Emily Dunham: Toy hypercube construction |
I think hypercubes are neat, so I tried to make one out of string to play with. In the process, I discovered that there are surprisingly many ways to fail to trace every edge of a drawing of a hypercube exactly once with a single continuous line.
This puzzle felt like the sort of problem that some nerd had probably solved before, so I searched the web and discovered that the shape I was trying to configure the string into is called an Eulerian Cycle.
I learned that any graph in which every vertex attaches to an even number of edges has such a cycle, which is useful for my craft project because the euler cycle is literally the path that the string needs to take to make a model of the object represented by the graph.
To construct a toy hypercube or any other graph, you need the graph. To make it from a single piece of string, every vertex should have an even number of edges.
Knowing the number of edges in the graph will be useful later, when marking the string.
For the edges of the toy, I wanted something that’s a bit flexible but can sort of stand up on its own. I found that cotton clothesline rope worked well: it’s easy to mark, easy to pin vertex numbers onto, and sturdy but still flexible. I realized after completing the construction that it would have been clever to string items like beads onto the edges to make the toy prettier and identify which edge is which.
For the vertices, I pierced jump rings through the rope, then soldered them shut, to create flexible attachment points. This worked better than a previous prototype in which I used flimsier string and made the vertices from beads.
Vertices could be knotted, glued, sewn, or safety pinned. A bookbinding awl came in handy for making holes in the rope for the rings to go through.
First, I drew the graph of the shape I was trying to make – in this case, a hypercube. I counted its edges per vertex, 4. I made sure to draw each vertex with spots to write numbers in, half as many numbers as there are edges, because each time the string passes through the vertex it makes 2 edges. So in this case, every vertex needs room to write 2 numbers on it.
Here’s the graph I started with. I drew the edges in a lighter color so I could see which had already been visited when drawing in the euler cycle.
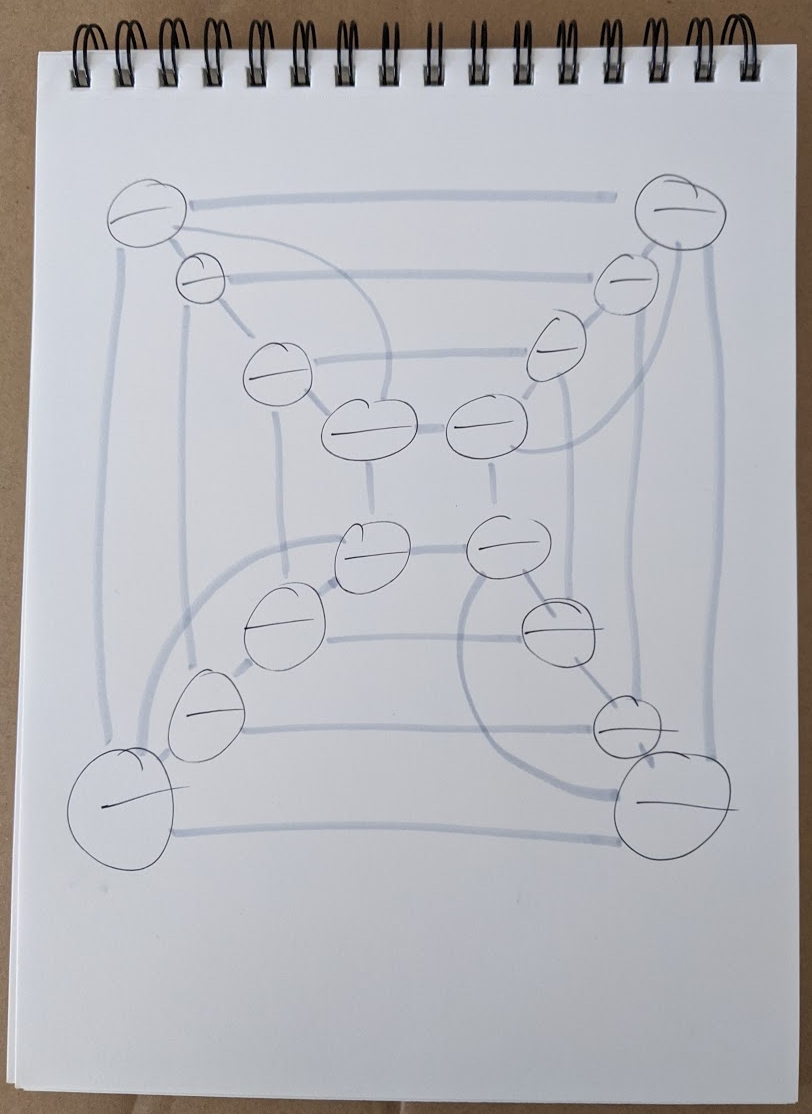
Then I started from an arbitrary vertex and drew in the line. Any algorithm for finding euler paths will suffice to draw the line. The important part of tracing the line on the graph is to mark each vertex it encounters, sequentially. So the vertex I start at is 1, the first vertex I visit is 2, and so forth.
Since the euler path visits every vertex of my particular hypercube twice, every vertex will have 2 numbers (the one I started at will have 3) when I finish the math puzzle. These pairs of numbers are what tell me which part of the string to attach to which other part.
Here’s what my graph looked like once I found an euler cycle in it and numbered the vertices that the cycle visited:
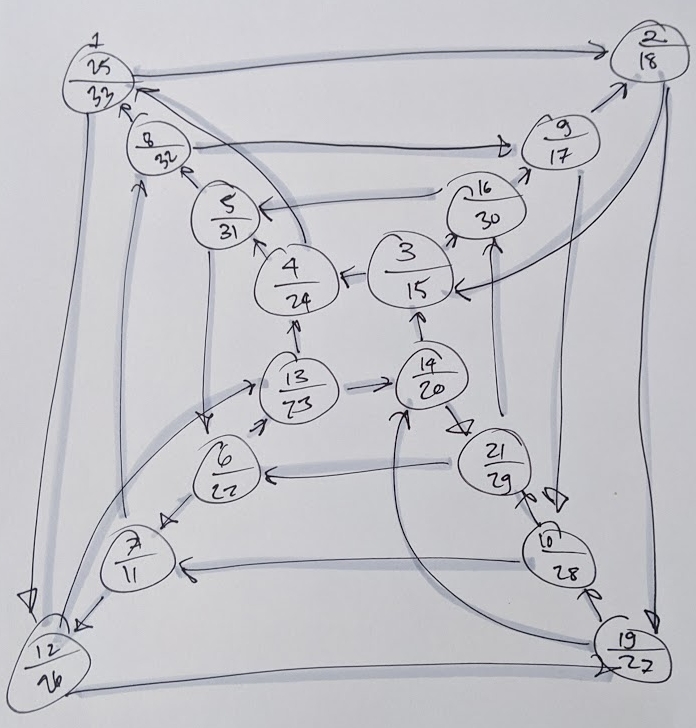
Since my graph has 32 edges, I made 33 evenly spaced marks on the string. I used an index card to measure them because that seemed like an ok size, but in retrospect it would have been fine if I’d made it smaller.

