Will Kahn-Greene: crashstats-tools v1.0.1 released! cli for Crash Stats. |
crashstats-tools is a set of command-line tools for working with Crash Stats (https://crash-stats.mozilla.org/).
crashstats-tools comes with two commands:
I extracted two commands we have in the Socorro local dev environment as a separate Python project. This allows anyone to use those two commands without having to set up a Socorro local dev environment.
The audience for this is pretty limited, but I think it'll help significantly for testing analysis tools.
Say I'm working on an analysis tool that looks at crash report minidump files and does some additional analysis on it. I could use supersearch command to get me a list of crash ids to download data for and the fetch-data command to download the requisite data.
$ export CRASHSTATS_API_TOKEN=foo $ mkdir crashdata $ supersearch --product=Firefox --num=10 | \ fetch-data --raw --dumps --no-processed crashdata
Then I can run my tools on the dumps in crashdata/upload_file_minidump/.
Make sure to use these tools in compliance with our data policy:
https://crash-stats.mozilla.org/documentation/memory_dump_access/
See the project on GitHub which includes a README which contains everything about the project including examples of usage, the issue tracker, and the source code:
https://github.com/willkg/crashstats-tools
Let me know whether this helps you!
https://bluesock.org/~willkg/blog/mozilla/crashstats_tools_v1_0_1.html
|
|
Dustin J. Mitchell: CODEOWNERS syntax |
The GitHub docs page for CODEOWNERS is not very helpful in terms of how the file is interpreted. I’ve done a little experimentation to figure out how it works, and here are the results.
For each modified file in a PR, GitHub examines the codeowners file and selects the last matching entry. It then combines the set of mentions for all files in the PR and assigns them as reviewers.
An entry can specify no reviewers by containing only a pattern and no mentions.
Consider this CODEOWNERS:
* @org/reviewers
*.js @org/js-reviewers
*.go @org/go-reviewers
security/** @org/sec-reviewers
generated/**
Then a change to:
README.md would get review from @org/reviewerssrc/foo.js would get review from @org/js-reviewersbar.go would get review from @org/go-reviewerssecurity/crypto.go would get review from @org/sec-reviewers (but not @org/go-reviewers!)generated/reference.go would get review from nobodyAnd thus a PR with, for example:
M src/foo.js
M security/crypto.go
M generated/reference.go
would get reviewed by @org/js-reviewers and @org/sec-reviewers.
If I wanted per-language reviews even under security/, then I’d use
security/** @org/sec-reviewers
security/**/*.js @org/sec-reviewers @org/js-reviewers
security/**/*.go @org/sec-reviewers @org/go-reviewers
|
|
Hacks.Mozilla.Org: New CSS Features in Firefox 68 |
Firefox 68 landed earlier this month with a bunch of CSS additions and changes. In this blog post we will take a look at some of the things you can expect to find, that might have been missed in earlier announcements.
The headline CSS feature this time round is CSS Scroll Snapping. I won’t spend much time on it here as you can read the blog post for more details. The update in Firefox 68 brings the Firefox implementation in line with Scroll Snap as implemented in Chrome and Safari. In addition, it removes the old properties which were part of the earlier Scroll Snap Points Specification.
::marker pseudo-elementThe ::marker pseudo-element lets you select the marker box of a list item. This will typically contain the list bullet, or a number. If you have ever used an image as a list bullet, or wrapped the text of a list item in a span in order to have different bullet and text colors, this pseudo-element is for you!
With the marker pseudo-element, you can target the bullet itself. The following code will turn the bullet on unordered lists to hot pink, and make the number on an ordered list item larger and blue.
ul ::marker {
color: hotpink;
}
ol ::marker {
color: blue;
font-size: 200%;
}
With ::marker we can style our list markers
There are only a few CSS properties that may be used on ::marker. These include all font properties. Therefore you can change the font-size or family to be something different to the text. You can also color the bullets as shown above, and insert generated content.
::marker on non-list itemsA marker can only be shown on list items, however you can turn any element into a list-item by using display: list-item. In the example below I use ::marker, along with generated content and a CSS counter. This code outputs the step number before each h2 heading in my page, preceded by the word “step”. You can see the full example on CodePen.
h2 {
display: list-item;
counter-increment: h2-counter;
}
h2::marker {
content: "Step: " counter(h2-counter) ". ";
}If you take a look at the bug for the implementation of ::marker you will discover that it is 16 years old! You might wonder why a browser has 16 year old implementation bugs and feature requests sitting around. To find out more read through the issue, where you can discover that it wasn’t clear originally if the ::marker pseudo-element would make it into the spec.
There were some Mozilla-specific properties that achieved the result developers were looking for with something like ::marker. The properties ::moz-list-bullet and ::moz-list-marker allowed for the styling of bullets and markers respectively, using a moz- vendor prefix.
The ::marker pseudo-element is standardized in CSS Lists Level 3, and CSS Pseudo-elements Level 4, and currently implemented as of Firefox 68, and Safari. Chrome has yet to implement ::marker. However, in most cases you should be able to use ::marker as an enhancement for those browsers which support it. You can allow the markers to fall back to the same color and size as the rest of the list text where it is not available.
It makes web developers sad when we run into a feature which is supported but works differently in different browsers. These interoperability issues are often caused by the sheer age of the web platform. In fact, some things were never fully specified in terms of how they should work. Many changes to our CSS specifications are made due to these interoperability issues. Developers depend on the browsers to update their implementations to match the clarified spec.
Most browser releases contain fixes for these issues, making the web platform incrementally better as there are fewer issues for you to run into when working with CSS. The latest Firefox release is no different – we’ve got fixes for the ch unit, and list numbering shipping.
In addition to changes to the implementation of CSS in Firefox, Firefox 68 brings you some great new additions to Developer Tools to help you work with CSS.
In the Rules Panel, look for the new print styles button. This button allows you to toggle to the print styles for your document, making it easier to test a print stylesheet that you are working on.

The print styles icon is top right of the Rules Panel.
Staying with the Rules Panel, Firefox 68 shows an icon next to any invalid or unsupported CSS. If you have ever spent a lot of time puzzling over why something isn’t working, only to realise you made a typo in the property name, this will really help!

In this example I have spelled padding as “pudding”. There is (sadly) no pudding property so it is highlighted as an error.
The console now shows more information about CSS errors and warnings. This includes a nodelist of places the property is used. You will need to click CSS in the filter bar to turn this on.

My pudding error is highlighted in the Console and I can see I used it on the body element.
So that’s my short roundup of the features you can start to use in Firefox 68. Take a look at the Firefox 68 release notes to get a full overview of all the changes and additions that Firefox 68 brings you.
The post New CSS Features in Firefox 68 appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/07/new-css-features-in-firefox-68/
|
|
Mozilla Future Releases Blog: DNS-over-HTTPS (DoH) Update – Detecting Managed Networks and User Choice |
At Mozilla, we are continuing to experiment with DNS-over-HTTPS (DoH), a new network protocol that encrypts Domain Name System (DNS) requests and responses. This post outlines a new study we will be conducting to gauge how many Firefox users in the United States are using parental controls or enterprise DNS configurations.
With previous studies, we have tried to understand the performance impacts of DoH, and the results have been very promising. We found that DoH queries are typically the same speed or slightly slower than DNS queries, and in some cases can be significantly faster. Furthermore, we found that web pages that are hosted by Akamai–a content distribution network, or “CDN”–have similar performance when DoH is enabled. As such, DoH has the potential to improve user privacy on the internet without impeding user experience.
Now that we’re satisfied with the performance of DoH, we are shifting our attention to how we will interact with existing DNS configurations that users have chosen. For example, network operators often want to filter out various kinds of content. Parents and schools in particular may use “parental controls”, which block access to websites that are considered unsuitable for children. These controls may also block access to malware and phishing websites. DNS is commonly used to implement this kind of content filtering.
Similarly, some enterprises set up their own DNS resolvers that behave in special ways. For example, these resolvers may return a different IP address for a domain name depending on whether the user that initiated the request is on a corporate network or a public network. This behavior is known as “split-horizon”, and it is often to host a production and development version of a website. Enabling DoH in this scenario could unintentionally prevent access to internal enterprise websites when using Firefox.
We want to understand how often users of Firefox are subject to these network configurations. To do that, we are performing a study within Firefox for United States-based users to collect metrics that will help answer this question. These metrics are based on common approaches to implementing filters and enterprise DNS resolvers.
This study will generate DNS lookups from participants’ browsers to detect DNS-based parental controls. First, we will resolve test domains operated by popular parental control providers to determine if parental controls are enabled on a network. For example, OpenDNS operates exampleadultsite.com. It is not actually an adult website, but it is present on the blocklists for several parental control providers. These providers often block access to such websites by returning an incorrect IP address for DNS lookups.
As part of this test, we will resolve exampleadultsite.com. According to OpenDNS, this domain name should only resolve to the address 146.112.255.155. Thus, if a different address is returned, we will infer that DNS-based parental controls have been configured. The browser will not connect to, or download any content from the website.
We will also attempt to detect when a network has forced “safe search” versions of Google and YouTube for its users. The way that safe search works is that the network administrator configures their resolver to redirect DNS requests for a search provider to a “safe” version of the website. For example, a network administrator may force all users that look up www.google.com to instead look up forcesafesearch.google.com. When the browser connects to the IP address for forcesafesearch.google.com, the search provider knows that safe search is enabled and returns filtered search results.
