Vivaldi 1.10 — маленькие радости широких возможностей |





|
Метки: author Shpankov разработка веб-сайтов браузеры блог компании vivaldi technologies as vivaldi vivaldi technologies финал 1.10 |
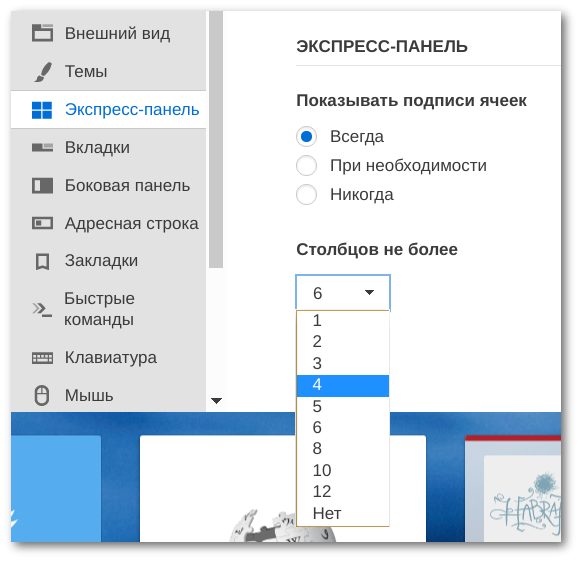
Microsoft Azure Media Services — обзор основных возможностей платформы |




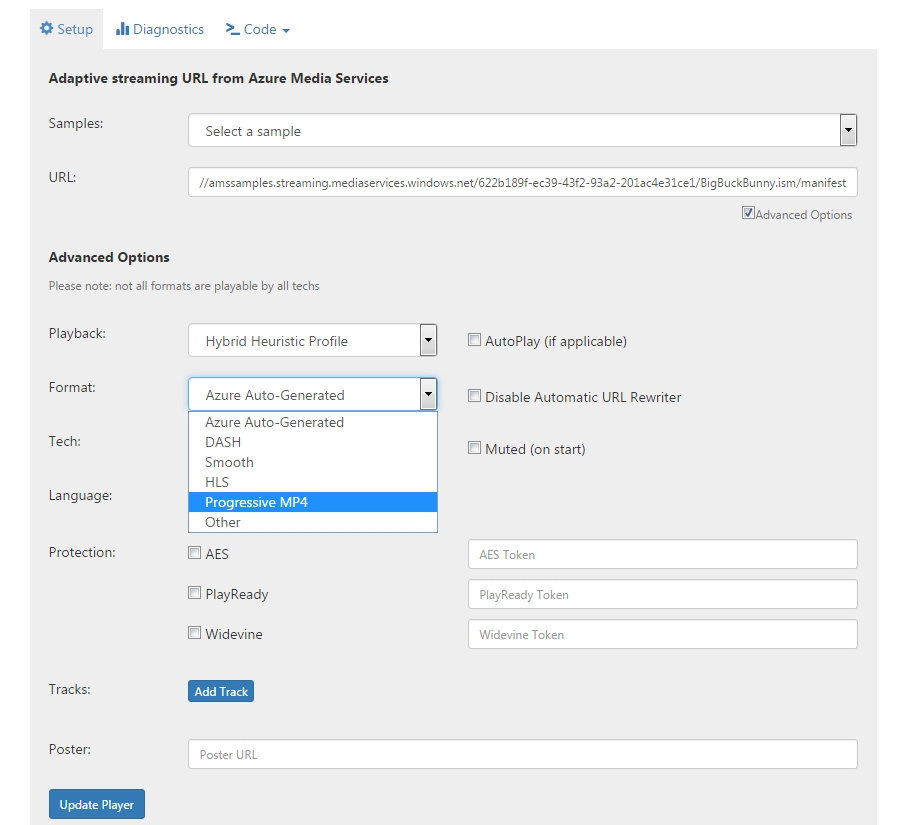



|
Метки: author Orest_ua разработка веб-сайтов microsoft azure it- стандарты блог компании мук microsoft azure media services |
Межпланетная файловая система — больше нет необходимости копировать в сеть |
InterPlanetary File System — это новая децентрализованная сеть обмена файлами (HTTP-сервер, Content Delivery Network). О ней я рассказывал в статье "Межпланетная файловая система IPFS".
Всем хороша идея IPFS но вот только был один недостаток у неё. Данные загружаемые в сеть копировались в хранилище блоков удваивая занимаемое ими место. Более того файл резался на блоки которые мало пригодны для повторного использования.
Появилась экспериментальная опция --nocopy, которая избавляет от этого недостатка. Для того чтобы пользоваться ей необходимо выполнить несколько условий.
Также появился новый тип идентификаторов. Его мы тоже разберём.

Это опция заставляет IPFS использовать как источник блоков исходные файлы. Тем самым файлы не копируются в хранилище блоков и не занимают в 2 раза больше места.
Для использования этой опции выполним следующие действия:
необходимо включить Filestore
ipfs config --json Experimental.FilestoreEnabled trueв каталог ".ipfs"(он в каталоге пользователя) нужно сделать ссылку на каталог или файл который надо загрузить в сеть
Файл можно связать hardlink'ом:
fsutil hardlink ".ipfs\[имя файла]" "[путь к файлу]\[имя файла]"или
mklink /h ".ipfs\[имя файла]" "[путь к файлу]\[имя файла]"Каталог можно связать символьной ссылкой:
linkd ".ipfs\[имя каталога]" "[путь к каталогу]\[имя каталога]"или
mklink /j ".ipfs\[имя каталога]" "[путь к каталогу]\[имя каталога]"И теперь добавляем
ipfs add -w --nocopy ".ipfs\[имя каталога или файла]"Ключ -w оборачивает цель в каталог тем самым сохраняя её имя.
Результатом будут идентификаторы CIDv1 и CIDv0 (мультихеш)
Теперь в магнит или торрент можно будет добавить WebSeed.
Для файла:
http://127.0.0.1:8080/ipfs/[идентификатор]/[имя файла]
http://ipfs.io/ipfs/[идентификатор]/[имя файла]Для каталога:
http://127.0.0.1:8080/ipfs/[идентификатор]/
http://ipfs.io/ipfs/[идентификатор]/Пример магнита c WebSeed
magnet:?xt=urn:btih:2F825A27112B0E5C89D20B656045920F1C10830C28&ws=https://ipfs.io/ipfs/QmPbs8syAxac39bcNuMLpHXnqjKUguqakCM8LN8sZVPD9R/Magnet-ссылка.txtВ связи с этими изменениями в IPFS появились RAW блоки. Ключ --nocopy автоматически включает использование RAW блоков. Но можно включить этот режим и ключом --raw-leaves. В связи с этим появился новый CID (Content IDentifier) или по русски "идентификатор контента".
Называется CIDv0 и обычно имеет постоянный префикс "Qm".
CIDv0 это просто мультихеш в Base58
[varint ID хеша][varint длинна хеша][хеш]Пример CIDv0: QmPbs8syAxac39bcNuMLpHXnqjKUguqakCM8LN8sZVPD9R
У RAW блоков свой CID. Его можно отличить по постоянному префиксу "zb2rh".
CIDv1 содержит в себе больше информации.
[префикс основания][varint версия CID][varint тип контента][varint ID хеша][varint длинна хеша][хеш]Пример CIDv1: zb2rhe143L6sgu2Nba4TZgFMdPidGMA6hmWhK9wLUoVGWYsR7
Разберём его на части
z — base58 Bitcoin [префикс основания]
base58: b2rhe143L6sgu2Nba4TZgFMdPidGMA6hmWhK9wLUoVGWYsR7
переводим в
HEX: 01 55 12 20 6D542257CBD1BE7FD0AE8914F42066BCBF1E79487EF67B959A86DBEE4670B386
01 — v1 [varint версия CID]55 — raw binary [varint тип контента]12 — sha2-256 [varint ID хеша]20 — 32 байта [varint длинна хеша]6D542257CBD1BE7FD0AE8914F42066BCBF1E79487EF67B959A86DBEE4670B386 — sha2-256 digest [хеш]Опция --nocopy очень помогает когда вы хотите поделиться с миром например дампом Википедии. Или другими полезными но очень большими по объёму массивами информации.
Ссылки в Windows, символьные и не только
ipfs command reference
List of experimental IPFS features
|
Метки: author ivan386 децентрализованные сети ipfs magnet links |
[Из песочницы] Система управления проектами Redmine + Mercurial на Ubuntu 16.04 |
$ sudo tasksel install lamp-server$ mysql -u root -p
(вводим пароль root базы данных MySQL)
> create database redmine character set utf8;
> create user 'redmine'@'localhost' identified by '[password]';
> grant all privileges on redmine.* to 'redmine'@'localhost';
> exit$ wget http://www.redmine.org/releases/redmine-3.3.3.tar.gz$ sudo cp /usr/share/redmine/config/database.yml.example /usr/share/redmine/config/database.yml
$ sudo nano /usr/share/redmine/config/database.ymlproduction:
adapter: mysql2
database: redmine
host: localhost
username: redmine
password: "[password]"
encoding: utf8$ sudo apt install ruby ruby-dev build-essential libmysqlclient-dev$ gem install bundler$ cd /usr/share/redmine
$ bundle install --without development test rmagick$ cd /usr/share/redmine
$ bundle exec rake generate_secret_token
$ RAILS_ENV=production bundle exec rake db:migrate
$ RAILS_ENV=production bundle exec rake redmine:load_default_data
$ cd /usr/share/redmine
$ sudo chown -R www-data:www-data files log tmp public/plugin_assets
$ sudo chmod -R 755 files log tmp public/plugin_assets
$ sudo -u www-data bundle exec rails server webrick -e productionhttp://localhost:3000/$ sudo apt-get install libapache2-mod-passenger$ sudo ln -s /usr/share/redmine/public /var/www/redmine$ sudo nano /etc/apache2/mods-available/passenger.confPassengerDefaultUser www-data
PassengerRoot /usr/lib/ruby/vendor_ruby/phusion_passenger/locations.ini
PassengerDefaultRuby /usr/bin/ruby
PassengerDefaultUser www-data
$ sudo nano /etc/apache2/sites-available/redmine.conf
ServerAdmin webmaster@localhost
DocumentRoot /var/www
ServerName myservername
RewriteEngine on
RewriteRule ^/$ /redmine [R]
$ sudo a2enmod passenger
$ sudo a2enmod rewrite$ sudo a2dissite 000-default
$ sudo a2ensite redminesudo chmod 777 /usr/share/redmine/tmp/cache$ sudo service apache2 reloadhttp://[my site or ip]/redmine или просто http://[my site or ip]. Должна появиться стартовая страничка системы Redmine.$ sudo apt-get install mercurial libapache2-mod-perl2 libapache-dbi-perl libdbd-mysql-perl$ sudo mkdir -p /var/hg/$ sudo nano /var/hg/hgwebdir.cgi#!/usr/bin/python
from mercurial import demandimport; demandimport.enable()
from mercurial.hgweb.hgwebdir_mod import hgwebdir
import mercurial.hgweb.wsgicgi as wsgicgi
application = hgwebdir('hgweb.config')
wsgicgi.launch(application)$ sudo nano /var/hg/hgweb.config
[paths]
/=/var/hg/**
[web]
allow_push = *
push_ssl = false
allowbz2 = yes
allowgz = yes
allowzip = yes$ sudo chown -R www-data:www-data /var/hg/*
$ sudo chmod gu+x /var/hg/hgwebdir.cgi$ sudo nano /etc/apache2/conf-available/hg.confPerlLoadModule Apache2::Redmine
ScriptAliasMatch ^/hg/(.*) /var/hg/hgwebdir.cgi/$1
$ sudo ln -s /etc/apache2/conf-available/hg.conf /etc/apache2/conf-enabled/
$ sudo ln -s /usr/share/redmine/extra/svn/Redmine.pm /usr/lib/x86_64-linux-gnu/perl5/5.22/Apache2/$ sudo a2enmod cgi
$ sudo service apache2 reloadhttp://[my site or ip]/hg/*. Например, для проекта project адрес будет таким http://[my site or ip]/hg/project. Если у проекта project будет подпроект subproject1, то его репозиторий будет доступен по адресу http://[my site or ip]/hg/project/subproject1.$ hg clone http://[my site or ip]/hg/projecthg init). $ sudo chown -R www-data:www-data /var/hg/[repository name] email_delivery:
delivery_method: :smtp
smtp_settings:
address: "10.11.12.13"
port: 25
authentification: :none
enable_starttls_auto: false
openssl_verify_mode: 'none'
--- OLD
+++ NEW
@@ -23,6 +23,7 @@
+
class AddRepositoriesIsDiffEmailAttached < ActiveRecord::Migration
def self.up
add_column :repositories, :is_diff_email_attached, :boolean, :default => false, :null => false
Repository.update_all(["is_diff_email_attached = ?", true])
Repository.update_all(["is_diff_email = ?", true])
end
def self.down
remove_column :repositories, :is_diff_email_attached
end
end
bundle exec rake redmine:plugins:migrate RAILS_ENV=production$ sudo service apache2 reload$ sudo nano /var/hg/fetch_changes#!/bin/sh
curl "http://localhost/redmine/sys/fetch_changesets?key=[your API key]" > /dev/null 2>&1$ sudo chown www-data:www-data /var/hg/fetch_changes
$ sudo chmod ug+x /var/hg/fetch_changes[hooks]
changegroup = /var/hg/fetch_changes|
Метки: author polytechnic системы управления версиями mercurial redmine apache2 |
Replication Framework • глубинное копирование и обобщённое сравнение связных графов объектов |

