Межпланетная файловая система — Переходим на localhost (локальный шлюз IPFS) |
Мало смысла в IPFS если использовать его только как бесплатный хостинг для сайта в сети интернет. Поэтому мы научимся здесь загружать наш сайт через локальный IPFS шлюз пользователя.
Пользователю это даст быстрый доступ к его локальной копии нашего сайта.
Также мы научимся переключать на локальный шлюз IPFS сайты которые этого ещё не делают.
Напомню: InterPlanetary File System — это новая децентрализованная сеть обмена файлами (HTTP-сервер, Content Delivery Network). О ней я рассказывал в статье "Межпланетная файловая система IPFS".

У нашего сайта на данный момент уже есть как минимум 3 DNS записи:
A [Наш домен] [IP адрес хостинга]
TXT [Наш домен] dnslink=/ipfs/[CID контента]
TXT _dnslink.[Наш домен] dnslink=/ipfs/[CID контента]Добавим к ним ещё 3:
A l.[Наш домен] 127.0.0.1
TXT l.[Наш домен] dnslink=/ipfs/[CID контента]
TXT _dnslink.l.[Наш домен] dnslink=/ipfs/[CID контента][CID контента] — Это идентификатор контента (CID) раньше назывался мультихеш. Его мы получаем публикуя сайт командой ipfs add в сети IPFS.
В HTML тегах script и link появились поля integrity и crossorigin. Они отвечают за проверку хеша до запуска скрипта или применения стилей. Их мы и используем для определения рабочего шлюза у посетителя сайта.
Расположить их лучше в конце страницы чтоб они не задерживали загрузку и отображение.
Варианты адресов которые нам надо проверить:
http://l.[наш домен]:8080
8080 это стандартный порт на котором по умолчанию запускается IPFS.
Если всё настроено правильно то с http версии сайта браузер загрузит скрипт или стиль.
https://l.[наш домен]:8443
8443 это порт на который пользователь может настроить stunnel.
Данный вариант нам понадобится если запрос идёт с HTTPS сайта и наш домен добавлен в локальный сертификат.
http://127.0.0.1:8080/ipns/[наш домен]
Этот вариант на случай если мы не задали l домен для нашего сайта и запрос идёт с http.
https://127.0.0.1:8443/ipns/[наш домен]l домен или не добавлен в локальный сертификат.Аналогичным образом мы можем проверить порты 80 для http и 443 для https.
Добавив этот скрипт к странице вашего сайта вы автоматически переключите посетителя на его локальный IPFS шлюз.
redirect_to_ipfs_gateway.js
var redirect_to_local;
/*
Эта функция добавляет к текущему домену третьим уровнем домен ```l```
*/
function l_hostname()
{
var l_hostname = window.location.hostname.split(".");
l_hostname.splice(-2,0,"l");
return l_hostname.join(".");
}
/*
Эта функция создаёт новый элемент script и с адресом скрипта который должен загрузиться через локальный шлюз пользователя.
Также она создаёт функцию которая будет вызвана этим скриптом в случае удачной загрузки.
В случае не удачи выполниться функция из переменной onerror которая присваивается соответствующему полю элемента script.
*/
function add_redirect_script(prtocol, port, use_ip, onerror){
var script = document.createElement("script");
script.onerror = onerror;
script.setAttribute("integrity", "sha384-dActyNwOxNY9fpUWleNW9Nuy3Suv8Dx3F2Tbj1QTZWUslB1h23+xUPillTDxprx7");
script.setAttribute("crossorigin", "anonymous");
script.setAttribute("defer", "");
script.setAttribute("async", "");
if ( use_ip )
script.setAttribute("src", prtocol+"//127.0.0.1:"+port+"/ipns/"+window.location.hostname+"/redirect_call.js");
else
script.setAttribute("src", prtocol+"//"+l_hostname()+":"+port+"/redirect_call.js");
redirect_to_local = function()
{
var a = document.createElement("a");
a.href = window.location;
a.protocol = prtocol;
a.port = port;
if ( use_ip ){
a.pathname = "/ipns/" + a.hostname + a.pathname;
a.hostname = "127.0.0.1";
}else{
var hostname = a.hostname.split(".");
hostname.splice(-2,0,"l");
a.hostname = hostname.join(".");
}
window.location = a.href;
};
document.head.appendChild(script);
}
/*
Это главная функция которая запускается сразу. Она проверяет не находимся ли мы уже по адресу шлюза. Если нет то начинает проверять его доступность перебирая варианты адресов и протоколов.
*/
!function(location){
if ( location.protocol.indexOf("http") == 0 &&
location.hostname.length > 0 &&
location.hostname.indexOf("l.") != 0 &&
location.hostname.indexOf(".l.") < 0 &&
location.hostname != "127.0.0.1" )
{
add_redirect_script( "http:", 8080, false,
function(){
add_redirect_script( "https:", 8443, false,
function(){
add_redirect_script( "http:", 8080, true,
function(){
add_redirect_script( "https:", 8443, true );
} );
} );
} );
}
}(window.location)В пару ему идет скрипт:
redirect_call.js (sha384-dActyNwOxNY9fpUWleNW9Nuy3Suv8Dx3F2Tbj1QTZWUslB1h23+xUPillTDxprx7)
redirect_to_local();Integrity этого скрипта можно посчитать командой:
openssl dgst -sha384 -binary < "redirect_call.js" | openssl enc -base64 -AУ меня соответственно результат этой команды:
dActyNwOxNY9fpUWleNW9Nuy3Suv8Dx3F2Tbj1QTZWUslB1h23+xUPillTDxprx7Если у вас результат другой замените это значение в скрипте выше на своё.
Теперь пользователь будет автоматически перенаправлен на подходящий локальный адрес шлюза с сохранением остальных параметров адреса.
Создадим CSS файл который будет маяком работы шлюза.
httpl.css (sha384-9LLp4PYTHwNvd5whc7IOL6JLDJ4aoPufAFts3rMLZOg5b//BLQZTfe7krAzWAm+a)
.httpl{display: block;}Скрываем элементы страницы которые будут показаны только при доступности локального шлюза.
Добавляем CSS маяк в конце страницы
Use your gateway: http://l.[ваш домен]:8080/
Теперь даже если у пользователя отключены скрипты он сможет перейти на шлюз самостоятельно по ссылке. Аналогично можно проверить и остальные варианты адреса шлюза.
Возьмём к примеру глобальный IPFS шлюз gateway.ipfs.io и перенаправим этот адрес на наш локальный IPFS шлюз.
Условие: У нас уже установлен и работает на стандартном порту 8080 IPFS шлюз.
В файл hosts добавляем домен который хотим загружать с IPFS шлюза.
127.0.0.1 gateway.ipfs.ioУстанавливаем и настраиваем Stunnel.
stunnel.conf:
; Открываем дополнительный защищённый порт шлюза для того чтобы сайты могли сами на него переключиться
[https gateway]
accept = 127.0.0.1:8443
connect = 127.0.0.1:8080
cert = stunnel.pem
TIMEOUTclose = 0
; Открываем стандартный порт 443 для HTTPS
[https]
accept = 127.0.0.1:443
connect = 127.0.0.1:8080
cert = stunnel.pem
TIMEOUTclose = 0
; Открываем стандартный порт 80 для HTTP
[http]
client = yes
accept = 127.0.0.1:80
connect = 127.0.0.1:443Таким образом мы открываем 3 дополнительных порта (433, 8443, 80) которые подключают клиента к шлюзу IPFS.
Создаём сертификаты и ключи.
3.1. В директорию c конфигом копируем makecert.cmd
echo off
%~d0
cd %~p0
set STUNNELBIN = ..\bin
set PATH=%STUNNELBIN%;%PATH%;
rem // Первый вызов openssl создаст ключ и корневой сертификат в формате PEM
rem // openssl попросит пользователя задать пароль которым будет защищён ключ и при каждой новой подписи сертификата шлюза этот пароль потребуется
rem // Второй вызов openssl конвертирует сертификат из PEM в DER формат понятный Windows
rem // Корневой сертификат в PEM формате понадобиться для Firefox
if not exist "rootkey.pem" (
echo [ req ] >openssl.root.cnf
echo distinguished_name = req_distinguished_name >>openssl.root.cnf
echo [v3_ca] >>openssl.root.cnf
echo subjectKeyIdentifier = hash >>openssl.root.cnf
echo authorityKeyIdentifier = keyid:always,issuer:always >>openssl.root.cnf
echo basicConstraints = critical, CA:TRUE >>openssl.root.cnf
echo keyUsage = keyCertSign, cRLSign >>openssl.root.cnf
echo [ req_distinguished_name ] >>openssl.root.cnf
openssl.exe req -newkey rsa:4096 -x509 -sha256 -days 5480 -config openssl.root.cnf -extensions v3_ca -utf8 -subj "/CN=127.0.0.1" -out rootcert.pem -keyout rootkey.pem
openssl.exe x509 -outform der -in rootcert.pem -out rootcert.crt
del openssl.root.cnf
)
rem // Теперь создаём ключ который будет использоваться шлюзом
if not exist "gatewaykey.pem" (
openssl genpkey -algorithm RSA -pkeyopt rsa_keygen_bits:2048 -out gatewaykey.pem
)
rem // Делаем запрос сертификата шлюза
if not exist "gateway.csr" (
echo [ req ] >openssl.req.cnf
echo req_extensions = v3_req >>openssl.req.cnf
echo distinguished_name = req_distinguished_name >>openssl.req.cnf
echo [ req_distinguished_name ] >>openssl.req.cnf
echo [ v3_req ] >>openssl.req.cnf
echo basicConstraints = CA:FALSE >>openssl.req.cnf
echo keyUsage = nonRepudiation, digitalSignature, keyEncipherment >>openssl.req.cnf
openssl req -new -key gatewaykey.pem -days 1096 -batch -utf8 -subj "/CN=127.0.0.1" -config openssl.req.cnf -out gateway.csr
del openssl.req.cnf
)
rem // Если это не первое выполнение данного скрипта то в index.txt может храниться индекс следующей DNS записи.
if exist "index.txt" (
set /p index=/ Мы создаём openssl.cnf один раз и в дальнейшем дополняем его новыми доменами.
if not exist "openssl.cnf" (
echo basicConstraints = CA:FALSE >openssl.cnf
echo extendedKeyUsage = serverAuth >>openssl.cnf
echo subjectAltName=@alt_names >>openssl.cnf
echo [alt_names] >>openssl.cnf
echo IP.1 = 127.0.0.1 >>openssl.cnf
echo DNS.1 = localhost >>openssl.cnf
set index=2
del "index.txt"
)
rem // В цикле добавляем в openssl.cnf домены которые заданы в командной строке либо будут введены пользователем.
:NEXT
set /a aindex=%index% + 1
set /a bindex=%index% + 2
set domain=%1
if !%domain% == ! (
set /p domain=enter domain name or space:
)
if not !%domain% == ! (
echo DNS.%index% = %domain% >>openssl.cnf
echo DNS.%aindex% = *.%domain% >>openssl.cnf
echo %bindex% >index.txt
set index=%bindex%
shift
goto NEXT
)
del gateway.pem
rem // Создаём сертификат IPFS шлюза
openssl x509 -req -sha256 -days 1096 -in gateway.csr -CAkey rootkey.pem -CA rootcert.pem -set_serial %RANDOM%%RANDOM%%RANDOM%%RANDOM% -extfile openssl.cnf -out gateway.pem
rem // Записываем ключ и сертификат в stunnel.pem который по умолчанию используется программой stunnel
copy /b gateway.pem+gatewaykey.pem stunnel.pem
rem // Даём пользователю прочитать ошибки или информацию
pause3.2. Запускаем
makecert.cmd ipfs.ioПри первом запуске данного скрипта будет создан корневой сертификат (rootcert.pem для firefox и rootcert.crt для остальных) ключ которому надо задать пароль. Корневой сертификат надо добавить в хранилище доверенных корневых сертификатов в браузере и операционной системе.
Далее автоматически будет создан сертификат для шлюза которому надо задать домены которые он будет обслуживать.
Пере/Запускаем stunnel
reload.cmd
echo off
%~d0
cd %~p0
set STUNNELBIN = ..\bin
set PATH=%STUNNELBIN%;%PATH%;
stunnel -install -quiet
stunnel -start -quiet
stunnel -reload -quietТеперь gateway.ipfs.io будет работать на локальном шлюзе. Аналогично можно поступить с любым сайтом который размещён в IPFS.
Сайт для теста: ivan386.tk
Другие мои статьи о "межпланетной файловой системе":
|
Метки: author ivan386 децентрализованные сети ipfs stunnel localhost dns ssl |
Использование вулканизации для polymer-модулей |

