Kim Moir: Talking about speaking up |
http://relengofthenerds.blogspot.com/2014/06/talking-about-speaking-up.html
|
|
Selena Deckelmann: Some thoughts on handling harassment and toxic behavior privately |
I’ve seen some calls for people like @shanley to handle their complaints about abuse and harassment privately, or maybe “more privately” than they have. So, today I just mused aloud for a few minutes on Twitter the thoughts I have about private handling of public acts of cruelty, harassment and abuse. Here’s those tweets, slightly edited, in a blog form. This is meant as a discussion of why public responses to public harassment are not only justified, but helpful. I don’t believe that those who are harassed are obligated in any way to respond publicly to harassment.
Why is it important to “handle in private” the responses to public odious, toxic, anti-social and harassing behavior? How does that help?
I believe in proportionate response. However, when the interactions are online and there is no physical public space, just “public media”, there’s a serious problem with the idea that a private response, particularly from the harassed, works at all.
My experience has been that private responses to people who harass me don’t help. Harassment continues, the harasser does not change. The only thing that has ever “changed behavior” is directing a complaint through the public or someone with authority over the harasser. And, that only worked for me a small percentage of the time that I asked for help. Asking for help has also increased harassment.
I’m not sold on the idea of private responses to public acts shared on the internet as “effective for behavior change”.
There’s also a difference between individual behavior change (personal reform), and cultural change (what we find acceptable as a group). Not everyone is aboard the cultural change train. And, I see twitter in particular as performance art, not a conversation happening “inside” a community.
The more time I spend thinking about this, the more I realize I haven’t spent enough time defining what my community is. Because for a long time I bought into the idea that there was some kind of global FOSS community protecting me, caring for me, backing me up.
But what I believe now is that I have a few close friends, some who know each other, some who don’t — but not a coherent community. And the reason why I don’t think there’s coherency, is because they don’t respond the way that a community does when there’s danger.
There is real, lasting damage done to people I care about by harassers and abusers. Things I hear about afterward, things that make me ill to think about and repeat. Things I wish I could prevent. That we could all prevent. But the worst damage done, I think, happens when those who come forward aren’t believed.
I didn’t go into detail about this in the twitter thread, but I have found that many people, who I come in contact with through FOSS, who are abusive on social media and on public mailing lists, are also abusive and harassing in private. Assuming that the public behavior is the worst behavior that a harasser exhibits is not a safe or reasonable assumption.
So. Handling things in public when we’re dealing with public acts, cruelty, harassment: Yes, I think we should.
|
|
Shane Tomlinson: v0.50 Release of the Persona WordPress Plugin – Ukrainian Translations |
Thanks to Michael Yunat from http://getvoip.com, the Persona WordPress plugin now supports Ukrainian!
The update was released as v0.50. If your site already has the plugin installed, a notice to update will appear automatically.
If you have not tried the plugin, give it a go – it can be installed from the WordPress Admin dashboard by clicking on Plugins, Add New, then searching for Mozilla Persona.
https://shanetomlinson.com/2014/v0-50-persona-wordpress-plugin-ukrainian-translations/
|
|
Michael Kaply: The Next Firefox ESR (31) is Almost Here |
Firefox 30 will be released tomorrow (June 10, 2014). That means the Firefox 31 ESR is only six weeks away (July 22, 2014). There will 12 weeks of overlap where both the Firefox 24 ESR and the Firefox 31 ESR are supported to allow for qualification. Support for the Firefox 24 ESR will official end with the release of Firefox 33 on October 14, 2014.
So what should you expect in the Firefox 31 ESR?
The biggest change is Australis. It's a completely revamped UI for Firefox. Besides changing the overall look and feel of Firefox, it also removed the add-on bar, as well as the ability to put the browser tabs on the bottom. Because of these changes, I will be deprecating my ancient add-on that tries to make things look more like Firefox 3.6. If you really want to make Firefox look like it was before Australis, you can use the Classic Theme Restorer add-on.
The Firefox 31 ESR also contains a completely rewritten version of Sync that uses Firefox Accounts. The current plan is to retire sync as soon as Firefox 31 comes out, so if you are using the old Sync in your organization, you should have your users migrate as soon as possible.
Another big change in the Firefox 31 ESR is the removal of Configurable security policies. These were actually removed in Firefox 29 by bug 913734. It was determined that the inability to link local files from web pages had a major impact on enterprises, so it was added back in bug 995943 (thanks Bobby Holley), but all other policies including clipboard access have been removed. I am working on an extension that will restore the clipboard policy, and I will probably add this to the CCK2 as well. If you need additional security policies, please comment on this post and I will investigate adding them.
If you're interested in finding out about other changes in the Firefox 31 ESR, you can read the end user release notes for the various releases (24.0, 25.0, 26.0, 27.0, 28.0, 29.0, 30.0). You can also read the developer notes for versions 25 through 31 for more detailed information.
If you're using CCK2, the latest version CCK2 already contains support for Australis. If you're not using it, you should be. It's the easiest way to customize Firefox for your organization.
http://mike.kaply.com/2014/06/09/the-next-firefox-esr-31-is-almost-here/
|
|
Doug Belshaw: Recording of the kick-off meeting for the Badge Alliance working group on Digital / Web Literacies |
As I wrote last week, I’m co-chair of the Digital / Web Literacy working group. The first call was today, and involved around 20 people getting oriented with the structure of the Badge Alliance groups as well as each others' work.

