Fr'ed'eric Wang: BlinkOn 9: Working on the Web Platform from a cooperative |
Last week, I attended BlinkOn 9. I was very happy to spend some time with my colleagues working on Chromium, including a new developer who will join my team next week (to be announced soon!).
This edition had the usual format with presentations, brainstorming, lightning talks and informal chats with Chromium developers. I attended several interesting presentations on web platform standardization, implementation and testing. It was also great to talk to Googlers in order to coordinate on some of Igalia’s projects such as the collaboration with AMP or MathML in Chromium.
In the previous edition, I realized that one can propose non-technical talks (e.g. the one about inclusion and diversity) and some people seemed curious about Igalia. Hence I proposed a presentation “Working on the Web Platform from a Cooperative” that gives:

From the feedback I got, people appreciated the presentation and liked to get more insight on Igalia. Unfortunately, I was not able to record the talk due to technical issues. Of course, thirty minutes is a bit short to develop all the ideas and reply properly to all the questions. But for those who are interested here are more pointers:
About “equal salary” VS “cost of living”, you might want to read Andy Wingo’s blog posts “time for money” and “a simple (local) solution to the pay gap”. Several years ago, Robert O’Callahan had already wondered whether it really made sense to take into account the cost of living to determine salaries. Personally, I believe that as long as our “target salary” is high enough for all places where we work, we don’t really need to worry about this issue and can instead spend time focusing on more interesting agreements to keep making Igalia a great working place.
About dependency on the customers, see the last paragraph of “work groups” in Andy’s blog post “but that would be anarchy!” especially treating customers as partners. As I said during the talk, as long as we have enough customers we have some freedom to accept contracts that are more interesting for our strategy and aligned with our values or negociate improvements to existing contracts ; without worrying about unstability and uncertainty.
About the meaning of “Igalia”, the simple answer is “it does not mean anything”. If you join Igalia and get the opportunity to learn about the company history, there is a more complete answer about how the name was found…
Regarding founders of Igalia in 2001: Dape (who attended BlinkOn), Alex, Juanjo, Xavi, Berto and Chema are indeed still working at Igalia and in general, very few people have left Igalia since its creation.
Finally we had two related tricky questions from Google employees:
How do you sync with the browser vendors’ own agenda?
What can Google (or any other browser vendor) could do to facilitate involvements of third-party contributors?
One could enumerate different situations but unfortunately there is not a generic answer. In some cases collaboration worked very well and was quite successful. In other cases, things were more complicated and we had to “fight” to convince browser vendors to keep some existing code or accept new features.
Communication is very important. We try to sync with browser vendors using video conferencing or by attending conferences, but some companies/teams are more or less inclined to reveal information (especially when strategic products are involved). In general, I have the impression that the more the teams work close to the Web Platform, the more they are used to the democratic and open-source culture and welcome third-party contributions.
Although the ideal is to work upstream, we have recently been developing skills to manage separate forks and rebase them regularly against the main branch. This is a good option to find a balance between the request of the customer to implement features and the need of the browser vendors to focus on their own tasks. Chromium for Wayland is a good example of that approach.
Hence probably one way to help third-party contributors is to improve communication. We had some issues with developers not even willing to talk to us or not taking time to review or comment on our patches/CLs. If browser vendors could indicate that they don’t like an approach as soon as possible or that they won’t accept patches until some refactoring is complete, that would help us a lot to discuss with clients, properly schedule our tasks and consider the option of an experimental branch.
Another way to help third-party contributors would be to advertize more that such contributions are actually possible. Indeed, many people think that “everything is implemented by browser vendors” which can make difficult to find clients for web platform development. When companies rant about Google not implementing feature X, fixing bug Y or participating to standard Z, instead of ignoring them or denying the importance of the request, it would probably be more constructive to mention that they can actually pay consulting companies to do that job. As I indicated in the talk, we recently had such successful collaborations with Bloomberg, Metrological or AMP and we would be happy to find more!
There are probably more to reply to these questions, but that’s my quick thought on the matter for now. I’ll try discussing with my colleagues and see if we have more ideas to share.
http://frederic-wang.fr/blink-on-9-working-on-the-web-platform-from-a-cooperative.html
|
|
Chris AtLee: Firefox release speed wins |
Sylvestre wrote about how we were able to ship new releases for Nightly, Beta, Release and ESR versions of Firefox for Desktop and Android in less than a day in response to the pwn2own contest.
People commented on how much faster the Beta and Release releases were compared to the ESR release, so I wanted to dive into the releases on the different branches to understand if this really was the case, and if so, why?
| Firefox ESR 52.7.2 | Firefox 59.0.1 | Firefox 60.0b4
------------------ | ------------------ | --------------- | --------------
Fix landed in HG | 23:33:06 | 23:31:28 | 23:29:54
en-US builds ready | 03:19:03 +3h45m | 01:16:41 +1h45m | 01:16:47 +1h46m
Updates ready | 08:43:03 +5h42m | 04:21:17 +3h04m | 04:41:02 +3h25m
Total | 9h09m | 4h49m | 5h11m
(All times UTC from 2018-03-15 -> 2018-03-16)
We can see that Firefox 59 and 60.0b4 were significantly faster to run than ESR 52 was! What's behind this speedup?
