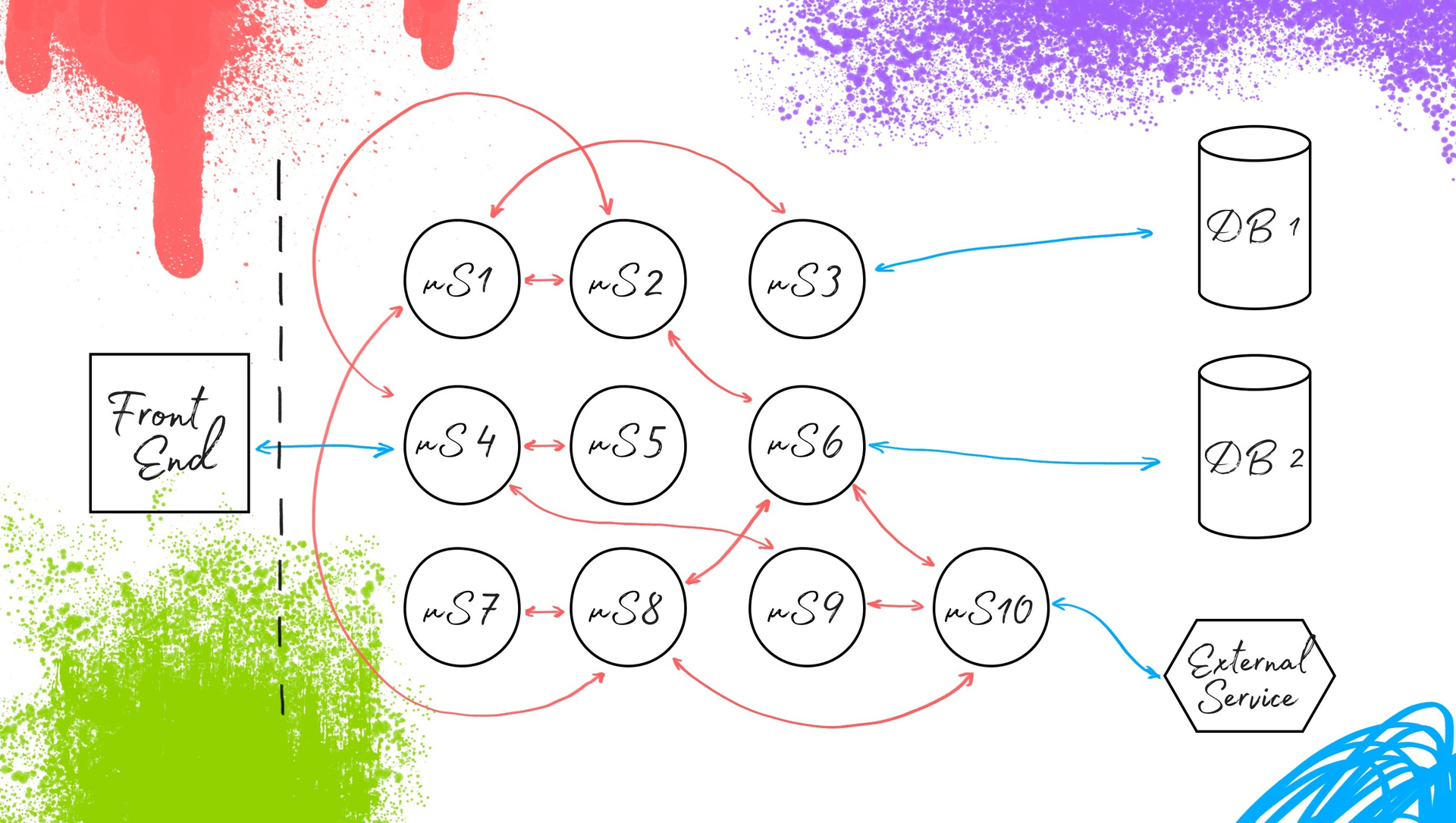
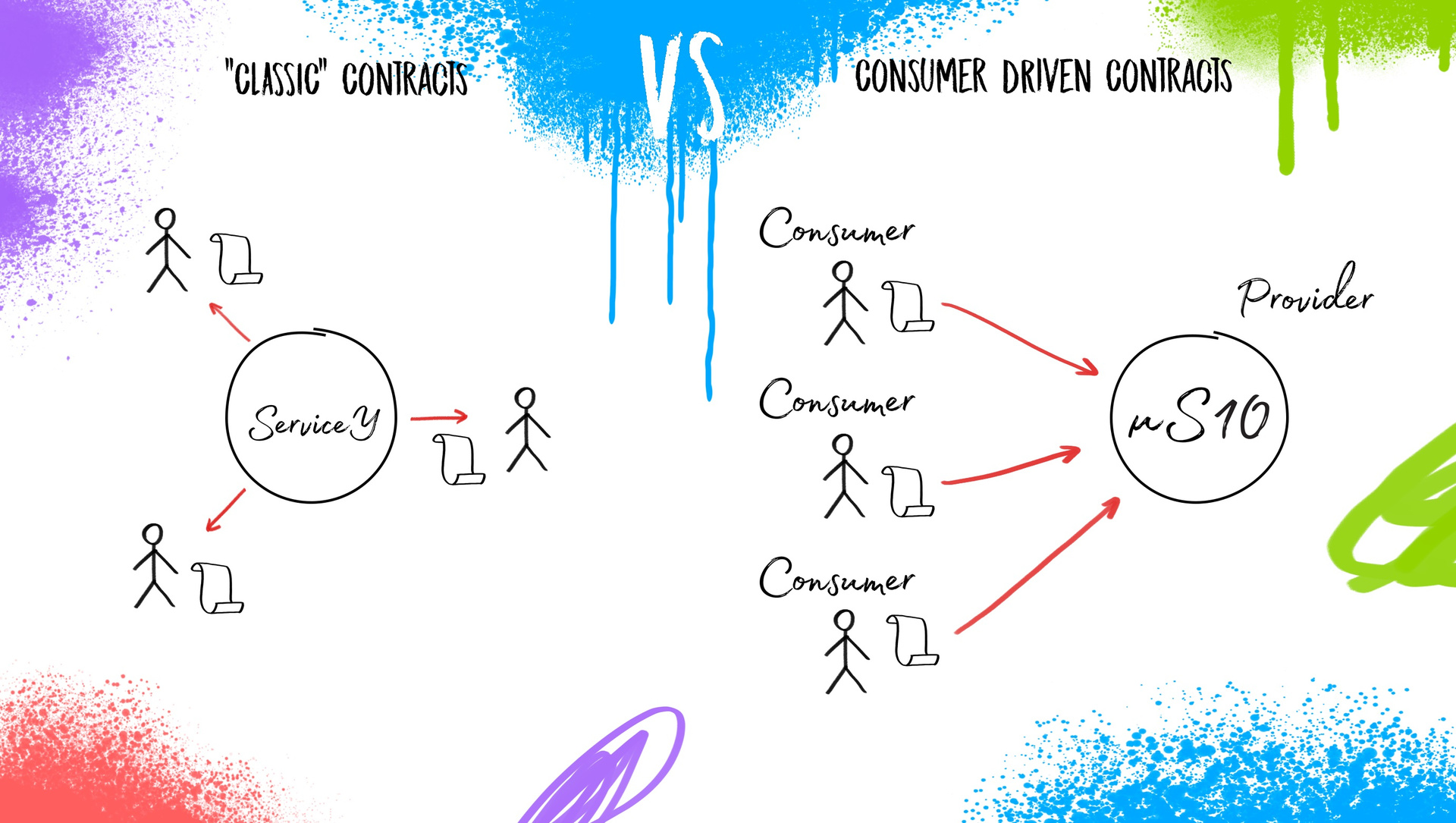
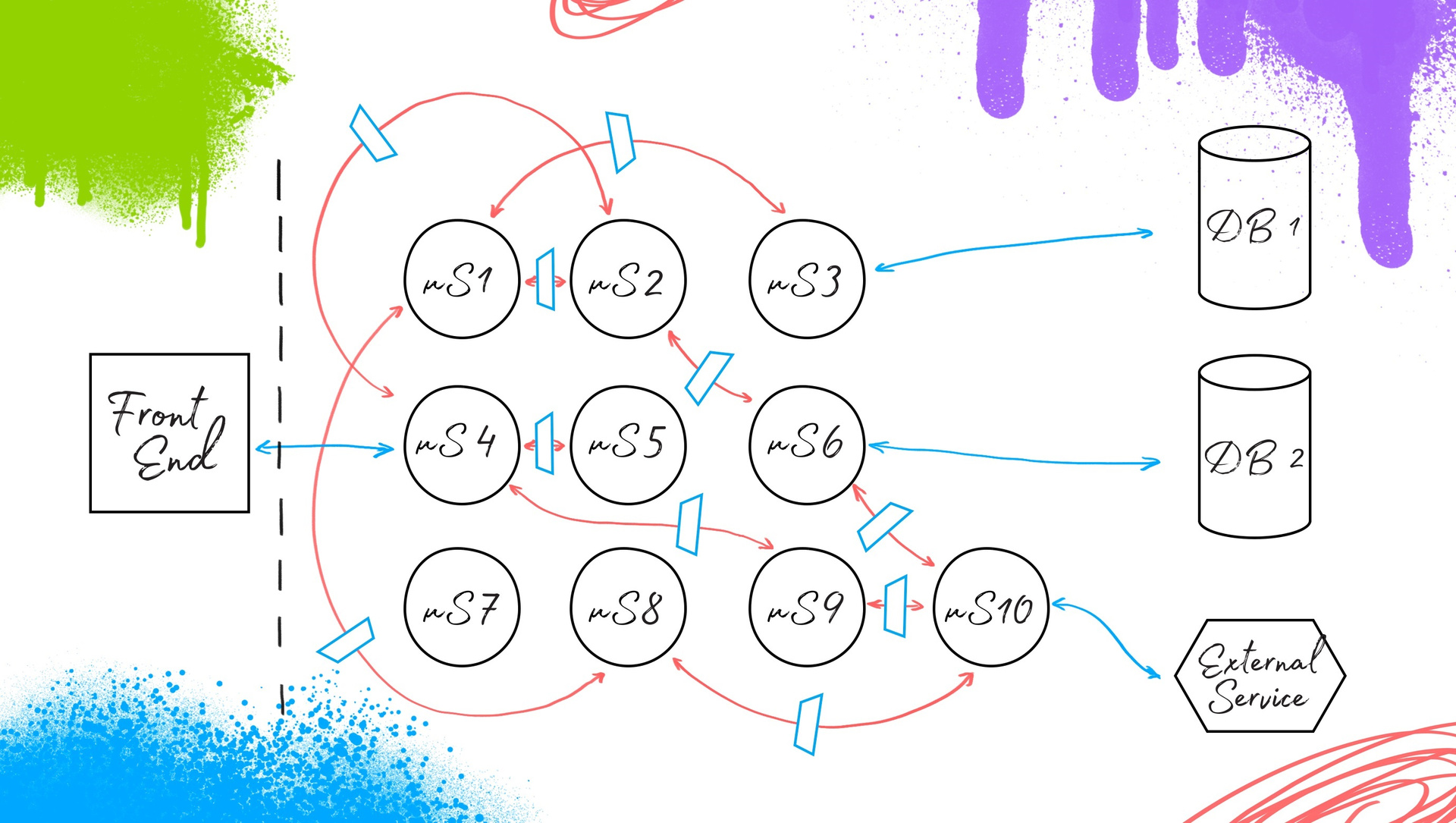
Ядро автоматизации тестирования в микросервисной архитектуре |
“An implementation should be conservative in its sending behavior, and liberal in its receiving behavior”.
Jonathan Bruce Postel, computer scientist
Пользователь 1: “Я слышал, вы поставляете яблоки. Мне нужны маленькие и зелёные”.
Пользователь 2: “А мне нужны огромные красные яблоки”.
Пользователь N: “А мне нужно, чтобы вы привезли три тонны яблок”.





|
Метки: author dkhimion тестирование it-систем блог компании avito автоматизация тестирования микросервисы тестирование consumer driven contracts cdc-testing |
Когда деревья были большими: как маленький дата-центр ураган пережил |

Лето 2017 года выдалось богатым на ураганы. А вот у нас тоже был случай. Ровно 7 лет назад наш первый дата-центр на Боровой пережил ураган, который похоронил чиллеры под слоем 10 тонн железа, прилетевшего с соседней крыши. Душещипательные фотографии искореженных чиллеров разошлись по интернету уже давно, а история про восстановление ЦОДа, оставшегося без холода, никогда не публиковалась. Решил поднять архивы и восполнить пробел.
В 2010 году DataLine был начинающим оператором дата-центров. На площадке OST успели запустить только три зала на 360 стоек, на севере Москвы (NORD) был один корпус с одним залом на 147 стоек.
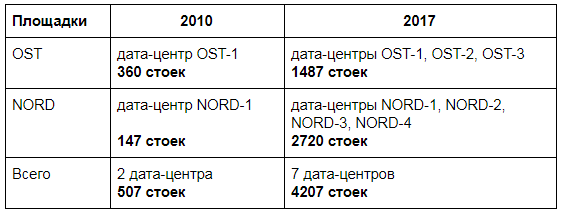
Вот как изменились масштабы нашей инфраструктуры с 2010 года.
Хотя мы сами проектировали и строили, тогда у нас не было выделенной службы эксплуатации. Не было, как сейчас, отдельных специалистов по ДГУ, кондиционерам, электриков – отдавали все по максимуму подрядчикам. Объемы инфраструктуры были небольшие, как, впрочем, и наш опыт. За инженерку тогда отвечали директор по производству, главный энергетик и я, технический директор. На подхвате были еще дежурные инженеры (трое в смене), но они занимались клиентскими запросами и мониторингом.

Один из первых залов дата-центра OST-1 в конце 2009 года.

Так выглядят новые залы в OST сегодня.
Три зала на Боровой были заполнены только наполовину. Клиентов было немного, для пересчета хватило бы пальцев одной руки.
На площадке работала чиллерная схема на этиленгликоле с тремя чиллерами Emicon в схеме резервирования 2+1. Надо сказать, эти чиллеры так и не вышли на заявленную производителем мощность, но, поскольку нагрузка была небольшая, одного чиллера почти хватало на все три зала.
20 июля стояла жара за тридцать. В такую погоду чиллерам было плохо, поэтому, когда ближе к концу рабочего дня пошел дождь, я обрадовался, надеясь, что чиллерам полегчает. Вместе с дождем поднялся сильный ветер, и вот я из окна своего кабинета вижу, как мимо пролетают листы металла. Вышел на улицу, а на другой стороне дороги валяются куски крыши. Удивительно, но ни одна из машин сотрудников, запаркованных рядом с ЦОД, сильно не пострадала.

Кровельное железо свисало с проводов, как белье.
Тут я подумал, что надо бы проверить чиллеры, потому что металл летел с их стороны. Вместе с коллегами залезли на крышу и увидели жуткую картину: все три чиллера завалены железными балками и листами.


По записи системы видеонаблюдения видно, что все железо прилетело за один мощный порыв ветра. Вот что мы потом увидели c записи одной из камер:
На видео часы отстают. Когда все произошло, было уже 18.18.
Масштабы бедствия оказались внушительными. У одного чиллера прилетевшее железо пробило теплообменник фрикулинга (внешний контур чиллера), у второго повреждены вентиляторы, у третьего, помимо всего перечисленного, вращающиеся искореженные вентиляторы успели задеть и порубить фреоновые трубки внутри чиллера. К тому моменту, как мы оказались на крыше, два чиллера из трех уже остановились.

Поврежденная рама и теплообменник фрикулинга первого чиллера. Теплообменник представляет собой “бутерброд”: снаружи рубашка фрикулинга, внутри, с зазором сантиметров пять, такой же на вид теплообменник фреонового конденсатора.

Искореженные вентиляторы одного из чиллеров.
Из пробитых теплообменников фрикулинга хлестал гликоль. Давление в системе холодоснабжения резко упало. Насосы остановились по защите от сухого хода, вырубился последний рабочий чиллер, и вся система холодоснабжения встала (времени было 18:32, две минуты как закончился рабочий день). Несколько секунд мы пребывали в ступоре и не знали, что делать. Потом позвонили подрядчику по холодоснабжению и вызвали аварийную бригаду. По телефону подрядчик посоветовал перекрыть внешний контур, объяснил, где находятся нужные вентили и краны системы подпитки. Мы перекрыли вентили, питающие внешние теплообменники, гликоль перестал течь.
В холодных коридорах машинных залов становилось жарко. Осознав, что быстро восстановить холодоснабжение мы не сможем, в 19:10 начали звонить клиентам уже не просто с оповещением об аварии, а с просьбой отключить вычислительное оборудование, чтобы избежать его выхода из строя. Иного варианта мы не видели. Некоторые клиенты отказались выключаться и взяли риски на себя. Некоторые привезли на площадку переносные кондиционеры для своих стоек.
В 18:51 начали дозаправлять гликолевые контуры водопроводной водой и постепенно довели давление в системе до рабочего.
В 19.45 приехала аварийная бригада.
В 19.53 насосы запустились, но заработал только один чиллер из трех. У другого были повреждены вентиляторы, а у третьего – еще и фреоновый контур.
Пока мы проделывали все эти упражнения, температура гликоля успела вырасти с рабочих значений (7–12° С) до 20 градусов. Один живой чиллер работал с перегрузкой, и периодически один из двух его контуров останавливался по ошибке. После этого нужно было вручную сбросить ошибку на пульте, и через пять минут (защитный интервал) компрессор запускался. Или не запускался. Тогда помогало полное обесточивание чиллера с перезагрузкой.
Все, кто был в этот момент в офисе, участвовали в освобождении чиллеров от “летающего” металлолома и помогали подъехавшей аварийной бригаде собрать из двух убитых чиллеров еще один рабочий.

