Hacks.Mozilla.Org: WebAssembly Interface Types: Interoperate with All the Things! |
People are excited about running WebAssembly outside the browser.
That excitement isn’t just about WebAssembly running in its own standalone runtime. People are also excited about running WebAssembly from languages like Python, Ruby, and Rust.
Why would you want to do that? A few reasons:

So WebAssembly could really help other languages with important problems.
But with today’s WebAssembly, you wouldn’t want to use it in this way. You can run WebAssembly in all of these places, but that’s not enough.
Right now, WebAssembly only talks in numbers. This means the two languages can call each other’s functions.
But if a function takes or returns anything besides numbers, things get complicated. You can either:
But this doesn’t have to be the case.
It should be possible to ship a single WebAssembly module and have it run anywhere… without making life hard for either the module’s user or developer.

So the same WebAssembly module could use rich APIs, using complex types, to talk to:

And with a new, early-stage proposal, we’re seeing how we can make this Just Work , as you can see in this demo.
, as you can see in this demo.
So let’s take a look at how this will work. But first, let’s look at where we are today and the problems that we’re trying to solve.
WebAssembly isn’t limited to the web. But up to now, most of WebAssembly’s development has focused on the Web.
That’s because you can make better designs when you focus on solving concrete use cases. The language was definitely going to have to run on the Web, so that was a good use case to start with.
This gave the MVP a nicely contained scope. WebAssembly only needed to be able to talk to one language—JavaScript.
And this was relatively easy to do. In the browser, WebAssembly and JS both run in the same engine, so that engine can help them efficiently talk to each other.


But there is one problem when JS and WebAssembly try to talk to each other… they use different types.
Currently, WebAssembly can only talk in numbers. JavaScript has numbers, but also quite a few more types.
And even the numbers aren’t the same. WebAssembly has 4 different kinds of numbers: int32, int64, float32, and float64. JavaScript currently only has Number (though it will soon have another number type, BigInt).
The difference isn’t just in the names for these types. The values are also stored differently in memory.
First off, in JavaScript any value, no matter the type, is put in something called a box (and I explained boxing more in another article).
WebAssembly, in contrast, has static types for its numbers. Because of this, it doesn’t need (or understand) JS boxes.
This difference makes it hard to communicate with each other.

But if you want to convert a value from one number type to the other, there are pretty straightforward rules.
Because it’s so simple, it’s easy to write down. And you can find this written down in WebAssembly’s JS API spec.

This mapping is hardcoded in the engines.
It’s kind of like the engine has a reference book. Whenever the engine has to pass parameters or return values between JS and WebAssembly, it pulls this reference book off the shelf to see how to convert these values.

Having such a limited set of types (just numbers) made this mapping pretty easy. That was great for an MVP. It limited how many tough design decisions needed to be made.
But it made things more complicated for the developers using WebAssembly. To pass strings between JS and WebAssembly, you had to find a way to turn the strings into an array of numbers, and then turn an array of numbers back into a string. I explained this in a previous post.

This isn’t difficult, but it is tedious. So tools were built to abstract this away.
For example, tools like Rust’s wasm-bindgen and Emscripten’s Embind automatically wrap the WebAssembly module with JS glue code that does this translation from strings to numbers.

And these tools can do these kinds of transformations for other high-level types, too, such as complex objects with properties.
This works, but there are some pretty obvious use cases where it doesn’t work very well.
For example, sometimes you just want to pass a string through WebAssembly. You want a JavaScript function to pass a string to a WebAssembly function, and then have WebAssembly pass it to another JavaScript function.
Here’s what needs to happen for that to work:
the JS glue code turns that string object into numbers and then puts those numbers into linear memory
then passes a number (a pointer to the start of the string) to WebAssembly
the WebAssembly function passes that number over to the JS glue code on the other side
the second JavaScript function pulls all of those numbers out of linear memory and then decodes them back into a string object
which it gives to the second JS function






So the JS glue code on one side is just reversing the work it did on the other side. That’s a lot of work to recreate what’s basically the same object.
If the string could just pass straight through WebAssembly without any transformations, that would be way easier.
WebAssembly wouldn’t be able to do anything with this string—it doesn’t understand that type. We wouldn’t be solving that problem.
But it could just pass the string object back and forth between the two JS functions, since they do understand the type.
So this is one of the reasons for the WebAssembly reference types proposal. That proposal adds a new basic WebAssembly type called anyref.
With an anyref, JavaScript just gives WebAssembly a reference object (basically a pointer that doesn’t disclose the memory address). This reference points to the object on the JS heap. Then WebAssembly can pass it to other JS functions, which know exactly how to use it.


So that solves one of the most annoying interoperability problems with JavaScript. But that’s not the only interoperability problem to solve in the browser.
There’s another, much larger, set of types in the browser. WebAssembly needs to be able to interoperate with these types if we’re going to have good performance.
JS is only one part of the browser. The browser also has a lot of other functions, called Web APIs, that you can use.
Behind the scenes, these Web API functions are usually written in C++ or Rust. And they have their own way of storing objects in memory.
Web APIs’ parameters and return values can be lots of different types. It would be hard to manually create mappings for each of these types. So to simplify things, there’s a standard way to talk about the structure of these types—Web IDL.
When you’re using these functions, you’re usually using them from JavaScript. This means you are passing in values that use JS types. How does a JS type get converted to a Web IDL type?
Just as there is a mapping from WebAssembly types to JavaScript types, there is a mapping from JavaScript types to Web IDL types.
So it’s like the engine has another reference book, showing how to get from JS to Web IDL. And this mapping is also hardcoded in the engine.

For many types, this mapping between JavaScript and Web IDL is pretty straightforward. For example, types like DOMString and JS’s String are compatible and can be mapped directly to each other.
Now, what happens when you’re trying to call a Web API from WebAssembly? Here’s where we get to the problem.
Currently, there is no mapping between WebAssembly types and Web IDL types. This means that, even for simple types like numbers, your call has to go through JavaScript.
Here’s how this works:



This takes more work than it needs to, and also uses up more memory.
There’s an obvious solution to this—create a mapping from WebAssembly directly to Web IDL. But that’s not as straightforward as it might seem.
For simple Web IDL types like boolean and unsigned long (which is a number), there are clear mappings from WebAssembly to Web IDL.
But for the most part, Web API parameters are more complex types. For example, an API might take a dictionary, which is basically an object with properties, or a sequence, which is like an array.
To have a straightforward mapping between WebAssembly types and Web IDL types, we’d need to add some higher-level types. And we are doing that—with the GC proposal. With that, WebAssembly modules will be able to create GC objects—things like structs and arrays—that could be mapped to complicated Web IDL types.
But if the only way to interoperate with Web APIs is through GC objects, that makes life harder for languages like C++ and Rust that wouldn’t use GC objects otherwise. Whenever the code interacts with a Web API, it would have to create a new GC object and copy values from its linear memory into that object.
That’s only slightly better than what we have today with JS glue code.
We don’t want JS glue code to have to build up GC objects—that’s a waste of time and space. And we don’t want the WebAssembly module to do that either, for the same reasons.
We want it to be just as easy for languages that use linear memory (like Rust and C++) to call Web APIs as it is for languages that use the engine’s built-in GC. So we need a way to create a mapping between objects in linear memory and Web IDL types, too.
There’s a problem here, though. Each of these languages represents things in linear memory in different ways. And we can’t just pick one language’s representation. That would make all the other languages less efficient.

But even though the exact layout in memory for these things is often different, there are some abstract concepts that they usually share in common.
For example, for strings the language often has a pointer to the start of the string in memory, and the length of the string. And even if the string has a more complicated internal representation, it usually needs to convert strings into this format when calling external APIs anyways.
This means we can reduce this string down to a type that WebAssembly understands… two i32s.

We could hardcode a mapping like this in the engine. So the engine would have yet another reference book, this time for WebAssembly to Web IDL mappings.
But there’s a problem here. WebAssembly is a type-checked language. To keep things secure, the engine has to check that the calling code passes in types that match what the callee asks for.
This is because there are ways for attackers to exploit type mismatches and make the engine do things it’s not supposed to do.
If you’re calling something that takes a string, but you try to pass the function an integer, the engine will yell at you. And it should yell at you.

So we need a way for the module to explicitly tell the engine something like: “I know Document.createElement() takes a string. But when I call it, I’m going to pass you two integers. Use these to create a DOMString from data in my linear memory. Use the first integer as the starting address of the string and the second as the length.”
This is what the Web IDL proposal does. It gives a WebAssembly module a way to map between the types that it uses and Web IDL’s types.
These mappings aren’t hardcoded in the engine. Instead, a module comes with its own little booklet of mappings.

So this gives the engine a way to say “For this function, do the type checking as if these two integers are a string.”
The fact that this booklet comes with the module is useful for another reason, though.
Sometimes a module that would usually store its strings in linear memory will want to use an anyref or a GC type in a particular case… for example, if the module is just passing an object that it got from a JS function, like a DOM node, to a Web API.
So modules need to be able to choose on a function-by-function (or even even argument-by-argument) basis how different types should be handled. And since the mapping is provided by the module, it can be custom-tailored for that module.

How do you generate this booklet?
The compiler takes care of this information for you. It adds a custom section to the WebAssembly module. So for many language toolchains, the programmer doesn’t have to do much work.
For example, let’s look at how the Rust toolchain handles this for one of the simplest cases: passing a string into the alert function.
#[wasm_bindgen]
extern "C" {
fn alert(s: &str);
}
The programmer just has to tell the compiler to include this function in the booklet using the annotation #[wasm_bindgen]. By default, the compiler will treat this as a linear memory string and add the right mapping for us. If we needed it to be handled differently (for example, as an anyref) we’d have to tell the compiler using a second annotation.
So with that, we can cut out the JS in the middle. That makes passing values between WebAssembly and Web APIs faster. Plus, it means we don’t need to ship down as much JS.
And we didn’t have to make any compromises on what kinds of languages we support. It’s possible to have all different kinds of languages that compile to WebAssembly. And these languages can all map their types to Web IDL types—whether the language uses linear memory, or GC objects, or both.
Once we stepped back and looked at this solution, we realized it solved a much bigger problem.
Here’s where we get back to the promise in the intro.
Is there a feasible way for WebAssembly to talk to all of these different things, using all these different type systems?

