Hannah Kane: I need to reprint my business cards |
Okay, so I don’t actually have business cards, but on this morning’s All Mofo call, it was announced that I’m leaving the wonderful Engagement team to serve as a product manager for the equally wonderful Learning Networks team. So, if I had business cards, I’d need new ones.
This is, for obvious reasons, bittersweet. I’ve LOVED working with the engaging folks on the Engagement team, and it provided a fantastic vantage point for learning the ins and outs of Mofo. I’m sending a big heartfelt thank you to Geoffrey and Co. for being so dang awsm to me ever since I joined.
Fortunately for me, I’m not going far. I’ve been admiring the work of both the Mentor Networks and the Product teams from a distance, so I’m thrilled with my new spot right smack in the middle of them.
Wait….Hannah, what do you know about product management? And Learning Networks?
It might seem strange at first blush, since I’ve been talking about scrum mastering and engagement-y stuff on this blog so far. But, lest you think I’m totally unqualified, let me share a few relevant experiences I haven’t shared here before:
OK, so what are you going to be working on?
The Big Picture answer is: developing products that serve the needs of our constituents in our ground game programs (Hive, Webmaker Clubs, Maker Parties). These products will be separate from, but complementary of, the Learning Products, which serve independent learners who aren’t (yet!) affiliated with our ground game programs.
In the short term, my top priorities are:
I’m so very excited to be working on these things. Like, I’m seriously being a nerd about it all.
At the same time, I’m already missing my Engagement team buddies (though that’s tempered by the fact that I still get to work with nearly all of them :)).
Questions? Want to discuss the Learning Networks products? Hit me up.

http://hannahgrams.com/2015/01/12/i-need-to-reprint-my-business-cards/
|
|
Lukas Blakk: Contribution opportunity: Early Feedback Community Release Manager |
Did you make a New Year’s resolution to build out your software development skillset with a focused contribution to an open source project? Do you want to work with a small team where you can have a big impact?
We’re once again looking for someone committed to learning the deepest, darkest secrets of release management when shipping a big, open source software project to half a billion users. Our small team of 3 employees already has one contributor who has been a consistent volunteer for Release Management since 2013 and has worked his way from these tasks to taking on coordination and growth strategy for the Extended Support releases. Our commitment to contributors is that we will do our best to keep you engaged and learning, this is not grunt work, it’s deep participation that matters to the organization and to the products we ship.
You’ll need to consistently commit a 1-3 hours a week to helping analyze our Nightly channel (aka mozilla-central or ‘trunk’) and raise issues that need prompt attention. The very fabulous volunteer who takes on this task will get mentoring on tools, process, and build up awareness around risks in shipping software, starting at the earliest stage in development. On our Nightly/trunk channel there can be over 3000 changes in a 6 week development cycle and you’d be the primary person calling out potentially critical issues so they are less likely to cause pain to the user-facing release channels with larger audiences.
A long time back, in a post about developing community IT positions, mrz recalled a post where I stated that to have successful integration of community volunteers with paid staff in an organization there has to be time dedicated to working with that community member that is included in an employees hours so that the experience can be positive for both parties. It can’t just be “off the side of the desk” for the employee because that creates the risk of burnout which can lead to communication irregularities with the volunteer and make them feel unappreciated. For this community release manager position I will dedicate 1-3 hours each week to actively on-board and guide this community Release Manager contributor in order to ensure they get the skills needed while we get the quality improvements in our product.
Here is the “official” call for help, come get in on the excitement with us!

I’ll be posting this around and looking to chat with people either in person (if you’re in the Bay Area) or over video chat. The best part is you can be anywhere in the world – we can figure out how to work a schedule that ensures you get the guidance and mentoring you’re looking for.
Look forward to hearing from you! Let’s roll up our sleeves and make Firefox even better for our users!

http://lukasblakk.com/contribution-opportunity-early-feedback-community-release-manager-2/
|
|
Christian Heilmann: A time of change… |
“The suspense is killing me,” said Arthur testily.
Stress and nervous tension are now serious social problems in all parts of the Galaxy, and it is in order that this situation should not in any way be exacerbated that the following facts will now be revealed in advance.
Hitchhiker’s Guide to the Galaxy

I am not returning to Mozilla in February but go on to bring the great messages of an open web somewhere else. Where, I do not know yet. I am open to offers and I am interested in quite a few things happening right now. I want something new, with a different audience. A challenge to open and share systems and help communication where the current modus operandi is to be secretive. I want to lead a team and have a clear career path for people to follow. If you have a good challenge for me, send me some information about it.
I love everything Mozilla has done and what it stands for. I also will continue being a Mozillian. I will keep in touch with the great community and contribute to MDN and other open resources.
Of course there are many reasons for this decision, none of which need to go here. Suffice to say, I think I have done in Mozilla what I set out to do and it now needs other people to fulfil the new challenges the company faces.
I came to Mozilla with the plan to make us the “Switzerland of HTML5”, or the calming negotiator and standards implementer in the browser wars raging at that time. I also wanted to build an evangelism team and support the community in outreach on a basis of shared information and trust. I am proud of having coached a lot of people in the Mozilla community. It was very rewarding seeing them grow and share their excitement. It was great to be a spokesperson for a misfit company. A company that doesn’t worry about turning over some apple-carts if the end result means more freedom for everyone. It was an incredibly interesting challenge to work with the press in a company that has many voices and not one single communication channel. It was also great to help a crazy idea like an HTML5 based mobile operating system come to fruition and be a player people take serious.
Returning to Mozilla I’d have to start from scratch with that. Maybe it is time for Mozilla not to have a dedicated evangelism team. It is more maintainable to build an internal information network. One that empowers people to represent Mozilla and makes it easy to always have newest information.
I am looking forward to seeing what happens with Mozilla next. There is a lot of change going on and change can be a great thing. It needs the right people to stand up and come up with new ideas, have a plan to execute them and a way to measure their success.
As for me, I am sure I will miss a few things I came to love working for Mozilla. The freedoms I had. The distributed working environment. The ability to talk about everything we did. The massive resource that is enthusiasts world-wide giving their time and effort to make the fox shine.
I am looking forward to being one of them and enjoy the support the company gives me. Mozilla will be the thing I want to support and point to as a great resource to use.

Making the web work, keeping our information secure and private and allowing people world-wide to publish and have a voice is the job of all the companies out there.
As enthusiastic supporters of these ideas we’re not reaching the biggest perpetrators. I am looking forward to giving my skills to a company that needs to move further into this mindset rather than having it as its manifesto. I also want to support developers who need to get a job done in a limited and fixed environment. We need to make the web better by changing it from the inside. Every day people create, build and code a part of the web. We need to empower them, not to tell them that they need a certain technology or change their ways to enable something new.
The web is independent of hardware, software, locale and ability. This is what makes it amazing. This means that we can not tell people to use a certain browser to get a better result. We need to find ways to get rid of hurtful solutions by offering upgrades for them.
We have a lot of excuses why things break on the web. We fail to offer solutions that are easy to implement, mature enough to use and give the implementers an immediate benefit. This is a good new challenge. We are good at impressing one another, time to impress others.
“Keep on rocking the free web”, as Potch says every Monday in the Mozilla meeting.
|
|
Ben Kero: The cost of ‘free’ relocation cars in New Zealand |
 Raspberries on the lawn of the Christchurch Riccarton Bush farmers market
Raspberries on the lawn of the Christchurch Riccarton Bush farmers marketAs many of my friends know, I’ve been spending the last few weeks in New Zealand. Primarily it’s been for a small holiday, but also in preparation inimitable Linux.conf.au 2015 conference. Leading up to that, one of the goals of my visit was to experience the variety of places across both islands.
A few weeks ago someone clued me in to a service called Transfercar. This is that this is a service for people who need to rent a car for one-way travel. The way it works is this: rental car companies often get one-way rental requests. At the end of the rental, the vehicles must be relocated to cities where they’re in demand. Therefore they need you (the lone backpacker) to help them get it there. Often these requests get posted with little notice. Thus you must remain flexible if you plan to catch one.
What this means for you is a ‘free’ rental. I use quotation marks here because it’s not entirely free. There are many ancillary costs that are not difficult to predict as long as you know they are there. These costs include semi-optional insurance, fuel ,and other transportation costs.
Through this site the identity of the rental agency and car model remain hidden until they accept your request. After they accept it they will reveal some details, such as their identity and where you can pick up the vehicle. The car models remains hidden from you until you pick it up from the agency.