vulcanize-polymer-module/
+-- imports.html
+-- vulcanize-utils.js
+-- rollup.config.js
+-- bower.json
+-- package.json
"dependencies": {
"polymer": "Polymer/polymer#^2.0.0",
"polymer-redux": "^1.0.0",
"iron-flex-layout": "PolymerElements/iron-flex-layout#^2.0.0",
"paper-button": "PolymerElements/paper-button#^2.0.0",
"paper-badge": "PolymerElements/paper-badge#^2.0.0",
"paper-icon-button": "PolymerElements/paper-icon-button#^2.0.0",
"paper-input": "PolymerElements/paper-input#^2.0.0",
"paper-item": "PolymerElements/paper-item#^2.0.0",
"paper-checkbox": "PolymerElements/paper-checkbox#^2.0.0",
"paper-tabs": "PolymerElements/paper-tabs#^2.0.0",
"paper-listbox": "PolymerElements/paper-listbox#^2.0.0",
"iron-a11y-keys": "PolymerElements/iron-a11y-keys#^2.0.0",
"iron-list": "PolymerElements/iron-list#^2.0.0",
"iron-icons": "PolymerElements/iron-icons#^2.0.0",
"paper-progress": "PolymerElements/paper-progress#^2.0.0",
"vaadin-split-layout": "vaadin/vaadin-split-layout#^2.0.0",
"vaadin-grid": "^3.0.0",
"iron-pages": "PolymerElements/iron-pages#^2.0.0",
"iron-collapse": "PolymerElements/iron-collapse#^2.0.0",
"iron-overlay-behavior": "PolymerElements/iron-overlay-behavior#^2.0.0",
"vaadin-context-menu": "^3.0.0"
}
"scripts": {
"build": "rollup -c",
"vulcanize": "vulcanize imports.html --inline-scripts --inline-css --strip-comments",
"run-vulcanize": "npm run vulcanize > imports.vulcanize.html",
"vulcanized": "vulcanize imports.html --inline-scripts --inline-css --strip-comments | crisper --html imports.vulcanized.html --js imports.vulcanized.js > imports.vulcanized.html",
"html-minifier": "html-minifier imports.vulcanized.html --remove-optional-tags --collapse-whitespace --preserve-line-breaks -o imports.vulcanized.min.html",
"build-all": "npm run vulcanized && npm run build && npm run html-minifier"
}npm install -g vulcanize
npm install -g crisper
npm install -g html-minifierimport progress from 'rollup-plugin-progress';
import cleanup from 'rollup-plugin-cleanup';
export default {
entry: 'imports.vulcanized.js',
dest: 'imports.vulcanized.js',
plugins: [
cleanup(),
progress({
}),
]
};|
Метки: author kolesoffac разработка веб-сайтов javascript polymer.js projection minification |
Oracle Storage Cloud Services - все, в чем нуждается корпоративное хранилище данных |
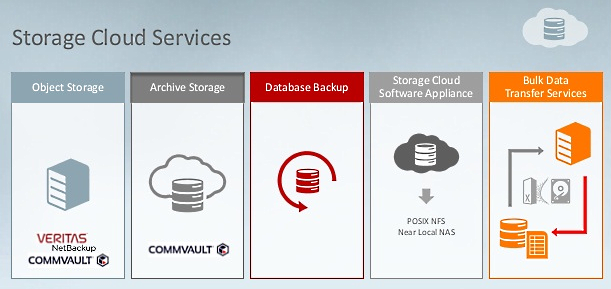
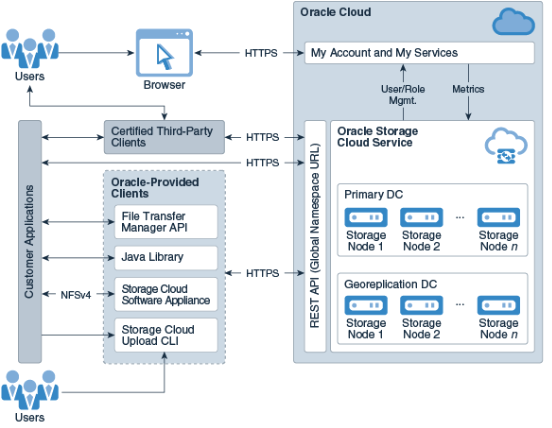
|
Метки: author Orest_ua хранилища данных хранение данных серверное администрирование серверная оптимизация блог компании мук oracle облачные технологии |
[Из песочницы] Как мы создали устройство быстрой обработки потока событий на FPGA |



|
Метки: author cepappliance я пиарюсь fpga low latency algorithmic trading hft- трейдинг high performance стартапы; команда; опыт pre-trade risk checks |
10 шагов настройки Create React App + TypeScript + Ant-Design |
В какой-то момент борьбы со Flow-Type на VSCode, я согласился, что нужно переезжать на TypeScript. Поддержка Flow-Type обеспечивается сторонним плагином и совсем-совсем не устраивает. Если файл невалиден с точки зрения Flow-Type, то переходы внутри кода между файлами перестают работать, например. А возвращаться на WebStorm после знакомства с VSCode — я не могу себя заставить. Microsoft, как обычно, затягивает полностью. Любишь VSCode, получи TypeScript.
Если бы мне кто сказал год назад, что я вернусь в поклонники Microsoft — сложно было такое представить. Но случаются и более удивительные вещи. Я в полном восторге от качества китайского набора React-компонентов от Ant-Design. И хотя он написан на TypeScript, чтобы его прикрурить, нужен babel-plugin-import.
Но как же остаться на Create React App (CRA) — у форка для TypeScript (CRA-TS) выпилили Babel. Поддерживать собственную вариацию CRA представляется безумием. Многообещающий Preact-CLI (как замена CRA) не обеспечивает необходимый уровень совместимости с React. Но, играясь с Preact-CLI, заметил, что preact.config.js очень похож на react-app-rewired, которым я активно пользуюсь для обхода ограничений конфигурации Webpack в CRA. Сопоставил этот факт с идеей перевода CRA-TS c ts-loader на awesome-typescript-loader, внутри которого можно включить Babel. И вуаля!
0) установить create-react-app
$ npm install -g create-react-app1) создать проект
$ create-react-app cra-ts-antd --scripts-version=react-scripts-ts
$ cd cra-ts-antd/2) добавить пакеты
$ yarn add react-app-rewired react-app-rewire-less awesome-typescript-loader babel-core babel-plugin-import babel-preset-react-app -D3) добавить config-overrides.js
module.exports = function override(config, env) {
const tsLoader = config.module.rules.find(conf => {
return conf.loader && conf.loader.includes('ts-loader')
})
tsLoader.loader = require.resolve('awesome-typescript-loader')
tsLoader.query = {
useBabel: true,
}
const tsLintLoader = config.module.rules.find(conf => {
return conf.loader && conf.loader.includes('tslint-loader')
})
tsLintLoader.options = tsLintLoader.options || {}
// FIXED Warning: The 'no-use-before-declare' rule requires type infomation.
tsLintLoader.options.typeCheck = true
const rewireLess = require('react-app-rewire-less')
config = rewireLess(config, env)
const path = require('path')
// For import with absolute path
config.resolve.modules = [path.resolve('src')].concat(config.resolve.modules)
return config
}4) изменить package.json; код подключает враппер react-app-rewired
"scripts": {
- "start": "react-scripts-ts start",
- "build": "react-scripts-ts build",
+ "start": "BROWSER=none react-app-rewired start --scripts-version react-scripts-ts",
+ "build": "react-app-rewired build --scripts-version react-scripts-ts",
}5) изменить tsconfig.json; код включает настройки для абсолютного импорта, помимо прочего
{
"compilerOptions": {
+ "allowSyntheticDefaultImports": true,
+ "baseUrl": ".",
+ "paths": {
+ "*": ["*", "src/*"]
+ },
- "jsx": "react",
+ "jsx": "preserve",
},
"exclude": [
+ "config-overrides.js",
]
}6) добавить .babelrc; код назначает требуемый пресет и подключает babel-plugin-import
{
"presets": ["react-app"],
"plugins": [
["import", { "libraryName": "antd", "style": false }]
]
}7) добавить antd; версия фиксированная, т.к. в следующей версии 2.12.3 обнаружена ошибка
$ yarn add antd@2.12.28) добавить src/resources/main.less; код переопределяет переменную
@import "~antd/dist/antd.less"; // import official less entry file
@primary-color: #1DA57A;9)… и подключить в index.tsx; импорт по абсолютному пути от src
+ import 'resources/main.less';10) изменить App.tsx
import * as React from 'react';
import './App.css';
+ import { Button } from 'antd';
const logo = require('./logo.svg');
class App extends React.Component<{}, {}> {
render() {
return (

Welcome to React
To get started, edit `src/App.tsx` and save to reload.
+
);
}
}
export default App;PS Ищу работу.
|
Метки: author comerc разработка веб-сайтов reactjs javascript вискас |
Обновление инфраструктуры рабочих мест трейдеров |



|
Метки: author GPeter блог компании райффайзенбанк wey трейдинг |
7 способов использования синего в цветах вашей фирмы |




















|
Метки: author Logomachine работа с векторной графикой графический дизайн блог компании логомашина бизнес дизайн цвет цветовая схема фирменный стиль логотип |
[Из песочницы] Дефейс ask.mcdonalds.ru |
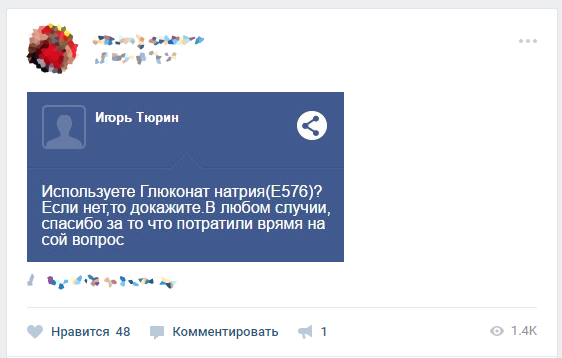
Краткий экскурс:
Согласно информации, опубликованной у них же, «Сайт призван максимально подробно ответить на вопросы, которые наиболее часто возникают у наших гостей: о составе, безопасности и качестве продукции Макдоналдс — от поля до прилавка. Поэтому в рамках Сайта мы отвечаем на вопросы, имеющие непосредственное отношение к продукции Макдоналдс.»
Я действительно порадовался, с точки зрения клиента здорово, когда я могу задать вопрос о продукции и получить на него адекватный ответ.




https://drive.google.com/file/d/AAAAAAAAAAAAAAAAAAA/view?usp=sharinghttps://drive.google.com/uc?export=download&id=

|
Метки: author anador тестирование веб-сервисов разработка веб-сайтов информационная безопасность уязвимость mcdonalds макдоналдс xss deface |
[Из песочницы] Разграничение прав доступа в PostgreSQL |

Хочу описать один из способов разграничения доступа к данным в СУБД, который мне кажется довольно гибким и интересным. Этот способ позволяет получать информацию о текущем пользователе с помощью вызова простой хранимой процедуры. Но сперва рассмотрим известные существующие способы с их плюсами и минусами, среди которых можно выделить использование встроенных механизмов аутентификации СУБД и контроль доступа на уровне приложения.
Для каждого бизнес-пользователя создаётся соответствующий пользователь в СУБД, которому раздаются необходимые права.
Плюсы такого подхода: его простота и прозрачность. По логам СУБД легко увидеть, какие запросы выполняют пользователи, несколько прав можно объединять в роли и раздавать их пользователям прямо "из коробки". Основной минус такого подхода — отсутствие контроля доступа на уровне строк. Да, в 9.5 появилась row-level security, но этот механизм работает не так быстро, как хотелось бы, особенно для JOIN.
К встроенным механизмам аутентификации также относятся LDAP, PAM, GSSAPI и прочие.
Многие осуществляют разграничение доступа прямо на уровне приложения. При этом можно использовать как внешний сервис для авторизации пользователей так и хранить хеши паролей непосредственно в базе и проверять их в приложении. Это не имеет значения. Главное то, что все пользователи в конечном итоге ходят в базу под одним пользователем. В таком подходе я вообще не вижу никаких плюсов, зато минусов предостаточно:
Несмотря на такое большое количество минусов, по моим наблюдениям это самый распостранённый способ разграничения доступа на сегодняшний день.
Об этом способе я сегодня и хочу рассказать поподробнее. Суть его проста: в базе данных создаётся процедура авторизации, которая проверяет логин и пароль пользователя и в случае успеха устанавливает значение некоторой сессионной переменной, которая была бы доступна на чтение до конца текущей сессии. Для хранения значения переменной будем использовать глобальный массив GD, доступный процедурам на языке Pl/Python:
create or replace
function set_current_user_id(user_id integer) as $$
GD['user_id'] = user_id
$$ language plpythonu;Сама же процедура авторизации будет выглядеть следующим образом:
create or replace
function login(user_ text, password_ text) returns integer as $$
declare
vuser_id integer; vis_admin boolean;
begin
select id, is_admin
into vuser_id, is_admin
from users where login = login_ and password = password_;
if found then
perform set_current_user_id(vuser_id);
/* код функции set_is_admin() аналогичен
коду функции set_current_user_id() */
perform set_is_admin(vis_admin);
else
raise exception 'Invalid login or password';
end if;
return vuser_id;
end;
$$ language plpgsql security definer;После этого осталось реализовать функцию, которая будет возвращать ID залогиненного пользователя:
create or replace
function get_current_user_id() returns integer as $$
return GD.get('user_id')
$$ language plpythonu stable;Теперь о том, как это всё использовать. А использовать очень просто. После авторизации пользователя внутри любой функции теперь можно легко узнать, что за пользователь запрашивает доступ к данным и какие у него есть права. Например:
create or replace
function delete_branch(branch_id_ integer) returns void as $$
begin
if not current_user_is_admin() then
raise exception 'Access denied: this operation needs admin privileges';
end if;
...
end;
$$ language plpgsql;Для демонстрации того, как будет работать разграничение доступа на уровне строк, напишем функцию, которая будет возвращать список счетов в банке, причём только тех, которые открыты в филиале, к которому принадлежит пользователь (branch_id).
create or replace
function get_accounts() returns table (account_number text) as $$
begin
return query
select a.account_number
from accounts a
join users u on u.branch_id = a.branch_id
where u.id = get_current_user_id();
end;
$$ language plpgsql;В чём плюсы и минусы такого подхода? Плюсы:
Несмотря на это, есть также и минусы:
Конечно, наверняка существуют проекты где описанный мной подход будет неуместен и я буду рад, если вы поделитесь своими мыслями на этот счёт, — возможно, данный метод можно доработать и улучшить. Но, в целом, такой подход кажется мне довольно интересным.
|
Метки: author pensnarik postgresql безопасность |
Машинное обучение для страховой компании: Оптимизация модели |
|
|
Четверть миллиона за «жука»: Microsoft начинает активную борьбу с багами |
 / Flickr / Mike Mozart / CC
/ Flickr / Mike Mozart / CC / Pixabay / VISHNU_KV / CC
/ Pixabay / VISHNU_KV / CC|
Метки: author 1cloud информационная безопасность блог компании 1cloud.ru 1cloud microsoft баги искусственный интеллект |
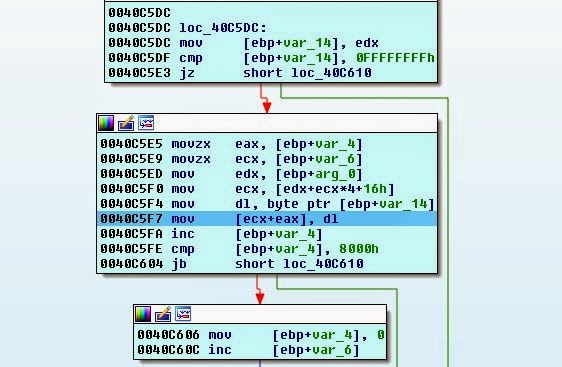
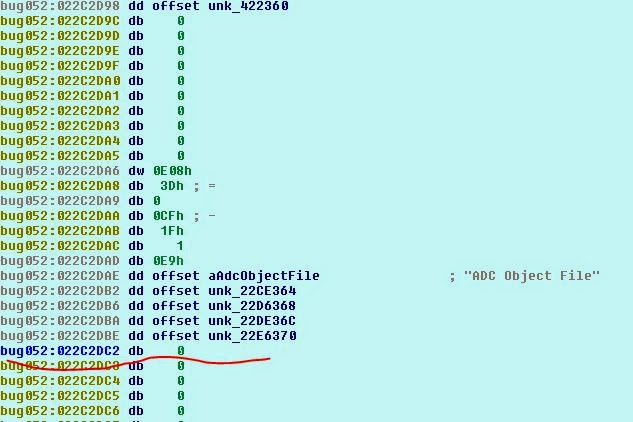
[Перевод] Взлом игры Clocktower — The First Fear |






