Karl Dubost: UA Detection and code libs legacy |
A Web site is a mix of technologies with different lifetimes. The HTML MarkUp is mostly rock-solid for years. CSS is not bad too, apart of the vendor prefixes. JavaScript, PHP, name-your-language are also not that bad. And then there's the full social and business infrastructure of these pieces put together. How do we create Web sites which are resilient and robust over time?
The business infrastructure of Web agencies is set up for the temporary. They receive a request from a client. They create the Web site with the mood of the moment. After 2 or 3 years, the client thinks the Web site is not up to the new fashion, new trends. The new Web agency (because it's often the case) praises that they will do a better job. They throw the old Web site, breaking at the same time old URIs. They create a new Web site with the technologies of the day. Best case scenario, they understand that keeping URIs is good for branding and karma. They release the site for the next 2-3 years.
Basically the full Web site has changed in terms of content and technologies and is working fine in current browser. It's a 2-3 years release cycle of maintenance.
Web browsers are being updated every 6 weeks or so. This is a very fast cycle. They are released with a lot of unstable technologies. Sometimes, they release entirely new browsers with new version numbers and new technologies. Device makers are releasing also new devices very often. It triggers both a consumerism habit and a difficulty for these to exist.
The Web developers design and focus their code on what is the most popular at the moment. Most of the time it's not their fault. These are the requirements from the business team in the Web agency or the clients. A lot of small Web agencies to not have the resources to invest in automated testing for the Web site. So they focus on two browsers. The one they develop with (the most popular of the moment) and the one the client said it was an absolute minimum bar (the most popular of the past).
Libraries of code are relying on User Agent detection for coping with bugs or unstable features of each browser. These libraries know only the past, never the future, not even the now. Libraries of code are often piles of legacy by design. Some are opensource, some have licenses fees attached to them. In both cases, they require a lot of maintenance and testing which are not planned into the budget of a Web site (which is already exploded by the development of the new shiny Web site).
The Web site will break for some users at a point in time. They chose to use a Web browser which didn't fit in the box of the current Web site. Last week, I went through WPTouch lib Web Compatibility bugs. Basically Firefox OS was not recognized by the User Agent detection code and in return WordPress Web sites didn't send the mobile version to the mobile devices. We opened that bug in August 2013. We contacted the BraveNewCode company which fixed the bug in March 2014. As of today, December 2014, there are still 7 sites in our list of 12 sites which have not switched to the new version of the library.
These were bugs reported by users of these sites. It means people who can't use their favorite browsers for accessing a particular Web site. I'm pretty sure that theree are more sites with the old version of WPTouch. Users either think their browser is broken or just don't understand what is happening.
Eventually these bugs will go away. It's one of my axioms in Web Compatibility: Wait long enough and the bug goes away. Usually the Web site doesn't exist anymore, or redesign from the ground up. In the meantime some users had a very bad experience.
We need a better story for code legacy, one with fallback, one which doesn't rely only on the past for making it work.
Otsukare.
|
|
Francois Marier: Mercurial and Bitbucket workflow for Gecko development |
While it sounds like I should really switch to a bookmark-based Mercurial workflow for my Gecko development, I figured that before I do that, I should document how I currently use patch queues and Bitbucket.
After creating a new bug in Bugzilla, I do the following:
mozilla-central-mq-BUGNUMBER repo on Bitbucket using the web
interface and use https://bugzilla.mozilla.org/show_bug.cgi?id=BUGNUMBER
as the description.hg qqueue -c BUGNUMBERhg init --mqhg qnew -Ue bugBUGNUMBER.patchhg commit --mq -m "Initial version"hg push ssh://hg@bitbucket.org/fmarier/mozilla-central-mq-BUGNUMBERMake the above URL the default for pull/push by putting this in
.hg/patches-BUGNUMBER/.hg/hgrc:
[paths]
default = https://bitbucket.org/fmarier/mozilla-central-mq-BUGNUMBER
default-push = ssh://hg@bitbucket.org/fmarier/mozilla-central-mq-BUGNUMBER
I like to preserve the history of the work I did on a patch. So once I've got some meaningful changes to commit to my patch queue repo, I do the following:
hg qrefhg diff --mqhg commit --mqhg push --mqSince I have one patch queue per bug, I can easily work on more than one bug at a time without having to clone the repository again and work from a different directory.
