Chris H-C: My StarCon 2019 Talk: Collecting Data Responsibly and at Scale |
Back in January I was privileged to speak at StarCon 2019 at the University of Waterloo about responsible data collection. It was a bitterly-cold weekend with beautiful sun dogs ringing the morning sun. I spent it inside talking about good ways to collect data and how Mozilla serves as a concrete example. It’s 15 minutes short and aimed at a general audience. I hope you like it.
I encourage you to also sample some of the other talks. Two I remember fondly are Aaron Levin’s “Conjure ye File System, transmorgifier” about video games that look like file systems and Cory Dominguez’s lovely analysis of Moby Dick editions in “or, the whale“. Since I missed a whole day, I now get to look forward to fondly discovering new ones from the full list.
:chutten
|
|
Mike Hoye: Ten More Simple Rules |

The Public Library of Science‘s Ten Simple Rules series can be fun reading; they’re introductory papers intended to provide novices or non-domain-experts with a set of quick, evidence-based guidelines for dealing with common problems in and around various fields, and it’s become a pretty popular, accessible format as far as scientific publication goes.
Topic-wise, they’re all over the place: protecting research integrity, creating a data-management plan and taking advantage of Github are right there next to developing good reading habits, organizing an unconference or drawing a scientific comic, and lots of them are kind of great.
I recently had the good fortune to be co-author on one of them that’s right in my wheelhouse and has recently been accepted for publication: Ten Simple Rules for Helping Newcomers Become Contributors to Open Projects. They are, as promised, simple:
You should read the whole thing, of course; what we’re proposing are evidence-based practices, and the details matter, but the citations are all there. It’s been a privilege to have been a small part of it, and to have done the work that’s put me in the position to contribute.
http://exple.tive.org/blarg/2019/08/07/ten-more-simple-rules/
|
|
Support.Mozilla.Org: Community Management Update |
Hello SUMO community,
I have a couple announcements for today. I’d like you all to welcome our two new community managers.
First off Kiki has officially joined the SUMO team as a community manager. Kiki has been filling in with Konstantina and Ruben on our social support activities. We had an opportunity to bring her onto the SUMO team full time starting last week. She will be transitioning out of her responsibilities at the Community Development Team and will be continuing her work on the social program as well as managing SUMO days going forward.
In addition, we have hired a new SUMO community manager to join the team. Please welcome Giulia Guizzardi to the SUMO team.
You can find her on the forums as gguizzardi. Below is a short introduction:
Hey everyone, my name is Giulia Guizzardi, and I will be working as a Support Community Manager for Mozilla.
I am currently based in Berlin, but I was born and raised in the north-east of Italy. I studied Digital Communication in Italy and Finland, and worked for half a year in Poland.
My greatest passion is music, I love participating in festivals and concerts along with collecting records and listening to new releases all day long. Other than that, I am often online, playing video games (Firewatch at the moment) or scrolling Youtube/Reddit.
I am really excited for this opportunity and happy to work alongside the community!
Now that we have two new community managers we will work with Konstantina and Ruben to transition their work to Kiki and Giulia. We’re also kicking off work to create a community strategy which we will be seeking feedback for soon. In the meantime, please help me welcome Kiki and Giulia to the team.
https://blog.mozilla.org/sumo/2019/08/07/community-management-update/
|
|
Henrik Skupin: Example in how to investigate CPU spikes in Firefox |
Note: This article is based on Firefox builds as available for download at least until August 7th, 2019. In case you want to go through those steps on your own, I cannot guarantee that it will lead to the same effects if newer builds are used.
So a couple of months ago when I was looking for some new interesting and challenging sport events, which I could participate in to reach my own limits, I was made aware of the Mega Hike event. It sounded like fun and it was also good to see that one particular event is annually organized in my own city since 2018. As such I accepted it together with a friend, and we had an amazing day. But hey… that’s not what I actually want to talk about in this post!
The thing I was actually more interested in while reading content on this web site, was the high CPU load of Firefox while the page was open in my browser. Once the tab got closed the CPU load dropped back to normal numbers, and went up again once I reopened the tab. Given that I haven’t had that much time to further investigate this behavior, I simply logged bug 1530071 to make people aware of the problem. Sadly the bug got lost in my incoming queue of daily bug mail, and I missed to respond, which itself lead in no further progress been made.
Yesterday I stumbled over the website again, and by any change have been made aware of the problem again. Nothing seemed to have been changed, and Firefox Nightly (70.0a1) was still using around 70% of CPU even with the tab’s content not visible; means moved to a background tab. Given that this is a serious performance and power related issue I thought that investigation might be pretty helpful for developers.
In the following sections I want to lay out the steps I did to nail down this problem.
While for the first look the Activity Monitor of MacOS is helpful to get an impression about the memory usage and CPU load of Firefox, it’s a bit hard to see how much each and every open tab is actually using.

You could try to match the listed process ids with a specific tab in the browser by hovering over the appropriate tab title, but the displayed tooltip only contains the process id in Firefox Nightly builds, but not in beta or final releases. Further multiple tabs will currently share the same process, and as such the displayed value in the Activity Monitor is a shared.
To further drill down the CPU load to a specific tab, Firefox has the about:performance page, which can be opened by typing the value into the location bar. It’s basically an internal task manager to inspect the energy impact and memory consumption of each tab.

Even more helpful is the option to expand the view for sub frames, which are usually used to embed external content. In case of the Megamarsch page there are three of those, and one actually spikes out with consuming nearly all the energy as used by the tab. As such it might be a good chance that this particular iframe from YouTube, which is embedding a video, is the problem.
To verify that the integrated Firefox Developer Tools can be used. Specially the Page Inspector will help us, which allows to search for specific nodes, CSS classes, or others, and then interact with them. To open it, check the Tools > Web Developer sub menu from inside the main menu.
Given that the URI of the iframe is known, lets search for it in the inspector:

When running the search it will not be the first result as found, so continue until the expected iframe is highlighted in the Inspector pane. Now that we found the embedded content lets delete the node by opening the context menu and clicking Delete Node. If it was the problem, the CPU load should be normal again.
Sadly, and as you will notice when doing it yourself, it’s not the case. Which also means something else on that page is causing it. The easiest solution to figure out which node really causes the spike, is to simply delete more nodes on that page. Start at a higher level and delete the header, footer, or any sidebars first. By doing that always keep an eye on the Activity Monitor, and check if the CPU load maybe has dropped. Once that is the case undo the last step, so that the causing node is getting inserted again. Then remove all sibling nodes, so only the causing node remains. Now drill down even further until no more child nodes remain.
As advice don’t forget to change the update frequency so that values are updated each second, and revert it back after you are done.
In our case the following node which is related to the cart icon remains:

So some kind of loading indicator seems to trigger Firefox to maybe repaint a specific area on the screen. To verify that remove the extra CSS class definitions. Once the icon-web-loading-spinner class has been removed it’s fine. Note that when hovering over the node and the class still be set, a spinning rectangle which is a placeholder for the real element can even be seen.
Checking the remaining stylesheets which get included, the one which remains (after removing all others without a notable effect) is from assets.jimstatic.com. And for the particular CSS class it holds the following animation:
@keyframes
spinit{0%{-webkit-transform:rotate(0deg);transform:rotate(0deg)}to{-webkit-transform:rotate(360deg);transform:rotate(360deg)}}
More interesting is that this specific class defines opacity: 0, which basically means that the node shouldn’t be visible at all, and no re-painting should happen until the node has been made visible.
