Alexander Surkov: Peculiarities of standardization |
This technique is well known and was standardized by Techniques for UAAG published at 2002:
In some authoring scenarios, empty content (e.g., alt="" in HTML) may make an appropriate text equivalent, such as when non-text content has no other function than pure decoration, or when an image is part of a "mosaic" of several images and does not make sense out of the mosaic.Neither browser nor assistive technology is supposed to repair the text equivalent for empty alt image or in other words it should be no image from the user perspective. This technique was supported by Firefox and by number of screen readers over the years. On implementation level the trick is accessible name of the image element is an empty string what is interpreted by screen reader the image should be ignored.http://asurkov.blogspot.com/2014/06/peculiarities-of-standartization.html
|
|
Mike Conley: Australis Performance Post-mortem Part 5: The Customize Mode Transition |
Another new thing that came out with Firefox 29 is a sexy new customization interface. We wanted to make UI customization something that anybody would feel comfortable doing, instead of something only a few mighty power users might do.
The new customization mode is accessible by pressing the Menu Button (
|
|
Daniel Stenberg: curl the next few years |
Roadmap of things Daniel Stenberg and Steve Holme want to work on next. It is intended to serve as a guideline for others for information, feedback and possible participation.
If you agree, disagree or would like to add stuff you want to work on, please join us on the curl-library list! This “roadmap” is likely to change over time. We’ll keep the updated ROADMAP in git.
http2 test suite
http2 multiplexing/pipelining
SPDY
SRV records
HTTPS to proxy
make sure there’s an easy handle passed in to curl_formadd(), curl_formget() and curl_formfree() by adding replacement functions and deprecating the old ones to allow custom mallocs and more
HTTP Digest authentication via Windows SSPI
GSSAPI authentication in the email protocols
add support for third-party SASL libraries such as Cyrus SASL – may need to move existing native and SSPI based authentication into vsasl folder after reworking HTTP and SASL code
SASL authentication in LDAP
Simplify the SMTP email interface so that programmers don’t have to construct the body of an email that contains all the headers, alternative content, images and attachments – maintain raw interface so that programmers that want to do this can
Allow the email protocols to return the capabilities before authenticating. This will allow an application to decide on the best authentication mechanism
Allow Windows threading model to be replaced by Win32 pthreads port
Implement a dynamic buffer size to allow SFTP to use much larger buffers and possibly allow the size to be customizable by applications. Use less memory when handles are not in use?
Embed a language interpreter (lua?). For that middle ground where curl isn’t enough and a libcurl binding feels “too much”. Build-time conditional of course.
Simplify the SMTP command line so that the headers and multi-part content don’t have to be constructed before calling curl
build for windows (considered hard by many users)
curl -h output (considered overwhelming to users)
we have > 160 command line options, is there a way to redo things to simplify or improve the situation as we are likely to keep adding features/options in the future too
docs (considered “bad” by users but how do we make it better?)
authentication framework (consider merging HTTP and SASL authentication to give one API for protocols to call)
Perform some of the clean up from the TODO document, removing old definitions and such like that are currently earmarked to be removed years ago
cmake support (nobody maintains it)
makefile.vc files as there is no point in maintaining two sets of Windows makefiles. Note: These are currently being used by the Windows autobuilds
http://daniel.haxx.se/blog/2014/06/19/curl-the-next-few-years/
|
|
Daniel Stenberg: The curl and libcurl 2014 survey |
Reading through the answers to the curl project’s survey “curl and libcurl 2014'' is very interesting and educational.
After having lead and participated in this project for so long I have my own picture of what we’re good and bad at. That’s not exactly the same image I get when I read the survey responses. That’s of course the educating part and I really want to learn from this poll and see where to put in some efforts and attempt to improve. At the same time I’ve been working for a while to put together a roadmap for the project, and the survey will help guide us with that work as well.
The full generated summary of the answers can be found on the site, but I thought I do the extra effort here and try to extrapolate data, compare and try to get to the real story that lurks in the shadows.