We will resolve the unrestricted domain names provided by Google and YouTube from the addon, and then resolve the safe search domain names. Importantly, the safe search domain names for Google and YouTube are hosted on fixed IP addresses. Thus, if the IP address for an unrestricted and safe search domain name match, we will infer that parental controls are enabled. The tables below show the domain names we will resolve to detect safe search.
| YouTube | |
| www.youtube.com | www.google.com |
| m.youtube.com | google.com |
| youtubeapi.googleapis.com | |
| youtube.googleapis.com | |
| www.youtube-nocookie.com |
Table 1: The unrestricted domain names provided by YouTube and Google
| YouTube | |
| restrict.youtube.com | forcesafesearch.google.com |
| restrictmoderate.youtube.com |
Table 2: The safe search domain names provided by YouTube and Google
We also want to understand how many Firefox users are behind networks that use split-horizon DNS resolvers, which are commonly configured by enterprises. We will perform two checks locally in the browser on DNS answers for websites that users visit during the study. First, we will check if the domain name does not contain a TLD that can be resolved by publicly-available DNS resolvers (such as .com). Second, if the domain name does contain such a TLD, we will check if the domain name resolves to a private IP address.
If either of these checks return true, we will infer that the user’s DNS resolver has configured split-horizon behavior. This is because the public DNS can only resolve domain names with particular TLDs, and it must resolve domain names to addresses that can be accessed over the public internet.
To be clear, we will not collect any DNS requests or responses. All checks will occur locally. We will count how many unique domain names appear to be resolved by a split-horizon resolver and then send only these counts to us.
Users that do not wish to participate in this study can opt-out by typing “about:studies’ in the navigation bar, looking for an active study titled “Detection Logic for DNS-over-HTTPS”, and disabling it. (Not all users will receive this study, so don’t be alarmed if you can’t find it.) Users may also opt out of participating in any future studies from this page.
As always, we are committed to maintaining a transparent relationship with our users. We believe that DoH significantly improves the privacy of our users. As we move toward a rollout of DoH to all United States-based Firefox users, we intend to provide explicit mechanisms allowing users and local DNS administrators to opt-out.
The post DNS-over-HTTPS (DoH) Update – Detecting Managed Networks and User Choice appeared first on Future Releases.
|
|
This Week In Rust: This Week in Rust 297 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
This week's crate is async-trait, a procedural macro to allow async fns in trait methods.
Thanks to Ehsan M. Kermani for the suggestion!
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
324 pull requests were merged in the last week
riscv32i-unknown-none-elf targetPin<&(mut) Self>uninit_arraytype_name intrinsic in core::anyVec(Deque) array PartialEq implswchar_t layout computation to happen later#[doc(include)] relative to the containing fileChanges to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
No new RFCs were proposed this week.
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Tweet us at @ThisWeekInRust to get your job offers listed here!
Rust clearly popularized the ownership model, with similar implementations being considered in D, Swift and other languages. This is great news for both performance and memory safety in general.
Also let's not forget that Rust is not the endgame. Someone may at one point find or invent a language that will offer an even better position in the safety-performance-ergonomics space. We should be careful not to get too attached to Rust, lest we stand in progress' way.
Thanks to Vikrant for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nasa42, llogiq, and Flavsditz.
https://this-week-in-rust.org/blog/2019/07/30/this-week-in-rust-297/
|
|
Eitan Isaacson: HTML Text Snippet Extension |
I often need to quickly test a snippet of HTML, mostly to see how it interacts with our accessibility APIs.
Instead of creating some throwaway HTML file each time, I find it easier to paste in the HTML in devtools, or even make a data URI.
Last week I spent an hour creating an extension that allows you to just paste some HTML into the address bar and have it rendered immediately.
You just need to prefix it with the html keyword, and you’re good to go. Like this html
You can download it from github.
There might be other extensions or ways of doing this, but it was a quick little project.
https://blog.monotonous.org/2019/07/30/html-snippet-extension/
|
|
IRL (podcast): The Tech Worker Resistance |
There's a movement building within tech. Workers are demanding higher standards from their companies — and because of their unique skills and talent, they have the leverage to get attention. Walkouts and sit-ins. Picket protests and petitions. Shareholder resolutions, and open letters. These are the new tools of tech workers, increasingly emboldened to speak out. And, as they do that, they expose the underbellies of their companies' ethics and values or perceived lack of them.
In this episode of IRL, host Manoush Zomorodi meets with Rebecca Stack-Martinez, an Uber driver fed up with being treated like an extension of the app; Jack Poulson, who left Google over ethical concerns with a secret search engine being built for China; and Rebecca Sheppard, who works at Amazon and pushes for innovation on climate change from within. EFF Executive Director Cindy Cohn explains why this movement is happening now, and why it matters for all of us.
IRL is an original podcast from Firefox. For more on the series go to irlpodcast.org
Rebecca Stack-Martinez is a committee member for Gig Workers Rising.
Here is Jack Poulson's resignation letter to Google. For more, read Google employees' open letter against Project Dragonfly.
Check out Amazon employees' open letter to Jeff Bezos and Board of Directors asking for a better plan to address climate change.
Cindy Cohn is the Executive Director of the Electronic Frontier Foundation. EFF is a nonprofit that defends civil liberties in the digital world. They champion user privacy, free expression, and innovation through impact litigation, policy analysis, grassroots activism, and technology development.
|
|
Mozilla VR Blog: MrEd, an Experiment in Mixed Reality Editing |

We are excited to tell you about our experimental Mixed Reality editor, an experiment we did in the spring to explore online editing in MR stories. What’s that? You haven’t heard of MrEd? Well please allow us to explain.
For the past several months Blair, Anselm and I have been working on a visual editor for WebXR called the Mixed Reality Editor, or MrEd. We started with this simple premise: non-programmers should be able to create interactive stories and experiences in Mixed Reality without having to embrace the complexity of game engines and other general purpose tools. We are not the first people to tackle this challenge; from visual programming tools to simplified authoring environments, researchers and hobbyists have grappled with this problem for decades.
Looking beyond Mixed Reality, there have been notable successes in other media. In the late 1980s Apple created a ground breaking tool for the Macintosh called Hypercard. It let people visually build applications at a time when programming the Mac required Pascal or assembly. It did this by using the concrete metaphor of a stack of cards. Anything could be turned into a button that would jump the user to another card. Within this simple framework people were able to create eBooks, simple games, art, and other interactive applications. Hypercard’s reliance on declaring possibly large numbers of “visual moments” (cards) and using simple “programming” to move between them is one of the inspirations for MrEd.
We also took inspiration from Twine, a web-based tool for building interactive hypertext novels. In Twine, each moment in the story (seen on the screen) is defined as a passage in the editor as a mix of HTML content and very simple programming expressions executed when a passage is displayed, or when the reader follows a link. Like Hypercard, the author directly builds what the user sees, annotating it with small bits of code to manage the state of the story.
No matter what the medium — text, pictures, film, or MR — people want to tell stories. Mixed Reality needs tools to let people easily tell stories by focusing on the story, not by writing a simulation. It needs content focused tools for authors, not programmers. This is what MrEd tries to be.