The prospect of driving in a new, unfamiliar country excited me. I would have the autonomy to take any pit stop or detour that I fancied. If you’re interested in exploring the country I would suggest procuring a vehicle. After spending considerable time here, it seems to be the best option.
That morning I packed my bag and departed my Airbnb accommodation. I needed to transfer between three buses to get close to the rental agency.
As I arrived I peered through the parking lot I found the usual suspects. There were late-model subcompacts , small SUVs, and some old familiar compact sedans.
It was then that I glanced over and my heart filled with boredom-induced terror. This terror was no dark beast, but a grey 1990s Nissan Sunny. This is car that Top Gear referred to as the most bland car ever made.
My shoulders slumped as I considered that it would be my fate to drive it. Devastated, I went inside to take my place at the end of a 3-deep queue. The two groups ahead of me seemed to be freshly-arrived airplane passengers.
This is where the problems start to arise. Although the vehicle rental fee was $0, there was no fuel included, so I had to pay for that myself. I was also forced to pay the $19/day insurance cost. Although this isn’t required, declining requires a $2000 bond. The credit limit on my only credit card is $1,000. I feared that if I decided to take the bond, it would later bounce. If that happened would they report it as stolen?
As per usual, getting out of there took over an hour. Vehicle rental agencies have a reputation of taking a long time for transactions. This was no exception. Afterwards I headed outside and waited for the agent. There she would meet me with my punishment-mobile.
I exhaled with relief when I saw the vehicle she brought forth. It was not the Nissan Sunny of my nightmares. Instead what emerged from the garage was an automatic white mid-1990s Mitsubishi Lancer. ‘Almost an Evo!’ I thought. ‘Alright, this will do.’
I looked over to sneak a peek at the rental sheet. The pre-existing damage figure made the car look like a hairy beast. Not a single door or body panel escaped the a hair, indicating a scratch or ding. I noticed a box indicating that this thing had already rolled 280,000km. We both had a laugh at the idea that any more scratches would reduce its value.
My particular drive was from Christchurch to Dunedin, which is about a 450km drive. I didn’t drop a single bead of sweat. A few hours on the deserted SH-1 motorway made that distance fly by.
On my way down I decided to make some small detours. I stopped at quaint road-side town and some amazing coastal bluffs. At one point I stopped by a farm and bought some farm-fresh cherries from a farmer out of his van.
When I finally arrived I knew I was going to be in for some financial damage. I had started thinking about it during my drive down, but only totaled the cost when it actually took its pound of flesh from me. This happened, and it’s what I’m writing to warn you about. If you’ve gotten this far then congratulations.
For comparison’s sake a one-way bus ticket between these two cities costs $19. There are 3 carriers that do this run, and each leaves several times per day.
Compounding the frustration were my return instructions. They asked me to return the car to the Dunedin airport, not the city center. Asking my accommodation for airport travel tips prompted a grave look.
There were no public buses or other services that ran there. The only cheap way to get to/from the airport was through a private shuttle. These run you door-to-door and cost roughly $30 on a good day. Now, by itself is not bad, but it does contribute to a large bill.
The drive had consumed almost entire fuel tank, which ended up being $62 to fill. The ‘optional’ insurance ended up being an extra $38 on top of that. Those summed with the airport shuttle fee ended up running me $130. That’s a $111 difference compared to the bus. Was the experience worth $111 for two days of vehicle? Maybe.
The moral of this story is to perform due diligence when deciding to rent a car. Although the car may be free, there are many other costs to consider.
Always look to see if the rental includes a free tank of fuel. In my case it wasn’t, but after looking around the site for a while I’ve noticed that it often is.
Additionally, check to see your allowed mileage. Often there will be a restricted distance you may travel. If you want to travel greater distances it will be an extra surcharge. Although my research indicates that the mileage is generous, it is still worth considering.
Double-check where you’ll be returning the vehicle to. Make sure you have a plan for how to get back to civilization. Being stuck at an airport with no cheap means of getting back to town is not a pleasant feeling.
If you’re cognizant of the pitfalls then this can be a fantastic way to explore. But if you’re unaware of them, you could have an awful experience.
Let me know if this information was useful to you. If you’re at all interested in travel or nature I would urge you to visit New Zealand.
http://bke.ro/the-cost-of-free-relocation-cars-in-new-zealand/
|
|
Nick Cameron: Recent syntactic changes to Rust |
http://featherweightmusings.blogspot.com/2015/01/recent-syntactic-changes-to-rust.html
|
|
Gervase Markham: Hippocratical Committers |
In the Subversion project, we choose committers primarily on the Hippocratic Principle: first, do no harm. Our main criterion is not technical skill or even knowledge of the code, but merely that the committer show good judgement.
— Karl Fogel, Producing Open Source Software
http://feedproxy.google.com/~r/HackingForChrist/~3/jkTfjEn0-Ao/
|
|
Brad Lassey: unsafe CPOW usage |
Cross Process Object Wrappers (aka CPOWs) are at the same time amazing and terrible. They are amazing in that they make things Just Work™ in Electrolysis (e10s). One of the major issues with converting Firefox code to work under e10s is chrome code that runs in the chrome process and would previously access content directly. Without CPOWs, this access would simply fail. With CPOWs in place, the code can carry on accessing these JavaScript objects that “live” in the content process. Having this mechanism in place has allowed us to have a working browser relatively quickly without the need to rewrite all of the code at once.
The trouble comes with the fact that in order to accomplish this magic, CPOWs send synchronous IPC messages to the content process. First of all, there is the general IPC overhead. Next, when you issue a synchronous IPC message from the chrome process, everything on the main thread of the chrome process comes to a complete stop until the content process gets around to handling that IPC message.
One of the scariest parts of CPOWs is that they allow synchronous messages to flow in both directions between the content and chrome processes. That kind of arrangement can be a recipe for deadlocks. We avoid them by forcing one side (the child) to process its incoming message while it waits for a response to its outgoing message. That has worked well so far. Other than some plugin-related issues that are solvable, we’re not aware of any CPOW-caused deadlocks in e10s right now (bugs are always possible of course). Unfortunately, performing this trick sometimes requires messages to be delivered in a different order than they were sent. In such situations, rather than deadlock or deliver messages out of order, we intentionally crash. Bug 1086684 is one example. We’ve been fixing these crashes on a case-by-case basis, but each one requires careful reasoning to fix.
There is, however, one circumstance where it is safe to do this, and that is while the chrome process is handling a synchronous message from the content process. In that circumstance, the content process is in a known good state and has nothing to do on the main thread other than handle the chrome process’s IPC messages. At this point the only downside is the IPC overhead.
So, with that context earlier this week I landed bug 1097998 which logs a warning to the console whenever CPOWs are used outside of this safe circumstance. Going forward we will be working to remove any instance of this unsafe usage from our code. Eventually, this may throw an exception (or some similar mechanism) to ensure we don’t regress.
|
|
Avi Halachmi: The simple story of activeTicks telemetry |
Our story begins with a fair request: let’s copy the activeTicks value which we have for Firefox-Health-Report - also to Telemetry, and so bug 1106122 was born.
Now, activeTicks is quite simple - it counts the duration a user has been interacting with Firefox. It’s part of the Firefox-Health-Report (FHR), but since it would be super useful to correlate this value with other telemetry values (such as number of hangs, etc), and since Telemetry and FHR live on different Clouds, we wanted to have a copy of this number also at telemetry. Fair enough.
I found the activeTicks code and played with it a bit to understand how it works. It turns out to simply count the number of “time units” (5s) at which the user moves the mouse over Firefox or otherwise interacted with it. There’s only one place at the code which counts this value, and it’s at services/datareporting/sessions.jsm. Great - this appears to be a simple task then.
While not strictly related to our story, I also found out that on Windows systems - it incorrectly kept counting also when the mouse pointer hovers Firefox even if the user is away from the computer. Georg Fritzsche, who maintains the data reporting modules took it and then also handled the request to keep both the “old” and the “fixed” values reported in parallel for a while - to better understand the relation between them. That story is on bug 1107779 and bug 1107782.
Back to our story.
Now, Telemetry mostly holds histograms - for which it has a decent API, but this activeTicks value is a plain scalar which doesn’t really fit nicely into a histogram. Telemetry also happens to have a “Simple Measurements” section which holds various values - most of them are scalars (such as various startup times, number of maximum concurrent threads, etc), but also some JSON strings which are compound UI related stuff, etc.
You can view the simple measurements values if you enter about:telemetry at the URL bar of Firefox and expand the SimpleMeasurements section.
