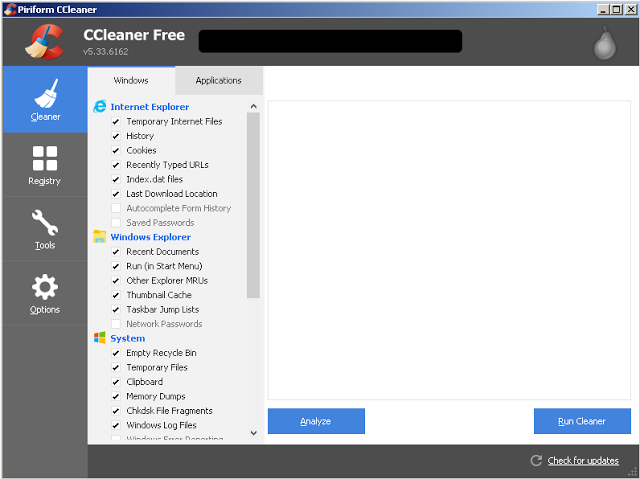
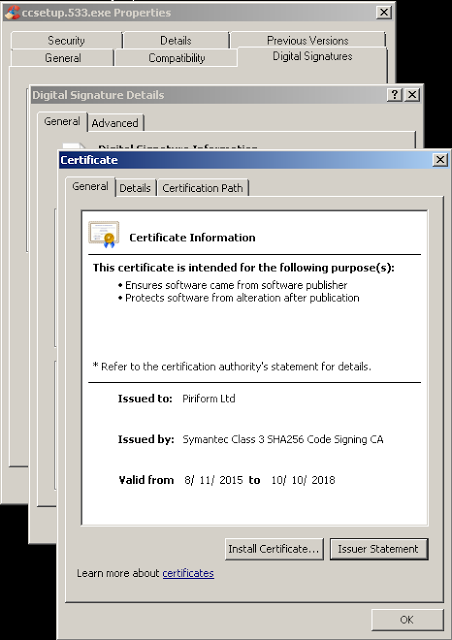
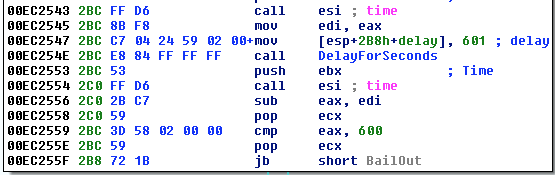
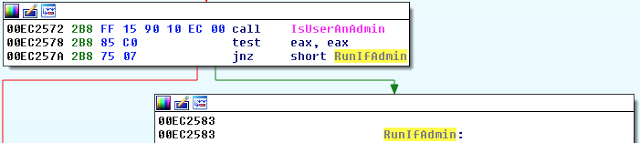
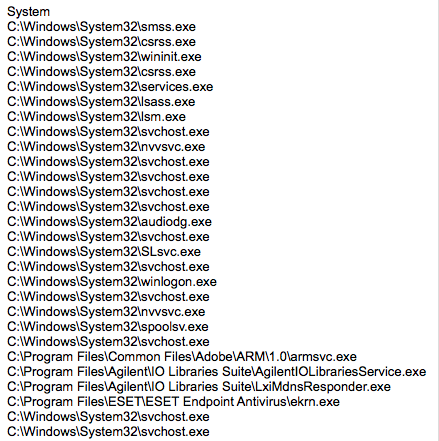
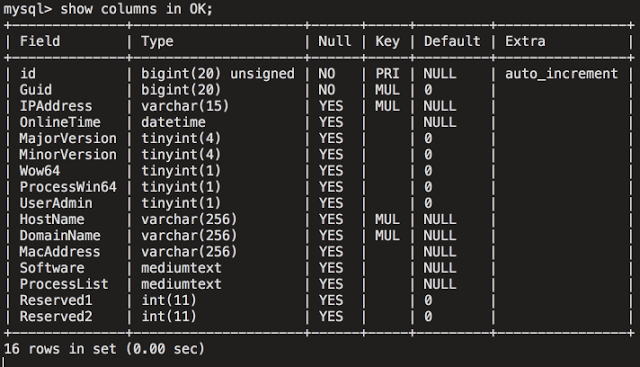
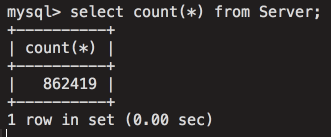
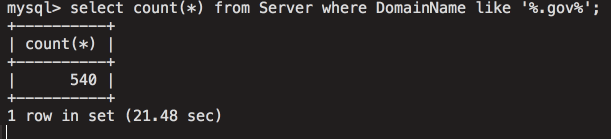
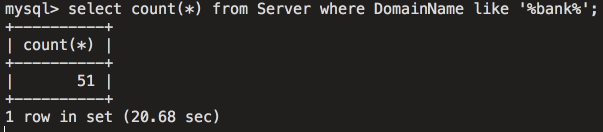
[Перевод] Что известно об атаке на цепи поставок CCleaner |




|
Метки: author Cloud4Y системное администрирование сетевые технологии антивирусная защита it- инфраструктура блог компании cloud4y ccleaner вирус троян |
Больше сюрпризов от Apple: обновленные правила размещения на App Store |

|
Метки: author nanton разработка под ios разработка мобильных приложений блог компании everyday tools apple app store ios публикация приложения |
CIS Benchmarks: лучшие практики, гайдлайны и рекомендации по информационной безопасности |
|
Метки: author LukaSafonov информационная безопасность блог компании pentestit cis benchmarks |
Blockchain стартап и Имбецилы. Можно ли не рождаться? |
|
Метки: author joint функциональное программирование высокая производительность c++ #blockchain #indico #indiecaps |
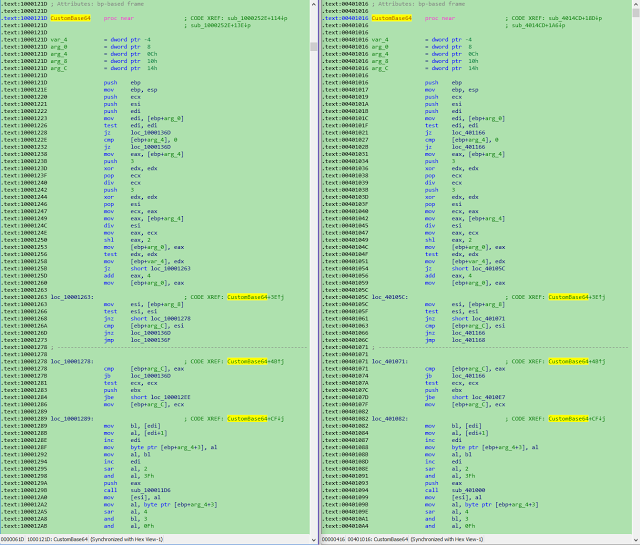
Обзор одной российской RTOS, часть 6. Средства синхронизации потоков |

void ProfEye::Tune()
{
ProfData::m_empty_call_overhead = 0;
ProfData::m_empty_constr_overhead = 0;
ProfData::m_embrace_overhead = 0;
CriticalSection _cs_;
loop ( int, i, 1000 ) {
PROF_DECL(PE_EMPTY_CALL, empty_call);
PROF_START(empty_call);
PROF_STOP(empty_call);
{ PROF_EYE(PE_EMBRACE, _embrace_);
{ PROF_EYE(PE_EMPTY_CONSTR, _empty_constr_);
}
}
}
ProfData::m_empty_call_overhead = prof_data[PE_EMPTY_CALL].TimeAvg();
ProfData::m_empty_constr_overhead = prof_data[PE_EMPTY_CONSTR].TimeAvg();
ProfData::m_embrace_overhead = prof_data[PE_EMBRACE].TimeAvg() + ProfData::ADJUSTMENT - 2 * ProfData::m_empty_constr_overhead;
}