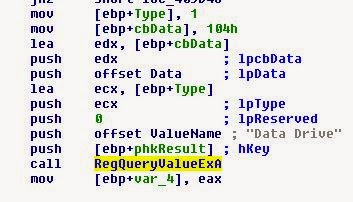
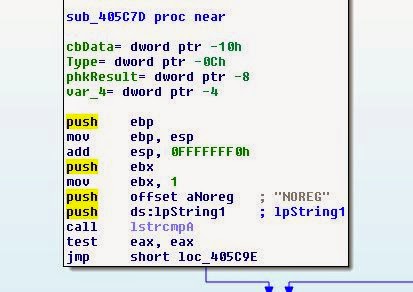
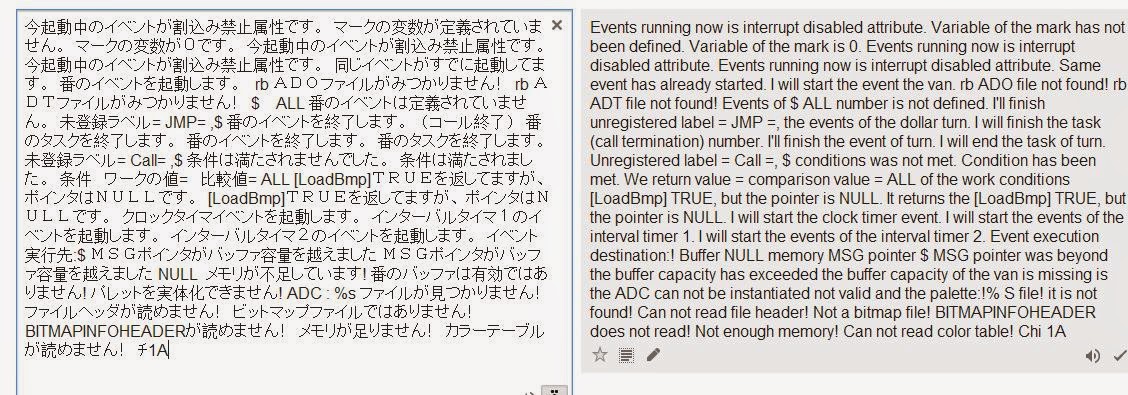





0xE92 25 blahblahblah'''
CTD - Clocktower Text Dumper by rFx
'''
import os,sys,struct,binascii
f = open("CT_J.ADO","rb")
data = f.read()
f.close()
g = open("ct_txt.txt","wb")
for i in range(0,len(data)-1):
if(data[i] == '\x33' and data[i+1] == '\xff'):
#Нам нужно пропускать 6 из-за опкодов и значений, изменения которых нам не важны.
i+=6
str_offset = i
str_end = data[i:].index('\xff') -1
newstr = data[i:i+str_end]
strlen = len(newstr)
newstr = newstr.replace("\x0a\x00","[NEWLINE]")
#Игра ставит нули после каждого символа ASCII, нам нужно удалить их.
newstr = newstr.replace("\x00","")
g.write("%#x\t%d\t" % (str_offset,strlen))
g.write(newstr)
g.write("\n")
g.close()#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
Clocktower Auto Translator by rFx
'''
import os,sys,binascii,struct
from translate import Translator
translator = Translator(to_lang="en") #Set to English by Default
f = open("ct_txt.txt","rb")
g = open("ct_txt_proc2.txt","wb")
proc_str = []
for line in f.readlines():
proc_str.append(line.rstrip())
for x in range(0,len(proc_str)):
line = proc_str[x]
o,l,instr = line.split("\t")
ts = translator.translate(instr.decode("SHIFT-JIS").encode("UTF-8"))
ts = ts.encode("SHIFT-JIS","replace")
proc_str[x] = "%s\t%s\t%s" % (o,l,ts)
g.write(proc_str[x]+"\n")
#for pc in proc_str:
# g.write(pc)
g.close()'''
Clocktower Text Injector by rFx
'''
import os,sys,struct,binascii
def is_ascii(s):
return all(ord(c) < 128 for c in s)
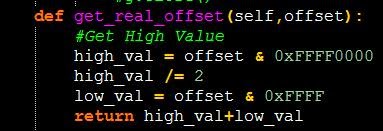
def get_real_offset(offset):
#Получаем верхнее значение
high_val = offset & 0xFFFF0000
high_val /= 2
low_val = offset & 0xFFFF
return high_val+low_val
def get_fake_offset(offset):
#Получаем верхнее значение
mult = int(offset / 0x8000)
shft_val = 0x8000 * mult
low_val = offset & 0xFFFF
return offset + shft_val
f = open("CT_J.ADO","rb")
data = f.read()
f.close()
offset_vals = []
adt_list = []
newdata = ""
f = open("ct_txt_proc.txt","rb")
lines = f.readlines()
o,l,s = lines[0].split("\t")
first_offset = int(o,16)
o,l,s = lines[0].split("\t")
last_offset_strend = int(o,16) + int(l)
newdata = data[:first_offset]
for i in range(0,len(lines)):
line = lines[i]
offset, osl, instr = line.split("\t")
offset = int(offset,16)
instr = instr.rstrip('\n')
instr = instr.replace("[NEWLINE]","\x0a")
#Исправляем символы ASCII.
instr = instr.decode("SHIFT-JIS")
newstr = ""
for char in instr:
if(is_ascii(char)):
newstr+=char+'\x00'
else:
newstr+=char
instr = newstr
instr = instr.encode("SHIFT-JIS")
newstrlen = len(instr)
osl = int(osl)
strldiff = newstrlen - osl
#Заменяем данные
if(i < len(lines)-1):
nextline = lines[i+1]
nextoffset,nsl,nstr = nextline.split("\t")
offset_vals.append({"offset":offset,"val":strldiff})
nextoffset = int(nextoffset,16)
newdata += instr+data[offset+osl:nextoffset]
else:
offset_vals.append({"offset":offset,"val":strldiff})
newdata += instr + data[offset+osl:]
#Конец последней строки до EOF
f.close()
#Записываем новый файл ADO.
g = open("CT.ADO","wb")
g.write(newdata)
g.close()
#Исправляем файл ADT.
f = open("CT_J.ADT","rb")
datat = f.read()
f.close()
g = open("CT.ADT","wb")
for i in range(0,len(datat),4):
cur_offset = get_real_offset(struct.unpack(" offset["offset"]):
final_adj += offset["val"]
g.write(struct.pack("code>