Here's how I switch between patch queues:
hg qpop -ahg qqueue BUGNUMBERhg qpush -aTo rebase my patch onto the latest mozilla-central tip, I do the following:
hg qpop -ahg pull -uhg qpush and resolve any conflictshg qrefhg commit --mq -m "Rebase patch"Thanks to Thinker Lee for telling me about
qqueue and Chris Pearce for explaining to me
how he uses mq repos on Bitbucket.
Of course, feel free to leave a comment if I missed anything useful or if there's a easier way to do any of the above.
http://feeding.cloud.geek.nz/posts/mercurial-bitbucket-workflow-for-gecko-development/
|
|
Daniel Glazman: Bloomberg |
Welcoming Bloomberg as a new customer of Disruptive Innovations. Just implemented the proposed caret-color property for them in Gecko.
http://www.glazman.org/weblog/dotclear/index.php?post/2014/12/21/Bloomberg
|
|
Patrick Cloke: The so-called IRC "specifications" |
In a previous post I had briefly gone over the "history of IRC" as I know it. I’m going to expand on this a bit as I’ve come to understand it a bit more while reading through documentation. (Hopefully it won’t sound too much like a rant, as it is all driving me crazy!)
So there’s the original specification (RFC 1459) in May 1993; this was expanded and replaced by four different specifications (RFC 2810, 2811, 2812, 2813) in April 2000. Seems pretty straightforward, right?
Well, kind of…there’s also the DCC/CTCP specifications, which is a separate protocol embedded/hidden within the IRC protocol (e.g. they’re sent as IRC messages and parsed specially by clients, the server sees them as normal messages). DCC/CTCP is used to send files as well as other particular messages (ACTION commands for roleplaying, SED for encrypting conversations, VERSION to get client information, etc.). Anyway, this get’s a bit more complicated — it starts with the DCC specification. This was replaced/updated by the CTCP specification (which fully includes the DCC specification) in 1994. An "updated" CTCP specification was released in February 1997. There’s also a CTCP/2 specification from October 1998, which was meant to reformulate a lot of the previous three versions. And finally, there’s the DCC2 specification (two parts: connection negotiation and file transfers) from April 2004.
But wait! I lied…that’s not really the end of DCC/CTCP, there’s also a bunch of extensions to it: Turbo DCC, XDCC (eXtended DCC) in 1993, DCC Whiteboard, and a few other variations of this: RDCC (Reverse DCC), SDD (Secure DCC), DCC Voice, etc. Wikipedia has a good summary.
Something else to note about the whole DCC/CTCP mess…parts of it just don’t have any documentation. There’s noneat all for SED (at least that I’ve found, I’d love to be proved wrong) and very little (really just a mention) for DCC Voice.
So, we’re about halfway through now. There’s a bunch of extensions to the IRC protocol specifications that add new commands to the actual protocol.
Originally IRC had no authentication ability except the PASS command, which very few servers seem to use, a variety of mechanisms have replaced this, including SASL authentication (both PLAIN and BLOWFISH methods, although BLOWFISH isn’t documented); and SASL itself is covered by at least four RFCs in this situation. There also seems to be a method called "Auth" which I haven’t been able to pin down, as well as Ident (which is a more general protocol authentication method I haven’t looked into yet).
This includes a few that generally add a way by which servers are able to tell their clients exactly what a server supports. The first of these was RPL_ISUPPORT, which was defined as a draft specification in January 2004, and updated in January of 2005.
A similar concept was defined as IRC Capabilities in March 2005.
IRCX, a Microsoft extension to IRC used (at one point) for some of it’s instant messaging products exists as a draft from June 1998.
There’s also:
To fill in some of the missing features of IRC, services were created (Wikipedia has a good summary again). This commonly includes ChanServ, NickServ, OperServ, and MemoServ. Not too hard, but different server packages include different services (or even the same services that behave differently), one of more common ones is Anope, however (plus they have awesome documentation, so they get a link).
There was an attempt to standardize how to interact with services called IRC+, which included three specifications: conference control protocol, identity protocol and subscriptions protocol. I don’t believe this are supported widely (if at all).
