Окно в сердце конференции Гейзенбаг 2017 Piter |


 10:30-11:20 Ilari Henrik Aegerter — Think Bigger – How to Truly Become World-Class in Testing
10:30-11:20 Ilari Henrik Aegerter — Think Bigger – How to Truly Become World-Class in Testing 11:40-12:30 Алексей Виноградов — Как улучшить автотесты: сеанс черной магии
11:40-12:30 Алексей Виноградов — Как улучшить автотесты: сеанс черной магии 12:50-13:40 Алексей Лавренюк — Учимся анализировать результаты нагрузочного тестирования
12:50-13:40 Алексей Лавренюк — Учимся анализировать результаты нагрузочного тестирования 14:25-15:15 Андрей Сатарин — Мойте руки перед едой, или Санитайзеры в тестировании
14:25-15:15 Андрей Сатарин — Мойте руки перед едой, или Санитайзеры в тестировании 15:35-16:25 Игорь Хрол — Тестирование в мире данных
15:35-16:25 Игорь Хрол — Тестирование в мире данных 16:45-17:35 Артем Ерошенко — Allure 2: тест-репорты нового поколения
16:45-17:35 Артем Ерошенко — Allure 2: тест-репорты нового поколения 17:50-18:40 Николай Алименков — Паттерны проектирования в автоматизации тестирования
17:50-18:40 Николай Алименков — Паттерны проектирования в автоматизации тестирования|
|
Интеграция SaltStack и Telegram |

В данной статье хотел бы рассказать об отправке уведомлений в Telegram чат при использовании SaltStack. Начиная с версии 2015.5.0, SaltStack предоставляет интеграцию со Slack из коробки, однако Telegram также является популярным мессенджером и активно используется среди российских пользователей. Поэтому надеюсь, что статья окажется полезна ее читателям.
Вообще говоря, SaltStack представляет собой конструктор и, как и многие другие инструменты, предоставляет возможности для кастомизации и расширения. В частности, собственные исполняемые модули.
О том, как можно создать Telegram бота на Python подробно рассказывается здесь. В качестве дополнения будет описано, как, используя небольшой Python-модуль, такой подход можно привязать к SaltStack.
Приступать к написанию модуля следует после того, как:
Примечание. Получить id чата можно с помощью следующего скрипта на python:
import requests
URL = 'https://api.telegram.org/bot'
TOKEN = <токен вашего бота>
try:
request = requests.post('{url}{token}/getUpdates'.format(url=URL, token=TOKEN))
print request.json()['result'][0]['message']['chat']['id']
except Exception,e:
print str(e)Итак, переходим к главному. Как описано в документации, SaltStack модуль должен располагаться в директории _modules/ и выглядеть следующим образом:
import requests
URL='https://api.telegram.org/bot'
def notify(message, token, chat_id):
message_data = {
'chat_id': chat_id,
'text': message
}
try:
request = requests.post('{url}{token}/sendMessage'.format(url=URL, token=token), data=message_data)
except Exception,e:
return False, str(e)
if not request.status_code == 200:
return False, "Return status is unsuccessful"
# для наглядности вторым значением возвращается строка со служебной информацией.
return True, "Message was successfully sent"Далее необходимо выполнить команду синхронизации модулей, чтобы они появились на миньонах:
salt '*' saltutil.sync_modules
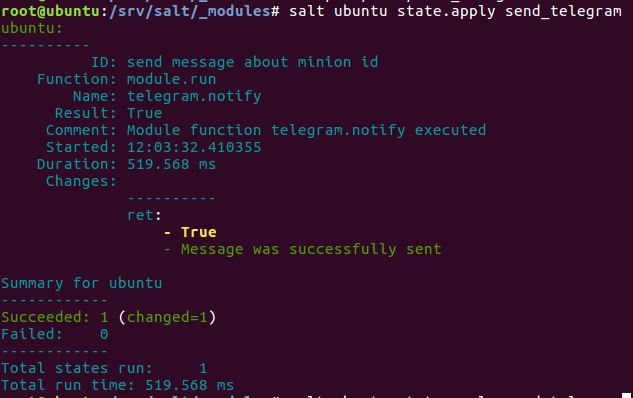
Если все завершилось успешно, результат будет примерно следующим:

И, напоследок, создаем файл состояния (в данном примере — send_telegram.sls)
send message about minion id:
module.run:
# telegram - имя python-модуля, notify - метод в этом модуле
- name: telegram.notify
- kwargs:
message: command executed on minion with id {{ grains['id'] }}
token: <токен вашего бота>
chat_id: Проверяем работоспособность созданного модуля:
salt '*' state.apply send_telegram
На стороне мастера:
В чате:
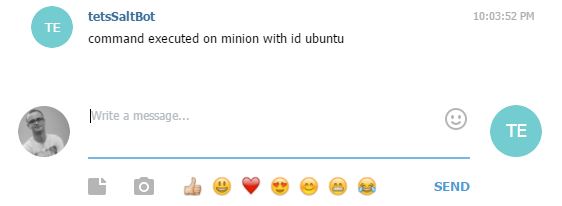
|
Метки: author tikhoa системное администрирование devops configuration management salt saltstack salt stack telegram telegram bot python |
Security Week 22: В Samba нашлась уязвимость, ShadowBrokers открыли подписку на эксплойты, фишеры массово освоили HTTPS |
 Говорят, что если долго смотреть в 445-й порт, оттуда выглянет сетевой червь. В последние недели он привлек столько внимания, что на свет вышли уязвимости даже в НЕУЯЗВИМОМ (как всем известно) Linux. Точнее, в популярной сетевой файловой системе Samba, без которой Linux с Windows в сети не подружиться.
Говорят, что если долго смотреть в 445-й порт, оттуда выглянет сетевой червь. В последние недели он привлек столько внимания, что на свет вышли уязвимости даже в НЕУЯЗВИМОМ (как всем известно) Linux. Точнее, в популярной сетевой файловой системе Samba, без которой Linux с Windows в сети не подружиться.nt pipe support = no. Просто на всякий случай. С одной стороны, снабжать деньгами откровенно киберкриминальную группировку не годится. С другой стороны, эти эксплойты и троянцы однозначно попадут в нехорошие руки, так что безопасникам надо быть готовыми. Промедление может караться эпидемией похуже воннакрая, так что кто-то из ИБ-компаний наверняка оформил подписку. Цена в 100 Zcash (примерно $23000) ежемесячно выглядит невысокой, учитывая мощную «рекламную кампанию», проведенную посредством WannaCry.
С одной стороны, снабжать деньгами откровенно киберкриминальную группировку не годится. С другой стороны, эти эксплойты и троянцы однозначно попадут в нехорошие руки, так что безопасникам надо быть готовыми. Промедление может караться эпидемией похуже воннакрая, так что кто-то из ИБ-компаний наверняка оформил подписку. Цена в 100 Zcash (примерно $23000) ежемесячно выглядит невысокой, учитывая мощную «рекламную кампанию», проведенную посредством WannaCry.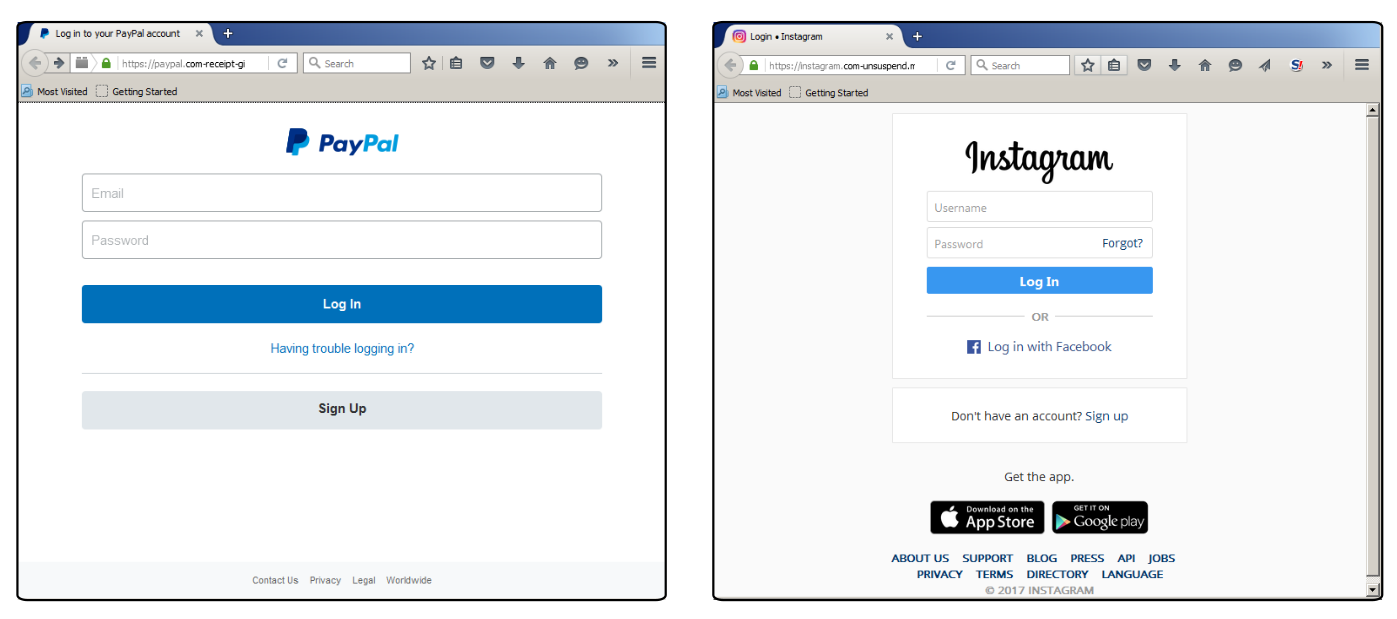 Что с этим делать, пока не очень ясно. Даже если научить пользователей внимательно читать url, это поможет лишь отчасти, так как не всегда понятно, фишинговый ли это домен, или лишь один из многочисленных легитимных доменов организации. Аналогично и с проверкой сертификата – каждый раз надо точно знать название юрлица. Рано или поздно помощь придет со стороны технологий, ну а пока что можно лишь посоветовать «разуть глаза».
Что с этим делать, пока не очень ясно. Даже если научить пользователей внимательно читать url, это поможет лишь отчасти, так как не всегда понятно, фишинговый ли это домен, или лишь один из многочисленных легитимных доменов организации. Аналогично и с проверкой сертификата – каждый раз надо точно знать название юрлица. Рано или поздно помощь придет со стороны технологий, ну а пока что можно лишь посоветовать «разуть глаза».
|
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» klsw wannacry let's encrypt shadowbrokers samba |
Сеть TOR в России полностью подконтрольна ФСБ |
|
Метки: author dimult читальный зал tor фсб тор взломан tor not safe in russia |
Dotty уже на пороге |
|
Метки: author barbalion scala scala3 dotty |
Интеграция сайта и прочего ПО с онлайн-кассами |
 Хочу поделиться опытом разработки ПО для бюджетной онлайн-кассы VikiPrint 57. В связи с вступлением в силу закона ФЗ-54, это может быть актуально и полезно техническим специалистам, которые впервые в жизни выполняют задачу по интеграции ПО или сайта с физическим оборудованием. Особенно с этих онлайн-касс «бзднут» вебмастеры, разрабатывающие на WordPress магазины и по-другому понимающие термин «онлайн».
Хочу поделиться опытом разработки ПО для бюджетной онлайн-кассы VikiPrint 57. В связи с вступлением в силу закона ФЗ-54, это может быть актуально и полезно техническим специалистам, которые впервые в жизни выполняют задачу по интеграции ПО или сайта с физическим оборудованием. Особенно с этих онлайн-касс «бзднут» вебмастеры, разрабатывающие на WordPress магазины и по-другому понимающие термин «онлайн».
//openPort
[DllImport("PiritLib.dll", CallingConvention = CallingConvention.StdCall)]
public static extern int openPort(string fileName, int speed);
//commandStart
[DllImport("PiritLib.dll", CharSet = CharSet.Auto, CallingConvention = CallingConvention.StdCall)]
public static extern int commandStart();
[DllImport("PiritLib.dll", CharSet = CharSet.Auto, CallingConvention = CallingConvention.StdCall)]
public static extern int libAddDiscount(byte typeDiscount, string nameDiscount, int sum);
//Создаем объект драйвера, передавая имя COM порта и его скорость
drivers.FiscalInterface driver = new VikiPrint("COM5", 57600);
//Открываем документ типа регистрации покупки:
driver.OpenDocument(2);
//Регистрируем нужный товар (название, артикул, кол-во, цена, номер позиции):
driver.RegisterProduct("Кроссовки", "33111", 1, 2099, 1);
//Регистрируем скидку (тип, примечание и размер). Типы: 0 - процент, 1 - фикс.
driver.RegisterDiscount(1, "За то, что ты был хорошим поцом", 1);
//Выводим итог
driver.PrintTotal();
//Регистрируем занесение в кассу денег (сумма, тип оплаты)
driver.RegisterPayment(2099, 0);
//Закрываем документ. При этом печатаетcя QR код
driver.CloseDocument();
|
Метки: author pistol разработка под windows c# онлайн-кассы фз54 драйвер vikiprint |
К вопросу о числах |

