Air Mozilla: The Joy of Coding - Episode 52 |
 mconley livehacks on real Firefox bugs while thinking aloud.
mconley livehacks on real Firefox bugs while thinking aloud.
|
|
Matjaz Horvat: Pontoon: Q1 report and Q2 roadmap |
Over the past 3 months, we deployed new Pontoon code to production servers 65 times, which means approximately once per workday. Most of the changes were incremental improvements, optimizations or bugfixes, but some of them require a brief introduction. We hope you’ll like them.
Progressive loading of strings
Instead of requesting all strings at once, we now only load the first 50 and add others progressively while you scroll down the string list (in batches of 50). The benefits are particularly noticable when loading resource files with 1000s of strings, with search & filters also becoming snappier. Kudos to jotes for implementing it!
The idea of progressive loading is simple, but its implications go far beyond what the name suggests. It allowed us to add the All Resources menu entry, which makes it easy to load, search and filter strings across the entire project. If you have 7 missing strings in 4 different files, you can finally translate them without manually loading each resource.
In Q2, we’ll make common filters (e.g. strings with pending suggestions) accessible directly from the dashboard.

Bulk actions
Some time ago my team decided to change the translation of cookie in Firefox. It would be a nightmare to do it for each string separately in Pontoon, so we had to fire up a text editor and use find & replace. This use case is now covered by Pontoon.
Translation status icons in the string list act as checkboxes, allowing you to select strings. (You can also hold Shift to select a range of strings or use Select All). 3 bulk actions are available (to Translators only) — Approve All, Delete All and Find & Replace.
In Q2, we’ll add new filters to help you with more interesting mass actions. For example, you will be able to delete all suggestions submitted by No Name, because they are spam. Or approve all suggestions from Annie, who was just granted Translator permission.

Improved translation helpers
Translation helpers are the three tabs below translation textarea, where we keep history of user translations (History), translation memory and machine translation suggestions (Machinery) and translations into other locales (Locales).
All helpers are loaded instantly after a string is opened for translation. Additionally, a number of suggestions is displayed in each tab title, so you don’t click on them in vain. Duplicate Machinery results are grouped and sorted by source (in addition to Levenshtein distance).
In Q2, we’ll make it possible for localizers to define a preferred list of locales to get suggestions from.
Homepage and dashboard optimization
Pontoon homepage now loads 70% faster, mostly due to smarter handling of the iframe and loading Persona script on demand. Dashboards are 30-60% faster, thanks to denormalized statistics data and optimized latest activity database queries.
On a related note, you can now access team and project dashboards directly from the main menu in the translate view. Thanks to Emin for submitting the patch!
In Q2, we’ll focus on optimizing sync, because we have a huge room for improvement there. We’ll continue with web interface optimization, but we’re getting to the point where it’s becoming more of a hardware than software problem.

Other improvements
Plans for Q2
We’d love to hear your feedback on the features we’ve shipped. In addition to that, we’d like to invite you to participate in developing our roadmap for Q2. Now is the best time to file feature requests and leave feedback on existing bugs (quarterly goals have priority set to P2).
|
|
Jean-Marc Valin: A Deringing Filter for Daala... And Beyond |

Here's the latest addition to the Daala demo series. This demo describes the new Daala deringing filter that replaces a previous attempt with a less complex algorithm that performs much better. Those who like the know all the math details can also check out the full paper.
|
|
QMO: Firefox 46 Beta 7 Testday Results |
Hello Mozillians!
As you may already know, last Friday – April 1st – we held a new Testday event, for Firefox 46 Beta 7.
Results:
We’d like to take this opportunity to thank Bolaram Paul, Karpenko Edgar, Kushagra Varade, Edoardo Viola, Iryna Thompson, gaby2300, Ilse Mac'ias, Moin Shaikh and the Bangladesh QA Community: Hossain Al Ikram, Rezaul Huque Nayeem, Saheda Reza Antora, Nazir Ahmed Sabbir, Md. Raihan Ali, Md. Rahimul Islam, Khalid Syfullah Zaman, Md.Ehsanul Hassan, israt jahan tanni, Maruf Hasan Hridoy, Samad Talukdar, Asiful Kabir Heemel, Saddam Hossain, Jobayer Ahmed Mickey, Maruf Rahman, Syed Nayeem Roman, Fahmida Noor, Mohammed Jawad Ibne Ishaque, Sayed Mohammad Amir, Tazin Ahmed, MD.Majedul islam, Badiuzzaman Pranto, Sauradeep Dutta, Fahim, ainul Kowsher, Forhad Hossain, Tanvir Rahman, Md. Almas Hossain, Sajedul Islam, akash, Asif MahmudShuvo, Mohammad Maruf Islam, Wahiduzzaman Hridoy for getting involved in this event and making Firefox as best as it could be.
