The Mozilla Blog: Today’s Firefox Blocks Third-Party Tracking Cookies and Cryptomining by Default |
Today, Firefox on desktop and Android will — by default — empower and protect all our users by blocking third-party tracking cookies and cryptominers. This milestone marks a major step in our multi-year effort to bring stronger, usable privacy protections to everyone using Firefox.
For today’s release, Enhanced Tracking Protection will automatically be turned on by default for all users worldwide as part of the ‘Standard’ setting in the Firefox browser and will block known “third-party tracking cookies” according to the Disconnect list. We first enabled this default feature for new users in June 2019. As part of this journey we rigorously tested, refined, and ultimately landed on a new approach to anti-tracking that is core to delivering on our promise of privacy and security as central aspects of your Firefox experience.
Currently over 20% of Firefox users have Enhanced Tracking Protection on. With today’s release, we expect to provide protection for 100% of ours users by default. Enhanced Tracking Protection works behind-the-scenes to keep a company from forming a profile of you based on their tracking of your browsing behavior across websites — often without your knowledge or consent. Those profiles and the information they contain may then be sold and used for purposes you never knew or intended. Enhanced Tracking Protection helps to mitigate this threat and puts you back in control of your online experience.
You’ll know when Enhanced Tracking Protection is working when you visit a site and see a shield icon in the address bar:

When you see the shield icon, you should feel safe that Firefox is blocking thousands of companies from your online activity.
For those who want to see which companies we block, you can click on the shield icon, go to the Content Blocking section, then Cookies. It should read Blocking Tracking Cookies. Then, click on the arrow on the right hand side, and you’ll see the companies listed as third party cookies that Firefox has blocked:
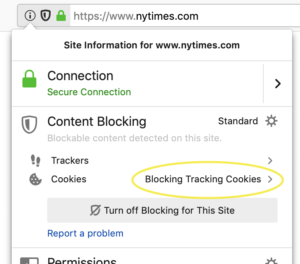
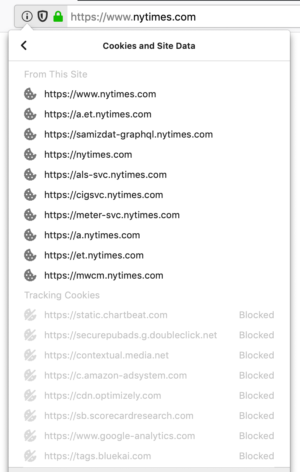
If you want to turn off blocking for a specific site, click on the Turn off Blocking for this Site button.
Cookies are not the only entities that follow you around on the web, trying to use what’s yours without your knowledge or consent. Cryptominers, for example, access your computer’s CPU, ultimately slowing it down and draining your battery, in order to generate cryptocurrency — not for yours but someone else’s benefit. We introduced the option to block cryptominers in previous versions of Firefox Nightly and Beta and are including it in the ‘Standard Mode‘ of your Content Blocking preferences as of today.
Another type of script that you may not want to run in your browser are Fingerprinting scripts. They harvest a snapshot of your computer’s configuration when you visit a website. The snapshot can then also be used to track you across the web, an issue that has been present for years. To get protection from fingerprinting scripts Firefox users can turn on ‘Strict Mode.’ In a future release, we plan to turn fingerprinting protections on by default.
To see what else is new or what we’ve changed in today’s release, you can check out our release notes.
Check out and download the latest version of Firefox available here.
The post Today’s Firefox Blocks Third-Party Tracking Cookies and Cryptomining by Default appeared first on The Mozilla Blog.
|
|
Cameron Kaiser: The deformed yet thoughtful offspring of AppleScript and Greasemonkey |
But, hey! If you're using TenFourFox, you're immune to Apple's latest self-stimulatory bright ideas. And while I'm trying to make progress on TenFourFox's various deficiencies, you still have the power to make sites work the way you want thanks to TenFourFox's AppleScript-to-JavaScript "bridge." The bridge lets you run JavaScript within the page and sample or expose data back to AppleScript. With AppleScript's other great powers, like even running arbitrary shell scripts, you can connect TenFourFox to anything else on the other end with AppleScript.
Here's a trivial example. Go to any Github wiki page, like, I dunno, the one for TenFourFox's AppleScript support. If there's a link there for more wiki entries, go ahead and click on it. It doesn't work (because of issue 521). Let's fix that!
You can either cut and paste the below examples directly into Script Editor and click the Run button to run them, or you can cut and paste them into a text file and run them from the command line with osascript filename, or you can be a totally lazy git and just download them from SourceForge. Unzip them and double click the file to open them in Script Editor.
In the below examples, change TenFourFoxWhatever to the name of your TenFourFox executable (TenFourFoxG5, etc.). Every line highlighted in the same colour is a continuous line. Don't forget the double quotes!
Here's the script for Github's wiki.
Now, have the current tab on any Github wiki page. Run the script. Poof! More links! (If you run it on a page that isn't Github, it will give you an error box.)
Most of you didn't care about that. Some of you use your Power Macs for extremely serious business like YouTube videos. I ain't judging. Let me help you get rid of the crap, starting with Weird Al's anthem to alumin(i)um foil.

With comments in the five figures from every egoist fruitbat on the interwebs with an opinion on Weird Al, that's gonna take your poor Power Mac a while to process. Plus all those suggested videos! Let's make those go away!
This script not only makes those areas invisible, it even nukes their internal contents. This persists from video to video unless you reload the page.

