David Lawrence: Happy BMO Push Day! |
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.

https://dlawrence.wordpress.com/2016/04/12/happy-bmo-push-day-13/
|
|
Air Mozilla: Sh!t mozillians say |
 "Keep on rocking the freeeeeeeeeeeee web.
"Keep on rocking the freeeeeeeeeeeee web.
|
|
Hannes Verschore: Perfherder and regression alerts |
In the dawn of arewefastyet only 2 machines were running and only three benchmarks were important. At that time it was quite easy to just iterate the different benchmarks once in a while and spot the regressions. Things have come a long way since. Due to the enormous increase in number of benchmarks and machines I created a regression detector, which wasn’t as easy as it sounds. False positives and false negative are the enemy of such a system. Bimodal benchmarks, noise, compiler perturbations, the amount of datapoints … all didn’t help. Also this had low priority, given I’m supposed to work on improving JIT performance and not recording JIT performance.
Perfherder came along, which aims to collect any performance data in a central place and to act on that information. Which has some dedicated people working on it. Since the beginning of 2016 AWFY has started to use that system more and more. We have been sending the performance data to Perfherder for a few months now and Perfherder has been improving to allow more and more functionality AWFY needs. Switching the regression detection from AWFY to Perfherder is coming closer, which will remove my largest time drain and allow me to focus even more on the JIT compiler!
The alerts perfherder creates are visible at:
https://treeherder.allizom.org/perf.html#/alerts?status=0&framework=5
Since last week we now can request alerts on the subscores of benchmark, which is quite important for JS benchmarks. Octane has a variance of about 2% and a subscore of the benchmark that regresses with 10% will only decrease the full benchmark score with 1%. As a result this is within the noise levels and won’t get detected. This week this feature was enabled on AWFY, which will increase the correctness and completeness of the alerts Perfherder creates.
I want to thank Joel Maher and William Lachance with the help of this.
|
|
Nicholas Nethercote: More compacting GC |
Jon Coppeard recently extended SpiderMonkey’s compacting GC abilities. Previously, the GC could only compact GC arena containing JavaScript objects. Now it can also compact arenas containing shapes (a data structure used within SpiderMonkey which isn’t visible to user code) and strings, which are two of the largest users of memory in the GC heap after objects.
These improvements should result in savings of multiple MiBs in most workloads, and they are on track to ship in Firefox 48, which will be released in early August. Great work, Jon!
https://blog.mozilla.org/nnethercote/2016/04/12/more-compacting-gc/
|
|
Matthew Ruttley: Mocking out an API call deep in your code |
With any actively developed (python) coding project, you’re and your team are going to be running the same set of tests sometimes hundreds of times per week. If there’s an HTTP request to any 3rd-party source in there, this can cause problems. API calls can be expense, excessive scraping of the same source can cause IP blacklisting and the calls could just slow down your whole test process, adding extra baggage to the code deployment process.
To fix this, we can use Python’s mock library. Mock is really useful for creating fake function calls, fake Classes and other fake objects which can return fake values. In most cases when testing, you are really just testing how the application parses data rather than the reliability of the 3rd party service. The API’s response is generally the same. Mock can let you simulate the API’s response and parse its data rather than actually have to make the call each time.
It’s quite tricky to set up so I thought I would write a tutorial. The situation set up has a few components but I’ll try and explain it as well as possible. Let’s say there is a service that provides some useful API response. There’s a site, HTTPBin, set up by Kenneth Reitz to test HTTP libraries, which we will use here. Check out: https://httpbin.org/ip. The content is as follows:
{
"origin": "123.123.123.123",
}Let’s say our program wants to grab the IP address in the origin field. Yup – a fairly pointless program but this will be analogous to many situations you’ll encounter.
Here’s a totally over-engineered class to get data from this service. When the class is initialized in __init__, it creates a base_url variable pointing to HTTPBin. The main handler function is the get_ip function, which simply grabs that field’s content. This first makes a call to api_call which uses requests.get to grab that HTTP data.
