Air Mozilla: 2018 Global Sprint Orientation Webinar 3 - April 17th, 2018 |
 Learn about working open at the Global Sprint and hear stories and tips from past participants.
Learn about working open at the Global Sprint and hear stories and tips from past participants.
https://air.mozilla.org/2018-global-sprint-orientation-webinar-3-april-17th-2018/
|
|
Air Mozilla: Holochain Meetup |
 Holochain Meetup 4/17/2018
Holochain Meetup 4/17/2018
|
|
Mozilla Open Policy & Advocacy Blog: Decision in Oracle v. Google Fair Use Case Could Hinder Innovation in Software Development |
The technology industry was dealt a major setback when the Federal Circuit recently decided in Oracle v. Google that Google’s use of Java “declaring code” was not a fair use. The copyright doctrine of Fair Use impacts a developer’s ability to learn from and improve on the work of others, which is a crucial part of software development. Because of this ruling, copyright law today is now at odds with how software is developed.*
This is the second time in this eight year case that the Federal Circuit’s ruling has diverged from how software is written. In 2014, the court decided that declaring code can be copyrighted, a ruling with which we disagreed. Last year we filed another amicus brief in this case, advocating that Google’s implementation of the APIs should be considered a fair use. In this recent decision, the court found that copying the Java declaring code was not a protected fair use of that code.
We believe that open source software is vital to security, privacy, and open access to the internet. We also believe that Fair Use is critical to developing better, more secure, more private, and more open software because it allows developers to learn from each other and improve on existing work. Even the Mozilla Public License explicitly acknowledges that it “is not intended to limit any rights” under applicable copyright doctrines such as fair use.
The Federal Circuit’s decision is a big step in the wrong direction. We hope Google appeals to the Supreme Court and that the Supreme Court sets us back on a better course.
* When Google released its Android operating system, it incorporated some code from Sun Microsystem’s Java APIs into the software. Google copied code in those APIs that merely names functions and performs other general housekeeping functions (called “declaring code”) but wrote all the substantive code (called “implementing code”) from scratch. Software developers generally use declaring code to define the names, format, and organization ideas for certain functions, and implementing code to do the actual work (telling the program how to perform the functions). Developers specifically rely on “declaring code” to enable their own programs to interact with other software, resulting in code that is efficient and easy for others to use.
The post Decision in Oracle v. Google Fair Use Case Could Hinder Innovation in Software Development appeared first on Open Policy & Advocacy.
|
|
The Mozilla Blog: An Open Call to Storytellers: Make Something Amazing With Virtual Reality and the Open Web |
“This is not about creating something that appeals to people simply because of its novel technical achievements; rather it is [about creating] something that has real meaning…”
– Kamal Sinclair, Director of New Frontier Lab Programs at the Sundance Institute
Virtual Reality is coming. In many ways, it’s already here.
Media outlets like the New York Times now regularly create VR content that is showcased alongside its other digital journalism efforts. On the entertainment side, serious buzz is building around the release of Steven Spielberg’s Ready Player One, and home VR headsets are becoming increasingly accessible.
These are all indications that the tides are shifting VR towards the mainstream, but significant obstacles remain for both creating content and enjoying most of the current immersive experiences. These include expensive hardware, confusing distribution methods, complicated configurations, and more.
The mixed reality team at Mozilla devoted two years to brainstorming and experimenting to find a way to bring virtual reality to the web. That’s because we believe the web is the best possible platform for virtual and augmented reality. The ability to share and access virtual experiences with a URL is a game-changer; the key needed to take this amazing technology and make it mainstream.
This type of direct access is critical for filmmakers and creators who wish to use VR as their next storytelling medium.
That’s why Mozilla convened our VR the People panel at this spring’s Sundance Festival. It was an opportunity to connect with some of the world’s most innovative visual storytellers and bring together some incredible names, including Mozilla’s own Sean White, VR journalist Nonny de la Pe~na, the creatively explosive Reggie Watts and immersive artist Chris Milk, CEO of WITHIN.

That Sundance panel was an extraordinary experience, but true to Mozilla’s mission, that panel had to be more than an isolated event. We want it to be a catalyst for an ongoing effort to blur (and eventually erase) the boundaries between VR, film-making, and visual storytelling. Next week, we’ll be traveling to Tribeca Film Festival in New York to continue the conversation. If you are around, let us know. We’d love to chat.
If you’re a creator reading this, I certainly hope you feel inspired, but I also hope you feel something more. I hope you feel empowered, and then you turn that empowerment into action. I hope you go on to create something amazing that inspires someone else to create something amazing. I hope you create things with VR that we can’t even imagine right now.
Check out https://mixedreality.mozilla.org/ to view the VR tools and resources Mozilla offers to help you create immersive experiences.
The post An Open Call to Storytellers: Make Something Amazing With Virtual Reality and the Open Web appeared first on The Mozilla Blog.
|
|
Hacks.Mozilla.Org: A new video series: Web Demystified |
We don’t have to tell you that video is a key channel for sharing information and instructional skills especially for students and developers who’ve grown up with YouTube. At Mozilla, we’ve always been a leader in supporting the open technologies that bring unencumbered video into the browser and onto the web.
But on top of the technology, there’s content. In 2018, Mozilla’s Developer Outreach team has launched some projects to share more knowledge in video. Earlier this year, Jen Simmons set a high bar with the launch of Layout Land, a series about “what’s now possible in graphic design on the web — layout, CSS Grid, and more.”
This post introduces Web Demystified, a new series targeting web makers. By web makers, I have in mind everyone who builds things for the web: designers, developers, project and team managers, students, hobbyists, and experts. Today we’ve released the opening two episodes on the Mozilla Hacks YouTube channel, introducing web basics.
Our goal is to provide basic information for beginner web makers, at the start of their web journey. The subject matter will also serve as a refresher on web fundamentals.
To begin, there is one question that needs to be answered: What is the web? And voila, here is our opener:
The next four episodes cover some basic technologies at the heart of the web (HTML, CSS, JavaScript, and SVG). We will release a new show every couple weeks for your viewing pleasure. And then we will continue our journey into details, covering stuff like: how the browser works, image formats for the web, domain names, WebAssembly, and more…
As an added attraction, here is Episode #1 (the second show). It’s all about HTML:
In true Mozilla fashion, we’d welcome your help sharing this new content and helping us promote it.
Enjoy Web Demystified! And see you in a fortnight.
https://hacks.mozilla.org/2018/04/a-new-video-series-web-demystified/
|
|
This Week In Rust: This Week in Rust 230 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
{:#?} pretty-printer flag.std::ops::Shl::shl not equal to <<?This week's crate is rain, a framework for large-scale distributed computations. Thanks to Vikrant for the suggestion!
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
143 pull requests were merged in the last week
#[repr(packed(n))] (RFC #1399)TokenStream more oftenFromIterator impl? repetition disambiguation! for erroneous identifier not&mut suggestionimpl Trait in unsupported positionGlobalAlloc trait + tweaks for initial stabilizationto_bytes and from_bytes to primitive integersOption::filterfetch_nandtake_set_limitRange*::contains to a single default impl on RangeBoundsfor_each(drop)std_unicode crate into the core crateLayout methodscargo metadataChanges to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
place <- expr) and RFC 809: box and placement in.Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now. This week's FCPs are:
The community team is trying to improve outreach to meetup organisers. Please fill out their call for contact info if you are running or used to run a meetup.
If you are running a Rust event please add it to the calendar to get it mentioned here. Email the Rust Community Team for access.
Tweet us at @ThisWeekInRust to get your job offers listed here!
Rust is one of those friends that take some time to get along with, but that you'll finally want to engage with for a long term relationship.
Thanks to u/rushmorem and saethlin for the suggestion!
Submit your quotes for next week!