Finally this brings us to the IRC URL scheme of which there are a few versions. A draft from August 1996 defines the original irc: URL scheme. This was updated/replaced by another draft which defines irc: and ircs: URL schemes.
As of right now that’s all that I’ve found…an awful lot. Plus it’s not all compatible with each other (and sometimes out right contradicts each other). Often newer specifications say not to support older specifications, but who knows what servers/clients you’ll end up talking to! It’s difficult to know what’s used in practice, especially since there’s an awful lot of IRC servers out there. Anyway, if someone does know of another specification, etc. that I missed please let me know!
http://patrick.cloke.us/posts/2011/03/08/so-called-irc-specifications/
|
|
Laura Thomson: 2014: Engineering Operations Year in Review |
On the first day of Mozlandia, Johnny Stenback and Doug Turner presented a list of key accomplishments in Platform Engineering/Engineering Operations in 2014.
I have been told a few times recently that people don’t know what my teams do, so in the interest of addressing that, I thought I’d share our part of the list. It was a pretty damn good year for us, all things considered, and especially given the level of organizational churn and other distractions.
We had a bit of organizational churn ourselves. I started the year managing Web Engineering, and between March and September ended up also managing the Release Engineering teams, Release Operations, SUMO and Input Development, and Developer Services. It’s been a challenging but very productive year.
Here’s the list of what we got done.
I’d like to thank the team for their hard work. You are amazing, and I look forward to working with you next year.
At the start of 2015, I’ll share our vision for the coming year. Watch this space!
http://www.laurathomson.com/2014/12/2014-engineering-operations-year-in-review/
|
|
Mozilla Fundraising: Thanks to Our Amazing Supporters: A New Goal |
https://fundraising.mozilla.org/thanks-to-our-amazing-supporters-a-new-goal/
|
|
Chris Pearce: Firefox video playback's skip-to-next-keyframe behavior |
http://blog.pearce.org.nz/2014/12/firefox-video-playbacks-skip-to-next.html
|
|
Gervase Markham: Global Posting Privileges on the Mozilla Discussion Forums |
Have you ever tried to post a message to a Mozilla discussion forum, particularly one you haven’t posted to before, and received back a “your message is held in a queue for the moderator” message?
Turns out, if you are subscribed to at least one forum in its mailing list form, you get global posting privileges to all forums via all mechanisms (mail, news or Google Groups). If you aren’t so subscribed, you have to be whitelisted by the moderator on a per-forum basis.
If this sounds good, and you are looking for a nice low-traffic list to use to get this privilege, try mozilla.announce.
http://feedproxy.google.com/~r/HackingForChrist/~3/lXB2PTfkqhk/
|
|
Wladimir Palant: Can Mozilla be trusted with privacy? |
A year ago I would have certainly answered the question in the title with “yes.” After all, who else if not Mozilla? Mozilla has been living the privacy principles which we took for the Adblock Plus project and called our own. “Limited data” is particularly something that is very hard to implement and defend against the argument of making informed decisions.
But maybe I’ve simply been a Mozilla contributor way too long and don’t see the obvious signs any more. My colleague Felix Dahlke brought my attention to the fact that Mozilla is using Google Analytics and Optimizely (trusted third parties?) on most of their web properties. I cannot really find a good argument why Mozilla couldn’t process this data in-house, insufficient resources certainly isn’t it.
And then there is Firefox Health Report and Telemetry. Maybe I should have been following the discussions, but I simply accepted the prompt when Firefox asked me — my assumption was that it’s anonymous data collection and cannot be used to track behavior of individual users. The more surprised I was to read this blog post explaining how useful unique client IDs are to analyze data. Mind you, not the slightest sign of concern about the privacy invasion here.
Maybe somebody else actually cared? I opened the bug but the only statement on privacy is far from being conclusive — yes, you can opt out and the user ID will be removed then. However, if you don’t opt out (e.g. because you trust Mozilla) then you will continue sending data that can be connected to a single user (and ultimately you). And then there is this old discussion about the privacy aspects of Firefox Health Reporting, a long and fruitless one it seems.
Am I missing something? Should I be disabling all feedback functionality in Firefox and recommend that everybody else do the same?