As an interesting side effect, you'll notice that the video area scaled to meet the new width of the browser, but the actual video didn't. I consider this a feature rather than a bug because the browser isn't trying to enable a higher-resolution stream or scale up the video for display, so the video "just plays better." Just make sure you keep the mouse pointer out of this larger area or the browser will now have to composite the playback controls.
You can add things to a page, too, instead of just taking things away. Issue 533 has been one of our long-playing issues which has been a particular challenge because it requires a large parser update to fix. Fortunately, Webpack has been moving away from uglify and as sites upgrade their support (Citibank recently did so), this problem should start disappearing. Unfortunately UPS doesn't upgrade as diligently, so right now you can't track packages with TenFourFox from the web interface; you just get this:

Let's fix it! This script is a little longer, so you will need to download it. Here are the major guts though:
A bit of snooping on UPS's site from the Network tab in Firefox 69 on my Talos II shows that it uses an internal JSON API. We can inject script to complete the request that TenFourFox can't yet make. Best of all, it will look to UPS like it's coming from inside the house the browser ... because it is. Even the cookies are passed. When we get the JSON response back, we can process that and display it:
');
So we just hit Run on the script, and ...

... my package arrives tomorrow.
Some of you will remember a related concept in Classilla called stelae, which were scraps of JavaScript that would automatically execute when you browse to a site the stela covers. I chose not to implement those in precisely that fashion in TenFourFox because the check imposes its own overhead on the browser on every request, and manipulating the DOM is a lot easier (and in TenFourFox, a lot more profitable) than manipulating the actual raw HTML and CSS that a stela does (and Classilla, because of its poorer DOM support, must). Plus, by being AppleScript, you can run them from anywhere at any time (even from the command line), including the very-convenient ever-present-if-you-enable-it Script menu, and they run only when you actually run them.
The next question I bet some of you will ask is, that's all fine for you because you're a super genius™, but how do us hoi polloi know the magic JavaScript incantations to chant? I wrote these examples to give you general templates. If you want to make a portion of the page disappear, you can work with the YouTube example and have a look with TenFourFox's built-in Inspector to find the ID or class of the element to nuke. Then, getElementById('x') will find the element with id="x", or getElementsByClassName('y') will find all elements with y in their class="..." (see the Github example). Make those changes and you can basically make it work. Remove the block limiting it to certain URLs if you don't care about it. If you do it wrong, look at the Browser Console window for the actual error message from JavaScript if you get an error back.
For adding functionality, though, this requires looking at what Firefox does on a later system. On my Talos II I had the Network tab in the Inspector open and ran a query for the tracking number and was able to see what came back, and then compared it with what TenFourFox was doing to find what was missing. I then simulated the missing request. This took about 15 minutes to do, granted given that I understood what was going on, but the script will still give you a template for how to do these kinds of specialized requests. (Be careful, though, about importing data from iffy sites that could be hacked or violating the same-origin policy. The script bridge has special privileges and assumes you know what you're doing.) Or, if you need more fields than the UPS script is providing, just look at the request the AppleScript sends and study the JSON object the response passes back, then add the missing fields you want to the block above. Tinker with the formatting. Sex it up a bit. It's your browser!
One last note. You will have noticed the scripts in the screen shot (and the ones you download) look a little different. That's because they use a little magic to figure out what TenFourFox you're actually running. It looks like this:
This group of commands runs a quick script through Perl to find the first TenFourFox instance running (another reason to start TenFourFox before running foxboxes). However, because we dynamically decide the application we'll send AppleEvents to (i.e., "tell-by-variable"), the Script Editor doesn't have a dictionary available, so we have to actually provide the raw classes and events the dictionary would ordinarily map to. Otherwise it is exactly identical to tell current tab of front browser window to run JavaScript " and this is actually the true underlying AppleEvent that gets sent to TenFourFox. If TenFourFox isn't actually found, then we can give you a nice error message instead of the annoying "Where is ?" window that AppleScript will give you for orphaned events. Again, if you don't want to type these scripts in, grab them here.
No, I'm not interested in porting this to mainline Firefox, but the source code is in our tree if someone else wants to. At least until Apple decides that all other scripting languages than the One True Swift Language, even AppleScript, must die.
http://tenfourfox.blogspot.com/2019/09/the-deformed-yet-thoughtful-offspring.html
|
|
Cameron Kaiser: TenFourFox FPR16 available |
http://tenfourfox.blogspot.com/2019/08/tenfourfox-fpr16-available.html
|
|
About:Community: Firefox 69 new contributors |
With the release of Firefox 69, we are pleased to welcome the 50 developers who contributed their first code change to Firefox in this release, 39 of whom were brand new volunteers! Please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
https://blog.mozilla.org/community/2019/08/30/firefox-69-new-contributors/
|
|
Hacks.Mozilla.Org: The Baseline Interpreter: a faster JS interpreter in Firefox 70 |
Modern web applications load and execute a lot more JavaScript code than they did just a few years ago. While JIT (just-in-time) compilers have been very successful in making JavaScript performant, we needed a better solution to deal with these new workloads.
To address this, we’ve added a new, generated JavaScript bytecode interpreter to the JavaScript engine in Firefox 70. The interpreter is available now in the Firefox Nightly channel, and will go to general release in October. Instead of writing or generating a new interpreter from scratch, we found a way to do this by sharing most code with our existing Baseline JIT.
The new Baseline Interpreter has resulted in performance improvements, memory usage reductions and code simplifications. Here’s how we got there:
In modern JavaScript engines, each function is initially executed in a bytecode interpreter. Functions that are called a lot (or perform many loop iterations) are compiled to native machine code. (This is called JIT compilation.)
Firefox has an interpreter written in C++ and multiple JIT tiers:
Ion JIT code for a function can be ‘deoptimized’ and thrown away for various reasons, for example when the function is called with a new argument type. This is called a bailout. When a bailout happens, execution continues in the Baseline code until the next Ion compilation.
Until Firefox 70, the execution pipeline for a very hot function looked like this:

