Добавить любой RSS - источник (включая журнал LiveJournal) в свою ленту друзей вы можете на странице синдикации.
Исходная информация - http://planet.mozilla.org/. Данный дневник сформирован из открытого RSS-источника по адресу http://planet.mozilla.org/rss20.xml, и дополняется в соответствии с дополнением данного источника. Он может не соответствовать содержимому оригинальной страницы. Трансляция создана автоматически по запросу читателей этой RSS ленты. По всем вопросам о работе данного сервиса обращаться со страницы контактной информации.[Обновить трансляцию]
Понедельник, 16 Декабря 2019 г. 19:15
+ в цитатник
Our newest Friend of Add-ons is Jocelyn Li! Jocelyn has been an active code contributor to addons.mozilla.org (AMO) since May 2018, when she found a frontend issue that involved broken CSS. She had known that Mozilla welcomed code contributions from community members, but hadn’t been sure if she was qualified to participate. As she looked at the CSS bug, she thought, “This doesn’t look that hard; maybe I can fix it,” and submitted her first patch a few hours later. She has been an avid contributor ever since.
Jocelyn says that contributing to a large public project like Mozilla has helped her grow professionally, thanks in part to positive interactions with staff members during code review. “They always give constructive comments and guide contributors,” she says. “When I learn either technical or non-technical skills, I can apply them to my own job.”
Mozilla and contributors alike benefit from the open source model, Jocelyn believes. “Mozilla receives contributions from the community. Contributors are like seeds all over the world and promote Mozilla’s projects or languages and improve their own companies at the same time.”
One of Jocelyn’s passions is learning new languages. Currently, she is learning Rust for a work project that uses node.js in typescript with tp-ts and Japanese to acclimate to Tokyo, where she moved earlier this year. “Every language provides different perspectives to us,” she notes. “One language may have terms or syntaxes that another language doesn’t have. It’s like acquiring a new skill.”
In her spare time, she enjoys reading, cooking, traveling, and learning how to play the cello. “I always feel like 24 hours in a day is not enough for me,” she says.
Thank you for your contributions, Jocelyn!
If you are interested in getting involved with the add-ons community, please take a look at our wiki for some opportunities to contribute to the project.
Понедельник, 16 Декабря 2019 г. 15:00
+ в цитатник
Over the weekend, this post by Dave Rupert made the rounds, and I totally agree with what he is saying.
In his post, Dave showcases a problem with the gap between intent and developer assumption about what a certain element or set of elements, are intended or should be used for, and what not to be used for. In this case, the details and summary elements being used as accordions, or not.
If you are running his example with Firefox and either NVDA or JAWS, you are actually very lucky, because all features of his accordion are supported, including the headings. Because unlike some other browsers, because h elements are allowed within summary elements, we do not nuke the heading semantics, and thus it is possible with both screen readers to navigate by heading even inside the summary elements, which get mapped to the button role. Since Firefox 70, both screen readers will even announce properly when you toggle the details open or closed.
However, this is not the case with all browser and screen reader combinations. And according to the spec, details and summary are not intended to be used as an accordion, even though the interaction model totally mimiks that. And here’s indeed one of the big problems I have encountered time and again when working with developers internally at Mozilla and on the outside: The specification does not always do a good job of explaining in an understandable form of English what an element is intended for or not. Especially if it mimiks a design pattern that fits the developers use case, but is for some reason not what the developer wants to use it for. This divide is made very obvious in Dave’s post. Even in accessibility land, there is this divide. For example, the spec allows for buttons or elements that map to buttons to have semantic children like headings. Why then do buttons, according to the accessibility specification, nuke their children’s semantics? Or should nuke them? Because traditional desktop buttons didn’t have headings?
The specifications have become a bit better in recent years to reflect current realities. But often enough, there is still this great divide between the HTML spec, the accessibility expectations which often enough stem from 25 year old concepts, such as “Buttons don’t have heading children”, and developer expectations when they see the visuals of what, for example, details/summary do, and think “hey cool, I combine a few of these and have an accessible accordion”! It is my hope that, in 2020 and beyond, we in the accessibility community will muster up some more courage to show some flexibility and not be afraid to adjust specifications to realities more, and give developers a bit more certainty. Yes, buttons can have semantic children. Firefox plus NVDA, and even the commercial JAWS, screen readers show that this is doable and the world doesn’t go to hell because of it. Sometimes things just work.
As we move into 2020, I also hope that each side, developers and spec authors and accessibility professionals, become more and more aligned on intent, reality of usage patterns, and implementation of richer building blocks for the web that are then specified in an understandable manner in HTML and accompanying specifications. We all want to move the web forward. Let’s do it in a more concerted manner and do more good together. The web needs it!
And Dave is right in demanding that more accessible HTML components get implemented by browsers and properly specified. We should move away from the “ARIA will fix it” mentality and put more effort into “Let’s give web authors more accessibility out of the box for richer components”, so those sad figures of 97% of inaccessible sites will hopefully drop to a much more satisfactory number in the next five years.
Понедельник, 16 Декабря 2019 г. 09:46
+ в цитатник
In the curl project we produce and ship a rock solid and reliable library for the masses, we must never exit, leak memory or do anything in an ungraceful manner. We must free all resources and error out nicely whatever problem we run into at whatever moment in the process.
To help us stay true to this, we have a way of testing we call “torture tests”. They’re very effective error path tests. They work like this:
Torture tests
They require that the code is built with a “debug” option.
The debug option adds wrapper functions for a lot of common functions that allocate and free resources, such as malloc, fopen, socket etc. Fallible functions provided by the system curl runs on.
Each such wrapper function logs what it does and can optionally either work just like it normally does or if instructed, return an error.
When running a torture test, the complete individual test case is first run once, the fallible function log is analyzed to count how many fallible functions this specific test case invoked. Then the script reruns that same test case that number of times and for each iteration it makes another of the fallible functions return error.
First make function 1 return an error. Then make function 2 return and error. Then 3, 4, 5 etc all the way through to the total number. Right now, a typical test case uses between 100 and 200 such function calls but some have magnitudes more.
The test script that iterates over these failure points also verifies that none of these invokes cause a memory leak or a crash.
Very slow
Running many torture tests takes a long time.
This test method is really effective and finds a lot of issues, but as we have thousands of tests and this iterative approach basically means they all need to run a few hundred times each, completing a full torture test round takes many hours even on the fastest of machines.
In the CI, most systems don’t allow jobs to run more than an hour.
The net result: the CI jobs only run torture tests on a few selected test cases and virtually no human ever runs the full torture test round due to lack of patience. So most test cases end up never getting “tortured” and therefore we miss out verifying error paths even though we can and we have the tests for it!