Директор по капитальному строительству тогда сорвал спину, скидывая стальные балки с чиллеров.
С чиллера с пробитыми фреоновыми трубками сняли вентиляторы. Не обошлось без пауэрлифтинга – каждый вентилятор весит под 30 кг.
К 23:00 худо-бедно собрали и запустили второй чиллер, и температура в залах начала медленно опускаться.
К тому времени стемнело, но самое интересное только начиналось. Чиллеры стало вышибать по защите из-за перегрева компрессоров: температура гликоля по-прежнему была высокой несмотря на отключение большей части клиентов.
Начальник производства съездил и купил керхеры, шланги и налобные фонари, чтобы можно было работать ночью. Мы поливали компрессоры чиллеров холодной водой, но это не очень помогало, так как компрессор – это кусок железа весом больше тонны и быстро его не охладить. Теперь, когда чиллер останавливался по ошибке, вместо пяти минут приходилось ждать несколько десятков минут, пока компрессор остынет и ошибка Compressor Overload пропадет.

Сообщение об ошибке, которое нам по очереди показывали то один, то другой чиллер.
Глубокой ночью случилось то, чего мы боялись: по аварии одновременно остановились оба чиллера и завести их вместе больше не удавалось. Из четырех юнитов первого и второго чиллеров работало один-два, остальные по очереди пребывали в коматозном состоянии по случаю перегрузки. Температура в залах остановилась на уровне около 30 градусов. Все двери в машинные залы были открыты. Это позволяло хоть как-то избавиться от накопившегося тепла.
Мы вместе с подрядчиками пошли изучать схемы чиллеров. После долгих и тяжких раздумий они предложили под нашу ответственность сделать то, чего делать нельзя: обойти защиту, поставив перемычки, т.е. накоротко замкнуть реле тепловой защиты. Это был прямой путь к тому, чтобы окончательно убить компрессоры, но других вариантов не было. В три часа ночи чиллеры завелись и больше не останавливались. Температура в холодных коридорах начала приходить в соответствие с SLA.
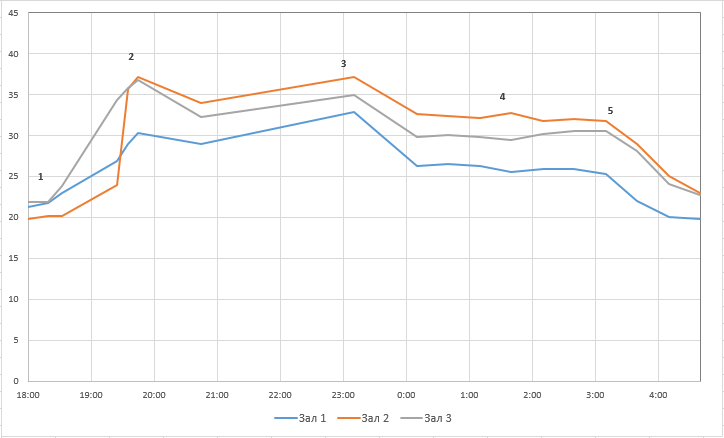
Изменение температуры в холодных коридорах с начала аварии и до ее устранения.
1 — время первой остановки всех чиллеров; 2 — время запуска первого чиллера; 3 — время запуска второго чиллера; 4 — повторная остановка чиллеров; 5 — запуск чиллеров с отключенной тепловой защитой.
С начала этого безобразия у нас впервые появилась возможность перевести дыхание и в чуть более спокойном режиме подумать, что делать дальше. По прогнозам завтра снова обещали жаркий день, а у нас два чиллера, работающих на честном слове.
Утро следующего дня застало нас за монтажом самодельной системы орошения: на крышу подвели трубы с водой и прокололи в садовом шланге дырки.
Гидрометцентр не обманул: снова пекло под 30° С. Из этой собранной на коленке системы и керхеров мы практически без остановки поливали чиллеры, которые продолжали работать с отключенной тепловой защитой.

А вот исторический кадр: чиллеры спасает дежурный сетевой инженер Григорий Атрепьев, ныне руководитель отдела комплексных проектов.
Температуру гликоля удалось вернуть в норму. В общей сложности в таком режиме проработали дня три, после чего восстановили тепловую защиту компрессоров. В течение пары дней запаяли пробитые фреоновые трубки третьего чиллера, вакуумировали и заправили фреоном. Пока ждали поставки вентиляторов взамен разбитых, работала только половина третьего чиллера.

Замена вентиляторов на третьем чиллере. Чиллер Emicon RAH1252F с опцией фрикулинга (свободного охлаждения) состоит из двух модулей, в каждом из которых стоит 8 осевых вентиляторов и компрессор Bitzer.




Заправка фреоном.

Вид на задний двор на следующий день. Еще долго вывозили металлолом.
Чиллеры. Повреждения были серьезными, и мы потратили еще какое-то время на ремонт. Компрессоры после пережитого издевательства прослужили около года, после чего начали выходить из строя: для двух чиллеров сказалась работа без защиты, в третьем чиллере мы, похоже, поторопились с заправкой фреонового контура (недостаточно хорошо вакуумировали, оставив следы влаги). Пробы масла, взятые из еще живых фреоновых контуров, показывали высокий уровень кислотности, предвещавший скорый конец обмотки электродвигателя. В течение второго года после аварии мы заменили почти все компрессоры пострадавших машин. Пробовали починить один из компрессоров, отдав его в перемотку, но после ремонта он протянул считанные месяцы и снова сгорел, так что мы сочли за благо в дальнейшем покупать новые.
Вода, которой мы дозаправили гликолевый контур, не повлияла на морозоустойчивость системы. Замеры показали, что концентрация этиленгликоля осталась на достаточном уровне.
Поскольку чиллеры так и не выдавали заявленной холодильной мощности (а ИТ-нагрузка росла по мере заполнения ЦОДа), приходилось и дальше поливать их в жару. Теплообменники не пережили водных процедур: с годами они обросли известковыми отложениями, а в зазор между теплообменником фрикулинга и фреоновым конденсатором набилась всякая грязь, удалить которую конструкция не позволяла. Через несколько лет мы планово заменили два из трех чиллеров (про это тоже будет увлекательная история, на этот раз без жертв), а на оставшемся срезали теплообменники фрикулинга. Сейчас на площадке OST работает 4 чиллера: два Stulz, Hiref (добавился, когда дата-центр подрос) и один старый Emicon.

Чиллеры на площадке OST в 2017 году.
Клиенты. Несмотря на этот кошмар эксплуататора, клиенты отнеслись с нашей беде с пониманием и даже никто от нас не съехал.
Запомнилось, что для получения страховки на чиллеры и для отчета перед пострадавшими клиентами долго добывали у Гидрометцентра справку о локальному урагане.
К таким форс-мажорам сложно подготовиться заранее, но важно из любой аварии сделать правильные выводы. Наши, добытые потом и кровью, были такими:
В Москве тоже бывают ураганы. Это сейчас что ни день, то штормовое предупреждение, а тогда это было в новинку. После той аварии при выборе площадки или готового здания под ЦОД особенно тщательно смотрим, нет ли в опасной близости условных сараев и прочих хлипких строений. Конечно, крышу, которая прилетела на наши чиллеры, соседи перекрывали уже под нашим чутким контролем.
Мы стали сами закупать ЗИП (вентиляторы, компрессоры, запас фреона и пр.) и хранить его у себя. Восстановление прошло бы быстрее, если бы у нас на площадке были хотя бы запасные вентиляторы. В тот раз поставку нужного количества пришлось ждать несколько недель.
Волей-неволей разобрались в устройстве чиллеров, они перестали быть для нас “черными ящиками”. Это нам пригодилось впоследствии, потому что замечательные холодильные машины не перестали ломаться.
Провели на крышу воду. Для новых дата-центров делаем это по умолчанию. Вода пригодится для промывки чиллеров или внешних блоков от грязи, скопившейся за осень-зиму, поможет отбиться от тополиного пуха летом и облегчит жизнь системе холодоснабжения в условиях аномальной жары.
Прокачали мониторинг и стали измерять все, что можно: давление в нескольких точках, состояние насосов, температуру прямого и обратного гликоля, электропотребление чиллеров и т.д. В той ситуации оповещения помогли бы нам обнаружить проблему раньше и начать действовать быстрее.
Настроили удаленное управление чиллерами из центра мониторинга.
Синхронизировали часы на всех системах, чтобы при разборах аварий иметь понятную картину развития событий.
Еще мы с особым тщанием занялись проработкой всех ключевых процессов, задокументировали и сопроводили схемами все, до чего смогли дотянуться, и ввели регулярные боевые учения. И если завтра случится какой-нибудь армагеддон, наши ЦОДы будут спасать не 3,5 человека в жанре импровизации, а большая и опытная служба эксплуатации с четкими, отработанными инструкциями. Это позволяет нам не только управлять постоянно растущей сетью из семи дата-центров, но и успешно проходить аудиты и сертификации самых уважаемых и строгих организаций вроде Uptime institute.
А какие стихийные бедствия пришлось пережить вашей серверной/дата-центру и какие полезные выводы вы для себя сделали?
|
Метки: author dataline it- инфраструктура блог компании dataline дата-центр цод чиллеры авария ураган dataline даталайн холодоснабжение |
Дели — сокращай, или как мы делали мобильный 2ГИС Онлайн |

Мобильный веб развивается семимильными шагами. На дворе 2017 год. Мобильный трафик превысил десктопный — больше половины всех страниц теперь открываются через телефоны или планшеты. В 2015 году Google объявил о предпочтении mobile-friendly сайтов при ранжировании выдачи, а в 2016 это сделал Яндекс. Юзеры проводят в интернете 60-70 часов в месяц с мобильных устройств и не готовы идти на компромисс и пользоваться неадаптивными сайтами. И 2ГИС — не исключение. За 2 года рост мобильного трафика 2ГИС Онлайн составил 74%, а месячная аудитория превысила 6 миллионов человек.
17 апреля мы зарелизили новый мобильный онлайн («Монлайн») — одностраничное приложение, доступное по адресу m.2gis.ru. Приложение запущено в двух городах: Уфе и Новосибирске, а в ближайшее время планируется релиз на всю Россию.
Мы знали, что при мобильной разработке столкнемся с тремя проблемами:
Мобильный интернет
Мобильный интернет (2G, 3G, 4G) или Wi-Fi медленнее и не такой стабильный, как кабельный.
Мобильные устройства
Проблема мобилок — слабый процессор. Это влияет на парсинг JS, рендеринг и анимации.
Мобильные браузеры
Некоторые популярные мобильные браузеры не поддерживают часть CSS-свойств или методов JS API. Иногда мы думали, что вернулись в темные времена разработки под IE8. Мобильный интернет и процессор не позволяли использовать полифилы, а значит, приходилось выкручиваться самостоятельно.
Мы сохранили функциональность десктопной онлайн-версии и заставили Монлайн работать даже на убитом телефоне вашего дедушки под Пензой. О том, как мы это сделали, расскажем ниже.
В мире мобильного веба JS-разработчик следует одному кредо: дели — сокращай. Конечный бандл мобильного приложения должен мало весить и быть разбит на куски.
Главным и единственным фреймворком фронтенда является Preact. Это не опечатка. Preact — легковесная альтернатива React, использующая тот же API и работающая с Virtual DOM. Преимуществами фреймворка является небольшой вес (3 kB gzip против 45 kB у React) и более высокая скорость рендеринга. Благодаря использованию Preact вместо React размер нашего вендора сократился на 90%.
Preact отличается от React. Например, у него отсутствуют propTypes, но эта проблема решилась введением статической типизации, о которой расскажем в п. 3. Подробно различия между фреймворками описаны в официальном репозитории на github.
Кроме того, мы стараемся писать самостоятельно и не подключать сторонние полифилы и тяжелые библиотеки. Необходимые полифилы грузятся асинхронно через require.ensure и не попадают в бандл. Каждый полифил подключается только в зависимости от условий. Например, в случае с полифилом для Android Browser — мы сэкономили 5 kB кода в gzip.

JS сформирован. Теперь пришло время его разбить. JS код делится на 3 группы:
Вендор минимизировали через выбор Preact, либы и полифилы подключаем асинхронно и по потребности. Остался последний герой. Гзипнутый app-бандл весом в 143 килобайта в gzip. Это роскошь для мобильной разработки. Так, если пользователь зашел в карточку организации, нет смысла моментально грузить код, отвечающий за рендеринг карточки метро или достопримечательности. Чтобы уменьшить размер app-бандла и доставлять клиенту как можно меньше кода, мы сделали ленивую загрузку.
Требования к коду № 1 в Монлайне гласит: «Код должен быть максимально простым и не знать или делать лишнего». На этом правиле базируется структура UI. В проекте 11 контейнеров и 85 «глупых» компонентов. «Глупые» компоненты не знают о существовании друг друга. Контейнеры объединяют компоненты в структуры и передают данные через пропсы. Карточка организации или отзыва, выдача зданий — примеры контейнеров. 6 контейнеров из 11 не связаны друг с другом, что позволяет разбить app-бандл на… интрига… 6 дополнительных чанков. При восстановлении браузер загружает app-бандл и нужный чанк, а затем асинхронно подгружаются остальные JS-файлы, отвечающие за неактивные контейнеры. Это не блокирует работу приложения. После релиза ленивой загрузки вес app-бандла сократился на 38%.
В мобильном вебе критически важно быстро отображать страницы. В Монлайне, как и у 99,9% SPA, часть информации в контейнерах пересекается. Возьмем выдачу фирм и карточку отдельной организации. В выдаче выводится заголовок, адрес, расписание и т. д. Та же информация отображается и в карточке фирмы. Такая информация не меняется, пока юзер пользуется приложением. Нет смысла ждать ответа от сервера, если пользователь уже просматривал эту информацию в прошлом, ведь ее можно хранить на клиенте в единственном экземпляре и показывать данные здесь и сейчас.
Нормализация данных на клиенте — это хранение уникальных данных в стейте, переиспользуемых в контейнерах. Хранение данных на клиенте увеличивает скорость отображения контента, а нормализация убирает дубли и разделяет статические данные и данные, зависящие от контекста.
Нормализация держит стейт в чистоте. Если статические данные просмотрены, то они сохраняются в стейте в отдельной таблице. Например, если пользователь открывает одну фирму несколько раз, то в стейте она хранится в одном экземпляре с доступом по id. И информация об этой фирме используется для любых нужд: в карточке самой организации, выдачах, отзывах, фотографиях и т. д. За форматирование данных отвечают селекторы контейнеров.
Приведем еще один пример. Попасть в карточку компании можно через поисковый запрос, переход по рубрике или просто восстановившись по ссылке с ее id. Поисковый запрос или id рубрики добавляется в URL, который роутер распарсивает при восстановлении. Если в URL есть что-то помимо id фирмы, в стейт сохраняются как информация о ней, так и данные о первых 10 фирмах, соответствующих поисковому запросу или рубрике. При переходе из карточки компании в выдачу пользователь мгновенно получает список организаций и так же быстро может открывать страницу каждой фирмы.
Люди не любят ждать не только загрузку контента, но и ответа при отправке данных через формы. Хранение данных на клиенте уменьшает время ожидания при сохранении информации. Информация в стейте развязывает руки при создании оптимистичных интерфейсов. Оптимистичный UI-дизайн показывает конечное состояние до того, как приложение в действительности заканчивает (или даже начинает) операцию. После сабмита данных пользователь мгновенно получает информацию об их сохранении благодаря тому, что информация юзера сохраняется в стейте и отправляется на сервер в фоновом режиме. Только если с сервера пришел ответ с ошибкой, приложение оповестит юзера соответствующим сообщением, в остальных случаях ответ сервера не выводится на экран.
В создании Монлайна поучаствовали 34 разработчика. В мастер слили 2 000 коммитов, написали 77 000 строк кода и создали 1425 файлов. В проекте участвовали люди из других команд, ребята приходили на стажировки. Мы хотели ускорить процесс разработки, сделать код понятным и документированным. Поэтому решили отказаться от динамической типизации в JavaScript.
Клиентская часть приложения написана на TypeScript. Статическая типизация — главное преимущество TypeScript над JS. Она бьет по рукам в случае ошибок при компиляции, документирует код изнутри и облегчает рефакторинг и отладку.
Для управление состоянием приложения в проекте используется Redux. Redux сочетается с TypeScript. Разработчик знает, что передается в payload или meta и, соответственно, что приходит в редьюсер. Например:
export const setScrollTop = (payload: number) => ({
type: APPCONTEXT_CHANGE_SCROLL_TOP,
payload
});
export const setErrorToFrame = (errorCode: ErrorCodeType) => ({
type: APPCONTEXT_SET_ERROR_TO_FRAME,
payload: { errorCode }
});TypeScript упрощает работу с редьюсерами (чистые функции, которые вычисляют новую версию стейта и возвращают ее). Например, редьюсер, отвечающий за обновления информации о текущем контексте приложения в стейте, обрабатывает 69 экшнов. На выходе получаем метод со свитчем в 100 строк кода, возвращающий новый стейт. Критически важно в таком большом полотне обрабатывать только нужные экшны.
export default function (state: AppContext = defaultState, action: AppAction): AppContext {
switch (action.type) {
case APPCONTEXT_ADD_FRAME:
return appAddFrame(state, action.payload);
case APPCONTEXT_REMOVE_ACTIVE_FRAME:
return appRemoveActiveFrame(state);
....
case APPCONTEXT_HIDE_MENU:
return { ...state, isSideMenuShown: false };
default:
return state;Избежать путаницы с набором экшнов в редьюсере и данными в payload или meta помогает Discriminated Unions. В коде выше видно, что аргумент action описан типом AppAction, который выглядит так:
export type AppAction = AppAddFrameAction | AppRemoveActiveFrame | AppChangeFramePos | AppChangeMode | AppChangeLandscape…AppAction объединяет в себя 60 интерфейсов (appAddFrameAction, AppRemoveActiveFrame и т. д.). Каждый интерфейс описывает экшн. Тип (type) экшна — строковый литерал — это дискриминант. Он определяет наличие и содержание внутренностей объекта, таких как payload или meta.
export interface AppAddFrameAction {
type: 'APPCONTEXT_ADD_FRAME';
payload: Frame;
}
export interface AppRemoveActiveFrame {
type: 'APPCONTEXT_REMOVE_ACTIVE_FRAME';
}
export interface AppChangeFramePos {
type: 'APPCONTEXT_CHANGE_FRAME_POS';
payload: FramePos;
}Так TypeScript понимает, что для экшна с дискриминантом 'APPCONTEXT_ADD_FRAME' нужно передать payload с интерфейсом Frame, а в случае 'APPCONTEXT_REMOVE_ACTIVE_FRAME' ничего передавать не нужно.
Preact также сочетается с TypeScript. В Preact отсутствуют реактовские propTypes, решающие проблемы проверки типов у компонента. Но TypeScript восполняет потерю. Например, разработчик знает, что передается через пропсы компоненту и что хранится в стейте.
export interface IconProps {
icon: SVGIcon;
width?: number;
height?: number;
color?: string;
className?: string;
}
export class Icon extends React.PureComponent {
constructor(props: IconProps) {
super(props);
}
public render() {
const { color, icon } = this.props;
const iconStyle = color ? { color: this.props.color } : undefined;
return (
);
}
}TypeScript задокументирован и имеет песочницу. Разумеется, язык не всесилен, на июль 2017 года открыто 2200 issues. Продукт Microsoft не поддерживает часть нововведений в ES6. Но медленно и верно эти проблемы решаются в каждом новом релизе.
В мобильном онлайне — 85 «глупых» компонентов. «Глупые» компоненты — визуальные сущности, отвечающие за представление полученных данных. В первую очередь мы хотели разделить верстку и интеграцию этих компонентов в приложении. Это позволило бы ускорить code review и тестирование ресурсом разработчиков. Для достижения этих целей используется Makeup.
Makeup — графический интерфейс для быстрого и комфортного ручного регрессионного тестирования верстки. Подробно почитать об инструменте можно здесь, а потрогать — здесь.
С помощью Makeup верстка компонентов делается на отдельном хосте с замоканными данными без привязки к приложению. Это позволяет тестировать визуализацию компонента на уровне разработки, подгонять верстку под pixel perfect и уже позже заниматься интегрированием.
Так в Makeup выглядят различия между тем, что нарисовал дизайнер, и тем, что сверстал разработчик.