You can catch up with the notes and audio from this call at the links below:
Comments? Questions? I’m @dajbelshaw
|
|
Clarista: Tails Hackfest 2014 |
Our dear Geb (https://mozillians.org/u/geb/) asked me to share with you this fantastic event. And so do I, with pleasure!
Join us at the Tails HackFest, 2014!
July 5-6, 2014 — Paris, France
Join us to make online anonymity and digital privacy usable by the masses! Whether you’re a writer, a software developer, a designer, a system administrator or just plain interested, come learn about the challenges faced by Tails, and how you can be part of the solution.
The Tails HackFest will bring together anyone interested in making Tails more usable and more secure. This open event will be an intense mix of teaching, drawing, coding, sharing, learning and celebrating.
* Where: the venue for the event is IRILL, Paris, France (https://www.irill.org/about/information-for-guests).
* Dates: Saturday, July 5, 2014 – Sunday, July 6, 2014
* Time: 10 AM – 10 PM
* Registration: if you want to attend, please consider dropping us a note about it. This is optional, but would help organizing
this event.
* Contact: <tails-hackfest-2014@boum.org>, #tails-hackfest on irc.oftc.net
* Details, scheduling and updates: https://tails.boum.org/blueprint/HackFest_2014_Paris/
Tails is a live operating system that can be started on almost any computer from a DVD, USB stick, or SD card. It is Free Software, and based on Debian GNU/Linux.
Tails provides a platform to solve many surveillance problems by "doing the right thing" out of the box by default, protecting even less tech-savvy users from the most likely and highest impact risks.
It aims at preserving privacy and anonymity, and helps to:
* use the Internet anonymously and circumvent censorship; all connections to the Internet are forced to go through the Tor network;
* leave no trace on the computer being used unless the user asks it explicitly;
* use state-of-the-art cryptographic tools to encrypt files, emails and instant messaging.
Tails is about usability: every feature and software is ready-to-use, thoroughly documented, and translated into many languages.
Tails is about cooperation: all products are released as Free and Open Source Software, and shared with other projects whenever possible.
People use Tails to write books and create movies. People use Tails to chat off-the-record, browse the web anonymously and share sensitive documents. Many people depend on Tails to do their daily work, if not simply to stay alive.
Looking forward to meet you on July 5-6! No doubt you’ll find a great way to contribute to Tails, regardless of what your field of expertise is!
Many thanks to Debian, IRILL, Mozilla and the Tor project for supporting this event!

http://claristamozilla.wordpress.com/2014/06/09/tails-hackfest-2014/
|
|
Christian Heilmann: Flight mode on |
Much like everybody else these days, I use my phone as an alarm clock. In addition to this, however, I also made a conscious decision to turn on flight mode on during the night. The reason is updates coming in that may or may not make it buzz or make a sound. Of course, I could turn that off. Of course I could not care about it. Of course that is nonsense as we are wired to react to sounds and blinking lights.

In many applications the option to turn audio or visual or buzz notifications off is hidden well as their sole business model is to keep you interacting with them. And we do. All the time. 24/7. Because we might miss something important. That can so not wait. And we need to know about it now, now, now…
I also started turning off my phone when I am on the go – on my bicycle or on the train and bus. There is no point for me keeping it on as there is no connectivity in trains in London and I get car sick trying to interact with my phone on a bus. Furthermore, so many apps are built with woefully bad offline and intermittent connection support. I am just tired of seeing spinners.

So what? Why am I telling you this? The reason is that I am starting to get bored and annoyed with social media. I sense a strong feeling of being part of a never-ending current of mediocrity, quick wins and pointless data consumption. Yes, I know the “irony” of me saying this, seeing how active I am on Twitter and how much “pointless” fluffy animal material I intersperse with technical updates.
The point for myself is that I miss the old times of slow connections and scarcity of technical information. Well, not really miss, but I think we are losing a lot by constantly chasing the newest and most amazing and being the first to break the “news” of some cool new script or solution.
When I started in web development I had a modem. I also paid for my connection by the minute. I didn’t have a laptop. At work I wasn’t allowed to read personal mails or surf the web – I was there to attend meetings, slice up photoshop files, add copy to pages and code.
At home I had a desktop. I connected to the internet, downloaded all my emails and newsgroup items (most of the time the headers only), surfed the web a bit, disconnected and started answering my emails. I subscribed to email forums like webdesign-l, evolt.org, CSS Discuss and many others. In these forums I found articles of A List Apart, Webmonkey, Digital Web and many others worth reading.
Sounds inconvenient and terrible by nowadays standards, when we are annoyed that TV series don’t stream without buffering while we are on planes. It was, but it also meant one thing I think we lost: I cherished every email and every article much more than I do now. I appreciated the work that went into them as they were more scarce. To get someone’s full attention these days you need to be either outrageous or overpromising. The wisdom of the crowds seems to get very dubious when limited to social media updates. Not the best bubbles up, but the most impressive.

I also forged close relationships with the people subscribed in these lists and forums by interacting more closely than 140 characters. A List Apart, for example, was not only about the articles – the more interesting and amazing solutions came from the discussions in the comments. I made my name by taking part in these discussions and agreeing and disagreeing with people. Many people I know now who speak, coach, run companies and have high positions in the mover and shaker companies of the web came from this crowd.
I took my time to digest things, I played with technology and tried it out and gave feedback. We took our time to whittle away the rough edges and come up with something more rounded.
We call this web of now social. We have amazing connections and collaboration tools. We have feedback channels beyond our dreams. But we rush through them. Instead of commenting and giving feedback we like, share and +1. Instead of writing a thought out response, we post a reaction GIF. Instead of communicating, we play catch up.
