалиста ServiceNow
Знакомство с интерфейсом платформы ServiceNow (видео)
О платформе ServiceNow и как она помогает в работе (видео)
Инновационные способы использования ServiceNow
Бюджетирование и оценка затрат в ServiceNow
Как внедрить процесс управления конфигурацией (часть 1)
Как внедрить процесс управления конфигурацией (часть 2)
4 мифа об управлении услугами, в которые вы не должны верить
Совместно используемые услуги
К 2030 году ITSM перестанет быть только «IT»
Управление разработкой ПО — Agile Development
IT Operations Management — управление ИТ-инфраструктурой
Корпоративный портал самообслуживания
Про стандарт ISO 20000
|
Метки: author it-guild service desk help desk software блог компании ит гильдия ит гильдия дайджест servicenow |
[Перевод] Google и Apple против инди-разработчиков |




|
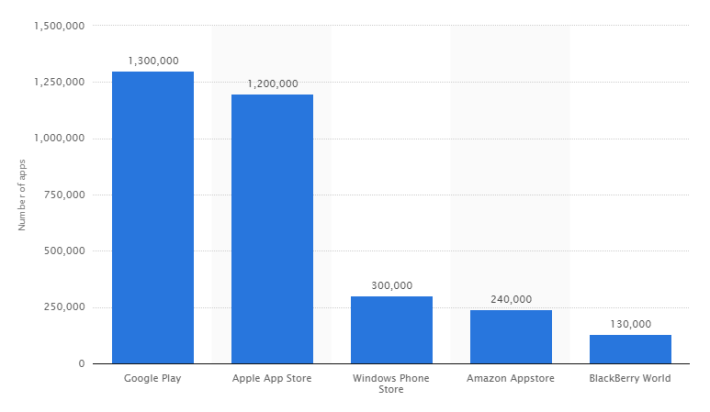
Метки: author PatientZero разработка под ios разработка под android разработка мобильных приложений разработка игр google play apple app store конкуренция магазин приложений |
Где в ZX Spectrum системный монитор? Загадка ПЭВМ Дуэт |
 ПЭВМ Дуэт — это российский клон ZX Spectrum 48k, производился Лианозовским электромеханическим заводом (ЛЭМЗ). Это мой самый первый компьютер и он со мной до сих пор. С юного возраста я начал постигать на нем азы программирования, микропроцессорных архитектур и проектирования цифровых схем. Но с тех пор мне не давал покоя вопрос: где системный монитор? Ведь он упоминается в документации. В стандартном ZX Spectrum я не припомню наличия какого-либо системного монитора. И в документации про системный монитор больше ни слова. Существует Монитор для 48к в ПЗУ версии от 1990г. Однако, после включения, ПЭВМ Дуэт выводит на экран вместо стандартного приветствия — "(с) 1982 sinclair research ltd" другое приветствие: "(с) DUET". А это значит, что ПЗУ там всё же изменено. А может быть есть аппаратные возможности мониторинга? К примеру, клон Орель БК-08 имеет целый ряд доработок: теневое ОЗУ, кнопка NMI и монитор MZ80. Было бы очень интересно, спустя столько лет, найти какие-то скрытые возможности своей железки.
ПЭВМ Дуэт — это российский клон ZX Spectrum 48k, производился Лианозовским электромеханическим заводом (ЛЭМЗ). Это мой самый первый компьютер и он со мной до сих пор. С юного возраста я начал постигать на нем азы программирования, микропроцессорных архитектур и проектирования цифровых схем. Но с тех пор мне не давал покоя вопрос: где системный монитор? Ведь он упоминается в документации. В стандартном ZX Spectrum я не припомню наличия какого-либо системного монитора. И в документации про системный монитор больше ни слова. Существует Монитор для 48к в ПЗУ версии от 1990г. Однако, после включения, ПЭВМ Дуэт выводит на экран вместо стандартного приветствия — "(с) 1982 sinclair research ltd" другое приветствие: "(с) DUET". А это значит, что ПЗУ там всё же изменено. А может быть есть аппаратные возможности мониторинга? К примеру, клон Орель БК-08 имеет целый ряд доработок: теневое ОЗУ, кнопка NMI и монитор MZ80. Было бы очень интересно, спустя столько лет, найти какие-то скрытые возможности своей железки.

Скорее всего под системным монитором понимается набор стандартных подпрограмм ПЗУ. Попробуйте:Ну не может быть, что все так просто! Изучение схемы показало, что никаких дополнительных ПЗУ там нет: две ПЗУ по 8Кб (составляющие стандартные 16кБ ПЗУ с бейсиком). Судя по фотографии внутренностей именно моего экземпляра, мой вариант ничем не отличается от схемы на сайте (на самом деле, есть мелкие доработки/изменения, о которых, может быть, в другой раз). Таким образом, аппаратных возможностей для существования монитора не обнаружено.
1. посмотреть на плате установленные ПЗУ, похоже что у вас стоит 2 шт по 8К, это 16К, если дополнительных ПЗУ нет, то искать нужно среди имеющихся 16К.
2. слить дамп ПЗУ и сравнить со стандартным синклеровским, обычно менялась только надпись в клонах. По различиям можно прикинуть есть-ли что-то интересное.