But what if…
It struck me that when running these torture tests on a large amount of tests, a lot of error paths are actually identical to error paths that were already tested and will just be tested again and again in subsequent tests.
If I could identify the full code paths that were already tested, we wouldn’t have to test them again. But getting that knowledge would require insights that our test script just doesn’t have and it will be really hard to make portable to even a fraction of the platforms we run and test curl on. Not the most feasible idea.
I went with something much simpler.
I simply estimate that most test cases actually have many code paths in common with other test cases. By randomly skipping a few iterations on each test, those skipped code paths might still very well be tested in another test. As long as the skipping is random and we do a large number of tests, chances are we cover most paths anyway. I say most because it certainly will not be all.
Random skips
In my first shot at this (after I had landed to change that allows me to control the torture tests this way) I limited the number of errors to 40 per test case. Now suddenly the CI machines can actually blaze through the test cases at a much higher speed and as a result, they ran torture tests on tests we hadn’t tortured in a long time.
I call this option to the runtests.pl script --shallow.
Already on this my first attempt in doing this, I struck gold and the script highlighted code paths that would create memory leaks or even crashes!
As a direct result of more test cases being tortured, I found and fixed nine independent bugs in curl already before I could land this in the master branch, and there seems to be more failures that pop up after the merge too! The randomness involved may of course delay the detection of some problems.
Room for polishing
The test script right now uses a fixed random seed so that repeated invokes will make it work exactly the same. Which is good when you want to reproduce it elsewhere. It is bad in the way that each test will have the exact same tests skipped every test round – as long as the set of fallible functions are unmodified.
The seed can be set by a command line argument so I imagine a future improvement would be to set the random seed based on the git commit hash at the point where the tests are run, or something. That way, torture tests on subsequent commits would get a different random spread.
Alternatively, I will let the CI systems use a true random seed to make it test a different set every time independent of git etc – as when it detects an error the informational output will still be enough for a user to reproduce the problem without the need of a seed.
Further, I’ve started out running --shallow=40 (on the Ubuntu version) which is highly unscientific and arbitrary. I will experiment altering this amount both up and down a bit to see what I learn from that.
Torture via strace?
Another idea that’s been brewing in my head for a while but I haven’t yet actually attempted to do this.
The next level of torture testing is probably to run the tests with strace and use its error injection ability, as then we don’t even need to build a debug version of our code and we don’t need to write wrapper code etc.
Понедельник, 16 Декабря 2019 г. 08:00
+ в цитатник
Webcompat bugs
Brian Birtles has a strange issue that he can reproduce only on Japanese Windows with Firefox. We tried on 3 different windows, and it reproduces. But it doesn't reproduce on Windows for Sergiu.
Flexbox issue. flex-basis: 100% doesn't resolve the same way in Firefox and Chrome. Usually you are on the safer side, if you use flex-basis: auto instead. Another site, same issue with the addition of using the first webkit version of Flexbox. Basically this site would be falling apart if it was not for the implementation of -webkit- prefixes for flexbox. Sad panda.
I haven't cracked down this one yet. The site deviantart is displaying the wrong contextual menu on double click.
On minecraft website, there is an infinite resize of the canvas. and it's growing, growing, growing.
Outreach Q42019
We decided to try to tackle the pile of issues which needed contacts. Before we had dedicated persons: Adam and myself. But we now kind of switched roles. So without daily love, the piles of needscontact (we need to find a contact) and contactready (we need to actually contact) tends to grow. So this week, I made a special effort specifically on the contactready list. One of my axioms for Webcompat:
If you wait long enough, a bug goes away.
Indeed. The site disappears, has been redesigned, the libraries have been changed. With Adam, we had determined that if we were doing the full process quickly, we had more chances to catch bugs and solve issues for users. Reality and the volume of incoming bugs make this difficult.
Fixing the Web requires a dedicated will from the whole industry to change its practices. Web compatibility issues share some of the aspects of the climate change (except no mass extinction if the Web disappears).
This outreach week was a mixed bag of not valid anymore bugs and still ongoing issues. Once contacted, it doesn't mean the issue will be fixed. Note that this process is open to everyone. If you want to help, you are more than welcome.
One week to wrap up the 2019Q4 projects. And to add to my misery of 2 weeks ago, I completely missed the meeting last Tuesday. Not in my calendar, but still a complete slip of mind. I'm glad holidays are coming soon. I probably need a good time resting.
It's verycool to see Kate and Guillaume practically handling the webcompat dashboards by themselves on a week to week basis. They do an awesome job. I have a lot of respect for them and their dedicated attention to details. Plus each time, I had to meet them face to face, it was a lovely time. I know that Kate might be looking for a (remote) job. She is in Italy. Give her a chance. She was previously an outreachy.
Firefox 72, currently in beta, received some fixes to the Accessibility Inspector this week. Here they are.
The first fix is to a longer standing issue. If you opened Accessibility Inspector by right-clicking an element and choosing Inspect Accessibility Properties, keyboard focus would not land on the Inspector or Properties tree view, but in limbo somewhere on the document. You had to tab a couple of times to get focus to the correct place. Well, that will be no more. From now on, keyboard focus will land in the properties tree, so you can directly start exploring the name, role, states etc., of the element you are interested in.
Related to that, if you selected to inspect an accessibility element’s property either from the browser or DOM Inspector context menus, the selected row in the Accessible Objects tree would not always scroll to actually show the selected item. That too has been fixed.
Moreover, if you’re already following along the betas, you may have noticed that within Accessibility Properties, the thing that was once called DOM Node, and which allows you to quickly jump to the HTML element that created this accessible object, was called “Node Front”. Well, that has also been addressed and will probably soon even be localized.
And last, but not least, resulting from direct feedback we received after Firefox 70 was released, if you have an SVG element which is properly labeled at its root, its children elements will no longer be flagged as having no proper label when auditing your site for accessibility problems. If an SVG has a role of “img” and is tagged, that will be sufficient to satisfy the auditing facility. In fact, this change is already in Firefox 72 Beta 5 or newer, whereas the other changes mentioned above will appear in Firefox 72 Beta 7 early next week.
Keep the feedback coming! We are constantly fixing bugs and improving the auditing tool to give you better results when testing or developing.
Home security cameras are in the news (again), featuring startling clips of hackers speaking creepily to children and sleeping adults through Ring cameras inside private homes. Ring says there has … Read more
Today, Mozilla continues the fight to preserve net neutrality protection as a fundamental digital right. Alongside other petitioners in our FCC challenge, Mozilla, Etsy, INCOMPAS, Vimeo and the Ad Hoc Telecom Users Committee filed a petition for rehearing and rehearing en banc in response to the D.C. Circuit decision upholding the FCC’s 2018 Order, which repealed safeguards for net neutrality.
