Doug Belshaw: The Safe, Literate Individual in Online Spaces |
The Open Badges work that Mozilla incubated for four years now has its very own global non-profit in the guise of the Badge Alliance. As part of this, a number of working groups have been set up. Michelle Thorne and I are co-chairs of the Digital / Web Literacies group - anyone with an interest in badging this area is very welcome to join it.
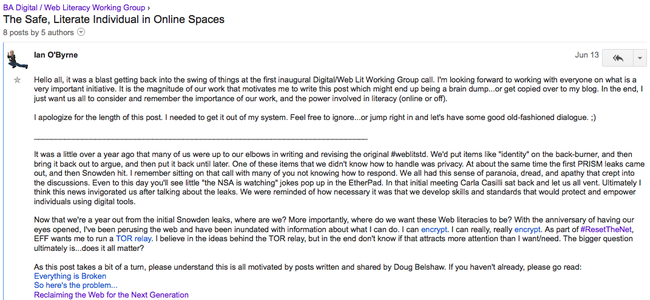
Last week, after our inaugural call, Ian O'Byrne kicked off a great discussion in a thread entitled The Safe, Literate Individual in Online Spaces. It’s a post worth reading in full, along with the responses.
Here’s an excerpt (line breaks added by me):
In our collective work on the Web Lit/Standards we’re developing a continuum of standards that individuals can consistently refer to as they “level up” and work to improve how digitally literate they are. More importantly (IMHO), teachers can use these literacies/standards to point out on the horizon to where they want their students to be.
But, as we develop and advocate for these elements, exactly what is out there on the horizon? As we increasingly have individuals work up these scales and competencies, what are they gaining and giving up? As they become more and more digitally literate or savvy, do we want them to host their own sites and develop their own infrastructure? Do we want them to increasingly become more self-actualized/paranoid/independent/self-reliant?
Additionally, as we set out for this independent spirit of the empowered web literate individual, will they ultimately be able to enact these aspects of their digital identity? Ultimately will the point be moot if/when (FCC breaks the Internet/Google turns on SkyNet/Insert doomsday scenario here) and we realize that online is online and we don’t really “own” anything in the digital space.
These are important questions which we need to discuss openly. You’re invited to do that in the Google Group, or in this thread as part of Webmaker Training.
I’m particularly interested in the following:
Comments? Questions? I’m @dajbelshaw or email doug@mozillafoundation.org
|
|
Jess Klein: Mobile Design Teaching Kit |


http://jessicaklein.blogspot.com/2014/06/mobile-design-teaching-kit.html
|
|
Ben Hearsum: How to not get spammed by Bugzilla |
Bugmail is a running joke at Mozilla. Nearly everyone I know that works with Bugzilla (especially engineers) complains about the amount of bugmail they get. I too suffered from this problem for years, but with some tweaks to preferences and workflow, this problem can be solved. Here’s how I do it:
Here’s what my full e-mail settings look like:

And here’s my Zimbra filter for changes made by me (I think the “from” header part is probably unnecessary, though):

This section is mostly just an advertisement for the “My Dashboard” feature on Mozilla’s Bugzilla. By default, it shows you your assigned bugs, requested flags, and flags requested of you. Look at it at regular intervals (I try to restrict myself to once in the morning, and once before my EOD), particularly the “flags requested of you” section.
The other important thing is to generally stop caring about a bug unless it’s either assigned to you, or there’s a flag requested of you specifically. This ties in to some of the e-mail pref changes above. Changing my default state from “I must keep track of all bugs I might care about” to “I will keep track of my bugs & my requests, and opt-in to keeping tracking of anything else” is a shift in mindset, but a game changer when it comes to the amount of e-mail (and cognitive load) that Bugzilla generates.
With these changes it takes me less than 15 minutes to go through my bugmail every morning (even on Mondays). I can even ignore it at times, because “My Dashboard” will make sure I don’t miss anything critical. Big thanks to the Bugzilla devs who made some of these new things possible, particularly glob and dkl. Glob also mentioned that even more filtering possibilities are being made possible by bug 990980. The preview he sent me looks infinitely customizable:

|
|
Dustin J. Mitchell: Introducing RelengAPI |
Mozilla's Release Engineering group provides a lot of information and services to the rest of the organization. To name just a few instances:
Release Engineering at Mozilla -- as, I'm sure, at many organizations -- moves quickly. That means tools get built when they're needed, quickly become critical to operations, and are then difficult to change. This works well for solving the problem of the moment, but it leaves a fragmented system, as you can see above.
For folks outside of Release Engineering, this is a scary "maze of twisty little passages, all alike". Building any kind of automation that interfaces with these systems is challenging, at best! And for folks inside release engineering, a chorus of unique systems means it takes a lot of time and headspace to come up to speed on each system. For example, when slaveapi breaks, the set of people who can fix it quickly is very small.
Although decoupled systems make correlated failure less likely and allow parallel, independent development efforts, in this case a failure of just about any of these systems is tree-closing (for you non-Mozillians, that basically means all work stops organization-wide -- bad).
In an ideal world, Release Engineering systems would interface with the outside world through a nice, well-documented API. Think of the Github API, or the APIs for the AWS tools.
Building such an interface will allow release engineering to continue to iterate quickly. In fact, it may allow the group to move more quickly: much of the friction of building a new feature comes from interfacing with other, existing systems. If those other systems are all available via the same REST API, then that interface becomes trivial.
Such an interface also encourages supportability and cross-pollination between projects. Since everything interacts with the API, everyone in release engineering knows how the API works and how it is implemented. If something goes wrong, there's no frantic search for expertise.