This Week in Rust is edited by: nasa42 and llogiq.
https://this-week-in-rust.org/blog/2018/04/17/this-week-in-rust-230/
|
|
Air Mozilla: Mozilla Weekly Project Meeting, 16 Apr 2018 |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20180416/
|
|
Mozilla Addons Blog: Apply to Join the Featured Extensions Advisory Board |
Are you an extensions enthusiast? Do you want to help people find excellent ways to improve their browsing experience? If so, please consider applying to join our Featured Extensions Community Board!
Every six months, we assemble a small group of dedicated community members to help nominate and select new featured extensions for addons.mozilla.org (AMO) each month. Their picks help millions of Firefox users discover top-quality extensions.
The current board is currently wrapping up their six-month term, and we are now assembling a new board of talented contributors for the months July – December.
All active members of the add-ons community — including fans, developers, and advocates — are invited to apply to join the board. Priority will be given to applicants who have not served on the board before, followed by those with previous experience, and finally from the outgoing board. You can learn more about the duties of the Featured Add-on Advisory Board on MDN web docs.
To apply, please send us an email at amo-featured [at] mozilla [dot] org with your name, a few sentences about how you’re involved with AMO, and why you are interested in joining the board. The deadline is Monday, April 30, 2018 at 23:59 PDT. The new board will be announced shortly thereafter.
The post Apply to Join the Featured Extensions Advisory Board appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2018/04/16/apply-to-join-the-featured-extensions-advisory-board/
|
|
Air Mozilla: Mozilla Weekly Project Meeting, 09 Apr 2018 |
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20180409/
|
|
Gregory Szorc: Release of python-zstandard 0.9 |
I have just released
python-zstandard 0.9.0. You can
install the latest release by running pip install zstandard==0.9.0.
Zstandard is a highly tunable and therefore flexible compression algorithm with support for modern features such as multi-threaded compression and dictionaries. Its performance is remarkable and if you use it as a drop-in replacement for zlib, bzip2, or other common algorithms, you'll frequently see more than a doubling in performance.
python-zstandard provides rich bindings to the zstandard C library without sacrificing performance, safety, features, or a Pythonic feel. The bindings run on Python 2.7, 3.4, 3.5, 3.6, 3.7 using either a C extension or CFFI bindings, so it works with CPython and PyPy.
I can make a compelling argument that python-zstandard is one of the richest compression packages available to Python programmers. Using it, you will be able to leverage compression in ways you couldn't with other packages (especially those in the standard library) all while achieving ridiculous performance. Due to my focus on performance, python-zstandard is able to outperform Python bindings to other compression libraries that should be faster. This is because python-zstandard is very diligent about minimizing memory allocations and copying, minimizing Python object creation, reusing state, etc.
While python-zstandard is formally marked as a beta-level project and hasn't yet reached a 1.0 release, it is suitable for production usage. python-zstandard 0.8 shipped with Mercurial and is in active production use there. I'm also aware of other consumers using it in production, including at Facebook and Mozilla.
The sections below document some of the new features of python-zstandard 0.9.
The 0.9 release contains a stream_reader() API on the compressor and
decompressor objects that allows you to treat those objects as readable file
objects. This means that you can pass a ZstdCompressor or ZstdDecompressor
around to things that accept file objects and things generally just work.
e.g.:
with open(compressed_file, 'rb') as ifh: cctx = zstd.ZstdDecompressor() with cctx.stream_reader(ifh) as reader: while True: chunk = reader.read(32768) if not chunk: break
This is probably the most requested python-zstandard feature.
While the feature is usable, it isn't complete. Support for readline(),
readinto(), and a few other APIs is not yet implemented. In addition,
you can't use these reader objects for opening zstandard compressed
tarball files because Python's tarfile package insists on doing
backward seeks when reading. The current implementation doesn't support
backwards seeking because that requires buffering decompressed output and that
is not trivial to implement. I recognize that all these features are useful
and I will try to work them into a subsequent release of 0.9.
The 1.3.4 release of zstandard (which python-zstandard 0.9 bundles) supports negative compression levels. I won't go into details, but negative compression levels disable extra compression features and allow you to trade compression ratio for more speed.
When compressing a 6,472,921,921 byte uncompressed bundle of the Firefox Mercurial repository, the previous fastest we could go with level 1 was ~510 MB/s (measured on the input side) yielding a 1,675,227,803 file (25.88% of original).
With level -1, we compress to 1,934,253,955 (29.88% of original) at
~590 MB/s. With level -5, we compress to 2,339,110,873 bytes (36.14% of
original) at ~720 MB/s.
On the decompress side, level 1 decompresses at ~1,150 MB/s (measured at the output side), -1 at ~1,320 MB/s, and -5 at ~1,350 MB/s (generally speaking, zstandard's decompression speeds are relatively similar - and fast - across compression levels).
And that's just with a single thread. zstandard supports using multiple threads to compress a single input and python-zstandard makes this feature easy to use. Using 8 threads on my 4+4 core i7-6700K, level 1 compresses at ~2,000 MB/s (3.9x speedup), -1 at ~2,300 MB/s (3.9x speedup), and -5 at ~2,700 MB/s (3.75x speedup).
That's with a large input. What about small inputs?
If we take 456,599 Mercurial commit objects spanning 298,609,254 bytes from the Firefox repository and compress them individually, at level 1 we yield a total of 133,457,198 bytes (44.7% of original) at ~112 MB/s. At level -1, we compress to 161,241,797 bytes (54.0% of original) at ~215 MB/s. And at level -5, we compress to 185,885,545 bytes (62.3% of original) at ~395 MB/s.
On the decompression side, level 1 decompresses at ~260 MB/s, -1 at ~1,000 MB/s, and -5 at ~1,150 MB/s.
Again, that's 456,599 operations on a single thread with Python.
python-zstandard has an experimental API where you can pass in a collection of inputs and it batch compresses or decompresses them in a single operation. It releases and GIL and uses multiple threads. It puts the results in shared buffers in order to minimize the overhead of memory allocations and Python object creation and garbage collection. Using this mode with 8 threads on my 4+4 core i7-6700K, level 1 compresses at ~525 MB/s, -1 at ~1,070 MB/s, and -5 at ~1,930 MB/s. On the decompression side, level 1 is ~1,320 MB/s, -1 at ~3,800 MB/s, and -5 at ~4,430 MB/s.
So, my consumer grade desktop i7-6700K is capable of emitting decompressed
data at over 4 GB/s with Python. That's pretty good if you ask me. (Full
disclosure: the timings were taken just around the compression operation
itself: overhead of loading data into memory was not taken into account. See
the bench.py script in the
source repository for more.
Negative compression levels take zstandard into performance territory that has historically been reserved for compression formats like lz4 that are optimized for that domain. Long distance matching takes zstandard in the other direction, towards compression formats that aim to achieve optimal compression ratios at the expense of time and memory usage.
python-zstandard 0.9 supports long distance matching and all the configurable parameters exposed by the zstandard API.
I'm not going to capture many performance numbers here because python-zstandard performs about the same as the C implementation because LDM mode spends most of its time in zstandard C code. If you are interested in numbers, I recommend reading the zstandard 1.3.2 and 1.3.4 release notes.
I will, however, underscore that zstandard can achieve close to lzma's
compression ratios (what the xz utility uses) while completely smoking
lzma on decompression speed. For a bundle of the Firefox Mercurial repository,
zstandard level 19 with a long distance window size of 512 MB using 8 threads
compresses to 1,033,633,309 bytes (16.0%) in ~260s wall, 1,730s CPU.
xz -T8 -8 compresses to 1,009,233,160 (15.6%) in ~367s wall, ~2,790s CPU.
On the decompression side, zstandard takes ~4.8s and runs at ~1,350 MB/s as
measured on the output side while xz takes ~54s and runs at ~114 MB/s.
