Mozilla VR Blog: Browsing from the Edge |

We are currently seeing two changes in computing: improvements in network bandwidth and latency brought on by the deployment of 5G networks, and a large number of low-power mobile devices and headsets. This provides an opportunity for rich web experiences, driven by off-device computing and rendering, delivered over a network to a lightweight user agent.
As we’ve improved our Firefox Reality browser for VR headsets and the content available on the web kept getting better, we have learned that the biggest things limiting more usage are the battery life and compute capabilities of head-worn devices. These are designed to be as lightweight, cool, and comfortable as possible - which is directly at odds with hours of heavy content consumption. Whether it’s for VR headsets or AR headsets, offloading the computation to a separate high-end machine that renders and encodes the content suitable for viewing on a mobile device or headset can enable potentially massive scenes to be rendered and streamed even to low-end devices.

Mozilla’s Mixed Reality team has been working on embedding Servo, a modern web engine which can take advantage of modern CPU and GPU architectures, into GStreamer, a streaming media platform capable of producing video in a variety of formats using hardware-accelerated encoding pipelines. We have a proof-of-concept implementation that uses Servo as a back end, rendering web content to a GStreamer pipeline, from which it can be encoded and streamed across a network. The plugin is designed to make use of GPUs for hardware-accelerated graphics and video encoding, and will avoid unnecessary readback from the GPU to the CPU which can otherwise lead to high power consumption, low frame rates, and additional latency. Together with Mozilla’s Webrender, this means web content will be rendered from CSS through to streaming video without ever leaving the GPU.
Today, the GStreamer Servo plugin is available from our Github repo, and can be used to stream 2D non-interactive video content across a network. This is still a work in progress! We are hoping to add immersive, interactive experiences, which will make it possible to view richer content on a wide set of mobile devices and headsets. Contact mr@mozilla.com if you’re looking for specific support for your hardware or platform!
|
|
The Mozilla Blog: More Questions About .org |
A couple of weeks ago, I posted a set of questions about the Internet Society’s plan to sell the non-profit Public Interest Registry (PIR) to Ethos capital here on the Mozilla blog.
As the EFF recently explained, the stakes of who runs PIR are high. PIR manages all of the dot org domain names in the world. It is the steward responsible for ensuring millions of public interest orgs have domain names with reliable uptime and freedom from censorship.
The importance of good dot org stewardship spurred not only Mozilla but also groups like EFF, Packet Clearing House and ICANN itself to raise serious questions about the sale.
As I noted in our original post, a private entity managing the dot org registry isn’t an inherently bad thing — but the bar for it being a good thing is pretty high. Strong rights protections, price controls and accountability mechanisms would need to be in place for a privately run PIR to be trusted by the dot org community. Aimed at the Internet Society, Ethos and ICANN, our questions focused on these topics, as well as the bidding process around the sale.
On Monday, Ethos CEO Erik Brooks published a blog post replying to Mozilla’s questions. The public response is appreciated — an open conversation means more oversight and more public engagement.
However, there are still critical questions about accountability and the bidding process that have yet to be answered before we can say whether this sale is good or bad for public interest organizations. These questions include:
1. For the Internet Society: what criteria, in addition to price, were used to review the bids for the purchase of PIR? Were the ICANN criteria originally applied to dot org bidders in 2002 considered? We realize that ISOC may not be able to disclose the specific bidders, but it’s well within reason to disclose the criteria that guided those bidders.
2. For Ethos: will accountability mechanisms such as the Stewardship Council and the incorporation of PIR as a public benefit corporation be in place before the sale closes? And, will outside parties be able to provide feedback on the charters for the B-corp before they are finalized? Both are essential if the mechanisms are going to be credible.
3. Finally, and possibly most importantly, for ICANN: will you put a new PIR contract in place as a condition of approving the deal? If so, will it provide robust oversight and accountability measures related to service quality and censorship issues?
We need much more information — and action — about this deal before it goes ahead. It is essential that Ethos and the Internet Society not close the PIR deal — and that ICANN does not approve the deal — until there are clear, strong provisions in place that protect service quality, prevent censorship and satisfy the dot org community.
As I wrote in my previous blog, Mozilla understands that a balance between commercial profit and public benefit is critical to a healthy internet. Much of the internet is and should be commercial. But significant parts of the internet — like the dot org ecosystem — must remain dedicated to the public interest.
The post More Questions About .org appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2019/12/19/more-questions-about-org/
|
|
Hacks.Mozilla.Org: Presenting the MDN Web Developer Needs Assessment (Web DNA) Report |
We are very happy to announce the launch of the first edition of a global, annual study of designer and developer needs on the web: The MDN Web Developer Needs Assessment. With your participation, this report is intended to shape the future of the web platform.
On single-vendor platforms, a single entity is responsible for researching developer needs. A single organization gets to decide how to address needs and prioritize for the future. On the web, it’s not that straightforward. Multiple organizations must participate in feature decisions, from browser vendors to standards bodies and the industry overall. As a result, change can be slow to come. Therefore, pain points may take a long time to address.
In discussions with people involved in the standardization and implementation of web platform features, they told us: “We need to hear more from developers.”
And that is how the MDN Web Developer Needs Assessment came to be. We aspire to represent the voices of developers and designers working on the web. We’ve analyzed the data you provided, and identified 28 discrete needs. Then, we sorted them into 14 different themes. Four of the top 5 needs relate to browser compatibility, our #1 theme. Documentation, Debugging, Frameworks, Security and Privacy round out the top 10.
Like the web community itself, this assessment is not owned by a single organization. The survey was not tailored to fit the priorities of participating browser vendors, nor to mirror other existing assessments. Our findings are published under the umbrella of the MDN Product Advisory Board (PAB). The survey used for data collection was designed with input from more than 30 stakeholders. They represented PAB member organizations, including browser vendors, the W3C, and industry colleagues.
This report would not exist without the input of more than 28,000 developers and designers from 173 countries. Thanks to the thousands of you who took the twenty minutes to complete the survey. Individual participants from around the world contributed more than 10,000 hours of insight. Your thoughtful responses are helping us understand the pain points, wants, and needs of people working to build the web.
The input provided by survey participants is already influencing how browser vendors prioritize feature development to address your needs, both on and off the web. By producing this report annually, we will have the means to track changing needs and pain points over time. In fact, we believe developers, designers, and all stakeholders should be able to see the impact of their efforts on the future of the web we share.
You can download the report in its entirety here:
Want to learn more about MDN Web Docs? Join the MDN Web Docs community, subscribe to our weekly newsletter, or follow MozDevNet on Twitter, to stay in the know.
Got a specific question about the MDN DNA Survey? Please share your constructive feedback and questions here or tweet us under the #mdnWebDNA hashtag.
The post Presenting the MDN Web Developer Needs Assessment (Web DNA) Report appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/12/presenting-the-mdn-web-developer-needs-assessment-web-dna-report/
|
|
Marco Zehe: On sale until December 31st: Threema seriously secure messaging |
Threema is an alternative to WhatsApp & friends, with a focus on privacy. It’s made in Switzerland, and it is on sale until December 31 for half the price.
Threema is a messenger alternative for smartphones and tablets, with a web version also available that connects through your installed app. All offerings are accessible to screen reader users. It is not a free app, and it is only partially open-source. But its privacy focus has won it several recognitions since it was started in 2012.
Threema offers text, voice messaging, voice calls, photo, video sharing, sharing of various other document types, you can send locations. It offers one-on-one as well as group chats. In group chats, it also offers polls so you can easily find common times or other agreement with friends without having to use any external services.
Unlike many other messengers, you don’t need to provide a phone number or e-mail address to use the service. You generate a completely anonymous ID on your device. You can share your phone number and/or e-mail address so others can find you, but you don’t have to. Likewise, you can share your contact info, and Threema will see if any of your other contacts are on Threema and have opted in to share their details.
Threema has three trust levels: Unverified, verified via e-mail or phone, and verified via personal contact and mutual scanning of QR codes. This verification also serves as a mechanism to guard against possible man-in-the-middle attacks. Threema have great documentation about all of this in their frequently asked questions.