Over the almost 10 days the poll was open, we received 194 responses. I was hoping for more participation, but on the other hand I don’t think more people would’ve given a much different view. My only concern would be that I’m not sure exactly how well we reached out.
Almost all curl users use it for HTTP and HTTPS. Sure, we also use a lot of other protocols and in fact all supported protocols did up having at least two users according to the survey, but only a single digit percentage did not mark HTTP and HTTPS as protocols they use. The least used supported protocol gopher, is used among 1.5% of the users who responded.
FTPS and SFTP are basically equally much used and they are the 4th and 5th most used protocols. HTTP, HTTPS and FTP are clearly our most popular protocols.
Only one in five users use curl on a single platform. All others use it on two or more, and one if four use it on four or more with an unexpectedly high 11% saying they use it on 5 or more platforms! That’s a pretty strong message to me that our multi-platform strategy is important.
Our users have been with us for a long time. Half of the users have been using curl for five years or more! A fifth has been with us for 8 years or more! And yet there seems to be a healthy amount of newcomers finding us as 14% is within their first year.
The above numbers combined, I’m not surprised but only happy to see that 4 out of 5 users are also involved in other open source projects. curl is just one piece in a large ecosystem and I think it is good that we all participate in several projects so that we learn and cross-pollinate where possible!
Less than half of the respondents are subscribed to a curl mailing list, and curl-library is the most popular one. This also reflects in subscriber numbers on the actual mailing lists where curl-library with its 1400+ members has almost twice as many subscribers as curl-users. One way to view this is that we are old enough, established enough and working enough so that users don’t have to subscribe to our lists to keep up. The less optimistic way to see it could be that this is because we haven’t reached out good enough or that our mailing list culture/setup isn’t welcoming enough.
Perhaps most surprising to me: that several persons got upset and reacted strongly to the question about how good we treat “female and other minorities” in the project. To me there’s no doubt that female contributors are a minority in the curl community and I want to learn if we’re doing our best to be inclusive and open to all possible contributors. Or at least how good/bad people think we are doing.
29% of the respondents have contributed patches, meaning 56 individuals. I think that tells more about the ones who took part of the survey than it measures participation level among “regular users”.
A big revelation for me was the question where I asked people to identify the “worst parts” of the project. The image here below is the look of the summary.
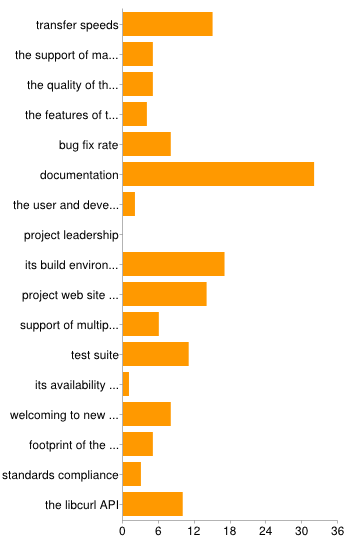
It quite clearly identifies “documentation” as the area in most need of improvements.
I don’t think the amount of docs is the problem. After discussing with people I think the primary issues are:

http://daniel.haxx.se/blog/2014/06/19/the-curl-and-libcurl-2014-survey/
|
|
John Zeller: Tupperware: Mozilla apps in Docker! |
Announcing Tupperware, a setup for Mozilla apps in Docker! Tupperware is portable, reusable, and containerized. But unlike typical tupperware, please do not put it in the Microwave.

Why?
This is a project born out of a need to lower the barriers to entry for new contributors to Release Engineering (RelEng) maintained apps and services. Historically, RelEng has had greater difficulty attracting community contributors than other parts of Mozilla, due in large part to how much knowledge is needed to get going in the first place. For a new contributor, it can be quite overwhelming to jump into any number of the code bases that RelEng maintains and often leads to quickly losing that new contributor out of exaspiration. Beyond new contributors, Tupperware is great for experienced contributors as well to assist in keeping an unpolluted development environment and testing patches.
