Mike Conley: DocShell in a Nutshell – Part 3: Maturation (2005 – 2010) |
First off, an apology. I’ve fallen behind on these posts, and that’s not good – the iron has cooled, and I was taught to strike it while it was hot. I was hit with classic blogcrastination.
Secondly, another apology – I made a few errors in my last post, and I’d like to correct them:
I’ve altered my last post to contain the above information, along with details on what I found in the time of that commit to Travis’s first landing. Maybe go back and give that a quick skim while I wait. Look for the string “correction” to see what I’ve changed.
I also got some confirmation from Travis himself over Twitter regarding my last post:
@mike_conley Looks like general right flow as far as 14 years ago memory can aid.
Many context points surround…
@mike_conley 1) At that time, Mozilla was still largely in walls of Netscape, so many reviews/ alignment happened in person vs public docs.
@mike_conley 2) XPCOM ideas were new and many parts of system were straddling C++ objects and Interface models.
@mike_conley 3) XUL was also new and boundaries of what rendering belonged in browser shell vs. general rendering we’re [sic] being defined.
@mike_conley 4) JS access to XPCOM was also new driving rethinking of JS control vs embedding control.
@mike_conley There was a massive unwinding of the monolith and (re)defining of what it meant to build a browser inside a rendered chrome.
It’s cool to hear from the guy who really got the ball rolling here. The web is wonderful!
Finally, one last apology – this is a long-ass blog post. I’ve been working on it off and on for about 3 months, and it’s gotten pretty massive. Strap yourself into whatever chair you’re near, grab a thermos, cancel any appointments, and flip on your answering machine. This is going to be a long ride.

Oh come on, it’s not that bad, right? … right?
OK, let’s get back down to it. Where were we?
Ah, yes – 2005 had just started. This was just a few weeks after a community driven effort put a full-page ad for Firefox in the New York Times. Only a month earlier, a New York Times article highlighted Firefox, and how it was starting to eat into Internet Explorer’s market share.
So what was going on in DocShell? Here are the bits I found most interesting. They’re kinda few and far between, since DocShell appears to have stabilized quite a bit by now. Mostly tiny bugfixes are landed, with the occasional interesting blip showing up. I guess this is a sign of a “mature” section of the codebase.
I found this commit on January 11th, 2005 pretty interesting. This patch fixes bug 103638 (and bug 273699 while it’s at it). What was going on was that if you had two Firefox windows open, both with ’s, where two
One of those new checks involved adding a new static function called CanAccessItem to nsDocShell.cpp, and having FindItemWithName (an nsDocShell instance method used to find some child nsIDocShellTreeItem with a particular name) take a new parameter of the “original requestor”, and ensuring that whichever nsIDocShellTreeItem we eventually landed on with the name that was requested passes the CanAccessItem test with the original requestor.
There are two commits, one on January 20th, 2005, and one on January 30th, 2005, both of which fix different bugs, but are interrelated and I want to talk about them for a second.
The first commit, for bug 277224, fixes a problem where if we change location to an anchor located within a document within a
http://mikeconley.ca/blog/2015/01/03/docshell-in-a-nutshell-part-3-maturation-2005-2010/
|
|
Gervase Markham: Test Driven Discouragement |
Some projects go even further, requiring that a new test accompany every bugfix or new feature. Whether this is a good idea or not depends on many factors: the nature of the software, the makeup of the development team, and the difficulty of writing new tests. The CVS (http://www.cvshome.org/) project has long had such a rule. It is a good policy in theory, since CVS is version control software and therefore very risk-averse about the possibility of munging or mishandling the user’s data. The problem in practice is that CVS’s regression test suite is a single huge shell script (amusingly named sanity.sh), hard to read and hard to modify or extend. The difficulty of adding new tests, combined with the requirement that patches be accompanied by new tests, means that CVS effectively discourages patches. When I used to work on CVS, I sometimes saw people start on and even complete a patch to CVS’s own code, but give up when told of the requirement to add a new test to sanity.sh.
It is normal to spend more time writing a new regression test than on fixing the original bug. But CVS carried this phenomenon to an extreme: one might spend hours trying to design one’s test properly, and still get it wrong, because there are just too many unpredictable complexities involved in changing a 35,000-line Bourne shell script. Even longtime CVS developers often grumbled when they had to add a new test. … It is true that switching to a real test framework—whether custom-built or off-the-shelf—would have been a major effort. But neglecting to do so has cost the project much more, over the years. How many bugfixes and new features are not in CVS today, because of the impediment of an awkward test suite?
— Karl Fogel, Producing Open Source Software
http://feedproxy.google.com/~r/HackingForChrist/~3/s30O2RG9DKg/
|
|
Francesco Lodolo: 2014 – My Q4 [:flod] |
 One of my many resolutions for 2015 is to blog more, both here in English and on my Italian blog, which just turned 10 last September.
One of my many resolutions for 2015 is to blog more, both here in English and on my Italian blog, which just turned 10 last September.
I probably spent most of my last quarter working on mozilla.org updates. My job, together with Pascal, consists in checking new pages for localizability issues at an early stage, extracting strings in .lang files, exposing them to localizers and pushing content to production. Luckily, on the other side there’s a wonderful team of people who help us making sure that localization is always treated as a first class citizen.
The new home page design went live in October, localized in 33 languages on day one (57 as I write this post). That’s a huge accomplishment.
Ignoring smaller updates, this quarter we also had the new Firefox for Android page (42 languages), the redesigned Get Involved page (25 languages, with some bumps on the road), and the new Firefox Developer Edition landing page (34 languages).
And then this tiny thing called #fx10 happened.
This was an interesting and exhausting experience. For example in order to localize the UI Tour (“Privacy Tour”) for 33.1 I had to manage communications with 26 teams using direct emails. And then organize the localization of subtitles for this video (I’ll talk about this in a separate post, long story). Everything trying to disclose as little information as possible to the public before the launch and avoid spoiling the surprise.
To give some numbers: we usually ask for 2/3 weeks for small localization projects, at least 4 weeks for bigger projects that require work from all ~90 locales supported across platforms (last case was Australis launch).
In this case the longest deadline was 3 weeks (privacy tour), most of the material became available 2 weeks from launch, with some edge cases (48 hours), a lot of changes, unplanned material and averted crises (huge shout-out to Erin Lancaster for coordinating so many teams and initiatives).
Size of the work requested to localizers: a rough estimate varies from a minimum of about 140 strings/1000 words, to about 330 strings/3000 words for bigger locales.
To track the localization status of web parts we rely on three different tools:
These are some of the improvements introduced in the last quarter.
I added support for a raw file type, currently used for text files. Unlike .lang file, where we can determine the exact status of localization (translated strings, missing, errors, etc.), we can only do minimal checks for this kind of files: does the file exist in locale X? Is it mandatory or optional? Was it updated before or after the last reference update? The main usage for this is to track localization of autoresponders for the new Get Involved page.
Also added command line scripts to import strings in .lang files using Transvision API, and improved the code detecting errors in translations (e.g. missing Python variables).
Besides displaying information about raw files, I focused on improving a very useful feature added last summer by our intern Th'eo, called “Project View”. Basically we can display on a single page the status of several files scattered across different repositories (example) and share it with other teams.
I didn’t have much time to work on Transvision this quarter, but I managed to land a change that I consider really important: now the list of supported products and supported locales for each product is fetched from an external source. The practical result is that we don’t have to release a new version of Transvision to support Gaia version X or add a new locale on Aurora, reducing the time necessary to deploy these changes from weeks or months (new manual release) to less than 24 hours (automated cronjob).
I also worked on a view to display “unchanged strings” (i.e. strings identical to English), and some small refactor/clean-up changes.
One my goals for next quarter is to figure out with other team members a plan/schedule to release more often.
Part of my job is also to take care of productization (p12n), which means landing settings for new locales, as well as organizing mass updates (e.g. switching Wikipedia to SLL) and making sure that we don’t ship anything broken.
Last quarter I did a complete rewrite of the tool I use to extract information from all repositories. The original code was never meant to be shared; for example I realized how counter-intuitive the data structure was only after trying to explain it to another person. It’s still clumsy Python code written by someone who never saw Python until two years ago, but now with tests ![]()
The same tool is at the base of this view on Transvision, or images like this one (all searchplugin images we’re shipping on Firefox Beta across locales).

As part of my daily job I also check all strings landing on master/trunk branches for Gaia, Firefox and Firefox for Android, and file bugs for any localizability issues. Some interesting things happened there (e.g. the new search UI), but that’s a discussion probably worth a different post (and more thinking on my side).