* По умолчанию, если класс имеет атрибуты DataContract или CollectionDataContract, то на снимок транслируются лишь члены с атрибутом DataMember, в ином же случае на снимок попадают все поля и свойства класса как публичные, так и нет.
var snapshot0 = instance0.CreateSnapshot(); /* use default ReplicationProfile */
var customReplicationProfile = new ReplicationProfile
{
MemberProviders = new List
{
//new MyCustomMemberProvider(), /* you may override and customize MemberProvider class! */
new CoreMemberProviderForKeyValuePair(),
//new CoreMemberProvider(BindingFlags.Public | BindingFlags.Instance, Member.CanReadWrite),
new ContractMemberProvider(BindingFlags.NonPublic | BindingFlags.Public | BindingFlags.Instance, Member.CanReadWrite)
}
};
var snapshot1 = instance1.CreateSnapshot(customReplicationProfile );
Snapshot.DefaultReplicationProfile = customReplicationProfile; var cache = new Dictionary();
var snapshot0 = graph0.CreateSnapshot(cache);
/* modify 'graph0' by any way */
var graphX = snapshot0.ReconstructGraph(cache);
/* graphX is the same reference that graph0, all items of the graph reverted to the previous state */* Следует помнить, что кэшированные объекты удерживаются от сборки мусора, а во время реконструкции все они возвращаются в исходное состояние.
var snapshot0 = graph0.CreateSnapshot(cache);
/* modify 'graph0' by any way */
var graph1 = snapshot0.ReplicateGraph(cache);
/* graph1 is a deep copy of the source graph0 */Копирование бывает двух видов — поверхностное и глубинное. Пускай даны объекты А и Б, причём А содержит ссылку на Б (граф А=>Б). При поверхностном копировании объекта А будет создан объект А', который также будет ссылаться на Б, то есть в итоге получится два графа А=>Б и А'=>Б. У них будет общая часть Б, поэтому при изменении объекта Б в первом графе, автоматически его состояние будет мутировать и во втором. Объекты же А и А' останутся независимы. Но наибольший интерес представляют графы с замкнутыми (циклическими) ссылками. Пускай А ссылается на Б и Б ссылается на А (А<=>Б), при поверхностном копировании объекта А в А' получим весьма необычный граф А'=>Б<=>А, то есть в итоговый граф попал изначальный объект, который подвергался клонированию. Глубинное же копирование предполагает клонирования всех объектов, входящих в граф. Для нашего случая А<=>Б преобразуется в А'<=>Б', в итоге оба графа совершенно изолированы друг от друга. В некоторых случаях достаточно поверхностного копирования, но далеко не всегда.
var snapshot0 = instance0.CreateSnapshot(); /* etalon */
var snapshot1 = instance1.CreateSnapshot(); /* sample */
var juxtapositions = snapshot0.Juxtapose(snapshot1).ToList();
var differences = juxtapositions.Where(j=>j.State == Etalon.State.Different);* Что немаловажно, результатом операции сопоставления является, что даёт возможность прервать процесс рекурсивного сопоставления в любой момент по достижении определённых условий, а не производить его полностью, это в свою очередь значимо для производительности.IEnumerable
using System;
using System.Collections.Generic;
using System.Runtime.Serialization;
namespace Art.Replication.Diagnostics
{
[DataContract]
public class Role
{
[DataMember] public string Name;
public string CodePhrase;
[DataMember] public DateTime LastOnline = DateTime.Now;
[DataMember] public Person Person;
}
public class Person
{
public string FirstName;
public string LastName;
public DateTime Birthday;
public List Roles = new List();
}
public static class DiagnosticsGraph
{
public static Person Create()
{
var person0 = new Person
{
FirstName = "Keanu",
LastName = "Reeves",
Birthday = new DateTime(1964, 9 ,2)
};
var roleA0 = new Role
{
Name = "Neo",
CodePhrase = "The Matrix has you...",
LastOnline = DateTime.Now,
Person = person0
};
var roleB0 = new Role
{
Name = "Thomas Anderson",
CodePhrase = "Follow the White Rabbit.",
LastOnline = DateTime.Now,
Person = person0
};
person0.Roles.Add(roleA0);
person0.Roles.Add(roleB0);
return person0;
}
}
} using Art;
using Art.Replication;
using Art.Replication.Replicators;
using Art.Replication.MemberProviders;
using Art.Serialization;
using Art.Serialization.Converters; public static void CreateAndSerializeSnapshot()
{
var person0 = DiagnosticsGraph.Create();
var snapshot0 = person0.CreateSnapshot();
string rawSnapsot0 = snapshot0.ToString();
Console.WriteLine(rawSnapsot0);
Console.ReadKey();
}{
#Id: 0,
#Type: "Art.Replication.Diagnostics.Person, Art.Replication.Diagnostics, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null",
FirstName: "Keanu",
LastName: "Reeves",
Birthday: "1964-09-02T00:00:00.0000000+03:00",
Roles: {
#Id: 1,
#Type: "System.Collections.Generic.List`1[[Art.Replication.Diagnostics.Role, Art.Replication.Diagnostics, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null]], mscorlib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089",
#Set: [
{
#Id: 2,
#Type: "Art.Replication.Diagnostics.Role, Art.Replication.Diagnostics, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null",
Name: "Neo",
LastOnline: "2017-06-14T14:42:44.0000575+03:00",
Person: {
#Id: 0
}
},
{
#Id: 3,
#Type: "Art.Replication.Diagnostics.Role, Art.Replication.Diagnostics, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null",
Name: "Thomas Anderson",
LastOnline: "2017-06-14T14:42:44.0000575+03:00",
Person: {
#Id: 0
}
}
]
}
}
Person: {
#Id: 0
}Birthday: "1964-09-02T00:00:00.0000000+03:00" public static void UseClassicalJsonSettings()
{
Snapshot.DefaultReplicationProfile.AttachId = false;
Snapshot.DefaultReplicationProfile.AttachType = false;
Snapshot.DefaultReplicationProfile.SimplifySets = true;
Snapshot.DefaultReplicationProfile.SimplifyMaps = true;
Snapshot.DefaultKeepProfile.SimplexConverter.AppendTypeInfo = false;
Snapshot.DefaultKeepProfile.SimplexConverter.Converters
.OfType().First().AppendSyffixes = false;
}
public static void CreateAndSerializeSnapshotToClassicJsonStyle()
{
UseClassicalJsonSettings();
var person0 = DiagnosticsGraph.Create();
var snapshot0 = person0.CreateSnapshot();
string rawSnapsot0 = snapshot0.ToString();
Console.WriteLine(rawSnapsot0);
var person0A = rawSnapsot0.ParseSnapshot().ReplicateGraph();
Console.WriteLine(person0A.FirstName);
Console.ReadKey();
} {
FirstName: "Keanu",
LastName: "Reeves",
Birthday: "1964-09-02T00:00:00.0000000+03:00",
Roles: [
{
Name: "Neo",
LastOnline: "2017-06-14T18:31:20.0000205+03:00",
Person: {
#Id: 0
}
},
{
Name: "Thomas Anderson",
LastOnline: "2017-06-14T18:31:20.0000205+03:00",
Person: {
#Id: 0
}
}
]
} public class Distorsion
{
public object[] AnyObjects =
{
Guid.NewGuid(), Guid.NewGuid().ToString(),
DateTime.Now, DateTime.Now.ToString("O"),
123, 123L,
};
} public static void Replicate()
{
var person0 = DiagnosticsGraph.Create();
var snapshot0 = person0.CreateSnapshot();
var person1 = snapshot0.ReplicateGraph();
person1.Roles[1].Name = "Agent Smith";
Console.WriteLine(person0.Roles[1].Name); // old graph value: Thomas Anderson
Console.WriteLine(person1.Roles[1].Name); // new graph value: Agent Smith
Console.ReadKey();
} public static void Reconstract()
{
var person0 = DiagnosticsGraph.Create();
var cache = new Dictionary();
var s = person0.CreateSnapshot(cache);
Console.WriteLine(person0.Roles[1].Name); // old graph value: Thomas Anderson
Console.WriteLine(person0.FirstName); // old graph value: Keanu
person0.Roles[1].Name = "Agent Smith";
person0.FirstName = "Zion";
person0.Roles.RemoveAt(0);
var person1 = (Person)s.ReconstructGraph(cache);
Console.WriteLine(person0.Roles[1].Name); // old graph value: Thomas Anderson
Console.WriteLine(person1.Roles[1].Name); // old graph value: Thomas Anderson
Console.WriteLine(person0.FirstName); // old graph value: Keanu
Console.WriteLine(person1.FirstName); // old graph value: Keanu
Console.ReadKey(); // result: person0 & person1 is the same one reconstructed graph
} public static void Justapose()
{
// set this settings for less details into output
Snapshot.DefaultReplicationProfile.AttachId = false;
Snapshot.DefaultReplicationProfile.AttachType = false;
Snapshot.DefaultReplicationProfile.SimplifySets = true;
Snapshot.DefaultReplicationProfile.SimplifyMaps = true;
var person0 = DiagnosticsGraph.Create();
var person1 = DiagnosticsGraph.Create();
person0.Roles[1].Name = "Agent Smith";
person0.FirstName = "Zion";
var snapshot0 = person0.CreateSnapshot();
var snapshot1 = person1.CreateSnapshot();
var results = snapshot0.Juxtapose(snapshot1);
foreach (var result in results)
{
Console.WriteLine(result);
}
Console.ReadKey();
}
[this.FirstName] {Zion} {Keanu}
[this.LastName] {Reeves} {Reeves}
[this.Birthday] {9/2/1964 12:00:00 AM} {9/2/1964 12:00:00 AM}
[this.Roles[0].Name] {Neo} {Neo}
[this.Roles[0].LastOnline] {6/14/2017 9:34:33 PM} {6/14/2017 9:34:33 PM}
[this.Roles[0].Person.#Id] {0} {0}
[this.Roles[1].Name] {Agent Smith} {Thomas Anderson}
[this.Roles[1].LastOnline] {6/14/2017 9:34:33 PM} {6/14/2017 9:34:33 PM}
[this.Roles[1].Person.#Id] {0} {0} * Сравнение производительности производилось с BinaryFormatter, Newtonsoft.Json, а также с DataContractJsonSerializer.
|
|
[Из песочницы] Шифрование БД под управлением Firebird 3.0 |