SAVE "ROM" CODE 0, 16384LOAD "" CODE 40000 загрузила данные оригинального ПЗУ в память, начиная с адреса 40000.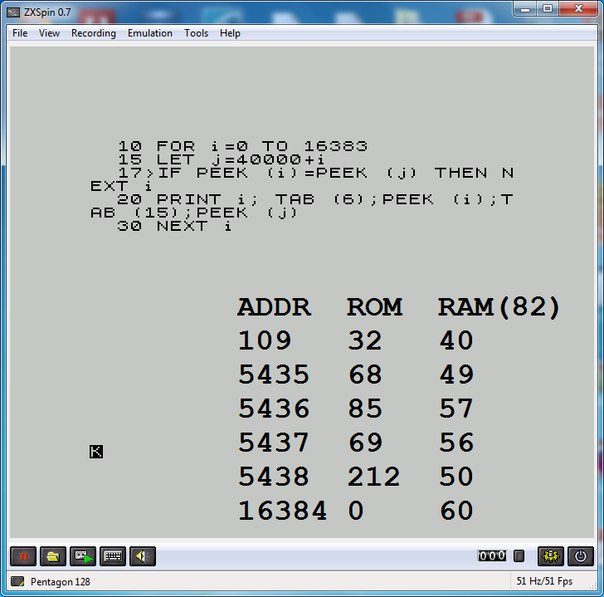

1539 (C)
153A пробел " "
153B 68 "D"
153C 85 "U"
153D 69 "E"
153E 212 последний символ. инвертированный. 212d + 80h = 54h - "T" ...
ПОЛНОЕ ОПИСАНИЕ ПЗУ КОМПЬЮТЕРА ZX SPECTRUM
...
ВВЕДЕНИЕ
Монитор Spectrum, объемом 16K, представляет собой сложную программу в машинных кодах
Z80. Ее можно разделить на три основные части:
а. Программы ввода/вывода.
б. Интерпретатор BASIC.
в. Вычислительные процедуры.
Однако, для подробного описания эти блоки слишком громоздки, и поэтому монитор
разделен еще на 10 частей. Каждая часть будет представлять собой элемент монитора. |
Метки: author UA3MQJ программирование отладка #zx spectrum #speccy #z80 |
Как с помощью блокчейна защитить свои данные |





|
Метки: author toxzic хранение данных децентрализованные сети блог компании acronis inc acronis asign notary блокчейн blockchain ethereum |
Возможности PostgreSQL для тех, кто перешел с MySQL |
Крутой varanio буквально на прошлой неделе прочитал на DevConf забойный доклад для всех кто пересел на Посгрес с MySQL, но до сих пор не использует новую базу данных в полной мере. По мотивам выступления родилась эта публикация.
Мы рады сообщить, что подготовка к PG Day'17 Russia идет полным ходом! Мы опубликовали полное расписание предстоящего мероприятия. Приглашаем всех желающих прийти и похоливарить с Антоном лично :-)

Поскольку доклад на DevConf вызвал в целом положительные отзывы, я решил оформить его в виде статьи для тех, кто по каким-то причинам не смог присутствовать на конференции.
Почему вообще возникла идея такого доклада? Дело в том, что PostgreSQL сейчас явно хайповая технология, и многие переходят на эту СУБД. Иногда — по объективным причинам, иногда — просто потому что это модно.
Но сплошь и рядом складывается такая ситуация, когда какой-нибудь условный программист Вася вчера писал на MySQL, а сегодня вдруг начал писать на Посгресе. Как он будет писать? Да в целом также, как и раньше, используя лишь самый минимальный набор возможностей новой базы. Практика показывает, что проходят годы, прежде чем СУБД начинает использоваться более менее полноценно.
Сразу disclaimer: это не статья "мускуль vs посгрес". Переходить на посгрес или нет — ваше дело. Uber, к примеру, перешел обратно на MySQL по своим каким-то причинам.
Надо отдать должное Oracle, они явно двигают MySQL в правильном направлении. В 5.7 сделали strict mode по умолчанию. В восьмой версии обещают CTE и оконные функции, а также избавление от движка MyISAM в системных таблицах. Т.е. видно, что в базу вкладываются ресурсы, и хотелки юзеров исследуются очень серьёзно.
Однако в PostgreSQL по прежнему полным полно уникальных фич. В итоге я попытался сделать краткий обзор возможностей базы для разработчика.
В базу встроено множество типов данных, помимо обычных числовых и строковых. А также операторы для их взаимодействия.
Например, есть типы cidr, inet, macaddr для работы с ip адресами.
-- проверяем, входит ли ip адрес '128.0.0.1' в cidr '127.0.0.0/24'
-- с помощью оператора &&
select '127.0.0.0/24'::cidr && '128.0.0.1';
-- вернет falseИли например, время с таймзоной (timestamptz), интервал времени и т.д.
-- Сколько сейчас времени в Нью-Йорке?
SELECT NOW() AT TIME ZONE 'America/New_York';
-- Сколько часов разницы сейчас между Москвой и Нью-Йорком?
SELECT NOW() AT TIME ZONE 'America/New_York'
- NOW() AT TIME ZONE 'Europe/Moscow';
-- результат: -07:00:00 Когда я готовил этот слайд, я решил из любопытства посмотреть, а какое смещение времени относительно UTC было 100 лет назад, в 2017 году:
select '1917-06-17 00:00:00 UTC' at time zone 'Europe/Moscow';
-- результат: 1917-06-17 02:31:19Т.е. москвичи жили по времени UTC+02:31:19.
Кроме перечисленных, есть и другие встроенные типы данных: UUID, JSONB, XML, битовые строки и т.д.
Отдельно надо рассмотреть тип "array". Массивы давно и хорошо интегрированы в PostgreSQL. Многомерные массивы, слайсы, операторы пересечения, объединения и т.д. Существует множество функций для работы с массивами.
--- Пример проверки пересечения массивов
SELECT ARRAY [1, 2, 8, 10] && ARRAY [1, 2, 3, 4, 5];
--- Входит ли один массив в другой?
SELECT ARRAY [1, 2] <@ ARRAY [1, 2, 3, 4, 5]Есть очень удобная функция, которая так и называется: array. В качестве аргумента подается некий SELECT-запрос, на выходе — результат запроса в виде массива.