I also briefly helped Mozilla Foundation organizing the localization process of the EOY fundraising campaign. I really hope we’ll manage to organize this better next year, and involve localization teams in the process if they have resources to help.
http://www.yetanothertechblog.com/2015/01/03/2014-my-q4-flod/
|
|
Liz Henry: Running mochitests for Firefox |
I’m experimenting with automated testing for Firefox and figured it may be useful to record what I learned. I had a look at the Mochitest page on MDN as well as the main page on Automated testing at Mozilla. It is hard to know how to even begin to explain this. Mochitests are a huge ball of tests for Firefox. They run every time a change is pushed to mozilla-central, which is the sort of tip of the current state of our code and is used every day to build the Nightly version of Firefox. They’re run automatically for changes on other code repositories too. And, you can run them locally on your own version of Firefox.
This is going to have ridiculous levels of detail and jargon. Warning!
The first thing to do is to download the current code from mozilla-central and build it on my laptop. Here are the Firefox build instructions!
As usual I need to do several other things before I can do those things. This means hours of twiddling around on the command line, installing things, trying different configurations, fixing directory permissions and so on. Here are a few of the sometimes non-trivial things I ended up doing:
* updated Xcode and command line tools
* ran brew doctor and brew update, fixed all errors with much help from Stack Overflow, ended up doing a hard reset of brew
* Also, if you need to install a specific version of a utility, for example, autoconf: brew tap homebrew/versions; brew install autoconf213
* re-installed mercurial and git since they were screwed up somehow from a move from one Mac to another
* tried two different sample .mozconfig files, read through other Mac build config files, several layers deep (very confusing)
* updating my Firefox mozilla-central directory (hg pull -u)
* filed a bug for a build error and fixed some minor points on MDN
The build takes around an hour the first time. After that, pulling the changes from mozilla-central and reticulating the splines takes much less time.

Now I’m to the point where I can have a little routine every morning:
* brew doctor
* brew upgrade
* cd mozilla-central, hg pull -u
* ./mach build
Then I’m set up to run tests. Running all the mochitest-plain tests takes a long time. Running a single test may fail because it has dependencies on other tests it expects to have run first. You can also run all the tests in a particular directory, which may work out better than single tests.
Here is an example of running a single test.
./mach mochitest-browser browser/base/content/test/general/browser_aboutHome.js
Your Nightly or Nightly-debug browser will open and run through some tests. There will be a ton of output. Nifty.
Here is that same test, run with e10s enabled.
./mach mochitest-browser —e10s browser/base/content/test/general/browser_aboutHome.js
BTW if you add “2>&1 | tee -a test.log” to those commands they will pipe the output into a log file.
Back to testing. I poked around to see if I could find a super easy to understand test. The first few, I read through the test code, the associated bugs, and some other stuff. A bit overwhelming. My coworker Juan and I then talked to Joel Maher who walked us through some of the details of how mochitests work and are organized. The tests are scattered throughout the “tree” of directories in the code repository. It is useful generally to use DXR to search but I also ended up just bouncing around and getting familiar with some of the structure of where things are. For example, scarily, I now know my way to testing/mochitest/tests/SimpleTest/. Just by trying different things and looking around you start to get familiar.
Meanwhile, my goal was still to find something easy enough to grasp in an afternoon and run through as much of the process to fix a simple bug as I could manage. I looked around for tests that are known not to work under e10s, and are marked in manifest files that they should be skipped if you’re testing with e10s on. I tried turning some of these tests on and off and reading through their bugs.
Also meanwhile I asked for commit access level 1 (for the try server) so when I start changing and fixing things I can at least throw them at a remote test server as well as my own local environment’s tests.
Then, hurray, Joel lobbed me a very easy test bug.
From reading his description and looking at the html file it links to, I got that I could try this test, but it might not fail. The failure was caused by god knows what other test. Here is how to try it on its own:
./mach mochitest-chrome browser/devtools/webide/test/test_zoom.html
I could see the test open up Nightly-debug and then try to zoom in and out. Joel had also described how the test opens a window, zooms, closes the window, then opens another window, zooms, but doesn’t close. I have not really looked at any JavaScript for several years and it was never my bag. But I can fake it. Hurray, this really is the simplest possible example. Not like the 600-line things I was ending up in at random. Danny looked at the test with me and walked through the JavaScript a bit. If you look at the test file, it is first loading up the SimpleTest harness and some other stuff. I did not really read through the other stuff. *handwave* Then in the main script, it says that when the window is loaded, first off wait till we really know SimpleTest is done because the script tells us so (Maybe in opposition to something like timing out.) Then a function opens the WebIDE interface, and (this is the main bit Danny explained) the viewer= winQuerInterface etc. bit is an object that shows you the state of the viewer. *more handwaving, I do not need to know* More handwaving about “yield” but I get the idea it is giving control over partly to the test window and partly keeping it. Then it zooms in a few times, then this bit is actually the meat of the test:
is(roundZoom, 0.6, "Reach min zoom");
Which is calling the “is” function in SimpleTest.js, Which I had already been reading, and so going back to it to think about what “is” was doing was useful. Way back several paragraphs ago I mentioned looking in testing/mochitest/tests/SimpleTest/. That is where this function lives. I also felt I did not entirely need to know the details of what the min and max zoom should be. Then, we close the window. Then open a new one. Now we see the other point of this test. We are checking to see that when you open a WebIDE window, then zoom to some zoomy state, then close the window, then re-open it, it should stay zoomed in or out to the state you left it in.
OK, now at this point I need to generate a patch with my tiny one line change. I went back to MDN to check how to do this in whatever way is Mozilla style. Ended up at How to Submit a Patch, then at How can I generate a patch for somebody else to check in for me?, and then messing about with mq which is I guess like Quilt. (Quilt is a nice name, but, welcome to hell.) I ended up feeling somewhat unnerved by mq and unsure of what it was doing. mq, or qnew, did not offer me a way to put a commit message onto my patch. After a lot of googling… not sure where I even found the answer to this, but after popping and then re-pushing and flailing some more, and my boyfriend watching over my shoulder and screeching “You’re going to RUIN IT ALL” (and desperately quoting Kent Beck at me) as I threatened to hand-edit the patch file, here is how I added a commit message:
hg qrefresh -m "Bug 1116802: closes the WebIDE a second time"
Should I keep using mq? Why add another layer into mercurial? Worth it?
To make sure my patch didn’t cause something shocking to happen (It was just one line and very simple, but, famous last words….) I ran the chrome tests that were in the same directory as my buggy test. (Piping the output into a log file and then looked for anything that mentioned test_zoom. ) The test output is a study in itself but not my focus right now as long as nothing says FAIL.
./mach mochitest-chrome browser/devtools/webide/test/
Then I exported the patch still using mq commands which I cannot feel entirely sure of.
hg export qtip > ~/bug-1116802-fix.patch
That looked fine and, yay, had my commit message. I attached it to the bug and asked Joel to have a look.
I still don’t have a way to make the test fail but it seems logical you would want to close the window.
That is a lot of setup to get to the point where I could make a useful one line change in a file! I feel very satisfied that I got to that point.
Only 30,000 more tests to go, many of which are probably out of date. As I contemplate the giant mass of tests I wonder how many of them are useful and what the maintenance cost is and how to ever keep up or straighten them out. It’s very interesting!
You can have a look at the complicated nature of the automated tests that run constantly to test Firefox at treeherder. For any batch of commits merged into mozilla-central, huge numbers of tests run on many different platforms. If you look at treeherder you can see a little (hopefully green) “dt” among the tests. I think that the zooming in WebIDE test that I just described is in the dt batch of tests (but I am not sure yet).
I hope describing the process of learning about this small part of Firefox’s test framework is useful to someone! I have always felt that I missed out by not having a college level background in CS or deep expertise in any particular language. And yet I have still been a developer on and off for the last 20 years and can jump back into the pool and figure stuff out. No genius badge necessary. I hope you can see that actually writing code is only one part of working in this kind of huge, collaborative environment. The main skill you need (like I keep saying) is the ability not to freak out about what you don’t know, and keep on playing around, while reading and learning and talking with people.
|
|
Manish Goregaokar: Mozlandia! |
http://inpursuitoflaziness.blogspot.com/2015/01/mozlandia.html
|
|
Aaron Klotz: Asynchronous Plugin Initialization: Nightly |
As of today’s Nightly, Asyncrhonous Plugin
Initialization is available for testing. It is deactivated by default, so in
order to try it out you will need to navigate to about:config and toggle the
dom.ipc.plugins.asyncInit preference to true.