| Наименование файла | Описание |
|---|---|
| CiKeyHolder.dll | расширение Firebird – хранитель секретного ключа |
| CiDbCrypt.dll | расширение Firebird – шифрования данных |
| CiFbEnc_x86.dll | модуль активации ключа шифрования для платформы 32 bit. |
| CiFbEnc_x86-64.dll | модуль активации ключа шифрования для платформы 64 bit. |
| ICiFbEncActivator.h | описание интерфейса модуля для С++ |
| CI.ICiFbEncActivator.pas | описание интерфейса модуля для Delphi |
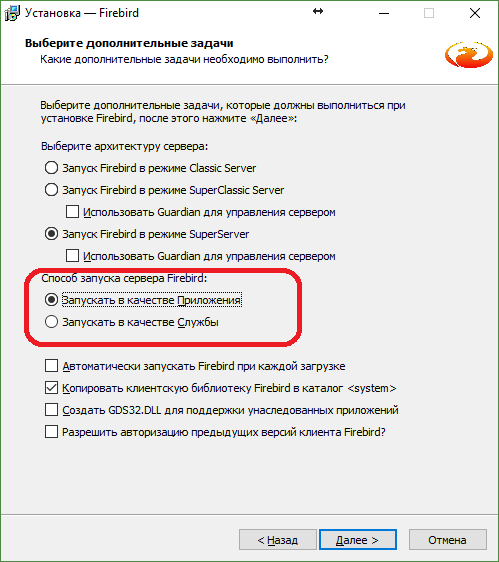
SYSDBA делаем по старинке masterkey и снимаем галочку отвечающую за запуск сервера после установки – пока не нужно.%ProgramW6432%\Firebird\Firebird_3_0.TESTDB = C:\TESTAPP\DB\TESTDB.FDBKeyHolderPlugin. Его можно указать или конкретно для выше описанного псевдонима или в файле firebird.conf. Добавляем или изменяем параметр конфигурации файла firebird.conf, определяя плагин хранитель секретного ключа:KeyHolderPlugin = CiKeyHolderPlugin = CiKeyHolder {
# Прописываем путь к плагину хранителю
Module = $(dir_plugins)/CiKeyHolder
}
Plugin = CiDbCrypt {
# Прописываем путь к плагину шифрования
Module = $(dir_plugins)/CiDbCrypt
}Win + R и выполняем следующую команду:%ProgramW6432%\Firebird\Firebird_3_0\isql -q -user SYSDBA -password masterkeySQL> create database 'TESTDB';
SQL> create table t_1 (i1 int, s1 varchar(15), s2 varchar(15));
SQL> insert into t_1 values (1,'value 1-1','value 1-2');
SQL> insert into t_1 values (2,'value 2-1','value 2-2');
SQL> commit;
SQL> select * from t_1;
I1 S1 S2
============ =============== ===============
1 value 1-1 value 1-2
2 value 2-1 value 2-2
SQL> show db;
Database: TESTDB
Owner: SYSDBA
PAGE_SIZE 8192
Number of DB pages allocated = 196
Number of DB pages used = 184
Number of DB pages free = 12
Sweep interval = 20000
Forced Writes are ON
Transaction - oldest = 4
Transaction - oldest active = 5
Transaction - oldest snapshot = 5
Transaction - Next = 9
ODS = 12.0
Database not encrypted
Default Character set: NONE
SQL> quit;show db;, созданная БД в данный момент не зашифрована — Database not encrypted.| Класс компонента | Наименование компонента | Параметр | Значение параметра |
|---|---|---|---|
| TFDPhysFBDriverLink | FDPhysFBDriverLink1 | - | - |
| TFDConnection | FDConnection1 | DriverName | FB |
| LoginPrompt | False | ||
| Params\Database | TESTDB | ||
| Params\UserName | SYSDBA | ||
| Params\Password | masterkey | ||
| Params\Protocol | ipTCPIP | ||
| Params\Server | localhost | ||
| TFDGUIxWaitCursor | FDGUIxWaitCursor1 | - | - |
| TFDTransaction | FDTransaction1 | - | - |
| TFDTable | FDTable1 | TableName | T_1 |
| TDataSource | DataSource1 | DataSet | FDTable1 |
| TDBGrid | DBGrid1 | DataSource | DataSource1 |
| TDBNavigator | DBNavigator1 | DataSource | DataSource1 |
| TButton | Button1 | Caption | Connect |
| TButton | Button2 | Caption | Disconnect |
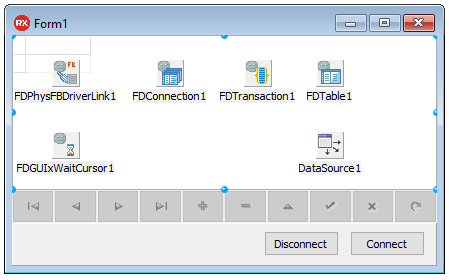
FDConnection1->Connected = true;
FDTable1->Active = true;FDTable1->Active = false;
FDConnection1->Connected = false;FDConnection1.Connected := True;
FDTable1.Active := True;
. . .
FDConnection1.Connected := False;
FDTable1.Active := False;Win + X -> Командная строка (администратор)“%ProgramW6432%\Firebird\Firebird_3_0\firebird” –a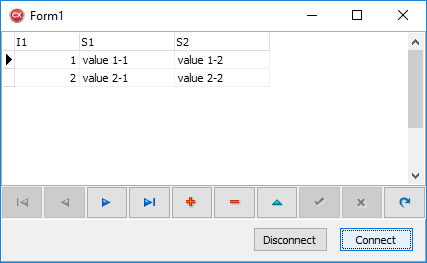
#include "ICiFbEncActivator.h"uses
. . . , CI.ICiFbEncActivator;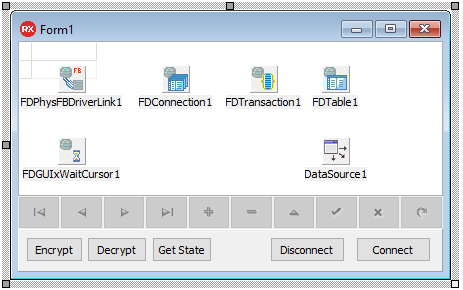
// C++ Builder
// Загружаем модуль
std::unique_ptr mHandle(
::LoadLibraryEx(L"C:\\TESTAPP\\CiFbEnc_x86.dll",0,LOAD_WITH_ALTERED_SEARCH_PATH),
&::FreeLibrary);
if (!mHandle)
{
MessageBox(
NULL,
L"Модуль CiFbEnc_x86.dll не найден или рядом с ним нет fbclient.dll",
L"Загрузка модуля",
MB_OK|MB_ICONERROR);
return;
}
// Получаем активатор
typedef CALL_CONV int(__stdcall *CREATEFUNCPTR)(CI::ICiFbEncActivator**);
CREATEFUNCPTR GetActivator =
(CREATEFUNCPTR)::GetProcAddress(mHandle.get(), "createCiFBEncActivator");
if (!GetActivator)
{
MessageBox(
NULL,
L"Не удалось получить из модуля CiFbEnc_x86.dll процедуру"
"createCiFBEncActivator"
" - попробуйте посмотреть, что пишет tdump.",
L"Загрузка модуля",
MB_OK|MB_ICONERROR);
return;
}
CI::ICiFbEncActivator* pActivator = NULL;
GetActivator(&pActivator);
if (!pActivator) { ShowMessage("ERROR GetActivator!"); return; }
// . . .
//
// обращения к объекту модуля активации
//
// . . .
// Уничтожаем экземпляр активатора
pActivator->Destroy();
pActivator = NULL;// Delphi
var
pActivator : ICiFbEncActivator;
res : Integer;
CreateActivator: TActivatorFunction;
mHandle : HINST;
. . .
begin
// Загружаем модуль
mHandle := LoadLibraryEx(
PChar('C:\TESTAPP\CiFbEnc_x86.dll'), 0, LOAD_WITH_ALTERED_SEARCH_PATH);
if mHandle = 0 then
begin
MessageBox(
Application.Handle,
'Модуль CiFbEnc_x86.dll не найден или рядом с ним нет fbclient.dll',
'Загрузка модуля',
MB_OK OR MB_ICONERROR);
Exit;
end;
// Получаем активатор
CreateActivator := GetProcAddress(mHandle, 'createCiFBEncActivator');
if not Assigned(CreateActivator) then
begin
MessageBox(
Application.Handle,
'Не удалось получить из модуля CiFbEnc_x86.dll процедуру createCiFBEncActivator'
+
' - попробуйте посмотреть, что пишет tdump.',
'Загрузка модуля',
MB_OK OR MB_ICONERROR);
Exit;
end;
pActivator := nil;
res := CreateActivator(pActivator);
if not Assigned(pActivator) then begin ShowMessage('ERROR CreateActivator!'); Exit; end;
// . . .
//
// обращения к объекту модуля активации
//
// . . .
// Уничтожаем экземпляр активатора
pActivator.Destroy;
pActivator := nil;
FreeLibrary(mHandle);
end;// C++ Builder
. . .
// Устанавливаем параметры подключения к БД
pActivator->SetDBAccess("localhost:TESTDB", "SYSDBA", "masterkey");
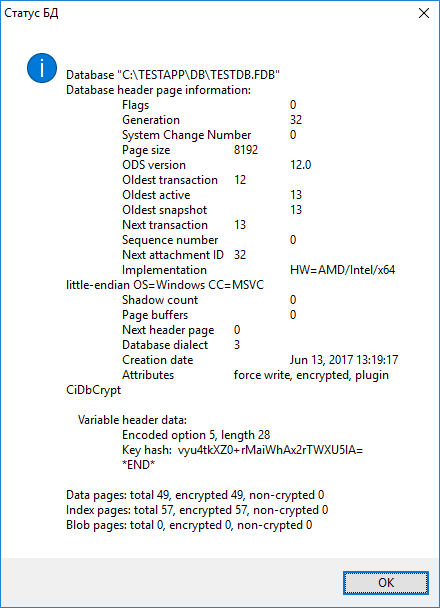
// Посмотрим, что нам расскажет о БД сервис Firebird
char stat_buf[1024] = { 0 };
size_t bufsize = sizeof(stat_buf);
int res = pActivator->GetStateSVC(stat_buf, bufsize);
String sStatMsg = (String)stat_buf;
if (Err_OK == res)
{
MessageBox(NULL, sStatMsg.c_str(), L"Статус БД", MB_OK|MB_ICONINFORMATION);
}
else
{
String sErrMsg = L"ERROR GetStateSVC: " + sStatMsg;
MessageBox(
NULL,
sErrMsg.c_str(),
L"Статус БД",
MB_OK|MB_ICONERROR);
}
. . .// Delphi
var
. . .
stat_buf : array[0..1023] of AnsiChar;
bufsize : NativeUInt;
. . .
// Устанавливаем параметры подключения к БД
res := pActivator.SetDBAccess('localhost:TESTDB', 'SYSDBA', 'masterkey');
// Посмотрим, что нам расскажет о БД сервис Firebird
bufsize := SizeOf(stat_buf);
ZeroMemory(@stat_buf, bufsize);
res := pActivator.GetStateSVC(stat_buf, bufsize);
if Err_OK = res then
begin
MessageBox(Application.Handle, PChar(String(stat_buf)),
'Статус БД', MB_OK OR MB_ICONINFORMATION);
end
else
begin
MessageBox(Application.Handle, PChar(String(stat_buf)),
'Ошибка', MB_OK OR MB_ICONERROR);
end;
. . .
// C++ Builder
// От куда-то у нас есть ключ 192 бита
const uint8_t key[24] =
{
0x06,0xDE,0x81,0xA1,0x30,0x55,0x1A,0xC9,
0x9C,0xA3,0x42,0xA9,0xB6,0x0F,0x54,0xF0,
0xB6,0xF9,0x70,0x18,0x85,0x04,0x83,0xBF
};// Delphi
const
key : array [0..23] of Byte =
(
$06,$DE,$81,$A1,$30,$55,$1A,$C9,
$9C,$A3,$42,$A9,$B6,$0F,$54,$F0,
$B6,$F9,$70,$18,$85,$04,$83,$BF
);// C++ Builder
. . .
// Устанавливаем параметры подключения к БД
pActivator->SetDBAccess("localhost:TESTDB", "SYSDBA", "masterkey");
// Устанавливаем ключ активатору
int res = pActivator->SetKey(&key, sizeof(key));
if (Err_OK != res) { ShowMessage("ERROR SetKey!"); pActivator->Destroy(); return; }
// Активируем доступ к ключу
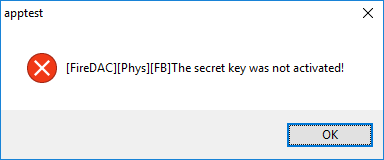
res = pActivator->Activate();
if (Err_OK != res)
{
// Обрабатываем ошибку
char errmsg[512] = {0};
size_t esize = sizeof(errmsg);
pActivator->GetFBStat(errmsg, esize);
String sErrMsg = "ERROR Activate: " + String(errmsg);
MessageBox(
NULL,
sErrMsg.w_str(),
L"Активация доступа к ключу",
MB_OK|MB_ICONERROR);
pActivator->Destroy();
return;
}
. . .// Delphi
. . .
// Устанавливаем параметры подключения к БД
res := pActivator.SetDBAccess('localhost:TESTDB', 'SYSDBA', 'masterkey');
// Устанавливаем ключ активатору
res := pActivator.SetKey(@key, Length(key));
if Err_OK <> res then begin ShowMessage('ERROR SetKey!'); pActivator.Destroy; Exit; end;
// Активируем доступ к ключу
res := pActivator.Activate;
if Err_OK <> res then
begin
bufsize := SizeOf(errmsg);
ZeroMemory(@errmsg, bufsize);
pActivator.GetFBStat(errmsg, bufsize);
MessageBox(
Application.Handle,
PChar('ERROR Activate: ' + String(errmsg)),
'Активация доступа к ключу',
MB_OK OR MB_ICONERROR);
pActivator.Destroy;
Exit;
end;
. . .// C++ Builder
// зашифровать
res = pActivator->Encrypt();
. . .
// расшифровать
res = pActivator->Decrypt();// Delphi
// зашифровать
res := pActivator.Encrypt;
. . .
// расшифровать
res := pActivator.Decrypt;
// C++ Builder
void __fastcall TForm1::Button1Click(TObject *Sender)
{
// Загружаем модуль
std::unique_ptr mHandle(
::LoadLibraryEx(L"C:\\TESTAPP\\CiFbEnc_x86.dll", 0,
LOAD_WITH_ALTERED_SEARCH_PATH),
&::FreeLibrary);
if (!mHandle)
{
MessageBox(
NULL,
L"Модуль CiFbEnc_x86.dll не найден или рядом с ним нет fbclient.dll",
L"Загрузка модуля",
MB_OK|MB_ICONERROR);
return;
}
// Получаем активатор
typedef CALL_CONV int(__stdcall *CREATEFUNCPTR)(CI::ICiFbEncActivator**);
CREATEFUNCPTR GetActivator =
(CREATEFUNCPTR)::GetProcAddress(mHandle.get(), "createCiFBEncActivator");
if (!GetActivator)
{
MessageBox(
NULL,
L"Не удалось получить из модуля CiFbEnc_x86.dll"
" процедуру createCiFBEncActivator"
" - попробуйте посмотреть, что пишет tdump.",
L"Загрузка модуля",
MB_OK|MB_ICONERROR);
return;
}
CI::ICiFbEncActivator* pActivator = NULL;
GetActivator(&pActivator);
if (!pActivator) { ShowMessage("ERROR GetActivator!"); return; }
// Устанавливаем параметры подключения к БД
pActivator->SetDBAccess("localhost:TESTDB", "SYSDBA", "masterkey");
// Устанавливаем ключ активатору
int res = pActivator->SetKey(&key, sizeof(key));
if (Err_OK != res) { ShowMessage("ERROR SetKey!"); pActivator->Destroy();return; }
// Активируем доступ к ключу
res = pActivator->Activate();
if (Err_OK != res)
{
// Обрабатываем ошибку
char errmsg[512] = {0};
size_t esize = sizeof(errmsg);
pActivator->GetFBStat(errmsg, esize);
String sErrMsg = "ERROR Activate: " + String(errmsg);
MessageBox(
NULL,
sErrMsg.w_str(),
L"Активация доступа к ключу",
MB_OK|MB_ICONERROR);
pActivator->Destroy();
return;
}
// Подключаемся к БД
try
{
FDConnection1->Connected = true;
FDTable1->Active = true;
}
catch(EFDDBEngineException &e)
{
String sErrMsg = L"Не удалось подключиться к БД. " + e.Message;
MessageBox(
NULL,
sErrMsg.w_str(),
L"Подключение к БД",
MB_OK|MB_ICONERROR);
}
// Уничтожаем экземпляр активатора
pActivator->Destroy();
pActivator = NULL;
}// Delphi
procedure TForm2.Button1Click(Sender: TObject);
var
pActivator : ICiFbEncActivator;
res : Integer;
CreateActivator: TActivatorFunction;
mHandle : HINST;
errmsg : array[0..511] of AnsiChar;
bufsize : NativeUInt;
begin
// Загружаем модуль
mHandle := LoadLibraryEx(PChar('C:\TESTAPP\CiFbEnc_x86.dll'), 0,
LOAD_WITH_ALTERED_SEARCH_PATH);
if mHandle = 0 then
begin
MessageBox(
Application.Handle,
'Модуль CiFbEnc_x86.dll не найден или рядом с ним нет fbclient.dll',
'Загрузка модуля',
MB_OK OR MB_ICONERROR);
Exit;
end;
// Получаем активатор
CreateActivator := GetProcAddress(mHandle, 'createCiFBEncActivator');
if not Assigned(CreateActivator) then
begin
MessageBox(
Application.Handle,
'Не удалось получить из модуля CiFbEnc_x86.dll процедуру createCiFBEncActivator'
+
' - попробуйте посмотреть, что пишет tdump.',
'Загрузка модуля',
MB_OK OR MB_ICONERROR);
Exit;
end;
pActivator := nil;
res := CreateActivator(pActivator);
if not Assigned(pActivator) then begin ShowMessage('ERROR CreateActivator!');Exit; end;
// Устанавливаем параметры подключения к БД
res := pActivator.SetDBAccess('localhost:TESTDB', 'SYSDBA', 'masterkey');
// Устанавливаем ключ активатору
res := pActivator.SetKey(@key, Length(key));
if Err_OK <> res then begin ShowMessage('ERROR SetKey!'); pActivator.Destroy;Exit; end;
// Активируем доступ к ключу
res := pActivator.Activate;
if Err_OK <> res then
begin
bufsize := SizeOf(errmsg);
ZeroMemory(@errmsg, bufsize);
pActivator.GetFBStat(errmsg, bufsize);
MessageBox(
Application.Handle,
PChar('ERROR Activate: ' + String(errmsg)),
'Активация доступа к ключу',
MB_OK OR MB_ICONERROR);
pActivator.Destroy;
Exit;
end;
// Подключаемся к БД
try
FDConnection1.Connected := True;
FDTable1.Active := True;
except
on E: EFDDBEngineException do begin
MessageBox(
Application.Handle,
PChar('Не удалось подключиться к БД. ' + String(E.Message)),
'Подключение к БД',
MB_OK OR MB_ICONERROR);
end;
end;
// Уничтожаем экземпляр активатора
pActivator.Destroy;
pActivator := nil;
FreeLibrary(mHandle);
end;|
Метки: author cipher-bis криптография информационная безопасность firebird/interbase firebird шифрование данных конфиденциальность данных |
MyTaskHelper.ru на практике: создание бесплатной БД для проверки результатов ОГЭ |
С конца мая до конца июня в российских школах проходит ОГЭ (основной государственный экзамен) по всем возможным предметам и ученики с нетерпением ждут своих результатов.
Раздумывая над темами будущих публикаций о нашем проекте MyTaskHelper, мы никак не могли остановиться на чем-то конкретном. Но идея пришла сама собой в тот момент, когда наш сервис начало использовать Министерство образования и науки Астраханской области. Да-да, вам не показалось: MTH активно используется государственными структурами. А в описанном выше конкретном случае администратор сайта astrcmo.ru создал и добавил на ресурс форму входа, позволяющую получить доступ к записи после заполнения требуемых данных (логина и пароля).
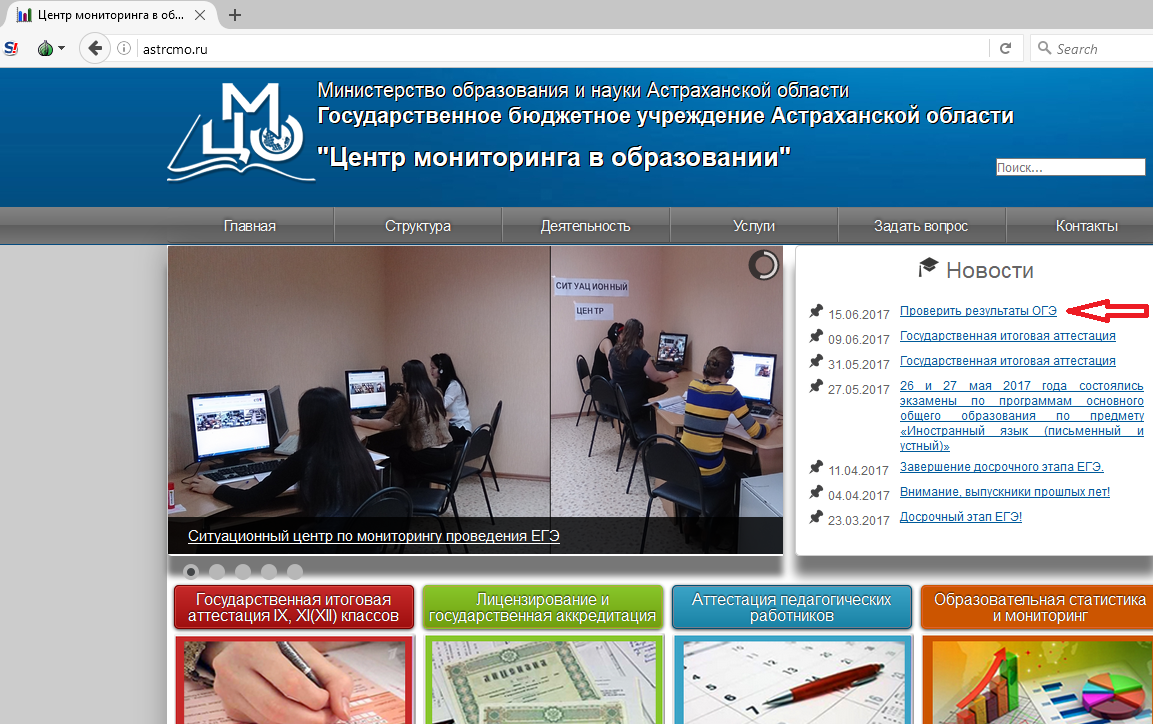
Рис. 1 Встроенный на сайт astrcmo.ru виджет
Алгоритм создания такого модуля: на сайте mytaskhelper.ru создается или импортируется база данных с персональной информацией учеников и их оценками и настраивается доступ к виджету записи по логину и паролю.
Выглядит это следующим образом (мы создали тестовую веб-форму с нуля (глянуть, как это делается, можно в теме, но можно и просто экспортировать свою готовую базу данных в формате CSV или Excel):
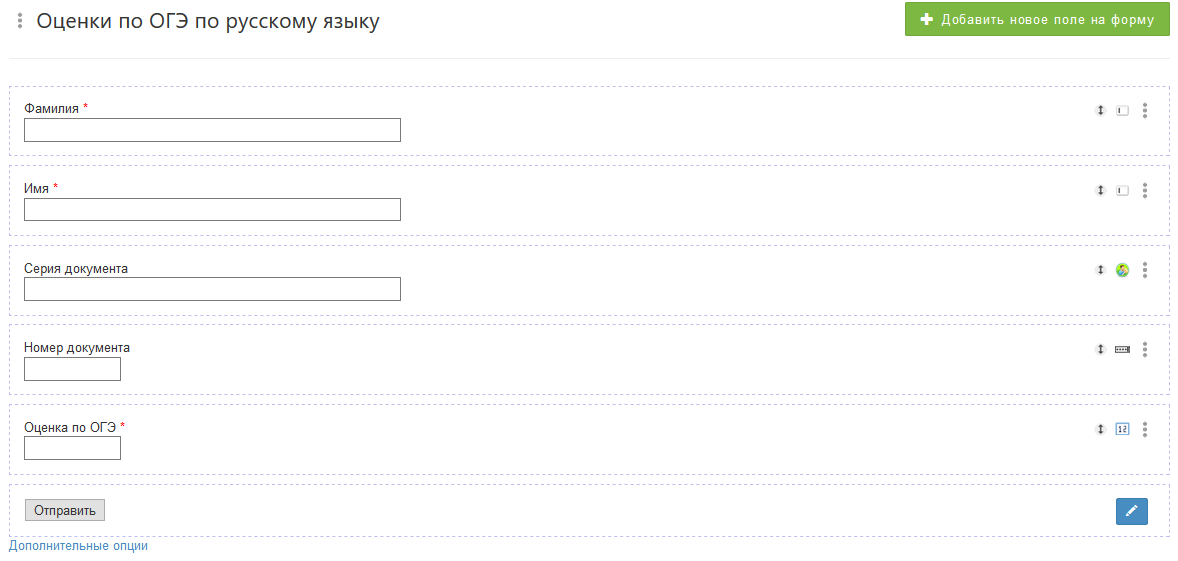
Рис.2 Поля сконструированной в MTH веб-формы, посредством которой можно добавлять информацию в БД.
В настройках поля под названием «Серия документа» выбираем тип данных «Логин», а «Номер документа» — «Пароль».
А так выглядит заполненная база данных.
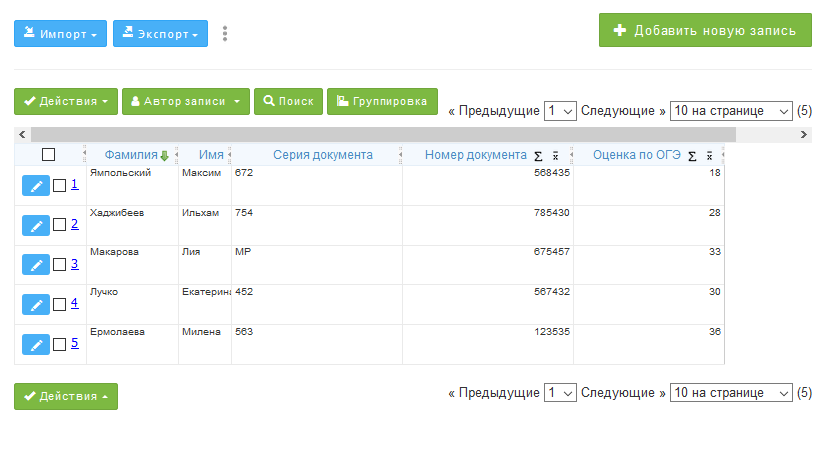
Рис. 3 Заполненная база данных с персональными данными и оценками
Для того, чтобы настроить доступ к записи по логину и паролю, переходим в меню Виджеты=>Форма входа и настраиваем режим доступа. После редактирования формы входа получаем следующий результат, который встраивается в любую страницу сайта. Для этого на вкладке «Интеграция» достаточно скопировать ссылку, iFrame или выбрать другой вариант поделиться виджетом и встроить в нужное место сайта.

