Cameron Kaiser: Something for the weekend: Classic MacOS Lua |
So in the meantime, since we're all classic Mac users here, try out MacLua, a new port of the Lua programming language to classic MacOS. I'm rather fond of Lua, which is an incredibly portable scripting language, ever since I learned it to write PalmOS applications in Plua (I maintained the Mac OS X cross-compiler for it). In fact, I still use Plua for my PalmOS-powered Hue light controller.
MacLua gives you a REPL which you can type Lua into and will run your Lua scripts, but it has two interesting features: first, you can use it as an MPW tool, and second, it allows plugins that could potentially connect it to the rest of the classic Mac Toolbox. The only included component is a simple one for querying Gestalt as an educational example, but a component for TCP sockets through MacTCP or OpenTransport or being able to display dialogue boxes and other kinds of system resources would seem like a logical next step. This was something really nice about Plua that it included GUI and network primitives built-in as included modules. The author of this port clearly has a similar idea in mind.
You can still compile Lua natively on 10.4, and that would probably be more useful if you wanted to write Lua scripts on an OS X Power Mac, but if you have a 68K or beige Power Mac around this Lua port can run on systems as early as 7.1.2 (probably any 68020 System 7 Mac if you install the CFM-68K Runtime Enabler). I look forward to seeing how it evolves, and the fact that it was built with QEMU as a Mac emulator not only is good evidence of how functional QEMU's classic Mac emulation is getting but also means there may be a chance at some other ports to the classic Mac OS in the future.
http://tenfourfox.blogspot.com/2018/11/something-for-weekend-classic-macos-lua.html
|
|
Mozilla Addons Blog: December’s Featured Extensions |

by Stefan vd
Go full screen with a single click.
“This is what I was searching for and now I have it!”
by Olivier de Broqueville
Search highlighted text on any web page using your preferred search engine. Just right-click (or Shift-click) on the text to launch the context menu. You can also perform searches using keywords in the URL address bar.
“Great add-on and very helpful! Thank you for the good work.”
by Iv'an Ruvalcaba
Simply click a button to close annoying pop-up overlays.
“I don’t think I’ve ever reviewed an extension, but man, what a find. I get very sick of closing overlays and finding the little ‘x’ in some corner of it or some light colored ‘close’ link. They get sneakier and sneakier about making you actually read the overlay to find a way to close it. Now when I see one, I know right away I can click on the X in the toolbar and it will disappear. So satisfying.”
If you’d like to nominate an extension for featuring, please send it to amo-featured [at] mozilla [dot] org for the board’s consideration. We welcome you to submit your own add-on!
The post December’s Featured Extensions appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2018/11/30/decembers-featured-extensions-2/
|
|
Wladimir Palant: Maximizing password manager attack surface: Learning from Kaspersky |
I looked at a number of password manager browser extensions already, and most of them have some obvious issues. Kaspersky Password Manager manages to stand out in the crowd however, the approach taken here is rather unique. You know how browser extensions are rather tough to exploit, with all that sandboxed JavaScript and restrictive default content security policy? Clearly, all that is meant for weaklings who don’t know how to write secure code, not the pros working at Kaspersky.
Kaspersky developers don’t like JavaScript, so they hand over control to their beloved C++ code as soon as possible. No stupid sandboxing, code is running with the privileges of the logged in user. No memory safety, dealing with buffer overflows is up to the developers. How they managed to do it? Browser extensions have that escape hatch called native messaging which allows connecting to an executable running on the user’s system. And that executable is what contains most of the logic in case of the Kaspersky Password Manager, with the browser extension being merely a dumb shell.
The extension uses website events to communicate with itself. As in: code running in the same scope (content script) uses events instead of direct calls. While seemingly pointless, this approach has a crucial advantage: it allows websites to mess with the communication and essentially make calls into the password manager’s executable. Because, if this communication channel weren’t open to websites, how could the developers possibly prove that they are capable of securing their application?
Now I’m pretty bad at reverse engineering binary code. But I managed to identify large chunks of custom-written code that can be triggered by websites more or less directly:
While the JSON parser is required by the native messaging protocol, you are probably wondering what the other two chunks are doing in the executable. After all, the browser already has a perfectly capable HTML parser. But why rely on it? Analyzing page structure to recognize login forms would have been too easy in the browser. Instead, the browser extension serializes the page back to HTML (with some additional attributes, e.g. to point out whether a particular field is visible) and sends it to the executable. The executable parses it, makes the neuronal network analyze the result and tells the extension which fields need to be filled with what values.
Doesn’t sound like proper attack surface maximization because serialized HTML code will always be well-formed? No problem, the HTML parser has its limitations. For example, it doesn’t know XML processing instructions and will treat them like regular tags. And document.createProcessingInstruction("foo", ">src=x>") is serialized as , so now the HTML parser will be processing HTML code that is no longer well-formed.
This was your quick overview, hope you learned a thing or two about maximizing the attack surface. Of course, you should only do that if you are a real pro and aren’t afraid of hardening your application against attacks!
https://palant.de/2018/11/30/maximizing-password-manager-attack-surface-leaning-from-kaspersky
|
|
Botond Ballo: Trip Report: C++ Standards Meeting in San Diego, November 2018 |
–>
| Project | What’s in it? | Status |
| C++17 | See list | Published! |
| C++20 | See below | On track |
| Library Fundamentals TS v3 | See below | Under active development |
| Concepts TS | Constrained templates | Merged into C++20, including (now) abbreviated function templates! |
| Parallelism TS v2 | Task blocks, library vector types and algorithms, and more | Published! |
| Executors | Abstraction for where/how code runs in a concurrent context | Subset headed for C++20, rest in C++23 |
| Concurrency TS v2 | See below | Under development. Depends on Executors. |
| Networking TS | Sockets library based on Boost.ASIO | Published! Not headed for C++20. |
| Ranges TS | Range-based algorithms and views | Merged into C++20! |
| Coroutines TS | Resumable functions, based on Microsoft’s await design |
Published! C++20 merge uncertain |
| Modules v1 | A component system to supersede the textual header file inclusion model | Published as a TS |
| Modules v2 | Improvements to Modules v1, including a better transition path | On track to be merged into C++20 |
| Numerics TS | Various numerical facilities | Under active development |
| Graphics TS | 2D drawing API | Future uncertain |
| Reflection TS | Static code reflection mechanisms | PDTS ballot underway; publication expected in early 2019 |
A few links in this blog post may not resolve until the committee’s post-meeting mailing is published (expected any day now). If you encounter such a link, please check back in a few days.
A few weeks ago I attended a meeting of the ISO C++ Standards Committee (also known as WG21) in San Diego, California. This was the third committee meeting in 2018; you can find my reports on preceding meetings here (June 2018, Rapperswil) and here (March 2018, Jacksonville), and earlier ones linked from those. These reports, particularly the Rapperswil one, provide useful context for this post.
This meeting broke records (by a significant margin) for both attendance (~180 people) and number of proposals submitted (~270). I think several factors contributed to this. First, the meeting was in California, for the first time in the five years that I’ve been attending meetings, thus making it easier to attend for Bay Area techies who weren’t up for farther travels. Second, we are at the phase of the C++20 cycle where the door is closing for new proposals targeting to C++20, so for people wanting to get features into C++20, it was now or never. Finally, there has been a general trend of growing interest in participation in C++ standardization, and thus attendance has been rising even independently of other factors.
This meeting was heavily focused on C++20. As discussed in the committee’s standardization schedule document, this was the last meeting to hear new proposals targeting C++20, and the last meeting for language features with significant library impact to gain design approval. A secondary focus was on in-flight Technical Specifications, such as Library Fundamentals v3.
To accommodate the unprecedented volume of new proposals, there has also been a procedural change at this meeting. Two new subgroups were formed: Evolution Incubator (“EWGI”) and Library Evolution Incubator (“LEWGI”), which would look at new proposals for language and library changes (respectively) before forwarding them to the Evolution or Library Evolution Working Groups (EWG and LEWG). The main purpose of the incubators is to reduce the workload on the main Evolution groups by pre-filtering proposals that need additional work before being productively reviewed by those groups. A secondary benefit was to allow the attendees to be spread out across more groups, as otherwise EWG and LEWG would have likely exceeded their room capacities.
Here are the new changes voted into C++20 Working Draft at this meeting. For a list of changes voted in at previous meetings, see my Rapperswil report.
std::is_constant_evaluated()try / catch blocks in constexpr functions.dynamic_cast and polymorphic typeid in constant expressions.constexprchar8_t: a type for UTF-8 characters and strings.operator>>(basic_istream&, CharT*).variant and optional should propagate copy/move triviality.visit: explicit return type for visit.zero(), min(), and max() should be noexcept.constexpr in std::pointer_traits.constexpr bits.unwrap_ref_decay and unwrap_referencereference_wrapper for incomplete typesvariant converting constructorstd::function move constructor should be noexceptstd::assume_alignedCommonReference requirement from StrictWeakOrdering (a.k.a fixing relations)span be Regular?operator+(basic_string))In addition to the C++ International Standard (IS), the committee publishes Technical Specifications (TS) which can be thought of experimental “feature branches”, where provisional specifications for new language or library features are published and the C++ community is invited to try them out and provide feedback before final standardization.
At this meeting, the committee iterated on a number of TSes under development.
The Reflection TS was sent out for its PDTS ballot at the last meeting. As described in previous reports, this is a process where a draft specification is circulated to national standards bodies, who have an opportunity to provide feedback on it. The committee can then make revisions based on the feedback, prior to final publication.
The PDTS ballot is still ongoing, so there wasn’t much to do on this front at this meeting. We expect the ballot results to be ready by the next meeting (February 2019, in Kona), at which time we’ll address the ballot comments and, time permitting, approve the revised TS for publication.