If you experience any problems, please file a bug that blocks bug 1116806.
Happy New Year!
http://dblohm7.ca/blog/2014/12/31/asynchronous-plugin-initialization-nightly/
|
|
Will Kahn-Greene: Input: 2014 retrospective |
2014 was a big year for Input. This is the year we hit a point where the project is mature and stable. This is the year we worked on making it easier for new people to start working on Input. This is the year we fixed all the issues that made it difficult for Input to support multiple products. This is the year we created an API that allowed anyone to access the data to let them write their own dashboards. This is the year we implemented a translation infrastructure so that non-English feedback can flow through our tools (previously, it was handled manually). It was a big year.
Let's look at some Bugzilla and git stats for the year:
Year 2014 (2014-01-01 -> 2014-12-31)
====================================
Bugzilla
========
Bugs created: 277
Creators:
Will Kahn-Greene [:willkg] : 240
[:Cww] : 8
Ricky Rosario [:rrosario, :r1c : 4
Swarnava Sengupta (:Swarnava) : 3
Nicolas Perriault (:NiKo`) — n : 1
vivek :) : 1
Trif Andrei-Alin[:AlinT] : 1
Kohei Yoshino [:kohei] : 1
t.schmittlauch+persona : 1
Mike "Pomax" Kamermans [:pomax : 1
Mark Filipak : 1
Matt Grimes [:Matt_G] : 1
Padraic Harley [:thelodger] : 1
deshrajdry : 1
Matt Brubeck (:mbrubeck) : 1
Christian Corrodi : 1
phaneendra.chiruvella : 1
vivek.kiran : 1
lgp171188 : 1
me : 1
Matthew N. [:MattN] : 1
David Weir (satdav) : 1
Hal Wine [:hwine] (use needinf : 1
Ian Kronquist (:muricula) : 1
EventHorizon : 1
Laura Thomson :laura : 1
Bugs resolved: 245
: 1
WONTFIX : 17
WORKSFORME : 8
DUPLICATE : 13
FIXED : 206
Tracebacks : 9
Research : 5
Tracker : 11
Research bugs: 5
788597: [research] Should we use a stacked graph on the dashboard?
792976: [research] swap jingo-minify for django-compressor and
django-jingo-offline-compressor
889370: [research] morelikethis for feedback responses
990774: [research] Investigate database schema changes for easier
extensibility
1048459: [research] check if updating from a tarball in a virtual
environment with peep removes files
Tracker bugs: 11
963275: [tracker] support Metro
964260: [tracker] overhaul mobile and desktop feedback forms
965791: [tracker] implement product table
966425: [tracker] create analyzer search view
985645: [tracker] Upgrade to Django 1.6
988612: [tracker] product dashboards
1040773: [tracker] dashboards for everyone
1042669: [tracker] reduce contributor pain
1052459: [tracker] heartbeat v1
1062429: [tracker] integrate spicedham classifier
1081412: [tracker] add tests for fjord_utils.js functions
Resolvers: 14
Will Kahn-Greene [:willkg] : 209
lgp171188 : 7
aokoye : 7
Ian Kronquist (:muricula) : 5
Ricky Rosario [:rrosario, :r1c : 4
Joshua Smith [:joshua-s] : 3
Swarnava Sengupta (:Swarnava) : 2
Rehan Dalal [:rehan, :rdalal] : 2
Ruben Vereecken : 1
Rob : 1
cww : 1
Schalk Neethling [:espressive] : 1
bhargav.kowshik : 1
Anna : 1
Commenters: 65
willkg : 1261
rrosario : 19
mgrimes : 17
cww : 14
MattN+bmo : 11
mcooper : 11
thewanuki : 7
aokoye : 7
swarnavasengupta : 7
padraic : 6
iankronquist : 6
MarkFilipak.mozilla : 5
nicolas.barbulesco : 5
schalk.neethling.bugs : 5
hwine : 4
rdalal : 4
lgp171188 : 4
stephen.donner : 4
educmale : 4
anthony : 4
mbrubeck : 4
ms.annaphilips : 4
nigelbabu : 3
rdaub : 3
me+bugzilla : 3
pomax : 3
deshrajdry : 3
bhargav.kowshik : 3
rubenvereecken : 3
rrayborn : 3
rajul.iitkgp : 2
kbrosnan : 2
christian : 2
glind : 2
peterbe : 2
hcondei : 2
david.weir : 2
dron.rathore : 1
pradeeppaddy : 1
tdowner : 1
margaret.leibovic : 1
aaron.train : 1
scottstensland : 1
senicar : 1
phaneendra.chiruvella : 1
trifandreialin : 1
jesse : 1
t.schmittlauch+persona : 1
viveknjadhav19 : 1
mozaakash : 1
me : 1
glob : 1
cturra : 1
nperriault : 1
rmcguigan : 1
vivek.kiran : 1
kdurant35rules : 1
vega.james : 1
fbraun : 1
326374 : 1
vivekb.balakrishnan : 1
mhoye : 1
mluna : 1
feer56 : 1
lorenzo567 : 1
git
===
Total commits: 651
Will Kahn-Greene : 561 (+243270, -205399, files 2746)
L. Guruprasad : 23 (+406, -78, files 33)
Adam Okoye : 22 (+213, -67, files 66)
Ian Kronquist : 12 (+402, -106, files 21)
Ricky Rosario : 10 (+165, -350, files 30)
ossreleasefeed : 3 (+197, -42, files 9)
Bhargav Kowshik : 3 (+114, -2, files 11)
Joshua Smith : 3 (+91, -36, files 10)
Anna Philips : 2 (+734, -6, files 24)
Ruben Vereecken : 2 (+69, -29, files 12)
Gregg Lind : 2 (+18, -16, files 6)
Deshraj Yadav : 2 (+2, -2, files 2)
Swarnava Sengupta : 2 (+2, -2, files 2)
Rehan Dalal : 2 (+315, -169, files 13)
aokoye : 2 (+42, -8, files 4)
Total lines added: 246040
Total lines deleted: 206312
Total files changed: 2989
Everyone
========
326374
aaron.train
Adam Okoye
Anna
Anna Philips
anthony
Bhargav Kowshik
christian
Christian Corrodi
cturra
cww
David Weir
Deshraj Yadav
deshrajdry
dron.rathore
educmale
EventHorizon
fbraun
feer56
glob
Gregg Lind
Hal Wine
hcondei
Ian Kronquist
jesse
Joshua Smith
kbrosnan
kdurant35rules
Kohei Yoshino [:kohei]
L. Guruprasad
Laura Thomson :laura
lorenzo567
margaret.leibovic
Mark Filipak
Matt Brubeck (:mbrubeck)
Matt Grimes
Matthew N. [:MattN]
Mike Cooper
me
me+bugzilla
mhoye
Mike "Pomax" Kamermans [:pomax]
mluna
mozaakash
ms.annaphilips
Nicolas Perriault
nicolas.barbulesco
nigelbabu
Padraic Harley [:thelodger]
peterbe
phaneendra.chiruvella
pomax
pradeeppaddy
rajul.iitkgp
Ralph Daub
Rehan Dalal
Ricky Rosario
rmcguigan
Rob
Robert Rayborn
Ruben Vereecken
Schalk Neethling
scottstensland
senicar
Stephen Donner
Swarnava Sengupta
t.schmittlauch+persona
Tyler Downer
thewanuki
Trif Andrei-Alin
vega.james
vivek.kiran
vivekb.balakrishnan
viveknjadhav19
Will Kahn-Greene
Some observations:
In 2013, we resolved more bugs than we created partially because we closed a bunch of bugs related to the old Input that weren't relevant anymore.
In 2014, we created more bugs than we closed by 10%. I think that's about what we want.
15 people had git commits. 26 people created bugs. 14 people resolved bugs. 65 people commented on bugs.
One thing I don't have is counts for who helped translate strings which is a really important part of development. My apologies.
Of all those people, only 1 is a "core developer"--that's me. Everyone else contributed their time and energies towards making Input better. I really appreciate that. Thank you!
That's the stats!
Things we did in 2014:
Site health dashboard: I wrote a site health dashboard that helps me understand how the site is performing before and after deployments as well as after releases and other events.
Client side smoke tests: I wrote smoke tests for the client side. I based it on the defunct input-tests code that QA was maintaining up until we rewrote Input. The smoke tests have been invaluable for reducing/eliminating data-loss bugs.
Vagrant: I took some inspiration from Erik Rose and DXR and wrote a Vagrant provisioning shell script. This includes a docs overhaul as well.