ProfEye::ProfEye(PROF_EYE eye, bool run)
{
m_eye = eye;
m_lost = 0;
m_run = false;
if ( run ) {
{ CriticalSection _cs_;
prof_data[m_eye].Lock(true);
m_up_eye = m_cur_eye;
m_cur_eye = this;
}
Start();
} else
m_up_eye = nullptr;
}
26: cnt++;
0x08004818 6B60 LDR r0,[r4,#0x34]
0x0800481A 1C40 ADDS r0,r0,#1
0x0800481C 6360 STR r0,[r4,#0x34]
{
CriticalSection cs;
cnt++
}
27: CriticalSection cs;
0x0800481A 4668 MOV r0,sp
0x0800481C F7FEFCE8 BL.W _ZN4maks15CriticalSectionC2Ev (0x080031F0)
28: cnt++;
0x08004820 6B60 LDR r0,[r4,#0x34]
0x08004822 1C40 ADDS r0,r0,#1
29: }
0x08004824 6360 STR r0,[r4,#0x34]
0x08004826 4668 MOV r0,sp
0x08004828 F7FEFDA0 BL.W _ZN4maks19InterruptMaskSetterD2Ev (0x0800336C)
0x080031F0 B510 PUSH {r4,lr}
0x080031F2 2150 MOVS r1,#0x50
0x080031F4 F000F8AE BL.W _ZN4maks19InterruptMaskSetterC2Ej (0x08003354)
0x080031F8 4901 LDR r1,[pc,#4] ; @0x08003200
0x080031FA 6001 STR r1,[r0,#0x00]
0x080031FC BD10 POP {r4,pc}
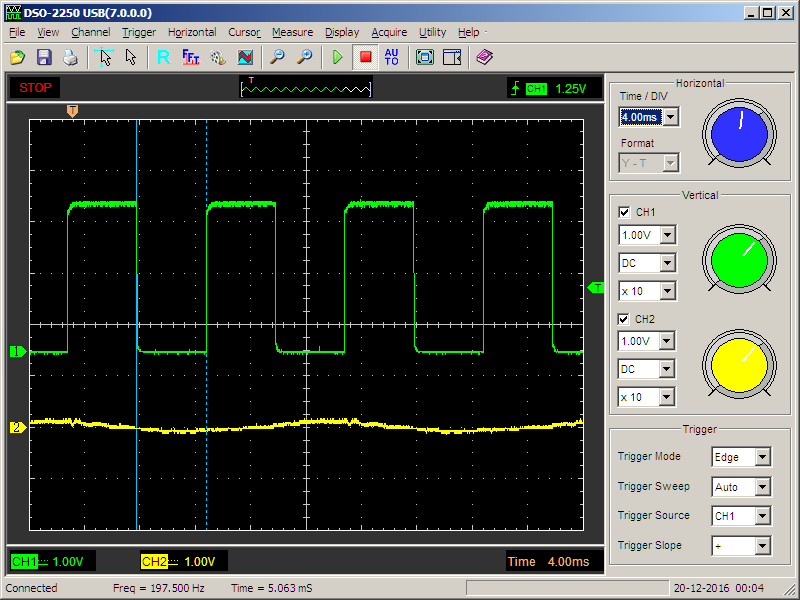
virtual void Execute()
{
while (true)
{
GPIOE->BSRR = (1<BSRR = (1<<(nBit+16));
Delay (5);
}
}

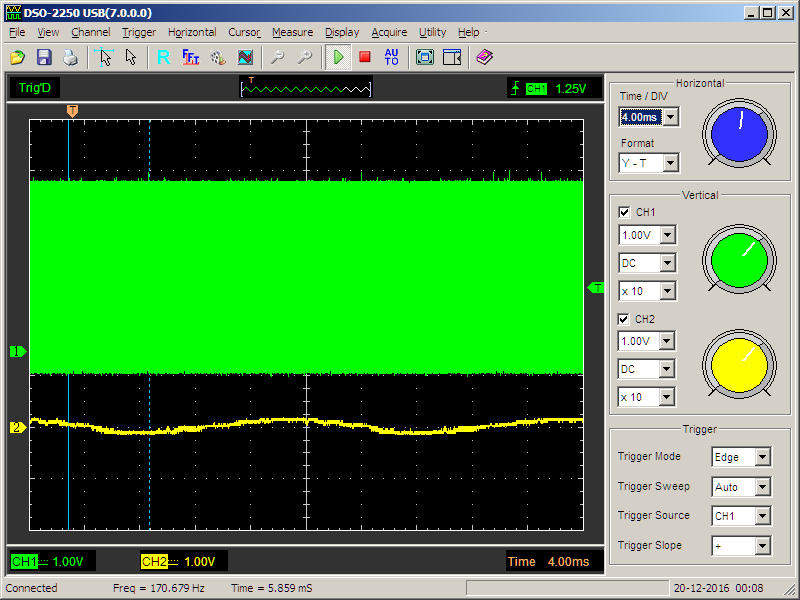
virtual void Execute()
{
CriticalSection cs;
while (true)
{
GPIOE->BSRR = (1<BSRR = (1<<(nBit+16));
Delay (5);
}
}
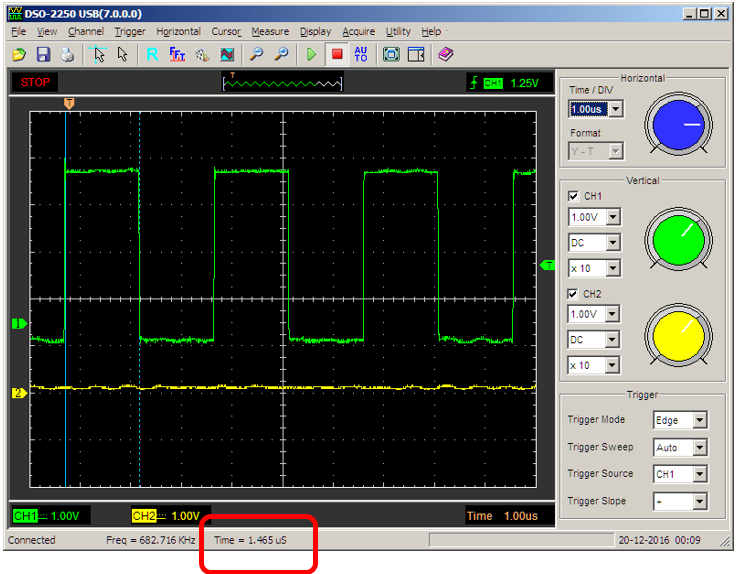
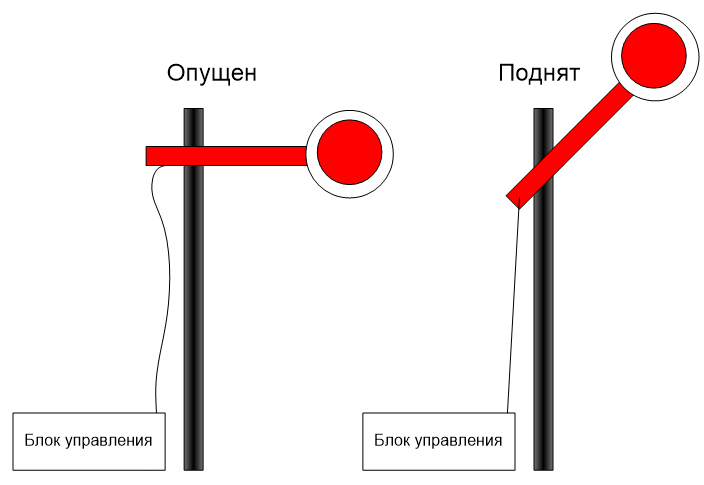
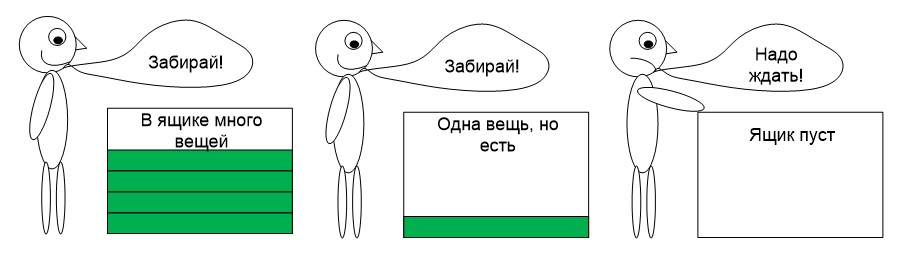
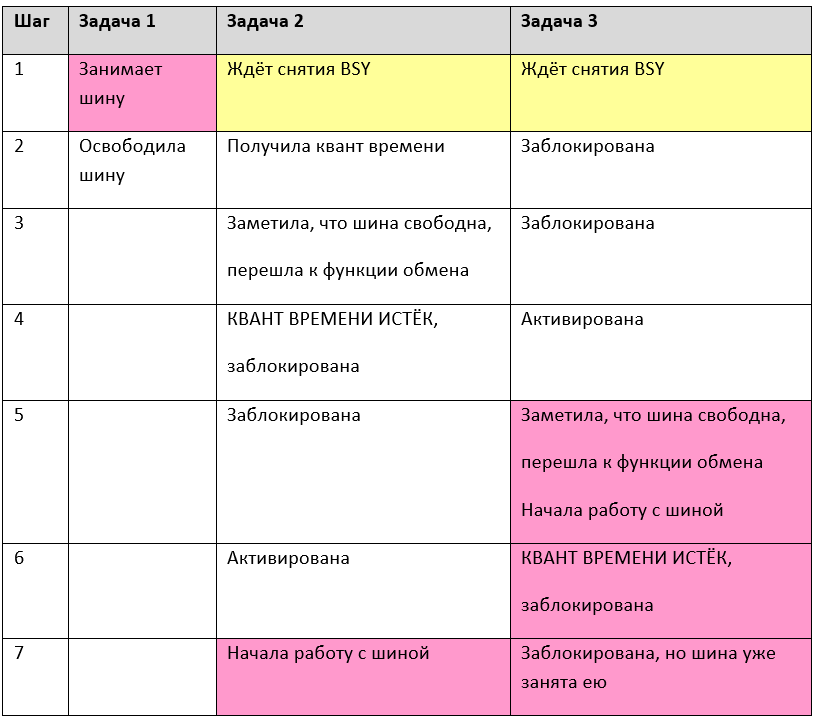