I then numbered each mark in sequence, from 1 to 33. I numbered them by writing the numbers on slips of paper and pinning the papers to the rope, but if I was using a ribbon or larger rope, the numbers could have been written directly on it. If you’re doing this at home, you could mark the numbers on masking tape on the rope just as well.

The really tedious step is applying the vertices. I just went through the graph, one vertex at a time, and attached the right points on the string together for it.
The first vertex had numbers 1, 25, and 33 on it for the euler cycle I drew and numbered on the graph, so I attached the string’s points 1, 25, and 33 together with a jump ring. The next vertex on the drawing had the numbers 2 and 18 on it, so I pierced together the points on the string that were labeled 2 and 18.
I don’t think it matters what order the vertices are assembled in, as long as the process ultimately results in all the vertices on the graph being represented by rings affixing the corresponding points on the string together.
I also soldered the rings shut, because after all that work I don’t want them falling out.

That’s all there is to it!

I’m going to have to find a faster way to apply the vertices before attempting a 6D hypercube. An ideal vertex would allow all edges to rotate and reposition themselves freely, but failing that, a lighter weight string and crimp fasteners large enough to hold 6 pieces of that string might do the trick.
The finished toy is not much to look at, but quite amusing to try to flatten into 3-space.

|
|
Cameron Kaiser: And now for something completely different: The dawning of the Age of Apple Aquarius |
In 1986 the 68K processor line was still going strong but showing its age, and a contingent of Apple management (famously led by then-Mac division head Jean-Louis Gass'ee and engineer Sam Holland) successfully persuaded then-CEO John Sculley that Apple should be master of its own fate with its own CPU. RISC was just emerging at that time, with the original MIPS R2000 CPU appearing around 1985, and was clearly where the market was going (arguably it still is, since virtually all major desktop and mobile processors are load-store at the hardware level today, even Intel); thus was the Aquarius project born. Indeed, Sculley's faith in the initiative was so great that he allocated a staff of fifty and even authorized a $15 million Cray supercomputer, which was smoothed over with investors by claiming it was for modeling Apple hardware (which, in a roundabout and overly optimistic way, it was).
Holland was placed in charge of the project and set about designing the CPU for Aquarius. The processor's proposed feature set was highly ambitious, including four cores and SIMD (vector) support with inter-processor communication features. Holland's specification was called Scorpius; the initial implementation of the Scorpius design was to be christened Antares. This initial specification is what was posted at the Internet Archive, dated around 1988.
Despite Sculley and Gass'ee's support, Aquarius was controversial at Apple from the very beginning: it required a substantial RandD investment, cash which Apple could ill afford to fritter away at the time, and even if the cash were there many within the company did not believe Apple had sufficient technical chops to get the CPU to silicon. Holland's complex specification worried senior management further as it required solving various technical problems that even large, highly experienced chip design companies at the time would have found difficult.
With only a proposal and no actual hardware by 1988, Sculley became impatient, and Holland was replaced by Al Alcorn. Alcorn was a legend in the industry by this time, best known for his work at Atari, where he designed Pong and was involved in the development of the Atari 400 and the ill-fated "holographic" Atari Cosmos. After leaving Atari in 1981, he consulted for various companies and was brought in by Apple as outside expertise to try to rescue Aquarius. Alcorn pitched the question to microprocessor expert Hugh Martin, who studied the specification and promptly pronounced it "ridiculous" to both Alcorn and Sculley. On this advice Sculley scuttled Aquarius in 1989 and hired Martin to design a computer instead using an existing CPU. Martin's assignment became the similarly ill-fated Jaguar project, which completed poorly with another simultaneous project led by veteran engineer Jack McHenry called Cognac. Cognac, unlike Jaguar and Aquarius, actually produced working hardware. The "RISC LC" that the Cognac team built, originally a heavily modified Macintosh LC with a Motorola 88100 CPU running Mac OS, became the direct ancestor of the Power Macintosh. The Cray supercomputer, now idle, eventually went to the industrial design group for case modeling until it was dismantled.
Now that we have an actual specification to read, how might this have compared to the PowerPC 601? Scorpius defined a big-endian 32-bit RISC chip addressing up to 4GB of RAM with four cores, which the technical specification refers to as processing units, or PUs. Each core shares instruction and data caches with the others and communicates over a 5x4 crossbar network, and because all cores on a CPU must execute within the same address space, are probably best considered most similar to modern hardware threads (such as the 32 threads on the SMT-4 eight core POWER9 I'm typing this on). An individual core has 16 32-bit general purpose registers (GPRs) and seven special purpose registers (SPRs), plus eight global SPRs common to the entire CPU, though there is no floating-point unit in the specification we see here. Like ARM, and unlike PowerPC and modern Power ISA, the link register (which saves return addresses) is a regular GPR and code can jump directly to an address in any register. However, despite having a 32-bit addressing space and 32-bit registers, Scorpius uses a fixed-size 16-bit instruction word. Typical of early RISC designs and still maintained in modern MIPS CPUs, it also has a branch delay slot, where the instruction following a branch (even if the branch is taken) is always executed. Besides the standard cache control instructions, there are also special instructions for a core to broadcast to other cores, and the four PUs could be directed to work on data in tandem to yield SIMD vector-like operations (such as what you would see with AltiVec and SSE). Holland's design even envisioned an "inter-processor bus" (IPB) connecting up to 16 CPUs, each with their own local memory, something not unlike what we would call a non-uniform memory access (NUMA) design today.