from requests import get
class MyClass:
def __init__(self):
self.base_url = "https://httpbin.org/ip"
def api_call(self):
"""Makes an API call"""
result = get(self.base_url)
if result.ok:
return result.json()
return False
def get_ip(self):
"""Gets the language from the API response"""
try:
data = self.api_call()
return data['origin']
except (TypeError, KeyError, IndexError):
return "HTTP request to {0} failed".format(self.base_url)To run this code its simply (in a Python Shell):
>>> import my_module >>> test = my_module.MyClass() >>> test.get_ip() u'123.123.123.123'
What if we want to mock out requests.get? The Mock module documentation is quite unclear on how to target a specific function deep within a class. It turns out the easiest way to do this is not MagicMock or return_value but instead to use the counter-intuitively named “side_effect” feature. This is the testing module pre-mocking:
import unittest
from my_module import MyClass
class TestClassifier(unittest.TestCase):
def setUp(self):
self.ip_grabber = MyClass()
def test_ip_grabber(self):
ip = self.ip_grabber.get_ip()
self.assertIsInstance(ip, basestring, "IP should be a string")
self.assertEqual(ip.count('.'), 3, "IP should have 3 dots")
if __name__ == '__main__':
unittest.main()As you can see, this is a standard set of tests to check that the ip_grabber function returns a valid-ish IP address. It is run as follows:
mruttley$ python test_my_module.py . ---------------------------------------------------------------------- Ran 1 test in 0.293s OK
However, the problem here is that it is going to call the actual API each time you run the tests. To stop this, let’s integrate the mock module:
import unittest
import mock
from my_module import MyClass
class fake_get():
def __init__(self, url):
self.ok = True
def json(self):
return {'origin': '123'}
class TestClassifier(unittest.TestCase):
def setUp(self):
self.ip_grabber = MyClass()
@mock.patch('my_module.get', side_effect=fake_get)
def test_ip_grabber(self, fake_get):
ip = self.ip_grabber.get_ip()
self.assertIsInstance(ip, basestring, "IP should be a string")
self.assertEqual(ip.count('.'), 3, "IP should have 3 dots")
if __name__ == '__main__':
unittest.main()Here we’ve:
Running this, we get:
mruttley$ python test_my_module.py
F
======================================================================
FAIL: test_ip_grabber (__main__.TestClassifier)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Library/Python/2.7/site-packages/mock/mock.py", line 1305, in patched
return func(*args, **keywargs)
File "test_my_module.py", line 19, in test_ip_grabber
self.assertEqual(ip.count('.'), 3, "IP should have 3 dots")
AssertionError: IP should have 3 dots
----------------------------------------------------------------------
Ran 1 test in 0.002s
FAILED (failures=1)Mock’s side_effect has replaced requests.get  To make this pass, just replace
To make this pass, just replace
return {'origin': '123'} with return {'origin': '123.123.123.123'} and run again:mruttley$ python test_my_module.py . ---------------------------------------------------------------------- Ran 1 test in 0.000s OK
Tests pass and zero HTTP traffic!
|
|
The Mozilla Blog: Welcome Sean White, Vice President of Technology Strategy |
Dr. Sean White joins the Mozilla leadership team this week as a Vice President of Technology Strategy.
In this role, Sean will help guide and consult on strategic projects across the organization, with an initial focus on emerging technology opportunities in the areas of VR & AR and Connected Devices.
 Sean was most recently the founder and CEO of BrightSky Labs as well as a Technologist-in-Residence at Greylock Partners, where he led tech evaluations for potential investments and provided strategy consulting to portfolio companies. Prior to this, he established and lead the Interaction Ecologies Group at Nokia, leading multiple innovative efforts in mobile forms and experiences in the areas of wearables, Internet of Things, and augmented reality. He has also held a variety of senior technology leadership roles at NeoCarta Ventures, Lycos and WhoWhere.
Sean was most recently the founder and CEO of BrightSky Labs as well as a Technologist-in-Residence at Greylock Partners, where he led tech evaluations for potential investments and provided strategy consulting to portfolio companies. Prior to this, he established and lead the Interaction Ecologies Group at Nokia, leading multiple innovative efforts in mobile forms and experiences in the areas of wearables, Internet of Things, and augmented reality. He has also held a variety of senior technology leadership roles at NeoCarta Ventures, Lycos and WhoWhere.
He will be based in the Bay Area, primarily working out of our headquarters in Mountain View.
Welcome Sean!
chris
Background:
Sean’s bio & Mozillians profile
https://blog.mozilla.org/blog/2016/04/11/welcome-sean-white-vice-president-of-technology-strategy/
|
|
Air Mozilla: Mozilla Weekly Project Meeting, 11 Apr 2016 |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20160404-2/
|
|
Chris Cooper: RelEng & RelOps Weekly highlights - April 11, 2016 |
 Freedom Friday!
