[Прим. пер.: оригинал статьи называется GPU Performance for Game Artists, но, как мне кажется, она будет полезной для всех, кто хочет иметь общее представление о работе видеопроцессора]
[Прим. пер.: оригинал статьи называется GPU Performance for Game Artists, но, как мне кажется, она будет полезной для всех, кто хочет иметь общее представление о работе видеопроцессора]
За скорость игры несут ответственность все члены команды, вне зависимости от должности. У нас, 3D-программистов, есть широкие возможности для управления производительностью видеопроцессора: мы можем оптимизировать шейдеры, жертвовать качеством картинки ради скорости, использовать более хитрые техники рендеринга… Однако есть аспект, который мы не можем полностью контролировать, и это графические ресурсы игры.
Мы надеемся, что художники создадут ресурсы, которые не только хорошо выглядят, но и будут эффективны при рендеринге. Если художники немного больше узнают о том, что происходит внутри видеопроцессора, это может оказать большое влияние на частоту кадров игры. Если вы художник и хотите понять, почему для производительности важны такие аспекты, как вызовы отрисовки (draw calls), уровни детализации (LOD) и MIP-текстуры, то прочитайте эту статью. Чтобы учитывать то влияние, которое имеют ваши графические ресурсы на производительность игры, вы должны знать, как полигональные сетки попадают из 3D-редактора на игровой экран. Это значит, что вам нужно понять работу видеопроцессора, микросхемы, управляющей графической картой и несущей ответственность за трёхмерный рендеринг в реальном времени. Вооружённые этим знанием, мы рассмотрим наиболее частые проблемы с производительностью, разберём, почему они являются проблемой, и объясним, как с ними справиться.
Прежде чем мы начнём, я хотел бы подчеркнуть, что буду намеренно упрощать многое ради краткости и понятности. Во многих случаях я обобщаю, описываю только наиболее типичные случае или просто отбрасываю некоторые понятия. В частности, ради простоты описанная в статье идеальная версия видеопроцессора больше всего похожа на предыдущее поколение (эры DX9). Однако когда дело доходит до производительности, все представленные ниже рассуждения вполне применимы к современному оборудованию PC и консолей (но, возможно, не ко всем мобильным видеопроцессорам). Если вы поймёте всё написанное в статье, то вам будет гораздо проще справляться с вариациями и сложностями, с которыми вы столкнётесь в дальнейшем, если захотите разбираться глубже.
Часть 1: конвейер рендеринга с высоты птичьего полёта
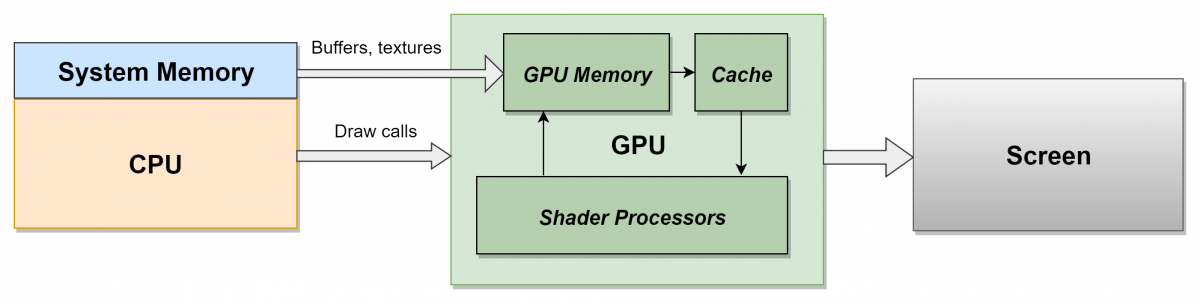
Чтобы отобразить на экране полигональную сетку, она должна пройти через видеопроцессор для обработки и рендеринга. Концептуально этот путь очень прост: сетка загружается, вершины группируются в треугольники, треугольники преобразуются в пиксели, каждому пикселю присваивается цвет, и конечное изображение готово. Давайте рассмотрим подробнее, что же происходит на каждом этапе.
После экспорта сетки из 3D-редактора (Maya, Max и т.д.) геометрия обычно загружается в движок игры двумя частями: буфером вершин (Vertex Buffer, VB), содержащим список вершин сетки со связанными с ними свойствами (положение, UV-координаты, нормаль, цвет и т.д.), и буфером индексов (Index Buffer, IB), в котором перечислены вершины из VB, соединённые в треугольники.
Вместе с этими буферами геометрии сетке также назначается материал, определяющий её внешний вид и поведение в различных условиях освещения. Для видеопроцессора этот материал принимает форму специально написанных
шейдеров — программ, определяющих способ обработки вершин и цвет конечных пикселей. При выборе материала для сетки нужно настраивать различные параметры материала (например, значение базового цвета или выбор текстуры для различных карт: albedo, roughness, карты нормалей и т.д.). Все они передаются программам-шейдерам в качестве входных данных.
Данные сетки и материала обрабатываются различными этапами конвейера видеопроцессора для создания пикселей окончательного
целевого рендера (изображения, в которое выполняет запись видеопроцессор). Этот целевой рендер в дальнейшем можно использовать как текстуру в последующих шейдерах и/или отображать на экране как конечное изображение кадра.
Для целей этой статьи важными частями конвейера видеопроцессора будут следующие, сверху вниз:

- Входная сборка (Input Assembly). Видеопроцессор считывает буферы вершин и индексов из памяти, определяет как соединены образующие треугольники вершины и передаёт остальное в конвейер.
- Затенение вершин (Vertex Shading). Вершинный шейдер выполняется для каждой из вершин сетки, обрабатывая по отдельной вершине за раз. Его основная задача — преобразовать вершину, получить её положение и использовать текущие настройки камеры и области просмотра для вычисления её расположения на экране.
- Растеризация (Rasterization). После того, как вершинный шейдер выполнен для каждой вершины треугольника и видеопроцессор знает, где она появится на экране, треугольник растеризируется — преобразуется в набор отдельных пикселей. Значения каждой вершины — UV-координаты, цвет вершины, нормаль и т.д. — интерполируются по пикселям треугольника. Поэтому если одна вершина треугольника имеет чёрный цвет, а другая — белый, то пиксель, растеризированный посередине между ними получит интерполированный серый цвет вершин.
- Затенение пикселей (Pixel Shading). Затем для каждого растеризированного пикселя выполняется пиксельный шейдер (хотя технически на этом этапе это ещё не пиксель, а «фрагмент», поэтому иногда пиксельный шейдер называют фрагментным). Этот шейдер запрограммированным образом придаёт пикселю цвет, сочетая свойства материала, текстуры, источники освещения и другие параметры, чтобы получить определённый внешний вид. Пикселей очень много (целевой рендер с разрешением 1080p содержит больше двух миллионов), и каждый из них нужно затенить хотя бы раз, поэтому обычно видеопроцессор тратит на пиксельный шейдер много времени.
- Вывод целевого рендера (Render Target Output). Наконец пиксель записывается в целевой рендер, но перед этим проходит некоторые проверки, чтобы убедиться в его правильности. Глубинный тест отбрасывает пиксели, которые находятся глубже, чем пиксель, уже присутствующий в целевом рендере. Но если пиксель проходит все проверки (глубины, альфа-канала, трафарета и т.д.), он записывается в хранящийся в памяти целевой рендер.
Действий выполняется гораздо больше, но таков основной процесс: для каждой вершины в сетке выполняется вершинный шейдер, каждый трёхвершинный треугольник растеризуется в пиксели, для каждого растеризированного пикселя выполняется пиксельный шейдер, а затем получившиеся цвета записываются в целевой рендер.
Программы шейдеров, задающие вид материала, пишутся на языке программирования шейдеров, например, на
HLSL. Эти шейдеры выполняются в видеопроцессоре почти так же, как обычные программы выполняются в центральном процессоре — получают данные, выполняют набор простых инструкций для изменения данных и выводят результат. Но если программы центрального процессора могут работать с любыми типами данных, то программы шейдеров специально разработаны для работы с вершинами и пикселями. Эти программы пишутся для того, чтобы придать отрендеренному объекту вид нужного материала — пластмассы, металла, бархата, кожи и т.д.