А так мы проверяем «одиннадцатиклассницу» и видим, что ничего не поехало:

Подытожим. Мы проделали большую работу по уменьшению бандла и увеличению скорости загрузки страницы. Данные хранятся на клиенте. Вендор весит на 90% меньше, чем изначально мог бы. Бандл не включает лишних библиотек и полифилов, а нужные отдаются кусочками по потребности. TypeScript дает больше контроля над приложением, а Makeup упрощает работу с визуальной составляющей Монлайна.
В планах разбить «жирные» модули в зависимости от контекста (например, карточку фирмы или геообъекта разделить на отдельные чанки) и попробовать разбить редьюсеры.
Статья посвящена JS-коду. Но разработческое кредо «дели — сокращай» распространяется и на CSS-бандл. В будущем мы также планируем заняться и сплиттингом стилей.
|
Метки: author galtr javascript блог компании 2гис typescript preact react makeup |
[Перевод] Мировые рынки: как добиться успеха в Индии и Бразилии |

|
|
Deep Learning, теперь и в OpenCV |

mkdir git && cd git
git clone https://github.com/opencv/opencv.gitcd ..
mkdir build && cd build
cmake ../git/opencv -DBUILD_EXAMPLES=ONmake -j5 (Linux)
cmake --build . --config Release -- /m:5 (Windows)import numpy as np
import cv2 as cv
# read names of classes
with open('synset_words.txt') as f:
classes = [x[x.find(' ') + 1:] for x in f]
image = cv.imread('space_shuttle.jpg')
# create tensor with 224x224 spatial size and subtract mean values (104, 117, 123)
# from corresponding channels (R, G, B)
input = cv.dnn.blobFromImage(image, 1, (224, 224), (104, 117, 123))
# load model from caffe
net = cv.dnn.readNetFromCaffe('bvlc_googlenet.prototxt', 'bvlc_googlenet.caffemodel')
# feed input tensor to the model
net.setInput(input)
# perform inference and get output
out = net.forward()
# get indices with the highest probability
indexes = np.argsort(out[0])[-5:]
for i in reversed(indexes):
print('class:', classes[i], ' probability:', out[0][i])| Модель (исходный фреймворк) |
Опубликованное значение acc@top-5 |
Измеренное значение acc@top-5 в исходном фреймворке |
Измеренное значение acc@top-5 в dnn |
Средняя разница на элемент между выходными тензорами фреймворка и dnn |
Максимальная разница между выходными тензорами фреймворка и dnn |
| AlexNet (Caffe) |
80.2% |
79.1% |
79.1% |
6.5E-10 |
3.01E-06 |
| GoogLeNet (Caffe) |
88.9% |
88.5% |
88.5% |
1.18E-09 |
1.33E-05 |
| GoogLeNet (TensorFlow) |
— | 89.4% |
89.4% |
1.84E-09 |
1.47E-05 |
| ResNet-50 (Caffe) |
92.2% |
91.8% |
91.8% |
8.73E-10 |
4.29E-06 |
| SqueezeNet v1.1 (Caffe) |
80.3% |
80.4% |
80.4% |
1.91E-09 |
6.77E-06 |
| Модель (фреймворк) |
Опубликованное значение mean IOU |
Измеренное значение mean IOU в исходном фреймворке |
Измеренное значение mean IOU в dnn |
Средняя разница на элемент между выходными тензорами фреймворка и dnn |
Максимальная разница между выходными тензорами фреймворка и dnn |
| FCN (Caffe) |
65.5% |
60.402874% |
60.402879% |
3.1E-7 |
1.53E-5 |
| ENet (Torch) |
58.3% |
59.1368% |
59.1369% |
3.2E-5 |
1.20 |
| Модель (исходный фреймворк) |
Разрешение изображения |
Производительность исходного фреймворка, CPU (библиотека акселерации); потребление памяти |
Производительность dnn, CPU (ускорение относительно исходного фреймворка); потребление памяти |
| AlexNet (Caffe) |
227x227 |
23.7 мс (MKL); 945 МБ |
14.7 мс (1.6x); 713 МБ |
| GoogLeNet (Caffe) |
224x224 |
44.6 мс (MKL); 197 МБ |
20.1 мс (2.2x); 172 МБ |
| ResNet-50 (Caffe) |
224x224 |
70.2 мс (MKL); 386 МБ |
58.8 мс (1.2x); 224 МБ |
| SqueezeNet v1.1 (Caffe) |
227x227 |
12.4 мс (MKL); 113 МБ |
5.3 мс (2.3x); 38 МБ |
| GoogLeNet (TensorFlow) |
224x224 |
17.9 мс (Eigen); 310 МБ |
21.1 мс (0.8x); 135 МБ |
| FCN (Caffe) |
различное (500x350 в среднем) |
3873.6 мс (MKL); 4453 МБ |
1229.8 мс (3.1x); 1332 МБ |
| ENet (Torch) |
1024x512 |
1105.0 мс; 828 МБ |
218.7 мс (5.1x); 190 МБ |
|
Метки: author arrybn обработка изображений open source блог компании intel opencv deep learning intel dnn |
ICO: основные юрисдикции и вопросы |


Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Menaskop финансы в it учебный процесс в it исследования и прогнозы в it ico первичное размещение токенов крипто-мир it- юрист |
Как писать на Spring в 2017 |
|
Метки: author alek_sys java spring framework spring mvc |
Критическая уязвимость в multisig кошельке Parity, хакерами выведен $31 миллион в ethereum |
"Edgeless casino, swarm city, and aeternity have all been drained" --CF Slack #parityhack
— CoinFund (@coinfund_io) July 19, 2017
invested in Aeternity
lol
and they lost like 18million
f#$@ morons…
It likes like it will be a eternity until you get your money back ;)
1. Ecosystem less mature then
— Vitalik Buterin (@VitalikButerin) July 19, 2017
2. More at stake then as % of all ETH
3 [most impt]. Today's attacker can just move funds, so HF is impossible
|
Метки: author ProRunner криптография информационная безопасность ethereum parity |
DevOps Days Riga 2017 |

|
Метки: author gmlexx devops devopsdays |
Укрощаем мультимедиа с помощью ffmpeg |
Внезапно ваш диск под завязку забит фотографиями и видео, а впереди новые поездки. Что делать, покупать новый, арендовать дисковое пространство на облаке, или может лучше сжать видео файлы через ffmpeg?
Впрочем зачем себя ограничивать экономией дискового пространства? Предлагаю узнать удивительные возможности обработки фотографий, аудио и видео данных, утилитами командной строки.
Библиотека с открытым исходным кодом ffmpeg скорее всего уже установлена на вашей операционной системе. Если же нет, установите его штатной программой управления пакетами, это не займет много времени.
ffmpeg -i file. [options] file.Уменьшаем видео, записанное на фотоаппарате:
ffmpeg -i MVI_4703.MOV MVI_4703.aviТо же самое, но с контролем качества.
ffmpeg -i MVI_4703.MOV -q:v 4 MVI_4703.aviРазмер изображения уменьшился более чем в 5 раз без ощутимой потери качества. Опция -qscale:v n, сокращенно -q:v n позволяет установить уровень качества генерируемого видеопотока, где n принимает значения в интервале от 1 до 31. Значение 1 соответствует самому лучшему качеству, а 31 — самому худшему.
-rw-r--r-- 1 mig users 124M июл 18 23:29 foto/MVI_4703.avi
-rw-r--r-- 1 mig users 686M июн 27 21:38 foto/MVI_4703.MOVДля того, чтобы выбрать нужный нам кодек используем ключи -c:a .
ffmpeg -i video.mp4 -c:v vp9 -c:a libvorbis video.mkvУвидеть все поддерживаемые кодеки можно командой ffpmeg -codecs.
Возьмем теперь такой юзкейс случай. Встроенный плеер вашего телевизора поддерживает формат mkv, но не поддерживает m4v. Для того, чтобы поменять контейнер воспользуемся следующей командой.
ffmpeg -i video.m4v -c:av copy video.mkvЕсли же нужно поменять только звук, а видео оставить как есть, запускаем эту команду. Почему-то телевизоры Филипс понимают только форматы звука AAC/AC3.
ffmpeg -i video.m4v -c:v copy -c:a aac video.mkvПросто перечисляем файлы ввода и задаем вывод.
ffmpeg -i video.mp4 -i audio.ogg video_sound.mp4Если нужно просто извлечь звук, то можно так.
ffmpeg -i video.MOV -vn audio.oggЗадаем формат извлекаемой звуковой дорожки.
ffmpeg -i video.MOV -vn -c:a flac audio.flacУказывает приемлемый битрейт, по умолчанию будет записано 128k.
ffmpeg -i video.MOV -vn -c:a flac -b:a 192k audio.flacТот самый случай, когда гладко было на бумаге. На практике приходится ходить по граблям, продираясь через разнобой форматов, кодеков, размеров и ориентации фотографий.
ffmpeg -r .3 -pix_fmt rgba -s 1280x720 -pattern_type glob -i "*.JPGЭ video.mkvТребуются некоторые пояснения.
ffmpeg -pix_fmts. Не со всему форматами получается выставить нужный размер кадра.printf, например image%03d.png для всех image0001.png, image0002.png и т. д.Допустим, вам нужен не весь видео файл, а лишь часть его. Данная команда вырежет 10 секунд видео, начиная с первой минуты.
ffmpeg -i video_full.m4v -c:av copy -ss 00:01:00 -t 10 video_short.m4vКак повысить качество потоков аудио или видео? Для этого используется ключ битрейта -b.
ffmpeg - video.webm -c:a copy -c:v vp9 -b:v 2M final.mkvДля захвата экрана используется устройство x11grab, а ffmpeg должен быть собран с опцией --enable-x11grab.
ffmpeg -f x11grab -framerate 25 -video_size 4cif -i :0.0 out.mpginfo ffmpeg-utils.Для автоматической обработки фотографий удобно работать с программой ImageMagick. Поменять размер всех фотографий в папке.
mogrify -resize 60% *.pngАккуратное повышение резкости изображения, наподобие Smart Sharpen с помощью Perl скрипта, использующего convert и composite из набора утилит ImageMagick.
|
Метки: author temujin сжатие данных настройка linux *nix ffmpeg imagemagick |
Текущая активность вокруг MIPSfpga и не только |

Есть несколько событий и тем, которыми хотелось бы поделиться с сообществом. По-хорошему, по каждой можно писать отдельную статью, но общий дефицит времени заставляет немного схалтурить. Наши сегодняшние темы:
Если тематика MIPSfpga-plus вам не безразлична, то в конце есть небольшой опрос на тему чего мне писать (или не писать) следующую статью. Ваш выбор поможет мне сориентироваться и расставить приоритеты. Welcome!
Спустя 2 года после первого релиза MIPSfpga компания Imagination Technologies выпустила вторую версию пакета: MIPSfpga 2.0 [L1].
На что следует обратить внимание:
1 Create a Project in Vivado or Quartus-II
2 Learn how to compile, debug and run C programs
3 Learn MIPS Assembly Programming system
4 More C Programming Practice (optional)
5 Expand the system to add 7-segment displays
6 Expand the system to add a counter
7 Expand the system to add a buzzer
8 Expand the system to add an SPI-Light Sensor
9 Expand the system to add a SPI-LCD
10 Interact with peripherals using interrupts
11 Build a DMA engine for transfers between peripherals
12 Build a Data Encryption Standard (DES) engine
13 Learn how to use the Performance Counters
14 Execution of ADD and other arithmetic instruction
15 Execution of AND and other logic instructions
16 Execution of LW and other related instructions
17 Execution of BEQ and other related instructions
18 Learn how the Hazard Unit is implemented
19 Learn how to use the CorExtend interface
20 Introduction to the caches available in MIPSfpga
21 Analyze the D$ and implement new configurations
22 Cache Controller: Analyze a cache hit and miss
23 Cache Controller: Analyze D$ management policies
24 Cache Controller: Analyze the Store and Fill Buffers
25 Implement an Instruction Scratchpad RAM