Also a big thank you goes to all our active moderators.
Keep an eye on QMO for upcoming events!
https://quality.mozilla.org/2016/04/firefox-46-beta-7-testday-results/
|
|
Gervase Markham: DMCA Section 512 Comments Submitted |
A small milestone: the first post in my name on the Mozilla Net Policy blog has just been published. It concerns our filing comments for a US Copyright Office consultation on section 512 of the DMCA – the section dealing with safe harbo(u)rs for intermediary liability. Section 512 contains the rules that mean Facebook, Twitter and other platforms actually let you have a conversation and upload images and videos to talk about, rather than restricting that capability because they are too afraid of immediate copyright liability.
This is not to be confused with section 1201 of the DMCA, which gives the rules for the 3-yearly process for getting DMCA exceptions for important things like phone unlocking. We also filed comments in a consultation on that recently.
We hope that the Copyright Office’s recent attention to these sections bodes well for useful reforms to US copyright law.
http://feedproxy.google.com/~r/HackingForChrist/~3/GpVkz_13bkU/
|
|
Mark Finkle: Fun with Telemetry: Improving Our User Analytics Story |
My last post talks about the initial work to create a real user analytics system based on the UI Telemetry event data collected in Firefox on Mobile. I’m happy to report that we’ve had much forward progress since then. Most importantly, we are no longer using the DIY setup on one of my Mac Minis. Working with the Mozilla Telemetry & Data team, we have a system that extracts data from UI Telemetry via Spark, imports the data into Presto-based storage, and allows SQL queries and visualization via Re:dash.
With data accessible via Re:dash, we can use SQL to focus on improving our analyses:



Roberto posted about how we’re using Parquet, Presto and Re:dash to create an SQL based query and visualization system.
http://starkravingfinkle.org/blog/2016/04/fun-with-telemetry-improving-our-user-analytics-story/
|
|
Mozilla Open Policy & Advocacy Blog: Reining in abuses of the DMCA notice system |
The Digital Millennium Copyright Act (DMCA) should be reformed to help promote openness online. We’ve made this case before, posting about section 1201 on the circumvention of technological protection measures. Now, the U.S. Copyright Office has sought comments on section 512, on liability for intermediaries whose services may facilitate activity that infringes copyright. In this area, too, we argue for changes to better support openness. So, we filed comments in response to this consultation last week.
Section 512 gives an exemption (also known as a “safe harbor”) to the normal presumption of liability for copyright infringement, if the intermediary (usually a website, platform or ISP) follows a set of defined processes to deal with copyright complaints. These processes are centered around DMCA notices and counter-notices, and are a common occurrence in online life for creators who take advantage of fair use and other exceptions to copyright to build upon the work of others. Section 512’s protections have enabled the massive growth both of online services and, thereby, of the market and opportunities for licensing copyrighted works. Both of these outcomes have delivered great benefits to Internet users. Some believe these benefits have come with huge costs to rightsholders and believe the current approach should be gutted and replaced with a more punitive “notice-and-staydown” strategy; we believe these proposals should be ignored. But, there is room for improvement.
Because of important nuances of copyright law, it is not just the content but also the context in which content is found that determines infringement. For example, a piece of content can be used as a parody or for criticism or comment – or the user may hold a license permitting the activity – which would not constitute infringement. However, automated systems which generate the majority of section 512 notices today work by detecting the presence of particular content. These systems cannot account for context, and thus many activities that are non-infringing trigger burdensome enforcement processes. This confusion, problematic in the current regime, would be amplified many times in a “notice-and-staydown” regime.