Our petition asks the original panel of judges or alternatively the full complement of D.C. Circuit judges to reconsider the decision both because it conflicts with D.C. Circuit or Supreme Court precedent and because it involves questions of exceptional importance.
Mozilla’s petition focuses on the FCC’s reclassification of broadband as an information service and on the FCC’s failure to properly address competition and market harm. We explain why we believe the Court can in fact overturn the FCC’s new treatment of broadband service despite some of the deciding judges’ belief that Supreme Court precedent prevents rejection of what they consider a nonsensical outcome. In addition, we point out that the Court should have done more than simply criticize the FCC’s assertion that existing antitrust and consumer protection laws are sufficient to address concerns about market harm without engaging in further analysis. We also note inconsistencies in how the FCC handled evidence of market harm, and the Court’s upholding of the FCC’s approach nonetheless.
We are excited to continue to lead this effort as part of a broad community pressing for net neutrality protections, and Mozilla supports other petitioners’ filings at this stage that address additional important issues for reconsideration. See below for copies of the petitions filed.
Petition for rehearing and rehearing en banc filed by:
Gutenberg, the WordPress block editor, is the new way to create content and build sites in WordPress. It is a rich web application that uses many modern techniques such as dynamic updates, toolbars, side bars and other items to completely update the posting experience. It can also be quite daunting at first. Let us try to shed a little light on some of the mysteries around it.
It is not mandatory
First things first: It is not mandatory yet to use Gutenberg. You can install the Classic Editor plugin, which is fully maintained by the WordPress team for the foreseeable future. Once installed, you change a setting in your user profile to make sure you get the Classic Editor experience. Once you change this, you will have the same well-known WordPress posting experience you’ve always had, with both a plain HTML text and the TinyMCE editor for more rich editing of your post.
Once you enable that setting, WordPress will take Gutenberg out of the mix. You will have your post types, categories, tags, and other information where you are used to in your WordPress Admin, Create A New Post interface.
A general overview
But if you decide to go all in on Gutenberg, here is a general overview. Gutenberg manages the whole posting experience from initial creation to proof-reading, rearranging content, adding categories and tags, adjusting the publishing date, to pressing the big scary Publish button. The interface consists of several more or less static elements as well as one central area that is very dynamic in nature.
The top of the editor contains two toolbars. One is labeled the document tools toolbar and contains buttons to insert a new block, undo changes, re-do them, and since Gutenberg 7.0, a toggle under the More Options menu that tells the editor whether it is in selection or editing mode. More on that later.
The other toolbar right below that contains options to save, enable or disable the Settings side bar, adjust Jetpack settings, and bring up the publishing panel. Its More Options menu contains items to control various other options, open a dialog with a current set of keyboard shortcuts, etc. This is all pretty standard and works great with a screen reader. Focus is managed correctly when opening and closing menus, etc. Feel free to explore.
The other pretty standard item is the side bar. This is located at the very bottom of the virtual buffer, if you are using a screen reader that has one, such as NVDA or JAWS. It shows either the document settings, or the settings for the currently selected paragraph. The document settings is where you set your categories, tags, maybe add a post excerpt, control whether your post can receive comments or trackbacks, etc. The block settings can vary. For paragraphs, you get items for adjusting font size and family, maybe colors, and more. For images, this is where you set the alternative text, among other things. A set of two tabs at the bottom switches between Document and Block settings.
One other item that appears here is the Jetpack settings if you select that from the main toolbar, and the Publishing settings. Many items in the Publishing panel are similar to the document settings described above, but if you have Social Media Sharing set up, for example, this is where you adjust your Tweet text for the initial post. These controls are also all pretty standard. The collapsible sections expand or collapse if you press Enter on them, and even items such as the calendar for adjusting the publishing date and time is very accessible.
The main block contents
The real fun begins in the central editor part. It begins with the post title, and then spans one or multiple blocks you add to your post or page. My workflow, for example, is to type the title, then press Enter. You could also press tab, which will then take you to the Copy Permalink item, and then onto the URL itself, plus into the actual first block.
Depending on your version of Gutenberg, after you press Enter after typing the title, the editor places you in either selection or editing mode. In 7 and later, it will default to editing mode, so you can continue typing your text. In 6.9, it will place you on a Paragraph block button. That is selection mode, and you have to press Enter once more to actually enter editing mode and being able to type. Caveat: Sometimes screen readers don’t speak the focus transition here. Best to turn off virtual cursor and check with your ScreenReaderModifier+Tab which item has focus. It should be an Empty Block item.
Once you are in the first block, and in editing mode, start typing to simply create a paragraph block. You can use arrow keys to navigate, and if you press Enter, you will create a new, empty block.
However, before typing text, you can also change the block type right from the keyboard. Type a forward slash, /, and a popover will open to allow you to select a block type. Start typing some characters, for example h and e for heading. This is an accessible autocomplete, and it will speak the first item it found. You can press up and down arrows to select a different block type, and Enter to accept. The editor will return you to editing mode, but now the screen reader might say something like “Heading block, level 2, editing”. You know that you are going to now type a heading level 2. Finish your sub section title and press Enter to create a new block below.
The blocks all have a dynamic toolbar attached to them. Most of that toolbar’s contents only becomes visible to sighted people if text is selected. Then, you can apply formatting such as bold, italic, underline, turn it into a link, etc. But if you opened and studied the shortcut keys above, you’ll know that you can also use keyboard shortcuts like CTRL+B for bold, or CTRL+K for link. However, if you want to access the toolbar, you can always do so from the keyboard by pressing Alt+F10. Yes, if you used TinyMCE before, that’s the same shortcut that brought you into its toolbar system as well. Once the toolbar opens, use left and right arrows to navigate between controls. Escape will bring you back to the text field. In a heading block, for example, you can use the toolbar to change its level from 2 to 3 to 4 etc.
There are a few more elements above the current block that are always there, which can either be tabbed or shift-tabbed to once the toolbar is open, or you can turn focus or forms mode off and use the virtual cursor to move upwards into the toolbar. One is a button to change the block type through a dropdown. This comes in handy if you already have text entered and therefore can no longer use the forward slash shortcut. The other two buttons are mover buttons. These move the current block up or down above or below other blocks. In some layouts, you may also have the option to move a block to the right into the next column, or to the left into the previous one.
My suggestion for the very dynamic nature of the blocks is to use mostly forms/focus mode in your screen reader to move among blocks. If you are on the first line of a block, and there is another block above it, an Up Arrow will take you into that block. There is a real focus change happening, so the experience is different than if you moved among paragraphs in a Word document, but that’s the quickest way to go from one block to the other. Also, to manipulate a block via the toolbar, use Alt+F10 to bring up the toolbar instead of trying to search for it using the virtual cursor.
