David Lawrence: Happy BMO Push Day! |
(https://github.com/mozilla-bteam/bmo/tree/release-20181106.1)
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.
https://dlawrence.wordpress.com/2018/11/07/happy-bmo-push-day-48/
|
|
Firefox UX: How do people decide where or not to get a browser extension? |
The Firefox Add-ons Team works to make sure people have all of the information they need to decide which browser extensions are right for them. Past research conducted by Bill Selman and the Add-ons Team taught us a lot about how people discover extensions, but there was more to learn. Our primary research question was: “How do people decide whether or not to get a specific browser extension?”
We recently conducted two complementary research studies to help answer that big question:
The survey ran from July 19, 2018 to July 26, 2018 on addons.mozilla.org (AMO). The survey prompt was displayed when visitors went to the site and was localized into 10 languages. The survey asked questions about why people were visiting the site, if they were looking to get a specific extension (and/or theme), and if so what information they used to decide to get it.

The think-aloud study took place at a Mozilla office in Vancouver, BC from July 30, 2018 to August 1, 2018. The study consisted of 45-minute individual sessions with nine participants, in which they answered questions about the browsers they use, and completed tasks on a Windows laptop related to acquiring a theme and an extension. To get a variety of perspectives, participants included three Firefox users and six Chrome users. Five of them were extension users and four were not.

Now we share some key results from both the survey and the think-aloud study.
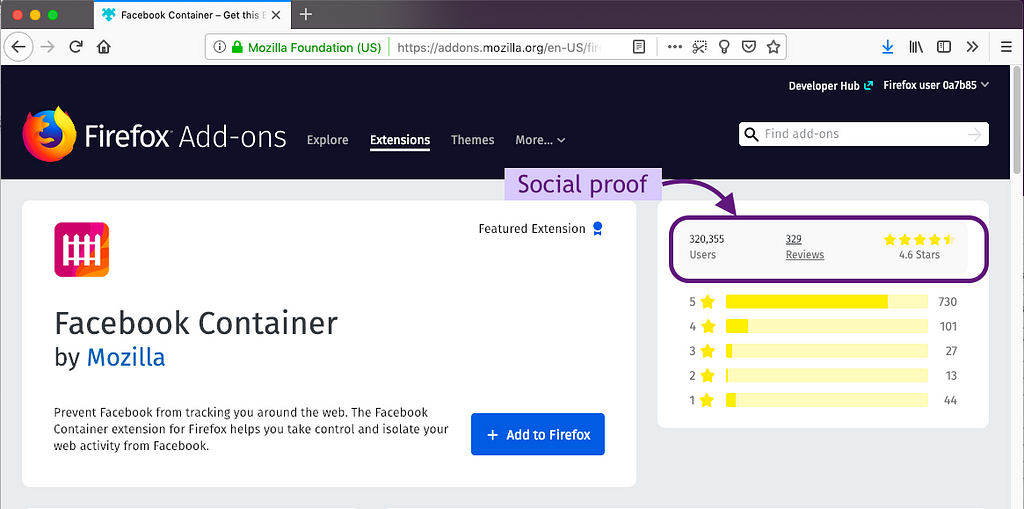
People use social proof on the extension’s product page
Ratings, reviews, and number of users proved important for making a decision to get the extension in both the survey and think-aloud study. Think-aloud participants used these metrics as a signal that an extension was good and safe. All except one think-aloud participant used this “social proof” before installing an extension. The importance of social proof was backed up by the survey responses where ratings, number of users, and reviews were among the top pieces of information used.
People use social proof outside of AMO
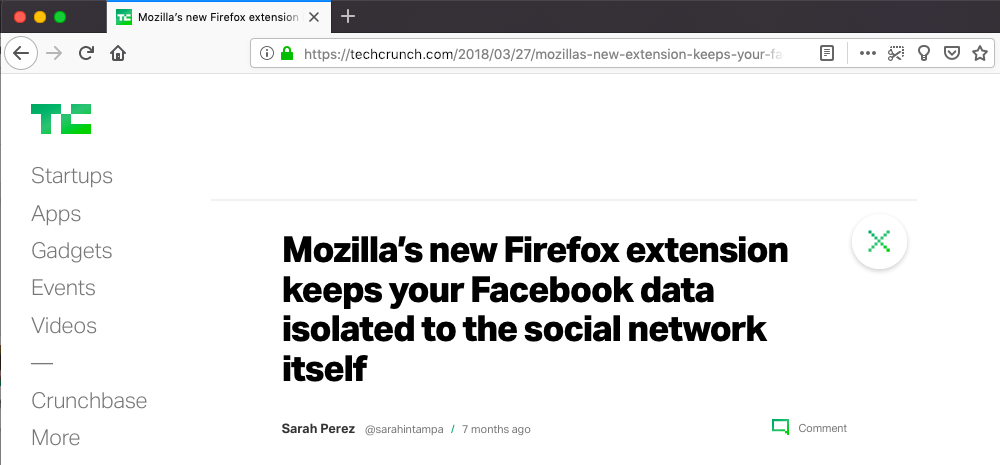
Think-aloud participants mentioned using outside sources to help them decide whether or not to get an extension. Outside sources included forums, advice from “high authority websites,” and recommendations from friends. The same result is seen among the survey respondents, where 40.6% of respondents used an article from the web and 16.2% relied on a recommendation from a friend or colleague. This is consistent with our previous user research, where participants used outside sources to build trust in an extension.

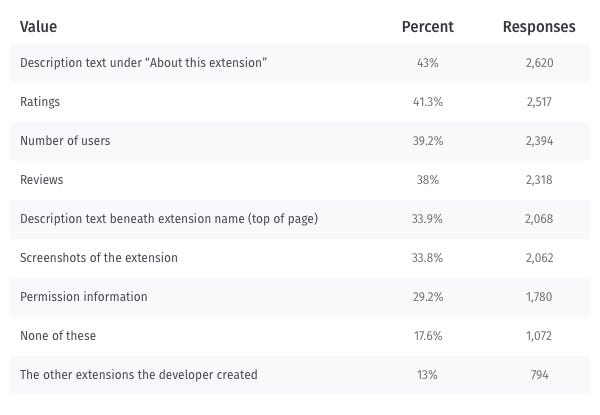
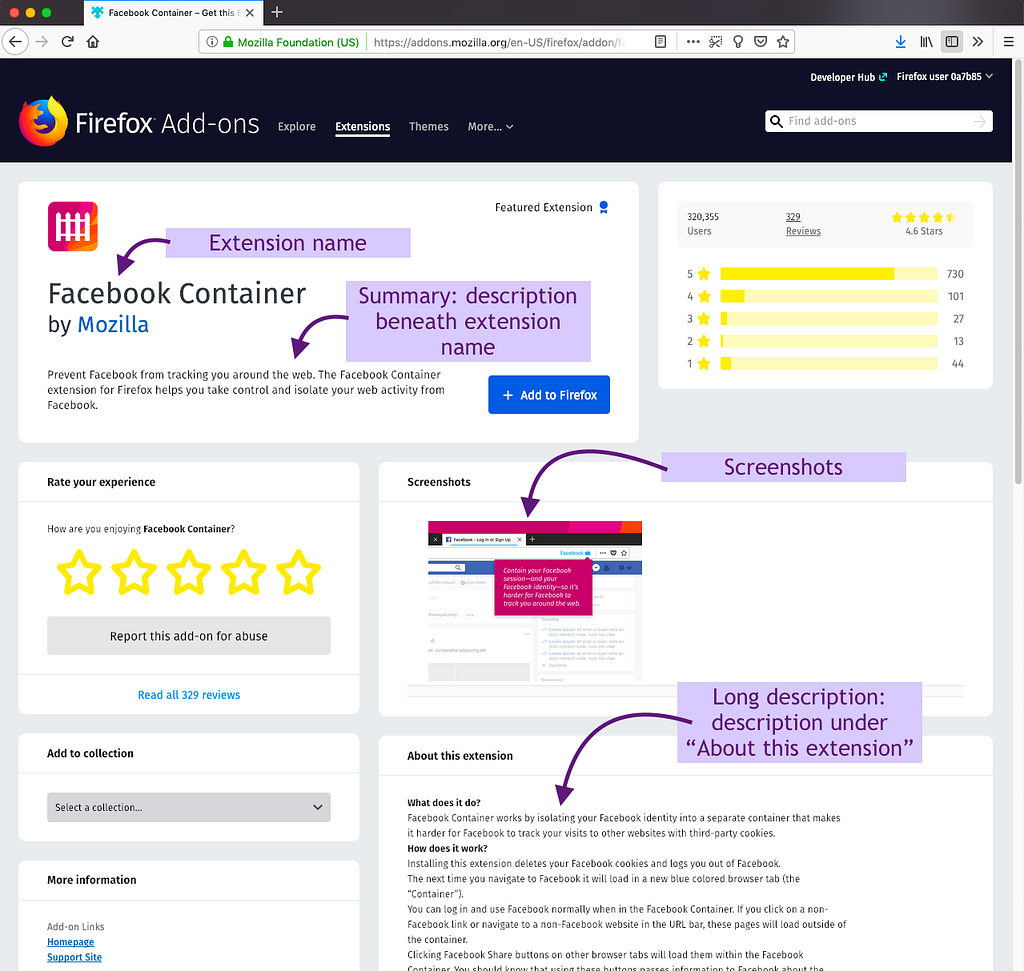
People use the description and extension name
Almost half of the survey respondents use the description to make a decision about the extension. While the description was the top piece of content use, we also see that over one-third of survey respondents use screenshots and the extension summary (“Description text beneath the extension name (top of page)”), which shows their importance as well.