Unfortunately, simple measurements is a bit of a hack. It doesn’t have an API, and each module which reports a simple measurement value also implements the interfacing with it. Also unfortunate - interfacing with it from the code which counts activeTicks was not straight forward.
So I looked a bit more on types of telemetry values and then I noticed Count Histograms. The docs were a bit sparse, but it was being tested and seemed to work well when I experimented with it, it was designed to hold a single value, and best of all - has an API which fits activeTicks perfectly: myHistogram.add(). Simple counting is exactly what we need! Did I mention it works?
Bump v1: while a count histogram has an almost-perfect semantic fit and a working API for our needs, apparently the telemetry dashboard currently doesn’t display count histograms as nicely or as usefully as it does for simple measurements.
Since we’re in a bit of a hurry with this, and since fixing the telemetry dashboard is likely to be a longer path, after some discussion we decided to use simple measurements after all - a fair request considering the factors.
But due to the lack of simple measurements API - instead of using the API right where activeTicks is incremented, it was suggested to collect the value where the telemetry values were collected - similar to some of the other simple measurements values.
However, since this part of the code doesn’t have an obvious interface to the SessionRecorder module (an object which exposes the activeTicks value and is an instance which the datareporting service - DRS - holds), it was suggested to simply take the preference value which counts activeTicks - since the only thing which incrementing activeTicks does is updating this pref.
While a bit hacky, it’s still quite safe, and it was suggested that such approach would still get approved. Fair enough.
Bump v2: the module owner isn’t happy to “bypass the FHR API”, but since such API didn’t exist, it was suggested to add an API. A fair request considering that it’s only a single function which exposes the SessionRecorder instance of the datareporting service.
Bump v3: while the patch was quite safe, it was preferred to also have some “basic-coverage test” for this new mechanism. A very fair request.
Unfortunately, the owner was unavailable for clarifications, but nevertheless, I evaluated what might fail, concluded that only the API could fail, and wrote a new xpcshell test which covers several cases of this new API.
Bump v4. Apparently I misinterpreted the request, and it was preferred to have more of a unit/black-box test where the telemetry payload is tested to contain -1 or actual activeTicks value - according to various cases, and it was suggested that we could add that to an existing test which already tests the telemetry payload - test_TelemetryPing.js . A fair request - black-box tests are good, and enhancing an existing test sounds reasonable.
Bump v5: Turns out that while the code itself is quite safe, it’s not trivial to create a case which ends up with activeTicks as -1 since it only happens when the DRS is present but FHR is completely disabled - which doesn’t happen at the code by default.
Still, it was deemed important to test this -1 case, and after several failed attempts to initialize the DRS later at the test (in order to check the payload before the DRS instantiates SessionRecorder - which should end up with activeTicks==-1), we came up with a “solution”: Let’s initialize the datareporting service twice!
First we’ll set this rarely-used preference to disable FHR, init the DRS, get a telemetry payload and check that it has activeTicks==-1, then restore the FHR pref, re-initialize the DRS (which luckily doesn’t do much - but does instantiates SessionRecorder according to this pref) - and then continue the test as usual.
And the patch lands.
Bump v6: and gets backed out for failure on some Android systems - which apparently are not compiled with the datareporting service and as a result part of the new test which uses it throws an exception. Whoops. My bad.
Patch v7: Fix it, do a try push with xpcshell tests on every platform I could select on trychooser - we’re green! re-land.
Bump v8: a day goes by, and it turns out the new test fails for Thunderbird, and the try-push didn’t cover Thunderbird. Apparently Thunderbird does have the datareporting service, but it doesn’t have the rarely-used FHR preference, and so when we try to read the pref initially such that we can restore its value later - it throws an exception.
Clone and build Thunderbird. Run this single test to check out what happens there.
The test doesn’t run. Apparently running xpcshell tests with Thunderbird works a bit differently than Firefox.
Search for docs, find docs, try again. Doesn’t work - I can’t run only this single test. I did manage to run all the xpcshell tests, but after about 15 mins where they were still running (and didn’t get to “my” test yet) I decided this is not practical and aborted.
Asked around, didn’t get too far, started experimenting with test invocations, found out how to invoke-a-Thunderbird-xpcshell-test-which-resides-at-the-mozilla-central-repository-copy-which-Thunderbird-depends-on, updated the wiki with this missing info (need to run from within the Thunderbird obj dir but with the test path relative to the m-c repo rather than relative to the Thunderbird repo).
Back to the test. Added some code to also test the case where the FHR preference doesn’t exist and expect activeTicks==-1 on this case. Run the test. Fails. It seems that while the preference doesn’t exist, the DRS still instantiates SessionRecorder, and activeTicks actually ends up as working - but the test expected it to have -1 since the FHR pref doesn’t exist.
Examined the DRS code - it reads the preference with a fallback to true, so it ends up with SessionRecorder and working activeTicks also when the pref doesn’t exist.
Hmm…
Falling back to true when the FHR-enabled pref doesn’t exist is a bit of a dodgy logic (even if it shouldn’t happen in practice), and I don’t like to duplicate logic, and especially not dodgy ones. But I need this logic at the test in order to know what kind of activeTicks value to expect on every platform which the test runs on.
I could expose this logic as yet another API of the datareporting service, and only use it at the test, but then who knows who might use it later and for what.
Or I could change the logic to be more reasonable and don’t instantiate SessionRecorder if the pref doesn’t exist, but I wouldn’t dare do that since I have no clue which other parts of the code rely on this behaviour. I need a solution…
This seems to work locally for both Thunderbird and Firefox for desktop.
Another try-push on all platforms with xpcshell tests to make sure everything still works everywhere.
Start this blog posts while the tests are running. They just turned out all green, ask a review for the new patch. Yay!
It’s probably a safe bet to say that the test will break before the code which it tests breaks. This can’t be a good thing…
There are probably few junctions where we could have taken a different path and possibly end up with better/simpler/safer/smaller code, and yet, this is where it stands now.
Moral? Not sure. All the requests were reasonable and each step kinda makes sense on its own. Maybe we should have done the right thing (TM) by keeping the first patch and fixing the telemetry dashboard instead? ;)
Easy to say in retrospective though, when we see how it evolved and which thing led to what.
But hey, we did end up with some more useful info at the Thunderbird-xpcshell-tests wiki page!
Edit - a day later and I decided to make it right. Gone are the double init and too much logic. The final patch is much cleaner, though still didn’t land. Tomorrow hopefully!
http://avih.github.com/blog/2015/01/10/the-simple-story-of-activeticks-telemetry/
|
|
Joshua Cranmer: A unified history for comm-central |
The first step and probably the hardest is getting the CVS history in DVCS form (I use hg because I'm more comfortable it, but there's effectively no difference between hg, git, or bzr here). There is a git version of mozilla's CVS tree available, but I've noticed after doing research that its last revision is about a month before the revision I need for Calendar's import. The documentation for how that repo was built is no longer on the web, although we eventually found a copy after I wrote this post on git.mozilla.org. I tried doing another conversion using hg convert to get CVS tags, but that rudely blew up in my face. For now, I've filed a bug on getting an official, branchy-and-tag-filled version of this repository, while using the current lack of history as a base. Calendar people will have to suffer missing a month of history.
CVS is famously hard to convert to more modern repositories, and, as I've done my research, Mozilla's CVS looks like it uses those features which make it difficult. In particular, both the calendar CVS import and the comm-central initial CVS import used a CVS tag HG_COMM_INITIAL_IMPORT. That tagging was done, on only a small portion of the tree, twice, about two months apart. Fortunately, mailnews code was never touched on CVS trunk after the import (there appears to be one commit on calendar after the tagging), so it is probably possible to salvage a repository-wide consistent tag.
