Armen Zambrano: Who doesn't like cheating on the Try server? |
 |
| Go crazy! |

|
|
Jess Klein: What's in my toolshed: the prototyping edition |









http://jessicaklein.blogspot.com/2014/06/whats-in-my-toolshed-prototyping-edition.html
|
|
William Lachance: Managing test manifests: ManifestDestiny -> manifestparser |
Just wanted to make a quick announcement that ManifestDestiny, the python package we use internally here at Mozilla for declaratively managing lists of tests in Mochitest and other places, has been renamed to manifestparser. We kept the versioning the same (0.6), so the only thing you should need to change in your python package dependencies is a quick substitution of “ManifestDestiny” with “manifestparser”. We will keep ManifestDestiny around indefinitely on pypi, but only to make sure old stuff doesn’t break. New versions of the software will only be released under the name “manifestparser”.
Quick history lesson: “Manifest destiny” refers to a philosophy of exceptionalism and expansionism that was widely held by American settlers in the 19th century. The concept is considered offensive by some, as it was used to justify displacing and dispossessing Native Americans. Wikipedia’s article on the subject has a good summary if you want to learn more.
Here at Mozilla Tools & Automation, we’re most interested in creating software that everyone can feel good about depending on, so we agreed to rename it. When I raised this with my peers, there were no objections. I know these things are often the source of much drama in the free software world, but there’s really none to see here.
Happy manifest parsing!
|
|
Doug Belshaw: Updated standalone graphic for the Web Literacy Map v1.1 |
Just a quick update to say that thanks to the work of Cassie McDaniel we now have an updated version of the Web Literacy Map. This harmonises with the colour scheme for the upcoming refresh of webmaker.org!
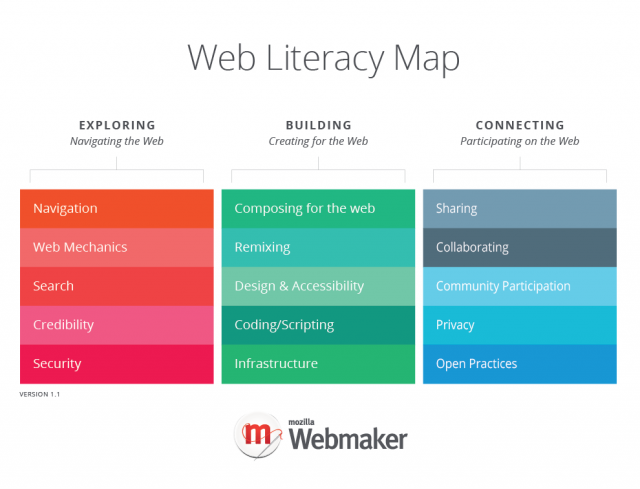
More about the Web Literacy Map at webmaker.org/literacy and on the Mozilla wiki.
Comments? Questions? I’m @dajbelshaw on Twitter, or you can email me at doug@mozillafoundation.org
|
|
Eric Shepherd: Sheppy at Open Help Conference 2014 |
I’ll be attending the Open Help Conference & Sprints event this weekend, arriving in Cincinnati on Friday afternoon and returning home on Tuesday morning after the first day of documentation sprinting. Mozilla is a proud sponsor of this event, which features a number of key influencers in the open source documentation arena. The mission: to exchange notes and ideas about how to improve the quality and quantity of good open source documentation, and to hold documentation sprints to get some writing projects done.
I’ll be giving a talk on Saturday morning (at 10 AM—the first presentation of the event) entitled “Help people so they can help you.” I’ll be covering the things the MDN team does to build, foster, and support its growing community of contributors. I’m looking forward to this, even though I’m nowhere near prepared yet. I enjoy sharing ideas about how to create and maintain excellent documentation. It’s my career’s mission, and as a Mozillian, I’m pleased to be able to share. Hopefully, too, I’ll get new ideas this weekend as well!
As an aside, if you have any thoughts on things I should be sure to mention, don’t hesitate to leave a comment or drop me an email!
If you’re going to be at Open Help, or are simply in the Cincinnati area, I hope to run into you!
http://www.bitstampede.com/2014/06/11/sheppy-at-open-help-conference-2014/
|
|
Rizky Ariestiyansyah: Valua Training & Consulting Logo |
|
|
Adam Lofting: When ‘less than the sum of our parts’ is a good thing |
 Here’s a happy update about our combined Mozilla Foundation (MoFo) and Mozilla Corporation (MoCo) contributor dashboards.
Here’s a happy update about our combined Mozilla Foundation (MoFo) and Mozilla Corporation (MoCo) contributor dashboards.
TL;DR: There’s a demo All Mozilla Contributor Dashboard you can see at areweamillionyet.org
It’s a demo, but it’s also real, and to explain why this is exciting might need a little context.
Since January, I’ve been working on MoFo specific metrics. Mostly because that’s my job, but also because this/these organisations/projects/communities take a little while to understand, and getting to know MoFo was enough to keep me busy.
We also wanted to ship something quickly so we know where we stand against our MoFo goals, even if the data isn’t perfect. That’s what we’ve built in our *interim* dashboard. It’s a non de-duped aggregation of the numbers we could get out of our current systems without building a full integration database. It gives us a sense of scale and shows us trends. While not precise and high resolution yet, this has still been helpful to us. Data can sometimes look obvious once you see it, but before this we were a little blind.
So naturally, we want to make this dashboard as accurate as possible, and the next step is integrating and de-duping the data so we can know if the people who run Webmaker events are the people who commit code, are the people who file bugs, are the people who write articles for Source, are the people who teach Software Carpentry Bootcamps, etc, etc.
The reason we didn’t start this project by building a MoFo integration database, is because MoCo were already working on that. And in less than typical Mozilla style (as I’m coming to understand it), we didn’t just build our own version of this. ![]() (though there might be some scope and value for integrating some of this data within the Foundation anyway, but that’s a separate thought).