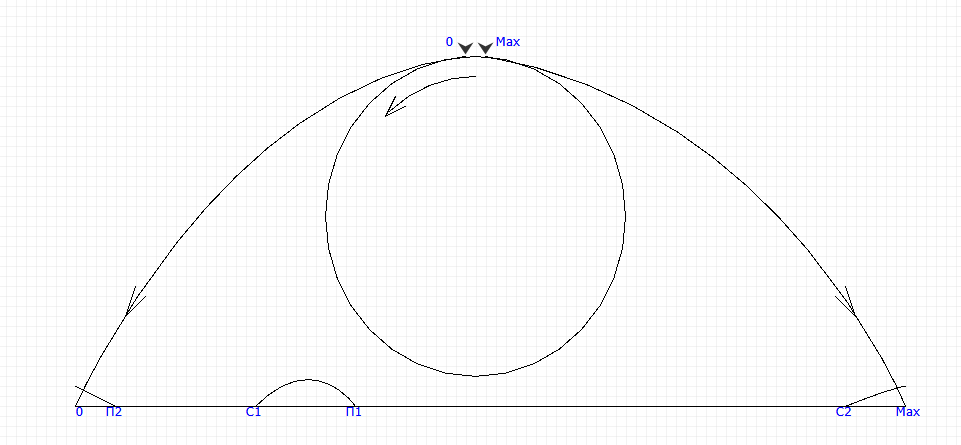
if ( (long) (Т - П) < 0) ....typedef unsigned char Timet;
Timet S = 0xF8, I = 12, T = S + I + 2;
// прости, MISRA, за предыдущую строку, я знаю, что так нельзя, но это в учебных целях
if ( (T - S) >= I) printf ( "time"); // не всегда срабатывает
register Timet D = (T - S);
if (D >= I) printf ("time"); // а вот это всегда if ( (c = uc ) == uc) printf ( "is equal");Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author GarryC программирование микроконтроллеров |
[Перевод] Как работать с отзывами в App Store (и с отрицательными тоже) |
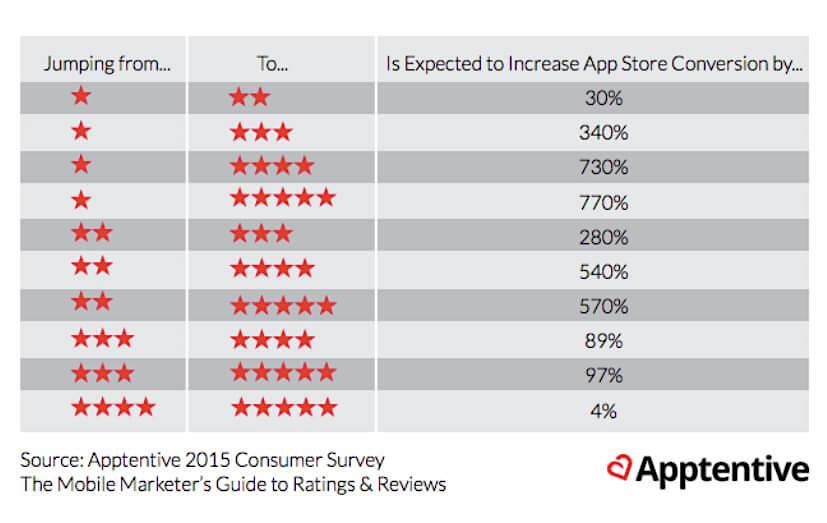


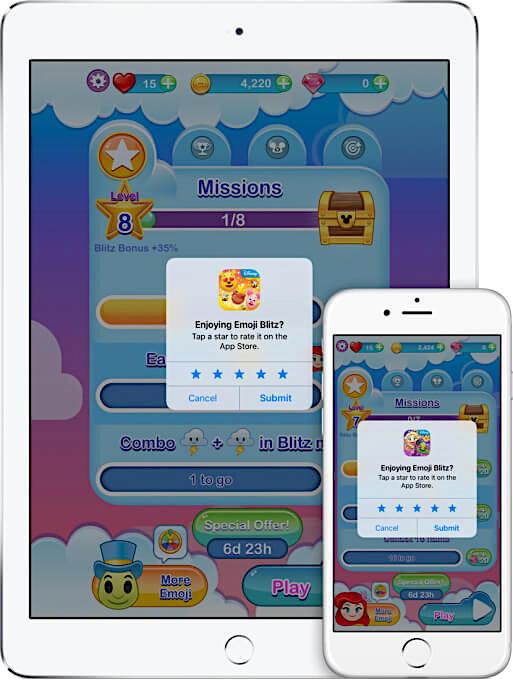
|
|
[Из песочницы] 19 бесплатных утилит и 89 скриптов для мониторинга и управления базами данных |





















|
Метки: author AntoniusFirst oracle mysql microsoft sql server ит-инфраструктура упрвление мощностями sql server |
В преддверии Гейзенбага: Grid Dynamics о тестировании |

 — Не все знают Grid Dynamics — расскажите вкратце, чем занимается компания?
— Не все знают Grid Dynamics — расскажите вкратце, чем занимается компания?  — Чем именно вы занимаетесь в Grid Dynamics?
— Чем именно вы занимаетесь в Grid Dynamics?
|
Метки: author phillennium тестирование веб-сервисов тестирование it-систем блог компании jug.ru group grid dynamics тестирование гейзенбаг конференция |
[Перевод] Как обучать вычислительному мышлению? |
































|
|
[Перевод] Как сделано интро на 64k |





bin2h.

// Listen to CTRL+S.
if (GetAsyncKeyState(VK_CONTROL) && GetAsyncKeyState('S'))
{
// Wait for a while to let the file system finish the file write.
if (system_get_millis() - last_load > 200) {
Sleep(100);
reloadShaders();
}
last_load = system_get_millis();
} imgui::Begin("Postprocessing");
imgui::SliderFloat("Bloom blur", &postproc_bloom_blur_steps, 1, 5);
imgui::SliderFloat("Luminance", &postproc_luminance, 0.0, 1.0, "%.3f", 1.0);
imgui::SliderFloat("Threshold", &postproc_threshold, 0.0, 1.0, "%.3f", 3.0);
imgui::End();
.cpp, нажав F6, так что после следующей компиляции она будет в демке. Это устраняет необходимость отдельного формата данных и соответствующего кода сериализации, но такое решение тоже может оказаться довольно неаккуратным./arch:IA32 и удалив вызовы к ftol с помощью флага /QIfst, который генерирует код, не сохраняющий флаги FPU для режима усечения. Это не проблема, потому что вы можете установить режим усечения с плавающей запятой в начале своей программы с помощью такого кода от Питера Шоффхаузера:// set rounding mode to truncate
// from http://www.musicdsp.org/showone.php?id=246
static short control_word;
static short control_word2;
inline void SetFloatingPointRoundingToTruncate()
{
__asm
{
fstcw control_word // store fpu control word
mov dx, word ptr [control_word]
or dx, 0x0C00 // rounding: truncate
mov control_word2, dx
fldcw control_word2 // load modfied control word
}
}pow по-прежнему генерирует вызов к внутренней функции __CIpow, которая не существует. Я никак не мог сам выяснить её сигнатуру, но нашёл реализацию в ntdll.dll из Wine — стало ясно, что она ожидает в регистрах два числа двойной точности. После этого стало возможным сделать враппер, который вызывает нашу собственную реализацию pow:double __cdecl _CIpow(void) {
// Load the values from registers to local variables.
double b, p;
__asm {
fstp qword ptr p
fstp qword ptr b
}
// Implementation: http://www.mindspring.com/~pfilandr/C/fs_math/fs_math.c
return fs_pow(b, p);
}













pp_index, который используется для переключения между профилями цветовой коррекции. Каждый профиль — просто разные ветки большого оператора ветвления в шейдере окончательной пост-обработки:vec3 cl = getFinalColor();
if (u_GradeId == 1) {
cl.gb *= UV.y * 0.7;
cl = pow(cl, vec3(1.1));
} else if (u_GradeId == 2) {
cl.gb *= UV.y * 0.6;
cl.g = 0.0+0.6*smoothstep(-0.05,0.9,cl.g*2.0);
cl = 0.005+pow(cl, vec3(1.2))*1.5;
} /* etc.. */
GL_POINTs, у которых модулировался размер, чтобы создать впечатление взмахов крыльев. Я думаю, такая техника рендеринга также использовалась в Half-Life 2.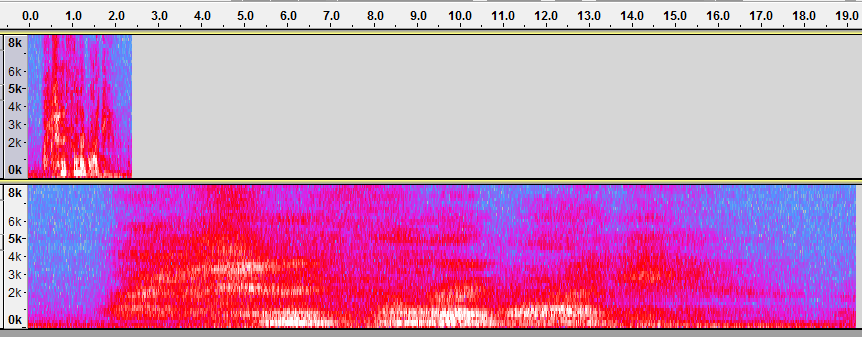
gm.dls — встроенный в Windows звуковой банк MIDI (опять старый трюк) и сделал песню с помощью MilkyTracker в формате модуля XM. Этот формат использовался ещё для многих демок под MS-DOS в 90-е годы.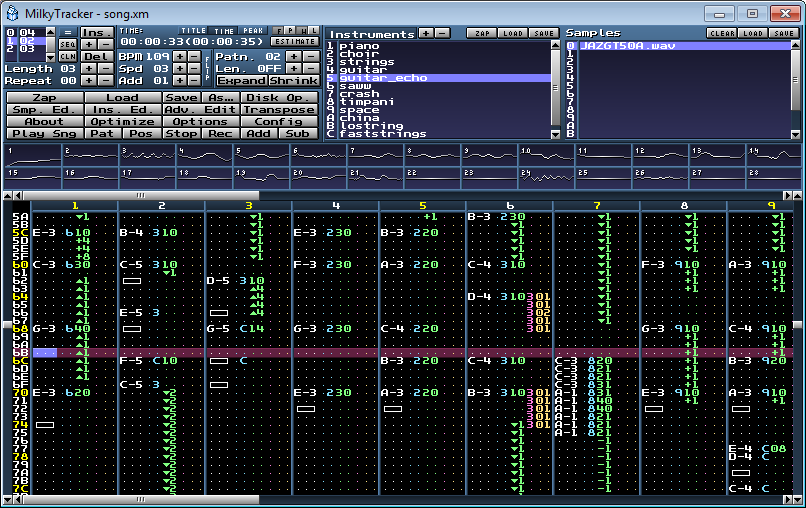
gm.dls gm.dls в том, что инструменты Roland от 1996 года звучат очень архаично и некачественно. Но оказалось, что в этом нет никакой проблемы, если погрузить их в тонну ревербераций! Вот пример, в котором сначала играет короткая тестовая песня, а затем растянутая версия:|
Метки: author m1rko работа со звуком работа с видео компьютерная анимация демосцена демка интро paulstretch рейкастинг gnu rocket |
[Из песочницы] Поиск по дереву методом Монте-Карло и крестики-нолики |
Так вышло, что для получение автомата по программированию бедным первокурам задали одну интересную задачу: написать программу, которая ищет по дереву методом Монте-Карло.
Конечно, всё началось с поиска информации в интернете. На великом и могучем русском языке было всего-лишь пара статей с Хабра, словесно объясняющие суть алгоритма, и статья из Википедии, перенаправляющая на проблему игры Го и компьютера. По мне — уже неплохое начало. Гуглю на английском языке для полноты и натыкаюсь на английскую статью с Википедии, в которой алгоритм так же словесно объясняется.
Метод Монте-Карло для поиска по дереву достаточно давно применяется в играх для искусственного интеллекта. Задача алгоритма — выбрать наиболее выигрышный вариант развития событий. Дерево представляет из себя структуру, в которой помимо хода и указателей есть количество сыгранных и количество выигранных партий. На основе этих двух параметров метод выбирает следующий шаг. Следующее изображение наглядно продемонстрирует работу алгоритма:
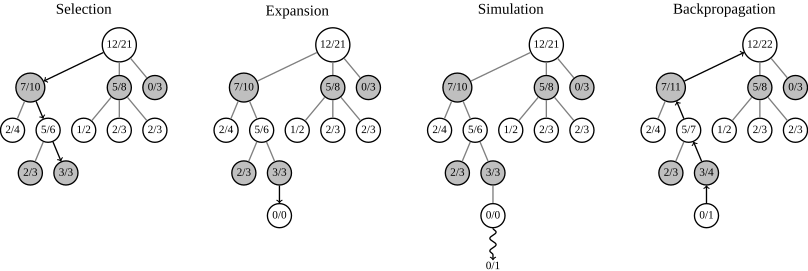
Шаг 1: Выбор — Selection. На этом шаге алгоритм выбирает ход своего противника. Если такой ход существует — мы его выберем, если нет — добавим.
Шаг 2: Расширение — Expansion. К выбранному узлу с ходом противника мы добавим узел со своим ходом и с нулевыми результатами.
Шаг 3: Симуляция — Simulation. Отыграем партию от текущего состояния игрового поля до чей-либо победы. Отсюда мы возьмём только первый ход (т.е. свой ход) и результаты.
Шаг 4: Обратное распространение — Backpropagation. Результаты из симуляции мы будем распространять от текущего до корня. Ко всем родительским узлам мы добавим единицу в количество сыгранных партий, а если мы наткнёмся на узел победителя — то в такой узел мы добавим единицу в количество выигранных партий.
В результате, бот с таким алгоритмом будет делать выигрышные для него ходы.
Собственно, алгоритм не такой сложный. Скорее, объёмный.
Алгоритм я решил реализовать в качестве бота для игры Крестики-нолики. Игра простая и для примера подойдёт отлично. Но дьявол кроется в деталях...
Проблема в том, что мы должны отыграть игру на шаге симуляции без реального игрока. Можно было, конечно, заставить алгоритм делать рандомные ходы в таких симуляциях, но мне хотелось какое-нибудь осмысленное поведение.
Тогда был написан простейший бот, который умел только две вещи — мешать игроку и делать рандомные ходы. Для симуляции этого было более чем достаточно.
Как и все, бот с алгоритмом располагал информацией о текущим состоянием поля, состоянием поля с прошлого хода, своим деревом ходов и текущим выбранным узлом в этом дереве. Начну с того, что я найду новый ход оппонента.
// 0. add node with new move.
bool exist = false;
int enemyx = -1, enemyy = -1;
this->FindNewStep ( __field, enemyx, enemyy );
for ( MCBTreeNode * node : this->mCurrent->Nodes )
{
if ( node->MoveX == enemyx && node->MoveY == enemyy )
{
exist = true;
this->mCurrent = node;
}
}
if ( !exist )
{
MCBTreeNode * enemymove = new MCBTreeNode;
enemymove->Parent = this->mCurrent;
enemymove->MoveX = enemyx;
enemymove->MoveY = enemyy;
enemymove->Player = (this->mFigure == TTT_CROSS) ? TTT_CIRCLE : TTT_CROSS;
this->mCurrent->Nodes.push_back ( enemymove );
this->mCurrent = enemymove;
}Как видно, если есть такой ход противника в дереве, то мы выберем его. Если нет — добавим.
// 1. selection
// select node with more wins.
MCBTreeNode * bestnode = this->mCurrent;
for ( MCBTreeNode * node : this->mCurrent->Nodes )
{
if ( node->Wins > bestnode->Wins )
bestnode = node;
}Здесь мы произведем выбор.
// 2. expanding
// create new node.
MCBTreeNode * newnode = new MCBTreeNode;
newnode->Parent = bestnode;
newnode->Player = this->mFigure;
this->mCurrent->Nodes.push_back ( newnode );Расширим дерево.
// 3. simulation
// simulate game.
TTTGame::Field field;
for ( int y = 0; y < TTT_FIELDSIZE; y++ )
for ( int x = 0; x < TTT_FIELDSIZE; x++ )
field[y][x] = __field[y][x];
Player * bot1 = new Bot ();
bot1->SetFigure ( (this->mFigure == TTT_CROSS) ? TTT_CIRCLE : TTT_CROSS );
Player * bot2 = new Bot ();
bot2->SetFigure ( this->mFigure );
Player * current = bot2;
while ( TTTGame::IsPlayable ( field ) )
{
current->MakeMove ( field );
if ( newnode->MoveX == -1 && newnode->MoveY == -1 )
this->FindNewStep ( field, newnode->MoveX, newnode->MoveY );
if ( current == bot1 )
current = bot2;
else
current = bot1;
}Сыграем игру между ботами. Думаю, здесь надо немного объясниться: текущее состояние поле копируется и боты доигрывают на этой копии, первым ходит второй бот и его первый ход мы запомним.
// 4. backpropagation.
int winner = TTTGame::CheckWin ( field );
MCBTreeNode * currentnode = newnode;
while ( currentnode != nullptr )
{
currentnode->Attempts++;
if ( currentnode->Player == winner )
currentnode->Wins++;
currentnode = currentnode->Parent;
}И последнее: получим результат и распространим его вверх по дереву.
// make move...
this->mCurrent = newnode;
TTTGame::MakeMove ( __field, this->mFigure, mCurrent->MoveX, mCurrent->MoveY );И в конце мы просто делаем ход и текущим узлом ставим наш новый узел из второго шага.
Как видно, алгоритм не такой страшный и сложный. Конечно, моя реализация далека от идеала, но суть и некоторое практическое применение она показывает.
Полный код доступен на моём GitHub.
Всем добра.
|
Метки: author nkozhevnikov программирование алгоритмы метод монте-карло c++ |
All Flash Isilon NAS: масштабируемое хранилище для неструктурированных данных |
 Еще недавно потенциал ИТ-инфраструктуры сдерживался зависимостью от механических жестких дисков. Но с появлением флеш-памяти у компаний возникла возможность повысить скорость обработки данных и усовершенствовать способ их хранения.
Еще недавно потенциал ИТ-инфраструктуры сдерживался зависимостью от механических жестких дисков. Но с появлением флеш-памяти у компаний возникла возможность повысить скорость обработки данных и усовершенствовать способ их хранения.