The start of my script for conversion looks like this:
#!/bin/bash set -e WORKDIR=/tmp HGCVS=$WORKDIR/mozilla-cvs-history MC=/src/trunk/mozilla-central CC=/src/trunk/comm-central OUTPUT=$WORKDIR/full-c-c # Bug 445146: m-c/editor/ui -> c-c/editor/ui MC_EDITOR_IMPORT=d8064eff0a17372c50014ee305271af8e577a204 # Bug 669040: m-c/db/mork -> c-c/db/mork MC_MORK_IMPORT=f2a50910befcf29eaa1a29dc088a8a33e64a609a # Bug 1027241, bug 611752 m-c/security/manager/ssl/** -> c-c/mailnews/mime/src/* MC_SMIME_IMPORT=e74c19c18f01a5340e00ecfbc44c774c9a71d11d # Step 0: Grab the mozilla CVS history. if [ ! -e $HGCVS ]; then hg clone git+https://github.com/jrmuizel/mozilla-cvs-history.git $HGCVS fi
Since I don't want to include the changesets useless to comm-central history, I trimmed the history by using hg convert to eliminate changesets that don't change the necessary files. Most of the files are simple directory-wide changes, but S/MIME only moved a few files over, so it requires a more complex way to grab the file list. In addition, I also replaced the % in the usernames with @ that they are used to appearing in hg. The relevant code is here:
# Step 1: Trim mozilla CVS history to include only the files we are ultimately # interested in. cat >$WORKDIR/convert-filemap.txt <span> # Revision e4f4569d451a include directory/xpcom include mail include mailnews include other-licenses/branding/thunderbird include suite # Revision 7c0bfdcda673 include calendar include other-licenses/branding/sunbird # Revision ee719a0502491fc663bda942dcfc52c0825938d3 include editor/ui # Revision 52efa9789800829c6f0ee6a005f83ed45a250396 include db/mork/ include db/mdb/ EOF # Add the S/MIME import files hg -R $MC log -r "children($MC_SMIME_IMPORT)" \ --template "{file_dels % 'include {file}\n'}" >>$WORKDIR/convert-filemap.txt if [ ! -e $WORKDIR/convert-authormap.txt ]; then hg -R $HGCVS log --template "{email(author)}={sub('%', '@', email(author))}\n" \ | sort -u > $WORKDIR/convert-authormap.txt fi cd $WORKDIR hg convert $HGCVS $OUTPUT --filemap convert-filemap.txt -A convert-authormap.txt
That last command provides us the subset of the CVS history that we need for unified history. Strictly speaking, I should be pulling a specific revision, but I happen to know that there's no need to (we're cloning the only head) in this case. At this point, we now need to pull in the mozilla-central changes before we pull in comm-central. Order is key; hg convert will only apply the graft points when converting the child changeset (which it does but once), and it needs the parents to exist before it can do that. We also need to ensure that the mozilla-central graft point is included before continuing, so we do that, and then pull mozilla-central:
CC_CVS_BASE=$(hg log -R $HGCVS -r 'tip' --template '{node}') CC_CVS_BASE=$(grep $CC_CVS_BASE $OUTPUT/.hg/shamap | cut -d' ' -f2) MC_CVS_BASE=$(hg log -R $HGCVS -r 'gitnode(215f52d06f4260fdcca797eebd78266524ea3d2c)' --template '{node}') MC_CVS_BASE=$(grep $MC_CVS_BASE $OUTPUT/.hg/shamap | cut -d' ' -f2) # Okay, now we need to build the map of revisions. cat >$WORKDIR/convert-revmap.txt <span> e4f4569d451a5e0d12a6aa33ebd916f979dd8faa $CC_CVS_BASE # Thunderbird / Suite 7c0bfdcda6731e77303f3c47b01736aaa93d5534 d4b728dc9da418f8d5601ed6735e9a00ac963c4e, $CC_CVS_BASE # Calendar 9b2a99adc05e53cd4010de512f50118594756650 $MC_CVS_BASE # Mozilla graft point ee719a0502491fc663bda942dcfc52c0825938d3 78b3d6c649f71eff41fe3f486c6cc4f4b899fd35, $MC_EDITOR_IMPORT # Editor 8cdfed92867f885fda98664395236b7829947a1d 4b5da7e5d0680c6617ec743109e6efc88ca413da, e4e612fcae9d0e5181a5543ed17f705a83a3de71 # Chat EOF # Next, import mozilla-central revisions for rev in $MC_MORK_IMPORT $MC_EDITOR_IMPORT $MC_SMIME_IMPORT; do hg convert $MC $OUTPUT -r $rev --splicemap $WORKDIR/convert-revmap.txt \ --filemap $WORKDIR/convert-filemap.txt done
Some notes about all of the revision ids in the script. The splicemap requires the full 40-character SHA ids; anything less and the thing complains. I also need to specify the parents of the revisions that deleted the code for the mozilla-central import, so if you go hunting for those revisions and are surprised that they don't remove the code in question, that's why.
I mentioned complications about the merges earlier. The Mork and S/MIME import codes here moved files, so that what was db/mdb in mozilla-central became db/mork. There's no support for causing the generated splice to record these as a move, so I have to manually construct those renamings:
# We need to execute a few hg move commands due to renamings. pushd $OUTPUT hg update -r $(grep $MC_MORK_IMPORT .hg/shamap | cut -d' ' -f2) (hg -R $MC log -r "children($MC_MORK_IMPORT)" \ --template "{file_dels % 'hg mv {file} {sub(\"db/mdb\", \"db/mork\", file)}\n'}") | bash hg commit -m 'Pseudo-changeset to move Mork files' -d '2011-08-06 17:25:21 +0200' MC_MORK_IMPORT=$(hg log -r tip --template '{node}') hg update -r $(grep $MC_SMIME_IMPORT .hg/shamap | cut -d' ' -f2) (hg -R $MC log -r "children($MC_SMIME_IMPORT)" \ --template "{file_dels % 'hg mv {file} {sub(\"security/manager/ssl\", \"mailnews/mime\", file)}\n'}") | bash hg commit -m 'Pseudo-changeset to move S/MIME files' -d '2014-06-15 20:51:51 -0700' MC_SMIME_IMPORT=$(hg log -r tip --template '{node}') popd # Echo the new move commands to the changeset conversion map. cat >>$WORKDIR/convert-revmap.txt <span> 52efa9789800829c6f0ee6a005f83ed45a250396 abfd23d7c5042bc87502506c9f34c965fb9a09d1, $MC_MORK_IMPORT # Mork 50f5b5fc3f53c680dba4f237856e530e2097adfd 97253b3cca68f1c287eb5729647ba6f9a5dab08a, $MC_SMIME_IMPORT # S/MIME EOF
Now that we have all of the graft points defined, and all of the external code ready, we can pull comm-central and do the conversion. That's not quite it, though—when we graft the S/MIME history to the original mozilla-central history, we have a small segment of abandoned converted history. A call to hg strip removes that.
# Now, import comm-central revisions that we need hg convert $CC $OUTPUT --splicemap $WORKDIR/convert-revmap.txt hg strip 2f69e0a3a05a
[1] I left out one of the graft points because I just didn't want to deal with it. I'll leave it as an exercise to the reader to figure out which one it was. Hint: it's the only one I didn't know about before I searched for the archive points [2].
[2] Since I wasn't sure I knew all of the graft points, I decided to try to comb through all of the changesets to figure out who imported code. It turns out that hg log -r 'adds("**")' narrows it down nicely (1667 changesets to look at instead of 17547), and using the {file_adds} template helps winnow it down more easily.
http://quetzalcoatal.blogspot.com/2015/01/a-unified-history-for-comm-central.html
|
|
Gregory Szorc: Code First and the Rise of the DVCS and GitHub |
The ascendancy of GitHub has very little to do with its namesake tool, Git.
What GitHub did that was so radical for its time and the strategy that GitHub continues to execute so well on today is the approach of putting code first and enabling change to be a frictionless process.
In case you weren't around for the pre-GitHub days or don't remember, they were not pleasant. Tools around code management were a far cry from where they are today (I still argue the tools are pretty bad, but that's for another post). Centralized version control systems were prevalent (CVS and Subversion in open source, Perforce, ClearCase, Team Foundation Server, and others in the corporate world). Tools for looking at and querying code had horrible, ugly interfaces and came out of a previous era of web design and browser capabilities. It felt like a chore to do anything, including committing code. Yes, the world had awesome services like SourceForge, but they weren't the same as GitHub is today.
Before I get to my central thesis, I want to highlight some supporting reasons for GitHub's success. There were two developments in the second half of the 2000s the contributed to the success of GitHub: the rises of the distributed version control system (DVCS) and the modern web.
While distributed version control systems like Sun WorkShop TeamWare and BitKeeper existed earlier, it wasn't until the second half of the 2000s that DVCS systems took off. You can argue part of the reason for this was open source: my recollection is there wasn't a well-known DVCS available as free software before 2005. Speaking of 2005, it was a big year for DVCS projects: Git, Mercurial, and Bazaar all had initial releases. Suddenly, there were old-but-new ideas on how to do source control being exposed to new and willing-to-experiment audiences. DVCS were a critical leap from traditional version control because they (theoretically) impose less process and workflow limitations on users. With traditional version control, you needed to be online to commit, meaning you were managing patches, not commits, in your local development workflow. There were some forms of branching and merging, but they were a far cry from what is available today and were often too complex for mere mortals to use. As more and more people were exposed to distributed version control, they welcomed its less-restrictive and more powerful workflows. They realized that source control tools don't have to be so limiting. Distributed version control also promised all kinds of revamped workflows that could be harnessed. There were potential wins all around.