In our filing, we offer three main proposals for reform to improve on the current system:
Considering how long ago it was written, and the major technological advancements since then, section 512 has aged very well. It should be viewed generally as a farsighted and well-designed attempt to promote the interests of users who want engaging online services. We hope that the reforms we propose will be adopted to ensure that it continues to maximally promote innovation and creativity online.
https://blog.mozilla.org/netpolicy/2016/04/05/reining-in-abuses-of-the-dmca-notice-system/
|
|
Mitchell Baker: All Change, All the Time |
http://blog.lizardwrangler.com/2016/04/05/all-change-all-the-time/
|
|
Air Mozilla: Connected Devices Weekly Program Review, 05 Apr 2016 |
 Weekly project updates from the Mozilla Connected Devices team.
Weekly project updates from the Mozilla Connected Devices team.
https://air.mozilla.org/connected-devices-weekly-program-review-20160405/
|
|
Air Mozilla: Webdev Extravaganza: April 2016 |
 Once a month web developers across the Mozilla community get together (in person and virtually) to share what cool stuff we've been working on.
Once a month web developers across the Mozilla community get together (in person and virtually) to share what cool stuff we've been working on.
|
|
David Lawrence: Happy BMO Push Day! |
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.

https://dlawrence.wordpress.com/2016/04/05/happy-bmo-push-day-12/
|
|
Rail Aliiev: Release Build Promotion Overview |
Hello from Release Engineering! Once a month we highlight one of our projects to help the Mozilla community discover a useful tool or an interesting contribution opportunity. This month's project is Release Build Promotion.
Release build promotion (or "build promotion", or "release promotion" for short), is the latest release pipeline for Firefox being developed by Release Engineering at Mozilla.
Release build promotion starts with the builds produced and tested by CI (e.g. on mozilla-beta or mozilla-release). We take these builds, and use them as the basis to generate all our l10n repacks, partial updates, etc. that are required to release Firefox. We "promote" the CI builds to the release channel.
The previous release pipeline also started with builds produced and tested by CI. However, when it came time to do a release, we would create an entirely new set of builds with slightly different build configuration. These builds would not get the regular CI testing.
Release build promotion improves the process by removing the second set of builds. This drastically improves the total time to do a release, and also increases our confidence in our products since we now are shipping exactly what's been tested. We also improve visibility of the release process; all the tasks that make up the release are now reported to Treeherder along with the corresponding CI builds.
Release build promotion is in use for Firefox desktop starting with the 46 beta cycle. ESR and release branches have not yet been switched over.
Firefox for Android is also not yet handled. We plan to have this ready for Firefox 47.
One of the major reasons of this project was our release end-to-end times. I pulled some data to compare:
Yes! We still have a lot of things to do and welcome everyone to contribute.
For more information, please refer to these other resources about build promotion:
There will be multiple blog posts regarding this project. You have probably seen Jordan's blog on how to be productive when distributed teams get together. It covers some of our experience we had during the project sprint week in Vancouver.
https://rail.merail.ca/posts/release-build-promotion-overview.html
|
|
Mozilla Addons Blog: Improving Review Time by Providing Links to Third Party Sources |
Earlier I wrote an article about submitting add-ons with sources attached, which is primarily needed for obfuscated or minified add-ons. I only briefly mentioned the specific cases where attaching sources is in fact NOT recommended. If you’ve determined you do not need to upload sources but you still want to profit from blazing fast review speeds, please read on.
To reiterate, you do not need to upload source code if your add-on only contains (minified) third-party libraries, or if the libraries you are calling via js-ctypes are system libraries or open source. What you need to do instead is provide links to the exact file versions in the repositories of the respective libraries. You should add these links in the “Notes to Reviewers” section when viewing or uploading your new version.
Just as with your add-on code, we review third-party library code for potential issues. When we notice a library is used more often, we can add the (sha256) checksum to a list of known libraries that are specially marked in the editor tools. Reviewers do not need to review this library again, which saves a lot of time.
The downside to using checksums is that the file must match exactly, down to the byte. A common issue we encounter is libraries being retrieved from non-official sites, for example CDNs. These sites may make slight changes, often something simple like white spaces, or adding/removing a source map URL. Similarly, some developers copy/paste the libraries into a text editor, which may result in different line endings.