Finally, and best of all, this model multiplies Mozilla's force by enabling other Mozillians to develop tools around release engineering. There are great ideas out there about analyzing build times over time, automatically bisecting failures, automatically landing patches, diagnosing failing slaves, and more. Today, many of these are difficult for someone outside of releng to work on. But with an open API, all of these ideas become self-serve: no need to ask for permission or get a release engineer to work on the project.
So how do we get there?
About a year ago, some members of Release Engineering met at the releng work-week in Boston to discuss application-development best practices. We decided on a few languages, tools, and processes that we could agree were "good enough", and where there was an advantage to using the same tools everywhere. This became the Release Engineering Development Best Practices document.
Taking that work a step further, it made sense to build a system that already implements all of those best practices. That system is the Releng API - your interface to release engineering automation.
It's a "batteries included" approach both for release engineers and API consumers. It implements lots of features, using the established best practices, and it implements them once -- no re-inventing the wheel required. Release engineers building a new feature can focus on the feature itself, with all of the usual concerns around deployment, security, management, and mointoring taken care of. Consumers can interface with the new feature immediately, since it uess exactly the same interface, flows, authentication, and so on as any other release engineering feature.
Development of the API itself is well underway, mirrored at Github. The service is up and running at https://api.pub.build.mozilla.org.
We're already building two substantial new features within the framework: mapper and SlaveLoan, and we have plans to port some existing systems to the API. We're targetting a 1.0.0 release for the next week or so, after which time we'll follow typical semantic versioning practices around compatibility.
We would love help and feedback on many aspects of the project, if you have particluar expertise. We are by no means experts on web security, API design, or UI design!
I will be writing some more technical entries about particular features of the Releng API over the next few weeks. If something jumps out at you as obviously wrong (or right!), please get in touch.
http://code.v.igoro.us/posts/2014/06/Introducing-Relengapi.html
|
|
David Burns: Introducing Bugsy - Client Library for interacting with Bugzilla |
I have created a library for interacting with Bugzilla using the native REST API. Bugsy allows you to get bugs from Bugzilla, change what you need to and then post it back to Bugzilla. I have created documentation to get you started.
For example to get a bug you would do
import bugsy bugzilla = bugsy.Bugsy() bug = bugzilla.get(123456)
and then to put it back, or if there is no bug ID (like if you were creating it) then you would do
import bugsy
bug = bugsy.Bug()
bug.summary = "I really realy love cheese"
bug.add_comment("and I really want sausages with it!")
bugzilla = bugsy.Bugsy("username", "password")
bugzilla.put(bug)
bug.id #returns the bug id from Bugzilla
Searching Bugzilla is not currently supported but will definitely be there for the next version.
Please raise issues on GitHub
|
|
Daniel Stenberg: Firefox and partial content |
 One of the first bugs that fell into my lap when I started working for Mozilla not a very long time ago, was bug 237623. Anyone involved in Mozilla knows a bug in that range is fairly old (we just recently passed one million filed bugs). This particular bug was filed in March 2004 and there are (right now) 26 other bugs marked as duplicates of this. Today, the fix for this problem has landed.
One of the first bugs that fell into my lap when I started working for Mozilla not a very long time ago, was bug 237623. Anyone involved in Mozilla knows a bug in that range is fairly old (we just recently passed one million filed bugs). This particular bug was filed in March 2004 and there are (right now) 26 other bugs marked as duplicates of this. Today, the fix for this problem has landed.
The core of the problem is that when a HTTP server sends contents back to a client, it can send a header along indicating the size of the data in the response. The header is called “Content-Length:”. If the connection gets broken during transfer for whatever reason and the browser hasn’t received as much data as was initially claimed to be delivered, that’s a very good hint that something is wrong and the transfer was incomplete.
The perhaps most annoying way this could be seen is when you download a huge DVD image or something and for some reason the connection gets cut off after only a short time, way before the entire file is downloaded, but Firefox just silently accept that as the end of the transfer and think everything was fine and dandy.
What complicates the issue is the eternal problem: not everything abides to the protocol. This said, if there are frequent violators of the protocol we can’t strictly fail on each case of problem we detect but we must instead do our best to handle it anyway.
Is Content-Length a frequently violated HTTP response header?
Let’s see…
My fix for this problem takes a slightly careful approach and only enforces the strictness for HTTP 1.1 or later servers. But then as a bonus, it has grown to also signal failure if a chunked encoded transfer ends without the ending trailer or if a SPDY or http2 transfer gets prematurely stopped.
This is basically a 6-line patch at its core. The rest is fixing up old test cases, added new tests etc.
As a counter-point, Eric Lawrence apparently worked on adding stricter checks in IE9 three years ago as he wrote about in Content-Length in the Real World. They apparently subsequently added the check again in IE10 which seems to have caused some problems for them. It remains to be seen how this change affects Firefox users out in the real world. I believe it’ll be fine.
This patch also introduces the error code for a few other similar network situations when the connection is closed prematurely and we know there are outstanding data that never arrived, and I got the opportunity to improve how Firefox behaves when downloading an image and it gets an error before the complete image has been transferred. Previously (when a partial transfer wasn’t an error), it would always throw away the image on an error and instead show the “image not found” picture. That really doesn’t make sense I believe, as a partial image is better than that default one – especially when a large portion of the image has been downloaded already.
Other effects of this change that possibly might be discovered and cause some new fun reports: prematurely cut off transfers of javascript or CSS will discard the entire javascript/CSS file. Previously the partial file would be used.