Freedom Friday!Modernize infrastructure:
Rail and Nick made taskcluster uploads more resilient to flaky network conditions. (https://bugzil.la/1250458)
Improve Release Pipeline
Rail blogged about our ongoing efforts with using build promotion for releases. Firefox 46 is being targeted as the first release build to use build promotion. A steady stream of beta builds have already been released via promotion, so we’re pretty confident in the process now. Promoted builds for Fennec won’t make the first pass, but we plan to add them in the Firefox 47 cycle.
Improve CI Pipeline:
I want to call out the recent work being done by the build team to modernize the build system. As David reports in his firefox-dev post, the team has recently managed to realize a drastic reduction in Windows PGO build times. This reduction brings the build time in line with those for Linux PGO builds. Since Windows PGO builds are currently a long pole in both the CI and release process, this allows us to provide more timely feedback about build quality to developers and sheriffs. Pretty graphs are available.
Release:
Last week we shipped Firefox 46.0b9, and there are several other releases still in flight. See the weekly post-mortem notes for further details.
See you next week!
|
|
Jan Odvarko: Inspecting WebSocket Traffic with Firefox Developer Tools |
WebSocket monitor is an extension to Firefox developer tools that can be used to monitor WebSocket connections in Firefox. It allows inspecting all data sent and received.
It's been a while since we published first version of our add-on for inspecting WebSocket traffic and it's good time to summarize all new features and show how it's integrated with Firefox Developer tools.
Download signed version of this add-on from AMO. The source code with further documentation is available on github.
WebSocket Monitor can be used to track any WS connection, but following protocols have an extra support: Socket.IO, SockJS, Plain JSON, WAMP, MQTT.

(click to enlarge)
After the add-on is installed, open Firefox Developer Tools (F12 on Win or
http://feedproxy.google.com/~r/SoftwareIsHardPlanetMozilla/~3/zxtVv_K_pus/
|
|
Mozilla Addons Blog: The “Why” of Electrolysis |
A multi-process architecture is finally coming to Firefox. Known by its codename, “Electrolysis” or “e10s,” this project aims to split the Firefox browser into a single process for the UI, and several processes for web content, media playback, plugins, etc.
Electrolysis represents a long overdue modernization of Firefox’s codebase: Internet Explorer has been multi-process since IE 8 Beta 1 in early 2008, Chrome followed six months later, and even Safari went multi-process in the summer of 2011. Put another way, Firefox has been the only major browser using a single process architecture for the past five years.
Though the result should be visually indistinguishable from a single-process Firefox, the multi-process model offers many compelling advantages in responsiveness, stability, performance, and security:
A common concern is that switching to a multi-processes architecture will dramatically increase Firefox’s memory usage. This is not the case. While multiple processes will have a greater memory footprint than a single process, the impact should be limited: we’re currently seeing multi-process Firefox use 10-20% more memory, however, it still uses half the memory of Chrome with the same sites loaded.
To ensure we don’t consume too much RAM, the first release of e10s will only use a single additional process for web content. We’ll add more processes in subsequent releases, as we become more memory efficient.
The move to multi-process is an investment in the future: we’re paying down technical debt and redesigning Firefox’s architecture at a fundamental level. Like any change of this magnitude, there are associated challenges:
1. Cross-Process Communication. Before e10s, add-ons were accustomed to having direct access to both the browser context and web page content. With e10s, those two contexts are now two separate processes which must communicate through asynchronous message passing.
Many, but not all, add-ons will require modification to work efficiently with this new design. Add-ons that do not access web content, only use high-level SDK APIs, or are written with the new WebExtension APIs will not need modification.
You can see the compatibility status of popular add-ons at AreWeE10SYet.com, or use the compatibility checker to see what changes your add-on might need.
2. Performance. To help with compatibility during the transition to multi-process, we’ve implemented several temporary shims that allow backwards-compatible, synchronous communication between the browser and web content. This lets add-ons work as if Firefox was still single-process, but with potentially worse performance than before, since these shims must completely block multiple processes and incur overhead for inter-process communication.
The shims are available to add-ons by default, but authors should always prefer asynchronous message passing, high-level SDK APIs, or WebExtensions instead of shims.
You can disable shims for your add-on by setting the multiprocess permission to true in your package.json, or set to true in your install.rdf. This is how we know your add-on is e10s-compatible and will ensure that it won’t be marked as incompatible when e10s ships with Firefox.