Есть и обратная функция: unnest. Она берет массив и возвращает его как результат запроса. Это бывает удобно, например, когда нужно вставить вручную несколько одинаковых записей с разными id, но не хочется заниматься копипастой:
INSERT INTO users
(id, status, added_at)
SELECT user_id, 5, '2010-03-03 10:56:40'
FROM unnest(array[123, 1232, 534, 233, 100500]) as u(user_id)Собственные типы можно создавать тремя способами. Во-первых, если вы знаете язык Си, то вы можете создать базовый тип, наравне с каким-нибудь int или varchar. Пример из мануала:
CREATE TYPE box (
INTERNALLENGTH = 16,
INPUT = my_box_in_function,
OUTPUT = my_box_out_function
);Т.е. создаете пару функций, которые умеют делать из cstring ваш тип и наоборот. После чего можно использовать этот тип, например, в объявлении таблицы:
CREATE TABLE myboxes (
id integer,
description box
);Второй способ — это композитный тип. Например, для хранения комплексных чисел:
CREATE TYPE complex AS (
r double precision,
i double precision
);И потом использовать это:
CREATE TABLE math (
result complex
);
INSERT INTO math
(result)
VALUES
((0.5, -0.6)::complex);
SELECT (result).i FROM math;
-- результат: -0.6Третий вид типа, который вы можете создать — это доменный тип. Доменный тип — это просто алиас к существующему типу с другим именем, т.е. именем, соответствующим вашей бизнес-логике.
CREATE DOMAIN us_postal_code AS TEXT;us_postal_code — это более семантично, чем некий абстрактный text или varchar.
Можно делать свои операторы. Например, сложение комплексных чисел (сам тип complex мы определили выше):
-- описываем функцию сложения, например, на языке SQL
CREATE OR REPLACE FUNCTION sum_complex(x COMPLEX, y COMPLEX)
RETURNS COMPLEX AS $$
SELECT x.r + y.r, x.i + y.i;
$$ language sql;
-- создаем оператор "плюс" для комплексных чисел
CREATE OPERATOR +
(
PROCEDURE = sum_complex,
LEFTARG = COMPLEX,
RIGHTARG = COMPLEX
);Давайте сделаем какой-нибудь сферический в вакууме пример. Создадим типы RUR и USD, и правило для преобразования одного типа в другой. Так как я плохо знаю си, то для примера сделаем простой композитный тип:
CREATE TYPE USD AS (
sum FLOAT
);
CREATE TYPE RUR AS (
sum FLOAT
);
-- функция преобразования долларов в рубли (по курсу 60, это же сферический пример)
CREATE FUNCTION usd2rur(value USD)
RETURNS RUR AS $$
SELECT value.sum * 60.0;
$$ LANGUAGE SQL;
-- описываем правило для посгреса, какой тип как "кастить".
CREATE CAST ( USD AS RUR )
WITH FUNCTION usd2rur(USD) AS ASSIGNMENT;Собственно, это всё, теперь можно использовать. Сколько там будет 100 баксов в рублях?
select '(100.0)'::usd::rur;Результат будет таким:
rur
--------
(6000)
(1 row)Существуют расширения, где описаны типы данных и все, что для них нужно. Например, расширение ip4r, описывающее типы для IP-адресов и их диапазонов.
Если вы посмотрите исходники https://github.com/RhodiumToad/ip4r/blob/master/ip4r--2.2.sql, то увидите, что расширение — это просто, по сути, набор иструкций CREATE TYPE, CREATE OPERATOR, CREATE CAST и т.д.
Описаны правила индексирования. Например, тип ip4r (диапазон IP-адресов) можно проиндексировать индексом GIST по оператору && (и другим). Таким образом, можно сделать таблицу для поиска городов по IP.
Или, например, есть расширение uri, которое делает тип, в котором вы сможете хранить вашу ссылку так, что из нее потом легко вытянуть схему или хост (в продакшене еще не пробовал, только планирую).
Помимо стандартного btree есть и другие: GIN (можно использовать для некоторых операций с массивами, для jsonb, для полнотекстового поиска), GIST, brin и т.д.
Бывают ситуации, когда у вас 10 миллионов строк в таблице, при чем из них только штук 100, допустим, в статусе "Платеж обрабатывается". И вы постоянно дергаете этот статус "обрабатывается" как-то так: select ... where status = 2.
Понятное дело, что здесь нужен индекс. Но такой индекс будет занимать много места, при этом реально вам нужна из него совсем малая часть.
В посгресе можно сделать индекс не по всей таблице, а по строкам, определенным по заданному условию:
CREATE INDEX my_money_status_idx on my_money(status) WHERE status = 2;Этот индекс будет хорошо работать на запросах select * from my_money where status = 2 и при этом занимать мало места.
В посгресе можно делать индексы не по одной колонке, а по любому выражению. Например, можно проиндексировать сразу имя с фамилией:
CREATE INDEX people_names
ON people ((first_name || ' ' || last_name));И потом такой запрос будет быстро работать:
SELECT *
FROM people
WHERE
(first_name || ' ' || last_name) = 'John Smith';Помимо стандартных UNIQUE и NOT NULL, в базе можно делать еще и другие проверки целостности. В доменном типе можно прописать check:
CREATE DOMAIN us_postal_code AS TEXT
CHECK(
VALUE ~ '^\d{5}$'
OR VALUE ~ '^\d{5}-\d{4}$'
);который проверяет, что в колонку типа us_postal_code попадут только 5 цифр или 5 цифр, дефис и 4 цифры. Разумеется, сюда можно писать не только регулярки, но и любые другие условия.
Также check можно прописать в таблице:
CREATE TABLE users (
id integer,
name text,
email text,
CHECK (length(name) >= 1 AND length(name) <= 300)
);Т.е. в имени должен быть хотя бы один символ, и не больше 300.
Вообще говоря, сами типы являются также и неким ограничением, дополнительной проверкой, которую делает база. Например, если у вас есть тип complex (смотри выше), состоящий, по сути, из двух чисел, то вы не вставите туда случайно строку:
INSERT INTO math (result) VALUES ((0.5, 'привет')::complex);
ERROR: invalid input syntax for type double precision: "привет"Таким образом, иногда композитный тип может быть предпочтительнее, чем jsonb, потому что в json вы можете напихать что угодно вообще.