Although this works pretty well, we ran into the following problems with the first part of the pipeline (C++ Interpreter and Baseline JIT):
We needed type information from the Baseline JIT to enable the more optimized tiers, and we wanted to use JIT compilation for runtime speed. However, the modern web has such large codebases that even the relatively fast Baseline JIT Compiler spent a lot of time compiling. To address this, Firefox 70 adds a new tier called the Baseline Interpreter to the pipeline:

The Baseline Interpreter sits between the C++ interpreter and the Baseline JIT and has elements from both. It executes all bytecode instructions with a fixed interpreter loop (like the C++ interpreter). In addition, it uses Inline Caches to improve performance and collect type information (like the Baseline JIT).
Generating an interpreter isn’t a new idea. However, we found a nice new way to do it by reusing most of the Baseline JIT Compiler code. The Baseline JIT is a template JIT, meaning each bytecode instruction is compiled to a mostly fixed sequence of machine instructions. We generate those sequences into an interpreter loop instead.
As mentioned above, the Baseline JIT uses Inline Caches (ICs) both to make it fast and to help Ion compilation. To get type information, the Ion JIT compiler can inspect the Baseline ICs.
Because we wanted the Baseline Interpreter to use exactly the same Inline Caches and type information as the Baseline JIT, we added a new data structure called JitScript. JitScript contains all type information and IC data structures used by both the Baseline Interpreter and JIT.
The diagram below shows what this looks like in memory. Each arrow is a pointer in C++. Initially, the function just has a JSScript with the bytecode that can be interpreted by the C++ interpreter. After a few calls/iterations we create the JitScript, attach it to the JSScript and can now run the script in the Baseline Interpreter.
As the code gets warmer we may also create the BaselineScript (Baseline JIT code) and then the IonScript (Ion JIT code).

Note that the Baseline JIT data for a function is now just the machine code. We’ve moved all the inline caches and profiling data into JitScript.
The Baseline Interpreter uses the same frame layout as the Baseline JIT, but we’ve added some interpreter-specific fields to the frame. For example, the bytecode PC (program counter), a pointer to the bytecode instruction we are currently executing, is not updated explicitly in Baseline JIT code. It can be determined from the return address if needed, but the Baseline Interpreter has to store it in the frame.
Sharing the frame layout like this has a lot of advantages. We’ve made almost no changes to C++ and IC code to support Baseline Interpreter frames—they’re just like Baseline JIT frames. Furthermore, When the script is warm enough for Baseline JIT compilation, switching from Baseline Interpreter code to Baseline JIT code is a matter of jumping from the interpreter code into JIT code.
Because the Baseline Interpreter and JIT are so similar, a lot of the code generation code can be shared too. To do this, we added a templated BaselineCodeGen base class with two derived classes:
BaselineCompiler: used by the Baseline JIT to compile a script’s bytecode to machine code.BaselineInterpreterGenerator: used to generate the Baseline Interpreter code.The base class has a Handler C++ template argument that can be used to specialize behavior for either the Baseline Interpreter or JIT. A lot of Baseline JIT code can be shared this way. For example, the implementation of the JSOP_GETPROP bytecode instruction (for a property access like obj.foo in JavaScript code) is shared code. It calls the emitNextIC helper method that’s specialized for either Interpreter or JIT mode.
With all these pieces in place, we were able to implement the BaselineInterpreterGenerator class to generate the Baseline Interpreter! It generates a threaded interpreter loop: The code for each bytecode instruction is followed by an indirect jump to the next bytecode instruction.
For example, on x64 we currently generate the following machine code to interpret JSOP_ZERO (bytecode instruction to push a zero value on the stack):
// Push Int32Value(0).
movabsq $-0x7800000000000, %r11
pushq %r11
// Increment bytecode pc register.
addq $0x1, %r14
// Patchable NOP for debugger support.
nopl (%rax,%rax)
// Load the next opcode.
movzbl (%r14), %ecx
// Jump to interpreter code for the next instruction.
leaq 0x432e(%rip), %rbx
jmpq *(%rbx,%rcx,8)
When we enabled the Baseline Interpreter in Firefox Nightly (version 70) back in July, we increased the Baseline JIT warm-up threshold from 10 to 100. The warm-up count is determined by counting the number of calls to the function + the number of loop iterations so far. The Baseline Interpreter has a threshold of 10, same as the old Baseline JIT threshold. This means that the Baseline JIT has a lot less code to compile.
After this landed in Firefox Nightly our performance testing infrastructure detected several improvements:
Note that we’ve landed more performance improvements since this first landed.
To measure how the Baseline Interpreter’s performance compares to the C++ Interpreter and the Baseline JIT, I ran Speedometer and Google Docs on Windows 10 64-bit on Mozilla’s Try server and enabled the tiers one by one. (The following numbers reflect the best of 7 runs.):

On Google Docs we see that the Baseline Interpreter is much faster than just the C++ Interpreter. Enabling the Baseline JIT too makes the page load only a little bit faster.
On the Speedometer benchmark we get noticeably better results when we enable the Baseline JIT tier. The Baseline Interpreter does again much better than just the C++ Interpreter:

We think these numbers are great: the Baseline Interpreter is much faster than the C++ Interpreter and its start-up time (JitScript allocation) is much faster than Baseline JIT compilation (at least 10 times faster).
After this all landed and stuck, we were able to simplify the Baseline JIT and Ion code by taking advantage of the Baseline Interpreter.
For example, deoptimization bailouts from Ion now resume in the Baseline Interpreter instead of in the Baseline JIT. The interpreter can re-enter Baseline JIT code at the next loop iteration in the JS code. Resuming in the interpreter is much easier than resuming in the middle of Baseline JIT code. We now have to record less metadata for Baseline JIT code, so Baseline JIT compilation got faster too. Similarly, we were able to remove a lot of complicated code for debugger support and exception handling.
With the Baseline Interpreter in place, it should now be possible to move Baseline JIT compilation off-thread. We will be working on that in the coming months, and we anticipate more performance improvements in this area.
Although I did most of the Baseline Interpreter work, many others contributed to this project. In particular Ted Campbell and Kannan Vijayan reviewed most of the code changes and had great design feedback.
Also thanks to Steven DeTar, Chris Fallin, Havi Hoffman, Yulia Startsev, and Luke Wagner for their feedback on this blog post.
The post The Baseline Interpreter: a faster JS interpreter in Firefox 70 appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/08/the-baseline-interpreter-a-faster-js-interpreter-in-firefox-70/
|
|
The Mozilla Blog: Thank you, Chris |
Thank you, Chris.
Chris Beard has been Mozilla Corporation’s CEO for 5 and a half years. Chris has announced 2019 will be his last year in this role. I want to thank Chris from the bottom of my heart for everything he has done for Mozilla. He has brought Mozilla enormous benefits — new ideas, new capabilities, new organizational approaches. As CEO Chris has put us on a new and better path. Chris’ tenure has seen the development of important organization capabilities and given us a much stronger foundation on which to build. This includes reinvigorating our flagship web browser Firefox to be once again a best-in-class product. It includes recharging our focus on meeting the online security and privacy needs facing people today. And it includes expanding our product offerings beyond the browser to include a suite of privacy and security-focused products and services from Facebook Container and Enhanced Tracking Protection to Firefox Monitor.
Chris will remain an advisor to the board. We recognize some people may think these words are a formula and have no deep meaning. We think differently. Chris is a true “Mozillian.” He has been devoted to Mozilla for the last 15 years, and has brought this dedication to many different roles at Mozilla. When Chris left Mozilla to join Greylock as an “executive-in-residence” in 2013, he remained an advisor to Mozilla Corporation. That was an important relationship, and Chris and I were in contact when it started to become clear that Chris could be the right CEO for MoCo. So over the coming years I expect to work with Chris on mission-related topics. And I’ll consider myself lucky to do so.
One of the accomplishments of Chris’ tenure is the strength and depth of Mozilla Corporation today. The team is strong. Our organization is strong, and our future full of opportunities. It is precisely the challenges of today’s world, and Mozilla’s opportunities to improve online life, that bring so many of us to Mozilla. I personally remain deeply focused on Mozilla. I’ll be here during Chris’ tenure, and I’ll be here after his tenure ends. I’m committed to Mozilla, and to making serious contributions to improving online life and developing new technical capabilities that are good for people.
Chris will remain as CEO during the transition. We will continue to develop the work on our new engagement model, our focus on privacy and user agency. To ensure continuity, I will increase my involvement in Mozilla Corporation’s internal activities. I will be ready to step in as interim CEO should the need arise.
The Board has retained Tuck Rickards of the recruiting firm Russell Reynolds for this search. We are confident that Tuck and team understand that Mozilla products and technology bring our mission to life, and that we are deeply different than other technology companies. We’ll say more about the search as we progress.
The internet stands at an inflection point today. Mozilla has the opportunity to make significant contributions to a better internet. This is why we exist, and it’s a key time to keep doing more. We offer heartfelt thanks to Chris for leading us to this spot, and for leading the rejuvenation of Mozilla Corporation so that we are fit for this purpose, and determined to address big issues.
Mozilla’s greatest strength is the people who respond to our mission and step forward to take on the challenge of building a better internet and online life. Chris is a shining example of this. I wish Chris the absolute best in all things.
I’ll close by stating a renewed determination to find ways for everyone who seeks safe, humane and exciting online experiences to help create this better world.
The post Thank you, Chris appeared first on The Mozilla Blog.
|
|
The Mozilla Blog: My Next Chapter |
Earlier this morning I shared the news internally that – while I’ve been a Mozillian for 15 years so far, and plan to be for many more years – this will be my last year as CEO.
When I returned to Mozilla just over five years ago, it was during a particularly tumultuous time in our history. Looking back it’s amazing to reflect on how far we’ve come, and I am so incredibly proud of all that our teams have accomplished over the years.
Today our products, technology and policy efforts are stronger and more resonant in the market than ever, and we have built significant new organizational capabilities and financial strength to fuel our work. From our new privacy-forward product strategy to initiatives like the State of the Internet we’re ready to seize the tremendous opportunity and challenges ahead to ensure we’re doing even more to put people in control of their connected lives and shape the future of the internet for the public good.
In short, Mozilla is an exceptionally better place today, and we have all the fundamentals in place for continued positive momentum for years to come.
It’s with that backdrop that I made the decision that it’s time for me to take a step back and start my own next chapter. This is a good place to recruit our next CEO and for me to take a meaningful break and recharge before considering what’s next for me. It may be a clich'e — but I’ll embrace it — as I’m also looking forward to spending more time with my family after a particularly intense but gratifying tour of duty.
However, I’m not wrapping up today or tomorrow, but at year’s end. I’m absolutely committed to ensuring that we sustain the positive momentum we have built. Mitchell Baker and I are working closely together with our Board of Directors to ensure leadership continuity and a smooth transition. We are conducting a search for my successor and I will continue to serve as CEO through that transition. If the search goes beyond the end of the year, Mitchell will step in as interim CEO if necessary, to ensure we don’t miss a beat. And I will stay engaged for the long-term as advisor to both Mitchell and the Board, as I’ve done before.
I am grateful to have had this opportunity to serve Mozilla again, and to Mitchell for her trust and partnership in building this foundation for the future.
Over the coming months I’m excited to share with you the new products, technology and policy work that’s in development now. I am more confident than ever that Mozilla’s brightest days are yet to come.
The post My Next Chapter appeared first on The Mozilla Blog.
|
|
Mozilla Thunderbird: What’s New in Thunderbird 68 |
Our newest release, Thunderbird version 68 is now available! Users on version 60, the last major release, will not be immediately updated – but will receive the update in the coming weeks. In this blog post, we’ll take a look at the features that are most noteworthy in the newest version. If you’d like to see all the changes in version 68, you can check out the release notes.
Thunderbird 68 focuses on polish and setting the stage for future releases. There was a lot of work that we had to do below the surface that has made Thunderbird more future-proof and has made it a solid base to continue to build upon. But we also managed to create some great features you can touch today.
Thunderbird 68 features a big update to the App Menu. The new menu is single pane with icons and separators that make it easier to navigate and reduce clutter. Animation when cycling through menu items produces a more engaging experience and results in the menu feeling more responsive and modern.

