The Rust Programming Language Blog: Procedural Macros in Rust 2018 |
Perhaps my favorite feature in the Rust 2018 edition is procedural macros. Procedural macros have had a long and storied history in Rust (and will continue to have a storied future!), and now is perhaps one of the best times to get involved with them because the 2018 edition has so dramatically improved the experience both defining and using them.
Here I'd like to explore what procedural macros are, what they're capable of, notable new features, and some fun use cases of procedural macros. I might even convince you that this is Rust 2018's best feature as well!
First defined over two years ago in RFC 1566, procedural macros are, in layman's terms, a function that takes a piece of syntax at compile time and produces a new bit of syntax. Procedural macros in Rust 2018 come in one of three flavors:
#[derive] mode macros have actually been stable since Rust 1.15
and bring all the goodness and ease of use of #[derive(Debug)] to
user-defined traits as well, such as Serde's #[derive(Deserialize)].
Function-like macros are newly stable to the 2018 edition and allow
defining macros like env!("FOO") or format_args!("...") in a
crates.io-based library. You can think of these as sort of "macro_rules!
macros" on steroids.
Attribute macros, my favorite, are also new in the 2018 edition and allow you to provide lightweight annotations on Rust functions which perform syntactical transformations over the code at compile time.
Each of these flavors of macros can be defined in a crate with proc-macro = true specified in its manifest. When used, a procedural macro is
loaded by the Rust compiler and executed as the invocation is expanded. This
means that Cargo is in control of versioning for procedural macros and you can
use them with all same ease of use you'd expect from other Cargo dependencies!
Each of the three types of procedural macros are defined in a slightly different
fashion, and here we'll single out attribute macros. First, we'll flag
Cargo.toml:
[lib]
proc-macro = true
and then in src/lib.rs we can write our macro:
extern crate proc_macro;
use proc_macro::TokenStream;
#[proc_macro_attribute]
pub fn hello(attr: TokenStream, item: TokenStream) -> TokenStream {
// ...
}
We can then write some unit tests in tests/smoke.rs:
#[my_crate::hello]
fn wrapped_function() {}
#[test]
fn works() {
wrapped_function();
}
... and that's it! When we execute cargo test Cargo will compile our
procedural macro. Afterwards it will compile our unit test which loads the macro
at compile time, executing the hello function and compiling the resulting
syntax.
Right off the bat we can see a few important properties of procedural macros:
TokenStream type we'll talk about more in a
bitBefore we take a look at implementing a procedural macro, let's first dive into some of these points.
First stabilized in Rust 1.30 (noticing a trend with 1.15?) macros are now
integrated with the module system in Rust. This mainly means that you no longer
need the clunky #[macro_use] attribute when importing macros! Instead of this:
#[macro_use]
extern crate log;
fn main() {
debug!("hello, ");
info!("world!");
}
you can do:
use log::info;
fn main() {
log::debug!("hello, ");
info!("world!");
}
Integration with the module system solves one of the most confusing parts about macros historically. They're now imported and namespaced just as you would any other item in Rust!
The benefits are not only limited to bang-style macro_rules macros, as you can
now transform code that looks like this:
#[macro_use]
extern crate serde_derive;
#[derive(Deserialize)]
struct Foo {
// ...
}
into
use serde::Deserialize;
#[derive(Deserialize)]
struct Foo {
// ...
}
and you don't even need to explicitly depend on serde_derive in Cargo.toml!
All you need is:
[dependencies]
serde = { version = '1.0.82', features = ['derive'] }
TokenStream?This mysterious TokenStream type comes from the compiler-provided
proc_macro crate. When it was first added all you could do with a
TokenStream was call convert it to or from a string using to_string() or parse().
As of Rust 2018, you can act on the tokens in a TokenStream directly.
A TokenStream is effectively "just" an iterator over TokenTree. All
syntax in Rust falls into one of these four categories, the four variants of
TokenTree:
Ident is any identifier like foo or bar. This also contains keywords
such as self and super.Literal include things like 1, "foo", and 'b'. All literals are one
token and represent constant values in a program.Punct represents some form of punctuation that's not a delimiter. For
example . is a Punct token in the field access of foo.bar.
Multi-character punctuation like => is represented as two Punct tokens,
one for = and one for >, and the Spacing enum says that the = is
adjacent to the >.Group is where the term "tree" is most relevant, as Group represents a
delimited sub-token-stream. For example (a, b) is a Group with parentheses
as delimiters, and the internal token stream is a, b.While this is conceptually simple, this may sound like there's not much we can
do with this! It's unclear, for example, how we might parse a function from a
TokenStream. The minimality of TokenTree is crucial, however, for
stabilization. It would be infeasible to stabilize the Rust AST because that
means we could never change it. (imagine if we couldn't have added the ?
operator!)
By using TokenStream to communicate with procedural macros, the compiler is
able to add new language syntax while also being able to compile
and work with older procedural macros. Let's see now, though, how we can
actually get useful information out of a TokenStream.
TokenStreamIf TokenStream is just a simple iterator, then we've got a long way to go from
that to an actual parsed function. Although the code is already lexed for us
we still need to write a whole Rust parser! Thankfully though the community has
been hard at work to make sure writing procedural macros in Rust is as smooth as
can be, so you need look no further than the syn crate.
With the syn crate we can parse any Rust AST as a one-liner:
#[proc_macro_attribute]
pub fn hello(attr: TokenStream, item: TokenStream) -> TokenStream {
let input = syn::parse_macro_input!(item as syn::ItemFn);
let name = &input.ident;
let abi = &input.abi;
// ...
}
The syn crate not only comes with the ability to parse built-in syntax
but you can also easily write a recursive descent parser for your own syntax.
The syn::parse module has more information about this capability.
TokenStreamNot only do we take a TokenStream as input with a procedural macro, but we
also need to produce a TokenStream as output. This output is typically
required to be valid Rust syntax, but like the input it's just list of tokens
that we need to build somehow.
Technically the only way to create a TokenStream is via its FromIterator
implementation, which means we'd have to create each token one-by-one and
collect it into a TokenStream. This is quite tedious, though, so let's take a
look at syn's sibling crate: quote.
The quote crate is a quasi-quoting implementation for Rust which primarily
provides a convenient macro for us to use:
use quote::quote;
#[proc_macro_attribute]
pub fn hello(attr: TokenStream, item: TokenStream) -> TokenStream {
let input = syn::parse_macro_input!(item as syn::ItemFn);
let name = &input.ident;
// Our input function is always equivalent to returning 42, right?
let result = quote! {
fn #name() -> u32 { 42 }
};
result.into()
}
The quote! macro allows you to write mostly-Rust syntax and interpolate
variables quickly from the environment with #foo. This removes much of the
tedium of creating a TokenStream token-by-token and allows quickly cobbling
together various pieces of syntax into one return value.