Если учесть, что компания Digilent искуственно ограничивает поставки своих плат на без ПЛИС Xilinx в Россию и на Украину, то картина получается не очень приятная. Но тут нам на помощь приходит MIPSfpga-plus — opensource проект по построению СнК на базе MIPSfpga с платформонезависимой периферией [L4]. Для корректного взаимодействия с MIPSfpga 2.0 его, возможно, придется немного доработать.
Сегодня в Новосибирске открылась Летняя школа юных программистов [L5]. Учебная программа школы предполагает разделение на мастерские [L6], одна из которых ориентирована на преподавание Verilog и архитектуры микросхем. Преподавателем у ребят будет Юрий Панчул YuriPanchul, который специально ради этого дела прилетел из Штатов.
Мастер: Юрий Панчул
Цифровое железо, от логических элементов до собственного процессора
Хотите узнать, как проектируют микросхемы в современных устройствах — от телефона до космического корабля? Последние 25 лет это делают с помощью методологии логического синтеза кода на языках описания аппаратуры. Именно эту технологию мы выучим в нашей мастерской и применим для проектирования собственных устройств.
Мы начнем с трех ключевых кирпичиков цифровой электроники — логического элемента, тактового сигнала и D-триггера, памяти для одного бита информации. Для наглядности мы освоим их старомодным способом, соединяя проводами микросхемы малой степени интеграции на макетной плате.
Затем мы повторим построенные схемы на языке описания аппаратуры SystemVerilog и промоделируем их на программе-симуляторе. Но как мы можем воплотить их в микросхемы? Ведь заказ коммерческой микросхемы на фабрике очень дорогой? К счастью, существуют “перестраиваемые” программируемые логические интегральные схемы (ПЛИС), платы с которыми которые мы и будем использовать для наших занятий.
Помимо упражнений с арифметическими блоками и конечными автоматами, мы попробуем построить простой процессор, похожий по микроархитектуре на процессор Mongoose-V внутри космического корабля New Horizons, который год назад пролетел мимо Плутона.
Заодно мы изучим немного программирования на ассемблере, концепцию прерываний, сравним свой процессор с промышленными микроконтроллерами и встроенными микропроцессора, вплоть до микропроцессора EyeQ5 для самодвижущегося автомобиля, который планируется для выпуска в 2020 году.
Это круто, и я, если честно, немного завидую этим школьникам — в моем детстве такого не было.
Специально для данного мероприятия мы написали небольшой процессор MIPS-архитектуры: schoolMIPS [L6], который планируется использовать в образовательном процессе. Он построен путем упрощения процессора Сары Харрис, описанного в H&H [L2]. Основные особенности:
В комплекте идет небольшая инструкция и слайды, описывающие построение процессорного ядра в стиле аналогичном H&H [L2].
Помимо написания процессора был выполнен достаточно масштабный перевод на русский язык различных образовательных материалов. Эту тему я затрагивать не буду, т.к. не участвовал, полагаю, что Юрий YuriPanchul в будущем об этом еще напишет.
С 18 по 22 сентября на базе Томского государственного университета пройдет Школа–семинар по цифровому дизайну и компьютерной архитектуре в эпоху систем на кристалле (SoC) и интернет технологий (IoT). Предварительная программа школы и список участников опубликованы на сайте [L8]. Там будет выступать и ваш покорный слуга: планирую рассказать про AHB-Lite, подключение периферии к MIPSfpga, работу с SDRAM — это со сцены. А неофициально можем обсудить Linux, подключение отладчика и любой код, который я принес в MIPSfpga-plus. Приходите!
Лабораторные работы MIPSfpga описывают запуск Linux на СнК, построенной с использованием Xilinx-специфических периферийных модулей. Вкупе с уже упомянутой выше проблемой с доступом к платам это создавало некоторые трудности. Необходимым минимумом для запуска ОС Linux являются: MMU (есть в составе MIPS fpga), достаточный объем памяти и UART. При этом большая часть работ по портированию системы уже выполнена Imagination Technologies, соответствующий код включен в основную ветку ядра [L9]. Буквально неделю назад у меня получилось запустить Linux на Terasic DE10-Lite и не скажу, что необходимый для этого патч получился очень сложным.
Основные особенности:
Linux version 4.12.2+ (stas@ubuntu) (gcc version 4.9.2 (Codescape GNU Tools 2016.05-03 for MIPS MTI Linux) ) #67 Wed Jul 19 00:07:19 MSK 2017
CPU0 revision is: 00019e60 (MIPS M14KEc)
MIPS: machine is terasic,de10lite
Determined physical RAM map:
memory: 04000000 @ 00000000 (usable)
Initrd not found or empty - disabling initrd
Primary instruction cache 4kB, VIPT, 2-way, linesize 16 bytes.
Primary data cache 4kB, 2-way, VIPT, no aliases, linesize 16 bytes
Zone ranges:
Normal [mem 0x0000000000000000-0x0000000003ffffff]
Movable zone start for each node
Early memory node ranges
node 0: [mem 0x0000000000000000-0x0000000003ffffff]
Initmem setup node 0 [mem 0x0000000000000000-0x0000000003ffffff]
Built 1 zonelists in Zone order, mobility grouping on. Total pages: 16256
Kernel command line: console=ttyS0,115200
PID hash table entries: 256 (order: -2, 1024 bytes)
Dentry cache hash table entries: 8192 (order: 3, 32768 bytes)
Inode-cache hash table entries: 4096 (order: 2, 16384 bytes)
Memory: 60512K/65536K available (1827K kernel code, 97K rwdata, 320K rodata, 948K init, 184K bss, 5024K reserved , 0K cma-reserved)
NR_IRQS:8
clocksource: MIPS: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 38225208935 ns
sched_clock: 32 bits at 50MHz, resolution 20ns, wraps every 42949672950ns
Console: colour dummy device 80x25
Calibrating delay loop... 10.81 BogoMIPS (lpj=21632)
pid_max: default: 32768 minimum: 301
Mount-cache hash table entries: 1024 (order: 0, 4096 bytes)
Mountpoint-cache hash table entries: 1024 (order: 0, 4096 bytes)
devtmpfs: initialized
clocksource: jiffies: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 7645041785100000 ns
futex hash table entries: 256 (order: -1, 3072 bytes)
clocksource: Switched to clocksource MIPS
random: fast init done
workingset: timestamp_bits=30 max_order=14 bucket_order=0
Serial: 8250/16550 driver, 4 ports, IRQ sharing disabled
console [ttyS0] disabled
b0400000.serial: ttyS0 at MMIO 0xb0401000 (irq = 0, base_baud = 3125000) is a 16550A
console [ttyS0] enabled
Freeing unused kernel memory: 948K
This architecture does not have kernel memory protection.
mount: mounting devpts on /dev/pts failed: No such device
mount: mounting tmpfs on /dev/shm failed: Invalid argument
mount: mounting tmpfs on /tmp failed: Invalid argument
mount: mounting tmpfs on /run failed: Invalid argument
Starting logging: OK
Initializing random number generator... done.
Starting network: ip: socket: Function not implemented
ip: socket: Function not implemented
FAIL
Welcome to MIPSfpga
mipsfpga login: root
Jan 1 00:00:09 login[43]: root login on 'console'
# uname -a
Linux mipsfpga 4.12.2+ #67 Wed Jul 19 00:07:19 MSK 2017 mips GNU/Linux
# free -m
total used free shared buffers cached
Mem: 60 3 56 0 0 2
-/+ buffers/cache: 0 59
Swap: 0 0 0В ближайшее время планирую подготовить небольшое HOWTO о том, как воспроизвести эти результаты. А большую статью, наверное, напишу после добавления в MIPSfpga-plus модуля для работы с mmc/sdcard, допиливания загрузчика и отладки всего, что необходимо для автономного запуска. Если кому-то нужно "вот прямо сейчас" — дайте знать.
В июне закончил работу по интеграции АЦП, который есть на борту Altera MAX10, в MIPSfpga-plus. Соответствующий код добавлен в основную ветку проекта [L11], с документацией [L12] и примером [L13]. Модуль, фактически, является конвертером между шиной AHB-Lite и Avalon-ST, выполненный учетом специфики конкретного АЦП. Он очень прост по архитектуре — старался сделать его программный интерфейс максимально похожим на АЦП микроконтроллера Atmel ATmega88.
Не обошлось, конечно, и без подводных камней, так на используемой в Terasic DE10-Lite ПЛИС доступно 2 канала АЦП (с независимым наборов вводов на каждом), при разводке этих вводов второй канал оказался целиком заземлен, т.о. параллельная работа каналов на DE10-Lite — невозможна:

Хочется верить, что в академических проектах будет чуть чаще использоваться MIPSfpga-plus там, где до этого ради встроенного АЦП нужно было брать микроконтроллер или конфигурацию MAX10 + NIOS-II.
Опять же, нужна ли отдельная статья, где детально разбирается работа с АЦП? Или для того, чтобы разобраться, вам достаточно уже приведенных мной ссылок на исходный код модуля, примера и документацию?
Как вы считаете, проект MIPSfpga-plus достаточно созрел для того, чтобы у него появился свой узнаваемый логотип? Мне, наверное, потратив на него не один десяток часов, уже хочется, чтобы он ассоциировался с какой-нибудь позитивной картинкой. Почему-то в голову приходит только Большой Ух из одноименного мультика (см. КДПВ), возможно, что из-за его конфедератки, которая хорошо ассоциируется с изначально образовательной направленностью проекта. Да и в принципе данный персонаж мне глубоко симпатичен.
Что думаете на эту тему? Может быть вы сможете предложить какой-то альтернативный вариант или, вдруг, среди читателей есть художник, который может изобразить "мультипликационного персонажа, отдаленно напоминающего Большого Уха, но не до степени смешения"?
Автор выражает благодарность коллективу переводчиков учебника Дэвида Харриса и Сары Харрис «Цифровая схемотехника и архитектура компьютера» [L2], компании Imagination Technologies [L1] за академическую лицензию на современное процессорное ядро и образовательные материалы, а также персонально Юрию Панчулу YuriPanchul за его работу по популяризации MIPSfpga. Отдельное большое спасибо Александру Романову (ВШЭ) [L15] за дельный и скрупулезный подход к микроархитектуре schoolMIPS, а также всем участникам списка рассылки Young Russian Chip Architects, принявшим участие в обсуждении.
[L1] — Пресс-релиз о выходе MIPSfpga 2.0;
[L2] — Цифровая схемотехника и архитектура компьютера;
[L3] — Workshop on Computer Architecture Education (Toronto);
[L4] — Проект MIPSfpga-plus на github;
[L5] — Летняя школа программистов (Новосибирск);
[L6] — Летняя школа программистов (Новосибирск). Учебная программа;
[L7] — Проект schoolMIPS на github;
[L8] — Школа–семинар по цифровому дизайну и компьютерной архитектуре (Томск);
[L9] — Поддержка MIPSfpga в ядре Linux;
[L10] — MIPSfpga и внутрисхемная отладка;
[L11] — MIPSfpga-plus. Модуль поддержки АЦП Altera MAX10;
[L12] — MIPSfpga-plus. Модуль поддержки АЦП Altera MAX10. Документация;
[L13] — MIPSfpga-plus. Модуль поддержки АЦП Altera MAX10. Пример;
[L14] — Practical experiences based on MIPSfpga;
[L15] — Профиль Александра Романова на сайте ВШЭ.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author SparF системное программирование программирование микроконтроллеров анализ и проектирование систем fpga verilog mips mipsfpga mips microaptiv up soc |
Visual Tcl. Разработка графического пользовательского интерфейса для утилит командной строки (Продолжение) |
bash-4.3$ /usr/local/bin64/ls11cloud_config
LS11CLOUD User Utility
usage: /usr/local/bin64/ls11cloud_config [-p ] [-n ]
Commands:
register - register new user on the server
duplicate - duplicate user account on other computer
change_pswd - change SESPAKE authentication password
status - display current configuration data
log - display server log file
recreate - re-create token to initial empty state
unregister - remove all user files from the server
NB: Don't use non-latin letters to avoid encoding problems!
Copyright(C) Ltd (http://soft.lissi.ru) 2017
bash-4.3$ bash-4.3$ cd ../vtcl.vtcl-8.6-master
bash-4.3$ ./configure
Using /bin/wish8.6
bash-4.3$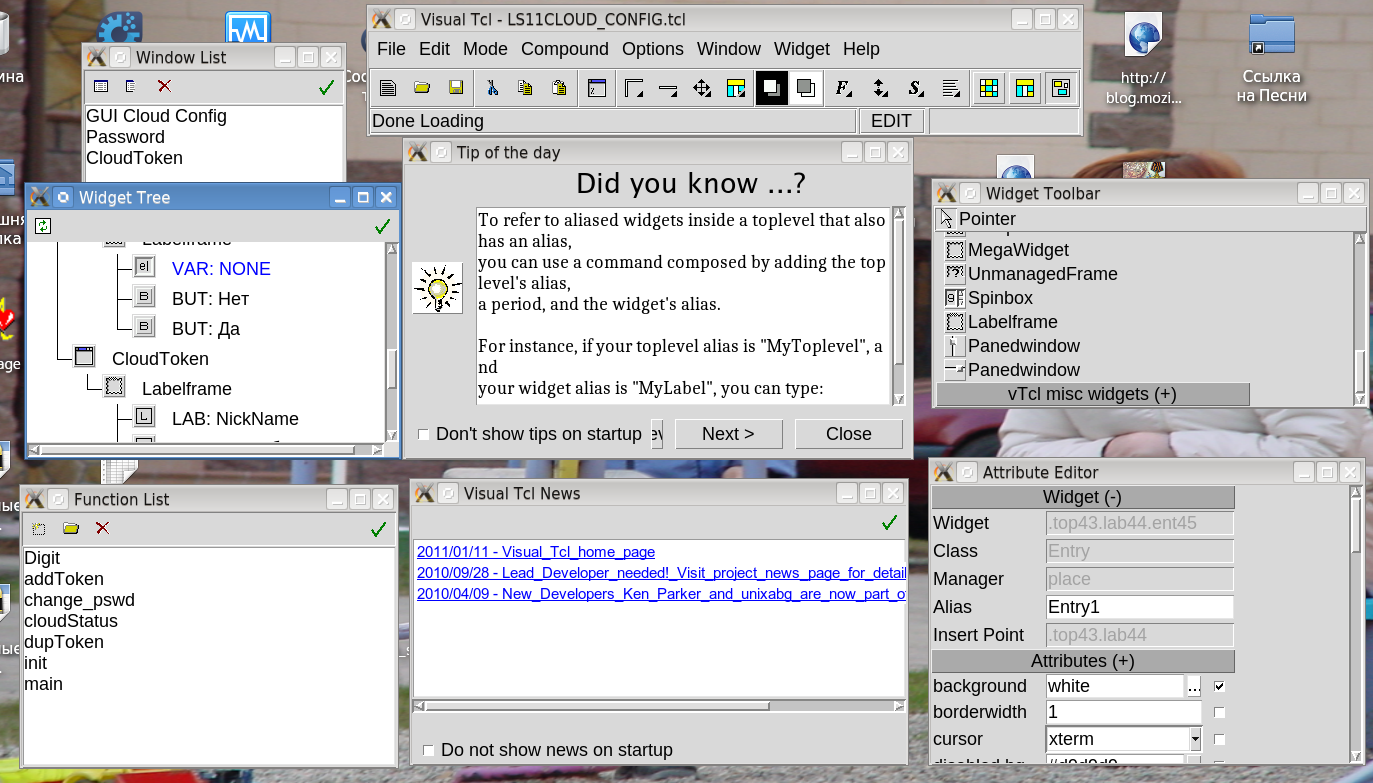
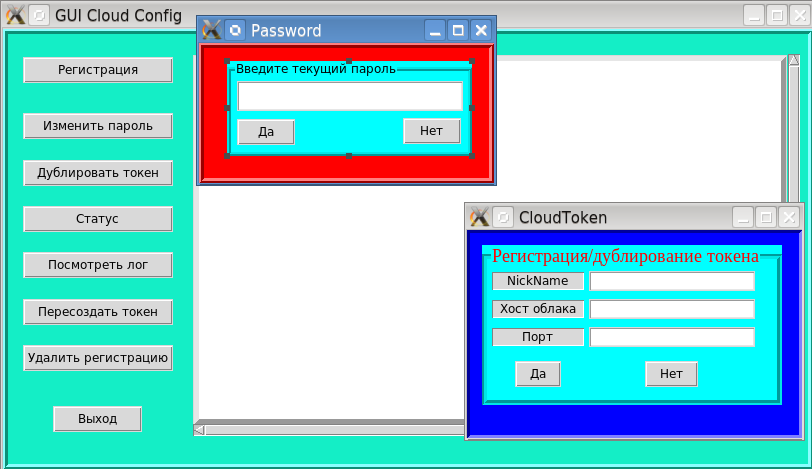



bash-4.3$ ls
GUITKP11Conf.tcl LS11CLOUD_CONFIG.tcl
bash-4.3$
bash-4.3$ freewrap GUITKP11Conf.tcl
bash-4.3$ freewrap LS11CLOUD_CONFIG.tcl
bash-4.3$ ls
GUITKP11Conf LS11CLOUD_CONFIG
GUITKP11Conf.tcl LS11CLOUD_CONFIG.tcl
bash-4.3$|
Метки: author saipr тестирование it-систем программирование криптография графические оболочки open source tcl/tk cloud visualisation pkcs#11 widgets графический дизайн |
Локализацию можно автоматизировать: опыт использования Lokalise в боевых условиях |

Команда Ambisafe занимается разработкой web-проектов и программного обеспечения с 2010 года. С этого же времени в недрах команды озаботились вопросом локализации на пару-тройку базовых языков, отличных от английского.