(though there might be some scope and value for integrating some of this data within the Foundation anyway, but that’s a separate thought).
The integration database in question is MoCo’s project Baloo, which Pierros, and many people on the MoCo side have been working on. It’s a complex project influenced by more than than just technical requirements. Scoping the system is the point at which many teams are first looking at their contributor data in detail and working out what their indicators of contribution look like.
Our plan is that our MoFo interim dashboard data-source can eventually be swapped out for the de-duped ‘single source of truth’ system, at which point it goes from being a fuzzy-interim thing to a finalized precise thing.
While MoCo and ‘Fo have been taking two different approaches to solving this problem, we’ve not worked in isolation. We meet regularly, follow each other’s progress and have been trying to find the point where these approaches can merge into a unified cross Mozilla solution.
The demo we shipped yesterday was the first point where we’ve joined up this work.
I want to throw in an internet based analogy here, for those who remember dial-up modems.
Let’s imagine this image shows us *all* the awesome Mozilla contributors and what they are doing. We want there to be 20k of them in 2014.

It’s not that we don’t know if we have contributors. We’ve seen individual contributors, and we’ve seen groups of contributors, but we haven’t seen them all in one place yet.
So to continue the dial-up modem analogy, let’s think of this big-picture view of contribution as a large uncompressed JPEG, which has been loading slowly for a few months.
The MoFo interim dashboard has been getting us part of this picture. Our approach has revealed the MoFo half of this picture with slowly increasing resolution and accuracy. It’s like an interlaced JPEG, and is about this accurate so far:

The Project Baloo approach is precise and can show MoCo and MoFo data, but adds data source at a time. It’s rolling out like a progressive JPEG. The areweamillionyet.org dashboard demo isn’t using Baloo yet, but the data it’s using is a good representation of how Baloo can work. What you can see in the demo dashboard is a picture like this:

(Original Photo Credit: Gen Kanai)
This is commit data extracted from cross team/org/project repositories via github. Even though code contribution is only one part of the big-picture. Seeing this much of the image tells us things we didn’t know before. It gives us scale, trends and ways to ask questions about how to effectively and intentionally grow the community.
The ‘commit history’ over time is also a fascinating data set, and I’ll follow up with a blog post on that soon.
With the goal of 20k active contributors this year, shared between MoCo and MoFo, we’re thinking about 10k active contributors to MoCo and to MoFo. And if we counted each org in isolation we could both say “here’s 10k active contributors”, and this would be a significant achievement. But, if we de-dupe these two sets it would be really worrying if there wasn’t an overlap between the people who contribute to MoCo and the people who contribute to MoFo projects.
Though we want to engage many many individual contributors, I think a good measure of our combined community building effectiveness will be how much these ‘pots’ of contributors overlap. When 10k MoFo contributors + 10k MoCo contributors = 15k combined Mozilla contributors, we should definitely celebrate.
That’s the thing I’m most excited about with regards to joining up the data. Understanding how contributors connect across projects; how they volunteer their time, energy and skills is many different ways, and understanding what ‘Many Voices, One Mozilla’ looks like. When we understand this, we can improve it, for the benefit of the project, and the individuals who care about the mission and want to find ways into the project so they can make a difference.
While legal processes define ‘Corporations’ and ‘Foundations’, the people who volunteer and contribute rarely give a **** about which org ‘owns’ the project they’re contributing too; they just want to build a better internet. Mozilla is bigger than the legal entities. And the legal entities are not what Mozilla is about, they are just one of the necessities to making it work.
So the org dashboards, and team dashboards we’re building can help us day-to-day with tactical and strategic decisions, but we always need to keep them in the context of the bigger picture. Even if the big picture takes a while to download.
Here’s to more cross org collaboration.
http://feedproxy.google.com/~r/adamlofting/blog/~3/Te2B1iBA0qE/
|
|
Henrik Skupin: Last Automation Training day for this quarter |
Today we hold our last Automation Training day for this quarter. So if you want to learn something about test automation at Mozilla, feel free to join at any time during the day. We are around all day, waiting to answer your questions, and to get you started if you want to contribute to one of our projects.
Please have a look at our etherpad for the current status:
https://etherpad.mozilla.org/automation-training
I’m looking forward to see some of you!
http://www.hskupin.info/2014/06/11/last-automation-training-day-for-this-quarter/
|
|
Just Browsing: Change Text Color Based on Background Color (and Much More!) Using CSS Clip |
During the development of our company website, we came across an interesting UX dilemma. The website uses full-width horizontal blocks of content with varying background colors. This caused problems with the fixed-position side navigation, since black text becomes hard to read when displayed over a non-white background.

While there are various ways to deal with this, we didn’t want to change the design of the site. Instead we decided to create something that would change the text color of the side navigation depending on the background color and update when user scrolls the page or generally moves around doing user-y things.

At first we were tempted to abuse CSS gradient text backgrounds and simply change the gradient stops based on the scroll offset, but that proved to have too many limitations (primarily the lack of a single element to apply the gradient to) and wonky browser support (I’m looking at you, Android stock browser). And what if we wanted to change more than just the text color? Suddenly we imagined a lot of scenarios where such a feature might be useful, spawning another question: how do we make all this reusable for others to enjoy?
Searching further and contemplating our options, one of the most underused CSS attributes came to mind: clip: rect(). Using this attribute we could “clone” the menu to create multiple layers with different CSS styles (like color) and clip those layers to produce the desired effect. So we did that.
And we call it: jq-clipthru.
Below is a rough mock of how the stacking works. The orange element overlaps the two gray blocks, spawning two new clones of the orange element. Those are clipped to only appear over the overlapped area and their CSS styles are determined by class of the cloned layers (making them yellow and purple in this case). Note that the whole orange block is merely overlayed by the yellow and purple clones. It would be visible underneath them if they had no background-color.

Surprisingly, the limited rectangular-only CSS clip feature has a few nice properties that make it a strong candidate for exactly this task.