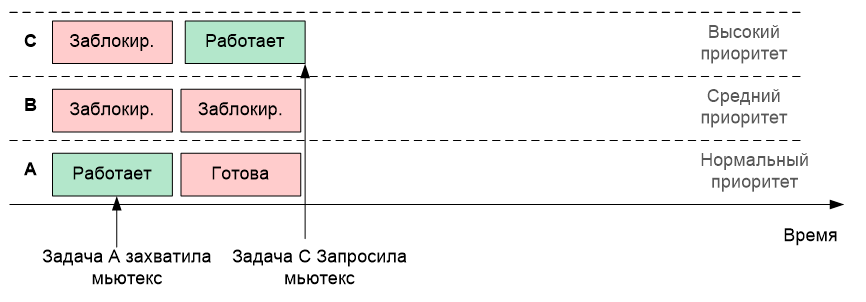
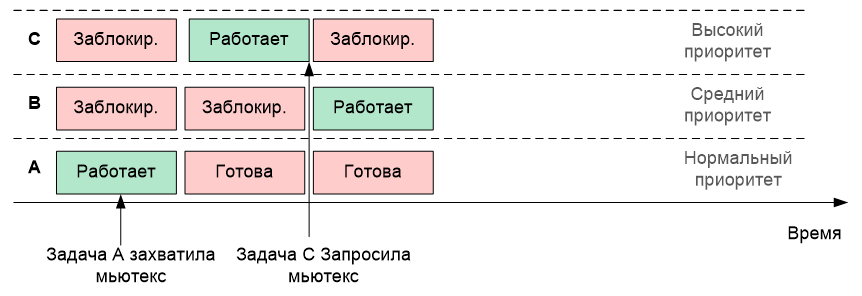

m_mutex.Lock();
switch (cond)
{
case 0x00:
....
return ResultCode1;
case 0x02:
....
return ResultCode2;
case 0x0a:
....
return ResultCode3;
case 0x15:
....
return ResultCode4;
}
....
m_mutex.Unlock();

{
MutexGuard (m_mutex);
switch (cond)
{
case 0x00:
....
return ResultCode1;
case 0x02:
....
return ResultCode2;
case 0x0a:
....
return ResultCode3;
case 0x15:
....
return ResultCode4;
}
....
}
|
Метки: author EasyLy программирование микроконтроллеров осрв макс rtos |
Национальный роуминг в разных странах мира |



|
Метки: author Yota4All читальный зал блог компании yota национальный роуминг цены на мобильную связь связь за границей мобильные операторы |
Как сделать gif-анимацию для Behance и Dribbble? |





|
Метки: author ilyasgaifullin дизайн мобильных приложений веб-дизайн блог компании mobileup gif animation dribbble behance gifbrewery after effects ezgif |
Изменился способ создания чат-ботов в Viber |
|
Метки: author nllm системы обмена сообщениями разработка под e-commerce программирование python viber чат-бот mrbot viber api |
[Из песочницы] FlashMapper — альтернатива автомапперу |
public class UserForm
{
public Guid? Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public string Town { get; set; }
public string State { get; set; }
public DateTime BirthDate { get; set; }
public string Login { get; set; }
public string Password { get; set; }
}
public class UserDb
{
public Guid Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public string Town { get; set; }
public string State { get; set; }
public DateTime BirthDate { get; set; }
public string Login { get; set; }
public string PasswordHash { get; set; }
public DateTime RegistrationTime { get; set; }
public byte[] Timestamp { get; set; }
public bool IsDeleted { get; set; }
}
public class FlashMapperInitializer : IInitializer // Не является частью FlashMapper'а
{
private readonly IMappingConfiguration mappingConfiguration; // Синглтон объект, который хранит в себе все конфигурации
private readonly IPasswordHashCalculator passwordHashCalculator;
public FlashMapperInitializer(IMappingConfiguration mappingConfiguration, IPasswordHashCalculator passwordHashCalculator)
{
this.mappingConfiguration = mappingConfiguration;
}
public void Init() // Код, который запускается во время инициализации приложения
{
mappingConfiguration.CreateMapping(u => new UserDb
{
Id = u.Id ?? Guid.NewGuid(),
Login = u.Id.HasValue ? MappingOptions.Ignore() : u.Login,
RegistrationTime = u.Id.HasValue ? MappingOptions.Ignore() : DateTime.Now,
Timestamp = MappingOptions.Ignore(),
IsDeleted = false,
PasswordHash = passwordHashCalculator.Calculate(u.Password)
});
//mappingConfiguration.CreateMapping <...> (...); // Прочие конфигурации
}
}
public class UserController : Controller
{
private readonly IMappingConfiguration mappingConfiguration;
private readonly IRepository usersRepository;
public UserController(IMappingConfiguration mappingConfiguration, IRepository usersRepository)
{
this.mappingConfiguration = mappingConfiguration;
this.usersRepository = usersRepository;
}
[HttpPost]
public ActionResult Edit(UserForm model)
{
if (!ModelState.IsValid)
return View(model);
var existingUser = usersRepository.Find(model.Id);
if (existingUser == null)
{
var newUser = mappingConfiguration.Convert(model).To();
usersRepository.Add(newUser);
}
else
{
mappingConfiguration.MapData(model, existingUser);
usersRepository.Update(existingUser);
}
return View(model);
}
}
mappingConfiguration.CreateMapping((s1, s2, s3) => new Destination { ... });
mappingConfiguration.CreateMapping((s1, s2, s3) => new Destination { ... }, o => o.CollisionBehavior(SelectSourceCollisionBehavior.ChooseAny));
public interface IUserDbBuilder : IBuilder { }
public class UserDbBuilder : FlashMapperBuilder, IUserDbBuilder
{
private readonly IPasswordHashCalculator passwordHashCalculator;
public UserDbBuilder(IMappingConfiguration mappingConfiguration, IPasswordHashCalculator passwordHashCalculator) : base(mappingConfiguration)
{
this.passwordHashCalculator = passwordHashCalculator;
}
protected override void ConfigureMapping(IFlashMapperBuilderConfigurator configurator)
{
configurator.CreateMapping(u => new UserDb
{
Id = u.Id ?? Guid.NewGuid(),
Login = u.Id.HasValue ? MappingOptions.Ignore() : u.Login,
RegistrationTime = u.Id.HasValue ? MappingOptions.Ignore() : DateTime.Now,
Timestamp = MappingOptions.Ignore(),
IsDeleted = false,
PasswordHash = passwordHashCalculator.Calculate(u.Password)
});
}
}
Kernel.Bind().To();
public static IBindingWhenInNamedWithOrOnSyntax AsFlashMapperBuilder(
this IBindingWhenInNamedWithOrOnSyntax builder) where T : IFlashMapperBuilder
{
builder.Kernel.AddBinding(new Binding(typeof(IFlashMapperBuilder), builder.BindingConfiguration));
return builder;
}
Kernel.Bind().To().AsFlashMapperBuilder();
public class UserController : Controller
{
private readonly IUserDbBuilder userDbBuilder;
private readonly IRepository usersRepository;
public UserController(IUserDbBuilder userDbBuilder, IRepository usersRepository)
{
this.userDbBuilder = userDbBuilder;
this.usersRepository = usersRepository;
}
[HttpPost]
public ActionResult Edit(UserForm model)
{
if (!ModelState.IsValid)
return View(model);
var existingUser = usersRepository.Find(model.Id);
if (existingUser == null)
{
var newUser = userDbBuilder.Build(model);
usersRepository.Add(newUser);
}
else
{
userDbBuilder.MapData(model, existingUser);
usersRepository.Update(existingUser);
}
return View(model);
}
}

|
Метки: author Birbone программирование c# .net automapper flashmapper |
Мониторинг инженерной инфраструктуры в дата-центре. Часть 3. Система холодоснабжения |
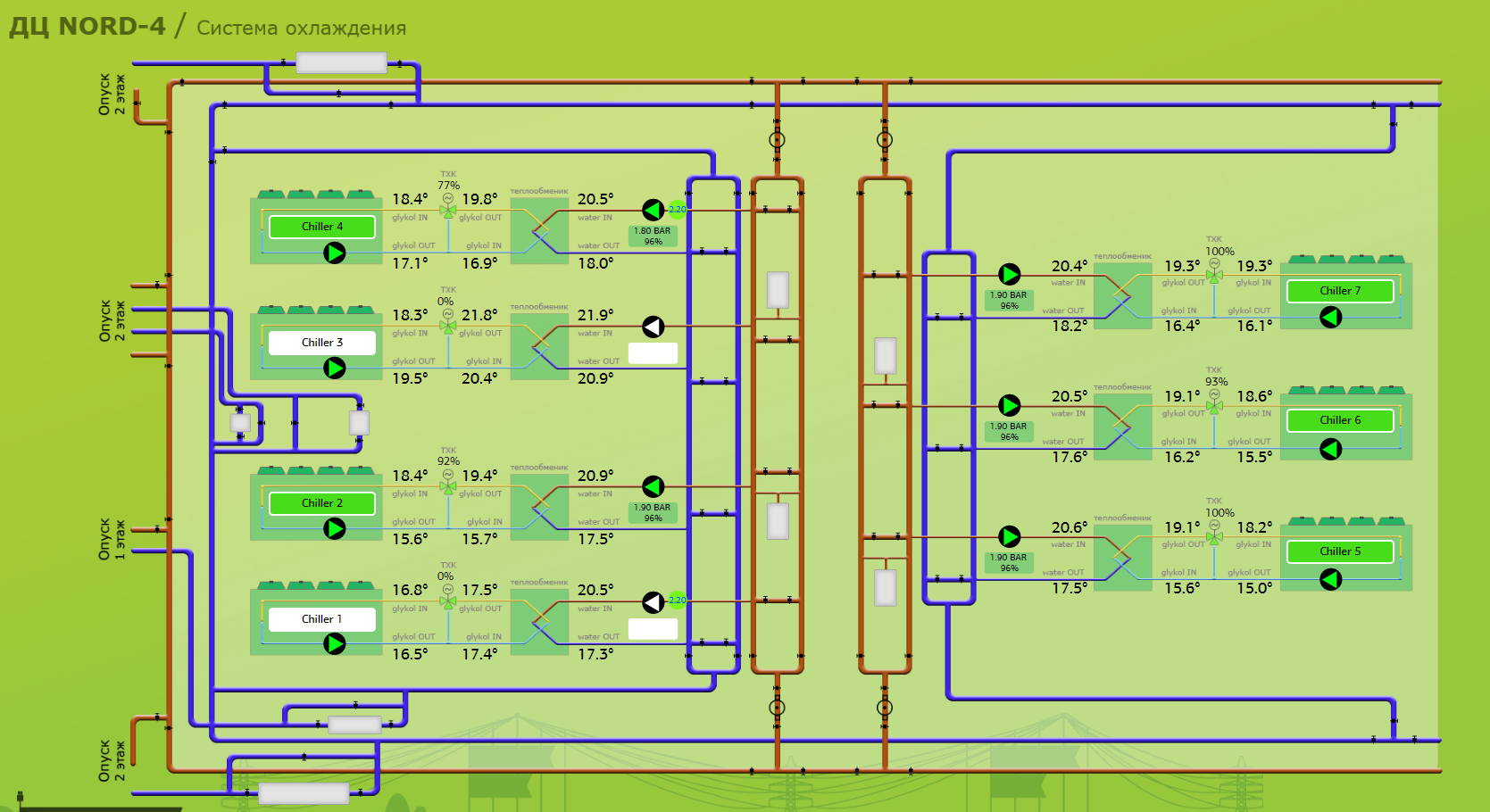