Release Engineering have been busy migrating release automation from buildbot to taskcluster . Much of ESR52 still runs on buildbot, while Firefox 59 is mostly done in Taskcluster, and Firefox 60 is entirely done in Taskcluster.
In ESR52 the initial builds are still done in buildbot, which has been missing out on many performance gains from the build system and AWS side. Update testing is done via buildbot on slower mac minis or windows hardware.
The Firefox 59 release had much faster builds, and update verification is done in Taskcluster on fast linux machines instead of the old mac minis or windows hardware.
The Firefox 60.0b4 release also had much faster builds, and ended up running in about the same time as Firefox 59. It turns out that we hit several intermittent infrastructure failures in 60.0b4 that caused this release to be slower than it could have been. Also, because we had multiple releases running simultaneously, we did see some resource contention for tasks like signing.
For comparison, here's what 60.0b11 looks like:
| Firefox 60.0b11
------------------ | ---------------
Fix landed in HG | 18:45:45
en-US builds ready | 20:41:53 +1h56m
Updates ready | 22:19:30 +1h37m
Total | 3h33m
Wow, down to 3.5 hours!
In addition to the faster builds and faster update tests, we're seeing a lot of wins from increased parallelization that we can do now using taskcluster's much more flexible scheduling engine. There's still more we can do to speed up certain types of tasks, fix up intermittent failures, and increase parallelization. I'm curious just how fast this pipeline can be :)
|
|
Air Mozilla: The Joy of Coding - Episode 137 |
 mconley livehacks on real Firefox bugs while thinking aloud.
mconley livehacks on real Firefox bugs while thinking aloud.
|
|
Air Mozilla: Weekly SUMO Community Meeting, 25 Apr 2018 |
 This is the SUMO weekly call
This is the SUMO weekly call
https://air.mozilla.org/weekly-sumo-community-meeting-20180425/
|
|
Air Mozilla: NYU MSPN Webinar Series - Product and Project Lifecycle Management |
 Each talk should be 10 to 15 minutes and there will be student questions after. The entire timeline is an hour to an hour and...
Each talk should be 10 to 15 minutes and there will be student questions after. The entire timeline is an hour to an hour and...
https://air.mozilla.org/nyu-mspn-webinar-series-product-management/
|
|
Air Mozilla: NYU MSPN Webinar Series - Product and Project Lifecycle Management |
Each talk should be 10 to 15 minutes and there will be student questions after. The entire timeline is an hour to an hour and...
https://air.mozilla.org:443/nyu-mspn-webinar-series-product-management/
|
|
Michael Kaply: Enterprise Policy Support in Firefox |
Last year, Mozilla ran a survey to find out top enterprise requirements for Firefox. Policy management (especially Windows Group Policy) was at the top of that list.
For the past few months we’ve been working to build that support into Firefox in the form of a policy engine. The policy engine adds desktop configuration and customization features for enterprise users to Firefox. It works with any tool that wants to set policies including Windows Group Policy.
I’m excited to announce that our work on the policy engine has reached a major milestone and is available in the latest Firefox 60 beta.
We’d really like for folks to take a look at what we’ve done and provide feedback. We would especially like to know what kinds of things folks are doing that require AutoConfig, so we can investigate adding those things to the policy engine. This is important because we are planning to sandbox AutoConfig to only its original API in Rapid Release, probably in version 62. You can get more detail about that in bug 1455601.
We’ve set up a survey to get a lot more details about requirements. Click here for that. (Yes, I know we’ve been doing lots of surveys. We appreciate your help as we define requirements.)
If you run into specific problems you can opens bugs Github or in Bugzilla.
For a detailed list of all the policies that are available and how to use them in a policies.json file, you can check out the README.
It also includes information on which policies only work on the ESR.
If you’re using Windows, you can download the ADMX templates.
We’re currently in the process of standing up more documentation and a support forum on support.mozilla.org.
In the meantime, we have some initial documentation.
Folks are also asking what this means for the future of CCK2. I’m planning to make as much CCK2 functionality as I can available for Firefox 60. I’ll be doing another blog post soon about that.
https://mike.kaply.com/2018/04/24/enterprise-policy-support-in-firefox/
|
|
Mozilla Open Policy & Advocacy Blog: Mozilla publishes recommendations on government vulnerability disclosure in Europe |
As we’ve argued on many occasions, effective government vulnerability disclosure (GVD) review processes can greatly enhance cybersecurity for governments, citizens, and companies, and help mitigate risk in an ever-broadening cyber threat landscape. In Europe, the EU is currently discussing a new legislative proposal to enhance cybersecurity across the bloc, the so-called ‘EU Cybersecurity Act’. In that context, we’ve just published our policy recommendations for lawmakers, in which we call on the EU to seize the opportunity to set a global policy norm for government vulnerability disclosure.
Specifically, our policy recommendations for lawmakers focus predominantly on the elements of the legislative proposal that concern the enhanced mandate for ENISA (the EU Cybersecurity agency), namely articles three to eleven. Therein, we recommend the EU co-legislators to include within ENISA’s reformed responsibilities a mandate to assist Member States in establishing and implementing policies and practices for the responsible management and coordinated disclosure of vulnerabilities in ICT products and services that are not publicly known.