The world would probably spin off its axis if CSS clip had no drawbacks. Fortunately, it does.
position: absolute or position: fixed. While this is generally quite impractical, it is not such a dealbreaker in this case. You will almost always be using this effect on an out-of-flow positioned element, or you can adjust your code to work around this limitation.And thus would end the story of jq-clipthru, if not for background transparency. Consider the following: in some scenarios (like our website) you will want to keep the background of the clipped elements transparent. This means that any user action that can change the design of the topmost cloned layer (like hovering over a link that has some :hover effects applied) might reveal the original layer below itself (containing a link that has no :hover style applied), because the user action isn’t shared across all clones. There are two different approaches to solving this problem:
Since calculating where the elements overlap is straightforward from this point, most of our work revolved around making it fast, flexible and polishing edge cases. As it turns out, jq-clipthru can be used for far more complex designs than merely changing the font color, and we’re quite curious about what others might use it for (hey, you can mount it on draggable!).
There are various configuration options to make the widget more robust in the face of more complicated use cases (find them in the Github documentation). At the same time, jq-clipthru is certainly not in its final state and has places to go and markup to see. Contributions, bug reports, words of praise or criticism are all highly welcome! You can see what it did for us live on our website, or you can check out the repo on Github.
http://feedproxy.google.com/~r/justdiscourse/browsing/~3/s8lbw-zLAe8/
|
|
Chris Double: Dual Booting Android and Firefox OS on the Nexus 5 |
I’ve gone through periods of using a Firefox OS phone as my main device but I’ve usually fallen back to Android due to needing to use some Android only programs and I don’t like carrying two phones around. Today I decided to investigate how to get dual boot Android with custom Firefox OS builds. Thankfully it was actually pretty easy.
The boot manager I used to get this to work is MultiROM Manager, available from the Play store for rooted phones. The source is for MultiROM Manager is available on github. The phone I used was the Nexus 5. The instructions here assume you are familiar with adb and fastboot already.
Be aware that all these changes may lose the data you have on the device if you haven’t already unlocked the boot loader and rooted the device.
With the device plugged in and visible from adb:
$ adb backup -apk -shared -allThis can be restored later if needed with:
$ adb restore backup.abThe Nexus 5, and other Google devices, make it easy to unlock the bootloader. With the device plugged in and visible from adb:
$ adb reboot bootloader
$ fastboot oem unlockFollow the screen instructions. This will erase everything on the device!
I used CF-Auto-Root. I downloaded the version for the Nexus 5 and used fastboot to boot the image inside of it:
$ unzip CF-Auto-Root-hammerhead-hammerhead-nexus5.zip
$ fastboot boot image/CF-Auto-Root-hammerhead-hammerhead-nexus5.imgThe device will reboot and perform the steps necessary to root it.
Install MultiROM Manager from the Play store. Run the app and choose Install after ticking the MultiROM, Recovery and Kernel check boxes. Follow the onscreen instructions.
The Mozilla Developer Network has instructions for building Firefox OS. Assuming all the pre-requisites are installed the steps are:
$ git clone git://github.com/mozilla-b2g/B2G b2g
$ cd b2g
$ ./config.sh nexus-5
$ PRODUCTION=1 MOZILLA_OFFICIAL=1 ./build.shDon’t flash the device from here. We’ll create a MultiROM compatible ROM file to boot from.
Create a directory to hold the ROM contents and copy the results of the build into it:
$ mkdir rom
$ cd rom
$ rsync -rL ../out/target/product/hammerhead/system .
$ rsync -rL ../out/target/product/hammerhead/data .
$ cp ../out/target/product/hammerhead/boot.img .For the rsync copy I deliberately choose not to copy symbolic links and to instead re-copy the original file. I had difficulty getting symbolic links working and need to investigate.
An Android ROM requires a META-INF directory containing a script that performs the update process. The following commands create this directory, copy the binary to run the script and the script itself:
$ mkdir -p META-INF/com/google/android/
$ cp ../tools/update-tools/bin/gonk/update-binary META-INF/com/google/android/
$ curl http://bluishcoder.co.nz/b2g/updater-script >META-INF/com/google/android/updater-scriptThe updater script is one I wrote based on existing ones. It’s pretty easy to follow if you want to read and change it.
The final step is to ZIP the directories, sign them and push to a directory on the device:
$ zip -r9 b2g.zip *
$ java -jar ../prebuilts/sdk/tools/lib/signapk.jar \
../build/target/product/security/testkey.x509.pem \
../build/target/product/security/testkey.pk8 \
b2g.zip signed_b2g.zip
$ adb push signed_b2g.zip /sdcard/Boot into recovery mode by pressing volume down and the power on button at the same time (or run adb reboot recovery). From the recovery menu choose ‘Advanced’ followed by ‘MultiROM’, then Add ROM.
Make sure Android is selected and Don't Share is chosen for “Share Kernel with Internal ROM”. Click Next, choose Zip file and select the file we created in the signing step previously. Swipe to confirm as requested.
If this succeeds, Reboot and touch the screen during the ‘Auto boot’ display to get the list of ROMS to run. Choosing the one we just installed should boot Firefox OS.
With MultiROM you can install other ROMS and even Ubuntu Touch. I’d like to get Inferno OS running under MultiROM as well so I can boot between all the operating systems I like to tinker with on one device.
I’ve placed a complete Firefox OS ROM for use with MultiROM on the Nexus 5 in b2g_nexus5.zip. This was built from B2G master branch so may be broken in various aspects (The camera doesn’t work for example) but will allow you to try the multi boot process out if you can’t do builds. This is not an official Mozilla build and was generated by me personally. Use at your own risk.
http://bluishcoder.co.nz/2014/06/11/dual-booting-android-and-firefox-os.html
|
|
Zbigniew Braniecki: Localization framework changes in Firefox OS 2.0 and plans for 2.1 |
On Monday we branched Firefox OS 2.0 which is the first branch to contain a new localization library that has been developed by my team.