With these kind of information found I updated the before mentioned bug with all the newly found details, and handed it over to the developers. Everyone who wants to follow the progress of fixing it, can subscribe as part of the CC list and will be automatically notified by Bugzilla for updates.
If you found this post useful please let me know, and I will write more of them in the future.
https://www.hskupin.info/2019/08/07/example-in-how-to-investigate-cpu-spikes-in-firefox/
|
|
Eric Shepherd: The Tall-Tale Clock: The myth of task estimates |
 One of my most dreaded tasks is that of estimating how long tasks will take to complete while doing sprint planning. I have never been good at this, and it has always felt like time stolen away from the pool of hours available to do what I can’t help thinking of as “real work.”
One of my most dreaded tasks is that of estimating how long tasks will take to complete while doing sprint planning. I have never been good at this, and it has always felt like time stolen away from the pool of hours available to do what I can’t help thinking of as “real work.”
While I’m quite a bit better at the time estimating process than I was a decade ago—and perhaps infinitely better at it than I was 20 years ago—I still find that I, like a lot of the creative and technical professionals I know, dread the process of poring over bug and task lists, project planning documents, and the like in order to estimate how long things will take to do.
This is a particularly frustrating process when dealing with tasks that may be nested, have multiple—often not easily detected ahead of time—dependencies, and may involve working with technologies that aren’t actually as ready for prime time as expected. Add to that the fact that your days are filled with distractions, interruptions, and other tasks you need to deal with, and predicting how long a given project will take can start to feel like a guessing game.
The problem isn’t just one of coming up with the estimates. There’s a more fundamental problem of how to measure time. Do you estimate projects in terms of the number of work hours you’ll invest in them? The number of days or weeks you’ll spend on each task? Or some other method of measuring duration?
On the MDN team, we have begun over the past year to use a time unit we call the hypothetical ideal day or simply ideal day. This is a theoretical time unit in which you are able to work, uninterrupted, on a project for an entire 8-hour work day. A given task may take any appropriate number of ideal days to complete, depending on its size and complexity. Some tasks may take less than a single ideal day, or may otherwise require a fractional number of ideal days (like 0.5 ideal days, or 1.25 ideal days).
There are a couple of additional guidelines we try to follow: we generally round to a quarter of a day, and we almost always keep our user stories’ estimates at five ideal days or less, with two or three being preferable. The larger a task is, the more likely it is that it’s really a group of related tasks.
There obviously isn’t actually any such thing as an ideal, uninterrupted day (hence the words “hypothetical” and “theoretical” a couple of paragraphs ago). Even on one’s best day, you have to stop to eat, to stretch, and do do any number of other things that you have to do during a day of work. But that’s the point to the ideal day unit: by building right into the unit the understanding that you’re not explicitly accounting for these interruptions in the time value, you can reinforce the idea that schedules are fragile, and that every time a colleague or your manager (or anyone else) causes you to be distracted from your planned tasks, the schedule will slip.
The goal, then, during sprint planning is to do your best to leave room for those distractions when mapping ideal days to the actual calendar. Our sprints on the MDN team are 12 business days long. When selecting tasks to attempt to accomplish during a sprint, we start by having each team member count up how many of those 12 days they will be available for work. This involves subtracting from that 12-day sprint any PTO days, company or local holidays, substantial meetings, and so forth.
When calculating my available days, I like to subtract a rough number of partial days to account for any appointments that I know I’ll have. We then typically subtract about 20% (or a day or two per sprint, although the actual amount varies from person to person based on how often they tend to get distracted and how quickly they rebound), to allow for distractions and sidetracking, and to cover typical administrative needs. The result is a rough estimate of the number of ideal days we’re available to work during the sprint.
With that in hand, each member of the team can select a group of tasks that can probably be completed during the number of ideal days we estimate they’ll have available during the sprint. But we know going in that these estimates are in terms of ideal days, not actual business days, and that if anything unanticipated happens, the mapping of ideal days to actual days we did won’t match up anymore, causing the work to take longer than anticipated. This understanding is fundamental to how the system works; by going into each sprint knowing that our mapping of ideal days to actual days is subject to external influences beyond our control, we avoid many of the anxieties that come from having rigid or rigid-feeling schedules.
For example, let’s consider a standard 12-business-day MDN sprint which spans my birthday as well as Martin Luther King, Jr. Day, which is a US Federal holiday. During those 12 days, I also have two doctor appointments scheduled which will have me out of the office for roughly half a day total, and I have about a day’s worth of meetings on my schedule as of sprint planning time. Doing the math, then, we find that I have 8.5 days available to work.
Knowing this, I then review the various task lists and find a total of around 8 to 8.5 days worth of work to do. Perhaps a little less if I think the odds are good that more time will be occupied with other things than the calendar suggests. For example, if my daughter is sick, there’s a decent chance I will be too in a few days, so I might take on just a little less work for the sprint.
As the sprint begins, then, I have an estimated 8 ideal days worth of work to do during the 12-day sprint. Because of the “ideal day” system, everyone on the team knows that if there are any additional interruptions—even short ones—the odds of completing everything on the list are reduced. As such, this system not only helps make it easier to estimate how long tasks will take, but also helps to reinforce with colleagues that we need to stay focused as much as possible, in order to finish everything on time.
If I don’t finish everything on the sprint plan by the end of the sprint, we will discuss it briefly during our end-of-sprint review to see if there’s any adjustment we need to make in future planning sessions, but it’s done with the understanding that life happens, and that sometimes delays just can’t be anticipated or avoided.
On the other hand, if I happen to finish before the sprint is over, I have time to get extra work done, so I go back to the task lists, or to my list of things I want to get done that are not on the priority list right now, and work on those things through the end of the sprint. That way, I’m able to continue to be productive regardless of how accurate my time estimates are.
In general, I really like this way of estimating task schedules. It does a much better job of allowing for the way I work than any other system I’ve been asked to work within. It’s not perfect, and the overhead is a little higher than I’d like, but by and large it does a pretty god job. That’s not to say we won’t try another, possibly better, way of handling the planning process in the future
But for now, my work days are as ideal as can be.
|
|
Bryce Van Dyk: Building Geckoview/Firefox for Android under Windows Subsystems for Linux (wsl) |
These are notes on my recent attempts to get Android builds of Firefox working under WSL 1. After tinkering with this I ultimately decided to do my Android builds in a full blown VM running Linux, but figure these notes may serve useful to myself or others.
This was done on Windows 10 using a Debian 9 WSL machine. The steps below assume an already cloned copy of mozilla-unified or mozilla-central.
Create a .mozconfig ensuring that LF line endings are used, CRLF seems to break parsing of the config under WSL:
# Build GeckoView/Firefox for Android:
ac_add_options --enable-application=mobile/android
# Targeting the following architecture.
# For regular phones, no --target is needed.
# For x86 emulators (and x86 devices, which are uncommon):
ac_add_options --target=i686
# For newer phones.
# ac_add_options --target=aarch64
# Write build artifacts to:
mk_add_options MOZ_OBJDIR=@TOPSRCDIR@/../mozilla-builds/objdir-droid-i686-opt
Bootstrap via ./mach bootstrap. After the bootstrap I found I still needed to install yasm in my package manager.
Now you should be ready to build with ./mach build. However, note that the object directory being built into needs to live on the WSL drive, i.e. mk_add_options MOZ_OBJDIR= should point to somewhere like ~/objdir and not /mnt/c/objdir.
This is because the build system will expect to files to be handled in a case sensitive manner and will create files like String.h and string.h in the same directory. Windows doesn't do this outside of WSL by default, and it causes issues with the build. I've got a larger discussion on the nuts and bolts of this, as well as a hacky work around below if you're interested in the details.