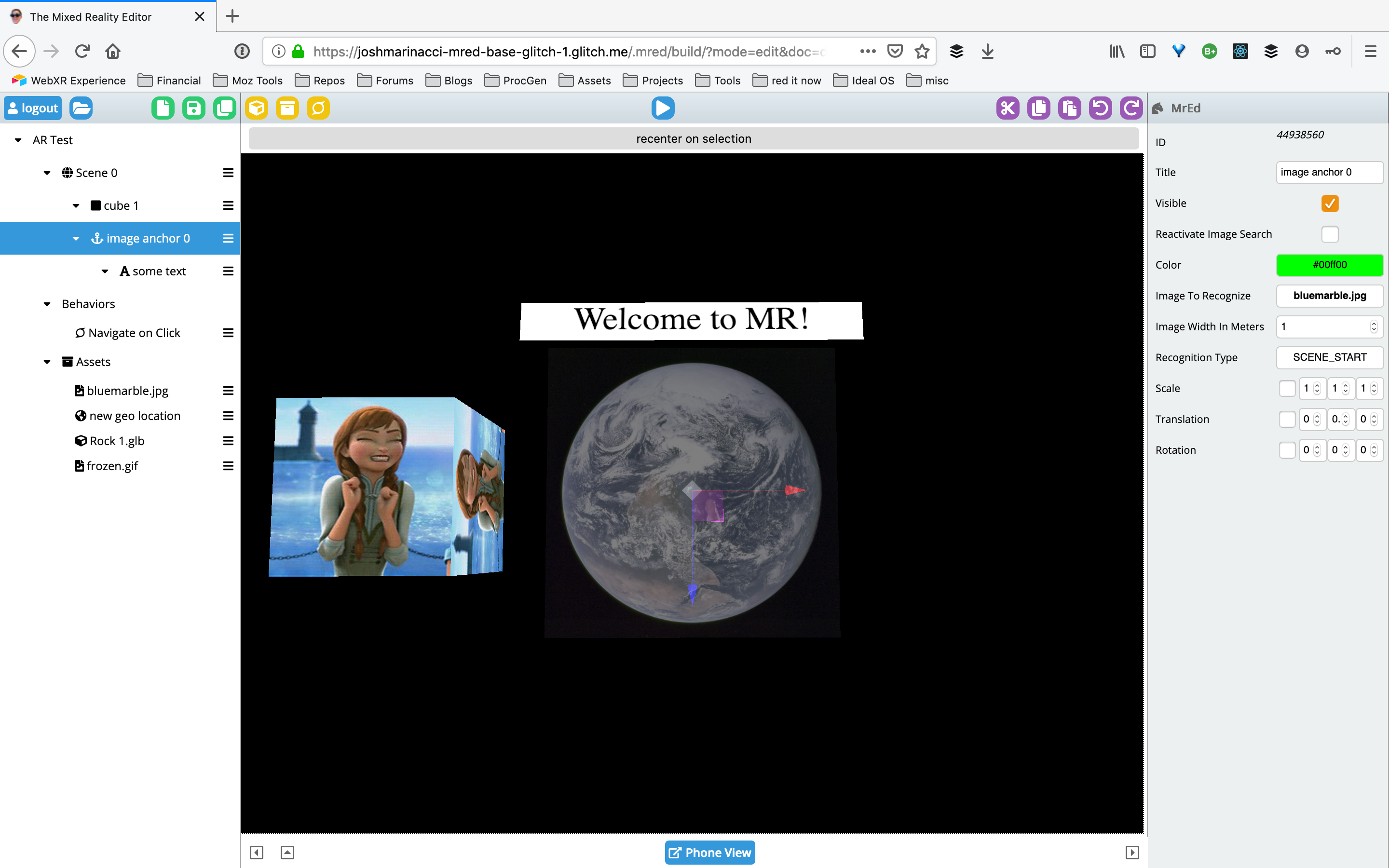
At first glance, MrEd looks a lot like other 3D editors, such as Unity3D or Amazon Sumerian. There is a scene graph on the left, letting authors create scenes, add anchors and attach content elements under them. Select an item in the graph or in the 3D windows, and a property pane appears on the right. Scripts can be attached to objects. And so on. You can position your objects in absolute space (good for VR) or relative to other objects using anchors. An anchor lets you do something like look for this poster in the real world, then position this text next to it, or look for this GPS location and put this model on it. Anchors aren’t limited to basic can also express more semantically meaningful concepts like find the floor and put this on it (we’ll dig into this in another article).
Dig into the scene graph on the left, and differences appear. Instead of editing a single world or game level, MrEd uses the metaphor of a series of scenes (inspired by Twine’s passages and Hypercard’s cards). All scenes in the project are listed, with each scene defining what you see at any given point: shapes, 3D models, images, 2D text and sounds. You can add interactivity by attaching behaviors to objects for things like ‘click to navigate’ and ‘spin around’. The story advances by moving from scene to scene; code to keep track of story state is typically executed on these scene transitions, like Hypercard and Twine. Where most 3D editors force users to build simulations for their experiences, MrEd lets authors create stores that feel more like “3D flip-books”. Within a scene, the individual elements can be animated, move around, and react to the user (via scripts), but the story progresses by moving from scene to scene. While it is possible to create complex individual scenes that begin to feel like a Unity scene, simple stories can be told through sequences of simple scenes.
We built MrEd on Glitch.com, a free web-based code editing and hosting service. With a little hacking we were able to put an entire IDE and document server into a glitch. This means anyone can share and remix their creations with others.
One key feature of MrEd is that it is built on top of a CRDT data structure to enable editing the same project on multiple devices simultaneously. This feature is critical for Mixed Reality tools because you are often switching between devices during development; the networked CRDT underpinnings also mean that logging messages from any device appear in any open editor console viewing that project, simplifying distributed development. We will tell you more details about the CRDT and Glitch in future posts.
We ran a two week class with a group of younger students in Atlanta using MrEd. The students were very interested in telling stories about their school, situating content in space around the buildings, and often using memes and ideas that were popular for them. We collected feedback on features, bugs and improvements and learned a lot from how the students wanted to use our tool.
As I said, this was an experiment, and no experiment is complete without reporting on what we learned. So what did we learn? A lot! And we are going to share it with you over the next couple of blog posts.
First we learned that idea of building a 3D story from a sequence of simple scenes worked for novice MR authors: direct manipulation with concrete metaphors, navigation between scenes as a way of telling stories, and the ability to easily import images and media from other places. The students were able to figure it out. Even more complex AR concepts like image targets and geospatial anchors were understandable when turned into concrete objects.
MrEd’s behaviors scripts are each a separate Javascript file and MrEd generates the property sheet from the definition of the behavior in the file, much like Unity’s behaviors. Compartmentalizing them in separate files means they are easy to update and share, and (like Unity) simple scripts are a great way to add interactivity without requiring complex coding. We leveraged Javascript’s runtime code parsing and execution to support scripts with simple code snippets as parameters (e.g., when the user finds a clue by getting close to it, a proximity behavior can set a global state flag to true, without requiring a new script to be written), while still giving authors the option to drop down to Javascript when necessary.
Second, we learned a lot about building such a tool. We really pushed Glitch to the limit, including using undocumented APIs, to create an IDE and doc server that is entirely remixable. We also built a custom CRDT to enable shared editing. Being able to jump back and forth between a full 2d browser with a keyboard and then XR Viewer running on an ARKit enabled iPhone is really powerful. The CRDT implementation makes this type of real time shared editing possible.
MrEd was an experiment in whether XR metaphors can map cleanly to a Hypercard-like visual tool. We are very happy to report that the answer is yes. Now that our experiment is over we are releasing it as open source, and have designed it to run in perpetuity on Glitch. While we plan to do some code updates for bug fixes and supporting the final WebXR 1.0 spec, we have no current plans to add new features.
Building a community around a new platform is difficult and takes a long time. We realized that our charter isn’t to create platforms and communities. Our charter is to help more people make Mixed Reality experiences on the web. It would be far better for us to help existing platforms add WebXR than for us to build a new community around a new tool.
Of course the source is open and freely usable on Github. And of course anyone can continue to use it on Glitch, or host their own copy. Open projects never truly end, but our work on it is complete. We will continue to do updates as the WebXR spec approaches 1.0, but there won’t be any major changes.
We are going to polish up the UI and fix some remaining bugs. MrEd will remain fully usable on Glitch, and hackable on GitHub. We also want to pull some of the more useful chunks into separate components, such as the editing framework and the CRDT implementation. And most importantly, we are going to document everything we learned over the next few weeks in a series of blogs.
If you are interested in integrating WebXR into your own rapid prototyping / educational programming platform, then please let us know. We are very happy to help you.
You can try MrEd live on Glitch today. You can get the source from the main MrEd github repo.
https://blog.mozvr.com/mred-an-experiment-in-mixed-reality-editing/
|
|
Botond Ballo: Trip Report: C++ Standards Meeting in Cologne, July 2019 |
| Project | What’s in it? | Status |
| C++20 | See below | On track |
| Library Fundamentals TS v3 | See below | Under development |
| Concepts | Constrained templates | In C++20 |
| Parallelism TS v2 | Task blocks, library vector types and algorithms, and more | Published! |
| Executors | Abstraction for where/how code runs in a concurrent context | Targeting C++23 |
| Concurrency TS v2 | See below | Under active development |
| Networking TS | Sockets library based on Boost.ASIO | Published! Not in C++20. |
| Ranges | Range-based algorithms and views | In C++20 |
| Coroutines | Resumable functions (generators, tasks, etc.) | In C++20 |
| Modules | A component system to supersede the textual header file inclusion model | In C++20 |
| Numerics TS | Various numerical facilities | Under active development |
| C++ Ecosystem TR | Guidance for build systems and other tools for dealing with Modules | Under active development |
| Contracts | Preconditions, postconditions, and assertions | Pulled from C++20, now targeting C++23 |
| Pattern matching | A match-like facility for C++ |
Under active development, targeting C++23 |
| Reflection TS | Static code reflection mechanisms | Publication imminent |
| Reflection v2 | A value-based constexpr formulation of the Reflection TS facilities |
Under active development, targeting C++23 |
| Metaclasses | Next-generation reflection facilities | Early development |
A few links in this blog post may not resolve until the committee’s post-meeting mailing is published (expected within a few days of August 5, 2019). If you encounter such a link, please check back in a few days.
Last week I attended a meeting of the ISO C++ Standards Committee (also known as WG21) in Cologne, Germany. This was the second committee meeting in 2019; you can find my reports on preceding meetings here (February 2019, Kona) and here (November 2018, San Diego), and previous ones linked from those. These reports, particularly the Kona one, provide useful context for this post.
This week the committee reached a very important milestone in the C++20 publication schedule: we approved the C++20 Committee Draft (CD), a feature-complete draft of the C++20 standard which includes wording for all of the new features we plan to ship in C++20.