The library itself landed exactly two months ago. In order to avoid any potential regressions, we’ve put a lot of work to ensure that it matches the behavior of the old code that it replaced. I believe we can now claim a success, because with two months of baking on master we didn’t get any serious regressions that would require us to change anything in our code.
The new library comes with a lot of unit tests and is stricter than the old code, so we had to fix a couple of small bugs where code has been passing an object instead of a string to our API and one related to one test failing on old machine with too little memory. That’s been simple to catch and fix.
We also got a few requests to improve the console log output and error output that the library produces in order to simplify developers work.
The major new thing that Stas completed in this cycle is the support for pseudo-locales. While this could be done with the old code, it was significantly easier with the new code thanks to some architectural decisions like separation of buildtime and runtime code.
Pseudo-locales allow developers to evaluate their UI’s localizability against an artificially generated english-like locale to catch any hardcoded strings. It also generates right-to-left locale for testing purposes. Before that, we’ve been relying on often outdated localizations that we kept with our source code. Now we can always test against fully generated pseudo localization.
Another new feature is the introduction of mozL10n.once wrapper. We identified that a lot of Gaia apps are waiting for localization to be ready before they initialize themselves. That makes sense since a lot of those apps want to work with UI and localized strings, but the challenge in asynchronous world is that you never know if your code has been fired after or before mozL10n is ready.
Because of that, simply setting an event listener and waiting for window.onlocalized event is not enough (what if it already has fired before your code was launched?). Developers were using mozL10n.ready wrapper, but the problem with that is that is has been designed to re-fire on reach retranslation which meant that your init code has been fired every time user changed language. That’s not an intended behavior, but admittedly a rare one. What’s worse is that we retained all the init code in memory.
Now, with mozL10n.once we can safely initialize code when l10n resources are available and free the memory right after that.
On top of adding new features, we’ve been mostly busy investigating and improving how the default Firefox OS apps interact with localization API. That led to multiple design decisions including introduction of the described above mozL10n.once.
Once we got the new wrapper, we started analyzing bootstrapping code of each and every Gaia app and updating it to use the proper L10n API. Twenty two fixed bugs later, we’re done!
It’s incredible how much we were able to accomplish in just two short months. We feel much better right now about the bootstrap process and we have a clear picture on what we want to do next.
Thank’s to Mounir’s work on navigator.languages API and implementation we were able to remove the only Mozilla specific API in mozL10n. That means that mozL10n should work in any modern browser now!
2.1 will be as ambitious for us as 2.0 was. The hashtag of the work is still #cleanup, but now it’s much more about modifying our API so that it’s more transparent to developers and requires less manual code in their apps.
First thing we were able to land is the transition away from assigning l10n entity attributes as node properties. We cleaned up the hacks that have been used and switched to entity attributes as node attributes.
Next, we have one leftover from the previous change and that is an infamous innerHTML. We currently don’t have any clear way to inject localizable DOMFragment in Gaia. Fortunately, we have one that fits perfectly in L20n. It’s called DOM Overlays, and we’re working on getting them into mozL10n. That will allow us to further secure L10n API and remove any innerHTML calls.
Majority of localizability code in Gaia apps is related to localization of DOM nodes. With Mutation Observers we will be able to significantly reduce the amount of manual calls to mozL10n API and make majority of calls be just about settings data-l10n-id attribute with Mutation Observers doing the rest.
Not only will it reduce the use cases of mozL10n.translate and mozL10n.localize, but I expect to be able to cut by over 50% the number of manual mozL10n.get calls and manual operations that are currently used to set the result of that call into the node.
Mutation Observers will simplify Gaia code, reduce the amount of bugs related to language switching and get us closer to runtime l10n API that we want to offer for Gecko.
There are still some interesting edge cases around how code boostrapping relies on particular pieces of environment. Does your code need DOM to be interactive? Does it need l10n resources to be loaded? Or maybe you need DOM to be localized? All those events happen asynchronously and we currently do not have a clean way to guard against any combination of those that your init code may require.
We’re working on a bootstrapping wrapper that will allow app developers to simply define which pieces of environment should their initialization be blocked by.
That will further secure the app boostrapping process and limit the risk of condition races.
One part of the bootstrap puzzle is how we fire event when certain bootstrap things happen. Right now we fire window.onlocalized event that means that mozL10n resources have been loaded, but doesn’t tell us anything about if document’s DOM has been localized (and is ready to be displayed).
With the work on the new event, we’ll be able to remove the global one, and settle on triggering on event on document and one on mozL10n object. Did I tell you that we’re still cleaning up? ![]()
We originally placed mozL10n object as a property on navigator object. Because our API is transitioning to be per-document, it becomes an inconsistency and an obstacle to keep mozL10n API on navigator object. It hardly fits the world with iframes, ShadowDOM and HTML Templates. We’re going to move it to document.mozL10n.
One of the built time optimizations that we have in Gaia is called inline l10n. We store some portion of the l10n resources within each HTML file in order to localize the UI before it is displayed. It’s not very scalable, costs us memory and performance, but historically helped us prevent flashes of untranslated content. We hope to be able to remove this optimization in this cycle which will significantly simplify our internal code and give us some small memory and performance wins.
While we introduce L20n concepts into mozL10n, we’re still pretty far from being able to say that we support L20n API in Gaia. There’s a lot of work to do and it’s going to be a challenging work as we port L20n concepts to Gaia, and merge lessons we learned while working on Gaia into L20n spec and implementation. What we hope to end up with is a single codebase used in Gaia and offered to web developers.
It’s an exciting journey and I’m so happy to make Firefox OS’s localizability the most modern among all OSes!
|
|
Chris McAvoy: Remember our old pal the Open Badges Standard? |

The specifications that make up the Open Badges Standard form the basis for the Open Badges Infrastructure; the collection of platforms and tools that make Open Badges possible. While the infrastructure has continued to grow, the standard has remained pretty stable over the last year. That’s not necessarily a bad thing, standards are standards because they’re stable. Despite its growth and reach, Open Badges is still a young project, there’s plenty of work to be done, so it’s time to start looking at the standard with a critical eye. Is it complete? What does it need?