Рис. 4 Форма входа на виджет записи
Отметим, что в настройках виджета можно выбрать следующие опции:
ВСЕ! Далее ученик, желающий узнать свои баллы, переходит на страницу сайта и введя логин (в нашем случае это – серия документа) и пароль (номер документа) (Рис. 4), получает доступ к записи из базы данных, в которой хранится искомый результат (Рис.5).
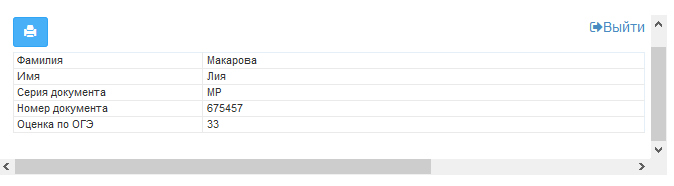
Рис. 5 Запись из базы данных, которую видит ученик, введя логин и пароль
Очевидно, что данная функция может применяться где угодно. Например, она востребована у владельцев интернет-магазинов, где с ее помощью можно настроить доступ клиентов к записям о товарах, их статусе и т.п. Полезной функция окажется и для учителей, которые смогут легко предоставить доступ родителям своих учеников к их текущим оценкам по логину (например, это будет фамилия) и паролю (индивидуальный числовой или буквенно-числовой код).
Для того, чтобы протестировать, как это выглядит в живую, можно перейти на виджет и введя логин/пароль из таблицы указанной выше или же test/test, убедиться, что функционал рабочий. Заметьте, что если в БД имеется одна запись с определенной комбинацией логина и пароля, на выходе мы и получим одну эту запись, если же их несколько (как для test/test), они будут выводиться в табличном варианте с возможностью осуществлять поиск и группировку по таблице (Рис. 6).

Пользуйтесь с удовольствием, а мы будем рады ответить на любые вопросы.
|
|
[recovery mode] Verizon завершили поглощение Yahoo |
 JD Hancock / Flickr / CC
JD Hancock / Flickr / CC На фото: Марисса Майер TechCrunch CC
На фото: Марисса Майер TechCrunch CC На фото: Джерри Янг Yahoo CC
На фото: Джерри Янг Yahoo CC|
Метки: author VASExperts управление e-commerce блог компании vas experts vas experts yahoo verizon |
Моделирование переходных процессов при коммутации электрической цепи средствами Python |



#!/usr/bin/python
# -*- coding: utf-8 -*-
import numpy as np
from scipy.integrate import odeint
import matplotlib.pyplot as plt
R1=10;R2=20;L=0.02;C=0.00005;E=100;tm=0.02; #параметры электрической цепи
def f(y, t):# дифференциальное уравнение переходного процесса.
y1,y2 = y
return [y2,-(R1/L)*y2-(1/(L*C))*y1+E/(L*C)]
t = np.linspace(0,tm,1000)
y0 = [E*R2/(R1+R2),0]#начальные условия
z = odeint(f, y0, t)#решение дифференциального уравнения
y1=z[:,0] # вектор значений решения
y2=100*C*z[:,1] # вектор значений производной
plt.title('Напряжение на конденсаторе и ток при размыкании цепи', size=12)
plt.plot(t*1000,y1,linewidth=2, label=' Uс(t)')
plt.plot(t*1000,y2,linewidth=2, label=' i3(t)=100*C*dUc(t)/dt')
plt.ylabel("Uc(t), i3(t)")
plt.xlabel("t*1000")
plt.legend(loc='best')
plt.grid(True)
plt.show()


#!/usr/bin/python
# -*- coding: utf-8 -*-
import numpy as np
from scipy.integrate import odeint
import matplotlib.pyplot as plt
R1=10;R2=20;L=0.02;C=0.00005;E=100;tm=0.02; # параметры электрической цепи
def f(y, t):# дифференциальное уравнение переходного процесса.
y1,y2 = y
return [y2,-((L+R1*R2*C)/(R2*L*C))*y2-((R1+R2)/(R2*L*C))*y1+E/(L*C)]
t = np.linspace(0,tm,1000)
y0 = [E,0]#начальные условия
z = odeint(f, y0, t)#решение дифференциального уравнения
y1=z[:,0] # вектор значений решения
y2=100*(C*z[:,1]+y1/R2)
y3=100*C*z[:,1]
y4=100*y1/R2
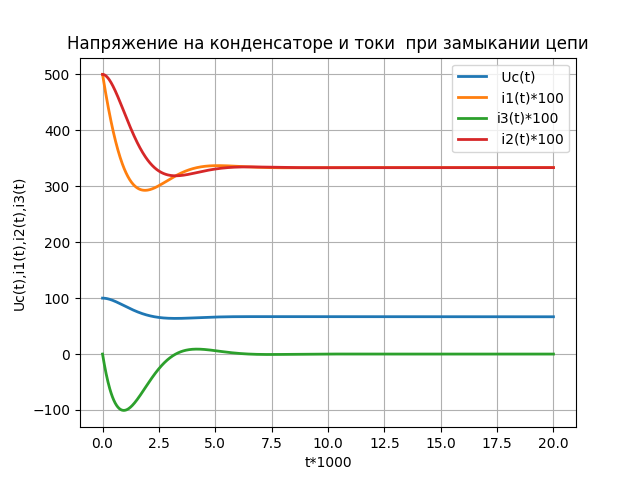
plt.title('Напряжение на конденсаторе и токи при замыкании цепи', size=12)
plt.plot(t*1000,y1,linewidth=2, label=' Uc(t)')
plt.plot(t*1000,y2,linewidth=2, label=' i1(t)*100')
plt.plot(t*1000,y3,linewidth=2, label='i3(t)*100')
plt.plot(t*1000,y4,linewidth=2, label=' i2*100')
plt.ylabel("Uc(t),i1(t),i2(t),i3(t)")
plt.xlabel("t*1000")
plt.legend(loc='best')
plt.grid(True)
plt.show()
|
Метки: author Scorobey python scipy numpy электрические цепи переходные процессы. |
Аналитика в рекрутменте: она вам не бигдата |








|
|
[Из песочницы] Энергоучет в составе SCADA системы торгового центра |
MeterDevice -> Mercury230 -> Mercury230_DatabaseSignalspublic enum error_type : int { none = 0,
AnswError = -5, // вернул один или несколько ошибочных ответов
CRCErr = -4,
NoAnsw = -2, // ничего не ответил на запрос после коннекта связи
WrongId = -3, // серийный номер не соответствует
NoConnect = -1 // отсутствие ответа
};
public struct RXmes
{
public error_type err;
public byte[] buff;
public byte[] trueCRC;
public void testCRC()
{
err = error_type.CRCErr;
if (buff.Length < 4)
{
err = error_type.CRCErr;
return;
}
byte[] newarr = buff;
Array.Resize(ref newarr, newarr.Length - 2);
byte[] trueCRC = Modbus.Utility.ModbusUtility.CalculateCrc(newarr);
if ((trueCRC[1] == buff.Last()) && (trueCRC[0] == buff[(buff.Length - 2)]))
{
err = error_type.none;
}
}
public void ReadArr(byte[] b)
{
buff = b;
testCRC();
}
}
public RXmes SendCmd(byte[] data)
{
RXmes RXmes_ = new RXmes();
byte[] crc = Modbus.Utility.ModbusUtility.CalculateCrc(data);
Array.Resize(ref data, data.Length + 2);
data[data.Length - 2] = crc[0];
data[data.Length - 1] = crc[1];
rs_port.Write(data, 0, data.Length);
System.Threading.Thread.Sleep(timeout);
if (rs_port.BytesToRead > 0)
{
byte[] answer = new byte[(int)rs_port.BytesToRead];
rs_port.Read(answer, 0, rs_port.BytesToRead);
RXmes_.ReadArr(answer);
if (RXmes_.err == error_type.none)
{
DataTime_last_contact = DateTime.Now;
}
return RXmes_;
}
RXmes_.err = error_type.NoConnect;
return RXmes_;
}public byte[] GiveSerialNumber()
{
byte[] mes = {address, 0x08 , 0};
RXmes RXmes = SendCmd(mes);
if (RXmes.err == error_type.none) {
byte[] bytebuf = new byte[7];
Array.Copy(RXmes.buff, 1, bytebuf, 0, 7);
return bytebuf;
}
return null;
}public MetersParameter() {
minalarm = false;
maxalarm = false;
}
public MetersParameter(float min, float max, float hist, float scalefactor = 1)
{
MinValue = min;
MaxValue = max;
Hist = hist;
minalarm = false;
maxalarm = false;
ScalingFactor = scalefactor;
}
public string alias{set; get;}
public float MaxValue { set; get; }
public float MinValue { set; get; }
public float ScalingFactor { set; get; } // коэффициент масштабирования. К примеру Коэффициент трансформации по току
public float Hist { set; get; }
private bool minalarm;
private bool maxalarm;
public bool ComAlarm { get { return MinValueAlarm || MaxValueAlarm ; } }
public virtual bool MinValueAlarm { get{
return minalarm;
} }
public virtual bool MaxValueAlarm { get{
return maxalarm;
} }
public virtual void RefreshData()
{
if (null != ParametrUpdated)
{
ParametrUpdated();
}
if ((MinValue == 0) && (MaxValue == 0))
{
return;
}
float calc_par = parametr * ScalingFactor;
if (calc_par < (MinValue - Hist))
{
minalarm = true;
}
if (calc_par > (MinValue + Hist))
{
minalarm = false;
}
if (calc_par < (MaxValue - Hist))
{
maxalarm = false;
}
if (calc_par > (MaxValue + Hist))
{
maxalarm = true;
}
}
float parametr;
public bool UseScaleForInput = false;
public virtual float Value {
set{
parametr = UseScaleForInput ? value / (ScalingFactor <= 0 ? 1 : ScalingFactor) : value;
RefreshData();
}
get
{
return parametr * ScalingFactor;
}
}
public void CopyLimits(MetersParameter ext_par)
{
this.MinValue = ext_par.MinValue;
this.MaxValue = ext_par.MaxValue;
this.Hist = ext_par.Hist;
}
}public enum peroidQuery : byte
{
afterReset = 0x0,
thisYear = 1,
lastYear = 2,
thisMonth = 3, thisDay = 4, lastDay = 5,
thisYear_beginning = 9,
lastYear_beginning = 0x0A,
thisMonth_beginning = 0x0B,
thisDay_beginning = 0x0C,
lastDay_beginning = 0x0D
}|
Метки: author levWi scada c# аскуэ меркурий230 |
Работа с периферией из JavaScript: от теории к практике |

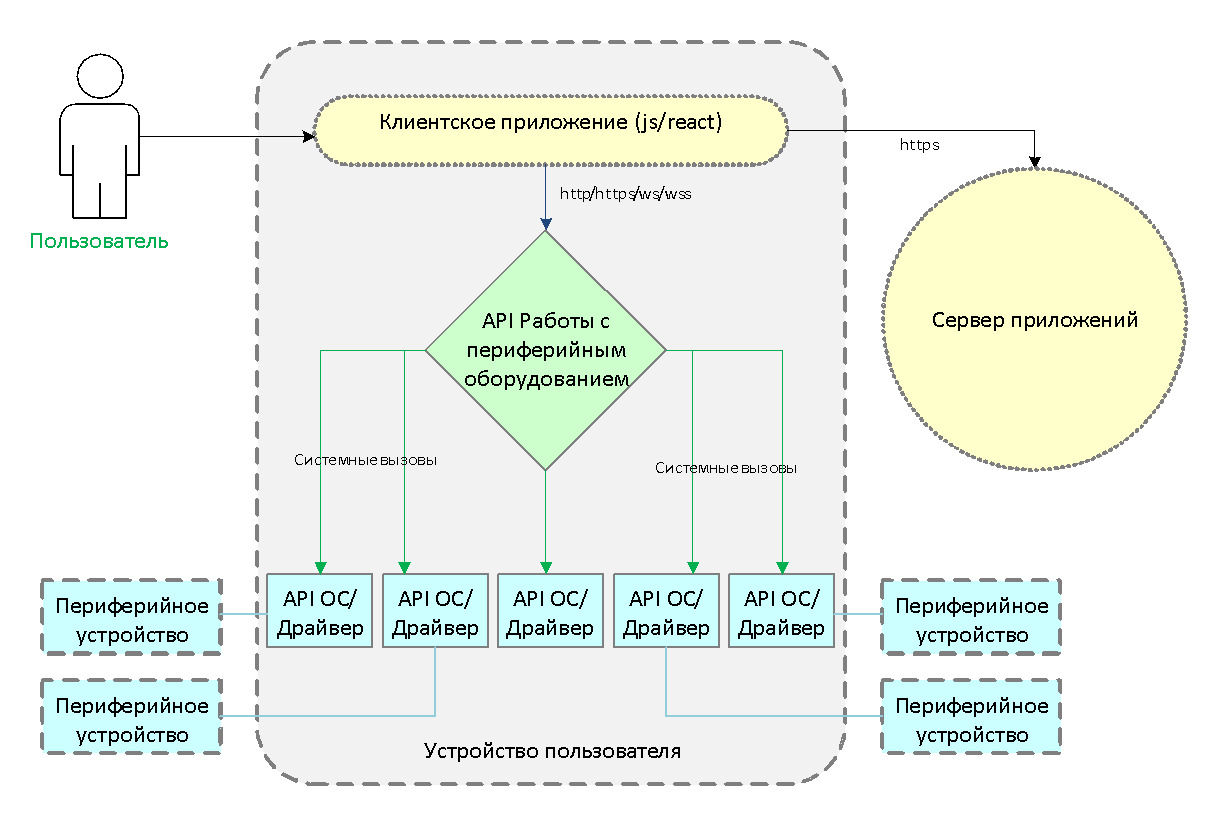 Мы попытались найти решение проблемы и проработали несколько вариантов.
Мы попытались найти решение проблемы и проработали несколько вариантов.var printer = new ActiveXObject("LocalPrinterComponent.Printer");
printer.print(data + "\r\n");




|
Метки: author EFS_programm программирование reactjs javascript bootstrap node.js react тонкие клиенты периферия |
Карьера в Digital: что такое, кому подойдет, где начать |

Это как большие данные — все говорят, но никто не знает что это на самом деле. Диджитал – это использование цифровых ресурсов/каналов для достижения целей компании. С диджитал связывают всё, что касается информационных технологий: контекстная реклама, медийная реклама, создание сайтов, SEO, веб-дизайн, SMM. Цель титанических усилий: продвижение бренда, повышение продаж, формирование лояльности аудитории, привлечение сотрудников и еще много-много всякого интересного.