Of course, I doubt that these are the files that are as commonly cut off as many other file types but still on a very slow and bad connection it may still happen and the new behavior will make Firefox act as if the file wasn’t loaded at all, instead of previously when it would happily used the portions of the files that it had actually received. Partial CSS and partial javascript of course could lead to some “fun” effects of brokenness.
http://daniel.haxx.se/blog/2014/06/16/firefox-and-partial-content/
|
|
Nicholas Nethercote: A browser benchmarking manifesto |
This post represents my own opinion, not the official position of Mozilla.
I’ve been working on Firefox for over five years and I’ve been unhappy with the state of browser benchmarking the entire time.
Most of the benchmark suites are terrible. Consider at Hennessy and Patterson’s categorization of benchmarks, from best to worst.
In my opinion, benchmark suites should only contain benchmarks in categories 1 and 2. There are certainly shades of grey in these categories, but I personally have a high bar, and I’m likely to consider most programs whose line count is in the hundreds as closer to a “toy benchmark” than a “real application”.
Very few browser benchmark suites contain benchmarks from category 1 or 2. I think six or seven of the benchmarks in Octane meet this standard. I’m having trouble thinking of any other existing benchmark suite that contains any that reach this standard. (This includes Mozilla’s own Kraken suite.)
Bad benchmark suites hurt the web, because every hour that browser vendors spend optimizing bad benchmarks is an hour they don’t spend improving browsers in ways that actually help users. I’ve seen first-hand how much time this wastes.
Some of the benchmark suites — including the best-known ones — come from browser vendors. The conflict of interest is so obvious I won’t bother discussing it further.
Some of them have opaque scoring systems. Octane (derived from V8bench) is my least favourite here. It also suffers from much higher levels of variance between runs than the benchmarks with time-based scoring systems.
Here’s how I think a new browser benchmark suite should be created. Some of these ideas are taken from the SPEC benchmark suiteswhich have been used for over 20 years to benchmark the performance of C, C++, Fortran and Java programs, among other things.
The suite shouldn’t be owned by a single browser vendor. Ideally, all the major browser vendors (Apple, Google, Microsoft, and Mozilla) would be involved. Involvement of experts from outside those companies would also be desirable.
This is a major political and organizational challenge, but it would avoid bias (both in appearance and reality), and would likely lead to a higher-quality suite, because low-quality benchmarks are likely to be shot down.
There should be a public submissions process, where people submit web
apps/sites for consideration. And obviously there needs to be a selection
process to go with that.
The benchmark suite should be open source and access should be free of
charge. It should be hosted on a public site not owned by a browser vendor.
There should also be an official process for modifying the suite: modifying benchmarks, removing benchmark, and adding new benchmarks. This process
shouldn’t be too fluid. Perhaps allowing changes once per year would be reasonable. The current trend of continually augmenting old suites should be resisted.
All benchmarks should be challenging, and based on real website/apps; they should all belong to category 1 or 2 on the above scale.
Each benchmark should have two or three inputs of different sizes. Only the
largest input would be used in official runs, but the smaller inputs
would be useful for browser developers for testing and profiling purposes.
All benchmarks should have side-effects of some kind that depend on most or
all of the computation. There should be no large chunks of computation whose
results are unused, because such benchmarks are subject to silly results due
to certain optimizations such as dead code elimination.
Any categorization of benchmarks should not be done by browser subsystems. E.g. there shouldn’t be groups like “DOM”, “CSS”, “hardware acceleration”, “code loading” because that encourages artificial benchmarks that stress a single
subsystem. Instead, any categories should be based on application domain:
“games”, “productivity”, “multimedia”, “social”, etc. If a grouping like
that ends up stressing some browser subsystems more than others, well that’s
fine, because it means that’s what real websites/apps are doing (assuming the
benchmark selection is balanced).
There is one possible exception to this rule, which is the JavaScript engine. At least some of the benchmarks will be dominated by JS execution time, and because JS engines can be built standalone, the relevant JS engine
teams will inevitably want to separate JS code from everything else so that
the code can be run in JS shells. It may be worthwhile to pre-emptively do that, where appropriate. If that were done, you wouldn’t run these JS-only sub-applications as part of an official suite run, but they would be present in the repository.
Scoring should be as straightforward as possible. Times are best because their meaning is more obvious than anything else, *especially* when multiple
times are combined. Opaque points systems are awful.
Using times for everything makes most sense when benchmarks are all
throughput-oriented. If some benchmarks are latency-oriented (or FPS, or
something else) this becomes trickier. Even still, a simple system that humans can intuitively understand is best.
It’s time the browser world paid attention to the performance and benchmarking lessons that the CPU and C/C++/Fortran worlds learned years ago. It’s time to grow up.
If you want to learn more, I highly recommend getting your hands on a copy of Hennessy & Patterson’s Computer Architecture and reading the section on measuring performance. This is section 1.5 (“Measuring and Reporting Performance”) in the 3rd edition, but I expect later editions have similar sections.
https://blog.mozilla.org/nnethercote/2014/06/16/a-browser-benchmarking-manifesto/
|
|
Nicholas Nethercote: MemShrink’s 3rd birthday |
June 14, 2014 was the third anniversary of the first MemShrink meeting. MemShrink is a mature effort at this point, and many of the problems that motivated its creation have been fixed. Nonetheless, there are still some areas for improvement. So, as I did at this time last year, I’ll take the opportunity to update the “big ticket items” list.
pdf.js is the PDF viewer that now ships by default in Firefox. I greatly reduced its memory usage in two rounds, first in February, and again in June. The first round of improvements were released in Firefox 29, and the second round is due to be released in Firefox 33, which should be out in mid-October.
pdf.js will still use more memory than native PDF viewers, but the situation has improved enough that it can be removed from this list.