Badge Alliance Standard Working Group is made up of organizations and individuals that ask those questions. We’ve worked together to evaluate the existing specifications and look for opportunities to improve and extend their reach.
The first issue we tackled was largely administrative. How do we function as a group? The Alliance built each working group with a chairperson, an Alliance liaison, and a cabinet the chair and liaison assemble. The Standard WG is a bit different, because we’re maintaining technical standards, we also decided we needed a more formal charter that explained how changes to the standard would be proposed, evaluated and accepted or rejected. We based the first draft on similar charters written by the W3C, and the Python Enhancement Proposal process the Python community created. The first draft of the BA-Standard WG charter is here.
The first task the group took on was to go back through the discussions on openbadges-discussion and pull out features that would make good candidates for discussion in the group.
It was pretty clear that the number one addition we all wanted to see added to the specification was a formal way to extend the assertion, both as a way to add information and as a way to experiment with future ideas.
We posted draft proposal to the openbadges-discussion, discussed, updated, discussed, iterated, and discussed some more.
We found that it was difficult to extend the schema if we couldn’t describe the schema in a machine readable way. We’ve put the extension specification on hold until we have a full json-schema representation of the 1.0 specification. After that, we’ll represent schema extensions in json-schema, most likely taking advantage of the json-schema ability to extend json-schema.
We expect the json-schema-fication of the 1.0 specification / schema by June 24th, and the extension specification by July 8th. After that, we need to sync up with the Endorsement Working Group and ask the difficult question, “After you issue a badge, is it mutable? Can we add information to it?”
If you’re an organization that relies on the Open Badges Standard, or if you’re just interested in schemas and specifications, we’d love your comments on all the above! Join the discussion on the BA-Standard WG Mailing List or join one of our bi-weekly calls.
http://chrismcavoy.org/2014/06/10/remember-our-old-pal-the-open-badges-standard/
|
|
Jan Odvarko: Firebug Internals II. – Unified object rendering |
Firebug 2 (released today!) uses number of internal architectural concepts that help to implement new features as well as effectively maintain the code base.
Using transparent architecture and well known design patterns has always been one of the key strategies of the (relatively small) Firebug team that allows us maintain rather large set of features in Firebug.
This post describes the way how Firebug deals with JavaScript object representation and the concept ensuring that an object is always rendered the same way across entire Firebug UI.
See also list of new features in Firebug 2
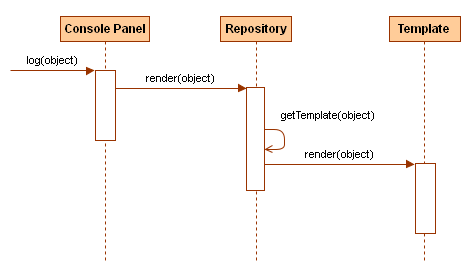
Firebug (as a web developer tool) is primarily dealing with JS objects coming from the currently debugged page. All these objects are displayed to the user allowing further exploration and inspection. Important aspect of the rendering logic is that an object is always rendered using the same scheme (a template) across Firebug UI. It doesn't matter if the object is displayed in the Console panel, DOM panel or inside the Watch panel when Firebug is halted at a breakpoint. It always look the same and also offers the same set of actions (through the context menu).
Let's see an example. Following three images show how element is displayed in different Firebug panels.
Here is logged in the Console panel.
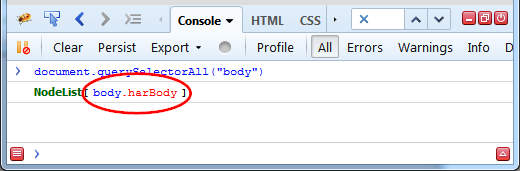
This screenshot displays in the DOM panel.
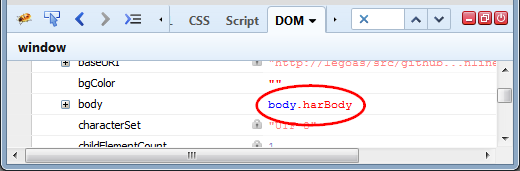
And the last screenshot shows how it looks like in the Watch side panel.
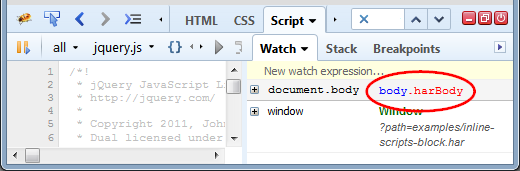
The element is always rendered using the same template and also the context menu associated with the object offers the same basic actions (plus those related to the current context).
The architecture behind unified rendering is relatively simple. The logic is based on a repository of templates where every template is associated with JS object type (number, string, etc.). When a panel needs to render an object it gets its type and asks the repository for a template that is associated with it. The template is consequently used to generate HTML markup.
Firebug uses Domplate engine fore templates, but any other templating system could be used instead.
Let's yet see a few code examples that show how (simplified) implementation looks like from JavaScript perspective.
Here is how getTemplate can implemented (note that Firebug implementation is a bit different):
An interface of a template object looks like as follows (again simplified).
supportsObject: function(object) { return false; },
getContextMenuItems: function(object) { return []; },
getTooltip: function(object) { return null; },
highlightObject: function(object, context) {},
inspectObject: function(object, context) { },
});
className Every template should have a classname so CSS styles can be associated.supportsObject Used to pick the right template for an objectgetContextMenuItems Used to get commands that are should be displayed in the context menu.getTooltip Provides a text that is displayed in a tooltip.highlightdObject Can be used to highlight the object within the page if mouse hovers over the object.inspectObject Can be used for further inspection of the object (e.g. selecting the right target panel when the user clicks on the object).See real repository of templates (a template in Firebug is called rep) on github.