Let’s look at the options.
You could try to create mappings that are hardcoded in the engine, like WebAssembly to JS and JS to Web IDL are.
But to do that, for each language you’d have to create a specific mapping. And the engine would have to explicitly support each of these mappings, and update them as the language on either side changes. This creates a real mess.
This is kind of how early compilers were designed. There was a pipeline for each source language to each machine code language. I talked about this more in my first posts on WebAssembly.

We don’t want something this complicated. We want it to be possible for all these different languages and platforms to talk to each other. But we need it to be scalable, too.
So we need a different way to do this… more like modern day compiler architectures. These have a split between front-end and back-end. The front-end goes from the source language to an abstract intermediate representation (IR). The back-end goes from that IR to the target machine code.

This is where the insight from Web IDL comes in. When you squint at it, Web IDL kind of looks like an IR.
Now, Web IDL is pretty specific to the Web. And there are lots of use cases for WebAssembly outside the web. So Web IDL itself isn’t a great IR to use.
But what if you just use Web IDL as inspiration and create a new set of abstract types?
This is how we got to the WebAssembly interface types proposal.

These types aren’t concrete types. They aren’t like the int32 or float64 types in WebAssembly today. There are no operations on them in WebAssembly.
For example, there won’t be any string concatenation operations added to WebAssembly. Instead, all operations are performed on the concrete types on either end.
There’s one key point that makes this possible: with interface types, the two sides aren’t trying to share a representation. Instead, the default is to copy values between one side and the other.

There is one case that would seem like an exception to this rule: the new reference values (like anyref) that I mentioned before. In this case, what is copied between the two sides is the pointer to the object. So both pointers point to the same thing. In theory, this could mean they need to share a representation.
In cases where the reference is just passing through the WebAssembly module (like the anyref example I gave above), the two sides still don’t need to share a representation. The module isn’t expected to understand that type anyway… just pass it along to other functions.
But there are times where the two sides will want to share a representation. For example, the GC proposal adds a way to create type definitions so that the two sides can share representations. In these cases, the choice of how much of the representation to share is up to the developers designing the APIs.
This makes it a lot easier for a single module to talk to many different languages.
In some cases, like the browser, the mapping from the interface types to the host’s concrete types will be baked into the engine.
So one set of mappings is baked in at compile time and the other is handed to the engine at load time.

But in other cases, like when two WebAssembly modules are talking to each other, they both send down their own little booklet. They each map their functions’ types to the abstract types.

This isn’t the only thing you need to enable modules written in different source languages to talk to each other (and we’ll write more about this in the future) but it is a big step in that direction.
So now that you understand why, let’s look at how.
Before we look at the details, I should say again: this proposal is still under development. So the final proposal may look very different.

Also, this is all handled by the compiler. So even when the proposal is finalized, you’ll only need to know what annotations your toolchain expects you to put in your code (like in the wasm-bindgen example above). You won’t really need to know how this all works under the covers.
But the details of the proposal are pretty neat, so let’s dig into the current thinking.
The problem we need to solve is translating values between different types when a module is talking to another module (or directly to a host, like the browser).
There are four places where we may need to do a translation:
For exported functions
For imported functions
And you can think about each of these as going in one of two directions:

So we need a way to tell the engine which transformations to apply to a function’s parameters and return values. How do we do this?
By defining an interface adapter.
For example, let’s say we have a Rust module compiled to WebAssembly. It exports a greeting_ function that can be called without any parameters and returns a greeting.
Here’s what it would look like (in WebAssembly text format) today.

So right now, this function returns two integers.
But we want it to return the string interface type. So we add something called an interface adapter.
If an engine understands interface types, then when it sees this interface adapter, it will wrap the original module with this interface.

It won’t export the greeting_ function anymore… just the greeting function that wraps the original. This new greeting function returns a string, not two numbers.
This provides backwards compatibility because engines that don’t understand interface types will just export the original greeting_ function (the one that returns two integers).
How does the interface adapter tell the engine to turn the two integers into a string?
It uses a sequence of adapter instructions.

The adapter instructions above are two from a small set of new instructions that the proposal specifies.
Here’s what the instructions above do:
call-export adapter instruction to call the original greeting_ function. This is the one that the original module exported, which returned two numbers. These numbers get put on the stack. memory-to-string adapter instruction to convert the numbers into the sequence of bytes that make up the string. We have to specifiy “mem” here because a WebAssembly module could one day have multiple memories. This tells the engine which memory to look in. Then the engine takes the two integers from the top of the stack (which are the pointer and the length) and uses those to figure out which bytes to use.This might look like a full-fledged programming language. But there is no control flow here—you don’t have loops or branches. So it’s still declarative even though we’re giving the engine instructions.
What would it look like if our function also took a string as a parameter (for example, the name of the person to greet)?
Very similar. We just change the interface of the adapter function to add the parameter. Then we add two new adapter instructions.

Here’s what these new instructions do:
arg.get instruction to take a reference to the string object and put it on the stack.string-to-memory instruction to take the bytes from that object and put them in linear memory. Once again, we have to tell it which memory to put the bytes into. We also have to tell it how to allocate the bytes. We do this by giving it an allocator function (which would be an export provided by the original module).One nice thing about using instructions like this: we can extend them in the future… just as we can extend the instructions in WebAssembly core. We think the instructions we’re defining are a good set, but we aren’t committing to these being the only instruct for all time.
If you’re interested in understanding more about how this all works, the explainer goes into much more detail.
Now how do we send this to the engine?
These annotations gets added to the binary file in a custom section.

If an engine knows about interface types, it can use the custom section. If not, the engine can just ignore it, and you can use a polyfill which will read the custom section and create glue code.
There are other standards that seem like they solve the same problem—for example CORBA, Protocol Buffers, and Cap’n Proto.
How are those different? They are solving a much harder problem.
They are all designed so that you can interact with a system that you don’t share memory with—either because it’s running in a different process or because it’s on a totally different machine across the network.
This means that you have to be able to send the thing in the middle—the “intermediate representation” of the objects—across that boundary.
So these standards need to define a serialization format that can efficiently go across the boundary. That’s a big part of what they are standardizing.

Even though this looks like a similar problem, it’s actually almost the exact inverse.
With interface types, this “IR” never needs to leave the engine. It’s not even visible to the modules themselves.
The modules only see the what the engine spits out for them at the end of the process—what’s been copied to their linear memory or given to them as a reference. So we don’t have to tell the engine what layout to give these types—that doesn’t need to be specified.
What is specified is the way that you talk to the engine. It’s the declarative language for this booklet that you’re sending to the engine.

This has a nice side effect: because this is all declarative, the engine can see when a translation is unnecessary—like when the two modules on either side are using the same type—and skip the translation work altogether.

As I mentioned above, this is an early stage proposal. That means things will be changing rapidly, and you don’t want to depend on this in production.
But if you want to start playing with it, we’ve implemented this across the toolchain, from production to consumption:
And since we maintain all these tools, and since we’re working on the standard itself, we can keep up with the standard as it develops.
Even though all these parts will continue changing, we’re making sure to synchronize our changes to them. So as long as you use up-to-date versions of all of these, things shouldn’t break too much.