See below.
Cervantes Yu, Thinker Li, and others succeeded in landing Nuwa, an impressive technical achievement that increased the amount of memory sharing between different processes on Firefox OS. This allows many more apps to run at once. I think this is present in Firefox OS 1.3 and later.
See below.
Timothy Nikkel completely fixed the massive spikes in decoded image data that we used to get on image-heavy pages. This was a fantastic improvement that shipped in Firefox 26.
In a break from tradition, I will present the items in alphabetical order, rather than ranking them. This reflects the fact that I don’t have a clear opinion on the relevant importance of these different items. (I view this as a good thing, because it means that I feel there aren’t any hair-on-fire problems.)
areweslimyet.com (a.k.a. AWSY) is our best tool for detecting memory usage regressions. It currently tracks Firefox and Firefox for Android, and there are plans to integrate Firefox OS.
Unfortunately, although AWSY has been successful at detecting large regressions, leading to them being fixed, its measurements are noisy enough that detecting smaller regressions is difficult. As a result, the general trend of the graphs has been upward. I do not think this is as bad as it looks at first glance, because Firefox’s behaviour in the worst cases — which matter more than the average case — is much better than it used to be. Nonetheless, improved sensitivity here would be an excellent thing, and Eric Rahm is actively working on this.
Developer-oriented memory profiling tools are under active development by Nick Fitzgerald, Jim Blandy, and others. A lot of the necessary profiling infrastructure is in place, and this seems to be progressing well, though I don’t know when it’s expected to be finished.
By the way, if you haven’t tried Firefox’s dev tools recently, you should! They have improved an incredible amount in the past year or so.
Generational GC landed a few months ago. I had been hoping that this would help reduce GC fragmentation, but the effect was small. It looks like compacting GC is what’s needed to make a big difference here, though some smaller tweaks may help things a little.
Tarako is the codename for the “$25 phone” running Firefox OS that will ship in India and other countries later this year. It has a paltry 128 MiB of RAM, so memory usage is critical. Since the hardware first became available to Mozilla employees at the start of the year, Tarako has improved from “almost unusable” to “not bad”. But apps still close due to OOMs fairly frequently, especially when a user does something that involves two apps working together in some way.
There is no single change that will decisively fix this problem for Tarako; further improvements will require an ongoing grind of work from many engineers. Improvements made for Tarako are also likely to benefit higher-end Firefox OS devices as well.
The number of out-of-memory (OOM) crashes that occur on Windows is relatively high. A sizeable fraction of these appear to be 32-bit virtual OOM crashes, caused by running out of address space.
Things that will mitigate this include modifications to jemalloc and the JS allocator, as well as Electrolysis. And some additional data and analysis may help us understand the problem better.
The ultimate solution, for users on 64-bit versions of Windows, is 64-bit Firefox builds for Windows, though it’ll be a while before those builds are in good enough shape to ship to regular users.
Three items from the old list (pdf.js, Nuwa, image handling) have been ticked off. Two items remain (devtools, GC fragmentation), the latter in altered form, and both are a lot closer to completion than they were. Three new items (regression detection, Tarako, and Windows OOMs) have been added.
Let me know if I’ve omitted anything important!
https://blog.mozilla.org/nnethercote/2014/06/16/memshrinks-3rd-birthday/
|
|
Nicholas Nethercote: An even slimmer pdf.js |
TL;DR: Firefox’s built-in PDF viewer is on track to benefit from additional large reductions in memory consumption when Firefox 33 is released in mid-October.
Earlier this year I made some major improvements to the memory usage and speed of pdf.js, Firefox’s built-in PDF viewer. At the time I was quite pleased with myself. I had picked all the low-hanging fruit and reached a point of diminishing returns.
Shortly after that, while on a plane I tried pdf.js on my Mac laptop. I was horrified to find that memory usage was much higher than on the Linux desktop machine on which I had done my optimizations. The first document I measured made Firefox’s RSS (resident set size, a.k.a. physical memory usage) peak at over 1,000 MiB. The corresponding number on my Linux desktop had been 400 MiB! What was going on?
The short answer is “canvases”. pdf.js uses HTML canvas elements to render each PDF page. These can be millions of pixels in size, and each canvas pixel takes 32-bits of RGBA data. But on Linux this data is not stored within the Firefox process. Instead, it gets passed to the X server. Firefox’s about:memory page does report the canvas usage under the “canvas-2d-pixels” and “gfx-surface-xlib” labels, but I hadn’t seen those — during my optimization work I had only measured the RSS of the Firefox process. RSS is usually the best single number to focus on, but in this case it was highly misleading.
In contrast, on Mac the canvas data is stored within the process, which is why Firefox’s RSS is so much higher on Mac. (There’s also the fact that my MacBook has a retina screen, which means the canvases used have approximately four times as many pixels as the canvases used on my Linux machine.)
It turns out that pdf.js was intentionally caching an overly generous number of canvases (20) and then unintentionally failing to dispose of them in a timely manner. This could result in hundreds of canvases being held onto unnecessarily if you scrolled quickly through a large document. On my MacBook each canvas is over 20 MiB, so the resultant memory spike could be enormous.
Happily, I was able to fix this behaviour with four tiny patches. pdf.js now caches only 10 canvases, and disposes of any excess ones immediately.
I measured the effects of both rounds of optimization on the following three documents on my Mac.
For each document, I measure the peak RSS while scrolling quickly from the first page to the last by holding down the “fn” and down keys at the same time. Although this is a stress test, it’s not unrealistic; it’s easy to imagine people quickly scrolling through 10s or even 100s of pages of a PDF to find a particular page.