I use Threema frequently as one of my main messengers now with friends, some colleagues, and in some grup chats. And if you like, you can drop me a line there as well.
https://marcozehe.de/2019/12/19/on-sale-until-december-31st-threema-seriously-secure-messaging/
|
|
Cameron Kaiser: And now for something completely different: Way more FPS than Counterstrike on PowerPC DOSBox |

If you're unfamiliar with it, DOSBox is an x86 emulator specializing in running PC DOS games (and, presumably, any PC DOS application). For many DOS-based titles, in fact, it may be the only way to run them on modern PCs, let alone Macs. Besides emulating old hardware like video cards and SoundBlasters sufficiently for games to run, one of its key features on supported platforms is dynamically recompiling x86 machine language for enhanced performance. Unfortunately, DOSBox on Power Macs, while it is still supported as of this writing (10.4 and up), runs x86 code strictly in an interpreter and as a result can be quite slow on low-spec systems. For certain games requiring 80486-level performance, only the G5 can realistically emulate those at any reasonable level, and even then uses a lot of CPU doing so or requires skipping some portion of frames to make the game at all playable.
Over on Vogons earlier this year one of the DOSBox contributors wrote up a PowerPC JIT for the dynrec core under Linux which was then ported to OS X. Like the TenFourFox JIT compiles JavaScript to PowerPC machine code, this patch compiles x86 machine code to PowerPC machine code and runs that instead of requiring labourious interpretation. There was briefly a build available on Dropbox with this JIT, which is currently not part of the DOSBox source tree, but that build can no longer be downloaded. So, I went ahead and reconstructed it against the current trunk (at the time I pulled it, r4301) along with a minor tweak and another of this developer's big-endian fixes, and have tidied it up for download.
To give you an idea of the improvement, I have a few DOS games I enjoy that were never ported to Mac (along with LucasArts' Dark Forces, shown here, which has an outstanding Mac port with up to double the resolution of the DOS version but only runs in Classic). On this Quad G5 set to Reduced performance, with interpreted mainline DOSBox I usually had to have it skip every other frame. This made games like Commander Keen in Goodbye, Galaxy!, Pinball Illusions and Extreme Pinball playable, but only just so, and also made the animation sadly a bit jerky. Even with this handicap some games were still unplayable unless I turned the machine to Maximum performance (and cooked the room), and even then Dark Forces and Death Rally usually ranged from stuttery to slideshow. With the JIT enabled, not only could I get rid of the frame skip entirely -- even in Reduced performance -- but all of the games became absolutely playable. In Maximum performance they run better than my real 486 DOS games box.
Explaining how DOSBox works is beyond the scope of this blog post, but fortunately there is excellent documentation. Once you've played with the official build, you can get a JIT-enabled build (there's an "all Power Macs" and a G5-specific version with different compiler settings) from the repository I set up at SourceForge. This uses a separate preferences file which is included with some default settings. Out of the box frameskipping is disabled, which is appropriate for pretty much any G5 system from 2GHz on up with most titles. If you're using a G4 or slower G5 system, edit this file and change frameskip=0 to frameskip=1 or frameskip=2 (my 1.25GHz iMac G4 needed frameskip=2 as a minimum, but an MDD or 7447 might be okay with a frameskip of 1). You should use OpenGL as your output if at all possible for maximal hardware assistance (which is the default in this file); rendering to a surface in software is rather slower. Copy it to ~/Library/Preferences and start playing your classic DOS games with Power.
No warranty for this build is expressed or implied and this may be the only build I ever offer. There are known bugs in this build which Mac builds from the SVN trunk have too and thus I have not attempted to fix them. The patch is included so you can roll your own; these preconfigured builds are merely offered as a convenience and to make more fun games practical on your already fun Power Mac. Eventually I'll rewrite this for ppc64le so my Raptor Talos II can play with Power too.
http://tenfourfox.blogspot.com/2019/12/and-now-for-something-completely.html
|
|
The Rust Programming Language Blog: Announcing Rust 1.40.0 |
The Rust team is happy to announce a new version of Rust, 1.40.0. Rust is a programming language that is empowering everyone to build reliable and efficient software.
If you have a previous version of Rust installed via rustup, getting Rust 1.40.0 is as easy as:
rustup update stable
If you don't have it already, you can get rustup from the appropriate page on our website, and check out the detailed release notes for 1.40.0 on GitHub.
The highlights of Rust 1.40.0 include #[non_exhaustive] and improvements to macros!() and #[attribute]s. Finally, borrow-check migration warnings have become hard errors in Rust 2015. See the detailed release notes for additional information.
#[non_exhaustive] structs, enums, and variantsSuppose you're a library author of a crate alpha, that has a pub struct Foo. You would like to make alpha::Foo's fields pub as well, but you're not sure whether you might be adding more fields to Foo in future releases. So now you have a dilemma: either you make the fields private, with the drawbacks that follow, or you risk users depending on the exact fields, breaking their code when you add a new one. Rust 1.40.0 introduces a way to break the logjam: #[non_exhaustive].
The attribute #[non_exhaustive], when attached to a struct or the variant of an enum, will prevent code outside of the crate defining it from constructing said struct or variant. To avoid future breakage, other crates are also prevented from exhaustively matching on the fields. The following example illustrates errors in beta which depends on alpha:
// alpha/lib.rs:
#[non_exhaustive]
struct Foo {
pub a: bool,
}
enum Bar {
#[non_exhaustive]
Variant { b: u8 }
}
fn make_foo() -> Foo { ... }
fn make_bar() -> Bar { ... }
// beta/lib.rs:
let x = Foo { a: true }; //~ ERROR
let Foo { a } = make_foo(); //~ ERROR
// `beta` will still compile when more fields are added.
let Foo { a, .. } = make_foo(); //~ OK
let x = Bar::Variant { b: 42 }; //~ ERROR
let Bar::Variant { b } = make_bar(); //~ ERROR
let Bar::Variant { b, .. } = make_bar(); //~ OK
// -- `beta` will still compile...
What happens behind the scenes is that the visibility of the constructors for a #[non_exhaustive] struct or enum variant is lowered to pub(crate), preventing access outside the crate defining it.
A perhaps more important aspect of #[non_exhaustive] is that it can also be attached to enums themselves. An example, taken from the standard library, is Ordering:
#[non_exhaustive]
pub enum Ordering { Relaxed, Release, Acquire, AcqRel, SeqCst }
The purpose of #[non_exhaustive] in this context is to ensure that more variants can be added over time. This is achieved by preventing other crates from exhaustively pattern match-ing on Ordering. That is, the compiler would reject:
match ordering {
// This is an error, since if a new variant is added,
// this would suddenly break on an upgrade of the compiler.
Relaxed | Release | Acquire | AcqRel | SeqCst => {
/* logic */
}
}
Instead, other crates need to account for the possibility of more variants by adding a wildcard arm using e.g. _:
match ordering {
Relaxed | Release | Acquire | AcqRel | SeqCst => { /* ... */ }
// OK; if more variants are added, nothing will break.
_ => { /* logic */ }
}
For more details on the #[non_exhaustive] attribute, see the stabilization report.
In 1.40.0, we have introduced several improvements to macros and attributes, including:
Calling procedural macros mac!() in type contexts.
For example, you may write type Foo = expand_to_type!(bar); where expand_to_type would be a procedural macro.
Macros in extern { ... } blocks.
This includes bang!() macros, for example:
macro_rules! make_item { ($name:ident) => { fn $name(); } }
extern {
make_item!(alpha);
make_item!(beta);
}
Procedural macro attributes on items in extern { ... } blocks are now also supported:
extern "C" {
// Let's assume that this expands to `fn foo();`.
#[my_identity_macro]
fn foo();
}
Generating macro_rules! items in procedural macros.
Function-like (mac!()) and attribute (#[mac]) macros can both now generate macro_rules! items. For details on hygiene, please refer to the attached stabilization report.
The $m:meta matcher supports arbitrary token-stream values.
That is, the following is now valid:
macro_rules! accept_meta { ($m:meta) => {} }
accept_meta!( my::path );
accept_meta!( my::path = "lit" );
accept_meta!( my::path ( a b c ) );
accept_meta!( my::path [ a b c ] );
accept_meta!( my::path { a b c } );
In the 1.35.0 release, we announced that NLL had come to Rust 2015 after first being released for the 2018 edition in Rust 1.31.