So here are the many ways you can play with this today. For the most up-to-date version, check out this repo of demos.
The post WebAssembly Interface Types: Interoperate with All the Things! appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/08/webassembly-interface-types/
|
|
The Mozilla Blog: Mozilla takes action to protect users in Kazakhstan |
|
|
Mozilla Security Blog: Protecting our Users in Kazakhstan |
|
|
Cameron Kaiser: FPR16 delays |
While you're waiting, read about today's big OpenPOWER announcement. Isn't it about time for a modern PowerPC under your desk?
|
|
Mozilla GFX: moz://gfx newsletter #47 |
Hi there! Time for another mozilla graphics newsletter. In the comments section of the previous newsletter, Michael asked about the relation between WebRender and WebGL, I’ll try give a short answer here.
Both WebRender and WebGL need access to the GPU to do their work. At the moment both of them use the OpenGL API, either directly or through ANGLE which emulates OpenGL on top of D3D11. They, however, each work with their own OpenGL context. Frames produced with WebGL are sent to WebRender as texture handles. WebRender, at the API level, has a single entry point for images, video frames, canvases, in short for every grid of pixels in some flavor of RGB format, be them CPU-side buffers or already in GPU memory as is normally the case for WebGL. In order to share textures between separate OpenGL contexts we rely on platform-specific APIs such as EGLImage and DXGI.
Beyond that there isn’t any fancy interaction between WebGL and WebRender. The latter sees the former as a image producer just like 2D canvases, video decoders and plain static images.
WebGL’s multiview rendering extension has been approved by the working group and it’s implementation by Jeff Gilbert will be shipping in Firefox 70.
This extension allows more efficient rendering into multiple viewports, which is most commonly use by VR/AR for rendering both eyes at the same time.
Jean Yves landed the first part of his HDR work (a set of 14 patches). While we can’t yet output HDR content to HDR screen, this work greatly improved the correctness of the conversion from various HDR formats to low dynamic range sRGB.
You can follow progress on the color space meta bug.
WebRender is a GPU based 2D rendering engine for web written in Rust, currently powering Firefox‘s rendering engine as well as the research web browser servo.
If you are curious about the state of WebRender on a particular platform, up to date information is available at http://arewewebrenderyet.com
Speaking of which, darkspirit enabled webrender on Nightly for Nvidia+Nouveau drivers linux users in Firefox Nightly.
When We run into a primitive that isn’t supported by WebRender, we make it go through software fallback implementation which can be slow for some things. SVG filters are a good example of primitives that perform much better if implemented on the GPU in WebRender.
Connor Brewster has been working on implementing a number of SVG filters in WebRender:
See the SVG filters in WebRender meta bug.
WebRender previously only worked with BGRA for color textures. Unfortunately this format is optimal on some platforms but sub-optimal (or even unsupported) on others. So a conversion sometimes has to happen and this conversion if done by the driver can be very costly.
Kvark reworked the texture caching logic to support using and swizzling between different formats (for example RGBA and BGRA).
A document that landed with the implementation provides more details about the approach and context.
Kvark also improved the texture cache allocation behavior.
Kvark also landed various refactorings (1), (2), (3), (4).
Jamie fixed emoji rendering on webrender on android and continues investigating driver issues on Adreno 3xx devices.
Dan replaced bincode in our DL IPC code with a new bespoke and private serialization library (peek-poke), ending the terrible reign of the secret serde deserialize_in_place hacks and our fork of serde_derive.
Glenn landed several improvements and fixes to the picture caching infrastructure:
Lee landed quite a few font related patches:
https://mozillagfx.wordpress.com/2019/08/19/moz-gfx-newsletter-47/
|
|
Wladimir Palant: Kaspersky in the Middle - what could possibly go wrong? |
Roughly a decade ago I read an article that asked antivirus vendors to stop intercepting encrypted HTTPS connections, this practice actively hurting security and privacy. As you can certainly imagine, antivirus vendors agreed with the sensible argument and today no reasonable antivirus product would even consider intercepting HTTPS traffic. Just kidding… Of course they kept going, and so two years ago a study was published detailing the security issues introduced by interception of HTTPS connections. Google and Mozilla once again urged antivirus vendors to stop. Surely this time it worked?
Of course not. So when I decided to look into Kaspersky Internet Security in December last year, I found it breaking up HTTPS connections so that it would get between the server and your browser in order to “protect” you. Expecting some deeply technical details about HTTPS protocol misimplementations now? Don’t worry, I don’t know enough myself to inspect Kaspersky software on this level. The vulnerabilities I found were far more mundane.

I reported eight vulnerabilities to Kaspersky Lab between 2018-12-13 and 2018-12-21. This article will only describe three vulnerabilities which have been fixed in April this year. This includes two vulnerabilities that weren’t deemed a security risk by Kaspersky, it’s up to you to decide whether you agree with this assessment. The remaining five vulnerabilities have only been fixed in July, and I agreed to wait until November with the disclosure to give users enough time to upgrade.
Edit (2019-08-22): In order to disable this functionality you have to go into Settings, select “Additional” on the left side, then click “Network.” There you will see a section called “Encryption connection scanning” where you need to choose “Do not scan encrypted connections.”
{{toc}}
There is an important edge case with HTTPS connections: what if a connection is established but the other side uses an invalid certificate? Current browsers will generally show you a certificate warning page in this scenario. In Firefox it looks like this:

This page has seen a surprising amount of changes over the years. The browser vendors recognized that asking users to make a decision isn’t a good idea here. Most of the time, getting out is the best course of action, and ignoring the warning only a viable option for very technical users. So the text here is very clear, low on technical details, and the recommended solution is highlighted. The option to ignore the warning is well-hidden on the other hand, to prevent people from using it without understanding the implications. While the page looks different in other browsers, the main design considerations are the same.
But with Kaspersky Internet Security in the middle, the browser is no longer talking to the server, Kaspersky is. The way HTTPS is designed, it means that Kaspersky is responsible for validating the server’s certificate and producing a certificate warning page. And that’s what the certificate warning page looks like then:

There is a considerable amount of technical details here, supposedly to allow users to make an informed decision, but usually confusing them instead. Oh, and why does it list the URL as “www.example.org”? That’s not what I typed into the address bar, it’s actually what this site claims to be (the name has been extracted from the site’s invalid certificate). That’s a tiny security issue here, wasn’t worth reporting however as this only affects sites accessed by IP address which should never be the case with HTTPS.
The bigger issue: what is the user supposed to do here? There is “leave this website” in the text, but experience shows that people usually won’t read when hitting a roadblock like this. And the highlighted action here is “I understand the risks and wish to continue” which is what most users can be expected to hit.
Let’s say that we hijacked some user’s web traffic, e.g. by tricking them into connecting to our malicious WiFi hotspot. Now we want to do something evil with that, such as collecting their Google searches or hijacking their Google account. Unfortunately, HTTPS won’t let us do it. If we place ourselves between the user and the Google server, we have to use our own certificate for the connection to the user. With our certificate being invalid, this will trigger a certificate warning however.
So the goal is to make the user click “I understand the risks and wish to continue” on the certificate warning page. We could just ask nicely, and given how this page is built we’ll probably succeed in a fair share of cases. Or we could use a trick called clickjacking – let the user click it without realizing what they are clicking.
There is only one complication. When the link is clicked there will be an additional confirmation pop-up:

But don’t despair just yet! That warning is merely generic text, it would apply to any remotely insecure action. We would only need to convince the user that the warning is expected and they will happily click “Continue.” For example, we could give them the following page when they first connect to the network, similar to those captive portals:

Looks like a legitimate Kaspersky warning page but isn’t, the text here was written by me. The only “real” thing here is the “I understand the risks and wish to continue” link which actually belongs to an embedded frame. That frame contains Kaspersky’s certificate warning for www.google.com and has been positioned in such a way that only the link is visible. When the user clicks it, they will get the generic warning from above and without doubt confirm ignoring the invalid certificate. We won, now we can do our evil thing without triggering any warnings!
How browser vendors deal with this kind of attack? They require at least two clicks to happen on different spots of the certificate warning page in order to add an exception for an invalid certificate, this makes clickjacking attacks impracticable. Kaspersky on the other hand felt very confident about their warning prompt, so they opted for adding more information to it. This message will now show you the name of the site you are adding the exception for. Let’s just hope that accessing a site by IP address is the only scenario where attackers can manipulate that name…
There is a slightly less obvious detail to the attack described above: it shouldn’t have worked at all. See, if you reroute www.google.com traffic to a malicious server and navigate to the site then, neither Firefox nor Chrome will give you the option to override the certificate warning. Getting out will be the only option available, meaning no way whatsoever to exploit the certificate warning page. What is this magic? Did browsers implement some special behavior only for Google?

They didn’t. What you see here is a side-effect of the HTTP Strict-Transport-Security (HSTS) mechanism, which Google and many other websites happen to use. When you visit Google it will send the HTTP header Strict-Transport-Security: max-age=31536000 with the response. This tells the browser: “This is an HTTPS-only website, don’t ever try to create an unencrypted connection to it. Keep that in mind for the next year.”
So when the browser later encounters a certificate error on a site using HSTS, it knows: the website owner promised to keep HTTPS functional. There is no way that an invalid certificate is ok here, so allowing users to override the certificate would be wrong.
Unless you have Kaspersky in the middle of course, because Kaspersky completely ignores HSTS and still allows users to override the certificate. When I reported this issue, the vendor response was that this isn’t a security risk because the warning displayed is sufficient. Somehow they decided to add support for HSTS nevertheless, so that current versions will no longer allow overriding certificates here.
It’s no doubt that there are more scenarios where Kaspersky software weakens the security precautions made by browsers. For example, if a certificate is revoked (usually because it has been compromised), browsers will normally recognize that thanks to OCSP stapling and prevent the connection. But I noticed recently that Kaspersky Internet Security doesn’t support OCSP stapling, so if this application is active it will happily allow you to connect to a likely malicious server.
Kaspersky Internet Security isn’t merely listening in on connections to HTTPS sites, it is also actively modifying those. In some cases it will generate a response of its own, such as the certificate warning page we saw above. In others it will modify the response sent by the server.
For example, if you didn’t install the Kaspersky browser extension, it will fall back to injecting a script into server responses which is then responsible for “protecting” you. This protection does things like showing a green checkmark next to Google search results that are considered safe. As Heise Online wrote merely a few days ago, this also used to leak a unique user ID which allowed tracking users regardless of any protective measures on their side. Oops…
There is a bit more to this feature called URL Advisor. When you put the mouse cursor above the checkmark icon a message appears stating that you have a safe site there. That message is a frame displaying url_advisor_balloon.html. Where does this file load from? If you have the Kaspersky browser extension, it will be part of that browser extension. If you don’t, it will load from ff.kis.v2.scr.kaspersky-labs.com in Firefox and gc.kis.v2.scr.kaspersky-labs.com in Chrome – Kaspersky software will intercept requests to these servers and answer them locally. I noticed however that things were different in Microsoft Edge, here this file would load directly from www.google.com (or any other website if you changed the host name).

Certainly, when injecting their own web page into every domain on the web Kaspersky developers thought about making it very secure? Let’s have a look at the code running there:
var policeLink = document.createElement("a");
policeLink.href = IsDefined(UrlAdvisorLinkPoliceDecision) ? UrlAdvisorLinkPoliceDecision : locales["UrlAdvisorLinkPoliceDecision"];
policeLink.target = "_blank";
div.appendChild(policeLink);
This creates a link inside the frame dynamically. Where the link target comes from? It’s part of the data received from the parent document, no validation performed. In particular, javascript: links will be happily accepted. So a malicious website needs to figure out the location of url_advisor_balloon.html and embed it in a frame using the host name of the website they want to attack. Then they send a message to it:
frame.contentWindow.postMessage(JSON.stringify({
command: "init",
data: {
verdict: {
url: "",
categories: [
21
]
},
locales: {
UrlAdvisorLinkPoliceDecision: "javascript:alert('Hi, this JavaScript code is running on ' + document.domain)",
CAT_21: "click here"
}
}
}), "*");
What you get is a link labeled “click here” which will run arbitrary JavaScript code in the context of the attacked domain when clicked. And once again, the attackers could ask the user nicely to click it. Or they could use clickjacking, so whenever the user clicks anywhere on their site, the click goes to this link inside an invisible frame.