Automated translation system (human and machine): I wrote an automated translation system. It's generalized so that it isn't model/field specific. It's also generalized so that we can add plugins for other translation systems. It's currently got plugins for Dennis, Gengo machine translation and Gengo human translation. We're machine translating most incoming feedback. We're human translating Firefox OS feedback. This was a HUGE project, but it's been immensely valuable.
Better query syntax: We were upgraded to Elasticsearch 0.90.10. I switched the query syntax for the dashboard search field to use Elasticsearch simple_query_string. That allows users to express search queries they weren't previously able to express.
utm_source and utm_campaign handling: I finished the support for handling utm_source and utm_campaign querystring parameters. This allows us to differentiate between organic feedback and non-organic feedback.
More like this: I added a "more like this" section to the response view. This makes it possible for UA analyzers to look at a response and see other responses that are similar.
Dashboards for everyone: We wrote an API and some compelling examples of dashboards you can build using the API. It's being used in a few places now. We'll grow it going forward as needs arise. I'm pretty psyched about this since it makes it possible for people with needs to help themselves and not have to wait for me to get around to their work.
Dashboards for everyone project plan.
Vagrant: We took the work I did last quarter and improved upon it, rewrote the docs and have a decent Vagrant setup now. L. Guruprasad improved on this and the documentation and setting up a Vagrant-based vm for Input development is much easier.
Reduce contributor pain project plan.
Abuse detection: Ian spent his internship working on an abuse classifier so that we can more proactively detect and prevent abusive feedback from littering Input. We gathered some interesting data and the next step is probably to change the approach we used and apply some more complex ML things to the problem. The key here is that we want to detect abuse with confidence and not accidentally catch swaths of non-abuse. Input feedback has some peculiar properties that make this difficult.
Reduce the abuse project plan.
Loop support: Loop is now using Input for user sentiment feedback.
Heartbeat support: User Advocacy is working on a project to give us a better baseline for user sentiment. This project was titled Heartbeat, but I'm not sure whether that'll change or not. Regardless, we added support for the initial prototype.
Data retention policy: We've been talking about a data retention policy for some time. We decided on one, finalized it and codified it in code.
Shed the last vestiges of Playdoh and funfactory: We shed the last bits of Playdoh and funfactory. Input uses the same protections and security decisions those two projects enforced, but without being tied to some of the infrastructure decisions. This made it easier to switch to peep-based requirements management.
Switched to FactoryBoy and overhauled tests: Tests run pretty fast in Fjord now. We switched to FactoryBoy, so writing model-based tests is a lot easier than the stuff we had before.
Python 2.7: Input is now running on Python 2.7. Thank you, Jake!
Remote troubleshooting data capture: The generic feedback form which is hosted on Input now has a section allowing users to opt-in to sending data about their browser along with their feedback. This data is crucial to helping us suss out problems with video playback, graphics cards/drivers and malicious addons.
This code is still "alpha". We'll be finishing it up in 2015q1.
Remote troubleshooting data capture project plan.
Heartbeat v1 and v2: People leave feedback on Input primarily when they're frustrated with something. Because of this, the sentiment numbers we get on Input tilt heavily negative and only represent people who are frustrated and were able to find the feedback form. Heartbeat will give us sentiment data that's more representative of our entire user base.
As a stop-gap to get the project going, Input is the backend collecting all the Heartbeat data. We rewrote the Heartbeat-related code for Heartbeat v2 in 2014q4.
Feedback form overhaul: We rewrote the feedback form to clean up the text, reduce confusion about what data is made public and what data is kept private, reduce the number of steps to leave feedback and improve the form for both desktop and mobile devices.
Feedback form overhaul project plan.
We also fixed the form so it supports multiple products because we're collecting feedback for multiple products on Input now.
Looking at the stats above, it's pretty clear that this is predominantly a one-person project. Ricky, Mike and Rehan do all my code review. Without them, things would be a lot worse.
Having said that, the "baby-factor" stinks on this project. That's something I'm going to work on over 2015:
Input is a great little Django application that collects feedback for Mozilla products. It's an important part of the Mozilla product ecosystem. Working on it helps millions of people. If you're interested in being a part of the team that develops it, here are some helpful links:
|
|
Will Kahn-Greene: Input: 2014q4 quarter in review |
2014q4 was interesting. Between the faux all-hands, holidays and production freezes, it was essentially a two-month quarter. I literally raced through the quarter getting things done as quickly as I could do them opting for the minimal viable implementation wherever possible. That's not a great thing, but so it goes.
Things to know:
I rewrote my script and the data is richer now.
Quarter 2014q4 (2014-10-01 -> 2014-12-31)
=========================================
Bugzilla
========
Bugs created: 95
Creators:
Will Kahn-Greene [:willkg] : 85
me : 1
Nicolas Perriault (:NiKo`) — n : 1
David Weir (satdav) : 1
Mark Filipak : 1
vivek :) : 1
Laura Thomson :laura : 1
Swarnava Sengupta (:Swarnava) : 1
[:Cww] : 1
deshrajdry : 1
phaneendra.chiruvella : 1
Bugs resolved: 89
WONTFIX : 13
WORKSFORME : 4
DUPLICATE : 5
FIXED : 67
Tracebacks : 1
Research : 4
Tracker : 7
Research bugs: 4
788597: [research] Should we use a stacked graph on the dashboard?
792976: [research] swap jingo-minify for django-compressor and
django-jingo-offline-compressor
889370: [research] morelikethis for feedback responses
1048459: [research] check if updating from a tarball in a virtual
environment with peep removes files
Tracker bugs: 7
964260: [tracker] overhaul mobile and desktop feedback forms
985645: [tracker] Upgrade to Django 1.6
988612: [tracker] product dashboards
1040773: [tracker] dashboards for everyone
1042669: [tracker] reduce contributor pain
1052459: [tracker] heartbeat v1
1081412: [tracker] add tests for fjord_utils.js functions
Resolvers: 7
Will Kahn-Greene [:willkg] : 75
aokoye : 7
lgp171188 : 4
cww : 1
bhargav.kowshik : 1
Rehan Dalal [:rehan, :rdalal] : 1
Commenters: 27
willkg : 420
aokoye : 7
mcooper : 6
padraic : 6
MarkFilipak.mozilla : 5
hwine : 4
rdalal : 4
stephen.donner : 4
nigelbabu : 3
deshrajdry : 3
bhargav.kowshik : 3
david.weir : 2
mgrimes : 2
dron.rathore : 1
lorenzo567 : 1
senicar : 1
viveknjadhav19 : 1
nperriault : 1
cww : 1
swarnavasengupta : 1
mozaakash : 1
me+bugzilla : 1
phaneendra.chiruvella : 1
me : 1
fbraun : 1
vivekb.balakrishnan : 1
rrosario : 1
git
===
Total commits: 239
Will Kahn-Greene : 191 (+27879, -10550, files 822)
Adam Okoye : 24 (+255, -75, files 70)
L. Guruprasad : 17 (+390, -42, files 27)
Bhargav Kowshik : 3 (+114, -2, files 11)
Gregg Lind : 2 (+18, -16, files 6)
Deshraj Yadav : 2 (+2, -2, files 2)
Total lines added: 28658
Total lines deleted: 10687
Total files changed: 938
Everyone
========
Adam Okoye
Bhargav Kowshik
cww
David Weir
Deshraj Yadav
deshrajdry
dron.rathore
fbraun
Gregg Lind
hwine
L. Guruprasad
Laura Thomson :laura
lorenzo567
Mark Filipak
mcooper
me
me+bugzilla
mgrimes
mozaakash
Nicolas Perriault (:NiKo`) — needinfo me if you need my attention
nigelbabu
nperriault
padraic
phaneendra.chiruvella
Rehan Dalal
rrosario
senicar
stephen.donner
Swarnava Sengupta
vivekb.balakrishnan
viveknjadhav19
Will Kahn-Greene
Code line counts:
2014q1: April 1st, 2014: 15195 total 6953 Python 2014q2: July 1st, 2014: 20456 total 9247 Python 2014q3: October 7th. 2014: 23466 total 11614 Python 2014q4: December 31st, 2014: 30158 total 13615 Python
Nothing wildly interesting there other than noting that the codebase for Input continues to grow.
Adam Okoye started as an intern through OPW on December 9th. He's contributed to Input in the past through the Ascend project. Over the course of the OPW internship, he'll be working on Input bugs and the Thank you page project.
L. Guruprasad spent a lot of time working on pre-commit linters, Vagrant provisioning and generally improving the experience contributors will have.
We had a few commits from other people, too.
Thank you everyone who contributed!