|
|
[Из песочницы] Аудит ИТ-инфраструктуры — как быть новичку |
Привет, %username%! Готов поспорить, что рано или поздно все сисадмины относительно небольших компаний сталкиваются с такой волшебной задачей от руководства, как составление проекта развития ИТ-инфраструктуры компании. Особенно если тебе предложили должность и сразу же попросили составить план развития и бюджетирования. Вот и мне однажды поставили такую задачу. О всех подводных камнях, с которыми можно столкнуться, я и напишу. Всем заинтересовавшимся велкам под кат!
Сразу поясню, что вы тут не найдете советов о том, какое оборудование выбирать для тех или иных решений, какие программные продукты выбирать, open source или платное ПО, с какими интеграторами общаться стоит, а с какими нет. Это все полностью индивидуально и будет напрямую зависеть от вас и того, что в итоге вы хотите — залатать дыры в текущем корыте или построить ИТ-инфраструктуру таким образом, чтобы любая задача сводилась к нажатию кнопки “СДЕЛАТЬ ХОРОШО” (да я ленивый).
Данная статья больше нацелена на тех, кто совсем мало в этой сфере работает и от него требуют всего и сразу. Думаю молодым сисадминам небольших компаний будет полезно.
Вот собственно примерный список проблем, с которыми можно столкнуться при проведении аудита ИТ-инфраструктуры:
1. Отсутствие тех, у кого можно хоть что-то спросить — именно такая проблема встала передо мной, когда руководство поручило провести аудит с целью улучшения инфраструктуры в целом. На тот момент я являлся самым старым сотрудником отдела компании и поинтересоваться мне было просто не у кого. По этой причине времени на ковыряние и попытку понять “за каким же это хреном сделано” было затрачено не мало, ведь пока я был простым сисадмином меня почти не посвящали в тонкости организации ИТ-инфраструктуры.
2. Отсутствие четко поставленных хотелок со стороны руководства — все думаю согласятся с тем, что нам — айтишникам — по долгу службы приходится быть немного экстрасенсами, т.к. довольно много приходится додумывать и допонимать, опираясь на контекст поставленной задачи. В моем случае приходилось додумывать варианты направления развития бизнеса в целом.
3. Отсутствие четкого (документированного) описания текущей инфраструктуры — увы (!) этого не было никогда ранее. Никто и никогда не составлял банальную карту сети офиса. Не описывал как организована связь между филиалами (коих более 10 штук по всей стране). Я уже не говорю про банальную маркировку кабелей на маршрутизаторах.
4. Полное отсутствие документации — вообще! Абсолютно никакой документации не велось в отделе никогда. И это категорически печально. Ведь банальные копии договоров (на телефонию, интернет, обслуживание 1С, аренду хостинга и прочее) хотя бы в электронном виде должны быть в отделе. И это одно из обязательных условий, ведь любой сотрудник отдела ИТ должен знать, к кому обратиться в случае если упал интернет в другом регионе (где время +3 к Москве).
5. Отсутствие общей базы паролей — все пароли были разные и менялись от случая к случаю. Весь этот ворох приходилось держать в голове, т.к. “все что записано однажды — может быть и считано”. Для того, чтобы предоставить новому сотруднику определенный доступ, необходимо переписать в почте (или на бумажке) все логины и пароли и передать их лично ему. А если ты еще не правильно пароль вспомнил… Ужас!
6. Отсутствие информации о том, как все организованно в регионах — имелась информация лишь о том, сколько там человек, кто руководитель и… всё! Т.е. имелась просто абстракция под названием “Региональное представительство в городе Мухосранске, где сидит 15 человек”. Никто никогда не задавался вопросом, как там устроена сеть, какие у нее слабые места, как происходит доступ сотрудников представительства в сеть Интернет, как организован доступ сотрудников к сетевым ресурсам центрального офиса.
И это еще не полный список, т.к. таких косяков просто огромное количество. И все они встретились мне на пути. Одним из тяжелейших моментов могу назвать тот факт, что я этим занимался впервые и ударить в грязь лицом не хотелось.
Понимая немного психологию в целом и учитывая, что огромная часть нас — айтишников — это интроверты, при составлении такого аудита в большинстве случаев побоятся обратиться к руководству компании с банальными вопросами. И мне было страшно. Но тем не менее я был вынужден переступить через свои страхи и задать те банальные вопросы, на которые мне способно дать ответ руководство.
Я не стану напоминать о том, что необходимо сделать инвентаризацию для того, чтобы понимать с чем работаешь, что является устаревшим, что можно заменить на более производительное. Это обязательное мероприятие. А вот о том, что после переписи всего оборудования надо все разделить всё на категории (активное сетевое, workstaion, bussiness-critical servers and service) напомню. При наличии доступа к административной панели сделать бэкапы конфигураций, описать “что”, “зачем” и “для чего” настроено в конкретной железке, переписать все сетевые адреса серверов, управляемых железок (да простят меня господа сетевики), сетевых хранилищ, принтеров и всего, что имеет доступ к сети (ну кроме рабочих станций).
Следующим этапом можно попытаться составить примерную схему того, как устроена сеть на план-схеме этажа, чтобы понимать где может быть бутылочное горлышко. В моем случае была проблема в том, что сеть этажа поделена на две части и в дальней от серверной части были проблемы с сетью, а оказалось все банально — не экранированная витая пара лежала вместе с силовой линией этажа бизнес-центра напряжением на 220 и 380 вольт — какая к черту сеть, ребята. После этого можно приступать к анализу железа.
Анализ железячной составляющей это одно из важных мероприятий. Необходимо понимать, насколько актуально на текущий момент времени используемое железо (как сетевое и серверное, так и пользовательские ПК). Обычно на этом этапе выясняется (с поддержкой от бухгалтерии, а так же коммерческих отделов), что вся bussiness-critical информация хранится в виде документов Excell на сервере, у которого жесткие диски работают уже третий гарантийный срок (!) и все удивляются тому, что “файлы по сети медленно открываются” и сам сервер шумит дисками как больной психиатрии стучащий ложкой по кастрюле. А сетевые железки сняты с производства еще за год до того, как их купили в компанию и по отзывам они ужасны. Или например wi-fi в офисе поднят на точках доступа, которые по всем отзывам считаются такой дрянью, которую врагу не пожелаешь.
Необходимо именно оценить серверные мощности. Т.е. необходимо оценить работу текущих серверов (физических и виртуальных, если в вашей организации присутствует виртуализация) и оценить то, насколько используются ресурсы. Может быть стоит какие-то сервера (или серверы?) ликвидировать вообще, т.к. необходимость в них отпала уже давно, а убрать их боялись. Какие-то сервисы может быть удобнее объединить, а какие-то наоборот разделить, потому что они несовместимы на одной машине и чрезмерно нагружают систему.
Когда парк ваших серверов и сервисов достигает критической массы и вы вынуждены заходя в серверную смотреть, что это за систменик или тыкаться по KVM в поисках нужного сервера, то вам явно требуется виртуализация. Все системы, которые можно запустить на виртуалке необходимо перевести в виртуальную среду (всяческие СКУДы, сервер корпоративного портала, корпоративное облако, etc). Современных, а главное удобных инструментов для этого предостаточно (VMware, Proxmox, Xen, Hyper-V). Просто определитесь с тем, что вам нужно/нравится/можно купить и запускайте в работу.
Не виртуализируйте критичные вещи — такие как шлюзы, маршрутизаторы, VPN-сервера используемые для аварийного доступа в сеть, сервера 1С (тут в меня могу полететь тухлые помидоры). Важно здраво оценивать все факторы, руководствуясь которыми вы принимаете решение о том, что загонять в виртуальную среду, а что нет. Идеальных решений не существует.
Вопрос довольно обширный и имеет множество решений. От самого простого — выделять каждому удаленному сотруднику логин и пароль для VPN, дорогого — арендовать L2-сеть у одного провайдера и до безумного — наставить самых различных сетевых железок от разных вендоров, с помощью которых организовать доступ в сеть на местах и доступ к сетевым ресурсам внутри компании (сетевые хранилища и т.п.). Оцените все “за” и “против” и примите верное и лучшее решение в конкретно вашем случае. Для простоты и понимания “что делать” и “как делать” смело приглашайте системных интеграторов и консультируйтесь с ними. За спрос не дадут по шее, а дадут понять как можно решить одну и ту же проблему разными способами (дешево и дорого). Уже после пары-тройки таких встреч вы сможете более точно и более четко описать для себя самого все свои хотелки и возможные способы их решения.
После всех выше описанных работ можно приступить к составлению примерного бюджета. Для выбора конкретных моделей оборудования обращайтесь за помощью в специализированные чаты (сам использовал чаты в Телеграм, т.к. там всегда живой народ и больше шансов получить быстрый ответ; список можно загуглить). Все оборудование, которое вы выбираете рассчитывайте с запасом на перспективу и рост потребностей ваших прямых клиентов — сотрудников компании. Больше общайтесь с руководством на тему дальнейшего развития бизнеса компании. Возможно они сами вам подскажут ответ на то, на что вы не знали ответа.
Правильно организуйте работу вашего отдела, особенно когда вас в отделе больше двух человек. Никогда не создавайте такую ситуацию, в которой какие-то вещи завязаны на одно человека. Это ваша точка отказа!
Старайтесь максимально документировать все свои действия на серверах в процессе изменения конфигураций сервисов. Это поможет и вам в дальнейшем, и вашим коллегам, которые будут работать вместе с вами (или вместо вас, когда вы пойдете на повышение/другую работу/отпуск).
И запомните две вещи:
P.S.: На этом все. Жду ваших комментариев и здравой критики.
|
Метки: author JTProg системное администрирование it- инфраструктура бюджетирование |
[Из песочницы] Пошаговый мануал как ввезти технику, на которую отсутствует нотификация ФСБ |
Заметил, что на Хабре (да и в Рунете), практически нет инструкций о том, что делать, если на технику, заказанную из-за рубежа, отсутствует нотификация ФСБ. Хотел бы поделиться опытом, приобретенным в процессе доставки ноутбука из Америки. Инструкция под катом.
Мой брат, решив сменить свой старый ноутбук, обратился ко мне за помощью в подборе модели. В одном из обзоров на сайте, в комментариях проскользнуло такое чудо инженерной мысли как LG Gram. Имея диагональ 15 дюймов, данный ноутбук весит меньше килограмма, имеет неплохую начинку и выглядит очень неплохо. В России данный ноутбук не продается, поэтому поиски продолжились на сайте Amazon. Изначально модель стоила около 1100 долларов, но я, имея годы опыта покупок за рубежом, решил подождать. В итоге цена упала до 830 долларов и решено было брать. Ноутбук успешно пришел на склад одного из mail-forward сервисов и был готов к отправке. Но тут начинается самое интересное. На почту приходит такое письмо:
Добрый день, %username%!
На предварительном согласовании данных о пересылаемых посылках с таможней, последняя не одобрила к отправке ноутбук из вашей посылки #****** из-за отсутствия на него нотификации ФСБ РФ. Поэтому мы не сможем отправить такую посылку методом ***.
Мы готовы отправить такую посылку только методами USPS Express/Priority без страховки. Однако важно понимать, что в таком случае есть риск возврата товара с таможни из-за отсутствия нотификации на устройство.
Советуем отменить отправку в разделе личного кабинета «Пакуется». После отмены отправки можно будет переоформить декларацию на USPS и создать новую исходящую посылку USPS Express/Priority.
Возможно, одним из решений в данный момент будет вернуть товар продавцу.
Я естественно ищу информацию и попадаю на сайт ЕЭК (достаточно неудобном, но что поделать), на котором действительно не нахожу данной модели. Возникают 4 варианта решения проблемы:
В общем брат сразу же предложил воспользоваться первым способом, взяв весь риск потери денег на себя. Самый главный минус данного способа в том, что он не подразумевал полную страховку ввиду частых краж на Почте России. Это давало дополнительный шанс не получить ноутбук. И я даже больше боялся не таможни, а именно Почты России, поскольку вероятность кражи там такой техники всегда была высока. В техподдержке сервиса получить какого то внятного ответа так и не получилось. В итоге пришлось решать все самому. Изначально я предлагал им разместить данную статью на их сайте в обмен на скидку в размере суммы, потраченной за платное превышение срока хранения, но видимо 15-20 долларов для них серьезные деньги и они отказали.
Была рассмотрена куча вариантов, типа отправки через Беларусь, Украину с последующим привозом знакомыми и даже такие экзотические варианты как отправка контейнером с запчастями, но все они были неосуществимы. Например в РБ и на Украине таможенные лимиты ниже 100 долларов.
Итак, как ввезти технику на территорию РФ официально? Существует 2 способа:
Первый способ практически неосуществим, либо стоит дорого. Насколько мне известно, нотификацию должен получать изготовитель техники, который вряд ли будет ради вас это делать. В интернете есть куча фирм, которые предлагают данные услуги, начинающиеся от 10000р. Как понимаете, данный вариант тоже не подходит, поскольку полностью убивает всю выгоду от скидок. Более интересен второй вариант. Как известно, под юрлицами подразумеваются не только ООО и прочие фирмы, но и ИП, коим является наверно каждый второй IT-специалист. Тут я вспомнил, что у меня тоже открыто ИП и задача упростилась.
Первый мой поход был в юротдел таможни, что на площади 3х вокзалов. Помимо кучи бесполезной информации, там мне сказали, что в таможне отбор посылок происходит достаточно быстро: если на посылке указана техника, на которую должна стоять нотификация, но данная нотификация не указана на посылке, то ее не вскрывая отправляют обратно, поскольку хранение посылок у них не предусмотрено.
Следующим был звонок в ФСБ, а именно ЦЛСЗ ФСБ России. Сразу хочу сказать, там работают достаточно вменяемые люди, которые все подробно объяснят и помогут правильно составить документы. Там мне сказали, что ИП действительно могут получить разрешение на ввоз техники для личного пользования. Порядок описан в данном документе. Для этого требуется отправить письмо на адрес канцелярии ЦЛСЗ ФСБ России (г.Москва. 107031, ул.Большая Лубянка, дом 1/3).
В письмо необходимо вложить:
Возможно список неполный, происходило это больше полугода назад, я что то мог упустить. Лучше все же позвонить в ЦЛСЗ ФСБ России и уточнить.
Заявление пишется в свободной форме, вот то, что писал я:
Начальнику Центра по лицензированию, сертификации
и защите государственной тайны ФСБ России
Васюкову Юрию Константиновичу
Заявление
Я, индивидуальный предприниматель Иванов Иван Иванович, ИНН XXXX, ОГРНИП XXXX, ПАСПОРТНЫЕ ДАННЫЕ, на основании приложения №9 к решению коллегии Евразийской экономической комиссии от 21 апреля 2015г №30, для собственных нужд в качестве индивидуального предпринимателя в интернет-магазине Amazon приобрел ноутбук LG Gram 15" (модель 15Z960). В связи с тем, что производитель не дал нотификацию на данную модель, прошу дать разрешение на его ввоз. Данный ноутбук, исходя из спецификации на сайте производителя, содержит средства шифрования, входящие в WiFi модуль, модуль Bluetooth (характеристики прилагаются) и операционную систему Windows XX (указать номер нотификации с сайта ЕЭК). Других функций шифрования ноутбук не имеет. Полный список технических характеристик прилагается. Данный ноутбук необходим мне для решения личных задач в качестве индивидуального предпринимателя. Обязуюсь использовать его только для личных целей без предоставления услуг шифрования третьим лицам. Прошу выдать разрешение мне на руки (либо его пришлют по почте на адрес регистрации ИП). Контактный телефон XXXX
30.06.2017 Иванов Иван Иванович
Заключение можно скачать тут. Там заполняется часть данных, чтобы это не делали в ФСБ. Какие, я уже не вспомню, но по телефону в ФСБ вам все это помогут заполнить.
Далее письмо шлется обычной почтой и в течение 30 дней вам позвонят на контактный телефон и сообщат о решении. Сразу хочу сказать, что в ФСБ мне сказали, что не стоит слать это на электронную почту, так будет гораздо дольше.
В моем случае положительный ответ пришел через 3 недели. Дальше вы едете на ул. Ярцевская, д. 30 и получаете разрешение. Скан разрешения вкладывается в посылку mail-forward сервисом и освобождает вас от проблем с таможней.
Хотел бы посоветовать всем (то же мне сказали в ФСБ), кто хочет воспользоватся данным способом, сделать это до момента покупки, чтобы избежать длительного ожидания. В моем случае я купил ноутбук в конце ноября 2016, а получил его только в конце марта 2017.
Надеюсь данный мануал будет полезен.
|
Метки: author noroots исследования и прогнозы в it нотификация таможня |
[Перевод] Starbucks следует открыть публичный доступ к своим API |


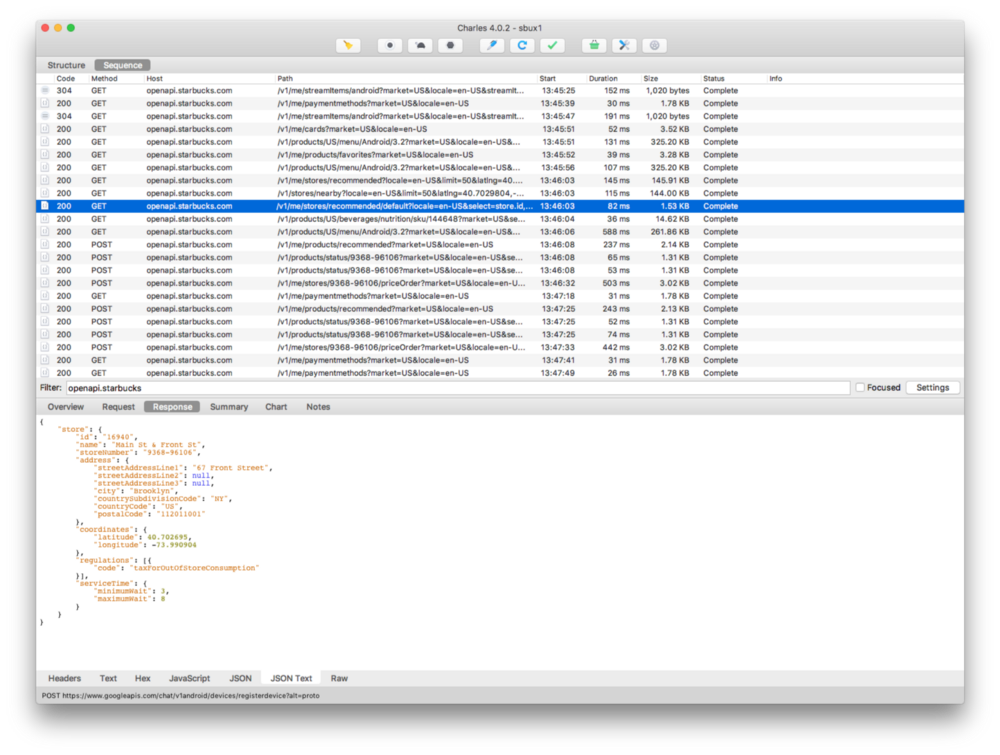
«Это легко», — думал я, — «Я просто размещу заказ, подключившись к прокси-серверу, и потом воспроизведу запросы!»

