Fabien Cazenave: KompoZer 0.8b2 |
![]()
KompoZer 0.8b2 is finally ready. Few visible changes, but a lot of bugfixes and code cleaning under the hood.
You can grab KompoZer 0.8b2 here: http://kompozer.net/download.php
Enjoy, and please report bugs!
We’ve tried to solve the most frequently reported bugs:
KompoZer 0.8b2 is now a more reliable editor: the regressions in the CSS editor were a complete blocker for myself, so I guess it’s been a real nightmare for most users. We’ve fixed a lot of small bugs and I think the overall user experience should be much better than with the previous versions.
C'edric Corazza, our l10n lead, has done a great job to release localized binaries for all the supported languages at once. This time he’s had much more work than for the previous beta:
C'edric, congrats! and go get some sleep, the Korean and Bulgarian locales are getting ready. ;-) I’ll definitely write a few scripts to ease your work for the next release.
The inline spell checker in KompoZer 0.7.10 was inherited from Nvu, it was implemented with a specific patch against the Gecko 1.7 core and it caused a lot of freezes and crashes. As a result, most users (including myself) disabled it and I didn’t see it as an important feature to bring back in KompoZer 0.8.
As you can guess, a lot of users had a very different opinion on this. :-)
Unlike Gecko 1.7, Gecko 1.8.1 has a very good built-in inline spell checker. I’ve had a look at Thunderbird’s code and I found out enabling the inline spell checker in KompoZer was a snap. I’m sorry I didn’t do it sooner — but now it’s done, and it’s working fine as far as I know.
I’m working with Fabien ’Kasparov’ Rocu on the next version of the DOM Explorer. As Fabien is implementing his ideas in an extension, I had to clean up the DOM Explorer and add a few hooks for his addon. To ease the development of his add-on, we’ve decided to implement a part of his work directly in KompoZer 0.8b2:
The real improvement will come with Fabien’s extension, which should be released in April 2010. I’ll come back to this in another blog post.
I’m known to be a dangerous pervert when it comes to computer keyboards — I admit I hate having to use a mouse when I’m editing a text. These new keyboard shortcuts aren’t documented, you can see them as a hidden bonus:
The Ctrl+Up/Down shortcut is more than a productivity booster. One of the known problems of the Mozilla editor component is that in some situations, it can be difficult to put the caret where you want it: for instance, there’s no easy way to put the caret right after a
…and I’m aware of that. Please configure KompoZer to use your favorite text editor to work on the HTML source, there’s a specific “HTML” button by default in the main toolbar for that. I can’t help it, I hate the “Source” view in Nvu and KompoZer 0.7:
The SeaMonkey-like plaintext editor, in my opinion, is much better at the moment — and on my first trunk builds (KompoZer 0.9a1pre / Gecko 1.9.3), Bespin is already working quite well.
Again, I understand a lot of users have a very different opinion on this, so I’ve tried an interesting experiment with this “Source” view: basically, I’ve re-written the main
Unfortunately, this new
…but we’re working on it. As you may have noticed, the HTML output of KompoZer 0.8 is already much cleaner than the one we had in KompoZer 0.7, especially if you check the “reformat HTML source” option: the most visible point is, there are (almost) no empty lines any more in the output files. But your well-defined indentation is still destroyed by KompoZer, which is a real pain when switching to “Source” mode.
Of course, you can use HTML Tidy as a workaround; I even used to design an Nvu extension for that. But this means dealing with temp files, serializing the files twice (once with KompoZer + reformatting with Tidy), and risking data losses (especially in utf-8, don’t ask me why). And the HTML code in the “Source” view is still a mess.
The great news is, Laurent Jouanneau has backported his XHTML serializer to Gecko 1.8.1 so I could use it for KompoZer 0.8 — and the first results look great! See this small example I saved with KompoZer 0.7.10, KompoZer 0.8b2 and KompoZer 0.8b3pre. Looks like we can finally get rid of HTML Tidy!
There are four main points to address before we can release a third (and hopefully last) beta:
Please test this new version and report bugs. Many thanks to all users who donated or gave some time to keep this project running!
|
|
Fabien Cazenave: KompoZer 0.8b3 |
![]()
We’ve just released KompoZer 0.8b3:
 kompozer-0.8b3.en-US.win32.exe (Windows™ installer) kompozer-0.8b3.en-US.win32.zip (Windows™ archive)
kompozer-0.8b3.en-US.win32.exe (Windows™ installer) kompozer-0.8b3.en-US.win32.zip (Windows™ archive) kompozer-0.8b3.en-US.mac-universal.dmg (Mac OS X™)
kompozer-0.8b3.en-US.mac-universal.dmg (Mac OS X™) kompozer-0.8b3.en-US.gcc4.2-i686.tar.gz (GNU/Linux)
kompozer-0.8b3.en-US.gcc4.2-i686.tar.gz (GNU/Linux) kompozer-0.8b3-src.tar.bz2 (source tarball)
kompozer-0.8b3-src.tar.bz2 (source tarball)Localized binaries are available on the official download page: http://kompozer.net/download.php.