As the producer of one of the world’s most popular web browsers, it is essential for us that vulnerabilities in our software are quickly identified and patched. Simply put, the safety and security of our users depend on it. More broadly, as witnessed in the recent Petya, and WannaCry cyberattacks, vulnerabilities can be exploited by cybercriminals to cause serious damage to citizens, enterprises, public services, and governments.
Vulnerability disclosure (and the processes that underpin it) is particularly important with respect to governments. Governments often have unique knowledge of vulnerabilities, and learn about vulnerabilities in many ways: through their own research and development, by purchasing them, through intelligence work, or by reports from third parties. Crucially, governments can face conflicting incentives as to whether to disclose the existence of such vulnerabilities to the vendor immediately, or to delay disclosure in order to support offensive intelligence-gathering and law enforcement activities (so-called government hacking).
In both the US and the EU, Mozilla has long led calls for governments to codify and improve their policies and processes for handling vulnerability disclosure, including speaking out strongly in favor of the Protecting Our Ability to Counter Hacking Act (PATCH Act) in the United States. Mozilla is also a member of the Centre for European Policy Studies’ Task Force on Software Vulnerability Disclosure, a multistakeholder effort dedicated to advancing thinking on this important topic, including mapping current practices and developing a model for government vulnerability disclosure review. We strongly believe that by putting in place such frameworks, governments can contribute to greater cybersecurity for their citizens, their businesses, and even themselves.
As our policy recommendation contends, the proposed EU Cybersecurity Act offers a unique opportunity to advance the norm that Member States should have robust, accountable, and transparent government vulnerability disclosure review processes, thereby fostering greater cybersecurity in Europe. Indeed, through its capacity to assist and advise on the development of policy and practices, a reformed ENISA is well-placed to support the EU Member States in developing government vulnerability disclosure review mechanisms and sharing best practices.
Over the coming months, we’ll be working closely with EU lawmakers to explain this issue and highlight its importance for cybersecurity in Europe.
If you’re interested in reading our recommendations in full, you can access them here.
The post Mozilla publishes recommendations on government vulnerability disclosure in Europe appeared first on Open Policy & Advocacy.
|
|
Anne van Kesteren: any.js |
Thanks to Ms2ger web-platform-tests is now even more awesome (not in the American sense). To avoid writing HTML boilerplate, web-platform-tests supports .window.js, .worker.js, and .any.js resources, for writing JavaScript that needs to run in a window, dedicated worker, or both at once. I very much recommend using these resource formats as they ease writing and reviewing tests and ensure APIs get tested across globals.
Ms2ger extended .any.js to also cover shared and service workers. To test all four globals, create a single your-test.any.js resource:
// META: global=window,worker
promise_test(async () => {
const json = await new Response(1).json()
assert_equals(json, 1);
}, "Response object: very basic JSON parsing test");
And then you can load it from your-test.any.html, your-test.any.worker.html, your-test.any.sharedworker.html, and your-test.https.any.serviceworker.html (requires enabling HTTPS) to see the results of running that code in those globals.
The default globals for your-test.any.js are a window and a dedicated worker. You can unset the default using !default. So if you just want to run some code in a service worker:
// META: global=!default,serviceworker
Please give this a try and donate some tests for your favorite API annoyances.
|
|
K Lars Lohn: Things Gateway - a Virtual Weather Station |
 Things Gateway from Mozilla and a developer account from Weather Underground. The two combined enable home automation control from weather events like temperature, wind, and precipitation.
Things Gateway from Mozilla and a developer account from Weather Underground. The two combined enable home automation control from weather events like temperature, wind, and precipitation.| Item | What's it for? | Where I got it |
|---|---|---|
| an RPi running the Things Gateway | It's our target to have the weather station provide values to the Things Gateway | General Download & Install Instructions or see my own install instructions: General Install & Zigbee setup, Philip Hue setup, IKEA TRADFRI setup, Z-Wave setup, TP-Link setup |
| A laptop or desktop PC | the machine to run the Virtual Weather Station. You can use the RPi itself. | My examples will be for a Linux machine |
| a couple things set up on the Things Gateway to control | this could be bulbs or switches | I'm using Aeotec Smart Switches to run red and green LED bulbs. |
| the webthing and configman Python3 packages | these are libraries used by the Virtual Weather Station | see the pip install directions below |
| a clone of the pywot github repository | it is where the the Virtual Weather Station code lives | see the git clone directions below |
| a developer key for online weather data | this gives you the ability to download data from Weather Underground | it's free from Weather Underground |
$ sudo pip3 install configman
$ sudo pip3 install webthing
$ git clone https://github.com/twobraids/pywot.git
$ cd pywot
$ export PYTHONPATH=$PYTHONPATH:$PWD
$ cd demo
$ ./virtual_weather_station.py -K YOUR_WU_API_KEY --city_name=Missoula --state_code=MT












That created a config file called: ./config.ini
$ ./virtual_weather_station.py -K YOUR_WU_API_KEY --admin.dump_conf=config.ini
Still too much typing? Instead of the config file, you could just set any/all of the parameters as environment variables:
$ ./virtual_weather_station.py -admin.conf=config.ini --city_name=Missoula --state_code=MT
$ weather_underground_api_key=YOUR_WU_KEY
$ city_name=Missoula
$ state_code=MT
$ ./virtual_weather_station.py
http://www.twobraids.com/2018/04/things-gateway-virtual-weather-station.html
|
|
Hacks.Mozilla.Org: Testing Strategies for React and Redux |
When the Firefox Add-ons team ported addons.mozilla.org to a single page app backed by an API, we chose React and Redux for powerful state management, delightful developer tools, and testability. Achieving the testability part isn’t completely obvious since there are competing tools and techniques.