The entire concept is also nicely extensible. This is great especially for extension (i.e. Mozilla add-ons) authors that can plug in into the logic and customize it.
http://feedproxy.google.com/~r/SoftwareIsHardPlanetMozilla/~3/srjR9SwTkuk/
|
|
Doug Belshaw: Mozilla Discover is now live! |
I’m delighted that some stellar work by my colleagues is now available for everyone to use. Mozilla Discover was funded by a grant from the Bill & Melinda Gates Foundation, with the aims being as follows:
Mozilla’s Discover project is a tool that empowers young people to take control of their career pathways. Using the Discover webpage, learners can browse careers and badges, connecting skills that can be combined to land a fantastic job. Real-world professionals are profiled to illustrate how a variety of experiences and interests can lead to a rewarding career. Learners can pledge to follow a similar path, or can design their own customized career pathway from scratch. These pathways are visualized as editable maps, with progress indicators and room for notes.
Here’s an example created after the team interviewed our colleague Brian Brennan:
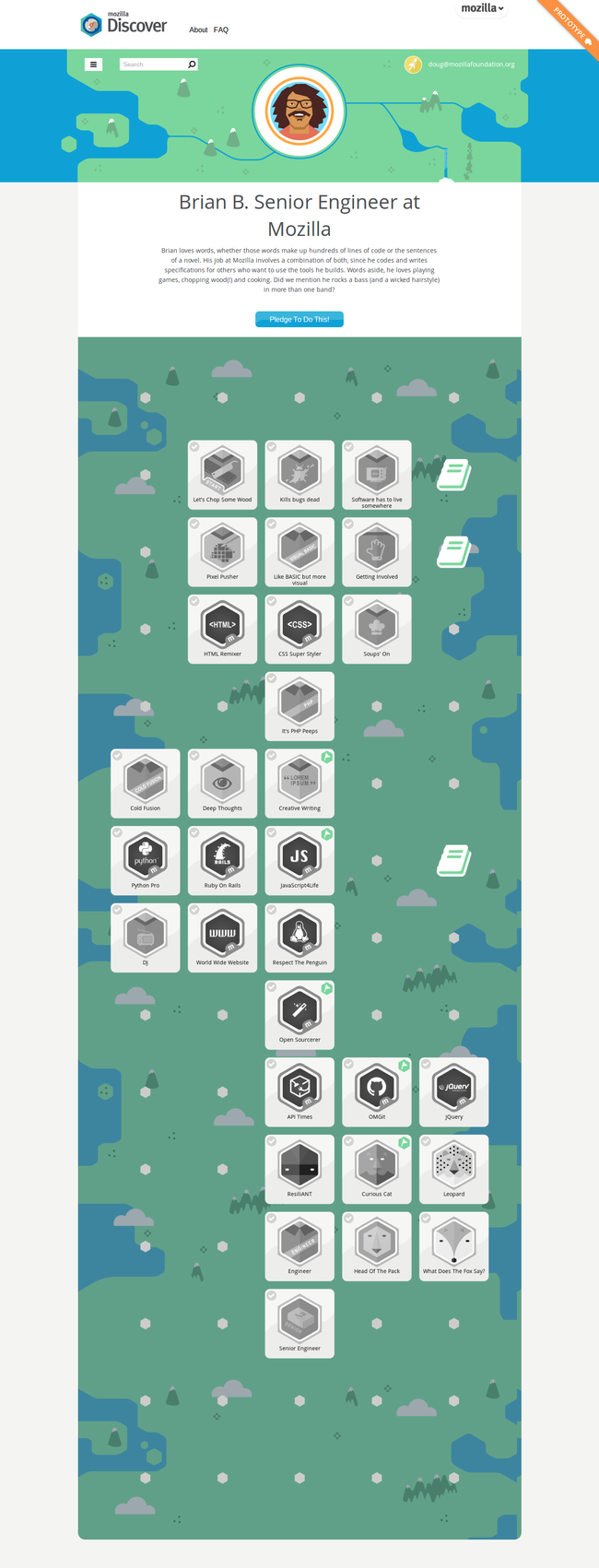
As the learner completes each activity, they tick off they have done it and the greyscale icon becomes coloured.
You can pledge to follow an existing pathway - or you can create your own. Here’s a brief one I made for learning JavaScript:
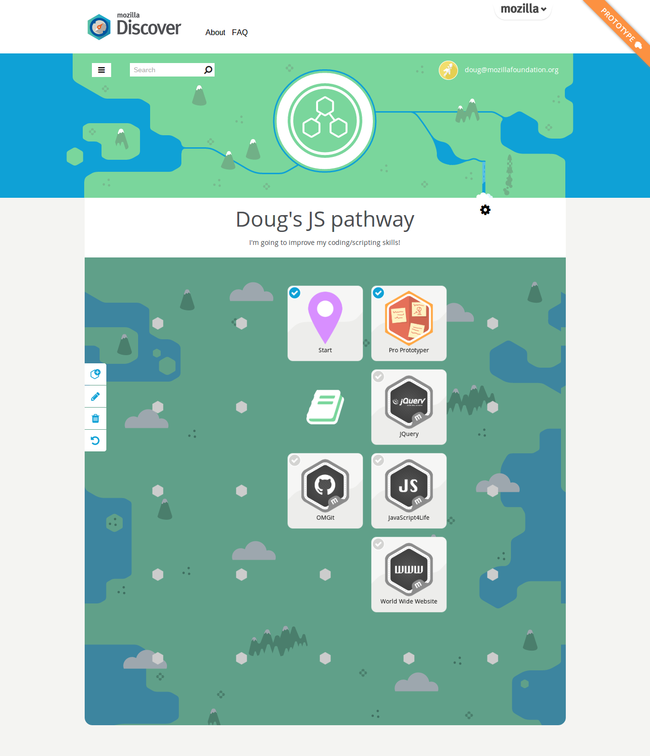
The team involved in creating Mozilla Discover included Chloe Varelidi, Mike Larsson, Grainne Hamilton, and Lucas Blair
I’m going to be doing some work with Chloe and others before MozFest to help scaffold Web Literacy and contribution within the Webmaker ecosystem. It’s early days, but you can follow our progress on this wiki page.