Приведу конкретный пример: вот простой пиксельный шейдер, выполняющий расчёт освещения по Ламберту (т.е. только простое рассеивание, без отражений) для цвета материала и текстуры. Это один из простейших шейдеров, но вам не нужно разбираться в нём, достаточно увидеть, как выглядят шейдеры в целом.
float3 MaterialColor;
Texture2D MaterialTexture;
SamplerState TexSampler;
float3 LightDirection;
float3 LightColor;
float4 MyPixelShader( float2 vUV : TEXCOORD0, float3 vNorm : NORMAL0 ) : SV_Target
{
float3 vertexNormal = normalize(vNorm);
float3 lighting = LightColor * dot( vertexNormal, LightDirection );
float3 material = MaterialColor * MaterialTexture.Sample( TexSampler, vUV ).rgb;
float3 color = material * lighting;
float alpha = 1; return float4(color, alpha);
}
Простой пиксельный шейдер, выполняющий расчёт базового освещения. Входные данные, такие как MaterialTexture и LightColor, передаются центральным процессором, а vUV и vNorm — это свойства вершин, интерполируемые по треугольнику при растеризации.
Вот сгенерированные инструкции шейдера:
dp3 r0.x, v1.xyzx, v1.xyzx
rsq r0.x, r0.x
mul r0.xyz, r0.xxxx, v1.xyzx
dp3 r0.x, r0.xyzx, cb0[1].xyzx
mul r0.xyz, r0.xxxx, cb0[2].xyzx
sample_indexable(texture2d)(float,float,float,float) r1.xyz, v0.xyxx, t0.xyzw, s0
mul r1.xyz, r1.xyzx, cb0[0].xyzx
mul o0.xyz, r0.xyzx, r1.xyzx
mov o0.w, l(1.000000)
ret
Компилятор шейдеров получает показанную выше программу и генерирует такие инструкции, которые выполняются в видеопроцессоре. Чем длиннее программа, тем больше инструкций, то есть больше работы для видеопроцессора.
Попутно замечу — можно увидеть, насколько изолированы этапы шейдера — каждый шейдер работает с отдельной вершиной или пикселем и ему не требуется знать ничего об окружающих вершинах/пикселях. Это сделано намеренно, потому что позволяет видеопроцессору параллельно обрабатывать огромные количества независимых вершин и пикселей, и это одна из причин того, почему видеопроцессоры настолько быстрее обрабатывают графику по сравнению с центральными процессорами.
Скоро мы вернёмся к конвейеру, чтобы увидеть, почему работа может замедляться, но сначала нам нужно сделать шаг назад и посмотреть, как вообще сетка и материал попадают в видеопроцессор. Здесь мы также встретим первую преграду производительности — вызов отрисовки.
Центральный процессор и вызовы отрисовки
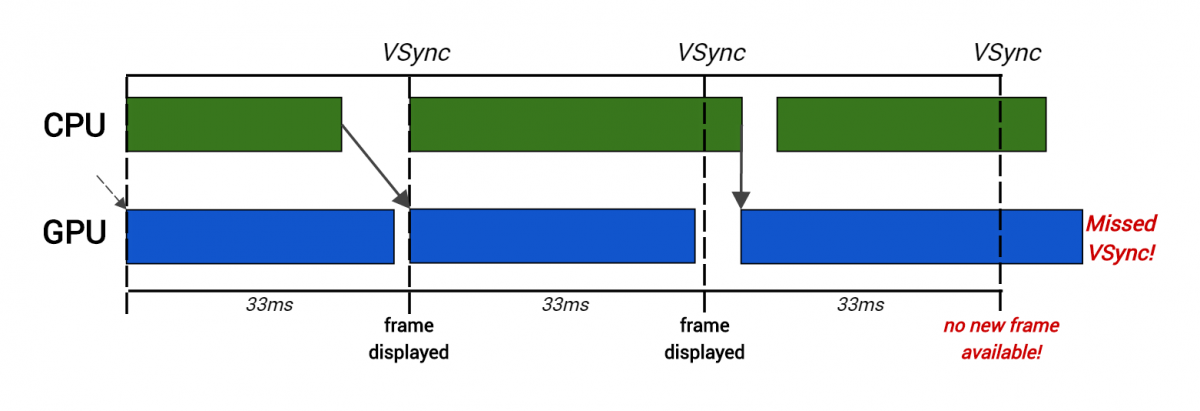
Видеопроцессор не может работать в одиночку: он зависит от кода игры, запущенного в главном процессоре компьютера — ЦП, который сообщает ему, что и как рендерить. Центральный процессор и видеопроцессор — это (обычно) отдельные микросхемы, работающие независимо и параллельно. Чтобы получить необходимую частоту кадров — обычно это 30 кадров в секунду — и ЦП, и видеопроцессор должны выполнить всю работу по созданию одного кадра за допустимое время (при 30fps это всего 33 миллисекунд на кадр).
Чтобы добиться этого, кадры часто
выстраиваются в конвейер: ЦП занимает для своей работы весь кадр (обрабатывает ИИ, физику, ввод пользователя, анимации и т.д.), а затем отправляет инструкции видеопроцессору в конце кадра, чтобы тот мог приняться за работу в следующем кадре. Это даёт каждому из процессоров полные 33 миллисекунды для выполнения работы, но ценой этому оказывается добавление
латентности (задержки) длиной в кадр. Это может быть проблемой для очень чувствительных ко времени игр, допустим, для шутеров от первого лица — серия Call of Duty, например, работает с частотой 60fps для снижения задержки между вводом игрока и рендерингом — но обычно лишний кадр игрок не замечает.
Каждые 33 мс конечный целевой рендер копируется и отображается на экране во
VSync — интервал, в течение которого ищет новый кадр для отображения. Но если видеопроцессору требуется для рендеринга кадра больше, чем 33 мс, то он пропускает это окно возможностей и монитору не достаётся нового кадра для отображения. Это приводит к мерцанию или паузам на экране и снижению частоты кадров, которого нужно избегать. Тот же результат получается, если слишком много времени занимает работа ЦП — это приводит к эффекту пропуска, потому что видеопроцессор не получает команды достаточно быстро, чтобы выполнить свою работу в допустимое время. Если вкратце, то стабильная частота кадров зависит от хорошей производительности обоих процессоров: центрального процессора и видеопроцессора.
Здесь создание команд рендеринга у ЦП заняло слишком много времени для второго кадра, поэтому видеопроцессор начинает рендеринг позже и пропускает VSync.
Для отображения сетки ЦП создаёт
вызов отрисовки, который является простой последовательностью команд, сообщающей видеопроцессору, что и как отрисовывать. В процессе прохождения вызова отрисовки по конвейеру видеопроцессора он использует различные конфигурируемые настройки, указанные в вызове отрисовки (в основном задаваемые материалом и параметрами сетки) для определения того, как рендерится сетка. Эти настройки, называемые
состоянием видеопроцессора (GPU state), влияют на все аспекты рендеринга и состоят из всего, что нужно знать видеопроцессору для рендеринга объекта. Наиболее важно для нас то, что видеопроцессор содержит текущие буферы вершин/индексов, текущие программы вершинных/пиксельных шейдеров и все входные данные шейдеров (например,
MaterialTexture или
LightColor из приведённого выше примера кода шейдера).
Это означает, что для изменения элемента состояния видеопроцессора (например, для замены текстуры или переключения шейдеров), необходимо создать новый вызов отрисовки. Это важно, потому что эти вызовы отрисовки затратны для видеопроцессора. Необходимо время на задание нужных изменений состояния видеопроцессора, а затем на создание вызова отрисовки. Кроме той работы, которую движку игры нужно выполнять при каждом вызове отрисовки, существуют ещё затраты на дополнительную проверку ошибок и хранение промежуточных результатов. добавляемые графическим
драйвером. Это промежуточный слой кода. написанный производителем видеопроцессора (NVIDIA, AMD etc.), преобразующий вызов отрисовки в низкоуровневые аппаратные инструкции. Слишком большое количество вызовов отрисовки ложится тяжёлой ношей на ЦП и приводит к серьёзным проблемам с производительностью.
Из-за этой нагрузки обычно приходится устанавливать верхний предел допустимого количества вызовов отрисовки на кадр. Если во время тестирования геймплея этот предел превышается, то необходимо предпринять шаги по уменьшению количества объектов, снижению глубины отрисовки и т.д. В играх для консолей количество вызовов отрисовки обычно ограничивается интервалом 2000-3000 (например, для Far Cry Primal мы стремились, чтобы их было не больше 2500 на кадр). Это кажется большим числом, но в него также включены специальные техники рендеринга —
каскадные тени, например, запросто могут удвоить количество вызовов отрисовки в кадре.
Как упомянуто выше, состояние видеопроцессора можно изменить только созданием нового вызова отрисовки. Это значит, что даже если вы создали единую сетку в 3D-редакторе, но в одной половине сетки используется одна текстура для карты albedo, а в другой половине — другая текстура, то сетка будет рендериться как два отдельных вызова отрисовки. То же самое справедливо, когда сетка состоит из нескольких материалов: необходимо использовать разные шейдеры, то есть создавать несколько вызовов отрисовки.