Python 2.7: Input is now running on Python 2.7. Thank you, Jake!
Remote troubleshooting data capture: The generic feedback form which is hosted on Input now has a section allowing users to opt-in to sending data about their browser along with their feedback. This data is crucial to helping us suss out problems with video playback, graphics cards/drivers and malicious addons.
This code is still "alpha". We'll be finishing it up in 2015q1.
Remote troubleshooting data capture project plan.
Heartbeat v1 and v2: People leave feedback on Input primarily when they're frustrated with something. Because of this, the sentiment numbers we get on Input tilt heavily negative and only represent people who are frustrated and were able to find the feedback form. Heartbeat will give us sentiment data that's more representative of our entire user base.
As a stop-gap to get the project going, Input is the backend collecting all the Heartbeat data. We rewrote the Heartbeat-related code for Heartbeat v2 in 2014q4.
Feedback form overhaul: We rewrote the feedback form to clean up the text, reduce confusion about what data is made public and what data is kept private, reduce the number of steps to leave feedback and improve the form for both desktop and mobile devices.
Feedback form overhaul project plan.
We also fixed the form so it supports multiple products because we're collecting feedback for multiple products on Input now.
2014q4 was tough because of the limited time, but it was a good quarter and we got a lot done.
The faux all-hands involved a bunch of discussions related to Input development. 2015q1 is going to be busy busy busy.
|
|
Jennie Rose Halperin: Bulbes: a soup zine. Call for Submissions! |
Please forward widely!
It’s that time of year, when hat hair is a reality and wet boots have to be left at the door. Frozen fingers and toes are warmed with lots of tea and hot cocoa, and you have heard so many Christmas songs that music is temporarily ruined.
I came to the conclusion a few years ago that soup is magic (influenced heavily by a friend, a soup evangelist) and decided to start a zine about soup, called
Bulbes.
It is currently filled mostly with recipes, but also some poems (written by myself and others) and essays and reflections and jokes about soup. Some of you have already submitted to the zine, which is why all this may sound familiar.
Unfortunately, I hit a wall at some point and never finished it, but this year is the year! I finally have both the funds and feelings to finish this project and I encourage all of you to send me
* Recipes (hot and cold soups are welcome)
* Artwork about soup (particularly cover artwork!)
* Soup poems
* Soup essays
* Soup songs
* Soup jokes
* Anything else that may be worth including in a zine about soup
Submissions can be original or found, new or old.
Submission deadline is January 20 (after all the craziness of this time of year and early enough so that I can finish it and send it out before the end of winter!) If you need more time, please tell me and I will plan accordingly.
If you want to snail mail me your submission, get in touch for my address.
Otherwise email is fine!
Happy holidaze to all of you.
Love,
Jennie
PS I got a big kick in the tuchus to actually finish this when I met Rachel Fershleiser, who kindly mailed me a copy of her much more punnily named “Stock Tips” last week. It was pretty surreal to meet someone else who made a zine about soup!
check it out!
https://www.kickstarter.com/projects/576518335/stock-tips-a-zine-about-soup
http://rachelfershleiser.com/tagged/stock+tips
|
|
Josh Aas: MozJPEG 3.0 Released |
Today we’re releasing mozjpeg 3.0, featuring a return to ABI compatibility with libjpeg-turbo, compression improvements, deringing for black-on-white text, and a large number of other fixes and improvements.
Code written against earlier versions of the mozjpeg library will need to be updated, see notes here. While this might be a bit of a pain, it’s a worthwhile change because applications can now easily switch between mozjpeg and libjpeg-turbo.
Thanks to Frank Bossen, Kornel Lesi'nski, Derek Buitenhuis, and Darrell Commander for their help with this release.
Here’s hoping you enjoy smaller JPEG files in the new year!

https://boomswaggerboom.wordpress.com/2014/12/30/mozjpeg-3-0-released/
|
|
Mozilla Fundraising: Saving the Best for Last |
|
|
Panos Astithas: Valence roadmap |
http://feedproxy.google.com/~r/PastMidnight/~3/7La2nO_pUOc/valence-roadmap.html
|
|
Gregory Szorc: Mercurial Pushlog Is Now Robust Against Interrupts |
hg.mozilla.org - Mozilla's Mercurial server - has functionality called the pushlog which records who pushed what when. Essentially, it's a log of when a repository was changed. This is separate from the commit log because the commit log can be spoofed and the commit log doesn't record when commits were actually pushed.
Since its inception, the pushlog has suffered from data consistency issues. If you aborted the push at a certain time, data was not inserted in the pushlog. If you aborted the push at another time, data existed in the pushlog but not in the repository (the repository would get rolled back but the pushlog data wouldn't).
I'm pleased to announce that the pushlog is now robust against interruptions and its updates are consistent with what is recorded by Mercurial. The pushlog database commit/rollback is tied to Mercurial's own transaction API. What Mercurial does to the push transaction, the pushlog follows.
This former inconsistency has caused numerous problems over the years. When data was inconsistent, we often had to close trees until someone could SSH into the machines and manually run SQL to fix the problems. This also contributed to a culture of don't press ctrl+c during push: it could corrupt Mercurial. (Ctrl+c should be safe to press any time: if it isn't, there is a bug to be filed.)
Any time you remove a source of tree closures is a cause for celebration. Please join me in celebrating your new freedom to abort pushes without concern for data inconsistency.
In case you want to test things out, aborting pushes and (and rolling back the pushlog) should now result in something like:
pushing to ssh://hg.mozilla.org/mozilla-central
searching for changes
adding changesets
adding manifests
adding file changes
added 1 changesets with 1 changes to 1 files
Trying to insert into pushlog.
Inserted into the pushlog db successfully.
^C
rolling back pushlog
transaction abort!
rollback completed
http://gregoryszorc.com/blog/2014/12/30/mercurial-pushlog-is-now-robust-against-interrupts
|
|
Gregory Szorc: Firefox Source Documentation Versus MDN |
The Firefox source tree has had in-tree documentation powered by Sphinx for a while now. However, its canonical home has been a hard-to-find URL on ci.mozilla.org. I finally scratched an itch and wrote patches to enable the docs to be built easier. So, starting today, the docs are now available on Read the Docs at https://gecko.readthedocs.org/en/latest/!
While I was scratching itches, I decided to play around with another documentation-related task: automatic API documentation. I have a limited proof-of-concept for automatically generating XPIDL interface documentation. Essentially, we use the in-tree XPIDL parser to parse .idl files and turn the Python object representation into reStructured Text, which Sphinx parses and renders into pretty HTML for us. The concept can be applied to any source input, such as WebIDL and JavaScript code. I chose XPIDL because a parser is readily available and I know Joshua Cranmer has expressed interest in automatic XPIDL documentation generation. (As an aside, JavaScript tooling that supports the flavor of JavaScript used internally by Firefox is very limited. We need to prioritize removing Mozilla extensions to JavaScript if we ever want to start using awesome tooling that exists in the wild.)
As I was implementing this proof-of-concept, I was looking at XPIDL interface documentation on MDN to see how things are presented today. After perusing MDN for a bit and comparing its content against what I was able to derive from the source, something became extremely clear: MDN has significantly more content than the canonical source code. Obviously the .idl files document the interfaces, their attributes, their methods, and all the types and names in between: that's the very definition of an IDL. But what was generally missing from the source code is comments. What does this method do? What is each argument used for? Things like example usage are almost non-existent in the source code. MDN, by contrast, typically has no shortage of all these things.
As I was grasping the reality that MDN has a lot of out-of-tree supplemental content, I started asking myself what's the point in automatic API docs? Is manual document curation on MDN good enough? This question has sort of been tearing me apart. Let me try to explain.
MDN is an amazing site. You can tell a lot of love has gone into making the experience and much of its content excellent. However, the content around the technical implementation / internals of Gecko/Firefox generally sucks. There are some exceptions to the rule. But I find that things like internal API documentation to be lackluster on average. It is rare for me to find documentation that is up-to-date and useful. It is common to find documentation that is partial and incomplete. It is very common to find things like JSMs not documented at all. I think this is a problem. I argue the lack of good documentation raises the barrier to contributing. Furthermore, writing and maintaining excellent low-level documentation is too much effort.
My current thoughts on API and low-level documentation are that I question the value of this documentation existing on MDN. Specifically, I think things like JSM API docs (like Sqlite.jsm) and XPIDL interface documentation (like nsIFile) don't belong on MDN - at least not in wiki form. Instead, I believe that documentation like this should live in and be derived from source code. Now, if the MDN site wants to expose this as read-only content or if MDN wants to enable the content to be annotated in a wiki-like manner (like how MSDN and PHP documentation allow user comments), that's perfectly fine by me. Here's why.