At this stage you should have an Android build. It can be packaged via ./mach package and then moved to the Windows mount – or if you have an Android emulator running under windows you can simply use ./mach install – this required required me to ~.mozbuild/android-sdk-linux/platform-tools/adb kill-server then ~.mozbuild/android-sdk-linux/platform-tools/adb start-serverafter enabling debugging on my emulated phone to get my WSLadb` to connect.
For other commands, your mileage may vary. For example ./mach crashtest fails, seemingly due to being unable to call su as expected under WSL.
When attempting to build Firefox for Android into an objdir on my Windows C drive I ended up getting a number of errors for due to files including String.h. This was a little confusing, as I recognize string.h, but the upper case S version not so much.
The cause is that the build system contains a list of headers and that there are several cases of headers with the same name only differing by uppercase initial letter, including the above string ones. In fact, there are 3 cases in that file: String.h, Strings.h, and Memory.h, and in my builds they can be safely removed to allow the build to progress.
I initially though this happened because the NTFS file system doesn't support case sensitive file names, whilst whatever file system was being used by WSL did. However, the reality is that NTFS does support case sensitivity and Windows itself is the one imposing case insensitivity.
Indeed, Windows is now exposing functionality to set case sensitivity on directories. Under WSL all directories are created with by default as case sensitive, but fsutil can be used to set the flag on directories outside WSL.
In fact, using fsutil to flag dirs as case sensitive allows for working around the issue with building to a objdir outside of WSL. For example I was able to do this fsutil.exe file setCaseSensitiveInfo ./dist/system_wrappers in the root of my objdir and then perform my build from WSL to outside WSL without issue. This isn't particularly ergonomic for normal use though, because Firefox's build system will destroy and recreate that dir which drops the flag. So I'd either need to manually restore it each time, or modify the build system.
The case sensitivity handling of files on Windows is interesting in a software archeology sense, and I plan to write more on it, but want to avoid this post (further) going off on a tangent around Windows architecture.
|
|
Daniel Stenberg: more tiny curl |
Without much fanfare or fireworks we put together and shipped a fresh new version of tiny-curl. We call it version 0.10 and it is based on the 7.65.3 curl tree.
tiny-curl is a patch set to build curl as tiny as possible while still being able to perform HTTPS GET requests and maintaining the libcurl API. Additionally, tiny-curl is ported to FreeRTOS.
As before, tiny-curl is an effort that is on a separate track from the main curl. Download tiny-curl from wolfssl.com!
|
|
Will Kahn-Greene: Socorro Engineering: July 2019 happenings and putting it on hold |
Socorro Engineering team covers several projects:
This blog post summarizes our activities in July.
Socorro: Added modules_in_stack field to super search allowing people to search the set of module/debugid for functions that are in teh stack of the crashing thread.
This lets us reprocess crash reports that have modules for which symbols were just uploaded.
Socorro: Added PHC related fields, dom_fission_enabled, and bug_1541161 to super search.
Socorro: Fixed some things further streamlining the local dev environment.
Socorro: Reformatted Python code with Black.
Socorro: Extracted supersearch and fetch-data commands as a separate Python library: https://github.com/willkg/crashstats-tools
Tecken: Upgraded to Python 3.7 and adjusted storage bucket code to work better for multiple storage providers.
Tecken: Added GCS emulator for local development environment.
PollBot: Updated to use Buildhub2.
In April, we picked up Tecken, Buildhub, Buildhub2, and PollBot in addition to working on Socorro. Since then, we've:
Buildhub is decomissioned now and is being dismantled.
We're passing Buildhub2 and PollBot off to another team. They'll take ownership of those projects going forward.
Socorro and Tecken are switching to maintenance mode as of last week. All Socorro/Tecken related projects are on hold. We'll continue to maintain the two sites doing "keep the lights on" type things:
All other non-urgent work will be pushed off.
As of August 1st, we've switched to Mozilla Location Services. We'll be auditing that project, getting it back into a healthy state, and bringing it in line with current standards and practices.
Given that, this is the last Socorro Engineering status post for a while.
Read more… (6 min remaining to read)
https://bluesock.org/~willkg/blog/mozilla/socorro_2019_07.html
|
|
Tantek Celik: Reflecting On IndieWeb Summit: A Start |
 Over a month ago we organized the ninth annual IndieWeb Summit in Portland, Oregon, June 29-30. As frequently happens to organizers, the combination of follow-ups, subsequent holiday, and other events did not allow for much time to blog afterwards. On the other hand, it did allow for at least some reflection and appreciation.
Over a month ago we organized the ninth annual IndieWeb Summit in Portland, Oregon, June 29-30. As frequently happens to organizers, the combination of follow-ups, subsequent holiday, and other events did not allow for much time to blog afterwards. On the other hand, it did allow for at least some reflection and appreciation.
 Saturday morning June 29th went relatively smoothly. We had everything setup in time. I finished preparing my “state of” outline. Everyone signed-in when they arrived, got a badge, chose their color of lanyard (more on that later), pronoun pin(s), and an array of decorative stickers to customize their badge.
Saturday morning June 29th went relatively smoothly. We had everything setup in time. I finished preparing my “state of” outline. Everyone signed-in when they arrived, got a badge, chose their color of lanyard (more on that later), pronoun pin(s), and an array of decorative stickers to customize their badge.
 For the first time we had an anonymous donor who chipped in enough in addition to the minimal $10 registration fee for us to afford IndieWebCamp t-shirts in a couple of shapes and a variety of sizes. We had a warm breakfast (vegetarian and vegan) ready to go for participants.
For the first time we had an anonymous donor who chipped in enough in addition to the minimal $10 registration fee for us to afford IndieWebCamp t-shirts in a couple of shapes and a variety of sizes. We had a warm breakfast (vegetarian and vegan) ready to go for participants.
Another first for any IndieWebCamp, we arranged a captioner who live-captioned the first two hours of Summit keynotes, introductions, and demos.
After welcoming everyone and introducing co-organizers Tiara and Aaron, I showed & briefly summarized our codes of conduct for the Summit:
In particular I emphasized the recent addition from XOXO 2018’s Code of Conduct regarding safety vs. comfort, which is worth its own blog post.
 Another Summit first, also inspired by XOXO (and other conferences like Open Source Bridge), color-coded lanyards for our photo policy. Which was a natural lead-in for the heads-up about session live-streaming and where to sit accordingly (based on personal preference). Lastly, pronoun pins and a huge thanks to Aaron Parecki for arranging the logistics of all those materials!
Another Summit first, also inspired by XOXO (and other conferences like Open Source Bridge), color-coded lanyards for our photo policy. Which was a natural lead-in for the heads-up about session live-streaming and where to sit accordingly (based on personal preference). Lastly, pronoun pins and a huge thanks to Aaron Parecki for arranging the logistics of all those materials!
I told people about the online tools that would help their Summit experience (chat, the wiki, Etherpad), summarized the day 1 schedule, and thanked the sponsors.
Here’s the 8 minute video of the Welcome. I think it went ok, especially with so many firsts for this Summit! In the future I’d like to: reduce it to no more than 5 minutes (one or two rounds of practice & edit should help), and consider what else could or should be included (while staying under 5 minutes). That being said, I feel pretty good about our continuous improvement with organizing and welcoming to IndieWebCamps. As we’ve learned from other inclusive conferences, I encourage all conference organizers to explicitly cover similar aspects (excerpted from the online outline I spoke from)
Consider these a minimum baseline, a place to build from, more than goals. Ideally we should aspire to provide a safe and inclusive experience for an increasingly diverse community. Two more ways conference organizers can do so is by recognizing what the conference has done better this year, and by choosing keynote speakers to provide diverse perspectives. More on that with State of the IndieWeb, and the IndieWeb Summit 2019 invited keynote speakers.