Now to the important part: how to specify the repository links. You don’t need to do this for the common libraries mentioned in our list (currently: angular, backbone, backbone.localStorage, crypto.js, dojo, jquery, jqueryui, moment, mootools, prototype.js, scriptaculous, swfobject.js, underscore, yui). For all other libraries, we need the link to an exact copy of the file you have submitted, from the official website or repository. Here is an example:
Let’s say you are using the minified version of mousetrap version 1.4.2 because you haven’t had the chance to update to the latest version.
If the library is on github, you can usually find this version under the “releases” link, then clicking on the small tag icon next to the version number, then navigating to the file in the repository. For bonus points, if you are using the minifed version, also provide a link to the unminifed version beside it. If the library does not use github releases but instead just gives you a zip to download, provide the link to the zip instead.
Mentioning the links upfront will shorten the review time since we can check the library right away instead of asking you about it, making reviews faster. Leave a comment if you have any questions!
https://blog.mozilla.org/addons/2016/04/05/improved-review-time-with-links-to-sources/
|
|
Mozilla Cloud Services Blog: Using VAPID with WebPush |
This post continues discussion about using the evolving WebPush feature.
One of the problems with offering a service that doesn’t require identification is that it’s hard to know who’s responsible for something. For instance, if a consumer is having problems, or not using the service correctly, it is a challenge to contact them. One option is to require strong identification to use the service, but there are plenty of reasons to not do that, notably privacy.
The answer is to have each publisher optionally identify themselves, but how do we prevent everyone from saying that they’re something popular like “CatFacts”? The Voluntary Application Server Identification for Web Push (VAPID) protocol was drafted to try and answer that question.
VAPID uses JSON Web Tokens (JWT) to carry identifying information. The core of the VAPID transaction is called a “claim”. A claim is a JSON object containing several common fields. It’s best to explain using an example, so let’s create a claim from a fictional CatFacts service.
{
"aud": "http://catfacts.example.com",
"exp": 1458679343,
"sub": "mailto:webpush_ops@catfacts.example.com"
}
Math.floor(Date.now() * .001 + 86400).I’ve added spaces and new lines to make things more readable. JWT objects normally strip those out.
A JWT object actually has three parts: a standard header, the claim (which we just built), and a signature.
The header is very simple and is standard to any VAPID JWT object.
{"typ": "JWT","alg":"ES256"}
If you’re curious, typ is the “type” of object (a “JWT”), and alg is the signing algorithm to use. In our case, we’re using Elliptic Curve Cryptography based on the NIST P-256 curve (or “ES256”).
We’ve already discussed what goes in the claim, so now, there’s just the signature. This is where things get complicated.
Here’s code to sign the claim using Python 2.7.
# This Source Code Form is subject to the terms of the Mozilla Public
# License, v. 2.0. If a copy of the MPL was not distributed with this
# file, You can obtain one at http://mozilla.org/MPL/2.0/.
import base64
import time
import json
import ecdsa
from jose import jws
def make_jwt(header, claims, key):
vk = key.get_verifying_key()
jwt = jws.sign(
claims,
key,
algorithm=header.get("alg", "ES256")).strip("=")
# The "0x04" octet indicates that the key is in the
# uncompressed form. This form is required by the
# server and DOM API. Other crypto libraries
# may prepend this prefix automatically.
raw_public_key = "\x04" + vk.to_string()
public_key = base64.urlsafe_b64encode(raw_public_key).strip("=")
return (jwt, public_key)
def main():
# This is a standard header for all VAPID objects:
header = {"typ": "JWT", "alg": "ES256"}
# These are our customized claims.
claims = {"aud": "https://catfacts.example.com",
"exp": int(time.time()) + 86400,
"sub": "mailto:webpush_ops@catfacts.example.com"}
my_key = ecdsa.SigningKey.generate(curve=ecdsa.NIST256p)
# You can store the private key by writing
# my_key.to_pem() to a file.
# You can reload the private key by reading
# my_key.from_pem(file_contents)
(jwt, public_key) = make_jwt(header, claims, my_key)
# Return the headers we'll use.
headers = {
"Authorization": "Bearer %s" % jwt,
"Crypto-Key": "p256ecdsa=%s" % public_key,
}
print json.dumps(headers, sort_keys=True, indent=4)
main()
There’s a little bit of cheating here in that I’m using the “python ecdsa” library and JOSE‘s jws library, but there are similar libraries for other languages. The important bit is that a key pair is created.