One minor snafu discovered at this meeting is that prior to the PDTS ballot, the Reflection TS, which depends on Concepts, has been rebased onto C++20, to take advantage of C++20 Concepts (previously, it was based on the Concepts TS). Unfortunately, ISO rules don’t allow publishing a TS before its base document is published, which means that to publish the Reflection TS as-is, we’d have to wait to do it concurrently with the C++20 publication in late 2020. We very much don’t want to wait that long, since the purpose of the Reflection TS is to gather feedback from users in preparation for revised Reflection features in C++23, and the earlier we start getting that feedback, the better. So, we’ll have to un-rebase the Reflection TS onto {C++17 + Concepts TS} to be able to publish it in early 2019 as planned. Isn’t red tape fun?
This third iteration (v3) of the Library Fundamentals TS is open for new features to be added. (The TS working draft currently contains features from v2 which haven’t been merged into the C++ IS yet.) The only changes voted in at this meeting were a rebase and some issue resolutions, but a number of new features are on the way.
As discussed below, the revised plans for Executors are for a subset of them to target C++20, and the rest C++23. An Executors TS is not planned at this time.
Turning now to Technical Specifications that have already been published, but not yet merged into the IS, the C++ community is eager to see some of these merge into C++20, thereby officially standardizing the features they contain.
The Ranges TS modernizes and Conceptifies significant parts of the standard library (the parts related to algorithms and iterators), as well as introducing exciting new features such as range views.
After years of hard work developing these features and going through the TS process, the Ranges TS was finally merged into C++20, paving the way for wider adoption of these features.
The approval of abbreviated function templates for C++20 at this meeting can be thought of as completing the merge of the Concepts TS into C++20: all the major features in the TS have now been merged, with some design modifications inspired by implementer and user feedback.
While the journey took longer than was initially hoped, in my opinion Concepts is a better feature for the design changes made relative to the Concepts TS, and as such this is an example of the TS process working as intended.
Modules remains one of the most highly anticipated features by the C++ user community. This meeting saw really good progress on Modules: a “merged” Modules design, combining aspects of the Modules TS and the alternative Atom proposal, gained design approval for C++20.
This outcome exceeded expectations in that previously, the merged proposal seemed more likely to target a Modules TS v2 or C++23, with a subset possibly targeting C++20; however, thanks in significant part to the special one-off Modules-focused Bellevue meeting in September, good enough progress was made on the merged design that the authors were comfortable proposing putting the entire thing into C++20, which EWG subsequently approved.
As this is a large proposal, wording review by the Core Working Group will take some time, and as such, a plenary vote to merge the reviewed wording into the C++20 working draft won’t take place until the next meeting or the one after; however, as all the major compiler implementers seem to be on board with this design, and there is overwhelming demand for the feature from the user community, I expect smooth sailing for that vote.
In fewer words: Modules is on track for C++20!
The Coroutines TS was once again proposed for merger into C++20 at this meeting. This is the third time this proposal was made (the other two times being at the previous two meetings). At the last meeting, the proposal got as far as a plenary vote at the end of the week, which narrowly failed.
The opposition to merging the TS into C++20 comes from the fact that a number of people have concerns about the Coroutines TS design (some of them are summarized in this paper), and an alternative proposal that addresses these concerns (called “Core Coroutines”) is under active development. Unfortunately, Core Coroutines is not sufficiently-baked to make C++20, so going with it would mean delaying Coroutines until C++23. Opinions differ on whether this is a worthwhile tradeoff: the Core Coroutines authors are of the view that C++ will remain a relevant language for 50 years or more, and waiting 3 years to improve a feature’s design is worthwhile; others have made it clear that they want Coroutines yesterday.
After the failure of last meeting’s merger proposal, it was hoped that waiting one more meeting would allow for the Core Coroutines proposal to mature a bit. While we knew it wouldn’t be ready for C++20, we figured the added maturity would allow us to better understand what we would be giving up by merging the Coroutines TS into C++20, and possibly identify changes we could make the Coroutines TS before C++20’s publication that would make incremental improvements inspired by Core Coroutines backwards-compatible, thereby allowing us to make a more informed decision on the C++20 merger.
Core Coroutines did make significant progress since the last meeting: the updated proposal is simpler, more fleshed out, and has a cleaner syntax. The impasse has also inspired efforts, led by Facebook, to combine the two proposals in such a way that would unblock the merger into C++20, and allow for backwards-comaptible improvements achieving many of the goals of Core Coroutines in C++23, but these efforts are at a relatively early stage (a paper describing the combined design in detail was circulated for the first time while the meeting was underway).
Ultimately, waiting a meeting doesn’t seem to have changed many people’s minds, and we saw a replay of what happened in Rapperswil: EWG narrowly passed the merger, and plenary narrowly rejected it; interestingly, the level of consensus in plenary appears to have decreased slightly since Rapperswil.
To keep C++20 on schedule, the final deadline for approving a TS merger is the next meeting, at Kona. The merger will undoubtedly be re-proposed then, and there remains some optimism that further development of Facebook’s combined proposal might allow us to gain the required confidence in a future evolution path to approve the merger for C++20; otherwise, we’re looking at getting Coroutines in C++23.
It’s looking like the Networking TS will not be merged into C++20, in large part due to the concerns presented this paper discussing usage experience. The TS will instead target C++23.
With the increased number of subgroups meeting in parallel, it’s becoming more challenging to follow what goes on in the committee.
I usually sit in EWG for the duration of the meeting, and summarize the design discussions that take place in that group. I will try to do so again, but I did miss some EWG time while sitting in some study group meetings and Evolution Incubator meetings, so expect some reduction in the amount of detail. If you have specific questions that I didn’t cover, feel free to ask in the comments.
This time, I’ll categorize proposals by topic. For your convenience, I still indicate whether each proposal was approved, had further work on it encouraged, or rejected. Proposals are targeting C++20 unless otherwise mentioned.
The headline item here is the approval of the compromise design for abbreviated function templates (AFTs). With this syntax, AFTs look like this:
void f(Concept auto x);
This makes both the “I want to write a function template without the template<...> notation” and the “I want to be able to tell syntactically if a function is a template” camps happy (the latter because the auto tells you the parameter has a deduced type, and therefore the function is a template).
You can also use Concept auto as a return type, and as the type of a variable. In each case, the type is deduced, and the deduced type has to satisy the concept. The paper as written would have allowed the return type and variable cases to omit the auto, but this didn’t have consensus and was removed.
Note that you can write just void f(auto x); as well, making functions consistent with lambdas which could already do this.
Finally, as part of this change, a restriction was imposed on the template notation, that T has to be a type. For non-type and template template parameters, constraints can only be specified using a requires-clause. The motivation here is to be able to tell syntactically what type of entity T is.
A few other Concepts-related proposals were looked at:
tuple) can be used as a parameter type as if it were a concept (with the concept being, roughly, “this type is a specialization of tuple“). The proposal was generally well-received, but there are some technical details to iron out, and design alternatives to consider (e.g. spelling it tuple), so this will be revisited for C++23.template . EWG didn’t feel the whitespace syntax was an improvement over other syntaxes that have been rejected, like template .EWG ran out of time to review the updated “constraining Concepts overload sets” proposal. However, there was some informal speculation that the chances of this proposal making C++20 have diminished, because the proposal has grown a lot more complex in an attempt to address EWG’s feedback on the previous version, which suggests that feedback had touched on some hard problems that we may not be in a good position to solve at this time.
As mentioned, perhaps the biggest high-point of this meeting was EWG’s approval of the merged Modules design for C++20. “Merged” here refers to the proposal combining aspects of the Modules TS design, and the alternative Atom proposal. Perhaps most significantly, the design borrows the Atom proposal’s legacy header imports feature, which is intended to better facilitate incremental transition of existing large codebases to Modules.
Several minor modifications to this design and related changes were also proposed:
module a context-sensitive keyword, take two. Following consistent feedback from many segments of the user community that making module a hard keyword would break too much code, a new proposal for making it context-sensitive, this time with simpler disambiguation rules, was approved.axioms) do not allow compilers to assume additional things they couldn’t already assume.constexprContinuing with the committee’s concerted effort to make clunkier forms of compile-time programming (such as template metaprogramming) unnecessary, EWG approved further extensions to constexpr:
dynamic_cast and polymorphic typeid in constant expressionsstd::typeinfo::operator= constexprconstexpr! to consteval because the former presented lexical concerns.for loops; they were previously proposed as tuple-based for loops. They’re called expansion statements because they are expanded (unrolled) at compile time, with the body of each “iteration” potentially working with different types. The current proposal contains two forms, for ... and for constexpr, and EWG expressed a desire to unify them.I mentioned above that EWG narrowly passed the latest version of a proposal to merge the Coroutines TS into C++20, only to have it rejected in a plenary vote.
The technical discussion of this topic centred around an updated version of the competing Core Coroutines proposal, and a paper by Facebook engineers arguing that most of the benefits of Core Coroutines could be achieved through extensions to the Coroutines TS, and we should therefore go ahead with the Coroutines TS in C++20.