Photos 1, 2, & 4 by Aaron Parecki
|
|
Eitan Isaacson: Revamping Firefox’s Reader Mode this Summer |
This is cross-posted from a Medium article by Akshitha Shetty, a Summer of Code student I have been mentoring. It’s been a pleasure and I wish her luck in her next endeavor!
For me, getting all set to read a book would mean spending hours hopping between stores to find the right lighting and mood to get started. But with Firefox’s Reader Mode it’s now much more convenient to get reading on the go. And this summer, I have been fortunate to shift roles from a user to a developer for the Reader Mode . As I write this blog, I have completed two months as a Google Summer of Code student developer with Mozilla. It has been a really enriching experience and thus I would like to share some glimpses of the project and my journey so far.
I began as an open-source contributor to Mozilla early this year. What really impressed me was how open and welcoming Mozillians were. Open-source contribution can be really intimidating at first. But in my case, the kind of documentation and direction that Mozilla provided helped me steer in the right direction really swiftly. Above all, it’s the underlying principle of the organization — “people first” that truly resonated with me. On going through the project idea list, the “Firefox Reader Mode Revamp” was of great interest to me. It was one of the projects where I would be directly enhancing the user-experience for Firefox users and also learning a lot more about user-experience and accessibility in the process.
The new design of the reader mode has the following features -
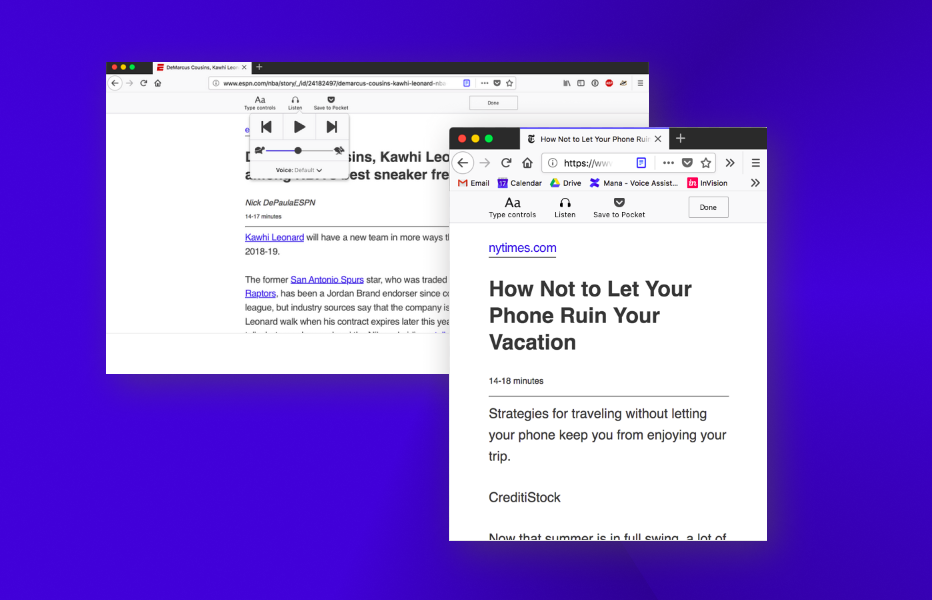
Thanks to Abraham Wallin for designing the new UI for the Reader mode.
Once the design was ready, I began with the coding of the UI. I thoroughly enjoyed the process and learnt a lot from the challenges I faced during this process. One of the challenges I faced during this phase was to make the toolbar adjust it’s width as per the content width of the main page. This required me to refactor certain portions of the existing code base as well make sure the newly coded toolbar follows the same.
All in all, it has been a really exciting process. I would like to thank my mentor — Eitan Isaacson for putting in the time and effort to mentor this project. Also I would like to thank — Gijs Kruitbosch and Yura Zenevich for reviewing my code at various points of time.
I hope this gets you excited to see the Reader Mode in its all new look ! Stay tuned for my next blog where I will be revealing the Revamped Reader Mode into action.
https://blog.monotonous.org/2019/08/06/revamping-reader-view-mode/
|
|
Daniel Stenberg: First HTTP/3 with curl |

In the afternoon of August 5 2019, I successfully made curl request a document over HTTP/3, retrieve it and then exit cleanly again.
(It got a 404 response code, two HTTP headers and 10 bytes of content so the actual response was certainly less thrilling to me than the fact that it actually delivered that response over HTTP version 3 over QUIC.)
The components necessary for this to work, if you want to play along at home, are reasonably up-to-date git clones of curl itself and the HTTP/3 library called quiche (and of course quiche’s dependencies too, like boringssl), then apply pull-request 4193 (build everything accordingly) and run a command line like:
curl --http3-direct https://quic.tech:8443
The host name used here (“quic.tech”) is a server run by friends at Cloudflare and it is there for testing and interop purposes and at the time of this test it ran QUIC draft-22 and HTTP/3.
The command line option --http3-direct tells curl to attempt HTTP/3 immediately, which includes using QUIC instead of TCP to the host name and port number – by default you should of course expect a HTTPS:// URL to use TCP + TLS.
The official way to bootstrap into HTTP/3 from HTTP/1 or HTTP/2 is via the server announcing it’s ability to speak HTTP/3 by returning an Alt-Svc: header saying so. curl supports this method as well, it just needs it to be explicitly enabled at build-time since that also is still an experimental feature.
To use alt-svc instead, you do it like this:
curl --alt-svc altcache https://quic.tech:8443
The alt-svc method won’t “take” on the first shot though since it needs to first connect over HTTP/2 (or HTTP/1) to get the alt-svc header and store that information in the “altcache” file, but if you then invoke it again and use the same alt-svc cache curl will know to use HTTP/3 then!
Be aware that I just made this tiny GET request work. The code is not cleaned up, there are gaps in functionality, we’re missing error checks, we don’t have tests and chances are the internals will change quite a lot going forward as we polish this.
You’re of course still more than welcome to join in, play with it, report bugs or submit pull requests! If you help out, we can make curl’s HTTP/3 support better and getting there sooner than otherwise.
curl currently supports two different QUIC/HTTP3 backends, ngtcp2 and quiche. Only the latter currently works this good though. I hope we can get up to speed with the ngtcp2 one too soon.
quiche uses and requires boringssl to be used while ngtcp2 is TLS library independent and will allow us to support QUIC and HTTP/3 with more TLS libraries going forward. Unfortunately it also makes it more complicated to use…
The official OpenSSL doesn’t offer APIs for QUIC. QUIC uses TLS 1.3 but in a way it was never used before when done over TCP so basically all TLS libraries have had to add APIs and do some adjustments to work for QUIC. The ngtcp2 team offers a patched version of OpenSSL that offers such an API so that OpenSSL be used.
Neither the QUIC nor the HTTP/3 protocols are entirely done and ready yet. We’re using the protocols as they are defined in the 22nd version of the protocol documents. They will probably change a little more before they get carved in stone and become the final RFC that they are on their way to.
The command line options mentioned above of course have their corresponding options for libcurl using apps as well.
Set the right bit with CURLOPT_H3 to get direct connect with QUIC and control how to do alt-svc using libcurl with CURLOPT_ALTSVC and CURLOPT_ALTSVC_CTRL.