I did this three times for each document and picked the highest value. The results are shown by the following graph. The “Fx28'' bars show the original peak RSS values; the “Fx29'' bars show the peak RSS values after my first round of optimizations; and the “Fx33'' bars show the peak RSS values after my second round of optimizations.

Comparing Firefox 28 and Firefox 33, the reductions in peak RSS for the three documents are 1.2x, 4.4x, and 7.8x. It makes sense that the relative improvements increase with the length of the documents.
Despite these major improvements, pdf.js still uses substantially more memory than native PDF viewers. So we need to keep chipping away… but it’s also worth recognizing how far we’ve come.
These patches have landed in the master pdf.js repository. They have not yet imported into Firefox’s code, but this will happen at some point during the development cycle for Firefox 33. Firefox 33 is on track to be released in mid-October.
https://blog.mozilla.org/nnethercote/2014/06/16/an-even-slimmer-pdf-js/
|
|
Eric Shepherd: Talking shop at Open Help |
I’m happy with how my talk at the Open Help conference went this morning. I gave a talk about how Mozilla builds, fosters, and provides useful information to our documentation community. I enjoyed giving it, and the questions were good ones.
I saw a lot of note-taking and nodding heads, and the discussions over the rest of the day definitely gave me the sense that people appreciated my thoughts on documentation community-building and processes. I hope there will be video available at some point; certainly it was recorded.
Our documentation status pages and other ways we present data about tasks that need to be performed really got a lot of attention, and Florian’s graph of our contributor growth really opened some eyes — especially when I pointed to the sharp uptick since we deployed our in-house grown, open source, Kuma documentation platform.
Also, I think our development team will be pleased that I heard a lot of “I wish we were using Kuma for our docs” today, and at least one person saying they’re going to look at setting up to try building it themselves.
Three or four people said that if it were separated from the Mozilla-specific bits, they’d be pushing to switch to Kuma. That made me smile; hopefully they will still feel that way if/when we manage to ever make the platform separate from the MDN-specific parts.
I’m with my people here; it’s really wonderful to just talk about documentation tactics without all the other stuff. It’s a great feeling, especially when it seems you’re able to give your peers ideas to take home and try for themselves.
View my slides below, or download them as a PDF.
http://www.bitstampede.com/2014/06/14/talking-shop-at-open-help/
|
|
Andy McKay: Unique US |
After the latest shootings in the US, their president said:
"A lot of people will say that, well, this is a mental-health problem, it's not a gun problem. The United States does not have a monopoly on crazy people. It's not the only country that has psychosis. And yet, we kill each other in these mass shootings at rates that are exponentially higher than anyplace else."
What does the US have a "monopoly" on?
It's foolish to say that in a large complicated society any single factor causes another. But you can look at the composition of that society through key indicators and see how it treats people for clues its behaviour.
Or to put it another way:
|
|
Ben Hearsum: This week in Mozilla RelEng – June 13th, 2014 – *double edition* |
I spaced and forgot to post this last week, so here’s a double edition covering everything so far this month. I’ll also be away for the next 3 Fridays, and Kim volunteered to take the reigns in my stead. Now, on with it!
Major highlights:
Completed work (resolution is ‘FIXED’):
In progress work (unresolved and not assigned to nobody):
http://hearsum.ca/blog/this-week-in-mozilla-releng-june-13th-2014-double-edition/
|
|
Smokey Ardisson: 663399 |
Some years ago now, long after nearly all web standards people had adopted Firefox or Safari, the great CSS guru Eric Meyer was (still) a Camino user. In that capacity, I interacted with him a few times in my role as a member of the Camino team.
Today I join with the global community of those who knew or were influenced by the Meyers in presenting a #663399Becca border on
|
|
Chris Double: Update on Tor on Firefox Proof of Concept |
Yesterday I wrote about Tor on Firefox OS. Further testing showed an issue when switching networks - a common thing to happen when carrying a mobile device. The iptables rule I was using didn’t exclude the tor process itself from having traffic redirected. When a network switch occurred tor would attempt to reestablish connections and this would fail.
A fix for this is to exclude tor from the iptables rules or to use rules for specific processes only. The processes that belong to an Firefox OS application be be viewed with b2g-ps:
APPLICATION SEC USER PID PPID VSIZE RSS NAME
b2g 0 root 181 1 494584 135544 /system/b2g/b2g
(Nuwa) 0 root 830 181 55052 20420 /system/b2g/plugin-container
Built-in Keyboa 2 u0_a912 912 830 67660 26048 /system/b2g/plugin-container
Vertical 2 u0_a1088 1088 830 103336 34428 /system/b2g/plugin-container
Usage 2 u0_a4478 4478 830 65544 23584 /system/b2g/plugin-container
Browser 2 u0_a26328 26328 830 75680 21164 /system/b2g/plugin-container
Settings 2 u0_a27897 27897 830 79840 28044 /system/b2g/plugin-container
(Preallocated a 2 u0_a28176 28176 830 62316 18556 /system/b2g/plugin-containerUnfortunately the iptables that ships with Firefox OS doesn’t seem to support the --pid-owner option for rule selection so I can’t select specifically the tor or application processes. I can however select based on user or group. Each application gets their own user so the option to redirect traffic for applications can use that. I wasn’t able to get this working reliably though so I switched to targeting the tor process itself.
In my writeup I ran tor as root. I need to run as a different user so that I can use --uid-owner on iptables. Firefox OS inherits the Android method of users and groups where specific users are hardcoded into the system. Since this is a proof of concept and I want to get things working quickly I decided to pick an existing user, system, and run tor as that. By setting the User option in the Tor configuration file I can have Tor switch to that user at run time. Nothing is ever that easy though as user does not have permission to do the many things that tor requires. It can’t create sockets for example.