The next step procedurally is to send out the C++20 CD to national standards bodies for a formal ISO ballot, where they have the opportunity to comment on it. The ballot period is a few months, and the results will be in by the next meeting, which will be in November in Belfast, Northern Ireland. We will then spend that meeting and the next one addressing the comments, and then publishing a revised draft standard. Importantly, as this is a feature-complete draft, new features cannot be added in response to comments; only bugfixes to existing features can be made, and in rare cases where a serious problem is discovered, a feature can be removed.
Attendance at this meeting once again broke previous records, with over 200 people present for the first time ever. It was observed that one of the likely reasons for the continued upward trend in attendance is the proliferation of domain-specific study groups such as SG 14 (Games and Low-Latency Programming) and SG 19 (Machine Learning) which is attracting new experts from those fields.
Note that the committe now tracks its proposals in GitHub. If you’re interested in the status of a proposal, you can find its issue on GitHub by searching for its title or paper number, and see its status — such as which subgroups it has been reviewed by and what the outcome of the reviews were — there.
Here are the new changes voted into C++20 Working Draft at this meeting. For a list of changes voted in at previous meetings, see my Kona report. (As a quick refresher, major features voted in at previous meetings include modules, coroutines, default comparisons (<=>), concepts, and ranges.)
constexpr improvements:
constexpr containers. This is the language change that allows the library changes mentioned below to make std::vector and std::string constexpr.constinit keywordconstexpr contextsconstexpr intrinsics by permitting unevaluated inline assembly in constexpr functions<=>):
using enum. This allows introducing the enumerators of a scoped enumeration into a local scope, and thereby avoiding the repetition of the enumeration name in that scope.[[nodiscard("should have a reason")]][[nodiscard]] for constructors. This is also a Defect Report against C++17.matrix[row, col]) in a future standard.volatile (only the core language portions; the library portions are still under review)memory_order_consume with release sequencesatomic_ref, and add wait/notify to atomicstd::vector constexprstd::string constexprsource_location for C++20. This provides a modern replacement for macros like __FILE__ and __LINE__.PascalCase to snake_case, for consistency with other standard library names, and tweaks the names further in cases where the mechanical rename results in a conflict or other issue.<=> to standard libary types)to_array from LFTS with updatesbasic_stringbuf‘s bufferconstexpr INVOKEbasic_istream_view::iterator should not be copyablechronochar8_t backward compatibility remediationbind_front should not unwrap reference_wrapperContiguousIteratorceil2constexpr feature macro concernsIn addition to the C++ International Standard (IS), the committee publishes Technical Specifications (TS) which can be thought of experimental “feature branches”, where provisional specifications for new language or library features are published and the C++ community is invited to try them out and provide feedback before final standardization.
At this meeting, the focus was on the C++20 CD, and not so much on TSes. In particular, there was no discussion of merging TSes into the C++ IS, because the deadline for doing so for C++20 was the last meeting (where Modules and Coroutines were merged, joining the ranks of Concepts which was merged a few meetings prior), and it’s too early to be discussing mergers into C++23.
Nonetheless, the committee does have a few TSes in progress, and I’ll mention their status:
The Reflection TS was approved for publication at the last meeting. The publication process for this TS is a little more involved than usual: due to the dependency on the Concepts TS, the Reflection TS needs to be rebased on top of C++14 (the Concepts TS’ base document) for publication. As a result, the official publication has not happened yet, but it’s imminent.
As mentioned before, the facilities in the Reflection TS are not planned to be merged into the IS in their current form. Rather, a formulation based on constexpr values (rather than types) is being worked on. This is a work in progress, but recent developments have been encouraging (see the SG7 (Reflection) section) and I’m hopeful about them making C++23.
This third iteration (v3) of the Library Fundamentals TS continues to be open for new features. It hasn’t received much attention in recent meetings, as the focus has been on libraries targeted at C++20, but I expect it will continue to pick up material in the coming meetings.
A concrete plan for Concurrency TS v2 is starting to take shape.
The following features are planned to definitely be included:
fiber_context. This is the latest formulation of stackful coroutines (fibers). It’s a very long time in the making, and has been bounced around various strudy groups for years; I’m glad to see it finally have a concrete ship vehicle!The following additional features might tag along if they’re ready in time:
I don’t think there’s a timeline for publication yet; it’s more “when the features in the first list are ready”.
As mentioned before, the Networking TS did not make C++20. As it’s now targeting C++23, we’ll likely see some proposal for design changes between now and its merger into C++23.
One such potential proposal is one that would see the Networking TS support TLS out of the box. JF Bastien from Apple has been trying to get browser implementers on board with such a proposal, which might materialize for the upcoming Belfast meeting.
As usual, I spent most of the week in EWG. Here I will list the papers that EWG reviewed, categorized by topic, and also indicate whether each proposal was approved, had further work on it encouraged, or rejected. Approved proposals are targeting C++20 unless otherwise mentioned; “further work” proposals are not.
standard_case for C++20, while we still can. Concepts have been part of the C++ literature long before the C++20 language feature that allows them to be expressed in code; for example, they are discussed in Stepanov’s Elements of Programming, and existing versions of the IS document describe the notional concepts that form the requirements for various algorithms. In this literature, concepts are conventionally named in PascalCase. As a result, the actual language-feature concepts added to the standard library in C++20 were named in PascalCase as well. However, it was observed that essentially every other name in the standard library uses snake_case, and remaining consistent with that might be more important than respecting naming conventions from non-code literature. This was contentious, for various reasons: (1) it was late in the cycle to make this change; (2) a pure mechanical rename resulted in some conflicts with existing names, necessitating additional changes that went beyond case; and (3) some people liked the visual distinction that PascalCase conferred onto concept names. Nonetheless, EWG approved the change.expression -> Type, because their semantics are not consistent with trailing return types which share the same syntax.Contracts were easily the most contentious and most heavily discussed topic of the week. In the weeks leading up the meeting, there were probably 500+ emails on the committee mailing lists about them.
The crux of the problem is that contracts can have a range of associated behaviours / semantics: whether they are checked, what happens if they are checked and fail, whether the compiler can assume them to be true in various scenarios, etc. The different behaviours lend themselves to different use cases, different programming models, different domains, and different stages of the software lifecycle. Given the diversity of all of the above represented at the committee, people are having a really hard time agreeing on what set of possible behaviours the standard should allow for, what the defaults should be, and what mechanisms should be available to control the behaviour in case you want something other than the defaults.
A prominent source of disagreement is around the possibility for contracts to introduce undefined behaviour (UB) if we allow compilers to assume their truth, particularly in cases where they are not checked, or where control flow is allowed to continue past a contract failure.
Contracts were voted into the C++20 working draft in June 2018; the design that was voted in was referred to as the “staus quo design” during this week’s discussions (since being in the working draft made it the status quo). In a nutshell, in the status quo design, the programmer could annotate contracts as having one of three levels — default, audit, or axiom — and the contract levels were mapped to behaviours using two global switches (controlled via an implementation-defined mechanism, such as a compiler flag): a “build level” and a “continuation mode”.
The status quo design clearly had consensus at the time it was voted in, but since then that consensus had begun to increasingly break down, leading to a slew of Contracts-related proposals submitted for the previous meeting and this one.
I’ll summarize the discussions that took place this week, but as mentioned above, the final outcome was that Contracts was removed from C++20 and is now targeting C++23.
EWG discussed Contracts on two occasions during the week, Monday and Wednesday. On Monday, we started with a scoping discussion, where we went through the list of proposals, and decided which of them we were even willing to discuss. Note that, as per the committee’s schedule for C++20, the deadline for making design changes to a C++20 feature had passed, and EWG was only supposed to consider bugfixes to the existing design, though as always that’s a blurry line.
Anyways, the following proposals were rejected with minimal discussion on the basis of being a design change:
That left the following proposals to be considered. I list them here in the order of discussion. Please note that the “approvals” from this discussion were effectively overturned by the subsequent removal of Contracts from C++20.
default, audit, and axiom), as well as the build level and continuation mode, and made the way the behaviour of a contract checking statement is determined completely implementation-defined. The second part essentially layered on top the “Contracts that work” proposal, which introduces literal semantics: rather than annotating contracts with “levels” which are somehow mapped onto behaviours, contracts are annotated with their desired behaviour directly; if the programmer wants different behaviours in different build modes, they can arrange for that themselves, using e.g. macros that expand to different semantics in different build modes. EWG approved both parts, which was somewhat surprising because “Contracts that work” was previously voted as not even being in scope for discussion. I think the sentiment was that, while this is a design change, it has more consensus than the status quo, and so it’s worth trying to sneak it in even though we’re past the design change deadline. Notably, while this proposal did pass, it was far from unanimous, and the dissenting minority was very vocal about their opposition, which ultimately led to the topic being revisited and Contracts being axed from C++20 on Wednesday.To sum up what happened on Monday: EWG made a design change to Contracts, and that design change had consensus among the people in the room at the time. Unfortunately, subsequent discussions with people not in the room, including heads of delegations from national standards bodies, made it clear that the design change was very unlikely to have the consensus of the committee at large in plenary session, largely for timing reasons (i.e. it being too late in the schedule to make such a nontrivial design change).
As people were unhappy with the status quo, but there wasn’t consensus for a design change either, that left removing contracts from C++20 and continuing to work on it in the C++23 cycle. A proposal to do so was drafted and discussed in EWG on Wednesday, with a larger group of people in attendance this time, and ultimately garnered consensus.