На самом деле всё просто. Диджитал – это технологии (кэп, да), которые используются в маркетинге для продвижения продуктов и/или услуг.
Диджитал — перспективная отрасль. В Cossa провели исследование, где проанализировали вакансии в диджитал направлениях и рассказали о средней заработной плате специалистов в Москве. Помимо материального, сами подумайте, у каждой компании есть продукт/услуга, который они продают. Вся выручка компаний зависит от продаж (не будем говорить про инвесторов и сложные вещи). Маркетинг и реклама — главные инструменты стимулирования спроса. Никакая компания не выживет без маркетинга, потому что конкуренты не спят! И чтобы вас запомнили (а вам оно надо) нужно постоянно о себе напоминать. Иначе ваша компания умрет банкротства, а вы — от голода.
// Аналитика
«Вот это поворот!» — скажете? Даже тут нужны аналитики: CTR, CTB, CTI, CTR, конверсия, посещаемость, охват, вовлеченность и еще куча важных рекламных показателей. Здесь явно нужен тот, кто способен запоминать расшифровки, и чей мозг не взорвется от множества информации.
Компания не может тратить деньги на рекламу впустую. аналитик должен исследовать рынок, найти потенциальных клиентов, заинтересованную аудиторию, проанализировать стратегию конкурентов и составить собственную. Это важно и нужно, иначе все усилия digital-подразделения будут напрасны. Направление подойдет тем, кто владеет парой навыков из нашей шпаргалки:
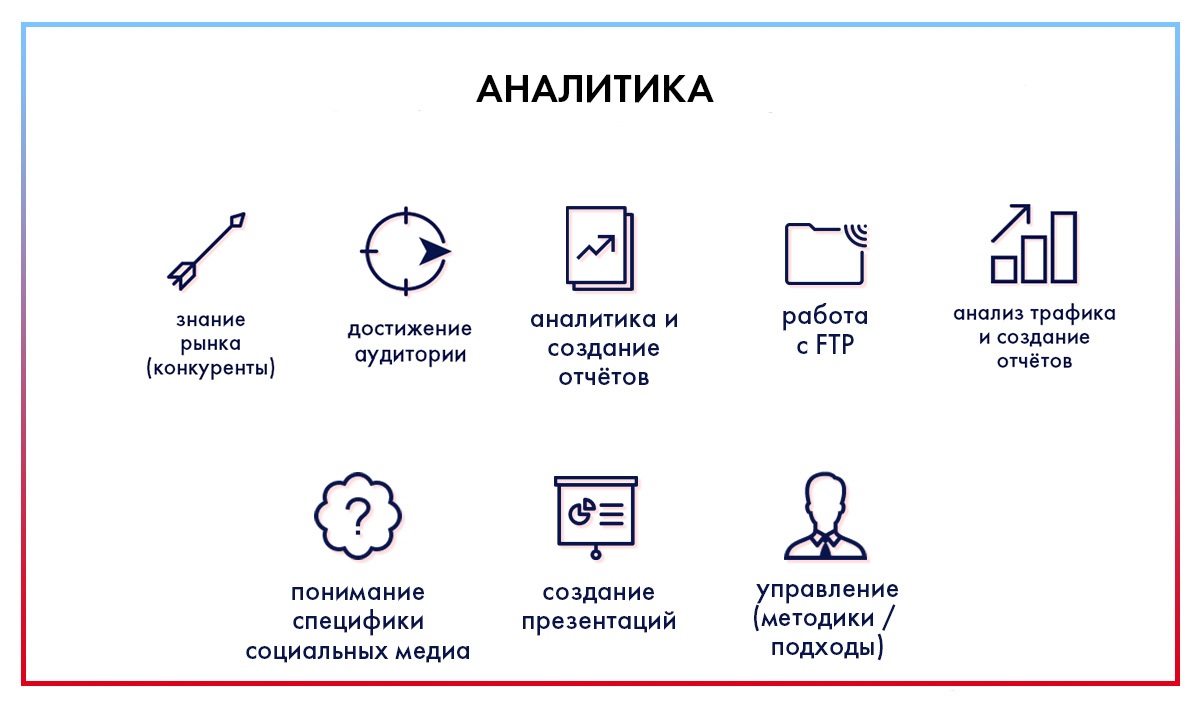
Если нужно подтянуть знания — ловите материалы из нашей библиотеки:
Бесплатные курсы по SQL: всё, что вы не знали о базах данных
11 курсов Excel для начинающих и гуру
51 бесплатная книга о Data Science
// Интернет-маркетинг
«Креаааатииив» — мы просто кричим вам! Это направление пропитано идеями, новинками, трендами и бесконечными потоками информации. SMM, медиа, инфоповоды, мемы, гифки, видео, писать классные материалы и подавать полезные материалы своим читателям. Вы — голос компании в информационном поле! Именно вы познакомите с продукцией компании и расскажете о том, чем можете быть полезны.
Работа с аудиторией, огромные рекламные кампании (да-да!) и создание полезного контента. В больших компаниях уже давно создаются целые отделы по работе с социальными сетями. Здесь сразу увидите эффективность своих действий — пользователи будут читать ваши материалы, ставить лайки, репостить, чаще посещать ресурс. Просто моментальная обратная связь! И если вы хорошо знаете свою аудиторию и креативно подходите к делу, то точно будете довольны результатом.
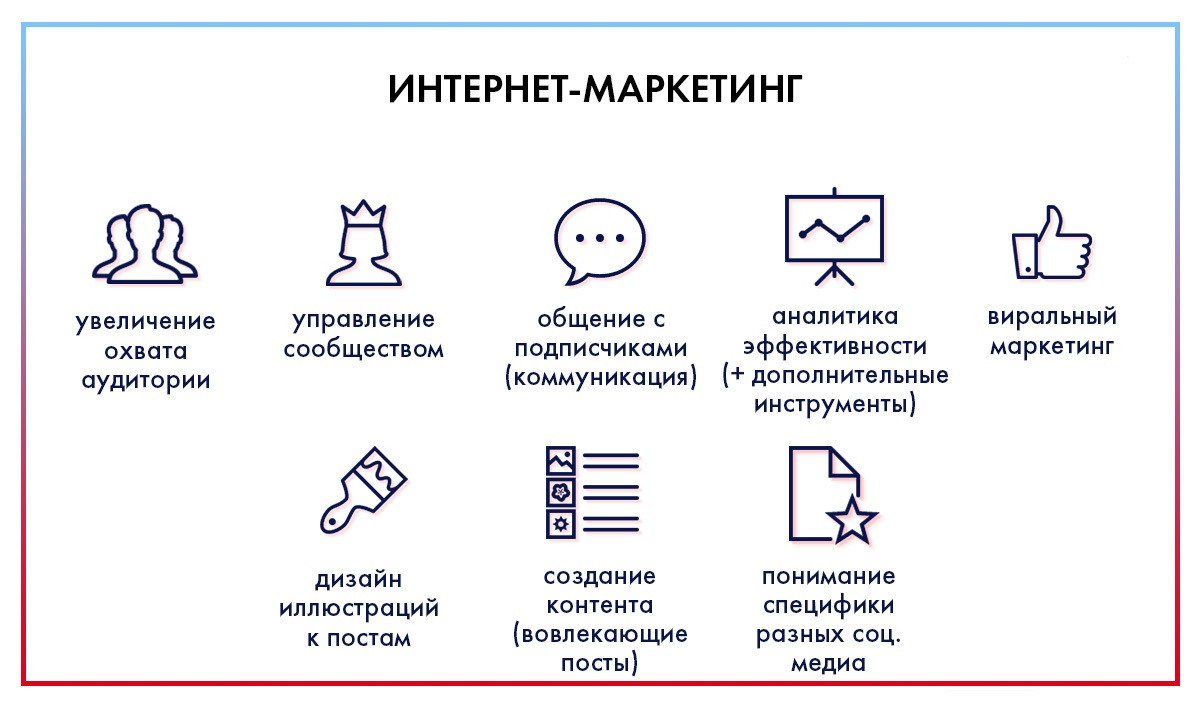
Скорее смотрите, какие навыки вам пригодятся, ищите себя и ловите полезные материалы:
72 полезных ссылки для тех, кто хочет шарить в маркетинге
9 инструментов для тех, кто пишет
22 онлайн курса, о которых вы не знали
// Web-разработка
Покажите компанию, у которой нет сайта или собственного мобильного приложения. То-то! Окей, если приложения нужны только компаниям оказывающим услуги, то сайт нужен всем. Поэтому все нуждаются в SEO, web-разработчиках и дизайнерах интерфейсов.
Кажется, что создание сайта случай вообще единичный — один раз сделал и поддерживай. Рынок быстро насытится и все эти web-мастеры остануться без работы, но вы ошибаетесь. Все меняется: появляются новые технологии, тренды, интерфейсы, платформы. Компании расширяются и создают несколько сайтов в зависимости от целей: карьерные, клиентские, партнерские. Старые сайты должны обновляться, чтобы держать свои позиции. Думаем, что вы точно не захотите пойти на собеседование или купить продукцию в
Space Is The Place :D
Показываем навыки, которые пригодятся в этой сфере. Совсем необязательно знать сразу всё и вся. Если хорошо владеете парой, остальное быстро подтянете в процессе работы или стажировки! :)
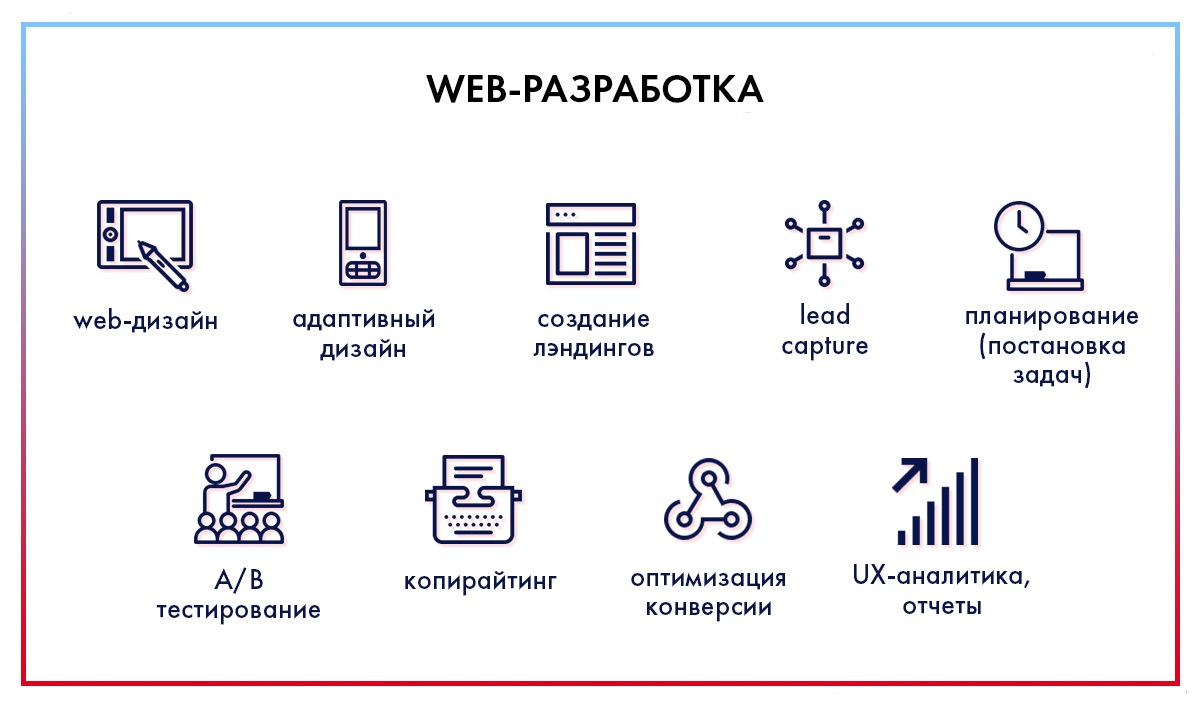
И немного полезных ссылок по теме:
7 курсов по web-программированию
15 ресурсов для изучения программирования
10 курсов, чтобы стать «тыжпрограммистом»
Если вы интересуетесь медиа, интернет СМИ, рекламой, маркетингом, понимаете (ну, или очень хотите разобраться) в таргете, метрике и прочих сложных инструментах. Вы постоянно интересуетесь происходящим. Вы в курсе событий интернет-тусовки: знаете все тренды и даже присматриваетесь к картинкам в постах.
Вы не представляетесь своей жизни без социальных сетей: 24/7 вы прокручиваете свою ленту не только в поисках новых мемасиков, а черпаете идеи и вдохновение. Вы технологичны, а еще любите писать, смотреть на красивые новые лендинги, анализировать рынок и вообще жить не можете вне инфополя. Поэтому монотонная работа вас убивает и вы ищите что-то динамичное и драйвовое! А у нас есть, что посоветовать.
Когда нет опыта, самый крутой путь — стажировка. Банк «Открытие» запустил набор в
research лабораторию и принимает заявки до 20 июня! Здесь подтянете знания, станете частью диджитал команды, будете работать над созданием реальных продуктов и получить редкий опыт.
|
Метки: author ksusha_icc интернет-маркетинг блог компании icanchoose.ru карьера digital |
[Из песочницы] Запуск Bare-metal приложения на Cyclone V SoC |

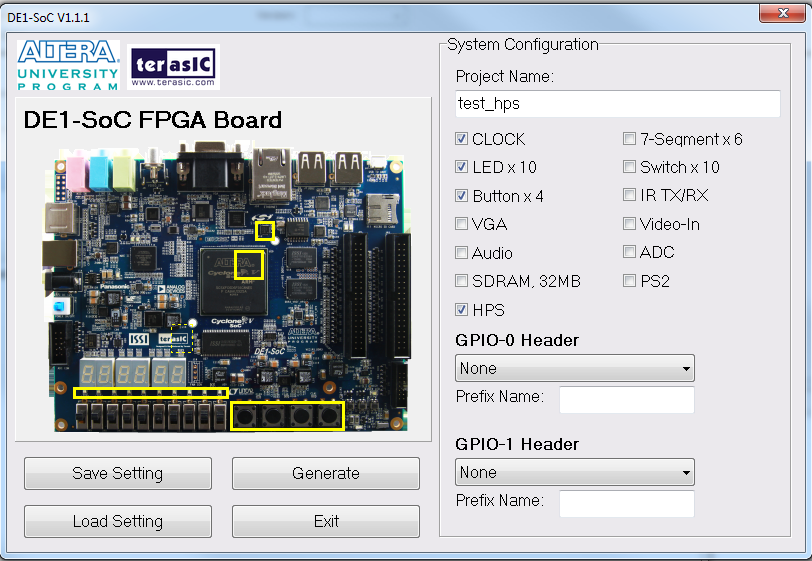
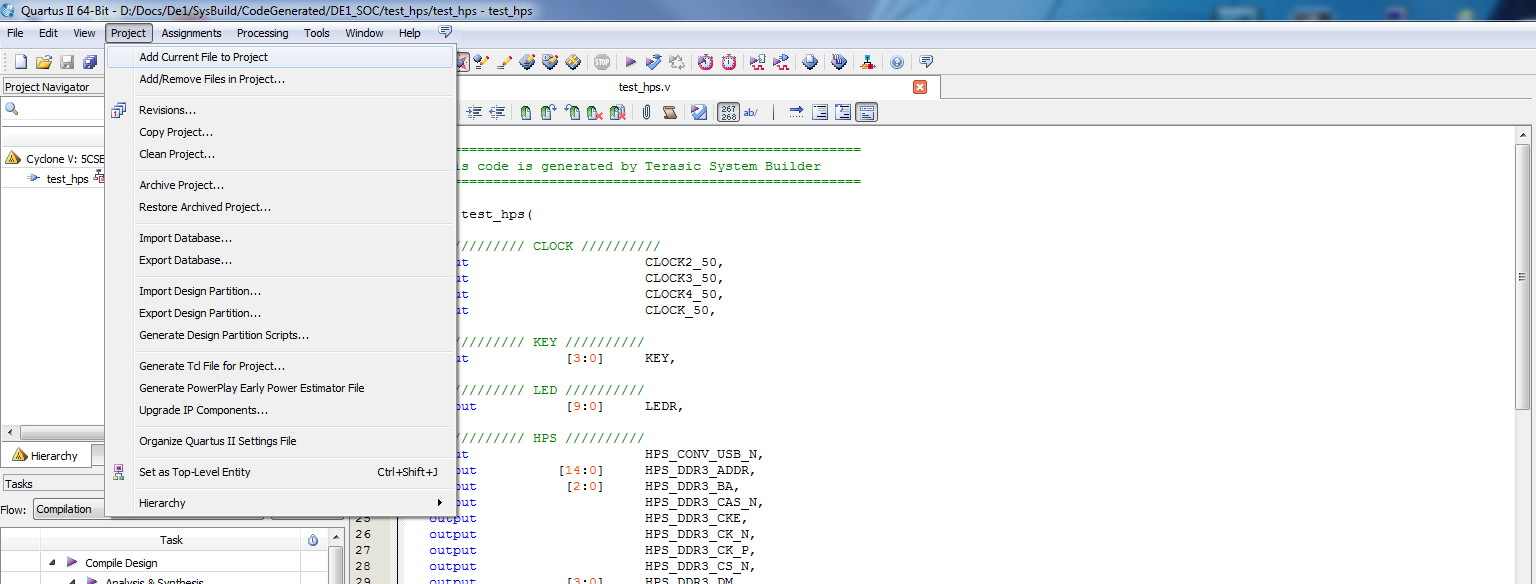