Zstandard, however, does use a lot more memory than xz for decompression,
so that performance comes with a cost (512 MB versus 32 MB for this
configuration).
python-zstandard now uses the advanced compression and decompression APIs everywhere. All tunable compression and decompression parameters are available to python-zstandard. This includes support for disabling magic headers in frames (saves 4 bytes per frame - this can matter for very small inputs, especially when using dictionary compression).
The full dictionary training API is exposed. Dictionary training can now use multiple threads.
There are a handful of utility functions for inspecting zstandard frames, querying the state of compressors, etc.
Lots of work has gone into shoring up the code base. We now build with warnings as errors in CI. I performed a number of focused auditing passes to fix various classes of deficiencies in the C code. This includes use of the buffer protocol: python-zstandard is now able to accept any Python object that provides a view into its underlying raw data.
Decompression contexts can now be constructed with a max memory threshold so attempts to decompress something that would require more memory will result in error.
See the full release notes for more.
Since I last released a major version of python-zstandard, a lot has changed in the zstandard world. As I blogged last year, zstandard circa early 2017 was a very compelling compression format: it already outperformed popular compression formats like zlib and bzip2 across the board. As a general purpose compression format, it made a compelling case for itself. In my mind, snappy was its only real challenger.
As I wrote then, zstandard isn't perfect. (Nothing is.) But a year later, it is refreshing to see advancements.
A criticism one year ago was zstandard was pretty good as a general purpose compression format but it wasn't great if you live at the fringes. If you were a speed freak, you'd probably use lz4. If you cared about compression ratios, you'd probably use lzma. But recent releases of zstandard have made huge strides into the territory of these niche formats. Negative compression levels allow zstandard to flirt with lz4's performance. Long distance matching allows zstandard to achieve close to lzma's compression ratios. This is a big friggin deal because it makes it much, much harder to justify a domain-specific compression format over zstandard. I think lzma still has a significant edge for ultra compression ratios when memory utilization is a concern. But for many consumers, memory is readily available and it is easy to justify trading potentially hundreds of megabytes of memory to achieve a 10x speedup for decompression. Even if you aren't willing to sacrifice more memory, the ability to tweak compression parameters is huge. You can do things like store multiple versions of a compressed document and conditionally serve the one most appropriate for the client, all while running the same zstandard-only code on the client. That's huge.
A year later, zstandard continues to impress me for its set of features and its versatility. The library is continuing to evolve - all while maintaining backwards compatibility on the decoding side. (That's a sign of a good format design if you ask me.) I was honestly shocked to see that zstandard was able to change its compression settings in a way that allowed it to compete with lz4 and lzma without requiring a format change.
Snappy is another promising modern compression format. However, the project appears to have died off. There are only 5 commits so far in 2018. (zstandard has 357.) Competition is good and I was hoping Google/snappy would provide some competitive pressure for Facebook/zstandard. But who knows what's happening on the snappy side of the world. Zstandard continues to make meaningful improvements, so I can't complain about its pace of progress.
The more I use zstandard, the more I think that everyone should use this and that popular compression formats just aren't cut out for modern computing any more. Every time I download a zlib/gz or bzip2 compressed archive, I'm thinking if only they used zstandard this archive would be smaller, it would have decompressed already, and I wouldn't be thinking about how annoying it is to wait for compression operations to complete. In my mind, zstandard is such an obvious advancement over the status quo and is such a versatile format - now covering the gamut of super fast compression to ultra ratios - that it is bordering on negligent to not use zstandard. With the removal of the controversial patent rights grant license clause in zstandard 1.3.1, that justifiable resistance to widespread adoption of zstandard has been eliminated. Zstandard is objectively superior for many workloads and I heavily encourage its use. I believe python-zstandard provides a high-quality interface to zstandard and I encourage you to give it and zstandard a try the next time you compress data.
If you run into any problems or want to get involved with development, python-zstandard lives at indygreg/python-zstandard on GitHub.
http://gregoryszorc.com/blog/2018/04/09/release-of-python-zstandard-0.9
|
|
Alex Vincent: Verbosio is dead… but I have a new code name, Aluminium, with the same ambition |
Perhaps the fastest evolution in the world today is knowledge, not software. This has become painfully clear in the last few years.
The way I see it, Mozilla and I are both going through major turns in our respective life cycles:
All of the above means that Verbosio, as a Mozilla Firefox-based XML editor with specific XML languages as add-ons to the editor, is truly and finally dead, and there’s no point trying to believe otherwise. Similarly, the need for a XUL IDE is dead as well. (Daniel Glazman and I need to get together to cry over a beer sometime.)
Enter a new code name, “Aluminium”.
I still want to build a stand-alone (but not too complex) web page editor supporting mathematics students at the high school, community college and university levels. Amaya remains my inspiration. I want to build a successor to that project, focusing on HTML5, MathML and SVG, with a conscious bias towards assisting students in doing their homework (but not doing the homework for them).
Of course, naming a future web page editor Aluminium, and basing it on arriving Mozilla technologies, leads to all sorts of bad puns:
I know, I know, that’s enough jokes for now. But about the editor project itself, I’m actually quite serious.
Right now, one of the classes I’m taking at California State University, East Bay is titled “Graphical User Interface Programming Using a Rapid Application Development Tool”. In short, it’s an introduction to building GUI windows (using Qt as a baseline and toolkit) as opposed to a command line application. This is a course I am extremely lucky, and extremely happy, to get: it doesn’t appear in the catalogs for any other CSU campus that I could find, much less go to, and the Computer Science department had told me repeatedly it wasn’t supposed to be in the CSUEB Catalog anymore. All my programming experience and studies to date have either been for command-line applications, inside a web page, or with Mozilla’s platform code. None of that taught me how to build GUI applications from scratch, or how to embed a web rendering engine like Servo. That’s going to change…
Later down the line, I’m not planning on taking easy courses either: I’m looking forward to classes on “Automata and Computation”, “Analysis of Algorithms”, “Numerical Analysis”, “Compiler Design”, and existing mathematics software. All of these can only be force-multipliers on my computer programming experience going forward.
So yes, the old, non-standardized technologies of the last twenty years are being eliminated in Darwinian fashion… and a whole new generation of standards-based and safe-to-program-in computer languages are arriving. The way I see it, I’m earning my Bachelor’s of Science degree at exactly the right time. I hope future employers see it the same way, to work on some truly ground-breaking software.
Thanks for reading!
Alex
|
|
Georg Fritzsche: Know your limits |
When building software systems, we usually deal with data from external sources. This can be user input, data coming from other systems, etc. My basic assumption on any external data is: don’t trust it!
Any data that we don’t know completely ahead of time can and will behave differently than what we expected. A classic example for this is user input, say a text field. If we don’t limit the length and contents, somebody will eventually enter a book lengths worth of data or try to use it to attack a system.
But the same problem extends to data from systems we control and that we might have faith in. At Mozilla we have a variety of teams and products which are deployed to a large and diverse population of users across the world. We may think we know how those products and the data they generate behave, but practically we always find surprises.
Let’s consider a hypothetical mobile application. The mobile application has a basic system to collect product data, and makes it easy to collect new string values. To make it easier and more flexible for our teams to add something, we don’t impose a hard limit on the length of the string. We have documentation on the various instrumentation options available, making it easy to choose the best for each use-case.
Now, this works great and everybody can add their instrumentation easily. Then one day a team needs data on a specific view in the application to better understand how it gets used. Specifically they need to know how long it was visible to the user, which buttons were interacted with in which order and what the screen size of the device was. This doesn’t seem to directly fit into our existing instrumentation options, but our string recording is flexible enough to accommodate different needs.
So they put that data together in a string, making it structured so it’s reasonable to use later and we start sending it out in our JSON data packages:
...
"view_data": "{\"visible_ms\": 35953, \"buttons_used\": [\"change_name\", \"confirm\", \"help\"], \"screen_size\": \"960x540\"}",
...