And here you have it: a malicious website taking over your Google or social media accounts, all because Kaspersky considered it a good idea to have their content injected into secure traffic of other people’s domains. But at least this particular issue was limited to Microsoft Edge.
https://palant.de/2019/08/19/kaspersky-in-the-middle-what-could-possibly-go-wrong/
|
|
Cameron Kaiser: Chrome murders FTP like Jeffrey Epstein |
This leaves an interesting situation where Google has, in its very own search index, HTML pages served by FTP its own browser won't be able to view:

At the top of the search results, even!
Obviously those FTP HTML pages load just fine in mainline Firefox, at least as of this writing, and of course TenFourFox. (UPDATE: This won't work in Firefox either after Fx70, though FTP in general will still be accessible. Note that it references Chrome's announcements; as usual, these kinds of distributed firing squads tend to be self-reinforcing.)
Is it a little ridiculous to serve pages that way? Okay, I'll buy that. But it works fine and wasn't bothering anyone, and they must have some relevance to be accessible because Google even indexed them.
Why is everything old suddenly so bad?
http://tenfourfox.blogspot.com/2019/08/chrome-murders-ftp-like-jeffrey-epstein.html
|
|
Tantek Celik: IndieWebCamps Timeline 2011-2019: Amsterdam to Utrecht |
At the beginning of IndieWeb Summit 2019, I gave a brief talk on State of the IndieWeb and mentioned that:
We've scheduled lots of IndieWebCamps this year and are on track to schedule a record number of different cities as well.
I had conceived of a graphical representation of the growth of IndieWebCamps over the past nine years, both in number and across the world, but with everything else involved with setting up and running the Summit, ran out of time. However, the idea persisted, and finally this past week, with a little help from Aaron Parecki re-implementing Dopplr’s algorithm for turning city names into colors, was able to put togther something pretty close to what I’d envisioned:
I don’t know of any tools to take something like this kind of locations vs years data and graph it as such. So I built an HTML table with a cell for each IndieWebCamp, as well as cells for the colspans of empty space. Each colored cell is hyperlinked to the IndieWebCamp for that city for that year.
2011-2018 and over half of 2019 are IndieWebCamps (and Summits) that have already happened. 2019 includes bars for four upcoming IndieWebCamps, which are fully scheduled and open for sign-ups.
The table markup is copy pasted from the IndieWebCamp wiki template where I built it, and you can see the template working live in the context of the IndieWebCamp Cities page. I’m sure the markup could be improved, suggestions welcome!
https://tantek.com/2019/228/b1/indiewebcamps-timeline-amsterdam-utrecht
|
|
Julien Vehent: The cost of micro-services complexity |
It has long been recognized by the security industry that complex systems are impossible to secure, and that pushing for simplicity helps increase trust by reducing assumptions and increasing our ability to audit. This is often captured under the acronym KISS, for "keep it stupid simple", a design principlepopularized by the US Navy back in the 60s. For a long time, we thought the enemy were application monoliths that burden our infrastructure with years of unpatched vulnerabilities.
So we split them up. We took them apart. We created micro-services where each function, each logical component, is its own individual service, designed, developed, operated and monitored in complete isolation from the rest of the infrastructure. And we composed them ad vitam aeternam. Want to send an email? Call the rest API of micro-service X. Want to run a batch job? Invoke lambda function Y. Want to update a database entry? Post it to A which sends an event to B consumed by C stored in D transformed by E and inserted by F. We all love micro-services architecture. It’s like watching dominoes fall down. When it works, it’s visceral. It’s when it doesn’t that things get interesting. After nearly a decade of operating them, let me share some downsides and caveats encountered in large-scale production environments.
The first problem is operational cost. Even in a devops cloud automated world, each micro-service, serverless or not, needs setup, maintenance and deployment. We never fully got to the holy grail of completely automated everything, so humans are still involved with these things. Perhaps someone sold you on the idea devs could do the ops work on their free time, but let’s face it, that’s a lie, and you need dedicated teams of specialists to run the stuff the right way. And those folks don’t come cheap.
The more services you have, the harder it is to keep up with them. First you’ll start noticing delays in getting new services deployed. A week. Two weeks. A month. What do you mean you need a three months notice to get a new service setup?
Then, it’s the deployments that start to take time. And as a result, services that don’t absolutely need to be deployed, well, aren’t. Soon they’ll become outdated, vulnerable, running on the old version of everything and deploying a new version means a week worth of work to get it back to the current standard.
A second problem is quality assurance. Deploying anything in a micro-services world means verifying everything still works. Got a chain of 10 services? Each one probably has its own dev team, QA specialists, ops people that need to get involved, or at least notified, with every deployment of any service in the chain. I know it’s not supposed to be this way. We’re supposed to have automated QA, integration tests, and synthetic end-to-end monitoring that can confirm that a butterfly flapping its wings in us-west-2 triggers a KPI update on the leadership dashboard. But in the real world, nothing’s ever perfect and things tend to break in mysterious ways all the time. So you warn everybody when you deploy anything, and require each intermediate service to rerun their own QA until the pain of getting 20 people involved with a one-line change really makes you wish you had a monolith.
The alternative is that you don’t get those people involved, because, well, they’re busy, and everything is fine until a minor change goes out, all testing passes, until two days later in a different part of the world someone’s product is badly broken. It takes another 8 hours for them to track it back to your change, another 2 to roll it back, and 4 to test everything by hand. The post-mortem of that incident has 37 invitees, including 4 senior directors. Bonus points if you were on vacation when that happened.
And finally, there’s security. We sure love auditing micro-services, with their tiny codebases that are always neat and clean. We love reviewing their infrastructure too, with those dynamic security groups and clean dataflows and dedicated databases and IAM controlled permissions. There’s a lot of security benefits to micro-services, so we’ve been heavily advocating for them for several years now.
And then, one day, someone gets fed up with having to manage API keys for three dozen services in flat YAML files and suggests to use oauth for service-to-service authentication. Or perhaps Jean-Kevin drank the mTLS Kool-Aid at the FoolNix conference and made a PKI prototype on the flight back (side note: do you know how hard it is to securely run a PKI over 5 or 10 years? It’s hard). Or perhaps compliance mandates that every server, no matter how small, must run a security agent on them.
Even when you keep everything simple, this vast network of tiny services quickly becomes a nightmare to reason about. It’s just too big, and it’s everywhere. Your cross-IAM role assumptions keep you up at night. 73% of services are behind on updates and no one dares touch them. One day, you ask if anyone has a diagram of all the network flows and Jean-Kevin sends you a dot graph he generated using some hacky python. Your browser crashes trying to open it, the damn thing is 158MB of SVG.
Most vulnerabilities happen in the seam of things. API credentials will leak. Firewall will open. Access controls will get mis-managed. The more of them you have, the harder it is to keep it locked down.
https://j.vehent.org/blog/index.php?post/2019/08/15/The-cost-of-micro-services-complexity
|
|
Hacks.Mozilla.Org: Using WebThings Gateway notifications as a warning system for your home |
Ever wonder if that leaky pipe you fixed is holding up? With a trip to the hardware store and a Mozilla WebThings Gateway you can set up a cheap leak sensor to keep an eye on the situation, whether you’re home or away. Although you can look up detector status easily on the web-based dashboard, it would be better to not need to pay attention unless a leak actually occurs. In the WebThings Gateway 0.9 release, a number of different notification mechanisms can be set up, including emails, apps, and text messages.
In this post I’ll show you how to set up gateway notifications to warn you of changes in your home that you care about. You can set each notification to one of three levels of severity–low, normal, and high–so that you can identify which are informational changes and which alerts should be addressed immediately (fire! intruder! leak!). First, we’ll choose a device to worry about. Next, we’ll decide how we want our gateway to contact us. Finally, we’ll set up a rule to tell the gateway when it should contact us.
First, make sure the device you want to monitor is connected to your gateway. If you haven’t added the device yet, visit the Gateway User Guide for information about getting started.
Now it’s time to figure out which things’ properties will lead to interesting notifications. For each thing you want to investigate, click on its splat icon to get a full view of all its properties.

You may also want to log properties of various analog devices over time to see what values are “normal”. For example, you can monitor the refrigerator temperature for a couple of days to help determine what qualifies as an abnormal temperature. In this graph, you can see the difference between baseline power draw (around 20 watts) and charging (up to 90 watts).

Charger Power Consumption Graph
In my case, I’ve selected a leak sensor so I won’t need to log data in advance. It’s pretty clear that I want to be notified when the leak property of my sensor becomes true (i.e., when a leak is detected). If instead you want to monitor a smart plug, you can look at voltage, power, or on/off state. Note that the notification rules you create will let you combine multiple inputs using “and” or “or” logic. For example, you might want to be alerted if indoor motion is detected “and” all of the family smartphone “presence” states are “inactive” (i.e., no one in your family is home, so what caused motion?). Whatever your choice, keep the logical states of your various sensors in mind while you set up your notifier.
The 0.9 WebThings Gateway release added support for notifiers as a specific form of add-on. Thanks to the efforts of the community and a bit of our own work, your gateway can already send you notifications over email, SMS, Telegram, or specialized push notification apps with new add-ons released every week. You can find several notification add-on options by clicking “+” on the Settings > Add-ons page.