Side-note: Am I the only one who is annoyed by the many Mozilla bugs lately which are created without a description and provide zero context information? Are there so many decisions being made behind closed doors or are people simply too lazy to add a link?
https://palant.de/2014/12/19/can-mozilla-be-trusted-with-privacy
|
|
Laura Hilliger: Web Literacy Lensing: Identity |

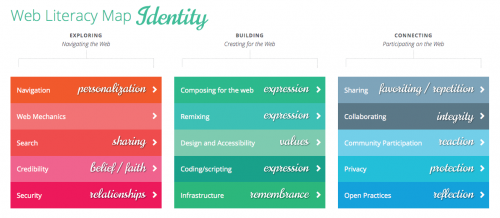
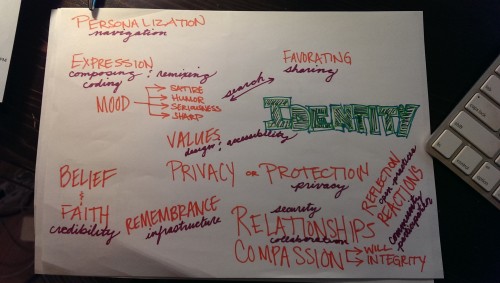 braindump[/caption]
braindump[/caption]
http://www.zythepsary.com/psycho/web-literacy-lensing-identity/
|
|
Gregory Szorc: Why hg.mozilla.org is Slow |
At Mozilla, I often hear statements like Mercurial is slow. That's a very general statement. Depending on the context, it can mean one or more of several things:
I want to spend time talking about a specific problem: why hg.mozilla.org (the server) is slow.
If you are talking to hg.mozilla.org over HTTP or HTTPS (https://hg.mozilla.org/), there should not currently be any server performance issues. Our Mercurial HTTP servers are pretty beefy and are able to absorb a lot of load.
If https://hg.mozilla.org/ is slow, chances are:
There have historically been network capacity issues in the datacenter where hg.mozilla.org is hosted (SCL3).
During Mozlandia, excessive traffic to ftp.mozilla.org essentially saturated the SCL3 network. During this time, requests to hg.mozilla.org were timing out: Mercurial traffic just couldn't traverse the network. Fortunately, events like this are quite rare.
Up until recently, Firefox release automation was effectively overwhelming the network by doing some clownshoesy things.
For example, gaia-central was being cloned all the time We had a ~1.6 GB repository being cloned over a thousand times per day. We were transferring close to 2 TB of gaia-central data out of Mercurial servers per day
We also found issues with pushlogs sending 100+ MB responses.
And the build/tools repo was getting cloned for every job. Ditto for mozharness.
In all, we identified a few terabytes of excessive Mercurial traffic that didn't need to exist. This excessive traffic was saturating the SCL3 network and slowing down not only Mercurial traffic, but other traffic in SCL3 as well.
Fortunately, people from Release Engineering were quick to respond to and fix the problems once they were identified. The problem is now firmly in control. Although, given the scale of Firefox's release automation, any new system that comes online that talks to version control is susceptible to causing server outages. I've already raised this concern when reviewing some TaskCluster code. The thundering herd of automation will be an ongoing concern. But I have plans to further mitigate risk in 2015. Stay tuned.
Looking back at our historical data, it appears that we hit these network saturation limits a few times before we reached a tipping point in early November 2014. Unfortunately, we didn't realize this because up until recently, we didn't have a good source of data coming from the servers. We lacked the tooling to analyze what we had. We lacked the experience to know what to look for. Outages are effective flashlights. We learned a lot and know what we need to do with the data moving forward.
One person pinged me on IRC with the comment Git is cloning much faster than Mercurial. I asked for timings and the Mercurial clone wall time for Firefox was much higher than I expected.
The reason was network bandwidth. This person was performing a Git clone between 2 hosts in EC2 but was performing the Mercurial clone between hg.mozilla.org and a host in EC2. In other words, they were partially comparing the performance of a 1 Gbps network against a link over the public internet! When they did a fair comparison by removing the network connection as a variable, the clone times rebounded to what I expected.
The single-homed nature of hg.mozilla.org in a single datacenter in northern California is not only bad for disaster recovery reasons, it also means that machines far away from SCL3 or connecting to SCL3 over a slow network aren't getting optimal performance.