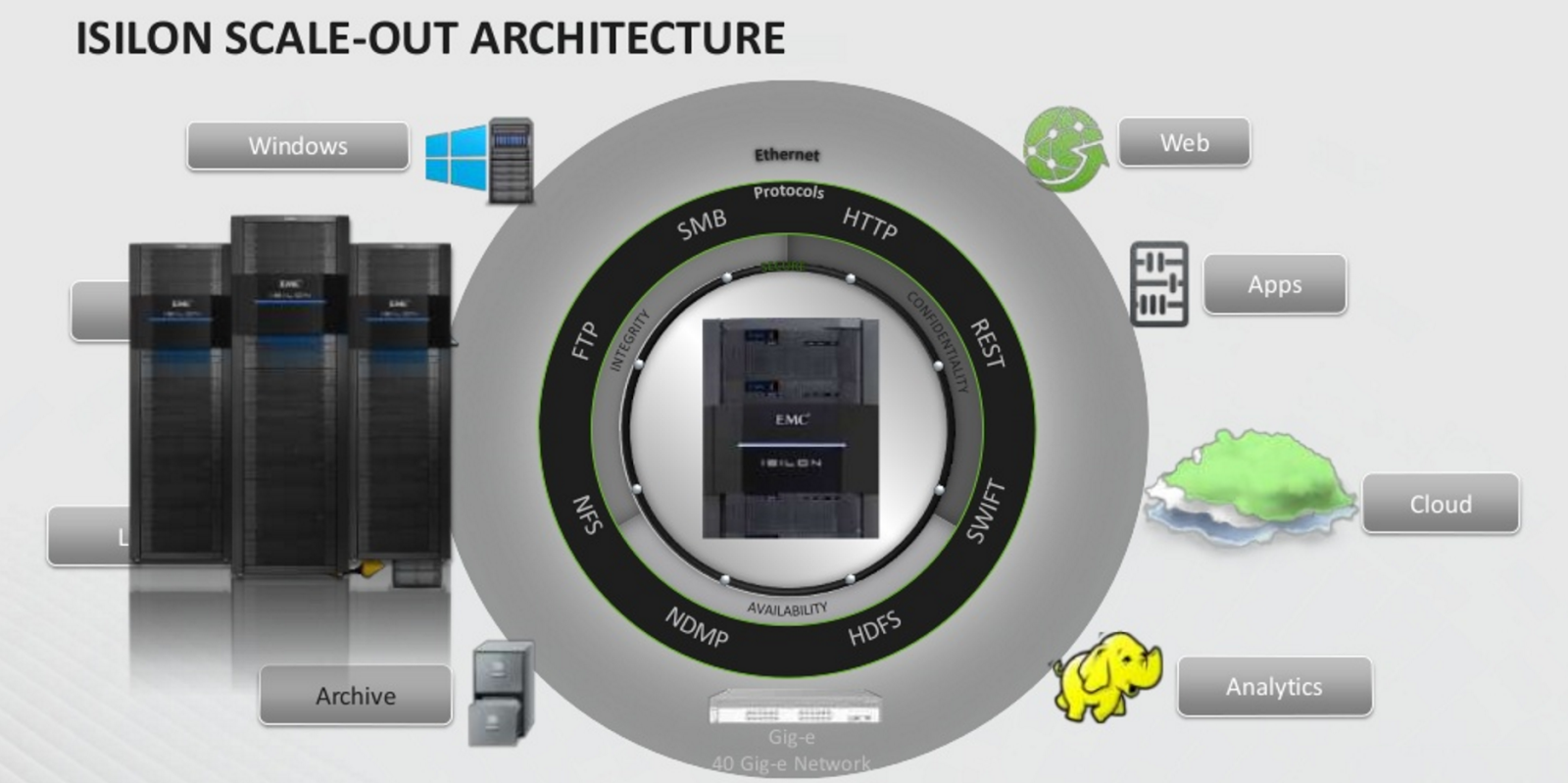
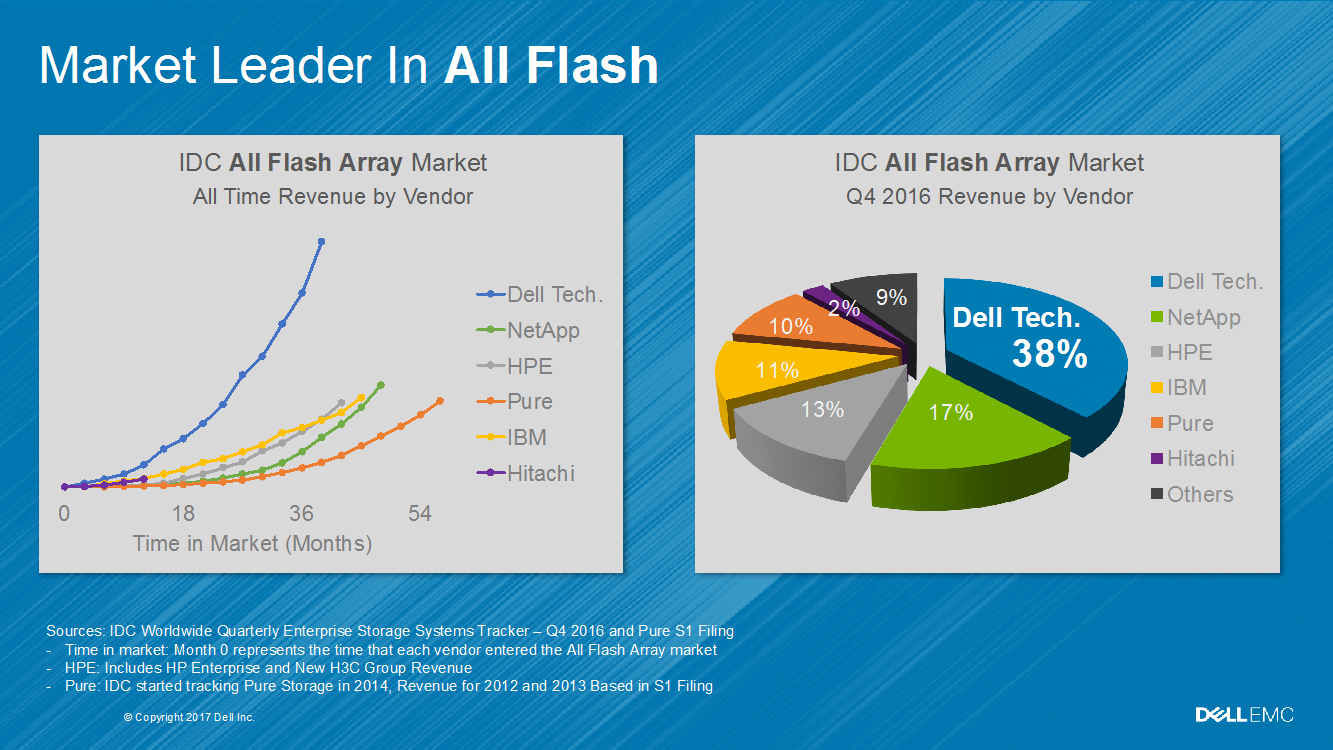

All Flash Isilon – это:• 924 Tбайт флеш-памяти в шасси 4U; • масштабируемость до более чем 92 Пбайт (100 шасси) с единой файловой системой; • многопротокольная поддержка (NFS, SMB, HDFS, SWIFT, FTP, HTTP, NDMP); • SmartPools и CloudPools: автоматическая миграция данных по уровням хранения, включая облако; • управление данными: дедупликация, квотирование, SmartConnect, InsightIQ; • защита данных: от N+1 до N+4 ECC, зеркалирование, снапшоты, репликация; • безопасность: WORM, аудит, шифрование, зоны доступа, ролевая аутентификация. |

|
Метки: author DellEMCTeam хранилища данных хранение данных сетевые технологии it- инфраструктура блог компании dell emc dell all flash isilon nas afa |
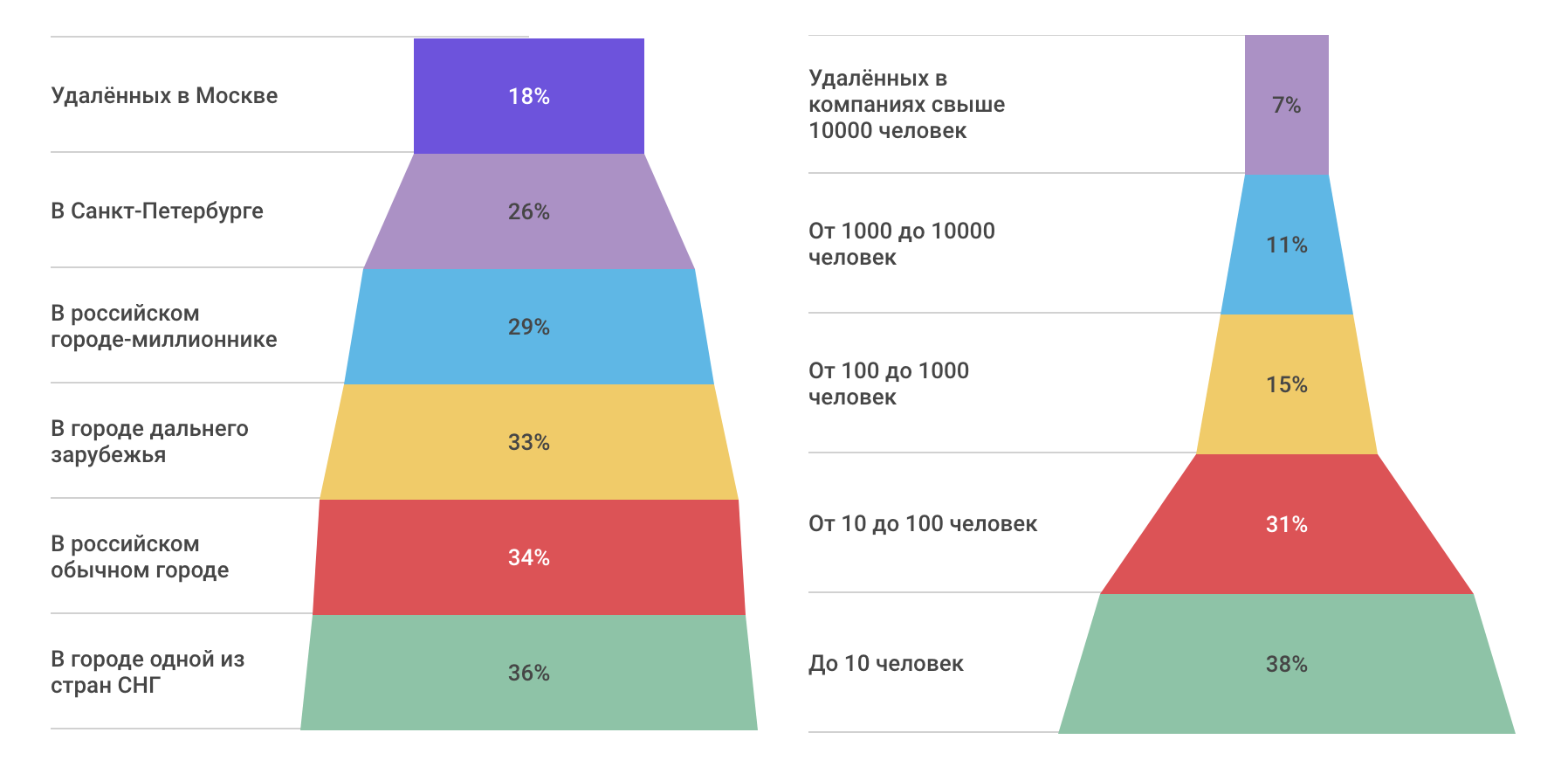
Удалённая работа в цифрах и диаграммах |



