Генерация документов. Проблемы и решения |
|
Метки: author PennyLane читальный зал генерация документа |
[Перевод] Руководство для начинающих по прогрессивным веб-приложениям и фронтенду |

Разрабатывать веб-фронтенд, придерживаясь JavaScript-экосистемы, всех этих новомодных штучек и пафосных фреймворков, может быть пугающим занятием, если не сказать больше. Я давно уже хотел окунуться в это, и наконец собрался с духом. К концу этой статьи, надеюсь, вы узнаете что-нибудь новое, или хотя бы чуть больше отточите свои навыки веб-разработки. Какая ирония, что длина статьи и обширное количество информации тоже могут отпугивать. Но я очень надеюсь, что вы найдёте время осилить хотя бы интересующие вас главы. В конце каждого раздела есть абзац TL;DR, так что вы можете быстро ориентироваться в содержании.
Первое, о чём я хочу рассказать, это концепция RESTful API. Термин REST, или RESTful API, всплывает во многих беседах между веб-разработчиками, и на то есть веская причина. REST (REpresentational State Transfer, передача состояния представления) API и веб-сервисы предоставляют простой способ взаимодействия с архитектурой бэкенда без необходимости разбираться в этой самой архитектуре.
Проще говоря, как фронтенд-разработчик вы будете взаимодействовать с одной или несколькими конечными точками (то есть URI), являющимися частью API, расположенного на сервере, в кластере или каком-то ином бэкенде, который кто-то создал для вас. Если API хорошо проработан, то в получите ясную и понятную документацию по запросам, созданию и редактированию ресурсов на бэкенде (при условии, что вы авторизованы), без необходимости писать код или лезть в базу, лежащую на упомянутом бэкенде.
RESTful API бывают самыми разными. Наиболее популярные из них возвращают JSON-объекты, которыми можно легко манипулировать посредством JavaScript на стороне клиента, что позволяет фронтенд-разработчикам эффективно работать с одними лишь частями View и Controller паттерна MVC (Model-View-Controller).
TL;DR: RESTful API очень популярны и предоставляют фронтенд-разработчикам возможность взаимодействовать с ресурсами в вебе, сосредоточившись на разработке фронтенда и не беспокоясь об архитектуре.
AJAX (Asyncronous JavaScript And XML) существует уже немало лет, и каждый разработчик так или иначе использовал его в своей работе (большинство из нас — посредством jQuery). Здесь я не будут углубляться в устройство AJAX, поскольку в сети есть сотни источников получше, но хочу отнять у вас минутку времени, чтобы просто восхититься теми возможностями, которые эта технология даёт фронтенд-разработчикам.
С помощью AJAX мы можем запрашивать ресурсы из одного одного или нескольких мест (или локально, если страница расположена на том же сервере, что и запрашиваемый URI) и в любое время, без замедления работы веб-приложений или необходимости начать отрисовку всех данных. Фактически, мы можем не грузить любой контент на страницу, а затем просто запрашивать его, как только будет загружена пустая HTML-страница. В сочетании с RESTful API получается невероятно гибкое, высокопортируемое и удобное в сопровождении решение для веб-приложений.
TL;DR: AJAX — очень мощный инструмент, который в сочетании с RESTful API позволяет создавать по-настоящему динамичные веб-приложения, которые быстро загружаются и отображают контент из ресурсов в вебе.
Поначалу создание вашей первой веб-страницы может показаться довольно трудной задачей, так что будем идти постепенно. Начнём с получения контента из RESTful API с помощью AJAX-вызовов.
Первым делом нужно найти высококачественный API, желательно такой, который возвращает JSON. Вот для примера несколько ресурсов, которые выводят placeholder-контент и пригодны для создания примера веб-приложения:
Мы воспользуемся этими тремя ресурсами, но вы можете прошерстить список в конце статьи в поисках более интересных API, пригодных для генерирования placeholder-контента для вашей страницы.
Первое, что нужно сделать, прежде чем начать писать код, это посетить конечную точку одного из API и посмотреть, что вы будете получать. Давайте отправим GET-запрос в Random User Generator, просто для проверки. Вы получите что-то подобное:

Это называется JSON-файл (JavaScript Object Notation), который должен выглядеть для вас знакомым, если вы когда-либо использовали объекты в JavaScript. Давайте запросим тот же ресурс программным способом:
// Отправляем 'GET'-запрос на заданный URL и после его завершения исполняем callback-функцию
function httpGetAsync(url, callback) {
var xmlHttp = new XMLHttpRequest();
xmlHttp.onreadystatechange = function() {
if (xmlHttp.readyState == 4 && xmlHttp.status == 200)
callback(xmlHttp.responseText);
};
xmlHttp.open('GET', url, true);
xmlHttp.send(null);
}Именно это и делает приведённый код, который занимает всего 10 строк (9 без комментария). Скармливаем соответствующую URL конечную точку API и функцию callback, и мы увидим какой-то контент. Допустим, вы создали пустую HTML-страницу и залинковали вышеприведённый JS-код. Теперь просто выполним её в браузерном инструментарии для разработчиков:
httpGetAsync(
'https://randomuser.me/api/',
function(e){console.log(e)}
);Вы получите результат, аналогичный предыдущему, только теперь он будет обёрнут в двойные кавычки. Естественно, ведь это строковое значение. И что ещё естественнее, теперь мы можем конвертировать его в JS-объект посредством JSON.parse(), а затем использовать так, как предполагалось.
Мы только что получили от API какой-то контент и вывели его в консоли. Прежде чем пойти дальше, давайте немного изучим этот API, чтобы впоследствии эффективнее его использовать.
В частности, я бы сосредоточился на параметрах seed и results, которые можно встроить в наш URL, чтобы каждый раз получать тот же набор пользователей. Для их добавления нужно просто добавить после URL знак ?, а затем {parameter_name}={value}, разделяя параметры с помощью &. Полагаю, все об этом знают, но всё же нужно было об этом упомянуть. В этой статье я также воспользуюсь параметром nationalities, чтобы быть уверенным, что в HTML не будет не-латинских символов, которые усложнят мне жизнь. Отныне и впредь, моей целевой конечной точкой для получения пользователей будет эта, она поможет мне получить тех же 25 пользователей, и всех из США.
TL;DR: Чтобы начать разрабатывать веб-приложение, нужно найти высококачественный JSON API. С помощью 10 строк JavaScript-кода можно легко запрашивать ресурсы у RESTful API, которые выдают случайных пользователей, и потом конвертировать их в JavaScript-объекты.
Решив задачу получения какого-то контента от API, мы теперь можем отрисовать его, чтобы показать пользователю. Но работа с CSS-стилями и селекторами может быть той ещё головной болью, так что многие прибегают к помощи CSS-фреймворка. Весьма популярен Bootstrap, он хорошо задокументирован, имеет большое и приятное сообщество, и богат своими возможностями. Но я воспользуюсь mini.css, который разработал сам и знаю лучше, чем Bootstrap. Подробнее об этом фреймворке можете почитать в других моих статьях.
Инструкции по использованию классов и селекторов фреймворка применимы только к mini.css, но с очень небольшими правками они будут верны и для Bootstrap (считайте представление веб-приложения своей домашней работой, потому что здесь я не буду вдаваться в подробности относительно CSS).
Прежде чем мы сможем что-то вывести на экран, нам нужно создать оболочку приложения. Ничего особенного, только панель навигации и маленький заголовок, ну ещё может быть футер. Я воспользуюсь элементом .drawer, который может быть заменён какими-нибудь кнопками, и, наконец, , чтобы приложение выглядело чисто и аккуратно:

Я буду понемногу показывать свой код (после добавления карточки пользователя), но сначала скажу, почему использование CSS-фреймворка является хорошей идей. Попросту говоря, когда вы строите для веба, то существует слишком много тестовых вариантов, и некоторые комбинации устройства/ОС/браузера получаются более своеобразными, чем другие. CSS-фреймворк работает с этим особенностями по своему усмотрению, хотя в то же время предоставляет вам базовый каркас, который поможет создать адаптивное приложение (responsive application). Адаптивность крайне важна в разработке для мобильных устройств, так что почитайте об этом побольше.
Допустим, нас всё устраивает в оболочке приложения, давайте перейдём к отрисовке данных, полученных от Random User Generator. Я не собираюсь усложнять эту процедуру и выведу для каждого пользователя имя, изображение, ник, почту, местоположение и день рождения. Но вы можете придумать свой набор позиций. Не забудьте обратиться к ключу .results вашего объекта после парсинга JSON-данных, потому что в него всё обёрнуто. Чтобы всё выглядело красиво, я воспользуюсь замечательным пакетом иконок Feather, а также классом .card из mini.css и кое-какими CSS-трюками.
Пример приложения с карточками случайно сгенерированных пользователей.
Теперь наше приложение динамически заполняется контентом, который мы выводим на экран с помощью JavaScript и HTML. Мы только что создали наше первое представление (View), являющееся причудливым способом сказать, что мы создали визуальное отображение данных, запрошенных у API.
TL;DR: Отзывчивость и стили крайне важны для любого веб-приложения, так что будет хорошей идеей использовать CSS-фреймворк для создания простой HTML-оболочки приложения, а затем отрисовки с помощью JavaScript данных, полученных от API.
Наш макет веб-приложения работает хорошо, но JavaScript-код, особенно метод renderUsers(), получился довольно запутанным и выглядит очень трудным в сопровождении. К счастью, есть хороший способ сделать всё то же самое, но с помощью инструмента, которым сегодня пользуются все клёвые пацаны — React. Если кто-то из вас о нём не слышал: это очень мощная JavaScript-библиотека, сильно облегчающая отрисовку и обновление страницы, при этом повышая скорость её работы с помощью виртуального DOM и методики, известной как diffing. В сети есть куча толковых публикаций на этот счёт.
Преобразовать наш код в React не сложно. Фактически, нужно лишь вынести цикл из процесса отрисовки, чтобы можно было извлекать функцию, которая отрисовывает по одному пользователю за раз, а затем итерировать по нашему массиву пользователей, отрисовывая их как раньше. Здесь несколько специфических для React моментом, вроде того факта, что имя нашей новой функции должно начинаться с прописной буквы, мы должны передавать её единственный аргумент props, а элементы из списка должны быть привязаны к ключам. Звучит громоздко, но на самом деле это совсем не трудно соблюдать.
Также React позволяет использовать JSX, благодаря чему мы можем писать HTML внутри JavaScript без необходимости оборачивать его в кавычки. Так что наш код может стать ещё немного чище. Однако помните, что придётся сделать некоторые преобразования, например из class в className. Но со временем вы привыкните, а отладочные сообщения в консоли действительно очень помогают в решении таких проблем.
Я также взял на себя смелость преобразовать три инлайненых SVG в их собственные функции, так что теперь весь процесс отрисовки выглядит так:
// Функциональный компонент для иконки почты.
function SvgMail(props){
return ;
}
// Функциональный компонент для иконки календаря.
function SvgCalendar(props){
return ;
}
// Функциональный компонент для иконки прикрепления к карте.
function SvgMapPin(props){
return ;
}
// Функциональный компонент для иконки пользовательской карточки.
function UserCard(props){
var user = props.user;
return