Think-aloud participants also used the extension’s description (both the summary and the longer description) to help them decide whether or not to get it.
While we did not ask about the extension name in the survey, it came up during our think-aloud studies. The name of the extension was cited as important to think-aloud participants. But they mentioned how some names were vague and therefore didn’t assist them in their decision to get an extension.
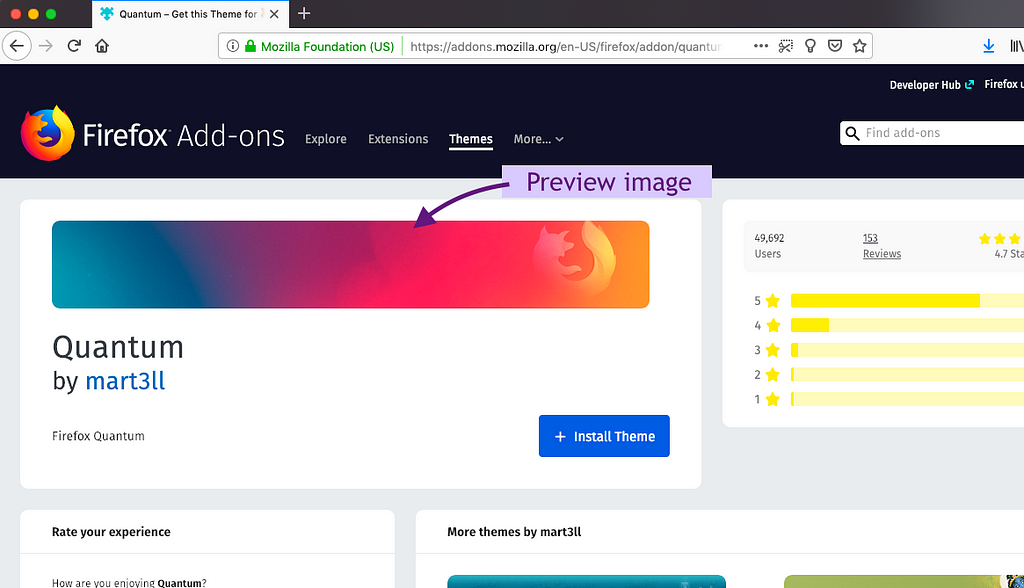
Themes are all about the picture
In addition to extensions, AMO offers themes for Firefox. From the survey responses, the most important part of a theme’s product page is the preview image. It’s clear that the imagery far surpasses any social proof or description.

All in all, we see that while social proof is important, great content on the extension’s product page and in external sources (such as forums and articles) are also key to people’s decisions about whether or not to get the extension. When we’re designing anything that requires people to make an adoption decision, we need to remember these studies and the importance of social proof and great content, within and outside of our products.
In alphabetical order by first name, thanks to Amy Tsay, Ben Miroglio, Caitlin Neiman, Chris Grebs, Emanuela Damiani, Gemma Petrie, Jorge Villalobos, Kev Needham, Kumar McMillan, Meridel Walkington, Mike Conca, Peiying Mo, Philip Walmsley, Raphael Raue, Richard Bloor, Rob Rayborn, Sharon Bautista, Stuart Colville, and Tyler Downer, for their help with the user research studies and/or reviewing this blog post.
How do people decide where or not to get a browser extension? was originally published in Firefox User Experience on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
Mozilla VR Blog: Lessons Learned while Designing for the Immersive Web |

In this Q&A, independent UX designer and creative catalyst Nadja Haldimann talks about how she approached working with Mozilla on the new Firefox Reality browser for virtual reality (VR). Before launch, Nadja and Mozilla’s Mixed Reality team worked with Seattle-based BlinkUX to do user testing. Here’s what they learned, and the solutions they found, to create a web browser that people can use strapped to their faces.
How difficult is it to design for an immersive, 3D environment, compared to 2D software?
It’s not necessarily more difficult – all the same design principles still apply – but it is quite different. One of the things that you have to account for is how the user perceives space in a headset – it seems huge. So instead of designing for a rectangular window inside a rectangular display, you’re suspending a window in what looks to be a very large room. The difficulty there is that people want to fill that room with a dozen browser windows, and maybe have a YouTube video, baseball game or stock ticker running in the background. But in reality, we only have these 2-inch screens to work with, one for each eye, and the pixels of just half a cell phone screen. But the perception is it’s 1,000 times bigger than a desktop. They think they’re in a movie theater.
OK, so here you have this massive 3D space. You can put anything in there you want. What did you create?
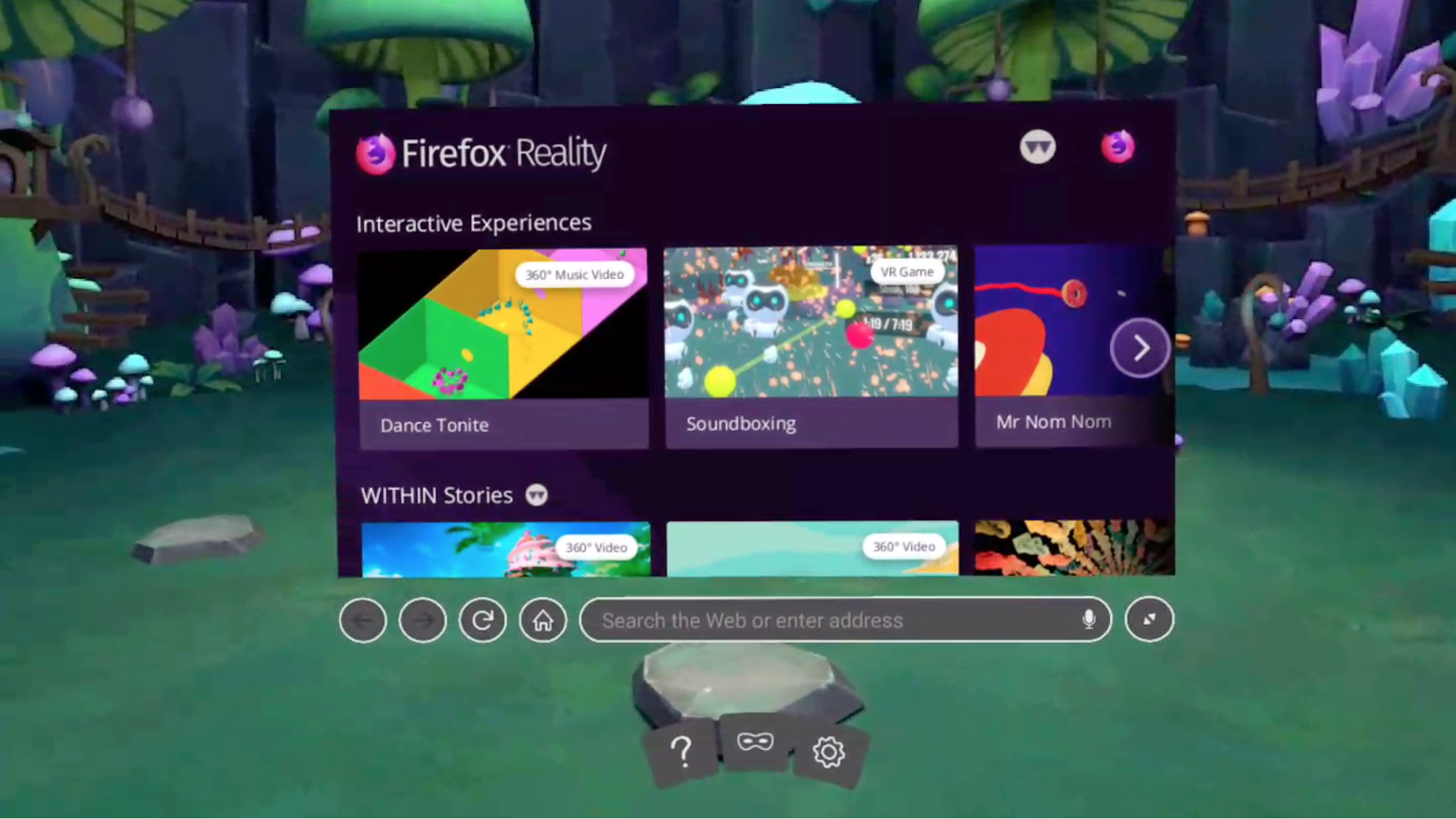
That was a really big question for us: what is the first thing people see when they open the browser? We built two things for the Firefox Reality home page. First, we worked with digital artists to create scenes users could choose as the background, because, just like on a 2D desktop browser, we found people want to customize their browser window with themes and images that mean something to them. The goal was to create environments that were grounding and inviting, especially for people who might be experiencing an immersive environment for the first time.

Magical cave, created by Jasmin Habezai-Fekri

Alpine meadow created by Lexie Mason-Davis.
Second, we created a content feed to help people find great new 3D experiences on the web. Immersive media is just getting off the ground, so content is somewhat limited today but growing quickly. The content feed showcases quality, family-friendly content that supports the WebVR API, so it’s easy to view on multiple devices.
What kinds of limitations or challenges did you run into while designing the browser’s UI?
In VR, the most important thing is to make the user comfortable. In the past, a significant number of people have had trouble with nausea and motion sickness — and women are more susceptible, according to research. You can avoid that by delivering a smooth, responsive experience, where the display can render the content very, very quickly. The best experience is one where the user actually forgets they’re in a VR environment. They’re happy spending time there and they want to keep exploring.