Edit and Selection Modes
As hinted before, Gutenberg knows two modes to operate in. One is Editing mode, which we have covered so far. The other is selection mode. In this mode, you can quickly navigate among blocks. To enter Selection mode, press Escape while editing a block. That will drop you into navigation mode. If you are using a screen reader, you may have to press Escape twice, since the first press might just turn off forms or focus mode and invoke your virtual reading cursor. However, once in Selection mode, I suggest to turn focus mode on by hand and navigate using tab or arrow keys, since that allows navigation among blocks using the native editor keyboard commands.
After selecting a different block, press enter to turn Edit Mode back on and return to manipulating text.
Version differences
WordPress comes with a version of Gutenberg that was available at the time of the release of your particular WordPress version. It gets updated each time WordPress gets updated. However, you can also decide to get on the two week release cycle of Gutenberg itself and therefore be independent from WordPress releases. The advantage is that you get new features and accessibility improvements faster than with a WordPress release. The disadvantage is that, as with any software, sometimes there can be bugs that get introduced and then take another two weeks to fix. Unless, of course, the team decides to put out an emergency fix release.
You get onto the two week release cycle by installing the Gutenberg plugin from the WordPress Plugin Repository. Yes, you can install that even though your WordPress already comes with a preinstalled version of Gutenberg. The only exception is if you run your blog on WordPress.com, the hosting service by Automattic, and are on the free, Personal or Premium plans, which don’t allow plugin installations. Then, you’ll always have to wait for Automattic to integrate newer versions of Gutenberg into the WordPress install that you get on WordPress.com.
Closing remarks
The dynamic nature, and seemingly weird keyboard behavior that results from that, can at times be quite unnerving. It is definitely a challenge to keep track of which mode you are in, which block you are editing, and what options are available. For screen reader users, who have very sequential access to web applications, some of these concepts may be difficult to grasp at first, and definitely incur a steeper learning curve than most sighted users will have with Gutenberg. But mastering it is not impossible. As with any complex web application like Gmail, Google Docs, Slack or the like: Know their shortcuts, know your screen reader and its powers, and you’ll be fine.
Let me close by thanking those from the Gutenberg development team who have reached out to me after my last post on the subject and asked for input. Together with the other members of the accessibility team, we’ve had some very good and productive conversations that hopefully will move things forward in interesting ways in the coming months. And I mean that in the most positive sense, without irony or sarcasm. I will post irregular updates on significant changes that make it into new Gutenberg releases. And I’ll hopefully keep this guide updated with new information as it becomes available.
Until then, have fun playing with Gutenberg! Hope these tips help you in finding your way around.
After I watched a talk by Marcus Olsson about docs as code (at foss-sthlm on December 12 2019), I got inspired to provide links on the curl web site to make it easier for users to report bugs on documentation.
Starting today, there are two new links on the top right side of all libcurl API function call documentation pages.
File a bug about this page – takes the user directly to a new issue in the github issue tracker with the title filled in with the name of the function call, and the label preset to ‘documentation’. All there’s left is for the user to actually provide a description of the problem and pressing submit (and yeah, a github account is also required).
View man page source – instead takes the user over to browsing that particular man pages’s source file in the github source code repository.
Click the image for full resolution version.
Since this is also already live on the site, you can also browse the documentation there. Like for example the curl_easy_init man page.
If you find mistakes or omissions in the docs – no matter how big or small – feel free to try out these links!
We have an important announcement to make today, regarding the future of the Testday and Bugday community events we have been holding for our desktop product.
The state of things
QMO events have been around for several years now, with many loyal Mozilla contributors engaged in various types of manual testing activities– some centered around verification of bug fixes, others on trying out exciting new features or significant changes made to the browser’s core ones. The feedback we received through them, during the Nightly and Beta phases, helped us ship polished products with each iteration, and it’s something that we’re very grateful for.
We also feel that we could do more with the Testday and Bugday events. Their format has remained unchanged since we introduced them and the lack of a fresh new take on these events is now more noticeable than ever, as the overall interest in them has been dialing down for the past couple of years.
We think it’s time to take a step back, review things and think about new ways to engage the community going forward.
Goodbye, for now
Starting 2020, we are going to take some time to figure out what our next plans are. Test Days and Bugdays will be paused as a result, but we do plan to hold a final Testday this year, on December 20– we hope to see all of you there!
As we move forward, the #qa IRC channel will remain the best way to connect with us, so don’t hesitate to drop by and say hi. You’ll still be able to contribute towards bug fix verification by looking at bugs with the [good first verify] keyword.
Thank you all for your passion, loyalty and dedication to Firefox! As always, it’s inspiring to work with such amazing people!
I'm ramping up on a project to understand how Firefox retains users.
Right now I'm trying to build some context quickly.
For example, what's our monthly retention? How about our annual retention?
There's a bunch of interesting and nuanced measurement questions
that we'll eventually have to answer,
but for now …
I've been working on some RSS/Atom blog aggregation software with my open source students. Recently we got everything working, and it let me do an analysis of the past 15 years of blogging by my students.
I wanted to answer the question, "What is a blog post?" That is, which HTML elements are used at all, and most often? Which are never used? My students have used every blogging platform you can think of over the years, from WordPress to Blogger to Medium, and many have rolled their own. Therefore, while not perfect, this is a pretty good view into what blogging software uses.
Analyzing many thousands of posts, and hundreds of thousands of elements, here's what I found. The top 5 elements account for 75% of all elements used. A blog post is mostly:
(35%)
(18%)
(10%)
(15%)
(8%)
I'm really surprised at being on top. The next 18% is made up of the following:
(3%)
(3%)
(3%)
(2%)
(2%)
(1.5%)
(1.3%)
(1.1%)
(1%)
And the remainder are all used infrequently (< 1%):
It's intresting to see the order of the heading levels match their frequency. I'm also interested in what isn't here. In all these posts, there's no , ever.
As part of our efforts to make add-ons safer for users, and to support evolving manifest v3 features, we are making changes to apply the Content Security Policy (CSP) to content scripts used in extensions. These changes will make it easier to enforce our long-standing policy of disallowing execution of remote code.
When this feature is completed and enabled, remotely hosted code will not run, and attempts to run them will result in a network error. We have taken our time implementing this change to decrease the likelihood of breaking extensions and to maintain compatibility. Programmatically limiting the execution of remotely hosted code is an important aspect of manifest v3, and we feel it is a good time to move forward with these changes now.
We have landed a new content script CSP, the first part of these changes, behind preferences in Firefox 72. We’d love for developers to test it out to see how their extensions will be affected.