The 16-bit instruction size greatly limits the breadth of available instructions compared to PowerPC's 32-bit instructions, but that would certainly be within the "letter" spirit of RISC. It also makes the code possibly more dense than PowerPC, though the limited amount of bits available for displacements and immediate values requires the use of a second prefix register and potentially multiple instructions which dampens this advantage somewhat. The use of multiple PUs in tandem for SIMD-like operations is analogous to AltiVec and rather more flexible, though the use of bespoke hardware support in later SIMD designs like the G4 is probably higher performance. The lack of a floating-point unit was probably not a major issue in 1986 but wasn't very forward-looking as every 601 shipped with an FPU standard from the factory; on the other hand, the NUMA IPB was very adventurous and certainly more advanced than multiprocessor PowerPC designs, something that wasn't even really possible until the 604 (or not without a lot of hacks, as in the case of the 603-based BeBox).
It's ultimately an academic exercise, of course, because this specification was effectively just a wish list whereas the 601 actually existed, though not for several more years. Plus, the first Power Macs, being descendants of the compatibility-oriented RISC LC, could still run 68K Mac software; while the specification doesn't say, Aquarius' radical differences from its ancestor suggests a completely isolated architecture intended for a totally new computer. Were Antares-based systems to actually emerge, it is quite possible that they would have eclipsed the Mac as a new and different machine, and in that alternate future I'd probably be writing a droll and informative article about the lost RISC Mac prototype instead.
http://tenfourfox.blogspot.com/2019/12/and-now-for-something-completely_29.html
|
|
Cameron Kaiser: TenFourFox FPR18b1 available |
In FPR18, Reader mode has two main changes: first, it is updated to the same release used in current versions of Firefox (I rewrote the glue module in TenFourFox so that current releases could be used unmodified, which helps maintainability), and second, Reader mode is now allowed on most web pages instead of only on ones Readability thinks it can render. By avoiding a page scan this makes the browser a teensy bit faster, but it also means that edge-case web pages that could still usefully display in Reader mode now can do so. When Reader mode can be enabled, a little "open book" icon appears in the address bar. Click that and it will turn orange and the page will switch to Reader mode. Click it again to return to the prior version of the page. Certain sites don't work well with this approach and are automatically filtered; we use the same list as Firefox. If you want the old method where the browser would scan the page first before offering reader mode, switch tenfourfox.reader.force-enable to false and reload the tab, and please mention what it was doing inappropriately so it can be investigated.
Reader mode isn't seamless, and in fairness wasn't designed to be. The most noticeable discontinuity is if you click a link within a Reader mode page, it renders that link in the regular browser (requiring you to re-enter Reader mode if you want to stay there), which kind of sucks for multipage documents. I'm considering a tweak to it such that you stay in Reader mode in a tab until you exit it but I don't know how well this would work and it would certainly alter the functionality of many pages. Post your thoughts in the comments. I might consider something like this for FPR19.
Besides the usual security updates, FPR18 also makes a minor compatibility fix to the browser and improves the comprehensiveness of removing browser data for privacy reasons. More work needs to be done on this because of currently missing APIs, but this first pass in FPR18 is a safe and easy improvement. As this is the first "fast four week" release, it will become live January 6.
I also wrote up another quickie script for those of you exploring TenFourFox's AppleScript support. Although Old Reddit appears to work just dandy with TenFourFox, the current React-based New Reddit is a basket case: it's slow, it uses newer JavaScript support that TenFourFox only allows incompletely, and its DOM is hard for extensions to navigate. If you're stuck on New Reddit and you can't read the comments because the "VIEW ENTIRE CONVERSATION" button doesn't work because React and if you work on React I hate you, you can now download Reddit Moar Comments. When the script is run, if a Reddit comments thread is in the current tab, it acts as if the View Entire Conversation button had been clicked and expands the thread. If you're like me, put the Scripts menu in the menu bar (using the AppleScript Utility), have a TenFourFox folder in your Scripts, and put this script in it so it's just a menu drop-down or two away. Don't forget to try the other possibly useful scripts in that folder, or see if you can write your own.
Merry Christmas to those of you who celebrate it, and a happy holiday to all.
http://tenfourfox.blogspot.com/2019/12/tenfourfox-fpr18b1-available.html
|
|
Armen Zambrano: Reducing Treeherder’s time to-deploy |
Up until September we had been using code merges from the master branch to the production one to cause production deployments.
A merge to production would trigger few automatic steps:

If a regression was to be found on production we would either `git revert` a change out of all merged changes OR use Heroku’s rollback feature to the last known working state (without using Git).
Using `git revert` to get us back into a good state would be very slow since it would take 15–20 minutes to run through Travis, a Heroku build and a Heroku release.
On the other hand, Heroku’s rollback feature would be an immediate step as it would skip steps 1 and 2. Rolling back is possible because a previous build of a commit would still be available and only the release step would be needed .
The procedural change I proposed was to use Heroku’s promotion feature (similar to Heroku’s rollback feature). This would reuse a build from the staging app with the production app. The promotion process is a one-click button event that only executes the release step since steps 1 & 2 had already run on the staging app. Promotions would take less than a minute to be live.

This change made day to day deployments a less involved process since all deployments would take less that a minute. I’ve been quite satisfied with the change since a deployment requires less waiting around to validate a deployment.
|
|
Marco Zehe: Happy Chanukka |
Wishing all of my readers who celebrate it, a very happy Chanukka!
This year, Chanukka started at sundown on December 22 and runs through December 30. It coincides with Christmas. And as it so happens, the muslim mayor of London kicked off the Chanukka celebrations from a Christmas tree last night. In a world where there are so many separating thoughts and actions becoming more prominent again, endangering the free and open societies of some western countries, these connecting events are more important than ever.
Welcome to london…where the Muslim mayor of London kicks off the Jewish festival of Chanukah metre from a giant Christmas tree on one of the most famous sites in the world @JLC_uk @JewishLondon @ChabadUK @JewishNewsUK @sadiqkhan pic.twitter.com/5V8sUtaeE5
— Justin Cohen (@CohenJust) December 22, 2019
Let me close by sharing with you a musical wish for a happy Chanukka by one of my favorite bands, the Canadians Walk Off The Earth, featuring Scott Helman.
|
|
Marco Zehe: WordPress accessibility team member, Gutenberg contributor |
My recent frequent blogging about Gutenberg has led to some really productive changes.
One change is that my profile on WordPress.org now shows that I am also contributing to the accessibility effort. The accessibility team mostly consists of volunteers. And now, I am one of them as well.
I also started contributing more than issues to Gutenberg. I can also review and label issues and pull requests now. There are some exciting changes ahead that I helped test and review in the past few days, and I promise I’ll blog about them once they are in an official plugin release.
It is my hope that my contributions will help bring the accessibility forward in a good direction for all. I’d like to thank both the other members of the WordPress accessibility team as well as the maintainers of Gutenberg for welcoming me to the community.
https://marcozehe.de/2019/12/22/wordpress-accessibility-team-member-gutenberg-contributor/
|
|
Cameron Kaiser: RIP, Chuck Peddle |
I will not recapitulate his life or biography except to say that when I saw him a number of years ago in a Skype appearance at Vintage Computer Festival East (in a big cowboy hat) he was a humble, knowledgeable and brilliant man. Computing has lost one of its most enduring pioneers, and I think it can be said without exaggeration that the personal computing era probably would not have happened without him.