First, if I must write separate-from-source-code API documentation on MDN (or any other platform for that matter), I must now perform extra work or forgo either the source code or external documentation. In other words, if I write in-line documentation in the source code, I must spend extra effort to essentially copy large parts of that to MDN. And I must continue to spend extra effort to keep updates in sync. If I don't want to spend that extra effort (I'm as lazy as you), I have to choose between documenting the source code or documenting MDN. If I choose the source code, people either have to read the source to read the docs (because we don't generate documentation from source today) or someone else has to duplicate the docs (overall more work). If I choose to document on MDN, then people reading the source code (probably because they want to change it) are deprived of additional context useful to make that process easier. This is a lose-lose scenario and it is a general waste of expensive people time.
Second, I prefer having API documentation derived from source code because I feel it results in more accurate documentation that has the higher liklihood of remaining accurate and in sync with reality. Think about it: when was the last time you reviewed changes to a JSM and searched MDN for content that needed updated? I'm sure there are some pockets of people that do this right. But I've written dozens of JavaScript patches for Firefox and I'm pretty sure I've been asked to update external documentation less than 5% of the time. Inline source documentation, however, is another matter entirely. Because the documentation is often proximal to code that changed, I frequently a) go ahead and make the documentation changes because everything is right there and it's low overhead to change as I adjust the source b) am asked to update in-line docs when a reviewer sees I forgot to. Generally speaking, things tend to stay in sync and fewer bugs form when everything is proximally located. By fragmenting documentation between source code and external services like MDN, we increase the liklihood that things become out of sync. This results in misleading information and increases the barriers to contribution and change. In other words, developer inefficiency.
Third, having API documentation derived from source code opens up numerous possibilities to further aid developer productivity and improve the usefullness of documentation. For example:
While we don't generally do these things today, they are all within the realm of possibility. Sphinx supports doing many of these things. Stop reading and run mach build-docs right now and look at the warnings from malformed documentation. I don't know about you, but I love when my tools tell me when I'm creating a burden for others.
There really is so much more we could be doing with source-derived documentation. And I argue managing it would take less overall work and would result in higher quality documentation.
But the world of source-derived documentation isn't all roses. MDN has a very important advantage: it's a wiki. Just log in, edit in a WYSIWYG, and save. It's so easy. The moment we move to source-derived documentation, we introduce the massive Firefox source repository, the Firefox code review process, bugs/Bugzilla, version control overhead (although versioning documentation is another plus for source-derived documentation), landing changes, extra cost to Mozilla for building and running those checkins (even if they contain docs-only changes, sadly), and the time and cognitive burden associated with each one. That's a lot of extra work compared to clicking a few buttons on MDN! Moving documentation editing out of MDN and into the Firefox patch submission world would be a step in the wrong direction in terms of fostering contributions. Should someone really have to go through all that just to correct a typo? I have no doubt we'd lose contributors if we switched the change contribution process. And considering our lackluster track record of writing inline documentation in source, I don't feel great about losing any person who contributes documentation, no matter how small the contribution.
And this is my dilemma: the existing source-or-MDN solution is sub-par for pretty much everything except ease of contribution on MDN and deploying nice tools (like Sphinx) to address the suckitude will result in more difficulty contributing. Both alternatives suck.
I intend to continue this train of thought in a subsequent post. Stay tuned.
http://gregoryszorc.com/blog/2014/12/30/firefox-source-documentation-versus-mdn
|
|
Mozilla Reps Community: Mozilla Reps in 2014 |
2014 has been an amazing year for the Mozilla Reps program, full of work, passion and awesome stories.
More than 450 Reps have been working hard to push the Mozilla mission and values around 90 countries in the world.
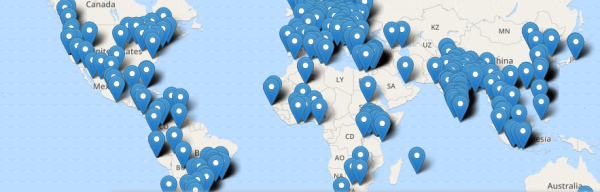
One of the main tools are events. This year Reps organized or attended more than 1400 events in 97 different countries.
Impressed? Well, let me tell you that just on events organized directly by Reps we reached more than 134 000 attendees!
And the most popular event categories this year? Firefox OS, Students and Webmaker.

Maker Party in Kochi, India
Reps work has been crucial to move Mozilla goals this year. Reps have been there at FOSDEM, MWC, Mozfest and many other big events where Mozilla took a key role.
Also, Reps have been in charge of most Firefox OS Launches in 15 new countries (Chile, India, Bangladesh, El Salvador, Panam'a, Nicaragua, Guatemala, Macedonia, Czech Republic , France, Australia, Costa Rica, Philippines, Russia and Japan) and also the Firefox 10th anniversary events around the world.
This year also there has been a lot of changes and challenges in the program, some of them:
What was your best moment as Rep in 2014?
Where do you want the program to go next year?
We don’t want to end the year without saying THANKS to everyone that makes the Reps program possible, specially our beloved mentors, Council and stunning Reps of the month.

Do you want to follow what Reps are doing? Check our portal, twitter, Facebook page, air mozilla channel and discussion forums.
https://blog.mozilla.org/mozillareps/2014/12/30/mozilla-reps-in-2014/
|
|
Bogomil Shopov: FOSDEM 2015 – hotels, information and facts (updated) |
If you are going to Fosdem 2015, here is some useful info.
Personally I can recommend CitaDines apartments, because there is a small kitchen included into the price and you can make a dinner or breakfast. If you are more than 2 people, they can offer you a really great offer and it’s near to the bus stop for FOSDEM bus. At the moment they have “Up to 36% off ” offer. Go grab one.

Just visit this site. I highly recommend the pub crawl tour for just 15 euro.
There is no food in Brussels. :)
Yes, it’s available. Click here to learn more. It’s every day from 11 in the morning and 2 afternoon. Pre-booking is welcomed :)
FOSDEM is a free and non-commercial event organized by the community for the community. The goal is to provide Free Software and Open Source developers and communities a place to meet to:
Sharing the knowledge and ideas is the most valuable think you can get during FOSDEM and it’s free. There is no excuse not to be there.

If you are worried about anything, just feel free to ask me and I will help you, especially if this will be your first visit. If you are living for Free software or Open Source – you must be there.
(cc) Image is under CC lisense by bertogg
|
|
Jared Wein: On volunteer and internship opportunities at Mozilla |
About a month ago on a flight from Seattle to New York I met a lady who said that her son was studying computer science. I told her about the work that is being done at Mozilla and how we have a lot of opportunities for people who want to contribute to one of the world’s largest open source software projects.
Today I got an email from her son asking about internship opportunities. Her son is just getting started in computer science and has yet to take his introductory courses in CS. There are many people that are in his position and I believe that they can still contribute to Mozilla and gain valuable experience for their future. Below is my response to him:
Hi ____,Thanks for the email. It was a pleasure to meet your mother on the flight.
Internships at Mozilla require a solid CS basis and will probably be too challenging to undertake before completing your introductory courses. However, that doesn’t mean that there is nothing that you can do at this point. With a basic understanding of HTML, CSS, and JavaScript, there are probably a number of bugs that you could fix today within Firefox.
I would recommend that you spend time this summer, either the whole summer or a period within, as a volunteer contributor to Mozilla. Many of our interns and full-time employees contributed to Mozilla or other open source software projects before joining Mozilla. There are two major benefits for doing so: familiarity with the project and what type of work people do; and practicing the skills necessary to succeed during an internship or full-time role.
I understand that volunteering can present its own time and financial challenges as it is unpaid, but one of the benefits of volunteering is that the work can be done at your own pace and on your own schedule.
You can take a look at the following bugs if you would like to see what the type of work may look like:
https://bugzilla.mozilla.org/show_bug.cgi?id=1026679
https://bugzilla.mozilla.org/show_bug.cgi?id=1043257
As you contribute, more responsibilities will be given to you and you’ll feel confident working on larger tasks.
Let me know if you are interested, and I will find some bugs that are available for you to fix.
Cheers,
Jared
That offer at the end of the email is not something that people can only get by bumping in to me while traveling. If you are reading this blog post and you would like to learn how you can contribute to Mozilla, please join the #introduction channel on irc.mozilla.org and ask how you can get started. Be patient however, it may take a couple hours to get a response from someone due to timezones and busy schedules.