The first problem we ran into was that people felt like they were floating above the floor. Part of that was because we had the camera height set to 5’ 6”, which is roughly the height of an adult standing up. But in user testing, people were sitting down. So there was a disconnect between what people were seeing in the headset and where they knew their physical bodies to be. The other part was that we were using colors to indicate floor, without enough texture. It’s textures that let our brains identify distance in VR. We created low poly environments with limited textures, so people could perceive the floor, and that helped people feel more comfortable in the environment.
Another surprise was how people perceive an app window size in the immersive environment. In 2D, people talk about making a window “smaller” or “bigger”, and everyone knows how to change that. In 3D, users were more likely to say they wanted to put a window “farther away” or “bring it closer”. It’s the same fix, design-wise: you just give people a way to resize the window. But it’s interesting how differently people relate to objects in 3D. It’s a more tactile, interactive mindset.
Who were you designing this browser for?
That’s a good question because, in the beginning, we didn’t know exactly. The Firefox Reality browser is one of the first standalone VR browsers that lets people surf the 3D web, and it is built to work with newer standalone headsets that are super-affordable and wireless, devices like the Oculus Go, HTC VIVE Focus, and Lenovo Mirage Solo (Google Daydream). So it’s a pretty new market.
Based on business and personal use cases, we came up with personas, most of which were familiar with VR and 3D already: Gamers, architects, students, business travelers, and grandparents. But really the market for this product is extremely wide. We expect that VR will create a new genre of media that I believe will become a new standard. And our testing bore that out: People were interested in watching video in VR, with friends, in a theater-like setting, so it’s interactive. One person was excited to watch in bed, because it was easier to stare straight up to the ceiling with his headset on than it was to mess around with a laptop.

What was the biggest design surprise?
We ran into a lot of issues with having a virtual keyboard in the interface. People complained that the keyboard was too wide and it was awkward to select the letters. It was too difficult to find special characters like umlauts.
We made a bunch of tweaks so the virtual keyboard was easier to use. We also accelerated our timeline for voice input. In the initial release, we added a microphone icon to the URL bar so the user can click on that and talk to the browser, instead of typing in a search query.
What else did you learn from user testing?
People brought up privacy. Could we add profiles, like Netflix has? Can they save programs for later viewing? Could they have a guest account? Also there’s a need to have parental controls, because adult content is a big interest in VR. VR content is still quite limited, but people are already thinking about how to manage access to it in their homes.
What design tools did you use to create a 3D UI?
We’re designers, not programmers and short of learning Unity which has a steep learning curve, we needed to find some in-VR design tools that allowed us to import 2D and 3D objects and place them in space. The design tools for 2D, like Adobe Illustrator, Photoshop, Sketch, and InVision, don’t work for 3D, and there are only a few immersive 3D design tools out there today. We tried Google Blocks, Gravity Sketch, and Tvori before landing on Sketchbox. It’s an early-stage in-VR design tool with just enough functionality to help us get a feel for size, distance, and spacing. It also helped us communicate those coordinates to our software engineers.
What’s next?
We’re now working on adding multi-window support, so people can multitask in a VR browser the same way they do in desktop browsers today. We’re also planning to create a Theater Video setting, to give people an option to watch movies in a theater mode that’s a bigger screen in a large dark room. So it’ll be a lot like a physical movie theater, but in a VR headset. In the next 1.1 release, we’re planning to add support for 360-degree movies, bookmarks, repositioning the browser window, and exploring additional voice input options as well as early design work for augmented reality devices. It’s a work in progress!
https://blog.mozvr.com/lessons-learned-while-designing-for-the-immersive-web/
|
|
Hacks.Mozilla.Org: Cross-language Performance Profile Exploration with speedscope |
|
|
Hacks.Mozilla.Org: Cross-language Performance Profile Exploration with speedscope |
|
|
Daniel Stenberg: Get the CA cert for curl |
When you use curl to communicate with a HTTPS site (or any other protocol that uses TLS), it will by default verify that the server is signed by a trusted Certificate Authority (CA). It does this by checking the CA bundle it was built to use, or instructed to use with the --cacert command line option.
Sometimes you end up in a situation where you don't have the necessary CA cert in your bundle. It could then look something like this:
$ curl https://example.com/
curl: (60) SSL certificate problem: self signed certificate
More details here: https://curl.haxx.se/docs/sslcerts.html
A first gut reaction could be to disable the certificate check. Don't do that. You'll just make that end up in production or get copied by someone else and then you'll spread the insecure use to other places and eventually cause a security problem.
I'll show you four different ways to fix this.
Operating systems come with a CA bundle of their own and on most of them, curl is setup to use the system CA store. A system update often makes curl work again.
This of course doesn't help you if you have a self-signed certificate or otherwise use a CA that your operating system doesn't have in its trust store.
curl can be told to use a separate stand-alone file as CA store, and conveniently enough curl provides an updated one on the curl web site. That one is automatically converted from the one Mozilla provides for Firefox, updated daily. It also provides a little backlog so the ten most recent CA stores are available.
If you agree to trust the same CAs that Firefox trusts. This is a good choice.
Now we're approaching the less good options. It's way better to get the CA certificates via other means than from the actual site you're trying to connect to!
This method uses the openssl command line tool. The servername option used below is there to set the SNI field, which often is necessary to tell the server which actual site's certificate you want.
$ echo quit | openssl s_client -showcerts -servername server -connect server:443 > cacert.pem
A real world example, getting the certs for daniel.haxx.se and then getting the main page with curl using them:
$ echo quit | openssl s_client -showcerts -servername daniel.haxx.se -connect daniel.haxx.se:443 > cacert.pem
$ curl --cacert cacert.pem https://daniel.haxx.se
Suppose you're browsing the site already fine with Firefox. Then you can do inspect it using the browser and export to use with curl.
Step 1 - click the i in the circle on the left of the URL in the address bar of your browser.
Step 2 - click the right arrow on the right side in the drop-down window that appeared.

Step 3 - new contents appeared, now click the "More Information" at the bottom, which pops up a new separate window...

Step 4 - Here you get security information from Firefox about the site you're visiting. Click the "View Certificate" button on the right. It pops up yet another separate window.

Step 5 - in this window full of certificate information, select the "Details" tab...

Step 6 - when switched to the details tab, there's the certificate hierarchy shown at the top and we select the top choice there. This list will of course look different for different sites
 Step 7 - now click the "Export" tab at the bottom left and save the file (that uses a .crt extension) somewhere suitable.
Step 7 - now click the "Export" tab at the bottom left and save the file (that uses a .crt extension) somewhere suitable.
If you for example saved the exported certificate using in /tmp, you could then use curl with that saved certificate something like this:
$ curl --cacert /tmp/GlobalSignRootCA-R3.crt https://curl.haxx.se
This description assumes you're using a curl that uses a CA bundle in the PEM format, which not all do - in particular not the ones built with NSS, Schannel (native Windows) or Secure Transport (native macOS and iOS) don't.
If you use one of those, you need to then add additional command to import the PEM formatted cert into the particular CA store of yours.
Just concatenate many different PEM files into a single file to create a CA store with multiple certificates.
https://daniel.haxx.se/blog/2018/11/07/get-the-ca-cert-for-curl/
|
|
Nicholas Nethercote: How to speed up the Rust compiler in 2018: NLL edition |
Niko Matsakis recently blogged about the Rust compiler’s new borrow checker, which implements non-lexical lifetimes (NLL). The new borrow checker is a really nice improvement to Rust, because it accepts many sound programs that the old borrow checker rejected.
In the blog post, Niko wrote briefly about the performance of the new borrow checker.
Finally, those of you who read the previous posts may remember that the performance of the NLL checker was a big stumbling block. I’m happy to report that the performance issues were largely addressed: there remains some slight overhead to using NLL, but it is largely not noticeable in practice, and I expect we’ll continue to improve it over time.
This paragraph is true, but glosses over a lot of details! This post will be about my contributions to this performance work.
Before I describe individual improvements, it’s worth mentioning that the new borrow checker uses bitsets (1D) and bit matrices (2D) heavily. A number of my wins involved these data structures.
#51869: This PR changed some code so that it overwrote an existing dense bitset rather than replacing it with a newly created one of the same size, reducing instruction counts for most benchmarks, the best by 1.5%.
#51870: This PR reused a structure containing two bitsets rather than recreating it afresh for every statement in a basic block, reducing instruction counts for numerous benchmarks, the best by 1%.
#52250: The compiler has a SparseBitMatrix type. Rows were added on demand, and each row was implemented as a sparse bitset using a BTreeMap. In practice, many of the rows were relatively dense, with 10–90% of the bits being set. This PR changed SparseBitMatrix to use a dense representation for rows, reducing instruction counts on one benchmark by 33% and by 1% on a few others. The PR had a mixed effect on memory usage, increasing the peak on some benchmarks and reducing it on others. (Never fear! #54318 below ended up fixing the regressions.)
#52342: This PR avoided a bunch of allocations in Canonicalizer methods, reducing instruction counts on numerous benchmarks, the best by 2%.
#53383: Further profiling showed that some dense bitsets were large, but had very few bits set within them, so the dense representation was wasteful. This PR implemented a new hybrid bitset type that uses a sparse representation for bitsets with up to 8 bits set and switches to a dense representation beyond that, and used it to replace dense bitsets in several places, reducing instruction counts on the five slowest benchmarks by 55%, 21%, 16%, 10% and 9%, and reducing peak memory usage of three benchmarks by 53%, 33%, and 9%.