This maintainance release fixes two regressions that have been introduced in the previous beta:
I didn’t want to take the risk of addressing other bugs but I did work on bug 1831943 by disabling line wrapping for Asian users. The relevant preference (editor.htmlWrapColumn) it now set to zero for Chinese (zh-CN, zh-TW) and Japanese (ja) builds, and it should be read properly by KompoZer — both when switching to “Source” mode and when saving HTML documents. This is still experimental, so your feedback will be welcome.
We’ve spent a few hours designing a bash/python script to make localized binaries for the 18 languages that are currently supported by KompoZer. This script works fine on Linux and OSX and it can build win32 installers by launching the InnoSetup compiler through Wine. It also checks that I haven't forgotten to include the MSVC7 DLLs in the win32 binaries, which should avoid us a few bad surprises for the next releases…
For the next beta we’ll focus on the “Source” view and the FTP module. We’ll do our best to release it in March.
EDIT In case you’ve downloaded a Windows build with missing MSVC7 dlls, I’ve just changed the path of all Windows binaries on SourceForge. Please download KompoZer 0.8b3 again, the problem should be solved. Sorry for the trouble. :-/
|
|
Chris Ilias: My Installed Add-ons – Context Search |
I love finding new extensions that do things I never even thought to search for. One of the best ways to find them is through word of mouth. In this case, I guess you can call it “word of blog”. I’d like to start a series of blog posts about the extensions I use, and maybe you’ll see one that you want to use.
The first one is Context Search. Context Search is one of those extensions I think should be part of Firefox. Context Search allows you to choose which search engine you use for each search. If it’s a word you aren’t familiar with, you can choose the Websters search engine. If it’s an acronym you aren’t familiar with, you can choose the Acronym Finder search engine.
Without the extension, when you highlight text then right-click, the menu will contain an item to search your preferred search engine for the text that is highlighted. With Context Search, you are instead given a list of your installed search engines, so you can pick which one to use. The search results will open in a new tab. I find myself using it more than the search bar.
Here’s a screenshot:

You can install it via the Mozilla Add-ons site.
http://ilias.ca/blog/2014/12/my-installed-add-ons-context-search/
|
|
Yunier Jos'e Sosa V'azquez: Actualizando complementos |
 Despu'es de un tiempo sin actualizar los complementos disponibles en nuestro AMO (Addons.Mozilla.Org), volvemos a ofrecerle este servicio.
Despu'es de un tiempo sin actualizar los complementos disponibles en nuestro AMO (Addons.Mozilla.Org), volvemos a ofrecerle este servicio.
Ofrecemos disculpas por las molestias ocasionadas, no hab'iamos publicado m'as porque una actualizaci'on en los servicios de Mozilla, hab'ia dejado desactualizada la carpeta en su FTP p'ublico — los complementos se guardan en otra ubicaci'on.
Poco a poco iremos actualizando y publicando nuevas extensiones para toda la comunidad cubana. Si existe un add-on que no ha sido actualizado — unos cuantos –, nos lo pueden decir y le damos prioridad en la cola.
|
|
Robert O'Callahan: rr 3.0 Released With x86-64 Support |
I just pushed the release of rr 3.0. The big milestone for this release is that x86-64 support is fully functional! On 64-bit machines, we build a 64-bit rr that can record and replay 64-bit processes with the same set of features and performance-enhancing tricks that we developed for 32-bit. Not only that, but 64-bit rr can also record and replay 32-bit processes or even a mix of 32-bit and 64-bit processes in the same process tree. 64-bit support is mostly due to Nathan Froyd and we hope it significantly lowers barriers to using rr.
Many other internal improvements and sundry bug fixes have landed since 2.0. Some highlights:
rr ps command lists the processes recorded in an rr trace, making it easier to select the process you want to debug. rr replay -p automatically attaches to the first exec of rr replay -p plugin-container. Development carries on; visit rr-dev for exciting updates.
Have fun using rr!
http://robert.ocallahan.org/2014/12/rr-30-released-with-x86-64-support.html
|
|
Nicholas Nethercote: Cumulative heap profiling in Firefox with DMD |
DMD is a tool that I originally created to help identify where new memory reporters should be added to Firefox in order to reduce the “heap-unclassified” measurement in about:memory. (The name is actually short for “Dark Matter Detector”, because we sometimes call the “heap-unclassified” measurement “dark matter“.)