|
|
Kotlin, puzzlers and 2 Kekses: Вы уверены, что знаете, как ведет себя Kotlin? |




package p1_nullean
val s: String? = null
if (s?.isEmpty()) println("true")

if (s?.isEmpty() ?: false) println("true")
package p2_nulleanExtended
val x: String? = null
print(x.isNullOrEmpty())


print(x?.isNullOrEmpty())
package p3_platformNulls
class Kotlin {
fun hello(name: String) = print("Hello $name")
}
fun main(args: Array) {
val prop = System.getProperty("key")
Kotlin().hello(prop)
}
val prop = System.getProperty("key")
Kotlin().hello(prop)
val prop: String? = System.getProperty("key")
val prop: String! = System.getProperty("key")
val prop: String = System.getProperty("key")
package p4_kotlinVsScala
fun main1() = print("Hello")
fun main2() = {
print("Hello2")
}
main1()
main2()
main2()()
fun main2() {
print("Hello 2")
}
fun main2() = { }
package p5_sneakyReturn
fun main(args: Array) {
listOf(1, 2, 3).forEach {
if (it > 2) return
print(it)
}
print("ok")
}

if (it > 2) return@forEach

fun main(args: Array) {
listOf(1, 2, 3).forEach(fun() {
if (it > 2) return
print(it)
})
print("ok")
}
package p5_sneakyReturn
fun hello(block: () -> Unit) = block()
inline fun helloInline(block: () -> Unit) = block()
inline fun helloNoInline(noinline block: () -> Unit) = hello(block)
inline fun helloCrossInline(crossinline block: () -> Unit) = runnable { block() }.run()
fun main(args: Array) {
hello {
println("hello")
//return - impossible
}
hello(fun() {
println("hello")
return
})
helloInline {
println("hello")
return
}
helloNoInline {
println("hello")
//return - impossible
}
helloCrossInline {
println("hello")
//return - impossible
}
package p6_getMeJohn
class Person(name: String) {
var name = name
get() = if (name == "John") "Jaan" else name
}
println(Person("John").name)
class Person(name: String) {
var name = name
get() = if (field == "John") "Jaan" else field
}
package p7_whatAmI
val whatAmI = {}()
println(whatAmI)
package p8_iAmThis
data class IAm(var foo: String) {
fun hello() = foo.apply {
return this
}
}
println(IAm("bar").hello())

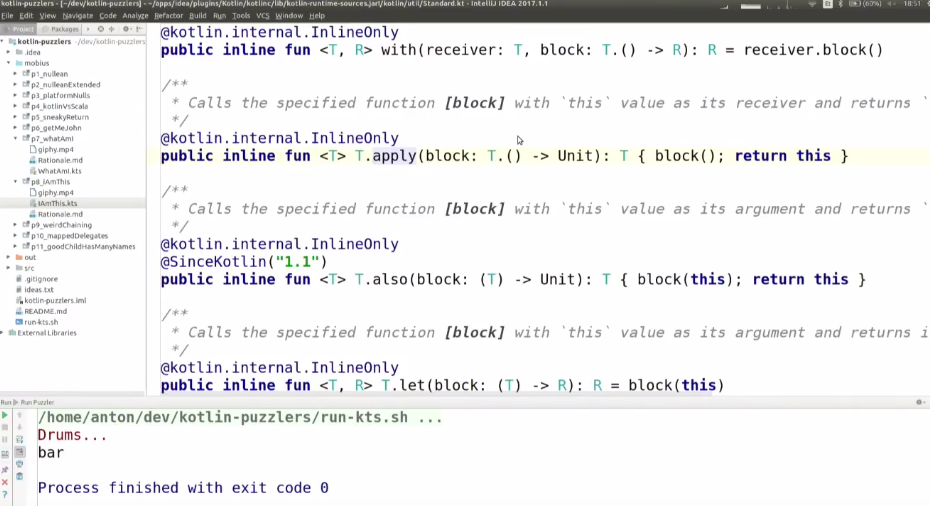
package p8_iAmThis
data class IAm(var foo: String) {
fun hello() = foo.let {
return it
}
}
println(IAm("bar").hello())
data class IAm(var foo: String) {
fun hello() = foo.apply {
}
}
package p9_weirdChaining
// by Kevin Most @kevinmost
fun printNumberSign(num; Int) {
if (num < 0) {
"negative"
} else if (num > 0) {
"positive"
} else {
"zero"
}.let { println(it) }
}
printNumberSign(-2)
printNumberSign(0)
printNumberSign(2)
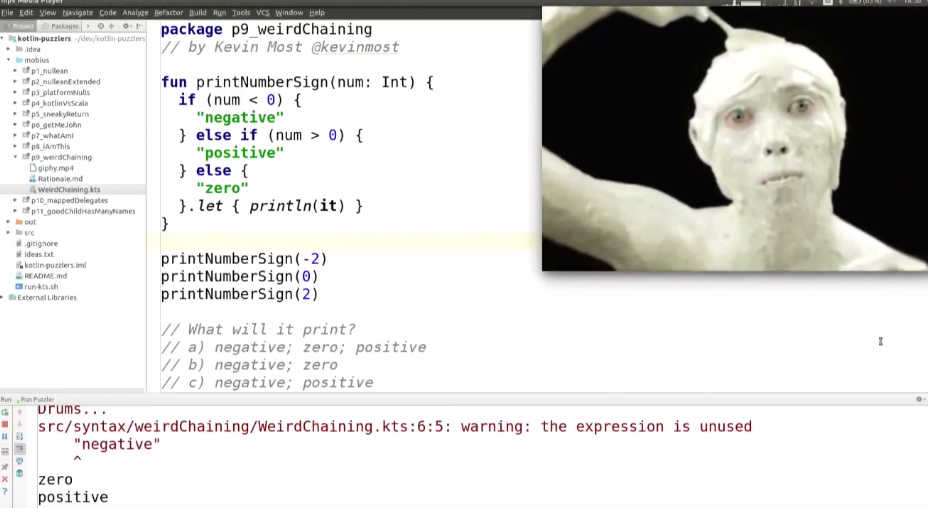
fun printNumberSign(num; Int) {
(if (num < 0) {
"negative"
} else if (num > 0) {
"positive"
} else {
"zero"
}).let { println(it) }
}
fun printNumberSign(num; Int) {
if (num < 0) {
"negative"
} else (if (num > 0) {
"positive"
} else {
"zero"
}).let { println(it) }
}
package p10_mappedDelegates
// by Daniil Vodopian @voddan
class Population(var cities: Map) {
val tallinn by cities
val kronstadt by cities
val st_petersburg by cities
}
val population = Population(mapOf(
"st_petersburg" to 5_281_579,
"tallinn" to 407_947,
"kronstadt" to 43_005
))
// Many years have passed, now all humans live on Mars
population.cities = emptyMap()
with(population) {
println("$tallinn; $kronstadt; $st_petersburg")
}