Multi-process has been enabled by default in Firefox Developer Edition since version 42, released last August. If you’re an add-on developer or Firefox enthusiast, we highly recommend you try it out and report any bugs you encounter, either in Bugzilla or in the comments below. The Mozilla Developer Network also hosts extensive documentation on multi-process Firefox, including migration guides for add-on authors. Check it out, and let us know what you think!
https://blog.mozilla.org/addons/2016/04/11/the-why-of-electrolysis/
|
|
This Week In Rust: This Week in Rust 126 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us an email! Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
This week's edition was edited by: Vikrant and llogiq.
.chars().count(). How to get the "length" of a string.This week's Crate of the Week is gcc, a crate to easily use the local C compiler, which makes FFI with a build script a breeze. Thanks to Ulrik Sverdrup for the suggestion!
Submit your suggestions for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Box instead of Box in HTMLCollection.If you are a Rust project owner and are looking for contributors, please submit tasks here.
89 pull requests were merged in the last week.
== for [T] and [u8] to memcmp (also Ord, PartialOrd)pub(restricted)pub(restricted)StructFieldChanges to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
union.Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now. This week's FCPs are:
#[repr(pack = "N")].-C overflow-checks command line argument.Atomic type.vis matcher to macro_rules! that matches valid visibility annotations.literal fragment specifier for macro_rules! patterns that matches literal constants.If you are running a Rust event please add it to the calendar to get it mentioned here. Email Erick Tryzelaar or Brian Anderson for access.
Tweet us at @ThisWeekInRust to get your job offers listed here!
No quote was selected for QotW.
Submit your quotes for next week!
https://this-week-in-rust.org/blog/2016/04/11/this-week-in-rust-126/
|
|
The Servo Blog: This Week In Servo 59 |
In the last week, we landed 111 PRs in the Servo organization’s repositories.
linux-dev builderoverflow: scrollgetActiveUniform() WebGL APIUniform{1iv, 2f, 2fv} WebGL APIsInterested in helping build a web browser? Take a look at our curated list of issues that are good for new contributors!
nox just got Servo working with an upgraded SpiderMonkey that has the new Promises support implemented by till!

Last week, we skipped the meeting, due to lack of agenda items.
|
|
Karl Dubost: [worklog] Daruma, draw one eye, wish for the rest |
Daruma is a little doll where you draw an eye on a status with a wish in mind. And finally draw the second eye, once the wishes has been realized. This week Tokyo Metro and Yahoo! Japan fixed their markup. Tune of the week: Pretty Eyed Baby - Eri Chiemi.
Progress this week:
Today: 2016-04-11T07:29:54.738014 368 open issues ---------------------- needsinfo 3 needsdiagnosis 124 needscontact 32 contactready 94 sitewait 116 ----------------------
You are welcome to participate
The feed of otsukare (this blog) doesn't have an updated element. That was bothering me too. There was an open issue about it on Pelican issues tracker. Let's propose a pull request. It was accepted after a couple of up and down.
We had a team meeting this week.
Understanding Web compatibility is hard. It doesn't mean the same exact thing for everyone. We probably need to better define for others what it means. Maybe the success stories could help with concrete examples to give the perimeter of what is a Web Compat issue.
Looking at who is opening issues on WebCompat.com I was pleasantly surprised by the results.
(a selection of some of the bugs worked on this week).
perspective to an arbitrary 0.0001px. I added the results to the issue. I contacted the Web site owners where we found the issue. Also funny details of implementation in Gecko, another codepen.transform: perspective(0.00000000000000000000000000000000001px) translate(260px, 0); is considered not zero.transform: perspective(0.000000000000000000000000000000000001px) translate(260px, 0); is considered something else, but not sure what.s/Apple/Market Share Gorilla/. Currently there are very similar thing in some ways happening for Chrome on the Desktop market. The other way around, aka implementing fancy APIs that Web developers rush to use on their site and create Web Compatibility issues. The issue is not that much about being late at implementing, or being early at implementing. The real issue is the market share dominance, which warps the way people think about the technology and in the end making it difficult for other players to even exist in the market. I have seen that for Opera on Desktop, and I have seen that for Firefox on Mobile. And bear with me, it was Microsoft (Desktop) in the past, it is Google (Desktop) and Apple (Mobile) now, it will be another company in the future, the one dominating the market share.widthOtsukare!