{user.name.title} {user.name.first} {user.name.last}
{user.login.username}
;
}
// Отрисовка списка пользователей в виде карточек.
function renderUsers(){
var userCards = users.map(
function(user, key){
return ;
}
);
ReactDOM.render( {userCards} ,contentArea);
} Мы просто извлекли из предыдущего кода функциональный компонент, сделав его многократно используемой сущностью. Стоит взглянуть, что происходит под капотом, когда Babel преобразует HTML, предоставленный по вызовам React.createElement():
function SvgMapPin(props) {
return React.createElement(
'svg',
{ xmlns: 'http://www.w3.org/2000/svg', width: '24', height: '24', viewBox: '0 0 24 24', fill: 'none', stroke: '#424242', strokeWidth: '2', strokeLinecap: 'round', strokeLinejoin: 'round' },
React.createElement('path', { d: 'M21 10c0 7-9 13-9 13s-9-6-9-13a9 9 0 0 1 18 0z' }),
React.createElement('circle', { cx: '12', cy: '10', r: '3' })
);
}C другой стороны, если вы хотите начать с более лёгкой версии React, без JSX и некоторых более причудливых и сложных вещей, то я очень рекомендую обратиться к Preact, потому что это прекрасная альтернатива, которая может уменьшить время загрузки на одну-две секунды.
TL;DR: Преобразование с помощью React неструктурированных вызовов HTML-отрисовки в функциональные компоненты — задача простая, и результат получается гораздо удобнее в сопровождении. При этом разработчик получает больше контроля над своим кодом, и повышается степень повторного использования.
В большинстве веб-приложений больше одного представления, так что этим мы и займёмся. Воспользуемся другими двумя API, упомянутыми в начале, чтобы создать второе представление, которое динамически заполняется и содержит текст и изображения, при перезагрузке страницы каждый раз новые. Если вы читали внимательно, то сделаете это без подсказок, но я очерчу направление действий:
https://jsonplaceholder.typicode.com/comments?postId={id}, что позволит получить 5 сегментов текста за раз в JSON-формате, инкрементируя {id}.https://unsplash.it/800/800?image={id}, при этом будем каждый раз получать какую-то картинку. Для этого воспользуемся кодом, который будет генерировать случайный {id} для каждого запроса. В моём Codepen-примере я также добавил массив неправильных значений {id}, которые я извлёк из API, так что у нас не будет ни одного ответа без изображения.После аккуратного кодирования всего упомянутого и последующего совершенствования, у вас получится нечто, схожее с Singe Page Application (SPA): https://codepen.io/chalarangelo/pen/zzXzBv
TL;DR: Чтобы ваш макет выглядел как настоящее веб-приложение, достаточно добавить второе представление и некоторые интерактивные элементы.
Если вы уже занимались веб-разработкой, то сразу же заметите, чего не хватает в нашем приложении: бесконечной прокрутки. Её суть: когда вы пролистываете вниз до определённой границы, подгружается новая порция контента, и так происходит до тех пор, пока не кончится контент. В нашем примере мы установим границу в 80 %, но вы можете настроить этот параметр. Для этого нам понадобится очень простой метод, вычисляющий долю прокрутки страницы.
// Получает степень прокрутки страницы.
function getScrollPercent() {
return (
(document.documentElement.scrollTop || document.body.scrollTop)
/ ( (document.documentElement.scrollHeight || document.body.scrollHeight)
- document.documentElement.clientHeight)
* 100);
}Метод подсчитывает все кейсы и возвращает значение в диапазоне [0,100] (включительно). Если забиндить на window события scroll и resize, то можно быть уверенным, что когда пользователь достигнет конца страницы, то будет подгружен ещё контент. Вот как выглядит наше веб-приложение после добавления бесконечной прокрутки в представление с постами.
TL;DR: Бесконечная прокрутка — главное свойство любого современного веб-приложения. Она легка в реализации и позволяет динамически подгружать контент по мере необходимости.
Примечание: Если вы всё читаете и следуете всем рекомендациям, то сделайте 10-минутный перерыв, потому что следующие несколько глав довольно сложны и требуют больше усилий.
Прежде чем мы сможем сказать, что действительно сделали веб-приложение (не говоря уже о прогрессивном веб-приложении), нам нужно поработать с файлом manifest.json, который состоит из кучи свойств нашего приложения, включая name, short_name, icons. Манифест предоставляет клиентскому браузеру информацию о нашем веб-приложении. Но прежде чем мы им займёмся, нам нужно с помощью npm и настройки React поднять приложение и запустить на localhost. Полагаю, что с обеими вещами вы уже знакомы и не столкнётесь с трудностями, поэтому переходим к манифесту.
По моему опыту, чтобы получилось работающее приложение, вам понадобится заполнить так много полей, что я предлагаю воспользоваться Web App Manifest Generator и заполнить, что хотите. Если у вас есть время, чтобы сделать аккуратную иконку, то в этом вам поможет Favicon & App Icon Generator.
После того как всё сделаете, ваш манифест будет выглядеть так:
{
"name": "Mockup Progressive Web App",
"short_name": "Mock PWA",
"description": "A mock progressive web app built with React and mini.css.",
"lang": "en-US",
"start_url": "./index.html",
"display": "standalone",
"theme_color": "#1a237e",
"icons": [
{
"src": "\/android-icon-48x48.png",
"sizes": "48x48",
"type": "image\/png",
"density": "1.0"
},
{
"src": "\/android-icon-72x72.png",
"sizes": "72x72",
"type": "image\/png",
"density": "1.5"
}
]
}Создав манифест, мы «отполировали» наше веб-приложение, сделав его поведение таким, как нужно. Но это только начало пути по превращению нашего веб-приложения в прогрессивное.
TL;DR: Файл manifest.json используется для определения конкретных свойств веб-приложения, прокладывая нам путь к созданию прогрессивного веб-приложения.
Последним шагом является создание сервис-воркеров. Это одно из ключевых требований к прогрессивному веб-приложению, чтобы оно в какой-то степени работать автономно. Хотя сервис-воркеры используются уже давно, документация для них выглядит всё ещё слишком технической и сложной. Но в последнее время эта тенденция начала меняться. Если хотите больше почитать о прогрессивных веб-приложениях и сервис-воркерах, обратитесь к источникам в конце статьи.
Мы будем создавать самый простой вариант сервис-воркера, позволяющий кэшировать ответы на запросы, передавая их по мере доступности. Сначала создадим файл service-worker.js, который и будет нашим сервис-воркером.
Теперь давайте разберёмся с тремя основными событиями, с которыми нам придётся работать:
install генерируется при первой загрузке и используется для выполнения начальной установки сервис-воркера, вроде настройки оффлайн-кэшей.activate генерируется после регистрации сервис-воркера и его успешной установки.fetch генерируется при каждом AJAX-запросе, отправленном по сети, и может использоваться для обслуживания закэшированных ресурсов (особенно полезно при отсутствии сети).Первое, что нам нужно сделать при установке, это воспользоваться CacheStorage Web API для создания кэша для веб-приложения и хранения любого статичного контента (иконок, HTML, CSS и JS-файлов). Это очень просто сделать:
// caches — это глобальная переменная только для чтения, являющаяся экземпляром CacheStorage
caches.open(cacheName).then(function(cache) {
// Что-нибудь делаем с кэшем
});
// Источник: https://developer.mozilla.org/en-US/docs/Web/API/CacheStorage/openМожно быстро создать простой обработчик события install, который кэширует наши index.html, JavaScript-файл и manifest.json. Но сначала нужно задать имя кэша. Это позволит нам отделить версии тех же файлов или данных от оболочки приложения. Здесь мы не будем вдаваться в подробности относительно кэшей, но в конце статьи есть полезные ссылки. Помимо имени кэша, нужно определить, какие файлы будут кэшироваться с помощью массива. Вот как выглядит обработчик install:
var cacheName = 'mockApp-v1.0.0';
var filesToCache = [
'./',
'./index.html',
'./manifest.json',
'./static/js/bundle.js'
];
self.addEventListener('install', function(e) {
e.waitUntil(caches.open(cacheName)
.then(function(cache) {
return cache.addAll(filesToCache)
.then(function() {
self.skipWaiting();
});
}));
});Меньше чем в 20 строках мы сделали так, что наше веб-приложение использует кэш для своих ресурсов. Позвольте пояснить оду вещь. В ходе разработки наш JS-код компилируется в файл ./static/js/bundle.js. Это одна из причуд нашего development/production-окружения, и мы разберёмся с ней на следующем этапе.
Обработчик activate тоже довольно прост. Его главная задача: обновлять кэшированные файлы, когда что-то меняется в оболочке приложения. Если нам нужно обновить любые файлы, то нам придётся изменить cacheName (желательно в стиле SemVer). Наконец, обработчик fetch проверит, хранится ли в кэше запрошенный ресурс. Если он там есть, то будет передан из кэша. В противном случае ресурс будет запрошен как обычно, а ответ будет сохранён в кэше, чтобы его можно было использовать в будущем. Соберём всё вместе:
self.addEventListener('activate', function(e) {
e.waitUntil(caches.keys()
.then(function(keyList) {
return Promise.all(keyList.map(function(key) {
if (key !== cacheName)
return caches.delete(key);
}));
}));
return self.clients.claim();
});
self.addEventListener('fetch', function(e) {
e.respondWith(caches.match(e.request)
.then(function(response) {
return response || fetch(e.request)
.then(function (resp){
return caches.open(cacheName)
.then(function(cache){
cache.put(e.request, resp.clone());
return resp;
})
}).catch(function(event){
console.log('Error fetching data!');
})
})
);
});Мы построили сервис-воркер, но его нужно зарегистрировать изнутри веб-приложения, чтобы воспользоваться его преимуществами. Достаточно добавить несколько строк кода в наш основной JS-файл, и мы готовы превратить наше веб-приложение в прогрессивное:
if ('serviceWorker' in navigator) {
navigator.serviceWorker
.register('./service-worker.js')
.then(function() { console.log('Registered service worker!'); });
}После всех настроек, откройте в Chrome Dev Tools окно Application и посмотрите, всё ли работает как нужно. Сервис-воркер должен правильно зарегистрироваться, активироваться и запуститься. Если пролистаете вниз, поставите галочку Offline и обновите, то начнёт работать оффлайн-версия страницы, использующая закэшированные ресурсы.
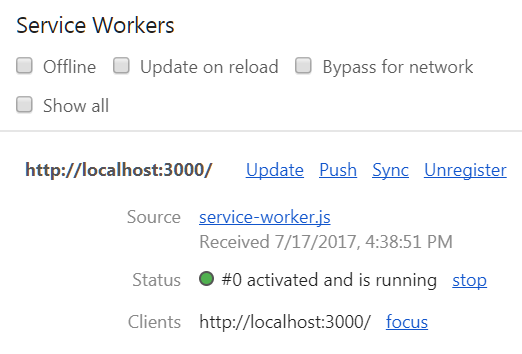
Мы только что превратили наше веб-приложение в прогрессивное, но разработка ещё не закончена. Последним шагом будет сборка для production.
TL;DR: Сервис-воркеры позволяют веб-приложениям настраивать кэши и использовать их для загрузки ресурсов без использования сети, превращая веб-приложения в прогрессивные.
Всё, что мы сделали, прекрасно работает на localhost, но осмотр production-файлов после быстрого выполнения npm run build обнаруживает кучу ошибок, которые нужно исправить. Прежде всего, многие файлы неправильно залинкованы на/из HTML-страницы. Для решения этой проблемы нужно добавить одну строку в package.json:
"homepage" : "."После пересборки и открытия HTML-страницы в браузере мы видим, что большая часть заработала правильно. Добавив строку со свойством "homepage", мы сказали системе собрать скрипт так, чтобы в ссылках все пути были изменены на ., то есть теперь они являются относительными путями.
Следующая проблема: наш сервис-воркер указывает на неправильные JS-файлы, потому что static/js/bundle.js больше не существует. Если внимательнее посмотреть на собранные файлы, то станет понятно, что наш JS был преобразован в файл main.{hash}.js, где часть {hash} отличается для каждой сборки. Нам нужно иметь возможность загружать из сервис-воркера файл main.js. Следовательно, нужно переименовать его, но этого сломает ссылку внутри index.html, чего мы не хотим. Для решения обеих проблем воспользуемся сборочными инструментами из реестра npm — renamer и replace. Также нам нужно минифицировать наш service-worker.js, поскольку по умолчанию он не слишком компактен, потому что является частью папки public, так что воспользуемся ещё и утилитой uglify-js.
npm install --save-dev renamer
npm install --save-dev replace
npm install --save-dev uglify-jsТри простые команды, и мы получаем нужные нам инструменты. Пользоваться ими сравнительно легко после ознакомления с документацией, так что я продолжу и покажу, как выглядит свойство "scripts" в моём package.json после создания всех необходимых скриптов.
"scripts": {
"start": "react-scripts start",
"build": "react-scripts build && npm run build-rename-replace && npm run build-sw",
"test": "react-scripts test --env=jsdom",
"eject": "react-scripts eject",
"build-sw" : "npm run build-replace-sw-refs && npm run build-minify-sw",
"build-rename-replace": "npm run build-rename && npm run build-replace",
"build-rename": "npm run build-rename-js && npm run build-rename-css",
"build-rename-js": "renamer --regex --find main\\.\\w+\\.js --replace main.js build/static/js/*.js",
"build-rename-css": "renamer --regex --find main\\.\\w+\\.css --replace main.css build/static/css/*.css",
"build-replace": "npm run build-replace-js && npm run build-replace-css",
"build-replace-js": "replace main\\.\\w+\\.js main.js build/index.html",
"build-replace-css": "replace main\\.\\w+\\.css main.css build/index.html",
"build-replace-sw-refs": "replace './static/js/bundle.js' './static/js/main.js','./static/css/main.css' build/service-worker.js",
"build-minify-sw" : "uglifyjs build/service-worker.js --output build/service-worker.js"
}Давайте разберёмся, что тут происходит:
build-rename запускает два скрипта, каждый из которых меняет имена JavaScript- и CSS-файлов, которые были созданы с желаемыми наименованиями (main.js и main.css соответственно).build-replace запускает два скрипта, каждый из которых меняет меняет ссылки на JavaScript- и CSS-файлы на переименованные версии.build-rename-replace собирает предыдущие две команды в одну.build-sw обновляет в сервис-воркере ссылку на static/js/bundle.js, которая теперь указывает на новый файл main.js, а также добавляет ссылку на main.css. Затем минифицирует сервис-воркер.build собирает вместе всё вышеперечисленное в наш процесс сборки по умолчанию, так что все файлы попадают в папку build и готовы к выкладыванию на сайт.Теперь при запуске npm run build должна генерироваться готовая к production версия нашего прогрессивного веб-приложения, которую можно хостить где угодно, просто копируя файлы из папки build.
TL;DR: Создание веб-приложения для production является интересной проблемой, требующей использования сборочных инструментов и разрешения скриптов. В нашем случае достаточно было обновить имена и ссылки.
Это был трудный путь, но теперь наше прогрессивное веб-приложение готово к production. Прежде чем поделиться им с миром, выложив куда-нибудь на Github, хорошо бы оценить его качество с помощью инструмента Lighthouse, который выставляет приложению баллы и выявляет проблемы.
После прогона моей development-сборки на localhost я обнаружил несколько моментов, требующих исправления, вроде того, что у картинок нет атрибутов alt, внешние ссылки не имеют атрибута rel="noopener", а само веб-приложение не имеет географической привязки (landmark region), что было легко исправлено с помощью HTML-тега . Исправив всё, что мог, я получил такой результат в Lighthouse:

Как видите, приложение получилось хорошо оптимизированным и качественным. Теперь я могу с гордостью выложить его на Github. Вот ссылка на законченное приложение; а вот ссылка на исходный код. Я взял на себя смелость добавить индикаторы Online/Offline, но вы можете их выкинуть. Теперь я могу установить приложение на смартфон и показать друзьям!