#53513: This PR force-inlined a function at one hot callsite, reducing instruction counts on two benchmarks by 1%.
#53551: This PR avoided some clone calls, reducing instruction counts for one benchmark by 0.5%.
#53733: This PR added special handling for a very common and simple case in unroll_place, reducing the instruction counts on one benchmark by 25%.
#53942: A function called precompute_borrows_out_of_scope does a traversal of one or more basic blocks. In order to detect whether a basic block had been previously visited, it recorded the ID of every visited statement in a hash table. Some basic blocks can have many statements, resulting in many hash table lookups. This PR changed the code to record the ID of visited basic blocks in the hash table instead of visited statements — trickier than it sounds because the analysis can start in the middle of a basic block, in which case the first half might need to be eventually visited — reducing instruction counts on one benchmark by 60%.
#54211: Liveness analysis created an array that could get very large. Each element in the array was a struct containing two u32s and a bool. Each of those elements took up 12 bytes, but only 9 of the bytes held data. This PR split the array into three separate arrays, one per field, making the code slightly less readable but reducing peak memory usage on one benchmark by 20%. (Fun fact: those u32s used to be usizes, but I shrunk them back in May.)
#54213: This PR tweaked some code so that the lifetimes of two large data structures didn’t overlap, reducing peak memory usage by 27% on one benchmark and 8% on another. (Note: those data structures are dominated by, you guessed it, bitsets!)
#54318: This PR changed SparseBitMatrix so that each instantiated row used the hybrid bitset representation from #53383 instead of the dense representation, reducing peak memory usage by 14–45% on four benchmarks, and 96% (from 29.1GB to 1.2GB) on one external crate! This PR also fixed the peak memory regression that #52250 introduced for a few benchmarks.
#54420: I subsequently realized that #54211 didn’t go far enough. Some debugging println! statements showed that both of the u32s in each liveness entry almost always held a special value that meant “invalid”. When data is repetitive, compression is possible: I could use a packed representation where the common (INVALID, INVALID, true) and (INVALID, INVALID, false) cases were represented by special u32 values, and all other triples were represented by a u32 index into an auxiliary table. This PR changed the representation as described, reducing instruction counts on numerous benchmarks, the best by 16%, and reducing peak memory usage on numerous benchmarks, the best by 38%. (I also tried a more compact representation where each element was a single byte; it reduced peak memory usage some more by the instruction count reduction was less, so I went with the earlier approach.)
You probably noticed that some of the improvements in the previous section were large, and I wasn’t the only one working on NLL performance; Niko Matsakis and David Wood also contributed some big wins. This is because the new borrow checker’s performance was originally, to be honest, terrible. This is understandable; the focus had been on functionality and correctness, which is fair enough for a large and complex new component. Nonetheless, in June I was very nervous about its performance.
To be more specific, “check” builds (which don’t generate code) ran as much as 50x slower with the new borrow checker on some benchmarks. And multiple benchmarks were disabled on CI because they were simply too slow or used too much memory.
Issue #52028 tells a representative story. It was originally filed because the html5ever benchmark was triggering out-of-memory failures on CI. Measurements with Massif and DHAT showed that its peak heap memory usage was over 14 GB, largely caused by a single 12 GB allocation! In comparison, the peak with the old borrow checker was roughly 200–300 MB. If you read through that issue, you can see that over a period of 2.5 months we reduced the memory usage from 14 GB, to 10 GB, to 2 GB, to 1.2 GB, to 600 MB, to 501 MB, and finally to 266 MB.
And things are pretty good now. The instruction counts on “check” builds for all benchmarks are at most 18% higher with the new borrow checker than the old borrow checker, and are typically around 5%. (And note that “check” builds are the worst-case scenario; non-“check” builds will see a smaller relative slowdown because of the extra time needed for code generation, which is unaffected by the borrow checker.) Memory usage is similar: all benchmarks except one have peak memory usage that is at most 20% higher, with the typical value around 3%. (The one remaining exceptional benchmark uses 2.7x memory.) The worse numbers generally occur on programs containing very large constants.
I’m not entirely happy even with this level of performance regression, but for now I have run out of ideas for improving it further. The new borrow checker is a lot more sophisticated and tracks a lot more data, so strict performance parity is a tough ask. Nonetheless, given how bad performance was a few months ago, I’m happy that we’ve got it down to a level where most people probably won’t notice any difference. Given that the new borrow checker makes Rust a significantly nicer and easier language to use, I hope it’s an acceptable trade-off.
|
|
Firefox Test Pilot: Understanding users’ wants and needs for linking Cloud Storage providers |
Note: this was written by two members of the Test Pilot team: Punam and Teon.
For our Cloud Storage experiment we sampled a small portion of Firefox users to gauge interest in saving downloads directly to their existing cloud storage, allowing the downloads to be accessible from all their devices. We used the Shield platform for this study.
Using learnings from the previous study, the Phase 2 study rolled out the Cloud Storage extension with a simpler and less disruptive interface by moving the option to save downloads into the Download Panel.
Key features of this experiment:
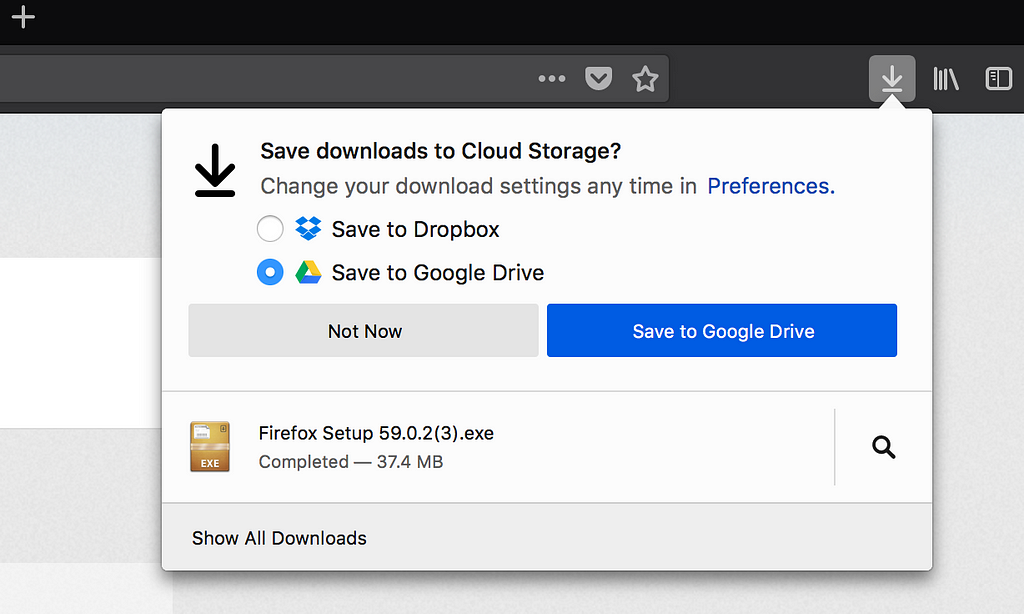
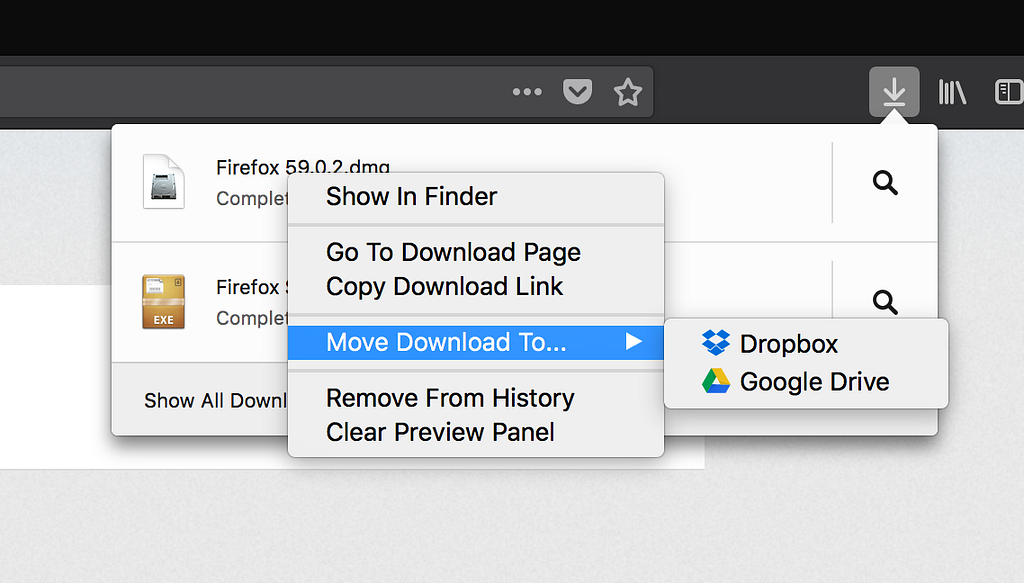
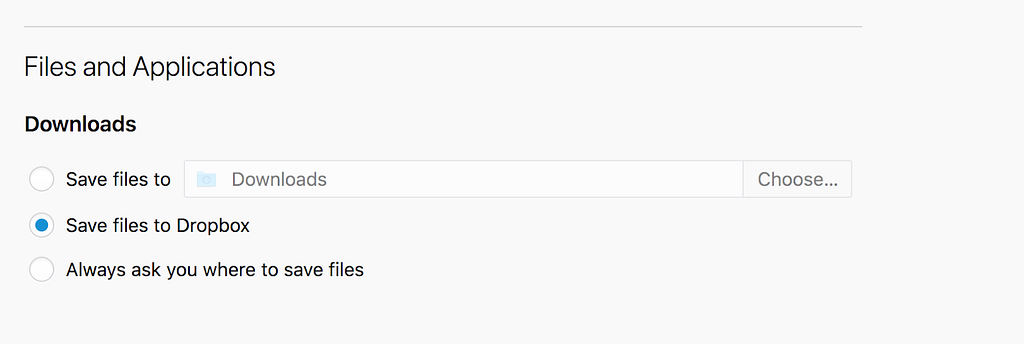
The Cloud Storage Phase 2 Study was a two week study, launching at the end of June. It targeted 1% of Firefox 60+ release users with the en-US locale. Users who were a part of this study were prompted to change their defaults. If they said no or didn’t reply, no changes were made.