class Population(var cities: MutableMap) {
val tallinn by cities
var kronstadt by cities
val st_petersburg by cities
}
val population = Population(mutablemapOf(
"st_petersburg" to 5_281_579,
"tallinn" to 407_947,
"kronstadt" to 43_005
))
// Many years have passed, now all humans live on Mars
population.kronstadt = 0
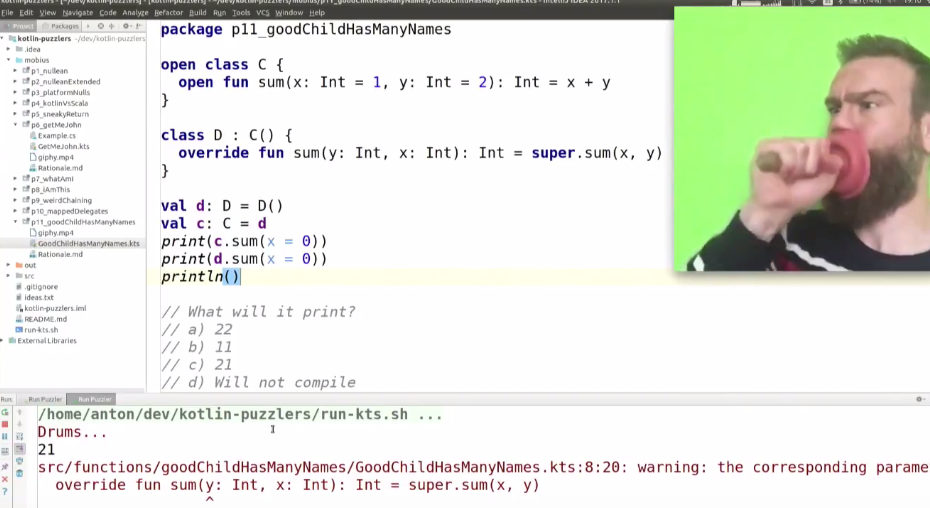
package p11_goodChildHasManyNames
open class C {
open fun sum(x: Int = 1, y: Int = 2): Int = x + y
}
class D : C() {
override fun sum(y: Int, x: Int): Int = super.sum(x, y)
}
val d: D = D()
val c: C = d
print(c.sum(x = 0))
print(d.sum(x = 0))
println()
|
Метки: author BigSolarWolf программирование kotlin блог компании jug.ru group пазлер кекс |
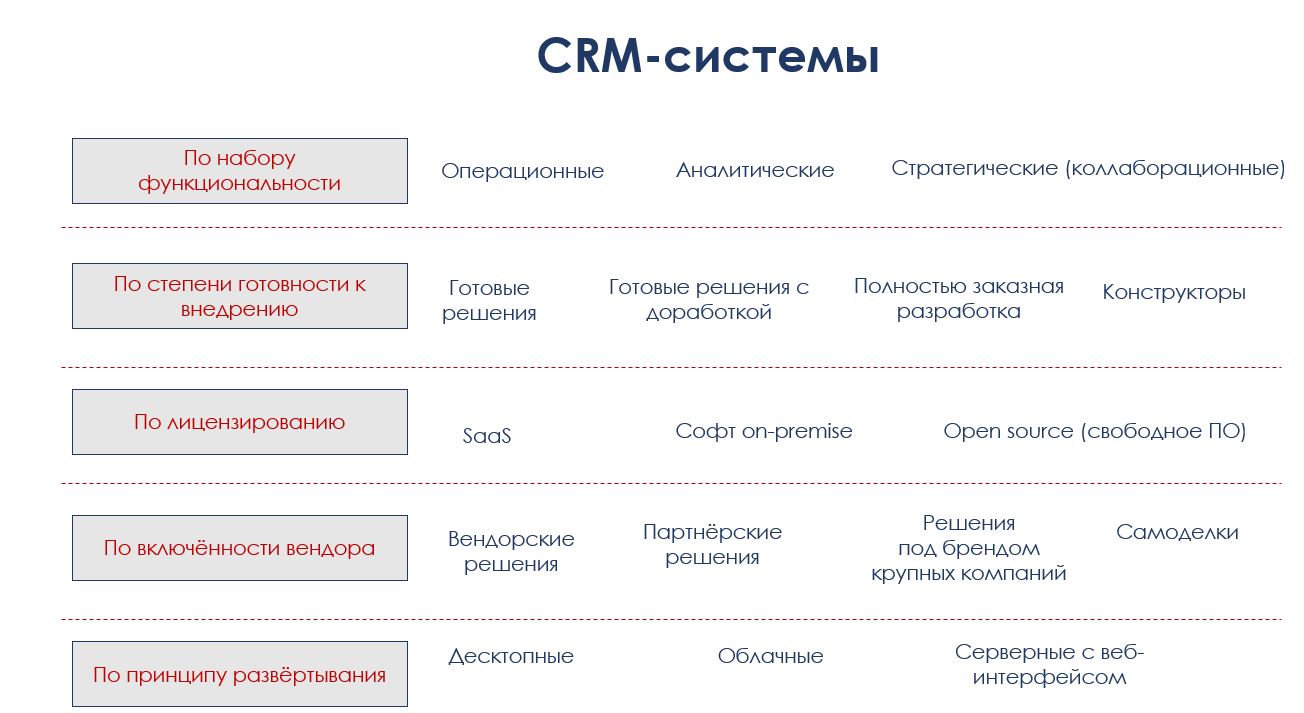
Действительно, а что такое CRM-система? |


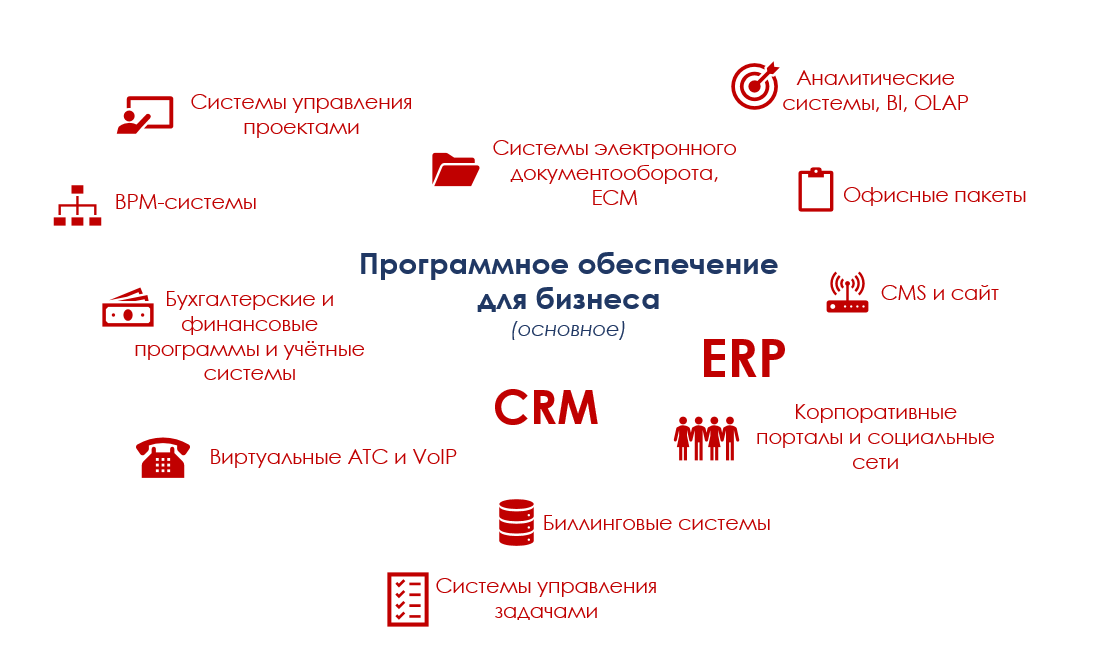
|
Метки: author Axelus управление проектами терминология it erp- системы crm- блог компании regionsoft developer studio crm что такое crm regionsoft crm |
Apache® Ignite™ + Persistent Data Store — In-Memory проникает на диски. Часть I — Durable Memory |
|
|
Атакуем DHCP часть 3. DHCP + Apple = MiTM |

В данной статье я расскажу о том как осуществить MiTM любого устройства компании Apple в WiFi сети. Прежде чем читать эту статью настоятельно рекомендую ознакомиться с первой и второй частью.
Ограничения все те же:
Как оказалось, macOS и iOS переплюнули всех в плане получения сетевых настроек по протоколу DHCP. Когда эти операционные системы отправляют DHCPREQUEST, DHCP-сервер отвечает им DHCPACK, и они выставляют сетевые настройки из ответа сервера. Вроде пока все как у всех:

Но проблема в том, что DHCPREQUEST широковещательный и злоумышленник, как правило, без особых проблем может его перехватить извлечь из него поля xid и chaddr, что бы сформировать правильный DHCPACK. Но злоумышленник отправит DHCPACK, конечно, позднее легитимного DHCP-сервера, то есть его ответ придет вторым. Все остальные DHCP-клиенты на других ОС просто проигнорируют второй DHCPACK, но не macOS и iOS.
Как вы думаете, какие сетевые настройки выставляют данные операционные системы? Ответ: те настройки, которые будут содержаться во втором DHCPACK (в DHCPACK злоумышленника).
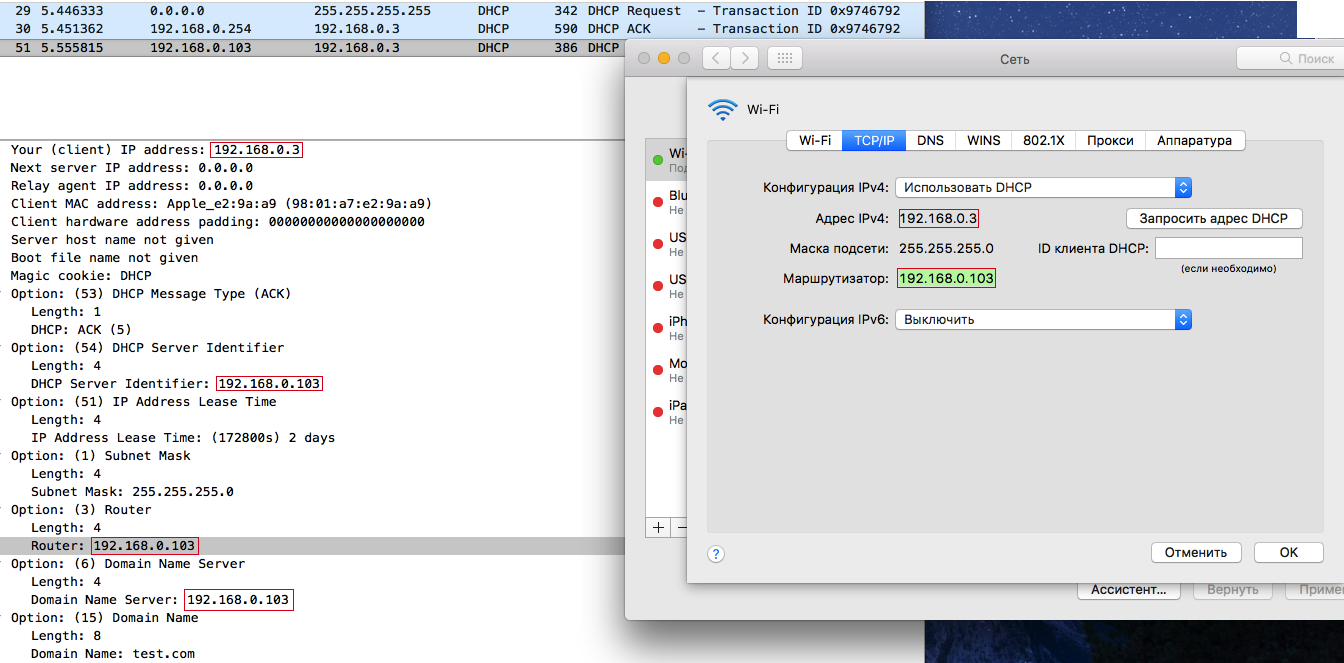
Видео демонстрации бага в DHCP-клиенте на macOS:
Как Вы думаете баг это или фича? Я подумал баг и на всякий случай завел заявку на Apple Bug Reporter этой заявке уже больше месяца, но ни одного комментария от специалистов Apple я так и не получил.
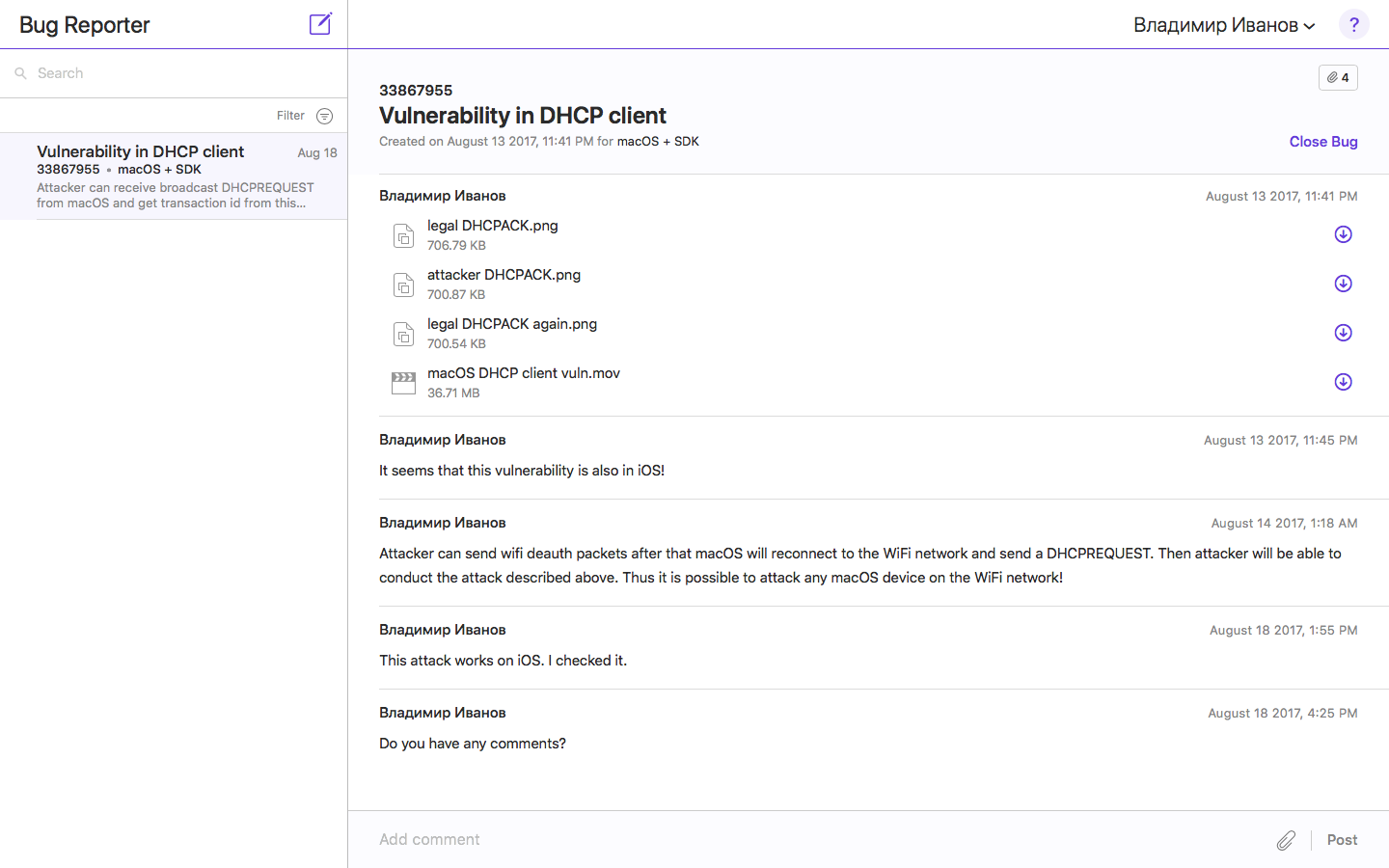
На заявке в Apple Bug Reporter я не остановился и написал письмо в product-security@apple.com

Специалисты Apple совсем не быстро, но все же ответили и сказали, что их DHCP-клиент работает в соответствии с RFC 2131. То есть это вовсе не баг, это фича. У меня все.

Для самых ленивых я подготовил скрипт apple_wifi_mitmer.py, который в автоматическом режиме находит все устройства компании Apple в Wi-Fi-сети, деаутентифицирует их и производит MiTM.
В аргументах скрипта всего-то нужно указать имя беспроводного интерфейса, который уже подключен к исследуемой Wi-Fi-сети, и еще один беспроводной интерфейс для отправки deauth-пакетов.
Видео демонстрации работы скрипта apple_wifi_mitmer.py:
Работает ли это на новой iOS 11? Ответ: Да, работает.
|
Метки: author vladimir-ivanov сетевые технологии беспроводные технологии dhcp wifi apple mitm |
Kubernetes 1.8: обзор основных новшеств |