As we noted back then, the old borrow checker had some bugs which would allow memory unsafety, and the NLL borrow checker fixed them. As these fixes break some stable code, we decided to gradually phase in the errors, by checking if the old borrow checker would accept the program and the NLL checker would reject it. In those cases, the errors would be downgraded to warnings.
The previous release, Rust 1.39.0, changes these warnings into errors for code using the 2018 edition. Rust 1.40.0 applies the same change for users of the 2015 edition, closing those soundness holes for good. This also allows us to clean up the old code from the compiler.
If your build breaks due to this change, or you want to learn more, check out Niko Matsakis's blog post.
const fns in the standard libraryWith Rust 1.40.0, the following function became const fn:
In Rust 1.40.0 the following functions and macros were stabilized:
A macro, which is a shorter, more memorable, and convenient version of unimplemented!().
Creates a Vec by repeating a slice n times.
This function takes the value out of a mutable reference and replaces it with the type's default. This is similar to Option::take and Cell::take and provides a convenient short-hand for mem::replace(&mut dst, Default::default()).
BTreeMap::get_key_value and HashMap::get_key_value
Returns the key-value pair corresponding to the supplied key.
Option::as_deref, Option::as_deref_mut
These work similarly to Option::as_ref and Option::as_mut but also use Deref and DerefMut respectively, so that opt_box.as_deref() and opt_box.as_deref_mut(), where opt_box: Option>, produce an Option<&T> and Option<&mut T> respectively.
This function flattens an Option> to Option producing Some(x) for Some(Some(x)) and None otherwise. The function is similar to Iterator::flatten.
Returns the socket address of the remote peer this socket was connected to.
{f32,f64}::to_be_bytes, {f32,f64}::to_le_bytes,{f32,f64}::to_ne_bytes, {f32,f64}::from_be_bytes, {f32,f64}::from_le_bytes, and {f32,f64}::from_ne_bytes
Return the memory representation of the floating point number as a byte array in big-endian (network), little-endian, and native-endian byte order.
There are other changes in the Rust 1.40.0 release: check out what changed in Rust, Cargo, and Clippy.
Please also see the compatibility notes to check if you're affected by those changes.
Many people came together to create Rust 1.40.0. We couldn't have done it without all of you. Thanks!
|
|
Daniel Stenberg: Internetmuseum |
The Internet Museum translated to Swedish becomes “internetmuseum“. It is a digital, online-only, museum that collects Internet- and Web related historical information, especially focused on the Swedish angle to all of this. It collects stories from people who did the things. The pioneers, the ground breakers, the leaders, the early visionaries. Most of their documentation is done in the form of video interviews.
I was approached and asked to be part of this – as an Internet Pioneer. Me? Internet Pioneer, really?
Internetmuseum’s page about me.
I’m humbled and honored to be considered and I certainly had a lot of fun doing this interview. To all my friends not (yet) fluent in Swedish: here’s your grand opportunity to practice, because this is done entirely in this language of curl founders and muppet chefs.

Back in the morning of October 18th 2019, two guys showed up as planned at my door and I let them in. One of my guests was a photographer who set up his gear in my living room for the interview, and then me and and guest number two, interviewer J"orgen, sat down and talked for almost an hour straight while being recorded.
The result can be seen here below.
This is in fact the second Swedish museum to feature me.
I have already been honored with a display about me, at the Tekniska Museet in Stockholm, the “Science museum” which has an exhibition about past Polhem Prize award winners.

|
|
The Mozilla Blog: Keeping the Internet Open & Accessible To All As It Evolves: Mozilla Research Grants |
We are very happy to announce the results of our Mozilla Research Grants for the second half of 2019. This was an extremely competitive process, and we selected proposals which address seven strategic priorities for the Internet and for Mozilla. This includes studies of privacy in India and Indonesia, proposals to rethink how we might manage personal data, and explorations of the future of voice interfaces. The Mozilla Research Grants program is part of our commitment to being a world-class example of using inclusive innovation to impact culture, and reflects Mozilla’s commitment to open innovation.
| 2019: | |||
| Lead Researchers | Institution | Project Title | |
|---|---|---|---|
| Nicola Dell | Information Science, Cornell University | New York, NY, USA | Analyzing Perceptions of Privacy and Security Among Small Business Owners in India and Indonesia | |
| Sangeeta Mahapatra | Institute of Asian Studies, German Institute of Global and Area Studies | Hamburg, Germany | Digital surveillance and its chilling effect on journalists: Finding strategies and solutions to safely seek and share information online | |
| Jennifer King | Center for Internet and Society, Stanford Law School | Stanford, CA, USA | Exploring User Perceptions of Personal Data Ownership and Management | |
| Nick Nikiforakis | Department of Computer Science, Stony Brook University | Stony Brook NY, USA | BreakHound: Automated and Scalable Detection of Website Breakage | |
| Janne Lindqvist | Aalto University | Espoo, Finland | Understanding Streaming Video User Experiences | |
| Jordan Wirfs-Brock | Department of Information Science, University of Colorado, Boulder | Boulder CO, USA | Creating an Open, Trustworthy News and Information Ecosystem for Voice | |
| Alisa Frik | International Computer Science Institute / UC Berkeley | Berkeley CA, USA | Exploring the Boundaries of Passive Listening in Voice Assistants | |
The post Keeping the Internet Open & Accessible To All As It Evolves: Mozilla Research Grants appeared first on The Mozilla Blog.
|
|
Firefox UX: Reflecting on “It’s Our Research” at Mozilla |
I thought we involved stakeholders in research pretty perfectly, here at Mozilla. Stakeholders come to research studies, listen attentively to research report-outs, and generally value the work our team does. Then I read “It’s Our Research”. I still think the Firefox User Research team has great buy-in across the organization, but after reading Tomer Sharon’s book, there are so many more things we could improve on! And what fun is a job, if there’s nothing to improve, right?
I’d like to call in some stakeholders to help me tell four short stories related to four pieces of advice Tomer Sharon provides in his book. (By the way, there are so many ideas in that book, it was hard to pick just four.)
This post is authored by Jennifer Davidson, with contributions from Julia Starkov, Jim Thomas, Marissa (Reese) Wood, and Michael Verdi
Let’s start with the “failures”. Failure is a big word, but they’re really two examples where I could’ve done better, as a user researcher.

An artistic bridge in Salem, Oregon with a clear blue sky. The weather was just too nice to debrief.
Tomer Sharon recommends that we never skip a debrief. A debrief includes those precious moments immediately after interviewing a participant or visiting a participants’ home. They capture your first reactions after the experience. Sharon details that they’re important because it helps prepare for analysis, and helps stakeholders remember the sessions. On the Firefox UX team, we have a great debrief culture. We reserve time after interviews, even if they’re remote interviews to capture initial thoughts. This practice is more formal when we do field research — where we not only have an individual debrief form that we fill out immediately after each visit, but we also do group debriefs together after each interview to talk together about what we observed. I would say we always do debriefs after every interview or session with our users, but then I’d be lying. Let’s have Julia Starkov, a Mozilla IT UX designer talk about her experience when we skipped a debrief in the field.
The time we skipped a debrief, as told by Julia:
We wrapped up our Salem user research on a Friday afternoon; we were staying in different cities and some of us had plans right after the interview. We were also parked outside of the participant’s house so we decided to skip the group debrief and get the weekend started. While this felt like a huge relief at the time, I regret not pushing for us to meet at a cafe and wrap up the research together. By the time the weekend came and went, and I flew back to California, it was hard to recall specific parts of that interview, but mainly, I felt we could have definitely benefited from starting synthesis right away as a group. Overall, I thought the research effort was a total success, but I feel like I would have retained more insights and memories from the experience with a bit more team-time at the end.
An executive summary is a few sentences, maybe one slide (if it’s in slide format) that summarizes a research study. I’ll tell you — it is the hardest part of a research study. Let’s have Marissa (Reese) Wood, Firefox VP of Product, explain the importance of an executive summary.
The importance of an executive summary, as explained by Reese:
The purpose of an executive summary is to describe the main and important points of your document in such a way that it will engage the readers. The intent is to have them want to learn more and continue to read the document. This is important because the reader will pay greater attention to detail and read the doc all the way through if they are engaged. In short, without a good executive summary, the document will likely not get the attention it deserves.