The change gets tested and works fine so it gets shipped. Some time later we get a report that our product dashboards are not updated. An investigation shows that the jobs to update the dashboards were timing out, due to unusually large strings being submitted. It turns out that some users click buttons in the view 100 times or more.
What’s more, a detailed review shows that the user churn rate in our dashboard started to increase slightly, but permanently, around the time the change shipped. The favored hypothesis is that the increased data size for some users leads to lower chances of the data getting uploaded.
To be clear, this is built as a bad example. There is a whole bunch of things that could be learnt from the above example; from getting expert review to adding instrumentation options to building the data system for robustness on both ends. However, here i want to highlight how the lack of a limit for the string length propagated through the system.

No software component exists in isolation. Looking at a high-level data flow through a product analytics system, any component in this system has a set of important parameters with resulting trade-offs from our design choices. The flexibility of a component in an early stage puts fewer constraints on the data that flows through, which propagates through the system and enlarges the problem space for each component after it.
The unbound string length of the data collection system here means that we know less about the shape of data we collect, which impacts all components in the later stages. Choosing explicit limits on incoming data is critical and allows us to reason about the behavior of the whole system.
Choosing a limit is important, but that doesn’t mean we should restrict our data input as much as we can. If we pick limits that are too strict, we end up blocking use-cases that are legitimate but not anticipated. For each system that we build, we have to make a design decision on the scale from most strict to arbitrary values and weigh the trade-offs.
For me, my take-away is: Have a limit. Reason about it. Document it. The right limit will come out of conversations and lessons learnt — as long as we have one.
Know your limits was originally published in Georg Fritzsche on Medium, where people are continuing the conversation by highlighting and responding to this story.
https://medium.com/georg-fritzsche/know-your-limits-c2152629ca5f?source=rss----9eb1bc803268---4
|
|
Mozilla VR Blog: This Week in Mixed Reality: Issue 1 |

In the spirit of This week in Firefox/Rust/Servo, we’ve decided to start sharing weekly updates on the progress of the Mozilla Mixed Reality team. Late last year, we brought together all of the people working on Virtual and Augmented Reality at Mozilla to work in our new Mixed Reality program.
As part of that program, we're working in three broad areas.
We recently announced Firefox Reality, a new browser for standalone AR/VR headsets based on the best pieces of Firefox with both GeckoView and Servo.
We are working on a new social platform for Mixed Reality.
In the last week, we have:
And of course without great experiences, there’s no reason to put on a headset in the first place! Making sure that developers - whether they are web-first or coming from tools such as Unity - are successful in targeting WebVR and later WebXR...
|
|
Support.Mozilla.Org: Proposal: Knowledge Base Spring Cleaning at SUMO – June 2018 |
People say that spring is a good time to try new things and refresh one’s body and mind. While our site does not really have a body (unless you count the HTML tags…) and its collective mind is made up of all of us (including you, reading these words), it does need refreshing every now and then, mostly due to the nature of the open, living web we are all part of.
That said, let’s get to the details, some of which may sound like Rosana’s post from about 4 years ago.
The localization coordinators across Mozilla want to consolidate Mozillians and our resources around active locales. In the context of SUMO’s Knowledge Base, this means taking a closer look at the Knowledge Base, which at the moment is available for 76 locales (at least “on paper”).
The proposal is to redirect the mostly inactive locales of the SUMO Knowledge Base to English (or another best equivalent locale). You can find the proposed (draft) list of all the locales here.
It is important to note that no content created so far would be deleted.
There are several reasons behind this proposal:
The 23 locales counted as “no change” will keep functioning as usual, with more locally driven activities coming this year – check the last section of this L10n blog post for just one of the many possibilities.
During April and May, I will reach out to all the contributors listed in SUMO and Pontoon for the 30 locales that are listed as candidates for the clean up – using Private Messages on SUMO or emails listed in Pontoon. Depending on the answers received, we may be keeping some of these locales online, and coming up with a realistic (but ambitious) localization progress timeline for each of them.
At the end of June (after the All Hands), all the locales that are not active will be redirected to English (or another best equivalent locale).
After that, localization for the redirected locales will be focused on Firefox and other Mozilla properties. If there is interest in reactivating a locale, it will happen according to a “re/launch plan” – including creating or participating in a SUMO Knowledge Base sprint event aimed at localizing at least the 20 most popular articles in the Knowledge Base as the minimum requirement, and additional sprints to localize an additional 80 most popular articles.
No, the Knowledge Base is a big enough project for now.
Still, this is just the start of this year’s clean up – we will also look into reviewing and reorganizing our contributor documentation, English Knowledge Base, and other properties containing content relevant to SUMO (for example our MozWiki pages).
Please let us know what you think about this in the comments or on our forums: SUMO / Discourse.
https://blog.mozilla.org/sumo/2018/04/06/spring-cleaning-at-sumo-coming-up-in-june/
|
|
The Rust Programming Language Blog: The Rust Team All Hands in Berlin: a Recap |
Last week we held an “All Hands” event in Berlin, which drew more than 50 people involved in 15 different Rust Teams or Working Groups, with a majority being volunteer contributors. This was the first such event, and its location reflects the current concentration of team members in Europe. The week was a smashing success which we plan to repeat on at least an annual basis.
The impetus for this get-together was, in part, our ambitious plans to ship Rust, 2018 edition later this year. A week of work-focused facetime was a great way to kick off these efforts!
We’ve also asked attendees to blog and tweet about their experiences at the #RustAllHands hashtag; the Content Team will be gathering up and summarizing this content as well.
Below we’ll go through the biggest items addressed last week. Note that, as always, reaching consensus in a meeting does not mean any final decision has been made. All major decisions will go through the usual RFC process.
use statements.derive: a proposal to make derive more ergonomic in Rust 2018.union semantics, Pin semantics, thread::abort and more.In addition to the work by existing teams, we had critical mass to form two new working groups:
The Verification WG has been formally announced, and the Codegen WG should be announced soon!
The combination of having a clear goal – Rust 2018 – and a solid majority of team member present made the All Hands extremely fun and productive. We strive to keep the Rust community open and inclusive through asynchronous online communication, but it’s important to occasionally come together in person. The mix of ambition and kindness at play last week really captured the spirit of the Rust Community.
Of course, an event like this is only possible with a lot of help, and I’d like to thank the co-organizers and Mozilla Berlin office staff:
as well as all the team leads who organized and led sessions!