To help organize further work on Contracts in the C++23 timeframe, a new Study Group, SG 21 (Contracts) was formed, which would incubate and refine an updated proposal before it comes back to EWG. It’s too early to say what the shape of that proposal might be.
I personally like literal semantics, though I agree it probably wouldn’t have been prudent to make a significant change like that for C++20. I would welcome a future proposal from SG 21 that includes literal semantics.
A notable procedural development in the area of Modules, is that the Modules Study Group (SG 2) was resurrected at the last meeting, and met during this meeting to look at all Modules-related proposals and make recommendations about them. EWG then looked at the ones SG 2 recommended for approval for C++20:
#include directives into module imports) optional, because it is problematic for some use cases, and solves the problems that motivated mandatory include translation in another way. (Aside: Richard Smith, the esteemed author of this paper and the previous one, clearly has too much time on his hands if he can come up with alliterations like this for paper titles. We should give him some more work to do. Perhaps we could ask him to be the editor of the C++ IS document? Oh, we already did that… Something else then. Finish implementing Concepts in clang perhaps? import rather than #include (without imposing any requirements (yet) that their contents actually be modularized). It also reserves module names whose first component is std, or std followed by a number, for use by the standard library.import keyword in such a way that tools can quickly scan source files and gather their module dependencies without having to do too much processing (and in particular without having to do a full run of the preprocessor).There were also some Modules-related proposals that SG2 looked at and decided not to advance for C++20, but instead continue iterating for C++23:
inline keyword is not in line with the design of modules. This proposal will be revised before EWG looks at it.inline keyword explicitly). Reactions were somewhat mixed, with some concerns about impacts on compile-time and runtime performance. Some felt that if we do this at all, we should do it in C++20, so our guidance to authors of modular code can be consistent from the get-go; while it seems to be too late to make this change in C++20 itself, the idea of a possible future C++20 Defect Report was raised.Finally, EWG favourably reviewed at the Tooling Study Group’s plans for a C++ Ecosystem Technical Report. One suggestion made was to give the TR a more narrowly scoped name to reflect its focus on Modules-related tooling (lest people are misled into expecting that it addresses every “C++ Ecosystem” concern).
EWG considered several proposed improvements to coroutines. All of them were rejected for C++20 due to being too big of a change at this late stage.
co_return; and co_return value; in the same coroutineco_await/co_yield/co_return ugliness by making yield etc. context-sensitive keywords.Coroutines will undoubtedly see improvements in the C++23 timeframe, including possibly having some of the above topics revisited, but of course we’ll now be limited to making changes that are backwards-compatible with the current design.
constexprconstexpr intrinsics by permitting unevaluated inline assembly in constexpr functions. With std::is_constant_evaluated(), you can already give an operation different implementations for runtime and compile-time evaluation. This proposal just allows the runtime implementations of such functions to use inline assembly.constinit: EWG was asked to clarify the intended rules for non-initializing declarations. The Core Working Group’s recommendation — that a non-initializing declaration of a variable be permitted to contain constinit, and if it does, the initializing declaration must be constinit as well — was accepted.In one of the meeting’s more exciting developments, Herb Sutter’s lightweight exceptions proposal (affectionately dubbed “Herbceptions” in casual conversation) was finally discussed in EWG. I view this proposal as being particularly important, because it aims to heal the current fracture of the C++ user community into those who use exceptions and those who do not.
The proposal has four largely independent parts:
std::logic_error, but rather via a contract violation.noexcept. However, that’s unlikely to fly, as there are good use cases for recovering from allocation failure, so more recent versions leave the choice of behaviour up to the allocator, and aim to make such functions conditionally noexcept.try keyword, not unlike Rust’s try! macro. Of course, unlike Rust, use of the annotation would have to be optional for backwards compatibility, though one can envision enforcing its use locally in a codebase (or part of a codebase) via static analysis.As can be expected from such an ambitious proposal, this prompted a lot of discussion in EWG. A brief summary of the outcome for each part:
noexcept, there was no consensus to move in the direction of making the default allocator non-throwing.I expect the proposal will return in revised form (and this will likely repeat for several iterations). The road towards achieving consensus on a significant change like this is a long one!
I’ll mention one interesting comment that was made during the proposal’s presentation: it was observed that since we need to revise the calling convention as part of this proposal anyways, perhaps we could take the opportunity to make other improvements to it as well, such as allowing small objects to be passed in registers, the lack of which is a pretty unfortunate performance problem today (certainly one we’ve run into at Mozilla multiple times). That seems intriguing.
for ...” construct which could be used to iterate at compile time over tuple-like objects and parameter packs. Prior to this meeting, it was discovered that the parameter pack formulation has an ambiguity problem. We couldn’t find a fix in time, so the support for parameter packs was dropped, leaving only tuple-like objects. However, “for ...” no longer seemed like an appropriate syntax if parameter packs are not supported, so the syntax was changed to “template for“. Unfortunately, while EWG approved “template for“, the Core Working Group ran out of time to review its wording, so (*) the feature didn’t make C++20. It will likely be revisited for C++23, possibly including ways to resolve the parameter pack issue.(Disclaimer: don’t read too much into the categorization here. One person’s bug fix is another’s feature.)
For C++20:
rethrow_exception must be allowed to copy. This is a small bugfix to an exception handling support utility.[[nodiscard]] for constructors. This fixes what was largely a wording oversight.For C++23:
operator new. This allows operator new to communicate to its caller how many bytes it actually allocated, which can sometimes be larger than the requested amount.enum classes from plan enums, which is not necessarily possible to do in pure library code.size_t and ptrdiff_t. The suffixes uz for size_t and z for ssize_t were approved. The suffixes t for ptrdiff_t and ut for a corresponding unsigned type had no consensus.[[always_inline]] and [[never_inline]]. EWG was generally supportive, but requested the author provide additional motivation, and also clarify if they are orders to the compiler (usable in cases where inlining or not actually has a semantic effect), or just strong optimization hints.As usual, there were papers EWG did not get to discussing at this meeting; see the committee website for a complete list. At the next meeting, after addressing any national body comments on the C++20 CD which are Evolutionary in nature, EWG expects to spend the majority of the meeting reviewing C++23-track proposals.
Evolution Incubator, which acts as a filter for new proposals incoming to EWG, met for two days, and reviewed numerous proposals, approving the following ones to advance to EWG at the next meeting:
auto(x): decay-copy in the language. This is a construct for performing explicitly the “decay” that values undergo implicitly today when being passed as a function argument by value.int... (more generally, A... where A is not a template parameter), where all elements of the pack have the same type.short float proposal. They will be seen by Library Evolution as well.Having sat in the Evolution group, I haven’t been able to follow the Library groups in any amount of detail, but I’ll call out some of the library proposals that have gained design approval at this meeting:
std::to_underlying()std::apply()constexpr bitsetbasic_string::resize_default_initstarts_with() and ends_with()volatile pointerssnapshot_source()contains() for stringNote that the above is all C++23 material; I listed library proposals which made C++20 at this meeting above.
There are also efforts in place to consolidate general design guidance that the Library Evolution group would like to apply to all proposals into a policy paper.
While still at the Incubator stage, I’d like to call attention to web_view, a proposal for embedding a view powered by a web browser engine into a C++ application, for the purpose of allowing C++ applications to leverage the wealth of web technologies for purposes such as graphical output, interaction, and so on. As mentioned in previous reports, I gathered feedback about this proposal from Mozilla engineers, and conveyed this feedback (which was a general discouragement for adding this type of facility to C++) both at previous meetings and this one. However, this was very much a minority view, and as a whole the groups which looked at this proposal (which included SG13 (I/O) and Library Evolution Incubator) largely viewed it favourably, as a promising way of allow C++ applications to do things like graphical output without having to standardize a graphics API ourselves, as previously attempted.
SG 1 has a busy week, approving numerous proposals that made it into C++20 (listed above), as well as reviewing material targeted for the Concurrency TS v2 (whose outline I gave above).
Another notable topic for SG 1 was Executors, where a consensus design was reviewed and approved. Error handling remains a contentious issue; out of two different proposed mechanics, the first one seems to have the greater consensus.
Progress was also made on memory model issues, aided by the presence of several memory model experts who are not regular attendees. It seems the group may have an approach for resolving the “out of thin air” (OOTA) problem (see relevant papers); according to SG 1 chair Olivier Giroux, this is the most optimistic the group has been about the OOTA problem in ~20 years!
The Compile-Time Programming Study Group (SG 7) met for half a day to discuss two main topics.
First on the agenda was introspection. As mentioned in previous reports, the committee put out a Reflection TS containing compile-time introspection facilities, but has since agreed that in the C++ IS, we’d like facilities with comparable expressive power but a different formulation (constexpr value-based metaprogramming rather than template metaprogramming). Up until recently, the nature of the new formulation was in dispute, with some favouring a monotype approach and others a richer type hierarchy. I’m pleased to report that at this meeting, a compromise approach was presented and favourably reviewed. With this newfound consensus, SG 7 is optimistic about being able to get these facilities into C++23. The compromise proposal does require a new language feature, parameter constraints, which will be presented to EWG at the next meeting.
(SG 7 also looked at a paper asking to revisit some of the previous design choices made regarding parameter names and access control in reflection. The group reaffirmed its previous decisions in these areas.)