SpanPerhaps the greatest feature of procedural macros in Rust 2018 is the ability to
customize and use Span information on each token, giving us the ability for
amazing syntactical error messages from procedural macros:
error: expected `fn`
--> src/main.rs:3:14
|
3 | my_annotate!(not_fn foo() {});
| ^^^^^^
as well as completely custom error messages:
error: imported methods must have at least one argument
--> invalid-imports.rs:12:5
|
12 | fn f1();
| ^^^^^^^^
A Span can be thought of as a pointer back into an original source file,
typically saying something like "the Ident token foo came from file
bar.rs, line 4, column 5, and was 3 bytes long". This information is
primarily used by the compiler's diagnostics with warnings and error messages.
In Rust 2018 each TokenTree has a Span associated with it. This means that
if you preserve the Span of all input tokens into the output then even
though you're producing brand new syntax the compiler's error messages are still
accurate!
For example, a small macro like:
#[proc_macro]
pub fn make_pub(item: TokenStream) -> TokenStream {
let result = quote! {
pub #item
};
result.into()
}
when invoked as:
my_macro::make_pub! {
static X: u32 = "foo";
}
is invalid because we're returning a string from a function that should return a
u32, and the compiler will helpfully diagnose the problem as:
error[E0308]: mismatched types
--> src/main.rs:1:37
|
1 | my_macro::make_pub!(static X: u32 = "foo");
| ^^^^^ expected u32, found reference
|
= note: expected type `u32`
found type `&'static str`
error: aborting due to previous error
And we can see here that although we're generating brand new syntax, the compiler can preserve span information to continue to provide targeted diagnostics about code that we've written.
Ok up to this point we've got a pretty good idea about what procedural macros can do and the various capabilities they have in the 2018 edition. As such a long-awaited feature, the ecosystem is already making use of these new capabilities! If you're interested, some projects to keep your eyes on are:
syn, quote, and proc-macro2 are your go-to libraries for
writing procedural macros. They make it easy to define custom parsers, parse
existing syntax, create new syntax, work with older versions of Rust, and much
more!
Serde and its derive macros for Serialize and Deserialize are likely the
most used macros in the ecosystem. They sport an impressive amount of
configuration and are a great example of how small annotations
can be so powerful.
The wasm-bindgen project uses attribute macros to easily define
interfaces in Rust and import interfaces from JS. The #[wasm_bindgen]
lightweight annotation makes it easy to understand what's coming in and out,
as well as removing lots of conversion boilerplate.
The gobject_gen! macro is an experimental IDL for the GNOME
project to define GObject objects safely in Rust, eschewing manually writing
all the glue necessary to talk to C and interface with other GObject
instances in Rust.
The Rocket framework has recently switched over to procedural macros, and showcases some of nightly-only features of procedural macros like custom diagnostics, custom span creation, and more. Expect to see these features stabilize in 2019!
That's just a taste of the power of procedural macros and some example usage throughout the ecosystem today. We're only 6 weeks out from the original release of procedural macros on stable, so we've surely only scratched the surface as well! I'm really excited to see where we can take Rust with procedural macros by empowering all kinds of lightweight additions and extensions to the language!
https://blog.rust-lang.org/2018/12/21/Procedural-Macros-in-Rust-2018.html
|
|
Mozilla Addons Blog: Extensions in Firefox 65 |
In lieu of the normal, detailed review of WebExtensions API coming out in Firefox 65, I’d like to simply say thank you to everyone for choosing Firefox. Now, more than ever, the web needs people who consciously decide to support an open, private, and safe online ecosystem.
Two weeks ago, nearly every Mozilla employee gathered in Orlando, Florida for the semi-annual all-hands meeting. It was an opportunity to connect with remote teammates, reflect on the past year and begin sharing ideas for the upcoming year. One of the highlights was the plenary talk by Mitchell Baker, Chairwoman of the Mozilla Foundation. If you have not seen it, it is well worth 15 minutes of your time.
Mitchell talks about Firefox continually adapting to a changing internet, shifting its engagement model over time to remain relevant while staying true to its original mission. Near the end, she notes that it is time, once again, for Mozilla and Firefox to evolve, to shift from being merely a gateway to the internet to being an advocate for users on the internet.
Extensions will need to be part of this movement. We started when Firefox migrated to the WebExtensions API (only a short year ago), ensuring that extensions operated with explicit user permissions within a well-defined sandbox. In 2018, we made a concerted effort to not just add new API, but to also highlight when an extension was using those API to control parts of the browser. In 2019, expect to see us sharpen our focus on user privacy, user security, and user agency.
Thank you again for choosing Firefox, you have our deepest gratitude and appreciation. As a famous Mozillian once said, keep on rockin’ the free web.
-Mike Conca
Highlights of new features and fixes in Firefox 65:
A huge thank you to the community contributors in this release, including: Ben Armstrong, Oriol Brufau, Tim Nguyen, Ryan Hendrickson, Sean Burke, Yuki “Piro” Hiroshi, Diego Pino, Jan Henning, Arshad Kazmi, Nicklas Boman.
The post Extensions in Firefox 65 appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2018/12/20/extensions-in-firefox-65/
|
|
The Mozilla Blog: Latest Firefox Focus provides more user control |
The Internet is a huge playground, but also has a few dark corners. In order to ensure that users still feel secure and protected while browsing, we’ve implemented features that offer privacy and control in all of our products, including Firefox Focus.
Today’s release truly reflects this philosophy: Android users can now individually decide which publishers they want to share data with and are warned when they access risky content. We also have an update for iOS users with Search Suggestions.
Enhanced privacy settings in Firefox Focus
We initially created Firefox Focus to provide smartphone users with a tracking-free browsing experience that allows them to feel safe when navigating the web, and do it faster, too. However, cookies and trackers can create snail-paced experiences, and are also used to follow users across the Internet – often times without their knowledge. At Firefox, we are committed to giving users control and letting them decide what information is collected about them, which is why we recently introduced our Enhanced Tracking Protection approach and added corresponding improvements to Firefox for desktop. Today we are pleased to announce that Firefox Focus is following this lead.
Now you have more choices. You can choose to block all cookies on a website, no cookies at all – the default so far –, third party cookies or only 3rd party tracking cookies as defined by Disconnect’s Tracking Protection list. If you go with the latter option, which is new to Firefox Focus and also the new default, cross-site tracking will be prevented. This enables you to allow cookies if they contribute to the user experience for a website while still preventing trackers from being able to track you across multiple sites, offering you the same products over and over again and recording your online behavior.
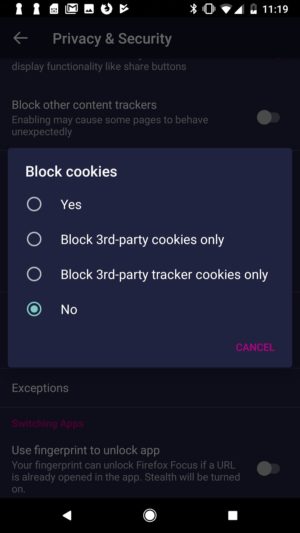 Firefox Focus now allows users to choose individually which cookies to accept.
Firefox Focus now allows users to choose individually which cookies to accept.