Reese puts it nicely, but I’ll reiterate, without an executive summary, people may not pay any attention to the study results (a researcher’s worst nightmare!). So over the past year, the Firefox UR team has been iterating on our executive summary style, to better fit the needs of our current executives. We try to be more succinct with our executive summaries than before, with clear takeaways and calls to action for each report.
Now let’s move on to talk about a couple of successes.

A picnic table overlooking the Puget Sound, with a coffee, a packet, and post-it notes on it. We took our research packets everywhere that week. Also, it’s never too nice to debrief.
Be prepared — not only with great research practices like doing a pilot (a practice research session before doing the rest of the study, to work out the kinks in a research protocol) — but also, by making it easy for stakeholders to participate. This means that the researcher, or a supportive operations manager, needs to do some administrative tasks. When you have stakeholders come with you on home visits, get them the materials they need to take notes or photos. With every field research trip I do, I find little tweaks I can make to improve the stakeholder experience. Earlier this year, I took a little extra planning time, and with a great example from other team members (particularly, Gemma!), created a packet in a waterproof (that’s important if you’re doing research in the rainy Pacific Northwest like we were) document folder for each stakeholder. It felt like making personalized goodie bags for a birthday party. The packet contained everything they needed to participate: pen, sharpie, note-taking guide, photograph shot list, post-its, a legal pad, and a label with their name on the packet. And Jim Thomas, Firefox Product Manager, will talk about his experience participating in field research.
The time I participated in field research, as told by Jim:
As a Product Manager, I know how important it is to spend time connecting with your users, learning how they think about your product, observing what they do and how they react. I’ve done this informally throughout my career, but formal field research seemed like it would involve a lot more rigor. In fact, it was even more rigorous, but it didn’t feel like it thanks to the prep work put in by the team. Every session had our roles and responsibilities planned ahead of time, with relevant materials in a convenient package. Debriefing after each session was simple even at restaurants or picnic tables because everything we needed was at our fingertips. All the process was handled for me so I was able to focus on my most important goal: learning about our users and their perspectives.

Lots of sticky notes about how people learn to use new software and apps that the team pulled together. This was one of four walls that were covered in sticky notes by the end of the analysis.
Sharon recommends analyzing results together with stakeholders. He mentions that ideal outcomes from analyzing together are:
Involving stakeholders in analysis can be tricky because analyzing data is difficult! It’s entirely too easy to use broad strokes to say what you think you saw, but to be rigorous with qualitative research analysis, we dive deep into the weeds with every action, every comment, to see if any themes or patterns emerge.
I mentioned earlier that Sharon recommends debriefing with stakeholders who are doing research with you. Notably, debriefs are not analysis. They may start the analysis juices going, but analysis is much more in-depth and complex.
We don’t always involve stakeholders in analysis, particularly if the timing is tight. However, in one case, I spent an extra few days in Germany, so we could do analysis immediately after field work. I think it went really well, and I was so happy to be about 80% done with analysis before even leaving Germany. Let’s hear what it was like for Michael Verdi, a Firefox UX designer and my partner on the project.
The time I participated in multiple days of analysis in Berlin, as told by Michael:
I’m really happy I got to participate in the analysis phase. I’d done it on a previous project and found it extremely valuable. In addition, I thought we were fortunate this time to be able to begin right away while everything was fresh. It’s so good to spend time digging into details and carefully considering everything we saw. It’s also difficult (but great practice) to hold off on trying to solve all the problems right away. I feel like by the time I did move on to design I’d really absorbed the things we learned.
While this blog post was a great reflection exercise about my practice as a user researcher with involving stakeholders in research, it is not the end of the story. The practice of user research is just that — a practice that takes practice, and continuous improvement. Next year, I hope to work on other concrete ideas that our Firefox UR team can implement to increase stakeholder involvement in user research even more.
Thank you to Gemma Petrie and Elisabeth Klann for reviewing this blog post.
Also published on medium.com.
https://blog.mozilla.org/ux/2019/12/reflecting-on-its-our-research-at-mozilla/
|
|
The Firefox Frontier: Think Google Docs, Hangouts and G Suite don’t work with Firefox? Think again |
If you’re waiting to switch to Firefox because you think that Google Docs or Hangouts won’t work as well, we’re happy to debunk this myth. You have nothing to worry … Read more
The post Think Google Docs, Hangouts and G Suite don’t work with Firefox? Think again appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/google-docs-works-with-firefox/
|
|
Marco Zehe: A few quick tips on Gutenberg on mobile devices |
The new WordPress block editor is also available in the WordPress app for iOS and Android. It uses the same basis as the editor on a self-hosted or hosted WordPress site, but is a bit simplified. And it is accessible. Here are a few quick tips to get around it.
You may first have to enable it. You’ll find the setting under each blog/site you have in the WordPress app. It is called “Use the new visual editor”. Check its checkbox, or turn on its toggle switch, to use it.
Now when you compose a new post, you have many of the features of Gutenberg available. With each release, new blog types are supported on mobile devices. If you are unsure of what blocks are, read my introduction to Gutenberg from recently.
Initially, you will land in the title, as usual. Enter it and press Enter.
Pressing Enter will by default create a new paragraph block. Unlike on the desktop, there is no Slash command available here to change the block type on the fly. But usually, the first block you want is a paragraph block anyway, and if not, you can add one and simply move it up as you wish.
To add a new block, find the Add Block toolbar item that is located above the keyboard, or if you are using an external one, in the lower left corner of your screen. That will open a popover with all the blocks it currently knows about. Choose a More block, a Heading block, a List block, etc., whatever you prefer. It is an intelligent list that shows you your last used block types first.
Go ahead and choose a new heading block. You can then write a heading. By default, this is a heading level 2. With each block, there is a toolbar associated with it. The elements except the Add Block, undo, redo, and some other common actions, each block has a few specific items. The Heading block, for example, has a group of buttons where you can switch which level the heading should have. You can easily switch to a heading of levels 3 or 4 here. In a paragraph block, you’ll find items to bold, italicize, underline text, or insert a link.
Notice as you are now in the Heading block, as you swipe left, you will encounter the previous paragraph block and the title. To the right of the currently focused block, you have buttons to move the block up a position, down (if available), or remove it alltogether. Depending on some blocks, you may even have the ability to move blocks right or left a column.
Each block item speaks its type nicely along with the text that is in the block. The order is pretty efficient: Block type, maybe the level if available, position information, followed by the text. This is a feature that is currently being worked on for the desktop/browser version, too, so when in selection mode, the blocks are spoken more nicely by screen readers as well. The aim is to unify the experiences so they are consistent across platforms.
Inserting a block is always relative to the current block, it does not insert a block at the end by default. So if you have 10 blocks already, and are focused on block 8, the next block you insert will be at position 9 of then 11 blocks, not at position 11. If you want to insert a new block at the end, pfocus the last existing block first, then either choose a new block from the Add Block popover, or go to the end of your text and press Enter to just insert a new paragraph block at the end.
Inserting a link can be a bit confusing. There is no OK button, you add the link, and just close the popover. The only explicit action there is to remove the linkage.
The mobile version of Gutenberg inside the WordPress apps is more consistent and less dynamic than the desktop counterpart currently is. There is work being done to better the situation there, too, and when the time comes, I will blog about it here. The mobile version is actually a great option to play around with blocks, move them, get a feel for what you can do with posts, see what happens in the preview, etc.
So if, after reading my introduction for the desktop, you find it daunting, this mobile option may be a way for you to familiarize yourself with blocks in a little more controlled environment. The toolbar buttons are always visible, regardless of whether text is selected in a block or not, for example. And with the mobile version being very touch friendly, there is also no mouse hover state that can do seemingly unpredictable things.
Have fun playing!
https://marcozehe.de/2019/12/18/a-few-quick-tips-on-gutenberg-on-mobile-devices/
|
|
Support.Mozilla.Org: Introducing Joel Johnson / JR (Rina’s Maternity cover) |
Hello everyone,
Please say hi to Joel Johnson who’s going to cover Rina Tambo Jensen while she’s away for her parental leave for the next 6 months. JR has an extensive background in starting and setting up support teams across different companies. We’re so excited to have him on our team.