Thunderbird’s New App Menu
Thunderbird’s Options/Preferences have been converted from a dialog window to its own dedicated tab. The new Preferences tab provides more space which allows for better organized content and is more consistent with the look and feel of the rest of Thunderbird. The new Preferences tab also makes it easier to multitask without the problem of losing track of where your preferences are when switching between windows.

Preferences in a Tab
Thunderbird now features full color support across the app. This means changing the color of the text of your email to any color you want or setting tags to any shade your heart desires.

Full Color Support
The dark theme available in Thunderbird has been enhanced with a dark message thread pane as well as many other small improvements.

Thunderbird Dark Theme
There are now more options available for managing attachments. You can “detach” an attachment to store it in a different folder while maintaining a link from the email to the new location. You can also open the folder containing a detached file via the “Open Containing Folder” option.

Attachment options for detached files.
Filelink attachments that have already been uploaded can now be linked to again instead of having to re-upload them. Also, an account is no longer required to use the default Filelink provider – WeTransfer.
Other Filelink providers like Box and Dropbox are not included by default but can be added by grabbing the Dropbox and Box add-ons.
There are many other smaller changes that make Thunderbird 68 feel polished and powerful including an updated To/CC/BCC selector in the compose window, filters can now be set to run periodically, and feed articles now show external attachments as links.
There are many other updates in this release, you can see a list of all of them in the Thunderbird 68 release notes. If you would like to try the newest Thunderbird, head to our website and download it today!
https://blog.mozilla.org/thunderbird/2019/08/whats-new-in-thunderbird-68/
|
|
Mozilla VR Blog: New Avatar Features in Hubs |
It is now easier than ever to customize avatars for Hubs! Choosing the way that you represent yourself in a 3D space is an important part of interacting in a virtual world, and we want to make it possible for anyone to have creative control over how they choose to show up in their communities. With the new avatar remixing update, members of the Hubs community can publish avatars that they create under a remixable, Creative Commons license, and grant others the ability to derive new works from those avatars. We’ve also added more options for creating custom avatars.
When you change your avatar in Hubs, you will now have the opportunity to browse through 'Featured' avatars and ‘Newest’ avatars. Avatars that are remixable will have an icon on them that allows you to save a version of that avatar to your own ‘My Avatars’ library, where you can customize the textures on the avatar to create your own spin on the original work. The ‘Red Panda’ avatar below is a remix of the original Panda Bot.
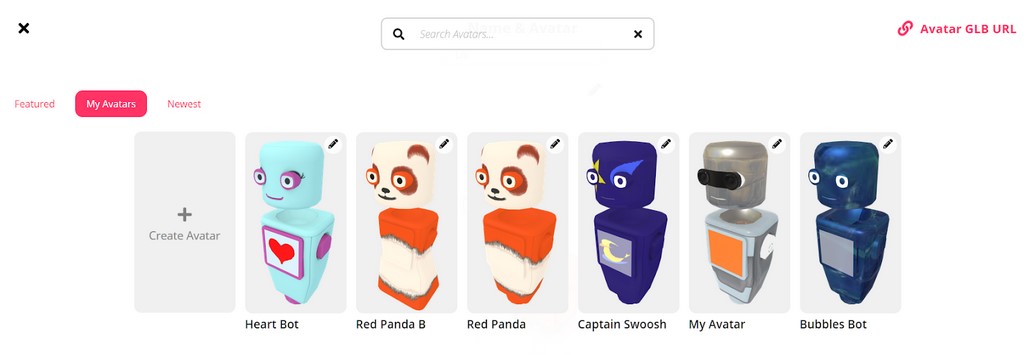
In addition to remixing avatars, you can create avatars by uploading a binary glTF file (or selecting one of the base bots that Hubs provides) and uploading up to four texture maps to the model. We have a number of resources available on GitHub for creating custom textures, as well as sets to get you started. You can also make your own designs with a 2D image editor or a 3D texture painting program.
The Hubs base avatar is a glTF model that has four texture maps and supports physically-based rendering (PBR) materials. This allows a great deal of flexibility in what kind of avatars can be created while still providing a quick way to create custom base color maps. For users who are familiar with 3D modeling, you can also create your own new avatar style from scratch, or by using the provided .blend files in the avatar-pipelines GitHub repo.
![]()
We’ve also made it easier to share avatars with one another inside a Hubs room. A tab for ‘Avatars’ now appears in the Create menu, and you can place thumbnails for avatars in the room you’re in to quickly swap between them. This will also allow others in the room to easily change to a specific avatar, which is a fun way to share avatars with a group.