When you block cookies, you might find that some pages may no longer work properly. But no worries, we’re here to offer a solution: With just 2 clicks you can now add websites to the new Firefox Focus “allowlist”, which unblocks cookies and trackers for the current page visit. As soon as you navigate to another website, the setting resets so you don’t have to worry about a forgotten setting that could weaken your privacy.
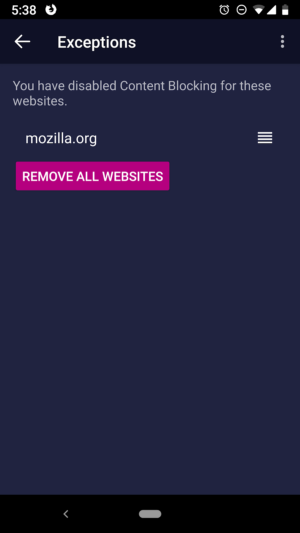 The new Firefox Focus allowlist unblocks cookies and trackers for the current page visit.
The new Firefox Focus allowlist unblocks cookies and trackers for the current page visit.
An update on GeckoView
In October we were happy to announce that Firefox Focus was going to be powered by Mozilla’s own mobile engine GeckoView. It allows us to implement many amazing new features. We are currently working on a good deal of under-the-hood improvements to enhance the performance of GeckoView. Occasionally some minor bugs may still occur and we’re looking forward to gathering your feedback, learning from your experiences with GeckoView and improving the engine accordingly.
In order to provide our users with another GeckoView sneak peek and something to test, we’re proud to also provide a new feature today: Thanks to in-browser security warnings, your mobile web browsing will now be a lot less risky. Firefox Focus will check URLs against Google’s constantly updated lists of unsafe web resources, which includes phishing and other fraudulent sites, and will provide an alert if you reach an unsafe site. You may then either follow to safety, or ignore to continue navigating to the requested site. After all, we value users’ right to choose how to browse, and want to make sure they’re able to make informed choices.
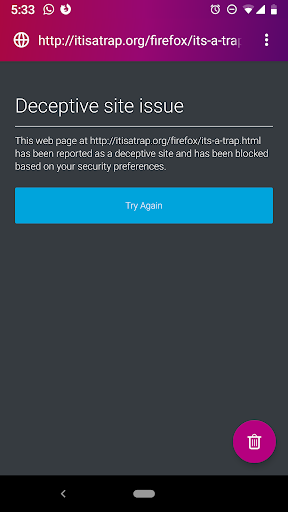 Firefox Focus now warns against phishing and other fraudulent sites.
Firefox Focus now warns against phishing and other fraudulent sites.
Firefox Focus for iOS now supports search suggestions
Search suggestions are an important component of searching the web and can make it so much more convenient. That’s why we’re making this feature available to iOS users today, after introducing it to Firefox Focus for Android in October. You can easily activate the feature by opening the app settings > click on “Search” > and select “Get search suggestions”.
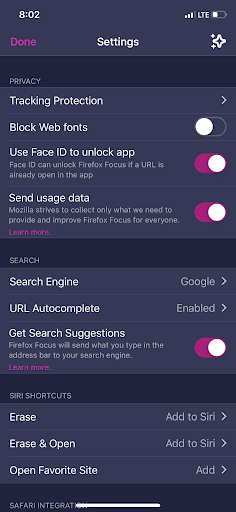 New for iOS users: get search suggestions and find what you’re looking for even faster!
New for iOS users: get search suggestions and find what you’re looking for even faster!
Get Firefox Focus now
The latest version of Firefox Focus for Android and iOS is now available for download on Google Play and in the App Store.
The post Latest Firefox Focus provides more user control appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2018/12/20/latest-firefox-focus-provides-more-user-control/
|
|
The Mozilla Blog: Create, test, innovate, repeat. |
Let’s imagine a not-too-distant future:
Imagine you are somewhere that is familiar to you such as your home, or your favorite park.
Imagine that everything around you is connected and it has a link.
Imagine you have the internet in your ears and you can speak directly to it.
Imagine that instead of 2D screens around you, the air is alive with knowledge and wonder.
Imagine that you are playing your favorite game with your friend while they are virtually sitting next to you.
Now, imagine what that looks like covered in ads. Malware is everywhere, and you have no control over what you see or hear.
Technology will continue to shape our lives and our future, but what that future looks like is up to us. We are excited about the internet growing and evolving, but new possibilities bring new challenges. We don’t need to give up control of our personal lives in exchange for great products that rely on personal data for ads. Here at Mozilla, we are working hard to make sure that new technologies evolve in a way that champion privacy and choice.
We do this by engaging with engineers, teachers, researchers, developers, creators, artists, and thinkers around the globe to ensure that every voice is heard. We are constantly building new prototypes and experimental products for platforms that have the potential to build a different kind of web experience.
Today, Mozilla is launching a new Mozilla Labs. This is our online space where anyone can find our latest creations, innovations, and cutting-edge technologies.
What will you find at Mozilla Labs?
Install Firefox Reality and browse the immersive web completely in virtual reality.
Those are just a few of the future technologies we worked on in 2018, and we are just getting started. As we ramp up for 2019, we will continue to innovate across platforms such as Virtual Reality, Augmented Reality, Internet of Things, Speech/Voice, Artificial Intelligence, Open Web Technologies, and so much more.
You can check out our cutting-edge projects on Mozilla Labs, or you can roll up your sleeves and contribute to one of our many open source projects. Together we can collectively build the future we want to see.
The post Create, test, innovate, repeat. appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2018/12/20/create-test-innovate-repeat/
|
|
The Rust Programming Language Blog: Announcing Rust 1.31.1 |
The Rust team is happy to announce a new version of Rust, 1.31.1. Rust is a systems programming language focused on safety, speed, and concurrency.
If you have a previous version of Rust installed via rustup, getting Rust 1.31.1 is as easy as:
$ rustup update stable
If you don't have it already, you can get rustup from the
appropriate page on our website, and check out the detailed release notes for
1.31.1 on GitHub.
This patch release fixes a build failure on powerpc-unknown-netbsd by
way of an update to the libc
crate used by the compiler.
Additionally, the Rust Language Server was updated to fix two critical bugs. First, hovering over the type with documentation above single-line attributes led to 100% CPU usage:
/// Some documentation
#[derive(Debug)] // Multiple, single-line
#[allow(missing_docs)] // attributes
pub struct MyStruct { /* ... */ }
Go to definition was fixed for std types:
Before, using the RLS on HashMap, for example, tried to open this file
~/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/libstd/collections/hash/map.rs
and now RLS goes to the correct location (for Rust 1.31, note the extra src):
~/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/src/libstd/collections/hash/map.rs
|
|
Daniel Stenberg: Why is curl different everywhere? |
At a talk I did a while ago, someone from the back of the audience raised this question. I found it to be such a great question that I decided to spend a few minutes and explain how this happens and why.
In this blog post I’ll stick to discussing the curl command line tool. “curl” is often also used as a shortcut for the library but let’s focus on the tool here.