|
|
Christian Heilmann: [Presenter tips] Gremlins in the machine – stage tech will fail |
In my role as a coach for other presenters I just ran into a common issue. A talented person giving their first talk and hating it. The reason: everything went wrong with stage technology. This lead to a loss of confidence and putting the blame on oneself. The irony was that the talk wasn’t in a place with tech issues, but in San Francisco. The wireless was not at all up to scratch. The presenter had planned for that: using a ServiceWorker powered HTML slide deck – state of the art what we consider bullet proof and highly portable. But there was no way to make the computer display on the big projector as there was no HDMI connection. That’s why they had to use someone else’s computer. None of the demos worked. Lacking experience, the presenter had a hard time describing what people should see. Furthermore, you don’t want to be the person to promise things without proving them.

There is no point in throwing blame. Of course, as a prepared speaker you should be able to do fine without your demos. But often we put a lot of effort into these demos and they excited us to write the talk in the first place. Of course the conference organiser should have all connectors and know about display issues. And of course the wireless should work in the middle of tech bubble central. Often conference organisers don’t control connectivity. They have to rely on venue installations and their promises. Shit happens. Time to learn from that. What can we as presenters expect and how can we prepare ourselves for Gremlins in the machinery?
I collected the following tips and ideas presenting at about 80 conferences in the last 4 years. In about 60 venues spread across the globe. So, if your experience was much better – lucky you. Fact is, that things go wrong all the time and often there is nothing you can do.

Let’s go back a bit. Van Halen required in their band contract to have a bowl of M&Ms in their room with all the brown ones removed. This has become a running joke when the topic is about entitlement and added to the “ridiculously needy rockstar” myth. The interesting part about this is that this rule served a purpose. Van Halen required a intrinsic stage setup to achieve their unique sound. Their rider describes the necessary stage tech in detail. The M&M rule at the end of the rider is a simple way of knowing if the concert organisers read and understood it. When there was no bowl in the room or it had brown M&Ms in it something was wrong. This needed fixing to avoid a disastrous concert.
The main difference between this story and presenting at conferences is that we’re not rockstars. We can’t demand the things they do, and – more importantly – we aren’t as organised as an industry. In far too many cases there is a massive miscommunication between conference organisers and presenters as to what is needed to give your talk. This is when bad things happen.
If your talk depends on a lot of things going right, be adamant about this in your talk proposal. Add reminders to your communication with the conference organisers. Outline in very easy to understand words what you need, as in:
Be there on time to set up and demand a dry run the day before. This could give you insight into issues and you can get them fixed before you go on stage.
Remember that in some cases, the conference organisers are not in charge. Make sure to get to know the venue AV and connectivity people and talk to them. Also make sure to find out which room you’ll be in and who will be there before you so you have time to set up. Connectivity and AV equipment can vary from room to room even in the same conference.
All this sounds like a lot of work – and it is. You made yourself dependent on your technology – it is up to you to ensure things go smooth. We don’t have roadies and riders for that.
As everything can go wrong, it is good to know the quirks and issues of your own hardware. It is prudent to ensure you bring everything you need:

The main thing I learned on my travels is to ensure your talk materials are available.That’s why you need a format that means whatever goes wrong, there is still a way out:
Often I found that as a presenter, you have to follow some rules you don’t like when it comes to stage technology. It is up to you to stand your ground and demand what you want to have. Or you could swallow your pride and reach audiences you might not reach otherwise. Here are a few things I encountered that are against my ideas of what I want to do as presenter but made sense:
Do yourself a favour and strive to liberate yourself from your demos and slides as a presenter. You will be able to do much more exciting work when your presentation is your wallpaper. You are the show and the source of information. It is exciting to see technical things going right. Many are hard to repeat for the audience and they are more of a show than an educational moment.
Instead, point to materials, show what they do and how people can use them. Tell the story of the materials and how they can make the life of your audience better. If that is what you convey, even a power cut won’t make a difference. You present and educate, you don’t run a demo.
|
|
Doug Belshaw: Mozilla releases Web Literacy Map v2.0 (with '21st century skills') |

Yesterday, Mozilla announced the launch of v2.0 of their Web Literacy Map. You can read about this in a post entitled Introducing Mozilla’s Web Literacy Map, Our New Blueprint for Teaching People About the Web.