|
|
The Firefox Frontier: uBlock Origin is Back-to-Back March Addonness Champion |
It’s been three weeks and we’ve almost run out of sports metaphors. We’re happy to announce that after three rounds and thousands of votes you have crowned uBlock Origin March … Read more
The post uBlock Origin is Back-to-Back March Addonness Champion appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/ublock-origin-is-back-to-back-march-addonness-champion/
|
|
Mozilla VR Blog: Progressive WebXR |
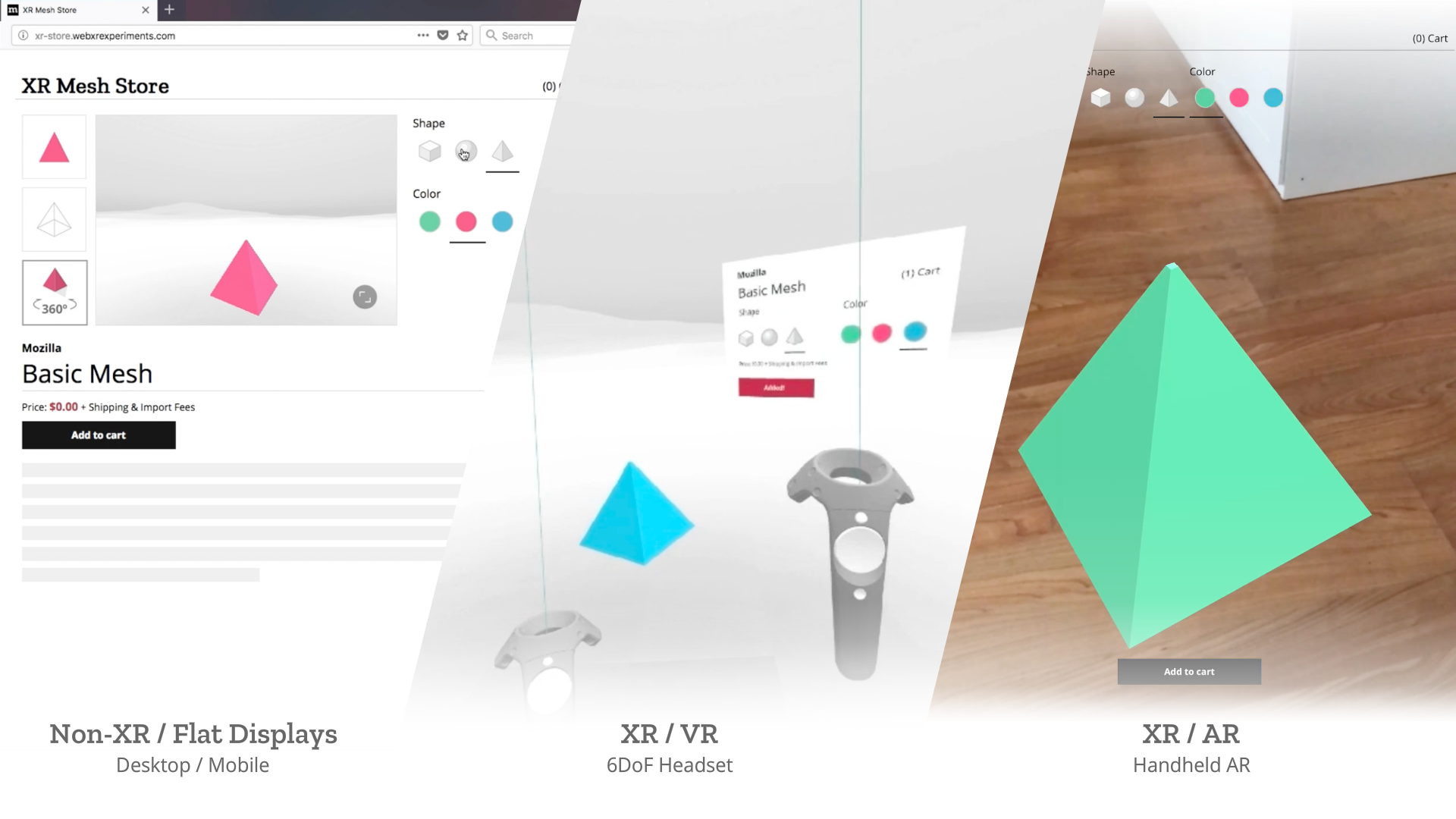
Imagine you wanted to have your store’s web page work in 2D, and also take advantage of the full range of AR and VR devices. WebXR will provide the foundation you need to create pages that work everywhere, and let you focus on compelling User Experiences on each of the devices.
In a recent blog post, we touched on one aspect of progressive WebXR, showcasing a version of A-Painter that was adapted to handheld AR and immersive VR. In this post, we will dive a bit deeper into the idea of progressive WebXR apps that are accessible across a much wider range of XR-supported devices.
The WebXR Device API expands on the WebVR API to include a broader range of mixed reality devices (i.e., AR/VR, immersive/handheld). By supporting all mixed reality devices in one API, the Immersive Web community hopes to make it easier for web apps to respond to the capabilities of a user’s chosen device, and present an appropriate UI for AR, VR, or traditional 2D displays.
At Mozilla, this move aligns with experiments we started last fall, when we created a draft WebXR API proposal, a WebXR polyfill based on it, and published our WebXR Viewer experimental web browser application to the iOS App Store. Publishing the app for iOS allowed us (and others) to experiment with WebXR on iOS, and is one of the target platforms for the XR Store demo that is the focus of this article. This demo shows how future sites can support the WebXR API across many different devices.
Before introducing the example store we've create, I’ll give an overview of the spectrum of devices that might need to be supported by a UX strategy to design this kind of WebXR-compatible site.
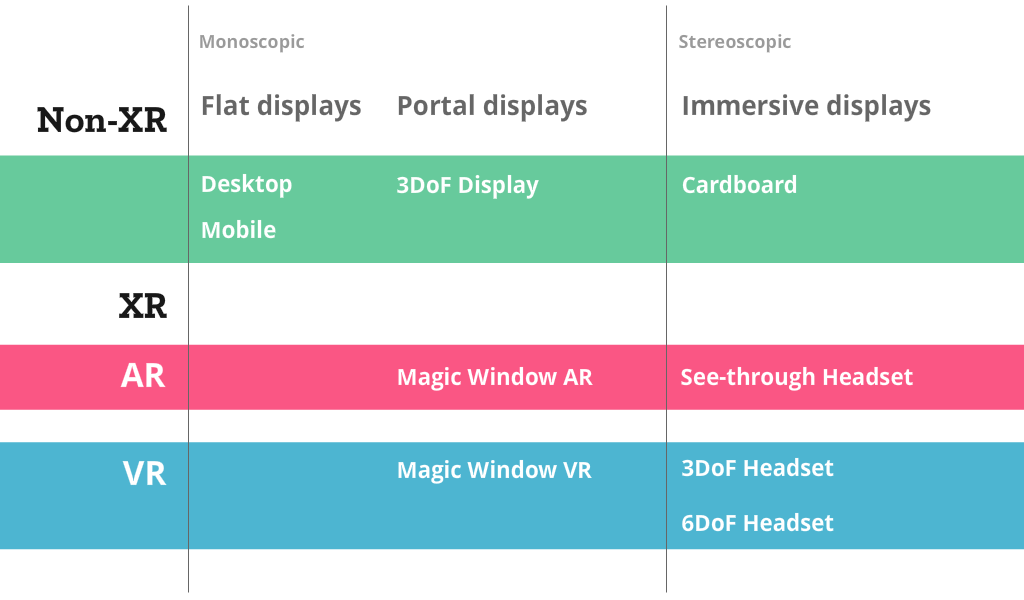
Broadly speaking, there are three categories of displays that need to be supported by a responsive WebXR application:
Current flat displays, such as desktop monitors, phones and tablets, may not have access to VR/AR capabilities via WebXR, although some will be able to simulate WebXR using a WebXR polyfill. Such desktop and mobile displays will remain the most common ways to consume web content for the forseeable future.
Mobile devices with 3DoF orientation sensors (that use accelerometers, gyroscopes, and magnetometers to give 3 Degrees of Freedom for the device pose) can simulate monoscopic 3D VR (and AR, if they use getUserMedia to access the video camera on the device), by leveraging the deviceorientation or Orientation Sensor APIs to access the device orientation.
Apps written for "Cardboard" display holders for these mobile devices (i.e., cases that use the phone's screen as their display, such as a Google Cardboard) use the same 3DoF sensors, but render stereoscopic VR on the phone display.
XR displays come in two sorts: AR and VR. The most common XR displays right now are Handheld or "Magic Window" AR, made possible by Apple’s ARKit for iOS (used by our WebXR Viewer) or Google’s ARCore for Android (used by the WebAROnARCore experimental browser). These give the user the illusion that the phone is a portal, or magic window, into an AR scene surrounding the user.
While currently less common, optically see-through headsets such as Microsoft’s Hololens provide an immersive 3D experience where virtual content can more convincingly surround the user. Other displays are in development or limited release, such as those from Magic Leap and Meta. We’ve shown the Meta 2 display working with WebVR in Firefox, and hope most upcoming AR displays will support WebXR eventually.