What?
Currently Tupperware includes the following Mozilla apps:
- BuildAPI – a Pylons project used by RelEng to surface information collected from two databases updated through our buildbot masters as they run jobs.
- BuildBot – a job (read: builds and tests) scheduling system to queue/execute jobs when the required resources are available, and reporting the results.
Dependency apps currently included:
- RabbitMQ – a messaging queue used by RelEng apps and services
- MySQL – Forked from orchardup/mysql
How?
Vagrant is used as a quick and easy way to provision the docker apps and make the setup truly plug n' play. The current setup only has a single Vagrantfile which launches BuildAPI and BuildBot, with their dependency apps RabbitMQ and MySQL.
How to run:
- Install Vagrant 1.6.3
- hg clone https://hg.mozilla.org/build/tupperware/ && cd tupperware && vagrant up (takes >10 minutes the first time)
Where to see apps:
- BuildAPI: http://127.0.0.1:8888/
- BuildBot: http://127.0.0.1:8000/
- RabbitMQ Management: http://127.0.0.1:15672/
Troubleshooting tips are available in the Tupperware README.
What's Next?
Now that Tupperware is out there, it's open to contributors! The setup does not need to stay solely usable for RelEng apps and services. So please submit bugs to add new ones! There are a few ideas for adding functionality to Tupperware already:
Have ideas? Submit a bug!
http://johnzeller.com/blog/2014/06/18/tupperware-mozilla-apps-in-docker/
|
|
Joel Maher: Firefox 32 leaves the train station- what does the performance look like |
Now that we have an uplift completed and enough future data has been collected to ensure sustained changes in data automatically, it is time for the triple fortnightly report of what performance looks like. For reference there is some data in a blog post about general talos numbers.
Firefox 32 uplift, m-c -> Aurora (tracking bug 1004427):
Firefox 31 uplift, m-c -> Aurora (tracking bug 990085):
Firefox 30 uplift, m-c -> Aurora:
As you can see Firefox32 has a lot of improvements and fewer regressions (of those 20 about half are related to rebasing numbers).
Lets look at bugs:
After reviewing the process of investigating alerts, it makes sense that we continue forward with the same process in 6 week intervals and any changes are made on uplift day and they would apply only to trunk. Some future changes we are considering:
Onward to Firefox 33!

|
|
Just Browsing: The Chrome Extension Skeleton: Building Modular Extensions with Grunt and Browserify |
At Salsita we implement a lot of browser extensions. We create them for our clients, for our own purposes or just for fun. We therefore decided a couple of years about to write a Chrome extension skeleton that provides boilerplate for the common code that every extension tends to need. The resulting skeleton has been a big help in accelerating development of subsequent browser extensions.
 As time passed, the original skeleton implementation has been slowly obsoleted by changes and improvements in the Chrome Platform APIs. At the same time, we have been working on a lot of Node.js projects and have come to appreciate the use of CommonJS modules designed for reusability and testability. While modularity was a goal even for the initial skeleton implementation, tens of thousands of npm packages can make a big difference when it comes to developer productivity.
As time passed, the original skeleton implementation has been slowly obsoleted by changes and improvements in the Chrome Platform APIs. At the same time, we have been working on a lot of Node.js projects and have come to appreciate the use of CommonJS modules designed for reusability and testability. While modularity was a goal even for the initial skeleton implementation, tens of thousands of npm packages can make a big difference when it comes to developer productivity.
When we went to update the skeleton to the latest APIs, we also decided to explore possibilities for coding browser extensions using CommonJS modules. The question was: how do we turn the modules into JavaScript code that browsers can run as extensions? We had already been using a great utility, Browserify, in our web app development projects. It turns out that Browserify, which bundles CommonJS modules into browser-friendly scripts, works perfectly for Chrome extensions as well.
