Nick Cameron: Rust in 2022 |
A response to the call for 2019 roadmap blog posts.
In case you missed it, we released our second edition of Rust this year! An edition is an opportunity to make backwards incompatible changes, but more than that it's an opportunity to bring attention to how programming in Rust has changed. With the 2018 edition out of the door, now is the time to think about the next edition: how do we want programming in Rust in 2022 to be different to programming in Rust today? Once we've worked that out, lets work backwards to what should be done in 2019.
Without thinking about the details, lets think about the timescale and cadence it gives us. It was three years from Rust 1.0 to Rust 2018 and I expect it will be three years until the next edition. Although I think the edition process went quite well, I think that if we'd planned in advance then it could have gone better. In particular, it felt like there were a lot of late changes which could have happened earlier so that we could get more experience with them. In order to avoid that I propose that we aim to avoid breaking changes and large new features landing after the end of 2020. That gives 2021 for finishing, polishing, and marketing with a release late that year. Working backwards, 2020 should be an 'impl year' - focussing on designing and implementing the things we know we want in place for the 2021 edition. 2019 should be a year to invest while we don't have any release pressure.
To me, investing means paying down technical debt, looking at our processes, infrastructure, tooling, governance, and overheads to see where we can be more efficient in the long run, and working on 'quality of life' improvements for users, the kind that don't make headlines but will make using Rust a better experience. It's also the time to investigate some high-risk, high-reward ideas that will need years of iteration to be user-ready; 2019 should be an exciting year!
I think Rust 2021 should be about Rust's maturity. But what does that mean? To me it means that for a programmer in 2022, Rust is a safe choice with many benefits, not a high-risk/high-reward choice. Choosing Rust for a project should be a competitive advantage (which I think it is today), but it should not require investment in libraries, training, or research.
Some areas that I think are important for the 2021 edition:
Ok-wrapping, throws in function signatures, etc.). I think this is an edition issue since it will probably require a breaking change, and at the least will change the style of programming.macro syntax.Let's keep focussing on areas where Rust has proven to be a good fit (systems, networking, embedded (both devices and as performance-critical components in larger systems), WASM, games) and looking for new areas to expand into.
So, with the above in mind, what should we be doing next year? Each team should be thinking about what are the high-risk experiments to try. How can we tackle technical (and community) debt? What can be polished? Lets spend the year making sure we are on the right track for the next edition and the long-term by encouraging people to dedicate more energy to strategy.
Of course we want to plan some concrete work too, so in no particular order here are some specific ideas I think are worth looking into:
And lets dive a tiny bit deeper into a few areas:
Even more than the other areas, the language team needs to think about development cadence in preparation for the next edition. We need to ensure that everything, especially breaking changes, get enough development and iteration time.
Some things I think we should consider in 2019:
Nothing really new here, but we need to keep pushing on compiler performance - it comes up again and again as a Rust negative. We should also take the timing opportunity to do some refactoring, for example, landing Chalk and doing something similar for name resolution.
|
|
Wladimir Palant: If your bug bounty program is private, why do you have it? |
The big bug bounty platforms are structured like icebergs: the public bug bounty programs that you can see are only a tiny portion of everything that is going on there. As you earn your reputation on these platforms, they will be inviting you to private bug bounty programs. The catch: you generally aren’t allowed to discuss issues reported via private bug bounty programs. In fact, you are not even allowed to discuss the very existence of that bug bounty program.
I’ve been playing along for a while on Bugcrowd and Hackerone and submitted a number of vulnerability reports to private bug bounty programs. As a result, I became convinced that these private bug bounty programs are good for the bottom line of the bug bounty platforms, but otherwise their impact is harmful. I’ll try to explain here.
When you collect a bug bounty, that’s not because you work for a vendor. There is no written contract that states your rights and obligations. In its original form, you simply stumble upon a security vulnerability in a product and you decide to do the right thing: you inform the vendor. In turn, the vendor gives you the bug bounty as a token of their appreciation. It could be a monetary value but also some swag or an entry in the Hall of Fame.
Why pay you when the vendor has no obligation to do so? Primarily to keep you doing the right thing. Some vulnerabilities could be turned into money on the black market. Some could be used to steal data or extort the vendor. Everybody prefers people to earn their compensation in a legal way. Hence bug bounties.
There are so many bug bounty programs around today that many people made them their main source of income. While there are various reasons for that, one thing should not be forgotten: there is no law guaranteeing that you will be paid fairly. No contract means that your reward is completely dependent on the vendor. And it is hard to know in advance, sometimes the vendor will claim that they cannot reproduce, or downplay severity, or mark your report as a duplicate of a barely related report. In at least some cases there appears to be intent behind this behavior, the vendor trying to fit the bug bounty program into a certain budget regardless of the volume of the reports. So any security researcher trying to make a living from bug bounties has to calculate pessimistically, e.g. expecting that only one out of five reports will get a decent reward.
On the vendor’s side, there is a clear desire for the bug bounty program to replace penetration tests. Bugcrowd noticed this trend and is tooting their bug bounty programs as the “next gen pen test.” The trouble is, bug bounty hunters are only paid for bugs where they can demonstrate impact. They have no incentives to report minor issues, not only will the effort of demonstrating the issue be too high for the expected reward, it also reduces their rating on the bug bounty platform. They have no incentives to point out structural weaknesses, because these reports will be closed as “informational” without demonstrated impact. They often have no incentives to go for the more obscure parts of the product, these require more time to get familiar with but won’t necessarily result in critical bugs being discovered. In short, a “penetration test” performed by bug bounty hunters will be everything but thorough.
If you feel that you are treated unfairly by the vendor, you have essentially two options. You can just accept it and vote with your feet: move on to another bug bounty program and learn how to recognize programs that are better avoided. The vendor won’t care as there will be plenty of others coming their way. Or you can make a fuzz about it. You could try to argue and probably escalate to the bug bounty platform vendor, but IMHO this rarely changes anything. Or you could publicly shame the vendor for their behavior and warn others.
The latter is made impossible by the conditions to participate in private bug bounty programs. Both Bugcrowd and Hackerone disallow you from talking about your experience with the program. Bug bounty hunters are always dependent on the good will of the vendor, but with private bug bounties it is considerably worse.
But it’s not only that. Usually, security researchers want recognition for their findings. Hackerone even has a process for disclosing vulnerability reports once the issue has been fixed. Public Bugcrowd programs also usually provision for coordinated disclosure. This gives the reporters the deserved recognition and allows everybody else to learn. But guess what: with private bug bounty programs, disclosure is always forbidden.
Why will people participate in private bug bounties at all? Main reason seems to be the reduced competition, finding unique issues is easier. In particular, when you join in the early days of a private bug bounty program, you have a good opportunity to generate cash with low hanging fruit.
If a bug bounty is about rewarding a random researcher who found a vulnerability in the product, how does a private bug bounty program make sense then? After all, it is like an exclusive club and unlikely to include the researcher in question. In fact, that researcher is unlikely to know about the bug bounty program, so they won’t have this incentive to do the right thing.
But the obvious answer is: the bug bounty platforms aren’t actually selling bug bounty management, they are selling penetration tests. They promise vendors to deliver high-quality reports from selected hackers instead of the usual noise that a public bug bounty program has to deal with. And that’s what many companies expect (but don’t receive) when they create a private bug bounty.
There is another explanation that seems to match many companies. These companies know perfectly well that they just aren’t ready for it yet. Sometimes they simply don’t have the necessary in-house expertise to write secure code, so even with they bug bounty program always pointing out the same mistakes they will keep repeating them. Or they won’t free up developers from feature work to tackle security issues, so every year they will fix five issues that seem particularly severe but leave all the others untouched. So they go for a private bug bounty program because doing the same thing in public would be disastrous for their PR. And they hope that this bug bounty program will somehow make their product more secure. Except it doesn’t.
On Hackerone I also see another mysterious category: private bug bounty programs with zero activity. So somebody went through the trouble of setting up a bug bounty program but failed to make it attractive to researchers. Either it offers no rewards, or it expects people to buy some hardware that they are unlikely to own already, or the description of the program is impossible to decipher. Just now I’ve been invited to a private bug bounty program where the company’s homepage was completely broken, and I still don’t really understand what they are doing. I suspect that these bug bounty programs are another example of features that somebody got a really nice bonus for but nobody cared putting any thought into.
Somebody told me that their company went with a private bug bounty because they work with selected researchers only. So it isn’t actually a bug bounty program but really a way to manage communication with that group. I hope that they still have some other way to engage with researchers outside that elite group, even if it doesn’t involve monetary rewards for reported vulnerabilities.
As a security researcher, I’ve collected plenty of bad experiences with private bug bounty programs, and I know that other people did as well. Let’s face it: the majority of private bug bounty programs shouldn’t have existed in the first place. They don’t really make the products in question more secure, and they increase frustration among security researchers. And while some people manage to benefit financially from these programs, others are bound to waste their time on them. The confidentiality clauses of these programs substantially weaken the position of the bug bounty hunters, which isn’t too strong to start with. These clauses are also an obstacle to learning on both sides, ideally security issues should always be publicized once fixed.
Now the ones who should do something to improve this situations are the bug bounty platforms. However, I realize that they have little incentive to change this situation and are in fact actively embracing it. So while one can ask for example for a way to comment on private bug bounty programs so that newcomers can learn from the experience that others made with this program, such control mechanisms are unlikely to materialize. Publishing anonymized reports from private bug bounty programs would also be nice and just as unlikely. I wonder whether the solution is to add such features via a browser extension and whether it would gain sufficient traction then.
But really, private bug bounty programs are usually a bad idea. Most companies doing that right now should either switch to a public bug bounty or just drop their bug bounty program altogether. Katie Moussouris is already very busy convincing companies to drop bug bounty programs they cannot make use of, please help her and join that effort.
https://palant.de/2018/12/10/if-your-bug-bounty-program-is-private-why-do-you-have-it
|
|
Wladimir Palant: If your bug bounty program is private, why do you have it? |
The big bug bounty platforms are structured like icebergs: the public bug bounty programs that you can see are only a tiny portion of everything that is going on there. As you earn your reputation on these platforms, they will be inviting you to private bug bounty programs. The catch: you generally aren’t allowed to discuss issues reported via private bug bounty programs. In fact, you are not even allowed to discuss the very existence of that bug bounty program.
I’ve been playing along for a while on Bugcrowd and Hackerone and submitted a number of vulnerability reports to private bug bounty programs. As a result, I became convinced that these private bug bounty programs are good for the bottom line of the bug bounty platforms, but otherwise their impact is harmful. I’ll try to explain here.
When you collect a bug bounty, that’s not because you work for a vendor. There is no written contract that states your rights and obligations. In its original form, you simply stumble upon a security vulnerability in a product and you decide to do the right thing: you inform the vendor. In turn, the vendor gives you the bug bounty as a token of their appreciation. It could be a monetary value but also some swag or an entry in the Hall of Fame.
Why pay you when the vendor has no obligation to do so? Primarily to keep you doing the right thing. Some vulnerabilities could be turned into money on the black market. Some could be used to steal data or extort the vendor. Everybody prefers people to earn their compensation in a legal way. Hence bug bounties.
There are so many bug bounty programs around today that many people made them their main source of income. While there are various reasons for that, one thing should not be forgotten: there is no law guaranteeing that you will be paid fairly. No contract means that your reward is completely dependent on the vendor. And it is hard to know in advance, sometimes the vendor will claim that they cannot reproduce, or downplay severity, or mark your report as a duplicate of a barely related report. In at least some cases there appears to be intent behind this behavior, the vendor trying to fit the bug bounty program into a certain budget regardless of the volume of the reports. So any security researcher trying to make a living from bug bounties has to calculate pessimistically, e.g. expecting that only one out of five reports will get a decent reward.
On the vendor’s side, there is a clear desire for the bug bounty program to replace penetration tests. Bugcrowd noticed this trend and is tooting their bug bounty programs as the “next gen pen test.” The trouble is, bug bounty hunters are only paid for bugs where they can demonstrate impact. They have no incentives to report minor issues, not only will the effort of demonstrating the issue be too high for the expected reward, it also reduces their rating on the bug bounty platform. They have no incentives to point out structural weaknesses, because these reports will be closed as “informational” without demonstrated impact. They often have no incentives to go for the more obscure parts of the product, these require more time to get familiar with but won’t necessarily result in critical bugs being discovered. In short, a “penetration test” performed by bug bounty hunters will be everything but thorough.
If you feel that you are treated unfairly by the vendor, you have essentially two options. You can just accept it and vote with your feet: move on to another bug bounty program and learn how to recognize programs that are better avoided. The vendor won’t care as there will be plenty of others coming their way. Or you can make a fuzz about it. You could try to argue and probably escalate to the bug bounty platform vendor, but IMHO this rarely changes anything. Or you could publicly shame the vendor for their behavior and warn others.
The latter is made impossible by the conditions to participate in private bug bounty programs. Both Bugcrowd and Hackerone disallow you from talking about your experience with the program. Bug bounty hunters are always dependent on the good will of the vendor, but with private bug bounties it is considerably worse.
But it’s not only that. Usually, security researchers want recognition for their findings. Hackerone even has a process for disclosing vulnerability reports once the issue has been fixed. Public Bugcrowd programs also usually provision for coordinated disclosure. This gives the reporters the deserved recognition and allows everybody else to learn. But guess what: with private bug bounty programs, disclosure is always forbidden.
Why will people participate in private bug bounties at all? Main reason seems to be the reduced competition, finding unique issues is easier. In particular, when you join in the early days of a private bug bounty program, you have a good opportunity to generate cash with low hanging fruit.
If a bug bounty is about rewarding a random researcher who found a vulnerability in the product, how does a private bug bounty program make sense then? After all, it is like an exclusive club and unlikely to include the researcher in question. In fact, that researcher is unlikely to know about the bug bounty program, so they won’t have this incentive to do the right thing.
But the obvious answer is: the bug bounty platforms aren’t actually selling bug bounty management, they are selling penetration tests. They promise vendors to deliver high-quality reports from selected hackers instead of the usual noise that a public bug bounty program has to deal with. And that’s what many companies expect (but don’t receive) when they create a private bug bounty.
There is another explanation that seems to match many companies. These companies know perfectly well that they just aren’t ready for it yet. Sometimes they simply don’t have the necessary in-house expertise to write secure code, so even with they bug bounty program always pointing out the same mistakes they will keep repeating them. Or they won’t free up developers from feature work to tackle security issues, so every year they will fix five issues that seem particularly severe but leave all the others untouched. So they go for a private bug bounty program because doing the same thing in public would be disastrous for their PR. And they hope that this bug bounty program will somehow make their product more secure. Except it doesn’t.
On Hackerone I also see another mysterious category: private bug bounty programs with zero activity. So somebody went through the trouble of setting up a bug bounty program but failed to make it attractive to researchers. Either it offers no rewards, or it expects people to buy some hardware that they are unlikely to own already, or the description of the program is impossible to decipher. Just now I’ve been invited to a private bug bounty program where the company’s homepage was completely broken, and I still don’t really understand what they are doing. I suspect that these bug bounty programs are another example of features that somebody got a really nice bonus for but nobody cared putting any thought into.
Somebody told me that their company went with a private bug bounty because they work with selected researchers only. So it isn’t actually a bug bounty program but really a way to manage communication with that group. I hope that they still have some other way to engage with researchers outside that elite group, even if it doesn’t involve monetary rewards for reported vulnerabilities.
As a security researcher, I’ve collected plenty of bad experiences with private bug bounty programs, and I know that other people did as well. Let’s face it: the majority of private bug bounty programs shouldn’t have existed in the first place. They don’t really make the products in question more secure, and they increase frustration among security researchers. And while some people manage to benefit financially from these programs, others are bound to waste their time on them. The confidentiality clauses of these programs substantially weaken the position of the bug bounty hunters, which isn’t too strong to start with. These clauses are also an obstacle to learning on both sides, ideally security issues should always be publicized once fixed.