Enter Linux capabilities. It is possible to grant a process certain capabilities which give it the right to perform priviledged actions without being a superuser. There is an existing Tor trac ticket about this and I used the sample code in that ticket to modify tor to keep the required capabilities when it switches user, I put the code I cobbled together to patch tor in tor.patch.
To use this change the Building tor section of my original post to use these commands:
$ cd $HOME/build
$ wget https://www.torproject.org/dist/tor-0.2.4.22.tar.gz
$ cd tor-0.2.4.22
$ curl http://bluishcoder.co.nz/b2g/tor.patch | patch -p1
$ ./configure --host=arm-linux-androideabi \
--prefix=$HOME/build/install \
--enable-static-libevent
$ make
$ make installChange the Tor configuration file to switch the user to system in the Packaging Tor for the device section:
DataDirectory /data/local/tor/tmp
SOCKSPort 127.0.0.1:9050 IsolateDestAddr
SOCKSPort 127.0.0.1:9063
RunAsDaemon 1
Log notice file /data/local/tor/tmp/tor.log
VirtualAddrNetwork 10.192.0.0/10
AutomapHostsOnResolve 1
TransPort 9040
DNSPort 9053
User systemI’ve also changed the location of the data files to be in a tmp directory which needs to be given the system user owner. Change the steps in Running tor to:
$ adb shell
# cd /data/local/tor
# mkdir tmp
# chown system:system tmp
# ./tor -f torrc &
# iptables -t nat -A OUTPUT ! -o lo
-m owner ! --uid-owner system \
-p udp --dport 53 -j REDIRECT --to-ports 9053
# iptables -t nat -A OUTPUT ! -o lo \
-m owner ! --uid-owner system \
-p tcp -j REDIRECT --to-ports 9040Now tor should work in the presence of network switching. I’ve updated the b2g_tor.tar.gz to include the new tor binary, the updated configuration file, and a couple of shell scripts that will run the iptables commands to redirect traffic to tor and to cancel the redirection.
As before the standard disclaimer applies:
All files and modifications described and provided here are at your own risk. This is a proof of concept. Don’t tinker on devices you depend on and don’t want to risk losing data. These changes are not an official Mozilla project and do not represent any future plans for Mozilla projects.
This is probably as far as I’ll take things for now with this proof of concept and see what happens from here after using it for a while.
http://bluishcoder.co.nz/2014/06/13/update-to-tor-on-firefox-proof-of-concept.html
|
|
Pierros Papadeas: Damned Lies and Contribution Metrics |
The power of numbers is unquestionable. I never fully understood though, what it is. Possibly the urge of everyone to explain the world rationally. Or the need for reference to make any decision an “informed one”. Whatever it is, it drives people. Mozilla wouldn’t be an exception.
The ask was simple enough:
How many active contributors do we have in Mozilla?
No one knew last year, that a year in today we would only have scratched the surface of this question. But in the process of doing so we laid a solid foundation to move us forward.
Yesterday Adam Lofting announced the unified Mozilla Foundation and Mozilla Corporation contributors dashboard which you can check out visiting areweamillionyet.org This has been a collaborative effort between both teams and an incredible journey so far exploring and articulating notions of contribution metrics across the Mozilla Project. Project Baloo (intro post here) is underway to supply all the data that will fuel the unified dashboard, starting with Bugzilla, and Github data, thanks to Sheeri and Anurag from BI team. Next in line are Reps, SuMo and MDN. All data will be gathered in a central database, in a common schema, updated almost instantly by the systems that activities are happening. You can track the progress here.
Project Baloo (intro post here) is underway to supply all the data that will fuel the unified dashboard, starting with Bugzilla, and Github data, thanks to Sheeri and Anurag from BI team. Next in line are Reps, SuMo and MDN. All data will be gathered in a central database, in a common schema, updated almost instantly by the systems that activities are happening. You can track the progress here.
Adam’s post has all the technical details about the current implementation (so I will not go into details here) but I would like to expand a bit around the importance of deduplication and cross-examination of metrics between different teams of Mozilla.
Being a Community Builder inside Mozilla you want metrics for your contribution area. You can see people come and go, but you have no idea whether those people are moving to other teams or leaving Mozilla completely. With cross examination of contribution metrics we will be able to see trends and movements of people across different projects and teams for the first time.
Using deduplication of identities (based on emails) we will get a much more accurate count of people, that will improve even more once we integrate with Mozillians.org and Workday so we can deduplicate people using multiple emails. Anecdotally (and based on the initial real data we have) we know for sure that the actual count of active contributors will be considerably lower that the sum of active contributors on all teams.
 Expect more updates to come as we roll new integrations in and new data-sets become available.
Expect more updates to come as we roll new integrations in and new data-sets become available.
|
|
Gervase Markham: Hotmail Certificate Oopsie |
https://www.hotmail.co.uk/ is throwing cert errors this morning. Looks like they renewed their cert recently and, among the many SANs included, forgot “www.hotmail.co.uk”. https://hotmail.co.uk/ works fine…
This issue was reported to me by my mother (who rang me when she had a cert problem rather than just clicking through it! :-), so it’s not just me…
http://feedproxy.google.com/~r/HackingForChrist/~3/yP6vy4BfWGg/
|
|
Peter Bengtsson: Crontabber |
Yesterday I had the good fortune to present Crontabber to the The San Francisco Bay Area PostgreSQL Meetup Group organized by my friend Josh Berkus.
To spare you having to watch the whole presentation I'm going to summarize some of it here.