When you use a particular curl version installed in a system near you, chances are that it differs slightly from the curl your neighbor runs or even the one that you use in the machines at work.
Why is this?
We release a new curl version every eight weeks. On average we ship over thirty releases in a five-year period.
A lot of people use curl versions that are a few years old, some even many years old. There are easily more than 30 different curl version in active use at any given moment.
Not every curl release introduce changes and new features, but it is very common and all releases are at least always corrected a lot of bugs from previous versions. New features and fixed bugs make curl different between releases.
Linux/OS distributions tend to also patch their curl versions at times, and then they all of course have different criteria and work flows, so the exact same curl version built and shipped from two different vendors can still differ!
curl builds on almost every platform you can imagine. When you build curl for your platform, it is designed to use features, native APIs and functions available and they will indeed differ between systems.
curl also relies on a number of different third party libraries. The set of libraries a particular curl build is set to use varies by platform, but even more so due to the decisions of the persons or group that built this particular curl executable. The exact set, and the exact versions of each of those third party libraries, will change curl’s feature set, from subtle and small changes up to large really noticeable differences.
As a special third party library, I want to especially highlight the importance of the TLS library that curl is built to use. It will change not only what SSL and TLS versions curl supports, but also how to handle CA certificates, it provides crypto support for authentication schemes such as NTLM and more. Not to mention that of course TLS libraries also develop over time so if curl is built to use an older release, it probably has less support for later features and protocol versions.
When building curl, you can switch features on and off to a very large extent, making it possible to quite literally build it in several million different combinations. The organizations, people and companies that build curl to ship with their operating systems or their package distribution systems decide what feature set they want or don’t want for their users. One builder’s decision and thought process certainly does not have to match the ones of the others’. With the same curl version, the same TLS library on the same operating system two curl builds might thus still end up different!
If you aren’t satisfied with the version or feature-set of your own locally installed curl – build your own!
https://daniel.haxx.se/blog/2018/12/19/why-is-curl-different-everywhere/
|
|
Chris H-C: Data Science is Festive: Christmas Light Reliability by Colour |
This past weekend was a balmy 5 degrees Celsius which was lucky for me as I had to once again climb onto the roof of my house to deal with my Christmas lights. The middle two strings had failed bulbs somewhere along their length and I had a decent expectation that it was the Blue ones. Again.
Two years ago was our first autumn at our new house. The house needed Christmas lights so we bought four strings of them. Over the course of their December tour they suffered devastating bulb failures rendering alternating strings inoperable. (The bulbs are wired in a single parallel strand making a single bulb failure take down the whole string. However, connectivity is maintained so power flows through the circuit.)

Last year I tested the four strings and found them all faulty. We bought two replacement strings and I scavenged all the working bulbs from one of the strings to make three working strings out of the old four. All five (four in use, one in reserve) survived the season in working order.

This year in performing my sanity check before climbing the ladder I had to replace lamps in all three of the original strings to get them back to operating condition. Again.
And then I had an idea. A nerdy idea.
I had myself a wonderful nerdy idea!
“I know just what to do!” I laughed like an old miser.
I’ll gather some data and then visualize’er!
The strings are penta-colour: Red, Orange, Yellow, Green, and Blue. Each string has about an equal number of each colour of bulb and an extra Red and Yellow replacement bulb. Each bulb is made up of an internal LED lamp and an external plastic globe.
The LED lamps are the things that fail either from corrosion on the contacts or from something internal to the diode.
So I started with 6N+12 lamps and 6N+12 globes in total: N of each colour with an extra 1 Red and 1 Yellow per string. Whenever a lamp died I kept its globe. So the losses over time should manifest themselves as a surplus of globes and a defecit of lamps.
If the losses were equal amongst the colours we’d see a equal surplus of Green, Orange, and Blue globes and a slightly lower surplus of Red and Yellow globes (because of the extras). This is not what I saw when I lined them all up, though:

Instead we find ourselves with no oranges (I fitted all the extra oranges into empty blue spots when consolidating), an equal number of lamps and globes of yellow (yellow being one of the colours adjacent to most broken bulbs and, thus, less likely to be chosen for replacement), a mild surplus of red (one red lamp had evidently failed at one point), a larger surplus of green globes (four failed green lamps isn’t great but isn’t bad)…
And 14 excess blue globes.
Now, my sampling frequency isn’t all that high. And my knowledge of confidence intervals is a little rusty. But that’s what I think I can safely call a statistical outlier. I’m pretty sure we can conclude that, on my original set of strings of Christmas lights, Blue LEDs are more likely to fail than any other colour. But why?
I know from my LED history that high-luminance blue LEDs took the longest to be invented (patents filed in 1993 over 30 years after the first red LED). I learned from my friend who works at a display company that blue LEDs are more expensive. If I take those together I can suppose that perhaps the manufacturers of my light strings cheaped out on their lot of blue LEDs one year and stuck me, the consumer, with substandard lamps.
Instead of bringing joy, it brought frustration. But also predictive power because, you know what? On those two broken strings I had to climb up to retrieve this past, unseasonably-warm Saturday two of the four failed bulbs were indeed, as I said at the top, the Blue ones. Again.
:chutten
|
|
This Week In Rust: This Week in Rust 265 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
Find all #Rust2019 posts at Read Rust.
This week's crate is yaserde, a specialized XML (de)serialization crate compatible with serde. Thanks to Marc Antoine Arnaud for the suggestion!
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
247 pull requests were merged in the last week
adx target feature to whitelistimpl Trait when suggesting lifetimeSelf ctor in typedefsAllocation sizes for pattern lengthAllocId managementsimd_select_bitmask intrinsicTokenStream improvementstokenstream::DelimitedFileSearch and SearchPathsSortedMap upgradesconst unsafe fn bodies unsafe#[must_use] on traits in stdlibBTreeMap UBmem feature for no_std targetschecked_add method to Instant time typeVecDeque: fix for stacked borrowsChanges to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
No RFCs are currently in final comment period.
#[repr(packed(N))] (tracking issue for RFC 1399).If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Tweet us at @ThisWeekInRust to get your job offers listed here!
impl Drop for Mic {}
– Nick Fitzgerald rapping about Rust
Thanks to mark-i-m for the suggestion!
Please submit your quotes for next week!
This Week in Rust is edited by: nasa42, llogiq, and Flavsditz.
https://this-week-in-rust.org/blog/2018/12/18/this-week-in-rust-265/
|
|
Wladimir Palant: BBN challenge resolution: Getting the flag from a browser extension |
My so far last BugBountyNotes challenge is called Can you get the flag from this browser extension?. Unlike the previous one, this isn’t about exploiting logical errors but the more straightforward Remote Code Execution. The goal is running your code in the context of the extension’s background page in order to extract the flag variable stored there.
If you haven’t looked at this challenge yet, feel free to stop reading at this point and go try it out. Mind you, this one is hard and only two people managed to solve it so far. Note also that I won’t look at any answers submitted at this point any more. Of course, you can also participate in any of the ongoing challenges as well.
Still here? Ok, I’m going to explain this challenge then.