The second main topic was reification, which can be thought of as the “next generation” of compile-time programming facilities, where you can not only introspect code at compile time, but perform processing on its representation and generate (“reify”) new code. A popular proposal in this area is Herb Sutter’s metaclasses, which allow you to “decorate” classes with metaprograms that transform the class definition in interesting ways. Metaclasses is intended to be built on a suite of underlying facilties such as code injection; there is now a concrete proposal for what those facilities could look like, and how metaclasses could be built on top of them. SG 7 looked at an overview of this proposal, although there wasn’t time for an in-depth design review at this stage.
The Tooling Study Group (SG 15) met for a full day, focusing on issues related to tooling around modules, and in particular proposals targeting the C++ Modules Ecosystem Technical Report mentioned above.
I couldn’t be in the room for this session as it ran concurrently with Reflection and then Herbceptions in EWG, but my understanding is that the main outcomes were:
clang-scan-deps), and the committee has made efforts to make them tractable (see e.g. the tweak to the context-sensitivity rules for import which EWG approved this week).A proposal for a file format for describing dependencies of source files was also reviewed, and will continue to be iterated on.
One observation that was made during informal discussion was that SG 15’s recent focus on modules-related tooling has meant less time available for other topics such as package management. It remains to be seen if this is a temporary state of affairs, or if we could use two different study groups working in parallel.
Other Study Groups that met at this meeting include:
web_view, 2D graphics (which continues to be iterated on in the hopes of a revised version gaining consensus), as well as few proposals related to callbacks which are relevant to the design of I/O facilities.In addition, as mentioned, a new Contracts Study Group (SG 21) was formed at this meeting; I expect it will have its inaugural meeting in Belfast.
Most Study Groups hold regular teleconferences in between meetings, which is a great low-barrier-to-entry way to get involved. Check out their mailing lists here or here for telecon scheduling information.
The next meeting of the Committee will be in Belfast, Northern Ireland, the week of November 4th, 2019.
My highlights for this meeting included:
constexpr dynamic allocation, including constexpr vector and string for C++20-fno-exceptions segment of C++ users back into the foldDue to the sheer number of proposals, there is a lot I didn’t cover in this post; if you’re curious about a specific proposal that I didn’t mention, please feel free to ask about it in the comments.
Other trip reports about this meeting include Herb Sutter’s and the collaborative Reddit trip report — I encourage you to check them out as well!
https://botondballo.wordpress.com/2019/07/26/trip-report-c-standards-meeting-in-cologne-july-2019/
|
|
Mozilla VR Blog: Firefox Reality for Oculus Quest |

We are excited to announce that Firefox Reality is now available for the Oculus Quest!
Following our releases for other 6DoF headsets including the HTC Vive Focus Plus and Lenovo Mirage, we are delighted to bring the Firefox Reality VR web browsing experience to Oculus' newest headset.
Whether you’re watching immersive video or meeting up with friends in Mozilla Hubs, Firefox Reality takes advantage of the Oculus Quest’s boost in performance and capabilities to deliver the best VR web browsing experience. Try the new featured content on the FxR home page or build your own to see what you can do in the next generation of standalone virtual reality headsets.
Enhanced Tracking Protection Blocks Sites from Tracking You
To protect our users from the pervasive tracking and collection of personal data by ad networks and tech companies, Firefox Reality has Enhanced Tracking Protection enabled by default. We strongly believe privacy shouldn’t be relegated to optional settings. As an added bonus, these protections work in the background and actually increase the speed of the browser.
Firefox Reality is available in 10 different languages, including Japanese, Korean, Simplified Chinese and Traditional Chinese, with more on the way. You can also use your voice to search the web instead of typing, making it faster and easier to get where you want to go.
Stay tuned in the coming months as we roll out support for the nearly VR-ready WebXR specification, multi-window browsing, bookmarks sync, additional language support and other exciting new features.
Like all Firefox browser products, Firefox Reality is available for free in the Oculus Quest store.
For more information: https://mixedreality.mozilla.org/firefox-reality/
|
|
Mozilla Open Innovation Team: Mozilla Voice Challenge: Defining The Voice Technology Space |
We are excited to announce the launch of the “Mozilla Voice Challenge,” a crowdsourcing competition sponsored by Mozilla and posted on the HeroX platform. The goal of the competition is to better define the voice technology space by creating a “stack” of open source technologies to support the development of new voice-enabled products.

The Power of the Voice
Voice-enabled products are in rapid ascent in both consumer and enterprise markets. The expectations are that in the near future voice interaction will become a key interface for people’s internet-connected lives.
Unfortunately, the current voice product market is heavily dominated by a few giant tech companies. This is unhealthy as it stifles the competition and prevents entry of smaller companies with new and innovative products. Mozilla wants to change that. We want to help opening up the ecosystem. So far there have been two major components in Mozilla’s open source voice tech efforts outside the Firefox browser:
(1) To solve for the lack of available training data for machine-learning algorithms that can power new voice-enabled applications, we launched the Common Voice project. The current release already represents the largest public domain transcribed voice dataset, with more than 2,400 hours of voice data and 28 languages represented.
(2) In addition to the data collection, Mozilla’s Machine Learning Group has applied sophisticated machine learning techniques and a variety of innovations to build an open-source speech-to-text engine that approaches human accuracy, as well as a text-to-speech engine. Together with the growing Common Voice dataset Mozilla believes this technology can and will enable a wave of innovative products and services, and that it should be available to everyone.
And this is exactly where this new “Mozilla Voice Challenge” fits in: Its objective is to better define the voice technology space by creating a “stack” of open source technologies to support the development of new voice-enabled products.
Stacking the Odds
For the purpose of this competition, we define voice-enabled technologies as technologies that use voice as an interface, allowing people to interact with various connected devices through verbal means — both when speaking and listening.
We envision that some elements of this stack would be the following technologies:
We want to improve this list by adding more relevant technologies and also identify any “gaps” in the stack where quality open source projects are not available (see the Challenge description for more details). We’ll then place the updated list in a public repository for open access — and to achieve this, all proposed technologies in the stack need to be open source licensed.
How to Participate
The competition was posted to the HeroX platform. The competition will run until August 20, 2019 and the submitted proposals will be evaluated by the members of Mozilla’s Voice team. Up to $6,000 in prizes will be awarded to the best proposals.
The challenge is open to everyone (except for Mozilla employees and their families), and we especially encourage members of Mozilla’s Common Voice community to take part in it.
Mozilla Voice Challenge: Defining The Voice Technology Space was originally published in Mozilla Open Innovation on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
The Firefox Frontier: Eight ways to reduce your digital carbon footprint |
Whether it’s from doing things like burning fossil fuels through driving, cranking up the furnace or grilling a steak, we are all responsible for releasing carbon dioxide into the atmosphere, … Read more
The post Eight ways to reduce your digital carbon footprint appeared first on The Firefox Frontier.
|
|
Hacks.Mozilla.Org: WebThings Gateway for Wireless Routers |
In April we announced that the Mozilla IoT team had been working on evolving WebThings Gateway into a full software distribution for consumer wireless routers.
Today, with the 0.9 release, we’re happy to announce the availability of the first experimental builds for our first target router hardware, the Turris Omnia.

Turris Omnia wireless router. Source: turris.cz
These builds are based on the open source OpenWrt operating system. They feature a new first-time setup experience which enables you to configure the gateway as a router and Wi-Fi access point itself, rather than connecting to an existing Wi-Fi network.

Router first time setup
So far, these experimental builds only offer extremely basic router configuration and are not ready to replace your existing wireless router. This is just our first step along the path to creating a full software distribution for wireless routers.

Router network settings
We’re planning to add support for other wireless routers and router developer boards in the near future. We want to ensure that the user community can access a range of affordable developer hardware.
As well as these new OpenWrt builds for routers, we will continue to support the existing Raspbian-based builds for the Raspberry Pi. In fact, the 0.9 release is also the first version of WebThings Gateway to support the new Raspberry Pi 4. You can now find a handy download link on the Raspberry Pi website.

Raspberry Pi 4 Model B. Source: raspberrypi.org
Another feature landing in the 0.9 release is a new type of add-on called notifier add-ons.

Notifier Add-ons
In previous versions of the gateway, the only way you could be notified of events was via browser push notifications. Unfortunately, this is not supported by all browsers, nor is it always the most convenient notification mechanism for users.
A workaround was available by creating add-ons with basic “send notification” actions to implement different types of notifications. However, these required the user to add “things” to their gateway which didn’t represent actual devices and actions had to be hard-coded in the add-on’s configuration.
To remedy this, we have introduced notifier add-ons. Essentially, a notifier creates a set of “outlets”, each of which can be used as an output for a rule. For example, you can now set up a rule to send you an SMS or an email when motion is detected in your home. Notifiers can be configured with a title, a message and a priority level. This allows users to be reached where and how they want, with a message and priority that makes sense to them.

Rule with email notification
For developers, the 0.9 release of the WebThings Gateway and 0.12 release of the WebThings Framework libraries also bring some small changes to Thing Descriptions. This will bring us more in line with the latest W3C drafts.