My colleague Lars also has a blog post about Crontabber and goes into a bit more details about the nitty gritty of using PostgreSQL.
It's a tool for running cron jobs. It's written in Python and PostgreSQL and it's a tool we need for Socorro which has lots and lots of stored procedures and cron jobs.
So it's basically a script that gets started by UNIX crontab and runs every 5 minutes. Internally it keeps an index of all the apps it needs to run and it manages dependencies between jobs and is self-healing meaning that if something goes wrong during run-time it just retries again and again until it works. Amongst many of the juicy features it offers on top of regular "cron wrappers" is something we call "backfilling".
Backfill jobs are jobs that happen on a periodic basis and get given a date. If all is working this date is the same as "now()" but if something was to go wrong it remembers all the dates that did not work and re-attempts with those exact dates. That means that you can guarantee that the job gets started with every date possible even if it needs to catch up on past dates.
There's plenty of documentation on how to install and create jobs but it all starts with a simple pip install crontabber.
To get a feel for how you write crontabber "apps", checkout the ones for Socorro or flick through the slides in the PDF.
Yes! It all started in early 2012 as a part of the Socorro code base and after some hard months of it stabalizing and maturing we decided to extract it out of Socorro and into its own project on GitHub under the Mozilla Public Licence 2.0 licence. Now it stands on its own legs and has no longer anything to do with Socorro and can be used for anything and anyone who has a lot of complicated cron jobs that need to run in Python with a PostgreSQL connection. In Socorro we use it primarily for executing stored procedures but that's just one type of app. You can also make it call out on to anything the command line with a "@with_subprocess" decorator.
No. It works really well for us but there's a decent list of features we want to add. The hope is that by open sourcing it we can get other organizations to adopt it and not only find bugs but also contribute code to add more juicy features.
One of the soon-to-come features we have in mind is to "internalize locking". At the moment you have to wrap it in a bash script that prevents it from being run concurrently. Crontabber is single-threaded and we don't have to worry about "dependent jobs" starting before "parent jobs" because the depdendencies and their state is stored in the database. But you might need to worry about the same job (the one due next) to be started concurrently. By internalizing the locking we can store, in the state database, that a particular job is being started on and thus not have to worry about it starting the same job twice.
I really hope this project can grow and continue to support us in our needs.
|
|
Nicholas Nethercote: areweslimyet.com data is now exportable and diffable |
areweslimyet.com (a.k.a. AWSY) tracks Firefox’s memory usage on a basic workload that opens lots of websites. It’s not a perfect tool — you shouldn’t consider its measurements as a reliable proxy for Firefox’s memory usage in general — but it does help detect regressions.
One thing it doesn’t support is doing diffs between separate runs. Until now, that is! Thanks to work done by Eric Rahm, it’s now possible to download the data for each snapshot done during a run. This file can then be loaded in about:memory. It’s also possible to download the data for two snapshots and diff them in about:memory. Yay! This diff workflow isn’t super slick, as it requires the downloading of two files and then the loading of them in about:memory. But it’s a lot better than manually eyeballing two sets of data in two separate AWSY tabs, which was the best we could do previously. Furthermore, AWSY and about:memory already duplicate some functionality, and this implementation avoids increasing the amount of duplication.
To do the export, select a single run (zooming in on the graph appropriately) and click on the red “[export]” link next to the appropriate snapshot, as seen in the following screenshot.

Once it has finished generating the data, the “[export]” link changes to “[download]“, and you can click on it again to do the download.
This is a first step towards improving AWSY so that it can detect memory usage regressions with much higher sensitivity than it currently has.
|
|
Chris Double: Using Tor with Firefox OS |
Update - Please read my followup post for some additional information and updated steps on building and installing tor on Firefox OS.
Please read the disclaimer at the end of this article. This is a proof of concept. It’s a manual process and you shouldn’t depend on it. Make sure you understand what you are doing.
I’m a fan of Tor. The Tor site explains what it does:
Tor is free software and an open network that helps you defend against traffic analysis, a form of network surveillance that threatens personal freedom and privacy, confidential business activities and relationships, and state security.
I make my personal website available as a Tor hidden service accessible from mh7mkfvezts5j6yu.onion. I try to make other sites I’m involved with also have a presence over Tor. I do a fair amount of my browsing over the Tor network for no reason other than I can and it limits the opportunity for people snooping on my data.
I want to be able to use Tor from Firefox OS. In particular I want it embedded as low level as possible so I have the option of all traffic going over Tor. I don’t want to have to configure socks proxies.
Firefox OS doesn’t allow native applications. The low level underlying system however is based on Linux and Android and can run native binaries. Starting with a rooted Firefox OS install I built Tor and used iptables to reroute all network traffic to work over it. This is a first step and is what this article demonstrates how to get going so power users can try it out. My next step would be to investigate integrating it into the build system of Firefox OS and providing ways to start/stop it from the OS interface.
The first stage of building is to have an Android standalone toolchain installed. I describe how to do this in my Wasp Lisp on Android post or you can use a Nix package I created for use with the Nix package manager.