Browserify is available as a Grunt task, so it fit nicely into our existing build system. So how does it all work altogether? Each browser extension needs JavaScript files for several contexts (background script, content scripts, popup windows, etc.). We have corresponding scripts (or rather “entry points”) stored in the code/js directory. These scripts, referenced from manifest.json or from HTML pages in the extension, use the CommonJS require() function to load other modules. These modules can either be part of the skeleton itself (e.g. the messaging module that I will be writing about next time), modules specific to the extension or any third-party CommonJS module (e.g. installed using npm install). Browserify also allows you to work with non-CommonJS modules like jQuery by using a special shim.
When building the browser extension, the Grunt tasks first checks the JavaScript code for problems using JSHint and then executes the unit test specifications (written with the Mocha testing framework). If all the tests pass, we create subdirectory in the build directory, copy in the non-JavaScript resources and use the grunt-browserify task to process the JavaScript “entry points”, creating the target JavaScript bundles with all external dependencies included.
For development the above is sufficient, as you can load unpacked extension into the browser to try it. For debugging purposes we can even make use of source maps included in the JavaScript produced by Browserify. For the production version of the extension, we process the JavaScript further, minifying and uglifying it with additional Grunt tasks. When all resources are prepared, we use grunt-crx to create the final package for distribution.
There is one last bonus addition to our build process. All our projects are built on CircleCI, so as the last step of the build procedure we check if we are building on CircleCI (by checking for the presence of the CIRCLECI environment variable). We then archive the packaged browser extension as a build artifact. This way our QA team can go directly to CircleCI to get the latest extension builds.
You can see the complete code for the Chrome extension skeleton on Github. We continue to improve and extend it, and we always appreciate comments and contributions.
http://feedproxy.google.com/~r/justdiscourse/browsing/~3/ASlY5l0JvxU/
|
|
Julien Vehent: Server Side TLS guidelines v3 update: say goodbye to RC4! |
@mozsec Server Side TLS guidelines v3 update: say goodbye to RC4! https://t.co/TVndKKKLb3
— jvehent (@jvehent) June 18, 2014|
|
Jen Fong-Adwent: Minimalism and Focus |
|
|
Pete Moore: Weekly review 2014-06-18 |
Have been working on:
Bug 847640 – db-based mapper on web cluster
This is now closed! Mapper is live in production.
Sample urls:
Bug 962853 – vcs-sync needs to be able to publish git-hg mappings to mapper
Done! Closed.
Bug 962863 – cut over l10n repos to the new vcs-sync system
Making a lot of progress here: work is here:
https://github.com/petemoore/build-mozharness/compare/bug962853…bug962863
Bug 1013511 – (byebyebuildduty) [tracking] Eliminate buildduty
Bug 1013885 – inband1.r202-4.console.scl3.mozilla.net is DOWN :PING CRITICAL - Packet loss = 100%
Bug 1018118 – Pending queue for tegras x3e 1000 and time between jobs per tegra is x3e 6 hours
Bug 1018284 – scl1 Move Train B releng config Work
Bug 1018531 – Panda tests retrying more than necessary
Bug 1019434 – update_maintenance_wiki.sh is truncating text content
Bug 1019438 – end_to_end_reconfig.sh should store logs from manage_foopies.py
Bug 1019847 – Ship and deploy relengapi-0.2.0, relengapi-mapper-0.2.0
Bug 1020131 – Request for a new hg repository: build/mapper
Bug 1020294 – Dynamic Jacuzzi Allocator shouldn’t allow a job to have zero builders
Bug 1020343 – Jacuzzi emails should go to release team
Bug 1020554 – Mapper should yield content when returning full mapfiles
Bug 1020613 – vcs sync should only push tags/heads that have changed since last successful push
Bug 1022431 – scl1 Move Train C releng config Work
Bug 1023555 – Please create a new mysql database for production mapper
Bug 1023576 – Deploy new vcs_sync into production with changes from bug 962853
Bug 1023843 – Possible bug in end_to_end_reconfig.sh when using -p option?