Around the same time that open source DVCS systems were emerging, web browsers were evolving from an application to render static pages to a platform for running web applications. Web sites using JavaScript to dynamically manipulate web page content (DHTML as it was known back then) were starting to hit their stride. I believe it was GMail that turned the most heads as to the full power of the modern web experience, with its novel-for-its-time extreme reliance on XMLHttpRequest for dynamically changing page content. People were realizing that powerful, desktop-like applications could be built for the web and could run everywhere.
GitHub launched in April 2008 standing on the shoulders of both the emerging interest in the Git content tracking tool and the capabilities of modern browsers.
I wasn't an early user of GitHub. My recollection is that GitHub was mostly a Rubyist's playground back then. I wasn't a Ruby programmer, so I had little reason to use GitHub in the early stages. But people did start using GitHub. And in the spirit of Ruby (on Rails), GitHub moved fast, or at least was projecting the notion that they were. While other services built on top of DVCS tools - like Bitbucket - did exist back then, GitHub seemed to have momentum associated with it. (Look at the archives for GitHub's and Bitbucket's respective blogs. GitHub has hundreds of blog entries; Bitbucket numbers in the dozens.) Developers everywhere up until this point had all been dealing with sub-optimal tools and workflows. Some of us realized it. Others hadn't. Many of those who did saw GitHub as a beacon of hope: we have all these new ideas and new potentials with distributed version control and here is a service under active development trying to figure out how to exploit that. Oh, and it's free for open source. Sign me up!
GitHub did capitalize on a market opportunity. They also capitalized on the value of marketing and the perception that they were moving fast and providing features that people - especially in open source - wanted. This captured the early adopters market. But I think what really set GitHub apart and led to the success they are enjoying today is their code first approach and their desire to make contribution easy, and even fun and sociable.
As developers, our job is to solve problems. We often do that by writing and changing code. And this often involves working as part of a team, or collaborating. To collaborate, we need tools. You eventually need some processes. And as I recently blogged, this can lead to process debt and inefficiencies associated with them.
Before GitHub, the process debt for contributing to other projects was high. You often had to subscribe to mailing lists in order to submit patches as emails. Or, you had to create an account on someone's bug tracker or code review tool before you could send patches. Then you had to figure out how to use these tools and any organization or project-specific extensions and workflows attached to them. It was quite involved and a lot could go wrong. Many projects and organizations (like Mozilla) still practice this traditional methology. Furthermore (and as I've written before), these traditional, single patch/commit-based tools often aren't effective at ensuring the desired output of high quality software.
Before GitHub solved process debt via commoditization of knowledge via market dominance, they took another approach: emphasizing code first development.
GitHub is all about the code. You load a project page and you see code. You may think a README with basic project information would be the first thing on a project page. But it isn't. Code, like data, is king.
Collaboration and contribution on GitHub revolve around the pull request. It's a way of saying, hey, I made a change, will you take it? There's nothing too novel in the concept of the pull request: it's fundamentally no different than sending emails with patches to a mailing list. But what is so special is GitHub's execution. Gone are the days of configuring and using one-off tools and processes. Instead, we have the friendly confines of a clean, friendly, and modern web experience. While GitHub is built upon the Git tool, you don't even need to use Git (a tool lampooned for its horrible usability and approachability) to contribute on GitHub! Instead, you can do everything from your browser. That warrants repeating: you don't need to leave your browser to contribute on GitHub. GitHub has essentially reduced process debt to edit a text document territory, and pretty much anybody who has used a computer can do that. This has enabled GitHub to dabble into non-code territory, such as its GitHub and Government initiative to foster community involvement in government. (GitHub is really a platform for easily seeing and changing any content or data. But, please, let me continue using code as a stand-in, since I want to focus on the developer audience.)
GitHub took an overly-complicated and fragmented world of varying contribution processes and made the new world revolve around code and a unified and simple process for change - the pull request.
Yes, there are other reasons for GitHub's success. You can make strong arguments that GitHub has capitalized on the social and psychological aspects of coding and human desire for success and happiness. I agree.
You can also argue GitHub succeeded because of Git. That statement is more or less technically accurate, but I don't think it is a sound argument. Git may have been the most feature complete open source DVCS at the time GitHub came into existence. But that doesn't mean there is something special about Git that no other DVCS has that makes GitHub popular. Had another tool been more feature complete or had the backing of a project as large as Linux at the time of GitHub's launch, we could very well be looking at a successful service built on something that isn't Git. Git had early market advantage and I argue its popularity today - a lot of it via GitHub - is largely a result of its early advantages over competing tools. And, I would go so far to say that when you consider the poor usability of Git and the pain that its users go through when first learning it, more accurate statements would be that GitHub succeeded in spite of Git and Git owes much of its success to GitHub.
When I look back at the rise of GitHub, I see a service that has succeeded by putting people first by allowing them to capitalize on more productive workflows and processes. They've done this by emphasizing code, not process, as the means for change. Organizations and projects should take note.
http://gregoryszorc.com/blog/2015/01/10/code-first-and-the-rise-of-the-dvcs-and-github
|
|
Daniel Stenberg: curl 7.40.0: unix domain sockets and smb |
curl and libcurl  7.40.0 was just released this morning. There’s a closer look at some of the perhaps more noteworthy changes. As usual, you can find the entire changelog on the curl web site.
7.40.0 was just released this morning. There’s a closer look at some of the perhaps more noteworthy changes. As usual, you can find the entire changelog on the curl web site.
So just before the feature window closed for the pending 7.40.0 release of curl, Peter Wu’s patch series was merged that brings the ability to curl and libcurl to do HTTP over unix domain sockets. This is a feature that’s been mentioned many times through the history of curl but never previously truly implemented. Peter also very nicely adjusted the test server and made two test cases that verify the functionality.
To use this with the curl command line, you specify the socket path to the new –unix-domain option and assuming your local HTTP server listens on that socket, you’ll get the response back just as with an ordinary TCP connection.
Doing the operation from libcurl means using the new CURLOPT_UNIX_SOCKET_PATH option.
This feature is actually not limited to HTTP, you can do all the TCP-based protocols except FTP over the unix domain socket, but it is to my knowledge only HTTP that is regularly used this way. The reason FTP isn’t supported is of course its use of two connections which would be even weirder to do like this.
SMB is also known as CIFS and is an old network protocol from the Microsoft world access files. curl and libcurl now support this protocol with SMB:// URLs thanks to work by Bill Nagel and Steve Holme.
Last year we had a large amount of security advisories published (eight to be precise), and this year we start out with two fresh ones already on the 8th day… The ones this time were of course discovered and researched already last year.
CVE-2014-8151 is a way we accidentally allowed an application to bypass the TLS server certificate check if a TLS Session-ID was already cached for a non-checked session – when using the Mac OS SecureTransport SSL backend.
CVE-2014-8150 is a URL request injection. When letting curl or libcurl speak over a HTTP proxy, it would copy the URL verbatim into the HTTP request going to the proxy, which means that if you craft the URL and insert CRLFs (carriage returns and linefeed characters) you can insert your own second request or even custom headers into the request that goes to the proxy.
You may enjoy taking a look at the curl vulnerabilities table.
The release notes mention no less than 120 specific bug fixes, which in comparison to other releases is more than average.
Enjoy!
http://daniel.haxx.se/blog/2015/01/08/curl-7-40-0-unix-domain-sockets-and-smb/
|
|
Allison Naaktgeboren: Applying Privacy Series: The 3rd meeting |
Engineer goes off and creates the initial plan & sends it around. At a high level,it looks like this:
Client side code
Set up
snippet lets users know there is a new options in preferences
if the app language pref does not map to a supported language, the pref panel is greyed out with a message that their language is not supported by the EU service
if it does, user clicks ToS, privacy policy checkbox, confirms language
app contacts server
if server not available, throw up offline error
if server available, upload device id, language, url list
notify user setup is complete
enable upload service
When new tab is opened or refreshed
using device id, send a sql query for matching row of url+device id
Server side code
Set up
poked by client, adds rows to table, one for each url (tab)
Periodic background translation job:
finds urls of rows where the translated blob is missing
for each url, submits untranslated blob to EU’s service
sticks the resulting translated text blob back into the table
Periodic background deletion job:
finds rows older than 2 days and evicts them
unless that is the last row for a given device id, in which case hold for 90 days
Database layout
table columns: device id, url, timestamp, language, untranslated text, translated text
The 3rd Meeting:
Engineer: Did y’all have a chance to look over the plan I sent out? I haven’t received any email feedback yet.