These improvements to our avatar tools are just the start of what we’re working on to increase opportunities that Hubs users have available to express themselves on the platform. Making it easy to change your avatar - over and over again - allows users to have flexibility over how much personal information they want their avatar to reveal, and easily change from one digital body to another depending on how they’re using Hubs at a given time. While, at Mozilla, we find Panda Robots to be perfectly suited to company meetings, other communities and groups will have their own established social norms for professional activities. We want to support a rich, creative ecosystem for our users, and we can't wait to see what you create!
|
|
This Week In Rust: This Week in Rust 301 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
This week's crate is include_flate, a variant of include_bytes!/include_str with compile-time DEFLATE compression and runtime lazy decompression.
Thanks to Willi Kappler for the suggestion!
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
No issues were proposed for CfP.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
221 pull requests were merged in the last week
async_await in Rust 1.39.0apply_mark in built-in macros + Remove default macro transparenciesOrd implementation for integersiter::Chain::size_hintnth_back for ChunksExactMutstd::io::Take::read_to_enderror:/warning: coloring inconsistency with rustcimpl Trait in inlined documentationChanges to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
No new RFCs were proposed this week.
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Tweet us at @ThisWeekInRust to get your job offers listed here!
Just as Bruce Lee practiced Jeet Kune Do, the style of all styles, Rust is not bound to any one paradigm. Instead of trying to put it into an existing box, it's best to just feel it out. Rust isn't Haskell and it's not C. It has aspects in common with each and it has traits unique to itself.
Thanks to Louis Cloete for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nasa42, llogiq, and Flavsditz.
https://this-week-in-rust.org/blog/2019/08/27/this-week-in-rust-301/
|
|
IRL (podcast): Making Privacy Law |
The word “regulation" gets tossed around a lot. And it’s often aimed at the internet’s Big Tech companies. Some worry that the size of these companies and the influence they wield is too much. On the other side, there’s the argument that any regulation is overreach — leave it to the market, and everything will sort itself out. But over the last year, in the midst of this regulation debate, a funny thing happened. Tech companies got regulated. And our right to privacy got a little easier to exercise.
Gabriela Zanfir-Fortuna gives us the highlights of Europe’s sweeping GDPR privacy law, and explains how the law netted a huge fine against Spain’s National Football League. Twitter’s Data Protection Officer, Damien Kieran explains how regulation has shaped his new job and is changing how Twitter works with our personal data. Julie Brill at Microsoft says the company wants legislators to go further, and bring a federal privacy law to the U.S. And Manoush chats with Alastair MacTaggart, the California resident whose work led to the passing of the California Consumer Privacy Act.
IRL is an original podcast from Firefox. For more on the series go to irlpodcast.org
Learn more about consumer rights under the GDPR, and for a top-level look at what the GDPR does for you, check out our GDPR summary.
Here’s more about the California Consumer Privacy Act and Alastair MacTaggart.
And, get commentary and analysis on data privacy from Julie Brill, Gabriela Zanfir-Fortuna, and Damien Kieran.
Firefox has a department dedicated to open policy and advocacy. We believe that privacy is a right, not a privilege. Follow our blog for more.
|
|
Cameron Kaiser: TenFourFox FPR16b1 available |
FPR16 got delayed because I really tried very hard to make some progress on our two biggest JavaScript deficiencies, the infamous issues 521 (async and await) and 533 (this is undefined). Unfortunately, not only did I make little progress on either, but the speculative fix I tried for issue 533 turned out to be the patch that unsettled the optimized build and had to be backed out. There is some partial work on issue 521, though, including a fully working parser patch. The problem is plumbing this into the browser runtime which is ripe for all kinds of regressions and is not currently implemented (instead, for compatibility, async functions get turned into a bytecode of null throw null return, essentially making any call to an async function throw an exception because it wouldn't have worked in the first place).
This wouldn't seem very useful except that effectively what the whole shebang does is convert a compile-time error into a runtime warning, such that other functions that previously might not have been able to load because of the error can now be parsed and hopefully run. With luck this should improve the functionality of sites using these functions even if everything still doesn't fully work, as a down payment hopefully on a future implementation. It may not be technically possible but it's a start.
Which reminds me, and since this blog is syndicated on Planet Mozilla: hey, front end devs, if you don't have to minify your source, how about you don't? Issue 533, in fact, is entirely caused because uglify took some fast and loose shortcuts that barf on older parsers, and it is nearly impossible to unwind errors that occur in minified code (this is now changing as sites slowly update, so perhaps this will be self-limited in the end, but in the meantime it's as annoying as Andy Samberg on crack). This is particularly acute given that the only thing fixing it in the regression range is a 2.5 megabyte patch that I'm only a small amount of the way through reading. On the flip side, I was able to find and fix several parser edge cases because Bugzilla itself was triggering them and the source file that was involved was not minified. That means I could actually read it and get error reports that made sense! Help support us lonely independent browser makers by keeping our lives a little less complicated. Thank you for your consideration!
Meanwhile, I have the parser changes on by default to see if it induces any regressions. Sites may or may not work any differently, but they should not work worse. If you find a site that seems to be behaving adversely in the beta, please toggle javascript.options.asyncfuncs to false and restart the browser, which will turn the warning back into an error. If even that doesn't fix it, make sure nothing on the site changed (like, I dunno, checking it in FPR15) before reporting it in the comments.
This version also "repairs" Firefox Sync support by connecting the browser back up to the right endpoints. You are reminded, however, that like add-on support Firefox Sync is only supported at a "best effort" level because I have no control over the backend server. I'll make reasonable attempts to keep it working, but things can break at any time, and it is possible that it will stay broken for good (and be removed from the UI) if data structures or the protocol change in a way I can't control for. There's a new FAQ entry for this I suggest you read.