Tor requires libevent to build. I’m using static libraries to make creating a standalone tor binary easier. The following will build libevent given the standalone toolchain on your path:
$ cd $HOME
$ mkdir build
$ cd build
$ wget https://github.com/downloads/libevent/libevent/libevent-2.0.21-stable.tar.gz
$ tar xvf libevent-2.0.21-stable.tar.gz
$ cd libevent-2.0.21-stable
$ ./configure --host=arm-linux-androideabi \
--prefix=$HOME/build/install \
--enable-static --disable-shared
$ make
$ make installTor requires openssl which in turn requires zlib:
$ cd $HOME/build
$ wget http://zlib.net/zlib-1.2.8.tar.gz
$ tar xvf zlib-1.2.8.tar.gz
$ cd zlib-1.2.8
$ CC=arm-linux-androideabi-gcc ./configure --prefix=$HOME/build/install --static
$ make
$ make install$ cd $HOME/build
$ wget http://www.openssl.org/source/openssl-1.0.1h.tar.gz
$ tar xvf openssl-1.0.1h.tar.gz
$ cd openssl-1.0.1h
$ CC=arm-linux-androideabi-gcc ./Configure android no-shared --prefix=$HOME/build/install
$ make
$ make install$ cd $HOME/build
$ wget https://www.torproject.org/dist/tor-0.2.4.22.tar.gz
$ cd tor-0.2.4.22
$ ./configure --host=arm-linux-androideabi \
--prefix=$HOME/build/install \
--enable-static-libevent
$ make
$ make installTo run on the Firefox OS device I just installed the tor binary and a configuration file that enables transaparent proxing as per the Tor documentation on the subject. I put these in a directory that I push to an easily accessible place on the device:
$ mkdir $HOME/build/device
$ cd $HOME/build/device
$ cp $HOME/build/install/bin/tor .
$ cat >torrc
...contents of configuration file...
$ adb push $HOME/build/device /data/local/torThe configuration file is:
DataDirectory /data/local/tor
Log notice file /data/local/tor/tor.log
RunAsDaemon 1
SOCKSPort 127.0.0.1:9050 IsolateDestAddr
SOCKSPort 127.0.0.1:9063
VirtualAddrNetwork 10.192.0.0/10
AutomapHostsOnResolve 1
TransPort 9040
DNSPort 9053I haven’t integrated tor into the device at all so for this proof of concept I adb shell into it to run it and configure the iptables to redirect traffic:
$ adb shell
# cd /data/local/tor
# ./tor -f torrc &
# iptables -t nat -A OUTPUT ! -o lo -p udp --dport 53 -j REDIRECT --to-ports 9053
# iptables -t nat -A OUTPUT ! -o lo -p tcp -j REDIRECT --to-ports 9040The device should now be sending traffic over Tor. You can test by visiting sites like whatismyip.com or icanhazip.com to see if it reports a different IP address and location to what you normally have. You can also try out hidden services like mh7mkfvezts5j6yu.onion which should show this site.
Killing the Tor process and removing the iptables entries will set the network back to normal:
$ adb shell ps|grep tor
$ adb shell
# kill ...process id of tor...
# iptables -t nat -FYou can optionally delete the /data/local/tor directory to remove all tor files:
$ adb shell rm -r /data/local/torThis is just a proof of concept. Don’t depend on this. You need to restart Tor and the iptables commands on reboot. I’m not sure how well interaction with switching to/from WiFi and GSM works. Ideally Tor would be integrated with Firefox OS so that you can start and stop it as a service and maybe whitelist or blacklist sites that should and shouldn’t use Tor. I hope to do some of this over time or hope someone else gets excited enough to work on it too.
Another privacy aspect I’d like to investigate is whether TextSecure (or a similar service) could be integrated in the way it’s done in CyanogenMod:
“The result is a system where a CyanogenMod user can choose to use any SMS app they’d like, and their communication with other CyanogenMod or TextSecure users will be transparently encrypted end-to-end over the data channel without requiring them to modify their work flow at all.”
Ideally my end goal would be to have something close to that described in the hardening Android post on the Tor Project blog.
I’m not sure how possible that is though. But Firefox OS is open source, easy to build and hack on, and runs on a lot of devices, including multi booting on some. Adding things like this to build your own custom phone OS that runs web applications is one of the great things the project enables. Users should feel like they can dive in and try things rather than wait for an OS release to support it (in my opinion of course).
A tar file containing a precompiled tor and the torrc is available at b2g_tor.tar.gz.
All files and modifications described and provided here are at your own risk. Don’t tinker on devices you depend on and don’t want to risk losing data. These changes are not an official Mozilla project and do not represent any future plans for Mozilla projects.
http://bluishcoder.co.nz/2014/06/12/using-tor-with-firefox-os.html
|
|
David Boswell: Enabling communities that have impact |
If I had to summarize the Town Hall about the goal to increase the number of active contributors by 10x this year, I would use the word ‘intention’. This word captures how this is the time we pivot from unplanned to planned community building.
To learn more about why we need to become intentional about community building, what our vision is of where we need to be going and what we’ll get by making this shift, take a look at the recording of the Town Hall presentation and Q&A.

We had the Town Hall in the San Francisco space and right outside the entrance is the Mozilla Monument. I think the monument provides a really great concrete example of this pivot toward intentional community building.
There are over 4,000 names on the monument that represent the first 15 years of Mozilla’s history. We’re planning on more than tripling that number of people in one year. This is only possible with an intentional, scalable and systematic approach.
The monument was created as a physical representation of the community (for instance, the globe is designed to let light through to demonstrate how we are a transparent community) and I’d love to see it also embody this increase in our community.

Updating the monument with the names of the new active contributors that join the community this year would be a great way to show progress toward this goal. Hopefully people have better ideas for adding names than the sticky note approach that Larissa and I took :)
Maybe the panels get replaced and we reduce the font size to make space for more names? Maybe we create a virtual monument that grows until it is as tall as the Mozilla office building or the nearby Bay Bridge? What ideas do you have for adding names of new contributors?

http://davidwboswell.wordpress.com/2014/06/11/including-new-contributors-on-the-mozilla-monument/
|
|