Recently, I’ve modified DMD to become a more general heap profiling tool. It now has three distinct modes of operation.
Most memory profilers (including as about:memory) are snapshot-based, and so work much like DMD’s “live” mode. But “cumulative” mode is equally interesting.
In particular, unlike “live” mode, “cumulative” mode tells you about parts of the code that are responsible for allocating many short-lived heap blocks (sometimes called “heap churn”). Such allocations can hurt performance: allocations and deallocations themselves aren’t free, particularly because they require obtaining a global lock; such code often involves unnecessary initialization or copying of heap data; and if these allocations come in a variety of sizes they can cause additional heap fragmentation.
Another nice thing about cumulative heap profiling is that, unlike live heap profiling, you don’t have to decide when to take snapshots. You can just profile an entire workload of interest and get the results at the end.
I’ve used DMD’s cumulative mode to find inefficiencies in SpiderMonkey’s source compression and code generation, SQLite, NSS, nsTArray, XDR encoding, Gnome start-up, IPC messaging, nsStreamLoader, cycle collection, and safe-browsing. There are “start doing something clever” optimizations and then there are “stop doing something stupid” optimizations, and every one of these fixes has been one of the latter. Each change has avoided cumulative heap allocations ranging from tens to thousands of MiBs.
It’s typically difficult to quantify any speed-ups from these changes, because the workloads are noisy and non-deterministic, but I’m convinced that simple changes to fix these issues are worthwhile. For one, I used cumulative profiling (via a different tool) to drive the major improvements I made to pdf.js earlier this year. Also, Chrome developers have found that “Chrome in general is *very* close to the threshold where heap lock contention causes noticeable UI lag”.
So far I have only profiled a few simple workloads. There are all sorts of things I haven’t tried: text-heavy pages, image-heavy pages, audio and video, WebRTC, WebGL, popular benchmarks… the list goes on. I intend to do more profiling and fix things where I can, but it would be great to have help from domain experts with this stuff. If you want to try out cumulative heap profiling in Firefox, please read the DMD instructions and feel free to ask me for help. In particular, I now have a good feel for which hot allocations are unavoidable and reasonable — plenty of them, of course — and which are avoidable. Let’s get rid of the avoidable ones.
https://blog.mozilla.org/nnethercote/2014/12/11/cumulative-heap-profiling-in-firefox-with-dmd/
|
|
Fabien Cazenave: Back from Mozilla |
During the last 3 years I’ve worked full-time for Mozilla Corp, and now it’s more than time to move on.
Leaving the MoCo has been a very difficult step for me. I’ve been a Mozillian for the last 8 years, and it’s been much more than a friendly community or a challenging job for me. I’ve had a lot of fun, met amazing people, worked on exciting technologies. I’m very proud of what we did, and I’m even prouder of why we did it. Working for Mozilla felt like a love story, and ending a love story is always painful.
I just took a long, refreshing, offline break. Sorry if you tried to reach me during this period — I’m getting through the mailbox hell, and I’ll do my best to reply to every message.
Best wishes to all Mozillians, especially to the folks in the Paris office, the Spanish Connection, and my drinking pals all around the globe. I’ll be happy to share a few beers with you at a web or FLOSS event someday. :-)
|
|
Jared Wein: Status Update – In-content Preferences, part 3 |

Since the last update, bug 1022582 (checkboxes and radio buttons in about:preferences lack any indication they’re checked/selected when using High Contrast mode) has been marked ready for check-in and should be marked fixed by late tomorrow.
This marks the last of the high-contrast bugs blocking the release :)
We also have had great progress on bug 1043346 (dialogs should have their dimensions reset after closing). This bug looks ready to land after the patch gets updated.
I’m optimistic that we can get a fix in for bug 1008172 ([linux-only] scrolling up and down on pages with scrollbars in about:preferences will change subgroups) soon. I put some tips in the bug, and Richard Marti has said that he will try to take a look at it.
As for bug 1056478 (resizer of sub-dialog follows only half of the movement of mouse pointer), I’m not sure if we should keep it as a blocker. This bug reveals an underlying issue in Gecko (bug 1105906) that exists with any centered resizable element. Webkit doesn’t suffer from this issue, so it’s hopeful that we will find a solution, but I don’t know if this quirk should stop us from shipping.