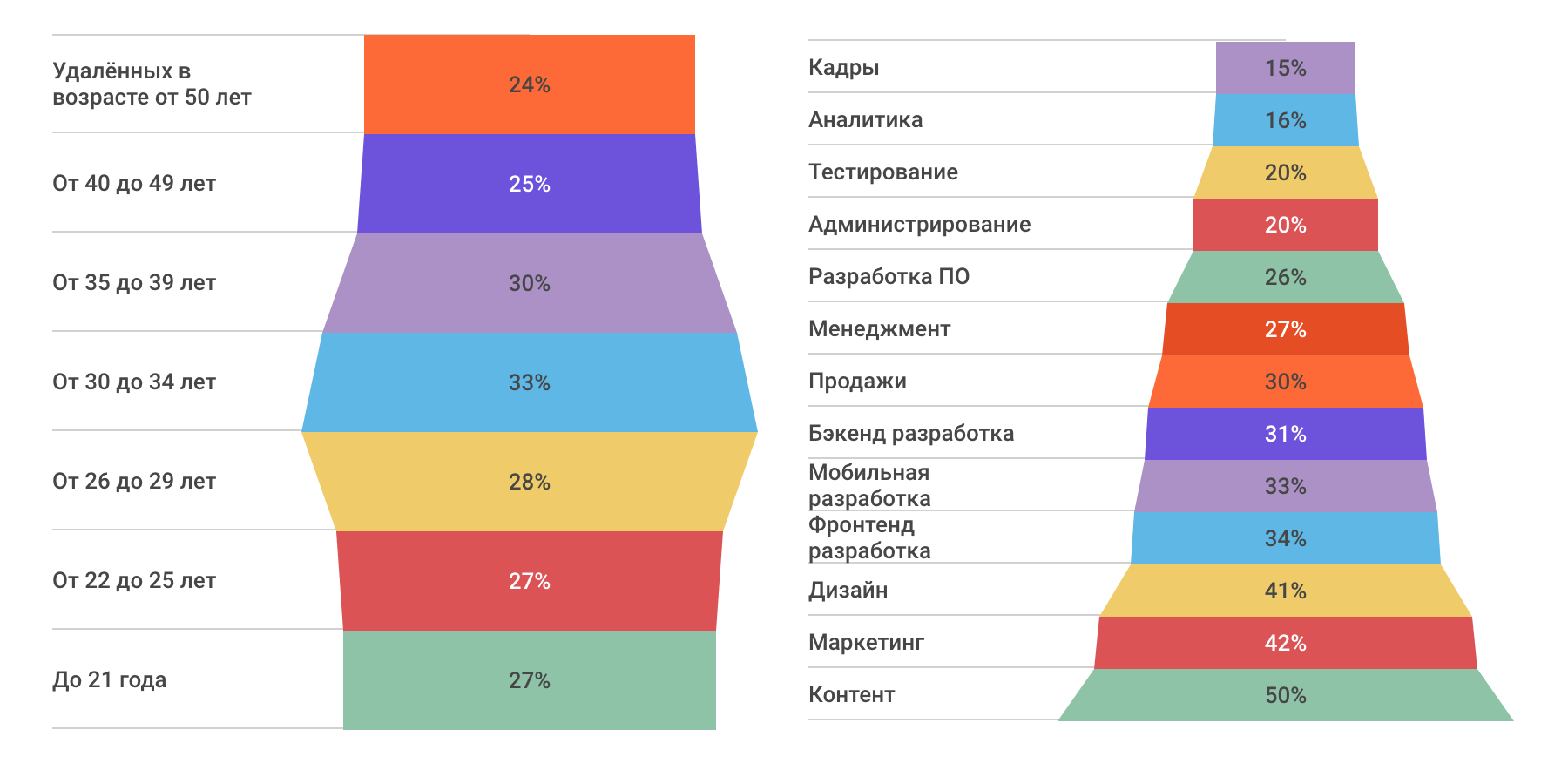
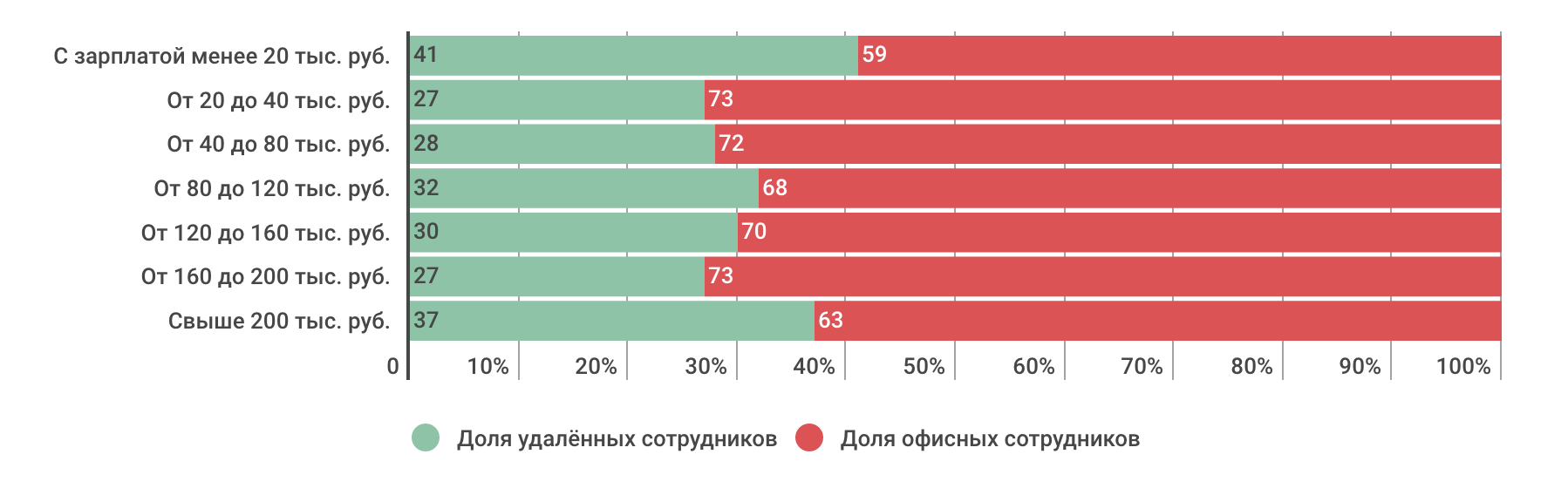
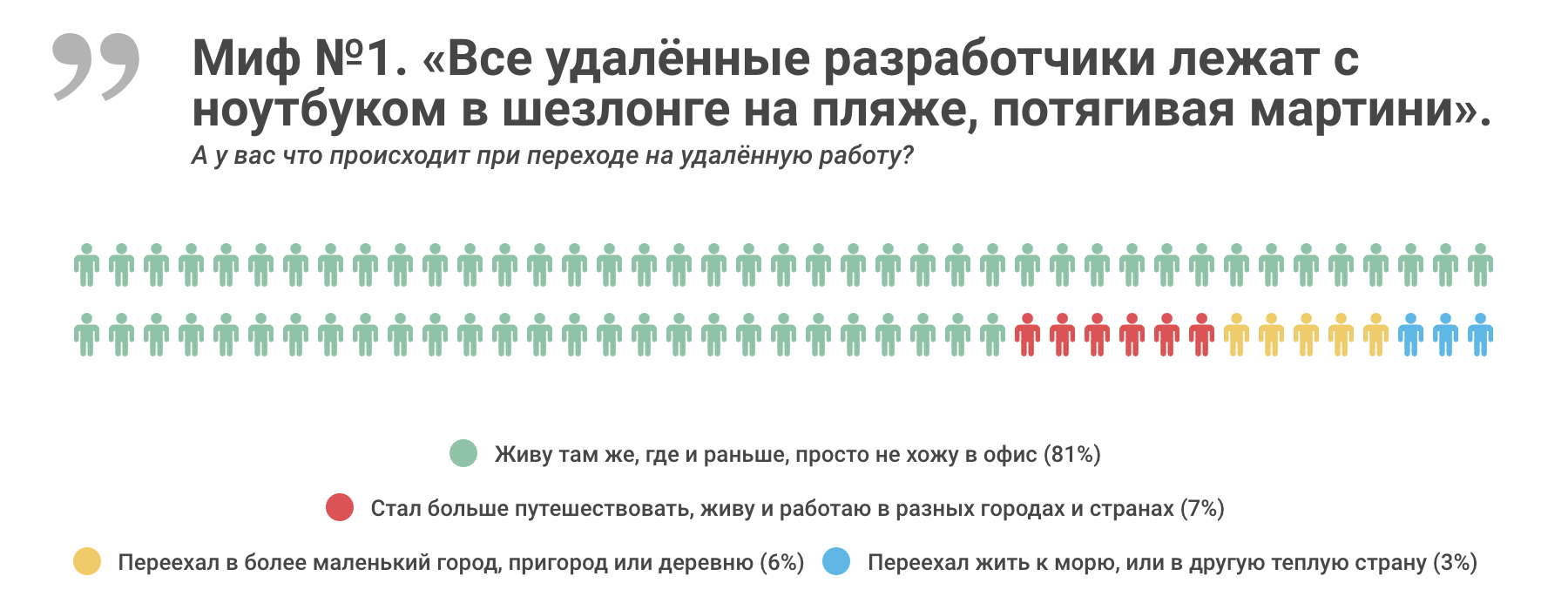
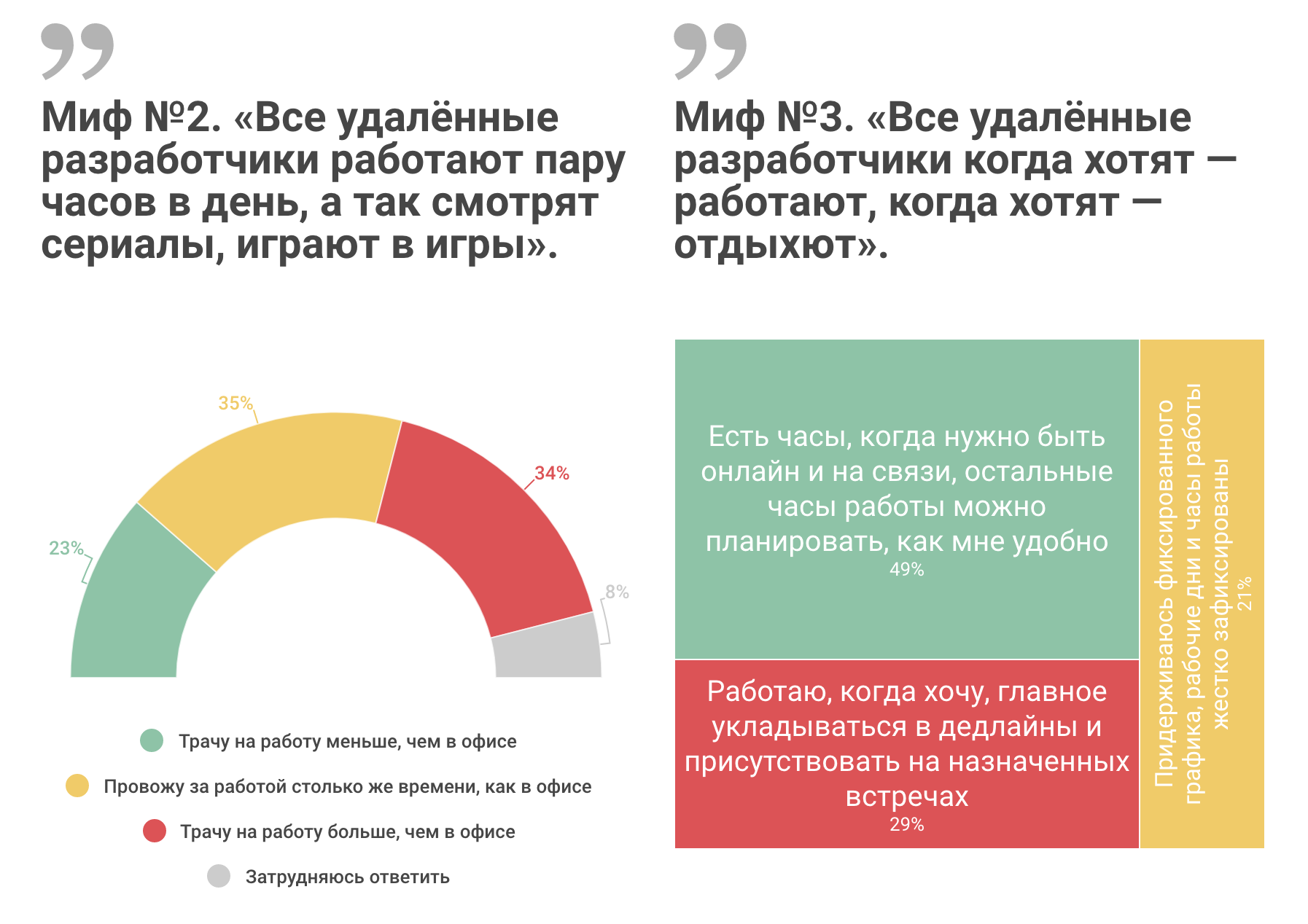
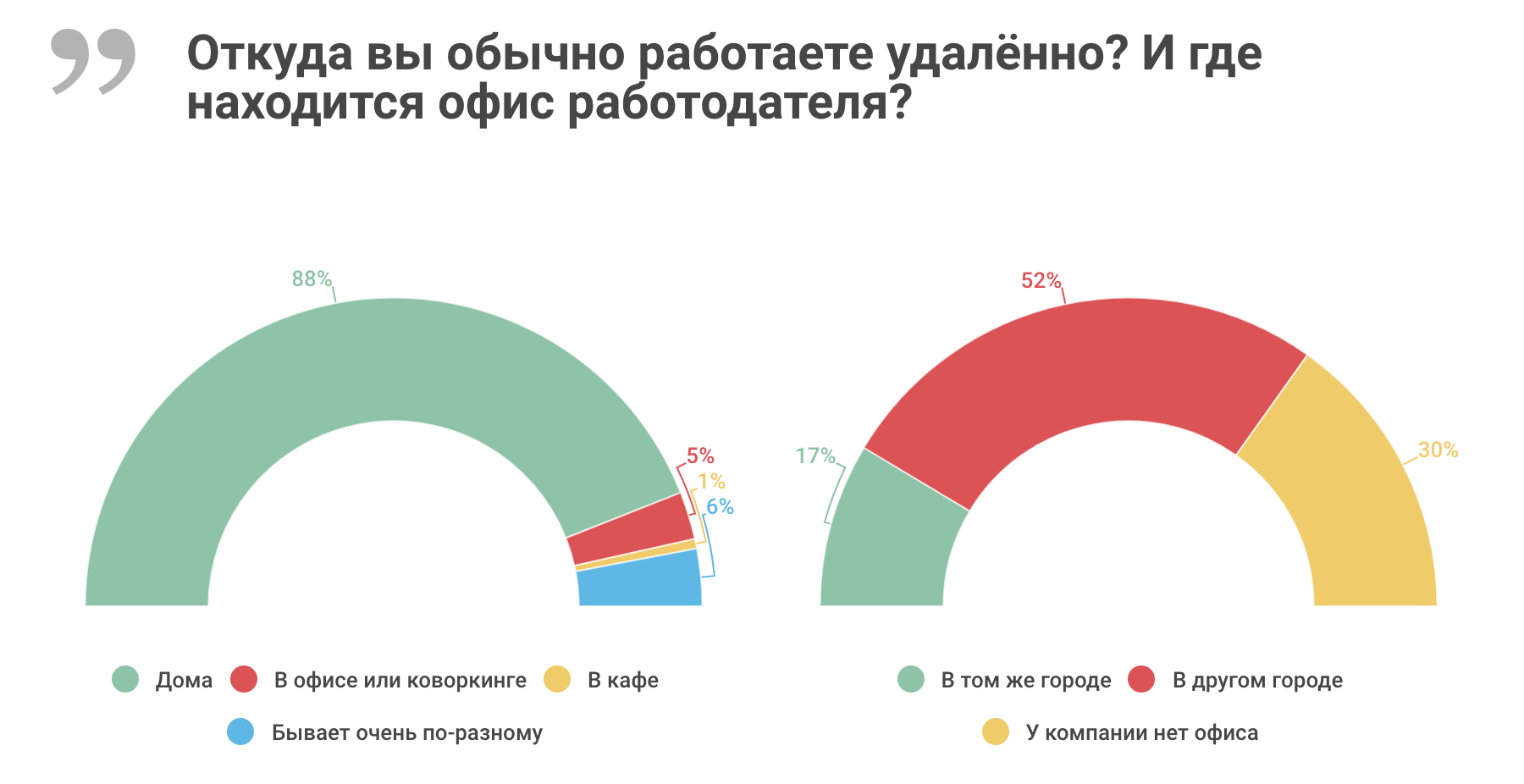
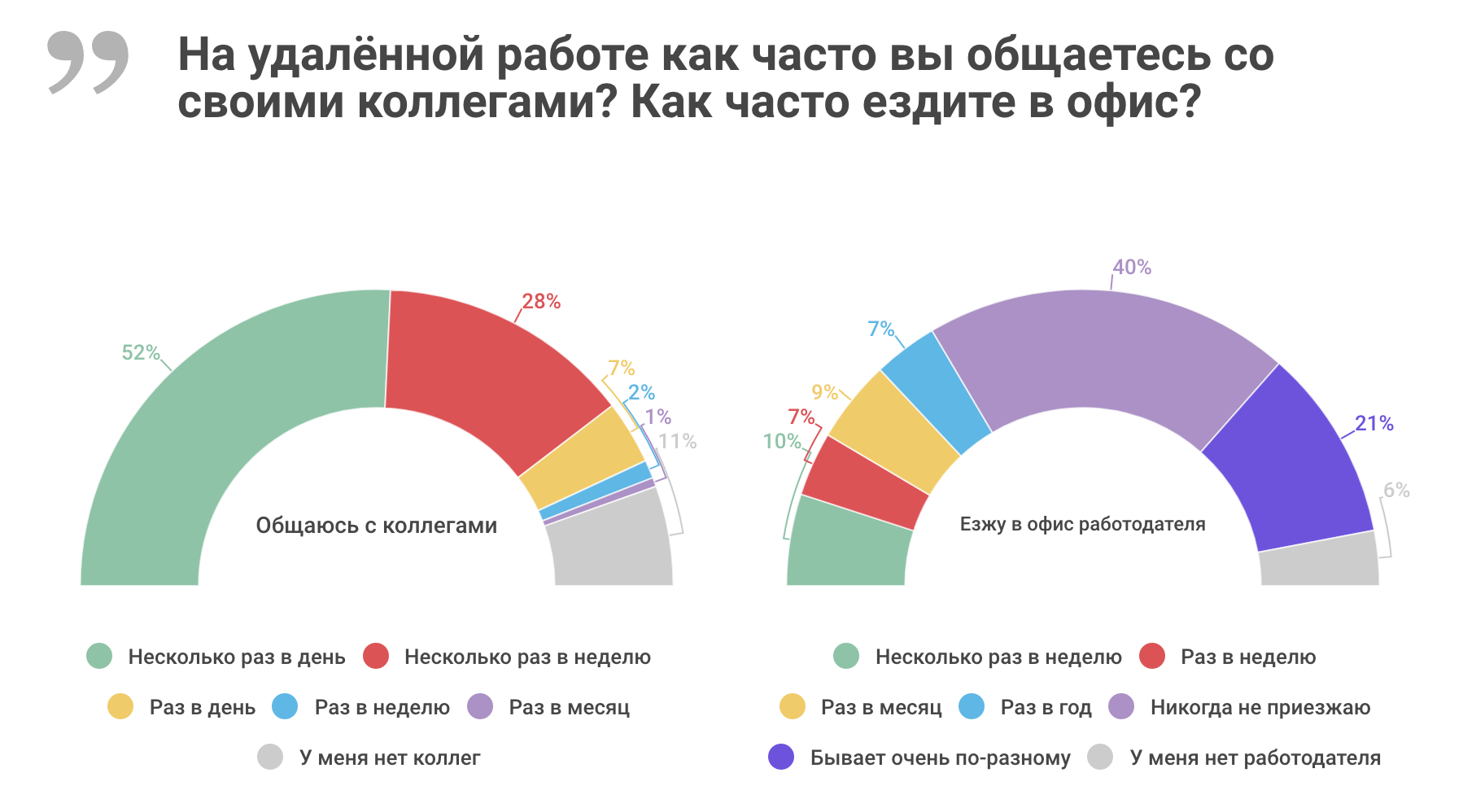