Testing instructions
Using a test profile in Firefox Beta or Nightly, please change the following preferences in about:config:
Set extensions.content_script_csp.enabled to true
Set extensions.content_script_csp.report_only to false to enable policy enforcement
This will apply the default CSP to the content scripts of all installed extensions in the profile.
Then, update your extension’s manifest to change your content_security_policy. With the new content script CSP, content_scripts works the same as extension_pages. This means that the original CSP value moves under the extension_pages key and the new content_scripts key will control content scripts.
Your CSP will change from something that looks like:
Next, load your extension in about:debugging. The default CSP now applied to your content scripts will prevent the loading of remote resources, much like what happens when you try to insert an image into a website over http, possibly causing your extension to fail. Similar to the old content_security_policy (as documented on MDN), you may make changes using the content_scripts key.
Please do not loosen the CSP to allow remote code, as we are working on upcoming changes to disallow remote scripts.
As a note, we don’t currently support any other keys in the content_security_policy object. We plan to be as compatible as possible with Chrome in this area will support the same key name they use for content_scripts in the future.
Please tell us about your testing experience on our community forums. If you think you’ve found a bug, please let us know on Bugzilla.
Implementation timeline
More changes to the CSP for extensions are expected to land behind preferences in the upcoming weeks. We will publish testing instructions once those updates are ready. The full set of changes should be finished and enabled by default in 2020, meaning that you will be able to use the new format without toggling any preferences in Firefox.
Even after the new CSP is turned on by default, extensions using manifest v2 will be able to continue using the string form of the CSP. The object format will only be required for extensions that use manifest v3 (which is not yet supported in Firefox).
There will be a transition period when Firefox supports both manifest v2 and manifest v3 so that developers have time to update their extensions. Stay tuned for updates about timing!
A special update for Firefox Reality is available today -- just in time for the holidays! Now you can send tabs from your phone or computer straight to your VR headset.
Say you’re waiting in line for your festive peppermint mocha, killing time on your phone. You stumble on an epic 3D roller coaster video that would be great to watch in VR. Since you’ve already signed in to your Firefox Account on Firefox Reality, you can send that video right to your headset, where it will be ready to watch next time you open the app. You can also send tabs from VR over to your phone or desktop, for when you eventually take your headset off.
When you use Firefox on multiple devices, you can sync your history and bookmarks too. No more waving the laser pointer around to type wonky URLs or trying retrace your steps back to that super funny site from yesterday. Stay tuned in the new year for more features like these that make using VR a more seamless part of your everyday life.
But wait, there's more
We’ve also added a few small-but-mighty features that our users have requested. First is the ability to copy and paste text and links. Similar to how you do it on your phone, you can press-and-hold to get a menu of choices. With this update you can also use your Bluetooth keyboard to type, if your device has Bluetooth capabilities.
And finally, we’ve added six new languages and custom keyboards for Swedish, Finnish, Norwegian, Danish, Dutch and Polish.
Full release notes for this and all our updates can be found in our GitHub repository.
PS: We want to hear from you! Starting now, we’ll be publishing a survey with each update. You can find the link inside Firefox Reality on the Settings page or just click here.
TL;DR: As a rule of thumb, if you label something via aria-label or aria-labelledby, make sure it has a proper widget or landmark role.
The longer version is that several elements created extraneous amount of announcements in screen readers in the past that were not really useful. Especially in the ARIA 1.0 days where a lot of things weren’t as clear and people were still gathering experience, this was an issue for elements or roles that mapped to regions, multiple landmarks of the same type on a page, etc. Therefore, best practice has become to label both widgets (which should be labeled anyway), and landmarks with means such as aria-label or aria-labelledby, to make them more useful. This is important for several reasons:
Assistive technologies don’t use all divs or span elements, and browsers filter them out if they’re not interesting enough, to keep the accessibility tree manageable.
“Section”, which is the accessible object role for an unlabeled section or div, is neither interactive nor specific, and neither is “TextFrame”, which is what gets rendered on Windows as the equivalent of a span element.
Such items are usually not focusable, so labeling them is largely superfluous.
So to give your aria-label or aria-labelledby more meaning, if you need to use these in the first place, it is best practice, and will probably soon be required, to give such elements a proper widget role such as “button” or “link”, or landmark role such as “complementary”, or “region”. In fact, there will, alongside this requirements change, probably be requirements for user agents in the future to no longer expose aria-label* if an associated role isn’t present. These assumptions I am making are based on the way practitioners have advised these techniques in recent times, as well as rumours and fragmented discussions in various channels among people close to the ARIA and HTML specifications.
I, for one, also recommend and welcome such changes. A div with an aria-label is much more meaningful if it is clear that it groups some elements together. It probably is meant to act as a composit widget or grouping element for true widgets anyway, so giving it a role of “group” in such situations is more correct anyway. That is, if you cannot use fieldset and legend for some reason.
Some of these rules are already enforced on the HTML side of things, for example an HTML section element is only mapped to a region if a label is provided. This all is to reduce the amount of noise certain elements can create if not labeled, and also make sure that if you label something, it also has a meaningful expression of what it is you’re labeling.
Screen readers use this better information to help users navigate complex pages. Hearing “complementary” multiple times is far less meaningful than actually telling users that it’s a certain type of side bar or adjacent element group to something else you’re interacting with.
I was talking about tooling with Mark Reid a few weeks ago.
I've been trying to find a way to simplify sharing analyses throughout the company.