|
Метки: author Fondy разработка мобильных приложений программирование открытые данные api блог компании fondy starbucks мобильные приложения fondy |
[Перевод] XBRL: Просто о сложном - Глава 2. Что такое XBRL? |
|
Метки: author r_udaltsov it- стандарты xbrl финансы отчетность цб рф |
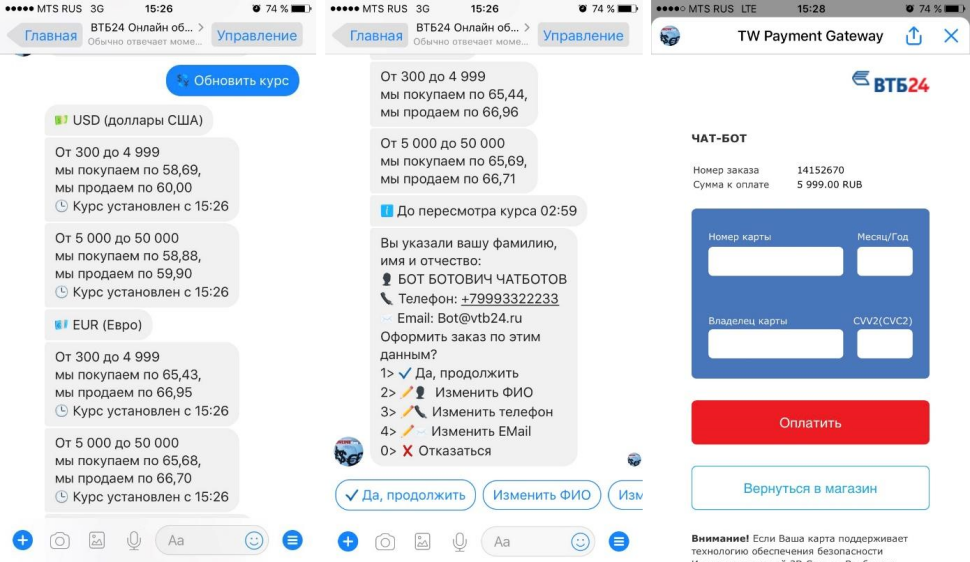
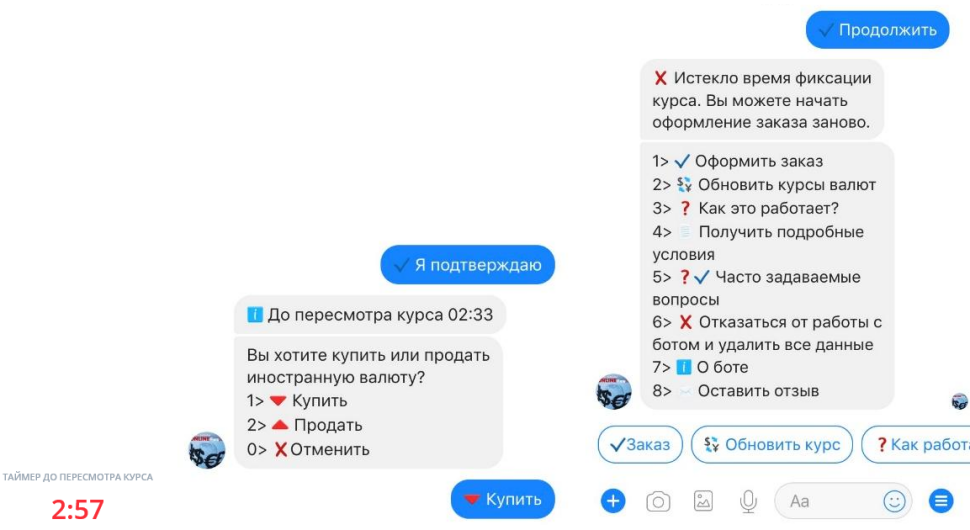
Обмен валюты: фиксируем курс для оффлайна в онлайне. Опыт ВТБ24 |


{
"deal_candidates":
[
{
"direction": "buy",
"amount":500,
"ISOCode": "USD"},
{
"direction": "sell",
"amount":500,
"ISOCode": "USD"}
]
}|
Метки: author tashanov платежные системы api блог компании втб втб24 сервис обмен валюты чат-бот |
Динамическая инструментация — не просто, а тривиально*: пишем yet another инструментацию для American Fuzzy Lop |
 (*) На самом деле, не совсем.
(*) На самом деле, не совсем.
Наверное, многие слышали про Valgrind — отладчик, который может сказать, где в вашей нативной программе утечка памяти, где ветвление зависит от неинициализированной переменной и многое другое (а ведь кроме memcheck, у него есть и другие режимы работы). Внутри себя эта чудо-программа перемалывает нативный код в некий промежуточный байткод, инструментирует его и генерирует новый машинный код — уже с run-time проверками. Но есть проблема: Valgrind не умеет работать под Windows. Когда мне это понадобилось, поиски привели меня к аналогичной утилите под названием DrMemory, также с ней в комплекте был аналог strace. Но речь не столько о них, сколько о библиотеке динамической инструментации, на базе которой они построены, DynamoRIO. В какой-то момент я заинтересовался этой библиотекой с точки зрения написания собственной инструментации, начал искать документацию, набрёл на большое количество примеров и был поражён тем, что простенькую, но законченную инструментацию вроде подсчёта инструкций вызова можно написать буквально в 237 строк сишного кода, 32 из которых — лицензия, а 8 — описание. Нет, это, конечно не "пишем убийцу Valgrind в 30 строк кода на JavaScript", но сильно проще, чем то, что можно представить для подобной задачи.
В качестве примера давайте напишем уже четвёртую реализацию инструментации для фаззера American Fuzzy Lop, о котором недавно уже писали на Хабре.
AFL — это инструмент для поиска багов и уязвимостей на основе guided fuzzing, собранный из железобетонных костылей эвристик, реализованных максимально тривиальным и эффективным способом. Вот так смотришь на инструмент, способный, наблюдая за поведением libjpeg, синтезировать валидные джипеги, и поражаешься, что всё это сделано на основе не такой уж и заумной механики. Вкратце, для полноценной работы AFL целевой бинарник должен быть инструментирован таким образом, чтобы в процессе выполнения собирать рёберное покрытие: представим себе каждый базовый блок (basic block, что-то вроде последовательности инструкций от метки и до ближайшей инструкции перехода) в качестве вершины графа. Рёбра — это возможные пути передачи управления между ББ. Соответственно, AFL интересует то, какие переходы и в каком примерно количестве происходили между базовыми блоками программы.
Основной способ инструментации в AFL — статическая на этапе компиляции с помощью обёрток afl-gcc / afl-g++ или их аналогов для clang. Что забавно, afl-gcc подменяет вызываемую команду as на обёртку, переписывающую ассемблерный листинг, сгенерированный компилятором. Есть и более продвинутый вариант, называемый llvm mode, который честно встраивается в процесс компиляции (производимой с помощью LLVM, естественно) и, теоретически, должен поэтому давать большую производительность генерируемого кода. Наконец, для фаззинга уже скомпилированных бинарников есть qemu mode — патч к QEMU в режиме эмуляции одного процесса, добавляющий необходимую инструментацию (изначально этот режим работы QEMU предназначался, чтобы запускать отдельные процессы, собранные для другой архитектуры, используя хостовое ядро).
DynamoRIO — это система динамической инструментации (то есть она инструментирует уже скомпилированные бинарники прямо во время выполнения), работающая на Windows, Linux и Android на архитектурах x86 и x86_64, а также ARM (поддержка AArch64 есть в release candidate версии 7.0). В отличие от QEMU, она предназначена не для исполнения программ "близко к тексту" на чужой архитектуре, а для лёгкого создания собственных инструментаций, модифицирующих поведение программы на родной архитектуре. При этом ставится цель по возможности не портить оптимизированный код. К сожалению, я так и не нашёл способ, при котором клиенты (так называются пользовательские библиотеки инструментации) могли бы не знать о целевом наборе инструкций (кроме каких-то тривиальных случаев, где достаточно кроссплатформенных обёрток для базовых инструкций), поскольку не происходит конверсии "машинный код -> байткод — [инструментация] -> новый байткод -> инструментированный машинный код". Вместо этого на каждый транслируемый базовый блок происходит передача клиенту списка декодированных инструкций, который он может изменять и дополнять с помощью удобных функций и макросов. То есть в машинных кодах программировать не нужно, но набор инструкций x86 (или другой платформы) знать, скорее всего, придётся.
В качестве небольшого бонуса: полез я посмотреть, что ещё есть интересного в их аккаунте на Гитхабе, и набрёл на занятный репозиторий: DRK. Репозиторий, похоже, заброшен и несколько потерял актуальность, но описание впечатляет:
DRK is DynamoRIO as a loadable Linux Kernel module. When DRK is loaded, all kernel-mode execution (system calls, interrupt & exception handlers, kernel threads, etc.) happens under the purview of DynamoRIO whereas user-mode execution is untouched — the inverse of normal DynamoRIO, which instruments a user-mode process and doesn't touch kernel-mode execution.
Для начала посмотрим, на что в принципе способен AFL. Нет, мы не будем брать уязвимую версию какой-нибудь библиотеки и ждать часы или сутки. Для теста напишем максимально тупую программу, которая разыменовывает нулевой указатель, если на stdin подать ей строку, начинающуюся с букв NULL. Это, конечно, не синтез джипега из ниоткуда, но зато и ждать почти не нужно.
Итак, скачаем AFL отсюда и соберём его. Как вы уже, наверное, догадались, собирать будем под GNU/Linux. Впрочем, другие Unix-like системы и Юниксы вроде Mac OS X тоже должны работать. Возьмём небольшую программку:
#include
#include
volatile int *ptr = NULL;
const char cmd[] = "NULL";
int main(int argc, char *argv[]) {
char buf[16];
fgets(buf, sizeof buf, stdin);
if (strncmp(buf, cmd, 4)) {
return 0;
}
*ptr = 1;
return 0;
}
Скомпилируем её и запустим фаззинг:
$ export AFL_PATH=~/tmp/build/afl-2.42b/
$ # Запустим стандартную обёртку, которая статически добавит инструментацию
$ $AFL_PATH/afl-gcc example-bug-libc.c -o example-bug-libc
$ # Создадим какой-нибудь пример входного файла (можно несколько)
$ mkdir input
$ echo test > input/1
$ # Запустим фаззер
$ $AFL_PATH/afl-fuzz -i input -o output -- ./example-bug-libcИ что же мы видим:

Как-то оно не работает… Обратите внимание на строчку last new path: AFL ругается, что по прошествии 91 тысячи запусков он так и не нашёл новый путь. На самом деле это вполне логично: напомню, мы использовали статическую инструментацию на этапе вызова ассемблера. Основное же сравнение делает функция из libc, которая не инструментирована, и поэтому не получится посчитать количество совпавших символов. Так я думал, пока не решил это проверить, но оказалось, что наш бинарник не импортирует функцию strncmp. Судя по выводу objdump -d, компилятор просто сгенерировал на месте strncmp инструкцию с префиксом вместо цикла, куда можно было бы впихнуть инструментацию.
00000000000007f0 <.plt.got>:
7f0: ff 25 82 17 20 00 jmpq *0x201782(%rip) # 201f78 <getenv@glibc_2.2.5>
7f6: 66 90 xchg %ax,%ax
7f8: ff 25 8a 17 20 00 jmpq *0x20178a(%rip) # 201f88 <_exit@GLIBC_2.2.5>
7fe: 66 90 xchg %ax,%ax
800: ff 25 8a 17 20 00 jmpq *0x20178a(%rip) # 201f90 <write@glibc_2.2.5>
806: 66 90 xchg %ax,%ax
808: ff 25 8a 17 20 00 jmpq *0x20178a(%rip) # 201f98 <__stack_chk_fail@GLIBC_2.4>
80e: 66 90 xchg %ax,%ax
810: ff 25 8a 17 20 00 jmpq *0x20178a(%rip) # 201fa0 <close@glibc_2.2.5>
816: 66 90 xchg %ax,%ax
818: ff 25 8a 17 20 00 jmpq *0x20178a(%rip) # 201fa8 <read@glibc_2.2.5>
81e: 66 90 xchg %ax,%ax
820: ff 25 92 17 20 00 jmpq *0x201792(%rip) # 201fb8 <fgets@glibc_2.2.5>
826: 66 90 xchg %ax,%ax
828: ff 25 9a 17 20 00 jmpq *0x20179a(%rip) # 201fc8 <waitpid@glibc_2.2.5>
82e: 66 90 xchg %ax,%ax
830: ff 25 a2 17 20 00 jmpq *0x2017a2(%rip) # 201fd8 <shmat@glibc_2.2.5>
836: 66 90 xchg %ax,%ax
838: ff 25 a2 17 20 00 jmpq *0x2017a2(%rip) # 201fe0 <atoi@glibc_2.2.5>
83e: 66 90 xchg %ax,%ax
840: ff 25 aa 17 20 00 jmpq *0x2017aa(%rip) # 201ff0 <__cxa_finalize@GLIBC_2.2.5>
846: 66 90 xchg %ax,%ax
848: ff 25 aa 17 20 00 jmpq *0x2017aa(%rip) # 201ff8 <fork@glibc_2.2.5>
84e: 66 90 xchg %ax,%ax
...
0000000000000850 :
850: 48 8d a4 24 68 ff ff lea -0x98(%rsp),%rsp
857: ff
858: 48 89 14 24 mov %rdx,(%rsp)
85c: 48 89 4c 24 08 mov %rcx,0x8(%rsp)
861: 48 89 44 24 10 mov %rax,0x10(%rsp)
866: 48 c7 c1 04 6a 00 00 mov $0x6a04,%rcx
86d: e8 9e 02 00 00 callq b10 <__afl_maybe_log>
872: 48 8b 44 24 10 mov 0x10(%rsp),%rax
877: 48 8b 4c 24 08 mov 0x8(%rsp),%rcx
87c: 48 8b 14 24 mov (%rsp),%rdx
880: 48 8d a4 24 98 00 00 lea 0x98(%rsp),%rsp
887: 00
888: 53 push %rbx
889: be 10 00 00 00 mov $0x10,%esi
88e: 48 83 ec 20 sub $0x20,%rsp
892: 48 8b 15 77 17 20 00 mov 0x201777(%rip),%rdx # 202010 <stdin@@glibc_2.2.5>
899: 48 89 e7 mov %rsp,%rdi
89c: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
8a3: 00 00
8a5: 48 89 44 24 18 mov %rax,0x18(%rsp)
8aa: 31 c0 xor %eax,%eax
8ac: e8 6f ff ff ff callq 820 <.plt.got+0x30>
8b1: 48 8d 3d dc 06 00 00 lea 0x6dc(%rip),%rdi # f94
8b8: b9 04 00 00 00 mov $0x4,%ecx
8bd: 48 89 e6 mov %rsp,%rsi
8c0: f3 a6 repz cmpsb %es:(%rdi),%ds:(%rsi)
8c2: 75 45 jne 909
8c4: 48 8d a4 24 68 ff ff lea -0x98(%rsp),%rsp
8cb: ff
8cc: 48 89 14 24 mov %rdx,(%rsp)
8d0: 48 89 4c 24 08 mov %rcx,0x8(%rsp)
8d5: 48 89 44 24 10 mov %rax,0x10(%rsp)
8da: 48 c7 c1 2d 5b 00 00 mov $0x5b2d,%rcx
8e1: e8 2a 02 00 00 callq b10 <__afl_maybe_log>
8e6: 48 8b 44 24 10 mov 0x10(%rsp),%rax
8eb: 48 8b 4c 24 08 mov 0x8(%rsp),%rcx
8f0: 48 8b 14 24 mov (%rsp),%rdx
8f4: 48 8d a4 24 98 00 00 lea 0x98(%rsp),%rsp
8fb: 00
8fc: 48 8b 05 1d 17 20 00 mov 0x20171d(%rip),%rax # 202020
903: c7 00 01 00 00 00 movl $0x1,(%rax)
909: 0f 1f 00 nopl (%rax)
90c: 48 8d a4 24 68 ff ff lea -0x98(%rsp),%rsp
913: ff
914: 48 89 14 24 mov %rdx,(%rsp)
918: 48 89 4c 24 08 mov %rcx,0x8(%rsp)
91d: 48 89 44 24 10 mov %rax,0x10(%rsp)
922: 48 c7 c1 8f 33 00 00 mov $0x338f,%rcx
929: e8 e2 01 00 00 callq b10 <__afl_maybe_log>
92e: 48 8b 44 24 10 mov 0x10(%rsp),%rax
933: 48 8b 4c 24 08 mov 0x8(%rsp),%rcx
938: 48 8b 14 24 mov (%rsp),%rdx
93c: 48 8d a4 24 98 00 00 lea 0x98(%rsp),%rsp
943: 00
944: 31 c0 xor %eax,%eax
946: 48 8b 54 24 18 mov 0x18(%rsp),%rdx
94b: 64 48 33 14 25 28 00 xor %fs:0x28,%rdx
952: 00 00
954: 75 40 jne 996
956: 66 90 xchg %ax,%ax
958: 48 8d a4 24 68 ff ff lea -0x98(%rsp),%rsp
95f: ff
960: 48 89 14 24 mov %rdx,(%rsp)
964: 48 89 4c 24 08 mov %rcx,0x8(%rsp)
969: 48 89 44 24 10 mov %rax,0x10(%rsp)
96e: 48 c7 c1 0a 7d 00 00 mov $0x7d0a,%rcx
975: e8 96 01 00 00 callq b10 <__afl_maybe_log>
97a: 48 8b 44 24 10 mov 0x10(%rsp),%rax
97f: 48 8b 4c 24 08 mov 0x8(%rsp),%rcx
984: 48 8b 14 24 mov (%rsp),%rdx
988: 48 8d a4 24 98 00 00 lea 0x98(%rsp),%rsp
98f: 00
990: 48 83 c4 20 add $0x20,%rsp
994: 5b pop %rbx
995: c3 retq
996: 66 90 xchg %ax,%ax
998: 48 8d a4 24 68 ff ff lea -0x98(%rsp),%rsp
99f: ff
9a0: 48 89 14 24 mov %rdx,(%rsp)
9a4: 48 89 4c 24 08 mov %rcx,0x8(%rsp)
9a9: 48 89 44 24 10 mov %rax,0x10(%rsp)
9ae: 48 c7 c1 a8 dc 00 00 mov $0xdca8,%rcx
9b5: e8 56 01 00 00 callq b10 <__afl_maybe_log>
9ba: 48 8b 44 24 10 mov 0x10(%rsp),%rax
9bf: 48 8b 4c 24 08 mov 0x8(%rsp),%rcx
9c4: 48 8b 14 24 mov (%rsp),%rdx
9c8: 48 8d a4 24 98 00 00 lea 0x98(%rsp),%rsp
9cf: 00
9d0: e8 33 fe ff ff callq 808 <.plt.got+0x18>
9d5: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
9dc: 00 00 00
9df: 90 nop 0000000000000630 <.plt.got>:
630: ff 25 82 09 20 00 jmpq *0x200982(%rip) # 200fb8 <strncmp@glibc_2.2.5>
636: 66 90 xchg %ax,%ax
638: ff 25 8a 09 20 00 jmpq *0x20098a(%rip) # 200fc8 <__stack_chk_fail@GLIBC_2.4>
63e: 66 90 xchg %ax,%ax
640: ff 25 92 09 20 00 jmpq *0x200992(%rip) # 200fd8 <fgets@glibc_2.2.5>
646: 66 90 xchg %ax,%ax
648: ff 25 aa 09 20 00 jmpq *0x2009aa(%rip) # 200ff8 <__cxa_finalize@GLIBC_2.2.5>
64e: 66 90 xchg %ax,%ax
...
0000000000000780 :
780: 55 push %rbp
781: 48 89 e5 mov %rsp,%rbp
784: 48 83 ec 30 sub $0x30,%rsp
788: 89 7d dc mov %edi,-0x24(%rbp)
78b: 48 89 75 d0 mov %rsi,-0x30(%rbp)
78f: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
796: 00 00
798: 48 89 45 f8 mov %rax,-0x8(%rbp)
79c: 31 c0 xor %eax,%eax
79e: 48 8b 15 6b 08 20 00 mov 0x20086b(%rip),%rdx # 201010 <stdin@@glibc_2.2.5>
7a5: 48 8d 45 e0 lea -0x20(%rbp),%rax
7a9: be 10 00 00 00 mov $0x10,%esi
7ae: 48 89 c7 mov %rax,%rdi
7b1: e8 8a fe ff ff callq 640 <.plt.got+0x10>
7b6: 48 8d 45 e0 lea -0x20(%rbp),%rax
7ba: ba 04 00 00 00 mov $0x4,%edx
7bf: 48 8d 35 ce 00 00 00 lea 0xce(%rip),%rsi # 894
7c6: 48 89 c7 mov %rax,%rdi
7c9: e8 62 fe ff ff callq 630 <.plt.got>
7ce: 85 c0 test %eax,%eax
7d0: 74 07 je 7d9
7d2: b8 00 00 00 00 mov $0x0,%eax
7d7: eb 12 jmp 7eb
7d9: 48 8b 05 40 08 20 00 mov 0x200840(%rip),%rax # 201020
7e0: c7 00 01 00 00 00 movl $0x1,(%rax)
7e6: b8 00 00 00 00 mov $0x0,%eax
7eb: 48 8b 4d f8 mov -0x8(%rbp),%rcx
7ef: 64 48 33 0c 25 28 00 xor %fs:0x28,%rcx
7f6: 00 00
7f8: 74 05 je 7ff
7fa: e8 39 fe ff ff callq 638 <.plt.got+0x8>
7ff: c9 leaveq
800: c3 retq
801: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
808: 00 00 00
80b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1) Что интересно, похоже, AFL сам включил оптимизацию, потому что в неинструментированном коде честно вызывается strncmp. Что же до разбухшей PLT в коде, собранном afl-gcc, то, судя по всему, мы видим функции, вызываемые forkserver-ом — его мы тоже напишем, но обо всём по порядку. Хорошо, сделаем вид, что этого не видели, и попробуем наивным образом переписать наш пример без библиотечных функций:
#include
volatile int *ptr = NULL;
const char cmd[] = "NULL";
int main(int argc, char *argv[]) {
char buf[16];
fgets(buf, sizeof buf, stdin);
for (int i = 0; i < sizeof cmd - 1; ++i) {
if (buf[i] != cmd[i])
return 0;
}
*ptr = 1;
return 0;
}Компилируем, запускаем и… тадам!