Thanks to WebVR, web-based VR is possible now on a range of immersive VR displays. The most common VR displays are 3DoF Headsets, such as Google Daydream or Samsung Gear VR. 6DoF Headsets (that provide position and orientation, giving 6 degrees of freedom), such as the HTC Vive, Oculus Rift, and Windows Mixed Reality-compatible headsets, can deliver fully immersive VR experiences where the user can move around.
The second category of VR displays are what we call Magic Window VR. These displays use flat 2D displays, but leverage 3D position and orientation tracking provided by the WebXR API to determine the pose of the camera and simulate a 3D scene around the user. Similar to Magic Window AR, these are possible now by leveraging the tracking capabilities of ARKit and ARCore, but not showing video of the world around the user.
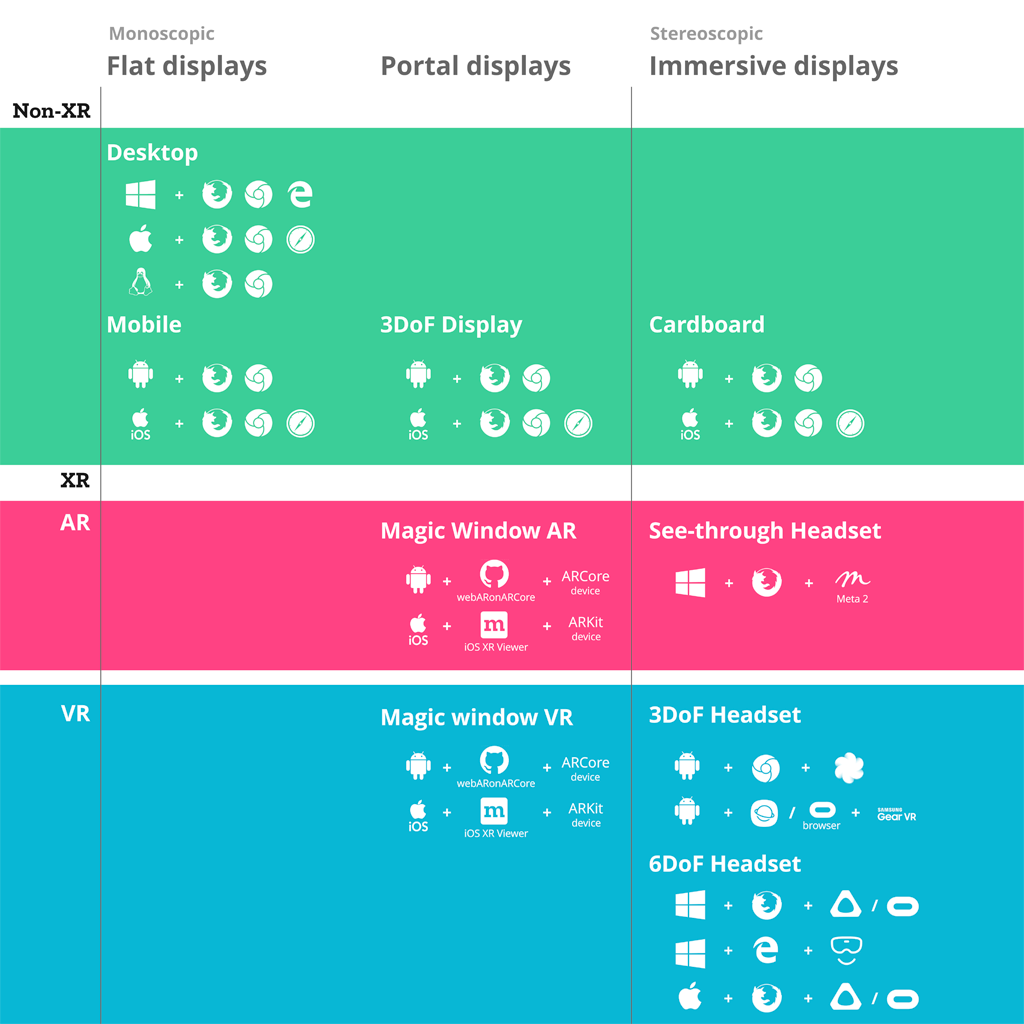
In the table below we have listed the common OS, browsers, and devices for each category.
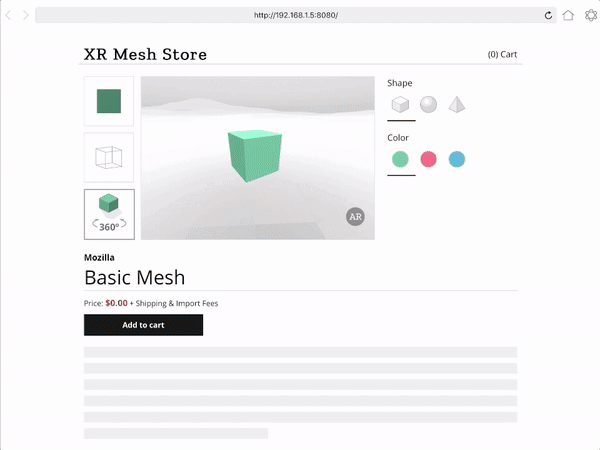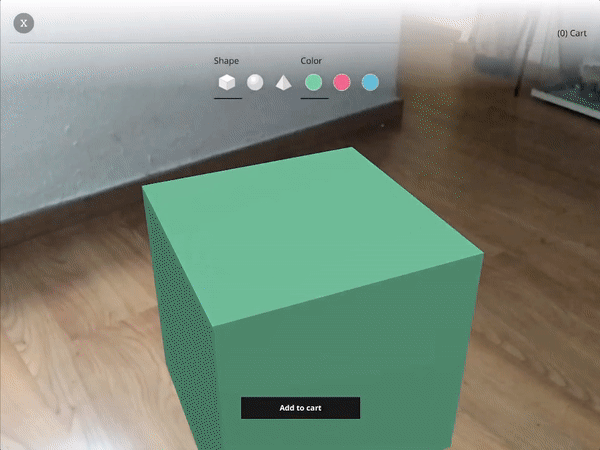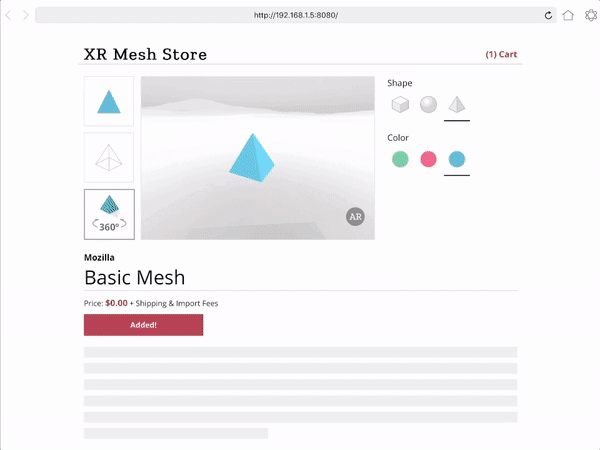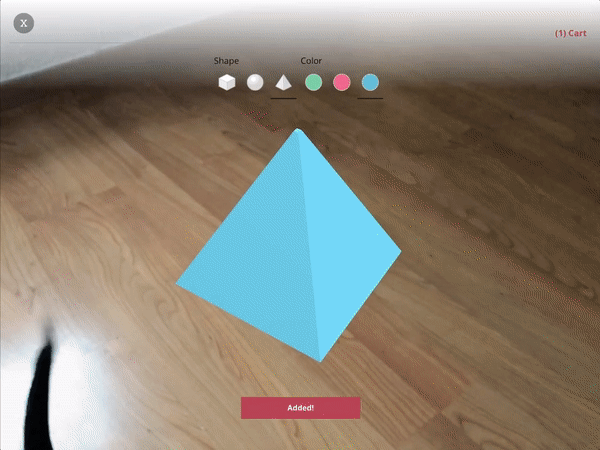
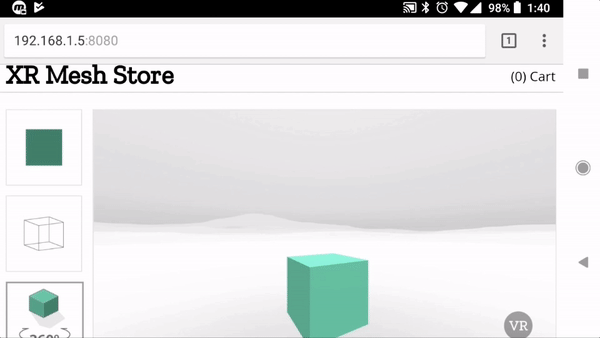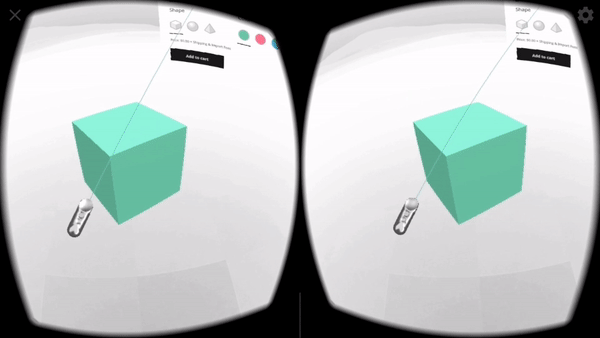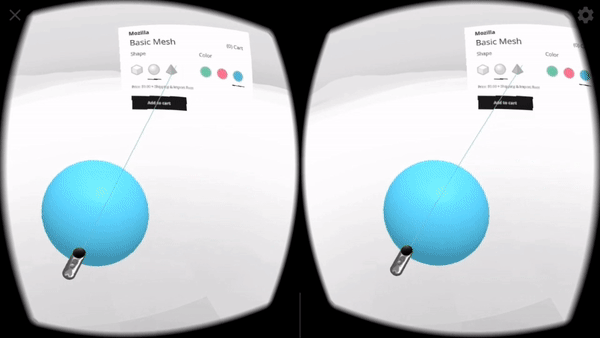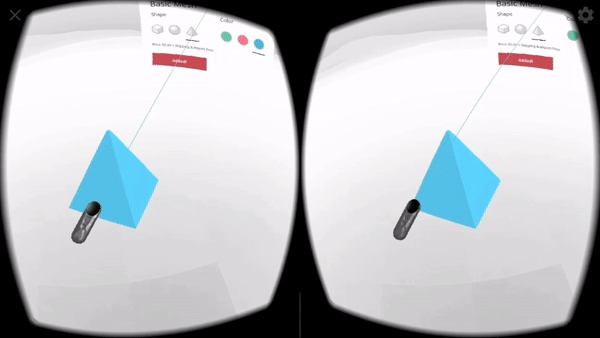