|
Метки: author moikrug управление персоналом карьера в it-индустрии блог компании мой круг мой круг moikrug.ru рекрутмент найм персонала удаленная работа опрос инфографика |
Анонс RamblerFront& #1 |

Максим расскажет о redux-rest-adapter — утилите, призванной облегчить работу с API в приложениях с Redux data flow.
Речь пойдет о том, из чего состоит счетчик ТОП-100 и как мы собираем информацию о посетителях сайта. Также разберем, с какими проблемами мы столкнулись, разрабатывая инструмент для большой аудитории.
Расскажем о том, как мы делали общую библиотеку компонент для сервисных вертикалей Рамблера. Речь пойдет о том, что там под капотом и как сделать так, чтобы разработчикам понравилось ей пользоваться.
В презентации будет рассказываться об SSP — одном из проектов Рамблер Рекламные Технологии. О том, в каком состоянии этот проект был несколько месяцев назад, какие шаги по рефакторингу были сделаны за это время и что из этого получилось, какие есть планы по дальнейшему развитию проекта. Будут предоставлены справочные материалы для тех, кто хочет побольше узнать о рефакторинге, разработке, тестировании и т.д. на реальных высоконагруженных проектах.
|
Метки: author SanDark7 reactjs javascript html css блог компании rambler co frontend react redux ssp |
How old are you? I’m 11 |