In 2015, expect us to build out a geo-distributed hg.mozilla.org so that connections are hitting a server that is closer and thus faster. This will probably be targeted at Firefox release automation in AWS first. We want those machines to have a fast connection to the server and we want their traffic isolated from the servers developers use so that hiccups in automation don't impact the ability for humans to access and interface with source code.
If you connect to http://hg.mozilla.org/ or https://hg.mozilla.org/, you are hitting a pool of servers behind a load balancer. These servers have repository data stored on local disk, where I/O is fast. In reality, most I/O is serviced by the page cache, so local disks don't come into play.
If you connect to ssh://hg.mozilla.org/, you are hitting a single, master server. Its repository data is hosted on an NFS mount. I/O on the NFS mount is horribly slow. Any I/O intensive operation performed on the master is much, much slower than it should be. Such is the nature of NFS.
We'll be exploring ways to mitigate this performance issue in 2015. But it isn't the biggest source of performance pain, so don't expect anything immediately.
When you hg push to hg.mozilla.org, the changes are first made on the SSH/NFS master server. They are subsequently mirrored out to the HTTP read-only slaves.
As is currently implemented, the mirroring process is performed synchronously during the push operation. The server waits for the mirrors to complete (to a reasonable state) before it tells the client the push has completed.
Depending on the repository, the size of the push, and server and network load, mirroring commonly adds 1 to 7 seconds to push times. This is time when a developer is sitting at a terminal, waiting for hg push to complete. The time for Try pushes can be larger: 10 to 20 seconds is not uncommon (but fortunately not the norm).
The current mirroring mechanism is overly simple and prone to many failures and sub-optimal behavior. I plan to work on fixing mirroring in 2015. When I'm done, there should be no user-visible mirroring delay.
Up until yesterday (when we deployed a rewritten pushlog extension, the replication of pushlog data from master to server was very inefficient. Instead of tranferring a delta of pushes since last pull, we were literally copying the underlying SQLite file across the network!
Try's pushlog is ~30 MB. mozilla-central and mozilla-inbound are in the same ballpark. 30 MB x 10 slaves is a lot of data to transfer. These operations were capable of periodically saturating the network, slowing everyone down.
The rewritten pushlog extension performs a delta transfer automatically as part of hg pull. Pushlog synchronization now completes in milliseconds while commonly only consuming a few kilobytes of network traffic.
Early indications reveal that deploying this change yesterday decreased the push times to repositories with long push history by 1-3s.
Pretty much any interaction with the Try repository is guaranteed to have poor performance. The Try repository is doing things that distributed versions control systems weren't designed to do. This includes Git.
If you are using Try, all bets are off. Performance will be problematic until we roll out the headless try repository.
That being said, we've made changes recently to make Try perform better. The median time for pushing to Try has decreased significantly in the past few weeks. The first dip in mid-November was due to upgrading the server from Mercurial 2.5 to Mercurial 3.1 and from converting Try to use generaldelta encoding. The dip this week has been from merging all heads and from deploying the aforementioned pushlog changes. Pushing to Try is now significantly faster than 3 months ago.
Many of the reasons for hg.mozilla.org slowness are known. More often than not, they are due to clownshoes or inefficiencies on Mozilla's part rather than fundamental issues with Mercurial.
We have made significant progress at making hg.mozilla.org faster. But we are not done. We are continuing to invest in fixing the sub-optimal parts and making hg.mozilla.org faster yet. I'm confident that within a few months, nobody will be able to say that the servers are a source of pain like they have been for years.
Furthermore, Mercurial is investing in features to make the wire protocol faster, more efficient, and more powerful. When deployed, these should make pushes faster on any server. They will also enable workflow enhancements, such as Facebook's experimental extension to perform rebases as part of push (eliminating push races and having to manually rebase when you lose the push race).
http://gregoryszorc.com/blog/2014/12/19/why-hg.mozilla.org-is-slow
|
|
Roberto A. Vitillo: ClientID in Telemetry submissions |
A new functionality landed recently that allows to group Telemetry sessions by profile ID. Being able to group sessions by profile turns out be extremely useful for several reasons. For instance, as some users tend to generate an enourmous amount of sessions daily, analyses tend to be skewed towards those users.