The map is visually different from version 1.5, as it’s represented in a wheel rather than as a table. Another difference is that the Explore / Build / Connect strands are replaced with Read / Write / Participate (which was present in the subtitles of the previous version). The 16 competencies around the outside of the circle are verb-based (good!) and aren’t too much of a departure from the 15 competencies of the previous version.
Perhaps the most important departure, however, is the 21st century skills that are layered on top of the wheel. These skills are identified as:
Version 2.0 of the Web Literacy Map is interactive. When you click on part of it, you can see which sub-skills make up each competency, as well as which 21st-century skills it aligns with. Most helpfully for teachers, you can view activities that align with teaching this particular competency. It’s done well.
I’m pleased that version 2.0 of Mozilla’s Web Literacy Map is both a continuation to, and an important update to, previous versions that the community help produce during my years with Mozilla!
Comments? Questions? I’m @dajbelshaw on Twitter, or you can email me: mail@dougbelshaw.com
|
|
Jared Wein: A story of bug fixing |
I spent some time last night looking in to a bug in the Firefox preferences as part of the Outreachy internship I’m mentoring. This bug is about how the context menus in our preferences were squished horizontally compared to normal context menus. I’ve put screenshots of the two below so you can compare.
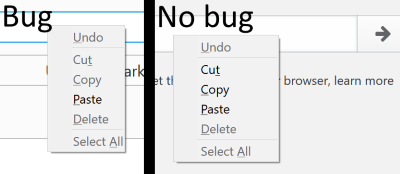
Looking at bug 1247214, I knew that context menus outside of the preferences looked fine but context menus in the preferences were broken. This meant I had something I could compare side-by-side when looking at the CSS.
I used the inspector and looked at the applied styles for a xul:menuitem and compared them between the preferences and non-preferences. I was surprised to see that they were nearly identical, and what differed was inconsequential.
After walking up the DOM from the xul:menuitem and seeing that the two instances were still nearly identical, I had to think of a different route. Somewhat by chance I realized/remembered that there were children nodes of the xul:menuitem that could possibly be affected. In the Inspector I expanded the xul:menuitem and looked at the rules for the xul:label inside of it. Immediately I noticed that the -moz-margin-start and -moz-margin-end were being set to zero and the rule looked like it wasn’t intended to affect context menus. Unsetting that rule fixed the bug.
So that describes how I found the issue with the bug. Figuring out a fix for it wouldn’t be that difficult now. I also wanted to find what changeset introduced the bug so I could learn more about why it was there.
Using MXR, I pulled up the `hg blame` for the file and went to the offending line. Clicking on the revision number on the left of the line brings up some of the diff from the changeset. At the top of this new page, I clicked on “changeset” to see the full changeset. This unfortunately was a refactoring changeset and wasn’t what actually introduced the offending lines. I then clicked on the parent changeset and based off of that revision found the file again and ran `hg blame` on it. Now the offending line was linked to the changeset that introduced the bug.
After reading through the bug that introduced the changeset I knew that I could safely make this change as the lines were never intended to alter context menus, and I also knew what to look for and test while making the change so I wouldn’t regress the original bugfix.
All of this being said, I probably could have found this quite a bit faster by using a tool called mozregression. mozregression is a tool that will help you run a binary search on all of our nightly builds (continuous integration ones too). As you are likely already aware, binary search is very fast, letting mozregression help narrow down the day that the regression got introduced from a range of 10 years to a single day in about 7 builds.
If I had taken the mozregression route I probably could have saved myself about 45 minutes of debugging and digging around. But both routes work well, and sometimes I learn more from one than the other.
I know this write-up was long, but I hope it was valuable.

https://msujaws.wordpress.com/2016/04/09/a-story-of-bug-fixing/
|
|
Support.Mozilla.Org: Thank you, Kadir! |

Hello, SUMO Nation!
A bitter-sweet piece of news to share with you, as we’re announcing Kadir’s move onwards to focus on MDN product management.
For those of you who haven’t been around for long, Kadir was the original SUMO Support Community Manager (so, basically a very early alpha version of those who help you help others today ;-)). Just click the link to his profile and read on. Quite a ride for the open web!
He has been the glue between users, contributors, developers, and the oceans of data that our platform produces every day, trying to make everyone’s life easier and the future of Kitsune clearer. His task prioritization and problem analysis skills will definitely make many future MDN projects a success.