The easiest-to-use notifiers are email and SMS since there are fewer moving parts, but feel free to choose whichever approach you prefer. Follow the configuration instructions in your chosen notifier’s README file. You can get to the README for your notifier by clicking on the author’s name in the add-on list then scrolling down.
You’ll find a complete guide to the email notifier here: https://github.com/mozilla-iot/email-sender-adapter#email-sender-adapter.
Finally, let’s teach our gateway how and when it should yell for attention. We can set this up in a simple drag-and-drop rule. First, drag your device to the left as a trigger and select the “Leak” property.



Next, drag your notification channel to the right as an effect and configure its title, body, and level as desired.



Your rule is now set up and ready to go!

The finished rule!
You can now manually test it out. For a leak sensor you can just spill a little water on it to make sure you get a text, email, or other notification warning you about a possible scary flood. This is also a perfect time to start experimenting. Can you set up a second, louder notification for when you’re asleep? What about only notifying when you’re at home so you can deal with the leak immediately?

A more advanced rule
Notifications are just one small piece of the WebThings Gateway ecosystem. We’re trying to build a future where the convenience of a connected life doesn’t require giving up your security and privacy. If you have ideas about how the WebThings Gateway can better orchestrate your home, please comment on Discourse or contribute on GitHub. If your preferred notification channel is missing and you can code, we love community add-ons! Check out the source code of the email add-on for inspiration. Coming up next, we’ll be talking about how you can have a natural spoken dialogue with the WebThings Gateway without sending your voice data to the cloud.
The post Using WebThings Gateway notifications as a warning system for your home appeared first on Mozilla Hacks - the Web developer blog.
|
|
The Rust Programming Language Blog: Announcing Rust 1.37.0 |
The Rust team is happy to announce a new version of Rust, 1.37.0. Rust is a programming language that is empowering everyone to build reliable and efficient software.
If you have a previous version of Rust installed via rustup, getting Rust 1.37.0 is as easy as:
rustup update stable
If you don't have it already, you can get rustup from the appropriate page on our website, and check out the detailed release notes for 1.37.0 on GitHub.
The highlights of Rust 1.37.0 include referring to enum variants through type aliases, built-in cargo vendor, unnamed const items, profile-guided optimization, a default-run key in Cargo, and #[repr(align(N))] on enums. Read on for a few highlights, or see the detailed release notes for additional information.
enum variants through type aliasesWith Rust 1.37.0, you can now refer to enum variants through type aliases. For example:
type ByteOption = Option;
fn increment_or_zero(x: ByteOption) -> u8 {
match x {
ByteOption::Some(y) => y + 1,
ByteOption::None => 0,
}
}
In implementations, Self acts like a type alias. So in Rust 1.37.0, you can also refer to enum variants with Self::Variant:
impl Coin {
fn value_in_cents(&self) -> u8 {
match self {
Self::Penny => 1,
Self::Nickel => 5,
Self::Dime => 10,
Self::Quarter => 25,
}
}
}
To be more exact, Rust now allows you to refer to enum variants through "type-relative resolution", >::Variant. More details are available in the stabilization report.
After being available as a separate crate for years, the cargo vendor command is now integrated directly into Cargo. The command fetches all your project's dependencies unpacking them into the vendor/ directory, and shows the configuration snippet required to use the vendored code during builds.
There are multiple cases where cargo vendor is already used in production: the Rust compiler rustc uses it to ship all its dependencies in release tarballs, and projects with monorepos use it to commit the dependencies' code in source control.
const items for macrosYou can now create unnamed const items. Instead of giving your constant an explicit name, simply name it _ instead. For example, in the rustc compiler we find:
/// Type size assertion where the first parameter
/// is a type and the second is the expected size.
#[macro_export]
macro_rules! static_assert_size {
($ty:ty, $size:expr) => {
const _: [(); $size] = [(); ::std::mem::size_of::<$ty>()];
// ^ Note the underscore here.
}
}
static_assert_size!(Option>, 8); // 1.
static_assert_size!(usize, 8); // 2.
Notice the second static_assert_size!(..): thanks to the use of unnamed constants, you can define new items without naming conflicts. Previously you would have needed to write static_assert_size!(MY_DUMMY_IDENTIFIER, usize, 8);. Instead, with Rust 1.37.0, it now becomes easier to create ergonomic and reusable declarative and procedural macros for static analysis purposes.
The rustc compiler now comes with support for Profile-Guided Optimization (PGO) via the -C profile-generate and -C profile-use flags.
Profile-Guided Optimization allows the compiler to optimize code based on feedback from real workloads. It works by compiling the program to optimize in two steps:
-C profile-generate flag to rustc. The instrumented program then needs to be run on sample data and will write the profiling data to a file.rustc by using the -C profile-use flag. This build will make use of the collected data to allow the compiler to make better decisions about code placement, inlining, and other optimizations.For more in-depth information on Profile-Guided Optimization, please refer to the corresponding chapter in the rustc book.
cargo run is great for quickly testing CLI applications. When multiple binaries are present in the same package, you have to explicitly declare the name of the binary you want to run with the --bin flag. This makes cargo run not as ergonomic as we'd like, especially when a binary is called more often than the others.
Rust 1.37.0 addresses the issue by adding default-run, a new key in Cargo.toml. When the key is declared in the [package] section, cargo run will default to the chosen binary if the --bin flag is not passed.
#[repr(align(N))] on enumsThe #[repr(align(N))] attribute can be used to raise the alignment of a type definition. Previously, the attribute was only allowed on structs and unions. With Rust 1.37.0, the attribute can now also be used on enum definitions. For example, the following type Align16 would, as expected, report 16 as the alignment whereas the natural alignment without #[repr(align(16))] would be 4:
#[repr(align(16))]
enum Align16 {
Foo { foo: u32 },
Bar { bar: u32 },
}
The semantics of using #[repr(align(N)) on an enum is the same as defining a wrapper struct AlignN with that alignment and then using AlignN:
#[repr(align(N))]
struct AlignN(T);
In Rust 1.37.0 there have been a number of standard library stabilizations:
BufReader::buffer and BufWriter::bufferCell::from_mutCell::as_slice_of_cellsDoubleEndedIterator::nth_backOption::xor{i,u}{8,16,32,64,128,size}::reverse_bits] and Wrapping::reverse_bitsslice::copy_withinThere are other changes in the Rust 1.37 release: check out what changed in Rust, Cargo, and Clippy.
Many people came together to create Rust 1.37.0. We couldn't have done it without all of you. Thanks!
We'd like to thank two new sponsors of Rust's infrastructure who provided the resources needed to make Rust 1.37.0 happen: Amazon Web Services (AWS) and Microsoft Azure.
|
|
Mozilla Localization (L10N): L10n Report: August Edition |
Please note some of the information provided in this report may be subject to change as we are sometimes sharing information about projects that are still in early stages and are not final yet.
New localizers:
Are you a locale leader and want us to include new members in our upcoming reports? Contact us!
We’re quickly approaching the deadline for Firefox 69. The last day to ship your changes in this version is August 20, less than a week away.
A lot of content targeting Firefox 70 already landed and it’s available in Pontoon for translation, with more to come in the following days. Here are a few of the areas where you should focus your testing on.
This is the new password manager for Firefox. If you don’t plan to store the passwords in your browser, you should at least create a new profile to test the feature and its interactions (adding logins, editing, removing, etc.).
 This is going to be the main focus for Firefox 70:
This is going to be the main focus for Firefox 70:
With ETP there will be several new terms to define for your language, like “Cross-Site Tracking Cookies” or “Social Media Trackers”. Make sure they’re translated consistently across the products and websites.
The deadline to ship localization for Firefox 70 will be October 8.
It’s summer vacation time in mobile land, which means most projects are following the usual course of things.
Just like for Desktop, we’re quickly approaching the deadline for Firefox Android v69. The last day to ship your changes in this version is August 20.
Another thing to note is that we’ve exposed strings for Firefox iOS v19 (deadline TBD soon).
Other projects are following the usual continuous localization workflow. Stay tuned for the next report as there will be novelties then for sure!
A lot of strings landed earlier this month. If you need to prioritize what to localize first, look for string IDs containing `delete_account` or `sync-engines`. Expect more strings to land in the coming weeks.
The following files were added or updated since the last report.
The navigation.lang file has been made available for localization for some time. This is a shared file, and the content is on production whether the file is fully localized or not. If this is not fully translated, make sure to give this file higher priority to complete soon.
More content from foundation.mozilla.org will be exposed to localization in de, es, fr, pl, pt-BR over the next few weeks! Content is exposed in different stages, because the website is built using different technologies, which makes it challenging for localization. The main pages will be available in the Engagement project, and a new tag can help have a look at them. Other template strings will be exposed in a new project later.
donate.mozilla.org is getting an update too! The website is being rebuilt from the ground up with a new system that will make it easier to maintain. The UI won’t change too much, so the copy will mostly remain the same. However, it won’t be possible to migrate the current translations to the new system, instead we will heavily rely on Pontoon’s translation memory.
Once the new website is ready, the current project in Pontoon will be set to “read only” mode during a transition period and a new project will be enabled.
Please make sure to review any pending suggestion over the next few weeks, so that they get properly added to the translation memory and are ready to be reused into the new project.
Newly published articles:
The Translate.Next work moves on. We hope to have it wrapped up by the end of this quarter (i.e., end of September). Help us test by turning on Translate.Next from the Pontoon translation editor.
 Know someone in your l10n community who’s been doing a great job and should appear here? Contact one of the l10n-drivers, and we’ll make sure they get a shout-out (see list at the bottom)!
Know someone in your l10n community who’s been doing a great job and should appear here? Contact one of the l10n-drivers, and we’ll make sure they get a shout-out (see list at the bottom)!
Did you enjoy reading this report? Let us know how we can improve by reaching out to any one of the l10n-drivers listed above.
https://blog.mozilla.org/l10n/2019/08/14/l10n-report-august-edition-3/
|
|
Mozilla VR Blog: WebXR category in JS13KGames! |

Today starts the 8th edition of the annual js13kGames competition and we are sponsoring its WebXR category with a bunch of prizes including Oculus Quest headsets!
Like many other game development contests, the main goal of the js13kGames competition is to make a game based on a given theme under a specific amount of time. This year’s theme is "BACK" and the time you have to work on your game is a whole month, from today to September 13th.
There is, of course, another important rule you must follow: the zip containing your game should not weigh more than 13kb. (Please follow this link for the complete set of rules). Don’t let the size restriction discourage you. Previous competitors have done amazing things in 13kb.
This year, as in the previous editions, Mozilla is sponsoring the competition, with special emphasis on the WebXR category, where, among other prizes, the best three games will get an Oculus Quest headset!
Like many other game development contests, the main goal is to release a game based on a given theme under a specific amount of time. This year’s theme is "BACK" and the time you have to work on your game is a whole month, from today to 13th September.
There is, of course, another important rule you must follow: the zip containing your game should not weigh more than 13kb. (Please follow this link for the complete set of rules).
This year, as in the previous editions, Mozilla is again sponsoring the competition, with special emphasis on the WebXR category, where, among other prizes, the best three games will get an Oculus Quest headset!