An interesting development that emerged mid-meeting is the Facebook folks coming up with a “unified coroutines” proposal that aims to achieve consensus by combining aspects of the two competing proposals. There wasn’t really enough time for the committee to digest this proposal, but we are all hopeful it will help us make an informed final decision (final for C++20, that is) at the next meeting.
static, thread_local, or constexpr; in each case, this applies to the entire composite object being destructured. Rules around linkage were also clarified. Capture of bindings by a lambda was deferred for further work.operator extract from an earlier pattern matching proposal.vector(MyAlloc()) ).Most comparison-related proposals involved early adopters trying out the spaceship operator (<=>) and discovering problems with it.
operator<=> (because that’s “the C++20 way” for all comparison use cases), and you pay a performance penalty that wouldn’t be there with hand-written code to deal with equality comparison only.) A related paper offers a solution, which is along the lines of making == be its own thing and not fall back to using <=>, since that’s where the inefficiency stems from (for types like string, if the lengths are different you can answer “not equal” much faster than if you’d have to answer “less” or “greater than”). A second part of the proposal, where a defaulted <=> would also generate a defaulted ==, so that users can be largely oblivious to this problem and just default one operator (<=>), was more controversial, but was still approved over some objections.<=>? The crux of this paper is that we’ve had to invent a library function compare_3way() wrapping <=> and that’s what we want to use most of the time, so we should just give <=> the semantics of that function.weak_equality considered harmful. This proposal has become moot as implementations of == are no longer generated in terms of <=>. (As a result, weak_equality and strong_equality are no longer used and will likely be removed in the future.)this. This proposal allows writing member functions where the type of this is deduced, thereby eliminating the need to duplicate implementations for things like const vs. non-const objects, and other sources of pain. There was a fair amount of technical discussion concerning recursive lambdas (which this proposal hopes to enable), name lookup rules, and other semantic details. The authors will return with a revised proposal.(Disclaimer: don’t read too much into the categorization here. One person’s bug fix is another’s feature.)
vector::emplace_back() to work for aggregates.noexcept and explicitly defaulted functions. The first option from the paper was approved.namespace foo::inline bar::baz { } is short for namespace foo { inline namespace bar { namespace baz { }}}. inline is not allowed in the leading position as people might mistakenly think it applies to the innermost namespace.[[constinit]] attribute. The motivation here is cases where you want to guarantee that a variable’s initial value is computed at compile time (so no dynamic initialization required), without making the variable const (so that you can assign new values to it at runtime). EWG liked the idea but preferred using a keyword rather than an attribute. An alternative to decorate the initializer rather than the variable had no consensus.short float. This proposal continues to face challenges due to concerns about different implementations using different sizes for it, or even different representations within the same size (number of bits in mantissa vs. exponent). As a result, there was no consensus for moving forward with it for C++20. There remains strong interest in the topic, so I expect it will come back for C++23, possibly under a different name (such as float16_t instead of short float, to specify the size more concretely).operator &. EWG didn’t feel that removal was realistic given that we don’t have a good handle on the breadth of usage in the wild, and didn’t want to entertain deprecation without an intention to remove as a follow-up.As mentioned above, due to the increased quantity of proposals, an “EWG Incubator” group (EWGI) was also spun up to do a preliminary round of review on some proposals that EWG couldn’t get to this week, in the hope of making them better-baked for their eventual EWG review at a future meeting.
I only attended EWGI for half a day, so I don’t have much to report about the discussions that went on, but I will list the papers the group forwarded to EWG:
char16_t/char32_t string literals be UTF-16/32using enumnodiscard should have a reasonThere were also a couple of papers EWGI referred for EWG review not necessarily because they’re sufficiently baked, but because they would benefit from evaluation by a larger group:
Numerous other proposals were asked to return to EWGI with revisions. I’ll call out a couple:
There were, of course, also papers that neither EWG nor EWGI had the time to look at during this meeting; among them was Herb’s static exceptions proposal, which is widely anticipated, but not targeting C++20.
I’ll also briefly mention the lifetimebound proposal which Mozillians have expressed a particular interest in due to the increased lifetime safety it would bring: the authors feel that Microsoft’s lifetime checker, whose model of operation is now described in a paper is doing an adequate job of satisfying this use case outside of the core language rules (via annotations + a separate static checker). Microsoft’s lifetime checker ships with MSVC, and has a work-in-progress implementation in Clang as well, which can be tried out in Compiler Explorer, and will hopefully be open-sourced soon. See also Roc’s blog post on this subject.
Having sat in the Evolution groups, I haven’t been able to follow the Library groups in any amount of detail, but I’ll call out some of the more notable library proposals that have gained design approval at this meeting:
std::span changes: not Regular, utility enhancementsto_array(), resource_adaptoratomic_flag::test and lock-free integral types. With this, the only portion of the Concurrency TS v1 that isn’t headed for C++20 in some form is future.then(), which is still to come (no pun intended).size() should be signed or unsigned: it will be unsigned, and a new std::ssize() free function will be added which will return a signed type.And a few notable proposals which are still undergoing design review, and are being treated with priority:
source_locationstd::optionalflat_setjthread (cooperatively interruptible joining thread)basic_string (not vector for now)There are numerous other proposals in both categories above, I’m just calling out a few that seem particularly noteworthy. Please see the committee’s website for a full list of proposals.
Most of the C++20-track work (jthread, Executors subset, synchronization omnibus paper, memory model fixes) has progressed out of the Concurrency Study Group and is mentioned above.
For Executors, the current plan is to put a subset of the unified proposal (specifically including “one way” and “bulk one way” executors, but not the other kinds) into C++20, and the rest into C++23; a TS is not planned at this time.
Coroutines-related library additions are not being reviewed yet; they need more bake time, and integration with the next revision of Executors.
SG 1 has opinions on freestanding implementations: they feel omitting thread_local from a freestanding implementation is fine, but omitting non-lock-free atomics or thread-safe statics is more controversial.
There were two meetings related to compile-time programming this week. The first was an evening session where the committee re-affirmed its preference for constexpr-based metaprogramming as the future of C++ metaprogramming, in preference to template metaprogramming (TMP). (There was some confusion in this regard, as there was a proposal to standardize Boost.Mp11, a TMP library. The feeling at the end of the meeting was that with constexpr metaprogramming just around the corner, it’s probably not the best use of committee time to standardize a TMP library.)
The second was an afternoon meeting of SG 7, where the main agenda item was reviewing two proposals for reflection based on constexpr metaprogramming: constexpr reflexpr, and scalable reflection in C++. The first is by the authors of the Reflection TS, and tries to carry over the Reflection TS facilities to the land of constexpr in a relatively straightforward way. The second is a variation of this approach that reflects experience gained from experimentation by some implementers. Both proposals also go further than the Reflection TS in functionality, by supporting reification, which involves going from meta-objects obtained via reflection back to the entities they represent.
One notable difference between the two proposals is that the first uses meta-objects of different types to represent different kinds of entities (e.g. meta::variable, meta::function, etc.), whereas the second uses just one type (meta::info) for all meta-objects, and requires using operations on them (e.g. is_variable()) to discriminate. The authors of the second proposal claim this is necessary for compile-time performance to be manageable; however, from an interface point of view the group preferred the different-types approach, and some implementers thought the performance issues could be solved. At the same time, there was agreement that while there should be different types, they should not form an inheritance hierarchy, but rather be type-erased by-value wrappers. In addition, the group felt that errors should be visible in the type system; that is, rather than having meta-objects admit an invalid state, reflection operations that can fail should return something like expected instead.
The target ship vehicle for a constexpr-based reflection facility is not set in stone yet, but people are hopeful for C++23.
In addition, SG 7 approved some guidelines for what kinds of library proposals should require SG 7 review.
The Human/Machine Interface Study Group (SG 13) deals with proposals for graphics, event handling, and other forms of user interaction.
Its main product so far has been the 2D graphics proposal, which had been making good progress until it lost consensus to move forward at the last meeting. As there was still significant interest in this proposal in many user communities (see e.g. this paper arguing strongly for it), the Convenor asked SG 13 to have another look at it, to see if consensus could somehow be re-attained. There wasn’t extensive technical discussion of the proposal at this meeting, but we did go over some feedback from potential implementers; it was suggested that the author and other interested parties spend some time talking to graphics experts, many of whom are found in the Bay area (though not the ones at Mozilla – our graphics folks are mostly in the Toronto office).
The group also discussed the web_view proposal, which was positioned as an alternative to rolling our own graphics API. As the proposal effectively involves shipping a web platform implementation as part of the C++ standard library, this proposal has a lot of relevance to Mozilla. As such, I solicited feedback on it on Mozilla’s platform mailing list, and the feedback was pretty universally that this is not a good fit for the C++ standard library. I relayed this feedback at this meeting; nonetheless, the group as a whole was in favour of continuing to pursue this proposal. In fact, the group felt this and 2D graphics serve different use cases and should both be pursued in parallel. (Admittedly, there’s some selection bias going on here: people who choose to attend a meeting of SG 13 are naturally likely to be in favour of proposals in this topic area. I’m curious to see how these proposals will fare in front of a larger voting audience.)
There was also some general discussion of other topics in scope for this group. There are plans for bring forward a proposal for an audio API, and there were also ideas thrown around about things like event handling, user input, sensors, and VR.
The Tooling Study Group (SG 15) met for an evening session, and numerous papers concerning a variety of topics were presented.
The most pressing topic was how to integrate Modules with build systems. The problem is nicely summarized in this paper, and proposed solutions range from a separate “module mapper” component to relying on conventions.
The other major topic was general discussion about where to go in the space of dependency and package management. Ideas presented here include a set of APIs to allow components of a package ecosystem to interface with each other without requiring a particular implementation for any one component, and ideas around package specification.
I don’t feel like a lot of decisions were made in this session, and the group as a whole seems to be conflicted about what its role is given that these areas are not in the purview of the C++ standards document itself, but I still think the evening served as a valuable opportunity for pioneers in these areas to exchange areas and build mindshare around the tooling problems facing the C++ community.
Other Study Groups that met at this meeting include:
Not a study group, but this didn’t really fit anywhere else: there was an evening session to try to clarify the committee’s approach to freestanding implementations.
Freestanding implementations are, roughly speaking, those which cannot assume the presence of a full complement of operating system services, because they’re e.g. targeting kernel code or other “bare metal” scenarios; such implementations cannot practically make use of all language features, such as exceptions.