DBA: I have a lot of concerns about the database table design. The double text blobs are going to take up a lot of space and make the server very slow for everyone.
Operations Engineer: ..and the device id really should not be in the main table. It should be in a separate database.
Engineer: why? That’s needless complexity!
Operations Engineer: Because it should be stored in a more secure part of the data center. Different parts of the data center have different physical & software security characteristics.
Engineer: “ oh”
Engineering Manager: You should design your interactions with the server to encapsulate where the data comes from inside the server. Just query the server for what you want and let it handle finding it. Building the assumption that it all comes from one table into your code is bad practice.
Engineer: ok
DBA: The double blobs of text is still a problem.
Engineer: Ok, well, let’s get rid of the untranslated text blob. I’ll take the url and load the page and acquire the text right before submitting it to the EU service. How does that sound?
Engineering Manager: I like that better. Also allows you to get newest content. Web pages do update.
Privacy Rep: I was wondering what your plans are for encryption? I didn’t see anything in your draft after it either way.
Engineer: If it’s on our server and we’re going to transmit it to an outside service anyway, why would we need encryption?
Privacy Officer: We’ll still have a slew of device ids stored. At the very least we’ll need to encrypt those. Risk mitigation.
Engineer: But they’re our servers!
Operations Engineer: Until someone else breaks in. We’ve agreed that the device ids will go in a separate secure table, so it makes sense to encrypt them.
Engineer: fine.
Privacy Officer: The good news is that if you design the url/text table well, I don’t think we’ll need to encrypt that.
Engineer: That’s your idea of good news?
Engineering Manager: Privacy Officer is here to help. We’re all here to help.
Engineer: Right, Sorry Privacy Officer.
Privacy Rep: It’s ok. Doing things right is often harder.
Privacy Officer: Anyway, I wanted to let you all know that I’ve started talking with Legal about the terms of service and privacy policy. They promise to get to it in detail next month. So, as long as we stay on the stage servers, it won’t block us.
Engineering Manager: thanks. Do you have any idea how long it might take them once they start?
Privacy Officer: Usually a couple weeks. Legal is very, very through. I think it’s a job requirement in that department.
Engineer: Fair enough.
Operations Engineer: Speaking of legal & privacy, do you/they care about the server logs?
Privacy Officer: I don’t think so. The device id is the most sensitive bit of information we’re handling here and that shouldn’t appear in the logs right? I’ll still talk it over with the other privacy folks in case there’s a timestamp to ip address identification problem.
Operations Engineer: That’s correct.
Engineering Manager: Always good to double check.
Privacy Officer: By the way, what happens to a user’s data when they turn the feature off?
Engineer: … I don’t know. Product Manager didn’t bring it up. I don’t have a mock from him about what should happen there.
Privacy Officer: we should probably figure that out.
Engineer: yeah
Engineering Manager: I look forward to seeing the next draft. I think after you’ve applied the changes & feedback here you should send it out to the public engineering feature list and get some broader feedback.
Engineer: will do. Thanks everyone
http://www.allisonnaaktgeboren.com/applying-privacy-series-the-3rd-meeting/
|
|
Benjamin Kerensa: Scale13x and Mozilla |
![]() Mozilla will be at Southern California Linux Expo (Scale13x) again this year with a booth so be sure to stop by if you live in the area or will be attending. This year the organizers have offered Mozillians a special promo code to get 50% off their registration simply use the code “MOZ” when registering!
Mozilla will be at Southern California Linux Expo (Scale13x) again this year with a booth so be sure to stop by if you live in the area or will be attending. This year the organizers have offered Mozillians a special promo code to get 50% off their registration simply use the code “MOZ” when registering!
http://feedproxy.google.com/~r/BenjaminKerensaDotComMozilla/~3/2RNBZuYNiJ0/scale13x-and-mozilla
|
|
Kim Moir: Mozilla pushes - December 2014 |



http://relengofthenerds.blogspot.com/2015/01/mozilla-pushes-december-2014.html
|
|
Doug Belshaw: What (some) people think about ‘radical participation’ |
Yesterday I was in Durham presenting on Radical Participation. At the start of the session each participant was given a couple of index cards. During my keynote I stopped and asked them to write or draw something on one of the four sides.
Today, I scanned in three of the four sides (the final one involved personal info that people may not have wanted to share more widely) and uploaded the images to this Flickr album. The header image is one person’s view of their institution’s ‘architecture of participation’. Interesting!
I did use Quicktime to record my screen during the presentation. That can be found on Vimeo. However, the audio is difficult to hear in places when I strayed away from the microphone.



Many thanks to Malcolm Murray and team for inviting me to take part in such a great event. Also: I got to stay in a castle! ![]()
@dajbelshaw It was a great keynote. Currently blogging about it and thinking about voluteering for @mozilla
— Rosie Hare (@RosieHare) January 8, 2015
http://dougbelshaw.com/blog/2015/01/08/what-some-people-think-about-radical-participation/
|
|
Gervase Markham: slic 1.0.0 Released |
I’ve just released version 1.0 of some new software called slic, which I’ve been using to do license analysis on Firefox OS. From the README:
This is slic, the Speedy LIcense Checker. It scans a codebase and identifies the license of each file. It can also optionally extract the license text and a list of copyright holders – this is very useful for meeting the obligations of licenses which require reproduction of license text. It outputs data in a JSON structure (by default) which can then be further processed by other tools.
It runs at about 120 files per second on a single core of a 3GHz Intel I7 (it’s CPU-bound, at least on a machine with an SSD). So you can do 100,000 files in less than 15 minutes. Parallel invocation is left as an exercise for the reader, but could easily be bolted on the side by dividing up the inputs.
The code is Python, and it uses a multi-stage regexp-based classifier, so that with families of licenses it starts with a more generic classification and then refines it via checking various sub-possibilities. Future potential enhancements include a hash-based cache to avoid doing the same work more than once, and integration with a popular online spreadsheet tool to help manage exceptions and manual license determinations.
http://feedproxy.google.com/~r/HackingForChrist/~3/rNtvvuK7s9s/
|
|
Christian Heilmann: Quick tip: conditional form fields with CSS |
As part of a tool I just wrote, I had the issue that one form field was dependent on another and I didn’t want to go the full way and create the field on demand with JavaScript but keep it to CSS. You can see the result here:
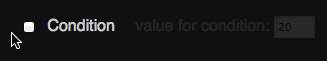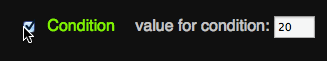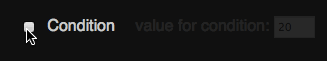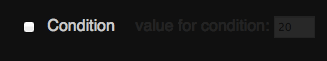
A simple way to achieve this visually is to use the :checked pseudo and + selectors as you can see in this Fiddle:
The HTML is the following:
> span> type="checkbox" id="moo"> span> for="moo">Condition> > value for condition: span> type="text" value="20"> > > |
And the important CSS are these few lines:
label + label { padding-left: 1em; opacity: 0.1; transition: 0.5s; } :checked + label + label { opacity: 1; } |
Once you publish something like this, you will get a lot of tweets that this is not accessible. The same happened here, and it doesn’t matter that I wrote about the shortcomings in the first version of this post. The debate is interesting and relevant. So let’s break it down:
It is disappointing that a simple problem like this still needs a lot of DOM manipulation and/or ARIA to really be accessible. Maybe we think too complex – a different way of solving this issue would be to cut this problem into several steps and reload the page in between. Overkill for one field, but for very complex JS-driven forms this might be a much saner solution. And it could result in smaller forms as we don’t need a framework or lots of libraries.
In this – simple – case I wonder what harm there is in the extra form field to be accessible to non-visual users. The label could say what it is. Say the checkbox has a label of “convert to JPG”. A label of “JPG quality” on the text field would make things understandable enough. Your backend could also be intelligent enough to realise that when a JPG quality was set that the user wanted a JPG to be generated. We can be intelligent in our validation that way.