Below are some testing strategies that are working really well for us.
We want our tests to be lightning fast so that we can ship high-quality features quickly and without discouragement. Waiting for tests can be discouraging, yet tests are crucial for preventing regressions, especially while restructuring an application to support new features.
Our strategy is to only test what’s necessary and only test it once. To achieve this we test each unit in isolation, faking out its dependencies. This is a technique known as unit testing and in our case, the unit is typically a single React component.
Unfortunately, it’s very difficult to do this safely in a dynamic language such as JavaScript since there is no fast way to make sure the fake objects are in sync with real ones. To solve this, we rely on the safety of static typing (via Flow) to alert us if one component is using another incorrectly — something a unit test might not catch.
A suite of unit tests combined with static type analysis is very fast and effective. We use Jest because it too is fast, and because it lets us focus on a subset of tests when needed.
The dangers of testing in isolation within a dynamic language are not entirely alleviated by static types, especially since third-party libraries often do not ship with type definitions (creating them from scratch is cumbersome). Also, Redux-connected components are hard to isolate because they depend on Redux functionality to keep their properties in sync with state. We settled on a strategy where we trigger all state changes with a real Redux store. Redux is crucial to how our application runs in the real world so this makes our tests very effective.
As it turns out, testing with a real Redux store is fast. The design of Redux lends itself very well to testing due to how actions, reducers, and state are decoupled from one another. The tests give the right feedback as we make changes to application state. This also makes it feel like a good fit for testing. Aside from testing, the Redux architecture is great for debugging, scaling, and especially development.
Consider this connected component as an example: (For brevity, the examples in this article do not define Flow types but you can learn about how to do that here.)
import { connect } from 'react-redux';
import { compose } from 'redux';
// Define a functional React component.
export function UserProfileBase(props) {
return (
{props.user.name}
);
}
// Define a function to map Redux state to properties.
function mapStateToProps(state, ownProps) {
return { user: state.users[ownProps.userId] };
}
// Export the final UserProfile component composed of
// a state mapper function.
export default compose(
connect(mapStateToProps),
)(UserProfileBase);
You may be tempted to test this by passing in a synthesized user property but that would bypass Redux and all of your state mapping logic. Instead, we test by dispatching a real action to load the user into state and make assertions about what the connected component rendered.
import { mount } from 'enzyme';
import UserProfile from 'src/UserProfile';
describe('', () => {
it('renders a name', () => {
const store = createNormalReduxStore();
// Simulate fetching a user from an API and loading it into state.
store.dispatch(actions.loadUser({ userId: 1, name: 'Kumar' }));
// Render with a user ID so it can retrieve the user from state.
const root = mount( Rendering the full component with Enzyme’s mount() makes sure mapStateToProps() is working and that the reducer did what this specific component expected. It simulates what would happen if the real application requested a user from the API and dispatched the result. However, since mount() renders all components including nested components, it doesn’t allow us to test UserProfile in isolation. For that we need a different approach using shallow rendering, explained below.
Let’s say the UserProfile component depends on a UserAvatar component to display the user’s photo. It might look like this:
export function UserProfileBase(props) {
const { user } = props;
return (
Since UserAvatar will have unit tests of its own, the UserProfile test just has to make sure it calls the interface of UserAvatar correctly. What is its interface? The interface to any React component is simply its properties. Flow helps to validate property data types but we also need tests to check the data values.
With Enzyme, we don’t have to replace dependencies with fakes in a traditional dependency injection sense. We can simply infer their existence through shallow rendering. A test would look something like this:
import UserProfile, { UserProfileBase } from 'src/UserProfile';
import UserAvatar from 'src/UserAvatar';
import { shallowUntilTarget } from './helpers';
describe('', () => {
it('renders a UserAvatar', () => {
const user = {
userId: 1, avatarURL: 'https://cdn/image.png',
};
store.dispatch(actions.loadUser(user));
const root = shallowUntilTarget(
Instead of calling mount(), this test renders the component using a custom helper called shallowUntilTarget(). You may already be familiar with Enzyme’s shallow() but that only renders the first component in a tree. We needed to create a helper called shallowUntilTarget() that will render all “wrapper” (or higher order) components until reaching our target, UserProfileBase.
Hopefully Enzyme will ship a feature similar to shallowUntilTarget() soon, but the implementation is simple. It calls root.dive() in a loop until root.is(TargetComponent) returns true.
With this shallow rendering approach, it is now possible to test UserProfile in isolation yet still dispatch Redux actions like a real application.
The test looks for the UserAvatar component in the tree and simply makes sure UserAvatar will receive the correct properties (the render() function of UserAvatar is never executed). If the properties of UserAvatar change and we forget to update the test, the test might still pass, but Flow will alert us about the violation.