Creating responsive web apps that adapt to the full range of non-XR and WebXR devices will allow web developers to reach the widest audience. The challenge is to create a site that provides an appropriate interface for each of the modalities, rather than designing for one modality and simulating it on the others. To demonstrate this, we created a realistic XR Store demo, implementing a common scenario for WebXR: a product sheet on a simulated e-commerce site that allows the visitor to see a product in 3D on a traditional display, in a virtual scene in VR, or in the world around them in AR.

We selected a representative set of current XR modes to let us experiment with a wide range of user experiences: Desktop / Mobile on Flat displays, AR Handheld on Portal Displays), and 3DoF / 6DoF Headsets on Immersive Displays.
The image below shows some initial design sketches of the interfaces and interactions for the XR Store application, focusing on the different user experiences for each platform.
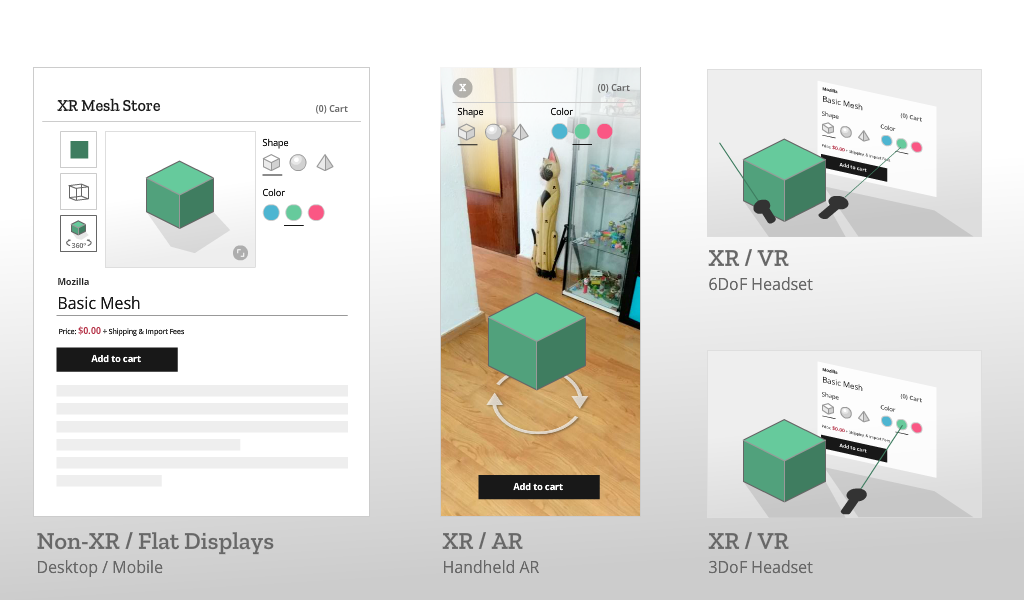
In the XR Store demo we used four types of User Interfaces (UIs), borrowing from terminology commonly used in 3D UIs (including in video games):
We also considered using these two types as well:
For Non-XR / Flat Displays we are using exclusively Page UI controls, and a Non-Diegetic element for a button to enter Fullscreen mode (a common pattern in UIs in 2D applications). We opted not to mix the page elements with diegetic controls embedded in the 3D scene, as page-based metaphors are what current web users would expect to find on a product detail page.