All of these marked EXPERIMENTAL still, so they might still change somewhat before they become stabilized.
Starting on August 8, the option is just --http3 and you ask libcurl to use HTTP/3 directly with CURLOPT_HTTP_VERSION.
https://daniel.haxx.se/blog/2019/08/05/first-http-3-with-curl/
|
|
Mozilla Security Blog: Web Authentication in Firefox for Android |
Firefox for Android (Fennec) now supports the Web Authentication API as of version 68. WebAuthn blends public-key cryptography into web application logins, and is our best technical response to credential phishing. Applications leveraging WebAuthn gain new second factor and “passwordless” biometric authentication capabilities. Now, Firefox for Android matches our support for Passwordless Logins using Windows Hello. As a result, even while mobile you can still obtain the highest level of anti-phishing account security.
Firefox for Android uses your device’s native capabilities: On certain devices, you can use built-in biometrics scanners for authentication. You can also use security keys that support Bluetooth, NFC, or can be plugged into the phone’s USB port.
The attached video shows the usage of Web Authentication with a built-in fingerprint scanner: The demo website enrolls a new security key in the account using the fingerprint, and then subsequently logs in using that fingerprint (and without requiring a password).
Adoption of Web Authentication by major websites is underway: Google, Microsoft, and Dropbox all support WebAuthn via their respective Account Security Settings’ “2-Step Verification” menu.
For technical reasons, Firefox for Android does not support the older, backwards-compatible FIDO U2F Javascript API, which we enabled on Desktop earlier in 2019. For details as to why, see bug 1550625.
Currently Firefox Preview for Android does not support Web Authentication. As Preview matures, Web Authentication will be joining its feature set.
The post Web Authentication in Firefox for Android appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2019/08/05/web-authentication-in-firefox-for-android/
|
|
Cameron Kaiser: Vintage Computer Festival West 2019 opens in one hour |




http://tenfourfox.blogspot.com/2019/08/vintage-computer-festival-west-2019.html
|
|
Mozilla VR Blog: Lessons from Hacking Glitch |

When we first started building MrEd we imagined it would be done as a traditional web service. A potential user goes to a website, creates an account, then can build experiences on the site and save them to the server. We’ve all written software like this before and had a good idea of the requirements. However, as we started actually building MrEd we realized there were additional challenges.
First, MrEd is targeted at students, many of them young. My experience with teaching kids during previous summers let me know that they often don’t have email addresses, and even if they do there are privacy and legal issues around tracking what the students do. Also, we knew that this was an experiment which would end one day, but we didn’t want the students to lose access to this tool they just had just learned.
After pondering these problems we thought Glitch might be an answer. It supports anonymous use out of the box and allows easy remixing. It also has a nice CDN built in; great for hosting models and 360 images. If it would be possible to host the editor as well as the documents then Glitch would be the perfect platform for a self contained tool that lives on after the experiment was done.
The downside of Glitch is that many of its advanced features are undocumented. After much research we figured out how to modify Glitch to solve many problems, so now we’d like to share our solutions with you.
Glitch’s editor is great for editing a small project, but not for building large software. We knew from the start that we’d need to edit on our local machines and store the code in a GitHub repo. The question was how to get that code initially into Glitch? It turns out Glitch supports creating a new project from an existing git repo. This was a fantastic advantage.
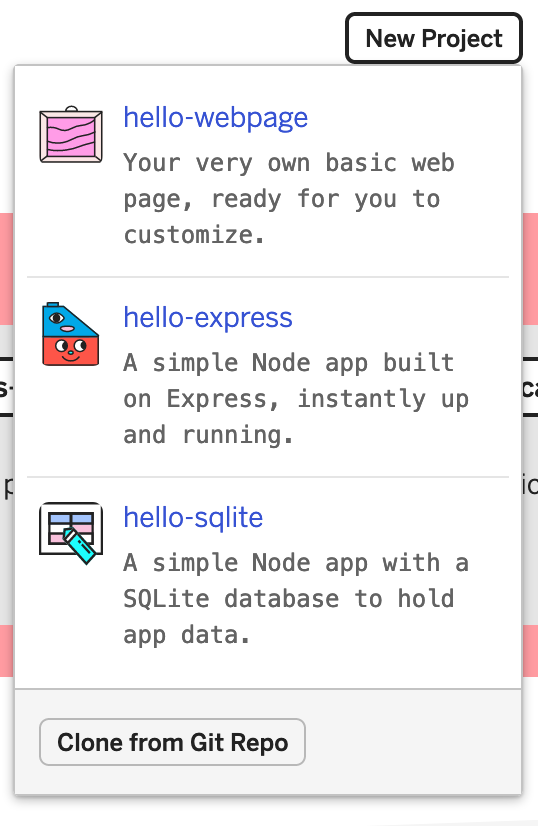
We could now create a build of the editor and set up the project just how we like, keep it versioned in Git, then make a new Glitch whenever we needed to. We built a new repo called mred-base-glitch specifically for this purpose and documented the steps to use it in the readme.
MrEd is built in React, so the next challenge was how to get a React app into Glitch. During development we ran the app locally using a hotreloading dev server. For final production, however, we need static files that could be hosted anywhere. Since our app was made with create-react-app we can build a static version with npm run build. The problem is that it requires you to set the hostname property in your package.json to calculate the final URL references. This wouldn’t work for us because someone’s Glitch could be renamed to anything. The solution was to set the hostname to ., so that all URLs are relative.
Next we wanted the editor to be hidden. In Glitch the user has a file list on the left side of the editor. While it’s fine to have assets and scripts be visible, we wanted the generated React code to be hidden. It turns out Glitch will hide any directory if it begins with dot: .. So in our base repo we put the code into public/.mred.
Finally we had the challenge of how to update the editor in an existing glitch without over-writing assets and documents the user had created.
Rather than putting everything into one git repo we made two. The first repo, mred, contains just the code to build the editor in React. The second repo, mred-base-glitch, contains the default documents and behaviors. This second repo integrates the first one as a git submodule. The compiled version of the editor also lives in the mred repo in the build directory. This way both the source and compiled versions of the editor can be versioned in git.
Whenever you want to update the editor in an existing glitch you can go to the Glitch console and run git submodule init and git submodule update to pull in just the editor changes. Then you can update the glitch UI with refresh. While this was a manual step, the students were able to do it easily with instruction.
The editor is a static React app hosted in the user’s Glitch, but it needs to save documents created in the editor at some location. Glitch doesn’t provide an API for programmatically loading and saving documents, but any Glitch can have a NodeJS server in it so we built a simple document server with express. The doc server scans the documents and scripts directories to produce a JSON API that the editor consumes.
For the launch page we wanted the user to see a list of their current projects before opening the editor. For this part the doc server has a route at / which returns a webpage containing the list as links. For URLs that need to be absolute the server uses a magic variable provided by Glitch to determine the hostname: process.env.PROJECT_DOMAIN.
The assets were a bit trickier than scripts and docs. The editor needs a list of available assets, but we can’t just scan the assets directory because assets aren’t actually stored in your Glitch. Instead they live on Glitch’s CDN using long generated URLs. However, the Glitch does have a hidden file called .glitch-assets which lists all of the assets as a JSON doc, including the mime types.
We discovered that a few of the files students wanted to use, like GLBs and WAVs, aren’t recognized by Glitch. You can still upload these files to the CDN but the .glitch-assets file won’t list the correct mime-type, so our little doc server also calculated new mime types for these files.
Having a tiny document server in the Glitch gave us a lot of flexibility to fix bugs and implement missing features. It was definitely a design win.