TL;DR: Прежде чем релизить веб-приложение, стоит проверить его качество с помощью Lighthouse и оптимизировать, насколько возможно.
Вот и всё мы создали с нуля прогрессивное веб-приложение. Надеюсь, вы чему-то научились. Спасибо за уделённое время!
|
Метки: author AloneCoder разработка веб-сайтов reactjs javascript css блог компании mail.ru group react js никто не читает теги |
[Перевод] Генеративные модели от OpenAI |
|
Метки: author mr-pickles машинное обучение алгоритмы блог компании wunder fund openai generative models deep learning gan machine learning wunder fund wunderfund |
Zimbra — выстраиваем коммуникации в компании |


|
Метки: author levashove управление персоналом блог компании zimbra zimbra zextras почта чат chat |
5 свежих примеров разбора и улучшения дизайна простыми способами |

















|
Метки: author Logomachine типографика работа с векторной графикой графический дизайн блог компании логомашина дизайн логотип бизнес советы помощь |
[Перевод] Сравнение цен на трафик у облачных провайдеров |
 В этой статье я сравниваю цены на внешний трафик из Amazon EC2, Google Cloud Platform, Microsoft Azure и Amazon Lightsail.
В этой статье я сравниваю цены на внешний трафик из Amazon EC2, Google Cloud Platform, Microsoft Azure и Amazon Lightsail.|
Метки: author m1rko хостинг облачные вычисления it- инфраструктура microsoft azure google cloud platform amazon ec2 amazon lightsail |
Поиграем в Firebase |
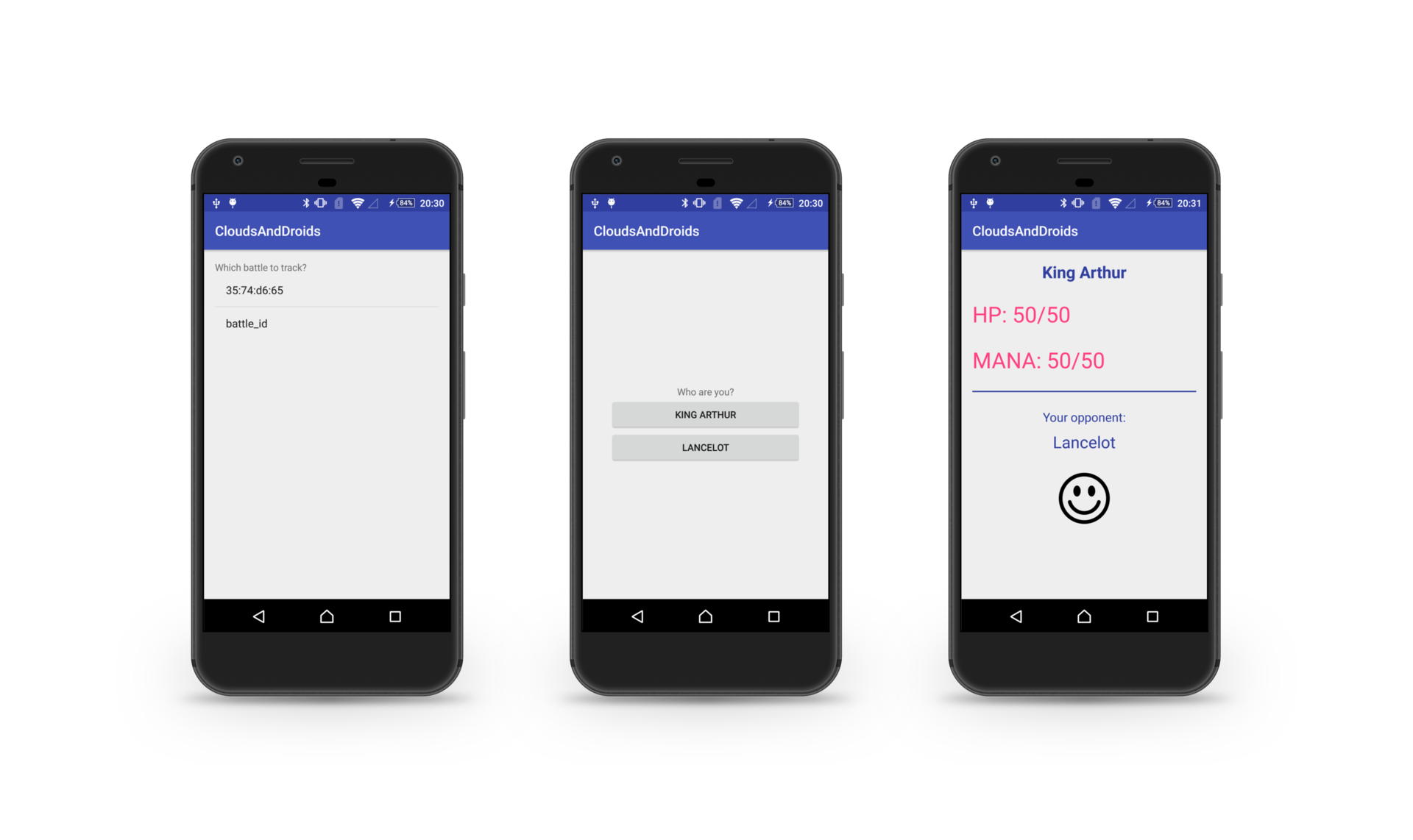
 Меня зовут Оксана и я Android-разработчик в небольшой, но очень классной команде Trinity Digital. Тут я буду рассказывать об опыте создания настольной игрушки на базе Firebase и всяких разных железяк.
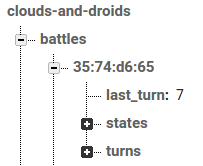
Меня зовут Оксана и я Android-разработчик в небольшой, но очень классной команде Trinity Digital. Тут я буду рассказывать об опыте создания настольной игрушки на базе Firebase и всяких разных железяк. 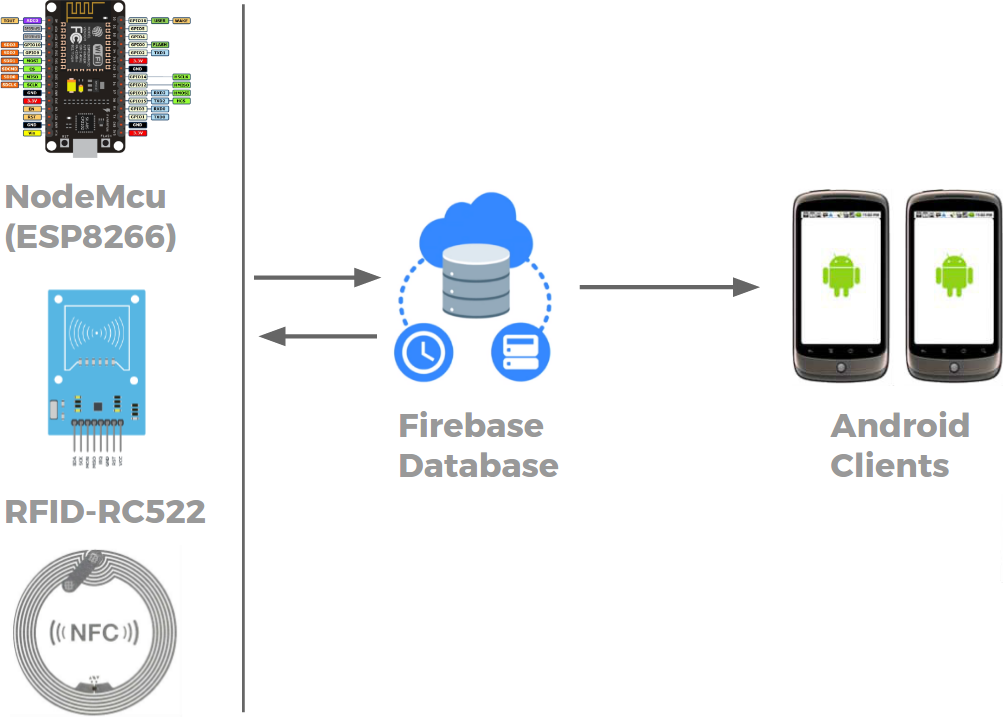


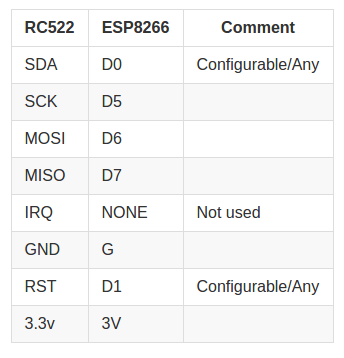
void Scanner::init() {
SPI.begin(); // включаем шину SPI
rc522->PCD_Init(); // инициализируем библиотеку
rc522->PCD_SetAntennaGain(rc522->RxGain_max); // задаем максимальную мощность
}
String Scanner::readCard() {
// если прочитали карту
if(rc522->PICC_IsNewCardPresent() && rc522->PICC_ReadCardSerial()) {
// переводим номер карты в вид XX:XX
String uid = "";
int uidSize = rc522->uid.size;
for (byte i = 0; i < uidSize; i++) {
if(i > 0)
uid = uid + ":";
if(rc522->uid.uidByte[i] < 0x10)
uid = uid + "0";
uid = uid + String(rc522->uid.uidByte[i], HEX);
}
return uid;
}
return "";
}
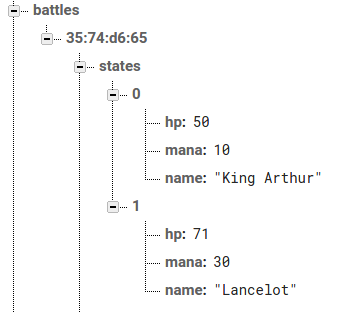
Firebase.setInt("battles/" + battleId + "/states/" + player + "/hp", 50);
if(firebaseFailed()) return;int Cloud::firebaseFailed() {
if (Firebase.failed()) {
digitalWrite(ERROR_PIN, HIGH); // мигаем лампочкой
Serial.print("setting or getting failed:");
Serial.println(Firebase.error()); // печатаем в консоль
delay(1000);
digitalWrite(ERROR_PIN, LOW); // мигаем лампочкой
return 1;
}
return 0;
}StaticJsonBuffer<200> jsonBuffer;
JsonObject& turn = jsonBuffer.createObject();
turn["card"] = cardUid;
turn["target"] = player;
Firebase.set("battles/" + battleId + "/turns/" + turnNumber, turn);
if(firebaseFailed()) return 1; 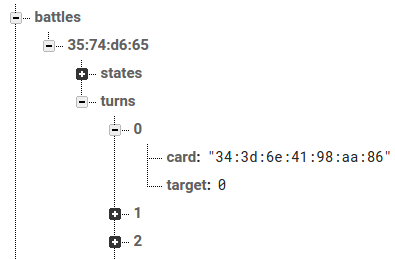
exports.newTurn = functions.database.ref('/battles/{battleId}/turns/{turnId}').onWrite(event => {
// нас интересует только создание нового хода, а не обновления
if (event.data.previous.val())
return;
// читаем ходы
admin.database().ref('/battles/' + event.params.battleId + '/turns').once('value')
.then(function(snapshot) {
// выясняем, кто кастит в этот ход
var whoCasts = (snapshot.numChildren() + 1) % 2;
// читаем игроков
admin.database().ref('/battles/' + event.params.battleId + '/states').once('value')
.then(function(snapshot) {
var states = snapshot.val();
var castingPlayer = states[whoCasts];
var notCastingPlayer = states[(whoCasts + 1) % 2];
var targetPlayer;
if (whoCasts == event.data.current.val().target)
targetPlayer = castingPlayer;
else
targetPlayer = notCastingPlayer;
// сколько маны нужно отнять
admin.database().ref('/cards/' + event.data.current.val().card).once('value')
.then(function(snapshot) {
var card = snapshot.val();
// отнимаем
castingPlayer.mana -= card.mana;
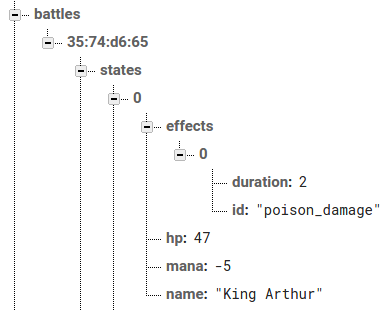
// применяем эффекты с текущей карты
var cardEffects = card.effects;
if (!targetPlayer.effects)
targetPlayer.effects = [];
for (var i = 0; i < cardEffects.length; i++)
targetPlayer.effects.push(cardEffects[i]);
// применяем все эффекты, которые уже есть на игроках
playEffects(castingPlayer);
playEffects(notCastingPlayer);
// обновляем игроков
return event.data.adminRef.root.child('battles').child(event.params.battleId)
.child('states').update(states);
})
})
})
});
function playEffects(player) {
if (!player.effects)
return;
for (var i = 0; i < player.effects.length; i++) {
var effect = player.effects[i];
if (effect.duration > 0) {
eval(effect.id + '(player)');
effect.duration--;
}
}
}
function fire_damage(targetPlayer) {
targetPlayer.hp -= getRandomInt(0, 11);
}
exports.effectFinished = functions.database.ref('/battles/{battleId}/states/{playerId}/effects/{effectIndex}')
.onWrite(event => {
effect = event.data.current.val();
if (effect.duration === 0)
return
event.data.adminRef.root.child('battles').child(event.params.battleId).child('states')
.child(event.params.playerId).child('effects').child(event.params.effectIndex).remove();
});

public class MainActivity extends AppCompatActivity {
// ...
@Override
protected void onCreate(Bundle savedInstanceState) {
// ...
FirebaseDatabase database = FirebaseDatabase.getInstance();
// слушатель на узле "battles" нашей базы (он получает данные когда добавлен,
// и потом каждый раз когда что-то изменилось в списке партий)
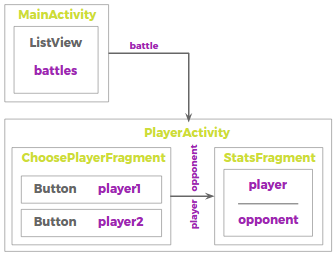
database.getReference().child("battles").addValueEventListener(new ValueEventListener() {
@Override
public void onDataChange(DataSnapshot battles) {
final List battleIds = new ArrayList();
for (DataSnapshot battle : battles.getChildren())
battleIds.add(battle.getKey());
ArrayAdapter adapter = new ArrayAdapter<>(MainActivity.this,
android.R.layout.simple_list_item_1,
battleIds.toArray(new String[battleIds.size()]));
battlesList.setAdapter(adapter);
battlesList.setOnItemClickListener(new AdapterView.OnItemClickListener() {
@Override
public void onItemClick(AdapterView |
Метки: author DaryaGhor разработка под android разработка для интернета вещей android iot game development firebase |
Android O: особенности поддержки новой операционной системы |
Всем привет! Совсем скоро состоится важное событие – выход Android O. Поддержка новых версий операционной системы – обязанность любого серьезного продукта. Каждое обновление Android заставляет многих разработчиков серьезно поработать для сохранения работоспособности имеющихся функций и привнесения нового благодаря возможностям новых версий Android.
В данной статье мы рассмотрим основные изменения Android O и оценим их возможное влияние.