The next bugs that I would like to see attention on are:
Bug 1043612: Persist the size of resizable in-content subdialogs
Bug 1044597: in-content preferences: resized dialogs should not push buttons into overflow
Bug 1044600: in-content preferences: empty dialogs after pressing backspace or the Back button
All three of these bugs are part of the subdialogs category. Thanks for the work to those contributing patches and helping test, we couldn’t do this without you! :)

http://msujaws.wordpress.com/2014/12/10/status-update-in-content-preferences-part-3/
|
|
Joel Maher: Language hacking – changing the choice of words we use |
Have you ever talked to someone who continues to use the same word over and over again? Then you find that many people you chat with end up using the same choice of words quite frequently. My wife and I see this quite often, usually with the word ‘Amazing’, ‘cool’, and ‘hope’.
Lets focus on the word “hope”. There are many places where hope is appropriate, but I find that most people misuse the word. For example:
I hope to show up at yoga on Saturday
I heard this sentence and wonder:
What could be said is:
I am planning to show up at yoga on Saturday
or:
I have a lot of things going on, if all goes well I will show up at yoga on Saturday
or:
I don’t want to hurt your feelings by saying no, so to make you feel good I will be non committal about showing up to yoga on Saturday even though I have no intentions.
There are many ways to replace the word “hope”, and all of them achieve a clearer communication between two people.
Now with that said, what am I hacking? For the last few months I have been reducing (almost removing) the words ‘awesome’, ‘amazing’, ‘hate’, and ‘hope’ from my vocabulary.
Why am I writing about this? I might as well be in the open about this and invite others to join me in being deliberate about how we speak. Once a month I will post a new word, feel free to join me in this effort and see how thinking about what you say and how you say it impacts your communications.
Also please leave comments on this post about specific words that you feel are overused – I could use suggestions of words.

https://elvis314.wordpress.com/2014/12/10/language-hacking-changing-the-choice-of-words-we-use/
|
|
Daniel Stenberg: libcurl multi_socket 3333 days later |
![]() On October 25, 2005 I sent out the announcement about “libcurl funding from the Swedish IIS Foundation“. It was the beginning of what would eventually become the curl_multi_socket_action() function and its related API features. The API we provide for event-driven applications. This API is the most suitable one in libcurl if you intend to scale up your client up to and beyond hundreds or thousands of simultaneous transfers.
On October 25, 2005 I sent out the announcement about “libcurl funding from the Swedish IIS Foundation“. It was the beginning of what would eventually become the curl_multi_socket_action() function and its related API features. The API we provide for event-driven applications. This API is the most suitable one in libcurl if you intend to scale up your client up to and beyond hundreds or thousands of simultaneous transfers.
Thanks to this funding from IIS, I could spend a couple of months working full-time on implementing the ideas I had. They paid me the equivalent of 19,000 USD back then. IIS is the non-profit foundation that runs the .se TLD and they fund projects that help internet and internet usage, in particular in Sweden. IIS usually just call themselves “.se” (dot ess ee) these days.
Event-based programming isn’t generally the easiest approach so most people don’t easily take this route without careful consideration, and also if you want your event-based application to be portable among multiple platforms you also need to use an event-based library that abstracts the underlying function calls. These are all reasons why this remains a niche API in libcurl, used only by a small portion of users. Still, there are users and they seem to be able to use this API fine. A success in my eyes.
 Part of that improvement project to make libcurl scale and perform better, was also to introduce HTTP pipelining support. I didn’t quite manage that part with in the scope of that project but the pipelining support in libcurl was born in that period (autumn 2006) but had to be improved several times over the years until it became decently good just a few years ago – and we’re just now (still) fixing more pipelining problems.
Part of that improvement project to make libcurl scale and perform better, was also to introduce HTTP pipelining support. I didn’t quite manage that part with in the scope of that project but the pipelining support in libcurl was born in that period (autumn 2006) but had to be improved several times over the years until it became decently good just a few years ago – and we’re just now (still) fixing more pipelining problems.
On December 10, 2014 there are exactly 3333 days since that initial announcement of mine. I’d like to highlight this occasion by thanking IIS again. Thanks IIS!
These days I’m spending a part of my daytime job working on curl with my employer’s blessing and that’s the funding I have – most of my personal time spent is still spare time. I certainly wouldn’t mind seeing others help out, but the best funding is provided as pure man power that can help out and not by trying to buy my time to add your features. Also, I will decline all (friendly) offers to host the web site on your servers since we already have a fairly stable and reliable infrastructure sponsored.
I’m not aware of anyone else that are spending (much) paid work time on curl code, although I’m know there are quite a few who do it every now and then – especially to fix problems that occur in commercial products or services or to add features to such.