This browser extension is a minimalist password manager: it doesn’t bother storing passwords, only login names. And the vulnerability is of a very common type: when generating HTML code, this extension forgets to escape HTML entities in the logins:
for (let login of logins)
html += `${login} `;Since the website can fill out and submit a form programmatically, it can make this extension remember whichever login it wants. Making the extension store something like login will result in JavaScript code executing whenever the user opens the website in future. Trouble is: the code executes in the context of the same website that injected this code in the first place, so nothing is gained by that.
What you’d really want is having your script run within the content script of the extension. There is an interesting fact: if you call eval() in a content script, code will be evaluated in the context of the content script rather than website context. This happens even if the extension’s content security policy forbids eval: content security policy only applies to extension pages, not to its content scripts. Why the browser vendors don’t tighten security here is beyond me.
And now comes something very non-obvious. The HTML code is being inserted using the following:
$container = $(html);
$login.parent().prepend($container);One would think that jQuery uses innerHTML or its moral equivalent here but that’s not actually true. innerHTML won’t execute JavaScript code within
https://palant.de/2018/12/17/bbn-challenge-resolution-getting-the-flag-from-a-browser-extension
|
|
Don Marti: Firefox extensions list 2018 |
One of the great things about Firefox is the ability to customize with extensions.A MIG-15 can climb and turn faster than an F-86. A MIG-15 is more heavily armed. But in actual dogfights the F-86 won 9 out of 10 times. Part of that is training, but part is that the Soviets used data to build for the average pilot, while the USA did a bigger study of pilots' measurements and recognized that adjustable seats and controls were necessary. Even in a group of pilots of average overall size, nobody was in the average range on all their measurements. Here is what I'm running right now.
Awesome RSS. Get the RSS button back. Works great with RSS Preview.
blind-reviews. This is an experiment to help break your own habits of bias when reviewing code contributions. It hides the contributor name and email when you first see the code, and you can reveal it later.
Cookie AutoDelete. Similar to the old "Self-Destructing Cookies". Cleans up cookies after leaving a site. Useful but requires me to whitelist the sites where I want to stay logged in. More time-consuming than other privacy tools. This is a good safety measure that helps protect me while I'm trying out new the new privacy settings in Firefox Nightly as my main data protection tool.
Copy as Markdown. Not quite as full-featured as the old "Copy as HTML Link" but still a time-saver for blogging. Copy both the page title and URL, formatted as Markdown, for pasting into a blog.
Facebook Container because, well, Facebook.
Facebook Political Ad Collector, even though I don't visit Facebook very often. This one reports sneaky Facebook ads to ProPublica.
Global Consent Manager, which provides an improved consent experience for European sites. More info coming soon.
HTTPS Everywhere. This is pretty basic. Use the encrypted version of a site where available.
Link Cleaner. Get rid of crappy tracking parameters in URLs, and speed up some navigation by skipping data collection redirects.
NJS. Minimal JavaScript disable/enable button that remembers the setting by site and defaults to "on". Most sites that use JavaScript for real applications are fine, but this is for handling sites that cut and pasted a "Promote your newsletter to people who haven't even read your blog yet" script from some "growth hacking" article.
Personal Blocklist is surprisingly handy for removing domains that are heavy on SEO but weak on actual information from search results. (the Ministry of Central Planning at Google is building the perfectly-measured MIG cockpit, while extension developers make stuff adjustable.)
RSS Preview. The other missing piece of the RSS experience. The upside to the unpopularity of RSS is that so many sites just leave the full-text RSS feeds, that came with their CMS, turned on.
'Artifact' Isn't a Game on Steam, It's Steam in a Game - Waypoint
Does It Matter Where You Go to College?
The Golden Age of Rich People Not Paying Their Taxes
Liberating Birds For A Cheap Electric Scooter
|
|
Nick Cameron: What to do in Christchurch |
LCA 2018 is happening in January in Christchurch (which is a great conference and has a few Rust talks this year). I'm not able to attend, but I am in town, so I hope to meet some of my internet friends (get in touch!).
I thought I'd write down a few things to do in Christchurch for those who are new to the city. Don't get your hopes up for lots of tourist fun though (unless you have time to see some of the surrounding country), it is not the most interesting city, even less so since half of it was flattened in an earthquake. For more ideas, I like the Neat Places website.
Any questions, ping me on twitter - @nick_r_cameron.
|
|
Cameron Kaiser: A thank you to Ginn Chen, whom Larry Ellison screwed |
To my consternation, however, there was no contributed build for 52.9, the last 52ESR. I had to walk all the way back to 52.0.2 to find the last Solaris 10 package, which was accompanied by this sad message:
This directory contains Solaris builds of Firefox 52.0.2 ESR, which are contributed by Oracle Solaris Desktop Beijing Team. If you have any problem with these builds, please send email to ginnchen at gmail dot comThis is the last contrib build before I leave Oracle.
My job is eliminated.
Thanks everyone for supporting me.
ginnchen@...
I don't know if anyone ever said to Ginn how much all that work was appreciated. Well, I'm saying it now. I hope for much greener pastures away from scum like Larry, who ruined Sun, Solaris and SPARC just by being his scummy self, and lays off good folks just so he can buy another island. Here is Ginn's last build:

To this day, in Solaris 11, Firefox 52.9 is the last Firefox available, probably using Ginn's work.
http://tenfourfox.blogspot.com/2018/12/a-thank-you-to-ginn-chen-whom-larry.html
|
|
Mozilla GFX: WebRender newsletter #33 |
Hi! The newsletter skipped a week because of Mozilla’s bi-annual allhands which took place in Orlando last week. We’ll probably skip a few others in December as a lot of the gfx folks are taking some time off. Before I get to the usual change list, I’ll continue answering the questions nic4r asked in the 31st newsletter’s comment section:
Is the interning work Glenn is doing related to picture caching?
Yes indeed. In order for picture caching to work across displaylists we must be able to detect what did not change after a new displaylist arrives. The interning mechanism introduced by Glenn in #3075 gives us this ability in addition to other goodies such as de-duplication of interned resources and less CPU-GPU data transfer.
What is blob tiling and what does it offer above normal blob rendering?
Tiling blobs means splitting blobs into square tiles. For very large blobs this means we can lazily rasterize tiles as they come into the viewport without throwing away the rest instead of either rasterizing excessively large blob images in one go or having to clip the blob against the viewport and re-rasterize everything during scrolling as the bounds of the blob change. It also lets us rasterize tiles in parallel.
Is there a bug to watch some of the document splitting work going on? My understanding is that document splitting will make the chrome more resilient against slow scene builds in the content frame? Is this right? How does this compare to push_iframe in the DL.
You can look at bug 1441308 although it doesn’t contain a lot of updates. In a nutshell, the bulk of the Gecko side work is done and there are WebRender side adjustments and some debugging to do. Currently WebRender can nest displaylists from different sources (content, UI, etc) by nesting iframes into a single document. Any change to the document more or less causes it to be re-rendered entirely (modulo caching optimizations).