Take uptime duration; if we just consider the uptime distribution of all sessions collected in a certain timeframe on Nightly we would get a distribution with a median duration of about 15 minutes. But that number isn’t really representative of the median uptime for our users. If we group the submissions by Client ID and compute the median uptime duration for each group, we can build a new distribution that is more representative of the general population:

And we can repeat the exercise for the startup duration, which is expressed in ms:
 Our dashboards are still based on the session distributions but it’s likely that we will provide both session and user based distributions in our next-gen telemetry dash.
Our dashboards are still based on the session distributions but it’s likely that we will provide both session and user based distributions in our next-gen telemetry dash.
edit:
Please keep in mind that:

http://robertovitillo.com/2014/12/19/clientid-in-telemetry-submissions/
|
|
Will Kahn-Greene: Input status: December 18th, 2014 |
It's been 3 months since the last status report. Crimey! That's not great, but it's even worse because it makes this report crazy long.
First off, lots of great work done by Adam Okoye, L. Guruprasad, Bhargav Kowshik, and Deshraj Yadav! w00t!
Second, we did a ton of stuff and broke 1,000 commits! w00t!
Third, I've promised to do more frequent status reports. I'll go back to one every two weeks.
Onward!
High-level summary:
Landed and deployed:
Landed, but not deployed:
Current head: f0ec99d
That's it!
http://bluesock.org/~willkg/blog/mozilla/input_status_20141218
|
|
Schalk Neethling: Getting “Cannot read property ‘contents’ of undefined” with grunt-contrib-less? Read this… |
|
|
Matej Cepl: Third Wave and Telecommuting |
I have been reading Tim Bray’s blogpost on how he started to work in Amazon, and I got ignited by the comment by len and particularly by this (he starts quoting Tim):
“First, I am totally sick of working remotely. I want to go and work in rooms with other people working on the same things that I am.”
And that says a lot. Whatever the web has enabled in terms of access, it has proven to be isolating where human emotions matter and exposing where business affairs matter. I can’t articulate that succinctly yet, but there are lessons to be learned worthy of articulation. A virtual glass of wine doesn’t afford the pleasure of wine. Lessons learned.
Although I generally agree with your sentiment (these are really not your Friends, except if they already are), I believe the situation with the telecommuting is more complex. I have been telecommuting for the past eight years (or so, yikes, the time fly!) and I do like it most of the time. However, it really requires special type of personality, special type of environment, special type of family, and special type of work to be able to do it well. I know plenty of people who do well working from home (with occasional stay in the coworking office) and some who just don’t. It has nothing to do with IQ or anything like that. Just for some people it works, and I have some colleagues who left Red Hat just because they cannot work from home and the nearest Red Hat office was just too far from them.
However, this trivial statement makes me think again about stuff which is much more profound in my opinion. I am a firm believer in the coming of what Alvin and Heidi Toffler called “The Third Wave”. That after the mainly agricultural and mainly industrial societies the world is changing, so that “much that once was is lost” and we don’t know exactly what is coming. One part of this change is substantial change in the way we organize our work. It really sounds weird but there were times when there were no factories, no offices, and most people were working from their homes. I am not saying that the future will be like the distant past, it never is, but the difference makes it clear to me that what is now is not the only possible world we could live in.
I believe that the standard of people leaving their home in the morning to work will be in future very very diminished. Probably some parts of the industrial world will remain around us (after all, there are still big parts of the agricultural world around us), but I think it might have the same impact (or so little impact) as the agricultural world has on the current world. If the trend of the offices dissolution will continue (and I don’t see the reason why it wouldn’t, in the end all those office buildings and commuting is terrible waste of money) we can expect really massive change in almost everything: ways we build homes (suddenly your home is not just the bedroom to survive night between two workshifts), transportation, ways we organize our communities (suddenly it does matter who is your neighbor), and of course a lot of social rules will have to change. I think we are absolutely not-prepared for this and also we are not talking about this enough. But we should.
https://luther.ceplovi.cz/blog/2014/12/19/third-wave-and-telecommuting/
|
|
Mozilla Reps Community: Reps Weekly Call – December 18th 2014 |
Last Thursday we had our regular weekly call about the Reps program, where we talk about what’s going on in the program and what Reps have been doing during the last week.