Работая над Android O, разработчики Google в первую очередь решали проблему быстрого расхода заряда аккумулятора на Android-устройствах, поэтому основные изменения связаны с оптимизацией фоновых задач и расхода ресурсов приложения.
Изменения в Android O можно разделить на две категории:
Потенциально «ломающие» текущую работоспособность и требующие дополнительных усилий для поддержки;
| Угроза | Target >= O | Target < O | Эффект |
|---|---|---|---|
| Background Location Limits | Affected | Affected | Ограничение на запрос геолокации |
| Background Execution Limits | Affected | OK | Изменение списка доступных бродкастов в манифесте; Изменение времени работы сервисов в фоне. |
| Notification Channels | Affected | OK | Доработки для каналов нотификаций |
| WindowManager | Affected | OK | Влияние на работу перекрывающих окон |
| Privacy (Build.Serial/net.dns/e.t.c.) | Affected | Affected | Изменение доступности пользовательских идентификаторов |
| AccountManager. getAccounts() |
Affected | OK | Запрос списка аккаунтов на устройстве возвращает null |
| Новые возможности | Применение |
|---|---|
| Android Enterprise | Улучшение контроля над девайсом |
| Autofill Framework | Автозаполнение полей ввода |
| Notification Channels | Улучшение UX |
| Picture in Picture | Улучшение UX |
| Adaptive Icon | Консистентность с прошивкой вендора |
| Accessibility button and fingerprint gestures | Улучшение UX (accessibility кнопка в navigation bar, отлавливание жестов по сканеру отпечатка пальцев) |
| Webview Apis (напр., Safebrowsing) | Улучшение встроенных возможностей Webview |
| Pinning shortcuts and Widgets | Программное создание ярлыков и виджетов в лаунчере |
На наш взгляд это наиболее значимые (по крайней мере для «Лаборатории Касперского») изменения в Android O. Рассмотрим каждое по отдельности.
Это ограничение на количество запросов местоположения для приложений, находящихся в фоне. Так, начиная с Android O и независимо от установленного TargetSDK, приложения смогут получать всего несколько обновлений местоположения в час. При этом, эти ограничения не распространяются на приложения, для которых справедлив хотя бы один из следующих параметров:
Таким образом, для Foreground-приложений поведение будет таким же, как и на предыдущих версиях Android.
В случае, если foreground service отсутствует, то запрос геолокации будет изменен:
Ограничение на фоновую работу приложения – ключевое изменение Android O, которое будет заметно в большой степени лишь при переходе на targetSdk “O”. В случае, если targetSdk <= 25, то если приложение находится в фоне и было переведено системой в Cached-состояние (когда система может свободно убить процесс в любой момент), и при этом оно не имеет активных компонентов, система отпустит все WakeLock (индикатор, что приложение не должно быть в состоянии сна) этого приложения. Важно отметить, что в случае, если приложение не targetSDK < O, то в настройках можно выставить политику поведения такую же, как если бы приложение было бы с targetSDK O.
Для приложений с targetSdk “O” background execution limits состоят из двух категорий:
Context.startForegroundService() необходимо в течение 5 секунд вызвать startForeground(), в противном случае система может показать ANR.Notification Channels — инструмент для группировки нотификаций в тематические группы, которыми пользователь сможет управлять напрямую. Если приложение собрано с target >= O, тогда необходимо поддержать хотя бы один из каналов нотификаций. В случае, если targetApi < O, тогда работа с нотификациями внутри продукта останется прежней.
В Android O вводится новый тип окон (для targetSDK O), которые могут быть выведены поверх других окон – TYPE_APPLICATION_OVERLAY. При этом несколько старых типов окон стали deprecated, и теперь при их использовании генерируется RuntimeException.
Эти типы окон теперь могут использоваться только системными приложениями:
В Android O появляются некоторые улучшения, призванные помочь пользователю управлять доступом к своим идентификаторам. Эти улучшения включают:
Начиная с Android O, разрешения GET_ACCOUNTS недостаточно для получения доступа к списку учетных записей. Теперь существует два варианта для приложений с targetSDK O:
AccountManager.newChooseAccountIntent().Google активно развивает Android for Work. В Android O они предоставили больше возможностей для контроля устройства. Например, для рабочего профиля можно заводить отдельную блокировку со своими настройками, узнавать информацию о доступных обновлениях системы.
C появлением Autofill Framework API появилась возможность более удобного заполнения пользовательских данных в приложения, чем при использовании Accessability. При вызове фреймворка нужно будет сопоставить packageName продукта, для которого произошел вызов на автозаполнение, после чего предоставить данные для ввода. Для верной идентификации полей логина и пароля нужно создать и поддерживать базу с resourceId контролов или другой служебной информацией, позволяющей верно идентифицировать UI-элементы для автозаполнения.
Android O позволяет запускать активности в режиме Picture-In-Picture, который является специальным типом multi-window mode. Google рекомендует использовать данный режим исключительно для приложений, отображающих видео.
Начиная с Android O для приложения можно предоставить еще один вариант Launcher Icon, который система сможет по маске легко обрезать до формы, которая используется производителем устройства. Также при наличии такой иконки система сможет делать некоторые анимации иконок приложений.
Новая возможность Android O — программное создание ярлыков и виждетов в лаунчере. Ярлык представляет собой отдельную иконку, позволяющую по клику выполнить задачу в приложении по заданному интенту. Для успешного прикрепления виджета или ярлыка требуется согласие пользователя в системном диалоге-подтверждении.
Время, когда Android позволял делать все что угодно, уходят в прошлое. Android расширяет «легальные» инструменты для создания новых функций, закрывает бреши для хаков и заставляет работать честно. Android O ломает часть существующих приложений, но старается сделать конечных пользователей счастливее. Ура, спасибо!
Желаю всем писать хорошие приложения, думать о пользователях и быть счастливыми владельцами Android-устройств.
P.S.
Автор статьи — Александр Шиндин ayushindin.
Саша написал статью и смело заболел, поэтому доверил выложить статью на Хабр мне =)
Пожелаем ему скорейшего выздоравления!
|
Метки: author xoxol_89 разработка под android разработка мобильных приложений java блог компании «лаборатория касперского» android android development mobile development android o |
Подлинность ваших видео теперь неоспорима благодаря Prover |

|
|
[Из песочницы] Кластеризация маркеров на карте Google Maps API |
const MAP = {
defaultZoom: 8,
defaultCenter: { lat: 60.814305, lng: 47.051773 },
options: {
maxZoom: 19,
},
};
state = {
mapOptions: {
center: MAP.defaultCenter,
zoom: MAP.defaultZoom,
},
clusters: [],
};
//JSX
{this.state.clusters.map(item => {
if (item.numPoints === 1) {
return (
const TOTAL_COUNT = 200;
export const susolvkaCoords = { lat: 60.814305, lng: 47.051773 };
export const markersData = [...Array(TOTAL_COUNT)]
.fill(0) // fill(0) for loose mode
.map((__, index) => ({
id: index,
lat:
susolvkaCoords.lat +
0.01 *
index *
Math.sin(30 * Math.PI * index / 180) *
Math.cos(50 * Math.PI * index / 180) +
Math.sin(5 * index / 180),
lng:
susolvkaCoords.lng +
0.01 *
index *
Math.cos(70 + 23 * Math.PI * index / 180) *
Math.cos(50 * Math.PI * index / 180) +
Math.sin(5 * index / 180),
}));
handleMapChange = ({ center, zoom, bounds }) => {
this.setState(
{
mapOptions: {
center,
zoom,
bounds,
},
},
() => {
this.createClusters(this.props);
}
);
};
createClusters = props => {
this.setState({
clusters: this.state.mapOptions.bounds
? this.getClusters(props).map(({ wx, wy, numPoints, points }) => ({
lat: wy,
lng: wx,
numPoints,
id: `${numPoints}_${points[0].id}`,
points,
}))
: [],
});
};
getClusters = () => {
const clusters = supercluster(markersData, {
minZoom: 0,
maxZoom: 16,
radius: 60,
});
return clusters(this.state.mapOptions);
};
|
Метки: author Tim152 reactjs javascript google api react.js maps |
Альтернативные планетарные данные для геоинформационных систем |
Современные геоинформационные системы и сервисы (QGIS, ArcGIS, MapBox и т.д.; далее ГИС) и используемые ими форматы данных стали стандартным средством для представления карт земной поверхности и даже поверхности некоторых соседних планет. Но есть разновидность карт, где средства геоинформационных систем пока практически нигде не применяются. И это карты, которые получаются в результате процедурной генерации, например, в видеоиграх.
Основные трудности на этом пути: большое количество вычислений для получения сколько-нибудь подробной карты даже маленькой планеты, усложнение способов генерации при переходе к сферической поверхности планеты, получение правдоподобного рельефа с реками и озерами. Так же некоторую трудность представляет из себя процедура выделения векторной картографической информации из полученного рельефа.