IIS still donates money to internet related projects in Sweden but I never applied for any funding from them again. Mostly because it has been hard to sync with my normal life and job situation. If you’re a Swede or just live in Sweden, do consider checking this out for your next internet adventure!
http://daniel.haxx.se/blog/2014/12/10/libcurl-multi_socket-3333-days-later/
|
|
Advancing Content: Getting Tiles Data Into Firefox |
A month ago, we announced that the new Tiles experience is available in the stable Firefox build. We experimented earlier this year and found that users do want more than empty boxes or screenshots in Firefox. The Mozilla project is also working hard to set higher standards for the industry around transparency and control of the use of a user’s data. With that in mind, we wanted to make it clear what data we do and do not pass from Mozilla servers to Firefox to enable the Tiles experience, and here, we’ll address how Tiles get into Firefox. You can, of course, inspect the source code, but this might be easier.
Typically, if a web page adds external content, it does so by embedding an unencrypted remote request with cookied identifiers, so the server can respond as fast as possible with relevant content. The server also wants to remember as much as possible about the context of the request such as IP addresses and referrals, so this all is tracked through a persistent identifier that could be shared and triangulated with other data sources. Frequently, where a server wants to gather as much data as possible about users, invisible image beacons and iframes/scripts may be used to gather more information. This is all done with little understanding by, or permission from, the user.

No special request headers or body data sent
What we are doing with Tiles is different
With the November 10th release, Firefox sends a single custom request once per day and then saves data locally to be used for as many new tabs opened by the user. The Mozilla server sees the IP address of the request, and uses that to determine geotargeting at a country level (e.g., nothing more granular than “United States” or “Germany”). The request URL contains the locale of the Firefox build to ensure the content Firefox shows is language and location appropriate.
Having received the request, we respond with the appropriate content and then delete the raw data with IP addresses within a week. Even with this minimal actionable data set, we are able to determine the volume of requests for specific country/locale pairs. This helps us decide which tiles to translate to provide a useful experience to new users in those regions.
The JSON response contains display information: Tiles graphics resources, URLs and titles, and is defined for a specific country/locale pair.

Sample en-US response with an array of tile data objects
Tiles is still evolving, and this is an initial release, but there are several things that we like about how we get Tiles data into Firefox.
Very importantly, this is an experience that is controlled by the user, involves the minimal actionable dataset. “Tracking” has become a loaded term, and we do not consider Tiles to be tracking. We do not need or try to identify an individual with these data requests, meaning that no cookies need to be set (and no other techniques to “fingerprint” are used). However, we assume that anyone who has previously set their DNT preference to “do not track” wishes to opt out of the experience, and so no request is sent. DNT is not how a user will opt out of the Tiles experience: a user who has Tiles can also set “do not track” independently of their Tiles settings.
The architecture reduces the latency requirements of our Tiles experience compared to traditional web pages: because Firefox can request and cache the data, it can pre-load assets, pre-compute personalization, and pre-populate the new tab page, so when users open a new tab, it’s fast and immediately usable.
And even though we send little data and save little data, we secure that data with transport encryption and prevent attacks with key pinning.
There are downsides to this approach: the data file could be outdated in both space and time. For example, a user could download tiles for their home country but then travels elsewhere, or we might accidentally show a Happy New Year tile after that date has passed. Also, because we package additional information in order to let Firefox make decisions, Firefox ends up with some title and URL data of Enhanced tiles that are not shown to users. These are all potential improvements we’re looking forward to making.

Happy New Year Tile… might be a day late!
I’m sure we can improve on our implementation. We would also love to hear your thoughts on our approach to getting relevant Tiles data to power the default Directory and Enhanced Tiles experiences. Next time, we will detail how we report data on interactions with Tiles.
– Ed Lee on behalf of the Tiles team.
https://blog.mozilla.org/advancingcontent/2014/12/09/getting-tiles-data-into-firefox/
|
|
Nicholas Nethercote: Better documentation for memory profiling and leak detection tools |
Until recently, the documentation for all of Mozilla’s memory profiling and leak detection tools had some major problems.
A little while back I fixed these problems.
Please take a look, and if you see any problems let me know. Or, if you’re feeling confident just fix things yourself! Thanks.
|
|
Laura Thomson: Try server performance |
In Q4, Greg Szorc and the Developer Services team generally have been working on a headless try implementation to solve try performance issues as the number of heads increases. In addition, he’s made a number of performance improvements to hg, independent of the headless implementation.
I think these graphs speak for themselves, so I’m just going to leave them here.