One small difference to be aware of is that “name” is now called “title”. There are also some experimental new base, security and securityDefinitions properties of the Thing Descriptions exposed by the gateway, which are still under active discussion at the W3C.
We invite you to download the new WebThings Gateway 0.9 and continue to build your own web things with the latest WebThings Framework libraries. If you already have WebThings Gateway installed on a Raspberry Pi, it should update itself automatically.
As always, we welcome your feedback on Discourse. Please submit issues and pull requests on GitHub.
The post WebThings Gateway for Wireless Routers appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/07/webthings-gateway-for-wireless-routers/
|
|
Mozilla Addons Blog: Upcoming deprecations in Firefox 70 |
Several planned code deprecations for Firefox 70, currently available on the Nightly pre-release channel, may impact extension and theme developers. Firefox 70 will be released on October 22, 2019.
In Firefox 65, we started deprecating the aliased theme properties accentcolor, textcolor, and headerURL. These properties will be removed in Firefox 70.
Themes listed on addons.mozilla.org (AMO) will be automatically updated to use supported properties. Most themes were updated back in April, but new themes have been created using the deprecated properties. If your theme is not listed on AMO, or if you are the developer of a dynamic theme, please update your theme’s manifest.json to use the supported properties.
accentcolor, please use frame headerURL, please use theme_frametextcolor, please use tab_background_textIn Firefox 70, the non-standard, Firefox-specific Array generic methods introduced with JavaScript 1.6 will be considered deprecated and scheduled for removal in the near future. For more information about which generics will be removed and suggested alternatives, please see the Firefox Site Compatibility blog.
The Site Compatibility working group also intends to remove the non-standard prototype toSource and uneval by the end of 2019.
The post Upcoming deprecations in Firefox 70 appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2019/07/25/upcoming-deprecations-in-firefox-70/
|
|
The Mozilla Blog: Empowering voters to combat election manipulation |
For the last year, Mozilla has been looking for ways to empower voters in light of the shifts in election dynamics caused by the internet and online advertising. This work included our participation in the EU’s Code of Practice on Disinformation to push for change in the industry which led to the launch of the Firefox EU Elections toolkit that provided people information on the voting process, how tracking and opaque online advertising influence their voting behavior and how they can easily protect themselves.
We also had hoped to lend our technical expertise to create an analysis dashboard that would help researchers and journalists monitor the elections. The dashboard would gather data on the political ads running on various platforms and provide a concise “behind the scenes” look at how these ads were shared and targeted.
But to achieve this we needed the platforms to follow through on their own commitment to make the data available through their Ad Archive APIs.
Here’s what happened.
On March 29, Facebook began releasing its political ad data through a publicly available API. We quickly concluded the API was inadequate.
The state of the API made it nearly impossible to extract the data needed to populate the dashboard we were hoping to create to make this information more accessible.
And although Google didn’t provide the targeting criteria advertisers use on the platform, it did provide access to the data in a format that allowed for real research and analysis.
That was not the case for Facebook.
It took the entire month of April to figure out ways to work within or rather, around, the API to collect any information about the political ads running on the Facebook platform.
After several weeks, hundreds of hours, and thousands of keystrokes, the Mozilla team created the EU Ad Transparency Reports. The reports contained aggregated statistics on spending and impressions about political ads on Facebook, Instagram, Google, and YouTube.
While this was not the dynamic tool we had envisioned at the beginning of this journey, we hoped it would help.
But despite our best efforts to help Facebook debug their system, the API broke again from May 18 through May 26, making it impossible to use the API and generate any reports in the last days leading up to the elections.
All of this was documented through dozens of bug reports provided to Facebook, identifying ways the API needed to be fixed.
Ultimately our contribution to this effort ended up looking very different than what we had first set out to do. Instead of a tool, we have detailed documentation of every time the API failed and every roadblock encountered and a series of tips and tricks to help others use the API.
This documentation provides Facebook a clear roadmap to make the necessary improvements for a functioning and useful API before the next election takes place. The EU elections have passed, but the need for political messaging transparency has not.
In fact, important elections are expected to take place almost every month until the end of the year and Facebook has recently rolled this tool out globally.
We need Facebook to be better. We need an API that actually helps – not hinders – researchers and journalists uncover who is buying ads, the way these ads are being targeted and to whom they’re being served. It’s this important work that informs the public and policymakers about the nature and consequences of misinformation.
This is too important to get wrong. That is why we plan to continue our work on this matter and continue to work with those pushing to shine a light on how online advertising impact elections.
The post Empowering voters to combat election manipulation appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2019/07/25/empowering-voters-to-combat-election-manipulation/
|
|
Nicholas Nethercote: The Rust compiler is still getting faster |
A key theme of the Rust 2019 roadmap is maturity. This covers a variety of topics, but a crucial one is compile times. For example, the roadmap itself has the following as the first main theme for the compiler team.
Improving “core strength” by lowering raw compilation times and also generating better code (which in turn can help with compilation times)
The roadmap explainer post has a “polish” section that has the following as the first example.
Compile times and IDE support
I previously wrote about one period of improvement in Rust compiler speed. How are things going in 2019?
The following image shows changes in time taken to compile the standard benchmarks used on the Rust performance tracker. It compares the compiler from 2019-01-01 with the compiler from 2019-07-24 (the most recent data at the time of writing).
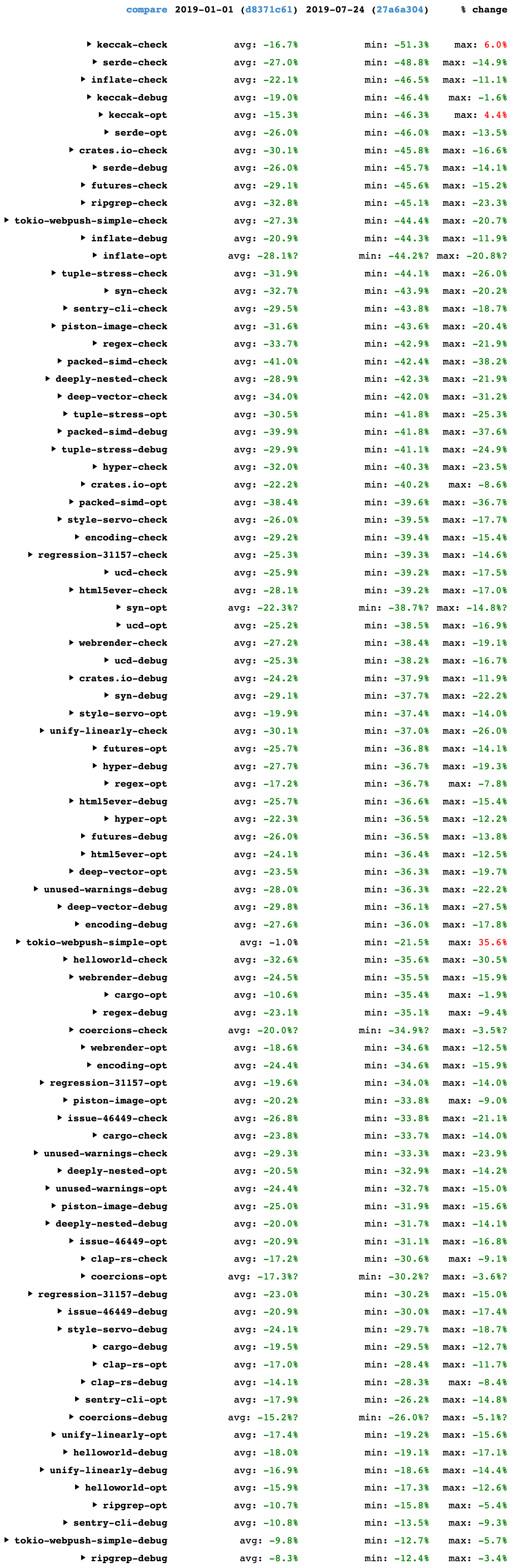
These are the wall-time results for 29 benchmarks. There are three different build kinds measured for each one: a debug build, an optimized build, and a check build (which detects errors but doesn’t generate code). For each build kind there is a mix of incremental and non-incremental runs done. The numbers for the individual runs aren’t shown here but you can see them if you view the results directly on the site and click around. The “avg” column shows the average change for those runs. The “min” and “max” columns show the minimum and maximum changes among those same runs.
The table has 261 numbers. The thing to take away is that 258 of them are negative, representing a decrease in compile time. Most of the “avg” values are in the range -20% to -40%. The “min” values (representing the best time reduction for each build kind) range from -12.4% to -51.3%. Even the “max” values (representing the worst time reduction for each build kind) are mostly better than -10%. These are pleasing results.
What happens if we look further back? The image below compares the compiler from 2017-11-12 (the earliest date for which I could get data from the site) against the compiler from 2019-07-24, a period of just over 20 months.