Comments? Questions? I’m @dajbelshaw on Twitter, or you can email me at doug@mozillafoundation.org
|
|
Yunier Jos'e Sosa V'azquez: Firefox OS Flame disponible en pre-orden |
El dispositivo Flame, catalogado por Mozilla como el tel'efono de referencia para desarrollar en Firefox OS estar'a a la venta muy pr'oximamente. Anunciado durante el Mobile Congress de este a~no y de la mano de T2Mobile, Flame se puede adquirir en 170 USD (incluyendo entrega sin costo desde everbuying.com).
 Sus caracter'isticas:
Sus caracter'isticas:Ordena un Flame ahora (algunas personas han recibido un 10% de descuento)
http://firefoxmania.uci.cu/firefox-os-flame-disponible-en-pre-orden/
|
|
Henrik Skupin: Firefox Automation report – week 17/18 2014 |
In this post you can find an overview about the work happened in the Firefox Automation team during week 17 and 18.
In one of the last automation reports I mentioned that we wanted to finish up the already in-progress Mozmill tests for Firefox Metro. With lots of work mostly done by Daniel we were finally able to close all the bugs as fixed. Now everyone is back on top of our new quarterly goals.
To allow new contributors of the mozmill-tests repository to pick appropriate reviewers for their patches more easily, Henrik requested to setup default reviewers on Bugzilla. The changes are now in place and the list points to Andreea, Andrei, and Henrik.
To follow our goals in educating more people about automation, we also have to reach out more on Github to actually find interested people. Therefore Henrik requested a Github mirror of our mozmill-tests repository. It’s available at https://github.com/mozilla/qa-mozmill-tests now.
With the last release of Mozmill 2.0.6 we got the mozcrash packages included. So far we aren’t able to process stacktraces, given that the necessary crashreporter symbols were not available for daily builds of Firefox on the FTP server. This has been fixed now for all kinds of daily builds.
As seen for the last beta and final releases of Firefox we still have a good amount of broken configuration files for ondemand update tests in Mozmill CI. Those are failures done by the person who runs those tests, but also by broken behavior in the mciconf tool. Given that, we want to put more focus on the full automation stack for update tests now. To get started we need appropriate notifications send out by Mozilla Pulse.
For more granular updates of each individual team member please visit our weekly team etherpad for week 17 and week 18.
If you are interested in further details and discussions you might also want to have a look at the meeting agenda, the video recording, and notes from the Firefox Automation meetings of week 17 and week 18.
http://www.hskupin.info/2014/06/10/firefox-automation-report-week-17-18-2014/
|
|
Robert Nyman: Douglas Crockford speaking at Geek Meet September 2014 |
All seats have been taken. Please write a comment to be put on a waiting list, there are always a number of cancellations, so there’s still a chance.
Douglas and I have talked about him speaking at Geek Meet a few times when we’re ran into each other at different conferences in the world, and we’ve said that if he’s nearby Sweden, we just make it happen. Now is that time!
Douglas is coming to Sweden to speak at the Nordic.js conference, where I’m also speaking, and I thought that we just can’t miss this opportunity when he’s here. I’ve synced with the great and helpful organizers of the conference, so we will do a Geek Meet in the evening after the second/last day of Nordic.js – that way, anyone attending the conference can go to Geek Meet as well!
Douglas is best known for his long work around JavaScript, and most notably discovering the JSON Data Interchange Format, that JavaScript has good parts and creating JSLint (JSLint on GitHub) to help developers write better JavaScript code and JSMin for minimizing it in a safe way.
When I got into JavaScript a long time ago, Douglas was a great inspiration and help to me with his work and pragmatic thoughts and experience around developing. Since then, I’ve been happy to bump into him at various conferences and to get the chance to talk about coding, travel, Lost and other interesting topics!
More information about Douglas can be found at:
Douglas will give a presentation entitled The Better Parts, in which he will talk about new features in ES6, and a bit about JSON and JSLint.
This Geek Meet will be sponsored by Creuna, and will take place September 19th at 19:00 in their office at Kungsholmsgatan 23 in Stockholm. Creuna will also provide beer/wine and pizza to every attendee, all free of charge.
The format is a bit different than usual at this time, with food and mingling at 19:00 and then a presentation starting 20:00 sharp by Douglas.
Please sign up with a comment below. Please only sign up if you know you can attend. There are 150 seats available, and you can only sign up yourself. Please use a valid name and e-mail address, since this will be used to identify you at the event to get in.
Geek Meet is available in a number of channels:
The hash tag used is #geekmeetsthlm.
All seats have been taken. Please write a comment to be put on a waiting list, there are always a number of cancellations, so there’s still a chance.
|
|
Byron Jones: happy bmo push day! |
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.
http://globau.wordpress.com/2014/06/10/happy-bmo-push-day-97/
|
|
Francois Marier: CrashPlan and non-executable /tmp directories |
If your computer's /tmp is non-executable, you will run into problems with
CrashPlan.
For example, the temp directory on my laptop is mounted using this line in
/etc/fstab:
tmpfs /tmp tmpfs size=1024M,noexec,nosuid,nodev 0 0
This configuration leads to two serious problems with CrashPlan.
The first one is that while the daemon is running, the client doesn't start up and doesn't print anything out to the console.