Now the ones who should do something to improve this situations are the bug bounty platforms. However, I realize that they have little incentive to change this situation and are in fact actively embracing it. So while one can ask for example for a way to comment on private bug bounty programs so that newcomers can learn from the experience that others made with this program, such control mechanisms are unlikely to materialize. Publishing anonymized reports from private bug bounty programs would also be nice and just as unlikely. I wonder whether the solution is to add such features via a browser extension and whether it would gain sufficient traction then.
But really, private bug bounty programs are usually a bad idea. Most companies doing that right now should either switch to a public bug bounty or just drop their bug bounty program altogether. Katie Moussouris is already very busy convincing companies to drop bug bounty programs they cannot make use of, please help her and join that effort.
https://palant.de/2018/12/10/if-your-bug-bounty-program-is-private-why-do-you-have-it
|
|
Wladimir Palant: BBN challenge resolution: Exploiting the Screenshotter.PRO browser extension |
The time has come to reveal the answer to my next BugBountyNotes challenge called Try out my Screenshotter.PRO browser extension. This challenge is a browser extension supposedly written by a naive developer for the purpose of taking webpage screenshots. While the extension is functional, the developer discovered that some websites are able to take a peek into their Gmail account. How does that work?
If you haven’t looked at this challenge yet, feel free to stop reading at this point and go try it out. Mind you, this one is hard and only two people managed to solve it so far. Note also that I won’t look at any answers submitted at this point any more. Of course, you can also participate in any of the ongoing challenges as well.
Still here? Ok, I’m going to explain this challenge then.
This challenge has been inspired by the vulnerabilities I discovered around the Firefox Screenshots feature. Firefox Screenshots is essentially a built-in browser extension in Firefox, and while it takes care to isolate its user interface in a frame protected by the same-origin policy, I discovered a race condition that allowed websites to change that frame into something they can access.
This race condition could not be reproduced in the challenge because the approach used works in Firefox only. So the challenge uses a different approach to protect its frame from unwanted access: it creates a frame pointing to https://example.com/ (the website cannot access it due to same-origin policy), then injects its user interface into this frame via a separate content script. And since a content script can only be injected into all frames of a tab, the content script uses the (random) frame name to distinguish the “correct” frame.
And here lies the issue of course. While the webpage cannot predict what the frame name will be, it can see the frame being injected and change the src attribute into something else. It can load a page from the same server, then it will be able to access the injected extension UI. A submission I received for this challenge solved this even more elegantly: by assigning window.name = frame.name it made sure that the extension UI was injected directly into their webpage!
Now the only issue is bringing up the extension UI. With Firefox Screenshots I had to rely on the user clicking “Take a screenshot.” The extension in the challenge allowed triggering its functionality via a hotkey however. And, like so often, it failed checking for event.isTrusted, so it would accept events generated by the webpage. Since the extension handles events synchronously, the following code is sufficient here:
window.dispatchEvent(new KeyboardEvent("keydown", {
key: "S",
ctrlKey: true,
shiftKey: true
}));
let frame = document.getElementsByTagName("iframe")[0];
frame.src = "blank.html";Recommendation for developers: Any content which you inject into websites should always be contained inside a frame that is part of your extension. This at least makes sure that the website cannot access the frame contents, but you still have to worry about clickjacking and spoofing attacks.
Also, if you ever attach event listeners to website content, always make sure that event.isTrusted is true, so it’s a real event rather than the website playing tricks on you.
Once the webpage can access the extension UI, clicking the “Screenshot to clipboard” button programmatically is trivial. Again Event.isTrusted is not being checked here. However, even though Firefox Screenshots only accepted trusted events, it didn’t help it much. At this point the webpage can make the button transparent and huge, so when the user clicks somewhere the button is always triggered.
The webpage can create a screenshot, but what’s the deal? With Firefox Screenshots I only realized it after creating the bug report, the big issue here is that the webpage can screenshot third-party pages. Just load some page in a frame and it will be part of the screenshot even though you normally cannot access its contents. Only trouble: really critical sites such as Gmail don’t allow being loaded in a frame these days.
Luckily, this challenge had to be compatible with Chrome. And while Firefox extensions can use tabs.captureTab method to capture a specific tab, there is nothing comparable for Chrome. The solution that the hypothetical extension author took was using tabs.captureVisibleTab method which works in any browser. Side-effect: the visible tab isn’t necessarily the tab where the screenshotting UI lives.
So the attacks starts by asking the user to click a button. When clicked, that button opens Gmail in a new tab. The original page stays in background and initiates screenshotting. When the screenshot is done it will contain Gmail, not the attacking website.
The last step is getting the screenshot which is being copied to clipboard. Here, a Firefox bug makes things a lot easier for attackers. Until very recently, the only way to copy something to clipboard was calling document.execCommand() on a text field. And Firefox doesn’t allow this action to be performed on the extension’s background page, so extensions will often resort to doing it in the context of web pages that they don’t control.
The most straight-forward solution is registering a copy event listener on the page, it will be triggered when the extension attempts to copy to the clipboard. That’s how I did it with Firefox Screenshots, and one of the submitted answers also uses this approach. But I actually forgot about it when I created my own solution for this challenge, so I used mutation observers to see when a text field is inserted into the page and read out its value (the actual screenshot URL):
let observer = new MutationObserver(mutationList =>
{
for (let mutation of mutationList)
{
if (mutation.addedNodes && mutation.addedNodes[0].localName == "textarea")
document.body.innerHTML = `Here is what Gmail looks like for you:
 `;
}
});
observer.observe(document.body, {childList: true});
`;
}
});
observer.observe(document.body, {childList: true});I hope that the new Clipboard API finally makes things sane here, so it isn’t merely more elegant but also gets rid of this huge footgun. But I didn’t have any chance to play with it yet, this API only being available since Chrome 66 and Firefox 63. So the recommendation is still: make sure to run any clipboard operations in a context that you control. If the background page doesn’t work, use a tab or frame belonging to your extension.
That’s pretty much it, everything else is only about visuals and timing. The attacking website needs to hide the extension UI so that the user doesn’t suspect anything. It also has no way of knowing when Gmail finishes loading, so it has to wait some arbitrary time. Here is what I got altogether. It is one way to solve this challenge but certainly not the only one.
|
|
Wladimir Palant: BBN challenge resolution: Exploiting the Screenshotter.PRO browser extension |
The time has come to reveal the answer to my next BugBountyNotes challenge called Try out my Screenshotter.PRO browser extension. This challenge is a browser extension supposedly written by a naive developer for the purpose of taking webpage screenshots. While the extension is functional, the developer discovered that some websites are able to take a peek into their Gmail account. How does that work?
If you haven’t looked at this challenge yet, feel free to stop reading at this point and go try it out. Mind you, this one is hard and only two people managed to solve it so far. Note also that I won’t look at any answers submitted at this point any more. Of course, you can also participate in any of the ongoing challenges as well.
Still here? Ok, I’m going to explain this challenge then.
This challenge has been inspired by the vulnerabilities I discovered around the Firefox Screenshots feature. Firefox Screenshots is essentially a built-in browser extension in Firefox, and while it takes care to isolate its user interface in a frame protected by the same-origin policy, I discovered a race condition that allowed websites to change that frame into something they can access.
This race condition could not be reproduced in the challenge because the approach used works in Firefox only. So the challenge uses a different approach to protect its frame from unwanted access: it creates a frame pointing to https://example.com/ (the website cannot access it due to same-origin policy), then injects its user interface into this frame via a separate content script. And since a content script can only be injected into all frames of a tab, the content script uses the (random) frame name to distinguish the “correct” frame.
And here lies the issue of course. While the webpage cannot predict what the frame name will be, it can see the frame being injected and change the src attribute into something else. It can load a page from the same server, then it will be able to access the injected extension UI. A submission I received for this challenge solved this even more elegantly: by assigning window.name = frame.name it made sure that the extension UI was injected directly into their webpage!
Now the only issue is bringing up the extension UI. With Firefox Screenshots I had to rely on the user clicking “Take a screenshot.” The extension in the challenge allowed triggering its functionality via a hotkey however. And, like so often, it failed checking for event.isTrusted, so it would accept events generated by the webpage. Since the extension handles events synchronously, the following code is sufficient here:
window.dispatchEvent(new KeyboardEvent("keydown", {
key: "S",
ctrlKey: true,
shiftKey: true
}));
let frame = document.getElementsByTagName("iframe")[0];
frame.src = "blank.html";Recommendation for developers: Any content which you inject into websites should always be contained inside a frame that is part of your extension. This at least makes sure that the website cannot access the frame contents, but you still have to worry about clickjacking and spoofing attacks.
Also, if you ever attach event listeners to website content, always make sure that event.isTrusted is true, so it’s a real event rather than the website playing tricks on you.
Once the webpage can access the extension UI, clicking the “Screenshot to clipboard” button programmatically is trivial. Again Event.isTrusted is not being checked here. However, even though Firefox Screenshots only accepted trusted events, it didn’t help it much. At this point the webpage can make the button transparent and huge, so when the user clicks somewhere the button is always triggered.
The webpage can create a screenshot, but what’s the deal? With Firefox Screenshots I only realized it after creating the bug report, the big issue here is that the webpage can screenshot third-party pages. Just load some page in a frame and it will be part of the screenshot even though you normally cannot access its contents. Only trouble: really critical sites such as Gmail don’t allow being loaded in a frame these days.
Luckily, this challenge had to be compatible with Chrome. And while Firefox extensions can use tabs.captureTab method to capture a specific tab, there is nothing comparable for Chrome. The solution that the hypothetical extension author took was using tabs.captureVisibleTab method which works in any browser. Side-effect: the visible tab isn’t necessarily the tab where the screenshotting UI lives.
So the attacks starts by asking the user to click a button. When clicked, that button opens Gmail in a new tab. The original page stays in background and initiates screenshotting. When the screenshot is done it will contain Gmail, not the attacking website.
The last step is getting the screenshot which is being copied to clipboard. Here, a Firefox bug makes things a lot easier for attackers. Until very recently, the only way to copy something to clipboard was calling document.execCommand() on a text field. And Firefox doesn’t allow this action to be performed on the extension’s background page, so extensions will often resort to doing it in the context of web pages that they don’t control.
The most straight-forward solution is registering a copy event listener on the page, it will be triggered when the extension attempts to copy to the clipboard. That’s how I did it with Firefox Screenshots, and one of the submitted answers also uses this approach. But I actually forgot about it when I created my own solution for this challenge, so I used mutation observers to see when a text field is inserted into the page and read out its value (the actual screenshot URL):
let observer = new MutationObserver(mutationList =>
{
for (let mutation of mutationList)
{
if (mutation.addedNodes && mutation.addedNodes[0].localName == "textarea")
document.body.innerHTML = `Here is what Gmail looks like for you:
`;
}
});
observer.observe(document.body, {childList: true});I hope that the new Clipboard API finally makes things sane here, so it isn’t merely more elegant but also gets rid of this huge footgun. But I didn’t have any chance to play with it yet, this API only being available since Chrome 66 and Firefox 63. So the recommendation is still: make sure to run any clipboard operations in a context that you control. If the background page doesn’t work, use a tab or frame belonging to your extension.
That’s pretty much it, everything else is only about visuals and timing. The attacking website needs to hide the extension UI so that the user doesn’t suspect anything. It also has no way of knowing when Gmail finishes loading, so it has to wait some arbitrary time. Here is what I got altogether. It is one way to solve this challenge but certainly not the only one.
|
|
Cameron Kaiser: TenFourFox FPR11 available |
FPR12 will be a smaller-scope release but there will still be some minor performance improvements and bugfixes, and with any luck we will also be shipping Rapha"el's enhanced AltiVec string matcher in this release as well. Because of the holidays, family visits, etc., however, don't expect a beta until around the second week of January.
http://tenfourfox.blogspot.com/2018/12/tenfourfox-fpr11-available.html
|
|
The Mozilla Blog: Goodbye, EdgeHTML |
Microsoft is officially giving up on an independent shared platform for the internet. By adopting Chromium, Microsoft hands over control of even more of online life to Google.
This may sound melodramatic, but it’s not. The “browser engines” — Chromium from Google and Gecko Quantum from Mozilla — are “inside baseball” pieces of software that actually determine a great deal of what each of us can do online. They determine core capabilities such as which content we as consumers can see, how secure we are when we watch content, and how much control we have over what websites and services can do to us. Microsoft’s decision gives Google more ability to single-handedly decide what possibilities are available to each one of us.
From a business point of view Microsoft’s decision may well make sense. Google is so close to almost complete control of the infrastructure of our online lives that it may not be profitable to continue to fight this. The interests of Microsoft’s shareholders may well be served by giving up on the freedom and choice that the internet once offered us. Google is a fierce competitor with highly talented employees and a monopolistic hold on unique assets. Google’s dominance across search, advertising, smartphones, and data capture creates a vastly tilted playing field that works against the rest of us.
From a social, civic and individual empowerment perspective ceding control of fundamental online infrastructure to a single company is terrible. This is why Mozilla exists. We compete with Google not because it’s a good business opportunity. We compete with Google because the health of the internet and online life depend on competition and choice. They depend on consumers being able to decide we want something better and to take action.
Will Microsoft’s decision make it harder for Firefox to prosper? It could. Making Google more powerful is risky on many fronts. And a big part of the answer depends on what the web developers and businesses who create services and websites do. If one product like Chromium has enough market share, then it becomes easier for web developers and businesses to decide not to worry if their services and sites work with anything other than Chromium. That’s what happened when Microsoft had a monopoly on browsers in the early 2000s before Firefox was released. And it could happen again.
If you care about what’s happening with online life today, take another look at Firefox. It’s radically better than it was 18 months ago — Firefox once again holds its own when it comes to speed and performance. Try Firefox as your default browser for a week and then decide. Making Firefox stronger won’t solve all the problems of online life — browsers are only one part of the equation. But if you find Firefox is a good product for you, then your use makes Firefox stronger. Your use helps web developers and businesses think beyond Chrome. And this helps Firefox and Mozilla make overall life on the internet better — more choice, more security options, more competition.
The post Goodbye, EdgeHTML appeared first on The Mozilla Blog.
|
|
Mozilla Future Releases Blog: Firefox Coming to the Windows 10 on Qualcomm Snapdragon Devices Ecosystem |
At Mozilla, we’ve been building browsers for 20 years and we’ve learned a thing or two over those decades. One of the most important lessons is putting people at the center of the web experience. We pioneered user-centric features like tabbed browsing, automatic pop-up blocking, integrated web search, and browser extensions for the ultimate in personalization. All of these innovations support real users’ needs first, putting business demands in the back seat.
Mozilla is uniquely positioned to build browsers that act as the user’s agent on the web and not simply as the top of an advertising funnel. Our mission not only allows us to put privacy and security at the forefront of our product strategy, it demands that we do so. You can see examples of this with Firefox’s Facebook Container extension, Firefox Monitor, and its private by design browser data syncing features. This will become even more apparent in upcoming releases of Firefox that will block certain cross-site and third-party tracking by default while delivering a fast, personal, and highly mobile experience.
When we set out several years ago to build a new version of Firefox called Quantum, one that utilized multiple computer processes the way an operating system does, we didn’t simply break the browser into as many processes as possible. We investigated what kinds of hardware people had and built a solution that took best advantage of processors with multiple cores, which also makes Firefox a great browser for Snapdragon. We also offloaded significant page loading tasks to the increasingly powerful GPUs shipping with modern PCs and we re-designed the browser front-end to bring more efficiency to everyday tasks.
Today, Mozilla is excited to be collaborating with Qualcomm and optimizing Firefox for the Snapdragon compute platform with a native ARM64 version of Firefox that takes full advantage of the capabilities of the Snapdragon compute platform and gives users the most performant out of the box experience possible. We can’t wait to see Firefox delivering blazing fast experiences for the always on, always connected, multi-core Snapdragon compute platform with Windows 10.
Stay tuned. It’s going to be great!
The post Firefox Coming to the Windows 10 on Qualcomm Snapdragon Devices Ecosystem appeared first on Future Releases.
|
|
Hacks.Mozilla.Org: Rust 2018 is here… but what is it? |
This post was written in collaboration with the Rust Team (the “we” in this article). You can also read their announcement on the Rust blog.
Starting today, the Rust 2018 edition is in its first release. With this edition, we’ve focused on productivity… on making Rust developers as productive as they can be.