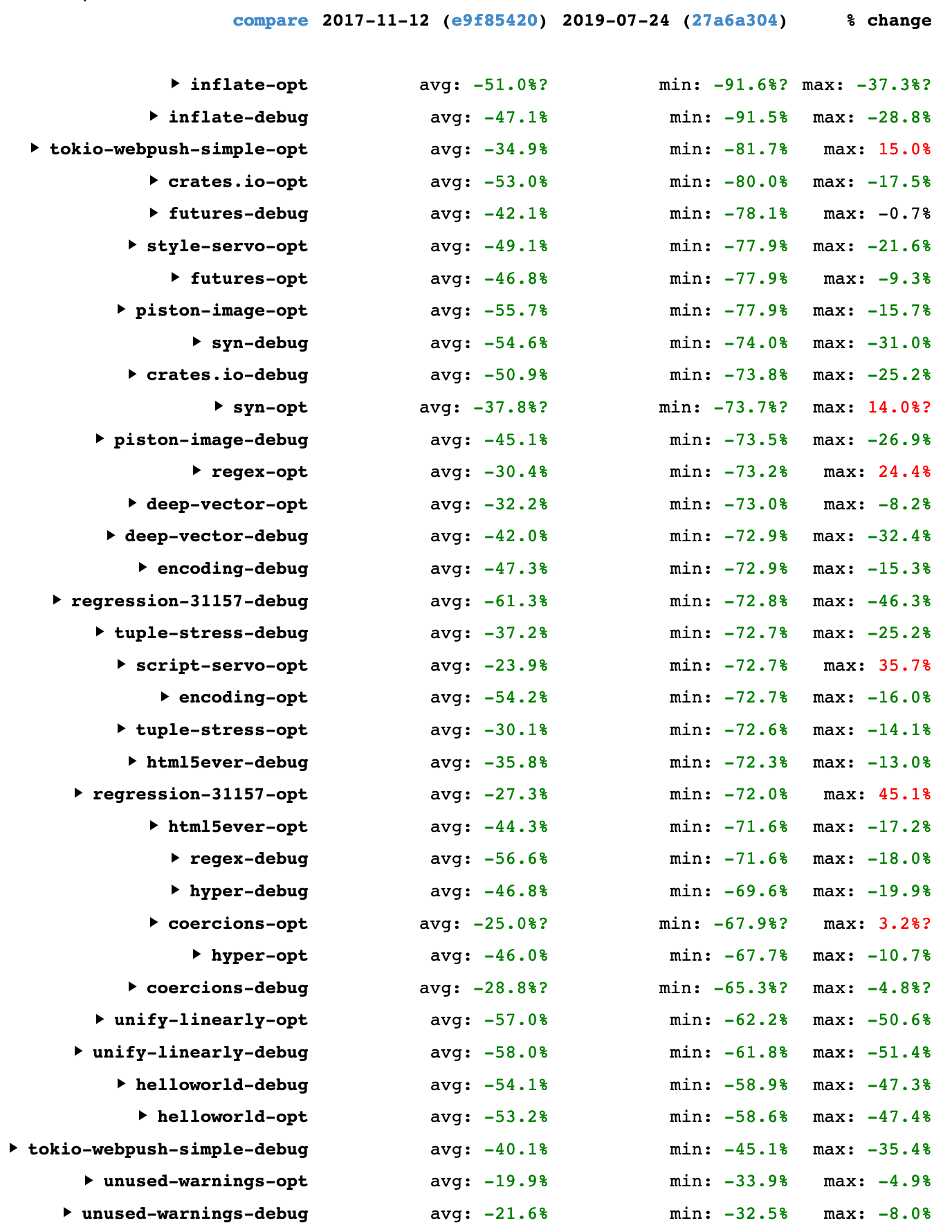
These are the wall-time results for only 18 benchmarks, because the benchmark suite was smaller in late 2017. Check builds were also not measured then. You can view the results directly on the site.
My initial thought from looking at the “avg” results was “the compiler is twice as fast” but closer inspection shows that’s not quite true; the average “avg” result is 42%. (I know that averaging averages is statistically dubious, I did it just to get a rough feel.) Overall, the results are significantly better than those for 2019: the “avg” values range from -19.9% to -61.3%, and the “min” values are mostly better than -60%.
(And don’t forget that time reduction percentages can be misleading when they get large. A 50% time reduction means the compiler is twice as fast; a 75% time reduction means the compiler is four times as fast; a 90% time reduction means the compiler is ten times as fast.)
All this is good news. The Rust compiler has long had a reputation for being slow. I still wouldn’t describe it as fast, but it is clearly a lot faster than it used to be. Many thanks to all those who made this happen, and I would be happy to hear from anyone who wants to help continue the trend!
Thanks to theZcuber for a Reddit post that was the starting point for this article.
https://blog.mozilla.org/nnethercote/2019/07/25/the-rust-compiler-is-still-getting-faster/
|
|
This Week In Rust: This Week in Rust 296 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
This week's crate is abscissa, a security-oriented Rust application framework. Thanks to Tony Arcieri for the suggestion!
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
230 pull requests were merged in the last week
<*mut _>::cast and <*const _>::castformat!()-> _ fn return typeas_ref suggestionsVaListImpl<'f> invariant over 'fOption::expect_none(msg) and unwrap_none()#[cargo_test_macro]Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
try! macro.--json-rendered flag.{:g?}.If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Tweet us at @ThisWeekInRust to get your job offers listed here!
Roses are red, Rust-lang is fine, cannot borrow `i` as mutable more than once at a time
Thanks to Jelte Fennema for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nasa42, llogiq, and Flavsditz.
https://this-week-in-rust.org/blog/2019/07/23/this-week-in-rust-296/
|
|
Daniel Stenberg: curl goez parallel |
The first curl release ever saw the light of day on March 20, 1998 and already then, curl could transfer any amount of URLs given on the command line. It would iterate over the entire list and transfer them one by one.
Not even 22 years later, we introduce the ability for the curl command line tool to do parallel transfers! Instead of doing all the provided URLs one by one and only start the next one once the previous has been completed, curl can now be told to do all of them, or at least many of them, at the same time!
This has the potential to drastically decrease the amount of time it takes to complete an operation that involves multiple URLs.
Doing transfers concurrently instead of serially of course changes behavior and thus this is not something that will be done by default. You as the user need to explicitly ask for this to be done, and you do this with the new –parallel option, which also as a short-hand in a single-letter version: -Z (that’s the upper case letter Z).
To avoid totally overloading the servers when many URLs are provided or just that curl runs out of sockets it can keep open at the same time, it limits the parallelism. By default curl will only try up to 50 transfers concurrently, so if there are more transfers given to curl those will wait to get started once one of the first transfers are completed. The new –parallel-max command line option can be used to change the concurrency limit.
Is different in this mode. The new progress meter that will show up for parallel transfers is one output for all transfers.
When doing many simultaneous transfers, how do you figure out how they all did individually, like from your script? That’s still to be figured out and implemented.
This functionality makes curl do URLs in parallel. It will still not download the same URL using multiple parallel transfers the way some other tools do. That might be something to implement and offer in a future fine tuning of this feature.
This is a new command line feature that uses the fact that libcurl can already do this just fine. Thanks to libcurl being a powerful transfer library that curl uses, enabling this feature was “only” a matter of making sure libcurl was used in a different way than before. This parallel change is entirely in the command line tool code.
This change has landed in curl’s git repository already (since b8894085000) and is scheduled to ship in curl 7.66.0 on September 11, 2019.
I hope and expect us to keep improving parallel transfers further and we welcome all the help we can get!
|
|
Cameron Kaiser: Clean out your fonts, people |
On startup, and to a lesser extent when browsing, TenFourFox (and Firefox) enumerates the fonts you have installed on your Power Mac so that sites requesting them can use locally available fonts and not download them unnecessarily. The reason for periodically rechecking is that people can, and do, move fonts around and it would be bad if TenFourFox had stale font information particularly for commonly requested ones. To speed this up, I actually added a TenFourFox-specific font directory cache so that subsequent enumerations are quicker. However, the heuristic for determining when fonts should be rescanned is imperfect and when in doubt I always err towards a fresh scan. That means a certain amount of work is unavoidable under normal circumstances.
Thus, the number of fonts you have currently installed directly affects TenFourFox's performance, and TenFourFox is definitely not the only application that needs to know what fonts are installed. If you have a large (as in several hundred) number of font files and particularly if you are not using an SSD, you should strongly consider thinning them out or using some sort of font management system. Even simply disabling the fonts in Font Book will help, because under the hood this will move the font to a disabled location, and TenFourFox and other applications will then not have to track it further.
How many is too many? On my quad G5, I have about 800 font files on my Samsung SSD. This takes about 3-4 seconds to initially populate the cache and then less than a second on subsequent enumerations. However, on a uniprocessor system and especially on systems without an SSD, I would strongly advise getting that number down below one hundred. Leave the fonts in /System/Library/Fonts alone, but on my vanilla Tiger Sawtooth G4 server, /Library/Fonts has just 87 files. Use Font Book to enable fonts later if you need them for stuff you're working on, or, if you know those fonts aren't ever being used, consider just deleting them entirely.
Due to a work crunch I will not be doing much work on FPR16 until August. However, I will be at the Vintage Computer Festival West again August 3 and 4 at the Computer History Museum in Mountain View. I've met a few readers of this blog in past years, and hopefully getting to play with various PowerPC (non-Power Mac), SPARC and PA-RISC laptops and portable workstations will tempt the rest of you. Come by, say hi, and play around a bit with the other great exhibits that aren't as cool as mine.
http://tenfourfox.blogspot.com/2019/07/clean-out-your-fonts-people.html
|
|