Here is a short introduction from JR:
Hello Everyone! My Name is JoelRodney Johnson and I go by JR. I am from Dallas, Texas and have lived most of my life there. I spent several years in San Fransisco where I got started in Support and started a career in Tech. My guilty pleasure is reading Sci-Fi/Fantasy novels and if you were to take a look at my audible account you might be surprised at the amount of books I have in my library. I am so happy to be joining the Mozilla team as the Product Support Manager overseeing customer service for Mozilla products. I look forward to an exciting future here in Support.
Please join us to welcome him!
https://blog.mozilla.org/sumo/2019/12/18/introducing-joel-johnson/
|
|
Mike Hoye: Poor Craft |

“It’s a poor craftsman that blames his tools” is an old line, and it took me a long time to understand it.
A friend of mine sent me this talk. And while I want to like it a lot, it reminded me uncomfortably of Dabblers and Blowhards, the canon rebuttal to “Hackers And Painters”, an early entry in Paul Graham’s long-running oeuvre elaborating how special and magical it is to be just like Paul Graham.
It’s surprisingly hard to pin Paul Graham down on the nature of the special bond he thinks hobbyist programmers and painters share. In his essays he tends to flit from metaphor to metaphor like a butterfly, never pausing long enough to for a suspicious reader to catch up with his chloroform jar. […] You can safely replace “painters” in this response with “poets”, “composers”, “pastry chefs” or “auto mechanics” with no loss of meaning or insight. There’s nothing whatsoever distinctive about the analogy to painters, except that Paul Graham likes to paint, and would like to feel that his programming allows him a similar level of self-expression.
There’s an old story about Soundcloud (possibly Spotify? DDG tends to the literal these days and Google is just all chaff) that’s possibly apocryphal but too good not to turn into a metaphor, about how for a long time their offices were pindrop-quiet. About how during that rapid-growth phase they hired people in part for their love of and passion for music, and how that looked absolutely reasonable until they realized their people didn’t love music: they loved their music. Your music, obviously, sucks. So everyone there wears fantastic headphones, nobody actually talks to each other, and all you can hear is in their office is keyboard noise and the HVAC.
I frequently wonder if the people who love Lisp or Smalltalk fall into that same broad category: that they don’t “love Lisp” so much as they love their Lisp, the Howl’s Moving Memory Palaces they’ve built for themselves, tailored to the precise cut of their own idiosyncracies. That if you really dig in and ask them you’ll find that other people’s Lisp, obviously, sucks.
It seems like an easy trap to fall in to, but I suspect it means we collectively spend a lot of time genuflecting this magical yesteryear and its imagined perfect crystal tools when the fact of it is that we spend almost all of our time in other people’s code, not our own.
I feel similarly about Joel Spolsky’s notion of “leaky abstractions”; maybe those abstractions aren’t “leaking” or “failing”. Instead it’s that you’ve found the point where your goals, priorities or assumptions have diverged from those of the abstraction’s author, and that’s ultimately not a problem with the abstraction.
The more time I spend in front of a keyboard, the more I think my core skills here aren’t any more complicated than humility, empathy and patience; that if you understand its authors the code will reveal itself. I’ve mentioned before that programming is, a lot more than most people realize, inherently political. You’re making decisions about how to allocate scarce resources in ways that affect other people; there’s no other word for it. So when you’re building on other people’s code, you’re inevitably building on their assumptions and values as well, and if that’s true – that you spend most of your time as a programmer trying to work with other people’s values and decisions – then it’s guaranteed that it’s a lot more important to think about how to best spend that time, or optimize those tools and interactions, rather than championing tools that amount to applied reminiscence, a nostalgia with a grammar. In any other context we’d have a term for that, we’d recognize it for what it is, and it’s unflattering.
What does a programming language optimized for ease-of-collaboration or even ease-of-empathy look like, I wonder? What does that development environment do, and how many of our assumptions about best collaborative practices are just accidental emergent properties of the shortcomings of our tools? Maybe compiler pragmas up front as expressions of preferred optimizations, and therefore priorities? Culture-of-origin tags, demarking the shared assumptions of developers? “Reds and yellows are celebratory colors here, recompile with western sensibilities to swap your alert and default palettes with muted blues/greens.” Read, Eval, Print looping feels for all its usefulness like a huge missed opportunity, an evolutionary dead end that was just the best model we could come up with forty years ago, and maybe we’ve accidentally spent a lot of time looking backwards without realizing it.
|
|
Hacks.Mozilla.Org: Mozilla Hacks’ 10 most-read posts of 2019 |
Like holiday music, lists are a seasonal cliche. They pique our interest year after year because we want a tl;dr for the 12 months gone by. To summarize, Mozilla Hacks celebrated its 10th birthday this past June, and now in December, we come to the end of a decade. Today, however, we’ll focus on the year that’s ending.
In fact, we covered plenty of interesting territory on Mozilla Hacks in 2019. Some of our most popular posts introduced experiments and special projects like Pyodide, extending the web platform for the scientific community. Mozilla WebThings, which also featured as one of 2018’s most popular posts, continued to engage attention and adoption. People want a smart home solution that is private, secure, and interoperable.
Not surprisingly, interest in Firefox release posts is stronger than ever. Firefox continues to deliver new developer tools and new consumer experiences to increase user agency, privacy, security, and choice — and our readers want the details.
Also, we’ve made remarkable progress on WebAssembly, as it extends beyond the browser and off the Web, via WASI (WebAssembly interface types) and associated tooling. Mozilla is a founding member of the Bytecode Alliance. Announced last month, this open source initiative is dedicated to creating secure new software foundations, built on new standards such as WebAssembly and WebAssembly System Interface (WASI). Plus, readers can’t get enough code cartoons, especially for visualizing complex concepts in programming.
Some of the most high-traffic posts of 2019 were written in earlier years, and continue to attract readers. These are not included here. Instead, we’ll focus on what was new this year. And here they are:
HTMLMediaElement API to make this work.Thank you for reading and sharing Mozilla Hacks in 2019. Here’s to the amazing decade that’s ending and the new one that’s almost here.
It’s always a good year to be learning. Want to keep up with Hacks? Follow @MozillaDev on Twitter, check out our new Mozilla Developer video channel, or subscribe to our always informative and unobtrusive weekly Mozilla Developer Newsletter below.
The post Mozilla Hacks’ 10 most-read posts of 2019 appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/12/mozilla-hacks-most-read-blog-posts-of-2019/
|
|
The Firefox Frontier: How much data are you sharing this holiday season? |
Let’s be real. Most of us don’t read the privacy policies when signing up to use a service. If you wanted to read all of the terms you’ve agreed to, … Read more
The post How much data are you sharing this holiday season? appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/how-much-data-are-you-sharing/
|
|
Mike Hoye: Long Term Support |
I bought a cordless drill from DeWalt a few years before they standardized on their current 20 volt form factor. Today the drill part of the drill is still in good shape, but its batteries won’t hold a charge – don’t store your batteries in the shed over the winter, folks, that’s rookie mistake – and I can’t replace them; they just don’t make them anymore. Nobody does.
I was thoroughly prepared to be annoyed about this, but it turns out DeWalt makes an adapter that slots right into my old drill and lets me use their new standard batteries. I’ll likely get another decade out of it as a result, and if the drill gives up the ghost in the meantime I’ll be able to use those batteries in its replacement.
Does any computer manufacturer out there anywhere care about longevity like that, today? The Cadillac answer to that used to be “Thinkpad”, but those days are long gone and as far as I can tell there’s nothing else in this space. I don’t care about thin or light at all. I’m happy to carry a few extra pounds; these are my tools, and if that’s the price of durable, maintainable and resilient tools means a bit of extra weight in the bag I’ll pay it and smile. I just want to be able to fix it; I want something I can strip all the way down to standard parts with a standard screwdriver and replace piecemeal when it needs piecemeal replacing. Does anyone make anything like this anymore, a tradesman’s machine? The MNTRE people are giving it a shot. Is anyone else, anywhere?
|
|
Marco Zehe: My review of Apple AirPods Pro |
Last week, I got my set of AirPods Pro. And after using them for a few days in various situations, can say: Best active noise cancelling headphones I’ve ever used!