The elegance of both React and shallow rendering just gave us dependency injection for free, without having to inject any dependencies! The key to this testing strategy is that the implementation of UserAvatar is free to evolve on its own in a way that won’t break the UserProfile tests. If changing the implementation of a unit forces you to fix a bunch of unrelated tests, it’s a sign that your testing strategy may need rethinking.
The power of React and shallow rendering really come into focus when you compose components using children instead of passing JSX via properties. For example, let’s say you wanted to wrap UserAvatar in a common InfoCard for layout purposes. Here’s how to compose them together as children:
export function UserProfileBase(props) {
const { user } = props;
return (
{user.name}
);
}
After making this change, the same assertion from above will still work! Here it is again:
expect(root.find(UserAvatar).prop('url'))
.toEqual(user.avatarURL);
In some cases, you may be tempted to pass JSX through properties instead of through children. However, common Enzyme selectors like root.find(UserAvatar) would no longer work. Let’s look at an example of passing UserAvatar to InfoCard through a content property:
export function UserProfileBase(props) {
const { user } = props;
const avatar = This is still a valid implementation but it’s not as easy to test.
Sometimes you really can’t avoid passing JSX through properties. Let’s imagine that InfoCard needs full control over rendering some header content.
export function UserProfileBase(props) {
const { user } = props;
return (
Avatar}>
{user.name}
);
}
How would you test this? You might be tempted to do a full Enzyme mount() as opposed to a shallow() render. You might think it will provide you with better test coverage but that additional coverage is not necessary — the InfoCard component will already have tests of its own. The UserProfile test just needs to make sure InfoCard gets the right properties. Here’s how to test that.
import { shallow } from 'enzyme';
import InfoCard from 'src/InfoCard';
import Localized from 'src/Localized';
import { shallowUntilTarget } from './helpers';
describe('', () => {
it('renders an InfoCard with a custom header', () => {
const user = {
userId: 1, avatarURL: 'https://cdn/image.png',
};
store.dispatch(actions.loadUser(user));
const root = shallowUntilTarget(
This is better than a full mount() because it allows the InfoCard implementation to evolve freely so long as its properties don’t change.
Aside from passing JSX through properties, it’s also common to pass callbacks to React components. Callback properties make it very easy to build abstractions around common functionality. Let’s imagine we are using a FormOverlay component to render an edit form in a UserProfileManager component.
import FormOverlay from 'src/FormOverlay';
export class UserProfileManagerBase extends React.Component {
onSubmit = () => {
// Pretend that the inputs are controlled form elements and
// their values have already been connected to this.state.
this.props.dispatch(actions.updateUser(this.state));
}
render() {
return (
);
}
}
// Export the final UserProfileManager component.
export default compose(
// Use connect() from react-redux to get props.dispatch()
connect(),
)(UserProfileManagerBase);
How do you test the integration of UserProfileManager with FormOverlay? You might be tempted once again to do a full mount(), especially if you’re testing integration with a third-party component, something like Autosuggest. However, a full mount() is not necessary.
Just like in previous examples, the UserProfileManager test can simply check the properties passed to FormOverlay. This is safe because FormOverlay will have tests of its own and Flow will validate the properties. Here is an example of testing the onSubmit property.
import FormOverlay from 'src/FormOverlay';
import { shallowUntilTarget } from './helpers';
describe('', () => {
it('updates user information', () => {
const store = createNormalReduxStore();
// Create a spy of the dispatch() method for test assertions.
const dispatchSpy = sinon.spy(store, 'dispatch');
const root = shallowUntilTarget(
This tests the integration of UserProfileManager and FormOverlay without relying on the implementation of FormOverlay. It uses sinon to spy on the store.dispatch() method to make sure the correct action is dispatched when the user invokes onSubmit().
The Redux architecture is simple: when you want to change application state, dispatch an action. In the last example of testing the onSubmit() callback, the test simply asserted a dispatch of actions.updateUser(...). That’s it. This test assumes that once the updateUser() action is dispatched, everything will fall into place.
So how would an application like ours actually update the user? We would connect a saga to the action type. The updateUser() saga would be responsible for making a request to the API and dispatching further actions when receiving a response. The saga itself will have unit tests of its own. Since the UserProfileManager test runs without any sagas, we don’t have to worry about mocking out the saga functionality. This architecture makes testing very easy; something like redux-thunk may offer similar benefits.
These examples illustrate patterns that work really well at addons.mozilla.org for solving common testing problems. Here is a recap of the concepts:
mount()) as much as possible.Want to get more involved in Firefox Add-ons community? There are a host of ways to contribute to the add-ons ecosystem – and plenty to learn, whatever your skills and level of experience.
https://hacks.mozilla.org/2018/04/testing-strategies-for-react-and-redux/
|
|
Air Mozilla: Martes Mozilleros, 24 Apr 2018 |
 Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos. Bi-weekly meeting to talk (in Spanish) about Mozilla status, community and...
Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos. Bi-weekly meeting to talk (in Spanish) about Mozilla status, community and...
|
|
Mozilla Security Blog: Supporting Same-Site Cookies in Firefox 60 |
Firefox 60 will introduce support for the same-site cookie attribute, which allows developers to gain more control over cookies. Since browsers will include cookies with every request to a website, most sites rely on this mechanism to determine whether users are logged in.