Try queue depth (people waiting on an in-flight push to complete before their push can go through):

Try push median wait times:

(Thanks, too, to Hal Wine for setting up a bunch of analytics so we can see the effects of the work represented in such shiny graphs.)
|
|
Karl Dubost: Pop Out The Table |
The CSS table display Web design pattern emerged among Web designers. CSS table display is very well supported across browsers. It gave the ability to use HTML table semantics but keeping the table layout properties.
But it also creates Web compatibility issues when combined with max-width: 100%;. This is a rendering of the current mobile Ebay site in Blink and Gecko. There is an open Web Compatibility bug about it.
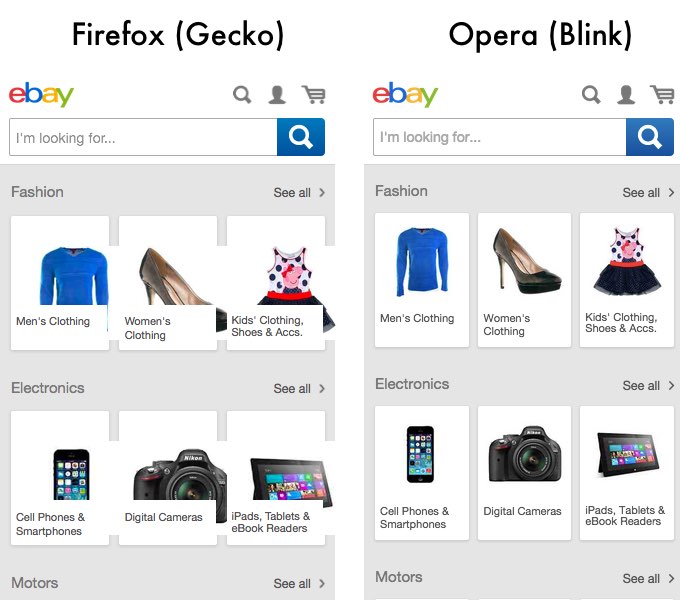
The markup for each individual items in the page is following this structure:
span> href="http://…">
span> class="verticalAlign">
span> class="stackImg" src="….jpg" data-src="….jpg">
associated with the following CSS:
.mainCatCntr .stackone .catImgBkg a { display: table; width: 100%; height: 100%; padding-bottom: 45px; padding-top: 10px; } .mainCatCntr .stackone .catImgBkg a .verticalAlign { display: table-cell; vertical-align: middle; } .mainCatCntr .stackone .stackImg { display: block; position: absolute; top: 0px; z-index: 1; max-height: 94px; max-width: 100%; border-radius: 2px 2px 0px 0px; }
As we can see a first nesting element with display: table; and then nested an element being display: table-cell;. Finally inside this element one which is specified with max-width:100%;.
The first approximation to fix it is to replace max-width:100%; with width:100%; but then when the space is bigger than the image size, the image stretches. It is not a very compelling fix, maybe it's alright for sweaters and mirrors, but less so for cameras.
The fix is this one:
.mainCatCntr .stackone .catImgBkg a { display: table; table-layout: fixed; width: 100%; /* height: 100%; */ padding-bottom: 45px; padding-top: 10px; }
We added table-layout: fixed; just after display: table;. It fixed the images going out of their boxes. We still had an issue with the vertical alignment which was fixed by removing the height: 100%; but that was not the core issue. Once these changes in place we get the same rendering than blink rendering engine.

And most important, the same fix doesn't break the layout in Blink. The work now is to convince ebay to modify their CSS so we can have a version which is working on Web Compatibility. Note that this type of issues could have been detected through automatic testing and screenshots.
But wait… it's not over yet. Which rendering engine is implementing the correct behavior? Note that the answer is always difficult, it can be one of the following:
The thing is that the users do not care which one of these two or other differences. What the user sees is that it is broken in one browser and not in the other one. The same way the designers use a dominant market share browsers with bugs considered as the normal behavior because they just don't know what should be the correct behavior. This is what Web Compatibility is about.
I found a couple of bugs at Mozilla talking about the same issue.
I let you read the comments of the two bugs and tries to decipher the interpretation of the specification text. If you have no issue and understand everything, you get your degree in Web Compatibility Shamanism. Maybe we should start deliver these. Web Compatibility Shaman should be as ridiculous as JavaScript Ninja or Python Rockstar?
Otsukare.
|
|
Nicholas Nethercote: mfbt/SegmentedVector.h |
I just landed a new container type called mozilla::SegmentedVector in MFBT. It’s similar to nsTArray and mozilla::Vector, but the the element storage is broken into segments rather than being contiguous. This makes it less flexible than those types — currently you can only append elements and iterate over all elements.