Apple released AirPods Pro earlier this autumn, and I was very curious to get my hands on them. I have always been a fan of the AirPods, even though the first generation still had quite some lag with VoiceOver. But I was totally sold on Apple’s wireless future from early on. Unlike many other blind users, I was never sad to see the 3.5 mm headphone jack go.
The AirPods 2, released in the spring of 2019, did away with almost the whole lagging problem when using VoiceOver on a relatively modern iOS device. I used them with my iPhone 7 from 2016, the X from 2017, and the new 11 Pro Max I got in September, as well as an iPad Air 3rd generation. And I, for one, no longer notice a lag since I started using these new AirPods. The reason is, no doubt, the H1 chip that is in these. I also learned from a friend that his PowerBeats Pro behave the same way with VoiceOver. They also contain the H1 chip.
So I was very curious when Apple announced AirPods Pro. These are AirPods, but with active noise cancelling (ANC). For someone who travels frequently, either by plane or, as is common in Europe, by train, headphones with active noise cancelling are an absolute must if you don’t want to constantly stress out your ears when you don’t need to, especially as a blind person. And I’ve tried many of them. So far, my personally best results were with two Bose ones, the wired Quiet Control 20, and the wireless Quiet Control 30. Both of these are in-ear ANC headphones with three adjustable earpiece sizes. My ears are actually shaped in a way that I have to use the slightly larger one on one side. The most annoying about the QC-30 were the plastic strap around the neck that holds all of the electronics, and the lag experienced with the Bluetooth connection.
I had also tried some over-ear headphones over the years. But the weight of these often quickly made my neck ache. I also experienced an uncomfortable pressure on the ears stemming from the noise cancelling techniques. I tried the Bose QC-35, Sony WH1000-X3, and also the Apple Beats Studio 3 Wireless. The Beats were the best experience with Apple devices, but had the weakest ANC.
And then came AirPods Pro.
Oh people, am I sold on these! They are in-ear pieces, with three differently sized tips so one can make them fit one’s ears best. Apple even provide a fitting test within Bluetooth settings so these AirPods can test themselves if they fit and close off the ear canal properly. The way they do that is extremely clever. The ANC is done through a set of microphones that take the outside noise and produce an inverse wave form of these noises. The cancelled out signal is then sent to the ears. This is, as you correctly interject, how all these ANC headphones do it.
The clue, however, with Apple’s AirPods Pro is that they also have a microphone inside the ear that is able to pick up one’s own body noises such as breathing. Those are also used to test how much of the test music that is played can escape and thus is an indication how well the ear pieces fit and channel the sound to the inner ear rather than the outside. And of course, they are used to reduce the noises one makes while breathing, swallowing etc. That adds an extra level of comfort that I have not seen in any other noise cancelling headphones.
This is also what lessens the uncomfortable feeling of pressure on the ears once ANC is active. Because they reduce the noises from within, the whole impression is far more balanced. I could wear these for hours without feeling the least bit uncomfortable while on a train to my mom’s birthday party on Sunday.
The battery life on the AirPods Pro is also pretty impressive. On average, they hold about 45 minutes longer than projected by Apple. Music sounds great, and VoiceOver has no lag either, as these also come with the H1 chip.
Unlike the regular AirPods, you do not tap on these to play or pause, fast-forward or skip back, or call Siri. Instead, you take the longer piece of an AirPod Pro between two fingers and press. One short press pauses and plays, two skip forward, three skip backward. If you long-press, you can configure either side to either switch between ANC and transparency modes, or bring up Siri. But you can also use Hey Siri to invoke your personal assistant.
Transparency is when noise cancelling stays in effect, but some frequencies, like those in human voices, are let through so you can talk to someone and hear what they’re saying. Apple doesn’t offer several levels of transparency, as the Bose headphones do, for example. It’s either on or off. In my experience, the quality of sound is quite good, and sounds more natural than other transparency modes I have tried on ANC headphones before.
The case is shaped differently than the ones for AirPods 1 and 2. It offers charging via Lightning port or a Qi wireless charger. Pairing is done as usual with Apple or Beats headphones: Hold the case close to an iOS device, open it, wait for the screen to come up and connect. It will then be available on all devices connected to the same iCloud account. It also connects to other Bluetooth-enabled devices via standard Bluetooth pairing procedures. But the true power of the speed and long battery life is definitely best with Apple hardware and the use of the H1 chip.
In mid December, Apple released firmware updates to both the AirPods 2 and AirPods Pro. Apple installs these transparently without any user interaction. Once the firmware has been downloaded to an iOS device, it will simply be installed onto the AirPods once they are connected the next time. This is so fast that I have never actually noticed it happening, I only find out that there was an update if I look at the device information in iOS Settings, General, Info, AirPods or AirPods Pro. The current firmware revision is 2C54 for both. The AirPods 2 were previously on 2A364, the Pro on 2B588. So Apple seem to have aligned these two now.
As you might have guessed: I am totally sold on AirPods Pro. The way they work, are made, and the clever details about ANC, taking what was there before, finding the remaining problems and fixing them for users, are Apple engineering at its finest! Well done, everyone!
https://marcozehe.de/2019/12/17/my-review-of-apple-airpods-pro/
|
|
The Mozilla Blog: Firefox Announces New Partner in Delivering Private and Secure DNS Services to Users |
|
|
David Humphrey: Teaching Open Source, Fall 2019 |
Today I've completed another semester of teaching open source, and wanted to write something about what happened, experiments I tried, and what I learned.
This fall I taught the first of our two open source classes, cross-listed in our degree and diploma programs as OSD600 and DPS909. This course focuses on getting students engaged in open source development practices, and has them participate in half-a-dozen different open source projects, making an average of 10 pull requests over 14 weeks. The emphasis is on learning git, GitHub, and how to cope in large open source projects, code bases, and communities.
This is the 15th year I've taught it, and I had one of my largest groups: 60 students spread across two sections. I don't think I could cope with more than this, especially when I'm also teaching other courses at the same time.
I ran an analysis this morning, and here's some data on the work the students did:
They worked on all kinds of things, big and small. I kept a list of projects and organizations I knew while I was marking this week, and some of what I saw included:
Whatever they worked on, I encouraged the students to progress as they went, which I define as building on previous experience, and trying to do a bit more with each PR. "More" could mean working on a larger project, moving from a smaller "good first issue" type fix to something larger, or fixing multiple small bugs where previously they only did one. I'm interested in seeing growth.
The students find their way into lots of projects I've never heard of, or wouldn't know to recommend. By following their own passions and interests, fascinating things happen.
For example, one student fixed a bunch of things in knitcodemonkey/hexagon-quilt-map, a web app for creating quilt patterns. Another got deeply involved in the community of a service mesh project called Layer5. A few women in one of my sections got excited about Microsoft’s recently open sourced C++ Standard Library. If you'd ask me which projects students would work on, I wouldn't have guessed the STL; and yet it turned out to be a really great fit. One of the students wrote it about it in her blog:
Why do I always pick issues from Microsoft/STL? It's because of the way they explain each bug. It is very well defined, there is a description of how to reproduce the bug and files that are crashing or need updates. Another reason is that there are only 20 contributors to this project and I'm 8th by the amount of contributing (even though it is only 31 line of code). The contributors are very quick to respond if I need any help or to review my PR.
Working on projects like those I've listed above isn't easy, but has its own set of rewards, not least that it adds useful experience to the students' resume. As one student put it in his blog:
I have officially contributed to Facebook, Angular, Microsoft, Mozilla and many more projects (feels kinda nice to say it).
Another wrote:
I contribute to various repositories all over the world and my work is being accepted and appreciated! My work and I are valued by the community of the Software Developers!
And another put it this way:
The most important thing — I am now a real Open-Source Developer!
Becoming a real open source developer means dealing with real problems, too. One student put it well in his blog:
Programming is not an easy thing.
No, it isn't. Despite the positive results, if you talked to the students during the labs, you would have heard them complaining about all sorts of problems doing this work, from wasting time finding things to work on, to problems with setting up their development environments, to difficulties understanding the code. However, regardless of their complaints, most manage to get things done, and a lot do quite interesting work.
There's no doubt that having real deadlines, and a course grade to motivate them to find and finish open source work helps a lot more of them get involved than would if they were doing this on the side. The students who don't take these courses could get involved in open source, but don't tend to--a lot more people are capable of this work than realize it. They just need to put in the time.