Bug 1024448 – Stale slaverebooter lockfile
Bug 1025335 – scl1 Move Train D releng config Work
Bug 1025842 – mock ‘archives’ are fragile on spot instances
Bug 1026117 – relengwebadm -x3e generic cluster
Bug 1026386 – pdu1.r102-2.build.scl1.mozilla.com is DOWN :PING CRITICAL - Packet loss = 100%
Bug 1026459 – git credentials missing for RelEng API deploy to production
To do before next review:
Bug 869051 – Race condition between builders that push updates to in-tree files
Need to review this, will try to do this tomorrow morning!
Reminder: I’m on PTO from Friday, for a week.
|
|
Fr'ed'eric Wang: Mozilla MathML Add-ons |
Four years ago I started to write some MathML add-ons using Jetpack 0.8, now called Add-on SDK. I've recently made progress on this project, so that all the initial features are now available as Firefox add-ons (my initial hope was that the Add-on SDK would eventually be compatible with all Gecko browsers but unfortunately that still does not seem to be the case at the moment). The Mathzilla collection is available on AMO but some of the add-ons are still undergoing review. Here is an overview:
The math editor feature is now provided by the TeXZilla add-on. The Arabic math support I experimented a bit later is also available.
The conversion of content MathML using David Carlisle's XSLT stylesheet is now in its own MathML-ctop add-on. There is another similar add-on to add MathML3 features missing in Gecko called MathML-mml3ff. Note that these add-ons do not rely on the Add-on SDK and will work in any Gecko browsers. However, they should probably be improved.
Another add-on that does not rely on the Add-on SDK is the one adding mathematical fonts called MathML-fonts. I uploaded version 2.0 to use the new OpenType MATH fonts supported in Gecko 31, but I hope that it will no longer be necessary in the future (more on this later).
The conversion of PNG images into MathML is now provided by the Image to MathML add-on. At the moment, it is still experimental, see the details on mozilla.dev.tech.mathml if you want to help. It only works for some Web sites using LaTeX in alt text but I wish I can find a solution for Wolfram Websites.
Since many Web sites are using MathJax and because in the meantime MathJax moved to its slow HTML-CSS output by default I had to write an add-on to force MathJax to use native MathML, which is available here. Actually, it's even better since it disables the mml2jax preprocessor to avoid useless work by MathJax for Web sites that already use MathML in the source code. It also prevents the MathJax menu to override the browser user interface (note that the three add-ons below provide some UI features similar to what one can find in MathJax).
The feature to copy a MathML formula is now provided by the MathML Copy add-on. Note that it actually copies two flavors (text and html). It is also possible to copy the original TeX source when it is provided (e.g. on MDN).
A new MathML Zoom add-on provides a zooming feature similar to what MathJax does.
A new MathML Font Settings add-on allows to configure font-family and font-size of mathematics similar to what MathJax provides. Note however, that the list of font-family choices in the context menu is based on the OpenType MATH fonts that will only be supported in Gecko 31.
I believe splitting the original Mathzilla add-on into many add-ons gives more flexibility to let people choose the desired features. As usual, help to localize the add-ons is very welcome.
http://www.maths-informatique-jeux.com/blog/frederic/?post/2014/06/18/Mozilla-MathML-Add-ons
|
|
Doug Belshaw: Working openly on the web: a manifesto |
Three years ago, Jon Udell wrote Seven ways to think like the web. It’s a popular post amongst people who straddle the worlds of education and technology – but hasn’t got the reputation it deserves outside of those circles. That could be because, although a well-structured post, Jon includes some language that’s not used in everyday discourse. It’s perhaps also because he applies it to a specific project he was working on at the time.
I’d like to take Jon’s seven points, originally created with a group of people at a conference in 2010, condense them, and try and make them as simple to understand as possible.
Services change their privacy settings, close down, and are taken over by megacorps. Having a corner of the web you control means being able to better control your digital identity.
Also, nobody cares as much about your data as you do. The data you control is as timely and accurate as you have the time to make it.
Just as by using a microphone offline we can address a larger group of people than we would be able to with our unamplified voice, so we can address audiences of different scopes in our digital communications. An email reaches a much smaller number of people than a blog post.