This key pair should be safely retained for the life of the subscription. In most cases, just the private key can be retained since the public key portion can be easily derived from it. You may want to save both private and public keys since we’re working on a dashboard that will use your public key to let you see info about your feeds.
The output of the above script looks like:
{
"Authorization": "Bearer eyJhbGciOiJFUzI1NiIsInR5cCI6IkpXVCJ9.eyJhdWQiOiJodHRwczovL2NhdGZhY3RzLmV4YW1wbGUuY29tIiwiZXhwIjoxNDU4Njc5MzQzLCJzdWIiOiJtYWlsdG86d2VicHVzaF9vcHNAY2F0ZmFjdHMuZXhhbXBsZS5jb20ifQ.U8MYqcQcwFcK2UkeiISahgZFvaOw56ZQvHYZc4zXC2Ed48-lk3MoYExGagKLwr4lSdbARZEbblAprQfXlap3jw",
"Crypto-Key": "p256ecdsa=EJwJZq_GN8jJbo1GGpyU70hmP2hbWAUpQFKDByKB81yldJ9GTklBM5xqEwuPM7VuQcyiLDhvovthPIXx-gsQRQ=="
}
These are the HTTP request headers that you should include in the POST request when you send a message. VAPID uses these headers to identify a subscription.
The “Crypto-Key” header may contain many sub-components, separated by a semi-colon (“;”). You can insert the “p256ecdsa” value, which contains the public key, anywhere in that list. This header is also used to relay the encryption key, if you’re sending a push message with data. The JWT is relayed in the “Authorization” header as a “Bearer” token. The server will use the pubic key to check the signature of the JWT and ensure that it’s correct.
Again, VAPID is purely optional. You don’t need it if you want to send messages. Including VAPID information will let us contact you if we see a problem. It will also be used for upcoming features such as restricted subscriptions, which will help minimize issues if the endpoint is ever lost, and the developer dashboard, which will provide you with information about your subscription and some other benefits. We’ll discuss those more when the features becomes available. We’ve also published a few tools that may help you understand and use VAPID. The Web Push Data Test Page (GitHub Repo) can help library authors develop and debug their code by presenting “known good” values. The VAPID verification page (GitHub Repo) is a simpler, “stand alone” version that can test and generate values.
As always, your input is welcome.
Updated to spell out what VAPID stands for.
https://blog.mozilla.org/services/2016/04/04/using-vapid-with-webpush/
|
|
Air Mozilla: Mozilla Weekly Project Meeting, 04 Apr 2016 |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20160404/
|
|
Chris Cooper: RelEng & RelOps Weekly highlights - April 4, 2016 |
We skipped a week of updates due to the Easter Holiday. I’ve also moved the timing of these update emails/posts From Friday afternoon to Monday so that more people will see them. Look for your releng/relops highlights on Mondays now going forward.
Improve CI Pipeline:
Aki submitted a pull request for generated async code+tests for taskcluster-client.py, with 100% async test coverage. (https://github.com/taskcluster/taskcluster-client.py/pull/49)
Callek got us running the mozharness-tests (CI tests for mozharness) [they used to run on Travis-CI, and that we lost when we moved Mozharness in tree[. Based on intree code with taskcluster. These tests only run when someone touches mozharness code. (http://bugzil.la/1240184)
Operational:
Callek closed out a bunch of old bugs that related to foopies, pandas, and a few lingering ones about tegras. Since we have retired that infrastructure in favor of Android Emulators.
Kendall, Jake, and Mark worked to patch much of our infrastructure against the git 0-day vulnerability. They’re finishing up the tail end of those machines that have significantly less exposure/risk.
Rob landed patches to increase the stability of our Windows AWS AMI generation, making that process more robust. There’s some additional work to be done around verifying certificate downloads to fix the remaining issues we know about.
Nick landed some patches to improve our AWS recovery time (by about an hour) when we terminate many instances at once.
Amy has initiated a purchase for another 192 mac minis to expand our existing OS X 10.10 test pool in support of e10s and other load.