But beyond that, it can be hard to explain exactly what Rust 2018 is.
Some people think of it as a new version of the language, which it is… kind of, but not really. I say “not really” because if this is a new version, it doesn’t work like versioning does in other languages.
In most other languages, when a new version of the language comes out, any new features are added to that new version. The previous version doesn’t get new features.
Rust editions are different. This is because of the way the language is evolving. Almost all of the new features are 100% compatible with Rust as it is. They don’t require any breaking changes. That means there’s no reason to limit them to Rust 2018 code. New versions of the compiler will continue to support “Rust 2015 mode”, which is what you get by default.
But sometimes to advance the language, you need to add things like new syntax. And this new syntax can break things in existing code bases.
An example of this is the async/await feature. Rust initially didn’t have the concepts of async and await. But it turns out that these primitives are really helpful. They make it easier to write code that is asynchronous without the code getting unwieldy.
To make it possible to add this feature, we need to add both async and await as keywords. But we also have to be careful that we’re not making old code invalid… code that might’ve used the words async or await as variable names.
So we’re adding the keywords as part of Rust 2018. Even though the feature hasn’t landed yet, the keywords are now reserved. All of the breaking changes needed for the next three years of development (like adding new keywords) are being made in one go, in Rust 1.31.

Even though there are breaking changes in Rust 2018, that doesn’t mean your code will break. Your code will continue compiling even if it has async or await as a variable name. Unless you tell it otherwise, the compiler assumes you want it to compile your code the same way that it has been up to this point.
But as soon as you want to use one of these new, breaking features, you can opt in to Rust 2018 mode. You just run cargo fix, which will tell you if you need to update your code to use the new features. It will also mostly automate the process of making the changes. Then you can add edition=2018 to your Cargo.toml to opt in and use the new features.
This edition specifier in Cargo.toml doesn’t apply to your whole project… it doesn’t apply to your dependencies. It’s scoped to just the one crate. This means you’ll be able to have crate graphs that have Rust 2015 and Rust 2018 interspersed.

Because of this, even once Rust 2018 is out there, it’s mostly going to look the same as Rust 2015. Most changes will land in both Rust 2018 and Rust 2015. Only the handful of features that require breaking changes won’t pass through. 
Rust 2018 isn’t just about changes to the core language, though. In fact, far from it.
Rust 2018 is a push to make Rust developers more productive. Many productivity wins come from things outside of the core language… things like tooling. They also come from focusing on specific use cases and figuring out how Rust can be the most productive language for those use cases.
So you could think of Rust 2018 as the specifier in Cargo.toml that you use to enable the handful of features that require breaking changes…

Or you can think about it as a moment in time, where Rust becomes one of the most productive languages you can use in many cases — whenever you need performance, light footprint, or high reliability.

In our minds, it’s the second. So let’s look at all that happened outside of the core language. Then we can dive into the core language itself.
A programming language can’t be productive by itself, in the abstract. It’s productive when put to some use. Because of this, the team knew we didn’t just need to make Rust as a language or Rust tooling better. We also needed to make it easier to use Rust in particular domains.

In some cases, this meant creating a whole new set of tools for a whole new ecosystem.
In other cases, it meant polishing what was already in the ecosystem and documenting it well so that it’s easy to get up and running.
The Rust team formed working groups focused on four domains:
For WebAssembly, the working group needed to create a whole new suite of tools.
Just last year, WebAssembly made it possible to compile languages like Rust to run on the web. Since then, Rust has quickly become the best language for integrating with existing web applications.

Rust is a good fit for web development for two reasons:
With the web-sys and js-sys crates, it’s easy to call web APIs like fetch or appendChild from Rust code. And wasm-bindgen makes it easy support high-level data types that WebAssembly doesn’t natively support.
Once you’ve coded up your Rust WebAssembly module, there are tools to make it easy to plug it into the rest of your web application. You can use wasm-pack to run these tools automatically, and push your new module up to npm if you want.
Check out the Rust and WebAssembly book to try it yourself.
Now that Rust 2018 has shipped, the working group is figuring out where to take things next. They’ll be working with the community to determine the next areas of focus.
For embedded development, the working group needed to make existing functionality stable.
In theory, Rust has always been a good language for embedded development. It gives embedded developers the modern day tooling that they are sorely lacking, and very convenient high-level language features. All this without sacrificing on resource usage. So Rust seemed like a great fit for embedded development.
However, in practice it was a bit of a wild ride. Necessary features weren’t in the stable channel. Plus, the standard library needed to be tweaked for use on embedded devices. That meant that people had to compile their own version of the Rust core crate (the crate which is used in every Rust app to provide Rust’s basic building blocks — intrinsics and primitives).

Together, these two things meant developers had to depend on the nightly version of Rust. And since there were no automated tests for micro-controller targets, nightly would often break for these targets.
To fix this, the working group needed to make sure that necessary features were in the stable channel. We also had to add tests to the CI system for micro-controller targets. This means a person adding something for a desktop component won’t break something for an embedded component.
With these changes, embedded development with Rust moves away from the bleeding edge and towards the plateau of productivity.
Check out the Embedded Rust book to try it yourself.
With this year’s push, Rust has really good support for ARM Cortex-M family of microprocessor cores, which are used in a lot of devices. However, there are lots of architectures used on embedded devices, and those aren’t as well supported. Rust needs to expand to have the same level of support for these other architectures.
For networking, the working group needed to build a core abstraction into the language—async/await. This way, developers can use idiomatic Rust even when the code is asynchronous.
For networking tasks, you often have to wait. For example, you may be waiting for a response to a request. If your code is synchronous, that means the work will stop—the CPU core that is running the code can’t do anything else until the request comes in. But if you code asynchronously, then the function that’s waiting for the response can go on hold while the CPU core takes care of running other functions.
Coding asynchronous Rust is possible even with Rust 2015. And there are lots of upsides to this. On the large scale, for things like server applications, it means that your code can handle many more connections per server. On the small scale, for things like embedded applications that are running on tiny, single threaded CPUs, it means you can make better use of your single thread.
But these upsides came with a major downside—you couldn’t use the borrow checker for that code, and you would have to write unidiomatic (and somewhat confusing) Rust. This is where async/await comes in. It gives the compiler the information it needs to borrow check across asynchronous function calls.
The keywords for async/await were introduced in 1.31, although they aren’t currently backed by an implementation. Much of that work is done, and you can expect the feature to be available in an upcoming release.
Beyond just enabling productive low-level development for networking applications, Rust could enable more productive development at a higher level.
Many servers need to do the same kinds of tasks. They need to parse URLs or work with HTTP. If these were turned into components—common abstractions that could be shared as crates—then it would be easy to plug them together to form all sorts of different servers and frameworks.
To drive the component development process, the Tide framework is providing a test bed for, and eventually example usage of, these components.
For command line tools, the working group needed to bring together smaller, low-level libraries into higher level abstractions, and polish some existing tools.
For some CLI scripts, you really want to use bash. For example, if you just need to call out to other shell tools and pipe data between them, then bash is best.
But Rust is a great fit for a lot of other kinds of CLI tools. For example, it’s great if you are building a complex tool like ripgrep or building a CLI tool on top of an existing library’s functionality.
Rust doesn’t require a runtime and allows you to compile to a single static binary, which makes it easy to distribute. And you get high-level abstractions that you don’t get with other languages like C and C++, so that already makes Rust CLI developers productive.
What did the working group need to make this better still? Even higher-level abstractions.
With these higher-level abstractions, it’s quick and easy to assemble a production ready CLI.
An example of one of these abstractions is the human panic library. Without this library, if your CLI code panics, it probably outputs the entire back trace. But that’s not very helpful for your end users. You could add custom error handling, but that requires effort.
If you use human panic, then the output will be automatically routed to an error dump file. What the user will see is a helpful message suggesting that they report the issue and upload the error dump file.

The working group also made it easier to get started with CLI development. For example, the confy library will automate a lot of setup for a new CLI tool. It only asks you two things:
From that, confy will figure out the rest for you.
The working group abstracted away a lot of different tasks that are common between CLIs. But there’s still more that could be abstracted away. The working group will be making more of these high level libraries, and fixing more paper cuts as they go.

When you experience a language, you experience it through tools. This starts with the editor that you use. It continues through every stage of the development process, and through maintenance.
This means that a productive language depends on productive tooling.
Here are some tools (and improvements to Rust’s existing tooling) that were introduced as part of Rust 2018.
Of course, productivity hinges on fluidly getting code from your mind to the screen quickly. IDE support is critical to this. To support IDEs, we need tools that can tell the IDE what Rust code actually means — for example, to tell the IDE what strings make sense for code completion.
In the Rust 2018 push, the community focused on the features that IDEs needed. With Rust Language Server and IntelliJ Rust, many IDEs now have fluid Rust support.
With compilation, faster means more productive. So we’ve made the compiler faster.
Before, when you would compile a Rust crate, the compiler would recompile every single file in the crate. But now, with incremental compilation, the compiler is smart and only recompiles the parts that have changed. This, along with other optimizations, has made the Rust compiler much faster.
Productivity also means not having to fix style nits (and never having to argue over formatting rules).
The rustfmt tool helps with this by automatically reformatting your code using a default code style (which the community reached consensus on). Using rustfmt ensures that all of your Rust code conforms to the same style, like clang format does for C++ and Prettier does for JavaScript.
Sometimes it’s nice to have an experienced advisor by your side… giving you tips on best practices as you code. That’s what Clippy does —it reviews your code as you go and tells you how to make that code more idiomatic.
But if you have an older code base that uses outmoded idioms, then just getting tips and correcting the code yourself can be tedious. You just want someone to go into your code base an make the corrections.
For these cases, rustfix will automate the process. It will both apply lints from tools like Clippy and update older code to match Rust 2018 idioms.
These changes in the ecosystem have brought lots of productivity wins. But some productivity issues could only be fixed with changes to the language itself.

As I talked about in the intro, most of the language changes are completely compatible with existing Rust code. These changes are all part of Rust 2018. But because they don’t break any code, they also work in any Rust code… even if that code doesn’t use Rust 2018.
Let’s look at a few of the big language features that were added to all editions. Then we can look at the small list of Rust 2018-specific features.
Here’s a small sample of the big new language features that are (or will be) in all language editions.
One big selling point for Rust is the borrow checker. The borrow checker helps ensure that your code is memory safe. But it has also been a pain point for new Rust developers.
Part of that is learning new concepts. But there was another big part… the borrow checker would sometimes reject code that seemed like it should work, even to those who understood the concepts.

This is because the lifetime of a borrow was assumed to go all the way to the end of its scope — for example, to the end of the function that the variable is in.
This meant that even though the variable was done with the value and wouldn’t try to access it anymore, other variables were still denied access to it until the end of the function.
To fix this, we’ve made the borrow checker smarter. Now it can see when a variable is actually done using a value. If it is done, then it doesn’t block other borrowers from using the data.

While this is only available in Rust 2018 as of today, it will be available in all editions in the near future. I’ll be writing more about all of this soon.
Macros in Rust have been around since before Rust 1.0. But with Rust 2018, we’ve made some big improvements, like introducing procedural macros.
With procedural macros, it’s kind of like you can add your own syntax to Rust.
Rust 2018 brings two kinds of procedural macros:
Function-like macros allow you to have things that look like regular function calls, but that are actually run during compilation. They take in some code and spit out different code, which the compiler then inserts into the binary.
They’ve been around for a while, but what you could do with them was limited. Your macro could only take the input code and run a match statement on it. It didn’t have access to look at all of the tokens in that input code.
But with procedural macros, you get the same input that a parser gets — a token stream. This means can create much more powerful function-like macros.
If you’re familiar with decorators in languages like JavaScript, attribute macros are pretty similar. They allow you to annotate bits of code in Rust that should be preprocessed and turned into something else.
The derive macro does exactly this kind of thing. When you put derive above a struct, the compiler will take that struct in (after it has been parsed as a list of tokens) and fiddle with it. Specifically, it will add a basic implementation of functions from a trait.
This change is pretty straight-forward.
Before, if you wanted to borrow something and tried to match on it, you had to add some weird looking syntax:

But now, you don’t need the &Some(ref s) anymore. You can just write Some(s), and Rust will figure it out from there.
The smallest part of Rust 2018 are the features specific to it. Here are the small handful of changes that using the Rust 2018 edition unlocks.
There are a few keywords that have been added to Rust 2018.
try keywordasync/await keywordThese features haven’t been fully implemented yet, but the keywords are being added in Rust 1.31. This means we don’t have to introduce new keywords (which would be a breaking change) in the future, once the features behind these keywords are implemented.
One big pain point for developers learning Rust is the module system. And we could see why. It was hard to reason about how Rust would choose which module to use.
To fix this, we made a few changes to the way paths work in Rust.
For example, if you imported a crate, you could use it in a path at the top level. But if you moved any of the code to a submodule, then it wouldn’t work anymore.
// top level module
extern crate serde;
// this works fine at the top level
impl serde::Serialize for MyType { ... }
mod foo {
// but it does *not* work in a sub-module
impl serde::Serialize for OtherType { ... }
}
Another example is the prefix ::, which used to refer to either the crate root or an external crate. It could be hard to tell which.
We’ve made this more explicit. Now, if you want to refer to the crate root, you use the prefix crate:: instead. And this is just one of the path clarity improvements we’ve made.
If you have existing Rust code and you want it to use Rust 2018, you’ll very likely need to update it for these new module paths. But that doesn’t mean that you’ll need to manually update your code. Run cargo fix before you add the edition specifier to Cargo.toml and rustfix will make all the changes for you.
Learn all about this edition in the Rust 2018 edition guide.
The post Rust 2018 is here… but what is it? appeared first on Mozilla Hacks - the Web developer blog.
|
|
The Servo Blog: Experience porting Servo to the Magic Leap One |
We now have nightly releases of Servo for the Magic Leap One augmented reality headset. You can head over to https://download.servo.org/, install the application, and browse the web in a virtual browser.