Unless it contains sensitive information, publish your work to a public URL that can be referenced by others. This allows ideas to build upon one another in a ‘slow hunch’ fashion. Likewise, with documents and other digital artefacts, publish and then share rather than deal with version control issues by sending the document itself.
In addition, use standard protocols and formats when creating digital artefacts. This helps prevent vendor lock-in and supports the most open kinds of collaboration.
The web is made up of machines, but also humans using those machines. It’s a hybrid, a chimera. Publishing digital artefacts in forms both humans and machines understand allows for ‘network effects’. An example of this in a message sent to a social network being re-shared thousands of times.
Use unique, memorable, well-structured URLs and tags. This enables data and digital artefacts to be managed and curated efficiently. An example of this would be promoting an ‘official’ hashtag at a conference or event.
Progress comes through discovery, serendipity and joining ideas together. Adding metadata in the form of machine-readable data helps with others find and build on your work.
If you’ve read both Jon’s post and this one, have I missed anything significant? What would you add/remove?
Comments? Questions? I’m @dajbelshaw or you can email me at doug@mozillafoundation.org
|
|
Byron Jones: happy bmo push day! |
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.
http://globau.wordpress.com/2014/06/18/happy-bmo-push-day-99/
|
|
Axel Hecht: Create your own dashboard |
We have a lot of data around localizations, but it’s hard to know what people might be looking for.
I just switched a new feature live, edit your own dashboard.
You can select branches of products, as well as the localizations you’re interested in, and get data you want.
Say you’re looking for mobile and India. You’d want Firefox OS and Firefox for Android aka Fennec. The latter is actively localized on aurora, so you’d want the gaia tree and fennec_aurora. You want Assamese, Bengali, Gujarati…. and 9 other languages. Select gu and pa, too, ’cause why not.
Or are you keen on Destop in Latin America? Again we’re looking at Aurora, so fx_aurora is our tree of choice this time. Locales are Spanish in its American Variants, and Brazilian Portuguese.
Select generously, you can always reduce your selection through the controls on the right side of the resulting dashboard.
Play around, and compare the Status and History columns. Try to find stories, and share them in the comments below.
A bit more details on fx-aurora vs Firefox 32. Right now, Firefox 32 is on the Aurora channel and repository branch. Thus, selecting either gives you the same data today. In six weeks, though, 32 is going to be on beta, so if you bookmark a link, it’d give you different data then. That’s why you can only select one or the other.
https://blog.mozilla.org/axel/2014/06/17/create-your-own-dashboard/
|
|
Byron Jones: happy bmo push day! |
the following changes have been pushed to bugzilla.mozilla.org:
after a herculean effort by dkl, this week’s update brings native bzapi support to bugzilla’s production infrastructure. bzapi operates as a proxy server external to bugzilla, developed and operated by gerv. it is a reflection of gerv’s commitment and abilities that bzapi is by far the primary api which mozilians use to interface with bzapi. moving bzapi into bugzilla itself should improve performance and stability.
the plan with regards to migration is to continue to run the current bzapi proxy server until we’re happy with this code. at that point we’ll redirect bzapi calls made against the api-dev endpoint to the new endpoint.
please help us test this by changing your endpoints from https://api-dev.bugzilla.mozilla.org/latest/ to https://bugzilla.mozilla.org/bzapi/
eg.
old: https://api-dev.bugzilla.mozilla.org/latest/bug/880669
new: https://bugzilla.mozilla.org/bzapi/bug/880669
if you find any issues don’t hesitate to file bugs in the bzapi-compatibility component.
discuss these changes on mozilla.tools.bmo.
http://globau.wordpress.com/2014/06/17/happy-bmo-push-day-98/
|
|
Aaron Klotz: Asynchronous Plugin Initialization: An Introduction |
I have spent a lot of time this quarter working on bug 998863, “Asynchronous Initialization of Out-of-process Plugins.” While the bug summary is fairly self explanatory, I would like to provide some more details about why I am doing this and what kind of work it entails. I would also like to wrap up the post with an early demonstration of this feature and present some profiles to illustrate the potential performance improvement.