Finally, there are performance improvements for HTML5 and URL parsing from later versions of Firefox as well as a minor update to same-site cookie support, plus a fix for a stupid bug with SVG backgrounds that I caused and Olga found, updates to basic adblock with new bad hosts, updates to the font blacklist with new bad fonts, and the usual security and stability updates from the ESRs.
I realize the delay means there won't be a great deal of time to test this, so let me know deficiencies as quickly as possible so they can be addressed before it goes live on or about September 2 Pacific time.
http://tenfourfox.blogspot.com/2019/08/tenfourfox-fpr16b1-available.html
|
|
Joel Maher: Digging into regressions |
Whenever a patch is landed on autoland, it will run many builds and tests to make sure there are no regressions. Unfortunately many times we find a regression and 99% of the time backout the changes so they can be fixed. This work is done by the Sheriff team at Mozilla- they monitor the trees and when something is wrong, they work to fix it (sometimes by a quick fix, usually by a backout). A quick fact, there were 1228 regressions in H1 (January-June) 2019.
My goal in writing is not to recommend change, but instead to start conversations and figure out what data we should be collecting in order to have data driven discussions. Only then would I expect that recommendations for changes would come forth.
What got me started in looking at regressions was trying to answer a question: “How many regressions did X catch?” This alone is a tough question, instead I think the question should be “If we were not running X, how many regressions would our end users see?” This is a much different question and has two distinct parts:
These can be more difficult to answer. For example, Product Fixes- maybe by editing the test case we are preventing a regression in the future because the test is more accurate.
In addition we need to understand how accurate the data we are using is. As the sheriffs do a great job, they are human and humans make judgement calls. In this case once a job is marked as “fixed_by_commit”, then we cannot go back in and edit it, so a typo or bad data will result in incorrect data. To add to it, often times multiple patches are backed out at the same time, so is it correct to say that changes from bug A and bug B should be considered?
This year I have looked at this data many times to answer:
This data is important to harvest because if we were to turn off a set of jobs or run them as tier-2 we would end up missing regressions. But if all we miss is editing manifests to disable failing tests, then we are getting no value from the test jobs- so it is important to look at what the regression outcome was.
In fact every time I did this I would run an active-data-recipe (fbc recipe in my repo) and have a large pile of data I needed to sort through and manually check. I spent some time every day for a few weeks looking at regressions and now I have looked at 700 (bugs/changesets). I found that in manually checking regressions, the end results fell into buckets:
| test | 196 | 28.00% |
| product | 272 | 38.86% |
| manifest | 134 | 19.14% |
| unknown | 48 | 6.86% |
| backout | 27 | 3.86% |
| infra | 23 | 3.29% |
Keep in mind that many of the changes which end up in mozilla-central are not only product bugs, but infrastructure bugs, test editing, etc.
After looking at many of these bugs, I found that ~80% of the time things are straightforward (single patch [set] landed, backed out once, relanded with clear comments). Data I would like to have easily available via a query:
Ideally this set of data would exist for not only backouts, but for anything that is landed to fix a regression (linting, build, manifest, typo).
https://elvis314.wordpress.com/2019/08/23/digging-into-regressions/
|
|
Mozilla Open Policy & Advocacy Blog: Mozilla Mornings on the future of EU content regulation |
On 10 September, Mozilla will host the next installment of our EU Mozilla Mornings series – regular breakfast meetings where we bring together policy experts, policymakers and practitioners for insight and discussion on the latest EU digital policy developments.
The next installment will focus on the future of EU content regulation. We’re bringing together a high-level panel to discuss how the European Commission should approach the mooted Digital Services Act, and to lay out a vision for a sustainable and rights-protective content regulation framework in Europe.
Featuring
Werner Stengg
Head of Unit, E-Commerce & Platforms, European Commission DG CNECT
Alan Davidson
Vice President of Global Policy, Trust & Security, Mozilla
Liz Carolan
Executive Director, Digital Action
Eliska Pirkova
Europe Policy Analyst, Access Now
Moderated by Brian Maguire, EURACTIV
Logistical information
10 September 2019
08:30-10:30
L42 Business Centre, rue de la Loi 42, Brussels 1040
Register your attendance here
The post Mozilla Mornings on the future of EU content regulation appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2019/08/22/mozilla-mornings_content-regulation/
|
|
Dustin J. Mitchell: Outreachy Round 20 |
Outreachy is a program that provides paid internships working on FOSS (Free and Open Source Software) to applicants from around the world. Internships are three months long and involve deep, technical work on a mentor-selected project, guided by mentors and other developers working on the FOSS application. At Mozilla, projects include work on Firefox itself, development of associated services and sites like Taskcluster and Treeherder, and analysis of Firefox telemetry data from a data-science perspective.
The program has an explicit focus on diversity: “Anyone who faces under-representation, systemic bias, or discrimination in the technology industry of their country is invited to apply.” It’s a small but very effective step in achieving better representation in this field. One of the interesting side-effects is that the program sees a number of career-changing participants. These people bring a wealth of interesting and valuable perspectives, but face challenges in a field where many have been programming since they were young.
Round 20 will involve full-time, remote work from mid-December 2019 to mid-March 2020. Initial applications for this round are now open.
New this year, applicants will need to make an “initial application” to determine eligibility before September 24. During this time, applicants can only see the titles of potential internship projects – not the details. On October 1, all applicants who have been deemed eligible will be able to see the full project descriptions. At that time, they’ll start communicating with project mentors and making small open-source contributions, and eventually prepare applications to one or more projects.
So, here’s the call to action:
outreachy-coordinators@mozilla.com.http://code.v.igoro.us/posts/2019/08/outreachy-round-20.html
|
|
Armen Zambrano: Frontend security — thoughts on Snyk |
I can’t remember why but few months ago I started looking into keeping my various React projects secure. Here’s some of what I discovered (more to come). I hope some will be valuable to you.
A while ago I discovered Snyk and I hooked it up my various projects with it. Snyk sends me a weekly security summary with the breakdown of various security issues across all of my projects.
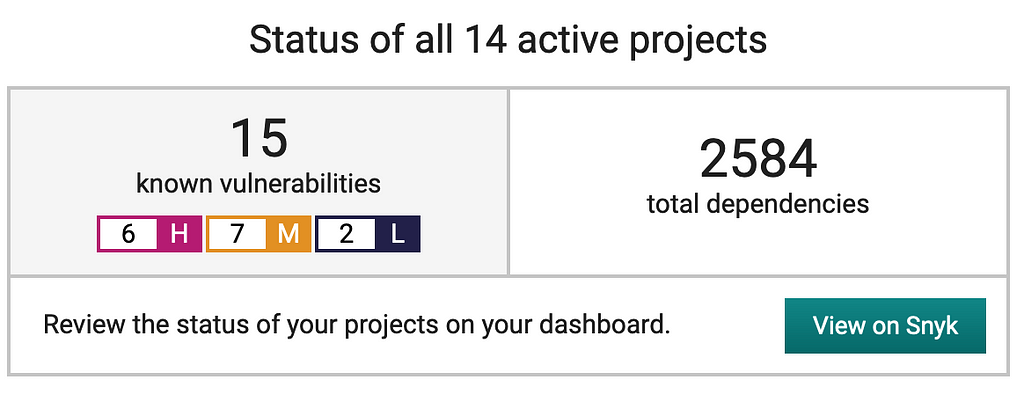
Snyk also gives me context about the particular security issues found:
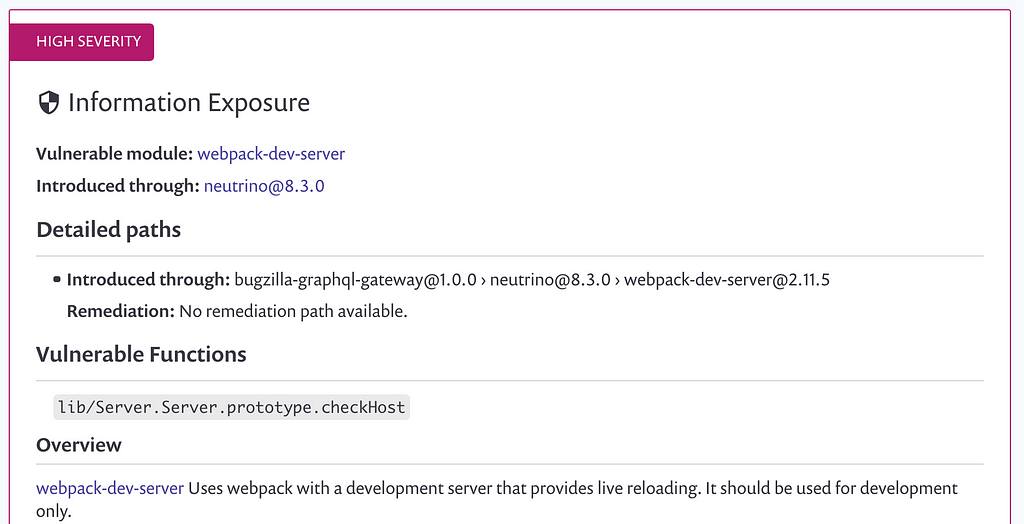
It also analyzes my dependencies on a per-PR level:

Other features that I’ve tried from Snyk:
The above features I have tried and I decided not to use them for the following reasons (listed in the same order as above):
Overall I’m very satisfied with Snyk and I highly recommend using it.
In the following posts I’m thinking of speaking on:
NOTE: This post is not sponsored by Snyk. I love what they do, I root for them and I hope they soon fix the issues I mention above.
|
|
Support.Mozilla.Org: Introducing Bryce and Brady |
Hello SUMO Community,
I’m thrilled to share this update with you today. Bryce and Brady have joined us last week and will be able to help out on Support for some of the new efforts Mozilla are working on towards creating a connected and integrated Firefox experience.
They are going to be involved with new products, but also they won’t forget to put extra effort in providing support on forums and as well as serving as an escalation point for hard to solve issues.
Here is a short introduction to Brady and Bryce:
Hi! My name is Brady, and I am one of the new members of the SUMO team. I am originally from Boise, Idaho and am currently going to school for a Computer Science degree at Boise State. In my free time, I’m normally playing video games, writing, drawing, or enjoying the Sawtooths. I will be providing support for Mozilla products and for the SUMO team.
Hello! My name is Bryce, I was born and raised in San Diego and I reside in Boise, Idaho. Growing up I spent a good portion of my life trying to be the best sponger(boogie boarder) and longboarder in North County San Diego. While out in the ocean I had all sorts of run-ins with sea creatures; but nothing to scary. I am also an IN-N-Out fan, as you may find me sporting their merchandise with boardshorts and the such. I am truly excited to be part of this amazing group of fun loving folks and I am looking forward to getting to know everyone.
Please welcome them warmly!
https://blog.mozilla.org/sumo/2019/08/21/introducing-bryce-and-brady/
|
|