На практике очень частым источником изменения состояния, то есть дополнительных вызовов отрисовки является переключение текстурных карт. Обычно для всей сетки используется одинаковый материал (а значит, и одинаковые шейдеры), но разные части сетки имеют разные наборы карт albedo/нормалей/roughness. В сцене с сотнями или даже тысячами объектов на использование нескольких вызовов отрисовки для каждого объекта тратится значительная часть времени центрального процессора, и это сильно влияет на частоту кадров в игре.
Чтобы избежать этого, часто применяют следующее решение — объединяют все текстурные карты, используемые сеткой, в одну большую текстуру, часто называемую
атласом. Затем UV-координаты сетки настраиваются таким образом, чтобы они искали нужные части атласа, при этом всю сетку (или даже несколько сеток) можно отрендерить за один вызов отрисовки. При создании атласа нужно быть аккуратным, чтобы при низких MIP-уровнях соседние текстуры не накладывались друг на друга, но эти проблемы менее серьёзны, чем преимущества такого подхода для обеспечения скорости.
Текстурный атлас из демо Infiltrator движка Unreal Engine
Многие движки поддерживают
клонирование (instancing), также известное как батчинг (batching) или кластеризация (clustering). Это способность использовать один вызов отрисовки для рендеринга нескольких объектов, которые практически одинаковы с точки зрения шейдеров и состояния, и различия в которых ограничены (обычно это их положение и поворот в мире). Обычно движок понимает, когда можно отрендерить несколько одинаковых объектов с помощью клонирования, поэтому по возможности всегда стоит стремиться использовать в сцене один объект несколько раз, а не несколько разных объектов, которые придётся рендерить в отдельных вызовах отрисовки.
Ещё одна популярная техника снижения числа вызовов отрисовки — ручное
объединение (merging) нескольких разных объектов с одинаковым материалом в одну сетку. Оно может быть эффективно, но следует избегать чрезмерного объединения, которое может ухудшить производительность, увеличив количество работы для видеопроцессора. Ещё до создания вызовов отрисовки система видимости движка может определить, находится ли вообще объект на экране. Если нет, то гораздо менее затратно просто пропустить его на этом начальном этапе и не тратить на него вызовы отрисовки и время видеопроцессора (эта техника также известна как
отсечение по видимости (visibility culling)). Этот способ обычно реализуется проверкой видимости ограничивающего объект объёма с точки обзора камеры и проверкой того, не блокируется ли он полностью (
occluded) в области видимости другими объектами.
Однако когда несколько сеток объединяется в один объект, их отдельные ограничивающие объёмы соединяются в один большой объём, который достаточно велик, чтобы вместить каждую из сеток. Это увеличивает вероятность того, что система видимости сможет увидеть часть объёма, а значит, посчитать видимым весь набор сеток. Это означает, что создастся вызов отрисовки, а потому вершинный шейдер должен быть выполнен для каждой вершины объекта, даже если на экране видно только несколько вершин. Это может привести к напрасной трате большой части времени видеопроцессора, потому что большинство вершин в результате никак не влияют на конечное изображение По этим причинам объединение сеток наиболее эффективно для групп небольших объектов, которые находятся близко друг к другу, потому что, скорее всего, они в любом случае будут видимы на одном экране.
В качестве наглядного примера возьмём кадр из XCOM 2, одной из моих любимых игр за последнюю пару лет. В каркасном виде показан вся сцена, передаваемая движком видеопроцессору, а чёрная область посередине — это геометрия, видимая из игровой камеры. Вся окружающая геометрия (серая) невидима и будет отсечена после выполнения вершинного шейдера, то есть впустую потратит время видеопроцессора. В частности, посмотрите на выделенную красным геометрию. Это несколько сеток кустов, соединённых и рендерящихся всего за несколько вызовов отрисовки. Система видимости определила, что по крайней мере некоторые из кустов видимы на экране, поэтому все они рендерятся и для них выполняется их вершинный шейдер, после чего распознаются те из них, которые можно отсечь (оказывается, что их большинство).
Поймите правильно, это я не обвиняю именно XCOM 2, просто во время написания статьи я много играл в неё! Во всех играх есть эта проблема, и всегда существует борьба за баланс между затратами времени видеопроцессора на более точные проверки видимости, затратами на отсечение невидимой геометрии и затратами на большее количество вызовов отрисовки.
Однако всё меняется, когда дело доходит до затрат на вызовы отрисовки. Как сказано выше, важная причина этих затрат — дополнительная нагрузка, создаваемая драйвером при преобразовании и проверке ошибок. Это было проблемой очень долго, но у большинства современных графических API (например, Direct3D 12 и Vulkan) структура изменена таким образом, чтобы избежать лишней работы. Хоть это и добавляет сложности движку рендеринга игры, однако приводит к менее затратным вызовам отрисовки, что позволяет нам рендерить гораздо больше объектов, чем было возможно раньше. Некоторые движки (наиболее заметный из них — последняя версия движка Assassin's Creed) даже пошли совершенно в другом направлении и используют возможности современных видеопроцессоров для управления рендерингом и эффективного избавления от вызовов отрисовки.
Большое количество вызовов отрисовки в основном снижает производительность центрального процессора. А почти все проблемы с производительностью, относящиеся к графике, связаны с видеопроцессором. Теперь мы узнаем, в чём заключаются «бутылочные горлышки», где они возникают и как с ними справиться.
Часть 2: обычные «бутылочные горлышки» видеопроцессора
Самый первый шаг в оптимизации — поиск существующего
«бутылочного горлышка» (bottleneck), чтобы можно было затем снизить его влияние или полностью от него избавиться. «Бутылочным горлышком» называется часть конвейера, замедляющая всю работу. В примере выше, где было слишком много затратных вызовов отрисовки, «бутылочным горлышком» был центральный процессор. Даже если бы мы выполнили оптимизации, ускоряющие работу видеопроцессора, это бы не повлияло на частоту кадров, потому что ЦП всё равно работал бы слишком медленно и не успевал создать кадр за требуемое время.
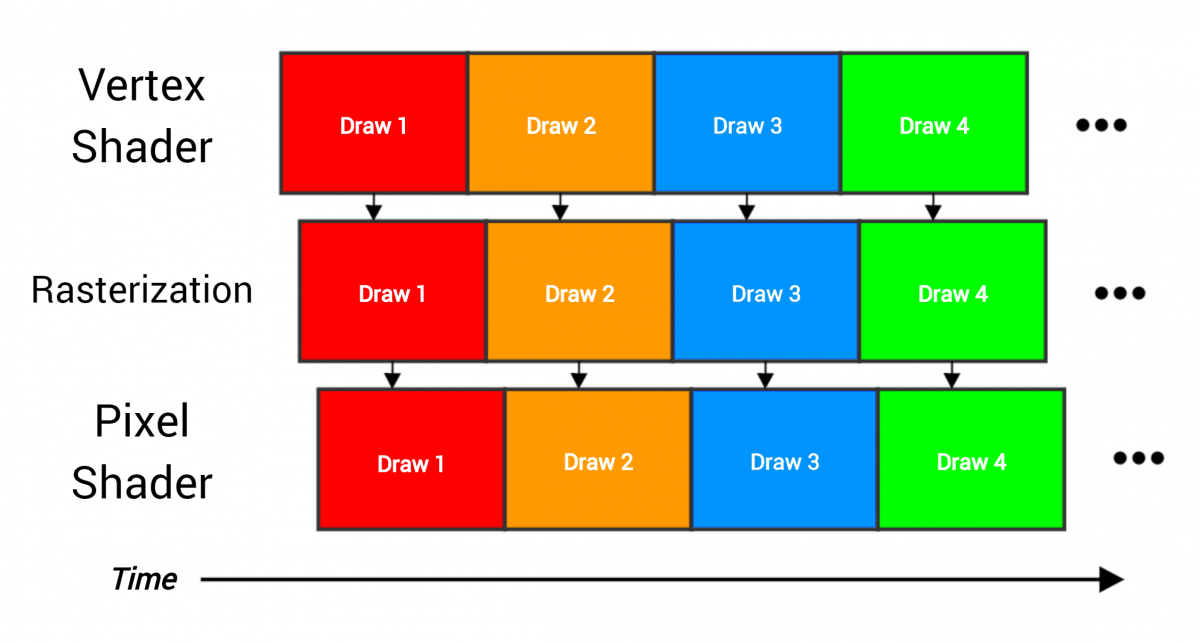
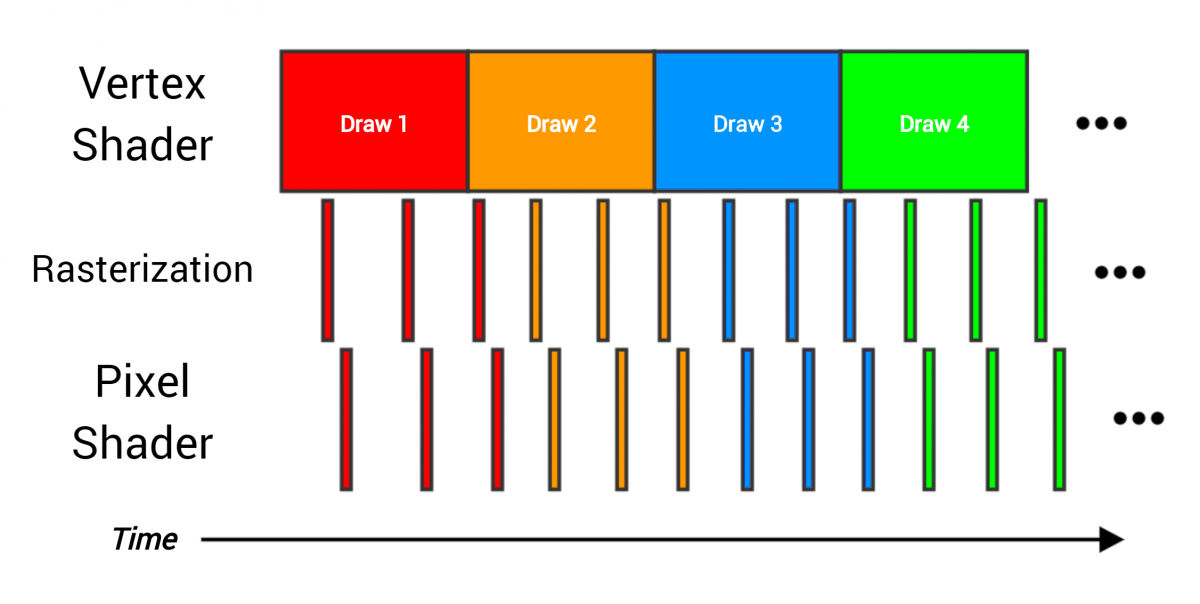
По конвейеру проходят четыре вызова отрисовки, каждый из который рендерит всю сетку, содержащую множество треугольников. Этапы накладываются, потому что как только заканчивается одна часть работы, её можно немедленно передать на следующий этап (например, когда три вершины обработаны вершинным шейдером, то треугольник можно передать для растеризации).