The sheer mass of tech articles, videos, software betas, updates and posts released every hour makes it almost impossible to catch up. Far too many great ideas, solutions and approaches fall through the cracks because ending up on Hackernews and getting lots of likes is the goal. This means you need to be talking about the newest thing, not the thing that interests you the most.
Maybe this makes me sound like an old fart. So be it. I think we deserve some downtime from time to time. And the content other people create and publish deserves more attention than a fly-by, glancing over it and sharing, hoping to be seen as the person with the cool news.
|
|
Daniel Stenberg: Http2 interim meeting NYC |
On June 5th, around thirty people sat down around a huge table in a conference room on the 4th floor in the Google offices in New York City, with a heavy rain pouring down outside.
It was time for another IETF http2 interim meeting. The attendees were all participants in the HTTPbis work group and came from a wide variety of companies and countries. The major browser vendors were represented there, and so were operators and big service providers and some proxy people. Most of the people who have been speaking up on the mailing list over the last year or so, unfortunately with a couple of people notably absent. (And before anyone asks, yes we are a group where the majority is old males like me.)
Most people present knew many of the others already, which helped to create a friendly familiar spirit and we quickly got started on the Thursday morning working our way through the rather long lits of issues to deal with. When we had our previous interim meeting in London, I think most of us though we would’ve been further along today but recent development and discussions on the list had actually brought back a lot of issues we though we were already done with and we now reiterated a whole slew of subjects. We weren’t allowed to take photographs indoors so you won’t see any pictures of this opportunity from me here.
![]()
We did close many issues and I’ll just quickly mention some of the noteworthy ones here…
We started out with the topic of “extensions”. Should we revert the decision from Zurich (where it was decided that we shouldn’t allow extensions in http2) or was the current state of the protocol the right one? The arguments for allowing extensions included that we’d keep getting requests for new things to add unless we have a way and that some of the recent stuff we’ve added really could’ve been done as extensions instead. An argument against it is that it makes things much simpler and reliable if we just document exactly what the protocol has and is, and removing “optional” behavior from the protocol has been one of the primary mantas along the design process.
The discussion went back and forth for a long time, and after almost three hours we had kind of a draw. Nobody was firmly against “the other” alternative but the two sides also seemed to have roughly the same amount of support. Then it was yet again time for the coin toss to guide us. Martin brought out an Australian coin and … the next protocol draft will allow extensions. Again. This also forces implementation to have to read and skip all unknown frames it receives compared to the existing situation where no unknown frames can ever occur.
A rather given first candidate for an extension was the BLOCKED frame. At the time BLOCKED was added to the protocol it was explicitly added into the spec because we didn’t have extensions – and it is now being lifted out into one.
What received slightly more resistance was the move to move out the ALTSVC frame as well. It was argued that the frame isn’t mandatory to support and therefore easily can be made into an extension.
Another small change of the wire format since draft-12 was the removal of the high byte for padding to simplify. It reduces the amount you can pad a single frame but you can easily pad more using other means if you really have to, and there were numbers presented that said that 255 bytes were enough with HTTP 1.1 already so probably it will be enough for version 2 as well.
There will be a new draft out really soon: draft -13. Martin, our editor of the spec, says he’ll be able to ship it in a week. That is intended to be the last draft, intended for implementation and it will then be expected to get deployed rather widely to allow us all in the industry to see how it works and be able to polish details or wordings that may still need it.
We had numerous vendors and HTTP stack implementers in the room and when we discussed schedule for when various products will be able to see daylight. If we all manage to stick to the plans. we may just have plenty of products and services that support http2 by the September/October time frame. If nothing major is found in this latest draft, we’re looking at RFC status not too far into 2015.
I think we’re closing in for real now and I have good hopes for the protocol and our progress to a really wide scale deployment across the Internet. The HTTPbis group is an awesome crowd to work with and I had a great time. Our hosts took good care of us and made sure we didn’t lack any services or supplies. Extra thanks go to those of you who bought me dinners and to those who took me out to good beer places!
Yeah, it will now become somewhat out of date and my plan is to update it once the next draft ships. I’ll also do another http2 presentation already this week so I hope to also post an updated slide set soonish. Stay tuned!
My plan is to cooperate with the other Wireshark hackers and help making sure we have the next draft version supported in Wireshark really soon after its published.
Most of the differences introduced are in the binary format so nghttp2 will need to be updated again – it is the library curl uses for the wire format of http2. The curl parts will need some adjustments, for example for Content-Encoding gzip that no longer is implicit but there should be little to do in the curl code for this draft bump.
http://daniel.haxx.se/blog/2014/06/08/http2-interim-meeting-nyc/
|
|
Soledad Penades: On CSSConf + JSConf 2014 |
TL;WR*: a mostly social event, great for meeting the authors of those modules you see scroll past when you run npm install and it installs half of the internet. Also, lots of presentations on somewhat hipster stuff which I not always understood, but that’s great–I like not understanding it all from the get go, so I can learn something. And some discussion about physical and mental health and better community building and other important non purely technical stuff that usually never gets the chance to be discussed in tech conferences.
~~~
My favourite ones, now that I realise it, were mostly about graphics, real time stuff, crazy hacks and the least technical of topics: mental/physical health and community building. Definitely not talks about JS frameworks and code organisation–for some reason I always find these pretty dull.
Because this is also about not agreeing about things. These are from JSConf:
Chicago.