The standard currently defines a subset of the library that is intended to be supported on freestanding implementations, but defines no such subset for the language. Attempts to define such a subset tend to be stymied by the fact that different environments have different constraints, so one subset does not fit all.
The session didn’t reach any firm conclusions, but one possible direction is to avoid trying to define subsets, and instead make it easier for target environments to not use features of the language that are not applicable or practical for it.
Two new Study Groups were announced at this meeting. Quoting their charters from Herb Sutter’s trip report:
SG 19 (Machine Learning):
We feel we can leverage C++’s strengths in generic programming, optimization and acceleration, as well as code portability, for the specific domain of Machine Learning. The aim of SG19 is to address and improve on C++’s ability to support fast iteration, better support for array, matrix, linear algebra, in memory passing of data for computation, scaling, and graphing, as well as optimization for graph programming.
SG 20 (Education):
We feel we have an opportunity to improve the quality of C++ education, to help software developers correctly use our language and ecosystem to write correct, maintainable, and performing software. SG20 aims to create curriculum guidelines for various levels of expertise and application domains, and to stimulate WG21 paper writers to include advise on how to teach the new feature they are proposing to add to the standard.
The next meeting of the Committee will be in Kona, Hawaii, the week of February 18th, 2019.
C++ standards development continues to progress at an unprecedented pace. My highlights for this meeting included:
With the big-ticket items above, not to mention Contracts, operator spaceship, and many other goodies, C++20 is shaping up to be a very impressive release!
Due to sheer number of proposals, there is a lot I didn’t cover in this post; if you’re curious about a specific proposal that I didn’t mention, please feel free to ask about it in the comments.
In addition to Herb’s, other trip reports about this meeting include Corentin Jabot’s, a collaborative Reddit report, and a podcast focused on Library Evolution by Ashley Hedberg. I encourage you to check them out as well!
|
|
Mark C^ot'e: A Tale of Two Commits |
|
|
Mozilla VR Blog: Firefox Reality update supports 360 videos and 7 additional languages |

Firefox Reality 1.1 is now available for download in the Viveport, Oculus, and Daydream app stores. This release includes some major new features, including localization to seven new languages (including voice search support), a new dedicated theater viewing mode, bookmarks, 360 video support, and significant improvements to the performance and quality of our user interface.
We also continue to expand the Firefox Reality content feed, and are excited to add cult director/designer Keiichi Matsuda’s video series, including his latest creation, Merger.
Keiichi’s work explores how emerging technologies will impact everyday life in the future. His acclaimed 2016 film HYPER-REALITY was a viral success, presenting a provocative and kaleidoscopic vision of the future city saturated in media. It was an extension and re-imagining of his earlier concept films made in 2010, also presented here. His new short film, Merger, is shot in 360 and explores the future of work, automated corporations and the cult of productivity. We follow an elite tele-operator fighting for her economic survival, in search of the ultimate interface.
New Features:
Improvements/Bug Fixes:
Full release notes can be found in our GitHub repo here.
Looking ahead, we are exploring content sharing and syncing across browsers (including bookmarks), multiple windows, tab support, as well as continuing to invest in baseline features like performance. We appreciate your ongoing feedback and suggestions — please keep it coming!
Download for Oculus
(supports Oculus Go)
Download for Daydream
(supports all-in-one devices)
Download for Viveport (Search for “Firefox Reality” in Viveport store)
(supports all-in-one devices running VIVE Wave)
https://blog.mozvr.com/firefox-reality-update-supports-360-videos-and-7-additional-languages/
|
|
Mozilla B-Team: happy bmo push day! |
We did another release today.
the following changes have been pushed to bugzilla.mozilla.org:
|
|
Daniel Pocock: Connecting software freedom and human rights |
2018 is the 70th anniversary of the Universal Declaration of Human Rights.

Over the last few days, while attending the UN Forum on Business and Human Rights, I've had various discussions with people about the relationship between software freedom, business and human rights.
In the information age, control of the software, source code and data translates into power and may contribute to inequality. Free software principles are not simply about the cost of the software, they lead to transparency and give people infinitely more choices.
Many people in the free software community have taken a particular interest in privacy, which is Article 12 in the declaration. The modern Internet challenges this right, while projects like TAILS and Tor Browser help to protect it. The UN's 70th anniversary slogan Stand up 4 human rights is a call to help those around us understand these problems and make effective use of the solutions.
We live in a time when human rights face serious challenges. Consider censorship: Saudi Arabia is accused of complicity in the disappearance of columnist Jamal Khashoggi and the White House is accused of using fake allegations to try and banish CNN journalist Jim Acosta. Arjen Kamphuis, co-author of Information Security for Journalists, vanished in mysterious circumstances. The last time I saw Arjen was at OSCAL'18 in Tirana.
For many of us, events like these may leave us feeling powerless. Nothing could be further from the truth. Standing up for human rights starts with looking at our own failures, both as individuals and organizations. For example, have we ever taken offense at something, judged somebody or rushed to make accusations without taking time to check facts and consider all sides of the story? Have we seen somebody we know treated unfairly and remained silent? Sometimes it may be desirable to speak out publicly, sometimes a difficult situation can be resolved by speaking to the person directly or having a meeting with them.
Being at the United Nations provided an acute reminder of these principles. In parallel to the event, the UN were hosting a conference on the mine ban treaty and the conference on Afghanistan, the Afghan president arriving as I walked up the corridor. These events reflect a legacy of hostilities and sincere efforts to come back from the brink.

There were many opportunities to have discussions with people from all the groups present. Several sessions raised issues that made me reflect on the relationship between corporations and the free software community and the risks for volunteers. At the end of the forum I had a brief discussion with Dante Pesce, Chair of the UN's Business and Human Rights working group.

Many people at the forum asked me how to get started with free software and I promised to keep adding to my blog. What would you regard as the best online resources, including videos and guides, for people with an interest in human rights to get started with free software, solving problems with privacy and equality? Please share them on the Libre Planet mailing list.
Are dogs entitled to danger pay when protecting heads of state?

https://danielpocock.com/connecting-free-software-and-human-rights
|
|
The Firefox Frontier: How to Use Firefox Reality on the Oculus Go VR Headset |
Virtual reality headsets are one of the hottest gifts of the season, but without an internet browser built for virtual reality the experience could fall flat. Enter, Firefox Reality, an … Read more
The post How to Use Firefox Reality on the Oculus Go VR Headset appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/firefox-reality-oculus-go-vr/
|
|
Mozilla B-Team: happy bmo push days |
a whole bunch of updates (including last week’s)
Last week’s pushes didn’t get posted because we had a few bug fixes, so below is yesterday’s push + last weeks, in reverse chronological order.
the following changes have been pushed to bugzilla.mozilla.org:
|
|
Mozilla Open Innovation Team: Prototyping with Intention |
In our first post of this series we introduced why, and a bit of how, we’re applying experience design to our Open Innovation projects and community collaboration. An integral part of experience design is growing an idea from a concept to a full-fledged product or service. In getting from one to the other, thinking and acting prototypically can make a significant difference in overall quality and sets us up for early, consistent feedback. We are then able to continually identify new questions and test our hypotheses with incremental work. So, what do we actually mean by thinking and acting prototypically?