http://msujaws.wordpress.com/2014/12/29/on-volunteer-and-internship-opportunities-at-mozilla/
|
|
Nigel Babu: Mozlandia - The rest of the work week |
I remember arriving in Portland pretty clearly and I remember leaving. But the days in between? They’re a complete blur. It involved so many meetings and so many people.
Over the last few months, frankly, Mozilla has eroded a lot of my trust. The keynotes on Tuesday and Wednesday won a lot of it back. The Tuesday keynotes talked about the next year at a very high level at the morning. In the afternoon, the platform meeting with dougt and jst, narrowed it down to the context of the platform team. Later in the day, the A-team and RelEng coordination meeting narrowed it down some more. Just before the start of the platform meeting, I noticed the tree was closed and Wes and I were trying to narrow down what’s wrong and trying to fix it. The good part about having everyone in one room is, I could just walk over to catlee and say, “Hey, the tree’s broken due to something that looks like RelEng, can you take a look?”. We did that later too, when Ryan just walked over and asked Rail for help, since we were all in the same room anyway. Much more responsive than IRC!

My strongest memory from Wednesday’s keynotes is jonath’s daughter’s picture. Now I know why he starts his presentations with her picture! I found Darren Herman’s talk the most memorable of the lot (Well, except for Andreas, but that’s because it’s hard to beat an entry with ‘Ride of the Valkyries’). I remember the outrage from when we introduced Sponsored Tiles as a concept. I remember hating him a bit (okay, okay, a lot) and wondering why Mozilla even hired someone like him (Sorry!). In the context of our #ChooseIndependent campaign, it makes quite a lot of sense. This also took me back to a conversation I had with a friend before I started contributing to Mozilla. My friend said that he doesn’t believe that Mozilla is useful. They are entirely funded by Google, their competitor and Google can kill them any time (In retrospect, I think this conversation drove me to contribute). This focus to try and widen our revenue stream so we’re not dependent on one source is something that I now understand.

On Thursday, the schedule looked fairly light in terms of A-team related meetings and there was an extravaganza to attend! I tried to get some work done on Who Owns What during the day. Coding at a work week didn’t seem like a productive use of time and my instincts kept fighting with me. I eventually sat down and tried to narrow down the features of a minimum viable product. gps had a session about Mercurial that helped grok the internals a bit, though I still find git easier. My best guess is, I’ve made enough mistakes with git to recover from most fuck ups. On the other hand, I work with the Mozilla trunk branches with Mercurial and I can’t risk making a mistake.

I was purely running on an extra large dose of will power on Friday. I was exhausted and craving my own bed and lots of sunlight. The AWS game night was so much fun, despite losing. And digi has an excellent career as a chaos monkey. The party. Oh dear. I have videos that need to be uploaded. And a few videos that need to be converted to gifs. I mean, who wouldn’t want a gif of potch dancing, right? I wish I had the full video of the Psycho Killer performance. It was very well done. And hell yeah, Mozillians can dress up. Hats off to the IT team, who all looked really spectacular. I didn’t even recognize cshields at first :P
")