Another challenge with using Glitch is user authentication. Glitch has a concept of users and will not let a user edit someone else’s glitch without permission, but this user system is not exposed as an API. Our code had no way to know if the person interacting with the editor is the owner of that glitch or not. There are rumors of such a feature in the future, but for now we made do with a password file.
It turns out glitches can have a special file called .env for storing passwords and other secure environment variables. This file can be read by code running in the glitch, but it is not copied when remixing, so if someone remixes your glitch they won’t find out your password. To use this we require students to set a password as soon as the remix the base glitch. Then the doc server will use the password for authenticating communication with the editor.
We managed to really modify Glitch to support our needs and it worked quite well. That said, there are a few features we’d like them to add in the future.
Documentation. Almost everything we did above came after lots of research in the support forums, and help from a few Glitch staffers. There is very little official documentation of how to do beyond basic project development. It would be nice if there was an official docs site beyond the FAQs.
A real authentication API. Using the .env file was a nice hack, but it would be nice if the editor itself could respond properly to the user. If the user isn’t logged in it could show a play only view of the experience. If the user is logged in but isn’t the owner of the glitch then it could show a remix button.
A way to populate assets programmatically. Everything you see in a glitch when you clone from GitHub comes from the underlying git repo except for the assets. To create a glitch with a pre-set list of assets (say for doing specific exercises in a class) requires manually uploading the files through the visual interface. There is no way (at least that we could find) to store the assets in the git repo or upload them programmatically.
Overall Glitch worked very well. We got an entire visual editor, assets, and document storage into a single conceptual chunk -- a glitch -- that can be shared and remixed by anyone. We couldn’t have done what we needed on such a short timeline without Glitch. We thank you Glitch Team!
|
|
Mozilla VR Blog: Hubs July Update |

We’ve introduced new features that make it easier to moderate and share your Hubs experience. July was a busy month for the team, and we’re excited to share some updates! As the community around Hubs has grown, we’ve had the chance to see different ways that groups meet in Hubs and are excited to explore new ways that groups can choose what types of experience they want to have. Different communities have different needs for how they’re meeting in Hubs, and we think that these features are a step towards helping people get co-present together in virtual spaces in the way that works best for them.
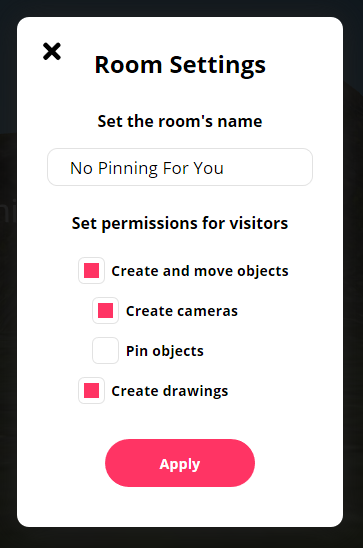
Room-Level Permissions