В отличие от простой уникальности UNIQUE или PRIMARY KEY, в посгресе можно сделать уникальность среди определенного набора строк, заданного условием. Например, email должен быть уникальным среди неудаленных юзеров:
CREATE UNIQUE INDEX users_unique_idx
ON users(email)
WHERE deleted = false;Еще забавная штука: можно сделать уникальность не по одному полю, а по любому выражению. К примеру, можно сделать так, что в таблице сумма двух колонок не будет повторяться:
CREATE TABLE test_summ (
a INT,
b INT
);
CREATE UNIQUE INDEX test_summ_unique_idx
ON test_summ ((a + b));
INSERT INTO test_summ VALUES (1, 2);
INSERT INTO test_summ VALUES (3, 0);
-- выдаст ошибку уникальностиКлючевое слово EXCLUDE позволяет делать так, что при вставке/обновлении строки, эта строка будет сравниваться с другими по заданному оператору. Например, таблица, содержащая непересекающиеся диапазоны IP (проверяется оператором пересечения &&):
CREATE TABLE ip_ranges (
ip_range ip4r,
EXCLUDE USING gist (ip_range WITH &&)
);Вообще, обычный UNIQUE — это, по сути, EXCLUDE с оператором =.
Хранимые процедуры можно писать на SQL, pl/pgsql, javascript, (pl/v8), python и т.д. Например, можно на языке R обсчитать какую-то статистику и вернуть из нее график с результатом.
Это отдельная большая тема, советую поискать доклад Ивана Панченко на этот счет.
Это будет и в MySQL 8, но всё равно давайте кратко остановимся на этом.
CTE — это просто. Вы берете какой-то кусок запроса и выносите его отдельно под каким-то именем.
WITH subquery1 AS (
SELECT ... -- тут куча всяких условий и тд.
),
subquery2 AS (
SELECT ... -- тут тоже куча условий, группировок
)
SELECT * -- начался основной запрос
FROM subquery1
JOIN subquery 2
ON ...С точки зрения оптимизации запросов, нужно учитывать, что каждый такой CTE-подзапрос выполняется отдельно. Это может быть как плюсом, так и минусом.
Например, если у вас 20 джойнов с подзапросами и группировками, планировщик запросов может не понять ваших намерений и план запроса будет неоптимальным. Тогда можно вынести часть запроса в cte-подзапрос, а остальное уже дофильтровать в основном запросе.
И наоборот, если вы решили просто для читабельности вынести часть запроса в CTE, то иногда это может выйти для вас боком.
В CTE можно использовать не только SELECT-запросы, но и UPDATE.
Пример: обновить юзеров с возрастом > 20 лет, и в том же запросе выдать имена обновленных вместе с какой-нибудь там страной.
with users_updated AS (
UPDATE users
SET status = 4
WHERE age > 20
RETURNING id
)
SELECT name, country
FROM users
JOIN countries
ON users.country_id = countries.id
WHERE id IN (
SELECT id
FROM users_updated
);Но тут надо понимать, что иногда с помощью CTE можно хорошо выстрелить себе в ногу.
Такой запрос синтаксически верен, но по смыслу полный бред:
WITH
update1 AS (
UPDATE test
SET money = money + 1
),
update2 AS (
UPDATE test
SET money = money - 1
)
SELECT money FROM test;Кажется, что мы прибавили рубль, потом отняли рубль, и должно остаться всё как есть.
Но дело в том, что update1 и update2 при своем выполнении будут брать начальную версию таблицы, т.е. по сути получится так, что один update затрет изменения другого. Поэтому с update внутри CTE надо точно знать, что ты делаешь и зачем.
Про оконные функции я уже когда-то подробно писал здесь: https://habrahabr.ru/post/268983/. Оконные функции тоже обещают в MySQL 8.
К агрегатным функциям (например, COUNT или SUM), можно дописывать условие FILTER, т.е. агрегировать не все строки, а только ограниченные неким выражением:
SELECT
count(*) FILTER (WHERE age > 20) AS old,
count(*) FILTER (WHERE age <= 20) AS young
FROM users;Т.е. мы посчитали людей, которым за двадцать, и тех, кому нет двадцати.
Все знают, что в psql есть команды для просмотра разных объектов, например \d, \dt+ и т.д.
Есть особая команда, называется \watch. Т.е. вы выполняете запрос, потом пишете
\watch 5 и ваш запрос будет выполняться каждые 5 секунд, пока не отмените.
Это работает не только с select, но и с любым другим, например с update (например, когда нужно большую таблицу медленно обновить по чуть-чуть).
Это как View, только закешированное (материализованное). Кеш можно обновлять с помощью команды REFRESH MATERIALIZED VIEW. Есть также ключевое слово CONCURRENTLY, чтобы Postgres не лочил при обновлении SELECT-запросы.
Я пока что не пробовал это в продакшене, поэтому не знаю, применимо ли это на практике (если кто использовал, поделитесь плиз опытом в комментариях). Суть в том, что можно подписаться на какое то событие, а также можно уведомить подписчиков, что событие произошло, передав при этом строку с доп. сведениями.
Механизм Foreign Data Wrappers позволяет использовать некоторые внешние данные, как простые таблицы. Т.е. к примеру, можно заджойнить постгресовую таблицу, мускульную таблицу, и csv файл.
SEQUENCE — это посгресовый аналог MySQL-ного AUTO_INCREMENT. В отличие от MySQL, sequence может существовать отдельно от таблиц или наоборот, "тикать" сразу для нескольких таблиц. Можно задавать различные параметры, например, размер инкремента, зацикливание и проч.