В качестве аналогии конвейера видеопроцессора можно привести сборочную линию. Как только каждый этап заканчивает со своими данными, он передаёт результаты на следующий этап и начинает выполнять следующую часть работы. В идеале каждый этап занят работой постоянно, а оборудование используется полностью и эффективно, как показано на рисунке выше — вершинный шейдер постоянно обрабатывает вершины, растеризатор постоянно растеризирует пиксели, и так далее. Но представьте, если один этап займёт гораздо больше времени, чем остальные:
Здесь затратный вершинный шейдер не может передать данные на следующие этапы достаточно быстро, а потому становится «бутылочным горлышком». Если у вас будет такой вызов отрисовки, ускорение работы пиксельного шейдера не сильно изменит полное время рендеринга всего вызова отрисовки. Единственный способ ускорить работу — снизить время, проводимое в вершинном шейдере. Способ решения зависит от того, что на этапе вершинного шейдера приводит к созданию «затора».
Не стоит забывать, что какое-нибудь «бутылочные горлышки» будет существовать почти всегда — если вы избавитесь от одного, его место просто займёт другое. Хитрость заключается в том, чтобы понимать, когда можно с ним справиться, а когда придётся просто с ним смириться, потому что это цена работы рендера. При оптимизации мы стремимся избавиться от необязательных «бутылочных горлышек». Но как определить, в чём же заключается «бутылочные горлышки»?
Профилирование
Чтобы определить, на что тратится всё время видеопроцессора, абсолютно необходимы инструменты профилирования. Лучшие из них даже могут указать на то, что нужно изменить, чтобы ускорить работу. Они делают это по-разному — некоторые просто явным образом показывают список «бутылочных горлышек», другие позволяют «экспериментировать» и наблюдать за последствиями (например, «как изменится время отрисовки, если сделать все текстуры мелкими», что помогает понять, ограничены ли вы полосой пропускания памяти или использованием кэша).
К сожалению, здесь всё становится сложнее, потому что одни из лучших инструментов профилирования доступны только для консолей, а потому подпадают под NDA. Если вы разрабатываете игру для Xbox или Playstation, обратитесь к программисту графики, чтобы он показал вам эти инструменты. Мы, программисты, любим, когда художники хотят влиять на производительность, и с радостью готовы отвечать на вопросы или даже писать инструкции по эффективному использованию инструментов.
Базовый встроеннный профилировщик видеопроцессора движка Unity
Для PC есть довольно неплохие (хотя и специфичные для оборудования) инструменты профилирования, которые можно получить от производителей видеопроцессоров, например
Nsight компании NVIDIA,
GPU PerfStudio компании AMD и
GPA Intel. Кроме того, существует
RenderDoc — лучший инструмент для отладки графики на PC, но в нём нет функций расширенного профилирования. Microsoft приступает к выпуску своего потрясающего инструмента для профилирования Xbox
PIX и под Windows, хоть только для приложений D3D12. Если предположить, что компания хочет создать такие же инструменты анализа «бутылочных горлышек», что и в версии для Xbox (а это сложно, учитывая огромное разнообразие оборудования), то это будет отличный ресурс для разработчиков на PC.
Эти инструменты могут дать вам всю информацию о скорости вашей графики. Также они дадут много подсказок о том, как составляется кадр в вашем движке и позволят выполнять отладку.
Важно осваивать работу с ними, потому что художники должны нести ответственность за скорость своей графики. Но не стоит ждать, что вы полностью разберётесь во всём самостоятельно — в любом хорошем движке должны быть собственные инструменты для анализа производительности, в идеале предоставляющие метрики и рекомендации, которые позволяют определить, укладываются ли ваши графические ресурсы в рамки производительности. Если вы хотите больше влиять на производительность, но чувствуете, что вам не хватает необходимых инструментов, поговорите с командой программистов. Есть вероятность, что такие инструменты уже есть — а если их нет, то их нужно написать!
Теперь, когда вы знаете, как работает видеопроцессор и что такое bottleneck, мы наконец можем заняться интересными вещами. Давайте углубимся в рассмотрение наиболее часто встречающихся в реальной жизни «бутылочных горлышек», которые могут возникнуть в конвейере, узнаем, как они появляются и что можно с ними сделать.
Инструкции шейдеров
Поскольку основная часть работы видеопроцессора выполняется шейдерами, они часто становятся источниками многих «бутылочных горлышек». Когда «бутылочным горлышком» называют инструкции шейдеров — это просто означает, что вершинный или пиксельный шейдер выполняет слишком много работы, и остальной части конвейера приходится ждать её завершения.
Часто слишком сложной оказывается программа вершинного или пиксельного шейдера, она содержит много инструкций и её выполнение занимает много времени. Или может быть, вершинный шейдер вполне приемлем, но в рендерящейся сетке слишком много вершин, и из-за них выполнение вершинного шейдера занимает слишком много времени. Или вызов отрисовки влияет на большую область экрана и много пикселей, что затрачивает много времени в пиксельном шейдере.
Неудивительно, что наилучший способ оптимизации «бутылочных горлышек» в инструкциях шейдеров — выполнение меньшего количества инструкций! Для пиксельных шейдеров это означает, что нужно выбрать более простой материал с меньшим количеством характеристик, чтобы снизить число инструкций, выполняемых на пиксель. Для вершинных шейдеров это означает, что нужно упросить сетку для уменьшения количества обрабатываемых вершин, а также использовать
LOD (Level Of Detail, уровни детализации — упрощённые версии сетки, используемые, когда объект находится далеко и занимает на экране мало места).
Однако иногда «заторы» в инструкциях шейдеров просто указывают на проблемы в другой области. Такие проблемы, как слишком большая перерисовка, плохая работы системы LOD и многие другие могут заставить видеопроцессор выполнять гораздо больше работы, чем необходимо. Эти проблемы могут возникать и со стороны движка, и со стороны контента. Тщательное профилирование, внимательное изучение и опыт помогут выяснить, что происходит.
Одна из самых частых таких проблем —
перерисовка (overdraw). Один и тот же пиксель на экране приходится затенять несколько раз, потому что его затрагивает множество вызовов отрисовки. Перерисовка является проблемой, потому что снижает общее время, которое видеопроцессор может потратить на рендеринг. Если каждый пиксель экрана нужно затенять дважды, то для сохранения той же частоты кадров видеопроцессор может потратить на каждый пиксель только половину времени.