This is an old problem at Mozilla that I've tried to address a couple of times
but I haven't found the silver bullet yet …
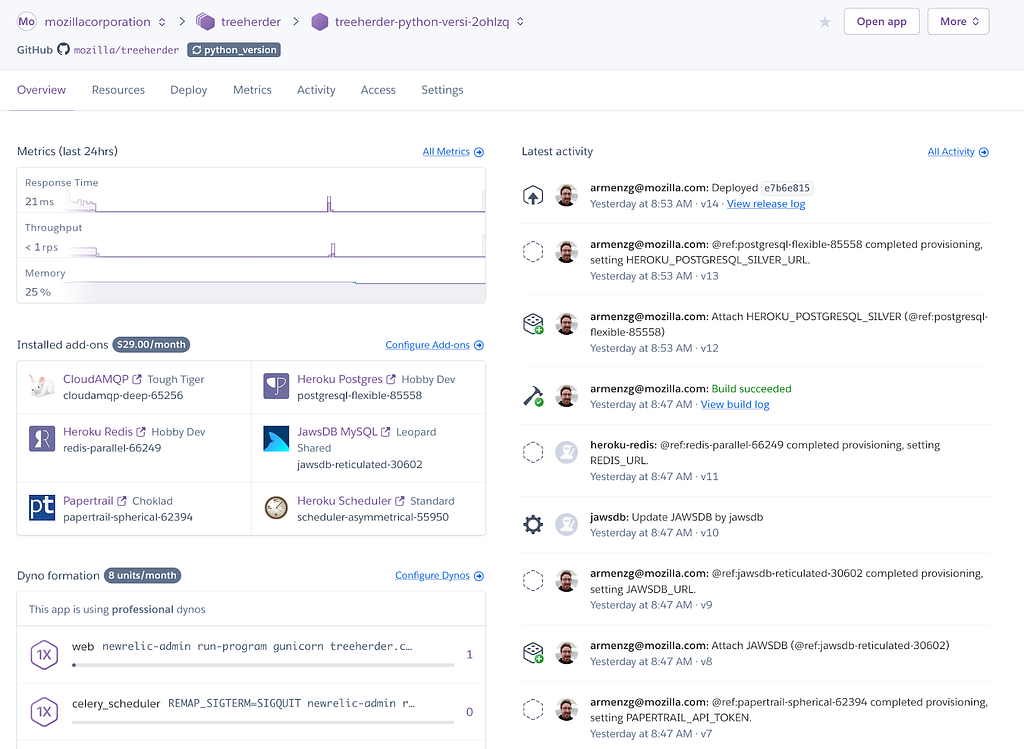
In bug 1566207 I added support for Heroku Review Apps (link to official docs). This feature allows creating a full Treeherder deployment (backend, frontend and data ingestion pipeline) for a pull request. This gives Treeherder engineers the ability to have their own deployment without having to compete over the Treeherder prototype app (a shared deployment). This is important as the number of engineers and contributors increases.
A Review app can be created from Heroku Pipelines page
Once created you get a complete Heroku environment with add-ons and workers configured and the deployment for it.
Heroku Review app ready for usage
Looking back, there are few new features that came out of the work, however, Heroku Review apps are not used as widely as I would have hoped for.
One of the benefits that came out of this project is that incidentally we solved a long standing Pulse consumption feature request (Thanks Dustin for the idea!) In order to consume data from Pulse, we need to provide a username and a password. There’s no guest or unauthenticated method for Pulse messages consumption. If credentials were to be shared we would have multiple consumers for the same queues with each consumer competing for the same set of messages. The solution to this problem is by creating queues dynamically with a couple of environment variables (see code). This means that each Heroku Review App will use the same set of credentials, however, consumer from different queues, thus, not competing for messages. This solution also solves the same problem for local development. The local development set up will be able to share credentials across Treeherder developers (each having their own queues).
Another good thing that came out of the project is that we can reduce the number of tasks the pipeline consumes. This is important for the Heroku Review App (as well as the local development set up) because we don’t need to set up too many Heroku workers to process all the data that comes out of Taskcluster (Firefox’s CI). In Heroku, we have close to 20 workers to handle the load. In order to keep the cost down for a Heroku Review App (workers + add-ons) I decided to limit the ingestion to autoland & android-components. This is accomplished with the PROJECTS_TO_INGEST environment variable which can be changed after the app is created. The day is nearer when the local ingestion pipeline could be started automatically without bringing your laptop to its knees.
One last advantage is that we can test different versions of MySql by simply changing one line for the JawsDB Heroku add-on. This is important because it will remove coordinating Treeherder RDS/Terraform changes with dividehex before we’re fully ready. We can also modify other add-ons, however, changing the MySql version is the most significant we can tweak.
Unfortunately, the Heroku Review Apps are not used as much as I would have wished for. Treeherder devs tend to borrow the Heroku treeherder-prototype app instead of creating a Heroku Review App. I know it will be useful in the future since I have experienced at least once where three of us wanted to use the shared Heroku app.
On a separate note, the configuration of the add-ons is not as advertised. You don’t have full control of what plans your add-ons get configured with. For instance, I could specify the Tiger plan for the CloudAMQP add-on yet get the Lemur plan instead. I found out that permitting certain add-ons needs to be requested via a Heroku support ticket. This is because I’m not a Mozilla Heroku org manager but one of the developers using the account. It seems that there are some default plan for each add-on configured at the org level. Fortunately, the Heroku folks were very quick to fix this for me.
Overall, I’m quite satisifed with how simple it is to set up Heroku Review Apps for your Heroku pipeline. Good job Heroku team!
After many months of discussion on the mozilla.dev.security.policy mailing list, our Root Store Policy governing Certificate Authorities (CAs) that are trusted in Mozilla products has been updated. Version 2.7 has an effective date of January 1st, 2020.
More than one dozen issues were addressed in this update, including the following changes:
Beginning on 1-July, 2020, end-entity certificates MUST include an Extended Key Usage (EKU) extension containing KeyPurposeId(s) describing the intended usage(s) of the certificate, and the EKU extension MUST NOT contain the KeyPurposeId anyExtendedKeyUsage. This requirement is driven by the issues we’ve had with non-TLS certificates that are technically capable of being used for TLS. Some CAs have argued that certificates not intended for TLS usage are not required to comply with TLS policies, however it is not possible to enforce policy based on intention alone.
Certificate Policy and Certificate Practice Statement (CP/CPS) versions dated after March 2020 can’t contain blank sections and must – in accordance with RFC 3647 – only use “No Stipulation” to mean that no requirements are imposed. That term cannot be used to mean that the section is “Not Applicable”. For example, “No Stipulation” in section 3.2.2.6 “Wildcard Domain Validation” means that the policy allows wildcard certificates to be issued.
Section 8 “Operational Changes” will apply to unconstrained subordinate CA certificates chaining up to root certificates in Mozilla’s program. With this change, any new unconstrained subordinate CA certificates that are transferred or signed for a different organization that doesn’t already have control of a subordinate CA certificate must undergo a public discussion before issuing certificates.
We’ve seen a number of instances in which a CA has multiple policy documents and there is no clear way to determine which policies apply to which certificates. Under our new policy, CAs must provide a way to clearly determine which CP/CPS applies to each root and intermediate certificate. This may require changes to CA’s policy documents.
Mozilla already has a “required practice” that forbids delegation of email validation to third parties for S/MIME certificates. With this update, we add this requirement to our policy. Specifically, CAs must not delegate validation of the domain part of an email address to a third party.
We’ve also added specific S/MIME revocation requirements to policy in place of the existing unclear requirement for S/MIME certificates to follow the BR 4.9.1 revocation requirements. The new policy does not include specific requirements on the time in which S/MIME certificates must be revoked.
Other changes include:
Detail the permitted signature algorithms and encodings for RSA keys and ECDSA keys in sections 5.1.1 and 5.1.2 (along with a note that Firefox does not currently support RSASSA-PSS encodings).
Add the P-521 exclusion in section 5.1 of the Mozilla policy to section 2.3 where we list exceptions to the BRs.