В моем недавнем стартапе я научился делать сферические процедурно-генерируемые карты планет с рельефом напоминающем Землю. Хотя не все еще выглядит как надо или как бы того хотелось (например, реки пока везде одинаковой ширины), но результат уже довольно обнадеживающий и может быть где-либо применен. Примеры планет можно увидеть на сайте. Там же можно ознакомится с описанием способа, который используется для получения карт планет (есть еще мой старый пост на эту тему, но информация там могла частично устареть).
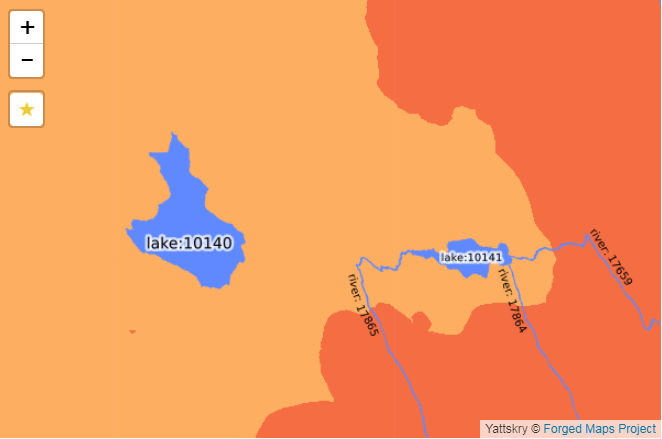
Результирующие данные представляются в виде понятном для ГИС. В настоящее время векторные данные выкладываются в ESRI Shapefile-ах, а растровая информация в GeoTiff-ах и SRTM DEM-ках. Соответственно к данным можно применять всю мощь современных ГИС и представлять их как заблагорассудится, вплоть до изменения проекции, отрисовывания хилшейдинга или контуров высот.
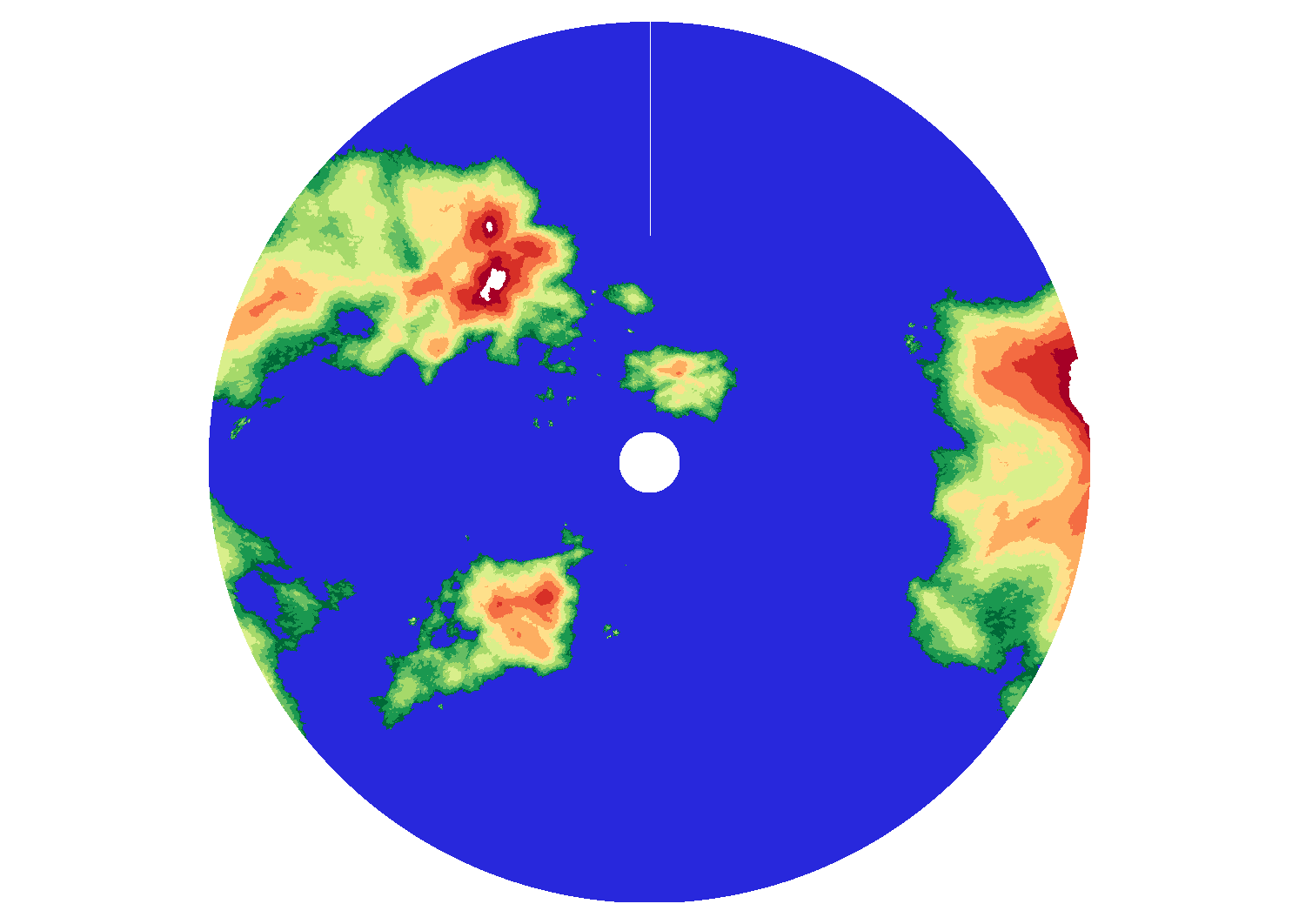
Побочным результатом всего этого процесса является возможность получения геоинформационных данных для объектов рельефа, которые маловероятны или даже в принципе невозможны на земной поверхности. Картинка в начале поста — это часть рельефа планеты Mandelbrot, а картинка ниже это единственный материк этой планеты.
Все представленные в этом посте изображения это выбранные проекции участков сферической карты соответствующих планет.
|
Метки: author igor720 геоинформационные сервисы процедурная генерация карт планета |
[Из песочницы] Внедрение зависимостей через поля — плохая практика |
private DependencyA dependencyA;
private DependencyB dependencyB;
private DependencyC dependencyC;
@Autowired
public DI(DependencyA dependencyA, DependencyB dependencyB, DependencyC dependencyC) {
this.dependencyA = dependencyA;
this.dependencyB = dependencyB;
this.dependencyC = dependencyC;
}private DependencyA dependencyA;
private DependencyB dependencyB;
private DependencyC dependencyC;
@Autowired
public void setDependencyA(DependencyA dependencyA) {
this.dependencyA = dependencyA;
}
@Autowired
public void setDependencyB(DependencyB dependencyB) {
this.dependencyB = dependencyB;
}
@Autowired
public void setDependencyC(DependencyC dependencyC) {
this.dependencyC = dependencyC;
}@Autowired
private DependencyA dependencyA;
@Autowired
private DependencyB dependencyB;
@Autowired
private DependencyC dependencyC;Команда Spring главным образом выступает за инъекцию через сеттеры, потому что большое количество аргументов конструктора может стать громоздким, особенно если свойства являются необязательными. Сеттеры также делают объекты этого класса пригодными для реконфигурации или повторной инъекции позже. Управление через JMX MBeans является ярким примером
Некоторые пуристы предпочитают инъекцию на основе конструктора. Предоставление всех зависимостей означает, что объект всегда возвращается в вызывающий код в полностью инициализированном состоянии. Недостатком является то, что объект становится менее поддающимся реконфигурации и повторной инъекции
Команда Spring главным образом выступает за инъекцию через конструктор, поскольку она позволяет реализовывать компоненты приложения как неизменяемые объекты и гарантировать, что требуемые зависимости не null. Более того, компоненты, внедренные через через конструктор, всегда возвращаются в клиентский код в полностью инициализированном состоянии. Как небольшое замечание, большое число аргументов конструктора является признаком «кода с запашком» и подразумевает, что у класса, вероятно, слишком много обязанностей, и его необходимо реорганизовать, чтобы лучше решать вопрос о разделении ответственности.
Инъекция через сеттер должна использоваться в первую очередь для опциональных зависимостей, которым могут быть присвоены значения по-умолчанию внутри класса. В противном случае, проверки на not-null должны быть использованы везде, где код использует эти зависимости. Одно из преимуществ использования внедрения через сеттеры заключается в том, что они делают объекты класса поддающимися реконфигурации и повторному инжектированию позже
|
Метки: author gmananton java перевод spring spring framework spring ioc dependency injection |
Как создать бизнес-предложение, в основе которого результат НИОКР и технологий |

|
Метки: author KateVo ниокр повышение квалификации онлайн обучение |
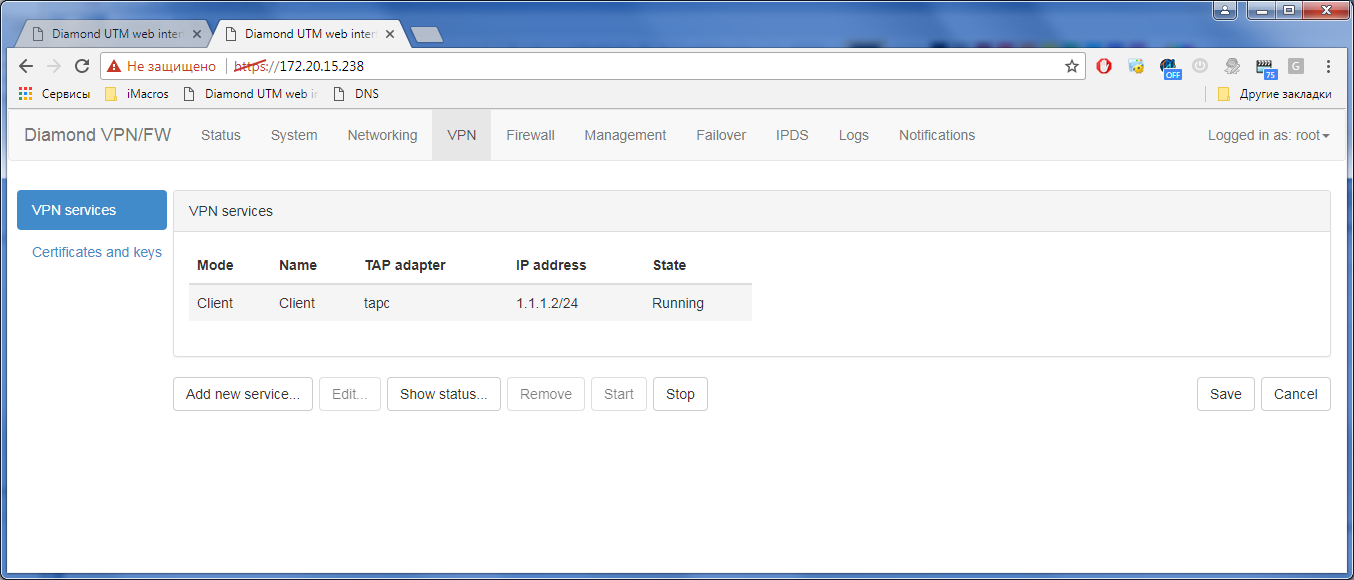
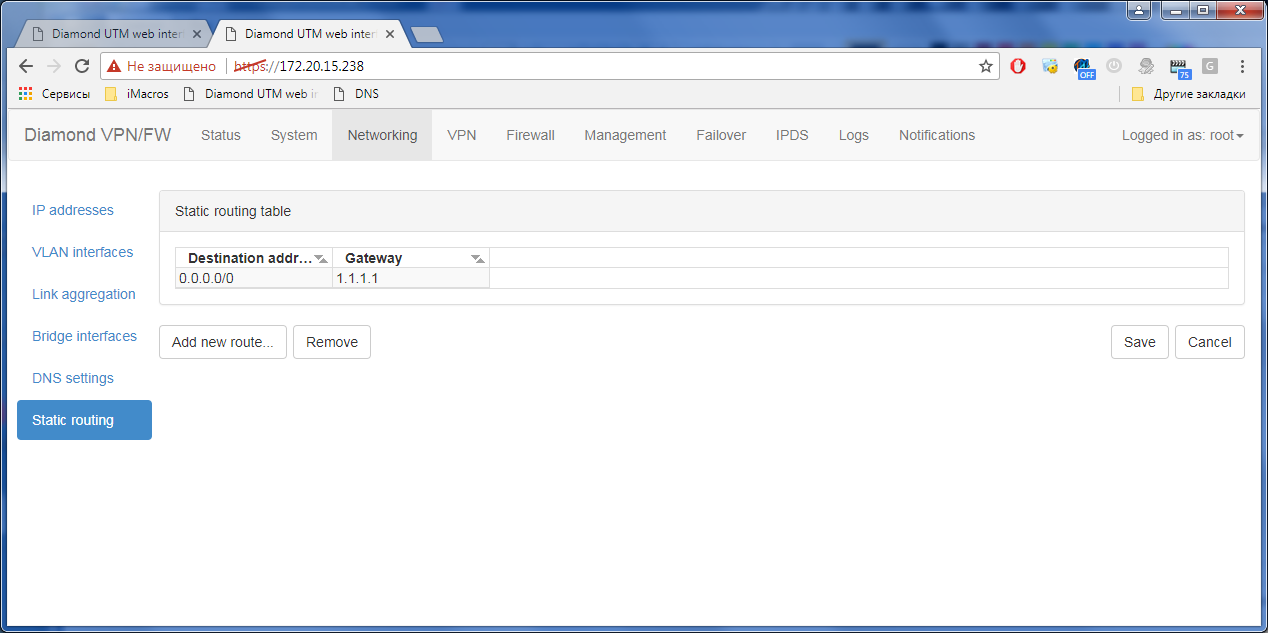
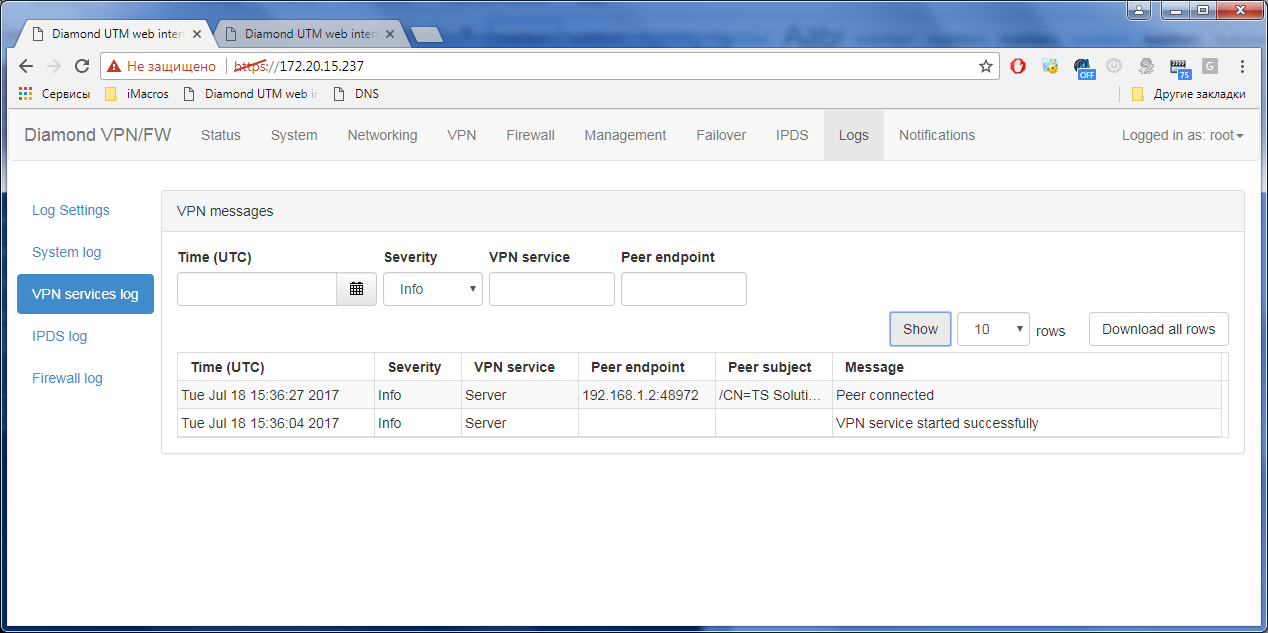
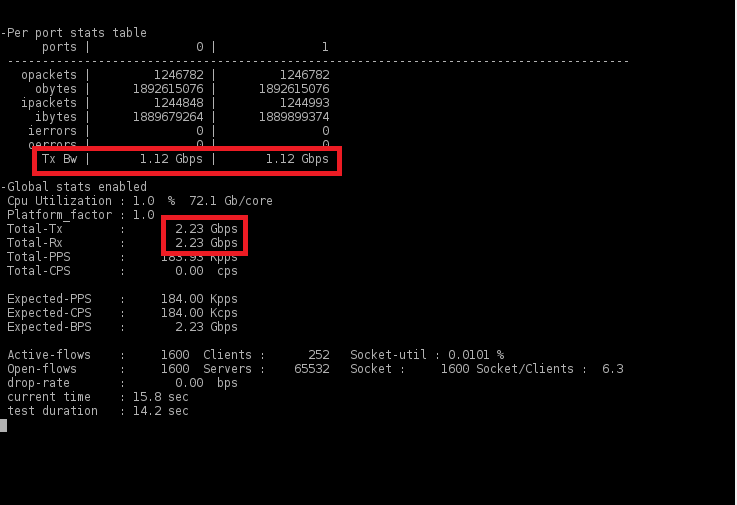
Гигабитный ГОСТ VPN. TSS Diamond |