Attackers can abuse the fact that cookies are automatically sent with every request to force a user to perform unwanted actions on the site where they are currently logged in. Such attacks, known as cross-site request forgeries (CSRF), allow attackers who control third-party code to perform fraudulent actions on the user’s behalf. Unfortunately current web architecture does not allow web applications to reliably distinguish between actions initiated by the user and those that are initiated by any of the third-party gadgets or scripts that they rely on.
To compensate, the same-site cookie attribute allows a web application to advise the browser that cookies should only be sent if the request originates from the website the cookie came from. Requests triggered from a URL different than the one that appears in the URL bar will not include any of the cookies tagged with this new attribute.
The same-site attribute can take one of two values: ‘strict’ or ‘lax’. In strict mode, same-site cookies will be withheld for any kind of cross-site usage. This includes all inbound links from external sites to the application. Visitors clicking on such a link will initially be treated as ‘not being logged in’ whether or not they have an active session with the site.
The lax mode caters to applications which are incompatible with these restrictions. In this mode, same-site cookies will be withheld on cross-domain subrequests (e.g. images or frames), but will be sent whenever a user navigates safely from an external site, for example by following a link.
For the Mozilla Security Team:
Christoph Kerschbaumer, Mark Goodwin, Francois Marier
The post Supporting Same-Site Cookies in Firefox 60 appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2018/04/24/same-site-cookies-in-firefox-60/
|
|
This Week In Rust: This Week in Rust 231 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
wasm-pack - a tool for assembling and packaging Rust crates that targets WebAssembly.This week's crate is human-panic, a crate to make Rust's error handling usable to end users. Thanks to Vikrant for the suggestion!
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
132 pull requests were merged in the last week
Lit variants from usize to u16[T], [u8], str, f32, and f64Alloc, GlobalAlloc}::oom with a lang itemChanges to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now. This week's FCPs are:
try for try { .. } block expressions.unless and until as reserved keywords to the Rust language.The community team is trying to improve outreach to meetup organisers. Please fill out their call for contact info if you are running or used to run a meetup.
If you are running a Rust event please add it to the calendar to get it mentioned here. Email the Rust Community Team for access.
No jobs listed for this week.
Tweet us at @ThisWeekInRust to get your job offers listed here!
I’ve become fearless in Rust, but it’s made me fear every other language…
Thanks to nasa42 for the suggestion!
Submit your quotes for next week!
This Week in Rust is edited by: nasa42 and llogiq.
https://this-week-in-rust.org/blog/2018/04/24/this-week-in-rust-231/
|
|
Niko Matsakis: Rust pattern: Precise closure capture clauses |
This is the second in a series of posts about Rust compiler errors. Each one will talk about a particular error that I got recently and try to explain (a) why I am getting it and (b) how I fixed it. The purpose of this series of posts is partly to explain Rust, but partly just to gain data for myself. I may also write posts about errors I’m not getting – basically places where I anticipated an error, and used a pattern to avoid it. I hope that after writing enough of these posts, I or others will be able to synthesize some of these facts to make intermediate Rust material, or perhaps to improve the language itself.
Other posts in this series:
In some code I am writing, I have a struct with two fields. One of
them (input) contains some data I am reading from; the other is some
data I am generating (output):
use std::collections::HashMap;
struct Context {
input: HashMap<String, u32>,
output: Vec<u32>,
}
I was writing a loop that would extend the output based on the input.
The exact process isn’t terribly important, but basically for each
input value v, we would look it up in the input map and use 0 if
not present:
impl Context {
fn process(&mut self, values: &[String]) {
self.output.extend(
values
.iter()
.map(|v| self.input.get(v).cloned().unwrap_or(0)),
);
}
}
However, this code will not compile:
error[E0502]: cannot borrow `self` as immutable because `*self.output` is also borrowed as mutable
--> src/main.rs:13:22
|
10 | self.output.extend(
| ----------- mutable borrow occurs here
...
13 | .map(|v| self.input.get(v).cloned().unwrap_or(0)),
| ^^^ ---- borrow occurs due to use of `self` in closure
| |
| immutable borrow occurs here
14 | );
| - mutable borrow ends here
As the various references to “closure” in the error may suggest, it
turns out that this error is tied to the closure I am creating in the
iterator. If I rewrite the loop to not use extend and an iterator,
but rather a for loop, everything builds:
impl Context {
fn process(&mut self, values: &[String]) {
for v in values {
self.output.push(
self.input.get(v).cloned().unwrap_or(0)
);
}
}
}
What is going on here?
The problem lies in how closures are desugared by the compiler. When you have a closure expression like this one, it corresponds to deferred code execution:
|v| self.input.get(v).cloned().unwrap_or(0)
That is, self.input.get(v).cloned().unwrap_or(0) doesn’t execute
immediately – rather, it executes later, each time the closure is
called with some specific v. So the closure expression itself just
corresponds to creating some kind of “thunk” that will hold on to all
the data it is going to need when it executes – this “thunk” is
effectively just a special, anonymous struct. Specifically, it is a struct
with one field for each local variable that appears in the closure body;
so, something like this:
MyThunk { this: &self }
where MyThunk is a dummy struct name. Then MyThunk implements
the Fn trait with the actual function body, but each place that we
wrote self it will substitute self.this:
impl Fn for MyThunk {
fn call(&self, v: &String) -> u32 {
self.this.input.get(v).cloned().unwrap_or(0)
}
}
(Note that you cannot, today, write this impl by hand, and I have simplified the trait in various ways, but hopefully you get the idea.)