http://tenfourfox.blogspot.com/2019/12/rip-chuck-peddle.html
|
|
Marco Zehe: Recap: The web accessibility basics |
Today, I am just quickly going to recommend you an old, but all-time reader favorite post of mine I published 4 years ago. And it is as current today as it was then, and most of it already was in the year 2000. Yes, I’m talking about the basics of web accessibility.
https://marcozehe.de/2019/12/21/recap-the-web-accessibility-basics/
|
|
Daniel Stenberg: Summing up My 2019 |
2019 is special in my heart. 2019 was different than many other years to me in several ways. It was a great year! This is what 2019 was to me.
I quit Mozilla last year and in the beginning of the year I could announce that I joined wolfSSL. For the first time in my life I could actually work with curl on my day job. As the project turned 21 I had spent somewhere in the neighborhood of 15,000 unpaid spare time hours on it and now I could finally do it “for real”. It’s huge.
Still working from home of course. My commute is still decent.

Just in November 2018 the name HTTP/3 was set and this year has been all about getting it ready. I was proud to land and promote HTTP/3 in curl just before the first browser (Chrome) announced their support. The standard is still in progress and we hope to see it ship not too long into next year.
Focusing on curl full time allows a different kind of focus. I’ve landed more commits in curl during 2019 than any other year going back all the way to 2005. We also reached 25,000 commits and 3,000 forks on github.
We’ve added HTTP/3, alt-svc, parallel transfers in the curl tool, tiny-curl, fixed hundreds of bugs and much, much more. Ten days before the end of the year, I’ve authored 57% (over 700) of all the commits done in curl during 2019.
We ran our curl up conference in Prague and it was awesome.
We also (re)started our own curl Bug Bounty in 2019 together with Hackerone and paid over 1000 USD in rewards through-out the year. It was so successful we’re determined to raise the amounts significantly going into 2020.
I’ve done 28 talks in six countries. A crazy amount in front of a lot of people.
Dagens Nyheter published this awesome article on me. I’m now shown on the internetmuseum. I was interviewed and highlighted in Bloomberg Businessweek’s “Open Source Code Will Survive the Apocalypse in an Arctic Cave” and Owen William’s Medium post The Internet Relies on People Working for Free.
When Github had their Github Universe event in November and talked about their new sponsors program on stage (which I am part of, you can sponsor me) this huge quote of mine was shown on the big screen.

Maybe not media, but in no less than two Mr Robot episodes we could see curl commands in a TV show!

I’ve participated in three podcast episodes this year, all in Swedish. Kompilator episode 5 and episode 8, and Kodsnack episode 331.
I’ve toyed with live-streamed programming and debugging sessions. That’s been a lot of fun and I hope to continue doing them on and off going forward as well. They also made me consider and get started on my libcurl video tutorial series. We’ll see where that will end…
I figure it can become another fun year too!
|
|
Firefox UX: People who listen to a lot of podcasts really are different |
|
|
Mozilla VR Blog: How much is that new VR headset really sharing about you? |