I wish I could say that I've found a guaranteed strategy to get students to come to class or do their homework, but alas, I haven't. Not all students do put in the time, and for them, this can be a really frustrating and defeating process, as they find out that you can't do this sort of work last minute. They might be able to stay up all night and cram for a test, or write a half-hearted paper; but you can't fix software bugs this way. Everything that can go wrong will (especially for those using Windows), and these Yaks won't shave themselves. You need hours of uninterrupted development, patience, and time to communicate with the community.
One of the themes that kept repeating in my head this term is that work like this is all about paying attention to small details. I'm amazed when I meet students taking an advanced programming course who can't be bothered with the details of this work. I don't mean being able to answer trivia questions about the latest tech craze. Rather, I mean being attuned to the importance and interplay of software, versions, libraries, tools, operating systems, syntax, and the like. Computers aren't forgiving. They don't care how hard you try. If you aren't interested in examining software at the cellular level, it's really hard to breath life into source code.
Everything matters. Students are amazed when they have to fix their commit messages ("too long", "wrong format", "reference this issue..."); squash and rebase commits (I warned them!), fix formatting (or vice versa when their editor got too ambitious autoformatting unrelated lines); change the names of variables; add comments; remove comments; add tests; fix tests; update version numbers; avoid updating version numbers! sign CLAs; add their name to AUTHORS files; don't add their name to other files! pay attention to the failures on CI; ignore these other CI failures.
Thankfully, a lot of them do understand this, and as they travel further down the stacks of the software they use, and fix bugs deep inside massive programs, the value of small, delicate changes starts to make sense. One of my students sent me a note to explain why one of her PRs was so small. She had worked for weeks on a fix to a Google project, and in the end, all that investment of research, time, and debugging had resulted in a single line of code being changed. Luckily I don't grade submissions by counting lines of code. To me, this was a perfect fix. I tried to reassure her by pointing out all the bugs she hadn't added by including more code than necessary. Google agreed, and merged her fix.
This term I also decided to try something new. We do a bunch of case studies, looking at successful open source projects (e.g., Redis, Prettier, VSCode) and I wanted to try and build an open source project together with the whole class using as much of the same tech and processes as possible.
I always get students involved in "external" projects (projects like those mentioned above, not run by me). But by adding an "internal" project (one we run), a whole new kind of learning takes place. Rather than showing up to an existing project, submitting a pull request and then moving on to the next, having our own project meant that students had to learn what it's like to be on the other side of a pull request, to become a maintainer vs. a contributor.
I've done smaller versions of this in the past, where I let students work in groups. But to be honest it rarely works out the way I want. Most students don't have enough experience designing and implementing software to be able to build something, and especially not something with lots of opportunity for people to contribute in parallel.
Our project was an RSS/Atom blog aggregator service and frontend called Telescope. The 60 of us wrote it in a month, and I'm pleased to say that "it works!" (though it doesn't "Just Work" yet). I recorded a visualization of the development process and put it on YouTube.
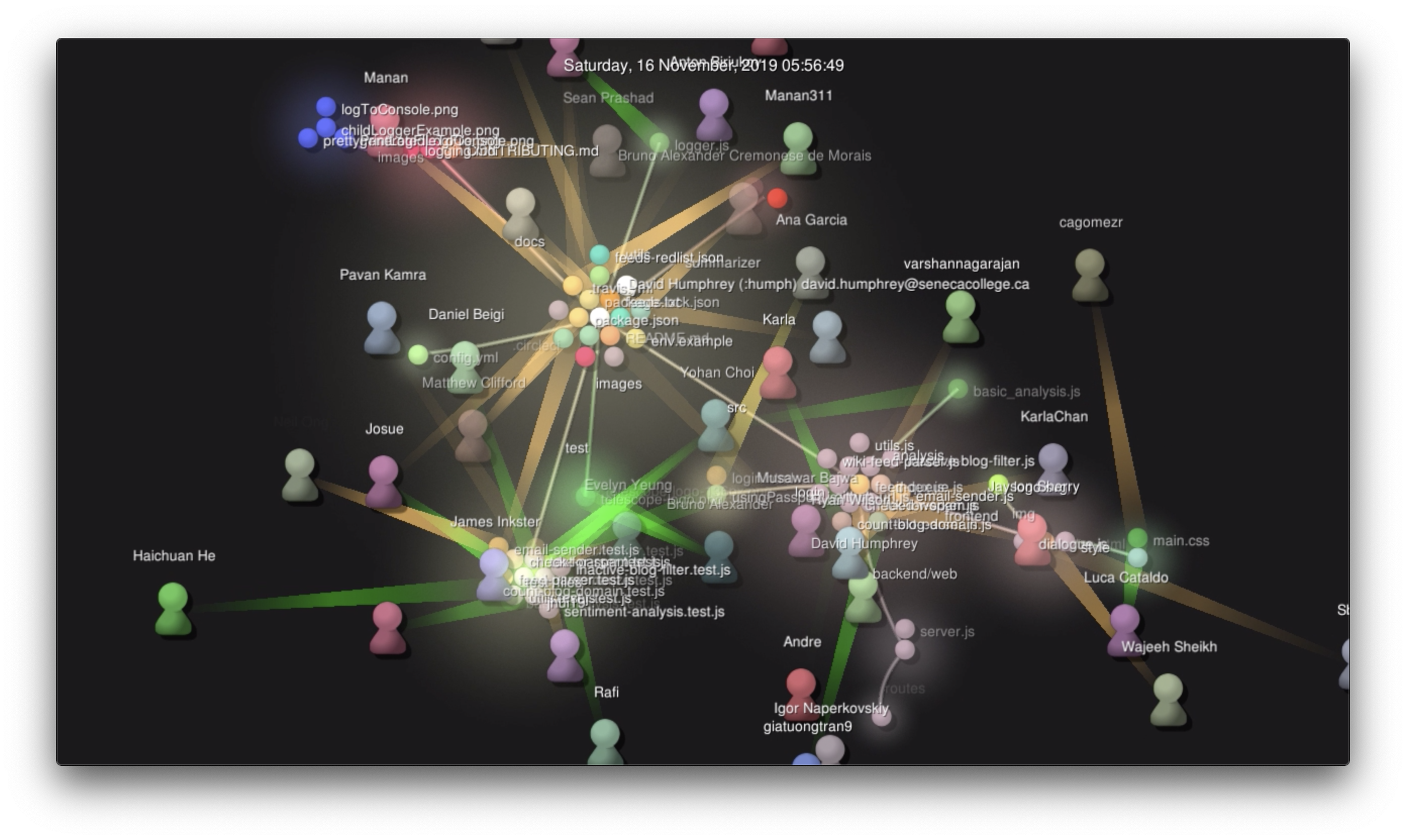
I've written a lot of open source software with students before, but never this many at once. It was an interesting experience. Here are some of my take-aways:
master into their branches over and over again, sometimes a dozen times in the same pull request. I still haven't figured out how to teach this perfectly. I love git, but it's still really hard for beginners to use properly. In the end I often did rebases myself to help get students out of a mess. But despite the problems, most people got the hang of it after a few weeks. One of the students put it this way in his blog: "This summer I knew very little about git/GitHub…it was pure hell. Now we are jumping between branches and rebasing commits as gracefully and confident as squirrels.".gitattributes fix for Windows line endings to make git happy in Windows CI.package-lock.json in git, and eventually removed it and went to exact versioning in package.json. The amount of churn it caused with this many people was unworkable, especially with people learning git and npm at the same time.master. Sometimes I used my admin rights to merge something fast, but for the most part this worked really well. One of the students commented in his blog how much he'd learned just by reviewing everyone's code. We also talked a lot about how to write changes so they'd be more reviewable, and this got better over time, especially as we studied Google's Code Review process. It's a real skill to know how to do a review, and unless you get to practice it, it's hard to make much progress. We also got to see the fallout of bad reviews, which let test failures land, or which removed code that they should not have.In the winter term I'm going to continue working on the project in the second course, and take them through the process of shipping it into production. Moving from fixing a bug to fixing enough bugs in order to ship is yet another experience they need to have. If you want to join us, you'd be welcome to do so.