virtual server и real server соответственно). Кроме того, он периодически синхронизирует их, поддерживая консистентность состояния IPVS. При запросе на доступ к сервису трафик перенаправляется на один из подов бэкенда. При этом IPVS предлагает различные алгоритмы для балансировки нагрузки (round-robin, least connection, destination hashing, source hashing, shortest expected delay, never queue). Такую возможность часто запрашивали в тикетах Kubernetes, и мы сами тоже очень её ждали.EgressRules в NetworkPolicy API, а также возможность (в том же NetworkPolicy) применения правил по CIDR источника/получателя (через ipBlockRule).PodSpec, пользователи определяют поле PriorityClassName, а Kubernetes на его основе выставляет Priority). Цель банальна: улучшить распределение ресурсов в случаях, когда их не хватает, а требуется одновременно выполнить по-настоящему критичные задачи и менее срочные/важные. Теперь поды с высоким приоритетом будут получать больший шанс на исполнение. Кроме того, при освобождении ресурсов в кластере (preemption) поды с меньшим приоритетом будут затронуты скорее подов с высоким приоритетом. В частности, для этого в kubelet была изменена стратегия по выборке подов (eviction strategy), в которой теперь учитываются одновременно и приоритет пода, и потребление им ресурсов. Реализация всех этих возможностей имеет статус альфа-версии. Приоритеты Kubernetes и работа с ними подробно описаны в документации по архитектуре.Condition, см. документацию) на узлах. Традиционно в этом поле фиксируются проблемные состояния узла — например, при отсутствии сети условие NetworkUnavailable ставится в True, в результате чего поды перестанут назначаться на этот узел. С помощью нового подхода Taints Node by Condition такая же ситуация приведёт к пометке узла определённым статусом (например, node.kubernetes.io/networkUnavailable=:NoSchedule), на основе которого (в спецификации пода) можно решить, что делать дальше (действительно ли не назначать под такому проблемному узлу).PersistentVolume появилось новое поле MountOptions для указания опций монтирования (вместо annotations);StorageClass появилось аналогичное поле MountOptions для динамически создаваемых томов.PersistentVolume для Azure File, CephFS, iSCSI, GlusterFS теперь можно ссылаться на ресурсы в пространствах имён.StorageClass добавлена бета-версия поддержки определения reclaim policy (аналогично PersistentVolume) вместо применения политики delete всегда по умолчанию;ephemeral-storage, который включает в себя всё дисковое пространство, доступное контейнеру, и позволяет устанавливать ограничения на возможный объём (quota management) и запросы к нему (limitrange) — подробнее см. в текущей документации;VolumeMount.Propagation для VolumeMount в контейнерах пода (альфа-версия) позволяет устанавливать значение Bidirectional для возможности использования того же примонтированного каталога на хосте и в других контейнерах;v1beta1.kubeadm init с флагом --feature-gates=SelfHosting=true). Сертификаты при этом могут храниться на диске (hostPath) или в секретах. А новая подкоманда kubeadm upgrade (находится в бета-статусе) позволяет автоматически выполнять обновление кластера self-hosted, созданного с помощью kubeadm.kubeadm init с помощью подкоманды phase (на текущий момент доступна как kubeadm alpha phase и будет приведена в официальный вид в следующем релизе Kubernetes). Основное предназначение — возможность лучшей интеграции kubeadm с provisioning-утилитами вроде kops и GKE.rollout и rollback в kubectl теперь поддерживают StatefulSet.APIListChunking — новый подход к выдаче ответов на запросы LIST. Теперь они разбиваются на небольшие куски и выдаются клиенту в соответствии с указанным им лимитом. В результате, сервер потребляет меньше памяти и CPU при выдаче очень больших списков, и такое поведение станет стандартным для всех инфомеров в Kubernetes 1.9.CustomResourceValidation в kube-apiserver.CustomResourceDefinition или агрегированные API-серверы. Поскольку обновления контроллера происходят периодически, между добавлением API и началом работы сборщика мусора для него стоит ожидать задержку около 30 секунд.DaemonSet, Deployment, ReplicaSet, StatefulSet. На данный момент эти API перенесены в группу apps и с релизом Kubernetes 1.8 получили версию v1beta2. Стабилизация же Workload API предполагает вынесение этих API в отдельную группу и достижение максимально возможной консистентности с помощью стандартизации этих API путём удаления/добавления/переименования имеющихся полей, определения однотипных значений по умолчанию, общей валидации. Например, стратегией spec.updateStrategy по умолчанию для StatefulSet и DaemonSet стал RollingUpdate, а выборка по умолчанию spec.selector для всех Workload API (из-за несовместимости с kubectl apply и strategic merge patch) отключена и теперь требует явного определения пользователем в манифесте. Обобщающий тикет с подробностями — #353.rbac.authorization.k8s.io для возможности конфигурации динамических политик, переведено в стабильный статус (GA), а также получило бета-версию нового API (SelfSubjectRulesReview) для просмотра действий, которые пользователь может выполнить с пространством имён;PodSecurityPolicies добавлена поддержка белого списка разрешённых путей для томов хоста;|
Метки: author distol системное администрирование серверное администрирование devops блог компании флант kubernetes docker |
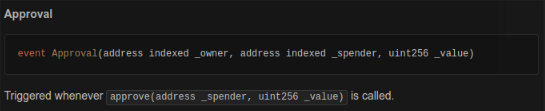
Как я искал (и нашел!) баги в смартконтракте проекта kickico |

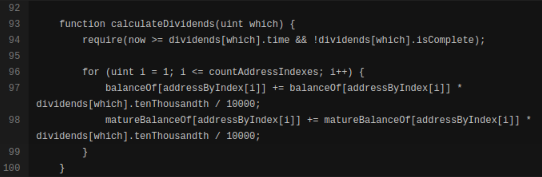
|
Метки: author quantum информационная безопасность solidity ethereum kickico |
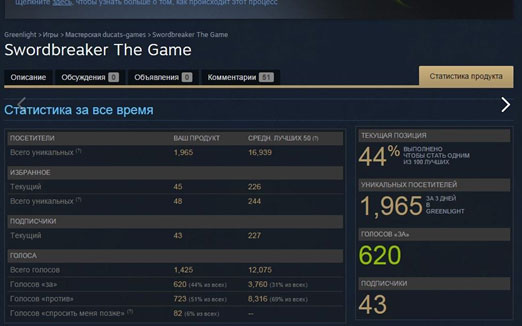
Классический 2д квест или как прошли наши два года разработки. Часть 2 |






|
Метки: author MaikShamrock разработка игр java продвижение игр steam greenlight corona sdk libgdx android google play |
Тайм-менеджмент для кинестетиков |
Время — самый ценный ресурс который у нас есть. Чтобы использовать его максимально продуктивно, существуют всякого рода техники тайм-менеджмента. Если говорить о тайм-менеджменте в масштабах рабочего дня, то одна из самых популярных техник называется Pomodoro. Но эта статья не про GTD, а про код (и немного про железо ^^).
Так вот, для техники Pomodoro есть инструмент Tomighty и у него открытый исходный код на C#, что побуждает к модификации этого самого кода с целью добавления новых возможностей и интеграции со всякими штуками.
Сегодня мы будем интегрировать клиент Tomighty с устройстовм "Большая Красная Кнопка". Нам для этого понадобится:

Зачем? Чтобы получить опыт работы с чужим кодом. В связи с грядущим Hacktoberfest, этот скилл будет крайне актуален.
Welcome!
С аппаратной стороны нет ничего сверхестесственного, посему подробно описывать каждый шаг не буду, всё должно работать, а код сам по себе довольно понятный.
mqtt.py. На ESP через WebREPL.main.py.Начнём с клонирования репозитория. Можно официальный, можно форк (где в соответствующем брэнче всё уже сделано). Открываем солюшн в студии.
Для того чтобы собрать проект Tomighty.Windows, необходимо устанвоить в него пакет UWPDesktop через NuGet. Это совершенно не очевидное действие, до которого мы относительно долго пытались додуматься и чуть менее долго догуглиться. Возможно это тривиально для тех кто имел дело со старомодными WinForms приложениями, зовущими новомодный UWP API, но для тех кто таким не занимался — не очень.
Таким образом, на данном этом этапе у меня получилось собираемое и запускаемое приложение, так что я приступил к поиску мест, в которые можно внедриться со своими костылями. С помощью CodeRush for Roslyn это оказалось совсем не сложно.
Задачи такие:
Для начала, выясним как запустить период Pomodoro, скорее всего этот путь приведет нас к основным архитектурным элементам приложения быстрее всего. Пробный запуск показал, что, похоже, основным источником управления тут является икнока в трэе, так что попробуем найти точку входа где-нибудь в папке Tomighty.Windows\Tray\. Действительно, в интерфейсе ITrayMenu есть похожий на правду метод, посмотрим где он используется.

Нашёлся очень мясистый файлик TrayMenuController.cs, а в нём и нужный метод
private void OnStartPomodoroClick(object sender, EventArgs e) => StartTimer(IntervalType.Pomodoro);
// ...
private void StartTimer(IntervalType intervalType) {
Task.Run(() => pomodoroEngine.StartTimer(intervalType));
}Окей, значит за основные операции типа запуска периодов отвечает объект pomodoroEngine. Он нам понадобится.
Название (да и содержимое) этого класса TrayMenuController как бы намекают на то что он является одним из интерфейсов программы с человеком, и скорее всего нам надо создать что-то похожее, чтобы добавить поддержку собственного интерфейса в виде красной кнопки. Воспользуемся той же Jump to менюшкой, чтобы найти где этот класс создается.

Отлично, мы нашли точку входа. Она выглядит как-то так:
internal class TomightyApplication : ApplicationContext {
public TomightyApplication() {
var eventHub = new SynchronousEventHub();
var timer = new Tomighty.Timer(eventHub);
var userPreferences = new UserPreferences();
var pomodoroEngine = new PomodoroEngine(timer, userPreferences, eventHub);
var trayMenu = new TrayMenu() as ITrayMenu;
var trayIcon = CreateTrayIcon(trayMenu);
var timerWindowPresenter = new TimerWindowPresenter(pomodoroEngine, timer, eventHub);
new TrayIconController(trayIcon, timerWindowPresenter, eventHub);
new TrayMenuController(trayMenu, this, pomodoroEngine, eventHub);
// ...
new StartupEvents(eventHub);
}
// ...
}Время совершить небольшую интервенцию: создадим еще один объект несуществующего класса, а потом с помощью фичи Declare Class добавим сам класс.

Я сразу передал еще и eventHub, потому что заметил что в TrayMenuController через него можно подписаться на ивенты старта и окончания таймера. Пригодится.
Сразу можно сделать два филда из автоматически сгенерированных параметров конструктора фичей Declare Field with Initializer:

Чтож, теперь мы можем подписываться на ивенты и управлять таймерами. Попробуем добавить пункт меню в трэй, который будет вызывать метод RedButtonController.Connect().
Довольно быстро пришло осознание, что лучше всё-таки сохранить инстанс нашего контроллера и передать его в TrayMenuController, чтобы тот мог спокойно напрямую позвать Connect() безо всяких ивентов и усложнений.
var redButton = new RedButtonController(eventHub);
// ...
new TrayMenuController(trayMenu, this, pomodoroEngine, eventHub, redButton);Чтобы пункт меню появился в списке, надо создать TrayMenu.redButtonConnectItem и везде его прокинуть по аналогии с теми что рядом. В поиске таких мест хорошо поможет Tab to Next Reference: Можно просто поставить курсор на любой референс, нажать Tab и перейти к следующему, при этом все референсы в поле зрения подсвечиваются.