Separating the UI and web content into separate documents mostly means we will update them independently and updating one won’t cause the other to be re-built and re-rendered. It will also let us render the the two in separate OS compositor windows.
One of the most complicated aspect of this is probably due to the way the browser is structured to nest the web content within the UI (there is both a background behind the web content and elements on top of it that belong to the UI). A lot of the work that went into this was to be able to split without introducing a lot of overdraw (needlessly allocating texture space for the background behind the web content and drawing it).
OMTA for color, gradients, etc? How much more of CSS can be feasibly calculated off thread and fed to WR using its Property Binding infra?
Anything is possible given enough time and motivation but with WebRender’s current architecture, any of the data that is fed directly to the shaders is a good candidate for animated property bindings. Colors are particularly appealing because it is the most commonly animated CSS property that we don’t already run as an off-main-thread animation (I don’t have the data handy though). We’ll likely tackle these nice perf optimizations after WebRender is shipped and stable.
In about:config, set the pref “gfx.webrender.all” to true and restart the browser.
The best place to report bugs related to WebRender in Firefox is the Graphics :: WebRender component in bugzilla.
Note that it is possible to log in with a github account.
https://mozillagfx.wordpress.com/2018/12/13/webrender-newsletter-33/
|
|
Daniel Stenberg: 7.63.0 – another step down the endless path |
This curl release was developed and put together over a period of six weeks (two weeks less than usual). This was done to accommodate to my personal traveling plans – and to avoid doing a release too close to Christmas in case we would ship any security fixes, but ironically, we have no security advisories this time!
the 178th release
3 changes
42 days (total: 7,572)
79 bug fixes (total: 4,837)
122 commits (total: 23,799)
0 new public libcurl functions (total: 80)
1 new curl_easy_setopt() options (total: 262)
0 new curl command line option (total: 219)
51 contributors, 21 new (total: 1,829)
31 authors, 14 new (total: 646)
0 security fixes (total: 84)
With the new CURLOPT_CURLU option, an application can now pass in an already parsed URL to libcurl instead of a string.
When using libcurl’s URL API, introduced in 7.62.0, the result is held in a “handle” and that handle is what now can be passed straight into libcurl when setting up a transfer.
In the command line tool, the –write-out option got the ability to optionally redirect its output to stderr. Previously it was always a given file or stdout but many people found that a bit limiting.
Weirdly enough we found and fixed a few cookie related bugs this time. I say “weirdly” because you’d think this is functionality that’s been around for a long time and should’ve been battle tested and hardened quite a lot already. As usual, I’m only covering some bugs here. The full list is in the changelog!
Cookie saving – One cookie bug that we fixed was related to libcurl not saving a cookie jar when no cookies are kept in memory (any more). This turned out to be a changed behavior due to us doing more aggressive expiry of old cookies since a while back, and one user had a use case where they would load cookies from a cookie jar and then expect that the cookies would update and write to the jar again, overwriting the old one – although when no cookies were left internally it didn’t touch the file and the application thus reread the old cookies again on the next invoke. Since this was subtly changed behavior, libcurl will now save an empty jar in this situation to make sure such apps will note the blank jar.
Cookie expiry – For the received cookies that get ‘Max-Age=0’ set, curl would treat the zero value the same way as any number and therefore have the cookie continue to exist during the whole second it arrived (time() + 0 basically). The cookie RFC is actually rather clear that receiving a zero for this parameter is a special case and means that it should rather expire it immediately and now curl does.
Timeout handling – when calling curl_easy_perform() to do a transfer, and you ask libcurl to timeout that transfer after say 5.1 seconds, the transfer hasn’t completed in that time and the connection is in fact totally idle at that time, a recent regression would make libcurl not figure this out until a full 6 seconds had elapsed.
NSS – we fixed several minor issues in the NSS back-end this time. Perhaps the most important issue was if the installed NSS library has been built with TLS 1.3 disabled while curl was built knowing about TLS 1.3, as then things like the ‘–tlsv1.2’ option would still cause errors. Now curl will fall back correctly. Fixes were also made to make sure curl again works with NSS versions back to 3.14.
OpenSSL – with TLS 1.3 session resumption was changed for TLS, but now curl will support it with OpenSSL.
snprintf – curl has always had its own implementation of the *printf() family of functions for portability reasons. First, traditionally snprintf() was not universally available but then also different implementations have different support for things like 64 bit integers or size_t fields and they would disagree on return values. Since curl’s snprintf() implementation doesn’t use the same return code as POSIX or other common implementations we decided we shouldn’t use the same name so that we don’t fool readers of code into believing that they are fully compatible. For that reason, we now also “ban” the use of snprintf() in the curl code.
URL parsing – there were several regressions from the URL parsing news introduced in curl 7.62.0. That os the first release that offers the new URL API for applications, and we also then switched the internals to use that new code. Perhaps the funniest error was how a short name plus port number (hello:80) was accidentally treated as a “scheme” by the parser and since the scheme was unknown the URL was rejected. The numerical IPv6 address parser was also badly broken – I take the blame for not writing good enough test cases for it which made me not realize this in time. Two related regressions that came from the URL work broke HTTP Digest auth and some LDAP transfers.
DoH over HTTP/1 – DNS-over-HTTPS was simply not enabled in the build if HTTP/2 support wasn’t there, which was an unnecessary restriction and now h2-disabled builds will also be able to resolve host names using DoH.
Trailing dots in host name – an old favorite subject came back to haunt us and starting in this version, curl will keep any trailing dot in the host name when it resolves the name, and strip it off for all the rest of the uses where the name will be passed in: for cookies, for the HTTP Host: header and for the TLS SNI field. This, since most resolver APIs makes a difference between resolving “host” compared to “host.” and we wouldn’t previously acknowledge or support the two versions.
HTTP/2 – When we enabled HTTP/2 by default for more transfers in 7.62.0, we of course knew that could force more latent bugs to float up to the surface and get noticed. We made curl understand HTTP_1_1_REQUIRED error when received over HTTP/2 and then retry over HTTP/1.1. and if NTLM is selected as the authentication to use curl now forces HTTP/1 use.
We have suggested new features already lined up waiting to get merged so the next version is likely to be called 7.64.0 and it is scheduled to happen on February 6th 2019.
https://daniel.haxx.se/blog/2018/12/12/7-63-0-the-endless-path/
|
|
Hacks.Mozilla.Org: Firefox 64 Released |
Firefox 64 is available today! Our new browser has a wealth of exciting developer additions both in terms of interface features and web platform features, and we can’t wait to tell you about them. You can find out all the news in the sections below — please check them out, have a play around, and let us know your feedback in the comment section below.
We’re excited to introduce multiple tab selection, which makes it easier to manage windows with many open tabs. Simply hold Control (Windows, Linux) or Command (macOS) and click on tabs to select them.
Once selected, click and drag to move the tabs as a group — either within a given window, or out into a new window.
Our Developer Tools also gained a notable new feature: when hovering over text, the Accessibility Inspector now displays text contrast ratios in the pop-up infobar.