 Кадр игры PIX с режимом визуализации перерисовки
Кадр игры PIX с режимом визуализации перерисовки
Иногда перерисовка неизбежна, например, при рендеринге просвечивающих объектов, таких как частицы или трава: объект на фоне видим сквозь объект на переднем плане, поэтому рендерить нужно оба. Но для непрозрачных объектов перерисовка абсолютно не требуется, потому что пиксель, содержащийся в буфере в конце процесса рендеринга, будет единственным, который нужно обрабатывать. В этом случае каждый перерисованный пиксель является лишней тратой времени видеопроцессора.
Видеопроцессор предпринимает шаги по снижению перерисовки непрозрачных объектов.
Начальный тест глубины (early depth test) (который выполняется перед пиксельным шейдером — см. схему конвейера в начале статьи) пропускает затенение пикселей, если определяет, что пиксель скрыт за другим объектом. Для этого он сравнивает затеняемый пиксель с
буфером глубины (depth buffer) — целевым рендером, в котором видеопроцессор хранит глубину всего кадра, чтобы объекты могли правильно перекрывать друг друга. Но чтобы начальный тест глубины был эффективным, другой объект должен попасть в буфер глубины, то есть быть полностью отрендеренным. Это значит, что очень важен порядок рендеринга объектов.
В идеале каждую сцену нужно рендерить спереди назад (т.е. ближайшие к камере объекты рендерятся первыми), чтобы затенялись только передние пиксели, а остальные отбрасывались на начальном тесте глубины, полностью избавляя от перерисовки. Но в реальном мире это не всегда получается, потому что в процессе рендеринга невозможно изменить порядок треугольников внутри вызова отрисовки. Сложные сетки могут несколько раз перекрывать себя, а объединение сеток может создавать множество накладывающихся друг на друга объектов, рендерящихся в «неправильном» порядке и приводящих к перерисовке. Простого ответа на эти вопросы не существует, и это ещё один из аспектов, который следует учитывать, когда принимается решение об объединении сеток.
Чтобы помочь начальному тесту глубины, некоторые игры выполняют частичный
предварительный проход глубины (depth prepass). Это подготовительный проход, при котором некоторые большие объекты, способные эффективно перекрывать другие объекты (большие здания, рельеф, главный герой и т.д.), рендерятся простым шейдером, который выполняет вывод только в буфер глубин, что относительно быстро, потому что при этом не выполняется работа пиксельного шейдера по освещению и текстурированию. Это «улучшает» буфер глубин и увеличивает объём работы пиксельных шейдеров, который можно пропустить на проходе полного рендеринга. Недостаток такого подхода в том, что двойной рендеринг перекрывающих объектов (сначала в проходе только для глубин, а потом в основном проходе) увеличивает количество вызовов отрисовки, плюс всегда существует вероятность того, что время на рендеринг прохода глубин окажется больше, чем время, сэкономленное на повышении эффективности начального теста глубин. Только подробное профилирование позволяет определить, стоит ли такой подход использования в конкретной сцене.
 Визуалиация перерисовки частиц взрыва в Prototype 2
Визуалиация перерисовки частиц взрыва в Prototype 2
Особенно важна перерисовка при
рендеринге частиц, учитывая то, что частицы прозрачны и часто сильно перекрывают друг друга. При создании эффектов работающие с частицами художники всегда должны помнить о перерисовке. Эффект густого облака можно создать с помощью испускания множества мелких перекрывающихся частиц, но это значительно повысит затраты на рендеринг эффекта. Лучше будет испустить меньшее количество крупных частиц, а для передачи эффекта густоты больше полагаться на текстуры и анимацию текстур. В этом случае результат часто более визуально эффективен, потому что такое ПО, как FumeFX и Houdini обычно может создавать гораздо более интересные эффекты через анимацию текстур, чем симулируемое в реальном времени поведение отдельных частиц.
Движок также может предпринимать шаги для избавления от ненужной работы видеопроцессора по расчёту частиц. Каждый отрендеренный пиксель, который в результате оказывается совершенно прозрачным — это пустая трата времени, поэтому обычно выполняют оптимизацию
обрезка частиц (particle trimming): вместо рендеринга частицы двумя треугольниками генерируется полигон, минимизирующий пустые области используемой текстуры.
 Инструмент «вырезания» частиц в Unreal Engine 4
Инструмент «вырезания» частиц в Unreal Engine 4
То же самое можно сделать и с другими частично прозрачными объектами, например, с растительностью. На самом деле, для растительности даже важнее использовать произвольную геометрию, позволяющую избавиться от больших объёмов пустого пространства текстур, потому что для растительности часто применяется
альфа-тестирование (alpha testing). В нём используется альфа-канал текстуры для определения необходимости отбрасывания пикселя на этапе пиксельного шейдера, что делает его прозрачным. В этом заключается проблема, потому что альфа-тестирование имеет побочный эффект, оно полностью отключает начальный текст глубин (потому что обесценивает допущения, которые видеопроцессор делает относительно пикселя), что приводит к гораздо большему объёму ненужной работы пиксельного шейдера. К тому же растительность часто содержит множество перерисовок (вспомните о всех перекрывающих друг друга листьях дерева) и если не быть внимательным, она быстро становится очень затратной при рендеринге.
Очень близким по воздействию к перерисовке является
излишнее затенение (overshading), причиной которого становятся мелкие или тонкие треугольники. Оно очень сильно может вредить производительности, напрасно тратя значительную часть времени видеопроцессора. Излишнее затенение — это последствие того, как видеопроцессор обрабатывает пиксели при затенении пикселей: не по одному за раз, а
«квадами» (quads). Это блоки из четырёх пикселей, выстроенные квадратом 2x2. Так делается затем, чтобы оборудование могло справляться с такими задачами, как сравнение UV между пикселями для вычисления подходящих уровней MIP-текстурирования.
Это значит, что если треугольник касается только одной точки квада (потому что треугольник мал или очень тонок), видеопроцессор всё равно обрабатывает весь квад и просто отбрасывает остальные три пикселя, впустую тратя 75% работы. Это растраченное время может накапливаться и особенно чувствительно для прямых (т.е. не отложенных) рендереров, выполняющих расчёт освещения и затенения за один проход в пиксельном шейдере. Такую нагрузку можно снизить использованием правильно настроенных LOD; кроме экономии на обработке вершинных шейдеров, они также значительно снижают количество излишнего затенения тем, что в среднем треугольники закрывают большую часть каждого из квадов.
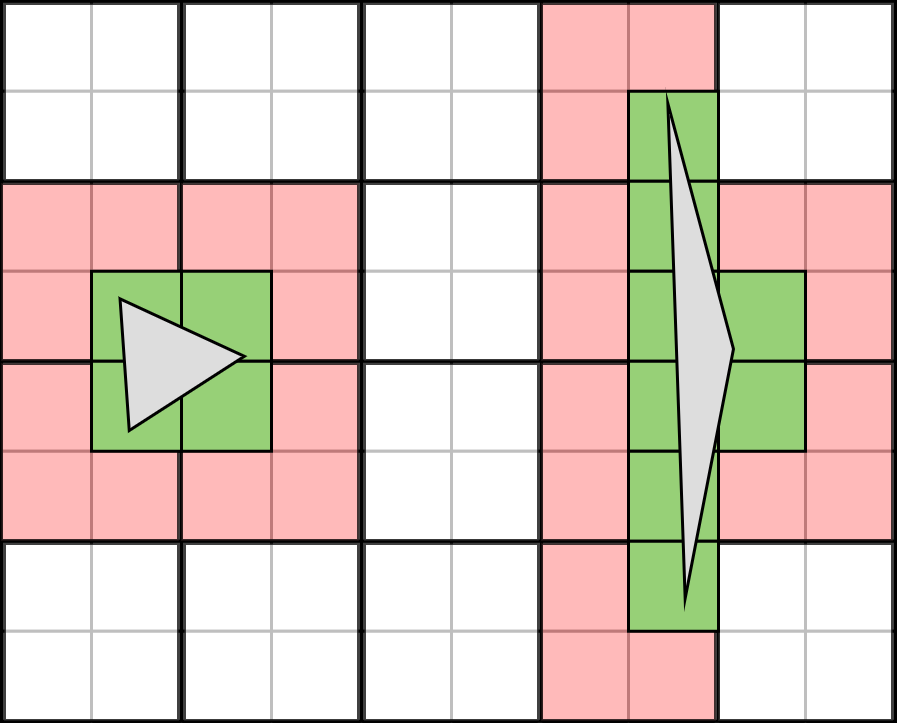 Пиксельный буфер 10x8 с квадами 5x4. Два треугольника плохо используют квады — левый слишком маленький, правый слишком тонкий. 10 красных квадов, которых касаются треугольники, должны быть полностью затенены, даже несмотря на то что на самом деле затенения требуют только 12 зелёных пикселей. В целом 70% работы видеопроцессора тратится впустую.