Ted had coordinated Mozlandia running groups and I had bought all this gear to run in Portland, so I had to give it a shot. The jet lag woke me up at 5 am on Tuesday, so I went out for a run at around 6 am. As I left the hotel, the receptionist warned me, “It’s awfully cold”. I didn’t fully appreciate the gravity of this until I could feel my ears freeze over and I had a bit of a coughing fit thanks to the cold air hitting my lungs. I gave up at the 3 km mark, but it was by far my fastest run ever! I hurt my shoulder that night with an awkward sleeping position, so that was it for my running at Mozlandia :(
PS: Cheers to Mardi and the team behind the event for having it run so smoothly!
|
|
Soledad Penades: Danger Dashboard: for the adventurous `dom.webcomponents.enabled` enablers |
You know the drill, you go to about:config, look for dom.webcomponents.enabled and turn it on because you want to try some new feature in Firefox. And then you visit some other website which relies on said support to be fully complete and all hell breaks loose… or it just breaks in variously spectacular degrees of fail.
Wait, no more–now you can install this fantabulous add-on called Danger Dashboard which will overlay a little dashboard on the bottom right corner of each website you visit, so you can
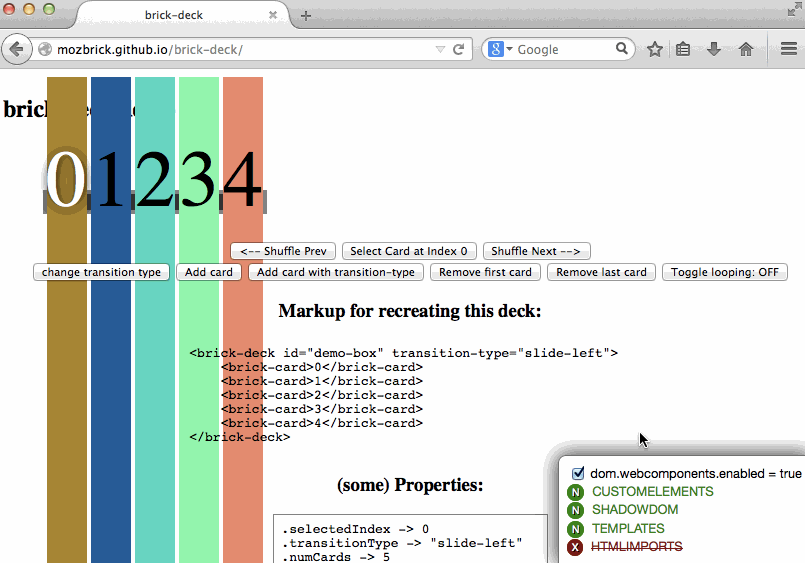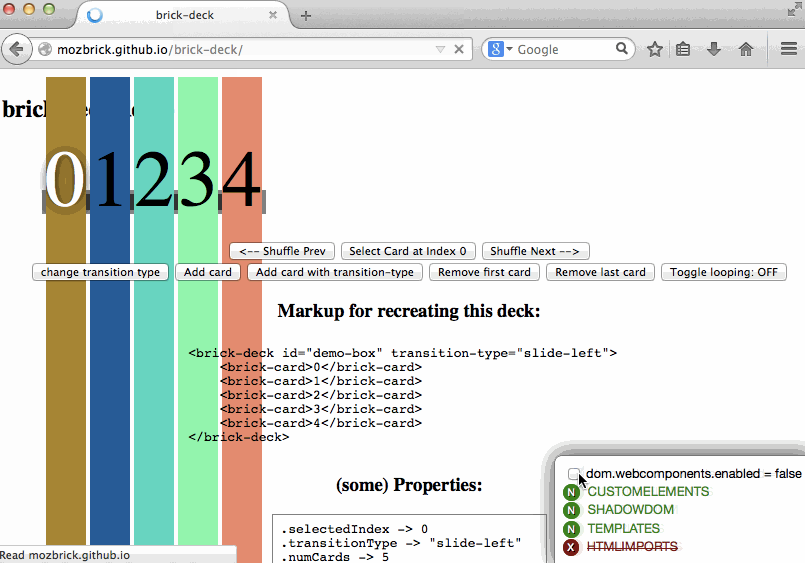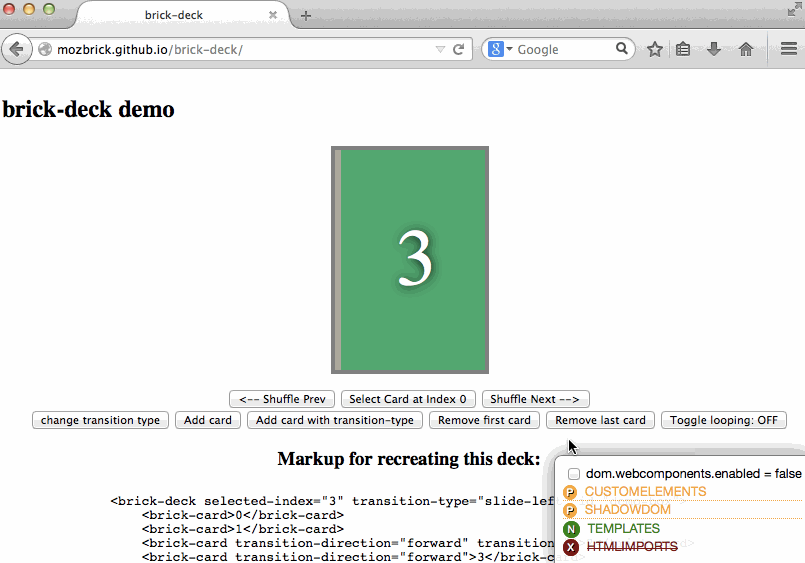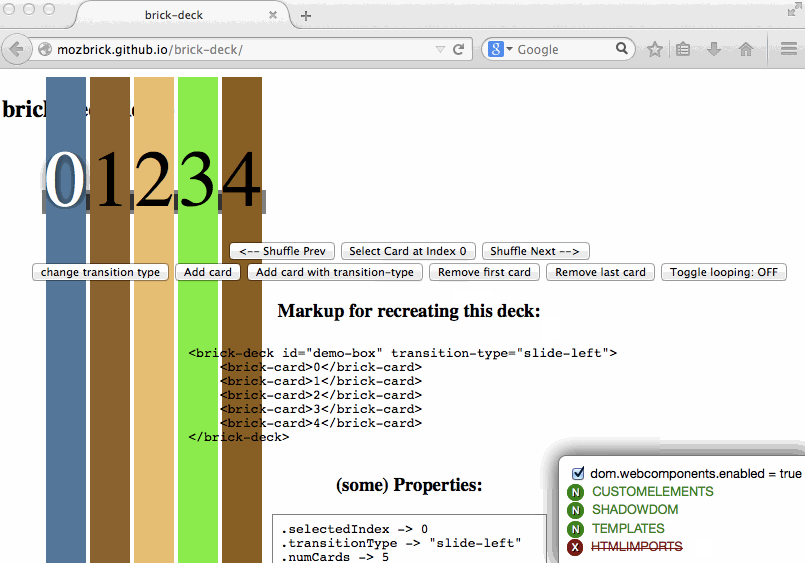
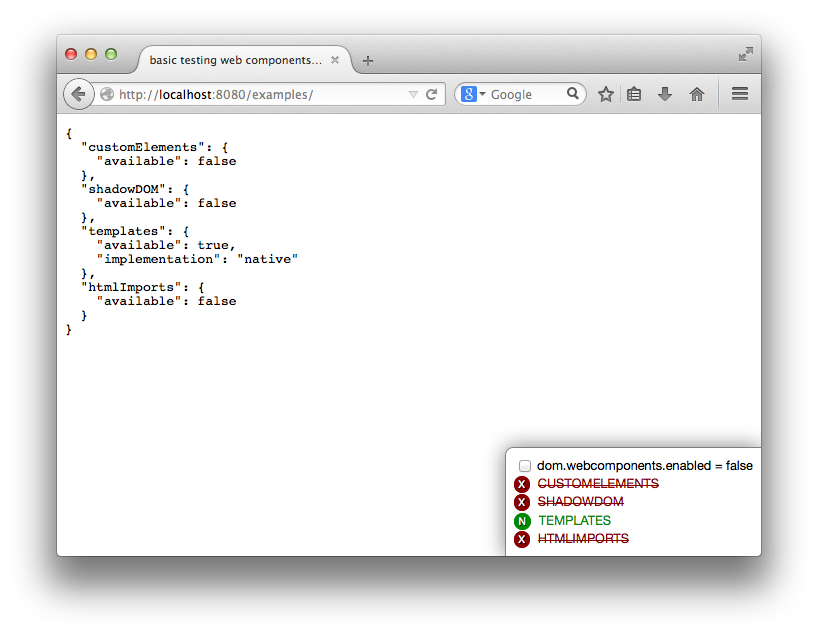
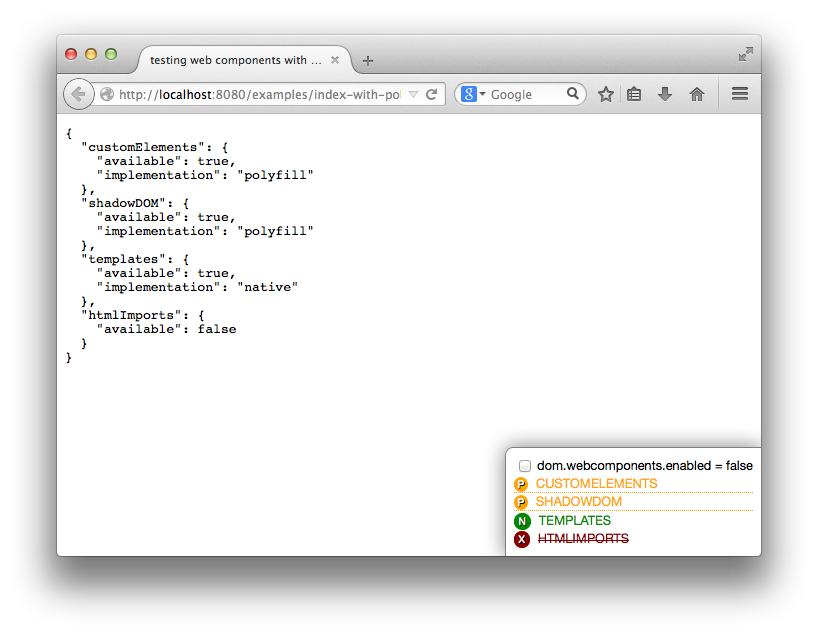
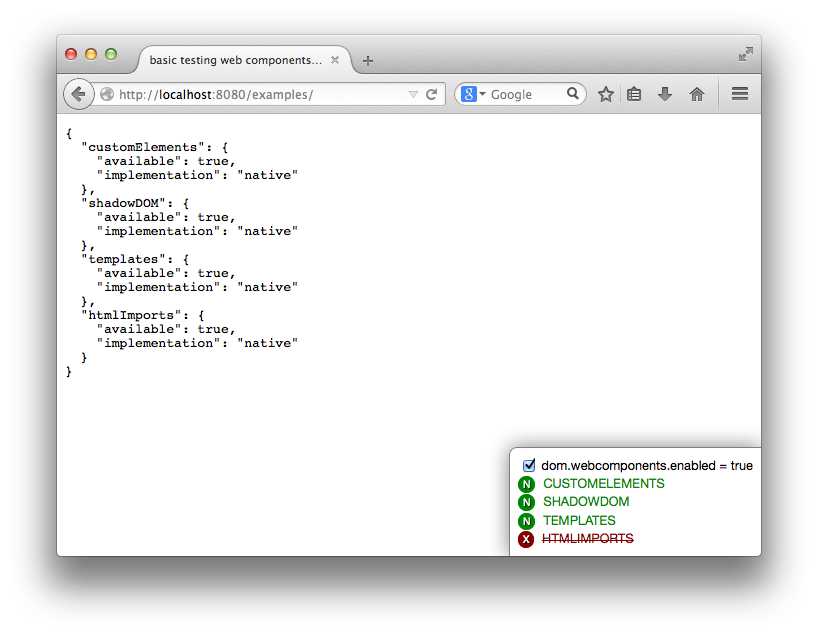
The core of the feature detection is actually performed in another little library I extracted out because modular code is the best. So you can actually perform detection in your own code using WebComponentsSupport.
I am not 100% sure if I’m doing the detection properly–specially I’m not sure at all about the HTML imports feature detection, and I have no means to make sure HTML templates are properly detected because I have no browser which does not have native support. If any Internet Explorer user wants to help… ![]()
I tried building addons a few years ago but they were still built with XUUUUL and that scared me away. Now the recommended method is with a tool called cfx which is easy enough, except it kind of looks like node but doesn’t quite work like that, so the fact that it uses package.json instead of any other filename is clashing with my hopes of using gulp and other things such as what I would use with any other npm module in a clean, standard way.
For example, I’d like to be able to clone the repository, run npm install and have it install a local gulp, then run a gulp task that lints code, and then calls cfx xpi and makes sure the .xpi is in a dist/ folder, so perhaps I could check that in with a git tag and people won’t need to do all this tooling dance if they just want the unstable .xpi file.
I’m also pretty proud that I got to implement one of Dr. Jenn Schiffer’s recommendations:
element {
--to-the-fucking-moon: 1000000;
}
#danger-dashboard {
z-index: var(--to-the-fucking-moon);
}I’ve scratched my own itch (sort of), and this add-on in its current state solves most of the main issues I have when working with preview support of web components in Firefox. Of course it’s not perfect (it’s my first add-on!!) but that’s where you get to play a part. If you can make things better, by all means do!
I’ve added a Contributing section in the repository to help people around.
So if you like what you see but think it could be better… do something about it! ![]()
![]()
|
|
Nick Cameron: My thoughts on Rust in 2015 |
http://featherweightmusings.blogspot.com/2014/12/my-thoughts-on-rust-in-2015.html
|
|