This is a developer preview release, designed for as a testbed for future products, and as a venue for experimenting with UI design. What should the web look like in augmented reality? We hope to use Servo to find out!
We are providing these nightly snapshots to encourage other developers to experiment with AR web experiences. There are still many missing features, such as immersive or 3D content, many types of user input, media, or a stable embedding API. We hope you forgive the rough edges.
This blog post will describe the experience of porting Servo to a new architecture, and is intended for system developers.
The Magic Leap software development kit (SDK) is based on commonly-used open-source
technologies. In particular, it uses the clang compiler and the gcc toolchain
for support tools such as ld, objcopy, ranlib and friends.
The architecture is 64-bit ARM, using the same application binary interface as Android.
Together these give the target as being aarch64-linux-android, the same as for many
64-bit Android devices. Unlike Android, Magic Leap applications are
native programs, and do not require a Java Native Interface (JNI) to the OS.
Magic Leap provides a lot of support for developing AR applications, in the form of the Lumin Runtime APIs, which include 3D scene descriptions, UI elements, input events including device placement and orientation in 3D space, and rendering to displays which provide users with 3D virtual visual and audio environments that interact with the world around them.
The Magic Leap and Lumin Runtime SDKs are available from https://creator.magicleap.com/ for Mac and Windows platforms.
The Magic Leap library is built using ./mach build --magicleap,
which under the hood calls cargo build
--target=aarch64-linux-android. For most of the Servo library and its
dependencies, this just works, but there are a couple of corner cases:
C/C++ libraries and crates with special treatment for Android.
Some of Servo’s dependencies are crates which link against C/C++
libraries, notably openssl-sys and mozjs-sys. Each of these
libraries uses slightly different build environments (such as Make,
CMake or Autoconf, often with custom build scripts). The challenge for
software like Servo that uses many such libraries is to find a
configuration which will work for all the dependencies. This comes
down to finding the right settings for environment variables such as
$CFLAGS, and is complicated by cross-compiling the libraries which
often means ensuring that the Magic Leap libraries are included, not
the host libraries.
The other main source of issues with the build is that since Magic
Leap uses the same ABI as Android, its target is
aarch64-linux-android, which is the same as for 64-bit ARM Android
devices. As a result, many crates which need special treatment for
Android (for example for JNI or to use libandroid) will treat the
Magic Leap build as an Android build rather than a Linux build. Some
care is needed to undo all of this special treatment. For example,
the build scripts of Servo, SpiderMonkey and OpenSSL all contain code
to guess the directory layout of the Android SDK, which needs to be
undone when building for Magic Leap.

One thing that just worked turned out to be debugging Rust code on the Magic Leap device. Magic Leap supports the Visual Studio Code IDE, and remote debugging of code running natively. It was great to see the debugging working out of the box for Rust code as well as it did for C++.
The first release of Servo for Magic Leap comes with a rudimentary application for browsing 2D web content. This is missing many features, such as immersive 3D content, audio or video media, or user input by anything other than the controller.
Magic Leap applications come in two flavors: universe applications, which are immersive experiences that have complete control over the device, and landscape applications, which co-exist and present the user with a blended experience where each application presents part of a virtual scene. Currently, Servo is a landscape application, though we expect to add a universe application for immersive web content.
Landscape applications can be designed using the Lumin Runtime Editor, which gives a visual presentation of the various UI components in the scene graph.

The most important object in Servo’s scene graph is the content
node, since it is a Quad that can contain a 2D resource. One of the
kinds of resource that a Quad can contain is an EGL context, that
Servo uses to render web content. The runtime editor generates C++
code that can be included in an application to render and access the
scene graph; Servo uses this to access the content node, and the EGL
context it contains.
The other hooks that the Magic Leap Servo application uses are for events such as moving the laser pointer, which are mapped to mouse events, a heartbeat for animations or other effects which must be performed on the main thread, and a logger which bridges Rust’s logging API to Lumin’s.
The Magic Leap application is built each night by Servo’s CI system, using the Mac builders since there is no Linux SDK for Magic Leap. This builds the Servo library, and packages it is a Magic Leap application, which is hosted on S3 and linked to from the Servo download page.
The pull request that added Magic Leap support to Servo is https://github.com/servo/servo/pull/21985 which adds about 1600 lines to Servo, mostly in the build scripts and the Magic Leap application. Work on the Magic Leap port of Servo started in early September 2018, and the pull request was merged at the end of October, so took about two person-months.
Much of the port was straightforward, due to the maturity of the Rust cross-compilation and build tools, and the use of common open-source technologies in the Magic Leap platform. Lumin OS contains many innovative features in its treatment of blending physical and virtual 3D environments, but it is built on a solid open-source foundation, which makes porting a complex application like Servo relatively straightforward.
Servo is now making its first steps onto the Magic Leap One, and is available for download and experimentation. Come try it out, and help us design the immersive web!
|
|
Cameron Kaiser: Edge gets Chrome-plated, and we're all worse off |
In the sense that Anaheim won't (at least in name) be Google, just Chromium, there's reason to believe that it won't have the repeated privacy erosions that have characterized Google's recent moves with Chrome itself. But given how much DNA WebKit and Blink share, that means there are effectively two current major rendering engines left: Chromium and Gecko (Firefox). The little ones like NetSurf, bless its heart, don't have enough marketshare (or currently features) to rate, Trident in Internet Explorer 11 is intentionally obsolete, and the rest are too deficient to be anywhere near usable (Dillo, etc.). So this means Chromium arrogates more browsershare to itself and Firefox will continue to be the second class citizen until it, too, has too small a marketshare to be relevant. Then Google has eaten the Web. And we are worse off for it.
Bet Mozilla's reconsidering that stupid embedding decision now.
http://tenfourfox.blogspot.com/2018/12/edge-gets-chrome-plated-and-were-all.html
|
|
Nick Cameron: More on RLS version numbering |
In a few days the 2018 edition is going to roll out, and that will include some new framing around Rust's tooling. We've got a core set of developer tools which are stable and ready for widespread use. We're going to have a blog post all about that, but for now I wanted to address the status of the RLS, since when I last blogged about a 1.0 pre-release there was a significant sentiment that it was not ready (and given the expectations that a lot of people have, we agree).
The RLS has been in 0.x-stage development. We think it has reached a certain level of stability and usefulness. While it is not at the level of quality you might expect from a mature IDE, it is likely to be useful for a majority of users.
The RLS is tightly coupled with the compiler, and as far as backwards compatibility is concerned, that is the important thing. So from the next release, the RLS will share a version number with the Rust distribution. We are not claiming this as a '1.0' release, work is certainly not finished, but we think it is worth taking the opportunity of the 2018 edition to highlight the RLS as a usable and useful tool.
In the rest of this blog post I'll go over how the RLS works in order to give you an idea of what works well and what does not, and where we are going (or might go) in the future.
The RLS is a language server for Rust - it is meant to handle the 'language knowledge' part of an IDE (c.f., editing, user interaction, etc.). The concept is that rather than having to develop Rust support from scratch in each editor or IDE, you can do it once in the language server and each editor can be a client. This is a recent approach to IDE development, in contrast to the approach of IntelliJ, Eclipse, and others, where the IDE is designed to make language support pluggable, but language support is closely tied to a specific IDE framework.
The RLS integrates with the Rust compiler, Cargo, and Racer to provide data. Cargo is used as a source of data for orchestrating builds. The compiler provides data for connecting references to definitions, and about types and docs (which is used for 'go to def', 'find all references', 'show type', etc.). Racer is used for code completion (and also to supply some docs). Racer can be thought of as a mini compiler which does as little as possible to provide code completion information as fast as possible.
The traditional approach to IDEs, and how Rust support in IntelliJ works, is to build a completely new compiler frontend, optimised for speed and incremental compilation. This compiler provides enough information to provide the IDE functionality, but usually doesn't do any code generation. This approach is much easier in fairly simple languages like Java, compared to Rust (macros, modules, and the trait system all make this a lot more complex).
There are trade-offs to the two approaches: using a separate compiler is fast and functionality can be limited to ensure it is fast enough. However, there is a risk that the two compilers do not agree on how to compiler a program, in particular, covering the whole of a language like Rust is difficult and so completeness can be an issue. Maintaining a separate compiler also takes a lot of work.
In the future, we hope to further optimise the Rust compiler for IDE cases so that it is fast enough that the user never has to wait, and to use the compiler for code completion. We also want to work with Cargo a bit differently so that there is less duplication of logic between Cargo and the RLS.
For each feature of the RLS, I measure its success along two axes: is it fast enough and is it complete (that is, does it work for all code). There are also non-functional issues of resource usage (how much battery and CPU the RLS is using), how often the RLS crashes, etc.
This is usually fast enough: if the RLS is ready, then it is pretty much instant. For large crates, it can take too long for the RLS to be ready, and thus we are not fast enough. However, usually using slightly stale data for 'go to def' is not a problem, so we're ok.
It is fairly complete. There are some issues around macros - if a definition is created by a macro, then we often have trouble. 'Go to def' is not implemented for lifetimes, and there are some places we don't have coverage (inside where clauses was recently fixed).
Showing types and documentation on hover has almost the same characteristics as 'go to definition'.
Renaming is similar to 'find all references' (and 'go to def'), but since we are modifying the user's code, there are some more things that can go wrong, and we want to be extra conservative. It is therefore a bit less complete than 'go to def', but similarly fast.
Code completion is generally pretty fast, but often incomplete. This is because method dispatch in Rust is really complicated! Eventually, we hope that using the compiler for code completion rather than Racer will solve this problem.
The RLS is typically pretty heavy on the CPU. That is because we prioritise having results quickly over minimising CPU usage. In the future, making the compiler more incremental should give big improvements here.
The RLS usually only crashes when it disagrees with Cargo about how to build a project, or when it exercises a code path in the compiler which would not be used by a normal compile, and that code path has a bug. While crashes are more common than I'd like, they're a lot rarer than they used to be, and should not affect most users.
There is a remarkable variety in the way a Rust project can be structured. Multiple crates can be arranged in many ways (using workspaces, or not), build scripts and procedural macros cause compile-time code execution, and there are Cargo features, different platforms, tests, examples, etc. This all interacts with code which is edited but not yet saved. Every different configuration can cause bugs.
I think we are mostly doing well here, as far as I know there are no project structures to avoid (but this has been a big source of trouble in the past).
The RLS is clearly not done. It's not in the same league as IDE support for more mature languages. However, I think that it is at a stage where it is worth trying for many users. Stability is good enough - it's unlikely you'll have a bad experience. It does somewhat depend on how you use an IDE: if you rely heavily on code completion (in particular, if you use code completion as a learning tool), then the RLS is probably not ready. However, we think we should encourage new users to Rust to try it out.
So, while I agree that the RLS is not 'done', neither is it badly unstable, likely to be disappear, or lacking in basic functionality. For better or worse, 1.0 releases seem to have special significance in the Rust community. I hope the version numbering decision sends the right message: we're ready for all Rust users to use the RLS, but we haven't reached 'mission accomplished' (well, maybe in a 'George W Bush' way).
The RLS will follow the Rust compiler's version number, i.e., the next release will be 1.31.0. From a strict semver point of view this makes sense since the RLS is only compatible with its corresponding Rust version, so incrementing the minor version with each Rust release is the right thing to do. By starting at 1.31, we're deliberately avoiding the 1.0 label.
In terms of readiness, it's important to note that the RLS is not a user-facing piece of software. I believe the 1.x version number is appropriate in that context - if you want to build an IDE, then the RLS is stable enough to use as a library. However, it is lacking some user-facing completeness and so an IDE built using the RLS should probably not use the 1.0 number (our VSCode extension will keep using 0.x).
There's been some discussion about how best to improve the IDE experience in Rust. I believe the language server approach is the correct one, but there are several options to make progress: continue making incremental improvements to the compiler and RLS, moving towards compiler-driven code completion; use an alternate compiler frontend (such as Rust analyzer); improve Racer and continue to rely on it for code completion; some hybrid approach using more than one of these ideas.
When assessing these options, we need to take into account the likely outcome, the risk of something bad happening, the amount of work needed, and the long-term maintenance burden. The main downside of the current path is the risk that the compiler will never get fast enough to support usable code completion. Implementation is also a lot of work, however, it would mostly help with compile time issues in general. With the other approaches there is a risk that we won't get the completeness needed for useful code completion. The implementation work is again significant, and depending on how things pan out, there is a risk of much costlier long-term maintenance.
I've been pondering the idea of a hybrid approach: using the compiler to provide information about definitions (and naming scopes), and either Racer or Rust Analyzer to do the 'last mile' work of turning that into code completion suggestions (and possibly resolving references too). That might mean getting the best of both worlds - the compiler can deal with a lot of complexity where speed is not as necessary, and the other tools get a helping hand with the stuff that has to be done quickly.
Orthogonally, there is also work planned to better integrate with Cargo and to support more features, as well as some 'technical debt' issues, such as better testing.
|
|
Mozilla VR Blog: A new browser for Magic Leap |