Как я уже говорил, AFL предполагает наличие инструментации, собирающей информацию о переходах между базовыми блоками исследуемой программы. Но есть и ещё одна оптимизация, добавляемая afl-gcc: forkserver. Смысл её в том, чтобы не перезапускать программу с помощью связки fork-execve, каждый раз выполняя динамическую линковку и т. д., а один раз внутри процесса фаззера сделать fork, потом execve в инструментированную программу. Как же мы будем перезапускать исследуемую программу? Смысл в том, что тестировать мы будем не этот запущенный процесс. Вместо этого в нём запускается код, который в бесконечном цикле ждёт команды от фаззера, делает fork, ждёт завершения дочернего процесса и отзванивается о результате. А вот отпочковавшийся процесс уже реально обрабатывает входные данные и собирает информацию о рёберном покрытии. В случае afl-gcc, если я правильно понимаю его логику, forkserver запускается при первом обращении к инструментированному коду. В случае же llvm mode также поддерживается режим deferred forkserver — таким образом можно пропустить не только динамическую линковку, но и стандартную для исследуемого процесса инициализацию, что потенциально может ускорить весь процесс на порядки, но нужно учитывать некоторые нюансы:
fork создаёт копию процесса, но в этой копии будет только тот поток, который и сделал вызов forkТакже в llvm mode поддерживается persistent mode, в котором несколько тестовых примеров подряд выполняются внутри одного отпочкованного процесса. Наверное, это ещё больше снижает накладные расходы, но при этом есть опасность, что результат выполнения программы на очередном тестовом примере будет зависеть не только от текущего примера, но и от истории запусков. Кстати, уже после начала написания статьи я наткнулся на информацию о том, что порт AFL на Windows тоже использует DynamoRIO для инструментации, и он как раз использует persistent mode. Ну а что ему ещё остаётся без поддержки fork?
Итак, нужно написать свой forkserver на DynamoRIO, но для начала нужно понять требуемый протокол его взаимодействия с процессом фаззера. Что-то можно почерпнуть по указанной выше ссылке на блог автора AFL, но проще найти в каталоге фаззера файл llvm_mode/afl-llvm-rt.o.c. В нём есть много интересного, но для начала посмотрим на функцию __afl_start_forkserver — там всё подробно описывается, даже с комментариями. Persistent mode нас не интересует, в остальном всё довольно понятно: нам дано два файловых дескриптора с известными номерами — из одного читаем, в другой пишем. Нам нужно:
child_stopped == 0, то что именно мы прочитали, значения не имеет.И вот мы, собственно, подошли к написанию своего клиента. Тут нужно сделать лирическое отступление о том, что хотя примеры из документации и занимают всего пару сотен строчек, но документацию почитать всё-таки стоит. Начать можно, например, отсюда, где, в частности, написано о том, чего делать не стоит. Например, перефразировав известного литературного персонажа, можно сказать, что "клиент инструментации — это очень уж странный предмет: вроде он есть, но его как бы нет", что в документации именуется client transparency: в частности, нужно пользоваться своими копиями системных библиотек (в чём поможет private loader), либо пользоваться API DynamoRIO (выделение памяти, разбор опций командной строки и многое другое). Также важная информация есть в документации на функции API: например, в описании функции dr_register_bb_event указан краткий список из 11 пунктов, чему должна удовлетворять получившаяся последовательность инструкций после инструментации.
Для управления сборкой клиентов для DynamoRIO рекомендуется использовать CMake — им мы и воспользуемся. О том, как это сделать, можно прочитать в документации, мы же перейдём к более интересным вопросам. Например, для того, чтобы сделать deferred forkserver, нам нужно как-то пометить место его запуска в исследуемой программе, а потом найти эту пометку в DynamoRIO (впрочем, вроде бы ничто не мешает сделать forkserver просто в виде вызова обычной функции внутри исследуемой программы, но ведь так же не интересно, правда?), К счастью, подобная функциональность встроена в DynamoRIO и называется аннотациями. Разработчик клиента должен собрать специальную статическую библиотеку, которую нужно прилинковать к исследуемой программе, и в требуемом месте вызвать функцию из этой библиотеки, последовательность инструкций в которой не делает ничего интересного при обычном исполнении, но при запуске под DynamoRIO распознаётся им и заменяется на определённую константу или вызов функции.
Не буду повторять официальный учебник, скажу лишь, что предлагается скопировать заголовочный файл из поставки DynamoRIO, переделать в нём "вызов" двух макросов под название и сигнатуру нашей аннотации (этот файл нужно будет подключить в тестируемую программу), а также создать сишный исходник с ещё одним вызовом макроса, который сгенерирует реализацию заглушки для аннотации (из него будет собрана статическая библиотека, которую нужно прилинковать к тестируемой программе).
По поводу реализации forkserver-а всё тоже довольно прямолинейно, за исключением того, что, вероятно, не очень правильно вызывать fork из нашей копии libc: например, автор AFL в указанной выше статье про особенности реализации forkserver говорил о том, что libc кеширует PID. В случае же вызова fork из копии libc исследуемого приложения и оно будет знать про произошедший вызов fork, и DynamoRIO это, хочется верить, тоже заметит. Поэтому пришлось написать что-то вроде
module_data_t *module = dr_lookup_module_by_name("libc.so.6");
EXIT_IF_FAILED(module != NULL, "Cannot lookup libc.\n", 1)
fork_fun_t fork_ptr = (fork_fun_t)dr_get_proc_address(module->handle, "fork");
EXIT_IF_FAILED(fork_ptr != NULL, "Cannot get fork function from libc.\n", 1)
dr_free_module_data(module);Поэтому, чтобы поддержать традиционный режим запуска forkserver-а при старте программы, нужно убедиться, что к этому моменту уже доступна libc.
Когда я попытался это протестировать, я столкнулся со странным поведением: тестируемая программа запускалась, а forkserver — нет. Я добавил в dr_client_main печать на консоль — её тоже не появилось. Переключился на сборочный каталог чернового варианта кода. Хм… работает. Сравнил вывод nm -D на рабочей и нерабочей библиотеке инструментации: и там, и там есть функция dr_client_main. Сравнил ещё раз — действительно есть… Указал для drrun опции -verbose -debug. В общем, после некого количества экспериментов выяснилось, что дело было не в библиотеке клиента, и даже не в тестовой программе. Просто для чернового сборочного каталога QtCreator создал путь .../build-afl-dr-Desktop_3fb6e5-Выпуск, а для "рабочего" — .../build-afl-dr-Desktop-По умолчанию. Ну вы поняли, во втором был пробел. Нет, я понимаю, что некоторые программы не работают, когда в пути есть пробелы, но втихаря выкинуть библиотеку инструментации, это, конечно, креативненько… (Да, я отправил баг-репорт.)
Тестируем:
$ ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug
Running forkserver...
Cannot connect to fuzzer.
1
$ ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug 198<&0 199>/dev/null
Running forkserver...
xxxx
1
Incorrect spawn command from fuzzer.Ну, более-менее работает. Проверим, как отнесётся к нему AFL. Для этого запустим его в dumb mode (не собирать рёберное покрытие), но попросим его всё-таки использовать forkserver:
$ AFL_DUMB_FORKSRV=1 $AFL_PATH/afl-fuzz -i input -o output -n -- ./example-bug
... что-то там про Fork server handshake failed -- правильно, инструментации нет ...
$ AFL_DUMB_FORKSRV=1 $AFL_PATH/afl-fuzz -i input -o output -n -- ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug
... что-то там про Timeout while initializing fork server (adjusting -t may help)
$ # изучаем логи strace-а и...
$ AFL_DUMB_FORKSRV=1 $AFL_PATH/afl-fuzz -i input -o output -n -m 2048 -- ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug
... всё работает, если дать больше памяти (опция -m)