Пиксельный буфер 10x8 с квадами 5x4. Два треугольника плохо используют квады — левый слишком маленький, правый слишком тонкий. 10 красных квадов, которых касаются треугольники, должны быть полностью затенены, даже несмотря на то что на самом деле затенения требуют только 12 зелёных пикселей. В целом 70% работы видеопроцессора тратится впустую.
(Дополнительная информация: излишнее затенение квадов также становится часто причиной того, что на мониторе часто отображаются полноэкранные постэффекты, использующие для перекрытия экрана один большой треугольник вместо двух прилегающих друг к другу треугольников. При использовании двух треугольников квады, занимающие общее ребро треугольников, впустую тратят часть работы, поэтому их избегают, чтобы сэкономить небольшую долю времени видеопроцессора.)
Кроме излишнего затенения, мелкие треугольники создают и ещё одну проблему: видеопроцессор обрабатывает и растеризирует треугольники с определённой скоростью, которая обычно относительно мала по сравнению с тем количеством пикселей, которое он может обработать за то же время. Если мелких треугольников слишком много, он не может создавать пиксели достаточно быстро, чтобы у шейдеров всегда была работа, что приводит к задержкам и простоям, настоящим врагам производительности видеопроцессора.
Длинные тонкие треугольники плохо влияют на производительность не только из-за использования квадов: видеопроцессор растеризирует пиксели квадратными или прямоугольными блоками, а не длинными полосами. По сравнению с равносторонними треугольниками, длинные тонкие треугольники создают для видеопроцессора множество дополнительной необязательной работы по растеризации их в пиксели, что может привести к появлению «бутылочного горлышка» на этапе растеризации. Именно поэтому обычно рекомендуется тесселировать сетки в равносторонние треугольники, даже если это немного увеличивает количество полигонов. Как и во всех других случаях, наилучшего баланса позволяют добиться эксперименты и профилирование.
Полоса пропускания памяти и текстуры
Как показано выше на схеме конвейера видеопроцессора, полисетки и текстуры хранятся в памяти, физически отделённой от шейдерных процессоров. Это значит, что когда видеопроцессору нужно получить доступ к какой-то части данных, например, запрашиваемой пиксельным шейдером текстуре, перед вычислениями ему нужно получить её из памяти.
Доступ к памяти аналогичен скачиванию файлов из Интернета. На скачивание файла требуется какое-то время, зависящее от
полосы пропускания (bandwidth) Интернет-подключения — скорости, с которой могут передаваться данные. Эта полоса пропускания общая для всех загрузок — если вы можете скачать один файл со скоростью 6МБ/с, два файла будут скачиваться со скоростью 3МБ/с каждый.
Это справедливо и для доступа к памяти: на доступ видеопроцессора к буферам индексов/вершин и текстурам требуется время, при этом скорость ограничена полосой пропускания памяти. Очевидно, что скорости намного быстрее, чем при Интернет-подключении — теоретически полоса пропускания видеопроцессора PS4 равна 176ГБ/с — но принцип остаётся тем же. Шейдер, обращающийся к нескольким текстурам, сильно зависит от полосы пропускания, ведь ему нужно передать все нужные данные вовремя.
Программы шейдеров выполняются в видеопроцессоре с учётом этих ограничений. Шейдер, которому нужно получить доступ к текстуре, стремится начать передачу как можно раньше, а потом заняться другой, несвязанной с ней работой (например, вычислением освещения), надеясь, что данные текстур уже будут получены из памяти к тому времени, когда он приступит к части программы, в которой они необходимы. Если данные не получены вовремя из-за того, что передача замедлена множеством других передач или потому, что вся другая работа закончилась (это особенно вероятно запросах взаимозависимых текстур), то выполнение останавливается, а шейдер простаивает и ожидает данные. Это называется
«бутылочным горлышком» полосы пропускания памяти: неважно, насколько быстро работает шейдер, если ему приходится останавливаться и ждать получения данных из памяти. Единственный способ оптимизации — снижение занимаемой полосы пропускания памяти или количества передаваемых данных, или то и другое одновременно.
Полосу пропускания памяти даже приходится делить с центральным процессором или асинхронной вычислительной работой, которую выполняет видеопроцессор в то же самое время. Это очень ценный ресурс. БОльшую часть полосы пропускания памяти обычно занимает передача текстур, потому что в них содержится очень много данных. Поэтому существуют разные механизмы для снижения объёма данных текстур, которые нужно передавать.
Первый и самый важный — это
кэш (cache). Это небольшая область высокоскоростной памяти, к которому видеопроцессор имеет очень быстрый доступ. В нём хранятся недавно полученные фрагменты памяти на случай, если они снова понадобятся видеопроцессору. Если продолжить аналогию с Интернет-подключением, то кэш — это жёсткий диск компьютера, на котором хранятся скачанные файлы для более быстрого доступа к ним в будущем.
При доступе к части памяти, например, к отдельному текселу в текстуре, окружающие текселы тоже загружаются в кэш в той же передаче данных памяти. Когда в следующий раз видеопрцоессор будет искать один из этих текселов, ему не придётся совершать весь путь к памяти и он может очень быстро получить тексел из кэша. На самом деле такая техника используется очень часто — когда тексел отображается на экране в одном пикселе, очень вероятно, что пиксель рядом с ним должен будет отобразить тот же тексел или соседний тексел текстуры. Когда такое случается, ничего не приходится передавать из памяти, полоса пропускания не используется, а видеопроцессор почти мгновенно может получить доступ к кэшированным данным. Поэтому кэши жизненно необходимы для избавления от связанных с памятью «узких мест». Особенно когда в расчёт принимается
фильтрация (filtering) — билинейная, трилинейная и анизотропная фильтрация при каждом поиске требуют нескольких пикселей, дополнительно нагружая полосу пропускания. Особенно сильно использует полосу пропускания высококачественная анизотропная фильтрация.
Теперь представьте, что произойдёт в кэше, если вы пытаетесь отобразить большую текстуру (например, 2048x2048) на объекте, который находится очень далеко и занимает на экране всего несколько пикселей. Каждый пиксель придётся получать из совершенно отдельной части текстуры, и кэш в этом случае будет полностью неэффективен, потому что он хранит только текселы, близкие к полученным при предыдущих доступах. Каждая операция доступа к текстуре пытается найти свой результат в кэше, но ей это не удаётся (так называемый «промах кэша» (cache miss)), поэтому данные необходимо получать из памяти, то есть тратиться дважды: занимать полосу пропускания и тратить время на передачу данных. Может возникнуть задержка, замедляющая весь шейдер. Это также может привести к тому, что другие (потенциально полезные) данные будут удалены из кэша, чтобы освободить место для соседних текселов, которые никогда не пригодятся, что снижает общую эффективность кэша. Это во всех отношениях плохие новости, не говоря уже о проблемах с качеством графики — небольшие движения камеры приводят к сэмплированию совершенно других текселов, в результате чего возникают искажения и мерцание.
И здесь на помощь приходит
MIP-текстурирование (mipmapping). При запросе за получение текстуры видеопроцессор может проанализировать координаты текстуры, испльзуемой в каждом пикселе, и определить, есть ли большой разрыв между координатами операций доступа к текстуре. Вместо «промахов кэша» для каждого тексела он получает доступ к меньшей MIP-текстуре, соответствующей нужному разрешению. Это значительно увеличивает эффективность кэша, снижает уровень использования полосы пропускания и вероятность возникновения связанного с полосой пропускания «узкого места». Меньшие MIP-текстуры и требуют передачи из памяти меньшего количества данных, ещё больше снижая нагрузку на полосу пропускания. И наконец, поскольку MIP-текстуры заранее проходят фильтрацию, их использование значительно снижает искажения и мерцания. Поэтому MIP-текстурирование стоит использовать почти всегда — его преимущества определённо стоят увеличения объёма занимаемой памяти.