The reason that I am undertaking this project is because NPAPI plugin startup is our most frequent cause of jank. In fact, at the time of this writing, our Chrome Hangs telemetry is showing that 4 out of our top 10 most frequent offending call stacks are related to plugin initialization and instantiation. Furthermore, creating the plugin-container.exe child process is the #1 most frequent chrome hang offender (Note that our Chrome Hang telemetry consists entirely of Windows builds, where process creation is quite expensive).
The typical steps involved can be broken down as follows:
plugin-container process;NP_Initialize to load the plugin;NPP_New;NPP_NewStream for instances that load stream data;NPP_GetValue to obtain information
about the plugin’s scriptable object.The patch that I am working on modifies steps 1 through 4 to run asynchronously. Step 5 is a special case — we asynchronously return a proxy object, but if a synchronous JS method is called on that object, we must wait for the plugin to initialize (if it has not yet done so). My hope is that if we have to call a synchronous JS method on the proxy object, plugin initialization will be far enough along that the wait will be minimal.
The following video compares two locally-built Nightlies that are identical except for the asynchronous initialization patch. After loading the browser with a page containing several embedded Flash objects, we can profile and observe the effects of this patch.
Here are links to some profiles:
Synchronous Plugin Initialization
Asynchronous Plugin Initialization
This patch requires some further work on scripting and stabilization. The information in this post is subject to change. :–)
http://dblohm7.ca/blog/2014/06/17/asynchronous-plugin-initialization-an-introduction/
|
|
Wil Clouser: Marketplace Update for Q2 |
Every quarter the apps team gets together to meet people and talk about all the pieces of the projects. This quarter we’re doing a little different format which I think will turn out to be a lot more social and hopefully keep things interesting. As part of the project I put together this short video talking about Q2 for the Marketplace. Thanks to all the developers working on the Marketplace, Andy McKay for the payments videos, and Katt Taylor for helping piece it together.
You can download this video.
…and yeah, when I say “mammoth feat” I’m totally thinking of “mammoth feet.”
http://micropipes.com/blog/2014/06/16/marketplace-update-for-q2/
|
|
Ben Hearsum: June 17th Nightly/Aurora updates of Firefox, Fennec, and Thunderbird will be slightly delayed |
As part of the ongoing work to move our Betas and Release builds to our new update server, I’ll be landing a fairly invasive change to it today. Because it requires a new schema for its data updates will be slightly delayed while the data repopulates in the new format as the nightlies stream in. While that’s happening, updates will continue to point at the builds from today (June 16th).
Once bug 1026070 is fixed, we will be able to do these sort of upgrades without any delay to users.
|
|
Mozilla Open Policy & Advocacy Blog: Tell the U.S. Congress to Protect Net Neutrality |
Over the past several weeks, the principle of Net Neutrality has gained broad, mainstream attention. Already, more than a hundred thousand people have made their voice heard through comments to the Federal Communication Commission — that voice is even being heard on late night TV.
Now is the time for the Mozilla community to add its voice. Today we’re launching a petition for Americans to ask their Congressperson to support Mozilla’s call for real authority to protect Net Neutrality. We’ll deliver each signature directly to members of Congress, showing our unified voice to protect the world’s largest public resource.
As of now, the Internet preserves our right to access all lawful content and software without interference. In other words, the Web is a level playing field: you can read, watch, play, browse and share on the same terms as everybody else. Net Neutrality enables that level playing field, but it is under threat. If we stand by and do nothing, the Internet could become increasingly closed, centrally controlled and designed to serve the few instead of the many.
It’s up to U.S. Congress through its oversight authority to make sure the FCC adopts rules to keep the Internet accessible to everyone. Mozilla already submitted a request asking the FCC to modernize its understanding of Internet access services and enact its real authority to maintain Net Neutrality. The FCC has since presented Mozilla’s proposal for comment, which is an important step, but we need to make our voices heard to ensure Congress follows through.