Seriously, never fly through Chicago. I thought Houston was bleak and depressing, but compared to Chicago O’Hare, Houston treated me like royalty. I should have heeded Potch’s advice but I didn’t, and it was painful: a delayed flight, an against-the-clock run from terminal B to C (new and LAST record, because I’m never going back there: 9 minutes), a missed connection by 5 minutes, a 1h+ queue for finding out what was next, and an extra night in an airport hotel. Not my idea of fun!
~~~
A SAD, SINGLE FOOT NOTE FLOATING AT THE BOTTOM OF THIS POST
TL;WR* Too Long; Won’t Read.
![]()
http://soledadpenades.com/2014/06/08/on-cssconf-jsconf-2014/
|
|
Soledad Penades: Inspecting the Web Audio Vocoder demo with Firefox’s new Web Audio inspector |
I wanted to understand how the Web Audio Vocoder demo by Chris Wilson worked but I didn’t feel like reading the whole code upfront, so I decided to open it using the new Web Audio inspector that you can find in Firefox Nightly.
The Web Audio inspector will render a graph with all the nodes in the current Audio Context, so it’s ideal to get a feel for the vocoder’s internal structure.
And the structure is PRETTY COMPLEX, as you can see in this massive GIF:
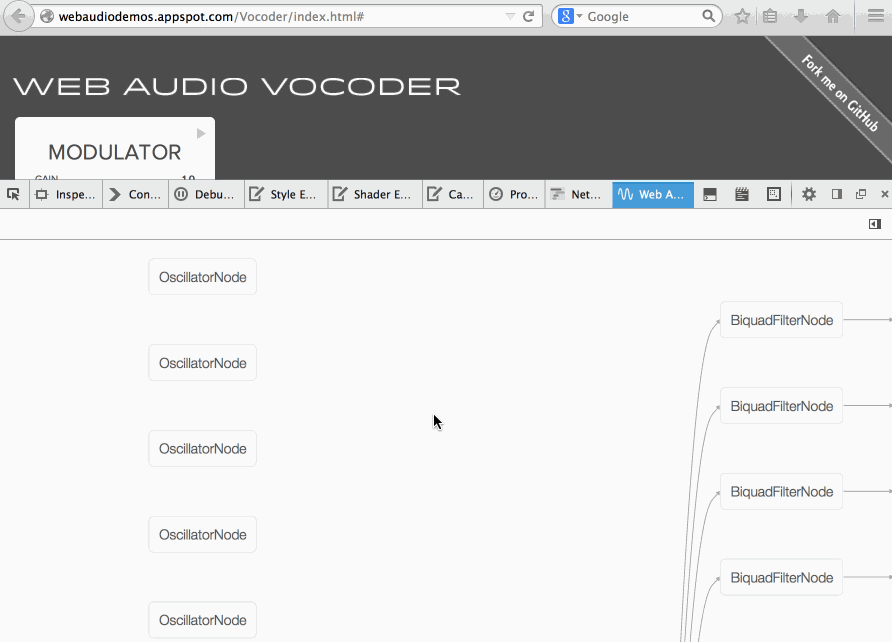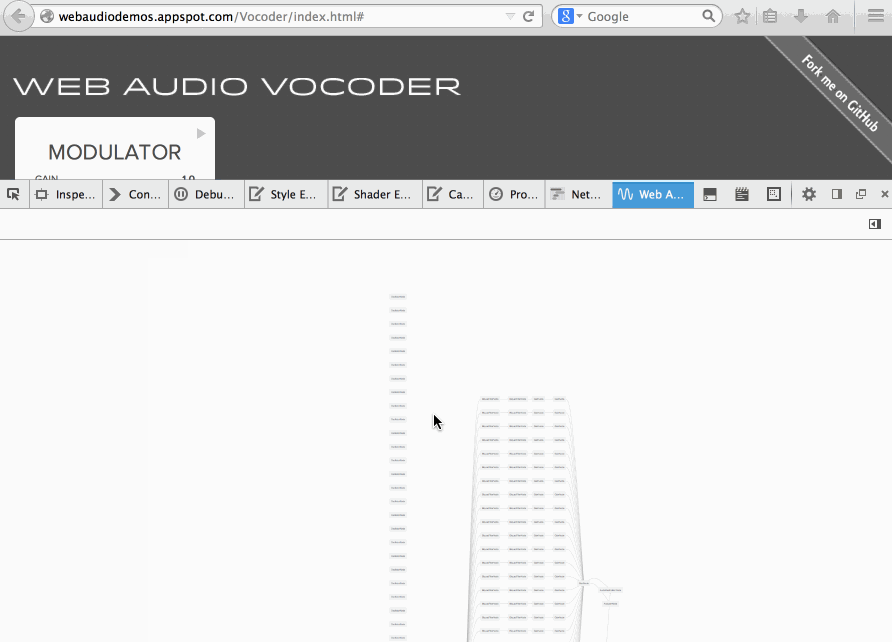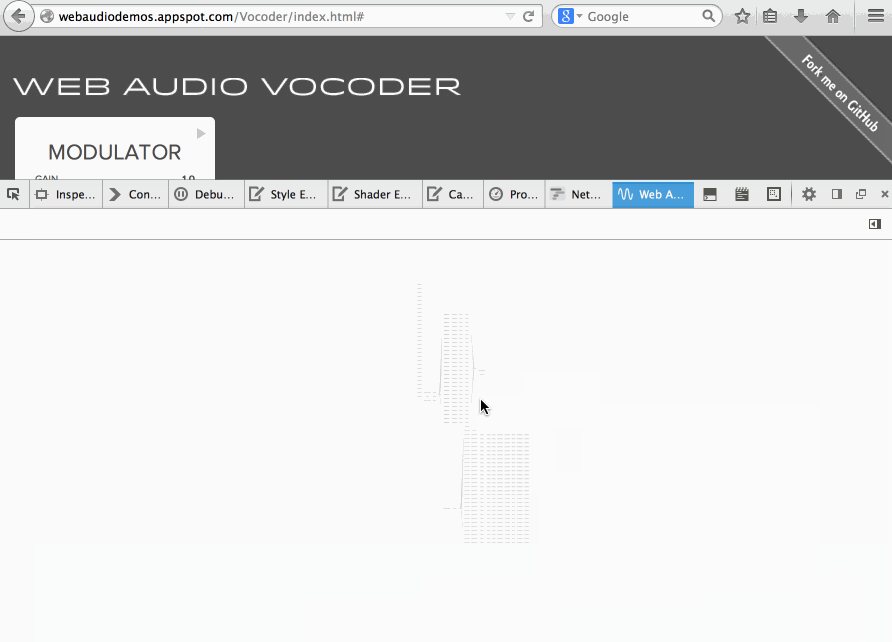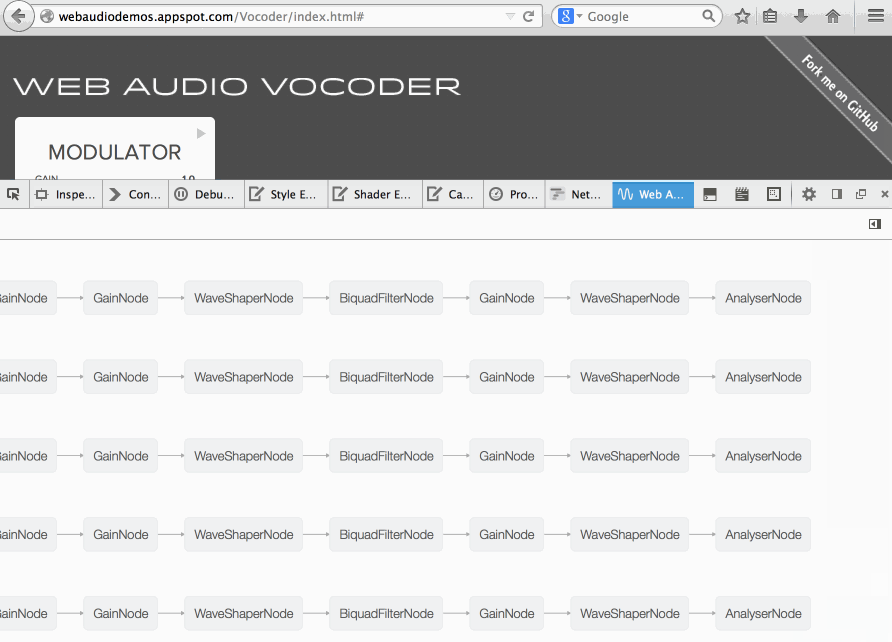
Here’s the Vocoder code, just in case you want to read it too!
Full credits for the Audio Inspector go to Jordan Santell, also of Dancer.js fame! :-)
![]()
|
|
Rizky Ariestiyansyah: Fix gem install mysql2 (Conflict MariaDB) on Fedora |
http://oonlab.com/fix-gem-install-mysql2-conflict-mariadb-on-fedora.onto
|
|
Monty Montgomery: Presentations, presentations, presentations and slide decks |
The spring 'conference tour' season is finally coming to a close. I'm a bit surprised by the number of people who have asked for my slide decks. Well, slide deck actually, since of course I mostly reused the same slides across the talks this spring.