So let’s go back to the example now and see if we can see why we are
getting an error. I will replace the closure itself with the MyThunk
creation that it desugars to:
impl Context {
fn process(&mut self, values: &[String]) {
self.output.extend(
values
.iter()
.map(MyThunk { this: &self }),
// ^^^^^^^^^^^^^^^^^^^^^^^
// really `|v| self.input.get(v).cloned().unwrap_or(0)`
);
}
}
Maybe now we can see the problem more clearly; the closure wants to
hold onto a shared reference to the entire self variable, but
then we also want to invoke self.output.extend(..), which requires a
mutable reference to self.output. This is a conflict! Since the
closure has shared access to the entirety of self, it might (in its
body) access self.output, but we need to be mutating that.
The root problem here is that the closure is capturing self but it
is only using self.input; this is because closures always
capture entire local variables. As discussed in the previous post in
this series, the compiler only sees one function at a time,
and in particular it does not consider the closure body while checking
the closure creator.
To fix this, we want to refine the closure so that instead of
capturing self it only captures self.input – but how can we do that,
given that closures only capture entire local variables? The way to do that
is to introduce a local variable, input, and initialize it with
&self.input. Then the closure can capture input:
impl Context {
fn process(&mut self, values: &[String]) {
let input = &self.input; // <-- I added this
self.output.extend(
values
.iter()
.map(|v| input.get(v).cloned().unwrap_or(0)),
// ----- and removed the `self.` here
);
}
}
As you can verify for yourself, this code compiles.
To see why it works, consider again the desugared output. In the new
version, the desugared closure will capture input, not self:
MyThunk { input: &input }
The borrow checker, meanwhile, sees two overlapping borrows in the function:
let input = &self.input – shared borrow of self.inputself.output.extend(..) – mutable borrow of self.outputNo error is reported because these two borrows affect different fields of self.
Sometimes, when I want to be very precise, I will write closures in a
stylized way that makes it crystal clear what they are capturing.
Instead of writing |v| ..., I first introduce a block that creates a
lot of local variables, with the final thing in the block being a
move closure (move closures take ownership of the things they use,
instead of borrowing them from the creator). This gives complete
control over what is borrowed and how. In this case, the closure might look like:
{
let input = &self.input;
move |v| input.get(v).cloned().unwrap_or(0)
}
Or, in context:
impl Context {
fn process(&mut self, values: &[String]) {
self.output.extend(values.iter().map({
let input = &self.input;
move |v| input.get(v).cloned().unwrap_or(0)
}));
}
}
In effect, these let statements become like the “capture clauses”
in C++, declaring how precisely variables from the environment are
captured. But they give added flexibility by also allowing us to
capture the results of small expressions, like self.input, instead
of local variables.
Another time that this pattern is useful is when you want to capture a clone of some data versus the data itself:
{
let data = data.clone();
move || ... do_something(&data) ...
}
There is actually a pending RFC, RFC #2229, that aims to modify closures so that they capture entire paths rather than local variables. There are various corner cases though that we have to be careful of, particularly with moving closures, as we don’t want to change the times that destructors run and hence change the semantics of existing code. Nonetheless, it would solve this particular case by changing the desugaring.
Alternatively, if we had some way for functions to capture a refence
to a “view” of a struct rather than the entire thing, then closures
might be able to capture a reference to a “view” of self rather than
capturing a reference to the field input directly. There is some
discussion of the view idea in this internals
thread;
I’ve also tinkered with the idea of merging views and traits, as
described in this internals
post. I
think that once we tackle NLL and a few other pending challenges,
finding some way to express “views” seems like a clear way to help
make Rust more ergonomic.
|
|
Mozilla Thunderbird: Thunderbird April News Update: GSoC, 60 Beta 4, New Thunderbird Council |
Due to lots of news coming out of the Thunderbird project, I’ve decided to combine three different blog posts I was working on into one news update that gives people an idea of what has been happening in the Thunderbird community this month. Enjoy and comment to let me know if you like or dislike this kind of post!
Great news! A student has been selected for the Enigmail/Thunderbird Google Summer of Code (GSoC) project. Enigmail, the OpenPGP privacy extension for Thunderbird, submitted its project to GSoC seeking a student to help update user interface elements and assist with other design work.
A new version of the Thunderbird 60 Beta is out, with version four beginning to roll out. Users of the Beta are testing what will ultimately be the next Extended Support Release (ESR), which acts as our stable release and is what most of our users see. There are a lot of changes between Thunderbird 52, that last ESR, and this release. Some of these changes include: An updated “Photon” UI (like that seen in Firefox), various updates to Thunder’s “Lightning” calendar, a new “Message from Template” command, and various others. You can find a full list here.
As with every Beta, but especially this one given it will become the new stable release, we hope that you will download it and give us feedback on your experience.