To have the biggest impact, Members of Congress need to hear directly from their constituents in the U.S. Please sign the petition to help Mozilla protect Net Neutrality and ensure openness, innovation and opportunity on the Web. If you are Mozillian outside of the U.S., please share this with your friends in the U.S.
Let’s stand together to let Congress know that the Mozilla community is watching. It’s time to protect the free and open Web. It’s time for real Net Neutrality. Sign the petition today.
https://blog.mozilla.org/netpolicy/2014/06/16/tell-the-u-s-congress-to-protect-net-neutrality/
|
|
Just Browsing: Kitt and the Battle of the iPhone Extension Ecosystems |
We recently launched the private beta of Kitt, an iPhone browser developed by Salsita with support for Chrome browser extensions. You can find out more about Kitt in the screencast below:
Around the time we were finalizing this screencast, Apple announced that they would be adding support for extensions to iOS 8, including Safari extensions that can access and modify a webpage’s DOM. When a large company encroaches on a startup’s territory, it is accepted industry practice for the startup to announce that they are delighted to see their target market validated by an established player. This always strikes me as either delusional or disingenuous. As iPhone users we are looking forward to the new extensibility features in iOS 8. Few observers expected Apple to open up their platform in such a decisive way, and it is heartening (and frankly impressive) to see them do so. As developers of an iPhone browser, however, we could have done without the extra competition.
Nevertheless, Kitt has two big advantages compared to the upcoming Safari release. First of all, it has many more of the features that desktop extension developers expect:


The second advantage is that Kitt extensions are written using the same Platform APIs used by Google Chrome. This means that Kitt extensions also run in Chrome (although the converse is not always true since we only support a subset of the Chrome APIs). Interested developers can see the source code for the extensions demoed in the screencast on the Kitt Github page.
This means that developers can easily adapt Chrome extensions to run in Kitt. They can also leverage the skills and experience they gained developing Chrome extensions to create new Kitt extensions. As Google’s documentation explains, Chrome extensions are “essentially web pages” that are developed using standard web languages and technologies. Contrast this with Safari extensions, which are written mostly in Objective-C using the same APIs as mobile apps. To install an extension for Mobile Safari you need to install an app. This eliminates broad swaths of extensions that are cool additions to the web browser but not full-fledged apps in their own right. Kitt extensions, like their counterparts on Chrome, are loaded directly into the browser just by clicking a link on a webpage.
The primary difference between Safari and Kitt extensions is thus a philosophical one: whether to be part of the web app ecosystem or the iPhone app ecosystem. The latter makes a lot of sense for extensions that serve mainly to send content to an app from inside Safari. I use the Evernote app on my iPhone, so I’ll welcome the inevitable Safari extension that lets me quickly dispatch webpages to Evernote (and in fact this seems to be the primary use case Apple had in mind when designing the iOS extensibility features). As a developer, I’m happy to use Apple technologies to integrate my app more deeply into their platform.
On the other hand, if my extension is designed primarily to add features to the web browser then I’d rather be part of the web app ecosystem and use the Chrome Platform APIs. In most cases these extensions are multi-platform and multi-browser, so the differences between browser extension frameworks are just a nuisance. It’s already a problem that I have to develop and maintain my extension for Chrome, Firefox and Internet Explorer separately. The new Mobile Safari extensions just add one more platform to the mix. It is therefore a huge advantage for developers that they can use familiar web technologies to write Chrome extensions that also run in Kitt.
Most iPhone users will never install a third-party browser, and they will doubtless be more than satisfied with Safari’s extensibility features. The kind of power users who regularly use extensions on desktop will be attracted to the much richer extensibility of Kitt. We encourage both developers and end users interested in trying out Kitt to sign up for our private beta.
http://feedproxy.google.com/~r/justdiscourse/browsing/~3/q2kexTNoU1g/
|
|