Turns out that adding visibility to the earlier example has the same visual presentation and fixes the tabbing issue:
The HTML is still the following:
> span> type="checkbox" id="moo"> span> for="moo">Condition> > value for condition: span> type="text" value="20"> > > |
And the updated CSS:
label + label { padding-left: 1em; opacity: 0.1; visibility: hidden; transition: 0.5s; } :checked + label + label { opacity: 1; visibility: visible; } |
http://christianheilmann.com/2015/01/08/quick-tip-conditional-form-fields-with-css/
|
|
Pomax: Taking React to the next level: Mixins, Gulp, and Browserify |
In a previous post I explored React because we're looking at using it for new apps in the Mozilla foundation engineering team, and I covered what you're going to run into when you pick it up for the first time.
The tl;dr: version is that React doesn't use HTML, anywhere. It only offers a convenient syntax shorthand that looks like HTML, but obeys XML rules, and is literally the same as writing React.createElement("tagname", {props object}). For a web UI framework, that might seem weird, but it frees you to think about your UI as functional blocks, where you don't have "divs in divs" but "functional components composed of other functional components", and model your UI logic and interaction that way. The fact that it renders into the browser is nice, because that's what we want, but in no way actually important to your design process.
So: I like React. But React can't do everything, and there are things that make no sense to do as a React component, like plain JS functionality. For instance, if you want an image manipulation component, then by all means write it, but you're not going to also include all the code for the under-the-hood image processing library. You want to keep that separate.
That post didn't cover everything, and hopefully it left some questions on the table, so let's address those: what's still missing?
Looking at a concrete example of what you might find missing: this blog uses React, and which updates its internal state whenever the user changes data. If the user clicks outside the editable area,
It would be easy to hard-code that into the MarkDown element:
var MarkDown = React.createElement({
...
render() {
var markedDown = marked(this.props.data);
return {markedDown}
},
...
});
But React knows we're technically injecting user-generated content here, and that's not guaranteed to be safe in the slightest. It won't let us do things this way. Instead, it requires us to do:
var MarkDown = React.createElement({
...
render() {
var markedDown = marked(this.props.data);
return
},
...
});
But now I disagree, because while I understand React's philosophy, I know that the markdown is simply "what it has to be". I'm not setting it "dangerously", I'm setting it intentionally. This is my blog, damnit!
Instead, we can use a "mixin", which is an object that you can give to React components, and they can be "mixed into" a component, so that it has this-level access to all the functions defined in the mixin. Looking at the markdown mixin I'm using for this blog, we see this code:
var MarkDownMixin = {
markdown: function(string) {
return {
dangerouslySetInnerHTML: {
__html : marked(string)
}
};
}
};
This mixin returns an object with a function markdown(...) that, when called, formats the input (using marked(string)) and then forms the non-JSX object that React builds when you transform the JSX code dangerouslySetInnerHTML="...". Using this mixin in the MarkDown component, we see:
var MarkDown = React.createClass({
mixins: [
MarkDownMixin
],
render: function() {
this.html = this.markdown(this.props.text)
return
},
getHTML: function() {
return this.html.dangerouslySetInnerHTML.__html;
}
});
Two things to note: (1) the substitution pattern uses ..., because the markdown function generates the full object representation rather than a JSX string. We can add those in bits that are using JSX by using the {...thing} syntax. It's not the most beautiful syntax, but it's a lot nicer than seeing dangerouslySetInnerHTML, and that's number (2): this code is no longer offensive.
Let's look at another example: onClickOutside. React itself has no way to make components react to clicks that originate "outside" of them. It has an onClick={...} but no onClickOutside={...} concept. This can be inconvenient to downright annoying: does that mean we have to write document.click handlers in every component we use? Thankfully: no. We can implement this as a mixin, adding the document level click handler when a component is mounted, and making sure to do clean up when it the component gets unmounts:
var OnClickOutside = {
componentDidMount: function() {
if(!this.handleClickOutside)
throw new Error("missing handleClickOutside(event) function in Component "+this.displayName);
var fn = (function(localNode, eventHandler) {
return function(evt) {
var source = evt.target;
var found = false;
// make sure event is not from something "owned" by this component:
while(source.parentNode) {
found = (source === localNode);
if(found) return;
source = source.parentNode;
}
eventHandler(evt);
}
}(this.getDOMNode(), this.handleClickOutside));
document.addEventListener("click", fn);
associate(this, fn);
},
componentWillUnmount: function() {
var fn = findAssociated(this);
document.removeEventListener("click", fn);
}
};
This mixin is used in the blog's
This mixing looks a little like a React component, in that it has functions that are named the same as the life cycle functions in a React component, and React will take any such function and make sure they gets called when a components associated life cycle function is called. Looking at the code for blog entries:
var Entry = React.createClass({
mixins: [
OnClickOutside
],
componentDidMount: function() {
// this code, *and the code from the mixin*, will run
var state = this.props.metadata;
state.postdata = this.props.postdata;
this.setState(state);
},
...
handleClickOutside: function(evt) {
// outside clicks simply tie into a function we already use:
this.view();
},
...
view: function() {
if(this.state.editing) {
// go from edit mode to view mode:
var self = this;
self.setState({ editing: false }, function() {
self.props.onSave(self);
});
}
},
...
});
When componentDidMount function is triggered, the code from the mixin also gets run. We don't need to write any code inside the component to make sure we trigger things at exactly the right time: we can simply exploit the life cycle of a component and rely on mixins to tie into their associated functions to do what we need.
Mixins are a good way to capture aspects that are shared by multiple components, even if they share nothing else. For instance, if you need a universal timestampToUUID() function so that all your components will be using the same format, you can write a mixin for that, and be assured that all your components now speak the same timestamp language.
In traditional OOP this would be handled through inheritance, but React doesn't do inheritance: its OOP is based on compositing uncoupled objects into meaningful structures, so having mixins solves the problem of how to give multiple components "the same something" to work with.
So far everything's been talking about loose files. Mixings and components alike have been written in code that doesn't really do much other than "be loaded into global context" and most developers will agree that's kind of bad. You might do that in combination with an index.dev.html or something, but seriously: bundle that stuff.
So let's look at how to bundle React code.
The most successful formula that I know of is the "write it in commonjs format, and use browserify" one, where we rewrite our code so that it follows the commonjs export/require methodology, so that we can run the code through a bundler that knows how to resolve all those requirements. My commonjs environment of choice is Node.js, and my bundler of choice is Browserify.
Let's do a quick rewrite. As demonstrator, I'll rewrite the MarkDown component that we saw earlier:
var React = require("react");
module.exports = React.createClass({
mixins: [
require("../mixins/markdown")
],
render: function() {
this.html = this.markdown(this.props.text)
return
},
getHTML: function() {
return this.html.dangerouslySetInnerHTML.__html;
}
});
A pretty straight forward rewrite, but the important part there is the mixin require call. We no longer have the mixin live in global context, we need to load it from "somewhere". Node.js can load either from an installed package location, or from a relative file path, so in this case we load React as an installed package, the mixin from a local file, and we're done. Of course we need to make sure the mixins are of the right commonjs format, too:
var marked = require("../bower_components/marked/lib/marked");
module.exports = {
markdown: function(string) {
return {
dangerouslySetInnerHTML: {
__html : marked(string)
}
};
}
};
And this is an equally simple rewrite. Instead of relying on marked living in global context, we explicitly require it in, and that's pretty much that.
Browserify can take Node.js code, walk through all the dependencies and requirements and then spit out a single, bundled file that shims the require mechanism for the browser, so that code that works in Node, also works in the browser. Normally this doesn't require anything special, in that you just point browserify at your main app.js file and it does the rest:
$> browserify main.js -o bundle.js
Done, that would grow your 10 line main.js file into a 400kb bundle of all your required in code plus all the required dependencies. Your users cache that bundle once, and from then on the browser simply reloads it from cache. One HTTP request, once, and you know that if your URL is reachable, then none of the dependencies your app has will cause your app to fail loading: it's all just there. And it'll be small over the wire, because gzip transmissions can compress javascript really well. The bigger the file, the better the compression can be because there's more data to mark as "the same" (there's an upper limit to that of course, but a 400kb single file will typically compress far better than a hundred 4kb files).
However, React comes with JSX syntax, so it's not quite as easy as just running Browserify and being done, but that's where Gulp comes in...
Gulp is very nice. It lets you set up "streams" to pipe data through some filter, and the hand it off to the next "thing that looks at the pipe". For using Browserify, we want to do something like "take code, transform its JSX, then bundle it all up", and with Gulp, that's really simple! Here's the gulp build script for compiling the JS bundle that this blog relies on:
var gulp = require('gulp');
var concat = require('gulp-concat');
/**
* Browserify bundling only.