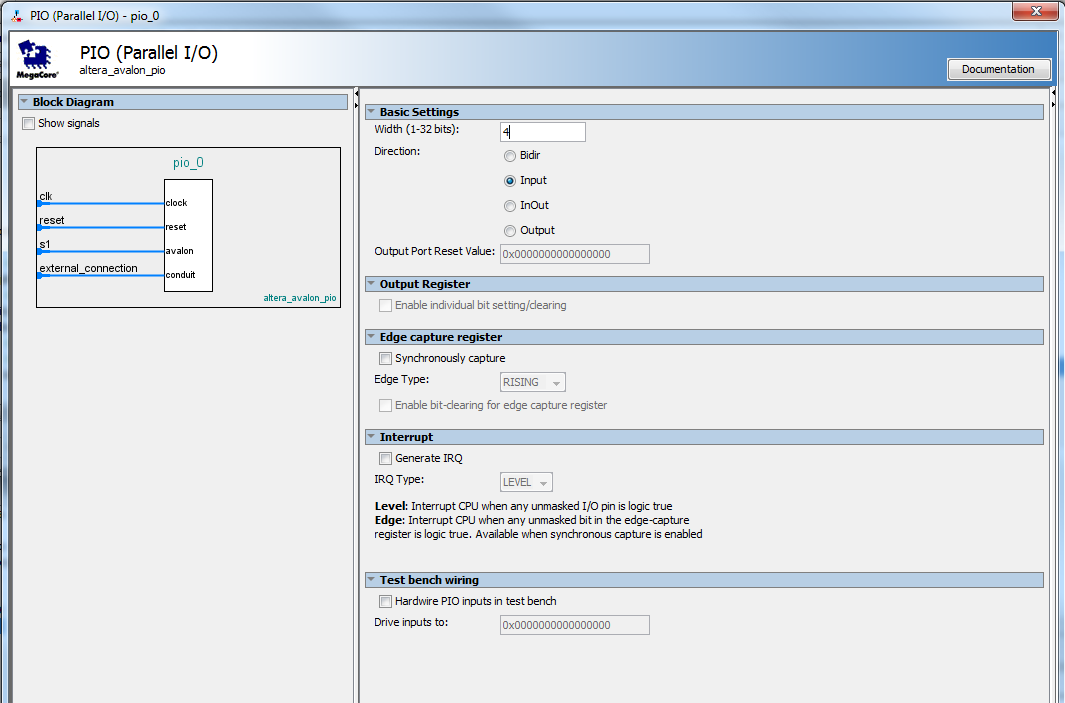
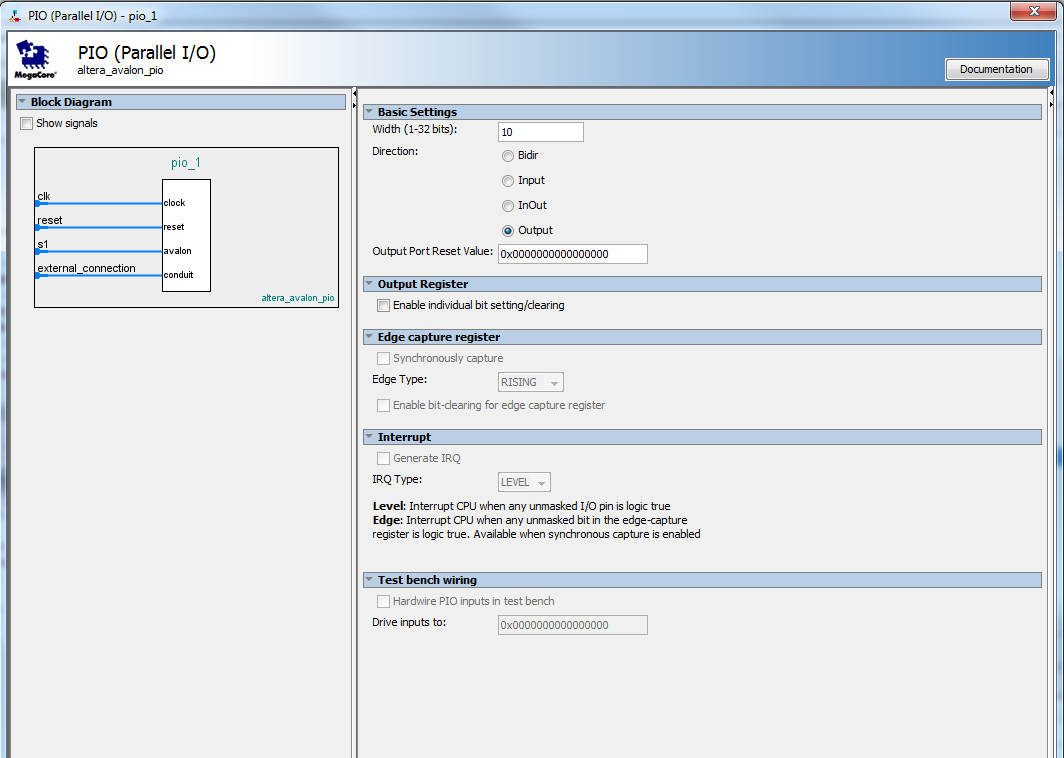
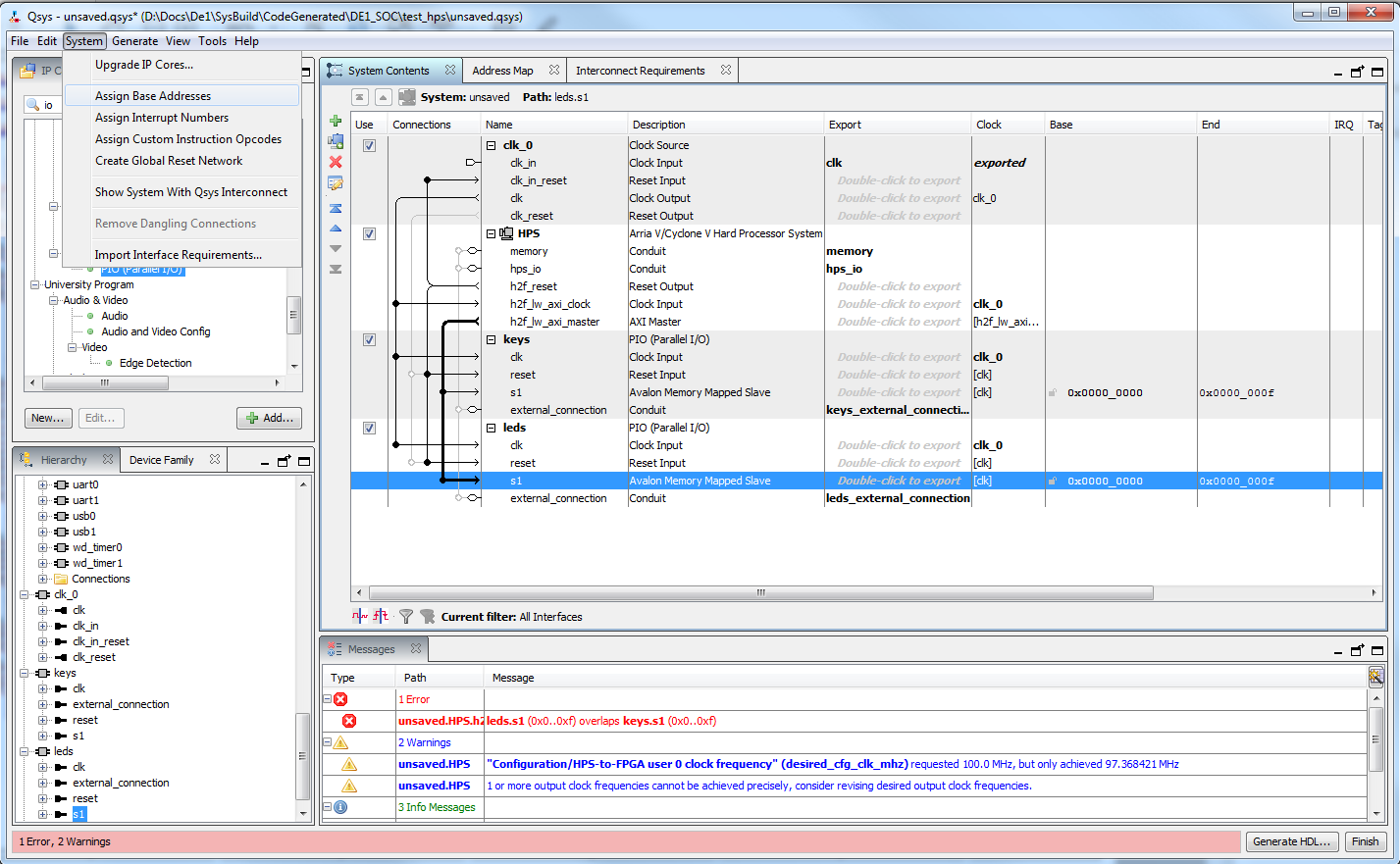
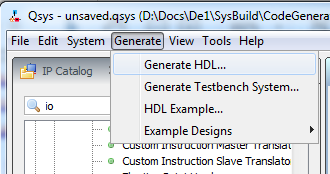
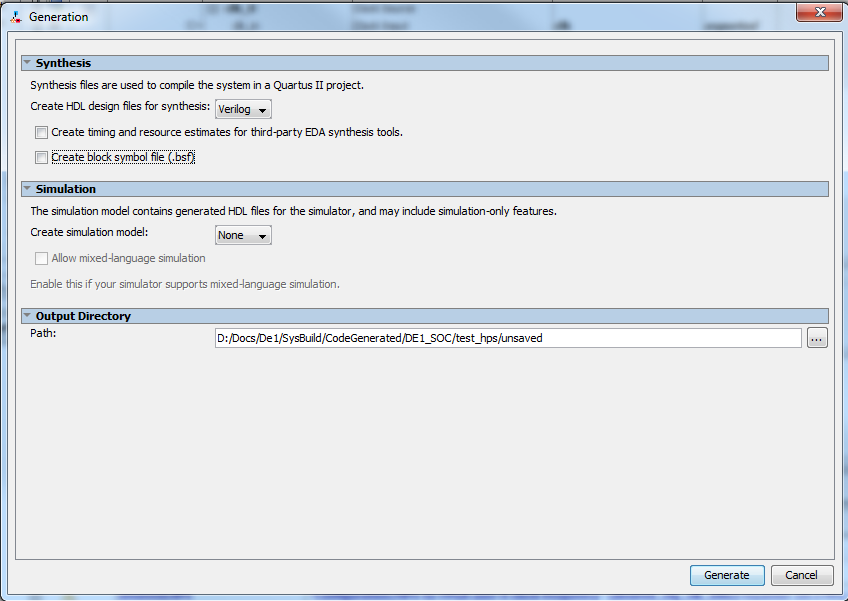

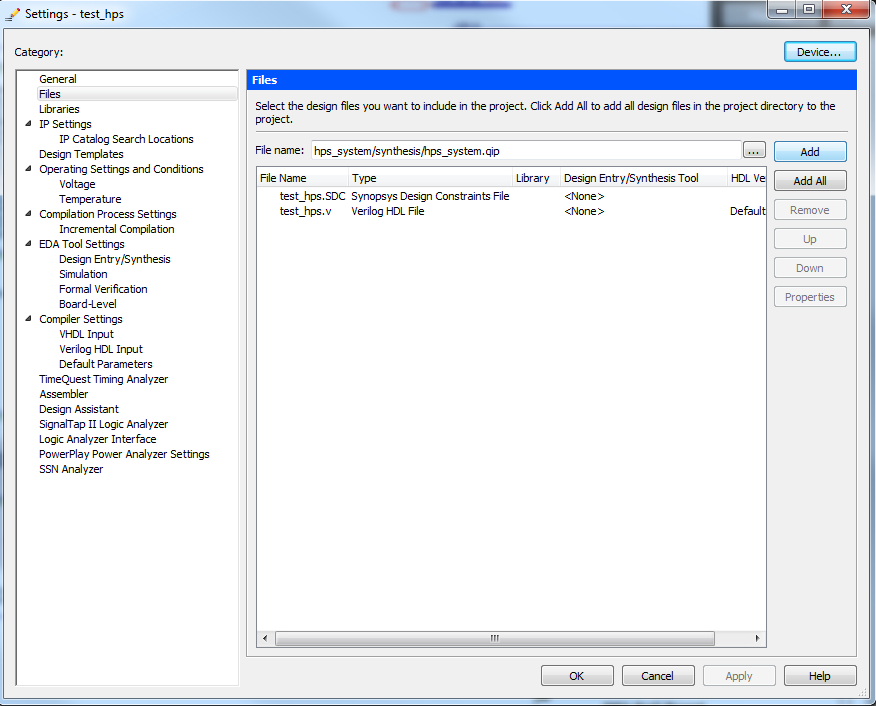
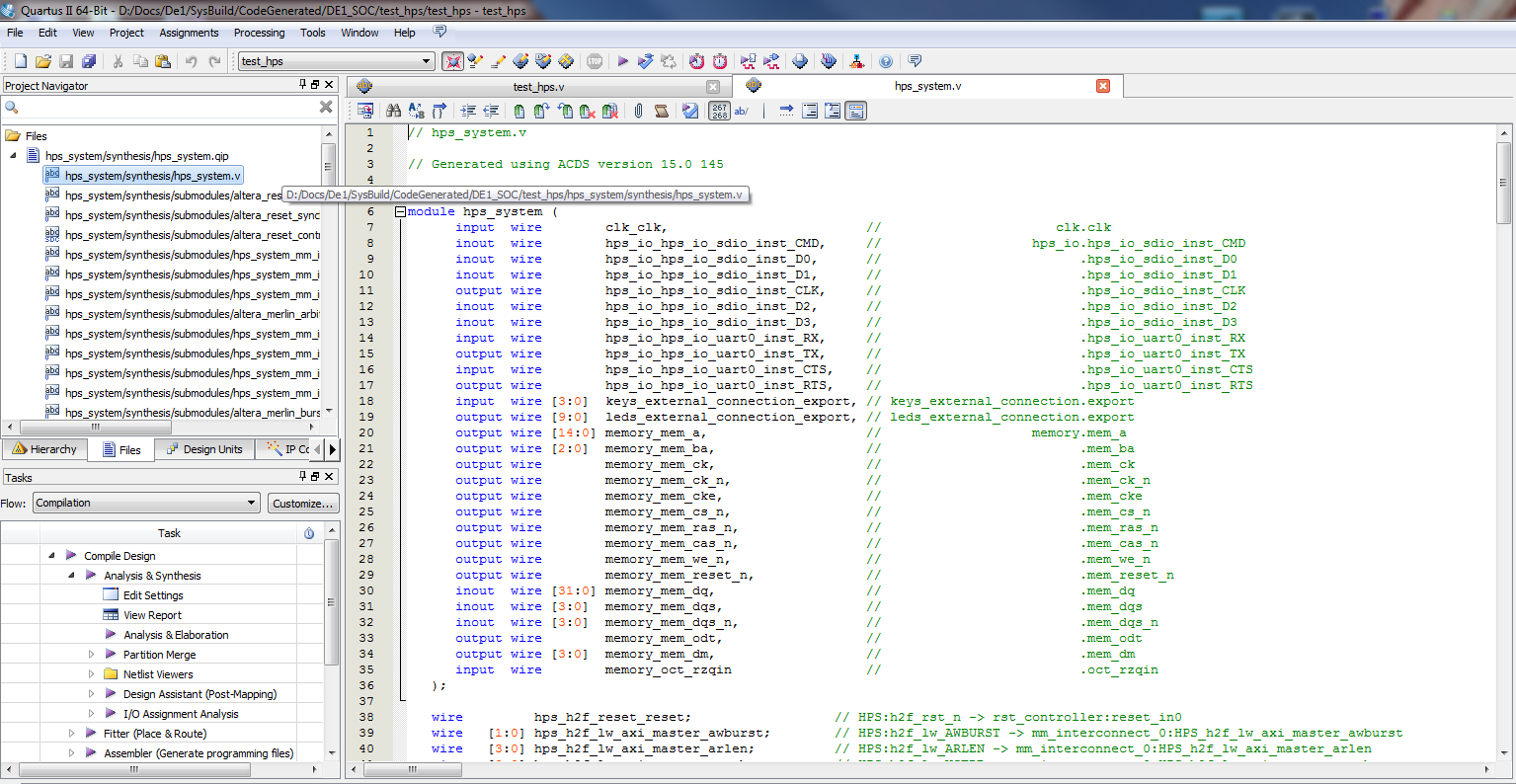
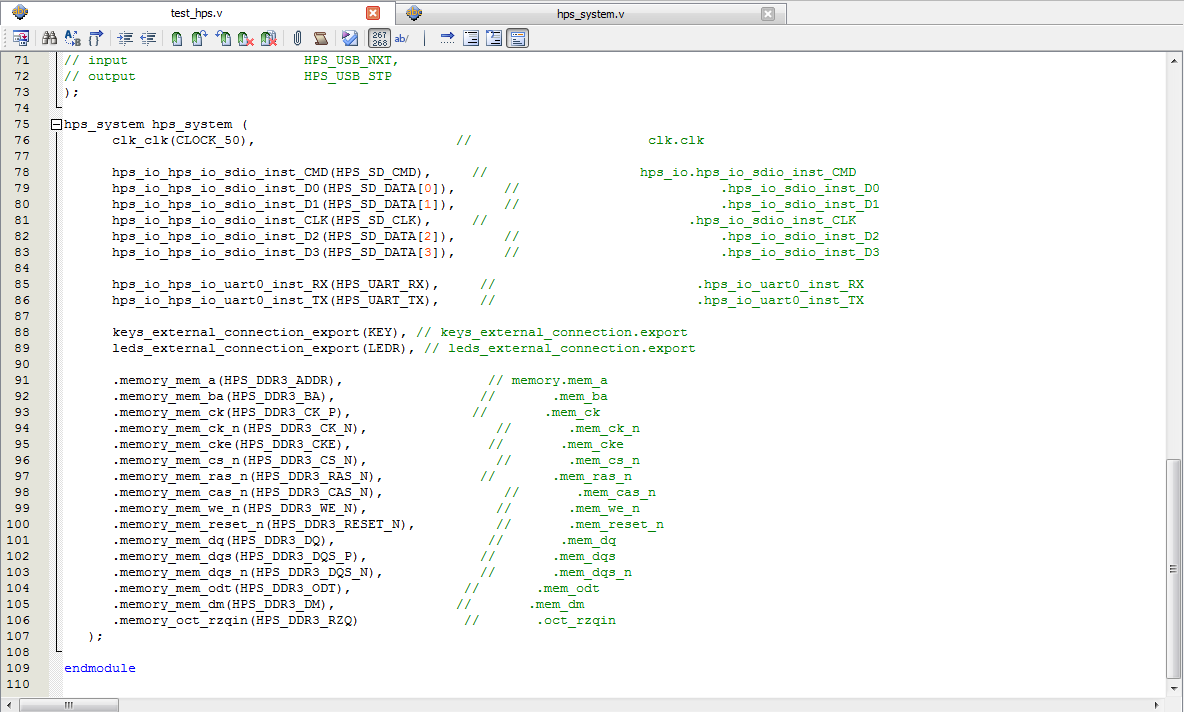
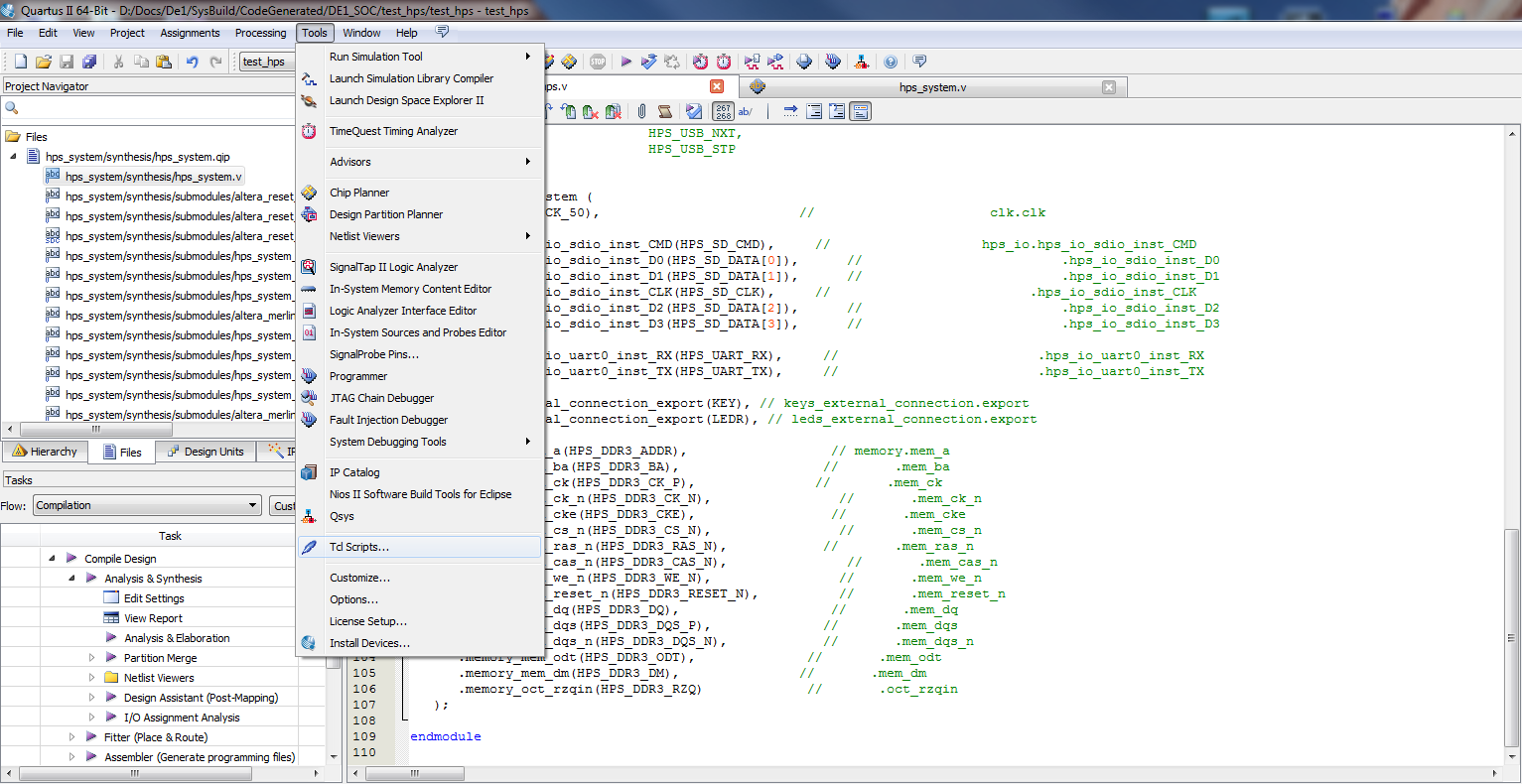