VR was big this holiday season - the Oculus Go sales hit the Amazon #1 electronics device list on Black Friday, and the Oculus Quest continues to sell. But in the spirit of Mozilla's Privacy Not Included guidelines, you might be wondering: what personal information is Oculus collecting while you use your device?
Reading the Oculus privacy policy, they say that they process and collect information like
That’s…a lot of data. Most of this data, like processing information about your physical movements is required for basic functionality of most MR experiences. For example, to track whether you avoid an obstacle in BeatSaber, your device needs to know the position of your head in space.
There’s a difference between processing and collecting. Like we mentioned, you can’t do much without processing certain data. Processing can either happen on the device itself, or on remote servers. Collecting data implies that it is stored remotely for a time period beyond what’s necessary for simply processing it.
Mozilla’s brand promise to our users is focused on security and privacy. So, while testing the Oculus Quest for Mozilla Mixed Reality products, we needed to know what kind of data was being sent to and from the device during a browsing session. The device has a developer mode that allows you to access advanced features by connecting it to your computer and using Android Debug Bridge (adb). From there, we used the developer mode and `adb` to install a custom trusted root certificate. This allows us to inspect the connections in depth.
So, what is Facebook transmitting from your device back to Facebook servers during a routine browsing session? From the data we saw, they’re reporting configuration and telemetry data, such as information about how long it took to fetch resources. For example, here’s a graph of the amount of data sent over time from the Oculus VR headset back to Facebook.
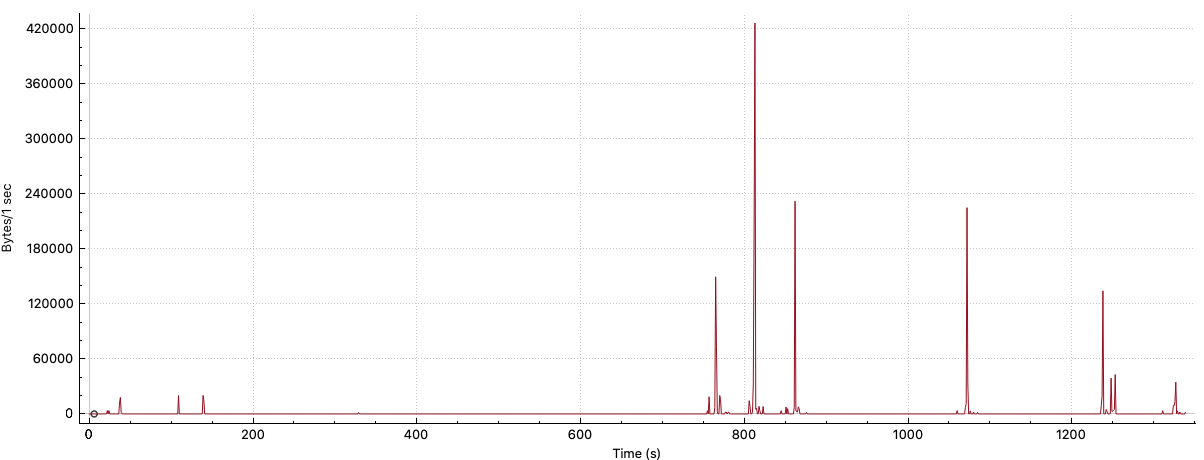
The data is identified by both an id, which is consistent across browsing sessions, and a session_id. The id appears to be linked to the device hardware, because linking a Facebook account didn’t change the identifier (or any other information as far as we detected).
In addition to general timing information, Facebook also receives reports on more granular, URL level timing information that uses a unique URL ID.
"time_to_fetch": "1",
"url_uid": "d8657582",
"firstbyte_time": "0",Like computers, mixed reality (MR) devices can collect data on the sites you visit and applications you interact with. They also have the ability to collect and transmit large amounts of other data, including biometrically-derived data (BDD). BDD includes any information that may be inferred from biometrics, like gaze, gait, and other nonverbal communication methods. 6DOF devices like the Oculus Quest track both head and body movement. Other devices, like the MagicLeap One and HoloLens 2, also track gaze. This type of data can reveal intrinsic characteristics about users, such as their height. Information about where they look can reveal details about a user’s sexual preferences and powerful insights into their psychology. Innocuous data like facial movements during a task have been used in research to predict high or low performers.
Fortunately, even though its privacy policy would allow it to, today Facebook does not appear to collect any of this MR-specific information from your Oculus VR headset. Instead, it focuses on collecting data about timing, application version, and other configuration and telemetry data. That doesn’t mean that they can’t do so in the future, according to their privacy policy.
In fact, Facebook just announced that Oculus VR data will now be used for ads if users are logged into Facebook. Horizon, Facebook's social VR experience, requires a linked Facebook account.
In addition to the difference between processing and collecting explained above, there’s a difference between committing to not collecting and simply not collecting. It’s not enough for Facebook to just not collect sensitive data now. They should commit not to collect it in the future. Otherwise, they could change the data they collect at any time without informing users of the change. Until BDD is protected and regulated, we need to be constantly vigilant.

Currently, BDD (and other data that MR devices can track) lacks protections beyond whatever is stipulated in the privacy policy (which is regulated by contract law), so companies often reserve the right to collect and disseminate all the information they might possibly want to, knowing that consumers rarely read (let alone comprehend) the legalese they agree to. It’s time for regulators and legislators to take action and protect sensitive health, biometric, and derived data from misuse by tech companies.
|
|
Marco Zehe: How to get around Matrix and Riot with a screen reader |
|
|
Daniel Stenberg: My 28 talks of 2019 |

In 2019 I did more public speaking than I’ve ever than before in a single year: 28 public appearances. More than 4,500 persons have seen my presentations live at both huge events (like 1,200 in the audience at FOSDEM 2019) but also some very small and up-close occasions. Many thousands more have also seen video recordings of some of the talks – my most viewed youtube talk of 2019 has been seen over 58,000 times. Do I need to say that it was about HTTP/3, a topic that was my most common one to talk about through-out the year? I suspect the desire to listen and learn more about that protocol version is far from saturated out there…

During the year I’ve done presentations in
Barcelona, Brussels, Copenhagen, Gothenburg, Mainz, Prague, Stockholm and Umea.
I’ve did many in Stockholm, two in Copenhagen.

During the year I’ve done presentations in
Belgium, Czechia, Denmark, Germany, Spain and Sweden.
Most of my talks were held in Sweden. I did one streamed from my home office!

14 of these talks had a title that included “HTTP/3” (example)
9 talks had “curl” in the title (one of them also had HTTP/3 in it) (example)
4 talks involved DNS-over-HTTPS (example)
2 talks were about writing secure code (example)

There will be talks by me in 2020 as well as the planning . Probably just a little bit fewer of them!
Sure, please invite me and I will consider it. I’ve written down some suggestions on how to do this the best way.