Release:
We released Firefox 45.0.1esr, 38.7.1esr as well as Firefox and Fennec 45.0.1, 46.0b2 and 46.0b4. Check out the post-mortem notes for more details: https://wiki.mozilla.org/Releases:Release_Post_Mortem:2016-03-23
See you next week!
|
|
Pascal Finette: Pascal on two Innovation Podcasts |
Recently I had the great pleasure of not only being on one Podcast but two – each with a slightly different twist:
First I talked with Bill Murphy from the amazing Redzone Podcast about “How to use Exponential Technologies to Innovate at the Edge”:
And then I was on Donnie SC Lygonis' Constant Innovation Podcast, talking about… Innovation:
|
|
Kevin Ngo: A Glimpse into Competitive VR Gaming |
 Ready Player One
Ready Player One
Just one more quarter. So close to beating that high score. Being at the local arcade, spaced out in front of a blipping machine with a display of flashing lights. That's the feeling I get when I play Space Pirate Trainer. But in this age, the leaderboard is global, the game is in virtual reality, and it's going to take a bit more skill.
Space Pirate Trainer is a game by I-llusions for the HTC Vive featuring full room-scale and hand-tracked controllers. You are standing on a docking bay in space. Waves of droids surround you. In each of your hands is a gun. The guns can be toggled to different modes (single, burst, auto, laser, and tickle beam), and you can reach behind your back to switch to a shield.
No more twitching with a mouse and clicking like you would Counter-Strike. You hold the controllers just as you would with a gun, pull the trigger just as you would with a gun. And you strafe, not with WASD, but with your entire body to dodge bullets in slow-motion.
It's great exercise well. I might play for 20 minutes at a time, though it's hard to tell how much time passes. And my heart is racing at the end of it.
I've been sort of a beta tester for the last couple months, having had a Vive DK1 and a Vive Pre at the Mozilla VR lab. Though I'm not alone. It recently updated to include a global leaderboard. At the top is Colin Northway, creator of Fantastic Contraption, with an insane score of 85K. He's damn accurate. For comparison, my current personal record is 20K, and it takes about 25K to get onto the top ten (at time of writing). Though once this game releases, I suspect it's about to get a lot more competitive.
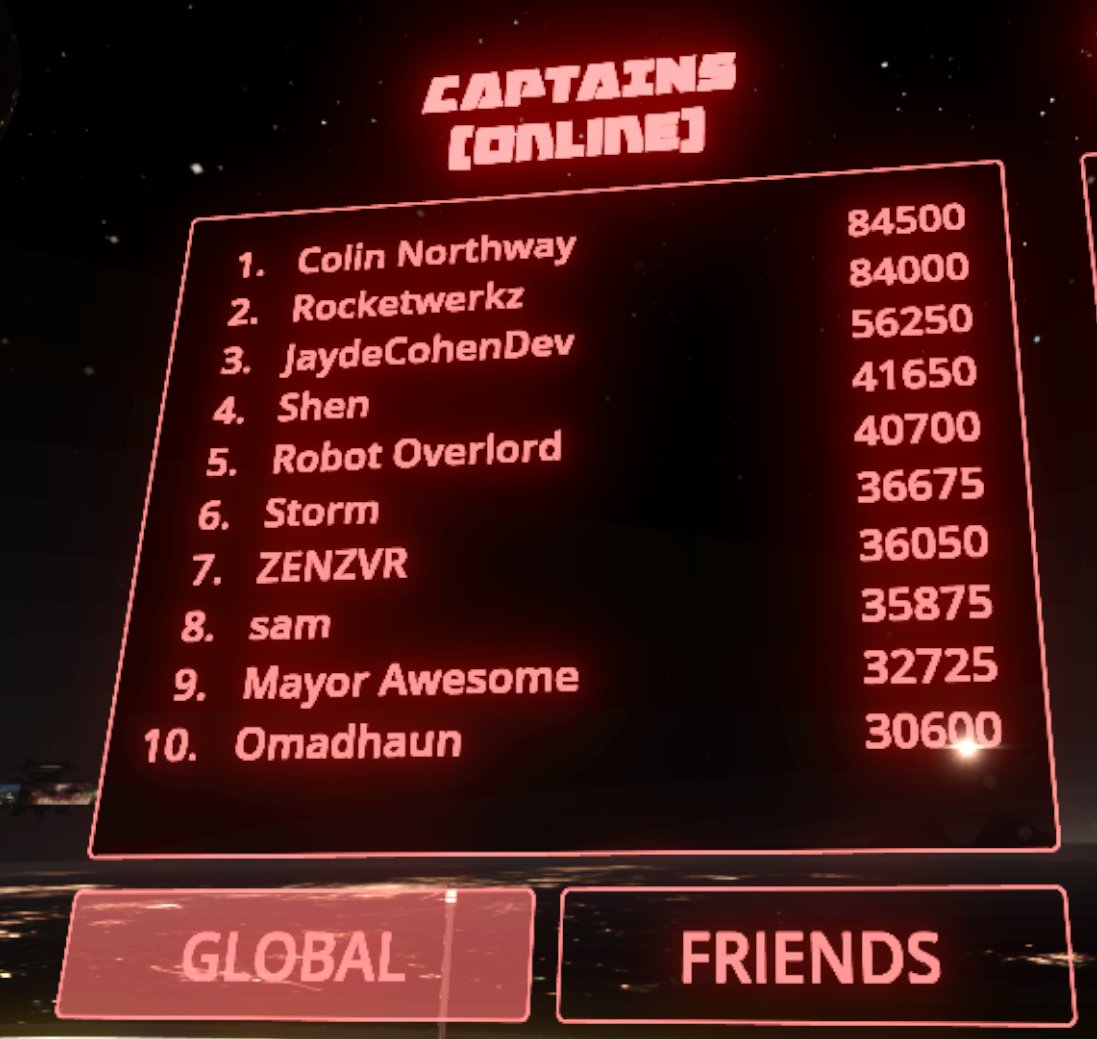
Between coding sessions, I take a break to blow up hunks of metal.
The biggest tip I can give is to use your ears. Droids will surround you, and you can tell which droids are about to attack from the noises they make. Paying attention to the spatial audio will let you know when and where you will need to evade.