You have to look in /usr/local/crashplan/log/ui_error.log to find the
following error message:
Exception in thread "main" java.lang.UnsatisfiedLinkError: Could not load SWT library. Reasons:
Can't load library: /tmp/.cpswt/libswt-gtk-4234.so
Can't load library: /tmp/.cpswt/libswt-gtk.so
no swt-gtk-4234 in java.library.path
no swt-gtk in java.library.path
/tmp/.cpswt/libswt-gtk-4234.so: /tmp/.cpswt/libswt-gtk-4234.so: failed to map segment from shared object: Operation not permitted
at org.eclipse.swt.internal.Library.loadLibrary(Unknown Source)
at org.eclipse.swt.internal.Library.loadLibrary(Unknown Source)
at org.eclipse.swt.internal.C.(Unknown Source)
at org.eclipse.swt.internal.Converter.wcsToMbcs(Unknown Source)
at org.eclipse.swt.internal.Converter.wcsToMbcs(Unknown Source)
at org.eclipse.swt.widgets.Display.(Unknown Source)
at com.backup42.desktop.CPDesktop.(CPDesktop.java:266)
at com.backup42.desktop.CPDesktop.main(CPDesktop.java:200)
To fix this, you must tell the client to use a different directory, one that
is executable and writable by users who need to use the GUI, by adding
something like this to the GUI_JAVA_OPTS variable of
/usr/local/crashplan/bin/run.conf:
-Djava.io.tmpdir=/home/username/.crashplan-tmp
The second problem is that once you're able to start the client, backups are
stuck at "waiting for backup"
and you can see the following in /usr/local/crashplan/log/engine_error.log:
Exception in thread "W87903837_ScanWrkr" java.lang.NoClassDefFoundError: Could not initialize class com.code42.jna.inotify.InotifyManager
at com.code42.jna.inotify.JNAInotifyFileWatcherDriver.(JNAInotifyFileWatcherDriver.java:21)
at com.code42.backup.path.BackupSetsManager.initFileWatcherDriver(BackupSetsManager.java:393)
at com.code42.backup.path.BackupSetsManager.startScheduledFileQueue(BackupSetsManager.java:331)
at com.code42.backup.path.BackupSetsManager.access$1600(BackupSetsManager.java:66)
at com.code42.backup.path.BackupSetsManager$ScanWorker.delay(BackupSetsManager.java:1073)
at com.code42.utils.AWorker.run(AWorker.java:158)
at java.lang.Thread.run(Thread.java:744)
This time, you must tell the server to use a different directory, one that
is executable and writable by the CrashPlan engine user (root on my
machine), by adding something like this to the SRV_JAVA_OPTS variable of
/usr/local/crashplan/bin/run.conf:
-Djava.io.tmpdir=/var/crashplan
http://feeding.cloud.geek.nz/posts/crashplan-and-non-executable-tmp-directories/
|
|
K Lars Lohn: Crontabber and Postgres |
# sets up postgres
@using_postgres()
# tells crontabber control transactions
@as_single_postgres_transaction()
def run(self, connection):
# connection is a standard psycopg2 connection instance.
# use it to do the two steps:
cursor = connection.cursor()
cursor.execute(
'update accounts set total = total - 10' where acc_num = '1'
)
do_something_dangerous_that_could_cause_an_exception()
cursor.execute(
'update accounts set total = total +10' where acc_num = '2'
)
# we cannot seem to connect to Postgres
2014-06-08 03:23:53,101 CRITICAL - MainThread - ... transaction error eligible for retry
OperationalError: ERROR: pgbouncer cannot connect to server
# the TransactorExector backs off, retrying in 10 seconds
2014-06-08 03:23:53,102 DEBUG - MainThread - retry in 10 seconds
2014-06-08 03:23:53,102 DEBUG - MainThread - waiting for retry ...: 0sec of 10sec
# it fails again, this time scheduling a retry in 30 seconds;
2014-06-08 03:24:03,159 CRITICAL - MainThread - ... transaction error eligible for retry
OperationalError: ERROR: pgbouncer cannot connect to server
2014-06-08 03:24:03,160 DEBUG - MainThread - retry in 30 seconds
2014-06-08 03:24:03,160 DEBUG - MainThread - waiting for retry ...: 0sec of 30sec
2014-06-08 03:24:13,211 DEBUG - MainThread - waiting for retry ...: 10sec of 30sec
2014-06-08 03:24:23,262 DEBUG - MainThread - waiting for retry ...: 20sec of 30sec
# it fails a third time, now opting to wait for a minute before retrying
2014-06-08 03:24:33,319 CRITICAL - MainThread - ... transaction error eligible for retry
2014-06-08 03:24:33,320 DEBUG - MainThread - retry in 60 seconds
2014-06-08 03:24:33,320 DEBUG - MainThread - waiting for retry ...: 0sec of 60sec
...
2014-06-08 03:25:23,576 DEBUG - MainThread - waiting for retry ...: 50sec of 60sec
2014-06-08 03:25:33,633 CRITICAL - MainThread - ... transaction error eligible for retry
2014-06-08 03:25:33,634 DEBUG - MainThread - retry in 120 seconds
2014-06-08 03:25:33,634 DEBUG - MainThread - waiting for retry ...: 0sec of 120sec
...
2014-06-08 03:27:24,205 DEBUG - MainThread - waiting for retry ...: 110sec of 120sec
# finally it works and the app goes on its way
2014-06-08 03:27:34,989 INFO - Thread-2 - starting job: 065ade70-d84e-4e5e-9c65-0e9ec2140606
2014-06-08 03:27:35,009 INFO - Thread-5 - starting job: 800f6100-c097-440d-b9d9-802842140606
2014-06-08 03:27:35,035 INFO - Thread-1 - starting job: a91870cf-4d66-4a24-a5c2-02d7b2140606
2014-06-08 03:27:35,045 INFO - Thread-9 - starting job: a9bfe628-9f2e-4d95-8745-887b42140606
2014-06-08 03:27:35,050 INFO - Thread-7 - starting job: 07c55898-9c64-421f-b1b3-c18b32140606
http://www.twobraids.com/2014/06/crontabber-and-postgres.html
|
|