A new Thunderbird Council was elected this month. This new council of seven members will serve for a year. The members of the new council are as follows:
This blog will try to lay out the new council’s visions and priorities in future posts.
https://blog.mozilla.org/thunderbird/2018/04/thunderbird-april-news-update/
|
|
Air Mozilla: Mozilla Weekly Project Meeting, 23 Apr 2018 |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20180423/
|
|
The Mozilla Blog: New Mozilla Poll: Support for Net Neutrality Grows, Trust in ISPs Dips |
“Today marks the ostensible effective date for the FCC’s net neutrality repeal order, but it does not mark the end of net neutrality,” says Denelle Dixon, Mozilla COO. “And not just because some procedural steps remain before the official overturning of the rules — but because Mozilla and other supporters of net neutrality are fighting to protect it in the courts and in Congress.”
Also today: Mozilla is publishing results from a nationwide poll that reveals where Americans stand on the issue. Our survey reinforces what grassroots action has already demonstrated: The repeal contradicts most Americans’ wishes. The nation wants strong net neutrality rules.
“The new Mozilla and Ipsos poll shows once again that Americans across the political spectrum overwhelmingly want strong net neutrality protections, and that they don’t trust their ISPs to provide it for them without oversight,” says Gigi Sohn, Mozilla Fellow and former FCC counselor.
“What should make policymakers stand up and take notice is that 78% of Americans, including 84% of adults under the age of 35, believe that equal access to the internet is a right, and not a luxury,” Sohn continues.
~
Mozilla and Ipsos conducted this public opinion poll in February of 2018, surveying 1,007 American adults from across 50 states. Among our key findings:
Outside of Washington, D.C., net neutrality isn’t a partisan issue. Americans from red and blue states alike agree that equal access to the internet is a right, including: 79% of Colorado residents, 81% of Arizona residents, and 80% of North Carolina residents.
91% of Americans believe consumers should be able to freely and quickly access their preferred content on the internet. Support for net neutrality is growing: When Mozilla and Ipsos asked this same question in 2017, 86% of Americans believed this.

78% of Americans believe equal access to the internet is a right. This opinion is most common among younger Americans (84% of adults under the age of 35).
76% of Americans believe internet service providers (ISPs) should treat all consumer data the same, and not speed up or slow down specific content. This opinion is most common among older Americans (80% of adults ages 55+) and Americans with a college degree (81%).

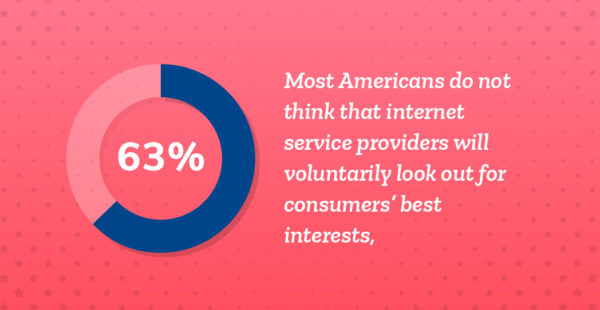
63% of Americans do not think that ISPs will voluntarily look out for consumers’ best interests, compared to 32% who agree with this statement. Faith in ISPs is declining: When Mozilla and Ipsos asked this same question in 2017, 37% of Americans trusted ISPs.
See the full results from our poll here. See results from the 2017 Mozilla/Ipsos net neutrality poll here.
~
“Today could be the start of a shift away from freedom and innovation,” adds Denelle Dixon. “Some opponents of net neutrality will say our concerns are misplaced, and that when April 24 fails to see a wave of blocking, throttling, and fast lanes, that they were right in their claims. But that’s not how the world without net neutrality will develop. The impact won’t be immediate, like a lightswitch. Instead, we’ll see more of a gradual chipping away — an erosion into a discriminatory internet, with ultimately a far worse experience for any users and businesses who don’t pay more for special treatment.”
“There is an active lawsuit on this matter in the case titled ‘Mozilla v. FCC’ — and today is also the last day that others can file additional challenges against the FCC, following Mozilla’s lead,” Dixon concludes. “We’ve been encouraged by the support we’ve seen with allies filing suit in the industry, and we hope to see more organizations joining us in the fight to protect net neutrality.”
At some point in the coming months, the Senate will likely vote whether to undo the FCC’s repeal of net neutrality. Per the Congressional Review Act, lawmakers can veto the FCC’s decision with a majority vote. If the Congressional Review Act resolution passes the Senate, it will move to the House, then (maybe) the president’s desk. (Learn more about the Congressional Review Act and net neutrality here.)
“Members of Congress can restore net neutrality protections right now by passing the Joint Resolution of Disapproval that has been introduced in both houses,” Gigi Sohn says. “Voters will make their displeasure known to anyone who doesn’t support this measure in November.”
In the meantime, Mozilla will continue its fierce advocacy for a free, open internet. Earlier this year, we sued the FCC for its decision to gut net neutrality. And right now, we’re running a campaign that makes calling your elected official easy. Visit https://advocacy.mozilla.org/en-US/net-neutrality/, pick up the phone, and urge your representative to save net neutrality.
The post New Mozilla Poll: Support for Net Neutrality Grows, Trust in ISPs Dips appeared first on The Mozilla Blog.
|
|







 SUMO - 04.13.2018
SUMO - 04.13.2018