In any case, I 've posted the latest iteration (from my presentation at the just-finished Google VP9 Summit) for anyone who's interested:
https://people.xiph.org/~xiphmont/demo/daala/daala-vp9summit-20140606.pdf
|
|
Nigel Babu: Migration Update - 1 |
About 2 weeks ago, I kicked off my “evil” plan to move as many things as possible off Google Apps. I’ve managed to move my Contacts, Calendar, and files off Google services so far.
I setup ownCloud for contacts, calandar, and files. It was incredibly painless to setup. I have the owncloud, CalDAV-sync, and CardDAV-Sync apps installed on my Android phone and it seems to work great. Good enough that the only thing I’m syncing from my Google account is email.
The ownCloud app was straight forward. I checked the option to instantly upload pictures. This allowed me to disable picture syncing with Google Photos.
The next app I tried was CardDAV-Sync. I tried the free one first. It didn’t actually sync anything to my server. Searching around a bit suggested that I might have to import the contacts to the server first. So, I backed up the contacts to a file and synced that to the ownCloud instance. When I clicked on the VCF file on the ownCloud server, it let me import the contacts from it immediately. The problem with Google syncing all my contacts it that there were 1000+ contacts that I had to clean up, purge, and finally arrive at close to 400. I should delete more, but I haven’t had spare time to do that.
CalDAV was fairly easy, exported the calendars, imported them into ownCloud, installed the app, and removed the Google calendars from being displayed.
Here’s the status so far on my roadmap:
I’m using a Google Spreadsheet to track my budget and this is where I anticipate trouble. I haven’t found an online tool that I can use as well I have managed with this spreadsheet that I’ve perfected over the last few years. If anyone has suggestions, please let me know.