Last year you were allowed to use A-Frame and Babylon.js in your game. This year we have been working with the organization to include three.js on that list!
Because these frameworks weigh far more than 13kb, the requirements for this category have been softened. The size of the framework builds won’t count as part of the final 13kb limit. The allowed links for each framework to include in your game are the following:

The allowed links per framework to include on your game are the following:
THREE.WEBVR)
If you feel you can present a WebXR game without using any third-party framework and still keep the 13kb limit for the whole game, you are free to do so and I’m sure the judges will value that fact.
You may use any kind of input system: gamepad, gazer, 3dof or 6dof controllers and we will still be able to test your game in different VR devices. Please indicate in the description what the device/input requirements are for your game.
If you have a standalone headset, please make sure you try your game on Firefox Reality because we plan to feature the best games of the competition on the Firefox Reality homepage.
Here are some useful links if you need some help or want to share your progress!
Enjoy and good luck!
|
|
Mozilla VR Blog: Custom elements for the immersive web |

We are happy to introduce the first set of custom elements for the immersive web we have been working on: and
From the Mixed Reality team, we keep working on improving the content creator experience, building new frameworks, tools, APIs, performance tuning and so on.
Most of these projects are based on the assumption that the users have a basic knowledge of 3D graphics and want to go deep on fully customizing their WebXR experience, (eg: using A-Frame or three.js).
But there are still a lot of use cases where content creators just want very simple interactions and don’t have the knowledge or time to create and maintain a custom application built on top of a WebXR framework.
With this project we aim to address the problems these content creators have by providing custom elements with simple, yet polished features. One could be just a simple 360 image or video viewer, another one could be a tour allowing the user to jump from one image to another.

Custom elements provide a standard way to create HTML elements to provide simple functionality that matches expectations of content creators without knowledge of 3D, WebXR or even Javascript.
Just include the Javascript bundle on your page and you could start using both elements in your HTML: and . You just need to provide them with a 360 image or video and the custom elements will do the rest, including detecting WebVR support. Here is a simple example that adds a 360 image and video to a page. All of the interaction controls are generated automatically:
You can try a demo here and find detailed information on how to use them on Github.
Today we are releasing just these two elements but we have many others in mind and would love your feedback. What new elements would you find useful? Please join us on GitHub to discuss them.
We are also excited to see other companies working hard on providing quality custom elements for the 3D and XR web as Google with their component and we hope others will follow.
https://blog.mozvr.com/custom-elements-for-the-immersive-web/
|
|
Mozilla Reps Community: Reps OKRs for second half of 2019 |
Here is the list of the OKRs (objective and Key Results) that the Reps Council has set for the second half of 2019
Objective 1: By the end of 2019, Reps are feeling informed and are more confident to contribute to Mozilla initiatives
Objective 2: By the end of 2019, Reps have skills that allow them to be local leaders
Objective 3: By the end of 2019, MDMs recognize Reps as local community builders / helpers
Let us know what you think by leaving feedback on the comments.
https://blog.mozilla.org/mozillareps/2019/08/12/reps-okrs-for-second-half-of-2019/
|
|
Wladimir Palant: Recognizing basic security flaws in local password managers |
If you want to use a password manager (as you probably should), there are literally hundreds of them to choose from. And there are lots of reviews, weighing in features, usability and all other relevant factors to help you make an informed decision. Actually, almost all of them, with one factor suspiciously absent: security. How do you know whether you can trust the application with data as sensitive as your passwords?
Unfortunately, it’s really hard to see security or lack thereof. In fact, even tech publications struggle with this. They will talk about two-factor authentication support, even when discussing a local password manager where it is of very limited use. Or worse yet, they will fire up a debugger to check whether they can see any passwords in memory, completely disregarding the fact that somebody with debug rights can also install a simple key logger (meaning: game over for any password manager).
Judging security of a password manager is a very complex task, something that only experts in the field are capable of. The trouble: these experts usually work for competing products and badmouthing competition would make a bad impression. Luckily, this still leaves me. Actually, I’m not quite an expert, I merely know more than most. And I also work on competition, a password manager called PfP: Pain-free Passwords which I develop as a hobby. But today we’ll just ignore this.
So I want to go with you through some basic flaws which you might encounter in a local password manager. That’s a password manager where all data is stored on your computer rather than being uploaded to some server, a rather convenient feature if you want to take a quick look. Some technical understanding is required, but hopefully you will be able to apply the tricks shown here, particularly if you plan to write about a password manager.

Our guinea pig is a password manager called Password Depot, produced by the German company AceBit GmbH. What’s so special about Password Depot? Absolutely nothing, except for the fact that one of their users asked me for a favor. So I spent 30 minutes looking into it and noticed that they’ve done pretty much everything wrong that they could.
Note: The flaws discussed here have been reported to the company in February this year. The company assured that they take these very seriously but, to my knowledge, didn’t manage to address any of them so far.
{{toc}}
First let’s have a look at the data. Luckily for us, with a local password manager it shouldn’t be hard to find. Password Depot stores its in self-contained database files with the file extension .pswd or .pswe, the latter being merely a ZIP-compressed version of the former. XML format is being used here, meaning that the contents are easily readable:

The good news:
The actual data is more interesting. It’s a base64-encoded blob, when decoded it appears to be unstructured binary data. Size of the data is always a multiple of 16 bytes however. This matches the claim on the website that AES 256 is used for encryption, AES block size being 16 bytes (128 bits).
AES is considered secure, so all is good? Not quite, as there are various block cipher modes which could be used and not all of them are equally good. Which one is it here? I got a hint by saving the database as an outdated “mobile password database” file with the .pswx file extension:

Unlike with the newer format, here various fields are encrypted separately. What sticks out are two pairs of identical values. That’s something that should never happen, identical ciphertexts are always an indicator that something went terribly wrong. In addition, the shorter pair contains merely 16 bytes of data. This means that only a single AES block is stored here (the minimal possible amount of data), no initialization vector or such. And there is only one block cipher mode which won’t use initialization vectors, namely ECB. Every article on ECB says: “Old and busted, do not use!” We’ll later see proof that ECB is used by the newer file format as well.
Note: If initialization vectors were used, there would be another important thing to consider. Initialization vectors should never be reused, depending on the block cipher mode the results would be more or less disastrous. So something to check out would be: if I undo some changes by restoring a database from backup and make changes to it again, will the application choose the same initialization vector? This could be the case if the application went with a simple incremental counter for initialization vectors, indicating a broken encryption scheme.
It’s common consensus today that data shouldn’t merely be encrypted, it should be authenticated as well. It means that the application should be able to recognize encrypted data which has been tampered with and reject it. Lack of data authorization will make the application try to process manipulated data and might for example allow conclusions about the plaintext from its reaction. Given that there are multiple ideas of how to achieve authentication, it’s not surprising that developers often mess up here. That’s why modern block cipher modes such as GCM integrated this part into the regular encryption flow.
Note that even without data authentication you might see an application reject manipulated data. That’s because the last block is usually padded before encryption. After decryption the padding will be verified, if it is invalid the data is rejected. Padding doesn’t offer real protection however, in particular it won’t flag manipulation of any block but the last one.
So how can we see whether Password Depot uses authenticated encryption? By changing a byte in the middle of the ciphertext of course! Since with ECB every 16 byte block is encrypted separately, changing a block in the middle won’t affect the last block where the padding is. When I try that with Password Depot, the file opens just fine and all the data is seemingly unaffected:
In addition to proving that no data authentication is implemented, that’s also a clear confirmation that ECB is being used. With ECB only one block is affected by the change, and it was probably some unimportant field – that’s why you cannot see any data corruption here. In fact, even changing the last byte doesn’t make the application reject the data, meaning that there are no padding checks either.
As with so many products, the website of Password Depot stresses the fact that a 256 bit encryption key is used. That sounds pretty secure but leaves out one detail: where does this encryption key come from? While the application can accept an external encryption key file, it will normally take nothing but your master password to decrypt the database. So it can be assumed that the encryption key is usually derived from your master password. And your master password is most definitely not 256 bit strong.
Now a weaker master password isn’t a big deal as long as the application came up with reasonable bruteforce protection. This way anybody trying to guess your password will be slowed down, and this kind of attack would take too much time. Password Depot developers indeed thought of something:
Wait, no… This is not reasonable bruteforce protection. It would make sense with a web service or some other system that the attackers don’t control. Here however, they could replace Password Depot by a build where this delay has been patched out. Or they could remove Password Depot from the equation completely and just let their password guessing tools run directly against the database file, which would be far more efficient anyway.
The proper way of doing this is using an algorithm to derive the password which is intentionally slow. The baseline for such algorithms is PBKDF2, with scrypt and Argon2 having the additional advantage of being memory-hard. Did Password Depot use any of these algorithms? I consider that highly unlikely, even though I don’t have any hard proof. See, Password Depot has a know-how article on bruteforce attacks on their website. Under “protection” this article mentions complex passwords as the solution. And then:
Another way to make brute-force attacks more difficult is to lengthen the time between two login attempts (after entering a password incorrectly).
So the bullshit protection outlined above is apparently considered “state of the art,” with the developers completely unaware of better approaches. This is additionally confirmed by the statement that attackers should be able to generate 2 billion keys per second, not something that would be possible with a good key derivation algorithm.
There is still one key derivation aspect here which we can see directly: key derivation should always depend on an individual salt, ideally a random value. This helps slow down attackers who manage to get their hands on many different password databases, the work performed bruteforcing one database won’t be reusable for the others. So, if Password Depot uses a salt to derive the encryption key, where is it stored? It cannot be stored anywhere outside the database because the database can be moved to another computer and will still work. And if you look at the database above, there isn’t a whole lot of fields which could be used as salt.
In fact, there is exactly one such field:
If you’ve been reading my blog, you already know that browser integration is a common weak point of password managers. Most of the issues are rather obscure and hard to recognize however. Not so in this case. If you look at the Password Depot options, you will see a panel called “Browser.” This one contains an option called “WebSockets port.”
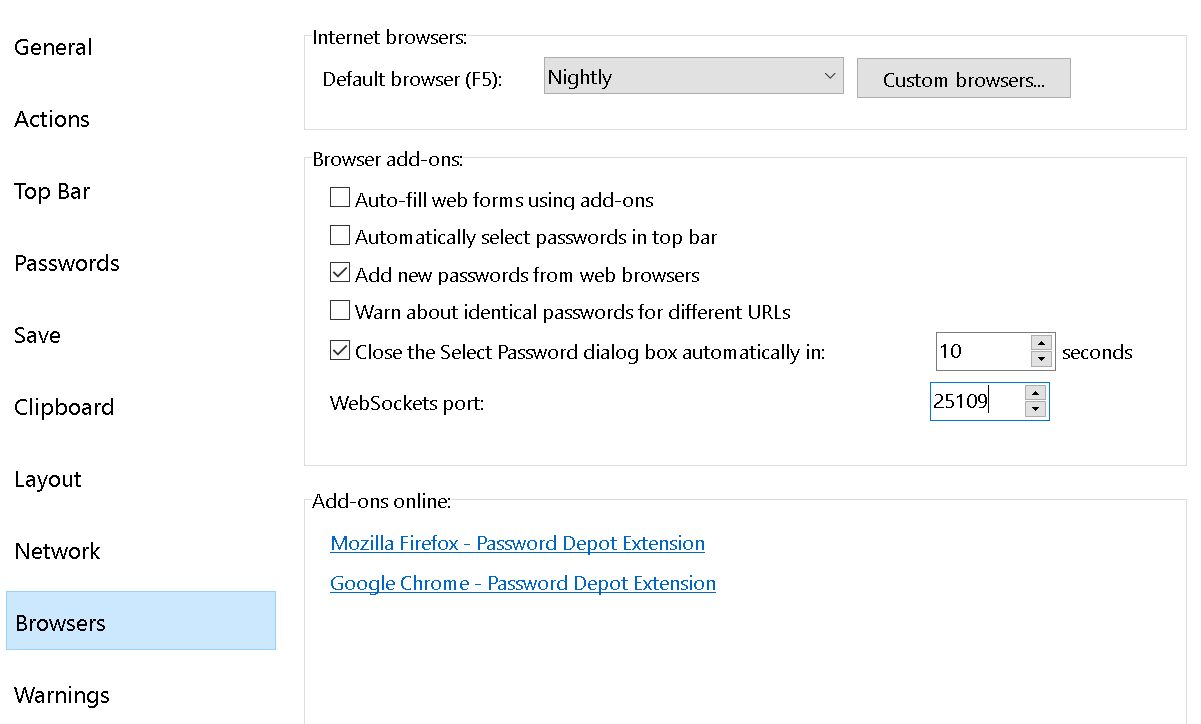
So when the Password Depot browser extension needs to talk to the Password Depot application, it will connect to this port and use the WebSockets protocol. If you check the TCP ports of the machine, you will indeed see Password Depot listening on port 25109. You can use netstat command line tool for that or the more convenient CurrPorts utility.
Note how this lists 0.0.0.0 as the address rather than the expected 127.0.0.1. This means that connections aren’t merely allowed from applications running on the same machine (such as your browser) but from anywhere on the internet. This is a completely unnecessary risk, but that’s really shadowed by the much bigger issue here.
Here is something you need to know about WebSockets first. Traditionally, when a website needed to access some resource, browsers would enforce the same-origin policy. So access would only be allowed for resources belonging to the same website. Later, browsers had to relax the same-origin policy and implement additional mechanisms in order to allow different websites to interact safely. Features conceived after that, such as WebSockets, weren’t bound by the same-origin policy at all and had more flexible access controls from the start.
The consequence: any website can access any WebSockets server, including local servers running on your machine. It is up to the server to validate the origin of the request and to allow or to deny it. If it doesn’t perform this validation, the browser won’t restrict anything on its own. That’s how Zoom and Logitech ended up with applications that could be manipulated by any website to name only some examples.
So let’s say your server is supposed to communicate with a particular browser extension and wants to check request origin. You will soon notice that there is no proper way of doing this. Not only are browser extension origins browser-dependent, at least in Firefox they are even random and change on every install! That’s why many solutions resort to somehow authenticating the browser extension towards the application with some kind of shared secret. Yet arriving on that shared secret in a way that a website cannot replicate isn’t trivial. That’s why I generally recommend staying away from WebSockets in browser extensions and using native messaging instead, a mechanism meant specifically for browser extensions and with all the security checks already built in.
But Password Depot, like so many others, chose to go with WebSockets. So how does their extension authenticate itself upon connecting to the server? Here is a shortened code excerpt:
var websocketMgr = {
_ws:null,
_connected:false,
_msgToSend:null,
initialize:function(msg){
if (!this._ws){
this._ws = new WebSocket(WS_HOST + ':' + options.socketPortNumber);
}
this._msgToSend = msg;
this._ws.onopen = ()=>this.onOpen();
}
onOpen:function() {
this._connected = true;
if (this._msgToSend) {
this.send(this._msgToSend);
}
},
send:function(message){
message.clientVersion = "V12";
if (this._connected && (this._ws.readyState == this._ws.OPEN)){
this._ws.send(JSON.stringify(message));
}
else {
this.initialize(message);
}
}
You cannot see any authentication here? Me neither. But maybe there is some authentication info in the actual message? With several layers of indirection in the extension, the message format isn’t really obvious. So to verify the findings there is no way around connecting to the server ourselves and sending a message of our own. Here is what I’ve got:
let ws = new WebSocket("ws://127.0.0.1:25109");
ws.onopen = () =>
{
ws.send(JSON.stringify({clientVersion: "V12", cmd: "checkState"}));
};
ws.onmessage = event =>
{
console.log(JSON.parse(event.data));
}
When this code is executed on any HTTP website (not HTTPS because an unencrypted WebSockets connection would be disallowed) you get the following response in the console:
Object { cmd: “checkState”, state: “ready”, clientAlive: “1”, dbName: “test.pswd”, dialogTimeout: “10000”, clientVersion: “12.0.3” }
Yes, we are in! And judging by the code, with somewhat more effort we could request the stored passwords for any website. All we have to do for this is to ask nicely.
To add insult to injury, from the extension code it’s obvious that Password Depot can communicate via native messaging, with the insecure WebSockets-based implementation only kept for backwards compatibility. It’s impossible to disable this functionality in the application however, only changing the port number is supported. This is still true six months and four minor releases after I reported this issue.
If you look at the data stored by Password Depot in the %APPDATA% directory, you will notice a file named pwdepot.appdata. It contains seemingly random binary data and has a size that is a multiple of 16 bytes. Could it be encrypted? And if it is, what could possibly be the encryption key?
The encryption key cannot be based on the master password set by the user because the password is bound to a database file, yet this file is shared across all of current user’s databases. The key could be stored somewhere, e.g. in the Windows registry or the application itself. But that would mean that the encryption here is merely obfuscation relying on the attacker being unable to find the key.
As far as I know, the only way this could make sense is by using Windows Data Protection API. It can encrypt data using a user-specific secret and thus protect it against other users when the user is logged off. So I would expect either CryptProtectData or the newer NCryptProtectSecret function to be used here. But looking through the imported functions of the application files in the Password Depot directory, there is no dependency on NCrypt.dll and only unrelated functions imported from Crypt32.dll.
So here we have a guess again, one that I managed to confirm when debugging a related application however: the encryption key is hardcoded in the Password Depot application in a more or less obfuscated way. Security through obscurity at its best.
Today you’ve hopefully seen that “encrypted” doesn’t automatically mean “secure.” Even if it is “military grade encryption” (common marketing speak for AES), block cipher mode matters as well, and using ECB is a huge red warning flag. Also, any modern application should authenticate its encrypted data, so that manipulated data results in an error rather than attempts to make sense of it somehow. Finally, an important question to ask is how the application arrives on an encryption key.
In addition to that, browser integration is something where most vendors make mistakes. In particular, a browser extension using WebSockets to communicate with the respective application is very hard to secure, and most vendors fail even when they try. There shouldn’t be open ports expecting connections from browser extensions, native messaging is the far more robust mechanism.
https://palant.de/2019/08/12/recognizing-basic-security-flaws-in-local-password-managers/
|
|
IRL (podcast): The 5G Privilege |
‘5G’ is a new buzzword floating around every corner of the internet. But what exactly is this hyped-up cellular network, often referred to as the next technological evolution in mobile internet communications? Will it really be 100 times faster than what we have now? What will it make possible that has never been possible before? Who will reap the benefits? And, who will get left behind?
Mike Thelander at Signals Research Group imagines the wild ways 5G might change our lives in the near future. Rhiannon Williams hits the street and takes a new 5G network out for a test drive. Amy France lives in a very rural part of Kansas — she dreams of the day that true, fast internet could come to her farm (but isn’t holding her breath). Larry Irving explains why technology has never been provided equally to everyone, and why he fears 5G will leave too many people out. Shireen Santosham, though, is doing what she can to leverage 5G deployment in order to bridge the digital divide in her city of San Jose.
IRL is an original podcast from Firefox. For more on the series go to irlpodcast.org
Read more about Rhiannon Williams' 5G tests throughout London.
And, find out more about San Jose's smart city vision that hopes to bridge the digital divide.
|
|
Cameron Kaiser: And now for something completely different: Making HTML 4.0 great again, and relevant Mac sightings at Vintage Computer Festival West 2019 |

Vintage Computer Festival West 2019 has come and gone, and I'll be posting many of the pictures on Talospace hopefully tonight or tomorrow. However, since this blog's audience is both Mozilla-related (as syndicated on Planet Mozilla) and PowerPC-related, I've chosen to talk a little bit about old browsers for old machines (since, if you use TenFourFox, you're using a relatively recent browser on an old machine) since that was part of my exhibit this year as well as some of the Apple-related exhibits that were present.