Hoever, in cases where those operations suffice, you should strongly consider using it. It uses multiple moderate-sized storage chunks instead of a single large storage chunk, which greatly reduces the likelihood of OOM crashes, especially on Win32 where large chunks of address space can be difficult to find. (See bug 1096624 for a good example; use of a large nsTArray was triggering ~1% of all OOM crashes.) It also avoids the need for repeatedly allocating new buffers and copying existing data into them as it grows.
The declaration is as follows.
templateclass SegmentedVector
T is the element type.IdealSegmentSize is the size of each segment, in bytes. It should be a power-of-two (to avoid slop), not too small (so you can fit a reasonable number of elements in each chunk, which keeps the per-segmente book-keeping overhead low) and not too big (so virtual OOM crashes are unlikely). A value like 4,096 or 8,192 or 16,384 is likely to be good.AllocPolicy is the allocation policy. A SegmentedVector can be made infallible by using InfallibleAllocPolicy from mozalloc.h.If you want to use SegmentedVector but it doesn’t support the operations you need, please talk to me. While it will never be as flexible as a contiguous vector type, there’s definitely scope for adding new operations.
https://blog.mozilla.org/nnethercote/2014/12/10/mfbtsegmentedvector-h/
|
|
Andreas Gal: It takes many to build the Web we want |
Mozilla is announcing today the creation of a WebRTC competency center jointly with Telenor.
Mozilla’s purpose is to build the Web. We do so by building Firefox and Firefox OS. The Web is pretty unusual when it comes to interoperable technology stacks, because it is not built by standards bodies. Instead, the Web is built by browser vendors that implement browsers that implement the Web, which in the end pretty much defines what the Web is.
The Web adds new technologies whenever a majority of browser vendors agree to extend it in an interoperable way. Standards bodies merely help coordinating this process. Very rarely do new Web capabilities originate in a standards body. New Web capabilities merely end up there eventually, once there is sufficient interest by multiple browser vendors to warrant standardization.
Mozilla doesn’t — and can’t — build the Web alone. What makes the Web unique is that it is owned by no-one, and cannot be held back by anyone. It doesn’t take unanimous consent to extend the Web. A mere majority of browser vendors can popularize a new Web capability, forcing the rest of the browser vendors to eventually come along.
While several browser vendors build the Web, Mozilla has a unique vision for the Web that is driven by our mission as a non-profit foundation. Whereas all other browser vendors are for-profit corporations, advancing the Web in the interest of their shareholders, Mozilla advances the Web for users.
The primary browser vendors today are Google, Apple, Microsoft and Mozilla. These four organizations have a direct path to bring new technologies to the Web. While many other technology companies have a strong interest in the Web, they lack the ability to directly move the Web ahead because only these four browser vendors develop a rendering engine that implements the Web stack.
There is one more aspect that sets Mozilla apart from its browser vendor competitors. We are several orders of magnitude smaller than our peers. While this might appear as a market disadvantage at first, combined with our neutral and non-profit status it actually creates a unique opportunity. Many more technology companies have an interest in working on the Web, but if you aren’t Google, Apple, or Microsoft its very difficult to contribute core technologies to the Web. These three companies have direct control over a rendering engine. No other technology company can equally influence the Web. Mozilla is looking to change that.
Jointly with Telenor we are launching a new initiative that will allow parties with a strong technology interest in WebRTC to participate as an equal in the development process of the WebRTC standard. Since standards are really just a result of delivering new Web technologies in a rendering engine, Telenor will assign Telenor engineering staff to work on Mozilla’s implementation of WebRTC in Firefox and Firefox OS.
The goal of this new center is to implement WebRTC with a broad, neutral vision that captures the technology needs of many, not just the technology needs of individual browser vendors.
Mozilla is an open source project where every opinion and technical contribution matters. The WebRTC Competency Center will accelerate the development of WebRTC, and ensure that WebRTC serves the diverse technology interests of many. If you would like to see WebRTC (or any other part of the Web) grow capabilities that are important to you, join us.







http://andreasgal.com/2014/12/09/it-takes-many-to-build-the-web-we-want/
|
|
Armen Zambrano: Running Mozharness in developer mode will only prompt once for credentials |

|
|
Joel Maher: 5 days in Portland with Mozillians and 10 great things that came from it |
I took a lot of notes in Portland last week. One might not know that based on the fact that I talked so much my voice ran out of steam by the second day. Either way, in chatting with some co-workers yesterday about what we took away from Portland, I realized that there is a long list of awesomeness.
Let me caveat this by saying that some of these ideas have been talked about in the past, but despite our efforts to work with others and field interesting and useful ideas, there is a big list of great things that came to light while chatting in person:
Those are 10 specific topics which despite everybody knowing how to contact me or the ateam and share great ideas or frustrations, these came out of being in the same place at the same time.