Graphs
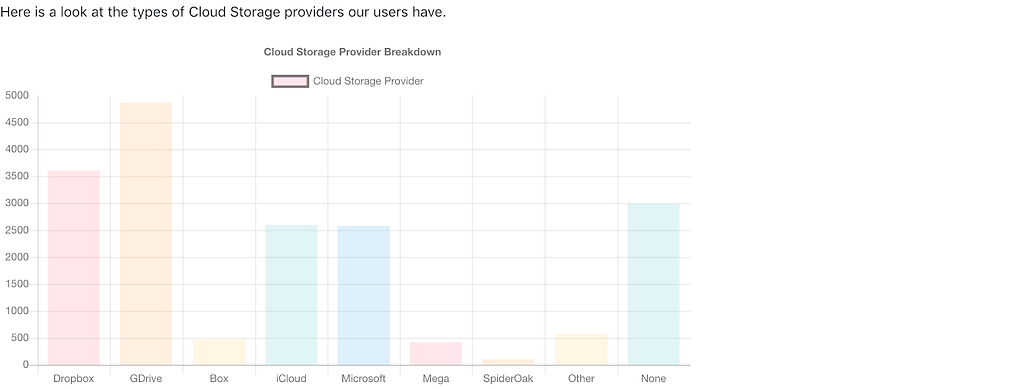
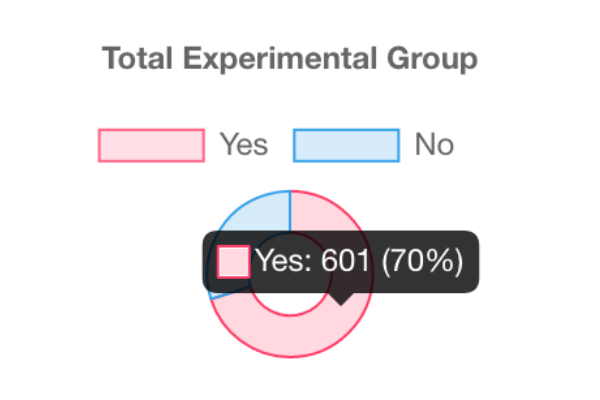
For detailed findings, you can visit this URL.
Lessons Learned
In the download manager, the ‘Move Download To’ feature was only discoverable by right-click and we should have made it easier to find.
We targeted 1% of Release Firefox, but only a small portion of those users had cloud storage providers, and even a smaller portion opted in to our study. It would have been nice to be able to more accurately target people with cloud storage providers.
Understanding users’ wants and needs for linking Cloud Storage providers was originally published in Firefox Test Pilot on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
Gregory Szorc: Absorbing Commit Changes in Mercurial 4.8 |
Every so often a tool you use introduces a feature that is so useful
that you can't imagine how things were before that feature existed.
The recent 4.8 release of the
Mercurial version control tool introduces
such a feature: the hg absorb command.
hg absorb is a mechanism to automatically and intelligently incorporate
uncommitted changes into prior commits. Think of it as hg histedit or
git rebase -i with auto squashing.
Imagine you have a set of changes to prior commits in your working
directory. hg absorb figures out which changes map to which commits
and absorbs each of those changes into the appropriate commit. Using
hg absorb, you can replace cumbersome and often merge conflict ridden
history editing workflows with a single command that often just works.
Read on for more details and examples.
Modern version control workflows often entail having multiple unlanded commits in flight. What this looks like varies heavily by the version control tool, standards and review workflows employed by the specific project/repository, and personal preferences.
A workflow practiced by a lot of projects is to author your commits into a sequence of standalone commits, with each commit representing a discrete, logical unit of work. Each commit is then reviewed/evaluated/tested on its own as part of a larger series. (This workflow is practiced by Firefox, the Git and Mercurial projects, and the Linux Kernel to name a few.)
A common task that arises when working with such a workflow is the need to incorporate changes into an old commit. For example, let's say we have a stack of the following commits:
$ hg show stack
@ 1c114a ansible/hg-web: serve static files as immutable content
o d2cf48 ansible/hg-web: synchronize templates earlier
o c29f28 ansible/hg-web: convert hgrc to a template
o 166549 ansible/hg-web: tell hgweb that static files are in /static/
o d46d6a ansible/hg-web: serve static template files from httpd
o 37fdad testing: only print when in verbose mode
/ (stack base)
o e44c2e (@) testing: install Mercurial 4.8 final
Contained within this stack are 5 commits changing the way that static files are served by hg.mozilla.org (but that's not important).
Let's say I submit this stack of commits for review. The reviewer spots a problem with the second commit (serve static template files from httpd) and wants me to make a change.
How do you go about making that change?
Again, this depends on the exact tool and workflow you are using.
A common workflow is to not rewrite the existing commits at all: you simply create a new fixup commit on top of the stack, leaving the existing commits as-is. e.g.:
$ hg show stack
o deadad fix typo in httpd config
o 1c114a ansible/hg-web: serve static files as immutable content
o d2cf48 ansible/hg-web: synchronize templates earlier
o c29f28 ansible/hg-web: convert hgrc to a template
o 166549 ansible/hg-web: tell hgweb that static files are in /static/
o d46d6a ansible/hg-web: serve static template files from httpd
o 37fdad testing: only print when in verbose mode
/ (stack base)
o e44c2e (@) testing: install Mercurial 4.8 final
When the entire series of commits is incorporated into the repository,
the end state of the files is the same, so all is well. But this strategy
of using fixup commits (while popular - especially with Git-based tooling
like GitHub that puts a larger emphasis on the end state of changes rather
than the individual commits) isn't practiced by all projects.
hg absorb will not help you if this is your workflow.
A popular variation of this fixup commit workflow is to author a new commit then incorporate this commit into a prior commit. This typically involves the following actions:
$ hg commit
$ hg histedit
OR
$ git add
$ git commit
$ git rebase --interactive
Essentially, you produce a new commit. Then you run a history editing command. You then tell that history editing command what to do (e.g. to squash or fold one commit into another), that command performs work and produces a set of rewritten commits.
In simple cases, you may make a simple change to a single file. Things are pretty straightforward. You need to know which two commits to squash together. This is often trivial. Although it can be cumbersome if there are several commits and it isn't clear which one should be receiving the new changes.
In more complex cases, you may make multiple modifications to multiple files. You may even want to squash your fixups into separate commits. And for some code reviews, this complex case can be quite common. It isn't uncommon for me to be incorporating dozens of reviewer-suggested changes across several commits!
These complex use cases are where things can get really complicated for version control tool interactions. Let's say we want to make multiple changes to a file and then incorporate those changes into multiple commits. To keep it simple, let's assume 2 modifications in a single file squashing into 2 commits:
$ hg commit --interactive
We can see that the number of actions required by users has already increased
substantially. Not captured by the number of lines is the effort that must go
into the interactive commands like hg commit --interactive,
git add --interactive, hg histedit, and git rebase --interactive. For
these commands, users must tell the VCS tool exactly what actions to take.
This takes time and requires some cognitive load. This ultimately distracts
the user from the task at hand, which is bad for concentration and productivity.
The user just wants to amend old commits: telling the VCS tool what actions
to take is an obstacle in their way. (A compelling argument can be made that
the work required with these workflows to produce a clean history is too much
effort and it is easier to make the trade-off favoring simpler workflows
versus cleaner history.)
These kinds of squash fixup workflows are what hg absorb is designed to
make easier. When using hg absorb, the above workflow can be reduced to:
$ hg absorb
OR
$ hg absorb --apply-changes
Let's assume the following changes are made in the working directory:
$ hg diff
diff --git a/ansible/roles/hg-web/templates/vhost.conf.j2 b/ansible/roles/hg-web/templates/vhost.conf.j2
--- a/ansible/roles/hg-web/templates/vhost.conf.j2
+++ b/ansible/roles/hg-web/templates/vhost.conf.j2
@@ -76,7 +76,7 @@ LimitRequestFields 1000
# Serve static files straight from disk.
That is, we have 2 separate uncommitted changes to
ansible/roles/hg-web/templates/vhost.conf.j2.
Here is what happens when we run hg absorb:
$ hg absorb
showing changes for ansible/roles/hg-web/templates/vhost.conf.j2
@@ -78,1 +78,1 @@
d46d6a7 - AllowOverride NoneTypo
d46d6a7 + AllowOverride None
@@ -88,1 +88,1 @@
1c114a3 - Header set Cache-Control "max-age=31536000, immutable, bad"
1c114a3 + Header set Cache-Control "max-age=31536000, immutable"
2 changesets affected
1c114a3 ansible/hg-web: serve static files as immutable content
d46d6a7 ansible/hg-web: serve static template files from httpd
apply changes (yn)?