(The top image is from Fullstackfest 2019)
|
|
Mozilla Localization (L10N): L10n Report: December Edition |
Please note some of the information provided in this report may be subject to change as we are sometimes sharing information about projects that are still in early stages and are not final yet.
Firefox 72 is currently in Beta. The deadline to ship localization changes in this version is approaching fast, and will be on December 24th. For the next version, the deadline will be on January 28th.
Most of the new strings are in the onboarding and Content Feature Recommendations (CFR). You can see them in the What’s New panel in the app menu.

There is a lot going on with mobile these days, especially in regards to the transition of Firefox for Android browser (internal name Fennec) to a brand new browser (currently Firefox Preview, internal name Fenix).
Since the transition is expected to happen some time early 2020 (exact plans are still being discussed internally), we wanted to make a call to action to localizers to start now. We are still waiting for the in-app language switcher to be implemented, but since it is planned for very soon, we think it’s important that localizers get access to strings so they can complete and test their work in time for the actual release of Fenix (final name to be determined still).
The full details about all this can be found in this thread here. Please reach out directly to Delphine in order to activate Fenix in Pontoon for your locale (requests from managers only please), or if you have any questions.
Looking forwards to the best localized Android browser yet!
We added a few more pages recently. Though some pages are quite long, they do contain a lot of useful information on the advantages of using Firefox over other browsers. They come in handy when you want to promote Firefox products in your language.
New:
Updates:
This is a brand new product. The Mozilla WebThings is an open platform for monitoring and controlling devices over the web. It is a software distribution for smart home gateways focused on privacy, security and interoperability.Essentially, it is a smart home platform for bridging new and existing Internet of Things (IoT) devices to the web in a private and secure way.
More information can be found on the website. Speaking of the website, there is a plan to make the site localizable early next year. Stay tuned!
The initial localized content was imported from GitHub, content localized by contributors. Once imported, the localized content is by default in “translated” state. Locale managers and translators, please review these strings soon as they go directly to production.
This past month has been really busy for the community and for our content manager, we got new and updated articles for Firefox 71 on desktop and the release of many products on mobile: Firefox Preview and Firefox Lite.
Following is a selection of interesting new articles that have been translated:
The Mozilla Localization Community page on Facebook has shut down. To find out how this decision was reached, please read it here.
Three localization events were organized this quarter.

Bengali localization community
The weekend event was widely reported in the local press and social media in Bengali:
Want to showcase an event coming up that your community is participating in? Reach out to any l10n-driver and we’ll include that (see links to emails at the bottom of this report)