On a more personal side, he’s always kept a sharp eye out for good movies and great desserts, making sure that every team meeting had a good backing of both culture and cuisine.
On behalf of all the current SUMO admins and contributors – thank you for all the awesomeness, Kadir! Good luck with all the new challenges and adventures in development and beyond!
photo courtesy of Roland
PS. More SUMO Developer news coming your way next week!
|
|
Mozilla Cloud Services Blog: Stolen Passwords Used to Break into Firefox Accounts |
We recently discovered a pattern of suspicious logins to Firefox Accounts. It appears that an attacker with access to passwords from data breaches at other websites has been attempting to use those passwords to log into users’ Firefox Accounts. In some cases where a user reused their Firefox Accounts password on another website and that website was breached, the attacker was able to take the password from the breach and use it to log into the user’s Firefox Account.
We’ve already taken steps to protect our users. We automatically reset the passwords of users whose accounts were broken into. We also notified these users with instructions on how to regain access to their accounts and further protect themselves going forward. This investigation is ongoing and we will notify users if we discover unauthorized activity on their account.
User security is paramount to us. It is part of our mission to help build an Internet that truly puts people first and where individuals are empowered, safe and independent. Events like this are a good reminder of the importance of good password hygiene. Using strong and different passwords across websites is important for staying safe online. We’re also working on additional rate-limiting and other security mechanisms to provide additional protection for our users.
https://blog.mozilla.org/services/2016/04/09/stolen-passwords-used-to-break-into-firefox-accounts/
|
|
Support.Mozilla.Org: SUMO l10n update |
Hello, Localizers of SUMO!
 First of all, thanks to all of you for taking the time to update the Knowledge Base in your locales in the last 3 months. I hope the next 3 months will be as awesome as the start – you make it happen!
First of all, thanks to all of you for taking the time to update the Knowledge Base in your locales in the last 3 months. I hope the next 3 months will be as awesome as the start – you make it happen!
Now, to share a few updates with you.
As you may remember, we are currently in partial development freeze, due to changes in team structure. Still, our awesome community (this means YOU!), supported by our relentless pull request herders, keeps tinkering with the platform and improving it, bit by bit. Thank you!
Thanks to Michal, Safwan, Mike, and others (both reporting and investigating issues), the l10n backlog is now shorter than ever! By the way, if you notice that an l10n bug is missing from it, please let me know or add it yourself.
I have also gathered feedback from some of our most active localizers, in order to see what could potentially be improved or experimented with to make using Kitsune for localization easier. Some of the findings are as follow:
Learn more about what’s happened with Pontoon in the last three months from this blog post by Matjaz, its lead developer.
The highlights include:
What’s more, all users of Pontoon are invited to develop the roadmap for the tool by filing new feature requests and commenting on existing ones. You can find more details about this in the blog post linked above.
… and if you’re curious about Pontoon, but haven’t started using it yet, take a look at this quick introductory video:
The L10n team has invested time and effort over the last three months into processes, tools, and resources to help everyone involved in l10n at Mozilla improve the overall quality. You can learn more about these efforts from this blog post.
The great news is that now it’s much easier to improve existing localizations in Transvision, one of the core l10n tools at Mozilla. To do so:
Finally, get together with your l10n community (offline or online) and try creating a draft of your locale’s style guide, using the existing template. If you think the instructions are too long, too short, too full of jargon, or require too much effort, send feedback to the L10n team that sets global l10n standards and best practices for Mozilla projects.
Remember about the upcoming L10n hackathons for your locale! Try to make the most of the upcoming opportunity to connect with your fellow localizers!
https://blog.mozilla.org/sumo/2016/04/08/sumo-l10n-update-2/
|
|
Doug Belshaw: 3 things I learned during my time at Mozilla |
On my to-do list for the last year has been ‘write up what I learned at Mozilla’. I didn’t want this anniversary week to go by without writing something, so despite this being nowhere near as comprehensive as what I’d like to write, it at least shifts that item from my to-do list!
The following are three (plus one bonus) personal learning points that I felt were some of my main takeaways from the three years I spent working for the Mozilla Foundation. After being a volunteer from 2011, I became a member of staff from 2012-15, working first as Badges & Skills Lead, and then transitioning to Web Literacy Lead.
Mozilla is radically open. Most meetings are available via public URLs, notes and projects are open for public scrutiny, and work is shared by default on the open web.