2 of 2 chunk(s) applied
hg absorb automatically figured out that the 2 separate uncommitted changes
mapped to 2 different changesets (Mercurial's term for commit). It
print a summary of what lines would be changed in what changesets and
prompted me to accept its plan for how to proceed. The human effort involved
is a quick review of the proposed changes and answering a prompt.
At a technical level, hg absorb finds all uncommitted changes and
attempts to map each changed line to an unambiguous prior commit. For
every change that can be mapped cleanly, the uncommitted changes are
absorbed into the appropriate prior commit. Commits impacted by the
operation are rebased automatically. If a change cannot be mapped to an
unambiguous prior commit, it is left uncommitted and users can fall back
to an existing workflow (e.g. using hg histedit).
But wait - there's more!
The automatic rewriting logic of hg absorb is implemented by following
the history of lines. This is fundamentally different from the approach
taken by hg histedit or git rebase, which tend to rely on merge
strategies based on the
3-way merge
to derive a new version of a file given multiple input versions. This
approach combined with the fact that hg absorb skips over changes with
an ambiguous application commit means that hg absorb will never
encounter merge conflicts! Now, you may be thinking if you ignore
lines with ambiguous application targets, the patch would always apply
cleanly using a classical 3-way merge. This statement logically sounds
correct. But it isn't: hg absorb can avoid merge conflicts when the
merging performed by hg histedit or git rebase -i would fail.
The above example attempts to exercise such a use case. Focusing on the initial change:
diff --git a/ansible/roles/hg-web/templates/vhost.conf.j2 b/ansible/roles/hg-web/templates/vhost.conf.j2
--- a/ansible/roles/hg-web/templates/vhost.conf.j2
+++ b/ansible/roles/hg-web/templates/vhost.conf.j2
@@ -76,7 +76,7 @@ LimitRequestFields 1000
# Serve static files straight from disk.
This patch needs to be applied against the commit which introduced it. That commit had the following diff:
diff --git a/ansible/roles/hg-web/templates/vhost.conf.j2 b/ansible/roles/hg-web/templates/vhost.conf.j2
--- a/ansible/roles/hg-web/templates/vhost.conf.j2
+++ b/ansible/roles/hg-web/templates/vhost.conf.j2
@@ -73,6 +73,15 @@ LimitRequestFields 1000
{% endfor %}
+ # Serve static files from templates directory straight from disk.
+ But after that commit was another commit with the following change:
diff --git a/ansible/roles/hg-web/templates/vhost.conf.j2 b/ansible/roles/hg-web/templates/vhost.conf.j2
--- a/ansible/roles/hg-web/templates/vhost.conf.j2
+++ b/ansible/roles/hg-web/templates/vhost.conf.j2
@@ -73,14 +73,21 @@ LimitRequestFields 1000
{% endfor %}
- # Serve static files from templates directory straight from disk.
- When we use hg histedit or git rebase -i to rewrite this history, the VCS
would first attempt to re-order commits before squashing 2 commits together.
When we attempt to reorder the fixup diff immediately after the commit that
introduces it, there is a good chance your VCS tool would encounter a merge
conflict. Essentially your VCS is thinking you changed this line but the
lines around the change in the final version are different from the lines
in the initial version: I don't know if those other lines matter and therefore
I don't know what the end state should be, so I'm giving up and letting the
user choose for me.
But since hg absorb operates at the line history level, it knows that this
individual line wasn't actually changed (even though the lines around it did),
assumes there is no conflict, and offers to absorb the change. So not only
is hg absorb significantly simpler than today's hg histedit or
git rebase -i workflows in terms of VCS command interactions, but it can
also avoid time-consuming merge conflict resolution as well!
Another feature of hg absorb is that all the rewriting occurs in memory
and the working directory is not touched when running the command. This means
that the operation is fast (working directory updates often account for a lot
of the execution time of hg histedit or git rebase commands). It also means
that tools looking at the last modified time of files (e.g. build systems
like GNU Make) won't rebuild extra (unrelated) files that were touched
as part of updating the working directory to an old commit in order to apply
changes. This makes hg absorb more friendly to edit-compile-test-commit
loops and allows developers to be more productive.
And that's hg absorb in a nutshell.
When I first saw a demo of hg absorb at a Mercurial developer meetup, my
jaw - along with those all over the room - hit the figurative floor. I thought
it was magical and too good to be true. I thought Facebook (the original authors
of the feature) were trolling us with an impossible demo. But it was all real.
And now hg absorb is available in the core Mercurial distribution for anyone
to use.
From my experience, hg absorb just works almost all of the time: I run
the command and it maps all of my uncommitted changes to the appropriate
commit and there's nothing more for me to do! In a word, it is magical.
To use hg absorb, you'll need to activate the absorb extension. Simply
put the following in your hgrc config file:
[extensions]
absorb =
hg absorb is currently an experimental feature. That means there is
no commitment to backwards compatibility and some rough edges are
expected. I also anticipate new features (such as hg absorb --interactive)
will be added before the experimental label is removed. If you encounter
problems or want to leave comments, file a bug,
make noise in #mercurial on Freenode, or
submit a patch.
But don't let the experimental label scare you away from using it:
hg absorb is being used by some large install bases and also by many
of the Mercurial core developers. The experimental label is mainly there
because it is a brand new feature in core Mercurial and the experimental
label is usually affixed to new features.
If you practice workflows that frequently require amending old commits, I
think you'll be shocked at how much easier hg absorb makes these workflows.
I think you'll find it to be a game changer: once you use hg abosrb, you'll
soon wonder how you managed to get work done without it.
http://gregoryszorc.com/blog/2018/11/05/absorbing-commit-changes-in-mercurial-4.8
|
|
Mozilla Localization (L10N): L10n Report: November edition |
|
|
Chris Pearce: On learning Go and a comparison with Rust |
 |
| CPU profile graph produced by Go's "profile" package and GraphViz. |
https://blog.pearce.org.nz/2018/11/on-learning-go-and-comparison-with-rust.html
|
|
The Servo Blog: This Week In Servo 118 |
In the past week, we merged 75 PRs in the Servo organization’s repositories.
Our roadmap is available online, including the overall plans for 2018.
This week’s status updates are here.
Interested in helping build a web browser? Take a look at our curated list of issues that are good for new contributors!
|
|
David Humphrey: Observations on Hacktoberfest 2018 |
This term I'm teaching two sections of our Topics in Open Source Development course. The course aims to take upper-semester CS students into open source projects, and get them working on real-world software.
My usual approach is to put the entire class on the same large open source project. I like this method, because it means that students can help mentor each other, and we can form a shadow-community off to the side of the main project. Typically I've used Mozilla as a place to do this work.
However, this term I've been experimenting with having students work more freely within open source projects on GitHub in general. I also wanted to try encouraging students to work on Hacktoberfest as part of their work.
Hacktoberfest is a yearly event sponsored by DigitalOcean, Twilio, and GitHub, which encourages new people to get involved in open source. Submit five pull requests on GitHub during October, get a T-Shirt and stickers. This year, many companies have joined in and offered to also give extra swag or prizes if people fix bugs in their repos (e.g., Microsoft).
Some of my students have done Hacktoberfest in the past and enjoyed it, so I thought I'd see what would happen if I got all my students involved. During the month of October, I asked my students to work on 1 pull request per week, and also to write a blog post about the experience, what they learned, what they fixed, and to share their thoughts.
Now that October has ended, I wanted to share what I learned by having my students do this. During the month I worked with them to answer questions, support their problems with git and GitHub, explain build failures on Travis, intervene in the comments of pull requests, etc. Along the way I got to see what happens when a lot of new people suddenly get thrust into open source.
You can find all the PRs and blog posts here, but let me take you through some raw numbers and interesting facts:
node_modules). Many PRs fixed bugs by simply deleting code. "Sir, are you sure this counts?" Yes, it most certainly does.One of the things I was interested in seeing was which languages the students would choose to work in, when given the choice. As a result, I tried to keep track of the languages being used in PRs. In no particular order:
I was also interested to see which projects the students would join. I'll discuss this more broadly below, but here are some of the more notable projects to which I saw the students submit fixes:
A number of students did enough work in the project that they were asked to become collaborators. In two cases, the students were asked to take over the project and become maintainers! Careful what you touch.
I think the most valuable feedback comes from the student blogs, which I'll share quotes from below. Before I do that, let me share a few things that I observed and learned through this process.
Because Hacktoberfest is a bit of a game, people game the system. I was surprised at the number of "Hacktoberfest-oriented" repos I saw. These were projects that were created specifically for Hacktoberfest in order to give people an easy way to contribute; or they were pre-existing but also provided a way to get started I hadn't foreseen. For example:
I'll admit that I was not anticipating this sort of thing when I sent students out to work on open source projects. However, after reading their blog posts about the experience, I have come to the conclusion that for many people, just gaining experience with git, GitHub, and the mechanics of contribution, is valuable no matter the significance of the "code."
For those students who focused too much on repos like those mentioned above, there was often a lot of frustration, since the "maintainers" were absent and the "community" was chaotic. People would steal issues from one another, merges would overwrite previous contributions, and there was little chance for personal growth. I saw many people tire of this treatment, and eventually decide, on their own, that they needed a better project. Eventually, the "easy" way became too crowded and untenable.