Additionally, this is not cheaper than using Google for sure. I’m definitely paying more in terms of server space and backup space for this.
|
|
Daniel Stenberg: Bye bye RFC 2616 |
In August 2007 the IETF HTTPbis work group started to make an update to the HTTP 1.1 specification RFC 2616 (from June 1999) which already was an update to RFC 2068 from 1996. I wasn’t part of the effort back then so I didn’t get to hear the back chatter or what exactly the expectations were on delivery time and time schedule, but I’m pretty sure nobody thought it would take almost seven long years for the update to reach publication status.
On June 6 2014 when RFC 7230 – RFC 7235 were released, the single 176 page document has turned into 6 documents with a total size that is now much larger, and there’s also a whole slew of additional related documents released at the same time.
2616 is deeply carved into my brain so it’ll take some time until I unlearn that, plus the fact that now we need to separate our pointers to one of those separate document instead of just one generic number for the whole thing. Source codes and documents all over now need to be carefully updated to instead refer to the new documents.
And the HTTP/2 work continues to progress at high speed. More about that in a separate blog post soon.
More details on the road from RFC2616 until today can be found in Mark Nottingham’s RFC 2616 is dead.
|
|
Fr'ed'eric Harper: Firefox OS `a la semaine des technologies EPITA |

Merci `a Laurent Tr'ebulle pour la photo – Cliquez pour voir en pleine r'esolution
Ce matin, j’avais le plaisir de pr'esenter `a propos de Firefox OS `a Paris lors de la semaine des conf'erences technologiques de l’EPITA. Une semaine fort occup'e pour les 'el`eves qui ont 'ecout'e et partag'es avec des intervenants de diff'erentes entreprises durant toute la semaine. Ce fut la premi`ere participation de Mozilla avec pas une, mais deux pr'esentations: l’autre 'etant du coll`egue Nicolas B. Pierron.
Pour ma part, comme la plupart du temps, j’ai pr'esent'e sur les technologies Web `a travers les lunettes de Firefox OS. J’avais une heure et demie pour ma session, ce qui je dois dire, m^eme pour quelqu’un comme moi, est assez long. Aucun probl`eme au niveau du contenu, car je pourrais en parler pendant des jours, mais une petite pause s’imposait apr`es ces quatre-vingt-dix minutes de pr'esentation. Bien que les 'etudiants, de tous les sp'ecialit'es, 'etaient oblig'es d’^etre pr'esents pour ma pr'esentation (quel honneur de la part d’EPITA – ce n’'etait pas ainsi pour chacune des sessions), j’ai senti un int'er^et marqu'e pour le web et Firefox OS. Pour ceux qui 'etaient pr'esents, voici mes diapositives:
Comme `a l’habitude, j’ai enregistr'e ma pr'esentation.
Je ne sais pas pourquoi il y a une bordure noir, mais au temps que cela m’a pris pour le mettre sur YouTube (connexion wifi lente), ca va faire l’affaire pour l’instant :)
Ce fut un plaisir pour moi de venir pr'esenter en France et j’esp`ere en avoir la chance `a nouveau: c’est plaisant de pr'esenter dans un autre pays, en francais! Merci `a tous les 'etudiants qui ont assist'e `a ma session (m^eme ceux en retard) et `a EPITA pour l’invitation.
--
Firefox OS `a la semaine des technologies EPITA is a post on Out of Comfort Zone from Fr'ed'eric Harper
Related posts:
|
|
Christie Koehler: Changes to Mozilla Wiki: New users must request accounts |
Note: The FAQ below is also available on the Mozilla Wiki at MozillaWiki:Accounts.
For some time now the Mozilla Wiki has been significant amounts of spam. To give you an idea of the magnitude of the problem: hundreds of spam accounts are created every week and a handful of admins each spend upwards of 4 hours per week identifying and deleting spam content and accounts.
To combat this problem, we have have implemented a change to the way user accounts are created.
Prior to this change, anyone could create an account and immediately start editing pages. After a short interval, a new user was then able to create pages as well.
Now, all new users are required to request an account and have that request approved prior to logging in and editing or creating pages.
We expect the impact of this change to valid users to be minimal. During a typical week, only a handful of legitimate user accounts are created. The rest are spam.
Below you’ll find a list of questions and answers to help aid in this transition. If you have any questions that we have not answered, please let us know.
Thank you to everyone who helped implement this change, including: Jake Maul, Jason Crowe, AlisonW, KaiRo, and Gordon Hemsley, as well as all those who agreed to help approve accounts.
The new work-flow for new users is as follows:
No, those users will login as they always have.
Please email wikimo-admins@mozilla.org or find us on IRC in #wiki.
Please email wikimo-admins@mozilla.org or find us on IRC in #wiki to let us know. We’ll do our best to have someone on hand during your event to approve requests.
Alternatively, we can create accounts for users ahead of time.
The volume of spam received by the Mozilla Wiki has been such that we’ve not always be able to keep up with it. The change we have made to new user account creation affects the creation of new spam, but does not address preexisting spam content. We will continue to work on identifying and removing content. If you see a page that is clearly spam, let us know via IRC in #wiki.
The best way to get involved with improving the wiki is to join the Wiki Working Group (and we’d love to have you!).
Note: This FAQ also available on the Mozilla Wiki at MozillaWiki:Accounts.
http://subfictional.com/2014/06/06/changes-to-mozilla-wiki-new-users-must-request-accounts/
|
|
Pierros Papadeas: Mozilla Location Services – A story of intentionality and growth |
Since the start of this year I joined the Community Building team with a task (among others) to abstract community building best practices and apply them to teams that haven’t had any dedicated community building resource, forming a strategy around community with them.
Over 7 months ago the Services team of Mozilla announced a new project. The Mozilla Location Service (MLS for short). Given the priority of the project, community excitement and my passion about geo-related projects I was assigned as a community builder in a supportive function.