Know someone in your l10n community who’s been doing a great job and should appear here? Contact on of the l10n-drivers and we’ll make sure they get a shout-out (see list at the bottom)!
Did you enjoy reading this report? Let us know how we can improve by reaching out to any one of the l10n-drivers listed above.
https://blog.mozilla.org/l10n/2019/12/20/l10n-report-december-edition-2/
|
|
Firefox UX: How people really, really use smart speakers |
More and more people are using smart speakers everyday. But how are they really using them? Tawfiq Ammari, a doctoral candidate at the University of Michigan, in conjunction with researchers at Mozilla and Yahoo, published a paper which sheds some light on the question. To do this, he gathered surveys and user logs from 170 Amazon Alexa and Google Home users, and interviewed another 19 users, to analyze their daily use of voice assistants.
Users of both Google Home and Alexa devices can access a log showing all the interactions they’ve had with their device. Our 170 users gave us a copy of this log after removing any personal information, which meant we could understand what people were really using their devices for, rather than just what they remembered using their devices for when asked later. Together, these logs contained around 259,164 commands.
We collected 193,665 commands on Amazon Alexa which were issued between May 2015 and August 2017, a period of 851 days. On average, the datasets for our 82 Amazon Alexa users span 210 days. On the days when they used their VA, Alexa users issued, on average,18.2 commands per day. We collected 65,499 commands on Google Home between September 2016 and July 2017, a period of 293 days. On average, the datasets for each of the 88 Google Home users spans 110 days. On days when they used their VA,Google Home users issued, on average, 23.2 commands per day with a median of 10.0 commands per day.
For both Amazon Alexa and Google Home, the top three command categories were listening to music, hands-free search, and controlling IoT devices. The most prevalent command for Amazon Alexa was listening to music, while Google Home was used most for hands-free search. We also found a lot of items in the logs reflecting that both devices didn’t often understand queries, or mis-heard other conversation as commands — that’s 17% in the case of Google Home and 11% in the case of Alexa, although those aren’t quite comparable because of the way that each device logs errors.
People used their smart speakers for all sorts of searches. For example, some of our respondents use VAs to convert measurement units while cooking. Others used their VAs to look up trivia with friends. Users also searched for an artist who sang a particular song, or looked for a music album under a specific genre (e.g., classical music).
The third largest category was controlling Internet of Things (IoT) devices, making up about 10% of the Google Home commands and about 17% of the Alexa commands. These were most frequently turning smart lights on and off, although also included controlling smart thermostats and changing light colors. Users told us in interviews that they were frustrated by some of the aspects of IoT control. For example, Brad told us that he was frustrated that when he asked the smart speaker in his kitchen to “turn the light off,” it wouldn’t work. He had to tell it to “turn the kitchen light off”.
We also found a long list of particular uses of smart speakers: asking for jokes, weather reports, and setting timers or alarms, for example. One thing we found interesting was that on both platforms there were nearly twice as many requests to turn the volume down than requests to turn the volume up, which suggests that default volume levels may be set too high for most homes.
Despite their use of voice assistants, our interviewees had some real concerns about their voice assistants. Both Amazon Alexa and Google Home provide user logs where users can view their voice commands. They both also provide a feature to “mute” their VAs. While most of our survey respondents were aware of the user history logs (~70%), more than a quarter of our respondents did not know that they could delete entries in their logs and only a small minority (~11%) had viewed or deleted entries in their logs.
Users also worried about whether their voice assistant was “listening all the time.” This was particularly contentious when family members and friends became “secondary users” of the voice assistant just by being in the same physical space. For example, Harriet told us that her “in-laws were mortified that someone could hack in and see what I’m doing, but what are they going to learn?”
Other users were worried about how their data was being processed on cloud services and shared with third party apps. John noted that he was concerned about how VAs “reach out to…third party services” when for example asking about the weather. He was concerned that he knew very little about what information is sent to third party services and how these data are stored.
While Mozilla has no plans to make a smart speaker, we do think it’s important to share our research as part of our mission to ensure that the Internet is a public resource, open and accessible to all. As more people install voice assistants in their homes, designers, engineers, and policy makers need to grapple with issues of usability and privacy. We take an advocacy stance, arguing that as personal assistance become part of people’s daily experiences, we have the responsibility to study their use, and make design and policy recommendations that incorporate users’ needs and address their concerns.
https://blog.mozilla.org/ux/2019/12/how-people-really-really-use-smart-speakers/
|
|
The Firefox Frontier: Survive the holidays at home with our tech support guide |
Ah, the holiday season. It’s the time of year when we celebrate with family and friends, eat delicious meals, and repeat that magical phrase: did you try turning it on … Read more
The post Survive the holidays at home with our tech support guide appeared first on The Firefox Frontier.
|
|
Mike Hoye: Over The Line |

[ This first appeared over on the Mozilla community discourse forums. ]
You can scroll down to the punchline if you like, but I want to start by thanking the Mozilla community, contributors, industry partners and colleagues alike, for the work everyone has put into this. Hundreds of invested people have weighed in on our hard requirements, nice-to-haves and long term goals, and tested our candidates with an eye not just to our immediate technical and community needs but to Mozilla’s mission, our tools as an expression of our values and a vision of a better future. Having so many people show up and give a damn has a rewarding, inspiring experience, and I’m grateful for the trust and patience everyone involved has shown us in helping us get this over the line.
We knew from the beginning that this was going to be a hard process; that it had to be not just transparent but open, not just legitimate but seen to be legitimate, that we had to meet our hard operational requirements while staying true to our values in the process. Today, after almost a year of research, consulting, gathering requirements, testing candidate stacks and distilling everything we’ve learned in the process down to the essentials, I think we’ve accomplished that.
I am delighted and honored to say that we have one candidate that unambiguously meets our institutional and operational needs: we have decided to replace IRC with Riot/Matrix, hosted by Modular.IM.
While all of the candidates proved to be excellent team collaboration and communication tools, Riot/Matrix has distinguished itself as an excellent open community collaboration tool, with robust support for accessibility and community safety that offers more agency and autonomy to the participants, teams and communities that make up Mozilla.
That Matrix gives individual community members effective tools for both reporting violations of Mozilla’s Community Participation Guidelines (“CPG”) and securing their own safety weighed heavily in our decision-making. While all of the candidates offered robust, mature APIs that would meet the needs of our developer, infrastructure and developer productivity teams, Riot/Matrix was the only candidate that included CPG reporting and enforcement tooling as a standard part of their offering, offering individual users the opportunity to raise their own shields on their own terms as well as supporting the general health and safety of the community.
Riot/Matrix was also the preferred choice of our accessibility team. Mozilla is committed to building a company, a community and a web without second class citizens, and from the beginning the accessibility team’s endorsement was a hard requirement for this process.
Speaking personally, it is an enormous relief that we weren’t forced to make “pick-two” sort of choice between community safety, developer support and accessibility, and it is a testament to the hard work the Matrix team has done that we can have all three.
Now that we’ve made our decision and formalized our relationship with the Modular.IM team, we’ll be standing up the new service in January. Soon after that we’ll start migrating tooling and forums over to the new system, and as previously mentioned no later than March of next year, we’ll shut down IRC.mozilla.org.
Thank you all for your help getting us here; I’m looking forward to seeing you on the new system.
– mhoye
|
|