Finding good bugs to work on continues to be hard. There are hundreds-of-thousands of bugs labeled "Hacktoberfest" on GitHub. But my students eventually gave up trying to use this label to find things. There were too many people trying to jump on the same bugs (~46K people participated in Hacktoberfest this year). I know that many of the students spent as much time looking for bugs as they did fixing them. This is an incredible statement, given that they are millions of open bugs on GitHub. The open source community in general needs to do a much better job connecting people with projects. Our current methods don't work. If you already know what you want to work on, then it's trivial. But if you are truly new (most of my students were), it's daunting. You should be able to match your skills to the kinds of work happening in repos, and then find things you can contribute toward. GitHub needs to do better here.
A lot of my students speak more than one language, and wanted to work on localization. However, Hacktoberfest only counts work done in PRs toward your total. Most projects use third-party tools (e.g., Transifex) outside of GitHub for localization. I think we should do more to recognize localization as first-order contribution. If you go and translate a big part of a project or app, that should count toward your total too.
Most of the students participated in three or more projects vs. focusing in just one. When you have as many students as I do all moving in and out of new projects, you come to realize how different open source projects are. For example, there are very few standards for how one "signs up" to work on something: some projects wanted an Issue; some wanted you to open a WIP PR with special tags; some wanted you to get permission; some wanted you to message a bot; etc. People (myself included) tend to work in their own projects, or within an ecosystem of projects, and don't realize how diverse and confusing this can be for new people. A project being on GitHub doesn't tell you that much about what the expectations are going to be, and simply having a CONTRIBUTING.md file isn't enough. Everyone has one, and they're all different!
More than the code they wrote, I was interested in the reflections of the students as they moved from being beginners to feeling more and more confident. You can find links to all of the blog posts and PRs here. Here are some examples of what it was like for the students, in their own words.
Many students began by choosing projects using tech they already knew.
"I decided to play to my strengths, and look at projects that had issues recommended for beginners, as well as developed in python"
"Having enjoyed working with Go during my summer internship, I was like: Hey, let's look for a smaller project that uses Go!"
Others started with something unknown, new, and different.
"my goal for this month is to contribute to at least two projects that use Rust"
"I'm in a position where I have to learn C# for another project in another course, so the first thing I did was search up issues on Github that were labeled 'hacktoberfest' and uses the C# language."
"My first pull request was on a new language I have not worked with before called Ruby...I chose to work with Ruby because it was a chance to work with something that I have not worked with before."
I was fascinated to see people evolve over the five weeks, and some who were scared to venture out of familiar territory at first, ended up in something completely new by the end.
"After I completed my pull request, I felt very proud of myself because I learned a new language which I did not think I was able to do at the beginning of this."
"I was able to learn a new programming language, Python, which was something I always wanted to do myself. If it wasn't for Hacktoberfest, I might keep procrastinating and never get started."
Perhaps the single greatest effect of working on five PRs (vs. one or two), is that it helped to slowly convince people that they despite how they felt initially, they could in fact contribute, and did belong.
"Everyone posting here (on GitHub) is a genius, and it's very daunting."
"In the beginning, I am afraid to find issues that people post on GitHub."
"As I am looking at the C code I am daunted by the sheer size of some of the function, and how different functions are interacting with each other. This is surprisingly different from my experience with C++, or Object Oriented Programming in general."
Small successes bring greater confidence:
"Fixing the bug wasn't as easy as I thought it would be - the solution wasn't too straightforward - but with the help of the existing code as reference, I was able to find a solution. When working on a project at school, the instructions are laid out for you. You know which functions to work on, what they should do, and what they shouldn't do. Working on OSS was a completely different experience. School work is straightforward and because of that I'd be able to jump straight in and code. Being used to coding in this way made my first day trying to fix the bug very frustrating. After a day of trying to fix functions that looked as if they could be related to the bug without success, I decided to look at it again the next day. This time, I decided to take my time. I removed all of my edits to the code and spent around an hour just reading the code and drawing out the dependencies. This finally allowed me to find a solution."
"I learned that it's not going to be easy to contribute to a project right away, and that's okay...it's important to not get overwhelmed with what you're working on, and continue 1 step at a time, and ask questions when you need help. Be confident, if I can do it, you can too."
"I learned that an issue didn't need to be tagged as 'beginner friendly' for it to be viable for me, that I could and should take on more challenging issues at this point, ones that would feel more rewarding and worthwhile."
Many students talked about being "proud" of their work, or expressed surprise when a project they use personally accepted their code:
"I do feel genuinely proud that I have 10 lines of code landed in the VSCode project"
"After solving this issue I felt very proud. Not only did I contribute to a project I cared about, I was able to tackle an issue that I had almost no knowledge of going in, and was able to solve it without giving up. I had never worked with React before, and was scared that I would not be able to understand anything. In actuality it was mostly similar to JavaScript and I could follow along pretty well. I also think I did a good job of quickly finding the issue in the codebase and isolating the part of code where the issue was located."
"I used to think those projects are maintained by much more capable people than me, now the thinking is 'yeah, I can contribute to that.' To be honest, I would never think I was able to participate in an event like Hacktoberfest and contribute to the open-source community in this way. Now, it is so rewarding to see my name amount the contributors."
Finally, a theme I saw again and again was students beginning to find their place within the larger, global, open source community. Many students had their blogs quoted or featured on social media, and were surprised that other people around the world had seen them and their work.
"I really liked how people from different backgrounds and ethnicity can help one another when it comes to diversifying their code with different cultures. I really like the fact I got to share my language (Punjabi) with other people in the community through localizing"
"getting to work with developers in St.Petersburg, Holland, Barcelona and America."
"Now I can say I have worked with people from around the world!"
I'm really impressed with Hacktoberfest, and thankful for DigitalOcean, Twilio, GitHub and others who take it upon themselves to sponsor this. We need events like this where everyone is aware that new people are joining, and it's OK to get involved. Having a sense that "during October, lots of new people are going to be coming" is important. Projects can label issues, people can approach reviews a bit differently, and everyone can use a bit more patience and support. And there's no need for any of that to end now that it's November.
Hopefully this helps you if you're thinking about having your students join Hacktoberfest next year. If you have other questions, get in touch. And if you'd like to help me grade all this work, I'd be happy for that contribution :)
|
|
Mozilla VR Blog: How to Run a UX XR Study |

This article is part four of the series that reviews the user testing conducted on Hubs by Mozilla, a social XR platform. Previous posts in this series have covered insights related to accessibility, user experience, and environmental design. The objective of this final post is to give an overview of how the Extended Mind and Mozilla collaborated to execute this study and make recommendations for best practices in user research on cross platform (2D and XR) devices.
PARTICIPANTS WILL MAKE OR BREAK THE STUDY
Research outcomes are driven by participant quality so plan to spend a lot of time up front recruiting. If you don’t already have defined target users, pick a user profile and recruit against that. In this study, Jessica Outlaw and Tyesha Snow of The Extended Mind sought people who were tech savvy enough to use social media and communicate on smartphones daily, but did not require that they owned head-mounted displays (HMDs) at home.
The researchers’ approach was to recruit for the future user of Hubs by Mozilla, not the current user who might be an early adopter. Across the ten participants in the study, a broad range of professions were represented (3D artist, engineer, realtor, psychologist, and more), which in this case was ideal because Hubs exists as a standalone product. However, if Hubs were in an earlier stage where only concepts or wireframes could be shown to users, it would have been better to include people with VR expertise because they could more easily imagine the potential it.
In qualitative research, substantial insights can be generated from between six and twelve users. Beyond twelve users, there tends to be redundancy in the feedback, which doesn’t justify the extra costs of recruiting and interviewing those folks. In general, there is more value in running two smaller studies of six people at different iterations of product development, rather than just one study with a larger sample size. In this study, there were ten participants, who provided both diversity of viewpoints and enough consistency that strong themes emerged.
The researchers wanted to test Hubs’ multi-user function by recruiting people to come in pairs. Having friends and romantic partners participate in the study allowed The Extended Mind to observe authentic interactions between people. While many of them were new to XR and some were really impressed by the immersive nature of the VR headset, they were grounded in a real experience of talking with a close companion
For testing a social XR product, consider having people come in with someone they already know. Beyond increasing user comfort, there is another advantage in that it was more efficient for the researchers. They completed research with ten people in a single day, which is a lot in user testing.
Summary of recruiting recommendations
COLLECTING DATA
It’s important to make users feel welcome when they arrive. Offer them water or snacks. Pay them an honorarium for their time. Give them payment before the interviews begin so that they know their payment is not conditional on them saying nice things about your product. In fact, give them explicit permission to say negative things about the product. Participants tend to want to please researchers so let them know you want their honest feedback. Let them know up front that they can end the study, especially if they become uncomfortable or motion sick.
The Extended Mind asked people to sign a consent form for audio, video, and screen recording. All forms should give people the choice to opt out from recordings.
In the Hubs by Mozilla study, the format of each interview session was:
Pairs were together for the opening and closing interviews, but separated into different conference rooms for actual product usage. Jessica and Tyesha each stayed with a participant at all times to observe their behaviors in Hubs and then aggregated their notes afterward.
One point that was essential was to give people some experience with the Oculus Go before actually showing them Hubs. This was part of the welcome and pre-Hubs interview in this study. Due to the nascent stage of VR, participants need extra time to learn about navigating the menus and controllers. Before people to arrive in any XR experience, people are going to need to have some familiarity with the device. As the prevalence of HMDs increases, taking time to give people an orientation will become less and less necessary. In the meantime, setting a baseline is an important piece for users about where your experiences exist in the context of the device’s ecosystem.