529B: 74 EB
BC7B: 2A 2E
BC8D: D0 CC
BD35: 2A 2E
BD62: 2A 2E
D4DA: 2A 2E
D4FC: 2A 2E
DA58: 2A 2E
DA79: 2A 2E
103DA: 2A 2E
10407: 2A 2E
104F8: 2A 2E
105BB: 2A 2E
105E8: 2A 2E
10703: 2A 2E
10730: 2A 2E
115FA: 2A 2E
116B2: 05 06
116E8: 05 06
11720: 2A 2E
11729: D0 CC
1195D: 05 06
1C50F: 20 00'''
Clocktower ADC Object File Disassembler by rFx
'''
import os,sys,binascii,struct
ADO_FILENAME = "CT_J.ADO"
ADT_FILENAME = "CT_J.ADT"
ADO_OP = {
0xFF00:"RETN", #Scene Prologue - 0 bytes of data. - Also an END value... the game looks to denote endings.
0xFF01:"UNK_01", # varying length data
0xFF02:"UNK_02", # 3 bytes of data
0xFF03:"UNK_03", # 3 bytes of data
0xFF04:"UNK_04", # 3 bytes of data
0xFF05:"UNK_05", # 3 bytes of data
0xFF06:"UNK_06", # 3 bytes of data
0xFF07:"UNK_07", # 3 bytes of data
0xFF0A:"UNK_0A", # 4 bytes of data. Looks like an offset to another link in the list?
0xFF0C:"UNK_0C", # 4 bytes of data
0xFF0D:"UNK_0D", # 4 bytes of data
0xFF10:"UNK_10", # 4 bytes of data
0xFF11:"UNK_11", # 4 bytes of data
0xFF12:"UNK_12", # 4 bytes of data
0xFF13:"UNK_13", # 4 bytes of data
0xFF14:"UNK_14", # 4 bytes of data
0xFF15:"UNK_15", # 4 bytes of data
0xFF16:"UNK_16", # 4 bytes of data
0xFF1F:"UNK_1F", # 0 bytes of data
0xFF20:"ALL", # 0 bytes of data. Only at the end of the ADO (twice)
#All opcodes above this are like... prologue opcodes (basically in some other list)
0xFF21:"ALLEND", # 2 bytes of data
0xFF22:"JMP", # 2 bytes of data - I think it uses the value for the int offset in adt as destination +adds 2
0xFF23:"CALL", # 6 bytes of data
0xFF24:"EVDEF", # Not used in the game
0xFF25:"!!!!!!", #Not used in the game
0xFF26:"!!!!!!", #Not used in the game
0xFF27:"!!!!!!", #Not used in the game
0xFF28:"!!!!!!", #0 bytes of data.
0xFF29:"END_IF", # 4 bytes of data
0xFF2A:"WHILE", # 4 bytes of data
0xFF2B:"NOP", # 0 bytes of data
0xFF2C:"BREAK", # Not used in the game
0xFF2D:"ENDIF", # 2 bytes of data
0xFF2E:"ENDWHILE", # 2 bytes of data
0xFF2F:"ELSE", # 2 bytes of data
0xFF30:"MSGINIT", # 10 bytes of data
0xFF31:"MSGTYPE", # Not used in the game
0xFF32:"MSGATTR", # 16 bytes of data
0xFF33:"MSGOUT", # Varying length, our in-game text uses this. :)
0xFF34:"SETMARK", #Varying length
0xFF35:"SETWAIT", #Not used in the game
0xFF36:"MSGWAIT", #0 bytes of data
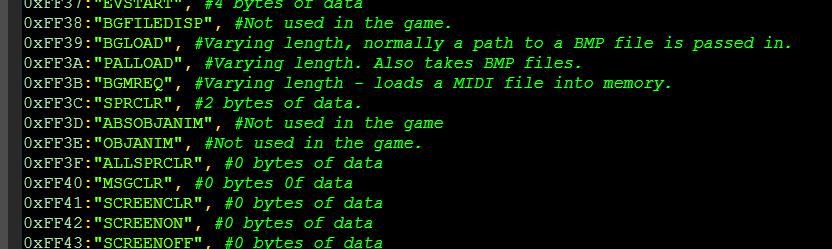
0xFF37:"EVSTART", #4 bytes of data
0xFF38:"BGFILEDISP", #Not used in the game.
0xFF39:"BGLOAD", #Varying length, normally a path to a BMP file is passed in.
0xFF3A:"PALLOAD", #Varying length. Also takes BMP files.
0xFF3B:"BGMREQ", #Varying length - loads a MIDI file into memory.
0xFF3C:"SPRCLR", #2 bytes of data.
0xFF3D:"ABSOBJANIM", #Not used in the game
0xFF3E:"OBJANIM", #Not used in the game.
0xFF3F:"ALLSPRCLR", #0 bytes of data
0xFF40:"MSGCLR", #0 bytes 0f data
0xFF41:"SCREENCLR", #0 bytes of data
0xFF42:"SCREENON", #0 bytes of data
0xFF43:"SCREENOFF", #0 bytes of data
0xFF44:"SCREENIN", # Not used in the game.
0xFF45:"SCREENOUT", # Not used in the game.
0xFF46:"BGDISP", # Always 12 bytes of data.
0xFF47:"BGANIM", #14 bytes of data.
0xFF48:"BGSCROLL",#10 bytes of data.
0xFF49:"PALSET", #10 bytes of data.
0xFF4A:"BGWAIT", #0 bytes of data.
0xFF4B:"WAIT", #4 bytes of data.
0xFF4C:"BWAIT", #Not used in the game.
0xFF4D:"BOXFILL", #14 bytes of data.
0xFF4E:"BGCLR", # Not used in the game.
0xFF4F:"SETBKCOL", #6 bytes of data.
0xFF50:"MSGCOL", #Not used in the game.
0xFF51:"MSGSPD", #2 bytes of data.
0xFF52:"MAPINIT", #12 bytes of data.
0xFF53:"MAPLOAD", #Two Paths... Sometimes NULL NULL - Loads the background blit bmp and the map file to load it.
0xFF54:"MAPDISP", #Not used in the game.
0xFF55:"SPRENT", #16 bytes of data.
0xFF56:"SETPROC", #2 bytes of data.
0xFF57:"SCEINIT", #0 bytes of data.
0xFF58:"USERCTL", #2 bytes of data.
0xFF59:"MAPATTR", #2 bytes of data.
0xFF5A:"MAPPOS", #6 bytes of data.
0xFF5B:"SPRPOS", #8 bytes of data.
0xFF5C:"SPRANIM", #8 bytes of data.
0xFF5D:"SPRDIR", #10 bytes of data.
0xFF5E:"GAMEINIT", #0 bytes of data.
0xFF5F:"CONTINIT", #0 bytes of data.
0xFF60:"SCEEND", #0 bytes of data.
0xFF61:"MAPSCROLL", #6 bytes of data.
0xFF62:"SPRLMT", #6 bytes of data.
0xFF63:"SPRWALKX", #10 bytes of data.
0xFF64:"ALLSPRDISP", #Not used in the game.
0xFF65:"MAPWRT", #Not used in the game.
0xFF66:"SPRWAIT", #2 bytes of data.
0xFF67:"SEREQ", #Varying length - loads a .WAV file.
0xFF68:"SNDSTOP", #0 bytes of data.
0xFF69:"SESTOP", #Varying length - specifies a .WAV to stop or ALL for all sounds.
0xFF6A:"BGMSTOP", #0 bytes of data.
0xFF6B:"DOORNOSET", #0 bytes of data.
0xFF6C:"RAND", #6 bytes of data.
0xFF6D:"BTWAIT", #2 bytes of data
0xFF6E:"FAWAIT", #0 bytes of data
0xFF6F:"SCLBLOCK", #Varying length - no idea.
0xFF70:"EVSTOP", #Not used in the game.
0xFF71:"SEREQPV", #Varying length - .WAV path input, I think this is to play and repeat.
0xFF72:"SEREQSPR", #Varying length - .WAV path input, I think this is like SEREQPV except different somehow.
0xFF73:"SCERESET", #0 bytes of data.
0xFF74:"BGSPRENT", #12 bytes of data.
0xFF75:"BGSPRPOS", #Not used in the game.
0xFF76:"BGSPRSET", #Not used in the game.
0xFF77:"SLANTSET", #8 bytes of data.
0xFF78:"SLANTCLR", #0 bytes of data.
0xFF79:"DUMMY", #Not used in the game.
0xFF7A:"SPCFUNC", #Varying length - usage uncertain.
0xFF7B:"SEPAN", #Varying length - guessing to set the L/R of Stereo SE.
0xFF7C:"SEVOL", #Varying length - guessing toe set the volume level of SE
0xFF7D:"BGDISPTRN", #14 bytes of data.
0xFF7E:"DEBUG", #Not used in the game.
0xFF7F:"TRACE", #Not used in the game.
0xFF80:"TMWAIT", #4 bytes of data.
0xFF81:"BGSPRANIM", #18 bytes of data.
0xFF82:"ABSSPRENT", #Not used in the game.
0xFF83:"NEXTCOM", #2 bytes of data.
0xFF84:"WORKCLR", #0 bytes of data.
0xFF85:"BGBUFCLR", #4 bytes of data.
0xFF86:"ABSBGSPRENT", #12 bytes of data.
0xFF87:"AVIPLAY", #This one is used only once - to load the intro AVI file.
0xFF88:"AVISTOP", #0 bytes of data.
0xFF89:"SPRMARK", #Only used in PSX Version.
0xFF8A:"BGMATTR",#Only used in PSX Version.
#BIG GAP IN OPCODES... maybe not even in existence.
0xFFA0:"UNK_A0", #12 bytes of data.
0xFFB0:"UNK_B0", #12 bytes of data.
0xFFDF:"UNK_DF", #2 bytes of data.
0xFFE0:"UNK_E0", #0 bytes of data.
0xFFEA:"UNK_EA", #0 bytes of data.
0xFFEF:"UNK_EF" #12 bytes of data.
}
if(__name__=="__main__"):
print("#Disassembling ADO/ADT...")
#Read ADO/ADT Data to memory.
f = open(ADO_FILENAME,"rb")
ado_data = f.read()
f.close()
f = open(ADT_FILENAME,"rb")
adt_data = f.read()
f.close()
scene_count = -1
#Skip ADO Header
i = 256
while i < (len(ado_data) -1):
cur_val = struct.unpack("|
Метки: author PatientZero реверс-инжиниринг разработка игр обратная разработка clocktower snes playstation 1 |
Характеристики анализатора PVS-Studio на примере EFL Core Libraries, 10-15% ложных срабатываний |
rules-config=/path/to/efl_settings.txtpvs-studio-analyzer analyze ... --cfg /path/to/PVS-Studio.cfg ...pvs-studio ... --cfg /patn/to/PVS-Studio.cfg .......
uint64_t callback_mask;
....
static void
_check_event_catcher_add(void *data, const Efl_Event *event)
{
....
Evas_Callback_Type type = EVAS_CALLBACK_LAST;
....
else if ((type = _legacy_evas_callback_type(array[i].desc)) !=
EVAS_CALLBACK_LAST)
{
obj->callback_mask |= (1 << type);
}
....
}obj->callback_mask |= (1 << type);static int
_ephysics_body_evas_stacking_sort_cb(const void *d1,
const void *d2)
{
const EPhysics_Body_Evas_Stacking *stacking1, *stacking2;
stacking1 = (const EPhysics_Body_Evas_Stacking *)d1;
stacking2 = (const EPhysics_Body_Evas_Stacking *)d2;
if (!stacking1) return 1;
if (!stacking2) return -1;
if (stacking1->stacking < stacking2->stacking) return -1;
if (stacking2->stacking > stacking2->stacking) return 1;
return 0;
}if (stacking1->stacking > stacking2->stacking) return 1;typedef struct _Eina_Array Eina_Array;
struct _Eina_Array
{
int version;
void **data;
unsigned int total;
unsigned int count;
unsigned int step;
Eina_Magic __magic;
};typedef struct _Eina_Accessor_Array Eina_Accessor_Array;
struct _Eina_Accessor_Array
{
Eina_Accessor accessor;
const Eina_Array *array;
Eina_Magic __magic;
};static Eina_Accessor *
eina_array_accessor_clone(const Eina_Array *array)
{
Eina_Accessor_Array *ac;
EINA_SAFETY_ON_NULL_RETURN_VAL(array, NULL);
EINA_MAGIC_CHECK_ARRAY(array);
ac = calloc(1, sizeof (Eina_Accessor_Array));
if (!ac) return NULL;
memcpy(ac, array, sizeof(Eina_Accessor_Array));
return &ac->accessor;
}.... eina_array_accessor_clone(const Eina_Array *array)
{
Eina_Accessor_Array *ac = calloc(1, sizeof (Eina_Accessor_Array));
memcpy(ac, array, sizeof(Eina_Accessor_Array));
}
static Eina_Bool _convert_etc2_rgb8_to_argb8888(....)
{
const uint8_t *in = src;
uint32_t *out = dst;
int out_step, x, y, k;
unsigned int bgra[16];
....
for (k = 0; k < 4; k++)
memcpy(out + x + k * out_step, bgra + k * 16, 16);
....
}#define MATRIX_XX(m) (m)->xx
typedef struct _Eina_Matrix4 Eina_Matrix4;
struct _Eina_Matrix4
{
double xx;
double xy;
double xz;
double xw;
double yx;
double yy;
double yz;
double yw;
double zx;
double zy;
double zz;
double zw;
double wx;
double wy;
double wz;
double ww;
};
EAPI void
eina_matrix4_array_set(Eina_Matrix4 *m, const double *v)
{
memcpy(&MATRIX_XX(m), v, sizeof(double) * 16);
}struct _Eina_Matrix4
{
union {
struct {
double xx;
double xy;
double xz;
double xw;
double yx;
double yy;
double yz;
double yw;
double zx;
double zy;
double zz;
double zw;
double wx;
double wy;
double wz;
double ww;
};
double RawArray[16];
};
};
EAPI void
void eina_matrix4_array_set(Eina_Matrix4 *m, const double *v)
{
memcpy(m->RawArray, v, sizeof(double) * 16);
}memcpy(&MATRIX_XX(m), v, sizeof(double) * 16); //-V512//-V:MATRIX_:512static Eina_Bool
evas_image_load_file_head_bmp(void *loader_data,
Evas_Image_Property *prop,
int *error)
{
....
if (header.comp == 0) // no compression
{
// handled
}
else if (header.comp == 3) // bit field
{
// handled
}
else if (header.comp == 4) // jpeg - only printer drivers
goto close_file;
else if (header.comp == 3) // png - only printer drivers
goto close_file;
else
goto close_file;
....
}EOLIAN static Efl_Object *
_efl_net_ssl_context_efl_object_finalize(....)
{
Efl_Net_Ssl_Ctx_Config cfg;
....
cfg.load_defaults = pd->load_defaults; // <=
cfg.certificates = &pd->certificates;
cfg.private_keys = &pd->private_keys;
cfg.certificate_revocation_lists =
&pd->certificate_revocation_lists;
cfg.certificate_authorities = &pd->certificate_authorities;
cfg.load_defaults = pd->load_defaults; // <=
....
}EAPI Eina_Bool
edje_edit_size_class_add(Evas_Object *obj, const char *name)
{
Eina_List *l;
Edje_Size_Class *sc, *s;
....
/* set default values for max */
s->maxh = -1;
s->maxh = -1;
....
}
if (!(el = malloc(sizeof(Evas_Stringshare_El) + slen + 1)))
return NULL;static Eina_Debug_Session *
_session_create(int fd)
{
Eina_Debug_Session *session = calloc(1, sizeof(*session));
session->dispatch_cb = eina_debug_dispatch;
session->fd = fd;
// start the monitor thread
_thread_start(session);
return session;
}static Reference *
_entry_reference_add(Entry *entry, Client *client,
unsigned int client_entry_id)
{
Reference *ref;
// increase reference for this file
ref = malloc(sizeof(*ref));
ref->client = client;
ref->entry = entry;
ref->client_entry_id = client_entry_id;
ref->count = 1;
entry->references = eina_list_append(entry->references, ref);
return ref;
}static void
_ecore_con_url_dialer_error(void *data, const Efl_Event *event)
{
Ecore_Con_Url *url_con = data;
Eina_Error *perr = event->info;
int status;
status =
efl_net_dialer_http_response_status_get(url_con->dialer);
if ((status < 500) && (status > 599))
{
DBG("HTTP error %d reset to 1", status);
status = 1; /* not a real HTTP error */
}
WRN("HTTP dialer error url='%s': %s",
efl_net_dialer_address_dial_get(url_con->dialer),
eina_error_msg_get(*perr));
_ecore_con_event_url_complete_add(url_con, status);
}if ((status < 500) || (status > 599))EAPI void
eina_rectangle_pool_release(Eina_Rectangle *rect)
{
Eina_Rectangle *match;
Eina_Rectangle_Alloc *new;
....
match = (Eina_Rectangle *) (new + 1);
if (match)
era->pool->empty = _eina_rectangle_skyline_list_update(
era->pool->empty, match);
....
}EAPI const void *
evas_object_smart_interface_get(const Evas_Object *eo_obj,
const char *name)
{
Evas_Smart *s;
....
s = evas_object_smart_smart_get(eo_obj);
if (!s) return NULL;
if (s)
....
}typedef enum _Elm_Image_Orient_Type
{
ELM_IMAGE_ORIENT_NONE = 0,
ELM_IMAGE_ORIENT_0 = 0,
ELM_IMAGE_ROTATE_90 = 1,
ELM_IMAGE_ORIENT_90 = 1,
ELM_IMAGE_ROTATE_180 = 2,
ELM_IMAGE_ORIENT_180 = 2,
ELM_IMAGE_ROTATE_270 = 3,
ELM_IMAGE_ORIENT_270 = 3,
ELM_IMAGE_FLIP_HORIZONTAL = 4,
ELM_IMAGE_FLIP_VERTICAL = 5,
ELM_IMAGE_FLIP_TRANSPOSE = 6,
ELM_IMAGE_FLIP_TRANSVERSE = 7
} Elm_Image_Orient;
typedef enum
{
EVAS_IMAGE_ORIENT_NONE = 0,
EVAS_IMAGE_ORIENT_0 = 0,
EVAS_IMAGE_ORIENT_90 = 1,
EVAS_IMAGE_ORIENT_180 = 2,
EVAS_IMAGE_ORIENT_270 = 3,
EVAS_IMAGE_FLIP_HORIZONTAL = 4,
EVAS_IMAGE_FLIP_VERTICAL = 5,
EVAS_IMAGE_FLIP_TRANSPOSE = 6,
EVAS_IMAGE_FLIP_TRANSVERSE = 7
} Evas_Image_Orient;EAPI void
elm_image_orient_set(Evas_Object *obj, Elm_Image_Orient orient)
{
Efl_Orient dir;
Efl_Flip flip;
EFL_UI_IMAGE_DATA_GET(obj, sd);
sd->image_orient = orient;
switch (orient)
{
case EVAS_IMAGE_ORIENT_0:
....
case EVAS_IMAGE_ORIENT_90:
....
case EVAS_IMAGE_FLIP_HORIZONTAL:
....
case EVAS_IMAGE_FLIP_VERTICAL:
....
}accessor_iterator& operator++(int)
{
accessor_iterator tmp(*this);
++*this;
return tmp;
} accessor_iterator operator++(int) static unsigned int read_compressed_channel(....)
{
....
signed char headbyte;
....
if (headbyte >= 0)
{
....
}
else if (headbyte >= -127 && headbyte <= -1) // <=
....
}static Eeze_Disk_Type
_eeze_disk_type_find(Eeze_Disk *disk)
{
const char *test;
....
test = udev_device_get_property_value(disk->device, "ID_BUS");
if (test)
{
if (!strcmp(test, "ata")) return EEZE_DISK_TYPE_INTERNAL;
if (!strcmp(test, "usb")) return EEZE_DISK_TYPE_USB;
return EEZE_DISK_TYPE_UNKNOWN;
}
if ((!test) && (!filesystem)) // <=
....
}EOLIAN static Eina_Error
_efl_net_server_tcp_efl_net_server_fd_socket_activate(....)
{
....
struct sockaddr_storage *addr;
socklen_t addrlen;
....
addrlen = sizeof(addr);
if (getsockname(fd, (struct sockaddr *)&addr, &addrlen) != 0)
....
}addrlen = sizeof(*addr);EAPI void eeze_disk_scan(Eeze_Disk *disk)
{
....
if (!disk->cache.vendor)
if (!disk->cache.vendor)
disk->cache.vendor = udev_device_get_sysattr_value(....);
....
}static void
free_buf(Eina_Evlog_Buf *b)
{
if (!b->buf) return;
b->size = 0;
b->top = 0;
# ifdef HAVE_MMAP
munmap(b->buf, b->size);
# else
free(b->buf);
# endif
b->buf = NULL;
}static void
free_buf(Eina_Evlog_Buf *b)
{
if (!b->buf) return;
b->top = 0;
# ifdef HAVE_MMAP
munmap(b->buf, b->size);
# else
free(b->buf);
# endif
b->buf = NULL;
b->size = 0;
}EAPI Eina_Bool
eina_simple_xml_parse(....)
{
....
else if ((itr + sizeof("") - 1 < itr_end) &&
(!memcmp(itr + 2, "", sizeof("") - 1)))
....
}static void
_edje_key_down_cb(....)
{
....
char *compres = NULL, *string = (char *)ev->string;
....
if (compres)
{
string = compres;
free_string = EINA_TRUE;
}
else free(compres);
....
}else free(compres);static void _fill_all_outs(char **outs, const char *val)
{
size_t vlen = strlen(val);
for (size_t i = 0; i < (sizeof(_dexts) / sizeof(char *)); ++i)
{
if (outs[i])
continue;
size_t dlen = strlen(_dexts[i]);
char *str = malloc(vlen + dlen + 1);
memcpy(str, val, vlen);
memcpy(str + vlen, _dexts[i], dlen);
str[vlen + dlen] = '\0';
outs[i] = str;
}
}void
_ecore_x_event_handle_focus_in(XEvent *xevent)
{
....
e->time = _ecore_x_event_last_time;
_ecore_x_event_last_time = e->time;
....
}static int command(void)
{
....
while (*lptr == ' ' && *lptr != '\0')
lptr++; /* skip whitespace */
....
}while (*lptr == ' ')_self_type& operator=(_self_type const& other)
{
_base_type::operator=(other);
}static void
eng_image_size_get(void *engine EINA_UNUSED, void *image,
int *w, int *h)
{
Evas_GL_Image *im;
if (!image)
{
*w = 0; // <=
*h = 0; // <=
return;
}
im = image;
if (im->orient == EVAS_IMAGE_ORIENT_90 ||
im->orient == EVAS_IMAGE_ORIENT_270 ||
im->orient == EVAS_IMAGE_FLIP_TRANSPOSE ||
im->orient == EVAS_IMAGE_FLIP_TRANSVERSE)
{
if (w) *w = im->h;
if (h) *h = im->w;
}
else
{
if (w) *w = im->w;
if (h) *h = im->h;
}
}eng_image_size_get(NULL, NULL, NULL, NULL);EAPI Eina_Binbuf *
emile_binbuf_decipher(Emile_Cipher_Algorithm algo,
const Eina_Binbuf *data,
const char *key,
unsigned int length)
{
....
Eina_Binbuf *result = NULL;
unsigned int *over;
EVP_CIPHER_CTX *ctx = NULL;
unsigned char ik[MAX_KEY_LEN];
unsigned char iv[MAX_IV_LEN];
....
on_error:
memset(iv, 0, sizeof (iv));
memset(ik, 0, sizeof (ik));
if (ctx)
EVP_CIPHER_CTX_free(ctx);
eina_binbuf_free(result);
return NULL;
}static inline size_t
eina_value_util_type_size(const Eina_Value_Type *type)
{
if (type == EINA_VALUE_TYPE_INT)
return sizeof(int32_t);
if (type == EINA_VALUE_TYPE_UCHAR)
return sizeof(unsigned char);
if ((type == EINA_VALUE_TYPE_STRING) ||
(type == EINA_VALUE_TYPE_STRINGSHARE))
return sizeof(char*);
if (type == EINA_VALUE_TYPE_TIMESTAMP)
return sizeof(time_t);
if (type == EINA_VALUE_TYPE_ARRAY)
return sizeof(Eina_Value_Array);
if (type == EINA_VALUE_TYPE_DOUBLE)
return sizeof(double);
if (type == EINA_VALUE_TYPE_STRUCT)
return sizeof(Eina_Value_Struct);
return 0;
}static inline unsigned int
eina_value_util_type_offset(const Eina_Value_Type *type,
unsigned int base)
{
unsigned size, padding;
size = eina_value_util_type_size(type);
if (!(base % size))
return base;
padding = ( (base > size) ? (base - size) : (size - base));
return base + padding;
}void fetch_linear_gradient(....)
{
....
if (t + inc*length < (float)(INT_MAX >> (FIXPT_BITS + 1)) &&
t+inc*length > (float)(INT_MIN >> (FIXPT_BITS + 1)))
....
}extern struct tm *gmtime (const time_t *__timer)
__attribute__ ((__nothrow__ , __leaf__));
static void
_set_headers(Evas_Object *obj)
{
static char part[] = "ch_0.text";
int i;
struct tm *t;
time_t temp;
ELM_CALENDAR_DATA_GET(obj, sd);
elm_layout_freeze(obj);
sd->filling = EINA_TRUE;
t = gmtime(&temp); // <=
....
}static void
_opcodes_unregister_all(Eina_Debug_Session *session)
{
Eina_List *l;
int i;
_opcode_reply_info *info = NULL;
if (!session) return;
session->cbs_length = 0;
for (i = 0; i < session->cbs_length; i++)
eina_list_free(session->cbs[i]);
....
}class btVector3
{
public:
....
btScalar m_floats[4];
inline btVector3() { }
....
};typedef struct _Simulation_Msg Simulation_Msg;
struct _Simulation_Msg {
EPhysics_Body *body_0;
EPhysics_Body *body_1;
btVector3 pos_a;
btVector3 pos_b;
Eina_Bool tick:1;
};_ephysics_world_tick_dispatch(EPhysics_World *world)
{
Simulation_Msg *msg;
if (!world->ticked)
return;
world->ticked = EINA_FALSE;
world->pending_ticks++;
msg = (Simulation_Msg *) calloc(1, sizeof(Simulation_Msg));
msg->tick = EINA_TRUE;
ecore_thread_feedback(world->cur_th, msg);
}int
evas_mem_free(int mem_required EINA_UNUSED)
{
return 0;
}
int
evas_mem_degrade(int mem_required EINA_UNUSED)
{
return 0;
}
void *
evas_mem_calloc(int size)
{
void *ptr;
ptr = calloc(1, size);
if (ptr) return ptr;
MERR_BAD();
while ((!ptr) && (evas_mem_free(size))) ptr = calloc(1, size);
if (ptr) return ptr;
while ((!ptr) && (evas_mem_degrade(size))) ptr = calloc(1, size);
if (ptr) return ptr;
MERR_FATAL();
return NULL;
}
EAPI void evas_common_font_query_size(....)
{
....
size_t cluster = 0;
size_t cur_cluster = 0;
....
do
{
cur_cluster = cluster + 1;
glyph--;
if (cur_w > ret_w)
{
ret_w = cur_w;
}
}
while ((glyph > first_glyph) && (cur_cluster == cluster));
....
}cur_cluster = cluster + 1;
static EPhysics_Body *
_ephysics_body_rigid_body_add(....)
{
....
motion_state = new btDefaultMotionState();
if (!motion_state)
{
ERR("Couldn't create a motion state.");
goto err_motion_state;
}
....
}|
|
Смок тестирование на небольшом проекте: как началось и какие результаты |
|
Метки: author sergei_kurenkov тестирование it-систем testng |
Artisto: опыт запуска нейросетей в production |