Никаких подводных камней замечено не было, всё заработало довольно быстро. redButtonConnectItem вызывает RedButtonController.Connect() через хэндлер TrayMenuController.OnRedButtonConnect()

(таскбар слева экономит вертикальное пространство и круче чем таскбар снизу)
А теперь, попробуем вызвать Toast (это такие новомодные нотификации). Когда я впервые запустил приложение, один такой прилатал с предложением настроиться после первого запуска. Попробуем его отыскать. Думаю, надо начать со строчки new StartupEvents(eventHub) в конце конструктора TomightyApplication. Пара нажатий на F12 (перейти к декларации) приводят в файл Tomighty.Windows\Events.cs с двумя пустыми ивентами:
namespace Tomighty.Windows.Events {
public class FirstRun { }
public class AppUpdated { }
}Чтож, ни один из этих нам не подходит, при чём даже формат пустого ивента не совсем подходит, хотелось бы передавать туда результат попытки подключиться. Создаём новый ивент, объявляем в нём филд и используем Smart Constructor для добавления конструктора с автоматической инициализацией филда.

Далее, пришлось пройтись по всем местам где что-то происходило с ивентом FirstRun и добавить подобные действия для нашего ивента RedButtonConnectionChanged.

Попутно пришлось добавить XML-документ с содержанимем нотификации и прописать путь к нему в ресурсы. Но, опять же, всё завелось без единой бряки. Вот что значит хорошая архитектура!

Окей, у нас есть pomodoroEngine, eventHub, пункт меню и нотификации, вроде бы всё что нужно, можно соединяться с MQTT и пробывать общаться с кнопкой. Для MQTT будем использовать самый гуглящийся клиент M2Mqtt:
PM> Install-Package M2MqttУ меня уже был простенький класс, для M2Mqtt, так что я его просто подключил и наслаждался ну-совсем-простым API:
public void Connect() {
mqtt = new MQTTClient("m10.cloudmqtt.com", 13633);
mqtt.Connect("%LOGIN%", "%PASSWORD%");
if (!mqtt.client.IsConnected) {
eventHub.Publish(new RedButtonConnectionChanged(false));
return;
}
eventHub.Publish(new RedButtonConnectionChanged(true));
mqtt.client.MqttMsgPublishReceived += onMsgReceived;
mqtt.Subscribe("esp");
}Добавить хэндлер можно с помощью Declare Method:

Осталось подписаться на TimerStarted и TimerStopped, и можно писать логику. А логика у меня в первом приближении получилась такая:

Тут можно много чего доработать, например, адекватно обработать ситуацию когда кнопка нажата во время перерыва, но это уже мелочи. А вот корпус уже куплен и скорее всего будет, осталось продырявить и скоммутировать. Дополнительной фичей получившегося девайса является то, что он сообщает коллегам когда вас можно отвлекать, а когда нельзя. А в остальном, довольно бесполезная штука :)
|
Метки: author Himura разработка для интернета вещей программирование микроконтроллеров visual studio c# блог компании devexpress coderush mqtt esp8266 micropython iot |
NetApp ONTAP - разложим все по полочкам |







|
Метки: author Orest_ua хранилища данных хранение данных сетевые технологии серверное администрирование блог компании мук netapp ontap облака |
Symfony + RabbitMQ Быстрый старт для молодых |
echo 'deb http://www.rabbitmq.com/debian/ testing main' | sudo tee /etc/apt/sources.list.d/rabbitmq.list
wget -O- https://www.rabbitmq.com/rabbitmq-release-signing-key.asc | sudo apt-key add -
sudo apt-get update
sudo apt-get install rabbitmq-server
sudo rabbitmq-plugins enable rabbitmq_management
composer require php-amqplib/rabbitmq-bundle// app/AppKernel.php
public function registerBundles()
{
$bundles = array(
new OldSound\RabbitMqBundle\OldSoundRabbitMqBundle(),
);
}
old_sound_rabbit_mq:
connections:
default:
host: 'localhost'
port: 5672
user: 'guest'
password: 'guest'
vhost: '/'
lazy: false
connection_timeout: 3
read_write_timeout: 3
keepalive: false
heartbeat: 0
use_socket: true
producers:
send_email:
connection: default
exchange_options: { name: 'notification.v1.send_email', type: direct }
consumers:
send_email:
connection: default
exchange_options: { name: 'notification.v1.send_email', type: direct }
queue_options: { name: 'notification.v1.send_email' }
callback: app.consumer.mail_sender
#app/config/services.yml
services:
app.consumer.mail_sender:
class: AppBundle\Consumer\MailSenderConsumer
namespace AppBundle\Consumer;
use OldSound\RabbitMqBundle\RabbitMq\ConsumerInterface;
use PhpAmqpLib\Message\AMQPMessage;
/**
* Class NotificationConsumer
*/
class MailSenderConsumer implements ConsumerInterface
{
/**
* @var AMQPMessage $msg
* @return void
*/
public function execute(AMQPMessage $msg)
{
echo 'Ну тут типа сообщение пытаюсь отправить: '.$msg->getBody().PHP_EOL;
echo 'Отправлено успешно!...';
}
}
namespace AppBundle\Command;
use Symfony\Bundle\FrameworkBundle\Command\ContainerAwareCommand;
use Symfony\Component\Console\Input\InputInterface;
use Symfony\Component\Console\Output\OutputInterface;
class TestConsumerCommand extends ContainerAwareCommand
{
/**
* {@inheritdoc}
*/
protected function configure()
{
$this
->setName('app:test-consumer')
->setDescription('Hello PhpStorm');
}
/**
* {@inheritdoc}
*/
protected function execute(InputInterface $input, OutputInterface $output)
{
$this->getContainer()->get('old_sound_rabbit_mq.send_email_producer')->publish('Сообщенька для отправки на мыло...');
}
bin/console rabbitmq:consumer send_email -vvvbin/console app:test-consumerproducers:
send_email:
connection: default
exchange_options: { name: 'notification.v1.send_email', type: direct }
delayed_send_email:
connection: default
exchange_options:
name: 'notification.v1.send_email_delayed_30000'
type: direct
queue_options:
name: 'notification.v1.send_email_delayed_30000'
arguments:
x-message-ttl: ['I', 30000]
x-dead-letter-exchange: ['S', 'notification.v1.send_email']
namespace AppBundle\Consumer;
use OldSound\RabbitMqBundle\RabbitMq\ConsumerInterface;
use OldSound\RabbitMqBundle\RabbitMq\ProducerInterface;
use PhpAmqpLib\Message\AMQPMessage;
/**
* Class NotificationConsumer
*/
class MailSenderConsumer implements ConsumerInterface
{
private $delayedProducer;
/**
* MailSenderConsumer constructor.
* @param ProducerInterface $delayedProducer
*/
public function __construct(ProducerInterface $delayedProducer)
{
$this->delayedProducer = $delayedProducer;
}
/**
* @var AMQPMessage $msg
* @return void
*/
public function execute(AMQPMessage $msg)
{
$body = $msg->getBody();
echo 'Ну тут типа сообщение отправляю '.$body.' ...'.PHP_EOL;
try {
if ($body == 'bad') {
throw new \Exception();
}
echo 'Успешно отправлено...'.PHP_EOL;
} catch (\Exception $exception) {
echo 'ERROR'.PHP_EOL;
$this->delayedProducer->publish($body);
}
}
}
#app/config/services.yml
services:
app.consumer.mail_sender:
class: AppBundle\Consumer\MailSenderConsumer
arguments: ['@old_sound_rabbit_mq.delayed_send_email_producer']
namespace AppBundle\Command;
use Symfony\Bundle\FrameworkBundle\Command\ContainerAwareCommand;
use Symfony\Component\Console\Input\InputInterface;
use Symfony\Component\Console\Output\OutputInterface;
class TestConsumerCommand extends ContainerAwareCommand
{
/**
* {@inheritdoc}
*/
protected function configure()
{
$this
->setName('app:test-consumer')
->setDescription('Hello PhpStorm');
}
/**
* {@inheritdoc}
*/
protected function execute(InputInterface $input, OutputInterface $output)
{
$this->getContainer()->get('old_sound_rabbit_mq.send_email_producer')->publish('Ура, сообщенька...');
$this->getContainer()->get('old_sound_rabbit_mq.send_email_producer')->publish('bad');
}
}
Ну тут типа сообщение отправляю Ура, сообщенька...
Успешно отправлено...
Ну тут типа сообщение отправляю bad...
ERROR
Ну тут типа сообщение отправляю bad...
ERROR
class MailSenderConsumer implements ConsumerInterface
{
private $delayedProducer;
private $entityManager;
/**
* MailSenderConsumer constructor.
* @param ProducerInterface $delayedProducer
* @param EntityManagerInterface $entityManager
*/
public function __construct(ProducerInterface $delayedProducer, EntityManagerInterface $entityManager)
{
$this->delayedProducer = $delayedProducer;
$this->entityManager = $entityManager;
gc_enable();
}
/**
* @var AMQPMessage $msg
* @return void
*/
public function execute(AMQPMessage $msg)
{
$body = $msg->getBody();
echo 'Ну тут типа сообщение отправляю '.$body.' ...'.PHP_EOL;
try {
if ($body == 'bad') {
throw new \Exception();
}
echo 'Успешно отправлено...'.PHP_EOL;
} catch (\Exception $exception) {
echo 'ERROR'.PHP_EOL;
$this->delayedProducer->publish($body);
}
$this->entityManager->clear();
$this->entityManager->getConnection()->close();
gc_collect_cycles();
}
}
|
Метки: author php_freelancer symfony php rabbitmq |