All in all, it was a busy term, and I'm ready for a break. I continue to be incredibly grateful to all the projects and maintainers who reviewed code and worked with my students this time. Thank you to all of you. I couldn't do any of this if you weren't so open and willing for us to show up in your projects.
|
|
Firefox UX: Designer, you can run a usability study: Usability Mentorship at Mozilla |
On the Firefox UX team, a human-centered design process and a “roll up your sleeves” attitude define our collaborative approach to shipping products and features that help further our mission. Over the past year, we’ve been piloting a Usability Mentorship program in an effort to train and empower designers to make regular research part of their design process, treating research as “a piece of the pie” rather than an extra slice on the side. What’s Mozilla’s Firefox UX team like? We have about twenty designers, a handful of user researchers, and a few content strategists.
This blog post is written by Holly (product designer, and mentee), and Jennifer (user researcher, and mentor).

photo: Holly Collier; A coozy gift from Gemma Petrie. Credit for the phrase goes to Leslie Reichelt at GDS.
Let’s start with Holly’s perspective.
I’m an interaction designer — I’ve been designing apps and websites (with and without the help of user research) for over a decade now, first in agencies and then in-house at an e-commerce giant. Part of what drew me to Mozilla and the Firefox UX team a year ago was the value that Mozillians place on user research. When I learned that we had an official Usability Mentorship program on the Firefox UX team, I was really excited — I had gotten a taste of helping to plan and run user research during my last gig, but I wanted to expand my skill set and to feel more confident conducting studies independently.
I think it’s really important to make user research an ongoing part of the product design process, and I’m always amazed by the insights it produces. By building up my own user research skill set, it means that I’m in a better position to identify user problems for us to solve and to improve the quality of the products I work on.
And now onto Jennifer. She’ll talk about how this all worked.
A little bit about me before we dive in. I’m a user researcher — I’ve been in the industry for 6 years now, and at Mozilla on the Firefox User Research team for 3 years. I’ve worked at a couple big tech companies (HP & Intel) before coming to Mozilla. Prior to that, I worked hard at internships and got a PhD in Computer Science, focused on Human Computer Interaction. I love working at Mozilla, especially with designers like Holly, who are passionate about user research informing product design!
At Mozilla, our research team conducts three types of research (as written by Raja Jacob and Gemma Petrie):
Like most organizations, we routinely have more designs that need usability testing than we have researchers. Gemma Petrie, our most senior User Researcher (a Principal User Researcher), started the mentorship program as a way to address this problem in her previous role as interim Director of User Research. By spreading usability testing abilities more broadly across the Firefox UX team, we could ensure that more designs got tested and ensure that our dedicated researchers could continue to do exploratory and generative research.
Because all of our designers and content strategists had different levels of familiarity with usability testing, Gemma brought in an external consultant to kick-off this effort and run a usability testing workshop with the entire UX team. This workshop was recorded so it can be cross-referenced later, and so that new team members can watch it as part of their onboarding.
At Mozilla, a mentorship project starts somewhat informally. Designers and content strategists “raise their hand” to show interest, and each researcher on the User Research team is a mentor. A designer gets paired with a mentor to figure out a (hopefully) low stress, low-stakes project to work on together. The designer takes the reins, and the researcher helps out along the way.
While we don’t have a strict curriculum, after a designer shows interest, each mentorship roughly follows these steps:
Let’s have Holly tell us about what she learned from her experience testing one of Firefox’s apps.
We identified a product that needed usability testing: Firefox Lockwise for Android (then called “Firefox Lockbox”), a new password manager app that works in conjunction with logins that are saved in the Firefox browser. It’s in my team’s practice area, so I thought it would be a good chance to get to know a new product, but it was also a good fit in terms of my experience with the Android platform (all of my previous involvement in user research was on mobile apps).
There were a lot of materials available to help me get started — sample protocols, decks, analysis spreadsheets. The Firefox User Research team is great about documenting and saving research artifacts. The Lockwise team also had conducted in-person usability testing on their iPhone app the previous summer, so I had some usability questions to start with.
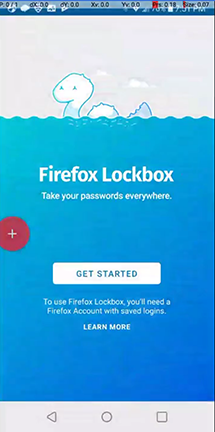
Firefox Lockbox prototype in the usertesting.com screen recorder.
The process of gathering requirements, designing, piloting and revising before releasing a usability test to participants felt similar to the process of problem definition, design, prototyping and iteration we use for product design:
Requirements Gathering (Problem Definition): This particular test had many constraints and requirements. Because this was a remote, unmoderated test, and because users had to have a Firefox account with Sync enabled in order to test the Lockbox app, the protocol for the test was pretty extensive.
Protocol Design (Product Design): Getting high-quality test results required thinking through the test experience from the test taker’s point of view while also achieving our research goals:
Piloting (Prototyping & Iteration): Before launching the real test, we launched a prototype of the test called a “pilot” and watched videos of a few participants to make sure the test instructions were understood and that the test was functioning as designed. Getting out of this pilot stage was challenging because of problems we discovered and had to troubleshoot along the way:

The prototype wouldn’t allow the screen recorder to capture participants’ screens.
Once we addressed the issues with the protocol and the prototype that we uncovered during our pilot, we launched the test, and I moved on to watching participant videos and taking lots of notes (direct quotes!) that I’d mine for insights later.
Analyzing the test data and delivering the findings (and recommendations!) was the most intimidating part of the process for me. As a designer, I’ve always looked to the research findings deck as a ‘beacon of truth’ in the design process. Now that I was running the research, I felt a lot of responsibility to deliver that same truth and guidance.
I worked through those feelings of intimidation by triple-checking my sources, mapping my data (including quotes) to the research questions and getting the following awesome perspective from Jennifer:
The distributed Firefox Lockwise team during the findings presentation.
As it turned out, giving the findings presentation to the Lockwise team actually ended up being one of my favorite parts of the whole process. Telling the story was fun and inspired great conversation, and the Lockwise team really appreciated the “How might we?” format I used for the design recommendations.
Jennifer, take it away!
Helping Holly out with this project helped make tacit knowledge explicit. I’ve done many, many usability tests. I am almost on auto-pilot when I conduct them. So it was a great exercise to actually explain the process with a co-worker and perform a needed amount of reflection on my process. Especially with Holly, who was willing to learn and asks great questions.
Here are some of those great questions that made me reflect on my process:
How do I know when the pilot phase is over? The pilot is over when the protocol “works” as intended. That means there are no show-stopping bugs in the platform that prevent someone from doing the task — and if there are showstoppers, adjusting the protocol. It also means that your questions have been phrased in a way that people understand. You can only determine this through observing a couple pilot participants.
Can I use my pilot data in the report? The academic in me says that if the protocol changes at all from the pilot to running the rest of the tests, no, you can’t use the pilot data in the report. The industry researcher in me says that sure, you can include the results as long as you mark it clearly as pilot data.
How do I present ‘bad news’ to a team? Most usability tests have at least some good news. Start with that! Be clear about when you’re going to deliver the bad news and come prepared with “How might we?” questions or recommendations on how to improve the experience.
How do I make sure I take my personal bias of how I understand this app out of the process? Acknowledge your bias. Know what it is going in and voice it to your mentor. Do exactly what Holly mentioned earlier and double and triple-check your results against the videos, direct quotes, and research questions. Do you still feel like you might be stretching the interpretation of a result? Check with your mentor, or anyone who’s done a usability test before. Have a co-worker who isn’t very close to the project review your results and recommendations before you present them to the wider team.
Holly, the designer & mentee says:
Designers, you can do user research! Since completing the mentorship, I have conducted conducted several other studies, including a usability/concept test and an information architecture research study. It’s become a regular part of my design practice, and I think the products I work on are better for it.
Jennifer, the user researcher & mentor says:
User researchers out there: you can run your own usability testing mentorship program!
In the spirit of open source, here are some examples:
Thank you to Gemma Petrie, Anthony Lam, and Elisabeth Klann for reviewing this blog post. And a special thanks to Gemma Petrie for setting up the Usability Mentorship Program at Mozilla.
Also published on medium.com.
|
|