It is now possible for room owners to specify which features are granted to other users in the room. This allows the owner of the room to decide if people can add media to the room, draw with the pen, pin objects, and create cameras. If you’re using Hubs for a meeting or event where there will be a larger number of attendees, this can help keep the room organized and free from distractions.
Promoting Moderators
For groups that hold larger events in Hubs, there is now the ability to promote other users in a Hubs room to also have the capabilities of the room owner. If you’ve been creating rooms using the Hubs Discord bot,you may already be familiar with rooms that have multiple owners. This feature can be especially valuable for groups that have a core set of administrators who are available in the room to help moderate and keep events running smoothly. Room owners can promote other users to moderators by opening up the user list and selecting the user from a list, then clicking ‘Promote’ on the action list. You should only promote trusted users to moderator, since they’ll have the same permissions as you do as the room owner. Users must be signed in to be promoted.
Camera Mode
Room owners can now hide the Hubs user interface by enabling camera mode, which was designed for groups that want to have a member in the room record or livestream their gathering. When in camera mode, the room owner will broadcast the view from their avatar and replace the Lobby camera, and non-essential UI elements will be hidden. The full UI can be hidden by clicking the ‘Hide All’ button, which allows for a clear, unobstructed view of what’s going on in the room.
Video Recording
The camera tool in Hubs can now be used to record videos as well as photos. When a camera is created in the room, you can toggle different recording options that can be used by using the UI on the camera itself. Like photos, videos that are taken with the in-room camera will be added to the room after they have finished capturing. Audio for videos will be recorded from the position of the avatar of the user who is recording. While recording video on a camera, users will have an indicator on their display name above their head to show that they are capturing video. The camera itself also contains a light to indicate when it is recording.
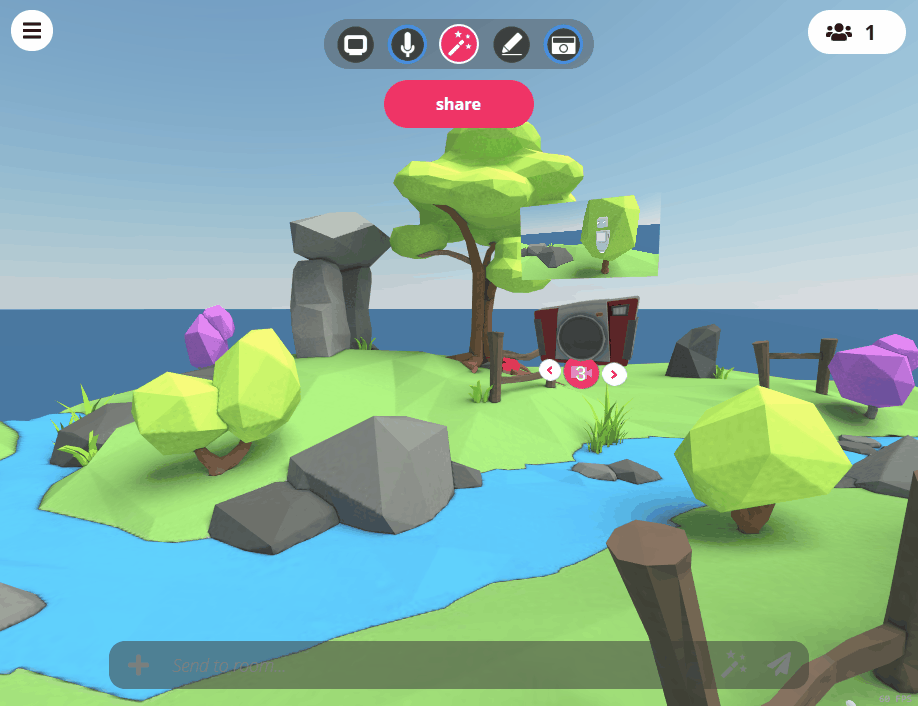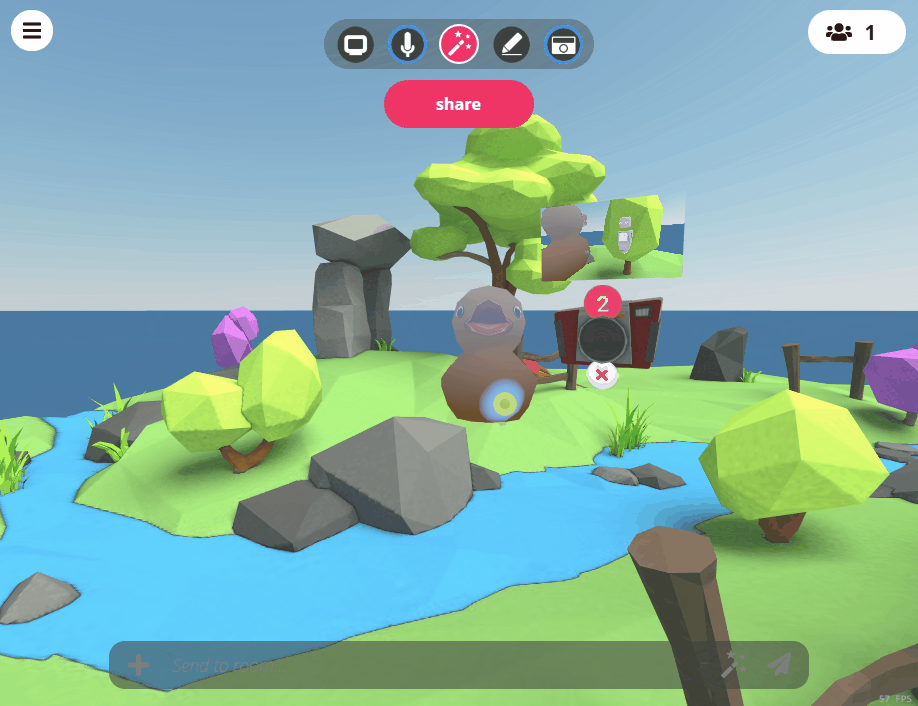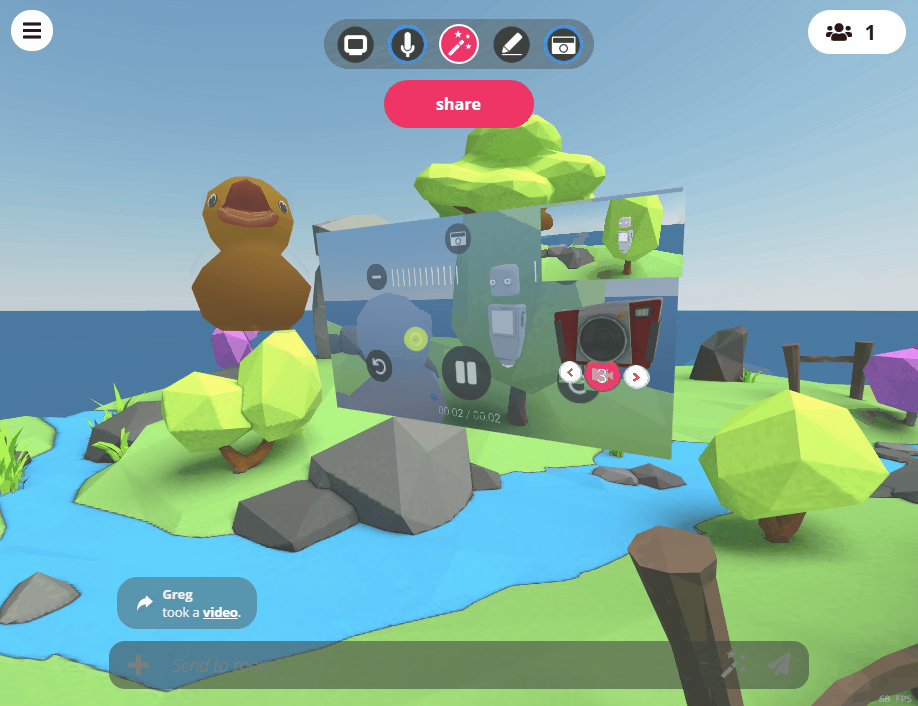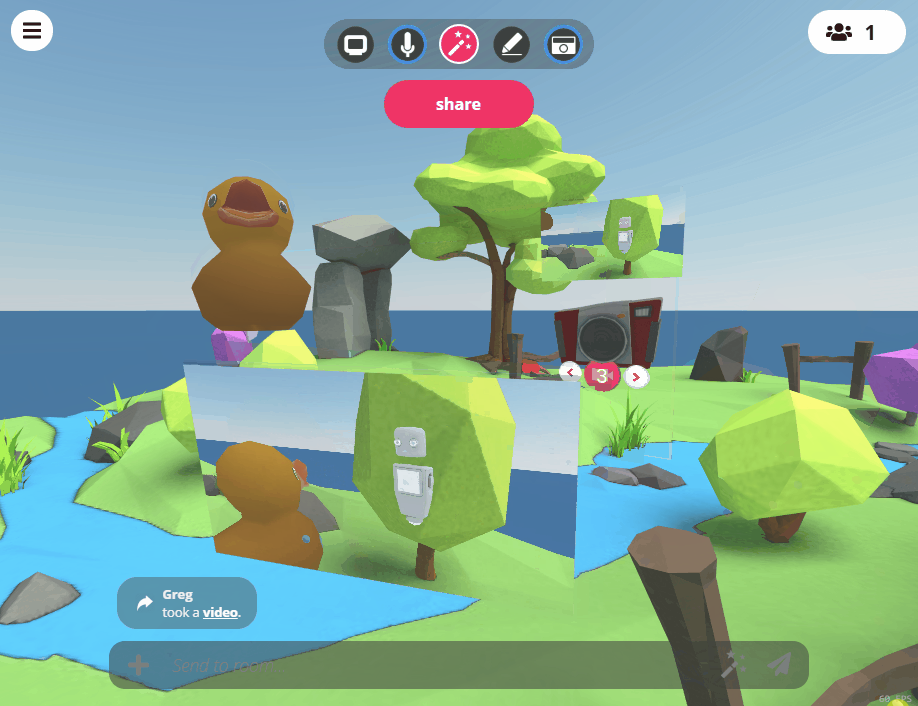
Tweet from Hubs
For users who want to share their photos, videos, and rooms through Twitter, you can now tweet from directly inside of Hubs when media is captured in a room. When you hover over a photo or video that was taken by the in-room camera, you will see a blue ‘Tweet’ button appear. The first time you share an image or video through Twitter, you will be prompted to authenticate to your Twitter account. You can review the Hubs Privacy Policy and third-party notices here, and revoke access to Hubs from your Twitter account by going to https://twitter.com/settings/applications.
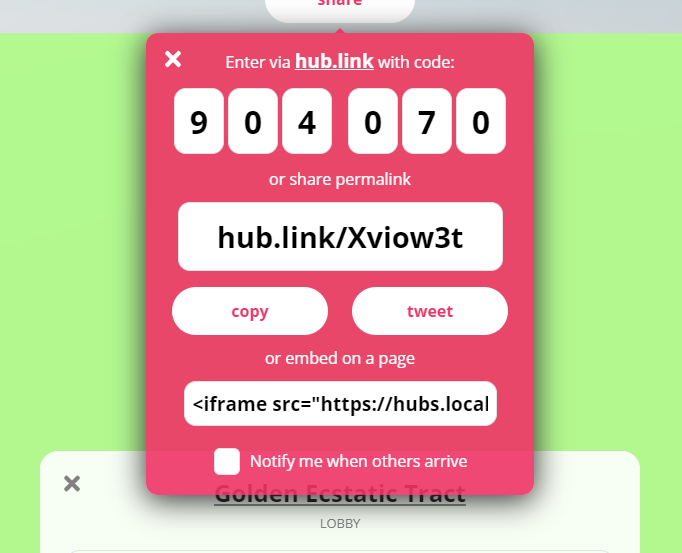
Embed Hubs Rooms
You can now embed a Hubs room directly into another web page in an iFrame. When you click the 'Share' button in a Hubs room, you can copy the embed code and paste it into the HTML on another site. Keep in mind that this means anyone who visits that page will be able to join!