Это верхушка айсберга, на самом деле. Есть еще куча нюансов, вообще никак не затронутых в статье, потому что на всё никакой статьи не хватит. По одним только хранимым процедурам можно написать книгу. Или посмотрите, к примеру, полный список sql-команд текущей версии: https://www.postgresql.org/docs/9.6/static/sql-commands.html
Главное, что я хотел показать в статье: несмотря на хайповость, PostgreSQL — очень старая СУБД, в которой очень много чего есть, и которая очень хорошо расширяется. Поэтому при переходе на нее с MySQL рекомендуется полистать мануал, почитать статьи и т.д.
|
Метки: author rdruzyagin разработка веб-сайтов sql postgresql mysql блог компании pg day'17 russia migration cte window functions stored procedures dml ddl |
Виртуальные твари и места их обитания: прошлое и настоящее TTY в Linux |
 Ubuntu интегрирована в Windows 10 Redstone, Visual Studio 2017 обзавелась поддержкой разработки под Linux – даже Microsoft сдает позиции в пользу растущего числа сторонников Торвальдса, а ты всё еще не знаешь тайны виртуального терминала в современных дистрибутивах?
Ubuntu интегрирована в Windows 10 Redstone, Visual Studio 2017 обзавелась поддержкой разработки под Linux – даже Microsoft сдает позиции в пользу растущего числа сторонников Торвальдса, а ты всё еще не знаешь тайны виртуального терминала в современных дистрибутивах? Мы шагнули прямиком в тридцатые годы XX века и оказались в совсем еще молодой Teletype Corporation. Прямо перед нами перед нами Тот-С-Которого-Всё-Началось – телетайп, представляющий из себя «буквопечатающий телеграф», который передает текстовые сообщения между двумя абонентами.
Мы шагнули прямиком в тридцатые годы XX века и оказались в совсем еще молодой Teletype Corporation. Прямо перед нами перед нами Тот-С-Которого-Всё-Началось – телетайп, представляющий из себя «буквопечатающий телеграф», который передает текстовые сообщения между двумя абонентами.
 Прошло сорок лет, мы в лаборатории Digital Equipment Corporation, любуемся первым мини-компьютером (интерактивным!) PDP-1. Для ввода и вывода информации, а также для обеспечения взаимодействия с пользователем к нему подключен уже знакомый нам телетайп.
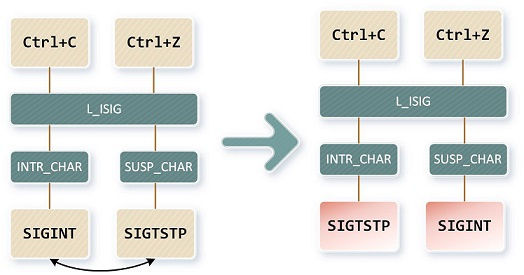
Прошло сорок лет, мы в лаборатории Digital Equipment Corporation, любуемся первым мини-компьютером (интерактивным!) PDP-1. Для ввода и вывода информации, а также для обеспечения взаимодействия с пользователем к нему подключен уже знакомый нам телетайп. Оказываемся в самом начале 80-ых годов, на этот раз в Bell Laboratories. Здесь только что выпущен один из важнейших релизов «раннего» UNIX – Version 7 для PDP-11. Особенности у этого релиза следующие: вводимая пользователем команда теперь отображается по принципу ECHO (набранный на клавиатуре символ сначала попадает в буфер накопления и только потом ОС отправляет инструкцию вывести этот символ на печать), поддерживаются простые возможности редактирования вводимых команд (можно «стирать» символ или целую строку, перемещать каретку), появляется разделение режимов:
Оказываемся в самом начале 80-ых годов, на этот раз в Bell Laboratories. Здесь только что выпущен один из важнейших релизов «раннего» UNIX – Version 7 для PDP-11. Особенности у этого релиза следующие: вводимая пользователем команда теперь отображается по принципу ECHO (набранный на клавиатуре символ сначала попадает в буфер накопления и только потом ОС отправляет инструкцию вывести этот символ на печать), поддерживаются простые возможности редактирования вводимых команд (можно «стирать» символ или целую строку, перемещать каретку), появляется разделение режимов: Кстати говоря, Digital Equipment Corporation за эти 20 лет не только разработала упомянутый PDP-11, но и подумала о том, как усовершенствовать телетайп: появились так называемые умные терминалы.
Кстати говоря, Digital Equipment Corporation за эти 20 лет не только разработала упомянутый PDP-11, но и подумала о том, как усовершенствовать телетайп: появились так называемые умные терминалы.
 Мы очутились в редакции журнала «PC MAGAZINE», рассматриваем свежий выпуск от 13 января 1987 года. Один из разворотов активно убеждает нас не жалеть денег на ПК с UNIX System V. Каковы аргументы? В частности – grep, awk, sort, split, cut, paste, vi, ed – word processing явно шагнул вперед. И самое интересное: к нашим услугам сейчас эмуляторы терминалов! Благодаря виртуальным консолям, уже можно запустить целых четыре сессии без нужды подключать всё новые и новые физические телетайпы.
Мы очутились в редакции журнала «PC MAGAZINE», рассматриваем свежий выпуск от 13 января 1987 года. Один из разворотов активно убеждает нас не жалеть денег на ПК с UNIX System V. Каковы аргументы? В частности – grep, awk, sort, split, cut, paste, vi, ed – word processing явно шагнул вперед. И самое интересное: к нашим услугам сейчас эмуляторы терминалов! Благодаря виртуальным консолям, уже можно запустить целых четыре сессии без нужды подключать всё новые и новые физические телетайпы.