Summary of data collection recommendations
GENERATING INSIGHTS
Once all the interviews have been completed, it’s time to start analyzing it the data. It is important to come up with a narrative to describe the user experience. In this example, Hubs was found to be accessible, fun, good for close conversations, and participants’ experiences were influenced by the environmental design. Those themes emerged early on and were supported by multiple data points across participants.
Using people’s actual words is more impactful than paraphrasing them or just reporting your own observations due to the emotional impact of a first-person experience. For example,
“The duck makes a delightful sound.”
is more descriptive than writing “Participant reported liking duck sound effects.”
There are instances where people make similar statements but each used their own words, which helps bolster the overall point. For example, three different participants said they thought Hubs improved communication with their companion, but each had a different way of conveying it:
[Hubs is] “better than a phone call.”
“Texting doesn’t capture our full [expression]”
“This makes it easier to talk because there are visual cues.”
Attempt to weave together multiple quotes to support each of the themes from the research.
User testing will uncover new uses of your product and people will likely spontaneously brainstorm new features they want and more. Expect that users will surprise you with their feedback. You may have planned to test and iterate on the UI of a particular page, but learn in the research that the page isn’t desirable and should be removed entirely.
Summary of generating insights recommendations
Mozilla & The Extended Mind Collaboration
In this study, Mozilla partnered with The Extended Mind to conduct the research and deliver recommendations on how to improve the Hubs product. For the day of testing, two Hubs developers observed all research sessions and had the opportunity to ask the participants questions. Having Mozilla team members onsite during testing let everyone sync up between test sessions and led to important revisions about how to re-phrase questions, which devices test on, and more.
Due to Jessica and Tyesha being outside of the core Hubs team, they were closer to the user perspective and could take a more naturalistic approach to learning about the product. Their goals were to represent the user perspective across the entire project and provide strategic insights that the development team could apply.
This post has provided some background on the Hubs by Mozilla user research study and given recommendations on best practices for people who are interested in conducting their own XR research. Get in touch with contact@extendedmind.io with research questions and, also, try Hubs with a friend. You can access it via https://hubs.mozilla.com/.
|
This is the final article in a series that reviews user testing conducted on Mozilla’s social XR platform, Hubs. Mozilla partnered with Jessica Outlaw and Tyesha Snow of The Extended Mind to validate that Hubs was accessible, safe, and scalable. The goal of the research was to generate insights about the user experience and deliver recommendations of how to improve the Hubs product. Links to the previous posts are below.
Part one on accessibility
Part two on the personal connections and playfulness of Hubs
Part three on how XR environments shape user behavior
|
|
Daniel Pocock: RHL'19 St-Cergue, Switzerland, 25-27 January 2019 |
(translated from original French version)
The Rencontres Hivernales du Libre (RHL) (Winter Meeting of Freedom) takes place 25-27 January 2019 at St-Cergue.
Swisslinux.org invites the free software community to come and share workshops, great meals and good times.
This year, we celebrate the 5th edition with the theme «Exploit».
Please think creatively and submit proposals exploring this theme: lectures, workshops, performances and other activities are all welcome.
RHL'19 is situated directly at the base of some family-friendly ski pistes suitable for beginners and more adventurous skiers. It is also a great location for alpine walking trails.
RHL'19 brings together the forces of freedom in the Leman basin, Romandy, neighbouring France and further afield (there is an excellent train connection from Geneva airport). Hackers and activists come together to share a relaxing weekend and discover new things with free technology and software.
If you have a project to present (in 5 minutes, an hour or another format) or activities to share with other geeks, please send an email to rhl-team@lists.swisslinux.org or submit it through the form.
If you have any specific venue requirements please contact the team.
You can find detailed information on the event web site.
Please ask if you need help finding accommodation or any other advice planning your trip to the region.

|
|
Daniel Stenberg: curl 7.62.0 MOAR STUFF |
This is a feature-packed release with more new stuff than usual.
the 177th release
10 changes
56 days (total: 7,419)
118 bug fixes (total: 4,758)
238 commits (total: 23,677)
5 new public libcurl functions (total: 80)
2 new curl_easy_setopt() options (total: 261)
1 new curl command line option (total: 219)
49 contributors, 21 new (total: 1,808)
38 authors, 19 new (total: 632)
3 security fixes (total: 84)
New since the previous release is the dedicated curl bug bounty program. I'm not sure if this program has caused any increase in reports as it feels like a little too early to tell.
CVE-2018-16839 - an integer overflow case that triggers on 32 bit machines given extremely long input user name argument, when using POP3, SMTP or IMAP.
CVE-2018-16840 - a use-after-free issue. Immediately after having freed a struct in the easy handle close function, libcurl might write a boolean to that struct!
CVE-2018-16842 - is a vulnerability in the curl command line tool's "warning" message display code which can make it read outside of a buffer and send unintended memory contents to stderr.
All three of these issues are deemed to have low severity and to be hard to exploit.
We introduce a brand new URL API, that lets applications parse and generate URLs, using libcurl's own parser. Five new public functions in one go there! The link goes to the separate blog entry that explained it.
A brand new function is introduced (curl_easy_upkeep) to let applications maintain idle connections while no transfers are in progress! Perfect to maintain HTTP/2 connections for example that have a PING frame that might need attention.
Applications using libcurl's multi interface will now get multiplexing enabled by default, and HTTP/2 will be selected for HTTPS connections. With these new changes of the default behavior, we hope that lots of applications out there just transparently and magically will start to perform better over time without anyone having to change anything!
We shipped DNS-over-HTTPS support. With DoH, your internet client can do secure and private name resolves easier. Follow the link for the full blog entry with details.
The good people at MesaLink has a TLS library written in rust, and in this release you can build libcurl to use that library. We haven't had a new TLS backend supported since 2012!
Our default IMAP handling is slightly changed, to use the proper standards compliant "UID FETCH" method instead of just "FETCH". This might introduce some changes in behavior so if you're doing IMAP transfers, I advice you to mind your step into this upgrade.
Starting in 7.62.0, applications can now set the buffer size libcurl will use for uploads. The buffers used for download and upload are separate and applications have been able to specify the download buffer size for a long time already and now they can finally do it for uploads too. Most applications won't need to bother about it, but for some edge case uses there are performance gains to be had by bumping this size up. For example when doing SFTP uploads over high latency high bandwidth connections.
curl builds that use libressl will now at last show the correct libressl version number in the "curl -V" output.
CURLOPT_DNS_USE_GLOBAL_CACHE is deprecated! If there's not a massive complaint uproar, this means this option will effectively be made pointless in April 2019. The global cache isn't thread-safe and has been called obsolete in the docs since 2002!
HTTP pipelining support is deprecated! Starting in this version, asking for pipelining will be ignored by libcurl. We strongly urge users to switch to and use HTTP/2, which in 99% of the cases is the better alternative to HTTP/1.1 Pipelining. The pipelining code in libcurl has stability problems. The impact of disabled pipelining should be minimal but some applications will of course notice. Also note the section about HTTP/2 and multiplexing by default under "changes" above.
To get an overview of all things marked for deprecation in curl and their individual status check out this page.
TLS 1.3 support for GnuTLS landed. Now you can build curl to support TLS 1.3 with most of the TLS libraries curl supports: GnuTLS, OpenSSL, BoringSSL, libressl, Secure Transport, WolfSSL, NSS and MesaLink.
curl got Windows VT Support and UTF-8 output enabled, which should make fancy things like "curl wttr.in" to render nice outputs out of the box on Windows as well!
The TLS backends got a little cleanup and error code use unification so that they should now all return the same error code for the same problem no matter which backend you use!
When you use curl to do URL "globbing" as for example "curl http://localhost/[1-22]" to fetch a range or a series of resources and accidentally mess up the range, curl would previously just say that it detected an error in the glob pattern. Starting now, it will also try to show exactly where in which pattern it found the error that made it stop processing it.
The curl for Windows CI builds on AppVeyor are now finally also running the test suite! Actually making sure that the Windows build is intact in every commit and PR is a huge step forward for us and our aim to keep curl functional. We also build several additional and different build combinations on Windows in the CI than we did previously. All in an effort to reduce regressions.
We've added four new checks to travis (that run on every pull-request and commit):
We're right now doing 40 builds on every commit, spending around 12 hours of CPU time for a full round. With >230 landed commits in the tree that originated from 150-something pull requests, with a lot of them having been worked out using multiple commits, we've done perhaps 500 full round CI builds in these 56 days.
This of course doesn't include all the CPU time developers spend locally before submitting PRs or even the autobuild system that currently runs somewhere in the order of 50 builds per day. If we assume an average time spent for each build+test to take 20 minutes, this adds another 930 hours of CI hours done from the time of the previous release until this release.
To sum up, that's about 7,000 hours of CI spent in 56 days, equaling about 520% non-stop CPU time!
We are grateful for all the help we get!
The next release will ship on December 12, 2018 unless something urgent happens before that.
Note that this date breaks the regular eight week release cycle and is only six weeks off. We do this since the originally planned date would happen in the middle of Christmas when "someone" plans to be off traveling...
The next release will probably become 7.63.0 since we already have new changes knocking on the door waiting to get merged that will warrant another minor number bump. Stay tuned for details!
https://daniel.haxx.se/blog/2018/10/31/curl-7-62-0-moar-stuff/
|
|