Discord Bot Notifications
If you have the Hubs Discord bot in your server and bridged to a channel, you can now set a reminder to notify you of a future event or meeting. Just type in the command !hubs notify set mm/dd/yyyy and your time zone, and the Hubs Bot will post a reminder when the time comes around.
Microphone Level Indicator
Have you ever found yourself wondering if other people in the room could hear you, or forgotten that you were muted? The microphone icon in the HUD now shows mic activity level, regardless of whether or not you have your mic muted. This is a handy little way to make sure that your microphone is picking up your audio, and a nice reminder that you’re talking while muted.
In the coming months, we will be continuing work on new features aimed at enabling communities to get together easily and effectively. We’ll also be exploring improvements to the avatar customization flow and new features for Spoke to improve the tools available to creators to build their own spaces for their Hubs rooms. To participate in the conversation about new features and join our weekly community meetups, join us on Discord using the invitation link here.
|
|
Mozilla Open Policy & Advocacy Blog: Mozilla calls for transparency in compelled access case |
Sometime last year, Facebook challenged a law enforcement request for access to encrypted communications through Facebook Messenger, and a federal judge denied the government’s demand. At least, that is what has been reported by the press. Troublingly, the details of this case are still not available to the public, as the opinion was issued “under seal.” We are trying to change that.
Mozilla, with Atlassian, has filed a friend of the court brief in a Ninth Circuit appeal arguing for unsealing portions of the opinion that don’t reveal sensitive or proprietary information or, alternatively, for releasing a summary of the court’s legal analysis. Our common law legal system is built on precedent, which depends on the public availability of court opinions for potential litigants and defendants to understand the direction of the law. This opinion would have been only the third since 2003 offering substantive precedent on compelled access—thus especially relevant input on an especially serious issue.
This case may have important implications for the current debate about whether and under what circumstances law enforcement can access encrypted data and encrypted communications. The opinion, if disclosed, could help all kinds of tech companies push back on overreaching law enforcement demands. We are deeply committed to building secure products and establishing transparency and control for our users, and this information is vital to enabling those ends. As thoughtful, mission-driven engineers and product designers, it’s critical for us as well as end users to understand the legal landscape around what the government can and cannot require.
The post Mozilla calls for transparency in compelled access case appeared first on Open Policy & Advocacy.
|
|
Daniel Stenberg: The slowest curl vendors of all time |
In the curl project we make an effort to ship security fixes as soon as possible after we’ve learned about a problem. We also “prenotify” (inform them about a problem before it gets known to the public) vendors of open source OSes ahead of the release to alert them about what is about to happen and to make it possible for them to be ready and prepared when we publish the security advisory of the particular problems we’ve found.
These distributors ship curl to their customers and users. They build curl from the sources they host and they apply (our and their own) security patches to the code over time to fix vulnerabilities. Usually they start out with the clean and unmodified version we released and then over time the curl version they maintain and ship gets old (by my standards) and the number of patches they apply grow, sometimes to several hundred.
The distros@openwall mailing list allows no more than 14 days of embargo, so they can never be told any further than so in advance.
We always ship at least one official patch for each security advisory. That patch is usually made for the previous version of curl and it will of course sometimes take a little work to backport to much older curl versions.

The other day I was reading LWN when I saw their regular notices about security updates from various vendors and couldn’t help checking out a mentioned curl security fix from Red Hat for Red Hat Enterprise Linux 7. It was dated July 29, 2019 and fixed CVE-2018-14618, which we announced on September 5th 2018. 327 days ago.
Not quite reaching Apple’s level, Red Hat positions themselves as number three in this toplist with this release.
An interesting detail here is that the curl version Red Hat fixed here was 7.29.0, which is the exact same version our winner also patched…
(Update after first publication: after talks with people who know things I’ve gotten some further details. Red Hat did ship a fix for this problem already in 2018. This 2019 one was a subsequent update for complicated reasons, which may or may not make this entry disqualified for my top-list.)

At times when I’ve thought it has been necessary, I’ve separately informed the product security team at Apple about a pending release with fixes that might affect their users, and almost every time I’ve done that they’ve responded to me and asked that I give them (much) longer time between alert and release in the future. (Requests I’ve ignored so far because it doesn’t match how we work nor how the open vendors want us to behave). Back in 2010, I noticed how one of the security fixes took 391 days for Apple to fix. I haven’t checked, but I hope they’re better at this these days.
With the 391 days, Apple takes place number two.

Oracle Linux published the curl errata named ELSA-2019-1880 on July 30 2019 and it apparently fixes nine different curl vulnerabilities. All nine were the result of the Cure53 security audit and we announced them on November 2 2016.
These problems had at that time been public knowledge for exactly 1000 days! The race is over and Oracle got this win by a pretty amazing margin.
In this case, they still ship curl 7.29.0 (released on February 6, 2013) when the latest curl version we ship is version 7.65.3. When I write this, we know about 47 security problems in curl 7.29.0. 14 of those problems were fixed after those nine problems that were reportedly fixed on July 30. It might mean, but doesn’t have to, that their shipped version still is vulnerable to some of those…
Summing up, here’s the top-3 list of all times:
I’m bundling and considering all problems as equals here, which probably isn’t entirely fair. Different vulnerabilities will have different degrees of severity and thus will be more or less important to fix in a short period of time.
Still, these were security releases done by these companies so someone there at least considered them to be security related, worth fixing and worth releasing.
This list is entirely unscientific, I might have missed some offenders. There might also be some that haven’t patched these or even older problems and then they are even harder to spot. If you know of a case suitable for this top-list, let me know!
https://daniel.haxx.se/blog/2019/08/01/the-slowest-curl-vendors-of-all-time/
|
|
Daniel Stenberg: 2000 contributors |
Today when I ran the script that counts the total number of contributors that have helped out in the curl project (called contrithanks.sh) the number showing up in my terminal was
2000
At 7804 days since the birthday, it means one new contributor roughly every 4 days. For over 21 years. Kind of impressive when you think of it.
A “contributor” here means everyone that has reported bugs, helped out with fixing bugs, written documentation or authored commits (and whom we recorded the name at the time it happened, but this is something we really make an effort to not miss out on). Out of the 2000 current contributors, 708 are recorded in git as authors.
Plotted out on a graph, with the numbers from the RELEASE-NOTES over time we can see an almost linear growth. (The graph starts at 2005 because that’s when we started to log the number in that file.)

We crossed the 1000 mark on April 12 2013. 1400 on May 30th 2016 and 1800 on October 30 2018.
It took us almost six years to go from 1000 to 2000; roughly one new contributor every second day.
Two years ago in the curl 7.55.0, we were at exactly 1571 contributors so we’ve received help from over two hundred new persons per year recently. (Barring the miscalculations that occur when we occasionally batch-correct names or go through records to collect previously missed out names etc)
The curl project would not be what it is without all the help we get from all these awesome people. I love you!
That’s the file in the git repo that contains all the names of all the contributors, but if you check that right now you will see that it isn’t exactly 2000 names yet and that is because we tend to update that in batches around release time. So by the time the next release is coming, we will gather all the new contributors that aren’t already mentioned in that file and add them then and by then I’m sure we will be able to boast more than 2000 contributors. I hope you are one of the names in that list!
|
|
The Firefox Frontier: The latest Facebook Container for Firefox |
Last year we helped you keep Facebook contained to Facebook, making it possible for you to stay connected to family and friends on the social network, while also keeping your … Read more
The post The latest Facebook Container for Firefox appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/facebook-container-for-firefox/
|
|