Впрочем, скорость не ахти. Но речь пока о работе на качественном уровне.
И тут обнаружилась проблема: хотя с тестовой программой такой forkserver работает нормально, некоторые программы с ним просто рушатся по SIGSEGV. После некого времени, потраченного на отладку, ответа так и не появилось, однако оказалось, что в качестве обходного пути можно вызывать fork из копии libc, принадлежащей клиенту, а не приложению. Ну что же, это повод познакомиться с extension под названием droption. Чтобы его использовать, нужно всего лишь объявить статическую переменную типа dr_option_t, в параметрах указав имя опции, описание и значение по умолчанию, а в начале dr_client_main вызвать droption_parser_t::parse_argv(...) (да, клиент теперь у нас получается на C++). Внезапно оказалось, что документация на сайте относится к версии 7.0 RC1, а в 6.2.0-2 документация на это расширение отсутствует, и стандартным способом через CMake именно droption почему-то не подключается. Но само расширение есть. Впрочем, нам нужен лишь путь к заголовочным файлам, поэтому просто подключим другое расширение с тем же путём, например, drutil.
В итоге получились следующие реализации:
// Based on dr_annotations.h from DynamoRIO sources
#ifndef _AFL_DR_ANNOTATIONS_H_
#define _AFL_DR_ANNOTATIONS_H_ 1
#include "annotations/dr_annotations_asm.h"
/* To simplify project configuration, this pragma excludes the file from GCC warnings. */
#ifdef __GNUC__
# pragma GCC system_header
#endif
#define RUN_FORKSERVER() \
DR_ANNOTATION(run_forkserver)
#ifdef __cplusplus
extern "C" {
#endif
DR_DECLARE_ANNOTATION(void, run_forkserver, ());
#ifdef __cplusplus
}
#endif
#endif#include "afl-annotations.h"
DR_DEFINE_ANNOTATION(void, run_forkserver, (), );#include
#include
#include
#include
#include opt_private_fork(DROPTION_SCOPE_CLIENT, "private-fork", false,
"Use fork function from the private libc",
"Use fork function from the private libc");
static void parse_options(int argc, const char *argv[]) {
std::string parse_err;
if (!droption_parser_t::parse_argv(DROPTION_SCOPE_CLIENT, argc, argv, &parse_err, NULL)) {
dr_fprintf(STDERR, "Incorrect client options: %s\n", parse_err.c_str());
dr_exit_process(1);
}
}
static void start_forkserver() {
// For references, see https://lcamtuf.blogspot.ru/2014/10/fuzzing-binaries-without-execve.html
// and __afl_start_forkserver in llvm_mode/afl-llvm-rt.o.c from AFL sources
static bool forkserver_is_running = false;
uint32_t unused_four_bytes = 0;
uint32_t was_killed;
if (!forkserver_is_running) {
dr_printf("Running forkserver...\n");
forkserver_is_running = true;
} else {
dr_printf("Warning: Attempt to re-run forkserver ignored.\n");
return;
}
if (write(TO_FUZZER_FD, &unused_four_bytes, 4) != 4) {
dr_printf("Cannot connect to fuzzer.\n");
return;
}
fork_fun_t fork_ptr;
// Lookup the fork function from target application, so both DynamoRIO
// and application's copy of libc know about fork
// Currently causes crashes sometimes, in that case use the private libc's fork.
if (!opt_private_fork.get_value()) {
module_data_t *module = dr_lookup_module_by_name("libc.so.6");
EXIT_IF_FAILED(module != NULL, "Cannot lookup libc.\n", 1)
fork_ptr = (fork_fun_t)dr_get_proc_address(module->handle, "fork");
EXIT_IF_FAILED(fork_ptr != NULL, "Cannot get fork function from libc.\n", 1)
dr_free_module_data(module);
} else {
fork_ptr = fork;
}
while (true) {
EXIT_IF_FAILED(read(FROM_FUZZER_FD, &was_killed, 4) == 4, "Incorrect spawn command from fuzzer.\n", 1)
int child_pid = fork_ptr();
EXIT_IF_FAILED(child_pid >= 0, "Cannot fork.\n", 1)
if (child_pid == 0) {
close(TO_FUZZER_FD);
close(FROM_FUZZER_FD);
return;
} else {
int status;
EXIT_IF_FAILED(write(TO_FUZZER_FD, &child_pid, 4) == 4, "Cannot write child PID.\n", 1)
EXIT_IF_FAILED(waitpid(child_pid, &status, 0) >= 0, "Wait for child failed.\n", 1)
EXIT_IF_FAILED(write(TO_FUZZER_FD, &status, 4) == 4, "Cannot write child exit status.\n", 1)
}
}
}
DR_EXPORT void dr_client_main(client_id_t id, int argc, const char *argv[]) {
parse_options(argc, argv);
EXIT_IF_FAILED(
dr_annotation_register_call("run_forkserver", (void *)start_forkserver, false, 0, DR_ANNOTATION_CALL_TYPE_FASTCALL),
"Cannot register forkserver annotation.\n", 1);
} И вот, наконец, настало время приступить к полноценному перекорёживанию машинного кода. Как и в прошлый раз, не будем изобретать велосипед, а посмотрим в исходниках AFL, как делается существующая инструментация. А именно, изменения вносимые afl-gcc описаны в afl-as.c, а сам вписываемый ассемблерный код находится в виде строковых литералов в afl-as.h. Подробности работы AFL и, в частности, используемая инструментация, описаны в официальном документе technical details. По сути, в места ветвления программы вписывается код эквивалентный
cur_location = ;
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;(псевдокод нагло позаимствован из документации AFL). Каждая локация помечается случайным идентификатором, а ребру в графе переходов соответствует байт в карте с номером, состоящим из поксоренных идентификаторов текущей и предыдущей локации, причём один из идентификаторов сдвигается на 1 — это позволяет сделать рёбра ориентированными. Для взаимодействия с процессом фаззера программе через переменную окружения передаётся ссылка на 64-килобайтную карту в shared memory, пример работы с которой можно посмотреть всё в том же файле llvm_mode/afl-llvm-rt.o.c.
О том, как это всё реализовать с помощью DynamoRIO, есть ещё один официальный учебник. Суть в том, что при наступлении некоторых событий (таких как трансляция очередного базового блока или, например, запуск / остановка потока) DynamoRIO вызывает зарегистрированные обработчики. Поскольку мы хотим дописывать машинный код в каждый базовый блок, то нам потребуется зарегистрировать свой обработчик с помощью функции dr_register_bb_event. Также, последуем совету из туториала, и вместо атомарных операций инкремента будем использовать thread-local карты, а по завершении потока всё суммировать, поэтому нам также понадобится подписаться на создание и завершение потоков и создать мьютекс для синхронизации обращения к глобальной карте. Наконец, по-хорошему, мьютекс надо бы удалить в конце работы, поэтому подпишемся ещё и на завершение работы программы:
// Внутри dr_client_main:
lock = dr_mutex_create();
dr_register_thread_init_event(event_thread_init);
dr_register_thread_exit_event(event_thread_exit);
dr_register_bb_event(event_basic_block);
dr_register_exit_event(event_exit);Обработчики создания и удаления потоков довольно бесхитростны:
typedef struct {
uint64_t scratch;
uint8_t map[MAP_SIZE];
} thread_data;
static void event_thread_init(void *drcontext) {
void *data = dr_thread_alloc(drcontext, sizeof(thread_data));
memset(data, 0, sizeof(thread_data));
dr_set_tls_field(drcontext, data);
}
static void event_thread_exit(void *drcontext) {
thread_data *data = (thread_data *) dr_get_tls_field(drcontext);
dr_mutex_lock(lock);
for (int i = 0; i < MAP_SIZE; ++i) {
shmem[i] += data->map[i];
}
dr_mutex_unlock(lock);
dr_thread_free(drcontext, data, sizeof(thread_data));
}… а удаление мьютекса я даже приводить не буду. Из интересного в этом коде стоит обратить внимание, во-первых, на то, что DynamoRIO имеет собственные функции и для выделения памяти, и для примитивов синхронизации, причём есть вариант аллокатора с thread-specific memory pool. Во-вторых, здесь мы видим создание глобальных-на-уровне-потока структур thread_data, чей адрес мы заносим в tls field.
И вот, мы подошли к сути происходящего: функции event_basic_block(void *drcontext, void *tag, instrlist_t *bb, bool for_trace, bool translating), которая и занимается переписыванием машинного кода. Как я и обещал, нам не придётся ворочать шестнадцатиричные коды инструкций и высчитывать байты — инструкции придут к нам уже в декодированном виде в параметре instrlist_t *bb. Есть даже несколько макросов для кроссплатформенной (в плане архитектуры процессора) генерации наиболее типичных инструкций, но, увы, нам всё же придётся разбираться с ассемблером amd64 aka x86_64. Читать документацию по используемым функциям DynamoRIO вообще полезно, а в случае с dr_register_bb_event это полезно вдвойне. Например, вот что понимается под basic block:
DR constructs dynamic basic blocks, which are distinct from a compiler's classic basic blocks. DR does not know all entry points ahead of time, and will end up duplicating the tail of a basic block if a later entry point is discovered that targets the middle of a block created earlier, or if a later entry point targets straight-line code that falls through into code already present in a block.
Также, там имеется список ограничений на результирующий машинный код, который может получаться после инструментации — при написании своих клиентов обязательно почитайте!
Для работы нашей инструментации нам понадобится два регистра. Также мы будем выполнять арифметические операции, целую одну штуку, поэтому нужно сохранить флаги вроде признака переполнения:
static dr_emit_flags_t event_basic_block(void *drcontext, void *tag, instrlist_t *bb,
bool for_trace, bool translating) {
instr_t *where = instrlist_first(bb);
reg_id_t tls_reg = DR_REG_XDI, offset_reg = DR_REG_XDX;
dr_save_arith_flags(drcontext, bb, where, SPILL_SLOT_1);
dr_save_reg(drcontext, bb, where, tls_reg, SPILL_SLOT_2);
dr_save_reg(drcontext, bb, where, offset_reg, SPILL_SLOT_3);
dr_insert_read_tls_field(drcontext, bb, where, tls_reg);
// здесь будет дописываться инструментация
dr_restore_reg(drcontext, bb, where, offset_reg, SPILL_SLOT_3);
dr_restore_reg(drcontext, bb, where, tls_reg, SPILL_SLOT_2);
dr_restore_arith_flags(drcontext, bb, where, SPILL_SLOT_1);
return DR_EMIT_DEFAULT;
}В tls_reg тут же положим адрес нашей структуры с временной картой для текущего потока. Также в приведённом выше псевдокоде из документации фигурирует COMPILE_TIME_RANDOM. Проблема с использованием случайных идентификаторов в том, что наш event_basic_block может вызываться несколько раз: обратите внимание на аргументы for_trace и translating. Дело в том, что, кроме трансляции отдельных блоков, наиболее часто встречающиеся цепочки блоков DynamoRIO собирает в трейсы. Перед тем, как добавить блок в трейс, ещё раз вызываются зарегистрированные обработчики трансляции базового блока, но уже с for_trace = true, в которых можно сгенерировать специальную инструментацию для помещения блока в трейс. Также иногда возникает необходимость понять, какому реальному адресу кода соответствует кешированный, на котором произошло некое событие, тогда наш обработчик вызывается с translating = true — тут уже, конечно, нужно повторить ровно те же преобразования, как с translating = false. Впрочем, можно вернуть из обработчика DR_EMIT_STORE_TRANSLATIONS вместо DR_EMIT_DEFAULT, и адреса будут запомнены за нас, но на это потребуются дополнительные ресурсы. Даже, если бы никаких повторных вызовов не предполагалось бы by design, всё равно пришлось бы хитро координировать наши случайные метки с учётом того, что часть будет создана уже после форка процесса. Поэтому просто будем давать идентификатор как функцию от адреса кода, где лежит basic block.
void *app_pc = dr_fragment_app_pc(tag);
uint32_t cur_location = ((uint32_t)(uintptr_t)app_pc * (uint32_t)33533) & 0xFFFF;Если уже после форка будут загружены дополнительные динамические библиотеки, то ASLR испортит нам планы, но будем считать это редким случаем. Кстати, "если припрёт", рандомизацию можно временно отключить для всей системы с помощью sysctl -w kernel.randomize_va_space=0.
Наконец, сам сбор рёберного покрытия. Нам нужно добавить четыре инструкции. Для этого в API имеются удобные функции и макросы для создания инструкций, операндов разных видов и т. д.:
instrlist_meta_preinsert(bb, where,
XINST_CREATE_load(drcontext,
opnd_create_reg(offset_reg),
OPND_CREATE_MEM64(tls_reg, offsetof(thread_data, scratch))));
instrlist_meta_preinsert(bb, where,
INSTR_CREATE_xor(drcontext,
opnd_create_reg(offset_reg),
OPND_CREATE_INT32(cur_location)));
instrlist_meta_preinsert(bb, where,
XINST_CREATE_store(drcontext,
OPND_CREATE_MEM32(tls_reg, offsetof(thread_data, scratch)),
OPND_CREATE_INT32(cur_location >> 1)));
instrlist_meta_preinsert(bb, where,
INSTR_CREATE_inc(drcontext,
opnd_create_base_disp(tls_reg, offset_reg, 1, offsetof(thread_data, map), OPSZ_1)));Кстати, если вы ошибётесь с инструкциями, то вместо подробного сообщения о том, что ай-ай-ай такие операнды задавать этой инструкции, вы получите просто Segmentation fault. Например, заменим в первой инстукции XINST_CREATE_load на XINST_CREATE_store и запустим:
$ ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so --private-fork -- ./example-bug
Cannot get SHM id from environment.
Creating dummy map.
Running forkserver...
Cannot connect to fuzzer.
^C
$ # Поменяли load на store
$ ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so --private-fork -- ./example-bug
Cannot get SHM id from environment.
Creating dummy map.
Что делать? Можно по одной комментировать инструкции, пока не перестанет падать. Можно задать опции командной строки вроде -debug -loglevel 1 -logdir /tmp/dynamorio/ и тогда вместо невразумительного падения на консоль будет написано о невозможности закодировать инструкцию, а в логе будет что-то вроде:
ERROR: Could not find encoding for: mov (%rdi)[8byte] -> %rdx
SYSLOG_ERROR: Application /path/to/example-bug (5192) DynamoRIO usage error : instr_encode error: no encoding found (see log)
SYSLOG_ERROR: Usage error: instr_encode error: no encoding found (see log) (/dynamorio_package/core/arch/x86/encode.c, line 2417)Пожалуй, оба способа имеют право на жизнь: второй позволяет понять что не понравилось, а первый — где оно происходит.
Что же, инструментация готова, можно запускать:
$ $AFL_PATH/afl-fuzz -i input -o output -m 2048 -- ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug
afl-fuzz 2.42b by <lcamtuf@google.com>
[+] You have 4 CPU cores and 1 runnable tasks (utilization: 25%).
[+] Try parallel jobs - see docs/parallel_fuzzing.txt.
[] Checking CPU core loadout...
[+] Found a free CPU core, binding to #0.
[] Checking core_pattern...
[] Checking CPU scaling governor...
[] Setting up output directories...
[+] Output directory exists but deemed OK to reuse.
[] Deleting old session data...
[+] Output dir cleanup successful.
[] Scanning 'input'...
[+] No auto-generated dictionary tokens to reuse.
[] Creating hard links for all input files...
[] Validating target binary...
[-] Looks like the target binary is not instrumented! The fuzzer depends on
compile-time instrumentation to isolate interesting test cases while
mutating the input data. For more information, and for tips on how to
instrument binaries, please see docs/README.
When source code is not available, you may be able to leverage QEMU
mode support. Consult the README for tips on how to enable this.
(It is also possible to use afl-fuzz as a traditional, "dumb" fuzzer.
For that, you can use the -n option - but expect much worse results.)
[-] PROGRAM ABORT : No instrumentation detected
Location : check_binary(), afl-fuzz.c:6894Но… У нас же есть инструментация… Неужели она не работает? На самом деле ситуация ещё смешнее: если посмотреть на лог strace для этой команды, то мы увидим, что drrun даже не запускался. И что же это за телепатия, как afl-fuzz видит отсутствие инструментации, даже не запуская программу? Помните, я говорил о том, что AFL — это подборка железобетонных эвристик? Так вот, идём куда послали, ну, в смысле, в afl-fuzz.c:6894, и видим:
f_data = mmap(0, f_len, PROT_READ, MAP_PRIVATE, fd, 0);
// ...
if (!qemu_mode && !dumb_mode &&
!memmem(f_data, f_len, SHM_ENV_VAR, strlen(SHM_ENV_VAR) + 1)) {
// ...
FATAL("No instrumentation detected");
}Да-да, именно так: AFL ищет в бинарнике строчку __AFL_SHM_ID — имя переменной окружения, через которую инструментированная программа получает идентификатор общей памяти. Теперь-то всё ясно, echo -ne "__AFL_SHM_ID\0" >> /path/to/drrunAFL_SKIP_BIN_CHECK и отключить проверку:
$ # Опция -d заставляет пропустить детерминированные шаги фаззинга
$ AFL_SKIP_BIN_CHECK=1 $AFL_PATH/afl-fuzz -i input -o output -m 2048 -d -- ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug
Ура, AFL признал нашу инструментацию, но что это, Бэрримор, total paths: 12, а раньше было только 4-5. Точно сказать сложно, но подозреваю, что это овсяlibc. Ведь теперь инструментации подвергается не только наш код из example-bug, но и всё, что исполняется в процессе (ну, кроме DynamoRIO, конечно). Да и скорость не ахти… Поэтому самое время начать делать
… и первой будет выбор, какие модули процесса мы хотим инструментировать. Точнее, пока просто будем ограничивать инструментацию главным модулем программы, и сделаем опцию "сделать как раньше". Для этого я заведу глобальную переменную типа module_data_t *, в dr_client_main проинициализирую её информацией о главном модуле программы, а в event_basic_block буду сразу прерывать обработку, если код "не наш":
module_data_t *main_module;
// В dr_client_main:
main_module = dr_get_main_module();
// В event_basic_block:
if (!opt_instrument_everything.get_value() && !dr_module_contains_addr(main_module, pc)) {
return DR_EMIT_DEFAULT;
}Для тестового примера это увеличило скорость фаззинга до 80 запусков в секунду (приблизительно в 2 раза), а в output/queue строка test за пару минут уже превратилась в NU — медленно, но как будто бы работает.
Далее, у DynamoRIO есть опция -thread_private, при указании которой он будет использовать отдельные кеши кода для каждого потока. В этом случае значение из tls field фактически становится константой, поэтому, хотя выкинуть использование регистра у меня не получилось, но инициализировать его можно immediate-константой:
if (dr_using_all_private_caches()) {
instrlist_meta_preinsert(bb, where,
INSTR_CREATE_mov_imm(drcontext,
opnd_create_reg(tls_reg),
OPND_CREATE_INTPTR(dr_get_tls_field(drcontext))));
} else {
dr_insert_read_tls_field(drcontext, bb, where, tls_reg);
}Запускаем с опцией -thread_private (но эта опция должна идти до -c libafl-dr.so, поскольку она принадлежит самому DynamoRIO, а не нашему клиенту), и получаем приблизительно на 5 запусков в секунду больше. Впрочем, даже если написать if (0 && dr_using_all_private_caches()), то результат идентичный — видимо, DynamoRIO просто эффективнее работает в таком режиме. :)
В принципе, мы можем указать ещё одну опцию командной строки: -disable_traces — она отключает создание трейсов, что, вероятно, негативно скажется на производительности долго живущих программ, но, как сказано в документации, может благотворно сказаться на скорости больших короткоживущих приложений. Попробуем… и получаем ещё плюс 10-15 запусков в секунду. Но, повторюсь, с этой опцией нужно экспериментировать, возможно, даже, уже после появления в очереди интересных test case-ов.
Напоследок скажу, что ещё чуть улучшить производительность можно, если "прогреть" тестируемую программу перед запуском forkserver-а: добавим в example-bug.c код
ungetc('1', stdin);
char ch;
fscanf(stdin, "%c", &ch);
RUN_FORKSERVER();… и получим ещё плюс 15 запусков в секунду. Впрочем, сложно с ходу сказать, в чём конкретно дело: возможно, за счёт этого кода какая-то затратная инициализация в libc произошла до запуска forkserver, а возможно, просто был транслирован какой-то ощутимый кусок кода.
За сим разрешите откланяться. В этом небольшом проекте ещё есть над чем подумать:
afl-as… но это уже совсем другая история. И помните, все врут: не стоит на вопрос "А правда ли эту функцию API / ассемблерную инструкцию можно так использовать?" отвечать, "Да, конечно, я так вон в той статье видел!" — сложно сказать, сколько разнокалиберных неожиданностей ещё предстоит вычистить из этого небольшого кода. Впрочем, надеюсь, вы убедились, что написание несложной, но полезной динамической инструментации — задача намного более выполнимая, чем кажется на первый взгляд.
Ссылки:
|
Метки: author atrosinenko системное программирование open source assembler инструментация динамическая инструментация dynamorio afl american fuzzy lop |