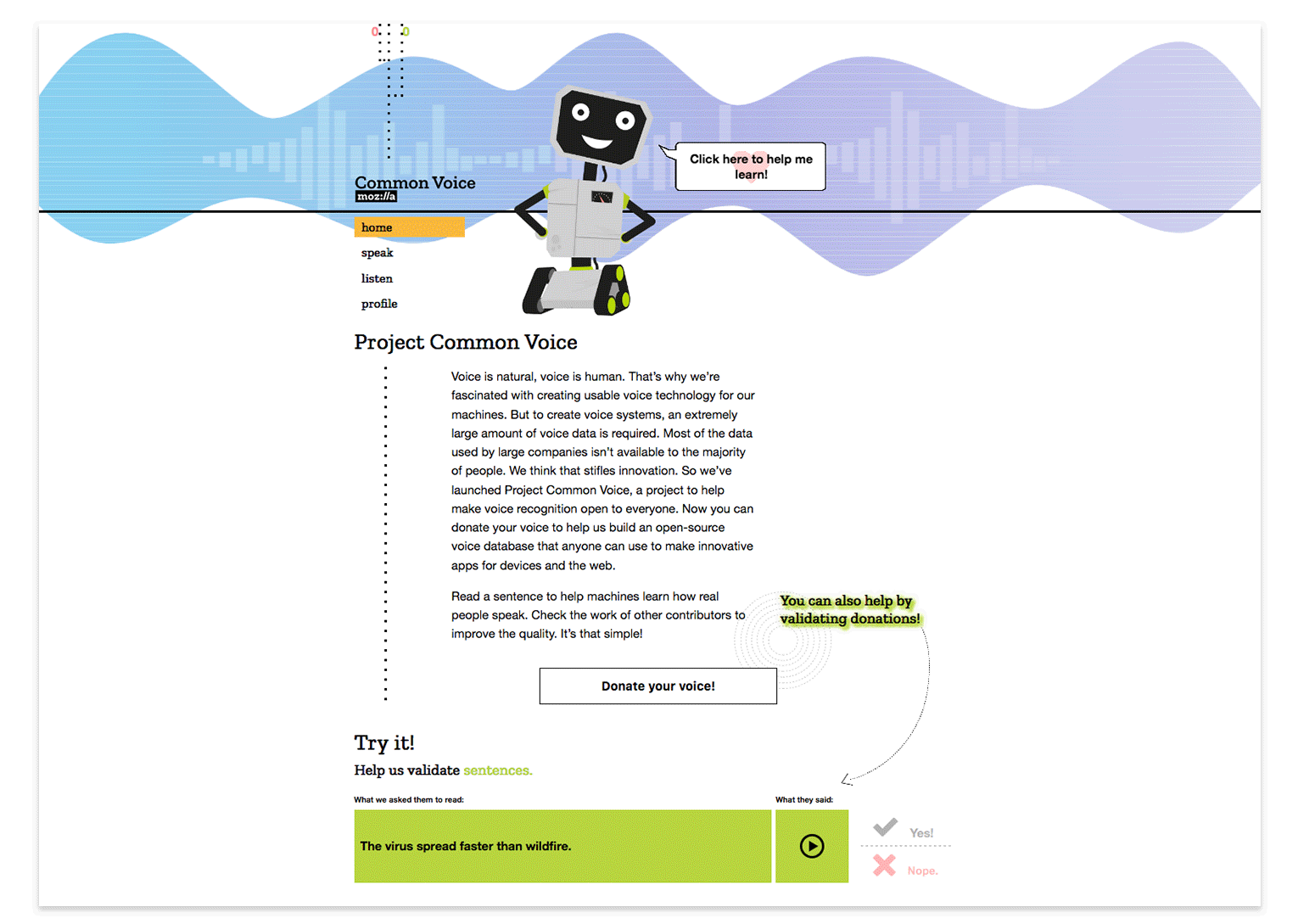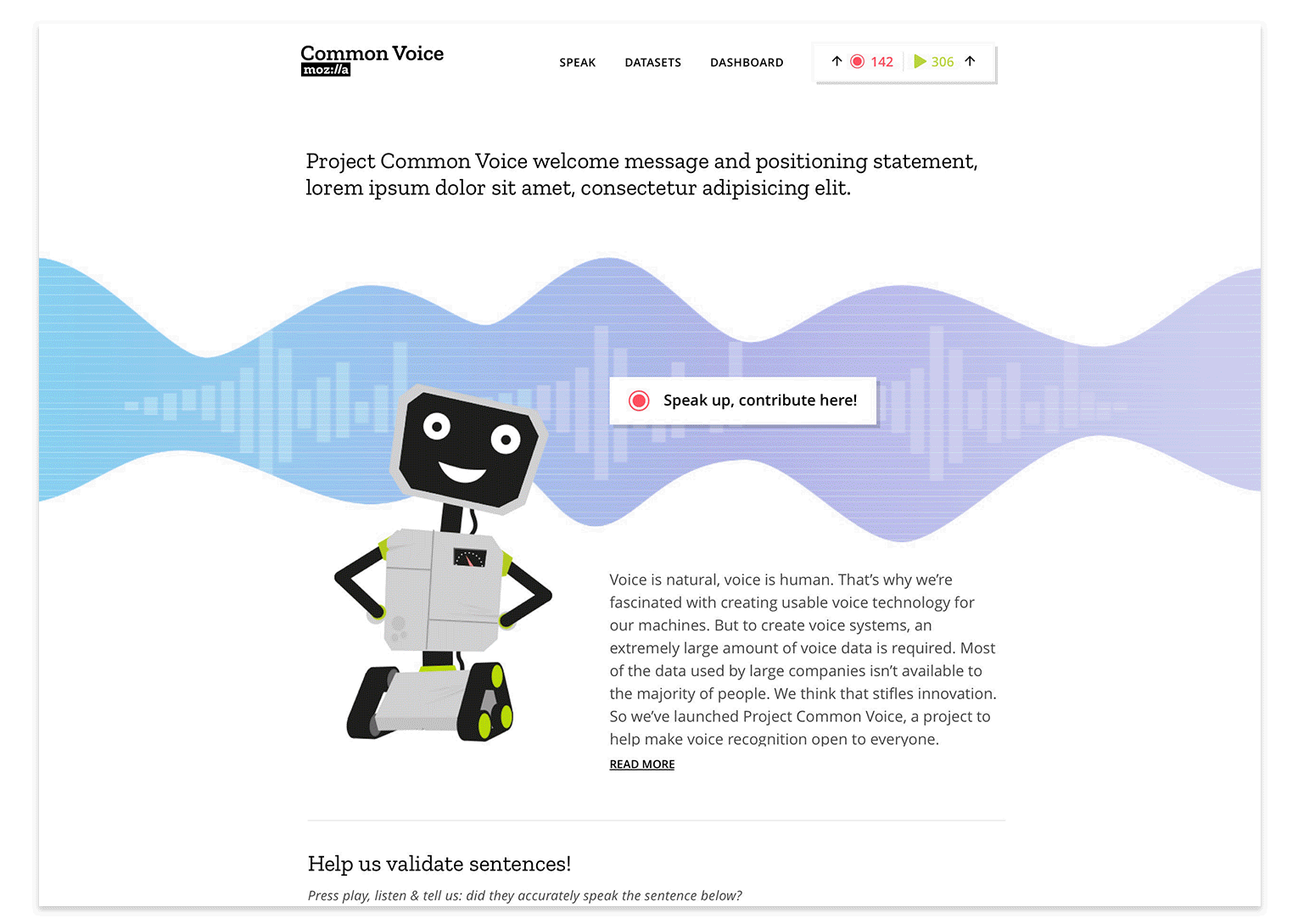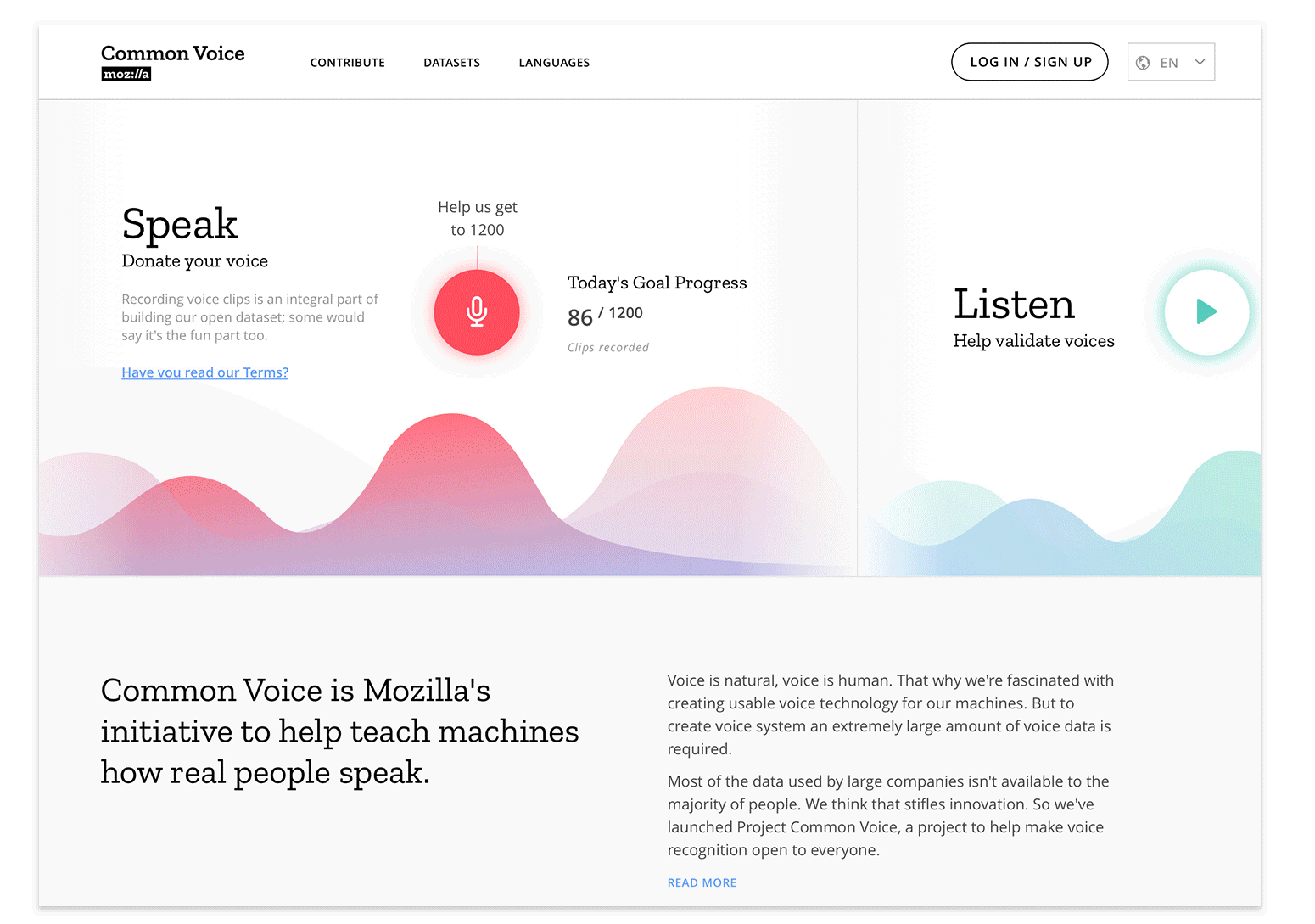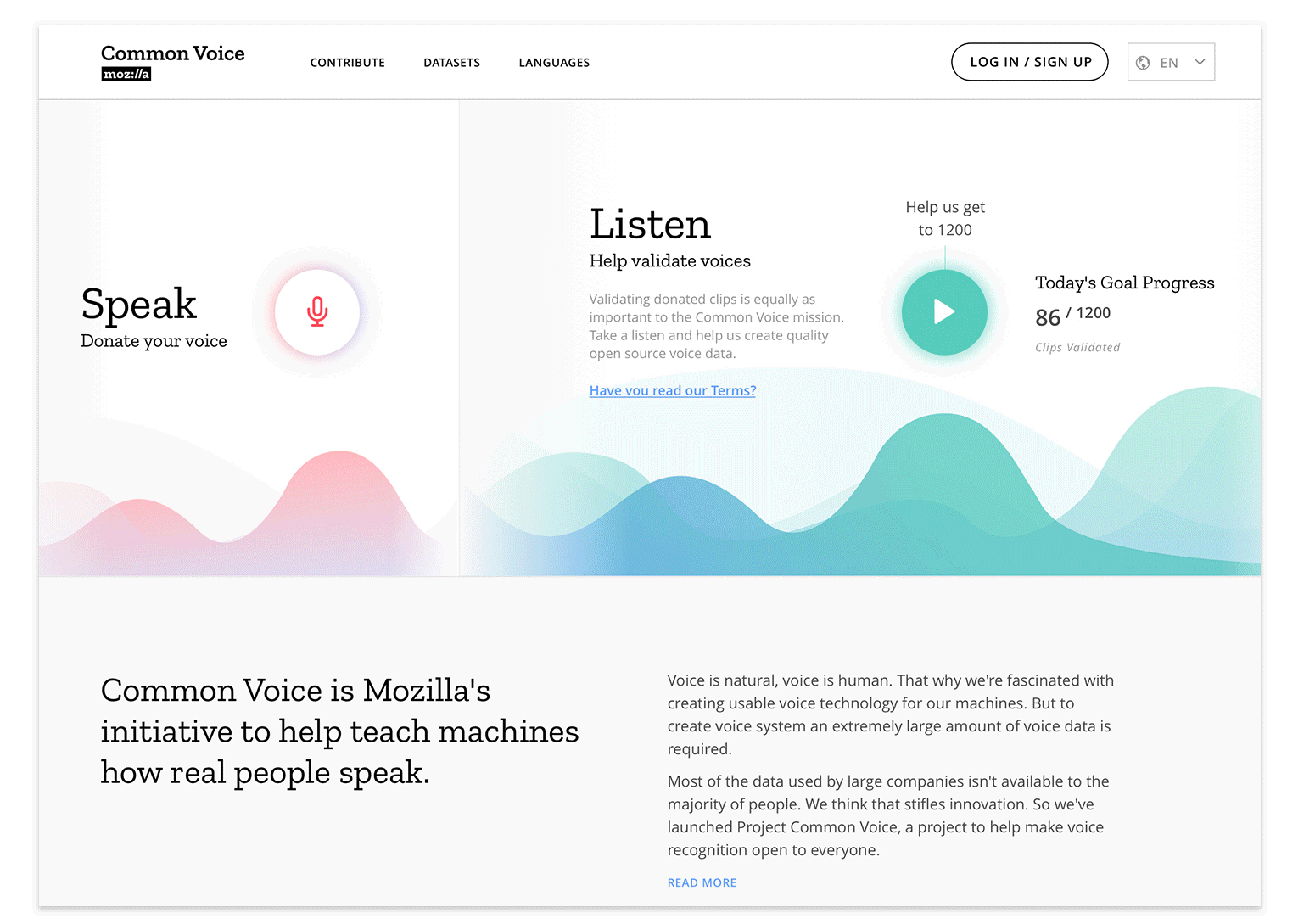
At the start of any project our Open Innovation team concepts with the intention that things will change. Whether it be wireframe prototypes or coded experiments, iteration is inevitable. First ideas are often far from perfect… it’s with help from new or returning contributors and collaborating project teams that we’re able to refine initial ideas more readily and efficiently. How? Through feedback loops designed with tools such as Discourse, GitHub, contact forms, on-site surveys and remote testing. Our overall goal being: Release assumptions early and learn from those engaging with the concept. In this way we set our experiences up for incremental, data influenced iteration.

To continue with our example of Common Voice, we see that this approach was applied in moving from paper prototype to first production prototype. The learnings and feedback from the design sprint exercises helped us realize the need for storytelling and a human interaction experience that would resonate with, well, humans. To achieve this we set out over a 6 week phase to create the experience via wireframes, basic UI design and code implementation. With the help of our community members we were gratefully able to QA the experience as we released it.
With a working prototype out in the wild our team sets their focus on observing and gathering info about performance and usability. In addition to 250+ technical contributors that file issues with feature requests and bug fixes, for Common Voice, our team made time to evaluate the prototype from a usability perspective.
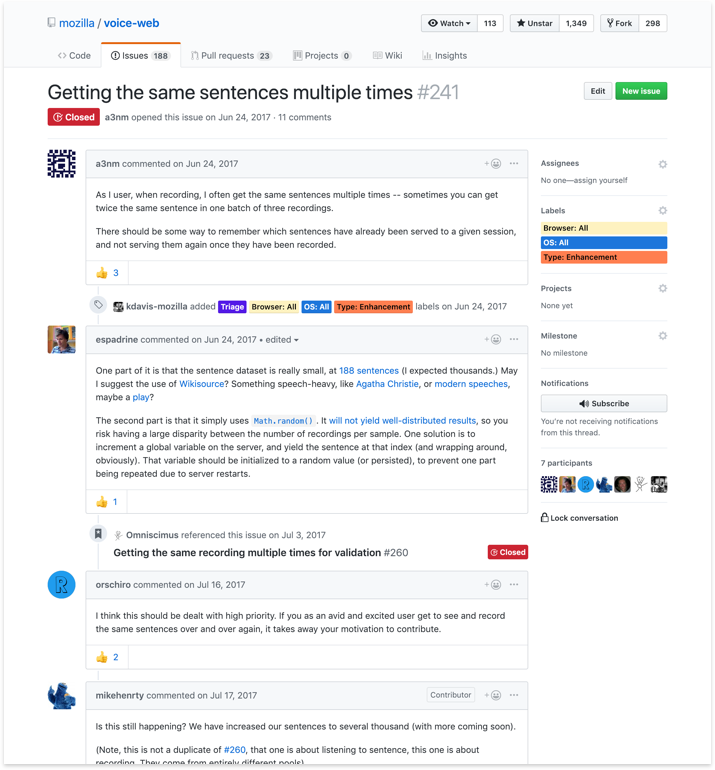
About three months in we performed a UX assessment reviewing initial prototype designs against what actually made it to production code. Comparing this against feature requests from product stakeholders and contributors, our experience design goal was to understand changes most needed to improve usability and engagement across the site.
This assessment information, combined with usability testing, supported decisions for improvements such as:

Completing the incremental work allows us to find our way to new questions and needs as a product or service evolves. Along with the feature requests and smaller production needs required of a live prototype, there are larger project strategy queries that can come to light. These are the types of queries you can only learn from experimenting.