The infobar also indicates whether or not the text meets WCAG 2.0 Level AA or AAA accessibility guidelines for minimum contrast.
Another great addition is related to Responsive Design Mode — device selection is now saved between sessions.
As part of our platform work, we’re trying to standardize some of the non-standard CSS features that have often caused developers cross-browser headaches. Landing in 64 we’ve got the following:
-webkit-appearance: To make the effects of the appearance property more consistent across browsers, Firefox has unshipped all of its own proprietary values from web content, and added support for all the -webkit-prefixed versions that are in common use. See https://developer.mozilla.org/en-US/docs/Web/CSS/appearance on MDN Web Docs for more information.-webkit-prefixed pseudo-element, that pseudo-element no longer invalidates the whole group.Firefox 64 sees the addition of new media queries from the Level 4 and Level 5 specifications for detecting pointers/touchscreens, whether the user can hover over something, and whether the user prefers reduced-motion.
CSS gradients now support multi-position color stops (e.g. see their use on linear gradients). So now yellow 25%, yellow 50% can now be written yellow 25% 50%, for example.
There were a lot of internal improvements this time around. In terms of developer facing improvements:
.call().Goodbye mozRequestFullScreen! The Fullscreen API is now available in Firefox without a prefix. The requestFullscreen and exitFullscreen APIs now also return promises that resolve once the browser finishes transitioning between states.
What’s more immersive than Fullscreen? Virtual reality, of course. And Firefox 64 now supports WebVR 1.1 on macOS!

On a completely unrelated note, pages with Service Workers can now use the startMessages() API to begin receiving queued worker messages, even before page loading has completed.
What follows are the highlights. For more details, see Extensions in Firefox 64.
Firefox 64 introduces an entirely new API, browser.menus.overrideContext, which allows complete customization of the context menu shown within add-on content like sidebars, popups, etc. These context menus can also automatically include custom entries from other add-ons, as though the user had right-clicked on a tab or bookmark. Piro’s blog post explains how it all works.

In addition:
viewTypes property in menus.create() and menus.update().button property of menus.OnClickData.Also, add-ons can now display custom content within the Dev Tools Inspector sidebar by calling the new sidebar.setPage() API.
For users, the add-on management interface, about:addons, was redesigned to match Firefox’s preferences page, and right-clicking an add-on icon in the browser toolbar now offers options to directly remove or manage that add-on.
Due to a history of malpractice, Firefox 64 will not trust TLS certificates issued by Symantec (including under their GeoTrust, RapidSSL, and Thawte brands). Microsoft, Google, and Apple are implementing similar measures for their respective browsers.
The Referrer-Policy header now applies to requests initiated by CSS (e.g., background-image: url("http://...") ). The default policy, no-referrer-when-downgrade, omits referrer information when a secure origin (https) requests data from an insecure origin (http).
Lastly, from now on the non-standard navigator.buildID property will always return a fixed timestamp, 20181001000000, to mitigate its potential abuse for fingerprinting.
For more information, see Firefox 64 for Developers on MDN, and the official Firefox 64 Release Notes. If you’re a web developer, you may also be interested in the Firefox 64 Site Compatibility notes.
The post Firefox 64 Released appeared first on Mozilla Hacks - the Web developer blog.
|
|
The Mozilla Blog: Latest Firefox Release Available Today |
It’s the season for spending time with family and friends over a nice meal and exchanging gifts. Whether it’s a monogrammed bag or a nicely curated 2019 calendar of family photos, it’s the practical gifts that get the most use.
For Firefox, we’re always looking for ways to simplify and personalize your online experience. For today’s version of Firefox for desktop, we have a couple new features that do just that. They include:
Aimed at people who are looking to get more out of their online experience or ways to level up. CFR is a system that proactively recommends Firefox features and add-ons based on how you use the web. For example, if you open multiple tabs and repeatedly use these tabs, we may offer a feature called “Pinned Tabs” and explain how it works. Firefox curates the suggested features and notifies you. With today’s release, we will start to rollout with three recommended extensions which include: Facebook Container, Enhancer for YouTube and To Google Translate. This feature is available for US users in regular browsing mode only. They will not appear in Private Browsing mode. Also, Mozilla does NOT receive a copy of your browser history. The entire process happens locally in your copy of Firefox.
When you go online, it’s not uncommon to have several tabs open on a variety of topics whether it’s dinner recipes or gift ideas for your family, it can add up to a lot of tabs. How does anyone ever organize all those tabs? In today’s release, you can now shift or ctrl-click multiple tabs from the tab bar, and organize them the way you want. You can mute, move, bookmark or pin them quickly and easily.
Here’s a link to our release notes for a complete list of what’s included in today’s release.
Check out and download the latest version of Firefox Quantum available here. For the latest version of Firefox for iOS, visit the App Store.
The post Latest Firefox Release Available Today appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2018/12/11/latest-firefox-release-available-today/
|
|
Nick Fitzgerald: Rust 2019: Think Bigger |
Rust shines when we find ways to have our cake and eat it too: memory safety without runtime garbage collection, abstraction without overhead, threading without data races. We must find new ways to continue this tradition for Rust 2019 and beyond.
On a day-to-day basis, I am dedicated to small, incremental progress. If a pull request is an improvement over the status quo, merge it now! Don’t wait for the pull request to be perfectly pristine or the feature to be 100% complete. Each day we drag reality inch by inch towards the ideal.
However, when planning on the scale of years, our vision must not be weighed down by discussion of incremental improvements: we must rise and collectively define the lofty ideals we aim for. It requires avoiding local maxima. Nick Cameron’s Rust in 2022 post, where he starts with what we might want in a Rust 2022 edition and then works backwards from there, is a great example.
With that out of the way, I will make a couple suggestions for the Rust 2019 roadmap. I will leave my thoughts for the Rust and WebAssembly domain working group’s 2019 roadmap for a future post.
Tired: make
rustcfaster.Wired: integrate distributed compilation and artifact caching into
cargoand crates.io.
Of course we should continue identifying and implementing performance wins in
rustc itself. We should even invest in larger scale rearchitecting like adding
finer-grained parallelism in with rayon (I won’t go into too many specifics
here because I’m largely ignorant of them!)
But we should also be thinking bigger.
The fastest compilation is the one that you didn’t have to do. If we integrate
something like sccache into cargo and crates.io, then individuals
can download pre-built artifacts for common dependencies from a shared cache and
save big on local CPU time. In comparison, a 5% speedup to trait resolution is
peanuts. This is an opportunity that is not available to most language
ecosystems! Most languages don’t have a compiler toolchain, build system, and
package manager that are widely used together and well integrated.
Tired: make
wasm-packreally good.Wired: make
wasm-packunnecessary by building generic task hooks intocargoitself.
Different domains have different workflows that extend past cargo build. With
WebAssembly, we must also generate JavaScript bindings, run tools like
wasm-opt, create a package.json to integrate with NPM and JavaScript
tooling, etc… For embedded development, you need to at minimum flash your
built program into your microcontroller’s persistent memory.