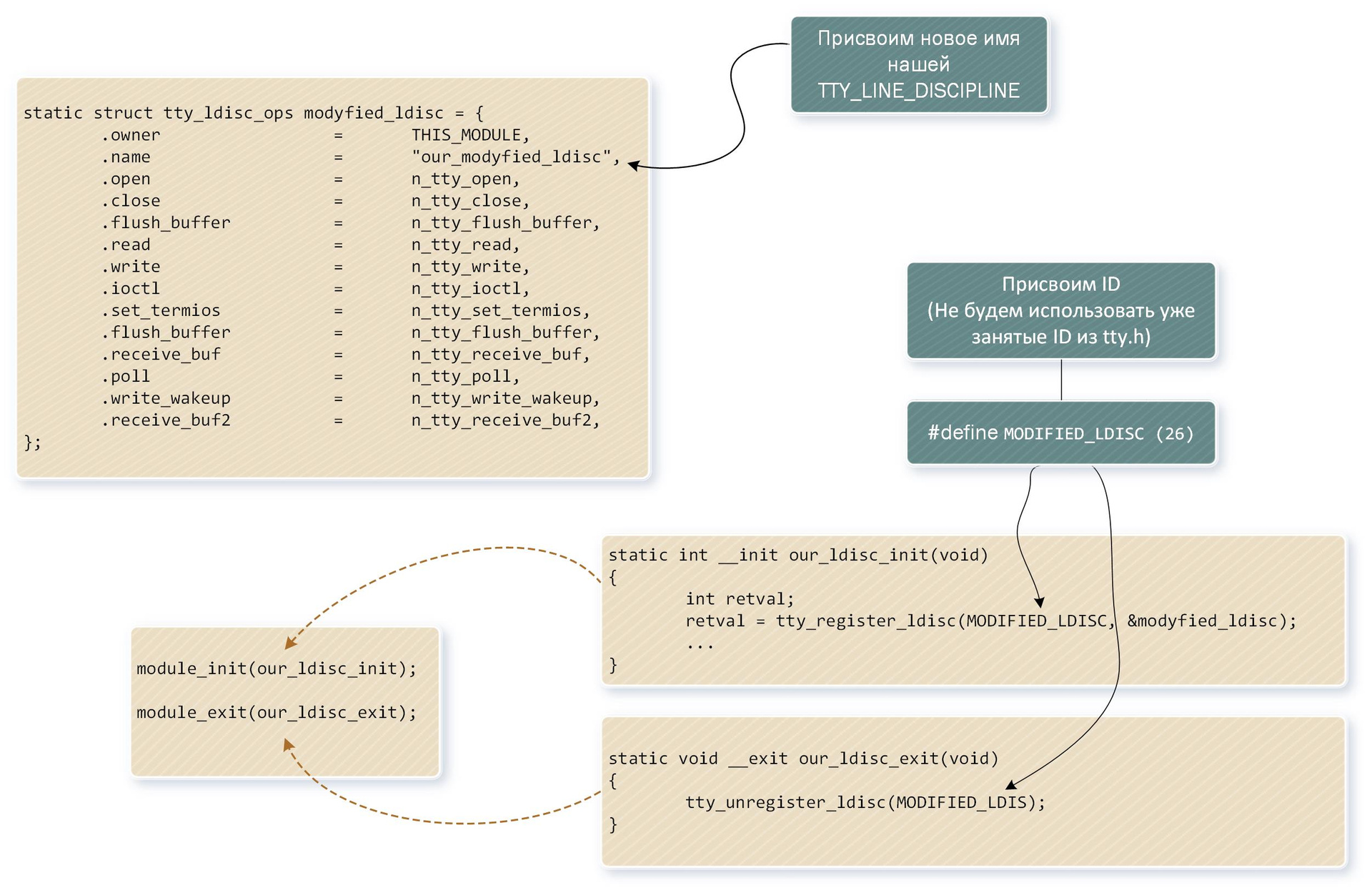
 Дело в том, что в Linux есть макрос MAX_NR_CONSOLES (64), определяющий максимально допустимое число виртуальных консолей, которые и представлены 64-мя файлами виртуальных устройств /dev/ttyX. Однако последнее слово остается за параметром ACTIVE_CONSOLES (/etc/default/console-setup), и параметр этот по умолчанию равен шести.
Дело в том, что в Linux есть макрос MAX_NR_CONSOLES (64), определяющий максимально допустимое число виртуальных консолей, которые и представлены 64-мя файлами виртуальных устройств /dev/ttyX. Однако последнее слово остается за параметром ACTIVE_CONSOLES (/etc/default/console-setup), и параметр этот по умолчанию равен шести. 