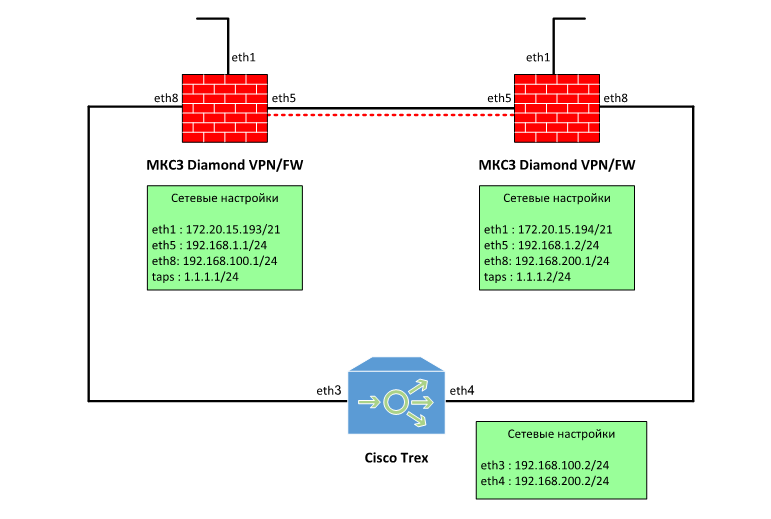
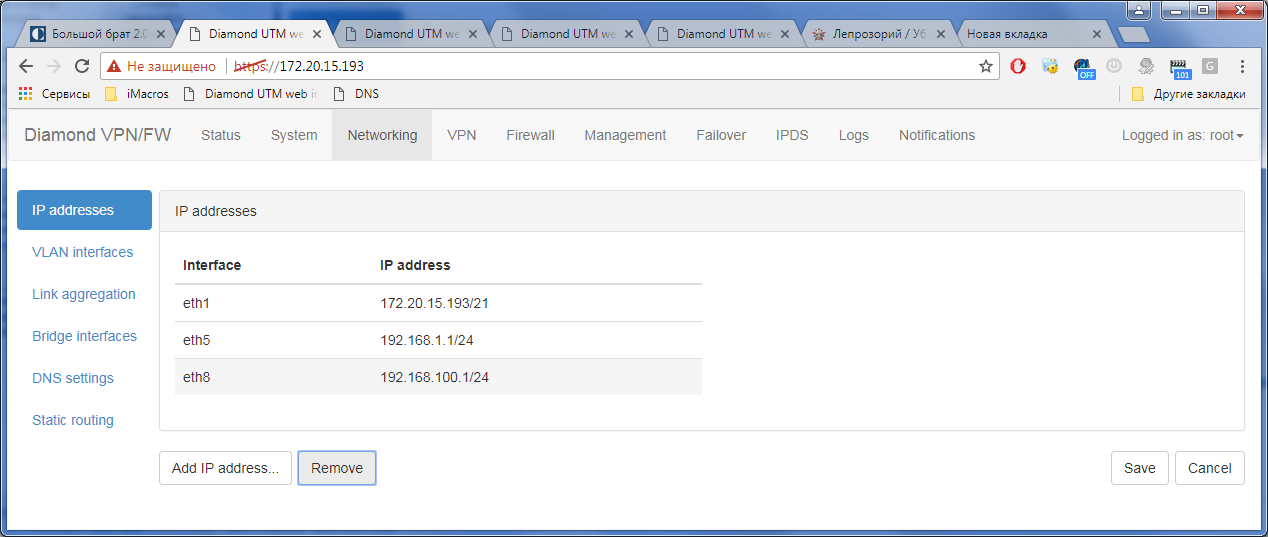
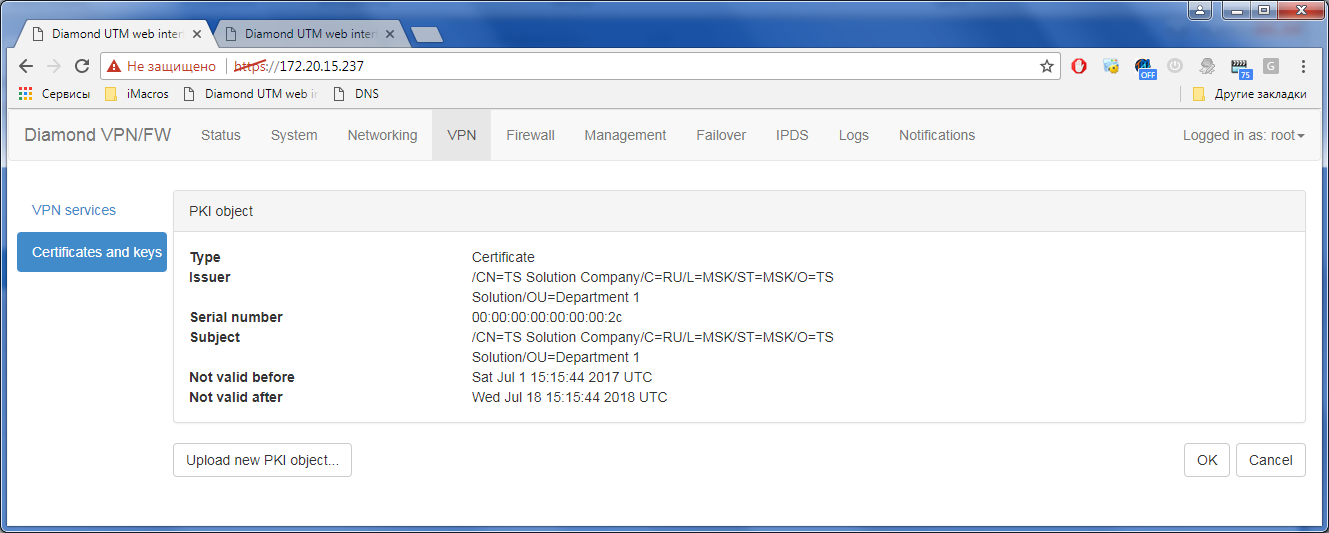
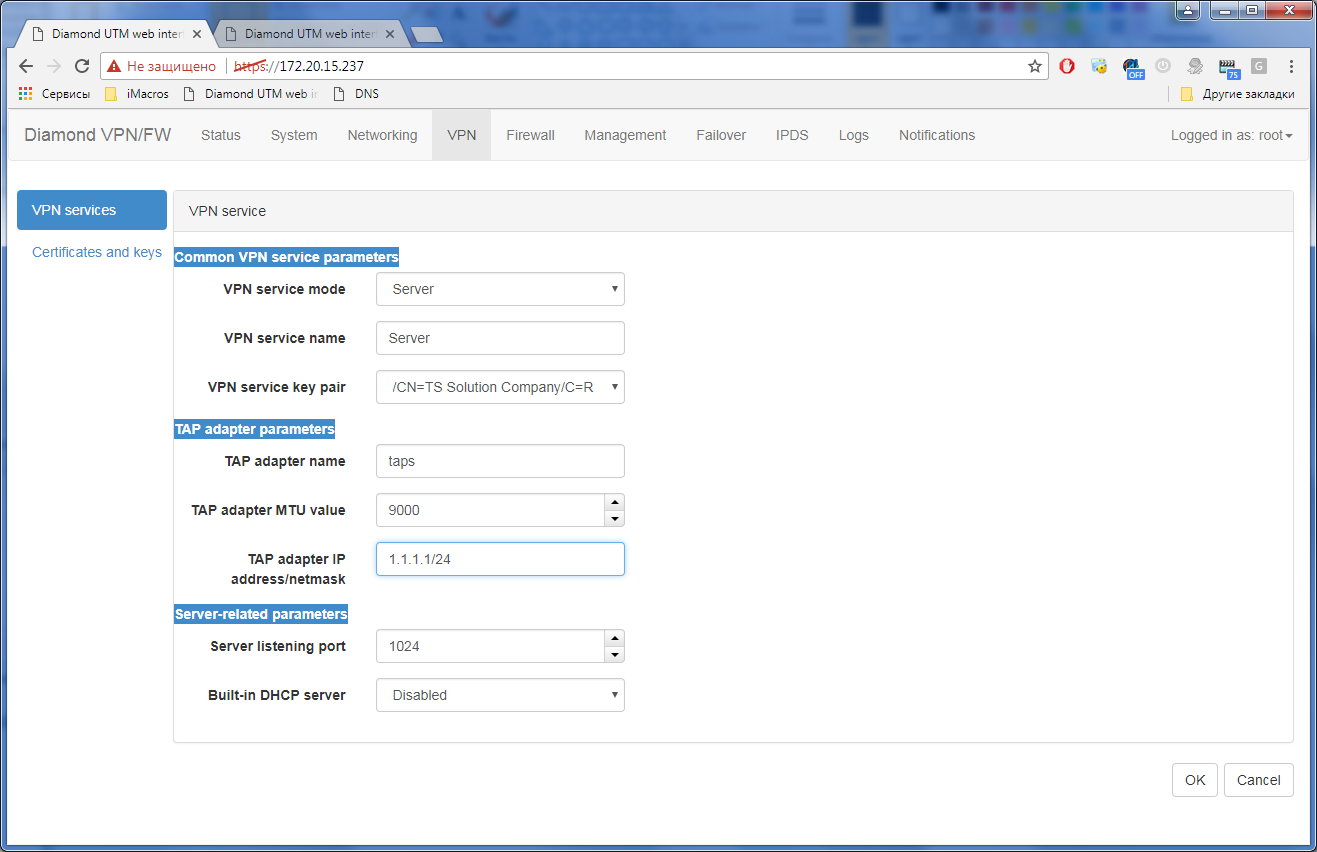
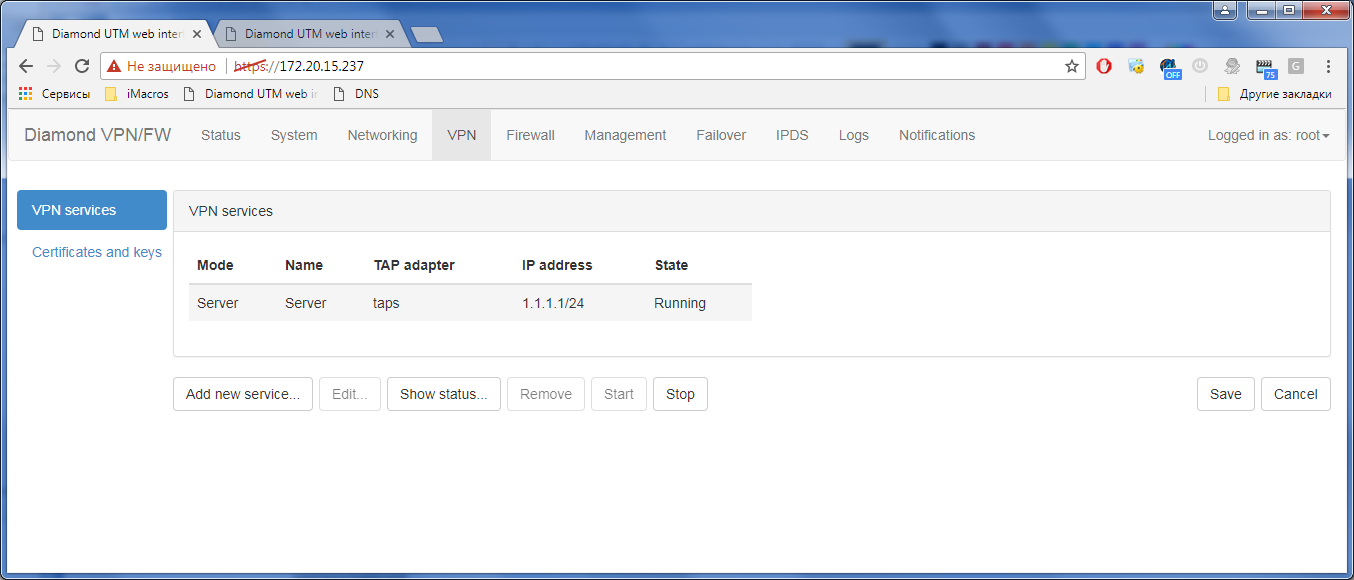




Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
|
Книга «jQuery в действии. 3-е издание» |
 Эта книга — для веб-разработчиков, желающих углубиться в jQuery. Цель авторов — сделать вас профессионалом jQuery, будь ваш уровень начальным или продвинутым. Книга охватывает всю библиотеку целиком, включая некоторые дополнительные инструменты и фреймворки, такие как Bower и QUnit, рекомендуя лучшие практики. Каждый метод API представлен в удобном для применения синтаксическом блоке, описывающем параметры и возвращаемые значения.
Эта книга — для веб-разработчиков, желающих углубиться в jQuery. Цель авторов — сделать вас профессионалом jQuery, будь ваш уровень начальным или продвинутым. Книга охватывает всю библиотеку целиком, включая некоторые дополнительные инструменты и фреймворки, такие как Bower и QUnit, рекомендуя лучшие практики. Каждый метод API представлен в удобном для применения синтаксическом блоке, описывающем параметры и возвращаемые значения. $.trim(value)var trimmedString = $.trim($('#some-field').val());var anArray = ['one', 'two', 'three'];
for (var i = 0; i < anArray.length; i++) {
// Здесь будет что-то делаться с anArray[i]
}
var anObject = {one: 1, two: 2, three: 3};
for (var prop in anObject) {
// Здесь будет что-то делаться с prop
}$.each(collection, callback)var anArray = ['one', 'two', 'three'];
$.each(anArray, function(i, value) {
// Здесь что-то делается
});
var anObject = {one:1, two:2, three:3};
$.each(anObject, function(name, value) {
// Здесь что-то делается
});$.each(anArray,someComplexFunction);var $divs = $('div');
for (var element of $divs) {
// Здесь что-то делается с элементом
}$.grep (array, callback[, invert])var bigNumbers = $.grep(originalArray, function(value) {
return value > 100;
});var badZips = $.grep(
originalArray,
function(value) {
return value.match(/^\d{5}(-\d{4})?$/) !== null;
},
true
);var oneBased = $.map(
[0, 1, 2, 3, 4],
function(value) {
return value + 1;
}
);[1, 2, 3, 4, 5]$.map(collection, callback)var strings = ['1', '2', '3', '4', 'S', '6'];
var values = $.map(strings, function(value) {
var result = new Number(value);
return isNaN(result) ? null : result;
});var characters = $.map(
['this', 'that'],
function(value) {
return value.split('');
}
);['t', 'h', 'i', 's', 't', 'h', 'a', 't']$.inArray(value, array[, fromIndex])var index = $.inArray(2, [1, 2, 3, 4, 5]);var images = document.getElementsByTagName('img');$.makeArray(object)function foo(a, b) {
// Аргументы сортировки здесь
}function foo(a, b) {
var sortedArgs = arguments.sort();
}function foo(a, b) {
var sortedArgs = $.makeArray(arguments).sort();
}var arr = $.makeArray({a: 1, b: 2});$.unique(array)foo
bar
baz
don
wowvar blackDivs = $('.black').get();
console.log('Черные div-ы: ' + blackDivs.length);
var allDivs = blackDivs.concat($('div').get());
console.log('Увеличенные div-ы: ' + allDivs.length);
var uniqueDivs = $.unique(allDivs);
console.log('Уникальные div-ы: ' + uniqueDivs.length);$.merge(array1,array2)var arr1 = [1, 2, 3, 4, 5];
var arr2 = [5, 6, 7, 8, 9];
var arr3 = $.merge(arr1, arr2);[1, 2, 3, 4, 5, 5, 6, 7, 8, 9]|
Метки: author ph_piter разработка веб-сайтов профессиональная литература jquery javascript блог компании издательский дом «питер» книги |
Распознавание дорожных знаков с помощью CNN: Инструменты для препроцессинга изображений |