 Текстура на двух квадах, один из который близко к камере, а другой гораздо дальше
Текстура на двух квадах, один из который близко к камере, а другой гораздо дальше
 Та же текстура с соответствующей цепочкой MIP-текстур, каждая из которых в два раза меньше предыдущей
Та же текстура с соответствующей цепочкой MIP-текстур, каждая из которых в два раза меньше предыдущей
И последнее — важный способ снижения уровня использования полосы пропускания и кэша — это
сжатие (compression) текстур (к тому же оно, очевидно, экономит место в памяти благодаря хранению меньшего количества данных текстур). С помощью BC (Block Compression, ранее известного как DXT-сжатие) текстуры можно ужать до четверти или даже одной шестой от исходного размера ценой всего лишь незначительного снижения качества. Это значительное уменьшение передаваемых и обрабатываемых данных, и большинство видеопроцессоров даже в кэше хранит сжатые текстуры, что оставляет больше места для хранения данных других текстур и повышает общую эффективность кэша.
Вся изложенная выше информация должна привесли к каким-то очевидным шагам по снижению или устранению «заторов» полосы пропускания при оптимизации текстур с точки зрения художников. Следует убедиться, что текстуры имеют MIP и что они сжаты. Не нужно использовать «тяжёлую» анизотропную фильтрацию 8x или 16x, если достаточно 2x, или даже трилинейной/билинейной фильтрации. Снижайте разрешение текстур, особенно если на экране часто отображаются MIP-текстуры максимальной детализации. Не используйте без необходимости функции материалов, требующие доступа к текстурам. И проверяйте, что все получаемые данные на самом деле используются — не сэмплируйте четыре текстуры RGBA, если в реальности вам необходимы данные только красного канала, объедините эти четыре канала в одну текстуру, избавившись от 75% нагрузки на полосу пропускания.
Текстуры являются основными, но не единственными «пользователями» полосы пропускания памяти. Данные сеток (буферы индексов и вершин) тоже нужно загружать из памяти. На первой схеме конвейера видеопроцессора можно заметить, что вывод конечного целевого рендера записывается в память. Все эти передачи обычно занимают одну общую полосу пропускания памяти.
При стандартном рендеринге все эти затраты обычно незаметны, потому что по сравнению с данными текстур этот объём данных относительно мал, но так бывает не всегда. В отличие от обычных вызовов отрисовки поведение
проходов теней (shadow passes) довольно сильно отличается, и они с гораздо большей вероятностью могут ограничивать полосу пропускания.
 Кадр из GTA V с картами теней, иллюстрация взята из отличного анализа кадра Адриана Корреже (оригинал статьи)
Кадр из GTA V с картами теней, иллюстрация взята из отличного анализа кадра Адриана Корреже (оригинал статьи)
Так происходит потому, что карта теней — это просто буфер глубин, представляющий расстояние от источника освещения до ближайшей полисетки, поэтому бОльшая часть необходимой работы по рендерингу теней заключается в передаче данных из памяти и в память: получение буферов вершин/индексов, выполнение простых вычислений для определения положения, а затем запись глубины сетки в карту теней. БОльшую часть времени пиксельный шейдер даже не выполняется, потому что вся необходимая информация о глубине поступает из данных вершин. Поэтому проходы теней особенно чувствительны к количеству вершин/треугольников и разрешению карт теней, ведь они напрямую влияют на необходимый объём полосы пропускания.
Последнее, о чём стоит упомянуть в отношении полосы пропускания памяти — это особый случай — Xbox. И у Xbox 360, и у Xbox One есть особая часть памяти, расположенная близко к видеопроцессору, называющаяся на 360
EDRAM, а на XB1
ESRAM. Это относительно небольшой объём памяти (10 МБ на 360 и 32 МБ на XB1), но он достаточно велик, чтобы хранить несколько целевых рендеров, и может быть некоторые часто используемые текстуры. При этом его полоса пропускания гораздо выше, чем у стандартной системной памяти (DRAM). Важна не только скорость, но и то, что эта полоса пропускания имеет свой канал, то есть не связана с передачами DRAM. Это добавляет сложности движку, но при эффективном использовании даёт дополнительный простор в ситуациях с ограничениями полосы пропускания. Художники обычно не имеют контроля над тем, что записывается в EDRAM/ESRAM, но стоит знать о них, когда дело доходит до профилирования. Подробнее об особенностях реализации в вашем движке вы можете узнать у 3D-программистов.
И многое другое...
Как вы уже наверно поняли, видеопроцессоры — это сложное оборудование. При продуманном способе передачи данных они способны обрабатывать огромные объёмы данных и выполнять миллиарды вычислений в секунду. С другой стороны, при некачественных данных и неэффективном использовании они будут едва ползать, что катастрофически скажется на частоте кадров игры.
Можно ещё многое обсудить и объяснить по этой теме, но для технически мыслящего художника такое объяснение станет хорошим началом. Понимая, как работает видеопроцессор, вы сможете создавать графику, которая не только хорошо выглядит, но и обеспечивает высокую скорость… а высокая скорость может ещё больше улучшить вашу графику и сделать игру красивее.
Из статьи можно многое почерпнуть, но не забывайте, что 3D-программисты вашей команды всегда готовы встретиться с вами и обсудить всё то, что требует глубокого объяснения.
Другие технические статьи
Примечание: эта статья изначально опубликована
на fragmentbuffer.com её автором Кейтом О'Конором (Keith O'Conor). Другие заметки Кейта можно прочитать в его
твиттере (@keithoconor).

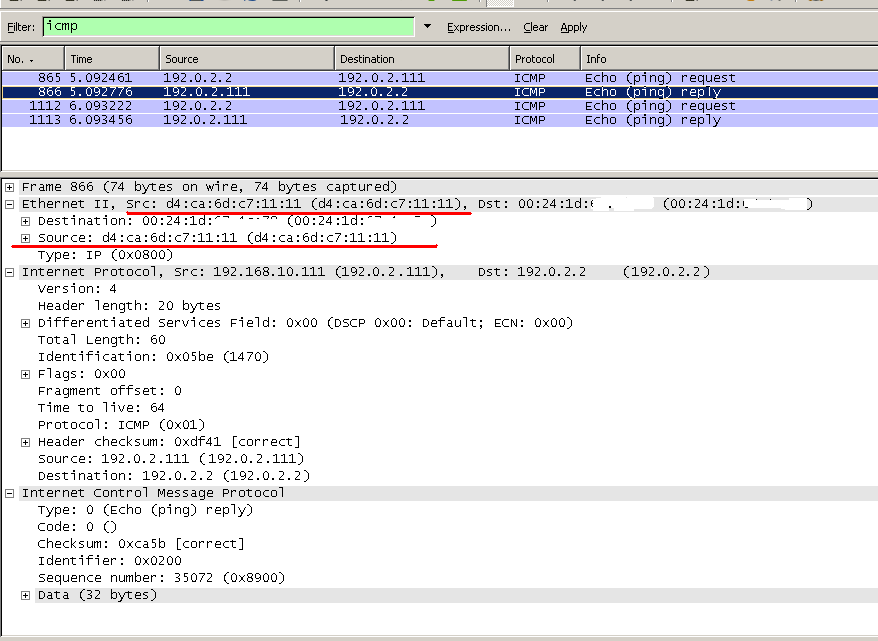
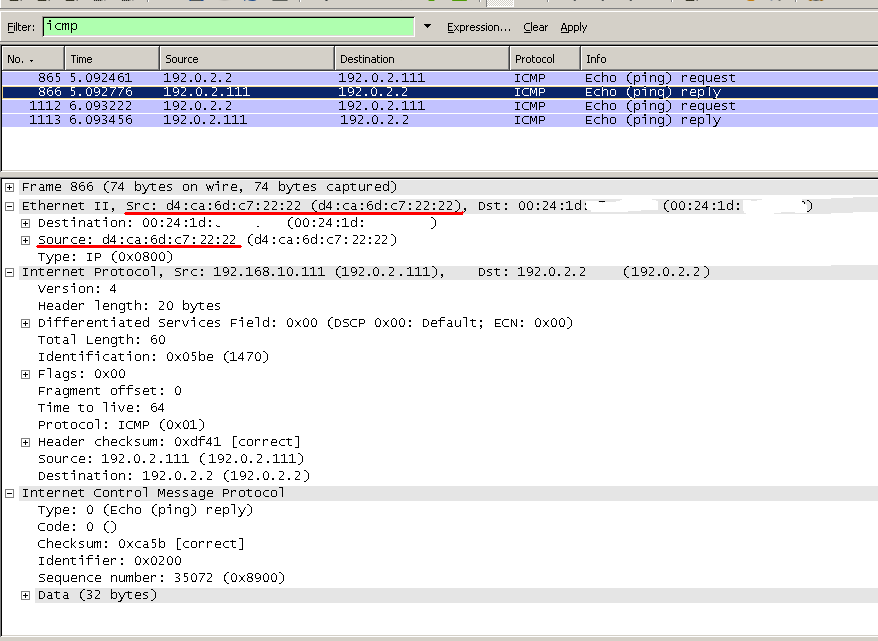
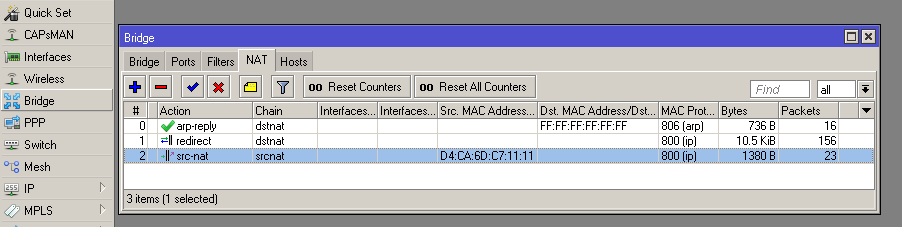



 Каким бы действенным ни был метод защиты «отрезать кабель в интернет», пользуются им чрезвычайно редко – даже те, кому стоило бы. Но исследователи не унимаются в попытках придумать самый курьезный способ преодоления «воздушного разрыва». То звуком, то светом, то теплом
Каким бы действенным ни был метод защиты «отрезать кабель в интернет», пользуются им чрезвычайно редко – даже те, кому стоило бы. Но исследователи не унимаются в попытках придумать самый курьезный способ преодоления «воздушного разрыва». То звуком, то светом, то теплом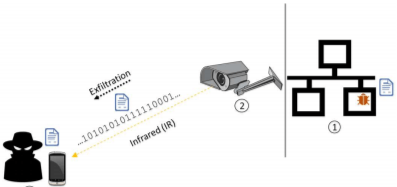
 Идея выглядит вполне себе логичной – если кто и может определить, по каким принципам люди придумывают себе пароли, то только нейросети. Генеративно-состязательные сети в последнее время часто используют для забав вроде улучшения порченых фото или автоматического построения реалистично выглядящих картинок зверушек (реалистично выглядят они только для самих экспертов по deep learning, а на самом деле пипец какие страшные, см. пруф).