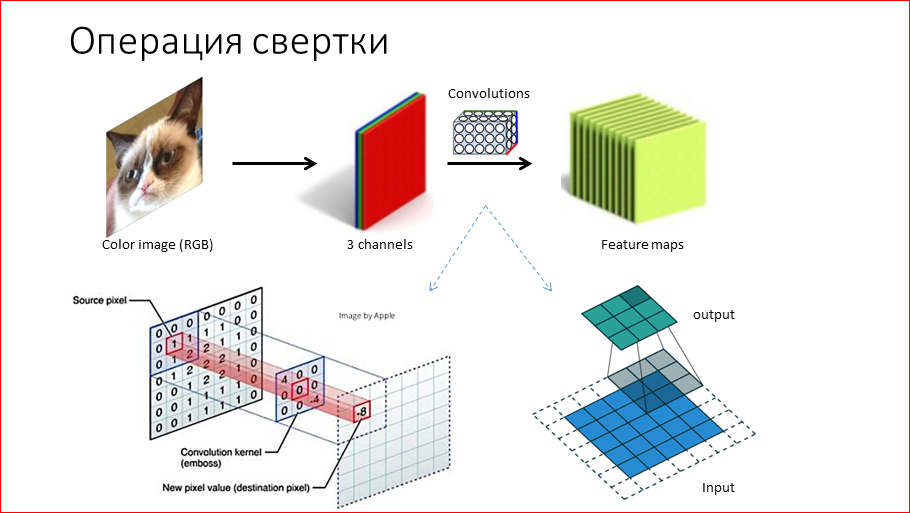

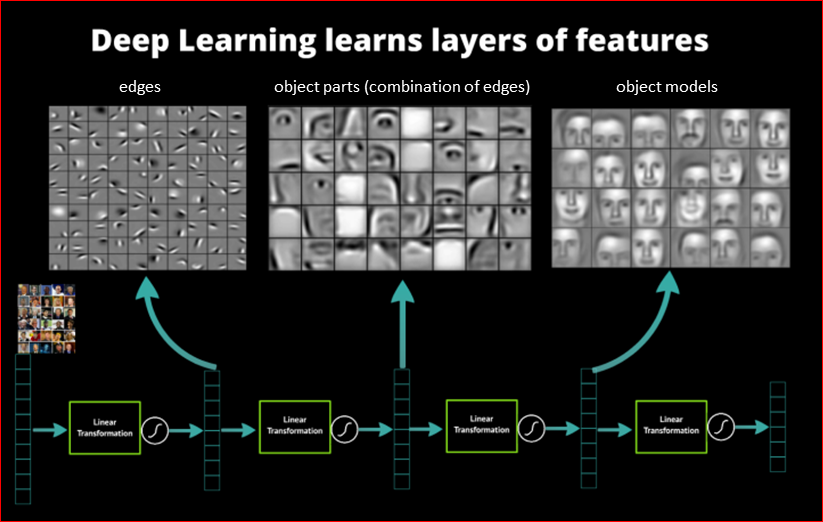




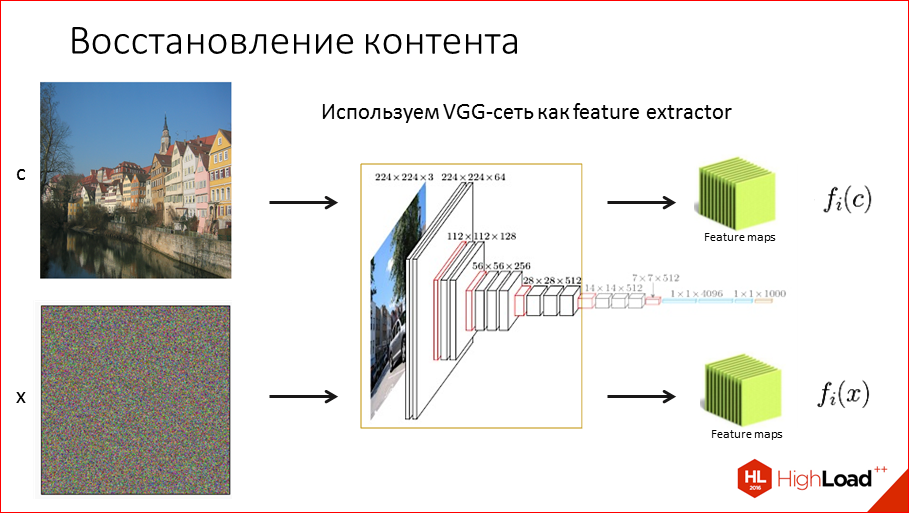
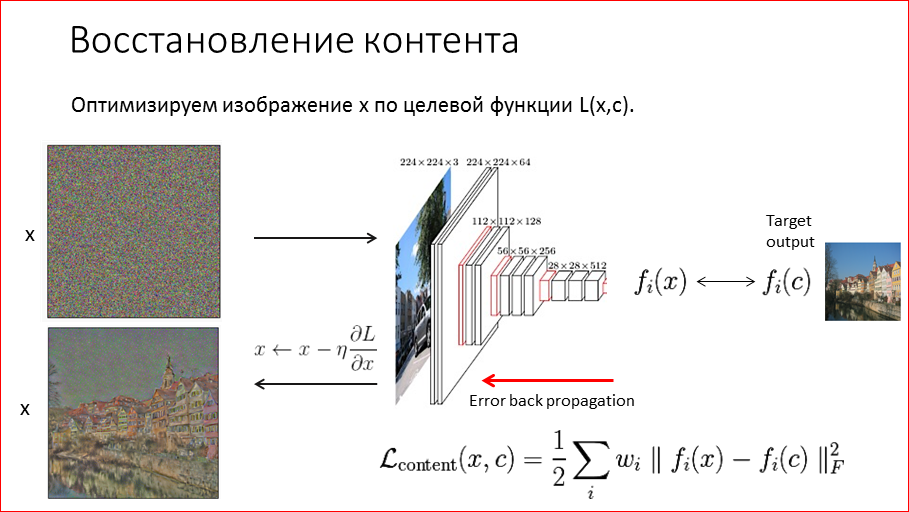