There are many unexpected benefits through doing this, including it being a lot easier to find out what your colleagues are working on. It’s therefore easy to co-ordinate efforts between teams, and to bring people into projects.
In fact, I think that working openly is such an advantage, that I’ve been advocating it to every client I’ve worked with since setting up Dynamic Skillset. Thankfully, there’s now a fantastic book to help with that evangelism entitled The Open Organization by the CEO of Red Hat, a $2bn Open Source tech firm.
This feels like an odd point to include and could, in fact, be seen as somewhat negative. However, for me, it was a positive, and one of the main reasons I decided to spend my time volunteering for Mozilla in the first place. When the mission and manifesto of an organisation are explicit and publicly-available, it’s immediately obvious whether what you’re working on is worthwhile in the eyes of your colleagues.
No organisation is without its politics, but working for Mozilla was the first time I’d experienced the peculiar politics of Open Source. Instead of the institutional politics of educational institutions, these were politics about the best way to further the mission of the organisation. Sometimes this led to people leaving the organisation. Sometimes it led to heated debates. But the great thing was that these discussions were all ultimately focused on achieving the same end goals.
I do like working remotely, but it’s difficult — and for reasons you might not immediately expect. The upsides of remote working are pretty obvious: no commute, live wherever you like, and structure your day more flexibly than you could do if you were based in an office.
What I learned pretty quickly is that there can be a fairly large downside to every interaction with colleagues being somewhat transactional. What I mean by that is there’s no corridor conversations, no wandering over to someone else’s desk to see how they are, no watercooler conversations.
There are huge efficiency gains to be had by having remote workers all around the globe — the sun never sets on your workforce — but it’s imperative that they come together from time to time. Thankfully, Mozilla were pretty good at flying us out to San Francisco, Toronto, and other places (like Portland, Oregon) to work together and have high-bandwidth conversations.
Perhaps the hardest thing about working remotely is that lack of bandwidth. Yes, I had frequent video conversations with colleagues, but a lot of interaction was text-based. When there’s no way to read the intention of a potentially-ambiguous sentence, dwelling on these interactions in the solitude of remote working can be anxiety-inducing.
Since leaving Mozilla I’ve read some studies that suggest that successful long-term remote working is best done based in teams. I can see the logic in that. The blend I’ve got now with some work being done face-to-face with clients, and some from home, seems to suit me better.
This is a bonus point, but one that I thought I should include. As you’d expect, Mozilla was an environment with the most technology-savvy people I’ve ever had the pleasure to work with. There were some drawbacks to this, including an element of what Evgeny Morozov would call ‘technological solutionism’, but on the whole it was extremely positive.
There were three specific ways in which having tech-savvy colleagues was helpful. First, it meant that you could assume a baseline. Mozilla can use tools with its staff and volunteers that may be uncomfortable or confusing for the average office worker. There is a high cognitive load, for example, when participating in a meeting via etherpad, chat, and voice call simultaneously. But being able to use exactly the right tool for the job rather than just a generic tool catering to the lowest common denominator has its advantages.
Second, tech-savvy colleagues means that things you discuss in meetings and at work weeks get prototyped quickly. I can still remember how shocked I was when Atul Varma created a version of the WebLitMapper a few days after I’d mentioned that such a thing would be useful!
The third point is somewhat related to the first. When you have a majority of people with a high level of technical skills, the default is towards upskilling, rather than dumbing down. There were numerous spontaneous ways in which this type of skillsharing occurred, especially when Mozilla started using GitHub for everything — including planning!
Although I’m genuinely happier than I’ve ever been in my current position as a self-employed, independent consultant, I wouldn’t trade my experience working for Mozilla for anything. It was a privilege to work alongside such talented colleagues and do work that was truly making the web a better place.
One of the reasons for writing this post was that I’ve found that I tend to introduce myself as someone who “used to work for Mozilla”. This week, one year on, marks a time at which I reflect happily on the time I had there, but ensure that my eyes are on the future.
Like so many former members of staff, I’ve found it difficult to disentangle my own identity from that of Mozilla. I purposely took this past year as time completely away from any Mozilla projects so I could gain some critical distance — and so that people realised I’d actually moved on!
So who am I? I’m Dr. Doug Belshaw, an independent consultant focusing on the intersection of education, technology, and productivity. But I remain a Mozillian. You can find me at mozillans.org here.
Image CC BY Paul Clarke (bonus points if you can spot me!)
|
|