Releasing our first dataset for Common Voice was the result of one such experiment. An achievement in itself, it also proved that our concept had merit. The prototype was working! Despite this, in equal measure it also highlighted quality gaps in our data: it could be more spontaneous, such as two humans naturally conversing would allow. It also reaffirmed something we already knew: our data could be far more diverse. Meaning more gender, accent, dialect and overall language diversity. There is an increasing need for a large, publicly open multi-language voice dataset. This has been clear from the start of this project. True to our desire to think and act prototypically we had to choose a single language to focus resources and first prove out the concept. With the successful release of the first dataset we were ready to take on some new questions and keep iterating:
Having already gained integral insights for Common Voice via an experience workshop, we planned another. In January of 2018 we brought together commercial and academic partners to join Mozilla team members, including various expert influencers, to help brainstorm and ideate potential solutions for these questions. The common interest of the attendees? Seeing this unique project succeed. Many had come up against these types of questions in different contexts across their work and were keen to ideate on ways to improve the site.
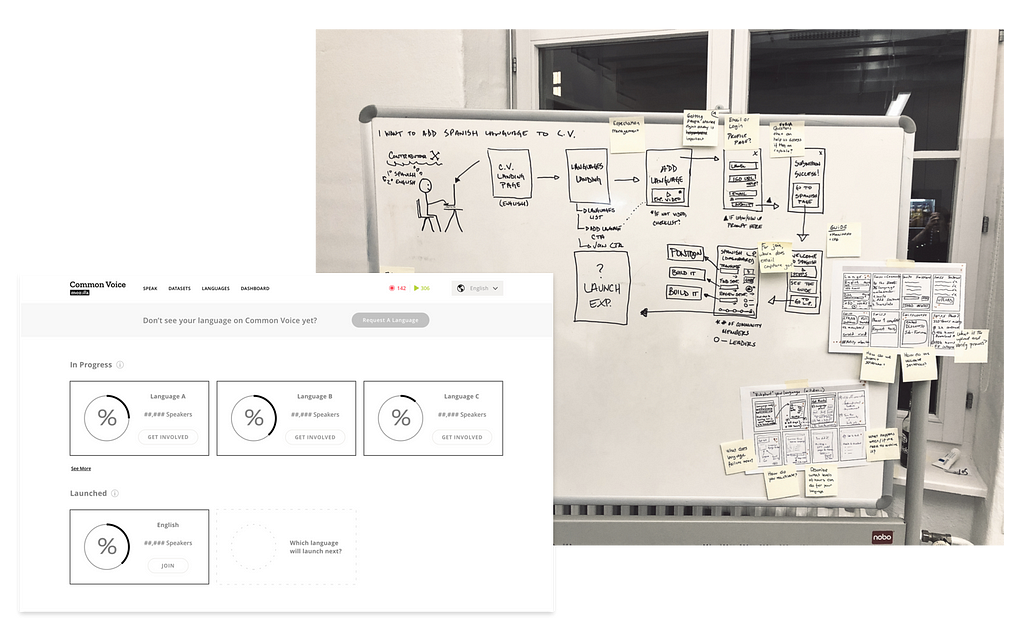
Workshopping the first question meant determining requirements (what does success look like) and mapping experience journeys to achieve those requirements (see the above image). What resulted was this realization: we have big, multi-feature dreams for the overall Common Voice multi-language experience. To make those dreams a reality we first focused on what was most needed first, providing people a way to contribute in their desired language(s). Other features, like building dedicated language pages and creating a community dashboard, are built into our roadmap. This feature prioritization enabled us to deliver a multi-language experience in May of this year. Reaching this milestone has made the second Common Voice dataset release — which will be our first multi-language dataset release — achievable by the end of 2018.