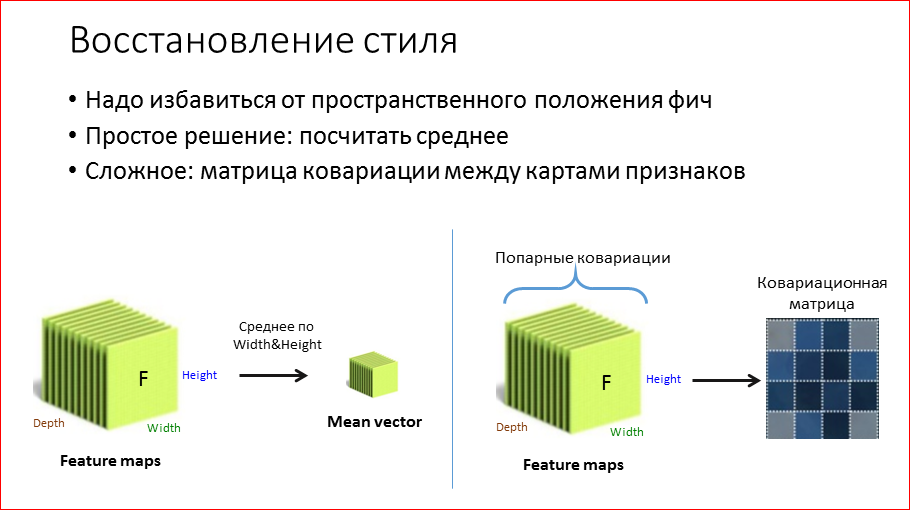
Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.


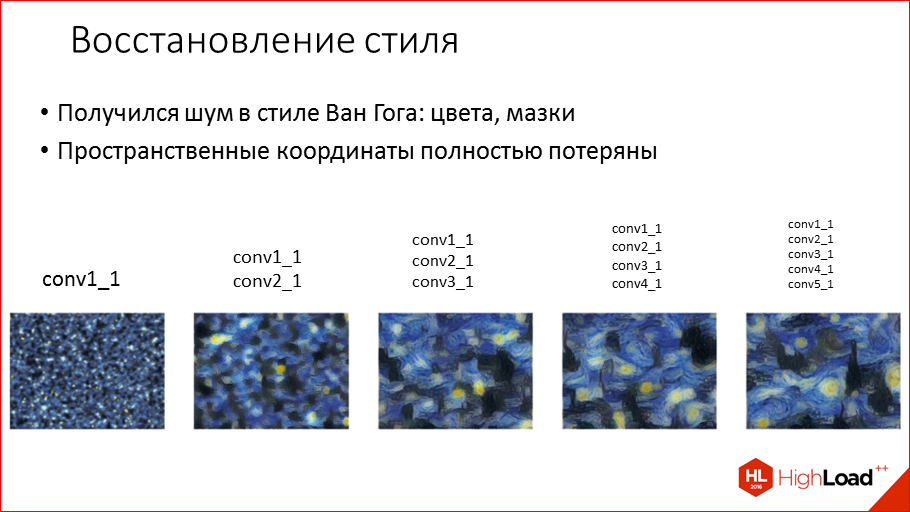
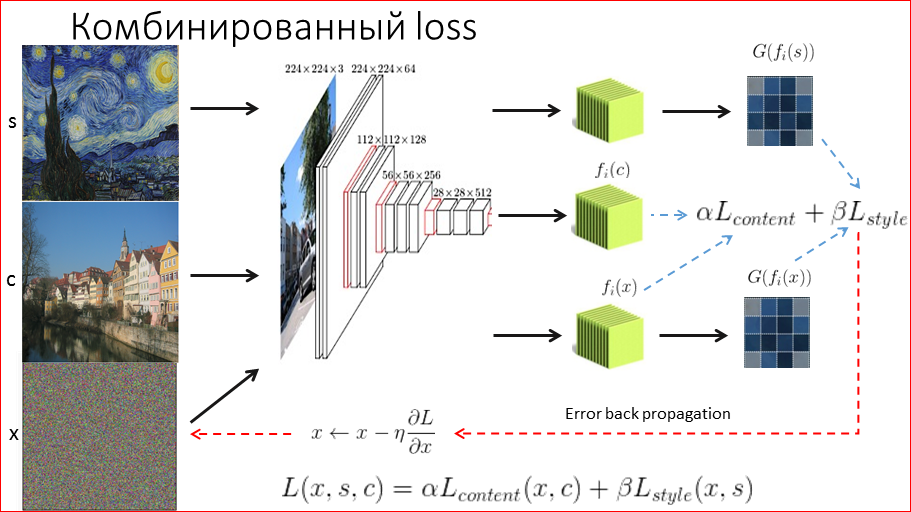


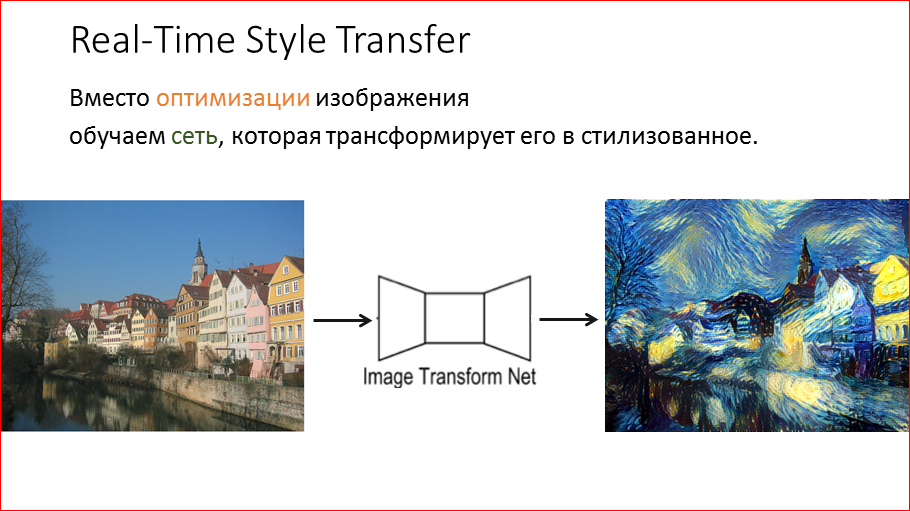
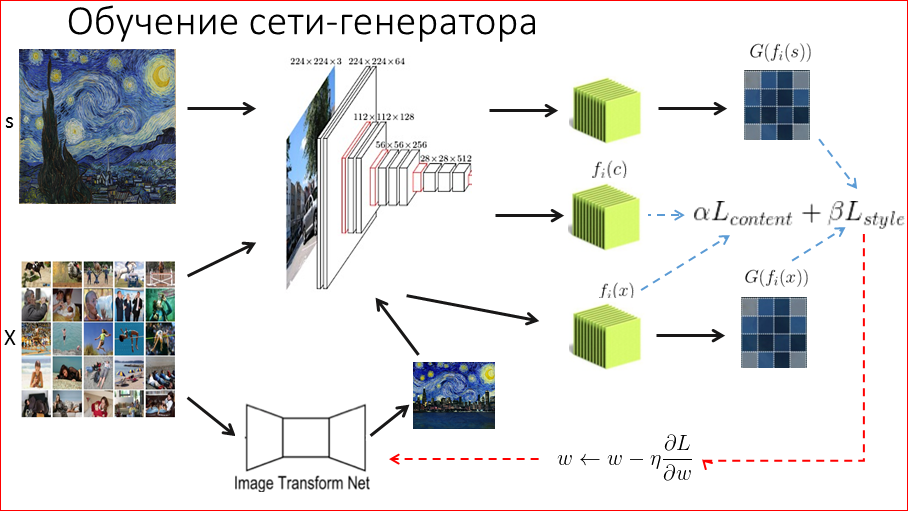