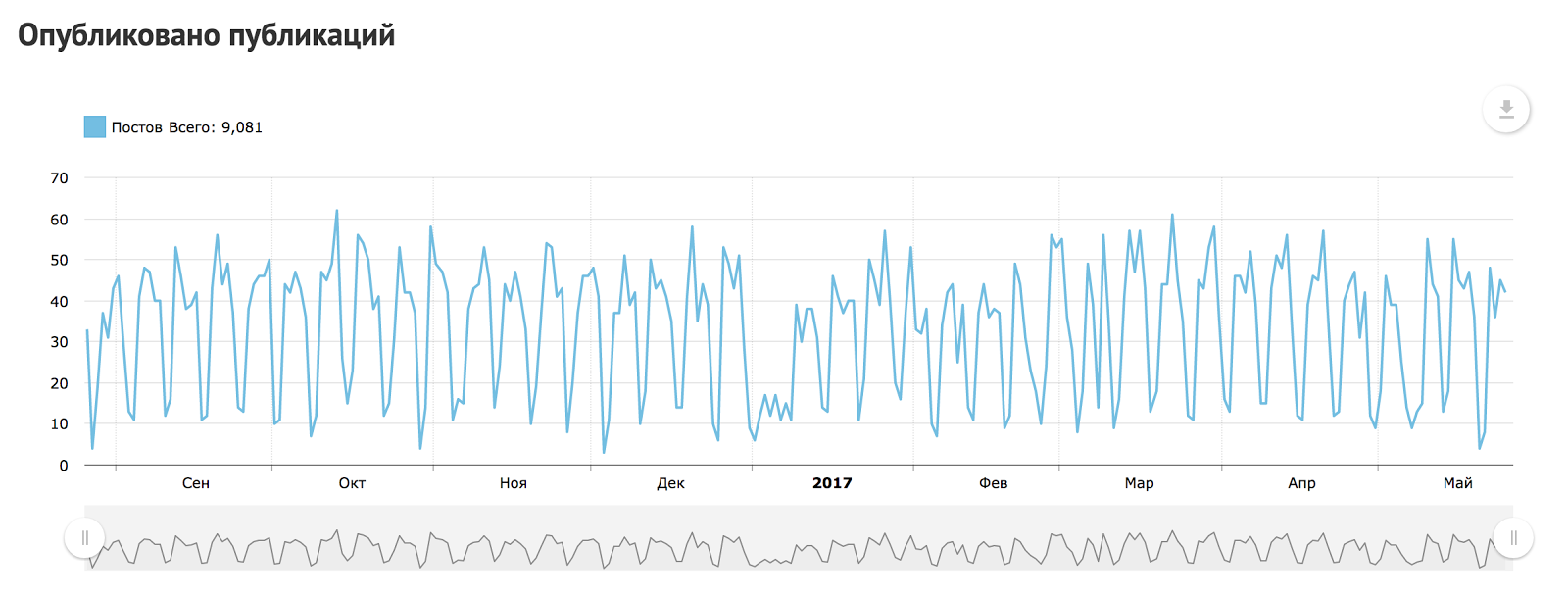
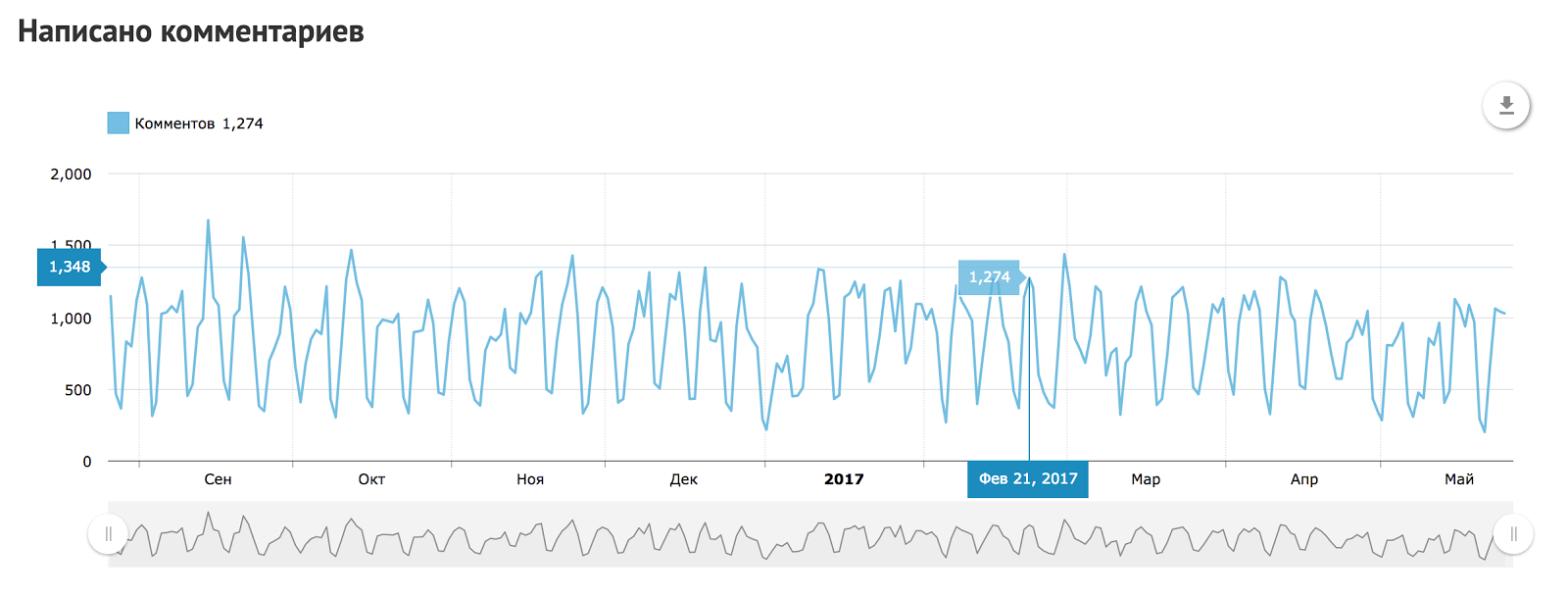
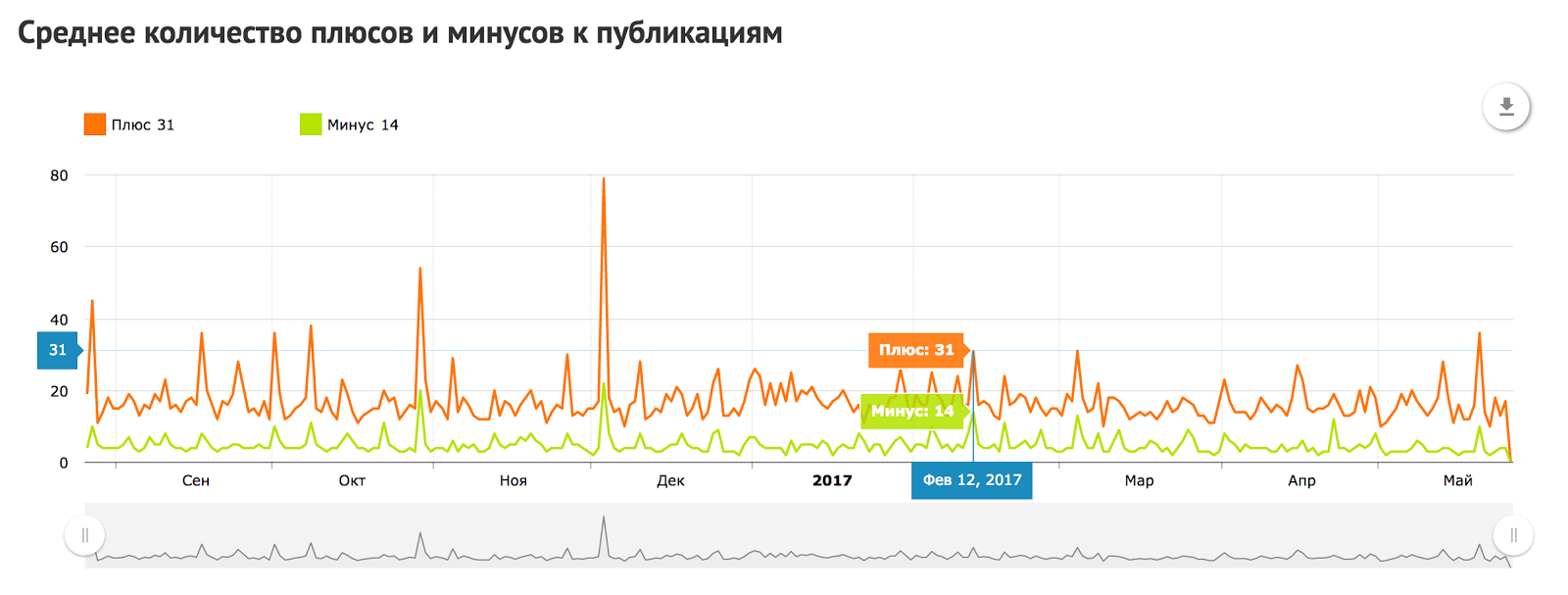
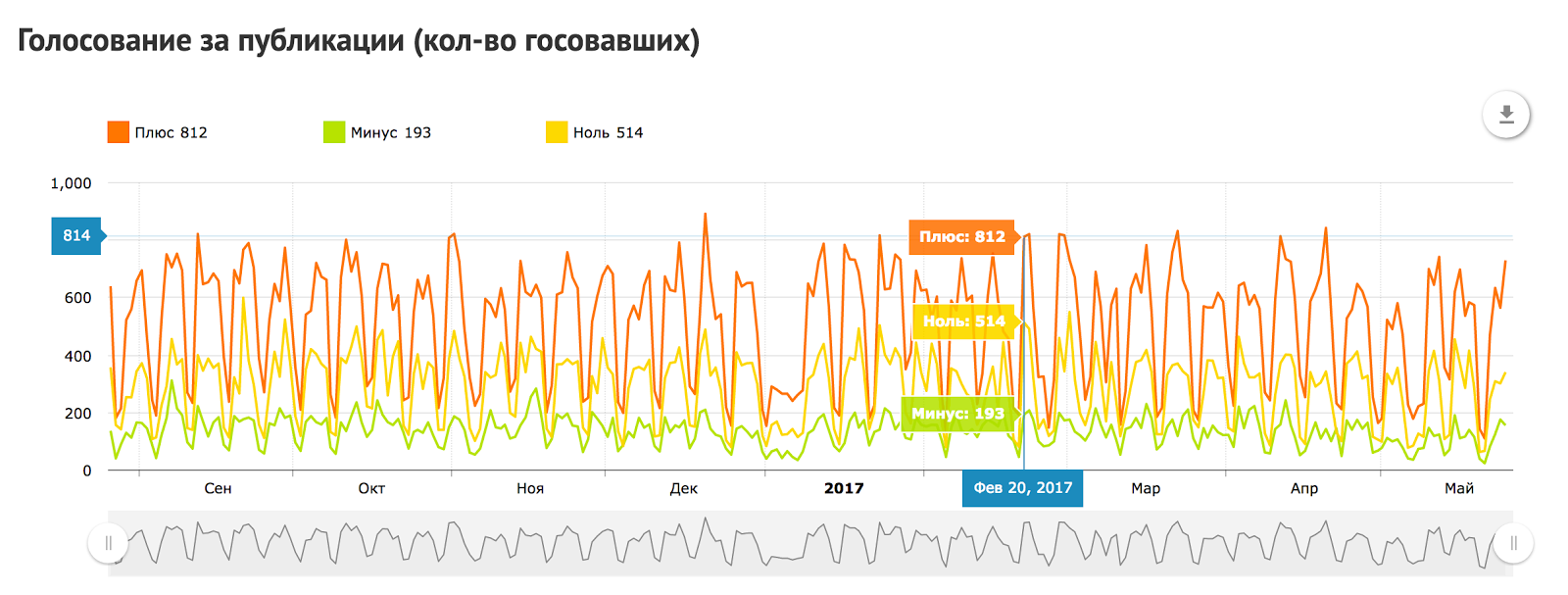

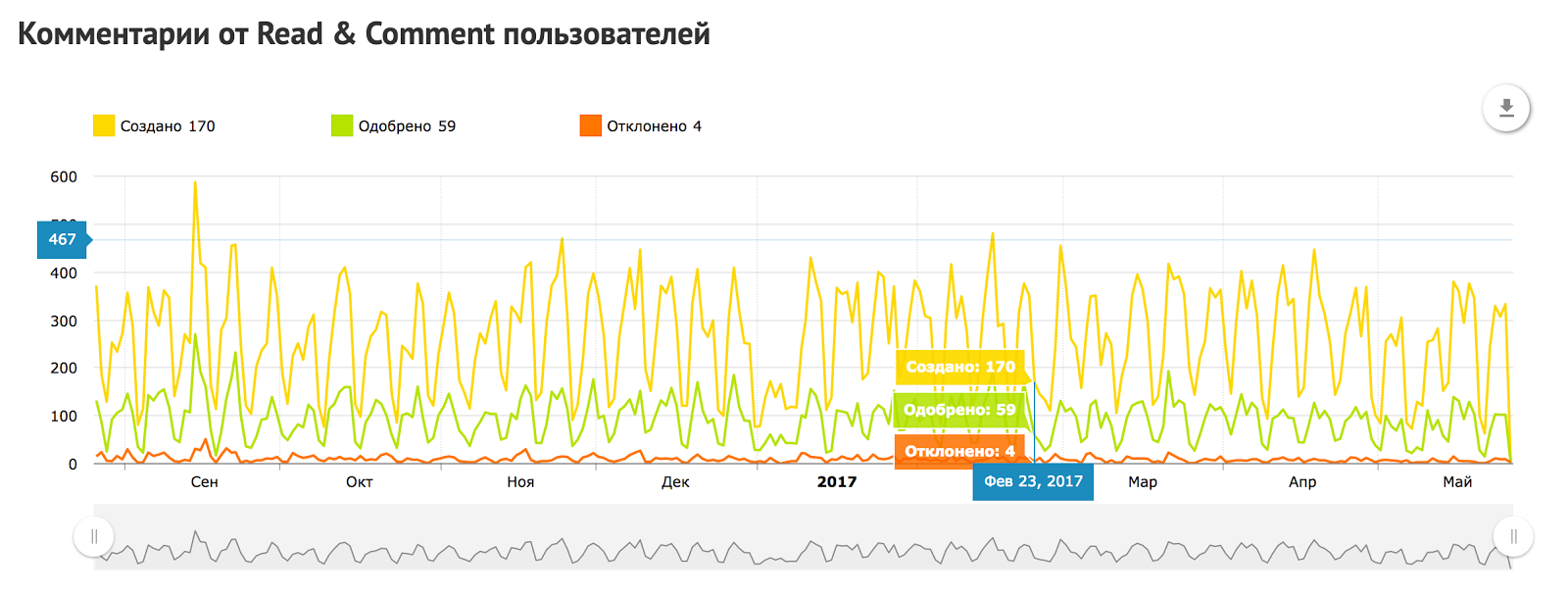
|
Метки: author habrahabr блог компании тechmedia хабрахабр рит день рождения |
OpenTl.Server — серверная реализация мессенджера |

|
Метки: author zarytskiy я пиарюсь c#.net |
[Из песочницы] Переосмысливая JavaScript: break и функциональный подход |
Привет Хабр! Предлагаю вам статьи Rethinking JavaScript: Replace break by going functional.

В моей предыдущей статье Rethinking JavaScript: Death of the For Loop (есть перевод: Переосмысление JavaScript: Смерть for) я пытался убедить вас отказаться от for в пользу функционального подхода. И вы задали хороший вопрос "Что на счет break?".
break это GOTO циклов и его следует избегать
Нам следует отказаться от break также, как мы когда-то отказались от GOTO.
Вы можете думать, "Да ладно, Джо, ты преувеличиваешь. Как это break это GOTO?"
// плохой код. не копируй!
outer:
for (var i in outerList) {
inner:
for (var j in innerList) {
break outer;
}
}Рассмотрим метки (прим. labels) для доказательства утверждения. В других языках метки работают в паре с GOTO. В JavaScript'e же метки работают вместе с break и continue, что сближает последних с GOTO.
JavaScript'вые метка, break и continue это пережиток GOTO и неструктурированного программирования