Since it started, over 4 thousand people have been contributing to the project. What is interesting about this contribution activity is that although engagement of potential contributors was relatively low, and the call to action was not widely advertised, the influx of people was steady and global. Though we can speculate in general about the source those contributions, we can also safely say that the vision behind the project and the low barrier to entry contributed a lot towards this influx of people.
As the months went by, location services team wanted to understand better the contribution that was happening, assess it, and act based on a community building strategy. The immediate need was the definition of a contribution path. Given the structure of the program that was fairly straightforward. A contributor downloads MozStumbler, installs it and then starts walking around. The next step for a contributor would be to opt-in for a nickname associated to his/her contributions so that he/she participate on the leaderboard and for us to have more meaningful contribution activity data. Articulating a pathway also helps on identifying bottlenecks and the overall health of the community, and we are now in the process of defining the active contribution thresholds.
At that point onwards, the question that was raised within our community building meetings for MLS was around the “intentionality” of the community building. It is one thing to have a program open for contributions and a totally different one to facilitate and encourage contributions, assessing the community health in parallel. The shift towards intentionality for community building, requires a significant resource commitment that any team within an organization would naturally be reluctant to make. As a supportive community builder I proposed a community building pilot approach to evaluate the community engagement and contribution possibilities.
Quoting Erin Lancaster, one of the key drivers of this effort:
A community builder is essential in order to connect the technical team directly to the very people who care enough about the project in order to devote their free time to helping us out. [A community builder is] also key to ensuring that the community is empowered with the details so they can hit the ground running and contribute while being able to distill information back to the dev team.
Our fantastic community in India was selected as the host for the first pilot. For our first event we would try to get people together for a stumbling-party in Bangalore and assess the contribution rates, spikes and ripples that the event would create, against our investment towards the event. Deb, Vineel and Galaxy, our awesome local leaders organized the event and by tweaking existing event-in-a-box templates from older Mozilla projects and using Mozilla Reps for supporting the event set the date for 26th of April.
 The event was really successful. 30 people showed up and started stumbling and the local team made some slight twists on the event structure to facilitate better community engagement. (extended stumbling period, assigned areas for stumbling etc). What was really important for our pilot was to evaluate the contribution activity that we got from this small scale, low on resource event, and the result was stunning. We saw a 10x spike in our contribution rates in India for the following 2 weeks, and once the spike was over we were already 3x from the rates before the event (contribution activity ripples).
The event was really successful. 30 people showed up and started stumbling and the local team made some slight twists on the event structure to facilitate better community engagement. (extended stumbling period, assigned areas for stumbling etc). What was really important for our pilot was to evaluate the contribution activity that we got from this small scale, low on resource event, and the result was stunning. We saw a 10x spike in our contribution rates in India for the following 2 weeks, and once the spike was over we were already 3x from the rates before the event (contribution activity ripples). There were some concrete learnings from our first pilot, especially regarding the format, structure and communications needed before and after the event. In order to fortify our learnings and fine-tune the event format (for larger scale implementation) we decided to run a second pilot in three Indian cities (8th of June) in parallel with the same core team. Our first pilot clearly showcased the value of community contributions in MLS and based on the combined results of those two events we will be forming a community building growth strategy for MLS team transitioning towards a fully intentional approach.
There were some concrete learnings from our first pilot, especially regarding the format, structure and communications needed before and after the event. In order to fortify our learnings and fine-tune the event format (for larger scale implementation) we decided to run a second pilot in three Indian cities (8th of June) in parallel with the same core team. Our first pilot clearly showcased the value of community contributions in MLS and based on the combined results of those two events we will be forming a community building growth strategy for MLS team transitioning towards a fully intentional approach.
All this would not be possible without the help of the fantastic people in MLS team (Vishy Krishnamoorthy, Erin Lancaster, Asa Dotzler, Richard Barnes, Hanno Schlichting, Ravikumar Dandu, Doug Turner) that have been really supportive since the early discussions around MLS community. A huge thanks, to all of you and onwards we go!
|
|
Vaibhav Agrawal: GSoC 2014 Progress: Coding Period Starts! |
In the last two weeks, I have started coding for the “Mochitest Failure Investigator” GSoC project (Bug 1014125). The work done in these two weeks:
The results on try were fantastic.
A typical binary search bisection algorithm on try looks like this:

A typical reverse search algorithm looks like this:
 The “TEST-BLEEDTHROUGH” shows the test responsible for the failure. As we would expect, reverse search performs better than binary search when the failure point is closer to the failing test and vice-versa. The bisection algorithms took 20 mins on an average to compute the result.
The “TEST-BLEEDTHROUGH” shows the test responsible for the failure. As we would expect, reverse search performs better than binary search when the failure point is closer to the failing test and vice-versa. The bisection algorithms took 20 mins on an average to compute the result.
How is all of this useful?
The contributors in mozilla spend large amount of effort to investigate test failures. This tool will help in increasing productivity, and saving on an average 4-6 hours of finding the test case down and also reduce the number of unnecessary try pushes. Once this tool is hooked up on try, it will monitor the tests and as soon as the first failure occurs, it will bisect and find the failure point. Also, we can use this tool to validate new tests and help reducing intermittent problems by adding tests in chunks and verifying whether they are passing and if not which tests are affecting the to be added test. We can also use this tool to find out the reason for timeout/crash of a chunk.
It has been quite exciting to tackle mochitest problems with :jmaher . He is an amazing mentor. In the coming weeks, I will be working on making the tool support intermittent problems and incorporating the logic of auto-bisection. Happy hacking!