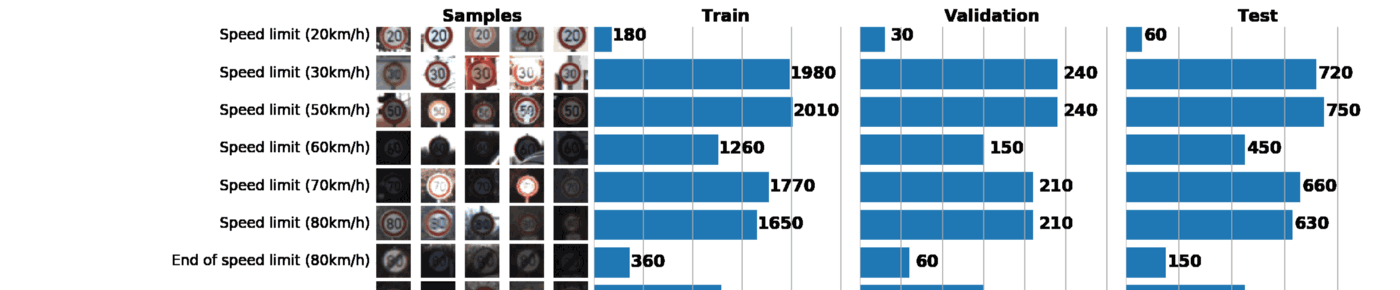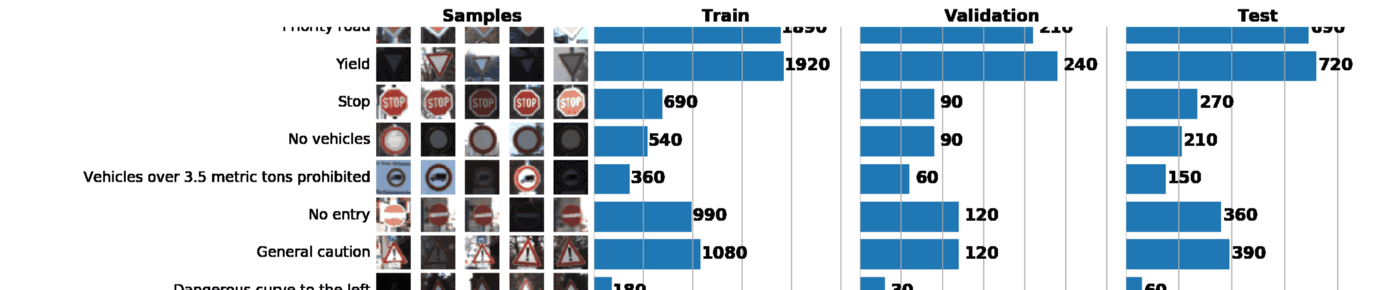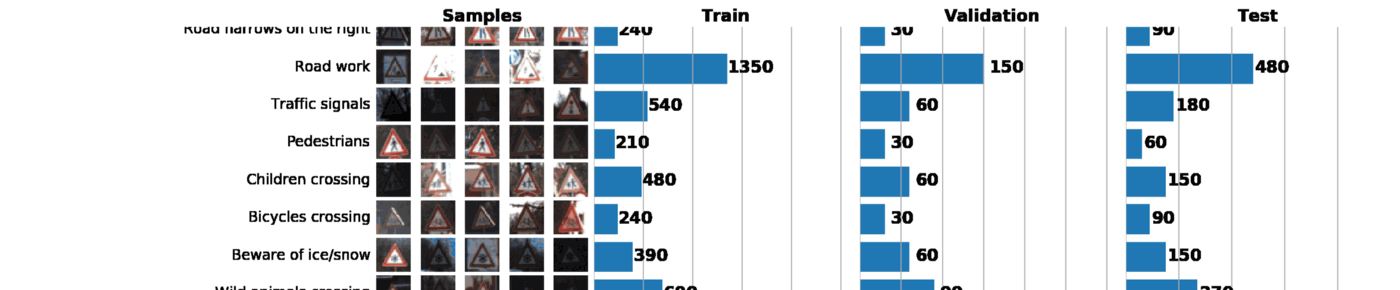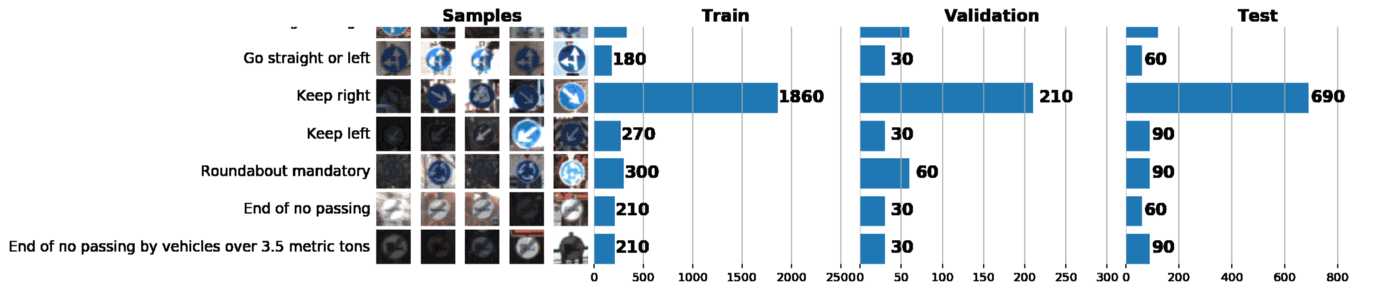
Number of training examples = 34799
Number of validation examples = 4410
Number of testing examples = 12630
Image data shape = (32, 32, 3)
Number of classes = 43matplotlib — ваш лучший друг. Несмотря на то, что используя лишь pyplot можно отлично визуализировать данные, matplotlib.gridspec позволяет слить 3 графика воедино:gs = gridspec.GridSpec(1, 3, wspace=0.25, hspace=0.1)
fig = plt.figure(figsize=(12,2))
ax1, ax2, ax3 = [plt.subplot(gs[:, i]) for i in range(3)]Gridspec очень гибок. К примеру, для каждой гистограммы можно установить свою ширину, как я это сделал выше. Gridspec рассматривает ось каждой гистограммы независимо от других, что позволяет создавать усложненные графики.
scipy)scikit-image, которая может быть легко установлена с помощью pip (OpenCV же требует самостоятельной компиляции с кучей зависимостей). Нормализация контрастности изображений будет осуществляться с помощью адаптивной нормализации гистограммы (CLAHE, contrast limited adaptive histogram equalization):skimage.exposure.equalize_adapthist.skimage обрабатывает изображения одно за другим, используя лишь одно ядро процессора, что, очевидно, неэффективно. Чтобы распараллелить предобработку изображений, используем библиотеку IPython Parallel (ipyparallel). Одно из преимуществ этой библиотеки — простота: реализовать распараллеленный CLAHE можно всего несколькими строчками кода. Сначала в консоли (с установленной ipyparallel) запустим локальный кластер ipyparallel:$ ipcluster start
from skimage import exposure
def grayscale_exposure_equalize(batch_x_y):
"""Processes a batch with images by grayscaling, normalization and
histogram equalization.
Args:
batch_x_y: a single batch of data containing a numpy array of images
and a list of corresponding labels.
Returns:
Numpy array of processed images and a list of labels (unchanged).
"""
x_sub, y_sub = batch_x_y[0], batch_x_y[1]
x_processed_sub = numpy.zeros(x_sub.shape[:-1])
for x in range(len(x_sub)):
# Grayscale
img_gray = numpy.dot(x_sub[x][...,:3], [0.299, 0.587, 0.114])
# Normalization
img_gray_norm = img_gray / (img_gray.max() + 1)
# CLAHE. num_bins will be initialized in ipyparallel client
img_gray_norm = exposure.equalize_adapthist(img_gray_norm, nbins=num_bins)
x_processed_sub[x,...] = img_gray_norm
return (x_processed_sub, y_sub)import multiprocessing
import ipyparallel as ipp
import numpy as np
def preprocess_equalize(X, y, bins=256, cpu=multiprocessing.cpu_count()):
""" A simplified version of a function which manages multiprocessing logic.
This function always grayscales input images, though it can be generalized
to apply any arbitrary function to batches.
Args:
X: numpy array of all images in dataset.
y: a list of corresponding labels.
bins: the amount of bins to be used in histogram equalization.
cpu: the number of cpu cores to use. Default: use all.
Returns:
Numpy array of processed images and a list of labels.
"""
rc = ipp.Client()
# Use a DirectView object to broadcast imports to all engines
with rc[:].sync_imports():
import numpy
from skimage import exposure, transform, color
# Use a DirectView object to set up the amount of bins on all engines
rc[:]['num_bins'] = bins
X_processed = np.zeros(X.shape[:-1])
y_processed = np.zeros(y.shape)
# Number of batches is equal to cpu count
batches_x = np.array_split(X, cpu)
batches_y = np.array_split(y, cpu)
batches_x_y = zip(batches_x, batches_y)
# Applying our function of choice to each batch with a DirectView method
preprocessed_subs = rc[:].map(grayscale_exposure_equalize, batches_x_y).get_dict()
# Combining the output batches into a single dataset
cnt = 0
for _,v in preprocessed_subs.items():
x_, y_ = v[0], v[1]
X_processed[cnt:cnt+len(x_)] = x_
y_processed[cnt:cnt+len(y_)] = y_
cnt += len(x_)
return X_processed.reshape(X_processed.shape + (1,)), y_processed# X_train: numpy array of (34799, 32, 32, 3) shape
# y_train: a list of (34799,) shape
X_tr, y_tr = preprocess_equalize(X_train, y_train, bins=128)