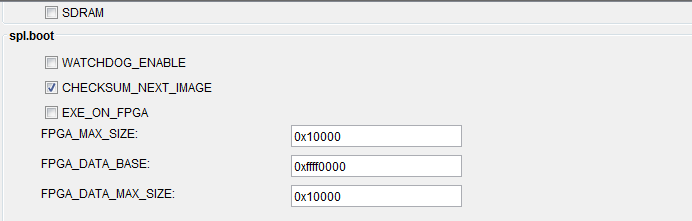
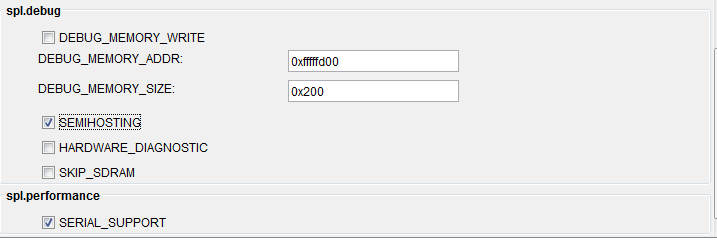

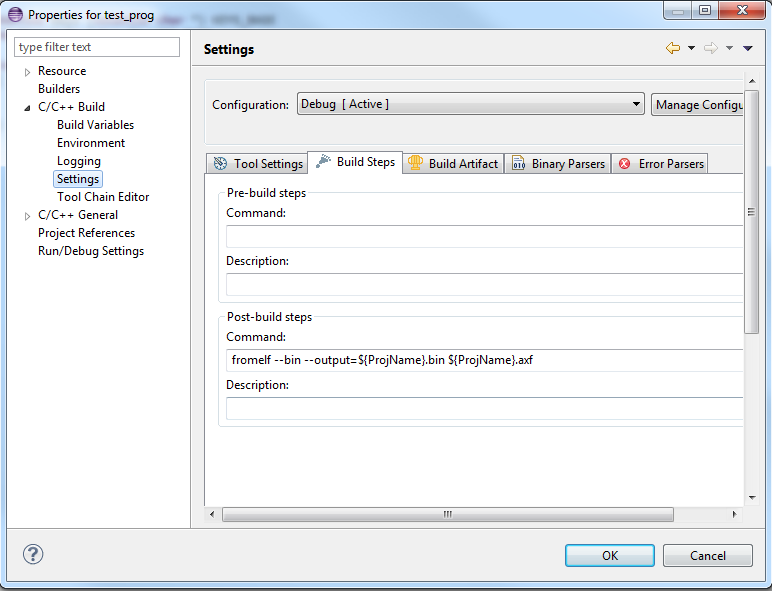
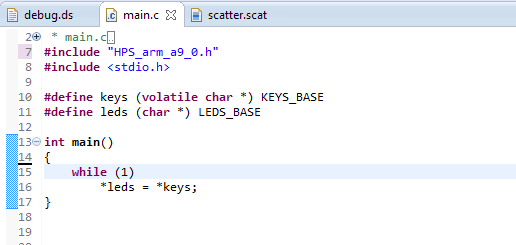
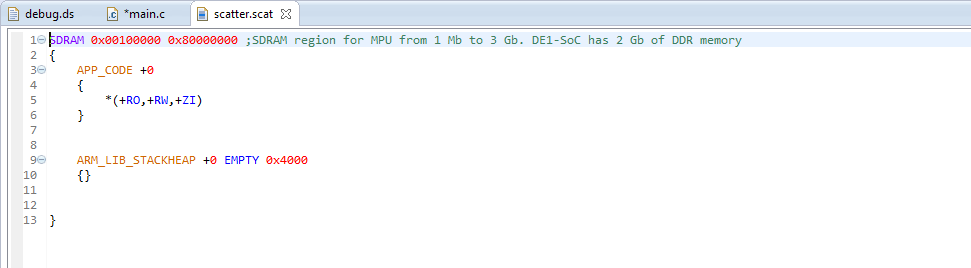
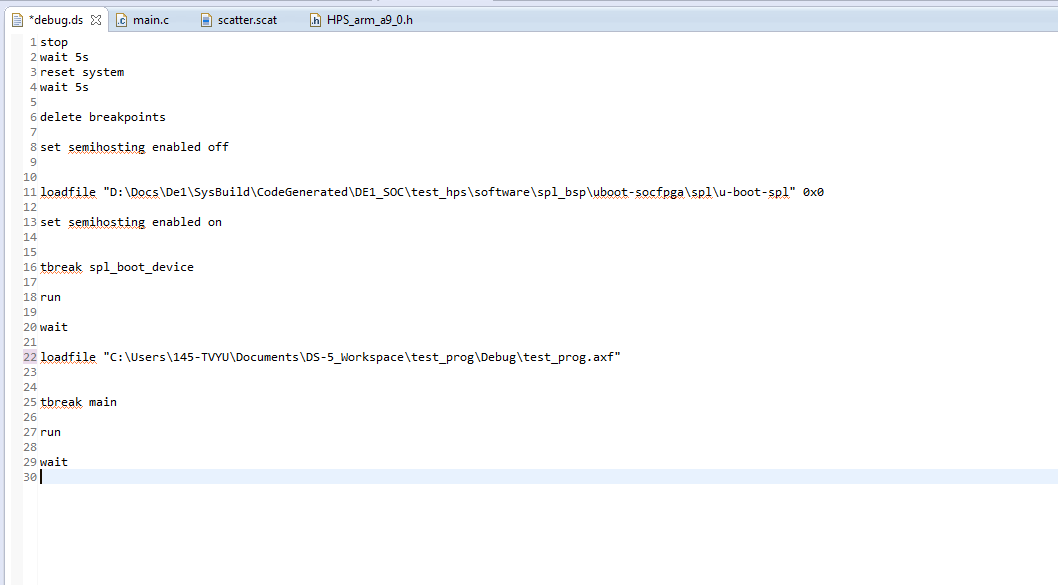
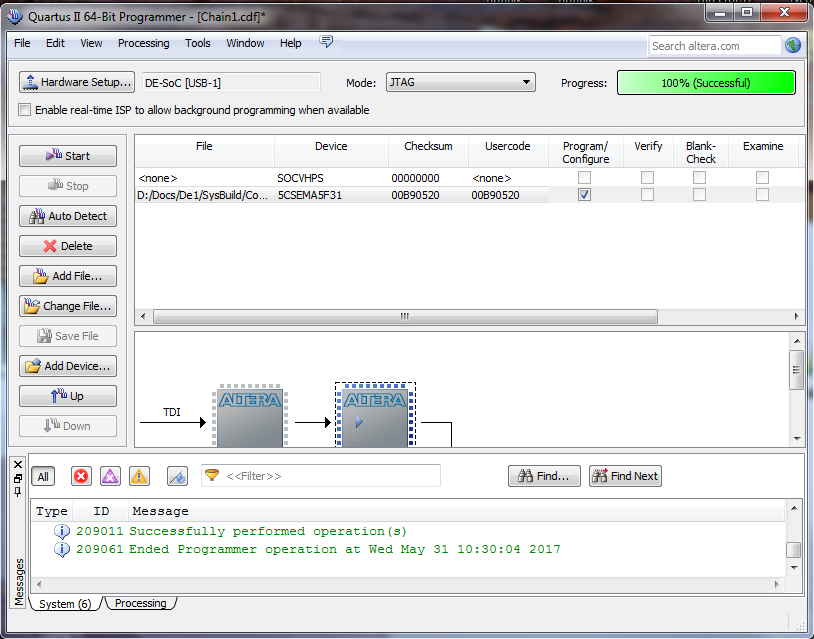
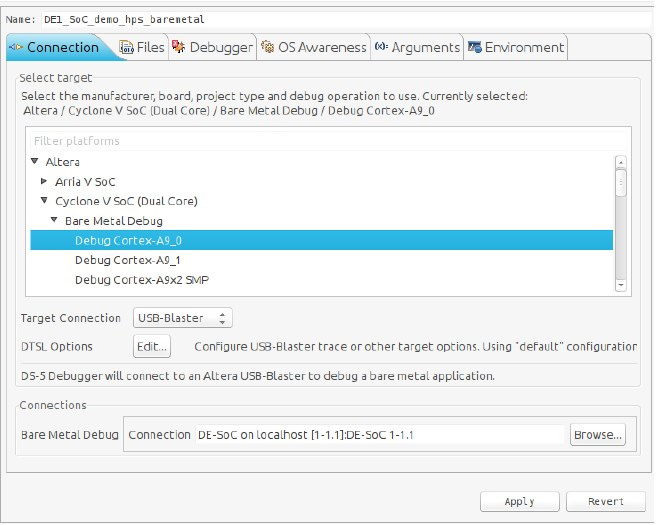
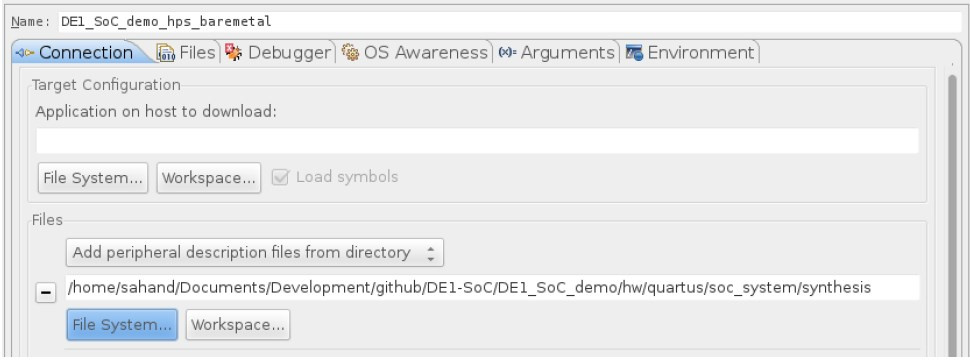
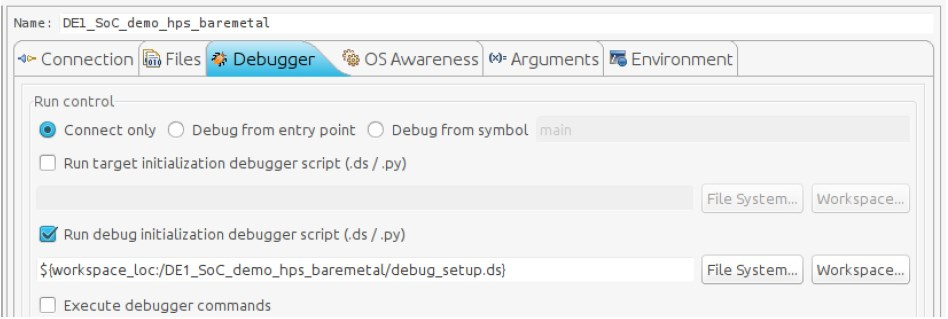
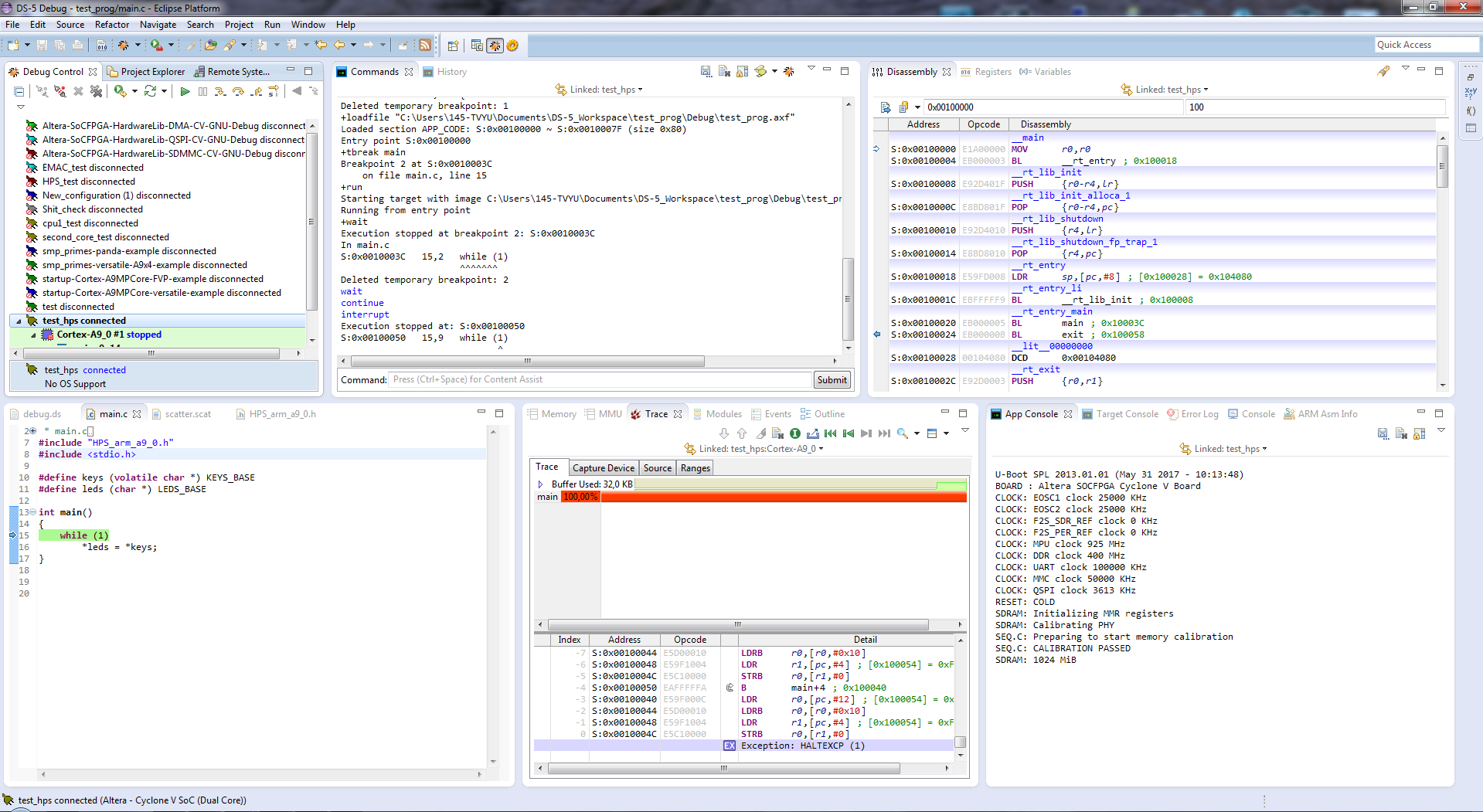
|
Метки: author pinchazer программирование fpga fpga altera system on chip |
Как работает закупщик |



|
Метки: author Milfgard управление проектами управление продажами блог компании мосигра закупка закупщик тяжелая работа бизнес |
Стартап дня (май 2017-го) |

Продолжая серию дайджестов «Стартап дня», сегодня я представляю самые интересные проекты за май. Если хотите ознакомиться с остальными, то прошу в мой блог. Записи доступны в Facebook, ICQ и Телеграм.
Американская вариация на тему поиска работы для миллениалов — стартап WayUp. Принципиально всё как в старом добром Хедхантере: есть профили соискателей, есть объявления о вакансиях, обе стороны могут искать друг друга по фильтрам, деньги берутся с работодателей, для кандидатов всё бесплатно.