"Но break никому не мешает, почему бы не оставить возможность его использовать?"
Это может звучать нелогично, но ограничения это хорошая вещь. Запрет GOTO прекрасный тому пример. Мы также с удовольствием ограничиваем себя директивой "use strict", а иногда даже осуждаем игнорирующих её.
"Ограничения могут сделать вещи лучше. Намного лучше" — Чарльз Скалфани
Ограничения заставляют нас писать лучше.
Я не буду врать. Не существует простого и быстрого способа заменить break. Здесь нужен совершенно иной стиль программирования. Совершенно иной стиль мышления. Функциональный стиль мышления.
Хорошая новость в том, что существует много библиотек и инструментов, которые могут нам помочь, такие как Lodash, Ramda, lazy.js, рекурсия и другие.
Например, у нас есть коллекция котов и функция isKitten:
const cats = [
{ name: 'Mojo', months: 84 },
{ name: 'Mao-Mao', months: 34 },
{ name: 'Waffles', months: 4 },
{ name: 'Pickles', months: 6 }
]
const isKitten = cat => cat.months < 7Начнем со старого доброго цикла for. Мы проитерируем наших котов и выйдем из цикла, когда найдем первого котенка.
var firstKitten
for (var i = 0; i < cats.length; i++) {
if (isKitten(cats[i])) {
firstKitten = cats[i]
break
}
}Сравним с аналогичным lodash вариантом
const firstKitten = _.find(cats, isKitten)Этот был довольно простой пример, давайте попробуем что-нибудь по-серьезнее. Будем перебирать наших котов пока не найдем 5 котят.
var first5Kittens = []
// старый добрый for
for (var i = 0; i < cats.length; i++) {
if (isKitten(cats[i])) {
first5Kittens.push(cats[i])
if (first5Kittens.length >= 5) {
break
}
}
}Прим. переводчика: позволил себе немного вольности и дополнил размышления о легком пути недостающими, по моему мнению, частями.
Мы можем использовать стандартные методы массива JavaScript.
const result = cats.filter(isKitten)
.slice(0, 5);Но это не очень функционально. Мы можем воспользоваться Lodash'ем.
const result = _.take(_.filter(cats, isKitten), 5)Это достаточно хорошее решение пока вы ищете котят в небольшой коллекции котов.
Lodash великолепен и умеет делать массу хороших вещей, но сейчас нам нужно что-то более специфичное. Тут нам поможет lazy.js. Он "Как underscore, но ленивый". Его ленивость нам и нужна.
const result = Lazy(cats)
.filter(isKitten)
.take(5)Дело в том, что ленивые последовательности (которые предоставляет lazy.js) сделают ровно столько преобразований (filter, map и тд) сколько элементов вы хотите получить в конце.
Библиотеки это весело, но иногда по настоящему весело сделать что-то самому!
Как на счет того, чтобы создать обобщенную (прим. generic) функцию, которая будет работать как filter, но вдобавок будет уметь останавливаться при нахождении определенного количества элементов?
Сначала обернем наш старый добрый цикл в функцию.
const get5Kittens = () => {
const newList = []
// старый добрый for
for (var i = 0; i < cats.length; i++) {
if (isKitten(cats[i])) {
newList.push(cats[i])
if (newList.length >= 5) {
break
}
}
}
return newList
}Теперь давайте обобщим функцию и вынесем всё котоспецифичное. Заменим 5 на limit, isKitten на predicate и cats на list и вынесем их в параметры функции.
const takeFirst = (limit, predicate, list) => {
const newList = []
for (var i = 0; i < list.length; i++) {
if (predicate(list[i])) {
newList.push(list[i])
if (newList.length >= limit) {
break
}
}
}
return newList
}В итоге у нас получилась готовая для повторного использования функция takeFirst, которая полностью отделена от нашей кошачьей бизнес логики!
takeFirst — чистая функция. Результат ее выполнения определяется только входными параметрами. Функция гарантированно вернет тот же результат получив те же параметры.
Функция до сих пор содержит противный for, так что продолжим рефакторинг. Следующим шагом переместим i и newList в параметры функции.
const takeFirst = (limit, predicate, list, i = 0, newList = []) => {
// ...
}Мы хотим закончить рекурсию (isDone) когда limit достигнет 0 (limit будет уменьшаться во время рекурсии) или когда закончится list.