num_bins, чтобы визуализировать их и выбрать наиболее подходящий:
num_bins увеличивает контрастность изображений, в то же время сильно выделяя их фон, что зашумляет данные. Разные значения num_bins также могут быть использованы для аугментации контрастности датасета путем контраста для того, чтобы нейросеть не переобучалась из-за фона изображений.%store, чтобы сохранить результаты для дальнейшего использования:# Same images, multiple bins (contrast augmentation)
%store X_tr_8
%store y_tr_8
# ...
%store X_tr_512
%store y_tr_512numpy и skimage:import numpy as np
from skimage import transform
from skimage.transform import warp, AffineTransform
def rotate_90_deg(X):
X_aug = np.zeros_like(X)
for i,img in enumerate(X):
X_aug[i] = transform.rotate(img, 270.0)
return X_aug
def rotate_180_deg(X):
X_aug = np.zeros_like(X)
for i,img in enumerate(X):
X_aug[i] = transform.rotate(img, 180.0)
return X_aug
def rotate_270_deg(X):
X_aug = np.zeros_like(X)
for i,img in enumerate(X):
X_aug[i] = transform.rotate(img, 90.0)
return X_aug
def rotate_up_to_20_deg(X):
X_aug = np.zeros_like(X)
delta = 20.
for i,img in enumerate(X):
X_aug[i] = transform.rotate(img, random.uniform(-delta, delta), mode='edge')
return X_aug
def flip_vert(X):
X_aug = deepcopy(X)
return X_aug[:, :, ::-1, :]
def flip_horiz(X):
X_aug = deepcopy(X)
return X_aug[:, ::-1, :, :]
def affine_transform(X, shear_angle=0.0, scale_margins=[0.8, 1.5], p=1.0):
"""This function allows applying shear and scale transformations
with the specified magnitude and probability p.
Args:
X: numpy array of images.
shear_angle: maximum shear angle in counter-clockwise direction as radians.
scale_margins: minimum and maximum margins to be used in scaling.
p: a fraction of images to be augmented.
"""
X_aug = deepcopy(X)
shear = shear_angle * np.random.rand()
for i in np.random.choice(len(X_aug), int(len(X_aug) * p), replace=False):
_scale = random.uniform(scale_margins[0], scale_margins[1])
X_aug[i] = warp(X_aug[i], AffineTransform(scale=(_scale, _scale), shear=shear), mode='edge')
return X_augrotate_up_to_20_deg увеличивают размер выборки, сохраняя принадлежность изображений к исходным классам. Отражения (flips) и вращения на 90, 180, 270 градусов могут, напротив, поменять смысл знака. Чтобы отслеживать такие переходы, создадим список возможных преобразований для каждого дорожного знака и классов, в которые они будут преобразованы (ниже приведен пример части такого списка):| label_class | label_name | rotate_90_deg | rotate_180_deg | rotate_270_deg | flip_horiz | flip_vert |
|---|---|---|---|---|---|---|
| 13 | Yield | 13 | ||||
| 14 | Stop | |||||
| 15 | No vehicles | 15 | 15 | 15 | 15 | 15 |
| 16 | Vehicles over 3.5 ton prohibited |
|||||
| 17 | No entry | 17 | 17 | 17 |
import pandas as pd
# Generate an augmented dataset using a transform table
augmentation_table = pd.read_csv('augmentation_table.csv', index_col='label_class')
augmentation_table.drop('label_name', axis=1, inplace=True)
augmentation_table.dropna(axis=0, how='all', inplace=True)
# Collect all global functions in global namespace
namespace = __import__(__name__)
def apply_augmentation(X, how=None):
"""Apply an augmentation function specified in `how` (string) to a numpy array X.
Args:
X: numpy array with images.
how: a string with a function name to be applied to X, should return
the same-shaped numpy array as in X.
Returns:
Augmented X dataset.
"""
assert augmentation_table.get(how) is not None
augmentator = getattr(namespace, how)
return augmentator(X)augmentation_table.csv ко всем классам:import numpy as np
def flips_rotations_augmentation(X, y):
"""A pipeline for applying augmentation functions listed in `augmentation_table`
to a numpy array with images X.
"""
# Initializing empty arrays to accumulate intermediate results of augmentation
X_out, y_out = np.empty([0] + list(X.shape[1:]), dtype=np.float32), np.empty([0])
# Cycling through all label classes and applying all available transformations
for in_label in augmentation_table.index.values:
available_augmentations = dict(augmentation_table.ix[in_label].dropna(axis=0))
images = X[y==in_label]
# Augment images and their labels
for kind, out_label in available_augmentations.items():
X_out = np.vstack([X_out, apply_augmentation(images, how=kind)])
y_out = np.hstack([y_out, [out_label] * len(images)])
# And stack with initial dataset
X_out = np.vstack([X_out, X])
y_out = np.hstack([y_out, y])
# Random rotation is explicitly included in this function's body
X_out_rotated = rotate_up_to_20_deg(X)
y_out_rotated = deepcopy(y)
X_out = np.vstack([X_out, X_out_rotated])
y_out = np.hstack([y_out, y_out_rotated])
return X_out, y_outaffine_transform: кастомизируемые аффинные преобразования без вращения (название я выбрал не очень удачное, потому что, что вращение является одним из аффинных преобразований).flips_rotations_augmentation: случайные вращения и преобразования на основе augmentation_table.csv, меняющие классы изображений.def augmented_batch_generator(X, y, batch_size, rotations=True, affine=True,
shear_angle=0.0, scale_margins=[0.8, 1.5], p=0.35):
"""Augmented batch generator. Splits the dataset into batches and augments each
batch independently.
Args:
X: numpy array with images.
y: list of labels.
batch_size: the size of the output batch.
rotations: whether to apply `flips_rotations_augmentation` function to dataset.
affine: whether to apply `affine_transform` function to dataset.
shear_angle: `shear_angle` argument for `affine_transform` function.
scale_margins: `scale_margins` argument for `affine_transform` function.
p: `p` argument for `affine_transform` function.
"""
X_aug, y_aug = shuffle(X, y)
# Batch generation
for offset in range(0, X_aug.shape[0], batch_size):
end = offset + batch_size
batch_x, batch_y = X_aug[offset:end,...], y_aug[offset:end]
# Batch augmentation
if affine is True:
batch_x = affine_transform(batch_x, shear_angle=shear_angle, scale_margins=scale_margins, p=p)
if rotations is True:
batch_x, batch_y = flips_rotations_augmentation(batch_x, batch_y)
yield batch_x, batch_ynum_bins в CLAHE в один большой train, подадим его в полученный генератор. Теперь у нас есть два вида аугментации: по контрастности и с помощью аффинных трансформаций, которые применяются к батчу на лету:
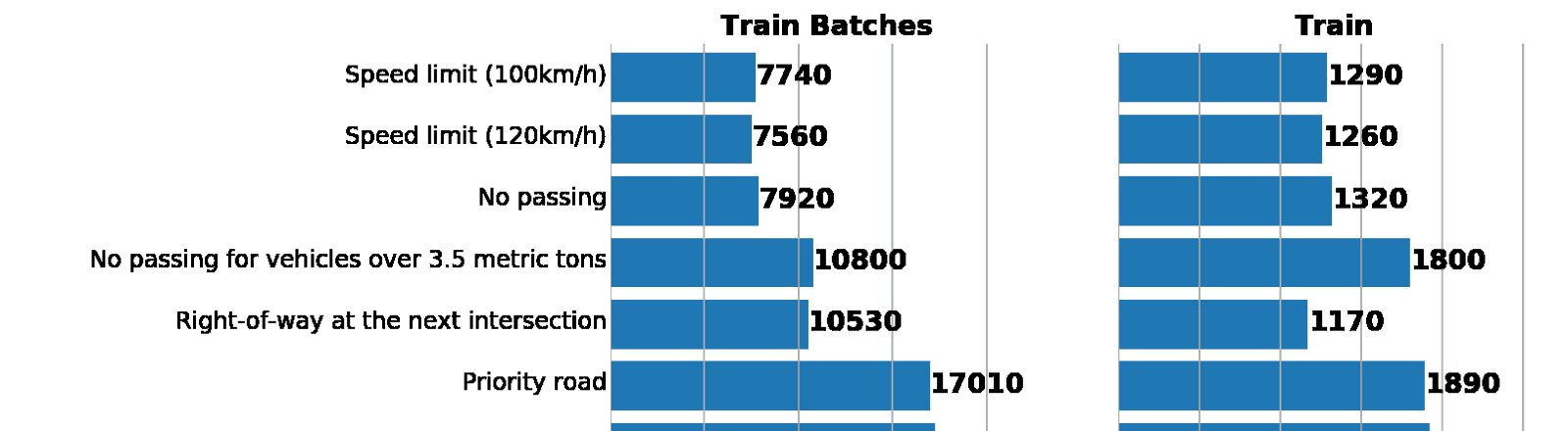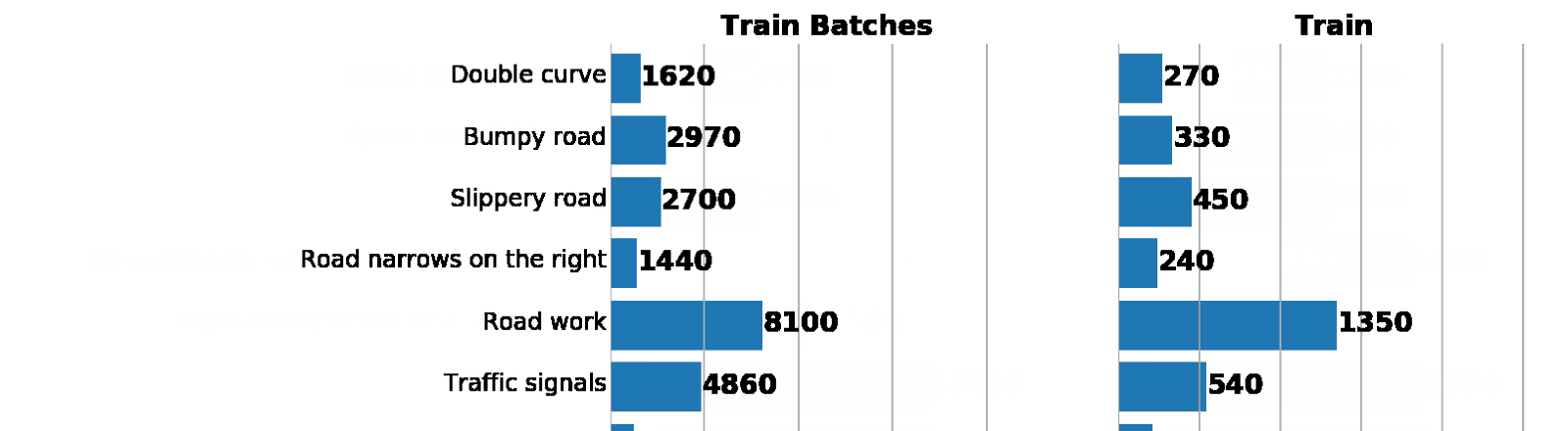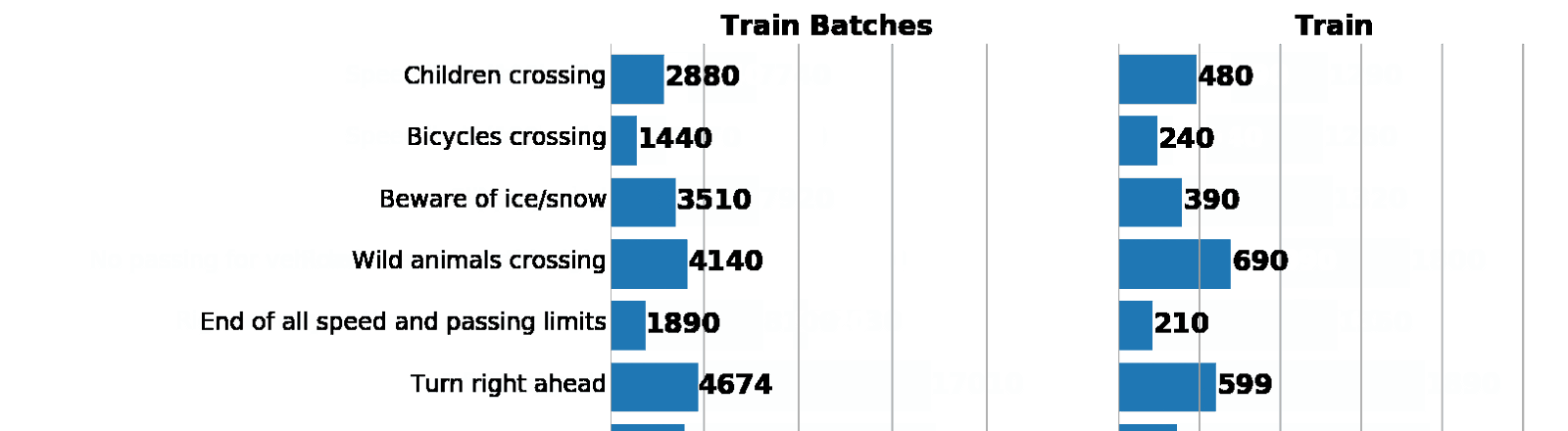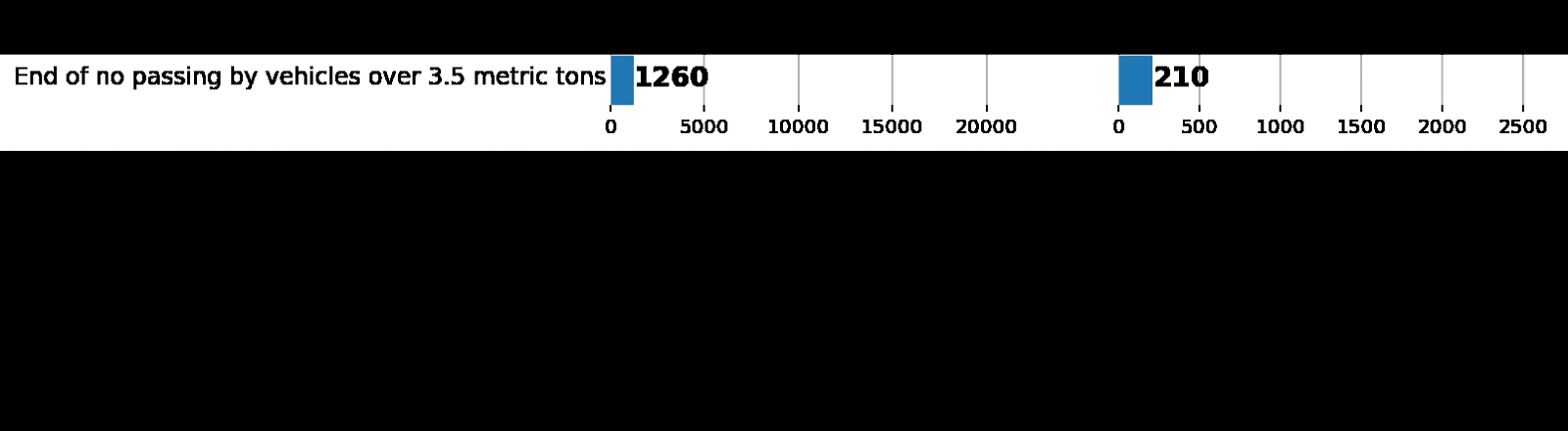

|
Метки: author a-pichugin обработка изображений data mining big data блог компании new professions lab распознавание изображений data augmentation предобработка данных |
[Из песочницы] 6 советов по запуску стартапа конструктора чего-угодно |
|
Метки: author sukubzzz повышение конверсии монетизация веб-сервисов интернет-маркетинг стартапы конструкторы |
[Перевод] Дотянуться до миллениалов: тренды и техники мобильного маркетинга |








|
Метки: author PayOnline финансы в it исследования и прогнозы в it блог компании payonline мобильная реклама маркетинг видеореклама нативная реклама payonline |
Hack. Sleep. Repeat |




— Кто там?
— Мы в хостел.
— Какой ещё хостел? Я тебя не знаю, я тебя не впущу.
— … ой, кажется, мы корпусом ошиблись.
— Да? Ну тогда пошёл на фиг!


|
Метки: author pik4ez хакатоны блог компании avito |
DeNet — платформа для децентрализованного web хостинга на базе блокчейн |
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author djdeniro совершенный код программирование анализ и проектирование систем it- стандарты децентрализация блокчейн хостинг сервера интернет |