https://vaibhavag.wordpress.com/2014/06/06/gsoc-2014-progress-coding-period-starts/
|
|
Honza Bambas: HTTP cache v1 API disabled |
Recently we landed the new HTTP cache for Firefox (“cache2'') on mozilla-central. It has been in nightly builds for a while now and seems very likely to stick on the tree and ship in Firefox 32.
Given the positive data we have so far, we’re taking another step today to making the new cache official: we have disabled the old APIs for accessing the HTTP cache, so addons will now need to use the cache2 APIs. One important benefit of this is that the cache2 APIs are more efficient and never block on the main thread. The other benefit is that the old cache APIs were no longer pointing at actual data any more (it’s in cache2) 
This means that the following interfaces are now no longer supported:
(Note: for now nsICacheService can still be obtained: however, calling any of its methods will throw NS_ERROR_NOT_IMPLEMENTED.)
Access to previously stored cache sessions is no longer possible, and the update also causes a one-time deletion of old cache data from users’ disks.
Going forward addons must instead use the cache2 equivalents:
Below are some examples of how to migrate code from the old to the new cache API. See the new HTTP cache v2 documentation for more details.
The new cache2 implementation gets rid of some of terrible features of the old cache (frequent total data loss, main thread jank during I/O), and significantly improves page load performance. We apologize for the developer inconvenience of needing to upgrade to a new API, but we hope the performance benefits outweight it in the long run.
var cacheService = Components.classes["@mozilla.org/network/cache-service;1"]
.getService(Components.interfaces.nsICacheService);
var session = cacheService.createSession(
"HTTP",
Components.interfaces.nsICache.STORE_ANYWHERE,
Components.interfaces.nsICache.STREAM_BASED
);
session.asyncOpenCacheEntry(
"http://foo.com/bar.html",
Components.interfaces.nsICache.ACCESS_READ_WRITE,
{
onCacheEntryAvailable: function (entry, access, status) {
// And here is the cache v1 entry
}
}
);
let {LoadContextInfo} = Components.utils.import(
"resource://gre/modules/LoadContextInfo.jsm", {}
);
var cacheService = Components.classes["@mozilla.org/netwerk/cache-storage-service;1"]
.getService(Components.interfaces.nsICacheStorageService);
var storage = cacheService.diskCacheStorage(
LoadContextInfo.default,
false
);
storage.asyncOpenURI(
makeURI("http://foo.com/bar.html"),
"",
Components.interfaces.nsICacheStorage.OPEN_NORMALLY,
{
onCacheEntryCheck: function (entry, appcache) {
return Ci.nsICacheEntryOpenCallback.ENTRY_WANTED;
},
onCacheEntryAvailable: function (entry, isnew, appcache, status) {
// And here is the cache v2 entry
}
}
);
There is a lot of similarities, instead of a cache session we now have a cache storage having a similar meaning – to represent a distinctive space in the whole cache storage – it’s just less generic as it was before so that it cannot be misused now. There is now a mandatory argument when getting a storage – nsILoadContextInfo object that distinguishes whether the cache entry belongs to a Private Browsing context, to an Anonymous load or has an App ID.
(Credits to Jason Duell for help with this blog post)
The post HTTP cache v1 API disabled appeared first on mayhemer's blog.
|
|
Mark Finkle: Firefox for Android: Casting videos and Roku support – Ready to test in Nightly |
Firefox for Android Nightly builds now support casting HTML5 videos from a web page to a TV via a connected Roku streaming player. Using the system is simple, but it does require you to install a viewer application on your Roku device. Firefox support for the Roku viewer and the viewer itself are both currently pre-release. We’re excited to invite our Nightly channel users to help us test these new features, share feedback and file any bugs so we can continue to make improvements to performance and functionality.
Setup
To begin testing, first you’ll need to install the viewer application to your Roku. The viewer app, called Firefox for Roku Nightly, is currently a private channel. You can install it via this link: Firefox Nightly
Once installed, try loading this test page into your Firefox for Android Nightly browser: Casting Test
When Firefox has discovered your Roku, you should see the Media Control Bar with Cast and Play icons:

The Cast icon on the left of the video controls allows you to send the video to a device. You can also long-tap on the video to get the context menu, and cast from there too.
Hint: Make sure Firefox and the Roku are on the same Wifi network!
Once you have sent a video to a device, Firefox will display the Media Control Bar in the bottom of the application. This allows you to pause, play and close the video. You don’t need to stay on the original web page either. The Media Control Bar will stay visible as long as the video is playing, even as you change tabs or visit new web pages.

You’ll notice that Firefox displays an “active casting” indicator in the URL Bar when a video on the current web page is being cast to a device.
Limitations and Troubleshooting
Firefox currently limits casting HTML5 video in H264 format. This is one of the formats most easily handled by Roku streaming players. We are working on other formats too.
Some web sites hide or customize the HTML5 video controls and some override the long-tap menu too. This can make starting to cast difficult, but the simple fallback is to start playing the video in the web page. If the video is H264 and Firefox can find your Roku, a “ready to cast” indicator will appear in the URL Bar. Just tap on that to start casting the video to your Roku.
If Firefox does not display the casting icons, it might be having a problem discovering your Roku on the network. Make sure your Android device and the Roku are on the same Wifi network. You can load about:devices into Firefox to see what devices Firefox has discovered.
This is a pre-release of video casting support. We need your help to test the system. Please remember to share your feedback and file any bugs. Happy testing!
|
|