Если мы не закончили, мы выполняем predicate. Если результат predicate истинен, мы вызываем takeFirst, уменьшаем limit и присоединяем элемент к newList.
Иначе берем следующий элемент списка.
const takeFirst = (limit, predicate, list, i = 0, newList = []) => {
const isDone = limit <= 0 || i >= list.length
const isMatch = isDone ? undefined : predicate(list[i])
if (isDone) {
return newList
} else if (isMatch) {
return takeFirst(limit - 1, predicate, list, i + 1, [...newList, list[i]])
} else {
return takeFirst(limit, predicate, list, i + 1, newList)
}
}Последний наш шаг замены if на тернарный оператор объяснен в моей статье Rethinking Javascript: the If Statement.
/*
* takeFirst работает как `filter`, но поддерживает ограничение.
*
* @param {number} limit - Максимальное количество возвращаемых соответствий
* @param {function} predicate - Функция соответствия, принимает item и возвращает true или false
* @param {array} list - Список, который будет отфильтрован
* @param {number} [i] - Индекс, с которого начать фильтрацию (по умолчанию 0)
*/
const takeFirst = (limit, predicate, list, i = 0, newList = []) => {
const isDone = limit <= 0 || i >= list.length
const isMatch = isDone ? undefined : predicate(list[i])
return isDone ? newList :
isMatch ? takeFirst(limit - 1, predicate, list, i + 1, [...newList, list[i]])
: takeFirst(limit, predicate, list, i + 1, newList)
}Теперь вызовем наш новый метод:
const first5Kittens = takeFirst(5, isKitten, cats)Чтобы сделать takeFirst ещё полезнее мы могли бы её каррировать (прим. currying) и использовать для создания других функций. (больше о карировании в другой статье)
const first5 = takeFirst(5)
const getFirst5Kittens = first5(isKitten)
const first5Kittens = getFirst5Kittens(cats)Есть много хороших библиотек (например lodash, ramda, lazy.js), но будучи достаточно смелыми, мы можем воспользоваться силой рекурсии чтобы создавать собственные решения!
Я должен предупредить, что хотя takeFirst невероятно крутая, с рекурсией приходит великая сила, но также и большая ответственность. Рекурсия в мире JavaScript может быть очень опасной и легко привести к ошибке переполнения стека Maximum call stack size exceeded.
Я расскажу о рекурсии в JavaScript в следующей статьей.
Я знаю что это мелочь, но меня очень радует когда кто-то подписывается на меня на Медиуме и Твиттере @joelnet. Если же вы думаете что я дурак, скажите это мне в комментах ниже.
-> Functional JavaScript: Functional Composition For Every Day Use.
-> Rethinking JavaScript: Death of the For Loop
(есть перевод: Переосмысление JavaScript: Смерть for)
-> Rethinking JavaScript: Elliminate the switch statement for better code
-> Functional JavaScript: Resolving Promises Sequentially
Прим. переводчика: выражаю благодарность Глебу Фокину и Богдану Добровольскому в написании перевода, а также Джо Томсу, без которого перевод был бы невозможен.
|
Метки: author crazymax11 javascript functional programming перевод |
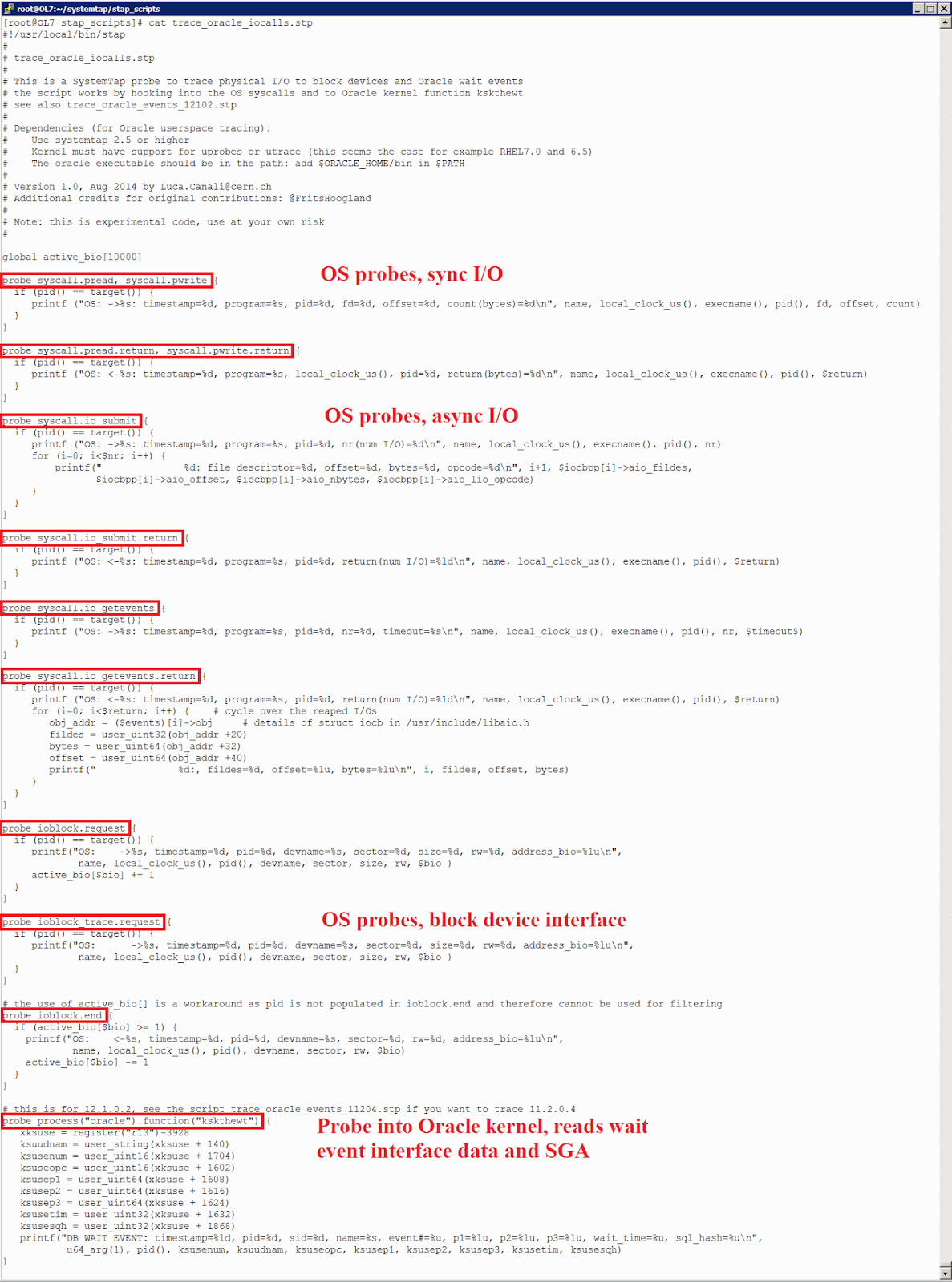
[Перевод] SystemTap в Oracle |
# grep CONFIG_UTRACE /boot/config-`uname -r`
CONFIG_UTRACE=y# grep CONFIG_UPROB /boot/config-`uname -r`
CONFIG_UPROBES=y
CONFIG_UPROBE_EVENT=y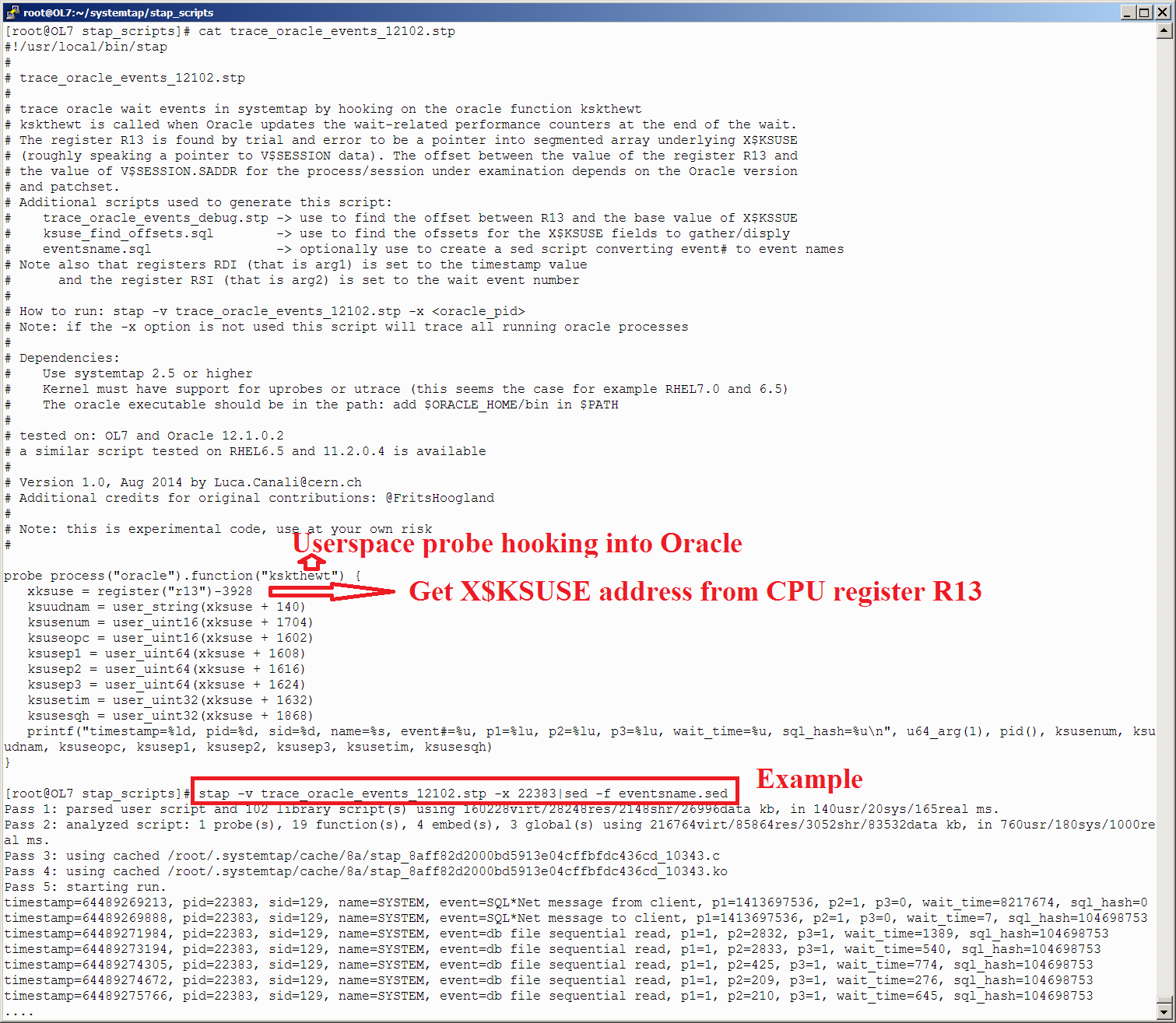
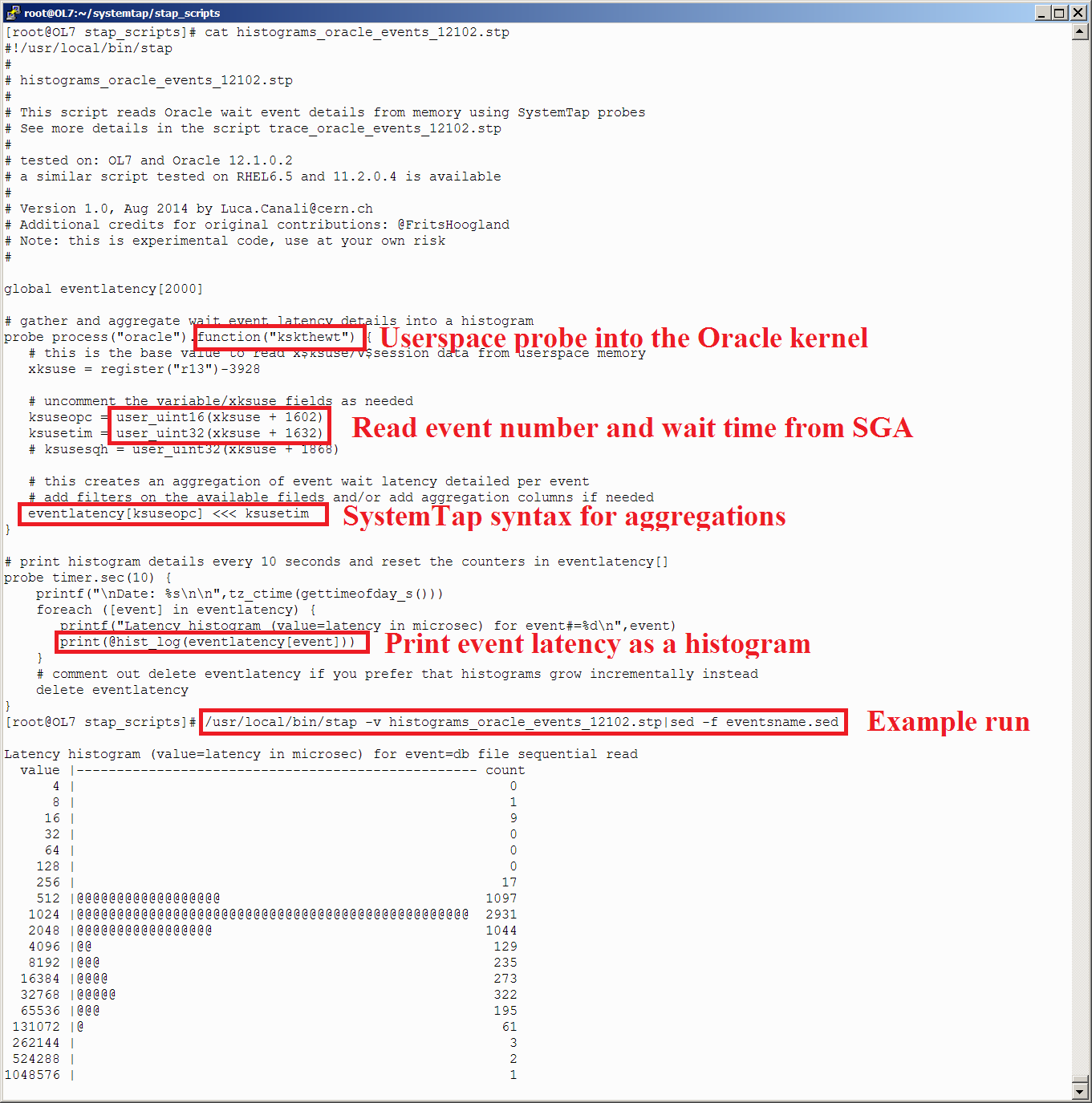
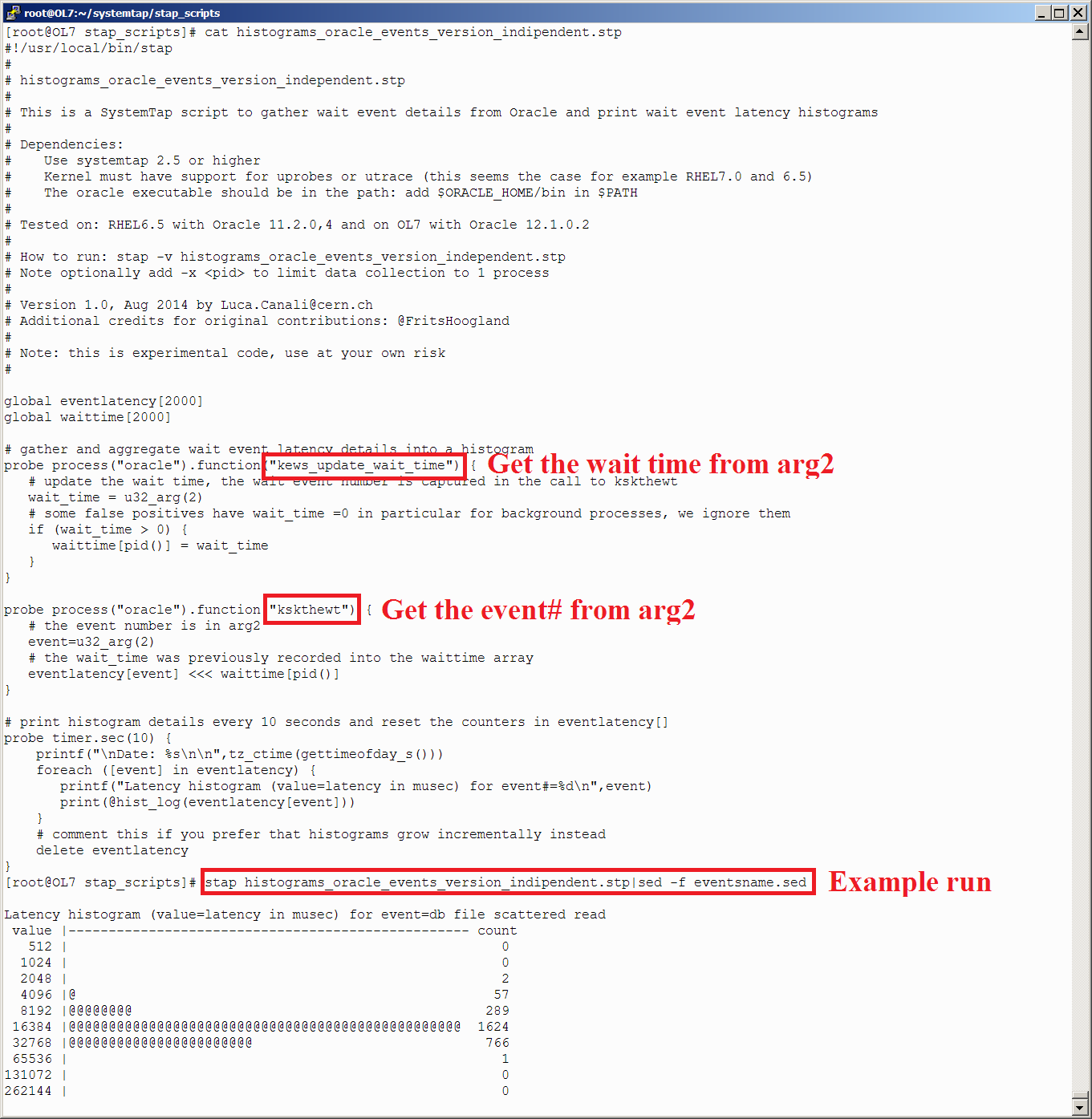
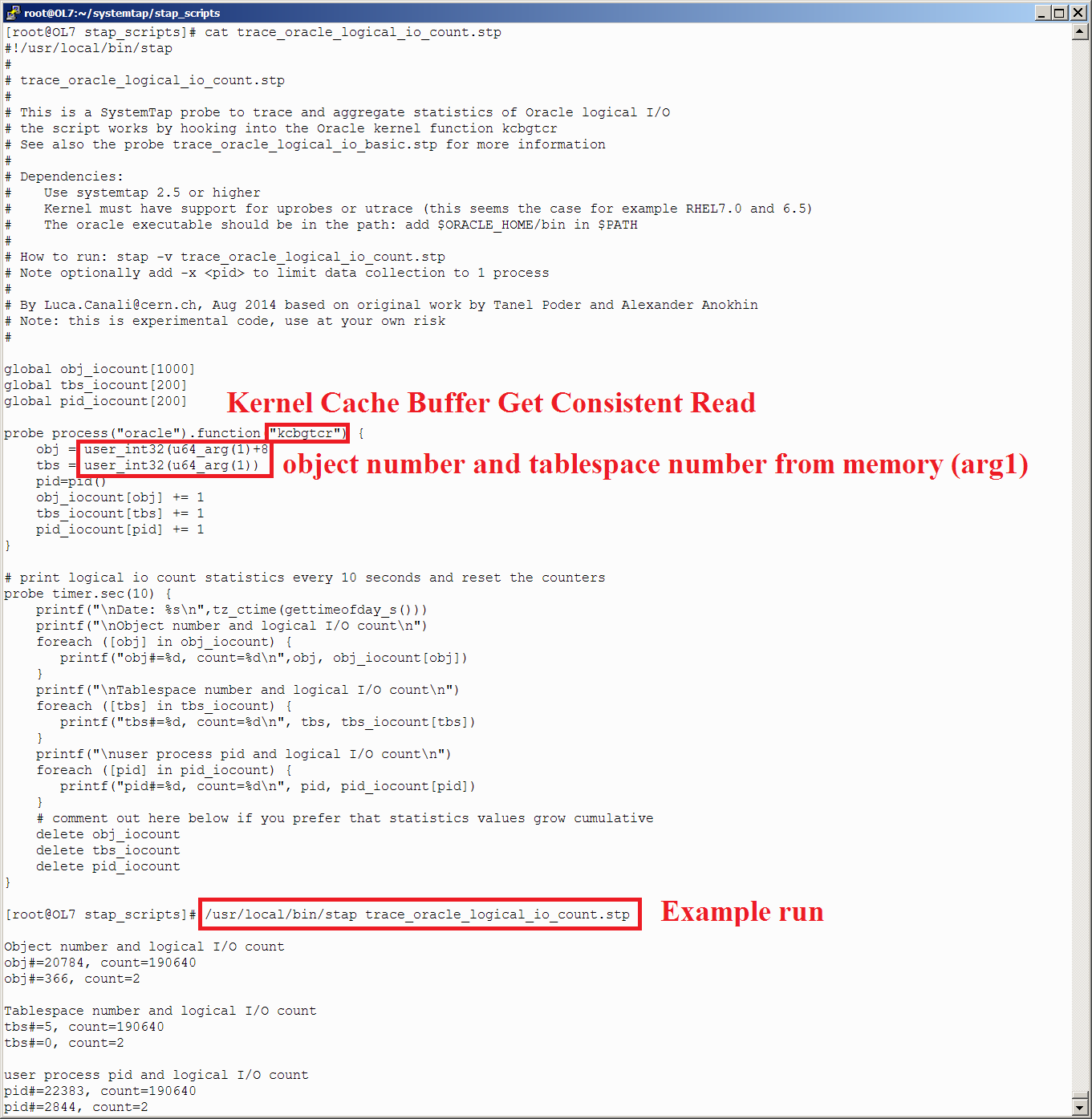
probe process("oracle").function("kcbgtcr") {
printf("tbs#=%d, rfile=%d, block#=%d, obj#=%d\n",user_int32(u64_arg(1)), user_int32(u64_arg(1)+4) >> 22 & 0x003FFFFF, user_int32(u64_arg(1)+4) & 0x003FFFFF, user_int32(u64_arg(1)+8))
}
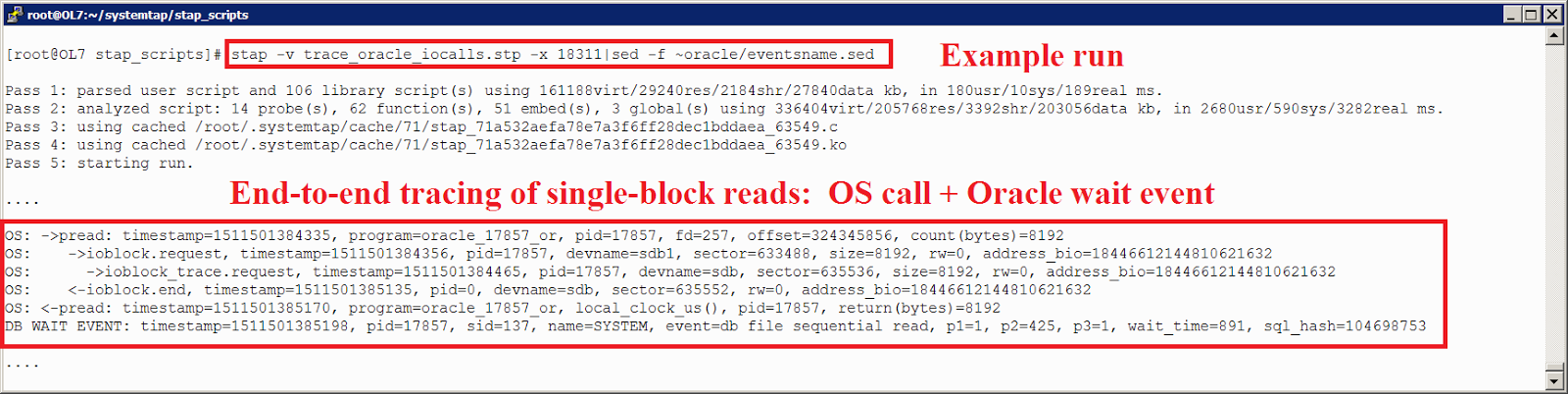

./configure
# вывод configure укажет, требуются ли дополнительные пакеты ОС; в этом случае, то установите их и повторите операцию
make
make installstap --help
|
Метки: author rdruzyagin отладка sql oracle блог компании pg day'17 russia performance tuning profiling tracing systemtap linux |