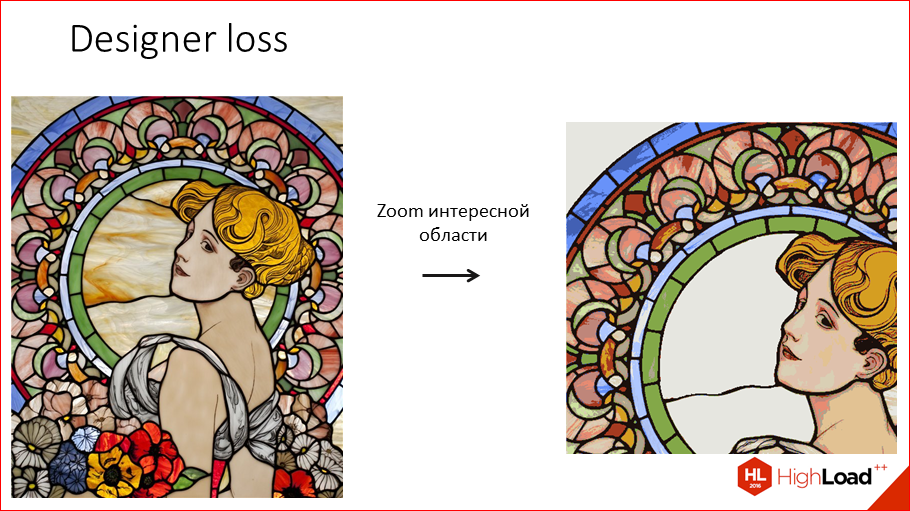





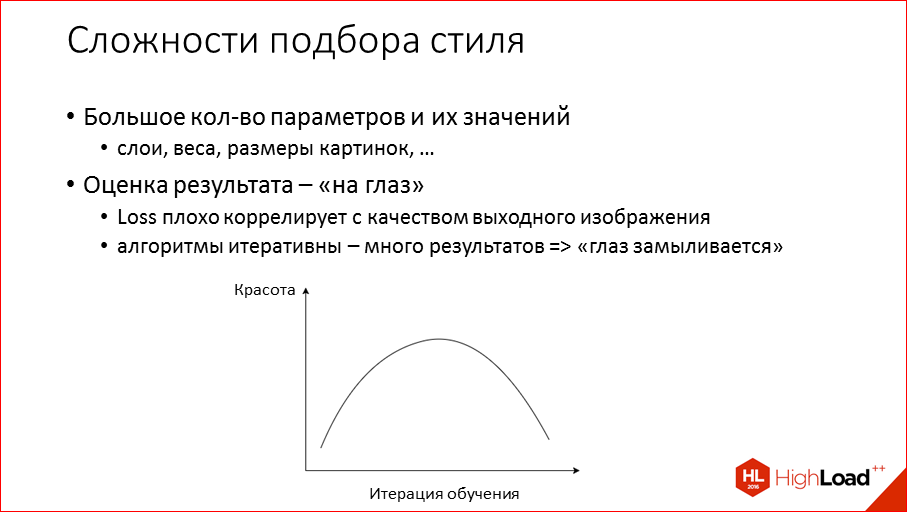






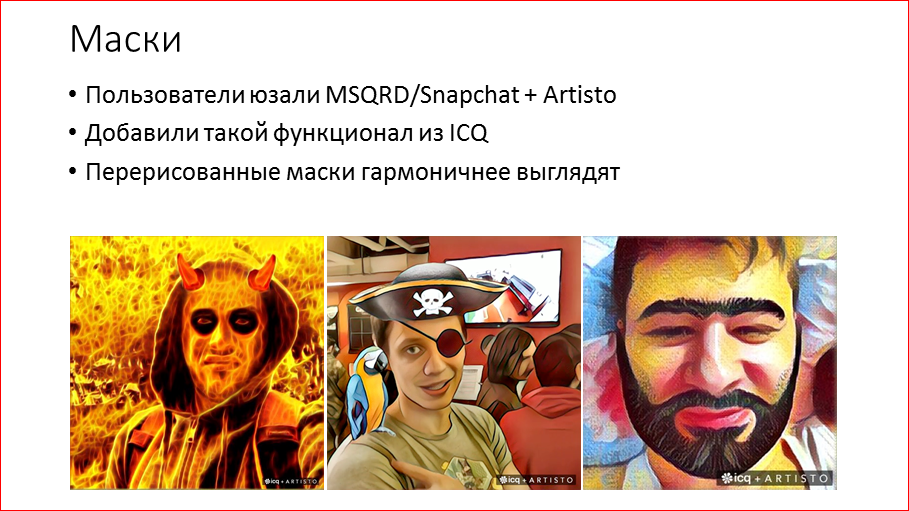
Этот доклад — расшифровка одного из лучших выступлений на профессиональной конференции разработчиков высоконагруженных систем HighLoad++.
Сейчас мы уже вовсю готовим конференцию 2017-года — самый большой HighLoad++
в истории. Если вам интересно и важна стоимость билетов — покупайте сейчас, пока цена ещё не высока!
Кстати, в этом году мы также будем проводить AI-секцию, посвящённую машинному обучению и нейронным сетям.
|
Метки: author olegbunin обработка изображений машинное обучение алгоритмы data mining блог компании конференции олега бунина (онтико) эдуард тянтов highload++ нейронные сети видео |
[Перевод] Собеседование для фронтенд-разработчика на JavaScript: самые лучшие вопросы |
|
Метки: author ru_vds разработка веб-сайтов javascript блог компании ruvds.com разработка поиск работы |
Как скрестить ежа с ужом. Используем GridView из Yii 2 в проекте на Laravel |
composer create-project laravel/laravel
...
composer require yiisoft/yii2
CREATE TABLE IF NOT EXISTS `users` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`email` varchar(100) NOT NULL,
`password` varchar(255) NOT NULL,
`remember_token` varchar(100) DEFAULT NULL,
`created_at` timestamp NULL DEFAULT NULL,
`updated_at` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `users_email_unique` (`email`)
) ENGINE=InnoDB;
CREATE TABLE IF NOT EXISTS `products` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`created_at` timestamp NULL DEFAULT NULL,
`updated_at` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
CREATE TABLE IF NOT EXISTS `orders` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(10) unsigned NOT NULL,
`created_at` timestamp NULL DEFAULT NULL,
`updated_at` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `orders-users` (`user_id`),
CONSTRAINT `orders-users` FOREIGN KEY (`user_id`) REFERENCES `users` (`id`) ON UPDATE CASCADE
) ENGINE=InnoDB;
CREATE TABLE IF NOT EXISTS `order_items` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`order_id` int(10) unsigned NOT NULL,
`product_id` int(10) unsigned NOT NULL,
`created_at` timestamp NULL DEFAULT NULL,
`updated_at` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `order_items-orders` (`order_id`),
KEY `order_items-products` (`product_id`),
CONSTRAINT `order_items-orders` FOREIGN KEY (`order_id`) REFERENCES `orders` (`id`) ON DELETE CASCADE ON UPDATE CASCADE,
CONSTRAINT `order_items-products` FOREIGN KEY (`product_id`) REFERENCES `products` (`id`) ON UPDATE CASCADE
) ENGINE=InnoDB;
routes/web.phpRoute::group(['prefix' => 'admin', 'as' => 'admin.', 'namespace' => 'Admin'], function () {
Route::get('/order', 'OrderController@index')->name('order.index');
Route::get('/order/view/{id}', 'OrderController@view')->name('order.view');
Route::get('/order/create', 'OrderController@create')->name('order.create');
Route::get('/order/update/{id}', 'OrderController@update')->name('order.update');
Route::post('/order/create', 'OrderController@create');
Route::post('/order/update/{id}', 'OrderController@update');
Route::post('/order/delete/{id}', 'OrderController@delete')->name('order.delete');
});
@include('layouts.nav')
@yield('content')
routes/web.php$initYii2Middleware = function ($request, $next)
{
define('YII_DEBUG', env('APP_DEBUG'));
include '../vendor/yiisoft/yii2/Yii.php';
spl_autoload_unregister(['Yii', 'autoload']);
$config = [
'id' => 'yii2-laravel',
'basePath' => '../',
'timezone' => 'UTC',
'components' => [
'assetManager' => [
'basePath' => '@webroot/yii-assets',
'baseUrl' => '@web/yii-assets',
'bundles' => [
'yii\web\JqueryAsset' => [
'sourcePath' => null,
'basePath' => null,
'baseUrl' => null,
'js' => [],
],
],
],
'request' => [
'class' => \App\Yii\Web\Request::class,
'csrfParam' => '_token',
],
'urlManager' => [
'enablePrettyUrl' => true,
'showScriptName' => false,
],
'formatter' => [
'dateFormat' => 'php:m/d/Y',
'datetimeFormat' => 'php:m/d/Y H:i:s',
'timeFormat' => 'php:H:i:s',
'defaultTimeZone' => 'UTC',
],
],
];
(new \yii\web\Application($config)); // initialization is in constructor
Yii::setAlias('@bower', Yii::getAlias('@vendor') . DIRECTORY_SEPARATOR . 'bower-asset');
return $next($request);
};
Route::group(['prefix' => 'admin', 'as' => 'admin.', 'namespace' => 'Admin', 'middleware' => $initYii2Middleware], function () {
...
});
spl_autoload_unregister(['Yii', 'autoload']); — лучше отключить, чтобы не мешался, достаточно автозагрузчиков Laravel. Он ищет файлы через getAlias('@'...) и конечно не находит.basePath — корневая директория приложения, при неправильной установке могут быть ошибки в путях. В этой же директории создается папка runtime.assetManager.basePath, assetManager.baseUrl — путь и URL для публикации ассетов, название папки произвольное.assetManager.bundles — отключаем публикацию jQuery, так как она подключается в главном шаблоне отдельно.request — переопределяем компонент запроса, в котором заменяем работу с CSRF-токеном, название поля такое же как в настройках Laravel.urlManager.enablePrettyUrl — надо включить, если нужны дополнительные модули типа Gii.(new \yii\web\Application($config)) — в конструкторе происходит присвоение Yii::$app = $this;app/Yii/Web/Request.phpnamespace App\Yii\Web;
class Request extends \yii\web\Request
{
public function getCsrfToken($regenerate = false)
{
return \Session::token();
}
}
app/Http/Controllers/Admin/OrderController.phppublic function index(Request $request)
{
$allModels = Order::query()->get()->all();
$gridViewConfig = [
'dataProvider' => new \yii\data\ArrayDataProvider([
'allModels' => $allModels,
'pagination' => ['route' => $request->route()->uri(), 'defaultPageSize' => 10],
'sort' => ['route' => $request->route()->uri(), 'attributes' => ['id']],
]),
'columns' => [
'id',
'user.name',
['label' => 'Items', 'format' => 'raw', 'value' => function ($model) {
$html = '';
foreach ($model->items as $item) {
$html .= '' . htmlspecialchars($item->product->name) . '';
}
return $html;
}],
'created_at:datetime',
'updated_at:datetime',
[
'class' => \yii\grid\ActionColumn::class,
'urlCreator' => function ($action, $model, $key) use ($request) {
$baseRoute = $request->route()->getName();
$baseRouteParts = explode('.', $baseRoute);
$baseRouteParts[count($baseRouteParts) - 1] = $action;
$route = implode('.', $baseRouteParts);
$params = is_array($key) ? $key : ['id' => (string) $key];
return route($route, $params, false);
}
],
],
];
return view('admin.order.index', ['gridViewConfig' => $gridViewConfig]);
}
@extends('layouts.main')
@section('title', 'Index')
@section('content')
Orders
{!! \yii\grid\GridView::widget($gridViewConfig) !!}
@endsection
dataProvider.pagination.route и dataProvider.sort.route, иначе произойдет обращение к Yii::$app->controller->getRoute(), а контроллер у нас null. Аналогично с ActionColumn, только там будет проверка и InvalidParamException. URL генерируется через \yii\web\UrlManager, но результат получается такой же, как с роутингом Laravel. Можно задать менеджер через dataProvider.pagination.urlManager, если нужно.\yii\web\View. Методы renderHeadHtml(), renderBodyBeginHtml(), renderBodyEndHtml() защищены (непонятно от кого, особенно учитывая, что все переменные public). Как ни странно, есть повод применить антипаттерн «public morozov». Или можно просто скопипастить их в главный шаблон.app/Yii/Web/View.phpnamespace App\Yii\Web;
class View extends \yii\web\View
{
public function getHeadHtml()
{
return parent::renderHeadHtml();
}
public function getBodyBeginHtml()
{
return parent::renderBodyBeginHtml();
}
public function getBodyEndHtml($ajaxMode = false)
{
return parent::renderBodyEndHtml($ajaxMode);
}
public function initAssets()
{
\yii\web\YiiAsset::register($this);
ob_start();
$this->beginBody();
$this->endBody();
ob_get_clean();
}
}
endBody(), а также весь рендеринг оборачивается в буфер, в котором потом производится замена магических констант CDATA на реальные ассеты. Эмуляция этого поведения находится в функции initAssets(). Заменять мы ничего не будем, нам нужно просто чтобы были заполнены свойства $this->js, $this->css и другие.'components' => [
...
'view' => [
'class' => \App\Yii\Web\View::class,
],
],
...
{!! \yii\helpers\Html::csrfMetaTags() !!}
{!! $view->getHeadHtml() !!}
{!! $view->getBodyBeginHtml() !!}
...
{!! $view->getBodyEndHtml() !!}
Html::csrfMetaTags() нужен, так как скрипт yii.js берет csrf-токен из HTML страницы.ArrayDataProvider работает, но надо сделать аналог ActiveDataProvider, чтобы получать из базы только то что нужно.app/Yii/Data/EloquentDataProvider.phpclass EloquentDataProvider extends \yii\data\BaseDataProvider
{
public $query;
public $key;
protected function prepareModels()
{
$query = clone $this->query;
if (($pagination = $this->getPagination()) !== false) {
$pagination->totalCount = $this->getTotalCount();
if ($pagination->totalCount === 0) {
return [];
}
$query->limit($pagination->getLimit())->offset($pagination->getOffset());
}
if (($sort = $this->getSort()) !== false) {
$this->addOrderBy($query, $sort->getOrders());
}
return $query->get()->all();
}
protected function prepareKeys($models)
{
$keys = [];
if ($this->key !== null) {
foreach ($models as $model) {
$keys[] = $model[$this->key];
}
return $keys;
} else {
$pks = $this->query->getModel()->getKeyName();
if (is_string($pks)) {
$pk = $pks;
foreach ($models as $model) {
$keys[] = $model[$pk];
}
} else {
foreach ($models as $model) {
$kk = [];
foreach ($pks as $pk) {
$kk[$pk] = $model[$pk];
}
$keys[] = $kk;
}
}
return $keys;
}
}
protected function prepareTotalCount()
{
$query = clone $this->query;
$query->orders = null;
$query->offset = null;
return (int) $query->limit(-1)->count('*');
}
protected function addOrderBy($query, $orders)
{
foreach ($orders as $attribute => $order) {
if ($order === SORT_ASC) {
$query->orderBy($attribute, 'asc');
} else {
$query->orderBy($attribute, 'desc');
}
}
}
}
'dataProvider' => new \App\Yii\Data\EloquentDataProvider([
'query' => Order::query(),
'pagination' => ['route' => $request->route()->uri(), 'defaultPageSize' => 10],
'sort' => ['route' => $request->route()->uri(), 'attributes' => ['id']],
]),
\yii\base\Model, которая будет возвращать гриду метки для колонок и правила полей для фильтрации. Для этого есть параметр filterModel. Сделаем ее конфигурируемой через конструктор.namespace App\Yii\Data;
use App\Yii\Data\EloquentDataProvider;
use Route;
class FilterModel extends \yii\base\Model
{
protected $labels;
protected $rules;
protected $attributes;
public function __construct($labels = [], $rules = [])
{
parent::__construct();
$this->labels = $labels;
$this->rules = $rules;
$safeAttributes = $this->safeAttributes();
$this->attributes = array_combine($safeAttributes, array_fill(0, count($safeAttributes), null));
}
public function __get($name)
{
if (array_key_exists($name, $this->attributes)) {
return $this->attributes[$name];
} else {
return parent::__get($name);
}
}
public function __set($name, $value)
{
if (array_key_exists($name, $this->attributes)) {
$this->attributes[$name] = $value;
} else {
parent::__set($name, $value);
}
}
public function rules()
{
return $this->rules;
}
public function attributeLabels()
{
return $this->labels;
}
public function initDataProvider($query, $sortAttirbutes = [], $route = null)
{
if ($route === null) { $route = Route::getCurrentRoute()->uri(); }
$dataProvider = new EloquentDataProvider([
'query' => $query,
'pagination' => ['route' => $route],
'sort' => ['route' => $route, 'attributes' => $sortAttirbutes],
]);
return $dataProvider;
}
public function applyFilter($params)
{
$query = null;
$dataProvider = $this->initDataProvider($query);
return $dataProvider;
}
}
namespace App\Forms\Admin;
use App\Yii\Data\FilterModel;
class OrderFilter extends FilterModel
{
public function rules()
{
return [
['id', 'safe'],
['user.name', 'safe'],
];
}
public function attributeLabels()
{
return [
'id' => 'ID',
'created_at' => 'Created At',
'updated_at' => 'Updated At',
'user.name' => 'User',
];
}
public function applyFilter($params)
{
$this->load($params);
$query = \App\Models\Order::query();
$query->join('users', 'users.id', '=', 'orders.user_id')->select('orders.*');
if ($this->id) $query->where('orders.id', '=', $this->id);
if ($this->{'user.name'}) $query->where('users.name', 'like', '%'.$this->{'user.name'}.'%');
$sortAttributes = [
'id',
'user.name' => ['asc' => ['users.name' => SORT_ASC], 'desc' => ['users.name' => SORT_DESC]],
];
$dataProvider = $this->initDataProvider($query, $sortAttributes);
$dataProvider->pagination->defaultPageSize = 10;
if (empty($dataProvider->sort->getAttributeOrders())) {
$dataProvider->query->orderBy('orders.id', 'asc');
}
return $dataProvider;
}
}
public function index(Request $request)
{
$filterModel = new \App\Forms\Admin\OrderFilter();
$dataProvider = $filterModel->applyFilter($request);
$gridViewConfig = [
'dataProvider' => $dataProvider,
'filterModel' => $filterModel,
...
];
...
}
app/Http/Controllers/Admin/OrderController.phppublic function view($id)
{
$model = Order::findOrFail($id);
$detailViewConfig = [
'model' => $model,
'attributes' => [
'id',
'user.name',
'created_at:datetime',
'updated_at:datetime',
],
];
$gridViewConfig = [
'dataProvider' => new \App\Yii\Data\EloquentDataProvider([
'query' => $model->items(),
'pagination' => false,
'sort' => false,
]),
'layout' => '{items}{summary}',
'columns' => [
'id',
'product.name',
'created_at:datetime',
'updated_at:datetime',
],
];
return view('admin.order.view', ['model' => $model, 'detailViewConfig' => $detailViewConfig, 'gridViewConfig' => $gridViewConfig]);
}
\yii\base\Model, чтобы компонент ActiveForm мог вызывать нужные методы.namespace App\Yii\Data;
use Illuminate\Database\Eloquent\Model as EloquentModel;
class FormModel extends \yii\base\Model
{
protected $model;
protected $labels;
protected $rules;
protected $attributes;
public function __construct(EloquentModel $model, $labels = [], $rules = [])
{
parent::__construct();
$this->model = $model;
$this->labels = $labels;
$this->rules = $rules;
$fillable = $model->getFillable();
$attributes = [];
foreach ($fillable as $field) {
$attributes[$field] = $model->$field;
}
$this->attributes = $attributes;
}
public function getModel()
{
return $model;
}
public function __get($name)
{
if (array_key_exists($name, $this->attributes)) {
return $this->attributes[$name];
} else {
return $this->model->{$name};
}
}
public function __set($name, $value)
{
if (array_key_exists($name, $this->attributes)) {
$this->attributes[$name] = $value;
} else {
$this->model->{$name} = $value;
}
}
public function rules()
{
return $this->rules;
}
public function attributeLabels()
{
return $this->labels;
}
public function save()
{
if (!$this->validate()) {
return false;
}
$this->model->fill($this->attributes);
return $this->model->save();
}
}
app/Http/Controllers/Admin/OrderController.php public function create(Request $request)
{
$model = new Order();
$formModel = new \App\Yii\Data\FormModel(
$model,
['user_id' => 'User'],
[['user_id', 'safe']]
);
if ($request->isMethod('post')) {
if ($formModel->load($request->input()) && $formModel->save()) {
return redirect()->route('admin.order.view', ['id' => $model->id]);
}
}
return view('admin.order.create', ['formModel' => $formModel]);
}
public function update($id, Request $request)
{
$model = Order::findOrFail($id);
$formModel = new \App\Yii\Data\FormModel(
$model,
['user_id' => 'User'],
[['user_id', 'safe']]
);
if ($request->isMethod('post')) {
if ($formModel->load($request->input()) && $formModel->save()) {
return redirect()->route('admin.order.view', ['id' => $model->id]);
}
}
return view('admin.order.update', ['formModel' => $formModel]);
}
{!! $form->field($formModel, 'user_id')->dropDownList(\App\User::pluck('name', 'id'), ['prompt' => '']) !!}
validate() и вызывать там валидатор Laravel. В данном примере мы этого делать не будем.ActiveForm::begin() и выводит теги и возвращает значение. Можно явно написать тег Blade::extend(), как советуют здесь, можно сделать обертку для ActiveForm. Пока оставим FormModel и поместить все объявления туда.namespace App\Forms\Admin;
class OrderForm extends FormModel
{
public function rules()
{
return [
['user_id', 'safe'],
];
}
public function attributeLabels()
{
return [
'id' => 'ID',
'user_id' => 'User',
'created_at' => 'Created At',
'updated_at' => 'Updated At',
'user.name' => 'User',
];
}
}
OrderForm, чтобы задать метки в методе app/Http/Controllers/Admin/OrderController.php.$formModel = new \App\Forms\Admin\OrderForm($model);
$detailViewConfig = [
'model' => $formModel,
...
];
app/Http/Controllers/Admin/OrderController.phppublic function delete($id)
{
$model = Order::findOrFail($id);
$model->delete();
return redirect()->route('admin.order.index');
}
composer require yiisoft/yii2-gii --dev
$config = [
'components' => [
...
'db' => [
'class' => \yii\db\Connection::class,
'dsn' => 'mysql:host='.env('DB_HOST', 'localhost')
.';port='.env('DB_PORT', '3306')
.';dbname='.env('DB_DATABASE', 'forge'),
'username' => env('DB_USERNAME', 'forge'),
'password' => env('DB_PASSWORD', ''),
'charset' => 'utf8',
],
...
],
];
if (YII_DEBUG) {
$config['modules']['gii'] = ['class' => \yii\gii\Module::class];
$config['bootstrap'][] = 'gii';
}
(new \yii\web\Application($config)); // initialization is in constructor
Yii::setAlias('@bower', Yii::getAlias('@vendor') . DIRECTORY_SEPARATOR . 'bower-asset');
Yii::setAlias('@App', Yii::getAlias('@app') . DIRECTORY_SEPARATOR . 'App');
...
Route::any('gii{params?}', function () {
$request = \Yii::$app->getRequest();
$request->setBaseUrl('/admin');
\Yii::$app->run();
return null;
})->where('params', '(.*)');
Yii::setAlias('@App') — путь к файлам определяется через Yii::getAlias('@'...), поэтому для класса App\Models\Order будет проверяться путь '@App/Models/Order.php'.setBaseUrl('/admin') — нужно, чтобы роутинг Yii обрабатывал только часть после '/admin'.Yii::setAlias('@App') и ['Yii', 'autoload'] есть такая проблема. Если не отключить автозагрузчик, то при неправильном названиии класса или неймспейса в существующем файле происходит ошибка, которая неправильно обрабатывается. Происходит это так. Он подключает файл, но потом не находит класс и бросает исключение UnknownClassException. Вызывается автозагрузчик Laravel, который проверяет фасады и алиасы и тоже ничего не находит. Потом вызывается автозагрузчик Composer, который снова подключает файл, и возникает уже другая ошибка 'Cannot declare class '...', because the name is already in use'. Приложение падает с ошибкой 500 без записи в лог.protected function resetGlobalSettings()
{
if (Yii::$app instanceof \yii\web\Application) {
Yii::$app->assetManager->bundles = [];
}
}
ActionColumn в отдельный класс, чтобы не копировать в разные гриды.namespace App\Yii\Widgets;
use URL;
use Route;
class ActionColumn extends \yii\grid\ActionColumn
{
public $keyAttribute = 'id';
public $baseRoute = null;
public $separator = '.';
/**
* Overrides URL generation to use Laravel routing system
*
* @inheritdoc
*/
public function createUrl($action, $model, $key, $index)
{
if (is_callable($this->urlCreator)) {
return call_user_func($this->urlCreator, $action, $model, $key, $index, $this);
} else {
if ($this->baseRoute === null) {
$this->baseRoute = Route::getCurrentRoute()->getName();
}
$baseRouteParts = explode($this->separator, $this->baseRoute);
$baseRouteParts[count($baseRouteParts) - 1] = $action;
$route = implode($this->separator, $baseRouteParts);
$params = is_array($key) ? $key : [$this->keyAttribute => (string) $key];
return URL::route($route, $params, false);
}
}
}
namespace App\Yii\Widgets;
use yii\widgets\ActiveForm;
use yii\helpers\Html;
class FormBuilder extends \yii\base\Component
{
protected $model;
protected $form;
public function __construct($model)
{
$this->model = $model;
}
public function getModel()
{
return $this->model;
}
public function setModel($model)
{
$this->model = $model;
}
public function getForm()
{
return $this->form;
}
public function open($params = ['successCssClass' => ''])
{
$this->form = ActiveForm::begin($params);
}
public function close()
{
ActiveForm::end();
}
public function field($attribute, $options = [])
{
return $this->form->field($this->model, $attribute, $options);
}
public function submitButton($content, $options = ['class' => 'btn btn-primary'])
{
return Html::submitButton($content, $options);
}
}
{!! $form->open() !!}
{!! $form->field('user_id')->dropDownList(
\App\User::pluck('name', 'id'),
['prompt' => ''])
!!}
{!! $form->submitButton('Submit'); !!}
{!! $form->close() !!}
php artisan migrate:refresh --seed
app/Yii.App\Yii\Web\Request
App\Yii\Data\EloquentDataProvider
App\Yii\Data\FormModel
App\Yii\Data\FilterModel
App\Yii\Web\View
App\Yii\Widgets\ActionColumn
App\Yii\Widgets\FormBuilder
|
Метки: author michael_vostrikov ненормальное программирование yii laravel yii2 gridview activeform |
Знакомство с Университетом ИТМО: дайджест практических работ |