Change references to “PITRA” in section 8 to “Point-in-Time Audit”, which is what we meant all along.
Update required minimum versions of audit criteria in section 3.1
A comparison of all the policy changes is available here.
A few of these changes may require that CAs revise their CP/CPS(s). Mozilla will send a CA Communication to alert CAs of the necessary changes, and ask CAs to provide the date by which their CP/CPS documents will be compliant.
We have also recently updated the Common CA Database (CCADB) Policy to provide specific guidance to CAs and auditors on audit statements. As a repository of information about publicly-trusted CAs, CCADB now automatically processes audit statements submitted by CAs. The requirements added in section 5.1 of the policy help to ensure that the automated processing is successful.
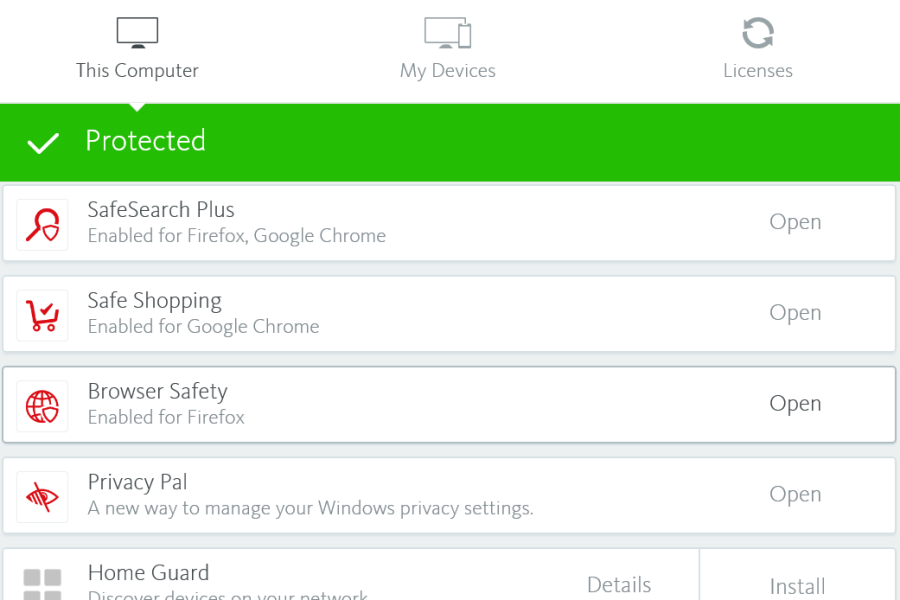
A while back we’ve seen how Avast monetizes their users. Today we have a much smaller fish to fry, largely because the Avira’s extensions in question aren’t installed by default and require explicit user action for the additional “protection.” So these have far fewer users, currently 400 thousands on Firefox and slightly above a million on Chrome according to official add-on store numbers. It doesn’t make their functionality any less problematic however.
That’s especially the case for Avira Browser Safety extension that Avira offers for Firefox and Opera. While the vendor’s homepage lists “Find the best deals on items you’re shopping for” as last feature in the list, the extension description in the add-on stores “forgets” to mention this monetization strategy. I’m not sure why the identical Chrome extension is called “Avira Safe Shopping” but at least here the users get some transparency.
Summary of the findings
The Avira Browser Safety extension is identical to Avira Safe Shopping and monetizes by offering “best shopping deals” to the users. This functionality is underdocumented, particularly in Avira’s privacy policy. It is also risky however, as Avira chose to implement it in such a way that it will execute JavaScript code from Avira’s servers on arbitrary websites as well as in the context of the extension itself. In theory, this allows Avira or anybody with control of this particular server to target individual users, spy on them or mess with their browsing experience in almost arbitrary ways.
In addition to that, the security part of the extension is implemented in a suboptimal way and will upload the entire browsing history of the users to Avira’s servers without even removing potentially sensitive data first. Again, Avira’s privacy policy is severely lacking and won’t make any clear statements as to what happens with this data.
How does this monetization approach work?
You’ve probably seen some of the numerous websites offering you coupon codes for certain shops to help you get the best deal. Or maybe you’ve even used browser extensions doing the same. If you ever asked yourself what these are getting out of it: the shop owners are paying them for referring customers to the shop. So even if you already were at this shop and selected the product you wanted to buy, if you then wandered off to a coupon deal website and had it send you back to the shop – the owner of the coupon deal website gets paid a certain percentage of your spending.
And that’s the reason why users of Avira Browser Safety, having installed that browser extension for protection, will occasionally see a message displayed on top of a website. Whenever some user takes advantage of the offers, the shop owners pay Avira. Not directly of course but via their partner Ciuvo GmbH which appears to provide the technology behind this feature.
Why is this feature problematic?
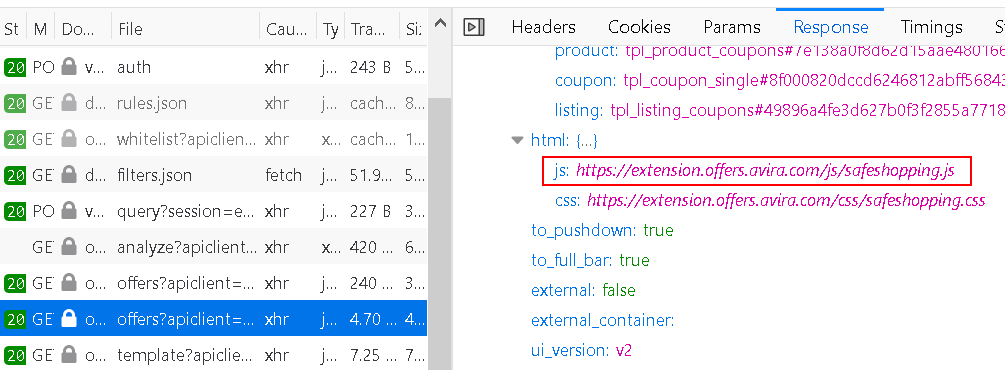
Monetizing a product in this way isn’t unusual. Ciuvo has their own browser extension sharing some code with Avira’s. And a bunch of other antivirus vendors also offer shopping extensions, without these being considered problematic as long as users install them by choice. However, Avira for some reason decided that they want full control over this feature without having to release a new extension version. So whenever the extension asks https://offers.avira.com/aviraoffers/api/v2/offers for a list of deals, the response contains a JavaScript URL among other things.
What does the extension do with this script? It runs it in the context of the extension where it can do anything that the extension can do (meaning: “Access your data for all websites”). Mind you, this functionality is specific to Avira, Ciuvo’s own browser extension gets along without it just fine.