Today, we’re making available an early developer preview of a browser for the Magic Leap One device. This browser is built on top of our Servo engine technology and shows off high quality 2D graphics and font rendering through our WebRender web rendering library, and more new features will soon follow.
While we only support basic 2D pages today and have not yet built the full Firefox Reality browser experience and published this into the Magic Leap store, we look forward to working alongside our partners and community to do that early in 2019! Please try out the builds, provide feedback, and get involved if you’re interested in the future of mixed reality on the web in a cutting-edge standalone headset. And for those looking at Magic Leap for the first time, we also have an article on how the work was done.
|
|
Henri Sivonen: encoding_rs: a Web-Compatible Character Encoding Library in Rust |
encoding_rs is a high-decode-performance, low-legacy-encode-footprint and high-correctness implementation of the WHATWG Encoding Standard written in Rust. In Firefox 56, encoding_rs replaced uconv as the character encoding library used in Firefox. This wasn’t an addition of a component but an actual replacement: uconv was removed when encoding_rs landed. This writeup covers the motivation and design of encoding_rs, as well as some benchmark results.
Additionally, encoding_rs contains a submodule called encoding_rs::mem that’s meant for efficient encoding-related operations on UTF-16, UTF-8, and Latin1 in-memory strings—i.e., the kind of strings that are used in Gecko C++ code. This module is discussed separately after describing encoding_rs proper.
The C++ integration of encoding_rs is not covered here and is covered in another write-up instead.
Rust’s borrow checker is used with on-stack structs that get optimized away to enforce an “at most once” property that matches reads and writes to buffer space availability checks in legacy CJK converters. Legacy CJK converters are the most risky area in terms of memory-safety bugs in a C or C++ implementation.
Decode is very fast relative to other libraries with the exception of some single-byte encodings on ARMv7. Particular effort has gone into validating UTF-8 and converting UTF-8 to UTF-16 efficiently. ASCII runs are handled using SIMD when it makes sense. There is tension between making ASCII even faster vs. making transitions between ASCII and non-ASCII more expensive. This tension is the clearest when encoding from UTF-16, but it’s there when decoding, too.
By default, there is no encode-specific data other than 32 bits per single-byte encoding. This makes legacy CJK encode extremely slow by default relative to other libraries but still fast enough in for the browser use cases. That is, the amount of text one could reasonably submit at a time in a form submission encodes so fast even on a Raspberry Pi 3 (standing in for a low-end phone) that the user will not notice. Even with only 32 bits of encode-oriented data, multiple single-byte encoders are competitive with ICU though only the windows-1252 applied to ASCII or almost ASCII input is competitive with Windows system encoders. Faster CJK legacy encode is available as a compile-time option. But ideally, you should only be using UTF-8 for output anyway.
(If you just want to see the benchmarks and don’t have time for the discussion of the API and implementation internals, you can skip to the benchmarking section.)
Excluding the encoding_rs::mem submodule, which is discussed after encoding_rs proper, encoding_rs implements the character encoding conversions defined in the Encoding Standard as well as the mapping from labels (i.e. strings in protocol text that identify encodings) to encodings.
Specifically, encoding_rs does the following:
u16).u16) into a sequence of bytes in an Encoding
Standard-defined character encoding as if the lone surrogates had been
replaced with the REPLACEMENT CHARACTER before performing the encode.
(Gecko’s UTF-16 is potentially invalid.)document.characterSet.Notably, the JavaScript APIs defined in the Encoding Standard are not implemented by encoding_rs directly. Instead, they are implemented in Gecko as a thin C++ layer that calls into encoding_rs.
The Web is UTF-8 these days and Rust uses UTF-8 as the in-RAM Unicode representation, so why is a character encoding conversion library even needed anymore? The answer is, of course, “for legacy reasons”.
While the HTML spec requires the use of UTF-8 and the Web is over 90% UTF-8 (according to W3Techs, whose methodology is questionable considering that they report e.g. ISO-8859-1 separately from windows-1252 and GB2312 separately from GBK even though the Web Platform makes no such distinctions, but Google hasn’t published their numbers since 2012), users still need to access the part of the Web that has not migrated to UTF-8 yet. That part does not consist only of ancient static pages, either. For example, in Japan there are still news sites that publish new content every day in Shift_JIS. Over here in Finland, I do my banking using a Web UI that is still encoded in ISO-8859-15.
Another side of the legacy is inside the browser engine. Gecko, JavaScript and the DOM API originate from the 1990s when the way to represent Unicode in RAM was in 16-bit units as can also been seen in other software from that era, such as Windows NT, Java, Qt and ICU. (Unicode was formally extended beyond 16 bits in Unicode 2.0 in 1996 but non-Private Use Characters were not assigned outside the Basic Multilingual Plane until Unicode 3.1 in 2001.)
Regardless of the implementation language, the character encoding library in Gecko was in need of a rewrite for three reasons:
The addition of Rust code in Firefox brought about the need to be able to convert to and from UTF-8 directly and in terms of binary size, it didn’t make sense to have distinct libraries for converting to and from UTF-16 and for converting to and from UTF-8. Instead, a unified library using the same lookup tables for both was needed. The old code wasn’t designed to yield both UTF-16-targeting and UTF-8-targeting machine code from the same source. The addition of an efficient capability to decode to UTF-8 or to encode from UTF-8 would have involved a level of change comparable to a rewrite.
The old library was crufty enough that it was easier to make correctness improvements by the means of a rewrite than by the means of incremental fixes.
In Firefox 43, I had already rewritten the Big5 decoder and encoder in C++, because a rewrite was easier than modifying the old code. In that particular case, the old code used the Private Use Area (PUA) of the Basic Multilingual Plane (BMP) for Hong Kong Supplementary Character Set (HKSCS) characters. However, after the old code was written, HKSCS characters had been assigned proper code points in Unicode, but many of the assignments are on the Supplementary Ideographic Plane (Plane 2). When a fundamental assumption, such as all the characters in an encoding mapping to the BMP, no longer holds, a rewrite is easier than an incremental change.
As another example (that showed up after the initial rewrite proposal but before the implementation got properly going), the ISO-2022-JP decoder had an XSS vulnerability that was difficult to fix without restructuring the existing code. I actually tried to write a patch for the old code and gave up.
In general, the code structure of the old multi-byte decoders differed from the spec text so much that it would have been harder to try to figure out if the code does what the spec requires than to write new code according to the spec.
The old code was written at a time when the exact set of behaviors that Web-exposed character encodings exhibit wasn’t fully understood. For this reason, the old code had generality that is no longer useful now that we know the full set of Web-exposed legacy encodings and can be confident that there will be no additional legacy encodings introduced with additional behaviors anymore.
As the most notable example, the old code assumed that the lower half of single-byte encodings might not be ASCII. By the time of planning encoding_rs, single-byte encodings whose lower half wasn’t ASCII had already been removed as part of previous Encoding Standard-compliance efforts. Some of the multi-byte encoding handling code also had configurability for the single-byte mode that allowed for non-ASCII single-byte mode. However, some multi-byte encodings had already been migrated off the generic two-byte encoding handling code years ago.
There had been generic two-byte encoding handling code, but it no longer made sense when only EUC-KR remained as an encoding exhibiting the generic characteristics. Big5 was able to decode to Plane 2, GBK had grown four-byte sequences as part of the evolution to GB18030, EUC-JP had grown support for three-byte sequences in order to support JIS X 0212 and Shift_JIS never had the EUC structure to begin with and had single-byte half-width katakana. Even EUC-KR itself had deviated from the original EUC structure by being extended to support all precomposed Hangul syllables (not just the ones in common use) in windows-949.
When a rewrite made sense in any case, it made sense to do the rewrite in Rust, because a rewrite of a clearly identifiable subsystem is exactly the kind of thing that is suitable for rewriting in Rust and the problem domain could use memory-safety. The old library was created in early 1999, but it still had a buffer overrun discovered in it in 2016 (in code added in the 2001 and 2002). This shows that the notion that code written in a memory-unsafe language becomes safe by being “battle-hardened” if it has been broadly deployed for an extended period of time is a myth. Memory-safety needs a systematic approach. Calendar time and broad deployment are not sufficient to turn unsafe code into safe code.
(The above-mentioned bug discovered in 2016 wasn’t the last uconv security bug to be fixed. In 2018, a memory-safety-relevant integer overflow bug was discovered in uconv after uconv had already been replaced with encoding_rs in non-ESR Firefox but uconv was still within security support in ESR. However, that bug was in the new Big5 code that I wrote for Firefox 43, so it can’t be held against the ancient uconv code. I had fixed the corresponding encoding_rs bug before encoding_rs landed in Firefox 56. The uconv bug was fixed in Firefox ESR 52.7.)
As noted above, a key requirement was the ability to decode to and from both UTF-16 and UTF-8, but ICU supports only decoding to and from UTF-16 and rust-encoding supports only decoding to and from UTF-8. Perhaps one might argue that pivoting via another UTF would be fast enough, but experience indicated that pivoting via another UTF posed at least a mental barrier: Even after the benefits of UTF-8 as an in-memory Unicode representation were known, Gecko subsystems had been written to use UTF-16 because that was what uconv decoded to.
A further problem with ICU is that it does not treat the Encoding Standard as its conformance target. Chrome patches ICU substantially for conformance. I didn’t want to maintain a similar patch set in the Gecko context and instead wanted a library that treats the Encoding Standard as its conformance target.
The invasiveness of the changes to rust-encoding that would have been needed to meet the API design, performance and UTF-16 targeting goals would have been large enough that it made sense to pursue them in a new project instead of trying to impose the requirements onto an existing project.
In addition to internal problems, uconv also had a couple of API design problems. First, the decoder API lacked the ability to signal the end of the stream. This meant that there was no way for the decoder to generate a REPLACEMENT CHARACTER when the input stream ended with an incomplete byte sequence. It was possible for the caller to determine from the status code if the last buffer passed to the decoder ended with an incomplete byte sequence, but then it was up to the caller to generate the REPLACEMENT CHARACTER in that situation even though the decoder was generally expected to provide this service. As a result, only one caller in the code base, the TextDecoder implementation, did the right thing. Furthermore, even though the encoder side had an explicit way to signal the end of the stream, it was a separate method leading to more complexity for callers than just being able to say that a buffer is the last buffer.
Additionally, the API contract was unclear on whether it was supposed to fill buffers exactly potentially splitting a surrogate pair across buffer boundaries or whether it was supposed to guarantee output validity on a per-method call basis. In a situation where the input and output buffers were exhausted simultaneously, it was unspecified whether the converter should signal that the input was exhausted or that the output was exhausted. In cases where it wasn’t the responsibility of the converter to handle the replacement of malformed byte sequences when decoding or unmappable characters when encoding, the API left needlessly much responsibility to the caller to advance over the faulty input and to figure out what the faulty input was in the case where that mattered, i.e. when encoding and producing numeric character references for unmappable characters.
Character encoding conversion APIs tend to exhibit common problems, so the above uconv issues didn’t make uconv particularly flawed compared to other character encoding conversion APIs out there. In fact, to uconv’s credit at least in the form that it had evolved into by the time I got involved, given enough output space uconv always consumed all the input provided to it. This is very important from the perspective of API usability. It’s all too common for character encoding conversion APIs to backtrack if the input buffer ends with an incomplete byte sequence and to report the incomplete byte sequence at the end of the input buffer as not consumed. This leaves it to the caller to take those unconsumed bytes and to copy them to the start of the next buffer so that they can be completed by the bytes that follow. Even worse, sometimes this behavior isn’t documented and is up to the caller of the API to discover by experimentation. This behavior also imposes a, typically undocumented, minimum input buffer size, because the input buffer has to be large enough for at least one complete byte sequence to fit. If the input trickles in byte by byte, it’s up to the caller to arrange them into chunks large enough to contain a complete byte sequence.
Sometimes, the API design problem described in the previous paragraph is conditional on requesting error reporting. When I was writing the Validator.nu HTML Parser, I discovered that the java.nio.charset character encoding conversion API was well-behaved when it was asked to handle errors on its own, but when the caller asked for the errors to be reported, the behavior undocumentedly changed to not consuming all the input offered even if there was enough output space. This was because the error reporting mechanism sought to designate the exact bytes in error by giving the caller the number of erroneous bytes corresponding to a single error. In order to make a single number make sense, the bytes always had to be counted backwards from the current position, which meant that the current position had to be placed such that it was at the end of the erroneous sequence and additionally the API sought to make it so that the entire erroneous sequence was in the buffer provided and not partially in a past already discarded buffer.
Additionally, as a more trivial to describe matter, but as a security-wise potentially very serious matter, some character encoding conversion APIs offer to provide a mode that ignores errors. Especially when decoding and especially in the context of input such as HTML that has executable (JavaScript) and non-executable parts, silently dropping erroneous byte sequences instead of replacing them with the REPLACEMENT CHARACTER is a security problem. Therefore, it’s a bad idea for character encoding conversion API to offer a mode where errors are neither signaled to the caller nor replaced with the REPLACEMENT CHARACTER.
Finally, some APIs fail to provide a high-performance streaming mode where the caller is responsible for output buffer allocation. (This means two potential failures: First, failure to provide a streaming mode and, second, providing a streaming mode but converter seeks to control the output buffer allocation.)
In summary, in my experience, common character encoding conversion API design problems are the following:
All but the last item are specific to a streaming mode. Streaming is hard.
There are other API design considerations that would be unfair to label as “problems”, but that are still very relevant to designing a new API. These relate mainly to error handling and byte order mark (BOM) handling.
It is typical for character encoding conversion APIs to treat error handling as a mode that is set on a converter object as opposed to treating error handling as a different API entry point. API-wise it makes sense to have different entry points in order to have different return values for the two cases. Specifically, when the converter handles errors, the status of the conversion call cannot be that conversion stopped on an error for the caller to handle. Additionally, when the converter handles errors, it may make sense to provide a flag that indicates whether there where errors even though they were automatically handled.
Implementation-wise, experience suggests that baking error handling into each converter complicates code considerably and adds opportunities for bugs. Making the converter implementation always signal errors and having an optional wrapper that deals with those errors so that the application developer doesn’t need to leads to a much cleaner design. This design is a natural match for exposing different entry points: one entry point goes directly to the underlying converter and the other goes through the wrapper.
BOM sniffing is subtle enough that it is a bad idea to leave it to the application. It’s more robust to bake it into the conversion library. In particular, getting BOM sniffing right when bytes arrive one at a time is not trivial for applications to handle. Like replacement of errors, different BOM handling modes can be implemented as wrappers around the underlying converters.
Especially in languages that provide a notion of inheritance, interfaces or traits it is alluring for the API designer to seek to define an abstract conversion API that others can write more converters for. However, in the case of the Web, the set of encodings is closed and includes only those that are defined in the Encoding Standard. As far as the use cases in the Web context go, extensibility is not needed. On the contrary, especially in a code base that is also used in a non-Web context like Gecko is used in Thunderbird in the email context, it is a feature that we can be confident on the Web side that if we have a type that represents an encoding defined in the Encoding Standard it can’t exhibit behaviors from outside the Encoding Standard. By design, encoding_rs is not extensible, so an encoding_rs Encoding does not represent any imaginable character encoding but instead represents a character encoding from the Encoding Standard. For example, we know from the type that we don’t accidentally have a UTF-7 decoder in Gecko code that has Web expectations even though Thunderbird contains a UTF-7 decoder in its codebase. (If you are interested in decoding email in Rust, there is a crate that wraps encoding_rs, adds UTF-7 decoding and maintains a type distinction between Web encodings and email encodings.)
Additionally, in the context of Rust and its Foreign Function Interface (FFI), it helps that references are references to plain structs and not trait objects. Whereas C++ puts a vtable pointer on the objects allowing pointers to polymorphic types to have the same size as C pointers, Rust’s type erasure puts the vtable pointer in the reference. A Rust reference to a struct has the same machine representation as a plain (non-null) C pointer. A Rust reference to a trait-typed thing is actually two pointers: one to the instance and another to the vtable appropriate for the concrete type of the instance. Since interoperability with C++ is a core design goal for encoding_rs, using the kind of types whose references are the same as C pointers avoids the problem of losing the vtable pointer when crossing the FFI boundary.
Conceptually a character encoding is a mapping from a stream of bytes onto a stream of Unicode scalar values and, in most cases, vice versa. Therefore, it would seem that the right abstraction for a converter is an iterator adaptor that consumes an iterator over bytes and yields Unicode scalar values (or vice versa).
There are two problems with modeling character encoding converters as iterator adaptors. First, it leaves optimization to the compiler, when manual optimizations across runs of code units are desirable. Specifically, it is a core goal for encoding_rs to make ASCII handling fast using SIMD, and the compiler does not have enough information about the data to know to produce ASCII-sequence-biased autovectorization. Second, Rust iterators are ill-suited for efficient and (from the C perspective) idiomatic exposure over the FFI.
The API style of unconv, java.nio.charset, iconv, etc., of providing input and output buffers of several code units at a time to the converter is friendly both to SIMD and to FFI (Rust slices trivially decompose to pointer and length in C). While this isn’t 100% rustic like iterators, slices still aren’t unrustic.
This finally brings us to the actual API. There are three public structs:
Encoding, Decoder and Encoder. From the point of view of the application developer, these act like traits (or interfaces or superclasses to use concepts from other languages) even though they are structs. Instead of using language implementation-provided vtables for dynamic dispatch, they internally have an enum that wraps private structs that are conceptually like subclasses. The use of private enum for dispatch avoids vtable pointers in FFI, makes the hierarchy intentionally non-extensible (see above) and allows BOM sniffing to change what encoding a Decoder is a decoder for.
There is one statically allocated instance of Encoding for each encoding defined in the Encoding Standard. These instances have publicly visible names that allow application code to statically refer to a specific encoding (commonly, you want to do this with UTF-8, windows-1252, and the replacement encoding). To find an Encoding instance dynamically at runtime based on a label obtained from protocol text, there is a static method fn Encoding::for_label(label: &[u8]) -> &'static Encoding.
The Encoding struct provides convenience methods for non-streaming conversions. These are “convenience” methods in the sense that they are implemented on top of Decoder and Encoder. An application that only uses non-streaming conversions only needs to deal with Encoding and doesn’t need to use Decoder and Encoder at all.
Decoder and Encoder provide streaming conversions and are allocated at runtime, because they encapsulate state related to the streaming conversion. On the Encoder side, only ISO-2022-JP is actually stateful, so most of the discussion here will focus on Decoder.
Internally, the encoding-specific structs wrapped by Decoder are macroized to generate decode to UTF-8 and decode to UTF-16 from the same source code (likewise for Encoder). Even though Rust applications are expected to use the UTF-8 case, I’m going to give examples using the UTF-16 case, because it doesn’t involve the distinction between &str and &[u8] which would distract from the more important issues.
The fundamental function that Decoder provides is:
fn decode_to_utf16_without_replacement(
&mut self,
src: &[u8],
dst: &mut [u16],
last: bool
) -> (DecoderResult, usize, usize)
This function wraps BOM sniffing around an underlying encoding-specific implementation that takes the same arguments and has the same return value. The Decoder-provided wrapper first exposes the input to a BOM sniffing state machine and once the state machine gets out of the way delegates to the underlying implementation. Decoder instances can’t be constructed by the application directly. Instead, they need to be obtained from factory functions on Encoding. The factory functions come in three flavors for three different BOM sniffing modes: full BOM sniffing (the default), which may cause the Decoder to morph into a decoder for a different encoding than initially (using enum for dispatch shows its usefulness here!), BOM removal (no morphing but the BOM for the encoding itself is skipped) and without BOM handling. The struct is the same in all cases, but the different factory methods initialize the state of the BOM sniffing state machine differently.
The method takes an input buffer (src) and an output
buffer (dst) both of which are caller-allocated. The method then decodes bytes from src into Unicode scalar values that are stored (as UTF-16) into dst until one of the following three things happens:
The return value is a tuple of a status indicating which one
of the three reasons to return happened, how many input bytes were read and
how many output code units were written. The status is a
DecoderResult enumeration (possibilities Malformed, InputEmpty and
OutputFull corresponding to the three cases listed above).
The output written into dst is guaranteed to be valid UTF-16,
and the output after each call is guaranteed to consist of
complete characters. (I.e. the code unit sequence for the last character is
guaranteed not to be split across output buffers.) This implies that the output buffer must be long enough for an astral character to fit (two UTF-16 code units) and the output buffer might not be fully filled. While it may seem wasteful not to fill the last slot of the output buffer in the common case, this design significantly simplifies the implementation while also simplifying callers by guaranteeing to the caller that it won’t have to deal with split surrogate pairs.
The boolean argument last indicates that the end of the stream is reached
when all the bytes in src have been consumed.
A Decoder object can be used to incrementally decode a byte stream. During the processing of a single stream, the caller must call the method
zero or more times with last set to false and then call decode_* at
least once with last set to true. If the decode_* with last set to true returns InputEmpty,
the processing of the stream has ended. Otherwise, the caller must call
decode_* again with last set to true (or treat a Malformed result as
a fatal error).
Once the stream has ended, the Decoder object must not be used anymore.
That is, you need to create another one to process another stream. Unlike with some other libraries that encourage callers to recycle converters that are expensive to create, encoding_rs guarantees that converters are extremely cheap to create. (More on this later.)
When the decoder returns OutputFull or the decoder returns Malformed and
the caller does not wish to treat it as a fatal error, the input buffer
src may not have been completely consumed. In that case, the caller must
pass the unconsumed contents of src to the method again upon the next
call.
Typically the application doesn’t wish to do its own error handling and just wants errors to be replaced with the REPLACEMENT CHARACTER. For this use case, there is another method that wraps the previous method and provides the replacement. The wrapper looks like this:
fn decode_to_utf16(
&mut self,
src: &[u8],
dst: &mut [u16],
last: bool
) -> (CoderResult, usize, usize, bool)
Notably, the status enum is different, because the case of malformed sequences doesn’t need to be communicated to the application. Also, the return tuple includes a boolean flag to indicate whether there where errors.
Additionally, there is a method for querying the worst case output size even the current state of the decoder and the length of an input buffer. If the length of the output buffer is at least the worst case, the decoder guarantees that it won’t return OutputFull.