Thinking through this, when I see these folks in a real office while working from there for a few days or a week, it seems as though the conversations are smaller and not as intense. Usually just small talk whilst waiting for a build to finish. I believe the idea where we are not expected to focus on our day to day work and instead make plans for the future is the real innovation behind getting these topics surfaced.

|
|
Kevin Ghim: Interest Dashboard Launch - Follow up |
A month ago, we released the first iteration of the our Interest Dashboard. This is a very ambitious project, interpreting and representing back to the user an analysis of their tasks and interests. Many online services already make some representation of this back to a user, (think of Amazon’s suggestions) but I cannot think of anyone who does this with the broad scope that the Firefox Interest Dashboard does, and at the control of the user. Rather than something like Amazon suggestions, when I looked at my Interest Dashboard, I was more reminded of a scene from You are what you eat where I was confronted with my intake of the Web.
Anyway: it’s often hard to understand the scope of the project and the current and planned features without the full product vision. And there were a couple of misconceptions that we evidently helped create last week which I would like to clear up.
First: we stated in our FAQ that data is stored in the client. That is the case. A few commentators noted that the Privacy Notice states that you may (with your express consent) share your data with other websites. The FAQ is correct, the data is stored in the client because this functionality is not yet enabled in the add-on. At such time as we have the functionality available, we will update the FAQ and sure sure to notify users of the add-on. We felt the best approach was to be transparent with the privacy notice about the direction we will go, but be very clear with the current FAQ (we felt this was a better approach than updating the privacy notice with the release). We do expect the user to be able to share their intention with Websites in the future, and as we make clear, this will be with the user’s express consent. That is in the future.
There were two other misapprehensions about the launch last week which I would like to clear up. I read at least one comment where a user stated they had cleared their browser’s cache but still saw data in the Interest Dashboard. This is fairly straightforward: the dashboard is constructed from the browser’s history, not what is in cache. Also, one commentator noted that some reviews had been removed from AMO (some are preserved here). This was actually news to us too, and on checking in with the AMO team, we understood these reviews were removed by members of the AMO community for violating their guidelines for relevance.
The last point that I read in the discussion was about whether or not Interest Dashboard would exacerbate the Filter Bubble problem. It’s an excellent point, and one we think about quite a bit. In fact, I believe we can help address the issue. The Web should not seduce the user into bad or repetitious habits. A first step here (just as in You Are What You Eat) is to be presented with what you consume (“What gets measured, gets managed”).
But this raises the principle question we’d like to answer through this experimental add-on: whether it’s possible to have a user-centered recommendation system. I use the word “recommendation” loosely because not everything we get recommended online needs to be in a form of an advertisement. We intend to build this recommendation system by first providing users transparency into how an interest categorization works - this is the current state of the Interest Dashboard. We are also intensely focused in providing in-depth analysis of the user’s long-term interests and dynamic short-term interests. Most recommendation systems, including ads, only focus on the short-term intent of the user in the hope of converting the user down the purchase funnel.
Shortly, we hope to connect the user’s long and short-term interests, with their explicit consent, to a piece of content that they might find interesting. The connection part can be done several different ways: 1) use content crawler and index them by categories or 2) partner up with an aggregation service. In the case of the latter, we can either get a daily massive dump of indexed content or use an API to send the user’s interest category that will return a matching piece of content. We are internally experimenting with these options before we release it as a feature on the add-on. That’s a long way to explain a part of the experimental feature is reflected on the privacy notice.
A content recommendation system is certainly not for everyone and there are some bad examples of how companies can abuse personal data. We want to counter the bad actors by providing choice.
If the user wants it, we can provide a platform based on what/how/when the user wants. We’re hoping the Interest Dashboard is the beginning of this exploration. But this is a sensitive area. Ideas and advice are always welcomed, as is scrutiny. We are serious about what we are building, and the only way it will be adopted is if it is trusted, and it will only be trusted if it is scrutinized. Please, keep the scrutiny coming.
|
|
Gervase Markham: Unanimity Is Not a Requirement |
People sometimes wonder how to best involve all of the affected/important/relevant parts of the Mozilla community in a decision. The prospect of doing this can lead to a certain amount of fear – of criticism, bike-shedding, etc.
At the last All Hands in October 2013, at a session in Brussels, we produced a Best Practices document called “Productive Discussion” to help with exactly this problem. Given Mitchell’s keynote at the recent All Hands, I thought it was worth reflagging its existence.
http://feedproxy.google.com/~r/HackingForChrist/~3/un0u5DsciH4/
|
|