Первое отличие от классики — специализация на студентах и выпускниках. Существенного опыта работы ни у кого нет, что, конечно, существенно ограничивает круг потенциальных вакансий, но зато подбор по формальным критериям работает лучше: подходящие вузы и средний балл можно поставить в фильтр, а больше в резюме ничего и нет, никакого поля для субъективного «не нравится». Да, во многом это преимущество выбранной категории, а не сервиса, но кто ж будет разбираться — процент подходящих кандидатов среди предложенных у WayUp высокое, HR-ы довольны, стартап хвастается.
Второй момент — хипстерский интерфейс. Стандартные фильтры есть, но припрятаны, главный элемент UI — подобранные умными алгоритмами вакансии «специально для меня», искать ничего не надо, надо сразу кликать. Это же ещё раз уменьшает процент отказов, алгоритм не так оптимистичен, как человек, и выбирает то, где больше шансов устроиться, а не то, где лучше всего платят.
Деньги WayUp берет за подписку, раньше пробовали брать за кандидата, но в итоге сменили модель на более привычную. Инвестиций проект поднял $27,5 млн, из них 18,5 — на днях. Любопытно, что за неизвестную часть «старых» девяти он успел купить клона-конкурента.

Хотите ли вы поучиться актерскому мастерству? Скорее нет. Хотите ли вы поучиться актерскому мастерству через интернет? Очевидно нет. А если через интернет, но у Дастина Хоффмана? И всего за $90? Кажется, это предложение звучит уже куда интереснее.
Так MasterClass и работает. Он находит звезд первой величины в каких-то не жизненно необходимых, но приятно-интересных почти любому человеку дисциплинах: кроме Хоффмана это Сирена Вильямс в теннисе, Кристина Агилера в пении, Гордон Рамзи в готовке, и записывает с ними серии видео-уроков о секретах мастерства. Доступ к урокам продается за те самые $90 (часть из них, естественно, достается преподавателю), кроме видео студент получает домашние задания и кросс-проверки их другими учениками. Да, в 2017-ом году можно задавать и проверять домашние задания даже по теннису — надо просто свои движения на видео записывать, а потом в систему загружать.
Некоторым везунчикам задания проверяет звезда, их ошибки освещаются публично для всех обучающихся — это и количество контента в курсе увеличивает, и некую лотерейную мотивацию при покупке создает, «вдруг и на меня сама Сирена посмотрит!»
Курсы в систему добавляются медленно, сейчас их всего четырнадцать, год назад было семь, два года назад — пять. Исходя из динамики предыдущих инвестиций, выходит, что стоимость производства роликов и разовый гонорар звезде — где-то миллиона полтора долларов за курс, а последнего раунда в $35 миллионов хватит ещё на 25 новых тем.
Стартап Tagged сам по себе совершенно неинтересен. Это старый дейтинговый сервис, нечто типа нашей дамочки.ру из начала нулевых (или конца девяностых?..). Мамбоподобная механика сочетается с нехитрыми играми, сейчас ещё что-то типа Тиндера рядом добавили, все обвешано-перевешано рекламой и платными функциями, но свои пользователи находятся и свои деньги оставляют, проект уже десять лет как прибыльный. Таких в сети много, знакомства — тема вечная, а существование лидера не убивает возможности для выживания аутсайдеров. Впрочем, всем бы быть такими аутсайдерами — выручка у них порядка 50 миллионов долларов в год, тема не только вечная, но и богатая.
Интересно же то, что Tagged провел эксперимент, который хоть раз хотела провести, наверное, любая большая компания. Рассуждали они просто: раз в несколько лет какой-нибудь студент придумывают какую-то офигенную социальную штуку и выходит новый Facebook-не Facebook, но хотя бы Foursquare, стоящий сотни миллионов, и приносящий славы куда больше, чем наш клон дамочки.
Мы умнее любого студента, у нас больше ресурсов, у нас опыт привлечения траффика, у нас лояльные пользователи, которых можно опрашивать или использовать для тестирования. Давайте сами начнем делать новые и интересные штуки, у нас будет получаться лучше, чем у студентов, и хоть раз-то мы и угадаем, ну а этот раз любые усилия окупит.
И они это действительно сделали, только до публичного использования дошло два собственных продукта с оригинальной механикой (соцсеть для соседей и няшный мессенджер) и ещё один мультимессенджер купили на ранней стадии. Ничего не взлетело, конечно… Но ведь попробовали! Все остальные останавливаются на том, что студентов пробует миллион, получается у одного, а они не в миллион раз умнее и эффективнее каждого отдельного экспериментатора.
Сейчас запал кончился, основатели компанию продали, дальше она будет просто деньги новым хозяевам приносить, мир остался не перевернутым.
В массовом сознании дополненная реальность — это часто что-то вроде прикольных стикеров в ICQ или Snapchat. Стартап Upskill использует технологию в куда более серьезных вопросах, он пытается повысить эффективность рабочих. Основных сценариев его использования не так много, но каждый из них очевидно полезен целым индустриям:
Формально всё это можно сделать и с помощью мобильного телефона, но, во-первых, это не так стильно выглядит, а во-вторых, рабочим часто нужны обе руки. Поэтому — очки, необязательно именно Google, но любые подобные. Понятно, что реальные требования любого заказчика к таким продуктам абсолютно уникальны, Upskill сделал что-то типа фреймворка, позволяющего эти требования быстро реализовать. И это работает. Среди довольных клиентов, например, Boeing, у которого очки получилось внедрить настолько хорошо, что он даже проинвестировал в стартап в последнем раунде. В общем, будущее приближается.

И в почти чистом оффлайне есть жизнь — стартап Carvana вышел на миллиардное IPO. Результат не самый громкий в мировой истории, но в любом случае отличный для компании возрастом в четыре года.
Чтобы понять причины этого успеха, нужно для начала съездить в большой салон к любому крупному автодилеру. Это почти всегда огромный стеклянный дворец, стоящий на какой-то хорошей земле, в городе или недалеко от города, и стоящий приблизительно целое состояние. Особенно дорого такое хранение обходится для подержанных автомобилей: ведь их надо держать там все, нельзя, как с новыми, показывать десяткам покупателей один и тот же образец, а продавать с дальнего склада другие идентичные экземпляры.
Бизнес-модель Carvana состоит в том, чтобы конкурировать с обычными дилерами (по сути — быть дилером), но отказаться от традиционных гигантских салонов и продавать подержанные автомобили через интернет. Часть сэкономленных денег при этом кладется в карман для будущих прибылей и счастья инвесторов, а частью стартап делится с пользователями, предоставляя дополнительные преимущества взамен потерянной возможности побродить среди продаваемых машин.
Всё начинается с безграничного выбора. Сейчас на сайте выставлено 7000 автомобилей, доступных каждому жителю зоны доставки. Это, конечно, немного по сравнению с любой доской объявлений, но куда больше, чем может предложить дилер в своем салоне. В каждую машину можно залезть внутрь с помощью красивой 3D-модели на Flash. 2017-ый год, стартап, Flash — сочетание выглядит несколько странно, но ни на каком auto.ru никогда не будет и такого.
Когда автомобиль выбран, приходит время удобной доставки, она не должна быть хуже, чем у обычного дилера. Самый обыденный, но эффективный вариант — машину могут просто привезти к дому. Вторая возможность более экзотическая — Carvana оплачивает иногороднему покупателю билет на самолет, чтобы он сам добрался до склада, сел и уехал. Ну и, наконец, визитная карточка стартапа — вендинговые аппараты по выдаче автомобилей: оплаченную машину доставляют в эту башню, новому владельцу высылают код, он приезжает с другом или на такси, вводит код и уезжает уже за рулем своего нового авто.
Таких вендингов пока всего два в стране, это явно не слишком значимый по объёмам способ доставки — но как красиво-то! И в прессе всегда их фотографии прикладывают, вот и я тоже не удержался.
Человек выбирал автомобиль через интернет, получил его, скажем, в вендинге, не пообщавшись ни с одной живой душой — естественно это страшно, вдруг машина убитая, хоть и было написано, что в идеальном состоянии. Чтобы страшно не было, Carvana дает гарантии. Во-первых, семидневный moneyback без каких-либо условий, не понравилось — можешь вернуть. Во-вторых, стодневная гарантия на какие-то всплывшие недостатки: если вдруг сам по себе забарахлил двигатель, то это будет проблема Carvana, а не покупателя.
Через интернет авто можно и продать, но цены будут не самыми лучшими, и это не слишком популярная возможность. Основной источник автомобилей для Carvana — дилерские B2B-аукционы и подобные олдскульные инструменты. Экономика стартапа пока не сходится, он уже научился извлекать прибыль из каждого проданного автомобиля, но общие расходы это не окупает. Впрочем, ежегодный рост продаж около 300 %, эффект от каждой продажи тоже улучшается, ещё пара лет — и компания в целом должна стать прибыльной. За 2016-й год через Carvana прошло около двадцати тысяч автомобилей, капитализация стартапа сейчас $1,7 млрд, до IPO в компанию вложили $300 млн инвестиций.
|
Метки: author gornal развитие стартапа венчурные инвестиции бизнес-модели блог компании mail.ru group стартапдня стартапы |
Впервые в России на робототехнической олимпиаде пройдут соревнования беспилотников |

|
|
AgeHack — первый онлайн-хакатон по продлению жизни на платформе MLBootCamp |

Сегодня, 15 июня, стартует чемпионат на платформе ML Boot Camp, посвященный проблемам здравоохранения и долголетия человечества. Чемпионат организован нами совместно с Insilico Medicine в сотрудничестве с Республиканским центром электронного здравоохранения при Министерстве здравоохранения Республики Казахстан. О том, почему это не очень обычный для нас конкурс — под катом.
Это уже третий по счету чемпионат в этом году, но он совершенно особенный по очень многим причинам. Во-первых, это первый чемпионат, который мы проводим не в одиночку — конкурс проводится в тесном партнерстве с Insilico Medicine и Республиканским центром электронного здравоохранения при Министерстве здравоохранения Республики Казахстан.
Во-вторых, тематика конкурса необычна и очень близка к актуальным проблемам человечества в целом. Это медицина. В этот раз программисты будут искать решение задачи по диагностике сердечно-сосудистых заболеваний. Это первый в Евразии чемпионат, в рамках которого участники используют технологии машинного обучения для поиска решений, обеспечивающих здоровье и долголетие. Нам кажется, что для участников это очень хороший шанс не просто решить интересную задачу, но и возможно способствовать решению таких важных вопросов, как общее здоровье человечества. Кто знает, может быть мы стоим сейчас у истоков совершенно новых средств диагностики и лечения. И это здорово!
В-третьих, датасет. Никаких логов, самые настоящие клинические данные, скрупулезно собранные в медицинских учреждениях. 100 тысяч анонимизированных клинических анализов. Кроме того, механика решения задачи немного отличается от того, что мы обычно делаем на наших чемпионатах (см. раздел «Задача»).
В-четвертых, призы. Наши постоянные участники уже в курсе сложившейся схемы «top6 призовых мест + 50 сувенирных». Но есть небольшой сюрприз, об этом ниже.
В остальном же, чемпионат проходит как обычно — в течение одного месяца, с 15 июня по 15 июля 2017 года, участники должны решить ровно одну задачу.
В рамках конкурса участникам нужно предсказать наличие сердечно-сосудистых заболеваний по результатам классического врачебного осмотра. Датасет сформирован из 100.000 реальных клинических анализов, и в нём используются признаки, которые можно разбить на 3 группы:
Объективные признаки:
Результаты измерения:
Субъективные признаки:
Возраст дан в днях. Значения показателей холестерина и глюкозы представлены одним из трех классов: норма, выше нормы, значительно выше нормы. Значения субъективных признаков — бинарны.
Все показатели даны на момент осмотра. Теперь немного необычного.

Последняя группа признаков не имеет однозначной интерпретации и более того, собрана со слов самого больного. Поэтому, для части данных в тестовых выборках мы специально исключили эти параметры. Участникам придется либо предсказать их самостоятельно для некоторых случаев, либо вовсе игнорировать.
Данные поделены в соотношении 70/10/20. Тренировочная выборка состоит из 70 тысяч результатов, еще по десяти тысячам считается публичная метрика, доступная участникам в ходе соревнования. Оставшиеся 20 тысяч отправились в скрытую проверочную выборку, подсчет метрики по которой и определит победителей в финале.
Поскольку мы имеем дело с бинарной классификацией, метрикой является логарифмическая функция потерь.
Распределение шести призовых мест в этот раз выглядит так:
Top1: MacBook Pro
Top2: NVIDIA 1080ti
Top3: NVIDIA 1060
Top4-5-6: WD My Cloud 6 TB
По традиции, 50 лучших участников получат майки с символикой чемпионата.
Участники с наиболее интересными для организаторов решениями получат возможность стажировки или сотрудничества с Mail.Ru Group, Insilico Medicine и Министерством здравоохранения Республики Казахстан. Кроме того, специальным призом от жюри является поездка в Астану для личной встречи с министром здравоохранения Республики Казахстан.
С каждым новым соревнованием наше сообщество в Telegram становится все больше. Профессионалы делятся опытом, новички учатся. Двери открыты для всех, так что присоединяйтесь.
Чемпионат стартует уже сегодня, в 18:00 по Москве. Регистрируемся здесь. Желаем удачи!
|
Метки: author sat2707 машинное обучение data mining big data блог компании mail.ru group mail.ru ml boot camp machine learning machine learning boot camp |
Облако как «новое электричество» |
|
Метки: author megapost microsoft azure azure oms microsoft |
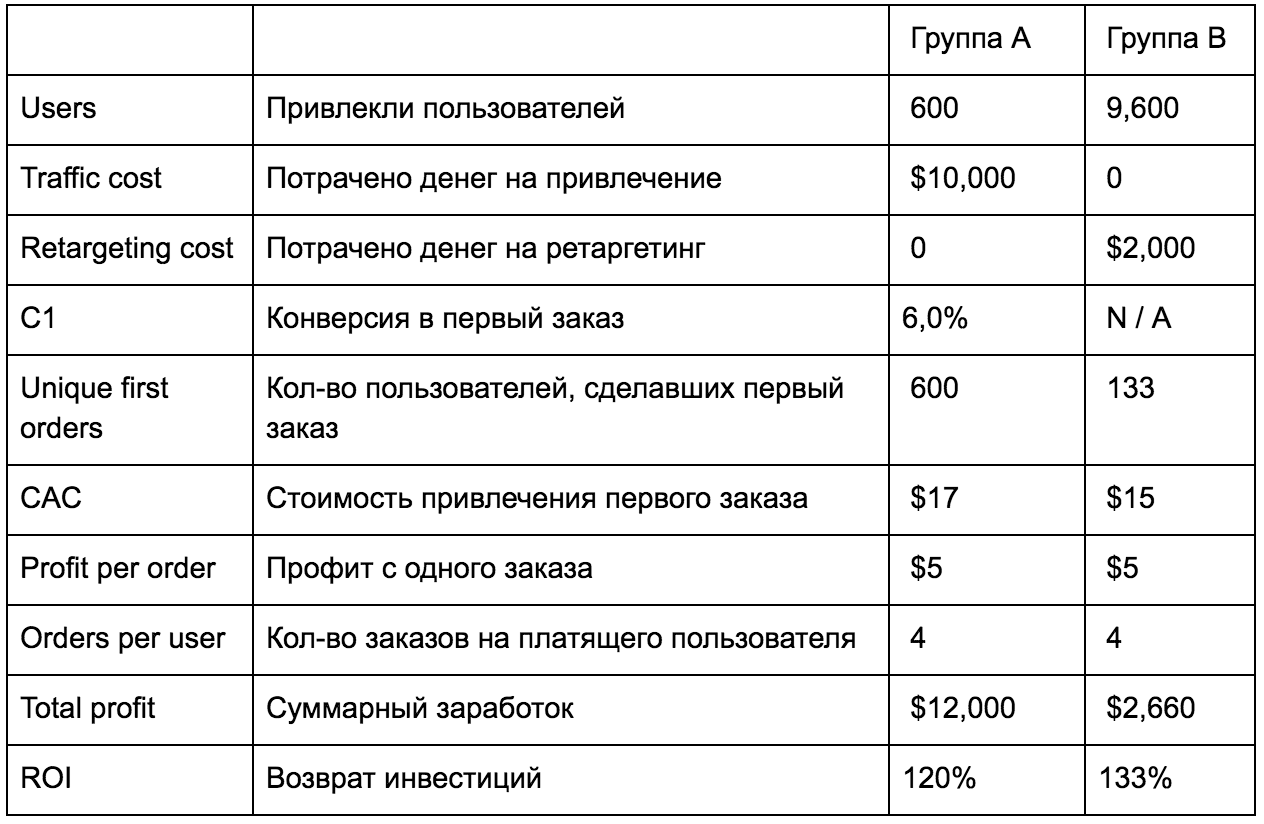
Мобильный ретаргетинг: как измерять эффективность |



|
|