Initially, the plan was simply not to support applications that need to identify which input bytes were in error, because I thought that it wasn’t possible to do so without complicating the API for everyone else. However, very early into the implementation phase, I realized that it is possible to identify which bytes are in error without burdening applications that don’t care if the applications that want to know are responsible for remembering the last N bytes decoded where N is relatively small. It turns out that N is 6.
For a malformed sequence that corresponds to a single decode error (i.e. a single REPLACEMENT CHARACTER) a DecoderResult::Malformed(u8, u8) is returned. The first wrapped integer indicates the length of the malformed byte sequence. The second wrapped integer indicates the number of bytes that were consumed after the malformed sequence. If the second integer is zero, the last byte that was consumed is the last byte of the malformed sequence. The malformed bytes may have been part of an earlier input buffer, which is why it is the responsibility of the application that wants to identify the bytes that were in error.
The first wrapped integer can have values 1, 2, 3 or 4. The second wrapped integer can have values 0, 1, 2 or 3. The worst-case sum of the two is 6, which happens with ISO-2022-JP.
When encoding to an encoding other than UTF-8 (the Encoding Standard does not support encoding into UTF-16LE or UTF-16BE, and there is one Unicode scalar value that cannot be encoded into gb18030), it is possible that the encoding cannot represent a character that is being encoded. In this case, instead of returning backward-looking indices EncoderResult::Unmappable(char) wraps the Unicode scalar value that needs to be replaced with a numeric character reference when performing replacement. In the case of ISO-2022-JP, this Unicode scalar value can be the REPLACEMENT CHARACTER instead of a value actually occurring in the input if the input contains U+000E, U+000F, or U+001B.
This asymmetry between how errors are signaled in the decoder and encoder scenarios makes the signaling appropriate for each scenario instead of optimizing for consistency where consistency isn’t needed.
As noted earlier, Encoding provides non-streaming convenience methods built on top of the streaming functionality. Instead of being simply wrappers for the streaming conversion, the non-streaming methods first try to check if the input is borrowable as output without conversion. For example, if the input is all ASCII and the encoding is ASCII-compatible, a Cow borrowing the input is returned. Likewise, the input is borrowed when the encoding is UTF-8 and the input is valid or when the encoding is ISO-2022-JP and the input contains no escape sequences. Here’s an example of a non-streaming conversion method:
fn decode_with_bom_removal<'a>(
&'static self,
bytes: &'a [u8]
) -> (Cow<'a, str>, bool)
(Cow is a Rust standard library type that wraps either an owned type or a corresponding borrowed type, so a heap allocation and copy can be avoided if the caller only needs a borrow. E.g., Cow<'a, str> wraps either a heap-allocated string or a pointer and a length designating a string view into memory owned by someone else. Lifetime 'a indicates that the lifetime of borrowed output depends on the lifetime of the input.)
Internally, there are five guiding design principles.
Even though in principle compile-time abstraction over UTF-8 and UTF-16 is a matter of monomorphizing over u8 and u16, handling the two cases using generics would be more complicated than handling them using macros. That’s why it’s handled using macros. The conversion algorithms are written as blocks of code that are inputs to macros that expand to provide the skeleton conversion loop and fill in the encoding-specific blocks of code. In the skeleton in the decode case, one instantiation uses a Utf8Destination struct and another uses a Utf16Destination struct both of which provide the same API for writing into them. In the encode case, the source struct varies similarly.
The old code in uconv was relatively ad hoc in how it accessed the input and output buffers. It maybe did stuff, advanced some pointers, checked if the pointers reached the end of the buffer and maybe even backed off a bit in some places. It didn’t have an overarching pattern to how space availability was checked and matched to memory accesses so that no accesses could happen without a space check having happened first. For encoding_rs, I wanted to make sure that buffer access only goes forwards without backtracking more than the one byte that might get unread in error cases and that no read happens without checking that there is still data to be read and no write happens without checking that there is space in the output buffer.
Rust’s lifetimes can be used to enforce an “at most once” property. Immediately upon entering a conversion function, the input and output slices are wrapped in source and destination structs that maintain the current read or write position. I’ll use the write case as the example, but the read case works analogously. A decoder that only ever produces characters in the basic multilingual plane uses a BMP space checking method on the destination that takes the destination as a mutable reference (&mut self). If the destination is a UTF-8 destination, the method checks that there is space for at least three additional bytes. If the destination is a UTF-16 destination, the method checks that there is space for at least one additional code unit. If there is enough space, the caller receives a BMP handle whose lifetime is tied to the the lifetime of the destination due to the handle containing the mutable reference to the destination. A mutable reference in Rust means exclusive access. Since a mutable reference to the destination is hidden inside the handle, no other method can be called on the destination until the handle goes out of scope. The handle provides a method for writing one BMP scalar value. That method takes the handle’s self by value consuming the handle and preventing reuse.
The general concept is that at the top of the loop, the conversion loop checks availability of data at the source and obtains a read handle or returns from the conversion function with InputEmpty and then checks availability of space at the destination and obtains a write handle or returns from the conversion function with OutputFull. If neither check caused a return out of the conversion function, the conversion loop now hasn’t read or written either buffer but can be fully confident that it can successfully read from the input at most once and write a predetermined amount of units to the output at most once during the loop body. The handles go out of scope at the end of the loop body, and once the loop starts again, it’s time to check for input availability and out space availability again.
As an added twist, the read operation yields not only a byte of input but also an unread handle for unreading it, because in various error cases the spec calls for prepending input that was already read back to the input stream. In practice, all the cases in the spec can be handled by being able to unread at most one unit of input even though the spec text occasionally prepends more than one unit.
In practice, the ISO-2022-JP converters, which don’t need to be fast for Web use cases, use the above concept in its general form. For the ASCII-compatible encodings that are actually performance-relevant for Web use cases, there are a couple of elaborations.
First, the UTF-8 destination and the UTF-16 destination know how to copy ASCII from a byte source in an efficient way that handles more than one ASCII character per register (either a SIMD register or even an ALU register). So the main conversion loop starts with a call to a method that first tries to copy ASCII from the source to the destination and then returns a non-ASCII byte and write handle if there’s space left the destination. Once a non-ASCII byte is found, another loop is entered into that actually works with the handles.
Second, the loop that works with the handles doesn’t have a single scope per loop body for multi-byte encodings. Once we’re done copying ASCII, the non-ASCII byte that we found is always a lead byte of a multi-byte sequence unless there is an error—and we are optimizing for the case where there is neither an error nor a buffer boundary. Therefore, it makes sense to start another scope that does the handle obtaining space check choreography again in the hope that the next byte will be a valid trail byte given the lead byte that we just saw. Then there is a third innermost loop for reading the next byte after that so that if non-ASCII we can continue the middle loop as if this non-ASCII byte had come from the end of the initial ASCII fast path and if the byte is ASCII punctuation, we can spin in the innermost loop without trying to handle a longer ASCII run using SIMD, which would likely fail within CJK plain text. However, if we see non-punctuation ASCII, we can continue the outermost loop and go back to the ASCII fast path.
Not matching on a state variable indicating whether we’re expecting a lead or trail byte on a per-byte basis and instead using the program counter for the state distinguishing between lead and trail byte expectations is good for performance. However, it poses a new problem: What if the input buffer ends in the middle of a multi-byte sequence? Since we are using the program counter for state, the code for handling the trail byte in a two-byte encoding is only reachable by first executing the code for handling the lead byte, and since Rust doesn’t have goto or a way to store continuations, after a buffer boundary we can’t just restore the local variables and jump directly to the trail byte handling. To deal with this, the macro structure that allows the reuse of code for decoding both to UTF-8 and to UTF-16 also duplicates the block for handling the trail byte such that the same block occurs between the function method entry and the conversion loop. If the previous buffer ended in the middle of a byte sequence, the next call to the conversion function handles the trail of that sequence before entering the actual conversion loop.
The UTF-8 decoder does not use the same structure as the other multi-byte decoders. Dealing with invalid byte sequences in the middle of the buffer or valid byte sequences that cross a buffer boundary is implemented na"ively from the spec in a way that is instantiated via macro from the same code both when converting to UTF-8 and when converting to UTF-16. However, once that outer tier of conversion gets to a state where it expects the next UTF-8 byte sequence, it calls into fast-track code that only deals with valid UTF-8 and returns back to the outer tier that’s capable of dealing with invalid UTF-8 or partial sequences when it discovers an incomplete sequence at the end of the buffer or an invalid sequence in the middle. This inner fast track is implemented separately for decoding UTF-8 to UTF-8 and for decoding UTF-8 to UTF-16.
The UTF-8 to UTF-16 case is close enough to one might expect from the above description of legacy multibyte encodings. At the top of the loop, there is the call to the ASCII fast path that zero-extends ASCII to UTF-16 Basic Latin multiple code units at a time and then byte sequences that start with a non-ASCII lead byte are handles as three cases: two-byte sequence, three-byte sequence or four-byte sequence. Lookup tables are used to check the validity of the combination of lead byte and second byte as explained below. The sequence is considered consumed only if it’s found to be valid. The corresponding UTF-8 code units are then written to the destination as normal u16 writes.
The UTF-8 to UTF-8 case is different. The input is read twice, but the writing is maximally efficient. First, a UTF-8 validation function is run on the input. This function only reads and doesn’t write and uses an ASCII validation fast path that checks more than one code unit at a time using SIMD or multiple code units per ALU word. The UTF-8 validation function is the UTF-8 to UTF-16 conversion function with all the writes removed. After the validation, the valid UTF-8 run is copied to the destination using std::ptr::copy_nonoverlapping(), which is the Rust interface to LLVM memcpy(). This way, the writing, which is generally less efficient than reading, can be done maximally efficiently instead of being done on a byte-by-byte basis for non-ASCII as would result from a read-once implementation. (Note that in the non-streaming case when the input is valid, both the second read and the writing are avoided. More on that later.)
It is not totally clear if this kind of double-reading is smart, since it is a pessimization for the 100% ASCII case. Intuitively, it should help the non-ASCII case, since even the non-ASCII parts can be written using SIMD. However, 100% ASCII UTF-8 to UTF-8 streaming case, which copies instead of borrowing, runs on Haswell at about two thirds of memcpy() speed while the 100% ASCII windows-1252 to UTF-8 case (which writes the SIMD vectors right away without re-reading) runs at about memcpy() speed.
The hard parts of looping over potentially-invalid UTF-8 are:
encoding_rs combines the solution for the first two problems. Once it’s known that the lead byte is not ASCII, the lead byte is used as an index to a lookup table that yields a byte whose lower two bits are always zero and that has exactly one of the other six bits set to represent the following cases:
The second byte is used as an index to a lookup table yielding a byte whose low two bits are always zere, whose bit in the position corresponding to the lead being illegal is always one and whose other five bits are zero if the second byte is legal given the type of lead the bit position represents and one otherwise. When the bytes from the two lookup tables are ANDed together, the result is zero if the combination of lead byte and second byte is legal and non-zero otherwise.
When a trail byte is always known to have the normal range, as the third byte in a three-byte sequence is, we can check that the most significant bit is 1 and the second-most significant bit is zero. Note how the ANDing described in the above paragraph always leaves the two least-significant bits of the AND result as zeros. We shift the third byte of a three-byte sequence right by six and OR it with the AND result from the previous paragraph. Now the validity of the three-byte sequence can be decided in a single branch: If the result is 0x2, the sequence is valid. Otherwise, it’s invalid.
In the case of four-byte sequences, the number computed per above is extended to 16 bits and the two most-significant bits of the fourth byte are masked and shifted to bit positions 8 and 9. Now the validitiy of the four-byte sequence can be decidded in a single branch: If the result is 0x202, the sequence is valid. Otherwise, it’s invalid.
The fast path checks that there is at least 4 bytes of input on each iteration, so the bytes of any valid byte sequence for a single scalar value can be read without further bound checks. The code does use branches to decide whether to try to match the bytes as a two-byte, three-byte or four-byte sequence. I tried to handle the distinction between two-byte sequences and three-byte sequences branchlessly when converting UTF-8 to UTF-16. In this case, the mask applied to the lead byte is taken from a lookup table and mask is taken from a lookup table to zero out the bits of the third byte and the third shift amount (from 6 to 0) in the two-byte case. The result was slower than just having a branch to distinguish between two-byte sequences and three-byte sequences.
Now that there is branching to categorize the sequence length, it becomes of interest to avoid that branching. It’s also of interest to avoid going back to the SIMD ASCII fast path when the next lead is not ASCII. After a non-ASCII byte sequence, instead of looping back to the ASCII fast path, the next byte is read and checked. After a two-byte sequence, the next lead is checked for ASCIIness. If it’s not ASCII, the code loops back to the point where the SIMD ASCII path has just exited. I.e. there’s a non-ASCII byte as when exiting the ASCII SIMD fast path, but its non-ASCIIness was decided without SIMD. If the byte is an ASCII byte, it is processed and then the code loops back to the ASCII SIMD fast path.
Obviously, this is far from ideal. Avoiding immediate return to ASCII fast path after a two-byte character works within a non-Latin-script word but it doesn’t really help to let one ASCII character signal a return to SIMD when the one ASCII character is a single space between two non-Latin words. Unfortunately, trying to be smarter about avoiding too early looping back to the SIMD fast path would mean more branching, which itself has a cost.
In the two-byte case, if the next lead is non-ASCII, looping back to immediately after the exit from the ASCII fast path means that the next branch is anyway the branch to check if the lead is for a two-byte sequence, so this works out OK for words in non-Latin scripts in the two-byte-per-character part of the Basic Multilingual Plane. In the three-byte case, however, looping back to the point where the ASCII SIMD fast path ends would first run the check for a two-byte lead even though after a three-byte sequence the next lead is more likely to be for another three-byte sequnces. Therefore, after a three-byte sequence, the first check performed on the next lead is to see if it, too, is for a three-byte sequence in which case the code loops back to the start of the three-byte sequence processing code.
UTF-16LE and UTF-16BE are rare enough on the Web that a browser can well get away with a totally na"ive and slow from-the-spec implementation. Indeed, that’s what landed in Firefox 56. However, when talking about encoding_rs, it was annoying to always have the figurative asterisk next to UTF-16LE and UTF-16BE to disclose slowness when the rest was fast. To get rid of the figurative asterisk, UTF-16LE and UTF-16BE decode is now optimized, too.
If you read The Unicode Standard, you might be left with the impression that the difference between UTF-16 as an in-memory Unicode representation and UTF-16 as an interchange format is byte order. This is not the full story. There are three additional concerns. First, there is a concern of memory alignment. In the case of UTF-16 as an in-memory Unicode representation, a buffer of UTF-16 code units is aligned to start at a memory address that is a multiple of the size of the code unit. That is, such a buffer always starts at an even address. When UTF-16 as an interchange format is read using a byte-oriented I/O interface, it may happen that a buffer starts at an odd address. Even on CPU architectures that don’t distinguish between aligned and unaligned 16-bit reads and writes on the ISA layer, merely reinterpreting a pointer to bytes starting at an odd address as a pointer pointing to 16-bit units and then accessing it as if was a normal buffer of 16-bit units is Undefined Behavior in C, C++, and Rust (as can in practice be revealed by autovectorization performed on the assumption of correct alignment). Second, there is the concern of buffers being an odd number of bytes in length, so the special logic is needed to handle the split UTF-16 code unit at the buffer boundary. Third, there is the concern of unpaired surrogates, so even when decoding to UTF-16, the input can’t be just be copied into right alignment, potentially with byte order swapping, without inspecting the data.
The structure of the UTF-16LE and UTF-16BE decoders is modeled on the structure of the UTF-8 decoders: There’s a na"ive from-the-spec outer tier that deals with invalid and partial sequences and an inner fast path that only deals with valid sequences.
At the core of the fast path is a struct called UnalignedU16Slice that wraps *const u8, i.e. a pointer that can point to either an ever or an odd address, and a length in 16-bit units. It provides a way to make the unaligned slice one code unit shorter (to exclude a trailing high surrogate when needed), a way to take a tail subslice and ways to read a u16 or, if SIMD is enabled, u16x8 in a way that assumes the slice might not be aligned. It also provides a way to copy, potentially with endianness swapping, Basic Multilingual Plane code units to a plain aligned &mut [u16] until the end of the buffer or surrogate code unit is reached. If SIMD is enabled, both the endianness swapping and the surrogate check are SIMD-accelerated.
When decoding to UTF-16, there’s a loop that first tries to use the above-mentioned Basic Multilingual Plane fast path and once a surrogate is found, handles the surrogates on a per-code-unit and returns back to the top of the loop if there was a valid pair.
When decoding to UTF-8, code copied and pasted from the UTF-16 to UTF-8 encoder is used. The difference is that instead of using &[u16] as the source, the source is an UnalignedU16Slice and, additionally, reads are followed with potential endian swapping. Additionally, unpaired surrogates are reported as errors in decode while UTF-16 to UTF-8 encode silently replaces unpaired surrogates with the REPLACEMENT CHARACTER. If SIMD is enabled, SIMD is used for the ASCII fast path. Both when decoding to UTF-8 and when decoding to UTF-16, endianness swapping is represented by a trait parameter, so the conversions are monomorphized into two copies: One that swaps endianness and one that doesn’t. This results in four conversion functions: Opposite-endian UTF-16 to UTF-8, same-endian UTF-16 to UTF-8, opposite-endian UTF-16 to UTF-16, same-endian UTF-16 to UTF-16. All these assume the worst for alignment. That is, code isn’t monomorphized for the aligned and unaligned cases. Unaligned access is fast on aarch64 and on the several most recent x86_64 microarchitectures, so optimizing performance of UTF-16LE and UTF-16BE in the aligned case for Core2 Duo-era x86_64 or for ARMv7 at the expense of binary size and source code complexity would be a bit too much considering that UTF-16LE and UTF-16BE performance doesn’t even really matter for Web use cases.
Unlike the other decoders, the x-user-defined decoder doesn’t have an optimized ASCII fast path. This is because the main remaining use case for x-user-defined it is loading binary data via XMLHttpRequest in code written before proper binary data support via ArrayBuffers was introduced to JavaScript. (Note that when HTML is declared as x-user-defined via the meta tag, the windows-1252 decoder is used in place of the x-user-defined decoder.)
When decoding to UTF-8, the byte length of the output varies depending on content, so the operation is not suitable for SIMD. The loop simply works in a per-byte basis. However, when decoding to UTF-16 with SIMD enabled, each u8x16 vector is zero-extended into two u16x8 vectors. A mask computed by a lane-wise greater-than comparison to see which lanes were not in the ASCII range. The mask is used to retain the corresponding lanes from a vector of all lanes set to 0xF700 and the result is added to the original u16x8 vector.
(Nightly) Rust provides access to portable SIMD which closely maps to LLVM’s notion of portable SIMD. There are portable types, such as the u8x16 and u16x8 types used by encoding_rs
|
|
Henri Sivonen: Using cargo-fuzz to Transfer Code Review of Simple Safe Code to Complex Code that Uses unsafe |
encoding_rs::mem is a Rust module for performing conversions between different in-RAM text representations that are relevant to Gecko. Specifically, it converts between potentially invalid UTF-16, Latin1 (in the sense that unsigned byte value equals the Unicode scalar value), potentially invalid UTF-8, and guaranteed-valid UTF-8, and provides some operations on buffers in these encodings, such as checking if a UTF-16 or UTF-8 buffer only has code points in the ASCII range or only has code points in the Latin1 range. (You can read more about encoding_rs::mem in a write-up about encoding_rs as a whole.)
The whole point of this module is to make things very fast using Rust’s (not-yet-stable) portable SIMD features. The code was written before slices in the standard library had the align_to method or the chunks_exact method. Moreover, to get speed competitive with the instruction set-specific and manually loop-unrolled C++ code that the Rust code replaced, some loop unrolling is necessary, but Rust does not yet support directives for the compiler that would allow the programmer to request specific loop unrolling from the compiler.
As a result, the code is a relatively unreviewable combination of manual alignment calculations, manual loop unrolling and manual raw pointer handling. This indeed achieves high speed, but by looking at the code, it isn’t at all clear whether the code is actually safe or otherwise correct.
To validate the correctness of the rather unreviewable code, I used model-based testing with cargo-fuzz. cargo-fuzz provides Rust integration for LLVM’s libFuzzer coverage-guided fuzzer. That is, the fuzzer varies the inputs it tries based on observing how the inputs affect the branches taken inside the code being fuzzed. The fuzzer runs with one of LLVM’s sanitizers enabled. By default, the Address Sanitizer (ASAN) is used. (Even though the sanitizers should never find bugs in safe Rust code, the sanitizers are relevant to bugs in Rust code that uses unsafe.)
I wrote a second implementation (the “model”) of the same API in the most obvious way possible using Rust standard-library facilities and without unsafe, except where required to be able to write into an &mut str. I also used the second implementation to validate the speed of the complex implementation. Obviously, there’d be no point in having a complex implementation if it wasn’t faster than the simple and obvious one. (The complex implementation is, indeed, faster.)
For example, the function for checking if a buffer of potentially invalid UTF-16 only contains characters in the Latin1 range is 8 lines (including the function name and the closing brace) in the safe version. In the fast version, it’s 3 lines that just call to another function expanded from a macro, where the expansion is either generated using either a 76-line SIMD-using macro or a 71-line ALU-using macro depending on whether the code was compiled with SIMD enabled. Of these macros, the SIMD calls another (tiny) function that has a specialized implementation for aarch64 and a portable implementation.
To use cargo-fuzz, you create a “fuzzer script”, which is a Rust function that gets a slice of bytes from the fuzzer and exercises the code being fuzzed. In the case of fuzzing encoding_rs::mem, the first byte is used to decide which function to exercise and the rest of the slice is used as the input to the function. When the function being called takes a slice of u16, a suitably aligned u16 subslice of the input is taken.
For each function, the fuzzer script calls both the complex implementation and the corresponding simple implementation with the same input and checks that the outputs match. The fuzzer finds a bug if the outputs don’t match, if there is a panic, or if the LLVM Address Sanitizer notices bad memory access, which could arise from the use of unsafe.
Once the fuzzer fails to find problems after having run for a few days, we can have high confidence that the complex implementation is correct in the sense that its observable behavior, ignoring speed, matches the observable behavior of the simple implementation. Therefore, a code review for the correctness of the simple implementation can, with high confidence, be considered to apply to the complex implementation as well.
|
|
Henri Sivonen: How I Wrote a Modern C++ Library in Rust |
|
|
Daniel Pocock: Smart home: where to start? |
My home automation plans have been progressing and I'd like to share some observations I've made about planning a project like this, especially for those with larger houses.
With so many products and technologies, it can be hard to know where to start. Some things have become straightforward, for example, Domoticz can soon be installed from a package on some distributions. Yet this simply leaves people contemplating what to do next.
For a small home, like an apartment, you can simply buy something like the Zigate, a single motion and temperature sensor, a couple of smart bulbs and expand from there.
For a large home, you can also get your feet wet with exactly the same approach in a single room. Once you are familiar with the products, use a more structured approach to plan a complete solution for every other space.
The Debian wiki has started gathering some notes on things that work easily on GNU/Linux systems like Debian as well as Fedora and others.