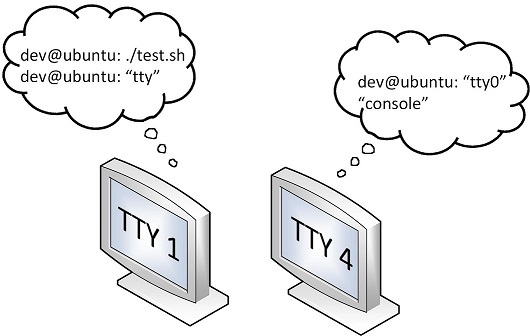
sleep 10
echo “tty0” > /dev/tty0
echo “tty” > /dev/tty
echo “console” > /dev/console

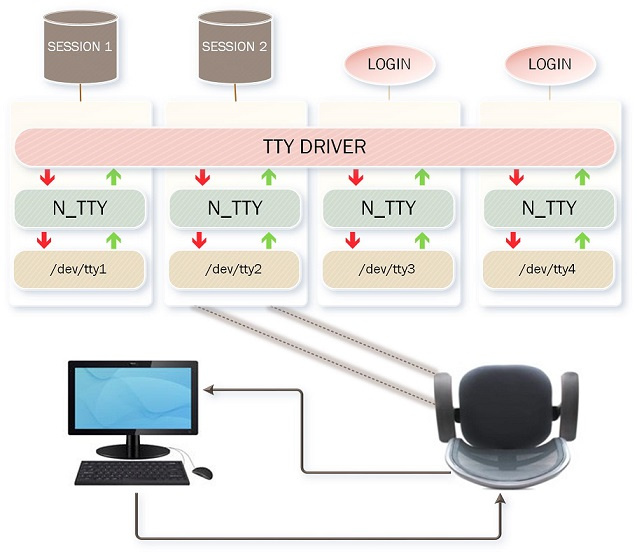

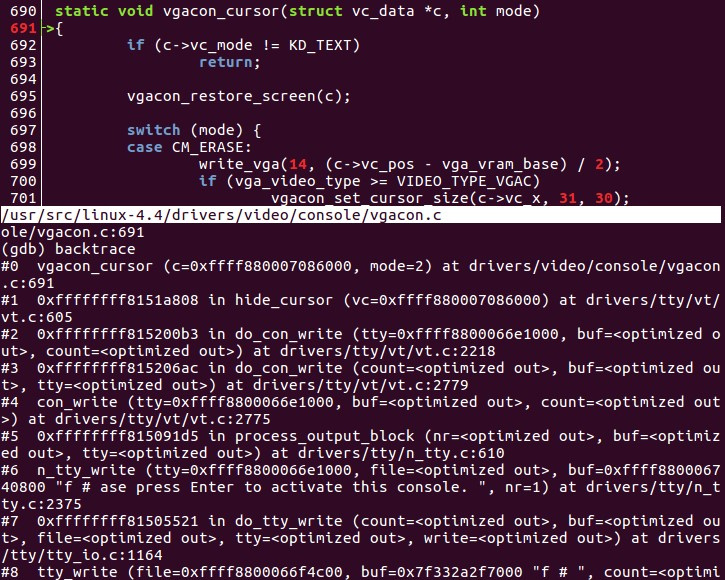
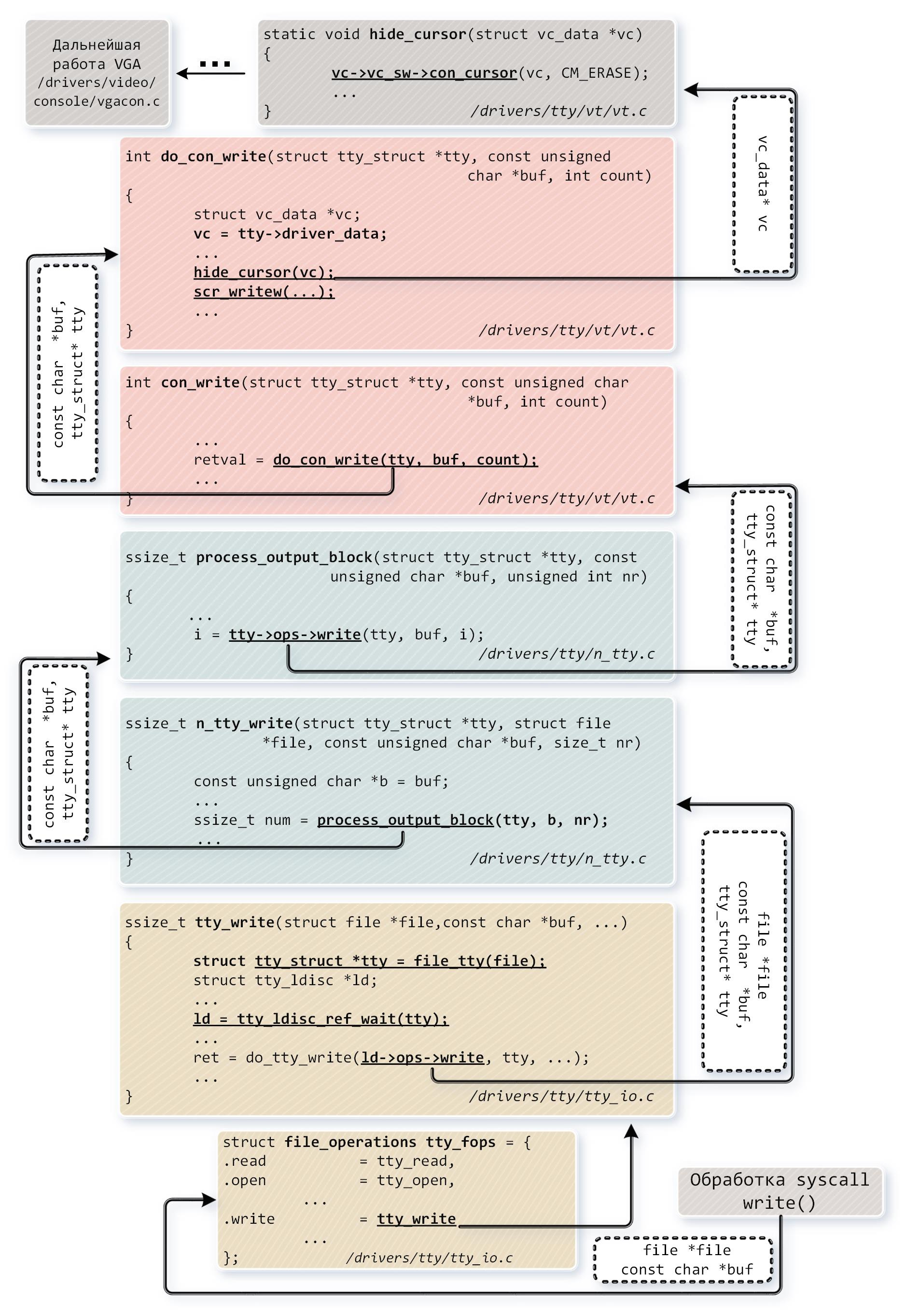


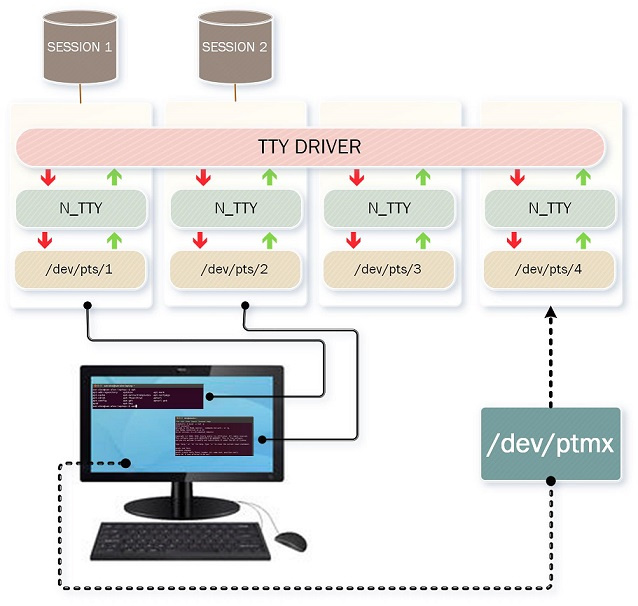




|
Метки: author NWOcs разработка под linux информационная безопасность занимательные задачки блог компании необит tty neoquest linux terminal |
История разработки и жизни одной маленькой игры. Релиз |


Всего было 2 797 876 игровых сессий, при этом средняя длительность игровой сессии 4.30 мин.