It also helps to try to focus and clear one side of the map at a time to reduce the surround enemies have on you. Once you hear droids attacking you from the other side, then you turn your attention.
Arsenal-wise, I went through several tactics:
I've gotten farthest with gripping a single laser pistol. No second gun, no shield. Focusing on two hands is a bit of a distraction for me. I'm starting to develop a good trigger finger. When you take out several droids in a row without a single miss, especially during a dodge or weave, you feel like a futuristic laser-firin' Dirty Harry.
Counter-Strike has been the king of competitive shooting games since forever. Though the core gameplay hasn't changed too much; the most notable changes are in looks. It's easy to imagine games like Space Pirate Trainer taking competitive gaming to another level. No longer does success rely on hand-eye coordination, but on overall fitness and dexterity. Will existing competitive gamers' skill translate?
Competitive gaming might start to look like Gun Gale arc of Sword Art Online or slashing up baddies in the Metaverse with a samurai sword. There is no longer a distinction between the player and the avatar, you are the player.
|
|
Kevin Ngo: A Glimpse into Competitive VR Gaming |
Ready Player One
Just one more quarter. So close to beating that high score. Being at the local arcade, spaced out in front of a blipping machine with a display of flashing lights. That's the feeling I get when I play Space Pirate Trainer. But in this age, the leaderboard is global, the game is in virtual reality, and it's going to take a bit more skill.
Space Pirate Trainer is a game by I-llusions for the HTC Vive featuring full room-scale and hand-tracked controllers. You are standing on a docking bay in space. Waves of robots surround you. In each of your hands is a gun. The guns can be toggled to different modes (single, burst, auto, laser, and tickle beam), and you can reach behind your back to switch to a shield.
No more twitching with a mouse and clicking like you would Counter-Strike. You hold the controllers just as you would with a gun, pull the trigger just as you would with a gun. And you strafe, not with WASD, but with your entire body to dodge bullets in slow-motion.
The biggest tip I can give is to use your ears. Robots will surround you, and you can tell which robots are about to attack from the noises they make. Paying attention to the spatial audio will let you know when and where you will need to evade.