What is your first goal? For example, are you excited about having smart lights or are you more concerned with improving your heating system efficiency with zoned logic?
Trying to do everything at once may be overwhelming. Make each of these things into a separate sub-project or milestone.
There are many technology choices:
Creating a spreadsheet table is extremely useful.
This helps estimate the correct quantity of sensors, bulbs, radiator valves and switches and it also helps to budget. Simply print it out, leave it under the Christmas tree and hope Santa will do the rest for you.
Looking at my own house, these are the things I counted in a first pass:
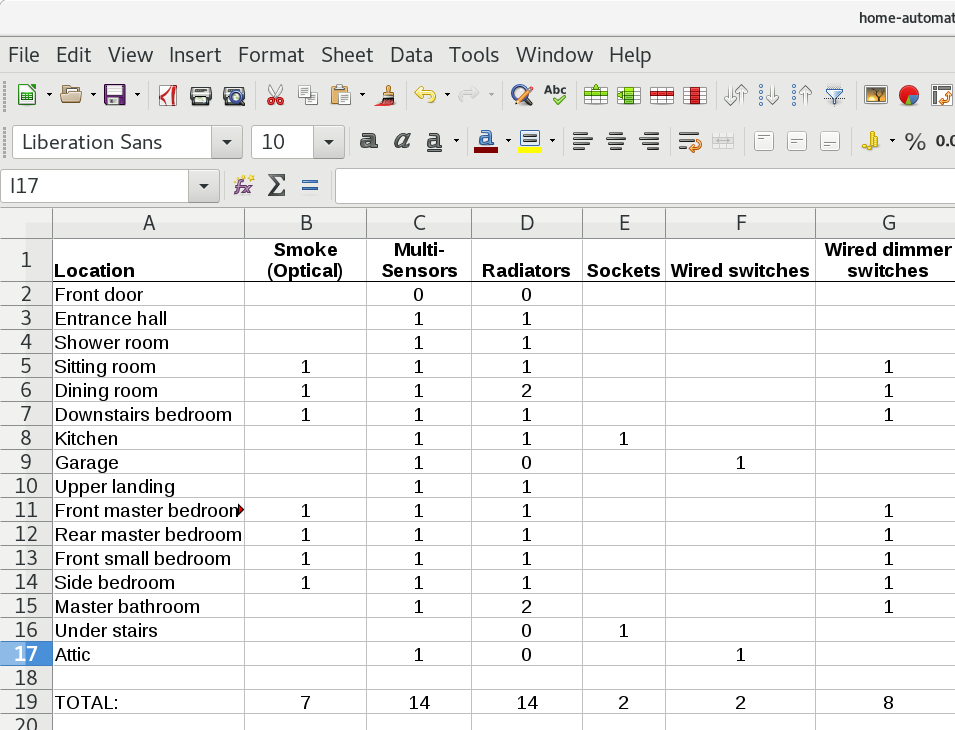
Don't forget to include all those unusual spaces like walk-in pantries, a large cupboard under the stairs, cellar, en-suite or enclosed porch. Each deserves a row in the table.
Whatever the aim of the project, sensors are likely to help obtain useful data about the space and this can help to choose and use other products more effectively.
Therefore, it is often a good idea to choose and deploy sensors through the home before choosing other products like radiator valves and smart bulbs.
When placing motion sensors, it is important to avoid putting them too close to doorways where they might detect motion in adjacent rooms or hallways. It is also a good idea to avoid putting the sensor too close to any light bulb: if the bulb attracts an insect, it will trigger the motion sensor repeatedly. Temperature sensors shouldn't be too close to heaters or potential draughts around doorways and windows.
There are a range of all-in-one sensors available, some have up to six features in one device smaller than an apple. In some rooms this is a convenient solution but in other rooms, it may be desirable to have separate motion and temperature sensors in different locations.
Consider the dining and sitting rooms in my own house, illustrated in the floorplan below. The sitting room is also a potential 6th bedroom or guest room with sofa bed, the downstairs shower room conveniently located across the hall. The dining room is joined to the sitting room by a sliding double door. When the sliding door is open, a 360 degree motion sensor in the ceiling of the sitting room may detect motion in the dining room and vice-versa. It appears that 180 degree motion sensors located at the points "1" and "2" in the floorplan may be a better solution.
These rooms have wall mounted radiators and fireplaces. To avoid any of these potential heat sources the temperature sensors should probably be in the middle of the room.
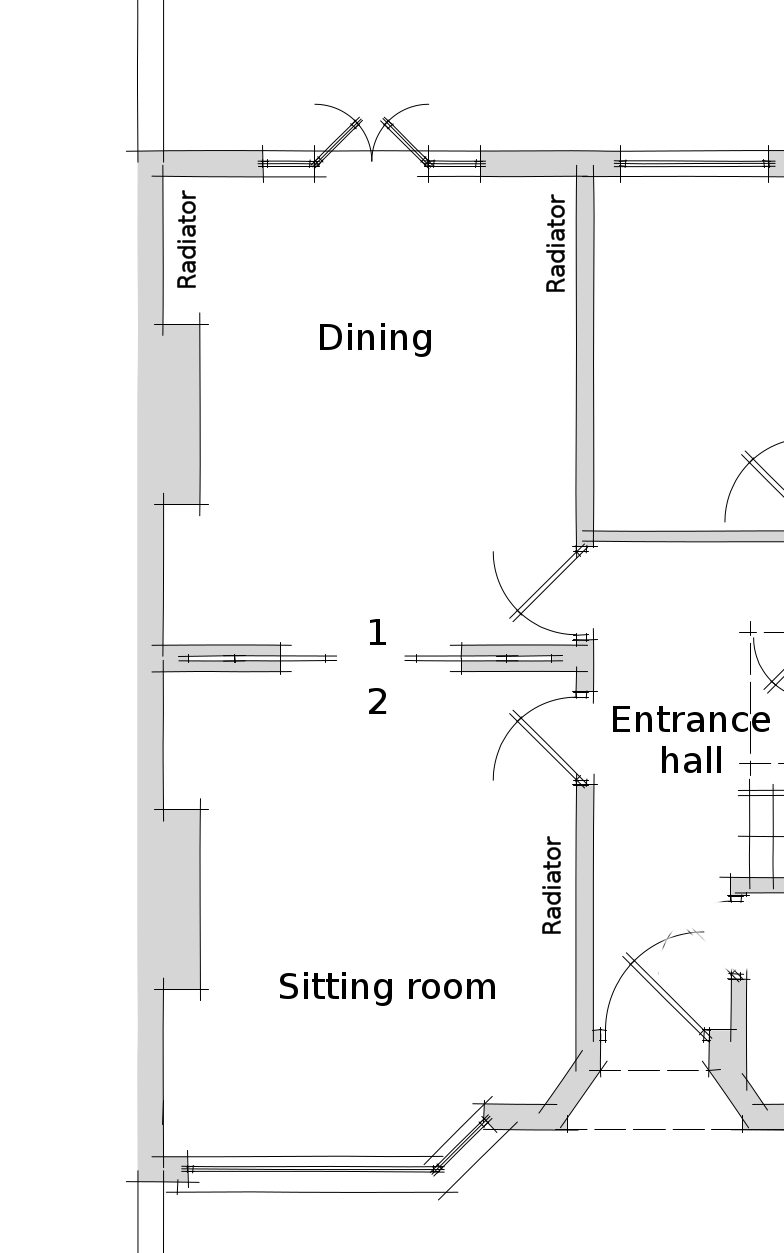
This photo shows the proposed location for the 180 degree motion sensor "2" on the wall above the double door:

To summarize, buy a Zigate and a small number of products to start experimenting with. Make an inventory of all the products potentially needed for your home. Try to mark sensor locations on a floorplan, thinking about the type of sensor (or multiple sensors) you need for each space.
|
|
David Humphrey: Processing.js 2008-2018 |
Yesterday Pomax DM'ed me on Twitter to let me know he'd archived the Processing.js GitHub repo. He's been maintaining it mostly on his own for quite a while, and now with the amazing p5js project, there isn't really a need to keep it going.
I spent the rest of the day thinking back over the project, and reflecting on what it meant to me. Like everyone else in May 2008, I was in awe when John Resig wrote his famous reverse birthday present blog post, showing the world what he'd been hacking together:
I've decided to release one of my largest projects, in recent memory. Processing.js is the project that I've been alluding to for quite some time now. I've ported the Processing visualization language to JavaScript, using the Canvas element. I've been working on this project, off-and-on now, for the past 7 months.
It was nothing short of epic. I had followed the development of Processing since I was an undergrad. I remember stumbling into the aesthetics + computation group website at MIT in my first year, and becoming aware of the work of Ben Fry, John Maeda, Casey Reas and others. I was smitten. As a student studying both humanities and CS, I didn't know anyone else who loved computers and art, and here was an entire lab devoted to it. For many years thereafter, I followed along from afar, always amazed at the work people there were doing.
Then, in the fall of 2009, as part of my work with Mozilla, Chris Blizzard approached me about helping Al MacDonald (f1lt3r) to work on getting Processing.js to 1.0, and adding the missing 3D API via WebGL. In the lead-up to Firefox 3.7, Mozilla was interested in getting more canvas based tech on the web, and in finding performance and other bugs in canvas and WebGL. Processing.js, they thought, would help to bring a community of artists, designers, educators, and other visual coders to the web.
Was I interested!? Here was a chance to finally work alongside some of my technical heroes, and to get to contribute to a space I'd only ever looked at from the other side of the glass. "Yes, I'm interested." I remember getting my first email from Ben, who started to explain what Processing was--I didn't need any introductions.
That term I used Processing.js as the main open source project in my open source class. As Al and I worked on the code, I taught the students how things worked, and got them fixing small bugs. The code was not the easiest first web project for students: take a hybrid of Java and make it work, unmodified, in the browser, using DOM and canvas APIs. This was before transpilers, node, and the current JS ecosystem. If you want to learn the web though, there was no better way than to come at it from underneath like this.
I had an energetic group of students with a nice set of complimentary skills. A few had been working with Vlad on 3D in the browser for a while, as he developed what would become WebGL. Andor Salga, Anna Sobiepanek, Daniel Hodgin, Scott Downe, Jon Buckley, and others would go on to continue working on it with me in our open source lab, CDOT.
Through 2009-11 we worked using the methods I'd learned from Mozilla: open bug tracker, irc, blogs, wikis, weekly community calls, regular dot-releases.
Because we were working in the open, and because the project had such an outsized reputation thanks to the intersections of "Ben & Casey" and Resig, all kinds of random (and amazing) people showed up in our irc channel. Every day someone new from the who's who of design, graphics, gaming, and the digital art worlds would pop in to show us a demo that had a bug, or to ask a question about how to make something work. I spent most of my time helping people debug things, and writing tests to put back into the project for performance issues, parser bugs, and API weirdness.
One day a musician and digital artist named Corban Brook showed up. He used Processing in his work, and was interested to help us fix some things he'd found while porting an old project. He never left. Over the months he'd help us rewrite huge amounts of the code, taught us git, and become a big brother to many of the students. I learned a ton from him about git and JS.
Then there was the time this mathematician came into the channel, complaining about how poor our font code and bezier curve implementation. It turned out he knew what he was talking about, and we never let him leave either. Pomax would go on to become one of the most important maintainers on the project, and a long time friend.
Another time an unknown nickname, "notmasteryet," appeared. He started submitting massive pull requests, but never really said anything. At one point he rewrote our entire Java-to-JavaScript parser from scratch and magically fixed hundreds of bugs we couldn't solve. "notmasteryet" turned out to be Yury Delendik, who would go on to join Mozilla and build every cool thing you've seen the web do in the past 10 years (pdf.js, shumway to name a few).
Being part of this eclectic mix of hackers and artists was intoxicating. Whatever skill one of you lacked, others in the group had it. At one point, the conversation moved toward how to use the browser to mix audio and visuals with processing.js. I had no idea how sound worked, but I did understand how to hack into Gecko and get the data, Corban was a master with FFTs, Al knew how to make the visuals work, and Yury knew everything the rest of us didn't.
We set out to see if we could connect all the dots, and began hacking on a new branch of our code that used a version of Firefox I modified to emit audio events. Our work would eventually be shipped in Firefox 4 as the Audio Data API, and lead to what is now the standardization of the Web Audio AI. I still remember the first time we got all of our pieces working together in the browser, and Corban filmed it. Magic!
From there the group only got larger, and the ideas for processing.js more ambitious. With the addition of people like CJ and Bobby, we started building big demos for Mozilla, which doubled as massive performance tests for browsers trying to compete for speed with WebGL: Flight of the Navigator, No Comply. And these led to yet more browser APIs for gaming, like Pointer Lock and Gamepad.
Since then it's been amazing to watch all the places that processing.js has gone. Twitter has always been full of people discovering it, and sharing their work, not least because of John and Khan Academy using it there in their curriculum. Years later, I even got to use it there with my own children to teach them to code.
I truly loved working on processing.js, probably more than any other project I've done in the past 10 years. It was my favourite kind of software to build for a few reasons:
While it's definitely time for processing.js to be archived and other projects to take its place, I wanted to at least say a proper goodbye. I'm thankful I got to spend so many years working in the middle of it, and to have had the chance to work with such a creative part of the internet.
Thanks, too, to Pomax for keeping the lights on years after the rest of us had gone to other projects.
And to processing.js, goodnight. Thanks for all the unit tests.
|
|
Nick Fitzgerald: wasm-bindgen — how does it work?! |
A month or so ago I gave a presentation on the inner workings of
wasm-bindgen to the WebAssembly Community Group. A
particular focus was the way that wasm-bindgen is forward-compatible with, and
acts as a sort of polyfill for, the host bindings proposal. A lot of this
material was originally supposed to appear in my SFHTML5 presentation, but
time constraints forced me to cut it out.
Unfortunately, the presentation was not recorded, but you can view the slide deck below, or open it in a new window. Navigate between slides with arrow keys or space bar.
http://fitzgeraldnick.com/2018/12/02/wasm-bindgen-how-does-it-work.html
|
|
Will Kahn-Greene: Socorro: November 2018 happenings |
Socorro is the crash ingestion pipeline for Mozilla's products like Firefox. When Firefox crashes, the Breakpad crash reporter asks the user if the user would like to send a crash report. If the user answers "yes!", then the Breakpad crash reporter collects data related to the crash, generates a crash report, and submits that crash report as an HTTP POST to Socorro. Socorro saves the crash report, processes it, and provides an interface for aggregating, searching, and looking at crash reports.
November was another busy month! This blog post covers what happened.
Read more… (5 mins to read)
http://bluesock.org/~willkg/blog/mozilla/socorro_2018_11.html
|
|