Линия связи, которую невозможно «прослушать» — защита за счет законов физики и принципов квантовой криптографии. Реализовать такую концепцию удалось сотрудникам одного из малых инновационных предприятий при Университете ИТМО. В этом материале мы рассказываем о том, как начинался данный проект, что лежит в его основе и как устроена его работа.
Продолжение «истории» со взломоустойчивыми технологиями. На этот раз основная задача заключается во внедрении квантовых систем защиты в работу распределенных ЦОД.
Рассказываем о принципах работы и возможностях для применения новых проектов. От импульсных источников света для дальномеров до компактного лазера для беспилотников.
Знакомим вас со Студенческим конструкторским бюро (Robotics engineering department или RED), историей проекта «RED», ходом работ и используемыми технологиями. Плюс говорим о практических наработках: роботе-промоутере и многоагентной системе на базе Robotino.
Наша тематическая подборка последних исследований и разработок в сфере робототехники. Здесь собраны публикации в журналах Университета ИТМО по самым разным направлениям: от стабилизации двуногих роботов до внедрения технологии дополненной реальности в пилотируемые космические комплексы.
 / Фото Rama V / CC
/ Фото Rama V / CCУченые Университета ИТМО работают над безопасностью спортивных мероприятий — занимаются моделированием поведения толпы в рамках проектов Института наукоемких компьютерных технологий (НИИ НКТ). Здесь мы рассказываем о том, почему это важно, приводим примеры проектов и методы сбора информации для анализа.
Продолжение знакомства с проектами НИИ НКТ. В этом материале мы рассказываем о дополнительных возможностях и сферах применения алгоритмов, разработанных учеными.
Социальные сквозняки, распространение информации, профилирование в соцсетях и анализ публикаций в Facebook и Instagram, плюс разбор Twitter-профиля Дональда Трампа. Обо всех этих исследованиях и направлениях для дальнейшей работы — в нашем хабрапосте.
Аналитические компании предсказывают рост объема рынка специализированного ПО, работающего с Big Data. А мы — рассказываем о том, какие аналитические задачи на стыке сфер страхования и «больших данных» решают проекты Университета ИТМО.
Университет ИТМО заинтересован в развитии инновационного бизнеса. На нашей площадке проходят десятки мероприятий: от тематических семинаров до хакатонов. Помимо этого мы занимаемся активной работой с международным сообществом и поддерживаем студенческие инициативы. Обо всем этом — наш тематический дайджест.
 / Фотография Университета ИТМО
/ Фотография Университета ИТМОРассказываем о премьере экспериментального проекта в жанре «нейротеатр», которая состоялась на фестивале Geek Picnic в Санкт-Петербурге. Кто все это сделал и как это работает – об этом в нашем материале.
Продолжая тему, говорим о нейроинтерфейсах, специальном приложении и тематическом проекте TuSion. Он является резидентом акселератора Future Technologies Университета ИТМО.
Немного о том, как мы работаем над улучшением образовательных платформ. Речь идет о массовых онлайн-курсах и анализе данных, получаемых от тысяч студентов. В этом нам помогают семантические технологии, а результаты исследований мы представляем на международных конференциях и в виде печатных работ в научных журналах.
Как работает «Дрон-сотрудник», построенный на базе платформы Ethereum. Рассказ о том, почему проект «опережает время» и немного о том, кто еще в Университете ИТМО исследует эти сферы.
Как и для кого выпускники Университета ИТМО разрабатывают протезы и даже экзоскелеты. Что можно предложить для улучшения качества реабилитации, как помочь слепым и слабовидящим людям ориентироваться в пространстве — ответы на все эти вопросы в нашем материале.
Один из многочисленных примеров разработок ученых из Университета ИТМО. На этот раз речь идет о беспроводной передаче энергии. Тесты показывают, что эффективность технологии достигает 90%. В этой статье мы разбираемся с перспективами развития проекта.
|
Метки: author itmo анализ и проектирование систем блог компании университет итмо университет итмо дайджест |
Обзор Lokalise — сервиса для локализации приложений и обновления переводов «по воздуху» |
|
|
GeekUniversity открывает набор студентов на факультет Python-разработки |

В нашем онлайн-университете для программистов открылся новый факультет. Теперь в GeekUniversity студенты смогут освоить Python-разработку на Middle-уровне и гарантированно начать карьеру сразу после обучения.
GeekUniversity — совместный образовательный проект Mail.Ru Group и IT-портала GeekBrains. Программу обучения и спецкурсы для факультета разрабатывают Avito, Альфа-банк, МТС, Тинькофф, DeliveryClub.
За один год студенты создают 2 самостоятельных и 2 командных проекта. Прогресс будет курировать наставник. После обучения выпускники умеют:
Поступить в GeekUniversity может любой желающий. Абитуриент должен обладать базовыми навыками программирования: для поступления нужно успешно пройти онлайн-тестирование на сайте GeekUniversity. Те, кто не справится с тестом, смогут добрать недостающие знания на подготовительных курсах университета. Программа обучения рассчитана на 350 академических часов, интенсивность занятий — три-четыре урока в неделю. Обучение платное. Выпускники получают свидетельство, подтверждающее приобретенную квалификацию.
Оставить заявку и получить подробную консультацию можно здесь.
|
Метки: author mary_arti программирование python блог компании mail.ru group mail.ru обучение программированию geekuniversity |