Идея выглядит вполне себе логичной – если кто и может определить, по каким принципам люди придумывают себе пароли, то только нейросети. Генеративно-состязательные сети в последнее время часто используют для забав вроде улучшения порченых фото или автоматического построения реалистично выглядящих картинок зверушек (реалистично выглядят они только для самих экспертов по deep learning, а на самом деле пипец какие страшные, см. пруф).





















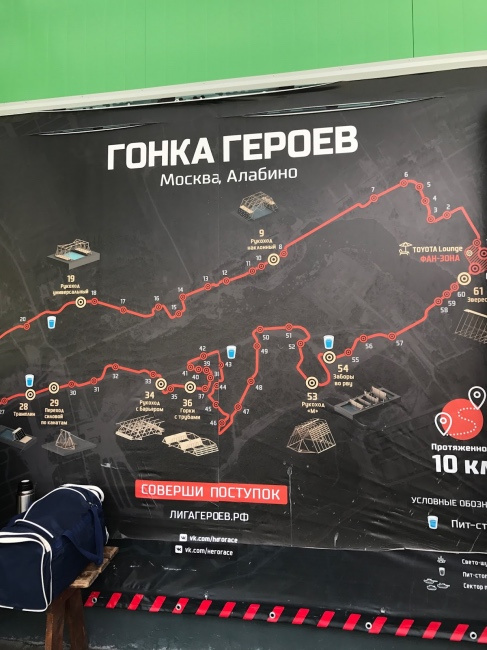
















 Еще одна возможность искупаться в прохладной водичке.
Еще одна возможность искупаться в прохладной водичке.


 Это наше самое любимое препятствие.
Это наше самое любимое препятствие.
 Высота взята.
Высота взята.



 Алексей познакомился с двумя девушками и галантно ведет обеих под руку во время легкой прогулки по парку.
Алексей познакомился с двумя девушками и галантно ведет обеих под руку во время легкой прогулки по парку.














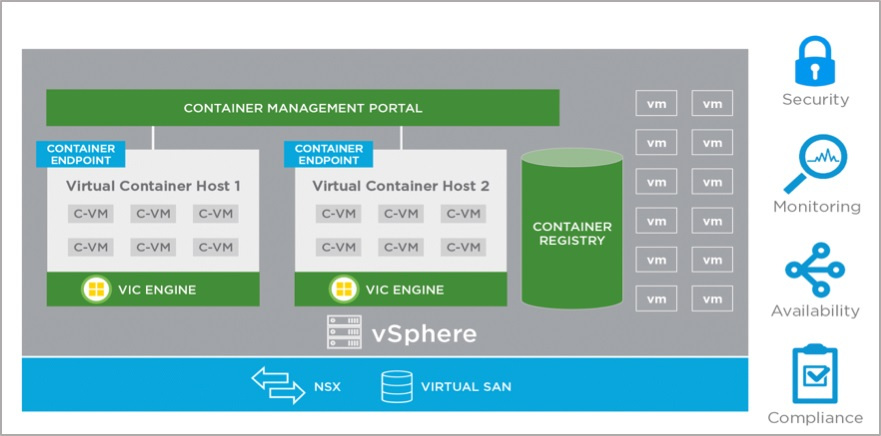


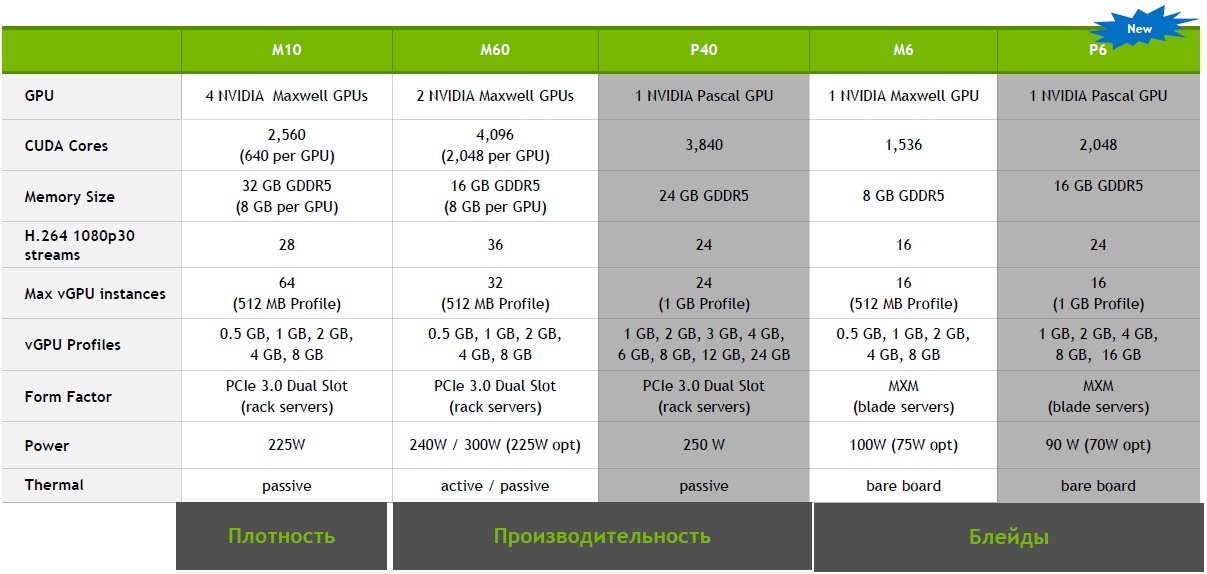










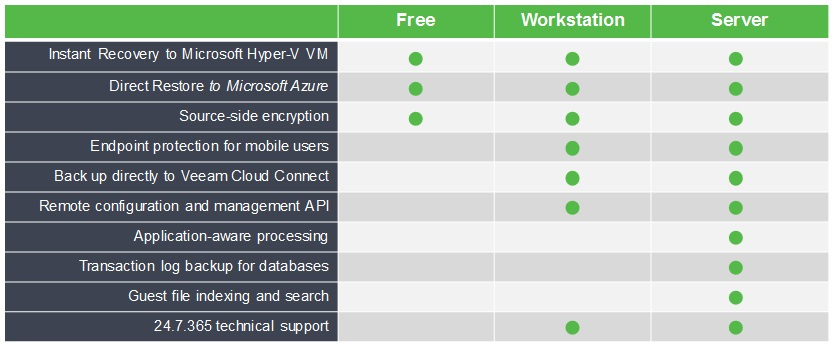


















 / Flickr / Robert Gourley / CC
/ Flickr / Robert Gourley / CC