Note: Due holiday dates, next weekly call will be January 8.
Don’t forget to comment about this call on Discourse and we hope to see you next year!
https://blog.mozilla.org/mozillareps/2014/12/19/reps-weekly-call-december-18th-2014/
|
|
Henrik Skupin: Firefox Automation report – week 45/46 2014 |
In this post you can find an overview about the work happened in the Firefox Automation team during week 45 and 46.
In our Mozmill-CI environment we had a couple of frozen Windows machines, which were running with 100% CPU load and 0MB of memory used. Those values came from the vSphere client, and didn’t give us that much information. Henrik checked the affected machines after a reboot, and none of them had any suspicious entries in the event viewer either. But he noticed that most of our VMs were running a very outdated version of the VMware tools. So he upgraded all of them, and activated the automatic install during a reboot. Since then the problem is gone. If you see something similar for your virtual machines, make sure to check that used version!
Further work has been done for Mozmill CI. So were finally able to get rid of all the traces for Firefox 24.0ESR since it is no longer supported. Further we also setup our new Ubuntu 14.04 (LTS) machines in staging and production, which will soon replace the old Ubuntu 12.04 (LTS) machines. A list of the changes can be found here.
Beside all that Henrik has started to work on the next Jenkins v1.580.1 (LTS) version bump for the new and more stable release of Jenkins. Lots of work might be necessary here.
For more granular updates of each individual team member please visit our weekly team etherpad for week 45 and week 46.
If you are interested in further details and discussions you might also want to have a look at the meeting agenda, the video recording, and notes from the Firefox Automation meetings of week 45 and week 46.
http://www.hskupin.info/2014/12/19/firefox-automation-report-week-45-46-2014/
|
|
Adam Okoye: OPW Week Two – Coming to a Close |
Ok so technically it’s the first full week because OPW started last Tuesday December 9th, but either way – my first almost two weeks of OPW are coming to a close. My experience has been really good so far and I think I’m starting to find my groove in terms of how and where I work best location wised. I also think I’ve been pretty productive considering this is the first internship or job I’ve had (not counting the Ascend Project) in over 5 years.
So far I’ve resolved three bugs (some of which were actually feature requests) and have a fourth pull request waiting. I’ve been working entirely in Django so far primarily editing model and template files. One of the really nice things that I’ve gotten out of my project is learning while and via working on bugs/features.
Four weeks ago I hadn’t done any work with Django and realized that it would likely behoove me to dive into some tutorials (originally my OPW project with Input was going to be primarily in JavaScript but in reality doing things in Python and Django makes a lot more sense and thus the switch despite the fact that I’m still working with Input). I started a three or four basic tutorials and completed one and a half of them – in short, I didn’t have a whole lot of experience with Django ten days ago. Despite that. all of the the looking through and editing of files that I’ve done has really improved my skills both in terms of syntax and also in terms of being able to find information – both where to take information from and also where to put it. I look forward to all of the new things that I will learn and put in to practice.
http://www.adamokoye.com/2014/12/opw-week-two-coming-to-a-close/
|
|
Mozilla Fundraising: A/B Testing: ‘Sequential form’ vs ‘Simple PayPal’ |
https://fundraising.mozilla.org/ab-testing-sequential-form-vs-simple-paypal/
|
|
Dietrich Ayala: Remixable Quilts for the Web |
Atul Varma set up a quilt for MozCamp Asia 2012 which I thought was a fantastic tool for that type of event. It provided an engaging visualization, was collaboratively created, and allowed a quick and easy way to dive further into the details about the participating groups.
 I wanted to use it for a couple of projects, but the code was tied pretty closely to that specific content and layout.
I wanted to use it for a couple of projects, but the code was tied pretty closely to that specific content and layout.
This week I finally got around to moving the code over to Mozilla Webmaker, so it could be easily copied and remixed. I made a couple of changes:
The JS code is still a bit too complex for what’s needed, but it works on Webmaker now!

View my demo quilt. Hit the “remix” button to clone it and make your own.
The source for the core JS and CSS is at https://github.com/autonome/quilt.

https://autonome.wordpress.com/2014/12/18/remixable-quilts-for-the-web/
|
|