It's great exercise well. I might play for 20 minutes at a time, though it's hard to tell how much time passes. And my heart is racing at the end of it.
I've been sort of a beta tester for the last month, having had a Vive DK1 and a Vive Pre at the Mozilla VR lab. Though I'm not alone. It recently updated to include a global leaderboard. At the top is Colin Northway, creator of Fantastic Contraption, with an insane score of 85K. He has a video up of his gameplay, he's damn accurate. For comparison, my current personal record is 20K, and it takes about 25K to get onto the top ten (at time of writing). Though once this game releases, I suspect it's about to get a lot more competitive.
Between coding sessions, I take a break to blow up hunks of metal. I went through several tactics:
I've gotten farthest with gripping a single laser pistol. No second gun, no shield. Focusing on two hands is a bit of a distraction for me. I'm starting to develop a good trigger finger. When you take out several robots in a row without a single miss, especially during a dodge or weave, you feel like a futuristic laser-firin' Dirty Harry.
Counter-Strike has been the king of competitive shooting games since forever. Though the core gameplay hasn't changed too much; the most notable changes are in looks. It's easy to image games like Space Pirate Trainer might take competitive gaming to another level. No longer does success rely on hand-eye coordination, but on overall fitness and dexterity. Will existing competitive gamers' skill translate?
Competitive gaming might soon look like Gun Gale arc of Sword Art Online or slashing up baddies in the Metaverse with a samurai sword; there is no longer a distinction between the player and the avatar, you are the player.
|
|
Eric Shepherd: A decade of writing at Mozilla |
Today—April 3, 2016—marks the tenth anniversary of the day I started working at Mozilla as a writer on the Mozilla Developer Center project (now, of course, the Mozilla Developer Network or MDN). This was after being interviewed many (many) times by Mozilla luminaries including Asa Dotzler, Mike Shaver, Deb Richardson, and others, both on the phone and in person after being flown to Mountain View.
Ironically, when I started at Mozilla, I didn’t care a lick about open source. I didn’t even like Firefox. I actually said as much in my interviews in Mountain View. I still got the job.
I dove in in those early days, learning how to create extensions and how to build Firefox, and I had so, so very much fun doing it.
Ironically, for the first year and a half I worked at Mozilla, I had to do my writing work in Safari, because a bug in the Firefox editor prevented me from efficiently using it for in-browser writing like we do on MDN.
Once Deb moved over to another team, I was the lone writer for a time. We didn’t have nearly as many highly-active volunteer contributors as we do today (and I salute you all!), so I almost single-handedly documented Firefox 2.0. One of my proudest moments was when Mitchell called me out by name for my success at having complete (more or less) developer documentation for Firefox 2.0—the first Firefox release to get there before launch.
Over the past ten years, I’ve documented a little of everything. Actually, a lot of everything. I’ve written about extensions, XPCOM interfaces, HTML, a broad swath of APIs, Firefox OS, building Firefox and other Mozilla-based projects, JavaScript, how to embed SpiderMonkey into your own project (I even did so myself in a freeware project for Mac OS X), and many other topics.
As of the moment of this writing, I have submitted 42,711 edits to the MDN wiki in those ten years. I mostly feel good about my work over the last ten years, although the last couple of years have been complicated due to my health problems. I am striving to defeat these problems—or at least battle them to a more comfortable stalemate—and get back to a better level of productivity.
Earlier, I said that when I took the job at Mozilla, I didn’t care about the Web or about Firefox. That’s changed. Completely.
Today, I love my job, and I love the open Web. When I talk to people about my job at Mozilla, I always eventually reach a point at which I’m describing how Mozilla is changing the world for the better by creating and protecting the open Web. We are one of the drivers of the modernization of the world. We help people in disadvantaged regions learn and grow and gain the opportunity to build something using the tools and software we provide. Our standards work helps to ensure that a child in Ghana can write a Web game that she and her friends can play on their phones, yet also share it with people all over the world to play on whatever device they happen to have access to.
The Web can be the world’s greatest unifying power in history if we let it be. I’m proud to be part of one of the main organizations trying to make that happen. Here’s to many more years!
https://www.bitstampede.com/2016/04/03/a-decade-of-writing-at-mozilla/
|
|