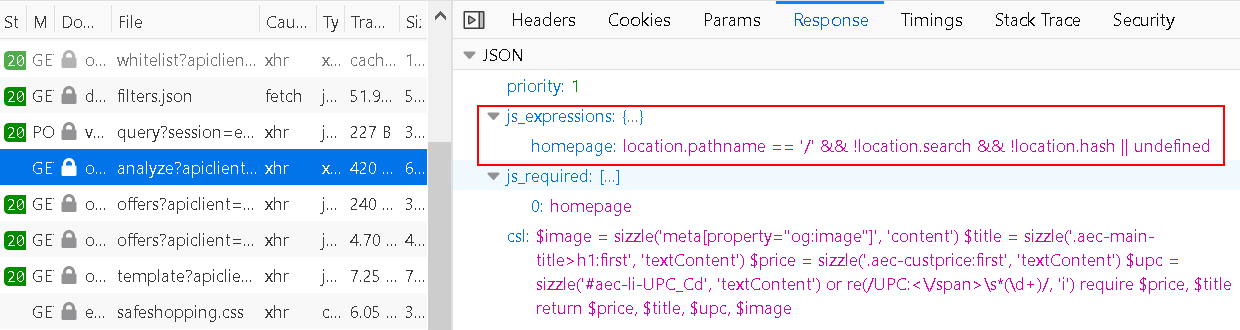
It’s not just that. Before the extension requests offers, it analyzes the page. The rules for performing this analysis are also determined by the server when responding to https://offers.avira.com/aviraoffers/api/v2/analyze request. The response contains a list of “JS expressions” which is essentially that: JavaScript code to be run in the context of the page, again functionality missing from the Ciuvo extension.
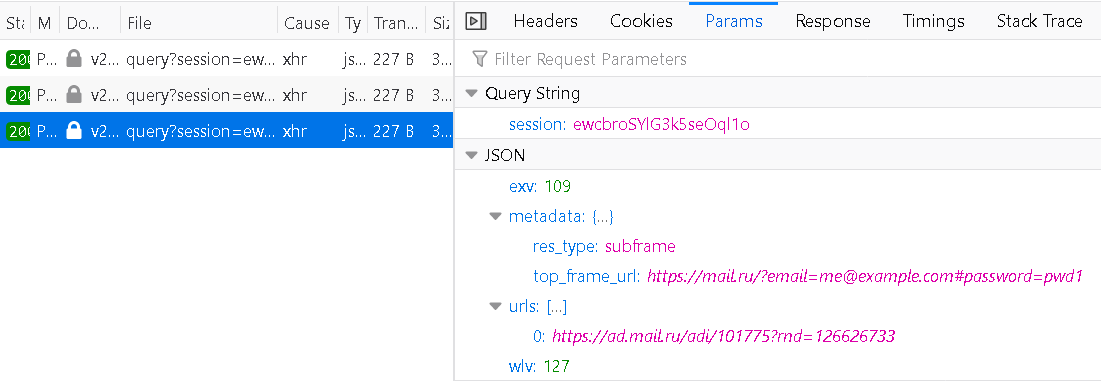
And how are the websites selected where these actions have to be performed? They are also determined by the Avira server of course, every now an then the extension will download a huge list from https://offers.avira.com/aviraoffers/api/v2/whitelist.
The end result is: Avira decides what websites this extension should mess with and it decides how the extension should mess with them. And while functionality in the released extension applies to all users, Avira (or anybody taking control of offers.avira.com) could target individual users to ship a malicious payload to them. In fact, they could even change the extension functionality completely, e.g. turning it into spyware or adware – but only for users in Brazil, so that it doesn’t get noticed. That’s a whole lot of trust to ask for, and it makes Avira infrastructure a very valuable hacking target.
Let’s talk about privacy
Even if you ignore the fact that Avira can repurpose this extension at any time, there is the question of privacy. In the process of “page analysis” the extension collects and transmits considerable amounts of data. You can see the script guiding this data collection as csl in the image above. Typically, it will extract the description of the product you are looking at as well as pricing information. Is there maybe some price comparison service out there running on this data? However, it will also transmit your Google search query for example if the search produces shopping results. All that data is being accompanied by a random albeit persistent user identifier.
Having access to that much data, Avira will certainly have a well-written privacy policy? Actually, the first challenge is finding it: Avira Browser Safety listing on Mozilla Add-ons doesn’t even link to the privacy policy. And while this privacy policy has individual sections for various products, Avira Browser Safety isn’t listed. But the identical Avira Safe Shopping extension is listed, so we can check there:
If you use Avira Safe Shopping, it is part of our contractual obligation to present you with suitable products from other providers or other providers’ conditions for the same product. Data processing is done exclusively in accordance with the performance of the contract.
Does this mean that Avira doesn’t store any of this data whatsoever? I’d certainly hope so, but I’m not sure that this is the meaning. Also, why send a user identifier along if you don’t keep the data?
There is also the question about what data third parties receive here. For example, if you select a coupon on the website displayed above you first get sent to https://offers.avira.com/aviraoffers/api/v2/tracker (no, doesn’t sound like Avira isn’t keeping any data) which redirects you to ciuvo.com which redirects you to savings.com which (after setting lots of cookies) redirects you to pjtra.com which redirects you to pepperjamnetwork.com which (after also setting lots of cookies) finally sends you back to the shop. For other websites you will see other redirect chains involving other companies.
And what about browsing history data?
There is also the actual security part of the extension, preventing you from visiting malicious websites. In order to decide which website is malicious it sends requests to https://v2.auc.avira.com/api/query. In the process it uploads your entire browsing history, along with any potentially sensitive URL parameters. While the session parameter seen here is temporary, a session is created by requesting https://v2.auc.avira.com/api/auth with a persistent user identifier, so in principle the entire browsing history for any user can be reconstructed on the server side.
There are two factors that distinguish this from the Avast case and make this look like lack of concern rather than outright spying. First, there is no context information being collected here. And second, the server responses are cached to some degree, so visiting a website won’t always result in a request to Avast servers.
Still, Avira would be well-advised to at least remove query and anchor parts from the addresses. Also, their privacy policy needs clear statements on how this data is processed and whether any of it is being retained.
Conclusions
The excessive data collection, incomplete privacy policy, unexpected functionality and execution of remote code are all issues that violate Mozilla Add-ons policies. I notified Mozilla and I assume that they will ask Avira to fix these. Maybe the Firefox extension will even be renamed to match the one for Chrome?
Update (2019-12-12): As of now, Avira Browser Safety extension is no longer listed on Mozilla Add-ons. I did not receive any reply from Mozilla yet other than “we are looking into this.”
I did not report any of this to Google, none of these issues have been considered a concern in the past. In particular, Google allows execution of remote code as long as there is no proof for it being used for malicious purposes. But I hope that Avira will improve their Chrome extension as well nevertheless.