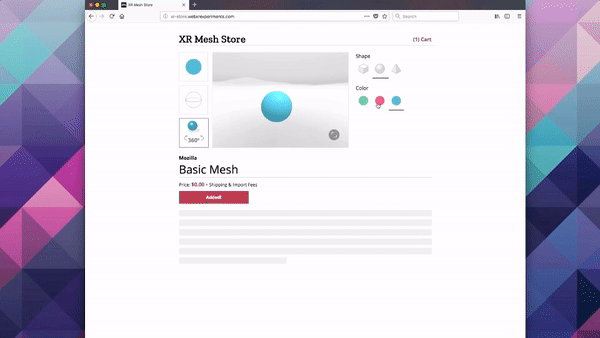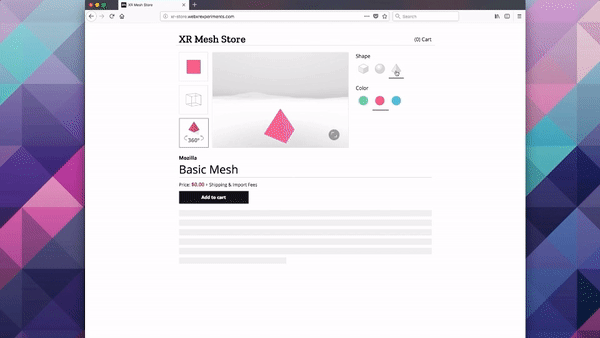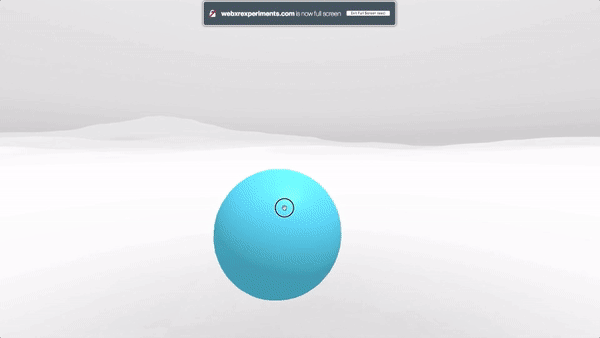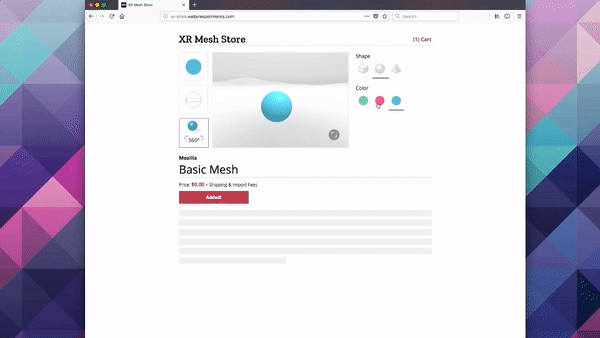
For XR / AR, we start with a very similar interface to the one used on Flat Displays (page controls, a diegetic button to switch to AR mode), but once in AR use Non-Diegetic UI elements over the 3D scene to make it easier to change the product properties. We could also have used a Direct Manipulation UI to scale, rotate, or move the product in the projected reality (but decided not to, in this example, for simplicity).
For XR / VR we are using Diegetic UI for interaction controllers and a Spatial UI to give the user a representation of the selectable part of the product sheet. We could have used an Anchored UI to make it easier to find this panel, as we did in the VR painting interface for A-Painter. We ended up using the same UI for 3DoF and 6DoF VR, but could have changed the UI slightly for these two different cases, such as (for example) moving the 2D panel to stay behind-and-to-the-right of the object as a 6DoF user walks around. Another option would have been to have the 2D panel slide into view whenever it goes offscreen, a common metaphor used in applications for Microsoft’s HoloLens. Each of these choices has its pros and cons; the important part is enabling designers to explore different options and use the one that is more appropriate for their particular use case.
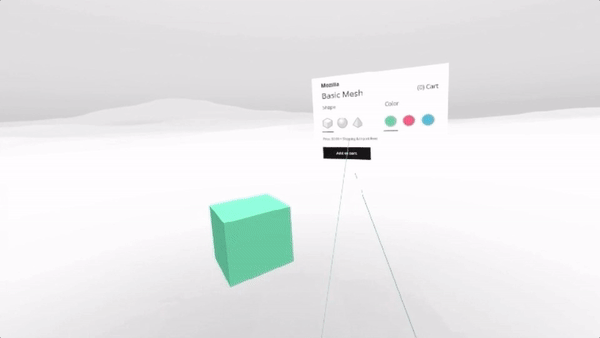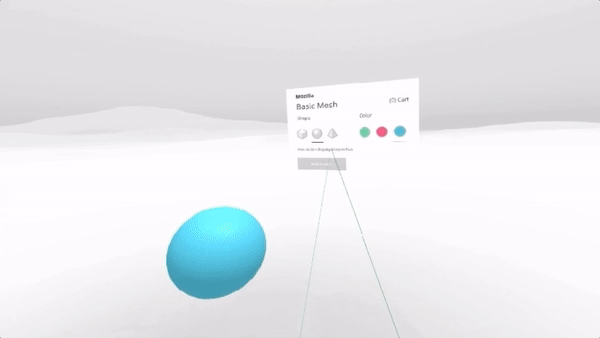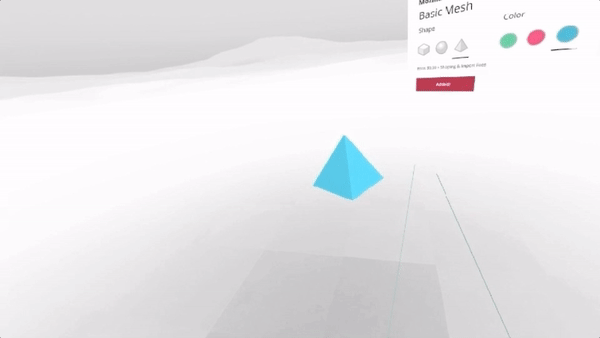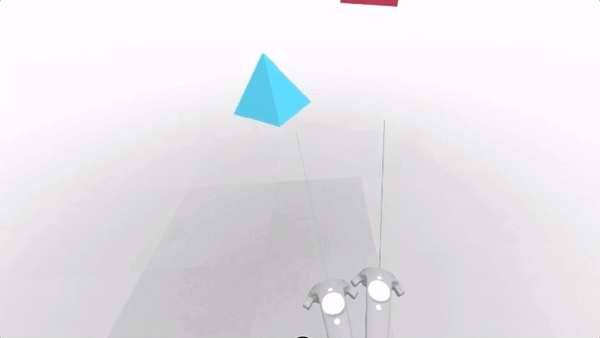
The source code for the XR Store demo currently uses a custom version of A-Frame combined with our aframe-xr WebXR binding for A-Frame. The aframe-xr bindings are based on our experimental webxr-polyfill and our three-xr WebXR bindings for three.js.
To try it out, visit XR Store on the appropriate device and browser. To try the 3DoF VR mode, you can use Google Chrome on an Android phone supporting Daydream, or the Samsung Internet/Oculus Browser on a phone supporting Gear VR. The demo supports any 6DoF VR device that works with Firefox, such as the HTC Vive or Oculus Rift, or Windows Mixed Reality headsets with Edge.
If you want to try the application in AR mode, you can use any iOS device that supports ARKit with our experimental WebXR Viewer app, or any Android device that supports ARCore with Google’s experimental WebAROnARCore (WebARonARCore has some limitations that limit entering and leaving AR mode).
This demo is an exploration of how the web could be accessed in the near future, where people will be able to connect from multiple devices with very diverse capabilities. Beyond the platforms implement here, we will soon face an explosion of AR see-through head-worn displays that will offer a new ways of interact with our content. Such displays will likely support voice commands and body gestures as input, rather than 3D controllers like their immersive VR counterparts. One day, people may have multiple devices they use simultaneously: instead of visiting a web page on their phone and then doing AR or VR on that phone, they may visit on their phone and then send the page to their AR or VR headset, and expect the two devices to coordinate with each other.
One interface we intentionally didn't explore here is the idea of presenting the full 2D web page in 3D (AR or VR) and having the product "pop" out of the 2D page into the 3D world. As web browsers evolve to displaying full HTML pages in 3D, such approaches might be possible, and desirable in some cases. One might imagine extensions to HTML that mark parts of the page as "3D capable" and provide 3D models that can be rendered instead of 2D content.
Regardless of how the technology evolves, designers should continue to focus on offering visitors the best options for each modality, as they do with 2D pages, rather than offering all the possible UI options in every possible modality. Designers should still focus on their users’ experience, and offering the best support for each of the possible displays that the users might have, building on the Progressive-Enhancement design strategy popular on todays 2D web.
Today, the Web is a 2D platform accessible by all, and with the WebXR API, we will soon be using it to connect with one another in the VR and AR. As we move toward this future, supporting the widest range of devices will continue to be a critical aspect of designing experiences for the web.
|
|
The Firefox Frontier: Facebook Container extension now includes Instagram and Facebook Messenger |
To help you control the amount of data Facebook can gather about you, we have updated the Facebook Container extension to include Instagram and Facebook Messenger. This way, users of … Read more
The post Facebook Container extension now includes Instagram and Facebook Messenger appeared first on The Firefox Frontier.
|
|