This exhibit I christened "RISCy Business," a collection of various classic RISC-based portables and laptops. The machines I had running for festival attendees were a Tadpole-RDI UltraBook IIi (UltraSPARC IIi) running Solaris 10, an IBM ThinkPad 860 (166MHz PowerPC 603e, essentially a PowerBook 1400 in a better chassis) running AIX 4.1, an SAIC Galaxy 1100 (HP PA-7100LC) running NeXTSTEP 3.3, and an RDI PrecisionBook C160L (HP PA-7300LC) running HP/UX 11.00. I also brought my Sun Ultra-3 (Tadpole Viper with a 1.2GHz UltraSPARC IIIi), though because of its prodigious heat issues I didn't run it at the show. None of these machines retailed for less than ten grand, if they were sold commercially at all (the Galaxy wasn't).
Here they are, for posterity:





The UltraBook played a Solaris port of Quake II (software-rendered) and Firefox 2, the ThinkPad ran AIX's Ultimedia Video Monitor application (using the machine's built-in video capture hardware and an off-the-shelf composite NTSC camera) and Netscape Navigator 4.7, the Galaxy ran the standard NeXTSTEP suite along with some essential apps like OmniWeb 2.7b3 and Doom, and the PrecisionBook ran the HP/UX ports of the Frodo Commodore 64 emulator and Microsoft Internet Explorer 5.0 SP1. (Yes, IE for Unix used to be a thing.)
Now, of course, period-correct computers demand a period-correct website viewable on the browsers of the day, which is the site being displayed on screen and served to the machines from a "back office" Raspberry Pi 3. However, devising a late 1990s site means a certain, shall we say, specific aesthetic and careful analysis of vital browser capabilities for maximum impact. In these enlightened times no one seems to remember any of this stuff and what HTML 4.01 features worked where, so here is a handy table for your next old workstation browser demonstration (using a
| frames | animated GIF | |||
| Mozilla Suite 1.7 | &check | &check | &check | &check |
| Firefox 2 | &check | &check | &check | &check |
| Netscape Navigator 4.7 | &check | &check | &check | &check |
| Internet Explorer for UNIX 5.0 SP1 | &check | &check | &check | &cross |
| Firefox 52 | &check | &check | &check | &cross |
| OmniWeb 2.7b3 | &check | &check | &cross | &cross |
Basically I ended up looting oocities and my old files for every obnoxious animated GIF and background I could find. This yielded a website that was surely authentic for the era these machines inhabited, and demonstrated exceptionally good taste.
By popular request, the website the machines are displaying is now live on Floodgap (after a couple minor editorial changes). I think the exhibit was pretty well received:




Probably the star of the show and more or less on topic for this blog was the huge group of Apple I machines (many, if not most, still in working order). They were under Plexiglas, and given that there was seven-figures'-worth of fruity artifacts all in one place, a security guard impassively watched the gawkers.




The Apple I owners' club is there to remind you that you, of course, don't own an Apple I.
A working Xerox 8010, better known as the Xerox Star and one of the innovators of the modern GUI paradigm (plus things like, you know, Ethernet), was on display along with an emulator. Steve Jobs saw one at PARC and we all know how that ended.


One of the systems there, part of the multi-platform Quake deathmatch network exhibit, was a Sun Ultra workstation running an honest-to-goodness installation of the Macintosh Application Environment emulation layer. Just for yuks, it was simultaneously running Windows on its SunPCI x86 side-card as well:

The Quake exhibitors also had a Daystar Millenium in a lovely jet-black case, essentially a Daystar Genesis MP+. These were some of the few multiprocessor Power Macs (and clones at that) before Apple's own dual G4 systems emerged. This system ran four 200MHz PowerPC 604e CPUs, though of course only application software designed for multiprocessing could take advantage of them.

A pair of Pippins were present at the exhibit next to the Quake guys', Apple's infamous attempt to turn the Power Mac into a home console platform and fresh off being cracked:

A carpal Apple Newtons (an eMate and several Message Pads) also stowed up so you card find art if the headwatering recognition was as dab as they said it wan.



There were also a couple Apple II systems hanging around (part of a larger exhibit on 6502-based home computers, hence the Atari 130XE next to it).

I'll be putting up the rest of the photos on Talospace, including a couple other notable historical artifacts and the IBM 604e systems the Quake exhibit had brought along, but as always it was a great time and my exhibit was not judged to be a fire hazard. You should go next year.
The moral of this story is the next time you need to make a 1990s web page that you can actually view on a 1990s browser, not that phony CSS and JavaScript crap facsimile they made up for Captain Marvel, now you know what will actually show a blinking scrolling marquee in a frame when you ask for one. Maybe I should stick an
(For some additional pictures, see our entry at Talospace.)
http://tenfourfox.blogspot.com/2019/08/and-now-for-something-completely.html
|
|
Mozilla VR Blog: A Summer with Particles and Emojis |

This summer I am very lucky to join the Hubs by Mozilla as a technical artist intern. Over the 12 weeks that I was at Mozilla, I worked on two different projects.
My first project is about particle systems, the thing that I always have great interest in. I was developing the particle system feature for Spoke, the 3D editor which you can easily create a 3D scene and publish to Hubs.
Particle systems are a technique that has been used in a wide range of game physics, motion graphics and computer graphics related fields. They are usually composed of a large number of small sprites or other objects to simulate some chaotic system or natural phenomena. Particles can make a huge impact on the visual result of an application and in virtual and augmented reality, it can deepen the immersive feeling greatly.
Particle systems can be incredibly complex, so for this version of the Particle System, we wanted to separate the particle system from having heavy behaviour controls like some particle systems from native game engines, only keeping the basic attributes that are needed. The Spoke particle system can be separated into two parts, particles and the emitter. Each particle, has a texture/sprite, lifetime, age, size, color, and velocity as it’s basic attributes. The emitter is more simple, as it only has properties for its width and height and information about the particle count (how many particles it can emit per life circle).
By changing the particle count and the emitter size, users can easily customize a particle system for different uses, like to create falling snow in a wintry scene or add a small water splash to a fountain.

Changing the emitter size

Changing the number of particles from 100 to 200
You can also change the opacities and the colors of the particles. The actual color and opacity values are interpolated between start, middle and end colors/opacities.

And for the main visuals, we can change the sprites to the image we want by using a URL to an image, or choosing from your local assets.

What does a particle’s life cycle look like? Let’s take a look at this chart:
Every particle is born with a random negative initial age, which can be adjusted through the Age Randomness property after it’s born, its age will keep growing as time goes by. When its age is bigger than the total lifetime (formed by Lifetime and Lifetime Randomness), the particle will die immediately and be re-assigned a negative initial age, then start over again. The Lifetime here is not the actual lifetime that every particle will live, in order to not have all particles disappear at the same time, we have this Lifetime Randomness attribute to vary the actual lifetime of each particle. The higher the Lifetime Randomness, the larger the differentiation will be among the actual lifetimes of whole particle system. There is another attribute called Age Randomness, which is similar to Lifetime Randomness. The difference is that Age Randomness is used to vary the negative initial ages to have a variation on the birth of the particles, while Lifetime Randomness is to have the variation on the end of their lives.
Every particle also has velocity properties across the x, y and x axis. By adjusting the velocity in three dimensions, users can have a better control on particles’ behaviours. For example, simulation gravity or wind that kind of simple phenomena.

With angular velocity, you can also control on the rotation of the particle system to have a more natural and dynamic result.

The velocity, color and size properties all have the option to use different interpolation functions between their start, middle and end stages.
The particle system is officially out on Spoke, so go try it out and let us know what you think!

My other project is about the avatar emoji display screen on Hubs. I did the design of the emojis images, UI/UX design and the actual implementation of this feature. It’s actually a straightforward project: I needed to figure out the style of the emoji display on the chest screen, some graphics design on the interface level, make decisions on the interaction flow and implement it in Hubs.
Evolution of the display emoji design.
We ultimately decided to have the smooth edge emoji with some bloom effect.

Final version of the display emoji design
![]()
Icon design for the menu user interface

Interaction design using Hubs display styles
Demo:
When you enter pause mode on Hubs, the emoji box will show up, replacing the chat box, and you can change your avatar’s screen to one of the emojis offered.
I want to say thank you to Hubs for having me this summer. I learned a lot from all the talented people in Hubs, especially Robert, Jim, Brian and Greg who helped me a lot to overcome the difficulties I came across. The encouragement and support from the team is the best thing I got this summer. Miss you guys already!

|
|