*/
gulp.task('browserify', function() {
var browserify = require('browserify');
var transform = require('vinyl-transform');
var reactify = require('reactify');
var source = require('vinyl-source-stream');
// Don't process react/octokit, because we can "bundle"
// those in far more efficiently at the cost of a global
// variable for React and Octokit. "oh no"
var donottouch = require('browserify-global-shim').configure({
'react': 'React',
'octokit': 'Octokit'
});
return browserify('./components/App.jsx')
.transform(reactify)
.transform(donottouch)
.bundle()
.pipe(source('bundle.js'))
.pipe(gulp.dest('./build/'));
});
/**
* Pack in the React and Octokit libraries, because this
* saves about 200kb on the final minified version compared
* to running both through browserify the usual way.
*/
gulp.task('enrich', ['browserify'], function() {
return gulp.src([
'./bower_components/react/react.min.js',
'./bower_components/octokit/octokit.js',
'./build/bundle.js'
])
.pipe(concat('enriched.js'))
.pipe(gulp.dest('./build/'));
});
/**
* Minify everything, using uglify.
*/
gulp.task('minify', ['enrich'], function() {
var uglify = require('gulp-uglify');
return gulp.src('./build/enriched.js')
.pipe(concat('gh-weblog.js'))
.pipe(uglify())
.pipe(gulp.dest('./dist/'));
});
/**
* our "default" task runs everything, but -crucially- it
* runs the subtasks in order. That means we'll wait for
* files to be written before we move on to the next task,
* because in this case we can't run parallel tasks.
*/
gulp.task('default', ['minify'], function() {
console.log("Finishing packing up.");
});
This runs three tasks: one to browserify everything, one to enrich the resulting bundle with additional dependencies, and one to minify the whole thing. Those familiar with Gulp might ask "why is this three tasks instead of just one massive pipe" to which the answer is that Browserify with Vinyl and Uglify does really weird things. Some of those parts generate streams, some of them generate buffers, and some of them really, really don't want to work together without an additional three modules designed specifically to do things like "Forcing things to buffers" or "injecting files in the middle of a pipe". It gets weird. Also, and this is the proper reason rather than just "it's more of a hassle": Gulp tasks should be written such that each tasks only does one job. If you need to do multiple things, you write one task per thing, and chain them. And that's exactly what we're doing here.
Fun fact: this is a limitation due to how Browserify works. By resolving require() statements to its dependency, Browserify will bundle up any code that is required, even if the code never actually makes use of that requirement when running in the browser. For instance: Octokit can run in the browser with a <60kb footprint, because the browser has virtually everything it needs. In Node.js it needs to shim a fair number of things so with all require()ments loaded its footprint is 320 kb. Browserify has no concept of "pruning after checking what gets loaded", so it just builds the full 320kb. Even React suffers from this: using the for-browsers version of React, as opposed to letting Browserify bundle it in, saves us about 25kb. It's not as much a difference as for Octokit, but still adds up for justifiable reason.
So we run the three tasks: use Browserify for everything we can bundle without bloating (so, without React and Octokit), then a task that adds React and Octokit on top, and then a task that minifies everything using the Uglify minifier. This recipe turns 17 files amounting to 250kb into a single file that's only 183kb. Fewer script includes AND less data. Very nice. Now we can load this up with a single script requirement on-page:
And thus we get production levels of happiness. Adding server-side gzipping will make this package only 50kb over the wire, which is perfectly acceptable for "everything the app needs to run".
Writing React code so that it can be efficiently bundled for production deployment is actually pretty simple, once you know which tools to use. The difference between a plain React component definition and a Node.js style definition is almost nothing (and there's even a Sublime Text plugin that'll just generate you a full Node.js style React component skeleton by typing "new R" and selecting "rcc"), but using the Node.js style code means we can run everything through Browserify and pipe filters, and end up with a highly optimised package, ready for delivery to the user.
Technology's not perfect: sweet as Gulp and Browserify are, in this case we had to mess around with what Browserify gets to require into the bundle and what we want to keep out, because we care about deploy size. For any project, that's a thing to take into consideration. Maybe you don't even want to bundle certain things in at all. For instance, we could have left React out of the bundle entirely and loaded it from CDN. I decided not to, because facebook's CDN for React is actually a redirect to an http URL, even when you're on HTTPS, so anyone loading the site over HTTPS will see the site header, and nothing else. So: remember you're working with computers!
|
|
Nick Alexander: What I intend to work on for the Firefox 38 cycle |
The Mozilla Corporation as a whole has been investing in a deliberate 2015 planning process, and some teams, in particular Cloud Services, have done a fantastic job of circulating their first quarter goals. I really applaud their efforts to be transparent, so I figured I would mimic them (the sincerest form of flattery and all that).
I was quite deliberate when choosing my Firefox 36 cycle goals, and then fell off the wagon for the 37 cycle. I found writing my goals for the 36 cycle personally helpful, but I only shared them with my direct supervisor (@mfinkle). One way that I surfaced them more broadly was that I included my goals as top-level items in my section of the weekly team meeting wiki page and updated my status over time.
In the spirit of transparency, and because I find knowing what my colleagues are building interesting, here’s what I anticipate working on for the reminder of the 37 cycle and the 38 cycle.
I have been pushing the Firefox for Android work that will migrate Old Sync users to Firefox Accounts. The work is tracked by meta Bug migratesyncandroid.
I’ve landed the Firefox Accounts client-side UI code that prompts the user to finish migrating by logging in (Bug 1098667). I’ve landed the Old Sync code that recognizes if another device in the same device constellation has migrated and uploaded a migration sentinel (Bug 1091189).
The final piece of functionality is to message Old Sync users who have not migrated (Bug 895526). We expect this set to be small, since all Android Old Sync users needed a Desktop Old Sync device in order to pair their Android device, and those users are certainly going to be convinced by our Desktop messaging. We hope. This messaging only needs to be on the release channel before we start deprecating the Old Sync server farm, which is some number of releases after the start of migration messaging (Firefox 37).
There’s an open request from rnewman for some tracking of the Android-side migration process, be it FHR, telemetry, or whatever. I intend to investigate this but I haven’t committed to it yet.
Sometime in the far future, we can rip out the existing Android Sync code (tracked by meta Bug 957845).
We intend to expose our first Firefox Account attached service (Reading List) on Firefox for Android in the 38 cycle. The auth layer will be FxA OAuth. I’ve written some of the OAuth code that we’ll use; Bug 1117829 tracks rehabilitating the old code and adding the Android Account authenticator to it. This is a hard blocker for the Reading List service, so it’s a high priority for me. (But there’s no particular reason another developer couldn’t pick it up.)
We have ongoing build system battles to fight and continual feature and improvement requests. Solidifying mach bootstrap for mobile/android provides outsize value relative to my time invested. I will try to maintain and incrementally improve the IntelliJ configuration that I have glued together, but really pushing the Gradle/IntelliJ integration forward is not going to happen in the 38 cycle. It is my opinion that investing effort into the build system to use new Google-provided features (split Google Play services, shrinkResources, etc) is a bad use of our time. We should instead put the effort into transitioning our build to Gradle (or a competitor) and get these incremental features cheaply. Given this assessment, I do not expect to spend time improving our APK size this cycle.
I’ll be building as much of the Firefox Accounts front-end and back-end as I can get done for Firefox for iOS. This is a soup-to-nuts affair, roughly tracked by meta Bug 1092561.
The first order of business is to decide between a native UI for signing in and signing up or whether to host this UI on the web, using a hybrid jelly-doughnut approach. We built a native UI for Firefox for Android, but we’ve used a hosted web UI in Firefox for Desktop. Both work; both have advantages and disadvantages. I’ll be evaluating and making a recommendation for which approach to pursue in the first weeks of the 38 cycle.
Concurrently, I’ll be writing the HTTP clients and token-passing plumbing required to keep a configured Firefox Account in a good state and prepare the client to Sync. The abstractions we built for this in Firefox for Android have weathered very well; this will be a "judicious re-implementation" of the same ideas into Swift.
That’s what I’m going to be doing. But I’m always trying to make things better for contributors and I love to mentor tickets. Get involved with Firefox for Android or help build and test Firefox for iOS.
Discussion is best conducted on the mobile-firefox-dev mailing list and I’m nalexander on irc.mozilla.org and @ncalexander on Twitter.
http://www.ncalexander.net/blog/2015/01/06/what-i-intend-to-work-on-for-the-firefox-38-cycle/
|
|
Alon Zakai: 2 recent Emscripten stories |
http://mozakai.blogspot.com/2015/01/2-recent-emscripten-stories.html
|
|