In the area of increasing quantity and quality of contributions, the workshop introduced concepts for improving spontaneous speech capture through potential, future experiments. Some examples include enabling spontaneous, conversational style recording sessions on the website; integrations with existing wearables for set session lengths; and a roaming event pop-up with recording booths. This ideation session even lingered in our minds well past the workshop and has prompted thoughts around an opt-in style recording space in collaboration with Hubs, a virtual spaces experiment by Mozilla’s Mixed Reality team.
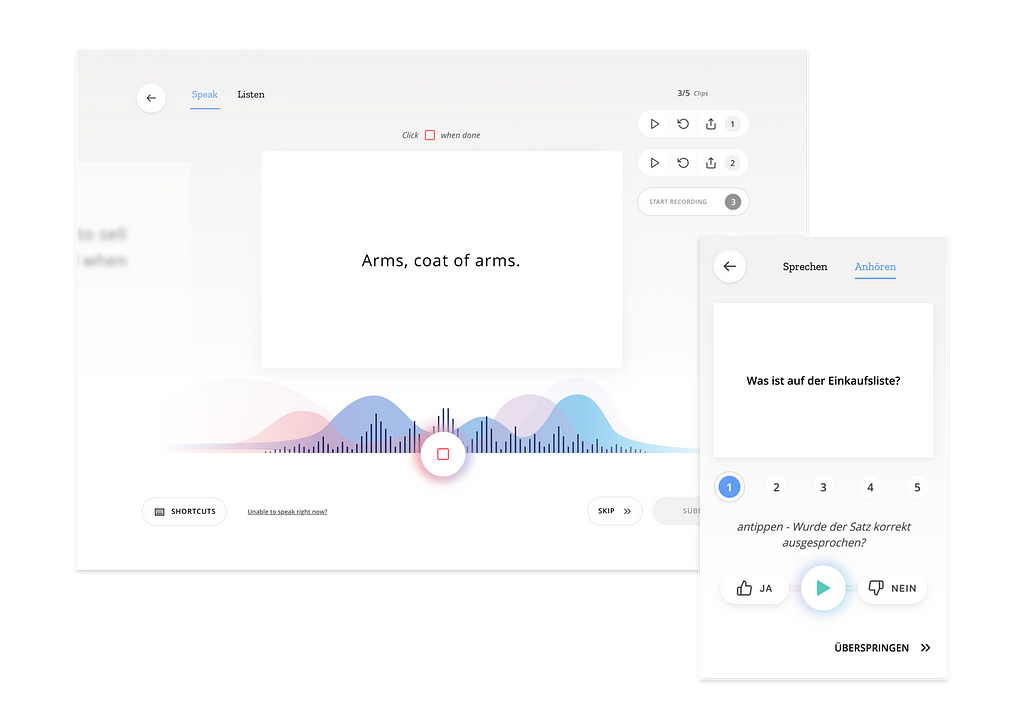
For the current online experience we solidified user journeys that enabled immediate impact of the website and began laying foundation that would enable more robust future experiments. Some of these, such as the new contribution experience and homepage, we’ve already seen land in production as iterations of the Common Voice MVP prototype. Other feature enhancements, like a new profile login experience — which enables contributors to save their progress across multiple languages and view that progress via a new dashboard — have launched this week and are undergoing collaborative QA with our communities. The goal of these features being to improve the human experience while increasing the quality and quantity of voice contributions.
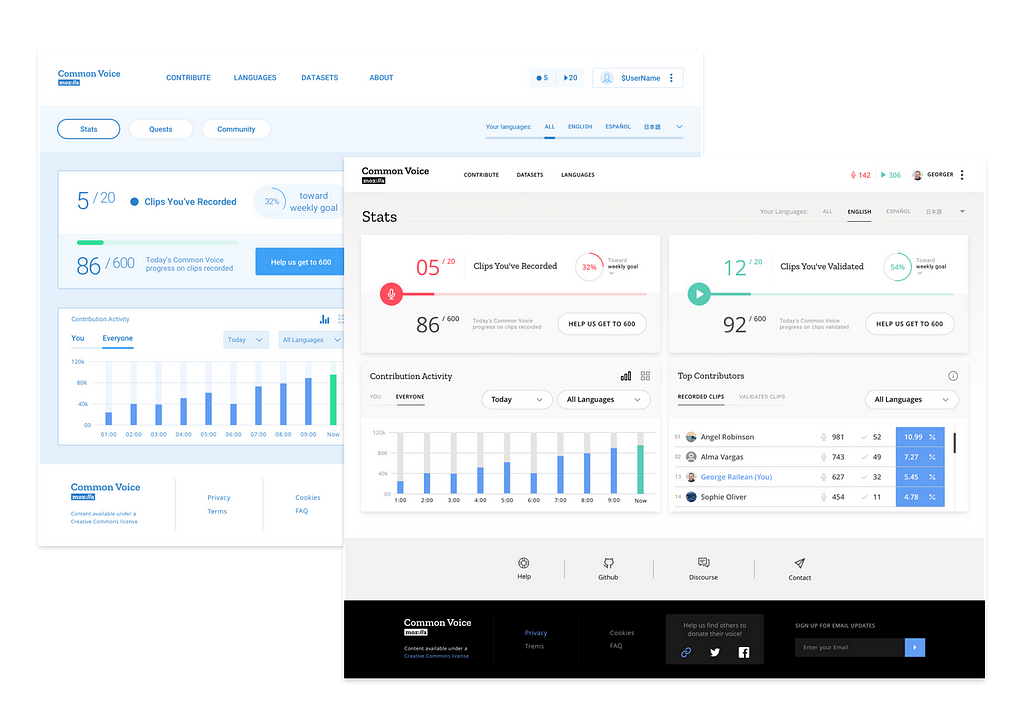
With Common Voice we see through incremental, open iteration that our team has been able to intentionally grow from the early prototype. In doing so we are actively working to create more avenues for contribution regardless of language, device or location. Our next post will take a deeper look at how we’re empowering contributions of all sizes, in Common Voice and elsewhere, for Open Innovation.
Prototyping with Intention was originally published in Mozilla Open Innovation on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
Mozilla B-Team: happy bmo push day! |
the following changes have been pushed to bugzilla.mozilla.org:
- [1505793] Add triage owner in /rest/bug
- [1506754] Group Membership report “include disabled users” doesn’t seem to work
- [1328665] Two issues with Project Review form for RRAs
- [1505050] make the request nagging script more robust
- [1504325] Mozilla Gear Request form broken: The requested format gear does not exist with a…
|
|
Mozilla GFX: WebRender newsletter #32 |
Hey there! Did you hear this? Me neither. The 32nd episode of WebRender’s newsletter made its way to your screen without a sound. In the previous episode, nic4r asked in the comments section a lot of technical and interesting questions. There is a lot to cover so I’ll start by answering a couple here by way of introduction and will go through the other questions in later posts.
How do the strategies for OMTP and WebRender relate? Would OMTP have benefits for expensive blob rasterization since that used Skia?
OMTP, for off-main-thread painting, is a project completely separate from WebRender that was implemented by Ryan. Without WebRender, painting used to happen on the main thread (the thread that runs the JS event loop). Since this thread is often the busiest, moving things out of it, for example painting, is a nice win for multi core processors since the main thread gets to go back to working on JS more quickly while painting is carried out in parallel. This work is pretty much done now and Ryan is working on project Fission.
What about WebRender? WebRender moved all of painting off of the main thread by default. The main thread translates Gecko’s displaylist into a WebRender displaylist which is sent to the GPU process and the latter renders everything. So WebRender and OMTP, while independent projects both fulfill the goal of OMTP which was to remove work from the main thread. OMTP can be seen as a very nice performance win while waiting for WebRender.
Expensive blob rasterization is already carried out asynchronously by the scene builder thread (helped by a thread pool) which means we get with blob rasterization the same property that OMTP provides. This is a good segue to another question:
How do APZ and async scene building tie together?
APZ (for Asynchronous Panning and Zooming) refers to how we organize the rendering architecture in such a way that panning and zooming can happen at a frame rate that is decoupled from the expensive parts of the rendering pipeline. This is important because the perceived performance of the browser largely relies on quickly and smoothly reacting to some basic interactions such as scrolling.
With WebRender there are some operations that can cost more than our frame budget such as scene building and blob image rasterization. In order to keep the nice and smooth feel of APZ we made these asynchronous. In practice this means that when layout changes happen, we re-build the scene and perform the rasterization of blob images on the side while still responding to input events so that we can continue scrolling the previous version of the scene until the new one is ready. I hope this answers the question. Async scene building is one of the ways we “preserve APZ” so to speak with WebRender.
In about:config, set the pref “gfx.webrender.all” to true and restart the browser.
The best place to report bugs related to WebRender in Firefox is the Graphics :: WebRender component in bugzilla.
Note that it is possible to log in with a github account.
https://mozillagfx.wordpress.com/2018/11/29/webrender-newsletter-32/
|
|
The Firefox Frontier: Firefox fights for you |
It’s been a year here on the internet, to say the least. We’ve landed in a place where misinformation—something we fought hard to combat—is the word of the year, where … Read more
The post Firefox fights for you appeared first on The Firefox Frontier.
|
|
The Mozilla Blog: Mozilla Funds Research Grants in Four Areas |
We’re happy to announce the recipients for the 2018 H2 round of Mozilla Research Grants. In this tightly focused round, we awarded grants to support research in four areas: Web of the Things, Core Web Technologies, Voice/Language/Speech, and Mixed Reality. These projects support Mozilla’s mission to ensure the Internet is a global public resource, open and accessible to all.