Было проведено 6 363 900 заездов
180 человек открыли все достижения (мне такое не разу не удалось =D )
174 человека поглотили весь игровой контент
Сервер знает о 250 000 игроках
Количество игроков: 451 007
Количество заездов на сервере: 12 553 441
Максимальное количество заездов, совершенных одним игроком: 3 054
Среднее количество заездов: 27,68
Медианное количество заездов: 9

|
Метки: author dampirik разработка под windows phone разработка мобильных приложений разработка игр с# gamedev windows phone разработка игр под windows phone первая игра |
HelpDesk и ServiceDesk. Что это и зачем это нужно вашей компании |



|
Метки: author ChiPer service desk help desk software блог компании deskun helpdesk servicedesk deskun хелпдеск itsm itil |
[Перевод] Уроки, извлечённые из трёх миллионов загрузок на AppStore |


|
Метки: author m1rko разработка под ios разработка мобильных приложений class timetable app store |
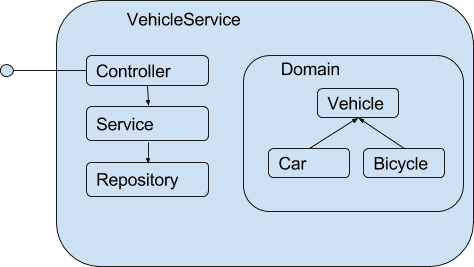
Это вопрос должен решать архитектор. Или нет? |

public abstract class Vehicle {
….
protected String model;
protected int wheelNumber;
protected Date manufactureYear;
protected EngineType engineType;
protected Producer producer;
}public class Car extends Vehicle {
public Car() {
wheelNumber = 4;
}
}public class Bicycle extends Vehicle {
public Bicycle() {
wheelNumber = 2;
}
}public class Customer {
private String firstName;
private String lastName;
private Date birthDay;
}public class Contract {
private long customerId;
private long vehicleId;
}
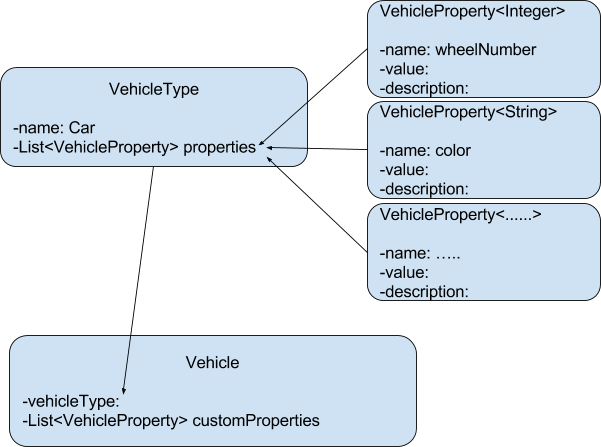
public class VehicleType {
private String name;
private List properties;
….
} public class VehicleProperty {
private String name;
private T value;
private String description;
…..
} public class Vehicle {
private VehicleType vehicleType ;
private List customProperties;
…...
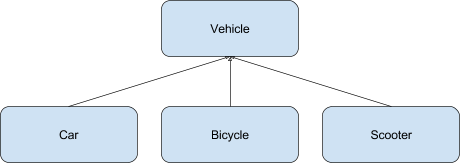
} VehicleProperty wheelNumberProperty = new VehicleProperty("wheelNumber", 2, "number of wheels");
…….
VehicleType scooterType = new VehicleType("Scooter");
scooterType.addProperty( wheelNumberProperty);
……..
Vehicle scooter1 = new Vehicle(scooterType);
….. 
public abstract class Vehicle {
…...
protected EngineType engineType;
public abstract class Vehicle {
…...
protected List engineTypes;
| Фамилия, Имя | Номер договора | Дата подписания договора | Машина |
|---|---|---|---|
| Пупкин, Вася | 12345 | 01.01.2017 | Audi Q4 |
| ...... | ...... | ...... | ...... |
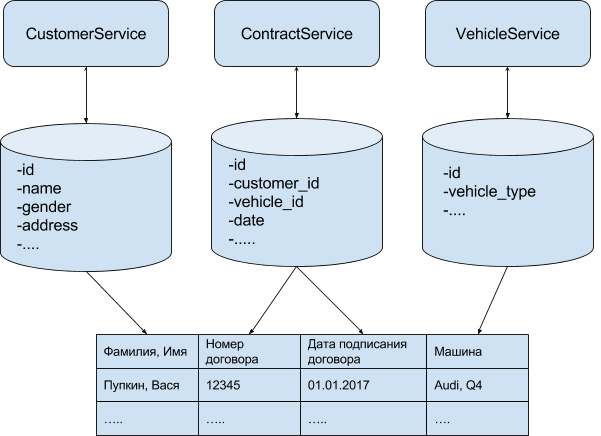
|
Метки: author schroeder программирование анализ и проектирование систем java microservices архитектура spring framework |
Использование музыки вместо лингафонного курса при изучении иностранного языка |
|
Метки: author olegsergeykin учебный процесс в it английский язык обучение |