To perform these tasks today, we typically write whole new tools that wrap
cargo (like wasm-pack), invoke external tools manually (like using openocd
by hand), or write a cargo-mytask package to add the cargo mytask
subcommand. These solutions suffer from either repetition and a lack of
automation, or they wrap cargo but fail to expose all the wonderful features
that cargo supports (for example, you can’t use the --feature flag yet with
wasm-pack). We should not write these tools that wrap cargo, we should write
generic build tasks, which are invoked automatically by cargo itself.
cargo should not just grow a post_build.rs hook, its build tasks and
dependencies between tasks and artifacts should become fully extensible. I
should be able to depend on wasm build tasks in my Cargo.toml, and then after
that cargo build should just Do The Right Thing. I shouldn’t have to compile
these wasm build tasks for every project I use them with. cargo and crates.io
should handle transparently distributing the wasm task binaries to me.
Tired: the Rust project should start a working group for
$PROJECT_OR_DOMAIN.Wired: the Rust project should have a working group template, and system of mentorship for new (and old!) working group leads.
The more we collaborate and work together, the better we can tackle problems that are larger than any one of us. The primary way we’ve been organizing technical efforts in the Rust project has been working groups. But starting a new working group is hard, and leading a working group is hard.
We should have a template for new working groups that comes with cookie-cutter steps to follow to help build an open community, articulate working group vision, and collectively organize. Of course these steps will need to evolve for each particular working group’s needs, but having something to help new working groups hit the ground running is incredibly valuable. It would have been so useful for me when we were kicking off the WebAssembly domain working group last year. A lot of things that are obvious in retrospect were not at the time: hold weekly meetings, adopt an RFC process, communicate(!!), create room for contributors to own sub-goals, etc…
Additionally, every working group lead should have a mentor who is in a leadership position within the Rust project: someone who is a member of the Rust core team or a lead of another working group or team. Someone to rubber duck with and seek guidance from in the context of leadership and organization.
Instead of enabling Rust users to ask Rust leadership for a working group for
X, we should empower them to start the working group for X themselves, and
we should continuously follow up to ensure that they succeed. To have our cake
and eat it too, Rust development must be a positive-sum game.
#Rust2019Whatever we end up with in the 2019 roadmap, I have faith that what we choose will be worthy. We don’t suffer from a lack of good options.
I hope we never stop dreaming big and being ambitious.
http://fitzgeraldnick.com/2018/12/11/rust-2019-think-bigger.html
|
|
Nick Fitzgerald: Rust 2019: Think Bigger |
Rust shines when we find ways to have our cake and eat it too: memory safety without runtime garbage collection, abstraction without overhead, threading without data races. We must find new ways to continue this tradition for Rust 2019 and beyond.
On a day-to-day basis, I am dedicated to small, incremental progress. If a pull request is an improvement over the status quo, merge it now! Don’t wait for the pull request to be perfectly pristine or the feature to be 100% complete. Each day we drag reality inch by inch towards the ideal.
However, when planning on the scale of years, our vision must not be weighed down by discussion of incremental improvements: we must rise and collectively define the lofty ideals we aim for. It requires avoiding local maxima. Nick Cameron’s Rust in 2022 post, where he starts with what we might want in a Rust 2022 edition and then works backwards from there, is a great example.
With that out of the way, I will make a couple suggestions for the Rust 2019 roadmap. I will leave my thoughts for the Rust and WebAssembly domain working group’s 2019 roadmap for a future post.
Tired: make
rustcfaster.Wired: integrate distributed compilation and artifact caching into
cargoand crates.io.
Of course we should continue identifying and implementing performance wins in
rustc itself. We should even invest in larger scale rearchitecting like adding
finer-grained parallelism in with rayon (I won’t go into too many specifics
here because I’m largely ignorant of them!)
But we should also be thinking bigger.
The fastest compilation is the one that you didn’t have to do. If we integrate
something like sccache into cargo and crates.io, then individuals
can download pre-built artifacts for common dependencies from a shared cache and
save big on local CPU time. In comparison, a 5% speedup to trait resolution is
peanuts. This is an opportunity that is not available to most language
ecosystems! Most languages don’t have a compiler toolchain, build system, and
package manager that are widely used together and well integrated.
Tired: make
wasm-packreally good.Wired: make
wasm-packunnecessary by building generic task hooks intocargoitself.
Different domains have different workflows that extend past cargo build. With
WebAssembly, we must also generate JavaScript bindings, run tools like
wasm-opt, create a package.json to integrate with NPM and JavaScript
tooling, etc… For embedded development, you need to at minimum flash your
built program into your microcontroller’s persistent memory.
To perform these tasks today, we typically write whole new tools that wrap
cargo (like wasm-pack), invoke external tools manually (like using openocd
by hand), or write a cargo-mytask package to add the cargo mytask
subcommand. These solutions suffer from either repetition and a lack of
automation, or they wrap cargo but fail to expose all the wonderful features
that cargo supports (for example, you can’t use the --feature flag yet with
wasm-pack). We should not write these tools that wrap cargo, we should write
generic build tasks, which are invoked automatically by cargo itself.
cargo should not just grow a post_build.rs hook, its build tasks and
dependencies between tasks and artifacts should become fully extensible. I
should be able to depend on wasm build tasks in my Cargo.toml, and then after
that cargo build should just Do The Right Thing. I shouldn’t have to compile
these wasm build tasks for every project I use them with. cargo and crates.io
should handle transparently distributing the wasm task binaries to me.
Tired: the Rust project should start a working group for
$PROJECT_OR_DOMAIN.Wired: the Rust project should have a working group template, and system of mentorship for new (and old!) working group leads.
The more we collaborate and work together, the better we can tackle problems that are larger than any one of us. The primary way we’ve been organizing technical efforts in the Rust project has been working groups. But starting a new working group is hard, and leading a working group is hard.
We should have a template for new working groups that comes with cookie-cutter steps to follow to help build an open community, articulate working group vision, and collectively organize. Of course these steps will need to evolve for each particular working group’s needs, but having something to help new working groups hit the ground running is incredibly valuable. It would have been so useful for me when we were kicking off the WebAssembly domain working group last year. A lot of things that are obvious in retrospect were not at the time: hold weekly meetings, adopt an RFC process, communicate(!!), create room for contributors to own sub-goals, etc…
Additionally, every working group lead should have a mentor who is in a leadership position within the Rust project: someone who is a member of the Rust core team or a lead of another working group or team. Someone to rubber duck with and seek guidance from in the context of leadership and organization.
Instead of enabling Rust users to ask Rust leadership for a working group for
X, we should empower them to start the working group for X themselves, and
we should continuously follow up to ensure that they succeed. To have our cake
and eat it too, Rust development must be a positive-sum game.
#Rust2019Whatever we end up with in the 2019 roadmap, I have faith that what we choose will be worthy. We don’t suffer from a lack of good options.
I hope we never stop dreaming big and being ambitious.
http://fitzgeraldnick.com/2018/12/11/rust-2019-think-bigger.html
|
|