We are funding University of Washington to support Assistant Professor of Interaction Design Audrey Desjardins in the School of Art + Art History + Design. Her project, titled (In)Visible Data: How home dwellers engage with domestic Web of Things data, will provide a detailed qualitative description of current practices of data engagement with the Web of Things in the home, and offer an exploration of novel areas of interest that are diverse, personal, and meaningful for future WoT data in the home.
Mozilla has been deeply involved in creating and releasing AV1: an open and royalty-free video encoding format. We are funding the Department of Control and Computer Engineering at Politecnico di Torino. This grant will support the research of Assistant Professor Luca Ardito and his project Algorithms clarity in Rust: advanced rate control and multi-thread support in rav1e. This project aims to understand how the Rust programming language improves the maintainability of code while implementing complex algorithms.
We are funding Indiana University Bloomington to support Suraj Chiplunkar’s project Uncovering Effective Auditory Feedback Methods to Promote Relevance Scanning and Acoustic Interactivity for Users with Visual Impairments. This project explores better ways to allow people to listen to the web. Suraj Chiplunkar is a graduate student in the Human-Computer Interaction Design program as part of the School of Informatics, Computing, and Engineering, and is working with Professor Jeffrey Bardzell.
Mozilla has a strong commitment to open standards in virtual and augmented reality, as evidenced by our browser, Firefox Reality. We’re happy to support the work of Assistant Professor Michael Nebeling at the University of Michigan’s School of Information and his project Rethinking the Web Browser as an Augmented Reality Application Delivery Platform. This project explores the possibilities for displaying elements from multiple augmented reality apps at once, pointing the way to a vibrant, open mixed reality ecosystem.
The Mozilla Research Grants program is part of Mozilla’s Emerging Technologies commitment to being a world-class example of inclusive innovation and impact culture, and reflects Mozilla’s commitment to open innovation, continuously exploring new possibilities with and for diverse communities. We plan to open the 2019H1 round in Spring 2019: see our Research Grant webpage for more details and to sign up to be notified when applications open.
Congratulations to all of our applicants!
Thumbnail image by Audrey Dejardins
The post Mozilla Funds Research Grants in Four Areas appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2018/11/28/mozilla-funds-research-grants-in-four-areas/
|
|
The Mozilla Blog: A Statement About Facebook and Color of Change |
Color of Change is one of the leading civil rights organizations of our time, and we at Mozilla have been immensely privileged to collaborate with them on the Ford-Mozilla Open Web Fellows initiative and on a number of areas around internet health.
Their work is pioneering, inspiring, and has been crucial for representing the voices of a key community in debates about the internet. As a technology community, we need more and diverse voices in the work to make the internet open, accessible, and safe for all.
Recently, some concerning allegations regarding practices by Facebook have been raised in high-profile media coverage, including a New York Times article. We are pleased that Facebook is meeting with Color of Change to discuss these issues. We hope Facebook and Color of Change can identify ways that we, as a tech community, can work together to address the biggest challenges facing the internet.
The post A Statement About Facebook and Color of Change appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2018/11/28/a-statement-about-facebook-and-color-of-change/
|
|
Wladimir Palant: BBN challenge resolutions: "A properly secured parameter" and "Exploiting a static page" |
BugBountyNotes is quickly becoming a great resource for security researches. Their challenges in particular are a fun way of learning ways to exploit vulnerable code. So a month ago I decided to contribute and created two challenges: A properly secured parameter (easy) and Exploiting a static page (medium). Unlike most other challenges, these don’t really have any hidden parts. Pretty much everything going on there is visible, yet exploiting the vulnerabilities still requires some thinking. So if you haven’t looked at these challenges, feel free to stop reading at this point and go try it out. You won’t be able to submit your answer any more, but as both are about exploiting XSS vulnerabilities you will know yourself when you are there. Of course, you can also participate in any of the ongoing challenges as well.
Still here? Ok, I’m going to explain these challenges then.
We’ll start with the easier challenge first, dedicated to all the custom URL parsers that developers seem to be very fond of for some reason. The client-side code makes it very obvious that the “message” parameter is vulnerable. With the parameter value being passed to innerHTML, we would want to pass something like innerHTML won’t execute
|
|
Robert O'Callahan: Capitalism, Competition And Microsoft Antitrust Action |
Kevin Williamson writes an ode to the benefits of competition and capitalism, one of his themes being the changing fortunes of Apple and Microsoft over the last two decades. I'm mostly sympathetic, but in a hurry to decry "government intervention in and regulation of the part of our economy that is, at the moment, working best", he forgets or neglects to mention the antitrust actions brought by the US government against Microsoft in the mid-to-late 1990s. Without those actions, there is a high chance things could have turned out very differently for Apple. At the very least, we do not know what would have happened without those actions, and no-one should use the Apple/Microsoft rivalry as an example of glorious laissez-faire capitalism that negates the arguments of those calling for antitrust action today.
Would Microsoft have invested $150M to save Apple in 1997 if they hadn't been under antitrust pressure since 1992? In 1994 Microsoft settled with the Department of Justice, agreeing to refrain from tying the sale of other Microsoft products to the sale of Windows. It is reasonable to assume that the demise of Apple, Microsoft's only significant competitor in desktop computer operating systems, would have increased the antitrust scrutiny on Microsoft. At that point Microsoft's market cap was $150B vs Apple's $2B, so $150M seems like a cheap and low-risk investment by Gates to keep the US government off his back. I do not know of any other rational justification for that investment. Without it, Apple would very likely have gone bankrupt.
In a world where the United States v. Microsoft Corporation (2001) antitrust lawsuit didn't happen, would the iPhone have been as successful? In 1999 I was so concerned about the potential domination of Microsoft over the World Wide Web that I started making volunteer contributions to (what became) Firefox (which drew me into working for Mozilla until 2016). At that time Microsoft was crushing Netscape with superior engineering, lowering the price of the browser to zero, bundling IE with Windows and other hardball tactics that had conquered all previous would-be Microsoft competitors. With total domination of the browser market, Microsoft would be able to take control of Web standards and lead Web developers to rely on Microsoft-only features like ActiveX (or later Avalon/WPF), making it practically impossible for anyone but Microsoft to create a browser that could view the bulk of the Web. Web browsing was an important feature for the first release of the iPhone in 2007; indeed for the first year, before the App Store launched, it was the only way to do anything on the phone other than use the built-in apps. We'll never know how successful the iPhone would have been without a viable Web browser, but it might have changed the competitive landscape significantly. Thankfully Mozilla managed to turn the tide to prevent Microsoft's total browser domination. As a participant in that battle, I'm convinced that the 2001 antitrust lawsuit played a big part in restraining Microsoft's worst behavior, creating space (along with Microsoft blunders) for Firefox to compete successfully during a narrow window of opportunity when creating a viable alternative browser was still possible. (It's also interesting to consider what Microsoft could have done to Google with complete browser domination and no antitrust concerns.)
We can't be sure what the no-antitrust world would have been like, but those who argue that Apple/Microsoft shows antitrust action was not needed bear the burden of showing that their counterfactual world is compelling.
http://robert.ocallahan.org/2018/11/capitalism-competition-and-microsoft.html
|
|
Mozilla Localization (L10N): Multilingual Gecko Status Update 2018.2 |
|
|
Mozilla Future Releases Blog: Next Steps in DNS-over-HTTPS Testing |
Over the past few months, Mozilla has experimented with DNS-over-HTTPS (DoH). The intention is to fix a part of a DNS ecosystem that simply isn’t up to the modern, secure standards that every Internet user should expect. Today, we want to let you know about our next test of the feature.
Our initial tests of DoH studied the time it takes to get a response from Cloudflare’s DoH resolver. The results were very positive – the slowest users show a huge performance improvement. A recent test in our Beta channel confirmed that DoH is fast and isn’t causing problems for our users. However, those tests only measure the DNS operation itself, which isn’t the whole story.
Content Delivery Networks (CDNs) provide localized DNS responses depending on where you are in the network, with the goal being to send you to a host which is near you on the network and therefore will give you the best performance. However, because of the way that Cloudflare resolves names [technical note: it’s a centralized resolver without EDNS Client Subnet], this process works less well when you are using DoH with Firefox.
The result is that the user might get less well-localized results that could result in a slow user experience even if the resolver itself is accurate and fast.
This is something we can test. We are going to study the total time it takes to get a response from the resolver and fetch a web page. To do that, we’re working with Akamai to help us understand more about the performance impact. Firefox users enrolled in the study will automatically fetch data once a day from four test web pages hosted by Akamai, collect information about how long it took to look up DNS and then send that performance information to Firefox engineers for analysis. These test pages aren’t ones that the user would automatically retrieve and just contain dummy content.
A soft rollout to a small portion of users in our Release channel in the United States will begin this week and end next week. As before, this study will use Cloudflare’s DNS-over-HTTPS service and will continue to provide in-browser notifications about the experiment so that everyone is fully informed and has a chance to decline participation in this particular experiment. Moving forward, we are working to build a larger ecosystem of trusted DoH providers, and we hope to be able to experiment with other providers soon.
We don’t yet have a date for the full release of this feature. We will give you a readout of the result of this test and will let you know our future plans at that time. So stay tuned.
The post Next Steps in DNS-over-HTTPS Testing appeared first on Future Releases.
https://blog.mozilla.org/futurereleases/2018/11/27/next-steps-in-dns-over-https-testing/
|
|






